
Мы используем куки, чтобы пользоваться сайтом
было удобно.
До конца раздачи бесплатных лицензий осталось 00:59:58. Забрать!

Многие статические анализаторы позволяют подавлять отдельные предупреждения прямо в коде с помощью специальных комментариев. Со временем таких меток в проектах накапливается всё больше. Часть из них теряет актуальность, и потом они просто висят в коде как магниты на холодильнике.
В этой статье мы решили оценить масштаб проблемы. Мы взяли несколько проектов и проверили их с помощью нового функционала PVS-Studio, который умеет находить устаревшие маркеры подавления. Посмотрим, что из этого получилось.

Метки подавления предупреждений появляются по нескольким причинам. Иногда разработчику просто не хочется сразу смотреть предупреждение, и он думает: "Гляну потом, когда будет время".

Рисунок 2. Мстители: Финал / Marvel Studios
Другой вариант — анализатор ошибся. Да, такое бывает: инструмент видит проблему там, где её нет, а разработчик смотрит, убеждается, что всё в порядке, и добавляет подавление.
Но анализаторы становятся умнее, старые ложные срабатывания исчезают, а подавления остаются. И вот та самая метка, которая когда-то спасала, может тихо прятать настоящие предупреждения. Со временем таких реликтов собирается целая коллекция и, если вы не коллекционер, от них лучше избавляться.
Итак, задачка: нужно сделать утилиту, которая на основе отчёта анализа найдёт в кодовой базе маркеры особого вида и удалит неактуальные. Мы видели два подхода для реализации.
Первый — утилита просто рекурсивно пройдётся по указанной директории, найдёт во всех файлах комментарии и удалит их на основе отчёта анализа. На первый взгляд звучит просто. Но, как и в известном анекдоте, возникли нюансы.
Во-первых, маркеры подавления могут находиться в разных местах, например:
1. В конце строки:
int a1; //-V8612. Среди нескольких маркеров:
int a2; //-V561 //-V861 //-V7733. Внутри комментария:
int a3; /* comment //-V861 */4. В строке:
std::string a4 = "//-V861"; //-V861
std::string a5 = "hello //-V861 \" world"; //-V861Т.е. утилита уже должна понимать контекст текстового файла с учётом языка программирования.
Во-вторых, а во все ли файлы необходимо заглядывать? Первое, что приходит в голову — утилита должна заглядывать только в текстовые файлы. Но какие из них попадают в итоговую программу? Проекты бывают кроссплатформенные, и файлы, участвующие в компиляции на одной платформе, могут вовсе не использоваться на другой.
Уже этих двух нюансов хватило для понимания, что придётся пойти другим путём. Мы хотели получить очень легковесную утилиту, которая просто удаляет из исходников комментарии.
Мы подошли к задаче с другой стороны. Анализатор уже выдаёт необходимые для работы утилиты предупреждения. Он уже собирает информацию о комментариях подавления. И он отлично знает контекст языка программирования, т.е. может отличить строковый литерал, содержащий комментарий, от искомого комментария. Что если анализатор сам будет вычислять и передавать точные координаты лишних комментариев? Это даёт нам:
Недостатков у этого подхода мы увидели немного:
Преимущества перевесили недостатки.
{
"version": 1,
"files": [
{
"path": "/path/to/file1",
"hash": "d82b7bac944b7da5c9a13d0c48d285345368790f",
"lines": [
{
"line": 1,
"markers": [
{
"code": 567,
"columns": { "begin": 1, "end": 2 },
"offsets": { "begin": 1, "end": 2 }
},
{
"code": 730,
"columns": { "begin": 34, "end": 43 },
"offsets": { "begin": 34, "end": 47 }
}
]
},
{
"line": 10,
"markers": [
{
"code": 568,
"columns": { "begin": 3, "end": 7 },
"offsets": { "begin": 3, "end": 7 }
},
{
"code": 609,
"columns": { "begin": 9, "end": 15 },
"offsets": { "begin": 9, "end": 20 }
}
]
}
]
},
{
"path": "/path/to/file2",
"hash": "9bc0ced475c2df7103f34db6c1b407b7db79b4a4",
"lines": [
{
"line": 1,
"markers": [
{
"code": 557,
"columns": { "begin": 5, "end": 8 },
"offsets": { "begin": 5, "end": 8 }
},
{
"code": 777,
"columns": { "begin": 63, "end": 79 },
"offsets": { "begin": 63, "end": 84 }
}
]
},
{
"line": 10,
"markers": [
{
"code": 501,
"columns": { "begin": 20, "end": 25 },
"offsets": { "begin": 20, "end": 27 }
},
{
"code": 509,
"columns": { "begin": 33, "end": 39 },
"offsets": { "begin": 33, "end": 42 }
}
]
}
]
}
]
}В таком отчёте мы:
Далее утилита просто читает этот отчёт и удаляет маркеры по заданным "координатам".
До сих пор мы рассматривали всё с условием, что анализируемый проект находится на одной платформе. Реальность же такова, что большая часть проектов прекрасно живёт между платформами. Проблема в том, что наборы предупреждений между платформами могут отличаться. Маркер может быть неактуален на одной платформе и при этом подавлять предупреждение на другой.
Поэтому пришлось добавить в утилиту режим слияния отчётов. Если информация об устаревшем маркере присутствует во всех отчётах, то маркер можно по-прежнему удалять. В ином случае стоит оставить этот маркер в исходном коде.
Итак, всё готово, информация о неактуальных маркерах собрана — можно менять файл. Открываем его и погнали модифицировать?
Прежде всего, удостоверяемся, что файл не поменялся с последнего прогона анализа. Благо, для этого мы добавили контрольную сумму. Но если что-то пойдёт не так? Никто не хочет видеть свои исходники испорченными. Поэтому мы сначала копируем исходный файл, модифицируем копию согласно входным данным и затем атомарно меняем файлы. Если процесс будет прерван, исходный файл остаётся нетронутым.
Чтобы решать описанную ранее проблему, в состав продукта PVS-Studio был добавлен специальный инструмент — pvs-fp-cleaner.
Для подавления ложноположительных предупреждений PVS-Studio поддерживает управляющие комментарии вида:
//-Vwarning-numberгде warning-number — номер диагностического правила.
Пример:
if (a == b && a == b && 0 / 0 == 0) //-V501 //-V609Если используется механизм подавления по хэш-коду строки (подавление убирается, если исходная строка изменилась), то обрабатываются и такие маркеры:
//-VH"hash"где hash — hash-код строки без учета комментариев.
Например:
if (a == b && a == b && 0 / 0 == 0) //-V501 //-V609 //-VH"12345678"Первый шаг — провести анализ проекта в специальном режиме, который собирает данные о потенциально устаревших маркерах подавления:
pvs-studio-analyzer analyze --redundant-false-alarms=/path/to/report.json \
--sourcetree-root=/path/to/project-root \
....В результате формируется отчёт с информацией о маркерах, которые больше не актуальны, на основе данных, собранных в ходе анализа.
Основные параметры:
--redundant-false-alarms — путь к отчёту;--sourcetree-root — корень проекта для корректного формирования относительных путей.Когда отчёты готовы, можно переходить к самой полезной части — очистке кодовой базы. Для этого используется pvs-fp-cleaner.
В кроссплатформенных проектах предупреждения могут отличаться на разных платформах, поэтому для корректной работы нужно указать отчёты, полученные под каждой из них.
Запуск:
pvs-fp-cleaner cleanup \
--sourcetree-root=/path/to/project \
PATH...где:
cleanup — режим очистки;--sourcetree-root — корневая директория проекта;PATH... — список отчётов.Пример:
pvs-fp-cleaner cleanup \
--sourcetree-root=/home/user/project \
/home/user/windows_report.json \
/home/user/linux_report.json \
/home/user/macOS_report.jsonЕсли отчётов несколько, например, для кроссплатформенного проекта, и хочется работать с единым набором данных, можно использовать режим merge:
pvs-fp-cleaner merge \
--sourcetree-root=/path/to/project \
--output-file=/path/to/merged_report.json \
PATH...где:
merge — режим объединения;--output-file — итоговый отчёт.Перед удалением маркеров подавления лучше оценить масштаб изменений в коде. Поэтому предусмотрен режим формирования отчёта для предпросмотра:
pvs-fp-cleaner report \
--sourcetree-root=/home/user/project \
--output-file=/home/user/report_for_IDE_plugin.json \
PATH...Полученный отчёт можно открыть в IDE, выглядеть это будет так:
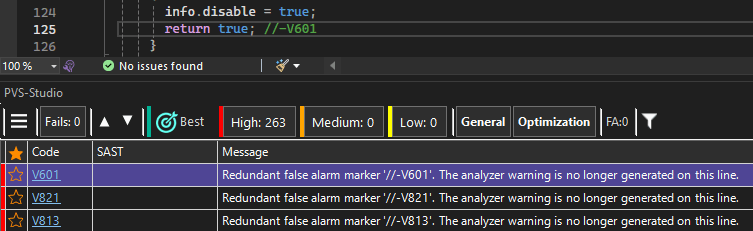
Мы испытали утилиту на трёх разных проектах:
Теперь давайте посмотрим, сколько маркеров подавления действительно живые, а сколько давно пора отправить на пенсию.
Начнём с себя.
Результаты получились такие:
Иными словами, примерно половина меток в проекте оказалась уже ненужной. Это наглядно показывает: анализатор с годами подучился.
Переходим к Unreal Engine.
Процент устаревших меток здесь заметно меньше, чем в PVS-Studio, но по абсолютным числам это всё ещё сотни. При этом у UE сложный код, много макросов и шаблонов — так что и ложных срабатываний больше.
Теперь посмотрим на проект, предоставленный Лабораторией Касперского:
Почти треть из подавленных маркеров оказалась неактуальной. Команда Лаборатории Касперского протестировала утилиту и оставила такой отзыв:
Считаю, что это отличный результат. Данная утилита не только улучшает читаемость кода, но и поднимает "боевой дух" команды - ведь чем больше анализатор "фолзит", тем больше у конкретного разработчика желания подавить предупреждение, не вдаваясь в подробности. Всячески приветствуем движение PVS-Studio не только в сторону новых детектов, но и улучшения качества срабатывания старых.
Спасибо им за тестирование и за то, что разрешили привести цифры в статье.
|
Проект |
Всего меток |
Неактуальных |
Доля |
|---|---|---|---|
|
PVS-Studio |
744 |
324 |
43.55% |
|
Проект Лаборатории Касперского |
250 |
74 |
29.6% |
|
Unreal Engine |
2 215 |
270 |
12.19% |
В большинстве случаев всё вполне ожидаемо. Например, одиночный маркер:
if ( Name.Contains(CtrlPrefix)
&& !DynamicHierarchy->Contains(....)) //-V1051Или несколько маркеров подряд:
for (....) //-V621 //-V654В таких случаях всё предельно просто: предупреждения больше не появляются — значит, метку можно удалить.
Но иногда встречаются более философские случаи. Например:
// The warning disable comment can can't be used in a macro: //-V501Тут маркер находится внутри комментария. Формально она неактуальна, но по смыслу — часть текста.
В итоге в команде разгорелась горячая дискуссия: одни считали, что раз подавление неактуальное — метку нужно удалить, другие утверждали, что это "комментарий в комментарии" и трогать его нельзя.
В итоге победила первая сторона, и сейчас утилита такие метки удаляет.
А вы как думаете? Делитесь мнением в комментариях!
Вот ещё один похожий случай:
LinkerSave.AdditionalDataToAppend.Add(....); \
// -V595 PVS believes that LinkerSave can potentially be nullptr atУтилита удаляет сам маркер, а остальной текст остаётся:
LinkerSave.AdditionalDataToAppend.Add(....); \
// PVS believes that LinkerSave can potentially be nullptr atИз-за всех этих случаев мы рекомендуем запускать pvs-fp-cleaner под присмотром системы контроля версий. В спорных ситуациях лучше заранее просмотреть диффы, обдумать изменения и лишь потом нажать на commit.
Посмотрев на результаты, можно сделать вывод: в активно развиваемых проектах накапливаются сотни неактуальных меток. Думаю, это можно назвать эффектом эволюции анализаторов: инструменты становятся умнее, а вот маркеры подавления — нет.
Автоматическая очистка таких меток снижает уровень шума, упрощает сопровождение кода и уменьшает риск того, что реальное предупреждение однажды окажется спрятанным за давно забытой меткой.
Функция поиска и удаления неактуальных меток подавления доступна в PVS-Studio с версии 7.41.
0
0
0


0