
Курс по разработке 64-битных приложений на языке C и C++ (одним файлом)
Данный курс был разработан в 2010 году. Однако он не потерял актуальность, и приведённая в нём информация вполне релевантна для современных версий Visual Studio.
Курс посвящён созданию 64-битных приложений на языке C/C++ и ориентирован на разработчиков Windows-приложений, использующих среду Visual Studio 2005/2008/2010. Разработчики для других 64-битных операционных систем также узнают много интересного. В курсе будут рассмотрены все этапы, позволяющие создать новое надежное 64-битное приложение или выполнить миграцию существующего 32-битного кода на 64-битную систему.
Курс состоит из 28 уроков, посвящённых знакомству с 64-битными системами, вопросам сборки 64-битных приложений, методам поиска специфичных для 64-битного кода ошибок и оптимизации кода. Рассматриваются такие вопросы, как оценка стоимости перехода на 64-битные системы и рациональность этого перехода.
Авторами курса являются:
- к.ф.-м.н. Карпов Андрей Николаевич;
- к.т.н. Рыжков Евгений Александрович.
Авторы занимаются вопросами обеспечения качества 64-битных приложений и участвуют в разработке статического анализатора кода PVS-Studio для верификации кода ресурсоемких приложений.
Правообладателем курса является ООО "Системы программной верификации".
- Сайт компании.
- Контактная информация: e-mail: support@viva64.com.
Содержание курса
- Урок 01. Что такое 64-битные системы.
- Урок 02. Поддержка 32-битных приложений.
- Урок 03. Перенос кода на 64-битные системы. За и против.
- Урок 04. Создание 64-битной конфигурации.
- Урок 05. Сборка 64-битного приложения.
- Урок 06. Ошибки в 64-битном коде.
- Урок 07. Проблемы выявления 64-битных ошибок.
- Урок 08. Статический анализ для выявления 64-битных ошибок.
- Урок 09. Паттерн 01. Магические числа.
- Урок 10. Паттерн 02. Функции с переменным количеством аргументов.
- Урок 11. Паттерн 03. Операции сдвига.
- Урок 12. Паттерн 04. Виртуальные функции.
- Урок 13. Паттерн 05. Адресная арифметика.
- Урок 14. Паттерн 06. Изменение типа массива.
- Урок 15. Паттерн 07. Упаковка указателей.
- Урок 16. Паттерн 08. Memsize-типы в объединениях.
- Урок 17. Паттерн 09. Смешанная арифметика.
- Урок 18. Паттерн 10. Хранение в double целочисленных значений.
- Урок 19. Паттерн 11. Сериализация и обмен данными.
- Урок 20. Паттерн 12. Исключения.
- Урок 21. Паттерн 13. Выравнивание данных.
- Урок 22. Паттерн 14. Перегруженные функции.
- Урок 23. Паттерн 15. Рост размеров структур.
- Урок 24. Фантомные ошибки.
- Урок 25. Практическое знакомство с паттернами 64-битных ошибок.
- Урок 26. Оптимизация 64-битных программ.
- Урок 27. Особенности создания инсталляторов для 64-битного окружения.
- Урок 28. Оценка стоимости процесса 64-битной миграции Си/Си++ приложений.
Объем курса: курс предполагает самостоятельное знакомство с каждым из 28 уроков в течение 20-40 минут. Общее время изучения материала составляет примерно 18 часов.
Вы можете открыть все уроки в виде одного файла (в том числе и версию для печати). Этот общий файл можно напечатать либо на обычном принтере, либо, к примеру, преобразовать в pdf-файл с помощью pdf-принтера.
Урок 1. Что такое 64-битные системы
На момент написания курса, наиболее известными являются две 64-битные архитектуры микропроцессоров: IA64 и Intel 64.
- IA-64 64-битная микропроцессорная архитектура, разработанная совместно компаниями Intel и Hewlett Packard. Реализована в микропроцессорах Itanium и Itanium 2. Для более подробного знакомства с архитектурой IA-64 можно обратиться к следующим статьям в Wikipedia: "IA-64", "Itanium", "Itanium 2".
- Intel 64 (EM64T / AMD64 / x86-64 / x64) - данная архитектура представляет собой расширение архитектуры x86 с полной обратной совместимостью. Существует множество вариантов названия данной архитектуры, что приводит к путанице, хотя, по сути, все эти названия обозначают одно и тоже: x86-64, AA-64, Hammer Architecture, AMD64, Yamhill Technology, EM64T, IA-32e, Intel 64, x64. Более подробно узнать о том, как появилось так много названий, можно в статье из Wikipedia: "X86-64".
Важно понимать, что IA-64 и Intel 64 - это совершенно разные, несовместимые друг с другом, микропроцессорные архитектуры. В рамках курса мы будем рассматривать только архитектуру Intel 64 (x64 / AMD64) как более популярную среди разработчиков прикладного программного обеспечения для операционной системы Windows. Соответственно, когда будет упоминаться операционная система Windows, то будут иметься в виду ее 64-битные версии для архитектуры Intel 64. Примеры: Windows XP Professional x64 Edition, Windows Vista x64, Windows 7 x64. Для краткости программную модель Intel 64, доступную программисту в 64-битной системе Windows, называют Win64.
Архитектура Intel 64
Представленная здесь информация основана на первом томе документации "AMD64 Architecture Programmer's Manual. Volume 1. Application Programming".
Рассматриваемая архитектура Intel 64 - простое, но в то же время мощное обратно совместимое расширение устаревшей промышленной архитектуры x86. Она добавляет 64-битное адресное пространство и расширяет регистровые ресурсы для поддержки большей производительности перекомпилированных 64-битных программ. Архитектура обеспечивает поддержку устаревшего 16-битного и 32-битного кода приложений и операционных систем без их модификации или перекомпиляции.
Необходимость 64-битной архитектуры определяется приложениями, которым необходимо большое адресное пространство. В первую очередь это высокопроизводительные серверы, системы управления базами данных, САПР и, конечно, игры. Такие приложения получат существенные преимущества от 64-битного адресного пространства и увеличения количества регистров. Малое количество регистров, доступное в устаревшей x86 архитектуре, ограничивает производительность в вычислительных задачах. Увеличенное количество регистров обеспечивает достаточную производительность для многих приложений.
Подчеркнем основные достоинства архитектуры x86-64:
- 64-битное адресное пространство;
- расширенный набор регистров;
- привычный для разработчиков набор команд;
- возможность запуска старых 32-битных приложений в 64-битной операционной системе;
- возможность использования 32-битных операционных систем.
64-битные операционные системы
Практически все современные операционные системы сейчас имеют версии для архитектуры Intel 64. Например, Microsoft предоставляет Windows XP x64. Крупнейшие разработчики UNIX систем также поставляют 64-битные версии, как, например, Linux Debian 3.5 x86-64. Однако это не означает, что весь код такой системы является полностью 64-битным. Часть кода ОС и многие приложения вполне могут оставаться 32-битными, так как Intel 64 обеспечивает обратную совместимость. Так, 64-битная версия Windows использует специальный режим WoW64 (Windows-on-Windows 64), который транслирует вызовы 32-битных приложений к ресурсам 64-битной операционной системы.
Адресное пространство
Хотя 64-битный процессор теоретически может адресовать 16 экзабайт памяти (2^64), Win64 в настоящий момент поддерживает 16 терабайт (2^44). Этому есть несколько причин. Текущие процессоры могут обеспечивать доступ лишь к 1 терабайту (2^40) физической памяти. Архитектура (но не аппаратная часть) может расширить это пространство до 4 петабайт (2^52). Однако в этом случае необходимо огромное количество памяти для страничных таблиц, отображающих память.
Помимо перечисленных ограничений, объем памяти, который доступен в той или иной версии 64-битной операционной системе Windows, зависит также от коммерческих соображений компании Microsoft. Различные версии Windows имеют различные ограничения, представленные в таблице.
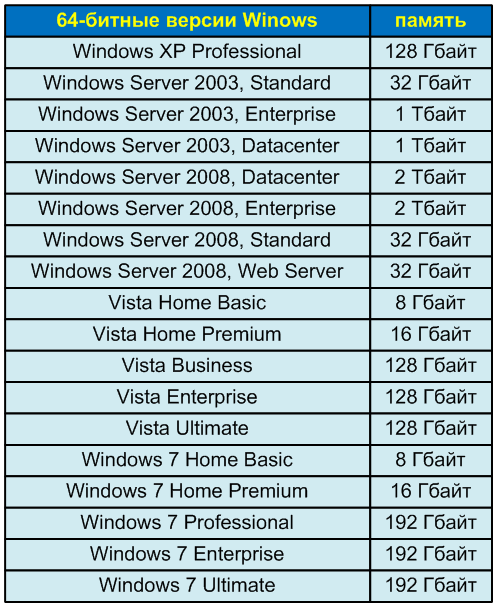
Таблица 1 - Поддерживаемый объем оперативной памяти в различных версиях Windows
Программная модель Win64
Также как и в Win32, размер страниц в Win64 составляет 4Кб. Первые 64Кб адресного пространства никогда не отображаются, то есть наименьший правильный адрес- это 0x10000. В отличие от Win32, системные DLL загружаются выше 4Гб.
Особенность компиляторов для Intel 64 в том, что они могут наиболее эффективно использовать регистры для передачи параметров в функции вместо использования стека. Это позволило разработчикам Win64 архитектуры избавиться от такого понятия, как соглашение о вызовах (calling convention). В Win32 можно использовать разные соглашения: __stdcall, __cdecl, __fastcall и так далее. В Win64 есть только одно соглашение о вызовах. Рассмотрим пример, как передаются в регистрах четыре аргумента типа integer:
- RCX: первый аргумент
- RDX: второй аргумент
- R8: третий аргумент
- R9: четвертый аргумент
Аргументы после первых четырех integer передаются на стеке. Для float аргументов используются XMM0-XMM3 регистры, а также стек.
Разница в соглашениях о вызове приводит к тому, что в одной программе нельзя использовать и 64-битный, и 32-битный код. Другими словами, если приложение скомпилировано для 64-битного режима, то все используемые библиотеки (DLL) также должны быть 64-битными.
Передача параметров через регистры является одним из новшеств, делающих 64-битные программы более производительными, чем 32-битные. Дополнительный выигрыш в производительности можно получить, используя 64-битные типы данных, о чем будет рассказано в соответствующем уроке.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 2. Поддержка 32-битных приложений в 64-битной среде Windows
- Накладные расходы
- Преимущество 64-битной среды для 32-битных программ
- Перенаправления
- Почему невозможно использовать в 64-битной программе 32-битные DLL? Можно ли это обойти?
- Постепенный отказ от поддержки 32-битных программ
- Дополнительная информация
Прежде чем приступить к тематике разработки кода 64-битных программ, остановимся на вопросе обратной совместимости 64-битных версий Windows с 32-битными приложениями. Обратная совместимость осуществляется за счет механизмов, реализованных в WoW64.
WoW64 (Windows-on-Windows 64-bit) - подсистема операционной системы Windows, позволяющая запускать 32-битные приложения на всех 64-битных версиях Windows.
Подсистема WoW64 не поддерживает следующие программы:
- программы, скомпилированные для 16-разрядных операционных систем;
- программы режима ядра, скомпилированные для 32-разрядных операционных систем.
Накладные расходы
Существуют различия WoW64 в зависимости от архитектуры процессора. Например, 64-битная версия Windows разработанная для процессора Intel Itanium 2 использует WoW64 для эмуляции x86 инструкций. Такая эмуляция весьма ресурсоемка по сравнению с WoW64 для архитектуры Intel 64, так как происходит переключение с 64-битного режима в режим совместимости при выполнении 32-битных программ.
WoW64 на архитектуре Intel 64 (AMD64 / x64) не требует эмуляции инструкций. Здесь подсистема WoW64 эмулирует только 32-битное окружение за счет дополнительной прослойки между 32-битным приложением и 64-битным Windows API. Где-то эта прослойка тонкая, где-то не очень. Для средней программы потери в производительности из-за наличия такой прослойки составят около 2%. Для некоторых программ это значение может быть больше. Два процента - это немного, но следует учитывать, что 32-битные приложения работают немного медленнее под управлением 64-битной операционной системы Windows, чем в 32-битной среде.
Компиляция 64-битного кода не только исключает необходимость в WoW64, но и дает дополнительный прирост производительности. Это связано с архитектурными изменениями в микропроцессоре, такими, как увеличение количества регистров общего назначения. Для средней программы можно ожидать в пределах 5-15% прироста производительности от простой перекомпиляции.
Преимущество 64-битной среды для 32-битных программ
Из-за наличия прослойки WoW64 32-битные программы работают менее эффективно в 64-битной среде, чем в 32-битной. Но все-таки простые 32-битные приложения могут получить одно преимущество от их запуска в 64-битной среде. Вы, наверное, знаете, что программа, собранная с ключом /LARGEADDRESSAWARE:YES, может выделять до 3-х гигабайт памяти, если 32-битная операционная система Windows запущена с ключом /3gb. Так вот, эта же 32-битная программа, запущенная на 64-битной системе, может выделить почти 4 GB памяти (на практике около 3.5 GB).
Перенаправления
Подсистема WoW64 изолирует 32-разрядные программы от 64-разрядных путем перенаправления обращений к файлам и реестру. Это предотвращает случайный доступ 32-битных программ к данным 64-битных приложений. Например, 32-битное приложение, которое запускает файл DLL из каталога %systemroot%\System32, может случайно обратиться к 64-разрядному файлу DLL, который несовместим с 32-битной программой. Во избежание этого подсистема WoW64 перенаправляет доступ из папки %systemroot%\System32 в папку %systemroot%\SysWOW64. Это перенаправление позволяет предотвратить ошибки совместимости, поскольку при этом требуется файл DLL, созданный специально для работы с 32-разрядными приложениями.
Подробнее с механизмами перенаправления файловой системы и реестра можно познакомиться в разделе MSDN "Running 32-bit Applications".
Почему невозможно использовать в 64-битной программе 32-битные DLL? Можно ли это обойти?
Загрузить 32-битную DLL из 64-битного процесса и выполнить код из неё невозможно. Невозможно в силу дизайна 64-битных систем. В принципе, невозможно. Не помогут ни хитрости, ни недокументированные пути. Для этого нужно загрузить и проинициализировать WoW64, не говоря уже о структурах в ядре. Фактически нужно будет на лету превратить 64-битный процесс в 32-х битный. Подробнее эта тема рассмотрена в посте "Недокументированные функции; Загрузка 32-х битных DLL в 64-х битный процесс". Единственное, что можно порекомендовать, - это создание суррогатного процесса и взаимодействия с ним посредством технологии COM. Об этом рассказывается в статье "Accessing 32-bit DLLs from 64-bit code".
А вот загрузить ресурсы из 32-битной DLL в 64-битный процесс совсем несложно. Это можно сделать, если при вызове LoadLibraryEx указать флаг LOAD_LIBRARY_AS_DATAFILE.
Постепенный отказ от поддержки 32-битных программ
Вполне естественно, если компания Microsoft будет стимулировать переход на 64-битные системы, постепенно отказываясь от поддержки 32-битных программ в ряде версий операционной системы Windows. Конечно, это будет очень медленный процесс. Но все-таки первые шаги в этом направлении уже сделаны.
Многие администраторы знают про относительно новый режим установки и работы серверной версии операционной системы под названием Server Core. Это тот режим, о котором участники войн "Windows vs Linux" говорили очень давно. Одним из аргументов сторонников использования Linux на сервере была возможность установить серверную ОС без графического интерфейса (GUI). Но вот и в Windows Server появилась такая возможность. Установка в этом режиме позволяет получить только командную строку без пользовательского интерфейса.
Эта возможность (установка Server Core) появилась в Windows Server 2008. Но в Windows Server 2008 R2 появилось нововведение, приближающее 64-битное будущее. При установке Windows Server 2008 R2 (Server Core) поддержка запуска 32-битных приложений стала опциональной. Причем по умолчанию эта поддержка выключена. И при попытке запуска 32-битного приложения в режиме Server Core пользователь получит сообщение о невозможности запуска. Конечно, можно добавить поддержку 32-битных программ:
start /w ocsetup ServerCore-WOW64
В обычном (Full Installation) режиме 32-битные приложения по умолчанию запускаются, а вот в Server Core уже нет.
Тенденция очевидна. Со временем все более рациональным будет создание 64-битных версий приложений, так как они смогут функционировать на большем числе версий операционных систем.
Дополнительная информация
Интересным источником информации по системе WoW64 является блог Алексея Пахунова: http://blog.not-a-kernel-guy.com/. Алексей является сотрудником компании Microsoft и принимает непосредственное участие в разработке подсистемы WoW64.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 3. Перенос кода на 64-битные системы. За и против
- Продолжительность жизненного цикла приложений
- Требования к производительности приложения
- Использование в проекте сторонних библиотек
- Зависимости сторонних разработчиков от ваших библиотек
- Наличие 16-битных приложений
- Наличие кода на ассемблере
- Инструментарий
Начать освоение 64-битных систем следует с вопроса: "Насколько рационально пересобрать проект для 64-битной системы?". На этот вопрос надо обязательно дать ответ, но не торопясь, подумав. С одной стороны, можно отстать от своих конкурентов, вовремя не предложив 64-битные решения. С другой стороны, можно впустую потратить время на 64-битное приложение, которое не даст никаких конкурентных преимуществ.
Рассмотрим ряд факторов, которые помогут сделать выбор.
Продолжительность жизненного цикла приложений
Не следует создавать 64-битную версию приложения с коротким жизненным циклом. Благодаря подсистеме WoW64 старые 32-битные приложения достаточно хорошо работают на 64-битных Windows системах. Нерационально делать программу 64-битной, если через 2 года она перестанет поддерживаться. Практика показала, что переход на 64-битные версии Windows будет очень медленным и плавным. Возможно, большинство ваших пользователей в краткосрочной перспективе будут использовать только 32-битный вариант вашего программного решения. Следует учитывать, что этот курс был написан в 2009 году, когда большинство пользователей работало с 32-битными версиями операционных систем. Но со временем использование 32-битных программ будет выглядеть все более неестественным и отсталым.
Если планируется длительное развитие и длительная поддержка программного продукта, то следует начинать работать над 64-битным вариантом вашего решения. Спешить, конечно, не следует, но учтите, что чем дольше у вас не будет полноценного 64-битного варианта, тем больше сложностей будет возникать с поддержкой такого приложения, устанавливаемого на 64-битные версии Windows.
Требования к производительности приложения
Перекомпиляция программы для 64-битной системы позволит ей использовать огромные объемы оперативной памяти, а также повысит скорость ее работы на 5-15%. Повышение скорости работы на 5-10% произойдет за счет использования архитектурных возможностей 64-битного процессора, например, большего количества регистров. Еще 1-5% прироста скорости обуславливается отсутствием прослойки WoW64, которая транслирует вызовы API между 32-битными приложениями и 64-битной операционной системой.
Например, компания Adobe заявляет, что новый 64-битный "Photoshop CS4" на 12% быстрее его 32-битной версии".
Колоссальный рост производительности могут получить приложения, работающие с большими объемами памяти. Такими программами могут быть графические редакторы, CAD-системы, САПР СБИС, базы данных, пакеты моделирования различных процессов. Возможность разместить все данные в памяти и, следовательно, отсутствие необходимости их подгрузки с жесткого диска может ускорить работу таких приложений уже не на проценты, а в разы.
В качестве примера можно привести интеграцию Альфа-Банком в свою IT-инфраструктуру платформы на базе Itanium 2. Рост инвестиционного бизнеса банка привел к тому, что система в имеющейся конфигурации перестала справляться с возрастающей нагрузкой: задержки в обслуживании пользователей временами достигали критической отметки. Анализ ситуации показал, что узким местом системы является не производительность процессоров, а ограничение 32-разрядной архитектуры, в части подсистемы памяти, не позволяющей эффективно использовать больше 4 Гбайт адресного пространства сервера. Объем базы данных превышал 9 Гбайт. Использовалась она весьма интенсивно, что приводило к критической загрузке подсистемы ввода-вывода. Альфа-Банк принял решение о закупке кластера из двух четырехпроцессорных серверов на базе Itanium 2 с объемом оперативной памяти 12 Гбайт. Это решение позволило обеспечить необходимый уровень быстродействия и отказоустойчивости системы. По словам представителей компании, внедрение серверов на основе Itanium 2 позволило ликвидировать проблемы и достигнуть значительной экономии средств.
Использование в проекте сторонних библиотек
Прежде чем планировать работу над созданием 64-битной версий вашего продукта, выясните, имеются ли 64-битные варианты библиотек и компонентов, которые в нем используются. Также узнайте, какова ценовая политика по отношению к 64-битному варианту библиотеки. Все это можно выяснить, посетив сайт разработчика библиотеки. Если поддержка отсутствует, то заранее поищите альтернативные решения, поддерживающие 64-битные системы.
Зависимости сторонних разработчиков от ваших библиотек
Если вы разрабатываете библиотеки, компоненты или иные элементы, с помощью которых сторонние разработчики создают свое программное обеспечение, то вы должны проявить оперативность в создании 64-битного варианта своей продукции. В противном случае, ваши клиенты, заинтересованные в выпуске 64-битных версий, будут вынуждены искать альтернативные решения. Например, некоторые разработчики программно-аппаратной защиты откликнулись с большой задержкой на появление 64-битных программ, что заставило ряд клиентов выбрать другие инструменты для защиты своих программных продуктов.
Дополнительным преимуществом от выпуска 64-битной версии библиотеки является то, что вы можете продавать ее как отдельный продукт. Таким образом, ваши клиенты, желающие создавать как 32-битные, так и 64-битные приложения, будут вынуждены приобретать 2 различные лицензии. Например, такая политика используется компанией Spatial Corporation при продаже библиотеки Spatial ACIS.
Наличие 16-битных приложений
Если в ваших решениях все еще присутствуют 16-битные модули, то пора от них избавиться. Работа 16-битных приложений в 64-битных версиях Windows не поддерживается.
Здесь следует пояснить один момент, связанный с использованием 16-битных инсталляторов. Они до сих пор используются для установки некоторых 32-битных приложений. Создан специальный механизм, который на лету подменяет ряд наиболее популярных 16-битных инсталляторов на более новые версии. Это может вызвать неверное мнение, что 16-битные программы по-прежнему работают в 64-битной среде. Помните, это не так.
Наличие кода на ассемблере
Не забывайте, что использование большого объема кода на ассемблере может существенно повысить стоимость создания 64-битной версии приложения.
Инструментарий
Если, опираясь на изложенные выше факторы, вы приняли решение о разработке 64-битной версии вашего продукта и готовы потратить на это время, успех еще не гарантирован. Дело в том, что вы должны обладать всем необходимым инструментарием, и здесь могут быть скрыты неприятные казусы.
Самой очевидной, как и самой непреодолимой, может стать проблема отсутствия 64-битного компилятора. Когда писался этот текст (2009 год), все еще не существовало 64-битного компилятора C++ Builder от Embarcadero. Его выпуск ожидается только к концу 2009 года. Невозможно обойти подобную проблему, если, конечно, не переписать весь проект, например, с использованием Microsoft Visual Studio. Но если с отсутствием 64-битного компилятора все понятно, то другие аналогичные проблемы могут оказаться неявными и проявить себя уже на этапе работ по переносу проекта на новую архитектуру. Разумно заранее провести исследование: существуют ли все необходимые компоненты, которые потребуются для реализации 64-битной версии вашего продукта. Вас могут поджидать неприятные сюрпризы.
Принимая решение, помните о последнем факторе, который не упоминался, но весьма важен. Это фактор стоимости модернизации программного кода для компиляции в 64-битном режиме. Как рассчитать эту стоимость, будет рассказано в одном из уроков. Стоимость переноса кода может быть достаточно высокой и должна внимательно учитываться при составлении планов и определении сроков.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 4. Создание 64-битной конфигурации
Компилятор
Вначале следует убедиться, что используемая вами редакция Visual Studio позволяет собирать 64-битный код. Если вы планируете разрабатывать 64-битные приложения с использованием последней версии (на момент написания курса) Visual Studio 2008, то следующая таблица поможет определить, какая из редакций Visual Studio вам необходима.

Таблица 1 - Возможности различных редакций Visual Studio 2008
Если ваша редакция Visual Studio позволяет создавать 64-битный код, то следует проверить, установлен ли 64-битный компилятор. На рисунке 1 показана страница устанавливаемых компонентов Visual Studio 2008, где не выбрана установка 64-битного компилятора.
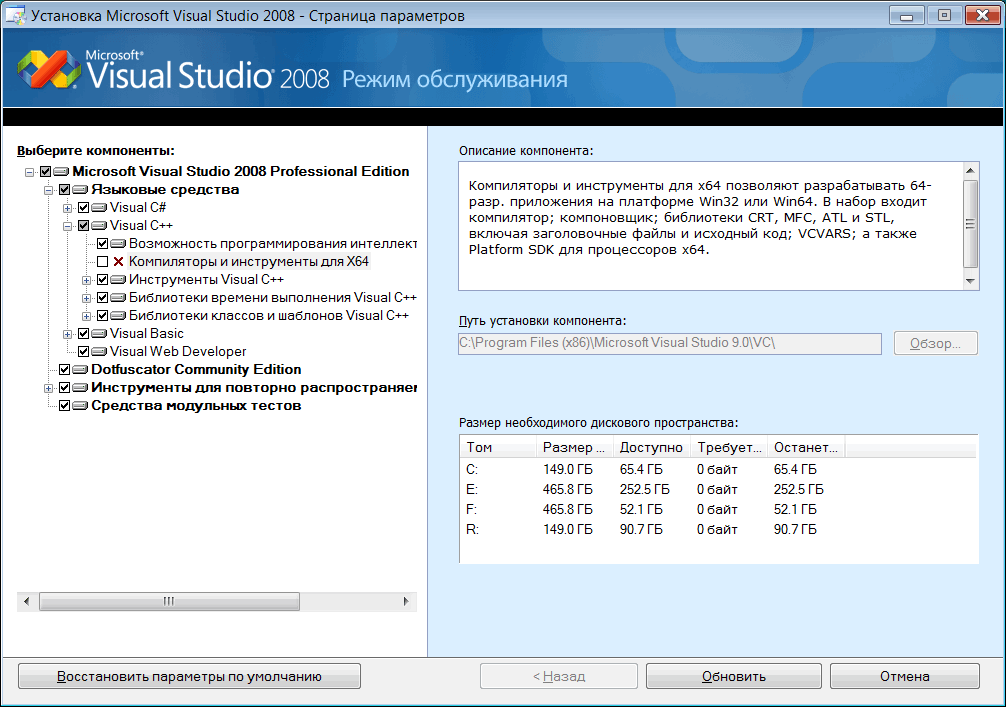
Рисунок 1 - При установке не выбран 64-битный компилятор
Создание 64-битной конфигурации
Создание 64-битной конфигурации проекта в Visual Studio 2005/2008 - достаточно простая операция. Сложности будут подстерегать вас позже на этапе сборки новой конфигурации и поиска в ней ошибок. Для создания 64-битной конфигурации достаточно выполнить следующие 4 шага:
Шаг 1
Запускаем менеджер конфигураций, как показано на рисунке 2:
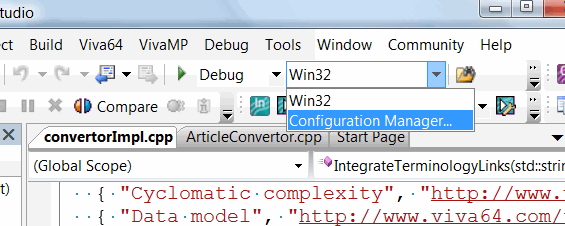
Рисунок 2 - Запуск менеджера конфигураций
Шаг 2
В менеджере конфигураций выбираем поддержку новой платформы (рисунок 3):
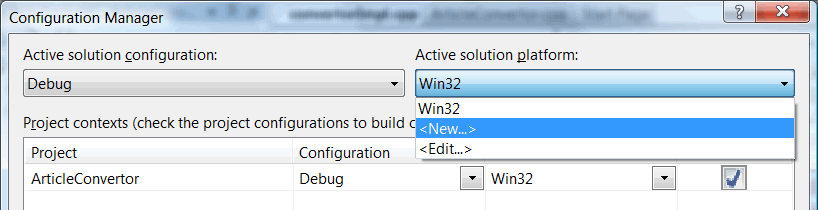
Рисунок 3 - Создание новой конфигурации
Шаг 3
Выбираем 64-битную платформу (x64), а в качестве основы выбираем настройки от 32-битной версии (рисунок 4). Те настройки, которые влияют на режим сборки, среда Visual Studio скорректирует сама.
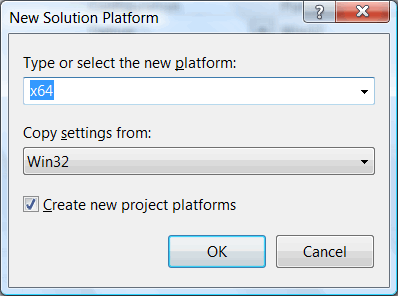
Рисунок 4 - Выбираем x64 в качестве платформы и берем за основу конфигурацию Win32
Шаг 4
Добавление новой конфигурации завершено, и мы можем выбрать 64-битный вариант конфигурации и приступить к компиляции 64-битного приложения. Выбор 64-битной конфигурации для сборки показан на рисунке 5.
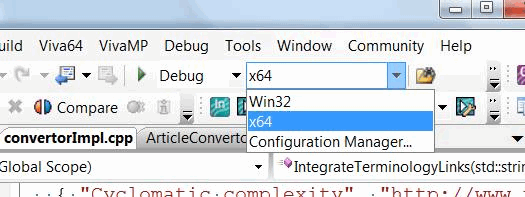
Рисунок 5 - Теперь доступна 32-битная и 64-битная конфигурация
Модификация параметров
Если вам повезет, то дополнительно заниматься настройкой 64-битного проекта, необходимости не будет. Но это сильно зависит от проекта, его сложности и количества используемых библиотек. Единственное, что стоит сразу изменить, это размер стека. В случае, если в вашем проекте используется стек размером по умолчанию, то есть в 1 мегабайт, есть смысл задать его размером в 2-3 мегабайта для 64-битной версии. Это не обязательно, но лучше заранее подстраховаться. Если у вас используется размер стека, отличный от размера по умолчанию, то есть смысл сделать его для 64-битной версии в 2-3 раза больше. Для этого в настройках проекта найдите и измените параметры Stack Reserve Size и Stack Commit Size (смотри рисунок 6).
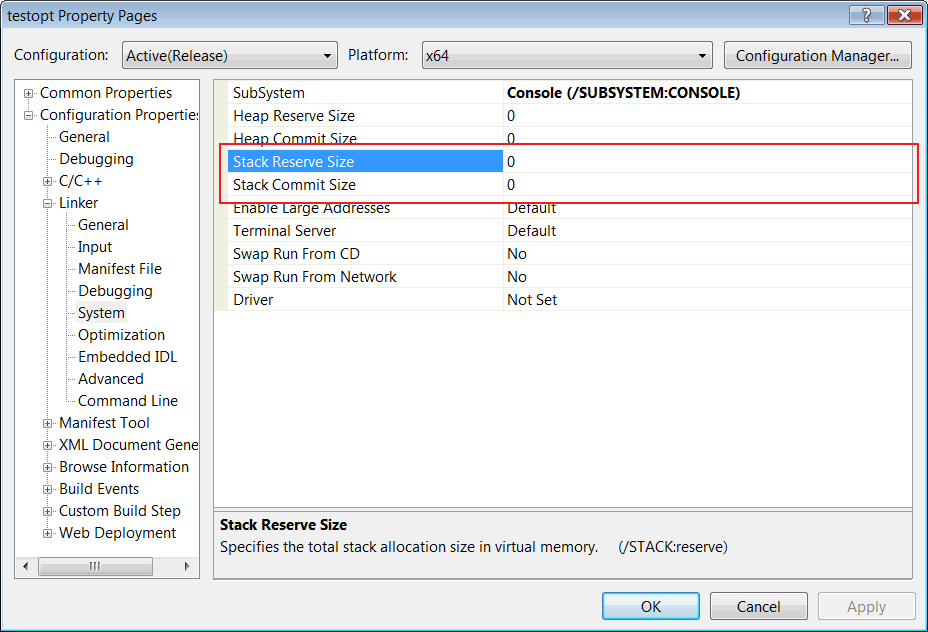
Рисунок 6 - Расположение настроек проекта, задающих размер стека
Что дальше?
Создание 64-битной конфигурации проекта не означает, что проект будет компилироваться или, тем более, корректно работать. Процессом компиляции и обнаружением скрытых ошибок мы займемся в следующих уроках.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 5. Сборка 64-битного приложения
Хочется сразу предупредить читателя, что невозможно всесторонне описать процесс сборки 64-битного приложения. Настройки любого проекта достаточно уникальны, поэтому к адаптации настроек для 64-битной системы всегда надо подходить внимательно. В уроке будут описаны только общие шаги, которые важны для любого проекта. Эти шаги подскажут вам, с чего начать процесс.
Библиотеки
Прежде чем попытаться собрать ваше 64-битное приложение, проверьте, что установлены все необходимые версии 64-битных библиотек и к ним корректно прописаны пути. Например, 32-битные и 64-битные библиотечные lib файлы отличаются и, как правило, находятся в различных каталогах. Исправьте найденные недочеты.
Примечание. Если библиотеки представлены в исходных кодах, то должна присутствовать 64-битная конфигурация проекта. Учтите, что самостоятельно занимаясь модернизацией библиотеки для сборки ее 64-битной версии, вы можете нарушить лицензионные соглашения.
Ассемблер
Visual C++ не поддерживает 64-битный встроенный ассемблер. Вы должны использовать или внешний 64-битный ассемблер (например, MASM), или иметь реализацию той же функциональности на языке Си/Си++.
Примеры ошибок и предупреждений при компиляции
Начав сборку проекта, вы обнаружите большое количество ошибок компиляции и предупреждений, связанных с явным и неявным приведением типов. Продемонстрируем пример возникновения одной из ошибок. Пусть мы имеем код:
void foo(unsigned char) {}
void foo(unsigned int) {}
void a(const char *str)
{
foo(strlen(str));
}Данный код успешно компилируется в 32-битном режиме. А в 64-битном компилятор Visual C++ выдаст сообщение:
error C2668: 'foo' : ambiguous call to overloaded function
.\xxxx.cpp(16): could be 'void foo(unsigned int)'
.\xxxx.cpp(15): or 'void foo(unsigned char)'
while trying to match the argument list '(size_t)'Функция strlen() возвращает тип size_t. На 32-битной системе тип size_t совпадает с типом unsigned int и компилятор выбирает для вызова функцию void foo(unsigned int). В 64-битном режиме типы size_t и unsigned int не совпадают. Тип size_t становится 64-битным, а тип unsigned int по-прежнему остается 32-битным. В результате компилятор не знает, какой функции foo() отдать предпочтение.
Теперь рассмотрим пример предупреждения, выдаваемого компилятором Visual C++ при сборке кода в 64-битном режиме:
CArray<char, char> v;
int len = v.GetSize();
warning C4244: 'initializing' : conversion from 'INT_PTR' to 'int',
possible loss of dataФункция GetSize() возвращает тип INT_PTR, который совпадает с типом int в 32-битном коде. В 64-битном коде тип INT_PTR имеет размер 64 бита, и происходит неявное приведение этого типа к 32-битному типу int. При этом теряются значения старших битов, о чем и предупреждает компилятор. Неявное приведение типа может привести к ошибке, если количество элементов в массиве превысит INT_MAX. Для устранения предупреждения и потенциальной ошибки следует использовать для переменной "len" тип INT_PTR или ptrdiff_t.
Не торопитесь исправлять предупреждения до того, как познакомитесь с паттернами 64-битных ошибок. Вы можете случайно, не исправив ошибку, замаскировать ее и тем самым сделать ее обнаружение в дальнейшем более сложной задачей. О паттернах 64-битных ошибок, методах их обнаружения и исправления вы сможете познакомиться в последующих уроках. Также вы можете обратиться к следующим статьям: "20 ловушек переноса Си++ - кода на 64-битную платформу", "64-битный конь, который умеет считать".
Типы size_t и ptrdiff_t
Поскольку большинство ошибок и предупреждений на этапе компиляции будет связано с несовместимостью типов данных, рассмотрим два типа size_t и ptrdiff_t, представляющих для нас наибольший интерес с точки зрения создания 64-битного кода. Если вы используете компилятор Visual C++, то эти типы являются для него встроенными и подключения библиотечных файлов не требуется. Если вы используете GCC, то вам потребуется использовать заголовочный файл stddef.h.
size_t - базовый беззнаковый целочисленный тип языка Си/Си++. Является типом результата, возвращаемого оператором sizeof. Размер типа выбирается таким образом, чтобы в него можно было записать максимальный размер теоретически возможного массива любого типа. Например, на 32-битной системе size_t будет занимать 32 бита, на 64-битной - 64 бита. Другими словами, в переменную типа size_t может быть безопасно помещен указатель. Исключение составляют указатели на функции классов, но это особый случай. Тип size_t обычно применяется для счетчиков циклов, индексации массивов, хранения размеров, адресной арифметики. Аналогами данному типу являются: SIZE_T, DWORD_PTR, WPARAM, ULONG_PTR. Хотя в size_t можно помещать указатель, для этих целей лучше подходит другой беззнаковый целочисленный тип uintptr_t, само название которого отражает эту возможность. Типы size_t и uintptr_t являются синонимами.
ptrdiff_t - базовый знаковый целочисленный тип языка Си/Си++. Размер типа выбирается таким образом, чтобы в него можно было записать максимальный размер теоретически возможного массива любого типа. На 32-битной системе ptrdiff_t будет занимать 32 бита, на 64-битной - 64 бита. Как и в size_t в переменную типа ptrdiff_t может быть безопасно помещен указатель, за исключением указателя на функцию класса. Также ptrdiff_t является результатом выражения, где один указатель вычитается из другого (ptr1-ptr2). Тип ptrdiff_t обычно применяется для счетчиков циклов, индексации массивов, хранения размеров, адресной арифметики. Аналогами данному типу являются: SSIZE_T, LPARAM, INT_PTR, LONG_PTR. У типа ptrdiff_t есть синоним intptr_t, название которого лучше отражает, что тип может хранить в себе указатель.
Типы size_t и ptrdiff_t были созданы для того, чтобы осуществлять корректную адресную арифметику. Долгое время было принято считать, что размер int совпадает с размером машинного слова (разрядностью процессора) и его можно использовать в качестве индексов для хранения размеров объектов или указателей. Соответственно адресная арифметика также строилась с использованием типов int и unsigned. Тип int используется в большинстве обучающих материалов по программированию на Си и Си++ в телах циклов и в качестве индексов. Практически каноническим является код:
for (int i = 0; i < n; i++)
a[i] = 0;С развитием процессоров и ростом их разрядности стало нерационально дальнейшее увеличение размерностей типа int. Причин для этого много: экономия используемой памяти, максимальная совместимость и так далее. В результате появилось несколько моделей данных, описывающих соотношение размеров базовых типов языков Си и Си++. Соответственно, не так просто стало выбрать тип переменной для хранения указателя или размера объекта. Чтобы наиболее красиво решить эту проблему , и появились типы size_t и ptrdiff_t. Они гарантированно могут использоваться для адресной арифметики. Теперь каноническим должен стать следующий код:
for (ptrdiff_t i = 0; i < n; i++)
a[i] = 0;Именно он может обеспечить надежность, переносимость, быстродействие. Почему - станет ясно из дальнейших уроков.
Описанные типы size_t и ptrdiff_t можно назвать memsize-типами. Термин "memsize" возник как попытка лаконично назвать все типы, которые способны хранить в себе размер указателей и индексов самых больших массивов. Под memsize-типом следует понимать все простые типы данных языка Си/Си++, которые на 32-битой архитектуре имеют размер 32-бита, а на 64-битной архитектуре - 64-бита. Примеры memsize-типов: size_t, ptrdiff_t, указатели, SIZE_T, LPARAM.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 6. Ошибки в 64-битном коде
Исправление всех ошибок компиляции и предупреждений не будет означать работоспособность 64-битного приложения. И именно: описанию и диагностике 64-битных ошибок будет посвящена основная часть уроков. Также не надейтесь на помощь ключа /Wp64, который многими часто без оснований преподносится при обсуждениях в форумах как чудесное средство поиска 64-битных ошибок.
Ключ /Wp64
Ключ /Wp64 позволяет программисту найти некоторые проблемы, которые могут возникнуть при компиляции кода для 64-битных систем. Проверка заключается в том, что типы, которые отмечены в 32-битном коде ключевым словом __w64, интерпретируются при проверке как 64-битные типы.
Например, пусть мы имеем следующий код:
typedef int MyInt32;
#ifdef _WIN64
typedef __int64 MySSizet;
#else
typedef int MySSizet;
#endif
void foo() {
MyInt32 value32 = 10;
MySSizet size = 20;
value32 = size;
}Выражение "value32 = size;" на 64-битной системе приведет к урезанию значения, а, следовательно, к потенциальной ошибке. Мы хотим это диагностировать. Но при компиляции 32-битного приложения все корректно, и мы не получим предупреждения.
Для того чтобы подготовиться к 64-битным системам, нам следует добавить ключ /Wp64 и вставить ключевое слово __w64 при описании типа MySSizet в 32-битном варианте. В результате код станет выглядеть так:
typedef int MyInt32;
#ifdef _WIN64
typedef __int64 MySSizet;
#else
typedef int __w64 MySSizet; // Add __w64 keyword
#endif
void foo() {
MyInt32 value32 = 10;
MySSizet size = 20;
value32 = size; // C4244 64-bit int assigned to 32-bit int
}Теперь мы получим предупреждение C4244, которое поможет подготовиться к переносу кода на 64-битную платформу.
Обратите внимание, что для 64-битного режима компиляции ключ /Wp64 игнорируется, так как все типы уже имеют необходимый размер, и компилятор произведет необходимые проверки. То есть при компиляции 64-битной версии даже с выключенным ключом /Wp64 мы получим предупреждение C4244.
Таким образом, ключ /Wp64 помогал разработчикам при работе еще с 32-битными приложениями немного подготовиться к 64-битному компилятору. Все предупреждения, которые обнаруживает /Wp64, превратятся при сборке 64-битного кода в ошибки компиляции или также останутся предупреждениями. Но никакой дополнительной помощи в выявлении ошибок ключ /Wp64 не дает.
Кстати, в Visual Studio 2008 ключ /Wp64 считается устаревшим, поскольку уже давно пора компилировать 64-битные приложения, а не продолжать готовиться к этому.
64-битные ошибки
Говоря о 64-битных ошибках, мы будем понимать под ними такие ситуации, когда фрагмент кода, успешно работавший в 32-битном варианте, приводит к возникновению ошибки после компиляции 64-битной версии приложения. Наиболее часто 64-битные ошибки проявляют себя в следующих участках кода:
- код, основанный на некорректных представлениях о размере типов (например, что размер указателя всегда равен 4 байтам);
- код, обрабатывающий большие массивы, размер которых на 64-битных системах превышает 2 гигабайта;
- код записи и чтения данных;
- код с битовыми операциями;
- код со сложной адресной арифметикой;
- старый код;
- и так далее.
В конечном итоге все ошибки в коде, проявляющие себя при компиляции для 64-битных систем, связаны с неточным следованием идеологии стандарта языка Си/Си++. Однако мы считаем нерациональным придерживаться позиции "пишите корректные программы, и тогда в них не будет 64-битных ошибок". С этим нельзя поспорить, но и пользы от такой рекомендации для реальных проектов мало. В мире накоплено огромное количество кода, который писался десятилетиями на языке Си/Си++. Задача этих уроков- сформулировать все 64-битные ошибки в виде набора паттернов, которые помогут выявить дефекты и дать рекомендации по их устранению.
Примеры 64-битных ошибок
О 64-битных ошибках еще будет сказано очень много. Но приведем 2 примера, чтобы стало более понятно, что могут представлять собой эти ошибки.
Пример использования магической константы 4, которая служит размером указателя, что некорректно для 64-битного кода. Обратите внимание, данный код, успешно функционировавший в 32-битном варианте, не диагностируется компилятором как опасный.
size_t pointersCount = 100;
int **arrayOfPointers = (int **)malloc(pointersCount * 4);Следующий пример демонстрирует ошибку в механизме чтения данных. Данный код корректно работает в 32-битном режиме и не обнаруживается компилятором. Однако такой код некорректно прочитает данные сохраненные 32-битной версией программы.
size_t PixelCount;
fread(&PixelCount, sizeof(PixelCount), 1, inFile);Комментарий искушенным программистам
Хочется заранее сделать комментарий о паттернах 64-битных ошибок и их примерах, которым будет уделено большое количество уроков. Нам часто возражают, что это на самом деле не ошибки 64-битности, а ошибки недостаточно корректно и недостаточно переносимо написанного кода. И что многие ошибки можно обнаружить не только при переходе на 64-битную архитектуру, но и просто на архитектуру с иными размерами базовых типов.
Да, это именно так! Мы помним про это. Но мы не ставим целью рассматривать переносимость кода вообще. В этих уроках мы хотим решить конкретную частную задачу, а именно: помочь разработчикам в освоении 64-битных платформ, которые получают все большее распространение.
Говоря о паттернах 64-битных ошибках, мы будем рассматривать примеры кода, который корректно функционирует на 32-битных системах, но может приводить к сбою при его переносе на 64-битную архитектуру.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 7. Проблемы выявления 64-битных ошибок
- Обзор кода
- Статический анализ кода
- Метод белого ящика
- Метод черного ящика (юнит-тесты)
- Ручное тестирование
Существуют различные подходы к выявлению ошибок в программном коде. Рассмотрим основные методологии и их эффективность в выявлении 64-битных ошибок.
Обзор кода
Самым старым, проверенным и надежным подходом к поиску дефектов является совместный обзор кода (англ. code review). Эта методика основана на совместном чтении кода с выполнением ряда правил и рекомендаций, хорошо описанных в книге Стива Макконнелла "Совершенный код". К сожалению, эта практика неприменима для крупномасштабной проверки современных программных систем в силу их большого объема.
Обзор кода в данном случае скорее можно рассматривать как хороший способ обучения и защиты от 64-битных ошибок в новом разрабатываемом коде. Для выявления же уже имеющихся ошибок данный способ неприемлем из-за его стоимости. Вам придется совместно внимательно прочитать весь код программного проекта, чтобы обнаружить все 64-битные ошибки.
Статический анализ кода
На помощь разработчикам, которые осознают необходимость регулярного просмотра кода, но не имеют достаточного количества времени, приходят средства статического анализа кода. Их основной задачей является сокращение объема кода, требующего внимания человека, и тем самым сокращение времени его просмотра. К статическим анализаторам кода относится достаточно большой класс программ, реализованных для различных языков программирования и имеющих разнообразный набор функций, от простейшего контроля выравнивания кода до сложного анализа потенциально опасных мест. Преимуществом статического анализа является его хорошая масштабируемость. С его помощью можно в разумные сроки проанализировать проект любого объема. А систематическое использование анализаторов позволяет выявлять многие ошибки еще на этапе написания кода.
Метод статического анализа является наиболее оптимальным решением для выявления 64-битных ошибок. В дальнейшем, рассматривая паттерны 64-битных ошибок, мы будем показывать, как данные ошибки можно диагностировать, используя статический анализатор Viva64, входящий в состав PVS-Studio. В следующем уроке вы также подробнее познакомитесь с методологией статического анализа и инструментом PVS-Studio.
Метод белого ящика
Под тестированием методом белого ящика будем понимать выполнение максимально доступного количества различных веток кода с использованием отладчика или иных средств. Чем большее покрытие кода было достигнуто, тем более полно выполнено тестирование. Под тестированием по методу белого ящика также иногда понимают простую отладку приложения с целью поиска известной ошибки. Полноценное тестирование методом белого ящика всего кода программ уже давно стало невозможным в силу огромного размера современных программ. Сейчас тестирование по методу белого ящика удобно применять на этапе, когда ошибка найдена, и необходимо понять причину ее возникновения. У тестирования методом белого ящика существуют оппоненты, отрицающие полезность отладки программ в реальном времени. Основной мотив заключается в том, что возможность наблюдать ход работы программы и при этом вносить изменения в ее состояние порождает недопустимый подход в программировании, основанный на большом количестве исправлений кода методом проб и ошибок. Мы не будем касаться данных споров, но заметим, что тестирование по методу белого ящика в любом случае очень дорогой способ повышения качества больших программных систем.
Читателю должно быть очевидно, что полная отладка приложения для выявления 64-битных ошибок также нереальна, как и полный обзор программного кода.
Дополнительно стоит заметить, что при отладке 64-битных приложений, обрабатывающих большие массивы данных, способ пошаговой отладки может стать неприменимым. Отладка таких приложений может занимать намного больше времени. Стоит заранее обдумать возможность использования систем протоколирования ("логирования") для отладки приложений или предусмотреть иные методы.
Метод черного ящика (юнит-тесты)
Намного лучше себя зарекомендовал метод черного ящика. К этому типу тестирования можно отнести юнит-тестирование (unit tests). Основная идея метода заключается в написании набора тестов для отдельных модулей и функций, проверяющего все основные режимы их работы. Ряд источников относят юнит-тестирование к методу белого ящика, поскольку оно основывается на знании устройства программы. Мы придерживаемся позиции, что тестируемые функции и модули следует рассматривать как черные ящики, так как юнит-тесты не должны учитывать внутреннее устройство функции. Обоснованием этому может служить такая методология, когда тесты разрабатываются до начала написания самих функций, что способствует повышению контроля их функциональности с точки зрения спецификации.
Юнит-тестирование хорошо зарекомендовало себя как при разработке простых, так и сложных проектов. Одним из преимуществ юнит-тестирования является то, что легко можно проверить корректность вносимых в программу исправлений прямо в ходе разработки. Стараются делать так, чтобы все тесты проходили в течение нескольких минут, что позволяет разработчику, который внес изменения в код, сразу заметить ошибку и исправить ее. Если прогон всех тестов невозможен, то обычно длительные тесты выносят отдельно и запускают, например, ночью. Это также способствует оперативному обнаружению ошибок, по крайней мере, на следующее утро.
C использованием юнит-тестов для поиска 64-битных ошибок связан ряд неприятных моментов. Стремясь сократить время выполнения тестов, при их разработке стараются использовать небольшой объем вычислений и объем обрабатываемых данных. Например, разрабатывая тест на функцию поиска элемента в массиве, не имеет большого значения, будет она обрабатывать 100 элементов или 10 000 000. Сотни элементов будет достаточно, а вот по сравнению с обработкой 10 000 000 элементов скорость выполнения теста может быть существенно выше. Но если вы хотите разработать полноценные тесты, чтобы проверить эту функцию на 64-битной системе, вам потребуется обработать более 4 миллиардов элементов! Вам кажется, что, если функция работает на 100 элементах, она будет работать и на миллиардах? Нет. Приведем пример.
bool FooFind(char *Array, char Value,
size_t Size)
{
for (unsigned i = 0; i != Size; ++i)
if (i % 5 == 0 && Array[i] == Value)
return true;
return false;
}
#ifdef _WIN64
const size_t BufSize = 5368709120ui64;
#else
const size_t BufSize = 5242880;
#endif
int _tmain(int, _TCHAR *) {
char *Array =
(char *)calloc(BufSize, sizeof(char));
if (Array == NULL)
std::cout << "Error allocate memory" << std::endl;
if (FooFind(Array, 33, BufSize))
std::cout << "Find" << std::endl;
free(Array);
}Ошибка кроется в использовании типа unsigned для счетчика. В результате на 64-битной системе при обработке большого массива происходит переполнение счетчика и возникает вечный цикл.
Примечание. Есть вероятность, что при определенных настройках компилятора данный пример не продемонстрирует ошибку. Чтобы понять это странное событие, предлагаем ознакомиться со статьей "64-битный конь, который умеет считать".
Как видно из примера, если ваша программа на 64-битной системе начнет обрабатывать больший объем данных, то не стоит рассчитывать на старые наборы юнит-тестов. Следует их обязательно расширить с учетом обработки больших объемов данных.
К сожалению, написать новые тесты недостаточно. Здесь мы сталкиваемся с проблемой скорости выполнения модифицированного набора тестов, охватывающего обработку больших объемов данных. Первым следствием станет то, что такие тесты нельзя будет добавить в набор тестов, запускаемых разработчиком в ходе разработки. С внесением их в ночные тесты тоже могут возникнуть сложности. Суммарное время выполнения всех тестов может вырасти на порядок или два, а то и более. В результате время выполнения теста может превысить 24 часа. Следует помнить об этом и подойти к доработке тестов для 64-битной версии программы со всей серьезностью.
Ручное тестирование
Это, пожалуй, завершающий этап любой разработки, но его не следует рассматривать как хорошую и надежную методику. Ручное тестирование обязательно должно существовать, так как невозможно обнаружить все ошибки в автоматическом режиме или просмотром кода. Но и рассчитывать на этот метод особенно не стоит. Если программа имеет низкое качество и большое количество внутренних дефектов, ее тестирование и исправление может затянуться на очень продолжительное время, и все равно при этом не будет достигнуто надлежащее качество. Единственный метод получения качественной программы - это качественный код. Поэтому мы не будем рассматривать ручное тестирование как полноценную методику выявления 64-битных ошибок.
Подводя итоги, хочется сказать, что не стоит полагаться на отдельную методику. Хотя статический анализ является наиболее эффективным методом выявления 64-битных ошибок, качественное приложение может быть разработано только с применением нескольких методологий тестирования.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 8. Статический анализ для выявления 64-битных ошибок
- Статический анализ кода
- Статический анализ для выявления 64-битных ошибок
- Анализатор Viva64, входящий в состав PVS-Studio
Статический анализ кода
Статический анализ кода - методология выявления ошибок в программном коде, основанная на просмотре программистом участков кода, помеченных статическим анализатором. Помеченные участки кода с большой вероятностью содержат ошибки определенного типа.
Другими словами, инструмент для статического анализа определяет в тексте программы места, содержащие ошибки, предрасположенные к ошибкам или имеющие плохое форматирование. Такие участки кода предоставляются программисту для изучения, и он может принять решение о модификации данного участка программы.
Статические анализаторы могут быть как общего назначения (например, Microsoft PREFast, Gimpel Software PC-lint, Parasoft C++test), так и специализированными для поиска определенных классов ошибок (например, Chord для верификации параллельных Java программ). Обычно инструменты статического анализа достаточно дороги, требуют знаний о методологии их использования, часто имеют достаточно гибкие, но сложные подсистемы настройки и подавления ложных сообщений. По этой причине статические анализаторы, как правило, используются в компаниях со зрелыми процессами разработки программного обеспечения. Взамен на сложность в использовании статические анализаторы кода позволяют выявить большое количество ошибок на самых ранних этапах разработки программного кода. Дополнительно использование методологии статического анализа дисциплинирует программистов и помогает контролировать работу молодых сотрудников.
Основное преимущество использования статических анализаторов кода состоит в возможности существенного снижения стоимости устранения дефектов в программе. Чем раньше ошибка выявлена, тем меньше стоимость ее исправления. Так, согласно данным, приведенным в книге Макконнелла "Совершенный Код", исправление ошибки на этапе тестирования обойдется в десять раз дороже, чем на этапе конструирования (кодирования):
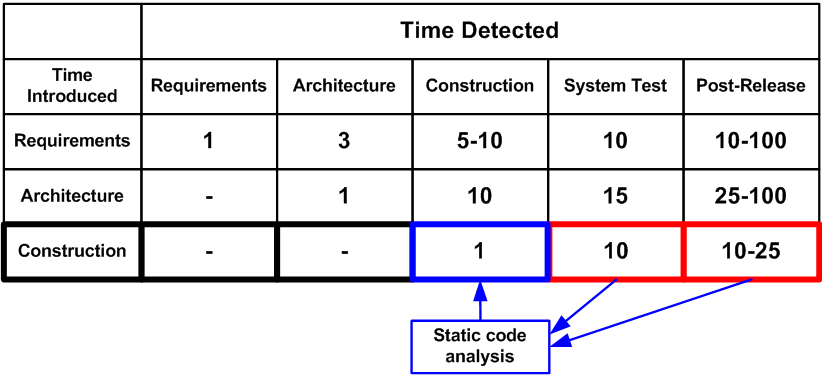
Рисунок 1 - Средняя стоимость исправления дефектов в зависимости от времени их внесения и обнаружения (данные для таблицы взяты из книги С. Макконнелла 'Совершенный Код')
Инструменты статического анализа, выявляя большое количество ошибок на этапе конструирования, существенно снижают стоимость разработки всего проекта.
Статический анализ для выявления 64-битных ошибок
Перечислим преимущества применения статического анализа кода, которые делают этот метод наиболее оптимальным для выявления ошибок в 64-битном коде:
- Возможность проверить ВЕСЬ код. Анализатор проверит даже тот код, который получает управление в самых редких случаях. Другими словами, у инструментов статического анализа покрытие кода практически полное. Это позволяет быть уверенным при переходе на 64-битную систему, что проверен весь код.
- Масштабируемость. Статический анализ позволяет одинаково просто осуществить как анализ маленького, так и большого проекта. Трудоемкость анализа проекта растет линейно с его размером. При этом работу по анализу проекта можно легко распараллелить между несколькими разработчиками. Достаточно только распределить части проекта между программистами.
- Разработчик, приступая к работе, даже не зная всех тонкостей 64-битного кода, все равно не пройдет мимо потенциальных проблем. Анализатор укажет опасные места, а справочная система снабдит его всей необходимой информацией.
- Снижение затрат за счет ранней диагностики ошибок.
- Возможность эффективно использовать инструменты статического анализа как при переносе кода на 64-битную систему, так и при разработке нового 64-битного кода.
Анализатор Viva64, входящий в состав PVS-Studio
PVS-Studio представляет собой комплект статических анализаторов кода для проверки современных и ресурсоемких приложений. В состав PVS-Studio входит статический анализатор Viva64, предназначенный для диагностики 64-битных ошибок.
Анализатор PVS-Studio предназначен для работы на Windows-платформе. При этом он интегрируется в среду разработки Microsoft Visual Studio 2005/2008/2010 (смотри рисунок 2). Интерфейс PVS-Studio позволяет фильтровать диагностические сообщения несколькими методами, сохранять и загружать список предупреждений.
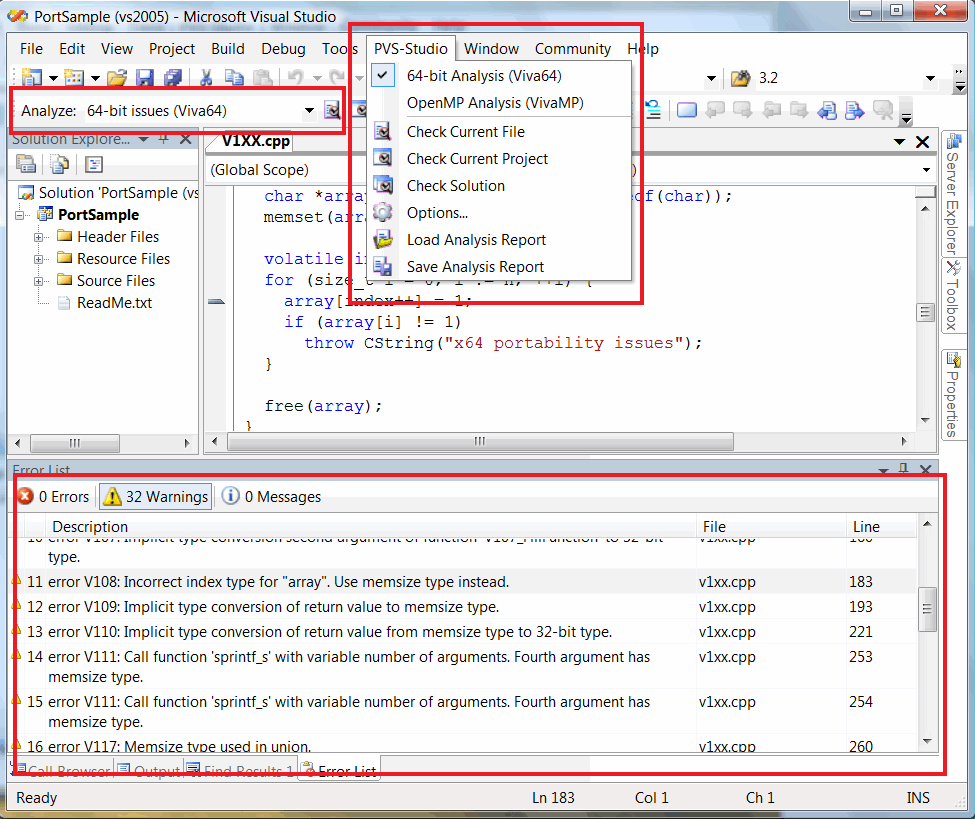
Рисунок 2 - Интеграция PVS-Studio в Microsoft Visual Studio
Системные требования к анализатору совпадают с требованиями к Microsoft Visual Studio:
- Операционная система: Windows 7/Vista/XP/2008/2003 x86 или x64. Внимание, для анализа 64-битных приложений операционная система не обязательно должна быть 64-битной.
- Среда разработки: Microsoft Visual Studio 2005/2008/2010 (Standard Edition, Professional Edition, Team Systems). Для анализа 64-битных приложений необходимо иметь установленный компонент Visual Studio под названием "X64 Compilers and Tools". Он входит во все перечисленные версии Visual Studio и может быть установлен через Visual Studio Setup. Обратите внимание, что работа PVS-Studio с Visual C++ Express Edition невозможна, поскольку эта система не поддерживает модули расширения.
- Аппаратная часть: PVS-Studio работает на системах с не менее, чем 1 гигабайтом оперативной памяти (рекомендуется 2 гигабайта и более); анализатор поддерживает работу на нескольких ядрах (чем больше ядер, тем быстрее выполняется анализ кода).
Все диагностируемые ошибки подробно описаны в справочной системе, которая доступна после установки PVS-Studio. Также справочная система по PVS-Studio доступна на нашем сайте в режиме online.
В дистрибутиве вместе с PVS-Studio поставляются специальные проекты-примеры дефектов кода, на которых можно изучить работу анализатора.
Для более полного ознакомления с PVS-Studio вы можете скачать демонстрационную версию. Демонстрационная версия имеет следующие ограничения:
- доступна для использования в течение 30 дней;
- ознакомительная версия показывает номера строк не всех дефектов с ошибками, а только некоторых из них (хотя обнаруживает все). Но для демонстрационных проектов, включенных в состав PVS-Studio, сделано исключение: для них отображаются номера строк для всех дефектов.
На данный момент анализатор PVS-Studio реализует самую полную диагностику 64-битных ошибок. Сравнительные характеристики представлены в статье "Сравнение PVS-Studio с другими анализаторами кода".
В последующих уроках, рассматривая различные паттерны ошибок, мы будем неоднократно ссылаться на PVS-Studio, чтобы продемонстрировать способы их обнаружения.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 9. Паттерн 1. Магические числа
В некачественном коде часто встречаются магические числовые константы, наличие которых опасно само по себе. При миграции кода на 64-битную платформу эти константы могут сделать код неработоспособным, если участвуют в операциях вычисления адреса, размера объектов или в битовых операциях.
В таблице 1 перечислены основные магические константы, которые могут влиять на работоспособность приложения на новой платформе.

Таблица 1 - Основные магические значения, опасные при переносе приложений с 32-битной на 64-битную платформу
Следует внимательно изучить код на предмет наличия магических констант и заменить их безопасными константами и выражениями. Для этого можно использовать оператор sizeof(), специальные значения из <limits.h>, <inttypes.h> и так далее.
Приведем несколько ошибок, связанных с использованием магических констант. Самой распространенной является запись в виде числовых значений размеров типов:
1) size_t ArraySize = N * 4;
intptr_t *Array = (intptr_t *)malloc(ArraySize);
2) size_t values[ARRAY_SIZE];
memset(values, 0, ARRAY_SIZE * 4);
3) size_t n, r;
n = n >> (32 - r);Во всех случаях предполагаем, что размер используемых типов всегда равен 4 байтам. Исправление кода заключается в использовании оператора sizeof():
1) size_t ArraySize = N * sizeof(intptr_t);
intptr_t *Array = (intptr_t *)malloc(ArraySize);
2) size_t values[ARRAY_SIZE];
memset(values, 0, ARRAY_SIZE * sizeof(size_t));или
memset(values, 0, sizeof(values)); //preferred alternative
3) size_t n, r;
n = n >> (CHAR_BIT * sizeof(n) - r);Иногда может потребоваться специфическая константа. В качестве примера мы возьмем значение size_t, где все биты, кроме 4 младших, должны быть заполнены единицами. В 32-битной программе эта константа может быть объявлена следующим образом:
// constant '1111..110000'
const size_t M = 0xFFFFFFF0u;Это некорректный код в случае 64-битной системы. Такие ошибки очень неприятны, так как запись магических констант может быть осуществлена различными способами и их поиск достаточно трудоемок. К сожалению, нет никаких других путей, кроме как найти и исправить этот код, используя директиву #ifdef или специальный макрос.
#ifdef _WIN64
#define CONST3264(a) (a##i64)
#else
#define CONST3264(a) (a)
#endif
const size_t M = ~CONST3264(0xFu);Иногда в качестве кода ошибки или другого специального маркера используют значение "-1", записывая его как "0xffffffff". На 64-битной платформе записанное выражение некорректно, и следует явно использовать значение -1. Пример некорректного кода, использующего значение 0xffffffff, как признак ошибки:
#define INVALID_RESULT (0xFFFFFFFFu)
size_t MyStrLen(const char *str) {
if (str == NULL)
return INVALID_RESULT;
...
return n;
}
size_t len = MyStrLen(str);
if (len == (size_t)(-1))
ShowError();На всякий случай уточним, чему равно значение "(size_t)(-1)" на 64-битной платформе. Можно ошибиться, назвав значение 0x00000000FFFFFFFFu. Согласно правилам языка Си++, сначала значение -1 преобразуется в знаковый эквивалент большего типа, а затем в беззнаковое значение:
int a = -1; // 0xFFFFFFFFi32
ptrdiff_t b = a; // 0xFFFFFFFFFFFFFFFFi64
size_t c = size_t(b); // 0xFFFFFFFFFFFFFFFFui64Таким образом, "(size_t)(-1)" на 64-битной архитектуре представляется значением 0xFFFFFFFFFFFFFFFFui64, которое является максимальным значением для 64-битного типа size_t.
Вернемся к ошибке с INVALID_RESULT. Использование константы 0xFFFFFFFFu приводит к невыполнению условия "len == (size_t)(-1)" в 64-битной программе. Наилучшее решение заключается в изменении кода так, чтобы специальных маркерных значений не требовалось. Если по какой-то причине Вы не можете от них отказаться или считаете нецелесообразным существенные правки кода, то просто используйте честное значение -1.
#define INVALID_RESULT (size_t(-1))
...Приведем еще один пример, связанный с использованием 0xFFFFFFFF. Код взят из реального приложения для трёхмерного моделирования:
hFileMapping = CreateFileMapping (
(HANDLE) 0xFFFFFFFF,
NULL,
PAGE_READWRITE,
(DWORD) 0,
(DWORD) (szBufIm),
(LPCTSTR) &FileShareNameMap[0]);Как вы уже правильно догадались, 0xFFFFFFFF здесь также приведет к ошибке на 64-битной системе. Первый аргумент функции CreateFileMapping может иметь значение INVALID_HANDLE_VALUE, объявленное следующим образом:
#define INVALID_HANDLE_VALUE ((HANDLE)(LONG_PTR)-1)
В результате INVALID_HANDLE_VALUE действительно совпадает в 32-битной системе со значением 0xFFFFFFFF. А вот в 64-битной системе в функцию CreateFileMapping будет передано значение 0x00000000FFFFFFFF, в результате чего система посчитает аргумент некорректным и вернет код ошибки. Причина в том, что значение 0xFFFFFFFF имеет БЕЗЗНАКОВЫЙ тип (unsigned int). Значение 0xFFFFFFFF не помещается в тип int и поэтому является типом unsigned. Это тонкий момент, на который следует обратить внимание при переходе на 64-битные системы. Поясним его на примере:
void foo(void *ptr)
{
cout << ptr << endl;
}
int _tmain(int, _TCHAR *[])
{
cout << "-1\t\t";
foo((void *)-1);
cout << "0xFFFFFFFF\t";
foo((void *)0xFFFFFFFF);
}Результат работы 32-битного варианта программы:
-1 FFFFFFFF
0xFFFFFFFF FFFFFFFFРезультат работы 64-битного варианта программы:
-1 FFFFFFFFFFFFFFFF
0xFFFFFFFF 00000000FFFFFFFFДиагностика
Статический анализатор PVS-Studio предупреждает о наличии в коде магических констант, имеющих наибольшую опасность при создании 64-битного приложения. Для этого используются диагностические сообщения V112 и V118. Учтите: анализатор сознательно не предупреждает о потенциальной ошибке, если магическая константа определена через макрос. Пример:
#define MB_YESNO 0x00000004L
MessageBox("Are you sure ?", "Question", MB_YESNO);Если совсем кратко, то причина такого поведения - защита от огромного количества ложных срабатываний. При этом считается, что если программист задает константу через макрос, то он делает это специально, чтобы подчеркнуть ее безопасность. Подробнее с данным вопросом можно познакомиться в записи блога на нашем сайте "Магические константы и функция malloc()".
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 10. Паттерн 2. Функции с переменным количеством аргументов
Классическими примерами, приводимыми во многих статьях по проблемам переноса программ на 64-битные системы, является некорректное использование функций printf, scanf и их разновидностей.
Пример 1:
const char *invalidFormat = "%u";
size_t value = SIZE_MAX;
printf(invalidFormat, value);Пример 2:
char buf[9];
sprintf(buf, "%p", pointer);В первом случае не учитывается, что тип size_t не эквивалентен типу unsigned на 64-битной платформе. Это приведет к выводу на печать некорректного результата в случае, если value > UINT_MAX.
Во втором случае автор кода не учел, что размер указателя в будущем может составить более 32 бит. В результате на 64-битной архитектуре данный код приведет к переполнению буфера.
Некорректное использование функций с перемененным количеством параметров является распространенной ошибкой на всех архитектурах, а не только 64-битных. Это связано с принципиальной опасностью использования данных конструкций языка Си++. Общепринятой практикой является отказ от них и использование безопасных методик программирования. Мы настоятельно рекомендуем модифицировать код и использовать безопасные методы. Например, можно заменить printf на cout, а sprintf на boost::format или std::stringstream.
Данную рекомендацию часто критикуют разработчики под Linux, аргументируя тем, что gcc проверяет соответствие строки форматирования фактическим параметрам, передаваемым в функцию printf. Однако они забывают, что строка форматирования может передаваться из другой части программы, загружаться из ресурсов. Другими словами, в реальной программе строка форматирования редко присутствует в явном виде в коде, и, соответственно, компилятор не может ее проверить. Если же разработчик использует Visual Studio 2005/2008, то он не сможет получить предупреждение на код вида "void *p = 0; printf("%x", p);", даже используя ключи /W4 и /Wall.
Для работы с memsize-типами в функциях вида sscanf, printf имеются спецификаторы размера. Если вы разрабатываете Windows-приложение, то вы можете использовать спецификатор размера "I". Пример использования:
size_t s = 1;
printf("%Iu", s);Если вы разрабатываете приложение под Linux, то вам будет доступен спецификатор размера "z". Пример использования:
size_t s = 1;
printf("%zu", s);Спецификаторы хорошо описаны в статье Wikipedia "printf".
Если вы вынуждены поддерживать переносимый код, использующий функции типа sscanf, то в формате управляющих строк можно использовать специальные макросы, раскрывающиеся в необходимые спецификаторы размера. Пример макроса, помогающего создавать переносимый код для разных систем:
// PR_SIZET on Win64 = "I"
// PR_SIZET on Win32 = ""
// PR_SIZET on Linux64 = "z"
// ...
size_t u;
scanf("%" PR_SIZET "u", &u);Рассмотрим еще один пример. Хотя этот пример выглядит наиболее странно, код, который приведен здесь в упрощенном виде, использовался в реальном приложении в подсистеме UNDO/REDO:
// Здесь указатели сохранялись в виде строки
int *p1, *p2;
....
char str[128];
sprintf(str, "%X %X", p1, p2);
// А в другой функции данная строка
// обрабатывалась следующим образом:
void foo(char *str)
{
int *p1, *p2;
sscanf(str, "%X %X", &p1, &p2);
// Результат - некорректное значение указателей p1 и p2.
...
}Результатом манипуляций указателями с использованием %X стало некорректное поведение программы на 64-битной системе. Данный пример показывает, как опасны потаенные дебри больших и сложных проектов, которые пишутся многими годами. Если проект достаточно велик и стар, то в нем можно встретить очень интересные фрагменты, подобные этому.
Диагностика
Опасность для функций с переменным количеством аргументов представляют типы, меняющие свой размер на 64-битной системе, то есть memsize типы. Статический анализатор PVS-Studio предупреждает об использовании таких типов диагностическим сообщением V111.
Если типы аргументов не изменили своей разрядности, то код считается корректным и предупреждающих сообщений выдано не будет. Пример корректного кода с точки зрения анализатора:
printf("%d", 10*5);
CString str;
size_t n = sizeof(float);
str.Format(StrFormat, static_cast<int>(n));Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 11. Паттерн 3. Операции сдвига
Легко сделать ошибку в коде, работающем с отдельными битами. Рассматриваемый паттерн 64-битных ошибок связан с операциями сдвига. Пример кода:
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum;
return value | mask;
}Приведенный код работоспособен на 32-битной архитектуре и позволяет выставлять бит с номерами от 0 до 31 в единицу. После переноса программы на 64-битную платформу возникнет необходимость выставлять биты от 0 до 63. Но данный код никогда не выставит биты с номерами 32-63. Обратите внимание, что числовой литерал "1" имеет тип int, и при сдвиге на 32 позиции произойдет переполнение, как показано на рисунке 1. Получим мы в результате 0 (рисунок 1-B) или 1 (рисунок 1-C) - зависит от реализации компилятора.

Рисунок 1 - a) корректная установка 31-ого бита в 32-битном коде; b,c) - Ошибка установки 32-ого бита на 64-битной системе (два варианта поведения)
Для исправления кода необходимо сделать константу "1" того же типа, что и переменная mask:
ptrdiff_t mask = ptrdiff_t(1) << bitNum;Заметим также, что неисправленный код приведет еще к одной интересной ошибке. При выставлении 31 бита на 64-битной системе результатом работы функции будет значение 0xffffffff80000000 (см. рисунок 2). Результатом выражения 1 << 31 является отрицательное число -2147483648. Это число представляется в 64-битной целой переменной как 0xffffffff80000000.

Рисунок 2 - Ошибка установки 31-ого бита на 64-битной системе.
Следует помнить и учитывать эффекты сдвига значений различных типов. Для лучшего понимания и наглядности изложенной информации в таблице 1 приведен ряд интересных выражений со сдвигами в 64-битной системе.
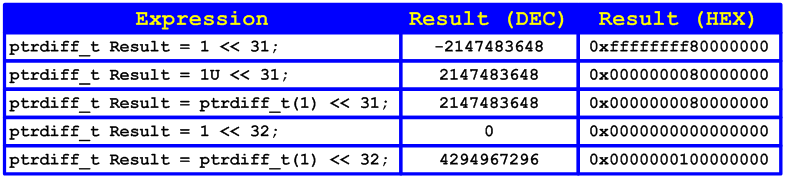
Таблица 1 - Выражения со сдвигами и результаты в 64-битной системе (использовался компилятор Visual C++ 2005)
Описанный вид ошибок можно считать опасным не только с точки зрения корректности работы программы, но и с точки зрения безопасности. Потенциально манипулируя с входными данными подобных некорректных функций, можно получить недопустимо высокие права, если, например, происходит обработка масок прав доступа, заданных отдельными битами. Вопросы, связанные с использованием ошибок в 64-битном коде для взлома и компрометации приложений, затронуты нами в статье "Безопасность 64-битного кода".
Рассмотрим теперь более тонкий пример:
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
BitFieldStruct obj;
obj.a = 0x4000;
size_t addr = obj.a << 17; //Sign Extension
printf("addr 0x%Ix\n", addr);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0xffffffff80000000В 32-битной среде порядок вычисления выражения будет выглядеть, как показано на рисунке 3.
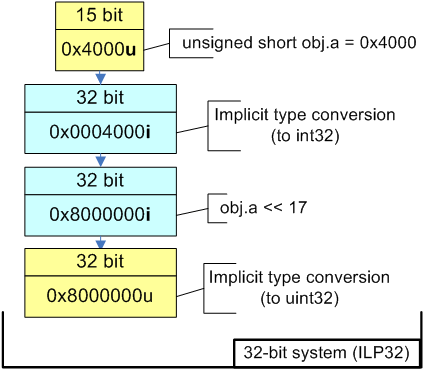
Рисунок 3 - Вычисление выражения в 32-битном коде
Обратим внимание, что при вычислении выражения "obj.a << 17" происходит знаковое расширение типа unsigned short до типа int. Более наглядно это может продемонстрировать следующий код:
#include <stdio.h>
template <typename T> void PrintType(T)
{
printf("type is %s %d-bit\n",
(T)-1 < 0 ? "signed" : "unsigned", sizeof(T)*8);
}
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
int main(void)
{
BitFieldStruct bf;
PrintType( bf.a );
PrintType( bf.a << 2);
return 0;
}
Result:
type is unsigned 16-bit
type is signed 32-bitТеперь посмотрим, к чему приводит наличие знакового расширения в 64-битном коде. Последовательность вычисления выражения показана на рисунке 4.
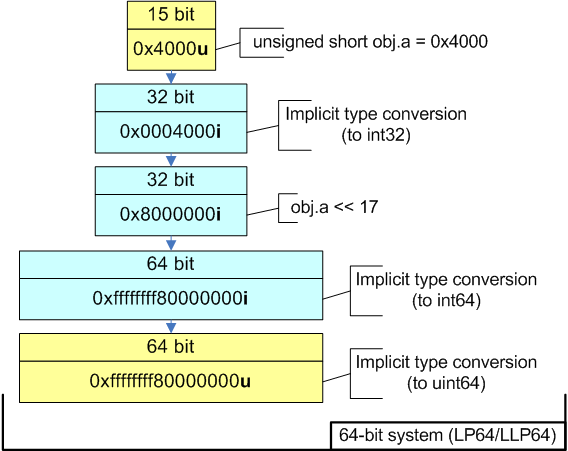
Рисунок 4 - Вычисление выражения в 64-битном коде.
Член структуры obj.a преобразуется из битового поля типа unsigned short в int. Выражение "obj.a << 17" имеет тип int, но оно преобразуется в ptrdiff_t и затем в size_t перед тем, как будет присвоено переменной addr. В результате мы получим значение 0xffffffff80000000, вместо ожидаемого 0x0000000080000000.
Будьте внимательны при работе с битовыми полями. Для предотвращения описанной ситуации в нашем примере достаточно явно привести obj.a к типу size_t.
...
size_t addr = size_t(obj.a) << 17;
printf("addr 0x%Ix\n", addr);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0x80000000Диагностика
Потенциально опасные сдвиги будут выявлены статическим анализатором PVS-Studio, когда он обнаружит неявное расширение 32-битного типа до memsize типа. Анализатор предупредит об опасной конструкции диагностическим сообщением V101. При этом сама по себе операция сдвига подозрения не вызывает. Но анализатор обнаруживает неявное расширение типа int до типа memsize при присваивании и информирует об этом программиста, который может обнаружить ошибку в коде. Соответственно, если расширения нет, то код считается анализатором безопасным. Пример: "int mask = 1 << bitNum;".
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 12. Паттерн 4. Виртуальные функции
Бывают ошибки, в которых, в общем-то, никто не виноват, но они от этого не перестают быть ошибками. Представьте, что давным-давно (в Visual Studio 6.0) был разработан проект, в котором присутствует класс CSampleApp, являющийся наследником от CWinApp. В базовом классе есть виртуальная функция WinHelp. Наследник перекрывает эту функцию и выполняет необходимые действия. Визуально это представлено на рисунке 1.
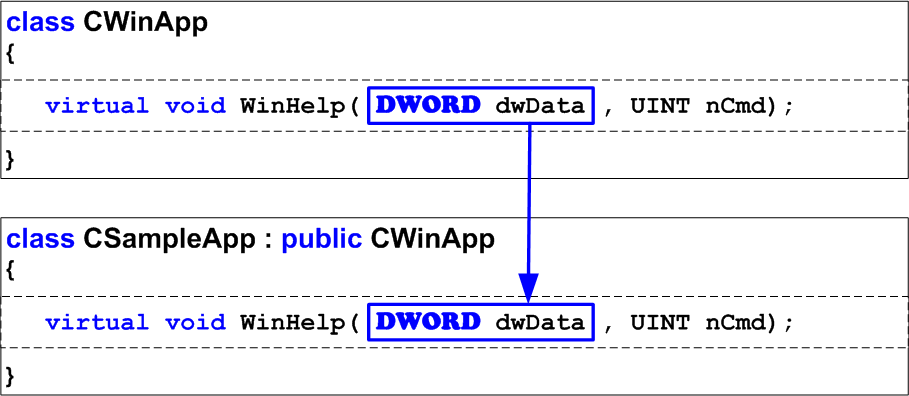
Рисунок 1 - Работоспособный корректный код, который создан в Visual Studio 6.0
Затем проект переносится на Visual Studio 2005, где прототип функции WinHelp изменился, но этого никто не замечает, так как в 32-битном режиме типы DWORD и DWORD_PTR совпадают и программа продолжает корректно работать (рисунок 2).
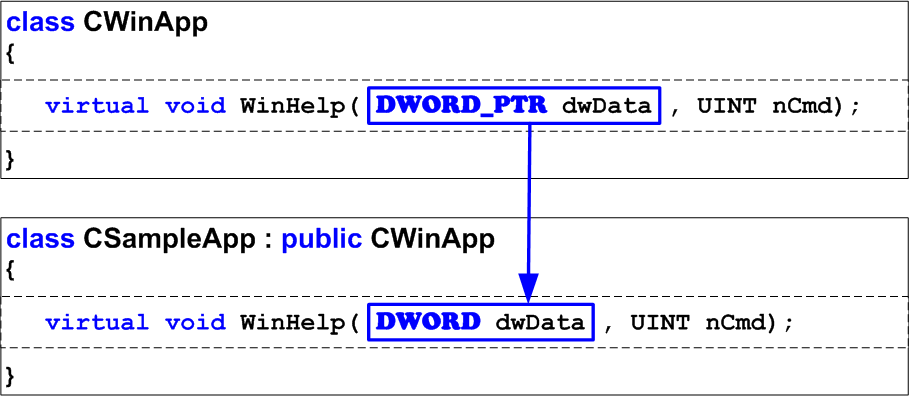
Рисунок 2 - Не корректный, но работоспособный 32-битный код
Ошибка ждет, чтобы проявить себя в 64-битной системе, где размер типов DWORD и DWORD_PTR различен (рисунок 3). Получается, что в 64-битном режиме классы содержат две РАЗНЫЕ функции WinHelp, что естественно некорректно. Учтите, что подобные ловушки могут скрываться не только в MFC, где часть функций изменили типы своих аргументов, но и в коде ваших приложений и сторонних библиотек.
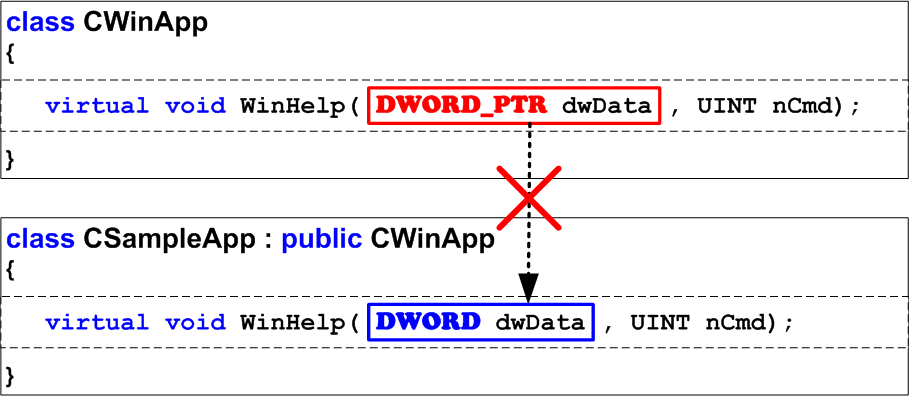
Рисунок 3 - Ошибка проявляет себя в 64-битном коде
Рассмотрим данную ошибку на реальном примере. Есть прекрасная библиотека компонентов BCGControlBar. Наверняка вы про нее слышали, поскольку компоненты компании BCGSoft Ltd включены в Microsoft Visual Studio 2008 Feature Pack. Так вот, если скачать ознакомительную версию этой библиотеки, установить ее и выполнить поиск слова "WinHelp" по .h-файлам... то мы увидим, что везде, где якобы перекрыта эта функция, используется параметр DWORD, вместо DWORD_PTR. А это означает, что справка в 64-битной системе в этих классах будет вести себя некорректно.
Почему подобная ошибка может до сих пор быть в коде такой известной библиотеки? Мы думаем, дело в том, что клиентам компании доступны исходные коды этой библиотеки и клиенты всегда могут поправить эти коды. Кроме того, в настоящее время функция WinHelp используется очень редко. Намного чаще используется HtmlHelp. А она-то в BCGControlBar имеет правильный параметр DWORD_PTR. Однако факт остается фактом. Ошибка есть в реальном коде и компилятор ее не обнаружит. Причем такие ошибки могут оставаться не выявленными годами.
Примечание. Статья писалась в октябре 2009 года, и, скорее всего, в следующих версиях эта ошибка будет исправлена, тем более что мы сообщили о ней разработчикам библиотеки.
Диагностика
Ошибки, связанные с виртуальными функциями в 64-битном коде, могут быть обнаружены статическим анализатором PVS-Studio. Анализатор предупредит об опасных виртуальных функциях диагностическим сообщением V301.
Виртуальная функция считается опасной, если:
- Функция объявлена в базовом классе и в классе-потомке.
- Типы аргументов функций не совпадают, но эквивалентны на 32-битной системе (например: unsigned, size_t) и не эквивалентны на 64-битной.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 13. Паттерн 5. Адресная арифметика
Мы специально выбрали номер "тринадцать" для этого урока, поскольку ошибки, связанные с адресной арифметикой в 64-битных системах, являются наиболее коварными. Надеемся, число 13 заставит вас быть внимательнее.
Суть паттерна: чтобы избежать ошибок в 64-битном коде используйте для адресной арифметики только memsize-типы.
Рассмотрим код:
unsigned short a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;Данный пример корректно работает с указателями, если значение выражения "a16 * b16 * c16" не превышает INT_MAX (2147483647). Такой код мог всегда корректно работать на 32-битной платформе. В рамках 32-битной архитектуры программе недоступен объем памяти для создания массива подобного размеров. На 64-битной архитектуре это ограничение снято, и размер массива легко может превысить INT_MAX элементов. Допустим, мы хотим сдвинуть значение указателя на 6.000.000.000 байт, и поэтому переменные a16, b16 и c16 имеют значения 3000, 2000 и 1000 соответственно. При вычислении выражения "a16 * b16 * c16" все переменные, согласно правилам языка Си++, будут приведены к типу int, а уже затем будет произведено их умножение. В ходе выполнения умножения произойдет переполнение. Некорректный результат выражения будет расширен до типа ptrdiff_t, и произойдет некорректное вычисление указателя.
Следует старательно избегать возможных переполнений в арифметике с указателями. Для этого лучше всего использовать memsize-типы или явное приведение типов в выражениях, где присутствуют указатели. Используя явное приведение типов, мы можем переписать код следующим образом:
short a16, b16, c16;
char *pointer;
...
pointer += static_cast<ptrdiff_t>(a16) *
static_cast<ptrdiff_t>(b16) *
static_cast<ptrdiff_t>(c16);Если вы думаете, что злоключения ждут неаккуратные программы только на больших объемах данных, то мы вынуждены вас огорчить. Рассмотрим интересный код для работы с массивом, содержащим всего 5 элементов. Этот пример работоспособен в 32-битном варианте и не работоспособен в 64-битном:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); //Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); //Access violation on 64-bit platformДавайте проследим, как происходит вычисление выражения "ptr + (A + B)":
- Согласно правилам языка Си++ переменная A типа int приводится к типу unsigned.
- Происходит сложение A и B. В результате мы получаем значение 0xFFFFFFFF типа unsigned.
- Вычисляется выражение "ptr + 0xFFFFFFFFu".
Что из этого выйдет, будет зависеть от размера указателя на данной архитектуре. Если сложение будет происходить в 32-битной программе, то данное выражение будет эквивалентно "ptr - 1", и мы успешно распечатаем число "3". В 64-битной программе к указателю честным образом прибавится значение 0xFFFFFFFFu, в результате чего указатель окажется далеко за пределами массива. И при доступе к элементу по данному указателю нас ждут неприятности.
Для предотвращения подобной ситуации, как и в первом случае, рекомендуем использовать в арифметике с указателями только memsize-типы. Два варианта исправления кода:
ptr = ptr + (ptrdiff_t(A) + ptrdiff_t(B));
ptrdiff_t A = -2;
size_t B = 1;
...
ptr = ptr + (A + B);Вы можете возразить и предложить следующий вариант исправления:
int A = -2;
int B = 1;
...
ptr = ptr + (A + B);Да, такой код будет работать, но он плох по ряду причин:
- Он будет приучать к неаккуратной работе с указателями. Через некоторое время вы можете забыть нюансы и по ошибке вновь сделать одну из переменных типа unsigned.
- Использование не memsize-типов совместно с указателями потенциально опасно само по себе. Допустим, что в выражении с указателем участвует переменная Delta типа int, и это выражение совершенно корректно. Ошибка может крыться в вычислении самой переменной Delta, так как 32 бит может не хватить для необходимых вычислений, при работе с большими массивами данных. Использование memsize-типа для переменной Delta автоматически устраняет такую опасность.
- Код, использующий при работе с указателями типы size_t, ptrdiff_t и другие memsize-типы, приводит к генерации более оптимального двоичного кода, о чем будет рассказано подробнее в одном из следующих уроков.
Индексация массивов
Данная разновидность ошибок выделена для лучшей структуризации изложения, так как индексация в массивах с использованием квадратных скобок - это всего лишь иная запись адресной арифметики, рассмотренной выше.
В программах, обрабатывающих большие объемы данных, могут встретиться ошибки связанные с индексацией больших массивов, или возникнуть вечные циклы. Следующий пример содержит сразу 2 ошибки:
const size_t size = ...;
char *array = ...;
char *end = array + size;
for (unsigned i = 0; i != size; ++i)
{
const int one = 1;
end[-i - one] = 0;
}Первая ошибка заключается в том, что если размер обрабатываемых данных превысит 4 гигабайта (0xFFFFFFFF), то возможно возникновение вечного цикла, поскольку переменная 'i' имеет тип 'unsigned' и никогда не достигнет значения больше чем 0xFFFFFFFF. Мы специально пишем, что возникновение возможно, но не обязательно оно произойдет. Это зависит от того, какой код построит компилятор. Например, в отладочном (debug) режиме вечный цикл будет присутствовать, а в release-коде зацикливание исчезнет, так компилятор примет решение оптимизировать код, используя для счетчика 64-битный регистр, и цикл будет корректным. Все это добавляет путаницы, и код, который работал вчера, неожиданно может перестать работать на следующий день.
Вторая ошибка связана с проходом по массиву от конца к началу, для чего используются отрицательные значения индексов. Приведенный код работоспособен в 32-битном режиме, но при его запуске на 64-битной машине на первой же итерации цикла произойдет доступ за границы массива, и программа аварийно завершится. Рассмотрим причину такого поведения.
Хотя то, что написано ниже, аналогично примеру с "ptr = ptr + (A + B);", это повторение делается сознательно. Важно показать, что опасность скрывается даже в простых конструкциях и может выглядеть по-разному.
Согласно правилам языка Си++ на 32-битной системе выражение "-i - one" будет вычисляться следующим образом (на первом шаге i = 0):
- Выражение "-i" имеет тип unsigned и имеет значение 0x00000000u.
- Переменная 'one' будет расширена от типа 'int' до типа unsigned и будет равна 0x00000001u. Примечание: Тип int расширяется (согласно стандарту языка Си++) до типа 'unsigned', если он участвует в операции, где второй аргумент имеет тип unsigned.
- Происходит операция вычитания, в котором участвуют два значения типа unsigned и результат выполнения операции равен 0x00000000u - 0x00000001u = 0xFFFFFFFFu. Обратите внимание, что результат имеет беззнаковый тип.
На 32-битной системе обращение к массиву по индексу 0xFFFFFFFFu эквивалентно использованию индекса -1. То есть end[0xFFFFFFFFu] является аналогом end[-1]. В результате происходит корректная обработка элемента массива. В 64-битной системе в последнем пункте картина будет иной. Произойдет расширение типа unsigned до знакового ptrdiff_t и индекс массива будет равен 0x00000000FFFFFFFFi64. В результате произойдет выход за рамки массива.
Для исправления кода необходимо использовать такие типы, как ptrdiff_t и size_t.
Чтобы окончательно убедить вас в необходимости использования только memsize-типов для индексации и в выражениях адресной арифметики, приведем еще один пример.
class Region {
float *array;
int Width, Height, Depth;
float Region::GetCell(int x, int y, int z) const;
...
};
float Region::GetCell(int x, int y, int z) const {
return array[x + y * Width + z * Width * Height];
}Данный код взят из реальной программы математического моделирования, в которой важным ресурсом является объем оперативной памяти, и возможность на 64-битной архитектуре использовать более 4 гигабайт памяти существенно увеличивает вычислительные возможности. В программах данного класса для экономии памяти часто используют одномерные массивы, осуществляя работу с ними как с трехмерными массивами. Для этого существуют функции, аналогичные GetCell, обеспечивающие доступ к необходимым элементам. Но приведенный код будет корректно работать только с массивами, содержащими менее INT_MAX элементов. Причина - использование 32-битных типов int для вычисления индекса элемента.
Программисты часто допускают ошибку, пытаясь исправить код следующим образом:
float Region::GetCell(int x, int y, int z) const {
return array[static_cast<ptrdiff_t>(x) + y * Width +
z * Width * Height];
}Они знают, что по правилам языка Си++ выражение для вычисления индекса будет иметь тип ptrdiff_t и надеются за счет этого избежать переполнения. Но переполнение может произойти внутри подвыражения "y * Width" или "z * Width * Height", так как для их вычисления по-прежнему используется тип int.
Если вы хотите исправить код, не изменяя типов переменных, участвующих в выражении, то вы можете явно привести каждую переменную к memsize-типу:
float Region::GetCell(int x, int y, int z) const {
return array[ptrdiff_t(x) +
ptrdiff_t(y) * ptrdiff_t(Width) +
ptrdiff_t(z) * ptrdiff_t(Width) *
ptrdiff_t(Height)];
}Другое, более верное решение - изменить типы переменных на memsize-тип:
typedef ptrdiff_t TCoord;
class Region {
float *array;
TCoord Width, Height, Depth;
float Region::GetCell(TCoord x, TCoord y, TCoord z) const;
...
};
float Region::GetCell(TCoord x, TCoord y, TCoord z) const {
return array[x + y * Width + z * Width * Height];
}Диагностика
Ошибки адресной арифметики хорошо диагностируются инструментом PVS-Studio. Анализатор предупреждает о потенциально опасных выражениях с помощью диагностических сообщений V102 и V108.
По возможности анализатор пытается понять, когда использование не memsize-типа в адресной арифметике безопасно и не выдавать в этом месте предупреждения. В результате, поведение анализатора иногда может показаться странным. В таких случаях мы просим не спешить и постараться разобраться. Рассмотрим следующий код:
char Arr[] = { '0', '1', '2', '3', '4' };
char *p = Arr + 2;
cout << p[0u + 1] << endl;
cout << p[0u - 1] << endl; //V108Данный код исправно работает в 32-битном режиме и печатает на экране числа 3 и 1. При проверке этого кода мы получим предупреждение только на одну строку с выражением "p[0u - 1]". И это совершенно верно! Если вы скомпилируете и запустите данный пример в 64-битном режиме, то увидите, как на экране будет распечатано значение 3, после чего произойдет аварийное завершение программы.
Если вы уверены в корректности индексации, то вы можете изменить соответствующую настройку анализатора на вкладке настроек Settings: General или использовать фильтры. Также можно использовать явное приведение типов.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 14. Паттерн 6. Изменение типа массива
Иногда в программах необходимо (или просто удобно) представлять элементы массива в виде элементов другого типа. Опасное и безопасное приведение типов представлено в следующем коде:
int array[4] = { 1, 2, 3, 4 };
enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };
//safe cast (for MSVC)
ENumbers *enumPtr = (ENumbers *)(array);
cout << enumPtr[1] << " ";
//unsafe cast
size_t *sizetPtr = (size_t *)(array);
cout << sizetPtr[1] << endl;
//Output on 32-bit system: 2 2
//Output on 64-bit system: 2 17179869187Как видите, результат вывода программы отличается в 32-битном и 64-битном варианте. На 32-битной системе доступ к элементам массива осуществляется корректно, так как размеры типов size_t и int совпадают, и мы видим вывод "2 2".
На 64-битной системе мы получили в выводе "2 17179869187", так как именно значение 17179869187 находится в 1-ом элементе массива sizetPtr (см. рисунок 1). В некоторых случаях именно такое поведение и бывает нужно, но обычно это является ошибкой.
Примечание. Тип enum в компиляторе Visual C++ по умолчанию совпадает размером с типом int, то есть является 32-битным типом. Использование enum другого размера возможно только с помощью расширения, считающимся нестандартным Visual C++. Поэтому приведенный пример корректен в Visual C++, но с точки зрения других компиляторов приведение указателя на элементы int к указателю на элементы enum может быть также некорректным.
Рисунок 1 - Расположение элементов массивов в памяти
Исправление описанной ситуации заключается в отказе от опасных приведений типов путем модернизации программы. Другим вариантом является создание нового массива и копирование в него значений из исходного массива.
В основном описанный паттерн ошибки встречается в коде, где в качестве уникальных 32-битных идентификаторов пытаются использовать значения указателей.
Диагностика
Опасные изменения типа массива диагностируются инструментом PVS-Studio. Анализатор предупреждает о потенциально опасных приведениях типа с помощью диагностических сообщений V114. Соответственно, выводятся предупреждения только о тех конструкциях, которые могут привести к ошибке на 64-битной системе. Например, следующий код является корректным и анализатор не обратит на него внимание программиста:
void **pointersArray;
ptrdiff_t correctID = ((ptrdiff_t *)pointersArray)[index];Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 15. Паттерн 7. Упаковка указателей
Большое количество ошибок при миграции на 64-битные системы связано с изменением соотношения между размером указателя и размером обычных целых. В среде с моделью данных ILP32 обычные целые и указатели имеют одинаковый размер. К сожалению, 32-битный код повсеместно опирается на это предположение. Указатели часто приводятся к int, unsigned, long, DWORD и другим неподходящим типам.
Следует четко помнить, что для целочисленного представления указателей следует использовать только memsize типы. Предпочтение, на наш взгляд, следует отдавать типу uintptr_t, так как он лучше выражает намерения и делает код более переносимым, предохраняя его от изменений в будущем.
Рассмотрим два небольших примера.
1) char *p;
p = (char *) ((int)p & PAGEOFFSET);
2) DWORD tmp = (DWORD)malloc(ArraySize);
...
int *ptr = (int *)tmp;Оба примера не учитывают, что размер указателя может отличаться от 32 бит. Используется явное приведение типа, отбрасывающее старшие биты в указателе, что является явной ошибкой на 64-битной системе. Исправленные варианты, использующие для упаковки указателей целочисленные memsize типы (intptr_t и DWORD_PTR), приведены ниже:
1) char *p;
p = (char *) ((intptr_t)p & PAGEOFFSET);
2) DWORD_PTR tmp = (DWORD_PTR)malloc(ArraySize);
...
int *ptr = (int *)tmp;Опасность двух рассмотренных примеров в том, что сбой в программе может быть обнаружен спустя очень большой промежуток времени. Программа может совершенно корректно работать с небольшим объемом данных на 64-битной системе, пока обрабатываемые адреса находятся в пространстве первых четырех гигабайт памяти. А затем, при запуске программы на больших производственных задачах, произойдет выделение памяти за пределами этой области. Рассмотренный в примерах код, обрабатывая указатель на объект вне данной области, приведет к неопределенному поведению программы.
Следующий приведенный код не будет таиться и проявит себя при первом выполнении:
void GetBufferAddr(void **retPtr) {
...
// Access violation on 64-bit system
*retPtr = p;
}
unsigned bufAddress;
GetBufferAddr((void **)&bufAddress);Исправление также заключается в выборе типа, способного вмещать в себя указатель.
size_t bufAddress;
GetBufferAddr((void **)&bufAddress); //OKБывают ситуации, когда упаковка указателя в 32-битный тип просто необходима. В основном такие ситуации возникают при необходимости работы со старыми API функциями. Для таких случаев следует прибегнуть к специальным функциям, таким как LongToIntPtr, PtrToUlong и так далее.
Резюмируя, хочется заметить, что плохим стилем будет упаковка указателя в типы, всегда равные 64 битам. Показанный ниже код вновь придется исправлять с приходом 128-битных систем:
PVOID p;
// Bad style. The 128-bit time will come.
__int64 n = __int64(p);
p = PVOID(n);Поговаривают, что уже сегодня разработчики Microsoft Research работают над проектом по обеспечению совместимости ядер Windows 8 и Windows 9 с 128-битной архитектурой. Так что пишите хороший код сразу.
Диагностика
Упаковка указателя в 32-битные типы диагностируется инструментом PVS-Studio посредством диагностических сообщений V114 и V202.
Следует заметить, что простые ошибки приведения указателей к 32-битным типам хорошо диагностируются компилятором Visual C++. Например, компилятор предупредит об ошибке в коде, рассмотренном выше:
char *p;
p = (char *) ((int)p & PAGEOFFSET);Visual C++ выдаст предупреждение "warning C4311: 'type cast' : pointer truncation from 'char *' to 'int'". Однако, пример с GetBufferAddr уже не вызовет у Visual C++ подозрений. Таким образом, PVS-Studio позволяет быть более уверенным в отсутствии таких ошибок, чем диагностика Visual C++.
Рассмотрим еще один важный момент, связанный с использованием анализатора PVS-Studio. Хотя некоторые из рассматриваемых в уроках ошибок могут быть обнаружены с использованием предупреждений Visual C++, это не всегда получается осуществить на практике. В больших и старых проектах, содержащих вдобавок большие сторонние библиотеки, часто отключены многие предупреждения, что снижает вероятность обнаружения 64-битных ошибок. Включать эти предупреждения бывает крайне нежелательно. Предупреждений будет много, но только часть из них может помочь выявить ошибки 64-битности. Остальные предупреждения не будут относиться к делу, и скорее будут свидетельствовать о неаккуратности кода, чем о потенциальных 64-битных проблемах.
В описанной ситуации PVS-Studio окажет неоценимую услугу. Он выделит в коде только те потенциальные ошибки, которые относятся к вопросам переноса проекта на 64-битную архитектуру.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 16. Паттерн 8. Memsize-типы в объединениях
Особенностью объединения (union) является то, что для всех элементов (членов) объединения выделяется одна и та же область памяти, то есть они перекрываются. Хотя доступ к этой области памяти возможен с использованием любого из элементов, элемент для этой цели должен выбираться так, чтобы полученный результат был осмысленным.
Следует внимательно отнестись к объединениям, имеющим в своем составе указатели и другие члены типа memsize.
Когда возникает необходимость работать с указателем как с целым числом, иногда удобно воспользоваться объединением, как показано в примере, и работать с числовым представлением типа без использования явных приведений:
union PtrNumUnion {
char *m_p;
unsigned m_n;
} u;
u.m_p = str;
u.m_n += delta;Данный код корректен на 32-битных системах и некорректен на 64-битных. Изменяя член m_n на 64-битной системе, мы работаем только с частью указателя m_p (смотри рисунок 1).
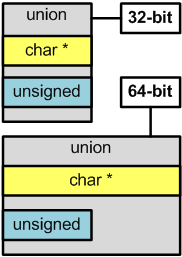
Рисунок 1 - Формат объединения на 32-битной и 64-битной системе
Следует использовать тип, который будет соответствовать размеру указателя:
union PtrNumUnion {
char *m_p;
size_t m_n; //type fixed
} u;Другое частое использование объединения - это представление одного члена, набором других более мелких. Например, нам может потребоваться разбить значение типа size_t на байты для реализации табличного алгоритма подсчета количества нулевых битов:
union SizetToBytesUnion {
size_t value;
struct {
unsigned char b0, b1, b2, b3;
} bytes;
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = TranslateTable[u.bytes.b0] +
TranslateTable[u.bytes.b1] +
TranslateTable[u.bytes.b2] +
TranslateTable[u.bytes.b3];Здесь допущена принципиальная алгоритмическая ошибка, заключающаяся в предположении, что тип size_t состоит из 4 байт. Возможность автоматического поиска алгоритмических ошибок пока вряд ли возможна, но мы можем осуществить поиск всех объединений и проверить наличие в них memsize-типов. Найдя такое объединение, мы можем обнаружить алгоритмическую ошибку и переписать код следующим образом.
union SizetToBytesUnion {
size_t value;
unsigned char bytes[sizeof(value)];
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = 0;
for (size_t i = 0; i != sizeof(bytes); ++i)
zeroBitsN += TranslateTable[bytes[i]];Диагностика
Инструмент PVS-Studio позволяет быстро найти и просмотреть в коде программы все объединения, содержащие memsize типы. Анализатор выдает диагностическое сообщение V117 для структур, на которые следует обратить внимание программисту при переносе кода на 64-битную систему.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 17. Паттерн 9. Смешанная арифметика
Надеемся, вы уже успели отдохнуть от 13 урока и теперь сможете рассмотреть еще один важный паттерн ошибок, связанный с арифметическими выражениями, в которых участвуют типы различной размерности.
Смешанное использование memsize- и не memsize-типов в выражениях может приводить к некорректным результатам на 64-битных системах и быть связано с изменением диапазона входных значений. Рассмотрим ряд примеров:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }Это пример вечного цикла, если Count > UINT_MAX. Предположим, что на 32-битных системах этот код работал с количеством итераций менее значения UINT_MAX. Но 64-битный вариант программы может обрабатывать больше данных, и ему может потребоваться большее количество итераций. Поскольку значения переменной Index лежат в диапазоне [0..UINT_MAX], то условие "Index != Count" никогда не выполнится, что и приводит к бесконечному циклу.
Примечание. Заметим, что при определенных настройках компилятора данный пример может успешно отработать. Из-за этого иногда, кажется, что код корректен, и возникает путаница. В одном из последующих уроков мы расскажем о фантомных ошибках, проявляющих себя только временами. Если вам интересно уже сейчас понять это странное поведение кода, то предлагаем ознакомиться со статьей "64-битный конь, который умеет считать".
Для исправления кода необходимо использовать в выражениях только memsize-типы. В данном примере можно заменить тип переменной Index с unsigned на size_t.
Другая часто встречающаяся ошибка - запись выражений следующего вида:
int x, y, z;
ptrdiff_t SizeValue = x * y * z;Ранее уже рассматривались подобные примеры, когда при вычислении значений с использованием не memsize-типов происходило арифметическое переполнение. И конечный результат был некорректен. Поиск и исправление приведенного кода осложняется тем, что компиляторы, как правило, не выдают на него никаких предупреждений. С точки зрения языка Си++ это совершенно корректная конструкция. Происходит умножение нескольких переменных типа int, после чего результат неявно расширяется до типа ptrdiff_t и происходит присваивание.
Приведем небольшой код, показывающий опасность неаккуратных выражений со смешанными типами (результаты получены с использованием Microsoft Visual C++ 2005, 64-битный режим компиляции):
int x = 100000;
int y = 100000;
int z = 100000;
ptrdiff_t size = 1; // Result:
ptrdiff_t v1 = x * y * z; // -1530494976
ptrdiff_t v2 = ptrdiff_t (x) * y * z; // 1000000000000000
ptrdiff_t v3 = x * y * ptrdiff_t (z); // 141006540800000
ptrdiff_t v4 = size * x * y * z; // 1000000000000000
ptrdiff_t v5 = x * y * z * size; // -1530494976
ptrdiff_t v6 = size * (x * y * z); // -1530494976
ptrdiff_t v7 = size * (x * y) * z; // 141006540800000
ptrdiff_t v8 = ((size * x) * y) * z; // 1000000000000000
ptrdiff_t v9 = size * (x * (y * z)); // -1530494976Необходимо чтобы все операнды в подобных выражениях были приведены в процессе вычисления к типу большей разрядности. Помните, что выражение вида
ptrdiff_t v2 = ptrdiff_t (x) + y * z;вовсе не гарантирует правильный результат. Оно гарантирует только то, что выражение " ptrdiff_t (x) + y * z" будет иметь тип ptrdiff_t.
Следовательно, если результатом выражения должен являться memsize-тип, то в выражении должны участвовать только memsize-типы. Или элементы, приведенные к memsize-типам. Правильный вариант:
ptrdiff_t v2 = ptrdiff_t (x) + ptrdiff_t (y) * ptrdiff_t (z); // OK!Впрочем не всегда необходимо приводить все аргументы к memsize-типу. Если выражение состоит из одинаковых операторов, то достаточно привести к memsize-типу только первый аргумент. Рассмотрим пример:
int c();
int d();
int a, b;
ptrdiff_t v2 = ptrdiff_t (a) * b * c() * d();Порядок вычисления выражения с операторами одинакового приоритета не определен. Точнее, компилятор волен вычислять подвыражения, например вызов функций c() и d() в том порядке, который он считает более эффективным, даже если подвыражения вызывают побочные эффекты. Порядок возникновения побочных эффектов не определен. Но поскольку операция умножения относится к лево-ассоциативным операторам, то вычисление будет происходить следующим образом:
ptrdiff_t v2 = ((ptrdiff_t (a) * b) * c()) * d();В результате каждый из операндов перед умножением будет преобразовываться к типу ptrdiff_t и мы получим корректный результат.
Примечание. Если у вас есть целочисленные вычисления, для которых крайне важен контроль над переполнениями, то мы предлагаем обратить внимание на класс SafeInt, реализацию и описание которого можно найти в MSDN.
Смешанное использование типов может проявляться и в изменении программной логики:
ptrdiff_t val_1 = -1;
unsigned int val_2 = 1;
if (val_1 > val_2)
printf ("val_1 is greater than val_2\n");
else
printf ("val_1 is not greater than val_2\n");
//Output on 32-bit system: "val_1 is greater than val_2"
//Output on 64-bit system: "val_1 is not greater than val_2"На 32-битной системе переменная val_1 согласно правилам языка Си++ расширялась до типа unsigned int и становилась значением 0xFFFFFFFFu. В результате условие "0xFFFFFFFFu > 1" выполнялось. На 64-битной системе наоборот расширяется переменная val_2 до типа ptrdiff_t. В этом случае уже проверяется выражение "-1 > 1". На рисунке 1 и 2 схематично отображены происходящие преобразования.
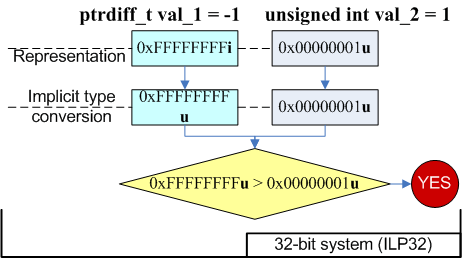
Рисунок 1 - Преобразования, происходящие в 32-битном коде
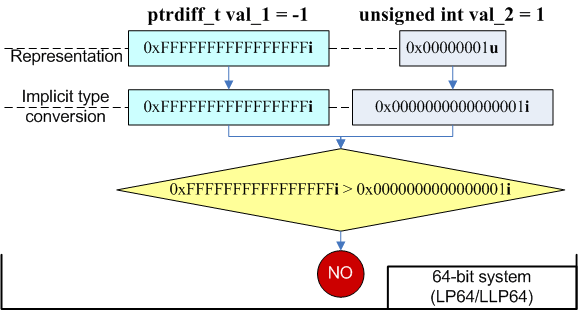
Рисунок 2 - Преобразования, происходящие в 64-битном коде
Если вам необходимо вернуть прежнее поведение кода - следует изменить тип переменной val_2:
ptrdiff_t val_1 = -1;
size_t val_2 = 1;
if (val_1 > val_2)
printf ("val_1 is greater than val_2\n");
else
printf ("val_1 is not greater than val_2\n");Правильнее вообще не сравнивать знаковые и беззнаковые типы, но это выходит за рамки обсуждаемой темы.
Мы рассмотрели только простые выражения. Но описываемые проблемы могут проявиться и при использовании других конструкций языка Си++:
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return x + y * Width + z * Width * Height;
}
...
MyArray[GetIndex(x, y, z)] = 0.0f;В случае работы с большими массивами (более INT_MAX элементов) данный код будет вести себя некорректно, и мы будем адресоваться не к тем элементам массива MyArray, к которым рассчитываем. Несмотря на то, что мы возвращаем значение типа size_t, выражение "x + y * Width + z * Width * Height" вычисляется с использованием типа int. Мы думаем, вы уже догадались, что исправленный код будет выглядеть следующим образом:
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return (size_t)(x) +
(size_t)(y) * (size_t)(Width) +
(size_t)(z) * (size_t)(Width) * (size_t)(Height);
}Или чуть более просто:
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return (size_t)(x) +
(size_t)(y) * Width +
(size_t)(z) * Widt) * Height;
}В следующем примере, у нас вновь смешивается memsize-тип (указатель) и 32-битный тип unsigned:
extern char *begin, *end;
unsigned GetSize() {
return end - begin;
}Результат выражения "end - begin" имеет тип ptrdiff_t. Поскольку функция возвращает тип unsigned, то происходит неявное приведение типа, при котором старшие биты результата теряются. Таким образом, если указатели begin и end ссылаются на начало и конец массива, по размеру большего UINT_MAX (4Gb), то функция вернет некорректное значение.
И еще один пример. На этот раз рассмотрим не возвращаемое значение, а формальный аргумент функции:
void foo(ptrdiff_t delta);
int i = -2;
unsigned k = 1;
foo(i + k);Этот код не напоминает вам пример с некорректной арифметикой указателей, рассмотренный в 13-том уроке? Да, здесь происходит то же самое. Некорректный результат возникает при неявном расширении фактического аргумента, имеющего значение 0xFFFFFFFF и тип unsigned, до типа ptrdiff_t.
Диагностика
Ошибки, возникающие на 64-битных системах при смешанном использование простых целочисленных типов и memsize-типов, представлены большим количеством синтаксических конструкций языка Си++. Для диагностики этих ошибок используется целый ряд диагностических сообщений. Анализатор PVS-Studio предупреждает о потенциально возможных ошибках, используя следующие сообщения: V101, V103, V104, V105, V106, V107, V109, V110, V121.
Вернемся к ранее рассмотренному примеру:
int c();
int d();
int a, b;
ptrdiff_t x = ptrdiff_t(a) * b * c() * d();Хотя само выражение перемножает аргументы, расширяя их тип до ptrdiff_t, ошибка может содержаться в вычислении самих этих аргументов. Поэтому анализатор все равно предупреждает о смешивании типов: "V104: Implicit type conversion to memsize type in an arithmetic expression".
Также инструмент PVS-Studio позволяет найти потенциально опасные выражения, которые скрываются за явным приведением типов. Для этого можно включить в настройках анализатора предупреждения V201 и V202. По умолчанию анализатор не выдает предупреждения связанные с приведением типа, в случае, когда приведение осуществляется явно. Пример:
TCHAR *begin, *end;
unsigned size = static_cast<unsigned>(end - begin);Выявить подобный некорректный код и позволяют сообщения V201 и V202.
При этом анализатор не обратит внимания на безопасные с точки зрения 64-битного кода приведения типов:
const int *constPtr;
int *ptr = const_cast<int>(constPtr);
float f = float(constPtr[0]);
char ch = static_cast<char>(sizeof(double));Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 18. Паттерн 10. Хранение в double целочисленных значений
Тип double имеет размер 64 бита, и совместим со стандартом IEEE-754 на 32-битных и 64-битных системах.
Примечание. IEEE 754 — широко распространённый стандарт формата представления числа с плавающей запятой, используемый как в программных реализациях арифметических действий, так и во многих аппаратных (CPU и FPU) реализациях. Многие компиляторы языков программирования используют этот стандарт для хранения и выполнения математических операций.
Некоторые программисты используют тип double для хранения и работы с целочисленными типами:
size_t a = size_t(-1);
double b = a;
--a;
--b;
size_t c = b; // x86: a == c
// x64: a != cДанный пример еще можно пытаться оправдать на 32-битной системе, так как тип double имеет 52 значащих бита и способен без потерь хранить 32-битное целое значение. Но при попытке сохранить в double 64-битное целое число точное значение может быть потеряно (см. рисунок 1).
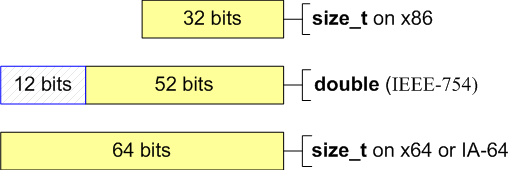
Рисунок 1 - Количество значащих битов в типах size_t и double
Возможно, приближенное значение вполне применимо в Вашей программе, но на всякий случай хочется сделать предупреждение о потенциальных эффектах на новой архитектуре. И в любом случае не рекомендуется смешивать целочисленную арифметику и арифметику с плавающей точкой.
Диагностика
Данный паттерн ошибок относится к редко встречающимся на практике. Тем не менее, редко встречающиеся ошибки не менее опасны. Анализатор PVS-Studio предупреждает о потенциально возможной ошибке с помощью диагностического сообщения V113. Если необходимо обнаружить явное приведение типов (от memsize к double и обратно), то можно включить предупреждение V203.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 19. Паттерн 11. Сериализация и обмен данными
Важным элементом переноса программного решения на новую платформу является преемственность к существующим протоколам обмена данными. Необходимо обеспечить чтение существующих форматов проектов, осуществлять обмен данными между 32-битными и 64-битными процессами и так далее.
В основном, ошибки данного рода заключаются в сериализации memsize-типов и операциях обмена данными с их использованием:
1) size_t PixelsCount;
fread(&PixelsCount, sizeof(PixelsCount), 1, inFile);
2) __int32 value_1;
SSIZE_T value_2;
inputStream >> value_1 >> value_2;В приведенных примерах имеются ошибки двух видов: использование типов непостоянной размерности в бинарных интерфейсах и игнорирование порядка байт.
Использование типов непостоянной размерности
Недопустимо использование типов, которые меняют свой размер в зависимости от среды разработки, в бинарных интерфейсах обмена данными. В языке Си++ все типы не имеют четкого размера и, следовательно, их все невозможно использовать для этих целей. Поэтому создатели средств разработки и сами программисты создают типы данных, имеющие строгий размер, такие как __int8, __int16, INT32, word64 и так далее.
Использование подобных типов обеспечивает переносимость данных между программами на различных платформах, хотя и требует дополнительных усилий. Два показанных примера написаны неаккуратно, что даст о себе знать при смене разрядности некоторых типов данных с 32 бит до 64 бит. Учитывая необходимость поддержки старых форматов данных, исправление может выглядеть следующим образом:
1) size_t PixelsCount;
__uint32 tmp;
fread(&tmp, sizeof(tmp), 1, inFile);
PixelsCount = static_cast<size_t>(tmp);
2) __int32 value_1;
__int32 value_2;
inputStream >> value_1 >> value_2;Но приведенный вариант исправления может являться не лучшим. При переходе на 64-битную систему программа может обрабатывать большее количество данных, и использование в данных 32-битных типов может стать существенным препятствием. В таком случае, можно оставить старый код для совместимости со старым форматом данных, исправив некорректные типы. И реализовать новый бинарный формат данных уже с учетом допущенных ранее ошибок. Еще одним вариантом может стать отказ от бинарных форматов и переход на текстовый формат или другие форматы, предоставляемые различными библиотеками.
Игнорирование порядка байт (byte order)
Даже после внесения исправлений, касающихся размеров типа, вы можете столкнуться с несовместимостью бинарных форматов. Причина кроется в ином представлении данных. Наиболее часто это связано с другой последовательностью байт.
Порядок байт - метод записи байтов многобайтовых чисел (см. также рисунок 1). Порядок от младшего к старшему (англ. little-endian) - запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86 и x86-64-процессорами. Порядок от старшего к младшему (англ. big-endian) - запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP. Поэтому, порядок байтов от старшего к младшему часто называют сетевым порядком байтов (англ. network byte order). Этот порядок байт используется процессорами Motorola 68000, SPARC.

Рисунок 1 - Порядок байт в 64-битном типе на little-endian и big-endian системах
Разрабатывая бинарный интерфейс или формат данных, следует помнить о последовательности байт. А если 64-битная система, на которую Вы переносите 32-битное приложение, имеет иную последовательность байт, то вы просто будете вынуждены учесть это в своем коде. Для преобразования между сетевым порядком байт (big-endian) и порядком байт (little-endian), можно использовать функции htonl(), htons(), bswap_64, и так далее.
Примечание. Во многих системах отсутствуют функции подобные bswap_64. А функция ntohl() позволяет перевертывать только 32-битные значения. Про вариант этой функции для 64-битных типов как-то забыли. Если вам нужно поменять порядок байт в 64-битной переменной, то на сайте stackoverflow.com имеется обсуждение темы "64 bit ntohl() in C++ ?" где приведено сразу несколько примеров реализации такой функции.
Диагностика
К сожалению PVS-Studio не реализует диагностику данного паттерна 64-битных ошибок, так как этот процесс не удается формализовать (составить диагностическое правило). Можно только порекомендовать внимательно просмотреть все участки кода, отвечающие за чтения и запись данных, а также за передачу их в другие процессы, например посредством технологии COM.
Мы также будем рады, если кто-то из читателей предложит практические шаги, как хотя бы частично выявлять ошибки описанного типа.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 20. Паттерн 12. Исключения
Генерирование и обработка исключений с участием целочисленных типов не является хорошей практикой программирования на языке Си++. Для этих целей следует использовать более информативные типы, например классы, производные от класса std::exception. Но иногда все-таки приходится работать с менее качественным кодом, таким как показано ниже:
char *ptr1;
char *ptr2;
try {
try {
throw ptr2 - ptr1;
}
catch (int) {
std::cout << "catch 1: on x86" << std::endl;
}
}
catch (ptrdiff_t) {
std::cout << "catch 2: on x64" << std::endl;
}Следует тщательно избегать генерирования или обработку исключений с использованием memsize-типов, так как это чревато изменением логики работы программы. Исправление данного кода может заключаться в замене "catch (int)" на "catch (ptrdiff_t)". А более правильным решением будет использование специального класса для передачи информации о возникшей ошибке.
Диагностика
На практике мы пока не встречали данный вид ошибки, хотя инструмент PVS-Studio позволяет их обнаружить. Диагностическое сообщение V115 будет выдано при попытке генерации исключения с помощью memsize-типа, а сообщение V116 при использовании memsize-типа в операторе catch.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 21. Паттерн 13. Выравнивание данных
Процессоры работают эффективнее, когда имеют дело с правильно выровненными данными. А некоторые процессоры вообще не умеют работать с не выровненными данными. Попытка работать с не выровненными данными на процессорах IA-64 (Itanium), как показано в следующем примере, приведет к возникновению исключения:
#pragma pack (1) // Also set by key /Zp in MSVC
struct AlignSample {
unsigned size;
void *pointer;
} object;
void foo(void *p) {
object.pointer = p; // Alignment fault
}Если вы вынуждены работать с не выровненными данными на Itanium, то следует явно указать это компилятору. Например, воспользоваться специальным макросом UNALIGNED:
#pragma pack (1) // Also set by key /Zp in MSVC
struct AlignSample {
unsigned size;
void *pointer;
} object;
void foo(void *p) {
*(UNALIGNED void *)&object.pointer = p; //Very slow
}В этом случае компилятор сгенерирует специальный код, который будет работать с не выровненными данными. Такое решение неэффективно, так как доступ к данным будет происходить в несколько раз медленнее. Если целью является уменьшение размера структуры, то лучшего результата можно достичь, располагая данные в порядке уменьшения их размера. Подробнее об этом будет рассказано в одном из следующих уроков.
На архитектуре x64 при обращении к не выровненным данным исключения не возникает, но их также следует избегать. Во-первых, из-за существенного замедления скорости доступа к таким данным, а во-вторых, из-за возможности переноса программы в будущем на платформу IA-64.
Рассмотрим еще один пример кода, не учитывающий выравнивание данных:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( sizeof(DWORD) + 5 * sizeof(PVOID) );
...Если мы хотим выделить объем памяти, необходимый для хранения объекта типа MyPointersArray, содержащего 5 указателей, то мы должны учесть, что начало массива m_arr будет выровнено по границе 8 байт. Расположение данных в памяти на разных системах (Win32/Win64) показано на рисунке 1.
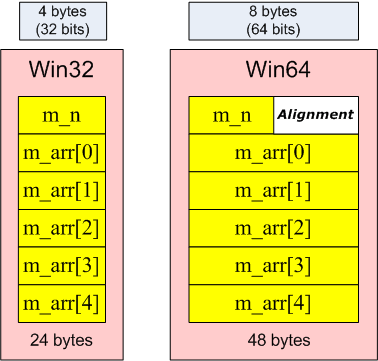
Рисунок 1- Выравнивание данных в памяти на системах Win32 и Win64
Корректный расчет размера должен выглядеть следующим образом:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( FIELD_OFFSET(struct MyPointersArray, m_arr) +
5 * sizeof(PVOID) );
...В приведенном коде мы узнаем смещение последнего члена структуры и суммируем это смещение с его размером. Смещение члена структуры или класса можно узнать с использованием макроса offsetof или FIELD_OFFSET.
Всегда используйте эти макросы для получения смещения в структуре, не опираясь на знание размеров типов и выравнивания. Пример кода с правильным вычислением адреса члена структуры:
struct TFoo {
DWORD_PTR whatever;
int value;
} object;
int *valuePtr =
(int *)((size_t)(&object) + offsetof(TFoo, value)); // OKРазработчиков Linux-приложений может ждать еще одна неприятность, связанная с выравниванием. О ней вы можете прочитать в нашем блоге в посте "Изменения выравнивания типов и последствия".
Диагностика
Поскольку работа с не выровненными данными не приводит к ошибке на архитектуре x64, а только к снижению производительности, инструмент PVS-Studio не предупреждает об упакованных структурах. Но если для вас критична производительность приложения, рекомендуем просмотреть все места в программе, где используется "#pragma pack". Для архитектуры IA-64 данная проверка более актуальна, но анализатор PVS-Studio пока не ориентирован на верификацию программ для IA-64. Если вы работаете с системами на базе Itanium и планируете приобрести PVS-Studio, напишите нам, и мы обсудим вопросы адаптации этого инструмента к особенностям IA-64.
Инструмент PVS-Studio позволяет обнаружить ошибки, связанные с вычислением размеров объектов и смещений. Анализатор обнаруживает опасные арифметические выражения, содержащие в себе несколько операторов sizeof(), что свидетельствует о возможной ошибке. Диагностическое сообщение имеет номер V119.
Однако во многих случаях использование нескольких операторов sizeof() в рамках одного выражения корректно и анализатор игнорирует подобные конструкции. Пример безопасных выражений с несколькими операторами sizeof:
int MyArray[] = { 1, 2, 3 };
size_t MyArraySize =
sizeof(MyArray) / sizeof(MyArray[0]); //OK
assert(sizeof(unsigned) < sizeof(size_t)); //OK
size_t strLen = sizeof(String) - sizeof(TCHAR); //OKПриложение
На рисунке 2 представлены размеры типов и их выравнивание. Для изучения размеров объектов и их выравнивания на различных платформах вы также можете воспользоваться примером кода, приведенным в записи блога "Изменения выравнивания типов и последствия".
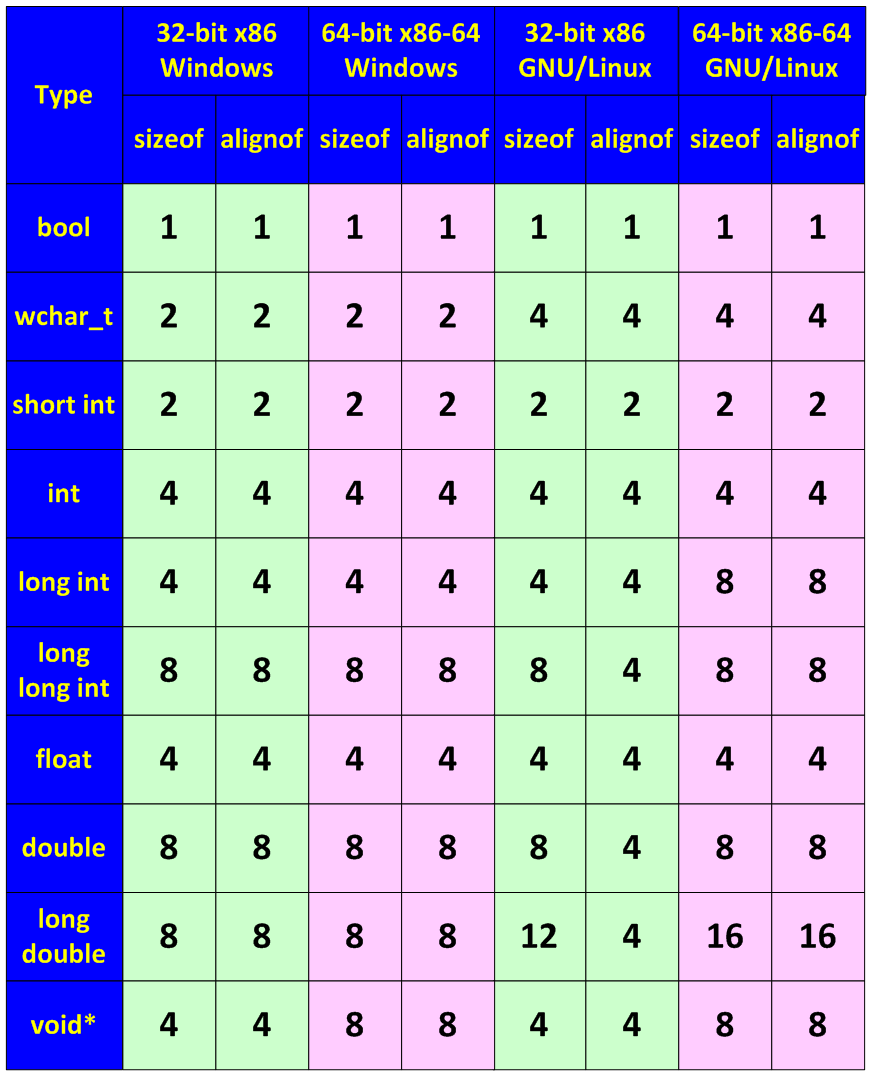
Рисунок 2 - Размеры типов и их выравнивание.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 22. Паттерн 14. Перегруженные функции
При переносе 32-битных программ на 64-битную платформу может наблюдаться изменение логики ее работы, связанное с использованием перегруженных функций. Если функция перекрыта для 32-битных и 64-битных значений, то обращение к ней с аргументом типа memsize будет транслироваться в различные вызовы на различных системах. Этот прием может быть полезен, как, например, в приведенном коде:
static size_t GetBitCount(const unsigned __int32 &) {
return 32;
}
static size_t GetBitCount(const unsigned __int64 &) {
return 64;
}
size_t a;
size_t bitCount = GetBitCount(a);Но такое изменение логики хранит в себе опасность. Представьте себе программу, где используется класс для организации стека. Особенность этого класса в том, что он позволяет хранить значения различных типов:
class MyStack {
...
public:
void Push(__int32 &);
void Push(__int64 &);
void Pop(__int32 &);
void Pop(__int64 &);
} stack;
ptrdiff_t value_1;
stack.Push(value_1);
...
int value_2;
stack.Pop(value_2);Неаккуратный программист помещал и затем выбирал из стека значения различных типов (ptrdiff_t и int). На 32-битной системе их размеры совпадали, все замечательно работало. Когда в 64-битной программе изменился размер типа ptrdiff_t, то в стек стало попадать больше байт, чем затем извлекаться.
Думаем, что вам понятен данный класс ошибок, и как внимательно следует относиться к вызову перегруженных функций, передавая фактические аргументы типа memsize.
Диагностика
PVS-Studio не диагностирует данный паттерн 64-битных ошибок. Во-первых, это связанно с тем, что мы пока не видели подобной ошибки в коде реального приложения, а во-вторых диагностика подобных конструкция связана с некоторыми трудностями. Просим написать нам, если встретите подобную ошибку в реальном коде.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 23. Паттерн 15. Рост размеров структур
Сам по себе рост размера структур не является ошибкой, но может приводить к потреблению необоснованного количества памяти и в результате к замедлению скорости работы программы. Будем рассматривать данный паттерн не как ошибку, но как причину неэффективности 64-битного кода.
Данные в структурах в языке Си++ выравниваются таким образом, чтобы обеспечить более эффективный к ним доступ. Некоторые микропроцессоры вообще не могут напрямую обращаться к не выровненным данным и компилятору приходиться генерировать специальный код для обращения к таким данным. Те же микропроцессоры, которые могут обращаться к не выровненным данным, все равно делают это намного менее эффективно. Поэтому компилятор Си++ оставляет пустые ячейки между полями структур, чтобы обеспечить их выравнивание по адресам машинных слов и тем самым ускорить к ним обращение. Можно отключить выравнивание, используя специальные директивы #pragma, чтобы сократить объем используемой памяти, но нас этот вариант сейчас не интересует. Часто можно значительно сократить объем расходуемой памяти простым изменением порядка полей в структуре, без потери производительности.
Рассмотрим следующую структуру:
struct MyStruct
{
bool m_bool;
char *m_pointer;
int m_int;
};На 32-битной системе эта структура займет 12 байт, и сократить этот размер не представляется возможным. Каждое поле выровнено по границе 4 байта. Даже если m_bool перенести в конец, это ничего не изменит. Компилятор все равно сделает размер структуры кратным 4 байтам для выравнивания таких структур в массивах.
В случае 64-битной сборки структура MyStruct займет уже 24 байта. Это понятно. В начале идет один байт под m_bool и 7 неиспользуемых байт для выравнивания, так как указатель занимает 8 байт и должен быть выровнен по границе 8 байт. Затем 4 байта для m_int и 4 неиспользуемых байта, для выравнивания структуры по границе 8 байт.
К счастью, дело можно легко поправить, переместив m_bool в конец структуры, как показано ниже:
struct MyStructOpt
{
char *m_pointer;
int m_int;
bool m_bool;
};Структура MyStructOpt займет уже не 24, а 16 байт. Визуально расположение полей представлено на рисунке 1. Весьма существенная экономия, если мы будем использовать, например, 10 миллионов элементов. В этом случае мы сэкономим 80 мегабайт памяти, но что еще более важно, можем повысить производительность. Если структур будет немного, то нет разницы, какого они размера. Доступ будет происходить с одинаковой скоростью. Но когда элементов много, то начинает играть роль кэш, количество обращений к памяти и так далее. И можно с уверенностью утверждать, что обработка 160 мегабайт данных займет меньше времени, чем 240 мегабайт. Даже простой доступ ко всем элементам массива для чтения, уже будет более быстр.
Рисунок 1 - Расположение полей в структурах MyStruct и MyStructOpt
Не всегда изменение последовательности полей в структурах возможно или удобно. Но если таких структур миллионы, то следует не пожалеть немного времени на рефакторинг. Результат такой простой оптимизации, как изменение последовательности полей, может дать весьма впечатляющие результаты.
Вы, наверное, зададите вопрос, по каким правилам компилятор выравнивает данные. Мы ответим кратко, а если интересно познакомиться с этой темой более подробно, то мы отсылаем вас к книге Джеффри Рихтер - Создание эффективных WIN32-приложений с учетом специфики 64-разрядной версии Windows. Там этот вопрос рассматривается достаточно подробно.
В целом правило выравнивание следующее: каждое поле выравнивается по адресу, кратному размеру данного поля. Поле типа size_t на 64-битной системе будет выровнено по границе 8 байт, int по границе 4 байта, short по границе 2 байта. Поля типа char не выравниваются. Размер структуры выравнивается до размера, кратному размеру его максимального элемента. Поясним это выравнивание на примере:
struct ABCD
{
size_t m_a;
char m_b;
};Элементы займут 8 + 1 = 9 байт. Но если размер структуры будет 9 байт, то, если мы захотим создать массив структур ABCD[2], поле m_a второй структуры будет лежать по не выровненному адресу. Вследствие этого компилятор дополнит структуру 7 пустыми байтами до размера 16 байт.
Может показаться сложным процесс оптимизации последовательности полей. Но можно предложить очень простой и очень эффективный способ. Достаточно расположить поля в порядке убывания их размера. Этого будет совершенно достаточно. В этом случае поля начнут располагаться без лишних зазоров. Например, возьмем следующую структуру размером 40 байт
struct MyStruct
{
int m_int;
size_t m_size_t;
short m_short;
void *m_ptr;
char m_char;
};и простой сортировкой последовательности полей по убыванию размера:
struct MyStructOpt
{
void *m_ptr;
size_t m_size_t;
int m_int;
short m_short;
char m_char;
};мы сделаем из нее структуру размером всего 24 байт.
Диагностика
Инструмент PVS-Studio позволяет обнаружить структуры в коде 64-битных приложений, перестановка полей в которых, позволит сократить их размер. На неоптимальные структуры анализатор выдает диагностическое сообщение V802.
Анализатор не всегда выдает сообщение о неэффективности структур, так как старается сократить количество излишних предупреждений. Например, анализатор не выдает предупреждение на сложные классы, являющимися наследниками, поскольку такие объекты обычно создаются в малом количестве. Пример:
class MyWindow : public CWnd {
bool m_isActive;
size_t m_sizeX, m_ sizeY;
char m_color[3];
...
};Размер данной структуры может быть сокращен, но это не имеет практического смысла.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 24. Фантомные ошибки
Мы закончили рассмотрение паттернов 64-битных ошибок. Последнее на чем мы остановимся в связи с этими ошибками, является то, как они могут проявляться в программах.
Дело в том, что не так просто показать в примере, что приведенный 64-битный код приведет к ошибке при большом значении N:
size_t N = ...
for (int i = 0; i != N; ++i)
{
...
}Вы можете попробовать подобный простой пример и увидеть, что код работает. Дело в том, каким образом построит код оптимизирующий компилятор. Будет работать код или нет зависит от размера тела цикла. В примерах он всегда маленький, и для счетчиков могут использоваться 64-битные регистры. В реальных программах, с большими телами циклов, ошибка легко возникает, когда компилятор будет сохранять значение переменной "i" в памяти. А теперь давайте попробуем разобраться с непонятным текстом, который вы только что прочитали.
При описании ошибок, очень часто использовался термин "потенциальная ошибка" или словосочетание "возможно возникновение ошибки". В основном это объясняется тем, что один и тот же код можно считать как корректным, так и некорректным в зависимости от его назначения. Простой пример - использование для индексации элементов массива переменной типа int. Если с помощью этой переменной мы обращаемся к массиву графических окон, то все корректно. Не бывает нужно, да и не получится работать с миллиардами окон. А вот индексация с использованием переменной типа int к элементам массива в 64-битных математических программах или базах данных, вполне может представлять собой проблему, когда количество элементов выйдет из диапазона 0..INT_MAX.
Но есть и еще одна, куда более тонкая причина называть ошибки "потенциальными". Дело в том, проявит себя ошибка или нет, зависит не только от входных данных, но и от настроения оптимизатора компилятора. Большинство из рассмотренных в уроках ошибок хорошо проявляют себя в debug-версии, и "потенциальны" в release-версиях. Однако не всякую программу, собранную как debug, можно отлаживать на больших объемах данных. Возникает ситуация, когда debug-версия тестируется только на самых простых наборах данных. А нагрузочное тестирование и тестирование конечными пользователями на реальных данных, выполняется на release-версиях, где ошибки могут быть временно скрыты.
Впервые мы столкнулись с особенностями оптимизации компилятора Visual C++ 2005 при подготовке программы OmniSample. Это проект, который входит в состав дистрибутива PVS-Studio и предназначен для демонстрации всех ошибок, которые диагностирует анализатор Viva64. Примеры, которые содержатся в этом проекте, должны корректно работать в 32-битном режиме и приводить к ошибкам в 64-битном варианте. В отладочной версии все работало замечательно, а вот с release версией возникли затруднения. Тот код, который в 64-битном режиме должен был зависать или приводить к аварийному завершению программы - успешно работал! Причина оказалась в оптимизации. Решением стало дополнительное избыточное усложнение кода примеров и расстановка ключевых слов "volatile", которые вы сможете наблюдать в коде проекта OmniSample.
То же самое относится и к Visual C++ 2008/2010. Код будет конечно несколько разным, но все что будет написано здесь можно отнести как к Visual C++ 2005, так и к Visual C++ 2008.
Если вам покажется, что это только хорошо, если некоторые ошибки не проявляют себя, то гоните скорее эту мысль прочь. Код с подобными ошибками становится крайне нестабильным. И малейшее изменение кода, напрямую не связанное с ошибкой, может приводить к изменению поведения. На всякий случай подчеркну, что виноват в этом не компилятор, а скрытые дефекты кода. Далее будут показаны примерные фантомные ошибки, которые исчезают и появляются в release-версиях при малейших изменениях кода, и на которых можно долго и утомительно охотиться.
Рассмотрим первый пример кода, который работает в release-режиме, хотя делать этого не должен:
int index = 0;
size_t arraySize = ...;
for (size_t i = 0; i != arraySize; i++)
array[index++] = BYTE(i);Данный код корректно заполняет весь массив значениями, даже если размер массива гораздо больше INT_MAX. Теоретически это невозможно, поскольку переменная index имеет тип int. Через некоторое время из-за переполнения должен произойти доступ к элементам по отрицательному индексу. Однако оптимизация приводит к генерации следующего кода:
0000000140001040 mov byte ptr [rcx+rax],cl
0000000140001043 add rcx,1
0000000140001047 cmp rcx,rbx
000000014000104A jne wmain+40h (140001040h)Как видите, используются 64-битные регистры и переполнение не происходит. Но сделаем совсем маленькое исправление кода:
int index = 0;
size_t arraySize = ...;
for (size_t i = 0; i != arraySize; i++)
{
array[index] = BYTE(index);
++index;
}Будем считать, что так код выглядит более красиво. Согласитесь, что функционально он остался прежним. А вот результат будет существенным - произойдет аварийное завершение программы. Рассмотрим сгенерированный компилятором код:
0000000140001040 movsxd rcx,r8d
0000000140001043 mov byte ptr [rcx+rbx],r8b
0000000140001047 add r8d,1
000000014000104B sub rax,1
000000014000104F jne wmain+40h (140001040h)Происходит то самое переполнение, которое должно было быть и в предыдущем примере. Значение регистра r8d = 0x80000000 расширяется в rcx как 0xffffffff80000000. И как следствие - запись за пределами массива.
Рассмотрим другой пример оптимизации и как легко все испортить. Пример:
unsigned index = 0;
for (size_t i = 0; i != arraySize; ++i) {
array[index++] = 1;
if (array[i] != 1) {
printf("Error\n");
break;
}
}Ассемблерный код:
0000000140001040 mov byte ptr [rdx],1
0000000140001043 add rdx,1
0000000140001047 cmp byte ptr [rcx+rax],1
000000014000104B jne wmain+58h (140001058h)
000000014000104D add rcx,1
0000000140001051 cmp rcx,rdi
0000000140001054 jne wmain+40h (140001040h)Компилятор решил использовать 64-битный регистр rdx для хранения переменной index. В результате код может корректно обрабатывать массивы размером более UINT_MAX.
Но мир хрупок. Достаточно немного усложнить код и он станет неверен:
volatile unsigned volatileVar = 1;
...
unsigned index = 0;
for (size_t i = 0; i != arraySize; ++i) {
array[index] = 1;
index += volatileVar;
if (array[i] != 1) {
printf("Error\n");
break;
}
}Использование вместо index++ выражения "index += volatileVar;" приводит к тому, что в коде начинают участвовать 32-битные регистры, из-за чего происходят переполнения:
0000000140001040 mov ecx,r8d
0000000140001043 add r8d,dword ptr [volatileVar (140003020h)]
000000014000104A mov byte ptr [rcx+rax],1
000000014000104E cmp byte ptr [rdx+rax],1
0000000140001052 jne wmain+5Fh (14000105Fh)
0000000140001054 add rdx,1
0000000140001058 cmp rdx,rdi
000000014000105B jne wmain+40h (140001040h)Напоследок приведем интересный, но большой пример. К сожалению, мы не смогли его сократить, чтобы сохранить необходимее поведение. Именно этим и опасны такие ошибки, так как невозможно предугадать к чему приводит простейшее изменение кода.
ptrdiff_t UnsafeCalcIndex(int x, int y, int width) {
int result = x + y * width;
return result;
}
...
int domainWidth = 50000;
int domainHeght = 50000;
for (int x = 0; x != domainWidth; ++x)
for (int y = 0; y != domainHeght; ++y)
array[UnsafeCalcIndex(x, y, domainWidth)] = 1;Данный код не может корректно заполнить массив, состоящий из 50000*50000 элементов. Невозможно это по той причине, что при вычислении "int result = x + y * width;" должно происходить переполнение.
Благодаря чуду массив все же корректно заполняется в release-варианте. Функция UnsafeCalcIndex встраивается внутрь цикла, используются 64-битные регистры:
0000000140001052 test rsi,rsi
0000000140001055 je wmain+6Ch (14000106Ch)
0000000140001057 lea rcx,[r9+rax]
000000014000105B mov rdx,rsi
000000014000105E xchg ax,ax
0000000140001060 mov byte ptr [rcx],1
0000000140001063 add rcx,rbx
0000000140001066 sub rdx,1
000000014000106A jne wmain+60h (140001060h)
000000014000106C add r9,1
0000000140001070 cmp r9,rbx
0000000140001073 jne wmain+52h (140001052h)Все это произошло из-за того, что функция UnsafeCalcIndex проста и может быть легко встроена. Стоит ее немного усложнить, или компилятору посчитать, что встраивать ее не стоит, и возникнет ошибка, которая проявит себя на больших объемах данных.
Немного модифицируем (усложним) функцию UnsafeCalcIndex. Обратите внимание, что логика функции ничуть не изменилась:
ptrdiff_t UnsafeCalcIndex(int x, int y, int width) {
int result = 0;
if (width != 0)
result = y * width;
return result + x;
}Результат - аварийное завершение программы, при выходе за границы массива:
0000000140001050 test esi,esi
0000000140001052 je wmain+7Ah (14000107Ah)
0000000140001054 mov r8d,ecx
0000000140001057 mov r9d,esi
000000014000105A xchg ax,ax
000000014000105D xchg ax,ax
0000000140001060 mov eax,ecx
0000000140001062 test ebx,ebx
0000000140001064 cmovne eax,r8d
0000000140001068 add r8d,ebx
000000014000106B cdqe
000000014000106D add rax,rdx
0000000140001070 sub r9,1
0000000140001074 mov byte ptr [rax+rdi],1
0000000140001078 jne wmain+60h (140001060h)
000000014000107A add rdx,1
000000014000107E cmp rdx,r12
0000000140001081 jne wmain+50h (140001050h)Надеемся, нам удалось продемонстрировать, как работающая 64-битная программа может легко стать неработающей, после того как вы внесете в нее самые безобидные правки или соберете другой версией компилятора.
Также вам теперь будут понятны некоторые странности и причудливости кода в проекте OmniSample, которые сделаны для того, чтобы продемонстрировать ошибку в простых примерах даже в режиме оптимизации кода.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 25. Практическое знакомство с паттернами 64-битных ошибок
Данная статья содержит различные примеры 64-битных ошибок, собранные в демонстрационном примере PortSample. Однако, начиная с версии PVS-Studio 3.63, вместо PortSample в дистрибутив PVS-Studio включается более новая версия примеров, которая называется OmniSample. Поэтому некоторые скриншоты в статье не соответствуют актуальному состоянию дел.
Знакомство с паттернами 64-битных ошибок закончено, и возможно у вас возникло желание на практике поэкспериментировать с опасными конструкциями и попробовать PVS-Studio для их обнаружения. Удовлетворить свой интерес вы можете, установив демонстрационный проект PortSample, входящий в состав PVS-Studio (рисунок 1).
Рисунок 1 - Установка проекта PortSample, входящего в состав PVS-Studio
PortSample представляет собой обыкновенный проект на языке Си++, который можно открыть как в Visual Studio 2005, так и в Visual Studio 2008 (рисунок 2).
Рисунок 2 - Для изучения PortSample можно использовать Visual Studio 2005 и Visual Studio 2008
В проекте PortSample собраны примеры для всех диагностических сообщений, которые выдает статический анализатор Viva64, входящий в состав PVS-Studio, при проверке 64-битных проектов. Количество предупреждений не велико (на момент написания данного текста их количество составляет 25 штук), но каждое диагностическое сообщение способно выявить большой спектр ошибочных конструкций. Это позволяет сгруппировать 64-битные ошибки в общие группы, к которым можно дать общее описание. Это позволяет обойтись в документации без бесконечных повторений описания одной и той же разновидности ошибок, закодированной в разных вариантах. В результате документацию к PVS-Studio можно не только пролистать, но и действительно прочитать, чтобы познакомиться со всеми тонкостями кодирования для 64-битных систем.
Русскоязычным читателям будет интересен тот факт, что документация по PVS-Studio доступна в online-режиме на русском языке: справочная система по PVS-Studio.
Программа PortSample имеет интерфейс, показанный на рисунке 3, который позволяет удобно запускать интересующие вас участки кода. Подробно о содержимом проекта рассказывать не имеет смысла. Вы сможете самостоятельно изучать интересующий вас код. Также вы можете обратиться к статье "Проблемы 64-битного кода на примерах", в которой подробно рассматриваются 64-битные ошибки на примере кода из проекта PortSample.
Рисунок 3 - Интерфейс программы
Обратим внимание на один важный момент, связанный с использованием демонстрационной версии PVS-Studio. Когда демонстрационная версия используется для проверки кода, то хотя и обнаруживаются все потенциальные ошибки, информация о том, где они расположены в тексте программы, показывается не во всех диагностических сообщениях. Вместо номера строки выводится текст "TRIAL RESTRICTION", как показано на рисунке 4.
Рисунок 4 - Использование демонстрационной версии PVS-Studio при проверке 64-битного проекта не позволяет просмотреть расположение в коде всех ошибок
Когда демонстрационная версия PVS-Studio работает с проектом PortSample, то показывается расположение всех ошибок. То есть PVS-Studio не имеет никаких ограничений при работе с примерами (смотри рисунок 5). Вы можете свободно модифицировать файлы PortSample содержащие ошибки и полноценно изучать поведение PVS-Studio на написанном вами коде.
Рисунок 5 - Демонстрационная версия PVS-Studio выводит номера всех строк с ошибками в проекте PortSample
Возникшие вопросы по использованию PVS-Studio и проекту PortSample вы можете обсудить с разработчиками анализатора. Мы будем рады комментариям, замечаниям и рекомендациям по улучшению анализатора PVS-Studio. Пишите нам по адресу support@viva64.com.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 26. Оптимизация 64-битных программ
- Снижение объема расходуемой памяти
- Использование memsize-типов в адресной арифметике
- Intrinsic-функции
- Выравнивание
- Другие способы повышения производительности
Снижение объема расходуемой памяти
После компиляции программы в 64-битном режиме она начинает потреблять большее количество памяти, чем ее 32-битный вариант. Часто это увеличение почти незаметно, но иногда потребление памяти может возрастать в 2 раза. Увеличение расхода памяти связано со следующими причинами:
- увеличение объема памяти для хранения некоторых объектов, например указателей;
- изменение правил выравнивания данных в структурах;
- увеличение расхода стековой памяти.
С увеличением потребляемой оперативной памяти часто можно мириться. Преимущество 64-битных систем как раз и заключается в том, что этой памяти много. Нет ничего плохого, что на 32-битной системе с 2 гигабайтами памяти программа занимала 300 Мбайт, а на 64-битной системе с 8 гигабайтами памяти программа займет 400 Мбайт. В относительных единицах мы получим, что программа на 64-битной системе занимает в 3 раза меньше доступной физической памяти. С описанным ростом потребляемой памяти нет смысла бороться. Проще добавить еще немного памяти.
Но существует и негативная сторона увеличения потребляемой памяти. Она связана с потерей производительности. Хотя 64-битный программный код работает быстрее, извлечение большего объема данных из памяти может свести на нет все преимущества и даже снизить производительность. Передача данных между памятью и микропроцессором (кэшем) не самая дешевая операция.
Одним из направления уменьшений расходуемой памяти является оптимизация структур данных, о чем подробно было рассказано в уроке 23.
Еще одним направлением экономии памяти является использование более экономных типов данных. Например, если необходимо хранить большое количество целых чисел, и их значение никогда не превысит UINT_MAX, то стоит использовать тип unsigned, а не тип size_t.
Использование memsize-типов в адресной арифметике
Использование типов ptrdiff_t и size_t в адресной арифметике помимо повышения надежности кода может дать дополнительный выигрыш в производительности. Например, использование в качестве индекса типа int, размерность которого отличается от размерности указателя, приводит к тому, что в двоичном коде будут присутствовать дополнительные команды преобразования данных. Речь идет о 64-битном коде, в котором размер указателей стал равен 64-битам, а размер типа int остался 32-битным.
Показать короткий пример преимущества size_t над unsigned не простая задача. Чтобы быть объективным необходимо использовать оптимизирующие возможности компилятора. А два варианта оптимизированного кода часто становятся слишком непохожими, чтобы легко было продемонстрировать отличие. Попытка создать нечто близкое к простому примеру увенчалась успехом только с шестого раза. И все равно пример не идеален, так как показывает не лишние преобразования типов данных, о которых сказано выше, а то, что компилятор смог построить более эффективный код при использовании типа size_t. Рассмотрим код программы, переставляющий элементы массива в обратном порядке:
unsigned arraySize;
...
for (unsigned i = 0; i < arraySize / 2; i++)
{
float value = array[i];
array[i] = array[arraySize - i - 1];
array[arraySize - i - 1] = value;
}В примере переменные "arraySize" и "i" имеют тип unsigned. Этот тип легко можно заменить на size_t и сравнить небольшой участок ассемблерного кода, показанный на рисунке 1.

Рисунок 1 - Сравнение 64-битного ассемблерного кода при использовании типов unsigned и size_t
Компилятор смог построить более лаконичный код, когда использовал 64-битные регистры. Мы не беремся утверждать, что код, созданный при использовании типа unsigned (текст слева), будет работать медленнее, чем код с использованием size_t (текст справа). Сравнить скорость выполнения кода на современных процессорах крайне сложная задача. Но из примера видно, что когда компилятор работает с массивами, используя 64-битные типы, он может строить более короткий и быстрый код.
Рассмотрим пример, демонстрирующий преимущества использования типов ptrdiff_t и size_t с точки зрения производительности. Для демонстрации возьмем простой алгоритм вычисления минимальной длины пути. С полным кодом программы можно познакомиться здесь.
Функция FindMinPath32 написана в классическом 32-битном стиле с использованием типов unsigned. Функция FindMinPath64 отличается от нее только тем, что в ней все типы unsigned заменены на типы size_t. Других отличий нет! Согласитесь, что это не является сложной модификацией программы. А теперь сравним скорости выполнения этих двух функций (таблица 1).

Таблица 1 - Время выполнения функций FindMinPath32 и FindMinPath64
В таблице 1 показано приведенное время относительно скорости выполнения функции FindMinPath32 на 32-битной системе. Это сделано для большей наглядности.
В первой строке время работы функции FindMinPath32 на 32-битной системе равно 1. Это связано с тем, что мы взяли время ее работы за единицу измерения.
Во второй строке мы видим, что время работы функции FindMinPath64 на 32-битной системе также равно 1. Это не удивительно, так как на 32-битной системе тип unsigned совпадает с типом size_t и никакой разницы между функцией FindMinPath32 и FindMinPath64 нет. Небольшое отклонение (1.002) говорит только о небольшой погрешности в измерениях.
В третьей строке мы видим прирост производительности, равный 7%. Это вполне ожидаемый результат от перекомпиляции кода для 64-битной системы.
Наибольший интерес представляет 4 строка. Прирост производительности составляет 15%. Это значит, что простое использование типа size_t вместо unsigned позволяет компилятору построить более эффективный код, работающий еще на 8% быстрее!
Это простой и наглядный пример, когда использование данных, не равных размеру машинного слова, снижает производительность алгоритма. Простая замена типов int и unsigned на типы ptrdiff_t и size_t может дать существенный прирост производительности. В первую очередь это относится к использованию этих типов данных для индексации массивов, адресной арифметики и организации циклов.
Примечание. Хотя статический анализатор PVS-Studio специально не ориентирован на оптимизацию программ, его использование способствует рефакторингу кода, делающего код более эффективным. Например, исправляя потенциальные ошибки, связанные с адресной арифметикой, вы будете использовать memsize-типы, что позволит компилятору строить более оптимизированный код.
Intrinsic-функции
Intrinsic-функции - это специальные системно-зависимые функции, выполняющие действия, которые невозможно выполнить на уровне Си/Си++ кода или выполняющие эти действия намного эффективнее. По сути, они позволяют избавиться от использования inline-ассемблера, т.к. его использование часто нежелательно или невозможно.
Программы могут использовать intrinsic-функции для создания более быстрого кода за счет отсутствия накладных расходов на вызов обычного вида функций. При этом, естественно, размер кода будет чуть-чуть больше. В MSDN приводится список функций, которые могут быть заменены их intrinsic-версией. Это, например, memcpy, strcmp и другие.
В компиляторе Microsoft Visual C++ есть специальная опция "/Oi", которая позволяет автоматически заменять вызовы некоторых функций на intrinsic-аналоги.
Помимо автоматической замены обычных функций на intrinsic-варианты, можно явно использовать в коде intrinsic-функции. Вот для чего это может быть нужно:
- Встроенный (inline) ассемблерный код не поддерживается компилятором Visual C++ в 64-битном режиме. Intrinsic-код поддерживается.
- Intrinsic-функции проще использовать, так как они не требуют знания регистров и других подобных низкоуровневых конструкций.
- Intrinsic-функции обновляются в компиляторах. Ассемблерный же код придется обновлять вручную.
- Встроенный оптимизатор не работает с ассемблерным кодом.
- Intrinsic-код легче переносить, чем ассемблерный.
Использование intrinsic-функций в автоматическом режиме (с помощью ключа компилятора) позволяет получить бесплатно несколько процентов прироста производительности, а "ручное" - даже больше. Поэтому использование intrinsic-функций вполне оправдано.
Более подробно с применением intrinsic-функций можно ознакомиться в блоге команды Visual C++.
Выравнивание
В некоторых случаях полезно явно помогать компилятору, задавая выравнивание вручную, чтобы увеличить производительность. Например, данные SSE должны быть выровнены по границе 16 байт. Вот как этого можно добиться:
// 16-byte aligned data
__declspec(align(16)) double init_val[2] = {3.14, 3.14};
// SSE2 movapd instruction
_m128d vector_var = __mm_load_pd(init_val);Источники "Porting and Optimizing Multimedia Codecs for AMD64 architecture on Microsoft Windows", "Porting and Optimizing Applications on 64-bit Windows for AMD64 Architecture" дают подробный обзор данных вопросов.
Другие способы повышения производительности
Подробно с вопросами оптимизации 64-битных приложений вы сможете познакомиться в документе "Software Optimization Guide for AMD64 Processors".
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 27. Особенности создания инсталляторов для 64-битного окружения
При разработке 64-битной версии приложения дополнительное внимание стоит уделить и вопросу дистрибуции программы. Ведь при установке на 64-битной операционной системе есть несколько нюансов, забыв о которых можно получить неработающий инсталляционный пакет.
Прежде всего, надо понимать, что сам дистрибутив программы (exe-файл, который запускает установку) может быть технически как 32-битным приложением, так и 64-битным. И если сделать этот дистрибутив 64-битным, то он не запустится на 32-битной системе. Обратите внимание, что он не сможет выдать сообщение вроде: "Вы пытаетесь установить дистрибутив 64-битной программы в 32-битной системе". Он просто выдаст сообщение о поврежденном файле. Таким образом, в большинстве случаев разумно делать инсталлятор всегда 32-битным приложением, даже если устанавливаться он должен только на 64-битной системе.
Важным аспектом функционирования 32-битных программ в 64-битной среде является механизм перенаправления, реализованный в Windows. Благодаря этому механизму старые 32-битные приложения, которые пытались обратиться, к примеру, к папке "c:\program files" автоматически будут обращаться к "c:\program files (x86)". А доступ к некоторым секциям реестра также будет автоматически перенаправлен.
Из-за механизма перенаправления при разработке инсталляторов часто бывает, что либо файлы оказываются не там, где ожидает разработчик, либо записи в реестре относятся не к тем разделам. Вы можете почитать о системе перенаправления в справочной системе MSDN: "File System Redirector",
Все эти нюансы настраиваются в любом современном инсталляторе, но об этом надо не забыть при подготовке дистрибутива, совместимого с 64-битными операционными системами.
При разработке инсталляторов для 64-битных версий часто делают один общий инсталлятор, который содержит в себе как 32-битные версии приложений и компонентов, так и 64-битные. В этом случае надо не забыть положить полные наборы компонентов, а также библиотеки зависимостей. Например, для приложений, разработанных с помощью Visual C++, часто в комплект кладут Visual C++ Redistributable Package. Этот пакет необходимо брать как в версии для x86, так и в x64 варианте.
Если инсталлятор использует какие-то сторонние модули для реализации сложной функциональности, то следует помнить об ограничении. Модули, собранные для 64-битного режима, не могут подгружать 32-битные динамические библиотеки и наоборот.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.
Урок 28. Оценка стоимости процесса 64-битной миграции Си/Си++ приложений
- Приобретение 64-битного аппаратного и программного обеспечения
- Приобретение компилятора для сборки 64-битных приложений
- Приобретение 64-битных версий библиотек
- Обучение персонала и приобретение дополнительных инструментов
- Модификация кода
- Адаптация системы тестирования
- Защита программных модулей
- Адаптация дистрибутива
Приступая к планированию переноса проекта на 64-битную систему, необходимо уметь оценить объем работ и материальные затраты. Рассмотрим те элементы, из которых будет складываться цена создания 64-битного программного проекта.
В случае затруднений с оценками стоимости перехода на 64-битные системы, вы можете обратиться за консультацией к специалистам нашей компании ООО "Системы программной верификации". Наша компания также может взять на себя часть работ или полностью выполнить адаптацию ваших проектов для 64-битных систем.
Приобретение 64-битного аппаратного и программного обеспечения
Сейчас уже сложно найти у разработчика компьютер, оснащенный 32-битным микропроцессором. Но все-таки следует помнить, что вы должны быть обеспечены 64-битными компьютерами для всех необходимых задач. Более реальной выглядит ситуация, когда на 64-битных аппаратных системах по-прежнему используются 32-битные операционные системы. Вы должны учесть расходы, связанные с приобретением и установкой 64-битных версий операционных систем. Учтите дополнительные расходы, связанные со сменой версии операционной системы, например переустановку различного программного обеспечения.
Приобретение компилятора для сборки 64-битных приложений
Заложите в цену покупку и освоение новых компиляторов, способных создавать 64-битный код.
Приобретение 64-битных версий библиотек
Вам может потребоваться купить 64-битные версии библиотек и иных компонентов. Узнайте заранее, какова ценовая политика компаний, чьи компоненты используются в вашем проекте. Иногда 32-битные и 64-битные версии компонентов продаются отдельно. Если вы используете библиотеки с открытым кодом, для которых пока не существуют 64-битных конфигураций, то будьте готовы потратить существенное время на их самостоятельную доработку.
Обучение персонала и приобретение дополнительных инструментов
Учтите время, необходимое для того, чтобы сотрудники познакомились со всей необходимой информацией по разработке 64-битных систем. Также может потребоваться приобретение дополнительных инструментальных средств, таких как, например, PVS-Studio.
Модификация кода
Как вы уже знаете из предыдущих уроков, скомпилировать 64-битную конфигурацию - это только начало работы. В большинстве случаев, необходимо обнаружить и исправить большое количество дефектов, которые проявят себя в 64-битном коде. Это, пожалуй, самый трудоемкий, но при этом наиболее плохо поддающийся оценке элемент. Однако можно предложить следующую методологию оценки, основанную на использовании статического анализатора PVS-Studio.
Итак, у вас есть несколько (десятков, сотен) мегабайт исходного кода, готового к миграции. Конфигурации для сборки 64-битного кода пока нет. Ни одного компилирующегося в 64-битном режиме файла, соответственно, тоже нет.
В PVS-Studio имеется возможность обнаружения проблем 64-битного кода даже в 32-битных проектах. Именно эта возможность и позволит оценить сложность миграции ДО этапа создания 64-битной конфигурации проекта.
Хочется обратить внимание читателей на то, как работает проверка кода в 32-битном режиме. Вы должны понимать, что эта проверка, не может считаться полноценной, и исправление даже всех обнаруженных проблем не является гарантией работоспособности кода в 64-битном режиме. В коде любого серьезного приложения будут подобные фрагменты:
#ifdef WIN64
...
#endifЕстественно, при проверке в 32-битном режиме подобный код будет пропущен. Вернее будет сказать так: на момент, когда 64-битной конфигурации пока еще нет, такого кода в приложении может не быть.
Другой важный момент - в зависимости от конфигурации проекта типы данных естественно отличаются. Поэтому проверка в 32-битном и в 64-битном режиме практически всегда будет давать разные результаты.
Однако сильно ли будут различаться эти результаты? По результатам экспериментов, проведенных в нашей компании, мы получили следующие данные: списки диагностических сообщений от анализатора кода PVS-Studio при проверке проектов в 32-битном и в 64-битном режимах совпадают на 95-97%. Это означает, что отличаются не более 5% диагностических сообщений.
Эти результаты были получены следующим образом. Мы взяли код реальных проектов, проверили его в 32-битном режиме, сохранили список диагностических сообщений. Затем проверили код этих же проектов в 64-битном режиме и вновь сохранили список диагностических сообщений. После чего сравнили полученные списки и определили, сколько процентов диагностических сообщений совпало. Поскольку вся процедура делалась в автоматизированном режиме, то количество проанализированных проектов было достаточным (больше 20 проектов с объемом кода в несколько мегабайт каждый). Можно сделать вывод, что цифры (5% различий) внушают доверие.
Конечно же, спешить исправлять выявленные потенциальные ошибки в 32-битной конфигурации проекта не стоит - лучше подождать, пока станет доступна 64-битная конфигурация. А вот оценить, сколько потребуется времени для разбора сообщений от анализатора кода, вполне возможно.
Для получения оценки времени рекомендуем поступить следующим образом:
- Выполнить анализ 32-битной конфигурации проекта с помощью PVS-Studio.
- В течение одного дня программист, понимающий проблемы 64-битного кода, просматривает сообщения анализатора кода и принимает решение о том, актуальна ли данная ошибка для данного проекта или нет. Если актуальна, то он исправляет ее.
- Общее количество сообщений от анализатора кода делится на количество проанализированных и обработанных программистом сообщений за день.
- Полученное число - это количество человеко-дней, необходимое для миграции кода приложения на 64-битную платформу.
Найденные ошибки человек должен обязательно исправлять. Недостаточно просто обнаружить ошибку и представить, что она исправлена. Обнаружить и исправить - это разные по времени действия. Исправление некоторых ошибок может потребовать модификации кода программы во многих файлах проекта. Чтобы оценка времени не оказалась заниженной, необходимо обязательно внести в код все необходимые правки.
Разумеется, в данном алгоритме оценки процесса миграции есть слабое место - профессионализм разработчика, который будет в течение одного дня разбирать сообщения от анализатора и модифицировать код. Поэтому мы рекомендуем очень серьезно подойти к назначению программиста, ответственного за оценку.
Вот несколько рекомендаций по выбору такого программиста:
- Он должен быть опытным программистом со стажем работы не менее трех лет и желательно со знанием конкретного проекта, который будет переноситься.
- Он должен быть знаком с проблемами 64-битного кода. Например, с этими уроками или статьей "20 ловушек переноса Си++ - кода на 64-битную платформу".
- Желательно, чтобы он понимал принципы работы со статическими анализаторами кода. Это необязательное требование, но понимание технологии статического анализа кода делает оценку процесса миграции более адекватной.
- Человек должен уметь удерживать себя в обыкновенном рабочем режиме в течение испытательного дня. Он не должен стараться поставить рекорд производительности, чтобы произвести впечатление на коллег. Все дни в таком режиме проработать не удастся, и сроки будут оценены не верно.
Соблюдение этих рекомендаций позволит получить адекватную оценку стоимости и времени процесса 64-битной миграции приложений.
Адаптация системы тестирования
Учтите стоимость адаптации вашей системы тестирования для полноценной проверки 64-битных модулей. Если ваши программы обрабатывают большие объемы данных, то должны появиться тесты, в которых используются объемы данных более 4 гигабайт. В свою очередь интеграция тяжелых тестов может повлечь за собой задачу распараллеливания тестов. В этом случае, возможно, вам придется приобрести дополнительные инструментальные средства.
Защита программных модулей
Если вы используете программные или программно-аппаратные системы защиты от копирования и от взлома программы, то вы должны учесть стоимость реализации защиты 64-битного кода. Возможно, вам придется освоить новые системы защиты, если используемые вами на данный момент не поддерживают работу с 64-битным кодом. Вы можете встретить иные неожиданные сложности и должны зарезервировать время для их разрешения.
Адаптация дистрибутива
Вам потребуется создать новый дистрибутив, что было подробно рассмотрено в предыдущем уроке.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса "Уроки разработки 64-битных приложений на языке Си/Си++" является ООО "Системы программной верификации". Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании.