
Мы используем куки, чтобы пользоваться сайтом
было удобно.

"I'll be back" (c). Думаю, все знают эту фразу. И хотя сегодня мы будем говорить не о возвращении терминатора, тема статьи в некотором роде схожа. Сегодня расскажем о проверке библиотеки машинного обучения TensorFlow и попробуем выяснить, можем ли мы спать спокойно, или час Skynet уже близок...

TensorFlow - это библиотека машинного обучения, разрабатываемая корпорацией Google, и доступная как open-source проект с 9 ноября 2015 года. В данный момент она используется в научно-исследовательской работе и в десятках коммерческих продуктов Google, в том числе в Google Search, Gmail, Photos, YouTube, Translate, Assistant и пр. Исходный код проекта доступен в репозитории на GitHub, а также на сайте открытых проектов Google.

Почему выбор пал на этот проект?
Само собой, мимо такого проекта пройти нельзя. Даже не знаю, почему мои коллеги не проверили его раньше. Что ж, исправлю это.
Если вы знаете, что такое PVS-Studio, то знаете и ответ на этот вопрос. Но не спешите читать дальше, вдруг вам не все известно о нашем анализаторе? Например, что у нас уже больше года есть C# анализатор и примерно полгода - версия для Linux.

Для тех же, кто совсем не в теме. Анализ исходного кода был проведён с помощью статического анализатора PVS-Studio, который ищет ошибки в программах, написанных на C, C++ и C#. PVS-Studio работает под Windows и Linux и на данный момент в нём реализовано свыше 400 диагностических правил, описание которых можно найти на соответствующей странице.
Помимо разработки анализатора мы проверяем open-source проекты и пишем статьи по результатам проверки. На данный момент мы проверили больше 280 проектов, в которых нашли более 10 800 ошибок. Причём это не какие-то рядовые проекты, а достаточно известные: Chromium, Clang, GCC, Roslyn, FreeBSD, Unreal Engine, Mono и пр.
PVS-Studio доступен для загрузки, так что советую попробовать на своём проекте и посмотреть, что интересного удастся найти.
Кстати, тэг PVS-Studio есть на Stack Overflow (ссылка). Рекомендую задавать вопросы именно там, чтобы в дальнейшем другие разработчики могли оперативно найти нужную им информацию, не ожидая наших ответов по почте. Мы, в свою очередь, всегда рады помочь нашим пользователям.
В этот раз я хочу отойти от традиционной последовательности проверки: 'Загрузил проект -> Проверил -> Написал о найденных ошибках' и рассказать поподробнее про некоторые настройки анализатора, и о том, чем они могут быть полезны. В частности, я покажу, как можно эффективно бороться с ложными срабатываниями, чем могут быть полезны отключения диагностик и исключение из проверки или вывода определённых файлов. Ну и, конечно же, посмотрим на то, что удалось найти PVS-Studio в исходном коде TensorFlow.
Теперь, когда PVS-Studio доступен и под Linux, есть выбор, где же выполнять проверку проекта: под Linux или Windows. Совсем недавно я проверял один проект под openSUSE, это было достаточно просто и удобно, но TensorFlow я всё же решил проверить под Windows. Так привычнее. К тому же, он может быть собран с использованием CMake, что подразумевает дальнейшую работу в среде разработки Visual Studio, для которой у нас есть плагин (кстати, в его последней версии появилось выделение строк с ошибочным кодом).
Официально сборка TensorFlow под Windows не поддерживается (согласно сайту). Тем не менее, там же есть ссылка, как собрать проект с использованием CMake.
В итоге получаем набор .vcxproj файлов, объединённых в .sln, а значит, дальше можно удобно работать с проектом из-под Visual Studio. И это радует. Я работал из-под IDE Visual Studio 2017, поддержка которой была добавлена в релизе PVS-Studio 6.14.
Примечание. Перед анализом неплохо бы собрать проект, убедиться, что всё нормально собирается и нет никаких ошибок. Это нужно для того, чтобы быть уверенным, что анализ пройдёт качественно и анализатору будет доступна необходимая синтаксическая и семантическая информация. Так вот, на сайте TensorFlow есть примечание: By default, building TensorFlow from sources consumes a lot of RAM. Ну, ничего страшного, ведь у меня на машине 16Gb RAM. И что вы думаете? В ходе сборки у меня возникла ошибка Fatal Error C1060 (compiler is out of heap space)! Не хватило памяти! Это было весьма неожиданно. И, нет, у меня одновременно со сборкой не было запущено 5 виртуальных машин. Справедливости ради отмечу, что при сборке через bazel можно ограничить количество используемой оперативной памяти (как именно - описано в инструкции сборки TensorFlow).
И вот уже не терпится нажать заветную кнопку "Analyze solution with PVS-Studio" и посмотреть, что же интересного удастся найти, но сначала было бы неплохо исключить из анализа те файлы, которые нам неинтересны, например, сторонние библиотеки. Делается это в настройках PVS-Studio достаточно просто: на вкладке 'Don't Check Files' задаём маски тех файлов и путей, анализ которых нам неинтересен. В настройках уже забит некоторый набор путей (например, /boost/). Я дополнил его двумя масками: /third_party/ и /external/. Это позволит не только исключить предупреждения из окна выдачи результатов, но и даже не выполнять анализ файлов в этих директориях, что положительно сказывается на времени анализа.
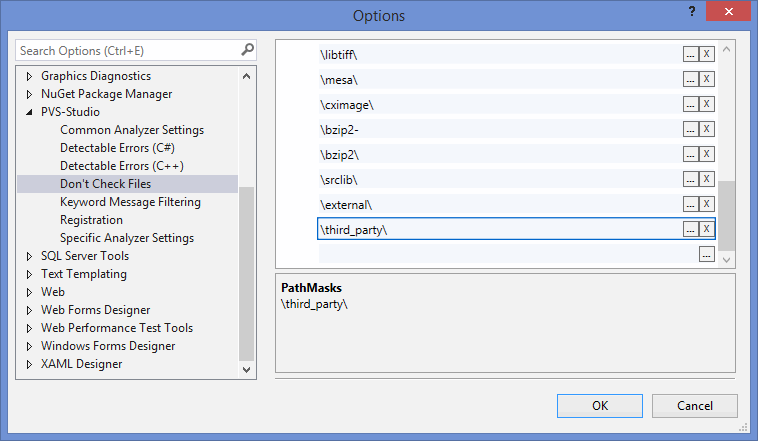
Рисунок 1 - Задаём исключения анализа в настройках PVS-Studio
А теперь можно запустить анализ и посмотреть, что же интересного удастся найти.
Примечание. 'Don't Check Files' можно настроить 'до' и 'после' анализа. Про первый случай я рассказал выше, во втором же будет выполнена фильтрация уже полученного лога, что тоже полезно и избавит от просмотра ненужных предупреждений. Об этом будет ниже.
Ложные срабатывания - головная боль для всех: и для нас, разработчиков статического анализатора, и для пользователей, так как засоряют полезный вывод. Большое количество ложных срабатываний может оттолкнуть людей от использования инструмента. К тому же часто люди оценивают анализаторы по критерию того, насколько много ложных срабатываний они выдают. Тут не всё так просто, и эта тема подходит для отдельной статьи и дискуссии. Мой коллега, кстати, недавно как раз писал статью на эту тему, рекомендую ознакомиться.
Наша задача состоит в том, чтобы постараться отсеять как можно больше ложных срабатываний на этапе анализа, чтобы пользователь вообще про них не знал. Для этого вводятся исключения в диагностические правила, т.е. особые случаи, в которых выдавать предупреждения не нужно. Количество этих исключений может сильно варьироваться от диагностики к диагностике: где-то их может не быть вообще, а где-то могут быть реализованы десятки таких исключений.
Тем не менее все случаи не покрыть (иногда они очень специфичны), поэтому наша вторая задача - дать пользователю возможность самостоятельно исключить ложные срабатывания из результатов анализа. Для этого в анализаторе PVS-Studio реализован ряд механизмов, таких как подавление ложных срабатываний через комментарии, конфигурационные файлы, базы подавления. Опять же, про это написана отдельная статья, так что здесь я не стану сильно копать вглубь.
К чему я вообще завёл разговор про ложные срабатывания? Во-первых, потому что борьба с ложными срабатываниями - это важно, а, во-вторых, потому что вот что я увидел, когда проверил TensorFlow и отфильтровал вывод по диагностическому правилу V654 (изображение кликабельно).
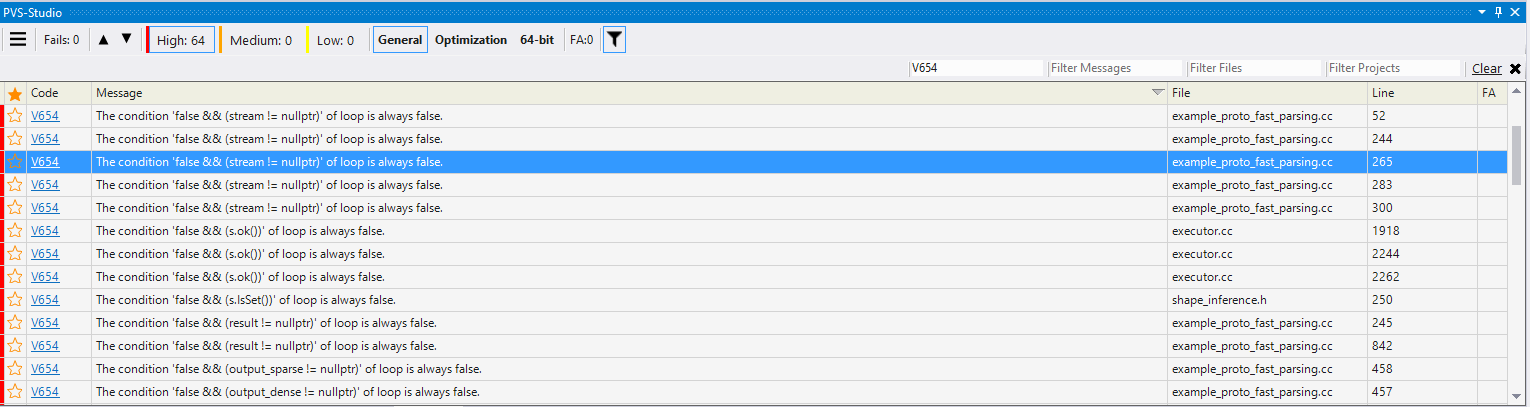
Рисунок 2 - Все найденные срабатывания V654 имеют схожий паттерн
64 срабатывания, и у всех, как у одного, один и тот же паттерн - код вида:
false && exprВ самом коде эти места выглядят так:
DCHECK(v);
DCHECK(stream != nullptr);
DCHECK(result != nullptr);А вот как объявлен макрос DCHECK:
#ifndef NDEBUG
....
#define DCHECK(condition) CHECK(condition)
....
#else
....
#define DCHECK(condition) \
while (false && (condition)) LOG(FATAL)
....
#endifЧто следует из этого кода? DCHECK - отладочный макрос. В отладочной версии кода он раскрывается в проверку условия (CHECK(condition)), в релизной - в цикл, который не будет выполнен ни разу - while (false && ....). Ввиду того, что я собирал релизную версию кода, раскрылся макрос соответствующим образом (в цикл while). В итоге выходит, что анализатор, казалось бы, ругается по делу - ведь результат выражения действительно всегда false. Но какой толк от этих предупреждений, если они выдаются на код, который так и задумывался? В итоге процент ложных срабатываний для данной диагностики будет таким, как на диаграмме ниже.
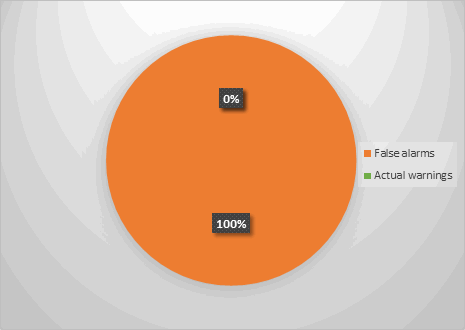
Рисунок 3 - Соотношение хороших и ложных срабатываний диагностики V654
Может быть вы подумали, что это шутка? Нет, не шутка, 100% ложных срабатываний. Вот про такие специфичные случаи я и говорил выше. А ещё говорил, что есть способы борьбы с ними. Лёгким движением руки и кнопкой 'Add selected messages to suppression base' мы можем исправить это соотношение в противоположную сторону (изображение кликабельно).
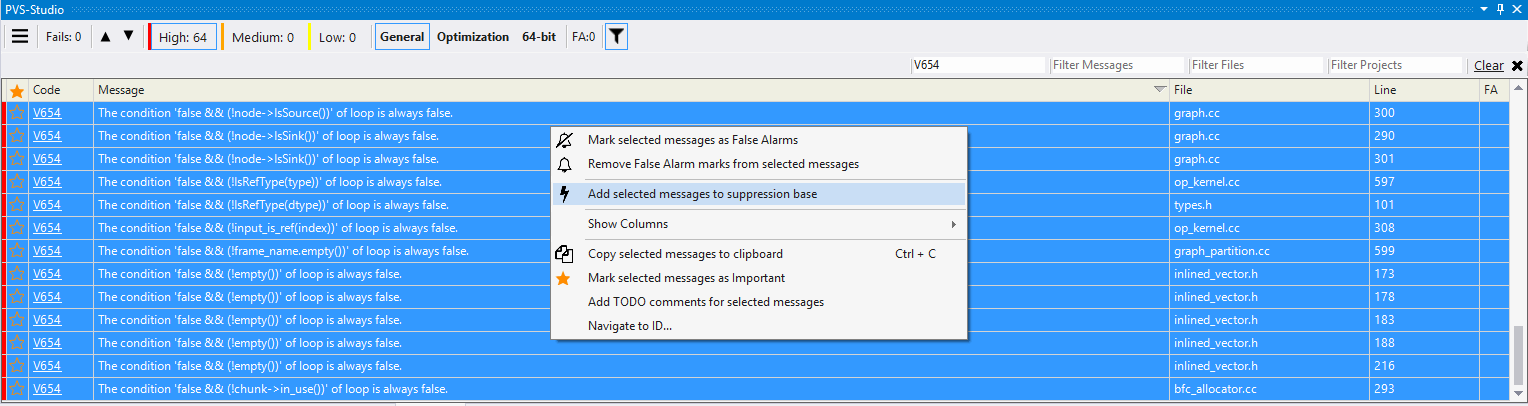
Рисунок 4 - Боремся с ложными срабатываниями
Так можно подавить все текущие предупреждения, убрав их из окна вывода. Но это не совсем правильно, так как в случае, если вы в ходе написания кода опять будете использовать макрос DCHECK, на него опять будут выданы предупреждения. Решение есть. Нужно подавить срабатывание в макросе, оставив комментарий специального вида. Код подавления будет выглядеть так:
//-V:DCHECK:654
#define DCHECK(condition) \
while (false && (condition)) LOG(FATAL)Комментарий следует разместить в том же заголовочном файле, где объявлен макрос.
Всё, теперь о макросе DCHECK можно больше не беспокоиться, т.к. предупреждение V654 на него выдаваться больше не будет. В итоге мы опять успешно сразились с ложными срабатываниями. Так или иначе, после этих действий диаграмма ложных срабатываний для V654 будет выглядеть следующим образом.
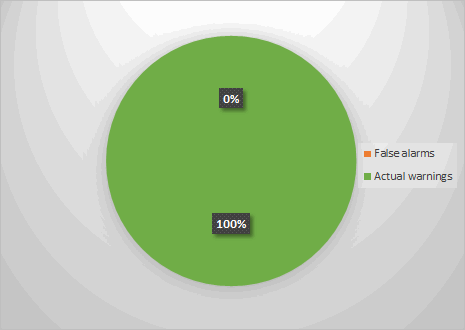
Рисунок 5 - Успешно устранили ложные срабатывания
Теперь картина выглядит совсем другим образом, ведь процент ложных срабатываний - 0. Такая вот занимательная арифметика. К чему весь этот разговор про ложные срабатывания? Я просто хотел объяснить, что ложные срабатывания - это неизбежность. Цель анализатора - избавиться от как можно большего их количества на этапе анализа, но из-за специфики проекта, возможно, вам придётся столкнуться с ними. Надеюсь, мне удалось донести, что бороться с ложными срабатываниями можно (и нужно), и делается это достаточно просто.
Наверняка вам уже не терпится посмотреть на найденные ошибки, но призываю к терпению и предлагаю рассмотреть ещё некоторые настройки, которые помогут облегчить жизнь при работе с результатами анализа.
В ходе анализа проверялся не только код, который самостоятельно писали программисты, но и автоматически сгенерированный. Просматривать предупреждения на таком коде нам неинтересно, поэтому нужно как-то их исключить из анализа. Здесь на помощь придут упомянутые ранее настройки 'Don't check files'. Конкретно для данного проекта я задал исключения по следующим именам файлов:
pywrap_*
*.pb.ccЭто позволило скрыть более 100 предупреждений общего назначения (GA), имеющих средний уровень достоверности (Medium).
Ещё одна настройка анализатора, которая оказалась полезна - отключение групп диагностических правил. Почему это может быть актуально? Например, на данном проекте было выдано порядка 70 предупреждений V730 (не все члены класса инициализируются в конструкторе). Не стоит проходить мимо этих предупреждений, т.к. они могут сигнализировать о трудно обнаруживаемых ошибках. Тем не менее, не знакомому с кодом человеку не всегда понятно, действительно ли неинициализированный член приведёт к проблемам, или есть какой-то хитрый способ его дальнейшей инициализации. Да и для статьи ошибки этого типа - не самые интересные. Поэтому их стоит просмотреть разработчикам, а мы заострять внимание на этом не будем. Отсюда формируется цель - отключение целой группы диагностических правил. Делается это легко и просто: в настройках плагина PVS-Studio достаточно снять выделение для 'Check box' у соответствующей диагностики.
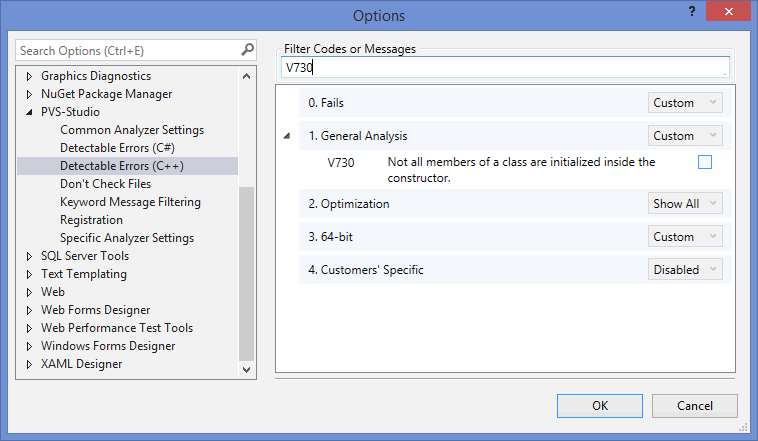
Рисунок 6 - Отключение неактуальных диагностик
Отключив те диагностические правила, которые не актуальны для вашего проекта, вы тем самым упрощаете себе дальнейшую работу с выводом анализатора.
Что ж, давайте перейдём к, пожалуй, наиболее интересной части - разбору тех фрагментов кода, которые PVS-Studio счёл подозрительными.
Обычно я люблю начинать с классической ошибки, которую допускают и в C++ проектах, и в C# - ошибка вида a == a, которую обнаруживают диагностические правила V501 и V3001. Но здесь нет таких ошибок! Да и вообще набор обнаруженных ошибок достаточно... специфичен. Но не будем тянуть, приступим к делу.
void ToGraphDef(const Graph* g, GraphDef* gdef, bool pretty) {
....
gtl::InlinedVector<const Edge*, 4> inputs;
....
for (const Edge* e : inputs) {
const string srcname = NewName(e->src(), pretty);
if (e == nullptr) {
ndef->add_input("unknown");
} else if (!e->src()->IsOp()) {
} else if (e->IsControlEdge()) {
ndef->add_input(strings::StrCat("^", srcname));
} else if (e->src_output() == 0) {
ndef->add_input(srcname);
} else {
ndef->add_input(strings::StrCat(srcname, ":", e->src_output()));
}
}
....
}Предупреждение PVS-Studio: V595 The 'e' pointer was utilized before it was verified against nullptr. Check lines: 1044, 1045. function.cc 1044
В цикле выполняется обход элементов вектора и, в зависимости от значения элемента, выполняются те или иные действия. Проверка e == nullptr подразумевает, что указатель может быть нулевым. Вот только строкой выше, во время вызова функции NewName, выполняется разыменование этого указателя: e->src(). Результат такой операции - неопределённое поведение, которое может привести, в том числе, к аварийному завершению программы.
Но код TensorFlow не так-то прост. Заполнение этого вектора (inputs) происходит выше и выглядит следующим образом:
for (const Edge* e : n->in_edges()) {
if (e->IsControlEdge()) {
inputs.push_back(e);
} else {
if (inputs[e->dst_input()] == nullptr) {
inputs[e->dst_input()] = e;
} else {
LOG(WARNING) << "Malformed graph node. multiple input edges: "
<< n->DebugString();
}
}
}Посмотрев внимательно на этот код, можно понять, что в вектор inputs никогда не будут записаны нулевые указатели, так как перед добавлением элементов всегда выполняется разыменование указателя, к тому же перед разыменованием указателя отсутствует его проверка на равенство nullptr. Так как вектор inputs не будет содержать нулевых указателей, выходит, что выражение e == nullptr, о котором мы говорили раньше, всегда будет иметь значение false.
Так или иначе, это код с подвохом, и PVS-Studio его успешно нашёл. Идём дальше.
Status MasterSession::StartStep(const BuildGraphOptions& opts,
int64* count,
ReffedClientGraph** rcg,
bool is_partial) {
....
ReffedClientGraph* to_unref = nullptr;
....
if (to_unref) to_unref->Unref();
....
}Предупреждение PVS-Studio: V547 Expression 'to_unref' is always false. master_session.cc 1114
В теле метода объявляется локальная переменная to_unref, инициализируемая значением nullptr. До оператора if этот указатель не используется, его значение не изменяется. Следовательно, так как указатель так и остался нулевым, тело оператора if никогда не будет выполнено. Возможно, этот код остался после рефакторинга. Может быть этот указатель должен был использоваться где-то между инициализацией и проверкой, но вместо него использовали другой (перепутали), однако я не нашёл схожих имен. Выглядит подозрительно.
Идём дальше.
struct LSTMBlockCellBprop ....
{
....
void operator()(...., bool use_peephole, ....) {
....
if (use_peephole) {
cs_prev_grad.device(d) =
cs_prev_grad +
di * wci.reshape(p_shape).broadcast(p_broadcast_shape) +
df * wcf.reshape(p_shape).broadcast(p_broadcast_shape);
}
if (use_peephole) {
wci_grad.device(d) =
(di * cs_prev).sum(Eigen::array<int, 1>({0}));
wcf_grad.device(d) =
(df * cs_prev).sum(Eigen::array<int, 1>({0}));
wco_grad.device(d) =
(do_ * cs).sum(Eigen::array<int, 1>({0}));
}
....
}
};Предупреждение PVS-Studio: V581 The conditional expressions of the 'if' operators situated alongside each other are identical. Check lines: 277, 284. lstm_ops.h 284
Есть два условных оператора с одинаковым условным выражением, при этом между этими операторами выражение (в данном случае - параметр use_peephole) не изменяется. Иногда это может свидетельствовать о достаточно серьёзной ошибке, когда в одном из случаев использовали не то выражение, которое подразумевалось, но в данном случае, отталкиваясь от контекста, можно сделать вывод, что просто продублировали условные операторы. Думаю, это не ошибка, но всё операции можно было бы разместить в одном условном операторе.
Нельзя написать статью и не посмотреть на ошибки copy-paste.
struct CompressFlags {
....
Format format;
....
int quality = 95;
....
bool progressive = false;
....
bool optimize_jpeg_size = false;
....
bool chroma_downsampling = true;
....
int density_unit = 1;
int x_density = 300;
int y_density = 300;
....
StringPiece xmp_metadata;
....
int stride = 0;
};
class EncodeJpegOp : public OpKernel {
....
explicit EncodeJpegOp(OpKernelConstruction* context) :
OpKernel(context) {
....
OP_REQUIRES_OK(context,
context->GetAttr("quality", &flags_.quality));
OP_REQUIRES(context,
0 <= flags_.quality && flags_.quality <= 100,
errors::InvalidArgument("quality must be in [0,100], got ",
flags_.quality));
OP_REQUIRES_OK(context,
context->GetAttr("progressive",
&flags_.progressive));
OP_REQUIRES_OK(context,
context->GetAttr("optimize_size",
&flags_.optimize_jpeg_size));
OP_REQUIRES_OK(context,
context->GetAttr("chroma_downsampling", // <=
&flags_.chroma_downsampling));
OP_REQUIRES_OK(context,
context->GetAttr("chroma_downsampling", // <=
&flags_.chroma_downsampling));
....
}
....
jpeg::CompressFlags flags_;
}Предупреждение PVS-Studio: V760 Two identical blocks of text were found. The second block begins from line 58. encode_jpeg_op.cc 56
Как видно из кода, в конструкторе класса EncodeJpegOp через макросы OP_REQUIRES_OK и OP_REQUIRES проверяют значения флагов, считываемых из поля flags_. Однако в последних строках приведённого фрагмента кода для конструктора проверяют значение одного и того же флага. Очень похоже на copy-paste: продублировали, но поправить забыли.
Самое интересное (и тяжёлое), что зачастую бывает в таких случаях - это понять, является ли copy-paste код избыточным, или подразумевалось что-то другое. Если код избыточен, как правило, ничего особо страшного нет, но совсем иной разговор, если подразумевался другой фрагмент кода, так как в этом случае получаем логическую ошибку.
Просмотрев тело конструктора, я не нашёл проверки поля stride. Возможно, что в одном из случаев подразумевалась как раз эта проверка. С другой стороны, в конструкторе порядок полей совпадает с порядком объявления полей в структуре CompressFlags. Так что здесь судить о том, как нужно исправить код, сложно, можно только выдвигать предположения. В любом случае, стоит обратить внимание на это место.
Нашёл анализатор и несколько подозрительных мест, связанных с битовым сдвигом. Посмотрим на них. И хочу напомнить, что неправильное использование операций сдвига может привести к неопределённому поведению.

class InferenceContext {
....
inline int64 Value(DimensionOrConstant d) const {
return d.dim.IsSet() ? d.dim->value_ : d.val;
}
....
}
REGISTER_OP("UnpackPath")
.Input("path: int32")
.Input("path_values: float")
.Output("unpacked_path: float")
.SetShapeFn([](InferenceContext* c) {
....
int64 num_nodes = InferenceContext::kUnknownDim;
if (c->ValueKnown(tree_depth)) {
num_nodes = (1 << c->Value(tree_depth)) - 1; // <=
}
....
})
....;Предупреждение PVS-Studio: V629 Consider inspecting the '1 << c->Value(tree_depth)' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type. unpack_path_op.cc 55
Подозрительность этого кода в том, что здесь в операциях сдвига и присваивания перемешаны 32-битные и 64-битные значения. Литерал 1 представляет собой 32-битное значение, для которого выполняется левосторонний сдвиг. Результат сдвига по-прежнему имеет 32-битный тип, но при этом записывается в 64-битную переменную. Это подозрительно, так как если значение, которое вернёт метод Value, будет больше 32, здесь возникнет неопределённое поведение.
Цитата из стандарта: The value of E1 << E2 is E1 left-shifted E2 bit positions; vacated bits are zero-filled. If E1 has an unsigned type, the value of the result is E1 * 2^E2, reduced modulo one more than the maximum value representable in the result type. Otherwise, if E1 has a signed type and non-negative value, and E1*2^E2 is representable in the result type, then that is the resulting value; otherwise, the behavior is undefined.
Данный код можно исправить, преднамеренно записав 1 как 64-битный литерал, или выполнив расширение типа через приведение. Подробнее про сдвиги написано в статье "Не зная брода, не лезь в воду. Часть третья".
Расширение через приведение, кстати, использовалось в другом месте. Вот этот код:
AlphaNum::AlphaNum(Hex hex) {
....
uint64 value = hex.value;
uint64 width = hex.spec;
// We accomplish minimum width by OR'ing in 0x10000 to the user's
// value,
// where 0x10000 is the smallest hex number that is as wide as the
// user
// asked for.
uint64 mask = ((static_cast<uint64>(1) << (width - 1) * 4)) | value;
....
}Предупреждение PVS-Studio: V592 The expression was enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or misprint is present. strcat.cc 43
Это корректный код, который анализатор счёл подозрительным, обнаружив дублирующиеся круглые скобки. Анализатор рассуждает так: двойные скобки не влияют на результат вычисления выражения, следовательно, возможно, одна пара скобок расположена не там, где надо.
Нельзя исключать, что скобки здесь хотели поставить для того, чтобы явно подчеркнуть последовательность вычислений, и чтобы не приходилось вспоминать приоритеты операций '<<' и '*'. Но, так как они стоят не в том месте, толку от них нет. Полагаю, что порядок выражений здесь верный (сначала задаётся величина сдвига, а потом выполняется сам сдвиг), так что нужно просто поставить верно скобки, чтобы они не вводили в заблуждение.
uint64 mask = (static_cast<uint64>(1) << ((width - 1) * 4)) | value;Идём дальше.
void Compute(OpKernelContext* context) override {
....
int64 v = floor(in_x);
....
v = ceil(in_x1);
x_interp.end = ceil(in_x1);
v = x_interp.end - 1;
....
}Предупреждение PVS-Studio: V519 The 'v' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 172, 174. resize_area_op.cc 174
Дважды выполняют запись в переменную v, при этом между присваиваниями значение этой переменной не используется. Более того, в x_interp.end записывают то же значение, которое перед этим было записано в переменную v. Даже если опустить факт лишнего вызова функции ceil, так как это не критично (хотя...), всё равно код выглядит странно: либо он просто странно написан, либо содержит хитрую ошибку.
Дальше:
void Compute(OpKernelContext* context) override {
....
int64 sparse_input_start; // <=
....
if (sparse_input) {
num_total_features += GetNumSparseFeatures(
sparse_input_indices, *it, &sparse_input_start); // <=
}
if (num_total_features == 0) {
LOG(WARNING) << "num total features is zero.";
break;
}
if (rand_feature < input_spec_.dense_features_size()) {
....
} else {
....
const int32 sparse_index = sparse_input_start + // <=
rand_feature - input_spec_.dense_features_size();
....
}
....
}Предупреждение PVS-Studio: V614 Potentially uninitialized variable 'sparse_input_start' used. sample_inputs_op.cc 351
Подозрительным в этом коде выглядит то, что при инициализации константы sparse_index может использоваться потенциально неинициализированная переменная sparse_input_start. В момент объявления эта переменная не инициализируется никаким значением, т.е. содержит какой-то мусор. Ниже, при условии истинности выражения sparse_input, адрес переменной sparse_input_start передаётся в функцию GetNumSparseFeatures, где, вероятно, и происходит инициализация этой переменной. Но ведь иначе, если тело этого условного оператора не будет выполнено, sparse_input_start так и останется неинициализированной.
Конечно, можно предположить, что в случае, если sparse_input_start так и останется неинициализированной, до её использования дело не дойдёт, но это слишком смело и неочевидно, так что неплохо было бы всё же задать для переменной некоторое стандартное значение.
И да, и нет. Если честно, я сам надеялся найти больше дефектов и хотел написать статью в духе проверки Qt, Mono, Unreal Engine 4 и им подобных, но не вышло. Ошибки не валялись тут и там, поэтому стоит отдать должное разработчикам проекта. Однако я надеялся, что проект будет больше по размеру, но в выбранной конфигурации проверялось только около 700 файлов, включая автосгенерированные.
К тому же, некоторое осталось за рамками этой статьи, например:
Тем не менее, как мы увидели, PVS-Studio нашёл ряд интересных фрагментов кода, которые и были рассмотрены в этой статье.
TensorFlow оказался достаточно интересным и качественным с точки зрения кода проектом, но, как мы увидели, не без изъянов. А PVS-Studio в очередной раз продемонстрировал, что способен находить ошибки даже в коде именитых разработчиков.
В заключение хотелось бы похвалить всех, кто трудится над TensorFlow, за качественный код, и пожелать им удачи в дальнейшем.
Ах, да, чуть не забыл.

Всем, кто дочитал до конца - спасибо за внимание, безбажного кода, и не забывайте пользоваться PVS-Studio!
0
0
0
0