
Технологии, используемые в PVS-Studio (соответствует ГОСТ Р 71207—2024)
- Определения
- Участие PVS-Studio в испытаниях статических анализаторов
- Поддерживаемые языки и методы анализа
- Анализ программы на синтаксическом уровне
- Внутрипроцедурный анализ потоков данных и управления
- Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных
- Чувствительный к путям выполнения анализ потоков данных и управления
- Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных
- Вспомогательные методы анализа
- Выявляемые типы критических ошибок
- Соответствие требованиям к методам анализа
- Соответствие требованиям к инструментам статического анализа исходных текстов
- Анализ проекта целиком, включая используемые заимствованные компоненты
- Время анализа проекта (замеры конца 2024 года)
- Время анализа проекта (замеры на испытаниях в 2025 году)
- Результаты применения анализатора
- Принятие решений и автоматизация разметки предупреждений
- Автоматизации действий
- Обеспечивается хранение результатов запуска, разметки и сравнения
- Документации с описанием всех типов ошибок
- Выдача результатов анализа в открытом документированном формате
- Доработки алгоритмов и правил пользователями
- Дополнительные ссылки по теме РБПО и ГОСТ Р 71207—2024
Инструментальное средство PVS-Studio разрабатывается с учётом требований, предъявляемых к статическим анализаторам в ГОСТ Р 71207—2024. Выявляет критические ошибки и может использоваться при разработке безопасного программного обеспечения по ГОСТ Р 56939—2024. Рассмотрим функциональные возможности, реализованные в PVS-Studio на начало 2026 года в отношении анализа исходного кода программного обеспечения, написанного на компилируемых языках программирования: C, C++, C#, Java.
Определения
ГОСТ Р 71207—2024 — РАЗРАБОТКА БЕЗОПАСНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ. Статический анализ программного обеспечения. Общие требования. Разработан ФСТЭК России и ИСП РАН. Впервые введён в действие 01.04.2024.
Ссылка на ГОСТ на сайте ФГБУ "Институт стандартизации": ГОСТ Р 71207—2024.
Обзор стандарта: ГОСТ Р 71207—2024 глазами разработчика статических анализаторов кода.
Примечание. Приводимые далее в тексте ссылки на разделы и пункты (п. x.x.x) относятся к стандарту ГОСТ Р 71207—2024. Если пункты относятся к другому стандарту или указу, он будет отмечен.
Стандарт устанавливает требования к:
- внедрению и выполнению статического анализа ПО (раздел 5);
- классификации критических ошибок (раздел 6);
- методам статического анализа (раздел 7);
- инструментам анализа (раздел 8);
- специалистам, участвующим в анализе (раздел 9);
- методике проверки соответствия статических анализаторов ГОСТ (раздел 10).
Входит в комплекс стандартов, направленных на предотвращение уязвимостей в программах, и применяется совместно с ГОСТ Р 56939.
Критическая ошибка в программе. Термин введён в ГОСТ Р 71207—2024 (п. 3.1.13). Это ошибка, которая может привести к нарушению безопасности обрабатываемой информации. С точки зрения безопасности это ошибки, которые должны обнаруживаться и исправляться в первую очередь.
Статические анализаторы должны выявлять следующие виды критических ошибок в коде программ на компилируемых языках (п. 6.3):
- ошибки непроверенного использования чувствительных данных;
- ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел;
- ошибки переполнения буфера;
- ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности;
- ошибки при работе с многопоточными примитивами.
Дополнительно для C и C++ (п. 6.5):
- ошибки разыменования нулевого указателя;
- ошибки деления на ноль;
- ошибки управления динамической памятью;
- ошибки использования форматной строки;
- ошибки использования неинициализированных переменных;
- ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений.
Примечание. Набор требований ГОСТ по обнаружению критических ошибок совпадает для языков C и C++. Анализатор PVS-Studio использует общее ядро для анализа программ на этих языках, поэтому далее для сокращения текста эти языки будут рассматриваться вместе, а не по отдельности.
PVS-Studio. Инструментальное средство статического анализа кода, разрабатываемое с учётом требований, изложенных в ГОСТ Р 71207—2024. Выявляет все виды критических ошибок, перечисленных в стандарте (п. 6.3, п. 6.5), и может использоваться для предотвращения появления и устранения уязвимостей при разработке безопасного ПО (РБПО).
Поддерживает языки: C, C++, C#, Java. В 2026 планируется выпуск первой версии, где будет добавлен анализ языков Go, JavaScript, TypeScript.
Запускается на большом количестве ОС, в том числе отечественных: Windows, macOS, Arch Linux, Astra Linux, CentOS, Debian GNU/Linux, Fedora, Linux Mint, openSUSE, Ubuntu, РЕД ОС и т.д.
Подтверждена техническая совместимость анализатора PVS-Studio с Astra Linux. Сертификат №31190/2025.
Анализатор содержит три ядра:
- Ядро для анализа С и C++ кода. Написано на C++.
- Ядро для анализа С# кода. Написано на C#.
- Ядро для анализа Java кода. Написано на Java.
Анализатор удовлетворяет требованиям ГОСТ Р 71207—2024 к методам анализа (раздел 7), что обеспечивает выявление всех видов критических ошибок для поддерживаемых языков. Выполняются требования, изложенные в разделе 8, такие как: выдача результатов в открытых форматах (например, SARIF), указание соответствия типа ошибки согласно системе классификации MITRE CWE и так далее.
Инструмент разрабатывается в России с 2008 года (запись в Едином Реестре российского ПО №9837) и содержит более 1000 диагностических правил. Возможно использование в полностью закрытом контуре. Является SAST-решением.
Участие PVS-Studio в испытаниях статических анализаторов
В 2025 году команда PVS-Studio приняла участие в испытаниях статических анализаторов исходных кодов компилируемых и динамических языков программирования под руководством ФСТЭК России.
В испытаниях участвовали:
- ООО "ПВС", PVS-Studio.
- АО "НПО "Эшелон", АК-ВС 3.
- ИСП РАН, Svace.
- АО "Позитив Текнолоджиз", Positive Technologies Application Inspector.
- АО "СОЛАР СЕКЬЮРИТИ", Solar AppScreene.
- Базальт СПО представляет CodeChecker, включающей связку из: Clang Static Analyzer, Clang-Tidy, Cppcheck и GCC.
Хронология испытаний:
- Анонс испытаний. ФСТЭК России объявила о начале масштабных испытаний статических анализаторов.
- Дмитрий Пономарев. Испытания статических анализаторов.
- Дмитрий Пономарев. Итоги этапа "Домашнее задание" испытаний статических анализаторов под патронажем ФСТЭК России.
- Андрей Карпов. Комментарий по итогам домашнего задания.
- Совместный вебинар ООО "ПВС, АО "НПО "Эшелон" и АО "Позитив Текнолоджиз". Техническая сторона первого этапа испытаний статических анализаторов кода под эгидой ФСТЭК.
Итоги испытаний были подведены в декабре 2025 года на открытой конференции ИСП РАН. С записью соответствующих докладов можно познакомиться здесь (06:05:10 — приблизительно начало).
Соответствующие презентации лежат здесь (в папке 2. 16-17 Стат. анализаторы).
Из-за сложности поставленных задач и большого объёма работ многое из намеченного во время испытаний не удалось реализовать и завершить. В целом все анализаторы продемонстрировали возможность выявления критических ошибок, перечисленных в стандарте. Все инструменты возможно запускать на отечественных операционных системах, анализировать большие проекты и т. д.
См. также публикацию Андрея Карпова: "Кратко об итогах испытаний статических анализаторов исходного кода в 2025 году".
Потому на момент написания данного текста нет принципиальных изменений в том, какие анализаторы можно и нужно использовать при построении процессов безопасной разработки ПО.
По-прежнему актуальна методическая рекомендация ФСТЭК № 2025-07-011. Можно выбирать разные удобные вам инструменты, обращая внимание на отмеченные в рекомендации нюансы. Также смотрите выдержку из эфира AM Live "Разработка безопасного программного обеспечения (РБПО)".
Поддерживаемые языки и методы анализа
На начало 2026 года PVS-Studio поддерживает анализ кода программ, написанных на языках программирования C, C++, C#, Java.
В ГОСТ Р 71207—2024 (п. 7.4) перечислены методы, которые должен реализовывать статический анализатор. PVS-Studio реализует все эти методы.
|
Виды анализа (п. 7.4) |
C и C++ |
C# |
Java |
|---|---|---|---|
|
Внутрипроцедурный анализ потоков данных и управления |
✓ |
✓ |
✓ |
|
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных |
✓ |
✓ |
✓ |
|
Чувствительный к путям выполнения анализ потоков данных и управления |
✓ |
✓ |
✓ |
|
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных |
✓ |
✓ |
✓ |
|
Анализ программы на синтаксическом уровне |
✓ |
✓ |
✓ |
Таблица N1. Виды анализа, которые должен реализовывать статический анализатор кода согласно ГОСТ Р 71207—2024 (п. 7.4). Данные приведены для анализатора PVS-Studio на начало 2026 года
Также в стандарте (п. 7.4) перечислены вспомогательные методы анализа, которые может реализовывать инструмент для поиска дополнительных типов ошибок. PVS-Studio поддерживает следующие из них.
|
Необязательные вспомогательные виды анализа (п. 7.4) |
C и C++ |
C# |
Java |
|---|---|---|---|
|
Сигнатурный поиск |
✓ |
✓ |
✓ |
|
Анализ псевдонимов |
✓ |
✓ |
|
|
Анализ косвенных вызовов |
✓ |
||
|
Статистический анализ |
✓ |
✓ |
✓ |
|
Анализ иерархии классов |
✓ |
✓ |
✓ |
Таблица N2. Виды анализа, которые, согласно ГОСТ Р 71207—2024 (п. 7.4), следует использовать в качестве вспомогательных методов. Данные приведены для анализатора PVS-Studio на начало 2026 года
Разберём перечисленные методы более подробно и приведём примеры их использования.
Анализ программы на синтаксическом уровне
Согласно ГОСТ (п 3.1.6) анализ программы на синтаксическом уровне — это статический анализ, при котором обрабатывается представление программы, полностью отражающее её синтаксическую структуру, например абстрактное синтаксическое дерево.
Хотя этот вид анализа приводится в списке последним, мы начнём именно с него, так как он является основой для всех остальных. Без разбора кода на синтаксическом уровне и построения абстрактного синтаксического дерева невозможно проведение полноценного анализа кода. Более того, обязательным также является и семантический анализ, позволяющий вывести типы данных и другую информацию, требуемую для реализации подавляющего числа диагностических правил.
В PVS-Studio все диагностические правила для всех языков работают с деревом, полученным в ходе синтаксического анализа кода. Поэтому примером использования анализа программы на синтаксическом уровне может являться любое из них.
Редчайшим исключением являются несколько диагностических правил, работающих на уровне лексем. Примером такого исключения является поиск невидимых символов, позволяющих проводить атаку Trojan Source.
Синтаксический анализ C и C++ кода
Для C и C++ построение дерева осуществляется собственным парсером, написанным на языке C++ и развиваемым силами команды PVS-Studio. Наши доклады и статьи на эту тему:
- Юрий Минаев: "Как забраться на дерево".
- C++ Zero Cost Conf 2024, Юрий Минаев: "Семантика для кремниевых мозгов".
- Вебинар, Олег Лысый: "Парсим С++".
Синтаксический анализ C# кода
Работа с C# кодом базируется на использовании .NET Compiler Platform (Roslyn). Наши доклады и статьи на эту тему:
- Сергей Васильев: "Введение в Roslyn. Использование для разработки инструментов статического анализа".
- DotNext 2022 Autumn, Сергей Васильев: "Анализ C# кода на Roslyn: от теории к практике".
- Валерий Комаров: "Создание статического анализатора для C# на основе Roslyn API".
Синтаксический анализ Java кода
Работа с Java кодом базируется на использовании Spoon. Наши статьи на эту тему:
- Егор Бредихин: "Разработка нового статического анализатора: PVS-Studio Java".
- Константин Волоховский: "Как скопировать дерево, но не точь-в-точь".
Пример использования синтаксического анализа для поиска ошибок
Синтаксический анализ — неотъемлемая часть всех диагностических правил, реализованных в PVS-Studio для всех поддерживаемых языков. Поэтому разберём только один пример.
Ошибка была найдена с помощью PVS-Studio в проекте LLVM (язык C++) и описана в этой статье.
std::unique_ptr<OptionDefinition> m_options_definition_up;
....
Status SetOptionsFromArray(StructuredData::Dictionary &options) {
Status error;
m_num_options = options.GetSize();
m_options_definition_up.reset(new OptionDefinition[m_num_options]);
....
}Предупреждение PVS-Studio: V554 Incorrect use of unique_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. CommandObjectCommands.cpp 1384
Умный указатель m_options_definition_up ориентирован на хранение одиночного элемента, но туда помещается указатель на массив. Результат — неопределённое поведение в момент разрушения объекта. Корректный вариант кода:
std::unique_ptr<OptionDefinition []> m_options_definition_up;Чтобы найти эту ошибку, необходимо в момент вызова функции reset иметь информацию, какой тип у переменной m_options_definition_up. Эта информация собирается при обходе дерева, построенного с помощью синтаксического разбора кода и механизма вывода типов переменных.
Внутрипроцедурный анализ потоков данных и управления
Определения:
- анализ потока данных (п 3.1.4) — статический анализ, при котором определяются свойства обрабатываемых программой данных. Могут определяться возможные значения переменных и констант, точки программы, в которых используются определённые переменные и прочее;
- анализ потока управления (п 3.1.5) — статический анализ, при котором выделяются процедуры программы, линейные участки кода процедур и условия переходов между этими участками.
Анализ потоков данных позволяет анализатору PVS-Studio делать предположения о значениях переменных и выражений в различных частях исходного кода. Некоторые виды предполагаемых значений:
- конкретные значения (числа, строки);
- диапазоны значений;
- множество возможных значений.
Бывают и более сложные виды данных, сопоставляемые с какой-то переменной. Например, анализатор может знать, что указатель находится в одном из следующих состояний:
- неинициализированный (нельзя разыменовывать и сравнивать с другим указателем);
- нулевой (нельзя разыменовывать);
- указывает на буфер памяти определённого размера (можно проверить выход за границу буфера);
- указывает на освобождённую память (нельзя разыменовывать или повторно освобождать);
- и так далее.
Анализ потока управления в PVS-Studio неразрывно связан с анализом потока данных. Поясним это примером на языке C++:
void foo()
{
int A = 1;
int B = 2;
if (A == 3)
{
B = 0;
}
A = 10 / B;
}В момент проверки (A == 3) анализатор благодаря анализу потока данных знает, что условие будет всегда ложным, так как переменная A равна 1. Следовательно, с точки зрения потока управления тело оператора if не выполняется, и переменной B не может быть присвоено значение 0.
Информация о потоке выполнения (что не выполняется код, где 0 записывается в переменную B) влияет на поток данных. Известно, что значение переменной B остаётся равно 2. Следовательно, деление 10 / B всегда безопасно, и анализатор не выдаёт предупреждение о потенциальном делении на ноль.
Анализ потоков данных и управления так или иначе участвует почти во всех алгоритмах выявления критических ошибок. Например, именно благодаря ему удаётся определить, каков размер массива, и происходит ли в определённой ветке кода запись за его границу.
Механизмы анализа потока данных схоже реализованы в PVS-Studio для всех языков и нет смысла их рассматривать отдельно. Дальнейшие разделы созданы с целью разделить ссылки на публикации и примеры для разных языков.
Пример внутрипроцедурного анализа потоков данных и управления для C и C++ кода
Хорошим примером использования внутрипроцедурного анализа потоков данных и управления является выявление ошибки в проекте Protocol Buffers (protobuf), которая описана в статье "31 февраля".
static const int kDaysInMonth[13] = {
0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31
};
bool ValidateDateTime(const DateTime& time) {
if (time.year < 1 || time.year > 9999 ||
time.month < 1 || time.month > 12 ||
time.day < 1 || time.day > 31 ||
time.hour < 0 || time.hour > 23 ||
time.minute < 0 || time.minute > 59 ||
time.second < 0 || time.second > 59) {
return false;
}
if (time.month == 2 && IsLeapYear(time.year)) {
return time.month <= kDaysInMonth[time.month] + 1;
} else {
return time.month <= kDaysInMonth[time.month];
}
}Функция ValidateDateTime принимает на вход дату и должна определить, корректна она или нет. Вначале выполняются основные проверки. Проверяется, что номер месяца лежит в диапазоне [1..12], дни находятся в диапазоне [1..31], минуты находятся в диапазоне [0..59] и так далее.
Затем идёт более сложная проверка: есть ли определённый день в определённом месяце. Чтобы проверить дни, используется вспомогательный массив kDaysInMonth. В массиве записано количество дней в различных месяцах. По номеру месяца из массива извлекается максимальное количество дней, которое и используется для проверки.
Дополнительно учитывается, что год может быть високосным, и тогда в феврале на один день больше.
Из-за опечатки дни проверяются неправильно. Обратите внимание, что с максимально возможным количеством дней в месяце сравнивается не день, а месяц.
if (time.month == 2 && IsLeapYear(time.year)) {
return time.month <= kDaysInMonth[time.month] + 1;
} else {
return time.month <= kDaysInMonth[time.month];
}В сравнениях "time.month <= ...." следует использовать day, а не month.
Номер месяца (от 1 до 12) всегда меньше количества дней в любом из месяцев.
Из-за этой ошибки корректными будут считаться такие дни, как 31 февраля или 31 ноября.
Предупреждения PVS-Studio:
- V547 Expression 'time.month <= kDaysInMonth[time.month] + 1' is always true. time.cc 83
- V547 Expression 'time.month <= kDaysInMonth[time.month]' is always true. time.cc 85
Обнаружение этой ошибки возможно благодаря одновременной работе анализа потоков данных и управления.
Если значение месяца лежит вне диапазона [1..12], то функция завершает работу. Следовательно, анализ потока управления будет выполняться дальше только в том случае, если значение переменной time.month лежит в диапазоне [1..12].
Анализатор заглядывает внутрь массива и понимает, что оттуда извлекаются значения в диапазоне [28..31]. Он учитывает, что 0 из массива kDaysInMonth не извлекается, так как возможный диапазон time.month, используемый в качестве индекса, равен [1..12].
В итоге анализатор видит, что происходят следующие сравнения диапазонов:
- [2..2] <= [28..31];
- [1..12] <= [29..32].
Условия всегда истинны, о чём анализатор и выдаёт предупреждения.
Почему первый диапазон [2..2] представлен только одним числом 2? Дело в том, что учитывается уточняющее условие time.month == 2.
Наши доклады и статьи на тему анализа потока данных C++ кода:
- Андрей Карпов: "Зачем PVS-Studio использует анализ потока данных: по мотивам интересной ошибки в Open Asset Import Library".
- CoreHard 2018, Павел Беликов: "Как работает анализ Data Flow в статическом анализаторе кода".
- Сергей Васильев: "Под капотом SAST: как инструменты анализа кода ищут дефекты безопасности".
Пример внутрипроцедурного анализа потоков данных и управления для C# кода
Пример для C# будет проще, но фактически всё работает аналогичным образом. Аномалия была выявлена в проекте Unity3D.
public NetworkConnection Get(int connId)
{
if (connId < 0)
{
return m_LocalConnections[Mathf.Abs(connId) - 1];
}
if (connId < 0 || connId > m_Connections.Count)
....
}Предупреждение PVS-Studio: V3063 A part of conditional expression is always false: connId < 0. ConnectionArray.cs 59
Если первое условие выполнилось (connId < 0), то поток управления прерывается (происходит выход из функции с помощью оператора return). Следовательно, функция продолжит выполнение только в том случае, если значение переменной connId больше или равно 0.
Анализ потока данных учитывает тот факт, что connId >= 0, и на его основе диагностическое правило V6063 делает вывод, что часть условия всегда ложна.
Наши публикации на тему анализа потока данных C# кода:
- Никита Липилин: "Эволюция PVS-Studio: анализ потока данных для связанных переменных".
- Артём Ровенский: "Анализ потока данных PVS-Studio распутывает всё больше связанных переменных".
Пример внутрипроцедурного анализа потоков данных и управления для Java кода
При создании ядра для анализа языка Java был переиспользован механизм анализа потока данных и управления, реализованный в ядре C++ анализатора. То есть Java анализатор использует часть функциональности C++ анализатора с помощью SWIG (средство для автоматической генерации врапперов и интерфейсов для связывания программ на C и C++ с программами, написанными на других языках).
Это позволило быстрее разработать первую версию Java анализатора, однако повлекло за собой ряд сложностей и усложнение процесса дальнейшего развития. Например, достаточно неудобно отлаживать код из-за этой связки: правки C++ ядра могут неожиданно влиять на Java анализатор и так далее.
Поэтому наша команда в 2025 году начала делать параллельный механизм анализа потока данных, который забирает на себя функции C++ ядра и постепенно полностью его заменит.
Использование анализа потоков данных и управления для Java кода будет показано на примере ошибки в проекте GeoGebra.
private void updateOrdering(GeoElement geo, ObjectMovement movement) {
....
if (index == firstIndex) {
if (index != 0) {
geo.setOrdering(orderingDepthMidpoint(index));
}
else {
geo.setOrdering(drawingOrder.get(index - 1).getOrdering() - 1);
}
}
....
}Предупреждение PVS-Studio: V6025 Index 'index - 1' is out of bounds. LayerManager.java 393
Анализируя поток управления, анализатор знает, что:
geo.setOrdering(drawingOrder.get(index - 1).getOrdering() - 1);Выполняется только в том случае, если переменная index равна 0. Следовательно, фактическим аргументом, передаваемым в функцию get, будет значение -1. Результат: генерация исключения типа IndexOutOfBoundsException.
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных
Определения:
- межмодульный анализ (п. 3.1.17) — статический анализ, при котором выполняется совместный анализ программы или нескольких программ, состоящих из нескольких программных модулей, и выявляемые свойства программы затрагивают процедуры или переменные из различных модулей;
- межпроцедурный контекстно-чувствительный анализ (п. 3.1.18) — статический анализ, при котором выявляемые свойства программы учитывают взаимодействие нескольких процедур, в том числе возникающее в результате выполнения нескольких процедур или вызовов процедурами друг друга, а также контексты их вызова. В ходе анализа учитывается контекст вызова процедуры при обработке её вызова, то есть сопоставляется информация из вызывающей и вызываемой процедур применительно к каждому месту вызова и его окружению: фактическим параметрам, состоянию глобальных переменных и тому подобное.
Статические анализаторы кода могут учитывать данные, которые передаются между процедурами/функциями, чтобы выявить больше критических ошибок. Это важно при выявлении таких ошибок, как утечки памяти, разыменование нулевых указателей, выход за границы массивов и так далее. Это связано с тем, что создание некого ресурса, его использование и освобождение часто разнесены по разным функциях.
Для выявления ошибок, возникающих при взаимодействии нескольких процедур, статические анализаторы используют технологию межпроцедурного контекстно-чувствительного анализа кода.
Ситуация усложняется, если требуется анализировать взаимодействие функций, находящихся в различных единицах трансляции/программных модулях. В этом случае говорят, что выполняется межмодульный анализ.
PVS-Studio реализует межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных для всех поддерживаемых языков. Однако межмодульный анализ С и C++ более сложен по сравнению с C# и Java, так как требует дополнительных действий по объединению информации, получаемой из различных единиц трансляции.
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных C и С++ кода
Межмодульный анализ в PVS-Studio для С и C++ выполняется в три этапа:
- Семантический анализ каждой отдельной единицы трансляции. Анализатор собирает информацию о каждом символе программы, для которого нашлись потенциально интересные факты. После эта информация записывается в файлы в специальном формате. Такая обработка может выполняться параллельно, что хорошо для многопоточной сборки.
- Слияние символов. На этом этапе анализатор объединяет информацию из разных файлов с фактами в один, попутно решая конфликты между символами. На выходе получаем один файл с необходимой для межмодульного анализа информацией.
- Запуск диагностических правил. Анализатор вновь проходит каждую единицу трансляции. Однако в отличие от режима с выключенным межмодульным анализом, во время выполнения правил загружается информация о символах из объединённого файла. Таким образом, становится доступной информация о фактах для символов из других модулей.
Наши доклады и статьи на эту тему:
- Олег Лысый, Сергей Ларин: "Межмодульный анализ C++ проектов в PVS-Studio".
- C++ Russia 2023, Олег Лысый: "Межмодульный анализ C++ проектов".
- Олег Лысый: "Межмодульный анализ C и C++ проектов в деталях: часть 1, часть 2".
В начале синтетический пример:
int get(int a, int b = 7)
{
return a + 2 - b;
}
int main()
{
int a = 5;
auto divider = get(a, 1);
return a / divider;
}PVS-Studio выдаёт предупреждение: V609 Divide by zero. Denominator 'divider' == 0.
Это возможно благодаря тому, что анализатор подсчитал возвращаемое значение функцией get на основании переданных ей аргументов. Если поменять фактические аргументы, то предупреждение о делении на ноль исчезнет:
int main()
{
int a = 5;
auto divider = get(a, 1);
return a / divider;
}Зато выявляется другой дефект: результат деления 5/6 не имеет смысла, так как в результате целочисленного деления всегда будет получаться 0. Про это будет другое предупреждение: V1064 The 'a' operand of integer division is less than the 'divider' one. The result will always be zero.
Теперь рассмотрим пример ошибки, найденной с помощью межмодульного контекстно-чувствительного анализа инструментом PVS-Studio в коде проекта Midnight Commander (язык C).
Начнём с функции widget_destroy в файле widget-common.c:
void widget_destroy (Widget * w)
{
send_message (w, NULL, MSG_DESTROY, 0, NULL);
g_free (w);
}Функция освобождает буфер памяти, адрес которого она получает через аргумент w.
Теперь посмотрим на код в файле editcmd.c:
gboolean edit_close_cmd (WEdit * edit)
{
Widget *w = WIDGET (edit);
....
widget_destroy (w); // <= Здесь освободили память
if (....) .... else
{
edit = find_editor (DIALOG (g));
if (edit != NULL)
widget_select (w); // <= Передаём указатель дальше
}
}Обратите внимание, что в начале адрес структуры Widget передаётся в функцию widget_destroy, где происходит освобождение буфера памяти. Далее этот указатель передаётся в функцию widget_select, приведённую ниже:
void widget_select (Widget * w)
{
WGroup *g;
if (!widget_get_options (w, WOP_SELECTABLE))
return;
....
}Она просто передаёт указатель дальше в функцию widget_get_options:
static inline gboolean
widget_get_options (const Widget * w, widget_options_t options)
{
return ((w->options & options) == options);
}Здесь мы добрались до места, где возникает неопределённое поведение, связанное с использованием данных в уже освобождённом буфере памяти. Анализатор PVS-Studio сигнализирует об этом предупреждением: V774 The 'w' pointer was used after the memory was released.
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных С# кода
.NET Compiler Platform предоставляет инфраструктуру для работы сразу со всеми файлами исходного кода, включёнными в проект. Это делает межмодульный анализ C# кода более простым в реализации, чем в случае с C++.
Рассмотрим два примера реального кода, первый из которых хорошо демонстрирует суть контекстно-чувствительного анализа, а второй — межмодульного анализа.
Первая ошибка найдена в проекте AvalonStudio. Рассмотрим вначале функцию IsBuiltInType. Обратите внимание, что если её входной аргумент cursor окажется нулевой ссылкой, то функция вернёт значение false. Другими словами, результат работы функции зависит от контекста её вызова.
private static bool IsBuiltInType(ClangType cursor)
{
var result = false;
if (cursor != null && ....)
{
return true;
}
return result;
}Теперь рассмотрим другой фрагмент кода, где вызывается рассмотренная функция:
private static StyledText InfoTextFromCursor(ClangCursor cursor)
{
....
if (cursor.ResultType != null)
{
result.Append(cursor.ResultType.Spelling + " ",
IsBuiltInType(cursor.ResultType) ? theme.Keyword
: theme.Type);
}
else if (cursor.CursorType != null)
{
switch (kind)
{
....
}
result.Append(cursor.CursorType.Spelling + " ",
IsBuiltInType(cursor.ResultType) ? theme.Keyword
: theme.Type);
}
....
}Если cursor.ResultType != null, то выполняется тело первого оператора if. Соответственно, если управление будет предано внутрь тела второго оператора if, то точно известно, что ссылка cursor.ResultType является нулевой.
Изучим место вызова рассмотренной ранее функции IsBuiltInType:
result.Append(cursor.CursorType.Spelling + " ",
IsBuiltInType(cursor.ResultType) ? theme.Keyword
: theme.Type);Анализатор знает, что cursor.ResultType — нулевая ссылка. Из этого он делает вывод, что при таком входном аргументе функция всегда возвращает false.
Это и есть межпроцедурный контекстно-чувствительный анализ.
Если условие тернарного оператора всегда ложно, то это подозрительно, о чём анализатор и сообщает, выдавая предупреждение: V3022 Expression 'IsBuiltInType(cursor.ResultType)' is always false.
Действительно, если присмотреться к коду, то можно заметить опечатку. В теле второго оператора if при вызове функции IsBuiltInType в качестве фактического аргумента следует передать переменную cursor.CursorType.
Рассмотрим второй пример кода из игры Starlight, где для выявления ошибки требуется межмодульный анализ. Здесь задействовано три файла:
- NavMeshGenerator.cs — метод ScanInternal;
- AstarData.cs — метод GetGraphIndex;
- TriangleMeshNode.cs — метод SetNavmeshHolder.
protected override IEnumerable<Progress> ScanInternal ()
{
....
TriangleMeshNode.SetNavmeshHolder(
AstarPath.active.data.GetGraphIndex(this), this);
....
}Предупреждение PVS-Studio: V3106 The 1st argument 'AstarPath.active.data.GetGraphIndex(this)' is potentially used inside method to point beyond collection's bounds. NavMeshGenerator.cs 225
Анализатор сообщает, что внутри метода TriangleMeshNode.SetNavmeshHolder происходит доступ по индексу за пределами допустимого диапазона. При этом в качестве индекса выступает первый аргумент.
Взглянем на метод AstarPath.active.data.GetGraphIndex:
public int GetGraphIndex (NavGraph graph) {
if (graph == null) throw new System.ArgumentNullException("graph");
var index = -1;
if (graphs != null) {
index = System.Array.IndexOf(graphs, graph);
if (index == -1) Debug.LogError("Graph doesn't exist");
}
return index;
}Как мы видим, метод может вернуть в качестве результата -1. Теперь взглянем на метод TriangleMeshNode.SetNavmeshHolder:
public static void SetNavmeshHolder (int graphIndex, INavmeshHolder graph) {
// We need to lock to make sure that
// the resize operation is thread safe
lock (lockObject) {
if (graphIndex >= _navmeshHolders.Length) {
var gg = new INavmeshHolder[graphIndex+1];
_navmeshHolders.CopyTo(gg, 0);
_navmeshHolders = gg;
}
_navmeshHolders[graphIndex] = graph; // <=
}
}Анализатор сообщает, что проблемный доступ происходит на последней строке. Доступ по индексу происходит без предварительной проверки.
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных Java кода
Библиотека Spoon предоставляет инфраструктуру для работы сразу со всеми файлами исходного кода, входящими в проект. Это делает межмодульный анализ Java кода схожим с анализом C# кода и более простым в реализации по сравнению с C++.
Для Java анализатора нашей командой пока собрано мало случаев реальных ошибок в открытых проектах, из которых можно подбирать примеры. Рассмотрим синтетический пример:
class Main {
static class NetworkTextTransmitter {
private final Socket socket = new Socket();
private final PrintWriter socketWriter;
public NetworkTextTransmitter(InetSocketAddress host,
InetSocketAddress source)
throws IOException {
socket.bind(host);
socket.connect(source);
socketWriter = new PrintWriter(socket.getOutputStream());
}
public void transmit(String message) {
socketWriter.println(message);
}
....
public void closeConnection() {
socketWriter.close();
}
}
public static void main(String[] args) throws IOException {
....
InetSocketAddress hostAddress =
new InetSocketAddress(Integer.parseInt(args[0]));
InetSocketAddress sourceAddress =
new InetSocketAddress(Integer.parseInt(args[1]));
NetworkTextTransmitter textTransmitter =
new NetworkTextTransmitter(hostAddress, sourceAddress);
Scanner scanner = new Scanner(System.in);
for (int i = 0; i < Integer.parseInt(args[0]); i++) {
textTransmitter.transmit(scanner.next());
}
textTransmitter.closeConnection();
}Предупреждение PVS-Studio: V6114 The 'NetworkTextTransmitter' class contains the 'socket' Closeable field, but the resources that the field is holding are not released inside the class. Main.java 10
Пример демонстрирует использование информации о состоянии класса (контекстно-чувствительный анализ) в процессе взаимодействия с ним (межпроцедурный анализ).
Программа выполняет передачу текстовых сообщений по сетевому подключению через сокет. Текстовые сообщения вводятся через консоль и передаются по подключению. Для передачи сообщений используется класс NetworkTextTransmitter, который создаёт подключение и поток передачи. По завершении передачи N сообщений метод main вызывает метод closeConnection. Внутри данного метода закрывается только поток передачи текстовых данных, однако само подключение через сокет остаётся открытым.
Чувствительный к путям выполнения анализ потоков данных и управления
Согласно ГОСТ чувствительный к путям выполнения анализ (3.1.36) — это статический анализ программы, при котором могут быть определены её свойства, проявляющиеся лишь на некоторых путях выполнения программы, и условия (или часть условий), при обращении которых в истину выполнение программы пойдёт по указанному анализатором пути.
Не очень понятно, почему стандарт выделяет чувствительность к путям выполнения в отдельный вид анализа потока данных и управления. На наш взгляд, анализ потока данных (п 3.1.4) и анализ потока управления (п 3.1.5) уже подразумевают учёт путей выполнения кода. В противном случае, если не учитывать пути выполнения, эти виды анализа становятся вырожденными и почти непригодными к практическому применению.
Возможно, стандарт содержит не очень удачную формулировку или не даёт дополнительных пояснений и примеров.
Мы интерпретируем этот вид анализа следующим образом: стандарт предлагает учитывать те ситуации, когда некоторое действие может как произойти, так и не произойти. Следует выдавать предупреждение с учётом того, что выполнение программы пойдёт по пути, приводящему к ошибке.
Поясним нашу интерпретацию синтетическим примером на языке C++:
void foo(bool A)
{
int *B = new int;
if (A)
{
delete B;
}
*B = 1;
}Если условие выполнится, то анализатор должен выдать предупреждение о том, что происходит запись в уже освобождённую память.
Если условие не выполнится, то анализатор должен выдать предупреждение об утечке памяти.
Если анализатор может вычислить с помощью межпроцедурного и межмодульного контекстно-чувствительного анализа потока данных, чему равна переменная A, то он должен выдать одно из двух предупреждений.
Если вычислить значение A невозможно или известно, что оно может быть как false, так и true, то помогает анализ потоков данных и управления, чувствительный к путям выполнения. Анализатор должен выдать оба предупреждения, по возможности показав пути выполнения программы, приводящие к ним.
Анализатор PVS-Studio использует чувствительный к путям выполнения анализ потоков данных, но не выделяет его в отдельную сущность или алгоритм. Фактически все три рассмотренные виды анализа:
- межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных;
- чувствительный к путям выполнения анализ потоков данных и управления;
- межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных.
Реализуются в каждом языковом ядре PVS-Studio в виде единого механизма (алгоритма).
Пример анализа потока данных и управления, чувствительных к путям выполнения C и C++ кода
Ошибка, используемая в качестве примера, была найдена в проекте MPC-HC (С++):
void CSyncAP::RenderThread()
{
....
REFERENCE_TIME rtRefClockTimeNow;
if (m_pRefClock) {
m_pRefClock->GetTime(&rtRefClockTimeNow);
}
LONG lLastVsyncTime =
(LONG)((m_llEstVBlankTime - rtRefClockTimeNow) / 10000);
....
}Предупреждение PVS-Studio: V614 Potentially uninitialized variable 'rtRefClockTimeNow' used. syncrenderer.cpp 3604
Переменная rtRefClockTimeNow останется неинициализированной, если указатель m_pRefClock является нулевым. Соответственно, возможен путь выполнения программы, приводящий к ошибке — использованию неинициализированной переменной. Однако этого может и не произойти, поэтому анализатор сообщает о потенциальной ошибке. Таким образом, анализ здесь чувствителен к путям выполнения.
В случае, если переменная не инициализирована всегда, анализатор будет более категоричен. Код из проекта Trans-Proteomic Pipeline (язык С++):
double mscore_c::dot_hr(unsigned long *_v)
{
....
int iSeqSize;
for (int a = 0; a < iSeqSize; a++) {
....
}Здесь нет вариантов, поэтому PVS-Studio выдаёт предупреждение: V614 Uninitialized variable 'iSeqSize' used. mscore_c.cpp 552
Пример анализа потока данных и управления, чувствительных к путям выполнения C# кода
Ошибка была обнаружена нами в проекте RunUO:
public static string ConstructFromString( .... )
{
object toSet;
bool isSerial = IsSerial( type );
if ( isSerial ) // mutate into int32
type = m_NumericTypes[4];
if ( IsEnum( type ) )
{
try
{
toSet = Enum.Parse( type, value, true ); // <= (А)
}
catch
{
return "That is not a valid enumeration member.";
}
}
else if ( IsType( type ) )
{
try
{
toSet = ScriptCompiler.FindTypeByName( value ); // <= (Б)
if ( toSet == null )
return "No type with that name was found.";
}
catch
{
return "No type with that name was found.";
}
}
....
else if ( value == null )
{
toSet = null; // <= (В)
}
....
if ( isSerial ) // mutate back
toSet = (Serial)((Int32)toSet);
constructed = toSet;
return null;
}Переменной toSet могут присваиваться как ссылки на существующие объекты (точки: А, Б), так и нулевая ссылка (точка В). Анализатор чувствителен к тому, что существуют эти различные пути выполнения, и предупреждает, что ссылка потенциально может оказаться нулевой.
Предупреждение PVS-Studio: V3148 Casting potential 'null' value of 'toSet' to a value type can lead to NullReferenceException. Properties.cs 502
Пример анализа потока данных и управления, чувствительных к путям выполнения Java кода
Рассмотрим ошибку возможного разыменования нулевой ссылки в проекте Keycloak:
private void checkRevocationUsingOCSP(X509Certificate[] certs)
throws GeneralSecurityException {
....
if (rs == null) { // <= (А)
if (_ocspFailOpen)
logger.warnf(....); // <= (Б)
else
throw new GeneralSecurityException(....); // <= (В)
}
if (rs.getRevocationStatus() == // <= (Г)
OCSPProvider.RevocationStatus.UNKNOWN) {
....
}Если rs хранит нулевую ссылку (точка А), то нормальный поток выполнения может быть прерван генерацией исключения (точка В). Но может и не прерываться (точка Б), что приведёт к доступу по нулевой ссылке (точка Г).
Итого ссылка может быть как нулевая, так и не нулевая. Если она нулевая, то до её использования управление может как дойти, так и не дойти. Таким образом, задействован анализ потока данных и управления, чувствительный к путям выполнения.
Анализатор PVS-Studio сообщает о потенциальной ошибке: V6008 Potential null dereference of 'rs'. CertificateValidator.java 701 , CertificateValidator.java 708
В общем случае подобные предупреждения могут быть ложными, если между ссылкой rs и переменной ocspFailOpen существует сложная косвенная взаимосвязь, которую анализатор не смог выявить (см. термин анализ псевдонимов и статью про связанные переменные). Собственно, об этом говорится и в стандарте (примечание к п. 3.1.2): анализ потока управления, анализ потока данных, анализ помеченных данных, анализ псевдонимов и анализ косвенных вызовов в общем случае дают приближённые результаты.
Однако даже в этом случае ложные предупреждения могут быть полезны, так как выявляют сложный, неочевидный код, который может быть непонятен не только анализатору, но и разработчикам. Целесообразно провести его рефакторинг или, по крайне мере, написать соответствующий комментарий про косвенную связь между переменными.
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных
Согласно ГОСТ анализ помеченных данных (3.1.3) — статический анализ, при котором анализируется течение потока данных от источников до стоков. Под источниками понимаются точки программы, в которых данные начинают иметь пометку — некоторое заданное свойство. Под стоками понимаются точки программы, в которых данные перестают иметь пометку. Распространённая (но не единственная) цель анализа помеченных данных — показать, что помеченные данные не могут попасть из источников процедуры записи (точек ввода пользователя в стоки) на диск или в сеть. Факт такого попадания означает утечку конфиденциальных данных.
Механизмы анализа помеченных данных схожи с механизмами анализа потоков данных, но имеют существенное различие. Основная задача анализа потока данных — попытаться выяснить состояние переменных в различных точках программы, чтобы в дальнейшем использовать эту информацию в диагностических правилах. Например, если известно, что значение целочисленной переменной A лежит в диапазоне от 0 до 10, то её нельзя использовать в качестве индекса для массива, содержащего только 5 элементов.
Контекстно-чувствительный анализ помеченных данных не ставит задачей определить значение переменных, а оперирует понятием недостоверности данных. Если значение целочисленной переменной A взято из ненадёжного источника и не проверено, его опасно использовать в качестве индекса массива. При этом диапазон значений A может быть полностью неизвестен. Он и не важен. Важен факт использования опасных данных.
Источники заражения. Первичным понятием в данной теме являются заражённые данные. Под этим термином подразумеваются некоторые значения, которые могут позволить злоумышленнику выполнить несанкционированные и, как правило, вредоносные операции при взаимодействии с системой. В зависимости от способа использования внешних данных приложение может быть уязвимо к тем или иным атакам. Например, если приложение использует непроверенные внешние данные при формировании запросов к БД, то оно может быть уязвимо к SQL injection.
Таким образом, внешние данные являются потенциально заражёнными. Точки, в которых приложение получает к ним доступ, называют источниками заражения. Например, источником заражения может быть операция получения значения параметра HTTP-запроса:
void ProcessRequest(HttpRequest request)
{
....
string name = request.Form["name"]; // источник
// теперь "name" содержит недостоверные/заражённые данные
....
}Передача заражения. Важным аспектом при проведении анализа помеченных данных является определение "трасс распространения" заражённых данных по приложению. В приведённом примере заражённые данные из источника передаются в переменную name. Впоследствии они могут также переходить в другие переменные или выступать в качестве аргументов функций:
void ProcessRequest(HttpRequest request)
{
string name = request.Form["name"]; // источник
// теперь "name" содержит недостоверные/заражённые данные
string sql = $"SELECT * FROM Users WHERE name='{name}'";
// недостоверные данные передаются далее как аргумент
ExecuteReaderCommand(sql);
....
}
void ExecuteReaderCommand(string sql)
{
// sql содержит недостоверные/заражённые данные
....
}Стоит отметить, что заражение может передаваться не только при присваивании и передаче аргументов. В примере выше переменная name, хранящая потенциально заражённые данные, используется для формирования строки, которая будет записана в переменную sql. В результате значение sql также будет потенциально заражённым.
Приёмники заражения (стоки). Приложение уязвимо в случае, если заражённые данные могут попасть в некоторые ключевые точки приложения. Их называют приёмниками заражения (taint sink). Каждой потенциальной уязвимости соответствуют свои приёмники. Для SQL injection, к примеру, приёмником может являться точка передачи строки запроса в объект SQL-команды:
void ProcessRequest(HttpRequest request)
{
string name = request.Form["name"]; // <= источник
// теперь "name" содержит недостоверные/заражённые данные
string sql = $"SELECT * FROM Users WHERE name='{name}'";
ExecuteReaderCommand(sql); // данные передаются далее как аргумент
....
}
void ExecuteReaderCommand(string sql)
{
using (var command = new SqlCommand(sql, _connection)) // <= sink
{
using (var reader = command.ExecuteReader()) { /*....*/ }
}
....
}Здесь внешние данные из источника (request.Form["name"]) непосредственно используются при формировании SQL-запроса, который далее передаётся в приёмник — конструктор SqlCommand. Задача анализа помеченных данных состоит в проверке наличия пути передачи заражённых данных от источника к приёмнику.
Если проверить вышеприведённый код с помощью PVS-Studio, то результатом станет следующее предупреждение: V5608 Possible SQL injection inside method. Potentially tainted data in the first argument 'sql' is used to create SQL command.
Устранение потенциальных уязвимостей. Для устранения потенциальной уязвимости внешние данные необходимо проверять или преобразовывать в некоторый безопасный вид. Конкретный способ защиты зависит от типа атаки. Например, в случае с SQL injection могут быть использованы параметризованные запросы:
String userName = Request.Form["userName"];
String query = "SELECT * FROM Users WHERE UserName = @userName";
using (var command = new SqlCommand(query, _connection))
{
var userNameParam = new SqlParameter("@userName", userName);
command.Parameters.Add(userNameParam);
using (var reader = command.ExecuteReader())
....
}Соответственно, при проведении статического анализа предупреждение на данный код выдано не будет.
Наши доклады и статьи на тему анализа помеченных данных:
- Описание уязвимости Path Traversal.
- Описание уязвимости XSS (межсайтовый скриптинг).
- Описание XEE-атаки (billion laughs attack).
- Описание XXE-атаки (XML External Entity).
- Heisenbug 2022 Spring, Сергей Васильев: "Правильно ли вы парсите XML? Разбираемся с уязвимостями".
- DotNext 2022, Сергей Васильев: "Обработка XML-файлов как причина появления уязвимостей".
- Сергей Васильев: "Уязвимость XSS в приложении ASP.NET: разбираем CVE-2023-24322 в CMS mojoPortal".
- Сергей Васильев: "Парсинг string в enum ценой в 50 Гб: разбираем уязвимость CVE-2020-36620".
- Сергей Васильев: "Почему моё приложение при открытии SVG-файла отправляет сетевые запросы?"
- Владислав Богданов: "Цепочка гаджетов в Java и как небезопасная десериализация приводит к RCE?"
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных C++ кода
Начнём с простого, но реального примера воспроизводимой уязвимости, обнаруженной в проекте FreeSWITCH:
static const char *basic_gets(int *cnt)
{
....
int c = getchar();
if (c < 0) {
if (fgets(command_buf, sizeof(command_buf) - 1, stdin)
!= command_buf) {
break;
}
command_buf[strlen(command_buf)-1] = '\0'; /* remove endline */
break;
}
....
}Предупреждение PVS-Studio: V1010 Unchecked tainted data is used in index: 'strlen(command_buf)'.
Анализатор предупреждает о подозрительном обращении по индексу к массиву command_buf. Подозрительным оно считается по той причине, что в качестве индекса используются непроверенные внешние данные. Внешние — потому что получены через функцию fgets из потока stdin, непроверенные — так как никакой проверки перед использованием выполнено не было. Выражение fgets(command_buf, ....) != command_buf не в счёт, так как таким образом проверяется только факт получения данных, но не их содержимое.
Проблема данного кода в том, что при определённых условиях произойдёт запись '\0' за пределы массива, что приведёт к возникновению неопределённого поведения. Для этого достаточно ввести строку нулевой длины. Более подробно найденный дефект и его воспроизведение описано в этой статье в главе про FreeSWITCH.
Рассмотренный реальный пример выявляется с помощью анализа помеченных данных. Однако он не очень интересен, так как всё происходит в одной функции на почти линейном участке кода.
Для демонстрации межпроцедурного анализа и контекстно-чувствительного анализа воспользуемся синтетическим примером:
int getindex() {
int index;
scanf("%d", &index);
return index;
}
void useindex(char *buf, int index) {
buf[index] = 1;
}
void foo() {
char buf[10];
int i = getindex();
useindex(buf, i);
}Предупреждение PVS-Studio: V1010 Unchecked tainted data is used in the second argument: 'i'. Check lines: 14, 20, 9.
Недостоверные чувствительные данные записываются в переменную index в процессе получения данных извне (вызов функции ввода scanf). Функция getindex возвращает эти недостоверные данные, и они попадают в функцию foo. Далее недостоверное значение передаётся в функцию useindex, где используется для обращения к массиву фиксированного размера.
Соответственно, если пользователь введёт, например, значение 33, то возникнет критическая ошибка выхода за границу массива.
Истоком здесь является функция scanf, а стоком — использование помеченных данных в качестве индекса. Приведённый код демонстрирует межпроцедурный контекстно-чувствительный анализ, так как помеченные данные передаются между функциями. Если функции будут находиться в разных файлах, то этот пример будет демонстрировать межпроцедурный контекстно-чувствительный анализ помеченных данных.
Если добавить валидацию введённых данных:
void foo() {
char buf[10];
int i = getindex();
if (i < 10)
useindex(buf, i);
}То анализатор PVS-Studio уже не будет выдавать предупреждение V1010.
Наши доклады и статьи на тему анализа помеченных данных C++ кода:
- C++ Russia 2018, Сергей Васильев: "Статический анализ: ищем ошибки... и уязвимости?"
- Сергей Васильев: "Стреляем в ногу, обрабатывая входные данные".
- Олег Лысый: "Taint-анализ в C и C++ анализаторе PVS-Studio".
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных C# кода
Рассмотрим анализ помеченных данных на примере XXE-уязвимости. Описание реального примера будет длинным (вы можете ознакомиться с одним из них здесь), поэтому рассмотрим синтетический вариант.
Представим приложение, которое принимает запросы в виде XML-файлов и обрабатывает товары с соответствующим идентификатором. Если идентификатор задан неверно, приложение сообщает об этом.
Формат XML-файла, с которым работает приложение:
<?xml version="1.0" encoding="utf-8" ?>
<shop>
<itemID>62</itemID>
</shop>Допустим, обработкой занимается следующий код:
static void ProcessItemWithID(String pathToXmlFile)
{
XmlReaderSettings settings = new XmlReaderSettings()
{
XmlResolver = new XmlUrlResolver(),
DtdProcessing = DtdProcessing.Parse
};
using (var fileReader = File.OpenRead(pathToXmlFile))
{
using (var reader = XmlReader.Create(fileReader, settings))
{
while (reader.Read())
{
if (reader.Name == "itemID")
{
var itemIDStr = reader.ReadElementContentAsString();
if (long.TryParse(itemIDStr, out var itemIDValue))
{
// Process item with the 'itemIDValue' value
Console.WriteLine(
$"An item with the '{itemIDValue}' ID was processed.");
}
else
{
Console.WriteLine($"{itemIDStr} is not valid 'itemID' value.");
}
}
}
}
}
}Предупреждение PVS-Studio: V5614. OWASP. Potential XXE vulnerability. Insecure XML parser is used to process potentially tainted data.
Для приведённого выше XML-файла приложение распечатает следующую строку:
An item with the '62' ID was processed.Если вместо номера в ID будет записано что-то другое (например, строка "Hello world"), приложение сообщит об ошибке:
"Hello world" is not valid 'itemID' value.Несмотря на то, что код делает то, что от него ожидается, он уязвим к XXE-атакам за счёт соблюдения всех перечисленных ранее факторов:
- содержимое XML поступает от пользователя;
- XML-парсер сконфигурирован таким образом, чтобы обрабатывать внешние сущности;
- вывод может передаваться обратно пользователю.
Ниже представлен XML-файл, через который можно скомпрометировать данный код:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE foo [
<!ENTITY xxe SYSTEM "file://D:/MySecrets.txt">
]>
<shop>
<itemID>&xxe;</itemID>
</shop>В этом файле объявляется внешняя сущность xxe, которая будет обработана парсером. Вследствие этого содержимое файла D:/MySecrets.txt (например, такое: 'This is an XXE attack target.'), находящегося на машине, где запущено приложение, будет выдано пользователю:
This is an XXE attack target. is not valid 'itemID' value.Для того чтобы обезопаситься от подобной атаки, можно запретить обработку внешних сущностей (присвоить свойству XmlResolver значение null), а также запретить или игнорировать обработку DTD (записать в свойство DtdProcessing значение Prohibit или Ignore соответственно).
Анализатор также учитывает и межпроцедурные вызовы. Рассмотрим пример:
static FileStream GetXmlFileStream(String pathToXmlFile)
{
return File.OpenRead(pathToXmlFile);
}
static XmlDocument GetXmlDocument()
{
XmlDocument xmlDoc = new XmlDocument()
{
XmlResolver = new XmlUrlResolver()
};
return xmlDoc;
}
static void LoadXmlInternal(XmlDocument xmlDoc, Stream input)
{
xmlDoc.Load(input);
Console.WriteLine(xmlDoc.InnerText);
}
static void XmlDocumentTest(String pathToXmlFile)
{
using (var xmlStream = GetXmlFileStream(pathToXmlFile))
{
var xmlDoc = GetXmlDocument();
LoadXmlInternal(xmlDoc, xmlStream);
}
}В данном случае анализатор выдаст предупреждение на вызов метода LoadXmlInternal, так как отследит, что:
- парсер, полученный из метода GetXmlDocument, может обрабатывать внешние сущности;
- поток, полученный из метода GetXmlStream, содержит данные, полученные из внешнего источника (прочитанные из файла);
- парсер и недостоверные данные передаются в метод LoadXmlInternal, где выполняется обработка XML-файла.
Наши доклады и статьи на тему анализа помеченных данных C# кода:
- Сергей Васильев: "Уязвимости из-за обработки XML-файлов: XXE в C# приложениях в теории и на практике".
- Сергей Васильев: "Под капотом SAST: как инструменты анализа кода ищут дефекты безопасности".
- TechLead Conf 2022, Сергей Васильев: "Под капотом SAST: как инструменты анализа кода ищут дефекты безопасности".
- Никита Липилин, Сергей Васильев: "Почему важно проверять значения параметров общедоступных методов".
- Никита Паневин: "Поймай уязвимость своими руками: пользовательские аннотации C# кода".
- Никита Липилин: "Как taint-анализ защищает код от атак? [SQL Injection] [Path traversal]".
- Сергей Васильев: "OWASP, уязвимости и taint-анализ в PVS-Studio C#. Смешать, но не взбалтывать".
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных Java кода
Рассмотрим синтетический пример (с использованием Spring Boot) межмодульного контекстно-чувствительного анализа помеченных данных, источником которых является сетевой запрос.
Первый файл — DemoController.java:
@Controller
public class DemoController {
@Autowired
private DemoService service;
@RequestMapping("demo")
public ResponseEntity<DemoObject>
demoEndpoint(@RequestParam(name="name") String name) {
return service.findByName(name)
.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
}Метод получает недостоверную информацию (строку). Далее эта строка передаётся без предварительной обработки/проверки в метод findByName.
Второй файл — DemoService.java:
@Service
public class DemoService {
@Autowired
DemoRepository demoRepository;
Optional<DemoObject> findByName(String name) {
return demoRepository.findByName(name);
}
}Здесь нет обработки/проверки, и метод передаёт строку далее в метод другого класса, который также имеет имя findByName.
Третий файл — DemoRepository.java:
public class DemoRepository {
@Autowired
private JdbcTemplate jdbcTemplate;
Optional<DemoObject> findByName(String name) {
var sql = "SELECT * FROM demoTable WHERE name = '" + name + "'";
if (name.equals("demoCondition")) {
sql = "SELECT * FROM demoTable WHERE name = demoName";
return Optional.ofNullable(
jdbcTemplate.queryForObject(sql, DemoObject.class));
}
return Optional.ofNullable(
jdbcTemplate.queryForObject(sql, DemoObject.class));
}
}Формируется SQL-запрос, в котором присутствует недостоверная строка. Это является уязвимостью типа SQL-инъекция.
Предупреждение PVS-Studio: V5309 Possible SQL injection. Potentially tainted data in 'sql' variable is used to create SQL command. DemoRepository.java 18, DemoController.java 15
Наши доклады и статьи на тему анализа помеченных данных Java кода:
- JPoint 2023, Сергей Васильев: "Как анализаторы кода ищут ошибки и дефекты безопасности".
- Константин Волоховский: "Поиск потенциальных уязвимостей в коде": часть 1 — теория, часть 2 — практика.
Вспомогательные методы анализа
В стандарте сказано (п. 7.4), что в состав реализуемых методов статического анализа следует включать следующие методы анализа для поиска дополнительных типов ошибок, а также в качестве вспомогательных анализов:
- сигнатурный поиск;
- анализ псевдонимов;
- анализ косвенных вызовов;
- статистический анализ;
- анализ иерархии классов.
Наличие этих видов анализа является не обязательными для статических анализаторов, но желательными. Разберёмся, в чём состоят эти анализы, и приведём примеры использования этих технологий в PVS-Studio.
Сигнатурный поиск
Сигнатурный анализ (п 3.1.28) — статический анализ, определяющий наличие свойства программы при помощи поиска строк в её исходном коде по некоторому образцу, в том числе заданному с помощью формального языка поиска, например, при помощи регулярных выражений.
Сигнатурный анализ используется в PVS-Studio для реализации диагностических правил для всех языков: C, C++, C#, Java.
Упоминание в определении регулярных выражений может вызвать неправильное представление о сути данной технологии. Большинство диагностических правил, выполняющих сигнатурный анализ, работают с абстрактным синтаксическим деревом и при этом учитывают дополнительную информацию, такую как типы переменных. Соответственно, это более сложный и комплексный вид анализа по сравнению с простым поиском текста по какому-то шаблону. Например, ядро PVS-Studio для анализа C и C++ кода использует регулярные выражения (причём для вспомогательных целей) только в 5 из примерно 750 правил, реализованных на момент написания этого раздела.
Пример диагностического правила для C++ кода
В среднем диагностические правила, построенные на сигнатурном поиске, достаточно просты. Однако это не значит, что выявляемые ими ошибки будут несущественными.
Например, достаточно простым выглядит правило, которое выявляет сравнение переменной с самой собой:
lowerBound[0] == lowerBound[0]Однако это не придуманный синтетический код, а реальный фрагмент из проекта LLVM (язык C++):
FailureOr<ConstantOrScalableBound>
ScalableValueBoundsConstraintSet::computeScalableBound(....)
{
....
SmallVector<AffineMap, 1> lowerBound(1), upperBound(1);
scalableCstr.cstr.getSliceBounds(pos, 1, value.getContext(), &lowerBound,
&upperBound, closedUB);
auto invalidBound = [](auto &bound) {
return !bound[0] || bound[0].getNumResults() != 1;
};
AffineMap bound = [&] {
if (boundType == BoundType::EQ && !invalidBound(lowerBound) &&
lowerBound[0] == lowerBound[0]) { // <=
return lowerBound[0];
} else if (boundType == BoundType::LB && !invalidBound(lowerBound)) {
return lowerBound[0];
....
}Предупреждение PVS-Studio: V501 There are identical sub-expressions to the left and to the right of the '==' operator: lowerBound[0] == lowerBound[0]. ScalableValueBoundsConstraintSet.cpp 110
Перед нами опечатка, от которой не застрахованы даже профессиональные разработчики компиляторов. Корректный вариант кода:
lowerBound[0] == upperBound[0]Примечание. Здесь можно познакомиться с публикациями, посвящёнными поиску ошибок в различных компиляторах с помощью PVS-Studio.
Теперь рассмотрим примеры сигнатурного анализа для C# и Java.
Проект Space Engineers (C#):
private static bool IsTriangleDangerous(int triIndex)
{
if (MyPerGameSettings.NavmeshPresumesDownwardGravity)
{
return triIndex == -1;
}
else
{
return triIndex == -1;
}
}Предупреждение PVS-Studio: V3004 The 'then' statement is equivalent to the 'else' statement. Sandbox.Game MyNavigationTriangle.cs 189
Проект jBullet (Java):
public class ConeTwistConstraint extends TypedConstraint {
....
private boolean solveTwistLimit;
private boolean solveSwingLimit;
....
public boolean getSolveTwistLimit() {
return solveTwistLimit;
}
public boolean getSolveSwingLimit() {
return solveTwistLimit;
}
}Предупреждение PVS-Studio: V6091 Suspicious getter implementation. The 'solveSwingLimit' field should probably be returned instead. ConeTwistConstraint.java(407), ConeTwistConstraint.java(74)
Анализ псевдонимов
Анализ псевдонимов (п. 3.1.7) — статический анализ, позволяющий установить наличие в программе доступа к одной и той же переменной или функции с помощью различных ссылок (указателей).
Синтетический пример для C++ кода
На данный момент анализ псевдонимов поддерживает только некоторые конструкции и типы данных, например ссылки для простых типов. Синтетический пример со ссылками:
int foo(int &a, const int &b)
{
a = b;
return a;
}
int get_0(int b = 1)
{
int a = 15;
int &c = b;
c = 0;
return foo(a, b);
}
int test()
{
return 100 / get_0(); //+V609
}Анализатор видит присваивание переменной c значения 0, но понимает, что 0 будет присвоен и переменной b. В результате он выявляет возникновение в коде деления на ноль: V609. Divide by zero. Denominator 'get_0()' == 0.
Синтетический пример для C# кода
object GetPotentialNull() {
Random random = new();
return random.NextDouble() > 0.5 ? new object() : null;
}
void Example_1() {
object potentialNull = GetPotentialNull();
ref object alias = ref potentialNull;
if (alias != null) {
// Правило V3080 не срабатывает,
// т. к. alias и potentialNull - одно и то же значение.
_ = potentialNull.ToString();
}
}
void Example_2()
{
var obj = new object();
ref object alias = ref obj;
alias = GetPotentialNull();
// Срабатывает правило V3080, так как при
// изменении значения alias, меняется и obj.
_ = obj.ToString(); // V3080: Possible null dereference.
}Анализ псевдонимов в Java коде
В таблице N2 для языка Java поддержка анализа псевдонимов не заявлена. Пока эта технология используется ограниченно в детекторах утечек ресурсов для снижения количества ложных срабатываний. Пример:
public void negative(File f, boolean bool) throws IOException {
FileOutputStream fs = new FileOutputStream(f); // Здесь нет V6127
FileOutputStream fs2 = fs;
if (bool) {
fs.close();
} else {
fs2.close();
}
}В обоих ветках файловый поток закрывается через разные ссылки. Анализатор учитывает, что они указывают на один объект, поэтому не выдаёт предупреждение про утечку ресурсов V6127.
Анализ косвенных вызовов
Анализ косвенных вызовов (3.1.2) — статический анализ, позволяющий в программе, использующей вызовы по указателю или вызовы виртуальных функций, установить множество процедур, которые могут вызываться при выполнении заданного косвенного вызова.
Синтетический пример для C++ кода
int foo(int x)
{
return x - 1;
}
int(*fptr)(int);
int bar()
{
fptr = foo;
return 1 / fptr(1);
}Если аргументом функции foo является единица, то она возвращает ноль. Анализ косвенных вызовов позволяет обнаружить, что вызов этой функции по указателю приводит к ошибке деления на ноль.
Предупреждение: V609 Divide by zero. Denominator 'fptr(1)' == 0.
Синтетический пример для C# кода
using System.Text.Json;
class DeserializationVulnerability
{
void Test(bool flag)
{
string taint = Console.ReadLine();
Func<string, Type, JsonSerializerOptions, object> deserialize;
if (flag)
deserialize = NoDeserialize;
else
deserialize = JsonSerializer.Deserialize;
if (!flag)
deserialize(taint, typeof(object), null); // <=
}
internal static object? NoDeserialize(string json,
Type returnType,
JsonSerializerOptions? options = null)
{
return new object();
}
}В данном примере объявляется делегат deserialize. В зависимости от значения параметра flag переменной deserialize присваивается либо ссылка на метод приёмник заражения (JsonSerializer.Deserialize), либо ссылка на безопасный метод (NoDeserialize).
Далее, в зависимости от значения параметра flag, вызывается делегат, в который передаются заражённые данные. Передача заражённых данных в метод JsonSerializer.Deserialize может привести к уязвимостям. Данную проблему диагностирует правило V5611 Potential insecure deserialization vulnerability. Potentially tainted data is used to create an object using deserialization.
Статистический анализ
Статистический анализ (п. 3.1.32) — статический анализ, определяющий статистику для некоторого свойства программы, например насколько часто в программе проверяется возвращаемое значение некоторой функции.
Статистический анализ используется в PVS-Studio для реализации диагностических правил для всех поддерживаемых языков (C, C++, C#, Java).
Например, для всех языков реализованы правила, выявляющие аномалию, описанную в определении из ГОСТ. Диагностические правила V1071 (C, C++), V3201 (C#) и V6121 (Java) проверяют, насколько часто в программе проверяется/используется возвращаемое значение некоторой функции.
Демонстрационные примеры для перечисленных правил рассматривать не будем, так как они достаточно длинные и не очень интересные. Рассмотрим статистический анализ на примере другого правила. Проект Linux Kernel (язык C):
static const
struct XGI330_LCDDataDesStruct2 XGI_LVDSNoScalingDesData[] = {
{0, 648, 448, 405, 96, 2}, /* 00 (320x200,320x400,
640x200,640x400) */
{0, 648, 448, 355, 96, 2}, /* 01 (320x350,640x350) */
{0, 648, 448, 405, 96, 2}, /* 02 (360x400,720x400) */
{0, 648, 448, 355, 96, 2}, /* 03 (720x350) */
{0, 648, 1, 483, 96, 2}, /* 04 (640x480x60Hz) */
{0, 840, 627, 600, 128, 4}, /* 05 (800x600x60Hz) */
{0, 1048, 805, 770, 136, 6}, /* 06 (1024x768x60Hz) */
{0, 1328, 0, 1025, 112, 3}, /* 07 (1280x1024x60Hz) */
{0, 1438, 0, 1051, 112, 3}, /* 08 (1400x1050x60Hz)*/
{0, 1664, 0, 1201, 192, 3}, /* 09 (1600x1200x60Hz) */
{0, 1328, 0, 0771, 112, 6} /* 0A (1280x768x60Hz) */
};Предупреждение PVS-Studio: V536 Be advised that the utilized constant value is represented by an octal form. Oct: 0771, Dec: 505. vb_table.h 1379
Статистическая аномалия состоит в том, что только одно число в массиве является восьмеричным (0771 в последней строке). Ноль, делающий литерал восьмеричным, лишний и вписан для выравнивания столбика чисел.
Анализ иерархии классов
Анализ иерархии классов (п 3.1.1) — статический анализ, позволяющий выявить в программах на объектно-ориентированных языках список классов, реализованных в программе, а также отношения наследования между этими классами.
Анализ иерархии классов используется в PVS-Studio для реализации диагностических правил для всех объектно-ориентированных языков (C++, C#, Java).
Данный вид анализа, так же как синтаксический анализ, является базовым и активно используется всеми ядрами анализатора PVS-Studio. Без него невозможно большинство других видов анализа.
Поскольку анализ иерархии классов является неотъемлемой частью всех ядер PVS-Studio и работает схожим образом для всех поддерживаемых языков, то рассмотрим только один пример использования.
Проект Blender (язык C++). Для начала рассмотрим базовый класс CurvesFieldInput:
typedef struct CurvesGeometry { .... };
namespace bke
{
....
class CurvesGeometry : public ::CurvesGeometry { .... };
class CurvesFieldInput : public fn::FieldInput
{
....
virtual std::optional<AttrDomain> preferred_domain(
const CurvesGeometry &curves) const;
};
....
}Обратим внимание, что виртуальная функция preferred_domain принимает параметр типа bke::CurvesGeometry. Теперь посмотрим на класс-наследник:
namespace blender::nodes::node_geo_input_curve_handles_cc
{
class HandlePositionFieldInput final : public bke::CurvesFieldInput
{
....
std::optional<AttrDomain> preferred_domain(
const CurvesGeometry & /*curves*/) const;
};
}Предупреждение PVS-Studio: V762 It is possible a virtual function was overridden incorrectly. See first argument of function 'preferred_domain' in derived class 'HandlePositionFieldInput' and base class 'CurvesFieldInput'. node_geo_input_curve_handles.cc 95
В базовом классе виртуальная функция принимает параметр с неквалифицированным именем CurvesGeometry. Когда компилятор будет осуществлять поиск этого типа, он начнёт с области видимости класса CurvesFieldInput и будет заглядывать во все обрамляющие области видимости, пока не встретит этот тип. В итоге будет найден тип bke::CurvesGeometry.
Теперь посмотрим на производный класс. Он определён в пространстве имён, отличном от того, где располагается базовый класс. Компилятор также начнёт поиск нужного имени CurvesGeometry, не найдёт его в обрамляющих областях видимости и дойдёт до глобального. А в глобальном пространстве имён тоже есть CurvesGeometry, только не тот, что нам нужен для переопределения функции.
Чтобы выявлять такую ошибку, анализатор должен собрать информацию о типах, иерархии классов и областях видимости.
Выявляемые типы критических ошибок
На момент обновления раздела (начало 2026 года) PVS-Studio выявляет все типы критических ошибок для языков C, C++, C#, Java. Список поддерживаемых языков в 2026 году будет расширен, но в данный момент говорить про них рано.
Для компилируемых языков PVS-Studio выявляет следующие типы критических ошибок, перечисленных в ГОСТ (п. 6.3).
|
Типы критических ошибок в компилируемых языках (п. 6.3) |
C и C++ |
C# |
Java |
|---|---|---|---|
|
Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.) |
✓ |
✓ |
✓ |
|
Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел |
✓ |
✓ |
✓ |
|
Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти) |
✓ |
✓ |
✓ |
|
Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.) |
✓ |
✓ |
✓ |
|
Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.) |
✓ |
✓ |
✓ |
Таблица N3. Выявляемые типы критических ошибок в компилируемых языках, перечисленные в ГОСТ Р 71207—2024 (п. 6.3). Данные приведены для анализатора PVS-Studio на начало 2026 года
Стандарт дополнительно перечисляет несколько типов критических ошибок, специфичных для языков C и C++ (п. 6.5). Анализатор PVS-Studio обеспечивает их обнаружение.
|
Дополнительные типы критических ошибок для C и C++ (п. 6.5) |
C и C++ |
|---|---|
|
Ошибки разыменования нулевого указателя |
✓ |
|
Ошибки деления на ноль |
✓ |
|
Ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти) |
✓ |
|
Ошибки использования форматной строки |
✓ |
|
Ошибки использования неинициализированных переменных |
✓ |
|
Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений |
✓ |
Таблица N4. Выявляемые типы критических ошибок, являющиеся дополнительными для языков C и C++ и перечисленные в ГОСТ Р 71207—2024 (п. 6.5). Данные приведены для анализатора PVS-Studio на начало 2026 года
Анализатор PVS-Studio умеет обнаруживать, например, деление на ноль не только в C и C++ коде, но и в C# и Java. Сейчас с точки зрения ГОСТ Р 71207—2024 деление на ноль в C# и Java коде не является критической ошибкой. Однако в ходе этапа "Домашнее задание" испытаний статических анализаторов кода в 2025 году обсуждалось, что хорошо расширить в стандарте список критических ошибок для некоторых языков. С высокой вероятностью это будет сделано в следующей редакции ГОСТ Р 71207.
Мы решили в PVS-Studio заранее дополнительно разметить некоторые C# и Java диагностики (детекторы) как критические. В разметке мы опирались на расширенный набор тестов, использованный для качественной оценки анализаторов на этапе "Домашнего задания". Для языков C# и Java дополнительно критическими ошибками считаются:
- ошибки разыменования нулевой ссылки;
- ошибки деления на ноль;
- ошибки управления динамической памятью;
- ошибки утечек памяти и ресурсов.
Более подробную информацию смотрите в статье "Фильтрация предупреждений PVS-Studio, выявляющих критические ошибки (согласно классификации ГОСТ Р 71207—2024)".
Расширенный набор ошибок для C# и Java, которые выявляются и размечаются в PVS-Studio как критические.
|
Типы ошибок, которые, скорее всего, будут включены в список критических в следующей редакции стандарта |
C# |
Java |
|---|---|---|
|
Ошибки разыменования нулевой ссылки |
✓ |
✓ |
|
Ошибки деления на ноль |
✓ |
✓ |
|
Ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти) |
✓ |
✓ |
|
Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений |
✓ |
✓ |
Таблица N5. Выявляемые типы ошибок, которые в дальнейшем также будут относиться к категории критических в новой редакции ГОСТ Р 71207. Данные приведены для анализатора PVS-Studio на начало 2026 года
Детекторы критических ошибок
Для выявления перечисленных выше типов критических ошибок в PVS-Studio реализованы следующие детекторы ошибок (диагностические правила). Приведённый список составлен в январе 2026 года. Актуальную информацию можно посмотреть здесь.
|
Типы критических ошибок, выявляемых PVS-Studio (п. 6.3) |
Детекторы (диагностические правила) |
|---|---|
|
Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.) |
C, C++: V541, V557, V575, V609, V610, V755, V1010, V1083 C#: 5608, V5609, V5610, V5611, V5614, V5615, V5616, V5618, V5619, V5620, V5621, V5622, V5623, V5624, V5626, V5627, V5628, V5631 Java: V5309, V5310, V5311, V5312, V5319, V5320, V5321, V5322, V5323, V5324, V5327, V5330, V5332, V5333, V5334, V5335, V5336, V5337, V5338 |
|
Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел |
C, C++: V569, V605, V610, V629, V642, V658, V724, V784, V1012, V1016, V1026, V1028, V1029, V1070, V1081, V1083, V1085, V1112 C#: 3134, V3200, V3204, V3217 Java: V5308, V6034, V6117, V6124, V6130, V6131 |
|
Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти) |
C, C++: V512, V518, V557, V575, V582, V594, V635, V643, V645, V752, V781, V783, V1038, V1111 C#: V3106, V3184, V3218 Java: V6025, V6079 |
|
Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.) |
C, C++: V597, V618, V631, V642, V698, V1001, V1057, V1072, V1109, V1118, V5014 C#: V3039, V5601, V5612, V5613, V5617 Java: V5305, V5307, V5313, V5314, V5315, V5316, V5317, V5318, V5325, V5326, V5328, V5329, V5331, V6109 |
|
Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.) |
C, C++: V513, V712, V720, V744, V1011, V1018, V1025, V1036, V1088, V1089 C#: V3032, V3054, V3079, V3082, V3083, V3089, V3090, V3147, V3167, V3190, V3223, V5604, V5605 Java: V5304, V6064, V6070, V6074, V6082, V6095, V6102, V6125, V6126, V6129 |
Таблица N6. Детекторы, реализованные в PVS-Studio для выявления критических ошибок в коде программ, написанных на компилируемых языках (C, C++, C#, Java) (п. 6.3)
ГОСТ Р 71207—2024 предписывает выявлять дополнительные типы ошибок в коде программ на языках C и C++. Для других языков эти типы ошибок не считаются критичными (пока).
|
Типы критических ошибок, выявляемых PVS-Studio (п. 6.5) |
Детекторы (диагностические правила) |
|---|---|
|
Ошибки разыменования нулевого указателя |
C, C++: V522, V575, V576, V595, V664, V713, V757, V769, V1004 |
|
Ошибки деления на ноль |
C, C++: V609 |
|
Ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти) |
C, C++: V515, V554, V558, V575, V585, V586, V599, V611, V613, V630, V641, V680, V689, V697, V723, V726, V748, V749, V752, V758, V772, V774, V782, V789, V1002, V1006, V1062 |
|
Ошибки использования форматной строки |
C, C++: V510, V541, V576, V618 |
|
Ошибки использования неинициализированных переменных |
C, C++: V546, V573, V575, V614, V670, V679, V788, V1007, V1050, V1077, V1086 |
|
Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений |
C, C++: V530, V599, V701, V773, V1005, V1020, V1023, V1100, V1106, V1110 |
Таблица N7. Дополнительные детекторы, реализованные в PVS-Studio для выявления критических ошибок в коде программ, написанных на C и C++ (п. 6.5)
Как было сказано в предыдущем разделе, список критических ошибок, перечисленных в стандарте, планируется расширить. PVS-Studio уже заранее учитывает это возможное расширение и позволяет обнаружить следующий набор критических ошибок для языков C# и Java.
|
Ошибки, которые PVS-Studio заранее классифицирует как критические |
Детекторы (диагностические правила) |
|---|---|
|
Ошибки разыменования нулевой ссылки |
C#: 3080, V3125, V3146, V3148, V3149, V3153, V3168, V3195 Java: V6008, V6093 |
|
Ошибки деления на ноль |
C#: V3064 Java: V6020 |
|
Ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти) |
C#: V3178 Java: V6128 |
|
Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений |
C#: V3114, V3222, V3226 Java: V6114, V6115, V6116, V6127 |
Таблица N8. Детекторы, реализованные в PVS-Studio для выявления ошибок в коде программ, написанных на C# и Java. С высокой вероятностью эти типы ошибок войдут как критические в новую редакцию стандарта ГОСТ Р 71207
Другие детекторы ошибок
Надо понимать, что список типов критических ошибок условен. Критическая ошибка, приводящая к записи за границу буфера в некотором приложении, максимум может только испортить какой-то рисунок, но не влияет на безопасность.
И наоборот, опечатка в коде, формально не попадающая ни под один тип перечисленных в ГОСТ Р 71207—2024 критических ошибок, может являться серьёзным дефектом безопасности. Из-за неё, например, неправильно происходит проверка каких-то приватных данных. Фактически эта ошибка является критической.
Рассмотрим в качестве примера баг, найденный нами в проекте RavenDB (язык C#):
public enum SecurityClearance
{
UnauthenticatedClients, //Default value
ClusterAdmin,
ClusterNode,
Operator,
ValidUser
}
public override void VerifyCanExecuteCommand(....)
{
....
var definition = JsonDeserializationServer.CertificateDefinition(read);
if (
definition.SecurityClearance != SecurityClearance.ClusterAdmin ||
definition.SecurityClearance != SecurityClearance.ClusterNode
)
return;
AssertClusterAdmin(isClusterAdmin);
}Предупреждение PVS-Studio: V3022 Expression is always true. Probably the '&&' operator should be used here. DeleteCertificateFromClusterCommand.cs 21
Проверка не имеет смысла. Переменная всегда будет не равна или одной, или другой константе. Поэтому результат проверки всегда истинный. Здесь должно быть написано:
definition.SecurityClearance != SecurityClearance.ClusterAdmin &&
definition.SecurityClearance != SecurityClearance.ClusterNodeИли:
definition.SecurityClearance == SecurityClearance.ClusterAdmin ||
definition.SecurityClearance == SecurityClearance.ClusterNodeОшибка связана с неправильной проверкой некоторого внутреннего состояния, что приводит к неверному пути выполнения программы. Это однозначно серьёзная ошибка в функции, связанной с логикой управления правами. Однако непонятно, к какому типу критической ошибки можно отнести найденную опечатку.
Мы рассмотрели пример, где сложно классифицировать опечатку как критическую ошибку, но по факту она ей является. Как же тогда интерпретировать типы критических ошибок, описанных в ГОСТ, и работать с предупреждениями анализаторов?
Одни ошибки с большей вероятностью могут привести к дефектам безопасности, чем другие. Выход за границу буфера потенциально более опасен, чем неправильное использование #pragma warning (V665).
ГОСТ Р 71207—2024 выделяет группу ошибок, которые с наибольшим шансом могут привести к возникновению уязвимости. Это и есть список критических ошибок. Эти ошибки должны выявляться в первую очередь и обязательно исправляться. Предупреждения про критические ошибки являются первоочерёдными в сравнении со всеми другими предупреждениями, так как их исправление вносят наибольший вклад в безопасность приложения.
Однако это не значит, что другие предупреждения должны быть проигнорированы. Их можно и нужно изучать, хотя не в таких жёстких временных рамках. Временные рамки поиска и исправления критических ошибок описаны в п. 5.6, п. 5.8, п. 5.9.
Анализатор PVS-Studio, помимо критических ошибок, выявляет множество других ошибок, которые также могут являться дефектами безопасности. С полным списком детекторов можно ознакомиться на этой странице.
Примеры выявления всех типов критических ошибок с помощью PVS-Studio
Кратко опишем каждый из типов критических ошибок и приведём примеры их выявления с помощью PVS-Studio. Предпочтение будет отдаваться реальным случаям выявления ошибок, взятых из нашей коллекции багов в открытых проектах. Эти ошибки не обязательно являются дефектами безопасности, но зато демонстрируют работу PVS-Studio в реальных условиях. В случае, если короткого и красивого примера нет, будет составлен синтетический пример.
Ошибки непроверенного использования чувствительных данных (п. 6.3.а)
Описание данного вида дефектов и соответствующие примеры уже были рассмотрены в главе "Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных".
Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел (п. 6.3.б)
Данный вид дефектов может быть использован в атаках для получения неких недопустимых значений, влияющих на ход выполнения программы, отличный от предусмотренного.
Дополнительные ссылки:
- Википедия. Целочисленное переполнение.
- CWE-190: Integer Overflow or Wraparound.
- CWE-680: Integer Overflow to Buffer Overflow.
- Peng Li and John Regehr: "Understanding Integer Overflow in C/C++".
- Дэвин МакКолл: "Почему перенос при целочисленном переполнении — не очень хорошая идея".
- Андрей Карпов, Дмитрий Свиридкин: "Путеводитель C++ программиста по неопределённому поведению: часть 2 из 11" (см. главу "Целые и вещественные числа: переполнение целых знаковых чисел").
Пример выявления ошибки в C или C++ коде (проект Hypertext Preprocessor, C)
PHP_CLI_API size_t sapi_cli_single_write(....)
{
....
size_t shell_wrote;
shell_wrote = cli_shell_callbacks.cli_shell_write(....);
if (shell_wrote > -1) {
return shell_wrote;
}
....
}Предупреждение PVS-Studio: V605 Consider verifying the expression: shell_wrote > - 1. An unsigned value is compared to the number -1. php_cli.c 266
Пример демонстрирует некорректное совместное использование знаковых и беззнаковых чисел. Перед сравнением числовой литерал -1 типа int будет неявно преобразован в значение SIZE_MAX типа size_t. Условие никогда не выполнится.
Пример выявления ошибки в C# коде
bool IsValidAddition(ushort x, ushort y)
{
if (x + y < x)
return false;
return true;
}Предупреждение PVS-Studio: V3204. The expression is always false due to implicit type conversion. Overflow check is incorrect.
Цель данного метода — проверить, произойдёт ли переполнение при сложении двух положительных чисел. В случае переполнения результат суммы должен оказаться меньше любого из её операндов.
Однако проверка не выполнит свою задачу, поскольку оператор '+' не имеет перегрузки для сложения чисел с типом ushort. В результате оба числа будут в начале приведены к типу int, после чего выполнится их сложение. Так как складываются значения типа int, никакого переполнения не произойдёт, и условие всегда будет давать значение false.
Пример выявления ошибки в Java коде (проект Apache Hive)
public void logSargResult(int stripeIx, boolean[] rgsToRead)
{
....
long val = 0;
for (int j = 0; j < 64; ++j) {
int ix = valOffset + j;
if (rgsToRead.length == ix) break;
if (!rgsToRead[ix]) continue;
val = val | (1 << j); // <=
}
....
}Предупреждение PVS-Studio: V6034 Shift by the value of 'j' could be inconsistent with the size of type: 'j' = [0 .. 63]. IoTrace.java 272
Ошибка заключается в невозможности корректно выставить 32 старших разряда в 64-битной переменной val.
В указанной строке индуктивная переменная (п. 3.1.10) j может принимать значение в диапазоне [0..63]. В выражении (1 << j) числовой литерал 1 имеет 32-битный тип int. Соответственно, при сдвиге единицы на 32 и более разрядов будет происходить переполнение.
Для исправления ситуации необходимо написать (1L << j).
Ошибки переполнения буфера (п. 6.3.в)
Переполнение буфера (Buffer Overflow) — запись или чтение программой данных за пределами выделенного для этого в памяти буфера. Обычно возникает из-за неправильной работы с данными и памятью. Усугубляется отсутствием жёсткой защиты со стороны подсистемы программирования и ОС.
Так как большинство языков программирования размещают данные программы в стеке процесса, смешивая их с управляющими данными, переполнение буфера является одним из способов атаки на ПО, который позволяет загрузить и выполнить произвольный машинный код от имени программы или повлиять на логику работы программы, модифицировав данные за пределом буфера.
Дополнительные ссылки:
- Brendan Watters: "Stack-Based Buffer Overflow Attacks: Explained and Examples".
- Dhaval Kapil: "Buffer Overflow Exploit".
- Андрей Карпов, Дмитрий Свиридкин: "Путеводитель C++ программиста по неопределённому поведению: часть 8 из 11" (см. главу "Исполнение программы: переполнение буфера").
Пример выявления ошибки в C или C++ коде (проект ICU, C)
static char plugin_file[2048] = "";
U_CAPI void U_EXPORT2 uplug_init(UErrorCode *status)
{
....
// uprv_strncat раскрывается в strncat
uprv_strncpy(plugin_file, plugin_dir, 2047);
uprv_strncat(plugin_file, U_FILE_SEP_STRING, 2047);
uprv_strncat(plugin_file, "icuplugins", 2047);
uprv_strncat(plugin_file, U_ICU_VERSION_SHORT, 2047);
uprv_strncat(plugin_file, ".txt", 2047);
....
}Здесь анализатор PVS-Studio выдаёт несколько однотипных предупреждений: V645 The 'strncat' function call could lead to the 'plugin_file' buffer overflow. The bounds should not contain the size of the buffer, but a number of characters it can hold. icuplug.c
Многие программисты используют эту функцию вместо strcat, чтобы предотвратить выход за границу буфера, но делают это неправильно. Это как раз такой случай. Третий аргумент функции strncat задаёт не размер буфера, а максимальное количество символов, которое можно добавить. В результате этот код конкатенации строк не защищён от переполнения буфера.
Пример выявления ошибки в C# коде (проект Flax Engine)
Выход за границу массива в C# не представляет существенную опасность, так как в этом случае будет сгенерировано исключение. Так что, пожалуй, для программ на языке C# эту ошибку не стоит считать критической. Но раз формально стандарт требует выявления в компилируемых языках данного вида дефекта, то рассмотрим соответствующий пример:
public Matrix2x2(float[] values)
{
....
if (values.Length != 4)
throw new ArgumentOutOfRangeException(....);
M11 = values[0];
M12 = values[1];
M21 = values[3];
M22 = values[4];
}Предупреждение PVS-Studio: V3106 Possibly index is out of bound. The '4' index is pointing beyond 'values' bound. Matrix2x2.cs 98
Выполняя анализ потока данных и управления, анализатор знает, что если управление дошло до извлечения значений массива, то этот массив содержит 4 элемента. Соответственно, последний индекс должен быть равен 3, а не 4.
Если присмотреться, то становится очевидна опечатки при написании кода: случайно написали 3 вместо 2, а затем 4 вместо 3. Так что, на самом деле, здесь даже не одна ошибка, а сразу две.
Пример выявления ошибки в Java коде (проект ELKI)
Как и в C#, выход за границу массива в Java не представляет существенную опасность, так как в этом случае будет сгенерировано исключение.
@Override
public double[] computeMean() {
return points.size() == 1 ? points.get(1) : null;
}Предупреждение PVS-Studio: V6025 Index '1' is out of bounds. GeneratorStatic.java(104)
Простая опечатка, приводящая к выходу за границу массива. Чтобы извлечь один единственный элемент из массива, следовало написать points.get(0).
Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (п. 6.3.г)
Достаточно обобщённое название критической ошибки, что, в общем-то, неизбежно. Существует огромное количество вариантов неправильного использования функций шифрования, разграничения доступа и так далее. Соответственно, решение этой задачи — в выявлении большого количества модельных вариантов ошибок (п. 3.1.19).
Пример выявления ошибки в C или C++ коде (проект Android, C)
static void FwdLockGlue_InitializeRoundKeys() {
unsigned char keyEncryptionKey[KEY_SIZE];
....
memset(keyEncryptionKey, 0, KEY_SIZE); // Zero out key data.
}Предупреждение PVS-Studio: V597 The compiler could delete the 'memset' function call, which is used to flush 'keyEncryptionKey' buffer. The memset_s() function should be used to erase the private data. FwdLockGlue.c 102
Компилятор вправе удалить вызов функции memset, так как это не изменит наблюдаемое поведение программы с точки зрения C и C++. После вызова memset буфер гарантированно не используется, следовательно, его не нужно заполнять нулями. В результате в памяти остаются приватные данные, которые потенциально могут быть куда-то переданы.
Детальнее про этот дефект безопасности:
- CWE-14: Compiler Removal of Code to Clear Buffers.
- Безопасная очистка приватных данных.
- Это очень распространённая ошибка. Примеры детектирования в различных проектах.
Пример выявления ошибки в C# коде
private static string CalculateSha1(string text, Encoding enc)
{
var buffer = enc.GetBytes(text);
using var cryptoTransformSha1 = new SHA1CryptoServiceProvider();
var hash = BitConverter.ToString(cryptoTransformSha1.ComputeHash(buffer))
.Replace("-", string.Empty);
return hash.ToLower();
}Предупреждение PVS-Studio: V5613. Use of outdated cryptographic algorithm is not recommended.
Используется устаревшая криптографическая функция.
Пример выявления ошибки в Java коде
public void foo() {
Random rnd = new Random(4040);
....
}Предупреждение PVS-Studio: V6109. Potentially predictable seed is used in pseudo-random number generator.
Анализатор обнаружил подозрительный код, инициализирующий генератор псевдослучайных чисел константным значением. Числа, сгенерированные таким генератором, можно предугадать: они будут воспроизводиться снова и снова при каждом запуске программы. Потенциально это может сказаться на безопасности приложения, использующего псевдослучайные числа в задачах, связанных с криптографией (см. также "CWE-336: Same Seed in Pseudo-Random Number Generator (PRNG)").
Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.) (п. 6.3.д)
Выявление ошибок, связанных с использованием многопоточных примитивов, — одна из самых сложных задач для статических анализаторов кода. Отслеживание взаимодействия различных частей программы, которые могут одновременно обращаться к одним и тем же ресурсам, обладает высокой вычислительной сложностью.
По причине сложности задачи выявление этого вида критических ошибок является необязательным для реализации в статических анализаторах (п. 7.3).
Как и в случае с предыдущим разделом, выявление ошибок при работе с многопоточными примитивами в основном сводится к обнаружению множества модельных вариантов ошибок (3.1.19).
Пример выявления ошибки в C или C++ коде (проект Zephyr, C)
static int nvs_startup(struct nvs_fs *fs)
{
....
k_mutex_lock(&fs->nvs_lock, K_FOREVER);
....
if (fs->ate_wra == fs->data_wra && last_ate.len) {
return -ESPIPE; // <= (A)
}
....
end:
k_mutex_unlock(&fs->nvs_lock);
return rc;
}Предупреждение PVS-Studio: V1020 The function exited without calling the 'k_mutex_unlock' function. Check lines: 620, 549. nvs.c 620
Мьютекс останется захваченным, если выход из программы произойдёт в точке (A).
Пример выявления ошибки в C# коде (проект RunUO)
private Packet m_RemovePacket;
....
private object _rpl = new object();
public Packet RemovePacket
{
get
{
if (m_RemovePacket == null)
{
lock (_rpl)
{
if (m_RemovePacket == null)
{
m_RemovePacket = new RemoveItem(this);
m_RemovePacket.SetStatic();
}
}
}
return m_RemovePacket;
}
}Предупреждение PVS-Studio: V3054 Potentially unsafe double-checked locking. Use volatile variable(s) or synchronization primitives to avoid this. Item.cs 1624
В коде паттерн блокировки с двойной проверкой реализован некорректно. При обращении к свойству RemovePacket геттер осуществляет проверку поля m_RemovePacket на равенство null. Если проверка проходит, то мы попадаем в тело оператора lock, где и происходит инициализация поля m_RemovePacket.
Сбой возникает в тот момент, когда главный поток уже инициализировал переменную m_RemovePacket посредством конструктора, но ещё не вызвал метод SetStatic. Теоретически другой поток может обратиться к свойству RemovePacket именно в этот самый неудачный момент. Проверка m_RemovePacket на равенство null уже не пройдёт, и вызывающий поток получит ссылку на неполностью готовый к использованию объект.
Пример выявления ошибки в Java коде (проект DBeaver)
public class MultiPageWizardDialog extends .... {
....
private volatile int runningOperations = 0;
....
@Override
public void run(....) {
....
try {
runningOperations++; // <=
ModalContext.run(
runnable,
true,
monitorPart,
getShell().getDisplay()
);
} finally {
runningOperations--; // <=
....
}
}
}Предупреждения PVS-Studio:
- V6074 Non-atomic modification of volatile variable. Inspect 'runningOperations'. MultiPageWizardDialog.java(590)
- V6074 Non-atomic modification of volatile variable. Inspect 'runningOperations'. MultiPageWizardDialog.java(593)
Неатомарное изменение volatile-переменной может привести к состоянию гонки. Известно, что использование модификатора volatile гарантирует, что все потоки будут видеть актуальное значение соответствующей переменной. К этому можно добавить, что модификатор volatile используется для того, чтобы указать JVM, что все операции присвоения этой переменной и все операции чтения из неё должны быть атомарными.
Можно посчитать, что пометки переменных как volatile будет достаточно, чтобы безопасно их использовать в многопоточном приложении, однако инкремент переменной — неатомарная операция, состоящая из чтения, изменения и записи данных. Подробнее суть проблемы описана здесь.
Ошибки разыменования нулевого указателя (6.5.а, только для C и C++)
Проблема разыменования нулевых указателей вечна и сложнее, чем может показаться на первый взгляд. Любое ли разыменование нулевого указателя приводит к неопределённому поведению? Есть ли исключения и нюансы? Обсуждение этих вопросов вы можете найти здесь:
- Андрей Карпов: "Разыменовывание нулевого указателя приводит к неопределённому поведению".
- Андрей Карпов, Дмитрий Свиридкин: "Путеводитель C++ программиста по неопределённому поведению: часть 9 из 11" (см. главу "Исполнение программы: разыменование нулевых указателей").
- Андрей Карпов: "Четыре причины проверять, что вернула функция malloc".
- C++ on Sea 2023, JF Bastien: "*(char*)0 = 0; - What Does the C++ Programmer Intend With This Code?"
Анализатор использует для поиска разыменования нулевых указателей несколько технологий:
- Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных;
- Чувствительный к путям выполнения анализ потоков данных и управления;
- Эмпирические диагностические правила (поиск модельных вариантов ошибок).
С первыми двумя всё понятно: анализатор пытается вычислить, может ли указатель быть нулевым в момент разыменования. Пример ошибки, найденной в проекте LLVM (язык C++).
Сначала рассмотрим функцию SetInsertPoint в файле IRBuilder.h:
void SetInsertPoint(Instruction *I)
{
BB = I->getParent();
InsertPt = I->getIterator();
assert(InsertPt != BB->end() && "Can't read debug loc from end()");
SetCurrentDebugLocation(I->getStableDebugLoc());
}Обратите внимание, что указатель I сразу разыменовывается без какой-либо проверки.
Теперь рассмотрим использование этой функции, происходящее в другом файле OMPIRBuilder.cpp (межмодульный анализ):
std::pair<Value *, Value *> OpenMPIRBuilder::emitAtomicUpdate
(InsertPointTy AllocaIP, ...., bool IsXBinopExpr)
{
....
if (UnreachableInst *ExitTI = dyn_cast<UnreachableInst>
(ExitBB->getTerminator()))
{
CurBBTI->eraseFromParent();
Builder.SetInsertPoint(ExitBB); // <= ненулевой указатель
}
else
{
Builder.SetInsertPoint(ExitTI); // <= нулевой указатель
}
return Res;
}Предупреждение PVS-Studio: V522 Dereferencing of the null pointer 'I' might take place. The null pointer is passed into 'SetInsertPoint' function. Inspect the first argument. Check lines: 'IRBuilder.h:188', 'OMPIRBuilder.cpp:5983'.
Если выполняется ветка else, то указатель ExitTI будет нулевым. Соответственно, в функцию SetInsertPoint будет передан нулевой указатель, где он и будет разыменован.
Однако в общем виде вычислить возможные значение указателей невозможно. Тогда могут помочь вспомогательные механизмы, построенные на эмпирических алгоритмах. Рассмотрим пример работы одного из таких детекторов ошибок (проект MuseScore, С++):
Ms::Segment* NotationSelectionRange::rangeStartSegment() const
{
Ms::Segment* startSegment = score()->selection().startSegment();
startSegment->measure()->firstEnabled(); // <= разыменование
if (!startSegment) { // <= проверка
return nullptr;
}
if (!startSegment->enabled()) {
startSegment = startSegment->next1MMenabled();
}
....
}Пусть анализатор не может вычислить значение startSegment, однако он замечает следующую аномалию: указатель сначала разыменовывается, а затем проверяется. Раз указатель проверяется, значит автор кода предполагает, что он может быть нулевым. Следовательно, разыменование является опасным.
Анализатор PVS-Studio выдаёт предупреждение: V595 The 'startSegment' pointer was utilized before it was verified against nullptr. Check lines: 129, 131. notationselectionrange.cpp 129 (подробнее про данный детектор — Пояснение про диагностическое правило V595).
Ошибки разыменования нулевой ссылки (дополнение для C# и Java)
Как было сказано в главе "Выявляемые типы критических ошибок", разыменование нулевой ссылки на данный момент не является критической ошибкой для C#/Java согласно ГОСТ Р 71207—2024, но, скорее всего, станет таковой. Анализатор PVS-Studio уже выявляет такие ошибки, что и будет продемонстрировано.
Пример выявления ошибки в C# коде (проект OpenRA)
public void DisguiseAs(Actor target)
{
....
var tooltip = target.TraitsImplementing<ITooltip>().FirstOrDefault();
AsPlayer = tooltip.Owner;
AsActor = target.Info;
AsTooltipInfo = tooltip.TooltipInfo;
....
}Если выборка пуста, то функция FirstOrDefault, в отличие от First, не выбросит исключение InvalidOperationException, а вернёт null для ссылочного типа.
Если target.TraitsImplementing<ITooltip>() вернёт пустую выборку, в tooltip будет записан null. Обращение к свойствам этого объекта, которое производится далее, приведёт к NullReferenceException.
Предупреждение PVS-Studio: V3146 Possible null dereference of 'tooltip'. The 'FirstOrDefault' can return default null value. Disguise.cs 192
Пример выявления ошибки в Java коде (проект OpenIDE)
Примечание. OpenIDE — это бесплатная среда разработки на базе IntelliJ IDEA Community Edition с открытым исходным кодом. Подкаст об OpenIDE: "Фёдор Сазонов: зачем нужна новая IDE на IntelliJ Platform?". Анализатор PVS-Studio может интегрироваться с ней как плагин. О проверке проекта мы писали в статье "Статический анализ OpenIDE".
public void decorate(....) {
....
Module module = ProjectRootManager.getInstance(project)
.getFileIndex()
.getModuleForFile(folder);
if (module == null && !module.isDisposed()) {
return;
}
....
}Разыменование нулевой ссылки возникнет из-за опечатки. Правильным вариантом будет использование в условии не оператора &&, а ||.
Предупреждение PVS-Studio: V6008 Null dereference of 'module'. BuildNodeDecorator.java 78
Ошибки деления на ноль (6.5.б, только для C и C++)
Известная классическая ошибка. Кстати, в силу того, что все программисты про неё знают, она встречается на практике в коде значительно реже, чем может казаться (см. доклад "Ошибки в коде: ожидания и реальность").
Проект VNL (язык C):
integer pow_ii(integer *ap, integer *bp)
{
integer pow, x, n;
....
if (x != -1)
return x == 0 ? 1/x : 0;
....
}Предупреждение PVS-Stuidio: V609 Divide by zero. Denominator 'x' == 0. pow_ii.c 28
Если x равен 0, то произойдёт деление на ноль. Видимо, это опечатка, и, скорее всего, программист планировал написать так:
return x != 0 ? 1/x : 0;Ошибки деления на ноль (дополнение для C# и Java)
Как было сказано в главе "Выявляемые типы критических ошибок", деление на ноль на данный момент не является критической ошибкой для C#/Java согласно ГОСТ Р 71207—2024, но, скорее всего, станет таковой. Анализатор PVS-Studio уже выявляет такие ошибки, что и будет продемонстрировано.
Пример выявления ошибки в C# коде (проект Stability Matrix)
private void DelayedClearProgress(TimeSpan delay)
{
Task.Delay(delay).ContinueWith(_ =>
{
TotalProgress = new ProgressReport(0, 0); // <= (A)
});
}
public ProgressReport(int current, int total, ....)
{
if (current < 0)
throw new ArgumentOutOfRangeException(nameof(current),
"Current progress cannot negative.");
if (total < 0)
throw new ArgumentOutOfRangeException(nameof(total),
"Total progress cannot be negative.");
....
Progress = (double)current / total; // <= (B)
....
}В конструктор структуры ProgressReport передаются два параметра со значениями 0 (точка A). Поэтому параметры current и total равны 0. Автор проверяет эти значения, но не проверяет их равенство с нулём, поэтому значения не попадут под условия. Затем при определении свойства Progress параметры делятся друг на друга (точка B). Такое деление на 0 приведёт к значению NaN, так как результат деления приводится к типу double.
Предупреждение PVS-Studio: V3064 Division inside method by the 2nd argument '0' which has zero value. HuggingFacePageViewModel.cs 226
Пример выявления ошибки в Java коде (проект AutoMQ)
/**
* ....
* @param buckets the number of buckets; must be at least 1
* ....
*/
public Frequencies(int buckets,
double min,
double max,
Frequency... frequencies) {
....
if (buckets < 1) {
throw new IllegalArgumentException("Must be at least 1 bucket");
}
if (buckets < frequencies.length) {
throw new IllegalArgumentException("More frequencies than buckets");
}
....
double halfBucketWidth = (max - min) / (buckets - 1) / 2.0;
....
}Комментарий утверждает, что значение переменной buckets должно быть не меньше 1. Но на самом деле минимальным корректным значением является 2. Если buckets окажется равным 1, то произойдёт деление на ноль в строке:
double halfBucketWidth = (max - min) / (buckets - 1) / 2.0;Предупреждение PVS-Studio: V6020. Divide by zero. Denominator range ['0'..'2147483646']. Frequencies.java 104
Ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти) (6.5.в, только для C и C++)
Первый пример
Проект Shareaza (язык C):
int SetSkinAsDefault()
{
TCHAR szXMLNorm[MAX_PATH];
....
else {
free(szXMLNorm);
return 0;
}
return 1;
}Предупреждение PVS-Studio: V726 An attempt to free memory containing the 'szXMLNorm' array by using the 'free' function. This is incorrect as 'szXMLNorm' was created on stack. utils.c 92
В одной из веток выполнения программы происходит попытка освобождения памяти, выделенной на стеке, с помощью функции free.
Второй пример
Проект CodeLite (язык C++):
int clSocketBase::ReadMessage(wxString& message, int timeout)
{
....
size_t message_len(0);
....
message_len = ::atoi(....);
....
std::unique_ptr<char> pBuff(new char[message_len]);
....
}Предупреждение PVS-Studio: V554 Incorrect use of unique_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. clSocketBase.cpp:282
Неправильное использование умного указателя. Для освобождения памяти будет использован оператор delete, а не delete []. Это приводит к неопределённому поведению (см. "Почему в С++ массивы нужно удалять через delete[]"). Правильный вариант кода:
std::unique_ptr<char []> pBuff(new char[message_len]);Ошибки управления динамической памятью (дополнение для C# и Java)
Как было сказано в главе "Выявляемые типы критических ошибок", ошибки управления динамической памятью на данный момент не являются критическими для C#/Java согласно ГОСТ Р 71207—2024, но, скорее всего, станут таковыми.
Данный класс дефектов не свойственен языкам C# и Javа, и у нас на момент написания текста нет примеров подобных ошибок, обнаруженных с помощью PVS-Studio в реальных проектах. С синтетическими примерами таких ошибок можно познакомиться в документации:
- C#. V3178. Calling method or accessing property of potentially disposed object may result in exception.
- Java. V6128. Using a Closeable object after it was closed can lead to an exception.
Возможно, попытка выделить эту категорию ошибок для C#/Java избыточна, и это сделано не будет. Как видите, хотя детекторы по этой тематике в PVS-Studio существуют, их мало, по крайней мере на данный момент времени.
Ошибки использования форматной строки (6.5.г., только для C и C++)
Некорректное использование форматной строки может приводить к разнообразным ошибкам, в том числе являться уязвимостью (см. публикацию "Не зная брода, не лезь в воду. Часть вторая").
Проект Open X-Ray Engine (язык C++):
void safe_verify(....)
{
....
printf("FATAL ERROR (%s): failed to verify data\n");
....
}Предупреждение PVS-Studio: V576 Incorrect format. A different number of actual arguments is expected while calling 'printf' function. Expected: 2. Present: 1. entry_point.cpp 41
Отсутствует аргумент, который должен быть распечатан в качестве строки.
Дополнительные ссылки:
- Михаил Зинин: "C++: сеанс спонтанной археологии и почему не стоит использовать вариативные функции в стиле C".
- LiveOverflow: "A simple Format String exploit example — bin 0x11".
Ошибки использования неинициализированных переменных (6.5.д, только для C и C++)
Проект System Shock (язык C):
errtype uiInit(uiSlab* slab)
{
....
errtype err;
....
// err = ui_init_cursors();
....
if (err != OK) return err;
....
}Предупреждение PVS-Studio: V614 Uninitialized variable 'err' used. EVENT.C 953
В какой-то момент строчка, где происходила запись в переменную err, была закомментирована, а проверка этой переменной осталась. Получается, что в условии используется неинициализированная переменная.
Дополнительные ссылки:
- Терминология. Неинициализированная переменная.
- Терминология. Использование неинициализированной памяти.
- Андрей Карпов, Дмитрий Свиридкин: "Путеводитель C++ программиста по неопределённому поведению: часть 10 из 11" (см. главу "Исполнение программы: неинициализированные переменные").
- Андрей Карпов: "Исследование COVID-19 и неинициализированная переменная".
Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений (6.5.е, только для C и C++)
Первый пример
Проект Notepad++ (язык C++):
bool ProjectPanel::openWorkSpace(const TCHAR *projectFileName)
{
TiXmlDocument *pXmlDocProject = new TiXmlDocument(....);
bool loadOkay = pXmlDocProject->LoadFile();
if (!loadOkay)
return false;
....
}Предупреждение PVS-Studio: V773 The function was exited without releasing the 'pXmlDocProject' pointer. A memory leak is possible. projectpanel.cpp 326
Утечка памяти. Если не удастся загрузить файл, то функция досрочно завершит работу, не освободив указатель pXmlDocProject.
Второй пример
Проект CMake (язык C):
RHASH_API int rhash_file(....)
{
FILE* fd;
rhash ctx;
int res;
hash_id &= RHASH_ALL_HASHES;
if (hash_id == 0) {
errno = EINVAL;
return -1;
}
if ((fd = fopen(filepath, "rb")) == NULL) return -1;
if ((ctx = rhash_init(hash_id)) == NULL) return -1;
....
}Предупреждение PVS-Studio: V773 The function was exited without closing the file referenced by the 'fd' handle. A resource leak is possible. rhash.c 450
Утечка файлового дескриптора. Если функция rhash_init вернёт NULL, то функция rhash_file досрочно завершится, вернув статус ошибки. При этом не будет закрыт файловый дескриптор, хранящийся в переменной fd.
Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений (дополнение для C# и Java)
Как было сказано в главе "Выявляемые типы критических ошибок", эти дефекты на данный момент не являются критическими ошибками для C#/Java согласно ГОСТ Р 71207—2024, но, скорее всего, станут таковыми. Анализатор PVS-Studio уже выявляет такие ошибки, что и будет продемонстрировано.
Пример выявления ошибки в C# коде (проект RocketMan)
private SceneInfo GetSceneInfo()
{
SceneInfo sceneInfo = new SceneInfo();
try
{
var reader = new StreamReader(sceneLoadDataPath);
....
while (!reader.EndOfStream)
{
sceneList.Add(reader.ReadLine());
}
sceneInfo.scenes = sceneList;
}
....
}После использования объекта типа StreamReader требуется явно освободить выделенную под сторонние (недоступные для GC) ресурсы память, вызвав метод Dispose.
Предупреждение PVS-Studio: V3114 IDisposable object 'reader' is not disposed before method returns. OVRSceneLoader.cs 212
Код можно исправить, воспользовавшись конструкцией using:
private SceneInfo GetSceneInfo()
{
SceneInfo sceneInfo = new SceneInfo();
try
{
using (var reader = new StreamReader(sceneLoadDataPath))
{
....
while (!reader.EndOfStream)
{
sceneList.Add(reader.ReadLine());
}
sceneInfo.scenes = sceneList;
}
}
....
}Пример выявления ошибки в Java коде (проект LanguageTool)
private Dictionary getDictionary(
Supplier<List<byte[]>> lines,
String dictPath,
String infoPath,
boolean isUserDict,
int userDictSize
){
....
InputStream metadata;
if (new File(infoPath).exists()) {
metadata = new FileInputStream(infoPath); // <=
} else {
metadata = getDataBroker().getFromResourceDirAsStream(infoPath);
}
Dictionary dict = Dictionary.read(fsaInStream, metadata);
if (!isUserDict) {
dicPathToDict.put(cacheKey, dict);
} else if (userDictCacheSize != null) {
getUserDictCache().put(userDictName, dict);
}
return dict;
}Предупреждение PVS-Studio: V6127 The 'metadata' Closeable object is not closed. This may lead to a resource leak. MorfologikMultiSpeller.java 320
Интерфейс Closeable сигнализирует, что этот объект может удерживать системный ресурс, который необходимо явно освободить по завершении работы. В нашем случае FileInputStream удерживает файловый дескриптор. Если ссылка на такой файловый дескриптор будет утеряна без предварительного вызова метода close, соответствующий ресурс останется удерживаемым операционной системой до тех пор, пока сборщик мусора не вызовет финализатор. Так как мы не можем гарантировать, когда это произойдёт и произойдёт ли вообще, есть вероятность утечки.
Можно предположить, что поток будет закрыт автоматически внутри метода Dictionary.read, однако документирующий комментарий к этому методу прямо указывает на обратное:
Attempts to load a dictionary from opened streams of FSA dictionary data and associated metadata. Input streams are not closed automatically.
То есть отсутствие явного вызова close приводит к утечке файлового дескриптора. В условиях длительной работы приложения или частого вызова подобного кода это может исчерпать лимит открытых файловых дескрипторов, что приведёт к критическим ошибкам ввода-вывода и потенциально к отказу в обслуживании. Рекомендуется всегда использовать конструкции, гарантирующие детерминированное освобождение ресурсов, например try-with-resources.
Соответствие требованиям к методам анализа
В предыдущих главах уже было подробно разобрано соответствие PVS-Studio требованиям, перечисленным в ГОСТ Р 71207—2024 (раздел 7):
- методы анализа обеспечивают поиск критических ошибок всех типов (п. 7.3);
- реализованы все основные методы и ряд вспомогательных анализов, перечисленные в стандарте (п. 7.4).
Остановимся на оставшихся пунктах из 7-го раздела стандарта.
Глубина поддерживаемого статическим анализатором межпроцедурного анализа
Согласно ГОСТ Р 71207—2024 (п. 7.4) максимальная глубина поддерживаемого межпроцедурного анализа (количество вызовов процедур, через которые может передаваться собираемая в ходе анализа информация о потоке данных программы) не должна быть заранее ограничена, но может определяться с учётом доступных для анализа вычислительных ресурсов.
В PVS-Studio нет фиксированного ограничения на глубину анализа. Остановка осуществляется на основании эмпирических алгоритмов, защищающих от зацикливания (рекурсивных вызовов), и слишком сложном/долгом анализе вызываемых процедур.
Учёт межмодульных связей и параметров сборки
Согласно ГОСТ Р 71207—2024 (п. 7.5) при анализе должны уточняться межмодульные связи и параметры компиляторов.
PVS-Studio учитывает параметры (ключи) компиляторов, используемые при сборке ПО. Это неотъемлемая часть выполнения анализа, так как без этого, например, невозможно в C++ программе корректно выяснить, какая модель данных используется (размеры типов), раскрыть макросы, найти подключаемые библиотеки и так далее. Анализатор учитывает межмодульные связи, так как без этого невозможен межмодульный анализ.
Примечание. В ходе испытаний статических анализаторов в 2025 году выяснилось разночтение участниками такого термина, как "контролируемая сборка ПО" (п. 3.1.12). В следующей редакции стандарта этот термин должен быть уточнён, как и разъяснено, как должен функционировать перехват сборки. Это уточнение, возможно, повлияет на будущую функциональность PVS-Studio.
Способы конфигурации анализа помеченных данных
Согласно ГОСТ Р 71207—2024 (п. 7.6), если статический анализатор для поиска ошибок (п. 6.3.а) применяет анализ помеченных данных, должна быть предоставлена возможность конфигурации анализа: должны задаваться процедуры-источники и процедуры-стоки чувствительных данных.
PVS-Studio поддерживает анализ помеченных данных для поиска критических ошибок, описанных в п. 6.3.а:
6.3. а) ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.).
Соответственно, PVS-Studio реализует и возможность конфигурации анализа.
Аннотация процедур-источников и стоков помеченных данных осуществляется с помощью специализированных файлов в формате JSON. Подключить файл аннотаций можно следующими способами:
Способ N1 (только для С, C++ и C# анализатора). Добавить специальный комментарий в исходный код или в файл конфигурации диагностических правил (.pvsconfig):
//V_PVS_ANNOTATIONS, language:%язык_проекта%, path:%путь/до/файла.json%Вместо символа подстановки %язык_проекта% предполагается использование одного из следующих значений:
- для С — с;
- для С++ — cpp;
- для С# — csharp.
Вместо символа подстановки %путь/до/файла.json% предполагается путь до подключаемого файла аннотаций. Поддерживаются как абсолютные, так и относительные пути. Относительные пути раскрываются относительно файла, в котором указан комментарий для подключения аннотации.
Способ N2 (только для С, C++ и Java анализатора). Указать специальный флаг ‑‑annotation-file (-A) при запуске pvs-studio-analyzer, CompilerCommandsAnalyzer или pvs-studio.jar:
pvs-studio-analyzer --annotation-file=%путь/до/файла.json%Вместо символа подстановки %путь/до/файла.json% предполагается путь до подключаемого файла аннотаций. Поддерживаются как абсолютные, так и относительные пути. Относительные пути раскрываются относительно текущей рабочей директории (CWD).
Способ N3 (только для Java анализатора). Автоматическое подключение по расширению файла.
Файлами аннотаций считаются все файлы с разрешением .annotations.json, находящиеся в директории .PVS-Studio в проекте.
Если проект находится в директории project-gradle, то все следующие файлы автоматически подтянутся анализатором как файлы аннотаций:
project-gradle/.PVS-Studio/test.annotations.json
project-gradle/.PVS-Studio/user.annotations.json
project-gradle/.PVS-Studio/sql.annotations.jsonПримечание. Могут быть подключены несколько файлов с аннотациями. Для каждого файла необходимо указать отдельный флаг или комментарий.
Написание аннотаций и примеры приводятся в следующих разделах документации:
- Аннотирование C и C++ кода в формате JSON.
- Аннотирование C# кода в формате JSON.
- Аннотирование Java кода в формате JSON.
Соответствие требованиям к инструментам статического анализа исходных текстов
Рассмотрим соответствие PVS-Studio различным функциональным требованиям, предъявляемых в ГОСТ Р 71207—2024 (раздел 8) к инструментальным средствам статического анализа исходного кода.
Анализ проекта целиком, включая используемые заимствованные компоненты
Согласно ГОСТ Р 71207—2024 (п. 8.2), статический анализатор должен поддерживать анализ ПО с используемыми заимствованными компонентами целиком, при этом удовлетворяя требованиям п. 7.3–7.6, п. 8.3 и п. 8.4.
Под этим понимается следующее:
- если вы используете код сторонних библиотек, то вы несёте риски в случае наличия в них уязвимостей. Если возможна эксплуатация уязвимости в вашем ПО, то нет разницы, где именно она возникла: в коде, написанном вашей командой, или в заимствованном коде. Соответственно, вы должны проводить поиск критических ошибок во всём исходном коде вашего проекта, включая заимствованные компоненты;
- статический анализатор должен обеспечивать поиск критических ошибок в коде заимствованных компонентов на том же уровне и с применением тех же технологий;
- при анализе заимствованных компонентов также должны учитываться параметры сборки, выполняться межмодульный анализ и так далее;
- следует использовать такой статический анализатор (набор анализаторов), чтобы поиск критических ошибок при полном анализе ПО с используемыми заимствованными компонентами занимал не более двух суток. Время анализа проектов будет обсуждено в следующей главе.
PVS-Studio удовлетворяет всем перечисленным требованиям и позволяет проводить анализ сторонних компонентов на наличие всех типов критических ошибок.
Проверка кода заимствованных компонентов не отличается от проверки кода разрабатываемого программного обеспечения. Код компонентов аналогичным образом должен быть включён в проект, если речь идёт об использовании таких сред разработки, как Visual Studio, IntelliJ IDEA, CLion и так далее. Плагины PVS-Studio используют получаемую от IDE информацию о проверяемых файлах и конфигурационных настройках. При этом необходимо убрать из настроек ряд популярных библиотек, которые PVS-Studio исключает из анализа (zlib, jpeglib и так далее), так как они фактически тоже являются заимствованными компонентами и должны проверяться.
В случае использования утилиты мониторинга компиляции заимствованные компоненты должны компилироваться вместе с исходным кодом проекта. Подробнее про утилиты мониторинга для проверки проектов независимо от сборочной системы (C и C++):
Время анализа проекта (замеры конца 2024 года)
В ГОСТ Р 71207—2024 (п. 8.3) сказано:
Следует использовать такой статический анализатор (набор анализаторов), чтобы на технических средствах разработчика ПО для поиска критических ошибок обеспечивался полный анализ ПО с используемыми заимствованными компонентами за время, не превышающее двое суток.
Разумное требование. С одной стороны, оно достаточно мягкое в плане требований к скорости работы инструментов анализа. С другой стороны, это приемлемое время, за которое разработчики получат результаты анализа всего проекта, который они, согласно ГОСТ, должны выполнять в течении 10 дней после изменения кода (п. 5.6).
Фактически это означает, что рационально настроить анализ всего разрабатываемого ПО, включая заимствованные компоненты, на выходные дни. Анализ как раз гарантированно должен проходить за два дня.
Примечание. В стандарте также сказано, что статический анализ добавленных или изменённых частей ПО следует выполнять после каждого внесённого изменения (п. 5.6). Зачем тогда нужен полный анализ? Дело в межмодульном анализе проекта. Допустим, были внесены изменения в файл AA, которые косвенно повлияли на работу функций в файле BB. Это приведёт к ошибкам в файле BB, но закладываться в систему контроля версий и проверяться с помощью статического анализа будет только файл AA, в котором ошибок нет. Чтобы выявить такую распределённую ошибку, нужен межмодульный анализ, то есть полная перепроверка проекта.
Таким образом, встаёт вопрос оценки верхней границы времени, которое требуется PVS-Studio для анализа проектов различного размера.
Проведённые измерения
Наиболее ресурсоёмким является межмодульный анализ C++ кода, в котором активно используются шаблоны и современные возможности языка. Размер проекта, выбранного для измерения скорости, составляет 10 млн. строк кода.
Конфигурация: 2 процессора Intel Xeon E5 2666 v3 (каждый процессор по 10 физических ядер / 20 логических ядер), частота 3.5 ГГц, 128 ГБ памяти, SSD диск.
Время анализа (включая межмодульный): 10 часов.
Обратите внимание, что ниже проводится оценка для одного процессора с 10 физическими ядрами, а не двух.
Расчёт ожидаемого времени для проектов различного размера:
- Для анализа 100 тыс. строк кода будет достаточно одного процессора класса Intel Xeon E5 2666 v3 (10 физических ядер / 20 логических ядер), частота 3.5 ГГц, 64 ГБ памяти. Ожидаемое время анализа: 12 минут.
- Для анализа 1 млн. строк кода будет достаточно одного процессора класса Intel Xeon E5 2666 v3 (10 физических ядер / 20 логических ядер), частота 3.5 ГГц, 64 ГБ памяти. Ожидаемое время анализа: 2 часа.
- Для анализа 10 млн. строк кода будет достаточно одного процессора класса Intel Xeon E5 2666 v3 (10 физических ядер / 20 логических ядер), частота 3.5 ГГц, 64 ГБ памяти. Ожидаемое время анализа: 20 часов.
Таким образом, PVS-Studio с запасом удовлетворяет требованиям по производительности, заданным в ГОСТ Р 71207—2024 (п. 8.3).
Если складывается ситуация, что анализ с помощью PVS-Studio занимает аномально длительное время, то, скорее всего, возникла одна из следующих ситуаций:
- Используется много процессорных ядер, но в системе мало оперативной памяти. В результате начинает использоваться файл подкачки, что может замедлять работу анализатора в десяток раз. Можно получить ускорение, указав в настройках анализатора, сколько ядер следует использовать, или увеличить в системе объём оперативной памяти.
- Существует какая-то ошибка в анализе кода, которая даёт существенное замедление на определённых конструкциях кода или даже приводит к зацикливанию, которое прерывается только по таймауту. В этом случае просим обратиться к нам в поддержку, и мы постараемся устранить проблему.
Дополнительно см. раздел документации "Советы по повышению скорости работы PVS-Studio".
Примечание. В документации PVS-Studio одним из советов является исключение из анализа лишних библиотек. С точки зрения ГОСТ Р 71207—2024 этим советом воспользоваться, возможно, не получится, так как все заимствованные компоненты должны проверяться при РБПО.
Время анализа проекта (замеры на испытаниях в 2025 году)
Испытаниях статических анализаторов в 2025 году включали в себя нагрузочное тестирование на больших проектах. Инструмент PVS-Studio хорошо показал себя на всех проектах. Полную таблицу вы можете найти на 13-м слайде презентации 10_SA_ponomarev_end , выложенной здесь.
Фрагмент таблицы, относящийся только к PVS-Studio:
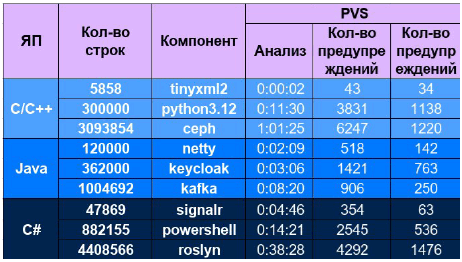
Результаты применения анализатора
Результаты применения статического анализатора PVS-Studio содержат всю информацию, перечисленную в ГОСТ Р 71207—2024 (п. 8.5):
- перечень предупреждений о найденных ошибках (п. 8.5.а);
- описание ошибок (п. 8.5.б);
- тип ошибок (п. 8.5.в);
- место в исходном коде программы, где найдены ошибки (п. 8.5.г).
Остановимся подробнее на пункте "Тип ошибок".
Согласно стандарту тип ошибки — это категория ошибок в программе, отражающая их общность в свойствах или характеристиках (п. 3.1.35).
Анализатор PVS-Studio детектирует более 1000 ошибок разного типа. Соответственно, для каждого типа ошибки есть своё предупреждение, состоящее из идентификатора (Vxxx), сообщения и документации. Полный список типов выявляемых ошибок.
Если смотреть более обобщённо, то анализатор PVS-Studio классифицирует свои предупреждения согласно типам критических ошибок, перечисленным в ГОСТ Р 71207—2024 (п. 6.3, п. 6.5).
Если вы включили опцию "маркировать предупреждения анализатора PVS-Studio согласно ГОСТ Р 71207—2024", то в поле SAST появятся следующие идентификаторы типа критических ошибок:
- SEC-TAINT — ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.);
- SEC-OVERFLOW-OR-INT-UINT — ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел;
- SEC-BUF-OVERFLOW — ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти);
- SEC-SECURITY — ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.);
- SEC-SYNCHRONIZATION — ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.);
- SEC-NULL — ошибки разыменования нулевого указателя;
- SEC-DIV-0 — ошибки деления на ноль;
- SEC-MEMORY — ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти);
- SEC-STR-FORMAT — ошибки использования форматной строки;
- SEC-UNINITIALIZED — ошибки использования неинициализированных переменных;
- SEC-LEAKS — ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений.
Вы можете использовать фильтрацию поля SAST в плагинах для IDE или в конверторе отчётов, чтобы выбрать для изучения только список критических ошибок или только конкретный тип критических ошибок.
Дополнительные ссылки:
- Александра Уварова, Андрей Карпов: Фильтрация предупреждений PVS-Studio, выявляющих критические ошибки (согласно классификации ГОСТ Р 71207—2024).
- Владислав Богданов: Ошибки Java по ГОСТу: обзор и примеры.
Принятие решений и автоматизация разметки предупреждений
В ГОСТ Р 71207—2024 (п. 8.6) говорится, что:
- В ходе разметки предупреждений (согласно п. 5.5) должна быть обеспечена возможность автоматизации с целью сокращения времени, затрачиваемого на принятие решения, к какой категории отнести предупреждение;
- Требуется возможность навигации по коду при работе с предупреждениями, обеспечено соотнесение выданных предупреждений с исходным кодом;
- Поддержка в принятии решения и автоматизация могут быть обеспечены как средствами статического анализатора, так и сторонними средствами;
- Поддержка в принятии решения и автоматизация могут быть реализованы графическим интерфейсом анализатора.
PVS-Studio соответствует всем требованиям и обеспечивает автоматизацию принятия решения с помощью следующих средств:
- Возможна навигация по коду и соотнесение предупреждений с кодом. Для этого можно использовать отчёты в различных форматах, а также плагины PVS-Studio для различных сред разработки (Visual Studio, Visual Studio Code, Qt Creator и т.д.);
- Фильтрация критических ошибок по их типу;
- Внутренний механизм задания baseline-уровня сообщений;
- Использование платформы SonarQube (реализован плагин для встраивания PVS-Studio в SonarQube);
- Использование платформы DefectDojo;
- Использование платформы CodeChecker;
- Использование платформы AppSec.Hub;
- Использование платформы Hexway;
- Использование платформы CyberCodeReview;
- Использование платформы TRON.ASOC;
- Утилита blame-notifier. Позволяет автоматически размечать предупреждения (назначение на разработчика, дата внесения дефекта, сортировка по группам) на основе информации из систем контроля версий (SVN, GIT, Mercurial, Perforce).
Автоматизации действий
Согласно стандарту (п. 8.7) статический анализатор должен обеспечивать возможность автоматизации действий, приведённых в п. 5.6, для использования в системах непрерывной интеграции.
Анализатор PVS-Studio поддерживает следующие системы непрерывной интеграции:
- Jenkins;
- TeamCity;
- CircleCI;
- Travis CI;
- GitLab;
- Azure DevOps;
- GitHub Actions;
- GitFlic;
- AppVeyor;
- Buddy.
Обеспечивается хранение результатов запуска, разметки и сравнения
Согласно п. 8.8 должно быть обеспечено хранение результатов запуска статического анализатора и разметки этих результатов. Предупреждение должно быть снабжено идентификатором, с помощью которого его можно найти в результатах анализа. Допускается использовать для хранения результатов сторонние системы.
Результатом анализа проекта с помощью PVS-Studio может быть:
- неотфильтрованный вывод анализатора (JSON);
- отфильтрованный XML-отчёт;
- отфильтрованный JSON-отчёт.
Эти файлы могут быть преобразованы с помощью специальных утилит в другие форматы. Их описание находится в документации в главе "Просмотр и конвертация результатов анализа (форматы SARIF, HTML и др.)".
|
Формат |
Расширение |
Инструменты |
Описание |
|---|---|---|---|
|
PVS-Studio Log (Plog) |
.plog |
Visual Studio, SonarQube, Compiler Monitoring UI |
Для Windows пользователей Visual Studio и SonarQube |
|
JSON |
.json |
Visual Studio IntelliJ IDEA Rider CLion |
Для пользователей плагинов PVS-Studio в IDE и SonarQube |
|
SARIF |
.sarif |
Visual Studio, Visual Studio Code, есть визуализация в GitHub Actions |
Универсальный формат отчёта статического анализатора |
|
TaskList |
.tasks |
Qt Creator |
Для работы с отчётом в Qt Creator |
|
TaskList Verbose |
.tasks |
Qt Creator |
Расширение формата TaskList с поддержкой отображения дополнительных позиций |
|
CSV |
.csv |
Microsoft Excel LibreOffice Calc |
Для просмотра предупреждений в табличном виде |
|
Simple Html |
.html |
Email Client Browser |
Для рассылки отчётов почтой |
|
Full Html |
Folder |
Browser |
Для просмотра предупреждений с навигацией по коду в браузере |
|
Error File |
.err |
IDEs, Vim, Emacs, etc |
Для просмотра отчётов в любом редакторе, поддерживающем формат вывода компилятора |
|
Error File Verbose |
.err |
IDEs, Vim, Emacs, etc |
Расширение формата Error File с поддержкой отображения дополнительных позиций |
|
TeamCity |
.txt |
TeamCity |
Для загрузки и просмотра предупреждений в TeamCity |
|
MISRA Compliance |
.html |
Email Client Browser |
Для проверки кода на соответствие стандартам MISRA |
|
GitLab |
.json |
GitLab |
Для просмотра предупреждений в формате GitLab Code Quality |
|
DefectDojo |
.json |
DefectDojo |
Для загрузки и просмотра предупреждений в DefectDojo |
|
Markdown |
.markdown |
VS Code, GitHub |
Для просмотра предупреждений в формате таблицы Markdown |
Таблица N9. Форматы поддерживаемых утилитой конвертации отчётов, входящих в комплект PVS-Studio
Разметка результатов осуществляется средствами плагинов PVS-Studio для различных IDE или сторонними системами, такими как SonarQube, DefectDojo, CodeChecker.
Для выполнения задачи сравнения результатов различных запусков стандарт допускает использование сторонних систем (п. 8.9). В случае PVS-Studio такими сторонними системами являются SonarQube, DefectDojo и CodeChecker. Также эти системы обеспечивают идентификацию предупреждений.
PVS-Studio Atlas
PVS-Studio Atlas — это решение для управления результатами анализа кода с возможностью разметки предупреждений. Проект имеет две редакции: Atlas Viewer и Atlas Server.
Atlas Viewer — десктопное приложение для работы с одним отчётом анализатора PVS-Studio. Основные возможности:
- Запуск на любой ОС: Windows, macOS, Linux (включая российские дистрибутивы).
- Открытие и просмотр отчётов от анализатора PVS-Studio в форматах .json и .plog.
- Фирменная таблица PVS-Studio для навигации по предупреждениям.
- Разметка результатов с помощью изменения уровня критичности, статуса и комментирования.
- Сохранение отчёта в формате .pvsmap с разметкой и исходными файлами (при необходимости).
- Сохранение отчёта с разметкой результатов (актуально для сертификационных лабораторий, ФСТЭК и отделов безопасности).
Atlas Server — серверное решение для работы с отчётами статических анализаторов кода в многопользовательском режиме. Основные возможности:
- Все возможности PVS-Studio Atlas Viewer.
- Управление качеством проектов (включая ветки разработки).
- Загрузка регулярных отчётов анализа для ведения статистики.
- Назначение исполнителей по исправлению предупреждений.
- Поддержка отчётов в формате SARIF.
На начало 2026 года находится на стадии разработки. Будет доступно для тестирования в 1–2 квартале 2026 года.
Документации с описанием всех типов ошибок
Ссылка на документацию статического анализатора кода PVS-Studio.
Дополнительно документация поставляется вместе с анализатором на случай его использования в закрытом контуре.
В случае использования анализатора без доступа в интернет (в закрытом контуре) рекомендуется включить настройку UseOfflineHelp. В этом случае плагины PVS-Studio при нажатии на идентификатор ошибки будут открывать не страницы сайта, а локальные файлы с описанием диагностических правил, поставляемые в составе анализатора.
Согласно ГОСТ Р 71207—2024 (п. 8.10) статический анализатор должен содержать в документации описание всех типов ошибок, которые он находит, с указанием:
- описания ошибки;
- возможных причин возникновения;
- примеров ошибочного кода, для которого выдаётся предупреждение о данном типе ошибки;
- примеров или рекомендаций исправления данного типа ошибки.
Описание диагностических правил PVS-Studio удовлетворяет всем требованиям, перечисленным в стандарте. Рассмотрим, например, описание правила V1085, предназначенного для выявления критических ошибок целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел (п. 6.3.б).

Рисунок 1. Пример документации для диагностического правила V1085
В документации присутствуют:
- (1) описание ошибки (п. 8.10.а);
- (2) пример ошибочного кода, для которого выдаётся предупреждение о данном типе ошибки (п. 8.10.в);
- (3) описание возможных причин возникновения (п. 8.10.б);
- (4) пример и рекомендация по исправлению данного типа ошибки (п. 8.10.г).
Также следует указывать соответствие типа ошибки в анализаторе одному или нескольким идентификаторам в системе классификации дефектов безопасности Common Weakness Enumeration (CWE) (п. 8.10). Соответствие присутствует в конце описания диагностического правила (5).
Выдача результатов анализа в открытом документированном формате
Статический анализатор должен поддерживать выдачу результатов анализа в открытом документированном формате (п. 8.11). Примером такого стандарта является формат SARIF.
PVS-Studio поддерживает выдачу результатов анализа в следующих открытых форматах:
- SARIF;
- TaskList;
- Html;
- Error File;
- TeamCity;
- GitLab;
- DefectDojo;
- Markdown.
Подробнее см. раздел документации "Просмотр и конвертация результатов анализа (форматы SARIF, HTML и др.)".
Доработки алгоритмов и правил пользователями
ГОСТ Р 71207—2024 (п. 8.12) не обязывает инструмент статического анализа предоставлять пользователям механизмы для доработки алгоритмов и создания новых правил, но упоминает такую возможность.
Анализатор PVS-Studio не предоставляет пользователям возможность изменять логику работы алгоритмов или добавлять новые диагностические правила. Но по запросу наша команда реализует специализированные диагностические правила, необходимые клиентам.
Дополнительные ссылки по теме РБПО и ГОСТ Р 71207—2024
- Андрей Карпов: "ГОСТ Р 71207—2024 глазами разработчика статических анализаторов кода".
- GigaConf 2024, Андрей Карпов: "Использование статического анализатора в разработке безопасного программного обеспечения (ГОСТ Р 71207—2024) на примере PVS-Studio".
- Валерий Филатов: "Использование статических анализаторов кода при разработке безопасного ПО".
- Информационный ресурс Центра компетенций ФСТЭК России и ИСП РАН: "РБПО.РФ".
- Подкаст. Ever Secure x PVS-Studio: Разбираем новый ГОСТ Р 56939—2024 — РБПО.
- Андрей Карпов: Необходимость статического анализа для РБПО на примере 190 багов в TDengine.
Была ли полезна эта страница документации?