
Документация по анализатору кода PVS-Studio (одной страницей)
- Введение
- Проверка проектов
- Регулярное использование в процессе разработки
- Интеграция результатов анализа PVS-Studio в инструменты контроля качества кода (веб дашборд)
- Развёртывание анализатора в облачных CI
- Работа с результатами анализа
- Дополнительная настройка и решение проблем
- Описание диагностируемых ошибок
- Дополнительная информация
Вы можете открыть всю документацию по PVS-Studio одной страницей.
Введение
- Как ввести лицензию PVS-Studio, и что делать дальше
- Ознакомительный режим PVS-Studio
- Системные требования
- Технологии, используемые в PVS-Studio
- История версий
- История версий для старых релизов PVS-Studio (до версии 7.00)
Проверка проектов
На Windows
- Знакомство со статическим анализатором кода PVS-Studio на Windows
- Проверка проектов независимо от сборочной системы (C и C++)
- Прямая интеграция анализатора в системы автоматизации сборки (C и C++)
На Linux и macOS
- Установка PVS-Studio C# на Linux и macOS
- Как запустить PVS-Studio C# на Linux и macOS
- Установка и обновление PVS-Studio C++ на Linux
- Установка и обновление PVS-Studio C++ на macOS
- Как запустить PVS-Studio C++ на Linux и macOS
Кроссплатформенное использование
- Работа с ядром Java анализатора из командной строки
- Кроссплатформенная проверка C и C++ проектов в PVS-Studio
- PVS-Studio для Embedded-разработки
- Анализ C и C++ проектов на основе JSON Compilation Database
Среды разработки
- Работа PVS-Studio в Visual Studio
- Работа PVS-Studio в JetBrains Rider и CLion
- Использование расширения PVS-Studio для Qt Creator
- Интеграция с Qt Creator без использования плагина PVS-Studio
- Использование расширения PVS-Studio для Visual Studio Code
- Работа PVS-Studio в IntelliJ IDEA и Android Studio
Сборочные системы
- Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio
- Интеграция PVS-Studio с помощью CMake-модуля
- Интеграция PVS-Studio Java в сборочную систему Gradle
- Интеграция PVS-Studio Java в сборочную систему Maven
Игровые движки
Регулярное использование в процессе разработки
- Запуск PVS-Studio в Docker
- Запуск PVS-Studio в Jenkins
- Запуск PVS-Studio в TeamCity
- Загрузка результатов анализа в Jira
- PVS-Studio и Continuous Integration
- Режим инкрементального анализа PVS-Studio
- Проверка коммитов и Pull Request'ов
- Автоматическое развертывание PVS-Studio
- Ускорение анализа C и C++ кода с помощью систем распределённой сборки (Incredibuild)
Интеграция результатов анализа PVS-Studio в инструменты контроля качества кода (веб дашборд)
- Интеграция результатов анализа PVS-Studio в DefectDojo
- Интеграция результатов анализа PVS-Studio в SonarQube
- Интеграция результатов анализа PVS-Studio в CodeChecker
- Интеграция результатов анализа PVS-Studio в AppSec.Hub
- Интеграция результатов анализа PVS-Studio в Hexway
- Интеграция результатов анализа PVS-Studio в Securitm
Развёртывание анализатора в облачных CI
- Использование в Travis CI
- Использование в CircleCI
- Использование в GitLab CI/CD
- Использование в GitHub Actions
- Использование в GitFlic
- Использование в Azure DevOps
- Использование в AppVeyor
- Использование в Buddy
Работа с результатами анализа
- Отображение наиболее интересных предупреждений анализатора
- Использование диагностических правил группы OWASP в PVS-Studio
- MISRA Coding Standards and Compliance
- Подавление сообщений анализатора (отключение выдачи предупреждений на существующий код)
- Работа со списком диагностических сообщений в Visual Studio
- Подавление ложноположительных предупреждений
- Просмотр и конвертация результатов анализа
- Использование относительных путей в файлах отчётов PVS-Studio
- Просмотр результатов анализа в приложении C and C++ Compiler Monitoring UI
- Оповещение команд разработчиков (утилита blame-notifier)
- Фильтрация и обработка вывода анализатора при помощи файлов конфигурации диагностик (.pvsconfig)
- Исключение из анализа файлов и каталогов
Дополнительная настройка и решение проблем
- Советы по повышению скорости работы PVS-Studio
- Устранение неисправностей при работе PVS-Studio
- Дополнительная настройка диагностик
- Механизм пользовательских аннотаций в формате JSON
- Предопределенный макрос PVS_STUDIO
- Файл конфигурации анализа Settings.xml
- Настройки анализатора (Visual Studio / C and C++ Compiler Monitoring UI)
Описание диагностируемых ошибок
- Сообщения PVS-Studio
- Диагностики общего назначения (General Analysis, C++)
- Диагностики общего назначения (General Analysis, C#)
- Диагностики общего назначения (General Analysis, Java)
- Микрооптимизации (C++)
- Микрооптимизации (C#)
- Диагностика 64-битных ошибок (Viva64, C++)
- Реализовано по запросам пользователей (C++)
- Cтандарт MISRA
- Стандарт AUTOSAR
- Стандарт OWASP (C++)
- Стандарт OWASP (C#)
- Стандарт OWASP (Java)
- Проблемы при работе анализатора кода
Дополнительная информация
- График количества диагностик в PVS-Studio
- Какие ошибки ловит PVS-Studio?
- Диагностические возможности PVS-Studio
- Список всех диагностик анализатора в XML
- Диагностики общего назначения (General Analysis, C++)
- Диагностики общего назначения (General Analysis, C#)
- Диагностики общего назначения (General Analysis, Java)
- Микрооптимизации (C++)
- Микрооптимизации (C#)
- Диагностика 64-битных ошибок (Viva64, C++)
- Реализовано по запросам пользователей (C++)
- Cтандарт MISRA
- Стандарт AUTOSAR
- Стандарт OWASP (C++)
- Стандарт OWASP (C#)
- Стандарт OWASP (Java)
- Проблемы при работе анализатора кода
Сообщения PVS-Studio
График количества диагностик в PVS-Studio
Анализатор PVS-Studio активно развивается. Например, наша команда постоянно совершенствует его интеграцию с различными CI/CD системами и средами разработки, добавляет поддержку новых платформ и компиляторов. Однако лучше всего развитие возможностей анализатора показывает график количества диагностик.

Рисунок 1. Увеличение количества диагностик в PVS-Studio
Как видите, мы активно совершенствуем возможности анализатора по выявлению новых паттернов ошибок. Более подробная информация по нововведениям в различных версиях анализатора представлена ниже. Вы также можете почитать об изменениях в PVS-Studio за последний год в нашем блоге.
Какие ошибки ловит PVS-Studio?
Мы постарались объединить большинство диагностик в несколько групп, чтобы вы могли получить общее представление о возможностях анализатора кода PVS-Studio.
Так как разделение весьма условно, некоторые диагностики входят в несколько групп. Например, неправильное условие if (abc == abc) можно одновременно интерпретировать и как простую опечатку, и как проблему безопасности, так как ошибка приводит к уязвимости кода при некорректных входных данных.
Некоторым ошибкам, наоборот, места в таблице не нашлось — уж слишком они специфичны. Тем не менее, таблица в целом даёт представление о функциональности статического анализатора кода.
Диагностические возможности PVS-Studio
|
Основные диагностические возможности PVS-Studio |
Диагностики |
|---|---|
|
64-битные ошибки |
C, C++: V101-V128, V201-V207, V220, V221, V301-V303 |
|
Адрес локальной переменной возвращается из функции по ссылке |
C, C++: V506, V507, V558, V723, V758, V1017, V1047 |
|
Арифметическое переполнение, потеря значимости |
C, C++: V569, V636, V658, V784, V786, V1012, V1026, V1028, V1029, V1033, V1070, V1081, V1083, V1085, V1112
C#: V3041, V3200, V3204, V3217
Java: V6011, V6088, V6117 |
|
Выход за границу массива |
C, C++: V557, V582, V643, V781, V1038, V1111
C#: V3106, V3218
Java: V6025, V6079 |
|
Двойное освобождение ресурсов |
C, C++: V586, V749, V1002, V1006 |
|
Мёртвый код |
C, C++: V606, V607
Java: V6021 |
|
Микрооптимизации |
C, C++: V801, V802, V803, V804, V805, V806, V807, V808, V809, V810, V811, V812, V813, V814, V815, V816, V817, V818, V819, V820, V821, V822, V823, V824, V825, V826, V827, V828, V829, V830, V831, V832, V833, V834, V835, V836, V837, V838, V839
C#: V4001, V4002, V4003, V4004, V4005, V4006, V4007, V4008 |
|
Недостижимый код |
C, C++: V517, V551, V695, V734, V776, V779, V785
C#: V3136, V3142, V3202
Java: V6018, V6019 |
|
Неинициализированные переменные |
C, C++: V573, V614, V679, V730, V737, V788, V1007, V1050, V1077, V1086
C#: V3070, V3128
Java: V6036, V6050, V6052, V6090 |
|
Неиспользуемые переменные |
C, C++: V603, V751, V763, V1001, V1079
C#: V3061, V3065, V3077, V3117, V3137, V3143, V3196, V3203, V3220
Java: V6021, V6022, V6023 |
|
Некорректные операции сдвига |
C, C++: V610, V629, V673, V684, V770, V1093
C#: V3134
Java: V6034, V6069 |
|
Неопределенное/неуточняемое поведение |
C, C++: V567, V610, V611, V681, V694, V704, V708, V726, V736, V772, V1007, V1016, V1026, V1032, V1061, V1066, V1069, V1082, V1091, V1094, V1097, V1099
Java: V6128 |
|
Неправильная работа с типами (HRESULT, BSTR, BOOL, VARIANT_BOOL, float, double) |
C, C++: V543, V544, V545, V556, V615, V636, V676, V716, V721, V724, V745, V750, V767, V768, V771, V772, V775, V1014, V1027, V1034, V1046, V1060, V1066, V1084
C#: V3041, V3059, V3076, V3111, V3121, V3148
Java: V6038, V6108 |
|
Неправильное представление о работе функции/класса |
C, C++: V515, V518, V530, V540, V541, V554, V575, V597, V598, V618, V630, V632, V663, V668, V698, V701, V702, V717, V718, V720, V723, V725, V727, V738, V742, V743, V748, V762, V764, V780, V789, V797, V1014, V1024, V1031, V1035, V1045, V1052, V1053, V1054, V1057, V1060, V1066, V1098, V1100, V1107, V1115
C#: V3010, V3057, V3068, V3072, V3073, V3074, V3078, V3082, V3084, V3094, V3096, V3097, V3102, V3103, V3104, V3108, V3114, V3115, V3118, V3123, V3126, V3145, V3178, V3186, V3192, V3194, V3195, V3197
Java: V6009, V6010, V6016, V6026, V6029, V6049, V6055, V6058, V6064, V6068, V6081, V6110, V6116, V6122, V6125 |
|
Опечатки |
C, C++: V501, V503, V504, V508, V511, V516, V519, V520, V521, V525, V527, V528, V529, V532, V533, V534, V535, V536, V537, V539, V546, V549, V552, V556, V559, V560, V561, V564, V568, V570, V571, V575, V577, V578, V584, V587, V588, V589, V590, V592, V602, V604, V606, V607, V616, V617, V620, V621, V622, V625, V626, V627, V633, V637, V638, V639, V644, V646, V650, V651, V653, V654, V655, V657, V660, V661, V662, V666, V669, V671, V672, V678, V682, V683, V693, V715, V722, V735, V741, V747, V753, V754, V756, V765, V767, V768, V770, V771, V787, V791, V792, V796, V1013, V1015, V1021, V1040, V1051, V1055, V1074, V1094, V1113
C#: V3001, V3003, V3005, V3007, V3008, V3009, V3011, V3012, V3014, V3015, V3016, V3020, V3028, V3029, V3034, V3035, V3036, V3037, V3038, V3050, V3055, V3056, V3057, V3060, V3062, V3063, V3066, V3081, V3086, V3091, V3092, V3093, V3102, V3107, V3109, V3110, V3112, V3113, V3116, V3118, V3122, V3124, V3132, V3140, V3170, V3174, V3185, V3187
Java: V6001, V6005, V6009, V6012, V6014, V6015, V6016, V6017, V6021, V6026, V6028, V6029, V6030, V6031, V6037, V6041, V6042, V6043, V6045, V6057, V6059, V6061, V6062, V6063, V6077, V6080, V6085, V6091, V6105, V6112 |
|
Отсутствие виртуального деструктора |
C, C++: V599, V689 |
|
Оформление кода не совпадает с логикой его работы |
C, C++: V563, V612, V628, V640, V646, V705, V709, V715, V1044, V1073
C#: V3007, V3018, V3033, V3043, V3067, V3069, V3138, V3150, V3172, V3183
Java: V6040, V6047, V6063, V6086, V6089 |
|
Ошибки из-за Copy-Paste |
C, C++: V501, V517, V519, V523, V524, V571, V581, V649, V656, V666, V691, V760, V766, V778, V1037
C#: V3001, V3003, V3004, V3008, V3012, V3013, V3021, V3030, V3058, V3127, V3139, V3140
Java: V6003, V6004, V6012, V6021, V6027, V6032, V6033, V6039, V6067, V6072 |
|
Ошибки при работе с исключениями |
C, C++: V509, V565, V596, V667, V668, V740, V741, V746, V759, V1022, V1045, V1067, V1090
C#: V3006, V3052, V3100, V3141, V3163, V3164, V5606, V5607
Java: V6006, V6051, V6103 |
|
Переполнение буфера |
C, C++: V512, V514, V594, V635, V641, V645, V752, V755 |
|
Проблемы безопасности |
C, C++: V505, V510, V511, V512, V518, V531, V541, V547, V559, V560, V569, V570, V575, V576, V579, V583, V597, V598, V618, V623, V631, V642, V645, V675, V676, V724, V727, V729, V733, V743, V745, V750, V771, V774, V782, V1003, V1005, V1010, V1017, V1055, V1072, V1076, V1113, V1118
C#: V3022, V3023, V3025, V3027, V3039, V3053, V3063, V5601, V5608, V5609, V5610, V5611, V5612, V5613, V5614, V5615, V5616, V5617, V5618, V5619, V5620, V5621, V5622, V5623, V5624, V5625, V5626, V5627, V5628, V5629
Java: V5305, V5309, V5312, V5313, V5314, V5315, V5316, V5317, V5318, V5319, V5320, V5321, V5322, V5323, V5325, V5326, V5327, V5328, V5329, V5330, V5331, V6007, V6046, V6054, V6109 |
|
Путаница с приоритетом операций |
C, C++: V502, V562, V593, V634, V648, V727, V733, V1003, V1104
C#: V3130, V3133, V3177, V3207
Java: V6044 |
|
Разыменование нулевого указателя/нулевой ссылки |
C, C++: V522, V595, V664, V713, V757, V769
C#: V3019, V3042, V3080, V3095, V3105, V3125, V3141, V3145, V3146, V3148, V3149, V3153, V3156, V3168
Java: V6008, V6060, V6093 |
|
Разыменование параметров без предварительной проверки |
C, C++: V595, V664, V783, V1004
C#: V3095
Java: V6060 |
|
Ошибки синхронизации |
C, C++: V712, V720, V744, V1011, V1018, V1025, V1036, V1088, V1089, V1114
C#: V3032, V3054, V3079, V3082, V3083, V3089, V3090, V3147, V3167, V3168, V3190
Java: V6064, V6070, V6074, V6082, V6095, V6102, V6125, V6126 |
|
Утечки ресурсов |
C, C++: V599, V701, V773, V1020, V1023, V1100, V1106, V1110
Java: V6114, V6115, V6127 |
|
Целочисленное деление на 0 |
C, C++: V609
C#: V3064, V3151, V3152
Java: V6020 |
|
Ошибки сериализации / десериализации |
C, C++: V513, V663, V739, V1024, V1095
C#: V3094, V3096, V3097, V3099, V3103, V3104, V3193, V5611
Java: V6065, V6075, V6076, V6083, V6087 |
|
Диагностики, созданные по специальным просьбам пользователей |
C, C++: V2001, V2002, V2003, V2004, V2005, V2006, V2007, V2008, V2009, V2010, V2011, V2012, V2013, V2014, V2022 |
Таблица 1 — Возможности PVS-Studio
Как видите, анализатор максимально проявляет себя в таких областях, как поиск ошибок, возникших из-за опечаток и Copy-Paste. Хорошо диагностирует проблемы, связанные с безопасностью кода.
О том, как всё это работает на практике, можно узнать, заглянув в базу ошибок. Мы собираем в эту базу все ошибки, найденные во время проверок различных открытых проектов с помощью PVS-Studio.
Список всех диагностик анализатора в XML
Список диагностик анализатора в формате XML, предназначенный для автоматического разбора, доступен по постоянной ссылке здесь.
Диагностики общего назначения (General Analysis, C++)
- V501. Identical sub-expressions to the left and to the right of 'foo' operator.
- V502. The '?:' operator may not work as expected. The '?:' operator has a lower priority than the 'foo' operator.
- V503. Nonsensical comparison: pointer < 0.
- V504. Semicolon ';' is probably missing after the 'return' keyword.
- V505. The 'alloca' function is used inside the loop. This can quickly overflow stack.
- V506. Pointer to local variable 'X' is stored outside the scope of this variable. Such a pointer will become invalid.
- V507. Pointer to local array 'X' is stored outside the scope of this array. Such a pointer will become invalid.
- V508. The 'new type(n)' pattern was detected. Probably meant: 'new type[n]'.
- V509. Exceptions raised inside noexcept functions must be wrapped in a try..catch block.
- V510. The 'Foo' function receives class-type variable as Nth actual argument. This is unexpected behavior.
- V511. The sizeof() operator returns pointer size instead of array size.
- V512. Call of the 'Foo' function will lead to buffer overflow.
- V513. Use _beginthreadex/_endthreadex functions instead of CreateThread/ExitThread functions.
- V514. Potential logical error. Size of a pointer is divided by another value.
- V515. The 'delete' operator is applied to non-pointer.
- V516. Non-null function pointer is compared to null. Consider inspecting the expression.
- V517. Potential logical error. The 'if (A) {...} else if (A) {...}' pattern was detected.
- V518. The 'malloc' function allocates suspicious amount of memory calculated by 'strlen(expr)'. Perhaps the correct expression is strlen(expr) + 1.
- V519. The 'x' variable is assigned values twice successively. Perhaps this is a mistake.
- V520. Comma operator ',' in array index expression.
- V521. Expressions that use comma operator ',' are dangerous. Make sure the expression is correct.
- V522. Possible null pointer dereference.
- V523. The 'then' statement is equivalent to the 'else' statement.
- V524. It is suspicious that the body of 'Foo_1' function is fully equivalent to the body of 'Foo_2' function.
- V525. Code contains collection of similar blocks. Check items X, Y, Z, ... in lines N1, N2, N3, ...
- V526. The 'strcmp' function returns 0 if corresponding strings are equal. Consider inspecting the condition for mistakes.
- V527. The 'zero' value is assigned to pointer. Probably meant: *ptr = zero.
- V528. Pointer is compared with 'zero' value. Probably meant: *ptr != zero.
- V529. Suspicious semicolon ';' after 'if/for/while' operator.
- V530. Return value of 'Foo' function is required to be used.
- V531. The sizeof() operator is multiplied by sizeof(). Consider inspecting the expression.
- V532. Consider inspecting the statement of '*pointer++' pattern. Probably meant: '(*pointer)++'.
- V533. It is possible that a wrong variable is incremented inside the 'for' operator. Consider inspecting 'X'.
- V534. It is possible that a wrong variable is compared inside the 'for' operator. Consider inspecting 'X'.
- V535. The 'X' variable is used for this loop and outer loops.
- V536. Constant value is represented by an octal form.
- V537. Potential incorrect use of item 'X'. Consider inspecting the expression.
- V538. The line contains control character 0x0B (vertical tabulation).
- V539. Iterators are passed as arguments to 'Foo' function. Consider inspecting the expression.
- V540. Member 'x' should point to string terminated by two 0 characters.
- V541. String is printed into itself. Consider inspecting the expression.
- V542. Suspicious type cast: 'Type1' to ' Type2'. Consider inspecting the expression.
- V543. It is suspicious that value 'X' is assigned to the variable 'Y' of HRESULT type.
- V544. It is suspicious that the value 'X' of HRESULT type is compared with 'Y'.
- V545. Conditional expression of 'if' statement is incorrect for the HRESULT type value 'Foo'. The SUCCEEDED or FAILED macro should be used instead.
- V546. The 'Foo(Foo)' class member is initialized with itself.
- V547. Expression is always true/false.
- V548. TYPE X[][] is not equivalent to TYPE **X. Consider inspecting type casting.
- V549. The 'first' argument of 'Foo' function is equal to the 'second' argument.
- V550. Suspicious precise comparison. Consider using a comparison with defined precision: fabs(A - B) < Epsilon or fabs(A - B) > Epsilon.
- V551. Unreachable code under a 'case' label.
- V552. A bool type variable is incremented. Perhaps another variable should be incremented instead.
- V553. Length of function body or class declaration is more than 2000 lines. Consider refactoring the code.
- V554. Incorrect use of smart pointer.
- V555. Expression of the 'A - B > 0' kind will work as 'A != B'.
- V556. Values of different enum types are compared.
- V557. Possible array overrun.
- V558. Function returns pointer/reference to temporary local object.
- V559. Suspicious assignment inside the conditional expression of 'if/while/for' statement.
- V560. Part of conditional expression is always true/false.
- V561. Consider assigning value to 'foo' variable instead of declaring it anew.
- V562. Bool type value is compared with value of N. Consider inspecting the expression.
- V563. An 'else' branch may apply to the previous 'if' statement.
- V564. The '&' or '|' operator is applied to bool type value. Check for missing parentheses or use the '&&' or '||' operator.
- V565. Empty exception handler. Silent suppression of exceptions can hide errors in source code during testing.
- V566. Integer constant is converted to pointer. Check for an error or bad coding style.
- V567. Modification of variable is unsequenced relative to another operation on the same variable. This may lead to undefined behavior.
- V568. It is suspicious that the argument of sizeof() operator is the expression.
- V569. Truncation of constant value.
- V570. Variable is assigned to itself.
- V571. Recurring check. This condition was already verified in previous line.
- V572. Object created using 'new' operator is immediately cast to another type. Consider inspecting the expression.
- V573. Use of uninitialized variable 'Foo'. The variable was used to initialize itself.
- V574. Pointer is used both as an array and as a pointer to single object.
- V575. Function receives suspicious argument.
- V576. Incorrect format. Consider checking the Nth actual argument of the 'Foo' function.
- V577. Label is present inside switch(). Check for typos and consider using the 'default:' operator instead.
- V578. Suspicious bitwise operation was detected. Consider inspecting it.
- V579. The 'Foo' function receives the pointer and its size as arguments. This may be a potential error. Inspect the Nth argument.
- V580. Suspicious explicit type casting. Consider inspecting the expression.
- V581. Conditional expressions of 'if' statements located next to each other are identical.
- V582. Consider reviewing the source code that uses the container.
- V583. The '?:' operator, regardless of its conditional expression, always returns the same value.
- V584. Same value is present on both sides of the operator. The expression is incorrect or can be simplified.
- V585. Attempt to release memory that stores the 'Foo' local variable.
- V586. The 'Foo' function is called twice to deallocate the same resource.
- V587. Suspicious sequence of assignments: A = B; B = A;.
- V588. Expression of the 'A =+ B' kind is used. Possibly meant: 'A += B'. Consider inspecting the expression.
- V589. Expression of the 'A =- B' kind is used. Possibly meant: 'A -= B'. Consider inspecting the expression.
- V590. Possible excessive expression or typo. Consider inspecting the expression.
- V591. Non-void function must return value.
- V592. Expression is enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or typo is present.
- V593. Expression 'A = B == C' is calculated as 'A = (B == C)'. Consider inspecting the expression.
- V594. Pointer to array is out of array bounds.
- V595. Pointer was used before its check for nullptr. Check lines: N1, N2.
- V596. Object was created but is not used. Check for missing 'throw' keyword.
- V597. Compiler may delete 'memset' function call that is used to clear 'Foo' buffer. Use the RtlSecureZeroMemory() function to erase private data.
- V598. Memory manipulation function is used to work with a class object containing a virtual table pointer. The result of such an operation may be unexpected.
- V599. The virtual destructor is not present, although the 'Foo' class contains virtual functions.
- V600. The 'Foo' pointer is always not equal to NULL. Consider inspecting the condition.
- V601. Suspicious implicit type casting.
- V602. The '<' operator should probably be replaced with '<<'. Consider inspecting this expression.
- V603. Object was created but not used. If you wish to call constructor, use 'this->Foo::Foo(....)'.
- V604. Number of iterations in loop equals size of a pointer. Consider inspecting the expression.
- V605. Unsigned value is compared to the NN number. Consider inspecting the expression.
- V606. Ownerless token 'Foo'.
- V607. Ownerless expression 'Foo'.
- V608. Recurring sequence of explicit type casts.
- V609. Possible division or mod by zero.
- V610. Undefined behavior. Check the shift operator.
- V611. Memory allocation and deallocation methods are incompatible.
- V612. Unconditional 'break/continue/return/goto' within a loop.
- V613. Suspicious pointer arithmetic with 'malloc/new'.
- V614. Use of 'Foo' uninitialized variable.
- V615. Suspicious explicit conversion from 'float *' type to 'double *' type.
- V616. Use of 'Foo' named constant with 0 value in bitwise operation.
- V617. Argument of the '|' bitwise operation always contains non-zero value. Consider inspecting the condition.
- V618. Dangerous call of 'Foo' function. The passed line may contain format specification. Example of safe code: printf("%s", str);
- V619. Array is used as pointer to single object.
- V620. Expression of sizeof(T)*N kind is summed up with pointer to T type. Consider inspecting the expression.
- V621. Loop may execute incorrectly or may not execute at all. Consider inspecting the 'for' operator.
- V622. First 'case' operator may be missing. Consider inspecting the 'switch' statement.
- V623. Temporary object is created and then destroyed. Consider inspecting the '?:' operator.
- V624. Use of constant NN. The resulting value may be inaccurate. Consider using the M_NN constant from <math.h>.
- V625. Initial and final values of the iterator are the same. Consider inspecting the 'for' operator.
- V626. It's possible that ',' should be replaced by ';'. Consider checking for typos.
- V627. Argument of sizeof() is a macro, which expands to a number. Consider inspecting the expression.
- V628. It is possible that a line was commented out improperly, thus altering the program's operation logic.
- V629. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type. Consider inspecting the expression.
- V630. The 'malloc' function is used to allocate memory for an array of objects that are classes containing constructors/destructors.
- V631. Defining absolute path to file or directory is considered a poor coding style. Consider inspecting the 'Foo' function call.
- V632. Argument is of the 'T' type. Consider inspecting the NN argument of the 'Foo' function.
- V633. The '!=' operator should probably be used here. Consider inspecting the expression.
- V634. Priority of '+' operation is higher than priority of '<<' operation. Consider using parentheses in the expression.
- V635. Length should be probably multiplied by sizeof(wchar_t). Consider inspecting the expression.
- V636. Expression was implicitly cast from integer type to real type. Consider using an explicit type cast to avoid overflow or loss of a fractional part.
- V637. Use of two opposite conditions. The second condition is always false.
- V638. Terminal null is present inside a string. Use of '\0xNN' characters. Probably meant: '\xNN'.
- V639. One of closing ')' parentheses is probably positioned incorrectly. Consider inspecting the expression for function call.
- V640. Code's operational logic does not correspond with its formatting.
- V641. Buffer size is not a multiple of element size.
- V642. Function result is saved inside the 'byte' type variable. Significant bits may be lost. This may break the program's logic.
- V643. Suspicious pointer arithmetic. Value of 'char' type is added to a string pointer.
- V644. Suspicious function declaration. Consider creating a 'T' type object.
- V645. Function call may lead to buffer overflow. Bounds should not contain size of a buffer, but a number of characters it can hold.
- V646. The 'else' keyword may be missing. Consider inspecting the program's logic.
- V647. Value of 'A' type is assigned to a pointer of 'B' type.
- V648. Priority of '&&' operation is higher than priority of '||' operation.
- V649. Two 'if' statements with identical conditional expressions. The first 'if' statement contains function return. This means that the second 'if' statement is senseless.
- V650. Type casting is used 2 times in a row. The '+' operation is executed. Probably meant: (T1)((T2)a + b).
- V651. Suspicious operation of 'sizeof(X)/sizeof(T)' kind, where 'X' is of the 'class' type.
- V652. Operation is executed 3 or more times in a row.
- V653. Suspicious string consisting of two parts is used for initialization. Comma may be missing.
- V654. Condition of a loop is always true/false.
- V655. Strings were concatenated but not used. Consider inspecting the expression.
- V656. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
- V657. Function always returns the same value of NN. Consider inspecting the function.
- V658. Value is subtracted from unsigned variable. It can result in an overflow. In such a case, the comparison operation may behave unexpectedly.
- V659. Functions' declarations with 'Foo' name differ in 'const' keyword only, while these functions' bodies have different composition. It is suspicious and can possibly be an error.
- V660. Program contains an unused label and function call: 'CC:AA()'. Probably meant: 'CC::AA()'.
- V661. Suspicious expression 'A[B < C]'. Probably meant 'A[B] < C'.
- V662. Different containers are used to set up initial and final values of iterator. Consider inspecting the loop expression.
- V663. Infinite loop is possible. The 'cin.eof()' condition is insufficient to break from the loop. Consider adding the 'cin.fail()' function call to the conditional expression.
- V664. Pointer is dereferenced in the member initializer list before it is checked for null in the body of a constructor.
- V665. Possible incorrect use of '#pragma warning(default: X)'. The '#pragma warning(push/pop)' should be used instead.
- V666. Value may not correspond with the length of a string passed with YY argument. Consider inspecting the NNth argument of the 'Foo' function.
- V667. The 'throw' operator does not have any arguments and is not located within the 'catch' block.
- V668. Possible meaningless check for null, as memory was allocated using 'new' operator. Memory allocation will lead to an exception.
- V669. Argument is a non-constant reference. The analyzer is unable to determine the position where this argument is modified. Consider checking the function for an error.
- V670. Uninitialized class member is used to initialize another member. Remember that members are initialized in the order of their declarations inside a class.
- V671. The 'swap' function may interchange a variable with itself.
- V672. It is possible that creating a new variable is unnecessary. One of the function's arguments has the same name and this argument is a reference.
- V673. More than N bits are required to store the value, but the expression evaluates to the T type which can only hold K bits.
- V674. Expression contains a suspicious mix of integer and real types.
- V675. Writing into read-only memory.
- V676. Incorrect comparison of BOOL type variable with TRUE.
- V677. Custom declaration of standard type. Consider using the declaration from system header files instead.
- V678. Object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' function.
- V679. The 'X' variable was not initialized. This variable is passed by reference to the 'Foo' function in which its value will be used.
- V680. The 'delete A, B' expression only destroys the 'A' object. Then the ',' operator returns a resulting value from the right side of the expression.
- V681. The language standard does not define order in which 'Foo' functions are called during evaluation of arguments.
- V682. Suspicious literal: '/r'. It is possible that a backslash should be used instead: '\r'.
- V683. The 'i' variable should probably be incremented instead of the 'n' variable. Consider inspecting the loop expression.
- V684. Value of variable is not modified. It is possible that '1' should be present instead of '0'. Consider inspecting the expression.
- V685. The expression contains a comma. Consider inspecting the return statement.
- V686. Pattern A || (A && ...) was detected. The expression is excessive or contains a logical error.
- V687. Size of array calculated by sizeof() operator was added to a pointer. It is possible that the number of elements should be calculated by sizeof(A)/sizeof(A[0]).
- V688. The 'foo' local variable has the same name as one of class members. This can result in confusion.
- V689. Destructor of 'Foo' class is not declared as virtual. A smart pointer may not destroy an object correctly.
- V690. The class implements a copy constructor/operator=, but lacks the operator=/copy constructor.
- V691. Empirical analysis. Possible typo inside the string literal. The 'foo' word is suspicious.
- V692. Inappropriate attempt to append a null character to a string. To determine the length of a string by 'strlen' function correctly, use a string ending with a null terminator in the first place.
- V693. It is possible that 'i < X.size()' should be used instead of 'X.size()'. Consider inspecting conditional expression of the loop.
- V694. The condition (ptr - const_value) is only false if the value of a pointer equals a magic constant.
- V695. Range intersections are possible within conditional expressions.
- V696. The 'continue' operator will terminate 'do { ... } while (FALSE)' loop because the condition is always false.
- V697. Number of elements in the allocated array equals the size of a pointer in bytes.
- V698. Functions of strcmp() kind can return any values, not only -1, 0, or 1.
- V699. It is possible that 'foo = bar == baz ? .... : ....' should be used here instead of 'foo = bar = baz ? .... : ....'. Consider inspecting the expression.
- V700. It is suspicious that variable is initialized through itself. Consider inspecting the 'T foo = foo = x;' expression.
- V701. Possible realloc() leak: when realloc() fails to allocate memory, original pointer is lost. Consider assigning realloc() to a temporary pointer.
- V702. Classes should always be derived from std::exception (and alike) as 'public'.
- V703. It is suspicious that the 'foo' field in derived class overwrites field in base class.
- V704. The expression is always false on newer compilers. Avoid using 'this == 0' comparison.
- V705. It is possible that 'else' block was forgotten or commented out, thus altering the program's operation logics.
- V706. Suspicious division: sizeof(X) / Value. Size of every element in X array is not equal to divisor.
- V707. Giving short names to global variables is considered to be bad practice.
- V708. Dangerous construction is used: 'm[x] = m.size()', where 'm' is of 'T' class. This may lead to undefined behavior.
- V709. Suspicious comparison found: 'a == b == c'. Remember that 'a == b == c' is not equal to 'a == b && b == c'.
- V710. Suspicious declaration. There is no point to declare constant reference to a number.
- V711. It is dangerous to create a local variable within a loop with a same name as a variable controlling this loop.
- V712. Compiler may optimize out this loop or make it infinite. Use volatile variable(s) or synchronization primitives to avoid this.
- V713. Pointer was used in the logical expression before its check for nullptr in the same logical expression.
- V714. Variable is not passed into foreach loop by reference, but its value is changed inside of the loop.
- V715. The 'while' operator has empty body. This pattern is suspicious.
- V716. Suspicious type conversion: HRESULT -> BOOL (BOOL -> HRESULT).
- V717. It is suspicious to cast object of base class V to derived class U.
- V718. The 'Foo' function should not be called from 'DllMain' function.
- V719. The switch statement does not cover all values of the enum.
- V720. The 'SuspendThread' function is usually used when developing a debugger. See documentation for details.
- V721. The VARIANT_BOOL type is used incorrectly. The true value (VARIANT_TRUE) is defined as -1.
- V722. Abnormality within similar comparisons. It is possible that a typo is present inside the expression.
- V723. Function returns a pointer to the internal string buffer of a local object, which will be destroyed.
- V724. Converting integers or pointers to BOOL can lead to a loss of high-order bits. Non-zero value can become 'FALSE'.
- V725. Dangerous cast of 'this' to 'void*' type in the 'Base' class, as it is followed by a subsequent cast to 'Class' type.
- V726. Attempt to free memory containing the 'int A[10]' array by using the 'free(A)' function.
- V727. Return value of 'wcslen' function is not multiplied by 'sizeof(wchar_t)'.
- V728. Excessive check can be simplified. The '||' operator is surrounded by opposite expressions 'x' and '!x'.
- V729. Function body contains the 'X' label that is not used by any 'goto' statements.
- V730. Not all members of a class are initialized inside the constructor.
- V731. The variable of char type is compared with pointer to string.
- V732. Unary minus operator does not modify a bool type value.
- V733. It is possible that macro expansion resulted in incorrect evaluation order.
- V734. Excessive expression. Examine the substrings "abc" and "abcd".
- V735. Possibly an incorrect HTML. The "</XX>" closing tag was encountered, while the "</YY>" tag was expected.
- V736. The behavior is undefined for arithmetic or comparisons with pointers that do not point to members of the same array.
- V737. It is possible that ',' comma is missing at the end of the string.
- V738. Temporary anonymous object is used.
- V739. EOF should not be compared with a value of the 'char' type. Consider using the 'int' type.
- V740. Exception is of the 'int' type because NULL is defined as 0. Keyword 'nullptr' can be used for 'pointer' type exception.
- V741. Use of the throw (a, b); pattern. It is possible that type name was omitted: throw MyException(a, b);.
- V742. Function receives an address of a 'char' type variable instead of pointer to a buffer.
- V743. The memory areas must not overlap. Use 'memmove' function.
- V744. Temporary object is immediately destroyed after being created. Consider naming the object.
- V745. A 'wchar_t *' type string is incorrectly converted to 'BSTR' type string.
- V746. Object slicing. An exception should be caught by reference rather than by value.
- V747. Suspicious expression inside parentheses. A function name may be missing.
- V748. Memory for 'getline' function should be allocated only by 'malloc' or 'realloc' functions. Consider inspecting the first parameter of 'getline' function.
- V749. Destructor of the object will be invoked a second time after leaving the object's scope.
- V750. BSTR string becomes invalid. Notice that BSTR strings store their length before start of the text.
- V751. Parameter is not used inside function's body.
- V752. Creating an object with placement new requires a buffer of large size.
- V753. The '&=' operation always sets a value of 'Foo' variable to zero.
- V754. The expression of 'foo(foo(x))' pattern is excessive or contains an error.
- V755. Copying from potentially tainted data source. Buffer overflow is possible.
- V756. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
- V757. It is possible that an incorrect variable is compared with null after type conversion using 'dynamic_cast'.
- V758. Reference was invalidated because of destruction of the temporary object returned by the function.
- V759. Violated order of exception handlers. Exception caught by handler for base class.
- V760. Two identical text blocks were detected. The second block starts with NN string.
- V761. NN identical blocks were found.
- V762. Consider inspecting virtual function arguments. See NN argument of function 'Foo' in derived class and base class.
- V763. Parameter is always rewritten in function body before being used.
- V764. Possible incorrect order of arguments passed to function.
- V765. Compound assignment expression 'X += X + N' is suspicious. Consider inspecting it for a possible error.
- V766. An item with the same key has already been added.
- V767. Suspicious access to element by a constant index inside a loop.
- V768. Variable is of enum type. It is suspicious that it is used as a variable of a Boolean-type.
- V769. The pointer in the expression equals nullptr. The resulting value is meaningless and should not be used.
- V770. Possible use of left shift operator instead of comparison operator.
- V771. The '?:' operator uses constants from different enums.
- V772. Calling the 'delete' operator for a void pointer will cause undefined behavior.
- V773. Function exited without releasing the pointer/handle. A memory/resource leak is possible.
- V774. Pointer was used after the memory was released.
- V775. It is suspicious that the BSTR data type is compared using a relational operator.
- V776. Potentially infinite loop. The variable in the loop exit condition does not change its value between iterations.
- V777. Dangerous widening type conversion from an array of derived-class objects to a base-class pointer.
- V778. Two similar code fragments. Perhaps, it is a typo and 'X' variable should be used instead of 'Y'.
- V779. Unreachable code was detected. It is possible that an error is present.
- V780. The object of non-passive (non-PDS) type cannot be used with the function.
- V781. Value of a variable is checked after it is used. Possible error in program's logic. Check lines: N1, N2.
- V782. It is pointless to compute the distance between the elements of different arrays.
- V783. Possible dereference of invalid iterator 'X'.
- V784. The size of the bit mask is less than the size of the first operand. This will cause the loss of the higher bits.
- V785. Constant expression in switch statement.
- V786. Assigning the value C to the X variable looks suspicious. The value range of the variable: [A, B].
- V787. Wrong variable is probably used in the for operator as an index.
- V788. Review captured variable in lambda expression.
- V789. Iterators for the container, used in the range-based for loop, become invalid upon a function call.
- V790. It is suspicious that the assignment operator takes an object by a non-constant reference and returns this object.
- V791. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
- V792. The function located to the right of the '|' and '&' operators will be called regardless of the value of the left operand. Consider using '||' and '&&' instead.
- V793. It is suspicious that the result of the statement is a part of the condition. Perhaps, this statement should have been compared with something else.
- V794. The assignment operator should be protected from the case of 'this == &src'.
- V795. Size of the 'time_t' type is not 64 bits. After the year 2038, the program will work incorrectly.
- V796. A 'break' statement is probably missing in a 'switch' statement.
- V797. The function is used as if it returned a bool type. The return value of the function should probably be compared with std::string::npos.
- V798. The size of the dynamic array can be less than the number of elements in the initializer.
- V799. Variable is not used after memory is allocated for it. Consider checking the use of this variable.
- V1001. Variable is assigned but not used by the end of the function.
- V1002. Class that contains pointers, constructor and destructor is copied by the automatically generated operator= or copy constructor.
- V1003. Macro expression is dangerous or suspicious.
- V1004. Pointer was used unsafely after its check for nullptr.
- V1005. The resource was acquired using 'X' function but was released using incompatible 'Y' function.
- V1006. Several shared_ptr objects are initialized by the same pointer. A double memory deallocation will occur.
- V1007. Value from the uninitialized optional is used. It may be an error.
- V1008. No more than one iteration of the loop will be performed. Consider inspecting the 'for' operator.
- V1009. Check the array initialization. Only the first element is initialized explicitly.
- V1010. Unchecked tainted data is used in expression.
- V1011. Function execution could be deferred. Consider specifying execution policy explicitly.
- V1012. The expression is always false. Overflow check is incorrect.
- V1013. Suspicious subexpression in a sequence of similar comparisons.
- V1014. Structures with members of real type are compared byte-wise.
- V1015. Suspicious simultaneous use of bitwise and logical operators.
- V1016. The value is out of range of enum values. This causes unspecified or undefined behavior.
- V1017. Variable of the 'string_view' type references a temporary object, which will be removed after evaluation of an expression.
- V1018. Usage of a suspicious mutex wrapper. It is probably unused, uninitialized, or already locked.
- V1019. Compound assignment expression is used inside condition.
- V1020. Function exited without performing epilogue actions. It is possible that there is an error.
- V1021. The variable is assigned the same value on several loop iterations.
- V1022. Exception was thrown by pointer. Consider throwing it by value instead.
- V1023. A pointer without owner is added to the container by the 'emplace_back' method. A memory leak will occur in case of an exception.
- V1024. Potential use of invalid data. The stream is checked for EOF before reading from it but is not checked after reading.
- V1025. New variable with default value is created instead of 'std::unique_lock' that locks on the mutex.
- V1026. The variable is incremented in the loop. Undefined behavior will occur in case of signed integer overflow.
- V1027. Pointer to an object of the class is cast to unrelated class.
- V1028. Possible overflow. Consider casting operands, not the result.
- V1029. Numeric Truncation Error. Return value of function is written to N-bit variable.
- V1030. Variable is used after it is moved.
- V1031. Function is not declared. The passing of data to or from this function may be affected.
- V1032. Pointer is cast to a more strictly aligned pointer type.
- V1033. Variable is declared as auto in C. Its default type is int.
- V1034. Do not use real-type variables as loop counters.
- V1035. Only values returned from fgetpos() can be used as arguments to fsetpos().
- V1036. Potentially unsafe double-checked locking.
- V1037. Two or more case-branches perform the same actions.
- V1038. It is suspicious that a char or string literal is added to a pointer.
- V1039. Character escape is used in multicharacter literal. This causes implementation-defined behavior.
- V1040. Possible typo in the spelling of a pre-defined macro name.
- V1041. Class member is initialized with dangling reference.
- V1042. This file is marked with copyleft license, which requires you to open the derived source code.
- V1043. A global object variable is declared in the header. Multiple copies of it will be created in all translation units that include this header file.
- V1044. Loop break conditions do not depend on the number of iterations.
- V1045. The DllMain function throws an exception. Consider wrapping the throw operator in a try..catch block.
- V1046. Unsafe usage of the 'bool' and integer types together in the operation '&='.
- V1047. Lifetime of the lambda is greater than lifetime of the local variable captured by reference.
- V1048. Variable 'foo' was assigned the same value.
- V1049. The 'foo' include guard is already defined in the 'bar1.h' header. The 'bar2.h' header will be excluded from compilation.
- V1050. Uninitialized class member is used when initializing the base class.
- V1051. It is possible that an assigned variable should be checked in the next condition. Consider checking for typos.
- V1052. Declaring virtual methods in a class marked as 'final' is pointless.
- V1053. Calling the 'foo' virtual function in the constructor/destructor may lead to unexpected result at runtime.
- V1054. Object slicing. Derived class object was copied to the base class object.
- V1055. The 'sizeof' expression returns the size of the container type, not the number of elements. Consider using the 'size()' function.
- V1056. The predefined identifier '__func__' always contains the string 'operator()' inside function body of the overloaded 'operator()'.
- V1057. Pseudo random sequence is the same at every program run. Consider assigning the seed to a value not known at compile-time.
- V1058. Nonsensical comparison of two different functions' addresses.
- V1059. Macro name overrides a keyword/reserved name. This may lead to undefined behavior.
- V1060. Passing 'BSTR ' to the 'SysAllocString' function may lead to incorrect object creation.
- V1061. Extending 'std' or 'posix' namespace may result in undefined behavior.
- V1062. Class defines a custom new or delete operator. The opposite operator must also be defined.
- V1063. The modulo by 1 operation is meaningless. The result will always be zero.
- V1064. The left operand of integer division is less than the right one. The result will always be zero.
- V1065. Expression can be simplified: check similar operands.
- V1066. The 'SysFreeString' function should be called only for objects of the 'BSTR' type.
- V1067. Throwing from exception constructor may lead to unexpected behavior.
- V1068. Do not define an unnamed namespace in a header file.
- V1069. Do not concatenate string literals with different prefixes.
- V1070. Signed value is converted to an unsigned one with subsequent expansion to a larger type in ternary operator.
- V1071. Return value is not always used. Consider inspecting the 'foo' function.
- V1072. Buffer needs to be securely cleared on all execution paths.
- V1073. Check the following code block after the 'if' statement. Consider checking for typos.
- V1074. Boundary between numeric escape sequence and string is unclear. The escape sequence ends with a letter and the next character is also a letter. Check for typos.
- V1075. The function expects the file to be opened in one mode, but it was opened in different mode.
- V1076. Code contains invisible characters that may alter its logic. Consider enabling the display of invisible characters in the code editor.
- V1077. Conditional initialization inside the constructor may leave some members uninitialized.
- V1078. An empty container is iterated. The loop will not be executed.
- V1079. Parameter of 'std::stop_token' type is not used inside function's body.
- V1080. Call of 'std::is_constant_evaluated' function always returns the same value.
- V1081. Argument of abs() function is minimal negative value. Such absolute value can't be represented in two's complement. This leads to undefined behavior.
- V1082. Function marked as 'noreturn' may return control. This will result in undefined behavior.
- V1083. Signed integer overflow in arithmetic expression. This leads to undefined behavior.
- V1084. The expression is always true/false. The value is out of range of enum values.
- V1085. Negative value is implicitly converted to unsigned integer type in arithmetic expression.
- V1086. Call of the 'Foo' function will lead to buffer underflow.
- V1087. Upper bound of case range is less than its lower bound. This case may be unreachable.
- V1088. No objects are passed to the 'std::scoped_lock' constructor. No locking will be performed. This can cause concurrency issues.
- V1089. Waiting on condition variable without predicate. A thread can wait indefinitely or experience a spurious wake-up.
- V1090. The 'std::uncaught_exception' function is deprecated since C++17 and is removed in C++20. Consider replacing this function with 'std::uncaught_exceptions'.
- V1091. The pointer is cast to an integer type of a larger size. Casting pointer to a type of a larger size is an implementation-defined behavior.
- V1092. Recursive function call during the static/thread_local variable initialization might occur. This may lead to undefined behavior.
- V1093. The result of the right shift operation will always be 0. The right operand is greater than or equal to the number of bits in the left operand.
- V1094. Conditional escape sequence in literal. Its representation is implementation-defined.
- V1095. Usage of potentially invalid handle. The value should be non-negative.
- V1096. Variable with static storage duration is declared inside the inline function with external linkage. This may lead to ODR violation.
- V1097. Line splice results in a character sequence that matches the syntax of a universal-character-name. Using this sequence lead to undefined behavior.
- V1098. The 'emplace' / 'insert' function call contains potentially dangerous move operation. Moved object can be destroyed even if there is no insertion.
- V1099. Using the function of uninitialized derived class while initializing the base class will lead to undefined behavior.
- V1100. Unreal Engine. Declaring a pointer to a type derived from 'UObject' in a class that is not derived from 'UObject' is dangerous. The pointer may start pointing to an invalid object after garbage collection.
- V1101. Changing the default argument of a virtual function parameter in a derived class may result in unexpected behavior.
- V1102. Unreal Engine. Violation of naming conventions may cause Unreal Header Tool to work incorrectly.
- V1103. The values of padding bytes are unspecified. Comparing objects with padding using 'memcmp' may lead to unexpected result.
- V1104. Priority of the 'M' operator is higher than that of the 'N' operator. Possible missing parentheses.
- V1105. Suspicious string modification using the 'operator+='. The right operand is implicitly converted to a character type.
- V1106. Qt. Class inherited from 'QObject' should contain at least one constructor that takes a pointer to 'QObject'.
- V1107. Function was declared as accepting unspecified number of parameters. Consider explicitly specifying the function parameters list.
- V1108. Constraint specified in a custom function annotation on the parameter is violated.
- V1109. Function is deprecated. Consider switching to an equivalent newer function.
- V1110. Constructor of a class inherited from 'QObject' does not use a pointer to a parent object.
- V1111. The index was used without check after it was checked in previous lines.
- V1112. Comparing expressions with different signedness can lead to unexpected results.
- V1113. Potential resource leak. Calling the 'memset' function will change the pointer itself, not the allocated resource. Check the first and third arguments.
- V1114. Suspicious use of type conversion operator when working with COM interfaces. Consider using the 'QueryInterface' member function.
- V1115. Function annotated with the 'pure' attribute has side effects.
- V1116. Creating an exception object without an explanatory message may result in insufficient logging.
- V1117. The declared function type is cv-qualified. The behavior when using this type is undefined.
- V1118. Excessive file permissions can lead to vulnerabilities. Consider restricting file permissions.
Диагностики общего назначения (General Analysis, C#)
- V3001. There are identical sub-expressions to the left and to the right of the 'foo' operator.
- V3002. The switch statement does not cover all values of the enum.
- V3003. The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence.
- V3004. The 'then' statement is equivalent to the 'else' statement.
- V3005. The 'x' variable is assigned to itself.
- V3006. The object was created but it is not being used. The 'throw' keyword could be missing.
- V3007. Odd semicolon ';' after 'if/for/while' operator.
- V3008. The 'x' variable is assigned values twice successively. Perhaps this is a mistake.
- V3009. It's odd that this method always returns one and the same value of NN.
- V3010. The return value of function 'Foo' is required to be utilized.
- V3011. Two opposite conditions were encountered. The second condition is always false.
- V3012. The '?:' operator, regardless of its conditional expression, always returns one and the same value.
- V3013. It is odd that the body of 'Foo_1' function is fully equivalent to the body of 'Foo_2' function.
- V3014. It is likely that a wrong variable is being incremented inside the 'for' operator. Consider reviewing 'X'.
- V3015. It is likely that a wrong variable is being compared inside the 'for' operator. Consider reviewing 'X'.
- V3016. The variable 'X' is being used for this loop and for the outer loop.
- V3017. A pattern was detected: A || (A && ...). The expression is excessive or contains a logical error.
- V3018. Consider inspecting the application's logic. It's possible that 'else' keyword is missing.
- V3019. It is possible that an incorrect variable is compared with null after type conversion using 'as' keyword.
- V3020. An unconditional 'break/continue/return/goto' within a loop.
- V3021. There are two 'if' statements with identical conditional expressions. The first 'if' statement contains method return. This means that the second 'if' statement is senseless.
- V3022. Expression is always true/false.
- V3023. Consider inspecting this expression. The expression is excessive or contains a misprint.
- V3024. An odd precise comparison. Consider using a comparison with defined precision: Math.Abs(A - B) < Epsilon or Math.Abs(A - B) > Epsilon.
- V3025. Incorrect format. Consider checking the N format items of the 'Foo' function.
- V3026. The constant NN is being utilized. The resulting value could be inaccurate. Consider using the KK constant.
- V3027. The variable was utilized in the logical expression before it was verified against null in the same logical expression.
- V3028. Consider inspecting the 'for' operator. Initial and final values of the iterator are the same.
- V3029. The conditional expressions of the 'if' statements situated alongside each other are identical.
- V3030. Recurring check. This condition was already verified in previous line.
- V3031. An excessive check can be simplified. The operator '||' operator is surrounded by opposite expressions 'x' and '!x'.
- V3032. Waiting on this expression is unreliable, as compiler may optimize some of the variables. Use volatile variable(s) or synchronization primitives to avoid this.
- V3033. It is possible that this 'else' branch must apply to the previous 'if' statement.
- V3034. Consider inspecting the expression. Probably the '!=' should be used here.
- V3035. Consider inspecting the expression. Probably the '+=' should be used here.
- V3036. Consider inspecting the expression. Probably the '-=' should be used here.
- V3037. An odd sequence of assignments of this kind: A = B; B = A;
- V3038. The argument was passed to method several times. It is possible that another argument should be passed instead.
- V3039. Consider inspecting the 'Foo' function call. Defining an absolute path to the file or directory is considered a poor style.
- V3040. The expression contains a suspicious mix of integer and real types.
- V3041. The expression was implicitly cast from integer type to real type. Consider utilizing an explicit type cast to avoid the loss of a fractional part.
- V3042. Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the same object.
- V3043. The code's operational logic does not correspond with its formatting.
- V3044. WPF: writing and reading are performed on a different Dependency Properties.
- V3045. WPF: the names of the property registered for DependencyProperty, and of the property used to access it, do not correspond with each other.
- V3046. WPF: the type registered for DependencyProperty does not correspond with the type of the property used to access it.
- V3047. WPF: A class containing registered property does not correspond with a type that is passed as the ownerType.type.
- V3048. WPF: several Dependency Properties are registered with a same name within the owner type.
- V3049. WPF: readonly field of 'DependencyProperty' type is not initialized.
- V3050. Possibly an incorrect HTML. The </XX> closing tag was encountered, while the </YY> tag was expected.
- V3051. An excessive type cast or check. The object is already of the same type.
- V3052. The original exception object was swallowed. Stack of original exception could be lost.
- V3053. An excessive expression. Examine the substrings "abc" and "abcd".
- V3054. Potentially unsafe double-checked locking. Use volatile variable(s) or synchronization primitives to avoid this.
- V3055. Suspicious assignment inside the condition expression of 'if/while/for' operator.
- V3056. Consider reviewing the correctness of 'X' item's usage.
- V3057. Function receives an odd argument.
- V3058. An item with the same key has already been added.
- V3059. Consider adding '[Flags]' attribute to the enum.
- V3060. A value of variable is not modified. Consider inspecting the expression. It is possible that other value should be present instead of '0'.
- V3061. Parameter 'A' is always rewritten in method body before being used.
- V3062. An object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' method.
- V3063. A part of conditional expression is always true/false if it is evaluated.
- V3064. Division or mod division by zero.
- V3065. Parameter is not utilized inside method's body.
- V3066. Possible incorrect order of arguments passed to method.
- V3067. It is possible that 'else' block was forgotten or commented out, thus altering the program's operation logics.
- V3068. Calling overrideable class member from constructor is dangerous.
- V3069. It's possible that the line was commented out improperly, thus altering the program's operation logics.
- V3070. Uninitialized variables are used when initializing the 'A' variable.
- V3071. The object is returned from inside 'using' block. 'Dispose' will be invoked before exiting method.
- V3072. The 'A' class containing IDisposable members does not itself implement IDisposable.
- V3073. Not all IDisposable members are properly disposed. Call 'Dispose' when disposing 'A' class.
- V3074. The 'A' class contains 'Dispose' method. Consider making it implement 'IDisposable' interface.
- V3075. The operation is executed 2 or more times in succession.
- V3076. Comparison with 'double.NaN' is meaningless. Use 'double.IsNaN()' method instead.
- V3077. Property setter / event accessor does not utilize its 'value' parameter.
- V3078. Sorting keys priority will be reversed relative to the order of 'OrderBy' method calls. Perhaps, 'ThenBy' should be used instead.
- V3079. The 'ThreadStatic' attribute is applied to a non-static 'A' field and will be ignored.
- V3080. Possible null dereference.
- V3081. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
- V3082. The 'Thread' object is created but is not started. It is possible that a call to 'Start' method is missing.
- V3083. Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it.
- V3084. Anonymous function is used to unsubscribe from event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration.
- V3085. The name of 'X' field/property in a nested type is ambiguous. The outer type contains static field/property with identical name.
- V3086. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
- V3087. Type of variable enumerated in 'foreach' is not guaranteed to be castable to the type of collection's elements.
- V3088. The expression was enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or misprint is present.
- V3089. Initializer of a field marked by [ThreadStatic] attribute will be called once on the first accessing thread. The field will have default value on different threads.
- V3090. Unsafe locking on an object.
- V3091. Empirical analysis. It is possible that a typo is present inside the string literal. The 'foo' word is suspicious.
- V3092. Range intersections are possible within conditional expressions.
- V3093. The operator evaluates both operands. Perhaps a short-circuit operator should be used instead.
- V3094. Possible exception when deserializing type. The Ctor(SerializationInfo, StreamingContext) constructor is missing.
- V3095. The object was used before it was verified against null. Check lines: N1, N2.
- V3096. Possible exception when serializing type. [Serializable] attribute is missing.
- V3097. Possible exception: type marked by [Serializable] contains non-serializable members not marked by [NonSerialized].
- V3098. The 'continue' operator will terminate 'do { ... } while (false)' loop because the condition is always false.
- V3099. Not all the members of type are serialized inside 'GetObjectData' method.
- V3100. NullReferenceException is possible. Unhandled exceptions in destructor lead to termination of runtime.
- V3101. Potential resurrection of 'this' object instance from destructor. Without re-registering for finalization, destructor will not be called a second time on resurrected object.
- V3102. Suspicious access to element by a constant index inside a loop.
- V3103. A private Ctor(SerializationInfo, StreamingContext) constructor in unsealed type will not be accessible when deserializing derived types.
- V3104. The 'GetObjectData' implementation in unsealed type is not virtual, incorrect serialization of derived type is possible.
- V3105. The 'a' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible.
- V3106. Possibly index is out of bound.
- V3107. Identical expression to the left and to the right of compound assignment.
- V3108. It is not recommended to return null or throw exceptions from 'ToString()' method.
- V3109. The same sub-expression is present on both sides of the operator. The expression is incorrect or it can be simplified.
- V3110. Possible infinite recursion.
- V3111. Checking value for null will always return false when generic type is instantiated with a value type.
- V3112. An abnormality within similar comparisons. It is possible that a typo is present inside the expression.
- V3113. Consider inspecting the loop expression. It is possible that different variables are used inside initializer and iterator.
- V3114. IDisposable object is not disposed before method returns.
- V3115. It is not recommended to throw exceptions from 'Equals(object obj)' method.
- V3116. Consider inspecting the 'for' operator. It's possible that the loop will be executed incorrectly or won't be executed at all.
- V3117. Constructor parameter is not used.
- V3118. A component of TimeSpan is used, which does not represent full time interval. Possibly 'Total*' value was intended instead.
- V3119. Calling a virtual (overridden) event may lead to unpredictable behavior. Consider implementing event accessors explicitly or use 'sealed' keyword.
- V3120. Potentially infinite loop. The variable from the loop exit condition does not change its value between iterations.
- V3121. An enumeration was declared with 'Flags' attribute, but does not set any initializers to override default values.
- V3122. Uppercase (lowercase) string is compared with a different lowercase (uppercase) string.
- V3123. Perhaps the '??' operator works in a different way than it was expected. Its priority is lower than priority of other operators in its left part.
- V3124. Appending an element and checking for key uniqueness is performed on two different variables.
- V3125. The object was used after it was verified against null. Check lines: N1, N2.
- V3126. Type implementing IEquatable<T> interface does not override 'GetHashCode' method.
- V3127. Two similar code fragments were found. Perhaps, this is a typo and 'X' variable should be used instead of 'Y'.
- V3128. The field (property) is used before it is initialized in constructor.
- V3129. The value of the captured variable will be overwritten on the next iteration of the loop in each instance of anonymous function that captures it.
- V3130. Priority of the '&&' operator is higher than that of the '||' operator. Possible missing parentheses.
- V3131. The expression is checked for compatibility with the type 'A', but is casted to the 'B' type.
- V3132. A terminal null is present inside a string. The '\0xNN' characters were encountered. Probably meant: '\xNN'.
- V3133. Postfix increment/decrement is senseless because this variable is overwritten.
- V3134. Shift by N bits is greater than the size of type.
- V3135. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
- V3136. Constant expression in switch statement.
- V3137. The variable is assigned but is not used by the end of the function.
- V3138. String literal contains potential interpolated expression.
- V3139. Two or more case-branches perform the same actions.
- V3140. Property accessors use different backing fields.
- V3141. Expression under 'throw' is a potential null, which can lead to NullReferenceException.
- V3142. Unreachable code detected. It is possible that an error is present.
- V3143. The 'value' parameter is rewritten inside a property setter, and is not used after that.
- V3144. This file is marked with copyleft license, which requires you to open the derived source code.
- V3145. Unsafe dereference of a WeakReference target. The object could have been garbage collected before the 'Target' property was accessed.
- V3146. Possible null dereference. A method can return default null value.
- V3147. Non-atomic modification of volatile variable.
- V3148. Casting potential 'null' value to a value type can lead to NullReferenceException.
- V3149. Dereferencing the result of 'as' operator can lead to NullReferenceException.
- V3150. Loop break conditions do not depend on the number of iterations.
- V3151. Potential division by zero. Variable was used as a divisor before it was compared to zero. Check lines: N1, N2.
- V3152. Potential division by zero. Variable was compared to zero before it was used as a divisor. Check lines: N1, N2.
- V3153. Dereferencing the result of null-conditional access operator can lead to NullReferenceException.
- V3154. The 'a % b' expression always evaluates to 0.
- V3155. The expression is incorrect or it can be simplified.
- V3156. The argument of the method is not expected to be null.
- V3157. Suspicious division. Absolute value of the left operand is less than the right operand.
- V3158. Suspicious division. Absolute values of both operands are equal.
- V3159. Modified value of the operand is not used after the increment/decrement operation.
- V3160. Argument of incorrect type is passed to the 'Enum.HasFlag' method.
- V3161. Comparing value type variables with 'ReferenceEquals' is incorrect because compared values will be boxed.
- V3162. Suspicious return of an always empty collection.
- V3163. An exception handling block does not contain any code.
- V3164. Exception classes should be publicly accessible.
- V3165. The expression of the 'char' type is passed as an argument of the 'A' type whereas similar overload with the string parameter exists.
- V3166. Calling the 'SingleOrDefault' method may lead to 'InvalidOperationException'.
- V3167. Parameter of 'CancellationToken' type is not used inside function's body.
- V3168. Awaiting on expression with potential null value can lead to throwing of 'NullReferenceException'.
- V3169. Suspicious return of a local reference variable which always equals null.
- V3170. Both operands of the '??' operator are identical.
- V3171. Potentially negative value is used as the size of an array.
- V3172. The 'if/if-else/for/while/foreach' statement and code block after it are not related. Inspect the program's logic.
- V3173. Possible incorrect initialization of variable. Consider verifying the initializer.
- V3174. Suspicious subexpression in a sequence of similar comparisons.
- V3175. Locking operations must be performed on the same thread. Using 'await' in a critical section may lead to a lock being released on a different thread.
- V3176. The '&=' or '|=' operator is redundant because the right operand is always true/false.
- V3177. Logical literal belongs to second operator with a higher priority. It is possible literal was intended to belong to '??' operator instead.
- V3178. Calling method or accessing property of potentially disposed object may result in exception.
- V3179. Calling element access method for potentially empty collection may result in exception.
- V3180. The 'HasFlag' method always returns 'true' because the value '0' is passed as its argument.
- V3181. The result of '&' operator is '0' because one of the operands is '0'.
- V3182. The result of '&' operator is always '0'.
- V3183. Code formatting implies that the statement should not be a part of the 'then' branch that belongs to the preceding 'if' statement.
- V3184. The argument's value is greater than the size of the collection. Passing the value into the 'Foo' method will result in an exception.
- V3185. An argument containing a file path could be mixed up with another argument. The other function parameter expects a file path instead.
- V3186. The arguments violate the bounds of collection. Passing these values into the method will result in an exception.
- V3187. Parts of an SQL query are not delimited by any separators or whitespaces. Executing this query may lead to an error.
- V3188. Unity Engine. The value of an expression is a potentially destroyed Unity object or null. Member invocation on this value may lead to an exception.
- V3189. The assignment to a member of the readonly field will have no effect when the field is of a value type. Consider restricting the type parameter to reference types.
- V3190. Concurrent modification of a variable may lead to errors.
- V3191. Iteration through collection makes no sense because it is always empty.
- V3192. Type member is used in the 'GetHashCode' method but is missing from the 'Equals' method.
- V3193. Data processing results are potentially used before asynchronous output reading is complete. Consider calling 'WaitForExit' overload with no arguments before using the data.
- V3194. Calling 'OfType' for collection will return an empty collection. It is not possible to cast collection elements to the type parameter.
- V3195. Collection initializer implicitly calls 'Add' method. Using it on member with default value of null will result in null dereference exception.
- V3196. Parameter is not utilized inside the method body, but an identifier with a similar name is used inside the same method.
- V3197. The compared value inside the 'Object.Equals' override is converted to a different type that does not contain the override.
- V3198. The variable is assigned the same value that it already holds.
- V3199. The index from end operator is used with the value that is less than or equal to zero. Collection index will be out of bounds.
- V3200. Possible overflow. The expression will be evaluated before casting. Consider casting one of the operands instead.
- V3201. Return value is not always used. Consider inspecting the 'foo' method.
- V3202. Unreachable code detected. The 'case' value is out of the range of the match expression.
- V3203. Method parameter is not used.
- V3204. The expression is always false due to implicit type conversion. Overflow check is incorrect.
- V3205. Unity Engine. Improper creation of 'MonoBehaviour' or 'ScriptableObject' object using the 'new' operator. Use the special object creation method instead.
- V3206. Unity Engine. A direct call to the coroutine-like method will not start it. Use the 'StartCoroutine' method instead.
- V3207. The 'not A or B' logical pattern may not work as expected. The 'not' pattern is matched only to the first expression from the 'or' pattern.
- V3208. Unity Engine. Using 'WeakReference' with 'UnityEngine.Object' is not supported. GC will not reclaim the object's memory because it is linked to a native object.
- V3209. Unity Engine. Using await on 'Awaitable' object more than once can lead to exception or deadlock, as such objects are returned to the pool after being awaited.
- V3210. Unity Engine. Unity does not allow removing the 'Transform' component using 'Destroy' or 'DestroyImmediate' methods. The method call will be ignored.
- V3211. Unity Engine. The operators '?.', '??' and '??=' do not correctly handle destroyed objects derived from 'UnityEngine.Object'.
- V3212. Unity Engine. Pattern matching does not correctly handle destroyed objects derived from 'UnityEngine.Object'.
- V3213. Unity Engine. The 'GetComponent' method must be instantiated with a type that inherits from 'UnityEngine.Component'.
- V3214. Unity Engine. Using Unity API in the background thread may result in an error.
- V3215. Unity Engine. Passing a method name as a string literal into the 'StartCoroutine' is unreliable.
- V3216. Unity Engine. Checking a field with a specific Unity Engine type for null may not work correctly due to implicit field initialization by the engine.
- V3217. Possible overflow as a result of an arithmetic operation.
- V3218. Loop condition may be incorrect due to an off-by-one error.
- V3219. The variable was changed after it was captured in a LINQ method with deferred execution. The original value will not be used when the method is executed.
- V3220. The result of the LINQ method with deferred execution is never used. The method will not be executed.
- V3221. Modifying a collection during its enumeration will lead to an exception.
Диагностики общего назначения (General Analysis, Java)
- V6001. There are identical sub-expressions to the left and to the right of the 'foo' operator.
- V6002. The switch statement does not cover all values of the enum.
- V6003. The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence.
- V6004. The 'then' statement is equivalent to the 'else' statement.
- V6005. The 'x' variable is assigned to itself.
- V6006. The object was created but it is not being used. The 'throw' keyword could be missing.
- V6007. Expression is always true/false.
- V6008. Potential null dereference.
- V6009. Function receives an odd argument.
- V6010. The return value of function 'Foo' is required to be utilized.
- V6011. The expression contains a suspicious mix of integer and real types.
- V6012. The '?:' operator, regardless of its conditional expression, always returns one and the same value.
- V6013. Comparison of arrays, strings, collections by reference. Possibly an equality comparison was intended.
- V6014. It's odd that this method always returns one and the same value of NN.
- V6015. Consider inspecting the expression. Probably the '!='/'-='/'+=' should be used here.
- V6016. Suspicious access to element by a constant index inside a loop.
- V6017. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
- V6018. Constant expression in switch statement.
- V6019. Unreachable code detected. It is possible that an error is present.
- V6020. Division or mod division by zero.
- V6021. The value is assigned to the 'x' variable but is not used.
- V6022. Parameter is not used inside method's body.
- V6023. Parameter 'A' is always rewritten in method body before being used.
- V6024. The 'continue' operator will terminate 'do { ... } while (false)' loop because the condition is always false.
- V6025. Possibly index is out of bound.
- V6026. This value is already assigned to the 'b' variable.
- V6027. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
- V6028. Identical expression to the left and to the right of compound assignment.
- V6029. Possible incorrect order of arguments passed to method.
- V6030. The function located to the right of the '|' and '&' operators will be called regardless of the value of the left operand. Consider using '||' and '&&' instead.
- V6031. The variable 'X' is being used for this loop and for the outer loop.
- V6032. It is odd that the body of 'Foo_1' function is fully equivalent to the body of 'Foo_2' function.
- V6033. An item with the same key has already been added.
- V6034. Shift by N bits is inconsistent with the size of type.
- V6035. Double negation is present in the expression: !!x.
- V6036. The value from the uninitialized optional is used.
- V6037. An unconditional 'break/continue/return/goto' within a loop.
- V6038. Comparison with 'double.NaN' is meaningless. Use 'double.isNaN()' method instead.
- V6039. There are two 'if' statements with identical conditional expressions. The first 'if' statement contains method return. This means that the second 'if' statement is senseless.
- V6040. The code's operational logic does not correspond with its formatting.
- V6041. Suspicious assignment inside the conditional expression of 'if/while/do...while' statement.
- V6042. The expression is checked for compatibility with type 'A', but is cast to type 'B'.
- V6043. Consider inspecting the 'for' operator. Initial and final values of the iterator are the same.
- V6044. Postfix increment/decrement is senseless because this variable is overwritten.
- V6045. Suspicious subexpression in a sequence of similar comparisons.
- V6046. Incorrect format. Consider checking the N format items of the 'Foo' function.
- V6047. It is possible that this 'else' branch must apply to the previous 'if' statement.
- V6048. This expression can be simplified. One of the operands in the operation equals NN. Probably it is a mistake.
- V6049. Classes that define 'equals' method must also define 'hashCode' method.
- V6050. Class initialization cycle is present.
- V6051. Use of jump statements in 'finally' block can lead to the loss of unhandled exceptions.
- V6052. Calling an overridden method in parent-class constructor may lead to use of uninitialized data.
- V6053. Collection is modified while iteration is in progress. ConcurrentModificationException may occur.
- V6054. Classes should not be compared by their name.
- V6055. Expression inside assert statement can change object's state.
- V6056. Implementation of 'compareTo' overloads the method from a base class. Possibly, an override was intended.
- V6057. Consider inspecting this expression. The expression is excessive or contains a misprint.
- V6058. Comparing objects of incompatible types.
- V6059. Odd use of special character in regular expression. Possibly, it was intended to be escaped.
- V6060. The reference was used before it was verified against null.
- V6061. The used constant value is represented by an octal form.
- V6062. Possible infinite recursion.
- V6063. Odd semicolon ';' after 'if/for/while' operator.
- V6064. Suspicious invocation of Thread.run().
- V6065. A non-serializable class should not be serialized.
- V6066. Passing objects of incompatible types to the method of collection.
- V6067. Two or more case-branches perform the same actions.
- V6068. Suspicious use of BigDecimal class.
- V6069. Unsigned right shift assignment of negative 'byte' / 'short' value.
- V6070. Unsafe synchronization on an object.
- V6071. This file is marked with copyleft license, which requires you to open the derived source code.
- V6072. Two similar code fragments were found. Perhaps, this is a typo and 'X' variable should be used instead of 'Y'.
- V6073. It is not recommended to return null or throw exceptions from 'toString' / 'clone' methods.
- V6074. Non-atomic modification of volatile variable.
- V6075. The signature of method 'X' does not conform to serialization requirements.
- V6076. Recurrent serialization will use cached object state from first serialization.
- V6077. A suspicious label is present inside a switch(). It is possible that these are misprints and 'default:' label should be used instead.
- V6078. Potential Java SE API compatibility issue.
- V6079. Value of variable is checked after use. Potential logical error is present. Check lines: N1, N2.
- V6080. Consider checking for misprints. It's possible that an assigned variable should be checked in the next condition.
- V6081. Annotation that does not have 'RUNTIME' retention policy will not be accessible through Reflection API.
- V6082. Unsafe double-checked locking.
- V6083. Serialization order of fields should be preserved during deserialization.
- V6084. Suspicious return of an always empty collection.
- V6085. An abnormality within similar comparisons. It is possible that a typo is present inside the expression.
- V6086. Suspicious code formatting. 'else' keyword is probably missing.
- V6087. InvalidClassException may occur during deserialization.
- V6088. Result of this expression will be implicitly cast to 'Type'. Check if program logic handles it correctly.
- V6089. It's possible that the line was commented out improperly, thus altering the program's operation logics.
- V6090. Field 'A' is being used before it was initialized.
- V6091. Suspicious getter/setter implementation. The 'A' field should probably be returned/assigned instead.
- V6092. A resource is returned from try-with-resources statement. It will be closed before the method exits.
- V6093. Automatic unboxing of a variable may cause NullPointerException.
- V6094. The expression was implicitly cast from integer type to real type. Consider utilizing an explicit type cast to avoid the loss of a fractional part.
- V6095. Thread.sleep() inside synchronized block/method may cause decreased performance.
- V6096. An odd precise comparison. Consider using a comparison with defined precision: Math.abs(A - B) < Epsilon or Math.abs(A - B) > Epsilon.
- V6097. Lowercase 'L' at the end of a long literal can be mistaken for '1'.
- V6098. The method does not override another method from the base class.
- V6099. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
- V6100. An object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' method.
- V6101. compareTo()-like methods can return not only the values -1, 0 and 1, but any values.
- V6102. Inconsistent synchronization of a field. Consider synchronizing the field on all usages.
- V6103. Ignored InterruptedException could lead to delayed thread shutdown.
- V6104. A pattern was detected: A || (A && ...). The expression is excessive or contains a logical error.
- V6105. Consider inspecting the loop expression. It is possible that different variables are used inside initializer and iterator.
- V6106. Casting expression to 'X' type before implicitly casting it to other type may be excessive or incorrect.
- V6107. The constant NN is being utilized. The resulting value could be inaccurate. Consider using the KK constant.
- V6108. Do not use real-type variables in 'for' loop counters.
- V6109. Potentially predictable seed is used in pseudo-random number generator.
- V6110. Using an environment variable could be unsafe or unreliable. Consider using trusted system property instead
- V6111. Potentially negative value is used as the size of an array.
- V6112. Calling the 'getClass' method repeatedly or on the value of the '.class' literal will always return the instance of the 'Class<Class>' type.
- V6113. Suspicious division. Absolute value of the left operand is less than the value of the right operand.
- V6114. The 'A' class containing Closeable members does not release the resources that the field is holding.
- V6115. Not all Closeable members are released inside the 'close' method.
- V6116. The class does not implement the Closeable interface, but it contains the 'close' method that releases resources.
- V6117. Possible overflow. The expression will be evaluated before casting. Consider casting one of the operands instead.
- V6118. The original exception object was swallowed. Cause of original exception could be lost.
- V6119. The result of '&' operator is always '0'.
- V6120. The result of the '&' operator is '0' because one of the operands is '0'.
- V6121. Return value is not always used. Consider inspecting the 'foo' method.
- V6122. The 'Y' (week year) pattern is used for date formatting. Check whether the 'y' (year) pattern was intended instead.
- V6123. Modified value of the operand is not used after the increment/decrement operation.
- V6124. Converting an integer literal to the type with a smaller value range will result in overflow.
- V6125. Calling the 'wait', 'notify', and 'notifyAll' methods outside of synchronized context will lead to 'IllegalMonitorStateException'.
- V6126. Native synchronization used on high-level concurrency class.
- V6127. Closeable object is not closed. This may lead to a resource leak.
- V6128. Using a Closeable object after it was closed can lead to an exception.
Микрооптимизации (C++)
- V801. Decreased performance. It is better to redefine the N function argument as a reference. Consider replacing 'const T' with 'const .. &T' / 'const .. *T'.
- V802. On 32-bit/64-bit platform, structure size can be reduced from N to K bytes by rearranging the fields according to their sizes in decreasing order.
- V803. Decreased performance. It is more effective to use the prefix form of ++it. Replace iterator++ with ++iterator.
- V804. Decreased performance. The 'Foo' function is called twice in the specified expression to calculate length of the same string.
- V805. Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) > 0' construct. A more efficient way is to check: str[0] != '\0'.
- V806. Decreased performance. The expression of strlen(MyStr.c_str()) kind can be rewritten as MyStr.length().
- V807. Decreased performance. Consider creating a pointer/reference to avoid using the same expression repeatedly.
- V808. An array/object was declared but was not utilized.
- V809. Verifying that a pointer value is not NULL is not required. The 'if (ptr != NULL)' check can be removed.
- V810. Decreased performance. The 'A' function was called several times with identical arguments. The result should possibly be saved to a temporary variable, which then could be used while calling the 'B' function.
- V811. Decreased performance. Excessive type casting: string -> char * -> string.
- V812. Decreased performance. Ineffective use of the 'count' function. It can possibly be replaced by the call to the 'find' function.
- V813. Decreased performance. The argument should probably be rendered as a constant pointer/reference.
- V814. Decreased performance. The 'strlen' function was called multiple times inside the body of a loop.
- V815. Decreased performance. Consider replacing the expression 'AA' with 'BB'.
- V816. It is more efficient to catch exception by reference rather than by value.
- V817. It is more efficient to search for 'X' character rather than a string.
- V818. It is more efficient to use an initialization list rather than an assignment operator.
- V819. Decreased performance. Memory is allocated and released multiple times inside the loop body.
- V820. The variable is not used after copying. Copying can be replaced with move/swap for optimization.
- V821. The variable can be constructed in a lower level scope.
- V822. Decreased performance. A new object is created, while a reference to an object is expected.
- V823. Decreased performance. Object may be created in-place in a container. Consider replacing methods: 'insert' -> 'emplace', 'push_*' -> 'emplace_*'.
- V824. It is recommended to use the 'make_unique/make_shared' function to create smart pointers.
- V825. Expression is equivalent to moving one unique pointer to another. Consider using 'std::move' instead.
- V826. Consider replacing standard container with a different one.
- V827. Maximum size of a vector is known at compile time. Consider pre-allocating it by calling reserve(N).
- V828. Decreased performance. Moving an object in a return statement prevents copy elision.
- V829. Lifetime of the heap-allocated variable is limited to the current function's scope. Consider allocating it on the stack instead.
- V830. Decreased performance. Consider replacing the use of 'std::optional::value()' with either the '*' or '->' operator.
- V831. Decreased performance. Consider replacing the call to the 'at()' method with the 'operator[]'.
- V832. It's better to use '= default;' syntax instead of empty body.
- V833. Using 'std::move' function's with const object disables move semantics.
- V834. Incorrect type of a loop variable. This leads to the variable binding to a temporary object instead of a range element.
- V835. Passing cheap-to-copy argument by reference may lead to decreased performance.
- V836. Expression's value is copied at the variable declaration. The variable is never modified. Consider declaring it as a reference.
- V837. The 'emplace' / 'insert' function does not guarantee that arguments will not be copied or moved if there is no insertion. Consider using the 'try_emplace' function.
- V838. Temporary object is constructed during lookup in ordered associative container. Consider using a container with heterogeneous lookup to avoid construction of temporary objects.
- V839. Function returns a constant value. This may interfere with move semantics.
Микрооптимизации (C#)
- V4001. Unity Engine. Boxing inside a frequently called method may decrease performance.
- V4002. Unity Engine. Avoid storing consecutive concatenations inside a single string in performance-sensitive context. Consider using StringBuilder to improve performance.
- V4003. Unity Engine. Avoid capturing variable in performance-sensitive context. This can lead to decreased performance.
- V4004. Unity Engine. New array object is returned from method or property. Using such member in performance-sensitive context can lead to decreased performance.
- V4005. Unity Engine. The expensive operation is performed inside method or property. Using such member in performance-sensitive context can lead to decreased performance.
- V4006. Unity Engine. Multiple operations between complex and numeric values. Prioritizing operations between numeric values can optimize execution time.
- V4007. Unity Engine. Avoid creating and destroying UnityEngine objects in performance-sensitive context. Consider activating and deactivating them instead.
- V4008. Unity Engine. Avoid using memory allocation Physics APIs in performance-sensitive context.
Диагностика 64-битных ошибок (Viva64, C++)
- V101. Implicit assignment type conversion to memsize type.
- V102. Usage of non memsize type for pointer arithmetic.
- V103. Implicit type conversion from memsize type to 32-bit type.
- V104. Implicit type conversion to memsize type in an arithmetic expression.
- V105. N operand of '?:' operation: implicit type conversion to memsize type.
- V106. Implicit type conversion N argument of function 'foo' to memsize type.
- V107. Implicit type conversion N argument of function 'foo' to 32-bit type.
- V108. Incorrect index type: 'foo[not a memsize-type]'. Use memsize type instead.
- V109. Implicit type conversion of return value to memsize type.
- V110. Implicit type conversion of return value from memsize type to 32-bit type.
- V111. Call of function 'foo' with variable number of arguments. N argument has memsize type.
- V112. Dangerous magic number N used.
- V113. Implicit type conversion from memsize to double type or vice versa.
- V114. Dangerous explicit type pointer conversion.
- V115. Memsize type is used for throw.
- V116. Memsize type is used for catch.
- V117. Memsize type is used in the union.
- V118. malloc() function accepts a dangerous expression in the capacity of an argument.
- V119. More than one sizeof() operator is used in one expression.
- V120. Member operator[] of object 'foo' is declared with 32-bit type argument, but is called with memsize type argument.
- V121. Implicit conversion of the type of 'new' operator's argument to size_t type.
- V122. Memsize type is used in the struct/class.
- V123. Allocation of memory by the pattern "(X*)malloc(sizeof(Y))" where the sizes of X and Y types are not equal.
- V124. Function 'Foo' writes/reads 'N' bytes. The alignment rules and type sizes have been changed. Consider reviewing this value.
- V125. It is not advised to declare type 'T' as 32-bit type.
- V126. Be advised that the size of the type 'long' varies between LLP64/LP64 data models.
- V127. An overflow of the 32-bit variable is possible inside a long cycle which utilizes a memsize-type loop counter.
- V128. A variable of the memsize type is read from a stream. Consider verifying the compatibility of 32 and 64 bit versions of the application in the context of a stored data.
- V201. Explicit conversion from 32-bit integer type to memsize type.
- V202. Explicit conversion from memsize type to 32-bit integer type.
- V203. Explicit type conversion from memsize to double type or vice versa.
- V204. Explicit conversion from 32-bit integer type to pointer type.
- V205. Explicit conversion of pointer type to 32-bit integer type.
- V206. Explicit conversion from 'void *' to 'int *'.
- V207. A 32-bit variable is utilized as a reference to a pointer. A write outside the bounds of this variable may occur.
- V220. Suspicious sequence of types castings: memsize -> 32-bit integer -> memsize.
- V221. Suspicious sequence of types castings: pointer -> memsize -> 32-bit integer.
- V301. Unexpected function overloading behavior. See N argument of function 'foo' in derived class 'derived' and base class 'base'.
- V302. Member operator[] of 'foo' class has a 32-bit type argument. Use memsize-type here.
- V303. The function is deprecated in the Win64 system. It is safer to use the 'foo' function.
Реализовано по запросам пользователей (C++)
- V2001. Consider using the extended version of the 'foo' function here.
- V2002. Consider using the 'Ptr' version of the 'foo' function here.
- V2003. Explicit conversion from 'float/double' type to signed integer type.
- V2004. Explicit conversion from 'float/double' type to unsigned integer type.
- V2005. C-style explicit type casting is utilized. Consider using: static_cast/const_cast/reinterpret_cast.
- V2006. Implicit type conversion from enum type to integer type.
- V2007. This expression can be simplified. One of the operands in the operation equals NN. Probably it is a mistake.
- V2008. Cyclomatic complexity: NN. Consider refactoring the 'Foo' function.
- V2009. Consider passing the 'Foo' argument as a pointer/reference to const.
- V2010. Handling of two different exception types is identical.
- V2011. Consider inspecting signed and unsigned function arguments. See NN argument of function 'Foo' in derived class and base class.
- V2012. Possibility of decreased performance. It is advised to pass arguments to std::unary_function/std::binary_function template as references.
- V2013. Consider inspecting the correctness of handling the N argument in the 'Foo' function.
- V2014. Don't use terminating functions in library code.
- V2015. An identifier declared in an inner scope should not hide an identifier in an outer scope.
- V2016. Consider inspecting the function call. The function was annotated as dangerous.
- V2017. String literal is identical to variable name. It is possible that the variable should be used instead of the string literal.
- V2018. Cast should not remove 'const' qualifier from the type that is pointed to by a pointer or a reference.
- V2019. Cast should not remove 'volatile' qualifier from the type that is pointed to by a pointer or a reference.
- V2020. The loop body contains the 'break;' / 'continue;' statement. This may complicate the control flow.
- V2021. Using assertions may cause the abnormal program termination in undesirable contexts.
- V2022. Implicit type conversion from integer type to enum type.
Cтандарт MISRA
- V2501. MISRA. Octal constants should not be used.
- V2502. MISRA. The 'goto' statement should not be used.
- V2503. MISRA. Implicitly specified enumeration constants should be unique – consider specifying non-unique constants explicitly.
- V2504. MISRA. Size of an array is not specified.
- V2505. MISRA. The 'goto' statement shouldn't jump to a label declared earlier.
- V2506. MISRA. A function should have a single point of exit at the end.
- V2507. MISRA. The body of a loop\conditional statement should be enclosed in braces.
- V2508. MISRA. The function with the 'atof/atoi/atol/atoll' name should not be used.
- V2509. MISRA. The function with the 'abort/exit/getenv/system' name should not be used.
- V2510. MISRA. The function with the 'qsort/bsearch' name should not be used.
- V2511. MISRA. Memory allocation and deallocation functions should not be used.
- V2512. MISRA. The macro with the 'setjmp' name and the function with the 'longjmp' name should not be used.
- V2513. MISRA. Unbounded functions performing string operations should not be used.
- V2514. MISRA. Unions should not be used.
- V2515. MISRA. Declaration should contain no more than two levels of pointer nesting.
- V2516. MISRA. The 'if' ... 'else if' construct should be terminated with an 'else' statement.
- V2517. MISRA. Literal suffixes should not contain lowercase characters.
- V2518. MISRA. The 'default' label should be either the first or the last label of a 'switch' statement.
- V2519. MISRA. Every 'switch' statement should have a 'default' label, which, in addition to the terminating 'break' statement, should contain either a statement or a comment.
- V2520. MISRA. Every switch-clause should be terminated by an unconditional 'break' or 'throw' statement.
- V2521. MISRA. Only the first member of enumerator list should be explicitly initialized, unless all members are explicitly initialized.
- V2522. MISRA. The 'switch' statement should have 'default' as the last label.
- V2523. MISRA. All integer constants of unsigned type should have 'u' or 'U' suffix.
- V2524. MISRA. A switch-label should only appear at the top level of the compound statement forming the body of a 'switch' statement.
- V2525. MISRA. Every 'switch' statement should contain non-empty switch-clauses.
- V2526. MISRA. The functions from time.h/ctime should not be used.
- V2527. MISRA. A switch-expression should not have Boolean type. Consider using of 'if-else' construct.
- V2528. MISRA. The comma operator should not be used.
- V2529. MISRA. Any label should be declared in the same block as 'goto' statement or in any block enclosing it.
- V2530. MISRA. Any loop should be terminated with no more than one 'break' or 'goto' statement.
- V2531. MISRA. Expression of essential type 'foo' should not be explicitly cast to essential type 'bar'.
- V2532. MISRA. String literal should not be assigned to object unless it has type of pointer to const-qualified char.
- V2533. MISRA. C-style and functional notation casts should not be performed.
- V2534. MISRA. The loop counter should not have floating-point type.
- V2535. MISRA. Unreachable code should not be present in the project.
- V2536. MISRA. Function should not contain labels not used by any 'goto' statements.
- V2537. MISRA. Functions should not have unused parameters.
- V2538. MISRA. The value of uninitialized variable should not be used.
- V2539. MISRA. Class destructor should not exit with an exception.
- V2540. MISRA. Arrays should not be partially initialized.
- V2541. MISRA. Function should not be declared implicitly.
- V2542. MISRA. Function with a non-void return type should return a value from all exit paths.
- V2543. MISRA. Value of the essential character type should be used appropriately in the addition/subtraction operations.
- V2544. MISRA. The values used in expressions should have appropriate essential types.
- V2545. MISRA. Conversion between pointers of different object types should not be performed.
- V2546. MISRA. Expression resulting from the macro expansion should be surrounded by parentheses.
- V2547. MISRA. The return value of non-void function should be used.
- V2548. MISRA. The address of an object with local scope should not be passed out of its scope.
- V2549. MISRA. Pointer to FILE should not be dereferenced.
- V2550. MISRA. Floating-point values should not be tested for equality or inequality.
- V2551. MISRA. Variable should be declared in a scope that minimizes its visibility.
- V2552. MISRA. Expressions with enum underlying type should have values corresponding to the enumerators of the enumeration.
- V2553. MISRA. Unary minus operator should not be applied to an expression of the unsigned type.
- V2554. MISRA. Expression containing increment (++) or decrement (--) should not have other side effects.
- V2555. MISRA. Incorrect shifting expression.
- V2556. MISRA. Use of a pointer to FILE when the associated stream has already been closed.
- V2557. MISRA. Operand of sizeof() operator should not have other side effects.
- V2558. MISRA. A pointer/reference parameter in a function should be declared as pointer/reference to const if the corresponding object was not modified.
- V2559. MISRA. Subtraction, >, >=, <, <= should be applied only to pointers that address elements of the same array.
- V2560. MISRA. There should be no user-defined variadic functions.
- V2561. MISRA. The result of an assignment expression should not be used.
- V2562. MISRA. Expressions with pointer type should not be used in the '+', '-', '+=' and '-=' operations.
- V2563. MISRA. Array indexing should be the only form of pointer arithmetic and it should be applied only to objects defined as an array type.
- V2564. MISRA. There should be no implicit integral-floating conversion.
- V2565. MISRA. A function should not call itself either directly or indirectly.
- V2566. MISRA. Constant expression evaluation should not result in an unsigned integer wrap-around.
- V2567. MISRA. Cast should not remove 'const' / 'volatile' qualification from the type that is pointed to by a pointer or a reference.
- V2568. MISRA. Both operands of an operator should be of the same type category.
- V2569. MISRA. The 'operator &&', 'operator ||', 'operator ,' and the unary 'operator &' should not be overloaded.
- V2570. MISRA. Operands of the logical '&&' or the '||' operators, the '!' operator should have 'bool' type.
- V2571. MISRA. Conversions between pointers to objects and integer types should not be performed.
- V2572. MISRA. Value of the expression should not be converted to the different essential type or the narrower essential type.
- V2573. MISRA. Identifiers that start with '__' or '_[A-Z]' are reserved.
- V2574. MISRA. Functions should not be declared at block scope.
- V2575. MISRA. The global namespace should only contain 'main', namespace declarations and 'extern "C"' declarations.
- V2576. MISRA. The identifier 'main' should not be used for a function other than the global function 'main'.
- V2577. MISRA. The function argument corresponding to a parameter declared to have an array type should have an appropriate number of elements.
- V2578. MISRA. An identifier with array type passed as a function argument should not decay to a pointer.
- V2579. MISRA. Macro should not be defined with the same name as a keyword.
- V2580. MISRA. The 'restrict' specifier should not be used.
- V2581. MISRA. Single-line comments should not end with a continuation token.
- V2582. MISRA. Block of memory should only be freed if it was allocated by a Standard Library function.
- V2583. MISRA. Line whose first token is '#' should be a valid preprocessing directive.
- V2584. MISRA. Expression used in condition should have essential Boolean type.
- V2585. MISRA. Casts between a void pointer and an arithmetic type should not be performed.
- V2586. MISRA. Flexible array members should not be declared.
- V2587. MISRA. The '//' and '/*' character sequences should not appear within comments.
- V2588. MISRA. All memory or resources allocated dynamically should be explicitly released.
- V2589. MISRA. Casts between a pointer and a non-integer arithmetic type should not be performed.
- V2590. MISRA. Conversions should not be performed between pointer to function and any other type.
- V2591. MISRA. Bit fields should only be declared with explicitly signed or unsigned integer type
- V2592. MISRA. An identifier declared in an inner scope should not hide an identifier in an outer scope.
- V2593. MISRA. Single-bit bit fields should not be declared as signed type.
- V2594. MISRA. Controlling expressions should not be invariant.
- V2595. MISRA. Array size should be specified explicitly when array declaration uses designated initialization.
- V2596. MISRA. The value of a composite expression should not be assigned to an object with wider essential type.
- V2597. MISRA. Cast should not convert pointer to function to any other pointer type.
- V2598. MISRA. Variable length array types are not allowed.
- V2599. MISRA. The standard signal handling functions should not be used.
- V2600. MISRA. The standard input/output functions should not be used.
- V2601. MISRA. Functions should be declared in prototype form with named parameters.
- V2602. MISRA. Octal and hexadecimal escape sequences should be terminated.
- V2603. MISRA. The 'static' keyword shall not be used between [] in the declaration of an array parameter.
- V2604. MISRA. Features from <stdarg.h> should not be used.
- V2605. MISRA. Features from <tgmath.h> should not be used.
- V2606. MISRA. There should be no attempt to write to a stream that has been opened for reading.
- V2607. MISRA. Inline functions should be declared with the static storage class.
- V2608. MISRA. The 'static' storage class specifier should be used in all declarations of object and functions that have internal linkage.
- V2609. MISRA. There should be no occurrence of undefined or critical unspecified behaviour.
- V2610. MISRA. The ', " or \ characters and the /* or // character sequences should not occur in a header file name.
- V2611. MISRA. Casts between a pointer to an incomplete type and any other type shouldn't be performed.
- V2612. MISRA. Array element should not be initialized more than once.
- V2613. MISRA. Operand that is a composite expression has more narrow essential type than the other operand.
- V2614. MISRA. External identifiers should be distinct.
- V2615. MISRA. A compatible declaration should be visible when an object or function with external linkage is defined.
- V2616. MISRA. All conditional inclusion preprocessor directives should reside in the same file as the conditional inclusion directive to which they are related.
- V2617. MISRA. Object should not be assigned or copied to an overlapping object.
- V2618. MISRA. Identifiers declared in the same scope and name space should be distinct.
- V2619. MISRA. Typedef names should be unique across all name spaces.
- V2620. MISRA. Value of a composite expression should not be cast to a different essential type category or a wider essential type.
- V2621. MISRA. Tag names should be unique across all name spaces.
- V2622. MISRA. External object or function should be declared once in one and only one file.
- V2623. MISRA. Macro identifiers should be distinct.
- V2624. MISRA. The initializer for an aggregate or union should be enclosed in braces.
- V2625. MISRA. Identifiers that define objects or functions with external linkage shall be unique.
- V2626. MISRA. The 'sizeof' operator should not have an operand which is a function parameter declared as 'array of type'.
- V2627. MISRA. Function type should not be type qualified.
- V2628. MISRA. The pointer arguments to the Standard Library functions memcpy, memmove and memcmp should be pointers to qualified or unqualified versions of compatible types.
- V2629. MISRA. Pointer arguments to the 'memcmp' function should point to an appropriate type.
- V2630. MISRA. Bit field should not be declared as a member of a union.
- V2631. MISRA. Pointers to variably-modified array types should not be used.
- V2632. MISRA. Object with temporary lifetime should not undergo array-to-pointer conversion.
- V2633. MISRA. Identifiers should be distinct from macro names.
- V2634. MISRA. Features from <fenv.h> should not be used.
- V2635. MISRA. The function with the 'system' name should not be used.
- V2636. MISRA. The functions with the 'rand' and 'srand' name of <stdlib.h> should not be used.
- V2637. MISRA. A 'noreturn' function should have 'void' return type.
- V2638. MISRA. Generic association should list an appropriate type.
- V2639. MISRA. Default association should appear as either the first or the last association of a generic selection.
- V2640. MISRA. Thread objects, thread synchronization objects and thread-specific storage pointers should have appropriate storage duration.
- V2641. MISRA. Types should be explicitly specified.
- V2642. MISRA. The '_Atomic' specifier should not be applied to the incomplete type 'void'.
- V2643. MISRA. All memory synchronization operation should be executed in sequentially consistent order.
Стандарт AUTOSAR
- V3501. AUTOSAR. Octal constants should not be used.
- V3502. AUTOSAR. Size of an array is not specified.
- V3503. AUTOSAR. The 'goto' statement shouldn't jump to a label declared earlier.
- V3504. AUTOSAR. The body of a loop\conditional statement should be enclosed in braces.
- V3505. AUTOSAR. The function with the 'atof/atoi/atol/atoll' name should not be used.
- V3506. AUTOSAR. The function with the 'abort/exit/getenv/system' name should not be used.
- V3507. AUTOSAR. The macro with the 'setjmp' name and the function with the 'longjmp' name should not be used.
- V3508. AUTOSAR. Unbounded functions performing string operations should not be used.
- V3509. AUTOSAR. Unions should not be used.
- V3510. AUTOSAR. Declaration should contain no more than two levels of pointer nesting.
- V3511. AUTOSAR. The 'if' ... 'else if' construct should be terminated with an 'else' statement.
- V3512. AUTOSAR. Literal suffixes should not contain lowercase characters.
- V3513. AUTOSAR. Every switch-clause should be terminated by an unconditional 'break' or 'throw' statement.
- V3514. AUTOSAR. The 'switch' statement should have 'default' as the last label.
- V3515. AUTOSAR. All integer constants of unsigned type should have 'U' suffix.
- V3516. AUTOSAR. A switch-label should only appear at the top level of the compound statement forming the body of a 'switch' statement.
- V3517. AUTOSAR. The functions from time.h/ctime should not be used.
- V3518. AUTOSAR. A switch-expression should not have Boolean type. Consider using of 'if-else' construct.
- V3519. AUTOSAR. The comma operator should not be used.
- V3520. AUTOSAR. Any label should be declared in the same block as 'goto' statement or in any block enclosing it.
- V3521. AUTOSAR. The loop counter should not have floating-point type.
- V3522. AUTOSAR. Unreachable code should not be present in the project.
- V3523. AUTOSAR. Functions should not have unused parameters.
- V3524. AUTOSAR. The value of uninitialized variable should not be used.
- V3525. AUTOSAR. Function with a non-void return type should return a value from all exit paths.
- V3526. AUTOSAR. Expression resulting from the macro expansion should be surrounded by parentheses.
- V3527. AUTOSAR. The return value of non-void function should be used.
- V3528. AUTOSAR. The address of an object with local scope should not be passed out of its scope.
- V3529. AUTOSAR. Floating-point values should not be tested for equality or inequality.
- V3530. AUTOSAR. Variable should be declared in a scope that minimizes its visibility.
- V3531. AUTOSAR. Expressions with enum underlying type should have values corresponding to the enumerators of the enumeration.
- V3532. AUTOSAR. Unary minus operator should not be applied to an expression of the unsigned type.
- V3533. AUTOSAR. Expression containing increment (++) or decrement (--) should not have other side effects.
- V3534. AUTOSAR. Incorrect shifting expression.
- V3535. AUTOSAR. Operand of sizeof() operator should not have other side effects.
- V3536. AUTOSAR. A pointer/reference parameter in a function should be declared as pointer/reference to const if the corresponding object was not modified.
- V3537. AUTOSAR. Subtraction, >, >=, <, <= should be applied only to pointers that address elements of the same array.
- V3538. AUTOSAR. The result of an assignment expression should not be used.
- V3539. AUTOSAR. Array indexing should be the only form of pointer arithmetic and it should be applied only to objects defined as an array type.
- V3540. AUTOSAR. There should be no implicit integral-floating conversion.
- V3541. AUTOSAR. A function should not call itself either directly or indirectly.
- V3542. AUTOSAR. Constant expression evaluation should not result in an unsigned integer wrap-around.
- V3543. AUTOSAR. Cast should not remove 'const' / 'volatile' qualification from the type that is pointed to by a pointer or a reference.
- V3544. AUTOSAR. The 'operator &&', 'operator ||', 'operator ,' and the unary 'operator &' should not be overloaded.
- V3545. AUTOSAR. Operands of the logical '&&' or the '||' operators, the '!' operator should have 'bool' type.
- V3546. AUTOSAR. Conversions between pointers to objects and integer types should not be performed.
- V3547. AUTOSAR. Identifiers that start with '__' or '_[A-Z]' are reserved.
- V3548. AUTOSAR. Functions should not be declared at block scope.
- V3549. AUTOSAR. The global namespace should only contain 'main', namespace declarations and 'extern "C"' declarations.
- V3550. AUTOSAR. The identifier 'main' should not be used for a function other than the global function 'main'.
- V3551. AUTOSAR. An identifier with array type passed as a function argument should not decay to a pointer.
- V3552. AUTOSAR. Cast should not convert a pointer to a function to any other pointer type, including a pointer to function type.
- V3553. AUTOSAR. The standard signal handling functions should not be used.
- V3554. AUTOSAR. The standard input/output functions should not be used.
- V3555. AUTOSAR. The 'static' storage class specifier should be used in all declarations of functions that have internal linkage.
Стандарт OWASP (C++)
- V5001. OWASP. It is highly probable that the semicolon ';' is missing after 'return' keyword.
- V5002. OWASP. An empty exception handler. Silent suppression of exceptions can hide the presence of bugs in source code during testing.
- V5003. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
- V5004. OWASP. Consider inspecting the expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
- V5005. OWASP. A value is being subtracted from the unsigned variable. This can result in an overflow. In such a case, the comparison operation can potentially behave unexpectedly.
- V5006. OWASP. More than N bits are required to store the value, but the expression evaluates to the T type which can only hold K bits.
- V5007. OWASP. Consider inspecting the loop expression. It is possible that the 'i' variable should be incremented instead of the 'n' variable.
- V5008. OWASP. Classes should always be derived from std::exception (and alike) as 'public'.
- V5009. OWASP. Unchecked tainted data is used in expression.
- V5010. OWASP. The variable is incremented in the loop. Undefined behavior will occur in case of signed integer overflow.
- V5011. OWASP. Possible overflow. Consider casting operands, not the result.
- V5012. OWASP. Potentially unsafe double-checked locking.
- V5013. OWASP. Storing credentials inside source code can lead to security issues.
- V5014. OWASP. Cryptographic function is deprecated. Its use can lead to security issues. Consider switching to an equivalent newer function.
Стандарт OWASP (C#)
- V5601. OWASP. Storing credentials inside source code can lead to security issues.
- V5602. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
- V5603. OWASP. The original exception object was swallowed. Stack of original exception could be lost.
- V5604. OWASP. Potentially unsafe double-checked locking. Use volatile variable(s) or synchronization primitives to avoid this.
- V5605. OWASP. Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it.
- V5606. OWASP. An exception handling block does not contain any code.
- V5607. OWASP. Exception classes should be publicly accessible.
- V5608. OWASP. Possible SQL injection. Potentially tainted data is used to create SQL command.
- V5609. OWASP. Possible path traversal vulnerability. Potentially tainted data is used as a path.
- V5610. OWASP. Possible XSS vulnerability. Potentially tainted data might be used to execute a malicious script.
- V5611. OWASP. Potential insecure deserialization vulnerability. Potentially tainted data is used to create an object using deserialization.
- V5612. OWASP. Do not use old versions of SSL/TLS protocols as it may cause security issues.
- V5613. OWASP. Use of outdated cryptographic algorithm is not recommended.
- V5614. OWASP. Potential XXE vulnerability. Insecure XML parser is used to process potentially tainted data.
- V5615. OWASP. Potential XEE vulnerability. Insecure XML parser is used to process potentially tainted data.
- V5616. OWASP. Possible command injection. Potentially tainted data is used to create OS command.
- V5617. OWASP. Assigning potentially negative or large value as timeout of HTTP session can lead to excessive session expiration time.
- V5618. OWASP. Possible server-side request forgery. Potentially tainted data is used in the URL.
- V5619. OWASP. Possible log injection. Potentially tainted data is written into logs.
- V5620. OWASP. Possible LDAP injection. Potentially tainted data is used in a search filter.
- V5621. OWASP. Error message contains potentially sensitive data that may be exposed.
- V5622. OWASP. Possible XPath injection. Potentially tainted data is used in the XPath expression.
- V5623. OWASP. Possible open redirect vulnerability. Potentially tainted data is used in the URL.
- V5624. OWASP. Use of potentially tainted data in configuration may lead to security issues.
- V5625. OWASP. Referenced package contains vulnerability.
- V5626. OWASP. Possible ReDoS vulnerability. Potentially tainted data is processed by regular expression that contains an unsafe pattern.
- V5627. OWASP. Possible NoSQL injection. Potentially tainted data is used to create query.
- V5628. OWASP. Possible Zip Slip vulnerability. Potentially tainted data is used in the path to extract the file.
- V5629. Code contains invisible characters that may alter its logic. Consider enabling the display of invisible characters in the code editor.
Стандарт OWASP (Java)
- V5301. OWASP. An exception handling block does not contain any code.
- V5302. OWASP. Exception classes should be publicly accessible.
- V5303. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
- V5304. OWASP. Unsafe double-checked locking.
- V5305. OWASP. Storing credentials inside source code can lead to security issues.
- V5306. OWASP. The original exception object was swallowed. Cause of original exception could be lost.
- V5307. OWASP. Potentially predictable seed is used in pseudo-random number generator.
- V5308. OWASP. Possible overflow. The expression will be evaluated before casting. Consider casting one of the operands instead.
- V5309. OWASP. Possible SQL injection. Potentially tainted data is used to create SQL command.
- V5310. OWASP. Possible command injection. Potentially tainted data is used to create OS command.
- V5311. OWASP. Possible argument injection. Potentially tainted data is used to create OS command.
- V5312. OWASP. Possible XPath injection. Potentially tainted data is used in the XPath expression.
- V5313. OWASP. Do not use old versions of SSL/TLS protocols as it may cause security issues.
- V5314. OWASP. Use of an outdated hash algorithm is not recommended.
- V5315. OWASP. Use of an outdated cryptographic algorithm is not recommended.
- V5316. Do not use the 'HttpServletRequest.getRequestedSessionId' method because it uses a session ID provided by a client.
- V5317. OWASP. Implementing a cryptographic algorithm is not advised because an attacker might break it.
- V5318. OWASP. Setting POSIX file permissions to 'all' or 'others' groups can lead to unintended access to files or directories.
- V5319. OWASP. Possible log injection. Potentially tainted data is written into logs.
- V5320. OWASP. Use of potentially tainted data in configuration may lead to security issues.
- V5321. OWASP. Possible LDAP injection. Potentially tainted data is used in a search filter.
- V5322. OWASP. Possible reflection injection. Potentially tainted data is used to select class or method.
- V5323. OWASP. Potentially tainted data is used to define 'Access-Control-Allow-Origin' header.
- V5324. OWASP. Possible open redirect vulnerability. Potentially tainted data is used in the URL.
- V5325. OWASP. Setting the value of the 'Access-Control-Allow-Origin' header to '*' is potentially insecure.
- V5326. OWASP. A password for a database connection should not be empty
- V5327. OWASP. Possible regex injection. Potentially tainted data is used to create regular expression
- V5328. OWASP. Using non-restrictive authorization checks could lead to security violations.
- V5329. OWASP. Using non-atomic file creation is not recommended because an attacker might intercept file ownership.
- V5330. OWASP. Possible XSS injection. Potentially tainted data might be used to execute a malicious script.
- V5331. Hardcoded IP addresses are not secure.
Проблемы при работе анализатора кода
- V001. A code fragment from 'file' cannot be analyzed.
- V002. Some diagnostic messages may contain incorrect line number.
- V003. Unrecognized error found...
- V004. Diagnostics from the 64-bit rule set are not entirely accurate without the appropriate 64-bit compiler. Consider utilizing 64-bit compiler if possible.
- V005. Cannot determine active configuration for project. Please check projects and solution configurations.
- V006. File cannot be processed. Analysis aborted by timeout.
- V007. Deprecated CLR switch was detected. Incorrect diagnostics are possible.
- V008. Unable to start the analysis on this file.
- V010. Analysis for the project type or platform toolsets is not supported in this tool. Use direct analyzer integration or compiler monitoring instead.
- V011. Presence of #line directives may cause some diagnostic messages to have incorrect file name and line number.
- V012. Some warnings could have been disabled.
- V013. Intermodular analysis may be incomplete, as it is not run on all source files.
- V014. The version of your suppress file is outdated. Appending new suppressed messages to it is not possible. Consider re-generating your suppress file to continue updating it.
- V015. All analyzer messages were filtered out or marked as false positive. Use filter buttons or 'Don't Check Files' settings to enable message display.
- V016. User annotation was not applied to a virtual function. To force the annotation, use the 'enable_on_virtual' flag.
- V017. The analyzer terminated abnormally due to lack of memory.
- V018. False Alarm marks without hash codes were ignored because the 'V_HASH_ONLY' option is enabled.
- V019. Error occurred while working with the user annotation mechanism.
- V020. Error occurred while working with rules configuration files.
- V051. Some of the references in project are missing or incorrect. The analysis results could be incomplete. Consider making the project fully compilable and building it before analysis.
- V052. A critical error had occurred.
- V061. An error has occurred.
- V062. Failed to run analyzer core. Make sure the correct 64-bit Java 11 or higher executable is used, or specify it manually.
- V063. Analysis aborted by timeout.
Как ввести лицензию PVS-Studio и что делать дальше
- Что включает в себя лицензия
- Способы активации через графический интерфейс
- Способы активации через интерфейс командной строки
- Быстрый старт или что дальше?
Анализатор PVS-Studio позволяет производить анализ проектов, написанных на языках программирования C, C++, C# и Java. Он может быть запущен на операционных системах Windows, Linux и macOS. Перед началом использования анализатора необходимо произвести активацию лицензии. В связи с большим числом сценариев использования продукта (например, в IDE, на локальных и облачных CI/CD), далее будут перечислены все возможные способы активации. Перейдите в раздел, который Вам подходит, и следуйте инструкции.
Важно. Все действия выполняются после установки анализатора. Вы можете скачать его на странице "Скачать PVS-Studio".
Что включает в себя лицензия
Лицензия анализатора состоит из имени пользователя и 16-символьного лицензионного ключа в формате "ХХХХ-ХХХХ-ХХХХ-ХХХХ". Если у вас отсутствует лицензия, ее можно получить через форму запроса триальной версии.
Ниже приведен пример того, как может выглядеть лицензионная информация:
JohnSmith <--- Имя пользователя
ASD1-DAS3-5KK3-LODR <--- Лицензионный ключСпособы активации через графический интерфейс
PVS-Studio Installer
Вы можете ввести лицензию во время установки PVS-Studio. В процессе установки вам предложат запросить лицензию или ввести существующую.

Выберите пункт I have a license and want to activate it и нажмите Next:

В поле 'License Name' необходимо подставить имя пользователя, а в 'License Key' – лицензионный ключ из своей лицензии. Если вы ввели валидные данные, то у вас отобразится сообщение с данными лицензии.
Microsoft Visual Studio
Перейдите в меню Visual Studio Extensions > PVS-Studio > Options (до 2015 версии Visual Studio просто PVS-Studio > Options):

После этого справа в меню перейдите на страницу PVS-Studio > Registration:

В поле 'Name' необходимо подставить имя пользователя, а в 'LicenseKey' – лицензионный ключ из своей лицензии. Если вы ввели валидные данные, то у вас отобразится сообщение с данными лицензии:

В случае если введённые данные лицензии недействительны, то вам также отобразится уведомление об этом:

JetBrains IntelliJ IDEA / Rider / CLion
Для ввода лицензии анализатора необходимо открыть любой проект, после чего открыть окно настроек вашей IDE:

В открывшемся окне настроек плагина перейти на страницу PVS-Studio > Registration.
В поле 'Name' необходимо подставить имя пользователя, а в 'License Key' – лицензионный ключ из своей лицензии:

Если вы ввели правильную лицензию, то надпись 'Invalid License' будет заменена на 'Valid License'. Для подтверждения и сохранения введённой лицензии нажмите кнопку Apply или OK.
C and C++ Compiler Monitoring UI
Перейдите в меню утилиты Tools > Options > Registration, чтобы ввести лицензию:

В поле 'Name' необходимо подставить имя пользователя, а в 'LicenseKey' – лицензионный ключ из своей лицензии.
Visual Studio Code
Для ввода лицензии в Visual Studio Code откройте View > Command Palette.

Введите в строку 'PVS-Studio: Show settings' и откройте их.

В открывшемся окне выберите вкладку 'License'.

В поле 'User name' необходимо подставить имя пользователя, а в 'Key' – лицензионный ключ из своей лицензии. Если вы ввели валидные данные, то у вас отобразится сообщение с данными лицензии:

Qt Creator
Для ввода лицензии в Qt Creator перейдите в Analyze > PVS-Studio > Options...

Далее выберите PVS-Studio и перейдите на вкладку Registration. В поле 'Name' необходимо подставить имя пользователя, а в 'License Key' – лицензионный ключ из своей лицензии. Если вы ввели валидные данные, то у вас отобразится сообщение с данными лицензии:

В случае если введённые данные лицензии недействительны, то вам также отобразится уведомление об этом:

Для подтверждения и сохранения введённой лицензии нажмите кнопку Apply или OK.
Способы активации через интерфейс командной строки
Windows
На Windows, когда нет возможности ввести лицензию через GUI, можно воспользоваться самим анализатором в специальном режиме.
Строка запуска может выглядеть следующим образом:
PVS-Studio_Cmd.exe credentials --userName %USER_NAME% ^
--licenseKey %LICENSE_KEY%Вместо переменной 'USER_NAME' необходимо подставить имя пользователя, а вместо 'LICENSE_KEY' – лицензионный ключ из своей лицензии.
При таком запуске анализатор запишет лицензию в файл настроек с расположением по умолчанию: "%APPDATA%/PVS-Studio/Settings.xml". Если файла настроек не существует, он будет создан. Используя флаг ‑‑settings, можно указать путь до файла настроек в нестандартном расположении.
С помощью флага ‑‑licInfo можно получить информацию о текущей лицензии.
Linux/macOS
При использовании анализатора на Linux/macOS платформах, когда нет возможности ввести лицензию при помощи GUI, используется специальная утилита pvs-studio-analyzer.
На Linux / macOS строка запуска может выглядеть следующим образом:
pvs-studio-analyzer credentials ${USER_NAME} ${LICENSE_KEY}Вместо переменной 'USER_NAME' необходимо подставить имя пользователя, а вместо 'LICENSE_KEY' – лицензионный ключ из своей лицензии.
При таком запуске анализатор запишет лицензию в файл настроек с расположением по умолчанию: "~/.config/PVS-Studio/PVS-Studio.lic". Если файла настроек не существует, он будет создан.
С помощью флага lic-info можно получить информацию о текущей лицензии:
pvs-studio-analyzer lic-infoJava анализатор
Поскольку Java анализатор может быть установлен независимо от других компонентов PVS-Studio, активацию лицензии можно также произвести через плагины для сборочных систем (Maven, Gradle) и ядро Java анализатора.
При использовании Maven команда для ввода лицензии может выглядеть следующим образом:
mvn pvsstudio:pvsCredentials "-Dpvsstudio.userName=${USER_NAME}" \
"-Dpvsstudio.licenseKey=${LICENSE_KEY}"При использовании Gradle активация происходит с помощью следующей команды:
./gradlew pvsCredentials "-Ppvsstudio.userName=${USER_NAME}" \
"-Ppvsstudio.licenseKey=${LICENSE_KEY}"При использовании ядра Java анализатора из консоли активировать лицензию возможно командой:
java -jar pvs-studio.jar --activate-license --user-name $USER_NAME \
--license-key $LICENSE_KEYВместо переменной 'USER_NAME' необходимо подставить имя пользователя, а вместо 'LICENSE_KEY' – лицензионный ключ из своей лицензии.
Быстрый старт или что дальше?
Способы запуска анализатора приведены на соответствующих страницах:
- Знакомство со статическим анализатором кода PVS-Studio на Windows
- Как запустить PVS-Studio в Linux и macOS (C, C++)
- Установка PVS-Studio C# на Linux и macOS
- Работа с ядром Java анализатора из командной строки
- Работа PVS-Studio в Visual Studio
- Работа PVS-Studio в JetBrains Rider и CLion
- Работа PVS-Studio в IntelliJ IDEA и Android Studio
- Использование PVS-Studio в среде Qt Creator
- PVS-Studio для Embedded-разработки
- Проверка Unreal Engine проектов
- Проверка проектов Visual Studio / MSBuild / .NET Core из командной строки с помощью PVS-Studio
- Анализ C++ проектов на основе JSON Compilation Database
- Проверка проектов независимо от сборочной системы (C и C++)
- Интеграция PVS-Studio в CMake с помощью CMake-модуля
- Интеграция PVS-Studio Java в сборочную систему Gradle
- Интеграция PVS-Studio Java в сборочную систему Maven
Ознакомительный режим PVS-Studio
После загрузки дистрибутива PVS-Studio и запроса ключа для знакомства с инструментом, вы получаете полнофункциональную версию, которая работает одну неделю. В этой версии нет совершенно никаких ограничений – это абсолютно полноценная лицензия. При заполнении формы вы можете выбрать, какой тип лицензии хотели бы испробовать: Team License или Enterprise License.
Отличия Enterprise License от Team License представлены на этой странице.
Если вам не хватило недели на знакомство с инструментом – просто напишите нам об этом в ответном письме. И мы пришлем еще один ключ.
Системные требования анализатора PVS-Studio
PVS-Studio работает на Windows (x86-64 и ARM), Linux (x86-64) и macOS (Intel и Apple Silicon). Поддерживается анализ кода для кроссплатформенных компиляторов, предназначенных для 32-битных, 64-битных, встраиваемых ARM платформ и других.
PVS-Studio требует как минимум 2 GB оперативной памяти (рекомендуется 4 GB и больше) для каждого процессорного ядра, когда анализатор работает на многоядерной системе (чем больше ядер, тем быстрее работает анализ кода).
Поддерживаемые языки программирования и компиляторы
Список поддерживаемых анализатором языков программирования и компиляторов доступен здесь.
Минимально поддерживаемая версия GCC — 4.2.
Кроссплатформенные IDE
Плагин PVS-Studio может быть интегрирован в:
- VS Code
- QtCreator:
- с 9 по 14 версии включительно;
- версия 14 для устройств с Apple Silicon
- Rider (версия 2022.2 и выше)
- CLion (версия 2022.2 и выше)
- IDEA и Android Studio (версия 2022.2 и выше)
Для всех IDE (кроме IDEA и Android Studio) необходимо иметь в системе установленное ядро анализатора для соответствующего языка (C, C++, C# или Java).
Windows
Поддерживаются Windows 11, Windows 10, Windows 8, Windows Server 2019, Windows Server 2016 и Windows Server 2012. PVS-Studio работает как на 64-битных версиях Windows, так и на версиях для ARM.
Для работы PVS-Studio требуется .NET Framework версии 4.7.2 или выше (будет автоматически установлен при установке PVS-Studio, если подходящей версии нет в системе).
Для анализа .NET, .NET Standard и .NET Framework SDK-style проектов требуется .NET SDK 9.0. Для анализа классических .NET Framework проектов достаточно .NET Framework 4.7.2 при наличии установленных в системе Visual Studio или MSBuild версий 2017, 2019 или 2022.
Плагин PVS-Studio может быть интегрирован в Microsoft Visual Studio 2022, 2019, 2017, 2015, 2013, 2012, 2010. Для анализа C и C++ кода для встраиваемых систем соответствующие компиляторы должны быть установлены в системе, на которой запускается анализатор.
Примечание: интеграция с Visual Studio 2022 для версий 17.12 и выше поддерживается, начиная с версии PVS-Studio 7.33.
Linux
PVS-Studio работает в 64-битных дистрибутивах Linux с ядром версий 3.2.0 и выше. Для анализа C и C++ проектов для Linux, кросс-платформенных приложений или встраиваемых систем, соответствующие компиляторы должны быть установлены в системе. Для утилиты оповещения команд разработчиков blame-notifier должен быть установлен .NET Runtime 9.0.
Список протестированных дистрибутивов, на которых работа PVS-Studio гарантируется:
- Arch Linux
- Astra Linux
- CentOS
- Debian GNU/Linux
- Fedora
- Linux Mint
- openSUSE
- Ubuntu
- РЕД ОС
РЕД ОС
Анализаторы PVS-Studio были проверены на совместимость и корректную работу с операционными системами РЕД ОС 7.3 и РЕД ОС 8.
macOS
PVS-Studio работает на процессорах Intel (x86-64) в macOS 10.13.2 High Sierra и выше. Также поддерживается работа на процессорах Apple Silicon (arm64) в macOS 11 Big Sur и выше. Для анализа C и C++ кода соответствующие компиляторы должны быть установлены в системе. Для утилиты оповещения команд разработчиков blame-notifier должен быть установлен .NET Runtime 9.0.
Java
PVS-Studio для Java работает на Windows (x86-64 и ARM), Linux (x86-64) и macOS (Intel и Apple Silicon). Java 11 (64-битная) является минимальной версией для работы анализатора. Анализируемый проект может использовать любую версию Java.
Технологии, используемые в PVS-Studio (соответствует ГОСТ Р 71207—2024)
- Определения
- Поддерживаемые языки и методы анализа
- Анализ программы на синтаксическом уровне
- Внутрипроцедурный анализ потоков данных и управления
- Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных
- Чувствительный к путям выполнения анализ потоков данных и управления
- Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных
- Вспомогательные методы анализа
- Выявляемые типы критических ошибок
- Соответствие требованиям к методам анализа
- Соответствие требованиям к инструментам статического анализа исходных текстов
- Анализ проекта целиком, включая используемые заимствованные компоненты
- Время анализа проекта
- Результаты применения анализатора
- Принятие решений и автоматизация разметки предупреждений
- Автоматизации действий
- Обеспечивается хранение результатов запуска, разметки и сравнения
- Документации с описанием всех типов ошибок
- Выдача результатов анализа в открытом документированном формате
- Доработки алгоритмов и правил пользователями
- Дополнительные ссылки по теме РБПО и ГОСТ Р 71207–2024
Инструментальное средство PVS-Studio разрабатывается с учётом требований, предъявляемых к статическим анализаторам в ГОСТ Р 71207–2024, выявляет критические ошибки и может использоваться при разработке безопасного программного обеспечения. Здесь рассмотрены функциональные возможности, реализованные в PVS-Studio на конец 2024 года в отношении анализа исходного кода программного обеспечения, написанного на компилируемых языках программирования C, C++, C#, Java.
Определения
ГОСТ Р 71207–2024 — РАЗРАБОТКА БЕЗОПАСНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ. Статический анализ программного обеспечения. Общие требования. Разработан ФСТЭК России и ИСП РАН. Впервые введён в действие 01.04.2024.
Примечание. Все приводимые далее в тексте ссылки на разделы и пункты (п. x.x.x.) относятся к стандарту ГОСТ Р 71207–2024.
Стандарт устанавливает требования к:
- внедрению и выполнению статического анализа ПО (раздел 5);
- классификации критических ошибок (раздел 6);
- методам статического анализа (раздел 7);
- инструментам анализа (раздел 8);
- специалистам, участвующим в анализе (раздел 9);
- методике проверки соответствия статических анализаторов ГОСТ (раздел 10).
Входит в комплекс стандартов, направленных на предотвращение уязвимостей в программах, и применяется совместно с ГОСТ Р 56939.
Критическая ошибка в программе. Термин введён в ГОСТ Р 71207–2024 (п. 3.1.13.). Это ошибка, которая может привести к нарушению безопасности обрабатываемой информации. С точки зрения безопасности, это ошибки, которые должны обнаруживаться и исправляться в первую очередь.
Статические анализаторы должны выявлять следующие виды критических ошибок в коде программ на компилируемых языках (п. 6.3.):
- ошибки непроверенного использования чувствительных данных;
- ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел;
- ошибки переполнения буфера;
- ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности;
- ошибки при работе с многопоточными примитивами.
Дополнительно для C и C++ (п. 6.5.):
- ошибки разыменования нулевого указателя;
- ошибки деления на ноль;
- ошибки управления динамической памятью;
- ошибки использования форматной строки;
- ошибки использования неинициализированных переменных;
- ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений.
Примечание. Набор требований ГОСТ по обнаружению критических ошибок совпадает для языков C и C++. Анализатор PVS-Studio использует общее ядро для анализа программ на этих языках, поэтому далее для сокращения текста эти языки будут рассматривать вместе, а не по отдельности.
PVS-Studio. Инструментальное средство статического анализа кода, разрабатываемое с учётом требований, изложенных в ГОСТ Р 71207–2024. Выявляет все виды критических ошибок, перечисленных в стандарте (п. 6.3., п. 6.5.), и может использоваться для предотвращения появления и устранения уязвимостей при разработке безопасного ПО (РБПО). Поддерживает языки: C, C++, C#, Java. Работает под управлением операционных систем Windows, Linux, macOS.
Анализатор содержит 3 ядра:
- Ядро для анализа С и C++ кода. Написано на C++.
- Ядро для анализа С# кода. Написано на C#.
- Ядро для анализа Java кода. Написано на Java.
Анализатор удовлетворяет требованиям ГОСТ Р 71207–2024 к методам анализа (раздел 7), что обеспечивает выявление всех видов критических ошибок для поддерживаемых языков. Выполняются требования, изложенные в разделе 8, такие как: выдача результатов в открытых форматах (например, SARIF), указание соответствия типа ошибки согласно системе классификации MITRE CWE и так далее.
Инструмент разрабатывается в России с 2008 года (запись в Едином Реестре российского ПО N9837) и содержит более 1000 диагностических правил. Возможно использование в полностью закрытом контуре. Является SAST-решением.
Поддерживаемые языки и методы анализа
PVS-Studio поддерживает анализ кода программ, написанных на языках программирования C, C++, C#, Java.
В ГОСТ Р 71207–2024 (п. 7.4.) перечислены методы, которые должен реализовывать статический анализатор. PVS-Studio реализует все эти методы.
|
Виды анализа (п. 7.4.) |
C и C++ |
C# |
Java |
|---|---|---|---|
|
Внутрипроцедурный анализ потоков данных и управления |
✓ |
✓ |
✓ |
|
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных |
✓ |
✓ |
✓ |
|
Чувствительный к путям выполнения анализ потоков данных и управления |
✓ |
✓ |
✓ |
|
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных |
✓ |
✓ |
✓* |
|
Анализ программы на синтаксическом уровне |
✓ |
✓ |
✓ |
Таблица N1. Виды анализа, которые должен реализовывать статический анализатор кода согласно ГОСТ Р 71207–2024 (п. 7.4.).
Примечание *. На момент написания этого раздела в 2024 году для Java реализован анализ помеченных данных, но отсутствует механизм пользовательских аннотаций для задания процедур-источников и процедур-стоков чувствительных данных (п. 7.6.). Реализация поддержки аннотаций запланирована на первую половину 2025 года.
Также в стандарте (п. 7.4.) перечислены вспомогательные методы анализа, которые может реализовывать инструмент для поиска дополнительных типов ошибок. PVS-Studio поддерживает следующие из них:
|
Необязательные вспомогательные виды анализа (п. 7.4.) |
C и C++ |
C# |
Java |
|---|---|---|---|
|
Сигнатурный поиск |
✓ |
✓ |
✓ |
|
Анализ псевдонимов |
✓ |
||
|
Анализ косвенных вызовов |
|||
|
Статистический анализ |
✓ |
✓ |
✓ |
|
Анализ иерархии классов |
✓ |
✓ |
✓ |
Таблица N2. Виды анализа, которые согласно ГОСТ Р 71207–2024 (п. 7.4.) следует использовать в качестве вспомогательных методов.
Разберём перечисленные методы более подробно и приведём примеры их использования.
Анализ программы на синтаксическом уровне
Согласно ГОСТ (п 3.1.6.), анализ программы на синтаксическом уровне — это статический анализ, при котором обрабатывается представление программы, полностью отражающее её синтаксическую структуру, например, абстрактное синтаксическое дерево.
Хотя этот вид анализа приводится в списке последним, мы начнём именно с него, так как он является основой для всех остальных. Без разбора кода на синтаксическом уровне и построения абстрактного синтаксического дерева невозможно проведение полноценного анализа кода. Более того, обязательным также является и семантический анализ, позволяющий вывести типы данных и другую информацию, требуемую для реализации подавляющего числа диагностических правил.
В PVS-Studio все диагностические правила для всех языков работают с деревом, полученным в ходе синтаксического анализа кода. Поэтому примером использования анализа программы на синтаксическом уровне может являться любое из них.
Редчайшим исключением являются несколько диагностических правил, работающих на уровне лексем. Примером такого исключения является поиск невидимых символов, позволяющих проводить атаку Trojan Source.
Синтаксический анализ C и C++ кода
Для C и C++ построение дерева осуществляется собственным парсером, написанным на языке C++ и развиваемым силами команды PVS-Studio. Наши доклады и статьи на эту тему:
- Юрий Минаев: "Как забраться на дерево".
- C++ Zero Cost Conf 2024, Юрий Минаев: "Семантика для кремниевых мозгов".
- Вебинар, Олег Лысый: "Парсим С++".
Синтаксический анализ C# кода
Работа с C# кодом базируется на использовании .NET Compiler Platform (Roslyn). Наши доклады и статьи на эту тему:
- Сергей Васильев: "Введение в Roslyn. Использование для разработки инструментов статического анализа".
- DotNext 2022 Autumn, Сергей Васильев: "Анализ C# кода на Roslyn: от теории к практике".
- Валерий Комаров: "Создание статического анализатора для C# на основе Roslyn API".
Синтаксический анализ Java кода
Работа с Java кодом базируется на использовании Spoon. Статья Егора Бредихина о том, почему была выбрана библиотека Spoon — "Разработка нового статического анализатора: PVS-Studio Java".
Пример использования синтаксического анализа для поиска ошибок
Синтаксический анализ — неотъемлемая часть всех диагностических правил, реализованных в PVS-Studio для всех поддерживаемых языков. Поэтому разберём только один пример.
Ошибка была найдена с помощью PVS-Studio в проекте LLVM (язык C++) и описана в этой статье.
std::unique_ptr<OptionDefinition> m_options_definition_up;
....
Status SetOptionsFromArray(StructuredData::Dictionary &options) {
Status error;
m_num_options = options.GetSize();
m_options_definition_up.reset(new OptionDefinition[m_num_options]);
....
}Предупреждение PVS-Studio: V554 Incorrect use of unique_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. CommandObjectCommands.cpp 1384
Умный указатель m_options_definition_up ориентирован на хранение одиночного элемента, но туда помещается указатель на массив. Результат — неопределённое поведение в момент разрушения объекта. Корректный вариант кода:
std::unique_ptr<OptionDefinition []> m_options_definition_up;Чтобы найти эту ошибку, необходимо в момент вызова функции reset иметь информацию, какой тип имеет переменная m_options_definition_up. Эта информация собирается при обходе дерева, построенного с помощью синтаксического разбора кода и механизма вывода типов переменных.
Внутрипроцедурный анализ потоков данных и управления
Определения:
- анализ потока данных (п 3.1.4.) — статический анализ, при котором определяются свойства обрабатываемых программой данных. Могут определяться возможные значения переменных и констант, точки программы, в которых используются определённые переменные и прочее;
- анализ потока управления (п 3.1.5.) — статический анализ, при котором выделяются процедуры программы, линейные участки кода процедур и условия переходов между этими участками.
Анализ потоков данных позволяет анализатору PVS-Studio делать предположения о значениях переменных и выражений в различных частях исходного кода. Некоторые виды предполагаемых значений:
- конкретные значения (числа, строки);
- диапазоны значений;
- множество возможных значений.
Бывают и более сложные виды данных, сопоставляемые с какой-то переменной. Например, анализатор может знать, что указатель находится в одном из следующих состояний:
- неинициализированный (нельзя разыменовывать и сравнивать с другим указателем);
- нулевой (нельзя разыменовывать);
- указывает на буфер памяти определённого размера (можно проверить выход за границу буфера);
- указывает на освобождённую память (нельзя разыменовывать или повторно освобождать);
- и так далее.
Анализ потока управления в PVS-Studio неразрывно связан с анализом потока данных. Поясним это примером на языке C++:
void foo()
{
int A = 1;
int B = 2;
if (A == 3)
{
B = 0;
}
A = 10 / B;
}В момент проверки (A == 3) анализатор благодаря анализу потока данных знает, что условие будет всегда ложным, так как переменная A равна 1. Следовательно, с точки зрения потока управления, тело оператора if не выполняется, и переменной B не может быть присвоено значение 0.
Информация о потоке выполнения (что не выполняется код, где 0 записывается в переменную B) влияет на поток данных. Известно, что значение переменной B остаётся равно 2. Следовательно, деление 10 / B всегда безопасно, и анализатор не выдаёт предупреждение о потенциальном делении на ноль.
Анализ потоков данных и управления так или иначе участвует почти во всех алгоритмах выявления критических ошибок. Например, именно благодаря ему удаётся определить, каков размер массива, и происходит ли в определённой ветке кода запись за его границу.
Механизмы анализа потока данных схоже реализованы в PVS-Studio для всех языков и нет смысла их рассматривать отдельно. Дальнейшие разделы созданы с целью разделить ссылки на публикации и примеры для разных языков.
Пример внутрипроцедурного анализа потоков данных и управления для C и C++ кода
Хорошим примером использования внутрипроцедурного анализа потоков данных и управления является выявление ошибки в проекте Protocol Buffers (protobuf), которая описана в статье "31 февраля".
static const int kDaysInMonth[13] = {
0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31
};
bool ValidateDateTime(const DateTime& time) {
if (time.year < 1 || time.year > 9999 ||
time.month < 1 || time.month > 12 ||
time.day < 1 || time.day > 31 ||
time.hour < 0 || time.hour > 23 ||
time.minute < 0 || time.minute > 59 ||
time.second < 0 || time.second > 59) {
return false;
}
if (time.month == 2 && IsLeapYear(time.year)) {
return time.month <= kDaysInMonth[time.month] + 1;
} else {
return time.month <= kDaysInMonth[time.month];
}
}Функция ValidateDateTime принимает на вход дату и должна определить, корректна она или нет. Вначале выполняются основные проверки. Проверяется, что номер месяца лежит в диапазоне [1..12], дни находятся в диапазоне [1..31], минуты находятся в диапазоне [0..59] и так далее.
Затем идёт более сложная проверка: есть ли определённый день в определённом месяце. Чтобы проверить дни, используется вспомогательный массив kDaysInMonth. В массиве записано количество дней в различных месяцах. По номеру месяца из массива извлекается максимальное количество дней, которое и используется для проверки.
Дополнительно учитывается, что год может быть високосным, и тогда в феврале на 1 день больше.
Из-за опечатки дни проверяются неправильно. Обратите внимание, что с максимально возможным количеством дней в месяце сравнивается не день, а месяц.
if (time.month == 2 && IsLeapYear(time.year)) {
return time.month <= kDaysInMonth[time.month] + 1;
} else {
return time.month <= kDaysInMonth[time.month];
}В сравнениях "time.month <= ...." следует использовать day, а не month.
Номер месяца (от 1 до 12) всегда меньше количества дней в любом из месяцев.
Из-за этой ошибки корректными будут считаться такие дни, как, например, 31 февраля или 31 ноября.
Предупреждения PVS-Studio:
- V547 Expression 'time.month <= kDaysInMonth[time.month] + 1' is always true. time.cc 83
- V547 Expression 'time.month <= kDaysInMonth[time.month]' is always true. time.cc 85
Обнаружение этой ошибки возможно благодаря одновременной работе анализа потоков данных и управления.
Если значение месяца лежит вне диапазона [1..12], то функция завершает работу. Следовательно, анализ потока управления будет выполняться дальше только в том случае, если значение переменной time.month лежит в диапазоне [1..12].
Анализатор заглядывает внутрь массива и понимает, что оттуда извлекаются значения в диапазоне [28..31]. Он учитывает, что 0 из массива kDaysInMonth не извлекается, так как возможный диапазон time.month, используемого в качестве индекса, равен [1..12].
В итоге анализатор видит, что происходят следующие сравнения диапазонов:
- [2..2] <= [28..31]
- [1..12] <= [29..32]
Условия всегда истинны, о чём анализатор и выдаёт предупреждения.
Почему первый диапазон [2..2] представлен только одним числом 2? Дело в том, что учитывается уточняющее условие time.month == 2.
Наши доклады и статьи на тему анализа потока данных C++ кода:
- Андрей Карпов: "Зачем PVS-Studio использует анализ потока данных: по мотивам интересной ошибки в Open Asset Import Library".
- CoreHard 2018, Павел Беликов: "Как работает анализ Data Flow в статическом анализаторе кода".
- Сергей Васильев: "Под капотом SAST: как инструменты анализа кода ищут дефекты безопасности".
Пример внутрипроцедурного анализа потоков данных и управления для C# кода
Пример для C# будет проще, но фактически всё работает аналогичным образом. Аномалия была выявлена в проекте Unity3D.
public NetworkConnection Get(int connId)
{
if (connId < 0)
{
return m_LocalConnections[Mathf.Abs(connId) - 1];
}
if (connId < 0 || connId > m_Connections.Count)
....
}Предупреждение PVS-Studio: V3063 A part of conditional expression is always false: connId < 0. ConnectionArray.cs 59
Если первое условие выполнилось (connId < 0), то поток управления прерывается (происходит выход из функции с помощью оператора return). Следовательно, функция продолжит выполнение только в том случае, если значение переменной connId больше или равно 0.
Анализ потока данных учитывает тот факт, что connId >= 0, и на его основе диагностическое правило V6063 делает вывод, что часть условия всегда ложна.
Наши публикации на тему анализа потока данных C# кода:
- Никита Липилин: "Эволюция PVS-Studio: анализ потока данных для связанных переменных".
- Артём Ровенский: "Анализ потока данных PVS-Studio распутывает всё больше связанных переменных".
Пример внутрипроцедурного анализа потоков данных и управления для Java кода
При создании ядра для анализа языка Java был переиспользован механизм анализа потока данных и управления, реализованный в ядре C++ анализатора. То есть Java анализатор использует часть функциональности C++ анализатора с помощью SWIG (средство для автоматической генерации врапперов и интерфейсов для связывания программ на C и C++ с программами, написанными на других языках).
Это позволило быстрее разработать первую версию Java анализатора, однако повлекло за собой ряд сложностей и усложнение процесса дальнейшего развития. Например, достаточно неудобно отлаживать код из-за этой связки. Правки C++ ядра могут неожиданно влиять на Java анализатор и так далее.
Поэтому наша команда планирует в 2025 году переписать используемые механизмы на Java и развивать их независимо.
Использование анализа потоков данных и управления для Java кода будет показано на примере ошибки в проекте GeoGebra.
private void updateOrdering(GeoElement geo, ObjectMovement movement) {
....
if (index == firstIndex) {
if (index != 0) {
geo.setOrdering(orderingDepthMidpoint(index));
}
else {
geo.setOrdering(drawingOrder.get(index - 1).getOrdering() - 1);
}
}
....
}Предупреждение PVS-Studio: V6025 Index 'index - 1' is out of bounds. LayerManager.java 393
Анализируя поток управления, анализатор знает, что:
geo.setOrdering(drawingOrder.get(index - 1).getOrdering() - 1);Выполняется только в том случае, если переменная index равна 0. Следовательно, фактическим аргументом, передаваемым в функцию get, будет значение -1. Результат: генерация исключения типа IndexOutOfBoundsException.
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных
Определения:
- межмодульный анализ (п. 3.1.17.) — статический анализ, при котором выполняется совместный анализ программы или нескольких программ, состоящих из нескольких программных модулей, и выявляемые свойства программы затрагивают процедуры или переменные из различных модулей.
- межпроцедурный контекстно-чувствительный анализ (п. 3.1.18.) — статический анализ, при котором выявляемые свойства программы учитывают взаимодействие нескольких процедур, в том числе возникающее в результате выполнения нескольких процедур или вызовов процедурами друг друга, а также контексты их вызова. В ходе анализа учитывается контекст вызова процедуры при обработке её вызова, то есть сопоставляется информация из вызывающей и вызываемой процедур применительно к каждому месту вызова и его окружению: фактическим параметрам, состоянию глобальных переменных и тому подобное.
Статические анализаторы кода могут учитывать данные, которые передаются между процедурами/функциями, чтобы выявить больше критических ошибок. Это важно при выявлении таких ошибок, как утечки памяти, разыменование нулевых указателей, выход за границы массивов и так далее. Это связано с тем, что создание некого ресурса, его использование и освобождение часто разнесены по разным функциях.
Для выявления ошибок, возникающих при взаимодействии нескольких процедур, статические анализаторы используют технологию межпроцедурного контекстно-чувствительного анализа кода.
Ситуация усложняется, если требуется анализировать взаимодействие функций, находящихся в различных единицах трансляции/программных модулях. В этом случае говорят, что выполняется межмодульный анализ.
PVS-Studio реализует межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных для всех поддерживаемых языков. Однако межмодульный анализ С и C++ более сложен по сравнению с C# и Java, так как требует дополнительных действий по объединению информации, получаемой из различных единиц трансляции.
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных C и С++ кода
Межмодульный анализ в PVS-Studio для С и C++ выполняется в 3 этапа:
- Семантический анализ каждой отдельной единицы трансляции. Анализатор собирает информацию о каждом символе программы, для которого нашлись потенциально интересные факты. После эта информация записывается в файлы в специальном формате. Такая обработка может выполняться параллельно, что хорошо для многопоточной сборки.
- Слияние символов. На этом этапе анализатор объединяет информацию из разных файлов с фактами в один, попутно решая конфликты между символами. На выходе получаем один файл с необходимой для межмодульного анализа информацией.
- Запуск диагностических правил. Анализатор вновь проходит каждую единицу трансляции. Однако в отличие от режима с выключенным межмодульным анализом, во время выполнения правил загружается информация о символах из объединённого файла. Таким образом, становится доступной информация о фактах для символов из других модулей.
Наши доклады и статьи на эту тему:
- Олег Лысый, Сергей Ларин: "Межмодульный анализ C++ проектов в PVS-Studio".
- C++ Russia 2023, Олег Лысый: "Межмодульный анализ C++ проектов".
- Олег Лысый: "Межмодульный анализ C и C++ проектов в деталях: часть 1, часть 2".
Рассмотрим пример ошибки, найденной с помощью межмодульного контекстно-чувствительного анализа инструментом PVS-Studio в коде проекта Midnight Commander (язык C).
Начнём с функции widget_destroy в файле widget-common.c:
void widget_destroy (Widget * w)
{
send_message (w, NULL, MSG_DESTROY, 0, NULL);
g_free (w);
}Функция освобождает буфер памяти, адрес которого она получает через аргумент w.
Теперь посмотрим на код в файле editcmd.c:
gboolean edit_close_cmd (WEdit * edit)
{
Widget *w = WIDGET (edit);
....
widget_destroy (w); // <= Здесь освободили память
if (....) .... else
{
edit = find_editor (DIALOG (g));
if (edit != NULL)
widget_select (w); // <= Передаём указатель дальше
}
}Обратите внимание, что в начале адрес структуры Widget передаётся в функцию widget_destroy, где происходит освобождение буфера памяти. Далее этот указатель передаётся в функцию widget_select, приведённую ниже:
void widget_select (Widget * w)
{
WGroup *g;
if (!widget_get_options (w, WOP_SELECTABLE))
return;
....
}Она просто передаёт указатель дальше в функцию widget_get_options:
static inline gboolean
widget_get_options (const Widget * w, widget_options_t options)
{
return ((w->options & options) == options);
}Здесь мы добрались до места, где возникает неопределённое поведение, связанное с использованием данных в уже освобождённом буфере памяти. Анализатор PVS-Studio сигнализирует об этом предупреждением: V774 The 'w' pointer was used after the memory was released.
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных С# кода
.NET Compiler Platform предоставляет инфраструктуру для работы сразу со всеми файлами исходного кода, включёнными в проект. Это делает межмодульный анализ C# кода более простым в реализации, чем в случае C++.
Рассмотрим два примера реального кода, первый из которых хорошо демонстрирует суть контекстно-чувствительного анализа, а второй — межмодульного анализа.
Первая ошибка найдена в проекте AvalonStudio. Рассмотрим вначале функцию IsBuiltInType. Обратите внимание, что, если её входной аргумент cursor окажется нулевой ссылкой, то функция вернёт значение false. Другими словами, результат работы функции зависит от контекста её вызова.
private static bool IsBuiltInType(ClangType cursor)
{
var result = false;
if (cursor != null && ....)
{
return true;
}
return result;
}Теперь рассмотрим другой фрагмент кода, где вызывается рассмотренная функция:
private static StyledText InfoTextFromCursor(ClangCursor cursor)
{
....
if (cursor.ResultType != null)
{
result.Append(cursor.ResultType.Spelling + " ",
IsBuiltInType(cursor.ResultType) ? theme.Keyword
: theme.Type);
}
else if (cursor.CursorType != null)
{
switch (kind)
{
....
}
result.Append(cursor.CursorType.Spelling + " ",
IsBuiltInType(cursor.ResultType) ? theme.Keyword
: theme.Type);
}
....
}Если cursor.ResultType != null, то выполняется тело первого оператора if. Соответственно, если управление будет предано внутрь тела второго оператора if, то точно известно, что ссылка cursor.ResultType является нулевой.
Изучим место вызова рассмотренной ранее функции IsBuiltInType:
result.Append(cursor.CursorType.Spelling + " ",
IsBuiltInType(cursor.ResultType) ? theme.Keyword
: theme.Type);Анализатор знает, что cursor.ResultType — нулевая ссылка. Из этого он делает вывод, что при таком входном аргументе функция всегда возвращает false.
Это и есть межпроцедурный контекстно-чувствительный анализ.
Если условие тернарного оператора всегда ложно, то это подозрительно, о чём анализатор и сообщает, выдавая предупреждение: V3022 Expression 'IsBuiltInType(cursor.ResultType)' is always false.
Действительно, если присмотреться к коду, то можно заметить опечатку. В теле второго оператора if при вызове функции IsBuiltInType в качестве фактического аргумента следует передать переменную cursor.CursorType.
Рассмотрим второй пример кода из игры Starlight, где для выявления ошибки требуется межмодульный анализ. Здесь задействовано 3 файла:
- NavMeshGenerator.cs — метод ScanInternal;
- AstarData.cs — метод GetGraphIndex;
- TriangleMeshNode.cs — метод SetNavmeshHolder.
protected override IEnumerable<Progress> ScanInternal ()
{
....
TriangleMeshNode.SetNavmeshHolder(
AstarPath.active.data.GetGraphIndex(this), this);
....
}Предупреждение PVS-Studio: V3106 The 1st argument 'AstarPath.active.data.GetGraphIndex(this)' is potentially used inside method to point beyond collection's bounds. NavMeshGenerator.cs 225
Анализатор сообщает о том, что внутри метода TriangleMeshNode.SetNavmeshHolder происходит доступ по индексу за пределами допустимого диапазона. При этом в качестве индекса выступает первый аргумент.
Взглянем на метод AstarPath.active.data.GetGraphIndex:
public int GetGraphIndex (NavGraph graph) {
if (graph == null) throw new System.ArgumentNullException("graph");
var index = -1;
if (graphs != null) {
index = System.Array.IndexOf(graphs, graph);
if (index == -1) Debug.LogError("Graph doesn't exist");
}
return index;
}Как мы видим, метод может вернуть в качестве результата -1. Теперь взглянем на метод TriangleMeshNode.SetNavmeshHolder:
public static void SetNavmeshHolder (int graphIndex, INavmeshHolder graph) {
// We need to lock to make sure that
// the resize operation is thread safe
lock (lockObject) {
if (graphIndex >= _navmeshHolders.Length) {
var gg = new INavmeshHolder[graphIndex+1];
_navmeshHolders.CopyTo(gg, 0);
_navmeshHolders = gg;
}
_navmeshHolders[graphIndex] = graph; // <=
}
}Анализатор сообщает, что проблемный доступ происходит на последней строке. Доступ по индексу происходит без предварительной проверки.
Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных Java кода
Библиотека Spoon предоставляет инфраструктуру для работы сразу со всеми файлами исходного кода, входящими в проект. Это делает межмодульный анализ Java кода схожим с анализом C# кода и более простым в реализации по сравнению с C++.
Для Java анализатора нашей командой пока собрано мало случаев реальных ошибок в открытых проектах, из которых можно подбирать примеры. Рассмотрим синтетический пример:
class Main {
static class NetworkTextTransmitter {
private final Socket socket = new Socket();
private final PrintWriter socketWriter;
public NetworkTextTransmitter(InetSocketAddress host,
InetSocketAddress source)
throws IOException {
socket.bind(host);
socket.connect(source);
socketWriter = new PrintWriter(socket.getOutputStream());
}
public void transmit(String message) {
socketWriter.println(message);
}
....
public void closeConnection() {
socketWriter.close();
}
}
public static void main(String[] args) throws IOException {
....
InetSocketAddress hostAddress =
new InetSocketAddress(Integer.parseInt(args[0]));
InetSocketAddress sourceAddress =
new InetSocketAddress(Integer.parseInt(args[1]));
NetworkTextTransmitter textTransmitter =
new NetworkTextTransmitter(hostAddress, sourceAddress);
Scanner scanner = new Scanner(System.in);
for (int i = 0; i < Integer.parseInt(args[0]); i++) {
textTransmitter.transmit(scanner.next());
}
textTransmitter.closeConnection();
}Предупреждение PVS-Studio: V6114 The 'NetworkTextTransmitter' class contains the 'socket' Closeable field, but the resources that the field is holding are not released inside the class. Main.java 10
Пример демонстрирует использование информации о состоянии класса (контекстно-чувствительный анализ) в процессе взаимодействия с ним (межпроцедурный анализ).
Программа выполняет передачу текстовых сообщений по сетевому подключению через сокет. Текстовые сообщения вводятся через консоль и передаются по подключению. Для передачи сообщений используется класс NetworkTextTransmitter, который создаёт подключение и поток передачи. По завершению передачи N сообщений метод main вызывает метод closeConnection. Внутри данного метода закрывается только поток передачи текстовых данных, однако само подключение через сокет остаётся открытым.
Чувствительный к путям выполнения анализ потоков данных и управления
Согласно ГОСТ, чувствительный к путям выполнения анализ (3.1.36.) — это статический анализ программы, при котором могут быть определены её свойства, проявляющиеся лишь на некоторых путях выполнения программы, и условия (или часть условий), при обращении которых в истину выполнение программы пойдёт по указанному анализатором пути.
Не очень понятно, почему стандарт выделяет чувствительность к путям выполнения в отдельный вид анализа потока данных и управления. На наш взгляд, анализ потока данных (п 3.1.4.) и анализ потока управления (п 3.1.5.) уже подразумевают учёт путей выполнения кода. В противном случае, если не учитывать пути выполнения, эти виды анализа становятся вырожденными и почти непригодными к практическому применению.
Возможно, стандарт содержит не очень удачную формулировку или не даёт дополнительных пояснений и примеров.
Мы интерпретируем этот вид анализа следующим образом: стандарт предлагает учитывать те ситуации, когда некоторое действие может как произойти, так и не произойти. Следует выдавать предупреждение с учётом того, что выполнение программы пойдёт по пути, приводящему к ошибке.
Поясним нашу интерпретацию синтетическим примером на языке C++:
void foo(bool A)
{
int *B = new int;
if (A)
{
delete B;
}
*B = 1;
}Если условие выполнится, то анализатор должен выдать предупреждение о том, что происходит запись в уже освобождённую память.
Если условие не выполнится, то анализатор должен выдать предупреждение об утечке памяти.
Если анализатор может вычислить с помощью межпроцедурного и межмодульного контекстно-чувствительного анализа потока данных чему равна переменная A, то он должен выдать одно предупреждение из двух.
Если вычислить значение A невозможно или известно, что оно может быть как false, так и true, то помогает анализ потоков данных и управления, чувствительный к путям выполнения. Анализатор должен выдать оба предупреждения, по возможности показав пути выполнения программы, приводящие к ним.
Анализатор PVS-Studio использует чувствительный к путям выполнения анализ потоков данных, но не выделяет его в отдельную сущность или алгоритм. Фактически все 3 рассмотренные виды анализа:
- межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных;
- чувствительный к путям выполнения анализ потоков данных и управления;
- межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных.
Реализуются в каждом языковом ядре PVS-Studio в виде единого механизма (алгоритма).
Пример анализа потока данных и управления, чувствительных путям выполнения C и C++ кода
Ошибка, используемая в качестве примера, была найдена в проекте MPC-HC (С++):
void CSyncAP::RenderThread()
{
....
REFERENCE_TIME rtRefClockTimeNow;
if (m_pRefClock) {
m_pRefClock->GetTime(&rtRefClockTimeNow);
}
LONG lLastVsyncTime =
(LONG)((m_llEstVBlankTime - rtRefClockTimeNow) / 10000);
....
}Предупреждение PVS-Studio: V614 Potentially uninitialized variable 'rtRefClockTimeNow' used. syncrenderer.cpp 3604
Переменная rtRefClockTimeNow останется неинициализированной, если указатель m_pRefClock является нулевым. Соответственно, возможен путь выполнения программы, приводящий к ошибке — использованию неинициализированной переменной. При этом это необязательно произойдёт, поэтому анализатор сообщает о потенциальной ошибке. Таким образом, анализ здесь чувствителен к путям выполнения.
В случае, если переменная не инициализирована всегда, анализатор будет более категоричен. Код из проекта Trans-Proteomic Pipeline (язык С++):
double mscore_c::dot_hr(unsigned long *_v)
{
....
int iSeqSize;
for (int a = 0; a < iSeqSize; a++) {
....
}Здесь нет вариантов, поэтому PVS-Studio выдаёт предупреждение: V614 Uninitialized variable 'iSeqSize' used. mscore_c.cpp 552
Пример анализа потока данных и управления, чувствительных путям выполнения C# кода
Ошибка была обнаружена нами в проекте RunUO:
public static string ConstructFromString( .... )
{
object toSet;
bool isSerial = IsSerial( type );
if ( isSerial ) // mutate into int32
type = m_NumericTypes[4];
if ( IsEnum( type ) )
{
try
{
toSet = Enum.Parse( type, value, true ); // <= (А)
}
catch
{
return "That is not a valid enumeration member.";
}
}
else if ( IsType( type ) )
{
try
{
toSet = ScriptCompiler.FindTypeByName( value ); // <= (Б)
if ( toSet == null )
return "No type with that name was found.";
}
catch
{
return "No type with that name was found.";
}
}
....
else if ( value == null )
{
toSet = null; // <= (В)
}
....
if ( isSerial ) // mutate back
toSet = (Serial)((Int32)toSet);
constructed = toSet;
return null;
}Переменной toSet могут присваиваться как ссылки на существующие объекты (точки: А, Б), так и нулевая ссылка (точка В). Анализатор чувствителен к тому, что существуют эти различные пути выполнения, и предупреждает, что ссылка потенциально может оказаться нулевой.
Предупреждение PVS-Studio: V3148 Casting potential 'null' value of 'toSet' to a value type can lead to NullReferenceException. Properties.cs 502
Пример анализа потока данных и управления, чувствительных путям выполнения Java кода
Рассмотрим ошибку возможного разыменования нулевой ссылки в проекте Keycloak:
private void checkRevocationUsingOCSP(X509Certificate[] certs)
throws GeneralSecurityException {
....
if (rs == null) { // <= (А)
if (_ocspFailOpen)
logger.warnf(....); // <= (Б)
else
throw new GeneralSecurityException(....); // <= (В)
}
if (rs.getRevocationStatus() == // <= (Г)
OCSPProvider.RevocationStatus.UNKNOWN) {
....
}Если rs хранит нулевую ссылку (точка А), то нормальный поток выполнения может быть прерван генерацией исключения (точка В). Но может быть и не прерван (точка Б), что приведёт к доступу по нулевой ссылке (точка Г).
Итого ссылка может быть как нулевая, так и не нулевая. Если она нулевая, то до её использования управление может как дойти, так и не дойти. Таким образом, задействован анализ потока данных и управления, чувствительный к путям выполнения.
Анализатор PVS-Studio сообщает о потенциальной ошибке: V6008 Potential null dereference of 'rs'. CertificateValidator.java 701 , CertificateValidator.java 708
В общем случае подобные предупреждения могут быть ложными, если между ссылкой rs и переменной ocspFailOpen существует сложная косвенная взаимосвязь, которую анализатор не смог выявить (см. статью про связанные переменные). Собственно, и в стандарте говорится (примечание к п. 3.1.2.): анализ потока управления, анализ потока данных, анализ помеченных данных, анализ псевдонимов и анализ косвенных вызовов в общем случае дают приближённые результаты.
Однако даже в этом случае ложные предупреждения могут быть полезны, так как выявляют сложный, неочевидный код, который может быть непонятен не только анализатору, но и разработчикам. Целесообразно провести его рефакторинг или, по крайне мере, написать соответствующий комментарий про косвенную связь между переменными.
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных
Согласно ГОСТ, анализ помеченных данных (3.1.3.) — статический анализ, при котором анализируется течение потока данных от источников до стоков. Под источниками понимаются точки программы, в которых данные начинают иметь пометку — некоторое заданное свойство. Под стоками понимаются точки программы, в которых данные перестают иметь пометку. Распространённая (но не единственная) цель анализа помеченных данных — показать, что помеченные данные не могут попасть из источников — точек ввода пользователя в стоки — процедуры записи на диск или в сеть. Факт такого попадания означает утечку конфиденциальных данных.
Механизмы анализа помеченных данных схожи с механизмами анализа потоков данных, но имеют существенное различие. Основная задача анализа потока данных — попытаться выяснить состояние переменных в различных точках программы, чтобы в дальнейшем использовать эту информацию в диагностических правилах. Например, если известно, что значение целочисленной переменной A лежит в диапазоне от 0 до 10, то её нельзя использовать в качестве индекса для массива, содержащего только 5 элементов.
Контекстно-чувствительный анализ помеченных данных не ставит задачей определить значение переменных, а оперирует понятием недостоверности данных. Если значение целочисленной переменной A взято из ненадёжного источника и не проверено, его опасно использовать в качестве индекса массива. При этом диапазон значений A может быть полностью неизвестен. Он и не важен. Важен факт использования опасных данных.
Источники заражения. Первичным понятием в данной теме являются заражённые данные. Под этим термином подразумеваются некоторые значения, которые могут позволить злоумышленнику выполнить несанкционированные и, как правило, вредоносные операции при взаимодействии с системой. В зависимости от способа использования внешних данных приложение может быть уязвимо к тем или иным атакам. Например, если приложение использует непроверенные внешние данные при формировании запросов к БД, то оно может быть уязвимо к SQL injection.
Таким образом, внешние данные являются потенциально заражёнными. Точки, в которых приложение получает к ним доступ, называют источниками заражения. Например, источником заражения может быть операция получения значения параметра HTTP-запроса:
void ProcessRequest(HttpRequest request)
{
....
string name = request.Form["name"]; // источник
// теперь "name" содержит недостоверные/заражённые данные
....
}Передача заражения. Важным аспектом при проведении анализа помеченных данных является определение "трасс распространения" заражённых данных по приложению. В приведённом примере заражённые данные из источника передаются в переменную name. Впоследствии они могут также переходить в другие переменные или выступать в качестве аргументов функций:
void ProcessRequest(HttpRequest request)
{
string name = request.Form["name"]; // источник
// теперь "name" содержит недостоверные/заражённые данные
string sql = $"SELECT * FROM Users WHERE name='{name}'";
// недостоверные данные передаются далее как аргумент
ExecuteReaderCommand(sql);
....
}
void ExecuteReaderCommand(string sql)
{
// sql содержит недостоверные/заражённые данные
....
}Стоит отметить, что заражение может передаваться далеко не только при присваивании и передаче аргументов. В примере выше переменная name, хранящая потенциально заражённые данные, используется для формирования строки, которая будет записана в переменную sql. В результате значение sql также будет потенциально заражённым.
Приёмники заражения (стоки). Приложение уязвимо в случае, если заражённые данные могут попасть в некоторые ключевые точки приложения. Их называют приёмниками заражения (taint sink). Каждой потенциальной уязвимости соответствуют свои приёмники. Для SQL injection, к примеру, приёмником может являться точка передачи строки запроса в объект SQL-команды:
void ProcessRequest(HttpRequest request)
{
string name = request.Form["name"]; // <= источник
// теперь "name" содержит недостоверные/заражённые данные
string sql = $"SELECT * FROM Users WHERE name='{name}'";
ExecuteReaderCommand(sql); // данные передаются далее как аргумент
....
}
void ExecuteReaderCommand(string sql)
{
using (var command = new SqlCommand(sql, _connection)) // <= sink
{
using (var reader = command.ExecuteReader()) { /*....*/ }
}
....
}Здесь внешние данные из источника (request.Form["name"]) непосредственно используются при формировании SQL-запроса, который далее передаётся в приёмник — конструктор SqlCommand. Задача анализа помеченных данных состоит в проверке наличия пути передачи заражённых данных от источника к приёмнику.
Если проверить вышеприведённый код с помощью PVS-Studio, то результатом станет следующее предупреждение: V5608 Possible SQL injection inside method. Potentially tainted data in the first argument 'sql' is used to create SQL command.
Устранение потенциальных уязвимостей. Для устранения потенциальной уязвимости внешние данные необходимо проверять или преобразовывать в некоторый безопасный вид. Конкретный способ защиты зависит от типа атаки. Например, в случае с SQL injection могут быть использованы параметризованные запросы:
String userName = Request.Form["userName"];
String query = "SELECT * FROM Users WHERE UserName = @userName";
using (var command = new SqlCommand(query, _connection))
{
var userNameParam = new SqlParameter("@userName", userName);
command.Parameters.Add(userNameParam);
using (var reader = command.ExecuteReader())
....
}Соответственно, при проведении статического анализа, предупреждение на данный код выдано не будет.
Наши доклады и статьи на тему анализа помеченных данных:
- Описание уязвимости Path Traversal.
- Описание уязвимости XSS (межсайтовый скриптинг).
- Описание XEE-атаки (billion laughs attack).
- Описание XXE-атаки (XML External Entity).
- Heisenbug 2022 Spring, Сергей Васильев: "Правильно ли вы парсите XML? Разбираемся с уязвимостями".
- DotNext 2022: "Обработка XML-файлов как причина появления уязвимостей".
- Сергей Васильев: "Уязвимость XSS в приложении ASP.NET: разбираем CVE-2023-24322 в CMS mojoPortal".
- Сергей Васильев: "Парсинг string в enum ценой в 50 Гб: разбираем уязвимость CVE-2020-36620".
- Сергей Васильев: "Почему моё приложение при открытии SVG-файла отправляет сетевые запросы?"
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных C++ кода
Начнём с простого, но реального примера воспроизводимой уязвимости, обнаруженной в проекте FreeSWITCH:
static const char *basic_gets(int *cnt)
{
....
int c = getchar();
if (c < 0) {
if (fgets(command_buf, sizeof(command_buf) - 1, stdin)
!= command_buf) {
break;
}
command_buf[strlen(command_buf)-1] = '\0'; /* remove endline */
break;
}
....
}Предупреждение PVS-Studio: V1010 Unchecked tainted data is used in index: 'strlen(command_buf)'.
Анализатор предупреждает о подозрительном обращении по индексу к массиву command_buf. Подозрительным оно считается по той причине, что в качестве индекса используются непроверенные внешние данные. Внешние — потому что получены через функцию fgets из потока stdin, непроверенные — так как никакой проверки перед использованием выполнено не было. Выражение fgets(command_buf, ....) != command_buf не в счёт, так как таким образом проверяется только факт получения данных, но не их содержимое.
Проблема данного кода в том, что при определённых условиях произойдёт запись '\0' за пределы массива, что приведёт к возникновению неопределённого поведения. Для этого достаточно ввести строку нулевой длины. Более подробно найденный дефект и его воспроизведение описано в этой статье в главе про FreeSWITCH.
Рассмотренный реальный пример выявляется с помощью анализа помеченных данных. Однако он не очень интересен, так как всё происходит в одной функции на почти линейном участке кода.
Для демонстрации межпроцедурного анализа и контекстно-чувствительного анализа воспользуемся синтетическим примером:
int getindex() {
int index;
scanf("%d", &index);
return index;
}
void useindex(char *buf, int index) {
buf[index] = 1;
}
void foo() {
char buf[10];
int i = getindex();
useindex(buf, i);
}Предупреждение PVS-Studio: V1010 Unchecked tainted data is used in the second argument: 'i'. Check lines: 14, 20, 9.
Недостоверные чувствительные данные записываются в переменную index в процессе получения данных извне (вызов функции ввода scanf). Функция getindex возвращает эти недостоверные данные, и они попадают в функцию foo. Далее недостоверное значение передаются в функцию useindex, где используется для обращения к массиву фиксированного размера.
Соответственно, если пользователь введёт, например, значение 33, то возникнет критическая ошибка выхода за границу массива.
Истоком здесь является функция scanf, а стоком — использование помеченных данных в качестве индекса. Приведённый код демонстрирует межпроцедурный контекстно-чувствительный анализ, так как помеченные данные передаются между функциями. Если функции будут находиться в разных файлах, то этот пример будет демонстрировать межпроцедурный контекстно-чувствительный анализ помеченных данных.
Если добавить валидацию введённых данных, например, так:
void foo() {
char buf[10];
int i = getindex();
if (i < 10)
useindex(buf, i);
}То анализатор PVS-Studio уже не будет выдавать предупреждение V1010.
Наши доклады и статьи на тему анализа помеченных данных C++ кода:
- C++ Russia 2018, Сергей Васильев: "Статический анализ: ищем ошибки... и уязвимости?"
- Сергей Васильев: "Стреляем в ногу, обрабатывая входные данные".
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных C# кода
Рассмотрим анализ помеченных данных на примере XXE-уязвимости. Описание реального примера будет длинным (вы можете ознакомиться с одним из них здесь), поэтому рассмотрим синтетический вариант.
Представим приложение, которое принимает запросы в виде XML-файлов и обрабатывает товары с соответствующим идентификатором. Если идентификатор задан неверно, приложение сообщает об этом.
Формат XML-файла, с которым работает приложение:
<?xml version="1.0" encoding="utf-8" ?>
<shop>
<itemID>62</itemID>
</shop>Допустим, обработкой занимается следующий код:
static void ProcessItemWithID(String pathToXmlFile)
{
XmlReaderSettings settings = new XmlReaderSettings()
{
XmlResolver = new XmlUrlResolver(),
DtdProcessing = DtdProcessing.Parse
};
using (var fileReader = File.OpenRead(pathToXmlFile))
{
using (var reader = XmlReader.Create(fileReader, settings))
{
while (reader.Read())
{
if (reader.Name == "itemID")
{
var itemIDStr = reader.ReadElementContentAsString();
if (long.TryParse(itemIDStr, out var itemIDValue))
{
// Process item with the 'itemIDValue' value
Console.WriteLine(
$"An item with the '{itemIDValue}' ID was processed.");
}
else
{
Console.WriteLine($"{itemIDStr} is not valid 'itemID' value.");
}
}
}
}
}
}Предупреждение PVS-Studio: V5614. OWASP. Potential XXE vulnerability. Insecure XML parser is used to process potentially tainted data.
Для приведённого выше XML-файла приложение распечатает следующую строку:
An item with the '62' ID was processed.Если вместо номера в ID будет записано что-то другое (например, строка "Hello world"), приложение сообщит об ошибке:
"Hello world" is not valid 'itemID' value.Несмотря на то, что код делает то, что от него ожидается, он уязвим к XXE-атакам за счёт соблюдения всех перечисленных ранее факторов:
- содержимое XML поступает от пользователя;
- XML-парсер сконфигурирован таким образом, чтобы обрабатывать внешние сущности;
- вывод может передаваться обратно пользователю.
Ниже представлен XML-файл, через который можно скомпрометировать данный код:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE foo [
<!ENTITY xxe SYSTEM "file://D:/MySecrets.txt">
]>
<shop>
<itemID>&xxe;</itemID>
</shop>В этом файле объявляется внешняя сущность xxe, которая будет обработана парсером. Вследствие этого содержимое файла D:/MySecrets.txt (например, такое: 'This is an XXE attack target.'), находящегося на машине, где запущено приложение, будет выдано пользователю:
This is an XXE attack target. is not valid 'itemID' value.Для того, чтобы обезопаситься от подобной атаки, можно запретить обработку внешних сущностей (присвоить свойству XmlResolver значение null), а также запретить или игнорировать обработку DTD (записать в свойство DtdProcessing значение Prohibit или Ignore соответственно).
Анализатор также учитывает и межпроцедурные вызовы. Рассмотрим пример:
static FileStream GetXmlFileStream(String pathToXmlFile)
{
return File.OpenRead(pathToXmlFile);
}
static XmlDocument GetXmlDocument()
{
XmlDocument xmlDoc = new XmlDocument()
{
XmlResolver = new XmlUrlResolver()
};
return xmlDoc;
}
static void LoadXmlInternal(XmlDocument xmlDoc, Stream input)
{
xmlDoc.Load(input);
Console.WriteLine(xmlDoc.InnerText);
}
static void XmlDocumentTest(String pathToXmlFile)
{
using (var xmlStream = GetXmlFileStream(pathToXmlFile))
{
var xmlDoc = GetXmlDocument();
LoadXmlInternal(xmlDoc, xmlStream);
}
}В данном случае анализатор выдаст предупреждение на вызов метода LoadXmlInternal, так как отследит, что:
- парсер, полученный из метода GetXmlDocument, может обрабатывать внешние сущности;
- поток, полученный из метода GetXmlStream, содержит данные, полученные из внешнего источника (прочитанные из файла);
- парсер и недостоверные данные передаются в метод LoadXmlInternal, где выполняется обработка XML-файла.
Наши доклады и статьи на тему анализа помеченных данных C# кода:
- Сергей Васильев: "Уязвимости из-за обработки XML-файлов: XXE в C# приложениях в теории и на практике".
- Сергей Васильев: "Под капотом SAST: как инструменты анализа кода ищут дефекты безопасности".
- TechLead Conf 2022, Сергей Васильев: "Под капотом SAST: как инструменты анализа кода ищут дефекты безопасности".
- Никита Липилин, Сергей Васильев: "Почему важно проверять значения параметров общедоступных методов".
- Никита Паневин: "Поймай уязвимость своими руками: пользовательские аннотации C# кода".
- Никита Липилин: "Как taint-анализ защищает код от атак? [SQL Injection] [Path traversal]".
- Сергей Васильев: "OWASP, уязвимости и taint-анализ в PVS-Studio C#. Смешать, но не взбалтывать".
Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных Java кода
Рассмотрим синтетический пример (с использованием Spring Boot) межмодульного контекстно-чувствительного анализа помеченных данных, источником которых является сетевой запрос.
Первый файл — DemoController.java:
@Controller
public class DemoController {
@Autowired
private DemoService service;
@RequestMapping("demo")
public ResponseEntity<DemoObject>
demoEndpoint(@RequestParam(name="name") String name) {
return service.findByName(name)
.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
}Метод получает недостоверную информацию (строку). Далее эта строка передаётся без предварительной обработки/проверки в метод findByName.
Второй файл — DemoService.java:
@Service
public class DemoService {
@Autowired
DemoRepository demoRepository;
Optional<DemoObject> findByName(String name) {
return demoRepository.findByName(name);
}
}Здесь нет обработки/проверки, и метод передаёт строку далее в метод другого класса, также имеющий имя findByName.
Третий файл — DemoRepository.java:
public class DemoRepository {
@Autowired
private JdbcTemplate jdbcTemplate;
Optional<DemoObject> findByName(String name) {
var sql = "SELECT * FROM demoTable WHERE name = '" + name + "'";
if (name.equals("demoCondition")) {
sql = "SELECT * FROM demoTable WHERE name = demoName";
return Optional.ofNullable(
jdbcTemplate.queryForObject(sql, DemoObject.class));
}
return Optional.ofNullable(
jdbcTemplate.queryForObject(sql, DemoObject.class));
}
}Формируется SQL-запрос, в котором присутствует недостоверная строка. Это является уязвимостью типа SQL-инъекция.
Предупреждение PVS-Studio: V5309 Possible SQL injection. Potentially tainted data in 'sql' variable is used to create SQL command. DemoRepository.java 18, DemoController.java 15
Наши доклады и статьи на тему анализа помеченных данных Java кода:
- JPoint 2023, Сергей Васильев: "Как анализаторы кода ищут ошибки и дефекты безопасности".
- Константин Волоховский: "Поиск потенциальных уязвимостей в коде".
Вспомогательные методы анализа
В стандарте сказано (п. 7.4.), что в состав реализуемых методов статического анализа следует включать следующие методы анализа для поиска дополнительных типов ошибок, а также в качестве вспомогательных анализов:
- Сигнатурный поиск;
- Анализ псевдонимов;
- Анализ косвенных вызовов;
- Статистический анализ;
- Анализ иерархии классов.
Наличие этих видов анализа является не обязательными для статических анализаторов, но желательными. Разберёмся, в чём состоят эти анализы, и приведём примеры использования этих технологий в PVS-Studio.
Сигнатурный поиск
Сигнатурный анализ (п 3.1.28.) — статический анализ, определяющий наличие свойства программы при помощи поиска строк в её исходном коде по некоторому образцу, в том числе заданному с помощью формального языка поиска, например, при помощи регулярных выражений.
Сигнатурный анализ используется в PVS-Studio для реализации диагностических правил для всех языков: C, C++, C#, Java.
Упоминание в определении регулярных выражений может вызвать неправильное представление о сути данной технологии. Большинство диагностических правил, выполняющих сигнатурный анализ, работают с абстрактным синтаксическим деревом и при этом учитывают дополнительную информацию, такую как типы переменных. Соответственно, это более сложный и комплексный вид анализа по сравнению с простым поиском текста по какому-то шаблону. Например, ядро PVS-Studio для анализа C и C++ кода использует регулярные выражения (причём для вспомогательных целей) только в 5 из примерно 700 правил, реализованных на момент написания этого раздела.
Пример диагностического правила для C++ кода
В среднем диагностические правила, построенные на сигнатурном поиске, достаточно просты. Однако это не значит, что выявляемые ими ошибки будут несущественными.
Например, достаточно простым выглядит правило, которое выявляет сравнение переменной с самой собой:
lowerBound[0] == lowerBound[0]Однако это не придуманный синтетический код, а реальный фрагмент из проекта LLVM (язык C++):
FailureOr<ConstantOrScalableBound>
ScalableValueBoundsConstraintSet::computeScalableBound(....)
{
....
SmallVector<AffineMap, 1> lowerBound(1), upperBound(1);
scalableCstr.cstr.getSliceBounds(pos, 1, value.getContext(), &lowerBound,
&upperBound, closedUB);
auto invalidBound = [](auto &bound) {
return !bound[0] || bound[0].getNumResults() != 1;
};
AffineMap bound = [&] {
if (boundType == BoundType::EQ && !invalidBound(lowerBound) &&
lowerBound[0] == lowerBound[0]) { // <=
return lowerBound[0];
} else if (boundType == BoundType::LB && !invalidBound(lowerBound)) {
return lowerBound[0];
....
}Предупреждение PVS-Studio: V501 There are identical sub-expressions to the left and to the right of the '==' operator: lowerBound[0] == lowerBound[0]. ScalableValueBoundsConstraintSet.cpp 110
Перед нами опечатка, от которой не застрахованы даже профессиональные разработчики компиляторов. Корректный вариант кода:
lowerBound[0] == upperBound[0]Примечание. Здесь можно познакомиться с публикациями, посвящёнными поиску ошибок в различных компиляторах с помощью PVS-Studio.
Теперь рассмотрим примеры сигнатурного анализа для C# и Java.
Проект Space Engineers (C#):
private static bool IsTriangleDangerous(int triIndex)
{
if (MyPerGameSettings.NavmeshPresumesDownwardGravity)
{
return triIndex == -1;
}
else
{
return triIndex == -1;
}
}Предупреждение PVS-Studio: V3004 The 'then' statement is equivalent to the 'else' statement. Sandbox.Game MyNavigationTriangle.cs 189
Проект jBullet (Java):
public class ConeTwistConstraint extends TypedConstraint {
....
private boolean solveTwistLimit;
private boolean solveSwingLimit;
....
public boolean getSolveTwistLimit() {
return solveTwistLimit;
}
public boolean getSolveSwingLimit() {
return solveTwistLimit;
}
}Предупреждение PVS-Studio: V6091 Suspicious getter implementation. The 'solveSwingLimit' field should probably be returned instead. ConeTwistConstraint.java(407), ConeTwistConstraint.java(74)
Анализ псевдонимов
Анализ псевдонимов (п. 3.1.7.) — статический анализ, позволяющий установить наличие в программе доступа к одной и той же переменной или функции с помощью различных ссылок (указателей).
На момент написания данного раздела анализ псевдонимов используется в PVS-Studio только при анализе C# кода. Продемонстрируем данный вид анализа на синтетическом коде:
object GetPotentialNull() {
Random random = new();
return random.NextDouble() > 0.5 ? new object() : null;
}
void Example_1() {
object potentialNull = GetPotentialNull();
ref object alias = ref potentialNull;
if (alias != null) {
// Правило V3080 не срабатывает,
// т. к. alias и potentialNull - одно и то же значение.
_ = potentialNull.ToString();
}
}
void Example_2()
{
var obj = new object();
ref object alias = ref obj;
alias = GetPotentialNull();
// Срабатывает правило V3080, так как при
// изменении значения alias, меняется и obj.
_ = obj.ToString(); // V3080: Possible null dereference.
}Анализ косвенных вызовов
Анализ косвенных вызовов (3.1.2.) — статический анализ, позволяющий в программе, использующей вызовы по указателю или вызовы виртуальных функций, установить множество процедур, которые могут вызываться при выполнении заданного косвенного вызова.
На данный момент анализатор PVS-Studio не поддерживает анализ косвенных вызовов. Однако на 2025 год запланирована реализация поиска, например, такой ошибки (язык C):
char *(*fp)(const char* str, int ch);
void f(void) {
char *c;
fp = strchr;
c = fp(0, 2); // Разыменование NULL
}Анализ косвенных вызовов позволит обнаружить, что первым аргументом функции strchr окажется нулевой указатель.
Статистический анализ
Статистический анализ (п. 3.1.32) — статический анализ, определяющий статистику для некоторого свойства программы, например, насколько часто в программе проверяется возвращаемое значение некоторой функции.
Статистический анализ используется в PVS-Studio для реализации диагностических правил для всех языков: C, C++, C#, Java.
Например, для всех языков реализованы правила, выявляющие аномалию, описанную в определении из ГОСТ. Диагностические правила V1071 (C, C++), V3201 (C#), V6121 (Java) проверяют, насколько часто в программе проверяется/используется возвращаемое значение некоторой функции.
Демонстрационные примеры для перечисленных правил рассматривать не будем, так как они будут достаточно длинные и не очень интересные. Рассмотрим статистический анализ на примере другого правила. Проект Linux Kernel (язык C):
static const
struct XGI330_LCDDataDesStruct2 XGI_LVDSNoScalingDesData[] = {
{0, 648, 448, 405, 96, 2}, /* 00 (320x200,320x400,
640x200,640x400) */
{0, 648, 448, 355, 96, 2}, /* 01 (320x350,640x350) */
{0, 648, 448, 405, 96, 2}, /* 02 (360x400,720x400) */
{0, 648, 448, 355, 96, 2}, /* 03 (720x350) */
{0, 648, 1, 483, 96, 2}, /* 04 (640x480x60Hz) */
{0, 840, 627, 600, 128, 4}, /* 05 (800x600x60Hz) */
{0, 1048, 805, 770, 136, 6}, /* 06 (1024x768x60Hz) */
{0, 1328, 0, 1025, 112, 3}, /* 07 (1280x1024x60Hz) */
{0, 1438, 0, 1051, 112, 3}, /* 08 (1400x1050x60Hz)*/
{0, 1664, 0, 1201, 192, 3}, /* 09 (1600x1200x60Hz) */
{0, 1328, 0, 0771, 112, 6} /* 0A (1280x768x60Hz) */
};Предупреждение PVS-Studio: V536 Be advised that the utilized constant value is represented by an octal form. Oct: 0771, Dec: 505. vb_table.h 1379
Статистическая аномалия состоит в том, что только одно число в массиве является восьмеричным (0771 в последней строке). Ноль, делающий литерал восьмеричным, лишний, и вписан для выравнивания столбика чисел.
Анализ иерархии классов
Анализ иерархии классов (п 3.1.1.) — статический анализ, позволяющий выявить в программах на объектно-ориентированных языках список классов, реализованных в программе, а также отношения наследования между этими классами.
Анализ иерархии классов используется в PVS-Studio для реализации диагностических правил для всех объектно-ориентированных языков: C++, C#, Java.
Данный вид анализа, также как синтаксический анализ, является базовым и активно используется всеми ядрами анализатора PVS-Studio. Без него невозможно большинство других видов анализа.
Поскольку анализ иерархии классов является неотъемлемой частью всех ядер PVS-Studio и работает схожим образом для всех поддерживаемых языков, то рассмотрим только один пример использования.
Проект Blender (язык C++). Для начала рассмотрим базовый класс CurvesFieldInput:
typedef struct CurvesGeometry { .... };
namespace bke
{
....
class CurvesGeometry : public ::CurvesGeometry { .... };
class CurvesFieldInput : public fn::FieldInput
{
....
virtual std::optional<AttrDomain> preferred_domain(
const CurvesGeometry &curves) const;
};
....
}Обратим внимание, что виртуальная функция preferred_domain принимает параметр типа bke::CurvesGeometry. Теперь посмотрим на класс-наследник:
namespace blender::nodes::node_geo_input_curve_handles_cc
{
class HandlePositionFieldInput final : public bke::CurvesFieldInput
{
....
std::optional<AttrDomain> preferred_domain(
const CurvesGeometry & /*curves*/) const;
};
}Предупреждение PVS-Studio: V762 It is possible a virtual function was overridden incorrectly. See first argument of function 'preferred_domain' in derived class 'HandlePositionFieldInput' and base class 'CurvesFieldInput'. node_geo_input_curve_handles.cc 95
В базовом классе виртуальная функция принимает параметр с неквалифицированным именем CurvesGeometry. Когда компилятор будет осуществлять поиск этого типа, он начнёт с области видимости класса CurvesFieldInput и будет заглядывать во все обрамляющие области видимости, пока не встретит этот тип. В итоге будет найден тип bke::CurvesGeometry.
Теперь посмотрим на производный класс. Он определён в пространстве имён, отличном от того, где располагается базовый класс. Компилятор также начнёт поиск нужного имени CurvesGeometry, не встретит его в обрамляющих областях видимости и дойдёт до глобального. А в глобальном пространстве имён тоже есть CurvesGeometry, только не тот, что нам нужен для переопределения функции.
Чтобы выявлять такую ошибку, анализатор должен собрать информацию о типах, иерархии классов и областях видимости.
Выявляемые типы критических ошибок
PVS-Studio выявляет все типы критических ошибок для поддерживаемых языков: C, C++, C#, Java. В будущем возможно расширение списка поддерживаемых языков.
Для компилируемых языков PVS-Studio выявляет следующие типы критических ошибок, перечисленных в ГОСТ (п. 6.3.).
|
Типы критических ошибок в компилируемых языках (п. 6.3.) |
C и C++ |
C# |
Java |
|---|---|---|---|
|
Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.) |
✓ |
✓ |
✓ |
|
Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел |
✓ |
✓ |
✓ |
|
Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти) |
✓ |
✓ |
✓ |
|
Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.) |
✓ |
✓ |
✓ |
|
Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.) |
✓ |
✓ |
✓ |
Таблица N3. Выявляемые типы критических ошибок в компилируемых языках, перечисленные в ГОСТ Р 71207–2024 (п. 6.3.).
Стандарт дополнительно перечисляет несколько типов критических ошибок, специфичных для языков C и C++ (п. 6.5.). Анализатор PVS-Studio обеспечивает их обнаружение.
|
Дополнительные типы критических ошибок для C и C++ (п. 6.5.) |
C и C++ |
|---|---|
|
Ошибки разыменования нулевого указателя |
✓ |
|
Ошибки деления на ноль |
✓ |
|
Ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти) |
✓ |
|
Ошибки использования форматной строки |
✓ |
|
Ошибки использования неинициализированных переменных |
✓ |
|
Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений |
✓ |
Таблица N4. Выявляемые типы критических ошибок, являющиеся дополнительными для языков C и C++ и перечисленные в ГОСТ Р 71207–2024 (п. 6.5.).
Пояснение. Анализатор PVS-Studio умеет обнаруживать, например, деление на ноль не только в C и C++ коде, но и в C# и Java. Однако с точки зрения ГОСТ Р 71207–2024 деление на ноль в C# и Java коде не является критической ошибкой. Этому есть обоснование. Деление на ноль в программе на языке C или C++ приводит к неопределённому поведению, то есть к серьёзной критической ошибке. Деление на ноль в C# или Java приведёт к возникновению исключения. Это тоже ошибка, но она, скорее всего, не вызовет критические последствия. Аналогично с доступом к нулевой ссылке и так далее.
Детекторы критических ошибок
Для выявления перечисленных выше типов критических ошибок в PVS-Studio реализованы детекторы ошибок (диагностические правила), со списком которых вы можете познакомиться здесь.
Другие детекторы ошибок
Надо понимать, что список типов критических ошибок условен. Критическая ошибка, приводящая к записи за границу буфера в некотором приложении, может максимум только испортить какой-то рисунок, но не влияет на безопасность.
И наоборот, опечатка в коде, формально не попадающая ни под один тип перечисленных в ГОСТ Р 71207–2024 критических ошибок, может являться серьёзным дефектом безопасности. Из-за неё, например, неправильно происходит проверка каких-то приватных данных. Фактически эта ошибка является критической.
Рассмотрим в качестве примера баг, найденный нами в проекте RavenDB (язык C#):
public enum SecurityClearance
{
UnauthenticatedClients, //Default value
ClusterAdmin,
ClusterNode,
Operator,
ValidUser
}
public override void VerifyCanExecuteCommand(....)
{
....
var definition = JsonDeserializationServer.CertificateDefinition(read);
if (
definition.SecurityClearance != SecurityClearance.ClusterAdmin ||
definition.SecurityClearance != SecurityClearance.ClusterNode
)
return;
AssertClusterAdmin(isClusterAdmin);
}Предупреждение PVS-Studio: V3022 Expression is always true. Probably the '&&' operator should be used here. DeleteCertificateFromClusterCommand.cs 21
Проверка не имеет смысла. Переменная всегда будет не равна или одной, или другой константе. Поэтому результат проверки всегда истинный. Здесь должно быть написано:
definition.SecurityClearance != SecurityClearance.ClusterAdmin &&
definition.SecurityClearance != SecurityClearance.ClusterNodeИли
definition.SecurityClearance == SecurityClearance.ClusterAdmin ||
definition.SecurityClearance == SecurityClearance.ClusterNodeОшибка связана с неправильной проверкой некоторого внутреннего состояния, что приводит к неверному пути выполнения программы. Это однозначно серьёзная ошибка в функции, связанной с логикой управления правами. Однако непонятно, каким типом критической ошибки можно классифицировать найденную опечатку.
Мы рассмотрели пример, где сложно классифицировать опечатку как критическую ошибку, но по факту она ей является. Как же тогда интерпретировать типы критических ошибок, описанных в ГОСТ, и работать с предупреждениями анализаторов?
Одни ошибки с большей вероятностью могут привести к дефектам безопасности, чем другие. Выход за границу буфера потенциально более опасен, чем неправильное использование #pragma warning (V665).
ГОСТ Р 71207–2024 выделяет группу ошибок, которые с наибольшим шансом могут привести к возникновению уязвимости. Это и есть список критических ошибок. Эти ошибки должны выявляться в первую очередь и обязательно исправляться. Предупреждения про критические ошибки являются первоочередными в сравнении со всеми другими предупреждениями анализаторов, так как их исправление вносят наибольший вклад в безопасность приложения.
Однако это не значит, что другие предупреждения должны быть проигнорированы. Их можно и нужно изучать, хотя не в таких жёстких временных рамках. Временные рамки поиска и исправления критических ошибок описаны в п.5.6., п.5.8., п.5.9.
Анализатор PVS-Studio, помимо критических ошибок, выявляет большое количество других ошибок, которые также могут являться дефектами безопасности. С полным списком детекторов можно ознакомиться на этой странице.
Примеры выявления всех типов критических ошибок с помощью PVS-Studio
Кратко опишем каждый из типов критических ошибок и приведём примеры их выявления с помощью PVS-Studio. Предпочтение будет отдаваться реальным случаям выявления ошибок, взятых из нашей коллекции багов в открытых проектах. Эти ошибки не обязательно являются дефектами безопасности, но зато демонстрируют работу PVS-Studio в реальных условиях. В случае, если короткого и красивого примера нет, будет составлен синтетический пример.
Ошибки непроверенного использования чувствительных данных (п. 6.3.а.)
Описание данного вида дефектов и соответствующие примеры уже были рассмотрены в главе "Межпроцедурный и межмодульный контекстно-чувствительный анализ помеченных данных".
Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел (п. 6.3.б.)
Данные вид дефектов может быть использован в атаках для получения неких недопустимых значений, влияющих на ход выполнения программы, отличный от предусмотренного.
Дополнительные ссылки:
- Википедия. Целочисленное переполнение.
- CWE-190: Integer Overflow or Wraparound.
- CWE-680: Integer Overflow to Buffer Overflow.
- Peng Li and John Regehr: "Understanding Integer Overflow in C/C++".
- Дэвин МакКолл: "Почему перенос при целочисленном переполнении - не очень хорошая идея".
- Андрей Карпов, Дмитрий Свиридкин: "Путеводитель C++ программиста по неопределённому поведению: часть 2 из 11" (см. главу "Целые и вещественные числа: переполнение целых знаковых чисел").
Пример выявления ошибки в C или C++ коде (проект Hypertext Preprocessor, C)
PHP_CLI_API size_t sapi_cli_single_write(....)
{
....
size_t shell_wrote;
shell_wrote = cli_shell_callbacks.cli_shell_write(....);
if (shell_wrote > -1) {
return shell_wrote;
}
....
}Предупреждение PVS-Studio: V605 Consider verifying the expression: shell_wrote > - 1. An unsigned value is compared to the number -1. php_cli.c 266
Пример демонстрирует некорректное совместное использование знаковых и беззнаковых чисел. Перед сравнением числовой литерал -1 типа int будет неявно преобразован в значение SIZE_MAX типа size_t. Условие никогда не выполнится.
Пример выявления ошибки в C# коде
bool IsValidAddition(ushort x, ushort y)
{
if (x + y < x)
return false;
return true;
}Предупреждение PVS-Studio: V3204. The expression is always false due to implicit type conversion. Overflow check is incorrect.
Цель данного метода — проверить, произойдёт ли переполнение при сложении двух положительных чисел. В случае переполнения результат суммы должен оказаться меньше любого из её операндов.
Однако проверка не выполнит свою задачу, поскольку оператор '+' не имеет перегрузки для сложения чисел с типом ushort. В результате оба числа будут в начале приведены к типу int, после чего выполнится их сложение. Так как складываются значения типа int, никакого переполнения не произойдёт, и условие всегда будет давать значение false.
Пример выявления ошибки в Java коде (проект Apache Hive)
public void logSargResult(int stripeIx, boolean[] rgsToRead)
{
....
long val = 0;
for (int j = 0; j < 64; ++j) {
int ix = valOffset + j;
if (rgsToRead.length == ix) break;
if (!rgsToRead[ix]) continue;
val = val | (1 << j); // <=
}
....
}Предупреждение PVS-Studio: V6034 Shift by the value of 'j' could be inconsistent with the size of type: 'j' = [0 .. 63]. IoTrace.java 272
Ошибка заключается в невозможности корректно выставить 32 старших разряда в 64-битной переменной val.
В указанной строке индуктивная переменная (п.3.1.10.) j может принимать значение в диапазоне [0..63]. В выражении (1 << j) числовой литерал 1 имеет 32-битный тип int. Соответственно, при сдвиге единицы на 32 и более разряда будет происходить переполнение.
Для исправления ситуации необходимо написать (1L << j).
Ошибки переполнения буфера (п. 6.3.в.)
Переполнение буфера (Buffer Overflow) — запись или чтение программой данных за пределами выделенного для этого в памяти буфера. Обычно возникает из-за неправильной работы с данными и памятью, при отсутствии жёсткой защиты со стороны подсистемы программирования и ОС.
Так как большинство языков программирования размещают данные программы в стеке процесса, смешивая их с управляющими данными, переполнение буфера является одним из способов атаки на ПО, позволяющим загрузить и выполнить произвольный машинный код от имени программы или повлиять на логику работы программы, модифицировав данные за пределом буфера.
Дополнительные ссылки:
- Brendan Watters: "Stack-Based Buffer Overflow Attacks: Explained and Examples".
- Dhaval Kapil: "Buffer Overflow Exploit".
- Андрей Карпов, Дмитрий Свиридкин: "Путеводитель C++ программиста по неопределённому поведению: часть 8 из 11" (см. главу "Исполнение программы: переполнение буфера").
Пример выявления ошибки в C или C++ коде (проект ICU, C)
static char plugin_file[2048] = "";
U_CAPI void U_EXPORT2 uplug_init(UErrorCode *status)
{
....
// uprv_strncat раскрывается в strncat
uprv_strncpy(plugin_file, plugin_dir, 2047);
uprv_strncat(plugin_file, U_FILE_SEP_STRING, 2047);
uprv_strncat(plugin_file, "icuplugins", 2047);
uprv_strncat(plugin_file, U_ICU_VERSION_SHORT, 2047);
uprv_strncat(plugin_file, ".txt", 2047);
....
}Здесь анализатор PVS-Studio выдаёт несколько однотипных предупреждений: V645 The 'strncat' function call could lead to the 'plugin_file' buffer overflow. The bounds should not contain the size of the buffer, but a number of characters it can hold. icuplug.c
Многие программисты используют эту функцию вместо strcat, чтобы предотвратить выход за границу буфера, но делают это неправильно. Это как раз такой случай. Третий аргумент функции strncat задаёт не размер буфера, а максимальное количество символов, которые можно добавить. В результате этот код конкатенации строк не защищён от переполнения буфера.
Пример выявления ошибки в C# коде (проект Flax Engine)
Выход за границу массива в C# не представляет существенную опасность, так как в этом случае будет сгенерировано исключение. Так что, пожалуй, для программ на языке C# эту ошибку, на самом деле, не стоит считать критической. Но раз формально стандарт требует выявления в компилируемых языках данного вида дефекта, то рассмотрим соответствующий пример:
public Matrix2x2(float[] values)
{
....
if (values.Length != 4)
throw new ArgumentOutOfRangeException(....);
M11 = values[0];
M12 = values[1];
M21 = values[3];
M22 = values[4];
}Предупреждение PVS-Studio: V3106 Possibly index is out of bound. The '4' index is pointing beyond 'values' bound. Matrix2x2.cs 98
Выполняя анализ потока данных и управления, анализатор знает, что, если управление дошло до извлечения значений массива, то этот массив содержит 4 элемента. Соответственно, последний индекс должен быть равен 3, а не 4.
Если присмотреться, то становится очевидна опечатки при написании кода — случайно написали 3 вместо 2, а затем 4 вместо 3. Так что, на самом деле, здесь даже не одна ошибка, а сразу две.
Пример выявления ошибки в Java коде (проект ELKI)
Как и в C#, выход за границу массива в Java не представляет существенную опасность, так как в этом случае будет сгенерировано исключение.
@Override
public double[] computeMean() {
return points.size() == 1 ? points.get(1) : null;
}Предупреждение PVS-Studio: V6025 Index '1' is out of bounds. GeneratorStatic.java(104)
Простая опечатка, приводящая к выходу за границу массива. Чтобы извлечь один единственный элемент из массива, следовало написать points.get(0).
Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (п. 6.3.г.)
Достаточно обобщённое название критической ошибки, что в общем-то неизбежно. Существует огромное количество вариантов неправильного использования функций шифрования, разграничения доступа и так далее. Соответственно, решение этой задачи — в выявлении большого количества модельных вариантов ошибок (п. 3.1.19.).
Пример выявления ошибки в C или C++ коде (проект Android, C)
static void FwdLockGlue_InitializeRoundKeys() {
unsigned char keyEncryptionKey[KEY_SIZE];
....
memset(keyEncryptionKey, 0, KEY_SIZE); // Zero out key data.
}Предупреждение PVS-Studio: V597 The compiler could delete the 'memset' function call, which is used to flush 'keyEncryptionKey' buffer. The memset_s() function should be used to erase the private data. FwdLockGlue.c 102
Компилятор вправе удалить вызов функции memset, так как это не изменит наблюдаемое поведение программы с точки зрения C и C++. После вызова memset буфер гарантированно не используется, следовательно, его не нужно заполнять нулями. В результате в памяти остаются приватные данные, которые потенциально могут быть куда-то переданы.
Детальнее про этот дефект безопасности:
- CWE-14: Compiler Removal of Code to Clear Buffers.
- Безопасная очистка приватных данных.
- Это очень распространённая ошибка. Примеры детектирования в различных проектах.
Пример выявления ошибки в C# коде
private static string CalculateSha1(string text, Encoding enc)
{
var buffer = enc.GetBytes(text);
using var cryptoTransformSha1 = new SHA1CryptoServiceProvider();
var hash = BitConverter.ToString(cryptoTransformSha1.ComputeHash(buffer))
.Replace("-", string.Empty);
return hash.ToLower();
}Предупреждение PVS-Studio: V5613. Use of outdated cryptographic algorithm is not recommended.
Используется устаревшая криптографическая функция.
Пример выявления ошибки в Java коде
public void foo() {
Random rnd = new Random(4040);
....
}Предупреждение PVS-Studio: V6109. Potentially predictable seed is used in pseudo-random number generator.
Анализатор обнаружил подозрительный код, инициализирующий генератор псевдослучайных чисел константным значением. Числа, сгенерированные таким генератором, можно предугадать — они будут воспроизводиться снова и снова при каждом запуске программы. Потенциально это может сказаться на безопасности приложения, использующего псевдослучайные числа в задачах, связанных с криптографией (см. также "CWE-336: Same Seed in Pseudo-Random Number Generator (PRNG)").
Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.) (п. 6.3.д.)
Выявление ошибок, связанных с использованием многопоточных примитивов, — одна из самых сложных задач для статических анализаторов кода. Отслеживание взаимодействия различных частей программы, которые могут одновременно обращаться к одним и тем же ресурсам, обладает высокой вычислительной сложностью.
По причине сложности задачи выявление этого вида критических ошибок является необязательным для реализации в статических анализаторах (п. 7.3.).
Как и в случае с предыдущим разделом, выявление ошибок при работе с многопоточными примитивами в основном сводится к обнаружению множества модельных вариантов ошибок (3.1.19).
Пример выявления ошибки в C или C++ коде (проект Zephyr, C)
static int nvs_startup(struct nvs_fs *fs)
{
....
k_mutex_lock(&fs->nvs_lock, K_FOREVER);
....
if (fs->ate_wra == fs->data_wra && last_ate.len) {
return -ESPIPE; // <= (A)
}
....
end:
k_mutex_unlock(&fs->nvs_lock);
return rc;
}Предупреждение PVS-Studio: V1020 The function exited without calling the 'k_mutex_unlock' function. Check lines: 620, 549. nvs.c 620
Мьютекс останется захваченным, если выход из программы произойдёт в точке (A).
Пример выявления ошибки в C# коде (проект RunUO)
private Packet m_RemovePacket;
....
private object _rpl = new object();
public Packet RemovePacket
{
get
{
if (m_RemovePacket == null)
{
lock (_rpl)
{
if (m_RemovePacket == null)
{
m_RemovePacket = new RemoveItem(this);
m_RemovePacket.SetStatic();
}
}
}
return m_RemovePacket;
}
}Предупреждение PVS-Studio: V3054 Potentially unsafe double-checked locking. Use volatile variable(s) or synchronization primitives to avoid this. Item.cs 1624
В данном коде паттерн блокировки с двойной проверкой реализован некорректно. При обращении к свойству RemovePacket геттер осуществляет проверку поля m_RemovePacket на равенство null. Если проверка проходит, то мы попадаем в тело оператора lock, где и происходит инициализация поля m_RemovePacket.
Сбой возникает в тот момент, когда главный поток уже инициализировал переменную m_RemovePacket посредством конструктора, но ещё не вызвал метод SetStatic. Теоретически другой поток может обратиться к свойству RemovePacket именно в этот самый неудачный момент. Проверка m_RemovePacket на равенство null уже не пройдёт, и вызывающий поток получит ссылку на неполностью готовый к использованию объект.
Пример выявления ошибки в Java коде (проект DBeaver)
public class MultiPageWizardDialog extends .... {
....
private volatile int runningOperations = 0;
....
@Override
public void run(....) {
....
try {
runningOperations++; // <=
ModalContext.run(
runnable,
true,
monitorPart,
getShell().getDisplay()
);
} finally {
runningOperations--; // <=
....
}
}
}Предупреждения PVS-Studio:
- V6074 Non-atomic modification of volatile variable. Inspect 'runningOperations'. MultiPageWizardDialog.java(590)
- V6074 Non-atomic modification of volatile variable. Inspect 'runningOperations'. MultiPageWizardDialog.java(593)
Неатомарное изменение volatile-переменной может привести к состоянию гонки. Известно, что использование модификатора volatile гарантирует, что все потоки будут видеть актуальное значение соответствующей переменной. К этому можно добавить, что модификатор volatile используется для того, чтобы указать JVM, что все операции присвоения этой переменной и все операции чтения из неё должны быть атомарными.
Можно посчитать, что пометки переменных как volatile будет достаточно, чтобы безопасно их использовать в многопоточном приложении. Однако инкремент переменной — неатомарная операция, состоящая из чтения, изменения и записи данных. Подробнее суть проблемы описана здесь.
Ошибки разыменования нулевого указателя (6.5.а., только для C и C++)
Проблема разыменования нулевых указателей вечна и сложнее, чем может показаться на первый взгляд. Любое ли разыменование нулевого указателя приводит к неопределённому поведению? Есть ли исключения и нюансы? Обсуждение этих вопросов вы можете найти здесь:
- Андрей Карпов: "Разыменовывание нулевого указателя приводит к неопределённому поведению".
- Андрей Карпов, Дмитрий Свиридкин: "Путеводитель C++ программиста по неопределённому поведению: часть 9 из 11" (см. главу "Исполнение программы: разыменование нулевых указателей").
- Андрей Карпов: "Четыре причины проверять, что вернула функция malloc".
- C++ on Sea 2023, JF Bastien: "*(char*)0 = 0; - What Does the C++ Programmer Intend With This Code?"
Анализатор использует для поиска разыменования нулевых указателей несколько технологий:
- Межпроцедурный и межмодульный контекстно-чувствительный анализ потока данных;
- Чувствительный к путям выполнения анализ потоков данных и управления;
- Эмпирические диагностические правила (поиск модельных вариантов ошибок).
С первыми двумя всё понятно: анализатор пытается вычислить, может ли указатель быть нулевым в момент разыменования. Пример ошибки, найденной в проекте LLVM (язык C++).
Вначале рассмотрим функцию SetInsertPoint в файле IRBuilder.h:
void SetInsertPoint(Instruction *I)
{
BB = I->getParent();
InsertPt = I->getIterator();
assert(InsertPt != BB->end() && "Can't read debug loc from end()");
SetCurrentDebugLocation(I->getStableDebugLoc());
}Обратите внимание, что указатель I сразу разыменовывается без какой-либо проверки.
Теперь рассмотрим использование это функции, происходящее в другом файле OMPIRBuilder.cpp (межмодульный анализ):
std::pair<Value *, Value *> OpenMPIRBuilder::emitAtomicUpdate
(InsertPointTy AllocaIP, ...., bool IsXBinopExpr)
{
....
if (UnreachableInst *ExitTI = dyn_cast<UnreachableInst>
(ExitBB->getTerminator()))
{
CurBBTI->eraseFromParent();
Builder.SetInsertPoint(ExitBB); // <= ненулевой указатель
}
else
{
Builder.SetInsertPoint(ExitTI); // <= нулевой указатель
}
return Res;
}Предупреждение PVS-Studio: V522 Dereferencing of the null pointer 'I' might take place. The null pointer is passed into 'SetInsertPoint' function. Inspect the first argument. Check lines: 'IRBuilder.h:188', 'OMPIRBuilder.cpp:5983'.
Если выполняется ветка else, то указатель ExitTI будет нулевым. Соответственно, в функцию SetInsertPoint будет передан нулевой указатель, где он и будет разыменован.
Однако в общем виде вычислить возможные значение указателей невозможно. Тогда могут помочь вспомогательные механизмы, построенные на эмпирических алгоритмах. Рассмотрим пример работы одного из таких детекторов ошибок (проект MuseScore, С++):
Ms::Segment* NotationSelectionRange::rangeStartSegment() const
{
Ms::Segment* startSegment = score()->selection().startSegment();
startSegment->measure()->firstEnabled(); // <= разыменование
if (!startSegment) { // <= проверка
return nullptr;
}
if (!startSegment->enabled()) {
startSegment = startSegment->next1MMenabled();
}
....
}Пусть анализатор не может вычислить значение startSegment. Однако он замечает следующую аномалию: указатель сначала разыменовывается, а затем проверяется. Раз указатель проверяется, значит автор кода предполагает, что он может быть нулевым. Следовательно, разыменование является опасным.
Анализатор PVS-Studio выдаёт предупреждение: V595 The 'startSegment' pointer was utilized before it was verified against nullptr. Check lines: 129, 131. notationselectionrange.cpp 129 (подробнее про данный детектор — Пояснение про диагностическое правило V595).
Ошибки деления на ноль (6.5.б., только для C и C++)
Известная классическая ошибка. Кстати, в силу того, что все программисты про неё знают, она встречается на практике в коде значительно реже, чем может казаться (см. доклад "Ошибки в коде: ожидания и реальность").
Проект VNL (язык C):
integer pow_ii(integer *ap, integer *bp)
{
integer pow, x, n;
....
if (x != -1)
return x == 0 ? 1/x : 0;
....
}Предупреждение PVS-Stuidio: V609 Divide by zero. Denominator 'x' == 0. pow_ii.c 28
Если x равен 0, то произойдёт деление на ноль. Видимо, это опечатка, и, скорее всего, программист планировал написать так:
return x != 0 ? 1/x : 0;Ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти) (6.5.в., только для C и C++)
Первый пример
Проект Shareaza (язык C):
int SetSkinAsDefault()
{
TCHAR szXMLNorm[MAX_PATH];
....
else {
free(szXMLNorm);
return 0;
}
return 1;
}Предупреждение PVS-Studio: V726 An attempt to free memory containing the 'szXMLNorm' array by using the 'free' function. This is incorrect as 'szXMLNorm' was created on stack. utils.c 92
В одной из веток выполнения программы происходит попытка освобождения памяти, выделенной на стеке, с помощью функции free.
Второй пример
Проект CodeLite (язык C++):
int clSocketBase::ReadMessage(wxString& message, int timeout)
{
....
size_t message_len(0);
....
message_len = ::atoi(....);
....
std::unique_ptr<char> pBuff(new char[message_len]);
....
}Предупреждение PVS-Studio: V554 Incorrect use of unique_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. clSocketBase.cpp:282
Неправильное использование умного указателя. Для освобождения памяти будет использован оператор delete, а не delete []. Это приводит к неопределённому поведению (см. "Почему в С++ массивы нужно удалять через delete[]"). Правильный вариант кода:
std::unique_ptr<char []> pBuff(new char[message_len]);Ошибки использования форматной строки (6.5.г., только для C и C++)
Некорректное использование форматной строки может приводить к разнообразным ошибкам, в том числе являться уязвимостью (см. публикацию "Не зная брода, не лезь в воду. Часть вторая").
Проект Open X-Ray Engine (язык C++):
void safe_verify(....)
{
....
printf("FATAL ERROR (%s): failed to verify data\n");
....
}Предупреждение PVS-Studio: V576 Incorrect format. A different number of actual arguments is expected while calling 'printf' function. Expected: 2. Present: 1. entry_point.cpp 41
Отсутствует аргумент, который должен быть распечатан в качестве строки.
Дополнительные ссылки:
- Михаил Зинин: "C++: сеанс спонтанной археологии и почему не стоит использовать вариативные функции в стиле C".
- LiveOverflow: "A simple Format String exploit example - bin 0x11".
Ошибки использования неинициализированных переменных (6.5.д., только для C и C++)
Проект System Shock (язык C):
errtype uiInit(uiSlab* slab)
{
....
errtype err;
....
// err = ui_init_cursors();
....
if (err != OK) return err;
....
}Предупреждение PVS-Studio: V614 Uninitialized variable 'err' used. EVENT.C 953
В какой-то момент строчка, где происходила запись в переменную err, была закомментирована, а проверка этой переменной осталась. Получается, что в условии используется неинициализированная переменная.
Дополнительные ссылки:
- Терминология. Неинициализированная переменная.
- Терминология. Использование неинициализированной памяти.
- Андрей Карпов, Дмитрий Свиридкин: "Путеводитель C++ программиста по неопределённому поведению: часть 10 из 11" (см. главу "Исполнение программы: неинициализированные переменные").
- Андрей Карпов: "Исследование COVID-19 и неинициализированная переменная".
Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений (6.5.е., только для C и C++)
Первый пример
Проект Notepad++ (язык C++):
bool ProjectPanel::openWorkSpace(const TCHAR *projectFileName)
{
TiXmlDocument *pXmlDocProject = new TiXmlDocument(....);
bool loadOkay = pXmlDocProject->LoadFile();
if (!loadOkay)
return false;
....
}Предупреждение PVS-Studio: V773 The function was exited without releasing the 'pXmlDocProject' pointer. A memory leak is possible. projectpanel.cpp 326
Утечка памяти. Если не удастся загрузить файл, то функция досрочно завершит работу, не освободив указатель pXmlDocProject.
Второй пример
Проект CMake (язык C):
RHASH_API int rhash_file(....)
{
FILE* fd;
rhash ctx;
int res;
hash_id &= RHASH_ALL_HASHES;
if (hash_id == 0) {
errno = EINVAL;
return -1;
}
if ((fd = fopen(filepath, "rb")) == NULL) return -1;
if ((ctx = rhash_init(hash_id)) == NULL) return -1;
....
}Предупреждение PVS-Studio: V773 The function was exited without closing the file referenced by the 'fd' handle. A resource leak is possible. rhash.c 450
Утечка файлового дескриптора. Если функция rhash_init вернёт NULL, то функция rhash_file досрочно завершится, вернув статус ошибки. При этом не будет закрыт файловый дескриптор, хранящийся в переменной fd.
Соответствие требованиям к методам анализа
В предыдущих главах уже было подробно разобрано соответствие PVS-Studio требованиям, перечисленным в ГОСТ Р 71207–2024 (раздел 7):
- методы анализа обеспечивают поиск критических ошибок всех типов (п. 7.3.);
- реализованы все основные методы и ряд вспомогательных анализов, перечисленные в стандарте (п. 7.4.).
Остановимся на оставшихся пунктах из 7-го раздела стандарта.
Глубина поддерживаемого статическим анализатором межпроцедурного анализа
Согласно ГОСТ Р 71207–2024 (п. 7.4.), максимальная глубина поддерживаемого межпроцедурного анализа (количество вызовов процедур, через которые может передаваться собираемая в ходе анализа информация о потоке данных программы) не должна быть заранее ограничена, но может определяться с учётом доступных для анализа вычислительных ресурсов.
В PVS-Studio нет фиксированного ограничения на глубину анализа. Остановка осуществляется на основании эмпирических алгоритмов, защищающих от зацикливания (рекурсивных вызовов), и слишком сложном/долгом анализе вызываемых процедур.
Учёт межмодульных связей и параметров сборки
Согласно ГОСТ Р 71207–2024 (п. 7.5.), при анализе должны уточняться межмодульные связи и параметры компиляторов.
PVS-Studio учитывает параметры (ключи) компиляторов, используемые при сборке ПО. Это неотъемлемая часть выполнения анализа, так как без этого, например, невозможно в C++ программе корректно выяснить, какая модель данных используется (размеры типов), раскрыть макросы, найти подключаемые библиотеки и так далее. Анализатор учитывает межмодульные связи, так как без этого невозможен межмодульный анализ.
Способы конфигурации анализа помеченных данных
Согласно ГОСТ Р 71207–2024 (п. 7.6.), если статический анализатор для поиска ошибок (п. 6.3.а.) применяет анализ помеченных данных, должна быть предоставлена возможность конфигурации анализа: должны задаваться процедуры-источники и процедуры-стоки чувствительных данных.
PVS-Studio поддерживает анализ помеченных данных для поиска критических ошибок, описанных в п. 6.3.а:
6.3. а) ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.).
Соответственно, PVS-Studio реализует и возможность конфигурации анализа.
Исключением является ядро Java анализатора, для которого на момент написания данного раздела возможность разметки истоков и стоков отсутствует. Поддержка данной функциональности запланирована на первую половину 2025 года.
Аннотация процедур-источников и стоков помеченных данных осуществляется с помощью специализированных файлов в формате JSON. Подключить файл аннотаций можно следующими способами:
Способ N1. Добавить специальный комментарий в исходный код или в файл конфигурации диагностических правил (.pvsconfig):
//V_PVS_ANNOTATIONS, language:%язык_проекта%, path:%путь/до/файла.json%Вместо символа подстановки %язык_проекта% предполагается использование одного из следующих значений:
- для С — с;
- для С++ — cpp;
- для С# — csharp.
Вместо символа подстановки %путь/до/файла.json% предполагается путь до подключаемого файла аннотаций. Поддерживаются как абсолютные, так и относительные пути. Относительные пути раскрываются относительно файла, в котором указан комментарий для подключения аннотации.
Способ N2 (только для С и C++ анализатора). Указать специальный флаг ‑‑annotation-file (-A) при запуске pvs-studio-analyzer или CompilerCommandsAnalyzer:
pvs-studio-analyzer --annotation-file=%путь/до/файла.json%Вместо символа подстановки %путь/до/файла.json% предполагается путь до подключаемого файла аннотаций. Поддерживаются как абсолютные, так и относительные пути. Относительные пути раскрываются относительно текущей рабочей директории (CWD).
Может быть подключено несколько файлов с аннотациями. Для каждого файла необходимо указать отдельный флаг или комментарий.
Формат файлов описан в разделе "Механизм пользовательских аннотаций в формате JSON". Пример разметки функции как источника недостоверных данных:
{
"version": 1,
"annotations": [
{
"type": "function",
"name": "ReadStrFromStream",
"params": [
{
"type": "std::istream &input"
},
{
"type": "std::string &str",
"attributes": [ "taint_source" ]
}
],
"returns": { "attributes": [ "taint_source" ] }
}
]
}Для облегчения знакомства с механизмом пользовательских аннотаций мы подготовили в документации примеры для наиболее часто встречающихся сценариев.
Соответствие требованиям к инструментам статического анализа исходных текстов
Рассмотрим соответствие PVS-Studio различным функциональным требованиям, предъявляемых в ГОСТ Р 71207–2024 (раздел 8) к инструментальным средствам статического анализа исходного кода.
Анализ проекта целиком, включая используемые заимствованные компоненты
Согласно ГОСТ Р 71207–2024 (п. 8.2.), статический анализатор должен поддерживать анализ ПО с используемыми заимствованными компонентами целиком, при этом удовлетворяя требованиям п. 7.3—7.6, п. 8.3 и п. 8.4.
Под этим понимается следующее:
- если вы используете код сторонних библиотек, то вы несёте риски от наличия в них уязвимостей. Если возможна эксплуатация уязвимости в вашем ПО, то нет разницы, где именно она возникла: в коде, написанном вашей командой, или в заимствованном коде. Соответственно, вы должны проводить поиск критических ошибок во всём исходном коде вашего проекта, включая заимствованные компоненты;
- статический анализатор должен обеспечивать поиск критических ошибок в коде заимствованных компонентов на том же уровне и с применением тех же технологий;
- при анализе заимствованных компонентов также должны учитываться параметры сборки, выполняться межмодульный анализ и так далее;
- следует использовать такой статический анализатор (набор анализаторов), чтобы поиск критических ошибок при полном анализе ПО с используемыми заимствованными компонентами занимал не более 2-х суток. Время анализа проектов будет обсуждено в следующей главе.
PVS-Studio удовлетворяет всем перечисленным требованиям и позволяет проводить анализ сторонних компонентов на наличие всех типов критических ошибок.
Проверка кода заимствованных компонентов не отличается от проверки кода разрабатываемого программного обеспечения. Код компонентов аналогичным образом должен быть включён в проект, если речь идёт об использовании таких сред разработки, как Visual Studio, IntelliJ IDEA, CLion и так далее. Плагины PVS-Studio используют информацию о проверяемых файлах и конфигурационных настройках, получаемую от IDE. При этом необходимо убрать из настроек ряд популярных библиотек, которые PVS-Studio исключает из анализа (zlib, jpeglib и так далее), так как они фактически тоже являются заимствованными компонентами и должны проверяться.
В случае использования утилиты мониторинга компиляции заимствованные компоненты должны компилироваться вместе с исходным кодом проекта. Подробнее про утилиты мониторинга для проверки проектов независимо от сборочной системы (C и C++):
Время анализа проекта
В ГОСТ Р 71207—2024 (п. 8.3.) сказано:
Следует использовать такой статический анализатор (набор анализаторов), чтобы на технических средствах разработчика ПО для поиска критических ошибок обеспечивался полный анализ ПО с используемыми заимствованными компонентами за время, не превышающее двое суток.
Разумное требование. С одной стороны, оно достаточно мягкое в плане требований к скорости работы инструментов анализа. С другой стороны, это приемлемое время, за которое разработчики получат результаты анализа всего проекта, который они, согласно ГОСТ, должны выполнять в течении 10 дней после изменения кода (п.5.6.).
Фактически это означает, что рационально настроить анализ всего разрабатываемого ПО, включая заимствованные компоненты, на выходные дни. Анализ как раз гарантированно должен проходить за 2 дня.
Примечание. В стандарте также сказано, что статический анализ добавленных или изменённых частей ПО следует выполнять после каждого внесённого изменения (п.5.6.). Зачем тогда нужен полный анализ? Дело в межмодульном анализе проекта. Допустим, были внесены изменения в файл AA, которые косвенно повлияли на работу функций в файле BB. Это приведёт к ошибкам в файле BB. Но закладываться в систему контроля версий и проверяться с помощью статического анализа будет только файл AA, в котором ошибок нет. Чтобы выявить такую распределённую ошибку, нужен межмодульный анализ, то есть полная перепроверка проекта.
Таким образом, встаёт вопрос оценки верхней границы времени, которое требуется PVS-Studio для анализа проектов различного размера.
Проведённые измерения
Наиболее ресурсоёмким является межмодульный анализ C++ кода, в котором активно используются шаблоны и современные возможности языка. Размер проекта, выбранного для измерения скорости, составляет 10 млн. строк кода.
Конфигурация: 2 процессора Intel Xeon E5 2666 v3 (каждый процессор по 10 физических ядер / 20 логических ядер), частота 3.5 ГГц, 128 ГБ памяти, SSD диск.
Время анализа (включая межмодульный): 10 часов.
Обратите внимание, что ниже оценка проводится для использования не двух, а одного процессора с 10 физическими ядрами.
Расчёт ожидаемого времени для проектов различного размера:
- Для анализа 100 тыс. строк кода будет достаточно одного процессора класса Intel Xeon E5 2666 v3 (10 физических ядер / 20 логических ядер), частота 3.5 ГГц, 64 ГБ памяти. Ожидаемое время анализа: 12 минут.
- Для анализа 1 млн. строк кода будет достаточно одного процессора класса Intel Xeon E5 2666 v3 (10 физических ядер / 20 логических ядер), частота 3.5 ГГц, 64 ГБ памяти. Ожидаемое время анализа: 2 часа.
- Для анализа 10 млн. строк кода будет достаточно одного процессора класса Intel Xeon E5 2666 v3 (10 физических ядер / 20 логических ядер), частота 3.5 ГГц, 64 ГБ памяти. Ожидаемое время анализа: 20 часов.
Таким образом, PVS-Studio с запасом удовлетворяет требованиям по производительности, заданных в ГОСТ Р 71207—2024 (п. 8.3.).
Если складывается ситуация, что анализ с помощью PVS-Studio занимает аномально длительное время, то, скорее всего, возникла одна из следующих ситуаций:
- Используется много процессорных ядер, но в системе мало оперативной памяти. В результате начинает использоваться файл подкачки, что может замедлять работу анализатора в десяток раз. Можно получить ускорение, указав в настройках анализатора, сколько ядер следует использовать, или увеличить в системе объём оперативной памяти.
- Существует какая-то ошибка в анализе кода, которая даёт существенное замедление на определённых конструкциях кода или даже приводит к зацикливанию, которое прерывается только по таймауту. В этом случае просим обратиться к нам в поддержку, и мы постараемся устранить проблему.
Дополнительно см. раздел "Советы по повышению скорости работы PVS-Studio".
Примечание. Одним из советов является исключение из анализа лишних библиотек. С точки зрения ГОСТ Р 71207—2024, этим советом воспользоваться, возможно, не получится, так как все заимствованные компоненты также должны проверяться при РБПО.
Результаты применения анализатора
Результаты применения статического анализатора PVS-Studio содержат всю информацию, перечисленную в ГОСТ Р 71207—2024 (п. 8.5.):
- перечень предупреждений о найденных ошибках (п. 8.5.а.);
- описание ошибок (п. 8.5.б.);
- тип ошибок (п. 8.5.в.);
- место в исходном коде программы, где найдены ошибки (п. 8.5.г.).
Остановимся подробнее на пункте "Тип ошибок".
Согласно стандарту, тип ошибки — это категория ошибок в программе, отражающая их общность в свойствах или характеристиках (п. 3.1.35).
Анализатор PVS-Studio детектирует более 1000 ошибок разного типа. Соответственно, для каждого типа ошибки есть своё предупреждение, состоящее из идентификатора (Vxxx), сообщения и документации. Полный список типов выявляемых ошибок.
Если смотреть более обобщённо, то анализатор PVS-Studio классифицирует свои предупреждения согласно типам критических ошибок, перечисленным в ГОСТ Р 71207—2024 (п.6.3, п.6.5.).
Если вы включили опцию "маркировать предупреждения анализатора PVS-Studio согласно ГОСТ Р 71207—2024", то в поле SAST появятся следующие идентификаторы типа критических ошибок:
- SEC-TAINT — ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.);
- SEC-OVERFLOW-OR-INT-UINT — ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел;
- SEC-BUF-OVERFLOW — ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти);
- SEC-SECURITY — ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.);
- SEC-SYNCHRONIZATION — ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.);
- SEC-NULL — ошибки разыменования нулевого указателя;
- SEC-DIV-0 — ошибки деления на ноль;
- SEC-MEMORY — ошибки управления динамической памятью (выделения, освобождения, использования освобождённой памяти);
- SEC-STR-FORMAT — ошибки использования форматной строки;
- SEC-UNINITIALIZED — ошибки использования неинициализированных переменных;
- SEC-LEAKS — ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений.
Вы можете использовать фильтрацию поля SAST в плагинах для IDE или в конверторе отчётов, чтобы выбрать для изучения только список критических ошибок или даже только один конкретный тип критических ошибок.
Принятие решений и автоматизация разметки предупреждений
В ГОСТ Р 71207—2024 (п. 8.6.) говорится, что:
- В ходе разметки предупреждений (согласно п. 5.5.) должна быть обеспечена возможность автоматизаций с целью сокращения времени, затрачиваемого на принятие решения к какой категории отнести предупреждение;
- Требуется возможность навигации по коду при работе с предупреждениями, обеспечено соотнесение выданных предупреждений с исходным кодом;
- Поддержка в принятии решения и автоматизация могут быть обеспечены как средствами статического анализатора, так и сторонними средствами;
- Поддержка в принятии решения и автоматизация могут быть реализованы графическим интерфейсом анализатора.
PVS-Studio соответствует всем требованиям и обеспечивает автоматизацию принятия решения с помощью следующих средств:
- Возможна навигация по коду и соотнесение предупреждений с кодом. Для этого можно использовать отчёты в различных форматах, а также плагины PVS-Studio для различных сред разработки (Visual Studio, Visual Studio Code, Qt Creator и т.д.);
- Фильтрация критических ошибок по их типу;
- Внутренний механизм задания base-line уровня сообщений;
- Использование платформы SonarQube (реализован плагин для встраивания PVS-Studio в SonarQube);
- Использование платформы DefectDojo;
- Утилита blame-notifier. Позволяет автоматически размечать предупреждения (назначение на разработчика, дата внесения дефекта, сортировка по группам) на основе информации из систем контроля версий (SVN, GIT, Mercurial, Perforce).
Автоматизации действий
Согласно стандарту (п. 8.7.), статический анализатор должен обеспечивать возможность автоматизации действий (приведённых в п. 5.6.) для использования в системах непрерывной интеграции.
Анализатор PVS-Studio поддерживает следующие системы непрерывной интеграции:
Обеспечивается хранение результатов запуска, разметки и сравнения
Согласно п. 8.8., должно быть обеспечено хранение результатов запуска статического анализатора и разметки этих результатов. Предупреждение должно быть снабжено идентификатором, с помощью которого его можно найти в результатах анализа. Допускается использовать для хранения результатов сторонние системы.
Результатом анализа проекта с помощью PVS-Studio может быть:
- неотфильтрованный вывод анализатора (JSON);
- отфильтрованный XML-отчёт;
- отфильтрованный JSON-отчёт.
Эти файлы могут быть преобразованы с помощью специальных утилит в другие форматы. Описание этих и других поддерживаемых форматов приведено в разделе "Просмотр и конвертация результатов анализа (форматы SARIF, HTML и др.)".
Разметка результатов осуществляется средствами плагинов PVS-Studio для различных IDE или сторонними системами, такими как SonarQube, DefectDojo, CodeChecker.
Для выполнения задачи сравнения результатов различных запусков стандарт допускает использование сторонних систем (п. 8.9.). В случае PVS-Studio такими сторонними системами являются SonarQube, DefectDojo и CodeChecker. Также эти системы обеспечивают идентификацию предупреждений.
Документации с описанием всех типов ошибок
Данная документация расположена на сайте и содержит раздел с описанием всех предупреждений (детекторов).
Дополнительно документация поставляется вместе с анализатором на случай его использования в закрытом контуре.
В случае использования анализатора без доступа в интернет (в закрытом контуре) рекомендуется включить настройку UseOfflineHelp. В этом случае плагины PVS-Studio при нажатии на идентификатор ошибки будут открывать не страницы сайта, а локальные файлы с описанием диагностических правил, поставляемые в составе анализатора.
Согласно ГОСТ Р 71207–2024 (п. 8.10.), статический анализатор должен содержать в документации описание всех типов ошибок, которые находит анализатор, с указанием:
- описания ошибки;
- возможных причин возникновения;
- примеров ошибочного кода, для которого выдаётся предупреждение о данном типе ошибки;
- примеров или рекомендаций исправления данного типа ошибки.
Описание диагностических правил PVS-Studio удовлетворяют всем требованиям, перечисленным в стандарте. Рассмотрим например описание правила V1085, предназначенного для выявления критических ошибок целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел (п. 6.3.б.).

Рисунок 1. Пример документации для диагностического правила V1085.
В документации присутствует:
- (1) описание ошибки (п. 8.10.а.);
- (2) пример ошибочного кода, для которого выдаётся предупреждение о данном типе ошибки (п. 8.10.в.);
- (3) описание возможных причин возникновения (п. 8.10.б.);
- (4) пример и рекомендация исправления данного типа ошибки (п. 8.10.г.).
Также следует (п. 8.10.) указывать соответствие типа ошибки в анализаторе одному или нескольким идентификаторам в системе классификации дефектов безопасности Common Weakness Enumeration (CWE). Соответствие присутствует в конце описания диагностического правила (5).
Выдача результатов анализа в открытом документированном формате
Статический анализатор должен (п. 8.11.) поддерживать выдачу результатов анализа в открытом документированном формате. Примером такого стандарта является формат SARIF.
PVS-Studio поддерживает выдачу результатов анализа в следующих открытых форматах:
- SARIF;
- TaskList;
- Html;
- Error File;
- TeamCity;
- GitLab;
- DefectDojo.
Подробнее см. раздел "Просмотр и конвертация результатов анализа (форматы SARIF, HTML и др.)".
Доработки алгоритмов и правил пользователями
ГОСТ Р 71207–2024 (п. 8.12.) не обязывает инструмент статического анализа представлять пользователям механизмы для доработки алгоритмов и создания новых правил, но упоминает такую возможность.
Анализатор PVS-Studio не представляет возможности пользователям изменять логику работы алгоритмов или добавлять новые диагностические правила. Но по запросу наша команда реализует специализированные диагностические правила, необходимые клиентам.
Дополнительные ссылки по теме РБПО и ГОСТ Р 71207–2024
- Андрей Карпов: "ГОСТ Р 71207–2024 глазами разработчика статических анализаторов кода".
- Giga Conf 2024, Андрей Карпов: "Использование статического анализатора в разработке безопасного программного обеспечения (ГОСТ Р 71207-2024) на примере PVS-Studio".
- МАСКОМ УЦ - Вебинар N7 серии вебинаров РБПО - Давайте разбираться вместе. Андрей Карпов. Доклад (начиная с 1:03:10): "Статический анализатор PVS-Studio на страже качества, защищённости и безопасности кода".
- Валерий Филатов: "Использование статических анализаторов кода при разработке безопасного ПО".
История версий PVS-Studio
- PVS-Studio 7.36 (9 апреля 2025)
- PVS-Studio 7.35 (12 февраля 2025)
- PVS-Studio 7.34 (11 декабря 2024)
- PVS-Studio 7.33 (7 октября 2024)
- PVS-Studio 7.32 (06 августа 2024)
- PVS-Studio 7.31 (11 июня 2024)
- PVS-Studio 7.30 (12 апреля 2024)
- PVS-Studio 7.29 (7 февраля 2024)
- PVS-Studio 7.28 (5 декабря 2023)
- PVS-Studio 7.27 (11 октября 2023)
- PVS-Studio 7.26 (9 августа 2023)
- PVS-Studio 7.25 (7 июня 2023)
- PVS-Studio 7.24 (5 апреля 2023)
- PVS-Studio 7.23 (8 февраля 2023)
- PVS-Studio 7.22 (7 декабря 2022)
- PVS-Studio 7.21 (11 октября 2022)
- PVS-Studio 7.20 (10 августа 2022)
- PVS-Studio 7.19 (8 июня 2022)
- PVS-Studio 7.18 (6 апреля 2022)
- PVS-Studio 7.17 (9 февраля 2022)
- PVS-Studio 7.16 (8 декабря 2021)
- PVS-Studio 7.15 (7 октября 2021)
- PVS-Studio 7.14 (9 августа 2021)
- PVS-Studio 7.13 (31 мая 2021)
- PVS-Studio 7.12 (11 марта 2021)
- PVS-Studio 7.11 (17 декабря 2020)
- PVS-Studio 7.10 (5 ноября 2020)
- PVS-Studio 7.09 (27 августа 2020)
- PVS-Studio 7.08 (18 июня 2020)
- PVS-Studio 7.07 (16 апреля 2020)
- PVS-Studio 7.06 (27 февраля 2020)
- PVS-Studio 7.05 (10 декабря 2019)
- PVS-Studio 7.04 (4 сентября 2019)
- PVS-Studio 7.03 (25 июня 2019)
- PVS-Studio 7.02 (25 апреля 2019)
- PVS-Studio 7.01 (13 марта 2019)
- PVS-Studio 7.00 (16 января 2019)
- Старая история версий
PVS-Studio 7.36 (9 апреля 2025)
- В C и C++ анализаторе PVS-Studio добавлена возможность задать версии стандартов MISRA C и MISRA C++. Выбрать используемую версию стандарта можно в настройках PVS-Studio плагина для Visual Studio. Поддерживаемые версии стандартов: MISRA C 2012, MISRA C 2023, MISRA C++ 2008, MISRA C++ 2023.
- Добавлена документация по использованию анализатора PVS-Studio в сервисе для хранения исходного кода GitFlic, а также в DevSecOps платформах Hexway и AppSec.Hub.
- В C# анализаторе появилась возможность аннотировать библиотеки с помощью JSON синтаксиса пользовательских аннотаций. Подробнее об этом написано в нашей документации.
- Плагин PVS-Studio стал доступен для Qt Creator версий 16.x. Прекращена поддержка плагина для версий Qt Creator 10.x. Мы стараемся обеспечивать обратную совместимость по поддержке последних версий плагинов для всех версий Qt Creator за два года с момента каждого релиза.
- В кроссплатформенную утилиту для проверки C и C++ проектов
pvs-studio-analyzerдобавлен новый флаг‑‑apply-pvs-configs. С помощью него включается режим автоматического поиска и применения файлов конфигурации правил.pvsconfigдля проверяемых исходных файлов. Сами файлы конфигурации правил ищутся в каталоге исходного файла и во всех родительских каталогах вплоть до корневой папки проекта, которая указывается с помощью нового флага‑‑project-root. Подробнее об этом можно прочитать в нашей документации. - Флаг
‑‑analysis-pathsв утилите командной строкиpvs-studio-analyzerполучил новый режимisolate-settings. Он позволяет изолировать настройки, задаваемые с помощью файлов конфигурации правил.pvsconfigвнутри заданной директории. Настройки, лежащие в родительских для этой директории папках, в этом режиме игнорируются. Подробнее об этом можно прочитать в нашей документации. Также для данного режима были добавлены настройки для файла.pvsconfig://V_ANALYSIS_PATHS isolate-settingsи//V_ISOLATE_CURRENT_DIR. Подробнее об этом можно прочитать в соответствующем разделе документации. - Настройки
//IGNORE_GLOBAL_PVSCONFIGи//CONFIG_PRIORITYиз файлов конфигурации.pvsconfigтеперь учитываются при анализе C и C++ проектов с помощью утилиты командной строкиpvs-studio-analyzer. О работе этих настроек можно подробнее прочитать в нашей документации. - В C и C++ анализаторе PVS-Studio улучшена поддержка стандартов C11 (квалификаторы
restrictи_Atomicи спецификаторы_Atomic(T)и_Thread_local) и C23 (спецификаторthread_local). - Для работы утилиты командной строки CLMonitor.exe в режиме Wrap Compilers, который гарантирует перехват всех процессов компиляции, больше не требуются права администратора. Теперь для работы утилиты в этом режиме нужны только права доступа к ветке реестра
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options. Подробнее об этом режиме можно прочитать в нашей документации. - Была добавлена возможность указывать версию C# анализатора PVS-Studio в файлах конфигурации .pvsconfig, если на компьютере установлено несколько версий PVS-Studio. Ранее такая функциональность была доступна только для C и C++ анализатора. Подробнее об этой функциональности можно прочитать в нашей документации.
- В плагине для интегрированной среды разработки Visual Studio Code оптимизирован процесс загрузки отчётов, содержащих большое количество срабатываний анализатора.
- [Breaking change] При анализе C и C++ проектов на основе
compile_commands.jsonв утилите командной строкиpvs-studio-analyzerтеперь игнорируются все вызовы не компиляторов. Для работы с компиляторами, имеющими нестандартные имена, которые не определяются PVS-Studio по умолчанию, можно использовать флаг‑‑compiler. Подробнее об этом можно узнать в соответствующем разделе нашей документации. - [Breaking change] Минимальная рекомендуемая версия macOS для запуска анализатора PVS-Studio на процессорах с архитектурой x86-64 поднята до версии macOS Big Sur (11.1).
- V2634. MISRA. Features from <fenv.h> should not be used.
- V2635. MISRA. The function with the 'system' name should not be used.
- V2636. MISRA. The functions with the 'rand' and 'srand' name of <stdlib.h> should not be used.
- V2637. MISRA. A 'noreturn' function should have 'void' return type.
- V2638. MISRA. Generic association should list an appropriate type.
- V2639. MISRA. Default association should appear as either the first or the last association of a generic selection.
- V2640. MISRA. Thread objects, thread synchronization objects and thread-specific storage pointers should have appropriate storage duration.
- V2641. MISRA. Types should be explicitly specified.
- V2642. MISRA. The '_Atomic' specifier should not be applied to the incomplete type 'void'.
- V2643. MISRA. All memory synchronization operation should be executed in sequentially consistent order.
- V3218. Cycle condition may be incorrect due to an off-by-one error.
- V3219. The variable was changed after it was captured in a LINQ method with deferred execution. The original value will not be used when the method is executed.
- V3220. The result of the LINQ method with deferred execution is never used. The method will not be executed.
- V3221. Modifying a collection during its enumeration will lead to an exception.
- V5629. OWASP. Code contains invisible characters that may alter its logic. Consider enabling the display of invisible characters in the code editor.
- V5320. OWASP. Use of potentially tainted data in configuration may lead to security issues.
- V5321. OWASP. Possible LDAP injection. Potentially tainted data is used in a search filter.
- V5322. OWASP. Possible reflection injection. Potentially tainted data is used to select class or method.
- V5323. OWASP. Potentially tainted data is used to define 'Access-Control-Allow-Origin' header.
- V5324. OWASP. Possible open redirect vulnerability. Potentially tainted data is used in the URL.
- V5325. OWASP. Setting the value of the 'Access-Control-Allow-Origin' header to '*' is potentially insecure.
- V5326. OWASP. OWASP. A password for a database connection should not be empty.
- V5327. OWASP. Possible regex injection. Potentially tainted data is used to create regular expression.
- V5328. OWASP. Using weak authorization checks could lead to security violations.
- V5329. OWASP. Using unsafe methods of file creation is not recommended because an attacker might access the files.
- V5330. OWASP. Possible XSS injection. Potentially tainted data might be used to execute a malicious script.
PVS-Studio 7.35 (12 февраля 2025)
- Команда PVS-Studio начала работу по увеличению покрытия стандарта MISRA C. В этом году мы планируем покрыть не менее 85% стандарта MISRA C, а также поддержать последнюю версию MISRA C 2023. Подробнее о поддержке стандартов MISRA в PVS-Studio можно прочитать здесь.
- Также ведётся работа по покрытию стандарта OWASP Top 10 2021 для Java анализатора. К этому релизу PVS-Studio для Java находит ошибки, соответствующие 7 категориям из 10.
- Плагин PVS-Studio стал доступен для Qt Creator версий 15.x. Прекращена поддержка плагина для версий Qt Creator 9.x. Мы стараемся обеспечивать обратную совместимость по поддержке последних версий плагинов для всех версий Qt Creator за два года с момента каждого релиза. В версии Qt Creator 15.0.0 наблюдаются проблемы с установкой плагинов через встроенный в IDE мастер установки. Подробнее об этом виде установки написано в нашей документации по ссылке.
- Режим анализа модифицированных файлов был добавлен в плагин для Visual Studio. В утилите командной строки
PVS-Studio_Cmd.exeбыл добавлен новый режим работы этого способа проверки, учитывающий неисправленные предупреждения и добавляющий файлы с ними на анализ помимо изменённых. Подробнее об этом можно прочитать в документации. Также был добавлен флаг для управления кэшами зависимостей компиляции в файл конфигурации анализатора.pvsconfig. Подробнее об этом в соответствующем разделе нашей документации. - В C# анализаторе был оптимизирован анализ блоков кода c большим количеством идентификаторов переменных (500 и более). Ранее были возможны замедления анализатора в подобных ситуациях.
- Улучшили запуск PVS-Studio на системах с корейской локалью и при использовании корейских символов в путях и именах файлов.
- В плагинах PVS-Studio для CLion, Rider и Visual Studio Code была добавлена возможность посмотреть анализируемые исходные файлы в случае, когда предупреждение выдано не на сам файл, а на включённый в него заголовочный файл.
- Улучшена работа инкрементального анализа в плагине PVS-Studio для IntelliJ IDEA. Теперь инкрементальный анализ запускается не только при запуске сборки из интерфейса IntelliJ IDEA, но и при запуске сборки из интерфейсов сборочных систем.
- [Breaking change] Изменился внутренний формат записи кэшей зависимостей компиляции. Обратная совместимость со старым форматом сохранена.
- [Breaking change] Исправлено ошибочное поведение при использовании аргументов
‑‑license-pathв ядре Java анализатора иlicensePathв плагинах PVS-Studio для Maven и Gradle. Теперь информация о лицензии записывается по указанному в параметре пути, а не по стандартному месту расположения лицензии. Подробнее можно прочитать в документации. - [Breaking change] В версии 7.34 было ошибочно изменено поведение анализатора при отсутствии срабатывания в отчёте. В текущей версии возвращено создание пустого suppress файла, если в передаваемом на подавление отчёте (с помощью флага
‑‑convertв значенииtoSuppress) нет срабатываний. - [Breaking change] Ядро C и C++ анализатора теперь выдает SAST-идентификатор с указанием версии стандарта MISRA (2012 или 2023) в срабатываниях диагностических правил группы MISRA.
- V2626. MISRA C 2023 12.5. The sizeof operator should not have an operand which is a function parameter declared as 'array of type'.
- V2627. MISRA C 2023 17.13. Function type should not be type qualified.
- V2628. MISRA C 2023 21.15. Pointer arguments to the Standard Library function 'Foo' should be pointers to qualified or unqualified versions of compatible types.
- V2629. MISRA C 2023 21.16. Pointer arguments to the Standard Library function memcmp should point to either a pointer type, an essentially signed type, an essentially unsigned type, an essentially Boolean type or an essentially enum type.
- V2630. MISRA C 2023 6.3. Bit field should not be declared as a member of a union.
- V2631. MISRA C 2023 18.10. Pointers to variably-modified array types should not be used.
- V2632. MISRA C 2023 18.9. Object with temporary lifetime should not undergo array-to-pointer conversion.
- V2633. MISRA C 2023 5.5. Identifiers should be distinct from macro names.
- V3211. Unity Engine. The operators '?.', '??' and '??=' do not correctly handle destroyed objects derived from 'UnityEngine.Object'.
- V3212. Unity Engine. Pattern matching does not correctly handle destroyed objects derived from 'UnityEngine.Object'.
- V3213. Unity Engine. The 'GetComponent' method must be instantiated with a type that inherits from 'UnityEngine.Component'.
- V3214. Unity Engine. Using Unity API in the background thread may result in an error.
- V3215. Unity Engine. Passing a method name as a string literal into the 'StartCoroutine' is unreliable.
- V3216. Unity Engine. Checking a field with a specific Unity Engine type for null may not work correctly due to implicit field initialization by the engine.
- V3217. Possible overflow as a result of an arithmetic operation.
- V4008. Unity Engine. Avoid using memory allocation Physics APIs in performance-sensitive context.
- V5310. OWASP. Possible command injection. Potentially tainted data is used to create OS command.
- V5311. OWASP. Possible argument injection. Potentially tainted data is used to create OS command.
- V5312. OWASP. Possible XPath injection. Potentially tainted data is used to create XPath expression.
- V5313. OWASP. Do not use the old versions of SSL/TLS protocols as it may cause security issues.
- V5314. OWASP. Use of an outdated hash algorithm is not recommended.
- V5315. OWASP. Use of an outdated cryptographic algorithm is not recommended.
- V5316. OWASP. Do not use the 'HttpServletRequest.getRequestedSessionId' method because it uses a session ID provided by a client.
- V5317. OWASP. Implementing a cryptographic algorithm is not advised because an attacker might break it.
- V5318. OWASP. Setting POSIX file permissions to 'all' or 'others' groups can lead to unintended access to files or directories.
- V5319. OWASP. Possible log injection. Potentially tainted data is written into logs.
PVS-Studio 7.34 (11 декабря 2024)
- Анализатор PVS-Studio для операционных систем семейства macOS портирован на процессоры Apple Silicon с архитектурой ARM64. Скачать PVS-Studio можно на странице загрузок.
- В C# анализатор PVS-Studio добавлена поддержка проектов для .NET 9.
- В Java анализаторе PVS-Studio появился механизм для проведения taint-анализа. На его основе была создана первая диагностика — поиск SQL-инъекций. В следующем году в Java анализаторе будет сделан упор на SAST, покрытие списка наиболее распространённых потенциальных уязвимостей OWASP Top 10, а также будет добавлено больше taint-диагностик.
- В утилиты командной строки
PVS-Studio_Cmdиpvs-studio-dotnetбыл добавлен режим проверки модифицированных файлов, позволяющий автоматически обнаружить изменённые между запусками анализа исходные файлы. Данный режим является альтернативой инкрементальному анализу и может быть полезен при проверке Pull Request'ов. Подробнее о новом режиме можно прочитать в документации. - В плагин PVS-Studio для Visual Studio Code и утилиту командной строки
plog-converterбыла добавлена возможность отображения критических ошибок согласно ГОСТ Р 71207-2024. - Добавлена возможность загрузки отчёта PVS-Studio в веб-интерфейс для просмотра и агрегации результатов анализа CodeChecker. Поддержка PVS-Studio при установке CodeChecker из пакетного менеджера pip появится с выходом версии 6.25.0. Подробнее об интеграции можно прочитать в документации.
- Добавлена возможность гибкой настройки включения или выключения из анализа исходных файлов и файлов настроек
.pvsconfig. Также данный механизм можно будет использовать для проверки Unreal Engine проектов с помощью Unreal Build Tool, начиная с версии 5.5.2. Подробнее можно прочитать в документации. - Анализаторы PVS-Studio были проверены на совместимость и корректную работу с операционными системами РЕД ОС 7.3 и РЕД ОС 8.
- [Breaking change] Изменились требования C# анализатора PVS-Studio на Windows. Для анализа .NET проектов теперь потребуется установка .NET 9 SDK. Для анализа .NET Standard и .NET Framework SDK-style проектов также потребуется .NET SDK 9. Требования по проверке не изменились для классических .NET Framework проектов: если в системе установлены Visual Studio или MSBuild версий 2017, 2019 или 2022, достаточно наличия в системе .NET Framework 4.7.2. Для классических .NET Framework проектов в системах с Visual Studio или MSBuild версий 2015 или более старых теперь также будет требоваться присутствие .NET 9 SDK. При использовании silent режима установки на Windows, если необходимо запускать анализ на проектах, которые теперь требуют наличия в системе .NET 9 SDK, потребуется указать компонент DOTNET для установки .NET 9 SDK, если SDK не был установлен в системе отдельно.
- [Breaking change] В утилите командной строки
pvs-studio-analyzerизменено поведение флага‑‑sourcetree-root (-r). При подмене путей в генерируемом отчёте путь до базовой директории проверяется на существование. Если часть путей не получилось подменить, то выдаётся сообщение с предупреждением, но код возврата остаётся равным 0. Если же не получилось подменить ни один путь, то помимо сообщения с предупреждением код возврата будет ненулевым. - V1116. Creating an exception object without an explanatory message may result in insufficient logging.
- V1117. The declared function type is cv-qualified. The behavior when using this type is undefined.
- V2022. Implicit type conversion from integer type to enum type.
- V5014. OWASP. Cryptographic function is deprecated. Its use can lead to security issues. Consider switching to an equivalent newer function.
- V3207. The 'not A or B' logical pattern may not work as expected. The 'not' pattern is matched only to the first expression from the 'or' pattern.
- V3208. Unity Engine. Using 'WeakReference' instance with 'UnityEngine.Object' is not supported. GC will not properly reclaim memory from this object because it is linked to a native object.
- V3209. Unity Engine. Re-applying await to an Awaitable object will result in an exception.
- V3210. Unity Engine. Unity does not allow removing the 'Transform' component using 'Destroy' or 'DestroyImmediate' methods. The method call will be ignored.
- V4007. Unity Engine. Avoid creating and destroying UnityEngine objects in performance-sensitive context. Consider activating and deactivating them instead.
- V6123. Modified value of the operand is not used after the increment/decrement operation.
- V6124. Converting an integer literal to the type with a smaller value range will result in overflow.
- V6125. Calling the 'wait', 'notify', and 'notifyAll' methods outside of synchronized context will lead to 'IllegalMonitorStateException'.
- V5309. OWASP. Possible SQL injection. Potentially tainted data is used to create SQL command.
PVS-Studio 7.33 (7 октября 2024)
- Плагин PVS-Studio для IDE Qt Creator портирован на комплект разработчика для операционной системы "Нейтрино". Поддержана работа с Qt Creator 6.0.2 (Qt 5.15) из данного комплекта разработчика.
- В утилиту командной строки PVS-Studio_Cmd была добавлена возможность отображения критических ошибок согласно ГОСТ Р 71207-2024. Для этого необходимо включить настройку "Security Related Issues" в плагине PVS-Studio для Visual Studio.
- В C++ анализаторе PVS-Studio было уменьшено потребление памяти при анализе инстанцирования шаблонов, а также инициализации большого количества глобальных переменных строковыми литералами.
- В C++ анализаторе PVS-Studio было уменьшено количество ложных срабатываний при анализе кода, относящегося к проектам Unreal Engine. Унифицирована обработка встроенных функций компилятора __builtin_expect и доработана обработка выражений явных приведений к bool. Это улучшило анализ check-функций, управляемых макросом DO_CHECK в проектах Unreal Engine.
- Для режима интеграции PVS-Studio с Unreal Engine была добавлена поддержка системы распределённой сборки SN-DBS. Подробнее об этом можно прочитать в нашей документации об интеграции анализатора PVS-Studio с Unreal Engine. Данные изменения актуальны для версии Unreal Engine 5.5.
- В C# анализаторе PVS-Studio была реализована возможность проставления пользовательских аннотаций функций и типов в формате JSON по аналогии со схожей функциональностью C++ анализатора PVS-Studio. Подробнее об этой функциональности можно прочитать в нашей документации.
- Была исправлена ошибка работы плагина PVS-Studio для Visual Studio при его использовании с Visual Studio версий 17.12 и выше.
- Были исправлены проблемы работы С# анализатора PVS-Studio в системе с установленным .NET версий 8.0.400 и выше.
- [Breaking change] Были подняты версии форматов отчётов анализаторов PVS-Studio .json и .plog до версий 3 и 9 соответственно. Теперь у C# проектов, имеющих несколько целевых фреймворков (target framework), имя фреймворка не приписывается к имени проекта.
- [Breaking change] В формат JSON отчёта C++ анализатора PVS-Studio было добавлено новое поле analyzedSourceFiles. В данное поле записывается дополнительная информация о том, в какой единице трансляции произошло срабатывание диагностического правила. Это полезно в случаях, когда потенциальная ошибка содержится в заголовочных файлах.
- [Breaking change] Версия JSON-схемы пользовательских аннотаций функций и типов PVS-Studio поднята до версии 2. В схему была добавлена новая сущность language. Она позволяет использовать пользовательские аннотации только в анализаторе для конкретного языка. Помимо этого, было изменено значение поля id.
- [Breaking change] В системе пользовательских аннотаций функций и типов PVS-Studio комментарий //V_PVS_ANNOTATIONS $path для включения пользовательских аннотаций помечен как устаревший. В качестве замены предлагается использовать комментарий вида //V_PVS_ANNOTATIONS, language: $lang, path: $path.
- [Breaking change] Минимальные поддерживаемые версии IDE JetBrains IDEA, CLion и Rider были подняты до версии 2022.2.
- [Breaking change] Изменено разрешение путей в плагине PVS-Studio для сборочной системы Gradle. Теперь относительные пути из конфигурации разрешаются относительно директории проекта, а не относительно директории gradle daemon.
- [Breaking change] Была удалена возможность конвертации отчёта PVS-Studio при помощи утилит plog converter в специфичный для Visual Studio Code формат SARIF, используемый в плагине SARIF Viewer. Конвертация в соответствующий стандарту отчёт формата SARIF сохранена.
- V1113. Potential resource leak. Calling the 'memset' function will change the pointer itself, not the allocated resource. Check the first and third arguments.
- V1114. Suspicious use of 'dynamic_cast' when working with COM interfaces. Consider using the 'QueryInterface' member function.
- V1115. Function annotated with the 'pure' attribute has side effects.
- V3204. The expression is always false due to implicit type conversion. Overflow check is incorrect.
- V3205. Unity Engine. Improper creation of 'MonoBehaviour' or 'ScriptableObject' object using the 'new' operator. Use the special object creation method instead.
- V3206. Unity Engine. A direct call to the coroutine-like method will not start it. Use the 'StartCoroutine' method instead.
- V4006. Unity Engine. Multiple operations between complex and numeric values. Prioritizing operations between numeric values can optimize execution time.
- V6118. The original exception object was swallowed. Cause of original exception could be lost.
- V6119. The result of '&' operator is always '0'.
- V6120. The result of the '&' operator is '0' because one of the operands is '0'.
- V6121. Return value is not always used. Consider inspecting the 'foo' method.
- V6122. The 'Y' (week year) pattern is used for date formatting. Check whether the 'y' (year) pattern was intended instead.
PVS-Studio 7.32 (06 августа 2024)
- В связи с изменениями в API платформы SonarQube был разработан новый плагин для интеграции анализатора PVS-Studio в платформу SonarQube. Начиная с версии SonarQube 10.1, необходимо использовать новую версию плагина. Версия плагина PVS-Studio для более ранних версий SonarQube продолжает поддерживаться и получать обновления параллельно с новым плагином.
- Добавлена поддержка интеграции анализатора PVS-Studio в проекты, использующие сборочные системы Bazel и Scons.
- Плагин PVS-Studio стал доступен для Qt Creator версий 14.x. Прекращена поддержка плагина для версий Qt Creator 8.x. Мы стараемся обеспечивать обратную совместимость по поддержке последних версий плагинов для всех версий Qt Creator за два года с момента каждого релиза.
- Оптимизировано потребление памяти С++ анализатора при анализе инстанцирования шаблонов. При этом сохранена возможность отключения анализа их инстанцирования с помощью флага настройки DisableTemplateInstantiationCpp в плагине PVS-Studio для Visual Studio или настройки //V_DISABLE_TEMPLATE_INSTANTIATION в файлах конфигурации pvsconfig в случае, если потребление памяти анализатором всё ещё остаётся избыточно высоким.
- Улучшен разбор стандартной библиотеки Microsoft Visual C++, используемой в версии Visual Studio 17.10.
- В C++ анализаторе PVS-Studio добавлена возможность разметки источников и приёмников при анализе помеченных (taint) данных. Она реализована в механизме пользовательских аннотаций в формате JSON.
- Добавлена возможность исключения из анализа проектов при анализе проектов для сборочной системы MSBuild с помощью файлов конфигурации анализатора .pvsconfig. Эта возможность реализуется включением флага V_EXCLUDE_PROJECT в файл конфигурации диагностик pvsconfig.
- Добавлена возможность использования файлов конфигурации диагностик pvsconfig в плагине PVS-Studio для IDE JetBrains CLion.
- [Breaking change] Изменён синтаксис пользовательских аннотаций в формате JSON для С++ анализатора PVS-Studio. Использование атрибутов nullable_initialized и nullable_uninitialized устарело. Вместо них введены атрибуты возвращаемого объекта not_null, maybe_null, always_null.
- [Breaking change] Изменён приоритет флага ‑‑sourceTreeRoot в утилите PVS-Studio_Cmd.exe, задающего корневую часть пути для конвертации путей из абсолютных в относительные. Теперь этот флаг имеет приоритет над настройками UseSolutionDirAsSourceTreeRoot в конфигурационном файле Settings.xml и //V_SOLUTION_DIR_AS_SOURCE_TREE_ROOT в файлах конфигурации диагностик pvsconfig.
- V1111. The index was used without check after it was checked in previous lines.
- V1112. Comparing expressions with different signedness can lead to unexpected results.
- V2021. Using assertions may cause the abnormal program termination in undesirable contexts.
- V3201. Return value is not always used. Consider inspecting the 'foo' method.
- V3202. Unreachable code detected. The 'case' value is out of the range of the match expression.
- V3203. Method parameter is not used.
- V6115. Not all Closeable members are released inside the 'close' method.
- V6116. The class does not implement the Closeable interface, but it contains the 'close' method that releases resources.
- V6117. Possible overflow. The expression will be evaluated before casting. Consider casting one of the operands instead.
PVS-Studio 7.31 (11 июня 2024)
- Добавлена возможность установки настроек в конфигурационных файлах .pvsconfig в зависимости от версии анализатора, использующего данные файлы. Эта возможность доступна в С++ анализаторе PVS-Studio.
- В утилите pvs-studio-analyzer была расширена система анализа отдельных файлов с помощью флага ‑‑source-files. Теперь использование утилиты в условиях отличия кэша зависимостей компиляций для C и C++ файлов от структуры проекта стало более удобным. Такая ситуация может возникнуть, например, при частом переключении веток в одном рабочем пространстве или запуске анализа на разных версиях проекта.
- В систему пользовательских аннотаций C++ анализатора была добавлена возможность задавать диапазон возможных и невозможных значений для целочисленных параметров функций.
- Была доработана и актуализирована документация об использовании анализаторов PVS-Studio в облачной CI-системе CircleCI.
- V1108. Constraint specified in a custom function annotation on the parameter is violated.
- V1109. Function is deprecated. Consider switching to an equivalent newer function.
- V1110. Constructor of a class inherited from 'QObject' does not use a pointer to a parent object.
- V3199. Index from end operator used with the value that is less than or equal to zero. Index is out of bound.
- V3200. Possible overflow. The expression will be evaluated before casting. Consider casting one of the operands instead.
- V6113. Suspicious division. Absolute value of the left operand is less than the value of the right operand.
- V6114. The 'A' class containing Closeable members does not implement the Closeable interface.
PVS-Studio 7.30 (12 апреля 2024)
- В C++ анализаторе PVS-Studio был реализован механизм пользовательских аннотаций —способ разметки типов и функций в формате JSON с целью дать анализатору дополнительную информацию. Благодаря этой информации анализатор может находить больше ошибок в коде. Такие аннотации необходимо поместить в специальный файл формата JSON. С помощью этих аннотаций возможно, помимо прочего, пометить функцию как опасную для использования, определить собственный тип как nullable и т.п. Больше об этом режиме можно узнать в документации.
- Было внесено множество улучшений в интеграцию PVS-Studio и Unreal Engine, доступных начиная с версии UE 5.4:
- Реализована многофайловая навигация по предупреждениям, содержащимся в отчёте анализатора PVS-Studio;
- Исправлена ошибка, приводящая к падению анализа в Unreal Engine 5.3 при запуске анализа через флаг компиляции -StaticAnalyzer=PVSStudio.
- Поддержка отключения стандартного вывода Unreal Build Tool в консоль при проведении анализа. Это может значительно сократить время постобработки отчёта анализатора в проектах с большим количеством предупреждений;
- Анализ автоматически сгенерированных файлов .gen.cpp теперь по умолчанию отключён. Включение анализа таких файлов возможно через специальную настройку;
- Добавлена настройка, позволяющая запускать анализатор только на файлах проекта, пропуская модуль ядра Unreal Engine. Использование этой настройки позволяет значительно ускорить процесс анализа.
- Была расширена система анализа отдельных файлов с помощью флага ‑‑sourceFiles и повторной генерации кэша зависимостей проекта. Теперь данный режим устойчив к ситуациям, когда кэш зависимостей находится в состоянии, не соответствующем структуре проекта. Такое может случиться, например, в случае использования множественных веток в системе контроля версий. Помимо этого, была добавлена возможность запуска с полным обновлением кэша: это позволяет проводить анализ с полностью корректным кэшем зависимостей в случае, если поддержание его в актуальном состоянии было невозможно.
- Была добавлена поддержка GNU RISC-V GCC Toolchain для платформы RISC-V для C++ анализатора PVS-Studio.
- Для C++ анализатора PVS-Studio был реализован анализ стандартного типа bool, появившегося в стандарте C23 языка С. Это улучшило поддержку MISRA Essential Type Model, а также диагностик, основанных на MISRA Essential Type Model.
- Для C++ анализатора PVS-Studio была улучшена работа со стандартной библиотекой С++, а также добавлена поддержка большего количества интринзиков компилятора, например, __add_lvalue_reference, __add_pointer, __add_rvalue_reference и других. Это привело к улучшению качества работы диагностик.
- Плагин PVS-Studio теперь доступен для Qt Creator версии 13.
- V1105. Suspicious string modification using the 'operator+='. The right operand is implicitly converted to a character type.
- V1106. Qt. Class inherited from 'QObject' does not contain a constructor that accepts a pointer to 'QObject'.
- V1107. Function was declared as accepting unspecified number of parameters. Consider explicitly specifying the function parameters list.
- V3196. Parameter is not utilized inside the method body, but an identifier with a similar name is used inside the same method.
- V3197. The compared value inside the 'Object.Equals' override is converted to a different type that does not contain the override.
- V3198. The variable is assigned the same value that it already holds.
- V6110. Using an environment variable could be unsafe or unreliable. Consider using trusted system property instead.
- V6111. Potentially negative value is used as the size of an array.
- V6112. Calling the 'getClass' method repeatedly or on the value of the '.class' literal will always return the instance of the 'Class' type.
PVS-Studio 7.29 (7 февраля 2024)
- Добавили поддержку анализа проектов на языке Java в плагине PVS-Studio для Visual Studio Code.
- В С++ анализаторе реализована поддержка умных указателей из библиотеки Boost: boost::unique_ptr и boost::shared_ptr. Теперь анализатор PVS-Studio определяет ошибки наподобие разыменовывания нулевого указателя при использовании данных классов.
- Добавлен режим учёта хэша строки исходного кода, вызвавшей срабатывание, при разметке ложно-позитивных срабатываний. Это позволяет понять, менялась ли строка кода с момента отметки срабатывания, как ложного. При использовании нового режима разметки, в случае наличия изменений в коде, отметка ложного срабатывания перестанет подавлять предупреждение анализатора. Поддержка этой функциональности присутствует в плагинах PVS-Studio для Microsoft Visual Studio.
- Добавили поддержку плагина PVS-Studio для Qt Creator 12 на операционных системах семейства macOS.
- V839. Decreased performance. Function returns a constant value. This may interfere with the move semantics.
- V1104. Priority of the 'M' operator is higher than that of the 'N' operator. Possible missing parentheses.
- V2625. MISRA. Identifier with external linkage should be unique.
- V3194. Calling 'OfType' for collection will return an empty collection. It is not possible to cast collection elements to the type parameter.
- V3195. Collection initializer implicitly calls 'Add' method. Using it on member with default value of null will result in null dereference exception.
- V6108. Do not use real-type variables in 'for' loop counters.
- V6109. Potentially predictable seed is used in pseudo-random number generator.
PVS-Studio 7.28 (5 декабря 2023)
- В анализаторы PVS-Studio добавлена поддержка работы на платформе ARM на операционной системе Windows. Поддержка работает в режиме совместимости с архитектурой x64. В будущем году планируется реализация также и нативной ARM версии анализатора для операционных систем семейства macOS.
- В PVS-Studio C# поддержали анализ проектов, использующих .NET 8. Сам C# анализатор под Linux и macOS теперь работает на .NET 8.
- Добавлена поддержка относительных путей в SARIF отчётах.
- При проверке Unreal Engine проектов с помощью PVS-Studio зачастую возникают проблемы с избыточным потреблением памяти и замедлением анализа, вызываемые использованием системы объединения единиц трансляции в один файл (Unity Build). Несмотря на то, что использование такой системы может положительно сказаться на времени компиляции, большой размер файла может привести к повышенному потреблению ресурсов, необходимых для анализа. Мы дополнили документацию по анализу Unreal Engine проектов пунктом про настройку запуска анализа без использования Unity Build, с возможностью сохранения использования этого режима для сборки проекта.
- Добавили поддержку плагина PVS-Studio для Qt Creator версии 12.0.x
- Добавили поддержку wildcard-паттернов в командах компиляции для утилиты мониторинга сборок на Windows (CLMonitor).
- В C# анализаторе доработана и унифицирована с другими анализаторами возможность включения и отключения отдельных диагностик с помощью файлов настройки анализатора (.pvsconfig). Подробнее о .pvsconfig можно прочитать в документации.
- В C# анализаторе улучшена работа с параметрами, имеющими null в качестве значения по умолчанию. Это позволяет диагностике V3080 находить больше проблем, связанных с разыменованием нулевых ссылок.
- Исправлена проблема совместной работы Visual Studio плагинов PVS-Studio и Visual Assist.
- V1103. The values of padding bytes are unspecified. Comparing objects with padding using 'memcmp' may lead to unexpected result.
- V2624. MISRA. The initializer for an aggregate or union should be enclosed in braces.
- V3193. Data processing results are potentially used before asynchronous output reading is complete. Consider calling 'WaitForExit' overload with no arguments before using the data.
- V4005. Unity Engine. The expensive operation is performed inside method or property. Using such member in performance-sensitive context can lead to decreased performance.
- V6107. The constant NN is being utilized. The resulting value could be inaccurate. Consider using the KK constant.
PVS-Studio 7.27 (11 октября 2023)
- Плагин PVS-Studio для Visual Studio Code теперь поддерживает работу с проектами под .NET. Функционал включает в себя возможности запуска анализа, просмотра отчёта, подавления предупреждений и т.д. Подробности в документации.
- Улучшен механизм разбора кода стандартной библиотеки C++ на операционных системах семейства macOS.
- Улучшен алгоритм автоматического выбора количества одновременно анализируемых файлов. Теперь учитываются не только доступные логические ядра, но и объём доступной в системе оперативной памяти. Это позволяет задавать более оптимальные значения для настроек по умолчанию.
- В плагине для Rider подержан запуск анализа в режиме прямого открытия проектов Unreal Engine. Также плагин стал доступен для Rider 2023.2. Документация доступна по ссылке.
- В файле конфигурации pvsconfig теперь можно указать, что пути в отчёте анализатора строятся относительно директории решения. Новая настройка поддерживается как при запуске анализа, так и при просмотре результатов работы анализатора в IDE плагинах. Это упрощает работу с отчётом в случае его передачи между машинами с разной структурой директорий. Документация по pvsconfig доступна здесь.
- Утилита CLMonitor теперь поддерживает platform toolset v80 и v90.
- Полностью переработана документация по Java анализатору. Теперь каждому сценарию работы с анализатором посвящён отдельный раздел: интеграция с Maven, интеграция с Gradle, работа в IntelliJ IDEA и Android Studio, а также работа с ядром анализатора из командной строки.
- V1102. Unreal Engine. Violation of naming conventions may cause Unreal Header Tools to work incorrectly.
- V2623. MISRA. Macro identifiers should be distinct.
- V3192. Type member is used in the 'GetHashCode' method but is missing from the 'Equals' method.
- V4004. Unity Engine. New array object is returned from method and property. Using such member in performance-sensitive context can lead to decreased performance.
PVS-Studio 7.26 (9 августа 2023)
- В плагине PVS-Studio для Visual Studio Code появилась возможность анализа C и С++ проектов, использующих сборочную систему CMake. Также добавлен функционал задания baseline-уровня предупреждений, позволяющий "очистить" старый код проекта от срабатываний PVS-Studio и начать использовать анализ только на коде, написанном после внедрения анализатора.
- Плагин PVS-Studio для Qt Creator теперь позволяет проверять проекты, ориентированные на QMake, CMake или Qbs. Кроме того, стало доступным подавление срабатываний через suppress-файлы. С документацией по плагину можно ознакомиться тут.
- Библиотека Spoon, используемая Java-анализатором для разбора кода, обновлена до версии 10.3.0. Это позволяет проверять проекты, использующие JDK 20 и языковые конструкции Java 20, сохраняя обратную совместимость со всеми предыдущими версиями.
- Результаты работы анализаторов PVS-Studio теперь можно интегрировать с DefectDojo — системой агрегации и управления результатами работы инструментов обеспечения безопасности. Документация по теме здесь.
- C# анализатор теперь учитывает атрибуты 'NotNullWhen' и 'NotNullIfNotNull' в проектах, использующих nullable context.
- В C++ анализаторе был доработан механизм пользовательского аннотирования функций. Теперь можно писать аннотации для функций, находящихся на любом уровне вложенности. Кроме того, при аннотировании допускается использование имени функции без указания класса и пространства имён. Инструкция по написанию аннотаций доступна здесь.
- Страница классификации предупреждений PVS-Studio согласно списку наиболее опасных и распространённых потенциальных уязвимостей CWE Top 25 обновлена до редакции 2023 года. Анализатор позволяет обнаруживать 64% типов уязвимостей из нового списка.
- V838. Temporary object is constructed during lookup in ordered associative container. Consider using a container with heterogeneous lookup to avoid construction of temporary objects.
- V1100. Unreal Engine. Declaring a pointer to a type derived from 'UObject' in a class that is not derived from 'UObject' is dangerous. The pointer may start pointing to an invalid object after garbage collection.
- V1101. Changing the default value of a virtual function parameter in a derived class may result in unexpected behavior.
- V3191. Iteration through collection makes no sense because it is always empty.
- V4002. Unity Engine. Avoid storing consecutive concatenations inside a single string in performance-sensitive context. Consider using StringBuilder to improve performance.
- V4003. Unity Engine. Avoid capturing variable in performance-sensitive context. This can lead to decreased performance.
PVS-Studio 7.25 (7 июня 2023)
- Переработана документация по анализу в режиме коммитов и слияния веток (pull/merge requests). Также появились отдельные страницы, посвящённые использованию анализатора в AppVeyor и Buddy.
- Добавлена инструкция по интеграции результатов работы C# анализатора в SonarQube под Linux. Найти её можно здесь.
- Плагин PVS-Studio для Qt Creator теперь доступен для версий 10.0.x, а плагин для Rider теперь поддерживает версии 2022.2.3 и выше.
- Обновлены используемые анализатором версии библиотек MSBuild и Roslyn. Это позволило решить проблемы анализа C# проектов, в которых с помощью атрибутов производится генерация кода.
- Исправлено падение производительности анализа на процессорах Intel 12 поколения. Это улучшение актуально при анализе C++ проектов для сборочной системы MSBuild.
- Добавлены новые возможности файлов настройки анализа и диагностических правил (pvsconfig): указание приоритета подключения этих файлов, активация отдельных диагностик (только для C++), а также возможность игнорировать глобальные настройки из Settings.xml (только при работе через Visual Studio или PVS-Studio_Cmd.exe). Подробности в документации.
- V837. The 'emplace' / 'insert' function does not guarantee that arguments will not be copied or moved if there is no insertion. Consider using the 'try_emplace' function.
- V1098. The 'emplace' / 'insert' function call contains potentially dangerous move operation. Moved object can be destroyed even if there is no insertion.
- V1099. Using the function of uninitialized derived class while initializing the base class will lead to undefined behavior.
- V2020. The loop body contains the 'break;' / 'continue;' statement. This may complicate the control flow.
- V3190. Concurrent modification of a variable may lead to errors.
- V4001. Unity Engine. Boxing inside a frequently called method may decrease performance.
PVS-Studio 7.24 (5 апреля 2023)
- Теперь анализатор лучше понимает особенности сравнения с 'null' в проектах, использующих игровой движок Unity. Ложных срабатываний в таких проектах стало гораздо меньше, что позволяет сконцентрироваться на работе с полезными предупреждениями.
- Улучшена поддержка C# 9: теперь анализатор учитывает, что выражения с постфиксом '!' (null-forgiving operator) не возвращают 'null'. Однако, вне зависимости от наличия постфикса анализатор продолжит выдавать предупреждения на разыменования выражений, значения которых точно равны 'null'.
- В плагине для Visual Studio был серьёзно расширен интерфейс для работы с файлами подавления (*.suppress). Теперь можно иметь несколько таких файлов в каждом проекте, просматривать предупреждения из выбранных suppress-файлов, перемещать срабатывания из одного suppress-файла в другой и т. д. Подробности в документации.
- В утилитах PVS-Studio_Cmd.exe и pvs-studio-dotnet появился новый режим suppression, позволяющий подавлять предупреждения по кодам диагностик, группе или путям к файлам, а также дающий возможность добавления новых suppress-файлов в проект и многое другое. Подробнее о новом режиме можно прочитать в документации.
- Улучшено нахождение специализаций шаблонов классов при работе диагностик C++ анализатора PVS-Studio.
- V1095. Usage of potentially invalid handle. The value should be non-negative.
- V1096. Variable with static storage duration is declared inside the inline function with external linkage. This may lead to ODR violation.
- V1097. Line splice results in a character sequence that matches the syntax of a universal-character-name. Using this sequence lead to undefined behavior.
- V3187. Parts of an SQL query are not delimited by any separators or whitespaces. Executing this query may lead to an error.
- V3188. The value of an expression is a potentially destroyed Unity object or null. Member invocation on this value may lead to an exception.
- V3189. The assignment to a member of the readonly field will have no effect when the field is of a value type. Consider restricting the type parameter to reference types.
PVS-Studio 7.23 (8 февраля 2023)
- Плагин PVS-Studio стал доступен для Qt Creator версий 9.0.x. Также его можно теперь использовать не только под Windows и Linux, но и под macOS на архитектуре x86-64.
- В документацию добавлено описание файла конфигурации Settings.xml, предназначенного для настройки анализа в IDE плагинах PVS-Studio.
- Исправлена проблема запуска Java анализатора PVS-Studio из-за ненайденных библиотек зависимостей на некоторых дистрибутивах Linux.
- Теперь CMake модуль корректно работает на проектах, использующих генератор NMake и содержащих большое количество файлов.
- V1093. The result of the right shift operation will always be 0. The right operand is greater than or equal to the number of bits in the left operand.
- V1094. Conditional escape sequence in literal. Its representation is implementation-defined.
- V3184. The argument's value is greater than the size of the collection. Passing the value into the 'Foo' method will result in an exception.
- V3185. An argument containing a file path could be mixed up with another argument. The other function parameter expects a file path instead.
- V3186. The arguments violate the bounds of collection. Passing these values into the method will result in an exception.
PVS-Studio 7.22 (7 декабря 2022)
- Выпустили плагин PVS-Studio для Visual Studio Code. В нём можно работать с отчётами анализатора: смотреть предупреждения, фильтровать их и т. п. Запускать анализ кода пока нельзя — планируем добавить эту возможность в следующих релизах. Документация — здесь.
- Выпустили плагин PVS-Studio для Qt Creator. Функциональность та же, что и у плагина для Visual Studio Code: можно работать с отчётами, но анализ пока запускать нельзя. Документация — здесь.
- Улучшили механизм Best Warnings: доработали алгоритмы и скорректировали "веса" диагностик — выборка самых интересных предупреждений должна стать лучше. Поменяли интерфейс: кнопка фильтрации теперь расположена на основной панели главного окна PVS-Studio. Если нужно, её можно скрыть в настройках (опция "Show Best Warnings Button"). Обновлённая документация о Best Warnings — по ссылке.
- Best Warnings теперь доступен не только в плагине для Visual Studio, но и в утилите C and C++ Compiler Monitoring UI, а также в плагинах для IntelliJ IDEA, Rider, CLion.
- В PVS-Studio C# поддержали анализ проектов, использующих .NET 7 и C# 11. Сам C# анализатор под Linux и macOS теперь работает на .NET 7.
- С помощью C# анализатора теперь можно проверять блоки @code в .razor файлах. Это поможет проводить более глубокий анализ веб-проектов.
- В утилитах PlogConverter и plog-converter доступны новые возможности фильтрации отчетов анализатора. Можно отфильтровать предупреждения и оставить только те, которые выданы на определённые файлы (флаг ‑‑includePaths). Можно сделать обратное: исключить из отчёта предупреждения, выданные на указанные файлы (‑‑excludePaths). Подробности описали в документации.
- V836. Decreased performance. Unnecessary copying is detected when declaring a variable. Consider declaring the variable as a reference.
- V2018. Cast should not remove 'const' qualifier from the type that is pointed to by a pointer or a reference.
- V2019. Cast should not remove 'volatile' qualifier from the type that is pointed to by a pointer or a reference.
- V3183. Code formatting implies that the statement should not be a part of the 'then' branch that belongs to the preceding 'if' statement.
- V5626. OWASP. Possible ReDoS vulnerability. Potentially tainted data is processed by regular expression that contains an unsafe pattern.
- V5627. OWASP. Possible NoSQL injection. Potentially tainted data is used to create query.
- V5628. OWASP. Possible Zip Slip vulnerability. Potentially tainted data is used in the path to extract the file.
PVS-Studio 7.21 (11 октября 2022)
- Добавили возможность конвертации результатов работы анализаторов PVS-Studio в отчёт, совместимый с GitLab Code Quality. В документации описали, как это сделать.
- Продолжаем улучшать интеграцию PVS-Studio с Unreal Engine. Сделали pull request, который позволит использовать больше настроек анализатора при работе с UE-проектами. Например, можно будет указывать таймаут для анализа файлов из UE-проекта. Изменения уже закоммичены в код движка и будут доступны в следующей версии Unreal Engine.
- Unreal Engine проекты теперь можно проверять не только на Windows, но и на Linux. Подробности описали в документации.
- PVS-Studio теперь лучше работает с большим количеством типов, специфичных для Unreal Engine.
- Собрали на отдельной странице документации всю информацию о файлах конфигурации диагностик (.pvsconfig-файлы).
- Добавили возможность автоматически фильтровать предупреждения анализатора, сообщения которых содержат указанный текст. Это позволит подавлять предупреждения конкретных диагностик по шаблону, не отключая диагностики целиком. Описать такой фильтр можно в .pvsconfig-файлах (C++, C#) или прямо в коде (только C++).
- Плагин PVS-Studio для Visual Studio теперь поддерживает работу с файлами подавления в формате JSON, который раньше поддерживался только в Linux и macOS утилитах. Это упрощает кроссплатформенные сценарии работы с подавленными предупреждениями. Внедрить PVS-Studio в кроссплатформенные проекты с legacy-кодом также станет легче.
- V1090. The 'std::uncaught_exception' function is deprecated since C++17 and is removed in C++20. Consider replacing this function with 'std::uncaught_exceptions'.
- V1091. The pointer is cast to an integer type of a larger size. Casting pointer to a type of a larger size is an implementation-defined behavior.
- V1092. Recursive function call during the static/thread_local variable initialization might occur. This may lead to undefined behavior.
- V3178. Calling method or accessing property of potentially disposed object may result in exception.
- V3179. Calling element access method for potentially empty collection may result in exception.
- V3180. The 'HasFlag' method always returns 'true' because the value '0' is passed as its argument.
- V3181. The result of '&' operator is '0' because one of the operands is '0'.
- V3182. The result of '&' operator is always '0'.
PVS-Studio 7.20 (10 августа 2022)
- В Unreal Engine 5.0.3 исправили баг с поиском PVS-Studio: теперь анализ можно проводить без workaround'ов.
- Улучшили анализ проектов на основе Unreal Engine. PVS-Studio теперь выдаёт меньше ложных предупреждений и больше знает о специфичных для движка типах. Например, об аналогах контейнеров из стандартной библиотеки C++.
- PVS-Studio теперь умеет искать зависимости с известными уязвимостями в C# проектах. Для этого он выполняет анализ компонентного состава ПО (SCA, Software Composition Analysis). Подробнее можно почитать в документации к диагностическому правилу V5625.
- PVS-Studio покрывает все категории из списка OWASP Top 10 2021. Последнюю, А06, мы покрыли, реализовав SCA. На специальной странице можно посмотреть, какие диагностические правила анализатора ищут дефекты безопасности из каждой категории OWASP Top 10 2021.
- Для кроссплатформенного анализа C и C++ проектов используются специальные утилиты: pvs-studio-analyzer и CompilerCommandsAnalyzer. Теперь они лучше определяют компиляторы, которые используется в проекте. Если понять тип компилятора не удастся, указать его можно явно. Это особенно полезно в сфере embedded-разработки, где компиляторы имеют множество разных имён. Подробнее можно почитать здесь: флаг '‑‑compiler'.
- В эти же утилиты (pvs-studio-analyzer и CompilerCommandsAnalyzer) мы внесли ряд улучшений, чтобы сделать кроссплатформенную проверку C и C++ проектов удобнее. Сценарии их использования, флаги запуска и коды возврата описали в новом разделе документации.
- Поддержали анализ проектов на основе базы данных компиляции (compile_commands.json), созданной в Qt Creator. Здесь можно прочитать, как её сгенерировать.
- Поддержали последние версии IDE от JetBrains (Rider, CLion, IntelliJ IDEA) – 2022.2.
- V1086. Call of the 'Foo' function will lead to buffer underflow.
- V1087. Upper bound of case range is less than its lower bound. This case may be unreachable.
- V1088. No objects are passed to the 'std::scoped_lock' constructor. No locking will be performed. This can cause concurrency issues.
- V1089. Waiting on condition variable without predicate. A thread can wait indefinitely or experience a spurious wake up.
- V3177. Logical literal belongs to second operator with a higher priority. It is possible literal was intended to belong to '??' operator instead.
- V5624. OWASP. Use of potentially tainted data in configuration may lead to security issues.
- V5625. OWASP. Referenced package contains vulnerability.
PVS-Studio 7.19 (8 июня 2022)
- Обновлена документация об использовании PVS-Studio для проверки проектов, использующих игровой движок Unreal Engine. Обновлённая версия описывает различия при настройке анализа для разных версий движка, настройки исключения файлов из анализа, интеграции с IDE, а также подавлении срабатываний анализатора на legacy коде. Важно: несмотря на то, что PVS-Studio можно использовать с последними версиями Unreal Engine версий 5.0 и выше, в механизме интеграции PVS-Studio и Unreal Engine 5 остаётся неразрешённая проблема, вызванная багом на стороне сборочной системы самого движка. Мы работаем с разработчиками движка для исправления данной проблемы. Доступные на данный момент workaround'ы для решения проблемы также описаны в документации PVS-Studio.
- В C++ анализаторе PVS-Studio улучшено определение целевой платформы для компиляторов семейства QNX Momentics QCC. Неправильное определение платформы в прошлых версиях анализатора могло приводить к ложным срабатываниям.
- В расширении PVS-Studio для системы непрерывного контроля качества кода SonarQube добавлена поддержка загрузки отчёта в кроссплатформенном формате JSON. Это позволяет использовать одинаковый формат отчёта независимо от платформы, на которой используется анализатор.
- В продолжение предыдущего пункта - подробнее про все виды отчётов, поддерживаемых различными утилитами PVS-Studio на разных платформах, а также про возможности преобразования отчётов из одних форматов в другие, можно прочитать в новом разделе документации на нашем сайте.
- В утилите для автоматического оповещения разработчиков blame-notifier добавлена возможность управлять содержимым отправляемых уведомлений: можно прикреплять к письму файлы (включая полный отчёт анализатора), а также задавать тему письма.
- Добавлена возможность проверять Unreal Engine проекты с помощью бесплатной лицензии PVS-Studio. Напомним, что бесплатная лицензия доступна для студентов при добавлении в проверяемый исходный код специальных комментариев. В предыдущих версиях PVS-Studio проверка Unreal Engine проектов ограничивалась только лицензиями Enterprise-уровня.
- V834. Incorrect type of a loop variable. This leads to the variable binding to a temporary object instead of a range element.
- V835. Passing cheap-to-copy argument by reference may lead to decreased performance.
- V1083. Signed integer overflow in arithmetic expression. This leads to undefined behavior.
- V1084. The expression is always true/false. The value is out of range of enum values.
- V1085. Negative value is implicitly converted to unsigned integer type in arithmetic expression.
- V3175. Locking operations must be performed on the same thread. Using 'await' in a critical section may lead to a lock being released on a different thread.
- V3176. The '&'= or '|=' operator is redundant because the right operand is always true/false.
- V5622. OWASP. Possible XPath injection. Potentially tainted data is used in the XPath expression.
- V5623. OWASP. Possible open redirect vulnerability. Potentially tainted data is used in the URL.
PVS-Studio 7.18 (6 апреля 2022)
- PVS-Studio расширил покрытие списка наиболее распространённых угроз защищённости Web-приложений OWASP Top 10 версии 2021 года. На данный момент покрыты 9 из 10 категорий. Мы планируем покрыть оставшуюся категорию, A6 Vulnerable and Outdated Components, в одном из будущих релизов, добавив в C# анализатор PVS-Studio проверку компонентного состава ПО (SCA, Software Composition Analysis).
- В этом релизе С и C++ анализатор PVS-Studio получает обновлённую систему семантического анализа, основанную на улучшенном представлении системы типов данных проверяемого кода. Внедрение нового представления системы типов данных позволило анализатору начать значительно лучше разбирать современный язык C++, сложные конструкции, использующие шаблоны, стандартную библиотеку языка. Благодаря этому очень многие диагностических правила анализатора смогут находить больше потенциально опасных мест, а также будут меньше ошибаться. Тем не менее, учитывая фундаментальный характер данного нововведения, возможно также и появление новых ложно-позитивных срабатываний. Если вы столкнулись с такими ложными срабатываниями после обновления на данную версию анализатора, пожалуйста, напишите о них в нашу поддержку - мы всегда стараемся оперативно исправлять ошибки в работе анализатора.
- В системе отслеживания компиляции для Windows поддержан режим "оборачивания" отслеживаемых процессов с помощью настроек IFEO (Image File Execution Options). Система отслеживания компиляции (compiler monitoring) - это универсальный способ "бесшовной" интеграции с любой сборочной системой, использующей компиляторы, поддерживаемые анализатором PVS-Studio. Новый режим запуска требует небольшой дополнительной конфигурации перед использованием, однако позволяет устранить существенный недостаток системы отслеживания компиляции - пропуск недолгоживущих процессов. Данная проблема особенна актуальна при компиляции C кода для embedded платформ. Новый режим анализа позволяет проверять такой код без пропусков файлов.
- В нашей документации появился раздел, описывающий работу с результатами анализа PVS-Studio в редакторе кода Visual Studio Code. Благодаря возможности преобразовать отчёт PVS-Studio в универсальный формат SARIF, этот отчёт можно теперь просматривать в Visual Studio Code с помощью расширения SARIF Viewer.
- В документации PVS-Studio появился раздел про прямую интеграцию с системой автоматизации сборки CMake с помощью специализированного PVS-Studio модуля. Поддержана работа CMake модуля PVS-Studio на операционных системах Microsoft Windows, а также работа с suppress файлами.
- Ещё один новый раздел документации PVS-Studio - интеграция статического анализа в платформу облачного CI GitHub Actions.
- В C++ анализаторе для Visual Studio поддержана проверка проектов Microsoft GDK (Game Development Kit).
- В утилите для преобразования отчётов plog-converter добавлена поддержка многострочной навигации для нескольких форматов: errorfile, tasklist, SARIF.
- V1079. Parameter of 'std::stop_token' type is not used inside function's body.
- V1080. Call of 'std::is_constant_evaluated' function always returns the same value.
- V1081. Argument of abs() function is minimal negative value. Such absolute value can't be represented in two's complement. This leads to undefined behavior.
- V1082. Function marked as 'noreturn' may return control. This will result in undefined behavior.
- V5619. OWASP. Possible log injection. Potentially tainted data is written into logs.
- V5620. OWASP. Possible LDAP injection. Potentially tainted data is used in a search filter.
- V5621. OWASP. Error message contains potentially sensitive data that may be exposed.
PVS-Studio 7.17 (9 февраля 2022)
- В анализатор PVS-Studio для языков C и C++ добавлена поддержка проверки проектов предназначенных для C6000-CGT - компилятора для встраиваемых систем от Texas Instruments. Полный список поддерживаемых PVS-Studio платформ и компиляторов можно посмотреть здесь.
- Добавлена возможность напрямую работать с файлами подавления предупреждений (подавлять и сбрасывать подавление) в Unreal Engine проектах из IDE расширений PVS-Studio для Microsoft Visual Studio и JetBrains Rider. Подробнее про подавление сообщений в Unreal Engine проектах из командной стоки и с помощью IDE можно почитать в нашей документации (разделы 'Подавление предупреждений в Unreal Engine проектах' и 'Подавление предупреждений анализатора в плагинах PVS-Studio для CLion и Rider.').
- В C# анализатор PVS-Studio добавлены новые аннотации для наиболее часто используемых классов из библиотек ASP.NET Core. Это позволит C# анализатору лучше понимать код, написанный для проектов, использующих ASP.NET.
- В кроссплатформенных инструментах для анализа LLVM Compilation Database и трассировки вызовов и конвертации отчётов (plog-converter и pvs-studio-analyzer) частично изменён алгоритм генерации хэш-сумм, используемых в файлах подавления предупреждений в json формате. Поддерживается работа с файлами подавления старого формата в режиме обратной совместимости. При необходимости пополнения файлов подавления мы рекомендуем перегенерировать файлы подавления в новом формате. Данное изменение направлено на обеспечение, в предстоящих релизах PVS-Studio, полной кроссплатформенности json файлов подавления во всех сценариях работы анализатора.
- V1077. Constructor contains potentially uninitialized members.
- V1078. An empty container is iterated. The loop will not be executed.
- V2017. String literal is identical to variable name. It is possible that the variable should be used instead of the string literal.
- V3174. Suspicious subexpression in a sequence of similar comparisons.
- V5617. OWASP. Assigning potentially negative or large value as timeout of HTTP session can lead to excessive session expiration time.
- V5618. OWASP. Possible server-side request forgery. Potentially tainted data is used in the URL.
PVS-Studio 7.16 (8 декабря 2021)
- В PVS-Studio добавлена поддержка Microsoft Visual Studio 2022. Анализатор можно использовать для работы с Visual C++ и C# проектами для новых версий компиляторов и стандартных C++ и .NET библиотек, которые стали доступны с новой версией данной IDE.
- В C# анализаторе PVS-Studio добавлена поддержка платформы Microsoft .NET 6 для Windows, Linux и macOS, а также новой версии языка: C# 10.0.
- Поддержка стандарта обеспечения безопасности и надёжности MISRA C в PVS-Studio доведена до 80%, полностью покрыта Mandatory, а также большая часть Required категорий. В предстоящих релизах мы планируем уделить больше внимания другим стандартам безопасности, а также диагностикам общего назначения.
- Механизм отключения выдачи предупреждений на существующем коде (baseline разметка, подавление предупреждений) дополнен для работы с Unreal Engine проектами. В данном релизе baseline механизм можно использовать для UE проектов в версии анализатора PVS-Studio для командной строки. В следующей версии PVS-Studio также будет расширена поддержка подавления предупреждений при работе с UE проектами напрямую из сред разработки Microsoft Visual Studio и JetBrains Rider.
- В документации появился новый раздел, в котором описано использование PVS-Studio для проверки проектов, позволяющих сгенерировать описание сборочного процесса в формате JSON Compilation Database. Данный метод подходит для проектов на основе CMake, QBS, Ninja, и т.п.
- В плагинах PVS-Studio для JetBrains IDEA, Rider и CLion добавлена возможность переназначения shortcut'ов для наиболее часто используемых действий по проверке проектов и работе с результатами анализа.
- V833. Using 'std::move' function with const object disables move semantics.
- V1076. Code contains invisible characters that may alter its logic. Consider enabling the display of invisible characters in the code editor.
- V2615. MISRA. A compatible declaration should be visible when an object or function with external linkage is defined.
- V2616. MISRA. All conditional inclusion preprocessor directives should reside in the same file as the conditional inclusion directive to which they are related.
- V2617. MISRA. Object should not be assigned or copied to an overlapping object.
- V2618. MISRA. Identifiers declared in the same scope and name space should be distinct.
- V2619. MISRA. Typedef names should be unique across all name spaces.
- V2620. MISRA. Value of a composite expression should not be cast to a different essential type category or a wider essential type.
- V2621. MISRA. Tag names should be unique across all name spaces.
- V2622. MISRA. External object or function should be declared once in one and only one file.
- V5616. OWASP. Possible command injection. Potentially tainted data is used to create OS command.
PVS-Studio 7.15 (7 октября 2021)
- В Visual Studio плагине PVS-Studio появилась возможность легко посмотреть лучшие срабатывания анализатора среди найденных в проверенном проекте. Мы называем этот новый режим Analyzer Best Warnings. PVS-Studio всегда группировал срабатывания анализатора по 3-м уровням достоверности, и эти уровни традиционно использовались для приоритезации просмотра результатов анализа - все лучшие предупреждения должны попадать на 1-ый уровень. В новой версии анализатора мы разработали более точный алгоритм оценки достоверности предупреждений, использующий, помимо уровней, много дополнительных критериев - как статических (средняя "ценность" диагностики), так и динамических, основанных на срабатываниях анализатора на конкретной кодовой базе (как, например, частота обнаружения). В будущих релизах мы планируем расширять возможности нового режима оценки предупреждений, а также добавить его поддержку в другие IDE плагины и режимы интеграции анализа. Подробнее про работу режима Analyzer Best Warnings можно почитать в нашем блоге и документации.
- На нашем сайте появилось сопоставление диагностик анализатора PVS-Studio со списком наиболее опасных и распространённых потенциальных уязвимостей CWE Top 25. Анализаторы PVS-Studio для языков C, C++, C# и Java покрывают уже более половины категорий в данном списке, и в будущих релизах мы планируем увеличивать процент его покрытия.
- Улучшено качество анализа проектов для Unreal Engine - в C++ анализаторе PVS-Studio были дополнительно проаннотированы несколько сотен стандартных функций из этого игрового движка.
- С этим релизом мы увеличили покрытие списка наиболее распространённых и опасных угроз защищённости приложений OWASP Top 10 2017 до 9-ти из 10-ти категорий. Таким образом, в данном списке осталась лишь одна не поддерживаемая в PVS-Studio категория - использование компонентов с известными уязвимостями. Данная категория относится к классу инструментов, известных, как SCA (Software Composition Analysis). В будущих релизах, для полного закрытия OWASP Top 10, мы планируем реализовать SCA в PVS-Studio C# анализаторе.
- Поддержка стандарта обеспечения безопасности и надёжности MISRA C в PVS-Studio достигла 70%. До конца этого года мы планируем увеличить поддержку MISRA C не менее, чем до 80%.
- В Visual Studio плагине добавлена возможность задавать shortcut'ы для операций подавления ложных срабатываний и разметки предупреждений.
- В утилитах для конвертации отчётов поддержана генерация отчёта соответствия на основе стандарта MISRA Compliance. Подробнее про этот формат и генерацию отчёта о соответствии MISRA можно почитать в нашем блоге.
- Очередная оптимизация производительности C# анализатора PVS-Studio позволит ускорить проверку крупных проектов за счёт значительного уменьшения времени подготовки (разбора) проекта перед анализом. Подробнее почитать про это можно в нашем блоге.
- В C++ анализаторе PVS-Studio был стандартизован формат выдачи диапазона значений переменных для больших чисел. Изменение текста некоторых сообщений может привести к тому, что они вновь появятся в отчёте, хотя ранее были подавлены с помощью baselining механизма. Если вы столкнулись с этим - пожалуйста, подавите эти предупреждения заново.
- V1075. The function expects the file to be opened in one mode, but it was opened in different mode.
- V2604. MISRA. Features from <stdarg.h> should not be used.
- V2605. MISRA. Features from <tgmath.h> should not be used.
- V2606. MISRA. There should be no attempt to write to a stream that has been opened for reading.
- V2607. MISRA. Inline functions should be declared with the static storage class.
- V2608. MISRA. The 'static' storage class specifier should be used in all declarations of object and functions that have internal linkage.
- V2609. MISRA. There should be no occurrence of undefined or critical unspecified behaviour.
- V2610. MISRA. The ', " or \ characters and the /* or // character sequences should not occur in a header file name.
- V2611. MISRA. Casts between a pointer to an incomplete type and any other type shouldn't be performed.
- V2612. MISRA. Array element should not be initialized more than once.
- V2613. MISRA. Operand that is a composite expression has more narrow essential type than the other operand.
- V2614. MISRA. External identifiers should be distinct.
- V3173. Possible incorrect initialization of variable. Consider verifying the initializer.
- V3555. AUTOSAR. The 'static' storage class specifier should be used in all declarations of functions that have internal linkage.
- V5612. OWASP. Do not use old versions of SSL/TLS protocols as it may cause security issues.
- V5613. OWASP. Use of outdated cryptographic algorithm is not recommended.
- V5614. OWASP. Potential XXE vulnerability. Insecure XML parser is used to process potentially tainted data.
- V5615. OWASP. Potential XEE vulnerability. Insecure XML parser is used to process potentially tainted data.
PVS-Studio 7.14 (9 августа 2021)
- PVS-Studio теперь можно удобно использовать в среде разработки JetBrains CLion с помощью плагина для данной IDE. Подробнее о том, с чем мы столкнулись при разработке CLion плагина, можно почитать в нашем блоге. А здесь можно посмотреть на все IDE от JetBrains, работу с которыми уже поддерживает PVS-Studio.
- В С++ анализатор PVS-Studio добавлена поддержка межмодульного анализа. В этом режиме анализатор при разборе кода учитывает результаты вызовов методов, объявленных в других единицах трансляции. Межмодульный анализ также есть в C# (на уровне проектов) и Java (на уровне пакетов) анализаторах PVS-Studio. В С++ анализаторе данный режим не активирован по умолчанию, т.к. он может замедлять скорость анализа. В нашем блоге можно почитать подробнее об особенностях его реализации и работы.
- Теперь PVS-Studio обеспечивает покрытие 6-ти из 10-ти категорий в OWASP Top 10 - списке наиболее распространённых и опасных угроз защищённости Web-приложений. В этом релизе мы добавили в анализатор диагностики для категорий A5 Broken Access Control, A7 Cross-Site Scripting (XSS) и A8 Insecure Deserialization. В будущих релизах в этом году мы планируем увеличить покрытие до 9-ти категорий.
- Поддержка стандарта обеспечения безопасности и надёжности MISRA C в PVS-Studio составляет теперь 60%. В предстоящих релизах в этом году мы планируем увеличить поддержку этого стандарта как минимум до 80%, а также реализовать поддержку стандарта проверки соответствия кода MISRA C Compliance.
- В плагин PVS-Studio для SonarQube добавлена поддержка версии SonarQube 8.9 LTS.
- Скорость анализа в C# анализаторе PVS-Studio была увеличена до 2-х раз при анализе крупных (более 10 000 исходных файлов) проектов. Также C# анализатор теперь значительно эффективнее использует многоядерные процессоры. В нашем блоге мы поделились методиками, которые использовали для ускорения работы C# анализатора, и которые могут подойти и для других классов .NET приложений.
- В C++ анализаторе PVS-Studio теперь можно отключать диагностические правила для заданного диапазона строк в исходном файле.
- V2015. An identifier declared in an inner scope should not hide an identifier in an outer scope.
- V2016. Consider inspecting the function call. The function was annotated as dangerous.
- V2584. MISRA. Expression used in condition should have essential Boolean type.
- V2585. MISRA. Casts between a void pointer and an arithmetic type should not be performed.
- V2586. MISRA. Flexible array members should not be declared.
- V2587. MISRA. The '//' and '/*' character sequences should not appear within comments.
- V2588. MISRA. All memory or resources allocated dynamically should be explicitly released.
- V2589. MISRA. Casts between a pointer and a non-integer arithmetic type should not be performed.
- V2590. MISRA. Conversions should not be performed between pointer to function and any other type.
- V2591. MISRA. Bit fields should only be declared with explicitly signed or unsigned integer type.
- V2592. MISRA. An identifier declared in an inner scope should not hide an identifier in an outer scope.
- V2593. MISRA. Single-bit bit fields should not be declared as signed type.
- V2594. MISRA. Controlling expressions should not be invariant.
- V2595. MISRA. Array size should be specified explicitly when array declaration uses designated initialization.
- V2596. MISRA. The value of a composite expression should not be assigned to an object with wider essential type.
- V2597. MISRA. Cast should not convert pointer to function to any other pointer type.
- V2598. MISRA. Variable length array types are not allowed.
- V2599. MISRA. The standard signal handling functions should not be used.
- V2600. MISRA. The standard input/output functions should not be used.
- V2601. MISRA. Functions should be declared in prototype form with named parameters.
- V2602. MISRA. Octal and hexadecimal escape sequences should be terminated.
- V2603. MISRA. The 'static' keyword shall not be used between [] in the declaration of an array parameter.
- V3172. The 'if/if-else/for/while/foreach' statement and code block after it are not related. Inspect the program's logic.
- V3552. AUTOSAR. Cast should not convert a pointer to a function to any other pointer type, including a pointer to function type.
- V3553. AUTOSAR. The standard signal handling functions should not be used.
- V3554. AUTOSAR. The standard input/output functions should not be used.
- V5609. OWASP. Possible path traversal vulnerability. Potentially tainted data is used as a path.
- V5610. OWASP. Possible XSS vulnerability. Potentially tainted data might be used to execute a malicious script.
- V5611. OWASP. Potential insecure deserialization vulnerability. Potentially tainted data is used to create an object using deserialization.
PVS-Studio 7.13 (31 мая 2021)
- C# анализатор PVS-Studio теперь поддерживает проверку проектов для платформы .NET 5. Подробнее про это можно прочитать в нашем блоге.
- В C# анализаторе PVS-Studio появилась первое диагностическое правило из стандарта OWASP ASVS, ищущее в коде ошибки, связанные с непроверенными данными (tainted data): поиск потенциальных SQL инъекций (диагностическое правило V5608). Данный класс ошибок занимает важное место в рейтинге OWASP Top 10, и в будущих релизах PVS-Studio мы будем добавлять диагностические правила для поиска множества других видов потенциальных tainted data уязвимостей.
- Утилита Blame Notifier для автоматической рассылки отчётов о найденных анализатором предупреждениях на основе blame информации из системы контроля версий теперь может сортировать предупреждения по номерам и датам коммитов. Это позволяет видеть предупреждения на код, появившиеся только за определённый день. Подробнее про новый режим работы можно почитать в нашем блоге.
- Продолжая тему автоматической публикации отчётов, теперь можно это делать не только с помощью Blame Notifier. Наш пользователь написал легковесный аналог (не требующий .NET для работы) данной утилиты, который вы можете попробовать на GitHub.
- В C++ анализаторе улучшена поддержка проверки Ninja проектов на Windows с использованием JSON Compilation Database (compile_commands.json).
- Использование компилятора Clang для сборки C++ анализатора PVS-Studio позволило ускорить до 10% его работу при проверке исходных файлов на операционных системах Windows.
- Плагин PVS-Studio для JetBrains Rider теперь поддерживает работу с версией Rider 2021.1.
- В утилиту для проверки C++ и C# Visual Studio проектов PVS-Studio_Cmd.exe добавлена возможность передавать файл подавленных сообщений напрямую через командную строку. До этого подавленные сообщения можно было добавлять только на уровне проектов и solution'а.
- V832. It's better to use '= default;' syntax instead of empty body.
- V1070. Signed value is converted to an unsigned one with subsequent expansion to a larger type in ternary operator.
- V1071. Consider inspecting the 'foo' function. The return value is not always used.
- V1072. The buffer is securely cleared not on all execution paths.
- V1073. Consider checking for misprints. Check the following code block after the 'if' statement.
- V1074. Boundary between numeric escape sequence and string is unclear. The escape sequence ends with a letter and the next character is also a letter. Check for typos.
- V2577. MISRA. The function argument corresponding to a parameter declared to have an array type should have an appropriate number of elements.
- V2578. MISRA. An identifier with array type passed as a function argument should not decay to a pointer.
- V2579. MISRA. Macro should not be defined with the same name as a keyword.
- V2580. MISRA. The 'restrict' specifier should not be used.
- V2581. MISRA. Single-line comments should not end with a continuation token.
- V2582. MISRA. Block of memory should only be freed if it was allocated by a Standard Library function.
- V2583. MISRA. Line whose first token is '#' should be a valid preprocessing directive.
- V3170. Both operands of the '??' operator are identical.
- V3171. Potentially negative value is used as the size of an array.
- V3551. AUTOSAR. An identifier with array type passed as a function argument should not decay to a pointer.
- V5013. OWASP. Storing credentials inside source code can lead to security issues.
- V5608. OWASP. Possible SQL injection. Potentially tainted data is used to create SQL command.
PVS-Studio 7.12 (11 марта 2021)
- Добавлено сопоставление диагностических правил PVS-Studio с рейтингом наиболее опасных угроз защищённости Web-приложений OWASP Top 10. Данный рейтинг основан на общем мнении экспертов по вопросам безопасности со всего мира и помогает разработчикам и экспертам по безопасности обнаруживать и своевременно устранять риски в разрабатываемых ими приложениях.
- Расширены возможности для работы со стандартами обеспечения безопасности (MISRA C, MISRA C++, AUTOSAR C++ 14 Coding Guidelines) и защищённости (SEI CERT, OWASP ASVS). Теперь сопоставление диагностических правил анализатора с этими стандартами доступно не только в виде таблиц на наших web ресурсах, но также выдаётся во всех видах отчётов анализатора (XML, Json, HTML и т.д.), поддержано в IDE интеграциях PVS-Studio (Visual Studio, IntelliJ IDEA, Jetbrains Rider), плагине для SonarQube (тэги и раздел Security Category). Подробнее про новые возможности PVS-Studio для работы с данными стандартами можно почитать в нашем блоге.
- Реализована поддержка ARM компилятора IAR и компилятора QNX для Linux версии C++ анализатора PVS-Studio
- В утилиту для отслеживания вызовов C++ компилятора CLMonitor.exe добавлен режим проверки списка файлов с учётом зависимостей компиляции между исходными и заголовочными файлами. Данный режим можно использовать для автоматизации проверки merge и pull request'ов.
- Добавлена возможность отключать отдельные диагностики и группы диагностик в .pvsconfig файлах и управляющих комментариях (только для C++ анализатора) в зависимости от уровней достоверности срабатываний. Подробнее об этом режиме можно прочитать в нашей документации (подраздел 'Полное отключение предупреждений').
- Добавлена поддержка проверки проектов, использующих компилятор MPLAB XC8.
- V1068. Do not define an unnamed namespace in a header file.
- V1069. Do not concatenate string literals with different prefixes.
- V2575. MISRA. The global namespace should only contain 'main', namespace declarations and 'extern "C"' declarations.
- V2576. The identifier 'main' should not be used for a function other than the global function 'main'.
- V3167. Parameter of 'CancellationToken' type is not used inside function's body.
- V3168. Awaiting on expression with potential null value can lead to throwing of 'NullReferenceException'.
- V3169. Suspicious return of a local reference variable which always equals null.
- V3501. AUTOSAR. Octal constants should not be used.
- V3502. AUTOSAR. Size of an array is not specified.
- V3503. AUTOSAR. The 'goto' statement shouldn't jump to a label declared earlier.
- V3504. AUTOSAR. The body of a loop\conditional statement should be enclosed in braces.
- V3505. AUTOSAR. The function with the 'atof/atoi/atoll/atoll' name should not be used.
- V3506. AUTOSAR. The function with the 'abort/exit/getenv/system' name should not be used.
- V3507. AUTOSAR. The macro with the 'setjmp' name and the function with the 'longjmp' name should not be used.
- V3508. AUTOSAR. Unbounded functions performing string operations should not be used.
- V3509. AUTOSAR. Unions should not be used.
- V3510. AUTOSAR. Declaration should contain no more than two levels of pointer nesting.
- V3511. AUTOSAR. The 'if' ... 'else if' construct should be terminated with an 'else' statement.
- V3512. AUTOSAR. Literal suffixes should not contain lowercase characters.
- V3513. AUTOSAR. Every switch-clause should be terminated by an unconditional 'break' or 'throw' statement.
- V3514. AUTOSAR. The 'switch' statement should have 'default' as the last label.
- V3515. AUTOSAR. All integer constants of unsigned type should have 'u' or 'U' suffix.
- V3516. AUTOSAR. A switch-label should only appear at the top level of the compound statement forming the body of a 'switch' statement.
- V3517. AUTOSAR. The functions from time.h/ctime should not be used.
- V3518. AUTOSAR. A switch-expression should not have Boolean type. Consider using of 'if-else' construct.
- V3519. AUTOSAR. The comma operator should not be used.
- V3520. AUTOSAR. Any label should be declared in the same block as 'goto' statement or in any block enclosing it.
- V3521. AUTOSAR. The loop counter should not have floating-point type.
- V3522. AUTOSAR. Unreachable code should not be present in the project.
- V3523. AUTOSAR. Functions should not have unused parameters.
- V3524. AUTOSAR. The value of uninitialized variable should not be used.
- V3525. AUTOSAR. Function with a non-void return type should return a value from all exit paths.
- V3526. AUTOSAR. Expression resulting from the macro expansion should be surrounded by parentheses.
- V3527. AUTOSAR. The return value of non-void function should be used.
- V3528. AUTOSAR. The address of an object with local scope should not be passed out of its scope.
- V3529. AUTOSAR. Floating-point values should not be tested for equality or inequality.
- V3530. AUTOSAR. Variable should be declared in a scope that minimizes its visibility.
- V3531. AUTOSAR. Expressions with enum underlying type should have values corresponding to the enumerators of the enumeration.
- V3532. AUTOSAR. Unary minus operator should not be applied to an expression of the unsigned type.
- V3533. AUTOSAR. Expression containing increment (++) or decrement (--) should not have other side effects.
- V3534. AUTOSAR. Incorrect shifting expression.
- V3535. AUTOSAR. Operand of sizeof() operator should not have other side effects.
- V3536. AUTOSAR. A pointer/reference parameter in a function should be declared as pointer/reference to const if the corresponding object was not modified.
- V3537. AUTOSAR. Subtraction, >, >=, <, <= should be applied only to pointers that address elements of the same array.
- V3538. AUTOSAR. The result of an assignment expression should not be used.
- V3539. AUTOSAR. Array indexing should be the only form of pointer arithmetic and it should be applied only to objects defined as an array type.
- V3540. AUTOSAR. There should be no implicit integral-floating conversion.
- V3541. AUTOSAR. A function should not call itself either directly or indirectly.
- V3542. AUTOSAR. Constant expression evaluation should not result in an unsigned integer wrap-around.
- V3543. AUTOSAR. Cast should not remove 'const' / 'volatile' qualification from the type that is pointed to by a pointer or a reference.
- V3544. AUTOSAR. The 'operator &&', 'operator ||', 'operator ,' and the unary 'operator &' should not be overloaded.
- V3545. AUTOSAR. Operands of the logical '&&' or the '||' operators, the '!' operator should have 'bool' type.
- V3546. AUTOSAR. Conversions between pointers to objects and integer types should not be performed.
- V3547. AUTOSAR. Identifiers that start with '__' or '_[A-Z]' are reserved.
- V3548. AUTOSAR. Functions should not be declared at block scope.
- V3549. AUTOSAR. The global namespace should only contain 'main', namespace declarations and 'extern "C"' declarations.
- V3550. AUTOSAR. The identifier 'main' should not be used for a function other than the global function 'main'.
- V5001. OWASP. It is highly probable that the semicolon ';' is missing after 'return' keyword.
- V5002. OWASP. An empty exception handler. Silent suppression of exceptions can hide the presence of bugs in source code during testing.
- V5003. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
- V5004. OWASP. Consider inspecting the expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
- V5005. OWASP. A value is being subtracted from the unsigned variable. This can result in an overflow. In such a case, the comparison operation can potentially behave unexpectedly.
- V5006. OWASP. More than N bits are required to store the value, but the expression evaluates to the T type which can only hold K bits.
- V5007. OWASP. Consider inspecting the loop expression. It is possible that the 'i' variable should be incremented instead of the 'n' variable.
- V5008. OWASP. Classes should always be derived from std::exception (and alike) as 'public'.
- V5009. OWASP. Unchecked tainted data is used in expression.
- V5010. OWASP. The variable is incremented in the loop. Undefined behavior will occur in case of signed integer overflow.
- V5011. OWASP. Possible overflow. Consider casting operands, not the result.
- V5012. OWASP. Potentially unsafe double-checked locking.
- V5301. OWASP. An exception handling block does not contain any code.
- V5302. OWASP. Exception classes should be publicly accessible.
- V5303. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
- V5304. OWASP. Unsafe double-checked locking.
- V5305. OWASP. Storing credentials inside source code can lead to security issues.
- V5601. OWASP. Storing credentials inside source code can lead to security issues.
- V5602. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
- V5603. OWASP. The original exception object was swallowed. Stack of original exception could be lost.
- V5604. OWASP. Potentially unsafe double-checked locking. Use volatile variable(s) or synchronization primitives to avoid this.
- V5605. OWASP. Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it.
- V5606. OWASP. An exception handling block does not contain any code.
- V5607. OWASP. Exception classes should be publicly accessible.
- V6102. Inconsistent synchronization of a field. Consider synchronizing the field on all usages.
- V6103. Ignored InterruptedException could lead to delayed thread shutdown.
- V6104. A pattern was detected: A || (A && ...). The expression is excessive or contains a logical error.
- V6105. Consider inspecting the loop expression. It is possible that different variables are used inside initializer and iterator.
- V6106. Casting expression to 'X' type before implicitly casting it to other type may be excessive or incorrect.
PVS-Studio 7.11 (17 декабря 2020)
- Изменился порядок активации утилиты pvs-studio-analyzer для бесплатной версии PVS-Studio, требующей добавления комментариев в начало каждого исходного файла. Теперь перед первым запуском анализа необходимо ввести специальный лицензионный ключ командой pvs-studio-analyzer credentials PVS-Studio Free FREE-FREE-FREE-FREE.
- Для более надёжной работы механизма массового подавления предупреждений был изменён расчёт хэша сообщения для случаев, когда строка кода, на которое было выдано сообщение, содержит нелатинские символы. Это возможно, например, когда строка кода содержит комментарий. Если подобные сообщения были ранее подавлены в suppress файлах, эти сообщения могут снова появиться в отчёте анализатора - такие сообщения потребуется подавить заново.
- В утилите pvs-studio-analyzer добавлена поддержка компиляторов IAR Arm.
- В утилите pvs-studio-analyzer добавлен перехват вызовов компиляторов через ld-linux.
- V2574. MISRA. Functions shall not be declared at block scope.
- V3165. The expression of the 'char' type is passed as an argument of the 'A' type whereas similar overload with the string parameter exists.
- V3166. Calling the 'SingleOrDefault' method may lead to 'InvalidOperationException'.
- V6100. An object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' method.
- V6101. compareTo()-like methods can return not only the values -1, 0 and 1, but any values.
PVS-Studio 7.10 (5 ноября 2020)
- Возможности PVS-Studio как SAST (Static Application Security Testing) инструмента были расширены началом работы над поддержкой стандартов OWASP ASVS и AUTOSAR C++14 Coding Guidelines. Стали доступны таблицы соответствия существующих диагностик анализатора этим стандартам. В будущих релизах анализатора мы будем расширять покрытие стандартов MISRA и AUTOSAR, а также реализовывать новые диагностические правила на основе списка наиболее распространённых и критичных уязвимостей OWASP Top 10.
- В плагин PVS-Studio для JetBrains Rider добавлена поддержка работы с результатами анализа при проверке проектов для Unreal Engine (JetBrains Rider для Unreal Engine доступен сейчас по программе раннего доступа).
- SonarQube плагин PVS-Studio теперь умеет ассоциировать сообщения анализатора, имеющие CWE (Common Weakness Enumeration) идентификатор, с сообщениями о дефектах защищённости на вкладке Security Category.
- Утилиты для преобразования результатов анализа PVS-Studio (PlogConverter.exe для Windows и plog-converter для Linux\macOS) теперь поддерживают конвертацию в формат SARIF (Static Analysis Results Interchange Format). SARIF - это универсальный открытый формат для представления результатов работы инструментов, осуществляющих поиск ошибок, дефектов безопасности и защищённости. Этот формат поддерживается многими статическими анализаторами, и позволяет совместно использовать различные инструменты контроля качества кода в единых экосистемах.
- V830. Decreased performance. Consider replacing the use of 'std::optional::value()' with either the '*' or '->' operator.
- V831. Decreased performance. Consider replacing the call to the 'at()' method with the 'operator[]'.
- V1064. The left operand of integer division is less than the right one. The result will always be zero.
- V1065. Expression can be simplified: check similar operands.
- V1066. The 'SysFreeString' function should be called only for objects of the 'BSTR' type.
- V1067. Throwing from exception constructor may lead to unexpected behavior.
- V3156. The argument of the method is not expected to be null.
- V3157. Suspicious division. Absolute value of the left operand is less than the right operand.
- V3158. Suspicious division. Absolute values of both operands are equal.
- V3159. Modified value of the operand is not used after the increment/decrement operation.
- V3160. Argument of incorrect type is passed to the 'Enum.HasFlag' method.
- V3161. Comparing value type variables with 'ReferenceEquals' is incorrect because compared values will be boxed.
- V3162. Suspicious return of an always empty collection.
- V3163. An exception handling block does not contain any code.
- V3164. Exception classes should be publicly accessible.
- V6093. Automatic unboxing of a variable may cause NullPointerException.
- V6094. The expression was implicitly cast from integer type to real type. Consider utilizing an explicit type cast to avoid the loss of a fractional part.
- V6095. Thread.sleep() inside synchronized block/method may cause decreased performance.
- V6096. An odd precise comparison. Consider using a comparison with defined precision: Math.abs(A - B) < Epsilon or Math.abs(A - B) > Epsilon.
- V6097. Lowercase 'L' at the end of a long literal can be mistaken for '1'.
- V6098. A method does not override another method from the base class.
- V6099. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
PVS-Studio 7.09 (27 августа 2020)
- PVS-Studio включён в отчёт "Now Tech: Static Application Security Testing, Q3 2020" как SAST-специализированный инструмент. Использование методологии статического тестирования защищённости приложений (Static Application Security Testing, SAST) позволяет улучшить безопасность тестируемого приложения и смягчить влияние дефектов безопасности на его жизненный цикл. Forrester Research является одним из ведущих исследователей влияния развития инновационных технологий на бизнес. Отчёт об исследовании доступен для покупки подписчикам и клиентам Forrester Research.
- В C# анализаторе PVS-Studio, для Visual Studio и Rider плагинов расширены возможности навигации по исходным файлам - для межпроцедурных срабатываний добавлена возможность перехода на потенциально опасные участки кода внутри методов, когда анализатор ругается на вызов такого метода.
- Для C# анализатора PVS-Studio добавлена поддержка переопределения уровней значимости предупреждений в файлах настройки диагностик (.pvsconfig).
- V012. Some warnings could have been disabled. Для C++ анализатора PVS-Studio добавлена возможность отображать в отчёте правила исключений из файлов настройки диагностик (.pvsconfig).
- V826. Consider replacing standard container with a different one.
- V827. Maximum size of a vector is known at compile time. Consider pre-allocating it by calling reserve(N).
- V828. Decreased performance. Moving an object in a return statement prevents copy elision.
- V829. Lifetime of the heap-allocated variable is limited to the current function's scope. Consider allocating it on the stack instead.
- V1059. Macro name overrides a keyword/reserved name. This may lead to undefined behavior.
- V1060. Passing 'BSTR ' to the 'SysAllocString' function may lead to incorrect object creation.
- V1061. Extending 'std' or 'posix' namespace may result in undefined behavior.
- V1062. Class defines a custom new or delete operator. The opposite operator must also be defined.
- V1063. The modulo by 1 operation is meaningless. The result will always be zero.
- V3154. The 'a % b' expression always evaluates to 0.
- V3155. The expression is incorrect or it can be simplified.
- V6082. Unsafe double-checked locking.
- V6083. Serialization order of fields should be preserved during deserialization.
- V6084. Suspicious return of an always empty collection.
- V6085. An abnormality within similar comparisons. It is possible that a typo is present inside the expression.
- V6086. Suspicious code formatting. 'else' keyword is probably missing.
- V6087. InvalidClassException may occur during deserialization.
- V6088. Result of this expression will be implicitly cast to 'Type'. Check if program logic handles it correctly.
- V6089. It's possible that the line was commented out improperly, thus altering the program's operation logics.
- V6090. Field 'A' is being used before it was initialized.
- V6091. Suspicious getter/setter implementation. The 'A' field should probably be returned/assigned instead.
- V6092. A resource is returned from try-with-resources statement. It will be closed before the method exits.
PVS-Studio 7.08 (18 июня 2020)
- Анализатор PVS-Studio C# для .NET Framework и .NET Core проектов теперь доступен на операционных системах Linux и macOS.
- Анализатор PVS-Studio C# теперь можно использовать вместе со средой разработки JetBrains Rider.
- Анализатор PVS-Studio теперь можно легко попробовать на примерах C и C++ кода, без необходимости скачивать и устанавливать дистрибутив анализатора, с помощью интеграции с сервисом Compiler Explorer. Обратите внимание - сервис Compiler Explorer позволяет попробовать анализатор на небольшом, изолированном фрагменте кода или синтетическом примере. Для того, чтобы полноценно оценить возможности анализатора, скачайте и установите полную версию PVS-Studio.
- Новый режим проверки списка файлов в утилите командной строки PVS-Studio_Cmd.exe на Windows теперь работает для C, C+ и C# файлов и умеет учитывать зависимости компиляции (исходных файлов от заголовочных файлов), что позволяет настраивать проверку pull и merge request'ов с помощью анализатора PVS-Studio.
- Улучшена работа PVS-Studio C# при проверке Unity проектов - добавлены дополнительные аннотации для самых распространённых типов из библиотек Unity.
- В утилиту для преобразования отчётов plog-converter (Linux, macOS) добавлена поддержка формата вывода для TeamCity.
- В утилиту для автоматического оповещения разработчиков Blame Notifier добавлена поддержка системы контроля версий Perforce.
- V824. It is recommended to use the 'make_unique/make_shared' function to create smart pointers.
- V825. Expression is equivalent to moving one unique pointer to another. Consider using 'std::move' instead.
- V1056. The predefined identifier '__func__' always contains the string 'operator()' inside function body of the overloaded 'operator()'.
- V1057. Pseudo random sequence is the same at every program run. Consider assigning the seed to a value not known at compile-time.
- V1058. Nonsensical comparison of two different functions' addresses.
- V6078. Potential Java SE API compatibility issue.
- V6079. Value of variable is checked after use. Potential logical error is present. Check lines: N1, N2.
- V6080. Consider checking for misprints. It's possible that an assigned variable should be checked in the next condition.
- V6081. Annotation that does not have 'RUNTIME' retention policy will not be accessible through Reflection API.
PVS-Studio 7.07 (16 апреля 2020)
- В С++ анализаторе PVS-Studio добавлен синтаксический разбор концептов. Концепты - интерфейсное расширение шаблонов языка C++, введенное стандартом C++20. Исправлена ошибка V003, возникавшая при использовании концептов в проверяемом коде.
- SonarQube плагин PVS-Studio теперь поддерживает работу в macOS.
- В утилите для преобразования XML отчётов анализатора (PlogConverter) добавлена поддержка формата для Continuous Integration сервера TeamCity.
- В command line анализаторе Visual Studio \ MSBuild проектов (PVS-Studio_Cmd.exe) добавлена возможность указывать и исключать из анализа отдельные проекты из командной строки, через флаги ‑‑selectProjects / ‑‑excludeProjects.
- Исправлено зависание Visual Studio плагина PVS-Studio, вызванное повторной инициализацией плагина при открытии solution файла в IDE.
- V1053. Calling the 'foo' virtual function in the constructor/destructor may lead to unexpected result at runtime.
- V1054. Object slicing. Derived class object was copied to the base class object.
- V1055. The 'sizeof' expression returns the size of the container type, not the number of elements. Consider using the 'size()' function.
- V2573. MISRA. Identifiers that start with '__' or '_[A-Z]' are reserved.
PVS-Studio 7.06 (27 февраля 2020)
- PVS-Studio теперь можно использовать совместно с кросс-платформенной IDE для embedded разработки PlatformIO. Подробнее про настройку PVS-Studio в PlatformIO можно почитать здесь.
- Оптимизировано выделение памяти C# анализатором PVS-Studio, что может давать ускорение анализа при проверке крупных проектов.
- В C# анализаторе PVS-Studio добавлены опции ‑‑excludeDefines / ‑‑appendDefines, позволяющие исключать/добавлять символы препроцессора, которые будут использоваться при анализе.
- C# анализатор PVS-Studio теперь понимает Unity-специфичные проверки переменных на null через их неявное преобразование к типу bool.
- V823. Decreased performance. Object may be created in-place in a container. Consider replacing methods: 'insert' -> 'emplace', 'push_*' -> 'emplace_*'.
- V1050. The uninitialized class member is used when initializing the base class.
- V1051. Consider checking for misprints. It's possible that an assigned variable should be checked in the next condition.
- V1052. Declaring virtual methods in a class marked as 'final' is pointless.
- V2562. MISRA. Expressions with pointer type should not be used in the '+', '-', '+=' and '-=' operations.
- V2563. MISRA. Array indexing should be the only form of pointer arithmetic and it should be applied only to objects defined as an array type.
- V2564. MISRA. There should be no implicit integral-floating conversion.
- V2565. MISRA. A function should not call itself either directly or indirectly.
- V2566. MISRA. Constant expression evaluation should not result in an unsigned integer wrap-around.
- V2567. MISRA. Cast should not remove 'const' / 'volatile' qualification from the type that is pointed to by a pointer or a reference.
- V2568. MISRA. Both operands of an operator should be of the same type category.
- V2569. MISRA. The 'operator &&', 'operator ||', 'operator ,' and the unary 'operator &' should not be overloaded.
- V2570. MISRA. Operands of the logical '&&' or the '||' operators, the '!' operator should have 'bool' type.
- V2571. MISRA. Conversions between pointers to objects and integer types should not be performed.
- V2572. MISRA. Value of the expression should not be converted to the different essential type or the narrower essential type.
- V3150. Loop break conditions do not depend on the number of iterations.
- V3151. Potential division by zero. Variable was used as a divisor before it was compared to zero. Check lines: N1, N2.
- V3152. Potential division by zero. Variable was compared to zero before it was used as a divisor. Check lines: N1, N2.
- V3153. Dereferencing the result of null-conditional access operator can lead to NullReferenceException. Consider removing parentheses around null-conditional access expression.
- V6077. Label is present inside a switch(). It is possible that these are misprints and 'default:' operator should be used instead.
PVS-Studio 7.05 (10 декабря 2019)
- Утилита для оповещения разработчиков о результатах анализа Blame Notifier теперь доступна на всех поддерживаемых анализатором платформах (Windows, Linux, macOS). Blame Notifier использует информацию из системы контроля версий (SVN, Git, Mercurial) для определения человека, написавшего код, на который анализатор выдаёт сообщение.
- PVS-Studio теперь можно установить с помощью менеджера пакетов Chocolatey.
- Добавлена поддержка проверки проектов .NET Core 3 и 3.1 для C# анализатора.
- В Windows версии анализатора появилась возможность задавать исключённые из анализа директории на уровне конкретного Visual Studio проекта или solution'а с помощью .pvsconfig файлов.
- Оптимизирован расход памяти C# анализатором PVS-Studio при проверке крупных проектов.
- V822. Decreased performance. A new object is created, while a reference to an object is expected.
- V1044. Loop break conditions do not depend on the number of iterations.
- V1045. The DllMain function throws an exception. Consider wrapping the throw operator in a try..catch block.
- V1046. Unsafe usage of the 'bool' and integer types together in the operation '&='.
- V1047. Lifetime of the lambda is greater than lifetime of the local variable captured by reference.
- V1048. Variable 'foo' was assigned the same value.
- V1049. The 'foo' include guard is already defined in the 'bar1.h' header. The 'bar2.h' header will be excluded from compilation.
- V2558. MISRA. A pointer/reference parameter in a function should be declared as pointer/reference to const if the corresponding object was not modified.
- V2559. MISRA. Subtraction, >, >=, <, <= should be applied only to pointers that address elements of the same array.
- V2560. MISRA. There should be no user-defined variadic functions.
- V2561. MISRA. The result of an assignment expression should not be used.
- V3146. Possible null dereference. A method can return default null value.
- V3147. Non-atomic modification of volatile variable.
- V3148. Casting potential 'null' value to a value type can lead to NullReferenceException.
- V3149. Dereferencing the result of 'as' operator can lead to NullReferenceException.
- V6072. Two similar code fragments were found. Perhaps, this is a typo and 'X' variable should be used instead of 'Y'.
- V6073. It is not recommended to return null or throw exceptions from 'toString' / 'clone' methods.
- V6074. Non-atomic modification of volatile variable.
- V6075. The signature of method 'X' does not conform to serialization requirements.
- V6076. Recurrent serialization will use cached object state from first serialization.
PVS-Studio 7.04 (4 сентября 2019)
- Добавлена поддержка IntelliJ IDEA версии 192 в PVS-Studio плагине для этой IDE.
- В PVS-Studio плагины для Visual Studio добавлена возможность автоматической загрузки логов анализа при проверке Unreal Engine проектов.
- Добавлена возможность проверки C# проектов под .NET Core 3 Preview.
- В C# анализаторе добавлено вычисление возвращаемых значений async методов, а также get и set методов у свойств.
- В утилите для отслеживания запусков компиляторов на Windows добавлена возможность отслеживать только дочерние процессы у заданного процесса.
- В утилите для отслеживания запусков компиляторов на Linux добавлен режим работы с игнорированием ccache кэша.
- Плагин для отображения результатов анализа PVS-Studio в Jenkins теперь можно также использовать на Linux\macOS хостах (раньше он был доступен только для Windows)
- Добавлена поддержка SonarQube 7.9 LTS в плагине PVS-Studio для SonarQube.
- V1040. Possible typo in the spelling of a pre-defined macro name.
- V1041. Class member is initialized with dangling reference.
- V1042. This file is marked with copyleft license, which requires you to open the derived source code.
- V1043. A global object variable is declared in the header. Multiple copies of it will be created in all translation units that include this header file.
- V2551. MISRA. Variable should be declared in a scope that minimizes its visibility.
- V2552. MISRA. Expressions with enum underlying type should have values corresponding to the enumerators of the enumeration.
- V2553. MISRA. Unary minus operator should not be applied to an expression of the unsigned type.
- V2554. MISRA. Expression containing increment (++) or decrement (--) should not have other side effects.
- V2555. MISRA. Incorrect shifting expression.
- V2556. MISRA. Use of a pointer to FILE when the associated stream has already been closed.
- V2557. MISRA. Operand of sizeof() operator should not have other side effects.
- V3140. Property accessors use different backing fields.
- V3141. Expression under 'throw' is a potential null, which can lead to NullReferenceException.
- V3142. Unreachable code detected. It is possible that an error is present.
- V3143. The 'value' parameter is rewritten inside a property setter, and is not used after that.
- V3144. This file is marked with copyleft license, which requires you to open the derived source code.
- V3145. Unsafe dereference of a WeakReference target. The object could have been garbage collected before the 'Target' property was accessed.
- V6068. Suspicious use of BigDecimal class.
- V6069. Unsigned right shift assignment of negative 'byte' / 'short' value.
- V6070. Unsafe synchronization on an object.
- V6071. This file is marked with copyleft license, which requires you to open the derived source code.
PVS-Studio 7.03 (25 июня 2019)
- В документации анализатора PVS-Studio теперь доступен раздел по использованию анализатора в контейнерах с помощью Docker.
- Добавлена поддержка проверки проектов для QNX Momentics, компилятора QCC.
- V1038. It's odd that a char or string literal is added to a pointer.
- V1039. Character escape is used in multicharacter literal. This causes implementation-defined behavior.
- V2543. MISRA. Value of the essential character type should be used appropriately in the addition/subtraction operations.
- V2544. MISRA. Values of the essential appropriate types should be used at expressions.
- V2545. MISRA. Conversion between pointers of different object types should not be performed.
- V2546. MISRA. Expression resulting from the macro expansion should be surrounded by parentheses.
- V2547. MISRA. The return value of non-void function should be used.
- V2548. MISRA. The address of an object with local scope should not be passed out of its scope.
- V2549. MISRA. Pointer to FILE should not be dereferenced.
- V2550. MISRA. Floating-point values should not be tested for equality or inequality.
- V3138. String literal contains potential interpolated expression.
- V3139. Two or more case-branches perform the same actions.
- V6067. Two or more case-branches perform the same actions.
PVS-Studio 7.02 (25 апреля 2019)
- В PVS-Studio появилась поддержка Visual Studio 2019. Visual C++, .NET Framework и .NET Core C# проекты Visual Studio 2019 можно проверять как из самой IDE, так и из командной строки с помощью утилиты PVS-Studio_Cmd.exe.
- Добавлена поддержка нового синтаксиса из C# 8.0 в PVS-Studio C# анализатор.
- PVS-Studio C# теперь может видеть потенциальные разыменования нулевых ссылок (диагностика V3080) внутри тел методов, когда значение потенциального null'а передаётся в качестве аргумента метода.
- Плагин PVS-Studio Java анализатора для IntelliJ IDEA теперь доступен в официальном репозитории плагинов JetBrains. Также плагин для IDEA теперь можно установить с помощью нашего Windows инсталлятора.
- В PVS-Studio Java плагины для IDEA, Maven и Gradle добавлен режим массового подавления предупреждений, который можно использовать для скрытия предупреждений на старом коде при внедрении анализатора в процесс разработки.
- Исправлена работа Compiler Monitoring на Windows при отслеживании сборки, запущенной из под Keil uVision в случае, когда имя пользователя в системе содержит нелатинские символы.
- V1037. Two or more case-branches perform the same actions.
- V2530. MISRA. The loop should be terminated with no more than one 'break' or 'goto' statement.
- V2531. MISRA. Expression of the essential 'foo' type should not be cast to the essential 'bar' type.
- V2532. MISRA. String literal should not be assigned to object unless it has type of pointer to const-qualified char.
- V2533. MISRA. C-style and functional notation casts should not be performed.
- V2534. MISRA. The loop counter should not have floating-point type.
- V2535. MISRA. Unreachable code should not be present in the project.
- V2536. MISRA. Function should not contain labels not used by any 'goto' statements.
- V2537. MISRA. Functions should not have unused parameters.
- V2538. MISRA. The value of uninitialized variable should not be used.
- V2539. MISRA. Class destructor should not exit with an exception.
- V2540. MISRA. Arrays should not be partially initialized.
- V2541. MISRA. Function should not be declared implicitly.
- V2542. MISRA. Function with a non-void return type should return a value from all exit paths.
PVS-Studio 7.01 (13 марта 2019)
- Ограничений количества переходов по сообщениям анализатора в Visual Studio в trial больше нет! В PVS-Studio для Windows теперь используется общая с остальными платформами trial модель - вы можете получить полнофункциональную лицензию, заполнив форму на странице загрузки анализатора.
- PVS-Studio C# диагностика V3080 (разыменование нулевой ссылки) теперь умеет находить потенциальные разыменования ссылок, которые могут принимать значение null в одной из веток выполнения. Улучшен межпроцедурный анализ.
- В Visual Studio плагине PVS-Studio добавлена возможность при работе с проектами, хранящимися в TFVC (Team Foundation Version Control), делать автоматический checkout suppress файлов (режим включается в Options... > Specific Analzyer Settings).
- V1036. Potentially unsafe double-checked locking.
- V2529. MISRA. Any label should be declared in the same block as 'goto' statement or in any block enclosing it.
PVS-Studio 7.00 (16 января 2019)
- В PVS-Studio версии 7.00 появился статический анализатор для Java. Подробнее обо всех нововведениях в PVS-Studio 7.00 можно почитать в нашем блоге.
- Плагин PVS-Studio для SonarQube обновлён для поддержки последней версии SonarQube 7.4. Минимальная версия SonarQube, поддерживаемая последней версией PVS-Studio плагина, увеличена до LTS версии SonarQube 6.7.
- V2526. MISRA. The function with the 'clock/time/difftime/ctime/ asctime/gmtime/localtime/mktime' name should not be used.
- V2527. MISRA. A switch-expression should not have Boolean type. Consider using of 'if-else' construct.
- V2528. MISRA. The comma operator should not be used.
- V6001. There are identical sub-expressions to the left and to the right of the 'foo' operator.
- V6002. The switch statement does not cover all values of the enum.
- V6003. The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence.
- V6004. The 'then' statement is equivalent to the 'else' statement.
- V6005. The 'x' variable is assigned to itself.
- V6006. The object was created but it is not being used. The 'throw' keyword could be missing.
- V6007. Expression is always true/false.
- V6008. Potential null dereference.
- V6009. Function receives an odd argument.
- V6010. The return value of function 'Foo' is required to be utilized.
- V6011. The expression contains a suspicious mix of integer and real types
- V6012. The '?:' operator, regardless of its conditional expression, always returns one and the same value.
- V6013. Comparison of arrays, strings, collections by reference. Possibly an equality comparison was intended.
- V6014. It's odd that this method always returns one and the same value of NN.
- V6015. Consider inspecting the expression. Probably the '!='/'-='/'+=' should be used here.
- V6016. Suspicious access to element by a constant index inside a loop.
- V6017. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
- V6018. Constant expression in switch statement.
- V6019. Unreachable code detected. It is possible that an error is present.
- V6020. Division or mod division by zero.
- V6021. The value is assigned to the 'x' variable but is not used.
- V6022. Parameter is not used inside method's body.
- V6023. Parameter 'A' is always rewritten in method body before being used.
- V6024. The 'continue' operator will terminate 'do { ... } while (false)' loop because the condition is always false.
- V6025. Possibly index is out of bound.
- V6026. This value is already assigned to the 'b' variable.
- V6027. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
- V6028. Identical expressions to the left and to the right of compound assignment.
- V6029. Possible incorrect order of arguments passed to method.
- V6030. The function located to the right of the '|' and '&' operators will be called regardless of the value of the left operand. Consider using '||' and '&&' instead.
- V6031. The variable 'X' is being used for this loop and for the outer loop.
- V6032. It is odd that the body of 'Foo_1' function is fully equivalent to the body of 'Foo_2' function.
- V6033. An item with the same key has already been added.
- V6034. Shift by N bits is inconsistent with the size of type.
- V6035. Double negation is present in the expression: !!x.
- V6036. The value from the uninitialized optional is used.
- V6037. An unconditional 'break/continue/return/goto' within a loop.
- V6038. Comparison with 'double.NaN' is meaningless. Use 'double.isNaN()' method instead.
- V6039. There are two 'if' statements with identical conditional expressions. The first 'if' statement contains method return. This means that the second 'if' statement is senseless.
- V6040. The code's operational logic does not correspond with its formatting.
- V6041. Suspicious assignment inside the conditional expression of 'if/while/do...while' statement.
- V6042. The expression is checked for compatibility with type 'A', but is cast to type 'B'.
- V6043. Consider inspecting the 'for' operator. Initial and final values of the iterator are the same.
- V6044. Postfix increment/decrement is senseless because this variable is overwritten.
- V6045. Suspicious subexpression in a sequence of similar comparisons.
- V6046. Incorrect format. Consider checking the N format items of the 'Foo' function.
- V6047. It is possible that this 'else' branch must apply to the previous 'if' statement.
- V6048. This expression can be simplified. One of the operands in the operation equals NN. Probably it is a mistake.
- V6049. Classes that define 'equals' method must also define 'hashCode' method.
- V6050. Class initialization cycle is present.
- V6051. Use of jump statements in 'finally' block can lead to the loss of unhandled exceptions.
- V6052. Calling an overridden method in parent-class constructor may lead to use of uninitialized data.
- V6053. Collection is modified while iteration is in progress. ConcurrentModificationException may occur.
- V6054. Classes should not be compared by their name.
- V6055. Expression inside assert statement can change object's state.
- V6056. Implementation of 'compareTo' overloads the method from a base class. Possibly, an override was intended.
- V6057. Consider inspecting this expression. The expression is excessive or contains a misprint.
- V6058. The 'X' function receives objects of incompatible types.
- V6059. Odd use of special character in regular expression. Possibly, it was intended to be escaped.
- V6060. The reference was used before it was verified against null.
- V6061. The used constant value is represented by an octal form.
- V6062. Possible infinite recursion.
- V6063. Odd semicolon ';' after 'if/foreach' operator.
- V6064. Suspicious invocation of Thread.run().
- V6065. A non-serializable class should not be serialized.
- V6066. Passing objects of incompatible types to the method of collection.
Старая история версий
Старую историю версий для прошлых релизов смотрите здесь.
Старая история версий PVS-Studio (до версии 7.00)
- PVS-Studio 6.27 (3 декабря 2018)
- PVS-Studio 6.26 (18 октября 2018)
- PVS-Studio 6.25 (20 августа 2018)
- PVS-Studio 6.24 (14 июня 2018)
- PVS-Studio 6.23 (28 марта 2018)
- PVS-Studio 6.22 (28 февраля 2018)
- PVS-Studio 6.21 (15 января 2018)
- PVS-Studio 6.20 (1 декабря 2017)
- PVS-Studio 6.19 (14 ноября 2017)
- PVS-Studio 6.18 (26 сентября 2017)
- PVS-Studio 6.17 (30 августа 2017)
- PVS-Studio 6.16 (28 июня 2017)
- PVS-Studio 6.15 (27 апреля 2017)
- PVS-Studio 6.14 (17 марта 2017)
- PVS-Studio 6.13 (27 января 2017)
- PVS-Studio 6.12 (22 декабря 2016)
- PVS-Studio 6.11 (29 ноября 2016)
- PVS-Studio 6.10 (25 октября 2016)
- PVS-Studio 6.09 (6 октября 2016)
- PVS-Studio 6.08 (22 августа 2016)
- PVS-Studio 6.07 (8 августа 2016)
- PVS-Studio 6.06 (7 июля 2016)
- PVS-Studio 6.05 (9 июня 2016)
- PVS-Studio 6.04 (16 мая 2016)
- PVS-Studio 6.03 (5 апреля 2016)
- PVS-Studio 6.02 (9 марта 2016)
- PVS-Studio 6.01 (3 февраля 2016)
- PVS-Studio 6.00 (22 декабря 2015)
- PVS-Studio 5.31 (3 ноября 2015)
- PVS-Studio 5.30 (29 октября 2015)
- PVS-Studio 5.29 (22 сентября 2015)
- PVS-Studio 5.28 (10 августа, 2015)
- PVS-Studio 5.27 (28 июля, 2015)
- PVS-Studio 5.26 (30 июня, 2015)
- PVS-Studio 5.25 (12 мая 2015)
- PVS-Studio 5.24 (10 апреля 2015)
- PVS-Studio 5.23 (17 марта 2015)
- PVS-Studio 5.22 (17 февраля 2015)
- PVS-Studio 5.21 (11 декабря 2014)
- PVS-Studio 5.20 (12 ноября 2014)
- PVS-Studio 5.19 (18 сентября 2014)
- PVS-Studio 5.18 (30 июля 2014)
- PVS-Studio 5.17 (20 мая 2014)
- PVS-Studio 5.16 (29 апреля 2014)
- PVS-Studio 5.15 (14 апреля 2014)
- PVS-Studio 5.14 (12 марта 2014)
- PVS-Studio 5.13 (5 февраля 2014)
- PVS-Studio 5.12 (23 декабря 2013)
- PVS-Studio 5.11 (6 ноября 2013)
- PVS-Studio 5.10 (7 октября 2013)
- PVS-Studio 5.06 (13 августа 2013)
- PVS-Studio 5.05 (28 мая 2013)
- PVS-Studio 5.04 (14 мая 2013)
- PVS-Studio 5.03 (16 апреля 2013)
- PVS-Studio 5.02 (6 марта 2013)
- PVS-Studio 5.01 (13 февраля 2013)
- PVS-Studio 5.00 (31 января 2013)
- PVS-Studio 4.77 (11 декабря 2012)
- PVS-Studio 4.76 (23 ноября 2012)
- PVS-Studio 4.75 (12 ноября 2012)
- PVS-Studio 4.74 (16 октября 2012)
- PVS-Studio 4.73 (17 сентября 2012)
- PVS-Studio 4.72 (30 августа 2012)
- PVS-Studio 4.71 (20 июля 2012)
- PVS-Studio 4.70 (4 июля 2012)
- PVS-Studio 4.62 (30 мая 2012)
- PVS-Studio 4.61 (22 мая 2012)
- PVS-Studio 4.60 (18 апреля 2012)
- PVS-Studio 4.56 (14 марта 2012)
- PVS-Studio 4.55 (28 февраля 2012)
- PVS-Studio 4.54 (1 февраля 2012)
- PVS-Studio 4.53 (19 января 2012)
- PVS-Studio 4.52 (28 декабря 2011)
- PVS-Studio 4.51 (21 декабря 2011)
- PVS-Studio 4.50 (15 декабря 2011)
- PVS-Studio 4.39 (25 ноября 2011)
- PVS-Studio 4.38 (12 октября 2011)
- PVS-Studio 4.37 (20 сентября 2011)
- PVS-Studio 4.36 (31 августа 2011)
- PVS-Studio 4.35 (12 августа 2011)
- PVS-Studio 4.34 (29 июля 2011)
- PVS-Studio 4.33 (21 июля 2011)
- PVS-Studio 4.32 (15 июля 2011)
- PVS-Studio 4.31 (6 июля 2011)
- PVS-Studio 4.30 (23 июня 2011)
- PVS-Studio 4.21 (20 мая 2011)
- PVS-Studio 4.20 (29 апреля 2011)
- PVS-Studio 4.17 (15 апреля 2011)
- PVS-Studio 4.16 (1 апреля 2011)
- PVS-Studio 4.15 (17 марта 2011)
- PVS-Studio 4.14 (2 марта 2011)
- PVS-Studio 4.13 (11 февраля 2011)
- PVS-Studio 4.12 (7 февраля 2011)
- PVS-Studio 4.11 (28 января 2011)
- PVS-Studio 4.10 (17 января 2011)
- PVS-Studio 4.00 (24 декабря 2010)
- PVS-Studio 4.00 BETA (24 ноября 2010)
- PVS-Studio 3.64 (28 сентября 2010)
- PVS-Studio 3.63 (10 сентября 2010)
- PVS-Studio 3.62 (16 августа 2010)
- PVS-Studio 3.61 (22 июля 2010)
- PVS-Studio 3.60 (10 июня 2010)
- PVS-Studio 3.53 (7 мая 2010)
- PVS-Studio 3.52 (27 апреля 2010)
- PVS-Studio 3.51 (16 апреля 2010)
- PVS-Studio 3.50 (26 марта 2010)
- PVS-Studio 3.45 (1 февраля 2010)
- PVS-Studio 3.44 (21 января 2010)
- PVS-Studio 3.43 (28 декабря 2009)
- PVS-Studio 3.42 (9 декабря 2009)
- PVS-Studio 3.41 (30 ноября 2009)
- PVS-Studio 3.40 (23 ноября 2009)
- PVS-Studio 3.30 (25 сентября 2009)
- PVS-Studio 3.20 (7 сентября 2009)
- PVS-Studio 3.10 (10 августа 2009)
- PVS-Studio 3.00 (27 июля 2009)
- VivaMP 1.10 (20 апреля 2009)
- VivaMP 1.00 (10 марта 2009)
- VivaMP 1.00 beta (27 ноября 2008)
- Viva64 2.30 (20 апреля 2009)
- Viva64 2.22 (10 марта 2009)
- Viva64 2.21 (27 ноября 2008)
- Viva64 2.20 (15 октября 2008)
- Viva64 2.10 (05 сентября 2008)
- Viva64 2.0 (09 июля 2008)
- Viva64 1.80 (03 февраля 2008)
- Viva64 1.70 (20 декабря 2007)
- Viva64 1.60 (28 августа 2007)
- Viva64 1.50 (15 мая 2007)
- Viva64 (1.40 - 1 мая 2007)
- Viva64 1.30 (17 марта 2007)
- Viva64 1.20 (26 января 2007)
- Viva64 1.10 (16 января 2007)
- Viva64 1.00 (31 декабря 2006)
Новую историю версий смотрите здесь.
PVS-Studio 6.27 (3 декабря 2018)
- Исходный код утилит для преобразования отчётов анализатора (plog converter) теперь доступен на нашем GitHub портале: https://github.com/viva64
- PVS-Studio теперь поддерживает стандарты написания кода MISRA C и MISRA C++. Список поддерживаемых диагностик будет постепенно расширяться в следующих версиях анализатора.
- V2501. MISRA. Octal constants should not be used.
- V2502. MISRA. The 'goto' statement should not be used.
- V2503. MISRA. Implicitly specified enumeration constants should be unique – consider specifying non-unique constants explicitly.
- V2504. MISRA. Size of an array is not specified.
- V2505. MISRA. The 'goto' statement shouldn't jump to a label declared earlier.
- V2506. MISRA. A function should have a single point of exit at the end.
- V2507. MISRA. The body of a loop\conditional statement should be enclosed in braces.
- V2508. MISRA. The function with the 'atof/atoi/atoll/atoll' name should not be used.
- V2509. MISRA. The function with the 'abort/exit/getenv/system' name should not be used.
- V2510. MISRA. The function with the 'qsort/bsearch' name should not be used.
- V2511. MISRA. Memory allocation and deallocation functions should not be used.
- V2512. MISRA. The macro with the 'setjmp' name and the function with the 'longjmp' name should not be used.
- V2513. MISRA. Unbounded functions performing string operations should not be used.
- V2514. MISRA. Unions should not be used.
- V2515. MISRA. Declaration should contain no more than two levels of pointer nesting.
- V2516. MISRA. The 'if' ... 'else if' construct shall be terminated with an 'else' statement.
- V2517. MISRA. Literal suffixes should not contain lowercase characters.
- V2518. MISRA. The 'default' label should be either the first or the last label of a 'switch' statement.
- V2519. MISRA. The 'default' label is missing in 'switch' statement.
- V2520. MISRA. Every switch-clause should be terminated by an unconditional 'break' or 'throw' statement.
- V2521. MISRA. Only the first member of enumerator list should be explicitly initialized, unless all members are explicitly initialized.
- V2522. MISRA. The 'switch' statement should have 'default' as the last label.
- V2523. MISRA. All integer constants of unsigned type should have 'u' or 'U' suffix.
- V2524. MISRA. A switch-label should only appear at the top level of the compound statement forming the body of a 'switch' statement.
- V2525. MISRA. Every 'switch' statement should contain non-empty switch-clauses.
PVS-Studio 6.26 (18 октября 2018)
- Добавлена поддержка проверки проектов для GNU Arm Embedded Toolchain, Arm Embedded GCC compiler.
- Добавлена возможность использовать pvsconfig файлы с CLMonitor/Standalone на Windows.
- При анализе проектов для Visual C++ компилятора (cl.exe, проекты vcxproj для Visual Studio/Standalone), в отчёте анализатора теперь сохраняется регистр в путях до проверенных файлов.
- Добавлен режим инкрементального анализа для pvs-studio-analzyer/CMake модуля. PVS-Studio CMake модуль можно теперь использовать на Windows для проектов, использующих компилятор Visual C++ (cl.exe).
- Добавлена поддержка инкрементального анализа для .NET Core/.NET Standard Visual Studio проектов.
- Добавлена возможность проверять проекты для сборочной системы WAF.
- V1021. The variable is assigned the same value on several loop iterations.
- V1022. An exception was thrown by pointer. Consider throwing it by value instead.
- V1023. A pointer without owner is added to the container by the 'emplace_back' method. A memory leak will occur in case of an exception.
- V1024. The stream is checked for EOF before reading from it, but is not checked after reading. Potential use of invalid data.
- V1025. Rather than creating 'std::unique_lock' to lock on the mutex, a new variable with default value is created.
- V1026. The variable is incremented in the loop. Undefined behavior will occur in case of signed integer overflow.
- V1027. Pointer to an object of the class is cast to unrelated class.
- V1028. Possible overflow. Consider casting operands, not the result.
- V1029. Numeric Truncation Error. Return value of function is written to N-bit variable.
- V1030. The variable is used after it was moved.
- V1031. Function is not declared. The passing of data to or from this function may be affected.
- V1032. Pointer is cast to a more strictly aligned pointer type.
- V1033. Variable is declared as auto in C. Its default type is int.
- V1034. Do not use real-type variables as loop counters.
- V1035. Only values that are returned from fgetpos() can be used as arguments to fsetpos().
- V2014. Don't use terminating functions in library code.
PVS-Studio 6.25 (20 августа 2018)
- Добавлена возможность в Visual Studio дабавлять в solution общий для всех проектов suppress файл.
- Для поддержки последних типов Visual Studio C++/C# проектов и новых возможностей языка C#, обновлены версии библиотек Roslyn и MSBuild.
- Улучшена проверка Multi-target C# проектов.
- В CMake модуле добавлена поддержка generator expressions и неявных зависимостей проверяемых файлов.
- У нас на сайте теперь можно посмотреть, как использовать PVS-Studio в рамках методологии безопасной разработки (SDL, Security Development Lifecycle) как SAST (Static Application Security Testing) инструмент. На этой странице есть отображение диагностических правил анализатора в формате CWE (Common Weakness Enumeration) и стандарте написания кода SEI CERT, прогресс по поддержке в PVS-Studio стандартов MISRA.
PVS-Studio 6.24 (14 июня 2018)
- Добавлена поддержка Texas Instruments Code Composer Studio, ARM компилятора для Windows\Linux
- Добавлена возможность сохранять дамп мониторинга и запускать анализ из этого дампа на Windows. Это позволяет перезапускать анализ без необходимости каждый раз пересобирать проект заново.
- Добавлен режим проверки отдельных файлов в cmd версии анализатора для Visual Studio проектов на Windows
- V1013. Suspicious subexpression in a sequence of similar comparisons.
- V1014. Structures with members of real type are compared byte-wise.
- V1015. Suspicious simultaneous use of bitwise and logical operators.
- V1016. The value is out of range of enum values. This causes unspecified or undefined behavior.
- V1017. Variable of the 'string_view' type references a temporary object which will be removed after evaluation of an expression.
- V1018. Usage of a suspicious mutex wrapper. It is probably unused, uninitialized, or already locked.
- V1019. Compound assignment expression is used inside condition.
- V1020. Function exited without performing epilogue actions. It is possible that there is an error.
PVS-Studio 6.23 (28 марта 2018)
- Мы выпустили PVS-Studio для macOS! Теперь проверять C и C++ код с помощью PVS-Studio можно не только в Windows/Linux, но и в macOS. Анализатор доступен в виде pkg-инсталлятора, tgz-архива и через менеджер пакетов Homebrew. Вы можете ознакомиться с документацией по работе с macOS-версией PVS-Studio здесь.
- V011. Presence of #line directives may cause some diagnostic messages to have incorrect file name and line number.
- V1011. Function execution could be deferred. Consider specifying execution policy explicitly.
- V1012. The expression is always false. Overflow check is incorrect.
PVS-Studio 6.22 (28 февраля 2018)
- Добавлена поддержка проверки проектов, использующих компиляторы Keil MDK ARM Compiler 5 и ARM Compiler 6.
- Добавлена поддержка проверки проектов, использующих компилятор IAR C/C++ Compiler for ARM.
- V1008. Consider inspecting the 'for' operator. No more than one iteration of the loop will be performed.
- V1009. Check the array initialization. Only the first element is initialized explicitly.
- V1010. Unchecked tainted data is used in expression.
PVS-Studio 6.21 (15 января 2018)
- Добавлена поддержка CWE (Common Weakness Enumeration) для C/C++/C# анализаторов.
- HTML отчёт с навигацией по коду можно теперь сохранять из Visual Studio плагинов и Standalone утилиты.
- Добавлена поддержка проверки WDK (Windows Driver Kit) проектов для Visual Studio 2017
- Плагин PVS-Studio для SonarQube обновлён для использования с последней LTS версией 6.7.
- V1007. The value from the uninitialized optional is used. Probably it is a mistake.
PVS-Studio 6.20 (1 декабря 2017)
- Вы можете сохранить результаты анализа в формате HTML с полной навигацией по коду.
- Добавлен режим NoNoise для отключения сообщений Low (третьего) уровня достоверности.
PVS-Studio 6.19 (14 ноября 2017)
- Добавлена возможность подавлять сообщения из XML отчёта (.plog) из командной строки в версии для Windows.
- Улучшены скорость и стабильности работы подавления сообщений и инкрементального анализа из Visual Studio плагинов при работе с очень большими (тысячи проектов) решениями.
- V1004. The pointer was used unsafely after it was verified against nullptr.
- V1005. The resource was acquired using 'X' function but was released using incompatible 'Y' function.
- V1006. Several shared_ptr objects are initialized by the same pointer. A double memory deallocation will occur.
PVS-Studio 6.18 (26 сентября 2017)
- В Linux-версии появилось расположение по умолчанию для файла лицензии.
- В Linux-версии появился механизм ввода лицензии (credentials).
- В Linux-версии появился отчет анализатора в HTML формате.
- В Windows-версии добавлена поддержка ASP.Net Core проектов.
- В Windows-версии улучшено масштабирование элементов интерфейса на разных DPI.
- В Windows-версии оптимизирована работа окна сообщений PVS-Studio при работе с большими отчётами, при выполнении сортировки по столбцам, при большом количестве выделенных сообщений.
- В плагине для Visual Studio удалена функциональность "Send to External Tool".
- В плагине для Visual Studio существенно изменены диалоги продления триала.
- V1002. A class, containing pointers, constructor and destructor, is copied by the automatically generated operator= or copy constructor.
- V1003. The macro is a dangerous, or the expression is suspicious.
PVS-Studio 6.17 (30 августа 2017)
- Поддержка обновления Visual Studio 2017 15.3.
- Добавлена возможность сохранять отчёт работы анализатора из Visual Studio плагина и Standalone в форматах txt\csv\html, без необходимости вручную вызывать PlogConverter.
- Лицензия и файл настроек теперь сохраняются в кодировке UTF-8.
- Добавлен список недавно открытых логов в меню Visual Studio плагина.
- Инкрементальный анализ в PVS-Studio_Cmd.exe - добавлена опция "AppendScan". Подробности в описании утилиты PVS-Studio_Cmd здесь.
- Добавлен плагин для отображения результатов анализа в системе непрерывной интеграции Jenkins (на Windows).
- Реализована версия плагина для системы непрерывного контроля качества SonarQube для Linux.
- Добавлена поддержка необработанного вывода C++ анализатора для утилиты PlogConverter.
- V821. The variable can be constructed in a lower level scope.
- V1001. The variable is assigned but is not used until the end of the function.
- V3135. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
- V3136. Constant expression in switch statement.
- V3137. The variable is assigned but is not used until the end of the function.
PVS-Studio 6.16 (28 июня 2017)
- Основанные на clang toolset'ы поддержаны для Visual Studio 2015/2017.
- Директория решения теперь может использоваться как Source Tree Root в Visual Studio.
- V788. Review captured variable in lambda expression.
- V789. Iterators for the container, used in the range-based for loop, become invalid upon a function call.
- V790. It is odd that the assignment operator takes an object by a non-constant reference and returns this object.
- V791. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
- V792. The function located to the right of the '|' and '&' operators will be called regardless of the value of the left operand. Consider using '||' and '&&' instead.
- V793. It is odd that the result of the statement is a part of the condition. Perhaps, this statement should have been compared with something else.
- V794. The copy operator should be protected from the case of this == &src.
- V795. Note that the size of the 'time_t' type is not 64 bits. After the year 2038, the program will work incorrectly.
- V796. A 'break' statement is probably missing in a 'switch' statement.
- V797. The function is used as if it returned a bool type. The return value of the function should probably be compared with std::string::npos.
- V798. The size of the dynamic array can be less than the number of elements in the initializer.
- V799. The variable is not used after memory has been allocated for it. Consider checking the use of this variable.
- V818. It is more efficient to use an initialization list rather than an assignment operator.
- V819. Decreased performance. Memory is allocated and released multiple times inside the loop body.
- V820. The variable is not used after copying. Copying can be replaced with move/swap for optimization.
PVS-Studio 6.15 (27 апреля 2017)
- Улучшена поддержка Visual Studio 2017.
- Исправлена ошибка с некоторыми .pch файлами.
- V782. It is pointless to compute the distance between the elements of different arrays.
- V783. Dereferencing of invalid iterator 'X' might take place.
- V784. The size of the bit mask is less than the size of the first operand. This will cause the loss of the higher bits.
- V785. Constant expression in switch statement.
- V786. Assigning the value C to the X variable looks suspicious. The value range of the variable: [A, B].
- V787. A wrong variable is probably used as an index in the for statement.
PVS-Studio 6.14 (17 марта 2017)
- Добавлена поддержка Visual Studio 2017.
- Добавлена поддержка Roslyn 2.0 / C# 7.0 в C# анализаторе PVS-Studio.
- Добавлена подсветка строк при просмотре сообщений анализатора в Visual Studio плагинах \ Standalone версии.
- Исправлена проблема проверки C++ проектов, которая могла возникнуть при запуске анализа на системе без установленной Visual Studio 2015 \ MSBuild 14.
- V780. The object of non-passive (non-PDS) type cannot be used with the function.
- V781. The value of the variable is checked after it was used. Perhaps there is a mistake in program logic. Check lines: N1, N2.
- V3131. The expression is checked for compatibility with type 'A' but is cast to type 'B'.
- V3132. A terminal null is present inside a string. '\0xNN' character sequence was encountered. Probably meant: '\xNN'.
- V3133. Postfix increment/decrement is meaningless because this variable is overwritten.
- V3134. Shift by N bits is greater than the size of type.
PVS-Studio 6.13 (27 января 2017)
- Добавлен режим инкрементального анализа для cmd версии анализатора (PVS-Studio_Cmd.exe). Подробности в документации.
- V779. Unreachable code detected. It is possible that an error is present.
- V3128. The field (property) is used before it is initialized in constructor.
- V3129. The value of the captured variable will be overwritten on the next iteration of the loop in each instance of anonymous function that captures it.
- V3130. Priority of the '&&' operator is higher than that of the '||' operator. Possible missing parentheses.
PVS-Studio 6.12 (22 декабря 2016)
- V773. The function was exited without releasing the pointer. A memory leak is possible.
- V774. The pointer was used after the memory was released.
- V775. It is odd that the BSTR data type is compared using a relational operator.
- V776. Potentially infinite loop. The variable in the loop exit condition does not change its value between iterations.
- V777. Dangerous widening type conversion from an array of derived-class objects to a base-class pointer.
- V778. Two similar code fragments were found. Perhaps, this is a typo and 'X' variable should be used instead of 'Y'.
- V3123. Perhaps the '??' operator works differently from what was expected. Its priority is lower than that of other operators in its left part.
- V3124. Appending an element and checking for key uniqueness is performed on two different variables.
- V3125. The object was used after it was verified against null. Check lines: N1, N2.
- V3126. Type implementing IEquatable<T> interface does not override 'GetHashCode' method.
PVS-Studio 6.11 (29 ноября 2016)
- V771. The '?:' operator uses constants from different enums.
- V772. Calling the 'delete' operator for a void pointer will cause undefined behavior.
- V817. It is more efficient to search for 'X' character rather than a string.
- V3119. Calling a virtual (overridden) event may lead to unpredictable behavior. Consider implementing event accessors explicitly or use 'sealed' keyword.
- V3120. Potentially infinite loop. The variable in the loop exit condition does not change its value between iterations.
- V3121. An enumeration was declared with 'Flags' attribute, but no initializers were set to override default values.
- V3122. Uppercase (lowercase) string is compared with a different lowercase (uppercase) string.
- Добавлена поддержка проверки Visual C++ проектов (.vcxproj) с Intel C++ toolset в плагине.
PVS-Studio 6.10 (25 октября 2016)
- Мы выпустили PVS-Studio для Linux! Теперь проверять C и C++ код с помощью PVS-Studio можно не только в Windows, но и в Linux. Анализатор доступен в виде пакетов для основных систем управления пакетами, легко интегрируется в распространённые системы сборки. Вы можете ознакомиться с документацией по работе с Linux-версией PVS-Studio здесь.
- В PVS-Studio для Windows новый интерфейс! Изменения произошли как в плагине для Visual Studio, так и в отдельном приложении Standalone.
- В PVS-Studio включена новая утилита BlameNotifier. С помощью нее можно легко организовать рассылку по e-mail сообщений PVS-Studio, сопоставленных с авторами кода в репозитории. Поддерживаются Git, Svn, Mercurial. Подробнее о работе с результатами анализа можно прочитать здесь.
- Добавлена поддержка проверки MSBuild проектов, использующих Intel C++ компилятор, при проверке кода из командной строки. Скоро мы добавим поддержку в плагине для Visual Studio.
- V769. The pointer in the expression equals nullptr. The resulting value is meaningless and should not be used.
- V770. Possible usage of a left shift operator instead of a comparison operator.
PVS-Studio 6.09 (6 октября 2016)
- При отключении всех групп диагностик анализатора (С++ или C#) анализ проектов для соответствующего языка запускаться не будет.
- Добавлена поддержка прокси с авторизацией при проверке обновлений и продлении триала.
- Поддержана возможность полностью отключать C/C++ или C# анализатор в .pvsconfig файлах (//-V::C++ и //-V::C#).
- В плагине SonarQube реализована функциональность для вычисления LOC и определения времени, необходимого для исправление найденных ошибок.
- V768. The '!' operator is applied to an enumerator.
- V3113. Consider inspecting the loop expression. It is possible that different variables are used inside initializer and iterator.
- V3114. IDisposable object is not disposed before method returns.
- V3115. It is not recommended to throw exceptions from 'Equals(object obj)' method.
- V3116. Consider inspecting the 'for' operator. It's possible that the loop will be executed incorrectly or won't be executed at all.
- V3117. Constructor parameter is not used.
- V3118. A component of TimeSpan is used, which does not represent full time interval. Possibly 'Total*' value was intended instead.
PVS-Studio 6.08 (22 августа 2016)
- В Visual Studio плагине отключена проверка из командной строки с помощью /command. Используйте отдельную утилиту PVS-Studio_Cmd.exe. Порядок работы с утилитой описан в документации.
- V3108. It is not recommended to return null or throw exceptions from 'ToSting()' method.
- V3109. The same sub-expression is present on both sides of the operator. The expression is incorrect or it can be simplified.
- V3110. Possible infinite recursion.
- V3111. Checking value for null will always return false when generic type is instantiated with a value type.
- V3112. An abnormality within similar comparisons. It is possible that a typo is present inside the expression.
PVS-Studio 6.07 (8 августа 2016)
- Мы движемся в сторону Linux! Пожалуйста, посмотрите, как запустить PVS-Studio в Linux.
- PVS-Studio больше не поддерживает работу на 32-битных операционных системах. Анализатор PVS-Studio (как C++, так и C# модули) для своей работы требует большого объёма оперативной памяти, особенно при параллельной проверке на нескольких ядрах процессора. Максимальный объём памяти, доступный в 32-битной системе, позволяет корректно использовать анализатор одновременно только на одном ядре (т.е. одновременно в один процесс). Причём в случае очень крупных проектов, даже этого объёма памяти может оказаться недостаточно. В связи с этим, а также по причине того, что очень небольшой процент наших пользователей всё ещё используют 32-битные ОС, мы решили прекратить поддержку 32-битной версии анализатора. Это позволит нам сконцентрировать все наши ресурсы на развитие 64-битной версии.
- В command line версии анализатора добавлена поддержка платформы непрерывного измерения качества SonarQube. Также в нашем дистрибутиве теперь есть плагин для интеграции результатов работы анализа с сервером SonarQube. Подробное описание плагина и новых режимов работы доступно здесь.
- V763. Parameter is always rewritten in function body before being used.
- V764. Possible incorrect order of arguments passed to function.
- V765. A compound assignment expression 'X += X + N' is suspicious. Consider inspecting it for a possible error.
- V766. An item with the same key has already been added.
- V767. Suspicious access to element by a constant index inside a loop.
- V3106. Possibly index is out of bound.
- V3107. Identical expressions to the left and to the right of compound assignment.
PVS-Studio 6.06 (7 июля 2016)
- V758. Reference invalidated, because of the destruction of the temporary object 'unique_ptr', returned by function.
- V759. Violated order of exception handlers. Exception caught by handler for base class.
- V760. Two identical text blocks detected. The second block starts with NN string.
- V761. NN identical blocks were found.
- V762. Consider inspecting virtual function arguments. See NN argument of function 'Foo' in derived class and base class.
- V3105. The 'a' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible.
PVS-Studio 6.05 (9 июня 2016)
- Добавлена отдельная command line версия PVS-Studio, поддерживающая проверку vcxproj и csproj проектов (C++ и C#). Теперь нет необходимости использовать devenv.exe для ночных проверок. Подробнее об этом инструменте можно почитать здесь.
- Прекращена поддержка MSBuild плагина. Вместо него предлагается использовать отдельную command line версию PVS-Studio.
- V755. Copying from unsafe data source. Buffer overflow is possible.
- V756. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
- V757. It is possible that an incorrect variable is compared with null after type conversion using 'dynamic_cast'.
- V3094. Possible exception when deserializing type. The Ctor(SerializationInfo, StreamingContext) constructor is missing.
- V3095. The object was used before it was verified against null. Check lines: N1, N2.
- V3096. Possible exception when serializing type. [Serializable] attribute is missing.
- V3097. Possible exception: type marked by [Serializable] contains non-serializable members not marked by [NonSerialized].
- V3098. The 'continue' operator will terminate 'do { ... } while (false)' loop because the condition is always false.
- V3099. Not all the members of type are serialized inside 'GetObjectData' method.
- V3100. Unhandled NullReferenceException is possible. Unhandled exceptions in destructor lead to termination of runtime.
- V3101. Potential resurrection of 'this' object instance from destructor. Without re-registering for finalization, destructor will not be called a second time on resurrected object.
- V3102. Suspicious access to element by a constant index inside a loop.
- V3103. A private Ctor(SerializationInfo, StreamingContext) constructor in unsealed type will not be accessible when deserializing derived types.
- V3104. 'GetObjectData' implementation in unsealed type is not virtual, incorrect serialization of derived type is possible.
PVS-Studio 6.04 (16 мая 2016)
- V753. The '&=' operation always sets a value of 'Foo' variable to zero.
- V754. The expression of 'foo(foo(x))' pattern is excessive or contains an error.
- V3082. The 'Thread' object is created but is not started. It is possible that a call to 'Start' method is missing.
- V3083. Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it.
- V3084. Anonymous function is used to unsubscribe from event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration.
- V3085. The name of 'X' field/property in a nested type is ambiguous. The outer type contains static field/property with identical name.
- V3086. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
- V3087. Type of variable enumerated in 'foreach' is not guaranteed to be castable to the type of collection's elements.
- V3088. The expression was enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or misprint is present.
- V3089. Initializer of a field marked by [ThreadStatic] attribute will be called once on the first accessing thread. The field will have default value on different threads.
- V3090. Unsafe locking on an object.
- V3091. Empirical analysis. It is possible that a typo is present inside the string literal. The 'foo' word is suspicious.
- V3092. Range intersections are possible within conditional expressions.
- V3093. The operator evaluates both operands. Perhaps a short-circuit operator should be used instead.
PVS-Studio 6.03 (5 апреля 2016)
- V751. Parameter is not used inside method's body.
- V752. Creating an object with placement new requires a buffer of large size.
- V3072. The 'A' class containing IDisposable members does not itself implement IDisposable.
- V3073. Not all IDisposable members are properly disposed. Call 'Dispose' when disposing 'A' class.
- V3074. The 'A' class contains 'Dispose' method. Consider making it implement 'IDisposable' interface.
- V3075. The operation is executed 2 or more times in succession.
- V3076. Comparison with 'double.NaN' is meaningless. Use 'double.IsNaN()' method instead.
- V3077. Property setter / event accessor does not utilize its 'value' parameter.
- V3078. Original sorting order will be lost after repetitive call to 'OrderBy' method. Use 'ThenBy' method to preserve the original sorting.
- V3079. 'ThreadStatic' attribute is applied to a non-static 'A' field and will be ignored.
- V3080. Possible null dereference.
- V3081. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
- V051. Some of the references in project are missing or incorrect. The analysis results could be incomplete. Consider making the project fully compilable and building it before analysis.
PVS-Studio 6.02 (9 марта 2016)
- V3057. Function receives an odd argument.
- V3058. An item with the same key has already been added.
- V3059. Consider adding '[Flags]' attribute to the enum.
- V3060. A value of variable is not modified. Consider inspecting the expression. It is possible that other value should be present instead of '0'.
- V3061. Parameter 'A' is always rewritten in method body before being used.
- V3062. An object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' method.
- V3063. A part of conditional expression is always true/false.
- V3064. Division or mod division by zero.
- V3065. Parameter is not utilized inside method's body.
- V3066. Possible incorrect order of arguments passed to 'Foo' method.
- V3067. It is possible that 'else' block was forgotten or commented out, thus altering the program's operation logics.
- V3068. Calling overrideable class member from constructor is dangerous.
- V3069. It's possible that the line was commented out improperly, thus altering the program's operation logics.
- V3070. Uninitialized variables are used when initializing the 'A' variable.
- V3071. The object is returned from inside 'using' block. 'Dispose' will be invoked before exiting method.
PVS-Studio 6.01 (3 февраля 2016)
- V736. The behavior is undefined for arithmetic or comparisons with pointers that do not point to members of the same array.
- V737. It is possible that ',' comma is missing at the end of the string.
- V738. Temporary anonymous object is used.
- V739. EOF should not be compared with a value of the 'char' type. Consider using the 'int' type.
- V740. Because NULL is defined as 0, the exception is of the 'int' type. Keyword 'nullptr' could be used for 'pointer' type exception.
- V741. The following pattern is used: throw (a, b);. It is possible that type name was omitted: throw MyException(a, b);..
- V742. Function receives an address of a 'char' type variable instead of pointer to a buffer.
- V743. The memory areas must not overlap. Use 'memmove' function.
- V744. Temporary object is immediately destroyed after being created. Consider naming the object.
- V745. A 'wchar_t *' type string is incorrectly converted to 'BSTR' type string.
- V746. Object slicing. An exception should be caught by reference rather than by value.
- V747. An odd expression inside parenthesis. It is possible that a function name is missing.
- V748. Memory for 'getline' function should be allocated only by 'malloc' or 'realloc' functions. Consider inspecting the first parameter of 'getline' function.
- V749. Destructor of the object will be invoked a second time after leaving the object's scope.
- V750. BSTR string becomes invalid. Notice that BSTR strings store their length before start of the text.
- V816. It is more efficient to catch exception by reference rather than by value.
- V3042. Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the same object.
- V3043. The code's operational logic does not correspond with its formatting.
- V3044. WPF: writing and reading are performed on a different Dependency Properties.
- V3045. WPF: the names of the property registered for DependencyProperty, and of the property used to access it, do not correspond with each other.
- V3046. WPF: the type registered for DependencyProperty does not correspond with the type of the property used to access it.
- V3047. WPF: A class containing registered property does not correspond with a type that is passed as the ownerType.type.
- V3048. WPF: several Dependency Properties are registered with a same name within the owner type.
- V3049. WPF: readonly field of 'DependencyProperty' type is not initialized.
- V3050. Possibly an incorrect HTML. The </XX> closing tag was encountered, while the </YY> tag was expected.
- V3051. An excessive type cast or check. The object is already of the same type.
- V3052. The original exception object was swallowed. Stack of original exception could be lost.
- V3053. An excessive expression. Examine the substrings "abc" and "abcd".
- V3054. Potentially unsafe double-checked locking. Use volatile variable(s) or synchronization primitives to avoid this.
- V3055. Suspicious assignment inside the condition expression of 'if/while/for' operator.
- V3056. Consider reviewing the correctness of 'X' item's usage.
PVS-Studio 6.00 (22 декабря 2015)
- Появился статический анализ кода для C#: в первой версии более 40 диагностик.
- Прекращена поддержка Visual Studio 2005 и Visual Studio 2008.
- V734. Searching for the longer substring is meaningless after searching for the shorter substring.
- V735. Possibly an incorrect HTML. The "</XX" closing tag was encountered, while the "</YY" tag was expected.
- V3001. There are identical sub-expressions to the left and to the right of the 'foo' operator.
- V3002. The switch statement does not cover all values of the enum.
- V3003. The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence.
- V3004. The 'then' statement is equivalent to the 'else' statement.
- V3005. The 'x' variable is assigned to itself.
- V3006. The object was created but it is not being used. The 'throw' keyword could be missing.
- V3007. Odd semicolon ';' after 'if/for/while' operator.
- V3008. The 'x' variable is assigned values twice successively. Perhaps this is a mistake.
- V3009. It's odd that this method always returns one and the same value of NN.
- V3010. The return value of function 'Foo' is required to be utilized.
- V3011. Two opposite conditions were encountered. The second condition is always false.
- V3012. The '?:' operator, regardless of its conditional expression, always returns one and the same value.
- V3013. It is odd that the body of 'Foo_1' function is fully equivalent to the body of 'Foo_2' function.
- V3014. It is likely that a wrong variable is being incremented inside the 'for' operator. Consider reviewing 'X'.
- V3015. It is likely that a wrong variable is being compared inside the 'for' operator. Consider reviewing 'X'.
- V3016. The variable 'X' is being used for this loop and for the outer loop.
- V3017. A pattern was detected: A || (A && ...). The expression is excessive or contains a logical error.
- V3018. Consider inspecting the application's logic. It's possible that 'else' keyword is missing.
- V3019. It is possible that an incorrect variable is compared with null after type conversion using 'as' keyword.
- V3020. An unconditional 'break/continue/return/goto' within a loop.
- V3021. There are two 'if' statements with identical conditional expressions. The first 'if' statement contains method return. This means that the second 'if' statement is senseless.
- V3022. Expression is always true/false.
- V3023. Consider inspecting this expression. The expression is excessive or contains a misprint.
- V3024. An odd precise comparison. Consider using a comparison with defined precision: Math.Abs(A - B) < Epsilon or Math.Abs(A - B) > Epsilon.
- V3025. Incorrect format. Consider checking the N format items of the 'Foo' function.
- V3026. The constant NN is being utilized. The resulting value could be inaccurate. Consider using the KK constant.
- V3027. The variable was utilized in the logical expression before it was verified against null in the same logical expression.
- V3028. Consider inspecting the 'for' operator. Initial and final values of the iterator are the same.
- V3029. The conditional expressions of the 'if' operators situated alongside each other are identical.
- V3030. Recurring check. This condition was already verified in previous line.
- V3031. An excessive check can be simplified. The operator '||' operator is surrounded by opposite expressions 'x' and '!x'.
- V3032. Waiting on this expression is unreliable, as compiler may optimize some of the variables. Use volatile variable(s) or synchronization primitives to avoid this.
- V3033. It is possible that this 'else' branch must apply to the previous 'if' statement.
- V3034. Consider inspecting the expression. Probably the '!=' should be used here.
- V3035. Consider inspecting the expression. Probably the '+=' should be used here.
- V3036. Consider inspecting the expression. Probably the '-=' should be used here.
- V3037. An odd sequence of assignments of this kind: A = B; B = A;.
- V3038. The 'first' argument of 'Foo' function is equal to the 'second' argument
- V3039. Consider inspecting the 'Foo' function call. Defining an absolute path to the file or directory is considered a poor style.
- V3040. The expression contains a suspicious mix of integer and real types.
- V3041. The expression was implicitly cast from integer type to real type. Consider utilizing an explicit type cast to avoid the loss of a fractional part.
PVS-Studio 5.31 (3 ноября 2015)
- Снижено количество ложных срабатываний для некоторых диагностик.
PVS-Studio 5.30 (29 октября 2015)
- Добавлена поддержка навигации по многострочным сообщениям с помощью двойного клика.
- Исправлена ошибка доступа при запуске препроцессора Visual C++ для проверки файлов, использующих директиву #import.
- Исправлена ошибка работы Compiler Monitoring при длительности препроцессирования более 10 минут.
- Исправлена некорректная работа инсталлятора на системах, имеющих только 2015 версию Visual Studio.
- Новая диагностика – V728. An excessive check can be simplified. The '||' operator is surrounded by opposite expressions 'x' and '!x'.
- Новая диагностика – V729. Function body contains the 'X' label that is not used by any 'goto' statements.
- Новая диагностика – V730. Not all members of a class are initialized inside the constructor.
- Новая диагностика – V731. The variable of char type is compared with pointer to string.
- Новая диагностика – V732. Unary minus operator does not modify a bool type value.
- Новая диагностика – V733. It is possible that macro expansion resulted in incorrect evaluation order.
PVS-Studio 5.29 (22 сентября 2015)
- Добавлена поддержка Visual Studio 2015.
- Добавлена поддержка Windows 10.
- Новая диагностика – V727. Return value of 'wcslen' function is not multiplied by 'sizeof(wchar_t)'.
PVS-Studio 5.28 (10 августа, 2015)
- Новый интерфейс страниц настроек Detectable Errors, Don't Check Files и Keyword Message Filering.
- Добавлена утилита PlogConverter для преобразования XML plog файлов в текстовый, html и CSV форматы. Подробности в документации.
PVS-Studio 5.27 (28 июля, 2015)
- Новая диагностика – V207. A 32-bit variable is utilized as a reference to a pointer. A write outside the bounds of this variable may occur.
- Новая диагностика - V726. An attempt to free memory containing the 'int A[10]' array by using the 'free(A)' function.
- Новая возможность - Формирование статистики работы анализатора в виде графиков. Анализатор PVS-Studio позволяет собирать статистику своей работы - количество найденных сообщений (включая подавленные) на разных уровнях и группах диагностик. Собранная статистика может быть отфильтрована и отображена в виде графика в документе Microsoft Excel, показывающего динамику изменения сообщений в проверяемом проекте.
- Удален режим проверки заранее препроцессированных файлов в Standalone.
PVS-Studio 5.26 (30 июня, 2015)
- Новая диагностика – V723. Function returns a pointer to the internal string buffer of a local object, which will be destroyed.
- Новая диагностика – V724. Converting integers or pointers to BOOL can lead to a loss of high-order bits. Non-zero value can become 'FALSE'.
- Новая диагностика – V725. A dangerous cast of 'this' to 'void*' type in the 'Base' class, as it is followed by a subsequent cast to 'Class' type.
- Добавлена поддержка подавления сообщений (Message Suppression) в CLMonitoring/Standalone.
- 2 и 3 уровни сообщений анализатора доступны в Trial режиме.
PVS-Studio 5.25 (12 мая 2015)
- Новая диагностика – V722. An abnormality within similar comparisons. It is possible that a typo is present inside the expression.
- Улучшена "отзывчивость" интерфейса функций выбора анализаторов и команды Quick Filters в окне PVS-Studio Output Window.
- Кнопка 'False Alarms' перемещена из окна PVS-Studio в настройки анализатора.
- Исправлена ошибка 'An item with the same key has already been added', возникающая при использовании механизма массового подавления сообщений.
PVS-Studio 5.24 (10 апреля 2015)
- Новая диагностика – V721. The VARIANT_BOOL type is utilized incorrectly. The true value (VARIANT_TRUE) is defined as -1.
- Новый ознакомительный режим работы. Подробности здесь.
- Возможность использования режима подавления сообщений (Message Suppression) вместе с запуском на проектных файлах (vcproj/vcxproj) из командной строки, для рассылки отчёта с новыми сообщениями (в plain text и html форматах) по почте. Подробнее про режим работы из командной строки и использование с системами непрерывной интеграции.
PVS-Studio 5.23 (17 марта 2015)
- Существенно улучшен анализатор проблем 64-битных приложений. Теперь если вы хотите исправить основные проблемы 64-битного кода, вам достаточно поправить все сообщения 1 уровня в 64-битном анализе.
- Теперь вы можете использовать автоматическое обновление PVS-Studio на билд-сервере. Подробнее здесь.
- Новая диагностика – V719. The switch statement does not cover all values of the enum.
- Новая диагностика – V720. It is advised to utilize the 'SuspendThread' function only when developing a debugger (see documentation for details).
- Новая диагностика – V221. Suspicious sequence of types castings: pointer -> memsize -> 32-bit integer.
- Новая диагностика – V2013. Consider inspecting the correctness of handling the N argument in the 'Foo' function.
PVS-Studio 5.22 (17 февраля 2015)
- Новая диагностика – V718. The 'Foo' function should not be called from 'DllMain' function.
- Исправлена работа CLMonitoring с C++/CLI проектами.
- Исправлена утечка памяти при длительной работе CLMonitoring.
- Новая система поиска include\символов в Standalone.
- Оптимизировано потребление памяти при использовании функции подавления сообщений (Message Suppression).
- В системе подавления (Message Suppression) добавлена поддержка сообщений, выдаваемых на несколько IDE проектов (например, сообщения на общие h файлы).
- Улучшена логика работы системы подавления сообщений (Message Suppression).
PVS-Studio 5.21 (11 декабря 2014)
- Мы прекратили поддержку среды разработки Embarcadero RAD Studio.
- Мы прекратили поддержку диагностик проблем OpenMP (набор правил VivaMP).
- Новая диагностика – V711. It is dangerous to create a local variable within a loop with a same name as a variable controlling this loop.
- Новая диагностика – V712. Be advised that compiler may delete this cycle or make it infinity. Use volatile variable(s) or synchronization primitives to avoid this.
- Новая диагностика – V713. The pointer was utilized in the logical expression before it was verified against nullptr in the same logical expression.
- Новая диагностика – V714. Variable is not passed into foreach loop by a reference, but its value is changed inside of the loop.
- Новая диагностика – V715. The 'while' operator has empty body. Suspicious pattern detected.
- Новая диагностика – V716. Suspicious type conversion: HRESULT -> BOOL (BOOL -> HRESULT).
- Новая диагностика – V717. It is strange to cast object of base class V to derived class U.
PVS-Studio 5.20 (12 ноября 2014)
- Новая диагностика – V706. Suspicious division: sizeof(X) / Value. Size of every element in X array does not equal to divisor.
- Новая диагностика – V707. Giving short names to global variables is considered to be bad practice.
- Новая диагностика – V708. Dangerous construction is used: 'm[x] = m.size()', where 'm' is of 'T' class. This may lead to undefined behavior.
- Новая диагностика – V709. Suspicious comparison found: 'a == b == c'. Remember that 'a == b == c' is not equal to 'a == b && b == c.
- Новая диагностика – V710. Suspicious declaration found. There is no point to declare constant reference to a number.
- Новая диагностика – V2012. Possibility of decreased performance. It is advised to pass arguments to std::unary_function/std::binary_function template as references.
- Новая возможность - Массовое подавление сообщений анализатора. Иногда на стадии внедрения статического анализа, особенно на крупных проектах, разработчик не хочет (или даже не имеет возможности) править сотни, а иногда и тысячи, сообщений анализатора, сгенерированных на существующую кодовую базу. В такой ситуации возникает необходимость "убрать" все выданные на текущий код сообщения, и в дальнейшем работать только с сообщениями, относящимися к вновь написанному или модифицированному коду, т.е. коду, который ещё не отлажен и может потенциально содержать большое количество ошибок.
PVS-Studio 5.19 (18 сентября 2014)
- Новая диагностика – V698. strcmp()-like functions can return not only the values -1, 0 and 1, but any values.
- Новая диагностика – V699. Consider inspecting the 'foo = bar = baz ? .... : ....' expression. It is possible that 'foo = bar == baz ? .... : ....' should be used here instead.
- Новая диагностика – V700. Consider inspecting the 'T foo = foo = x;' expression. It is odd that variable is initialized through itself.
- Новая диагностика – V701. realloc() possible leak: when realloc() fails in allocating memory, original pointer is lost. Consider assigning realloc() to a temporary pointer.
- Новая диагностика – V702. Classes should always be derived from std::exception (and alike) as 'public'.
- Новая диагностика – V703. It is odd that the 'foo' field in derived class overwrites field in base class.
- Новая диагностика – V704. 'this == 0' comparison should be avoided - this comparison is always false on newer compilers.
- Новая диагностика – V705. It is possible that 'else' block was forgotten or commented out, thus altering the program's operation logics.
PVS-Studio 5.18 (30 июля 2014)
- ClMonitoring - автоматическое определение платформы компилятора.
- ClMonitoring - увеличение скорости работы за счёт уменьшения влияния антивирусов на этапе препроцессирования проверяемых файлов.
- CLMonitoring - исправлена некорректная обработка 64-битных процессов после системного обновления .NET Framework 4.
- Новая диагностика – V695. Range intersections are possible within conditional expressions.
- Новая диагностика – V696. The 'continue' operator will terminate 'do { ... } while (FALSE)' loop because the condition is always false.
- Новая диагностика – V697. A number of elements in the allocated array is equal to size of a pointer in bytes.
- Новая диагностика – V206. Explicit conversion from 'void *' to 'int *'.
- Новая диагностика – V2011. Consider inspecting signed and unsigned function arguments. See NN argument of function 'Foo' in derived class and base class.
PVS-Studio 5.17 (20 мая 2014)
- Новая диагностика – V690. The class implements a copy constructor/operator=, but lacks the the operator=/copy constructor.
- Новая диагностика – V691. Empirical analysis. It is possible that a typo is present inside the string literal. The 'foo' word is suspicious.
- Новая диагностика – V692. An inappropriate attempt to append a null character to a string. To determine the length of a string by 'strlen' function correctly, a string ending with a null terminator should be used in the first place.
- Новая диагностика – V693. Consider inspecting conditional expression of the loop. It is possible that 'i < X.size()' should be used instead of 'X.size()'.
- Новая диагностика – V694. The condition (ptr - const_value) is only false if the value of a pointer equals a magic constant.
- Новая диагностика – V815. Decreased performance. Consider replacing the expression 'AA' with 'BB'.
- Новая диагностика – V2010. Handling of two different exception types is identical.
PVS-Studio 5.16 (29 апреля 2014)
- Существенно улучшена поддержка С++/CLI. проектов.
- Плагин TFSRipper был удален.
- Исправлено падение в Standalone при установке в место не по умолчанию на 64-битных системах.
- Исправлена ошибка из-за которой в некоторых ситуациях не показывались некоторые диагностические сообщения.
PVS-Studio 5.15 (14 апреля 2014)
- Новая диагностика – V689. The destructor of the 'Foo' class is not declared as a virtual. It is possible that a smart pointer will not destroy an object correctly.
- Существенные улучшения в подсистеме Мониторинг компилятора в PVS-Studio.
PVS-Studio 5.14 (12 марта 2014)
- Новая опция "DIsable 64-bit Analysis" в специальных настройках анализатора позволяет немного увеличить скорость анализа и существенно уменьшить размер .plog файла.
- Новая возможность: Мониторинг компилятора в PVS-Studio.
- Исправлена проблема с нотификацией при инкрементальном анализе и окне PVS-Studio со стилем auto hide.
- Новая диагностика – V687. Size of an array calculated by the sizeof() operator was added to a pointer. It is possible that the number of elements should be calculated by sizeof(A)/sizeof(A[0]).
- Новая диагностика – V688. The 'foo' local variable possesses the same name as one of the class members, which can result in a confusion.
PVS-Studio 5.13 (5 февраля 2014)
- Добавлена поддержка для Emarcadero RAD Studio XE5.
- Новая диагностика – V684. A value of variable is not modified. Consider inspecting the expression. It is possible that '1' should be present instead of '0'.
- Новая диагностика – V685. Consider inspecting the return statement. The expression contains a comma.
- Новая диагностика – V686. A pattern was detected: A || (A && ...). The expression is excessive or contains a logical error.
PVS-Studio 5.12 (23 декабря 2013)
- Исправлена ошибка при работе в режиме прямой интеграции в сборку MSBuild для проектов, использующих свойство SolutionDir.
- Появилась возможность запуска проверки из контекстного меню Solution Explorer.
- Теперь в окне PVS-Studio Output Window по умолчанию не показывается ID сообщения об ошибке. Вернуть показ ID можно с помощью команды Show Columns -> ID.
- Новая диагностика – V682. Suspicious literal is present: '/r'. It is possible that a backslash should be used here instead: '\r'.
- Новая диагностика – V683. Consider inspecting the loop expression. It is possible that the 'i' variable should be incremented instead of the 'n' variable.
PVS-Studio 5.11 (6 ноября 2013)
- Поддержана release-версия Microsoft Visual Studio 2013.
- Новая диагностика – V680. The 'delete A, B' expression only destroys the 'A' object. Then the ',' operator returns a resulting value from the right side of the expression.
- Новая диагностика – V681. The language standard does not define an order in which the 'Foo' functions will be called during evaluation of arguments.
PVS-Studio 5.10 (7 октября 2013)
- Исправлена работа анализатора при запуске Visual Studio с параметром /useenv: devenv.exe /useenv.
- В VS2012 наконец-то стало возможно использовать Clang в качестве препроцессора. Для пользователей PVS-Studio это означает существенное увеличение скорости работы анализатора в VS2012.
- Серьезно улучшена работа анализатора при разборе кода в среде VS2012.
- В дистрибутиве PVS-Studio появилось новое приложение Standalone.
- Появилась возможность экспорта результатов анализа в .CSV-файл для дальнейшей работы с ним из Excel.
- Существенно улучшена поддержка precompiled headers в Visual Studio и MSBuild.
- Новая диагностика – V676. It is incorrect to compare the variable of BOOL type with TRUE.
- Новая диагностика – V677. Custom declaration of a standard type. The declaration from system header files should be used instead.
- Новая диагностика – V678. An object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' function.
- Новая диагностика – V679. The 'X' variable was not initialized. This variable is passed by a reference to the 'Foo' function in which its value will be utilized.
PVS-Studio 5.06 (13 августа 2013)
- Исправлено некорректное определение числа файлов при использовании команды 'Check Open File(s)' в среде Visual Studio 2010.
- Новая диагностика – V673. More than N bits are required to store the value, but the expression evaluates to the T type which can only hold K bits.
- Новая диагностика – V674. The expression contains a suspicious mix of integer and real types.
- Новая диагностика – V675. Writing into the read-only memory.
- Новая диагностика – V814. Decreased performance. The 'strlen' function was called multiple times inside the body of a loop.
PVS-Studio 5.05 (28 мая 2013)
- Добавлена поддержка прокси-сервера с авторизацией для окна продления триал-режима.
- Исправлена проблема с использованием некоторых специальных символов в фильтрах диагностических сообщений.
- Часть настроек страницы Common Analyzer Settings и все настройки страницы Customer Specific Settings объединены в новую страницу настроек: Specific Analyzer Settings.
- Реализована настройка SaveModifiedLog, позволяющая определить поведение диалога сохранения нового\модифицированного отчёта работы анализатора (всегда спрашивать, сохранять автоматически, не сохранять).
- Пользовательские диагностики (V20xx) выделены в отдельную группу (CS – Customer Specific).
- Добавлена новая команда меню "Check Open File(s)", позволяющая проверить все открытые в редакторе IDE исходные C/C++ файлы.
PVS-Studio 5.04 (14 мая 2013)
- Добавлена поддержка C++Builder XE4. Теперь PVS-Studio поддерживает следующие версии C++Builder: XE4, XE3 Update 1, XE2, XE, 2010, 2009.
- Новая диагностика – V669. The argument is a non-constant reference. The analyzer is unable to determine the position at which this argument is being modified. It is possible that the function contains an error.
- Новая диагностика – V670. An uninitialized class member is used to initialize another member. Remember that members are initialized in the order of their declarations inside a class.
- Новая диагностика – V671. It is possible that the 'swap' function interchanges a variable with itself.
- Новая диагностика – V672. There is probably no need in creating a new variable here. One of the function's arguments possesses the same name and this argument is a reference.
- Новая диагностика – V128. A variable of the memsize type is read from a stream. Consider verifying the compatibility of 32 and 64 bit versions of the application in the context of a stored data.
- Новая диагностика – V813. Decreased performance. The argument should probably be rendered as a constant pointer/reference.
- Новая диагностика – V2009. Consider passing the 'Foo' argument as a constant pointer/reference.
PVS-Studio 5.03 (16 апреля 2013)
- Улучшена производительность анализа/интерфейса при проверке крупных проектов и генерации большого числа диагностических сообщений (имеется в виду общее количество неотфильтрованных сообщений).
- Исправлена некорректная интеграция плагина PVS-Studio в среды разработки C++Builder 2009/2010/XE после установки.
- Исправлена ошибка работы в trial-режиме.
- Добавлена возможность использовать относительные пути в файлах-отчётах анализатора.
- Реализована поддержка прямой интеграции анализатора в сборочную систему MSBuild.
- Появилась настройка IntegratedHelpLanguage на странице Customer's Settings. Настройка позволяет задать язык для встроенной справки по диагностическим сообщениям (клик по коду ошибки в окне вывода сообщений PVS-Studio) и документации (команда меню PVS-Studio -> Help -> Open PVS-Studio Documentation (html, online)) PVS-Studio, доступных на нашем сайте. Данная настройка не изменяет языка интерфейса IDE плагина PVS-Studio или выдаваемых анализатором диагностических сообщений.
- Исправлен режим запуска анализа из командной строки для Visual Studio 2012 в случае фоновой подгрузки проектов.
- Новая диагностика – V665. Possibly, the usage of '#pragma warning(default: X)' is incorrect in this context. The '#pragma warning(push/pop)' should be used instead.
- Новая диагностика – V666. Consider inspecting NN argument of the function 'Foo'. It is possible that the value does not correspond with the length of a string which was passed with the YY argument.
- Новая диагностика – V667. The 'throw' operator does not possess any arguments and is not situated within the 'catch' block.
- Новая диагностика – V668. There is no sense in testing the pointer against null, as the memory was allocated using the 'new' operator. The exception will be generated in the case of memory allocation error.
- Новая диагностика – V812. Decreased performance. Ineffective use of the 'count' function. It can possibly be replaced by the call to the 'find' function.
PVS-Studio 5.02 (6 марта 2013)
- Исправлена некорректная навигация у C++Builder модулей, содержащих несколько заголовочных\исходных файлов.
- Добавлена возможность вставки пользовательских комментариев (например, для использования в системах автоматической генерации документации) при разметке кода маркерами ложных срабатываний (False Alarm).
- Исправлен некорректный запуск C++ препроцессора у некоторых файлов, использующих precompiled заголовки.
- Новая диагностика – V663. Infinite loop is possible. The 'cin.eof()' condition is insufficient to break from the loop. Consider adding the 'cin.fail()' function call to the conditional expression.
- Новая диагностика – V664. The pointer is being dereferenced on the initialization list before it is verified against null inside the body of the constructor function.
- Новая диагностика – V811. Decreased performance. Excessive type casting: string -> char * -> string.
PVS-Studio 5.01 (13 февраля 2013)
- Добавлена поддержка некоторых прошлых версий C++Builder. Теперь PVS-Studio поддерживает следующие версии C++Builder: XE3 Update 1, XE2, XE, 2010, 2009.
- Исправлена ошибка, связанная с некорректным запуском инкрементального анализа в версии для C++Builder в некоторых ситуациях.
- Исправлена ошибка с функцией Mark As False Alarm в версии для C++Builder.
- Исправлена ошибка связанная неправильным отображением локализованных имен файлов в версии для C++Builder.
- Исправлена проблема с открытием исходных файлов при переходе по диагностическому сообщению в версии для C++Buidler.
- Исправлена неполная обработка системных include путей при запуске препроцессора для анализатора в версии для C++Builder.
- Новая диагностика – V661. A suspicious expression 'A[B < C]'. Probably meant 'A[B] < C'.
- Новая диагностика – V662. Consider inspecting the loop expression. Different containers are utilized for setting up initial and final values of the iterator.
PVS-Studio 5.00 (31 января 2013)
- Появилась интеграция в Embarcadero RAD Studio, точнее в Embarcadero C++Builder! Теперь пользователям C++Builder доступны диагностические возможности PVS-Studio. Если раньше PVS-Studio можно было удобно использовать только в Visual Studio окружении, то теперь C++-разработчики, выбравшие продукты Embarcadero также могут использовать инструмент статического анализа PVS-Studio. В настоящее время поддерживаются версии XE2 и XE3, включая XE3 Update 1 с поддержкой 64-битного компилятора.
- Реализована поддержка Microsoft Design Language (ранее известного как Metro Language) C++/CX проектов для Windows 8 Store (WinRT) на платформах x86/ARM и Windows Phone 8 проектов.
- Исправление для пользователей Clang-препроцессора в версии для Visual Studio. Раньше при проверке Boost-проектов были ошибки препроцессирования, из-за которых в таких проектах нельзя было использовать Clang в качестве препроцессора. В настоящее время эти ошибки устранены. Это позволяет существенно быстрее проверять проекты с Boost при использовании препроцессора Clang.
- Удалена страница настроек Viva64, так как она устарела.
- Переименовано сообщение V004 – теперь оно более корректно.
- Новая диагностика – V810. Decreased performance. The 'A' function was called several times with identical arguments. The result should possibly be saved to a temporary variable, which then could be used while calling the 'B' function.
- Новая диагностика – V2008. Cyclomatic complexity: NN. Consider refactoring the 'Foo' function.
- Новая диагностика – V657. It's odd that this function always returns one and the same value of NN.
- Новая диагностика – V658. A value is being subtracted from the unsigned variable. This can result in an overflow. In such a case, the comparison operation can potentially behave unexpectedly.
- Новая диагностика – V659. Declarations of functions with 'Foo' name differ in the 'const' keyword only, but the bodies of these functions have different composition. This is suspicious and can possibly be an error.
- Новая диагностика – V660. The program contains an unused label and a function call: 'CC:AA()'. It's possible that the following was intended: 'CC::AA()'.
PVS-Studio 4.77 (11 декабря 2012)
- Улучшен сбор параметров компиляции для VS2012 и VS2010 за счет расширения поддержки MSBuild.
- Новая диагностика – V654. The condition of loop is always true/false.
- Новая диагностика – V655. The strings was concatenated but are not utilized. Consider inspecting the expression.
- Новая диагностика – V656. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
- Новая диагностика – V809. Verifying that a pointer value is not NULL is not required. The 'if (ptr != NULL)' check can be removed.
PVS-Studio 4.76 (23 ноября 2012)
- Исправлены некоторые ошибки.
PVS-Studio 4.75 (12 ноября 2012)
- Исправлена ошибка, проявляющаяся в некоторых определенных условиях при проверке проектов на основе библиотеки Qt (подробности в блоге).
- Новая диагностика – V646. Consider inspecting the application's logic. It's possible that 'else' keyword is missing.
- Новая диагностика – V647. The value of 'A' type is assigned to the pointer of 'B' type.
- Новая диагностика – V648. Priority of the '&&' operation is higher than that of the '||' operation.
- Новая диагностика – V649. There are two 'if' statements with identical conditional expressions. The first 'if' statement contains function return. This means that the second 'if' statement is senseless.
- Новая диагностика – V650. Type casting operation is utilized 2 times in succession. Next, the '+' operation is executed. Probably meant: (T1)((T2)a + b).
- Новая диагностика – V651. An odd operation of the 'sizeof(X)/sizeof(T)' kind is performed, where 'X' is of the 'class' type.
- Новая диагностика – V652. The operation is executed 3 or more times in succession.
- Новая диагностика – V653. A suspicious string consisting of two parts is used for array initialization. It is possible that a comma is missing.
- Новая диагностика – V808. An array/object was declared but was not utilized.
- Новая диагностика – V2007. This expression can be simplified. One of the operands in the operation equals NN. Probably it is a mistake.
PVS-Studio 4.74 (16 октября 2012)
- Новая опция "Incremental Results Display Depth". Настройка задаёт режим отображения уровней сообщений в окне PVS-Studio Output для результатов работы инкрементального анализа. Установка в данном поле глубины уровня отображения (соответственно, только 1 уровень; 1 и 2 уровни; 1, 2 и 3 уровни) приведёт к автоматическому включению данных уровней после завершения инкрементального анализа.
- Новая опция "External Tool Path". Данное поле позволяет задать абсолютный путь до любой внешней утилиты, которую можно запустить с помощью команды контекстного меню "Send this message to external tool" окна PVS-Studio Output. Данная команда доступна для одного одновременно выделенного сообщения в таблице результатов, позволяя передать в заданную здесь утилиту определённые в поле настроек ExternalToolCommandLine параметры командной строки. Подробное описание этого режима с примерами доступно по этой ссылке.
PVS-Studio 4.73 (17 сентября 2012)
- Исправлены ошибки в обработке некоторых C++11 конструкций из Visual Studio 2012.
- Реализована полная поддержка тем для Visual Studio 2012.
- Добавлен быстрый по полю Project в окне PVS-Studio Output Window.
- Обновлена версия Clang, используемого в качестве препроцессора.
- Добавлена поддержка TenAsys INtime.
PVS-Studio 4.72 (30 августа 2012)
- Поддержка финальной версии Microsoft Visual Studio 2012.
- Используется новая версия компонента SourceGrid благодаря чему исправлено несколько недостатков, проявляющихся при работе с окном PVS-Studio Output Window.
- Поддержана диагностика проблем в библиотеке STL при использовании STLport.
- Новая диагностика – V636. The expression was implicitly casted from integer type to real type. Consider utilizing an explicit type cast to avoid overflow or loss of a fractional part.
- Новая диагностика – V637. Two opposite conditions were encountered. The second condition is always false.
- Новая диагностика – V638. A terminal null is present inside a string. The '\0xNN' characters were encountered. Probably meant: '\xNN'.
- Новая диагностика – V639. Consider inspecting the expression for function call. It is possible that one of the closing ')' brackets was positioned incorrectly.
- Новая диагностика – V640. Consider inspecting the application's logic. It is possible that several statements should be braced.
- Новая диагностика – V641. The size of the allocated memory buffer is not a multiple of the element size.
- Новая диагностика – V642. Saving the function result inside the 'byte' type variable is inappropriate. The significant bits could be lost breaking the program's logic.
- Новая диагностика – V643. Unusual pointer arithmetic. The value of the 'char' type is being added to the string pointer.
- Новая диагностика – V644. A suspicious function declaration. It is possible that the T type object was meant to be created.
- Новая диагностика – V645. The function call could lead to the buffer overflow. The bounds should not contain the size of the buffer, but a number of characters it can hold.
PVS-Studio 4.71 (20 июля 2012)
- Новая диагностика – V629. Consider inspecting the expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
- Новая диагностика – V630. The 'malloc' function is used to allocate memory for an array of objects which are classes containing constructors/destructors.
- Новая диагностика – V631. Consider inspecting the 'Foo' function call. Defining an absolute path to the file or directory is considered a poor style.
- Новая диагностика – V632. Consider inspecting the NN argument of the 'Foo' function. It is odd that the argument is of the 'T' type.
- Новая диагностика – V633. Consider inspecting the expression. Probably the '!=' should be used here.
- Новая диагностика – V634. The priority of the '+' operation is higher than that of the '<<' operation. It's possible that parentheses should be used in the expression.
- Новая диагностика – V635. Consider inspecting the expression. The length should probably be multiplied by the sizeof(wchar_t).
PVS-Studio 4.70 (4 июля 2012)
- Добавлена поддержка Visual Studio 2012 RC. В настоящее время анализатор не полностью поддерживает все синтаксические конструкции, реализованные в Visual C++ 2012. Кроме того есть проблема со скоростью работы анализатора. Для повышения скорости работы мы используем препроцессор из Clang. В настоящее время Clang не полностью разбирает заголовочные файлы Visual C++ 2012. Поэтому в большинстве случаев будет использоваться препроцессор cl.exe из состава Visual C++, который работает существенно медленнее. Для пользователя выбор корректного препроцессора происходит автоматически и об этом не надо как-то специально заботиться. Несмотря на эти ограничения работать с PVS-Studio в Visual Studio 2012 RC уже можно.
- Новая диагностика – V615. An odd explicit conversion from 'float *' type to 'double *' type.
- Новая диагностика – V616. The 'Foo' named constant with the value of 0 is used in the bitwise operation.
- Новая диагностика – V617. Consider inspecting the condition. An argument of the '|' bitwise operation always contains a non-zero value.
- Новая диагностика – V618. It's dangerous to call the 'Foo' function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf("%s", str);.
- Новая диагностика – V619. An array is being utilized as a pointer to single object.
- Новая диагностика – V620. It's unusual that the expression of sizeof(T)*N kind is being summed with the pointer to T type.
- Новая диагностика – V621. Consider inspecting the 'for' operator. It's possible that the loop will be executed incorrectly or won't be executed at all.
- Новая диагностика – V622. Consider inspecting the 'switch' statement. It's possible that the first 'case' operator in missing.
- Новая диагностика – V623. Consider inspecting the '?:' operator. A temporary object is being created and subsequently destroyed.
- Новая диагностика – V624. The constant NN is being utilized. The resulting value could be inaccurate. Consider using the M_NN constant from <math.h>.
- Новая диагностика – V625. Consider inspecting the 'for' operator. Initial and final values of the iterator are the same.
- Новая диагностика – V626. Consider checking for misprints. It's possible that ',' should be replaced by ';'.
- Новая диагностика – V627. Consider inspecting the expression. The argument of sizeof() is the macro which expands to a number.
- Новая диагностика – V628. It's possible that the line was commented out improperly, thus altering the program's operation logics.
- Новая диагностика – V2006. Implicit type conversion from enum type to integer type.
PVS-Studio 4.62 (30 мая 2012)
- Реализована возможность использования препроцессора MinGW gcc для проверки проектов, поддерживающих сборку компиляторами MinGW. При этом интеграция анализатора в сборочную систему подобного проекта аналогична использованию анализатора в других проектах без MSVC .sln-файлов, подробно описанному в документации. Стоит помнить, что при наличии у проекта .sln файлов, проверка из командной строки может быть выполнена и обычным способом, без необходимости прямой интеграции анализатора в сборочную систему.
PVS-Studio 4.61 (22 мая 2012)
- Навигация для сообщений с несколькими номерами строк. Некоторые сообщения (например, V595) относятся к нескольким строкам кода. Раньше в окне PVS-Studio Output Window выдавался в столбце Line только один номер строки, а остальные строки указывались в тексте сообщения. Из-за этого навигация была затруднена. Теперь в поле Line могут выводиться несколько номеров строк, по которым возможно осуществлять навигацию.
- Новая сборка Clang включена в дистрибутив. В PVS-Studio используется Clang в качестве препроцессора. В новой сборке исправлено несколько незначительных ошибок. Обратите внимание, что мы не используем Clang для диагностики ошибок.
- Новая диагностика – V612. An unconditional 'break/continue/return/goto' within a loop.
- Новая диагностика – V613. Strange pointer arithmetic with 'malloc/new'.
- Новая диагностика – V614. Uninitialized variable 'Foo' used.
PVS-Studio 4.60 (18 апреля 2012)
- Новая группа диагностических сообщений "Оптимизация" (OP) предлагает диагностику возможных оптимизаций. Это набор правил статического анализа для выявления участков кода в программах на языке C/C++/C++11, которые можно оптимизировать. Следует понимать, что статический анализатор решает задачи оптимизации в узкой нише микро-оптимизаций. Полный список диагностируемых ситуаций приведен в документации (коды V801-V807).
- Существенно сокращено количество ложных срабатываний в анализаторе 64-битных ошибок (Viva64).
- Теперь игнорируются ошибки в автогенерируемых файлах (MIDL).
- Изменения в логике показа диалога сохранения отчета.
- Исправлена работа на локализованной китайской версии Visual Studio (локаль zh).
- Новая диагностика – V610. Undefined behavior. Check the shift operator.
- Новая диагностика – V611. The memory allocation and deallocation methods are incompatible.
PVS-Studio 4.56 (14 марта 2012)
- Добавлена опция TraceMode в Common Analyzer Settings. Настройка задаёт режим трассировки (протоколирования хода выполнения программы).
- Исправлена ошибка при проверке Itanium-проектов.
- Исправлена проблема вызова 64-битной версии clang.exe вместо 32-битной на 32-битной версии Windows при проверке проекта с выбранной платформой x64.
- Изменено количество используемых при анализе ядер в инкрементальном режиме. Теперь для обычного анализа (Check solution/project/file) используется количество ядер, указанное в настройках. Для инкрементального анализа же используется другое количество ядер: если в настройках больше чем (количество ядер-1) и в системе несколько ядер, то (количество ядер-1); иначе – также как в настройках. Проще говоря, в инкрементальном анализе используется на одно ядро меньше, чтобы такой тип анализа не грузил систему.
- Новая диагностика – V608. Recurring sequence of explicit type casts.
- Новая диагностика – V609. Divide or mod by zero.
PVS-Studio 4.55 (28 февраля 2012)
- Новое окно для продления триал-режима (без необходимости написания письма).
- Исправлено падение при перезагрузке проекта во время работы анализатора кода.
- В инсталляторе (при первой установке на машине) выдается запрос на включение инкрементального анализа в PVS-Studio. Если ранее PVS-Studio на машине уже устанавливалась, то запрос выдан не будет. Включить или выключить инкрементальный анализ можно также с помощью команды "Incremental Analysis after Build" в меню PVS-Studio.
- Количество используемых ядер по умолчанию устанавливается как значение, равное количеству ядер минус один. Это можно изменить с помощью опции ThreadCount в настройках PVS-Studio.
- Новая статья в документации: "Режим инкрементального анализа PVS-Studio".
- Изменения в версии для командной строки – теперь возможна обработка нескольких файлов за один запуск PVS-Studio.exe по аналогии с компилятором (cl.exe file1.cpp file2.cpp). Раньше можно было в командной версии только один файл обрабатывать за раз. Подробнее об использовании версии для командной строки смотрите в документации.
- Возможность проверки проектов Microsoft Visual Studio для ARMv4 архитектуры удалена.
- Новая диагностика V604. It is odd that the number of iterations in the loop equals to the size of the pointer.
- Новая диагностика V605. Consider verifying the expression. An unsigned value is compared to the number – NN.
- Новая диагностика V606. Ownerless token 'Foo'.
- Новая диагностика V607. Ownerless expression 'Foo'.
PVS-Studio 4.54 (1 февраля 2012)
- Новый trial-режим. Теперь ограничиваются только клики. Подробности в блоге и в документации.
- Новая команда меню "Disable Incremental Analysis until IDE restart". Иногда бывает полезно отключить инкрементальный анализ. Например, при редактировании базовых h-файлов, что приводит к перекомпиляции большого количества файлов. Но отключить не навсегда, ведь тогда его можно забыть включить, а временно. Команда также доступна в системном трее во время инкрементального анализа.
- Новая диагностика V602. Consider inspecting this expression. '<' possibly should be replaced with '<<'.
- Новая диагностика V603. The object was created but it is not being used. If you wish to call constructor, 'this->Foo::Foo(....)' should be used.
- Новая диагностика V807. Decreased performance. Consider creating a pointer/reference to avoid using the same expression repeatedly.
- Новая статья в документации: "Команды меню PVS-Studio".
PVS-Studio 4.53 (19 января 2012)
- Новая команда для совместной (групповой) работы над кодом "Add TODO comment for Task List". PVS-Studio позволяет автоматически сгенерировать и внести в код комментарий TODO специального вида, содержащий всю необходимую информацию для оценки и анализа отмеченного им фрагмента программы. Такой комментарий будет сразу отображён в окне Task List в Visual Studio.
- Новая диагностика V599. The virtual destructor is not present, although the 'Foo' class contains virtual functions.
- Новая диагностика V600. Consider inspecting the condition. The 'Foo' pointer is always not equal to NULL.
- Новая диагностика V601. An odd implicit type casting.
PVS-Studio 4.52 (28 декабря 2011)
- Изменения в режиме работы анализатора из командной строки без использования .sln-файла. Теперь анализатор можно запускать в несколько процессов одновременно, выходной файл (‑‑output-file) не будет потерян. Также в параметр ‑‑cl-params надо передавать всю строку параметров cl.exe вместе с именем файла: ‑‑cl-params $(CFLAGS) $**.
- Исправлена ошибка "Analysis aborted by timeout", появляющаяся при проверке .sln-файла из командной строки через PVS-Studio.exe.
- Новая диагностика V597. The compiler could delete the 'memset' function call, which is used to flush 'Foo' buffer. The RtlSecureZeroMemory() function should be used to erase the private data.
- Новая диагностика V598. The 'memset/memcpy' function is used to nullify/copy the fields of 'Foo' class. Virtual method table will be damaged by this.
PVS-Studio 4.51 (21 декабря 2011)
- Исправлена проблема, связанная с директивой #import при использовании Clang в качестве препроцессора. Clang не поддерживает #import так, как это реализовано в Microsoft Visual C++, поэтому использовать Clang для таких файлов нельзя. Это определяется автоматически и для подобных файлов запускается препроцессор Visual C++.
- Существенно переделана настройка в PVS-Studio исключения из анализа файлов и папок Don't Check Files. Теперь отдельно указываются исключаемые папки (по короткому или полному пути или маске) и отдельно – исключаемые файлы (по имени, расширению или также маске).
- Некоторые библиотеки добавлены в список исключаемых путей по умолчанию. Можно настроить на вкладке Don't Check Files.
PVS-Studio 4.50 (15 декабря 2011)
- Для препроцессирования файлов в PVS-Studio используется внешний препроцессор. Раньше у нас использовался только один препроцессор от Microsoft Visual C++. В PVS-Studio 4.50 появилась поддержка второго препроцессора Clang, который работает существенно быстрее и лишен ряда недостатков препроцессора от Microsoft (хотя и имеет свои недостатки). Тем не менее, в большинстве случаев использование препроцессора Clang позволяет повысить скорость работы в 1.5-1.7 раз. Однако здесь есть нюанс, который надо учитывать. Указать используемый препроцессор можно в настройках PVS-Studio Options -> Common Analyzer Settings -> Preprocessor. Доступны варианты: VisualCPP, Clang и VisualCPPAfterClang. Первые два варианта очевидны, а третий вариант означает, что сначала будет использоваться Clang, в случае если при препроцессировании будут ошибки, то затем файл будет заново препроцессирован с помощью Visual C++. По умолчанию выбрана именно эта опция (VisualCPPAfterClang).
- Анализатор по умолчанию не выдает диагностические сообщения на библиотеки zlib и libpng (это можно отключить).
- Новая диагностика V596. The object was created but it is not being used. The 'throw' keyword could be missing.
PVS-Studio 4.39 (25 ноября 2011)
- Добавлены новые диагностические правила (V594, V595).
- Анализатор по умолчанию не выдает диагностические сообщения на библиотеку Boost (это можно отключить).
- При инкрементальном анализе не выводится диалог прогресса, вместо него в трее показывается иконка, с помощью которой можно сделать паузу или прервать анализ.
- В контекстном меню результатов анализа появилась команда "Don't Check Files and hide all messages from ...". С её помощью можно удалить сообщения и в дальнейшем не проверять файлы из определенной папки. Список исключенных папок можно посмотреть в настройках Don't Check Files.
- Улучшено определение использования Intel C++ Compiler - PVS-Studio не работает с проектами, которые собираются этим компилятором, нужно сменить компилятор на Visual C++.
- Добавлена функция "Quick Filters", позволяющая фильтровать все сообщения, не удовлетворяющие заданным фильтрам.
PVS-Studio 4.38 (12 октября 2011)
- Повышена скорость работы анализатора (примерно на 25% для четырехъядерных машин).
- В контекстное меню окна PVS-Studio добавлена команда перехода по ID ("Navigate to ID").
- Новое окно "Find in PVS-Studio Output" позволяет осуществлять поиск по ключевым словам в результатах анализа.
- Добавлены новые диагностические правила (V2005).
- Кнопка Options переименована в Suppression, и в ней только три вкладки.
PVS-Studio 4.37 (20 сентября 2011)
- Добавлены новые диагностические правила (V008, V2003, V2004).
- Появилась возможность экспортировать результаты анализа в текстовый файл.
- Теперь мы используем расширенный номер сборки в некоторых случаях.
PVS-Studio 4.36 (31 августа 2011)
- Добавлены новые диагностические правила (V588, V589, V590, V591, V592, V593).
PVS-Studio 4.35 (12 августа 2011)
- Добавлены новые диагностические правила (V583, V584, V806, V585, V586, V587).
PVS-Studio 4.34 (29 июля 2011)
- 64-битный анализ по умолчанию отключен.
- Инкрементальный анализ по умолчанию включен.
- Изменения в поведении в ознакомительном режиме.
- Появился предопределенный макрос PVS_STUDIO.
- Исправлена проблема с инкрементальным анализом на локализованных версиях Visual Studio.
- Всплывающие уведомления и иконка в трее добавлены (по завершении анализа).
- Добавлены новые диагностические правила (V582).
- Изменена картинка для показа с левой стороны мастера установки в дистрибутиве.
PVS-Studio 4.33 (21 июля 2011)
- Режим работы "Incremental Analysis" теперь доступен во всех версиях Microsoft Visual Studio (2005/2008/2010), а не только в VS2010.
- Повышена скорость работы анализатора (примерно на 20% для четырехъядерных машин).
- Добавлены новые диагностические правила (V127, V579, V580, V581).
PVS-Studio 4.32 (15 июля 2011)
- Изменения в лицензионной политике PVS-Studio.
- Реализована динамическая балансировка загрузки процессора.
- Кнопка останова анализа работает быстрее.
PVS-Studio 4.31 (6 июля 2011)
- Исправлена проблема взаимодействия с некоторыми плагинами, включая Visual Assist.
- Добавлены новые диагностические правила (V577, V578, V805).
PVS-Studio 4.30 (23 июня 2011)
- Появилась полноценная поддержка работы анализатора из командной строки. Можно проверять отдельные файлы или группы файлов, вызывая анализатор из Makefile. При этом сообщения анализатора можно видеть не только на экране (для каждого файла), но и записать в один файл, который в дальнейшем можно открыть в Visual Studio и уже получить полноценную работу с результатами анализа: настройки кодов ошибок, фильтры сообщений, навигация по коду, сортировка и т.п. Подробнее.
- Новый важный режим работы Incremental Analysis. PVS-Studio теперь может автоматически запускать анализ измененных файлов, которые надо пересобрать с помощью команды Build в Visual Studio. Теперь все разработчики команды могут сразу же видеть проблемы в новом только что написанном коде без необходимости явно запускать проверку кода – это происходит автоматически. Incremental Analysis работает подобно IntelliSense в Visual Studio. Возможность доступна только в Visual Studio 2010. Подробнее.
- Добавлена команда "Check Selected Item(s)".
- Изменения в запуске команды "Check Solution" при старте из командной строки. Подробнее.
- Добавлены новые диагностические правила (V576).
PVS-Studio 4.21 (20 мая 2011)
- Добавлены новые диагностические правила (V220, V573, V574, V575).
- Добавлена поддержка TFS 2005/2008/2010.
PVS-Studio 4.20 (29 апреля 2011)
- Добавлены новые диагностические правила (V571, V572).
- Добавлена экспериментальная поддержка архитектур ARMV4/ARMV4I для Visual Studio 2005/2008 (Windows Mobile 5/6, PocketPC 2003, Smartphone 2003).
- Новая опция "Show License Expired Message".
PVS-Studio 4.17 (15 апреля 2011)
- Добавлены новые диагностические правила (V007, V570, V804).
- Исправлено неправильное отображение времени анализа файлов при некоторых настройках локали.
- Новая опция "Analysis Timeout". Данная настройка позволяет задать лимит времени, по истечении которого анализ отдельных файлов завершается с ошибкой V006, или совсем отключить прерывание анализа по лимиту времени.
- Новая опция " Save File After False Alarm Mark". Сохранять или нет файл каждый раз после пометки как False Alarm.
- Новая опция " Use Solution Folder As Initial". Определяет папку, которая открывается при сохранении файла с результатами анализа.
PVS-Studio 4.16 (1 апреля 2011)
- При запуске инструмента из командной строки теперь можно задать список файлов, которые будут проверяться. Это можно использовать для проверки, к примеру, только тех файлов, которые были обновлены в системе контроля версий. Подробнее.
- В настройки инструмента добавлена опция "Check only Files Modified In". Данное поле позволяет задать временной интервал, для которого будет осуществляться проверка наличия изменений в анализируемых файлах с использованием файлового атрибута "Date Modified". Другими словами, такой подход позволит проверять "все файлы, которые были изменены за последний день". Подробнее.
PVS-Studio 4.15 (17 марта 2011)
- Значительно уменьшено количество ложных срабатываний для 64-битного анализа.
- Изменения в интерфейсе задания безопасных типов (safe-types).
- Исправлена ошибка с обработкой stdafx.h в некоторых особых случаях.
- Улучшена работа с файлом отчета.
- Улучшен диалог прогресса: показывается затраченное время и сколько осталось.
PVS-Studio 4.14 (2 марта 2011)
- Значительно уменьшено количество ложных срабатываний для 64-битного анализа.
- Добавлены новые диагностические правила (V566, V567, V568, V569, V803).
- В окне сообщений PVS-Studio появилась новая колонка "Звездочка". Теперь вы можете отметить интересные диагностики звездочкой для того, чтобы в дальнейшем обсудить их с коллегами. Пометки сохраняются в файл отчета.
- Опции PVS-Studio теперь доступны не только из меню (в обычном диалоге настроек), но и в окне PVS-Studio. Благодаря этому настройка инструмента теперь делается быстрее и удобнее.
- Добавлена возможность сохранять и восстанавливать настройки PVS-Studio. Это позволяет переносить настройки между различными компьютерами и рабочими местами. Также появилась команда "Восстановить настройки по умолчанию".
- Добавлено сохранение статус кнопок окна PVS-Studio (включено/выключено) при следующем запуске Microsoft Visual Studio.
PVS-Studio 4.13 (11 февраля 2011)
- Добавлены новые диагностические правила (V563, V564, V565).
- Команда "Check for updates" добавлена в меню PVS-Studio.
- Команда "Hide all VXXX errors" для выключения ошибок по их коду добавлена в контекстное меню окна PVS-Studio. Если вы хотите включить обратно показ диагностик VXXX вы можете сделать это через страницу настроек PVS-Studio->Options->Detectable errors.
- Подавление ложных предупреждений в макросах (#define) добавлено.
PVS-Studio 4.12 (7 февраля 2011)
- Добавлены новые диагностические правила (V006, V204, V205, V559, V560, V561, V562).
- Изменения в диагностических правилах V201 и V202.
PVS-Studio 4.11 (28 января 2011)
- Диагностическое правило V401 заменено на V802.
- Исправлена проблема с копированием сообщений в буфер обмена.
PVS-Studio 4.10 (17 января 2011)
- Добавлены новые диагностические правила (V558).
PVS-Studio 4.00 (24 декабря 2010)
- Добавлены новые диагностические правила (V546-V557).
- Исправлена проблема с обработкой property sheets в Visual Studio 2010.
- Исправлена ошибка с обходом дерева проектов.
- В окно PVS-Studio добавлено поле "Project" - проект, к которому относится диагностическое сообщение.
- Исправлена установка PVS-Studio для Visual Studio 2010 – теперь PVS-Studio устанавливается для всех пользователей, а не только для текущего.
- Исправлено падение при попытке сохранить пустой файл отчета.
- Исправлена проблема с отсутствующим файлом safe_types.txt.
- Исправлена ошибка, возникающая при попытке проверить файлы, которые включены в проект, но реально на диске не существуют (например, это автогенерируемые файлы).
- Добавлена индикация процесса обработки дерева проекта.
- Файл с результатами анализа PVS-Studio (расширение .plog) теперь загружается по двойному клику.
- Изменения в лицензионной политике.
PVS-Studio 4.00 BETA (24 ноября 2010)
- Новый набор правил статического анализа общего назначения (V501-V545, V801).
- Добавлены новые правила (V124-V126).
- Изменения в лицензионной политике.
- Новое окно для диагностических сообщений, выдаваемых анализатором.
- Повышение скорости работы.
PVS-Studio 3.64 (28 сентября 2010)
- Существенное обновление документации по PVS-Studio, добавлены новые разделы.
PVS-Studio 3.63 (10 сентября 2010)
- Исправлена проблема, иногда возникающая при анализе файлов с не системного диска.
- Исправлена проблема с вычислением значений макросов для отдельных файлов (а не всего проекта).
- Команда "What Is It?" удалена.
- Демонстрационные примеры проблем 64-битного кода (PortSample) и параллельного кода (ParallelSample) объединены в единый пример OmniSample, который подробно описан в документации.
- Исправлено падение при наличии в решении выгруженного (unloaded) проекта.
PVS-Studio 3.62 (16 августа 2010)
- Добавлено новое правило V123: Allocation of memory by the pattern "(X*)malloc(sizeof(Y))" where the sizes of X and Y types are not equal.
- Упрощена работа с PVS-Studio из командной строки (без файла проекта Visual Studio).
- По умолчанию не выдаются сообщения об ошибках в tli/tlh файлах.
PVS-Studio 3.61 (22 июля 2010)
- Исправлено падение в VS2010 при выставленном параметре EnableAllWarnings в настройках проекта.
- Исправлена ошибка – проверялись даже те проекты, которые были исключены из сборки в Configuration Manager.
- Улучшен анализ кода.
PVS-Studio 3.60 (10 июня 2010)
- Добавлено новое правило V122: Memsize type is used in the struct/class.
- Добавлено новое правило V303: The function is deprecated in the Win64 system. It is safer to use the NewFOO function.
- Добавлено новое правило V2001: Consider using the extended version of the FOO function here.
- Добавлено новое правило V2002: Consider using the 'Ptr' version of the FOO function here.
PVS-Studio 3.53 (7 мая 2010)
- Добавлена возможность задать вопрос разработчикам PVS-Studio про сообщения, выдаваемые анализатором кода (команда "What Is It").
- Значительно улучшен анализ кода, связанного с использованием неименованных структур.
- Исправлена ошибка, приводившая в некоторых случаях к неверному вычислению размера структур.
PVS-Studio 3.52 (27 апреля 2010)
- Добавлена новая online справочная система. Старая справочная система интегрировалась в MSDN. По некоторым причинам это неудобно (как пользователям, так и разработчикам). Теперь PVS-Studio будет открывать справку на нашем сайте. От интеграции с MSDN мы отказались. И, как и прежде, доступна pdf-версия документации.
- Отказались от поддержки Windows 2000.
- Удалена страница настроек "Exclude From Analysis" - вместо нее страница "Don't Check Files".
- Улучшена работа в Visual Studio 2010.
- Исправлена проблема с интеграцией в VS2010 при повторной инсталляции.
- Исправлена работа функции "Mark As False Alarm" с read-only файлами.
PVS-Studio 3.51 (16 апреля 2010)
- PVS-Studio поддерживает работу в Visual Studio 2010 RTM.
- Добавлено новое правило V003: Unrecognized error found...
- Добавлено новое правило V121: Implicit conversion of the type of 'new' operator's argument to size_t type.
- Добавлена возможность исключить из анализа файлы по маске (PVS-Studio Options, вкладка Don't Check Files).
- Переделан интерфейс страницы настроек Exclude From Analysis.
- Убрана опция MoreThan2Gb из страницы настроек Viva64 (опция устарела и более не имеет смысла).
- При проверке кода из командной строки надо указывать тип анализатора (Viva64 или VivaMP).
- Снижен приоритет процесса анализатора, что позволяет комфортно работать на машине во время проверки кода.
PVS-Studio 3.50 (26 марта 2010)
- PVS-Studio поддерживает работу в Visual Studio 2010 RC. Хотя официальный выпуск Visual Studio еще не состоялся, мы уже добавили поддержку этой среды в анализатор. Сейчас PVS-Studio интегрируется в Visual Studio 2010 и может проверять проекты в этой среде. В Visual Studio 2010 изменена справочная система, поэтому пока справка от PVS-Studio не интегрируется в документацию, как это делается в Visual Studio 2005/2008. Но вы по-прежнему можете пользоваться online-справкой. Поддержка Visual Studio 2010 RC реализована не полностью.
- Доступна PDF-версия справочной системы. Теперь в дистрибутиве с PVS-Studio идет 50-страничный PDF-документ. Это полная копия нашей справочной системы (которая интегрируется в MSDN в Visual Studio 2005/2008 или доступна online).
- В PVS-Studio появился механизм автоматического определения новых версий инструмента на нашем сайте. Определение новых версий контролируется через опцию CheckForNewVersions вкладки настроек "Common Analyzer Settings". В случае если опция CheckForNewVersions имеет значения True, то при запуске проверки кода (команды Check Current File, Check Current Project, Check Solution меню PVS-Studio) выполняется загрузка специального текстового файла с сайта pvs-studio.com. В этом файле прописан номер самой последней версии PVS-Studio, доступной на сайте. Если версия на сайте окажется новее, чем версия, установленная у пользователя, то пользователь увидит запрос на обновление. В случае разрешения этого обновления запустится специальное отдельное приложение PVS-Studio-Updater, которое автоматически загрузит новый дистрибутив PVS-Studio с сайта и запустит его установку. В случае если опция CheckForNewVersions установлена в False, то проверка новой версии производиться не будет.
- Реализована поддержка стандарта C++0x на уровне, на котором она осуществлена в Visual Studio 2010. Реализована поддержка лямбда-выражений, auto, decltype, static_assert, nullptr и так далее. В дальнейшем, с развитием поддержки C++0x в Visual C++, анализатор PVS-Studio также будет поддерживать новые возможности языка Си++.
- Стало возможно запускать проверку проектов с помощью PVS-Studio не из Visual Studio, а с помощью командой строки. Обратите внимание, что речь идет все равно о проверке из Visual Studio с использованием файлов проектов (.vcproj) и решений (.sln), но при этом запуск анализа будет осуществляться не из IDE, а из командной строки. Такой вариант запуска удобен для регулярной проверки кода с помощью систем сборки (build system) или систем непрерывной интеграции (continuous integration system).
- Добавлено новое правило V1212: Data race risk. When accessing the array 'foo' in a parallel loop, different indexes are used for writing and reading.
- В этой версии инструмента мы ввели сертификат подписи кода. Это позволит пользователям быть уверенным в подлинности дистрибутива и получать меньше сообщений от операционной системы при установке приложения.
PVS-Studio 3.45 (1 февраля 2010)
- Существенно улучшена работа анализатора с шаблонами.
- Улучшена работа на многоядерных системах.
PVS-Studio 3.44 (21 января 2010)
- Частичная поддержка проверки кода для процессоров Itanium. Теперь код, который собирается в Visual Studio Team System для процессоров Itanium также можно проверять с помощью анализатора. Анализ выполняется на системах x86 и x64, запуск на Itanium пока не реализован.
- Сокращение количества ложных срабатываний анализатора при анализе доступа к массивам. Теперь анализатор в ряде случаев "понимает" диапазоны значений в цикле for и не выводит лишних сообщений про доступе к массивам с помощью таких индексов. Например: for (int i = 0; i < 8; i++) arr[i] = foo(); // нет сообщения анализатора.
- Сокращенено количество ложных сообщений анализатора - введен список типов данных, которые не образуют большие массивы. Например, HWND, CButton. Пользователь может составлять свои списки типов.
- Исправлена ошибка в работе инсталятора при установке программы в папку, отличную от папки по умолчанию.
PVS-Studio 3.43 (28 декабря 2009)
- Удалена опция ShowAllErrorsInString (теперь она всегда имеет значение true).
- Новое правило V120: Member operator[] of object 'foo' declared with 32-bit type argument, but called with memsize type argument.
- Новое правило V302: Member operator[] of 'foo' class has a 32-bit type argument. Use memsize-type here.
- Улучшен анализ operator[].
- Исправлена ошибка с долгим удалением программы при многократной установке "поверх".
- Исправлена ошибка анализа файлов с символом "^" в имени.
PVS-Studio 3.42 (9 декабря 2009)
- Улучшена диагностика ошибок с магическими числами. Теперь в сообщении о проблеме выдается больше информации, что позволяет более гибко использовать фильтры.
- Исправлена ошибка при работе с прекомпилированными заголовочными файлами специального типа.
- Опция DoTemplateInstantiate (выполнять инстанцирования шаблонов) теперь по умолчанию включена.
- Исправлена ошибка с зависанием препроцессора при большом количестве сообщений препроцессора.
- Улучшен анализ operator[].
PVS-Studio 3.41 (30 ноября 2009)
- Исправлена ошибка анализа файлов с одинаковыми именами при работе на многоядерной машине.
- Исправлена ошибка некорректной диагностики некоторых типов cast-выражений.
- Существенно улучшен разбор перегруженных функций в анализаторе.
- Добавлена диагностика некорректного использования time_t типа.
- Добавлена обработка специальных параметров в настройках файлов проекта Visual C++.
PVS-Studio 3.40 (23 ноября 2009)
- Добавлена возможность "Mark as False Alarm". Благодаря этому возможно пометить в исходном коде те строки, в которых происходит ложное срабатывание анализатора кода. После разметки, анализатор более не будет выдавать диагностических сообщений на такой код. Это позволяет более удобно постоянно использовать анализатор в процессе разработки программного обеспечения для проверки нового кода.
- Добавлена поддержка Project Property Sheets - механизма удобной настройки проектов Visual Studio.
- При проверке параллельных программ анализатор может выполнять два прохода по коду, что позволяет собрать больше информации и выполнить более точную диагностику некоторых ошибок.
PVS-Studio 3.30 (25 сентября 2009)
- В PVS-Studio добавлена возможность проверки 32-битных проектов для оценки сложности и стоимости миграции кода на 64-битные системы.
- Добавлено новое правило для анализа 64-битного кода V118: malloc() function accepts a dangerous expression in the capacity of an argument.
- Добавлено новое правило для анализа 64-битного кода V119: More than one sizeof() operators are used in one expression.
- Добавлено новое правило для анализа параллельного кода V1211: The use of 'flush' directive has no sense for private '%1%' variable, and can reduce performance.
- Улучшена совместная работа с Intel C++ Compiler (исправлено падение при попытке проверки кода с установленным Intel C++ Compiler).
- Улучшена поддержка локализованных версий Visual Studio.
PVS-Studio 3.20 (7 сентября 2009)
- Исправлена ошибка с некорректным выводом некоторых сообщений в локализованных версиях Visual Studio.
- Улучшена загрузка log-файла.
- Улучшена обработка критических ошибок - теперь о возможных проблемах с инструментов сообщить нам стало просто.
- Улучшена работа инсталлятора.
- Исправлена ошибка перебора файлов проекта.
PVS-Studio 3.10 (10 августа 2009)
- Добавлена поддержка инстанцирования шаблонов. Теперь поиск потенциальных ошибок выполняется не просто по телу шаблонов (как ранее), но и еще выполняется подстановка аргументов шаблона для более тщательной диагностики.
- Теперь анализатор кода может работать в режиме имитации Linux-окружения. Мы добавили поддержку различных моделей данных. Поэтому теперь на Windows-системе можно проверять кросс-платформенные программы также, как это делалось бы на Linux-системе.
- Исправлена ошибка, связанная с некорректной работой анализатора параллельных ошибок в 32-битном окружении.
- Существенно улучшена работа анализатора с шаблонами.
PVS-Studio 3.00 (27 июля 2009)
- Программные продукты Viva64 и VivaMP объединены в один программный комплекс PVS-Studio.
- Новая версия представляет собой существенно модернизированный программный продукт.
- Существенно повышена стабильность работы модуля интеграции в Visual Studio.
- Повышена скорость работы на многопроцессорных системах: анализ выполняется в несколько потоков. Причем количество рабочих потоков анализатора можно настраивать с помощью опции "Thread Count". По умолчанию количество потоков соответствует количеству ядер в процессоре, однако количество потоков можно уменьшить.
- Добавлена возможность работы анализатора из командной строки. В настройки программы добавлена новая опция "Remove Intermediate Files" ("Удалять промежуточные файлы"), которая позволяет не удалять командные файлы, создаваемые во время работы анализатора кода. Эти командные файлы можно запускать отдельно, без Visual Studio для выполнения анализа. Кроме того, создавая новые командные файлы по аналогии можно выполнять анализ всего проекта без использования Visual Studio.
- Управлять диагностикой отдельных ошибок стало проще, удобнее и быстрее. Теперь можно включать и выключать показ отдельных ошибок в результатах анализа. Самое главное, что изменение списка сообщений происходит автоматически, без необходимости перезапуска анализа. Выполнив анализ, вы можете просмотреть список ошибок и просто выключить показ тех из них, которые для вашего проекта не актуальны.
- Значительно улучшена работа с фильтрами ошибок. Фильтры для сокрытия отдельных сообщений теперь задаются просто как список строк. Причем применение фильтров также как и управление диагностикой отдельных ошибок не требует перезапуска анализа.
- Изменение лицензионной политики. Хотя PVS-Studio является единым продуктом, лицензирование возможно и для отдельных модулей анализа, таких как Viva64 и VivaMP, и для всех модулей сразу. Кроме того, появились лицензии для одного пользователя и для команды разработчиков. Все эти изменения нашли отражение в регистрационных ключах.
- Поддержка локализованных версий Visual Studio существенно улучшена.
- Интегрирующаяся в MSDN справочная система для новой версии PVS-Studio была значительно переработана и усовершенствована. Описание новых разделов позволяет лучше изучить работу с программным продуктом.
- Улучшено графическое оформление программного продукта. Новые иконки и графика в инсталляторе придали анализатору более красивый вид.
VivaMP 1.10 (20 апреля 2009)
- Улучшен анализ кода, содержащего вызовы статических функций класса.
- Реализованы новые диагностические правила для анализа ошибок связанных с исключениями: V1301, V1302, V1303.
- Исправлена ошибка с некорректным отображением индикатора прогресса анализа на компьютерах с нестандартным DPI.
- Реализованы некоторые другие усовершенствования.
VivaMP 1.00 (10 марта 2009)
- Выпущена финальная версия VivaMP.
VivaMP 1.00 beta (27 ноября 2008)
- Первая публичная бета-версия VivaMP выложена в Интернете.
Viva64 2.30 (20 апреля 2009)
- Реализовано новое диагностическое правило V401.
- Улучшена обработка констант, что в ряде случаев сокращает количество ложных диагностических предупреждений.
- Исправлена ошибка с некорректным отображением индикатора прогресса анализа на компьютерах с нестандартным DPI.
- Исправлен ряд недочетов.
Viva64 2.22 (10 марта 2009)
- Улучшена совместная работа Viva64 и VivaMP.
- Увеличена скорость работы анализатора кода на 10%.
Viva64 2.21 (27 ноября 2008)
- Добавлена поддержка совместной работы Viva64 и VivaMP.
Viva64 2.20 (15 октября 2008)
- Улучшена диагностика потенциально опасных конструкций. В результате примерно на 20% сократилось количество "ложных срабатываний" анализатора кода. Теперь разработчик потратит меньше времени на анализ кода, диагностируемого как потенциально опасный.
- Изменения в справочной системе. Справка было расширена и дополнена новыми примерами. Так как в данной версии улучшена диагностика потенциально опасных конструкций, то в справочную систему также были добавлены пояснения, касающиеся того, какие конструкции теперь не считаются опасными.
- Увеличена скорость анализа структуры проекта. Теперь же такая работа выполняется примерно в 10 раз быстрее. В конечном итоге это сокращает общее время анализа всего проекта.
- Улучшен анализ шаблонов в языке Си++. Не секрет, что далеко не все анализаторы кода полностью понимают шаблоны (template). Мы постоянно работаем над улучшением диагностики потенциально опасных конструкций в шаблонах. Очередное подобное улучшение сделано в этой версии.
- Изменен формат ряда сообщений анализатора кода для возможности осуществления более тонкой настройки фильтров. Так, например, теперь анализатор не просто сообщает о некорректном типе индекса при доступе к массиву, но при этом и указывает имя самого массива. Если разработчик уверен, что подобный массив никак не может быть источником проблем для 64-битного режима работы, то он может отфильтровать все сообщения, относящиеся к данному массиву по его имени.
Viva64 2.10 (05 сентября 2008)
- Добавлена поддержка Visual C++ 2008 Service Pack 1.
Viva64 2.0 (09 июля 2008)
- Добавлена поддержка Visual C++ 2008 Feature Pack (и TR1).
- Добавлен режим Pedantic, позволяющий в случае необходимости находить конструкции, представляющие потенциальную опасность, но редко приводящие к ошибкам.
- Улучшена диагностика шаблонных функций.
Viva64 1.80 (03 февраля 2008)
- Visual Studio 2008 полностью поддерживается.
- Увеличена скорость анализа кода.
- Улучшен установщик. Теперь возможно установить Viva64 без прав администратора.
Viva64 1.70 (20 декабря 2007)
- Добавлена поддержка нового диагностического сообщения (V117). Memsize type used in union.
- Исправлена серьезная проблема связанная с диагностикой нескольких ошибок в одной строке кода.
- Исправлена ошибка вычисления типов в сложных синтаксических конструкциях.
- Улучшен интерфейс пользователя. Индикатор прогресса отслеживает анализ всего решения (solution).
- Visual Studio 2008 частично поддерживается(BETA).
Viva64 1.60 (28 августа 2007)
- Добавлена поддержка нового диагностического сообщения (V112). Dangerous magic number used.
- Добавлена поддержка нового диагностического сообщения (V115). Memsize type used for throw.
- Добавлена поддержка нового диагностического сообщения (V116). Memsize type used for catch.
- Изменены ограничения ознакомительной версии. Для каждого анализируемого файла показываются только несколько диагностических сообщений.
Viva64 1.50 (15 мая 2007)
- Добавлена поддежка анализа кода на языке Си.
Viva64 (1.40 - 1 мая 2007)
- Добавлена возможность подавления некоторых сообщений. Вы можете задавать свои фильтры на странице настроек "Message Suppression". Например, вы можете захотеть пропускать сообщения с определенным кодом ошибки или сообщения, содержащие определенные имена функций. (См. Settings: Message Suppression).
- Появилась возможность сохранять/загружать результаты анализа..
- Улучшено представление результатов работы анализатора. Результаты теперь выдаются в стандартном окне Visual Studio под названием Error List, подобно сообщениям компилятора.
Viva64 1.30 (17 марта 2007)
- Улучшено представление процесса анализа кода. Убраны лишние переключения окон, создан общий индикатор прогресса.
- Добавлена панель инструментов Viva64.
- Пользователь может указать анализатору, что проверяемая программа может использовать более 2Гб оперативной памяти. Для программ, использующих меньше 2Гб памяти некоторые диагностические сообщения будут отключены.
- Добавлена поддержка нового диагностического сообщения (V113). Implicit type conversion from memsize to double type or vice versa.
- Добавлена поддержка нового диагностического сообщения (V114). Dangerous explicit type pointer conversion.
- Добавлена поддержка нового диагностического сообщения (V203). Explicit type conversion from memsize to double type or vice versa.
Viva64 1.20 (26 января 2007)
- Добавлена фильтрация повторяющихся сообщений. Речь идет об ошибках в h-файлах. Ранее если *.h файл с ошибкой включался в различные *.cpp файлы, то диагностические сообщения выдавались несколько раз. Теперь же будет только одно диагностическое сообщение.
- Теперь Viva64 сообщает о количестве ошибок, обнаруженных после анализа кода. Вы всегда можете определить: - сколько кода осталось проверить; - как много ошибок уже исправлено; - какие модули содержат наибольшее количество ошибок.
- Добавлена поддержка горячих клавиш. Теперь можно прервать работу анализатора с помощью Ctrl+Break. А для проверки текущего файла достаточно нажать Ctrl+Shift+F7.
- Исправлены некоторые ошибки в работе анализатора.
Viva64 1.10 (16 января 2007)
- С помощью анализатора Viva64 мы подготовили 64-битную версию Viva64! Но пользователю не надо беспокоиться о выборе подходящей версии. Правильная версия выбирается автоматически во время установки.
- Добавлена поддержка нового диагностического сообщения (V111).
- Удалена ненужная диагностика на доступ к массивам с помощью enum-значений.
- Удалена ненужная диагностика ошибок на конструкции вида int a = sizeof(int).
- Улучшения справочной системы.
Viva64 1.00 (31 декабря 2006)
- Первая публичная версия Viva64 выложена в Интернете.
Работа PVS-Studio в Visual Studio
- Смотри, а не читай (ВК Видео)
- Установка плагина из Visual Studio Marketplace
- Ввод лицензии
- Настройки плагина
- Запуск анализа PVS-Studio
- Работа с результатами анализа
- Горячие клавиши плагина PVS-Studio в Visual Studio
- Полезные ссылки
Плагин PVS-Studio для среды разработки Microsoft Visual Studio не только предоставляет удобный графический интерфейс и возможности статического анализа, но и широкий спектр дополнительных возможностей по работе с сообщениями анализатора.
Установить его вы можете как из официального репозитория плагинов, так и при помощи нашего установщика для Windows, который доступен на странице загрузки.
Смотри, а не читай (ВК Видео)
Установка плагина из Visual Studio Marketplace
Чтобы установить плагин PVS-Studio для Visual Studio из Marketplace, нужно перейти в управление плагинами (Manage Extensions) с помощью команды Extensions -> Manage Extensions и ввести в поиске PVS-Studio. В результатах поиска появится нужный плагин:

После нажатия на кнопку Download начнётся автоматическая загрузка установщика PVS-Studio для Windows, который содержит не только сам плагин, но также ядро анализатора и вспомогательные инструменты.
Установщик попросит закрыть все активные процессы в доступных средах разработки и предложит на выбор плагины для всех установленных IDE:

Ввод лицензии
Первое, что нужно сделать после установки – ввести лицензию. Процесс ввода лицензии в Visual Studio подробно описан в документации.
Настройки плагина
Помимо Registration есть и другие настройки – давайте рассмотрим их подробнее.
Common Analyzer Settings
Первый раздел в списке – это Common Analyzer Settings:

По умолчанию в этой вкладке выставляются оптимальные для использования настройки. Так ThreadCount (количество потоков) равно числу ядер на используемом процессоре.
RemoveIntermediateFiles же может понадобиться, если будет обнаружена какая-либо проблема в работе анализатора и нужно будет сообщить о ней нам. При выборе false после анализа останутся артефакты (препроцессированные файлы и файлы конфигурации), которые помогут обнаружить проблему.
Detectable Errors
Этот раздел позволяет выбрать, какие именно предупреждения вы хотите получать. Можно скрыть или показать не только отдельные срабатывания, но и целые классы диагностик:
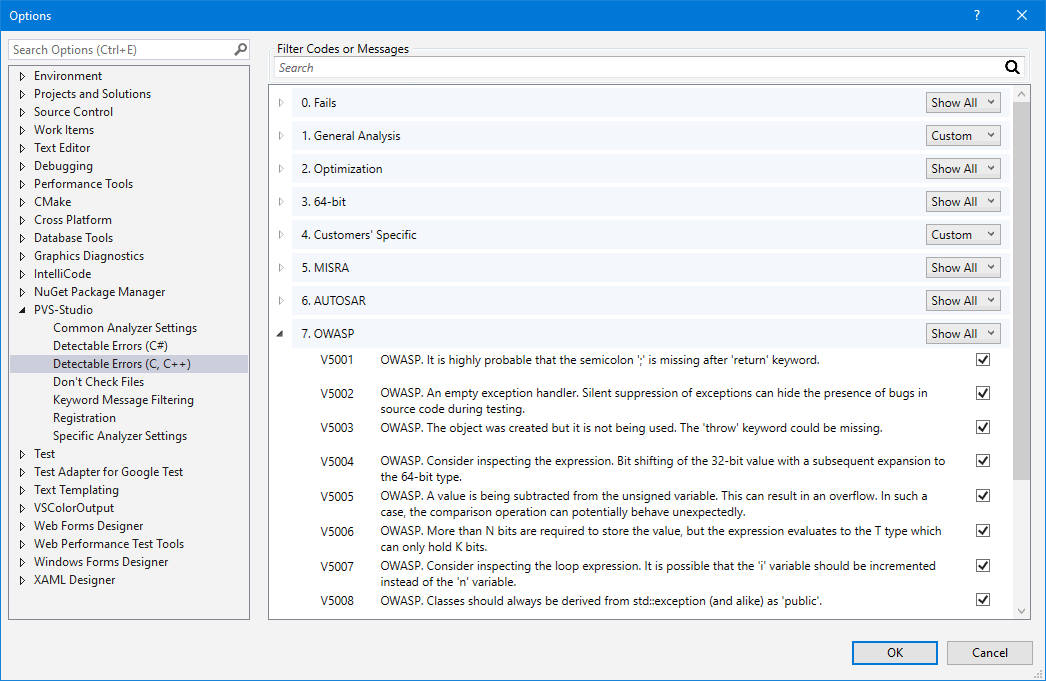
Don't Check Files
Крайне полезный раздел, который поможет улучшить качество и скорость анализа при помощи исключения лишних файлов, которые, например, не относятся напрямую к проекту:
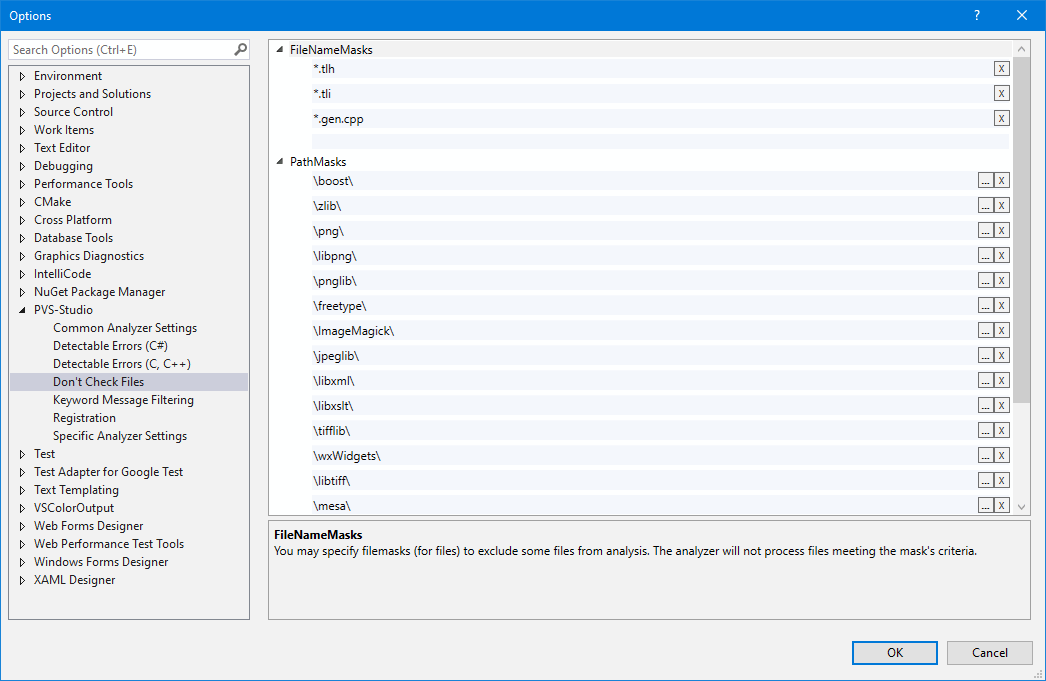
По умолчанию уже указаны самые распространённые исключаемые директории и расширения. Если у вас будут срабатывания, например, на third party код, то стоит добавить его в PathMasks.
Подробнее про Don't Check Files можно посмотреть в соответствующем разделе документации.
Keyword Message Filtering
При помощи Keyword Message Filtering можно указать ключевые слова, которые нужно исключить из результатов анализа:

Например, если вам встречаются сообщения об ошибках, связанные с printf, а вы считаете, что ошибок, связанных с ними, быть не может, то добавьте ключевое слово printf. Сообщения, содержащие указанное значение, сразу же будут отфильтрованы без перезапуска анализа.
Specific Analyzer Settings
По умолчанию плагин настроен для работы в самых распространённых условиях, однако если проект имеет специфичные особенности, то можно дополнительно настроить анализатор при помощи раздела Specific Analyzer Settings:

Подробное описание дополнительных настроек можно найти в специальном разделе документации.
Запуск анализа PVS-Studio
В плагине PVS-Studio поддерживается анализ не только всего решения, но также отдельных проектов и файлов. Для запуска анализа можно выбрать интересующие файлы и проекты, и запустить на них анализ из контекстного меню:
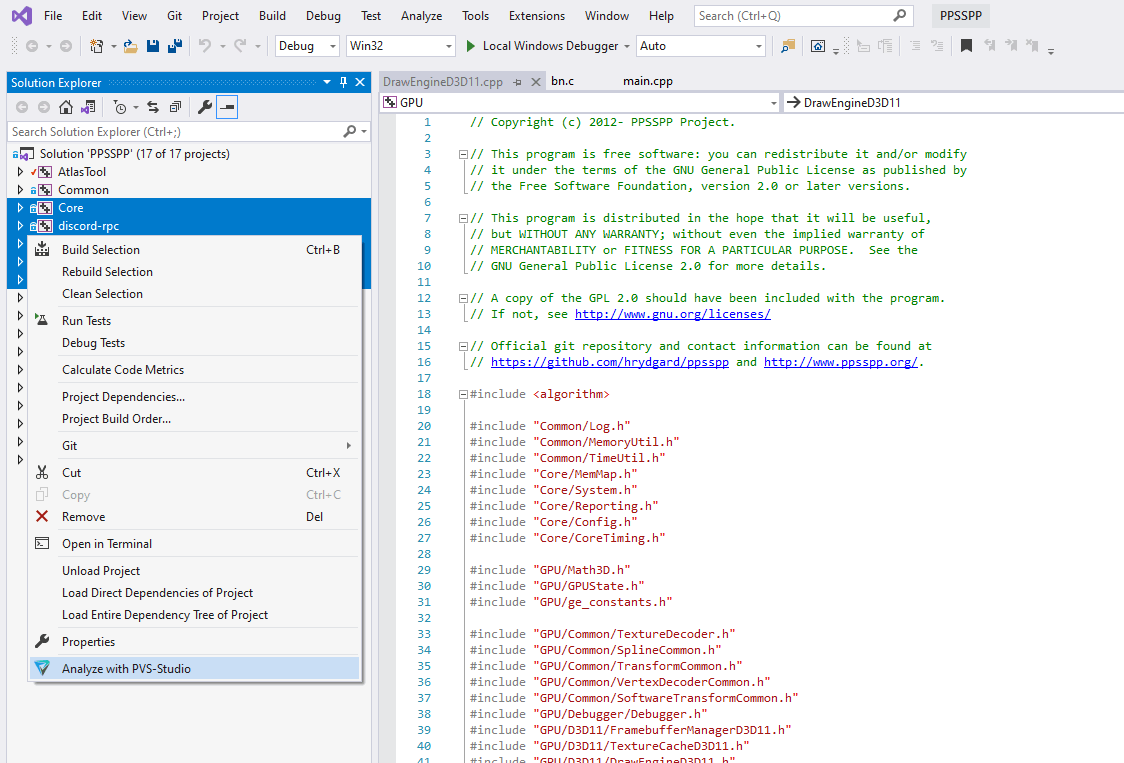
Также всегда можно запустить анализ для текущего файла:
- из меню плагина PVS-Studio;
- из контекстного меню файла;
- из контекстного меню заголовка файла в редакторе файла.
Дополнительно в элементе меню "Check" имеется несколько пунктов меню для более специфичных вариантов анализа:
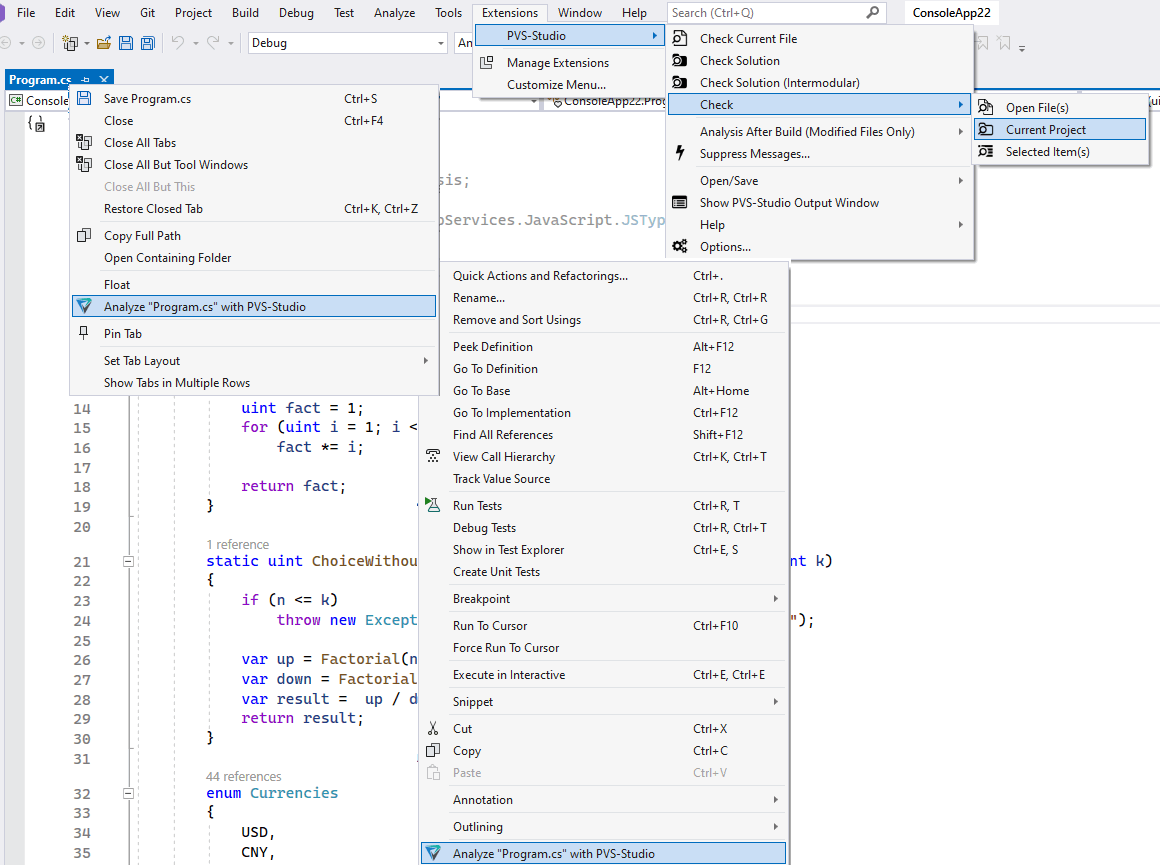
Плагин PVS-Studio для Visual Studio поддерживает проверку проектов и исходных файлов для языков C, С++ и C#. Для языка C++ поддерживается проверка стандартных Visual C++ проектов, использующих сборочную систему MSBuild.
Для проверки специфичных проектов, таких, как, например, NMake проекты, можно воспользоваться системой отслеживания вызовов компилятора.
Работа с результатами анализа
После анализа в IDE появится панель с результатами анализа:
Здесь можно помечать заинтересовавшие вас сообщения, подавлять ложно-позитивные срабатывания, сортировать их по разным категориям, выбирать уровни достоверности, открывать документацию к диагностикам, а также совершать многие другие манипуляции с предупреждениями.
При помощи двойного клика по строке можно легко перейти на участок кода, содержащий подозрительное место:
А при нажатии на три полоски открывается дополнительное меню панели PVS-Studio:
Подробнее про работу со списком предупреждений можно прочитать в документации.
Подавление предупреждений анализатора на старом (legacy) коде
При первом запуске анализатора на большом проекте может быть действительно много срабатываний. Разумеется, стоит выписать себе самые интересные, а вот остальные можно со спокойной душой скрыть при помощи механизма подавления предупреждений, ведь ваш код уже протестирован и работает. Так как маловероятно, что вы найдете среди них критичные для работы приложения проблемы (однако и такое может быть).
Для подавления всех предупреждений нужно выбрать пункт Suppress All Messages в дополнительной панели плагина:
После этого они будут добавлены в специальные *.suppress файлы. Так как при подавлении учитываются и соседние строки, при смещении кода сообщения не появятся вновь. Однако, если внести правку рядом с предупреждением, тогда оно будет вновь показано при последующем запуске анализа.
Подробное описание подавления предупреждений и работы с *.suppress файлами вы найдёте в разделе документации Подавление сообщений анализатора.
Также предлагаем познакомиться со статьёй "Как внедрить статический анализатор кода в legacy проект и не демотивировать команду".
Работа с ложными срабатываниями
Так или иначе во время работы с анализатором будут появляться ложные срабатывания (false positive). Для таких ситуаций предусмотрен специальный механизм подавления и фильтрации.
Чтобы пометить сообщение как ложное, кликните на строку с предупреждением правой кнопкой мыши и выберите Mark selected messages as False Alarms:
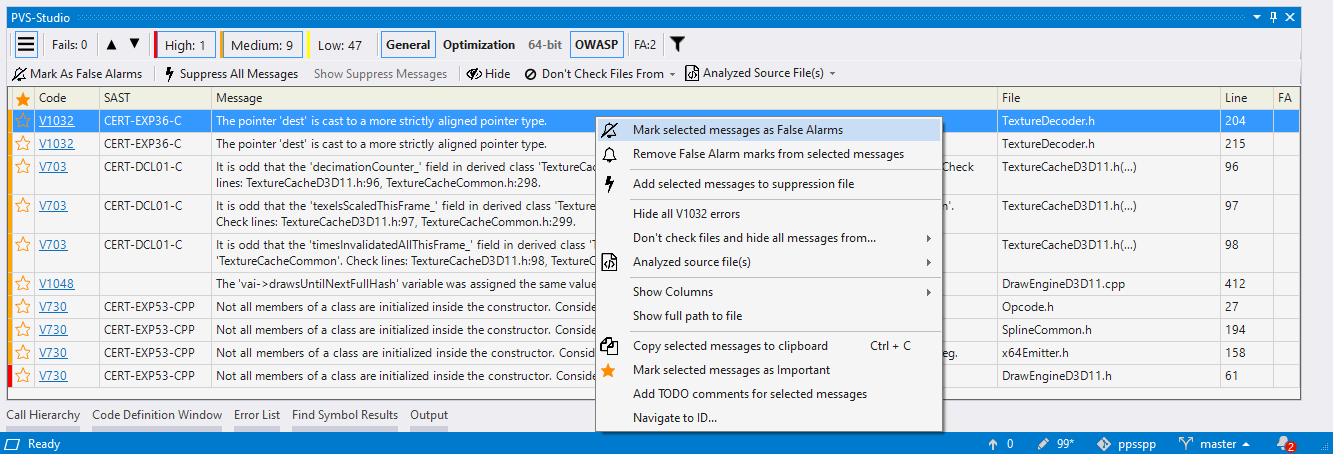
После этого к строке с предупреждением добавится комментарий типа //-Vxxx, где xxx – это номер диагностического правила PVS-Studio. Такой комментарий также можно добавить в код вручную. При помощи команды контекстного меню Remove False Alarm marks from selected messages можно удалить отметку ложного срабатывания с выбранных сообщений.
Если же вы не хотите добавлять комментарии в код, тогда можно воспользоваться механизмом подавления сообщений и добавить предупреждение в *.suppress файл. Чтобы это сделать, выберите другой пункт контекстного меню Add selected messages to suppression file:
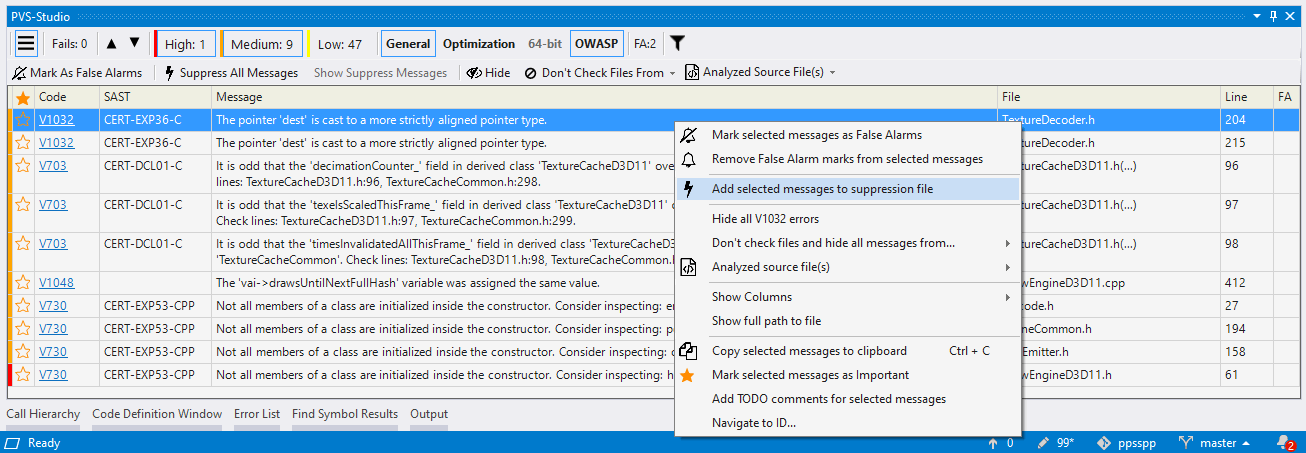
Подробное описание работы механизма подавления ложных срабатываний вы найдёте в разделе документации Подавление ложно-позитивных предупреждений.
Просмотр интересных предупреждений анализатора
Если Вы только начали изучать инструмент статического анализа и хотели бы узнать на что он способен, то можете воспользоваться механизмом Best Warnings. Данный механизм покажет вам наиболее важные и достоверные предупреждения.
Чтобы посмотреть наиболее интересные предупреждения с точки зрения анализатора нажмите на кнопку 'Best', как показано на скриншоте ниже:
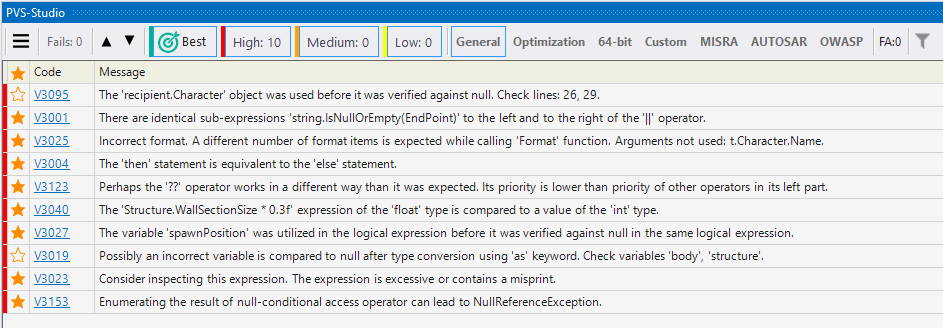
После чего в таблице с результатами анализа останутся максимум десять наиболее критичных предупреждений анализатора.
Горячие клавиши плагина PVS-Studio в Visual Studio
Плагин для Visual Studio добавляет окно просмотра результатов анализа PVS-Studio, которое имеет контекстное меню, появляющееся при нажатии правой кнопкой мыши в окне с результатами анализа:

Некоторым действиям из этого меню назначены горячие клавиши, что позволяет выполнять их без использования мыши.
Кнопки со стрелками, предназначенные для навигации по сообщениям анализатора, также имеют горячие клавиши:
- перейти к предыдущему сообщению: Alt + [;
- перейти к следующему сообщению: Alt + ].
Использование горячие клавиш полезно, потому что позволяет ускорить процесс обработки результатов анализа. Их можно назначать\переопределять в настройках: Tools -> Options -> Keyboard. Чтобы быстрее их найти, необходимо ввести 'PVSStudio' в поле поиска окна Keyboard.
Полезные ссылки
- Режим инкрементального анализа PVS-Studio
- Массовое подавление предупреждений
- Подавление ложных предупреждений
- Отображение лучших предупреждений анализатора (Best Warnings)
PVS-Studio для Embedded-разработки
- Смотри, а не читай (YouTube)
- Анализ проектов в Linux и macOS
- Анализ проектов в Windows
- Предупреждения с номером V001
- Используемый компилятор отсутствует в списке
- Static Application Security Testing (SAST)
- Анализ проекта в среде PlatformIO
- Дополнительные ссылки
Разработка для встраиваемых систем имеет свою специфику и подходы, но контроль качества кода в этой сфере не менее важен, чем в других. PVS-Studio поддерживает анализ проектов, которые используют следующие компиляторы:
- IAR Embedded Workbench
- Keil Embedded Development Tools for Arm
- TI ARM Code Generation Tools
- GNU Embedded Toolchain
Поддерживаемыми платформами для разработки являются Windows, Linux и macOS.
Смотри, а не читай (YouTube)
Анализ проектов в Linux и macOS
После установки анализатора в Linux или macOS станет доступна утилита для анализа проектов — pvs-studio-analyzer. Подробнее о работе утилиты можно узнать тут.
В утилиту добавлено автоматическое определение поддерживаемых компиляторов, но если используется модифицированный или расширенный пакет разработки, то с помощью параметра-compiler можно перечислить имена используемых embedded-компиляторов:
-C [COMPILER_NAME...], --compiler [COMPILER_NAME...]
Filter compiler commands by compiler nameАнализ проектов в Windows
После установки анализатора в Windows будет доступен большой набор различных утилит, предназначенных для разных режимов работы анализатора.
Консольный режим
Анализ проекта можно автоматизировать с помощью последовательного запуска следующих команд утилиты CLMonitor:
"C:\Program Files (x86)\PVS-Studio\CLMonitor.exe" monitor
<build command for your project>
"C:\Program Files (x86)\PVS-Studio\CLMonitor.exe" analyze ... -l report.plog ...Примечание. Команда monitor запускает процесс в неблокирующем режиме.
Графический режим
В утилите Сompiler Monitoring UI необходимо перейти в режим мониторинга сборки в меню Tools > Analyze Your Files (C/C++) или щёлкнув по значку "око" на панели инструментов:

Перед запуском мониторинга сборки будет доступно следующее меню для дополнительной настройки анализа:

После запуска мониторинга следует выполнить сборку проекта в IDE или с помощью сборочных скриптов, после чего в следующем окне нажать Stop Monitoring:

Результаты анализа будут доступны в утилите Сompiler Monitoring UI после анализа файлов, участвующих в компиляции.
Примечание: Используемый по умолчанию метод отслеживания запусков компиляторов может не успеть определить все файлы исходного кода. Эта проблема особенно актуальна для Embedded проектов, поскольку они состоят из быстро компилирующихся файлов на языке C. Чтобы отследить все компилируемые файлы, читайте раздел Wrap Compilers документации утилиты мониторинга.
Предупреждения с номером V001
В отчёте анализатора могут встречаться подобные предупреждения:
V001: A code fragment from 'source.cpp' cannot be analyzed.Разработчики компиляторов для встраиваемых систем часто отходят от стандартов и добавляют в компилятор нестандартные расширения. В сфере микроконтроллеров это особенно распространено и не является чем-то необычным для разработчиков.
Но для анализатора кода это нестандартный C или C++ код, который требует дополнительной поддержки. Если на вашем коде возникают такие предупреждения, пришлите нам архив с препроцессированными *.i файлами, полученными из проблемных исходников, и мы добавим поддержку новых расширений компилятора.
Включить режим сохранения таких файлов во время анализа можно следующими способами:
- в утилите Сompiler Monitoring UI в меню Tools > Options... > Common Analyzer Settings > RemoveIntermediateFiles выставить значение false;
- утилите pvs-studio-analyzer передать параметр ‑‑verbose.
Используемый компилятор отсутствует в списке
Рынок пакетов разработки для встраиваемых систем очень обширен, поэтому, если вы не нашли свой компилятор в списке поддерживаемых, сообщите нам через форму обратной связи о своём желании попробовать PVS-Studio, подробно описав используемые инструменты разработки.
Static Application Security Testing (SAST)
Для повышения качества кода или безопасности устройств в сфере разработки для встраиваемых систем часто следуют различным стандартам кодирования, например SEI CERT Coding Standard и MISRA, а также стараются избегать появления потенциальных уязвимостей, руководствуясь списком Common Weakness Enumeration (CWE). Проверка соответствия кода таким критериям присутствует и в PVS-Studio.
Анализ проекта в среде PlatformIO
Для проверки embedded проектов с помощью PVS-Studio можно использовать мультиплатформенную среду разработки PlatformIO. Она берёт на себя работу по поддержке инструментов сборки и отладки, а также по управлению библиотеками. Запускается под основными операционными системами, такими как Windows, macOS и Linux.
Для включения анализа с помощью PVS-Studio нужно добавить в конфигурационный файл проекта (platformio.ini):
check_tool = pvs-studio
check_flags = pvs-studio: --analysis-mode=4После чего вызвать в терминале команду:
pio checkБолее подробно о поддержке статического анализа в PlatformIO можно узнать на сайте проекта, а также на странице, посвящённой конфигурации PVS-Studio.
Дополнительные ссылки
В этом документе собраны особенности запуска анализатора и проверки проектов для встраиваемых систем. В остальном запуск анализатора и его настройка производятся так же, как и для других типов проектов. Перед началом использования анализатора рекомендуется ознакомиться со следующими страницами документации:
- Знакомство со статическим анализатором кода PVS-Studio;
- Система мониторинга компиляции в PVS-Studio;
- Как запустить PVS-Studio в Linux и macOS;
- PVS-Studio SAST (Static Application Security Testing, SAST).
Использование диагностических правил группы OWASP в PVS-Studio
В данном разделе описаны различные способы проверки кода на соответствие OWASP ASVS с помощью PVS-Studio.
Включение правил из группы OWASP
Все существующие диагностические правила описаны на странице "Сообщения PVS-Studio". Если вас интересуют именно правила из группы OWASP, то вам также могут быть полезны соответствия предупреждений PVS-Studio согласно:
Как было отмечено выше, правила, связанные с OWASP, по умолчанию отключены. Далее представлены различные возможности их включения и настройки.
Использование плагина для IDE
Если вы запускаете анализ PVS-Studio при помощи плагина для Visual Studio или какой-либо другой IDE, то активировать правила из группы OWASP можно через графический интерфейс.
Для этого необходимо перейти в настройки анализатора. К примеру, в Visual Studio 2019 нужно перейти в Extensions -> PVS-Studio -> Options:

Для других IDE способы их открытия могут немного отличаться. Более подробную информацию, включая информацию о способах открытия настроек в других IDE, можно найти в разделе "Знакомство со статическим анализатором кода PVS-Studio на Windows".
В настройках необходимо перейти на вкладку "Detectable Errors" для интересующего вас языка. Здесь нужно изменить значение для группы OWASP:
По умолчанию для группы OWASP выбрано значение 'Disabled'. Оно приводит к полному отключению соответствующих диагностик для данного языка. Чтобы включить их, нужно выбрать 'Custom', 'Show All' или 'Hide All' в зависимости от ваших целей. Подробнее об этих и других настройках можно прочитать в документации. Например, описание вкладки "Detectable Errors" представлено в разделе "Настройки: Detectable Errors".
Если было выбрано значение 'Show All', то все правила из группы будут включены и соответствующие предупреждения будут отображаться в окне вывода PVS-Studio. При этом в верхней части окна появится кнопка, отвечающая за отображение или скрытие предупреждений из соответствующей группы:

Здесь можно обратить внимание, что для предупреждений из группы OWASP указан соответствующий SAST-идентификатор. Кроме того, почти для всех предупреждений указывается подходящий им CWE. Подробно о способах настройки окна вывода предупреждений можно прочесть в разделе "Работа со списком диагностических сообщений в Visual Studio". Работа с окном в других IDE производится схожим образом.
Использование анализатора из командной строки
Если анализ запускается через интерфейс командной строки, то скорее всего файл настроек будет нужно отредактировать вручную (то есть не через графический интерфейс).
В некоторых случаях настройка анализатора для разных языков отличается; также может отличаться работа под разными ОС. Ниже представлены краткие описания способов включения OWASP-правил в различных ситуациях.
Включение OWASP в C# анализаторе
Главным образом настройка C#-анализатора под любой ОС состоит в редактировании файла Settings.xml. Стоит заметить, что это тот же самый файл, который используется плагинами для Visual Studio, CLion и Rider.
По умолчанию файл лежит по пути:
- "%APPDATA%\PVS-Studio\Settings.xml" на Windows;
- "~/.config/PVS-Studio/Settings.xml" на Linux/macOS.
Также путь к настройкам может быть передан в качестве аргумента командной строки при запуске анализа. Подробнее об этом можно прочитать в разделе "Проверка проектов Visual Studio/MSBuild/.NET из командной строки с помощью PVS-Studio".
Настройки анализатора хранятся в формате XML. Для включения правил из группы OWASP необходимо обратить внимание на следующие узлы:
- DisableOWASPAnalysisCs – если false, то правила из группы OWASP для C# анализатора будут включены, если true, то наоборот - отключены;
- DisableDetectableErrors – узел, содержащий список кодов правил, разделяемых пробелом (примеры кодов диагностик: V3163, V5608, V3022). Отображение этих правил будет отключено.
Соответственно, для включения проверки соответствия кода стандарту OWASP необходимо записать в 'DisableOWASPAnalysis' и 'DisableOWASPAnalysisCs' соответствующие значения, а также убедиться, что интересующие вас правила не записаны в узле 'DisableDetectableErrors'.
Включение OWASP в C++ анализаторе
Windows
Для настройки C++ анализатора на Windows также может быть использован файл Settings.xml (описание выше). Это возможно, если для анализа используется:
- плагин для Visual Studio, Rider или CLion;
- консольная утилита PVS-Studio_Cmd;
- C and C++ Compiler Monitoring UI.
Для включения правил из группы OWASP необходимо установить подходящие значения для узлов 'DisableOWASPAnalysis' (аналог 'DisableOWASPAnalysisCs' для C++) и 'DisableDetectableErrors'.
Иногда может возникать необходимость в запуске C++ анализатора напрямую (через PVS-Studio.exe). Задание настроек в таком случае будет производиться с помощью файла '*.cfg'. Путь к нему должен передаваться в качестве значения параметра '‑‑cfg':
PVS-Studio.exe --cfg "myConfig.cfg"Подробно про запуск анализа таким образом можно прочитать в разделе "Прямая интеграция анализатора в системы автоматизации сборки (C/C++)". Для включения же правил группы OWASP в конфигурационном файле необходимо проверить значение параметра 'analysis-mode'. Оно позволяет управлять включёнными группами диагностик. Оно должно быть суммой чисел, соответствующих включённым группам. К примеру, '4' соответствует анализу общего назначения, а '128' – анализу с использованием правил группы OWASP. Для того, чтобы использовать только эти 2 группы, в 'analysis-mode' нужно передать '132'. Если данный параметр не задан (или значение 0), то при анализе будут использоваться все доступные группы, в том числе и OWASP.
Кроме того, аналогичный параметр можно задавать в качестве аргумента командной строки:
PVS-Studio.exe --analysis-mode 132 ....Linux
Задание настроек под Linux производится примерно так же, как и при использовании 'PVS-Studio.exe'. Анализ производится с помощью команды 'pvs-studio-analyzer analyze'. Среди её параметров стоит отметить 'analysis-mode' и 'cfg'.
'‑‑analysis-mode' (или '-a') устанавливает группы предупреждений, которые будут включены при анализе. Для включения правил из группы OWASP необходимо, чтобы в списке групп, разделяемых ';', присутствовало значение 'OWASP'. Например:
pvs-studio-analyzer analyze .... -a GA;MISRA;OWASP'‑‑cfg' (или '-c') позволяет задать путь к специальному файлу конфигурации '*.cfg', который аналогичен тому, что используется для работы 'PVS-Studio.exe' (описание приведено чуть выше).
Подробную информацию можно найти в разделе "Как запустить PVS-Studio в Linux и macOS".
Включение OWASP в Java анализаторе
Работе с Java анализатором посвящён раздел "Работа с ядром Java анализатора из командной строки". В нём представлена вся информация, необходимая для запуска анализа, включения диагностик группы OWASP и т. д. Ниже записаны краткие сведения о настройках, которые нужно задать для активации OWASP.
В зависимости от того, каким именно образом вы производите анализ проектов, меняется и способ включения правил группы OWASP.
К примеру, если вы используете плагин для Maven ('pvsstudio-maven-plugin'), то в его конфигурации (в файле 'pom.xml') необходимо добавить в узел <analysisMode> значение 'OWASP', а также проверить значения в узлах <enabledWarnings> и <disabledWarnings>. Пример:
<build>
<plugins>
<plugin>
<groupId>com.pvsstudio</groupId>
<artifactId>pvsstudio-maven-plugin</artifactId>
<version>7.14.50353</version>
<configuration>
<analyzer>
<outputType>text</outputType>
<outputFile>path/to/output.txt</outputFile>
<analysisMode>GA,OWASP</analysisMode>
</analyzer>
</configuration>
</plugin>
</plugins>
</build>Если для анализа используется плагин для Gradle, необходимо открыть файл 'build.gradle' и отредактировать в блоке 'pvsstudio' значение 'analysisMode', а также проверить 'enabledWarnings' и 'disabledWarnings'. Пример:
apply plugin: com.pvsstudio.PvsStudioGradlePlugin
pvsstudio {
outputType = 'text'
outputFile = 'path/to/output.txt'
analysisMode = ["GA", "OWASP"]
}Для обоих плагинов существует и возможность конфигурирования через командную строку.
Отключение и настройка отдельных диагностических правил
После включения правил из группы OWASP может оказаться, что срабатывания некоторых из них на вашем проекте неактуальны. Например, V5606 отвечает за проверку соответствия кода позиции 7.4.2 из OWASP ASVS:
Verify that exception handling (or a functional equivalent) is used across the codebase to account for expected and unexpected error conditions.
В соответствии с указанным требованием, правило V5606 генерирует сообщение в случае, если обнаруживает пустой блок catch или finally.
Вполне возможно, что в вашем проекте наличие пустых блоков обработки исключений является приемлемым. В этом случае сообщения V5606 вам совершенно не интересны и для удобства их стоит убрать из вывода анализатора, использовав один из описанных далее способов.
Использование общих настроек
Одним из вариантов в описанной ситуации является скрытие сообщений некоторых правил с помощью общих настроек анализатора. Для этого можно либо вручную отредактировать настройки (этот момент описан выше), либо сделать это с помощью плагина для IDE:
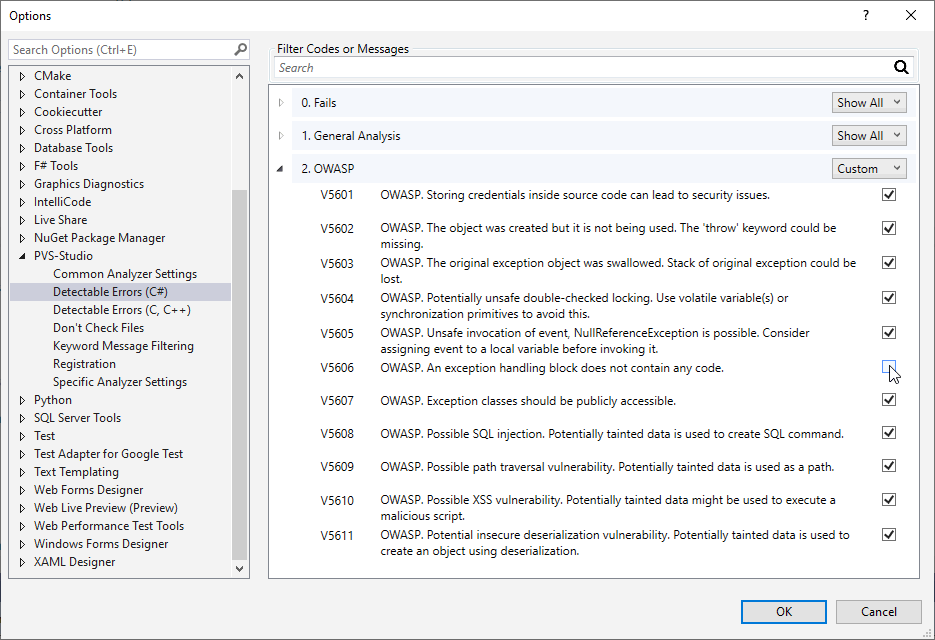
Использование файлов pvsconfig
Преимущества использования pvsconfig
Стоит отметить, что при использовании настроек в плагине для IDE или редактировании 'Settings.xml' отдельные диагностики нельзя по-настоящему отключить (только группы целиком). Вместо этого генерируемые сообщения просто будут скрыты при просмотре лога в IDE. В некоторых случаях такое поведение может быть удобным, однако в других логичнее будет полностью отключить диагностику.
Кроме того, бывают ситуации, когда необходимо отключить срабатывания определённых уровней.
К примеру, некоторые правила, реализующие taint-анализ, считают параметры публично доступных методов источниками потенциально заражённых данных. Пояснение такого поведения можно найти в заметке "Почему важно проверять значения параметров общедоступных методов". Предупреждение, в котором источником заражения является параметр метода, выдаётся с низким уровнем.
Вполне возможно, что для вашего проекта предупреждения о необходимости валидации параметров неактуальны, однако полностью отключать правило или скрывать его предупреждения тоже не хочется. Было бы куда удобнее отключить предупреждения с конкретным уровнем.
Такую возможность, а также полное отключение диагностики, переопределение уровня и т.д. предоставляют файлы pvsconfig.
Создание pvsconfig
Файлы с расширением pvsconfig позволяют обеспечить дополнительную настройку анализа. На данный момент они могут быть использованы при анализе проектов на C++ и C#.
На странице "Подавление ложных предупреждений" описаны как возможности отключения диагностик с помощью pvsconfig, так и другие способы исключения нежелательных срабатываний. Прочие возможности, такие как изменение уровней предупреждений или замена подстрок в сообщениях, описаны в разделе "Дополнительная настройка диагностик".
В общем для использования функционала достаточно просто добавить файл с расширением pvsconfig в проект или решение.
Удобнее всего pvsconfig создавать через IDE, используя специальный шаблон:
В этом случае созданный файл будет заполнен различными закомментированными примерами, что серьёзно упростит написание собственных инструкций:
# Example of PVS-Studio rules configuration file.
# Full documentation is available at
# https://pvs-studio.com/en/docs/manual/full/
# https://pvs-studio.com/en/docs/manual/0040/
#
# Filtering out messages by specifying a fragment from source code:
# //-V:textFromSourceCode:3001,3002,3003
#
# Turning off specific analyzer rules:
# //-V::3021,3022
#
# Changing in analyzer's output message:
# //+V3022:RENAME:{oldText0:newText0},{oldText1:newText1}
#
# Appends message to analyzer's message:
# //+V3023:ADD:{Message}
#
# Excluding directories from the analysis:
# //V_EXCLUDE_PATH \thirdParty\
# //V_EXCLUDE_PATH C:\TheBestProject\thirdParty
# //V_EXCLUDE_PATH *\UE4\Engine\*
#
# Redefining levels:
# //V_LEVEL_1::501,502
# //V_LEVEL_2::522,783,579
# //V_LEVEL_3::773
#
# Disabling groups of diagnostics:
# //-V::GA
# //-V::GA,OWASP
#
# Disabling messages with specified warning levels:
# //-V::3002:3
# //-V::3002,3008:3
# //-V::3002,3008:2,3
#
# Rule filters should be written without '#' character.Несложно заметить, что pvsconfig предоставляет достаточно большое количество различных способов настройки анализа – от изменения уровня до изменения самих выводимых сообщений или полного отключения диагностик. Далее представлены примеры использования некоторых возможностей pvsconfig.
Примечание. Некоторые функции могут быть доступны только для конкретных анализаторов – подробнее об этом в разделах "Подавление ложных предупреждений" и "Дополнительная настройка диагностик".
Пример отключения правила
Для отключения, к примеру, правила V5606 (о пустых catch и finally), необходимо добавить в файл следующую строку:
//-V::5606Пример отключения предупреждений заданного уровня
Также можно и отключить выдачу диагностикой предупреждений конкретного уровня. Ранее мы рассматривали пример с taint-диагностиками, выдающими предупреждения на 3 уровне, если источником заражения является параметр. Если вам нужно, к примеру, убрать предупреждения о потенциальных SQL-инъекциях, где источником заражения будет являться параметр, то в pvsconfig нужно добавить строку
//-V::5608:3В результате предупреждения 3 уровня диагностики V5608 будут исключены из результатов анализа.
Пример переопределения уровня
Ещё одной удобной возможностью pvsconfig является переопределение уровня выдаваемых диагностикой предупреждений. К примеру, можно переопределить уровень всех срабатываний V5609:
//V_LEVEL_2::5609Данная строка проинструктирует анализатор формировать предупреждения правила V5609 со 2 (средним) уровнем достоверности.
MISRA Coding Standards and Compliance
Стандарт MISRA
MISRA — это стандарт разработки программного обеспечения, созданный организацией MISRA (Motor Industry Software Reliability Association). Цель стандартов — улучшить безопасность, переносимость и надёжность программ для встраиваемых систем.
Самые отличительные черты MISRA: внимание к деталям и обеспечение безопасности. Авторы тщательно проработали международные стандарты C и C++ и выписали все возможные способы ошибиться. Стандарты MISRA C и MISRA C++ содержат список указаний для того, чтобы уменьшить вероятность ошибок, а также улучшить читаемость и сопровождаемость кода.
Указания делятся на две категории: директивы и правила.
Директива — это указание, для которого невозможно предоставить полное описание, необходимое для проведения проверки на соответствие. Для проверки требуется дополнительная информация, которая может быть представлена в проектной документации или спецификациях требований. Статические анализаторы могут помочь в проверке соответствия директивам, но разные инструменты могут давать совершенно разные интерпретации того, что является несоответствием.
Правило — это указание, для которого дано полное описание требования. Должна быть возможность проверить соответствие исходного кода правилу без необходимости использования какой-либо другой информации. Статические анализаторы способны проверять соответствие правилам с учётом ограничений.
В MISRA C 2012 правила делятся на три основных категории: Mandatory, Required и Advisory.
Mandatory — это правила, которые нельзя нарушать ни под каким предлогом. Например, в этот раздел входит правило "не используйте значение неинициализированной переменной".
Правила категории Required менее строги, они допускают возможность отклонения, но только если эти отклонения тщательно документируются и письменно обосновываются. Процесс описания формальных отклонений описан в документе MISRA Compliance 2020.
Остальные правила входят в категорию Advisory — это правила, имеющие статус рекомендательных. Но это не означает, что их можно игнорировать: их следует соблюдать в той мере, в какой это целесообразно. Соблюдать процесс описания формальных отклонений для них необязательно, однако если он не соблюдается, то должны быть приняты альтернативные меры для документирования и обоснования отклонений.
В MISRA C++ 2008 по-другому:
- указания типа директива выражены правилами категории Document;
- правила категории Mandatory отсутствуют. Большинство правил принадлежит к категории Required. Поэтому необязательно придерживаться всех правил, необходимо только документировать все отклонения.
Помимо описания проблематики, в стандарте содержится большое количество советов о том, что нужно знать перед началом работы:
- как наладить процесс разработки по MISRA;
- как использовать статические анализаторы для проверки кода на соответствие;
- какие документы нужно вести, как их заполнять и так далее.
Также в конце имеются приложения, в которых содержатся: краткий список и сводная таблица правил, пример документации отклонения от правила, а также несколько чек-листов.
MISRA — это не просто набор указаний, а практически целая инфраструктура по написанию безопасного кода для встраиваемых систем.
PVS-Studio помогает искать отклонения от этого стандарта. Здесь представлена таблица соответствия диагностических правил PVS-Studio: MISRA C и MISRA C++ Coding Standards. При работе со стандартами MISRA будет полезен отчёт MISRA Compliance. Его можно сгенерировать при помощи утилит из состава PVS-Studio.
MISRA Compliance
MISRA Compliance — это стандарт, который позволяет понять, соответствует ли проект стандарту MISRA C и/или MISRA C++ с учётом всех отклонений и рекатегоризаций. MISRA Compliance применим ко всем стандартам ассоциации MISRA, но рассмотрим его использование на примере стандарта MISRA C 2012.
В указаниях MISRA C 2012 говорится, что в некоторых ситуациях соблюдение требований неоправданно или даже невозможно. В случаях отклонений от правил всё должно быть задокументировано. Однако после может быть проблематично понять, соответствует ли в итоге программа данному стандарту. Здесь на помощь и приходит стандарт MISRA Compliance.
Правила получения MISRA Compliance
Главное — понять, соответствует ли проект MISRA C 2012 или нет. Для этого необходимо получить GCS (Guideline Compliance Summary). GCS представляет собой таблицу, где каждая запись содержит следующий набор признаков: наименование указания, его уровень и информацию о том, соответствует ли проект ему. Вот пример, как это должно выглядеть:

Номер указания и его категория по умолчанию берутся из стандарта. Однако MISRA Compliance позволяет изменять (рекатегоризировать) уровень указаний, хоть это и необязательно. Делается это каждым конкретным пользователем для конкретного проекта в соответствии с GRP (Guideline Re-categorization Plan). GRP — это такой допустимый набор преобразований из одного уровня в другой. Вот так это выглядит в виде таблицы:

Например, есть правило 1.1, у которого уровень равен Required. Согласно таблице можно повысить уровень предупреждения до Mandatory или оставить его неизменным. Это отображено зелёными ячейками. При этом понижение уровня до Advisory или Disapplied не допускается. Это отображено красными ячейками.
На основе получившихся категорий указаний можно задать соответствия. Возможные варианты соответствий для MISRA категорий выглядят так:

Эта таблица используется для того, чтобы показать, соответствует ли проект стандарту MISRA C 2012. Если есть хотя бы одно соответствие, которое попадает в красную секцию (таблица выше), то проект не соответствует стандарту.
Чтобы было проще, опять возьмём правило 1.1 со стандартным значением категории, равной Required. В таблице видим, что допустимые значения соответствия для Required — это Compliance или Deviations (чуть подробнее о смысле этих статусов будет в пункте ниже). То есть, если проект соответствует правилу 1.1, либо соответствует, но с отклонениями, то всё хорошо и можно смотреть следующее правило. Если хотя бы одно соответствие попадает в красную зону (таблица выше), то проект не соответствуете стандарту MISRA C 2012. Если все правила имеют только допустимые значения (попадают только в зелёную зону), то проект соответствует стандарту MISRA C 2012.
Перейдём к генерации MISRA Compliance отчёта.
Генерация отчёта MISRA Compliance в PVS-Studio
Чтобы сгенерировать отчёт, нужно воспользоваться утилитой PlogConverter.exe (Windows) или plog-converter (Linux, macOS). Данные утилиты также распространяются в составе дистрибутивов. На момент написания статьи PVS-Studio умеет выдавать отчёт соответствия только для стандарта MISRA C 2012.
Для генерации отчёта MISRA Compliance необходимо выполнить анализ (Windows, для Linux / macOS). Обратите внимание, что следует включить все диагностические правила, связанные с MISRA, иначе уменьшается покрытие MISRA правил. Как проверить, включены ли все правила, описано в предоставленных ссылках на документацию про анализ.
Затем нужно использовать одну из утилит конвертации отчёта. Пример запуска PlogConverter.exe:
"C:\Program Files (x86)\PVS-Studio\PlogConverter.exe" "path_to_report_file" ^
-t MisraCompliance -o "path_to_MISRA_report" --grp "path_to_grp.txt"И пример команды для plog-converter:
plog-converter "path_to_report_file" -t misra-compliance \
-o "path_to_MISRA_report" --grp "path_to_grp.txt"Сам отчёт представляет собой HTML-страницу, которая удобно подходит для печати. Вот пример отчёта, когда проект не соответствует MISRA C 2012:

Пример отчёта, когда проект соответствует MISRA C 2012:

Итак, пройдёмся по столбцам:
- Guideline содержит номера правил и директив стандарта MISRA C;
- Category содержит категорию правила или директивы, указанную в стандарте;
- Recategorication содержит категорию после рекатегоризации в соответствии с GRP;
- Compliance содержит статус соответствия проверяемого кода правилу или директиве. Красным цветом выделено то, что мешает соответствию стандарту MISRA C 2012.
В нашем случае GRP представляет собой txt-файл. Пример содержания файла с допустимыми переходами:
Rule 2.1 = Mandatory
Rule 8.13 = Required
Directive 4.3 = Mandatory
Rule 2.6 = DisappliedЕсли этот файл содержит понижение категории, то утилита выдаст сообщение об ошибке и не сгенерирует отчёт. Исключением является категория Advisory, которая может понижаться до Disapplied. Вот так располагаются категории от наиболее важной к наименее важной:

Статусы соответствия проверяемого кода означают следующее:
- Compliant — в проекте нет отклонений по данному указанию;
- Deviations — отклонения от указания обнаружены и задокументированы. Чтобы утилита трактовала конкретное предупреждение как Deviation вместо Violation, его следует разметить как ложное (Mark as False Alarm). В скобочках указывается число подтверждённых отклонений.
- Violations — существует хотя бы одно отклонение от указания, которое не было задокументировано. В скобочках указывается число таких отклонений. Если кроме Violations для указания обнаружены Deviations, то будут отображены оба статуса.
- Disapplied — указание не применяется для проекта и никак не будет учитываться. Применимо только к указаниям категории Advisory.
- Not Supported — данное указание не поддерживается анализатором.
И самое главное — это заключение о соответствии или несоответствии проекта стандарту MISRA C 2012. Код соответствует стандарту, если:
- все указания категории Mandatory имеют статус Compliant;
- все указания категории Required имеют статус Compliant и/или Deviations;
- все указания категории Advisory могут иметь любой статус;
- все указания категории Disapplied игнорируются.
Работа PVS-Studio в IntelliJ IDEA и Android Studio
- Установка плагина из официального репозитория JetBrains
- Установка плагина из репозитория PVS-Studio
- Настройки плагина
- Проверка кода из IntelliJ IDEA и Android Studio с помощью PVS-Studio
- Работа с результатами анализа
- Обновление PVS-Studio Java
Анализатор PVS-Studio можно использовать при работе в средах разработки IntelliJ IDEA и Android Studio. Плагин PVS-Studio для этих IDE предоставляет удобный графический интерфейс для запуска анализа проектов и отдельных файлов, а также для работы с предупреждениями анализатора.
Плагины PVS-Studio для IntelliJ IDEA и Android Studio можно установить из официального репозитория плагинов JetBrains или из репозитория на нашем сайте. Ещё один способ установки — через установщик PVS-Studio для Windows, доступный на странице загрузки.
Установка плагина из официального репозитория JetBrains
Для установки плагина PVS-Studio из официального репозитория JetBrains нужно открыть окно настроек с помощью команды 'File -> Settings -> Plugins', выбрать в окне вкладку 'Marketplace', и ввести в строке поиска "PVS-Studio". В результатах поиска появится плагин PVS-Studio:
Далее нужно нажать кнопку 'Install' напротив найденного плагина PVS-Studio. После того как установка плагина будет завершена, нужно нажать кнопку 'Restart IDE':
Перезапустив среду разработки, можно начать пользоваться плагином PVS-Studio для проверки кода.
Примечание: нет необходимости загружать и устанавливать отдельно ядро Java анализатора — плагин сам загрузит и установит необходимую версию ядра при запуске анализа в IntelliJ IDEA или Android Studio.
Установка плагина из репозитория PVS-Studio
Помимо официального репозитория JetBrains, плагин PVS-Studio также доступен из собственного репозитория PVS-Studio. Для установки плагина из репозитория PVS-Studio сначала нужно добавить репозиторий в IDE. Для этого нужно открыть окно установки плагинов с помощью команды меню 'File -> Settings -> Plugins', нажать на шестеренку в правом верхнем углу и в выпадающем списке выбрать 'Manage Plugin Repositories':
В открывшемся окне добавьте путь: https://files.pvs-studio.com/java/pvsstudio-idea-plugins/updatePlugins.xml. И нажмите 'ОК':

Последний шаг установки аналогичен установке плагина из официального репозитория — нужно открыть вкладку 'Marketplace', где в поиск ввести "PVS-Studio". После применения данного фильтра выбрать плагин 'PVS-Studio for IDEA and Android Studio', нажать 'Install' и перезапустить среду разработки.
Настройки плагина
Панель настроек плагина состоит из нескольких вкладок. Рассмотрим каждую из них подробнее.
Misc — настройки ядра анализатора PVS-Studio. При наведении курсора мыши на название настройки появляется подсказка с описанием того, для чего эта настройка предназначена.
Warnings — список типов всех предупреждений, поддерживаемых анализатором. Если убрать галочку у предупреждения, то все предупреждения данного типа в таблице вывода результатов работы анализатора будут отфильтрованы, а при следующем запуске анализа соответствующее правило анализатора не будет запущено (не выдаст никаких предупреждений):
Excludes – содержит пути до файлов или директорий, которые будут исключены из анализа. Вы можете указать как абсолютный путь, так и путь относительно корневой директории проекта:
API Compatibility Issue Detection – настройки для диагностики V6078 (по умолчанию отключена). Данная диагностика позволяет узнать, изменится ли или вообще исчезнет API JDK, которое вы используете в проекте, в одной из следующих версий JDK:
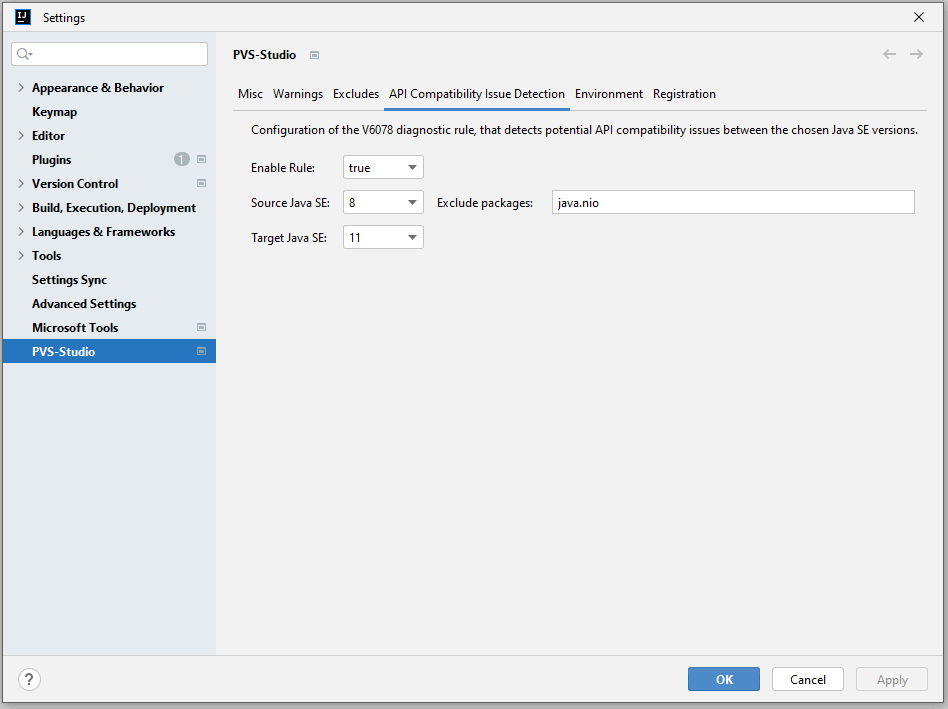
Environment – настройки, которые будут использованы плагином для запуска ядра Java анализатора (отдельного JVM процесса pvs-studio.jar). Стандартные значения этих настроек берутся из файла global.json. Если вы измените настройки на этой вкладке, они сохранятся в отдельный файл, переопределяющий настройки из global.json при запуске анализа. Сами измененные настройки никак не влияют на содержимое global.json файла:
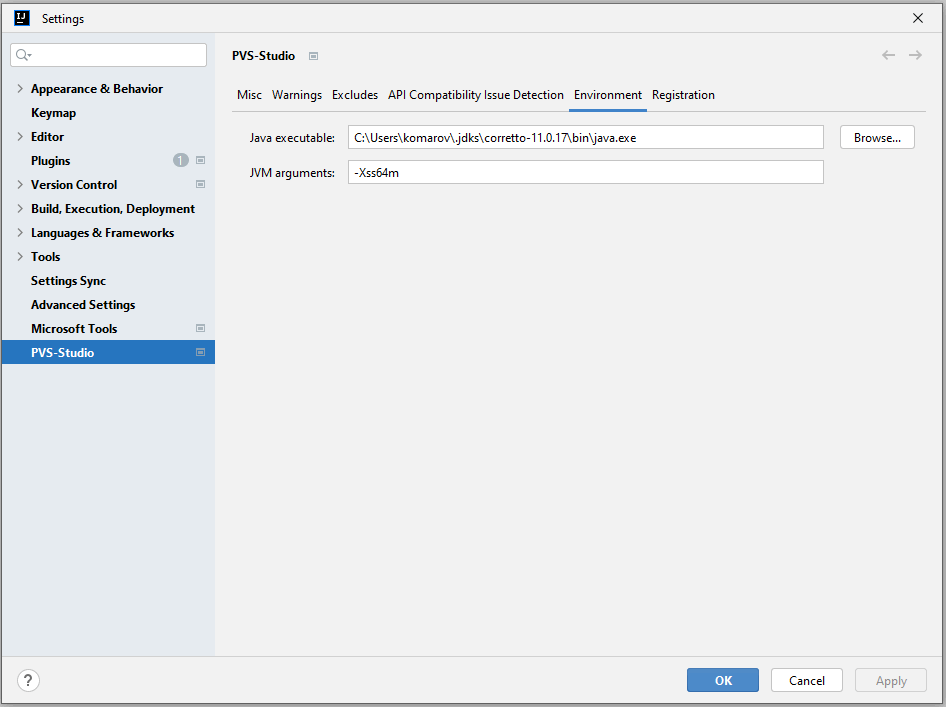
Registration — отображает информацию о действующей в системе лицензии PVS-Studio. Также на этой вкладке вы можете изменить эти данные и убедиться, что введенная лицензия валидна.
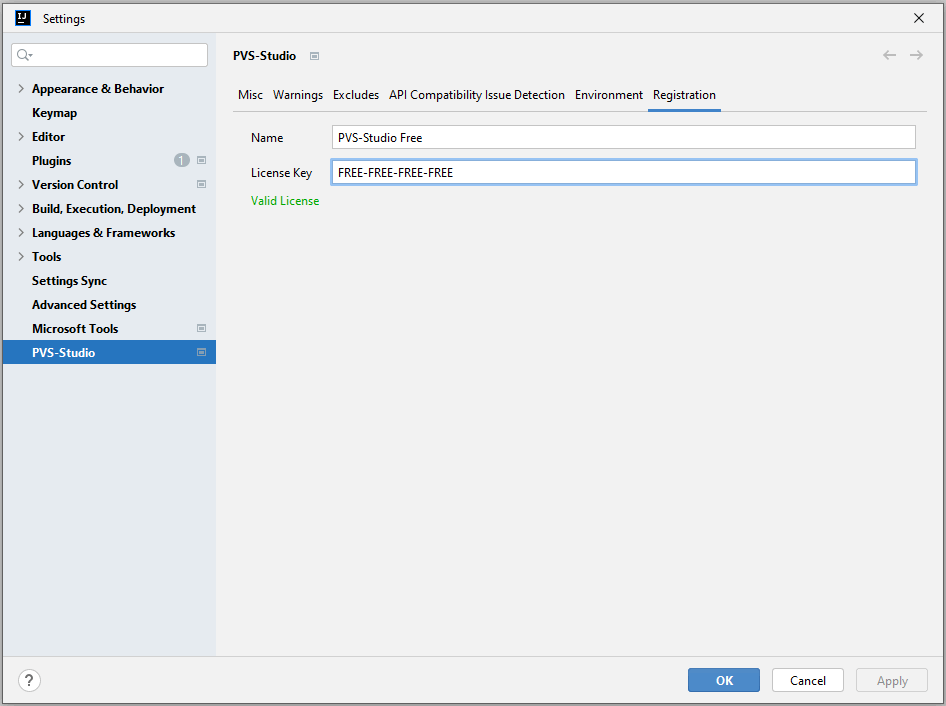
Как изменить версию Java для запуска анализатора
По умолчанию анализатор запускает ядро с java из переменной окружения PATH. Если вам необходимо запустить анализ с какой-то другой версией, ее можно указать вручную. Для этого на вкладке 'Environment' в настройках плагина необходимо в поле 'Java executable' указать путь до java файла из JDK. Версия этой JDK (версия языка Java) будет использована при анализе исходного кода проекта:
Проверка кода из IntelliJ IDEA и Android Studio с помощью PVS-Studio
Перед запуском анализа вам необходимо ввести лицензию. Как это сделать, можно узнать в этой документации.
Имеется возможность анализировать:
- текущий проект;
- элементы, выбранные в окне Project;
- файл, открытый в данный момент для редактирования.
Обратите внимание: при анализе проекта плагин запускает ядро Java анализатора. При запуске ядра анализатора будет использована версия языка Java, соответствующая версии JDK, из которого используется файл java для запуска ядра Java анализатора (поле Java executable на вкладке Environment в настройках плагина). Если хотите изменить версию языка Java, которая будет использована при анализе, то используйте для запуска ядра Java анализатора файл java из JDK соответствующей версии.
Для анализа текущего проекта можно воспользоваться пунктом меню 'Tools -> PVS-Studio -> Check Project':

Для анализа файла, открытого на редактирование, можно использовать:
- пункт меню 'Tools -> PVS-Studio -> Check Current File';
- пункт контекстного меню файла;
- пункт контекстного меню заголовка файла в редакторе файла.

Также можно выбрать несколько элементов в окне 'Explorer' через CTRL/SHIFT + левая кнопка мыши, после чего нажать правую кнопку мыши и выбрать 'Analyze with PVS-Studio':

В примерах, приведенных выше, будут проанализированы:
- *.java файлы (из пакета com.pvsstudio.formats);
- файл JsonEvaluator (из пакета com.pvsstudio.projects);
- файл Main (из пакета com.pvsstudio);
- файл Box из модуля common (из пакета com.pvsstudio).
Работа с результатами анализа
Во время анализа результаты работы анализатора выводятся в таблицу окна 'PVS-Studio':
Таблица состоит из 7 столбцов (слева направо: 'Favorite', 'Code', 'CWE', 'SAST', 'Message', 'Position', 'False Alarms'). Имеется возможность сортировать сообщения в таблице по любому столбцу. Для изменения порядка сортировки необходимо кликнуть на заголовок столбца. Крайний левый столбец ('Favorite') используется для пометки предупреждений, которая позволяет быстро найти все помеченные предупреждения, включив сортировку по столбцу 'Favorite':

При нажатии на строку в столбцах 'Code'/'CWE' будет открыта страница в браузере с подробным описанием предупреждения или потенциальной уязвимости. В столбце 'SAST' указывается идентификатор уязвимости кода по стандарту OWASP ASVS, для предупреждения. В столбце 'Message' содержится краткое описание предупреждения. Столбец 'Position' содержит список файлов, связанных с сообщением. Крайний правый столбец 'False Alarms' — служит для отображения сообщений, помеченных, как ложные срабатывания. Подробнее про работу с ложными срабатываниями будет описано дальше, в соответствующем подразделе.
Чтобы открыть файл на строке, в которой было найдено предупреждение анализатора, дважды нажмите левой кнопкой мыши на предупреждение в таблице:
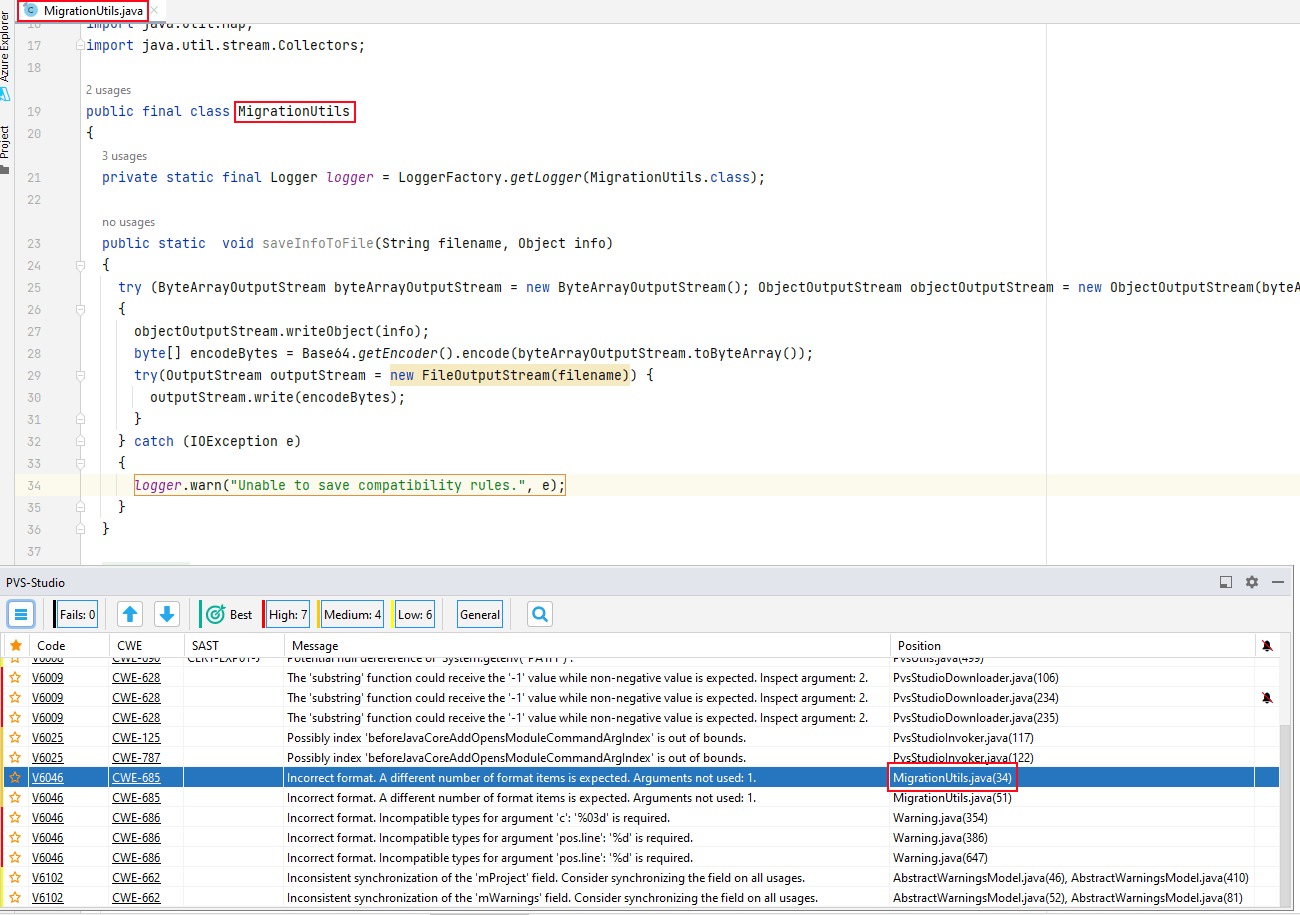
Также над таблицей имеются стрелки, позволяющие переключаться между предыдущим/следующим сообщением анализатора, и открывать файл, на который это предупреждение выдано, в редакторе кода. Над таблицей имеется несколько фильтров по уровню опасности предупреждений: High, Medium, Low и Fails (ошибки анализатора):
При нажатии на лупу откроется дополнительная панель с полями ввода для столбцов 'Code', 'CWE', 'SAST', 'Message' и 'Position'. Каждое поле – это строковый фильтр для столбца, позволяющий отфильтровать сообщения из таблицы по введённому в эти поля тексту:

В левом верхнем углу, над таблицей, расположена кнопка с тремя горизонтальными полосками. При нажатии на эту кнопку откроется дополнительная панель настроек:

При нажатии на шестеренку открывается главное окно настроек плагина, также доступное через команду меню 'Tools -> PVS-Studio -> Settings'.
Просмотр интересных предупреждений анализатора
Если Вы только начали изучать инструмент статического анализа и хотели бы узнать на что он способен, то можете воспользоваться механизмом Best Warnings. Данный механизм покажет вам наиболее важные и достоверные предупреждения.
Чтобы посмотреть наиболее интересные предупреждения с точки зрения анализатора, нажмите на кнопку 'Best', как показано на скриншоте ниже:
После чего в таблице с результатами анализа останутся максимум десять наиболее критичных предупреждений анализатора.
Работа с ложными срабатываниями
Бывают ситуации, когда сообщение анализатора указывает на код, но программисту совершенно очевидно, что в этом коде нет ошибки. Такая ситуация называется ложным срабатыванием (false positive).
В плагине PVS-Studio имеется возможность пометить сообщение анализатора как ложное срабатывание. Такая пометка позволяет скрывать эти сообщения анализатора при последующем анализе кода.
Для разметки ложных срабатываний необходимо выбрать одно или несколько сообщений анализатора в таблице 'PVS-Studio', нажать правой кнопкой мыши на любой строке в таблице и в контекстном меню выбрать пункт 'Mark selected messages as False Alarms':

После выполнения данной команды анализатор добавит к строке, на которую выдаётся предупреждение анализатора, комментарий специального вида: \\-Vxxxx, где xxxx – это номер диагностического правила PVS-Studio. Такой комментарий также можно добавить в код вручную.
Помеченные ранее ложные срабатывания можно показать в таблице окна PVS-Studio с помощью настройки 'Show False Alarms', доступной через команду меню 'Tools -> PVS-Studio -> Settings':

С помощью команды контекстного меню 'Remove False Alarm marks from selected messages' можно удалить отметку ложного срабатывания с выбранных сообщений.
Подробную информацию о подавлении предупреждений, выдаваемых анализатором PVS-Studio, а также сведения о других способах подавления сообщений анализатора, можно найти в разделе документации Подавление ложных предупреждений.
Подавление предупреждений анализатора на legacy-коде
Часто начать регулярно использовать статический анализ мешают многочисленные срабатывания на legacy-коде. Такой код обычно уже хорошо оттестирован и стабильно работает, поэтому править в нём все срабатывания анализатора может оказаться нецелесообразно. Тем более, если размер кодовой базы достаточно велик, такая правка может потребовать большого времени. При этом, такие сообщения на существующий код мешают смотреть сообщения на новый код, находящийся в разработке.
Чтобы решить данную проблему и начать сразу регулярно использовать статический анализ, PVS-Studio предлагает возможность "отключить" сообщения на старом коде. Чтобы подавить сообщения анализатора на старом коде можно воспользоваться кнопкой 'Suppress All Messages' на панели окна PVS-Studio. Механизм подавления работает с помощью специального suppress-файла. В него добавляются подавленные сообщения анализатора после выполнения команды 'Suppress All Messages'. При последующем запуске анализа все сообщения, добавленные в suppress-файл, не попадут в отчёт анализатора. Система подавления через suppress-файл достаточно гибкая и способна "отслеживать" подавленные сообщения даже при модификации и сдвигах участков кода, в которых выдаётся подавленное сообщение.
В IDEA подавленные сообщения добавляются в suppress-файл suppress_base.json, который записывается в директорию .PVS-Studio, в корневой директории открытого в IDEA проекта. Чтобы вернуть все сообщения в вывод анализатора, необходимо удалить этот файл и перезапустить анализ.
Более подробное описание подавления предупреждений анализатора, и описание работы с suppress-файлами, можно прочитать в разделе документации Массовое подавление сообщений анализатора.
Также предлагаем познакомиться со статьей: "Как внедрить статический анализатор кода в legacy проект и не демотивировать команду".
Контекстное меню таблицы предупреждений
При нажатии правой кнопкой мыши, на строке с сообщением анализатора в таблице окна PVS-Studio откроется контекстное меню, содержащее дополнительные команды для выбранных сообщений анализатора.
Команда 'Copy Selected Messages To Clipboard' копирует все выбранные в окне с результатами анализа плагина PVS-Studio предупреждения в буфер обмена.
Команда 'Mark Selected Messages As Important' позволяет пометить звёздочкой предупреждение, чтобы в дальнейшем легко его найти при сортировке по столбцу 'Favorite' (крайний левый столбец).
Команда 'Mark selected messages as False Alarms / Remove false alarm masks' позволяет разметить сообщение анализатора, как ложное срабатывание, добавив в код, на который выдано предупреждение, комментарий специального вида.
Команда 'Add Selected Messages To Suppression File' позволяет подавить предупреждения анализатора, выбранные в окне с результатами анализа плагина PVS-Studio. При следующих запусках анализа эти предупреждения не будут добавлены в окно с результатами анализа PVS-Studio.
Пункт меню 'Show Columns' открывает список с именами столбцов, которые можно скрыть или отобразить.
Команда 'Exclude from analysis' позволяет добавить путь или часть пути к файлу, в котором найдено предупреждение анализатора, в список исключённых из анализа директорий. Все файлы, пути до которых попадут под данный фильтр, будут исключены из анализа.
Сохранение и загрузка результатов анализа
Для сохранения или загрузки результатов работы анализатора можно воспользоваться командами главного меню, доступными через 'Tools -> PVS-Studio':
Команда 'Open Report' открывает .json-файл отчёта и загружает его содержимое в таблицу окна 'PVS-Studio'.
Подменю 'Recent Reports' показывает список из нескольких последних открытых файлов отчетов. При нажатии на элемент в списке будет открыт соответствующий отчет (если отчет еще существует по такому пути), и его содержимое будет загружено в таблицу окна 'PVS-Studio'.
Команда 'Save Report' сохраняет все сообщения из таблицы (даже отфильтрованные) в .json-файл отчёта. Если текущий результат анализа ещё ни разу не сохранялся, то будет предложено задать имя и место для сохранения отчёта.
Аналогично, команда 'Save Report As' сохраняет все предупреждения из таблицы (даже отфильтрованные) в .json-файл отчёта, всегда предлагая выбрать место сохранения отчёта на диске.
Команда 'Export Report To...' позволяет сохранить отчёт анализатора в разных форматах (xml, txt, tasks, pvslog, log, html, err). Каждый формат может быть полезен в различных ситуациях и утилитах.
Команда 'Export Report To HTML...' позволяет сохранить отчёт анализатора в выбранную папку в формате HTML. Этот формат позволяет прямо в браузере просматривать предупреждения анализатора и проводить навигацию по файлам исходного кода в браузере. В выбранной папке будет создана папка с именем 'fullhtml', содержащая файл отчёта анализатора (index.html).
Внимание. Вместо использования команды 'Export Report To HTML...' более предпочтительным сценарием является использование консольных утилит PlogConverter (Windows) и plog-converter (Linux и macOS). Эти утилиты позволяют конвертировать отчёт анализатора в большее количество форматов (например, SARIF), а также предоставляют дополнительные возможности: фильтрация предупреждений из отчёта, преобразование путей в отчёте с абсолютных на относительные и наоборот, получение разницы между отчётами и др.;
Горячие клавиши PVS-Studio в IntelliJ IDEA и Android Studio
Плагины PVS-Studio для IntelliJ IDEA и Android Studio добавляют окно просмотра результатов анализа PVS-Studio, которое имеет контекстное меню, появляющееся при нажатии правой кнопкой мыши в окне с результатами анализа:

Некоторым действиям из этого меню назначены горячие клавиши, что позволяет выполнять их без использования мыши.
Кнопки со стрелками, предназначенные для навигации по сообщениям анализатора, также имеют горячие клавиши:
- Перейти к предыдущему сообщению: Alt + [.
- Перейти к следующему сообщению: Alt + ].
Использование горячих клавиш полезно, потому что позволяет ускорить процесс обработки результатов анализа. Их можно назначать/переопределять в настройках: 'File -> Settings -> Keymap'. Чтобы быстрее их найти, введите 'PVS-Studio' в поле поиска окна 'Keymap'.
Обновление PVS-Studio Java
В случае наличия обновления PVS-Studio сообщение об этом выведется в отчёт по завершению анализа.

Для обновления плагина нужно открыть окно настроек плагинов 'File -> Settings -> Plugins', найти в списке Installed плагин PVS-Studio for IDEA and Android Studio, нажать 'Update' и перезапустить среду разработки.
Использование прокси
При использовании прокси вам необходимо загрузить при помощи прокси ZIP архив для Java на странице загрузки. В этом архиве содержится ядро Java анализатора (папка с именем 7.36.93539 в директории pvs-studio-java). Ядро Java анализатора надо распаковать по стандартному пути установки ядра Java анализатора:
- Windows: %APPDATA%/PVS-Studio-Java;
- Linux и macOS: ~/.config/PVS-Studio-Java.
В результате в папке по стандартному пути установки ядра Java анализатора должна находиться папка с именем версии ядра Java анализатора, скопированная из архива.
Интеграция PVS-Studio Java в сборочную систему Gradle
- Интеграция плагина PVS-Studio в Gradle
- Запуск анализа
- Запуск анализа без доступа к сети
- Конфигурация
- Обновление PVS-Studio Java
Статический анализатор кода PVS-Studio Java состоит из 2-х основных частей: ядра, выполняющего анализ, и плагинов для интеграции в сборочные системы (Maven и Gradle) и IDE (PVS-Studio для IntelliJ IDEA и Android Studio).
Функции плагинов:
- Предоставление удобного интерфейса для запуска и настройки анализатора;
- Развёртывание в системе ядра анализатора;
- Сбор и передача данных (наборы исходных файлов и classpath) о структуре проекта ядру анализатора.
Интеграция плагина PVS-Studio в Gradle
Для интеграции плагина необходимо добавить следующий код в скрипт сборки build.gradle:
buildscript {
repositories {
mavenCentral()
maven {
url uri('https://cdn.pvs-studio.com/java/pvsstudio-maven-repository/')
}
}
dependencies {
classpath 'com.pvsstudio:pvsstudio-gradle-plugin:latest.release'
}
}
apply plugin: com.pvsstudio.PvsStudioGradlePlugin
pvsstudio {
outputType = 'text'
outputFile = 'path/to/output.txt'
analysisMode = ['GA', 'OWASP']
}Запуск анализа
Перед первым запуском анализа вам необходимо будет ввести лицензию. Как это сделать — можно узнать в этой документации.
Для запуска анализа выполните команду:
./gradlew pvsAnalyzeОбратите внимание: при анализе проекта плагин запускает ядро Java анализатора. При запуске ядра анализатора будет использована версия языка Java, соответствующая версии JDK, из которого используется файл java для запуска ядра Java анализатора (настройка плагина javaPath). Если хотите изменить версию языка Java, которая будет использована при анализе, то используйте для запуска ядра Java анализатора файл java из JDK соответствующей версии.
Запуск анализа без доступа к сети
Для работы плагина нужно скачать его зависимости. Если вам нужно работать с плагином в системе без доступа в сеть, вы должны создать офлайн репозиторий c зависимостями плагина.
Для загрузки зависимостей и подготовки к офлайн использованию примените такую команду:
./gradlew build --refresh-dependenciesЗапускать эту команду нужно из директории с файлом build.gradle (корневой директории проекта). В этом случае все необходимые зависимости для сборки и анализа проекта будут сохранены в стандартной папке локального репозитория: %userprofile%/.gradle/caches/modules-2/files-2.1 на Windows или ~/.gradle/caches/modules-2/files-2.1 на Linux/macOS.
Вы должны иметь подключение к сети во время запуска этой команды, чтобы зависимости могли загрузиться. Для последующей работы интернет-соединение уже не нужно.
В системе должно быть установлено ядро Java той же версии, что и плагин. Узнать, как установить ядро Java анализатора, можно в отдельной документации.
Использование анализатора в таком случае не отличается от обычного. Для того чтобы gradle не начинал скачивать зависимости, используйте флаг ‑‑offline. Команда запуска анализа в офлайн режиме:
./gradlew pvsAnalyze –-offlineКонфигурация
Ниже представлен список настроек анализатора, которые могут быть указаны в блоке pvsstudio файла build.gradle:
- outputType = "TYPE" — формат, в котором будет представлен отчёт анализатора (text, log, json, xml, tasklist, html, fullhtml, errorfile). Значение по умолчанию: json;
- outputFile = "PATH" — путь до файла с отчётом, куда будут записаны результаты анализа. Формат содержимого не зависит от расширения файла, указанного в данном параметре. Значение по умолчанию: $projectDir/PVS-Studio + расширение формата из настройки outputType. Для отчёта в формате fullhtml необходимо указать директорию, в которой будет создана папка с именем 'fullhtml', содержащая файл отчёта анализатора (index.html). Значение по умолчанию: $projectDir/fullhtml. Внимание. Вместо использования настройки outputFile более предпочтительным сценарием является использование консольных утилит PlogConverter (Windows) и plog-converter (Linux и macOS). Эти утилиты позволяют конвертировать отчёт анализатора в большее количество форматов (например, SARIF), а также предоставляют дополнительные возможности: фильтрация предупреждений из отчёта, преобразование путей в отчёте с абсолютных на относительные и наоборот, получение разницы между отчётами и др.;
- licensePath = "PATH" — путь до файла с лицензией. Допустимые расширения файла: .xml, .lic. Значение по умолчанию: %APPDATA%/PVS-Studio/Settings.xml (Windows) или ~/.config/PVS-Studio/PVS-Studio.lic (macOS и Linux);
- threadsNum = NUMBER — данный параметр позволяет задать число потоков, на которое будет распараллелен анализ. Возможно задать эту настройку для всей системы в файле global.json. Значение по умолчанию: число доступных процессоров;
- sourceTreeRoot = "PATH" — корневая часть пути, которую анализатор будет использовать при генерации относительных путей в диагностических сообщениях. По умолчанию при генерации диагностических сообщений PVS-Studio выдаёт абсолютные пути до файлов, на которые анализатор выдал срабатывания. С помощью данной настройки можно задать корневую часть пути (путь до директории), которую анализатор будет автоматически подменять на специальный маркер. Замена произойдет, если путь до файла начинается с заданной корневой части. В дальнейшем отчёт с относительными путями возможно использовать для просмотра результатов анализа в окружении с отличающимся расположением исходных файлов. Например, в разных операционных системах. Значение по умолчанию отсутствует;
- analysisMode = ["GA", ....] — список активных групп диагностических правил. Доступные группы: GA (правила общего назначения), OWASP (правила согласно OWASP ASVS). Настройки enabledWarnings, disabledWarnings и additionalWarnings имеют больший приоритет, чем эта настройка. То есть, если диагностическая группа отключена (или включена), то можно при анализе включить (или отключить) отдельные диагностики при помощи этих настроек. Значение по умолчанию: GA;
- enabledWarnings = ["VXXXX", ....] — список активных диагностик. Во время анализа будут использованы только те диагностики, которые заданы в этом списке. При отсутствии значения данной настройки все диагностики считаются включёнными, если дополнительно не задана настройка disabledWarnings. Эта настройка имеет меньший приоритет чем, настройка disabledWarnings и additionalWarnings, но больший, чем настройка analysisMode. Значение по умолчанию отсутствует;
- disabledWarnings = ["VXXXX", ....] — список выключенных диагностик. Диагностики, перечисленные в этом списке, не будут применены во время анализа. При отсутствии данной настройки все диагностики считаются включёнными, если дополнительно не задана настройка enabledWarnings. Эта настройка имеет больший приоритет, чем настройки enabledWarnings и analysisMode, но меньший, чем additionalWarnings. Значение по умолчанию отсутствует;
- additionalWarnings = ["VXXXX", ....] — список включённых по умолчанию диагностик, которые будут добавлены к анализу. Если диагностика добавлена в этот список, то наличие её в списках enabledWarnings и disabledWarnings игнорируется. Кроме того, эта диагностика будет включена, даже если группа диагностик, в которую она входит, отключена (т.е. в analysisMode не содержится этой группы). Эта настройка имеет больший приоритет, чем настройки enabledWarnings, disabledWarnings и analysisMode. Значение по умолчанию отсутствует;
- exclude = ["PATH", ....] — список файлов и/или директорий, которые нужно исключить из анализа (абсолютные или относительные пути, которые будут раскрыты относительно корневой директории проекта). При отсутствии данной настройки будут проанализированы все файлы, если дополнительно не задана настройка analyzeOnly или analyzeOnlyList. Эта настройка имеет больший приоритет, чем настройки analyzeOnly и analyzeOnlyList. Значение по умолчанию отсутствует;
- analyzeOnly = ["PATH", ....] — список файлов и/или директорий, которые нужно проанализировать (абсолютные или относительные пути, которые будут раскрыты относительно корневой директории проекта). Также можно записать эти пути построчно в файл и передать путь до этого файла в настройку analyzeOnlyList. При отсутствии данной настройки будут проанализированы все файлы, если дополнительно не задана настройка exclude или analyzeOnlyList. Эта настройка имеет меньший приоритет, чем настройка exclude. Файлы и/или директории, переданные в этой настройке, объединяются в общий список с файлами и/или директориями из настройки analyzeOnlyList. Значение по умолчанию отсутствует;
- analyzeOnlyList = "PATH" — путь к текстовому файлу, содержащему список путей к файлам и/или каталогам для анализа (каждая запись должна быть на отдельной строке). Поддерживаются относительные (будут раскрыты относительно корневой директории проекта) и абсолютные пути. При отсутствии данной настройки будут проанализированы все файлы, если дополнительно не задана настройка exclude или analyzeOnly. Эта настройка имеет меньший приоритет, чем настройка exclude. Файлы и/или директории, считанные из файла, указанного в этой настройке, объединяются в общий список с файлами и/или директориями из настройки analyzeOnly. Значение по умолчанию отсутствует;
- suppressBase = "PATH" — путь до suppress-файла, содержащего подавленные сообщения анализатора. Сообщения из suppress-файла не попадут в отчёт при последующих проверках проекта. Добавить сообщения в suppress-файл можно через интерфейс плагина PVS-Studio для IntelliJ IDEA и Android Studio, а также при помощи задачи pvsSuppress из плагина pvsstudio-gradle-plugin. Значение по умолчанию: $projectDir/.PVS-Studio/suppress_base.json;
- failOnWarnings = BOOLEAN — флаг, позволяющий завершить задачу pvsAnalyze неудачей, если анализатор выдал какое-либо предупреждение. Этот флаг позволяет отслеживать наличие предупреждений анализатора в отчёте, полученном при анализе. Данное поведение может быть удобным при интеграции в CI/CD. Значение по умолчанию: false;
- incremental = BOOLEAN — флаг, позволяющий запустить анализ инкрементально. В этом режиме анализируются только изменившиеся файлы. Значение по умолчанию: false;
- forceRebuild = BOOLEAN — флаг, позволяющий принудительно перестроить целиком закэшированную метамодель программы, содержащую информацию о её структуре и типах данных. Перестройка метамодели проекта может быть необходима при обновлении версии анализатора или если метамодель проекта оказалась повреждена. При использовании данной настройки отключается инкрементальный режим анализа проекта (настройка incremental). Значение по умолчанию: false;
- disableCache = BOOLEAN — флаг, позволяющий отключить кэширование метамодели программы. При отключённом кэше модель проекта не кэшируется и строится каждый раз заново. Этот флаг бывает полезно использовать при выяснении причин ошибок в анализаторе. При отключении кэширования метамодели проекта также отключается инкрементальный режим анализа проекта (настройка incremental). Значение по умолчанию: false;
- timeout = NUMBER — таймаут анализа одного файла (в минутах). Позволяет увеличивать или уменьшать максимальное время, которое анализатор будет тратить на анализ одного файла. Возможно задать эту настройку для всей системы в файле global.json. Значение по умолчанию: 10;
- javaPath = "PATH" — задаёт путь до java интерпретатора, с которым будет запускаться ядро анализатора. Возможно задать эту настройку для всей системы в файле global.json. Для анализа файлов исходного кода будет использована версия языка Java, соответствующая версии JDK, путь до которой указан в этом параметре. По умолчанию PVS-Studio попытается использовать путь из переменной окружения PATH;
- jvmArguments = ["FLAG", ....] — дополнительные флаги JVM, с которыми будет запускаться ядро анализатора. Этот флаг позволяет настраивать JVM, которая будет запускать ядро Java анализатора. Возможно задать эту настройку для всей системы в файле global.json. Значение по умолчанию: ["-Xss64m"];
- compatibility = BOOLEAN — флаг, активирующий диагностическое правило V6078, которое обнаруживает потенциальные проблемы совместимости API между выбранными версиями Java SE. Диагностика V6078 позволяет убедиться, что API JDK, которое вы используете в проекте, не изменится или не исчезнет в более поздних версиях JDK. Значение по умолчанию: false;
- sourceJava = NUMBER — версия Java SE, на которой разработано ваше приложение. Эта настройка используется диагностикой анализатора V6078, если включена настройка compatibility. Минимальное значение: 8. Максимальное значение: 14;
- targetJava = NUMBER — версия Java SE, на совместимость с которой вы хотите проверить API, используемое в вашем приложении (sourceJava). Эта настройка используется диагностикой анализатора V6078, если включена настройка compatibility. Минимальное значение: 8. Максимальное значение: 14;
- excludePackages = ["PACK", ....] — пакеты, которые вы хотите исключить из анализа совместимости (диагностика V6078). Эта настройка используется диагностикой анализатора V6078, если включена настройка compatibility. Значение по умолчанию отсутствует.
Настройки могут быть переданы через командную строку в момент запуска анализа. Формат определения:
-Ppvsstudio.<nameSingleParam>=value
-Ppvsstudio.<nameMultipleParam>=value1;value2;value3Пример:
./gradlew pvsAnalyze -Ppvsstudio.outputType=text
-Ppvsstudio.outputFile=path/to/output.txt
-Ppvsstudio.disabledWarnings=V6001;V6002;V6003Обратите внимание, что параметры, явно переданные в командной строке, имеют наивысший приоритет.
Как изменить версию Java для запуска анализатора
По умолчанию анализатор запускает ядро с java из переменной окружения PATH. Если необходимо запустить анализ с другой версией, её можно указать вручную. Для этого в настройке анализатора javaPath укажите путь до java из JDK. Версия этой JDK (версия языка Java) будет использована при анализе исходного кода проекта:
....
javaPath = "C:/Program Files/Java/jdk19.0.5/bin/java"
....Обновление PVS-Studio Java
Благодаря использованию latest.release в качестве версии плагина в файле build.gradle у вас всегда будет использоваться последняя версия PVS-Studio для анализа.
Использование прокси
При использовании прокси необходимо указать логин и пароль для корректной загрузки ядра анализатора.
Это можно сделать через аргументы:
- -Dhttp.proxyUser, -Dhttp.proxyPassword
- -Dhttps.proxyUser, -Dhttps.proxyPassword
- -Djava.net.socks.username, -Djava.net.socks.password
- -Dftp.proxyUser, -Dftp.proxyPassword
Команда для запуска анализа через плагин для Gradle с прокси:
./gradlew pvsAnalyze "-Dhttp.proxyUser=USER" "-Dhttp.proxyPassword=PASS"Интеграция PVS-Studio Java в сборочную систему Maven
- Интеграция плагина PVS-Studio в Maven
- Запуск анализа
- Запуск анализа без доступа к сети
- Конфигурация
- Обновление PVS-Studio Java
Статический анализатор кода PVS-Studio Java состоит из 2-х основных частей: ядра, выполняющего анализ и плагинов для интеграции в сборочные системы (Maven и Gradle) и IDE (PVS-Studio для IntelliJ IDEA и Android Studio).
Функции плагинов:
- Предоставление удобного интерфейса для запуска и настройки анализатора;
- Развёртывание в системе ядра анализатора;
- Сбор и передача данных (наборы исходных файлов и classpath) о структуре проекта ядру анализатора.
Интеграция плагина PVS-Studio в Maven
Для интеграции плагина необходимо добавить следующий код в файл pom.xml:
<pluginRepositories>
<pluginRepository>
<id>pvsstudio-maven-repo</id>
<url>https://cdn.pvs-studio.com/java/pvsstudio-maven-repository/</url>
</pluginRepository>
</pluginRepositories>
<build>
<plugins>
<plugin>
<groupId>com.pvsstudio</groupId>
<artifactId>pvsstudio-maven-plugin</artifactId>
<version>7.36.93539</version>
<configuration>
<analyzer>
<outputType>text</outputType>
<outputFile>path/to/output.txt</outputFile>
<analysisMode>GA,OWASP</analysisMode>
</analyzer>
</configuration>
</plugin>
</plugins>
</build>Запуск анализа
Перед запуском анализа вам необходимо будет ввести лицензию. Как это сделать — можно узнать в этой документации.
Для запуска анализа выполните команду:
mvn pvsstudio:pvsAnalyzeКроме того, анализ можно включить в цикл сборки проекта, добавив элемент <execution>:
<plugin>
<groupId>com.pvsstudio</groupId>
<artifactId>pvsstudio-maven-plugin</artifactId>
<version>7.36.93539</version>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>pvsAnalyze</goal>
</goals>
</execution>
</executions>
</plugin>Обратите внимание: при анализе проекта плагин запускает ядро Java анализатора. При запуске ядра анализатора будет использована версия языка Java, соответствующая версии JDK, из которого используется файл java для запуска ядра Java анализатора (настройка плагина <javaPath>). Если хотите изменить версию языка Java, которая будет использована при анализе, то используйте для запуска ядра Java анализатора файл java из JDK соответствующей версии.
Запуск анализа без доступа к сети
Для работы плагина нужно скачать его зависимости. Если вам нужно работать с плагином в системе без доступа в сеть, вы должны создать офлайн репозиторий c зависимостями плагина. Для этого вы можете использовать maven-dependency-plugin.
Для загрузки зависимостей и подготовки к офлайн использованию примените такую команду:
mvn dependency:go-offlineЗапускать эту команду нужно из директории с файлом pom.xml (корневой директории проекта). В этом случае все необходимые зависимости для сборки и анализа проекта будут сохранены в стандартной папке локального репозитория: %userprofile%/.m2/repository на Windows или ~/.m2/repository на Linux/macOS.
Для сохранения офлайн репозитория в другую папку используйте параметр maven.repo.local. Команда в таком случае будет выглядеть так:
mvn dependency:go-offline -Dmaven.repo.local=/custom/pathВы должны иметь подключение к сети во время запуска этой команды, чтобы зависимости могли загрузиться. Для последующей работы интернет-соединение уже не нужно.
В системе должно быть установлено ядро Java той же версии, что и плагин. Узнать, как установить ядро Java анализатора, можно в отдельной документации.
Использование анализатора в таком случае не отличается от обычного. Для того чтобы maven не начинал скачивать зависимости, используйте флаг ‑‑offline(-o). Пример команды запуска анализа в офлайн режиме с использованием пользовательского локального репозитория:
mvn -o pvsstudio:pvsAnalyze -Dmaven.repo.local=/custom/pathКонфигурация
В блоке <analyzer> производится настройка анализатора. Ниже представлен список настроек анализатора.
- <outputType>TYPE</outputType> — формат, в котором будет представлен отчёт анализатора (text, log, json, xml, tasklist, html, fullhtml, errorfile). Значение по умолчанию: json;
- <outputFile>PATH</outputFile> — путь до файла с отчётом анализатора, куда будут записаны результаты анализа. Формат содержимого отчёта анализатора не зависит от расширения файла, указанного в этой настройке. Значение по умолчанию: ${basedir}/PVS-Studio + расширение формата из настройки <outputType>. Для отчёта в формате fullhtml необходимо указать директорию, в которой будет создана папка с именем fullhtml, содержащая файл отчёта анализатора (index.html). Значение по умолчанию: ${basedir}/fullhtml. Внимание. Вместо использования настройки <outputFile> более предпочтительным сценарием является использование консольных утилит PlogConverter (Windows) и plog-converter (Linux и macOS). Эти утилиты позволяют конвертировать отчёт анализатора в большее количество форматов (например, SARIF), а также предоставляют дополнительные возможности: фильтрация предупреждений из отчёта, преобразование путей в отчёте с абсолютных на относительные и наоборот, получение разницы между отчётами и др.;
- <licensePath>PATH</licensePath> — путь до файла с лицензией. Допустимые расширения файла: .xml, .lic. Значение по умолчанию: %APPDATA%/PVS-Studio/Settings.xml (Windows) или ~/.config/PVS-Studio/PVS-Studio.lic (macOS и Linux);
- <threadsNum>NUMBER</threadsNum> — данный параметр позволяет задать число потоков, на которое будет распараллелен анализ. Возможно задать эту настройку для всей системы в файле global.json. Значение по умолчанию: число доступных процессоров;
- <sourceTreeRoot>PATH</sourceTreeRoot> — корневая часть пути, которую анализатор будет использовать при генерации относительных путей в диагностических сообщениях. По умолчанию при генерации диагностических сообщений PVS-Studio выдаёт абсолютные пути до файлов, на которые анализатор выдал срабатывания. С помощью данной настройки можно задать корневую часть пути (путь до директории), которую анализатор будет автоматически подменять на специальный маркер. Замена произойдет, если путь до файла начинается с заданной корневой части. В дальнейшем отчёт с относительными путями возможно использовать для просмотра результатов анализа в окружении с отличающимся расположением исходных файлов. Например, в разных операционных системах. Значение по умолчанию отсутствует;
- <analysisMode>GA, ....</analysisMode> — список активных групп диагностических правил. Доступные группы: GA (правила общего назначения), OWASP (правила согласно OWASP ASVS). Настройки <enabledWarnings>, <disabledWarnings> и <additionalWarnings> имеют больший приоритет, чем эта настройка. То есть, если диагностическая группа отключена (или включена), то можно включить (или отключить) отдельные диагностики при помощи этих настроек. Значение по умолчанию: GA;
- <enabledWarnings>VXXXX, ....</enabledWarnings> — список активных диагностик. Во время анализа будут использованы только те диагностики, которые заданы в этом списке. При отсутствии значения данной настройки все диагностики считаются включенными, если дополнительно не задана настройка <disabledWarnings>. Эта настройка имеет меньший приоритет чем, настройки <disabledWarnings> и <additionalWarnings>, но больший, чем настройка <analysisMode>. Значение по умолчанию отсутствует;
- <disabledWarnings>VXXXX, ....</disabledWarnings> — список выключенных диагностик. Диагностики, перечисленные в этом списке, не будут применены во время анализа. При отсутствии данной настройки все диагностики считаются включёнными, если дополнительно не задана настройка <enabledWarnings>. Эта настройка имеет больший приоритет, чем настройки <enabledWarnings> и <analysisMode>, но меньший, чем <additionalWarnings>. Значение по умолчанию отсутствует;
- <additionalWarnings>VXXXX, ....</additionalWarnings> — список включённых по умолчанию диагностик, которые будут добавлены к анализу. Если диагностика добавлена в этот список, то наличие её в списках <enabledWarnings> и disabledWarnings> игнорируется. Кроме того, эта диагностика будет включена, даже если группа диагностик, в которую она входит, отключена (т.е. в <analysisMode> не содержится этой группы). Эта настройка имеет больший приоритет, чем настройки <disabledWarnings>, <enabledWarnings> и <analysisMode>. Значение по умолчанию отсутствует;
- <exclude>PATH, ....</exclude> — список файлов и/или директорий, которые нужно исключить из анализа (абсолютные или относительные пути, которые будут раскрыты относительно корневой директории проекта). При отсутствии данной настройки будут проанализированы все файлы, если дополнительно не заданы настройки <analyzeOnly> или <analyzeOnlyList>. Эта настройка имеет больший приоритет, чем настройки <analyzeOnly> и <analyzeOnlyList>. Значение по умолчанию отсутствует;
- <analyzeOnly>PATH, ....</analyzeOnly> — список файлов и/или директорий, которые нужно проанализировать (абсолютные или относительные пути, которые будут раскрыты относительно корневой директории проекта). Также можно записать эти пути построчно в файл и передать путь до этого файла в настройку <analyzeOnlyList>. При отсутствии данной настройки будут проанализированы все файлы, если дополнительно не задана настройка <exclude> или <analyzeOnlyList>. Эта настройка имеет меньший приоритет, чем настройка <exclude>. Файлы и/или директории, переданные в этой настройке, объединяются в общий список с файлами и/или директориями из настройки <analyzeOnlyList>. Значение по умолчанию отсутствует;
- <analyzeOnlyList>PATH</analyzeOnlyList> — аналог настройки <analyzeOnly>. Путь к текстовому файлу, содержащему список путей к файлам и/или каталогам для анализа (каждая запись должна быть на отдельной строке). Поддерживаются относительные (будут раскрыты относительно корневой директории проекта) и абсолютные пути. При отсутствии данной настройки будут проанализированы все файлы, если дополнительно не задана настройка <exclude> или <analyzeOnly>. Эта настройка имеет меньший приоритет, чем настройка <exclude>. Файлы и/или директории, считанные из файла, указанного в этой настройке, объединяются в общий список с файлами и/или директориями из настройки <analyzeOnly>. Значение по умолчанию отсутствует;
- <suppressBase>PATH</suppressBase> — путь до suppress-файла, содержащего подавленные сообщения анализатора. Сообщения из suppress-файла не попадут в отчёт при последующих проверках проекта. Добавить сообщения в suppress-файл можно через интерфейс плагина PVS-Studio для IntelliJ IDEA и Android Studio, а также при помощи задачи pvsstudio:pvsSuppress из плагина pvsstudio-maven-plugin. Значение по умолчанию: ${basedir}/.PVS-Studio/suppress_base.json;
- <failOnWarnings>BOOLEAN</failOnWarnings> — флаг, позволяющий завершить задачу pvsstudio:pvsAnalyze неудачей, если анализатор выдал какое-либо предупреждение. Этот флаг позволяет отлеживать наличие предупреждений анализатора в отчёте, полученном при анализе. Данное поведение может быть удобным при интеграции в CI/CD. Значение по умолчанию: false;
- <incremental>BOOLEAN</incremental> — флаг, позволяющий запустить анализ инкрементально. В этом режиме анализируются только изменившиеся файлы. Значение по умолчанию: false;
- <forceRebuild>BOOLEAN</forceRebuild> — флаг, позволяющий принудительно перестроить целиком закэшированную метамодель программы, содержащую информацию о её структуре и типах данных. Перестройка метамодели проекта может быть необходима при обновлении версии анализатора или если метамодель проекта оказалась повреждена. При использовании данной настройки отключается инкрементальный режим анализа проекта (настройка <incremental>). Значение по умолчанию: false;
- <disableCache>BOOLEAN</disableCache> — флаг, позволяющий отключить кэширование метамодели программы. При отключённом кэше модель проекта не кэшируется и строится каждый раз заново. Этот флаг бывает полезно использовать при выяснении причин ошибок в анализаторе. При использовании данной настройки отключается инкрементальный режим анализа проекта (настройка <incremental>). Значение по умолчанию: false;
- <timeout>NUMBER</timeout> — таймаут анализа одного файла (в минутах). Позволяет увеличивать или уменьшать максимальное время, которое анализатор будет тратить на анализ одного файла. Возможно задать эту настройку для всей системы в файле global.json. Значение по умолчанию: 10;
- <javaPath>PATH</javaPath> — задаёт путь до java интерпретатора, с которым будет запускаться ядро анализатора. Возможно задать эту настройку для всей системы в файле global.json. Для анализа файлов исходного кода будет использована версия языка Java, соответствующая версии JDK, путь до которой указан в этом параметре. По умолчанию PVS-Studio попытается использовать путь из переменной окружения PATH;
- <jvmArguments>FLAG, ....</jvmArguments> — дополнительные флаги JVM, с которыми будет запускаться ядро анализатора. Этот флаг позволяет настраивать JVM, которая будет запускать ядро Java анализатора. Возможно задать эту настройку для всей системы в файле global.json. Значение по умолчанию: ["-Xss64m"];
- <compatibility>BOOLEAN</compatibility> — флаг, активирующий диагностическое правило V6078, которое обнаруживает потенциальные проблемы совместимости API между выбранными версиями Java SE. Диагностика V6078 позволяет убедиться, что API JDK, которое вы используете в проекте, не изменится или не исчезнет в более поздних версиях JDK. Значение по умолчанию: false;
- <sourceJava>NUMBER</sourceJava> — версия Java SE, на которой разработано ваше приложение. Эта настройка используется диагностикой анализатора V6078, если включена настройка <compatibility>. Минимальное значение: 8. Максимальное значение: 14;
- <targetJava>NUMBER</targetJava> — версия Java SE, на совместимость с которой вы хотите проверить API, используемое в вашем приложении (<sourceJava>). Эта настройка используется диагностикой анализатора V6078, если включена настройка <compatibility>. Минимальное значение: 8. Максимальное значение: 14;
- <excludePackages>"PACK", ....</excludePackages> — пакеты, которые вы хотите исключить из анализа совместимости JDK API (диагностика V6078). Эта настройка используется диагностикой анализатора V6078, если включена настройка <compatibility>. Значение по умолчанию отсутствует.
Настройки могут быть переданы через командную строку в момент запуска анализа. Формат определения:
-Dpvsstudio.<nameSingleParam>=value
-Dpvsstudio.<nameMultipleParam>=value1;value2;value3Пример:
mvn pvsstudio:pvsAnalyze -Dpvsstudio.outputType=text
-Dpvsstudio.outputFile=path/to/output.txt
-Dpvsstudio.disabledWarnings=V6001;V6002;V6003Обратите внимание, что параметры, явно переданные в командной строке, имеют наивысший приоритет.
Как изменить версию Java для запуска анализатора
По умолчанию анализатор запускает ядро с java из переменной окружения PATH. Если необходимо запустить анализ с другой версией, её можно указать вручную. Для этого в настройке анализатора <javaPath> укажите путь до java из JDK. Версия этой JDK (версия языка Java) будет использована при анализе исходного кода проекта:
....
<javaPath>C:/Program Files/Java/jdk19.0.5/bin/java</javaPath>
....Обновление PVS-Studio Java
Для обновления pvsstudio-maven-plugin необходимо изменить версию плагина в файле pom.xml.
Использование прокси
При использовании прокси необходимо указать логин и пароль для корректной загрузки ядра анализатора.
Это можно сделать через аргументы:
- -Dhttp.proxyUser, -Dhttp.proxyPassword
- -Dhttps.proxyUser, -Dhttps.proxyPassword
- -Djava.net.socks.username, -Djava.net.socks.password
- -Dftp.proxyUser, -Dftp.proxyPassword
Команда для запуска анализа через плагин для Maven с прокси:
mvn pvsstudio:pvsAnalyze "-Dhttp.proxyUser=USER" "-Dhttp.proxyPassword=PASS"Знакомство со статическим анализатором кода PVS-Studio на Windows
- Преимущества использования статического анализатора
- Краткий обзор возможностей
- Системные требования и установка PVS-Studio
- Основы работы с PVS-Studio
- Работа со списком диагностических сообщений
- Надо ли добиваться исправления всех потенциальных ошибок, на которые указывает анализатор?
PVS-Studio - статический анализатор С, С++, C# и Java кода, предназначенный для облегчения задачи поиска и исправления различного рода ошибок. Анализатор можно использовать в Windows, Linux и macOS.
При работе с Windows анализатор интегрируется в Visual Studio в качестве плагина, предоставляя программисту удобный интерфейс для ориентации в коде и поиска проблемных мест. Также присутствует приложение C and C++ Compiler Monitoring UI (Standalone.exe), независимое от Visual Studio и позволяющее проверять файлы, компилируемые не только с помощью Visual C++, но и с использованием GCC (MinGW), Clang. Консольная утилита PVS-Studio_Cmd.exe позволит выполнять проверку MSBuild / Visual Studio проектов без запуска IDE или Compiler Monitoring UI, что позволит, например, использовать анализатор как часть процесса CI.
PVS-Studio для Linux представляет собой консольное приложение.
В данном документе описываются основы работы с PVS-Studio на операционных системах семейства Windows. Для получения информации о работе в среде Linux обратитесь к разделам документации "Установка и обновление PVS-Studio в Linux" и "Как запустить PVS-Studio в Linux и macOS".
Преимущества использования статического анализатора
Статический анализатор не заменяет другие инструменты поиска ошибок - он дополняет их. Внедрение такого инструмента позволяет устранять многие ошибки на этапе "зарождения", тем самым экономя время и ресурсы на их последующее устранение. Ведь чем раньше найдена ошибка, тем дешевле стоимость её исправления. Из этого следует ещё один вывод - статический анализатор необходимо использовать регулярно, именно в таком случае он проявит себя наиболее эффективно.
Краткий обзор возможностей
Уровни предупреждений и наборы диагностических правил
PVS-Studio разделяет все предупреждения по 3 уровням достоверности: High, Medium и Low. Также некоторые сообщения относятся к особой категории Fails. Рассмотрим эти уровни подробнее:
- High (1) - включает в себя предупреждения с максимальным уровнем достоверности. Такие предупреждения часто указывают на ошибки, требующие немедленного исправления.
- Medium (2) - содержит менее достоверные предупреждения, на которые все же стоит обратить пристальное внимание.
- Low (3) - предупреждения с минимальным уровнем достоверности, указывающие на несущественные неточности в коде. Среди таких предупреждений обычно велик процент ложных срабатываний.
- Fails - внутренние сообщения анализатора, информирующие о возникновении каких-то проблем при работе. В группу Fails попадают сообщения об ошибках анализатора (например, сообщения с кодами V001, V003 и т.п.), а также любой необработанный вывод вспомогательных программ, используемых самим анализатором во время анализа (препроцессор, командный процессор cmd), выдаваемый ими в stdout/stderr. Например, в группу Fails может попасть сообщение препроцессора об ошибках препроцессирования, доступа к файлам (файл не существует или заблокирован антивирусом) и т.п.
Стоит помнить, что конкретный код ошибки не обязательно привязывает её к определённому уровню достоверности, а распределение сообщений по уровням сильно зависит от контекста, в котором они были сгенерированы. При использовании плагина для Microsoft Visual Studio или в приложении C and C++ Compiler Monitoring UI окно вывода диагностических сообщений содержит кнопки уровней, позволяющие сортировать сообщения по мере необходимости.
Также имеется возможность упростить ознакомление и начальную работу с отчетом с помощью механизма отображения наиболее интересных предупреждений.
Анализатор содержит 5 видов диагностических правил:
- General (GA) - диагностики общего плана. Основной набор диагностических правил PVS-Studio.
- Optimization (OP) - диагностики микрооптимизации. Указания по повышению эффективности и безопасности кода.
- 64-bit (64) - диагностики, позволяющие выявлять специфические ошибки, связанные с разработкой 64-битных приложений, а также переносом кода с 32-битной на 64-битную платформу.
- Customers' Specific (CS) - узкоспециализированные диагностики, разработанные по просьбам пользователей. По умолчанию этот набор диагностик отключен.
- MISRA - диагностики, разработанные в соответствии со стандартом MISRA (Motor Industry Software Reliability Association). По умолчанию этот набор диагностик отключен.
Краткие обозначения групп диагностик (GA, OP, 64, CS, MISRA), наряду с номерами уровней достоверности предупреждений (1, 2, 3), используются для сокращенной формы записи, например, в параметрах командной строки. Пример: GA:1,2.
Выбор группы диагностических правил отображает или скрывает соответствующие сообщения.

С подробным списком диагностических правил вы можете ознакомиться в соответствующем разделе документации.
Сообщения анализатора можно группировать и фильтровать по различным критериям. Для получения более подробной информации о работе со списком предупреждений анализатора обратитесь к разделу документации "Работа со списком диагностических сообщений".
PVS-Studio и Microsoft Visual Studio
При установке PVS-Studio присутствует возможность выбора того, в какие среды Microsoft Visual Studio необходимо провести интеграцию.
После выбора необходимых пунктов и установки, PVS-Studio интегрируется IDE. На скриншоте ниже можно увидеть соответствующий пункт в меню Visual Studio, а также окно вывода диагностических сообщений.
В меню настроек есть возможность настроить PVS-Studio оптимальным образом для удобства работы. Например, присутствуют следующие возможности:
- Выбор препроцессора;
- Исключение файлов и папок из проверки;
- Выбор типов диагностических сообщений, выводящихся при проверке;
- Множество прочих настроек.
Скорее всего, для первого знакомства все эти настройки вам не понадобятся, но в будущем они позволят оптимизировать работу с PVS-Studio.
Подробное описание возможностей плагина для Visual Studio можно найти в разделе документации "Работа PVS-Studio в Visual Studio".
PVS-Studio и IntelliJ IDEA
При установке анализатора присутствует возможность интеграции плагина PVS-Studio в IDE IntelliJ IDEA, что позволит проводить анализ и работать с отчётами анализатора непосредственно из IDE.
После установки плагин будет доступен в меню 'Tools' ('Tools' > 'PVS-Studio'). Ниже представлен скриншот IntelliJ IDEA с интегрированным плагином PVS-Studio.

В меню настроек, как и в случае с плагином для Visual Studio, также присутствуют возможности отключения диагностических правил, исключение файлов / директорий из анализа и пр.
Особенности работы Java анализатора, а также альтернативные способы установки (включая установку плагинов для Maven, Gradle) описаны в разделе документации "Работа с ядром Java анализатора из командной строки".
PVS-Studio и JetBrains Rider
При установке анализатора присутствует возможность интеграции плагина PVS-Studio в IDE JetBrains Rider, что позволит проводить анализ и работать с отчётами анализатора непосредственно из IDE.
После установки плагин доступен в меню 'Tools'. Анализ текущего solution / проекта можно выполнить следующим образом: 'Tools' > 'PVS-Studio' > 'Check Current Solution/Project'.
Ниже представлен скриншот IDE JetBrains Rider с интегрированным плагином PVS-Studio.

Более подробно использование плагина PVS-Studio для IDE JetBrains Rider описано в разделе документации "Работа PVS-Studio в JetBrains Rider".
C and C++ Compiler Monitoring UI (Standalone.exe)
PVS-Studio может использоваться независимо от интегрированной среды разработки Microsoft Visual Studio. Compiler Monitoring UI позволяет проверять проекты в процессе их сборки. В этой версии также поддерживаются переходы по коду по диагностическим сообщениям, поиск фрагментов кода, определений макросов и типов данных. Более подробно работа с этим приложением описана в разделе документации "Просмотр результатов анализа в приложении C and C++ Compiler Monitoring UI".
PVS-Studio_Cmd.exe
PVS-Studio_Cmd.exe - модуль, позволяющий выполнять анализ решений Visual Studio (.sln), а также Visual C++ и Visual C# проектов (.vcxproj, .csproj) из командной строки. Это может быть полезно, например, в случае необходимости интеграции статического анализа на сборочном сервере. PVS-Studio_Cmd.exe позволяет проводить как полный анализ целевого проекта, так и инкрементальный (анализ файлов, изменившихся с момента последний сборки). Представление кода возврата работы утилиты в виде битовой маски позволяет получить подробную информацию о результатах анализа и идентифицировать проблемы, в случае их наличия. Таким образом, используя модуль PVS-Studio_Cmd.exe, можно достаточно 'тонко' настроить сценарий статического анализа кода и внедрить его в процесс CI. Более подробно использование модуля PVS-Studio_Cmd.exe описано в разделе документации "Проверка Visual C++ (.vcxproj) и Visual C# (.csproj) проектов из командной строки с помощью PVS-Studio".
Справочная система и техническая поддержка
PVS-Studio обладает обширной справочной системой диагностических сообщений. Эта база доступна как при работе с инструментом PVS-Studio, так и на официальном сайте. К различным диагностическим сообщениям прилагаются примеры кода, содержащего подобные ошибки, описание проблемы, а также возможные варианты исправления.
Чтобы изучить описание той или иной диагностики, достаточно кликнуть левой кнопкой мыши по номеру диагностики в окне вывода сообщений. Эти номера оформлены как гиперссылки.
Поддержка для PVS-Studio осуществляется посредством электронной почты. Так как с клиентами общаются непосредственно разработчики анализатора, это позволяет быстро получать ответы на самые разные вопросы.
Системные требования и установка PVS-Studio
Анализатор PVS-Studio интегрируется в среды разработки Microsoft Visual Studio 2022, 2019, 2017, 2015, 2013, 2012, 2010. Системные требования к анализатору можно найти в соответствующем разделе документации.
Получив установочный пакет PVS-Studio, можно приступить к установке программы.

После подтверждения лицензионного соглашения будет предоставлен выбор вариантов интеграции PVS-Studio в поддерживаемые среды разработки: Microsoft Visual Studio. Варианты интеграции, недоступные на текущей системе, будут затемнены. В случае, если на машине установлено несколько версий одной или разных IDE, возможна интеграция анализатора во все имеющиеся версии.

Для того чтобы удостовериться, что инструмент PVS-Studio корректно установлен, можно запустить IDE и открыть окно About (пункт меню Help). При этом анализатор PVS-Studio должен присутствовать в списке установленных компонентов.

Основы работы с PVS-Studio
При работе в IDE Visual Studio можно запускать различные варианты анализа - на решение, проект, файл, выбранные элементы и т.п. Например, запуск анализа решения выполняется следующим образом: "PVS-Studio -> Check -> Solution".

После запуска проверки на экране появится индикатор прогресса с кнопками Pause (приостановить анализ) и Stop (прервать анализ). Обнаруженные потенциально опасные конструкции во время анализа будут выводиться в окно найденных дефектов.

Термин "потенциально опасная конструкция" означает, что данную конкретную строку кода анализатор посчитал дефектом. Является ли эта строка реальным дефектом в приложении или нет - определить может только программист, основываясь на своем знании приложения. Этот принцип работы с анализаторами кода очень важно правильно понимать. Никакой инструмент не может полностью заменить программиста в работе по исправлению ошибок в программах. Только программист, основываясь на своих знаниях, может это сделать. Но инструмент может и должен помочь программисту в этом. Поэтому задача анализатора кода - это сократить количество мест в программе, которое должен просмотреть и разобрать программист.
Работа со списком диагностических сообщений
Скорее всего, в больших реальных проектах диагностических сообщений будет не несколько десятков, а несколько сотен или даже тысяч. И просмотр всех подобных сообщений может быть непростой задачей. Для того чтобы облегчить ее, в анализаторе PVS-Studio имеются несколько механизмов, таких как фильтрация сообщений по коду ошибки, фильтрация по содержимому текста диагностического сообщения, фильтрация на основе путей к файлам и другие. Рассмотрим примеры использования систем фильтрации.
Предположим, что вы уверены, что диагностические сообщения с кодом V112 (использование магических чисел) никогда не являются реальными ошибками в вашем приложении. Тогда можно отключить показ этих диагностических сообщений с помощью настроек анализатора кода на вкладке "Detectable Errors (C++)".

После отключения предупреждения с определённым кодом соответствующие предупреждения будут отфильтрованы в окне вывода, перезапускать анализ не требуется. Если же включить обратно показ таких сообщений, то они вновь появятся в списке предупреждений.
Теперь рассмотрим другой вариант фильтрации на основе текста диагностических сообщений. Рассмотрим пример предупреждения анализатора и кода, на который оно было выдано:
obj.specialFunc(obj);Предупреждение анализатора: V678 An object is used as an argument to its own method. Consider checking the first actual argument of the 'specialFunc' function.
Анализатор счёл подозрительным, что в качестве аргумента методу передаётся тот же объект, у которого этот метод и вызывается. Программисту, в отличии от анализатора, может быть известно о том, что такое использование данного метода вполне допустимо. Поэтому может возникнуть необходимость отфильтровать все подобные предупреждения. Сделать это можно, добавив соответствующий фильтр в настройках "Keyword Message Filtering".
После этого все диагностические сообщения, текст которых содержит указанное выражение, пропадут из списка без необходимости перезапускать анализатора кода. Вернуть их можно просто удалив выражение из фильтра.
Ещё одним механизмом сокращения количества диагностических сообщений является фильтрация по маскам имён файлов проекта и путям к ним.
Предположим, в вашем проекте используется библиотека Boost. Анализатор будет, конечно же, сообщать и о потенциальных проблемах в этой библиотеке. Скорее всего, вас эти предупреждения интересовать не будут, поэтому целесообразно отфильтровать их. Сделать это можно, просто добавив путь к папке с Boost на странице "Don't check files":

После этого диагностические сообщения, относящиеся к файлам в этой папке, не будут показаны.
Также в PVS-Studio имеется функция "Mark as False Alarm". Благодаря ей возможно пометить в исходном коде те строки, на которые анализатор выдал предупреждения, являющиеся ложными. После разметки анализатор более не будет выдавать диагностических сообщений на этот код.
Так в этом примере отключен вывод диагностического сообщения с кодом V640:
for (int i = 0; i < m; ++i)
for (int j = 0; j < n; ++j)
matrix[i][j] = Square(i) + 2*Square(j);
cout << "Matrix initialization." << endl; //-V640
....Подробно этот механизм описана в разделе "Подавление ложных предупреждений".
Есть также ряд других способов повлиять на выводимые диагностические сообщения путем настроек анализатора кода, но в рамках данного документа они не рассматриваются. Рекомендуем обратиться к документации по настройкам анализатора кода.
Надо ли добиваться исправления всех потенциальных ошибок, на которые указывает анализатор?
Когда вы просмотрите все сообщения, которые выдал анализатор кода, то вы найдете как реальные ошибки в программах, так и конструкции, не являющиеся ошибочными. Дело в том, что анализатор не может на 100% точно определить все ошибки в программах без так называемых "ложных срабатываний". Только программист, зная и понимая программу, может определить есть в конкретном месте ошибка или нет. Анализатор кода же только существенно сокращает количество мест, которые необходимо просмотреть разработчику.
Таким образом, добиваться исправления всех потенциальных проблем, на которые указывает анализатор кода, смысла, конечно же, нет.
Механизмы подавления отдельных предупреждений и массового подавления сообщений анализатора описаны в разделах документации "Подавление ложных предупреждений" и "Массовое подавление сообщений анализатора" соответственно.
Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio
- Запуск анализа sln и csproj/vcxproj файлов
- Задание отдельных файлов для проверки
- Фильтрация списка анализируемых файлов по маске
- Режим межмодульного анализа
- Коды возврата command-line утилит
- Запуск анализа из командной строки для C/C++ проектов, не использующих сборочную систему Visual Studio
- Влияние настроек PVS-Studio на запуск из командной строки; фильтрация и преобразование результатов анализа (plog\json файла)
В данном документе описывается использование command line утилит для анализа MSBuild проектов (.vcxproj / .csproj) и решений Visual Studio (solutions).
В данном документе описывается использование command-line утилит. Использование плагинов для IDE Visual Studio и Rider описано в соответствующих разделах документации: "Знакомство со статическим анализатором кода PVS-Studio на Windows", "Работа PVS-Studio в JetBrains Rider".
Для анализа C# проектов может потребоваться установка дополнительных .NET SDK. Подробнее про это можно узнать в документации "Системные требования анализатора PVS-Studio".
Command line анализатор MSBuild / .NET Core проектов имеет разные имена на разных поддерживаемых анализатором платформах:
- PVS-Studio_Cmd (анализ решений, C#, C++ проектов на Windows);
- pvs-studio-dotnet (анализ решений, C# проектов на Linux / macOS).
Описываемые ниже особенности актуальны для обеих утилит. Примеры с PVS-Studio_Cmd / pvs-studio-dotnet являются взаимозаменяемыми, если явно не указано обратное.
Примечание. Для анализа C++ проектов, не использующих сборочную систему MSBuild, на Windows следует воспользоваться системой мониторинга компиляции или прямой интеграцией анализатора в сборочную систему. Анализ C++ проектов на Linux / macOS подробно описан в этом разделе документации.
Запуск анализа sln и csproj/vcxproj файлов
Command line утилиты по умолчанию распаковываются в следующие директории:
- PVS-Studio_Cmd.exe
- Windows: "C:\Program Files (x86)\PVS-Studio\";
- pvs-studio-dotnet
- Linux: "/usr/share/pvs-studio-dotnet/";
- macOS: "/usr/local/share/pvs-studio-dotnet".
Команда '‑‑help' выведет все доступные аргументы анализатора:
PVS-Studio_Cmd.exe --helpПриведём пример запуска проверки решения "mysolution.sln":
PVS-Studio_Cmd.exe -t "mysolution.sln" -o "mylog.plog"Рассмотрим основные аргументы анализатора:
- ‑‑target (-t): обязательный параметр. Позволяет указать объект для проверки (sln или csproj/vcxproj файл);
- ‑‑output (-o): путь до файла, в который будут записаны результаты анализа. Если данный параметр пропущен, файл отчёта анализатора будет создан рядом с файлом, указанным через флаг '‑‑target'. Поддерживается сохранение отчёта анализатора в 2 форматах: .json и .plog. Тип формата определяется по указанному расширению. По умолчанию, без указания данного флага, на Windows будет создан отчёт в формате .plog, а на Linux и macOS — в формате .json;
- ‑‑platform (-p) и ‑‑configuration (-c): платформа и конфигурация, для которых будет запущена проверка. Если данные параметры не указаны, будет выбрана первая из доступных пар "платформа|конфигурация" (при проверке sln файла) либо "Debug|AnyCPU" (при проверке отдельного csproj проекта) или "Debug|Win32" (при проверке отдельного vcxproj проекта);
- ‑‑sourceFiles (-f): путь до текстового файла, содержащего список путей до исходных файлов для анализа (каждый должен быть на отдельной строке). Нельзя использовать вместе с флагом '‑‑regenerateDependencyCacheWithoutAnalysis' (-W). Поддерживаются относительные и абсолютные пути. В данном режиме при анализе C и C++ файлов генерируется (и используется) файл кэша зависимостей единиц компиляции от заголовочных файлов, расположением которого можно управлять с помощью флага '‑‑dependencyRoot' (-D). Важно: при использовании этого аргумента с аргументами '‑‑selectProjects' (-S) и/или '‑‑excludeProjects' (-E) вначале будет применена фильтрация проектов, а после среди файлов оставшихся проектов будет произведён поиск и анализ файлов из '‑‑sourceFiles' (-f);
- ‑‑analyzeMoifiedFiles (-F): запускает анализ только модифицированных файлов. Информация о модификации файлов определяется путём сравнения хэша, вычисленного на основе содержимого исходных файлов. Вычисленные хэши хранятся в кэше зависимостей. Кэш конфигурируется с помощью флагов '‑‑dependencyRoot' (-D) и '‑‑dependencyCacheSourcesRoot' (-R). Нельзя использовать вместе с флагами '‑‑regenerateDependencyCache' (-G), '‑‑regenerateDependencyCacheWithoutAnalysis' (-W) и '‑‑sourceFiles' (-f). Важно: при использовании этого аргумента с аргументами '‑‑selectProjects' (-S) и/или '‑‑excludeProjects' (-E) вначале будет применена фильтрация проектов, а после среди файлов оставшихся проектов будет произведён поиск и анализ измененных файлов;
- ‑‑regenerateDependencyCache (-G): генерирует или обновляет для всех исходных файлов проектов кэш зависимостей компиляции, который используются вместе с флагом '‑‑sourceFiles' (-f) и запускает анализ всех исходных файлов проектов. Отфильтровать проекты возможно при помощи флагов '‑‑selectProjects' (-S) и '‑‑excludeProjects' (-E). При передаче вместе с этим флагом флага '‑‑sourceFiles' (-f), будет произведена полная перегенерация кэшей зависимостей для всех исходных файлов проектов, а анализ будет запущен только для списка файлов, переданных в '‑‑sourceFiles' (-f). Нельзя использовать вместе с флагом '‑‑analyzeMoifiedFiles (-F)';
- ‑‑regenerateDependencyCacheWithoutAnalysis (-W): генерирует или обновляет для всех исходных файлов проектов кэш зависимостей компиляции, который используется вместе с флагом '‑‑sourceFiles' (-f), без запуска анализа. Отфильтровать проекты возможно при помощи флагов '‑‑selectProjects' (-S) и '‑‑excludeProjects' (-E). Нельзя использовать вместе с флагами '‑‑sourceFiles' (-f) и '‑‑analyzeMoifiedFiles (-F)';
- ‑‑appendHashToCache (-H): Включает добавление хэша исходных файлов в файл кэша зависимостей при генерации или модификации его с помощью флагов '‑‑regenerateDependencyCache' (-G), '‑‑regenerateDependencyCacheWithoutAnalysis' (-W) и '‑‑sourceFiles' (-f).
- ‑‑dependencyRoot (-D): опциональный путь к директории для размещения кэшей зависимости исходных файлов. Работает в дополнение к флагам '‑‑sourceFiles' (-f), '‑‑regenerateDependencyCache' (-G) и '‑‑analyzeMoifiedFiles' (-F);
- ‑‑dependencyCacheSourcesRoot (-R): опциональный путь, который используется для создания относительных путей в кэшах зависимостей исходных файлов, генерируемом при использовании флагов '‑‑sourceFiles' (-f), '‑‑regenerateDependencyCache' (-G) и '‑‑analyzeMoifiedFiles' (-F);
- ‑‑settings (-s): путь до файла настроек PVS-Studio. Если параметр опущен, будет использован файл настроек Settings.xml, находящийся в директории "%AppData%\PVS-Studio\" на Windows или "~/.config/PVS-Studio/" на Linux / macOS. Эти же файлы настроек используются плагинами (Visual Studio, Rider), что даёт возможность их редактирования с помощью интерфейса PVS-Studio плагина в данных IDE. Обратите внимание, что для работы анализатора под Windows файл настроек должен содержать регистрационную информацию. Различные способы ввода лицензии описаны здесь. В зависимости от используемого файла настроек, применяются следующие правила:
- при использовании файла настроек по умолчанию он должен содержать регистрационную информацию;
- при явном указании пути до файла настроек регистрационная информация должна быть записана или в указанном файле настроек, или в файле настроек, используемом по умолчанию;
- ‑‑licFile (-l): путь до файла лицензии PVS-Studio. Данный флаг доступен только в pvs-studio-dotnet. Если параметр опущен, будет использован файл лицензии PVS-Studio.lic, находящийся в директории "~/.config/PVS-Studio/ ".
- ‑‑progress (-r): включение режима подробного логгирования в stdout прогресса проверки (по умолчанию выключено);
- ‑‑suppressAll (-a): добавить неподавленные сообщения в suppress файлы соответствующих проектов (по умолчанию выключено). При наличии данного флага все сообщения будут добавлены в базу подавленных сообщений после сохранения результата проверки. Флаг поддерживает 2 режима работы.
- SuppressOnly добавляет сообщения из переданного отчёта о работе анализатора в suppress файлы без запуска анализа;
- AnalyzeAndSuppress запускает анализ, сохраняет отчёт о работе анализатора, и только затем подавляет найденные в нём сообщения. Этот режим позволит вам при регулярных запусках получать отчёт анализатора, в котором содержатся только новые сообщения на изменённый \ написанный код, т.е. новые сообщения попадают в новый лог и сразу же подавляются - при последующей проверке их уже не будет выдано. Тем не менее, если вам всё же потребуется посмотреть старые сообщения (без перепроверки), рядом с отчётом о работе анализатора, содержащим новые сообщения, будет сохранён файл с полным отчётом о проверке (только для .plog отчётов анализатора). Подробнее про режим подавления сообщений можно прочитать в этом разделе документации.
- ‑‑sourceTreeRoot (-e): корневая часть пути, которую PVS-Studio будет использовать при генерации относительных путей в диагностических сообщениях. Задание этого параметра переопределяет значение 'SourceTreeRoot' в настройках PVS-Studio;
- ‑‑incremental (-i): режим инкрементального анализа. Для получения подробной информации об инкрементальном анализе в PVS-Studio обратитесь к разделу "Режим инкрементального анализа PVS-Studio". Обратите внимание что этот режим доступен только для Enterprise лицензии PVS-Studio. Доступны следующие режимы работы инкрементального анализа:
- Scan – проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ. Непосредственно анализ выполнен не будет. Будут учтены изменения, произведенные с момента последней сборки, предыдущая история изменений будет удалена.
- AppendScan – проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ. Непосредственно анализ выполнен не будет. Будут учтены изменения, произведенные с момента последней сборки, а также все предыдущие изменения.
- Analyze – выполнить инкрементальный анализ. Этот шаг должен выполняться после выполнения шагов Scan или AppendScan, и может выполняться как до, так и после сборки решения или проекта. Статический анализ будет выполнен только для файлов из списка, полученного в результате выполнения команд Scan или AppendScan.
- ScanAndAnalyze - проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ, и сразу же выполнить инкрементальный анализ измененных файлов с исходным кодом. Будут учтены изменения, произведенные с момента последней сборки.
- ‑‑msBuildProperties (-m): позволяет задать или переопределить свойства уровня проекта. Для задания или переопределения нескольких свойств уровня проекта, используйте символ "|", например: ‑‑msBuildProperties "WarningLevel=2|OutDir=bin\OUT32\"
- ‑‑excludeDefines (-x): список символов, которые будут исключены из текущего набора при анализе проекта. При необходимости перечисления нескольких символов в качестве разделителя используется ';'. Пример: ‑‑excludeDefines "DEF1;DEF2". Данная опция учитывается только при анализе C# проектов.
- ‑‑appendDefines (-d): список символов, которые будут добавлены к текущему набору при анализе проекта. При необходимости перечисления нескольких символов в качестве разделителя используется ';'. Пример: ‑‑appendDefines "DEF1;DEF2". Данная опция учитывается только при анализе C# проектов.
- ‑‑selectProjects (-S): список проектов анализируемого решения (sln), которые будут проанализированы. Остальные проекты будут исключены из анализа. Поддерживается перечисление проектов через имя проектного файла (c расширением или с без него), по абсолютному или относительному пути. При необходимости перечисления нескольких проектов в качестве разделителя используется ';'. Пример: ‑‑selectProjects Project1;"Project 2.vcxproj";".\Project3\Project3.csproj".
- ‑‑excludeProjects (-E): список проектов анализируемого решения (sln), которые будут исключены из анализа. Поддерживается перечисление проектов через имя проектного файла (c расширением или с без него), по абсолютному или относительному пути. При необходимости перечисления нескольких проектов в качестве разделителя используется ';'. Пример: ‑‑excludeProjects Project1;"Project 2.vcxproj";".\Project3\Project3.csproj".
- ‑‑rulesConfig (-C): путь к файлу конфигурации диагностик .pvsconfig. Может быть использован совместно с файлами конфигурации из проектов / решения и файлами конфигурации из каталогов:
- Windows: "%AppData%\PVS-Studio\";
- Linux / macOS: "~/.config/PVS-Studio/".
- ‑‑useSuppressFile (-u): путь до suppress файлов. Через этот параметр можно указать несколько suppress файлов. В качестве разделителя используется символ ';'. Например: -u "path\to\test.suppress;path\to\test.suppress.json". Подробнее про режим подавления сообщений можно прочитать в этом разделе документации.
- ‑‑disableLicenseExpirationCheck (-h): cбрасывает код возврата и отключает предупреждение об истечении срока действия лицензии, когда срок действия лицензии подходит к концу.
- ‑‑intermodular (-I): включает межмодульный режим анализа C и С++ проектов. Анализатор выполняет более глубокий анализ кода, но тратит на это больше времени. Анализатор C# по умолчанию обеспечивает межмодульный анализ.
- ‑‑redirectOutputToLog: перенаправляет сообщения об ошибках из StdErr/StdOut в отчёт анализатора.
- ‑‑saveFilteredOutMessagses: сохраняет отчёты с подавленными или помеченными как False Alarm сообщениями. У флага есть следующие опции:
- OnlyFalseAlarms - сохранение дополнительного отчёта, содержащего сообщения, помеченные как False Alarm;
- OnlySuppressed - сохранение дополнительного отчёта, содержащего подавленные сообщения;
- SuppressedAndFalseAlarms - сохранение дополнительного отчёта, содержащего подавленные и помеченные как False Alarm сообщения;
- All - сохранение всех вышеперечисленных дополнительных отчётов.
- ‑‑misraCppVersion: задает стандарт MISRA C++. Поддерживаемые стандарты MISRA C++: 2008, 2023.
- ‑‑misraCVersion: задает стандарт MISRA C. Поддерживаемые стандарты MISRA C: 2012, 2023.
У консольной утилиты также имеются дополнительные режимы работы:
- сredentials – предназначен для активации лицензии;
- suppression – предназначен для специфичных действий с файлами подавления (создание пустых suppress файлов, подавление/расподавление отдельных предупреждений, получение статистики по suppress файлам).
В режиме "suppression" имеются дополнительные флаги, которых нет в основном режиме (или у них отличается название):
- ‑‑mode (-m): в этом флаге указывается подрежим работы с suppress файлами:
- CreateEmptySuppressFiles создаёт пустые suppress файлы рядом с проектными файлами (.csproj/.vcxproj) по заданному паттерну имени файла (флаг ‑‑suppressFilePattern). Если флаг паттерна не передан, то создаются пустые suppress файлы с именем проекта. Этот режим учитывает флаг пометки suppress файлов primary меткой (‑‑markAsPrimary). Primary suppress файлы используются для подавления нескольких предупреждений, выбранных в окне вывода результатов для Visual Studio;
- Suppress позволяет подавить отдельные предупреждения из файла отчёта анализатора (‑‑analyzerReport). Подавляемые предупреждения из отчёта анализатора отбираются при помощи фильтров: групп (‑‑groups), кодов диагностик (‑‑errorCodes), путей (‑‑files). Этот режим учитывает флаг –markAsPrimary;
- UnSuppress режим расподавляет предупреждения из переданного отчёта анализатора. UnSuppress аналогичен Suppress режиму по используемым флагам, кроме флага ‑‑markAsPrimary, который не используется в данном режиме;
- FilterFromSuppress фильтрует сообщения в существующем файле отчёта (.plog, .json или 'сырой' вывод C++ ядра) без запуска анализа при помощи suppress файлов, расположенных рядом с файлами проектов/решения. Ещё один вариант: передать путь до suppress файлов в параметре ‑‑useSuppressFile (-u). Файл с результатами фильтрации сохраняется рядом с переданным файлом отчёта. Имя этого файла имеет постфикс '_filtered'. В флаге ‑‑analyzerReport (-R) указывается путь до файла отчёта анализатора;
- CountSuppressedMessages подсчитывает количество подавленных сообщений во всех suppress файлах. Данный режим также может подсчитать количество актуальных сообщений в suppress файлах. Если передать полный файл отчёта (через флаг ‑‑analyzerReport), то можно узнать, сколько сообщений в базе подавления ещё актуальны. Вы можете узнать статистику по каждому suppress файлу, если запустите данный режим с флагом '-r';
- UpdateSuppressFiles выполняет обновление suppress файлов, удаляя из них сообщения, которые не содержатся в переданном файле отчёта (флаг ‑‑analyzerReport). Обратите внимание, что для работы этого режима требуется полный отчёт, содержащий подавленные сообщения. Полный отчёт создаётся каждый раз при запуске анализа, если есть подавленные сообщения. Файл полного отчёта имеет имя "*_WithSuppressedMessages.*" и располагается рядом с основным отчётом. Если вы запустите данный режим c файлом отчёта, не содержащим подавленные сообщения, все suppress файлы будут очищены.
- ‑‑analyzerReport (-R): путь до отчёта анализатора, предупреждения из которого должны быть использованы при обработке. Аналогичен флагу -o из основного режима;
- ‑‑msBuildProperties (-b): пары ключ-значение, аналогичен флагу –msBuildProperties (-m) из основного режима работы PVS-Studio-Cmd.exe;
- ‑‑markAsPrimary (-M): помечает suppress файлы как primary suppress файлы;
- ‑‑suppressFilePattern (-P): паттерн имени для создания/использования suppress файлов;
- ‑‑logModifiedFiles (-l): в файл, переданный в этом флаге, записываются пути до всех модифицированных проектных и suppress файлов. Можно использовать и абсолютные, и относительные пути до файла. Файл будет создан или перезаписан, если был модифицирован хотя бы один проектный или suppress файл. Эта же информация выводится в консоль, если указан флаг ‑‑progress (-r);‑‑groups (-g): фильтр предупреждений из отчёта анализатора (-R) по группам диагностик с уровнями достоверности. Пример: GA:1,2,3|OWASP|64:2;
- ‑‑errorCodes (-E): фильтр предупреждений из отчёта анализатора (-R) по кодам диагностик анализатора. Пример: V501,V1001,V3001;
- ‑‑files (-f): фильтр предупреждений из отчёта анализатора (-R) по путям. Пример: ‑‑files absolute/path/directory*3,8,11|relative/path/file*1|fileName
Command line версия анализатора PVS-Studio поддерживает все настройки по фильтрации\отключению сообщений, доступные в плагинах для Visual Studio и Rider. Вы можете как задать их вручную в xml файле, переданном с помощью аргумента '‑‑settings', так и использовать настройки, заданные через UI плагина, не передавая данного аргумента. Обратите внимание, что IDE плагин PVS-Studio использует отдельный набор настроек для каждого пользователя в системе.
Актуально только для PVS-Studio_Cmd. Если вы установили несколько экземпляров PVS-Studio различных версий для текущего пользователя системы, то все экземпляры программы будут использовать установочную директорию, указанную при последней установке. Во избежание конфликтов в работе анализатора в настройках, передаваемых с аргументом ‑‑settings (-s), необходимо указать путь до установочной директории (значение элемента <InstallDir>).
Задание отдельных файлов для проверки
PVS-Studio_Cmd позволяет провести выборочную проверку отдельных файлов (например, только файлов, в которых были внесены изменения), заданных в списке, передаваемом с помощью флага '‑‑sourceFiles' (-f). Это позволяет значительно уменьшить время, необходимое для анализа, а также получить отчёт анализатора только для определённых изменений в исходном коде.
Список файлов представляет собой простой текстовый файл, в котором построчно указаны пути к проверяемым файлам. Относительные пути к файлам будут раскрыты относительно текущей рабочей директории. Можно указывать как исходные компилируемые файлы (c/cpp для C++ и cs для C#), так и заголовочные файлы (h/hpp для C++).
Для получения списка изменившихся файлов для флага '‑‑sourceFiles' (-f) можно использовать системы контроля версий (SVN, Git и тд.). Это позволит предоставлять анализатору актуальную информацию об изменениях в коде.
При использовании данного режима для анализа C и C++ файлов генерируется кэш зависимостей компиляции, который будет использован при последующих запусках анализа. По умолчанию кэши зависимостей сохраняются в специальной поддиректории '.pvs-studio', рядом с проектными файлами (.vcxproj). При необходимости можно изменить место их хранения при помощи флага '‑‑dependencyRoot' (-D). Также возможно использовать флаг ‑‑dependencyCacheSourcesRoot (-R), который позволяет создавать файлы кэшей зависимостей с относительными путями, что позволяет использовать один и тот же файл кэша зависимостей на разных системах.
Более подробную информацию о кэшах зависимостей вы можете найти в одноименном разделе документации для C++ проектов.
Фильтрация списка анализируемых файлов по маске
Для того, чтобы определить набор анализируемых файлов, пути и названия которых соответствуют определенному шаблону, флагу '‑‑sourceFiles' (-f) должен быть передан специально сформированный XML файл. В нем могут содержаться списки абсолютных и относительных путей и/или масок до проверяемых файлов.
<SourceFilesFilters>
<SourceFiles>
<Path>C:\Projects\Project1\source1.cpp</Path>
<Path>\Project2\*</Path>
<Path>source_*.cpp</Path>
</SourceFiles>
<SourcesRoot>C:\Projects\</SourcesRoot>
</SourceFilesFilters>Кэш зависимостей не генерируется при использовании такого формата списка анализируемых файлов и на анализ будут поставлены только те файлы исходного кода, которые были перечислены в файле. Заголовочные файлы будут проигнорированы. Для их проверки воспользуйтесь списком файлов в текстовом формате.
Режим межмодульного анализа
Включение данного режима позволяет анализатору учитывать информацию не только из анализируемого файла, но и из связанных с ним файлов. Это позволяет производить более глубокий и качественный анализ. Однако, на сбор необходимой информации требуется дополнительное время, что отразится на времени анализа вашего проекта.
Данный режим актуален для C и C++ проектов. C# проекты обеспечивают межмодульный анализ по умолчанию.
Для запуска межмодульного анализа необходимо передать флаг ‑‑intermodular в консольную утилиту.
Коды возврата command-line утилит
Утилиты PVS-Studio_Cmd / pvs-studio-dotnet имеют несколько ненулевых кодов возврата, которые не означают проблемы в работе самой утилиты, т.е. даже если утилита вернула не '0', это ещё не означает, что она "упала". Код возврата представляет собой битовую маску, маскирующую все возможные состояния, возникшие во время работы утилиты. Например, утилита вернёт ненулевой код возврата в случае, если анализатор нашёл в проверяемом коде потенциальные ошибки. Это позволяет обрабатывать такую ситуацию отдельно, например, на сборочном сервере, когда политика использования анализатора не подразумевает наличия срабатываний в коде, заложенном в систему контроля версий.
Коды возврата PVS-Studio_Cmd (Windows)
Рассмотрим далее все возможные коды состояния утилиты, из которых формируется битовая маска кода возврата.
- '0' - анализ успешно завершён, ошибок в проверяемом коде не найдено;
- '1' - ошибка (падение) анализатора при проверке одного из файлов;
- '2' - общая (неспецифичная) ошибка при работе анализатора, перехваченное исключение при работе. Обычно это сигнализирует о наличии ошибки в коде самого анализатора и сопровождается выведением stack trace'а этой ошибки в stderr. Если вам встретилась подобная ошибка, пожалуйста, помогите нам улучшить анализатор и пришлите этот stack trace нам;
- '4' - какие-то из переданных аргументов командной строки некорректны. Возможные причины возникновения: неправильный или пустой путь до файла, неправильный выходной формат отчёта анализатора;
- '8' - не найден заданный проект, solution или файл настроек анализатора. Возможные причины возникновения: неправильный или пустой путь до файла, проект внутри solution был переименован или удалён;
- '16' - заданная конфигурация и (или) платформа не найдены в файле решения. Возможная причина возникновения: в проекте не настроена, переименована, удалена конфигурация (платформа);
- '32' - файл решения или проекта не поддерживается или содержит ошибки. Возможные причины возникновения: повреждена структура файла решения или проекта, запуск проверки проекта Unreal Engine не через интеграцию Unreal Build Tool, некорректное значение макроса VCTargetsPath в проектах MSBuild;
- '64' - некорректное расширение проверяемого решения или проекта;
- '128' - некорректная или просроченная лицензия на анализатор. Возникает при использовании функционала Enterprise версии c Team лицензией или окончании срока действия лицензии;
- '256' - в проверяемом коде найдены потенциальные ошибки. Возникает при наличии хотя бы одного сообщения не из группы Fails;
- '512' - произошла ошибка при выполнении подавления сообщений (режим suppression или использование флага ‑‑suppressAll). Возникает при загрузке некорректного файла отчёта или suppress-файла;
- '1024' - показывает, что лицензия на анализатор истечёт в течение месяца;
Приведём пример скрипта Windows batch для расшифровки кода возврата утилиты PVS-Studio_Cmd:
@echo off
"C:\Program Files (x86)\PVS-Studio\PVS-Studio_Cmd.exe"
-t "YourSolution.sln" -o "YourSolution.plog"
set /A FilesFail = "(%errorlevel% & 1) / 1"
set /A GeneralExeption = "(%errorlevel% & 2) / 2"
set /A IncorrectArguments = "(%errorlevel% & 4) / 4"
set /A FileNotFound = "(%errorlevel% & 8) / 8"
set /A IncorrectCfg = "(%errorlevel% & 16) / 16"
set /A InvalidSolution = "(%errorlevel% & 32) / 32"
set /A IncorrectExtension = "(%errorlevel% & 64) / 64"
set /A IncorrectLicense = "(%errorlevel% & 128) / 128"
set /A AnalysisDiff = "(%errorlevel% & 256) / 256"
set /A SuppressFail = "(%errorlevel% & 512) / 512"
set /A LicenseRenewal = "(%errorlevel% & 1024) / 1024"
if %FilesFail% == 1 echo FilesFail
if %GeneralExeption% == 1 echo GeneralExeption
if %IncorrectArguments% == 1 echo IncorrectArguments
if %FileNotFound% == 1 echo FileNotFound
if %IncorrectCfg% == 1 echo IncorrectConfiguration
if %InvalidSolution% == 1 echo IncorrectCfg
if %IncorrectExtension% == 1 echo IncorrectExtension
if %IncorrectLicense% == 1 echo IncorrectLicense
if %AnalysisDiff% == 1 echo AnalysisDiff
if %SuppressFail% == 1 echo SuppressFail
if %LicenseRenewal% == 1 echo LicenseRenewalКоды возврата pvs-studio-dotnet (Linux / macOS)
Примечание. Так как максимальное значение кода возврата под Unix ограничено 255, коды возврата утилит PVS-Studio_Cmd (где может возвращаться значение больше 255) и pvs-studio-dotnet отличаются.
Рассмотрим далее все возможные коды состояния утилиты, из которых формируется битовая маска кода возврата.
- '0' - анализ успешно завершён, ошибок в проверяемом коде не найдено;
- '1' - некорректная или просроченная лицензия на анализатор. Возникает при использовании функционала Enterprise версии c Team лицензией или окончании срока действия лицензии;
- '2' - общая ошибка при работе анализатора. Эта ошибка включает пропущенные аргументы командной строки, некорректный solution или проект, заданный для анализа, ошибки внутри анализатора и т.п. Если ошибка сопровождается stack trace, пожалуйста, помогите нам улучшить анализатор и пришлите этот stack trace нам;
- '4' - показывает, что лицензия на анализатор истечёт в течение месяца;
- '8' - в проверяемом коде найдены потенциальные ошибки. Возникает при наличии хотя бы одного сообщения не из группы Fails;
Запуск анализа из командной строки для C/C++ проектов, не использующих сборочную систему Visual Studio
Примечание. Данный раздел актуален для Windows. Анализ C++ проектов на Linux / macOS описан в соответствующем разделе документации.
Если ваш C/C++ проект не использует стандартные сборочные системы Visual Studio (VCBuild/MSBuild) или даже использует собственную сборочную систему / make-файлы через NMake проекты Visual Studio, то вы не сможете проверить такой проект с помощью PVS-Studio_Cmd.
В таком случае вы можете воспользоваться системой отслеживания компиляторов, которая позволяет анализировать проекты, независимо от их сборочной системы, "перехватывая" запуск процессов компиляции. Система отслеживания компиляции может использоваться как из командной строки, так и через пользовательский интерфейс приложения C and C++ Compiler Monitoring UI.
Также вы можете напрямую встроить запуск command line ядра анализатора непосредственно в вашу сборочную систему. Заметьте, что это потребует прописывать вызов ядра анализатора PVS-Studio.exe для каждого компилируемого файла, по аналогии с тем, как вызывается C++ компилятор.
Влияние настроек PVS-Studio на запуск из командной строки; фильтрация и преобразование результатов анализа (plog\json файла)
При запуске анализа кода из командной строки по умолчанию используются те же настройки, что и при запуске анализа из IDE (Visual Studio / Rider). Также можно указать, какой файл настроек использовать, с помощью аргумента ‑‑settings, как было описано выше.
Что касается, к примеру, системы фильтров (Keyword Message Filtering и Detectable Errors), то она НЕ применяется при анализе из командной строки. В том смысле, что в файле отчета независимо от заданных параметров будут все сообщения об ошибках. Но при загрузке файла с результатами в IDE фильтры уже будут применены. Это происходит из-за того, что фильтры применяются динамически к результатам (и при запуске из IDE также). Это очень удобно, поскольку, получив список сообщений, вы можете захотеть отключить некоторые из них (например, V201). Достаточно отключить их в настройках и соответствующие сообщения пропадут из списка БЕЗ перезапуска анализа.
Формат отчёта анализатора не предназначен для прямого отображения или чтения человеком. Однако, если необходимо каким-либо образом отфильтровать результаты анализа и преобразовать их в "читаемый" вид, можно воспользоваться утилитой PlogConverter, распространяемой вместе с PVS-Studio.
Для работы с отчётами разных форматов требуется использование разных утилит:
- .plog – PlogConverter.exe (доступна только на Windows);
- .json – plog-converter (Linux, macOS).
Исходный код обеих утилит открыт и доступен для загрузки: PlogConverter; plog-converter, что позволяет достаточно просто добавлять поддержку новых форматов на основе существующих алгоритмов.
Более подробно данные утилиты описываются в соответствующих разделах документации:
- PlogConverter – "Работа с XML отчётом (.plog файл)" (подраздел "Конвертация результатов анализа");
- plog-converter – "Как запустить PVS-Studio в Linux и macOS" (подраздел "Утилита Plog Converter").
Проверка проектов независимо от сборочной системы (C и C++)
- Введение
- Принцип работы
- Использование CLMonitor.exe
- Сохранение дампа мониторинга компиляции и запуск анализа из дампа
- Использование системы отслеживания компиляции из приложения C and C++ Compiler Monitoring UI
- Использование системы отслеживания компиляции из Visual Studio
- Особенности использования CLMonitor.exe вместе с Incredibuild
- Особенности мониторинга сборки проектов в среде IAR Embedded Workbench for ARM
- Инкрементальный анализ
- Режим межмодульного анализа
- Задание отдельных файлов для проверки
- Режим перехвата Wrap Compilers
- Заключение
В данном документе описывается система мониторинга компиляции для Windows. Мониторинг проектов под Linux описан здесь (подраздел "Любой проект (только для Linux)").
Введение
Система мониторинга компиляции (PVS-Studio Compiler Monitoring, CLMonitoring) предназначена для "бесшовной" интеграции статического анализа PVS-Studio в любую сборочную систему на ОС семейства Windows. Эта сборочная система должна использовать для компиляции файлов один из препроцессоров, поддерживаемых command-line анализатором PVS-Studio.exe (Visual C++, GCC, Clang, Keil MDK ARM Compiler 5/6, IAR C/C++ Compiler for ARM).
Анализатору PVS-Studio.exe для корректного анализа исходных C/C++ файлов требуется промежуточный .i (intermediate) файл — результат работы препроцессора, содержащий все включённые в исходный файл заголовки и раскрытые макросы. Это требование обуславливает невозможность "просто проверить" исходные файлы на диске. Ведь помимо содержимого самих файлов статическому анализатору требуется также информация, необходимая для генерации такого .i файла. Заметим, что PVS-Studio не содержит в себе препроцессора и при своей работе полагается на внешний.
Рассматриваемая система, как следует из её названия, основана на "отслеживании" запусков компилятора во время сборки проекта. Она позволяет собрать всю необходимую информацию для запуска анализа (т.е. для генерации препроцессированных .i файлов) на исходниках, сборка которых была отслежена. Это, в свою очередь, позволяет проанализировать проект, просто запустив его пересборку, без необходимости от пользователя как-либо модифицировать свои сборочные сценарии.
Система представлена сервером, отслеживающим компиляцию (command-line утилита CLMonitor.exe), и приложением C and C++ Compiler Monitoring UI (Standalone.exe), осуществляющим непосредственный запуск статического анализа. При необходимости использования из командной строки CLMonitor.exe может также быть использован и в качестве клиента.
В режиме работы по умолчанию система не производит анализа иерархии запущенных процессов, а отслеживает запуск всех процессов в системе. Это значит, что, если будет запущена параллельная сборка нескольких проектов, система также отследит запуски компиляторов у обоих проектов.
CLMonitor.exe также умеет отслеживать только такие запуски процессов компилятора, которые были порождены от указанного (по PID) родительского процесса. Такой режим работы предусмотрен для случая, когда в системе была запущена параллельная сборка нескольких проектов, но вам нужно отследить запуски процессов компилятора только для определённого собираемого проекта или solution'а. Режим отслеживания дочерних процессов будет описан ниже.
Принцип работы
Сервер мониторинга (CLMonitor.exe) отслеживает запуск процессов, соответствующих целевому компилятору (например, cl.exe в случае Visual C++ или g++.exe в случае GCC) и собирает информацию об окружении этих процессов. Сервер мониторинга отслеживает запуски процессов только для того пользователя, из-под которого он сам запущен. Эта информация необходима для последующего запуска статического анализа и включает:
- рабочую директорию процесса;
- полную строку запуска процесса (т.е. имя исполняемого файла и все аргументы, с которыми он был запущен);
- полный путь до исполняемого файла процесса;
- системные переменные окружения процесса.
После завершения сборки проекта серверу мониторинга (CLMonitor.exe) необходимо послать сигнал о прекращении отслеживания. Это можно сделать как с помощью того же CLMonitor.exe, запустив его в режиме клиента, так и через интерфейс Compiler Monitoring UI.
По завершении мониторинга сервер, используя собранную о процессах информацию, запускает генерацию промежуточных (intermediate) файлов для исходных файлов, которые были скомпилированы во время работы мониторинга. Затем уже выполняется запуск непосредственно статического анализатора (PVS-Studio.exe), выдавая на выход стандартный отчёт о работе PVS-Studio, с которым можно работать как из Compiler Monitoring UI, так и из любого IDE плагина PVS-Studio.
Использование CLMonitor.exe
Примечание: далее будет описано использование CLMonitor.exe для интеграции анализа в автоматизированную систему сборки. Если вы хотите просто проверить свой проект, то воспользуйтесь приложением Compiler Monitoring UI.
CLMonitor.exe представляет собой сервер мониторинга, который осуществляет непосредственно само отслеживание запусков компиляторов. Его необходимо запустить непосредственно перед началом сборки вашего проекта. В режиме отслеживания сервер будет перехватывать запуски всех поддерживаемых компиляторов.
Перечислим далее поддерживаемые компиляторы:
- компиляторы семейства Microsoft Visual C++ (cl.exe);
- C/C++ компиляторы из GNU Compiler Collection (gcc.exe, g++.exe) и их производные;
- компилятор Clang (clang.exe) и его производные;
- Borland C++;
- QCC;
- Keil MDK ARM Compiler 5/6;
- IAR C/C++ Compiler for ARM;
- Texas Instruments ARM Compiler;
- GNU Arm Embedded Toolchain.
Но, если вы хотите интегрировать анализ непосредственно в вашу сборочную систему (или систему непрерывной интеграции и т.п.), вы не можете "просто" запустить сервер мониторинга. Ведь данный процесс на время своей работы блокирует остальную сборку. Поэтому вам нужно запустить CLMonitor.exe с аргументом monitor:
CLMonitor.exe monitorВ этом режиме CLMonitor запустит сам себя в режиме отслеживания и завершит свою работу, а ваша сборочная система сможет продолжить выполнять свои оставшиеся задачи. При этом второй (запущенный из первого) процесс CLMonitor будет оставаться запущенным и производить отслеживание сборки.
Т.к. в таком режиме работы ни одна консоль не подключена к процессу CLMonitor, то помимо стандартных потоков ввода\вывода (stdin\stdout) сервер мониторинга также выводит свои сообщения в журнал событий Windows (Event Logs -> Windows Logs -> Application).
Также можно отслеживать только те запуски компиляторов, которые были порождены от определённого указанного по PID процесса. Для этого необходимо запустить CLMonitor.exe в режиме отслеживания с аргументами trace и ‑‑parentProcessID ('-p' сокращённый вариант). Аргумент ‑‑parentProcessID в качестве параметра должен принимать PID процесса, который, как предполагается, будет выступать родительским для запускаемых процессов компилятора. Строка запуска СLMonitor.exe в таком режиме может выглядеть следующим образом:
CLMonitor.exe trace –-parentProcessID 10256Если вы выполняете сборку из консоли и хотите, чтобы CLMonitor.exe отследил только сборку, запускаемую из этой же консоли, то вы можете запустить CLMonitor.exe с аргументом ‑‑attach (-a):
CLMonitor.exe monitor –-attachВ таком режиме работы программа отследит только те запуски компиляторов, которые были дочерними по отношению к процессу консоли, из-под которой была запущена сборка.
Стоит учитывать, что при сборке проектов, использующих сборочную систему MSBuild, оставшиеся с момента выполнения предыдущих сборок процессы MSBuild.exe не всегда завершаются. В этом случае CLMonitor.exe, запускаемый в режиме отслеживания дочерних процессов, не сможет отследить запуски компиляторов, которые были порождены от оставшихся в системе работающих процессов MSBuild.exe. Ведь данные процессы MSBuild.exe, скорее всего, не входят в иерархию процесса, указанного с помощью аргумента ‑‑parentProcessID. В связи с этим, перед запуском CLMonitor.exe в режиме отслеживания дочерних процессов рекомендуется завершать процессы MSBuild.exe, оставшиеся в системе с момента выполнения предыдущей сборки.
Примечание: для корректной работы сервера отслеживания он должен быть запущен с правами, эквивалентными правам, с которыми запускаются и сами процессы компиляторов.
Для корректной записи сообщений в системные журналы событий процесс CLMonitor.exe необходимо запустить от имени администратора хотя бы один раз. Если процесс ни разу не стартовал с правами администратора, сообщения об ошибках не будут попадать с системный журнал.
Обратите внимание, что в системные логи сервер записывает только сообщения об ошибках в своей работе (обработанных исключениях), а не диагностические сообщения от анализатора!
После завершения сборки запустите CLMonitor.exe в режиме клиента для генерации препроцессированных файлов и непосредственного запуска статического анализа:
CLMonitor.exe analyze -l "d:\ptest.plog"В качестве параметра '-l' передаётся полный путь до файла, в который будут записаны непосредственные результаты работы статического анализатора.
После запуска в режиме клиента CLMonitor.exe подключится к запущенному ранее серверу и получит от него информацию обо всех отловленных процессах компиляторов, после чего сервер завершит свою работу. Клиент же начнёт запуск препроцессоров и анализаторов PVS-Studio.exe для всех отслеженных исходных файлов.
В результате работы CLMonitor.exe будет получен файл-отчёта (D:\ptest.plog), который можно открыть в любом IDE плагине PVS-Studio или в Compiler Monitoring UI (PVS-Studio|Open/Save|Open Analysis Report).
Вы можете использовать в CLMonitor подавление сообщений анализатора с помощью аргумента '-u':
CLMonitor.exe analyze -l "d:\ptest.plog" -u "d:\ptest.suppress" -sВ параметре '-u' передаётся путь до suppress файла, полученного с помощью диалога Message Suppression в Compiler Monitoring UI (Tools|Message Suppression...). Параметр '-s' является необязательным и позволяет дописывать в переданный через '-u' suppress файл все новые сообщения текущей проверки.
Также возможно запустить CLMonitor.exe в режиме клиента для генерации препроцессированных файлов и непосредственного запуска анализатора в режиме межмодульного анализа:
CLMonitor.exe analyze -l "d:\ptest.plog" --intermodularФлаг ‑‑intermodular включает режим межмодульного анализа. В этом режиме анализатор выполняет более глубокий анализ кода, но тратит на это больше времени.
Для задания дополнительных параметров отображения и фильтрации сообщений вы можете передать путь до файла конфигурации диагностик (.pvsconfig) с помощью аргумента '-c':
CLMonitor.exe analyze -l "d:\ptest.plog" -c "d:\filter.pvsconfig"При необходимости завершить мониторинг без запуска анализа следует воспользоваться командой abortTrace:
CLMonitor.exe abortTraceСохранение дампа мониторинга компиляции и запуск анализа из дампа
CLMonitor.exe позволяет сохранять отловленную информацию о компиляции в отдельном дамп-файле. Это позволит в дальнейшем перезапустить анализ без необходимости повторно собирать проект и мониторить эту сборку. Для сохранения дампа мониторинга компиляции нужно сначала запустить мониторинг в обычном режиме командами trace или monitor, как было описано выше. После того как сборка завершена, можно завершить мониторинг и сохранить файл дампа. Для этого нужно запустить CLMonitor.exe с командой saveDump:
CLMonitor.exe saveDump -d d:\monitoring.zipТакже можно завершить мониторинг, сохранить файл дампа и запустить анализ отловленных файлов. Это можно сделать, дополнительно указав команде CLMonitor.exe analyze путь до места сохранения дампа:
CLMonitor.exe analyze -l "d:\ptest.plog" -d d:\monitoring.zipЗапустить анализ из уже готового dump файла можно без предварительного запуска мониторинга:
CLMonitor.exe analyzeFromDump -l "d:\ptest.plog"
-d d:\monitoring.zipФайл дампа представляет собой обычный zip архив, содержащий список отловленных у процессов параметров (параметры запуска, текущая директория, переменные окружения и т.п.) в формате XML. Команда analyzeFromDump поддерживает запуск как из заархивированного в zip дампа, так и из неупакованного XML файла. Если вы используете разархивированный xml файл, убедитесь, что у него расширение xml.
Анализ из дампа также поддерживает возможность запуска анализа в межмодульном режиме. Для этого, как и в режиме анализа, необходимо передать флаг ‑‑intermodular:
CLMonitor.exe analyzeFromDump -l "d:\ptest.plog"
-d d:\monitoring.zip --intermodularИспользование системы отслеживания компиляции из приложения C and C++ Compiler Monitoring UI
Для "ручной" проверки отдельных проектов через CLMonitor можно воспользоваться интерфейсом приложения Compiler Monitoring UI, который можно запустить из меню Start.
Для запуска отслеживания откройте диалог через Tools -> Analyze Your Files... (рисунок 1):

Рисунок 1 — Диалог запуска мониторинга сборки
Нажмите "Start Monitoring". После этого будет запущен CLMonitor.exe, а основное окно среды будет свёрнуто.
Выполните сборку, а по её завершении нажмите на кнопку "Stop Monitoring" в окне в правом нижнем углу экрана (рисунок 2):

Рисунок 2 — Диалог управления мониторингом
Если серверу мониторинга удалось отследить запуски компиляторов, будет запущен статический анализ исходных файлов. По окончании вы получите обычный отчёт о работе PVS-Studio (рисунок 3):
Рисунок 3 — Результаты работы сервера мониторинга и статического анализатора
Результаты работы могут быть сохранены в виде XML файла (файла с расширением plog) с помощью команды меню File -> Save PVS-Studio Log As...
Использование системы отслеживания компиляции из Visual Studio
Удобная навигация по сообщениям анализатора и навигации по коду среды доступна в среде разработки Visual Studio с помощью плагина PVS-Studio. Если проверяемый проект можно открывать в Visual Studio, но при этом "обычная" проверка (PVS-Studio|Check|Solution) не работает (например, это актуально для makefile проектов), можно использовать преимущества работы из IDE, загрузив полученные результаты анализа (plog файл) в PVS-Studio с помощью команды (PVS-Studio|Open/Save|Open Analysis Report...). Данное действие можно также автоматизировать с помощью средств автоматизации Visual Studio, привязав его, а также саму проверку, например, к сборке проекта. Приведём в качестве примера интеграцию анализа с помощью системы отслеживания вызовов компилятора PVS-Studio в makefile проект. Такой тип проектов, например, используется системой сборки Unreal Engine проектов на Windows.
В качестве команды запуска сборки впишем файл run.bat:
Рисунок 4 — настройка сборки makefile проекта.
Содержимое файла run.bat:
set slnPath=%1
set plogPath="%~2test.plog"
"%ProgramFiles(X86)%\PVS-Studio\CLMonitor.exe" monitor
waitfor aaa /t 10 2> NUL
nmake
"%ProgramFiles(X86)%\PVS-Studio\CLMonitor.exe" analyze -l %plogPath%
cscript LoadPlog.vbs %slnPath% %plogPath%В качестве параметров в run.bat мы передаём пути до solution'а и проекта. Мы запускаем отслеживание запусков компиляторов с помощью CLMonitor.exe. Команда waitfor нужна для создания задержки между запуском отслеживания компиляторов и запуском сборки. Без неё мониторинг может "не успеть" отловить первые запуски компиляторов. Далее мы запускаем сборку проекта через nmake. По завершении сборки мы запускаем анализ и, когда анализ завершится (результат анализа будет записан рядом с проектным файлом), мы загружаем результаты анализа в Visual Studio с помощью другого скрипта — LoadPlog.vbs. Вот его содержимое:
Set objArgs = Wscript.Arguments
Dim objSln
Set objSln = GetObject(objArgs(0))
Call objSln.DTE.ExecuteCommand("PVSStudio.OpenAnalysisReport",
objArgs(1))Здесь мы используем команду автоматизации Visual Studio DTE.ExecuteCommand для обращения из командной строки напрямую к запущенному экземпляру Visual Studio, в котором открыт наш проект. Фактически, выполнение данной команды эквивалентно клику по PVS-Studio|Open/Save|Open Analysis Report...
Для нахождения запущенного экземпляра Visual Studio мы использовали метод GetObject. Обратите внимание, что это метод идентифицирует запущенную Visual Studio по открытому в ней solution'у. При его использовании не следует держать открытыми несколько IDE с одинаковыми загруженными solution'ами. Он может "промахнуться", и результаты анализа откроются не в той IDE, в которой вы запускали сборку\анализ.
Особенности использования CLMonitor.exe вместе с Incredibuild
Использование Incredibuild позволяет снизить время анализа проекта в разы при распределении нагрузки по нескольким машинам. Однако утилита CLMonitor.exe не может отслеживать удалённые вызовы компилятора и поддерживает трассировку только для локальных сборок. Поэтому результат анализа мониторинга компилятора, запущенного Incredibuild-ом, может оказаться некорректным.
Вы можете запустить анализ через мониторинг компилятора с использованием распределённых сборок. Для этого необходимо получить дамп мониторинга локального компилятора при помощи CLMonitor.exe (получение дампа описано в предыдущих разделах) и запустить анализ дампа в распределённом режиме при помощи Incredibuild. Более подробная информация о настройке Incredibuild для данного режима имеется в соответствующем разделе документации: "Ускорение анализа C/C++ кода с помощью систем распределённой сборки (Incredibuild)".
Особенности мониторинга сборки проектов в среде IAR Embedded Workbench for ARM
При сборке проекта в среде IAR Embedded Workbench текущая рабочая директория процесса компилятора(iccarm.exe) в некоторых случаях может быть установлена средой в C:\Windows\System32. Такое поведение может вызывать проблемы, так как CLMonitoring сохраняет промежуточные файлы в текущей рабочей директории процесса компилятора.
Чтобы избежать записи промежуточных файлов в C:\Windows\System32, а также ошибок, связанных с недостаточными правами для записи в C:\Windows\System32, необходимо открывать рабочее пространство(workspace) двойным щелчком мыши на файле с расширением eww из проводника Windows. В этом случае промежуточные файлы будут сохранены в директории рабочего пространства.
Инкрементальный анализ
В случае необходимости инкрементального анализа при использовании системы мониторинга компиляции, достаточно "отслеживать" инкрементальную сборку, т.е. компиляцию тех файлов, которые были изменены с момента последней сборки. Этот сценарий использования позволит анализировать только изменённый/новый код.
Такой сценарий использования естественен для системы мониторинга компиляции. Соответственно, режим анализа (полный или анализ только модифицированных файлов) зависит только от того, какая сборка отслеживается: полная или инкрементальная.
Режим межмодульного анализа
Включение данного режима позволяет анализатору учитывать информацию не только из анализируемого файла, но и из связанных с ним файлов. Это позволяет производить более глубокий и качественный анализ. Однако на сбор необходимой информации требуется дополнительное время, что отразится на времени анализа вашего проекта.
Для запуска межмодульного анализа (режим 'analyze') или межмодульного анализа из дампа (режим 'analyzeFromDump') необходимо передать флаг ‑‑intermodular.
Задание отдельных файлов для проверки
Режимы 'analyze' и 'analyzeFromDump' позволяют провести выборочную проверку группы файлов. С помощью флага '‑‑sourceFiles' (-f) задается путь к текстовому файлу, в котором построчно указываются пути к проверяемым файлам. Относительные пути к файлам будут раскрыты в соответствии с текущей рабочей директорией. Можно указывать как исходные компилируемые файлы (.c, .cpp и т.д.), так и заголовочные файлы (.h/.hpp).
В режиме проверки списка файлов генерируется кэш зависимостей компиляции, который будет использован при последующих запусках анализа. По умолчанию кэш зависимостей сохраняются в специальной поддиректории '.pvs-studio' рабочей директории под названием 'CLMonitor.deps.json'. При необходимости можно указать другое место сохранения/загрузки при помощи флага '‑‑dependencyRoot' (-D).
По умолчанию, в кэше зависимостей сохраняются абсолютные пути к файлам исходного кода. Для того чтобы сделать переносимый кэш, можно указать произвольную корневую папку проекта (относительно которой будут сохраняться и загружаться пути) при помощи флага '‑‑dependencyCacheSourcesRoot' (-R).
Режим перехвата Wrap Compilers
Используемый по умолчанию метод отслеживания запусков компиляторов может не успеть определить все файлы исходного кода. Эта проблема особенно актуальна для Embedded проектов, поскольку они состоят из быстро компилирующихся файлов на языке C. Для того чтобы гарантировать перехват всех процессов компиляции, утилита мониторинга может использовать более агрессивный подход — через механизм Image File Execution Options (IFEO) в реестре Windows. Этот механизм позволяет запустить специальный обработчик перед непосредственным запуском каждого процесса компиляции. Затем обработчик передаст серверу мониторинга необходимую информацию и продолжит запуск компилятора. Работа этого режима прозрачна для сборочной системы и требует доступ к редактированию пути реестра "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options" (запуск утилиты от имени администратора или выдача утилите прав на запись в реестр).
Чтобы включить этот метод отслеживания в консольном варианте мониторинга нужно передать утилите CLMonitor.exe в режимах 'monitor' или 'trace' флаг '‑‑wrapCompilers (-W)' со списком компиляторов. Список компиляторов разделяется запятой, например:
CLMonitor.exe trace --wrapCompilers gcc.exe,g++.exeОбратите внимание, что нужно указывать имена исполняемых файлов компилятора с расширением .exe и без путей.
Для того чтобы включить данный режим перехвата при использовании графического интерфейса, заполните поле Wrap Compilers в окне запуска мониторинга.

Несмотря на преимущества использования механизма IFEO, необходимо соблюдать некоторые меры предосторожности.
Для того чтобы подключить обработчик перед запуском процессов, монитор модифицирует путь реестра "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options". В нём создаётся новый ключ с именем исполняемого файла процесса, с полем "Debugger". В этом поле указывается команда запуска обработчика, который будет запущен вместо процесса с указанным именем исполняемого файла. Ошибка в этом поле может сделать невозможным запуск некоторых процессов. PVS-Studio не позволяет использовать этот режим с произвольным набором исполняемых файлов, а только с теми, которые опознаются как известные компиляторы. После успешного завершения процесса мониторинга записи реестра будут возвращены в исходное состояние. Если процесс мониторинга будет завершен нештатно (в случае принудительного завершения, ошибки или выключения компьютера), реестр автоматически восстановлен не будет. Однако при модификации реестра утилита мониторинга создаст файл восстановления в "%AppData%\PVS-Studio\wrapperBackup.reg", при использовании которого модифицированные ключи реестра будут возвращены в исходное состояние. Если при очередном запуске монитора файл восстановления существует, он будет применен автоматически. Перед автоматическим восстановлением файл восстановления проходит проверку. Если этот файл содержит подозрительные записи, он не будет использован и будет переименован в "wrapperBackup-rejected.reg". В этом случае отклонённый файл восстановления должен быть проверен ответственным лицом. Возможно, это свидетельствует о неправильной настройке или наличии вредоносного ПО на компьютере.
Заключение
Несмотря на удобство используемой в данном режиме работы "бесшовной" интеграции анализа в автоматизированный сборочный процесс (через CLMonitor.exe), тем не менее, необходимо помнить и о естественных ограничениях, присущих данному режиму. А именно, о невозможности на 100% гарантировать перехват всех запусков компилятора при сборке. Это в свою очередь, может быть вызвано как влиянием внешнего окружения (например, антивирусами), так и особенностями аппаратно-программного окружения (например, компилятор может отработать слишком быстро при использовании SSD диска, а при этом производительности CPU может оказаться недостаточно для того, чтобы "успеть" отловить такой запуск).
Поэтому мы рекомендуем, по возможности, выполнить полноценную интеграцию статического анализатора PVS-Studio.exe в вашу сборочную систему (если вы используете сборочную систему, отличную от MSBuild), либо же воспользоваться IDE плагином PVS-Studio.
Прямая интеграция анализатора в системы автоматизации сборки (C и C++)
- Независимый режим работы анализатора PVS-Studio
- Использование режима независимого запуска анализатора на примере Makefile проекта
- Работа с результатами анализа, полученными при использовании режима запуска из командной строки
- Инкрементальный анализ в версии для командной строки
- Использование Microsoft IntelliSense в независимом режиме работы анализатора
- Разница в поведении консольной версии PVS-Studio.exe при обработке одного файла и при обработке нескольких файлов
Этот раздел документации описывает устаревший метод запуска анализа, который может быть удалён в будущих версиях.
Мы рекомендуем всем использовать PVS-Studio из сред разработки Microsoft Visual Studio, куда инструмент прекрасно интегрируется. Однако, бывают ситуации, когда необходим запуск из командной строки, например, для кроссплатформенных проектов, использующих сборочную систему, основанную на makefile'ах.
В случае, если у вас есть файлы проектов (.vcproj/.vcxproj) и решения (.sln), и запуск из командной строки нужен, к примеру, для ежедневных проверок, то рекомендуем ознакомиться со статьей "Проверка Visual C++ (.vcxproj) и Visual C# (.csproj) проектов из командной строки с помощью PVS-Studio".
Также, независимо от сборочной системы, вы можете воспользоваться системой отслеживания вызовов компилятора.
Независимый режим работы анализатора PVS-Studio
Итак, как работает С++ анализатор кода (PVS-Studio или любой другой)?
Когда пользователь анализатора дает команду проверить какой-либо файл (например, file.cpp), то анализатор сначала выполняет препроцессирование этого файла. В результате раскрываются все макросы, подставляются #include-файлы. Препроцессированный i-файл уже может разбирать анализатор кода. Обратите внимание, что анализатор не может разбирать файл, который не был препроцессирован. Поскольку тогда он не будет иметь информации об используемых типах, функциях, классах. Работа любого анализатора кода состоит как минимум из двух этапов: препроцессирование и собственно анализ.
Возможна ситуация, в которой программы не имеют связанных с ними проектных файлов, например, в случае мультиплатформенного ПО или старых проектов, собираемых с помощью пакетных утилит командной строки. Зачастую в таких случаях для управления сборочным процессом используют различные Make системы, например, Microsoft NMake, GNU Make и т.п.
Для проверки подобных проектов потребуется встроить в сборочный процесс прямой вызов анализатора (по умолчанию, файл расположен в %programfiles%\PVS-Studio\x64\PVS-Studio.exe) и передать ему все необходимые для препроцессирования аргументы. Фактически анализатор необходимо вызывать для тех же файлов, для которых вызывается компилятор (cl.exe в случае Visual C++).
Анализатор PVS-Studio должен быть вызван в пакетном режиме для каждого C/C++ файла проекта либо для целой группы файлов (файлы с расширением c/cpp/cxx и т.п., анализатор не нужно вызывать для заголовочных h файлов) с аргументами следующего вида:
PVS-Studio.exe --cl-params %ClArgs% --source-file %cppFile%
--lic-file %licPath% --cfg %cfgPath% --output-file %ExtFilePath%%ClArgs% — все аргументы, передаваемые используемому компилятору при обычной компиляции, в том числе и путь до файла (или файлов) с исходным кодом.
%cppFile% — путь до анализируемого C/C++ файла или пути до группы C/C++ файлов (имена файлов, разделённые пробелами)
Параметры %ClArgs% и %cppFile% должны быть переданы анализатору PVS-Studio аналогично тому, как они передаются компилятору Visual C++ , т.е. полный путь до файла должен быть передан дважды, в каждом параметре.
%licPath% — путь до файла с лицензией PVS-Studio.
%cfgPath% — путь до конфигурационного файла PVS-Studio.cfg. Этот файл общий для всех C/C++ файлов, который может быть создан вручную (пример будет показан ниже).
%ExtFilePath% — необязательный параметр, путь до внешнего файла, в который будут сохранены результаты работы анализатора. Если данный параметр не указан, анализатор будет выдавать сообщения о найденных ошибках в stdout. Полученные здесь результаты анализа можно открыть в окне PVS-Studio среды Visual Studio с помощью команды PVS-Studio/Open Analysis Report (выбрав в качестве типа файла Unparsed output). Обратите внимание на то, что, начиная с версии PVS-Studio 4.52, анализатор при запуске из командной строки поддерживает работу с одним выходным файлом (‑‑output-file) из нескольких процессов PVS-Studio.exe. Это сделано для того, чтобы, как и в обычных makefile, при компиляции можно было запускать несколько процессов анализатора. При этом выходной файл не будет перезаписан и потерян, так как используется механизм блокировок файла.
Приведём пример вызова анализатора в независимом режиме для отдельного файла с препроцессором Visual C++ (cl.exe):
PVS-Studio.exe --cl-params "C:\Test\test.cpp" /D"WIN32" /I"C:\Test\"
--source-file "C:\Test\test.cpp" --cfg "C:\Test\PVS-Studio.cfg"
--output-file "C:\Test\test.log" --lic-file ...Конфигурационный файл PVS-Studio.cfg (параметр ‑‑cfg) должен содержать следующие строки:
exclude-path = C:\Program Files (x86)\Microsoft Visual Studio 10.0
vcinstalldir = C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\
platform = Win32
preprocessor = visualcpp
language = C++
skip-cl-exe = noРассмотрим эти параметры:
- Параметр exclude-path содержит папку, файлы из которой проверять не надо. Если не указать папку, в которой содержатся файлы Visual Studio, то анализатор выдаст сообщения на заголовочные .h-файлы, что довольно бессмысленно. Ведь поправить эти ошибки нельзя. Поэтому мы рекомендуем всегда добавлять этот путь в исключения. Параметров exclude-path может быть несколько.
- Параметр vcinstalldir задает папку, в которой находится используемый препроцессор. Поддерживаются препроцессоры: Microsoft Visual C++ (cl.exe), Clang(clang.exe) и MinGW (gcc.exe).
- Параметр platform показывает, какую версию компилятора использовать - Win32, x64, Itanium или ARMV4. Обычно это Win32 или x64.
- Параметр preprocessor показывает, какой препроцессор должен находиться в vcinstalldir. Поддерживаемые значения: visualcpp, clang, gcc. В общем случае следует выбирать препроцессор в соответствии с используемым в сборочной системе компилятором.
- Параметр language определяет версию языков C/C++ в коде проверяемого файла (‑‑source-file), которую анализатор ожидает найти при его разборе. Возможные значения: C, C++, C++CX, C++CLI. Поскольку каждый из поддерживаемых языковых вариантов содержит специфичные ключевые слова, неправильное указание данного параметра может привести к ошибкам разбора вида V001.
Вы можете фильтровать диагностические сообщения анализатора с помощью опций analyzer-errors и analysis-mode (заданных или в cfg-файле, или в командной строке). Это необязательные параметры:
- Параметр analyzer-errors позволяет перечислить только те коды ошибок, которые интересны. Пример: analyzer-errors=V112 V111. Рекомендуем не указывать этот параметр.
- Параметр analysis-mode позволяет управлять используемыми анализаторами. Значения: 0 - полный анализ (по умолчанию), 1 - только 64-битный анализ, 4 - только анализ общего назначения, 8 - только анализ оптимизации". Рекомендуем указывать значение 4.
Также существует возможность подать на вход анализатору готовый препроцессированный файл (i-файл), пропустив этап препроцессирования и сразу приступив к анализу. Для этого необходимо использовать параметр skip-cl-exe, указав значение yes. В этом режиме не требуется использование параметра cl-params. Вместо этого необходимо указать путь к i-файлу (‑‑i-file) и задать тип препроцессора, использованного для создания этого i-файла. Указание пути к файлу исходного кода (‑‑source-file) также необходимо. Несмотря на то, что i-файл уже содержит достаточную информацию для анализа, иногда может потребоваться сравнение i-файла с файлом исходного кода, например, когда анализатору требуется посмотреть на нераскрытый макрос. Таким образом, вызов анализатора в независимом режиме с заданным i-файлом для препроцессора Visual C++ (cl.exe) мог бы иметь вид:
PVS-Studio.exe --source-file "C:\Test\test.cpp"
--cfg "C:\Test\PVS-Studio.cfg" --output-file "C:\Test\test.log"Конфигурационный файл PVS-Studio.cfg (параметр ‑‑cfg) должен содержать следующие строки:
exclude-path = C:\Program Files (x86)\Microsoft Visual Studio 10.0
vcinstalldir = C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\
platform = Win32
preprocessor = visualcpp
language = C++
skip-cl-exe = yes
i-file = C:\Test\test.iПолный список параметров командной строки можно получить с помощью запуска:
PVS-Studio.exe –helpСледует отметить, что при явном вызове PVS-Studio.exe, лицензионная информация, сохранённая в файле 'Settings.xml', не учитывается. При запуске следует явно указывать путь до файла с лицензией. Это текстовый файл в кодировке UTF-8, состоящий из двух строк – имени и ключа.
Путь до файла с лицензией можно указать как в конфигурационном файле PVS-Studio, так и передать как аргумент командной строки. Соответствующий параметр: lic-file.
Например, чтобы указать путь до файла с лицензией в .cfg файле, следует добавить следующую строку:
lic-file = D:\Test\license.licИспользование режима независимого запуска анализатора на примере Makefile проекта
Возьмём для примера Makefile проект, в котором сборка осуществляется компилятором Visual C++, и она описана в makefile проекта следующим правилом:
$(CC) $(CFLAGS) $<
Здесь $(CC) вызывает cl.exe, которому передаются параметры компиляции $(CFLAGS), и наконец с помощью макроса $< осуществляется подстановка всех С\С++ файлов, от которых зависит текущая цель сборки. Таким образом, для всех файлов с исходным кодом будет вызван компилятор cl.exe с необходимыми параметрами.
Модифицируем данный сценарий таким образом, чтобы перед вызовом компилятора для каждого файла осуществлялась проверка статическим анализатором PVS-Studio:
$(PVS) --source-file $< --cl-params $(CFLAGS) $<
--cfg "C:\CPP\PVS-Studio.cfg"
$(CC) $(CFLAGS) $<Здесь $(PVS) - путь до исполняемого файла анализатора (%programfiles%\PVS-Studio\x64\PVS-Studio.exe). Обратите внимание, что после вызова анализатора на следующей строке вызывается компилятор Visual C++ с теми же параметрами, что и изначально. Это делается для того, чтобы были построены правильные цели (targets) и сборка не остановился из-за отсутствия .obj-файлов.
Работа с результатами анализа, полученными при использовании режима запуска из командной строки
Инструмент PVS-Studio разрабатывался для работы в рамках сред Visual Studio. И его работа из командной строки - это дополнение к основному режиму работы. Тем не менее, все его диагностические возможности доступны.
Полученные в данном режиме ошибки могут быть также перенаправлены в файл с помощью аргумента командной строки ‑‑output-file. Данный файл будет содержать необработанный и неотфильтрованный вывод анализатора.
Такой файл можно открыть в IDE окне PVS-Studio или приложении C and C++ Compiler Monitoring UI (Standalone.exe) командой Open Analysis Report (выбрав в качестве типа файла 'Unparsed output') и в дальнейшем его можно будет сохранить в стандартном формате отчета PVS-Studio log file (plog), что позволит избежать дублирования сообщений, а также использовать все стандартные механизмы фильтрации сообщений.
Также 'сырой' отчёт можно преобразовать в один из поддерживаемых форматов (xml, html, csv и т.п.) с помощью консольной утилиты PlogConverter.
Инкрементальный анализ в версии для командной строки
Пользователи, знакомые с режимом инкрементального анализа в PVS-Studio, при работе из IDE естественно не хотят от него отказываться и в версии для командной строки. К счастью, любая система сборки автоматически позволяет получить инкрементальный анализ "из коробки". Ведь говоря "make" мы компилируем только изменившиеся файлы. Соответственно и PVS-Studio.exe будет вызван только для изменившихся файлов. Так что инкрементальный анализ в версии для командной строки есть автоматически.
Использование Microsoft IntelliSense в независимом режиме работы анализатора
Несмотря на то, что полученный в независимом режиме неотфильтрованный текстовый файл с диагностическими сообщениями анализатора возможно открыть в окне PVS-Studio среды разработки (что в свою очередь позволит использовать навигацию по файлам и механизмы фильтрации), в самой среде Visual Studio будет работать фактически только текстовый редактор, а дополнительная функциональность системы IntelliSense (автодополнение, переход к местам декларации типов и телам функций, и т.п.) будет недоступна. А это, в свою очередь, создаёт очень большие неудобства при работе с результатами анализа, особенно для крупных проектов, вынуждая каждый раз вручную искать объявления классов и функций и значительно увеличивая время работы над каждым диагностическим сообщением.
Решить рассматриваемую проблему можно, создав пустой проект Visual C++ (например, Makefile проект) в одной директории с проверяемыми анализатором исходными C++ файлами (vcproj/vcxproj файл при этом должен находиться в папке, являющейся корневой для всех проверяемых исходных файлов). После этого можно включить режим Show All Files проекта (кнопка Show All Files в окне Solution Explorer), что позволит увидеть в древовидной структуре окна Solution Explorer все файлы, располагающиеся в нижележащих директориях файловой системы. Затем через контекстную команду Include in Project можно добавить в проект все необходимые cpp, с и h файлы (возможно, что для некоторых файлов также придётся прописать пути до include директорий, если в них, например, присутствуют включения из сторонних библиотек). Стоит помнить, что при включении в проект лишь части от всех проверяемых файлов, IntelliSense может не распознать часть из упоминаемых в них типов, если эти типы определяются как раз в отсутствующих файлах.

Рисунок 1 — добавление файлов в проект
Созданный таким образом проектный файл Visual C++ не может быть использован для сборки или анализа исходного кода с помощью PVS-Studio, но всё же позволит значительно упростить работу с результатами анализа, и может быть сохранён для дальнейшего использования на следующих итерациях работы анализатора в независимом режиме.
Разница в поведении консольной версии PVS-Studio.exe при обработке одного файла и при обработке нескольких файлов
Как известно, компилятор cl.exe может обрабатывать файлы как по одному, так и группой. В первом случае вызов компилятора происходит в несколько запусков:
cl.exe ... file1.cpp
cl.exe ... file2.cpp
cl.exe ... file2.cppВо втором случае - за один запуск:
cl.exe ... file1.cpp file2.cpp file3.cppИ тот, и другой режим работы поддерживается в консольной версии PVS-Sudio.exe, примеры приведены выше.
Пользователю может оказаться полезно понимать логику работы программы в первом и втором случае. При раздельном запуске PVS-Studio.exe для каждого файла сначала вызывает препроцессор, а затем выполняется анализ. При обработке нескольких файлов за раз PVS-Studio.exe сначала выполняет препроцессирование всех файлов, а затем для каждого файла еще раз запускается PVS-Studio.exe для анализа уже препроцессированных файлов.
Проверка Unreal Engine проектов
- Проверка с помощью отслеживания вызовов компилятора
- Запуск анализа Unreal Engine проекта под Linux
- Проблемы с запуском анализатора PVS-Studio на Unreal Engine версии 5.0.0, 5.0.1 и 5.0.2
- Что делать, если UnrealBuildTool не может найти .pvslog файл
- Проверка с помощью интеграции в UnrealBuildTool
- Интеграция PVS-Studio через флаг UnrealBuildTool
- Интеграция PVS-Studio через файл target файл
- Интеграция PVS-Studio через Build Configuration файл
- Инкрементальный анализ
- Использование анализатора совместно со сборкой проекта (актуально с версии Unreal Engine 4.22 и выше)
- Вычисление пути до файла кэша действий UnrealBuildTool при модификации сборочных скриптов
- Проверка исходного кода Unreal Engine
- Включение различных групп диагностик и других дополнительных настроек
- Оптимизация производительности анализа Unreal Engine проектов
- Автоматический запуск анализа
- Запуск анализа в Rider
- Работа с результатами анализа
- Исключение файлов из анализа при помощи PathMasks
- Подавление предупреждений анализатора в Unreal Engine проектах
- Интеграция с SN-DBS
- Проблемы с анализом
Проверка Unreal Engine проектов доступна только для Enterprise лицензии PVS-Studio. Вы можете запросить пробную Enterprise лицензию здесь.
Для сборки проектов для Unreal Engine под Windows используется специализированная сборочная система Unreal Build System. Данная система интегрируется поверх сборочной системы, используемой средой Visual Studio \ JetBrains Rider (MSBuild), с помощью автогенерируемых makefile проектов MSBuild. Это специальный тип Visual C++ (vcxproj) проектов, в которых для непосредственного выполнения сборки выполняется команда, вызывающая стороннюю утилиту, например, (но далеко не обязательно) Make. Использование makefile проектов позволяет работать с кодом Unreal Engine из среды Visual Studio \ JetBrains Rider, используя такие преимущества, как автодополнение, подсветка синтаксиса, навигация по символам и т.п.
В связи с тем, что makefile проекты MSBuild сами по себе не содержат полной информации, необходимой для компиляции, а, следовательно, и препроцессирования исходных C/C++ файлов, PVS-Studio не поддерживает проверку таких проектов с помощью Visual Studio плагина или консольной утилиты PVS-Studio_Cmd.exe. Поэтому, для проверки таких проектов с помощью PVS-Studio можно пойти двумя путями - отслеживание вызовов компилятора (Compiler Monitoring) и прямая интеграция C/C++ анализатора PVS-Studio.exe в сборочную утилиту UnrealBuildTool. Рассмотрим эти варианты подробнее.
Проверка с помощью отслеживания вызовов компилятора
Для сборки на Windows Unreal Build System использует компилятор Visual C++ - cl.exe. Этот компилятор поддерживается системой отслеживания компиляторов PVS-Studio на Windows. Эту систему можно использовать как из приложения C and C++ Compiler Monitoring UI, так и с помощью консольной утилиты CLMonitor.exe.
Запуск мониторинга компиляций можно осуществлять вручную из приложения Compiler Monitoring UI, или назначить на событие начала\окончания сборки в Visual Studio. Результатом работы системы мониторинга является XML файл отчёта plog, который можно открыть в Visual Studio плагине PVS-Studio, или преобразовать к одному из стандартных форматов (txt, html, csv) с помощью специальной утилиты PlogConverter.
Подробное описание системы отслеживания вызовов компилятора доступно в данном разделе документации. Мы рекомендуем использовать данный способ запуска анализа для знакомства с анализатором, как наиболее простой в настройке.
Запуск анализа Unreal Engine проекта под Linux
Для того чтобы проанализировать проект, необходимо предварительно провести трассировку его полной сборки. Сборка проекта под Linux выполняется при помощи скрипта AutomationTool.
pvs-studio-analyzer trace -- \
<UnrealEngine source location>/UnrealEngine/Engine/
Build/BatchFiles/RunUAT.sh \
BuildCookRun -project="<Project path>/<Project name>.uproject" \
-build -Clean -targetplatform=Linux ....
pvs-studio-analyzer analyze ....Подробная документация к утилите pvs-studio-analyzer находится на странице "Кроссплатформенная проверка C и C++ проектов в PVS-Studio".
Инструкции для работы с полученным после анализа отчётом находятся на странице "Просмотр и конвертация результатов анализа".
Проблемы с запуском анализатора PVS-Studio на Unreal Engine версии 5.0.0, 5.0.1 и 5.0.2
В Unreal Engine версии от 5.0.0, 5.0.1 и 5.0.2 имеется баг, из-за которого Unreal Engine Build Tool не находит ядро анализатора по пути по умолчанию: %ProgramFiles(x86)%\PVS-Studio\x64\PVS-Studio.exe:

На данный момент существует временное решение данной проблемы - необходимо скопировать файл PVS-Studio.exe расположенный в папке "%ProgramFiles(x86)%\PVS-Studio\x64" в папку "...\UE_5.0\Engine\Restricted\NoRedist\Extras\ThirdPartyNotUE\PVS-Studio".
Важно. Этот баг исправлен в релизной версии Unreal Engine 5.0.3.
В данном разделе рассматривается проверка Unreal Engine проектов на операционной системе Windows.
Что делать, если UnrealBuildTool не может найти .pvslog файл
UnrealBuildTool является драйвером анализа. Он запускает анализ отдельных файлов, сохраняет отдельные отчёты, после чего на финальной стадии собирает отдельные отчёты в финальный отчёт анализатора PVS-Studio.
Для того, чтобы анализатор мог проверить файл, UnrealBuildTool предварительно препроцессирует его для того, чтобы передать анализатору .i файл. В некоторых случаях, UnrealBuildTool может не справиться с данным шагом, и тогда анализатор, в свою очередь, не сможет проверить файл и создать выходной отчёт для этого файла. После этого, UnrealBuildTool не сможет использовать этот отчёт для сборки единого отчёта PVS-Studio.
При этом, в консольном выводе UnrealBuildTool можно будет увидеть информацию о поднятом исключении следующего вида:
Unhandled exception: System.IO.FileNotFoundException:
Could not find file <FILE>.i.pvslog'.В случае получения подобной ошибки проверьте флаги компилятора, используемые при компиляции и при анализе – они должны быть идентичны. Если вы уверены, что флаги идентичны, но компиляций проходит, а анализ – нет, то обязательно напишите нам в поддержку.
Проверка с помощью интеграции в UnrealBuildTool
В случае с Unreal Build System, разработчики из Epic Games предоставляют возможность использовать PVS-Studio с помощью интеграции со сборочной утилитой UnrealBuildTool, начиная с версии Unreal Engine 4.17.
Перед началом анализа вам будет необходимо ввести лицензию на анализатор. Для этого нужно ввести ваши данные в IDE:
- 'PVS-Studio|Options...|Registration' в Visual Studio;
- 'Toos|PVS-Studio|Settings...|Registaration' в JetBrains Rider.
Обратите внимание, что до версии Unreal Engine 4.20, UBT не умел подхватывать лицензию из общего файла настроек PVS-Studio. В случае, если UBT не видит лицензию, введённую через интерфейс, вам необходимо создать отдельный файл лицензии с именем PVS-Studio.lic вручную и подложить его в директорию '%USERPROFILE%\AppData\Roaming\PVS-Studio'.
Примечание 1. При интеграции PVS-Studio со сборочной утилитой UnrealBuildTool сборки проекта не происходит. Это связано с тем, что UnrealBuildTool заменяет процесс сборки на процесс анализа.
Интеграция PVS-Studio через флаг UnrealBuildTool
UnrealBuildTool позволяет запускать анализ PVS-Studio, добавив данный флаг в строку запуска:
-StaticAnalyzer=PVSStudioНапример, полная строка запуска UnrealBuildTool может выглядеть так:
UnrealBuildTool.exe UE4Client Win32 Debug -WaitMutex -FromMsBuild
-StaticAnalyzer=PVSStudio -DEPLOYДля включения анализа при запуске из IDE, откройте свойства проекта для выбранной конфигурации:
- 'Properties|Configuration Properties|NMake' в Visual Studio;
- 'Properties|NMake' в JetBrains Rider;
и добавьте флаг -StaticAnalyzer=PVSStudio в опции сборки и пересборки (Build Command Line / Rebuild All Command Line).
Примечание 1. Обратите внимание, что при таком сценарии использования сборка проекта выполняться не будет. Вместо этого будет выполнено препроцессирование всех (команда Rebuild) или изменившихся (команда Build) файлов проекта, а после запущен его анализ.
Примечание 2. Интеграция PVS-Studio с UnrealBuildTool поддерживает не все настройки анализатора, доступные из Visual Studio (PVS-Studio|Options...). В данный момент поддерживается выбор групп диагностик для анализа, добавление директорий-исключений через 'PVS-Studio|Options...|Don't Check Files' и фильтрация загруженных результатов анализа через 'Detectable Errors'.
Примечание 3. При открытии файла проекта uproject напрямую (не sln файла) данный способ не поддерживается. Используйте способы, описанные ниже.
Примечание 4. При использовании Unreal Engine версии 5.3 может возникнуть падение анализа из-за невозможности найти generated.h файлы самого Unreal Engine. Проблема связана с тем, как UE 5.3 запускает анализ. При запуске анализа с помощью флага, Unreal Build Tool создаёт в папке для промежуточных файлов ещё одну папку 'UnrealEditorSA'. Эта папка определяется как та, в которой нужно искать заголовочные файлы. Проектные файлы попадают в эту папку, а самого UE - нет. При этом, заголовочные файлы движка могут использоваться в проекте. Данная проблема была исправлена в Unreal Engine 5.4. Для решения проблемы, продолжая использовать в Unreal Engine 5.3, используйте интеграция через target-файл.
Интеграция PVS-Studio через файл target файл
Вы можете интегрировать PVS-Studio в процесс сборки, модифицировав target-файл. Такой сценарий будет удобен при частой перегенерации проектных файлов.
Для интеграции вам необходимо добавить параметр 'StaticAnalyzer' со значением ' PVSStudio':
Для версии 5.0 и ниже:
public MyProjectTarget(TargetInfo Target) : base(Target)
{
...
WindowsPlatform.StaticAnalyzer = WindowsStaticAnalyzer.PVSStudio;
...
}Для версии 5.1 и выше:
public MyProjectTarget(TargetInfo Target) : base(Target)
{
...
StaticAnalyzer = StaticAnalyzer.PVSStudio;
...
}Теперь UnrealBuildTool будет автоматически запускать анализ вашего проекта.
Интеграция PVS-Studio через Build Configuration файл
Вы можете интегрировать PVS-Studio в процесс сборки, модифицировав BuildConfiguration.xml файл.
Данный файл может быть найден по следующим путям:
- Engine/Saved/UnrealBuildTool/BuildConfiguration.xml
- User Folder/AppData/Roaming/Unreal Engine/UnrealBuildTool/BuildConfiguration.xml
- My Documents/Unreal Engine/UnrealBuildTool/BuildConfiguration.xml
Ниже приводим минимальный рабочий пример такого файла:
<?xml version="1.0" encoding="utf-8" ?>
<Configuration xmlns="https://www.unrealengine.com/BuildConfiguration">
<BuildConfiguration>
<StaticAnalyzer>
PVSStudio
</StaticAnalyzer>
</BuildConfiguration>
</Configuration>Примечание 1. Пример выше будет отличаться в версии Unreal Engine ниже 5.1. Приводим ссылку на документацию и минимальный пример для этих версий:
<?xml version="1.0" encoding="utf-8" ?>
<Configuration xmlns="https://www.unrealengine.com/BuildConfiguration">
<WindowsPlatform>
<StaticAnalyzer>
PVSStudio
</StaticAnalyzer>
</WindowsPlatform>
</Configuration>Инкрементальный анализ
Анализ всего проекта может занять много времени. Инкрементный анализ помогает ускорить анализ, проверяя только те файлы, которые были изменены с момента последней сборки. Инкрементальный анализ запускается только, если ранее была произведена полная сборка проекта. Чтобы запустить инкрементный анализ, вам необходимо выполнить сборку Unreal Engine проекта (Build).
Например, если в проекте имеются файлы A.cpp, B.cpp и C.cpp, то в таком случае при первой "сборке" (анализе) проекта в Unreal Engine до версии 4.25 будут проанализированы все файлы. При следующей "сборке" (анализе) проекта, если не было изменено ни одного файла, то ни один файл и не будет проанализирован. Однако, если файлы A.cpp и B.cpp измененить, то проанализированы будут только эти два файла.
Важно. В версии UE 4.25 или новее вместо анализа измененных файлов, при "сборке" (анализе) проекта будут проанализированы все файлы из тех Unreal Engine модулей, в которые включены измененные файлы. Например, если имеется собранный ранее проект с двумя модулями "A_Module" и "B_Module", и в модуль "A_Module" включены файлы A1.cpp и A2.cpp, а в модуль "B_Module"файлы B1.cpp и B2.cpp, то при изменении файла B2.cpp и "сборке" (анализе) проекта будут проанализированы файлы B1.cpp и B2.cpp из модуля "B_Module". Это изменение ухудшило инкрементальный анализ тем, что теперь анализируются все файлы из модуля, если в нём был изменён хотя бы один файл. Однако, даже такой инкрементальный анализ позволяет ускорить время анализа проекта, если проект поделен на модули.
Использование анализатора совместно со сборкой проекта (актуально с версии Unreal Engine 4.22 и выше)
Если вам требуется настроить одновременную сборку проекта и его анализ в рамках одной конфигурации Visual Studio, для этого можно создать вспомогательные скрипты (в нашем примере назовём их, соответственно, BuildAndAnalyze и RebuildAndAnalyze) на основе стандартных скриптов Build и Rebuild. Основное изменение в скрипте RebuildAndAnalyze - вызов для сборки нового скрипта BuildAndAnalyze.bat, а не Build.bat.
В скрипт BuildAndAnalyze необходимо добавить удаление кэша действий и запуск UnrealBuildTool с флагом анализа после проведения успешной сборки.
В кэш сохраняются действия, выполняемые UBT в ходе работы (сборки, анализ и т.п.).
Восстановление кэша из бэкапа после анализа необходимо для того, чтобы вновь получить сохранённые действия сборки. Если UBT не обнаружит сохранённых действий сборки - она будет выполнена заново.
Удаление/восстановление кэша необходимо для того, чтобы не сохранять действия анализа, но при этом и не потерять действия по сборке проекта. Не сохранять действия анализа в кэш необходимо, потому что, если анализ будет проведен обновленной версией анализатора, в которой добавлены новые диагностические правила, то не модифицированные файлы проверены не будут. Удаление/восстановление кэша позволяет избежать подобной ситуации. Благодаря этому даже неизменные файлы будут проверены новыми диагностиками, В результате, эти диагностики могут обнаружить потенциальные ошибки или уязвимости, которые ранее не были обнаружены.
Примечание 1. Изменения, описанные ниже, основываются на стандартном скрипте Build и стандартной строке запуска скрипта. В случае, если используется модифицированный скрипт или нестандартный порядок аргументов, может потребоваться внесение дополнительных изменений.
Первоначально необходимо определить ряд переменных, которые будут необходимы для удаления/восстановления файла кэша действий.
Примечание 2. Файлы кэша действий в разных версиях движка Unreal Engine могут отличаться как расширением, так и расположением. Примите это во внимание при формировании скриптов.
SET PROJECT_NAME=%1%
SET PLATFORM=%2%
SET CONFIGURATION=%3%
SET UPROJECT_FILE=%~5
for %%i in ("%UPROJECT_FILE%") do SET "PROJECT_PATH=%%~dpi"
SET PREFIX=%PROJECT_PATH%Intermediate\Build\%PLATFORM%
SET ACTIONHISTORY_PATH=....
SET ACTIONHISTORY_BAC_PATH= "%ACTIONHISTORY_PATH:"=%.bac"Для разных версий движка во фрагменте скрипта, приведённом выше, необходимо задать соответствующее значение ACTIONHISTORY_PATH.
Вычисление пути до файла кэша действий UnrealBuildTool при модификации сборочных скриптов
Для версии 4.21 и 4.22
SET ACTIONHISTORY_PATH="%PREFIX%\%PROJECT_NAME%\ActionHistory.bin"Для версии 4.23 и 4.24
SET ACTIONHISTORY_PATH="%PREFIX%\%PLATFORM%\%PROJECT_NAME%\ActionHistory.dat"Для версии 4.25
SET ACTIONHISTORY_PATH="%PREFIX%\%PROJECT_NAME%\ActionHistory.dat"Для версии 4.26 и 4.27
REM Если у вас есть конфигурации сборки для Client/Server,
REM то вам необходимо учесть их при определении переменной UE_FOLDER.
echo %PROJECT_NAME% | findstr /c:"Editor">nul ^
&& (SET UE_FOLDER=UE4Editor) || (SET UE_FOLDER=UE4)
SET ACTIONHISTORY_PATH="%PREFIX%\%UE_FOLDER%\%CONFIGURATION%\ActionHistory.bin"Для версии 5.0 и выше
REM Если у вас есть конфигурации сборки для Client/Server,
REM то вам необходимо учесть их при определении переменной UE_FOLDER.
echo %PROJECT_NAME% | findstr /c:"Editor">nul ^
&& (SET UE_FOLDER=UnrealEditor) || (SET UE_FOLDER=UnrealGame)
SET ACTIONHISTORY_PATH="%PREFIX%\%UE_FOLDER%\%CONFIGURATION%\ActionHistory.bin"После вызова UnrealBuildTool для сборки (и команды 'popd') необходимо добавить следующий код:
SET "UBT_ERR_LEVEL=!ERRORLEVEL!"
SET "NEED_TO_PERFORM_ANALYSIS="
IF "!UBT_ERR_LEVEL!"=="0" (
SET "NEED_TO_PERFORM_ANALYSIS=TRUE"
)
IF "!UBT_ERR_LEVEL!"=="2" (
SET "NEED_TO_PERFORM_ANALYSIS=TRUE"
)
IF DEFINED NEED_TO_PERFORM_ANALYSIS (
pushd "%~dp0\..\..\Source"
ECHO Running static analysis
IF EXIST %ACTIONHISTORY_PATH% (
ECHO Backup %ACTIONHISTORY_PATH%
COPY %ACTIONHISTORY_PATH% %ACTIONHISTORY_BAC_PATH%
ECHO Removing %ACTIONHISTORY_PATH%
DEL %ACTIONHISTORY_PATH%
)
..\..\Engine\Binaries\DotNET\UnrealBuildTool.exe
%* -StaticAnalyzer=PVSStudio -DEPLOY
popd
IF EXIST %ACTIONHISTORY_BAC_PATH% (
ECHO Recovering %ACTIONHISTORY_PATH%
COPY %ACTIONHISTORY_BAC_PATH% %ACTIONHISTORY_PATH%
ECHO Removing %ACTIONHISTORY_BAC_PATH%
DEL %ACTIONHISTORY_BAC_PATH%
)
)Наиболее важными операциями из приведённого выше кода являются удаление и восстановление кэша, а также запуск UnrealBuildTool с флагом -StaticAnalyzer=PVSStudio для проведения анализа.
При необходимости можно использовать модифицированный скрипт при работе из IDE. Для этого необходимо указать его в качестве используемого в свойствах проекта:
- 'Properties|Configuration Properties|NMake|Build Command Line' в Visual Studio;
- 'Properties |NMake|Build Command Line' в JetBrains Rider.
Примечание. Обратите внимание, что при использовании модифицированных скриптов флаг -StaticAnalyzer=PVSStudio в аргументах запуска скрипта указывать не нужно, так как он уже выставляется в скрипте при запуске UnrealBuildTool для анализа.
Проверка исходного кода Unreal Engine
Проверка самого Unreal Engine не отличается от проверки другого UE проекта.
В обоих случаях будут проанализированы все файлы, переданные на сборку. Если при сборке проекта должны собираться модули самого Unreal Engine, то они тоже будут проверены.
Для анализа отдельного решения Unreal Engine добавьте код, представленный в пункте интеграции через target файл в UnrealEditor.Target.cs (располагается в директории UnrealEngine/Engine/Source):
После этого запустите сборку с таргетом Editor (например, Development Editor).
Вы также можете воспользоваться вторым способом запуска анализа: откройте свойства проекта UE*, выберите в пункте NMake поле Build Command Line и добавьте в команду флаг
-StaticAnalyzer=PVSStudioПосле этого запустите сборку Unreal Engine.
Включение различных групп диагностик и других дополнительных настроек
Через модификацию target файлов
Включение различных групп диагностик анализатора доступно начиная с версии Unreal Engine 4.25.
Для выбора нужных групп диагностик необходимо модифицировать target-файлы проекта.
Например, включить диагностики микро-оптимизаций можно следующим образом:
public MyUEProjectTarget( TargetInfo Target) : base(Target)
{
....
WindowsPlatform.PVS.ModeFlags =
UnrealBuildTool.PVSAnalysisModeFlags.Optimizations;
}Допустимые значения для включения соответствующих групп диагностик:
- Check64BitPortability;
- GeneralAnalysis;
- Optimizations;
- CustomerSpecific;
- MISRA.
Для включения нескольких групп диагностик используйте оператор '|':
WindowsPlatform.PVS.ModeFlags =
UnrealBuildTool.PVSAnalysisModeFlags.GeneralAnalysis
| UnrealBuildTool.PVSAnalysisModeFlags.Optimizations;C версии Unreal Engine 5.1 стали доступны ещё несколько настроек, которые можно задать в target-файлах:
- AnalysisTimeoutFlag;
- EnableNoNoise;
- EnableReportDisabledRules.
WindowsPlatform.PVS.AnalysisTimeoutFlag — задаёт таймаут для анализа одного файла. Этому свойству возможно присвоить одно из значений перечисления AnalysisTimeoutFlags:
- After_10_minutes (10 минут на файл);
- After_30_minutes (30 минут на файл);
- After_60_minutes (60 минут на файл);
- No_timeout (нет ограничения по времени на анализ одного файла).
WindowsPlatform.PVS.EnableNoNoise — отключает выдачу всех предупреждений 3-его уровня (Low).
WindowsPlatform.PVS.EnableReportDisabledRules — включает отображение исключений из правил анализатора, которые могут быть указаны в комментариях и файлах .pvsconfig. Сообщения о том, откуда взята информация об исключении правил анализатора, выводятся в результаты анализа в виде предупреждений с кодом V012.
Через интерфейс плагина для Visual Studio или Rider
Если в target-файле включено использование настроек из Settings.xml файла:
public MyUEProjectTarget( TargetInfo Target) : base(Target)
{
....
WindowsPlatform.PVS.UseApplicationSettings = true;
}то можно задать настройки через интерфейсы плагинов для Visual Studio или Rider.
Настройки по включению и отключению групп диагностик в Visual Studio находятся в 'Extensions -> PVS-Studio -> Options... -> Detectable Errors (C, C++)':

В Rider настройки по включению и отключению групп диагностик находятся в 'Tools -> PVS-Studio -> Settings... -> Warnings':

С версии Unreal Engine 5.1 также доступны некоторые дополнительные настройки через интерфейс плагинов для Visual Studio и Rider.
В Visual Studio в 'Extensions -> PVS-Studio -> Options... -> Specific Analyzer Settings -> Analysis':

В Rider в 'Tools -> PVS-Studio -> Settings... -> Analysis -> Analysis Timeout':

Оптимизация производительности анализа Unreal Engine проектов
Отключение Unity Build при анализе
По умолчанию, UnrealBuildTool объединяет единицы трансляции в файлы большого размера для оптимизации сборки. Такое поведение помогает оптимизировать время сборки, однако может помешать при анализе кода. Т.к. на анализ идут файлы большого размера, то возможна ситуация нехватки памяти.
Мы настоятельно рекомендуем отключать Unity Build, чтобы избежать проблемы нехватки памяти при анализе.
Unity Build можно отключить в *.Traget.cs файле, указав bUseUnityBuild = false;
Чтобы данная настройка влияла только на процесс анализа, не замедляя сборку, вы можете добавить в *.Target.cs файл следующий код:
Для Unreal Engine версии 5.0 и ниже:
public UE4ClientTarget(TargetInfo Target) : base(Target)
{
...
if (WindowsPlatform.StaticAnalyzer == WindowsStaticAnalyzer.PVSStudio)
{
bUseUnityBuild = false;
}
...
}Для Unreal Engine версии 5.1 и выше:
public UE5ClientTarget(TargetInfo Target) : base(Target)
{
...
if (StaticAnalyzer == StaticAnalyzer.PVSStudio)
{
bUseUnityBuild = false;
}
...
}Для запуска анализа вам достаточно указать флаг -StaticAnalyzer=PVSStudio в команде сборки NMake. UnrealBuildTool будет выключать Unity Build, если для параметра StaticAnalyzer указано значение PVSStudio.
Отключение анализа ядра Unreal Engine
В Unreal Engine, начиная с версии 5.4, доступна настройка, позволяющая запускать анализатор только на файлах проекта (пропуская модуль ядра Unreal Engine). Использование этой настройки позволяет значительно ускорить процесс анализа.
Включить настройку можно добавлением в строку запуска UnrealBuildTool флага:
-StaticAnalyzerProjectOnlyВ target.cs файле эта настройка включается так:
bStaticAnalyzerProjectOnly = true;Отключение анализа автогенерируемых файлов
Для отключения анализа автогенерируемых файлов воспользуйтесь инструкцией по исключению файлов из анализа при помощи PathMasks. Добавьте маску *.gen.cpp в настройку плагина PathMasks.
Примечание: начиная с Unreal Engine 5.4, анализ автогенерируемых файлов отключён по умолчанию. Для возвращения этой функциональности вы можете использовать флаг ‑StaticAnalyzerIncludeGenerated.
Настройка вывода предупреждений в вывод UnrealBuildTool
В Unreal Engine 5.4 добавили настройку, которая задаёт уровень предупреждений, выдаваемых UnrealBuildTool при анализе. Она не влияет на работу PVS-Studio, однако может приводить к замедлению при получении отчёта. По умолчанию настройка включена (значение = 1).
Выключение (значение = 0) помогает избежать вышеуказанной проблемы. Для этого нужно добавить в строку запуска UnrealBuildTool флаг:
-StaticAnalyzerPVSPrintLevel=0В target.cs файле настройка задаётся так:
StaticAnalyzerPVSPrintLevel = 0;Автоматический запуск анализа
Для автоматического запуска анализа, например, в CI/CD системах или скриптах, достаточно вызвать команду сборки проекта.
Для получения команды сборки откройте свойства проекта, выберите пункт NMake. В поле Build Command Line будет содержаться искомая команда.
Если вы интегрируете PVS-Studio через .target.cs файл или BuildConfiguration.xml файл, то просто используйте полученную команду сборки. Если используете интеграцию через флаг UnrealBuildTool, то добавьте его в команду сборки.
Команда сборки может выглядеть так:
"Path_to_UE\Engine\Build\BatchFiles\Build.bat" ProjectGame Win64 DebugGame ^
-Project="Path_to_projet\ProjcetGame.uproject" ^
-WaitMutex -FromMsBuild -StaticAnalyzer=PVSStudioЗапуск анализа в Rider
При запуске анализа в Rider непосредственно из .uproject файла есть несколько вариантов запуска анализа.
О первых двух вариантах написано в пунктах выше: Интеграция PVS-Studio через файл target файл и Интеграция PVS-Studio через Build Configuration файл.
Третий вариант заключается в генерации .sln файла и открытии проекта через него. В таком случае появится возможность добавить -StaticAnalyzer=PVSStudio флаг в команду сборки NMake.
Примечание. Открытие Unreal Engine проектов непосредственно через .uproject файл доступно в версиях Rider 2022.3 и выше. В остальных версиях возможно открыть проект только с помощью .sln файла.
Работа с результатами анализа
Путь до файла с результатами анализа будет выведен в Output (Build) окно IDE (или stdout, если вы запускали UnrealBuildTool вручную из командной строки). Данный файл с результатами анализа имеет "нераспарсенный" вид - его можно открыть в IDE:
- командой 'PVS-Studio|Open/Save|Open Analysis Report', выбрав тип файла 'unparsed output', в Visual Studio;
- командой 'Tools|PVS-Studio|Open Report' в JetBrains Rider.
А также результаты анализа можно преобразовать с помощью утилиты PlogConverter, как это было описано в разделе выше для XML лога.
Особенности работы со списком диагностических предупреждений более подробно описаны в статье "Работа со списком диагностических сообщений", а работа с отчётом анализатора - в статье "Работа с XML отчётом (.plog файл)".
Автоматическая загрузка логов в IDE
Более удобным вариантом использования является автоматическая загрузка лога анализа в окно вывода PVS-Studio при работе в IDE. Для такого сценария необходимо включить соответствующую опцию:
- 'PVS-Studio|Options|Specific Analyzer Settings|Save/Load (analyzer report)|AutoloadUnrealEngineLog' в Visual Studio;
- 'Tools | PVS-Studio|Settings...|Settings|Save/Load (analyzer report)|Autoload Unreal Engine Log' в JetBrains Rider.
Исключение файлов из анализа при помощи PathMasks
В настройках плагинов PVS-Studio для Visual Studio и PVS-Studio for Rider и утилиты C and C++ Compiler Monitoring UI (Standalone.exe) имеется возможность указать маски директорий. Если в полном пути до файла имеется фрагмент, совпадающий с одной из масок в PathMasks, то этот файл исключается из анализа.
Важно. Для Unreal Engine проектов актуальны только маски директорий (PathMasks), но не маски имен файлов (FileNameMasks).
В плагине для Visual Studio данные настройки находятся в Extensions > PVS-Studio > Options... > Don't Check Files:

В Rider маски для исключения директорий из анализа находятся в Tools > PVS-Studio > Settings > Excludes:
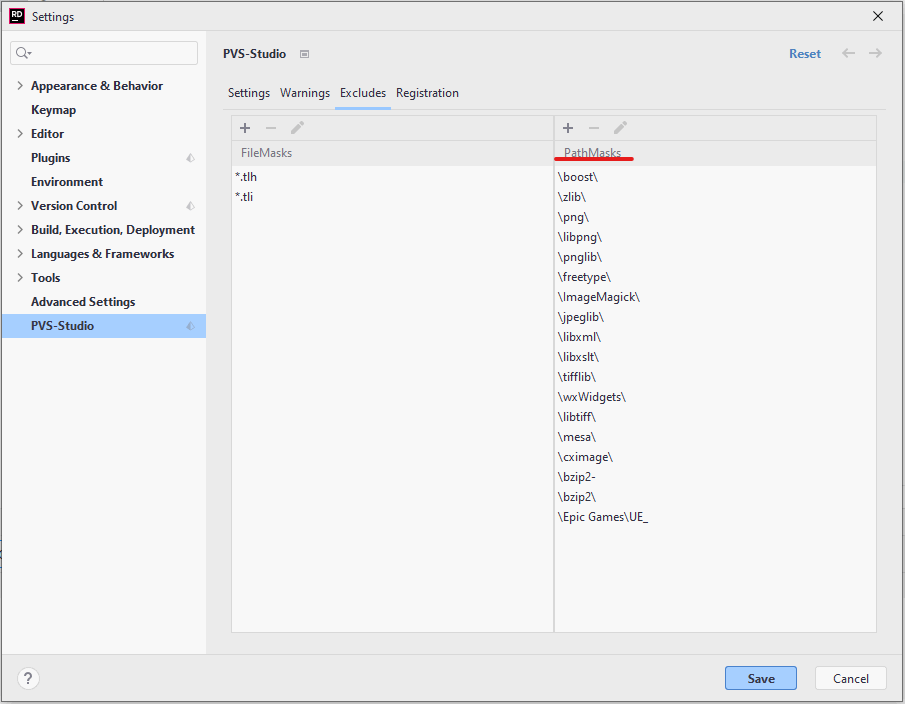
Аналогичные настройки имеются и в C and C++ Compiler Monitoring UI (Standalone.exe) в Tools > Options... > Don't Check Files:

Среди этих масок по умолчанию имеется специальная маска для исключения исходного кода Unreal Engine: \Epic Games\UE_. Эта маска добавлена по умолчанию, чтобы результаты анализа не засорялись лишними предупреждениями, информация о которых вряд ли окажется полезной большинству разработчиков.
Примечание. Если Unreal Engine установлен не по пути по умолчанию, то в отчёт анализатора будут попадать предупреждения, выдающиеся на исходный код Unreal Engine. Если они вам мешают, то добавьте в PathMasks директорию, в которую установлен Unreal Engine.
Более подробная информация об исключении файлов из анализа описана в разделе "Настройки: Don't Check Files".
Подавление предупреждений анализатора в Unreal Engine проектах
Многочисленные срабатывания анализатора на старом legacy коде часто мешают регулярному использованию статического анализа. Такой код обычно уже хорошо оттестирован и стабильно работает, поэтому править в нём все срабатывания может быть нецелесообразно. Тем более, если размер кодовой базы достаточно велик, такая правка может занять огромное количество сил и времени. Если же срабатывания анализатора на существующий код не трогать, то они будут мешать работать со срабатываниями на свежий код.
Чтобы решить данную проблему и начать сразу регулярно использовать статический анализ, PVS-Studio предлагает возможность "отключить" сообщения на старом коде. Для этого в плагинах PVS-Studio для Visual Studio и JetBrains Rider имеются элементы интерфейса, которые позволяют подавлять предупреждения анализатора в этих IDE.
Имеется единственное отличие для пользователя в механизме подавления предупреждений для Unreal Engine проектов в этих IDE. Заключается оно в том, что для UE проектов пользователю необходимо добавить вручную один suppress файл к solution, а для не-UE проектов suppress файлы также могут добавляться автоматически к каждому проекту.
Если вы попытаетесь подавить предупреждения в Visual Studio или Rider для UE проекта, когда solution suppress файл не существует, то вы получите предупреждение. В Visual Studio:

И в Rider:

В этих сообщениях содержится описание действий для добавления suppress файла уровня solution.
Более подробную информацию о подавлении предупреждений в этих IDE вы найдете в соответствующих разделах документации:
- Подавление предупреждений анализатора в плагинах PVS-Studio для CLion и Rider;
- Подавление предупреждений анализатора на старом (legacy) коде в Visual Studio.
Более подробная информация о механизме подавления предупреждений находится в разделе документации "Подавление сообщений анализатора (отключение выдачи предупреждений на существующий код)".
Подавление предупреждений анализатора из командной строки
Если вы запускаете сборку Unreal Engine проекта через командную сроку (с помощью UnrealBuildTool.exe через пакетные файлы Build.bat или Rebuild.bat), вам может быть удобно использовать подавления предупреждений анализатора через консольную утилиту PVS-Studio_Cmd.exe. Для этого в ней имеются режимы SuppressOnly и FilterFromSuppress.
Режим SuppressOnly позволяет сохранить полученные ранее предупреждения анализатора в suppress файл. Пример команды создания suppress файла:
PVS-Studio_Cmd.exe -t path/to/solution/file ^
-a SuppressOnly ^
-o path/to/report.pvslog ^
-u path/to/suppress_file.suppressВ результате выполнения данной команды все предупреждения анализатора из отчёта path/to/report.pvslog будут добавлены в path/to/suppress_file.suppress. Если suppress файла из аргумента -u не существует, то он будет создан.
Режим FilterFromSuppress позволяет использовать suppress файл для фильтрации сообщений из отчёта. Пример команды фильтрации отчёта анализатора при помощи suppress файла:
PVS-Studio_Cmd.exe -t path/to/solution/file ^
-a FilterFromSuppress ^
-o path/to/report.pvslog ^
-u path/to/suppress_file.suppressВ результате выполнения этой команды рядом с отчётом path/to/report.pvslog будет создан файл path/to/report_filtered.plog. В него будут записаны все предупреждения анализатора, которые отсутствуют в path/to/suppress_file.suppress.
Чтобы иметь в отчете предупреждения анализатора только для нового или измененного кода, изначально необходимо получить suppress файл, который будет служить начальной "точкой отсчёта". Для получения suppress файла необходимо выполнить следующие действия:
- запустить анализ Unreal Engine проекта и получить .pvslog отчёт (по умолчанию он располагается в папке ProjectDir/Saved/PVS-Studio);
- получить suppress файл для отчёта анализатора при помощи режима SuppressOnly;
- в дальнейшем фильтровать полученные отчёты анализатора при помощи режима FilterFromSuppress, используя полученный ранее suppress файл.
Отчёт анализатора в формате .plog, полученный после фильтрации в режиме FilterFromSuppress, возможно открыть в Visual Studio с установленным плагином для PVS-Studio или в утилите C and C++ Compiler Monitoring UI. Также возможно конвертировать .plog отчет в другие форматы при помощи утилиты PlogConverter.exe в Windows.
Подавление предупреждений анализатора c помощью ".Build.cs" файла
Начиная с релиза Unreal Engine 5.5, появилась возможность подавления предупреждений с помощью файла '.Build.cs'. Для этого необходимо прописать в файле следующую строку:
StaticAnalyzerPVSDisabledErrors.Add("V###");где "V###" - номер диагностического правила, которое необходимо отключить.
Если необходимо отключить несколько предупреждений, их номера можно перечислить через пробел:
StaticAnalyzerPVSDisabledErrors.Add("V### V###");Важно отметить, что файл '.Build.cs' генерируется для каждой директории проекта, и диагностические правила, прописанные в этом файле, отключаются только для той директории, в которой он находится.
Интеграция с SN-DBS
SN-DBS – это система распределённой сборки приложений, разрабатываемая компанией SN Systems. До версии UE 5.5 интеграция PVS-Studio не работала вместе с интеграцией SN-DBS. При попытке запуска параллельного анализа проекта анализ проходил только на части файлов, анализируемых на мастер-ноде SN-DBS. Логи сборки при этом содержали сообщение "fatal error C1510: Cannot load language resource clui.dll."
Способы решения:
- Перейти на версию UE 5.5.
- Применить данный патч к файлу "Engine/Source/Programs/UnrealBuildTool/Platform/Windows/PVSToolChain.cs" в случае, если вы собирали UBT из исходных файлов.
Данная проблема была исправлена в релизе UE 5.5.
Проблемы с анализом
Связка UnrealBuildTool + PVS-Studio работает следующим образом:
- UnrealBuildTool подготавливает необходимую информацию для PVS-Studio (команды запуска, опции компилятора и так далее);
- Запускается ядро C++ анализатора PVS-Studio для каждой единицы компиляции ('.cpp'):
- Подготавливается препроцессированный файл ('.i');
- Анализируется код;
- Сохраняется отчет в '.pvslog';
- После анализа всех файлов, UnrealBuildTool объединяет все '.pvslog' в один, который обычно лежит в "$PROJECT\Saved\PVS-Studio\*.pvslog";
На любом из вышеперечисленных этапов может возникнуть ошибка - например, если анализатор не смог проверить один из исходных файлов. Поэтому, если анализ завершился неудачно, то для выяснения и исправления причин сразу же пишите нам, и мы постараемся исправить проблему как можно быстрее.
Пожалуйста, прикрепите к письму дополнительные файлы, которые помогут нам понять причину ошибки и воспроизвести её:
- лог сборки, который был получен с дополнительной опцией '-verbose';
- '.pvslog' файлы. Пути до '.pvslog' могут отличаться на разных версиях Unreal Engine, но в основе формирования, как правило, лежат {PLATFORM} и {CONFIGURATION}. Например, в UE 4.26 их можно найти в '{PROJECT}\Intermediate\Build\{PLATFORM}\UE4|UE4Editor\{CONFIGURATION}\{PROJECT}\PVS\'.
Анализ проектов на Unity с помощью PVS-Studio
- Проверка с помощью плагинов PVS-Studio для IDE
- Проверка проекта из командной строки
- Проблемы при анализе
Unity проекты, написанные на C#, можно проверить с помощью PVS-Studio из консоли или IDE. Проверяемый Unity проект должен успешно собираться, чтобы результаты проверки были максимально корректными и полными.
Загрузить анализатор можно на этой странице.
Перед началом работы с PVS-Studio нужно ввести данные лицензии. Здесь написано, как это сделать.
Проверка с помощью плагинов PVS-Studio для IDE
Открытие Unity проекта в Visual Studio и JetBrains Rider
Перед началом работы с кодом Unity проекта необходимо установить в настройках Unity предпочитаемый редактор скриптов. Это можно сделать с помощью параметра "External Script Editor" на вкладке "External Tools" в окне "Preferences". Чтобы открыть это окно, используйте опцию меню "Edit" -> "Preferences" в редакторе Unity:

После этого открыть Unity проект в IDE можно, используя опцию "Assets" -> "Open C# Project" в редакторе Unity:

Также вы можете открыть сгенерированный Unity .sln файл из IDE. Если .sln файл отсутствует, то необходимо произвести вышеописанные действия в редакторе Unity. Тогда .sln будет сгенерирован.
Использование анализатора в Visual Studio
Проанализировать Unity проект можно из Visual Studio. Руководство по использованию плагина доступно по ссылке.
Анализ может быть выполнен для следующих элементов:
- весь Unity проект (.sln);
- .csproj проекты, сгенерированные по Assembly Definition;
- отдельные файлы .cs.
Запустить анализ можно из подменю плагина PVS-Studio в меню "Extensions" на верхней панели меню:

Также запуск анализа доступен из окна "Solution Explorer" через контекстное меню по нажатию на элементе решения.
Отчёт об анализе доступен в окне "PVS-Studio":

Использование анализатора в JetBrains Rider
Проанализировать Unity проект можно из JetBrains Rider. Возможности этого плагина и его применение аналогичны таковым для плагина Visual Studio. Подробная инструкция по использованию плагина для JetBrains Rider доступна по ссылке.
Запустить анализ можно через главное меню:

Проверка проекта из командной строки
PVS-Studio можно запускать из командной строки. Это удобно, если вы хотите интегрировать анализ проекта в вашу инфраструктуру CI/CD.
Руководство по использованию CLI версии PVS-Studio доступно по ссылке.
Вы можете проверить всё решение (sln), отдельные проекты (csproj) или некоторый набор файлов исходного кода. В последнем случае путь к .sln/.csproj файлу также обязателен.
Для анализа C# проектов на Windows используется "PVS-Studio_Cmd.exe", на Unix-like системах "pvs-studio-dotnet".
Пример запуска PVS-Studio через CLI на Windows:
PVS-Studio_Cmd.exe -t D:\UnityProjects\MyProject\MyProject.slnПример запуска PVS-Studio через CLI на Unix-like системах:
pvs-studio-dotnet -t ./MyUnityProject.slnПо умолчанию анализатор генерирует отчёты в формате:
- plog на Windows;
- json на Linux и macOS.
Отчёты можно открывать с помощью IDE плагинов PVS-Studio.
Примечание: отчёты в формате plog не поддерживается в Rider. Кроме того, под Linux и macOS не поддерживается конвертация таких отчётов.
Ниже представлено меню плагина под Visual Studio:

Отчёты можно сконвертировать в более удобный для восприятия человеком формат.
Для конвертации используется CLI утилита PlogConverter. На Windows используется "PlogConverter.exe", на Unix-like системах "plog-converter". Руководство к утилите доступно здесь.
Пример конвертации отчёта в формат HTML на Windows (вводится в одну строку):
PlogConverter.exe D:\UnityProjects\MyProject\MyProject.plog
-t FullHtml
-o D:\UnityProjects\MyProject\Пример конвертации отчёта в формат HTML на Unix-like системах:
plog-converter –t fullhtml ./ ./MyProject.plogЭти команды конвертируют отчёт в формат HTML, который удобен для просмотра в браузере и для рассылки по почте. Пример отчёта в формате FullHTML:
Проблемы при анализе
The solution file has two projects named "UnityEngine.UI"
Если в Unity в настройках генерации C# проектов выбрана опция "Player projects", то происходит создание solution файла с дубликатами названий проектов. При анализе проекта с помощью PVS-Studio это может приводить к ошибке следующего вида: The solution file has two projects named "UnityEngine.UI". Для проведения анализа эту опцию требуется отключить.

После этого может понадобиться заново сгенерировать проектные файлы. Для этого есть кнопка ниже – "Regenerate project files".
После того как дубликаты из sln-файла пропадут, анализ должен работать нормально. Подробнее эта проблема с повторяющимися именами проектов описана здесь.
Не изменяйте файлы проекта во время анализа
Во время анализа мы рекомендуем не совершать действий, которые могут привести к изменению sln/csproj файлов или файлов исходного кода. Например, это такие действия, как изменение или создание Assembly Definitions и Assembly Definition References, добавление новых скриптов.
Работа с ядром Java анализатора из командной строки
- Установка ядра Java анализатора
- Аргументы ядра Java анализатора
- Запуск анализа
- Файл конфигурации Java анализатора
- Глобальный файл настроек Java анализатора
- Коды возврата ядра Java анализатора
- Обновление PVS-Studio Java
Статический анализатор кода PVS-Studio Java состоит из 2-х основных частей: ядра, выполняющего анализ, и плагинов для интеграции в сборочные системы (Maven, Gradle) и IDE (PVS-Studio для IntelliJ IDEA и Android Studio).
Функции плагинов:
- Предоставление удобного интерфейса для запуска и настройки анализатора;
- Удобный просмотр и фильтрация результатов анализа (IDE);
- Сбор и передача данных (наборы исходных файлов и classpath) о структуре проекта ядру анализатора;
- Развёртывание в системе ядра анализатора версии, соответствующей версии плагина.
Установка ядра Java анализатора
На Windows ядро Java анализатора возможно установить через инсталлятор PVS-Studio для Windows. Скачать его можно на странице загрузки.
Кроме этого, на всех операционных системах возможно скачать ZIP архив для Java на странице загрузки. В этом архиве содержится ядро Java анализатора (папка с именем 7.36.93539 в директории pvs-studio-java). Ядро анализатора надо распаковать в необходимое вам место или по стандартному пусти установки ядра Java анализатора:
- Windows: %APPDATA%/PVS-Studio-Java;
- Linux и macOS: ~/.config/PVS-Studio-Java.
Аргументы ядра Java анализатора
Для получения информации про все доступные аргументы анализатора, необходимо выполнить команду ‑‑help:
java -jar pvs-studio.jar --helpАргументы анализатора:
- ‑‑src (-s) — набор файлов или директорий для анализа. Значение по умолчанию отсутствует. При перечислении нескольких файлов или директорий в качестве разделителя используется пробел. Пример: ‑‑src "path/to/file1" "path/to/file2" "path/to/dir";
- ‑‑ext (-e) — определение classpath (*.jar/*.class файлы, директории). Значение по умолчанию отсутствует. При перечислении нескольких сущностей classpath в качестве разделителя используется пробел. Пример: ‑‑ext "path/to/file.jar" "path/to/dirJars";
- ‑‑ext-file — путь до файла с classpath. Значение по умолчанию отсутствует. В качестве разделителя classpath используется ':' в *nix системах и ';' — в Windows системах. Пример: ‑‑ext-file "path/to/project_classpath_file";
- ‑‑cfg (-c) — конфигурационный файл для запуска ядра анализатора. В этом файле должны быть сохранены значения аргументов командной строки ядра Java анализатора в JSON формате. Более подробная информация об этом файле находится в следующем разделе документации. Значение по умолчанию отсутствует;
- ‑‑help (-h) — вывод в консоль справочной информации об аргументах ядра Java анализатора;
- ‑‑user-name — имя пользователя;
- ‑‑license-key — лицензионный ключ;
- ‑‑license-path — путь до файла с лицензией. Допустимые расширения файла: .xml, .lic. Значение по умолчанию: %APPDATA%/PVS-Studio/Settings.xml (Windows) или ~/.config/PVS-Studio/PVS-Studio.lic (macOS и Linux);
- --activate-license — флаг, позволяющий сохранить информацию о лицензии, указанную в аргументах ‑‑user-name и ‑‑license-key, в файл. Значение по умолчанию: false;
- ‑‑convert — запуск в режиме конвертации. Режимы:
- toFullhtml — преобразует отчет с предупреждениями в формат fullhtml;
- toSuppress — преобразует отчет с предупреждениями в формат файла подавления (suppress файл);
- ‑‑src-convert — путь до отчёта анализатора с предупреждениями (*.json);
- ‑‑dst-convert — путь до файла или каталога, куда будет записан результат преобразования (файл для toSuppress, директория для toFullhtml);
- ‑‑output-type (-O) — формат, в котором будет представлен отчет анализатора (text, log, json, xml, tasklist, html, fullhtml, errorfile). Значение по умолчанию: json. Пример: ‑‑output-type txt;
- ‑‑output-file (-o) — путь до файла с отчётом анализатора. Формат содержимого отчёта анализатора не зависит от расширения файла, указанного в этом аргументе. Значение по умолчанию: ./PVS-Studio + расширение формата из аргумента ‑‑output-type. Для отчёта в формате fullhtml необходимо указать директорию, в которой будет создана папка с именем fullhtml, содержащая файл отчёта анализатора (index.html). Значение по умолчанию: ./fullhtml. Внимание. Вместо использования аргумента ‑‑output-file более предпочтительным сценарием является использование консольных утилит PlogConverter (Windows) и plog-converter (Linux и macOS). Эти утилиты позволяют конвертировать отчёт анализатора в большее количество форматов (например, SARIF), а также предоставляют дополнительные возможности: фильтрация предупреждений из отчёта, преобразование путей в отчёте с абсолютных на относительные и наоборот, получение разницы между отчётами и др.;
- ‑‑threads (-j) — число потоков анализа. Количество потоков анализа позволяет ускорить процесс анализа, тратя на это больше ресурсов системы. Также возможно задать эту настройку для всей системы в файле global.json. Значение по умолчанию: число доступных процессоров;
- ‑‑sourcetree-root — корневая часть пути, которую анализатор будет использовать при генерации относительных путей в диагностических сообщениях. По умолчанию при генерации диагностических сообщений PVS-Studio выдаёт абсолютные пути до файлов, на которые анализатор выдал срабатывания. С помощью данной настройки можно задать корневую часть пути (путь до директории), которую анализатор будет автоматически подменять на специальный маркер. Замена произойдет, если путь до файла начинается с заданной корневой части. В дальнейшем отчёт с относительными путями возможно использовать для просмотра результатов анализа в окружении с отличающимся расположением исходных файлов. Например, в разных операционных системах. Значение по умолчанию отсутствует; Пример: ‑‑sourcetree-root /path/to/project/directory;
- ‑‑analysis-mode — список активных групп диагностических правил. Доступные группы: GA (правила общего назначения), OWASP (правила согласно OWASP ASVS). Настройки ‑‑enabled-warnings, ‑‑disabled-warnings и ‑‑additional-warnings имеют больший приоритет, чем эта настройка. То есть если диагностическая группа отключена (или включена), то при анализе возможно включить (или отключить) отдельные диагностики при помощи этих настроек. При перечислении нескольких групп в качестве разделителя используется пробел. Значение по умолчанию: GA. Пример: ‑‑analysis-mode GA OWASP;
- ‑‑enabled-warnings — список активных диагностик. Во время анализа будут использованы только те диагностики, которые перечислены в этом списке. При отсутствии значения данной настройки все диагностики считаются включенными, если дополнительно не задано значение для настройки ‑‑disabled-warnings. Эта настройка имеет меньший приоритет, чем настройка ‑‑disabled-warnings и ‑‑additional-warnings, но больший, чем настройка ‑‑analysis-mode. Значение по умолчанию отсутствует. При перечислении нескольких правил в качестве разделителя используется пробел. Пример: ‑‑enabled-warnings V6001 V6002 V6003;
- ‑‑disabled-warnings — список выключенных диагностик. Диагностики, перечисленные в этом списке, не будут применены во время анализа. При отсутствии данной настройки все диагностики считаются включёнными, если дополнительно не задана настройка ‑‑enabledWarnings. Эта настройка имеет больший приоритет чем настройки ‑‑enabledWarnings и ‑‑analysisMode, но меньший чем ‑‑additionalWarnings. Значение по умолчанию отсутствует;
- ‑‑additional-warnings — список включенных по умолчанию диагностик, которые будут добавлены к анализу. Если диагностика добавлена в этот список, то наличие её в списках ‑‑enabledWarnings и ‑‑disabledWarnings игнорируется. Кроме того, эта диагностика будет включена, даже если группа диагностик, в которую она входит, отключена (т.е. в ‑‑analysisMode не содержится этой группы). Эта настройка имеет больший приоритет, чем настройки --enabled-warnings, --disabled-warnings и ‑‑analysis-mode. Значение по умолчанию отсутствует. При перечислении нескольких правил в качестве разделителя используется пробел. Пример: ‑‑additional-warnings V6001 V6002 V6003;
- ‑‑exclude — список файлов и/или директорий, которые нужно исключить из анализа (абсолютные или относительные пути, которые будут раскрыты относительно каталога запуска). При отсутствии значения для данной настройки будут проанализированы все файлы, если дополнительно не задано значение для настройки ‑‑analyze-only или ‑‑analyze-only-list. Эта настройка имеет больший приоритет, чем настройки —analyze-only и —analyze-only-list. Значение по умолчанию отсутствует. При перечислении нескольких файлов или директорий в качестве разделителя используется пробел. Пример: --exclude "path/to/file1" "path/to/file2" "path/to/dir";
- ‑‑analyze-only — список файлов и/или директорий, которые нужно проанализировать (абсолютные или относительный пути, которые будут раскрыты относительно каталога запуска). Кроме этого, возможно записать эти пути построчно в файл и передать путь до этого файла в аргумент ‑‑analyze-only-list. При отсутствии значения для данной настройки будут проанализированы все файлы, если дополнительно не задано значение для настройки ‑‑exclude или ‑‑analyze-only-list. Эта настройка имеет меньший приоритет, чем настройка ‑‑exclude. Файлы и/или директории, переданные в этом аргументе, объединяются в общий список с файлами и/или директориями из файла из аргумента ‑‑analyze-only-list. Значение по умолчанию отсутствует. При перечислении нескольких файлов или директорий в качестве разделителя используется пробел. Пример: ‑‑analyze-only "path/to/file1" "path/to/file2" "path/to/dir";
- ‑‑analyze-only-list — путь к текстовому файлу, содержащему список путей к файлам и/или каталогам для анализа (каждая запись должна быть на отдельной строке). Поддерживаются относительные (будут раскрыты относительно каталога запуска) и абсолютные пути. При отсутствии значения для данной настройки будут проанализированы все файлы, если дополнительно не задано значение для настройки ‑‑exclude или ‑‑analyze-only. Этот настройка имеет меньший приоритет, чем настройка ‑‑exclude. Файлы и/или директории, считанные из файла, указанного в этом аргументе, объединяются в общий список с файлами и/или директориями из аргумента ‑‑analyze-only. Значение по умолчанию отсутствует;
- ‑‑suppress-base — путь до suppress файла, содержащего подавленные сообщения анализатора. Сообщения из suppress-файла не попадут в отчёт при последующих проверках проекта. Добавить сообщения в suppress файл можно через интерфейс плагина PVS-Studio для IntelliJ IDEA и Android Studio, при помощи задачи pvsSuppress из плагинов для Gradle и Maven, а также при помощи использования аргумента ‑‑convert со значением toSuppress. Значение по умолчанию: ./.PVS-Studio/suppress_base.json;
- ‑‑fail-on-warnings — флаг, позволяющий вернуть ненулевой код возврата, если анализатор выдал какое-либо предупреждение на проекте. Этот флаг позволяет отслеживать наличие предупреждений анализатора в отчёте, полученном при анализе. Данное поведение может быть удобным при интеграции в CI/CD. Значение по умолчанию: false;
- ‑‑incremental (-i) — флаг, позволяющий запускать анализ инкрементально. В этом режиме анализируются только изменившиеся файлы, что позволяет ускорить процесс анализа. Значение по умолчанию: false;
- ‑‑force-rebuild — флаг, позволяющий принудительно перестроить целиком закэшированную метамодель программы, содержащую информацию о её структуре и типах данных. Перестройка метамодели проекта бывает иногда необходима при обновлении версии анализатора или если метамодель проекта оказалась повреждена. При использовании данного флага отключается инкрементальный режим анализа проекта (флаг ‑‑incremental). Значение по умолчанию: false;
- ‑‑disable-cache — флаг, позволяющий отключить кэширование метамодели программы. При отключенном кэше модель проекта не кэшируется и строится каждый раз заново. Этот флаг бывает полезно использовать при выяснении причин ошибок в анализаторе. При отключении кэширования метамодели проекта также отключается инкрементальный режим анализа проекта (флаг ‑‑incremental). Значение по умолчанию: false;
- ‑‑timeout — таймаут анализа одного файла (в минутах). Позволяет увеличивать или уменьшать максимальное время, которое анализатор будет тратить на анализ одного файла. Также возможно задать эту настройку для всей системы в файле global.json. Значение по умолчанию: 10;
- ‑‑compatibility — флаг, активирующий диагностическое правило V6078, которое обнаруживает потенциальные проблемы совместимости API между выбранными версиями Java SE. Диагностика V6078 позволяет убедится, что API JDK, которое вы используете, не изменится или не исчезнет в более поздних версиях JDK. Значение по умолчанию: false;
- ‑‑source-java — версия Java SE, на которой разработано ваше приложение. Эта настройка используется диагностикой анализатора V6078, если включена настройка ‑‑compatibility. Минимальное значение: 8. Максимальное значение: 14;
- ‑‑target-java — версия Java SE, на совместимость с которой вы хотите проверить API, используемое в вашем приложении (‑‑source-java). Эта настройка используется диагностикой анализатора V6078, если включена настройка ‑‑compatibility. Минимальное значение: 8. Максимальное значение: 14;
- ‑‑exclude-packages — пакеты, которые вы хотите исключить из анализа совместимости (диагностика V6078). Эта настройка используется диагностикой анализатора V6078, если включена настройка ‑‑compatibility. Пример: ‑‑exclude-packages "package1" "package2" "package3".
Запуск анализа
Перед запуском анализа вам необходимо будет ввести лицензию. Как это сделать — можно узнать в этой документации.
Примеры быстрого запуска ядра Java анализатора:
java -jar pvs-studio.jar -s A.java B.java C.java -e Lib1.jar Lib2.jar -j4
-o report.txt -O text --user-name someName –-license-key someSerial
java -jar pvs-studio.jar -s src/main/java --ext-file classpath.txt -j4
-o report.txt -O text --license-path PVS-Studio.licОбратите внимание:
- анализатору для работы необходим набор исходных файлов (или директорий с исходными файлами) для анализа, а также classpath, чтобы корректно построить метамодель программы;
- при анализе проекта будет использована версия языка Java, соответствующая версии JDK, из которого используется файл java для запуска ядра Java анализатора. Если хотите изменить версию языка Java, которая будет использована при анализе, то используйте для запуска ядра Java анализатора (pvs-studio.jar) файл java из JDK соответствующей версии.
Как изменить версию Java для запуска анализатора?
По умолчанию анализатор запускает ядро с java из переменной окружения PATH. Если необходимо запустить анализ с какой-то другой версией, ее можно указать вручную. Для этого запустите ядро Java анализатора, используя полный путь до java файла из JDK. Версия этой JDK (версия языка Java) будет использована при анализе исходного кода проекта:
/path/to/jdk_folder/bin/java -jar pvs-studio.jar ^
-s A.java B.java C.java -e Lib1.jar Lib2.jar -j4 ^
-o report.txt -O text --user-name someName –-license-key someSerialФайл конфигурации Java анализатора
Для упрощения команды запуска анализа можно вынести аргументы командной строки в специальный JSON-файл. В дальнейшем этот файл можно передать в ядро анализатора через флаг ‑‑cfg.
Синтаксис файла выглядит следующим образом:
{
"single-value-parameter": "value",
"multiple-values-parameter": ["value1", "value2", "value3"]
}Каждый параметр в файле конфигурации представляет собой полное имя флага командной строки со значением, которое будет передано в этом флаге.
Пример файла конфигурации:
{
"src": ["A.java", "B.java", "C.java"],
"threads": 4,
"output-file": "report.txt",
"output-type": "text",
"user-name": "someName",
"license-key": "someSerial"
....
}В таком случае запуск анализатора сведётся к следующей строке:
java -jar pvs-studio.jar –-cfg cfg.jsonОбратите внимание, что параметры, переданные через командную строку, имеют более высокий приоритет, чем параметры, заданные в файле конфигурации.
Глобальный файл настроек Java анализатора
Часть настроек ядро Java анализатора берёт из файла global.json. Этот файл расположен в папке по стандартному пути установки ядра Java анализатора:
- Windows: %APPDATA%/PVS-Studio-Java/global.json;
- Linux и macOS: ~/.config/PVS-Studio-Java/global.json.
Вот список этих настроек:
- java — Значение по умолчанию: java;
- jvm-arguments — Значение по умолчанию: ["-Xss64m"];
- threads — Значение по умолчанию: число доступных процессоров. Это значение возможно переопределить через аргумент ‑‑threads командной строки ядра Java анализатора;
- timeout — Значение по умолчанию: 10. Это значение возможно переопределить через аргумент ‑‑timeout командной строки ядра Java анализатора;
- verbose — Значение по умолчанию: true.
Эти значения по умолчанию используются для всех ядер Java анализатора в системе, а также плагинами PVS-Studio для Java. При необходимости значения этих параметров можно изменить. Например, чтобы все плагины PVS-Studio для Java использовали одно и то же количество потоков для анализа.
Информацию о том, какие из этих настроек возможно переопределить в плагинах PVS-Studio для Java, вы найдёте в соответствующих разделах документации:
Коды возврата ядра Java анализатора
- '0' – анализ успешно завершён. Ошибки могут быть как найдены, так и не найдены;
- '50' – произошла ошибка при анализе;
- '51' – переданы невалидные аргументы при запуске анализа;
- '52' – при анализе используется невалидная или просроченная лицензия;
- '53' – анализ успешно завершен, и анализатор нашёл потенциальные ошибки в коде проекта. Этот код возврата будет возвращен только при использовании флага ядра Java анализатора ‑‑fail-on-warnings;
- '54' – при анализе попытались использовать Enterprise возможности ядра Java анализатора, но при этом использовали не Enterprise лицензию.
Обновление PVS-Studio Java
Каждый раз при запуске анализа проверяется наличие новой версии анализатора PVS-Studio. Если вышла новая версия анализатора, то в файле с результатами анализа будет содержаться сообщение: "A newer version of PVS-Studio is available (7.36.93539)". Это сообщение содержит последнюю версию ядра Java анализатора.
Кроме этого, получить последнюю версию PVS-Studio можно из файла по ссылке.
Для обновления ядра Java анализатора скачайте ZIP архив на странице загрузки. В этом архиве содержится ядро Java анализатора (папка с именем 7.36.93539 в директории pvs-studio-java). Ядро Java анализатора надо распаковать в необходимое место или в стандартную директорию:
- Windows: %APPDATA%/PVS-Studio-Java;
- Linux и macOS: ~/.config/PVS-Studio-Java.
Весь этот процесс можно автоматизировать при помощи различных скриптов, что позволит всегда использовать последнюю версию ядра Java анализатора.
Как запустить PVS-Studio в Linux и macOS
- Введение
- Установка и обновление PVS-Studio
- Информация о файле лицензии
- Запуск анализа
- Режим инкрементального анализа
- Режим анализа списков файлов
- Интеграция PVS-Studio в сборочные системы и IDE
- Интеграция PVS-Studio с системами Continuous Integration
- Просмотр и фильтрация отчёта анализатора
- Рассылка результатов анализа (утилита blame-notifier)
- Массовое подавление сообщений анализатора
- Описание распространённых проблем и их решение
- Заключение
Введение
Статический анализатор С/C++ кода PVS-Studio представляет собой консольное приложение с именем pvs-studio и несколько вспомогательных утилит. Также присутствуют интеграции с VS Code, Qt Creator, CLion в качестве плагина, предоставляющие удобный интерфейс для анализа проектов. Для работы программы необходимо иметь настроенное окружение для сборки вашего проекта.
Существуют три основных режима работы анализатора:
- Интеграция вызова pvs-studio в сборочную систему;
- Интеграция анализатора с помощью модулей для CMake;
- Анализ проекта без интеграции с помощью утилиты pvs-studio-analyzer.
Установка и обновление PVS-Studio
Примеры команд для установки анализатора из пакетов и репозиториев приведены на этих страницах:
Информация о файле лицензии
Вы можете запросить лицензию для знакомства с PVS-Studio через форму. О том, как ввести полученную лицензию в Linux и macOS, написано здесь.
Запуск анализа
Перед запуском анализа необходимо выполнить один из следующих шагов для получения модели сборки проекта.
Важно. Проект должен успешно компилироваться и быть собран перед анализом.
JSON Compilation Database
На этой странице приведены инструкции для запуска анализа на основе файлов compile_commands.json. Он подходит для широко используемых инструментов сборки, таких как: CMake, Ninja, GNU Make, Qt Build System, Xcode.
Трассировка компиляции (только для Linux)
Для работы этого метода необходима установленная утилита strace. С её помощью анализатор может собрать необходимую информацию о компиляции проекта во время его сборки.
Собрать проект и отследить процесс его компиляции можно с помощью команды:
pvs-studio-analyzer trace -- makeВместо команды make может быть любая команда запуска сборки проекта со всеми необходимыми параметрами, например:
pvs-studio-analyzer trace -- make debugВ результате трассировки по умолчанию будет сформирован файл strace_out. Подробнее о режиме трассировки можно узнать здесь.
Запуск анализа проекта
После получения файла трассировки компиляции (strace_out) или JSON Compilation Database (compile_commands.json) можно запустить анализ, выполнив команду:
pvs-studio-analyzer analyze -o /path/to/PVS-Studio.log \
-e /path/to/exclude-path \
-j<N>
plog-converter -a GA:1,2 \
-t json \
-o /path/to/Analysis_Report.json \
/path/to/PVS-Studio.logКоманда analyze предполагает наличие файлов strace_out или compile_commands.json в текущем рабочем каталоге. Можно указать явно расположение этих файлов при помощи флага ‑‑file (-f).
Предупреждения анализатора будут сохранены в указанный Analysis_Report.json файл. Разные способы просмотра и фильтрации полученного отчёта приведены в разделе этого документа "Просмотр и фильтрация отчёта анализатора".
Если вы используете кросс-компиляторы
В таком случае компиляторы могут иметь специальные имена и анализатор не сможет их найти. Для проверки такого проекта необходимо явно перечислить имена компиляторов без путей:
pvs-studio-analyzer analyze ... --compiler COMPILER_NAME
--compiler gcc --compiler g++ --compiler COMPILER_NAME
plog-converter ...Также при использовании кросс-компиляторов изменится каталог с заголовочными файлами компилятора. Чтобы анализатор не выдавал предупреждения на эти файлы, необходимо исключить такие директории из анализа с помощью флага -e:
pvs-studio-analyzer ... -e /path/to/exclude-path ...Если pvs-studio-analyzer неправильно определяет тип кросс-компилятора и, как следствие, неправильно запускает препроцессор, вы также можете задать его явно через этот флаг:
pvs-studio-analyzer analyze ... ‑‑compiler CustomCompiler=gcc
Теперь pvs-studio-analyzer запустит CustomCompiler с флагами препроцессирования gcc. Подробнее об этом можно прочитать тут.
При интеграции анализатора в сборочную систему проблем с кросс-компиляторами не возникает.
Response-файлы
Вы можете передавать response-файлы в pvs-studio-analyzer. Response-файл – это файл, содержащий аргументы командной строки.
Response-файл можно передать через параметр командной строки, который начинается на символ '@'. После этого символа следует путь до response-файла (например, '@/путь/до/файла.txt'). Аргументы в response-файле разделены пробелами/табуляцией/переносами строк. Если вы хотите передать аргумент, который содержит пробельный символ, то вы можете экранировать этот символ с помощью обратного слэша (\) или обернуть весь аргумент в одинарные ('') или двойные ("") кавычки. Кавычки внутри кавычек экранировать нельзя. Разницы между одинарными и двойными кавычками нет. Обратите внимание, что аргументы передаются без изменений, подстановок значений переменных среды и раскрытия glob'ов не происходит. Рекурсивные response-файлы поддерживаются.
Режим инкрементального анализа
Для утилиты pvs-studio-analyzer доступен режим инкрементального анализа (анализ только изменённых файлов). Для этого необходимо запустить утилиту с параметром ‑‑incremental:
pvs-studio-analyzer analyze ... --incremental ...Этот режим работает независимо от инкрементальной сборки проекта. Т.е. если Ваш проект полностью скомпилирован, то первый запуск инкрементального анализа всё равно будет анализировать все файлы. А при следующем запуске будут анализироваться только изменённые.
Для отслеживания изменённых файлов, анализатор сохраняет служебную информацию в каталоге с именем .PVS-Studio в директории запуска. Поэтому для использования этого режима необходимо всегда запускать анализатор в одной и той же директории.
Режим анализа списков файлов
Утилита pvs-studio-analyzer позволяет анализировать списки указанных файлов проекта. С помощью этого режима можно настроить анализатор для проверки коммитов и Pull Requests. Для анализа необходимо запустить утилиту с параметром ‑‑source-files или -S и указать путь к файлу со списком исходных файлов для анализа:
pvs-studio-analyzer analyze ... -S source_file_list ...Более подробно изучить анализ списков файлов можно на странице "Проверка коммитов и Pull Requests".
Интеграция PVS-Studio в сборочные системы и IDE
Примеры интеграции в CMake, QMake, Makefile и WAF
Тестовые проекты доступны в официальном репозитории PVS-Studio на GitHub:
- pvs-studio-cmake-examples, сам CMake модуль в GitHub репозитории
- pvs-studio-qmake-examples
- pvs-studio-makefile-examples
- pvs-studio-waf-examples
Как выглядит интеграция с CLion и QtCreator
На рисунке 1 представлен пример просмотра предупреждений анализатора в CLion (подробнее здесь):
Рисунок 1 - Просмотр предупреждений PVS-Studio в CLion
На рисунке 2 представлен пример просмотра предупреждений анализатора в QtCreator:
Рисунок 2 - Просмотр предупреждений PVS-Studio в QtCreator
Инструкция по проверке CMake проектов в среде Qt Creator находится на странице "Использование PVS-Studio в среде Qt Creator".
Для QtCreator существует расширение PVS-Studio for QtCreator, о нём больше информации тут.
Параметры препроцессора
Анализатор проверяет не исходные файлы, а препроцессированные файлы. Такой способ позволяет проводить более глубокий и качественный анализ исходного кода.
В связи с этим, у нас есть ограничения на передаваемые параметры компиляции. К ним относятся параметры, мешающие запуску компилятора в режиме препроцессора, либо "портящие" вывод препроцессора. Ряд флажков оптимизации и отладки, например, -O2, -O3, -g3, -ggdb3 и другие, вносят изменения, "портящие" вывод препроцессора. Информация о недопустимых параметрах будет выведена анализатором при их обнаружении.
Этот факт ни в коем случае не обязывает вносить изменения в настройки проверяемого проекта, но для правильного запуска анализатора часть параметров необходимо исключить.
Конфигурационный файл *.cfg
При интеграции анализатора в сборочную систему ему необходимо передать файл с настройками (*.cfg). Имя конфигурационного файла может быть произвольным, и его необходимо передать с флагом "‑‑cfg".
Возможные значения настроек в конфигурационном файле:
- exclude-path (опционально) задаёт директорию, файлы из которой проверять не надо. Обычно это каталоги системных файлов или подключаемых библиотек. Параметров exclude-path может быть несколько.
- analysis-paths (опционально) определяет поведение анализа на указанных путях. Доступны следующие режимы:
'skip-analysis' - задаёт директорию, файлы из которой проверять не надо. Обычно это каталоги системных файлов или подключаемых библиотек.
'skip-settings' - игнорирует настройки, расположенные в исходных файлах и файлах '.pvsconfig' по указанному пути.
'skip' - игнорирует настройки, расположенные в исходных файлах и файлах '.pvsconfig' по указанному пути. Также будут отфильтрованы предупреждения, сгенерированные для файлов исходного кода по указанному пути или маске.
- platform (обязателен) задаёт используемую платформу. Возможные варианты: linux32 или linux64.
- preprocessor (обязателен) задаёт используемый препроцессор. Возможные варианты: gcc, clang, keil.
- language (обязателен) задаёт язык проверяемого файла, который анализатор ожидает найти при его разборе. Возможные значения: C, C++. Поскольку каждый из поддерживаемых языковых диалектов содержит специфичные ключевые слова, неправильное указание данного параметра может привести к ошибкам разбора кода V001.
- lic-file (опционально) содержит абсолютный путь до файла с лицензией.
- analysis-mode (опционально) задаёт тип выдаваемых предупреждений. Рекомендуется использовать значение "4" (General Analysis, подходит подавляющему большинству пользователей).
- output-file (опционально) задаёт полный путь к файлу, в который будет записываться отчёт работы анализатора. При отсутствии этого параметра в конфигурационном файле все сообщения о найденных ошибках будут выводиться в консоль.
- sourcetree-root (опционально) по умолчанию, при генерации диагностических сообщений, PVS-Studio выдаёт абсолютные, полные пути до файлов, в которых анализатор нашёл ошибки. С помощью данной настройки можно задать корневую часть пути, которую анализатор будет автоматически подменять на специальный маркер. Например, абсолютный путь до файла /home/project/main.cpp будет заменён на относительный путь |?|/main.cpp, если /home/project был указан в качестве корня.
- source-file (обязателен) содержит абсолютный путь до проверяемого исходного файла.
- i-file (обязателен) содержит абсолютный путь до препроцессированного файла.
- no-noise (опционально) отключает выдачу сообщений низкого уровня достоверности (3-ий уровень). При работе на больших проектах анализатор может выдать большое число предупреждений. Используйте эту настройку, если вы не можете исправить все сообщения анализатора сразу, и вам нужно сконцентрироваться на правке наиболее важных срабатываний в первую очередь.
Необязательно создавать новый конфигурационный файл для проверки каждого файла. В него достаточно сохранить постоянные настройки, например, lic-file и т.п.
Интеграция PVS-Studio с системами Continuous Integration
Любой из перечисленных способов интеграции анализатора в сборочную систему можно автоматизировать в системе Continuous Integration. Это можно сделать в Jenkins, TeamCity и других, настроив автоматический запуск анализа и уведомление о найденных ошибках.
Также возможна интеграция с платформой непрерывного анализа SonarQube с помощью плагина PVS-Studio. Плагин предоставляется с анализатором в .tgz архиве, доступном для загрузки. Инструкция по настройке доступна на странице: "Интеграция результатов анализа PVS-Studio в SonarQube".
Результаты анализа PVS-Studio можно загружать в DevSecOps платформу DefectDojo, преобразовав в специальный формат. Подробнее об интеграции отчетов можно прочесть тут.
Просмотр и фильтрация отчёта анализатора
Утилита Plog Converter
Для конвертации отчёта анализатора о найденных ошибках в различные форматы (*.xml, *.tasks и т.п.) можно воспользоваться утилитой Plog Converter, которая распространяется с открытым исходным кодом. Подробнее об утилите можно прочесть тут.
Просмотр отчёта анализатора в QtCreator
Пример команды, которая подойдёт большинству пользователей для открытия отчёта в QtCreator:
plog-converter -a GA:1,2 -t tasklist
-o /path/to/project.tasks /path/to/project.logНа рисунке 3 представлен пример просмотра .tasks файла в QtCreator:
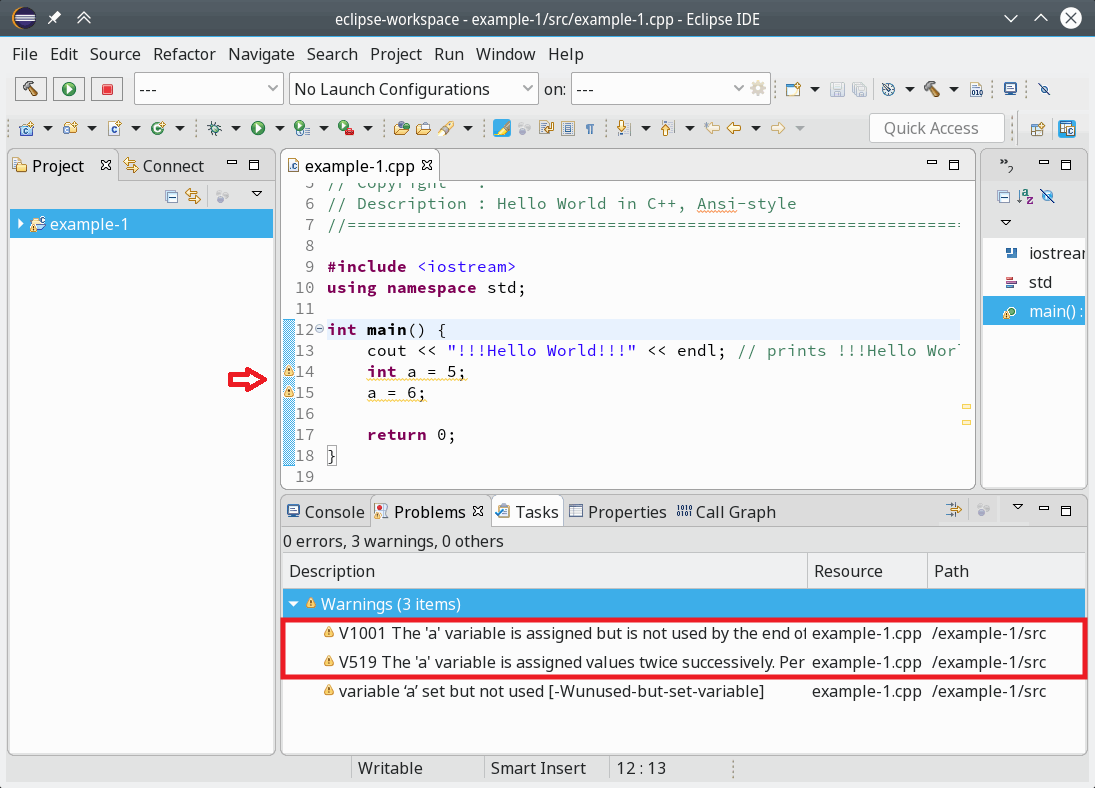
Рисунок 3 - Просмотр .tasks файла в QtCreator
Просмотр Html отчёта в браузере или почтовом клиенте
Конвертер отчётов анализатора позволяет генерировать Html отчёт двух видов:
1. FullHtml - полноценный отчёт для просмотра результатов анализа. Есть возможность поиска и сортировки сообщений по типу, файлу, уровню, коду и тексту предупреждения. Особенностью этого отчёта является возможность навигации к месту ошибки в файле с исходным кодом. Сами файлы с исходным кодом, на которых были предупреждения анализатора, копируются в html и являются частью отчёта. Примеры отчёта приведены на рисунках 4-5.
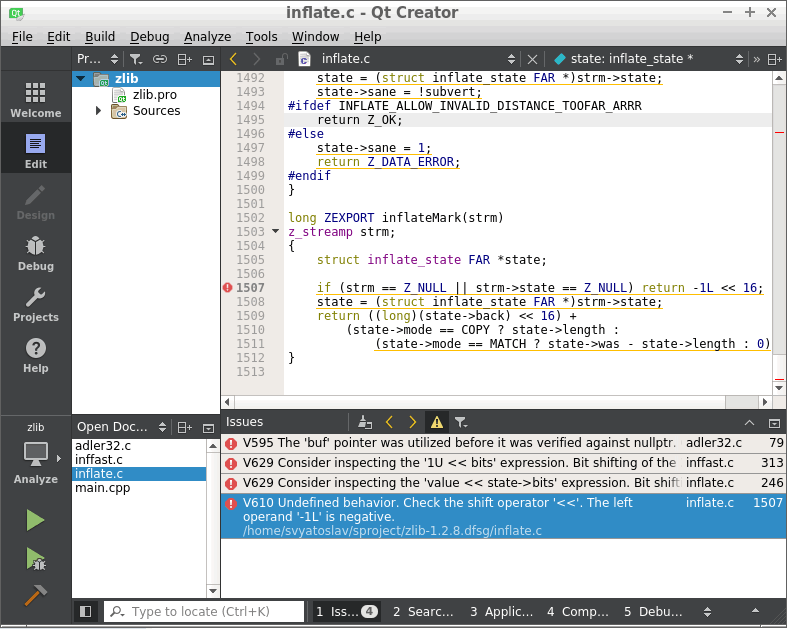
Рисунок 4 - Пример главной страницы Html отчёта

Рисунок 5 - Просмотр предупреждения в коде
Пример команды для получения такого отчёта:
plog-converter -a GA:1,2 -t fullhtml
/path/to/project.log -o /path/to/report_dirТакой отчёт удобно рассылать в архиве или предоставлять к нему доступ по локальной сети с помощью любого веб-сервера, например, Lighttpd и т.п.
2. Html - легковесный отчёт, состоящий из одного файла в формате .html. Содержит краткую информацию о найденных предупреждениях и подходит для уведомления о результатах по электронной почте. Пример отчёта приведен на рисунке 6.
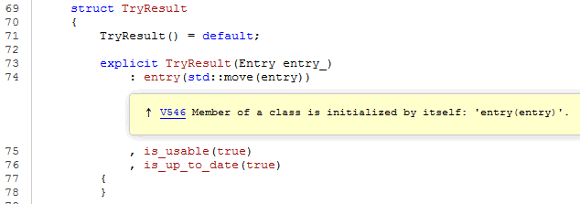
Рисунок 6 - Пример простой Html страницы
Пример команды для получения такого отчёта:
plog-converter -a GA:1,2 -t html
/path/to/project.log -o /path/to/project.htmlПросмотр отчёта анализатора в Vim/gVim
Пример команд для открытия отчёта в редакторе gVim:
$ plog-converter -a GA:1,2 -t errorfile
-o /path/to/project.err /path/to/project.log
$ gvim /path/to/project.err
:set makeprg=cat\ %
:silent make
:cwНа рисунке 7 представлен пример просмотра .err файла в gVim:

Рисунок 7 - Просмотр .err файла в gVim
Просмотр отчёта анализатора в GNU Emacs
Пример команд для открытия отчёта в редакторе Emacs:
plog-converter -a GA:1,2 -t errorfile
-o /path/to/project.err /path/to/project.log
emacs
M-x compile
cat /path/to/project.err 2>&1На рисунке 8 представлен пример просмотра .err файла в Emacs:

Рисунок 8 - Просмотр .err файла в Emacs
Просмотр отчёта анализатора в LibreOffice Calc
Пример команд для конвертации отчёта в CSV формат
plog-converter -a GA:1,2 -t csv
-o /path/to/project.csv /path/to/project.logПосле открытия файла project.csv в LibreOffice Calc необходимо добавить автофильтр: Menu Bar --> Data --> AutoFilter. На рисунке 9 представлен пример просмотра .csv файла в LibreOffice Calc:

Рисунок 9 - Просмотр .csv файла в LibreOffice Calc
Файл конфигурации
Более объёмные настройки можно сохранить в файл конфигурации со следующими опциями:
- enabled-analyzers - опция, аналогичная опции -a в параметрах консольной строки.
- sourcetree-root - строка, задающая путь к корню исходных файлов проверяемого проекта. Если указана неправильно, дальнейшая работа с результатом работы утилиты будет затруднена.
- errors-off - глобально выключенные номера предупреждений, перечисленные через пробел.
- exclude-path - файлы, путь к которым содержит одно из значений этой опции, не будут проанализированы.
- disabled-keywords - ключевые слова. Сообщения, указывающие на строки, содержащие эти ключевые слова, будут исключены из обработки.
Имя опции отделяется от значений символом '='. Каждая опция указывается на отдельной строке. Комментарии пишутся на отдельных строках, перед комментарием ставится символ #.
Рассылка результатов анализа (утилита blame-notifier)
Утилита blame-notifier предназначена для автоматизации процесса оповещения разработчиков, заложивших в репозиторий код, на который анализатор PVS-Studio выдал предупреждения. Отчет анализатора подается на вход blame-notifier с указанием дополнительных параметров; утилита находит файлы, в которых были обнаружены предупреждения и формирует HTML-отчет на каждого "виновного" разработчика. Также возможен вариант рассылки полного отчета: внутри него будут содержаться все предупреждения, относящиеся к каждому "виновному" разработчику.
Способы установки и использования утилиты описаны в соответствующем разделе документации: "Оповещение команд разработчиков (утилита blame-notifier)".
Массовое подавление сообщений анализатора
Массовое подавление предупреждений позволяет легко внедрить анализатор в любой проект и сразу начать получать выгоду от этого, т.е. находить новые ошибки. Этот механизм позволяет запланировать исправление пропущенных предупреждений в будущем, не отвлекая разработчиков от выполнения текущих задач.
Есть несколько способов использования этого механизма, в зависимости от варианта интеграции анализатора. О том, как использовать механизм подавления в pvs-studio-analyzer можно узнать тут.
Прямая интеграция анализатора в сборочную систему
Прямая интеграция анализатора может выглядеть следующим образом:
.cpp.o:
$(CXX) $(CFLAGS) $(DFLAGS) $(INCLUDES) $< -o $@
$(CXX) $(CFLAGS) $< $(DFLAGS) $(INCLUDES) -E -o $@.PVS-Studio.i
pvs-studio --cfg $(PVS_CFG) --source-file $< --i-file $@.PVS-Studio.i
--output-file $@.PVS-Studio.logВ этом режиме анализатор не может одновременно проверять исходные файлы и фильтровать их. Поэтому для фильтрации и подавления предупреждений потребуются дополнительные команды.
Для подавления всех предупреждений анализатора также необходимо выполнять команду:
pvs-studio-analyzer suppress /path/to/report.logДля фильтрации нового лога необходимо воспользоваться следующими командами:
pvs-studio-analyzer filter-suppressed /path/to/report.log
plog-converter ...Файл с подавленными предупреждениями также имеет имя по умолчанию suppress_file.suppress.json, для которого при необходимости можно задать произвольное имя.
Описание распространённых проблем и их решение
1. Утилита strace выдаёт сообщение вида:
strace: invalid option -- 'y'Вам необходимо обновить версию программы strace. Анализ проекта без интеграции в сборочную систему - сложная задача, а с этой опцией анализатору удаётся получить важную информацию о компиляции проекта.
2. Утилита strace выдаёт сообщение вида:
strace: umovestr: short read (512 < 2049) @0x7ffe...: Bad addressТакие ошибки возникают в системных процессах и на сборку/анализ проекта не влияют.
3. Утилита pvs-studio-analyzer выдаёт сообщение вида:
No compilation units foundАнализатору не удалось обнаружить файлы для анализа. Возможно, вы используете кросс-компиляторы для сборки проекта. Смотрите раздел "Если вы используете кросс-компиляторы" в этой документации.
4. Отчёт анализатора состоит из подобных строк:
r-vUVbw<6y|D3 h22y|D3xJGy|D3pzp(=a'(ah9f(ah9fJ}*wJ}*}x(->'2h_u(ahАнализатор сохраняет отчёт в промежуточном формате. Для просмотра отчёта его необходимо преобразовать в читабельный формат с помощью утилиты plog-converter, которая устанавливается вместе с анализатором.
5. Анализатор выдаёт ошибку:
Incorrect parameter syntax:
The ... parameter does not support multiple instances.При вызове анализатора какой-то из параметров задали несколько раз.
Такое может возникнуть, если часть параметров анализатора определили в конфигурационном файле, а часть передали через параметры командной строки. При этом случайно определив какой-нибудь параметр несколько раз.
При использовании утилиты pvs-studio-analyzer почти все параметры определяются автоматически, поэтому она может работать без конфигурационного файла. Дублирование таких параметров тоже может приводить к такой ошибке.
6. Анализатор выдаёт предупреждение:
V001 A code fragment from 'path/to/file' cannot be analyzed.Если анализатору не удаётся понять какой-нибудь фрагмент кода, то он его пропускает и выдаёт предупреждение V001. На анализ других фрагментов кода такая ситуация обычно не влияет, но если такой код находится в заголовочном файле, то таких предупреждений может быть очень много. Для поддержки проблемной конструкции пришлите нам препроцессированный файл (.i) для проблемного файла с исходным кодом.
Заключение
Если у вас возникли вопросы или проблемы с запуском анализатора, то напишите нам.
Интеграция с Qt Creator без использования плагина PVS-Studio
- Просмотр отчётов
- Анализ QMake-проектов
- Анализ проектов, основанных на CMake
- Просмотр отчета под Windows с набором инструментов MSVC
Просмотр отчётов
Для удобного просмотра результатов анализа можно использовать расширение (плагин) PVS‑Studio для Qt Creator. Подробнее про его установку и использование описано в документации "Использование расширения PVS‑Studio для Qt Creator".
Анализ QMake-проектов
Проанализировать такие проекты можно через встроенный механизм генерации файла compile_commands.json.
Анализ проектов, основанных на CMake
Анализатор PVS-Studio может быть использован для анализа CMake проектов в среде Qt Creator.
Важно. Перед использованием CMake-модуля необходимо ввести лицензию PVS-Studio при помощи специальных команд для Windows и Linux/macOS.
Затем добавьте к вашему проекту CMake-модуль PVS-Studio. После чего добавьте код для создания цели анализа в файл CMakeLists.txt вашего проекта:
include(PVS-Studio.cmake)
pvs_studio_add_target(TARGET ${PROJECT_NAME}.analyze ALL
OUTPUT
FORMAT errorfile
ANALYZE ${PROJECT_NAME}
MODE GA:1,2
LOG ${PROJECT_NAME}.log
ARGS -e C:/Qt/
HIDE_HELP)По умолчанию, при открытии CMakeLists.txt проекта, Qt Creator скрывает дополнительные цели сборки. Чтобы их отобразить, отключите опцию 'Hide Generated Files' в фильтрах обозревателя проекта:

Для сборки и запуска анализа нажмите Build "ИмяПроекта.analyze" из контекстного меню цели анализа:

После завершения анализа найденные анализатором ошибки будут добавлены в панель 'Issues':

Просмотр отчета под Windows с набором инструментов MSVC
Если для сборки проектов под Windows вы используете набор инструментов MSVC, Qt Creator поменяет механизм разбора предупреждений на совместимый с выводом компиляторов Visual Studio. Этот формат вывода не совместим с форматами вывода PVS-Studio, в результате сообщения анализатора не появятся в панели 'Issues'. Чтобы настроить поддержку формата errorfile нужно выполнить следующие шаги:
- Перейдите в режим настройки проектов 'Projects' (Ctrl+5). В секции 'Build & Run' выберите нужный набор инструментов. Внизу страницы в секции 'Custom Output Parsers' нажмите на ссылку 'here'.

2. В открывшемся окне нажмите на кнопку 'Add...'. В строках 'Error message capture pattern' вставьте следующие регулярные выражения:
Во вкладке Error
(.*):(\d+): error: (.*)Во вкладке Warning
(.*):(\d+): warning: (.*)Либо, если нужно отображение предупреждений низкого уровня
(.*):(\d+): (?:warning|note): (.*)
3. После настройки регулярный выражений нажмите 'Ok'. Выберите новый парсер и перезапустите анализ.

В результате предупреждения анализатора появятся в панели 'Issues'.

Использование расширения PVS-Studio для Qt Creator
- Установка и обновление расширения PVS-Studio
- Интерфейс
- Запуск анализа PVS-Studio
- Работа с результатами анализа
- Конфигурация плагина
Плагин PVS-Studio для Qt Creator предоставляет удобный графический интерфейс для запуска анализа проектов и отдельных файлов, а также для работы с предупреждениями анализатора. Далее будут описаны установка, настройка и основные сценарии использования.
Установка и обновление расширения PVS-Studio
Для начала необходимо получить нужную версию расширения. Её можно найти в директории установки PVS-Studio.
- Для Windows путь по умолчанию: 'C:\Program Files (x86)\PVS-Studio\QtCreatorPlugins.
- Для Linux/macOS: '$PREFIX/lib/pvs-studio/plugins', где '$PREFIX' – префикс установки (чаще всего '/usr').
Поддерживаемые версии Qt Creator
Из-за ограничений интегрированной среды разработки Qt Creator, в ней могут быть запущены только те версии плагина, что были сделаны специально для неё. Список поддерживаемых версий IDE указан в таблице ниже:
|
Версия IDE Qt Creator |
Статус поддержки плагинов PVS-Studio |
|---|---|
|
8.0.x |
Поддержка окончена. Последняя доступная версия — 7.31 |
|
9.0.x |
Поддержка окончена. Последняя доступная версия — 7.34 |
|
10.0.x |
Поддержка окончена. Последняя доступная версия — 7.35 |
|
11.0.x |
Поддерживается |
|
12.0.x |
Поддерживается |
|
13.0.x |
Поддерживается |
|
14.0.x |
Поддерживается |
|
15.0.x |
Поддерживается |
|
16.0.x |
Поддерживается |
Символ 'х' в названии файла плагина означает, что на его месте может быть любая цифра. То есть поддержка версии 9.0.х означает, что работоспособность плагина проверена на версиях 9.0.0, 9.0.1 и 9.0.2.
Целевая версия Qt Creator и платформа указаны в названии архива плагина. Например, 'pvs-studio-qtcreator-11.0.x-7.25.73595.503.windows.zip' или 'libpvs-studio-qtcreator-11.0.x-7.25.73595.503.linux.tar.gz'.
Установка с помощью мастера установки Qt Creator
Примечание. В Qt Creator версии 15.0.0 возникает проблема при установке плагинов для конкретного пользователя с помощью мастера установки. Путь, по которому устанавливаются плагины, не совпадает с путём, по которому эти плагины ищутся. Данная проблема исправлена с версии 15.0.1.
Чтобы установить расширение PVS-Studio откройте Qt Creator и выберите в строке меню пункт 'Help' -> 'About Plugins':

Нажмите кнопку 'Install Plugin...':

В появившемся мастере установки укажите местоположение архива плагина (с расширением '.zip' или '.tar.gz' в зависимости от платформы).
Замечание: не нужно распаковывать архив с плагином перед установкой. Мастер установки плагинов QtCreator заявляет, что поддерживает установку плагинов напрямую, но на практике этот способ часто приводит к сбоям. Поэтому мы советуем устанавливать плагины, не извлекая из архивов.

Далее мастер установки спросит место для установки плагина. Выберите подходящий вам вариант, нажмите далее и подтвердите установку.
Замечание: для установки в "Qt Creator installation" могут потребоваться права администратора. В противном случае будет выдана ошибка об отсутствии прав для записи файла.

По окончанию установки плагина не будет выдано никакого окна подтверждения. Сразу после закрытия мастера установки плагинов нужно нажать кнопку "ОК". В таком случае появится сообщение о том, что новые плагины будут доступны только после перезапуска QtCreator. Соглашаемся, и IDE перезапустится автоматически.

Ручная установка
В случае невозможности установки плагина с помощью мастера установки, можно воспользоваться ручной установкой. Для этого необходимо скопировать файл плагина (файл с расширением '.dll' или '.so' в зависимости от вашей платформы) в директорию с плагинами для Qt Creator. По умолчанию, Qt Creator ищет плагины в следующих директориях:
Windows:
%директория_установки_Qt%\Tools\QtCreator\lib\qtcreator\plugins
%APPDATA%\Local\QtProject\qtcreator\plugins\%версия_qt_creator%Linux:
/opt/Qt/Tools/QtCreator/lib/qtcreator/pluginsРучная установка (альтернативный способ)
Данный способ можно использовать при невозможности установить плагин в стандартные директории. При запуске Qt Creator можно указать дополнительные директории для поиска плагинов с помощью флага '-pluginpath'.
Например, запуск IDE можно произвести с помощью следующей команды:
- Windows: qtcreator.exe -pluginpath "%путь_до_директории_с_плагином%"
- Linux: qtcreator -pluginpath "$путь_до_директории_с_плагином"
Обновление плагина
Для обновления плагина достаточно удалить файлы прошлых версий плагина и установить новую версию удобным для вас способом. Найти место расположения плагина можно, выбрав пункт 'Details' в списке установленных плагинов.

Решение проблем с запуском плагина
В случае, если при запуске Qt Creator появляется сообщение, что плагин PVS-Studio не может быть загружен, т.к. не найдены подходящие зависимости (например, как рисунке ниже), то необходимо проверить используемую версию плагина и Qt Creator. Используемую версию Qt Creator можно узнать в меню 'Help' -> 'About Qt Creator', а версия используемого плагина указана в названии его файла.

Так как Qt Creator не обладает системой обновления плагинов, то после очередного обновления плагина может появиться следующее окно.

Данное сообщение означает, что плагин обнаружил одновременное использование нескольких версий и автоматически выключил все версии, кроме самой последней. Крайне желательно удалить старые версии. Для вашего удобства в сообщении также перечислены все обнаруженные версии плагина и пути, где они расположены. Текущий активный плагин отмечен записью [Active].
Интерфейс
Плагин PVS-Studio для IDE Qt Creator интегрируется в главное меню среды разработки и панель вывода.
Интеграция в главное меню
В главном меню появляется дополнительный пункт в разделе 'Analyze', содержащий следующие пункты:
Check – подменю, позволяющее запустить анализ;
Analysis after Build – быстрый доступ к настройке для активации инкрементального анализа;
Open/Save – подменю, позволяющее загружать и сохранять отчёты;
Recent Reports – хранит список последних открытых отчётов для их быстрой загрузки. Клик по пункту меню инициирует загрузку выбранного файла;
Help – подменю, содержащее в себе ссылки на документацию и наиболее важные разделы сайта анализатора;
Options – открывает настройки IDE Qt Creator в разделе PVS-Studio.

Интеграция в панели вывода
В области вывода появляется дополнительная панель с именем 'PVS-Studio'.

Панель вывода PVS-Studio состоит из следующих элементов:
1 – панель управления отчётом. Первая кнопка позволяет очистить текущую таблицу, предупреждений, а две другие (со стрелочками) позволяют перемещаться между позициями в таблице. Обратите внимание, что навигация будет производиться именно между позициями (т.е. будут открываться указанные в предупреждениях файлы), а не просто строками таблицы.
2 – панель быстрых фильтров. Содержит кнопки показа дополнительного меню, показа расширенных фильтров, а также переключатели отображаемых уровней и категорий предупреждений. При клике по кнопке дополнительного меню появляется всплывающее меню со следующими пунктами:

- Check – содержит варианты для запуска анализа.
- Open/Save – позволяет загрузить/сохранить отчёт.
- Show False Alarms – показывает/скрывает предупреждения, отмеченные как ложные. Число в скобках показывает количество предупреждений, отмеченных как ложные, в текущем отчёте. При активации, в таблице предупреждений появляется дополнительный столбец.
- Options... – показывает окно настроек IDE Qt Creator с активным разделом PVS-Studio.
- Edit Source Tree Root... – позволяет быстро изменить настройку Source Tree Root. При активации вызывается диалоговое окно для выбора существующей директории. Обратите внимание, что данный пункт виден только если отчёт содержит предупреждения с относительными путями до файлов. Подробнее о работе этой настройки рассказано в разделе дополнительного функционала.
3 – основная область просмотра. Целиком состоит из таблицы предупреждений. Подробно этот элемент будет рассмотрен позже.
4 – элементы управления панелью. Первая кнопка позволяет развернуть область просмотра по высоте, а вторая – скрыть панель.
5 – кнопка для показа панели PVS-Studio.
Интеграция в настройки
Интеграция в настройки состоит из добавления нового раздела "PVS-Studio" в список уже существующих разделов.
Раздел настроек PVS-Studio разделён на 5 разделов (по вкладке на каждый). Более подробно о назначении каждого раздела и настроек, входящих в них, описано в разделе "Конфигурация плагина".
Запуск анализа PVS-Studio
Плагин поддерживает анализ проектов, их частей, а также отдельных файлов. На данный момент поддерживаются следующие типы проектов:
- CMake;
- Qmake;
- Qbs.
Запуск анализа можно произвести несколькими способами:
- через меню Analyze (Анализ) в строке меню главного окна Qt Creator;
- с помощью контекстного меню в дереве проекта (поддерживаются проекты, папки, отдельные файлы);
- через меню в панели вывода PVS-Studio;
- через контекстное меню текущего файла.
При запуске любым из перечисленных способов в области уведомлений появится окно с прогрессом анализа, а в таблице, по мере поступления, начнут появляться предупреждения анализатора. Остановить уже запущенный процесс анализа можно с помощью специальной кнопки в заголовке панели вывода или с помощью "крестика", который находится в конце прогресс-бара уведомления (виден только при наведении курсора на прогресс-бар).

При запуске анализа также проверяется содержимое папки '.PVS-Studio' в директории исходного кода проекта. Если в ней будут найдены пользовательские файлы конфигурации (с расширением *.pvsconfig) или suppress-файлы (с суффиксом *.suppress.json), то они будут переданы анализатору для дальнейшей обработки.
Внимание: на данный момент плагин PVS-Studio для Qt Creator поддерживает работу только с одним suppress-файлом. Если при запуске будет найдено несколько файлов, то в отчёте появится соответствующая запись. В ней также будет указано, какой файл используется при анализе.
В случае каких-либо проблем с запуском будет выведено всплывающее окно с подробным описанием проблемы.
Дополнительные режимы анализа
В плагине реализована поддержка инкрементального анализа. В этом режиме после каждой успешной сборки проекта будет автоматически запускаться его анализ. Однако проанализированы будут только те файлы, что изменились с момента прошлого запуска анализатора. Подробнее о режиме инкрементального анализа можно узнать в отдельной документации.
Активировать инкрементальный анализ можно в настройках плагина (General->Incremental analysis) или с помощью пункта меню 'Analysis after Build' в подменю PVS-Studio главного окна.

Также в плагине доступен режим межмодульного анализа. Под межмодульным анализом в PVS-Studio понимается расширение возможностей межпроцедурного анализа на функции, объявленные в единицах трансляции, отличных от той, к которой относится текущий проверяемый файл. Более подробную информацию о том, что такое межмодульный анализ и чем он может быть полезен, можно найти в документации.
Для запуска межмодульного анализа необходимо выбрать пункт 'Analyze with PVS-Studio (Intermodular)' в контекстном меню проекта верхнего уровня. Межмодульный анализ отдельных частей проекта невозможен.

Работа с результатами анализа
Обратите внимание: расширение PVS-Studio для Qt Creator поддерживает только отчёты в формате JSON. Для отображения отчёта в другом формате вам потребуется выполнить его преобразование в JSON-формат.
Для преобразования можно воспользоваться утилитами командной строки PlogConverter.exe для Windows и plog-converter для Linux / macOS. Эти утилиты позволяют не только конвертировать отчёт PVS-Studio в разные форматы, но и дополнительно обрабатывать его. Например, проводить фильтрацию предупреждений. Подробнее о них можно прочитать здесь.
Пример команды конвертации отчёта PVS-Studio в JSON-формат при помощи PlogConverter.exe (Windows):
PlogConverter.exe path\to\report.plog -t json ^
-n PVS-StudioПример команды конвертации отчёта PVS-Studio в JSON-формат при помощи plog-converter (Linux и macOS):
plog-converter path/to/report/file.json -t json \
-o PVS-Studio.jsonЗагрузка уже существующего JSON отчёта PVS-Studio в Qt Creator
В случае если у вас уже есть готовый отчёт анализатора, и вы хотите посмотреть его в Qt Creator, то откройте панель PVS-Studio, нажмите на кнопку меню и выберите пункт 'Open/Save -> Open Report...':

Также отчёт может быть открыт с помощью пункта меню 'Analyze -> PVS-Studio -> Open/Save -> Open Report...':

После выбора и загрузки отчёта появится область просмотра предупреждений, а сами предупреждения отобразятся в таблице:

Навигация в отчёте
Окно вывода результатов PVS-Studio в первую очередь предназначено для упрощения навигации по коду проекта и переходу к участкам кода, содержащим потенциальные ошибки. Двойной клик по предупреждению в таблице автоматически откроет позицию (файл и строку), на которую оно выдано.
Клик левой кнопкой мыши по заголовку таблицы сортирует содержимое по выбранному столбцу.
Клик правой кнопкой мыши по заголовку таблицы открывает всплывающее меню, с помощью которого можно скрыть/отобразить дополнительные столбцы, а также активировать отображение полных путей до файлов в столбце позиций.

В таблице предупреждений поддерживается множественный выбор. Для его активации можно использовать протяжку с зажатой левой кнопкой мыши, а также привычные сочетания клавиш:
- 'Shift+Клик' или 'Shift+стрелочки' – множественный выбора/отмена
- 'Ctrl+Клик' – для единичного выбора/отмены
Примечание: практически все элементы в плагине имеют всплывающие подсказки. Для их активации достаточно задержать курсор мыши над элементом на пару секунд.
Столбцы в отчёте и их назначение
Level – неименованный первый столбец, отображает соответствие между уровнем предупреждения и цветом (в порядке убывания важности/достоверности): красный – 1 уровень, оранжевый – 2 уровень, жёлтый – 3 уровень.
Star – показывает, отмечено ли срабатывание как избранное. Клик по ячейке в этом столбце устанавливает/снимает отметку "избранное" с соответствующего предупреждения. Полезно для выделения интересных предупреждений, например, тех, к которым имеет смысл вернуться позже.
ID – показывает порядковый номер предупреждения в отчёте. Полезно при необходимости отсортировать отчёт в порядке получения предупреждений от анализатора.
Code – указывает к какой диагностике относится те или иные предупреждения. Клик по значению в данном столбце открывает документацию по соответствующей диагностике.
CWE – отображает соответствие предупреждения согласно классификации CWE. Клик по значениям в данном столбце открывает документацию с описанием соответствующего недостатка безопасности.
SAST – отображает соответствие предупреждения согласно различным стандартам защищённости или безопасности, например, SEI CERT, MISRA, AUTOSAR, и т.д.
Message – текст предупреждения, выданного анализатором.
Project – содержит название проекта, анализ которого привёл к выдаче предупреждения.
Position – показывает позицию (имя файла и строка через двоеточие), к которой относится срабатывание. В случае необходимости отобразить полный путь до файла – необходимо кликнуть правой кнопкой мыши по заголовку таблицы и выбрать пункт 'Show full path to file'. Если предупреждение анализатора содержит сразу несколько позиций, то в его конце появляется метка (...). В таком случае при клике в столбце позиции появится список со всеми дополнительными позициями.

FA – показывает, установлена ли для предупреждения отметка ложного срабатывания.
Примечание: некоторые столбцы могут быть скрыты по умолчанию. Для их отображения /скрытия необходимо кликнуть правой кнопкой мыши по заголовку таблицы и в появившемся меню выбрать пункт 'Show Columns', а в нем столбец, который вас интересует.
Контекстное меню
При клике на каком-либо предупреждении правой кнопкой мыши появляется всплывающее меню с перечнем доступных дополнительных действий:

Меню 'Mark As' – содержит команды для быстрой установки/снятия отметок с выбранных предупреждений. На данный момент доступны отметки предупреждений как избранные и ложные. Обратите внимание, что содержимое этого меню меняется в зависимости от состояния выбранных на данный момент предупреждений.
'Suppress selected messages' – позволяет подавить текущие выбранные предупреждения в файл подавления. Подробнее о подавлении предупреждений написано в пункте "Подавление предупреждений".
Меню 'Copy to clipboard' – позволяет скопировать информацию о выбранных предупреждениях. Содержит несколько подпунктов:
- All – копирует полную информацию о срабатывании (номер диагностики, классификаторы безопасности, полное сообщение анализатора, имя файла и строка). Обратите внимание, что классификаторы безопасности (CWE и/или SAST) будут включены в сообщение только при включённом отображении соответствующих столбцов таблицы;
- Message – копирует только текст предупреждения;
- Path to file – копирует полный путь до файла.
'Hide all %N errors' – позволяет скрыть из отчёта все предупреждения, относящиеся к данной диагностике. При клике появляется всплывающее меню для подтверждения операции. В случае положительного выбора сообщения будут отфильтрованы мгновенно.

'Don't check files from' – подменю, содержащее части пути до файла позиции. Используется, если вам необходимо скрыть из отчёта все срабатывания, полученные на файлы из выбранной директории. При выборе какого-либо значения появится всплывающее окно для подтверждения фильтрации и описанием как её отключить в будущем:

Меню 'Analyzed source files' – содержит список файлов, анализ которых привёл к появлению данного предупреждения. Полезно при выдаче срабатывания на заголовочных файлах.
Фильтрация отчёта
Механизмы фильтрации окна вывода PVS-Studio позволяют быстро найти и отобразить как отдельные диагностические сообщения, так и целые их группы.
Все перечисленные ниже механизмы фильтрации предупреждений (быстрые и расширенные фильтры) можно совмещать между собой одновременно, а также с сортировкой. Например, можно отфильтровать сообщения по уровню и группам отображаемых предупреждений, исключить все сообщения кроме тех, что содержат определённый текст и дополнительно отсортировать по позициям.
Быстрые фильтры
Панель инструментов содержит ряд переключателей, позволяющих включить либо отключить отображение предупреждений из соответствующих им групп. При изменении состава активных категорий также будут пересчитаны счётчики.

Примечание: переключатель группы 'Fails' отображается только при наличии ошибок от анализатора (их 'Code' начинается с V0..) в отчёте.
Детальное описание уровней достоверности предупреждений и групп диагностических правил приведено в разделе документации "Знакомство со статическим анализатором кода PVS-Studio".
Расширенные фильтры
Расширенные фильтры отображаются при нажатии кнопки 'Quick Filters'. Состояние панели дополнительных фильтров (показана/скрыта) не влияет на активные фильтры. Т.е. их можно скрыть и при этом фильтры не будут сброшены.

При её активации появляется дополнительная панель, которая содержит поля ввода для фильтрации всех столбцов таблицы, а также кнопка для быстрой очистки всех фильтров (Clear All).

После ввода текста в поля ввода необходимо нажать 'Enter' для активации фильтра. Обратите внимание, что некоторые поля поддерживают множественную фильтрацию (например, Code), о чём сообщается во всплывающей подсказке при наведении курсора мыши на поле ввода.
Подавление предупреждений
При первом запуске анализатора на большом проекте может быть действительно много срабатываний. Разумеется, стоит выписать себе самые интересные, а вот остальные можно скрыть при помощи механизма подавления предупреждений.
Для подавления всех предупреждений нужно выбрать пункт 'Suppress All Messages' в меню плагина:

При его активации появится дополнительное окно с вопросом, какие именно предупреждения вы хотите подавить:
- All подавит все предупреждения в таблице (даже скрытые через фильтры и настройки);
- Only Filtered подавит только те предупреждения, что сейчас присутствуют в таблице.

При выборе нужного пункта предупреждения будут подавлены в существующий файл подавления предупреждений. Если файл подавления предупреждений не будет найден, то будет создан в следующей директории: '%корневой_каталог_исходного_код_проекта%/.PVS-Studio'.
Если предложенный выше вариант вам не подходит, то можно воспользоваться точечным подавлением предупреждений. Для этого необходимо выбрать нужные строки в таблице, открыть контекстное меню и выбрать 'Add message to suppression file'.

Конфигурация плагина
В настройки плагина PVS-Studio для IDE Qt Creator можно попасть с помощью выбора раздела PVS-Studio в общем списке настроек или с помощью пунктов меню 'Options...' плагина.
Настройки плагина хранятся в файле 'qtcsettings.json', который расположен:
- Windows: '%APPDATA%\PVS-Studio\qtcsettings.json';
- Linux/macOS: '~/.config/PVS-Studio/qtcsettings.json '.
Все настройки плагина разделены на 5 вкладок:
- General – основные настройки плагина;
- Detectable Errors – настройка активных предупреждений;
- Don't Check Files – фильтрация предупреждений по маскам путей или имён файлов;
- Keyboard Message Filtering – фильтрация сообщений по ключевым словам;
- Registration – ввод лицензии для анализатора.
Вкладка 'General'
Содержит основные настройки анализатора и плагина.

Incremental analysis – включает режим инкрементального запуска анализатора.
Remove intermediate files – автоматическое удаление временных файлов, создаваемых анализатором в процессе работы.
Analysis Timeout – позволяет задать временя (в секундах), после которого проверка текущего файла будет пропущена.
Thread Count – количество потоков, используемых при анализе. Указание большего значения может ускорить анализ, но также может привести к аварийному завершению работы анализатора в связи с нехваткой памяти. Оптимальное значение равно количеству физических ядер используемого процессора.
Display false alarms – включает/отключает отображение ложных срабатываний в отчёте. При активации появляется дополнительный столбец в таблице визуализации отчёта.
Save file after False Alarm mark – если активно, то сохраняет изменённый файл после вставки комментария ложного срабатывания.
Source Tree Root – содержит путь, который должен использоваться при открытии позиций, использующих относительные пути. Например, если в предупреждении записан относительный путь '\test\mylist.cpp', а настройка Source Tree Root содержит путь 'C:\dev\mylib', то при попытке перехода на позицию из предупреждения будет открыт файл 'C:\dev\mylib\test\mylist.cpp'.
Детальное описание использования относительных путей в файлах отчётов PVS-Studio смотрите здесь.
Help Language – указывает, на какой язык предпочтительно открывать документацию анализатора. Используется при переходе в документацию на сайте анализатора.
Вкладка 'Detectable Errors'
Данная вкладка содержит список и описание всех предупреждений анализатора, а также позволяет включать/выключать как отдельные диагностики, так и целые категории.

В верхней части окна доступен полнотекстовый поиск по описанию диагностики и её номеру. При клике на код диагностики открывается её документация. При наведении на текст появляется всплывающее сообщение с полным текстом. При нажатии 'OK' или 'Apply' происходит обновление таблицы предупреждений для соответствия текущим фильтрам.
Все диагностики сгруппированы в категории. Для них можно выставить следующие состояния:
- Disabled – категория отключена и все её элементы не будут показываться в списке предупреждений. Также её кнопка будет скрыта с панели быстрых фильтров (кроме категории General).
- Custom – категория активна, элементы имеют различные состояния.
- Show All – активирует категорию и всё дочерние элементы.
- Hide All – деактивирует категорию и все дочерние элементы. Кнопка категории не пропадает с панели быстрых фильтров.
Полный список диагностик всегда доступен в разделе "Сообщения PVS-Studio".
Вкладка 'Don't Check Files'
Содержит списки для фильтрации предупреждений по маскам имён файлов или путей. Если имя или путь будет удовлетворять хотя бы одной маске – он будет скрыт из отчёта.

Поддерживаются следующие символы подстановки:
* – любое количество любых символов
? – один любой символ
Для добавления записи необходимо нажать кнопку 'Add' и ввести текст в появившееся поле. Для удаления необходимо выбрать запись и нажать кнопку 'Remove'. Записи с пустыми полями будут удалены автоматически. Редактировать уже существующие записи можно при помощи двойного клика по ней или выбора и нажатия кнопки 'Edit'.
При нажатии кнопок 'OK' или 'Apply' происходит обновление таблицы предупреждений для соответствия текущим фильтрам.
Вкладка 'Keyword Message Filtering'
Вкладка содержит редактор ключевых слов, предупреждения с которыми будут скрыты в отчётах. Ключевые слова из этого списка проверяются только по данным в столбце 'Message'.

Функция может быть полезна при необходимости скрыть предупреждения от определённой функции или класса, достаточно указать их здесь.
Вкладка 'Registration'
Вкладка содержит форму для ввода данных лицензии, которая будет использоваться при запуске анализатора. Процесс ввода лицензии в Qt Creator подробно описан в документации.

Горячие клавиши
Использование горячих клавиш позволяет ускорить процесс обработки полученных результатов анализа. Их можно назначать/переопределять в настройках 'Options -> Environment -> Keyboard'. Чтобы быстрее их найти, необходимо ввести 'PVS-Studio' в поле поиска окна 'Keyboard Shortcuts'.

Анализ C и C++ проектов на основе JSON Compilation Database
- Основные положения
- Запуск анализа и получение отчета
- Генерация compile_commands.json
- CMake-проект
- Ninja-проект
- QBS-проект
- Использование утилиты Text Toolkit
- Использование утилиты Bear (только для Linux и macOS)
- Использование утилиты intercept-build (только для Linux и macOS)
- Использование утилиты Compilation Database Generator (только для Linux и macOS)
- Xcode-проект (только для macOS)
- qmake-проект
- SCons-проект
- Bazel-проект
Основные положения
Одним из способов представления структуры C++ проекта является формат JSON Compilation Database. Это файл, в котором записаны параметры компиляции, необходимые для создания объектных файлов из исходного кода проекта. Обычно он имеет имя 'compile_commands.json'. База данных компиляции в JSON-формате состоит из массива "командных объектов", где каждый объект определяет один из способов компиляции единицы трансляции в проекте.
Файл 'compile_commands.json' может использоваться для компиляции проекта или для анализа сторонними утилитами. C и C++ анализатор PVS-Studio тоже умеет работать с этим форматом.
Запуск анализа и получение отчета
Анализ проекта на Linux и macOS выполняется с помощью утилиты 'pvs-studio-analyzer'. Анализ на Windows – c помощью утилиты 'CompileCommandsAnalyzer.exe', которая обычно размещена в папке 'C:\Program Files (x86)\PVS-Studio'. Дополнительную информацию о CompileCommandsAnalyzer и pvs-studio-analyzer можно узнать тут.

Важно: Проект должен успешно компилироваться и быть собран перед запуском анализа.
Для запуска анализа и получения отчета необходимо выполнить две команды.
Пример команд для Linux и macOS:
pvs-studio-analyzer analyze -f path_to_compile_commands.json \
-o pvs.log -e excludepath -j<N>
plog-converter -a GA:1,2 -t tasklist -o project.tasks pvs.logПример команд для Windows:
CompilerCommandsAnalyzer.exe analyze
-f path_to_compile_commands.json ^
-o pvs.log -e exclude-path -j<N>
PlogConverter.exe -a GA:1,2 -t Plog -o path_to_output_directory ^
-n analysis_report pvs.logЕсли анализ выполняется из директории с файлом 'compile_commands.json', флаг '-f' можно опустить.
Чтобы исключить из анализа директории с third-party библиотеками и/или тестами, можно использовать флаг '-e'. Если путей несколько, необходимо писать флаг '-e' для каждого пути:
-e third-party -e testsАнализ может быть распараллелен на несколько потоков с помощью флага '-j'.
Более подробные инструкции по утилитам на Linux/macOS и Windows доступны здесь и здесь.
Генерация compile_commands.json
Если проект по умолчанию не содержит 'compile_commands.json', то можно воспользоваться одним из способов генерации такого файла.
CMake-проект
Для генерации 'compile_commands.json необходимо добавить один флаг к вызову CMake:
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On .Создание 'compile_commands.json' происходит только в том случае, если генератор поддерживает JSON-формат. Такими генераторами являются, например, Makefile и Ninja:
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On -G Ninja .
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On -G "NMake Makefiles" .Для использования генератора Ninja под Windows часто требуется выполнять команды из командной строки разработчика от Visual Studio (например, 'x64 Native Tools Command Prompt for VS', и т.п.).
Ninja-проект
Если сборка проекта осуществляется напрямую с помощью Ninja и в папке проекта есть файл 'build.ninja', то можно воспользоваться следующей командой для генерации 'compile_commands.json':
ninja -t compdb > compile_commands.jsonQBS-проект
Для генерации 'compile_commands.json' в проекте, использующем Qt Build System, необходимо выполнить следующую команду:
qbs generate --generator clangdbИспользование утилиты Text Toolkit
Когда сборка проекта происходит с использованием GNU make, и получить 'compile_commands.json' не получается, то следует попробовать инструмент Text Toolkit. Сгенерировать базу данных компиляции можно либо через Web-интерфейс (только для Linux и macOS), либо запустив скрипт на Python. Для генерации online нужно:
- выполнить команду 'make -nwi > output.txt';
- скопировать содержимое файла 'output.txt' в окно на сайте Text Toolkit;
- нажать кнопку 'Generate' для генерации базы данных компиляции в формате JSON;
- скопировать полученные команды в файл 'compile_commands.json'.
Для генерации 'compile_commands.json' с помощью Python, нужно клонировать репозиторий с GitHub и выполнить следующую команду:
ninja -nv | python path_to_texttoolkit_dir\cdg.pyИспользование утилиты Bear (только для Linux и macOS)
Утилита Bear (версии 2.4 или выше) собирает параметры компиляции, перехватывая вызовы компилятора во время сборки проекта. Для генерации 'compile_commands.json' используется следующая команда
bear -- <build_command>В качестве 'build_command' может быть любая команда для сборки, например 'make all' или './build.sh'.
Использование утилиты intercept-build (только для Linux и macOS)
Утилита 'intercept-build' в scan-build аналогична утилите Bear. Команда для генерации 'compile_commands.json':
intercept-build <build_command>Использование утилиты Compilation Database Generator (только для Linux и macOS)
Compile Database Generator (compiledb) – это утилита для генерации базы данных компиляции для Makefile-based сборочных систем. Пример генерации 'compile_commands.json':
compiledb -n makeФлаг '-n' означает, что сборка не произойдет (dry run).
Xcode-проект (только для macOS)
С помощью утилиты xcpretty можно сгенерировать 'compile_commands.json'. Для этого необходимо выполнить следующую команду:
xcodebuild [flags] | xcpretty -r json-compilation-databaseqmake-проект
Для генерации 'compile_commands.json' в проекте, использующем qmake, можно воспользоваться IDE QtCreator версии 4.8 и выше. Для этого необходимо открыть в ней нужный проект и выбрать в строке меню пункт 'Сборка -> Создать базу данных компиляции для %название_проекта%' ('Build->Generate Compilation Database for %название_проекта%'):

Сгенерированный файл 'compile_commands.json' появится в директории сборки проекта.
Примечание: данный способ получения 'compile_commands.json' не предусматривает автоматизации и рекомендуется к использованию только в целях тестирования.
SCons-проект
Для генерации 'compile_commands.json' в проекте, использующем систему сборки SCons, необходимо в файл SConstruct (аналог Makefile файла для утилиты Make) в директории проекта добавить следующие строчки:
env = Environment(COMPILATIONDB_USE_ABSPATH=True)
env.Tool('compilation_db')
env.CompilationDatabase()
env.Program('programm_for_build.c')После этого для создания файла 'compile_commands.json' необходимо запустить в директории проекта (где расположен файл SConstruct) команду:
scons -QБолее подробное описание создания 'compile_commands.json' в SCons находится в соответствующем разделе документации SCons.
Bazel-проект
Для генерации 'compile_commands.json' в проекте, использующем систему сборки Bazel, используйте утилиту bazel-compile-commands-extractor (это утилита, которая не требует полной сборки проекта, и основана на Action Graph Query (aquery)). Инструкция по её настройке расположена здесь.
Есть несколько других вариантов создания файла 'compile_commands.json' для Bazel проекта кроме bazel-compile-commands-extractor:
- github.com/google/kythe: tools/cpp/generate_compilation_database.sh - Использует experimental_action_listener для создания базы данных компиляции;
- github.com/grailbio/bazel-compilation-database – Быстрее, чем experimental_action_listener от Kythe, проще в настройке и не требует полной сборки, но менее точен. Этот репозиторий заморожен с 17 марта 2024;
- github.com/stackb/bazel-stack-vscode-cc – Расширение для VS Code, которое добавляет команду для создания 'compile_commands.json' для проекта.
Использование PVS-Studio с помощью CMake-модуля
Помимо режима работы с compile_commands.json, работать с PVS-Studio в CMake можно с помощью специального CMake-модуля. Он позволяет вам интегрировать анализатор в проект на основе CMake более глубоким образом. Например, вы можете указать конкретные цели для анализа, чтобы не проверять весь проект полностью, а лишь те части, которые вам нужны.
Прежде чем начать
Убедитесь, что вы ввели лицензионный ключ, иначе анализ не заработает. О том, как это сделать, подробно написано здесь.
Добавление модуля в проект
Самый простой и рекомендованный способ добавить модуль в проект — это использовать FetchContent для автоматической загрузки. Сделать это можно примерно так:
include(FetchContent)
FetchContent_Declare(
PVS_CMakeModule
GIT_REPOSITORY "https://github.com/viva64/pvs-studio-cmake-module.git"
GIT_TAG "master"
)
FetchContent_MakeAvailable(PVS_CMakeModule)
include("${pvs_cmakemodule_SOURCE_DIR}/PVS-Studio.cmake")Этот код самостоятельно загрузит Git-репозиторий с модулем в генерируемую папку кэша и позволит интегрировать анализатор в ваш проект. Обратите внимание, что master — это самая свежая версия. Если у вас возникнут проблемы с ней, то попробуйте взять последний релизный тег текущей версии анализатора.
Вы также можете загрузить файл с модулем PVS-Studio.cmake самостоятельно, если вы не хотите иметь лишних зависимостей от FetchContent.
Пожалуйста, не забывайте обновлять модуль с выходом новой версии анализатора во избежание проблем в его работе. В параметре GIT_TAG также можно указать master-ветку, чтобы всегда использовать последнюю версию модуля.
Настройка модуля
Для запуска анализатора CMake-модуль добавляет отдельную цель для сборки. При запуске сборки этой цели на самом деле будет запущен анализ с параметрами, которые были указаны при добавлении этой цели. Чтобы добавить цель для анализа, нужно использовать команду pvs_studio_add_target. Например:
cmake_minimum_required(VERSION 3.5)
project(pvs-studio-cmake-example CXX)
add_executable(example main.cpp)
# Optional:
# include(FetchContent)
# FetchContent_Declare(....)
# FetchContent_MakeAvailable(....)
include(PVS-Studio.cmake)
pvs_studio_add_target(TARGET example.analyze ALL
OUTPUT FORMAT json
ANALYZE example
MODE GA:1,2
LOG target.err
ARGS -e /path/to/exclude-path)Этот небольшой CMake-файл содержит одну цель для сборки исполняемого файла и одну цель для запуска анализа. Разберем параметры команды pvs_studio_add_target:
Опции целей
- ALL — анализ будет запускаться автоматически при сборке цели all, т. е. будет работать при каждой сборке проекта;
- TARGET — название создаваемой цели для анализа. Чтобы запустить анализ, достаточно собрать эту цель;
- ANALYZE — цели, которые нужно проанализировать. Должны быть уникальны при параллельной сборке нескольких целей CMake-модулем. Чтобы также проанализировать зависимости этих целей, стоит добавить флаг RECURSIVE;
- RECURSIVE — рекурсивно анализировать зависимости целей;
- COMPILE_COMMANDS — использовать compile_commands.json вместо указания целей в опции ANALYZE. Работает за счет CMAKE_EXPORT_COMPILE_COMMANDS, доступно только при использовании Makefile или Ninja генераторов.
Опции вывода
- OUTPUT — печатать вывод анализатора в лог сборки;
- LOG — файл отчета. Если его не указывать, будет использоваться файл PVS-Studio.log в директории с CMake кэшем;
- FORMAT — формат отчета. В данном случае json — формат ошибок с поддержкой многофайловой навигации. Список доступных форматов можно найти здесь (раздел "Утилита Plog Converter"). Можно использовать несколько форматов (пример:
FORMAT "gitlab,tasklist-verbose"); - MODE — включение групп диагностик и их уровней.
Опции анализа
- PLATFORM — название платформы, доступные опции: win32, x64/win64, linux32, linux64, macos, arm (IAR Embedded Workbench), pic8 (MPLAB XC8), tms (Texas Instruments C6000);
- PREPROCESSOR — формат препроцессированного файла (clang/visualcpp/gcc);
- LICENSE — путь до .lic файла;
- CONFIG — путь до .cfg файла;
- CFG_TEXT — содержимое .cfg файла;
- SUPPRESS_BASE — путь до suppress-файла в формате .suppress.json;
- KEEP_COMBINED_PLOG — не удалять совмещенный файл .pvs.raw для последующей обработки утилитой plog-converter.
Прочие опции
- DEPENDS — дополнительные зависимости для цели;
- SOURCES — список исходных файлов для анализа;
- BIN — путь до pvs-studio-analyzer (macOS/Linux) или CompilerCommandsAnalyzer.exe (Windows);
- CONVERTER — путь до plog-converter (macOS/Linux) или HtmlGenerator.exe (Windows);
- C_FLAGS — дополнительные флаги для C компилятора;
- CXX_FLAGS — дополнительные флаги для C++ компилятора;
- ARGS — дополнительные аргументы для pvs-studio-analyzer/CompilerCommandsAnalyzer.exe;
- CONVERTER_ARGS — дополнительные аргументы для plog-converter/HtmlGenerator.exe.
Исключение файлов из анализа
Для исключения файлов из анализа можно воспользоваться опцией ARGS, передав пути через флаг -e (‑‑exclude-path), как указано в примере выше. Вы можете задать абсолютные, относительные пути или маску поиска (glob). Учтите, что относительные пути будут раскрыты относительно каталога сборки. Такой подход позволяет, например, исключить из анализа сторонние библиотеки.
Запуск анализа
Для запуска анализа надо собрать цель, которая была добавлена в pvs_studio_add_target. Например, так выглядит запуск анализа для примера выше:
cmake --build <path-to-cache-dir> --target example.analyzeПеред запуском будут собраны все цели, указанные для анализа в параметре ANALYZE.
Здесь вы можете найти примеры интеграции PVS-Studio в CMake.
Запуск PVS-Studio в Docker
- Docker-образы с Linux для C и C++ проектов
- Docker-образы с Linux для Java проектов
- Docker-образы с Windows для C, C++ и C# проектов
- Docker-образы с Windows для Java проектов
- Дополнительные ссылки
Docker — программное обеспечение для автоматизации развёртывания и управления приложениями в средах с поддержкой контейнеризации. Позволяет "упаковать" приложение со всем его окружением и зависимостями в контейнер, который может быть перенесён на любую систему, где установлен Docker.
Ниже будут рассмотрены:
- способы получения Docker-образов с последней версией PVS-Studio для разных ОС и языков программирования;
- примеры запуска анализа в контейнере;
- способы настройки анализатора.
Docker-образы с Linux для C и C++ проектов
Подготовка образа
Для сборки готового образа с последней версией анализатора PVS-Studio можно использовать Dockerfile.
Для debian-based систем:
FROM gcc:7
# INSTALL DEPENDENCIES
RUN apt update -yq \
&& apt install -yq --no-install-recommends wget \
&& apt clean -yq
# INSTALL PVS-Studio
RUN wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt | apt-key add - \
&& wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list \
&& apt update -yq \
&& apt install -yq pvs-studio strace \
&& pvs-studio --version \
&& apt clean -yqДля zypper-based систем:
FROM opensuse:42.3
# INSTALL DEPENDENCIES
RUN zypper update -y \
&& zypper install -y --no-recommends wget \
&& zypper clean --all
# INSTALL PVS-Studio
RUN wget -q -O /tmp/viva64.key https://files.pvs-studio.com/etc/pubkey.txt \
&& rpm --import /tmp/viva64.key \
&& zypper ar -f https://files.pvs-studio.com/rpm viva64 \
&& zypper update -y \
&& zypper install -y --no-recommends pvs-studio strace \
&& pvs-studio --version \
&& zypper clean -allДля yum-based систем:
FROM centos:7
# INSTALL DEPENDENCIES
RUN yum update -y -q \
&& yum install -y -q wget \
&& yum clean all -y -q
# INSTALL PVS-Studio
RUN wget -q -O /etc/yum.repos.d/viva64.repo \
https://files.pvs-studio.com/etc/viva64.repo \
&& yum install -y -q pvs-studio strace \
&& pvs-studio --version \
&& yum clean all -y -qПримечание. PVS-Studio для Linux также может быть скачан по следующим постоянным ссылкам:
- https://files.pvs-studio.com/pvs-studio-latest.deb
- https://files.pvs-studio.com/pvs-studio-latest.tgz
- https://files.pvs-studio.com/pvs-studio-latest.rpm
Команда для сборки образа:
docker build -t viva64/pvs-studio:7.36 -f DockerfileПримечание. Базовый образ и зависимости необходимо изменить для целевого проекта.
Запуск контейнера
Запустить анализ, например, CMake-проекта можно с помощью следующей команды:
docker run --rm -v "~/Project":"/mnt/Project" \
-w "/mnt/Project" viva64/pvs-studio:7.36 \
sh -c 'mkdir build && cd build &&
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On .. && make -j8 &&
pvs-studio-analyzer analyze ... -o report.log -j8 ...'При этом конвертер отчётов анализатора (plog-converter) рекомендуется запускать вне контейнера, чтобы отчёты содержали корректные пути до исходных файлов. Единственный тип отчёта, который имеет смысл сгенерировать в контейнере, это fullhtml, (HTML отчёт с сортировкой предупреждений и навигацией по коду). Для получения других типов отчёта требуется дополнительная настройка анализатора.
При проверке не CMake-проектов в контейнере в режиме трассировки вызовов компилятора может возникнуть такая ошибка:
strace: ptrace(PTRACE_TRACEME, ...): Operation not permitted
Error: Command strace returned 1 code.Для исправления ошибки необходимо запустить докер с дополнительными правами:
docker run ... --security-opt seccomp:unconfined ...или так:
docker run ... --cap-add SYS_PTRACE ...Настройка анализатора
Указание лицензии анализатора
Т.к. время жизни контейнера ограничено, файл лицензии анализатора необходимо закоммитить в образ, либо указывать анализатору через смонтированный каталог:
pvs-studio-analyzer analyze ... -l /path/to/PVS-Studio.lic ...Восстановление путей к исходникам в отчёте
Чтобы получить отчёт анализатора с корректными путями до файлов с исходным кодом, анализатору предварительно необходимо указать директорию проекта:
pvs-studio-analyzer analyze ... -r /path/to/project/in/container ...После чего запустить конвертер отчёта вне контейнера.
На Linux или macOS:
plog-converter ... -r /path/to/project/on/host ...на Windows:
PlogConverter.exe ... -r /path/to/project/on/hostТакже в Windows можно открыть отчёт без конвертации в утилите Compiler Monitoring UI.
Исключение директорий из анализа
Исключить из анализа директории со сторонними библиотеками, тестами и директорию компилятора можно с помощью параметра -e:
pvs-studio-analyzer analyze ... -e /path/to/tests ... -e /path/to/contrib ...Настройка кросс-компилятора
Если контейнер содержит кросс-компилятор или компилятор без алиасов (например, g++-7), то имя компилятора надо указать дополнительно:
pvs-studio-analyzer analyze ... -C g++-7 -C compilerName ...Docker-образы с Linux для Java проектов
Подготовка образа
Вариант установки из архива
FROM openkbs/ubuntu-bionic-jdk-mvn-py3
ARG PVS_CORE="7.36.93539"
RUN wget "https://files.pvs-studio.com/java/pvsstudio-cores/${PVS_CORE}.zip"\
-O ${PVS_CORE}.zip \
&& mkdir -p ~/.config/PVS-Studio-Java \
&& unzip ${PVS_CORE}.zip -d ~/.config/PVS-Studio-Java \
&& rm -rf ${PVS_CORE}.zipКоманда для сборки образа:
docker build -t viva64/pvs-studio:7.36 -f DockerfileВариант коммита слоя с анализатором
Анализатор выкачивается автоматически при первом анализе проекта. Можно предварительно задать имя контейнера и выполнить анализ проекта:
docker run --name analyzer
-v "D:\Project":"/mnt/Project"
openkbs/ubuntu-bionic-jdk-mvn-py3
sh -c "cd /mnt/Project && mvn package
&& mvn pvsstudio:pvsAnalyze -Dpvsstudio.licensePath=/path/to/PVS-Studio.lic"после чего выполнить коммит в новый образ:
docker commit analyzer viva64/pvs-studio:7.36Примечание. Базовый образ и зависимости необходимо изменить для целевого проекта. Установку и запуск анализатора следует выполнять от имени одного и того же пользователя.
Запуск контейнера
Регулярно запускать анализ проекта следует аналогичным образом, добавив параметр ‑‑rm:
docker run --rm -v "D:\Project":"/mnt/Project"
openkbs/ubuntu-bionic-jdk-mvn-py3
sh -c "cd /mnt/Project
&& mvn package
&& mvn pvsstudio:pvsAnalyze -Dpvsstudio.licensePath=/path/to/PVS-Studio.lic"Настройка анализатора
Настройку анализатора при интегрировании в сборочную систему Maven или Gradle можно производить согласно инструкциям из документации:
- Интеграция PVS-Studio Java в сборочную систему Gradle
- Интеграция PVS-Studio Java в сборочную систему Maven
Docker-образы с Windows для C, C++ и C# проектов
Подготовка образа
Для сборки готового образа с последней версией анализатора PVS-Studio можно использовать следующий Dockerfile:
# escape=`
FROM mcr.microsoft.com/dotnet/framework/runtime:4.8
SHELL ["cmd", "/S", "/C"]
# INSTALL chocolatey
RUN `
@"%SystemRoot%\System32\WindowsPowerShell\v1.0\powershell.exe" -NoProfile`
-InputFormat None -ExecutionPolicy Bypass `
-Command " [System.Net.ServicePointManager]::SecurityProtocol = 3072; `
iex ((New-Object System.Net.WebClient).DownloadString `
('https://chocolatey.org/install.ps1'))" `
&& `
SET "PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin"
# INSTALL Visual Studio Build Tools components (minimal)
RUN `
choco install -y visualstudio2019buildtools `
--package-parameters "--quiet --wait --norestart --nocache `
--add Microsoft.VisualStudio.Workload.VCTools;includeRecommended `
--add Microsoft.VisualStudio.Workload.ManagedDesktopBuildTools`
;includeRecommended"
# INSTALL PVS-Studio
RUN `
choco install -y pvs-studioВыполнив в директории Dockerfile следующую команду, можно получить готовый образ:
docker build -t viva64/pvs-studio:7.36 .Полученный Docker образ будет иметь минимальные зависимости, чтобы проанализировать С++/С# "Hello Word" проекты. Если ваш проект требует дополнительные компоненты Visual Studio Build Tools, то нужно их установить, скорректировав скрипт. С перечнем доступных компонентов можно ознакомиться здесь.
В данном образе устанавливаются последние из доступных версий Build Tools для Visual Studio 2019 и PVS-Studio при помощи Chocolatey. Чтобы установить конкретную версию Build Tools 2019, нужно явно указать ее при установке. Например,
choco install visualstudio2019buildtools --version=16.10.0.0 ...О доступных версиях можно узнать здесь.
Если вам нужно установить Build Tools для Visual Studio 2017, то инструкция для установки идентична.
Если установка через Chocolatey по каким-либо соображениям не подходит, то можно всё установить самостоятельно, подготовив все необходимые инсталляторы. Рядом с Dockerfile вам необходимо будет создать директорию с инсталляторами нужных версий (PVS-Studio, VS Build Tools и т.д.). Dockerfile:
# escape=`
FROM mcr.microsoft.com/dotnet/framework/runtime:4.8
SHELL ["cmd", "/S", "/C"]
ADD .\installers C:\Installers
# INSTALL Visual Studio Build Tools components (minimal)
RUN `
C:\Installers\vs_BuildTools.exe --quiet --wait --norestart --nocache `
--add Microsoft.VisualStudio.Workload.VCTools;includeRecommended `
--add Microsoft.VisualStudio.Workload.ManagedDesktopBuildTools`
;includeRecommended `
|| IF "%ERRORLEVEL%"=="3010" EXIT 0
# INSTALL PVS-Studio
RUN `
C:\Installers\PVS-Studio_setup.exe `
/verysilent /suppressmsgboxes /norestart /nocloseapplications
# Cleanup
RUN `
RMDIR /S /Q C:\InstallersПримечание. Если ваш проект потребует дополнительной настройки окружения и зависимостей, то необходимо будет самостоятельно модифицировать Dockerfile соответствующим образом.
Запуск контейнера
Чтобы запустить анализ, при запуске контейнера нужно смонтировать все необходимые внешние зависимости: директорию с проектом, файл с настройками анализатора (Settings.xml) и т.д.
Команда запуска анализа может выглядеть следующим образом:
docker run --rm -v "path\to\files":"C:\mnt" -w "C:\mnt" \
viva64/pvs-studio:7.36 \
"C:\Program Files (x86)\PVS-Studio\PVS-Studio_Cmd.exe" \
--target ".\Project\Project.sln" --output ".\Report.plog" \
--settings ".\Settings.xml" --sourceTreeRoot "C:\mnt"После чего у вас появится отчет "path\to\files\Report.plog", который вы можете открыть в Visual Studio плагине или в утилите Compiler Monitoring UI.
Примечание. Опция 'sourceTreeRoot' - корневая часть пути, которую PVS-Studio будет использовать при генерации относительных путей в диагностических сообщениях. Это позволит избежать недействительных путей в отчете.
Настройка анализатора
Настраивать анализатор можно через:
- командную строку при запуске анализа;
- специальный файл настроек 'Settings.xml'. Его можно заранее подготовить, например, при помощи графического интерфейса Visual Studio плагина. По умолчанию этот файл располагается в директории"%AppData%\PVS-Studio\".
Docker-образы с Windows для Java проектов
Подготовка образа
Чтобы ядро анализатора работало, необходимо иметь лишь Java 11+. Если вы используете сборочную систему (Maven, Gradle), то вам также необходимо иметь настроенное для неё окружение.
Чтобы получить Docker образ с Maven и последней версией ядра анализатора PVS-Studio, можно воспользоваться одним из следующих вариантов.
Вариант установки из архива
# escape=`
FROM csanchez/maven:3.8.3-azulzulu-11-windowsservercore-ltsc2019
SHELL ["cmd", "/S", "/C"]
ARG PVS_CORE="7.36.93539"
RUN `
powershell -Command `
Invoke-WebRequest `
"https://files.pvs-studio.com/java/pvsstudio-cores/%PVS_CORE%.zip" `
-OutFile .\pvs-studio.zip`
&& `
powershell -Command `
Expand-Archive `
-LiteralPath '.\pvs-studio.zip' `
-DestinationPath \"%APPDATA%\PVS-Studio-Java\" `
&& `
DEL /f .\pvs-studio.zipВыполнив в директории Dockerfile следующую команду, можно получить готовый образ:
docker build -t viva64/pvs-studio:7.36 .Вариант коммита слоя с анализатором
Анализатор выкачивается автоматически при первом анализе проекта. Можно предварительно задать имя контейнера и выполнить анализ проекта:
docker run --name analyzer ^
-v "path\to\project":"C:/mnt/Project" ^
-w C:\mnt\Project ^
csanchez/maven:3.8.3-azulzulu-11-windowsservercore-ltsc2019 ^
mvn package pvsstudio:pvsAnalyzeПосле чего выполнить коммит в новый образ:
docker commit analyzer viva64/pvs-studio:7.36Примечание. В случае с Gradle иметь предустановленную сборочную систему необязательно, так как gradlew сделает все за вас. Поэтому за основу Dockerfile достаточно взять образ только с Java 11+.
Запуск контейнера
Регулярно запускать анализ проекта следует аналогичным образом:
docker run --name analyzer ^
--rm ^
-v "path\to\project":"C:/mnt/Project"^
-w C:\mnt\Project^
viva64/pvs-studio:7.36 ^
mvn package pvsstudio:pvsAnalyze '-Dpvsstudio.licensePath=./PVS-Studio.lic'Отличие запуска в том, что указывается опция '‑‑rm', чтобы после запуска контейнер не оставался в памяти. А также нужно указать путь до лицензии. В данном примере лицензия была помещена в корень проекта.
Стоит учесть, что при каждом запуске анализа Maven будет скачивать все необходимые зависимости в свой локальный репозиторий. Чтобы этого избежать, при запуске можно смонтировать локальный репозиторий Maven хостовой машины. Например:
docker run ... -v "%M2_REPO%":"C:\Users\ContainerUser\.m2" ...Настройка анализатора
Настройку анализатора при интегрировании в сборочную систему Maven или Gradle можно производить согласно инструкциям из документации:
- Интеграция PVS-Studio Java в сборочную систему Gradle
- Интеграция PVS-Studio Java в сборочную систему Maven
Дополнительные ссылки
- Установка и обновление PVS-Studio в Linux.
- Установка и обновление PVS-Studio в macOS.
- Как запустить PVS-Studio в Linux и macOS.
- Работа с ядром Java анализатора из командной строки.
Запуск PVS-Studio в Jenkins
Автоматизирование запуска анализатора
Для автоматизации процедуры анализа в CI (Continuous Integration) необходимо запускать анализатор как консольное приложение.
В Jenkins Вы можете создать один из следующих шагов сборки:
- Execute Windows batch command
- Windows PowerShell
- Execute shell
и вписать команду анализа (и команду конвертации отчёта в нужный формат).
Примеры команд запуска анализатора и интеграции в сборочные системы приведены на следующих страницах документации:
- Как запустить PVS-Studio в Linux и macOS;
- Как запустить PVS-Studio в Windows;
- Как запустить PVS-Studio Java.
Warnings Next Generation Plugin
Warnings NG Plugin поддерживает отчёты анализатора PVS-Studio, начиная с версии плагина 6.0.0. Этот плагин предназначен для визуализации результатов работы различных анализаторов.
Установить плагин можно из стандартного репозитория Jenkins в меню Manage Jenkins > Manage Plugins > Available > Warnings Next Generation Plugin:

Для публикации результатов анализа в настройках проекта необходимо добавить послесборочный шаг (секция Post-build Actions) Record compiler warnings and static analysis results. Далее необходимо раскрыть список Tool и выбрать PVS-Studio. В поле Report File Pattern можно указать маску или путь к отчёту анализатора. Поддерживаются отчёты с расширением .plog и .xml.
В поле Report Encoding указывается кодировка, в которой будет считан файл отчета. Если поле пустое, то будет использована кодировка операционной системы, в которой запущен Jenkins. Поля Custom ID и Custom Name переопределяют отображаемые в интерфейсе идентификатор и имя выбранной утилиты соответственно.
Для публикации результатов анализа через pipeline скрипты добавьте следующее:
recordIssues enabledForFailure: true,sourceCodeEncoding:'UTF-8',
tool: PVSStudio(pattern: 'report.plog')где report.plog отчет анализатора.
Сгенерировать отчёт в нужном формате можно следующими способами.
Windows: C, C++, C#
Отчёты с расширением .plog являются стандартными для Windows.
Linux/macOS: C, C++
plog-converter ... --renderTypes xml ...Windows/Linux/macOS: Java
В настройках плагинов для Maven и Gradle в поле outputType указать значение xml.
После сборки проекта слева в списке появится новый элемент меню PVS-Studio Warnings. По нажатию на него открывается страница, где представлена визуализация данных отчета, созданного анализатором PVS-Studio:
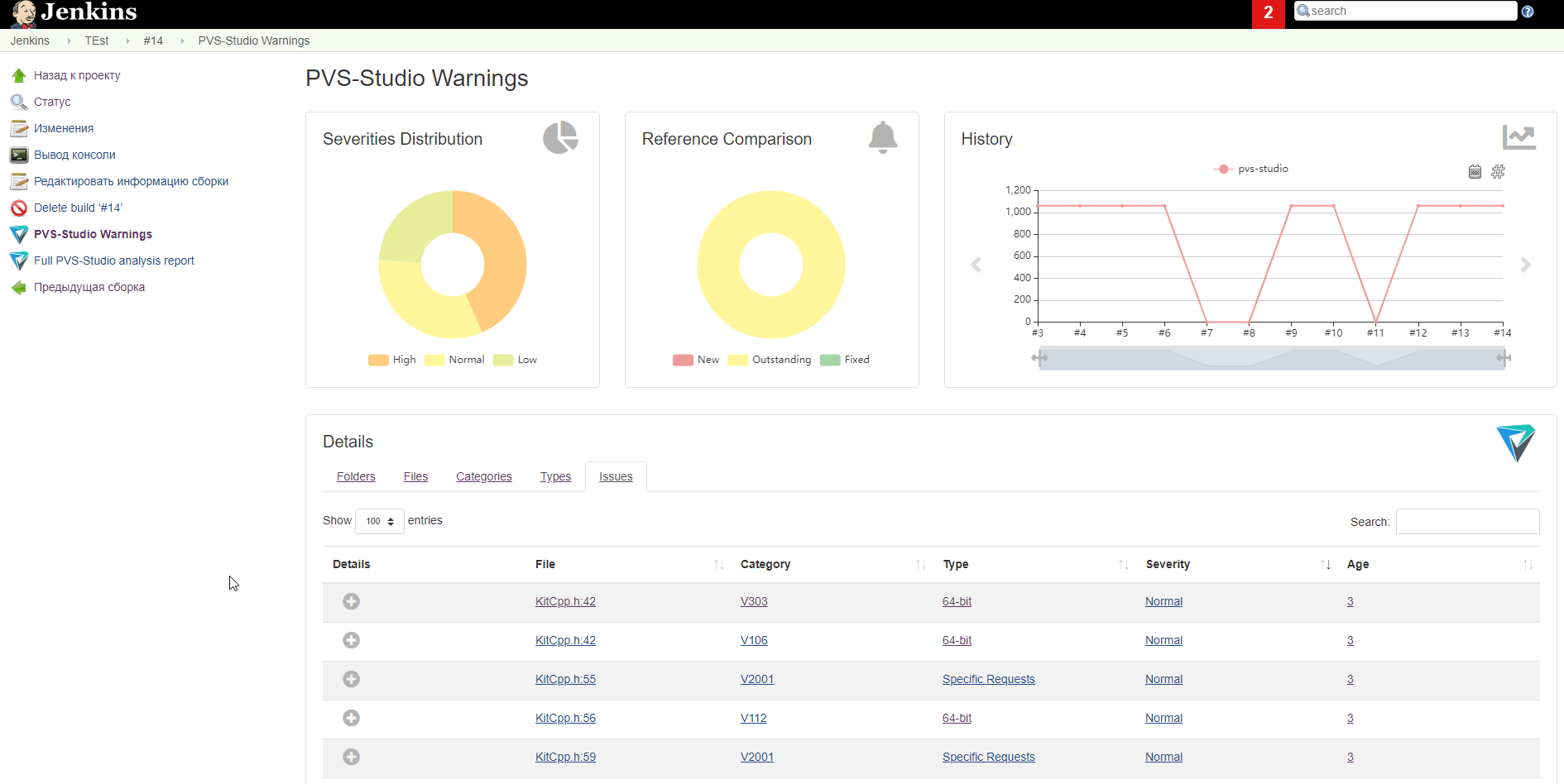
Также при нажатии на значение в столбце File в браузере будет открыт файл с исходным кодом на строчке, где была найдена ошибка.
Примечание. Просмотр предупреждений из загруженного отчёта анализатора в файлах исходного кода в Jenkins (ссылки в столбце File) работает, только если в момент запуска шага Record compiler warnings and static analysis results (секция Post-build Actions) в рабочей директории Jenkins задачи расположены файлы проекта, пути до которых указываются в отчёте анализатора (*.plog файл). Файлы исходного кода, на которые были выданы предупреждения анализатора, кэшируются для каждой сборки Jenkins задачи. Поэтому после прохождения шага Record compiler warnings and static analysis results (секция Post-build Actions) можно очищать рабочую директорию Jenkins задачи без потери возможности просмотра предупреждений в файлах исходного кода в Jenkins. Если открытие файла не работает, значит отчёт был сформирован вне рабочей директории Jenkins задачи или кэшированные файлы исходного кода из в директории сборки Jenkins задачи, участвовавшие в составлении отчёта, перемещены или удалены.
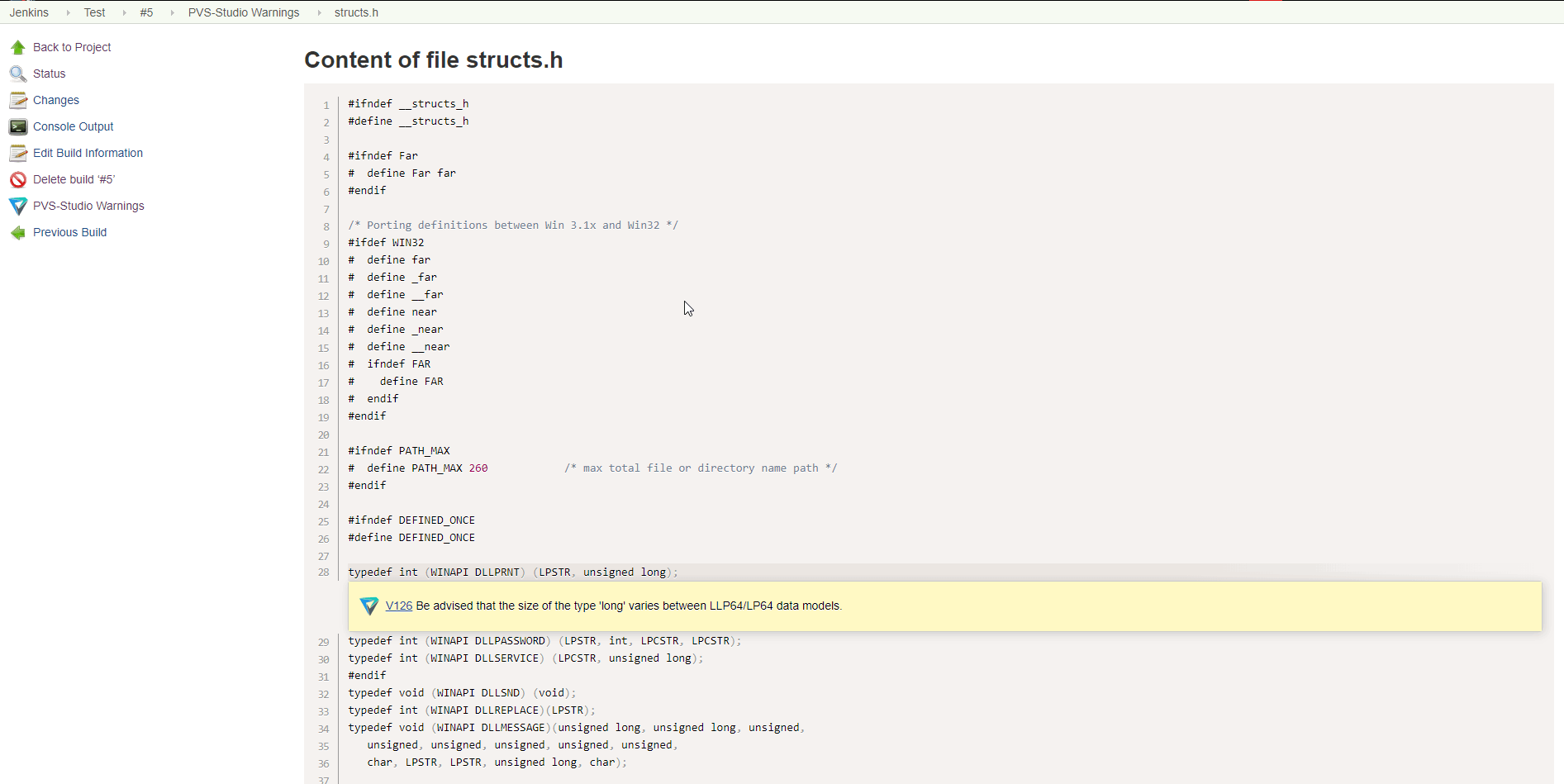
В других CI настройка запуска анализатора и работа с отчётом выполняются аналогичным образом.
Дополнительные ссылки
- Warnings NG Plugin Documentation (GitHub);
- Запуск PVS-Studio в TeamCity;
- PVS-Studio и Continuous Integration;
- Интеграция результатов анализа PVS-Studio в SonarQube.
Запуск PVS-Studio в TeamCity
Для автоматизации процесса анализа в TeamCity необходимо запускать анализатор как консольное приложение.
В TeamCity необходимо создать Build Step со следующими параметрами:
- Runner type: Command Line;
- Step Name: <name>;
- Run: Custom script;
- Custom script: <script>.
В скрипте напишите команду анализа и опционально команду конвертации отчёта в нужный формат.
Примеры команд для запуска анализатора, обработки результатов анализа и интеграции в сборочные системы приведены на следующих страницах документации:
- Как запустить PVS-Studio в Linux и macOS;
- Как запустить PVS-Studio в Windows;
- Как запустить PVS-Studio Java.
Смотри, а не читай (YouTube)
Просмотр результатов анализа
HTML отчеты
В TeamCity можно прикреплять отчёты анализатора в формате HTML к сборкам, указав их в артефактах.
Сгенерировать HTML-отчёт с навигацией по коду можно следующими способами:
Windows: C, C++, C#
PlogConverter.exe ... --renderTypes FullHtml ...Linux/macOS: C, C++
plog-converter ... --renderTypes fullhtml ...Windows/Linux/macOS: Java
В настройках плагинов для Maven и Gradle в поле 'outputType' указать значение 'fullhtml'.
В меню 'Edit Configuration Settings -> General Settings -> Artifact paths' укажите каталог с HTML-отчётом.
После успешного выполнения сборки отчёт анализатора формате fullhtml будет доступен в артефактах. Чтобы открыть его, нужно кликнуть на файл 'index.html' на вкладке 'Artifacts'. Также можно сделать так, чтобы отчёт анализатора отображался на специальной вкладке отчёта о сеансе сборки. Для этого необходимо перейти в настройки проекта, открыть 'Report Tabs' и добавить новую вкладку отчёта сборки ('Create new build report tab').
В окне добавления вкладки в поле 'Start page' необходимо указать путь к файлу 'index.html' относительно корневой папки артефактов. Например, если содержимое вкладки 'Artifacts' выглядит примерно так:

то в поле 'Start Page' нужно записать путь 'fullhtml/index.html'. После добавления вкладки результаты анализа можно будет просматривать на ней:
При переходе к предупреждениям анализатора будет открываться дополнительная вкладка браузера:
Стандартные отчеты TeamCity
Утилита "plog-converter" поддерживает стандартные отчёты для TeamCity - TeamCity Inspections Type. После генерации отчёта его необходимо вывести в stdout на любом шаге сборки.
Сгенерировать такой отчёт и вывести его в stdout можно следующими способами:
Windows: C, C++, C#
PlogConverter.exe ... –-renderTypes=TeamCity -o TCLogsDir ...
Type TCLogsDir\MyProject.plog_TeamCity.txtLinux/macOS: C, C++
plog-converter ... -t teamcity -o report_tc.txt ...
cat report_tc.txtWindows/Linux/macOS: Java
Поддержка скоро появится.
После успешного выполнения сборки отчёт анализатора появится на новой вкладке в информации об этой сборке:
Навигацию по коду можно осуществить при помощи нажатия на номер строки слева от диагностического правила. Переход осуществится при условии наличия абсолютного пути к исходному файлу, открытого проекта в IDE (Visual Studio, IntelliJ IDEA) и установленного плагина TeamCity.
Запуск PVS-Studio в Travis CI
Travis CI – сервис для сборки и тестирования программного обеспечения, использующего GitHub в качестве хранилища. Travis CI не требует изменения программного кода для использования сервиса, все настройки происходят в файле '.travis.yml', расположенном в корне репозитория.
В данной документации рассматривается пример по интеграции PVS-Studio для анализа C и C++ кода. Команды запуска PVS-Studio для анализа C# или Java кода будут отличаться. Смотрите соответствующие разделы документации: "Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio" и "Работа с ядром Java анализатора из командной строки".
Подготовка CI
Для начала создайте переменные, которые используются для формирования файла лицензии анализатора и отсылки его отчетов. Перейдите на страницу настроек - кнопка "Settings" справа от нужного репозитория.

Откроется окно настроек.

Краткое описание настроек:
- Секция "General" – настройка триггеров автозапуска задачи;
- Секция "Auto Cancellation" – позволяет настроить автоотмену сборки;
- Секция "Environment Variables" – позволяет определить переменные окружения, содержащие как открытую, так и конфиденциальную информацию, такие как учетные данные, ssh-ключи;
- Секция "Cron Jobs" – настройка расписания запуска задачи.
В секции "Environment Variables" создайте переменные 'PVS_USERNAME' и 'PVS_KEY', содержащие, соответственно, имя пользователя и лицензионный ключ для статического анализатора.

Тут же добавьте переменные 'MAIL_USER' и 'MAIL_PASSWORD', содержащие имя пользователя и пароль от почтового ящика, который нужно использовать для отправки отчетов.

При запуске задачи Travis CI берет инструкции из файла '.travis.yml', лежащего в корне репозитория.
Используя Travis CI, можно запускать статический анализ как в виртуальной машине, так и используя для этого предварительно настроенный контейнер. Результаты этих подходов ничем не отличаются друг от друга, но использование предварительно настроенного контейнера может пригодиться, например, если у нас уже есть контейнер с каким-то специфическим окружением, внутри которого собирается и тестируется программный продукт, и нет желания восстанавливать это окружение в Travis CI.
Запуск анализатора в виртуальной машине
В качестве примера для сборки и тестирования используется виртуальная машина на базе Ubuntu Trusty, ее описание можно посмотреть по ссылке.
Первым делом указывается язык, на котором написан проект (в данном случае это С) и перечисляются компиляторы, которые используются для сборки:
language: c
compiler:
- gcc
- clangПримечание: при указании более одного компилятора, задачи будут запускаться параллельно для каждого из них. Подробнее можно прочитать в документации.
Перед началом сборки нам необходимо добавить репозиторий анализатора, установить зависимости и дополнительные пакеты:
before_install:
- sudo add-apt-repository ppa:ubuntu-lxc/daily -y
- wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt |sudo apt-key add -
- sudo wget -O /etc/apt/sources.list.d/viva64.list
https://files.pvs-studio.com/etc/viva64.list
- sudo apt-get update -qq
- sudo apt-get install -qq coccinelle parallel
libapparmor-dev libcap-dev libseccomp-dev
python3-dev python3-setuptools docbook2x
libgnutls-dev libselinux1-dev linux-libc-dev pvs-studio
libio-socket-ssl-perl libnet-ssleay-perl sendemail
ca-certificatesПеред сборкой проекта необходимо подготовить окружение:
script:
- ./coccinelle/run-coccinelle.sh -i
- git diff --exit-code
- export CFLAGS="-Wall -Werror"
- export LDFLAGS="-pthread -lpthread"
- ./autogen.sh
- rm -Rf build
- mkdir build
- cd build
- ../configure --enable-tests --with-distro=unknownДалее нам необходимо создать файл с лицензией и запустить анализ проекта.
Первой командой создаем файл с лицензией для анализатора. Данные для переменных '$PVS_USERNAME' и '$PVS_KEY' берутся из настроек проекта.
- pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY -o PVS-Studio.licСледующей командой запускаем трассировку сборки проекта:
- pvs-studio-analyzer trace -- make -j4После запускаем статический анализ.
Примечание: при использовании триальной лицензии необходимо указывать параметр '‑‑disableLicenseExpirationCheck'.
- pvs-studio-analyzer analyze -j2 -l PVS-Studio.lic
-o PVS-Studio-${CC}.log
–-disableLicenseExpirationCheckПоследней командой файл с результатами работы анализатора конвертируется в html-отчет.
- plog-converter -t html PVS-Studio-${CC}.log
-o PVS-Studio-${CC}.htmlТак как TravisCI не позволяет изменять формат почтовых уведомлений, то для отсылки отчетов на последнем шаге воспользуемся пакетом 'sendemail':
- sendemail -t mail@domain.com
-u "PVS-Studio $CC report, commit:$TRAVIS_COMMIT"
-m "PVS-Studio $CC report, commit:$TRAVIS_COMMIT"
-s smtp.gmail.com:587
-xu $MAIL_USER
-xp $MAIL_PASSWORD
-o tls=yes
-f $MAIL_USER
-a PVS-Studio-${CC}.log PVS-Studio-${CC}.htmlПолный текст конфигурационного файла для запуска анализатора в виртуальной машине:
language: c
compiler:
- gcc
- clang
before_install:
- sudo add-apt-repository ppa:ubuntu-lxc/daily -y
- wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt |sudo apt-key add -
- sudo wget -O /etc/apt/sources.list.d/viva64.list
https://files.pvs-studio.com/etc/viva64.list
- sudo apt-get update -qq
- sudo apt-get install -qq coccinelle parallel
libapparmor-dev libcap-dev libseccomp-dev
python3-dev python3-setuptools docbook2x
libgnutls-dev libselinux1-dev linux-libc-dev pvs-studio
libio-socket-ssl-perl libnet-ssleay-perl sendemail
ca-certificates
script:
- ./coccinelle/run-coccinelle.sh -i
- git diff --exit-code
- export CFLAGS="-Wall -Werror"
- export LDFLAGS="-pthread -lpthread"
- ./autogen.sh
- rm -Rf build
- mkdir build
- cd build
- ../configure --enable-tests --with-distro=unknown
- pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY -o PVS-Studio.lic
- pvs-studio-analyzer trace -- make -j4
- pvs-studio-analyzer analyze -j2 -l PVS-Studio.lic
-o PVS-Studio-${CC}.log
--disableLicenseExpirationCheck
- plog-converter -t html PVS-Studio-${CC}.log -o PVS-Studio-${CC}.html
- sendemail -t mail@domain.com
-u "PVS-Studio $CC report, commit:$TRAVIS_COMMIT"
-m "PVS-Studio $CC report, commit:$TRAVIS_COMMIT"
-s smtp.gmail.com:587
-xu $MAIL_USER
-xp $MAIL_PASSWORD
-o tls=yes
-f $MAIL_USER
-a PVS-Studio-${CC}.log PVS-Studio-${CC}.htmlЗапуск анализатора в контейнере
Для запуска статического анализатора в контейнере, предварительно создайте его, используя следующий 'Dockerfile':
FROM docker.io/ubuntu:trusty
ENV CFLAGS="-Wall -Werror"
ENV LDFLAGS="-pthread -lpthread"
RUN apt-get update && apt-get install -y software-properties-common wget \
&& wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt |
sudo apt-key add - \
&& wget -O /etc/apt/sources.list.d/viva64.list
https://files.pvs-studio.com/etc/viva64.list \
&& apt-get update \
&& apt-get install -yqq coccinelle parallel
libapparmor-dev libcap-dev libseccomp-dev
python3-dev python3-setuptools docbook2x
libgnutls-dev libselinux1-dev linux-libc-dev
pvs-studio git libtool autotools-dev automake
pkg-config clang make libio-socket-ssl-perl
libnet-ssleay-perl sendemail ca-certificates \
&& rm -rf /var/lib/apt/lists/*Конфигурационный файл для запуска контейнера может выглядеть так:
before_install:
- docker pull docker.io/oandreev/lxc
env:
- CC=gcc
- CC=clang
script:
- docker run
--rm
--cap-add SYS_PTRACE
-v $(pwd):/pvs
-w /pvs
docker.io/oandreev/lxc
/bin/bash -c " ./coccinelle/run-coccinelle.sh -i
&& git diff --exit-code
&& ./autogen.sh
&& mkdir build && cd build
&& ../configure CC=$CC
&& pvs-studio-analyzer credentials
$PVS_USERNAME $PVS_KEY -o PVS-Studio.lic
&& pvs-studio-analyzer trace -- make -j4
&& pvs-studio-analyzer analyze -j2
-l PVS-Studio.lic
-o PVS-Studio-$CC.log
--disableLicenseExpirationCheck
&& plog-converter -t html
-o PVS-Studio-$CC.html
PVS-Studio-$CC.log
&& sendemail -t mail@domain.com
-u 'PVS-Studio $CC report, commit:$TRAVIS_COMMIT'
-m 'PVS-Studio $CC report, commit:$TRAVIS_COMMIT'
-s smtp.gmail.com:587
-xu $MAIL_USER -xp $MAIL_PASSWORD
-o tls=yes -f $MAIL_USER
-a PVS-Studio-${CC}.log PVS-Studio-${CC}.html"Примечание: при запуске контейнера необходимо указывать параметр '‑‑cap-add SYS_PTRACE' либо '‑‑security-opt seccomp:unconfined', так как для трассировки компиляции используется системный вызов 'ptrace'.
Получение результатов анализа
После загрузки конфигурационного файла '.travis.yml' в корень репозитория, Travis CI получит уведомление о наличии изменений в проекте и автоматически запустит сборку.
Подробную информацию о ходе сборки и проверке анализатором можно увидеть в консоли.

После окончания тестов на почту будет отправлено 2 письма: одно с результатами статического анализа при сборке проекта с использованием 'gcc', а второе с использованием 'clang'.
Запуск PVS-Studio в CircleCI
CircleCI – облачный CI-сервис для автоматизации сборки, тестирования и публикации программного обеспечения. Поддерживает сборку проектов как в контейнерах, так и в виртуальных машинах с ОС Windows, Linux и macOS.
В данной документации рассматривается пример по интеграции PVS-Studio для анализа C и C++ кода. Команды запуска PVS-Studio для анализа C# или Java кода будут отличаться. Смотрите соответствующие разделы документации: "Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio" и "Работа с ядром Java анализатора из командной строки".
Подготовка CI
При запуске сборки проекта CircleCI читает конфигурацию задачи из файла в репозитории по пути '.circleci/config.yml'.
Перед добавлением файла с конфигурацией необходимо добавить в проект переменные, содержащие лицензионные данные для анализатора. Для этого в левой панели навигации необходимо нажать 'Settings', потом в группе 'ORGANIZATION' выбрать пункт 'Projects' и нажать на шестерёнку справа от нужного проекта.

В открытом окне с настройками в разделе 'Environment Variables' создайте переменные 'PVS_USERNAME' и 'PVS_KEY', содержащие имя пользователя и лицензионный ключ для PVS-Studio.

Теперь создадим '.circleci/config.yml'.
Вначале необходимо указать образ виртуальной машины, на которой будет происходить сборка и анализ. Полный список образов доступен по ссылке.
version: 2.1
jobs:
build:
machine:
image: ubuntu-2204:currentДалее надо загрузить исходники проекта. А также, через менеджер пакетов, необходимо добавить репозитории и установить инструменты и зависимости проекта:
steps:
# Downloading sources from the Github repository
- checkout
# Setting up the environment
- run: sudo apt-get install -y cmake
- run: sudo apt-get update
- run: sudo apt-get install -y build-essentialДалее добавляется репозиторий PVS-Studio и устанавливается анализатор:
- run: wget -q -O - https://cdn.pvs-studio.com/etc/pubkey.txt
| sudo apt-key add –
- run: sudo wget -O /etc/apt/sources.list.d/viva64.list
https://cdn.pvs-studio.com/etc/viva64.list
- run: sudo apt-get -y update && sudo apt-get -y install pvs-studioРегистрация и запуск PVS-Studio
Зарегистрировать лицензию анализатора можно следующей командой:
- run: pvs-studio-analyzer credentials -o PVS.lic ${PVS_USERNAME}
${PVS_KEY}Одним из возможных вариантов анализа (C++) является создание файла compile_commands.json при сборке проекта:
- run: mkdir build && cd build && cmake ..
-DCMAKE_EXPORT_COMPILE_COMMANDS=OnПосле получения файла compile_commands.json анализ производится следующей командой:
- run: pvs-studio-analyzer analyze -j2 -l PVS.lic -o PVS-Studio.log
-f ./build/compile_commands.json
--disableLicenseExpirationCheckПолученный файл с "сырыми" результатами работы анализатора необходимо сконвертировать в html-отчет:
- run: plog-converter -t html -o PVS-Studio.html PVS-Studio.logПосле завершения тестов отчеты анализатора сохраняются как артефакт:
- run: mkdir PVS_Result && cp PVS-Studio.* ./PVS_Result/
- store_artifacts:
path: ./PVS_ResultПолный текст файла конфигурации проекта для CircleCI
Полный текст '.circleci/config.yml':
version: 2.1
jobs:
build:
machine:
image: ubuntu-2204:current
steps:
# Downloading sources from the Github repository
- checkout
# Setting up the environment
- run: sudo apt-get install -y cmake
- run: sudo apt-get update
- run: sudo apt-get install -y build-essential
# Installation of PVS-Studio
- run: wget -q -O - https://cdn.pvs-studio.com/etc/pubkey.txt
| sudo apt-key add -
- run: sudo wget -O /etc/apt/sources.list.d/viva64.list
https://cdn.pvs-studio.com/etc/viva64.list
- run: sudo apt-get -y update && sudo apt-get -y install pvs-studio
# PVS-Studio license activation
- run: pvs-studio-analyzer credentials -o PVS.lic ${PVS_ PVS_USERNAME}
${PVS_KEY}
# Building the project
- run: mkdir build && cd build && cmake ..
-DCMAKE_EXPORT_COMPILE_COMMANDS=On
# Running analysis. The compile_commands.json file obtained
# when building the project is used
- run: pvs-studio-analyzer analyze -j2 -l PVS.lic -o PVS-Studio.log
-f ./build/compile_commands.json
--disableLicenseExpirationCheck
# Converting the analyzer report to HTML format
- run: plog-converter -t html -o PVS-Studio.html PVS-Studio.log
# Creating a directory with analysis artifacts
# and copying analyzer reports (PVS-Studio.log and PVS-Studio.html)
# into it
- run: mkdir PVS_Result && cp PVS-Studio.* ./PVS_Result/
# Saving workflow artifacts
- store_artifacts:
path: ./PVS_ResultПосле загрузки сценария в репозиторий, CircleCI автоматически начнет сборку проекта.
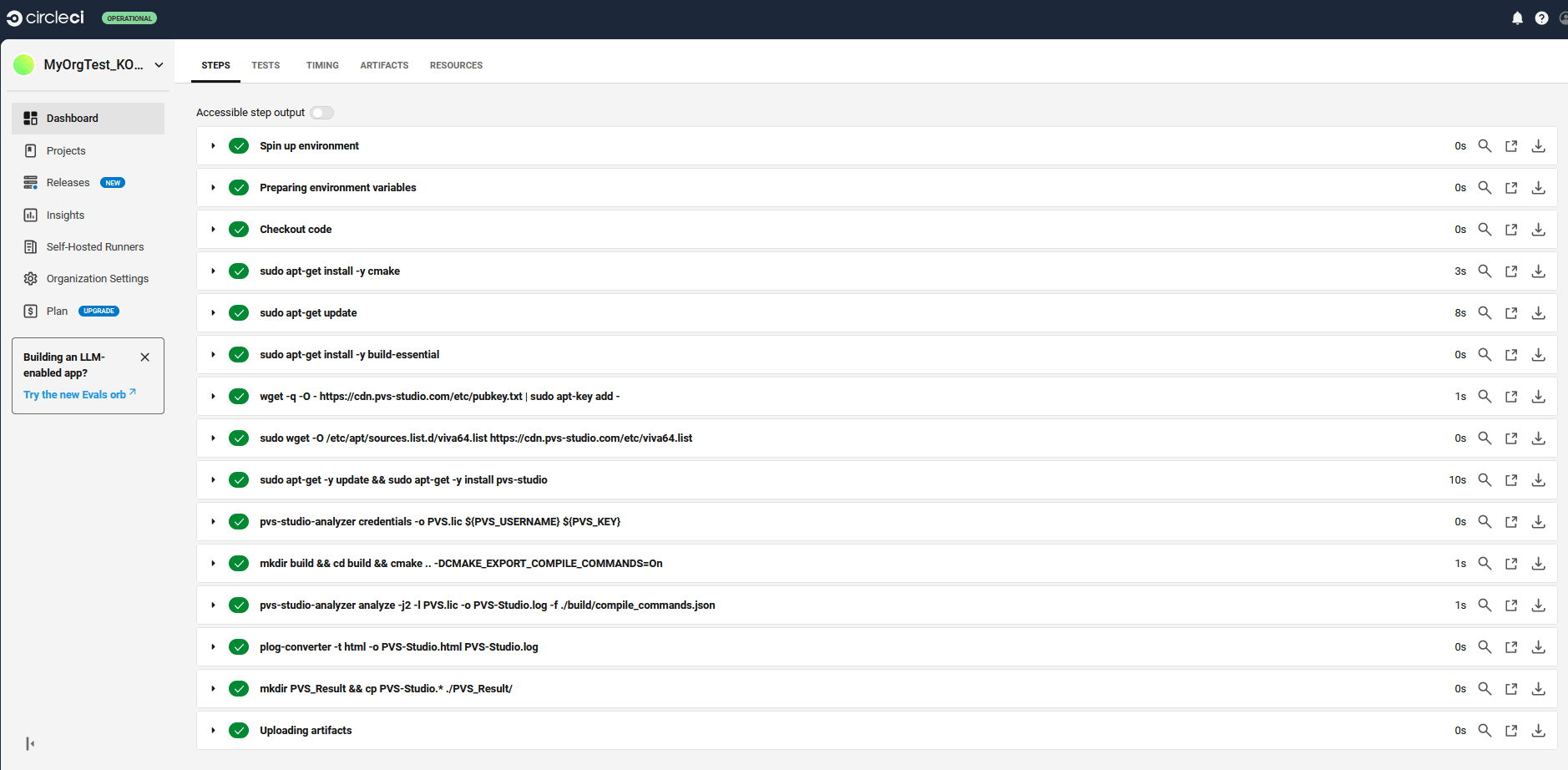
По окончании работы сценария, файлы с результатами работы анализатора можно скачать через вкладку 'Artifacts'.

Запуск PVS-Studio в GitLab CI/CD
Запуск PVS-Studio в GitLab CI/CD
GitLab – это онлайн-сервис, предназначенный для управления репозиториями. Его можно использовать прямо в браузере на официальном сайте, зарегистрировав аккаунт, или установить и развернуть на собственном сервере.
В данной документации рассматривается пример по интеграции PVS-Studio для анализа C и C++ кода. Команды запуска PVS-Studio для анализа C# или Java кода будут отличаться. Смотрите соответствующие разделы документации: "Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio" и "Работа с ядром Java анализатора из командной строки".
При запуске задачи GitLab CI берет инструкции из файла '.gitlab-ci.yml'. Его можно добавить либо кликнув на кнопку 'Set up CI/CD', либо создав в локальном репозитории и загрузив на сайт. Воспользуемся первым вариантом:
Составим пример для скрипта:
image: debian
job:
script:Скачиваем анализатор и утилиту 'sendemail', которая понадобится нам в дальнейшем:
- apt-get update && apt-get -y install wget gnupg
- wget -O - https://files.pvs-studio.com/etc/pubkey.txt | apt-key add -
- wget -O /etc/apt/sources.list.d/viva64.list
https://files.pvs-studio.com/etc/viva64.list
- apt-get update && apt-get -y install pvs-studio
sendemailДалее, устанавливаются зависимости и утилиты для сборки. Для примера показана сборка OBS:
- apt-get -y install build-essential cmake
make pkg-config libx11-dev libgl1-mesa-dev
libpulse-dev libxcomposite-dev
libxinerama-dev libv4l-dev libudev-dev libfreetype6-dev
libfontconfig-dev qtbase5-dev
libqt5x11extras5-dev libx264-dev libxcb-xinerama0-dev
libxcb-shm0-dev libjack-jackd2-dev libcurl4-openssl-dev
libavcodec-dev libqt5svg5 libavfilter-dev
libavdevice-dev libsdl2-dev ffmpeg
qt5-default qtscript5-dev libssl-dev
qttools5-dev qttools5-dev-tools qtmultimedia5-dev
libqt5svg5-dev libqt5webkit5-dev libasound2
libxmu-dev libxi-dev freeglut3-dev libasound2-dev
libjack-jackd2-dev libxrandr-dev libqt5xmlpatterns5-dev
libqt5xmlpatterns5 coccinelle parallel
libapparmor-dev libcap-dev libseccomp-dev
python3-dev python3-setuptools docbook2x
libgnutls28-dev libselinux1-dev linux-libc-dev
libtool autotools-dev
libio-socket-ssl-perl
libnet-ssleay-perl ca-certificatesТеперь нужно создать файл с лицензией анализатора. По умолчанию будет создан файл 'PVS-Studio.lic' в директории '~/.config/PVS-Studio'. В этом случае файл лицензии можно не указывать в параметрах запуска анализатора, он будет подхвачен автоматически:
- pvs-studio-analyzer credentials $PVS_NAME $PVS_KEY
Здесь 'PVS_NAME' и 'PVS_KEY' – переменные для имени пользователя и лицензионного ключа PVS-Studio, значения которых задаются в настройках репозитория. Чтобы установить их перейдём в 'Settings -> CI/CD -> Variables'.

Сборка проекта осуществляется, используя 'cmake':
- cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On /builds/Stolyarrrov/obscheck/
- make -j4Далее запускается анализатор:
- pvs-studio-analyzer analyze -o PVS-Studio.logВ полученном 'PVS-Studio.log' хранятся результаты анализа в "сыром" виде. Их необходимо сконвертировать в один из необходимых форматов при помощи утилиты 'plog-converter'.
Перевод отчета в html формат:
- plog-converter -t html PVS-Studio.log -o PVS-Studio.htmlОтчёт можно выгрузить при помощи артефактов. Но в данном примере предлагаем воспользоваться отправкой отчета на почту при помощи утилиты 'sendemail':
- sendemail -t $MAIL_TO
-m "PVS-Studio report, commit:$CI_COMMIT_SHORT_SHA"
-s $GMAIL_PORT
-o tls=auto
-f $MAIL_FROM
-xu $MAIL_FROM
-xp $MAIL_FROM_PASS
-a PVS-Studio.log PVS-Studio.htmlПолный '.gitlab-ci.yml':
image: debian
job:
script:
- apt-get update && apt-get -y install wget gnupg
- wget -O - https://files.pvs-studio.com/etc/pubkey.txt | apt-key add -
- wget -O /etc/apt/sources.list.d/viva64.list
https://files.pvs-studio.com/etc/viva64.list
- apt-get update && apt-get -y install pvs-studio
sendemail
- apt-get -y install build-essential cmake
pkg-config libx11-dev libgl1-mesa-dev
libpulse-dev libxcomposite-dev
libxinerama-dev libv4l-dev libudev-dev libfreetype6-dev
libfontconfig-dev qtbase5-dev
libqt5x11extras5-dev libx264-dev libxcb-xinerama0-dev
libxcb-shm0-dev libjack-jackd2-dev libcurl4-openssl-dev
libavcodec-dev libqt5svg5 libavfilter-dev
libavdevice-dev libsdl2-dev ffmpeg
qt5-default qtscript5-dev libssl-dev
qttools5-dev qttools5-dev-tools qtmultimedia5-dev
libqt5svg5-dev libqt5webkit5-dev libasound2
libxmu-dev libxi-dev freeglut3-dev libasound2-dev
libjack-jackd2-dev libxrandr-dev libqt5xmlpatterns5-dev
libqt5xmlpatterns5 coccinelle parallel
libapparmor-dev libcap-dev libseccomp-dev
python3-dev python3-setuptools docbook2x
libgnutls28-dev libselinux1-dev linux-libc-dev
libtool autotools-dev
make libio-socket-ssl-perl
libnet-ssleay-perl ca-certificates
- pvs-studio-analyzer credentials $PVS_NAME $PVS_KEY
- cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On /builds/Stolyarrrov/obscheck/
- make -j4
- pvs-studio-analyzer analyze -o PVS-Studio.log
- plog-converter -t html PVS-Studio.log -o PVS-Studio.html
- sendemail -t $MAIL_TO
-m "PVS-Studio report, commit:$CI_COMMIT_SHORT_SHA"
-s $GMAIL_PORT
-o tls=auto
-f $MAIL_FROM
-xu $MAIL_FROM
-xp $MAIL_FROM_PASS
-a PVS-Studio.log PVS-Studio.htmlЕсли всё сделано правильно, при нажатии на кнопку 'commit changes', появится надпись: 'This GitLab CI configuration is valid'. Чтобы отследить прогресс выполнения задачи перейдите во вкладку 'CI/CD -> Pipelines'.

Нажав на кнопку 'running' можно увидеть окно терминала виртуальной машины, на которой выполняется заданный сценарий сборки и анализа. Спустя некоторое время получаем сообщение: 'Job succeeded'.

Конвертация результатов анализа в Code Quality отчет
Для преобразования результатов анализа PVS-Studio в отчет Code Quality воспользуйтесь утилитой Plog Converter.
Чтобы пути до исходных файлов в отчете отобразились корректно, нужно использовать флаг ‑‑sourcetree-root (-r) при запуске анализа. Команда запуска анализа:
- pvs-studio-analyzer analyze -r "path/to/build/project" -o PVS-Studio.logКоманда конвертации:
- plog-converter -t gitlab -o PVS-Studio.log.gitlab.json PVS-Studio.logДля задач на Widows используйте команду:
- PlogConverter.exe -t GitLab -o .\ PVS-Studio.plogПосле того как отчет сформирован, его необходимо сохранить как артефакт. Для этого добавьте в конфигурационный файл '.gitlab-ci.yml' следующий шаг:
artifacts:
reports:
codequality: [./PVS-Studio.log.gitlab.json]В результатах выполненной задачи во вкладке Сode Quality добавятся предупреждения анализатора.
Использование PVS-Studio в GitHub Actions
GitHub Actions — это платформа, позволяющая решать CI/CD задачи, связанные с кодом в репозиториях GitHub. При помощи скриптованных Workflows она автоматизирует реакции на события, происходящие в репозитории. Это позволяет автоматически проверять собираемость проекта и проводить тестирование сразу, как только в репозиторий добавляют новый код. Средой выполнения рабочих нагрузок могут выступать как облачные виртуальные машины, так и локальные агенты с предоставленной вами конфигурацией.
В данной документации рассматривается пример по интеграции PVS-Studio для анализа C и C++ кода. Команды запуска PVS-Studio для анализа C# или Java кода будут отличаться. Смотрите соответствующие разделы документации: "Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio" и "Работа с ядром Java анализатора из командной строки".
Ручной запуск полного анализа
Для того чтобы создать новый Workflow, нужно добавить YAML скрипт в директорию '.github/workflows' репозитория.
Рассмотрим следующий пример скрипта 'build-analyze.yml', который позволяет полностью проверить проект в PVS-Studio:
name: PVS-Studio build analysis
on: workflow_dispatch
jobs:
build-analyze:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- name: Install tools
run: |
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt \
| sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt update
sudo apt install pvs-studio
pvs-studio-analyzer credentials ${{ secrets.PVS_STUDIO_CREDENTIALS }}
- name: Build
run: |
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On -B build .
cmake --build build -j
- name: Analyze
run: |
pvs-studio-analyzer analyze -f build/compile_commands.json -j
- name: Convert report
run: |
plog-converter -t sarif -o pvs-report.sarif PVS-Studio.log
- name: Publish report
uses: github/codeql-action/upload-sarif@v1
with:
sarif_file: pvs-report.sarif
category: PVS-StudioПоле 'name' в начале задаёт имя текущего Workflow, которое будет отображаться в интерфейсе GitHub.
Поле 'on' определяет, при каком событии Workflow должен запуститься. Значение 'workflow_dispatch' указывает, что задача запускается вручную. Чтобы её запустить, нужно нажать кнопку 'Run workflow' у соответствующего Workflow.
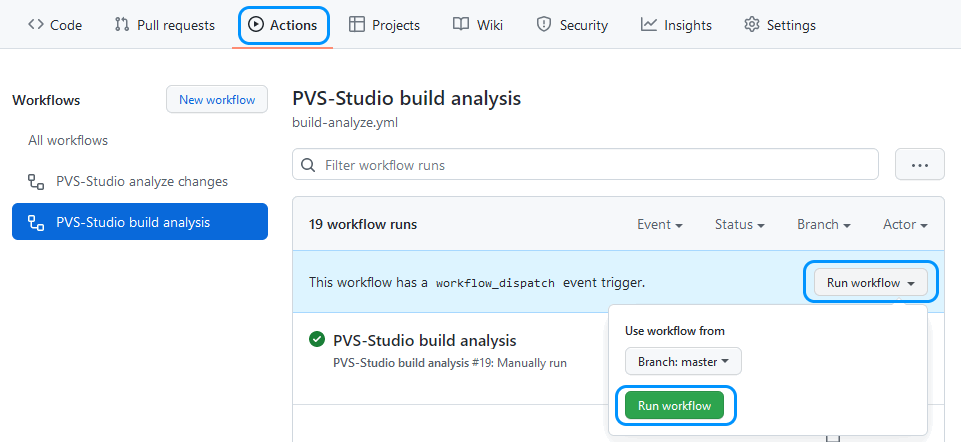
Поле 'runs-on' указывает, на какой системе должна выполняться задача. GitHub Actions предоставляет облачные серверы на системах Windows, Linux, macOS. В данном случае используется Ubuntu.
Далее идёт последовательность шагов 'steps', которые выполняют некоторые действия или последовательность команд оболочки.
Шаг 'Check out repository code' скачивает текущую версию кода репозитория.
Шаг 'Install tools' устанавливает и активирует PVS-Studio регистрационными данными в систему. Для активации PVS-Studio используется шифрованная переменная 'secrets.PVS_STUDIO_CREDENTIALS', которая содержит идентификатор пользователя и ключ.
Чтобы создать секрет, перейдите во вкладку 'Settings > Secrets > Actions' и нажмите кнопку 'New repository secret'.
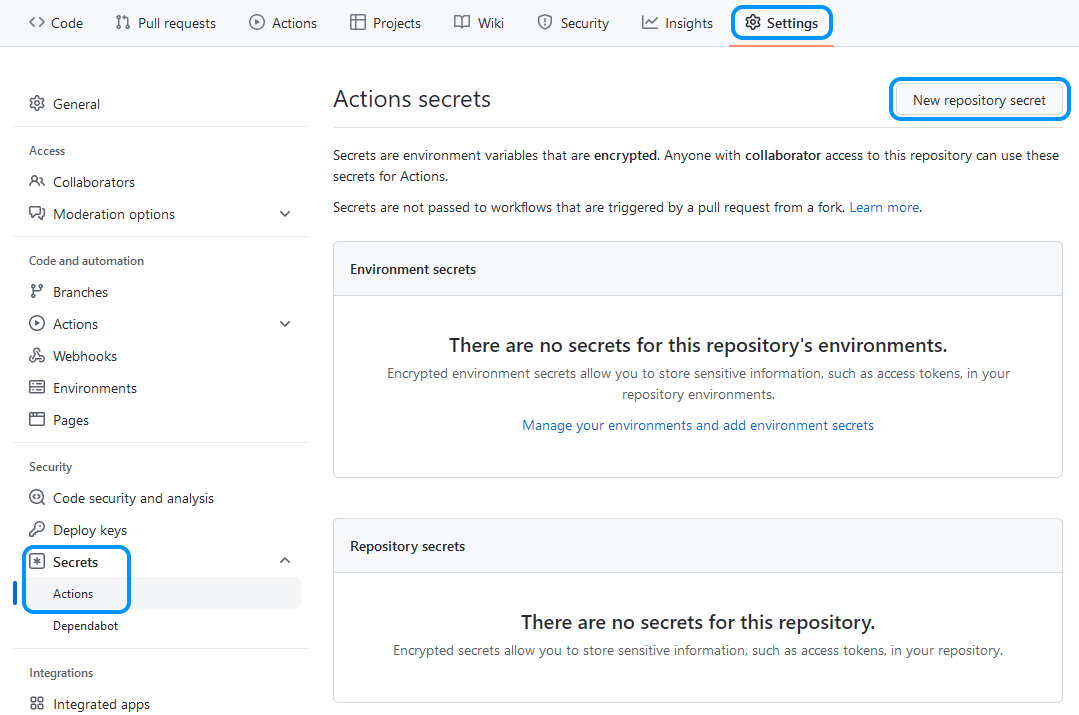
Создайте новую переменную с именем пользователя и ключом. GitHub сохранит её в зашифрованном виде, после чего её нельзя будет посмотреть. Даже в выводе консоли текст переменной будет видоизменен.

Шаг 'Build' выполняет сборку проекта, в данном случае при помощи CMake. Также в нем генерируется файл 'compile_commands.json', который используется анализатором для определения целей анализа.
Шаг 'Analyze' запускает анализ проекта и сохраняет результат в виде внутреннего представления в файл по умолчанию 'PVS-Studio.log'.
Более подробно о параметрах запуска pvs-studio-analyzer смотрите в документации.
Шаг 'Convert report' преобразует отчёт анализатора в требуемое представление, в данном случае – SARIF. Утилита plog-converter позволяет преобразовывать, объединять отчёты с разных запусков анализа и фильтровать сообщения в них.
Наконец, шаг 'Publish report' публикует итоговый отчёт, после чего его можно просмотреть во вкладке 'Security'.
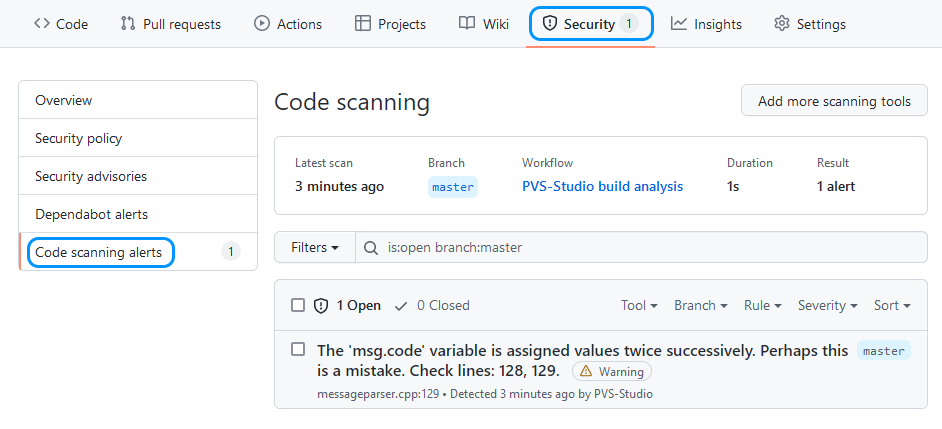
Анализ при изменениях в репозитории
Для того чтобы анализировать изменения файлов сразу после того, как они были отправлены в репозиторий, создайте новый скрипт 'analyze-changes.yml'.
name: PVS-Studio analyze changes
on:
push:
paths:
- '**.h'
- '**.c'
- '**.cpp'
jobs:
analyze-changes:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
....
- name: Get list of changed source files
run: |
echo "$(git diff --name-only \
${{ github.event.before }}..${{ github.event.after }})" \
> source-files.txt
cat source-files.txt
- name: Install tools
....
- name: Build
run: |
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On -B build .
cmake --build build -j
- name: Analyze
run: |
pvs-studio-analyzer analyze -f build/compile_commands.json \
-S source-files.txt -j
- name: Convert report
....
- name: Publish report
....В нём используется событие запуска 'push', которое стартует, когда в репозитории происходят изменения. При этом в нём заданы фильтры путей 'paths', чтобы анализ запускался только при изменении файлов с исходным кодом.
Шаг 'Get list of changed source files' для шага 'Analyze' получает список изменившихся файлов, которые необходимо проанализировать.
Сборка проекта при этом происходит на случай, если в нём есть генерируемые файлы, содержимое которых появляется только в процессе сборки.
Используя средства GitHub Actions, возможно реализовать самые разные сценарии, в том числе при изменениях не только в главной ветке, но и в других ветках или Pull Request'ах.
Работа с SARIF-отчётами
Чтобы GitHub начал анализировать SARIF-файлы, сначала необходимо настроить репозиторий. Открываем свой репозиторий и нажимаем на раздел Security.
Находим пункт Code scanning alerts и нажимаем на кнопку Set up code scanning.

Далее нажимаем на пункт Set up this workflow.

Теперь нужно изменить скрипт анализа. Чтобы участки кода, на которые выдано срабатывание, корректно отображались в разделе Security, перед публикацией SARIF-отчёта нужно преобразовать его пути в относительные при помощи утилиты plog-converter. Для этого нужно использовать флаг ‑‑pathTransformationMode (или -R) и ‑‑srcRoot (или -r). Подробнее о параметрах утилиты plog-converter можно прочитать здесь. Пример конвертации отчёта:
- plog-converter report.log -t json -n relative -R toRelative -r $PWD
- plog-converter relative.json -t sarif -n PVSSarif -r file://Полные скрипты анализа будет выглядеть так:
name: PVS-Studio build analysis
on: workflow_dispatch
jobs:
build-analyze:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- name: Install tools
run: |
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt \
| sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt update
sudo apt install pvs-studio
pvs-studio-analyzer credentials ${{ secrets.PVS_STUDIO_CREDENTIALS }}
- name: Build
run: |
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On -B build .
cmake --build build -j
- name: Analyze
run: |
pvs-studio-analyzer analyze -f build/compile_commands.json -j
- name: Convert report
run: |
plog-converter PVS-Studio.log -t json -n relative
-R toRelative -r $PWD
plog-converter relative.json -t sarif -n pvs-report -r file://
- name: Publish report
uses: github/codeql-action/upload-sarif@v1
with:
sarif_file: pvs-report.sarif
category: PVS-StudioПосле исполнения задачи можно будет посмотреть срабатывания статического анализатора в разделе Security.

Кликнув на срабатывание анализатора, можно посмотреть участок кода, на котором есть потенциальная ошибка.

Запуск PVS-Studio в GitFlic
Запуск PVS-Studio в GitFlic
GitFlic — сервис для хранения исходного кода и работы с ним. Основан на системе контроля версий Git.
В данной документации рассматривается пример по интеграции PVS-Studio для анализа C и C++ кода. Команды запуска PVS-Studio для анализа C# или Java кода будут отличаться. Смотрите соответствующие разделы документации: "Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio" и "Работа с ядром Java анализатора из командной строки".
При запуске задачи CI/CD используется инструкция из файла 'gitflic-ci.yaml'. Его можно добавить, кликнув на ссылку 'создайте новый', либо создав в локальном репозитории и загрузив на сайт. Воспользуемся первым вариантом. Перейдя по ссылке, нажмём кнопку 'Использовать':

После этого откроется базовый шаблон, который мы отредактируем для интеграции статического анализатора PVS-Studio. Составим пример скрипта работы на примере С++ проекта:
Сперва нужно установить зависимости и утилиты для сборки проекта:
- apt install cmake
- apt-get install gcc
- apt-get install doxygenТеперь установим анализатор PVS-Studio.
- wget -O - https://files.pvs-studio.com/etc/pubkey.txt
| apt-key add -
- wget -O /etc/apt/sources.list.d/viva64.list
https://files.pvs-studio.com/etc/viva64.list
- apt-get update && apt-get -y install pvs-studio
- pvs-studio-analyzer credentials $PVS_NAME $PVS_KEYЗдесь PVS_NAME и PVS_KEY — переменные для имени пользователя и лицензионного ключа PVS-Studio, значения которых задаются в настройках репозитория. Чтобы установить их, перейдём в Настройки -> Настройки CI/CD -> Переменные для задачи.

Сборка проекта осуществляется с cmake:
- cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On .Далее запускается анализатор:
- pvs-studio-analyzer analyze -o report.logЧтобы отобразить результаты анализа во вкладке Безопасность, их необходимо сконвертировать в формат .sarif при помощи утилиты plog-converter. Также необходимо перевести пути к файлам в относительные, чтобы файлы корректно отображались в разделе ошибок. Для этого нужно использовать флаг ‑‑pathTransformationMode (или -R) и ‑‑srcRoot (или -r). Подробнее о параметрах утилиты plog-converter можно прочитать здесь.
- plog-converter report.log -t json -n relative -R toRelative -r $PWD
- plog-converter relative.json -t sarif -n PVSSarif -r file://Отчёт можно выгрузить при помощи артефактов, он сразу отобразится в разделе Безопасность.
artifacts:
reports:
sast:
paths:
- 'PVSSarif.sarif'Полное содержание файла gitflic-ci.yaml:
analyze-job:
stage: build
scripts:
- apt install cmake
- apt-get install gcc
- apt-get install doxygen
- wget -O - https://files.pvs-studio.com/etc/pubkey.txt | apt-key add -
- wget -O /etc/apt/sources.list.d/viva64.list
https://files.pvs-studio.com/etc/viva64.list
- apt-get update && apt-get -y install pvs-studio
- pvs-studio-analyzer credentials ${USER_NAME} ${LICENSE_KEY}
- cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On .
- pvs-studio-analyzer analyze -o report.log
- plog-converter report.log -t json -n relative -R toRelative -r $PWD
- plog-converter relative.json -t sarif -n PVSSarif -r file://
artifacts:
reports:
sast:
paths:
- 'PVSSarif.sarif'После этого в разделе Безопасность откроется отчёт об ошибках.

В данном разделе можно выбрать необходимое срабатывание и подробнее изучить его.

При нажатии на кнопки Подробнее можно увидеть полную информацию о срабатывании.
Запуск PVS-Studio в Azure DevOps
Azure DevOps – облачная платформа, предоставляющая возможность разработки, выполнения приложений и хранения данных на удаленных серверах. В состав платформы входят инструменты Azure Pipeline, Azure Board, Azure Artifacts и другие, позволяющие ускорить процесс создания программного обеспечения и повысить его качество.
В данной документации рассматривается пример по интеграции PVS-Studio для анализа C# кода. Команды запуска PVS-Studio для анализа C, C++ или Java кода будут отличаться. Смотрите соответствующие разделы документации: "Кроссплатформенная проверка C и C++ проектов в PVS-Studio" и "Работа с ядром Java анализатора из командной строки".
Рассмотрим пример для интеграции анализа в сборку проекта.
Перейдите в раздел 'Pipelines -> Builds' и создайте новый Build pipeline.

Укажите источник проекта. Например, GitHub.

Авторизуйте приложение Azure Pipelines и укажите репозиторий с проектом.

В окне выбора шаблона укажите 'Starter pipeline'.

Запустить статический анализ кода проекта можно, используя Microsoft-hosted либо self-hosted агенты.
Использование Microsoft-hosted агента
Microsoft-hosted агенты представляют собой обычные виртуальные машины, которые запускаются при запуске Pipeline и удаляются после завершения задачи. Использование таких агентов позволяет не тратить время на их поддержку и обновление.
Заменим сценарий сборки по умолчанию следующим образом:
# Настройка триггеров запуска. Запуск для изменений только в master-ветке
trigger:
- master
# Так как установка произвольного ПО в виртуальные машины
# запрещена, воспользуемся Docker-контейнером,
# запущенном в виртуальной машине с Windows Server 1803
pool:
vmImage: 'win1803'
container: microsoft/dotnet-framework:4.7.2-sdk-windowsservercore-1803
steps:
# Загрузка дистрибутива анализатора
- task: PowerShell@2
inputs:
targetType: 'inline'
script: 'Invoke-WebRequest
-Uri https://files.pvs-studio.com/PVS-Studio_setup.exe
-OutFile PVS-Studio_setup.exe'
- task: CmdLine@2
inputs:
workingDirectory: $(System.DefaultWorkingDirectory)
script: |
# Восстанавливаем проект и скачиваем зависимости
nuget restore .\ShareX.sln
# Создаем директорию, куда будут сохранены файлы с отчетами анализатора
md .\PVSTestResults
# Устанавка анализатора
PVS-Studio_setup.exe /VERYSILENT /SUPPRESSMSGBOXES
/NORESTART /COMPONENTS=Core
# Регистрация лицензионной информации
"C:\Program Files (x86)\PVS-Studio\PVS-Studio_Cmd.exe"
credentials
-u $(PVS_USERNAME)
-n $(PVS_KEY)
# Запуск анализа PVS-Studio
"C:\Program Files (x86)\PVS-Studio\PVS-Studio_Cmd.exe"
-t .\ShareX.sln
-o .\PVSTestResults\ShareX.plog
# Преобразование отчета в html формат.
"C:\Program Files (x86)\PVS-Studio\PlogConverter.exe"
-t html
-o .\PVSTestResults\
.\PVSTestResults\ShareX.plog
# Публикация отчетов анализатора
- task: PublishBuildArtifacts@1
inputs:
pathToPublish: PVSTestResults
artifactName: PVSTestResultsДалее нужно добавить переменные, которые используются для создания файла лицензии. Для этого откройте окно редактирования Pipeline, и в правом верхнем углу нажмем кнопку 'Variables'.

Добавьте переменные – 'PVS_USERNAME' и 'PVS_KEY', содержащие имя пользователя и лицензионный ключ соответственно. При создании переменной 'PVS_KEY' не забудьте отметить пункт 'Keep this value secret' для шифрования значения переменной, а также подавления вывода значения переменной в лог выполнения задачи.

Для проверки запустите Pipeline кнопкой 'Run'.
Использование self-hosted агента
Второй вариант запуска анализа – использовать self-hosted агент. Self-hosted агенты - это агенты, настраиваемые и управляемые самостоятельно. Такие агенты дают больше возможностей для установки программного обеспечения, которое необходимо для сборки и тестирования программного продукта.
Перед использованием таких агентов их необходимо настроить согласно инструкции, а также установить и настроить статический анализатор.
Для запуска задачи на self-hosted агенте заменим предлагаемую конфигурацию по умолчанию на следующую:
# Настройка триггеров запуска. Анализ для master-ветки
trigger:
- master
# Задача запускается на self-hosted агенте из пула 'MyPool'
pool: 'MyPool'
steps:
- task: CmdLine@2
inputs:
workingDirectory: $(System.DefaultWorkingDirectory)
script: |
# Восстанавливаем проект и скачиваем зависимости
nuget restore .\ShareX.sln
# Создаем директорию, куда будут сохранены файлы с отчетами анализатора
md .\PVSTestResults
# Запуск анализа PVS-Studio.
"C:\Program Files (x86)\PVS-Studio\PVS-Studio_Cmd.exe"
-t .\ShareX.sln
-o .\PVSTestResults\ShareX.plog
# Преобразование отчета в html формат.
"C:\Program Files (x86)\PVS-Studio\PlogConverter.exe"
-t html
-o .\PVSTestResults\
.\PVSTestResults\ShareX.plog
# Публикация отчетов анализатора
- task: PublishBuildArtifacts@1
inputs:
pathToPublish: PVSTestResults
artifactName: PVSTestResultsПосле выполнения задачи, архив с отчетами анализатора можно скачать во вкладке 'Summary', либо можно воспользоваться расширением Send Mail, позволяющим настроить отправку электронной почты.

Дополнительные возможности
Завершение задачи с ошибкой
Если вы хотите, чтобы при наличии предупреждений анализатора сборочный шаг завершился и выдал сообщение об ошибке, вы можете использовать утилиту PlogConverter. С помощью PlogConverter можно задать порог, при котором будет происходить остановка работы. Далее приведен пример кода по добавлению в конец конфигурации шага остановки:
- task : PowerShell@2
inputs:
targetType: 'inline'
script: |
& "C:\Program Files (x86)\PVS-Studio\PlogConverter.exe" -t json -a GA:1
-o .\PVSTestResults\ .\PVSTestResults\TestTask.plog
--indicateWarnings --noHelpMessages
IF ($LASTEXITCODE -eq 0) {exit 0} ELSE {Write-Host
"##vso[task.logissue type=error]Analysis log contains High level warnings.";
Write-Host "##vso[task.complete result=Failed;]"; exit 0 }Что бы изменить тип предупреждений, на которые будет реагировать задача, воспользуйтесь флагом ‑‑analyzer (-a) утилиты PlogConverter.
Просмотр результатов анализа
Для просмотра отчета анализатора на странице результатов выполнения можно воспользоваться расширением SARIF SAST Scans Tab.
Чтобы конвертировать отчет в формат SARIF и воспользоваться расширением, добавьте следующие шаги:
- task: CmdLine@2
inputs:
workingDirectory: $(System.DefaultWorkingDirectory)
script: "C:\Program Files (x86)\PVS-Studio\PlogConverter.exe" -t sarif
-o .\PVSTestResults\ .\PVSTestResults\TestTask.plog
- task: PublishBuildArtifacts@1
inputs:
PathtoPublish: .\PVSTestResults\TestTask.plog.sarif
ArtifactName: CodeAnalysisLogsПосле выполнения задачи на странице с результатами во вкладке Scans будет добавлен отчет анализатора.

Использование PVS-Studio в AppVeyor
AppVeyor — web-сервис непрерывной интеграции. Он предназначен для сборки и тестирования ПО, расположенного на GitHub и ряде других сервисов хранения исходного кода.
В данной документации рассматривается пример по интеграции PVS-Studio для анализа C и C++ кода. Команды запуска PVS-Studio для анализа C# или Java кода будут отличаться. Смотрите соответствующие разделы документации: "Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio" и "Работа с ядром Java анализатора из командной строки".
Общие настройки
Необходимо задать переменные окружения, с помощью которых сформируется файл лицензии. Для этого необходимо перейти в интересующий проект, открыть вкладку 'Settings', в появившейся боковой панели перейти на вкладку 'Environment'. Далее нужно добавить две переменные — 'PVS_KEY' и 'PVS_USERNAME':

Они будут содержать лицензионный ключ и имя пользователя соответственно. Эти переменные необходимы для проверки лицензии анализатора.
Запуск PVS-Studio в AppVeyor на примере C++ проекта
Анализ всего проекта
Чтобы запустить анализ, необходимо добавить скрипт. Для этого на панели настроек нужно перейти на вкладку 'Tests', в появившемся окне нажать 'Script':

В появившуюся форму нужно добавить код:
sudo apt-get update && sudo apt-get -y install jq
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt \
| sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt-get update && sudo apt-get -y install pvs-studio
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
PWD=$(pwd -L)
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
plog-converter -t errorfile PVS-Studio.log --cerr -wПримечание. Присваивание значения команды 'pwd' переменной '$PWD' необходимо для корректной работы анализатора, поскольку AppVeyor модифицирует переменную для своих служебных целей в другое значение.
Результат анализа проекта будет сохранён в файл 'PVS-Studio.errorfile'.
Документация по использующимся утилитам:
Анализ pull requests
Для анализа pull requests необходимо произвести дополнительные настройки.
На вкладке 'General' нужно включить сохранение кэша для сборки Pull Requests (checkbox находится внизу страницы):

Далее необходимо прейти на вкладку 'Environment', где нужно указать папку для кэширования (поле для добавления находится внизу страницы):

Без данной настройки проект будет анализироваться целиком.
Чтобы запустить анализ, необходимо добавить скрипт. Для этого на панели настроек нужно перейти на вкладку 'Tests', в появившемся окне нажать 'Script':
В появившуюся форму нужно добавить код:
sudo apt-get update && sudo apt-get -y install jq
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt \
| sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt-get update && sudo apt-get -y install pvs-studio
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
PWD=$(pwd -L)
if [ "$APPVEYOR_PULL_REQUEST_NUMBER" != '' ]; then
PULL_REQUEST_ID="pulls/$APPVEYOR_PULL_REQUEST_NUMBER"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${APPVEYOR_REPO_NAME}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck \
--dump-files --dump-log pvs-dump.log \
-S .pvs-pr.list
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -wПримечание. Присваивание значения команды 'pwd' переменной '$PWD' необходимо для корректной работы анализатора, поскольку AppVeyor модифицирует переменную для своих служебных целей в другое значение.
Если анализируется pull request, то будет получена разница между ветками. После этого запустится анализ для изменённых файлов. В противном случае проект будет проанализирован полностью.
Результат анализа проекта будет сохранён в файл 'PVS-Studio.errorfile'.
Документация по использующимся утилитам:
С документацией по анализу pull/merge requests можно ознакомиться здесь.
Использование PVS-Studio в Buddy
Buddy — платформа, позволяющая автоматизировать сборку, тестирование и публикацию программного обеспечения. Поддерживает сервисы хостинга: GitHub, Bitbucket, GitLab.
В данной документации рассматривается пример по интеграции PVS-Studio для анализа C и C++ кода. Команды запуска PVS-Studio для анализа C# или Java кода будут отличаться. Смотрите соответствующие разделы документации: "Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio" и "Работа с ядром Java анализатора из командной строки".
Общие настройки
Создание pipeline'а
В первую очередь необходимо создать pipeline, в котором будет запускаться анализ. Для этого нужно перейти в настройки проекта, после чего нажать 'New pipeline':

В появившемся окне необходимо указать конфигурацию, название pipeline'а и условие для его запуска. После внесения данных нужно нажать 'Add pipeline':

Настройка pipeline'а (только для анализа pull requests)
Для анализа pull requests в качестве триггера необходимо выбрать 'On events'. Событие для срабатывания — 'Git create branch, tag or PR'. Далее необходимо прейти в настройки триггера, где на вкладке 'Wildcard' нужно добавить 'all pull requests':

Выбор компилятора
После создания pipeline'а нужно указать компилятор, который будет использоваться для сборки проекта. Разберём на примере GCC, написав его название в поиск:

В списке найденных компиляторов выберите нужный.
Создание переменных окружения
После выбора компилятора необходимо задать переменные окружения, с помощью которых будет сформирован файл лицензии. Для этого нужно нажать на 'Variables' и добавить переменные 'PVS_USERNAME' и 'PVS_KEY', которые будут содержать имя пользователя и лицензионный ключ соответственно:

Установка анализатора
Необходимо перейти на вкладку 'Docker' и нажать 'Package & Tools':

В появившуюся форму нужно ввести команды установки анализатора:
apt-get update && apt-get -y install wget gnupg jq
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt | apt-key add -
wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
apt-get update && apt-get -y install pvs-studioЗапуск PVS-Studio в AppVeyor на примере C++ проекта
Анализ всего проекта
Для анализа всего проекта необходимо перейти на вкладку 'Run':

В появившуюся форму нужно ввести команды запуска анализатора:
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
plog-converter -t errorfile PVS-Studio.log --cerr -wПосле внесения данных необходимо нажать 'Add this action'.
При выполнении данного pipeline'а сформируется отчёт с результатом анализа. Он будет сохранён в файл 'PVS-Studio.errorfile'.
Документация по использующимся утилитам:
Анализ pull requests
Для анализа pull requests необходимо перейти на вкладку 'Run'.
В появившуюся форму нужно ввести команды анализа pull/merge requests:
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
if [ "$BUDDY_EXECUTION_PULL_REQUEST_NO" != '' ]; then
PULL_REQUEST_ID="pulls/$BUDDY_EXECUTION_PULL_REQUEST_NO"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${BUDDY_REPO_SLUG}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git fetch origin
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck \
-S .pvs-pr.list
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -wПосле внесения данных необходимо нажать 'Add this action'.
При выполнении данного pipeline'а сформируется отчёт с результатом проверки изменённых файлов. Он будет сохранён в 'PVS-Studio.errorfile'.
Документация по использующимся утилитам:
С документацией по анализу pull/merge requests можно ознакомиться здесь.
Оповещение команд разработчиков (утилита blame-notifier)
Утилита blame-notifier предназначена для автоматизации процесса оповещения разработчиков, заложивших в репозиторий код, на который анализатор PVS-Studio выдал предупреждения. Отчет анализатора подается на вход blame-notifier с указанием дополнительных параметров; утилита находит файлы, в которых были обнаружены предупреждения и формирует HTML-отчет на каждого "виновного" разработчика. Также возможен вариант рассылки полного отчета: внутри него будут содержаться все предупреждения, относящиеся к каждому "виновному" разработчику.
Утилита blame-notifier доступна только при наличии Enterprise лицензии. Вы можете запросить пробную Enterprise лицензию здесь.
Примечание. Название утилиты различается под разными платформами. Под Windows она имеет название BlameNotifier.exe, под Linux и macOS - blame-notifier. Если речь не идёт про утилиту под конкретную ОС, во избежание дублирования в данном документе используется название blame-notifier.
Для работы утилиты blame-notifier под Linux и macOS требуется .NET Runtime 8.0.
Смотри, а не читай (YouTube)
Установка
На Windows
Утилиту BlameNotifier можно найти в установочной директории PVS-Studio (по умолчанию это путь "C:\Program Files (x86)\PVS-Studio\").
На Linux
Установка из репозиториев
Для debian-based систем:
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt | \
sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt-get update
sudo apt-get install blame-notifierДля yum-based систем:
wget -O /etc/yum.repos.d/viva64.repo \
https://files.pvs-studio.com/etc/viva64.repo
yum update
yum install blame-notifierДля zypper-based систем:
wget -q -O /tmp/viva64.key https://files.pvs-studio.com/etc/pubkey.txt
sudo rpm --import /tmp/viva64.key
sudo zypper ar -f https://files.pvs-studio.com/rpm viva64
sudo zypper update
sudo zypper install blame-notifierПрямые ссылки для загрузки.
На macOS
Установка из Homebrew
Установка:
brew install viva64/pvs-studio/blame-notifierОбновление:
brew upgrade blame-notifierПрямые ссылки для загрузки.
Использование
Флаг "‑‑help" выводит основную информацию об утилите:
blame-notifier --helpПример использования утилиты blame-notifier (одной строкой):
blame-notifier path/to/PVS-Studio.log
--VCS Git
--recipientsList recipients.txt
--server ... --sender ... --login ... --password ...Параметры утилиты
Ниже приводится краткое описание параметров утилиты:
- ‑‑VCS (или -v): обязательный параметр: тип системы контроля версий, с которой будет работать утилита. Поддерживаемые системы: Git, Svn, Mercurial, Perforce.
- ‑‑recipientsList (или -r): путь до текстового файла, содержащего список получателей отчетов. Формат файла описывается ниже.
- ‑‑srcRoot (или -t): задаёт замену для специального "SourceTreeRoot" маркера. Если лог анализатора был сгенерирован с этим маркером, данный параметр необходим для восстановления путей до файлов.
- ‑‑analyzer (или -a): производит фильтрацию предупреждений согласно маске. Более подробно маски фильтрации описываются ниже.
- ‑‑excludedCodes (или -e): задает список предупреждений (через ","), которые не следует включать в результирующий отчет.
- ‑‑settings (или -c): задает путь к файлу настроек PVS-Studio. Данный флаг актуален только при работе под Windows. BlameNotifier прочитает настройки отключенных предупреждений из переданного файла настроек. По сути, этот параметр расширяет список отключаемых предупреждений параметра "‑‑excludedCodes".
- ‑‑server (или -x): обязательный параметр: SMTP-сервер для отправки отчетов.
- ‑‑sender (или -s): обязательный параметр: email адрес отправителя писем.
- ‑‑login (или -l): обязательный параметр: имя пользователя для авторизации.
- ‑‑password (или -w): пароль пользователя для авторизации.
- ‑‑port (или -p): номер порта для отправления писем. По умолчанию указан порт N25.
- ‑‑days (или -d): показывать предупреждения анализатора за последние N дней, где N положительное значение. Если значение не задано или равно 0, то будут показаны все предупреждения за весь период времени.
- ‑‑sortByDate (или -S): сортировать отчет анализатора по дате изменения исходного кода, из-за которого было выдано предупреждение анализатора. По умолчанию выключено.
- ‑‑maxTasks (или -m): максимальное число параллельно запущенных blame-процессов. По умолчанию, или если задано отрицательное число, blame-notifier будет использовать 2 * N процессов (где N - число ядер процессора).
- ‑‑progress (или -g): включить или отключить логирование. По умолчанию логирование выключено.
- ‑‑enableSSL: включить использование протокола SSL. По умолчанию выключено.
- ‑‑vcsBasedRecipientsList: использовать данные из СКВ для составления списка получателей отчётов. Поддерживаемые СКВ: Perforce. По умолчанию опция выключена.
- ‑‑messageSubject: тема письма. Если параметр не указан, blame-notifier отправит письмо с темой по умолчанию: "Full PVS-Studio Analysis Results for Solution: <SolutionName>"
- ‑‑messageAttachment: список путей до файлов, которые должны быть прикреплены к письму. Если необходимо прикрепить несколько файлов, следует разделить их символом ';' и обрамить весь список в кавычки.
- ‑‑svnUsername: имя пользователя для авторизации в SVN.
- ‑‑svnPassword: пароль для авторизации в SVN
При использовании утилиты должен быть указан как минимум один из флагов, через который задаётся список получателей отчётов: '‑‑recipientsList' или '‑‑vcsBasedRecipientsList'. При необходимости эти флаги могут использоваться совместно.
Формат файла получателей отчёта
Формат файла со списком получателей отчётов:
# Получатели полного отчёта
username_1 *email_1
...
username_N *email_N
# Получатели собственных ошибок
username_1 email_1
...
username_N email_NЗакомментировать строку можно символом "#". Для получателей полных отчетов необходимо добавить символ "*" в начале или в конце email адреса. Полный отчет будет включать все предупреждения, отсортированные по разработчикам.
Формат масок фильтрации
Маски фильтрации имеют следующим вид: MessageType:MessageLevels.
MessageType может принимать одно из следующих значений: GA, OP, 64, CS, MISRA, Fail.
MessageLevels может принимать значение от 1 до 3.
Возможна комбинация разных масок через ";" (без пробелов), например:
--analyzer=GA:1,2;64:1В таком случае будут обработаны предупреждения общего назначения (GA) уровней 1 и 2 и 64-битные предупреждения (64) уровня 1.
PVS-Studio и Continuous Integration
- Наиболее эффективный сценарий использования статического анализа
- Подготовка к непрерывной интеграции
- Встраивание PVS-Studio в процесс непрерывной интеграции
- Анализ исходного кода MSBuild / Visual Studio проектов
- Анализ исходного кода проектов со специфичными сборочными системами
- Работа с результатами анализа
- Рассылка результатов анализа по электронной почте с помощью BlameNotifier
- Заключение
В данной статье рассматривается встраивание PVS-Studio в процесс непрерывной интеграции в среде Windows. Встраивание в процесс CI в среде Linux описано в статье "Как запустить PVS-Studio в Linux".
Наиболее эффективный сценарий использования статического анализа
Прежде чем перейти к основной теме данной статьи, стоит отметить, что использование PVS-Studio исключительно на сборочном сервере эффективно, но не оптимально. Лучшим вариантом будет построение двухуровневой системы проверки исходного кода - локально на машинах разработчиков и на сборочном сервере.
Этот принцип происходит из того факта, что чем раньше обнаружена ошибка, тем меньше стоимость и сложность её исправления. Поэтому необходимо стремиться к как можно более раннему обнаружению и исправлению ошибок, для чего и необходимо использование PVS-Studio на машинах разработчиков. Рекомендуется использование режима инкрементального анализа, позволяющего автоматически запускать проверку только изменённого кода после сборки проекта.
Тем не менее использование PVS-Studio на машинах разработчиков не исключает возможности попадания ошибок в систему контроля версий. Для отслеживания таких ситуаций и нужно иметь второй уровень защиты - регулярный запуск статического анализатора на сборочном сервере. Даже в случае попадания ошибки в систему контроля версий, её удастся своевременно выявить и исправить. Встраивание анализа в процесс ночных сборок позволит на следующий день получать информацию обо всех ошибках, допущенных в течение прошлого дня, и оперативно поправить проблемный код.
Примечание. Не рекомендуется конфигурировать статический анализ кода на сервере таким образом, чтобы он запускался на каждый коммит, так как анализ может занимать продолжительное время. Если необходим именно такой сценарий использования и при этом сборочной системой проекта является MSBuild, можно воспользоваться режимом инкрементального анализа command line модуля 'PVS-Studio_Cmd.exe'. За дополнительной информацией обратитесь к разделу "Инкрементальный анализ в command line модуле 'PVS-Studio_Cmd.exe'" текущего документа. Также для анализа файлов при инкрементальной сборке (вне зависимости от сборочной системы) можно использовать утилиту 'CLMonitor.exe' (только для анализа C, C++ кода). Более подробно использование утилиты 'CLMonitor.exe' описано в разделе "Система мониторинга компиляции" текущего документа.
Подготовка к непрерывной интеграции
Подготовка к встраиванию PVS-Studio в процесс непрерывной интеграции - важный этап, позволяющий сэкономить время в дальнейшем и использовать статический анализатор более эффективно. В этом разделе будут рассмотрены те особенности настройки PVS-Studio, которые упростят последующую работу.
Автоматическое развёртывание PVS-Studio
Для установки PVS-Studio требуются права администратора. Автоматическая установка осуществляется следующей командой, выполненной в командной строке (одной строкой):
PVS-Studio_setup.exe /verysilent /suppressmsgboxes
/norestart /nocloseapplicationsВыполнение этой команды приведёт к установке всех доступных компонентов PVS-Studio. Обратите внимание, что PVS-Studio может потребоваться перезагрузка компьютера в случае, например, если обновляемые файлы были заблокированы. Если установщик запустить без флага 'NORESTART', перезагрузка может произойти без предварительных уведомлений или диалогов.
В состав дистрибутива входит утилита 'PVS-Studio-Updater.exe', позволяющая проверять наличие обновлений анализатора, а в случае их наличия, загрузить и установить их на локальной машине. Для запуска утилиты в 'silent' режиме следует использовать те же параметры, что и для установки дистрибутива:
PVS-Studio-Updater.exe /verysilent /suppressmsgboxesФайл настроек генерируется автоматически при запуске Visual Studio с установленным плагином PVS-Studio или приложением C and C++ Compiler Monitoring UI (Standalone.exe), и в дальнейшем он может быть отредактирован или скопирован на другие машины. Информация о лицензии также хранится в файле настроек. Расположение файла по умолчанию:
%AppData%\PVS-Studio\Settings.xmlДля более детальной информации по автоматическому развёртыванию PVS-Studio обратитесь к статье "Автоматическое развёртывание PVS-Studio".
Предварительная настройка анализатора
Перед использованием анализатора необходимо выполнить его предварительную настройку, что поможет оптимизировать работу со списком предупреждений, а также (возможно) повысить скорость проведения анализа.
Примечание. Описанные ниже опции можно изменить, напрямую отредактировав файл настроек, или воспользовавшись интерфейсом страницы настроек в плагине к Visual Studio или в приложении C and C++ Compiler Monitoring UI.
Часто бывает полезно исключить из анализа определённые файлы или даже целые директории. Это позволит не анализировать код сторонних библиотек, сократив общее время анализа, и оставив в выводе только те предупреждения, которые актуальны именно для вашего проекта. По умолчанию в настройках анализатора уже присутствуют исключения для некоторых файлов или путей, например, для библиотеки boost. Более подробно исключение файлов из анализа описано в статье "Настройки: Don't Check Files".
На этапе внедрения также следует отключить те диагностические правила PVS-Studio, которые неактуальны для проверяемого проекта. Существует возможность отключения как отдельных диагностических правил, так и целых групп. Если вы изначально знаете диагностики, неактуальные для вашего проекта (например, 64-битные ошибки), есть смысл отключить их сразу. Это также может ускорить работу анализатора. Если список таких диагностических правил неизвестен, то при необходимости их можно будет отключить позже. Более подробно отключение диагностических правил описано в статье "Настройки: Detectable Errors".
Отключение предупреждений на старый код
В случае внедрения статического анализа в существующий проект, когда объём кодовой базы уже существенен, проверка исходного кода может выявить большое количество ошибок в существующем коде. Команда разработчиков, занимающихся данным проектом, может не иметь ресурсов, необходимых для исправления всех этих предупреждений. В таком случае возникает необходимость убрать все предупреждения, обнаруженные в старом коде, чтобы с текущего момента видеть только те предупреждения анализатора, которые были выданы на вновь написанный/модифицированный код.
Достичь желаемого результата можно с использованием механизма массового подавления сообщений анализатора. Более подробно про это написано в статье: "Массовое подавление сообщений анализатора".
Примечание 1. Если необходимо скрыть только отдельные предупреждения анализатора, следует воспользоваться механизмом подавления ложных срабатываний, описанном в статье "Подавление ложных предупреждений".
Примечание 2. Используя SonarQube, можно изменять отображение предупреждений, найденных за определённый период времени. Таким образом, можно настроить отображение только тех предупреждений, которые были найдены после внедрения анализатора (т.е. отключить отображение предупреждений на старый код).
Встраивание PVS-Studio в процесс непрерывной интеграции
PVS-Studio достаточно просто встраивается в процесс непрерывной интеграции, а также предоставляет средства для удобной обработки результатов работы анализатора.
Интеграция PVS-Studio с платформой SonarQube доступна только при наличии Enterprise лицензии. Вы можете запросить пробную Enterprise лицензию здесь.
Ниже будут описаны принципы анализа проектов, основанных на различных сборочных системах, а также утилиты для работы с результатами анализа.
Анализ исходного кода MSBuild / Visual Studio проектов
В данном разделе будет описан наиболее эффективный вариант анализа MSBuild / Visual Studio проектов, то есть файлов решений Visual Studio (.sln), проектов Visual C++ (.vcxproj) и Visual C# (.csproj).
Основные сведения
Анализ из командной строки проектов, перечисленных выше, производится за счёт использования модуля 'PVS-Studio_Cmd.exe', находящегося в установочной директории PVS-Studio. Расположение установочной директории по умолчанию - 'C:\Program Files (x86)\PVS-Studio\'.
Передавая модулю 'PVS-Studio_Cmd.exe' различные аргументы, можно регулировать параметры анализа. Увидеть список всех доступных аргументов можно, выполнив команду:
PVS-Studio_Cmd.exe --helpАнализатор имеет один обязательный аргумент - '‑‑target', с помощью которого задаётся объект для проверки (.sln, .vcxproj или .csproj файл). Остальные аргументы являются опциональными и подробно описываются в статье "Проверка Visual C++ (.vcxproj) и Visual C# (.csproj) проектов из командной строки с помощью PVS-Studio".
Рассмотрим пример запуска анализа на .sln файле (одной строкой):
PVS-Studio_Cmd.exe --target "targetsolution.sln" --platform "Any CPU"
--output "results.plog" --configuration "Release"Исполнение этой команды запустит анализ .sln файла 'targetsolution.sln' для платформы 'Any CPU' и конфигурации 'Release'. Выходной файл ('results.plog') будет создан в директории проверяемого проекта. При анализе будут использоваться стандартные настройки анализатора, так как явно не указано обратное.
Модуль 'PVS-Studio_Cmd.exe' имеет ряд ненулевых кодов возврата, посредством которых информирует о результирующем состоянии анализа. Код возврата представляет собой битовую маску, маскирующую все возможные состояния, возникшие во время работы утилиты. То есть ненулевой код не является свидетельством того, что утилита закончила свою работу некорректно. Подробное описание кодов возврата приведено в упомянутой выше статье "Проверка Visual C++ (.vcxproj) и Visual C# (.csproj) проектов из командной строки с помощью PVS-Studio".
Примечание. Если перед анализом нужно выполнить команды из CustomBuild task (например, для генерации файлов с кодом), можно указать PVS-Studio специальную директиву. В таком случае анализатор сначала выполнит необходимые команды и только затем запустит анализ. Подробности описаны в разделе "Выполнение команд из CustomBuild task перед анализом".
Получение результатов анализа только нового / модифицированного кода
При регулярном запуске анализатора может возникнуть необходимость в получении отчёта анализатора, содержащего предупреждения, выданные только на вновь написанный / модифицированный код. При ночном анализе на сборочном сервере это позволит видеть только те предупреждения, которые были допущены в течение предыдущего дня.
В случае необходимости получения такого результата при запуске модуля 'PVS-Studio_Cmd.exe' необходимо указывать аргумент командной строки '‑‑suppressAll'. При наличии этого флага все сообщения будут добавлены в базу подавленных сообщений (.suppress файлы соответствующих проектов) после сохранения результатов проверки. Следовательно, при следующей проверке эти сообщения выданы не будут. Если всё же потребуется посмотреть старые сообщения, рядом с .plog файлом, содержащим новые сообщения, будет сохранён полный лог проверки.
Механизм массового подавления предупреждений анализатора более подробно описан в статье "Массовое подавление сообщений анализатора".
Примечание. При использовании платформы SonarQube можно наблюдать только за новыми предупреждениями, не используя механизмы подавления. Для этого необходимо настроить отображение результатов анализа таким образом, чтобы видеть изменения только за последний день.
Инкрементальный анализ в command line модуле 'PVS-Studio_Cmd.exe'
Режим инкрементального анализа в PVS-Studio позволяет проверять только файлы, изменённые/затронутые с момента последней сборки проекта. Этот режим доступен как при работе с использованием плагина для Visual Studio, так и при проверке проектов с использованием command line модуля PVS-Studio. Использование режима инкрементального анализа позволит получить предупреждения только на модифицированный код, а также сократить время анализа, так как те части проекта, которые не изменялись, проанализированы не будут.
Данный режим актуален, если система непрерывной интеграции настроена на автоматическую инкрементальную сборку после обнаружения изменений в системе контроля версий, то есть, если сборка и анализ проекта на сервере происходит неоднократно в течение дня.
Использование инкрементального анализа в модуле 'PVS-Studio_Cmd.exe' регулируется с помощью флага '‑‑incremental'. Доступны следующие режимы работы:
- Scan - проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ. Непосредственно анализ выполнен не будет.
- Analyze - выполнить инкрементальный анализ. Этот шаг должен выполняться после выполнения шага Scan, и может выполняться как до, так и после сборки решения или проекта. Статический анализ будет выполнен только для измененных файлов с момента последней сборки.
- ScanAndAnalyze - проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ, и сразу же выполнить инкрементальный анализ измененных файлов с исходным кодом.
Для получения подробной информации об инкрементальном анализе в PVS-Studio обратитесь к статье "Режим инкрементального анализа PVS-Studio".
Примечание. При использовании режима инкрементального анализа следует учитывать некоторые особенности. Если PVS-Studio использует препроцессор Visual C++ ('cl.exe'), возможно возникновение ситуации с блокировкой файлов. Это связано с тем, что при попытке записи файла, он может быть заблокирован компилятором 'cl.exe', выполняющим препроцессирование. При использовании препроцессора Clang данная ситуация возникает значительно реже. Это следует учитывать при решении конфигурирования сервера в пользу инкрементального анализа вместо полноценного анализа по ночам.
Анализ CMake проектов
Если стоит задача анализа CMake проектов, рекомендуется генерировать из них решения для среды Visual Studio и в дальнейшем работать с ними. Это позволит полноценно использовать модуль 'PVS-Studio_Cmd.exe' и все связанные с этим фактом преимущества.
Анализ исходного кода проектов со специфичными сборочными системами
В случае, если проект не использует сборочную систему MSBuild, его не получится проанализировать с использованием command line модуля 'PVS-Studio_Cmd.exe'. Тем не менее, в состав дистрибутива входят утилиты, с помощью которых можно проверить даже проекты со специфичными сборочными системами.
Система мониторинга компиляции
Система мониторинга компиляции (PVS-Studio Compiler Monitoring, CLMonitoring) предназначена для 'бесшовной' интеграции статического анализа PVS-Studio в любую сборочную систему на ОС семейства Windows, использующую для компиляции файлов один из препроцессоров, поддерживаемых command line анализатором 'PVS-Studio.exe'.
Принцип работы сервера мониторинга (CLMonitor.exe) основан на отслеживании запуска процессов, соответствующих целевому компилятору, и сборе информации об окружении этих процессов. Сервер мониторинга отслеживает запуски процессов только для того пользователя, из-под которого он сам запущен.
Поддерживаемые компиляторы:
- компиляторы семейства Microsoft Visual C++ (cl.exe);
- C/C++ компиляторы из GNU Compiler Collection (gcc.exe, g++.exe);
- компилятор Clang (clang.exe), а также компиляторы на основе Clang.
При интеграции сервера мониторинга в сборочный процесс первоначально необходимо запустить модуль 'CLMonitor.exe' с аргументом 'monitor':
CLMonitor.exe monitorЭто позволит серверу мониторинга запустить самого себя в режиме отслеживания и завершить работу, а сборочной системе - продолжить выполнять оставшиеся задачи. При этом второй (запущенный из первого) процесс CLMonitor будет оставаться запущенным и производить отслеживание сборки.
После завершения сборки необходимо запустить модуль 'CLMonitor.exe' в режиме клиента для генерации препроцессированных файлов и непосредственного запуска статического анализа:
CLMonitor.exe analyze -l "c:\ptest.plog" -u "c:\ptest.suppress" -sРассмотрим эту команду более подробно:
- analyze - запуск модуля 'CLMonitor.exe' для анализа;
- -l - полный путь до файла, в который будут записаны результаты статического анализа;
- -u - путь до базы подавления (suppress файл);
- -s - дописать в базу подавления все новые сообщения текущей проверки.
Более подробно использование системы мониторинга компиляции описано в статье "Система мониторинга компиляции в PVS-Studio".
Примечание. Системе мониторинга компиляции присущ ряд недостатков, связанный с естественными ограничениями такого подхода, а именно - невозможность гарантировать на 100% перехват всех запусков компилятора при сборке (например, при сильной загрузке системы). Также следует помнить о том, что если параллельно выполняются несколько сборок, система может отследить запуски компиляторов сторонней сборки.
Прямая интеграция анализатора в системы автоматизированной сборки
Примечание. Прямая интеграция анализатора возможна только для проверки С/С++ кода.
Прямая интеграция анализатора может быть необходима в случаях отсутствия возможности использования command line модуля 'PVS-Studio_Cmd.exe' (проект собирается не с помощью сборочной системы MSBuild) и системы мониторинга компиляции (см. примечание соответствующего раздела).
В таком случае может потребоваться встроить в сборочный процесс прямой вызов анализатора ('PVS-Studio.exe') и передать ему все необходимые для препроцессирования аргументы. То есть анализатор необходимо вызвать для тех же файлов, для которых вызывается компилятор.
Подробное описание прямой интеграции анализатора в системы автоматизированной сборки приведено в статье "Прямая интеграция анализатора в системы автоматизации сборки (C/C++)".
Работа с результатами анализа
Результатом работы анализатора является .plog файл, имеющий формат XML. Этот файл не предназначен для ручной обработки, например, для чтения программистом. Тем не менее, в состав дистрибутива входят специальные утилиты, цель которых - сделать работу с .plog файлом максимально удобной.
Предварительная фильтрация результатов анализа
Отчёт анализатора можно отфильтровать ещё перед запуском анализа с помощью настройки No Noise. При работе на большой кодовой базе, анализатор неизбежно генерирует большое количество предупреждений. При этом, часто нет возможности поправить все предупреждения сразу. Для того, чтобы иметь возможность сконцентрироваться на правке наиболее важных предупреждений, можно сделать анализ менее "шумным" с помощью данной настройки. Она позволяет полностью отключить генерацию предупреждений низкого уровня достоверности (Low Certainty, 3-ий уровень предупреждений). После перезапуска анализа, сообщения этого уровня полностью пропадут из вывода анализатора.
Когда обстоятельства позволят и более существенные предупреждения анализатора будут исправлены, можно выключить режим No Noise - при следующем анализе все пропавшие ранее предупреждения станут вновь доступны.
Для включения этой настройки используйте окно Specific Analyzer Settings.
PlogConverter
Для преобразования результатов работы анализатора в один из форматов для непосредственной работы предназначена утилита 'PlogConverter.exe', входящая в состав дистрибутива. 'PlogConverter.exe' позволяет выполнять преобразование .plog файлов в следующие форматы:
- текстовый файл с результатами анализа. Может быть удобен для вывода результатов анализа (например, новых сообщений анализатора) в лог сборочной системы \ сервера непрерывной интеграции;
- отчёт HTML с кратким описанием результатов анализа. Подходит для рассылки уведомлений электронной почтой;
- отчёт HTML с сортировкой результатов анализа по разных параметрам и навигацией по исходному коду;
- CSV таблица с результатами анализа;
- Tasks файл для просмотра в QtCreator;
- текстовый файл, содержащий сводную таблицу количества сообщений на разных уровнях\группах диагностик.
Пример запуска утилиты 'PlogConverter.exe' (одной строкой):
PlogConverter.exe test1.plog -o "C:\Results" -r "C:\Test"
-a GA:1 -t HtmlДанная команда преобразует файл 'test1.plog' в формат .html с отображением диагностических правил первого уровня категории GA (диагностики общего назначения). Результат будет записан в директорию 'C:\Results'. Оригинальный .plog файл изменён не будет.
Получить подробную справка по всем параметрам утилиты 'PlogConverter' можно с помощью команды:
PlogConverter.exe --helpПримечание. Утилита 'PlogConverter' поставляется вместе с исходными файлами (C#), которые доступны в архиве 'PlogConverter_src.zip'. Для создания собственного формата вывода результатов анализа можно переиспользовать алгоритм разбора структуры .plog файла.
Более подробно утилита 'PlogConverter' описана в статье "Работа с результатами анализа (.plog файл)".
SonarQube
Результаты статического анализа могут быть импортированы платформой непрерывного анализа и измерения качества кода SonarQube. Для импорта результатов анализа предназначен плагин 'sonar-pvs-studio-plugin', входящий в состав дистрибутива. Использование плагина позволяет добавлять сообщения, найденные анализатором PVS-Studio, в базу сообщений сервера SonarQube. Это, в свою очередь, даёт возможность видеть статистику появления / исправления ошибок, осуществлять навигацию по предупреждениям анализатора, просматривать документацию к диагностическим правилам и многое другое.
Все сообщения PVS-Studio, добавленные в SonarQube, имеют тип Bug. В интерфейсе SonarQube сохранено разделение сообщений по группам диагностик аналогично тому, как это сделано в анализаторе.
Более подробная информация об интеграции результатов анализа в SonarQube приведена в статье "Интеграция результатов анализа PVS-Studio в SonarQube".
Рассылка результатов анализа по электронной почте с помощью BlameNotifier
Эффективным способом оповещения разработчиков о результатах анализа является их рассылка с использованием специализированных утилит, например, SendEmail. При использовании платформы контроля качества кода SonarQube, выполнять рассылку писем можно её средствами.
Ещё одним вариантом оповещения разработчиков является использование утилиты 'BlameNotifier', поставляемой в составе дистрибутива PVS-Studio. Она позволяет формировать вариативные отчёты. Например, разработчики, заложившие код с ошибками в систему контроля версий, получат индивидуальный отчёт. Лидеры команд, руководитель разработки и т.д. могут получить полный лог отчёта, включающий в себя информацию обо всех найденных ошибках и разработчиках, которые эти ошибки допустили.
Следующая команда выведет основную информацию об утилите:
BlameNotifier.exe --helpБолее подробно утилита 'BlameNotifier' рассматривается в статье "Работа с результатами анализа (.plog файл)" в разделе "Оповещение разработчиков".
Заключение
Если у вас остались вопросы, пожалуйста, воспользуйтесь формой обратной связи.
Режим инкрементального анализа PVS-Studio
- Смотри, а не читай (YouTube)
- Windows: C, C++, C#
- Linux/macOS: C, C++
- Linux/macOS: C#
- Windows/Linux/macOS: Java
- Дополнительные ссылки
Режим серверного инкрементального анализа из командной строки доступен только для Enterprise лицензии PVS-Studio. Вы можете запросить пробную Enterprise лицензию здесь. Инкрементальный анализ из IDE при работе на машине разработчика доступен для всех типов лицензий PVS-Studio.
Полный анализ можно регулярно запускать отдельно, например, раз в сутки во время ночных сборок. Однако наибольшего эффекта от использования анализатора можно добиться только за счёт более раннего обнаружения и исправления выявленных им дефектов. То есть самым оптимальным вариантом использования статического анализатора является проверка нового кода сразу после его написания. Такой сценарий работы, несомненно, осложняется необходимостью постоянно вручную запускать проверку для всех модифицированных файлов и каждый раз ждать завершения анализа. Это несовместимо с интенсивной разработкой и отладкой нового кода. Да и просто неудобно. Однако PVS-Studio предлагает решение этой проблемы.
Стоит помнить, что после первой полной проверки проекта желательно просмотреть все диагностические сообщения для нужных файлов и исправить найденные в коде ошибки. А остальные сообщения либо разметить как ложные срабатывания, либо отключить отображение неактуальных для проекта кодов сообщений или групп диагностик, либо подавить оставшиеся срабатывания, и, возможно, вернуться к их правке позже. Такой подход позволит иметь список сообщений, не забитый бессмысленными и ненужными предупреждениями.
Смотри, а не читай (YouTube)
Windows: C, C++, C#
Microsoft Visual Studio
Включить режим послесборочного инкрементального анализа можно в меню Extensions > PVS-Studio > Analysis after Build (Modified Files Only):

Данный пункт активирован в PVS-Studio по умолчанию.
После активации режима инкрементального анализа PVS-Studio станет автоматически в фоновом режиме производить анализ всех затронутых модификациями файлов сразу после окончания сборки проекта. После окончания инкрементальной сборки, когда запустится анализ, в области уведомлений Windows появится анимированная иконка PVS-Studio:

Контекстное меню области уведомлений позволяет на время приостановить (команда Pause) или отменить (команда Abort) текущую проверку.
Анализатор ориентируется на сборочную систему для определения изменившихся файлов, которые необходимо проверить. Полная пересборка проекта приведёт к анализу всех его файлов - используйте инкрементальную сборку для проверки только изменившихся файлов. В случае, если анализатор во время инкрементального анализа обнаружит ошибки в коде, в названии открытой в Visual Studio вкладки окна PVS-Studio отразится число найденных ошибок, и будет показано Windows уведомление:

Клик по иконке в области уведомлений (либо по самому уведомлению) откроет окно PVS-Studio Output.
При работе из Visual Studio можно задать ограничение на время работы инкрементального анализа или уровень выводимых предупреждений. Данные настройки можно регулировать в меню PVS-Studio > Options > Special Analyzer Settings > IncrementalAnalysisTimeout и PVS-Studio > Options > Specific Analyzer Settings > IncrementalResultsDisplayDepth.
Command-line analyzer for MSBuild projects (PVS-Studio_Cmd.exe)
Режим инкрементального анализа для решений Visual Studio доступен также в модуле командной строки (PVS-Studio_Cmd.exe). Этот режим позволяет ускорить статический анализ на сервере непрерывной интеграции. В нём реализованы подходы, аналогичные подходам MSBuild для инкрементальной сборки.
Настроить инкрементальный анализ на сервере можно с помощью нескольких команд:
PVS-Studio_Cmd.exe ... --incremental Scan ...
MSBuild.exe ... -t:Build ...
PVS-Studio_Cmd.exe ... --incremental Analyze ...Все режимы работы инкрементального анализа выглядят так:
- Scan - проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ. Непосредственно анализ выполнен не будет. Этот шаг должен выполняться перед сборкой решения или проекта. Результаты сканирования будут записаны во временные директории .pvs-studio, расположенные в тех же директориях, где находятся проектные файлы. При этом будут учтены изменения, произведенные с момента последней сборки, предыдущая история изменений сохранённая в каталоге .pvs-studio, будет удалена.
- AppendScan - проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ. Непосредственно анализ выполнен не будет. Этот шаг должен выполняться перед сборкой решения или проекта. Результаты сканирования будут записаны во временные директории .pvs-studio, расположенные в тех же директориях, где находятся проектные файлы. Будут учтены изменения, произведенные с момента последней сборки, а также все предыдущие изменения.
- Analyze - выполнить инкрементальный анализ. Этот шаг должен выполняться после выполнения шагов Scan или AppendScan, и может выполняться как до, так и после сборки решения или проекта. Статический анализ будет выполнен только для файлов из списка, полученного в результате выполнения команд Scan или AppendScan. Если в настройках PVS-Studio опция 'Remove Intermediate Files' установлена в True, временные директории .pvs-studio будут удалены.
- ScanAndAnalyze - проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ, и сразу же выполнить инкрементальный анализ измененных файлов с исходным кодом. Этот шаг необходимо выполнить перед сборкой проекта\решения. Будут учтены изменения, произведенные с момента последней сборки.
Compiler Monitoring UI
В случае необходимости инкрементального анализа при использовании системы мониторинга компиляции, достаточно "отслеживать" инкрементальную сборку, т.е. компиляцию тех файлов, которые были изменены с момента последней сборки. Этот сценарий использования позволит анализировать только изменённый/новый код.
Такой сценарий использования естественен для системы мониторинга компиляции, т.к. она основана на "отслеживании" запусков компилятора во время сборки проекта, что позволяет получить всю необходимую информацию для запуска анализа на исходных файлах, компиляция которых была отслежена. Следовательно, режимы анализа зависят от того, какая сборка отслеживается: полная или инкрементальная.
Более подробно система мониторинга компиляции описана в статье "Система мониторинга компиляции в PVS-Studio".
Linux/macOS: C, C++
CMake-проекты
Для проверки CMake-проекта можно использовать файл JSON Compilation Database. Для получения необходимого анализатору файла compile_commands.json необходимо добавить один флаг к вызову CMake:
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On <src-tree-root>Для инкрементального анализа такого проекта необходимо добавить флаг ‑‑incremental к команде анализа:
pvs-studio-analyzer analyze ... --incremental ...В каталоге .PVS-Studio будут сохраняться зависимости между файлами и время модификаций, т.к. в этом режиме анализатор работает независимо от сборочной системы. Этот каталог необходимо сохранять для работы этого режима анализа.
Если используемый CMake генератор не поддерживает создание файла compile_commands.json, или генерация такого файла неудобна, можно воспользоваться прямой интеграцией PVS-Studio с CMake - использование модуля прямой интеграции позволит выполнять инкрементальный анализ одновременно с инкрементальной сборкой.
Makefile-проекты
В скрипты сборочной системы Make и подобных можно прописать вызов анализатора рядом с компилятором:
$(CXX) $(CFLAGS) $< ...
pvs-studio --source-file $< ...В таком случае инкрементальный анализ и инкрементальная сборка будут работать совместно, получая информацию об изменённых файлах от сборочной системы.
Примеры интеграции PVS-Studio в Makefile собраны в репозитории на GitHub: pvs-studio-makefile-examples.
Другие проекты (только для Linux)
Проверить любой проект без интеграции анализатора в сборочную систему можно с помощью следующих команд:
pvs-studio-analyzer trace – make
pvs-studio-analyzer analyze ...Вместо команды make может быть любая команда запуска сборки проекта со всеми необходимыми параметрами.
В этом режиме анализатор отслеживает и производит логирование дочерних процессов сборочной системы и ищет среди них процессы компиляции. Если собирать проект в режиме инкрементальной сборки, то и проверяться будут только изменённые файлы.
Linux/macOS: C#
Режим инкрементального анализа C# проектов под Linux и macOS аналогичен описанному выше в разделе "Command line analyzer for MSBuild projects (PVS-Studio_Cmd.exe)" с поправками на то, что:
- используется 'pvs-studio-dotnet', а не 'PVS-Studio_Cmd.exe';
- для сборки используется 'dotnet', а не 'MSBuild.exe'.
Windows/Linux/macOS: Java
IntelliJ IDEA
Включить режим послесборочного инкрементального анализа можно в плагине для IntelliJ IDEA в меню Analyze > PVS-Studio > Settings > PVS-Studio > Misc > Run incremental analysis on every build:

После активации режима инкрементального анализа PVS-Studio станет автоматически в фоновом режиме производить анализ изменённых файлов сразу после окончания сборки проекта. Если PVS-Studio выдаст предупреждения, то они будут выведены в окне PVS-Studio:

Maven Plugin
В maven плагине инкрементальный режим включается флажком incremental:
<plugin>
<groupId>com.pvsstudio</groupId>
<artifactId>pvsstudio-maven-plugin</artifactId>
....
<configuration>
<analyzer>
....
<incremental>true</incremental>
....
</analyzer>
</configuration>
</plugin>После активации режима инкрементального анализа команда pvsstudio:pvsAnalyze будет запускать анализ только на измененных файлах относительно последнего запуска.
Gradle Plugin
В gradle плагине инкрементальный режим включается аналогичным флажком incremental:
apply plugin: com.pvsstudio.PvsStudioGradlePlugin
pvsstudio {
....
incremental = true
....
}После активации режима инкрементального анализа команда pvsAnalyze будет запускать анализ только на измененных файлах относительно последнего запуска.
Дополнительные ссылки
- Проверка Visual Studio проектов из командной строки
- Как запустить PVS-Studio в Linux и macOS
- Работа с ядром Java анализатора из командной строки
- PVS-Studio и Continuous Integration
Анализ в режиме коммитов и слияния веток (pull/merge requests). Анализ модифицированных файлов.
- Общие принципы анализа запросов на слияние
- Интеграция анализа в систему контроля версий
- Режим проверки модифицированных файлов
- Режим проверки списка файлов
- Анализ C# файлов
- Анализ C и С++ файлов
- Анализ Java файлов
Проверка запросов на слияние и модифицированных файлов доступна только при наличии Enterprise лицензии. Вы можете запросить пробную Enterprise лицензию здесь.
С помощью режима анализа коммитов и слияния веток можно проанализировать только те файлы, которые были изменены относительно текущего состояния ветки (в которую производится коммит или запрос на слияние). Это сократит время анализа и упростит просмотр его результатов: отчёт анализатора будет содержать предупреждения, выданные из-за ошибок в изменённых файлах.
Этот документ описывает общие принципы анализа запросов на слияние. Примеры для конкретных CI можно найти в следующих разделах документации:
Общие принципы анализа запросов на слияние
Для анализа файлов, изменённых при слиянии веток, эти файлы необходимо выделить из всех остальных файлов проекта. Для этого после прохождения слияния нужно получить разницу между HEAD веткой, из которой производится запрос на слияние, и той, куда будут вноситься изменения.
Рассмотрим дерево коммитов:

В данном случае была создана ветка quickFix. После работы в ней открывается запрос на слияние. Для получения разницы между текущим состоянием ветки master и последним коммитом в ветке quickFix можно использовать следующую команду (на момент её выполнения нужно находиться в ветке quickFix):
git diff --name-only HEAD master > .pvs-pr.listТак мы получим список изменённых файлов относительно последних коммитов в ветках master и quickFix. Названия изменённых файлов будут сохранены в .pvs-pr.list.
Примечание. В примере получения файлов для анализа используется система контроля версий git. Однако подойдёт любая система контроля версий, позволяющая получить список изменённых файлов.
Для проверки отправленного запроса на слияние нужно проанализировать полученный список файлов.
Получение списка изменённых файлов
В данном разделе приведены примеры команд для получения списка модифицированных файлов.
Для Git:
Для получения списка изменённых файлов перед коммитом, выполните команду:
git diff --cached --name-only > .pvs-pr.listДля получения списка изменённых файлов между двумя коммитами, выполните команду:
git diff --name-only CommitA CommitB > .pvs-pr.listДля SVN:
На Windows можно выполнить следующую команду в PowerShell:
Write-Host (svn status | Select-String -Pattern `^[AM]\W*(.*)`
| %{$_.Matches.Groups[1].value}) -Separator "`b`n" > .pvs-pr.litsНа Linux:
svn status -q | grep -oP "^[M|A]\W*\K(.*)" > .pvs-pr.listДля Mercurial:
hg log --template "{files % `{file}\n`}\n" > .pvs-pr.listДля Perforce:
p4 diff -f -sa > .pvs-pr.listИнтеграция анализа в систему контроля версий
Большинство систем контроля версий поддерживают возможность отслеживания событий в репозитории с помощью специальных хуков. Как правило, хуки представляют из себя обычные файлы скриптов, которые запускает VCS. Они могут быть использованы как на стороне клиента (локальная машина разработчика), так и на стороне сервера системы контроля версии (если у вас развёрнут собственный сервер VCS (Version Control System)). Использование хуков на сервере VCS позволяет настроить глобальную политику для всех разработчиков компании.
Сценарии использования хуков индивидуальны для каждой системы контроля версий. Подробнее об этом лучше узнать в документации по вашей системе контроля версий.
Вы можете попробовать интегрировать PVS-Studio непосредственно на сервер VCS, следуя этому плану:
- Определить событие, при котором следует запускать анализ. Хук должен выполняться до того, как система контроля версий применит новые изменения. Например, это может быть коммит или операция отправки изменений (push).
- Далее нужно решить, где будет запускаться анализ. Вы можете это делать как на сервере VCS, так и на отдельной машине. Учтите, что для успешного анализа ваш проект должен собираться на той машине, на которой будет выполняться анализ.
- Написать хук, который будет:
- Получать список изменений при коммите или операции push. Вам может потребоваться не только список модифицированных файлов, но и сами изменения в виде patch-файла (например, требуется для Git). В режиме проверки модифицированных файлов достаточно иметь только patch-файл.
- Если вы планируете анализ на сервере VCS, вам может потребоваться иметь там же локальную копию вашего репозитория. К этой копии необходимо применить patch-файл и запустить анализ в режиме проверки списка файлов.
- Если вы планируете запускать анализ на отдельной машине, вам нужно специальной командой (например, по
ssh) отправить изменения на удалённую машину, применить там patch-файл и запустить анализ в режиме проверки списка файлов или проверки модифицированных файлов. - Далее нужно обработать результат анализа. Чтобы отклонить операцию при наличии сообщений анализатора, вам нужно будет завершить хук не нулевым кодом. Это можно сделать с помощью утилиты преобразования отчётов PlogConverter. Флаг
-wуказывает, что утилита должна завершать свою работу с кодом возврата 2, если в отфильтрованном отчёте есть срабатывания.
Стоит учесть, что, как правило, операция выполнения хуков является блокирующей. Это означает, что пока хук не пройдет, операция коммита или отправки изменений не завершится. Следовательно, использование хуков может замедлить отправку изменений в репозиторий.
Обратите внимание, что такой сценарий довольно труден в реализации, и мы настоятельно рекомендуем использовать хуки VCS только для создания триггеров CI систем.
Режим проверки модифицированных файлов
В качестве альтернативы режиму проверки списка файлов существует режим проверки модифицированных файлов. С помощью режима анализа модифицированных файлов можно проанализировать только те файлы, которые были изменены относительно сохраненного состояния директории проекта. Информацию о модификации файлов анализатор получает и сохраняет в кэш зависимостей компиляции. Кэш зависимостей представляет собой список файлов исходного кода проекта и их зависимостей. В режиме модифицированных файлов для каждого исходного файла, представленного в кэше, вычисляется хэш этого файла. При последующем запуске хэш в кэше зависимостей сравнивается с фактическим значением хэша файла. Если хэши различаются, файл будет проанализирован.
В текущий момент анализ модифицированных файлов доступен на Windows для MSBuild С, С++ и С# проектов с помощь утилиты PVS-Studio_Cmd и плагина для Visual Studio, а также на Linux/macOS для С# проектов с помощью утилиты pvs-studio-dotnet.
Анализ модифицированных файлов в PVS-Studio_Cmd и pvs-studio-dotnet включается с помощью флага ‑‑analyzeModifiedFiles (-F).
Пример команды запуска анализа модифицированных файлов:
PVS-Studio_Cmd.exe -t MyProject.sln -F ^
-D path\to\depCacheDir ^
-R depCacheRoot ^
-o analysis_report.jsonВ результате работы этой команды проанализируются изменённые и добавленные в проекты файлы, которые содержатся в решении MyProject.sln. Для получения информации об изменениях будут использованы файлы кэшей зависимостей, расположенные по пути, указанном во флаге -D. Пути в файлах кэшей будут записаны относительно пути, указанного в флаге -R. Результаты анализа будут сохранены в файл analysis_report.json.
Вы можете использовать флаг //V_SOLUTION_DIR_AS_DEPENDENCY_CACHE_SOURCE_TREE_ROOT в файле *.pvsconfig для использования пути каталога решения (папка, где расположен файл *.sln), в качестве корневой части пути, которая будет использована для построения относительных путей файлов в кэше зависимостей компиляции.
Также для управления построением относительных путей файлов в кэше зависимостей компиляции можно использовать флаг //V_DEPENDENCY_CACHE_SOURCE_ROOT. С помощью него можно указать директорию, которая будет использоваться в качестве корневой части пути для построения относительных путей.
С помощью флага //V_DEPENDENCY_CACHE_ROOT можно указать директорию, в которой будут сохраняться файлы кэша зависимостей компиляции. Без указания этой настройки кэш зависимостей записывается в папку .pvs-studio в директории проектного файла.
Если файл кэша зависимостей компиляции отсутствует, то он будет сгенерирован, и при этом запустится анализ всех исходных файлов из проекта. Для того, чтобы не запускался анализ всех файлов из проекта при первом запуске анализа, можно запустить анализатор в режиме генерации файлов кэшей зависимостей без непосредственного запуска анализа (флаг -W) с вычислением хэшей для файлов исходного кода (флаг -H). Для этого воспользуйтесь следующей командой:
PVS-Studio_Cmd.exe -t MyProject.sln -W -H ^
-D path\to\depCacheDir ^
-R depCacheRootВ этом случае будут сгенерированы файлы кэшей зависимостей, но не будет запущен анализ. Следующий запуск анализа модифицированных файлов (флаг -F) будет анализировать уже только добавленные или изменившиеся файлы исходного кода из проектов.
Для проверки коммита или запроса на слияние воспользуйтесь следующим алгоритмом:
- Запустите генерацию кэшей компиляции для исходной ветки;
- Получите и примените изменения из коммита/запроса на слияние;
- Запустите анализ модифицированных файлов.
Если вам нужно проверять не только измененные файлы, но и оставлять в отчёте предупреждения, которые не были обработаны после анализа, то вы можете воспользоваться флагом //V_DEPENDENCY_CACHE_TRACKING_MODE в режиме ModifiedAndWarningsContainingFiles. С этим флагом в режиме анализа модифицированных файлов будут проанализированы файлы, которые изменились с предыдущего запуска анализа, и файлы, в которых остались предупреждения анализатора. Для анализа только модифицированных файлов выставьте значение флага ModifiedFilesOnly.
Если вы хотите проверить только модифицированные файлы в плагине для Visual Studio, то нужно записать в .pvsconfig флаг //V_DEPENDENCY_CACHE_TRACKING_MODE или включить настройку DependencyCacheTrackingMode в одном из режимов отслеживания кэша. После этого в плагине появится пункт меню Extension > PVS-Studio > Check > Modified Files и пункт Analyze Modified Files with PVS-Studio в контекстном меню решений и проектов, при запуске которых начнется анализ модифицированных файлов.

Если включена настройка //V_DEPENDENCY_CACHE_TRACKING_MODE, то при любом запуске анализа будет происходить обновление кэша зависимостей компиляции для актуализации информации о модифицированных файлах и наличии файлов с предупреждениями.
Режим проверки списка файлов
Для проверки списка файлов анализатору необходимо передать текстовый файл, который содержит абсолютные или относительные пути к файлам для анализа (относительные пути будут раскрыты относительно рабочей директории). Каждый из путей должен быть записан на новой строке. Текст, который не является путём к файлу с исходным кодом, игнорируется (может быть полезно для комментирования).
Пример содержимого файла с путями:
D:\MyProj\Tests.cs
D:\MyProj\Common.cpp
D:\MyProj\Form.hДалее будут рассмотрены варианты запуска анализа для разных языков и ОС.
Анализ C# файлов
Для проверки C# файлов используется утилита PVS-Studio_Cmd для Windows и pvs-studio-dotnet для Linux и macOS.
Путь к файлу, который содержит список файлов для анализа, передаётся с помощью аргумента -f (подробную информацию об аргументах можно найти в документации). О формате этого файла написано выше в разделе Режим проверки списка файлов.
Для получения информации о наличии предупреждений анализатора можно проверить код возврата. Коды возврата описаны в документации.
Windows
Пример команды запуска анализа:
PVS-Studio_Cmd.exe -t MyProject.sln ^
-f .pvs-pr.list ^
-o Analysis_Report.jsonБудут проанализированы файлы из .pvs-pr.list, которые содержатся в решении MyProject.sln. Результаты анализа будут сохранены в файл Analysis_Report.json.
Linux и macOS
Пример команды запуска анализа:
pvs-studio-dotnet -t MyProject.sln \
-f .pvs-pr.list \
-o Analysis_Report.jsonБудут проанализированы файлы из .pvs-pr.list, которые содержатся в решении MyProject.sln. Результаты анализа будут сохранены в файл Analysis_Report.json.
Анализ C и С++ файлов
Для проверки C и C++ файлов можно использовать утилиты:
- pvs-studio-analyzer / CompilerCommandsAnalyzer (Windows, Linux и macOS);
- CLMonitor (Windows);
- PVS-Studio_Cmd (Windows).
Способ проверки для каждой утилиты описан далее.
При первом запуске анализа генерируется файл зависимостей всех исходных файлов проекта от заголовочных. При последующих запусках он будет обновляться анализатором автоматически. Существует возможность создания/обновления этого файла без запуска анализа. Данный процесс будет описан для каждой из утилит в соответствующем разделе.
Кэш зависимостей компиляции для С и C++ проектов
В данном разделе более подробно расписывается механизм работы файлов кэшей зависимостей компиляции в консольных утилитах PVS-Studio_Cmd.exe и pvs-studio-analyzer/CompilerCommandsAnalyzer.exe.
В этих утилитах имеются специальные флаги:
- Флаг для анализа списка файлов. В этом флаге указан путь до файла, в котором построчно перечислены пути до файлов исходного кода, которые надо проанализировать:
- PVS-Studio_Cmd.exe:
‑‑sourceFiles (-f); - pvs-studio-analyzer/CompilerCommandsAnalyzer.exe:
‑‑source-files(-S).
- PVS-Studio_Cmd.exe:
- Флаг для перегенерации кэшей зависимостей С и С++ проектов с запуском анализа. Этот флаг запускает перегенерацию файлов кэшей зависимостей для всех файлов проекта(-ов) с запуском анализа всех файлов из проекта(-ов) или переданного через флаг списка файлов:
- PVS-Studio_Cmd.exe:
‑‑regenerateDependencyCache(-G); - pvs-studio-analyzer/CompilerCommandsAnalyzer.exe:
‑‑regenerate-depend-info.
- PVS-Studio_Cmd.exe:
- Флаг для перегенерации кэшей зависимостей С и С++ проектов без запуска анализа. Этот флаг запускает перегенерацию файлов кэшей зависимостей проекта(-ов) без запуска анализа:
- PVS-Studio_Cmd.exe:
‑‑regenerateDependencyCacheWithoutAnalysis(-W); - pvs-studio-analyzer/CompilerCommandsAnalyzer.exe:
‑‑regenerate-depend-info-without-analysis.
- PVS-Studio_Cmd.exe:
При первом запуске анализа с использованием флага анализа списка файлов анализатор препроцессирует все C и C++ файлы из проектов, переданных на анализ. Эта информация о зависимостях сохраняется в отдельный файл кэша зависимостей для каждого проекта.
При последующих запусках анализатора с флагом анализа списка файлов информация в кэше зависимости добавляется/обновляется для:
- файлов, указанных в списке из флага, в котором содержится список файлов для анализа;
- файлов, для которых ещё нет записи в файле кэша зависимостей. Например, новые файлы, добавленные в проект;
- файлов, которые ранее зависели от файлов, указанных в списке из флага анализа списка файлов. Информация о зависимостях берётся из файла кэша зависимости, который был сформирован/обновлён при прошлом запуске анализа с флагом анализа списка файлов.
После этапа обновления информации о зависимостях производится анализ всех файлов, указанных в списке файлов для анализа, а также файлов, зависящих от них (используется информация о зависимостях, полученная на предыдущем этапе).
Перед каждым запуском анализа кэш зависимостей компиляции будет обновлён для всех файлов, переданных на анализ, и файлов, в зависимостях которых есть файлы, переданные в списке файлов для анализа. При наличии изменений в зависимостях файлов по отношению к закэшированным зависимостям эти изменения будут учтены уже в текущем запуске анализа, а кэш обновлён для последующих запусков.
Для поддержания кэша зависимостей в актуальном состоянии требуется запускать анализ с флагом для анализа списка файлов для каждого изменения исходных файлов, либо одновременно для всех изменившихся файлов из нескольких коммитов.
Пропуск анализа изменений исходных файлов, либо отдельные запуски анализа изменённых файлов в порядке, отличающемся от порядка их модификации, может привести к последующему пропуску анализа из-за изменений в структуре зависимостей проекта. Так, например, если в .cpp файл была добавлена зависимость от .h файла, то этот .cpp файл должен попасть в список файлов на проверку для обновления его кэша зависимостей. Иначе при попадании вновь добавленного .h файла в список файлов на анализ анализатор не сможет найти единицу трансляции, для которой необходимо выполнить препроцессирование.
Если вы не можете обеспечить гарантированную передачу всех изменяющихся файлов проекта в режиме анализа списка файлов, мы рекомендуем использовать режим анализа списка файлов совместно с режимом перегенерации кэшей зависимостей с запуском анализа. В таком случае время работы анализатора несколько возрастёт (для перегенерации кэша необходимо произвести препроцессирование всех единиц трансляции проектов), однако оно всё равно будет значительно меньше, чем время полного анализа (т.к. будет производиться только препроцессирование всех исходных файлов проектов, без анализа). При этом актуальность кэша будет гарантирована на каждом запуске анализа независимо от возможного пропуска изменившихся файлов или от порядка, в котором файлы передавались на анализ.
pvs-studio-analyzer / CompilerCommandsAnalyzer.exe (Windows, Linux и macOS)
Примечание. Сценарий анализа файлов проекта, который использует сборочную систему MSBuild, описан в разделе PVS-Studio_Cmd (Windows, Visual Studio\MSBuild).
В зависимости от ОС, на которой выполняется анализ, утилита будет иметь разные названия:
- Windows:
CompilerCommandsAnalyzer.exe; - Linux и macOS:
pvs-studio-analyzer.
В примерах данной документации используется название pvs-studio-analyzer. Способ анализа файлов для CompilerCommandsAnalyzer.exe аналогичен описанным здесь.
Для использования pvs-studio-analyzer нужно сгенерировать либо файл compile_commands.json, либо файл с результатами трассировки компиляции (актуально только для Linux). Они необходимы для того, чтобы анализатор имел информацию о компиляции конкретных файлов.
Получение compile_commands.json
Со способами получения файла compile_commands.json можно ознакомится в документации.
Получение файла трассировки (только для Linux)
Со способами получения файла трассировки можно ознакомиться в документации. По умолчанию результат трассировки записывается в файл strace_out.
Существует два варианта анализа с использованием файла трассировки. Можно либо производить полную трассировку сборки всего проекта при каждом запуске, либо кэшировать результат трассировки и использовать его.
Минус первого способа в том, что полная трассировка противоречит идее быстрой проверки коммитов или запросов на слияние.
Второй способ плох тем, что результат анализа может оказаться неполным, если после трассировки поменяется структура зависимостей исходных файлов (например, в один из исходных файлов будет добавлен новый #include).
Из-за этого мы не рекомендуем использовать режим проверки списка файлов с логом трассировки для проверки коммитов или запросов на слияние. В случае, если вы можете делать инкрементальную сборку при проверке коммита, рассмотрите возможность использовать режим инкрементального анализа.
Пример команд для анализа файлов и обновления зависимостей
Рассмотрим пример использования pvs-studio-analyzer. Путь к файлу, который содержит список файлов для анализа, передаётся с помощью аргумента -S (подробную информацию об аргументах утилиты можно найти в документации). О формате этого файла написано выше в разделе Режим проверки списка файлов.
Примечание. Если информация о компиляции была получена с использованием режима трассировки компиляции, с помощью флага -f передаётся файл трассировки (по умолчанию его название — strace_out).
Пример команды для анализа файлов:
pvs-studio-analyzer analyze -S .pvs-pr.list \
-f compile_commands.json \
-o Analysis_Report.jsonПри выполнении данной команды сгенерируется отчёт с результатом проверки файлов, содержащихся в .pvs-pr.list. Результаты анализа будут сохранены в файл Analysis_Report.json.
Для генерации или обновления файла зависимостей без запуска анализа используется флаг ‑‑regenerate-depend-info-without-analysis. Вместе с этим флагом нельзя использовать флаг -S. Команда для обновления будет выглядеть следующим образом:
pvs-studio-analyzer analyze -f compile_commands.json \
–-regenerate-depend-info-without-analysisДля принудительного обновления кэша зависимостей с последующим запуском анализа используется флаг ‑‑regenerate-depend-info. Его также можно использовать вместе с флагом -S. В этом случае для всех файлов из проекта обновится кэш зависимостей. Однако анализироваться при этом будут:
- файлы, переданные на анализ (в флаге
-Sуказан путь до файла, в котором построчно перечислены пути до файлов исходного кода, которые надо проанализировать); - файлы, зависящие от файлов, переданных на анализ (вначале происходит актуализация информации о зависимостях, а после эта информация используется при определении зависимостей файлов).
Команда для обновления кэша зависимостей для всего проекта и анализа переданных файлов будет выглядеть следующим образом:
pvs-studio-analyzer analyze -S .pvs-pr.list \
-f compile_commands.json \
-o Analysis_Report.json \
–-regenerate-depend-infoПо умолчанию файл с кэшем зависимостей генерируется в папку .PVS-Studio, которая создаётся в рабочей директории. Сам кэш содержится в файле depend_info.json.
Получение информации о наличии/отсутствии предупреждений в отчёте анализатора
Есть срабатывания в отчёте анализатора или нет, можно понять по коду возврата консольных утилит:
- Windows:
PlogConverter.exe; - Linux и macOS:
plog-converter.
С документацией по данным утилитам можно ознакомиться здесь.
Пример использования PlogConverter.exe:
PlogConverter.exe Analysis_Report.json ^
-t html ^
-n PVS-Studio ^
--indicateWarningsПример использования plog-converter:
plog-converter Analysis_Report.json \
-t html \
-n PVS-Studio \
--indicate-warningsВ качестве первого аргумента командной строки передается путь до файла с результатами анализа. С помощью аргумента -t указывается формат, в котором необходимо сохранить отчёт. При помощи аргумента -n задаётся имя файла с преобразованным отчётом. Флаги ‑‑indicateWarnings для PlogConverter.exe и ‑‑indicate-warnings для plog-converter позволяют установить код возврата 2, если в отчёте есть предупреждения анализатора.
CLMonitor (Windows)
Путь к файлу, который содержит список файлов для анализа, передаётся с помощью аргумента -f (подробную информацию об аргументах можно найти в документации). О формате этого файла написано в разделе "Режим проверки списка файлов".
Пример команды запуска анализа:
CLMonitor.exe analyze -l "Analysis_Report.json" ^
-f ".pvs-pr.list"При выполнении данной команды будет сгенерирован отчёт с результатом проверки файлов, содержащихся в .pvs-pr.list. Результаты анализа будут сохранены в файл Analysis_Report.json.
По коду возврата консольной утилиты PlogConverter.exe можно понять, есть срабатывания в отчёте анализатора или нет. Если предупреждения анализатора отсутствуют, код возврата — 0. При наличии предупреждений код возврата — 2. С документацией по данным утилитам можно ознакомиться здесь.
Пример использования PlogConverter.exe:
PlogConverter.exe Analysis_Report.json \
-t html \
-n PVS-Studio \
--indicate-warningsВ качестве первого аргумента командной строки передается путь до файла с результатами анализа. С помощью аргумента -t указывается формат, в котором необходимо сохранить отчёт. При помощи аргумента -n задаётся имя файла с преобразованным отчётом. Флаг ‑‑indicateWarnings для PlogConverter.exe позволяет задать код возврата 2, если в отчёте есть предупреждения анализатора.
PVS-Studio_Cmd (Windows, Visual Studio\MSBuild)
Если нужные файлы с кодом включены в проект Visual Studio, который использует сборочную систему MSBuild, то анализ производится с помощью утилиты PVS-Studio_Cmd.
Путь к файлу, который содержит список файлов для анализа, передаётся с помощью аргумента -f (подробную информацию об аргументах утилит можно найти в документации). О формате этого файла написано выше в разделе Режим проверки списка файлов.
Для получения информации о наличии предупреждений анализатора можно проверить код возврата. Коды возврата описаны в документации.
Пример команды запуска анализа:
PVS-Studio_Cmd.exe -t MyProject.sln ^
-f .pvs-pr.list ^
-o Analysis_Report.jsonБудут проанализированы файлы из .pvs-pr.list, которые содержатся в решении MyProject.sln. Результаты анализа будут сохранены в файл Analysis_Report.json.
Для обновления зависимостей без запуска анализа используется флаг -W. Вместе с ним нельзя использовать флаг -f:
PVS-Studio_Cmd.exe -t MyProject.sln ^
-WДля принудительного обновления кэша зависимостей с последующим запуском анализа используется флаг -G. Его также можно использовать вместе с флагом -f. В этом случае для всех файлов исходного кода из проектов, переданных для анализа, будут обновлены кэши зависимостей. Однако, анализироваться при этом будут:
- файлы, переданные на анализ (во флаге
-fуказан путь до файла, в котором построчно перечислены пути до файлов исходного кода, которые надо проанализировать); - файлы, зависящие от файлов, переданных на анализ (вначале происходит актуализация информации о зависимостях, а после эта информация используется при определении зависимостей файлов).
Команда для обновления кэшей зависимостей для всех проектов и анализа переданных файлов будет выглядеть следующим образом:
PVS-Studio_Cmd.exe -t MyProject.sln ^
-f .pvs-pr.list ^
-GПо умолчанию файл с кэшем зависимостей генерируется на уровне проекта и сохраняется в папку .pvs-studio. Файл, содержащий кэш, имеет название вида projectName.vcxproj.deps.json (часть имени файла, в данном случае projectName.vcxproj, соответствует имени проекта). Соответственно, если проанализировать файлы, относящиеся к одному решению, но к разным проектам, то в директории каждого из проектов будет создана папка .pvs-studio с файлом зависимостей.
Существует возможность изменить директорию сохранения кэша. Для этого используется параметр -D. В качестве его значения передаётся путь до директории, в которую необходимо сохранить кэш.
Для задания относительных путей в кэшах зависимостей используется флаг -R. В качестве аргумента ему необходимо передать путь, относительно которого будут раскрыты пути в файлах кэшей зависимостей.
Получение информации о наличии/отсутствии предупреждений в отчёте анализатора
По коду возврата консольной утилиты PVS-Studio_Cmd.exe можно понять, есть срабатывания в отчёте анализатора или нет. Код возврата 256 означает, что в отчёте есть предупреждения анализатора.
Также возможно использование консольных утилит PlogConverter.exe (Windows) или plog-converter (Linux/macOS) с флагом ‑‑indicateWarnings. При использовании этих флагов, если в отчёте анализатора имелись предупреждения, код возврата будет равен 2.
Пример использования PlogConverter.exe:
PlogConverter.exe Analysis_Report.json ^
-t html ^
-n PVS-Studio ^
--indicateWarningsПример использования plog-converter:
plog-converter Analysis_Report.json \
-t html \
-n PVS-Studio \
--indicate-warningsАнализ Java файлов
Для проверки Java файлов используется утилита pvs-studio.jar. Подробную информацию о самой утилите и её аргументах можно найти в документации.
Windows, Linux и macOS
Путь к файлу, который содержит список файлов для анализа, передаётся с помощью флага ‑‑analyze-only-list. О формате этого файла написано выше в разделе Режим проверки списка файлов.
Для анализа списка файлов также необходимо передать путь до проекта, содержащего их. Делается это при помощи аргумента -s. С помощью аргумента -e определяется classpath. Если требуется использовать несколько сущностей classpath, то они разделяются пробелом.
Пример команды запуска анализа:
java -jar pvs-studio.jar -s projectDir ^
--analyze-only-list .pvs-pr.list ^
-e Lib1.jar Lib2.jar ^
-j4 ^
-o report.json ^
-O json ^
--user-name userName ^
--license-key keyВ результате будут проанализированы файлы, записанные в .pvs-pr.list. Результаты анализа сохранятся в файл report.json.
Для получения информации о наличии срабатываний можно воспользоваться флагом ‑‑fail-on-warnings. При его использовании анализатор вернёт код 53, если в результате анализа будут выданы предупреждения.
Интеграция результатов анализа PVS-Studio в DefectDojo
- Преобразование отчёта в совместимый с DefectDojo формат
- Загрузка отчёта PVS-Studio в DefectDojo
- Просмотр отчёта PVS-Studio в DefectDojo
- Работа с ложными предупреждениями
- Quality Gate в DefectDojo
- Рассылка результатов анализа
DefectDojo – это DevSecOps платформа, инструмент для отслеживания ошибок и уязвимостей. Он предоставляет функции для работы с отчётами, включая возможность объединения результатов, запоминания ложных срабатываний и удаления дубликатов срабатываний, умеет сохранять метрики и строить графики их изменения. Используя его, можно удобно работать с результатами анализа PVS-Studio и управлять процессом устранения ошибок.
DefectDojo имеет несколько вариантов разворачивания. Здесь описано, как его можно установить и настроить. На этой странице находится общая документация по эксплуатации.
Преобразование отчёта в совместимый с DefectDojo формат
Для работы с отчётом PVS-Studio в DefectDojo нужно преобразовать его в специальный формат.
Для преобразования можно воспользоваться утилитами командной строки PlogConverter.exe для Windows и plog-converter для Linux/macOS. Эти утилиты позволяют не только конвертировать отчёт PVS-Studio в разные форматы, но и дополнительно обрабатывать его. Например, проводить фильтрацию сообщений.
Пример команды конвертации отчёта PVS-Studio для DefectDojo при помощи PlogConverter.exe (Windows):
PlogConverter.exe path\to\report.plog ^
-t DefectDojo ^
-o output\dir ^
-n converted_report_nameПример команды конвертации отчёта PVS-Studio для DefectDojo при помощи plog-converter (Linux/macOS):
plog-converter path/to/report.json \
-t defectdojo \
-o path/to/report.defectdojo.json \
-n converted_report_nameЗагрузка отчёта PVS-Studio в DefectDojo
После того как вы преобразовали отчёт, его необходимо загрузить в DefectDojo. Для этого нужно добавить в DefectDojo новый engagement, в котором будут находиться результаты анализа. Для добавления engagement нужно выбрать пункт 'Add New Interactive Engagement'.

Далее нужно загрузить получившийся отчёт в созданный engagement. Для этого можно использовать API DefectDojo или вручную загрузить отчёт.
Для ручной загрузки отчёта откройте engagement, нажмите на кнопку меню в таблице 'Tests' и выберите пункт 'Import Scan Result'.

В открывшемся окне в поле 'Scan type' укажите 'Generic Findings Imports', в поле 'Choose report file' укажите отчёт, который нужно загрузить.
Для автоматизации загрузки отчёта используйте API DefectDojo. Пример команды загрузки отчёта:
curl -X POST
-H Authorization:"Token 44ac826dc4f3b6add1161dab11b49402618efaba"
-F scan_type="Generic Findings Import"
-F file=@"path/to/report.json"
-F engagement=1
-H Content-Type:multipart/form-data
-H accept:application/json defctdojohost/api/v2/import-scan/Токен для авторизации можно найти в меню пользователя DefectDojo, выбрав пункт 'API v2 Key'.

В параметре 'engagement' указывается идентификатор того engagement, в который нужно загрузить отчёт. Идентификатор можно узнать из URL выбранного engagement.

В параметре 'file' нужно указать путь до отчёта.
Просмотр отчёта PVS-Studio в DefectDojo
После загрузки отчёта, его можно посмотреть в DefectDojo. Выберите engagement, в который загрузили отчёт, и откройте нужный результат анализа. Последний загруженный отчёт будет первым в списке.

В результате откроется страница, которая будет содержать список предупреждений анализатора.

DefectDojo поддерживает фильтрацию и сортировку предупреждений по разным параметрам. Например, можно оставить только некоторые диагностики или предупреждения с определённым идентификатором CWE.

При нажатии кнопки 'Column visibility' открывается меню со списком для скрытия/отображения столбцов.

Поле 'Name' содержит номер диагностического правила. Нажмите на это поле для просмотра более подробной информации о предупреждении.

На открывшейся странице содержится следующая информация:
- Уровень достоверности предупреждения;
- Статус предупреждения;
- Идентификатор CWE и ссылка на официальный сайт Common Weakness Enumeration c описанием проблемы;
- Путь до файла и строка кода в этом файле, на которую анализатор выдал предупреждение;
- Краткое описание предупреждения;
- Ссылка на подробное описание предупреждения на сайте PVS-Studio.
Работа с ложными предупреждениями
DefectDojo позволяет отмечать предупреждения как False Positive.
Для того чтобы разметка ложных сообщений сохранялась при загрузке нового отчёта, требуется дополнительная настройка DefectDojo.
Откройте настройки DefectDojo ('Configuration -> System Settings' или 'http://defectdojohost/system_settings') и включите опцию 'False positive history'.
Затем добавьте следующую запись в файл 'local_settings.py':
HASHCODE_FIELDS_PER_SCANNER=
{"PVS-Studio Scan (Generic Findings Import)":["unique_id_from_tool"]}Файл должен быть расположен в директории 'dojo/settings/'. Если вы запускаете DefectDojo через 'docker-compose.yml', то файл ('local_settings.py') нужно расположить в папке 'docker/extra_settings/'. В этом случае 'local_settings.py' копируется в папку 'dojo/settings/' при старте docker контейнера.
Эти настройки обеспечивают то, что предупреждения, отмеченные как False Positive, при загрузке нового отчёта не потеряют этот статус. Статус не изменится, даже если строка кода, на которую было выдано срабатывание, сдвинулась.

Дополнительно можно включить настройку 'Deduplicate findings'. В этом случае, когда в отчёте встретится уже загруженное предупреждение, оно будет иметь дополнительный статус 'Duplicate'.
Для того чтобы отметить предупреждение как ложное, нужно выделить его, нажать на кнопку 'Bulk Edit', выделить пункты 'Status' и 'False Positive'.

Quality Gate в DefectDojo
Quality Gate — это индикатор соответствия кода проекта заданным пороговым значениям метрик. В DefectDojo нет функционала для настройки Quality Gate через Веб-интерфейс. Однако с помощью API можно получить необходимую информацию для реализации механизма Quality Gate.
Пример скрипта для использования Quality Gate в DefectDojo можно найти здесь.
Для работы скрипта нужно выставить две переменные окружения:
- DD_HOST – адрес хоста DefectDojo,
- DD_API_TOKEN – текущий API v2 Key
Пример команды запуска скрипта:
python ./qualitygate.py --engagement 6 --critical 0 --high 10 ^
--medium 50 --low 250'engagement' – номер engagement, в который загружается отчёт.
'critical', 'high', 'medium', 'low' – пороговые значения количества предупреждений PVS-Studio различных уровней достоверности.
Скрипт получает последний отчёт из предоставленного engagement и определяет количество сообщений по уровням достоверности. После этого происходит проверка, что количество предупреждений меньше переданных.
Например, из приведённого выше примера следует, что скрипт вернёт код 1, если в отчёте будет хотя бы одно Critical предупреждение или больше 10 High, 50 Medium, 250 Low предупреждений.
Вы можете указать свою логику Quality Gate, изменив функцию quality_gate().
Рассылка результатов анализа
Есть несколько вариантов отправки оповещений в DefectDojo. Рассмотрим только отправку оповещений на примере почты.
Настройка рассылки результатов анализа происходит в два этапа: настройки почты отправителя и настройки оповещений в интерфейсе DefectDojo.
Для настройки отправителя в файл docker-compose.yml нужно добавить строки, в которых будут указаны данные для подключения к почте, с которой будут отправляться сообщения.
uwsgi:
....
DD_EMAIL_URL: "smtp+tls://email%40domain.com:YourPassword@YourSMTPServer:port"
celeryworker:
....
DD_EMAIL_URL: "smtp+tls://email%40domain.com:YourPassword@YourSMTPServer:port"Теперь перейдем к настройке оповещений в интерфейсе DefectDojo. Сначала нужно выбрать почту как способ отправки отчетов. Для этого у пользователя с правами SuperUser нужно перейти в Configuration > System Settings. В поле Email from указать почту, с которой будут отправляться сообщения. А также выбрать пункт Enable mail notifications, чтобы можно было выбрать оповещения для отправки на почту.

Далее нужно настроить пользователя. В поле Email address нужно указать почту, на которую будут приходить оповещения.

Затем нужно перейти в Configuration > Notifications. Здесь можно выбрать необходимые оповещения. Чтобы они приходили на почту, нужно выбрать соответствующую колонку.

Также оповещения можно настроить для конкретного проекта. Для этого нужно перейти в Products, выбрать проект и в разделе Notifications выбрать все нужные оповещения.

После этого оповещения будут приходить на почту с адреса, указанного в настройках в файле docker-compose.yml.
Интеграция результатов анализа PVS-Studio в SonarQube
- Смотри, а не читай (Вк Видео)
- Системные требования
- Плагины PVS-Studio и их установка
- Сохранение совместимости репозиториев при переходе на новую версию SonarCXX плагина
- Интеграция PVS-Studio в Docker-образ SonarQube
- Создание и настройка Quality Profile
- Анализ кода и импорт результатов в SonarQube
- Соответствие уровней достоверности предупреждения PVS-Studio уровням Severity предупреждений в SonarQube
- Исследователям безопасности приложений
- Дополнительные возможности плагина PVS-Studio
- Предварительная настройка анализатора
- Автоматическое обновление плагинов PVS-Studio
- Рассылка результатов анализа
- Рекомендации и ограничения
Интеграция PVS-Studio с платформой SonarQube доступна только при наличии Enterprise лицензии. Вы можете запросить пробную Enterprise лицензию здесь.
SonarQube — это открытая платформа для обеспечения непрерывного контроля качества исходного кода, поддерживающая большое количество языков программирования и позволяющая получать отчеты по таким метрикам, как дублирование кода, соответствие стандартам кодирования, покрытие тестами, сложность кода, потенциальные ошибки и т.д. SonarQube удобно визуализирует результаты анализа и позволяет отслеживать динамику развития проекта во времени.
Демонстрация возможностей платформы SonarQube доступна здесь.
Для импорта результатов анализа в SonarQube PVS-Studio предоставляет плагин. Использование плагина позволяет добавлять сообщения, найденные анализатором PVS-Studio, в базу сообщений сервера SonarQube. С помощью Web интерфейса SonarQube можно фильтровать сообщения, осуществлять навигацию по коду для анализа ошибок, назначать задачи на исполнителей и контролировать их выполнение, анализировать динамику количества ошибок и оценивать уровень качества кода проекта.
Смотри, а не читай (Вк Видео)
Системные требования
- Операционная система: Windows, Linux; macOS
- Версия Java: 8 и выше;
- SonarQube: 7.9 или выше;
- Анализатор PVS-Studio;
- Enterprise-лицензия PVS-Studio.
Плагины PVS-Studio и их установка
Важно: Начиная с версии 9.5, версия SonarQube Plugin API стала отличаться от фактической версии SonarQube. Эта версия API используется для того, чтобы узнать, совместим ли плагин PVS-Studio с SonarQube. Маппинг версий SonarQube в версии SonarQube Plugin API можно посмотреть в разделе Compatibility на GitHub. Также узнать версию SonarQube Plugin API можно из файла по пути sonarqube-VERSION/lib/sonar-application-VERSION.jar/sonar-api-version.txt, где sonarqube-VERSION — это папка установки SonarQube.
Дополнительно при загрузке отчёта анализатора PVS-Studio в SonarQube в лог выводится сообщение c текущей версией SonarQube Plugin API, например:
INFO Edition: COMMUNITY, SonarQube Plugin API Version: 10.1.0.809Пользователям PVS-Studio доступны следующие плагины для SonarQube:
sonar-pvs-studio-plugin.jar— плагин для импорта результатов PVS-Studio в проект на сервере SonarQube. В зависимости от версии SonarQube, необходимо использовать определённый файл плагина:- SonarQube всех изданий версии 7.9 ̶ 10.1 (до SonarQube Plugin API 9.17.0.587 включительно) —
sonar-pvs-studio-plugin-old-versions-before-10.2 .jar; - SonarQube Community Build и SonarQube Server версии 10.2 и выше (начиная с SonarQube Plugin API 10.1.0.809 и выше) —
sonar-pvs-studio-plugin.jar. После версии 10.7 изменилась схема управления версиями изданий SonarQube. Новый шаблон версии SonarQube Community:YY.M.0.BUILDNumber. Пример: SonarQube Community Build 25.1.0.102122. Новый шаблон версии SonarQube Developer/Enterprise/Data Center:YYYY.RELEASENumber.PATCHNumber.BUILDNumber. Пример: SonarQube Developer 2025.1.0.102418).
- SonarQube всех изданий версии 7.9 ̶ 10.1 (до SonarQube Plugin API 9.17.0.587 включительно) —
sonar-pvs-studio-lang-plugin.jar— плагин, позволяющий создавать профиль (quality profile) с языком C/C++/C#. Он предоставляется для совместимости перехода плагинов PVS-Studio со старых версий SonarQube с сохранением ранее полученных метрик/статистики. В будущих релизах его поддержка может прекратиться. Если вы создаёте новый проект, используйте профиль с одним из стандартных языков (C++, C#, Java).
После установки сервера SonarQube скопируйте плагин (sonar-pvs-studio-plugin.jar) в следующую директорию:
SONARQUBE_HOME/extensions/pluginsВ зависимости от языка, для которого вы загружаете результаты анализа, установите также соответствующие плагины из списка (часть из них может быть установлена по умолчанию, в зависимости от используемой вами редакции SonarQube):
- SonarCXX plugin (GitHub)
- SonarC# plugin (Marketplace)
- SonarJava plugin (Marketplace)
- SonarCFamily (Marketplace). Этот плагин предназначен только для SonarQube Developer Edition.
После этого перезапустите сервер SonarQube.
Сохранение совместимости репозиториев при переходе на новую версию SonarCXX плагина
Примечание: Если вы сразу начали использовать обновленную версию плагина SonarCXX (2.0.+) для своего проекта, использующего языки C/C++, то для вас нижеизложенная информация неактуальна.
В SonarCXX 2.0.+ разработчиками были внесены многочисленные изменения с учетом опыта предыдущих версий. Одно из кардинальных изменений – переименование языкового ключа с C++ на CXX. Это изменение привело к тому, что PVS-Studio плагин теперь по умолчанию формирует разные несвязанные между собой репозитории для этих языков. Поэтому, если вы загрузите отчет PVS-Studio после обновления SonarCXX плагина без предварительной настройки, то все существующие ранее Issues от PVS-Studio, будут считаться удаленными, а все Issues из отчета будут считаться новыми.
Если вам необходимо обновить SonarCXX с сохранением истории Issues от PVS-Studio (например, сохранить статус Won't Fix или False Positive со всеми комментариями), то вам необходимо следовать данной инструкции:
- если вы используете Quality Profile для языка C++, который вы долго настраивали, то сделайте его резервную копию и в сохраненном файле замените
<language>c++</language>на<language>cxx</language>; - остановите сервер SonarQube;
- в файле конфигурации SonarQube сервера
SonarQubeFolder/conf/sonar.propertiesдобавьте строчкуsonar.pvs-studio.enableCompatibilitySonarCXXRepositories=true; - замените файл SonarCXX плагина в папке
SonarQubeFolder/extentions/plugins/на новую версию плагина (>= 2.0.0); - запустите SonarQube сервер (
SonarQubeFolder/bin/windows-x86-64/StartSonar.bat); - восстановите (restore) сохраненный ранее Quality Profile или создайте новый для языка CXX;
- если требуется, активируйте в Quality Profile для языка CXX правила из PVS-Studio репозитория;
- установите, загруженный/созданный ранее Quality Profile, профилем по умолчанию (Set as Default).
После этого вы сможете загружать отчеты PVS-Studio для проектов с использованием Quality Profile для языка CXX.
Важно: Если вы ранее загружали отчеты PVS-Studio с использованием плагина SonarCXX версии 2.0.+ без добавления строки из инструкции в файл SonarQubeFolder/conf/sonar.properties, то все Issues, которые были ранее загружены, изменят свой статус на Removed и будут удалены со временем (по умолчанию 30 дней).
Интеграция PVS-Studio в Docker-образ SonarQube
Самый простой и быстрый способ развёртывания сервера SonarQube — это использование образа SonarQube из Dockerhub.
Для загрузки отчётов анализатора PVS-Studio в SonarQube необходимо установить последнюю версию плагина PVS-Studio для SonarQube (которую можно скачать на этой странице), а также один из плагинов для C/C++, если в анализируемых вами проектах используются эти языки.
Ниже приведён пример Docker-файла, который позволит создать образ с SonarQube Community Edition и всеми необходимыми плагинами:
# Для использования SonarQube Enterprise Edition замените "lts-community"
# на "lts" в теге базового docker образа.
FROM sonarqube:lts-community
USER root
# Установка утилиты curl
RUN apk add curl || (apt-get update && apt-get install -y curl)
# Используйте последнюю версию плагина.
# Найти её можно по на странице:
# https://pvs-studio.com/en/pvs-studio/download-all/
ARG PVS_VER=7.27.75620.2023
# Установка плагина PVS-Studio для SonarQube.
RUN curl -Lo \
/opt/sonarqube/extensions/plugins/sonar-pvs-studio-plugin-$PVS_VER.jar \
https://cdn.pvs-studio.com/sonar-pvs-studio-plugin-$PVS_VER.jar
# Если вам необходима другая версия плагина CXX, измените её здесь.
ARG C_VER=cxx-2.1.1
ARG C_JAR=sonar-cxx-plugin-2.1.1.488.jar
# Установка плагина SonarCXX (нужен для работы с C/C++ проектами).
RUN curl -Lo \
/opt/sonarqube/extensions/plugins/$C_JAR \
https://github.com/SonarOpenCommunity/sonar-cxx/releases/download/$C_VER/$C_JAR
# Смена пользователя, который будет использоваться в контейнере
USER sonarqubeПосле создания файла необходимо собрать Docker-образ при помощи команды:
docker build -f dockerfile -t sonarqube-pvs-studio ./Для запуска контейнера SonarQube из ранее собранного образа, используйте команду:
docker run -p 9000:9000 sonarqube-pvs-studioВажно: чтобы не потерять данные из SonarQube при удалении контейнера, монтируйте каталоги по путям, определённым в инструкции к контейнеру SonarQube в DockerHub. Вот пример команды запуска контейнера с монтированными каталогами:
docker run -v /path/to/data:/opt/sonarqube/data
-v /path/to/logs:/opt/sonarqube/logs
-v /path/to/extentions:/opt/sonarqube/extensions
-p 9000:9000 sonarqube-pvs-studioЧтобы увидеть в браузере SonarQube запущенный в Docker-контейнере, перейдите по ссылке http://localhost:9000/.
Для входа введите стандартные значения login-а и пароля администратора SonarQube:
Login: admin
Password: adminПосле входа установите новый пароль для аккаунта администратора.
Создание и настройка Quality Profile
Примечание: Ниже приведена настройка Quality Profile с предустановленными плагинами PVS-Studio и Sonar C++ Community(v2.0.4). Примите во внимание то, что, если Вы используете Sonar C++ Community плагин версии ниже 2.0+, то вместо языка CXX, будут С++(Community) / С(Community).
Quality Profile - это коллекция диагностик, которые выполняются во время анализа. Вы можете включать диагностики PVS-Studio в существующие профили, либо создать новый. Профиль привязывается к конкретному языку программирования, но вы можете создавать несколько профилей с разными наборами правил. Все действия доступны пользователям из группы sonar-administrators.
Создать новый профиль можно в меню Quality Profiles > Create:

Для включения диагностик анализатора в активный профиль, выберите интересующий вас репозиторий в меню Rules > Repository:

Далее добавьте все диагностические правила в свой профиль, нажав на кнопку Bulk Change, или выберите конкретные правила вручную.
Окно активации диагностик выглядит следующим образом:

Вы также можете фильтровать правила по тегам, прежде чем выбрать их для профиля:

После создания/настройки соответствующего профиля, назначьте один из них профилем по умолчанию:

Профиль по умолчанию запускается на файлах для указанного языка программирования. Профили не обязательно делить по используемым утилитам. Вы можете создать единый профиль для вашего проекта, добавив туда диагностические правила из разных утилит.
Так как в SonarQube каждое расширение анализируемого файла должно быть однозначно присвоено одному языку программирования, Sonar C++ Community плагин версии 2.0+ во избежание конфликтов с другими языковыми плагинами по умолчанию не определяет расширения файлов. Для этого Вам нужно самостоятельно их определить:
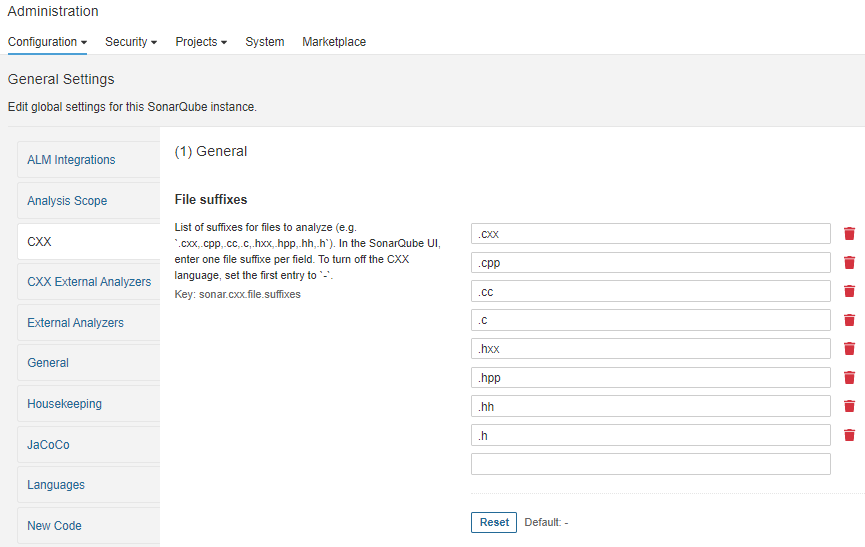
При выходе новой версии PVS-Studio могут добавиться новые диагностики, поэтому нужно обновить версию плагина на сервере SonarQube и добавить новые диагностики в Quality Profile, который использует диагностики PVS-Studio. Настройка автоматического обновления описана ниже, в отдельном разделе.
Анализ кода и импорт результатов в SonarQube
Для импорта результатов анализа в SonarQube используется утилита SonarQube Scanner. Для работы ей требуется конфигурационный файл с именем sonar-project.properties, размещённый в корневом каталоге проекта. Конфигурационный файл содержит настройки для анализа заданного проекта, при этом часть или все настройки можно перенести в параметры запуска утилиты SonarQube Scanner.
Перед первым запуском анализа вам необходимо ввести лицензию. Как это сделать — можно узнать в этой документации.
Далее будут рассмотрены типовые режимы запуска сканера для импорта результатов анализа PVS-Studio в SonarQube на разных платформах. SonarQube Scanner будет автоматически подхватывать конфигурационный файл с именем sonar-project.properties в текущей директории запуска.
SonarScanner for .NET для C# проектов
Для C# проектов возможно использовать два варианта SonarScanner-а:
- SonarQube Scanner (нужен
sonar-project.properties); - SonarQube Scanner for .NET (не нужен
sonar-project.properties).
Разница между ними заключается в том, что SonarQube Scanner for .NET является более специализированным. Он отображает больше статистики, которую предоставляет SonarQube для C# проекта, чем SonarQube Scanner. Например, для отчёта, загруженного SonarQube Scanner, на вкладке со списком проектов (превью проектов) в SonarQube не отображается краткая статистика по проекту, в отличии от проекта, загруженного при помощи SonarQube Scanner for .NET:
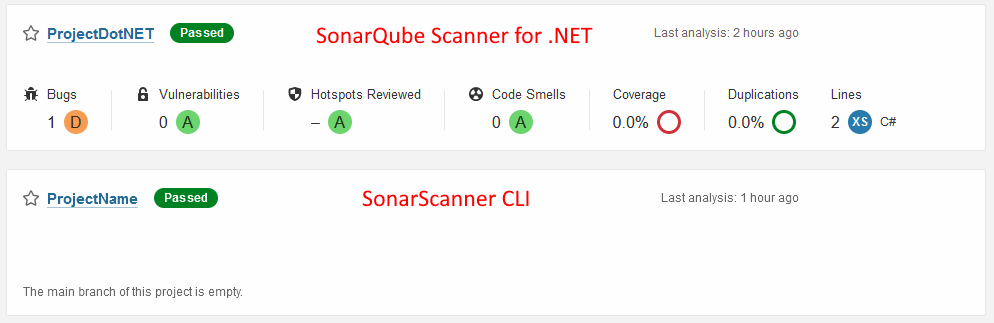
Windows: C, C++, C#
MSBuild-проекты проверяются с помощью утилиты PVS-Studio_Cmd.exe.
Вариант 1
Одним запуском PVS-Studio_Cmd вы можете получить отчёт анализатора и конфигурационный файл sonar-project.properties:
PVS-Studio_Cmd.exe ... -o Project.plog --sonarqubedata ...Команда запуска сканера будет выглядеть следующим образом:
sonar-scanner.bat ^
-Dsonar.projectKey=ProjectKey ^
-Dsonar.projectName=ProjectName ^
-Dsonar.projectVersion=1.0 ^
-Dsonar.pvs-studio.reportPath=Project.plog ^
-Dsonar.login=admin ^
-Dsonar.password=NEW_ADMIN_PASSWORDВариант 2
При использовании SonarQube Scanner for .NET для C# проектов необходимо использовать специальный набор команд, а также не нужно генерировать файл sonar-project.properties (аргумент ‑‑sonarqubedata из PVS-Studio_Cmd.exe) при запуске анализа:
- SonarQube Scanner for .NET Framework:
SonarScanner.MSBuild.exe begin ... /d:sonar.pvs-studio.reportPath=Project.plog
MSBuild.exe Project.sln /t:Rebuild ...
PVS-Studio_Cmd.exe -t Project.sln ... -o Project.plog
SonarScanner.MSBuild.exe end- SonarQube Scanner for .NET:
dotnet <path to SonarScanner.MSBuild.dll>
begin /d:sonar.pvs-studio.reportPath=Project.plog
dotnet build Project.sln /t:Rebuild ...
PVS-Studio_Cmd.exe -t Project.sln ... -o Project.plog
dotnet <path to SonarScanner.MSBuild.dll> endWindows, Linux, macOS: Java
Добавьте следующие строки в проверяемый анализатором PVS-Studio Java проект (в зависимости от типа проверяемого проекта):
Maven
<outputType>json</outputType>
<outputFile>output.json</outputFile>
<sonarQubeData>sonar-project.properties</sonarQubeData>Gradle
outputType = 'json'
outputFile = 'output.json'
sonarQubeData='sonar-project.properties'Ядро Java анализатора
Windows:
java -jar pvs-studio.jar ^
-s ./ ^
--ext-file /path/to/file/with/classpath/entries ^
-o output.json ^
--output-type json ^
--sonarqubedata sonar-project.propertiesLinux/macOS:
java -jar pvs-studio.jar \
-s ./ \
--ext-file /path/to/file/with/classpath/entries \
-o output.json \
--output-type json \
--sonarqubedata sonar-project.propertiesПосле завершения работы Java анализатора конфигурационный файл SonarQube также будет создан автоматически.
Команда запуска сканера будет выглядеть следующим образом:
Windows:
sonar-scanner.bat ^
-Dsonar.projectKey=ProjectKey ^
-Dsonar.projectName=ProjectName ^
-Dsonar.projectVersion=1.0 ^
-Dsonar.pvs-studio.reportPath=output.json ^
-Dsonar.login=admin ^
-Dsonar.password=NEW_ADMIN_PASSWORDLinux/macOS:
sonar-scanner \
-Dsonar.projectKey=ProjectKey \
-Dsonar.projectName=ProjectName \
-Dsonar.projectVersion=1.0 \
-Dsonar.pvs-studio.reportPath=output.json \
-Dsonar.login=admin \
-Dsonar.password=NEW_ADMIN_PASSWORDLinux, macOS: C, C++, C#
В случае С/C++ проекта, конфигурационный файл необходимо создать самостоятельно. Например, он может быть с таким содержимым:
sonar.projectKey=my:project
sonar.projectName=My project
sonar.projectVersion=1.0
sonar.pvs-studio.reportPath=report.json
sonar.sources=path/to/directory/with/project/sourcesВариант 1
В случае C# проекта получить отчет анализатора вместе с конфигурационным файлом можно с помощью следующей команды:
pvs-studio-dotnet .... -o report.json –sonarqubedataЗапуск sonar-scanner осуществляется следующим образом:
sonar-scanner\
-Dsonar.projectKey=ProjectKey \
-Dsonar.projectName=ProjectName \
-Dsonar.projectVersion=1.0 \
-Dsonar.pvs-studio.reportPath=report.json \
-Dsonar.login=admin \
-Dsonar.password=NEW_ADMIN_PASSWORDВариант 2
При использовании SonarQube Scanner for .NET для C# проектов необходимо использовать специальный набор команд, а также не нужно генерировать файл sonar-project.properties (аргумент ‑‑sonarqubedata из pvs-studio-dotnet) при запуске анализа:
dotnet <path to SonarScanner.MSBuild.dll>
begin /d:sonar.pvs-studio.reportPath=report.json
dotnet build Project.sln /t:Rebuild ...
pvs-studio-dotnet .... -o report.json
dotnet <path to SonarScanner.MSBuild.dll> endC SonarQube 2025.1 свойство -Dsonar.password было удалено, поэтому вместо него нужно использовать токен -Dsonar.token.
Команда в таком случае будет выглядеть так:
-Dsonar.projectKey=ProjectKey ^
-Dsonar.projectName=ProjectName ^
-Dsonar.projectVersion=1.0 ^
-Dsonar.pvs-studio.reportPath=Project.plog ^
-Dsonar.token=TOKENsonar-project.properties
Для более глубокой настройки анализа своего проекта, вы можете самостоятельно составить конфигурационный файл из следующих настроек (или отредактировать создаваемый по умолчанию файл при проверке MSBuild и Java проектов):
sonar.pvs-studio.reportPath— путь к отчёту анализатора в формате .plog (для MSBuild проектов) или .json;sonar.pvs-studio.licensePath— путь к лицензии анализатора PVS-Studio (если проверяется MSBuild проект, вы можете передать эту настройку с помощью параметраsonar.pvs-studio.settingsPath). Путь до файла по умолчанию-- ~/.config/PVS-Studio/PVS-Studio.licна Linux и macOS;sonar.pvs-studio.sourceTreeRoot— путь к директории проекта на текущем компьютере, если отчёт анализатора был получен на другом компьютере, Docker-контейнере и т.п. Задание данного пути позволяет передавать вsonar.pvs-studio.reportPathотчёт, сгенерированный с относительными путями (если проверяется MSBuild проект, вы можете передать эту настройку с помощью параметраsonar.pvs-studio.settingsPath);sonar.pvs-studio.settingsPath— путь кSettings.xmlдля MSBuild проектов, проверяемых на Windows. В этом файле уже содержится информация оlicencePathиsourceTreeRoot, поэтому эти параметры можно не указывать отдельно. Путь по умолчанию-- %AppData%\PVS-Studio\Settings.xml. Файл используется только на Windows;sonar.pvs-studio.cwe— включает добавление CWE ID к предупреждениям анализатора. По умолчанию эта опция выключена. Используйте значение active для включения;sonar.pvs-studio.misra— включает добавление идентификатора MISRA к предупреждениям анализатора. По умолчанию эта опция выключена. Используйте значение active для включения;sonar.pvs-studio.language— включает языковой плагин C/C++/C#. По умолчанию эта опция выключена. Используйте значение active для включения. Используйте данную настройку, если вы используете профиль с языком C/C++/C#, добавляемым отдельным плагином PVS-Studio. Данный плагин предоставляется для совместимости перехода со старых версий SonarQube плагинов PVS-Studio с сохранением ранее полученных метрик\статистики, в будущих релизах его поддержка может быть прекращена.
Описание остальных стандартных параметров конфигурации сканера доступно в общей документации SonarQube.
Загрузка отчёта при использовании плагина SonarCFamily
При использовании плагина PVS-Studio вместе с плагином SonarCFamily необходимо дополнительно использовать SonarSource Build Wrapper или Compilation Database (с версии SonarQube 9.1) при загрузке отчёта PVS-Studio. Подробная инструкция об их использовании находится на сайте SonarQube.
При загрузке отчёта необходимо будет указать свойство sonar.cfamily.build-wrapper-output или sonar.cfamily.compile-commands как аргумент при запуске sonar-scanner (например: -Dsonar.cfamily.build-wrapper-output=директория_с_результатами_работы_Build_Wrapper) или добавить его в файл sonar-project.properties.
Многомодульный проект
Когда директории подпроектов расположены на разных уровнях, загрузить в SonarQube результаты анализа нескольких подпроектов в один проект со стандартными настройками становится невозможным. Это связано с тем, что для такой структуры подпроектов требуется дополнительная настройка индексатора в утилите SonarScanner.
Правильно настроить такой проект можно с помощью модулей, где каждый модуль настраивается для одного подпроекта:
sonar.projectKey=org.mycompany.myproject
sonar.projectName=My Project
sonar.projectVersion=1.0
sonar.sources=src
sonar.modules=module1,module2
module1.sonar.projectName=Module 1
module1.sonar.projectBaseDir=modules/mod1
module2.sonar.projectName=Module 2
module2.sonar.projectBaseDir=modules/mod2Для указания пути к файлу с результатами анализа PVS-Studio есть 2 пути.
Первый способ
Указать разные отчёты для модулей:
....
sonar.modules=module1,module2
module1.sonar.projectName=Module 1
module1.sonar.projectBaseDir=modules/mod1
module1.sonar.pvs-studio.reportPath=/path/to/report1.plog
module2.sonar.projectName=Module 2
module2.sonar.projectBaseDir=modules/mod2
module2.sonar.pvs-studio.reportPath=/path/to/report2.plogВторой способ
Указать один отчёт на уровне проекта:
sonar.projectKey=org.mycompany.myproject
sonar.projectName=My Project
sonar.projectVersion=1.0
sonar.sources=src
sonar.pvs-studio.reportPath=/path/to/report.plog
sonar.modules=module1,module2
....В этом случае каждый модуль загрузит из отчёта только те предупреждения, которые относятся к нему. К сожалению, на файлы из других модулей будет выдан WARN об отсутствии файлов в вывод утилиты SonarScanner, но все результаты анализа будет загружены корректно.
Соответствие уровней достоверности предупреждения PVS-Studio уровням Severity предупреждений в SonarQube
В отчётах анализатора PVS-Studio каждое предупреждение имеет такую характеристику, как уровень достоверности:
- High (1) — высокий уровень вероятности ошибки в коде;
- Medium (2) — средний уровень вероятности ошибки в коде;
- Low (3) — низкий уровень вероятности ошибки в коде;
- Fails (0) — специальная категория, к которой относятся внутренние сообщения анализатора, информирующие о возникновении каких-то проблем при его работе.
В SonarQube у Issues есть похожая характеристика — Severity. Количество уровней Severity у Issue в SonarQube отличается (их 5, а в PVS-Studio их 4). Кроме этого, сервер SonarQube в определённый момент стал поддерживать два режима, в которых отличается отображение Severity уровней на вкладке Issues:


Соответствие уровня достоверности предупреждения PVS-Studio уровню Severity у Issue в SonarQube представлена в таблице:
|
PVS-Studio Warning |
Standard Experience Mode |
Multi-Quality Rule Mode |
|---|---|---|
|
Fails (0) |
Info |
Info |
|
High (1) |
Critical |
High |
|
Medium (2) |
Major |
Medium |
|
Low (3) |
Minor |
Low |
|
- |
Blocker |
Blocker |
Исследователям безопасности приложений
Со всеми возможности анализатора по поиску потенциальных уязвимостей в коде вы можете ознакомиться на странице PVS-Studio SAST (Static Application Security Testing).
Информация о безопасности проверяемого кода, предоставляемая анализатором PVS-Studio, дополнительно помечается в отображаемых SonarQube результатах анализа.
Теги cwe, cert, misra
В меню Issues > Tag или Rules > Tag доступны следующие теги для группировки предупреждений PVS-Studio по разным стандартам безопасности:
- misra
- cert
- cwe
Также вы можете выбрать конкретный CWE ID, если такой доступен (если сообщение анализатора соответствует нескольким идентификаторам CWE, оно будет отмечено одним общим тегом cwe - используйте префиксы в тексте предупреждений для фильтрации таких идентификаторов):

Security Category
В SonarQube 7.8 и 8.4, на страницах Issues и Rules доступен новый фильтр по категориям безопасности. При помощи этого фильтра SonarQube позволяет классифицировать правила в соответствии стандартам безопасности, таким как:
- Sans Top 25
- OWASP Top 10
- CWE
Правила и проблемы от PVS-Studio, которые сопоставлены с CWE ID, также можно группировать в этом меню (Security Category > CWE):
Примечание. Начиная с версии SonarQube 8.5, во вкладку Security Category могут попасть только Issues/Rules, связанные с безопасностью, а именно те Issues/Rules, у которых тип Vulnerability или Security Hotspot.
PVS-Studio предупреждения как потенциальные уязвимости
Все правила PVS-Studio по умолчанию имеют тип Bug. Если вам необходимо изменить тип правила с Bug на 'Vulnerability при наличии CWE ID или если правило относится к рейтингу OWASP Top 10, то для этого необходимо в конфигурационном файле сервера $SONARQUBE_HOME\conf \sonar.properties добавить следующую строчку:
sonar.pvs-studio.treatPVSWarningsAsVulnerabilities=activeЧтобы изменения вступили в силу нужно перезапустить сервер SonarQube. После того как вы это сделали, правила с CWE ID или относящиеся к рейтингу OWASP Top 10 будут иметь тип Vulnerability, а новые сгенерированные проблемы уже будут учитывать это изменение.
Примечание. Если у вас до этого были старые проблемы, то это изменение их не коснется. Для этого вам необходимо вручную изменить тип у этих проблем.
Префиксы CWE и MISRA у предупреждений
В конфигурационном файле sonar-project.properties доступны следующие опции:
sonar.pvs-studio.cwe=active
sonar.pvs-studio.misra=activeОни включают режим добавления идентификаторов CWE и MISRA к предупреждениям анализатора. Выглядит это следующим образом:

Возможность фильтровать предупреждения по соответствующим тегам доступна всегда и не зависит от указанных опций.
Статистика по найденным CWE и MISRA
На вкладке Projects > Your Project > Measures доступны различные метрики кода, вычисляемые после каждого запуска анализа. Всю собираемую информацию можно выводить в полезные графики. В секции Security вы можете следить за количеством предупреждений, выдаваемых на проект с пометкой CWE и MISRA:

Остальные, общие метрики сообщений анализатора PVS-Studio, доступны в отдельной секции PVS-Studio.
Дополнительные возможности плагина PVS-Studio
Большинство действий, доступных для пользователей SonarQube, являются стандартными для этой платформы. Например, просмотр и сортировка результатов анализа, изменение статуса предупреждения и т.п. Поэтому в этом разделе будут описаны только дополнительные возможности, появляющиеся с установкой плагина PVS-Studio.
Сортировка предупреждений по группам
Предупреждения PVS-Studio делятся на несколько групп, из которых не все могут быть интересны для конкретного проекта. Поэтому вы можете фильтровать диагностики по следующим тегам при создании профиля или просмотре результатов анализа:
|
Группа диагностик в PVS-Studio |
Тег в SonarQube |
|---|---|
|
Диагностики общего назначения |
pvs-studio#ga |
|
Диагностики микро-оптимизаций |
pvs-studio#op |
|
Диагностики 64-битных ошибок |
pvs-studio#64 |
|
Стандарт MISRA |
pvs-studio#misra |
|
Диагностики, реализованные по запросам пользователей |
pvs-studio#cs |
|
Проблемы при работе анализатора кода |
pvs-studio#fails |
И стандартные теги, которые используются для предупреждений PVS-Studio:
|
Стандарты контроля качества кода |
Тег в SonarQube |
|---|---|
|
Стандарт CWE |
cwe |
|
Стандарт CERT |
cert |
|
Стандарт MISRA |
misra |
Стандартные теги SonarQube, в отличии от группы тегов pvs-studio#, могут включать, в зависимости от используемого quality-профиля, сообщения и от других инструментов, помимо PVS-Studio.
Просмотр метрик кода
На вкладке Projects > Your Project > Measures доступны различные метрики кода, вычисляемые после каждого запуска анализа. С плагином добавляется секция PVS-Studio, где вы можете найти полезную информацию для проекта и строить графики:

Предварительная настройка анализатора
При работе на большой кодовой базе, анализатор неизбежно генерирует большое количество предупреждений. При этом часто нет возможности поправить все предупреждения сразу. Для того, чтобы иметь возможность сконцентрироваться на правке наиболее важных предупреждений и не "засорять" статистику, можно провести предварительную настройку анализатора и фильтрацию лога до запуска SonarQube Scanner. Это можно сделать несколькими способами.
1. Анализ можно сделать менее "шумным" с помощью настройки No Noise. Она позволяет полностью отключить генерацию предупреждений низкого уровня достоверности (Low Certainty, третий уровень предупреждений). После перезапуска анализа, сообщения этого уровня полностью пропадут из вывода анализатора. Для включения этой настройки в анализаторе, воспользуйтесь окном настроек Specific Analyzer Settings в Windows и общей документацией для Linux и macOS.
2. Анализ можно ускорить, исключив из проверки внешние библиотеки, код тестов и т.д. Для добавления файлов и каталогов в исключения, воспользуйтесь окном настроек Don't Check Files в Windows и общей документацией для Linux и macOS.
3. Если вам нужен дополнительный контроль над тем, какие сообщения анализатора будут попадать в отображаемые результаты, например, по уровню достоверности или кодам ошибок, воспользуйтесь утилитой для фильтрации и преобразования результатов (Plog Converter) на соответствующей платформе.
4. Если вам необходимо изменить важность предупреждения, это делается в настройках самого анализатора, а не в SonarQube. Сообщения PVS-Studio имеют следующие уровни достоверности: High, Medium, Low и Fails. В SonarQube им соответствуют уровни Critical, Major, Minor и Info. Изменение уровней описано на странице "Дополнительная настройка диагностик"
Автоматическое обновление плагинов PVS-Studio
Автоматизировать процесс обновления позволяет SonarQube Web Api. Предположим, на вашем билд-сервере настроена система автоматического обновления PVS-Studio (как это описано в статье Развертывание PVS-Studio в больших командах). Для того, чтобы обновить плагины PVS-Studio и добавить новые диагностики в Quality Profile без использования веб-интерфейса, выполните следующие шаги (пример для Windows, на других ОС данная процедура выполняется аналогично):
- Скопируйте файл
sonar-pvs-studio-plugin.jarиз директории установки PVS-Studio в директорию$SONARQUBE_HOME\extensions\plugins. - Перезапустите сервер SonarQube.
Допустим, сервер SonarQube установлен в директории C:\Sonarqube\ и запущен как сервис. PVS-Studio установлена в директории C:\Program Files (x86)\PVS-Studio\. Тогда скрипт для автоматического обновления дистрибутива PVS-Studio и плагина sonar-pvs-studio-plugin будет иметь вид:
set PVS-Studio_Dir="C:\Program Files (x86)\PVS-Studio"
set SQDir="C:\Sonarqube\extensions\plugins\"
rem Update PVS-Studio
cd /d "C:\temp\"
xcopy %PVS-Studio_Dir%\PVS-Studio-Updater.exe . /Y
call PVS-Studio-Updater.exe /VERYSILENT /SUPPRESSMSGBOXES
del PVS-Studio-Updater.exe
rem Stop the SonarQube server
sc stop SonarQube
rem Wait until the server is stopped
ping -n 60 127.0.0.1 >nul
xcopy %PVS-Studio_Dir%\sonar-pvs-studio-plugin.jar %SQDir% /Y
sc start SonarQube
rem Wait until the server is started
ping -n 60 127.0.0.1 >nul- Определите ключ Quality Profile, в котором необходимо активировать диагностики. Получить этот ключ можно с помощью GET-запроса
api/qualityprofiles/search, например (одной строкой):
curl http://localhost:9000/api/qualityprofiles/search
-v -u admin:adminОтвет сервера имеет следующий формат:
{
"profiles": [
{
"key":"c++-sonar-way-90129",
"name":"Sonar way",
"language":"c++",
"languageName":"c++",
"isInherited":false,
"isDefault":true,
"activeRuleCount":674,
"rulesUpdatedAt":"2016-07-28T12:50:55+0000"
},
{
"key":"c-c++-c-pvs-studio-60287",
"name":"PVS-Studio",
"language":"c/c++/c#",
"languageName":"c/c++/c#",
"isInherited":false,
"isDefault":true,
"activeRuleCount":347,
"rulesUpdatedAt":"2016-08-05T09:02:21+0000"
}
]
}Допустим, нам нужно добавить новые диагностики в профиль PVS-Studio для языка c/c++/c#. Его ключом является значение c-c++-c-pvs-studio-60287.
- Выполните POST-запрос
api/qualityprofiles/activate_rulesи укажите параметрыprofile_key(обязательный параметр) иtags. Обязательный параметрprofile_keyопределяет ключ профиля в SonarQube, в котором будут активированы диагностики. В рассматриваемом примере этот параметр имеет значение c-c++-c-pvs-studio-60287.
Обратите внимание на то, что ключ профиля может содержать специальные символы, и при отправке его в POST-запросе нужно произвести экранирование URL символов. Так, ключ профиля c-c++-c-pvs-studio-60287 должен быть преобразован в c-c%2B%2B-c-pvs-studio-60287
В параметре tags передайте теги диагностик, которые нужно активировать в профиле. Чтобы активировать все диагностики PVS-Studio, укажите тег pvs-studio.
В результате, запрос на добавление всех диагностик в профиль PVS-Studio будет иметь вид (одной строкой):
curl --request POST -v -u admin:admin -data
"profile_key=c-c%2B%2B-c-pvs-studio-60287&tags=pvs-studio"
http://localhost:9000/api/qualityprofiles/activate_rulesРассылка результатов анализа
Настройка рассылки результата анализа происходит в несколько этапов. Сначала нужно настроить почту, с которой будут приходить оповещения. После этого каждый пользователь может выбрать необходимые оповещения.
Для настройки почты, находясь в роли Администратора, нужно перейти в раздел Administration > Configuration > General.
После этого необходимо заполнить параметры:
SMTP host(email.smtp_host.secured)— SMTP-сервер для отправки оповещений;SMTP port(email.smtp_port.secured)-— номер порта для отправления писем;SMTP username(email.smtp_username.secured)— имя пользователя для авторизации;SMTP password(email.smtp_password.secured)— пароль пользователя для авторизации;From address(email.from)— email адрес отправителя писем;From name(email.fromName)— наименование отправителя писем;Email prefix(email.prefix)— префикс исходящего письма.
Примечание. В качестве Server base URL (sonar.core.serverBaseURL) нужно указать тот IP-адрес, на котором находится SonarQube. Это нужно, чтобы гиперссылки в письме ссылались на правильный сервер (по умолчанию они всегда будут отправлять на localhost).
Данные параметры можно задать в файле настроек сервера SonarQube, расположенном по пути sonarqube\conf\sonar.properties.
Чтобы проверить подключение к почте, можно отправить тестовое письмо в разделе Test Configuration.

После настройки отправителя каждый пользователь может выбрать нужные оповещения. Для этого нужно перейти в раздел My Account > Notifications. Есть различные типы оповещений, которые может выбрать пользователь. Отдельно можно выбрать оповещения для каждого проекта.

Рекомендации и ограничения
- Сервер SonarQube по умолчанию удаляет сообщения, закрытые более 30 дней назад. Мы рекомендуем отключить эту функцию, чтобы по истечению длительного периода времени (года, например) иметь возможность проанализировать, сколько сообщений, найденных PVS-Studio, было исправлено;
- Если в файле
sonar-project.propertiesопределены модули, и у вас есть отдельный отчёт анализатора для каждого модуля, то необходимо объединить отчёты в один с помощью утилиты PlogConverter и указать отчёт один раз вsonar.pvs-studio.reportPath. - Для анализа проектов MSBuild разработчики SonarQube рекомендуют использовать SonarQube Scanner for MSBuild. Этот сканер представляет собой обертку над стандартным сканером SonarQube и облегчает процесс создания конфигурационного файла сканера sonar-project.properties, автоматически добавляя в него модули (проекты в решении) и записывая пути до исходных файлов, которые необходимо проанализировать. Однако мы столкнулись с ограничениями, из-за которых для сложных проектов создаются некорректные конфигурационные файлы, поэтому для импорта результатов анализа PVS-Studio мы рекомендуем использовать стандартный сканер SonarQube.
- Все исходные файлы для анализа должны располагаться на одном диске. Это ограничение налагается платформой SonarQube. Исходные файлы, расположенные на дисках, отличных от диска, указанного в свойстве
sonar.projectBaseDir, не будут проиндексированы, и сообщения, найденные в этих файлах, будут проигнорированы.
Интеграция результатов анализа PVS-Studio в CodeChecker
- Установка CodeChecker
- Преобразование отчёта в совместимый с CodeChecker формат
- Просмотр отчёта PVS-Studio
CodeChecker — это интерфейс для работы со статическими анализаторами для Linux и macOS. С помощью данного инструмента можно удобно просматривать результаты анализа PVS-Studio и управлять ими.
Установка CodeChecker
Для того, чтобы запустить CodeChecker нужно создать виртуальное окружение Python (версии >= 3.8) и установить инструмент с помощью пакетного менеджера pip:
python3 -m venv .venv
source ./.venv/bin/activate
pip3 install codecheckerПримечание. Интеграция результатов анализа PVS-Studio доступна с версии CodeChecker 6.25.0.
Для корректного отображения severity у диагностических правил PVS-Studio необходимо скачать файл CodeChecker.json и положить его в этом виртуальном окружении Python, по пути .venv/share/codechecker/config/labels/analyzers с названием pvs-studio.json.
Теперь для запуска веб-сервера CodeChecker потребуется выполнить следующую команду:
CodeChecker serverПо умолчанию веб-сервер CodeChecker доступен по адресу http://localhost:8001.
О других способах установки и развёртывания CodeChecker можно прочитать в специальном разделе документации самого инструмента.
Преобразование отчёта в совместимый с CodeChecker формат
Для работы с отчётом PVS-Studio в CodeChecker его нужно привести в нужный формат. Помочь нам с этим может встроенный инструмент CodeChecker — report-converter.
Важно, что report-converter может преобразовать только JSON-отчёт PVS-Studio. Для преобразования отчёта PVS-Studio другого формата в JSON или фильтрации предупреждений необходимо использовать утилиты PlogConverter.exe для Windows и plog-converter для Linux/macOS:
Пример команды конвертации отчёта PVS-Studio при помощи plog-converter (Linux/macOS):
plog-converter -t json -a 'GA:1,2;OWASP:1'
-o /home/user/Logs/PVS-Studio.json PVS-Studio.logПример команды конвертации отчёта PVS-Studio при помощи PlogConverter.exe (Windows):
PlogConverter.exe -t Json -a 'GA:1,2;OWASP:1' -o /home/user/Logs
-n PVS-Studio PVS-Studio.plogДля преобразования отчёта PVS-Studio в формат CodeChecker необходимо выполнить следующую команду:
report-converter -t pvs-studio -o ./pvs_studio_reports ./PVS-Studio.jsonФлаг -t указывает формат входного отчёта, -o – директорию, в которую будут сохранены преобразованные предупреждения. Подробнее об остальных функциях report-converter можно прочитать в его документации.
Чтобы сохранить преобразованный отчёт на веб-сервере для дальнейшей работы с ним, необходимо выполнить следующую команду:
CodeChecker store ./codechecker_pvs_studio_reports -n defaultПосле флага -n необходимо передать название запуска CodeChecker.
Просмотр отчёта PVS-Studio
После выполнения описанных выше действий в списке запусков для проекта появится запуск с указанным названием.

Нажав на его название, можно увидеть список предупреждений для этого проекта:

На данной странице можно фильтровать и сортировать предупреждения по определённым параметрам, например по уровню достоверности или названию диагностического правила.
Нажав на локацию конкретного срабатывания, можно увидеть место в коде, где это срабатывание произошло:

На этой же странице можно поменять Review status открытого срабатывания. Эта функция может быть полезна при разметке предупреждений анализатора после проведения анализа. Каждому срабатыванию можно поставить один из следующих статусов:
- Confirmed bug – срабатывание истинно и требует исправления
- False positive – срабатывание ложно
- Intentional – срабатывание истинно, но не требует исправления
При пометке срабатывания как False Positive оно будет исключено из отображения отчёта, в том числе при всех следующих запусках.
Срабатывания, которых не было при предыдущих запусках помечаются в списке специальным значком, а также есть возможность просматривать разницу между конкретными запусками:

После нажатия кнопки Diff отобразится список только различающихся срабатываний:

Интеграция PVS-Studio с AppSec.Hub
- Преобразование отчёта PVS-Studio в совместимый с AppSec.Hub формат
- Импорт отчёта в AppSec.Hub
- Использование отчёта PVS-Studio в AppSec.Hub
Компания PVS-Studio и платформа AppSec.Hub заключили технологическое партнёрство для обеспечения интеграции статического анализатора кода PVS-Studio в экосистему DevSecOps. PVS-Studio — это инструмент для обнаружения потенциальных ошибок и уязвимостей в исходном коде на языках C, C++, C# и Java. AppSec.Hub — это платформа для автоматизации процессов Application Security, которая позволяет объединять различные инструменты анализа, тестирования и мониторинга безопасности приложений.
На данный момент прямая интеграция PVS-Studio через пользовательский интерфейс (UI) AppSec.Hub отсутствует. Однако в AppSec.Hub можно загрузить результаты анализа PVS-Studio в виде отчёта и после этого работать с конкретными ошибками так же, как это позволяют и другие инструменты. Загрузка возможна двумя способами: через пользовательский интерфейс и командную строку с использованием CLI-инструментов.
Преобразование отчёта PVS-Studio в совместимый с AppSec.Hub формат
Оба доступных варианта подразумевают работу с результатами анализатора (его отчётом) в формате, поддерживаемом AppSec.Hub. Для получения отчёта PVS-Studio в таком формате необходимо сделать следующие шаги.
- Запустите анализ вашего проекта с помощью PVS-Studio. В нашей документации можно подробно прочитать о том, как запускать анализатор PVS-Studio на операционной системе Windows, а также на операционных системах Linux и macOS.
- Используйте утилиту
PlogConverterна Windows иplog-converterна Linux и macOS, входящую в состав PVS-Studio, чтобы преобразовать отчёт анализатора в формат SARIF (Static Analysis Results Interchange Format). О том, как это сделать, можно прочитать в нашей документации. - Используйте конвертер, предоставленный AppSec.Hub, для преобразования файла SARIF в формат, который поддерживается платформой.
Клонируйте репозиторий AppSec.Hub с конвертерами:
git clone https://github.com/Swordfish-Security/hub-tool-converters.gitПерейдите в директорию конвертера:
cd hub-tool-convertersВыполните команду для конвертации:
python main.py -s pvs-Studio -t CODEBASE --format sarif \
-f <PATH_TO_REPORT_IN_SARIF> -o <OUTPUT_REPORT_FILE> \
-n <CODEBASE_NAME> -u <REPOSITORY_URL>Импорт отчёта в AppSec.Hub
Импорт отчёта через UI AppSec.Hub
Данный способ подразумевает ручную загрузку отчёта через UI AppSec.Hub. Сделать это можно следующим образом:
1. Откройте веб-интерфейс AppSec.Hub.

2. Перейдите в раздел Applications -> <Application Name> -> Issues.

3. Нажмите кнопку Actions в правом верхнем углу и выберите пункт Import from report.

4. Выберите файл отчёта анализатора PVS-Studio в формате AppSec.Hub, полученный в результате осуществления предварительных шагов.

5. Подтвердите импорт.
Подробнее об этом способе можно прочитать в официальной документации AppSec.Hub.
Импорт отчёта через CLI AppSec.Hub
Такой способ подразумевает использование утилиты hub-cli, входящей в поставку AppSec.Hub, для автоматической загрузки отчёта. Сделать это можно следующим образом:
1. Убедитесь, что у вас установлена утилита hub-cli. Она должна идти в комплекте поставки AppSec.Hub.
2. Выполните команду для импорта отчёта:
python -m src.import_report --url <URL_TO_YOUR_APPSECHUB> --token <TOKEN> \
--appcode <APP_CODE> --application-name <APP_NAME> \
--report-file <OUTPUT_REPORT_FILE>Больше об этой программе можно узнать в официальной документации AppSec.Hub.
Использование отчёта PVS-Studio в AppSec.Hub
После загрузки отчёта во вкладке Issues появится список предупреждений, выданных анализаторов PVS-Studio.

На странице можно фильтровать и сортировать предупреждения по определённым параметрам, например, по уровню достоверности или названию диагностического правила. Подробнее о работе с дефектами безопасности можно прочитать в официальной документации AppSec.Hub.
Если у вас возникнут вопросы или сложности с интеграцией, обратитесь в техническую поддержку PVS-Studio или AppSec.Hub.
Интеграция PVS-Studio с Hexway
- Преобразование отчёта PVS-Studio в совместимый с Hexway формат
- Импорт отчёта в Hexway
- Использование отчёта PVS-Studio в Hexway
Компания PVS-Studio и платформа Hexway заключили технологическое партнёрство для обеспечения интеграции статического анализатора кода PVS-Studio в экосистему DevSecOps. PVS-Studio — это инструмент для обнаружения потенциальных ошибок и уязвимостей в исходном коде на языках C, C++, C# и Java. Hexway VamPy — это решение, агрегирующее данные о безопасности из разных источников для работы с уязвимостями.
В Hexway можно загрузить результаты анализа PVS-Studio в виде отчёта и работать с конкретными ошибками так же, как это позволяют другие инструменты. Загрузка возможна двумя способами: через пользовательский интерфейс или командную строку с использованием CLI-инструментов.
Преобразование отчёта PVS-Studio в совместимый с Hexway формат
Интеграция происходит с помощью преобразования отчёта PVS-Studio в формат SARIF. Для этого:
- Запустите анализ вашего проекта с помощью PVS-Studio. В нашей документации можно подробно прочитать о том, как запускать анализатор PVS-Studio на операционной системе Windows, а также на операционных системах Linux и macOS;
- Используйте утилиту
PlogConverterна Windows иplog-converterна Linux и macOS, входящую в состав PVS-Studio, чтобы преобразовать отчёт анализатора в формат SARIF (Static Analysis Results Interchange Format). О том, как это сделать, можно прочитать в нашей документации. Например, на Linux это можно сделать следующим образом:
plog-converter -t sarif -o pvs-studio.sarif pvs-studio.jsonИмпорт отчёта в Hexway
Импорт отчёта через UI
Для импорта отчёта через UI необходимо сделать следующее:
1. Перейдите на вкладку Repositories и выберете нужный репозиторий;

2. Нажмите на клавишу Scan внизу экрана;

3. Заполните поля и выберете файл для загрузки, затем нажмите клавишу Submit;

Импорт отчёта через CLI
Импорт отчёта через утилиту vampy-cli
Импорт отчёта происходит с помощью утилиты vampy-cli, которая доступна на сайте Hexway. Полная команда загрузки отчёта выглядит следующим образом:
vampy-cli upload \
--scanner SARIF \
--file <PATH_TO_PVS_STUDIO_REPORT>
--repository <REPOSITORY>
--vampy-url <VAPMPY_URL>
--api-token <TOKEN>Больше об этом способе можно узнать в официальной документации Hexway.
Импорт отчёта через утилиту CURL
Импорт отчёта происходит с помощью утилиты curl или иной утилиты, позволяющей посылать POST запросы на указанный адрес. Полная команда загрузки отчёта выглядит следующим образом:
curl -X POST "<YOUR_ADDRESS>/api/ext/v1/scan_uploads/" \
-H "accept: */*" \
-H "Content-Type: multipart/form-data" \
-H "Authentication: <TOKEN>"\
-F "repository=<REPO_NAME>" \
-F "repositoryBranch=<REPO_BRANCH>" \
-F "scannerResultFile=@<PATH_TO_PVS_STUDIO_REPORT>" \
-F "scannerType=SARIF"Больше об этом способе можно узнать в официальной документации Hexway.
Использование отчёта PVS-Studio в Hexway
После загрузки отчёта во вкладке Issues появится список предупреждений, выданных анализатором PVS-Studio.

На странице можно фильтровать и сортировать предупреждения по определённым параметрам, например, по уровню достоверности или названию диагностического правила. Подробнее о работе с дефектами безопасности можно прочитать в официальной документации Hexway.
Для разметки каждого предупреждения выберете нужное вам и нажмите на указанную кнопку.

Таким образом можно размечать сообщения, например, как исправленные, ложные, принятые и так далее.
Если у вас возникнут вопросы или сложности с интеграцией, обратитесь в техническую поддержку PVS-Studio или Hexway.
Интеграция результатов анализа PVS-Studio в Securitm
Облачный сервис и программное обеспечение SGRC Securitm позволяют построить управление информационной безопасностью на базе риск-ориентированного подхода и единой информационной модели компании.
Отчёт анализатора PVS-Studio можно загрузить в Securitm для дальнейшего использования.
Примечание. О работе непосредственно Securitm можно прочитать в документации этого инструмента.
Конвертация отчёта
Чтобы загрузить отчёт анализатора PVS-Studio в Securitm, его предварительно необходимо преобразовать в формат Sarif. Поможет с этим инструмент PlogConverter.
Пример команды на Windows:
PlogConverter.exe -t sarif -o ./ PVS-Studio.plogПример команды на Linux/macOS:
plog-converter -t sarif -o ./ PVS-Studio.jsonВ приведённых выше примерах команд флаг -t указывает на формат выходного отчёта, -o — на директорию, куда будет сохранён преобразованный отчёт. Последним параметром указывается путь до отчёта PVS-Studio, который нужно преобразовать.
Примечание. О том, какие ещё есть опции при конвертации отчёта, можно прочитать в специальном разделе документации.
Импорт результатов анализа
Для того, чтобы импортировать результаты анализа PVS-Studio из полученного ранее отчёта, нужно в интерфейсе Securitm перейти во вкладку Технические уязвимости и нажать на кнопку Импорт в правой верхней части страницы:
После этого откроется окно, в котором можно выбрать файл отчёта PVS-Studio, а после нажать на кнопку Импорт. При удачном импорте результатов в нижней части окна появится соответствующее уведомление, а также статистика:
После импорта срабатывания анализатора PVS-Studio появятся в списке уязвимостей во вкладке Технические уязвимости:
В серверной версии Securitm также есть возможность интеграции результатов анализа с помощью встроенного API. Подробнее об этом можно прочитать в этом разделе документации Securitm.
Работа с результатами анализа
Если нажать на любое из срабатываний анализатора в списке, можно подробнее узнать о нём. Например, на вкладке срабатывания можно найти ссылку на документацию, классификацию срабатывания по Common Weakness Enumeration (CWE) или сообщение анализатора:
Также каждое из срабатываний можно отправить в список принятых технических уязвимостей, а можно сразу открыть задачу на её исправление с помощью соответствующей кнопки Создать задачу:
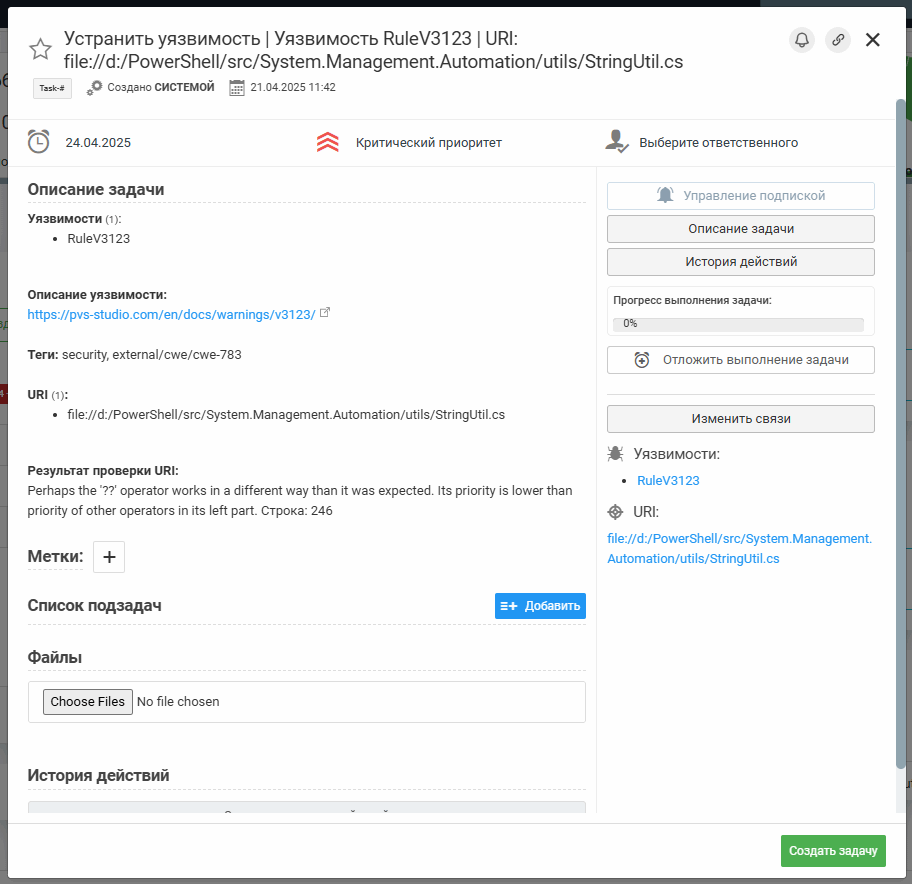
В появившемся окне можно задать дополнительную информацию для задачи, а также выбрать ответственного за исправление уязвимости.
Список задач по устранению технических уязвимостей можно найти на той же странице, что и список срабатываний анализатора:
Рассылка результатов
Securitm поддерживает рассылку результатов с помощью Telegram, а также интеграцию в Microsoft Teams. Этому посвящён раздел в документации инструмента.
Также есть возможность интеграции Securitm со многими другими инструментами, например Jira или Yandex Tracker. Об этом можно прочитать в этом разделе документации инструмента.
Загрузка результатов анализа в Jira
Jira – система управления задачами и проектами. Исправлять предупреждения от статического анализатора кода может быть удобно в рамках оформленной задачи.
Оформлять новую задачу на каждое предупреждение не рекомендуется по следующим причинам:
- Предупреждений может быть много (большая команда, много коммитов)
- Отчёт анализатора может содержать ложные или неотфильтрованные предупреждения
- Некоторые предупреждения быстрее исправить, чем оформлять задачу
Тем не менее, исправление некоторых предупреждений или ошибок требует фиксации и контроля в системе управления задачами.
У пользователей, которые используют PVS-Studio, SonarQube и Jira одновременно, есть возможность в полуавтоматическом режиме создавать задачи из предупреждений анализатора. Делается это с помощью встроенного в Jira приложения SonarQube Connector for Jira. Добавить его к своему проекту можно в меню Jira Software > Apps > Find new apps > SonarQube Connector for Jira.
Для создания задачи из предупреждения PVS-Studio надо проделать несколько шагов:
- Проанализировать проект и сохранить отчёт в формате .xml
- Загрузить отчёт в SonarQube с помощью плагина PVS-Studio
- Синхронизировать SonarQube Connector for Jira с сервером SonarQube
- Вручную выбрать предупреждения, которые преобразовать в задачи
Создание задач из выбранных предупреждений выглядит так:

Важно: для загрузки предупреждений анализатора в SonarQube требуется Enterprise лицензия PVS-Studio. Вы можете запросить пробную Enterprise лицензию здесь.
Автоматическое развёртывание PVS-Studio
- Автоматическое развертывание
- Настройка источника обновления
- Установка с использованием пакетного менеджера Chocolatey
- Установка лицензий и настройка приложения
- Развёртывание анализатора без установки
В данной статье рассматривается работа в среде Windows. Работа в среде Linux описана в статье "Как запустить PVS-Studio в Linux".
Автоматическое развертывание
Для установки PVS-Studio требуются права администратора.
Автоматическая установка выполняется указанием дополнительных параметров командной строки:
PVS-Studio_setup.exe /verysilent /suppressmsgboxes
/norestart /nocloseapplicationsPVS-Studio может потребоваться перезагрузка компьютера в случае, например, если обновляемые файлы были заблокированы. Для установки без перезагрузки необходимо использовать флаг 'NORESTART'. Обратите внимание, что без этого флага при запуске установщика PVS-Studio в silent режиме перезагрузка может произойти без предварительных уведомлений или диалогов.
По умолчанию будут установлены все доступные компоненты PVS-Studio. В случае, если это не желательно, возможно указание компонентов для установки с помощью флага 'COMPONENTS' (далее перечислены все доступные компоненты):
PVS-Studio_setup.exe /verysilent /suppressmsgboxes
/nocloseapplications /norestart /components= Core,
Standalone,MSVS,MSVS\2010,MSVS\2012,MSVS\2013,MSVS\2015,MSVS\2017,
MSVS\2019,MSVS\2022,IDEA,JavaCore,Rider,CLion,VSCode,DOTNETВы можете использовать нотацию /components="Core,*MSVS" для установки плагинов для всех Visual Studio одновременно.
Краткое описание компонентов:
- компонент 'Core' является обязательным и содержит набор утилит необходимый для анализа С, С++ и С# проектов, без него не смогут работать IDE модули расширения.
- компоненты с префиксом 'MSVS' в названии соответствуют плагинам среды Microsoft Visual Studio;
- компонент Standalone задаёт установку системы отслеживания вызовов компилятора, позволяющую проверить любой C, C++ проект, если этот проект использует один из поддерживаемых компиляторов;
- компонент 'IDEA' соответствует плагину PVS-Studio для среды разработки IntelliJ IDEA;
- компонент 'JavaCore' соответствует ядру анализатора для Java;
- компонент 'Rider' соответствует плагину PVS-Studio для среды разработки Rider;
- компонент 'CLion' соответствует плагину PVS-Studio для среды разработки CLion;
- Компонент 'VSCode' соответствует плагину PVS-Studio для редактора кода Visual Studio Code;
- Компонент 'DOTNET' устанавливает пакет .NET SDK последней поддерживаемой версии PVS-Studio, если он не найден на компьютере. Он необходим для анализа .NET проектов и .NET Framework проектов в SDK стиле. Этот компонент доступен начиная с PVS-Studio 7.34.
Во время установки PVS-Studio все экземпляры Visual Studio / IntelliJ IDEA / Rider должны быть выключены, однако для предотвращения потерь несохраненных документов установочный пакет не выгружает Visual Studio / IntelliJ IDEA / Rider самостоятельно.
Инсталлятор завершит работу с кодом завершения 100 в случае, если не сможет установить модуль расширения (*.vsix) для какой-либо из выбранных версий Visual Studio.
Получить дополнительную информацию о флагах можно с помощью 'HELP':
PVS-Studio_setup.exe /helpУтилита PVS-Studio-Updater.exe позволяет проверить наличие обновлений анализатора, а в случае их наличия, скачать и установить их на локальной машине. Для запуска утилиты обновления в "тихом" режиме можно использовать те же параметры, что и для дистрибутива:
PVS-Studio-Updater.exe /VERYSILENT /SUPPRESSMSGBOXESВ случае отсутствия обновлений на сервере, утилита завершит работу с кодом 0. Т.к. PVS-Studio-Updater.exe производит локальную установку PVS-Studio, во время его работы в системе также не должен быть запущен процесс devenv.exe.
Если в вашей системе используется прокси с авторизацией, утилита PVS-Studio-Updater.exe предложит вам ввести учетные данные для авторизации. Если учетные данные были введены корректно, PVS-Studio-Updater.exe сохранит их в Windows Credential Manager, и в дальнейшем будет использовать эти учетные данные для авторизации на прокси. Если вы хотите использовать утилиту с прокси без авторизации, вы можете сделать это с помощью флага proxy (/proxy=ip:port).
Настройка источника обновления
Начиная с версии 7.24 PVS-Studio для Windows поддерживает возможность изменения источника обновлений. Это может быть полезно, если вы не хотите, чтобы разработчики обновляли PVS-Studio сразу после выхода релиза.
Например, вы можете создать группу пользователей, которые получат обновления первыми и группу пользователей, которые должны получить обновление после того, как первая группа протестирует продукт.
Для первой группы никаких изменений в настройках не требуется, они будут получать обновления из релизного канала PVS-Studio.
Для второй группы необходимо развернуть альтернативный канал обновления. Для этого достаточно на своем сервере разместить файл version.xml и дистрибутив для установки PVS-Studio. После этого нужно изменить источник обновления на машинах разработчиков второй группы.
Информация об источнике обновления хранится в системном реестре: 'HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\ProgramVerificationSystems\PVS-Studio' в ключе 'UpdateUrl'. По умолчанию, там прописан стандартный адрес до файла version.xml, который содержит информацию об обновлении. Вы можете указать адрес до альтернативного файла version.xml, расположенного на вашем сервере. Например: https://myserver.com/version.xml
Файл version.xml имеет следующую структуру:
<ApplicationUpdate>
<!--Версия обновления PVS-Studio-->
<Version>7.23</Version>
<!--Ссылка для скачивания-->
<FileURL>https://myserver.com/PVS-Studio_setup.exe</FileURL>
<CompatibilityVersion>1</CompatibilityVersion>
</ApplicationUpdate>Теперь PVS-Studio будет проверять обновления через файл version.xml, который лежит на сервере myserver.com и при наличии обновления, скачает его с этого сервера.
Установка с использованием пакетного менеджера Chocolatey
Ещё один возможный вариант установки заключается в использовании менеджера пакетов Chocolatey. При использовании этого варианта установке в системе уже должен быть установлен сам пакетный менеджер.
Команда установки последней доступной версии пакета PVS-Studio:
choco install pvs-studioКоманда установки конкретной версии пакета PVS-Studio:
choco install pvs-studio --version=7.05.35617.2075При установке пакета также можно задать список устанавливаемых компонентов по аналогии с перечисленными в разделе "Автоматическое развёртывание" данного документа. Для указания компонентов используется флаг '‑‑package-parameters'. Компоненты эквивалентны описанным выше и отличаются только синтаксисом некоторых параметров:
- Standalone;
- JavaCore;
- IDEA;
- Rider;
- MSVS2010;
- MSVS2012;
- MSVS2013;
- MSVS2015;
- MSVS2017;
- MSVS2019.
По умолчанию устанавливается только компонент 'Core'. При перечислении компонентов установки 'Core' указывать не нужно.
Пример команды, которая установит анализатор с компонентами 'Core' и 'Standalone':
choco install pvs-studio --package-parameters="'/Standalone'"Установка лицензий и настройка приложения
Способы ввода лицензии при использовании различного окружения описаны в разделе документации "Как ввести лицензию PVS-Studio, и что делать дальше".
При развертывании на большое количество машин можно установить лицензию без ручного ввода ключа. Для этого необходимо скопировать файл настроек в папку, находящуюся в профиле пользователя.
Если несколько пользователей используют один и тот же компьютер, лицензия должна быть скопирована для каждого.
Расположение файла настроек по умолчанию:
%USERPROFILE%\AppData\Roaming\PVS-Studio\Settings.xmlЭтот файл можно редактировать любым текстовым редактором - это простой xml-файл. Следует отметить, что некоторые настройки могут отсутствовать в этом файле. В этом случае будут применены настройки по умолчанию.
Развёртывание анализатора без установки
Работа анализатора PVS-Studio зависит от окружения, поэтому невозможно его использование в полностью portable режиме, без предварительной настройки. Однако, если на нескольких машинах настроено одинаковое окружение, необходимое для корректной работы анализатора, то можно скопировать файлы анализатора с одного компьютера на другой. Это позволит использовать PVS-Studio на разных компьютерах без непосредственной установки на каждый из них.
Также, вы можете заложить файлы анализатора в систему контроля версий. Это облегчает развертывание и обновление PVS-Studio на большом количестве машин.
Развёртывание анализатора на Windows для C, C++, C#
Шаг 1. Скачайте установщик PVS-Studio (.exe) с сайта и запустите его.
Шаг 2. После окончания установки введите лицензию как указано в документации.
Шаг 3. Скопируйте папку 'C:\Program Files (x86)\PVS-Studio' и файл настроек 'Settings.xml' на другой компьютер. Расположение файла настроек по умолчанию:
%USERPROFILE%\AppData\Roaming\PVS-Studio\Settings.xmlВ результате станет возможно запускать 'PVS-Studio_Cmd.exe' из папки, которая была скопирована на компьютер пользователя. При запуске анализа в аргументе '-s' необходимо указать путь до файла настроек:
PVS-Studio_Cmd.exe .... -s <pathToSettingsXml> ....Настройка Portable режима работы PVS-Studio на Windows для Java
Шаг 1. Скачайте установщик PVS-Studio (.exe) с сайта и запустите его;
Шаг 2. Cоздайте файл 'PVS-Studio.lic' с данными о лицензии рядом с ядром Java анализатора по пути 'C:\Program Files (x86)\PVS-Studio-Java'. В файле лицензии на отдельных строках должны быть указаны имя пользователя и серийный номер лицензии, например:
UserName
ХХХХ-ХХХХ-ХХХХ-ХХХХПосле этого вы сможете перенести папку 'C:\Program Files (x86)\PVS-Studio-Java' на другой компьютер, где установлена Java версии 8 и выше. Это позволит использовать Java анализатор из скопированной папки, указав в аргументе '‑‑license-path' путь до файла лицензии, созданный ранее:
java -jar pvs-studio.jar .... --license-path PVS-Studio.lic ....Ускорение анализа C и C++ кода с помощью систем распределённой сборки (Incredibuild)
- Пример настройки Incredibuild
- Использование распределённого анализа вместе с системой отслеживания вызовов компиляторов
Для ускорения прохождения анализа можно использовать системы распределённой сборки, например, Incredibuild. Анализ C/C++ кода в PVS-Studio можно разделить на 2 этапа: препроцессирование и собственно анализ. Каждый из этих этапов может быть выполнен удалённо системой распределённой сборки. Для анализа каждого проверяемого C/C++ компилируемого файла, PVS-Studio запускает сначала внешний препроцессор, а затем непосредственно C++ анализатор. Каждый такой процесс может быть выполнен удалённо.
В зависимости от типа проверяемого проекта, анализ PVS-Studio запускается либо через утилиту PVS-Studio_Cmd.exe (для MSBuild проектов), либо с помощью утилиты для отслеживания вызовов компилятора CLMonitor.exe \ Standalone.exe (для любой сборочной системы). Далее, одна из этих утилит будет запускать для каждого проверяемого файла сначала препроцессор (cl.exe, clang.exe для Visual C++ проектов, для остальных – тот же процесс, что использовался при компиляции), а затем C++ анализатор PVS-Studio.exe.
Задание для настройки 'ThreadCount' значения, большего '16' (или большего, чем количество ядер процессора, если у процессора более 16 ядер), доступно только при наличии Enterprise лицензии PVS-Studio. Вы можете запросить пробную Enterprise лицензию здесь.
Данные процессы запускаются параллельно, в зависимости от настройки PVS-Studio|Options...|Common AnalyzerSettings|ThreadCount. Увеличивая количество параллельно проверяемых файлов с помощью этой настройки, и разнеся выполнение этих процессов дополнительно на удалённые машины, можно существенно (в несколько раз) сократить полное время анализа.
Пример настройки Incredibuild
Приведём пример ускорения анализа PVS-Studio c использованием распределённой системы Incredibuild. Для этого нам потребуется консольная утилита управления IBConsole. Мы будем использовать интерфейс для автоматического перехвата (Automatic Interception Interface), который позволяет удалённо выполнять любой процесс, перехваченный этой системой. Запуск утилиты IBConsole для распределённого анализа с помощью PVS-Studio будет иметь следующий вид:
ibconsole /command=analyze.bat /profile=profile.xmlФайл analyze.bat должен содержать строку запуска анализатора, PVS-Studio_Cmd.exe или CLMonitor.exe, со всеми необходимыми им параметрами (более подробно можно посмотреть в соответствующем разделе документации). Файл profile.xml содержит конфигурацию для интерфейса автоматического перехвата. Вот пример такой конфигурации для анализа MSBuild проекта с помощью PVS-Studio_Cmd.exe:
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<Profile FormatVersion="1">
<Tools>
<Tool Filename="PVS-Studio_Cmd" AllowIntercept="true" />
<Tool Filename="cl" AllowRemote="true" />
<Tool Filename="clang" AllowRemote="true" />
<Tool Filename="PVS-Studio" AllowRemote="true" />
</Tools>
</Profile>Посмотрим, что означает каждая запись в этом файле. Мы видим, что для PVS-Studio_Cmd задан атрибут AllowIntercept со значением 'true'. Это означает, что процесс с таким именем не будет сам запускаться распределённо, но система автоматического перехвата будет следить за порождаемыми этим процессом дочерними процессами.
Для процессов препроцессора cl и clang и C/C++ анализатора PVS-Studio задан атрибут AllowRemote. Это означает, что процессы с такими именами, будучи отловленными у процессов с AllowIntercept, будут потенциально выполнены на других (удалённых) агентах Incredibuild.
Перед запуском IBConsole необходимо задать настройку PVS-Studio|Options...|Common AnalyzerSettings|ThreadCount в соответствии с суммарным количеством ядер, доступных на всех Incredibuild агентах. Если этого не сделать, эффекта от использования Incredibuild не будет!
Примечание: во время анализа Visual C++ проектов, PVS-Studio использует clang.exe, поставляемый в дистрибутиве PVS-Studio, для препроцессирования C/C++ файлов перед анализом, вместо препроцессора cl.exe. Это сделано для ускорения препроцессирования, т.к. clang работает быстрее, чем cl. Некоторые старые версии Incredibuild выполняют распределённый запуск препроцессора clang.exe не совсем корректно, что приводит к ошибкам препероцессирования. Поэтому, clang не стоит прописывать в файле конфигурации IBConsole, если ваша версия Incredibuild работает с clang некорректно.
Используемый тип препроцессора во время анализа задаётся настройкой PVS-Studio|Options...|Common AnalyzerSettings|Preprocessor. Если выбрать для этой настройки значение 'VisualCpp', PVS-Studio будет использовать для препроцессирования только cl.exe, который будет выполняться распределённо, но медленне чем clang, который распределённо выполняться не может. Данную настройку стоит выбрать в зависимости от типа проекта и количества доступных для анализа агентов – при большом количестве агентов выбор VisualCpp будет оправдан. При небольшом количестве агентов, локальное препроцессирование с помощью clang может оказаться быстрее.
Использование распределённого анализа вместе с системой отслеживания вызовов компиляторов
Имеется возможность использования системы отслеживания вызовов компиляторов (утилиты CLMonitor.exe и Compiler Monitoring UI) при распределенном анализе проекта с помощью Incredibuild. Подобная связка позволит намного быстрее провести анализ проекта, однако, имеет свои особенности. Системы отслеживания вызовов компиляторов не могут отслеживать удаленные вызовы компилятора, и CLMonitor.exe поддерживает трассировку только для локальных сборок.
Анализ мониторинга компилятора, запущенного Incredibuild-ом, может оказаться некорректным, потому что системы отслеживания вызовов компиляторов не отловят вызовы компилятора на других машинах. Тем не менее, имеется возможность распараллелить при помощи Incredibuild анализ дампа, полученного при помощи систем отслеживания вызовов компиляторов. Для этого необходимо получить дамп запуска компилятора.
В случае использования CLMonitor.exe порядок действий для получения дампа мониторинга компилятора такой:
- запустить мониторинг компиляторов:
CLMonitor.exe monitor;- собрать проект без использования Incredibuild. В результате CLMonitor.exe отловит запуск компилятора;
- cохранить дамп мониторинга компилятора:
CLMonitor.exe saveDump -d c:\monitoring.zipВ случае использования Compiler Monitoring UI дамп возможно получить выполнив следующие действия после запуска Compiler Monitoring UI:
- запустить мониторинг компиляторов через Tools -> Analyze Your Files...:

- нажать на Start Monitoring;
- в появившемся окне прогресса мониторинга поставить галочку для сохранения файла дампа:

- собрать проект;
- остановить мониторинг;
- сохранить файл дампа:

Аналогично предыдущему примеру для распределенного анализа дампа используем ibconsole:
ibconsole /command=analyze.bat /profile=profile.xmlОднако теперь в файле analyze.bat вместо вызова PVS-Studio_Cmd.exe необходимо вызвать CLMonitor.exe в режиме анализа дампа файла:
CLMonitor.exe analyzeFromDump -l "с:\ptest.plog" -d "c:\monitoring.zip"В случае с Compiler Monitoring UI вместо PVS-Studio_Cmd.exe необходимо вызвать Standalone.exe:
Standalone.exeВ файле настроек же необходимо заменить PVS-Studio_Cmd на CLMonitor / Standalone и cl, при необходимости, заменить на тот тип препроцессора, который используется при сборке (gcc, clang). Например:
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<Profile FormatVersion="1">
<Tools>
<Tool Filename="CLMonitor" AllowIntercept="true" />
<Tool Filename="gcc" AllowRemote="true" />
<Tool Filename="PVS-Studio" AllowRemote="true" />
</Tools>
</Profile>Также не забываем задать настройку PVS-Studio|Options...|Common AnalyzerSettings|ThreadCount в соответствии с суммарным количеством ядер, доступных на всех Incredibuild агентах. Если этого не сделать, эффекта от использования Incredibuild не будет!
При задании настройки ThreadCount следует помнить, что машина-координатор анализа (т.е. та, на которой будет работать PVS-Studio_Cmd/CLMonitor/Standalone) будет заниматься обработкой результатов, приходящих ото всех процессов PVS-Studio.exe. Данная задача сейчас не может быть распределена – поэтому, особенно когда ThreadCount задаётся очень большим (более 50 процессов одновременно), стоит подумать о том, чтобы "разгрузить" машину-координатор от непосредственно задач анализа (т.е. выполнения процессов анализатора и препроцессора). Это можно сделать с помощью флага IBConsole '/AvoidLocal' или в настройках локального агента Incredibuild на машине координаторе.
При использовании Compiler Monitoring UI для запуска анализа файла дампа мониторинга компиляции необходимо выбрать пункт меню Tools -> Analyze Your Files... и указать путь до файла дампа, прежде чем запустить анализ дампа:

Итогом распределенного анализа дампа будет файл с:\ptest.plog при использовании CLMonitor.exe или предупреждения анализатора в таблице в интерфейсе Compiler Monitoring UI:

Сообщения из таблицы возможно сохранить в файлы в различных форматах используя пункты меню:
- File -> Save PVS-Studio Log;
- File -> Save PVS-Studio Log As...;
- File -> Save Filtered Log As HTML....
При подобном варианте анализа процессы PVS-Studio.exe будут распределены Incredibuild-ом по всем используемым машинам, а CLMonitor.exe распараллелен не будет.
Больше всего пользы подобный вид анализа принесет на большом проекте, в котором редко изменяется структура проекта (добавление, удаление, переименование файлов и т.п.), но часто изменяется их содержимое.
Установка и обновление PVS-Studio в Linux
PVS-Studio распространяется в виде Deb/Rpm пакетов или архива. Воспользовавшись установкой из репозитория, вы сможете получать обновления о выходе новой версии программы.
В дистрибутиве содержатся следующие файлы:
- pvs-studio - ядро анализатора;
- pvs-studio-analyzer - утилита для проверки проектов без интеграции;
- plog-converter - утилита для преобразования отчёта анализатора в различные форматы;
Установить анализатор можно следующими способами:
Установка из репозиториев
Для debian-based систем:
До Debian 11 и Ubuntu 22.04:
wget -q -O - https://cdn.pvs-studio.com/etc/pubkey.txt | \
sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://cdn.pvs-studio.com/etc/viva64.list
sudo apt-get update
sudo apt-get install pvs-studioПосле Debian 11 и Ubuntu 22.04:
wget -qO- https://cdn.pvs-studio.com/etc/pubkey.txt | \
sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/viva64.gpg
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://cdn.pvs-studio.com/etc/viva64.list
sudo apt-get update
sudo apt-get install pvs-studioДля yum-based систем:
wget -O /etc/yum.repos.d/viva64.repo \
https://cdn.pvs-studio.com/etc/viva64.repo
yum update
yum install pvs-studioДля zypper-based систем:
wget -q -O /tmp/viva64.key https://cdn.pvs-studio.com/etc/pubkey.txt
sudo rpm --import /tmp/viva64.key
sudo zypper ar -f https://cdn.pvs-studio.com/rpm viva64
sudo zypper update
sudo zypper install pvs-studioРучная установка
Вы можете скачать PVS-Studio для Linux здесь.
Также вам необходимо установить утилиту strace версии 4.11 или выше для функционирования режима трассировки компиляции.
Deb пакет
sudo gdebi pvs-studio-VERSION.debили
sudo dpkg -i pvs-studio-VERSION.deb
sudo apt-get -f installRpm пакет
sudo dnf install pvs-studio-VERSION.rpmили
sudo zypper install pvs-studio-VERSION.rpmили
sudo yum install pvs-studio-VERSION.rpmили
sudo rpm -i pvs-studio-VERSION.rpmАрхив
tar -xzf pvs-studio-VERSION.tgz
sudo ./install.shЗапуск анализатора
После успешной установки анализатора на ваш компьютер, для проверки проекта следуйте инструкциям на этой странице: "Как запустить PVS-Studio в Linux".
Установка и обновление PVS-Studio в macOS
PVS-Studio распространяется в виде графического инсталлятора, архива или через Homebrew репозиторий. Воспользовавшись установкой из репозитория, вы сможете получать обновления анализатора автоматически.
В дистрибутиве содержатся следующие файлы:
- pvs-studio - ядро анализатора;
- pvs-studio-analyzer - утилита для проверки проектов без интеграции;
- plog-converter - утилита для преобразования отчёта анализатора в различные форматы;
Установить анализатор можно следующими способами:
Установка из Homebrew
Установка:
brew install viva64/pvs-studio/pvs-studioОбновление:
brew upgrade pvs-studioРучная установка
Инсталлятор
Запуститите .pkg файл и следуйте инструкциям инсталлятора:

Архив
Распакуйте архив и поместите исполняемые файлы в каталог, доступный в PATH.
tar -xzf pvs-studio-VERSION.tgzЗапуск анализатора
После успешной установки анализатора на ваш компьютер, для проверки проекта следуйте инструкциям на этой странице: "Как запустить PVS-Studio в Linux и macOS".
Отображение наиболее интересных предупреждений анализатора
Анализатор PVS-Studiо позволяет легко посмотреть наиболее интересные предупреждения, чтобы ускорить и упростить ознакомление и начальную работу с отчетом. Это предупреждения наших самых интересных и опасных диагностических правил, которые с наибольшей вероятностью являются реальными ошибками.
Данный механизм предназначен прежде всего для знакомства с возможностями анализатора.
Режим отображения интересных предупреждений не является заменой работы с полным отчётом анализатора, т.к. в полном отчёте могут содержаться не менее опасные потенциальные ошибки, на которые также нужно обратить внимание.
Принцип работы
В основе механизма отбора интересных предупреждений лежит оценка срабатываний анализатора на основе ряда критериев, которые мы называем весами. Для каждой диагностики задан изначальный вес, который отражает вероятность обнаружить с её помощью качественную (интересную) ошибку. Веса были проставлены в соответствие с нашим многолетним опытом работы со статическим анализатором и статистикой анализа разнообразных проектов. Далее эти веса корректируются с учетом:
- уровня предупреждения;
- имени файла и каталога до него. Ищем ключевые слова, указывающие, что предупреждение выдано на тесты;
- частоты появления одной и той же диагностики в проекте, для уменьшения количества однообразных типов предупреждений;
- количества выданных предупреждений на одну строку одного и того же файла.
В итоге на выходе получается список пар "предупреждение-вес". Из этого списка будет выбрано не более десяти самых "тяжелых" предупреждений.
Visual Studio (C, C++ и C#)
Для Microsoft Visual Studio доступен плагин PVS-Studio, удобно интегрированный в IDE. Он позволяет запускать анализ всего solution'а, конкретных проектов или отдельных файлов, а также поддерживает инкрементальный анализ.
Механизм отображения интересных предупреждений находится в специальном окне просмотра результатов анализа в Visual Studio:

Данное окно появляется автоматически, например, при выполнении анализа проекта. Если же его необходимо отобразить вручную, то это делается из настроек расширения PVS-Studio:

Само окно позволяет выполнять навигацию по найденным предупреждениям и переходить к коду для его исправления. Также оно предоставляет широкие возможности фильтрации и сортировки результатов. Дополнительно присутствует возможность быстрого перехода к документации выбранной диагностики.
Чтобы отобразить лучшие срабатывания, необходимо нажать на кнопку 'Best'.
В результате в окне окажутся только лучшие предупреждения. При повторном нажатии в окне будут отображаться все найденные ошибки.
IntelliJ IDEA, Rider и CLion
Начиная с версии PVS-Studio 7.22 механизм Best Warning поддерживается в плагинах Rider, IntelliJ IDEA и СLion. Чтобы посмотреть наиболее интересные предупреждения с точки зрения анализатора, нажмите на кнопку 'Best', как показано на скриншоте ниже:

После чего в таблице с результатами анализа останутся максимум десять наиболее критичных предупреждений анализатора. При повторном нажатии в окне будут отображаться все найденные ошибки.
Дополнительные ссылки
Если вы новый пользователь, то также рекомендуем ознакомиться с:
- Подавление ложно-позитивных предупреждений
- Советы по повышению скорости работы PVS-Studio
- Устранение неисправностей при работе PVS-Studio
- Дополнительная настройка диагностик
- Режим инкрементального анализа PVS-Studio
Подавление сообщений анализатора (отключение выдачи предупреждений на существующий код)
- Принцип работы
- Windows: Visual Studio (анализ C, C++ и C#)
- Windows: C and C++ Compiler Monitoring UI
- Проекты на C и C++ в Linux/macOS
- Проекты на Java в Windows/Linux/macOS
- Подавление предупреждений в Unreal Engine проектах
- Подавление предупреждений анализатора в плагинах PVS-Studio для CLion и Rider.
- Система контроля версий
- Подавление предупреждений в SonarQube
- Совместное использование возможностей подавления сообщений анализатора PVS-Studio в CI и IDE
- Что делать после подавления всех предупреждений?
- Дополнительные ссылки
Механизм подавления предупреждений анализатора, также называемый созданием baseline-уровня сообщений, подходит для следующих сценариев:
- PVS-Studio впервые внедряется в проект и выдаёт большое количество предупреждений на весь код. Руководитель разработки решает начать регулярное использование анализатора только на новом коде, планируя вернуться к текущим предупреждениям позже;
- PVS-Studio используется в проекте на регулярной основе. В процессе разработки в отчёте анализатора попадаются ложные предупреждения, и их хочется подавить без модификации файлов с исходным кодом.
В этих ситуациях предупреждения анализатора можно подавить специальным образом, чтобы они больше не попадали в новые отчёты. Использование этого режима не требует модификации файлов с исходным кодом проекта.
Анализатор поддерживает анализ исходного кода для языков программирования C, C++, C# и Java. Анализ может быть выполнен на операционных системах Windows, Linux и macOS. В связи с этим, способы подавления предупреждений могут отличаться в зависимости от используемой платформы и типа проектов, поэтому перейдите в раздел, который Вам подходит, и следуйте приведённой там инструкции.
Принцип работы
Механизм подавления сообщений основан на использовании специальных файлов, которые добавляются рядом с проектом (или в любом заданном месте). Такие файлы подавления содержат сообщения, размеченные для данного проекта как "ненужные". Заметим, что модификация исходного файла, содержащего размеченные сообщения, и, в частности, сдвиг строк, не приведёт к повторному появлению подавленных сообщений. Однако, правка строки, содержащей сообщение анализатора, может привести к его повторному появлению, т.к. такое сообщение уже считается "новым".
Предупреждение считается подавленным, если в suppress-файле имеется запись, элементы которой эквивалентны соответствующим полям предупреждения из отчёта анализатора (всего их 6):
- Хэш-код предыдущей строки;
- Хэш-код текущей строки (на которую указывает предупреждение анализатора);
- Хэш-код следующей строки;
- Имя файла (с учётом регистра);
- Уникальный код диагностики (VXXX или VXXXX, где X – символ числа от '0' до '9');
- Сообщение из предупреждения анализатора.
При записи в файл подавления сообщение предупреждения нормализуется, а именно:
- Идущие подряд числовые символы (0-9) заменяются на один символ нижнего подчёркивания ('_');
- Идущие подряд пробельные символы заменяются на один пробел.
При вычислении хэш-кодов обрабатывается не вся строка, а только символы до первого комментария ложного срабатывания (строчный комментарий, попадающий под один из паттернов: //-VXXXX, //-VXXX, //-vXXXX или //-vXXX, где X – это символ числа от 0 до 9). При этом символы табуляции и пробелов игнорируются.
Изменения исходного кода, которые отменяют подавление предупреждений:
- Изменение строки, на которую указывает предупреждение анализатора, и/или предыдущей и/или следующей строки (игнорируются символы табуляции и пробелов);
- Изменение имени файла (регистр учитывается), в котором содержится подавленное предупреждение;
- Изменение сообщения анализатора. В сообщении анализатора часто указывается часть кода из строки, на которую выдано предупреждение. В этом случае при изменении этой части кода в строке соответственно изменится и сообщение анализатора. Важно: сообщение анализатора также может быть изменено с нашей стороны, однако это случается очень редко, и мы стараемся не менять сообщения предупреждений анализатора;
- Изменение уникального идентификатора диагностики (VXXX или VXXXX, где X – число от 0 до 9).
Изменения исходного кода, которые не отменяют подавление предупреждений:
- Смещение группы соседних 3х строк (строка, на которую выдано предупреждение анализатора, предыдущая и следующая строка) на любое количество строк вверх или вниз;
- Добавление в строку (удаление из строки), на которую указывает предупреждение анализатора, или в соседние строки любого количества символов табуляции или пробелов;
- Добавление в конец строки (удаление с конца строки), на которую указывает предупреждение анализатора, и/или предыдущей и/или следующей строки комментариев ложных срабатываний (строчный комментарий, попадающий под один из паттернов: //-VXXXX, //-VXXX, //-vXXXX или //-vXXX, где X – это символ числа от 0 до 9). В конец строки может быть добавлено несколько комментариев ложных срабатываний.
Windows: Visual Studio (анализ C, C++ и C#)
Для Microsoft Visual Studio доступен плагин PVS-Studio, удобно интегрированный в IDE. Он позволяет запускать анализ всего solution'а, конкретных проектов или отдельных файлов, а также поддерживает инкрементальный анализ.
Подавление сообщений анализатора в плагине для Visual Studio
В меню PVS-Studio доступен пункт Suppress Messages, открывающий окно для работы с подавленными предупреждениями анализатора.

В открывшемся окне доступно несколько действий:
- Suppress All - подавление всех предупреждений анализатора;
- Suppress Filtered - подавление сообщений, которые в данный момент отображены в окне результатов работы PVS-Studio, без учёта отфильтрованных сообщений;
- Un-Suppress from Selected - восстановление скрытых предупреждений для выделенных проектов;
- Display Suppressed Messages - отображение скрытых предупреждений анализатора в окне (PVS-Studio Output Window) с остальными предупреждениями. В этом режиме можно вернуться к исправлению подавленных ранее предупреждений. Такие сообщения будут помечены особым образом (зачёркнуты), поэтому их невозможно спутать с другими.
Для просмотра результатов анализа в Visual Studio существует специальное окно.

Специальное окно позволяет выполнять навигацию по найденным предупреждениям и переходить к коду для его исправления. Окно PVS-Studio предоставляет широкие возможности фильтрации и сортировки результатов. Также присутствует возможность быстрого перехода к документации выбранной диагностики.
Дополнительные возможности работы с каждым сообщением доступны в контекстном меню по нажатию на правый клик мыши на сообщении.

Для добавления нескольких выбранных предупреждений во все suppress файлы, связанные с предупреждениями, имеется пункт меню "Add selected messages to all suppression files". Кроме этого пункта меню имеется пункт "Add selected messages to primary suppression files". Он позволяет подавить несколько выбранных предупреждений только в primary suppress файлы, связанные с выбранными предупреждениями.

Primary – это метка для suppress файлов, позволяющая приоритизировать использование файлов с такой меткой при подавлении предупреждений. По умолчанию при использовании обычных suppress файлов выбранные предупреждения будут подавлены во все suppress файлы проекта или решения. Если вы хотите подавлять новые предупреждения анализатора только в какой-то конкретный suppress файл, но при этом у вас имеются другие suppress файлы с подавленными ранее предупреждениями, которые вы не хотите модифицировать, то пометьте ваш suppress файл для новых срабатываний как primary.
Использование primary метки позволяет разделить предупреждения, подавленные при внедрении PVS-Studio в проект, от предупреждений, которые были подавлены в ходе дальнейшего регулярного использования анализатора. В таком случае подавленные первоначально предупреждения обычно требуют обработки в будущем (так как их обычно не изучают внимательно), а предупреждения, полученные в результате регулярного использования анализатора, уже по определению просмотрены пользователем.
Primary suppress файлы в выпадающих списках обозначаются дополнительным текстом в скобках:

Добавление Primary suppress файла в проект или решение происходит аналогично добавлению обычного suppress файла через пункт меню "New item..." в контекстном меню проекта/решения:

Также имеется возможность пометить все suppress файлы как primary при подавлении всех предупреждений ("Suppress All") или только отфильтрованных предупреждений ("Suppress Filtered"). Для этого необходимо выбрать чекбокс в окне сообщения, которое выдаётся при подавлении:

Для расподавления нескольких выделенных предупреждений имеется пункт меню "Remove selected messages from all suppression files". Этот пункт отображается в контекстном меню окна вывода результатов, если выбрано более одного предупреждения и хотя бы одно из них подавлено:

При выборе одного предупреждения в контекстном меню доступны пункты не только для подавления/расподавления, но и для перемещения. При перемещении предупреждение удаляется из всех suppress файлов и добавляется в выбранные suppress файлы:

Также при выборе одного предупреждения в окне вывода результатов при наведении мыши на пункты меню, связанные с suppress файлами, появляются выпадающие списки suppress файлов:

В этих выпадающих списках возможно выбрать один suppress файл, все suppress файлы или все primary suppress файлы из списка. Выбранные suppress файлы будут использованы при выполнении команды подавления/расподавления, перемещения.
Пролистывать список suppress файлов возможно при помощи элементов интерфейса сверху и снизу списка со стрелками, либо при помощи клавиш стрелок "Вверх" и "Вниз". Выбрать элемент из списка можно при помощи клавиши "Enter" или левой кнопки мыши.
Работа в плагине для Visual Studio с подавленными предупреждениями
Из подменю окна вывода результатов плагина возможно включить отображения подавленных предупреждений:

Также включить отображение подавленных предупреждений возможно в окне работы с suppress файлами "Extensions -> PVS-Studio -> Suppress Messages...":

Кроме этого, в подменю таблицы при отображении подавленных предупреждений появляется список с отображаемыми suppress файлами. Убирая или выставляя галочку в чекбоксах из этого списка, возможно включать или отключать отображение подавленных предупреждений из определённых suppress файлов:
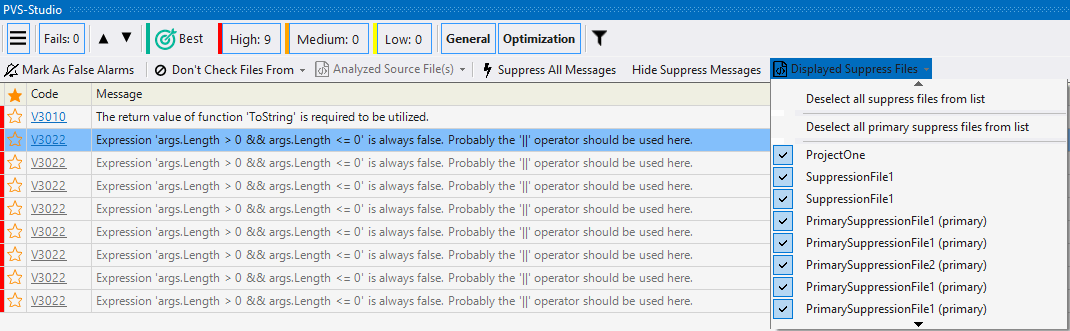
Изменения отображения подавленных предупреждений в окне вывода результатов происходят только после закрытия списка отображаемых suppress файлов.
Пролистывать список отображаемых suppress файлов возможно при помощи элементов интерфейсаI сверху и снизу списка со стрелками, либо при помощи клавиш стрелок "Вверх" и "Вниз". Выбирать элемент из списка при помощи клавиши "Enter" или левой кнопки мыши.
Добавление suppress файлов в MSBuild \ Visual Studio проекты
Вы можете добавить suppress файл в проект как некомпилируемый\текстовый файл с помощью команд меню 'Add New Item...' или 'Add Existing Item...'. Такое добавление позволяет держать suppress файлы и файлы проектов в разных директориях. Поддерживается добавление нескольких suppress файлов в проект.
Добавление suppress файлов в Visual Studio solution
Вы можете добавить suppress файл в решение (solution). Сделать это можно с помощью команд меню 'Add New Item...' или 'Add Existing Item...'. Как и для проектов, для решений поддерживается добавление нескольких suppress файлов.
Suppress файл уровня solution позволяет подавлять сообщения во всех проектах соответствующего solution. Если у проектов есть отдельные suppress файлы, анализатор будет учитывать как предупреждения, подавленные в suppress файле solution, так и в suppress файле проекта.
Подавление сообщений анализатора из командной строки
Подавление всех сообщений анализатора
Механизм подавления сообщений можно также использовать напрямую из командной строки. Утилита командной строки PVS-Studio_Cmd.exe автоматически подхватывает существующие suppress файлы при проверке. Также её можно использовать для подавления ранее сгенерированных сообщений анализатора, сохранённых в plog файле. Для подавления сообщений из существующего plog файла необходимо запустить PVS-Studio_Cmd.exe с флагом '‑‑suppressAll'. Например (в одну строку):
"C:\Program Files (x86)\PVS-Studio\PVS-Studio_Cmd.exe"
-t "Solution.sln" -o "results.plog" --suppressAll SuppressOnlyИсполнение команды сгенерирует suppress файлы для всех проектов, содержащихся в Solution.sln, на которые были сгенерированы сообщения в results.plog.
Флаг '‑‑suppressAll' поддерживает два режима работы:
- AnalyzeAndSuppress сначала выполнит анализ, запишет выходной файл (.plog, .json) и затем подавит все сообщения из него. Такой режим запуска позволит видеть только новые сообщения анализатора в каждом последующем запуске (так как сообщения с предыдущих запусков будут подавлены);
- SuppressOnly запустит подавление всех сообщений из переданного файла отчёта без перезапуска анализа.
Также через аргумент -u возможно указать путь до suppress файла. Этот suppress файл будет создан, если он ещё не существовал. В этот suppress файл будут добавлены все предупреждения анализатора.
Подавление определённых сообщений анализатора из командной строки
В PVS-Studio-Cmd.exe имеется режим работы suppression. Он предназначен для:
- фильтрации (FilterFromSuppress) предупреждений из отчёта анализатора;
- фильтрации подавленных предупреждений в suppress файлах (UpdateSuppressFiles);
- вычисления статистики по suppress файлам (CountSuppressedMessages);
- подавления (Suppress) и расподавления (UnSuppress) предупреждений из отчёта анализатора.
В этом режиме, аналогично основному режиму работы PVS-Studio-Cmd.exe через флаг -u возможно передать пути до suppress файлов. Эти suppress файлы будут использованы наравне с suppress файлами проектов и решения.
В режиме "suppression" в PVS-Studio_Cmd.exe через флаг -m указывается режим работы:
- CreateEmptySuppressFiles создаёт пустые suppress файлы рядом с проектными файлами (.csproj/.vcxproj) по заданному паттерну имени файла (флаг ‑‑suppressFilePattern). Если флаг паттерна не передан, то создаются пустые suppress файлы с именем проекта. Этот режим учитывает флаг пометки suppress файлов primary меткой (‑‑markAsPrimary);
- Suppress позволяет подавить отдельные предупреждения из файла отчёта (‑‑analyzerReport). Подавляемые предупреждения из отчёта анализатора отбираются при помощи фильтров: групп (‑‑groups), кодов диагностик (‑‑errorCodes), путей до директорий с файлами исходного кода или путей до файлов исходного кода (возможно указать просто имена файлов исходного кода). Порядок применения фильтров: группы, коды диагностик, пути. Если не передано ни одного фильтра, то будут подавлены все предупреждения из переданного отчёта анализатора (‑‑analyzerReport). Если передан паттерн имени suppress файла (‑‑suppressFilePattern), то предупреждения подавляются только в suppress файлы, чьи имена совпали с переданным паттерном имени suppress файла (suppress файл будет создан если его не существует). Этот режим учитывает флаг пометки suppress файлов primary меткой (‑‑markAsPrimary);
- UnSuppress режим расподавляет предупреждения из переданного отчёта анализатора. UnSuppress аналогичен Suppress режиму по используемым флагам, кроме флага ‑‑markAsPrimary, который не используется в данном режиме;
- FilterFromSuppress фильтрует сообщения в существующем файле отчёта (.plog, .json или 'сырой' вывод C++ ядра ) без запуска анализа при помощи suppress файлов, расположенных рядом с файлами проектов/решения. Ещё один вариант: передать путь до suppress файлов в параметре ‑‑useSuppressFile (-u). Файл с результатами фильтрации сохраняется рядом с переданным файлом отчёта. Имя этого файла имеет постфикс '_filtered'. В флаге ‑‑analyzerReport (-R) указывается путь до файла отчёта анализатора;
- CountSuppressedMessages подсчитывает количество подавленных сообщений во всех suppress файлах. Данный режим также может подсчитать количество актуальных сообщений в suppress файлах. Если передать полный файл отчёта (через флаг ‑‑analyzerReport), то можно узнать, сколько сообщений в базе подавления ещё актуальны. Вы можете узнать статистику по каждому suppress файлу, если запустите данный режим с флагом '-r';
- UpdateSuppressFiles выполняет обновление suppress файлов, удаляя из них сообщения, которые не содержатся в переданном файле отчёта (флаг ‑‑analyzerReport). Обратите внимание, что для работы этого режима требуется полный отчёт, содержащий подавленные сообщения. Полный отчёт создается каждый раз при запуске анализа, если есть подавленные сообщения. Файл полного отчёта имеет имя "*_WithSuppressedMessages.*" и располагается рядом с основным отчётом. Если вы запустите данный режим c файлом отчета, не содержащим подавленные сообщения, все suppress файлы будут очищены.
В режимах CreateEmptySuppressFiles, Suppress и UnSuppress будут использоваться только suppress файлы, чьи имена совпали с паттерном имени suppress файлов (флаг -P). В этом паттерне имеется переменная %projName%, вместо которой подставляется имя проекта.
Пометка suppress файлов как primary (флаг -M) происходит только в режимах CreateEmptySuppressFiles и Suppress.
В режимах Suppress и UnSuppress возможно указать фильтры для предупреждений из отчёта анализатора через флаги фильтров:
- ‑‑groups (-g): фильтр предупреждений из отчёта анализатора (-R) по группам диагностик (GA, 64, OP, CS, MISRA, AUTOSAR, OWASP) с уровнями достоверности предупреждений (1-High, 2-Medium, 3-Low). Пример: GA:1,2,3|OWASP|64:2;
- ‑‑errorCodes (-E): фильтр предупреждений из отчёта анализатора (-R) по кодам диагностик анализатора. Пример: V501,V1001,V3001;
- ‑‑files (-f): фильтр предупреждений из отчёта анализатора (-R) по абсолютным/относительным путям до директорий с файлами исходного кода, файлам исходного кода или именам файлов исходного кода. Дополнительно для каждого пути возможно указать номер строки, на которую было выдано предупреждение. Пример: ‑‑files absolute/path/directory*3,8,11|relative/path/file*1|fileName.
Пример команды запуска PVS-Studio_Cmd.exe в режиме suppression:
"C:\Program Files (x86)\PVS-Studio\PVS-Studio_Cmd.exe" suppression
-t "Solution.sln" -R "results.plog" --mode Suppress
-g GA:1,2,3|OWASP:2|64 -E V501,V1001,V3001
-f filename*11,54|absolute/path/filename*1|relative/path/to/directory
-P Prefix_%projName%_Postifx -MWindows: C and C++ Compiler Monitoring UI
PVS-Studio на Windows можно использовать не только для проверки MSBuild \ Visual Studio проектов. С помощью системы отслеживания вызовов компилятора, вы можете запустить статический анализ любых типов проектов, использующих один из поддерживаемых в PVS-Studio C++ компиляторов.
При запуске анализа, после мониторинга сборки, с помощью команды
clmonitor.exe analyze --useSuppressFile %PathToSuppressFile%можно с помощью дополнительного флага ‑‑useSuppressFile (-u) передать анализатору путь до suppress файла, который будет использован при проверке.
Помимо консольного инструмента CLMonitor.exe, использовать мониторинг компиляции можно также и с помощью графической утилиты C and C++ Compiler Monitoring UI. Эта утилита предоставляет возможности для проверки кода, независимо от используемого компилятора или сборочной системы, а затем позволяет работать с результатами анализа, предоставляя пользовательский интерфейс, схожий с Visual Studio плагином PVS-Studio.
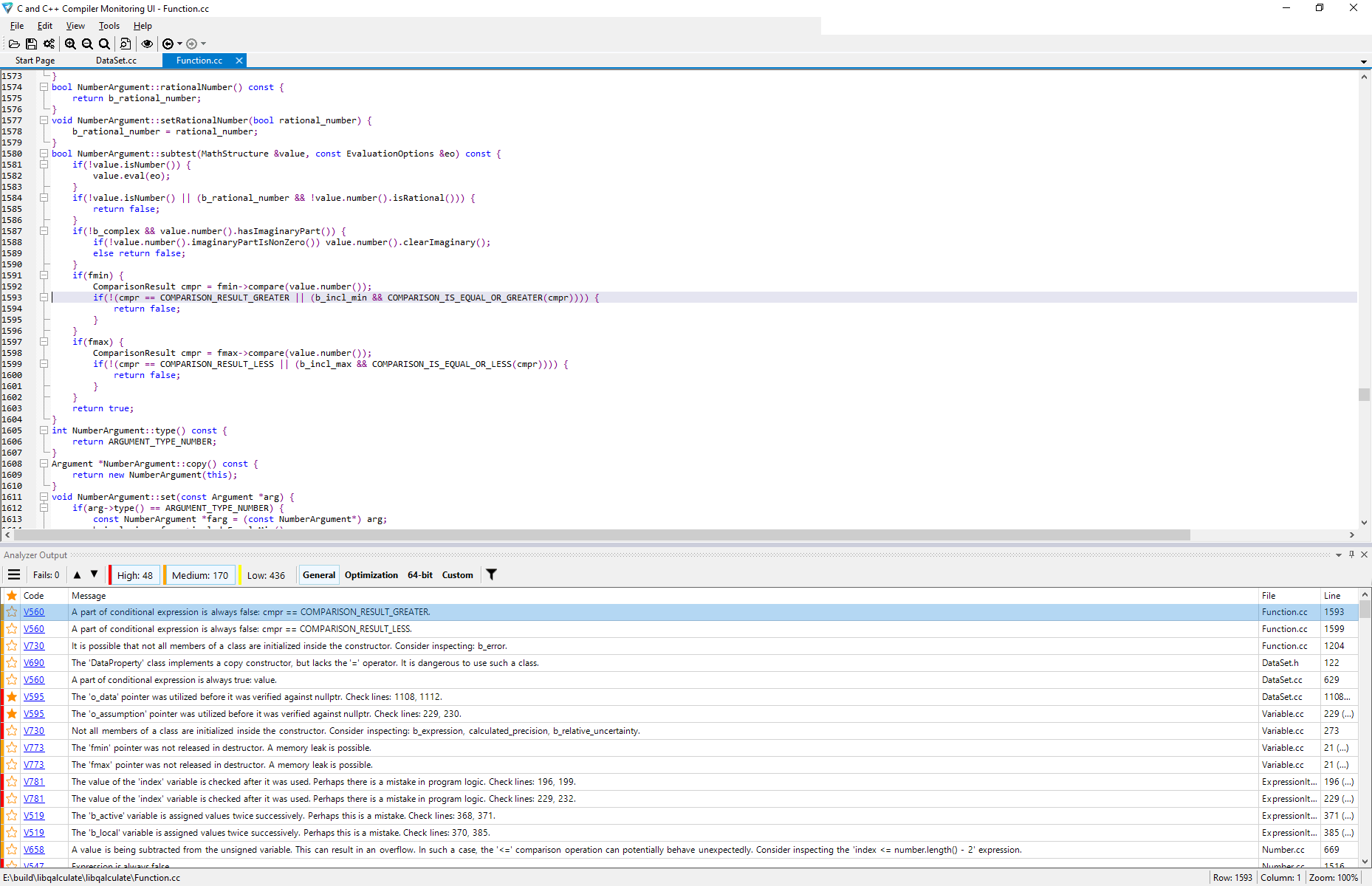
Тем не менее, если у вас есть проект, который можно открыть в Visual Studio, мы рекомендуем вам, для просмотра результатов анализа использовать Visual Studio плагин PVS-Studio, т.к. возможности встроенного в Compiler Monitoring UI редактора кода значительно уступают редактору кода Visual Studio. Для этого вы можете сохранить отчёт анализатора и переоткрыть его в Visual Studio.
Меню для запуска анализа и подавления предупреждений выглядит следующим образом.

При выборе пункта меню для запуска анализа появится окно "Compiler Monitoring (C and C++)".

Для фильтрации предупреждений анализатора, перед анализом необходимо указать файл с подавленными ранее предупреждениями. Создать и пополнять такой файл можно через меню "Message Suppression...", которое является таким же, как было представлено в разделе про Visual Studio на рисунке 2. После завершения анализа в окне PVS-Studio будут отображены только новые ошибки. Без указания файла анализатор выдаст все результаты.
Проекты на C и C++ в Linux/macOS
В Linux/macOS команды подавления и фильтрации сообщений анализатора выполняются только в консоли, при необходимости этот процесс может быть автоматизирован на сервере, выполняющем автоматический запуск анализа. Есть несколько способов использования этого механизма, в зависимости от варианта интеграции анализатора.
Подавление с помощью утилиты pvs-studio-analyzer
Для подавления всех предупреждений анализатора (первый раз и в последующих случаях) необходимо выполнять команду:
pvs-studio-analyzer suppress /path/to/report.logЕсли вы хотите подавить предупреждение для какого-либо конкретного файла, воспользуйтесь флагом ‑‑file(-f):
pvs-studio-analyzer suppress -f test.c /path/to/report.logПомимо самого файла, вы можете явно указать номер строки для подавления:
pvs-studio-analyzer suppress -f test.c:22 /path/to/report.logПри такой записи будут подавлены все предупреждения, которые находятся на строке 22 файла 'test.c'.
Этот флаг можно указывать несколько раз, тем самым подавив предупреждения сразу в нескольких файлах.
Помимо явного указания файла, есть механизм подавления конкретных диагностик:
pvs-studio-analyzer suppress -v512 /path/to/report.logФлаг ‑‑warning(-v) так же можно указывать несколько раз:
pvs-studio-analyzer suppress -v1040 -v512 /path/to/report.logУказанные выше флаги ‑‑file и ‑‑warning можно комбинировать для более точечного подавления предупреждений:
pvs-studio-analyzer suppress -f test.c:22 -v512 /path/to/report.logТак, указанная выше команда подавит все предупреждения диагностики V512 на 22 строке файла 'test.c'.
Анализ проекта можно запускать как прежде. При этом подавленные предупреждения будут фильтроваться:
pvs-studio-analyzer analyze ... -o /path/to/report.log
plog-converter ...При таком запуске подавленные предупреждения будут сохраняться в текущем каталоге, в файле с именем suppress_file.suppress.json, который надо хранить с проектом. Новые подавленные предупреждения будут дописываться в этот файл. Если необходимо указать другое имя или расположение файла, то команды выше можно дополнить, указав путь до файла с подавленными предупреждениями.
Прямая интеграция анализатора в сборочную систему
Прямая интеграция анализатора может выглядеть следующим образом:
.cpp.o:
$(CXX) $(CFLAGS) $(DFLAGS) $(INCLUDES) $< -o $@
pvs-studio --cfg $(CFG_PATH) --source-file $< --language C++
--cl-params $(CFLAGS) $(DFLAGS) $(INCLUDES) $<В этом режиме интеграции происходит вызов C++ ядра анализатора напрямую, поэтому анализатор не может одновременно проверять исходные файлы и фильтровать их. Поэтому для фильтрации и подавления предупреждений потребуется вызывать дополнительные команды.
Для подавления всех предупреждений анализатора необходимо выполнить команду:
pvs-studio-analyzer suppress /path/to/report.logДля фильтрации нового лога по ранее сгенерированному файлу подавления, необходимо воспользоваться следующими командами:
pvs-studio-analyzer filter-suppressed /path/to/report.log
plog-converter ...Файл с подавленными предупреждениями также имеет имя по умолчанию suppress_file.suppress.json, для которого при необходимости можно задать произвольное имя.
Проекты на Java в Windows/Linux/macOS
Подавление сообщений в IntelliJ IDEA
Для просмотра результатов анализа в IntelliJ IDEA существует специальное окно.

Специальное окно позволяет выполнять навигацию по найденным предупреждениям и переходить к коду для его исправления. Окно PVS-Studio предоставляет широкие возможности фильтрации и сортировки результатов. Также присутствует возможность быстрого перехода к документации выбранной диагностики.
Дополнительные возможности работы с каждым сообщением доступны в контекстном меню по нажатию на правый клик мыши на сообщении. Здесь доступна команда для подавления выделенного предупреждения.

В плагине PVS-Studio для IntelliJ IDEA есть механизм, который позволяет подавить сразу все сообщения одним нажатием кнопки:

По умолчанию файл подавления расположен по пути {projectPath}/.PVS-Studio/suppress_base.json, но в настройках плагина есть возможность изменить этот путь:

Какой бы способ подавления Вы не использовали, при следующем анализе подавленные Вами сообщения не попадут в отчет.
Подавление сообщений анализатора в Gradle
Для подавления предупреждений анализатора необходимо выполнять команду:
./gradlew pvsSuppress "-Ppvsstudio.report=/path/to/report.json"
"-Ppvsstudio.output=/path/to/suppress_base.json"Подавление сообщений анализатора в Maven
Для подавления предупреждений анализатора необходимо выполнять команду:
mvn pvsstudio:pvsSuppress "-Dpvsstudio.report=/path/to/report.json"
"-Dpvsstudio.output=/path/to/suppress_base.json"Прямая интеграция анализатора в сборочную систему
Для подавления предупреждений анализатора необходимо выполнять команду:
java -jar pvs-studio.jar --convert toSuppress
--src-convert "/path/to/report.json"
--dst-convert "/path/to/suppress_base.json"Подавление предупреждений в Unreal Engine проектах
Использование baseline-инга для Unreal Engine проектов описано в отдельном разделе про использование PVS-Studio для Unreal Engine проектов.
Подавление предупреждений анализатора в плагинах PVS-Studio для CLion и Rider.
В плагинах PVS-Studio for CLion и PVS-Studio for Rider на данный момент имеется возможность подавления всех сообщений анализатора. Чтобы подавить сообщения анализатора на старом коде, можно воспользоваться кнопкой 'Suppress All Messages' на панели окна PVS-Studio:
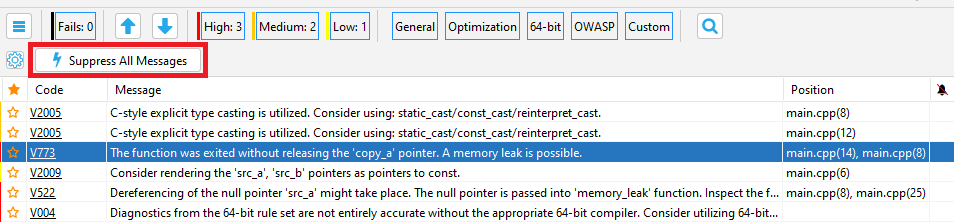
В Rider также имеется возможность подавить все сообщения из главного меню 'Tools -> PVS-Studio -> Suppress All Messages':

Механизм подавления работает с помощью специальных *.suppress файлов, в которые добавляются подавленные сообщения анализатора после выполнения команды 'Suppress All Messages'. При последующем запуске анализа все сообщения, добавленные в *.suppress файлы, не попадут в отчёт анализатора. Система подавления через *.suppress файлы достаточно гибкая и способна "отслеживать" подавленные сообщения даже при модификации и сдвигах участков кода, в которых выдаётся подавленное сообщение.
При работе с Rider файлы *.suppress создаются на уровне проекта, рядом с каждым проектным файлом, но их также можно добавить в любой проект или solution (например, чтобы использовать один общий *.suppress файл для нескольких проектов или всего solution'а). Чтобы вернуть подавленные сообщения анализатора, необходимо удалить *.suppress файлы для соответствующих проектов и перезапустить анализ.
В CLion подавленные сообщения добавляются в файл suppress_file.suppress.json, который записывается в директорию .PVS-Studio, которая находится в корневой директории CLion проекта. Чтобы вернуть все сообщения анализатора, необходимо удалить этот файл и перезапустить анализ.
Система контроля версий
С версии PVS-Studio 7.27 внутреннее содержимое файлов подавления сортируется. Это требуется для корректного использования в системе контроля версий и избежания проблем слияния файлов.
Сообщения сортируются в таком порядке: имя исходного файла, код диагностики, хэш строки, описание диагностики.
Подавление предупреждений в SonarQube
SonarQube (бывший Sonar) — платформа с открытым исходным кодом для непрерывного анализа (англ. continuous inspection) и измерения качества кода.Пользователям этой системы доступен плагин для PVS-Studio. SonarQube сводит результаты анализа к единой информационной панели, ведя историю прогонов и позволяя тем самым увидеть общую тенденцию изменения качества программного обеспечения в ходе разработки. Дополнительным преимуществом является возможность объединять результаты разных анализаторов.
Так, получив результаты анализа одного или нескольких анализаторов, необходимо перейти к списку предупреждений и кликнуть на кнопку "Bulk Change", после чего откроется следующее меню.

В этом окне можно разметить все предупреждения анализатора как "won't fix" и в дальнейшем работать только с новыми ошибками.
Совместное использование возможностей подавления сообщений анализатора PVS-Studio в CI и IDE
PVS-Studio можно быстро интегрировать в новый проект, настроить его автоматическую ежедневную проверку в CI и одновременно постепенно разбираться с подавленными предупреждениями в IDE.
Выглядеть это будет примерно так:
- Интегрируя анализатор PVS-Studio в новый проект, вы получите первый отчёт анализатора.
- Далее вы подавите все найденные предупреждения через PVS-Studio_Cmd.exe в режиме SuppressOnly или через интерфейс плагинов PVS-Studio для IDE. В результате у вас появится suppress-файл, который далее будет использоваться для фильтрации предупреждений из отчётов анализатора.
- Этот suppress-файл вы коммитите в систему контроля версий или сохраняете любым удобным вам способом.
- Следующим шагом вы настраиваете задачу в CI, которая запускает анализ проекта при помощи PVS-Studio и фильтрует предупреждения из полученного отчёта. В фильтрации используется полученный ранее suppress-файл. Фильтрация происходит при помощи PVS-Studio_Cmd.exe в режиме suppression с флагом -m FilterFromSuppress. В результате выполнения задачи вы получаете отчёт с предупреждениями только на новый или измененный код.
- После этого отчёт отправляется членам команды при помощи утилиты BlameNotifier.exe.
- Каждый член команды исправляет код с учетом полученного отчёта.
- Также постепенно ваша команда может разбираться с подавленными сообщениями. Для этого необходимо включить отображение подавленных предупреждений в IDE. Обработав подавленное предупреждение, вы удаляете его из suppress-файла и коммитите изменение, чтобы это сообщение не мешало в дальнейшем при фильтрации следующих отчётов анализатора при помощи suppress-файла.
- Кроме удаления возможно и добавление новых предупреждений в suppress-файл при помощи интерфейса плагина PVS-Studio для Visual Studio или через PVS-Studio_Cmd.exe в режиме SuppressOnly с указанием в аргументе '-u' пути до ранее созданного suppress-файла. Таким образом можно откладывать обработку предупреждений (злоупотреблять этим не следует), и при этом они не будут мешать в отчёте анализатора.
Что делать после подавления всех предупреждений?
Настроить статический анализ на сборочном сервере и компьютерах разработчиков. В дальнейшем исправлять новые предупреждения анализатора и не давать им накапливаться. Также стоит запланировать поиск и исправление ошибок среди подавленных предупреждений.
Дополнительный контроль за качеством кода поможет обеспечить рассылка результатов по почте. Рассылать предупреждения только для тех разработчиков, которые внесли ошибочный код, возможно с помощью утилиты BlameNotifier, которая входит в Windows дистрибутив PVS-Studio.
Некоторым может быть удобно загружать результаты в Jenkins или TeamCity с помощью плагина PVS-Studio, и рассылать ссылку на эту страницу.
Дополнительные ссылки
На странице приведены все возможные способы подавления предупреждений анализатора на данный момент. Описание этого механизма основывается на документации к анализатору PVS-Studio, но детали по этой теме были рассмотрены подробнее. Общие сведения могут быть не очень информативны для новых пользователей, поэтому следует ознакомиться с документацией по ссылкам ниже.
- Просмотр результатов анализа в приложении C and C++ Compiler Monitoring UI;
- Как запустить PVS-Studio в Linux и macOS;
- Встраивание PVS-Studio в процесс непрерывной интеграции;
- Интеграция результатов анализа PVS-Studio в SonarQube;
- Работа с результатами анализа (.plog файл).
Работа со списком диагностических сообщений в Visual Studio
- Просмотр интересных предупреждений анализатора
- Навигация и сортировка
- Фильтрация сообщений
- Быстрый переход к отдельным сообщениям
- Организация работы с помощью Visual Studio Task List
При работе с большим количеством сообщений (а при первичной проверке крупных проектов, когда ещё не настроены фильтры и не размечены ложные срабатывания, число сообщений может достигать десятков тысяч), разумно воспользоваться средствами навигации поиска, и фильтрации встроенными в окно вывода результатов PVS-Studio.
Просмотр интересных предупреждений анализатора
Если Вы только начали изучать инструмент статического анализа и хотели бы узнать на что он способен, то можете воспользоваться механизмом Best Warnings. Данный механизм покажет вам наиболее важные и достоверные предупреждения.
Чтобы посмотреть наиболее интересные предупреждения с точки зрения анализатора, нажмите на кнопку 'Best', как показано на скриншоте ниже:
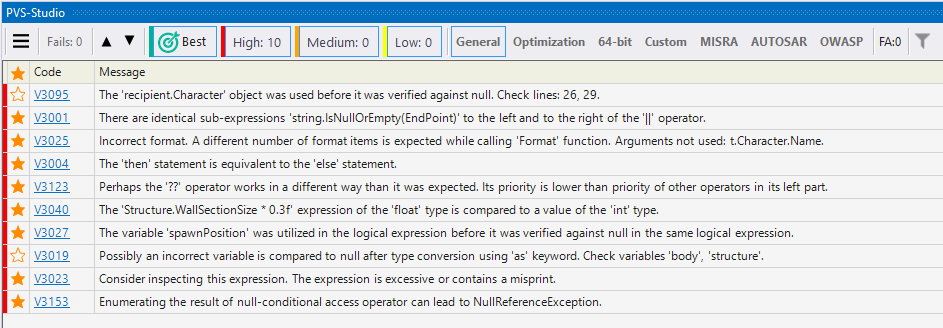
После чего в таблице с результатами анализа останутся максимум десять наиболее критичных предупреждений анализатора.
Навигация и сортировка
Окно вывода результатов PVS-Studio в первую очередь предназначено для упрощения навигации по коду анализируемого проекта и переходу к участкам кода, содержащим потенциальные ошибки. Двойной щелчок мыши по любому из сообщений в списке автоматически откроет в редакторе кода файл, на который данное сообщение указывает, переведёт курсор на интересующую строку и выделит её. Кнопки быстрой навигации (рисунок 1) позволяют легко просматривать обнаруженные потенциально опасные места в исходном коде без необходимости постоянно переключаться между окнами среды разработки.
Рисунок 1 — Кнопки быстрого перехода
Для представления результатов анализа окно PVS-Studio использует виртуальную таблицу, позволяющую быстро отображать и осуществлять сортировку сгенерированных сообщений даже для очень крупных проектов (виртуальная таблица позволяет работать со списками из сотен тысяч строк без заметного ущерба для производительности). Крайний левый столбец таблицы предназначен для пометки интересных сообщений, например, тех, к которым имеет смысл вернуться повторно. Данный столбец также поддерживает сортировку, поэтому найти все сообщения, размеченные подобным образом, не составит труда. Пункт контекстного меню "Show Columns" позволяет настроить отображаемые в таблице столбцы (рисунок 2):

Рисунок 2 — Настройка отображения таблицы вывода результатов
Таблица поддерживает множественное выделение с помощью стандартных комбинаций Ctrl и Shift, при этом выделение строк сохраняется и после пересортировки по любой другой колонке. Пункт меню "Copy selected messages to clipboard" (либо сочетание Ctrl+C) позволяет скопировать в буфер обмена содержимое всех выделенных в таблице строк.
Фильтрация сообщений
Механизмы фильтрации окна вывода PVS-Studio позволяют быстро найти и отобразить как отдельные диагностические сообщения, так целые их группы. Панель инструментов окна содержит ряд переключателей, позволяющих включить либо отключить отображение сообщений из соответствующих им групп сообщений (рисунок 3).

Рисунок 3 — Группы фильтрации сообщений
Все переключатели можно разбить на 3 группы: фильтры по уровню диагностической достоверности сообщений, фильтры по принадлежности сообщения к определённому типу диагностических правил, фильтр размеченных в коде ложных срабатываний. Отключение этих фильтров мгновенно отключает отображение соответствующих им сообщений в списке.
Детальное описание уровней достоверности предупреждений и наборов диагностических правил приведено в разделе документации "Знакомство со статическим анализатором кода PVS-Studio".
Механизм быстрой фильтрации (quick filters) позволяет отфильтровать отчёт анализатора по заданным ключевым словам. Открыть панель быстрой фильтрации можно с помощью кнопки Quick Filters панели инструментов окна (рисунок 4).

Рисунок 4 — Панель быстрой фильтрации
Быстрая фильтрация позволяет отобразить сообщения в соответствии с фильтрами по 3-м ключевым словам: по коду сообщения, по тексту сообщения и по файлу, содержащему данное сообщение. Например, отобразить все сообщения, содержащие слово 'odd' из файла 'command.cpp'. Изменения в списке сообщений становятся видны сразу после выхода из поля ввода ключевого слова (при потере фокуса). Кнопка Reset Filters очищает заданные в данный момент ключевые слова.
Все перечисленные механизмы фильтрации сообщений можно совмещать между собой, фильтруя, например, уровень отображаемых сообщений и файл, к которому сообщения должны относиться, исключая сообщения, помеченные как ложные срабатывания.
Быстрый переход к отдельным сообщениям
При необходимости перехода на какое-либо конкретное сообщение в таблице можно воспользоваться диалогом быстрого перехода к строке, который вызывается через пункт контекстного меню "Navigate to ID..."(рисунок 5):

Рисунок 5 - Вызов диалога быстрого перехода

Рисунок 6 - Диалог быстрого перехода к сообщению
Каждое сообщение в списке вывода PVS-Studio имеет уникальный идентификатор — порядковый номер добавления этого сообщения в таблицу, который отображён в колонке ID. Диалог быстрого перехода позволяет выделить и автоматически сфокусировать сообщение с заданным идентификатором ID, независимо от текущей сортировки таблицы и выделенных строк. Обратите внимание, что ID идентификаторы отображённых в таблице сообщений не всегда идут последовательно, т.к. часть сообщений может быть скрыта с помощью механизмов фильтрации. Переход к таким сообщениям невозможен.
Организация работы с помощью Visual Studio Task List
Зачастую в разработке крупных проектов принимают участие распределённые группы разработчиков, а поэтому очень часто один человек не имеет возможности оценить каждое из сообщений статического анализатора на предмет ложно-позитивного срабатывания и, тем более, внести исправления в соответствующий участок исходного кода. В такой ситуации имеет смысл делегировать рассмотрение подобного сообщения разработчику, непосредственно отвечающему за данный участок.
PVS-Studio позволяет автоматически сгенерировать и внести в код комментарий TODO специального вида, содержащий всю необходимую информацию для оценки и анализа отмеченного им фрагмента программы. Такой комментарий будет сразу отображён в окне задач Visual Studio (окно Task List, для версии Visual Studio 2010 необходимо включить разбор комментариев в настройках Tools->Options->Text Editor->C++->Formatting->Enumerate Comment Tasks->true) при условии, что в настройках Tools->Options->Environment->Task List->Tokens задана соответствующая TODO лексема (присутствует в настройках по умолчанию). Комментарий может быть добавлен с помощью команды контекстного меню 'Add TODO comments for selected messages' (рисунок 7)

Рисунок 7 - Вставка TODO комментария
TODO комментарий будет вставлен в строку, сгенерировавшую сообщение анализатора, и будет содержать код ошибки, текст сообщения анализатора и ссылку на online документацию для данного типа ошибок. Благодаря окну заданий (Task List) данный комментарий может быть легко найден любым имеющим доступ к исходному коду разработчиком, а сам текст комментария позволит выявить и исправить потенциальную ошибку даже в случае отсутствия у программиста установленной версии PVS-Studio или полного отчёта о работе анализатора (рисунок 8).
Рисунок 8 - Окно заданий Visual Studio
В Visual Studio открыть окно Task List можно через меню View->Other Windows->Task List. Комментарии TODO отображаются в разделе Comments окна.
Подавление ложноположительных предупреждений
- Смотри, а не читай (YouTube)
- Механизм подавления отдельных ложных срабатываний (Mark as False Alarm)
- Ручное подавление ложных срабатываний
- Подавление ложных срабатываний через контекстное меню плагинов
- Подавление ложных предупреждений в С/С++ макросах (#define) и для других фрагментов кода
- Включение и выключение определенных диагностик для блока кода
- Подавление ложных предупреждений с помощью файлов конфигурации диагностик (.pvsconfig)
- Другие способы фильтрации сообщений в анализаторе PVS-Studio (Detectable Errors, Don't Check Files, Keyword Message Filtering)
- Массовое подавление сообщений анализатора (baselining)
- Возможные проблемы
В данном разделе описаны механизмы подавления ложноположительных предупреждений, выдаваемых анализатором. С помощью описанных здесь механизмов можно управлять как отдельными сообщениями, выдаваемыми на определённые строки кода, так и подавлять множественные срабатывания, возникающие, например, из-за использования C/C++ макросов. Описан способ, как с помощью комментариев указать анализатору выключить то или иное сообщение анализатора или изменить выдаваемый текст сообщения.
Механизмы, описанные в данном разделе, применимы как для C/C++, так и для C# анализаторов PVS-Studio, если явно не указано обратное.
Смотри, а не читай (YouTube)
Механизм подавления отдельных ложных срабатываний (Mark as False Alarm)
Любой анализатор кода всегда выдает помимо полезных сообщений об ошибках еще множество так называемых "ложных срабатываний". Это ситуации, когда программисту совершенно очевидно, что в коде нет ошибки, а анализатору это не очевидно. Такие ложные срабатывания называют False Alarm. Рассмотрим пример кода:
obj.specialFunc(obj);Анализатор считает подозрительным, что у объекта вызывается метод, в качестве аргумента в который передаётся тот же самый объект, поэтому он выдаст на данный код предупреждение V678. Программист же может знать, что использование метода 'specialFunc' таким образом вполне допустимо, поэтому предупреждение анализатора в данном случае является ложным срабатыванием. О том, что предупреждение V678, выданное на этот код, является ложным, можно сообщить анализатору.
Это можно сделать либо вручную, либо с помощью команды контекстного меню. По умолчанию, ложные срабатывания не отображаются в итоговом отчете или плагине. Для включения отображения размеченных подобным образом сообщений можно воспользоваться настройкой 'PVS-Studio -> Options... -> Specific Analyzer Settings -> DisplayFalseAlarms'.
Не рекомендуется использовать разметку сообщений как ложных предупреждений без предварительного просмотра соответствующего кода, так как это противоречит идеологии статического анализа. Только программист может определить, является ли сообщение об ошибке ложным.
Ручное подавление ложных срабатываний
Обычно в компиляторах для подавления отдельных сообщений об ошибках используют '#pragma'-директивы. Приведём пример кода:
unsigned arraySize = n * sizeof(float);Компилятор выдает сообщение:
warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data x64Sample.cpp 151
Это сообщение можно подавить с помощью следующей конструкции:
#pragma warning (disable:4267)Точнее, чтобы подавить конкретно это сообщение, лучше оформить код так:
#pragma warning(push)
#pragma warning (disable:4267)
unsigned arraySize = n * sizeof(float);
#pragma warning(pop)Анализатор PVS-Studio в качестве разметки использует комментарии специального вида. Для той же строчки кода подавление сообщения PVS-Studio будет выглядеть так:
unsigned arraySize = n * sizeof(INT_PTR); //-V103Теперь анализатор пометит предупреждение V103 на эту строку как ложное. Такой подход был выбран для повышения наглядности конечного кода. Дело в том, что PVS-Studio может сообщать о проблемах в середине многострочных выражений, как, например, здесь:
size_t n = 100;
for (unsigned i = 0;
i < n; // <= анализатор сообщит о проблеме здесь
i++)
{
// ...
}Чтобы подавить это сообщение при использовании комментария, достаточно написать:
size_t n = 100;
for (unsigned i = 0;
i < n; //-V104
i++)
{
// ...
}Если же в это выражение пришлось бы добавлять '#pragma'-директиву, то код выглядел бы значительно менее наглядно.
Хранение разметки в исходном коде позволяет вносить в него модификации без опасения потерять информацию о строках с ошибками.
Иногда необходимо подавить более одного срабатывания на одной строке. В этом случае следует указать отдельный комментарий для каждого из них. Вот пара примеров:
1) подавление срабатываний разных диагностик:
struct Small { int *pointer; };
struct Big { int *array[20]; };
int Add(const Small &a, Big b) //-V835 //-V813
{
return *a.pointer + *b.array[10];
}2) подавление срабатываний одной диагностики:
struct Small { int *pointer; };
int Add(const Small &a, const Small &b) //-V835 //-V835
{
return *a.pointer + *b.pointer;
}Можно также использовать отдельную базу, в которой хранить информацию примерно так: код ошибки, имя файла, номер строки. Данный подход отдельно реализован в PVS-Studio и называется "Mass Suppression".
Подавление ложных срабатываний через контекстное меню плагинов
Для работы с ложными срабатываниями пользователю предоставляется две команды, доступные из контекстного меню PVS-Studio (рисунок 1).

Рисунок 1 - Команды для работы с механизмом подавления ложных предупреждений
Рассмотрим команды, относящиеся к подавлению ложных предупреждений:
1. Mark selected messages as False Alarms. Вы можете выбрать одно или несколько предупреждений в списке (рисунок 2) и воспользоваться этой командой для разметки соответствующего кода, как безопасного.

Рисунок 2 - Выбор предупреждений перед выполнением команды "Mark selected messages as False Alarms"
2. Remove False Alarm marks from selected messages. Убирает комментарий, помечающий код как безопасный. Функция, например, может быть полезна, если вы поспешили и ошибочно отметили код как безопасный. Как и в предыдущем случае, вы должны выбрать сообщения из списка, которые планируете обработать.
Подавление ложных предупреждений в С/С++ макросах (#define) и для других фрагментов кода
В макросах (#define) анализатор также, разумеется, может находить потенциальные проблемы и выдавать на них диагностические сообщения. Но при этом анализатор будет выдавать сообщения в тех местах, где макрос используется, то есть где фактически происходит подстановка тела макроса в код. Пример:
#define TEST_MACRO \
int a = 0; \
size_t b = 0; \
b = a;
void func1()
{
TEST_MACRO // V1001 here
}
void func2()
{
TEST_MACRO // V1001 here
}Чтобы подавить это сообщение, можно использовать команду "Mark as False Alarm". Тогда код с расставленными командами подавления будет выглядеть так:
#define TEST_MACRO \
int a = 0; \
size_t b = 0; \
b = a;
void func1()
{
TEST_MACRO //-V1001
}
void func2()
{
TEST_MACRO //-V1001
}Однако если макрос используется очень активно, то везде размечать его как False Alarm не очень удобно. Есть возможность в коде сделать вручную специальную пометку, чтобы анализатор автоматически размечал диагностики в этом макросе как False Alarm. С этой пометкой код будет выглядеть так:
//-V:TEST_MACRO:1001
#define TEST_MACRO \
int a = 0; \
size_t b = 0; \
b = a;
void func1()
{
TEST_MACRO
}
void func2()
{
TEST_MACRO
}При проверке такого кода сообщения о проблемах в макросе уже сразу будут помечены как False Alarm. Причём можно указывать несколько диагностик сразу, через запятую:
//-V:TEST_MACRO:1001, 105, 201Обратите внимание, что если макрос содержит вложенные макросы, то для автоматической пометки нужно указывать всё равно имя макроса самого верхнего уровня:
#define NO_ERROR 0
#define VB_NODATA ((long)(77))
size_t stat;
#define CHECK_ERROR_STAT \
if( stat != NO_ERROR && stat != VB_NODATA ) \
return stat;
size_t testFunc()
{
{
CHECK_ERROR_STAT // #1
}
{
CHECK_ERROR_STAT // #2
}
return VB_NODATA; // #3
}В указанном примере диагностика V126 появляется в трех местах. Чтобы автоматически помечать ее как False Alarm в местах #1 и #2 нужно добавить такой код:
//-V:CHECK_ERROR_STAT:126А чтобы и в #3 это сработало, необходимо указать еще:
//-V:VB_NODATA:126К сожалению, просто указать "сразу помечать V126 в макросе VB_NODATA" и не указывать про макрос CHECK_ERROR_STAT нельзя из-за технических особенностей механизма препроцессирования.
Всё написанное в этом разделе про макросы справедливо также и для любого фрагмента кода. То есть если, например, вы хотите подавить все срабатывания диагностики V103 на вызов функции 'MyFunction', необходимо добавить такую строку:
//-V:MyFunction:103Включение и выключение определенных диагностик для блока кода
Этот пункт относится только к анализатору языков C и C++.
Иногда нужно отключить некоторое правило не глобально, а для определенной части кода. Например, нужно отключить диагностику для определенного файла или части файла, при этом остальные диагностики должны продолжать работать. Подавленное предупреждение должно продолжать выдаваться при анализе остального кода.
Анализатор предоставляет механизм подавления с использованием специальных директив 'pragma'. Этот способ аналогичен тому, который используется в компиляторе для управления предупреждениями.
Анализатор использует следующие директивы:
- #pragma pvs(push) – сохраняет текущие настройки включения/отключения диагностик;
- #pragma pvs(disable: XXXX, YYYY, ...) – выключает диагностики с номерами из списка;
- #pragma pvs(enable: XXXX, YYYY, ...) – включает диагностики с номерами из списка;
- #pragma pvs(pop) – восстанавливает предыдущие сохраненные настройки.
Так же, как и в случае с '#pragma warning', поддерживается вложенность.
Пример:
void func(int* p1, int* p2, int* p3)
{
if (!p1 || !p2 || !p3)
return;
#pragma pvs(push)
#pragma pvs(disable: 547)
if (p1) // V547 off
do_something();
#pragma pvs(push)
#pragma pvs(enable: 547)
if (p2) // V547 Expression 'p2' is always true.
do_something_else();
#pragma pvs(pop)
if (p3) // V547 off
do_other();
#pragma pvs(pop)
}Примечание: хотя компиляторы игнорируют неизвестные директивы 'pragma', в зависимости от настроек, они могут выдавать предупреждения о таких директивах. В этом случае предупреждение можно отключить, передав специальный параметр в командную строку компилятора:
- для GCC и Clang: -Wno-unknown-pragmas
- для MSVC: -wd4068
Подавление ложных предупреждений с помощью файлов конфигурации диагностик (.pvsconfig)
Отображением и фильтрацией сообщений можно управлять с помощью комментариев специального вида. Такие комментарии можно писать в специальных файлах конфигурации (.pvsconfig) для всех анализаторов, либо непосредственно в коде проекта (только для C/C++ анализатора).
Файлы конфигурации диагностик анализатора представляют собой простые текстовые файлы, добавляемые в Visual Studio проект либо solution. Для добавления файла конфигурации, выделите интересующий вас проект или solution в окне Solution Explorer среды Visual Studio и выберите пункт контекстного меню 'Add New Item...'. В появившемся окне выберите тип файла 'PVS-Studio Filters File' (рисунок 3):
Рисунок 3 - Добавление в solution файла конфигурации диагностик анализатора.
Из-за особенностей некоторых версий среды Visual Studio, тип файлов 'PVS-Studio Filters File' может отсутствовать на некоторых версиях и редакциях Visual Studio в окне добавления нового файла для solution и\или проекта. В таком случае, можно добавить в проект обычный текстовый файл, задав ему расширение 'pvsconfig'. В свойствах этого файла (после добавления), должно быть указано, что файл не участвует в сборке.
Файл конфигурации, добавленный в проект, действует на все файлы данного проекта. Файл конфигурации, добавленный в solution, действует на все файлы всех проектов, добавленных в данный solution.
Также можно разместить файл конфигурации .pvsconfig в текущей папке пользовательских данных (%AppData%\PVS-Studio\) - такой файл будет подхвачен автоматически при запуске проверки, без необходимости как-либо модифицировать проектные файлы.
Примечание. '.pvsconfig' файлов в '%AppData%\PVS-Studio\' может быть несколько, и все они будут автоматически подхвачены анализатором. Стоит также учитывать, что конфигурация из '%AppData%\PVS-Studio\' будет глобальна для анализатора и будет безусловно использоваться при каждом запуске.
При использовании инструмента командной строки PVS-Studio_Cmd указать путь к файлу конфигурации .pvsconfig можно через параметр ‑‑rulesConfig (-C), например:
PVS-Studio_Cmd.exe -t D:\project\project.sln
-C D:\project\rules.pvsconfigФайлы конфигурации диагностик .pvsconfig имеют простой синтаксис. Любая строка, начинающаяся с символа '#' считается комментарием и игнорируется. Фильтры записываются в формате однострочных C++/C# комментариев, т.е. должны начинаться с символов '//'.
Для C/C++ кода, фильтры также могут быть записаны в виде комментариев непосредственно в исходном коде. Обратите внимание, что такой формат записи не поддерживается в C# проектах!
Далее рассмотрим различные варианты фильтров, допустимых в файлах конфигурации диагностик.
Фильтрация сообщений по фрагменту исходного кода (например, имена макросов, переменных и функций)
Предположим, есть следующая структура:
struct MYRGBA
{
unsigned data;
};И ряд функций, которые её используют:
void f1(const struct MYRGBA aaa)
{
}
long int f2(int b, const struct MYRGBA aaa)
{
return int();
}
long int f3(float b, const struct MYRGBA aaa, char c)
{
return int();
}На все эти функции анализатор выдаст три сообщения V801: Decreased performance. It is better to redefine the N function argument as a reference. Сообщение в подобном коде будет ложным, так как компилятор сам оптимизирует код, и проблемы не будет.
Можно, конечно, каждое сообщение пометить как False Alarm с помощью функции Mark As False Alarm. Однако, есть способ лучше. Достаточно добавить в код строку:
//-V:MYRGBA:801Для C/C++ проектов, мы рекомендуем добавлять такую строку в .h-файл рядом с объявлением структуры, но если это невозможно (например, структура в системном .h-файле), то можно прописать это в stdafx.h.
И тогда, после перепроверки, все три сообщения V801 будут автоматически помечены как False Alarm.
Обратите внимание: при использовании комментариев вида //-V:MY_STRING:Vxxx PVS-Studio будет подавлять все сообщения Vxxx, выданные на строки, в которых содержится подстрока MY_STRING.
Описанный механизм может применяться для подавления предупреждений не только для отдельных слов. Иногда, это очень удобно.
Рассмотрим несколько примеров:
//-V:<<:128Подавит предупреждения V128 в строках, где имеется оператор <<.
buf << my_vector.size();Если вы хотите подавлять предупреждение V128 только при записи данных в объект с именем 'log', то можно написать так:
//-V:log<<:128
buf << my_vector.size(); // Есть предупреждение
log << my_vector.size(); // Нет предупрежденияПримечание. Обратите внимание, что строка для поиска не должна содержать пробелов.
Правильно: //-V:log<<:128
Неправильно: //-V:log <<:128При поиске подстроки пробелы игнорируются. Но не беспокойтесь, следующая ситуация обработается корректно:
//-V:ABC:501
AB C = x == x; // Есть предупреждение
AB y = ABC == ABC; // Нет предупрежденияПолное отключение предупреждений
Существует возможность с помощью комментария полностью выключить предупреждение. В этом случае после двух двоеточий указывается номер отключаемой диагностики. Синтаксис:
//-V::(number)Если требуется проигнорировать предупреждение V122, то можно указать в начале файла:
//-V::122Для отключения нескольких диагностик можно перечислить их номера через запятую. Синтаксис:
//-V::(number1),(number2),...,(numberN)Если требуется, например, игнорировать предупреждения V502, V507 и V525, то в начале файла можно указать:
//-V::502,507,525При необходимости можно отключать предупреждения определённых диагностик на указанных уровнях. Синтаксис:
//-V::(number1),(number2),...,(numberN):1,2,3Например, если требуется игнорировать предупреждения V3161 и V3165 на уровнях 'Medium' и 'Low', можно указать:
//-V::3161,3165:2,3Анализатор также поддерживает возможность фильтрации предупреждений по номеру диагностики и подстроке. Синтаксис:
//-V::(number1),(number2),...,(numberN)::{substring}Например, можно исключить из отчёта все предупреждения V3022 и V3063, содержащие подстроку "always true":
//-V::3022,3063::{always true}Этот функционал можно комбинировать с фильтрацией по уровню:
//-V::(number1),(number2),...,(numberN):1,2,3:{substring}Например, можно исключить все срабатывания V5625, имеющие 2 уровень и содержащие подстроку "Google.Protobuf 3.6.1":
//-V::5625:2:{Google.Protobuf 3.6.1}Существует также возможность отключить группу диагностик. Синтаксис:
//-V::GA
//-V::X64
//-V::OP
//-V::CS
//-V::MISRAДля отключения сразу нескольких групп диагностик их можно перечислить через запятую. Синтаксис:
//-V::X64,CS,...Для отключения всех диагностик C++ или C# анализатора следует использовать следующую форму:
//-V::C++
//-V::C#Поскольку анализатор не будет выдавать указанные предупреждения, то это может значительно уменьшить размер лога проверки, если какая-то диагностика даёт слишком много ложных срабатываний.
Исключение из анализа файлов по маскам
В случае необходимости можно задать исключение из анализа файлов / директорий, которые попадают под заданные маски. Это может быть удобно, например, для исключения из анализа кода сторонних библиотек или автоматически сгенерированных файлов.
Несколько примеров масок:
//V_EXCLUDE_PATH C:\TheBestProject\thirdParty
//V_EXCLUDE_PATH *\UE4\Engine\*
//V_EXCLUDE_PATH *.autogen.csСинтаксис масок идентичен синтаксису для опций 'FileNameMasks' и 'PathMasks', описанному в документе "Настройки: Don't Check Files".
Игнорирование глобальных файлов конфигурации
Перед запуском анализа 'PVS-Studio_Cmd' формирует конфигурацию диагностических правил из:
- глобальных файлов в '%AppData%\PVS-Studio\';
- файла, переданного через опцию ‑‑rulesConfig (-C);
- файлов, добавленных в решение;
- файлов, добавленных в проект.
Если у вас большое количество проектов, для которых конфигурация формируется разными способами, то в некоторых случаях конфигурация из глобальных файлов может приводить к путанице в результирующей конфигурации. Это связано с тем, что конфигурация из глобальных файлов применяется всегда над каким бы проектом вы ни работали. Другими словами, настройки, которые характерны только для проекта X, будут также применены к другим проектам.
Поэтому, если вам необходимо проигнорировать конфигурацию из глобальных файлов, нужно добавить специальный флаг в соответствующий '.pvsconfig' файл:
//IGNORE_GLOBAL_PVSCONFIGПравила действия флага следующие:
- если указан в одном из глобальных файлов, то глобальная конфигурация будет игнорироваться всегда.
- если указан на уровне решения, то глобальная конфигурация игнорируется для конкретного решения;
- если указан на уровне проекта, то глобальная конфигурация игнорируется для конкретного проекта.
Использование этого флага позволит гибко выключать глобальные настройки для определенных случаев.
Другие способы фильтрации сообщений в анализаторе PVS-Studio (Detectable Errors, Don't Check Files, Keyword Message Filtering)
Возможны ситуации, в которых определённый тип диагностик не актуален для анализируемого проекта, или какая-либо из диагностик анализатора выдаёт предупреждения на код, в корректности которого вы уверены. В таком случае можно воспользоваться системой группового подавления сообщений, основанной на фильтрации полученных результатов анализа. Список доступных режимов фильтрации можно открыть через общее меню PVS-Studio -> Options.
Следует отметить, что применение фильтров для группового подавления ложных срабатываний не требует перезапуска анализа, результаты фильтрации будут сразу отображены в окне вывода PVS-Studio.
Во-первых, можно отключить диагностику тех или иных ошибок по их коду. Это делается с помощью вкладки "Настройки: Detectable Errors". На вкладке обнаруживаемых ошибок можно указать номера ошибок, которые не надо показывать в отчете по анализу. Иногда бывает целесообразно убрать в отчете ошибки с определенными кодами. Например, если вы уверены, что ошибки, связанные с явным приведением типа (коды V201, V202, V203), вас не интересуют, то вы можете скрыть их показ. Также отображение ошибок определённого типа можно отключить с использованием команды контекстного меню "Hide all Vxxx errors". Соответственно, в случае, если необходимо включить отображение обратно, настроить это можно на упоминавшейся выше вкладке "Detectable Errors".
Во-вторых, можно отключить анализ некоторых частей проекта (некоторых папок или файлов проекта). Раздел "Настройки: Don't Check Files". На этой вкладке можно ввести информацию о библиотеках, включения (через директиву #include) из файлов которых анализировать не надо. Это может потребоваться для уменьшения количества лишних диагностических сообщений. Например, в проекте используется библиотека Boost. И хотя на какой-то код из этой библиотеки анализатор выдает диагностические сообщения, вы считаете, что эта библиотека является достаточно надежной и написана хорошо. Поэтому, возможно, не имеет смысла получать диагностические сообщения по поводу кода в этой библиотеке. В этом случае можно отключить анализ файлов из этой библиотеки, указав путь к ней на странице настроек. Кроме того, возможно ввести файловые маски для исключения некоторых файлов из анализа. Анализатор не будет проверять файлы, удовлетворяющие условиям маски. Например, подобным образом можно исключить из анализа автогенерируемые файлы.
Маски путей для файлов, сообщения из которых попали в текущий сгенерированный отчёт, можно автоматически добавить в список Don't Check Files с помощью команды контекстного меню "Don't check files and hide all messages from..." для выделенного в окне PVS-Studio Output сообщения (рисунок 4).

Рисунок 4 - Добавление масок путей через контекстное меню
Данная команда позволит добавить в фильтры исключений как отдельный выбранный файл, так и маску по целой директории, в которой данный файл находится.
В-третьих, можно подавлять отдельные сообщения по тексту. На вкладке "Настройки: Keyword Message Filtering" можно настроить фильтрацию ошибок по содержащемуся в них тексту, а не по коду. При необходимости можно скрыть из отчета сообщения о диагностированных ошибках, содержащих определенные слова или фразы. Например, если в отчете есть ошибки, в которых указаны названия функций printf и scanf, а вы считаете, что ошибок, связанных с ними, быть не может, то просто добавьте эти два слова с помощью редактора подавляемых сообщений.
Массовое подавление сообщений анализатора (baselining)
Иногда, особенно на стадии внедрения статического анализа в крупных проектах, может возникнуть необходимость 'подавить' все предупреждения анализатора на имеющуюся кодовую базу, т.к. разработчики могут не иметь необходимых ресурсов для исправления найденных анализатором ошибок в старом коде. В таком случае может быть полезно 'скрыть' все предупреждения, выданные на имеющийся код, чтобы отслеживать только вновь появляющиеся ошибки. Этого можно достичь за счёт использования механизма "массового подавления сообщений анализатора". Использование соответствующего механизма в среде Windows описано в документе "Массовое подавление сообщений анализатора", в среде Linux – в соответствующем разделе документа "Как запустить PVS-Studio в Linux".
Возможные проблемы
В редких случаях автоматически расставленные разметки могут быть поставлены не в том месте, где должны быть. И тогда анализатор вновь выдаст эти же сообщения об ошибках, так как маркер не будет найден. Это проблема препроцессора, связанная с многострочными #pragma-директивами определенного типа, из-за которых также сбивается нумерация строк. Решением проблемы является пометка сообщений, на которых заметен сбой, вручную. PVS-Studio всегда сообщает о подобных ошибках сообщением "V002. Some diagnostic messages may contain incorrect line number".
Как и с любой другой процедурой, включающей в себя массовую обработку файлов, при использовании разметки сообщений как ложных стоит помнить о потенциально возможных конфликтах доступа. Так как во время разметки файлов один из файлов может быть открыт во внешнем редакторе и там модифицирован, результат совместной работы с файлом предсказать невозможно. Поэтому мы рекомендуем либо иметь копию исходного кода, либо пользоваться системами контроля версий.
Просмотр и конвертация результатов анализа (форматы SARIF, HTML и др.)
- Поддерживаемые форматы
- Утилита PlogConverter (Windows)
- Утилита plog-converter (Linux, macOS)
- Автоматическое оповещение о предупреждениях анализатора
Результатом анализа проекта с помощью PVS-Studio может быть:
- необработанный вывод анализатора;
- Plog-отчёт;
- JSON-отчёт.
Полученные файлы можно просматривать в плагине PVS-Studio для IDE или в приложении C and C++ Compiler Monitoring UI.
Эти форматы отчёта неудобны для прямого просмотра в текстовом редакторе или рассылки по электронной почте. Поэтому в состав дистрибутива PVS-Studio входит специальная утилита, позволяющая преобразовывать результаты анализа в другие форматы.
Название утилиты преобразования отчётов зависит от платформы:
- Windows: PlogConverter.exe;
- Linux, macOS: plog-converter.
Поддерживаемые форматы
Приведём далее список форматов, поддерживаемых утилитой конвертации отчётов.
|
Формат |
Расширение |
Инструменты |
Описание |
|---|---|---|---|
|
PVS-Studio Log (Plog) |
.plog |
Visual Studio, SonarQube, Compiler Monitoring UI |
Для Windows пользователей Visual Studio и SonarQube |
|
JSON |
.json |
Visual Studio IntelliJ IDEA Rider CLion |
Для пользователей плагинов PVS-Studio в IDE и SonarQube |
|
SARIF |
.sarif |
Visual Studio, Visual Studio Code, есть визуализация в GitHub Actions |
Универсальный формат отчёта статического анализатора |
|
TaskList |
.tasks |
Qt Creator |
Для работы с отчётом в Qt Creator |
|
TaskList Verbose |
.tasks |
Qt Creator |
Расширение формата TaskList с поддержкой отображения дополнительных позиций |
|
CSV |
.csv |
Microsoft Excel LibreOffice Calc |
Для просмотра предупреждений в табличном виде |
|
Simple Html |
.html |
Email Client Browser |
Для рассылки отчётов почтой |
|
Full Html |
Folder |
Browser |
Для просмотра предупреждений с навигацией по коду в браузере |
|
Error File |
.err |
IDEs, Vim, Emacs, etc |
Для просмотра отчётов в любом редакторе, поддерживающем формат вывода компилятора |
|
Error File Verbose |
.err |
IDEs, Vim, Emacs, etc |
Расширение формата Error File с поддержкой отображения дополнительных позиций |
|
TeamCity |
.txt |
TeamCity |
Для загрузки и просмотра предупреждений в TeamCity |
|
MISRA Compliance |
.html |
Email Client Browser |
Для проверки кода на соответствие стандартам MISRA |
|
GitLab |
.json |
GitLab |
Для просмотра предупреждений в формате GitLab Code Quality |
|
DefectDojo |
.json |
DefectDojo |
Для загрузки и просмотра предупреждений в DefectDojo |
|
Markdown |
.markdown |
VS Code, GitHub |
Для просмотра предупреждений в формате таблицы Markdown |
Утилита PlogConverter (Windows)
Описание
Для преобразования отчёта PVS-Studio в один из перечисленных форматов можно воспользоваться утилитой PlogConverter, поставляемой в дистрибутиве PVS-Studio для Windows. Утилиту PlogConverter можно найти в установочной директории PVS-Studio (по умолчанию это путь C:\Program Files (x86)\PVS-Studio). Кроме этого, исходный код утилиты доступен на GitHub.
Параметры
Флаг "‑‑help" выведет основную информацию об утилите:
PlogConverter.exe –-helpДля запуска утилиты в командной строке терминала выполнить:
PlogConverter.exe [options] <path to PVS-Studio log>Параметры утилиты:
- ‑‑renderTypes (или -t): указывает форматы, в которые будет преобразован отчёт. Возможна комбинация разных форматов: для этого их нужно перечислить через запятую. Если конкретный формат не указан, то отчёт конвертируется во все форматы.
- JSON: рекомендуемый для использования формат отчёта. Поддерживается всеми плагинами PVS-Studio для IDE и утилитами. Этот формат рекомендуется, если нужно объединить несколько отчётов в один или сконвертировать Plog-отчёт в JSON-формат.
- Plog: формат отчёта для просмотра на Windows. Вместо него рекомендуется использовать более универсальный формат JSON. Формат Plog можно выбрать, если нужно объединить несколько отчётов в один или сконвертировать JSON-отчёт в Plog-формат.
- Html: формат отчёта в виде html-файла. Такой отчёт удобно использовать для автоматических рассылок на email.
- FullHtml: формат отчёта в виде html-файла. При выборе этого формата PlogConverter конвертирует сообщения анализатора и исходные файлы в html-файлы. Это позволяет просматривать отчёт анализатора в браузере с сортировкой по сообщениям и навигацией по коду. Результатом конвертации будет директория с именем 'fullhtml', которая будет находиться по пути, указанному через флаг '-o'. При этом если указан параметр '-n', то директория будет иметь заданное название и постфикс '.fullhtml';
- Txt: формат отчёта с plaintext-представлением сообщений анализатора.
- Csv: формат отчёта с разделителями. Такой отчёт удобно читать в Microsoft Excel.
- Totals: формат отчёта, содержащий суммарную информацию о количестве предупреждений разных типов (GA, OP, 64, CS, MISRA, ...) и разных уровней достоверности. Детальное описание уровней достоверности предупреждений и наборов диагностических правил приведено в разделе документации "Знакомство со статическим анализатором кода PVS-Studio".
- TaskList: формат отчёта для просмотра в Qt Creator.
- TeamCity: формат отчёта, предназначенный для загрузки и просмотра в TeamCity CI.
- Sarif: открытый формат для обмена данными между инструментами статического анализа. Более подробно о нём можно прочитать здесь.
- MisraCompliance: формат отчёта о проверке кода на соответствие стандарту MISRA.
- GitLab: формат отчёта совместимый с GitLab Code Quality.
- DefectDojo: формат отчёта, предназначенный для загрузки и просмотра в DefectDojo.
- Markdown: формат отчета в виде таблицы Markdown.
- ‑‑analyzer (или -a): производит фильтрацию предупреждений по маске. Маска фильтрации имеет вид: 'MessageType:MessageLevels'. 'MessageType' может принимать один из следующих типов: GA, OP, 64, CS, MISRA, Fail, OWASP, AUTOSAR. 'MessageLevels' может принимать значения от 1 до 3.
- ‑‑excludedCodes (или -d): задает список предупреждений (через ","), которые нужно исключить из результирующего отчёта. Например:
-d V595,V730. - ‑‑includePaths (или -i): позволяет включить в отчет предупреждения, выданные только в определенных файлах. Через этот параметр вы можете передать список путей (абсолютных или относительных) или wildcard-масок. В качестве разделителя используется символ ';'. Обратите внимание, что фильтрация путей возможно только для отчетов, не содержащих SourceTreeRoot-маркер.
- ‑‑excludePaths (или -e): позволяет исключить все предупреждения, выданные в определенных файлах. Через этот параметр вы можете передать список путей (абсолютных или относительных) или wildcard-масок. В качестве разделителя используется символ ';'. Обратите внимание, что исключение путей возможно только для отчетов, не содержащих SourceTreeRoot-маркер.
- ‑‑settings (или -s): задаёт путь к файлу настроек PVS-Studio. Он содержит различные настройки для анализатора. PlogConverter прочитает из переданного файла параметр 'DisableDetectableErrors' и исключит предупреждения указанных диагностик из отчёта.
- ‑‑srcRoot (или -r): задаёт замену "SourceTreeRoot" маркера. Если при проверке путь до корневого каталога проекта был заменен на "SourceTreeRoot" маркер (|?|), то этот параметр становится обязательным (иначе файлы проекта не будут найдены).
- ‑‑outputDir (или -o): задаёт директорию, куда будут сохранены сконвертированные отчёты. Если параметр не задан, то файлы записываются в директорию запуска.
- ‑‑outputNameTemplate (или -n): задаёт шаблонное имя файла без расширения. Все сконвертированные отчёты будут иметь одно и то же имя, но разные расширения.
- ‑‑errorCodeMapping (или -m): позволяет включить отображение CWE ID и/или SAST ID для найденных предупреждений: "-m cwe,misra,autosar,owasp". Если указано значение 'cwe', то для предупреждений в отчёте будет указано CWE ID. Если указано 'misra', 'autosar' или 'owasp', то для правил соответствующего стандарта будет включено отображение SAST ID.
- ‑‑indicateWarnings (или -w): устанавливает возвращаемый код утилиты PlogConverter, равный '2', если после фильтрации лога остались предупреждения.
- ‑‑pathTransformationMode (или -R): устанавливает режим преобразования путей при конвертации отчёта. Опция требует "‑‑srcRoot". Опция работает только для тех форматов, которые поддерживают относительные пути: JSON, Plog. Допустимые значения:
- toAbsolute – пути преобразуются в абсолютные;
- toRelative – пути преобразуются в относительные.
- ‑‑misraDeviations: правила MISRA, для которых не будут учитываться нарушения. Правила отделяются друг от друга символом ";". Если все найденные анализатором нарушения MISRA указаны в опции ‑‑misraDeviations, то в итоговом отчёте проект будет считаться удовлетворяющим стандарту MISRA.
- ‑‑grp: путь до текстового файла Guideline Re-categorization Plan. Эту опцию следует использовать только при генерации отчёта MISRA Compliance. Guideline Re-categorization Plan — это файл, в котором указаны изменения категорий для правил MISRA. Подробнее о том, что такое категория правила MISRA, можно прочитать здесь.
- ‑‑noHelpMessages: исключить из предупреждений анализатора ссылки на документацию диагностических правил.
- ‑‑keepFalseAlarms (или -f): сохранить в отчете предупреждения, отмеченные как ложные.
- ‑‑countWarnings (или -с): позволяет отобразить количества сообщений, соответствующее аргументам данной команды. Формат команды -c {Группы или Коды диагностик}:{Уровни };{Другие аргументы }... Пример команд: -c GA:1,2;OP:1 | -c V003 | -c V502,V504:1 | -c ALL.
- ‑‑generateDiffWith (или -D): генерирует отчёт с различиями между отчётом указанном в данной опции и входным отчётом.
- ‑‑filterSecurityRelatedIssues: оставляет в результирующем отчёте только сообщения, имеющие маркировку по ГОСТ Р 71207-2024.
- ‑‑csvSeparator: задаёт разделитель столбцов для CSV файлов.
Коды возврата
Утилита PlogConverter имеет несколько ненулевых кодов возврата, которые не означают проблемы в работе самой утилиты. Если утилита вернула не '0', это ещё не значит, что она отработала с ошибкой.
Описание кодов возврата PlogConverter:
- '0' — конвертация отчёта прошла успешно;
- '1' — при генерации одного из выходных файлов возникла ошибка;
- '2' — выходной отчёт содержит неотфильтрованные или неподавленные предупреждения. Чтобы этот режим работал, утилите нужно передать флаг ‑‑indicateWarnings (-w);
- '3' — общая (неспецифичная) ошибка при работе утилиты, перехваченное исключение при работе. Обычно это сигнализирует о наличии ошибки в коде самого PlogConverter;
- '4' — утилите были переданы неверные аргументы командной строки или один из файлов, переданный как аргумент, не был найден.
- '5' — ошибка при попытке заменить абсолютные пути на относительные в формате отчёта, который это не поддерживает.
Пример команды конвертации
PlogConverter.exe -t Json,Csv -a GA:1,2;OWASP:1 -o D:\Logs -r
D:\projects\projectName -m CWE,OWASP -n PVS-Log PVS-Studio.logВ данном примере происходит следующее:
- лог с названием 'PVS-Studio.log' конвертируется в форматы JSON и CSV;
- в итоговый отчёт попадут только предупреждения 1-го и 2-го уровней диагностик общего назначения, а также предупреждения 1-го уровня диагностик OWASP;
- маркер '|?|' в путях до файлов с ошибками будет заменён на 'D:\projects\projectName';
- предупреждения анализатора будут содержать CWE_ID и SAST_ID;
- сконвертированные отчёты будут находиться в директории 'D:\Logs' и называться 'PVS-Log.json' и 'PVS-Log.csv'.
Утилита plog-converter (Linux, macOS)
Описание
Для преобразования отчёта PVS-Studio в один из перечисленных форматов можно воспользоваться утилитой plog-converter, поставляемой вместе с пакетами и архивами PVS-Studio С/C++ для Linux и macOS. После установки пакета или из архива PVS-Studio C/C++ вы сможете использовать утилиту plog-converter для конвертации отчётов анализатора в различные форматы (*.xml, *.tasks и т.п.). Кроме этого, исходный код утилиты доступен на GitHub.
Параметры
Флаг "‑‑help" выведет основную информацию об утилите:
plog-converter --helpДля запуска утилиты в командной строке терминала выполнить:
plog-converter [options] <path to PVS-Studio log>Все опции могут быть указаны в произвольном порядке.
Доступные опции:
- ‑‑renderTypes (или -t): задает возможные варианты конвертации отчёта. Это обязательный аргумент запуска утилиты. Возможна комбинация разных форматов перечислением через повторение ‑‑renderTypes (-t) перед каждым форматом или через запятую в качестве аргумента флага:
- json: рекомендуемый для использования формат отчёта. Поддерживается всеми плагинами PVS-Studio для IDE и утилитами. Этот формат рекомендуется, если нужно объединить несколько отчётов в один или сконвертировать Plog-отчёт в JSON-формат;
- html: формат отчёта в виде HTML-файла. Такой отчёт удобно использовать для автоматических рассылок на email;
- fullhtml: формат отчёта в виде HTML-файла. При выборе этого формата plog-converter конвертирует сообщения анализатора и исходные файлы в html-файлы. Это позволяет просматривать отчёт анализатора в браузере с сортировкой по сообщениям и навигацией по коду. При передаче этого значения нужно обязательно передать аргумент ‑‑output (-o). Результатом конвертации будет директория по пути, указанному через флаг '-o'. При этом если указан параметр '-n', либо указано два или более форматов отчета, то результирующая директория будет иметь постфикс '.fullhtml';
- errorfile: формат вывода GCC и Clang;
- errorfile-verbose: расширенный формат вывода 'errorfile' с поддержкой отображения дополнительных позиций (при их наличии);
- csv: формат отчёта с разделителями. Такой отчёт удобно читать в Microsoft Excel;
- tasklist: формат отчёта для просмотра в Qt Creator;
- tasklist-verbose: расширенный формат вывода 'tasklist' с поддержкой отображения дополнительных позиций (при их наличии);
- teamcity: формат отчёта, предназначенный для загрузки и просмотра в TeamCity CI;
- sarif: открытый формат для обмена данными между инструментами статического анализа. Более подробно можно прочитать здесь;
- totals: формат отчёта, содержащий суммарную информацию о количестве предупреждений разных типов (GA, OP, 64, CS, MISRA, ...) и разных уровней достоверности. Детальное описание уровней достоверности предупреждений и наборов диагностических правил приведено в разделе документации "Знакомство со статическим анализатором кода PVS-Studio";
- misra-compliance: формат отчёта о проверке кода на соответствие стандарту MISRA. При передаче этого значения нужно обязательно передать аргумент ‑‑output (-o);
- gitlab: формат отчёта совместимый с GitLab Code Quality;
- defectdojo: формат отчёта, предназначенный для загрузки и просмотра в DefectDojo.
- ‑‑analyzer (или -a): производит фильтрацию предупреждений согласно маске. Маска фильтрации имеет следующий вид: 'MessageType:MessageLevels'. 'MessageType' может принимать один из следующих типов: GA, OP, 64, CS, MISRA, Fail, OWASP. 'MessageLevels' может принимать значения от 1 до 3. Возможна комбинация разных масок через ";" (без пробелов). По умолчанию в созданном отчёте останутся только предупреждения General Analysis 1 и 2 уровня. Значение по умолчанию: GA:1,2
- ‑‑output (или -o): путь к файлу или директории, куда будет осуществляться вывод. Если флаг не указан, то вывод будет осуществляться в стандартный поток вывода. При этом:
- Если указано два или более формата отчета, этот параметр интерпретируется как путь до результирующей директории, в которой будут находиться все сгенерированные отчеты. При генерации к каждому файлу добавится расширение, соответствующее формату.
- Если указан один формат отчета, то результатом будет либо файл, либо директория, в зависимости от формата.
- ‑‑stdout: позволяет дублировать текст отчета в стандартный поток вывода, если указан флаг ‑‑output.
- ‑‑settings (или -s): путь к файлу конфигурации. Файл аналогичен файлу конфигурации анализатора PVS-Studio.cfg. Из этого файла используется информация об исключённых директориях (exclude-path).
- ‑‑srcRoot (или -r): задает замену "SourceTreeRoot" маркера. Если при проверке путь до корневого каталога проекта был заменён на "SourceTreeRoot" маркер (|?|), то этот параметр становится обязательным (иначе файлы проекта не будут найдены).
- ‑‑excludedCodes (или -d): список исключённых диагностик, разделённых запятыми: "-d V595,V730".
- ‑‑errorCodeMapping (или -m): включить отображение CWE ID и/или SAST ID для найденных предупреждений: "-m cwe -m misra -m autosar -m owasp". Если указано значение 'cwe', то для предупреждений в отчёте будет указано CWE ID. Если указано 'misra', 'autosar' или 'owasp', то для правил соответствующего стандарта будет включено отображение SAST ID.
- ‑‑includePaths (или -I): включить в отчёт только предупреждения, выданные в указанных файлах. Через этот параметр вы можете передать путь (абсолютный или относительный) или шаблон glob. Если путей несколько, то передайте каждый их них через этот параметр. Обратите внимание, что фильтрация путей возможно только для отчетов, не содержащих SourceTreeRoot-маркер.
- ‑‑excludePaths (или -E): позволяет исключить все предупреждения, выданные в определенных файлах. Через этот параметр вы можете передать путь (абсолютный или относительный) или шаблон glob. Если путей несколько, то передайте каждый их них через этот параметр. Обратите внимание, что исключение путей возможно только для отчетов, не содержащих SourceTreeRoot-маркер.
- ‑‑cerr (или -e): использовать stderr вместо stdout.
- ‑‑grp: путь к текстовому файлу Guideline Re-categorization Plan. Используется только при генерации отчёта в формате MISRA Compliance. Guideline Re-categorization Plan — это файл, в котором указаны изменения категорий для правил MISRA. Подробнее о том, что такое категория правила MISRA, можно прочитать здесь.
- ‑‑indicateWarnings (или -w): устанавливает возвращаемый код утилиты plog-converter, равный '2', если после фильтрации лога в отфильтрованном выходном файле (файлах) остались предупреждения.
- ‑‑pathTransformationMode (или -R): устанавливает режим преобразования путей при конвертации отчёта. Опция требует "‑‑srcRoot". Опция работает только для тех форматов, которые поддерживают относительные пути: json. Допустимые значения:
- toAbsolute – пути преобразуются в абсолютные;
- toRelative – пути преобразуются в относительные.
- ‑‑misraDeviations: позволяет указать нарушения MISRA. Нужно перечислить через ";" правила MISRA, для которых не будут учитываться нарушения. Если все найденные анализатором нарушения MISRA указаны в опции ‑‑misraDeviations, то в итоговом отчёте проект будет считаться удовлетворяющим стандарту MISRA.
- ‑‑noHelpMessages: исключить из предупреждений анализатора ссылки на документацию диагностических правил.
- ‑‑name (или -n): шаблонное имя для результирующих отчетов. Используется для генерации двух и более форматов отчета – во время работы к шаблонному имени будет добавлено соответствующее расширение. По умолчанию при генерации нескольких отчетов используется имя входного отчета без расширения. При этом если входных отчетов несколько, то имя будет 'MergedReport'.
- ‑‑keepFalseAlarms: сохранить в отчете предупреждения, отмеченные как ложные.
- ‑‑filterSecurityRelatedIssues: оставляет в результирующем отчёте только сообщения, имеющие маркировку по ГОСТ Р 71207-2024.
Коды возврата
Описание кодов возврата plog-converter:
- '0' — конвертация отчёта прошла успешно;
- '1' — общая (неспецифичная) ошибка при работе утилиты, перехваченное исключение при работе. Обычно это сигнализирует о наличии ошибки в коде 'plog-converter'а;
- '2' — выходной отчёт содержит неотфильтрованные или неподавленные предупреждения. Чтобы этот режим работал, утилите нужно передать флаг ‑‑indicate-warnings (-w).
- '5' — ошибка при попытке заменить абсолютные пути на относительные в формате отчёта, который это не поддерживает.
Пример команды конвертации
plog-converter -t json -t csv -a 'GA:1,2;OWASP:1' -o /home/user/Logs
-r /home/user/projects/projectName -m cwe -m owasp -n PVS-Log PVS-Studio.logВ данном примере происходит следующее:
- лог с названием 'PVS-Studio.log' конвертируется в форматы JSON и CSV;
- в итоговый отчёт попадут только предупреждения 1-го и 2-го уровней диагностик общего назначения, а также предупреждения 1-го уровня диагностик OWASP;
- в путях до файлов с ошибками маркер '|?|' будет заменён на '/home/user/projects/projectName';
- предупреждения анализатора будут содержать CWE_ID и SAST_ID;
- сконвертированные отчёты будут находиться в папке '/home/user/Logs' и называться 'PVS-Log.json' и 'PVS-Log.csv'.
Автоматическое оповещение о предупреждениях анализатора
В составе дистрибутива PVS-Studio поставляется утилита BlameNotifier. Она позволяет оповещать разработчиков, заложивших в репозиторий код, на который анализатор выдал предупреждения. Также возможна настройка оповещения обо всех обнаруженных предупреждениях определённого круга лиц. Это может быть полезно менеджерам и руководителям команд.
Более подробно данная утилита описана в соответствующем разделе документации: "Оповещение команд разработчиков (утилита blame-notifier)".
Использование относительных путей в файлах отчётов PVS-Studio
По умолчанию, при генерации диагностических сообщений, PVS-Studio выдаёт абсолютные, полные пути до файлов, в которых анализатор нашёл ошибки. Поэтому при сохранении отчёта именно эти полные пути и попадут в результирующий файл (XML plog файл). В дальнейшем это может вызывать неудобства, например, при необходимости работы с таким файлом отчёта на машине, отличной от той, на которой отчёт был сгенерирован. Ведь пути до файлов с исходным кодом на двух машинах могут и различаться. А это приведёт к невозможности открывать файлы и использовать встроенный механизм навигации по коду в таком лог-файле.
Хотя решить данную проблему можно и ручной правкой путей в XML отчёте, гораздо удобнее сразу получать от анализатора сообщения с путями, записанными относительно какой-нибудь фиксированной директории (например, корневой директории дерева исходников проекта). Такой порядок работы позволяет получить файл отчёта с корректными путями и на любой другой машине путём простой замены "корня", относительно которого раскрываются все пути в файле отчёта PVS-Studio. PVS-Studio может автоматически производить такую генерацию относительных путей и подмену их "корня" с помощью настройки 'SourceTreeRoot' на странице "PVS-Studio -> Options -> Specific Analyzer Settings".
Приведём пример использования данного режима работы. По умолчанию поле настроек 'SourceTreeRoot' пусто, а анализатор всегда генерирует полные пути в выдаваемых диагностических сообщениях. Предположим, что проверяемый проект расположен в директории "C:\MyProjects\Project1". В нашем примере в качестве "корня" дерева исходников проекта можно взять путь "C:\MyProjects\", запишем этот путь в поле 'SourceTreeRoot' и запустим анализ.
По завершению анализа PVS-Studio автоматически заменит заданную нами корневую директорию исходников на специальный маркер, т.е. в сообщении на файл "C:\MyProjects\Project1\main.cpp", путь до данного файла будет передан, как "|?|Project1\main.cpp." Сообщения же на файлы, лежащие вне заданной корневой директории, затронуты не будут. Т.е. сообщение на файл из директории "C:\MyCommonLib\lib1.cpp" будет содержать абсолютный, полный путь до данного файла.
В дальнейшем, при работе с таким фалом отчёта через IDE плагин PVS-Studio, маркер |?| будет автоматически заменяться на значение настройки 'SourceTreeRoot', например, при использовании False Alarm разметки или навигации по сообщениям. Если же будет необходимо работать с данным файлом отчёта на другой машине, достаточно лишь указать в настройках IDE плагина новый путь до корня дерева исходников, например, "C:\Users\User\Projects\", и плагин будет автоматически осуществлять корректное раскрытие полных путей.
Данный режим можно также использовать и в Independent режиме анализатора, при прямой его интеграции в сборочную систему (make, msbuild и т.п.). Это позволяет распределить процесс полного анализа исходников и дальнейшую работу с результатами анализа, что может быть особенно полезно на крупном проекте. Например, проект может быть полностью проверен один раз на сборочном сервере, а с результатами проверки уже может работать сразу несколько разработчиков на своих локальных машинах.
Вы также можете использовать настройку 'UseSolutionDirAsSourceTreeRoot', представленную на той же странице. Данная настройка включает или выключает режим использования пути до папки, содержащей файл решения *.sln, в качестве параметра 'SourceTreeRoot'. При включении этого режима (True) в поле 'SourceTreeRoot' будет отображено значение '<Using solution path>'. При этом фактическое значение параметра 'SourceTreeRoot', сохраненное в файле настроек, не меняется. При выключении настройки 'UseSolutionDirAsSourceTreeRoot' (False) это значение (если ранее оно было задано) будет вновь отображено в поле 'SourceTreeRoot'. Таким образом, настройка 'UseSolutionDirAsSourceTreeRoot' просто меняет механизм генерации пути до файла, позволяя использовать в качестве параметра 'SourceTreeRoot' либо указанное пользователем значение, либо путь до папки, содержащей файл решения.
С версии PVS-Studio 7.27 вы можете указать параметр '//V_SOLUTION_DIR_AS_SOURCE_TREE_ROOT' в файле конфигурации диагностик (.pvsconfig). Данный параметр копирует поведение настройки 'UseSolutionDirAsSourceTreeRoot'. Приоритет этого параметра выше, чем настройки из Settings.xml.
Просмотр результатов анализа в приложении C and C++ Compiler Monitoring UI
- Введение
- Анализ исходных файлов с помощью отслеживания запуска компиляторов
- Инкрементальный анализ при использовании системы мониторинга компиляции
- Работа со списком диагностических сообщений
- Навигация и поиск в исходном коде
Введение
PVS-Studio можно использовать независимо от интегрированной среды разработки Visual Studio. Ядро анализатора представляет собой command-line утилиту, позволяющую проверять C/C++ файлы, компилируемые с помощью Visual C++, GCC или Clang. Поэтому мы разработали отдельное приложение, которое представляет оболочку для command-line утилиты и помогает работать с полученным логом сообщений.
PVS-Studio предоставляет удобное расширение среды Visual Studio, позволяющее "в один клик" проверять vcproj/vcxproj-проекты этой IDE. Однако существуют и другие сборочные системы, которые желательно поддержать. Хотя ядро PVS-Studio не зависит от конкретного формата, используемого той или иной сборочной системой (как например MSBuild, GNU Make, NMake, CMake, ninja и т.п.), для интеграции статического анализа PVS-Studio в систему сборки, отличную от поддерживаемых средой Visual Studio проектов VCBuild/MSBuild, от пользователя потребуется самостоятельно выполнить ряд действий. Перечислим их:
- Во-первых, потребуется встроить вызов анализатора PVS-Studio.exe непосредственно в сборочный сценарий (при его наличии) конкретной системы. Либо потребуется модифицировать саму сборочную систему. Более подробно про это можно почитать в данном разделе документации. Сразу заметим, что такой сценарий использования может оказаться не всегда удобным, или даже невозможным, т.к. пользователь статического анализатора не всегда имеет возможность модифицировать сборочный сценарий проекта, с которым он работает.
- После непосредственной интеграции в сборочный процесс статического анализа PVS-Studio, у пользователя возникает необходимость как-то изучать результаты работы анализатора. Это, в свою очередь, может потребовать создания специальной утилиты для преобразования отчета анализатора в формат, удобный для пользователя. Стоит отметить, что при наличии среды Visual Studio, отчёт ядра анализатора PVS-Studio.exe всегда можно просмотреть с помощью плагина-расширения PVS-Studio для данной среды.
- Наконец, в случае, когда анализатор находит в коде реальные ошибки, возникает необходимость исправить их в исходных файлах проверяемого проекта.
Для решения этих проблем можно воспользоваться инструментом C and C++ Compiler Monitoring UI (Standalone.exe).
Рисунок 1 - Compiler Monitoring UI
Compiler Monitoring UI предоставляет возможности для "бесшовной" проверки кода, независимо от используемых компилятора или сборочной системы, а затем позволяет работать с результатами анализа, предоставляя пользовательский интерфейс, схожий с Visual Studio плагином PVS-Studio. Также Compiler Monitoring UI позволяет работать и с отчётом анализатора, полученным с помощью прямой его интеграции в сборочную систему, при отсутствии у пользователя среды Visual Studio. Рассмотрим далее эти возможности.
Анализ исходных файлов с помощью отслеживания запуска компиляторов
Compiler Monitoring UI предоставляет пользовательский интерфейс для системы отслеживания компиляции. Сама система отслеживания (консольная утилита CLMonitor.exe) может использоваться и независимо от Compiler Monitoring UI, например, для интеграции статического анализа в систему автоматизированной сборки. Подробнее об использовании системы отслеживания компилятора можно почитать в этом разделе документации.
Для запуска отслеживания откройте диалог через Tools -> Analyze Your Files... (рисунок 2):

Рисунок 2 - Диалог запуска мониторинга сборки
Нажмите "Start Monitoring". После этого будет запущен CLMonitor.exe, а основное окно среды будет свёрнуто.
Выполните сборку, а по её завершении нажмите на кнопку "Stop Monitoring" в окне в правом нижнем углу экрана (рисунок 3):

Рисунок 3 - Диалог управления мониторингом
Если серверу мониторинга удалось отследить запуски компиляторов, будет запущен статический анализ исходных файлов. По окончании вы получите обычный отчёт о работе PVS-Studio (рисунок 4):
Рисунок 4 - Результаты работы сервера мониторинга и статического анализатора
Результаты работы могут быть сохранены в виде XML файла (файла с расширением plog) для дальнейшего использования с помощью команды меню File -> Save PVS-Studio Log As...
Инкрементальный анализ при использовании системы мониторинга компиляции
Способ проведения инкрементального анализа аналогичен тому, как проводится анализ всего проекта. Ключевое отличие состоит в необходимости выполнения не полной, а инкрементальной сборки. В таком случае будут отслежены запуски компиляторов для модифицированных файлов, что позволит проверить только их. В остальном процесс анализа полностью идентичен тому, что описан выше, в разделе "Анализ исходных файлов с помощью отслеживания запуска компиляторов".
Работа со списком диагностических сообщений
После того, как был получен отчёт с предупреждениями анализатора, можно сразу начать просматривать сообщения и править код. Также в Compiler Monitoring UI можно загрузить и отчёт, полученный ранее. Для этого нужно воспользоваться пунктом меню 'File|Open PVS-Studio Log...'.
Различные механизмы подавления и фильтрации сообщений идентичны плагину Visual Studio и доступны в окне настроек 'Tools|Options...' (рисунок 5).

Рисунок 5 - Настройки анализа и механизмы фильтрации сообщений
С помощью окна Analyzer Output можно осуществлять навигацию по предупреждениям анализатора, размечать сообщения как ложные срабатывания и добавлять фильтры для сообщений. Интерфейс для работы с предупреждениями анализатора в Compiler Monitoring UI идентичен интерфейсу окна вывода в плагине для Visual Studio. С подробным описанием окна вывода сообщений можно ознакомиться в данном разделе документации.
Если Вы только начали изучать инструмент статического анализа и хотели бы узнать на что он способен, то можете воспользоваться механизмом Best Warnings. Данный механизм покажет вам наиболее важные и достоверные предупреждения.
Чтобы посмотреть наиболее интересные предупреждения с точки зрения анализатора, нажмите на кнопку 'Best', как показано на скриншоте ниже:

После чего в таблице с результатами анализа останутся максимум десять наиболее критичных предупреждений анализатора.
Навигация и поиск в исходном коде
Хотя встроенный редактор Compiler Monitoring UI не имеет такой же мощной и удобной системы навигации и автодополнения, как Microsoft IntelliSense в среде Visual Studio или им подобным, Compiler Monitoring UI предоставляет несколько механизмов поиска, которые могут упростить работу с результатами анализа.
Помимо обычного поиска в открытом файле (Ctrl + F), Compiler Monitoring UI имеет также диалог Code Search для текстового поиска в открытых файлах и директориях файловой системы. Этот диалог доступен через пункт меню 'Edit|Find & Replace|Search in Source Files...' (Рисунок 6):

Рисунок 6 - Диалог поиска Compiler Monitoring UI
Диалог поддерживает поиск в текущем файле, всех открытых файлах, либо в произвольной директории файловой системы. Поиск можно в любой момент остановить, нажав Cancel в появившемся модальном окне. Результаты, при появлении первого совпадения, сразу начнут отображаться в дочернем окне Code Search Results (рисунок 7):
Рисунок 7 - Результаты текстового поиска в исходных файлах проекта
Конечно, при необходимости найти места объявления и\или использования какого-либо идентификатора или макроса, обычный текстовый поиск может оказаться чересчур громоздким или долгим. В этом случае вы можете воспользоваться механизмом поиска по зависимостям и навигации по #include макросам.
Поиск по зависимостям в файлах позволяет искать символ\макрос именно в тех файлах, которые непосредственно участвовали при компиляции, а точнее, при последующем препроцессировании файлов, при их проверке анализатором. Для запуска поиска по зависимостям, откройте контекстное меню на символе, использование которого вы хотите посмотреть (рисунок 8):
Рисунок 8 - Поиск символа по зависимостям
Результаты поиска, по аналогии с текстовым поиском, начнут выдаваться в отдельном дочернем окне Find Symbol Results. Поиск можно в любой момент остановить, нажав на Cancel в status bar'е главного окна Compiler Monitoring UI рядом с индикатором прогресса.
Навигация по #include макросам позволяет открывать в редакторе кода Compiler Monitoring UI файл, добавленный в текущий файл через такой макрос. Для открытия include'а также нужно воспользоваться контекстным меню редактора (рисунок 9):
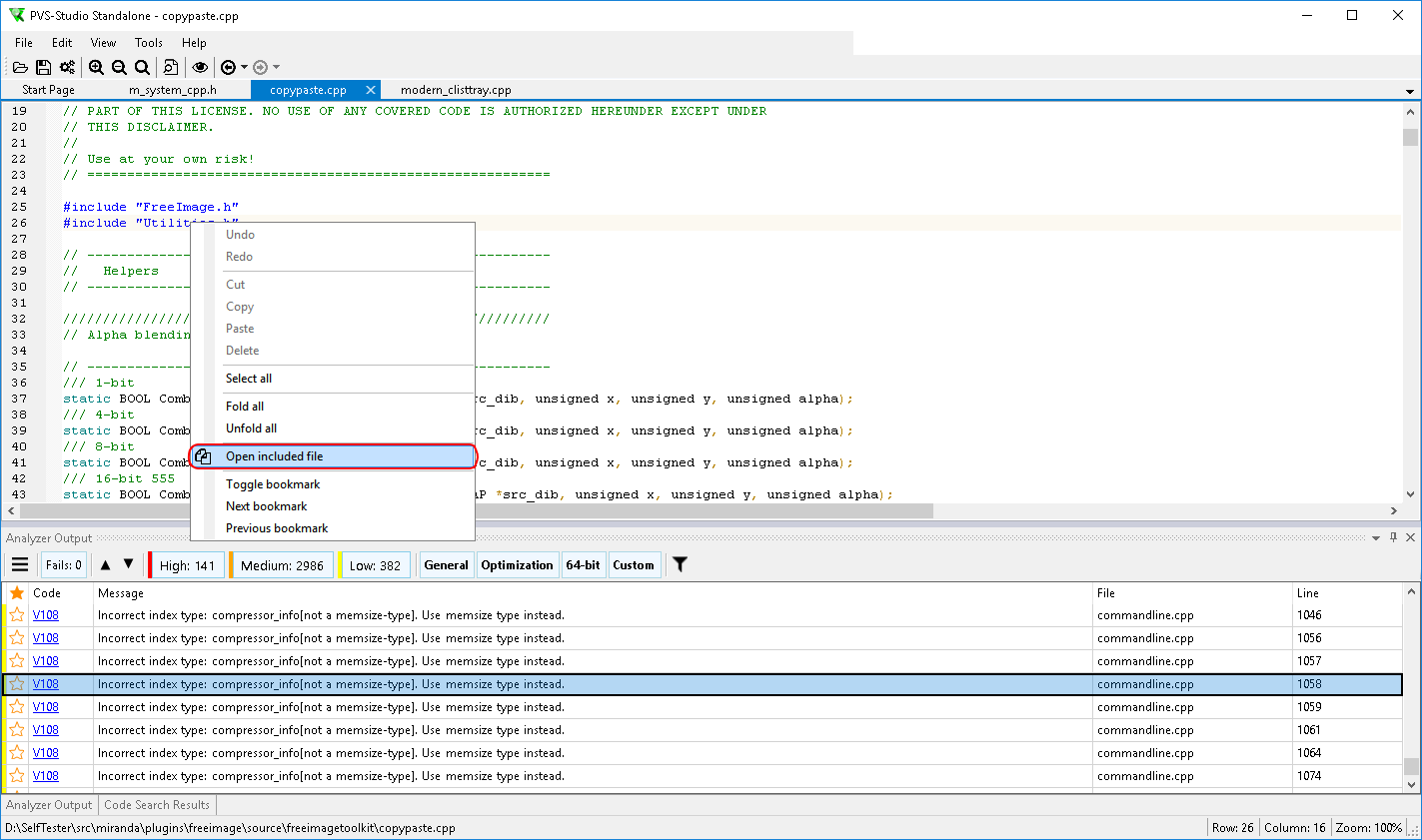
Рисунок 9 - Навигация по include'ам
Стоит помнить, что информация о зависимостях доступна не для любого исходного файла, открытого в Compiler Monitoring UI. В ситуации, когда база зависимостей недоступна для Compiler Monitoring UI, описанные выше пункты контекстного меню доступны также не будут.
База зависимостей создаётся только тогда, когда анализ запущен непосредственно из самого Compiler Monitoring UI. При открытии произвольного C/C++ исходника такой информации у Compiler Monitoring UI не будет. Заметим, что при сохранении результата работы анализатора в виде plog файла, в случае если этот результат был получен в самом приложении Compiler Monitoring UI, рядом с plog файлом будет создан также соответствующий ему специальный dpn файл, содержащий зависимости проверенных файлов. Наличие dpn файла рядом с plog файлом отчёта сделает возможным поиск по зависимостям, если такой plog файл будет открыт в Compiler Monitoring UI.
Фильтрация и обработка вывода анализатора при помощи файлов конфигурации диагностик (.pvsconfig)
- Добавление/использование файлов конфигурации в IDE и других инструментах анализа
- Использование .pvsconfig в Visual Studio
- Использование .pvsconfig файла в CLion
- Использование .pvsconfig файла в Rider
- Использование .pvsconfig в PVS-Studio_Cmd.exe и pvs-studio-dotnet
- Использование .pvsconfig в CLMonitor.exe
- Использование .pvsconfig в CompilerCommandsAnalyzer.exe
- Использование .pvsconfig в Standalone.exe
- Использование глобального файла .pvsconfig
- Общий функционал файлов конфигурации
- Добавление записей в файл конфигурации
- Фильтрация срабатываний анализатора
- Исключение файлов из анализа
- Исключение проектов из анализа
- Игнорирование файлов конфигурации
- Изоляция настроек для каталогов
- Игнорирование глобальных файлов конфигурации
- Указание timeout-а анализа файлов для проекта/solution/системы
- Изменение уровня срабатываний диагностики
- Изменения текста сообщений анализатора
- Управление синхронизацией suppress файлов
- Выбор версии PVS-Studio для анализа
- Приоритезация файлов конфигурации
- Выполнение команд из CustomBuild task перед анализом
- Подавление ошибок парсинга
- Игнорирование настроек анализа из Settings.xml
- Использование каталога решения в качестве значения SourceTreeRoot
- Использование каталога решения для построения относительных путей в кэше зависимостей компиляции
- Управление сортировкой suppress файлов
- Секции настроек в .pvsconfig
- Обнаружение начальной позиции сдвига строк (для V002)
- Управление кэшем зависимостей компиляции
- Режим отслеживания исходных файлов в кэше зависимостей
Файл конфигурации служит для отображения и фильтрации сообщений анализатора. Также в нём можно задать дополнительные настройки анализа. Использование данных файлов возможно только для проектов, написанных на C, C++ или C#.
Файлы конфигурации поддерживаются плагинами для следующих IDE:
- Visual Studio;
- Rider.
Утилиты, поддерживающие файлы конфигурации:
PVS-Studio_Cmd.exe;CLMonitor.exe(только в режимеanalyzeилиanalyzeFromDump);- C and C++ Compiler Monitoring UI (
Standalone.exe); CompileCommandsAnalyzer.exe(в режимеanalyze).
Добавление/использование файлов конфигурации в IDE и других инструментах анализа
Использование .pvsconfig в Visual Studio
Для использования файла конфигурации в Visual Studio необходимо добавить его на уровне проекта или решения. Для этого выделите интересующий проект или решение в окне Solution Explorer среды Visual Studio. Выберите пункт контекстного меню Add New Item... . В появившемся окне выберите тип файла PVS-Studio Filters File.

Если шаблона нет, то вы можете просто добавить в проект или решение обычный текстовый файл с расширением .pvsconfig.
Для каждого проекта/решения можно добавить несколько файлов конфигурации.
Файлы конфигурации, добавленные на уровне проекта, действуют на все файлы данного проекта. Файлы конфигурации, добавленные на уровне решения, будут действовать на все файлы всех проектов в этом решении.
Использование .pvsconfig файла в CLion
Специального шаблона для добавления файла конфигурации для CLion нет.
Добавить файл конфигурации для CLion можно только на уровне проекта. Чтобы использовать его в CLion, добавьте в папку .PVS-Studio новый файл с расширением .pvsconfig через контекстное меню New > File.

Использование .pvsconfig файла в Rider
Специального шаблона для добавления файла конфигурации для Rider нет.
Добавить файл конфигурации для Rider можно только на уровне проекта. Чтобы использовать файл конфигурации диагностик в Rider, добавьте в проект новый файл с расширением .pvsconfig через Solution Explorer.

Использование .pvsconfig в PVS-Studio_Cmd.exe и pvs-studio-dotnet
При анализе через PVS-Studio_Cmd.exe или pvs-studio-dotnet автоматически используются файлы конфигурации из анализируемого проекта или решения. Также можно передать путь к дополнительному файлу .pvsconfig с помощью параметра ‑‑rulesConfig (-C):
PVS-Studio_Cmd.exe -t ProjName.sln -C \path\to\.pvsconfig
pvs-studio-dotnet -t ProjName.sln -C /path/to/.pvsconfigВ этом случае при анализе учитываются настройки и из файлов в проекте/решении, и из файла, переданного в качестве аргумента.
Использование .pvsconfig в CLMonitor.exe
Путь к файлу конфигурации необходимо передать в качестве аргумента командной строки (параметр -c):
CLMonitor.exe analyzeFromDump -d /path/to/compileDump.gz -c /path/to/.pvsconfigИспользование .pvsconfig в CompilerCommandsAnalyzer.exe
Если вы используете утилиту CompilerCommandsAnalyzer.exe, то можете передать путь до .pvsconfig файла через параметр -R:
CompilerCommandsAnalyzer.exe analyze ... -R /path/to/.pvsconfigИспользование .pvsconfig в Standalone.exe
В Standalone.exe вы можете указать путь к файлу при запуске мониторинга.

Использование глобального файла .pvsconfig
Глобальный файл конфигурации диагностик используется при проверке всех проектов. Таких файлов конфигурации .pvsconfig может быть несколько, и все они будут использованы инструментами PVS-Studio.
Для добавления глобального файла конфигурации создайте файл с расширением .pvsconfig в папке:
- Для Windows:
%APPDATA%\PVS-Studio; - Для Linux и macOS:
~/.config/PVS-Studio.
Общий функционал файлов конфигурации
Добавление записей в файл конфигурации
Задание настроек в файлах конфигурации производится при помощи специальных директив, начинающихся с символов //. Каждая директива пишется с новой строки.
Пример:
//-V::122
//-V::123Также существует возможность добавлять комментарии. Для этого необходимо написать символ # в начало строки.
Пример:
# I am a commentФильтрация срабатываний анализатора
Отключение отдельных диагностик
Для полного отключения определённой диагностики используется запись:
//-V::numbernumber — номер диагностики, которую нужно выключить (например, 3022).
Пример использования:
//-V::3022В данном случае будут игнорироваться срабатывания диагностики V3022.
Для отключения нескольких диагностик перечислите номера через запятую:
//-V::number1,number2,...,numberNПример:
//-V::3022,3080При использовании этой директивы будут полностью отключены диагностики V3022 и V3080.
Отключение диагностик из определённых категорий
Для отключения диагностик некоторой категории используются следующие директивы:
//-V::GA
//-V::X64
//-V::OP
//-V::CS
//-V::MISRA
//-V::OWASPПояснение для каждой из категорий:
- GA (General Analysis) — диагностики общего плана. Основной набор диагностических правил PVS-Studio;
- OP (Optimization) — диагностики оптимизации. Указания по повышению эффективности;
- X64 (64-bit) — диагностики, позволяющие выявлять специфические ошибки, связанные с разработкой 64-битных приложений, а также переносом кода с 32-битной на 64-битную платформу;
- CS (Customers' Specific) — узкоспециализированные диагностики, разработанные по просьбам пользователей. По умолчанию этот набор диагностик отключен;
- MISRA — диагностики, разработанные в соответствии со стандартом MISRA (Motor Industry Software Reliability Association). По умолчанию этот набор диагностик отключен;
- OWASP — диагностики, направленные на поиск проблем с безопасностью и проверяющие соответствие кода стандарту OWASP ASVS. По умолчанию отключено.
Можно комбинировать фильтры категорий, перечисляя их через запятую.
Пример комбинации:
//-V::GA,MISRAОтключение всех C++ или C# диагностик
Для отключения всех диагностик C++ или C# анализатора используются директивы:
//-V::C++
//-V::C#Исключение предупреждений определённого уровня
Если требуется исключить срабатывания определённого уровня, используйте запись вида:
//-V::number1,number2,...,numberN:levelnumber1,number2и т.д. — номера диагностик, срабатывания которых нужно исключить (например, 3022).level— уровень предупреждения (1, 2 или 3).
Цифре 1 соответствуют срабатывания уровня High, цифре 2 — Medium', цифре 3 — Low.
Можно исключать предупреждения сразу нескольких уровней. Для этого нужно написать уровни через запятую.
Пример:
//-V::3022,5623:1,3Эта запись позволит исключить срабатывания диагностик V3022 и V5623 уровня High и Low.
Исключение предупреждений по подстроке в сообщении
Анализатор поддерживает возможность исключения предупреждений по номеру диагностики и подстроке, содержащейся в сообщении.
Запись для подавления:
//-V::number::{substring}number— номер диагностики, сообщение которой нужно подавить (например, 3080).substring— подстрока, содержащаяся в сообщении анализатора.
При использовании такого шаблона будут игнорироваться срабатывания диагностик с номером number, сообщения которых содержат подстроку substring.
Пример подавления по подстроке:
//-V::3022::{always true}В данном случае будут отключены срабатывания V3022, в сообщении которых есть подстрока 'always true'.
Исключение предупреждений по уровню и подстроке в сообщении
Также можно добавить фильтрацию по уровню и подстроке. Такая запись будет иметь вид:
//-V::number1,number2,...,numberN:level:{substring}number1,number2и т.д. — номера диагностик, срабатывания которых нужно исключить (например, 3022).level — уровень предупреждения (1, 2 или 3).substring— подстрока, содержащаяся в сообщении анализатора.
Цифре 1 соответствуют срабатывания уровня High, цифре 2 — Medium, цифре 3 — Low.
Можно исключать предупреждения диагностик сразу нескольких уровней. Для этого нужно написать уровни через запятую.
Пример:
//-V::3022,5623:1,3:{always true}Будут исключены срабатывания уровня High и Low диагностик V3022, V5623, в сообщении которых есть подстрока always true.
Исключение предупреждений из определённых категорий по уровням
Для исключения предупреждений некоторых категорий по уровням используется запись вида:
//-V::category1,category2,...,categoryN:levelcategory1,category2и т. д. — имена категорий, срабатывания которых нужно исключить (например, GA). Перечень категорий и их описание можно найти в разделе Отключение диагностик из определённых категорий этой документации;level— уровень предупреждения (1, 2 или 3).
Можно комбинировать фильтры категорий и уровней, перечисляя их через запятую.
Пример комбинации:
//-V::GA,MISRA:1,3Будут исключены срабатывания уровня High и Low диагностик, которые относятся к категориям GA и MISRA.
Включение отдельных диагностик
Примечание: Данная настройка доступна только для C, С++ и C# проектов.
Для включения определённой диагностики используется запись:
//+V::numbernumber — номер диагностики, которую нужно включить (например, 3022).
Пример использования:
//+V::3022В данном случае будут включены срабатывания диагностики V3022.
Для включения нескольких диагностик перечислите номера через запятую:
//+V::number1,number2,...,numberNПример:
//+V::3022,3080При использовании этой директивы будут полностью включены диагностики V3022 и V3080.
Включение диагностик из определённых категорий
Примечание: Данная настройка доступна только для C, С++ и C# проектов.
Для включения диагностик некоторой категории используются следующие директивы:
//+V::GA
//+V::X64
//+V::OP
//+V::CS
//+V::MISRA
//+V::OWASPМожно комбинировать фильтры категорий, перечисляя их через запятую.
Пример комбинации:
//+V::GA,MISRAДобавление метки False Alarm для срабатываний на строки, содержащие указанный фрагмент
Добавление False Alarm метки для предупреждений на строки с некоторым фрагментом производится с помощью следующей директивы:
//-V:substring:numbersubstring— подстрока, содержащаяся в строке, на которую указывает анализатор;number— номер диагностики, сообщение которой нужно подавить (например, 3080).
Примечание 1. Искомая подстрока (substring) не должна содержать пробелов.
Примечание 2. Сообщения, отфильтрованные данным способом, не будут удалены из отчёта. Они будут отмечены как False Alarm (FA).
Пример использования:
public string GetNull()
{
return null;
}
public void Foo()
{
string nullStr = GetNull();
Console.WriteLine(nullStr.Length);
}На данный код анализатор выдаст предупреждение: "V3080 Possible null dereference. Consider inspecting 'nullStr'."
Для добавления FA-метки для срабатываний на такой код используйте в .pvsconfig следующую запись:
//-V:Console:3080Такая директива добавит отметку False Alarm на все предупреждения V3080, указывающие на строку кода, в которой есть Console.
Аналогичным образом можно добавлять отметку False Alarm на срабатывания сразу нескольких диагностик. Для этого перечислите их номера через запятую:
//-V:substring:number1,number2,...,numberПример:
//-V:str:3080,3022,3175Сообщения диагностик V3080, V3082, V3175 будут помечены как False Alarm, если в строке, на которую указывает анализатор, есть подстрока str.
Добавления хэш-кода к метке False Alarm
С PVS-Studio версии 7.28 появилась возможность ставить дополнительный хэш-код к метке False Alarm. При изменении строки с этим хэш-кодом предупреждения, выданные на эту строку, не будут отмечены как ложные срабатывания, так как хэш-код изменённой строки отличается от хэш кода метки.
Эта настройка помогает распознавать ситуации, когда строка с меткой False Alarm изменяется.
Для включения этой функции добавьте в файл конфигурации следующий флаг:
//V_ENABLE_FALSE_ALARMS_WITH_HASHВ коде метка False Alarm c хэш-кодом выглядит следующим образом:
//-V817 //-VH"3652460326"С версии PVS-Studio 7.30 появилась возможность для подавления только тех сообщений, к False Alarm метке которых поставлен дополнительный хэш-код:
//V_HASH_ONLY ENABLE
//V_HASH_ONLY ENABLE_VERBOSEВ случае применения данной настройки те строчки, которые имеют метку False Alarm, но не имеют хэш-кода, не будут подавлены.
Настройка ENABLE приведёт к попаданию одного на весь проект сообщения V018 в отчёт. В случае применения настройки ENABLE_VERBOSE такое предупреждение будет выдаваться на каждую строчку кода, в которой присутствует метка False Alarm без хэш-кода.
Выключение настройки выполняется следующим образом:
//V_HASH_ONLY DISABLEДанная ситуация может возникнуть в случае, если применение данной настройки необходимо только на определённой части кода.
Исключение файлов из анализа
Для исключения из анализа файла или группы файлов используйте шаблон:
//V_EXCLUDE_PATH fileMask'fileMask' — маска файла.
Пример использования некоторых масок:
//V_EXCLUDE_PATH C:\TheBestProject\thirdParty
//V_EXCLUDE_PATH *\UE4\Engine\*
//V_EXCLUDE_PATH *.autogen.csНачиная с версии 7.34 PVS-Studio можно использовать шаблон //V_ANALYSIS_PATHS с режимом skip-analysis.
Например:
//V_ANALYSIS_PATHS skip-analysis=C:\TheBestProject\thirdParty
//V_ANALYSIS_PATHS skip-analysis=*\UE4\Engine\*
//V_ANALYSIS_PATHS skip-analysis=*.autogen.csС синтаксисом формирования масок можно ознакомится в документации.
Исключение проектов из анализа
Начиная с версии 7.32, утилита PVS-Studio_Cmd.exe и плагин для Visual Studio поддерживают исключение из анализа проектов по шаблону:
//V_EXCLUDE_PROJECT projMaskprojMask — маска файла проекта.
Пример использования некоторых масок:
//V_EXCLUDE_PROJECT C:\TheBestProject\thirdParty\3rdparty.vcxproj
//V_EXCLUDE_PROJECT *\TOCSharp.csproj
//V_EXCLUDE_PROJECT *\elsewhere\*.*projСинтаксис формирования масок совпадает с синтаксисом, используемым для исключения файлов из анализа. Исключить из проверки можно только .vcxproj и .csproj проекты.
Также вы можете исключить проект из анализа, указав аналогичный путь для флага //V_EXCLUDE_PATH.
Игнорирование файлов конфигурации
Примечание: Данная настройка доступна только для C и С++ проектов.
Начиная с версии 7.34 PVS-Studio поддерживает возможность игнорировать настройки, которые находятся в исходных файлах и файлах конфигурации диагностик '.pvsconfig'.
Для этого можно использовать флаг //V_ANALYSIS_PATHS с режимом skip-settings.
Например:
//V_ANALYSIS_PATHS skip-settings=*\path\to\folder\*
//V_ANALYSIS_PATHS skip-settings=*\path\*\custom_pvsconfig
//V_ANALYSIS_PATHS skip-settings=*custom_settings.hЕсли необходимо исключить файлы из анализа и одновременно игнорировать настройки для этих файлов, можно использовать флаг //V_ANALYSIS_PATHS с режимом skip.
Например:
//V_ANALYSIS_PATHS skip=*\path\to\source_or_pvsconfigС синтаксисом формирования масок можно ознакомится в документации.
Изоляция настроек для каталогов
Примечание: данная настройка доступная только при использовании утилиты pvs-studio-analyzer.
Начиная с версии 7.36, утилита pvs-studio-analyzer поддерживает режим, при котором в каждом каталоге (и его родительских каталогах) для каждой единицы трансляции выполняется поиск файлов конфигурации правил (.pvsconfig). Каждый найденный файл *.pvsconfig будет применён для всех единиц трансляции в каталоге и его подкаталогах. Для включения этого режима следует воспользоваться флагом командной строки ‑‑apply-pvs-configs. Подробнее об этом можно узнать в документации по утилите pvs-studio-analyzer.
Вы можете изолировать настройки в каталоге от настроек из родительских директорий. Это полезно, если вам необходимо отделить настройки в подпроектах или third-party библиотеках. В таком случае никакие файлы конфигурации правил из родительских каталогов не будут применены для указных директорий и их подкаталогов.
Для изоляции настроек с помощью файла конфигурации правил есть два способа:
- через флаг
V_ANALYSIS_PATHSс режимомisolate-settings. Данную опцию можно указать в любом файле конфигураций правил. Поддерживаются абсолютные и относительные пути. Относительные пути раскрываются через путь до файла конфигураций правил, например:
//V_ANALYSIS_PATHS isolate-settings=path/to/isolate;isolate-settings=ThirdParty- через флаг
//V_ISOLATE_CURRENT_DIR. Включает изоляцию каталога, в котором расположен файл конфигурации с данным флагом.
Игнорирование глобальных файлов конфигурации
Перед запуском анализа PVS-Studio_Cmd формирует конфигурацию диагностических правил из:
- глобальных файлов конфигурации (в папке
%APPDATA%\PVS-Studioдля Windows и в папке~/.config/PVS-Studioдля Linux и macOS); - файла, переданного через опцию
‑‑rulesConfig (-C); - файлов, добавленных в решение;
- файлов, добавленных в проект.
Может возникнуть ситуация, когда глобальная конфигурация не должна применяться при анализе каких-либо проектов или решений. Для её отключения добавьте в соответствующий файл конфигурации следующий флаг:
//IGNORE_GLOBAL_PVSCONFIGНачиная с версии 7.36, этот флаг поддерживается и в pvs-studio-analyzer.
Указание timeout-а анализа файлов для проекта/solution/системы
При запуске анализа через интерфейс плагинов (Visual Studio, Rider и CLion) или в C and C++ Compiler Monitoring UI (Standalone.exe) имеется возможность указания timeout-а по истечению которого анализ файла будет прерван. При превышении timeout-а анализа в результаты анализа будет добавлено предупреждение V006 с информацией о том, на каком файле был превышен timeout.
Настройки timeout-а анализа файлов можно указать и в .pvsconfig. Например, этой строчкой указывается timeout в 10 минут (600 секунд):
//V_ANALYSIS_TIMEOUT 600Если в .pvsconfig указана строка с timeout-ом равным 0, то файлы будут анализироваться без ограничения по времени.
Благодаря настройке timeout-ов через .pvsconfig файлы разных уровней, можно ограничить время анализа файлов в определенных проектах, solution-ах или во всей системе.:
- аргумент
‑‑rulesConfig (-c)вPVS-Studio_Cmd.exe(переопределяет timeout анализа файлов для текущего анализа solution/проекта); - системный (
%AppData% в Windows, ~/.config в Linux, macOS); - solution (
.sln); - уровень проекта (
.csproj,.vcxproj).
Изменение уровня срабатываний диагностики
Предупреждения анализатора имеют три уровня достоверности: High, Medium, Low. В зависимости от используемых в коде конструкций анализатор оценивает достоверность предупреждений и присваивает им соответствующий уровень в отчёте.
В некоторых проектах поиск определённых типов ошибок может быть очень важен, независимо от степени достоверности предупреждения. Бывает и обратная ситуация, когда сообщения малополезны, но совсем их отключать не хочется. В таких случаях для диагностик можно вручную задать уровень High/Medium/Low. Для этого следует использовать следующие директивы:
- Директива
//V_LEVEL_1изменяет уровень срабатываний на High; - Директива
//V_LEVEL_2изменяет уровень срабатываний на Medium; - Директива
//V_LEVEL_3изменяет уровень срабатываний на Low.
Для изменения уровня используйте директиву следующего вида:
//V_LEVEL_1::numbernumber — номер диагностики.
Например, чтобы изменить уровень предупреждений для диагностики V3176 на третий, используйте запись:
//V_LEVEL_3::3176Изменения текста сообщений анализатора
Для изменения подстроки в сообщении анализатора используйте следующий синтаксис:
//+Vnnn:RENAME:{originalString:replacementString}, ...Vnnn— название диагностики, сообщение которой необходимо модифицировать (например, V624);originalString— исходная подстрока;replacementString— строка на которую нужно заменить.
Разберём работу директивы на примере. Диагностика V624, встречая в коде число 3.1415, предлагает заменить его на M_PI из библиотеки <math.h>. Но в проекте используется специальная математическая библиотека, и нужно использовать математические константы именно из неё. Для корректной работы следует добавить директиву в файл конфигурации.
Эта директива будет иметь следующий вид:
//+V624:RENAME:{M_PI:OUR_PI},{<math.h>:"math/MMath.h"}Теперь анализатор сообщит, что нужно использовать константу OUR_PI из заголовочного файла math/MMath.h.
Существует возможность добавить строку к сообщению.
Директива, позволяющая сделать это, имеет следующий вид:
//+Vnnn:ADD:{message}Vnnn— название диагностики, сообщение которой необходимо модифицировать (например, V2003);message— строка для добавления;
Разберём пример. Для этого рассмотрим сообщение диагностики V2003: "Explicit conversion from 'float/double' type to signed integer type.".
Чтобы добавить дополнительную информацию в это сообщение, нужно использовать директиву следующего вида:
//+V2003:ADD:{ Consider using boost::numeric_cast instead.}Теперь анализатор будет выдавать модифицированное сообщение: "Explicit conversion from 'float/double' type to signed integer type. Consider using boost::numeric_cast instead.".
Управление синхронизацией suppress файлов
При запуске анализа через интерфейс плагина Visual Studio или в C and C++ Compiler Monitoring UI (Standalone.exe) имеется возможность отключить синхронизацию suppress файлов с помощью настройки Specific Analyzer Settings/DisableSynchronizationOfSuppressFiles.
Отключить синхронизацию также можно через .pvsconfig файл уровня решения. Для этого необходимо добавить в соответствующий конфигурационный файл следующий флаг:
//DISABLE_SUPPRESS_FILE_SYNCДля включения синхронизации через .pvsconfig независимо от значения настройки DisableSynchronizationOfSuppressFiles необходимо использовать флаг:
//ENFORCE_SUPPRESS_FILE_SYNCЭтот флаг применим только в .pvsconfig уровня решения.
Выбор версии PVS-Studio для анализа
Начиная с версии 7.24 утилита PVS-Studio_Cmd.exe и плагин для Visual Studio поддерживают возможность указать версию ядра PVS-Studio для анализа C++ проектов, если на компьютере установлено несколько версий PVS-Studio.
Начиная с версии 7.36 утилита PVS-Studio_Cmd.exe и плагин для Visual Studio поддерживают возможность указать версию ядра PVS-Studio для анализа C# проектов, если на компьютере установлено несколько версий PVS-Studio.
Для того, чтобы PVS-Studio_Cmd.exe запускал анализ на нужной версии ядра PVS-Studio необходимо в файл .pvsconfig уровня решения добавить флаг //PVS_VERSION::Major.Minor, где
Major — мажорное число версии, а Minor — минорное число.
Например:
//PVS_VERSION::7.26PVS-Studio_Cmd.exe вычисляет путь до ядра используя информацию из системного реестра, которую пишет инсталлятор при установке PVS-Studio.
Для C++ проектов минимальная поддерживаемая версия значения настройки PVS_VERSION — это 7.26 (минимальное значение для C++ проектов было добавлено в версии 7.36). Это означает, что при использовании этой настройки при анализе C++ проектов можно запустить версию ядра PVS-Studio 7.26 или выше.
Для C# проектов минимальная поддерживаемая версия значения настройки PVS_VERSION — это 7.15. Это означает, что при использовании этой настройки при анализе C# проектов можно запустить только версию ядра PVS-Studio 7.15 или выше.
В случае установки новой версии PVS-Studio в уже существующую директорию, содержащую другую версию PVS-Studio, номер версии в реестре для этой директории будет обновлён.
Последняя установка PVS-Studio, считается установкой по умолчанию. А значит, если последней была установлена версия PVS-Studio 7.23, то такой же версии будут все плагины и PVS-Studio_Cmd.exe. Следовательно, вы не сможете воспользоваться механизмом выбора версий ядра PVS-Studio. Поэтому, если вы хотите использовать старые версии PVS-Studio (7.23 и ниже), то вам нужно в начале установить их и только потом поставить последнюю версию PVS-Studio 7.24 или выше.
Для всех версий ниже 7.24 необходимо в реестре прописать соотношение версии и пути до каталога установки этой версии, чтобы PVS-Studio_Cmd.exe смог найти путь до ядра PVS-Studio. Информация записывается в раздел Computer\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\ProgramVerificationSystems\PVS-Studio\Versions.
Приоритезация файлов конфигурации
Начина с версии 7.25 утилита PVS-Studio_Cmd.exe и плагин для Visual Studio поддерживают возможность явно задать приоритет файлов конфигурации одного уровня. Для этого необходимо использовать флаг //CONFIG_PRIORITY::number, где number — номер приоритета.
Начиная с версии 7.36, этот флаг поддерживается в утилите pvs-studio-analyzer.
Например:
//CONFIG_PRIORITY::1Чем меньше номер, тем приоритетней файл конфигурации. Файлы, в которых нет данного флага, имеют минимальный приоритет. Файлы имеющий одинаковый приоритет применяются в алфавитном порядке. Например, среди файлов Filter1.pvsconfig, Filter2.pvsconfig, Filter3.pvsconfig настройки из Filter3.pvsconfig будут приоритетными.
Флаг //CONFIG_PRIORITY влияет только на файлы конфигурации одного уровня. В порядке возрастания приоритета файлы настроек применяются так:
- Глобальный файл конфигурации;
- Файлы конфигурации уровня решения;
- Файлы конфигурации уровня проекта;
- Файл, переданный через аргумент
‑‑rulesConfig (-c)утилитеPVS-Studio_Cmd.
Выполнение команд из CustomBuild task перед анализом
Чтобы PVS-Studio перед анализом выполнил команды из CustomBuild task, в файл .pvsconfig нужно добавить следующую директиву:
//EXECUTE_CUSTOM_BUILD_COMMANDSЭта директива применима только для .pvsconfig файлов, передаваемых через командную строку, а также расположенных на глобальном уровне или уровне решения.
Рассмотрим случай, в котором директива может пригодиться.
Некоторые Visual C++ проекты при сборке могут генерировать исходный код с помощью команд, записанных в CustomBuild task. Запуск анализа без генерации этих файлов может привести к ошибкам. Если нужно только сгенерировать файлы, то выполнять полную сборку смысла нет (это может быть долго).
В таком случае будет полезно указать PVS-Studio соответствующую директиву, чтобы анализатор сначала выполнил команды генерации файлов, а затем провёл анализ.
Подавление ошибок парсинга
Иногда анализатор может выдавать сообщение об ошибке парсинга на полностью компилирующийся проект. Эти ошибки могут быть не критичны для качества анализа. В таком случае их можно подавить.
Ошибка парсинга имеет код:
Подавление V051 (C# анализатор)
C# анализатор выдаёт V051 при наличии хотя бы одной ошибки компиляции. Увидеть все ошибки можно запустив command line версию анализатора с флагом ‑‑logCompilerErrors. Синтаксис для подавления этих ошибок выглядит следующим образом:
//V_EXCLUDE_PARSING_ERROR:V051:{"ProjectName": "MyProject", "ErrorCode": "CS0012", "Message": "Some message"}
В данном случае для проекта (.csproj) MyProject будет подавлена ошибка компиляции с кодом CS0012 и сообщением "Some message".
Также не обязательно комбинировать информацию для подавления:
- //V_EXCLUDE_PARSING_ERROR:V051:{"ProjectName": "MyProject"} — подавить все ошибки на проекте MyProject
- //V_EXCLUDE_PARSING_ERROR:V051:{"ErrorCode": "CS0012"} — подавить все ошибки с кодом CS0012 для всех проектов
- //V_EXCLUDE_PARSING_ERROR:V051:{"Message": "Some message"} — подавить все ошибки с сообщением "Some message".
При указании сообщения вы можете воспользоваться масками. Например:
//V_EXCLUDE_PARSING_ERROR:V051:{Message: "Some*"}
Примечание: на данный момент подавление ошибок парсинга доступно только для V051 (C# анализатор).
Игнорирование настроек анализа из Settings.xml
В глобальном файле конфигурации Settings.xml есть ряд опций, которые влияют на результат анализа. Например, настройки выключения диагностических групп.
Вы можете использовать флаг //V_IGNORE_GLOBAL_SETTINGS ON для того, чтобы настройки из Settings.xml не учитывались при анализе. В этом случае включаются все диагностические группы и не применяются фильтры путей.
Для гибкой настройки анализа используйте файлы конфигурации (.pvsconfig).
Эта опция доступна только в файле конфигурации уровня решения и влияет на работу только PVS-Studio_Cmd.exe и плагинов для Visual Studio.
Использование каталога решения в качестве значения SourceTreeRoot
Вы можете использовать флаг //V_SOLUTION_DIR_AS_SOURCE_TREE_ROOT для того, чтобы включить использование каталога решения в качестве значения SourceTreeRoot.
С настройкой SourceTreeRoot можно ознакомиться в отдельной документации.
Параметр является более приоритетным, чем UseSolutionDirAsSourceTreeRoot из файла настроек Settings.xml.
Эта опция доступна только в файле конфигурации уровня решения и влияет на работу только PVS-Studio_Cmd.exe и плагинов для Visual Studio.
Использование каталога решения для построения относительных путей в кэше зависимостей компиляции
Начиная с PVS-Studio версии 7.34 вы можете использовать флаг //V_SOLUTION_DIR_AS_DEPENDENCY_CACHE_SOURCE_TREE_ROOT для того, чтобы включить использование каталога решения в качестве корневой части пути, который будет использован для построения относительных путей файлов в кэше зависимостей компиляции.
Этот флаг следует использовать в режиме проверки списка файлов и в режиме проверки модифицированных файлов. Данная настройка позволяет получить файлы кэшей зависимостей компиляции, которые затем можно использовать на машинах с отличающимся расположением проверяемых исходных файлов.
Эта настройка похожа на //V_SOLUTION_DIR_AS_SOURCE_TREE_ROOT, только относительные пути для файлов будут строиться в файлах кэшей зависимостей компиляции, а не в отчёте анализатора.
Эта опция доступна только в файле конфигурации уровня решения и влияет на работу только PVS-Studio_Cmd.exe.
Управление сортировкой suppress файлов
С версии PVS-Studio 7.27 внутреннее содержимое файлов подавления сортируется. Это требуется для корректного использования в системе контроля версий и избегании проблем слияния файлов.
Сообщения сортируются в следующем порядке: имя исходного файла, код диагностики, хэш строки, описание диагностики.
Если вам требуется сохранить старое поведение и отключить сортировку, вы можете указать параметр //V_DISABLE_SUPPRESS_FILE_SORTING.
Секции настроек в .pvsconfig
Существует возможность указания специфичных правил для определённой версии PVS-Studio.
Синтаксис:
//V_SECTION_BEGIN
//V_WHEN_VERSION: <CONDITION_SEQUENCE>
....
//V_SECTION_ENDКаждая секция содержит три обязательных элемента:
- //V_SECTION_BEGIN — метка начала секции;
- //V_WHEN_VERSION: — условие для определения применимости секции;
- //V_SECTION_END — метка конца секции.
Синтаксис условий:
<CONDITION_SEQUENCE> ::= <CONDITION> | <CONDITION_SEQUENCE> "|" <CONDTION>
<CONDITION> ::= <SINGLE_VERSION_COMPARISON> | <RANGE_VERSIONS_COMPARISON>
<SINGLE_VERSION_COMPARISON> ::= <OP> <VERSION>
<RANGE_VERSIONS_COMPARISON> ::= "IN" <VERSION> "," <VERSION>
<OP> ::= "EQ" | "NE" | "LT" | "LE" | "GT" | "GE"
<VERSION> ::= <NUMBER> [ "." <NUMBER> ]Условия в V_WHEN_VERSION могут быть скомбинированы с помощью символа | (аналог оператора ИЛИ). Каждое подвыражение вычисляется по отдельности. Если хотя бы одно из них истинно, то секция со всеми директивами внутри неё применяется. В противном случае — отбрасывается.
Если необходимо указать не точную версию, а диапазон, то можно воспользоваться оператором IN. Значения указываются через запятую включительно. Например, так можно указать все версии с 7.20 до 7.25 (включительно):
....
//V_WHEN_VERSION: in 7.20,7.25
....Поддерживаемые операторы в условиях, их псевдонимы и описание:
|
# |
Оператор |
Alias |
Описание |
|---|---|---|---|
|
1 |
EQ |
== |
Равно |
|
2 |
NE |
!= |
Не равно |
|
3 |
LT |
< |
Меньше |
|
4 |
LE |
<= |
Меньше или равно |
|
5 |
GT |
> |
Больше |
|
6 |
GE |
>= |
Больше или равно |
|
7 |
IN |
отсутствует |
Диапазон значений |
Регистр текстовых операторов не имеет значения. Такая запись условия также будет корректной:
....
//V_WHEN_VERSION: == 7.17 | In 7.20,7.25 | GT 8
....Ограничения:
- каждая открытая секция должна быть корректно закрыта (конец файла не является корректным завершением секции);
- вложенные секции не допускаются;
- при сравнении версий допускается использовать только мажорную и минорную версии анализатора, разделённые точкой;
- условия могут быть использованы только после открытия секции;
- управляющие директивы допустимо использовать только после условия.
Примечания:
- директивы вне секций применяются для всех версий;
- при указании только Major версии, Minor будет неявно считаться как 0;
- при использовании старой версии анализатора (до 7.31) все директивы будут применяться вне зависимости от наличия секций;
- в случае некорректной работы с секциями будет выдана соответствующая ошибка.
Пример секции:
//V_SECTION_BEGIN
//V_WHEN_VERSION: eq 7.30 | in 7.32,7.35 | gt 8
//+V::860
//V_ASSERT_CONTRACT
//-V::1100
//V_SECTION_ENDОбнаружение начальной позиции сдвига строк (для V002)
Начиная с версии 7.35 PVS-Studio поддерживает возможность вывода позиции, с которой начался сдвиг. Механизм будет полезен, если позиции предупреждений анализатора указывают на неправильные строки.
Чтобы вывести начальные позиции сдвига, добавьте флаг //+V002,VERBOSE. Анализатор будет выдавать расширенное сообщение V002 на каждый первый потенциальный сдвиг в файле. Сообщение будет содержать строку, которую анализатор ожидал увидеть на указанной позиции.
Пример:
#include <iostream>
//+V002,VERBOSE
#pragma \
\
warning(push)
// The message V002 will be output here
void bar(int i) // This is the first line for which we detected a shift
{
auto x = i % 5;
// This would be the wrong position for V609
if ( i/x) // This is the correct position of V609
std::cout << "bar" << std::endl;
}
void x()
{
bar(5);
}Важно: анализатор не всегда может корректно вычислить позицию начала сдвига. Это связано с особенностями сравнения исходного и препроцессированного файла, где требуется учитывать раскрытие макросов и дополнительную информацию, которую подставляет препроцессор в .i файл.
Управление кэшем зависимостей компиляции
Начиная с PVS-Studio версии 7.35 появилась возможность управлять директорией сохранения и построения относительных путей для файлов кэша зависимостей компиляции.
Для указания директории сохранения файлов кэша используйте флаг //V_DEPENDENCY_CACHE_ROOT. Данная настройка позволяет централизовать хранение кэшей зависимостей компиляции разных проектов.
Используйте флаг //V_DEPENDENCY_CACHE_SOURCE_ROOT для указания директории используемой в качестве корневой части пути, который будет использован для построения относительных путей файлов в кэше зависимостей компиляции. Данная настройка позволяет получить файлы кэшей зависимостей компиляции, которые затем можно использовать на машинах с отличающимся расположением проверяемых исходных файлов.
Эти флаги следует использовать в режиме проверки списка файлов и в режиме проверки модифицированных файлов.
Пример использования:
//V_DEPENDENCY_CACHE_ROOT C:\Project\cache
//V_DEPENDENCY_CACHE_SOURCE_ROOT C:\ProjectРежим отслеживания исходных файлов в кэше зависимостей
В PVS-Studio 7.35 появилась возможность указывать режим отслеживания исходных файлов в кэше зависимостей компиляции. Для этого используется флаг //V_DEPENDENCY_CACHE_TRACKING_MODE. Он может принимать одно из следующих значений:
- ModifiedFilesOnly — в хэше отслеживаются только модификации исходных файлов.
- ModifiedAndWarningsContainingFiles — дополнительно отслеживаются файлы с предупреждениями, найденными в предыдущих прогонах анализа. Исходный файл будет анализироваться до тех пор, пока в нем содержатся предупреждения анализатора.
- Disabled — отключает отслеживание файлов и обновление кэша зависимостей.
Если значение этого флага не Disabled, то в плагине для Visual Studio появляется возможность запускать анализ модифицированных файлов через пункт меню Extension > PVS-Studio > Check > Modified Files и пункт Analyze Modified Files with PVS-Studio в контекстном меню решений и проектов.
При использовании этого флага кэш зависимостей компиляции будет обновляться независимо от режима анализа — как при анализе модифицированных файлов, так и в обычном режиме.
Исключение из анализа файлов и каталогов
- Исключение файлов через настройки IDE
- Исключение файлов через файл настроек Settings.xml
- Исключение файлов через файл конфигурации диагностик .pvsconfig
- Для утилит CompilerCommandsAnalyzer.exe и pvs-studio-analyzer
При проверке проектов с большим количеством сторонних библиотек бывает необходимо отсеять лишний шум и сосредоточиться на потенциальных проблемах в своём коде. Для таких целей в инструментах PVS-Studio предусмотрен механизм исключения файлов из анализа. Благодаря механизму исключений вы можете не только убрать ненужные предупреждения, но и значительно увеличить скорость анализа вашего проекта.
Исключение файлов через настройки IDE
Visual Studio и С and C++ Compiler Monitoring UI
Для Visual Studio откройте настройки плагина Extensions -> PVS-Studio -> Options -> Don't Check Files.
Если Вы используете утилиту C and C++ Compiler Monitoring UI, то откройте Tools -> Option... -> Don't Check Files.
В появившимся окне вы можете указать файлы и каталоги, которые должны быть исключены из анализа. Вы также можете использовать wildcard-маски.

Стоит отметить, что не все маски в плагине для Visual Studio можно применить для фильтрации существующего отчёта. Если маска неприменима для фильтрации, вы получите сообщение о необходимости перезапуска анализа для её применения. Маски, в которых используется символ '*' в начале и/или в конце, сразу применяются для фильтрации предупреждений в таблице плагина.
Подробнее об исключении файлов через настройки плагина для Visual Studio можно прочесть тут.
Вы также можете исключить файлы из анализа через контекстное меню в отчёте анализатора. Для этого щёлкните правой кнопкой мыши по срабатыванию и выберите пункт 'Don't check files and hide all messages from...', в раскрывшемся меню вы сможете выбрать уровень вложенности каталогов, с которого следует исключить файлы.
Обратите внимание, что информация об исключаемых каталогах и файлах записывается в глобальный файл настроек Settings.xml и может быть использована другими инструментами PVS-Studio, если им не передан путь для файла настроек.
Плагины для CLion и Rider
Чтобы исключить файлы или каталоги из анализа, перейдите в настройки плагина PVS-Studio (Tools -> PVS-Studio -> Settings) и выберите раздел Excludes.

В этом разделе вы можете управлять масками имён файлов и путей, которые будут исключены из анализа.
Вы также можете исключить из анализа файл или каталог непосредственно через контекстное меню отчёта PVS-Studio. Для этого нажмите правой кнопкой мыши по сообщению и выберите пункт 'Exclude From Analysis', в раскрывшемся меню вы сможете выбрать уровень вложенности каталогов, с которого следует исключить файлы из анализа.

Обратите внимание, что информация об исключаемых каталогах и файлах записывается в глобальный файл настроек Settings.xml и может быть использована другими инструментами PVS-Studio, если им не передан путь для альтернативного файла настроек.
Исключение файлов через файл настроек Settings.xml
Консольные инструменты могут использовать как глобальный файл настроек Settings.xml, так и специфичный, переданный в качестве аргумента командной строки. Использование специфичного файла может быть полезно, если у вас есть специальные настройки анализа для проекта, которые не должны повлиять на результаты анализа других проектов. Например, список исключаемых каталогов.
Чтобы создать альтернативный файл настроек, скопируйте файл Settings.xml из каталога '%APPDATA%/PVS-Studio/' (Windows) или '~/.config/PVS-Studio' (Linux) в любое место (например, в каталог проверяемого проекта). Затем добавьте исключаемые файлы и каталоги в узел ApplicationSettings/PathMasks (если это каталог) или в ApplicationSettings/FileMasks (если это файл).
Например, так:
<ApplicationSettings ...>
...
<PathMasks>
...
<string>\EU*\Engine\Source</string>
</PathMasks>
...
</ApplicationSettings>Теперь, для того чтобы передать собственный файл настроек в PVS-Studio_Cmd.exe или pvs-studio-dotnet (Linux и macOS), используйте параметр ‑‑settings (-s):
PVS-Studio_Cmd.exe -t ProjName.sln -s /path/to/NonDefaultSettings.xmlДля передачи параметра в CLMonitor.exe используйте флаг ‑‑settings (-t) в любом режиме запуска:
CLMonitor.exe monitor -t /path/to/NonDefaultSettings.xmlИсключение файлов через файл конфигурации диагностик .pvsconfig
Вы можете создать файл .pvsconfig (файл конфигурации диагностик анализатора), в котором с помощью специальных комментариев можно описать файлы и каталоги, исключаемые из анализа. Подробнее про файл .pvsconfig можно узнать тут.
Для исключения файла или каталога файлов из анализа вам достаточно указать до него путь или маску пути, используя специальный комментарий //V_EXCLUDE_PATH.
Например:
//V_EXCLUDE_PATH C:\TheBestProject\ThirdParty
//V_EXCLUDE_PATH *\UE*\Engine\Source\*
//V_EXCLUDE_PATH *.autogen.csНачиная с версии 7.34 PVS-Studio можно использовать комментарий //V_ANALYSIS_PATHS с режимом skip-analysis.
Например:
//V_ANALYSIS_PATHS skip-analysis=C:\TheBestProject\ThirdParty
//V_ANALYSIS_PATHS skip-analysis=*\UE*\Engine\Source\*
//V_ANALYSIS_PATHS skip-analysis=*.autogen.csТеперь вы можете использовать файл .pvsconfig с утилитами PVS-Studio:
Для CLMonitor.exe через флаг -с (‑‑pvsconfig):
CLMonitor.exe analyze ... -c /path/to/.pvsconfigДля PVS-Studio_Cmd.exe и pvs-studio-dotnet через флаг -С (‑‑rulesConfig):
PVS-Studio_Cmd.exe -t target.sln -o PVS-Studio.log -C /path/to/.pvsconfig
pvs-studio-dotnet -t target.csproj -o PVS-Studio.log -C /path/to/.pvsconfigДля CompilerCommandsAnalyzer.exe (Windows) и pvs-studio-analyzer (Linux, macOS) через флаг -R (‑‑rules-config):
CompilerCommandsAnalyzer analyze --cfg /path/to/PVS-Studio.cfg \
-R /path/to/.pvsconfigЕсли вы используете утилиту C and C++ Compiler Monitoring UI, то путь до файла .pvsconfig можно передать через интерфейс запуска мониторинга:

Плагины PVS-Studio (для Visual Studio, Rider) умеют автоматически определять файл .pvsconfig, если он добавлен в Solution или проект и имеет расширение .pvsconfig. Файлы конфигурации, добавленные в Solution, имеют глобальную область видимости и распространяются на все проекты этого Solution'a. Файлы .pvsconfig, добавленные в проект, применяются только для проекта, в который они добавлены.
Для утилит CompilerCommandsAnalyzer.exe и pvs-studio-analyzer
Если для проверки C и C++ проектов используется кроссплатформенная утилита pvs-studio-analyzer(Linux, macOS) / CompilerCommandsAnalyzer.exe (Windows), то исключить файлы из анализа возможно следующими способами.
Прямая передача исключаемых файлов и каталогов
Позволяет исключить файлы из анализа, передав пути до них в качестве аргументов запуска pvs-studio-analyzer/CompilerCommandsAnalyzer.exe через флаг -e (‑‑exclude-path):
pvs-studio-analyzer analyze ... -e /third-party/ \
-e /test/ \
-e /path/to*/exclude-pathИли через флаг ‑‑analysis-paths с режимом skip-analysis:
pvs-studio-analyzer analyze ... \
--analysis-paths skip-analysis=/third-party/ \
--analysis-paths skip-analysis=/test/ \
--analysis-paths skip-analysis=/path/to*/exclude-pathПри указании пути вы также можете использовать шаблоны командных оболочек (glob).
Через файл конфигурации *.cfg
Создайте текстовый файл (например, MyProject.cfg). Поместите в него список исключаемых каталогов через параметр exclude-path.
Пример:
exclude-path=/third-party/
exclude-path=*/test/*
exclude-path=*/lib-*/*Или используя параметр analysis-paths с режимом skip-analysis:
analysis-paths=skip-analysis=/third-party/
analysis-paths=skip-analysis=*/test/*
analysis-paths=skip-analysis=*/lib-*/*Затем запустите анализ, передав путь до файла конфигурации через флаг ‑‑cfg:
pvs-studio-analyzer analyze ... --cfg ./MyProject.cfgВы можете вынести в файл конфигурации и другие параметры запуска. Подробнее об этом написано тут.
Использование расширения PVS-Studio для Visual Studio Code
- Смотри, а не читай (ВК Видео)
- Установка расширения PVS-Studio
- Запуск анализа
- Работа с результатами анализа
- Конфигурация плагина
- Работа с версиями плагина PVS-Studio
Смотреть отчёты PVS-Studio в Visual Studio Code можно с помощью специального расширения PVS-Studio. Ниже описано, как установить расширение, запустить анализ проекта или открыть уже существующий отчёт PVS-Studio и работать с ним.
Обратите внимание, что предварительно вам потребуется скачать и установить анализатор.
Смотри, а не читай (ВК Видео)
Установка расширения PVS-Studio
Чтобы установить расширение PVS-Studio, откройте Visual Studio Code и перейдите на вкладку 'Extensions', затем введите в поле поиска 'PVS-Studio' и кликните по кнопке 'Install':

При установке анализатора на Windows вы можете выбрать пункт 'Integration with Visual Studio Code', и тогда расширение добавится в Visual Studio Code автоматически.

Также на Windows можно выполнить установку расширения, используя файл pvs-studio-vscode-*.vsix, расположенный в каталоге PVS-Studio (по умолчанию "%PROGRAMFILES(x86)%\PVS-Studio").
Для установки плагина из .vsix-файла на вкладке 'Extensions' в правом верхнем углу необходимо нажать на три точки и в появившемся меню выбрать пункт 'Install from VSIX...':

В открывшемся окне выберите .vsix файл плагина PVS-Studio. После установки плагина перезапустите Visual Studio Code.
Также установить расширение или скачать .vsix файл можно cо страницы PVS-Studio в Visual Studio Marketplace.
После установки расширения окно PVS-Studio появится в качестве одной из вкладок на нижней панели Visual Studio Code. В случае если окно PVS-Studio было скрыто, вы можете снова отобразить его с помощью команды 'PVS-Studio: Show window' в палитре команд (Ctrl + Shift + P).

Запуск анализа
Запустить анализ можно несколькими способами:
1. С помощью кнопки 'Analyze project' в окне PVS-Studio:

В этом случае будет запущен анализ всего решения.
2. Через контекстное меню редактора кода:

В этом случае будет запущен анализ только одного файла. Обратите внимание, что отсутствие данного пункта меню означает, что анализ текущего файла не поддерживается.
3. Через контекстное меню проводника.

В этом случае будут проанализированы все поддерживаемые файлы, которые были выделены. Кроме того, если среди выделенных элементов имеется папка, все поддерживаемые файлы, содержащиеся в ней и в её поддиректориях, будут проанализированы.
4. Через меню группы вкладок редактора:

В этом случае будут проанализированы все поддерживаемые файлы, открытые в текущей группе вкладок.
5. С помощью команд 'Run regular analysis' и 'Run intermodular analysis' в палитре команд (Ctrl+Shift+P):

Обе команды запускают общий анализ решения. Разница между ними имеет значение только при анализе C и C++ кода. В этом режиме анализатор выполняет более глубокий анализ, но тратит на это больше времени.
Если в открытой в VS Code директории не найдено подходящей цели для анализа, вы получите соответствующее сообщение:

В обратном случае вам, возможно, будет предложено настроить параметры, специфичные для анализа проектов, использующих ту или иную сборочную систему. Больше информации об анализе проекта конкретного типа можно найти в разделах этой документации: 'Анализ C, C++ (CMake) проектов', 'Анализ C# (MSBuild) проектов' и 'Анализ Java проектов'.
В случае успешного запуска анализа окно PVS-Studio примет следующий вид:

В правом верхнем углу окна будет отображаться прогресс анализа в процентах. Рядом с ним появится кнопка, с помощью которой можно прервать анализ. Срабатывания будут появляться в таблице по мере поступления.
Анализ C, C++ (CMake) проектов
Перед запуском анализа необходимо установить расширение CMake Tools для VSCode.
Плагин совместим со следующими генераторами для сборки проектов:
- Ninja;
- Makefile Generators.
При обнаружении неподдерживаемого генератора или его отсутствии появится сообщение, предлагающее задать этот параметр в настройках CMake-Tools:

При клике по кнопке 'Edit setting' будет открыта страница с этой настройкой.

Перед запуском анализа вам будет предложено выбрать его тип: межмодульный анализ (Intermodular analysis) или обычный анализ (Regular analysis). Их отличие заключается в том, что межмодульный анализ выполняется дольше, чем обычный, но даёт лучший результат. Подробнее про этот режим вы можете прочитать в документации.
При запуске анализа также учитывается содержимое папки '.PVS-Studio' в директории исходного кода проекта. Если в ней будут найдены пользовательские файлы конфигурации (с расширением *.pvsconfig) или suppress-файлы (с суффиксом *.suppress.json), то они будут переданы анализатору для дальнейшей обработки.
Внимание: на данный момент при проверке CMake проектов поддерживается работа только с одним suppress-файлом. Если при запуске будет найдено несколько файлов, то в отчёте появится соответствующая запись. В ней также будет указано, какой файл используется при анализе.
Анализ C# (MSBuild) проектов
При первом анализе решения вы получите уведомление о создании файла в "[workspace folder]/.PVS-Studio/MSBuildAnalyzerConfig.json", в котором можно задать некоторые настройки анализа, аналогичные параметрам консольной версии анализатора.

Варианты действий:
- Edit — открыть только что созданный файл, анализ запущен не будет;
- Continue — запустить анализ с параметрами по умолчанию;
- Cancel — отменить запуск анализа.
В этом файле вы можете указать файлы и параметры, которые будут учитываться при анализе:
- suppress-файлы (с расширением *.suppress.json);
- файлы конфигурации (с расширением *.pvsconfig);
- платформу и конфигурацию сборки;
- конкретные проекты (.csproj и .vcxproj) и файлы (.cs, .cpp и др.) для анализа;
- а также другие настройки, описание которых вы можете найти как в самом файле, так и в документации.
Внимание: при запуске анализа конкретных файлов через контекстные меню или меню групп вкладок редактора будут проанализированы только файлы, включённые в выбранное решение.
Кроме того, если среди анализируемых файлов окажется файл проекта (файл с расширением .csproj), будет выполнен анализ всех поддерживаемых файлов с кодом, которые включены в этот проект.
Анализ Java проектов
Внимание: чтобы расширение смогло определить ваш проект в открытой директории, в VS Code также должно быть установлено и активировано расширение "Project manager for Java".
По умолчанию расширение ищет ядро анализатора в одной из следующих директорий:
- "C:\Users\[User]\AppData\Roaming\PVS-Studio-Java (на Windows)";
- "~/.config/PVS-Studio-Java (на Linux и macOS)".
Если ядро находится в другой папке, следует указать путь к ней в настройках расширения (File > Preferences > Settings > PVS-Studio: Java Projects Analyzer)
Для запуска ядра анализатора требуется JDK с 11-19 версией. По умолчанию используется JDK, путь к которому задан в переменных окружения. Если версия вашего JDK не входит в допустимый диапазон, установите поддерживаемый JDK и укажите путь к нему в настройках VS Code (File > Preferences > Settings > PVS-Studio: Java For Running Analyzer).
Перед анализом рекомендуется выполнить команду "Java: Reload Projects" в палитре команд (Ctrl + Shift + P). Если после этого появится выпадающий список с модулями вашего проекта, убедитесь, что галочкой отмечены все модули, которые нужно проанализировать.

Запускаем анализ
При первом анализе проекта вы получите уведомление о создании файла в "[workspace folder]/.PVS-Studio/JavaAnalyzerConfig.json", в котором можно задать некоторые настройки анализа, аналогичные параметрам консольной версии анализатора.
Варианты действий:
- Edit — открыть только что созданный файл, анализ запущен не будет;
- Continue — запустить анализ с параметрами по умолчанию;
- Cancel — отменить запуск анализа (файл создан не будет).
В этом файле вы можете указать параметры, которые будут учитываться при анализе, например:
- Путь к suppress-файлу (с расширением *.json);
- Включить/отключить инкрементальный анализ (по умолчанию отключен);
- Включить/отключить специальную диагностику V6078, обнаруживающую потенциальные проблемы совместимости API между выбранными версиями Java SE (версии указываются в качестве отдельных параметров).
Работа с результатами анализа
Преобразование отчёта PVS-Studio в формат JSON
Обратите внимание: расширение PVS-Studio для Visual Studio Code поддерживает только отчёты в формате JSON. В зависимости от типа проверяемого проекта и способа запуска анализа, PVS-Studio может генерировать отчёт в нескольких форматах. Чтобы отобразить отчёт в расширении, вам потребуется выполнить его преобразование в JSON-формат.
Для преобразования можно воспользоваться утилитами командной строки PlogConverter.exe для Windows и plog-converter для Linux и macOS. Эти утилиты позволяют не только конвертировать отчёт PVS-Studio в разные форматы, но и дополнительно обрабатывать его. Например, проводить фильтрацию предупреждений. Подробнее о них можно прочитать здесь.
Пример команды конвертации отчёта PVS-Studio в JSON-формат при помощи PlogConverter.exe (Windows):
PlogConverter.exe path\to\report.plog -t json ^
-n PVS-StudioПример команды конвертации отчёта PVS-Studio в JSON-формат при помощи plog-converter (Linux и macOS):
plog-converter path/to/report/file.plog -t json \
-o PVS-Studio.jsonПросмотр преобразованного отчёта PVS-Studio в VS Code
Для просмотра отчёта в Visual Studio Code нажмите 'Open report' в окне PVS-Studio и выберите нужный файл. Также открыть отчёт можно, выбрав в палитре команд (Ctrl+Shift+P) 'PVS-Studio: Load Report'.

После этого предупреждения из отчёта отобразятся в таблице:

Для удобной работы с таблицей закрепите её на панели. Для этого кликните правой кнопкой мыши на заголовке панели и выберите "Keep 'PVS-Studio'".

Для работы с отчётом, содержащим относительные пути, необходимо воспользоваться настройкой 'Source Tree Root'. Для этого откройте окно настроек, во вкладке 'Other' нажмите кнопку 'Browse' и выберите директорию, относительно которой будут разворачиваться все пути в файле отчёта.

Фильтрация предупреждений
Механизмы фильтрации окна вывода PVS-Studio позволяют быстро найти и отобразить как отдельные диагностические сообщения, так и целые их группы. Среди инструментов окна есть ряд переключателей, позволяющих включить либо отключить отображение предупреждений из соответствующих им групп.
Все переключатели можно разбить на 3 группы: фильтры по уровню достоверности предупреждений, фильтры сообщений по диагностическим группам, фильтры по ключевым словам. Отфильтровать можно по коду сообщения, по тексту сообщения и по файлу, содержащему сообщение анализатора.
Детальное описание уровней достоверности предупреждений и групп диагностических правил приведено в разделе документации 'Знакомство со статическим анализатором кода PVS-Studio'.
Переключить видимость группы фильтраций можно с помощью кнопок 'Column', 'Level', 'Group'.

Все перечисленные механизмы фильтрации предупреждений можно совмещать между собой. Например, фильтровать сообщения по уровню и группам отображаемых предупреждений, исключать сообщения, помеченные как ложные срабатывания и т.п.
Подавление предупреждений
При первом запуске анализатора на большом проекте может быть действительно много срабатываний. Разумеется, стоит выписать себе самые интересные, а вот остальные можно скрыть при помощи механизма подавления предупреждений.
Для подавления всех предупреждений нужно нажать кнопку 'Suppress All Messages' в правой верхней части окна:

При её активации появится дополнительное окно с вопросом, какие именно предупреждения вы хотите подавить:
- Suppress All — подавит все предупреждения в таблице (даже скрытые через фильтры и настройки);
- Suppress Filtered — подавит только те предупреждения, что сейчас присутствуют в таблице.

При выборе нужного пункта предупреждения будут подавлены в существующий файл подавления предупреждений. Если файл подавления предупреждений не будет найден, то будет создан в следующей директории: "[корневой каталог исходного кода проекта]/.PVS-Studio".
Если предложенный выше вариант вам не подходит, то можно воспользоваться точечным подавлением предупреждений. Для этого необходимо выбрать нужные строки в таблице, открыть контекстное меню и выбрать "Add message to suppression file".

Навигация и сортировка
Окно вывода результатов PVS-Studio в первую очередь предназначено для упрощения навигации по коду проекта и переходу к участкам кода, содержащим потенциальные ошибки. Двойной щелчок мыши по любому из предупреждений в списке автоматически откроет файл, на который данное сообщение указывает.
Для выделения интересных предупреждений, например, тех, к которым имеет смысл вернуться повторно, можно использовать "звёздочку" в соответствующей колонке.
Правый клик по заголовку таблицы вызывает контекстное меню, с помощью которого можно настроить отображаемые столбцы.

Другие возможности
Таблица поддерживает множественное выделение с помощью стандартных комбинаций 'Ctrl' и 'Shift '. Контекстное меню таблицы предупреждений содержит несколько подпунктов:

- Mark as Favorite — отмечает выбранные сообщения как избранные;
- Mark as False Alarm — помечает выбранные сообщения как ложные срабатывания и добавляет специальный комментарий в исходный код;
- Copy message — копирует номер и сообщение диагностики, файл, на котором выдано предупреждение, в буфер обмена;
- Exclude diagnostic — исключает показ всех предупреждений с тем же кодом, что и у выделенного;
- Exclude paths — позволяет исключить путь к выделенному файлу либо часть этого пути. Все предупреждения на файлах, содержащих выбранный путь, не будут показаны.

Кнопки в правой части панели предназначены, соответственно, для запуска анализа, подавления предупреждений, сохранения отчёта, открытия нового отчёта, открытия настроек расширения. При наличии изменений в отчёте кнопка сохранения отчёта поменяет свой фон на красный, как показано на скриншоте ниже.

Конфигурация плагина
Для открытия окна настроек нажмите на крайнюю правую кнопку окна PVS-Studio или нажмите 'Ctrl+Shift+P' и введите 'PVS-Studio: Show Settings'.
Кнопка 'Save settings' сохраняет настройки в формате JSON. Для загрузки сохранённых настроек воспользуйтесь кнопкой 'Load settings'.
False alarms
Во вкладке False alarms можно настроить:
- показывать или нет ложные срабатывания;
- сохранять ли автоматически исходные файлы при отметке предупреждения как ложного;
- добавлять ли дополнительное сообщение к комментарию о ложном срабатывании.

Columns
Данная вкладка настроек позволяет отметить какие столбцы должны отображаться в таблице срабатываний.
Diagnostics
Вкладка Diagnostics позволяет отметить, какие предупреждения должны отображаться в таблице срабатываний. Все срабатывания разбиты на группы. Для поиска определённого диагностического правила можно воспользоваться полем 'Code and Messages'. Кнопки 'Check all/Uncheck all' предназначены для включения/выключения отображения всех диагностик из определённой группы. При отключении всех диагностик из соответствующей группы переключатель этой группы убирается из соответствующей группы фильтрации в окне PVS-Studio.

Exclude paths
Во вкладке Exclude paths в поле 'New excluded path' можно ввести пути или маски путей. Сообщения, выданные на файлы, удовлетворяющие условиям маски, не будут отображаться в таблице срабатываний.
Analysis
Во вкладке Analysis в поле 'Timeout' можно ввести время в секундах, по истечению которого анализ будет прерван. В поле 'Thread Count' можно ввести количество параллельно запускаемых процессов ядра анализатора, которые будут задействованы при анализе.
License
Во вкладке License можно ввести имя пользователя и лицензионный ключ из своей лицензии. Если вы ввели валидные данные, то у вас отобразится сообщение с данными лицензии.

Other
Documentation language. Настройка позволяет задать язык для встроенной справки по диагностическим сообщениям PVS-Studio, доступных на нашем сайте.
Данная настройка не меняет язык интерфейса расширения PVS-Studio или выдаваемых анализатором диагностических сообщений.
Source Tree Root. Для работы с отчётом PVS-Studio, содержащим пути до файлов в относительной форме нужно заменить их на абсолютные. Настройка позволяет задать директорию, относительно которой раскрываются все пути в файле отчёта.
Детальное описание использования относительных путей в файлах отчётов PVS-Studio смотрите здесь.
Security Related Issues. Сообщения в отчёте, классифицируемые по ГОСТ Р 71207-2024, будут выделены дополнительной маркировкой в столбце 'SAST'.
Работа с версиями плагина PVS-Studio
У плагина для VS Code есть жёсткая привязка к установленной версии анализатора. Проблема в том, что плагины для VS Code обновляются автоматически по умолчанию. Это может приводит к рассинхронизации версий плагина и анализатора. Чтобы не возникало проблем в работе плагина, можно отключить его автообновление либо обновить версию анализатора PVS-Studio.
Чтобы отключить автообновление плагина в VS Code, нужно перейти в Extensions, найти плагин PVS-Studio, открыть его и убрать галочку рядом с Auto Update. После этого плагин не будет обновляться в VS Code.

VS Code позволяет установить необходимую версию плагина. Для этого нужно нажать на стрелку рядом с кнопкой Uninstall, в появившемся меню выбрать Install Specific Version.

После этого можно выбрать нужную версию, которая установится автоматически.

Советы по повышению скорости работы PVS-Studio
- Используйте многоядерный компьютер с большим объемом оперативной памяти
- Используйте SSD диск и для системы, и для проверяемого проекта
- Настройте (или выключите) антивирус
- В Visual Studio 2010 и 2012, по возможности используйте Clang в качестве препроцессора вместо Visual C++ (задается в настройках PVS-Studio)
- Исключите из анализа лишние библиотеки (задается в настройках PVS-Studio)
- Итоги
Любой статический анализатор кода работает медленнее компилятора. Это объясняется тем, что компилятор должен отработать очень быстро, пусть и в ущерб глубине анализа. Статические анализаторы вынуждены хранить дерево разбора, чтобы иметь возможность собрать большее количество информации. Хранение дерева увеличивает расход памяти, а множество проверок делает обход дерева ресурсоемкой и медленной операцией. На самом деле всё это не так критично, так как анализ более редкая операция, чем компиляция и пользователи готовы подождать. Тем не менее, всегда хочется, чтобы инструмент работал быстрее. В статье собраны рекомендации, позволяющие существенно увеличить скорость работы PVS-Studio.
Сначала перечислим коротко все рекомендации для того, чтобы пользователи сразу же могли понять, как им улучшить время работы анализатора:
- Используйте многоядерный компьютер с большим объемом оперативной памяти.
- Используйте SSD диск и для системы, и для проверяемого проекта.
- Настройте (или выключите) антивирус.
- По возможности используйте Clang в качестве препроцессора вместо Visual C++ (задается в настройках PVS-Studio) на Visual Studio 2010 и 2012.
- Исключите из анализа лишние библиотеки (задается в настройках PVS-Studio).
Рассмотрим все эти рекомендации более подробно, с пояснениями, почему они позволяют работать быстрее.
Используйте многоядерный компьютер с большим объемом оперативной памяти
PVS-Studio давно (с версии 3.00, вышедшей в 2009 году) поддерживает работу в несколько потоков. Распараллеливание выполняется на уровне файлов. Если анализ выполняется на четырех ядрах, то одновременно проверяется четыре файла. Такой уровень параллелизма позволяет обеспечить существенное повышение производительности. По нашим замерам разница во времени работы на тестовых проектах очень заметна. Анализ в один поток выполняется за 3 часа 11 минут, в то время как анализ в четыре потока выполняется за 1 час 11 минут (данные получены на машине с четырьмя ядрами и восемью гигабайтами оперативной памяти). Отличие в 2.7 раза.
Для каждого потока анализатора рекомендуется иметь не менее одного гигабайта оперативной памяти. В противном случае (если будет много потоков и мало оперативной памяти) будет использоваться файл подкачки, что приведет к замедлению работы. При необходимости можно ограничить количество потоков анализатора с помощью настроек PVS-Studio Options -> Common Analyzer Settings -> Thread Count (документация). По умолчанию запускается столько потоков, сколько ядер в системе.
Рекомендуем использовать машину с четырьмя ядрами и восемью гигабайтами оперативной памяти или мощнее.
Используйте SSD диск и для системы, и для проверяемого проекта
Медленный жесткий диск, как ни странно, является очень слабым местом в работе анализатора кода. Но надо пояснить механизм работы анализатора для того, чтобы было понятно, почему это так. Для того, чтобы выполнить анализ файла, необходимо сначала его препроцессировать, т.е. раскрыть все #define, подставить все #include и т.п. Файл после препроцессинга имеет размер в среднем 10 мегабайт и записывается на диск в папку проекта. Затем уже читается анализатором и начинается его разбор. Рост файла происходит как раз за счет вставки содержимого #include-файлов, которые читаются из системных папок.
Привести конкретные результаты измерений влияния SSD на скорость анализа сложно, так как для этого надо тестировать абсолютно одинаковые машины, различающиеся лишь типом диска, однако, на глаз ускорение очень существенно.
Настройте (или выключите) антивирус
Анализатор кода является сложной и подозрительной программой с точки зрения антивируса по характеру своей работы. Сразу оговоримся, что речь не идет о том, что анализатор распознается как вирус - мы это регулярно проверяем. Кроме того, мы используем сертификат подписи кода. Обратимся опять к описанию работы анализатора кода.
На каждый анализируемый файл запускается отдельный процесс анализатора (модуль PVS-Studio.exe). Если в проекте 3000 файлов, то столько раз и будет запущен PVS-Studio.exe. Для своей работы PVS-Studio.exe вызывает настройку переменных окружения Visual C++ (файлы vcvars*.bat). Также во время работы создается большое количество препроцессированных файлов (*.i), по одному на каждый компилируемый файл. Используются вспомогательные командные (.cmd) файлы.
Все это хоть и не является вирусной активностью, тем не менее, заставляет любой антивирус тратить большое количество ресурсов на бесполезную проверку одного и того же.
Мы рекомендуем сделать следующие исключения в настройках антивируса:
- Не проверять системные папки с Visual Studio:
- C:\Program Files (x86)\Microsoft Visual Studio 11.0
- C:\Program Files (x86)\Microsoft Visual Studio 12.0
- C:\Program Files (x86)\Microsoft Visual Studio 14.0
- и т.д.
- Не проверять папку с PVS-Studio:
- C:\Program Files (x86)\PVS-Studio
- Не проверять папку проекта с кодом:
- Например, C:\Users\UserName\Documents\MyProject
- Не проверять исполняемые файлы Visual Studio:
- C:\Program Files (x86)\Microsoft Visual Studio 11.0\Common7\IDE\devenv.exe
- C:\Program Files (x86)\Microsoft Visual Studio 12.0\Common7\IDE\devenv.exe
- C:\Program Files (x86)\Microsoft Visual Studio 14.0\Common7\IDE\devenv.exe
- и т.п.
- Не проверять исполняемые файлы компилятора cl.exe (разных версий):
- C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC\bin\cl.exe
- C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC\bin\x86_amd64\cl.exe
- C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC\bin\amd64\cl.exe
- C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\cl.exe
- C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\x86_amd64\cl.exe
- C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\amd64\cl.exe
- C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin\cl.exe
- C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin\x86_amd64\cl.exe
- C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin\amd64\cl.exe
- и т.п.
- Не проверять исполняемые файлы PVS-Studio и Clang (разных версий):
- C:\Program Files (x86)\PVS-Studio\x86\PVS-Studio.exe
- C:\Program Files (x86)\PVS-Studio\x86\clang.exe
- C:\Program Files (x86)\PVS-Studio\x64\PVS-Studio.exe
- C:\Program Files (x86)\PVS-Studio\x64\clang.exe
Возможно, приведенный список избыточен, но он дан именно в таком виде для того, чтобы можно было вне зависимости от конкретного антивируса указать, какие файлы и процессы проверять не надо.
Иногда, может быть, антивирус вообще не используется на машине (например, на специальном компьютере для сборок и запуска анализатора кода). В этом случае скорость работы будет наибольшая. Так как даже если в антивирусе указаны перечисленные выше исключения, на их проверку все равно будет тратиться время.
Наши тестовые измерения показывают, что агрессивно настроенный антивирус может давать замедление работы анализатора кода в два и более раз.
В Visual Studio 2010 и 2012, по возможности используйте Clang в качестве препроцессора вместо Visual C++ (задается в настройках PVS-Studio)
Для препроцессирования файлов в PVS-Studio используется внешний препроцессор. В среде Visual Studio по умолчанию используется нативный препроцессор Microsoft Visual C++ - cl.exe. В PVS-Studio 4.50 появилась поддержка второго независимого препроцессора Clang, который лишен ряда недостатков препроцессора от Microsoft (хотя и имеет свои недостатки).
В некоторых старых версия Visual Studio (2010 и 2012), препроцессор cl.exe работает значительно медленнее, чем clang. Использование препроцессора Clang в этих средах позволяет повысить скорость работы в 1.5-1.7 раз.
Однако, здесь есть нюанс, который надо учитывать. Указать используемый препроцессор можно в настройках PVS-Studio Options -> Common Analyzer Settings -> Preprocessor (документация). Доступны варианты: VisualCPP, Clang и VisualCPPAfterClang. Первые два варианта очевидны, а третий вариант означает, что сначала будет использоваться Clang. В случае, если при препроцессировании будут ошибки, то затем файл будет заново препроцессирован с помощью Visual C++.
Если ваш проект проверяется без проблем с помощью Clang, то вы можете использовать стандартное значение VisualCPPAfterClang или Clang - без разницы. Однако, если ваш проект может быть проверен только с помощью Visual C++, рекомендуем указать именно это значение, чтобы анализатор не запускал напрасно Clang в попытках препроцессировать им.
Исключите из анализа лишние библиотеки (задается в настройках PVS-Studio)
Любой крупный программный проект использует много сторонних библиотек, таких как zlib, libjpeg, Boost и др. Иногда эти библиотеки собираются отдельно, и тогда в основном проекте доступны только заголовочные и библиотечные (lib) файлы. А иногда библиотеки очень плотно интегрированы в проект, фактически становясь его частью. В этом случае при компиляции основного проекта компилируются также и файлы с кодом от этих библиотек.
Анализатору PVS-Studio можно указать, чтобы он не проверял код сторонних библиотек. Ведь даже если там и будут найдены какие-то ошибки, то, скорее всего, вы их править не станете. Но исключая из анализа такие папки можно существенно увеличить общую скорость анализа.
Также есть смысл исключить из анализа код, который долгое время не будет гарантированно меняться.
Для того чтобы исключить из анализа какие-то папки или отдельные файлы, используйте настройки PVS-Studio -> Don't Check Files (документация).
Для исключения папок можно указать в списке папок либо одну общую папку вроде c:\external-libs, либо явно перечислить некоторые из них: c:\external-libs\zlib, c:\external-libs\libjpeg и т.д. Можно указывать полный путь, относительный путь или маску. Например, достаточно указать zlib и libjpeg в списке папок - это автоматически будет трактоваться как папка с маской *zlib* и *libjpeg*. Подробнее смотрите в документации.
Итоги
Перечислим еще раз способы повысить скорость работы PVS-Studio:
- Используйте многоядерный компьютер с большим объемом оперативной памяти.
- Используйте SSD диск и для системы, и для проверяемого проекта (Update: для PVS-Studio версии 5.22 и выше, размещение самого проекта на SSD уже не оказывает влияние на скорость проверки).
- Настройте (или выключите) антивирус.
- В Visual Studio 2010 и 2012 по возможности используйте Clang в качестве препроцессора вместо Visual C++ (задается в настройках PVS-Studio).
- Исключите из анализа лишние библиотеки (задается в настройках PVS-Studio).
Наибольший эффект достигается при одновременном применении наибольшего числа из этих рекомендаций.
Устранение неисправностей при работе PVS-Studio
- Что необходимо знать в первую очередь о принципах работы PVS-Studio
- Не получается проверить файл\проект из IDE плагина PVS-Studio
- Некорректное препроцессирование исходного файла при запуске анализа из IDE плагина. Ошибка V008
- Падение IDE плагина с сообщением PVS-Studio internal error
- Необработанное падение IDE при использовании PVS-Studio
- Падение анализатора PVS-Studio.exe
- Ошибки V001/V003
- Анализатор не находит ошибку в некорректном коде либо генерирует большое количество ложных срабатываний
- Проблемы при работе с файлом отчёта PVS-Studio из IDE плагина
- Анализ кода из IDE плагина работает слишком медленно. Не используются все логические процессоры в многопроцессорной системе
- При проверке группы проектов или отдельного проекта C или C++ выдаётся сообщение "Files with C or C++ source code for analysis not found."
- Проект, который успешно компилируется в Visual Studio, не удаётся проверить в PVS-Studio с ошибками вида "Cannot open include file", "use the /MD switch for _AFXDLL builds". Ошибочная подстановка при использовании предкомпилированных заголовков при препроцессировании
- Сообщение 'PVS-Studio is unable to continue due to IDE being busy' при работе на Windows 8. Ошибки вида 'Library not registered'
- После установки среды разработки Visual Studio на машине с установленной до этого PVS-Studio, во вновь установленной версии Visual Studio отсутствует пункт меню 'PVS-Studio'
- Не удаётся проверить Unity проект. The solution file has two projects named "UnityEngine.UI"
- Аварийное завершение работы PVS-Studio_Cmd.exe при некорректном определении пути до импортируемого файла
- Возникает "GC overhead limit exceeded" или завершение анализа по таймауту
- Не удается запустить анализ (возникают ошибки V06X)
Что необходимо знать в первую очередь о принципах работы PVS-Studio
В PVS-Studio можно выделить 2 главных компонента: command-line анализатор PVS-Studio.exe и IDE плагин, интегрирующий этот command-line анализатор в одну из поддерживаемых сред разработки (Microsoft Visual Studio). При этом сам command-line анализатор по принципу своей работы очень схож с компилятором — он вызывается для каждого из проверяемых файлов с параметрами, включающими в себя, в том числе, и оригинальные параметры компиляции этого файла. Затем анализатор вызывает необходимый ему препроцессор (опять, в соответствии с препроцессором, используемым при компиляции проверяемого файла) и производит непосредственный анализ полученного препроцессированного временного файла, т.е. файла, в котором раскрыты все include и define директивы.
Таким образом, command-line анализатор, как, впрочем, и компилятор (например, компилятор Visual C++ cl.exe), не предназначен для непосредственного использования конечным пользователем. Продолжая аналогию, компиляторы используются в большинстве случаев не напрямую, а с помощью специальной сборочной системы. Такая система подготавливает параметры запуска для каждого из собираемых файлов, а также, обычно, осуществляет распараллеливание самой сборки по имеющимся логическим процессорам для оптимизации затрачиваемого времени. Аналогом как раз такой сборочной системы для конечного пользователя и выступает IDE плагин PVS-Studio.
Но использование анализатора PVS-Studio.exe не ограничивается IDE плагинами. Как уже было сказано выше, command-line анализатор очень близок в своём использовании непосредственно к компилятору. Соответственно, его вызов можно встроить, при необходимости, и напрямую в сборочную систему, наравне с самим компилятором. Такой вариант может оказаться полезным при использовании для сборки не поддерживаемого нами сценария, такого как, например, custom-made сборочная система или IDE, отличная от Visual Studio. Заметьте, что PVS-Studio.exe поддерживает проверку исходных файлов, предназначенных для компиляторов gcc, clang и cl (включая специфические ключевые слова и конструкции).
Помимо IDE плагинов в дистрибутиве мы предоставляем также плагин для сборочной системы Microsoft MSBuild, которая используется для сборки Visual C++ проектах в IDE Visual Studio, начиная с версии 2010. Но, не стоит путать этот плагин с IDE плагином для Visual Studio!
Таким образом, проекты в Visual Studio (2010 версии и выше), можно проверить двумя различными способами: напрямую через наш IDE плагин, либо интегрировав проверку в сборочную систему (MSBuild плагин). Но ничто не мешает вам, при необходимости, написать и свой плагин для вызова статического анализа, как для MSBuild, так и для любой другой сборочной системы, либо даже встроить вызов PVS-Studio.exe напрямую, если это возможно, как в случае с make сборочными сценариями.
Не получается проверить файл\проект из IDE плагина PVS-Studio
Если PVS-Studio выдаёт для вашего файла сообщение вида "C/C++ код не найден", убедитесь, что файл, который вы пытаетесь проверить, включён в сборочный проект (исключённые из сборки файлы PVS-Studio игнорирует). Если вы получаете такое сообщение на всём проекте, убедитесь, что ваш проект является C/C++ проектом поддерживаемого типа. В Visual Studio поддерживаются только Visual C++ проекты для версий 2005 и выше, и соответствующие им Platform Toolset. Проверка расширений проектов, использующих другие компиляторы (например, проекты для компилятора C++ от Intel) или параметры (Windows DDK драйверы) не поддерживается. Несмотря на то, что сам command-line анализатор PVS-Studio.exe поддерживает проверку файлов для компиляторов gcc/clang, проектные расширения IDE, использующие данные компиляторы, не поддерживаются.
Если ваш случай не подходит под описанное выше, вы можете обратиться в нашу поддержку. По возможности, предоставьте нам временные конфигурационные файлы для проблемных файлов. Их можно получить, переключив настройку PVS-Studio -> Options -> Common Analyzer Settings -> Remove Intermediate Files в False, файлы с именем вида %SourceFilename.cpp%.PVS-Studio.cfg должны появиться в той же директории, где лежит проектный файл (.vcxproj). Если это возможно, создайте пустой тестовый проект, на котором будет повторяться ваша проблема, и также пришлите его нам.
Некорректное препроцессирование исходного файла при запуске анализа из IDE плагина. Ошибка V008
Если после проверки вашего файла\проекта PVS-Studio выдаёт в окне отчёта сообщения с кодом V008 и\или сообщения об ошибке от препроцессора (clang/cl), удостоверьтесь, что файл(ы), который вы пытаетесь проверять, компилируются без ошибок. Для работы анализатора PVS-Studio требуются корректно компилируемые исходные C/C++ файлы. Ошибки линковки же для работы анализатора не имеют значения.
Ошибка V008 означает, что отработавший препроцессор вернул ненулевой код. Обычно сообщение V008 сопровождается сообщением от самого препроцессора о причине ошибки (например, не найден include файл). Заметьте, что в IDE Visual Studio наш плагин, для оптимизации времени работы, использует специальный режим дуального препроцессирования: сначала файл будет препроцессирован с помощью более быстрого препроцессора clang, а в случае ошибки препроцессирования (clang не поддерживает некоторые специфичные для Visual C++ конструкции) будет запущен стандартный препроцессор cl.exe. Если у вас возникают ошибки препроцессирования clang, вы можете попробовать переключить IDE плагин на постоянное использование одного препроцессора (настройка PVS-Studio -> Options -> Common Analyzer Settings -> Preprocessor).
Иногда V008 может возникать из-за слишком длинных путей к исходным файлам. Если вы используете Windows, то можете попробовать увеличить максимальное значение длины путей. Как это сделать описано вот тут.
Если вы уверены, что ваш файл корректно собирается в IDE/сборочной системе, то, возможно, какие-то из его параметров компиляции некорректно передаются в анализатор PVS-Studio.exe. В таком случае отправьте, пожалуйста, в нашу поддержку временные конфигурационные файлы для этих файлов, а также текст сообщения из лога PVS-Studio. Временные конфигурационные файлы можно получить, переключив настройку PVS-Studio -> Options -> Common Analyzer Settings -> Remove Intermediate Files в False, файлы с именем вида %SourceFilename.cpp%.PVS-Studio.cfg должны появиться в той же директории, где лежит проектный файл (.vcxproj). Если это возможно, создайте пустой тестовый проект, на котором будет повторяться ваша проблема, и также пришлите его нам.
Падение IDE плагина с сообщением PVS-Studio internal error
Если вы столкнулись с аварийной остановкой работы плагина с выдачей диалога PVS-Studio Internal Error, пришлите, пожалуйста, в нашу поддержку стек работы анализатора, который можно скопировать из данного диалогового окна.
Если вам удаётся стабильно повторить ошибку, то помимо стека падения пришлите нам лог трассировки работы плагина. Его можно получить, включив режим трассировки в настройках PVS-Studio -> Options -> Specific Analyzer Settings -> TraceMode (режим Verbose). Лог трассировки будет сохранён в стандартную пользовательскую директорию Application Data\Roaming\PVS-Studio с именем PVSTracexxxx_yyy.log, где xxxx- PID процесса devenv.exe / bds.exe, yyy - номер лога для данного процесса.
Необработанное падение IDE при использовании PVS-Studio
Если вы наблюдаете систематическое падение вашей среды разработки, предположительно вызванное работой PVS-Studio, проверьте, пожалуйста, системные event логи Windows (Event Viewer) и пришлите в нашу поддержку сигнатуру и стек падения (при наличии) для приложения devenv.exe \ bds.exe (уровень сообщения Error), доступные в списке Windows Logs -> Application.
Падение анализатора PVS-Studio.exe
Если вы наблюдаете систематическое необработанное падение анализатора PVS-Studio.exe, то просим вас повторить шаги, описанные в пункте "Падение IDE при использовании PVS-Studio", только для процесса PVS-Studio.exe.
Ошибки V001/V003
Ошибка V003 означает, что файл не был проверен анализатором PVS-Studio.exe из-за обработанного внутреннего исключения. Если вы видите в логе анализатора ошибки с кодом V003, просим вас прислать нам временный файл препроцессора (i-файл, содержащий все раскрытые include и define директивы) для файла, который вызывает ошибку v003 (можно посмотреть имя в поле file). Получить такой файл можно, переключив настройку PVS-Studio -> Options -> Common Analyzer Settings -> Remove Intermediate Files в False. Intermediate файлы с именами вида SourceFileName.i будут появляться после перезапуска анализа в директории проверяемого проекта (т.е. директории, где находятся файлы vcproj/vcxproj/cbproj и т.п.).
Также, анализатор не всегда может полностью проанализировать файл с исходным кодом. Это не всегда происходит по вине PVS-Studio и подробнее с причинами можно ознакомиться в документации для ошибки V001. Независимо от причины выдачи сообщения V001, это сообщение не критично. Как правило, неполный разбор файла несущественен с точки зрения анализа. PVS-Studio просто пропускает функцию/класс с ошибкой и продолжает анализ файла. Непроанализированным остается совсем небольшой участок кода. Если же данный участок содержит критичные для вас фрагменты, вы можете также прислать нам i-файл, полученный для данного исходного файла.
Анализатор не находит ошибку в некорректном коде либо генерирует большое количество ложных срабатываний
Если вам кажется, что анализатор не находит ошибки во фрагменте вашего кода, содержащем её, или же, наоборот, анализатор генерирует ложные срабатывания для фрагмента кода, который, по вашему мнению, корректен, просим вас прислать нам временный файл препроцессора. Получить такой файл можно, переключив настройку PVS-Studio -> Options -> Common Analyzer Settings -> Remove Intermediate Files в False. Intermediate файлы с именами вида SourceFileName.i будут появляться после перезапуска анализа в директории проверяемого проекта (т.е. директории, где находятся файлы vcproj/vcxproj/cbproj и т.п.). Также включите в ваше письмо фрагмент кода из исходного файла, который вызывает проблемы.
Мы обязательно рассмотрим возможность реализации диагностики вашего примера, либо правки имеющихся диагностик для уменьшения числа ложных срабатываний в вашем коде.
Проблемы при работе с файлом отчёта PVS-Studio из IDE плагина
Если вы столкнулись с проблемами при работе с отчётом PVS-Studio из окна нашего IDE плагина, а именно: некорректно осуществляется навигация по проверенным исходным файлам и\или файлы вообще не открываются для навигации, происходит некорректная разметка вашего кода маркерами ложных срабатываний или комментариями и т.п. В таком случае просим вас прислать в поддержку лог трассировки работы плагина. Его можно получить, включив режим трассировки в настройках PVS-Studio -> Options -> Specific Analyzer Settings -> TraceMode (режим Verbose). Лог трассировки будет сохранён в стандартную пользовательскую директорию Application Data\Roaming\PVS-Studio с именем PVSTracexxxx_yyy.log, где xxxx- PID процесса devenv.exe /bds.exe, yyy - номер лога для данного процесса.
Также, если это возможно, создайте пустой тестовый проект, на котором будет повторяться ваша проблема, и тоже пришлите его нам.
Анализ кода из IDE плагина работает слишком медленно. Не используются все логические процессоры в многопроцессорной системе
IDE плагин PVS-Studio способен распараллеливать анализ кода на уровне проверяемых файлов, т.е. возможен параллельный запуск проверки для любых проверяемых файлов, даже внутри одного проекта. По умолчанию плагин устанавливает количество потоков для проверки в соответствии с количеством процессоров в системе. Изменить количество параллельно запускаемых анализаторов можно с помощью настройки PVS-Studio -> Options -> Common Analyzer Settings -> ThreadCount.
Если вам кажется, что не все логические процессоры вашей системы достаточно загружены, вы можете увеличить количество параллельных потоков для анализа. Однако следует учитывать, что статический анализ, в отличие от компиляции, более требователен к ресурсам основной памяти системы: на каждый экземпляр анализатора требуется примерно 1.5 гигабайта памяти.
Если ваша система, даже при наличии многоядерного процессора, не удовлетворяет данным требованиям, возможно резкое проседание производительности анализатора, вызываемое необходимостью задействования файла подкачки. В таком случае мы рекомендуем снизить количество параллельных потоков анализатора до удовлетворения требования в 1.5 гигабайта на поток, даже если это значение будет ниже количества ядер в системе.
Следует учитывать, что при большом количестве параллельных потоков, узким местом может стать жесткий диск, где создаются временные препроцессированные *.i файлы. Иногда размер этих файлов достаточно велик. Одним из способов существенно уменьшить время анализа является использование SSD дисков или RAID массива.
Падение производительности возможно также и при использовании ненастроенного антивирусного ПО. В связи с тем, что плагин PVS-Studio запускает множество экземпляров анализатора и интерпретатора командной строки cmd.exe, антивирус может находить такое поведение подозрительным. Для оптимизации времени выполнения анализа мы рекомендуем добавлять PVS-Studio.exe, а также все соответствующие директории в исключения вашего антивируса, либо отключать real-time защиту на время выполнения анализа.
Если же вы используете антивирус Security Essentials (ставший частью Windows Defender начиная с Windows 8), то возможно резкое падение производительности анализа для некоторых проектов/настроек. Вы можете ознакомиться с соответствующей статьёй нашего блога для более подробного разъяснения причин этого явления.
При проверке группы проектов или отдельного проекта C или C++ выдаётся сообщение "Files with C or C++ source code for analysis not found."
Не проверяются проекты, выключенные в общей сборке через окно Configuration Manager среды Visual Studio.
Для корректного анализа C или C++ проектов с помощью статического анализатора PVS-Studio эти проекты должны быть компилируемы в Visual C++ и собираться без ошибок. Поэтому при проверке группы проектов или отдельного проекта PVS-Studio произведёт анализ только для проектов, включённых в общую сборку.

Не включённые в сборку проекты будут пропущены. Если ни один из имеющихся проектов не включён в сборку, либо если выбрана проверка одного не включённого в сборку проекта, будет выдано сообщение "Files with C or C++ source code for analysis not found" и анализ не будет запущен. Посмотреть, какие проекты включены, а какие выключены в общей сборке можно с помощью окна Configuration Manager для текущего решения Visual Studio.
Проект, который успешно компилируется в Visual Studio, не удаётся проверить в PVS-Studio с ошибками вида "Cannot open include file", "use the /MD switch for _AFXDLL builds". Ошибочная подстановка при использовании предкомпилированных заголовков при препроцессировании
Если при проверке анализатором проекта, который компилируется в Visual Studio без ошибок, на некоторых файлах возникают ошибки, связанные с ненайденными заголовочными файлами, некорректно заданными флагами компиляции (например, флаг /MD) или макросами препроцессора, то возможно, что такое поведение является проявлением проблемы с некорректно подставленными при препроцессировании файлами, используемыми для создания предкомпилированных заголовков.
Такая проблема возникает из-за различий в поведении компилятора Visual C++ (cl.exe) в режимах компиляции и препроцессирования. При обычной сборке компилятор работает в "стандартном" режиме компиляции (т.е. результатом его работы являются объектные, бинарные файлы). Однако, для осуществления статического анализа, PVS-Studio запускает компилятор в режиме препроцессора. В таком режиме компилятор осуществляет раскрытие директив подстановки и макросов.
Но, если компилируемый файл использует предкомпилированный заголовок, компилятор не будет использовать сам заголовочный файл, когда он встретится в директиве #include. Вместо этого компилятор возьмёт заранее предкомпилированный pch файл. Однако, в режиме препроцессирования компилятор проигнорирует факт наличия предкомпилированного pch, и попробует раскрыть такой #include "обычным способом", т.е. вставив содержимое самого заголовочного файла.
Очень часто в рамках одного решения Visual Studio сразу несколько проектов используют предкомпилированные заголовки с одинаковыми именами (чаще всего это stdafx.h). Это зачастую может приводить к тому, что, из-за описанного выше различия в поведении компилятора, препроцессор включает в файл предкомпилированный заголовок, относящийся к другому проекту. Это может случиться по разным причинам. Например, файлу корректно указан необходимый pch, но в списке Include директорий содержатся несколько путей, содержащих несколько разных stdafx.h, и неправильная версия оказывается в приоритете для включения (т.е. путь до её директории встретится первым в строке запуска компилятора). Ещё один возможный сценарий - несколько проектов содержат один и тот же C++ файл. Этот файл собирается с разными параметрами в разных проектах и использует, соответственно, разные pch. Но такой файл физически лежит в одном месте, и рядом с ним лежит stdafx.h от одного из проектов, в который он включен. Если же в этот файл stdafx.h включён через директиву #include, использующую кавычки, то препроцессор всегда будет отдавать при включении приоритет файлу из текущей директории, какие бы пути и в каком бы порядке не были указаны в его Include'ах.
Включение неправильного файла предкомпилированных заголовков не всегда будет приводить к ошибке препроцессирования. Однако, если, например, один из проектов использует MFC, а другой не использует, или проекты используют разные наборы Include'ов, файлы предкомпилированных заголовков окажутся несовместимыми и возникнет ошибка - статический анализ для такого файла работать не будет.
К сожалению, со стороны анализатора нет возможности как-либо обойти подобную проблему, т.к. она связана с поведением препроцессора cl.exe. Если вы столкнулись с ней на одном из ваших проектов, вы можете решить её одним из следующих способов, в зависимости от причины её возникновения.
Если файл предкомпилированных заголовков некорректно подхватывается из-за того, что include с путём до его директории передан в командной строке компилятора раньше пути до корректной директории, вы можете просто разместить путь до корректной директории самым первым в списке Include'ов.
Если же некорректный файл предкомпилированных заголовков подхватился из-за нахождения его в одной директории с использующим его исходным файлом, вы можете использовать для его включения директиву #include с угловыми скобками, например:
#include <stdafx.h>При такой форме записи компилятор будет игнорировать файлы из текущей директории при подстановке.
Сообщение 'PVS-Studio is unable to continue due to IDE being busy' при работе на Windows 8. Ошибки вида 'Library not registered'
При проверке крупных (более 1000 файлов) проектов в PVS-Studio на операционной системе Windows 8 с использованием Visual Studio 2010 или более поздних версий возможно возникновение ошибок вида 'Library not registered' или остановка анализа в произвольный момент с сообщением 'PVS-Studio is unable to continue due to IDE being busy'.
Подобные ошибки могут возникать из-за нескольких причин: некорректно завершённый процесс установки среды Visual Studio или конфликты совместимости нескольких разных версий среды, установленных в системе. Даже если в вашей системе установлена только одна версия среды Visual Studio, но была раньше установлена и затем удалена другая версия IDE, есть вероятность, что удаление предыдущей версии прошло некорректно. В частности, конфликт совместимости может возникнуть, если в вашей системе установлены одновременно одна из Visual Studio 2010\2012\2013\2015\2017\2019\2022 и Visual Studio 2005 и\или 2008.
К сожалению, PVS-Studio не может самостоятельно обойти подобные ошибки, т.к. они вызваны конфликтами в COM интерфейсах, используемых в API среды Visual Studio. Если вы столкнулись с подобной проблемой, вы можете решить её несколькими способами. Использование PVS-Studio на системе с "чистой" установкой Visual Studio одной версии должно решить данную проблему. Если это невозможно, вы можете попробовать проверить ваш проект частями, в несколько заходов. Также следует заметить, что описанная ошибка возникает обычно в ситуации, когда помимо непосредственной работы анализатора PVS-Studio, IDE выполняет в фоновом режиме ещё какую-либо операцию (например, разбор #include директив системой автодополнения IntelliSense). Если вы дождётесь завершения этой операции перед запуском анализатора, это, возможно, позволит вам проверить проект полностью.
Вы также можете воспользоваться альтернативными способами запуска анализатора для проверки ваших файлов. Например, проверить любой проект с помощью режима отслеживания запусков компилятора из приложения C and C++ Compiler Monitoring UI (Standalone.exe).
После установки среды разработки Visual Studio на машине с установленной до этого PVS-Studio, во вновь установленной версии Visual Studio отсутствует пункт меню 'PVS-Studio'
К сожалению, из-за особенностей реализации механизма расширений для среды Visual Studio, PVS-Studio не может автоматически "подхватить" вновь установленную версию Visual Studio, если сама инсталляция новой версии запускалась после инсталляции PVS-Studio.
Приведём пример. Предположим, что перед установкой PVS-Studio на машине присутствовала только Visual Studio 2013. После установки анализатора, в меню Visual Studio 2013 появится пункт 'PVS-Studio' (если была выбрана соответствующая опция установщика), который позволит проверять ваши проекты в этой IDE. Теперь если на этой же машине установить Visual Studio 2015 (уже после того, как была установлена PVS-Studio), меню этой версии среды не будет содержать пункта 'PVS-Studio'.
Для того, чтобы добавить во вновь установленную IDE интеграцию анализатора, необходимо перезапустить инсталлятор PVS-Studio (файл PVS-Studio_Setup.exe). Если у вас не осталось этого файла, вы можете скачать его с нашего сайта. На странице выбора версий Visual Studio в инсталляторе, checkbox напротив нужной вам версии должен стать доступен для выбора после установки соответствующей ему версии IDE.
Не удаётся проверить Unity проект. The solution file has two projects named "UnityEngine.UI"
Причины возникновения проблемы и способы её решения описаны в отдельной заметке.
Аварийное завершение работы PVS-Studio_Cmd.exe при некорректном определении пути до импортируемого файла
Иногда PVS-Studio может некорректно производить расчёт нужной для анализа версии Visual Studio. Это может приводить к аварийному завершению работы анализатора с различными ошибками.
Пример ошибки:
Can't reevaluate project MyProj.vcxproj with parameters: Project ToolsVersion 'Current'; PlatformToolset 'v142'. Previous evaluation error: 'The imported project "C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\MSBuild\Microsoft\VC\v170\Microsoft.Cpp.Default.props" was not found.
Как видно из сообщения, PVS-Studio неправильно сформировал путь до Microsoft.Cpp.Default.props. Жирным шрифтом выделен некорректный фрагмент. v170 используется для Visual Studio 2022. В данном случае требуется Visual Studio 2019, а следовательно, корректным фрагментом является v160.
Данная проблема может появляться по множеству причин. Вот некоторые из них:
- неправильное значение переменной окружения VisualStudioVersion;
- существуют файлы Visual Studio, оставшиеся при некорректном её удалении;
- проект не собирается нужной Visual Studio.
С решением проблем может помочь установка корректного значения переменной окружения VisualStudioVersion. Например, Visual Studio 2019 соответствует значение 16.0, а Visual Studio 2022 – 17.0.
Ошибка маловероятна при использовании плагина для Visual Studio, так как при запуске анализа из IDE нужное значение записывается в VisualStudioVersion автоматически.
Возникает "GC overhead limit exceeded" или завершение анализа по таймауту
Проблему нехватки памяти можно решить увеличением доступного объема памяти и стека.
В плагине для Maven:
<jvmArguments>-Xmx4096m, -Xss256m</jvmArguments>
В плагине для Gradle:
jvmArguments = ["-Xmx4096m", "-Xss256m"]
В плагине для IntelliJ IDEA:
1) Analyze -> PVS-Studio -> Settings
2) Вкладка Environment -> JVM arguments
Обычно объема памяти по умолчанию может не хватать при анализе сгенерированного кода с большим количеством вложенных конструкций.
Возможно, стоит исключить этот код из анализа (с помощью exclude), чтобы не тратить на него лишнее время.
Не удается запустить анализ (возникают ошибки V06X)
В случае если не удается запустить анализ, пожалуйста, напишите нам в поддержку и приложите *.json файлы из директории .PVS-Studio (находится в директории с проектом).
Дополнительная настройка диагностических правил C и C++ анализатора
- Принудительное включение диагностических правил для проектов на основе Unreal Engine
- Функция может / не может возвращать нулевой указатель
- Настройка обработки макроса assert()
- Псевдоним для системной функции
- Пользовательская функция форматного ввода/вывода
Пользовательские аннотации представляют собой комментарии специального вида, которые можно указать в исходном коде для дополнительной настройки диагностических правил. Аннотация может быть расположена в одном из следующих мест:
- В анализируемом файле (*.c, *.cpp, *.cxx, ....). Аннотация будет работать только в контексте этого файла.
- В заголовочном файле (*.h, *.hxx, ....). Аннотация будет работать на всех анализируемых файлах, включающих этот заголовочный файл.
- В файле конфигурации диагностических правил (.pvsconfig). Аннотация будет работать на всех анализируемых файлах проекта/решения.
Далее представлен список пользовательских аннотаций для изменения поведения диагностических правил. Этот функционал доступен только для С и C++ анализатора. При проверке проектов, написанных на других языках, описанные здесь аннотации будут игнорироваться.
Примечание. По умолчанию пользовательские аннотации не применяются к виртуальным функциям. О том, как включить данный функционал, вы можете прочитать здесь.
Принудительное включение диагностических правил для проектов на основе Unreal Engine
Если ваш проект основан на игровом движке Unreal Engine, то анализатор также применяет ряд диагностических правил (например, V1100, V1102), находящих характерные UE-проектам ошибки. Диагностические правила активируются лишь тогда, когда анализатор обнаруживает включение заголовочных файлов из директории с исходным кодом UE.
Если в проекте присутствуют компилируемые файлы, которые не включают такие заголовочные файлы, то диагностические правила не применяются даже если они включены. Это сделано для того, чтобы не генерировать нерелевантные предупреждения для проектов, не использующих UE.
Если вы хотите принудительно активировать набор диагностических правил для произвольного компилируемого файла или группы файлов, то добавьте следующий комментарий:
//V_TREAT_AS_UNREAL_ENGINE_FILEФункция может / не может возвращать нулевой указатель
Существует множество системных функций, которые при определённых условиях возвращают нулевой указатель. Хорошими примерами являются такие функции, как 'malloc', 'realloc', 'calloc'. Эти функции возвращают нулевой указатель в случае, когда невозможно выделить буфер памяти указанного размера.
Можно изменить поведение анализатора и заставить его считать, что, например, функция 'malloc' не может вернуть нулевой указатель. Например, это может потребоваться, если пользователь использует системные библиотеки, в которых ситуации нехватки памяти обрабатываются особым образом.
Также возможна обратная ситуация. Пользователь может помочь анализатору, подсказав ему, что определённая системная или его собственная функция может вернуть нулевой указатель.
Для этого существует возможность с помощью пользовательских аннотаций указать анализатору, что функция может или, наоборот, не может вернуть нулевой указатель.
- V_RET_NULL - функция может вернуть нулевой указатель
- V_RET_NOT_NULL - функция не может вернуть нулевой указатель
Формат аннотации:
//V_RET_[NOT]_NULL, function: [namespace::][class::]functionName- Ключ 'function' – после ':' нужно указать полное имя функции. Оно состоит из названия пространства имён, названия класса и названия функции. Пространство имён и/или класс могут отсутствовать.
Предположим, пользователь хочет подсказать анализатору, что функция 'Foo' класса 'Bar', лежащего в пространстве имён 'Space', не может возвращать нулевой указатель. Тогда аннотация будет выглядеть следующим образом:
//V_RET_NOT_NULL, function: Space::Bar::FooАннотации поддерживают вложенные пространства имён и вложенные классы. Предположим, в пространстве имён 'Space1' лежит пространство имён 'Space2'. В пространстве имён 'Space2' лежит класс 'Bar1'. В классе 'Bar1' лежит класс 'Bar2'. У класса 'Bar2' есть функция 'Foo', которая не может возвращать нулевой указатель. Тогда можно проаннотировать эту функцию следующим образом:
//V_RET_NOT_NULL, function: Space1::Space2::Bar1::Bar2::FooДля системных функций аннотация может быть расположена в глобальном заголовочном файле (например, предкомпилированный заголовочный файл) или файле конфигурации диагностических правил.
Для наглядности рассмотрим два примера аннотации системных функций.
Функция не возвращает нулевой указатель:
//V_RET_NOT_NULL, function:mallocТеперь анализатор считает, что функция 'malloc' не может вернуть нулевой указатель и не будет выдавать предупреждение V522 для следующего фрагмента кода:
int *p = (int *)malloc(sizeof(int) * 100);
p[0] = 12345; // okФункция возвращает потенциально нулевой указатель:
//V_RET_NULL, function: Memory::QuickAllocПосле добавления этого комментария анализатор начнёт выдавать предупреждение для следующего кода:
char *p = Memory::QuickAlloc(strlen(src) + 1);
strcpy(p, src); // Warning!В проектах с особыми требованиями качества может понадобится найти все функции, возвращающие указатель. Для этого можно воспользоваться следующим комментарием:
//V_RET_NULL_ALLМы не рекомендуем использовать этот режим из-за выдачи очень большого количества предупреждений. Но если в вашем проекте это действительно необходимо, то вы можете воспользоваться этим специальным комментарием, чтобы добавить в код проверку возвращаемого указателя для всех таких функций.
Настройка обработки макроса assert()
По умолчанию анализатор одинаково проверяет код, в котором присутствует макрос 'assert', независимо от конфигурации проекта (Debug, Release, ...). А именно – не учитывает, что при ложном условии в макросе выполнение кода прерывается.
Чтобы задать иное поведение анализатора, используйте следующий комментарий в коде:
//V_ASSERT_CONTRACTОбратите внимание, что в таком режиме результаты анализа могут отличаться в зависимости от того, как раскрывается макрос в проверяемой конфигурации проекта.
Для пояснения рассмотрим следующий код:
MyClass *p = dynamic_cast<MyClass *>(x);
assert(p);
p->foo();Оператор 'dynamic_cast' может вернуть значение 'nullptr'. Поэтому в стандартном режиме анализатор выдаст предупреждение, что при вызове функции 'foo' может произойти разыменовывание нулевого указателя.
После добавления комментария '//V_ASSERT_CONTRACT' предупреждение исчезнет.
Можно указать имя макроса, который анализатор будет обрабатывать так же, как 'assert'. Для этого используйте следующую аннотацию:
//V_ASSERT_CONTRACT, assertMacro:[MACRO_NAME]Ключ 'assetMacro' – имя макроса, который анализатор будет обрабатывать как 'assert'. Вместо '[MACRO_NAME]' необходимо подставить имя аннотируемого макроса.
Пример:
//V_ASSERT_CONTRACT, assertMacro:MY_CUSTOM_MACRO_NAMEТеперь анализатор будет обрабатывать макрос 'MY_CUSTOM_MACRO_NAME' как 'assert'.
Если необходимо указать несколько имен макросов, для каждого из них следует добавить отдельную директиву '//V_ASSERT_CONTRACT'.
Псевдоним для системной функции
Иногда в проектах используются собственные реализации разных системных функций, например, 'memcpy', 'malloc' и т.п. В этом случае анализатор не будет понимать, что поведение таких функций идентично стандартным аналогам. Существует возможность ставить имена своих функций в соответствие системным.
Формат записи:
//V_FUNC_ALIAS, implementation:imp, function:f, namespace:n, class:c- Ключ 'implementation' – имя стандартной функции, для которой определяется псевдоним;
- Ключ 'function' – имя псевдонима. Сигнатура функции, имя которой указано в этом ключе, должна совпадать с сигнатурой функции, указанной в ключе 'implementation';
- Ключ 'class' – имя класса. Может отсутствовать;
- Ключ 'namespace' – имя пространства имен. Может отсутствовать.
Пример использования:
//V_FUNC_ALIAS, implementation:memcpy, function:MyMemCpyТеперь анализатор будет обрабатывать вызовы функции 'MyMemCpy' так же, как вызовы 'memcpy'.
Пользовательская функция форматного ввода/вывода
Можно самостоятельно указать имена своих собственных функций, для которых следует выполнять проверку формата. Подразумевается, что принцип форматирования строк совпадает с функцией 'printf'.
Для этого используется специальная пользовательская аннотация. Пример использования:
//V_FORMATTED_IO_FUNC, function:Log, format_arg:1, ellipsis_arg:2
void Log(const char *fmt, ...);
Log("%f", time(NULL)); // <= V576Формат аннотации:
- Ключ 'function' задаёт полное имя функции, состоящее из названия пространства имён, имени класса и имени функции. Поддерживаются вложенные пространства имён и вложенные классы.
- Ключ 'format_arg' задаёт номер аргумента функции, в котором будет находиться форматная строка. Номера также считаются с единицы и также не должны превышать число 14. Это обязательный аргумент.
- Ключ 'ellipsis_arg' задаёт номер аргумента функции с эллипсисом (то есть многоточием). Считается с единицы и также не должен быть больше 14. Более того, номер аргумента с эллипсисом должен быть больше номера аргумента с форматной строкой (всё-таки эллипсис – исключительно последний аргумент). Это тоже обязательный аргумент.
Наиболее полный пример использования:
namespace A
{
class B
{
void C(int, const char *fmt, ...);
};
}
//V_FORMATTED_IO_FUNC, function:A::B::C, format_arg:2, ellipsis_arg:3Механизм пользовательских аннотаций в формате JSON
Механизм JSON аннотаций — это способ разметки пользовательских функций и типов в файлах формата JSON с целью дать анализатору дополнительную информацию о пользовательском коде. Благодаря этой информации анализатор может как находить больше ошибок, так и выдавать меньше ложных срабатываний.
Использование отдельных файлов с аннотациями позволяет решить следующие проблемы:
- разметка (аннотирование) стороннего (third-party) кода, библиотек и компонентов;
- применение разных наборов аннотаций в зависимости от сценариев использования анализатора.
В случае, если данные сценарии для вас не актуальны, и вы хотели бы проводить разметку прямо в исходном коде, то стоит ознакомиться с отдельной документацией.
На данный момент механизм доступен для следующих языков:
- C и С++ (начиная с версии 7.31);
- С# (начиная с версии 7.33).
Для того, чтобы воспользоваться механизмом, необходимо:
- Создать файл формата JSON;
- Написать необходимые аннотации согласно JSON-схемам;
- Подключить файлы аннотаций при анализе удобным вам способом.
Доступный функционал отличается в зависимости от используемого языка. После ознакомления с общей документацией желательно также ознакомиться с языко-специфичной частью:
Способы подключения файлов с аннотациями
Подключить уже готовый файл аннотаций можно следующими способами:
Способ N1. Добавить специальный комментарий в исходный код или в файл конфигурации диагностических правил (.pvsconfig):
//V_PVS_ANNOTATIONS, language:%язык_проекта%, path:%путь/до/файла.json%Вместо символа подстановки %язык_проекта% предполагается использование одного из следующих значений:
- для С — с;
- для С++ — cpp;
- для С# — csharp.
Вместо символа подстановки %путь/до/файла.json% предполагается путь до подключаемого файла аннотаций. Поддерживаются как абсолютные, так и относительные пути. Относительные пути раскрываются относительно файла, в котором указан комментарий для подключения аннотации.
Способ N2 (только для С и C++ анализатора). Указать специальный флаг ‑‑annotation-file (-A) при запуске pvs-studio-analyzer или CompilerCommandsAnalyzer:
pvs-studio-analyzer --annotation-file=%путь/до/файла.json%Вместо символа подстановки %путь/до/файла.json% предполагается путь до подключаемого файла аннотаций. Поддерживаются как абсолютные, так и относительные пути. Относительные пути раскрываются относительно текущей рабочей директории (CWD).
Примечание 1. Может быть подключено несколько файлов с аннотациями. Для каждого файла необходимо указать отдельный флаг или комментарий.
Примечание 2. До версии 7.33, для языков С и С++ аннотации можно было подключить с помощью комментария следующего вида:
//V_PVS_ANNOTATIONS %путь/до/файла%Начиная с версии 7.33, в таком случае будет выдаться специальное сообщение об использовании устаревшего синтаксиса и предложение перейти на новый.
Упрощения для комфортной работы с аннотациями
Готовые примеры
Для облегчения знакомства с механизмом пользовательских аннотаций мы подготовили коллекцию примеров для наиболее часто встречающихся сценариев.
- Как проаннотировать свой nullable тип (С++)?
- Как пометить функцию как опасную или устаревшую (С++)?
- Как пометить функцию как источник/приёмник недостоверных данных (C, С++, C#)?
Больше примеров использования можно увидеть в документации механизма для конкретного языка:
JSON-схемы
Для каждого доступного языка составлена JSON-схема с поддержкой версионирования. Благодаря этим схемам современные текстовые редакторы и IDE могут проводить валидацию, а также показывать подсказки прямо во время редактирования.
Для этого при составлении собственного файла аннотаций необходимо добавить в него поле $schema, в котором следует указать схему для необходимого языка. Например, для C и С++ анализатора поле будет выглядеть так:
{
"version": 1,
"$schema": "https://files.pvs-studio.com/media/custom_annotations/v1/cpp-annotations.schema.json",
"annotations": [
{ .... }
]
}
Например, так Visual Studio Code сможет давать подсказки при составлении аннотаций:

На данный момент JSON-схемы доступны для аннотаций на следующих языках:
Предупреждения анализатора
Далеко не все проблемы можно диагностировать на уровне валидации JSON-схемы. Если при работе с файлом с аннотациями произошла ошибка, то анализатор сгенерирует предупреждение V019. Оно даст подсказку, что пошло не так. Например: файл с аннотациями отсутствует, произошла ошибка при разборе, аннотация пропущена из-за допущенных в ней ошибок и т.д.

Аннотирование C и C++ кода в формате JSON
- Быстрый старт
- Способы подключения файла c аннотациями
- Структура файла с аннотациями
- Аннотации типов
- Аннотации функций
- Схема JSON
- Примеры
- Как проаннотировать свой nullable тип
- Как добавить контракт "всегда валидный" на параметр функции nullable-типа
- Как разметить пользовательскую функцию форматного ввода/вывода
- Как пользоваться символом подстановки для аннотирования нескольких перегрузок
- Как пометить функцию как опасную для использования (или устаревшую)
- Как пометить функцию как источник/приёмник недостоверных данных
- Как проаннотировать пользовательское исключение, которое не должно создаваться без поясняющего сообщения
Механизм пользовательских аннотаций — это способ разметки типов и функций в формате JSON с целью дать анализатору дополнительную информацию. Благодаря этой информации анализатор сможет находить больше ошибок в коде. Механизм работает только для языков С и С++.
Быстрый старт
Допустим, что в проекте требуется запретить вызов некоторой функции, т.к. она нежелательна к использованию:
void DeprecatedFunction(); // should not be used
void foo()
{
DeprecatedFunction(); // unwanted call site
}Для того, чтобы анализатор сгенерировал предупреждение V2016 в месте вызова этой функции, необходимо создать специальный файл формата JSON со следующим содержимым:
{
"version": 1,
"annotations": [
{
"type": "function",
"name": "DeprecatedFunction",
"attributes": [ "dangerous" ]
}
]
}После этого достаточно подключить файл (все способы подключения рассмотрены здесь):
//V_PVS_ANNOTATIONS, language: cpp, path: %path/to/annotations.json%
void DeprecatedFunction();
void foo()
{
DeprecatedFunction(); // <= V2016 will be issued here
}Примечание. По умолчанию диагностическое правило V2016 отключена. Для выдачи предупреждений включите диагностику в настройках.
Способы подключения файла c аннотациями
Подробнее о способе подключения файла аннотаций вы можете узнать в этой документации.
Структура файла с аннотациями
Содержимое файла — JSON-объект, состоящий из двух обязательных полей: version и annotations.
Поле version принимает значение целого типа и задаёт версию механизма. В зависимости от значения файл с разметкой может обрабатываться по-разному. На данный момент поддерживается только одно значение — 1.
Поле annotations — массив объектов "аннотация":
{
"version": 1,
"annotations":
[
{
...
},
{
...
}
]
}Аннотации могут быть двух видов:
- аннотации типов;
- аннотации функций.
Если аннотация объявляется непосредственно в массиве annotations, то она считается аннотацией верхнего уровня. В ином случае считается, что это вложенная аннотация.
Аннотации типов
Объект аннотации типа состоит из следующих полей:
Поле "type"
Обязательное поле. Принимает строку с одним из значений: "record", "class", "struct", "union". Последние три варианта являются псевдонимами "record" и добавлены для удобства.
Поле "name"
Обязательное поле. Принимает строку с квалифицированным (полным) именем сущности. Анализатор будет искать эту сущность, начиная с глобальной области видимости. Если сущность находится в глобальной области, то "::" в начале имени может быть опущено.
Поле "members"
Опциональное поле. Массив объектов вложенных аннотаций.
Поле "attributes"
Опциональное поле. Массив строк, который задаёт свойства сущности. Для аннотаций типов доступны следующие атрибуты:
Умные указатели
- "unique_ptr" — тип имеет интерфейс std::unique_ptr;
- "shared_ptr" — тип имеет интерфейс std::shared_ptr;
- "auto_ptr" — тип имеет интерфейс std::auto_ptr;
Контейнеры
- "string" — тип имеет интерфейс std::basic_string;
- "string_view" — тип имеет интерфейс std::basic_string_view;
- "array" — тип имеет интерфейс std::array;
- "vector" — тип имеет интерфейс std::vector;
- "map" — тип имеет интерфейс std::map;
- "set" — тип имеет интерфейс std::set;
- "list" — тип имеет интерфейс std::list;
- "unordered" — в сочетании с "set" или "map" задаёт типу интерфейс std::unordered_set или std::unordered_map соответственно.
- "multi" — в сочетании с "map" или "set" задаёт типу интерфейс std::multiset или std::multimap. Если также присутствует "unordered", то типу задаётся семантика std::unordered_multiset или std::unordered_multimap.
Другие типы
- "nullable" — тип имеет семантику nullable-типа. Объекты таких типов могут находиться в одном из двух состояний: "валидный" или "невалидный". Доступ к объекту в состоянии "невалидный" приведёт к ошибке. Примерами таких типов являются указатели и std::optional.
- "exception" – тип используется для создания объекта, который будет выброшен как исключение. Пример использования можно посмотреть здесь.
Семантика
- "cheap_to_copy" — объект типа может передаваться в функцию по копии без накладных расходов;
- "expensive_to_copy" — объект типа следует передавать в функцию только по указателю/ссылке;
- "copy_on_write" — тип имеет семантику copy-on-write.
Аннотации функций
Объект аннотации функции состоит из следующих полей:
Поле "type"
Обязательное поле. Принимает строку со значением function. Для вложенных аннотаций функций (в поле members аннотаций типов) также становится доступным значение ctor. Оно показывает, что аннотируется конструктор пользовательского типа.
Поле "name"
Принимает строку с именем функции. Поле обязательно, если type имеет значение "function", иначе должно быть опущено. По этому имени анализатор будет искать аннотируемую сущность, начиная с глобальной области видимости.
Для аннотаций верхнего уровня указывается квалифицированное (полное) имя, для вложенных — неквалифицированное.
Если функция находится в глобальной области видимости, то '::' в начале имени может быть опущено.
Поле "params"
Опциональное поле. Массив объектов, описывающих формальные параметры. Данное поле совместно с name задаёт сигнатуру функции, по которой анализатор будет сравнивать аннотацию с её объявлением в коде программы. В случае с функциями-членами анализатор также рассматривает поле qualifiers.
Каждый объект содержит следующие поля:
- "type" (обязательное) — тип формального параметра в виде строки. Например, первый формальный параметр функции memset имеет тип void *. Его и следует записать в строку. Существует возможность пропустить не интересующие параметры и проаннотировать несколько перегрузок функции с помощью одной аннотации: для этого в типе можно написать символ подстановки:
- Символ "*" означает, что на его месте может быть 0 или более параметров любого типа. Должен идти последним в списке параметров.
- Символ "?" означает, что на его месте может быть параметр любого типа.
- "attributes" (опциональное) — массив строк, который задаёт свойства параметра. Возможные атрибуты параметров описаны далее в документации.
- "constraint" (опциональное) — объект, содержащий информацию об ограничениях параметра. Если анализатор находит возможное нарушение ограничений, то пользователю будет выдано предупреждение V1108. Возможные поля объекта описаны далее в документации.
Если аннотацию нужно применить для всех перегрузок вне зависимости от параметров, то поле можно опустить:
// Code
void foo(); // dangerous
void foo(int); // dangerous
void foo(float); // dangerous
// Annotation
{
....
"type": "function",
"name": "foo",
"attributes": [ "dangerous" ]
....
}Если же интересует перегрузка, не принимающая параметров, следует явно указать пустой массив:
// Code
void foo(); // dangerous
void foo(int); // ok
void foo(float); // ok
// Annotation
{
....
"type": "function",
"name": "foo",
"attributes": [ "dangerous" ],
"params": []
....
}Возможные значения атрибутов параметров
|
# |
Название атрибута |
Описание атрибута |
|---|---|---|
|
1 |
immutable |
Подсказывает анализатору, что после вызова функции переданный аргумент не был модифицирован. Например, функция |
|
2 |
not_null |
Действует только для параметров nullable-типа. В функцию необходимо передавать аргумент в состоянии "валидный". |
|
3 |
unique_arg |
Передаваемые аргументы должны отличаться. Например, нет смысла передавать в |
|
4 |
format_arg |
Параметр обозначает форматную строку. Анализатор будет проверять аргументы согласно форматной спецификации |
|
5 |
pointer_to_free |
Указатель, по которому в функции будет освобождена память с помощью |
|
6 |
pointer_to_gfree |
Указатель, по которому в функции будет освобождена память с помощью |
|
7 |
pointer_to_delete |
Указатель, по которому в функции будет освобождена память с помощью 'operator delete'. Указатель может быть нулевым. |
|
8 |
pointer_to_delete[] |
Указатель, по которому в функции будет освобождена память с помощью 'operator delete[]'. Указатель может быть нулевым. |
|
9 |
pointer_to_unmap |
Указатель, по которому в функции будет освобождена память с помощью 'munmap'. Указатель может быть нулевым. |
|
10 |
taint_source |
Данные, возвращающиеся через параметр, получены из недостоверного источника. |
|
11 |
taint_sink |
Данные, передаваемые через параметр, могут привести к эксплуатации уязвимости, если они получены из недостоверного источника. |
|
12 |
non_empty_string |
Параметр должен принимать любую непустую строку. |
|
13 |
lower_bound |
Параметр обозначает нижнюю границу некоторого диапазона. Например, второй параметр |
|
14 |
upper_bound |
Параметр обозначает верхнюю границу некоторого диапазона. Например, третий параметр |
|
15 |
in_range_value |
Значение, переданное в параметр, проверяется на вхождение в диапазон. Например, первый параметр |
Возможные поля ограничений параметров
Все поля ограничений — опциональные. Далее приведён список полей, которые задают условия ограничения.
Поля, задающие список разрешённых и запрещённых значений параметра:
- Поле allowed — массив строк. Задаёт список разрешённых интегральных значений, которые может принимать параметр функции. По умолчанию значения, не перечисленные в этом списке, запрещены.
- Поле disallowed — массив строк. Задаёт список запрещённых интегральных значений, которые может принимать параметр функции. По умолчанию значения, не перечисленные в этом списке, разрешены.
Каждая строка внутри массива — это интервал от минимальной до максимальной границы включительно. Строка с интервалами указывается в формате "x..y", где 'x' и 'y' — это левая и правая границы соответственно. Одну из границ можно опустить. Тогда строка будет иметь вид "x.." или "..y". В таком случае интервал будет от 'x' до плюс бесконечности и от минус бесконечности до 'y' соответственно.
Примеры интервалов:
- "0..10" — строка, задающая интервал от 0 до 10 включительно.
- "..10" — строка, задающая интервал от минус бесконечности до 10 включительно.
- "0.." — строка, задающая интервал от 0 до плюс бесконечности.
Массив может содержать несколько интервалов. При их чтении анализатор нормализует все интервалы в массиве, т.е. объединяет пересекающиеся и рядом стоящие интервалы, располагая их в порядке возрастания.
Если поля allowed и disallowed указаны одновременно, то анализатор вычитает "disallowed" интервалы из "allowed", чтобы получить множество разрешённых значений. Если значения из поля disallowed полностью перекрывают значения из allowed, то пользователю будет выдано предупреждение V019.
Поле "returns"
Опциональное поле. Объект, внутри которого возможно использование только поля attributes — массива строк, который позволяет задать атрибуты возвращаемого значения.
Возможные значения атрибутов возвращаемого результата
|
# |
Название атрибута |
Описание атрибута |
|---|---|---|
|
1 |
not_null |
Функция всегда возвращает объект nullable-типа в состоянии "валидный". |
|
2 |
maybe_null |
Функция может вернуть объект nullable-типа в состоянии "невалидный", и его стоит проверить перед разыменованием. |
|
3 |
taint_source |
Функция может вернуть данные из недостоверного источника. |
Поле "template_params"
Опциональное поле. Массив строк, позволяющий задать шаблонные параметры функции. Поле необходимо, когда шаблонные параметры используются в сигнатуре функции:
// Code
template <typename T1, class T2>
void MySwap(T1 &lhs, T2 &rhs);
// Annotation
{
....
"template_params": [ "typename T1", "class T2" ],
"name": "MySwap",
"params": [
{ "type": "T1 &", attributes: [ "unique_arg" ] },
{ "type": "T2 &", attributes: [ "unique_arg" ] }
]
....
}Поле "qualifiers"
Опциональное поле. Позволяет применить аннотацию только к функции-члену с определённым набором cvref-квалификаторов. Доступно только для вложенных аннотаций, у которых поле type имеет значение "function". Данное поле совместно с name и params задаёт сигнатуру нестатической функции-члена, по которой анализатор будет сравнивать аннотацию с её объявлением в коде программы. Принимает массив строк со следующими возможными значениями: "const", "volatile", "&" или "&&".
Пример:
// Code
struct Foo
{
void Bar(); // don't need to annotate this overload
void Bar() const; // want to annotate this overload
void Bar() const volatile; // and this one
};
// Annotation
{
....
"type": "record",
"name": "Foo",
"members": [
{
"type": "function",
"name": "Bar",
"qualifiers": [ "const" ]
},
{
"type": "function",
"name": "Bar",
"qualifiers": [ "const", "volatile" ]
}
]
....
}Если аннотацию надо применить ко всем квалифицированным и неквалифицированным версиям, то нужно опустить поле:
// Code
struct Foo
{
void Bar(); // want to annotate this overload
void Bar() const; // and this one
};
// Annotation
{
....
"type": "record",
"name": "Foo",
"members": [
{
"type": "function",
"name": "Bar",
}
]
....
}Если надо применить аннотацию только к неквалифицированной версии, то значением поля должен быть пустой массив:
// Code
struct Foo
{
void Bar(); // want to annotate this overload
void Bar() const; // but NOT this one
};
// Annotation
{
....
"type": "record",
"name": "Foo",
"members": [
{
"type": "function",
"name": "Bar",
"qualifiers": []
}
]
....
}Поле "attributes"
Опциональное поле. Массив строк, который задаёт свойства сущности.
Возможные атрибуты функций и конструкторов
|
# |
Название атрибута |
Описание атрибута |
Примечание |
|---|---|---|---|
|
1 |
pure |
Функция считается чистой. |
Функция чистая, когда она не имеет побочных эффектов, не модифицирует переданные аргументы, и результат функции одинаков при исполнении на одном и том же наборе аргументов. |
|
2 |
noreturn |
Функция не возвращает управление вызывающей функции. |
|
|
3 |
nodiscard |
Результат функции должен использоваться. |
|
|
4 |
nullable_uninitialized |
Функция-член пользовательского nullable-типа переводит объект в состоянии "невалидный". |
|
|
5 |
nullable_initialized |
Функция-член пользовательского nullable-типа переводит объект в состоянии "валидный". |
|
|
6 |
nullable_checker |
Функция проверяет состояние пользовательского nullable-типа. Если функция возвращает true, то объект считается в состоянии "валидный", не возвращает — "невалидный". Результат функции должен неявно конвертироваться к типу bool. |
|
|
7 |
nullable_getter |
Функция производит доступ к внутренним данным пользовательского nullable-типа. Объект при этом должен быть в состоянии "валидный". |
|
|
8 |
dangerous |
Функция помечена как опасная, и код программы не должен содержать её вызова. |
Можно использовать в качестве пометки функции как устаревшей (deprecated). Для выдачи предупреждений требуется включить диагностическое правило V2016 в настройках. |
Ниже приведена таблица применимости различных атрибутов с аннотациями функций:
|
# |
Атрибут |
Свободная функция |
Конструктор |
Функция-член |
|---|---|---|---|---|
|
1 |
pure |
✓ |
✕ |
✓ |
|
2 |
noreturn |
✓ |
✕ |
✓ |
|
3 |
nodiscard |
✓ |
✓ |
✓ |
|
4 |
nullable_uninitialized |
✕ |
✓ |
✓ |
|
5 |
nullable_initialized |
✕ |
✓ |
✓ |
|
6 |
nullable_checker |
✕ |
✕ |
✓ |
|
7 |
nullable_getter |
✕ |
✕ |
✓ |
|
8 |
dangerous |
✓ |
✕ |
✓ |
Схема JSON
JSON схемы поставляется в дистрибутиве, а также доступны по ссылкам ниже:
Примеры
Как проаннотировать свой nullable тип
Допустим, есть следующий пользовательский nullable-тип:
constexpr struct MyNullopt { /* .... */ } my_nullopt;
template <typename T>
class MyOptional
{
public:
MyOptional();
MyOptional(MyNullopt);
template <typename U>
MyOptional(U &&val);
public:
bool HasValue() const;
T& Value();
const T& Value() const;
private:
/* implementation */
};Примечания по коду:
- Конструктор по умолчанию и конструктор от типа MyNullopt инициализируют объект в состоянии "невалидный".
- Шаблон конструктора, принимающий параметр типа U&&, инициализирует объект в состоянии "валидный".
- Функция-член HasValue проверяет состояние объекта nullable-типа. Если объект в состоянии "валидный", то возвращается true, в обратном случае — false. Функция не меняет состояния объекта nullable-типа.
- Перегрузки функций-членов Value возвращают нижележащий объект. Функции не меняют состояние объекта nullable-типа.
Тогда аннотация класса и его функций-членов будет выглядеть следующим образом:
{
"version": 1,
"annotations": [
{
"type": "class",
"name": "MyOptional",
"attributes": [ "nullable" ],
"members": [
{
"type": "ctor",
"attributes": [ "nullable_uninitialized" ]
},
{
"type": "ctor",
"attributes": [ "nullable_uninitialized" ],
"params": [
{
"type": "MyNullopt"
}
]
},
{
"type": "ctor",
"template_params": [ "typename U" ],
"attributes": [ "nullable_initialized" ],
"params": [
{
"type": "U &&val"
}
]
},
{
"type": "function",
"name": "HasValue",
"attributes": [ "nullable_checker", "pure", "nodiscard" ]
},
{
"type": "function",
"name": "Value",
"attributes": [ "nullable_getter", "nodiscard" ]
}
]
}
]
}Как добавить контракт "всегда валидный" на параметр функции nullable-типа
Допустим, есть следующий код:
namespace Foo
{
template <typaname CharT>
size_t my_strlen(const CharT *ptr);
}Функция Foo::my_strlen имеет следующие свойства:
- Первый параметр всегда должен быть ненулевым, т.е. в состоянии "валидный".
- Функция чистая и ничего не модифицирует.
Тогда аннотация функции будет выглядеть следующим образом:
{
"version": 1,
"annotations":
[
{
"type": "function",
"name": "Foo::my_strlen",
"attributes": [ "pure" ],
"template_params": [ "typename CharT" ],
"params": [
{
"type": "const CharT *",
"attributes": [ "not_null" ]
}
]
}
]
}Как разметить пользовательскую функцию форматного ввода/вывода
Допустим, есть следующая функция Foo::LogAtError:
namespace Foo
{
void LogAtError(const char *, ...);
}О ней известны следующие факты:
- Первым параметром она принимает форматную строку согласно спецификации printf. Аргумент не должен быть нулевым.
- Соответствующие форматной строке аргументы передаются, начиная со второго.
- Функция не модифицирует переданные аргументы.
- Функция не возвращает управление после вызова.
Анализатор может проверять переданные аргументы согласно форматной строке, а также понимать, что после вызова этой функции код недостижим. Для этого надо разметить функцию следующим образом:
{
"version": 1,
"annotations": [
{
"type": "function",
"name": "Foo::LogAtError",
"attributes": [ "noreturn" ],
"params": [
{
"type": "const char *",
"attributes" : [ "format_arg", "not_null", "immutable" ]
},
{
"type": "...",
"attributes": [ "immutable" ]
}
]
}
]
}Как пользоваться символом подстановки для аннотирования нескольких перегрузок
Допустим, что в предыдущем примере программист добавил несколько перегрузок функции Foo::LogAtExit:
namespace Foo
{
void LogAtExit(const char *fmt, ...);
void LogAtExit(const char8_t *fmt, ...);
void LogAtExit(const wchar_t *fmt, ...);
void LogAtExit(const char16_t *fmt, ...);
void LogAtExit(const char32_t *fmt, ...);
}В этом случае можно не писать аннотации для всех перегрузок, а лишь для одной, воспользовавшись символом подстановки:
{
"version": 1,
"annotations": [
{
"type": "function",
"name": "Foo::LogAtExit",
"attributes": [ "noreturn" ],
"params": [
{
"type": "?",
"attributes" : [ "format_arg", "not_null", "immutable" ]
},
{
"type": "...",
"attributes": [ "immutable" ]
}
]
}
]
}Как пометить функцию как опасную для использования (или устаревшую)
Допустим, есть две перегрузки функции Foo::Bar:
namespace Foo
{
void Bar(int i);
void Bar(double d);
}Требуется запретить использование первой перегрузки. Для этого надо разметить функцию следующим образом:
{
"version": 1,
"annotations": [
{
"type": "function",
"name": "Foo::Bar",
"attributes": [ "dangerous" ],
"params": [
{
"type": "int"
}
]
}
]
}Как пометить функцию как источник/приёмник недостоверных данных
Допустим, что есть функция, которая возвращает внешние данные через out-параметр и возвращаемое значение.
std::string ReadStrFromStream(std::istream &input, std::string &str)
{
....
input >> str;
return str;
....
}Для того, чтобы пометить эту функцию как источник недостоверных данных, необходимо её разметить следующим образом:
{
"version": 1,
"annotations": [
{
"type": "function",
"name": "ReadStrFromStream",
"params": [
{
"type": "std::istream &input"
},
{
"type": "std::string &str",
"attributes": [ "taint_source" ]
}
],
"returns": { "attributes": [ "taint_source" ] }
}
]
}Предположим, что существует функция, при попадании в которую недостоверных данных может быть эксплуатирована какая-либо уязвимость.
void DoSomethingWithData(std::string &str)
{
.... // Some vulnerability
}Чтобы пометить такую функцию как приемник недостоверных данных (функцию-сток), необходимо написать следующую аннотацию:
{
"version": 1,
"annotations": [
{
{
"type": "function",
"name": "DoSomethingWithData",
"params": [ { "type": "std::string &str",
"attributes": [ "taint_sink" ] }]
}
}
]
}Как проаннотировать пользовательское исключение, которое не должно создаваться без поясняющего сообщения
В C++ анализаторе есть диагностическое правило V1116, которое срабатывает при обнаружении создания объекта исключения с пустым сообщением. По умолчанию данное правило работает только с типами исключений из стандартной библиотеки C++. Для поддержки пользовательских типов исключений необходимо добавить специальную аннотацию.
Предположим, есть класс, определяющий объекты, которые будут использованы для выброса исключения:
class MyException: public std::runtime_error
{
public:
MyException(const std::string& what_arg )
: std::runtime_error(what_arg){}
MyException(const char *what_arg)
: std::runtime_error(what_arg){}
};В аннотации необходимо определить тип исключения с атрибутом 'exception' и затем конструкторы, способные принимать поясняющие сообщения. Для каждого параметра конструктора, который должен принимать сообщение, следует указать атрибут 'non_empty_string'.
Например, аннотация класса 'MyException' может выглядеть так:
{
"version": 2,
"language": "cpp",
"annotations": [
{
"type": "class",
"name": "MyException",
"attributes": ["exception"],
"members": [
{
"type": "ctor",
"params": [{ "type": "const char*",
"attributes": ["non_empty_string"]}]
},
{
"type": "ctor",
"params": [{ "type": "const std::string&",
"attributes": ["non_empty_string"]}]
}
]
}
]
}Аннотирование C# кода в формате JSON
- Структура файла с аннотациями
- Аннотации для taint-анализа
- Аннотации методов
- Аннотации конструкторов
- Аннотации свойств
- Аннотации параметров
- Схема JSON
- Примеры
Способы подключения файла c аннотациями
Подробнее о способе подключения файла аннотаций вы можете узнать в этой документации.
Структура файла с аннотациями
Содержимое файла — JSON-объект, состоящий из трёх обязательных полей: language, version и annotations.
Поле language должно иметь значение csharp. Поле version принимает значение целого типа и задаёт версию механизма. В зависимости от значения файл с разметкой может обрабатываться по-разному. На данный момент поддерживается только одно значение — 1.
Поле annotations — массив объектов "аннотация":
{
"language": "csharp",
"version": 1,
"annotations":
[
{
...
},
{
...
}
]
}Аннотации могут быть трёх типов:
- аннотации методов;
- аннотации конструкторов;
- аннотации свойств.
Аннотации для taint-анализа
В анализаторе существует ряд аннотаций для taint-анализа. С их помощью можно размечать источники и приёмники заражения. Также существует возможность помечать методы/конструкторы, которые производят валидацию taint-данных. Таким образом, если taint-данные прошли валидацию, то при их попадании в приёмник предупреждения анализатора не будет.
За каждый из видов уязвимостей отвечает отдельное диагностическое правило. На данный момент в анализаторе представлены следующие taint-диагностики:
- V5608 — SQL injection;
- V5609 — Path traversal vulnerability;
- V5610 — XSS vulnerability;
- V5611 — Insecure deserialization vulnerability;
- V5614 — XXE vulnerability;
- V5615 — XEE vulnerability;
- V5616 — Command injection;
- V5618 — Server-side request forgery;
- V5619 — Log injection;
- V5620 — LDAP injection;
- V5622 — XPath injection;
- V5623 — Open redirect vulnerability;
- V5624 — Configuration vulnerability;
- V5626 — ReDoS vulnerability;
- V5627 — NoSQL injection;
- V5628 — Zip Slip vulnerability.
Принцип работы taint-аннотаций
Для каждого из диагностических правил существуют специальные аннотации, которые позволяют разметить приёмники и методы/конструкторы, производящие валидацию.
Что касается источников taint-данных, то они являются общими для всех диагностик. Такие данные также можно разметить с помощью аннотаций.
Примечание. Атрибуты для разметки taint-аннотаций описаны в следующих разделах.
Стоит отметить, что, помимо пользовательских аннотаций, в анализаторе уже имеется ряд taint-аннотаций для различных библиотек. Например, при передаче результата выполнения метода System.Console.ReadLine в конструктор System.Data.SqlClient.SqlCommand возможно возникновение SQL injection. В анализаторе есть аннотации, которые говорят, что System.Console.ReadLine — источник taint-данных, а System.Data.SqlClient.SqlCommand — приёмник, при попадании в который taint-данных может возникнуть SQL injection.
Таким образом, размечая источники taint-данных, анализатор будет учитывать их для уже существующих приёмников и наоборот. Если добавить аннотацию приёмника, то анализатор будет выдавать предупреждение при попадании в него уже размеченных источников taint-данных (например, System.Console.ReadLine).
Аннотации методов
Примечание. Объект аннотации метода должен содержать хотя бы одно опциональное поле.
Объект аннотации метода состоит из следующих полей:
Поле "type"
Обязательное поле. Принимает строку со значением method.
Поле "namespace_name"
Обязательное поле. Принимает строку с именем пространства имён, которое содержит метод.
Поле "type_name"
Обязательное поле. Принимает строку с именем класса, в котором определён метод.
Поле "method_name"
Обязательное поле. Принимает строку с именем метода.
Поле "attributes"
Опциональное поле. Массив строк, который задаёт свойства сущности.
Возможные атрибуты метода
|
# |
Название атрибута |
Описание атрибута |
|---|---|---|
|
1 |
not_apply_to_child_class |
Аннотация не будет применяться при вызове проаннотированного метода у объекта дочернего класса. |
|
2 |
caller_is_xml_parser |
Объект, вызывающий метод, является XML-парсером, который может быть уязвим (V5614, V5615). |
|
3 |
use_return |
Необходимо использовать возвращаемое значение метода. |
|
4 |
dispose_equivalent |
Метод работает аналогично методу |
|
5 |
returns_new_value |
При каждом вызове метод возвращает новый объект. |
|
6 |
external_modification |
Метод изменяет что-то внешнее (печать в консоли, создание файлов и т. п.). |
|
7 |
empty_collection_exception |
При вызове этого метода у пустой коллекции будет выброшено исключение. |
Поле "params"
Опциональное поле. Данное поле описано в разделе "Аннотации параметров".
Поле "returns"
Примечание. Объект аннотации возвращаемого значения должен либо содержать поля namespace_name и type_name, либо оба поля должны отсутствовать (или иметь значение null). Если оба поля отсутствуют, то при выборе аннотации не будет учитываться тип возвращаемого значения.
Опциональное поле. Объект возвращаемого значения, состоит из следующих полей:
Поле "namespace_name"
Опциональное поле. Принимает строку с именем пространства имён, которое содержит тип возвращаемого значения метода.
Поле "type_name"
Опциональное поле. Принимает строку с именем класса, в котором определён тип возвращаемого значения метода.
Поле "attributes"
Опциональное поле. Массив строк, который задаёт свойства возвращаемого значения метода.
Возможные атрибуты возвращаемого значения
|
# |
Название атрибута |
Описание атрибута |
|---|---|---|
|
1 |
not_apply_to_child_class |
Аннотация не будет применяться для методов, тип возвращаемого значения которых является дочерним для проаннотированного типа. |
|
2 |
always_taint |
Метод возвращает taint-данные. |
|
3 |
transfer_annotations_from_caller |
Если вызывающий объект содержит аннотацию, она будет перенесена на возвращаемое значение метода. |
|
4 |
not_null |
Метод никогда не возвращает |
|
5 |
file_path |
Метод возвращает путь до файла. |
|
6 |
sensitive_data |
Метод возвращает sensitive-данные. |
Особенности аннотирования методов расширения
При аннотировании методов расширения необходимо указывать тип, в котором определён метод расширения. Например, есть метод расширения для класса System.String — MyNamespace.StringExtensions.CustomizeString(this string str). Нужно писать аннотацию для типа MyNamespace.StringExtensions, а не для System.String. Стоит учесть, что все методы расширения будут иметь как минимум один аргумент.
Существует возможность аннотировать не тип, в котором определён метод расширения, а расширяемый тип. Если обратиться к примеру, описанному выше, то это System.String. Однако данный способ является нежелательным, так как накладывает ряд ограничений на обработку анализатором аннотации такого вида. Например, нельзя сделать аннотацию для первого параметра (с модификатором this).
Аннотации конструкторов
Примечание. Объект аннотации конструктора должен содержать хотя бы одно опциональное поле.
Объект аннотации конструктора состоит из следующих полей:
Поле "type"
Обязательное поле. Принимает строку со значением ctor.
Поле "namespace_name"
Обязательное поле. Принимает строку с именем пространства имён, которое содержит конструктор.
Поле "type_name"
Обязательное поле. Принимает строку с именем класса, в котором определён конструктор.
Поле "attributes"
Опциональное поле. Массив строк, который задаёт свойства сущности.
Возможные атрибуты конструкторов
|
# |
Название атрибута |
Описание атрибута |
|---|---|---|
|
1 |
not_apply_to_child_class |
Аннотация не будет применяться для дочерних реализаций проаннотированного конструктора. |
|
2 |
create_taint_object |
Созданный конструктором объект — taint. |
Поле "params"
Опциональное поле. Данное поле описано в разделе "Аннотации параметров".
Аннотации свойств
Объект аннотации свойства состоит из следующих полей:
Поле "type"
Обязательное поле. Принимает строку со значением property.
Поле "namespace_name"
Обязательное поле. Принимает строку с именем пространства имён, которое содержит свойство.
Поле "type_name"
Обязательное поле. Принимает строку с именем класса, в котором определено свойство.
Поле "attributes"
Опциональное поле. Массив строк, который задаёт свойства сущности.
Возможные атрибуты свойств
Примечание. К каждому из атрибутов taint-приёмников прикреплена ссылка на соответствующую диагностику.
|
# |
Название атрибута |
Описание атрибута |
|---|---|---|
|
1 |
not_apply_to_child_class |
Аннотация не будет применяться при обращении к проаннотированному свойству у объекта дочернего класса. |
|
2 |
transfer_annotation_to_return_value |
Если на вызывающем объекте есть аннотация, то она будет перенесена на возвращаемое значение. |
|
3 |
transfer_annotation_to_caller |
Если свойству присваивается значение, то аннотации этого значения будут перенесены на вызывающий объект свойства. |
|
4 |
return_taint |
Свойство возвращает taint-данные. |
|
5 |
sql_injection_target |
Запись в это свойство заражённых данных приводит к SQL Injection (V5608). |
|
6 |
path_traversal_target |
Запись в это свойство заражённых данных приводит к Path Traversal (V5609). |
|
7 |
xss_injection_target |
Запись в это свойство заражённых данных приводит к XSS Injection (V5610). |
|
8 |
insecure_deserialization_target |
Запись в это свойство заражённых данных приводит к Insecure Deserialization (V5611). |
|
9 |
command_injection_target |
Запись в это свойство заражённых данных приводит к Command Injection (V5616). |
|
10 |
ssrf_target |
Запись в это свойство заражённых данных приводит к Server-Side Request Forgery (V5618). |
|
11 |
log_injection_target |
Запись в это свойство заражённых данных приводит к Log Injection (V5619). |
|
12 |
ldapi_injection_target |
Запись в это свойство заражённых данных приводит к LDAP Injection (V5620). |
|
13 |
xpath_injection_target |
Запись в это свойство заражённых данных приводит к XPath Injection (V5622). |
|
14 |
open_redirect_target |
Запись в это свойство заражённых данных приводит к Open Redirect (V5623). |
|
15 |
configuration_attack_target |
Запись в это свойство заражённых данных приводит к Configuration Attack (5624). |
|
16 |
nosql_injection_target |
Запись в это свойство заражённых данных приводит к NoSQL Injection (V5627). |
|
17 |
redos_target |
Запись в это свойство заражённых данных приводит к ReDoS (V5626). |
|
18 |
zipslip_target |
Запись в это свойство заражённых данных приводит к ZipSlip (V5628). |
|
19 |
modified_in_another_thread |
Свойство может измениться в другом потоке. |
|
20 |
sensitive_data |
Свойство содержит sensitive-данные. |
|
21 |
file_path |
Свойство содержит путь до файла. |
Аннотации параметров
Примечание 1. Объект аннотации параметра может находиться только внутри массива params, объекта аннотации метода или конструктора.
Примечание 2. Объект аннотации параметра должен либо содержать поля namespace_name и type_name, либо оба поля должны отсутствовать (или иметь значение null).
Объект аннотации параметра состоит из следующих полей:
Поле "namespace_name"
Обязательное поле. Принимает строку с именем пространства имён, которое содержит тип параметра.
Поле "type_name"
Обязательное поле. Принимает строку с именем класса, в котором определён тип параметра.
Поле "attributes"
Опциональное поле. Массив строк, который задаёт свойства сущности.
Возможные атрибуты параметров
Примечание. К каждому из атрибутов taint-приёмников и taint-валидации прикреплена ссылка на соответствующую диагностику.
|
# |
Название атрибута |
Описание атрибута |
|---|---|---|
|
1 |
ignore_current_and_next |
При подборе соответствующей аннотации не будут учитываться текущий и следующие параметры (данная аннотация может быть только у последнего аргумента). |
|
2 |
transfer_annotation_to_return_value |
Если параметр содержит аннотацию, она будет перенесена на возвращаемое значение метода. |
|
3 |
object_creation_infector |
Заражение нового созданного объекта происходит через этот параметр (актуально только для конструкторов). |
|
4 |
sql_injection_target |
Передача в этот параметр заражённых данных приводит к SQL Injection (V5608). |
|
5 |
sql_injection_validation |
Вызов метода сбрасывает SQL Injection taint-статус для данного параметра (V5608). |
|
6 |
path_traversal_target |
Передача в этот параметр заражённых данных приводит к Path Traversal (V5609). |
|
7 |
path_traversal_validation |
Вызов метода сбрасывает Path Traversal taint-статус для данного параметра (V5609). |
|
8 |
xss_injection_target |
Передача в этот параметр заражённых данных приводит к XSS Injection (V5610). |
|
9 |
xss_injection_validation |
Вызов метода сбрасывает XSS Injection taint-статус для данного параметра (V5610). |
|
10 |
insecure_deserialization_target |
Передача в этот параметр заражённых данных приводит к Insecure Deserialization (V5611). |
|
11 |
insecure_deserialization_validation |
Вызов метода сбрасывает Insecure Deserialization taint-статус для данного параметра (V5611). |
|
12 |
command_injection_target |
Передача в этот параметр заражённых данных приводит к Command Injection (V5616). |
|
13 |
command_injection_validation |
Вызов метода сбрасывает Command Injection taint-статус для данного параметра (V5616). |
|
14 |
xml_source_to_parse |
Параметр - источник XML, который будет парситься. Это может быть сам XML-файл, путь до него, поток с XML-файлов, парсер, содержащий поток XML-файла, и т. п. (V5614, V5615). |
|
15 |
transfer_xml_settings_to_return |
Передаёт настройки XML-парсера из этого аргумента в возвращаемое значение. (V5614, V5615). |
|
16 |
ssrf_target |
Передача в этот параметр заражённых данных приводит к Server-Side Request Forgery (V5618). |
|
17 |
ssrf_validation |
Вызов метода сбрасывает Server-Side Request Forgery taint-статус для данного параметра (V5618). |
|
18 |
log_injection_target |
Передача в этот параметр заражённых данных приводит к Log Injection (V5619). |
|
19 |
log_injection_validation |
Вызов метода сбрасывает Log Injection taint-статус для данного параметра (V5619). |
|
20 |
ldapi_injection_target |
Передача в этот параметр заражённых данных приводит к LDAP Injection (V5620). |
|
21 |
ldapi_injection_validation |
Вызов метода сбрасывает LDAP Injection taint-статус для данного параметра (V5620). |
|
22 |
xpath_injection_target |
Передача в этот параметр заражённых данных приводит к XPath Injection (V5622). |
|
23 |
xpath_injection_validation |
Вызов метода сбрасывает XPath Injection taint-статус для данного параметра (V5622). |
|
24 |
open_redirect_target |
Передача в этот параметр заражённых данных приводит к Open Redirect (V5623). |
|
25 |
open_redirect_validation |
Вызов метода сбрасывает Open Redirect taint-статус для данного параметра (V5623). |
|
26 |
configuration_attack_target |
Передача в этот параметр заражённых данных приводит к Configuration Attack (5624). |
|
27 |
configuration_attack_validation |
Вызов метода сбрасывает Configuration Attack taint-статус для данного параметра (5624). |
|
28 |
nosql_injection_target |
Передача в этот параметр заражённых данных приводит к NoSQL Injection (V5627). |
|
29 |
nosql_injection_validation |
Вызов метода сбрасывает NoSQL Injection taint-статус для данного параметра (V5627). |
|
30 |
redos_target |
Строка, которая разбирается с помощью регулярного выражения. Передача в этот параметр заражённых данных приводит к ReDoS, если регулярное выражение небезопасно (V5626). |
|
31 |
redos_validation |
Вызов метода сбрасывает ReDoS taint-статус для данного параметра (V5626). |
|
32 |
zipslip_target |
Строка, которая может быть использована как путь для извлечения файла из архива. Передача в этот параметр заражённых данных приводит к ZipSlip (V5628). |
|
33 |
zipslip_validation |
Вызов метода сбрасывает ZipSlip taint-статус для данного параметра (V5628). |
|
34 |
regex |
Параметр является регулярным выражением. |
|
35 |
format_string |
Параметр является строкой формата. |
|
36 |
params |
Параметр имеет модификатор |
|
37 |
ref_or_out |
Параметр имеет модификатор |
|
38 |
file_path |
Параметр является путём до файла. |
|
39 |
greater_than_zero |
Параметр должен быть строго больше нуля. |
|
40 |
greater_than_or_equal_to_zero |
Параметр должен быть больше или равен нулю. |
|
41 |
not_null |
Параметр не должен быть |
|
42 |
not_null_after_method_call |
Значение, соответствующее параметру, точно не будет |
|
43 |
sensitive_data |
Данный параметр не должен содержать sensitive-данные. |
Игнорирование типа параметра
Чтобы проигнорировать тип параметра, не нужно указывать поля namespace_name и type_name или нужно записать в оба поля null.
Схема JSON
Схема JSON поставляется в дистрибутиве или доступна по ссылке.
Примеры
Аннотация метода
Рассмотрим метод:
namespace MyNamespace
{
public class MyClass
{
public string GetUserInput()
{
....
}
}
}Допустим, данный метод возвращает пользовательский ввод, который может содержать taint-данные. Аннотация, которая позволит анализатору понять это, будет выглядеть следующим образом:
{
"version": 1,
"language": "csharp",
"annotations": [
{
"type": "method",
"namespace_name": "MyNamespace",
"type_name": "MyClass",
"method_name": "GetUserInput",
"returns": {
"attributes": [ "always_taint" ]
}
}
]
}Аннотация конструктора
Рассмотрим конструктор:
namespace MyNamespace
{
public class MyClass
{
public MyClass()
{
....
}
}
}Допустим, данный конструктор создаёт объект, который может содержать taint-данные. Аннотация, которая позволит анализатору понять это, будет выглядеть следующим образом:
{
"version": 1,
"language": "csharp",
"annotations": [
{
"type": "ctor",
"namespace_name": "MyNamespace",
"type_name": "MyClass",
"attributes": [ "create_taint_object" ]
}
]
}Аннотация свойства
Рассмотрим свойство:
namespace MyNamespace
{
public class MyClass
{
public string UserInput
{
get
{
....
}
}
}
}Допустим, данное свойство возвращает пользовательский ввод, который может содержать taint-данные. Аннотация, которая позволит анализатору понять это, будет выглядеть следующим образом:
{
"version": 1,
"language": "csharp",
"annotations": [
{
"type": "property",
"namespace_name": "MyNamespace",
"type_name": "MyClass",
"property_name": "UserInput",
"attributes": [ "return_taint" ]
}
]
}Аннотация метода/конструктора, тип параметра которых неважен
Примечание. В качестве примера используется аннотация метода. Игнорирование типа параметров конструктора производится аналогичным образом (не указывать type_name и namespace_name у аннотации параметра).
Рассмотрим две перегрузки метода GetUserInput:
namespace MyNamespace
{
public class MyClass
{
public string GetUserInput(string str)
{
....
}
public string GetUserInput(int index)
{
....
}
}
}Допустим, данный метод возвращает пользовательский ввод, который может содержать taint-данные, вне зависимости от типа параметра. Аннотация, которая позволит анализатору понять это, будет выглядеть следующим образом:
{
"version": 1,
"language": "csharp",
"annotations": [
{
"type": "method",
"namespace_name": "MyNamespace",
"type_name": "MyClass",
"method_name": "GetUserInput",
"params": [
{ }
],
"returns": {
"attributes": [ "always_taint" ]
}
}
]
}В данном случае для первого параметра нет аннотаций. Также при подборе аннотации метода неважно, какой тип будет иметь первый параметр. Поэтому аннотация параметра представлена пустым объектом.
Аннотация метода/конструктора, игнорируя некоторые параметры
Примечание. В качестве примера используется аннотация метода. Игнорирование параметров конструктора производится аналогичным образом (с помощью аннотации ignore_current_and_next).
Рассмотрим две перегрузки метода GetUserInput:
namespace MyNamespace
{
public class MyClass
{
public string GetUserInput(string str)
{
....
}
public string GetUserInput(string str, bool flag1, bool flag2)
{
....
}
}
}Допустим, данный метод возвращает пользовательский ввод, который может содержать taint-данные, если использована перегрузка с одним или более параметрами. Также, если в первый параметр передать taint-данные, возникнет SQL injection. Аннотация, которая позволит анализатору понять это, будет выглядеть следующим образом:
{
"version": 1,
"language": "csharp",
"annotations": [
{
"type": "method",
"namespace_name": "MyNamespace",
"type_name": "MyClass",
"method_name": "GetUserInput",
"params": [
{
"namespace_name": "System",
"type_name": "String",
"attributes": [ "sql_injection_target" ]
},
{
"attributes": [ "ignore_current_and_next" ]
}
],
"returns": {
"attributes": [ "always_taint" ]
}
}
]
}Для второго параметра есть аннотация ignore_current_and_next. Она позволяет игнорировать количество параметров (включая проаннотированный параметр) при обработке аннотации.
Предопределённый макрос PVS_STUDIO
Наряду со многими другими способами фильтрации и подавления диагностических сообщений, в PVS-Studio есть предопределённый макрос PVS_STUDIO.
Первый случай, когда он может пригодиться — чтобы какой-то код не попадал в анализатор на проверку. Например, анализатор выдаёт диагностическое сообщение на такой код:
int rawArray[5];
rawArray[-1] = 0;Однако, если его "обернуть" с помощью этого макроса, то сообщения не будет:
int rawArray[5];
#ifndef PVS_STUDIO
rawArray[-1] = 0;
#endifВторой случай — переопределение стандартных и пользовательских макросов. Например, на следующем коде будет выдано предупреждение о разыменовании потенциально нулевого указателя:
char *st = (char*)malloc(10);
TEST_MACRO(st != NULL);
st[0] = '\0'; //V522Чтобы подсказать анализатору, что выполнение программы прерывается при неверном условии, можно переопределить макрос следующим образом:
#ifdef PVS_STUDIO
#undef TEST_MACRO
#define TEST_MACRO(expr) if (!(expr)) throw "PVS-Studio";
#endif
char *st = (char*)malloc(10);
TEST_MACRO(st != NULL);
st[0] = '\0';Этот способ позволяет устранить предупреждения анализатора на коде, тестируемом с помощью разных библиотек, а также на любых других макросах, использующихся для отладки и тестирования.
См. также обсуждение "Mark variable as not NULL after BOOST_REQUIRE in PVS-Studio" на сайте StackOverflow.com.
Начиная с версии 7.30, в PVS-Studio были добавлены макросы PVS_STUDIO_MAJOR и PVS_STUDIO_MINOR, которые отражают мажорную и минорную версии ядра анализатора.
При помощи этих макросов можно настраивать поведение анализа для блока кода в зависимости от версии анализатора. Например, можно включать или отключать диагностические правила только для определённых версий PVS-Studio:
// Auxiliary macros
#if defined(PVS_STUDIO) \
&& defined(PVS_VERSION_MAJOR) \
&& defined(PVS_VERSION_MINOR) \
#define PVS_VERSION_MACROS_INTRODUCED 1
#define PVS_MAKE_VERSION(major, minor) ( ((major) << 16) | (minor) )
#define PVS_CURRENT_VERSION \
PVS_MAKE_VERSION(PVS_VERSION_MAJOR, PVS_VERSION_MINOR)
#else
#define PVS_VERSION_MACROS_INTRODUCED 0
#endif
// ....
// Need to disable V691 on code block
#if PVS_VERSION_MACROS_INTRODUCED
#if PVS_CURRENT_VERSION < PVS_MAKE_VERSION(7, 35)
#pragma pvs(push)
#pragma pvs(disable: 591)
#endif
#endif
// code block
#if PVS_VERSION_MACROS_INTRODUCED
#if PVS_CURRENT_VERSION < PVS_MAKE_VERSION(7, 35)
#pragma pvs(pop)
#endif
#endifМакросы PVS_STUDIO, PVS_STUDIO_MAJOR и PVS_STUDIO_MINOR будут автоматически подставлены при проверке кода из IDE и утилит PVS-Studio_Cmd.exe, pvs-studio-analyzer / CompilerCommandsAnalyzer. Если же для проверки проекта вы используете прямой вызов ядра анализатора, то по умолчанию макросы не передаются анализатору, и это нужно сделать вручную.
Файл конфигурации анализа Settings.xml
- Глобальный файл конфигурации
- Пользовательский файл конфигурации
- Описание формата файла и отдельных настроек
Глобальный файл конфигурации
Многие инструменты PVS-Studio используют XML-файл для хранения конфигурации.
Такой файл может использоваться неявно (глобальный файл Settings.xml, расположенный в специальном каталоге), или передаваться явно инструментам PVS-Studio через специальный флаг.
По умолчанию инструменты PVS-Studio используют глобальный файл конфигурации Settings.xml, расположенный:
- в Windows: '%APPDATA%\PVS-Studio\Settings.xml'
- в Linux, macOS: '~/.config/PVS-Studio/Settings.xml'
Глобальный файл конфигурации используется практически всеми инструментами PVS-Studio, если им не передан альтернативный файл. Ниже перечислены инструменты, которые не используют глобальный файл конфигурации:
- pvs-studio-analyzer\CompileCommandsAnalyzer.exe под Linux, macOS и Windows;
- plog-converter под Linux и macOS.
Примечание: Плагины PVS-Studio для Visual Studio, Rider и CLion, а также утилита C and C++ Compiler Monitoring UI используют только глобальный файл Settings.xml.
Пользовательский файл конфигурации
Вы можете вынести настройки анализа для проекта в специальный XML-файл, который затем может быть передан консольным инструментам PVS-Studio через специальный флаг.
Обратите внимание: чтобы не допустить ошибку при написании файла конфигурации, мы рекомендуем скопировать глобальный файл Settings.xml и модифицировать его.
Ниже приведены примеры запуска утилит со специальным файлом конфигурации CustomSettings.xml (вы можете назвать его так, как вам удобно).
Для утилиты PVS-Studio_Cmd.exe:
PVS-Studio_Cmd.exe -t "path\to\Solution.sln" ... \
--settings "path\to\CustomSettings.xml"CLMonitor.exe [analyze|monitor|analyzeFromDump|trace] ... \
--settings "\path\to\CustomSettings.xml"Для утилиты BlameNotifier.exe:
BlameNotifier.exe "path\to\PVS-Studio.plog" \
--VCS Git \
--recipientsList "path\to\recipients.txt" \
--server ... --sender ... \
--login ... --password ... \
--settings "path\to\CustomSettings.xml"Для утилиты PlogConverter.exe (only Windows):
PlogConverter.exe -t json ... --settings "path\to\CustomSettings.xml" \
"path\to\PVS-Studio.plog"Описание формата файла и отдельных настроек
Формат файла
Файл конфигурации имеет формат XML со следующей структурой:
<?xml version="1.0" encoding="utf-8"?>
<ApplicationSettings>
...
<Tag>Value</Tag>
...
</ApplicationSettings>Вместо Tag записывается идентификатор опции (например, FileMasks), а вместо Value — её значение. Описание доступных опций и их значений будет приведено ниже.
Значения опций могут быть следующих типов:
- ListString — теги этого типа принимают в качестве значения список строк. Каждое значение списка определяется тегом string;
- string — теги этого типа принимают в качестве значения строку;
- bool — теги этого типа принимают в качестве значения true или false;
- Int — теги этого типа принимают в качестве значения целое число;
- Enum — теги этого типа принимают в качестве значения константы, определённые типом соответствующей настройки.
Описание тегов отдельных настроек
Далее будет дано описание ключевых опций файла конфигурации и области их применения.
FileMasks (ListString)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio, Rider и СLion.
Тег описывает список файловых масок, которые будут применены для исключения файлов из анализа. Маски данного типа используются только для фильтрации по именам файлов, без учета директорий. Вы можете указать как полное имя файла, так и маску, используя wildcard-символы: '*' - любое число символов, '?' - один любой символ.
Тег FileMasks принимает список тегов <string>, каждый из которых содержит файловую маску.
Например, следующая запись исключает все файлы SourceTest.cpp и C*Test.cpp из анализа:
<FileMasks>
<string>SourceTest.cpp</string>
<string>C*Test.cpp</string>
</FileMasks>PathMasks (ListString)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio, Rider и СLion.
Тег описывает список Path-масок, используемых для исключения каталогов из анализа. Маски данного типа позволяют исключить файлы из анализа на основе их расположения.
Тег PathMasks принимает список тегов <string>, каждый из которых содержит маску пути.
Например, следующая запись исключит все cpp и hpp файлы, расположенные в каталогах ThirdParty и Tests:
<PathMasks>
<string>*/ThirdParty/*.?pp</string>
<string>*/Tests/*.?pp</string>
</PathMasks>DisableSynchronizeSuppressFiles (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio.
Данная опция отключает синхронизацию suppress-файлов между проектами одного решения. Это может быть полезно, если вы хотите, чтобы сообщение, подавленное в одном проекте, не подавлялось в других.
Тег DisableSynchronizeSuppressFiles может принимать одно из двух значений: true, false. Если установлено значение true, то автоматическая синхронизация suppress-файлов отключена. По умолчанию устанавливается значение false.
Пример:
<DisableSynchronizeSuppressFiles>true</DisableSynchronizeSuppressFiles>DisableDetectableErrors (string)
Используется в: PlogConverter.exe (Windows), BlameNotifier, IDE плагины для Visual Studio и Rider
Тег задаёт список диагностик, которые должны быть скрыты в отчёте при его просмотре в IDE плагине PVS-Studio.
Тег DisableDetectableErrors принимает список диагностических правил, разделённый пробелами. Обратите внимание, что после последнего кода должен быть также указан пробел.
Данная опция используется утилитами PlogConverter.exe (Windows) и BlameNotifier ещё и для исключения предупреждений из результирующего отчёта.
Например, можно использовать такую запись, чтобы исключить не интересующие вас диагностики при конвертации отчёта с помощью PlogConverter.exe:
<DisableDetectableErrors>V126 V203 V2001 V2006 </DisableDetectableErrors>Таким образом, вы можете передать файл *.xml в PlogConverter.exe через флаг ‑‑setting и получить отчёт без предупреждений V126, V203, V2001, V2006.
UserName (string)
Используется в: PVS-Studio_Cmd, CLMonitor, BlameNotifier, IDE плагины для Visual Studio, Rider и СLion.
Тег задает имя, необходимое для проверки валидности лицензии.
Примечание: вы можете игнорировать данный тег в специальном файле настроек, если вы уже выполняли активацию. Тогда PVS-Studio будет искать лицензионные данные в глобальном файле Settings.xml.
Пример:
<UserName>Name</UserName>SerialNumber (string)
Используется в: PVS-Studio_Cmd, CLMonitor, BlameNotifier, IDE плагины для Visual Studio, Rider и СLion.
Тег задаёт лицензионный ключ для проверки валидности лицензии.
Примечание: вы можете игнорировать данный тег в специальном файле настроек, если вы уже выполняли активацию. Тогда PVS-Studio будет искать лицензионные данные в глобальном файле Settings.xml.
Пример:
<SerialNumber>XXXX-XXXX-XXXX-XXXX</SerialNumber>RemoveIntermediateFiles (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio, Rider и СLion.
Данный тег включает/выключает автоматическое удаление временных файлов анализатора, таких как файлы конфигурации ядра анализатора и препроцессированные файлы.
Тег RemoveIntermediateFiles принимает значение true или false. Если true, все временные файлы будут удалены.
По умолчанию принимает значение true. Сохранение временных файлов бывает полезным при исследовании проблем работы анализатора.
Пример:
<RemoveIntermediateFiles>false</RemoveIntermediateFiles>ReportDisabledRules (bool)
Используется в: PVS-Studio_Cmd, IDE плагины для Visual Studio.
Тег позволяет включать отображение источников подавления предупреждений. Опция помогает узнать, какие механизмы учaствуют в отключении диагностик.
Тег ReportDisabledRules принимает значение true или false. Если true, то отчёт будет содержать сообщения с кодом V012 и информацией об источниках отключения диагностик.
По умолчанию установлено значение false.
Пример:
<ReportDisabledRules>true</ReportDisabledRules>Disable64BitAnalysis (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio и СLion.
Тег отключает группу 64-битных диагностик. Диагностические правила из отключённой группы не будут применены.
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<Disable64BitAnalysis>true</Disable64BitAnalysis>DisableGAAnalysis (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio и СLion.
Тег отключает группу диагностик общего назначения для C и C++ (General Analysis).
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<DisableGAAnalysis>true</DisableGAAnalysis>DisableOPAnalysis (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio, Rider и СLion.
Тег отключает группу диагностик микрооптимизаций для C и C++.
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<DisableOPAnalysis>true</DisableOPAnalysis>DisableCSAnalysis (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio, Rider и СLion.
Тег отключает группу специфичных диагностических правил, добавленных по просьбе пользователей (Customer Specific), для C и C++.
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<DisableCSAnalysis>true</DisableCSAnalysis>DisableMISRAAnalysis (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio и СLion.
Тег отключает группу диагностик, проверяющих C и C++ код на соответствие стандартам MISRA.
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<DisableMISRAAnalysis>true</DisableMISRAAnalysis>DisableAUTOSARAnalysis (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio и СLion.
Тег отключает группу диагностик, проверяющих C++ код на соответствие стандартам AUTOSAR.
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<DisableAUTOSARAnalysis>true</DisableAUTOSARAnalysis>DisableOWASPAnalysis (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio и СLion.
Тег отключает группу диагностик, проверяющих C и C++ код на соответствие стандарту OWASP ASVS.
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<DisableOWASPAnalysis>true</DisableOWASPAnalysis>DisableOWASPAnalysisCs (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio и Rider.
Тег отключает группу диагностик, проверяющих C# код на соответствие стандарту OWASP ASVS.
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<DisableOWASPAnalysisCs>true</DisableOWASPAnalysisCs>DisableGAAnalysisCs (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio и Rider.
Тег отключает группу диагностик общего назначения для C# (General Analysis).
Если установлено значение true, все диагностики этой группы будут отключены.
Пример:
<DisableGAAnalysisCs>true</DisableGAAnalysisCs>PerformPreBuildStep (bool)
Используется в: PVS-Studio_Cmd, IDE плагины для Visual Studio.
Включение данной настройки позволяет выполнять действия, записанные в секции Custom Build Step проектного файла Visual Studio (vcproj/vcxproj), перед запуском анализа. Заметим, что анализатору для корректной работы необходим компилирующийся код. Так, например, если Custom Build Step используется для генерации *.h файлов перед компиляцией, его необходимо будет выполнить (включив данную настройку) и перед анализом проекта.
Тег PerformPreBuildStep принимает значение true/false.
Если значение true, настройка включена.
Пример:
<PerformPreBuildStep>true</PerformPreBuildStep>AutoSettingsImport (bool)
Используется в: PVS-Studio_Cmd, CLMonitor, BlameNotifier, IDE плагины для Visual Studio.
Тег включает автоматический импорт настроек (xml-файлов) из каталога '%APPDATA%\PVS-Studio\SettingsImports'. При импорте настройки-флаги (true\false), а также настройки, хранящие одно значение (например, строку), заменяются настройками из 'SettingsImports'. Настройки, имеющие несколько значений (например, исключаемые директории), объединяются.
При наличии в папке 'SettingsImports' нескольких xml-файлов, эти файлы будут применены к текущим настройкам последовательно по порядку, в соответствии с их именем.
Тег AutoSettingsImport принимает значение true/false.
Если значение true, автоматический импорт включён.
Пример:
<AutoSettingsImport>true</AutoSettingsImport>NoNoise (bool)
Используется в: PVS-Studio_Cmd, IDE плагины для Visual Studio.
Тег отключает генерацию предупреждений низкого уровня достоверности.
Если установлено значение true, в отчёт не попадут сообщения 3-го уровня достоверности.
Пример:
<NoNoise>false</NoNoise>ThreadCount (int)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio, Rider и СLion
Тег устанавливает количество параллельно запускаемых процессов ядра анализатора, которые будут задействованы при анализе. По умолчанию устанавливается значение, равное количеству ядер процессора.
Обратите внимание, что не рекомендуется задавать значение данной настройки больше, чем количество процессорных ядер. Также стоит учесть, что для не Enterprise-лицензий действует ограничение в 16 ядер.
Пример:
<ThreadCount>8</ThreadCount>SourceTreeRoot (string)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio, Rider и СLion.
Опция позволяет указать корневую часть пути до исходных файлов в отчёте анализатора. При формировании отчёта корневая часть будет заменена на специальный маркер |?|. По умолчанию данная опция пуста и анализатор всегда генерирует отчёт с абсолютными путями до файлов. Настройка позволяет получить отчёт анализатора с относительными путями, который затем можно использовать на машинах с отличающимся расположением проверяемых исходных файлов.
Пример:
<SourceTreeRoot>D:\ProjectRoot\</SourceTreeRoot>Подробнее об этом можно узнать в разделе документации "Использование относительных путей в файлах отчётов PVS-Studio".
UseSolutionDirAsSourceTreeRoot (bool)
Используется в: PVS-Studio_Cmd, IDE плагины для Visual Studio, Rider и СLion.
Тег позволяет включить использование каталога решения в качестве значения SourceTreeRoot.
Если значение true, то часть пути, содержащая путь до каталога решения, будет заменена на специальный маркер, параметр SourceTreeRoot будет проигнорирован.
Пример:
<UseSolutionDirAsSourceTreeRoot>false</UseSolutionDirAsSourceTreeRoot>AnalysisTimeout (Enum)
Используется в: PVS-Studio_Cmd, CLMonitor, IDE плагины для Visual Studio, Rider и СLion.
Тег задает время, по истечению которого анализ файла будет прерван. Параметр может принимать следующие значения:
- After_10_minutes — ограничивает время анализа файла 10 минутами;
- After_30_minutes — ограничивает время анализа файла 30 минутами;
- After_60_minutes — ограничивает время анализа файла часом;
- No_timeout — снимает временные ограничения анализа файла.
Обратите внимание, что снятие временного ограничения может привести к зависанию анализа.
Пример:
<AnalysisTimeout>After_10_minutes</AnalysisTimeout>IncrementalAnalysisTimeout (Enum)
Используется в: PVS-Studio_Cmd, IDE плагины для Visual Studio, Rider и СLion.
Тег задаёт ограничение по времени для инкрементального анализа. Возможные значения:
- After_1_minute — ограничить инкрементальный анализ 1 минутой;
- After_2_minutes — ограничить инкрементальный анализ 2 минутами;
- After_5_minutes — ограничить инкрементальный анализ 5 минутами;
- After_10_minutes — ограничить инкрементальный анализ 10 минутами;
- No_timeout — снять ограничение по времени.
Обратите внимание, что снятие ограничения может привести к зависанию анализа.
Пример:
<IncrementalAnalysisTimeout>After_2_minutes</IncrementalAnalysisTimeout>SecurityRelatedIssues (bool)
Используется в: PVS-Studio_Cmd, IDE плагин для Visual Studio.
Тег включает добавление маркировки по ГОСТ Р 71207-2024 в поле сообщений SAST. Возможные значения:
- true;
- false.
Пример:
<SecurityRelatedIssues>true</SecurityRelatedIssues>Настройки: Общее
При разработке PVS-Studio простота использования ставилась во главу угла. Мы учли наш опыт общения с традиционными lint-подобными анализаторами кода. Именно поэтому возможность сразу же приступить к работе является одним из основных преимуществ PVS-Studio по сравнению с другими анализаторами кода. Кроме того, PVS-Studio проектировалась так, чтобы разработчику, который будет использовать анализатор, вообще не пришлось его настраивать. Эту задачу удалось решить: разработчик имеет мощнейший анализатор кода, который нет необходимости настраивать при первом запуске.
Однако надо понимать, что анализатор кода - это мощный инструмент, который нуждается в грамотном применении. Именно грамотное применение анализатора (благодаря системе настроек) позволяет добиться по-настоящему значительных результатов. Работа с анализатором кода предполагает, что есть инструмент (программа), которая делает рутинную работу по поиску потенциально опасных конструкций в коде, и есть мастер (разработчик), который на основе знаний о проверяемом проекте может принимать те или иные решения. Так, например, разработчик может сообщить анализатору о том, что:
- какие-то типы ошибок (то есть потенциально опасных конструкций) в данном проекте возникнуть в принципе не могут (отключив соответствующие диагностические сообщения, Detectable Errors);
- проект не содержит некорректных приведений типов (отключив соответствующие диагностические сообщения, Detectable Errors).
Корректная настройка данных параметров может во много раз уменьшить количество диагностических сообщений, выдаваемых анализатором кода. Это означает, что если разработчик поможет анализатору и сообщит ему некоторую дополнительную информацию в виде настроек, то анализатор, в свою очередь, значительно сократит количество мест, на которые разработчик должен будет обратить внимание при анализе результатов проверки.
Настройки PVS-Studio можно открыть через команду главного меню IDE: PVS-Studio -> Options. Выбрав эту команду, Вы увидите диалог настройки PVS-Studio.
Каждая страница настроек подробно описана в документации к PVS-Studio.
Настройки: Common Analyzer Settings
На вкладке общих настроек анализатора кода указываются настройки, не зависящие от конкретного используемого модуля анализа.
Check For New Versions
Анализатор может автоматически проверять наличие своей новой версии на сайте pvs-studio.com. Для этого используется собственный модуль обновления.
В случае, если опция CheckForNewVersions имеет значение True, то при запуске проверки кода (команды Check Current File, Check Current Project, Check Solution меню PVS-Studio) выполняется загрузка специального текстового файла с сайта pvs-studio.com. В этом файле указан номер самой последней версии PVS-Studio, доступной на сайте. Если версия на сайте окажется новее, чем версия, установленная у пользователя, то пользователь увидит запрос на обновление. В случае разрешения этого обновления, будет запущено специальное отдельное приложение PVS-Studio-Updater, которое автоматически загрузит новый дистрибутив PVS-Studio с сайта и запустит его установку. В случае, если опция CheckForNewVersions установлена в False, проверка новой версии производиться не будет.
Thread Count
Анализ файлов выполняется быстрее на многоядерных машинах. Так, на четырех-ядерном компьютере анализатор может использовать все четыре ядра для своей работы. Однако, если по каким-то причинам надо ограничить количество используемых ядер, то это вполне можно сделать, указав допустимое количество. По умолчанию устанавливается значение, равное количеству ядер процессора.
Задание для настройки 'ThreadCount' значения, большего '16' (или большего, чем количество ядер процессора, если у процессора более 16 ядер), доступно только при наличии Enterprise лицензии. Вы можете запросить пробную Enterprise лицензию здесь.
При запуске анализа на одной машине, мы не рекомендуем задавать значение этой настройки более, чем количество процессорных ядер. Задание большего значения может замедлить анализ в целом. Если вы хотите запускать больше одновременных задач анализа, вы можете воспользоваться системой распределённой сборки, например, Incredibuild. Подробнее про такой режим использования PVS-Studio можно почитать в соответствующем разделе документации.
Remove Intermediate Files
Для своей работы анализатор создает большое количество временных командных файлов для запуска собственно модуля анализа, выполнения препроцессинга и управления общим процессом анализа. Подобные файлы создаются для каждого анализируемого файла проекта. Обычно они не представляют интереса для пользователя и поэтому после анализа сразу же удаляются. Однако, в некоторых случаях может быть полезно посмотреть на эти файлы. Поэтому можно указать анализатору не удалять их. В таком случае можно будет запускать анализатор вне IDE из командной строки.
Настройки: Detectable Errors
Данная страница настроек позволяет управлять отображением типов сообщений анализатора в списке результатов PVS-Studio.
Все диагностические предупреждения анализатора разделены на несколько групп. Отображением каждого типа сообщений (показывать/скрывать) можно управлять по отдельности, а для всей группы сообщений можно выполнить следующие действия:
- Disabled - полностью отключает группу диагностик. Ошибки из данной группы не будут попадать в список результатов анализа. Обратное включение потребует перезапуска анализа;
- Show All - отобразить в списке результатов все сообщения данной группы;
- Hide All - скрыть в списке результатов все сообщения данной группы.
Иногда бывает целесообразно убрать в отчете ошибки с определенными кодами. Например, если вы уверены, что ошибки с кодом V505 и V506 вас не интересуют, то вы можете скрыть их показ, сняв галочку в соответствующей строчке.
Обратите внимание! При включении "Show All" и "Hide All" нет необходимости перезапускать анализ проекта заново. Анализатор всегда выдаёт все типы ошибок, при этом показ тех или иных ошибок задается настройками на этой странице. При включении/выключении отображения ошибок, они сразу будут показаны/скрыты в отчете без перезапуска анализа всего проекта.
Полное отключение группы диагностик (Disabled) можно использовать для того, чтобы ускорить работу анализатора и получить файлы с отчетами (plog-файлы) меньшего размера.
Настройки: Don't Check Files
На вкладке "Don't Check Files" настроек можно ввести файловые маски для исключения некоторых файлов или папок из анализа. Анализатор не будет проверять файлы, удовлетворяющие условиям масок.
Например, подобным образом можно исключить из анализа автогенерируемые файлы. Кроме того, можно исключить файлы по имени папки, в которой они находятся.
Маска задается с помощью специальных wildcard символов: "*" (раскрывается в любое количество произвольных символов) и "?" (раскрывается в один произвольный символ).
Регистр символов не имеет значения. Символ "*" может быть добавлен в любой части маски. После задания масок вида '*\mask\*', сообщения из соответствующих им файлов исчезнут из окна вывода PVS-Studio, а в следующую проверку они включены уже не будут. Таким образом, исключение файлов и директорий посредством масок может позволить существенно сократить общее время анализа всего проекта.
Примечание: маски вида 'a*b' будут применены только после перезапуска анализа.
В окне можно задавать 2 типа масок: маски по путям (Path Mask) и маски по именам файлов (FileName Mask). Маски, заданные в списке FileNameMasks, используются для фильтрации сообщений только непосредственно по именам файлов, без учёта директории, в которой эти файлы находятся. Маски из списка PathMasks фильтруют диагностические сообщения с учётом расположения фалов в файловой системе на диске и позволяют подавлять сообщения как для отдельных файлов, так и для целых директорий и поддиректорий. Так, для фильтрации сообщений в одном конкретном файле, полный путь до него необходимо добавить в список PathMasks, а для фильтрации всех файлов с одинаковыми (либо удовлетворяющими wildcard маске) именами можно добавить такое имя или маску в список FileNameMasks.
Примеры допустимых масок для списка FileNameMasks:
- *ex.c — будут исключены все файлы с именем, оканчивающимся на символы "ex", и имеющие расширение "c";
- *.cpp — будут исключены все файлы, имеющие расширение "cpp" ;
- stdafx.cpp — будут исключены все встречающиеся в проекте файлы с такими именами, независимо от их местоположения на диске.
- *.?pp - будут исключены все файлы расширение которых оканчивается на 'pp'.
Примеры допустимых масок для списка PathMasks:
- c:\Libs\ — будут исключены все файлы проекта, расположенные в данной папке и её подпапках;
- \Libs\ или *\Libs\* — будут исключены все файлы, расположенные в директориях, путь до которых содержит подпапку Libs;
- Libs или *Libs* — исключены будут все файлы, путь до которых содержит подпапку, имеющую 'Libs' в качестве имени либо фрагмента имени. Также в этом случае будут исключены файлы, содержащие Libs в имени, например, c:\project\mylibs.cpp. Поэтому, чтобы избежать путаницы, рекомендуем папки задавать всегда со слешами;
- c:\proj\includes.cpp — будет исключён только один файл с заданным именем, находящийся в директории c:\proj\.
Примечание. Если в PathMasks символы "*" не указаны, они все равно будут автоматически добавлены.
Настройки: Keyword Message Filtering
На вкладке подавления отдельных сообщений по ключевым словам можно настроить фильтрацию ошибок по содержащемуся в них тексту.
При необходимости можно скрыть из отчета сообщения о диагностированных ошибках, содержащих определенные слова или фразы. Например, если в отчете есть ошибки, в которых указаны названия функций printf и scanf, а вы считаете, что ошибок, связанных с ними быть не может, то просто добавьте эти два слова с помощью редактора подавляемых сообщений.
Обратите внимание! При изменении списка скрываемых сообщений нет необходимости перезапускать анализ проекта заново. Анализатор всегда генерирует все диагностические сообщения, при этом показ тех или иных диагностических сообщений управляется с помощью этой страницы настроек. При модификации фильтров сообщений изменения сразу же покажутся в отчете без перезапуска анализа всего проекта.
Настройки: Registration
Откройте страницу настроек PVS-Studio (PVS-Studio Menu -> Options...).
На вкладке регистрации вводится лицензионная информация.
После покупки анализатора вы получите регистрационную информацию: имя и серийный номер. Эти данные должны быть введены на этой странице. При этом в поле LicenseType будет указан режим лицензирования.
Информацию по условиям лицензирования смотрите на странице заказа на сайте.
Настройки: Specific Analyzer Settings
- Analysis Timeout
- Incremental Analysis Timeout
- MISRACppVersion и MISRACVersion
- Disable Incremental PCH Tracking
- No Noise
- Intermodular Analysis Cpp
- Perform Custom Build Step
- Perform TFVC Checkout
- Save File After False Alarm Mark
- Display False Alarms
- Enable False Alarms With Hash
- Disable Synchronization Of Suppress Files
- Integrated Help Language
- Use Offline Help
- Show Best Warnings Button
- Show Tray Icon
- Incremental Results Display Depth
- Trace Mode
- Automatic Settings Import
- Use Solution Folder As Initial
- Save Modified Log
- Source Tree Root
- Use Solution Dir As Source Tree Root
- Autoload Unreal Engine Log
- Dependency Cache Tracking Mode
На вкладке "Specific Analyzer Settings" размещены дополнительные расширенные настройки анализатора.
Analysis Timeout
Данная настройка позволяет задать лимит времени, по истечении которого анализ отдельных файлов завершается с ошибкой V006. File cannot be processed. Analysis aborted by timeout, или совсем отключить прерывание анализа по лимиту времени. Перед изменением данной настройки мы рекомендуем внимательно ознакомиться с описанием ошибки, приведенным по указанной выше ссылке. Часто бывает, что таймаут возникает из-за нехватки оперативной памяти. В этом случае рационально не увеличивать время, а уменьшить количество используемых параллельных потоков. Это может дать существенный прирост производительности, когда процессорных ядер много, а оперативной памяти мало.
Incremental Analysis Timeout
Данная настройка позволяет задать лимит времени, по истечении которого инкрементальный анализ файлов будет остановлен. Все предупреждения, обнаруженные на момент остановки анализа, будут выданы в окно PVS-Studio. Дополнительно к ним будет выдано предупреждение о том, что анализатор не успел обработать все изменённые файлы, а также информация суммарном и проанализированном количестве файлов.
Данная опция актуальна только при работе из IDE Visual Studio.
MISRACppVersion и MISRACVersion
Данная настройка позволяет выбрать версию стандарта MISRA. Для C++ доступны версии 2008 и 2023, а для C – 2012 и 2023.
Disable Incremental PCH Tracking
Данная настройка отключает инкрементальный анализ исходных файлов кода на C и C++, затрагиваемых изменениями в предварительно компилируемом заголовочном файле и заголовочных файлах, включенных в него. Настройка полезна в ситуациях, когда эти файлы часто меняются и из-за этого время инкрементального анализа значительно увеличивается.
При изменении настройки из IDE Visual Studio изменения вступят в силу после следующего открытия решения или проекта. Если анализ запускается через консольную утилиту PVS-Studio_Cmd, то анализатор сразу задействует новое значение настройки.
No Noise
При работе на большой кодовой базе, анализатор неизбежно генерирует большое количество предупреждений. При этом, часто нет возможности поправить все предупреждения сразу. Для того, чтобы иметь возможность сконцентрироваться на правке наиболее важных предупреждений, можно сделать анализ менее "шумным" с помощью данной настройки. Она позволяет полностью отключить генерацию предупреждений низкого уровня достоверности (Low Certainty, 3-ий уровень предупреждений). После перезапуска анализа, сообщения этого уровня полностью пропадут из вывода анализатора.
Когда обстоятельства позволят и более существенные предупреждения анализатора будут исправлены, можно выключить режим No Noise – при следующем анализе все пропавшие ранее предупреждения станут вновь доступны.
Intermodular Analysis Cpp
Включение данной настройки позволяет анализатору учитывать информацию не только из анализируемого файла, но и из связанных с ним файлов. Это позволяет производить более глубокий и качественный анализ. Однако, на сбор необходимой информации требуется дополнительное время, что отразится на времени анализа вашего проекта.
Данный режим актуален для C и C++ проектов. C# проекты обеспечивают межмодульный анализ по умолчанию.
Начиная с версии PVS-Studio 7.26 настройка убрана. Теперь для запуска межмодульного анализа нужно использовать меню запуска анализа.
Perform Custom Build Step
Включение данной настройки позволяет выполнять действия, записанные в секции Custom Build Step проектного файла Visual Studio (vcproj/vcxproj), перед запуском анализа. Заметим, что анализатору для корректной работы необходим компилирующийся код. Так, например, если Custom Build Step используется для генерации h файлов перед компиляцией, его необходимо будет выполнить (включив данную настройку) и перед анализом проекта. Если же на данном шаге выполняются действия, относящиеся, например, к линковке, они не повлияют на результат работы анализатора. Действия Custom Build Step задаются на уровне проекта и будут выполнены PVS-Studio при первоначальном обходе дерева проектов. Если данная настройка включена и в результате её выполнения получен ненулевой код, проверка такого проекта не будет запущена.
Perform TFVC Checkout
Включение данной настройки позволяет автоматически выполнять checkout с использованием Team Foundation Version Control Tool при редактировании файлов, содержащих подавленные предупреждения анализатора (.suppress файлы). Включение данной настройки не повлияет на работу с проектами, не находящимися под управлением системы контроля версий TF или не добавленными в workspace Visual Studio.
Дополнительная информация, в случае её наличия (в т.ч. информация об ошибках), будет выводиться в окно PVS-Studio.
Данная опция актуальна только при работе из IDE Visual Studio.
Save File After False Alarm Mark
Пометка сообщения как ложного срабатывания требует внесения изменений в файлы с исходным кодом. По умолчанию анализатор сохраняет каждый файл с исходным кодом после каждой такой пометки. Однако, если подобное частое сохранение не желательно (например, если файлы находятся на другой машине локальной сети), оно может быть отключено с помощью данного пункта настроек.
Будьте осторожны при изменении данной настройки, т.к. отсутствие сохранений файлов с исходным кодом после их разметки на ложные срабатывания может привести к потере результатов работы в случае закрытия среды разработки.
Display False Alarms
Позволяет включить отображение сообщений, размеченных как 'Ложные Срабатывания', в окне вывода PVS-Studio. Эта настройка будет применена в окне сообщений PVS-Studio сразу, без необходимости запускать анализ повторно. Когда выставлено значение 'True', специальный индикатор 'FA', отображающий количество ложных срабатываний, появится на панели окна вывода.
Enable False Alarms With Hash
Настройка включает добавление дополнительного хэш-кода к метке ложного срабатывания. Хэш-код вычисляется на основе содержимого строки кода. Если строка кода изменится, предупреждения с тем же хэш-кодом, выданные для этой строки, больше не будут считаться ложными срабатываниями.
Disable Synchronization Of Suppress Files
Данная настройка отключает автоматическую синхронизацию suppress-файлов между проектами в рамках одного решения.
По умолчанию синхронизация suppress-файлов включена. Если какой-либо файл исходного кода используется в нескольких проектах и предупреждения из этого файла были добавлены в suppress-файл хотя бы одного проекта, то при анализе других проектов эти предупреждения автоматически будут дописаны в suppress-файлы анализируемых проектов.
Integrated Help Language
Настройка позволяет задать язык для встроенной справки по диагностическим сообщениям (клик по коду ошибки в окне вывода сообщений PVS-Studio) и документации (команда меню PVS-Studio -> Help -> Open PVS-Studio Documentation (html, online)) PVS-Studio, доступных на нашем сайте.
Данная настройка не меняет язык интерфейса IDE плагина PVS-Studio или выдаваемых анализатором диагностических сообщений.
Use Offline Help
Настройка позволяет использовать офлайн справку по диагностическим сообщениям (клик по коду ошибки в окне вывода сообщений PVS-Studio).
Show Best Warnings Button
Данная опция отвечает за отображение кнопки 'Best' в интерфейсе PVS-Studio. По умолчанию опция включена и кнопка 'Best' доступна в таблице срабатываний. Используя её, можно просмотреть 10 наиболее интересных предупреждений анализатора. Вы можете скрыть эту кнопку, определив данный параметр как 'False'.
Show Tray Icon
Данная настройка позволяет управлять уведомлениями о работе анализатора PVS-Studio. После завершения анализа, в случае, если окно PVS-Studio Output содержит сообщения об ошибках (сообщения об ошибках могут быть скрыты фильтрами как ложные срабатывания, по именам проверяемых файлов и т.п.; такие сообщения не попадают в окно PVS-Studio), анализатор проинформирует об их наличии с помощью всплывающего сообщения в области уведомления Windows (notification area, system tray). Одинарный щелчок мыши по данному сообщению, либо по значку PVS-Studio, откроет окно вывода сообщений PVS-Studio, содержащее найденные ошибки.
Incremental Results Display Depth
Настройка задаёт режим отображения уровней сообщений в окне PVS-Studio Output для результатов работы инкрементального анализа. Установка в данном поле глубины уровня отображения (соответственно, только 1 уровень; 1 и 2 уровни; 1, 2 и 3 уровни) приведёт к автоматическому включению данных уровней после завершения инкрементального анализа. Значение "Preserve_Current_Levels" сохранит существующие настройки уровней без изменений.
Данная опция может быть полезна при регулярном совместном использовании инкрементального и обычного режимов запуска, т.к. случайное отключение, например, 1 уровня анализа при просмотре большого отчёта обычной проверки, приведёт к сокрытию результатов работы уже инкрементального анализа. А так как инкрементальный анализ работает в фоновом режиме, подобная ситуация может привести к потере для пользователя диагностик о реальных ошибках, найденных анализатором в этом режиме работы.
Trace Mode
Настройка задаёт режим трассировки (протоколирования хода выполнения программы) для IDE пакета расширения PVS-Studio (плагина для сред Visual Studio). Трассировка имеет несколько уровней детализации вывода (режим Verbose соответствует наиболее подробному протоколированию). При включении режима трассировки, PVS-Studio автоматически создаёт лог-файл в директории AppData\PVS-Studio с расширением log (например, c:\Users\admin\AppData\Roaming\PVS-Studio\PVSTrace2168_000.log). При этом каждый запущенный процесс IDE будет использовать отдельный лог-файл для сохранения результатов своей трассировки.
Automatic Settings Import
Данная настройка позволяет включить автоматический импорт настроек (xml файлов) из директории %AppData%\PVS-Studio\SettingsImports\. Настройки импортируются при каждой загрузке сохранённых настроек, т.е. при запуске Visual Studio или command line версии анализатора, при сбросе настроек и т.п. При импорте, настройки-флаги (true\false), а также настройки, хранящие одно значение (например, строку), заменяются настройками из SettingsImports. Настройки, имеющие несколько значений (например, исключаемые директории) объединяются.
При наличии в папке SettingsImports нескольких xml файлов, эти файлы будут применены к текущим настройкам последовательно по порядку, в соответствии с их именем.
Use Solution Folder As Initial
По умолчанию PVS-Studio предлагает сохранять файл отчета (.plog) в той же папке, что и .sln-файл.
Изменение данной настройки позволяет восстановить стандартное поведение файловых диалогов Windows, т.е. диалог будет помнить последнюю открытую в нём папку и использовать именно её в качестве начальной.
Save Modified Log
Эта настройка задаёт то, как будет отображаться запрос на сохранение отчёта работы анализатора перед началом нового анализа или загрузкой другого отчёта в случае, если окно вывода уже содержит новые, не сохранённые или модифицированные результаты работы анализатора. Установка настройки 'Yes' включит автоматическое сохранение результатов в текущий файл отчёта (после того, как такой файл в первый раз будет указан в диалоге о сохранении файла). После установки настройки 'No' IDE плагин будет перезаписывать текущие результаты работы анализатора без сохранения. Выбор значения 'Ask_Always' (используется по умолчанию) приведет к выдаче запроса на сохранение отчёта каждый раз, позволяя пользователю самому сделать выбор.
Source Tree Root
По умолчанию, при генерации диагностических сообщений, PVS-Studio выдаёт абсолютные, полные пути до файлов, в которых анализатор нашёл ошибки. С помощью данной настройки можно задать корневую часть пути, которую анализатор будет автоматически подменять на специальный маркер в случае, если путь до файла, на который сгенерировано данное сообщение, начинается с заданного здесь корня. Например, абсолютный путь до файла C:\Projects\Project1\main.cpp будет заменён на относительный путь |?|Project1\main.cpp, если C:\Projects\ был указан в качестве корня.
При работе с отчётом PVS-Studio, содержащим пути до файлов в такой относительной форме, IDE плагин автоматически подставляет значение данной настройки вместо маркера |?|. Тем самым, использование данной настройки позволит работать с фалом отчёта PVS-Studio на любой машине, имеющей доступ к проверенным исходникам, вне зависимости от их местоположения в файловой системе.
Детальное описание данного режима работы доступно здесь.
Use Solution Dir As Source Tree Root
Данная настройка включает или выключает режим использования пути до папки, содержащей файл решения *.sln, в качестве параметра Source Tree Root.
Autoload Unreal Engine Log
Данная настройка позволяет автоматически загружать отчёт, полученный в результате анализа Unreal Engine проекта, в окно вывода сообщений PVS-Studio.
Данная опция актуальна только при работе из IDE Visual Studio.
Dependency Cache Tracking Mode
Определяет режим отслеживания исходных файлов в кэше зависимостей.
ModifiedFilesOnly - в хэше отслеживаются только модификации исходных файлов.
ModifiedAndWarningsContainingFiles - дополнительно отслеживаются файлы с предупреждениями, найденными в предыдущих прогонах анализа. Исходный файл остается помеченным для анализа до тех пор, пока в нем содержаться предупреждения анализатора.
Disabled - отключает отслеживание файлов и обновление кэша зависимостей.
Установка PVS-Studio C# на Linux и macOS
- Зависимости PVS-Studio C#
- Установка анализатора в операционных системах Linux
- Установка анализатора в macOS
- Ввод лицензии
- Анализ проектов
Примечание. Для установки анализатора на операционных системах семейства Windows можно воспользоваться инсталлятором, доступным на странице загрузки анализатора. Windows инсталлятор поддерживает установку как в графическом, так и в unattended (установка из командной строки) режимах.
Зависимости PVS-Studio C#
Для работы C# анализатора PVS-Studio требуется ряд дополнительных пакетов. В зависимости от того, каким образом будет произведена установка PVS-Studio C#, эти зависимые пакеты будут автоматически установлены пакетным менеджером, либо их нужно будет установить вручную.
.NET SDK
Для работы анализатора на машине должен быть установлен .NET SDK 9.0. Инструкции для добавления репозитория .NET в различные дистрибутивы Linux можно найти здесь.
Инсталлятор .NET SDK для macOS можно загрузить с этой страницы.
Примечание. При установке pvs-studio-dotnet с использованием пакетного менеджера на Linux необходимая для работы анализатора версия пакета .NET SDK будет установлена автоматически, но репозиторий .NET необходимо предварительно добавить вручную.
pvs-studio
Для работы C# анализатору PVS-Studio требуется наличие C++ анализатора PVS-Studio (pvs-studio).
Примечание. При установке пакета C# анализатора PVS-Studio (pvs-studio-dotnet) через пакетный менеджер, пакет C++ анализатора (pvs-studio) будет установлен автоматически, и этот шаг можно пропустить.
При установке C# анализатора через распаковку архива необходимо также установить C++ анализатор (pvs-studio). С++ анализатор должен быть установлен в следующие директории:
- Linux: любая директория, путь до которой записан в переменной окружения 'PATH';
- macOS: /usr/local/bin/pvs-studio
Инструкции по установке pvs-studio доступны в соответствующих разделах документации: Linux; macOS.
Установка анализатора в операционных системах Linux
Установка из репозиториев
Установка из репозитория – рекомендуемый способ, позволяющий автоматически установить необходимые зависимости и получать обновления.
Для debian-based систем
wget -q -O - https://cdn.pvs-studio.com/etc/pubkey.txt | \
sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://cdn.pvs-studio.com/etc/viva64.list
sudo apt-get update
sudo apt-get install pvs-studio-dotnetДля yum-based систем
wget -O /etc/yum.repos.d/viva64.repo \
https://cdn.pvs-studio.com/etc/viva64.repo
yum update
yum install pvs-studio-dotnetДля zypper-based систем
wget -q -O /tmp/viva64.key https://cdn.pvs-studio.com/etc/pubkey.txt
sudo rpm --import /tmp/viva64.key
sudo zypper ar -f https://cdn.pvs-studio.com/rpm viva64
sudo zypper update
sudo zypper install pvs-studio-dotnetРучная установка
Прямые ссылки для загрузки пакетов / архива доступны на странице загрузки. Ниже представлены команды установки / распаковки.
Deb пакет
sudo gdebi pvs-studio-dotnet-VERSION.debили
sudo apt-get -f install pvs-studio-dotnet-VERSION.debRpm пакет
sudo dnf install pvs-studio-dotnet-VERSION.rpmили
sudo zypper install pvs-studio-dotnet-VERSION.rpmили
sudo yum install pvs-studio-dotnet-VERSION.rpmили
sudo rpm -i pvs-studio-dotnet-VERSION.rpmАрхив
tar -xzf pvs-studio-dotnet-VERSION.tar.gz
sudo ./install.shУстановка анализатора в macOS
Установка из Homebrew
Команды установки:
brew install viva64/pvs-studio/pvs-studio
brew install viva64/pvs-studio/pvs-studio-dotnetКоманды обновления:
brew upgrade pvs-studio
brew upgrade pvs-studio-dotnetРучная установка
Команда распаковки архива:
tar -xzf pvs-studio-dotnet-VERSION.tar.gz
sudo sh install.shВвод лицензии
Прежде, чем начать использовать анализатор PVS-Studio, нужно ввести лицензию. О том, как сделать это, вы можете подробно прочитать здесь.
Анализ проектов
Использование анализатора описано в соответствующем разделе документации.
Работа PVS-Studio в JetBrains Rider и CLion
- Смотри, а не читай (YouTube)
- Установка плагина из официального репозитория JetBrains
- Установка плагина из репозитория PVS-Studio
- Установка анализатора PVS-Studio
- Ввод лицензии
- Настройки плагина
- Проверка кода из Rider с помощью PVS-Studio
- Проверка проектов Unreal Engine из Rider с помощью PVS-Studio
- Проверка кода из CLion с помощью PVS-Studio
- Работа с результатами анализа
Анализатор PVS-Studio можно использовать при работе в средах разработки JetBrains Rider и CLion. Плагины PVS-Studio для этих IDE предоставляют удобный графический интерфейс для запуска анализа проектов и отдельных файлов, а также для работы с предупреждениями анализатора.
Плагины PVS-Studio для Rider и CLion можно установить из официального репозитория плагинов JetBrains или из репозитория на нашем сайте. Ещё один способ установки - через установщик PVS-Studio для Windows, доступный на странице загрузки.
Смотри, а не читай (YouTube)
Установка плагина из официального репозитория JetBrains
Для установки плагина PVS-Studio из официального репозитория JetBrains нужно открыть окно настроек с помощью команды 'File -> Settings -> Plugins', выбрать в окне вкладку Marketplace, и ввести в строке поиска 'PVS-Studio'. В результатах поиска появится плагин PVS-Studio.
Установка плагина PVS-Studio в Rider:
Установка плагина PVS-Studio в CLion:
Далее нужно нажать кнопку Install напротив найденного плагина PVS-Studio. После того как установка плагина будет завершена, нужно нажать кнопку Restart IDE.
В Rider:
В CLion:
Перезапустив среду разработки, можно начать пользоваться плагином PVS-Studio для проверки кода. Следующим шагом необходимо установить анализатор PVS-Studio.
Установка плагина из репозитория PVS-Studio
Помимо официального репозитория JetBrains, плагин PVS-Studio также доступен из собственного репозитория PVS-Studio. Для установки плагина из репозитория PVS-Studio сначала нужно добавить репозиторий в IDE. Для этого нужно открыть окно установки плагинов с помощью команды меню File -> Settings -> Plugins.
Для Rider это будет выглядеть так:

В CLion:
Далее, нажать на шестеренку в правом верхнем углу и в выпадающем списке выбрать Manage Plugin Repositories.
Для Rider:

Для CLion:
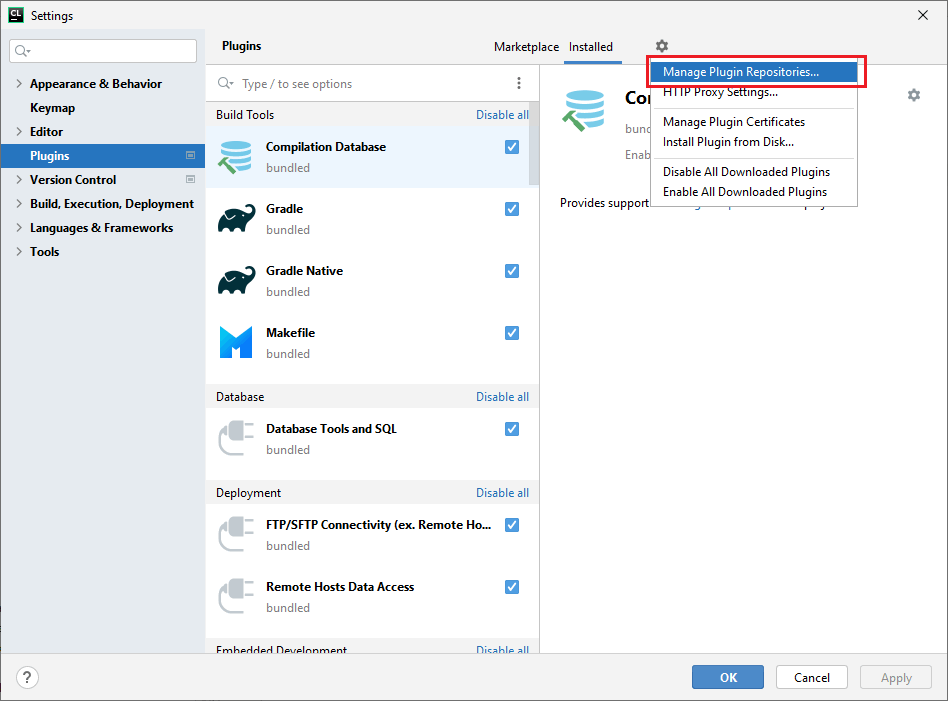
В открывшемся окне добавьте путь:
- для Rider - http://files.pvs-studio.com/java/pvsstudio-rider-plugins/updatePlugins.xml
- для CLion - http://files.pvs-studio.com/java/pvsstudio-clion-plugins/updatePlugins.xml
И нажмите Ок.
В Rider:

В CLion:

Последний шаг установки аналогичен установке плагина из официального репозитория - нужно открыть вкладку Marketplace, где в поиск ввести "PVS-Studio". После применения данного фильтра выбрать плагин 'PVS-Studio for Rider' или 'PVS-Studio for CLion', нажать Install и перезапустить среду разработки.
Установка анализатора PVS-Studio
Для работы анализатора PVS-Studio в средах Rider и CLion, помимо установки IDE плагина, также требуется установить ядро анализатора и его зависимости.
Если вы устанавливали плагин через Windows установщик PVS-Studio, то все необходимые для работы компоненты уже должны быть установлены в системе и можно пропустить этот шаг.
Если же плагин ставился отдельно (добавлением репозитория или из официального репозитория JetBrains), необходимо перед началом работы скачать и установить С++ или C# анализатор для необходимой платформы отсюда.
Ввод лицензии
Первое, что нужно сделать после установки – ввести лицензию. Процесс ввода лицензии в Rider/CLion подробно описан в документации.
Настройки плагина
Панель настроек плагина состоит из нескольких вкладок. Рассмотрим каждую из них подробнее.
Settings - настройки ядра анализатора PVS-Studio. При наведении курсора мыши на название настройки появляется подсказка с описанием того, для чего эта настройка предназначена. Для Rider настройки выглядят так:
Для CLion:
Warnings - список типов всех предупреждений, поддерживаемых анализатором. Если убрать галочку у предупреждения, то все предупреждения данного типа в таблице вывода результатов работы анализатора будут отфильтрованы:
Excludes - содержит маски для имен файлов и путей, которые будут исключены из анализа.
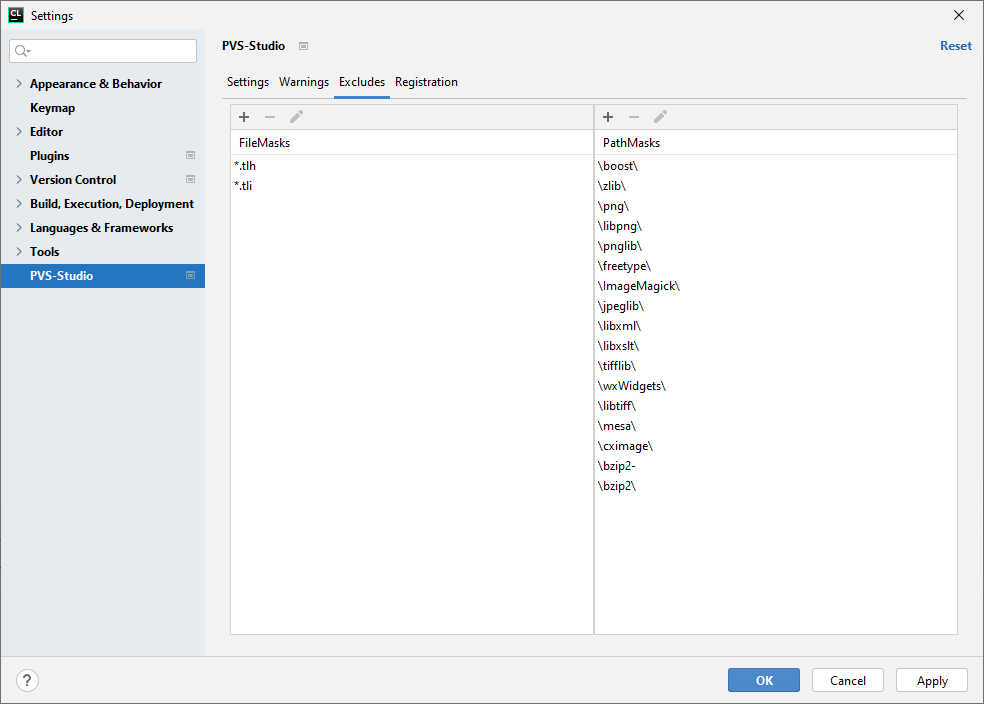
Registration - содержит информацию о действующей лицензии.

Проверка кода из Rider с помощью PVS-Studio
JetBrains Rider может открывать проекты в 2-х режимах - непосредственно проект, и директорию с исходниками. При открытии проекта Rider может открывать как отдельные csproj файлы, так и solution, содержащий один или несколько таких проектов.
Если открыт файл проекта или solution'а, то имеется возможность анализировать:
- Текущий проект/решение.
- Текущий проект/решение в межмодульном режиме.
- Элементы, выбранные в окне Explorer.
- Файл, открытый в данный момент для редактирования.
Для анализа текущего проекта или solution'а можно воспользоваться пунктом меню Tools -> PVS-Studio -> Check Current Solution/Project. Также имеется пункт меню для запуска межмодульного анализа. В этом режиме анализатор выполняет более глубокий анализ кода, но тратит на это больше времени:

Для анализа файла, открытого на редактирование, можно использовать:
- пункт меню Tools -> PVS-Studio -> Check Open File;
- пункт контекстного меню файла;
- пункт контекстного меню заголовка файла в редакторе файла.

Также можно выбрать несколько элементов в окне Explorer через CTRL/SHIFT + mouse Left Click, после чего выбрать пункт меню Tools -> PVS-Studio -> Check Selected Items:

Или аналогичный пункт меню (Check Selected Items) в контекстном меню Explorer, которое вызывается нажатием правой кнопки мыши:

В примерах, приведенных выше, будут проанализированы все *.cs и *.csproj файлы из папок Core, Controllers, а также файл Startup.cs.
Если в Rider открыта директория, PVS-Studio не может точно знать, какой именно проект, файл или solution нужно анализировать, поэтому команда проверки текущего проекта \ solution'а и команда проверки открытого файла не доступны. Доступна только проверка solution'а, при помощи команды Tools -> PVS-Studio -> Check Selected Items:
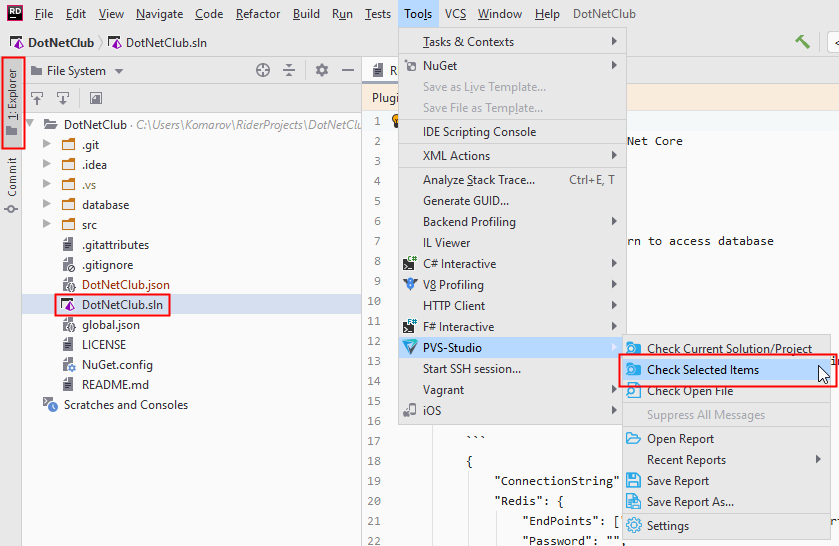
Или через контекстное меню в окне Explorer (Check Selected Items):

Проверка проектов Unreal Engine из Rider с помощью PVS-Studio
В Rider есть возможность работать с проектами Unreal Engine. Стандартный сценарий работы отличается от описанного здесь. Подробнее читайте об этом в специальной документации.
Проверка кода из CLion с помощью PVS-Studio
JetBrains CLion позволяет открывать CMake проекты.
Имеется возможность анализировать:
- Текущий проект.
- Текущий проект в межмодульном режиме.
- Элементы, выбранные в окне Project.
- Файл, открытый в данный момент для редактирования.
Для анализа текущего проекта можно воспользоваться пунктом меню Tools -> PVS-Studio -> Check Project. Также имеется пункт меню для запуска межмодульного анализа. При межмодульном режиме происходит более глубокий анализ кода проекта, но на это тратится больше времени:

Для анализа файла, открытого на редактирование, можно использовать:
- пункт меню Tools -> PVS-Studio -> Check Current File;
- пункт контекстного меню файла;
- пункт контекстного меню заголовка файла в редакторе файла.
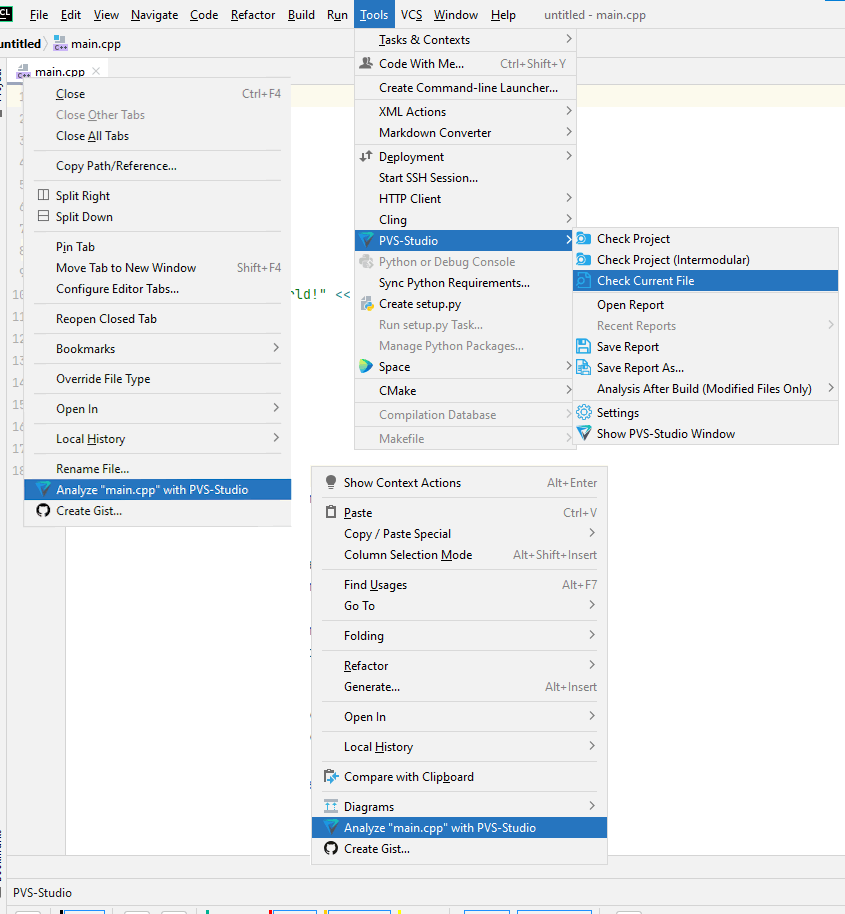
Также можно выбрать несколько элементов в окне Explorer через CTRL/SHIFT + mouse Left Click, после чего нажать правую кнопку мыши -> Analyze with PVS-Studio:

В примерах, приведенных выше, будут проанализированы все *.cpp файлы из папок 3rdparty, parallel, а также файл samples.cpp.
Работа с результатами анализа
Во время анализа результаты работы анализатора выводятся в таблицу окна 'PVS-Studio', для Rider окно выглядит так:

Для CLion:
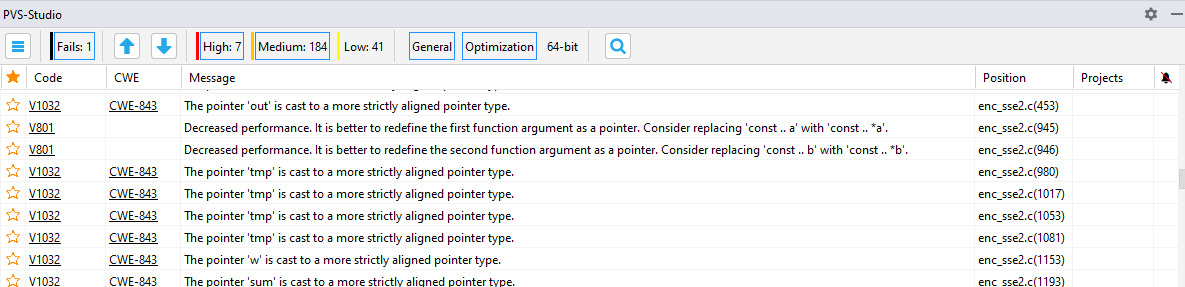
Таблица состоит из 8 столбцов (слева направо: Favorite, Code, CWE, SAST, Message, Position, Projects, False Alarms). Имеется возможность сортировать сообщения в таблице по любому столбцу. Для изменения порядка сортировки необходимо кликнуть на заголовок столбца. Крайний левый столбец (Favorite) используется для пометки предупреждений, которая позволяет быстро найти все помеченные предупреждения, включив сортировку по столбцу Favorite.

При клике на строке в столбце Code / CWE в браузере будет открыта страница с подробным описанием предупреждения или потенциальной уязвимости. В столбце Message содержится краткое описание предупреждения. Столбец Position содержит список файлов, связанных с сообщением. Столбец Projects - список проектов, включающих в себя файл, на который выдано предупреждение анализатора. Крайний правый столбец False Alarms - служит для отображения сообщений, помеченных, как ложные срабатывания. Подробнее про работу с ложными срабатываниями будет описано дальше, в соответствующем подразделе.
При двойном клике левой кнопкой мыши на строке в таблице будет открыт файл на строке, в которой было найдено предупреждение анализатора:

Также над таблицей имеются кнопки-стрелки, позволяющие переключаться между предыдущим / следующим сообщением анализатора, и открывать файл, на который это предупреждение выдано, в редакторе кода. Над таблицей имеется несколько фильтров по уровню опасности предупреждений: High, Medium, Low и Fails (ошибки анализатора).
При нажатии на кнопку-лупу откроется дополнительная панель с полями ввода для столбцов Code, CWE, Message и Position. Каждое поле – это строковый фильтр для столбца, позволяющий отфильтровать сообщения из таблицы по введённому в эти поля тексту.

В левом верхнем углу, над таблицей, расположена кнопка с тремя горизонтальными полосками. При нажатии на эту кнопку откроется дополнительная панель настроек:

При нажатии на кнопку-шестеренку открывается главное окно настроек плагина, также доступное через команду меню 'Tools -> PVS-Studio -> Settings'.
Просмотр интересных предупреждений анализатора
Если Вы только начали изучать инструмент статического анализа и хотели бы узнать на что он способен, то можете воспользоваться механизмом Best Warnings. Данный механизм покажет вам наиболее важные и достоверные предупреждения.
Чтобы посмотреть наиболее интересные предупреждения с точки зрения анализатора, нажмите на кнопку 'Best', как показано на скриншоте ниже:
После чего в таблице с результатами анализа останутся максимум десять наиболее критичных предупреждений анализатора.
Работа с ложными срабатываниями
Бывают ситуации, когда сообщение анализатора указывает на код, но программисту совершенно очевидно, что в этом коде нет ошибки. Такая ситуация называется ложным срабатыванием (false positive).
В плагине PVS-Studio имеется возможность пометить сообщение анализатора как ложное срабатывание. Такая пометка позволяет скрывать эти сообщения анализатора при последующем анализе кода.
Для разметки ложных срабатываний необходимо выбрать одно или несколько сообщений анализатора в таблице 'PVS-Studio', кликнуть правой кнопкой мыши на любой строке в таблице и в контекстном меню выбрать пункт 'Mark selected messages as False Alarms':

После выполнения данной команды анализатор добавит к строке, на которую выдаётся предупреждение анализатора, комментарий специального вида: \\-Vxxx, где xxx – это номер диагностического правила PVS-Studio. Такой комментарий также можно добавить в код вручную.
Помеченные ранее ложные срабатывания можно показать в таблице окна PVS-Studio с помощью настройки 'Show False Alarms', доступной через команду меню 'Tools -> PVS-Studio -> Settings', для Rider:
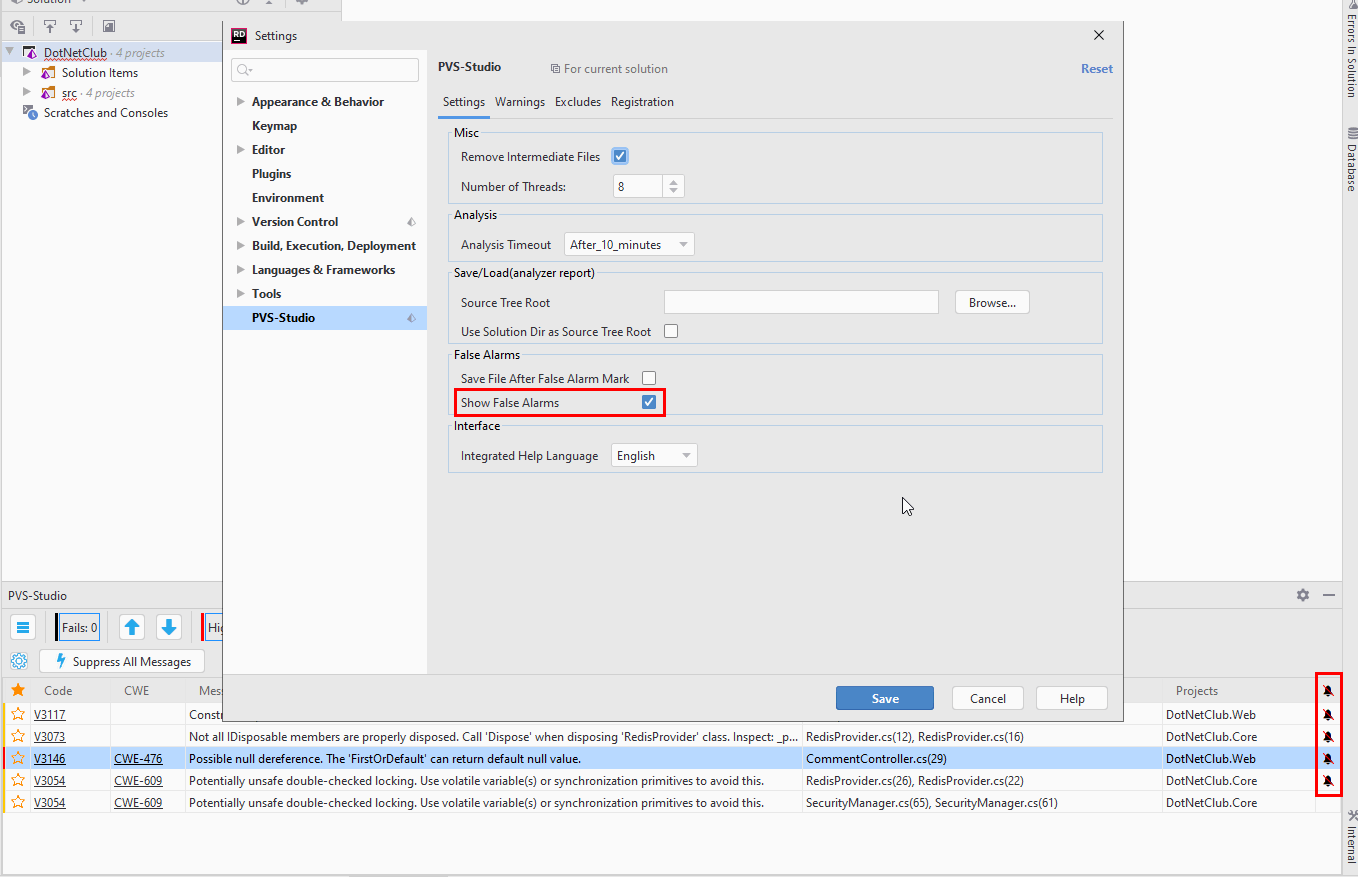
Для CLion:
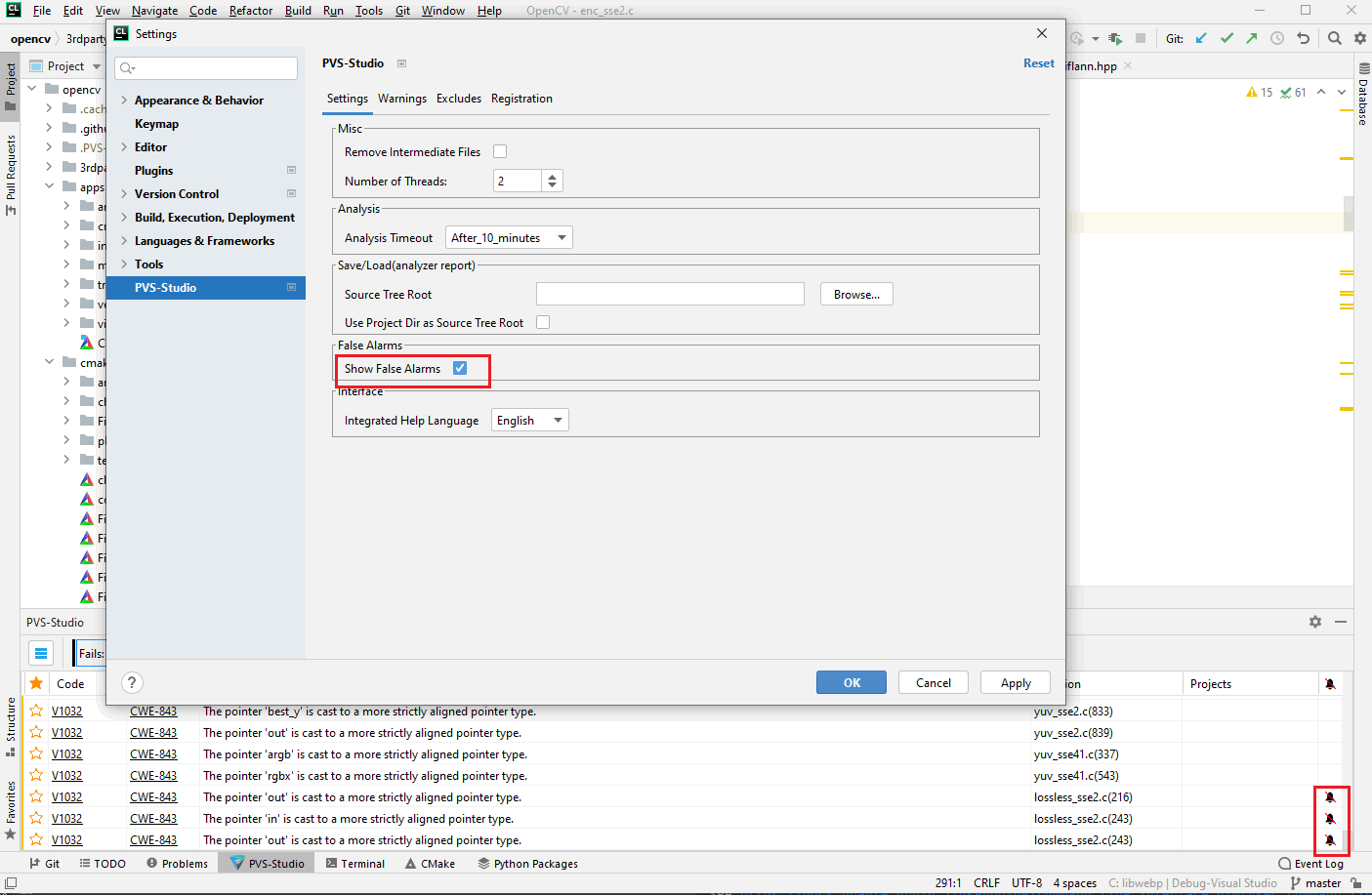
С помощью команды контекстного меню 'Remove False Alarm marks from selected messages' можно удалить отметку ложного срабатывания с выбранных сообщений.
Подробную информацию о подавлении предупреждений, выдаваемых анализатором PVS-Studio, а также сведения о других способах подавления сообщений анализатора с помощью файлов конфигурации (.pvsconfig), добавляемых в проект, можно найти в разделе документации Подавление ложных предупреждений.
Подавление предупреждений анализатора на старом (legacy) коде
Часто начать регулярно использовать статический анализ мешают многочисленные срабатывания на старом legacy коде. Такой код обычно уже хорошо оттестирован и стабильно работает, поэтому править в нём все срабатывания анализатора может оказаться нецелесообразно. Тем более, если размер кодовой базы достаточно велик, такая правка может потребовать большого времени. При этом, такие сообщения на существующий код мешают смотреть сообщения на новый код, находящийся в разработке.
Чтобы решить данную проблему и начать сразу регулярно использовать статический анализ, PVS-Studio предлагает возможность "отключить" сообщения на старом коде. Чтобы подавить сообщения анализатора на старом коде можно воспользоваться командой главного меню 'Tools -> PVS-Studio -> Suppress All Messages' или кнопкой 'Suppress All Messages' на панели окна PVS-Studio. Механизм подавления работает с помощью специальных *.suppress файлов, в которые добавляются подавленные сообщения анализатора после выполнения команды 'Suppress All Messages'. При последующем запуске анализа все сообщения, добавленные в такие *.suppress файлы, не попадут в отчёт анализатора. Система подавления через *.suppress файлы достаточно гибкая и способна "отслеживать" подавленные сообщения даже при модификации и сдвигах участков кода, в которых выдаётся подавленное сообщение.
При работе с Rider файлы *.suppress создаются на уровне проекта, рядом с каждым проектным файлов, но их также можно добавить в любой проект или solution (например, чтобы использовать один общий suppress файл для нескольких проектов или всего soulution'а). Чтобы вернуть сообщения в вывод анализатора, необходимо удалить suppress файлы для соответствующих проектов и перезапустить анализ.
В CLion подавленные сообщения добавляются в suppress файл suppress_file.suppress.json, который записывается в директорию .PVS-Studio, в корневой директории открытого в CLion проекта. Чтобы вернуть все сообщения в вывод анализатора, необходимо удалить этот файл и перезапустить анализ.
Более подробное описание подавления предупреждений анализатора, и описание работы с *.suppress файлами, можно прочитать в разделе документации Массовое подавление сообщений анализатора.
Также предлагаем познакомиться со статьёй "Как внедрить статический анализатор кода в legacy проект и не демотивировать команду".
Контекстное меню таблицы предупреждений
При нажатии правой кнопкой мыши на строке с сообщением анализатора в таблице окна PVS-Studio, откроется контекстное меню, содержащее дополнительные команды для выбранных сообщений анализатора.
Команда 'Mark selected messages as False Alarms / Remove false alarm masks' позволяет разметить сообщение анализатора, как ложное срабатывание, добавив в код, на который выдано предупреждение, комментарий специального вида (более подробно про работу с ложными срабатываниями рассказано, в соответствующем подразделе).
Команда 'Exclude from analysis' позволяет добавить путь или часть пути к файлу, в котором найдено предупреждение анализатора, в список исключённых из анализа директорий. Все файлы, пути до которых попадут под данный фильтр, будут исключены из анализа.
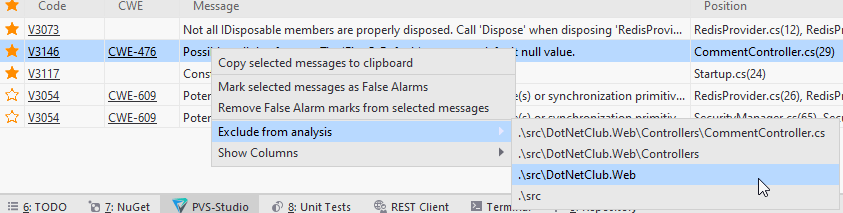
Сохранение и загрузка результатов анализа
Для сохранения или загрузки результатов работы анализатора можно воспользоваться командами главного меню, доступными через 'Tools -> PVS-Studio':
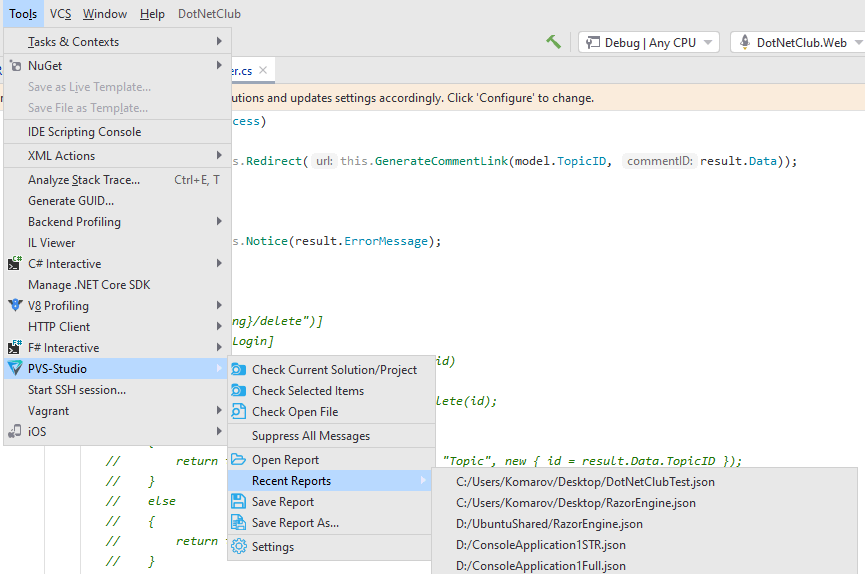
Команда 'Open Report' открывает .json файл отчета и загружает его содержимое в таблицу окна 'PVS-Studio'.
Подменю 'Recent Reports' показывает список из нескольких последних открытых файлов отчетов. При нажатии на элемент в списке будет открыт соответствующий отчет (если отчет еще существует по такому пути), и его содержимое будет загружено в таблицу окна 'PVS-Studio'.
Команда 'Save Report' сохраняет все сообщения из таблицы (даже отфильтрованные) в .json файл отчета. Если текущий результат анализа еще ни разу не сохранялся, то будет предложено задать имя и место для сохранения отчета.
Аналогично, команда 'Save Report As' сохраняет все предупреждения из таблицы (даже отфильтрованные) в .json файл отчета, всегда предлагая выбрать место сохранения отчёта на диске.
Горячие клавиши PVS-Studio в Rider и CLion
Плагины для Rider и CLion добавляют окно просмотра результатов анализа PVS-Studio, которое имеет контекстное меню, появляющееся при нажатии правой кнопкой мыши в окне с результатами анализа:

Некоторым действиям из этого меню назначены горячие клавиши, что позволяет выполнять их без использования мыши.
Кнопки со стрелками, предназначенные для навигации по сообщениям анализатора, также имеют горячие клавиши:
- перейти к предыдущему сообщению: Alt + [;
- перейти к следующему сообщению: Alt + ].
Использование горячих клавиш полезно, потому что позволяет ускорить процесс обработки результатов анализа. Их можно назначать\переопределять в настройках: File -> Settings -> Keymap. Чтобы быстрее их найти, введите 'PVS-Studio' в поле поиска окна Keymap.
V001. A code fragment from 'file' cannot be analyzed.
Анализатор не всегда может полностью проанализировать файл с исходным кодом.
Это может произойти по трем причинам:
1) Ошибка в коде
В коде имеется шаблонный класс или шаблонная функция с ошибкой в коде. Если эта функция не инстанцируется, то компилятор не диагностирует в ней наличие некоторых ошибок. Другими словами наличие такой ошибки не мешает компиляции. Анализатор PVS-Studio пытается искать потенциальные ошибки даже в классах и функциях, которые нигде не используются. В случае если анализатор не может разобрать код, то он и выдаст предупреждение V001. Рассмотрим пример кода:
template <class T>
class A
{
public:
void Foo()
{
//Забыли ;
int x
}
};Этот код будет скомпилирован Visual C++, если класс A не будет нигде использоваться. Однако ошибка в нем присутствует, что мешает работе PVS-Studio.
2) Ошибка в препроцессоре Visual C++
Анализатор в процессе своей работы использует препроцессор Visual C++. Этот препроцессор очень редко, но все же допускает ошибки при генерации препроцессированных *.i файлов. В результате анализатор получает на вход некорректные данные. Рассмотрим пример:
hWnd = CreateWindow (
wndclass.lpszClassName, // window class name
__T("NcFTPBatch"), // window caption
WS_OVERLAPPED | WS_CAPTION | WS_SYSMENU | WS_MINIMIZEBOX,
// window style
100, // initial x position
100, // initial y position
450, // initial x size
100, // initial y size
NULL, // parent window handle
NULL, // window menu handle
hInstance, // program instance handle
NULL); // creation parameters
if (hWnd == NULL) {
...Приведенный фрагмент кода, препроцессор Visual C++ превратил в:
hWnd = // window class name// window caption// window style//
initial x position// initial y position// initial x size//
initial y size// parent window handle// window menu handle//
program instance handleCreateWindowExA(0L,
wndclass.lpszClassName, "NcFTPBatch", 0x00000000L | 0x00C00000L |
0x00080000L | 0x00020000L, 100, 100,450, 100, ((void *)0),
((void *)0), hInstance, ((void *)0)); // creation parameters
if (hWnd == NULL) {
...Получается, что в коде написано следующее:
hWnd = // длинный комментарий
if (hWnd == NULL) {
...Этот код некорректен, о чем и выдаст сообщение PVS-Studio. Конечно, это недоработка PVS-Studio и со временем мы это исправим.
Отметим также, что Visual C++ успешно компилирует этот код, так как алгоритмы, используемые в нем для компиляции и для генерации препроцессированных *.i-файлов различны.
3) Недоработка внутри PVS-Studio
В редких случаях PVS-Studio неспособен разобрать сложный шаблонный код.
Какова не была бы причина выдачи сообщения V001, это сообщение не критично. Как правило, неполный разбор файла не несущественен с точки зрения анализа. PVS-Studio просто пропускает функцию/класс с ошибкой и продолжает анализ файла. Непроанализированным остается совсем небольшой участок кода.
V002. Some diagnostic messages may contain incorrect line number.
Анализатор обнаружил проблему, из-за которой позиции предупреждений могут указывать на некорректные строки кода. Это может происходить либо из-за некорректной работы внешнего препроцессора, либо из-за вставленных разработчиком директив '#line' в исходный код.
Анализатор PVS-Studio для языков C и C++ работает только с препроцессированными файлами, т.е. с файлами, в которых раскрыты все макросы ('#define') и подставлены все включаемые файлы ('#include'). При этом в препроцессированном файле содержится информация о том, какие файлы куда подставились и в какие позиции. Осуществляется это как раз с помощью директив '#line', имеющих следующий формат:
#line linenum "filename" // MSVC
# linenum "filename" // GCC-likeСледующая строка после этой директивы в препроцессированном файле интерпретируется как пришедшая из файла 'filename' и имеющая номер 'linenum'. Таким образом, в препроцессированных файлах помимо готового к анализу кода содержится также информация о том, из какого файла поступил тот или иной участок.
Препроцессирование выполняется в любом случае. Для пользователя эта процедура происходит незаметно. Иногда препроцессор является частью анализатора кода, а иногда (как в случае с PVS-Studio) используется внешний препроцессор. Утилита анализа запускает компилятор, которым собирается проверяемый проект, для каждого проверяемого файла на языке C или C++. С его помощью генерируется препроцессированный файл с расширением '*.PVS-Studio.i'.
Рассмотрим ситуацию, при которой происходит сбой в позиционировании предупреждений анализатора. Речь пойдёт о написании директив '#pragma' в несколько строк с применением лексемы продолжения предыдущей строки ('\'):
#pragma \
warning(push)
void test()
{
int a;
if (a == 1) // V614 должно быть выдано здесь,
return; // а выдастся здесь
}Компилятор MSVC неверно формирует директивы '#line' в препроцессированном файле при написании такого кода, при этом GCC и Clang делают всё верно. Однако если немного изменить пример, то все внешние препроцессоры отрабатывают корректно:
#pragma warning \
(push)
void test()
{
int a;
if (a == 1) // V614 теперь выдаётся корректно
return;
}Наша рекомендация — это либо не использовать многострочные директивы '#pragma', либо писать их так, чтобы они корректно обрабатывались внешним препроцессором.
Анализатор пытается обнаружить сдвиг строк в обрабатываемом файле и сообщить об этом пользователю предупреждением V002. При этом он не пытается скорректировать позиции выданных предупреждений в коде программы. Алгоритм нахождения сдвига строк работает следующим образом.
Шаг N1. Анализатор открывает исходный файл и ищет самую последнюю лексему. Выбираются только те лексемы, которые не короче трех символов. Например, для следующего кода последней лексемой будет считаться 'return':
1 #include "stdafx.h"
2
3 int foo(int a)
4 {
5 assert( a >= 0
6 && a <= 1000);
7 int b = a + 1;
8 return b;
9 }Шаг N2. Найдя последнюю лексему, анализатор определит номер строки, в которой она находится. В примере это строка под номером 8. Далее анализатор ищет последнюю лексему в уже препроцессированном файле. Если последние лексемы не совпадают, то, видимо, в конце файла раскрылся макрос. В такой ситуации анализатор не сможет понять, корректно ли расположены строки. Но подобное происходит крайне редко, и почти во всех случаях последние лексемы в исходном и препроцессированном файле совпадают. Если это так, определяется номер строки, в которой расположена лексема в препроцессированном файле.
Шаг N3. После двух предыдущих шагов имеются номера строк, где расположена последняя лексема в исходном файле и в препроцессированном файле соответственно. Если эти номера строк не совпадают, то произошёл сдвиг в нумерации строк. И в данном случае анализатор сгенерирует предупреждение V002.
Примечание N1. Следует учитывать, что если некорректная директива '#line' будет находиться в файле ниже всех найденных подозрительных участков кода, то все позиции выданных предупреждений будут корректны. И хотя анализатор сгенерирует дополнительно предупреждение V002, это не помешает вам работать с результатами анализа.
Примечание N2. Хоть это и не ошибка непосредственно анализатора кода PVS-Studio, тем не менее, это приводит к его некорректной работе.
Если пользователь хочет попытаться самостоятельно найти строку в исходном файле, из-за которой возник сдвиг, то можно попробовать воспользоваться следующим алгоритмом:
Шаг N1. Перезапустите анализ решения/проекта/файла, сохранив промежуточные файлы анализа (выключив настройку "Remove Intermediate Files").
Шаг N2. Откройте отчёт в одном из плагинов для IDE.
Шаг N3. Отфильтруйте предупреждения согласно файлу, в котором произошёл сдвиг позиций. Если производился анализ единичного файла, то фильтровать ничего не требуется.
Шаг N4. Отсортируйте предупреждения по номерам строк или позиций (колонка 'Line' или 'Positions').
Шаг N5. Найдите первое предупреждение, позиция которого смещена.
Шаг N6. Откройте препроцессированный файл, соответствующий исходному, с расширением '*.PVS-Studio.i'.
Шаг N7. Найдите строку, полученную на шаге N5, в препроцессированном файле.
Шаг N8. Двигайтесь вверх по препроцессированному файлу, начиная от полученной на шаге N7 позиции, и найдите первую ближайшую директиву '#line'.
Шаг N9. В исходном файле перейдите на соответствующую строку, указанную в директиве '#line', полученную на шаге N8. Между этой строкой и строкой, на которой выдано предупреждение, находится код, который приводит к сдвигу. Это могут быть многострочные вызовы макросов, многострочные директивы компиляторов и т.д.
Схематически работу алгоритма можно отобразить следующим образом:

Начиная с версии 7.35 анализатор может сам вычислить приблизительную позицию начала сдвига. В таком случае поиск проблемного фрагмента можно начинать с 6 пункта. Чтобы включить механизм, добавьте специальный комментарий //+V002,VERBOSE в исходный файл или файл конфигурации диагностик. Подробнее об этом можно узнать в документации.
V003. Unrecognized error found...
Наличие предупреждения V003 в отчёте означает, что произошла критическая ошибка внутри анализатора. Скорее всего, в этом случае вообще никаких других предупреждений про анализируемый файл не будет выдано.
Диагностика неполадок
Хотя предупреждение V003 возникает достаточно редко, мы будем благодарны, если вы поможете нам исправить проблему, которая привела к этому предупреждению. Для этого пришлите, пожалуйста, нам файлы, описанные далее, через форму обратной связи.
Файл с трассировкой стека (stack trace)
При получении предупреждения вида:
V003 Unrecognized error found: stacktrace was written to the file
source.cpp.PVS-Studio.stacktrace.txt 1Вы можете перейти к текстовому файлу, который имеет примерно следующий вид:
PVS-Studio version: 7.XX.XXXXX.XXXX
#NN Object "[0xffffffffffffffff]", at 0xffffffffffffffff, in
....
#1 Object "[0xb39b7e]", at 0xb39b7e, in
#0 Object "[0xcfac19]", at 0xcfac19, inВ файле содержатся только адреса функций, т.к. дистрибутив PVS-Studio распространяется без отладочной информации. Однако мы сможем расшифровать этот файл на нашей стороне и определить источник ошибки.
Примечание. Файл с трассировкой стека не содержит никакой информации об исходном коде.
Промежуточные файлы для запуска анализа
Анализ исходного кода на языках C и C++ осуществляется на основе препроцессированного ('*.PVS-Studio.i') и конфигурационного ('*.PVS-Studio.cfg') файлов. Препроцессированный файл формируется из исходного файла (например, 'file.cpp') препроцессором путём раскрытия макросов и директив '#include'. Конфигурационный файл содержит настройки, необходимые для корректного запуска анализа на файле. Набор этих файлов позволяет локализовать проблему в ядре C и C++ анализатора.
Далее описаны способы генерации этих файлов различными компонентами продукта.
Плагины для IDE. На вкладке 'Common Analyzer Settings' настроек PVS-Studio установите опцию 'RemoveIntermediateFiles' в 'False' и заново выполните анализ файлов, на которых происходит падение.
PVS-Studio_Cmd / pvs-studio-dotnet. В файле конфигурации анализа ('Settings.xml') установите опцию 'RemoveIntermediateFiles' в 'False' и заново выполните анализ файлов, на которых происходит падение.
CompilerCommandsAnalyzer / pvs-studio-analyzer. Добавьте флаг '‑‑dump-files' в строку запуска анализа:
pvs-studio-analyzer analyze .... --dump-filesПосле этого в папке проекта надо найти соответствующий i-файл (например, 'file.PVS-Studio.i') и соответствующий ему 'file.PVS-Studio.cfg'.
Примечание. Препроцессированные файлы содержат часть исходного кода проекта. Мы понимаем, что политика компании может запрещать распространение фрагментов исходного кода проекта. Поэтому в случае необходимости мы готовы заключить NDA. Передача препроцессированных и конфигурационных файлов может существенно упростить и ускорить процесс исправления ошибки в анализаторе.
V004. Diagnostics from the 64-bit rule set are not entirely accurate without the appropriate 64-bit compiler. Consider utilizing 64-bit compiler if possible.
Анализатор, выявляя проблемы 64-битного кода, всегда должен проверять именно 64-битную конфигурацию проекта. Ведь именно в 64-битной конфигурации правильно раскрываются типы данных, правильно выбираются ветки вида "#ifdef WIN64" и так далее. Пытаться выявлять проблемы 64-битного кода в 32-битной конфигурации некорректно.
Однако иногда может оказаться полезным проверить 32-битную конфигурацию проекта. Сделать это можно в том случае, когда 64-битной конфигурации пока нет, но требуется оценить предстоящий объем работ по миграции кода на 64-битную платформу. Тогда можно проверить проект в 32-битном режиме. Проверка 32-битной конфигурации вместо 64-битной покажет, сколько диагностических сообщений выдаст анализатор при проверке 64-битной конфигурации. Наши эксперименты показывают, что, конечно же, далеко не все диагностические сообщения выдаются при проверке 32-битной конфигурации. Однако порядка 95% диагностических сообщений при проверке 32-битной конфигурации проекта совпадают с сообщениями при проверке 64-битной конфигурации. Это позволяет оценить предстоящий объем работ.
Обратите внимание! Если вы исправите даже все ошибки, выявленные при проверке 32-битной конфигурации проекта, то нельзя считать код полностью совместимым с 64-битными системами. Необходимо обязательно выполнять окончательную проверку в 64-битной конфигурации проекта.
Сообщение V004 выдается только один раз на каждый проект, который проверяется в режиме 32-битной конфигурации. Предупреждение относится к файлу, который будет проанализирован первым при проверке проекта. Это сделано для того, чтобы не выводить множество однотипных предупреждений в отчет.
V005. Cannot determine active configuration for project. Please check projects and solution configurations.
Данная проблема в работе PVS-Studio вызвана несоответствием для рассматриваемого проекта платформенных конфигураций заданных в solution файле и платформенных конфигураций в самом файле данного проекта.
В частности, в solution файле рассматриваемого проекта могут присутствовать строки следующего вида:
{F56ECFEC-45F9-4485-8A1B-6269E0D27E49}.Release|x64.ActiveCfg = Release|x64
Однако в самом файле проекта может отсутствовать упоминание конфигурации Release|x64. Поэтому, при попытке проверки данного проекта PVS-Studio не может найти конфигурацию Release|x64. В такой ситуации ожидается, что среда Visual Studio должна добавить в автоматически сгенерированный solution-файл строку следующего вида:
{F56ECFEC-45F9-4485-8A1B-6269E0D27E49}.Release|x64.ActiveCfg = Release|Win32
В данном автоматически сгенерированном файле активной конфигурации solution файла (Release|x64.ActiveCfg) для рассматриваемого проекта приравнивается одна из существующих конфигураций данного проекта (т.е. в данном случае Release|Win32). Подобная ситуация является ожидаемой и отрабатывается PVS-Studio корректно.
V006. File cannot be processed. Analysis aborted by timeout.
Сообщение V006 возникает, когда анализатор не может обработать файл за определённое время и аварийно завершает работу.
Причины возникновения
Первая возможная причина — ошибка в анализаторе, при которой не удаётся разобрать определённый фрагмент кода. Несмотря на то, что подобная ситуация возникает нечасто, она всё же возможна. Хотя сообщение V006 возникает достаточно редко, мы будем благодарны, если вы поможете нам устранить проблему, которая привела к его появлению. Если вы работали с проектом на языках C/C++, пришлите, пожалуйста, препроцессированный i-файл, на котором возникла проблема, и соответствующие ему конфигурационные файлы запуска (*.PVS-Studio.cfg и *.PVS-Studio.cmd) через форму обратной связи.
Примечание. Препроцессированный i-файл формируется из исходного файла (например, file.cpp) после работы препроцессора. Чтобы получить препроцессированный файл и конфигурационные файлы запуска, выставите RemoveIntermediateFiles в значение False во вкладке Common Analyzer Settings настроек PVS-Studio и повторно выполните анализ этого файла После этого в папке проекта появится соответствующий i-файл (например, file.i), а также соответствующие ему file.PVS-Studio.cfg и file.PVS-Studio.cmd.
Вторая возможная причина — недостаточное количество системных ресурсов из-за загруженности процессора. Хотя анализатор мог обработать файл корректно, он не успевает сделать это за отведённое время. По умолчанию запускается столько потоков для анализа, сколько имеется ядер в процессоре. Например, на машине с четырьмя ядрами файлы будут анализироваться одновременно в четыре потока. Каждый экземпляр процесса анализатора требует примерно 1,5 гигабайта оперативной памяти. Если её недостаточно, то из-за использования файла подкачки анализ может работать медленно и не успеть в отведённый временной интервал. Кроме того, если на компьютере кроме анализатора запущены другие ресурсоёмкие приложения, то это тоже может вызвать проблему.
В качестве решения можно ограничить количество использованных ядер. Количество используемых при анализе ядер можно задать в настройках PVS-Studio > Common Analyzer Settings > ThreadCount.
V007. Deprecated CLR switch was detected. Incorrect diagnostics are possible.
Сообщение V007 возникает, когда для анализа выбираются проекты, использующие спецификацию Microsoft C++/Common Language Infrastructure, которые содержат один из устаревших /clr флагов компилятора. Хотя вы можете продолжать проверять такие проекты, PVS-Studio не поддерживает работу с данными флагами компилятора, поэтому некоторые диагностические сообщения анализатора могут оказаться некорректными.
V008. Unable to start the analysis on this file.
PVS-Studio не смог запустить анализ указанного файла. Данное сообщение означает, что внешний C++ препроцессор, запущенный анализатором для создания препроцессированного файла с исходным кодом, завершил свою работу с ненулевым выходным кодом ошибки. При этом std error зачастую будет содержать подробное описание произошедшей ошибки, которое также можно увидеть в окне PVS-Studio Output для данного файла.
Ошибка V008 может возникнуть по следующим причинам:
1) Код не компилируется
Если исходный C++ код по какой то причине не компилируется (например, не найден включаемый заголовочный файл), препроцессор завершает свою работу с ненулевым кодом и выдаёт в std error сообщение об ошибке вида "fatal compilation error". PVS-Studio не сможет начать анализ в случае, если C++ файл не был успешно препроцессирован. Для устранения ошибки необходимо обеспечить компилируемость проверяемого файла.
2) Повреждён\заблокирован исполняемый файл препроцессора
Такая ситуация возможна в случаях, когда исполняемый файл препроцессора повреждён или заблокирован системным антивирусом. Окно вывода PVS-Studio может также содержать сообщения вида " The system cannot execute the specified program ". Для устранения ошибки необходимо убедиться в целостности исполняемого файла используемого препроцессора и смягчить политики безопасности системного антивирусного ПО.
3) Заблокирован один из вспомогательных командных файлов PVS-Studio
Анализатор PVS-Studio не запускает C++ препроцессор напрямую, а использует для этого собственные предварительно сгенерированные командные файлы. В случае жёстких системных политик безопасности, антивирусное ПО может препятствовать корректному запуску C++ препроцессора. В этом случае ошибка также может быть устранена путём смягчения политики безопасности в отношении анализатора.
4) Используются файлы, в пути которых присутствуют не латинские символы. Эти символы могут некорректно отображаться для текущей кодовой страницы консоли.
PVS-Studio использует бат-файл 'preprocessing.cmd' (в директории установки PVS-Studio) для запуска препроцессирования. В этом файле можно выставить корректную кодовую страницу (при помощи chcp).
V009. To use free version of PVS-Studio, source code files are required to start with a special comment.
Вы ввели лицензионный ключ, предназначенный для бесплатного использования анализатора. Чтобы этот ключ работал, исходные файлы в вашем проекте должны содержать комментарии специального вида. Комментарии должны быть вставлены в файлы с расширением: .c, .cc, .cpp, .cp, .cxx, .c++, .cs, .java. Заголовочные файлы модифицировать не требуется.
Вы можете вставить комментарии вручную или использовать специальную open source утилиту, скачав её с сайта GitHub: how-to-use-pvs-studio-free.
Варианты комментариев:
Комментарии для студентов (академическая лицензия):
// This is a personal academic project. Dear PVS-Studio, please check it.
// PVS-Studio Static Code Analyzer for C, C++, C#, and Java: https://pvs-studio.com
Комментарии для открытых бесплатных проектов:
// This is an open source non-commercial project. Dear PVS-Studio, please check it.
// PVS-Studio Static Code Analyzer for C, C++, C#, and Java: https://pvs-studio.com
Комментарии для индивидуальных разработчиков:
// This is an independent project of an individual developer. Dear PVS-Studio, please check it.
// PVS-Studio Static Code Analyzer for C, C++, C#, and Java: https://pvs-studio.com
Некоторые разработчики могут не хотеть видеть в начале файла строчки с комментарием, не относящимся к сути проекта. Это их право, и они могут просто не использовать анализатор. Или они могут приобрести коммерческую лицензию и использовать анализатор без ограничений. Мы рассматриваем наличие этих комментариев, как благодарность за предоставленную лицензию и, заодно, как дополнительную рекламу нашего продукта.
По всем вопросам просим обращаться в поддержку.
V010. Analysis for the project type or platform toolsets is not supported in this tool. Use direct analyzer integration or compiler monitoring instead.
Предупреждение V010 выдаётся при попытке проверки .vcxproj-проектов, имеющих конфигурационный тип Makefile или Utility. PVS-Studio не поддерживает работу с такими проектами при использовании плагина или command line версии анализатора. Это связано с тем, что в Makefile/Utility проектах необходимая анализатору информация (в частности, параметры компиляции) о деталях сборки недоступна.
Это же предупреждение выдаётся, если структура .vcxproj-проекта отличается от стандартного Microsoft Visual C++ проекта или если не удалось определить используемый в проекте набор инструментов. В таком случае текст предупреждения будет отличаться:
Unable to determine platform toolset for project: D:\path\to\project.vcxprojПри необходимости проверки таких проектов, пожалуйста, воспользуйтесь системой мониторинга компиляции или прямой интеграцией анализатора. Также вы можете отключить это предупреждение на странице настроек PVS-Studio (вкладка Detectable Errors (C++), список Fails).
Если PVS-Studio успешно определил набор инструментов, но он им не поддерживается, вы увидите следующее сообщение:
Platform toolset of this project is not supported.
If you wish to discuss the feasibility of PVS-Studio supporting this toolset,
please contact our support service.Вы также можете проверить такие проекты с помощью системы мониторинга компиляции. Если вы хотите, чтобы анализатор поддерживал используемый вами нестандартный набор инструментов, обратитесь к нам в техническую поддержку, чтобы обсудить эту возможность.
V011. Presence of #line directives may cause some diagnostic messages to have incorrect file name and line number.
Директива #line генерируется препроцессором и предназначена для того, чтобы понять, какому файлу и строке соответствует та или иная строка в препроцессированном файле.
Поясним это с помощью примера.
#line 20 "a.h"
void X(); // Объявление функции X находится в 20 строке в файле a.h
void Y(); // Объявление функции Y находится в 21 строке в файле a.h
void Z(); // Объявление функции Z находится в 22 строке в файле a.h
#line 5 "a.cpp"
int foo; // Переменная foo объявлена в 5 строке в файле a.cpp
int X() { // Реализация функции X начинается в 6 строке в файле a.cpp
return 0; // 7 строка
} // 8 строкаДирективы #line используют различные инструменты, в том числе и анализатор PVS-Studio, чтобы осуществлять навигацию по файлу.
Иногда бывает так, что по какой-то причине директивы #line содержатся в файлах с исходным кодом (*.c; *.cpp; *.h и т.д.). Например, такое может произойти, если файл был сгенерирован каким-либо способом автоматически (пример).
При препроцессировании эти директивы #line будут добавлены в препроцессированный *.i файл. Например, пусть есть файл A.cpp следующего вида:
int a;
#line 30 "My.y"
int b = 10 / 0;После препроцессирования получится файл A.i следующего содержания:
#line 1 "A.cpp"
int a;
#line 30 "My.y"
int b = 10 / 0;В результате, навигация будет сломана. Анализатор обнаружит деление на ноль и выдаст сообщение, что эта ошибка находится в 30 строке в файле My.y. Формально анализатор прав, ведь ошибка действительно появилась из-за некорректного текста программы в файле My.y. Однако навигация сломана, и вы не сможете просмотреть файл My.y, так как этого файла может просто не быть в проекте. При этом вы не узнаете, что сейчас деление на 0 на самом деле возникает в 3 строке файла A.cpp.
Чтобы исправить ситуацию, мы предлагаем удалить все директивы #line, которые присутствуют в исходных файлах вашего проекта. Как правило, эти директивы оказались в файле случайно и никому не помогают, а только вносят путаницу, мешая работе различных инструментов, таких как анализаторы кода.
Чтобы обнаружить вредные #line в исходном коде и предназначена диагностика V011. Анализатор указывает на 10 первых #line в файле. Большее количество указывать не рационально. Вы можете самостоятельно легко найти с помощью поиска в используемом вами редакторе кода все директивы #line и удалить их.
Исправленный вариант кода:
int a;
int b = 10 / 0;После препроцессирования будет получен *.i файл следующего содержания:
#line 1 "A.cpp"
int a;
int b = 10 / 0;Теперь навигация будет работать правильно и анализатор предупредит, что деление на 0 возникнет во второй строке файла A.cpp.
V012. Some warnings could have been disabled.
Некоторые способы подавления ложных срабатываний позволяют полностью отключать диагностики анализатора. В результате часть сообщений будет не просто отмечена как ложные срабатывания, а могут совсем не появиться в отчете.
Чтобы выяснить, какие механизмы участвуют в отключении диагностик, можно включить добавление специальных сообщений в отчёт анализатора.
- При использовании анализатора с Visual Studio, перейдите в настройки плагина, и активируйте опцию ReportDisabledRules в пункте 'Specific Analyzer Settings'

- При использовании анализатора на Linux и macOS, добавьте опцию 'report-disabled-rules=yes' в .cfg файл.
pvs-studio-analyzer analyze ... --cfg source.cpp.PVS-Studio.cfgВ результате, в отчете анализатора появятся сообщения с кодом V012 и информацией об источниках отключения диагностик. IDE плагины PVS-Studio поддерживают навигацию к причине отключения диагностик в файлах исходного кода и файлах конфигурации правил (.pvsconfig). Пути до файлов конфигурации, содержащих правила исключения срабатываний анализатора, также будут добавлены в отчёт анализатора, в виде сообщений V012.
V013. Intermodular analysis may be incomplete, as it is not run on all source files.
Запуск межмодульного анализа на ограниченном списке файлов проекта приведет к потере межпроцедурной информации. Данное предупреждение актуально только для C и C++ проектов.
Межмодульный анализ выполняется в 3 этапа:
- Сбор межпроцедурных фактов по каждой единице трансляции в соответствующий '.dfo' файл.
- Слияние межпроцедурных фактов из каждого '.dfo' файла в один общий.
- Анализ проекта с использованием межпроцедурных фактов.
Для обеспечения наибольшей эффективности межмодульного анализа рекомендуется запускать его на всём проекте целиком. В таком случае объем собранных межпроцедурных фактов будет максимальным, и, следовательно, тем более качественным будет анализ и тем больше сообщений гипотетически анализатор сможет найти.
V014. The version of your suppress file is outdated. Appending new suppressed messages to it is not possible. Consider re-generating your suppress file to continue updating it.
Ваш suppress файл имеет старый формат. Вы все еще можете использовать его для подавления предупреждений, однако для добавления новых вам придется его перегенерировать.
Для создания нового suppress файла вам нужно:
- Удалить старый suppress файл.
- Запустить анализ без него. Обратите внимание - если suppress файл использовался в нескольких проектах, то вам придется проанализировать их все, чтобы сообщения не потерялись.
- Добавить сообщения из полученного отчёта в новый suppress файл.
Подробнее про работу с suppress файлом можно прочитать в документации.
V015. All analyzer messages were filtered out or marked as false positive. Use filter buttons or 'Don't Check Files' settings to enable message display.
Предупреждение V015 говорит о том, что у вас имеются предупреждения анализатора, но они не отображены в окне PVS-Studio. Это может происходить как из-за настроек фильтрации в окне PVS-Studio, так из-за глобальных настроек анализатора.
Чтобы отобразить все "спрятанные" предупреждения, необходимо убедиться в том, что настроенные фильтры ничего не скрывают. Ниже приведено более подробное описание фильтров.
Фильтрация в окне PVS-Studio
Первое, на что нужно обратить внимание – активные фильтры для просмотра предупреждений. Очень часто именно эти фильтры скрывают от вас предупреждения.

Окно PVS-Studio предоставляет следующие механизмы фильтрации:
- По уровням достоверности предупреждений (High, Medium, Low) и ошибкам работы анализатора (Fails);
- По группам предупреждений (General, Optimization, 64-bit, MISRA, AUTOSAR, OWASP);
- По пользовательским фильтрам (по коду, сообщению, файлу, CWE и SAST идентификаторам предупреждения).
Убедитесь в том, что перечисленные фильтры не скрывают срабатывания анализатора. Для этого активируйте кнопки-фильтры, щелкнув на них мышкой, и сбросьте все пользовательские фильтры по предупреждениям, нажав на 'Clear'.
Настройки во вкладке 'Don't Check Files'
Также на отображение предупреждений влияет настройка вкладки 'PVS-Studio > Options ... > Don't Check Files', в которой прописаны файловые маски для исключения некоторых файлов или папок из анализа. Убедитесь в том, что среди файловых масок нет таких, которые исключают предупреждения по интересующим вас файлам/путям.
Отображение FA предупреждений
Если V015 по-прежнему не пропадает, проверьте предупреждения, помеченные как FA (false alarm). По умолчанию эти предупреждения не отображаются в окне PVS-Studio. Чтобы они отображались, вам нужно активировать соответствующую настройку: 'PVS-Studio > Options ... > Specific Analyzer Settings > False Alarms > DisplayFalseAlarms > True'. После этого в окне PVS-Studio отобразятся предупреждения из группы FA, если они у вас были.
V016. User annotation was not applied to a virtual function. To force the annotation, use the 'enable_on_virtual' flag.
При помощи механизма пользовательских аннотаций можно дополнительно настроить диагностические правила анализатора. Одним из вариантов пользовательских аннотаций являются аннотации функций.
Пример такой аннотации:
//V_FORMATTED_IO_FUNC, function:Log, format_arg:1, ellipsis_arg:2
void Log(const char *fmt, ...);Однако аннотации по умолчанию не применяются к виртуальным функциям. Диагностическое предупреждение V016 сообщает пользователю о том, что его аннотация не была применена к виртуальной функции, и рекомендует исправить это при помощи специальных флагов, которые дописываются в аннотацию:
- 'enable_on_virtual' – включает работу пользовательской аннотации на виртуальной функции.
- 'propagate_on_virtual' – распространяет эффекты аннотации на переопределения виртуальной функции в дочерних классах. Кроме этого, неявно включает флаг 'enable_on_virtual'.
Например, аннотация для виртуальной функции 'Log' класса 'Base' будет выглядеть следующим образом:
// Комментарий должен быть расположен на одной линии
//V_FORMATTED_IO_FUNC, function:Base::Log,
format_arg:1, ellipsis_arg:2,
enable_on_virtual
struct Base
{
virtual void Log(const char *fmt, ...);
}Вместо 'enable_on_virtual' может быть указан флаг 'propagate_on_virtual'. Тогда аннотация будет применена и к переопределениям функции в дочерних классах:
// Комментарий должен быть расположен на одной линии
//V_FORMATTED_IO_FUNC, function: Base::Log,
format_arg:1, ellipsis_arg:2,
propagate_on_virtual
struct Base
{
virtual void Log(const char *fmt, ...);
}
struct Derived
{
// Аннотация будет действовать и на эту функцию
virtual void Log(const char *fmt, ...) override;
}V017. The analyzer terminated abnormally due to lack of memory.
Наличие предупреждения V017 в отчёте означает, что анализ был экстренно остановлен из-за нехватки свободной оперативной памяти, необходимой для работы. Обычно такое происходит, когда анализ запускается с большим количеством потоков относительно малого количества свободной оперативной памяти.
Возможные способы решения проблемы
Для стабильной работы ядра C и C++ анализатора на каждый поток анализа требуется не менее 2 ГБ памяти. Существуют несколько вариантов решения проблемы:
- снизить число потоков анализа;
- увеличить размер файла подкачки.
Примечание. Попытка решить проблему только путём увеличения размера файла подкачки может привести к предупреждению V006.
Далее описаны способы снижения числа потоков анализа в различных компонентах продукта.
Плагины для IDE. В настройках плагина PVS-Studio установите опцию 'ThreadCount' в меньшее значение.
PVS-Studio_Cmd / pvs-studio-dotnet. В файле конфигурации анализа ('Settings.xml') установите опцию 'ThreadCount' в меньшее значение.
CompilerCommandsAnalyzer / pvs-studio-analyzer. Уменьшите число, передаваемое в параметр '-j' / '‑‑threads'.
Интеграция с Unreal Build Tool. Воспользуйтесь файлом 'BuildConfiguration.xml' со следующими опциями:
<?xml version="1.0" encoding="utf-8" ?>
<Configuration xmlns="https://www.unrealengine.com/BuildConfiguration">
<ParallelExecutor>
<MaxProcessorCount>1</MaxProcessorCount>
</ParallelExecutor>
</Configuration>Если после применения всех советов в отчёте продолжает появляться предупреждение V017, мы будем благодарны, если вы пришлёте нам файлы, описанные здесь, через форму обратной связи.
V018. False Alarm marks without hash codes were ignored because the 'V_HASH_ONLY' option is enabled.
Наличие предупреждения V018 в отчёте означает, что в исходном коде анализируемой программы содержатся строчки, отмеченные False Alarm меткой без хэша, и при этом в настройках анализатора включена опция V_HASH_ONLY.
//V_HASH_ONLY ENABLEЕсли включить эту настройку, то в следующем фрагменте False Alarm метка на первой строчке не сработает:
int b = a; //-V614
int* c = nullptr;
b = *c; //-V522 //-VH"1949"Подробнее об этой настройке можно прочитать в документации.
Возможные способы исправления
Чтобы исправить данное срабатывание, можно добавить хеши к тем False Alarm меткам, в которых они отсутствуют. В этом случае предупреждения будут выдаваться, только если строчка, содержащая False Alarm метку с хэшем, изменилась после добавления этого хэша. Подробнее об этом режиме можно прочитать в этой и этой документации.
Помимо этого, можно убрать False Alarm метки без хешей.
Если способы, указанные выше, не подходят, то удалите настройку:
//V_HASH_ONLY ENABLEТакже настройку можно выключить через директиву:
//V_HASH_ONLY DISABLEПодобное отключение директивы может быть полезно в случае, если необходимо применить настройку к конкретному блоку кода.
V019. Error occurred while working with the user annotation mechanism.
Наличие предупреждения V019 в отчёте означает, что возникли проблемы при работе с пользовательскими аннотациями.
Предупреждение может быть выдано в следующих ситуациях:
- Файл с аннотациями не существует. В данном случае стоит перепроверить указанный путь до файла с аннотациями либо убедиться, что по данному пути файл существует.
- При чтении файла с аннотациями произошла ошибка. Такое может произойти, например, если системный вызов операционной системы завершился с ошибкой. Убедитесь, что файл валидный, и анализатор имеет доступ на его чтение.
- Аннотация была пропущена из-за наличия в ней ошибки. В сообщении будет указана причина, из-за которой аннотацию не удалось применить. Например, может отсутствовать обязательное поле, или в какое-либо поле записано недопустимое для него значение.
- Аннотация была пропущена из-за критической ошибки. Мы будем благодарны, если вы поможете нам исправить проблему, которая привела к такому предупреждению. Для этого пришлите, пожалуйста, нам следующие файлы через форму обратной связи:
- файл с аннотациями в формате JSON;
- препроцессированный ('*.PVS-Studio.i') файл;
- конфигурационный ('*.PVS-Studio.cfg') файл.
V020. Error occurred while working with rules configuration files.
Наличие предупреждения V020 в отчёте означает, что возникли проблемы при работе с файлами конфигурации диагностических правил (.pvsconfig). Конкретная причина ошибки указывается вместе с сообщением диагностики.
В случае, если проблему не удалось устранить самостоятельно, мы будем рады вам помочь. Для этого вы можете написать нам через форму обратной связи, какие именно настройки (или их сочетание) привели к появлению проблемы. Для упрощения её выявления просим также приложить к сообщению файл конфигурации, который стал причиной появления предупреждения.
V051. Some of the references in project are missing or incorrect. The analysis results could be incomplete. Consider making the project fully compilable and building it before analysis.
Сообщение V051 означает, что после загрузки в анализатор, C# проект содержит ошибки компиляции. Обычно к таким ошибкам относятся неизвестные типы данных, пространства имён и сборки (dll файлы). Чаще всего подобная ошибка возникает, когда производится попытка проверить проект, имеющий в зависимостях сборки из nuget пакетов, отсутствующие на локальной машине, либо сторонние библиотеки, отсутствующие среди проектов в выбранном решении.
Несмотря на данную ошибку, анализатор попытается проверить ту часть кода, которая не содержит неопределённых типов, однако результаты такого анализа могут быть неполными - часть сообщений анализатора может быть потеряна. Это связано с тем, что для корректной работы большинству диагностик анализатора требуется полная информация обо всех типах данных, встречающихся в проверяемых исходных файлах, в том числе и о типах, реализованных в сторонних сборках.
Даже если восстановление файлов зависимостей проекта включено в его сборочный сценарий, анализатор не будет выполнять полной пересборки проекта самостоятельно. Поэтому перед проверкой проекта мы рекомендуем обеспечить его полную собираемость, включая наличие всех сборок (dll файлов), от которых проект зависит.
Иногда анализатор может ошибаться, и выдавать такое сообщение на полностью компилирующийся проект, содержащий все зависимости. Это может произойти, например, если проект использует нестандартный сборочный сценарий MSBuild. Например, проектные файлы csproj импортируют какие-либо дополнительные props и target файлы. В таком случае вы можете игнорировать сообщение V051 либо отключить его отображение в настройках анализатора.
Если вы хотите узнать, какая именно ошибка компилятора приводит к V051, запустите анализ вашего проекта с помощью cmd версии анализатора, добавив к строке запуска флаг '‑‑logCompilerErrors' (одной строчкой):
PVS-Studio_Cmd.exe –t MyProject.sln –p "Any CPU" –c "Debug"
--logCompilerErrorsВы можете подавить ошибки, которые приводят к выдаче V051, с помощью .pvsconfig файла. Подробнее про это можно почитать в документации.
V052. A critical error had occurred.
Сообщение V052 предупреждает, что произошла критическая ошибка в анализаторе. Скорее всего, в этом случае часть файлов не будет проанализирована.
Дополнительную информацию об этой ошибке можно получить из двух источников: файла отчёта анализатора plog и стандартного потока вывода сообщений об ошибках stderr (при использовании command line версии).
При использовании Visual Studio IDE или standalone-приложения PVS-Studio, стек ошибки выводится в окно PVS-Studio, a также записывается в начало файла plog. При этом стек разбивается на подстроки, каждая из которых фиксируется и отображается как отдельная ошибка без номера.
В случае работы из командной строки вы можете проанализировать код возврата command line версии, понять, что произошло исключение, и уже затем изучить plog, не открывая его в Visual Studio IDE или standalone-приложении. Для этого отчёт можно преобразовать, например, в текстовый файл при помощи утилиты PlogConverter. Коды возврата command line версии описаны в разделе документации "Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio". Информацию об использовании PlogConverter можно найти в соответствующей документации: "Просмотр и конвертация результатов анализа (форматы SARIF, HTML и др.)".
Хотя сообщение V052 возникает достаточно редко, мы будем вам благодарны, если вы поможете нам устранить проблему, которая привела к его появлению. Для этого пришлите, пожалуйста, стек ошибки из окна PVS-Studio (или из stderr в случае использования command line версии) через форму обратной связи.
V061. An error has occurred.
Сообщение V061 означает, что во время работы анализатора произошла какая-то ошибка.
Например, возникло непредвиденное исключение в анализаторе, не удалось построить семантическую модель программы и т.п.
Пожалуйста, напишите нам в поддержку и приложите текстовые файлы из директории .PVS-Studio (находится в директории с проектом), чтобы мы смогли как можно скорее исправить данную ошибку.
Кроме того, можно использовать параметр 'verbose', чтобы анализатор в процессе работы сохранял дополнительную информацию в директории .PVS-Studio. Эта информация также будет для нас полезна.
В плагине для Maven:
<verbose>true</verbose>В плагине для Gradle:
verbose = trueВ плагине для IntelliJ IDEA:
1) Analyze -> PVS-Studio -> Settings
2) Вкладка Misc -> убрать 'Remove intermediate files'
V062. Failed to run analyzer core. Make sure the correct 64-bit Java 11 or higher executable is used, or specify it manually.
Сообщение V062 означает, что плагину не удалось запустить ядро анализатора. Скорее всего это связано с тем, что ядро запускалось с некорректной версией Java. Для корректной работы ядро должно запускаться с 64-битной Java версией 11 или выше. По умолчанию анализатор использует Java интерпретатор из переменной окружения PATH.
Путь до требуемого Java интерпретатора можно указать вручную.
В плагине для Maven:
<javaPath>C:/Program Files/Java/jdk11.0.17/bin/java.exe</javaPath>В плагине для Gradle:
javaPath = "C:/Program Files/Java/jdk11.0.17/bin/java.exe"В плагине для IntelliJ IDEA:
1) Analyze -> PVS-Studio -> Settings
2) Вкладка Environment -> Java executable
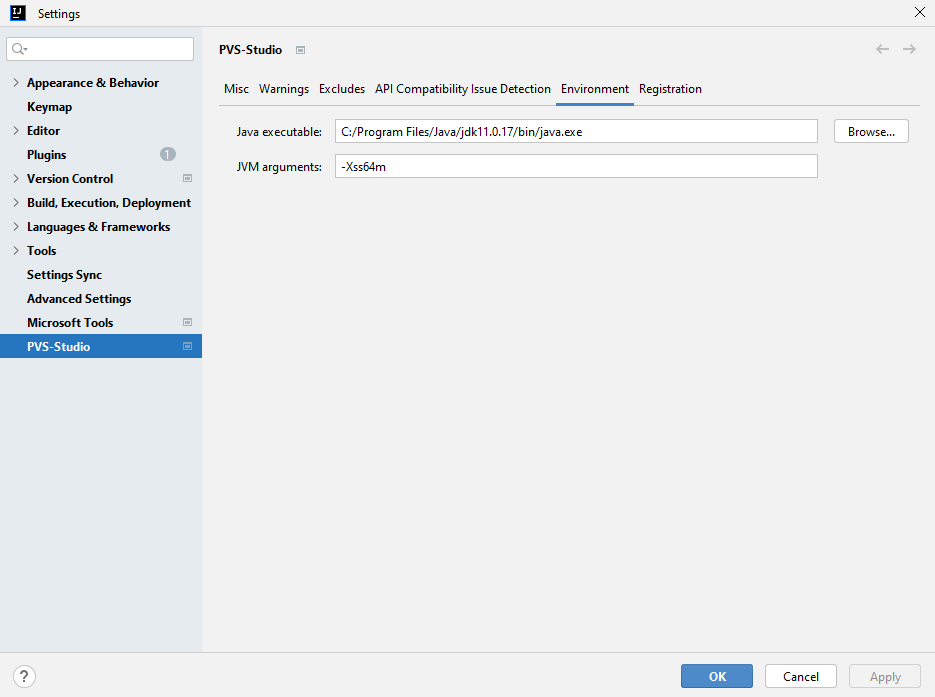
В случае если все же не удается запустить анализ, пожалуйста, напишите нам в поддержку и приложите текстовые файлы из директории .PVS-Studio (находится в директории с проектом). Мы постараемся как можно скорее разобраться в Вашей проблеме.
V063. Analysis aborted by timeout.
Сообщение V063 означает, что анализатор не смог проанализировать какой-либо файл за отведенное время (по умолчанию 10 минут). Зачастую подобные сообщения также сопровождаются сообщениями "GC overhead limit exceeded".
Иногда эту проблему можно решить просто увеличив доступный анализатору объем памяти и стека.
В плагине для Maven:
<jvmArguments>-Xmx4096m, -Xss256m</jvmArguments>В плагине для Gradle:
jvmArguments = ["-Xmx4096m", "-Xss256m"]В плагине для IntelliJ IDEA:
1) Analyze -> PVS-Studio -> Settings
2) Вкладка Environment -> JVM arguments
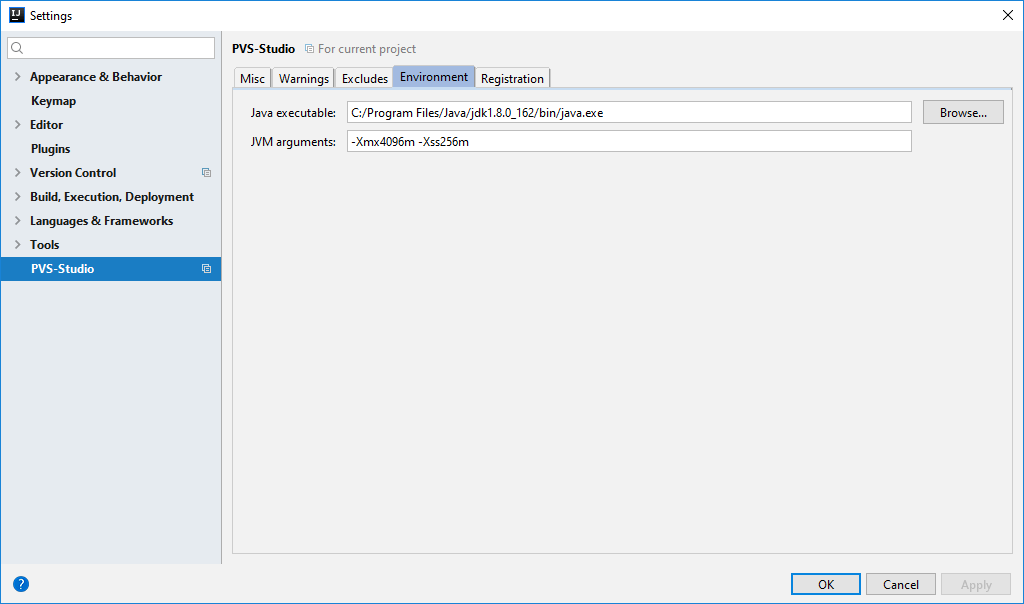
Обычно объема памяти по умолчанию может не хватать при анализе сгенерированного кода с большим количеством вложенных конструкций.
Возможно, стоит исключить этот код из анализа (с помощью 'exclude'), чтобы не тратить на него лишнее время.
Кроме того, V063 может возникать, если из-за загруженности процессора анализатору достается мало системных ресурсов и, хотя файл он мог бы обработать корректно, он не успевает сделать это за отведенное время.
Если все же не удается проверить какой-то файл, это может свидетельствовать об ошибке в анализаторе. В таком случае, пожалуйста, напишите нам в поддержку и приложите текстовые файлы из директории .PVS-Studio (находится в директории с проектом), а также примерный код, на котором возникает проблема, чтобы мы смогли как можно скорее исправить данную ошибку.
V101. Implicit assignment type conversion to memsize type.
Анализатор обнаружил потенциально возможную ошибку, связанную с неявным приведением типа при выполнении оператора присваивания "=". Ошибка может заключаться в некорректном вычислении значения выражения, стоящего справа от оператора присваивания "=".
Пример кода, вызывающего предупреждение:
size_t a;
unsigned b;
...
a = b; // V101Сама по себе операция приведения 32-битного типа к memsize-типу безопасна, поскольку не происходит потери данных. Например, в переменной типа size_t всегда можно сохранить значение переменной типа unsigned. Но наличие такого приведения типа может указывать на скрытую ошибку, допущенную ранее.
Первой причиной возникновения ошибки на 64-битной системе может служить изменение процесса вычисления выражений. Рассмотрим пример:
unsigned a = 10;
int b = -11;
ptrdiff_t c = a + b; //V101
cout << c << endl;Данный код на 32-битной системе распечатает значение -1, а на 64-битной системе 4294967295. Данное поведение полностью согласуется с правилами приведения типов в языке Си++, но скорее всего приведет к ошибке в реальном коде.
Поясним приведенный пример. Согласно правилам языка Си++ выражение a+b имеет тип unsigned и содержит значение 0xFFFFFFFFu. На 32-битной системе тип ptrdiff_t представляет собой знаковый 32-битный тип. После присвоения 32-битной знаковой переменной значения 0xFFFFFFFFu она будет содержать значение -1. На 64-битной системе тип ptrdiff_t представляет собой знаковый 64-битный тип. Это означает, что число 0xFFFFFFFFu будет представлено как оно есть. То есть значение переменной после присваивания будет равняться 4294967295.
Ошибку можно исправить, исключив смешанное использования memsize и не memsize-типов в одном выражении. Пример исправления кода:
size_t a = 10;
ptrdiff_t b = -11;
ptrdiff_t c = a + b;
cout << c << endl;Еще более корректным способом исправления будет отказ от смешенного использования знаковых и беззнаковых типов данных.
Второй причиной ошибки может стать переполнение, возникающее в 32-битных типах данных. В этом случае ошибка может содержаться раньше самого оператора присваивания, но обнаружить ее можно только косвенно. Такие ошибки часто встречаются в коде, выделяющим большие объемы памяти. Рассмотрим пример:
unsigned Width = 1800;
unsigned Height = 1800;
unsigned Depth = 1800;
// Real error is here
unsigned CellCount = Width * Height * Depth;
// Here we get a diagnostic message V101
size_t ArraySize = CellCount * sizeof(char);
cout << ArraySize << endl;
void *Array = malloc(ArraySize);Предположим, что на 64-битной системе мы решили обрабатывать массивы данных более 4 гигабайт. В этом случае показанный код приведет к выделению ошибочного объема памяти. Программист планирует выделить 5832000000 байт оперативной памяти, а вместо этого получит в свое распоряжение только 1537032704. Это происходит из-за переполнения при вычислении выражения Width * Height * Depth. К сожалению мы не можем диагностировать ошибку в строке с этим выражением, но мы можем косвенно указать на наличие ошибки, обнаружив приведение типа в строке:
size_t ArraySize = CellCount * sizeof(char); //V101Исправление ошибки заключается в использовании типов, позволяющих хранить необходимый диапозон значений. Заметьте, что исправлние следующего вида не является корректным:
size_t CellCount = Width * Height * Depth;Здесь мы по-прежнему имеем переполнение. Приведем два примера корректного исправления кода:
// 1)
unsigned Width = 1800;
unsigned Height = 1800;
unsigned Depth = 1800;
size_t CellCount =
static_cast<size_t>(Width) *
static_cast<size_t>(Height) *
static_cast<size_t>(Depth);// 2)
size_t Width = 1800;
size_t Height = 1800;
size_t Depth = 1800;
size_t CellCount = Width * Height * Depth;Следует учитывать, что ошибка может находиться не просто выше, а вообще в другом модуле. Приведем соответствующий пример. В нем ошибка заключается в некорректном вычислении индекса, если размер массива превысит 4 Гб.
Пусть приложение использует большой одномерный массив, и функция CalcIndex позволяет адресоваться к этому массиву как к двумерному массиву.
extern unsigned ArrayWidth;
unsigned CalcIndex(unsigned x, unsigned y) {
return x + y * ArrayWidth;
}
...
const size_t index = CalcIndex(x, y); //V101Анализатор сообщит о проблеме в строке: const size_t index = CalcIndex(x, y). Но ошибка заключается в неправильной реализации функции CalcIndex. Если взять функцию CalcIndex отдельно, то она абсолютно корректна. Типом выходного и входных значений является unsigned. Вычисления также происходят с участием только типов unsigned. Никаких явных или неявных приведений типов нет, и анализатор не имеет возможности распознать логическую проблему, связанную с функцией CalcIndex. Ошибка заключается в том, что неверно выбран результат, возвращаемый функцией, а возможно и входных значений. Результат функции должен иметь тип memsize.
К счастью анализатор смог обнаружить неявное приведение результата функции CalcIndex к типу size_t. Это позволяет вам проанализировать ситуацию и внести в программу необходимые изменения. Исправление ошибки, например, может выглядеть следующим образом:
extern size_t ArrayWidth;
size_t CalcIndex(size_t x, size_t y) {
return x + y * ArrayWidth;
}
...
const size_t index = CalcIndex(x, y);Если вы уверены, что код верен и размер массива никогда не приблизится к границе в 4Гб, вы можете подавить предупреждение анализатора, используя явное приведение типа:
extern unsigned ArrayWidth;
unsigned CalcIndex(unsigned x, unsigned y) {
return x + y * ArrayWidth;
}
...
const size_t index = static_cast<size_t>(CalcIndex(x, y));В ряде случаев и сам анализатор может понять, что переполнение при вычислении невозможно и предупреждение не будет распечатано.
Рассмотрим последний пример, связанный с некорректными операциями сдвига.
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum; //V101
return value | mask;
}Выражение " mask = 1 << bitNum " является опасным, так как данный код не может выставить в единицы старшие разряды 64-битной переменной mask. Если попробовать использовать функцию SetBitN для выставления, например, 33-го бита, то произойдет переполнение при выполнении операции сдвига и желаемый результат не будет достигнут.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 11. Паттерн 3. Операции сдвига.
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V102. Usage of non memsize type for pointer arithmetic.
Анализатор обнаружил потенциально возможную ошибку в адресной арифметике с указателями. Ошибка может заключаться в переполнении при вычислении выражения.
Рассмотрим пример.
short a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;Данный пример корректно работает с указателями, если значение выражения "a16 * b16 * c16" не превышает 'INT_MAX' (2Гб). Такой код мог всегда корректно работать на 32-битной платформе, в силу того, что программа никогда не выделяла массивов больших размеров. На 64-битной архитектуре программиста, использующего старый код для работы с массивом большего размера, ждет разочарование. Допустим, мы хотим сдвинуть значение указателя на 3000000000 байт, и по этому переменные 'a16', 'b16' и 'c16' имеют значения 3000, 1000 и 1000 соответственно. При вычислении выражения "a16 * b16 * c16" все переменные, согласно правилам языка Си++, будут приведены к типу int, а уже затем будет произведено их умножение. В ходе выполнения умножения, произойдет переполнение, в результате которого будет получено число -1294967296. Некорректный результат выражения будет расширен до типа 'ptrdiff_t' и произойдет вычисление указателя. В результате нас будет ожидать аварийное завершение программы, при попытке использования некорректного указателя.
Для предотвращения подобных ошибок следует использовать memsize типы. В нашем случае будет корректно заменить типы переменных 'a16', 'b16', 'c16' или использовать их явное приведение к типу 'ptrdiff_t', как показано ниже:
short a16, b16, c16;
char *pointer;
...
pointer += static_cast<ptrdiff_t>(a16) *
static_cast<ptrdiff_t>(b16) *
static_cast<ptrdiff_t>(c16)Хочется отметить, что не всегда использование в арифметике с указателями не memsize типов является ошибочным. Рассмотрим следующую ситуацию:
char ch;
short a16;
int *pointer;
...
int *decodePtr = pointer + ch * a16;Анализатор не выдает на нее сообщения, в силу ее корректности. Здесь не происходит вычислений, которые могли бы привести к переполнению и результат этого выражения всегда будет корректен как на 32-битной, так и на 64-битной платформе.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 13. Паттерн 5. Адресная арифметика.
V103. Implicit type conversion from memsize type to 32-bit type.
Анализатор обнаружил потенциально возможную ошибку, связанную с неявным приведением memsize типа к 32-битному типу. Ошибка заключается в потере старших бит в 64-битном типе, что влечет потерю значения. Компилятор также диагностирует подобные приведения типов и выдает предупреждения. К сожалению, часто подобные предупреждения отключают, особенно когда в проекте присутствует много старого унаследованного кода или используются старые библиотеки. Чтобы не заставлять программиста просматривать сотни и тысячи подобных предупреждений, выдаваемых компилятором, анализатор информирует только о тех из них, которые могут быть причиной некорректной работы кода на 64-битной платформе.
Первый пример.
Наше приложение работает с видеоизображениями, и мы хотим посчитать, какой размер файла нам потребуется, чтобы сохранить все кадры, находящиеся в памяти, в файл.
size_t Width, Height, FrameCount;
...
unsigned BufferSizeForWrite = Width * Height * FrameCount *
sizeof(RGBStruct);Раньше общий объем видеокадров в памяти никогда не мог превышать 4 Гб (на практике 2-3 Гб, в зависимости от разновидности ОС Windows). На 64-битной платформе мы получили возможность хранить в памяти намного больше кадров, и предположим, что их общий объем составляет 10 Гб. В результате при помещении результата выражения "Width * Height * FrameCount * sizeof(RGBStruct)" в переменную 'BufferSizeForWrite', мы отбросим старшие биты и будем работать с некорректным значением.
Правильным решением будет замена типа переменной 'BufferSizeForWrite' на тип 'size_t'.
size_t Width, Height, FrameCount;
...
size_t BufferSizeForWrite = Width * Height * FrameCount *
sizeof(RGBStruct);Второй пример.
Сохранение в 32-битном типе результата вычитания одного указателя из другого.
char *ptr_1, *ptr_2;
...
int diff = ptr_2 - ptr_1;Если указатели различаются более чем на 'INT_MAX' байт (2 Гб), то произойдет обрезание значения при присваивании. В результате переменная 'diff' будет иметь некорректное значение. Для хранения полученного значения следует использовать тип 'ptrdiff_t' или другой memsize тип.
char *ptr_1, *ptr_2;
...
ptrdiff_t diff = ptr_2 - ptr_1;В тех случаях, когда вы точно уверены в корректности кода, и неявное приведение типа не влечет ошибок при переходе на 64-битную архитектуру, вы можете использовать явное приведение типа для того, чтобы избежать вывода диагностических сообщений в этой строке. Пример:
unsigned BitCount = static_cast<unsigned>(sizeof(RGBStruct) * 8);В том случае, если вы подозреваете наличие в своем коде некорректных явных приведений memsize типов к 32-битным типам, на которые анализатор не выдает предупреждения, то вы можете воспользоваться правилом V202.
Как было сказано ранее, анализатор информирует только о тех приведениях типов, которые могут быть причиной некорректной работы кода на 64-битной платформе. Приведенный ниже код не будет диагностироваться как ошибочный, хотя в нем происходит приведение memsize типов к типу int:
int size = sizeof(float);Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V104. Implicit type conversion to memsize type in an arithmetic expression.
Анализатор обнаружил потенциально возможную ошибку внутри арифметического выражения, связанную с неявным приведением к типу memsize. Ошибка переполнения может быть связана с изменением допустимого интервала значений переменных, входящих в выражение.
Первый пример.
Некорректные выражения сравнения. Рассмотрим код:
size_t n;
unsigned i;
// Infinite loop (n > UINT_MAX).
for (i = 0; i != n; ++i) { ... }В примере показана ошибка, связанная с неявным приведением типа 'unsigned' к типу 'size_t' при выполнении операции сравнения.
На 64-битной платформе у вас может появиться возможность обрабатывать больший объем данных, и значение переменной 'n' может превысить число 'UINT_MAX' (4 Гб). В результате, условие "i != n" всегда будет истинно, что приведет к вечному циклу.
Пример исправленного кода:
size_t n;
size_t i;
for (i = 0; i != n; ++i) { ... }Второй пример.
char *begin, *end;
int bufLen, bufCount;
...
ptrdiff_t diff = begin - end + bufLen * bufCount;Неявное приведение типа 'int' к типу 'ptrdiff_t' зачастую служит признаком ошибки. Следует обратить внимание, что приведение происходит не при выполнении оператора "=" (так как выражение "begin - end + bufLen * bufCount" имеет тип 'ptrdiff_t'), а внутри этого выражения. Подвыражение "begin - end" согласно правилам языка С++ имеет тип 'ptrdiff_t', а правая "bufLen * bufCount" тип 'int'. При переходе на 64-битную платформу программа может начать обрабатывать больший объем данных, в результате чего может произойти переполнение при вычислении подвыражения "bufLen * bufCount".
Следует изменить тип переменных 'bufLen' и 'bufCount' на memsize тип или использовать явное приведение типа, как показано на примере:
char *begin, *end;
int bufLen, bufCount;
...
ptrdiff_t diff = begin - end +
ptrdiff_t(bufLen) * ptrdiff_t(bufCount);Отметим, что неявное приведение к типу memsize внутри выражений не всегда является ошибочным. Рассмотрим следующую ситуацию:
size_t value;
char c1, c2;
size_t result = value + c1 * c2;Анализатор не выдает сообщения, хотя здесь происходит приведение типа 'int' к 'size_t', так как при вычислении подвыражения "c1 * c2" переполнения произойти не может.
Если вы подозреваете в программе наличие ошибок, связанных с некорректным явным приведением типов в выражениях, то Вы можете воспользоваться правилом V201. Пример ситуации, при которой явное приведение типа к 'size_t' скрывает ошибку, представлен ниже:
int i;
size_t st;
...
st = size_t(i * i * i) * st;Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V105. N operand of '?:' operation: implicit type conversion to memsize type.
Анализатор обнаружил потенциально возможную ошибку внутри арифметического выражения, связанную с неявным приведением к типу memsize. Ошибка переполнения может быть связана с изменением допустимого интервала значений переменных, входящих в выражение. Данное предупреждение практически эквивалентно предупреждению V104, за тем исключением, что неявное приведение типа возникает за счет использования операции '?:'.
Приведем пример неявного приведения типов при использовании операции:
int i32;
float f = b != 1 ? sizeof(int) : i32;В арифметическом выражении используется тернарная операция '?:', имеющая три операнда:
- b != 1 - первый операнд;
- sizeof(int) - второй операнд;
- i32 - третий операнд.
Результатом выражения "b != 1 ? sizeof(int) : i32" является значение типа 'size_t', которое затем преобразуется в значение типа 'float'. Таким образом, неявное приведение типа осуществляется для 3-его операнда операции '?:'.
Рассмотрим пример некорректного кода:
bool useDefaultVolume;
size_t defaultVolume;
unsigned width, height, depth;
...
size_t volume = useDefaultVolume ?
defaultVolume :
width * height * depth;Предположим, мы разрабатываем приложение численного моделирования, для которого требуется трехмерная счетная область. Количество используемых счетных элементов определяется в зависимости от значения переменной 'useDefaultSize' и задается по умолчанию или произведением длинны, высоты и глубины счетной области. На 32-битной платформе объем уже выделенной памяти не может превышать 2-3 Гб (в зависимости от версии ОС Windows) и, соответственно, результат выражения "width * height * depth" всегда будет корректен. На 64-битной платформе, пользуясь возможностью работать с большим объемом памяти, количество счетных элементов может превысить значение 'UINT_MAX' (4 Гб). В этом случае произойдет переполнение при вычислении выражения "width * height * depth", так как результат этого выражения имеет тип 'unsigned'.
Исправление кода может заключаться в изменении типа переменных 'width', 'height' и 'depth' на memsize тип, как показано ниже:
...
size_t width, height, depth;
...
size_t volume = useDefaultVolume ?
defaultVolume :
width * height * depth;Или использовании явного приведения типов:
unsigned width, height, depth;
...
size_t volume = useDefaultVolume ?
defaultVolume :
size_t(width) * size_t(height) * size_t(depth);Дополнительно мы рекомендуем изучить описание аналогичного предупреждения V104, где можно ознакомиться с другими эффектами неявного приведения к типу memsize.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V106. Implicit type conversion N argument of function 'foo' to memsize type.
Анализатор обнаружил потенциально возможную ошибку, связанную с неявным приведением фактического аргумента функции к memsize типу.
Первый пример.
Программа работает с большими массивами, используя контейнер 'CArray' из библиотеки MFC. На 64-битной платформе количество элементов массиве может превысить значение 'INT_MAX' (2Гб), что приведет к неработоспособности следующего кода:
CArray<int, int> myArray;
...
int invalidIndex = 0;
INT_PTR validIndex = 0;
while (validIndex != myArray.GetSize()) {
myArray.SetAt(invalidIndex, 123);
++invalidIndex;
++validIndex;
}Данный код заполняет все элементы массива 'myArray' значением 123. Он выглядит совершенно корректно, и вы не получите от компилятора никаких предупреждений, несмотря на его неработоспособность на 64-битной архитектуре. Ошибка заключается в использовании в качестве индекса переменной 'invalidIndex' типа 'int'. Когда значение переменной 'invalidIndex' превысит 'INT_MAX', произойдет ее переполнение, и оно получит значение равное "-1". Анализатор диагностирует данную ошибку, предупреждая, что первый аргумент функции 'SetAt' неявно приводится к memsize типу (которым в данном случае является тип 'INT_PTR'). Получив такое предупреждение, вы можете исправить ошибку, изменив тип 'int' на более подходящий.
Данный пример показателен тем, что обвинять программиста в некачественном коде не очень честно. Дело в том, что в старой версии библиотеки MFC функция 'SetAt' в классе 'CArray' была объявлена следующим образом:
void SetAt(int nIndex, ARG_TYPE newElement);А в новой:
void SetAt(INT_PTR nIndex, ARG_TYPE newElement);Даже разработчики Microsoft, создавая MFC, не смогли учесть все возможные последствия использования типа 'int' для индексации в массиве, и можно простить простого разработчика, написавшего такой код.
Приведем исправленный пример:
...
INT_PTR invalidIndex = 0;
INT_PTR validIndex = 0;
while (validIndex != myArray.GetSize()) {
myArray.SetAt(invalidIndex, 123);
++invalidIndex;
++validIndex;
}Второй пример.
Программа вычисляет необходимый ей размер массива данных, а затем выделяет его с использованием функции 'malloc', как показано ниже:
unsigned GetArraySize();
...
unsigned size = GetArraySize();
void *p = malloc(size);Анализатор выдаст предупреждение на строку "void *p = malloc(size);". Посмотрев определение функции 'malloc', мы увидим, что ее формальный аргумент, задающий размер выделяемой памяти, представлен типом 'size_t'. В программе же в качестве фактического аргумента используется переменная 'size' типа 'unsigned'. Если вашей программе на 64-битной архитектуре понадобится массив более 'UINT_MAX' байт (4Гб), то можно с уверенностью утверждать, что приведенный код неверен, так как тип 'unsigned' не может хранить значение более 'UINT_MAX'. Исправление программы заключается в изменении типов переменных и функций, участвующих в вычислении размера массива данных. В приведенном примере необходимо заменить тип 'unsigned' на один из memsize типов, а также, если это необходимо модифицировать код функции 'GetArraySize'.
...
size_t GetArraySize();
...
size_t size = GetArraySize();
void *p = malloc(size);Анализатор выдает предупреждения на неявное приведение типа только в том случае, если оно может привести к ошибке при переносе программы на 64-битную платформу. Ниже приведен код, в котором присутствует неявное приведения типов, но которое не вызывает ошибок:
void MyFoo(SSIZE_T index);
...
char c = 'z';
MyFoo(0);
MyFoo(c);Если вы точно уверены, что неявное приведение типа фактического аргумента функции совершенно корректно, то для подавления предупреждения анализатора вы можете использовать явное приведение типа, как показано ниже:
typedef size_t TYear;
void MyFoo(TYear year);
int year;
...
MyFoo(static_cast<TYear>(year));Иногда явное приведение типа может маскировать ошибку. В этом случае вы можете воспользоваться правилом V201.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V107. Implicit type conversion N argument of function 'foo' to 32-bit type.
Анализатор обнаружил потенциально возможную ошибку, связанную с неявным приведением фактического аргумента функции, имеющего тип memsize к 32-битному типу.
Рассмотрим пример кода, в котором реализована функция поиска максимального элемента в массиве:
float FindMaxItem(float *array, int arraySize) {
float max = -FLT_MAX;
for (int i = 0; i != arraySize; ++i) {
float item = *array++;
if (max < item)
max = item;
}
return max;
}
...
float *beginArray;
float *endArray;
float maxValue = FindMaxItem(beginArray, endArray - beginArray);Данный код успешно может работать на 32-битной платформе, но не сможет обрабатывать массивы, состоящие более чем из 'INT_MAX' (2Гб) элементов на 64-битной архитектуре. Это ограничение вызвано использованием типа 'int' для аргумента 'arraySize'. Обратите внимание, что код функции выглядит совершенно корректно не только с точки зрения компилятора, но и анализатора. В этой функции отсутствует приведение типов, и невозможно выявить потенциальную проблему.
Анализатор предупредит о неявном приведении memsize типа к 32-битному типу при вызове функции 'FindMaxItem'. Попробуем разобраться, почему это происходит. Согласно правилам языка Си++, результат вычитания одного указателя из другого имеет тип 'ptrdiff_t'. При вызове функции 'FindMaxItem' произойдет неявное приведение типа 'ptrdiff_t' к типу 'int', в результате чего произойдет потеря старших битов. Это может стать причиной некорректного поведения программы, при обработке большого объема данных.
Правильным решением будет заменить тип 'int' на тип 'ptrdiff_t', так как он позволит хранить весь диапазон допустимых значений. Исправленный код:
float FindMaxItem(float *array, ptrdiff_t arraySize) {
float max = -FLT_MAX;
for (ptrdiff_t i = 0; i != arraySize; ++i) {
float item = *array++;
if (max < item)
max = item;
}
return max;
}Анализатор по возможности старается распознать безопасные приведения типов и не выдавать на них предупреждения. Например, анализатор не выдаст предупреждение на вызов функции FindMaxItem в следующем коде:
float Arr[1000];
float maxValue =
FindMaxItem(Arr, sizeof(Arr)/sizeof(float));В тех случаях, когда вы точно уверены в корректности кода и неявное приведение типа фактического аргумента функции не влечет ошибок, вы можете использовать явное приведение типа для того, чтобы избежать вывода диагностических сообщений. Пример:
extern int nPenStyle
extern size_t nWidth;
extern COLORREF crColor;
...
// Call constructor CPen::CPen(int, int, COLORREF)
CPen myPen(nPenStyle, static_cast<int>(nWidth), crColor);В том случае, если вы подозреваете наличие в своем коде некорректных явных приведений memsize типов к 32-битным типам, на которые анализатор не выдает предупреждения, то вы можете воспользоваться правилом V202.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V108. Incorrect index type: 'foo[not a memsize-type]'. Use memsize type instead.
Анализатор обнаружил потенциально возможную ошибку индексации больших массивов. Ошибка может заключаться в некорректном вычислении индекса.
Первый пример.
extern char *longString;
extern bool *isAlnum;
...
unsigned i = 0;
while (*longString) {
isAlnum[i] = isalnum(*longString++);
++i;
}Данный код совершенно корректен для 32-битной платформы, где принципиально невозможна обработка массивов более 'UINT_MAX' байт (4 Гб). На 64-битной платформе можно обработать массив размером более 4 Гб, что иногда очень удобно. Но корректно обработать большой массив приведенным алгоритмом невозможно. Ошибка заключается в использовании для индексации массива 'isAlnum' переменной типа 'unsigned'. Когда мы заполним первые 'UINT_MAX' элементов, произойдет переполнение переменной 'i', и она приравняется нулю. В результате мы начнем перезаписывать элементы массива 'isAlnum' расположенные в начале, а часть элементов оставим неинициализированными.
Корректным исправлением является изменения типа переменной 'i' на memsize тип:
...
size_t i = 0;
while (*longString)
isAlnum[i++] = isalnum(*longString++);Второй пример.
class Region {
float *array;
int Width, Height, Depth;
float Region::GetCell(int x, int y, int z) const;
...
};
float Region::GetCell(int x, int y, int z) const {
return array[x + y * Width + z * Width * Height];
}Для программ численного моделирования важным ресурсом является объем оперативной памяти, и возможность на 64-битной архитектуре использовать более 4 Гб памяти существенно увеличивает вычислительные возможности. В таких программах часто используют одномерные массивы, работая затем с ними как с трехмерными. Для этого существуют функции, аналогичные 'GetCell', обеспечивающие доступ к необходимым элементам счетной области. Но приведенный код может корректно работать с массивами, содержащими не более 'INT_MAX' (2 Гб) элементов. Причина заключается в использовании 32-битных типов 'int', участвующих в вычислении индекса элемента. Если количество элементов в массиве 'array' превысит 'INT_MAX' (2 Гб), то произойдет переполнение и значение индекса будет вычислено некорректно. Программисты часто допускают ошибку, пытаясь исправить код следующим образом:
float Region::GetCell(int x, int y, int z) const {
return array[static_cast<ptrdiff_t>(x) + y * Width +
z * Width * Height];
}Они знают, что по правилам языка Си++ выражение для вычисления индекса будет иметь тип 'ptrdiff_t' и надеются за счет этого избежать переполнения. К сожалению, переполнение может произойти внутри подвыражения "y * Width или z * Width * Height" ,так как для их вычисления по-прежнему используется тип 'int'.
Если вы хотите исправить код, не изменяя типов переменных, участвующих в выражении, то вы должны явно привести каждую переменную к memsize типу:
float Region::GetCell(int x, int y, int z) const {
return array[ptrdiff_t(x) +
ptrdiff_t(y) * ptrdiff_t(Width) +
ptrdiff_t(z) * ptrdiff_t(Width) *
ptrdiff_t(Height)];
}Другое решение - изменить типы переменных на memsize тип:
class Region {
float *array;
ptrdiff_t Width, Height, Depth;
float
Region::GetCell(ptrdiff_t x, ptrdiff_t y, ptrdiff_t z) const;
...
};
float Region::GetCell(ptrdiff_t x, ptrdiff_t y, ptrdiff_t z) const
{
return array[x + y * Width + z * Width * Height];
}Если вы используете для индексации выражения, имеющие тип отличный от memsize, но при этом точно уверены в корректности кода, то для подавления диагностирующих сообщений анализатора можно использовать явное приведение типов, как показано ниже.
bool *Seconds;
int min, sec;
...
bool flag = Seconds[static_cast<size_t>(min * 60 + sec)];Если вы подозреваете в программе наличие ошибок, связанных с некорректным явным приведением типов в выражениях, то вы можете воспользоваться предупреждением V201.
По возможности анализатор пытается понять, когда использование не memsize-типа в качестве индекса массива безопасно и не выдавать в этом месте предупреждения. В результате поведение анализатора иногда может показаться странным. В таких ситуациях мы просим не спешить и постараться разобраться, в ситуации. Рассмотрим следующий код:
char Arr[] = { '0', '1', '2', '3', '4' };
char *p = Arr + 2;
cout << p[0u + 1] << endl;
cout << p[0u - 1] << endl; //V108Данный код исправно работает в 32-битном режиме и печатает на экране числа 3 и 1. При проверке этого кода мы получим предупреждение только на одну строку с выражением "p[0u - 1]". И это совершенно верно. Если вы скомпилируете и запустите данный пример в 64-битном режиме, то увидите, как на экране будет распечатано значение 3, после чего произойдет аварийное завершений программы.
Ошибка связана с тем, что индексация "p[0u - 1]" на 64-битной системе некорректна, о чем и предупреждает анализатор. Согласно правилам языка Си++ выражение "0u - 1" будет иметь тип unsigned и равняться 0xFFFFFFFFu. На 32-битной архитектуре сложение указателя с этим числом будет эквивалентно вычитанию единицы. А на 64-битной системе к указателю будет честно прибавлено 0xFFFFFFFFu и произойдет обращение к памяти за приделами массива.
Конечно, часто индексация к массивам с использованием таких типов как int и unsigned безопасна. В этом случае предупреждения анализатора могут казаться не уместными. Но следует учитывать, что такой код все равно может оказаться ненадежным в случае его модернизации для обработки другого набора данных. Код с использованием типов int и unsigned может оказаться менее производительным, чем это возможно на 64-битной архитектуре.
Если вы уверены в корректности индексации, то вы можете воспользоваться функцией "Suppression of false alarms" или использовать фильтры. Можно использовать явное приведение типов в коде:
for (int i = 0; i != n; ++i)
Array[static_cast<ptrdiff_t>(i)] = 0;Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 13. Паттерн 5. Адресная арифметика.
V109. Implicit type conversion of return value to memsize type.
Анализатор обнаружил потенциально возможную ошибку, связанную с неявным приведением типа возвращаемого значения. Ошибка может заключаться в некорректном вычислении возвращаемого значения.
Рассмотрим пример.
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return x + y * Width + z * Width * Height;
}
...
array[GetIndex(x, y, z)] = 0.0f;В случае работы с большими массивами (более 'INT_MAX' элементов) данный код будет вести себя некорректно, и мы будет адресоваться не к тем элементам массива 'array', к которым рассчитываем. Но анализатор не выдаст предупреждение на строчку "array[GetIndex(x, y, z)] = 0.0f;",так как она совершенно корректна. Анализатор информирует о потенциальной ошибке внутри функции и совершенно прав, так как ошибка находится именно там и связана с арифметическим переполнением. Несмотря на то, что мы возвращаем значение типа 'size_t', выражение "x + y * Width + z * Width * Height" вычисляется с использованием типа 'int'.
Для исправления ошибки следует использовать явное приведение всех переменных участвующих в выражении к memsize типам.
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return (size_t)(x) +
(size_t)(y) * (size_t)(Width) +
(size_t)(z) * (size_t)(Width) * (size_t)(Height);
}Другим вариантом исправления является использование других типов для переменных, участвующих в выражении.
extern size_t Width, Height, Depth;
size_t GetIndex(size_t x, size_t y, size_t z) {
return x + y * Width + z * Width * Height;
}В тех случаях, когда вы точно уверены в корректности кода, и неявное приведение типа не влечет ошибок при переходе на 64-битную архитектуру, вы можете использовать явное приведение типа для того, чтобы избежать вывода диагностических сообщений в этой строке. Пример:
DWORD_PTR Calc(unsigned a) {
return (DWORD_PTR)(10 * a);
}В том случае, если вы подозреваете, наличие в своем коде некорректных явных приведений к memsize типам, на которые анализатор не выдает предупреждения, то вы можете воспользоваться правилом V201.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V110. Implicit type conversion of return value from memsize type to 32-bit type.
Анализатор обнаружил потенциально возможную ошибку, связанную с неявным приведением возвращаемого значения. Ошибка заключается в отбрасывании старших бит в 64-битном типе, что влечет потерю значения.
Рассмотрим пример.
extern char *begin, *end;
unsigned GetSize() {
return end - begin;
}Результат выражения "end - begin" имеет тип 'ptrdiff_t'. Но поскольку функция возвращает тип 'unsigned', то происходит неявное приведение типа, при котором старшие биты результата теряются. Таким образом, если указатели 'begin' и 'end' ссылаются на начало и конец массива, по размеру большего 'UINT_MAX' (4 Гб), то функция вернет некорректное значение.
Исправление должно заключаться в модификации программы таким образом, чтобы размеры массивов хранились и передавались в memsize типах. Тогда правильный код функции 'GetSize' должен выглядеть следующим образом:
extern char *begin, *end;
size_t GetSize() {
return end - begin;
}В ряде случаев анализатор не выдает предупреждение на приведение типа, если оно явно корректно. Например, анализатор не выдаст предупреждение на следующий код, где результатом оператора sizeof() хотя и является тип size_t, но результат безопасно может быть помещен в тип unsigned:
unsigned GetSize() {
return sizeof(double);
}В тех случаях, когда вы точно уверены в корректности кода и неявное приведение типа не влечет ошибок при переходе на 64-битную архитектуру, вы можете использовать явное приведение типа для того, чтобы избежать вывода диагностических сообщений. Пример:
unsigned GetBitCount() {
return static_cast<unsigned>(sizeof(TypeRGBA) * 8);
}Если вы подозреваете наличие в своем коде некорректных явных приведений типов возвращаемых значений, на которые анализатор не выдает предупреждения, то вы можете воспользоваться правилом V202.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V111. Call of function 'foo' with variable number of arguments. N argument has memsize type.
Анализатор обнаружил потенциально возможную ошибку, связанную с передачей фактического аргумента типа memsize в функцию с переменным количеством аргументов. Потенциальная ошибка может заключаться в изменении требований, предъявляемых к функции на 64-битной системе.
Рассмотрим первый пример.
const char *invalidFormat = "%u";
size_t value = SIZE_MAX;
printf(invalidFormat, value);Данный код не учитывает, что тип 'size_t' не эквивалентен типу 'unsigned' на 64-битной платформе. Это приведет к выводу на печать некорректного результата, в случае если "value > UINT_MAX". Анализатор предупреждает вас, что в качестве фактического аргумента используется тип memsize. А это значит, что вам следует проверить строку 'invalidFormat', задающую формат вывода. Исправленный вариант может выглядеть, как показано ниже.
const char *validFormat = "%Iu";
size_t value = SIZE_MAX;
printf(validFormat, value);В коде реального приложения эта ошибка может встретиться, например, в следующем виде:
wsprintf(szDebugMessage,
_T("%s location %08x caused an access violation.\r\n"),
readwrite,
Exception->m_pAddr);Второй пример.
char buf[9];
sprintf(buf, "%p", pointer);Автор этого неаккуратного кода не учел, что размер указателя в будущем может стать более 32 бит. В результате данный код на 64-битной архитектуре приведет к переполнению буфера. Проанализировав код, на который выдано предупреждение V111, вы можете пойти двумя путями. Увеличить размер буфера, или переписать код с использованием безопасных конструкций.
char buf[sizeof(pointer) * 2 + 1];
sprintf(buf, "%p", pointer);
// --- or ---
std::stringstream s;
s << pointer;Третий пример.
char buf[9];
sprintf_s(buf, sizeof(buf), "%p", pointer);Рассматривая второй пример, вы могли справедливо заметить, что для предотвращения переполнения следует использовать функции with security enhancements. В этом случае переполнение буфера не произойдет, но, к сожалению, и не будет получен корректный результат.
Если типы аргументов не изменили своей разрядности, то код считается корректным и предупреждающих сообщений выдано не будет. Пример:
printf("%d", 10*5);
CString str;
size_t n = sizeof(float);
str.Format(StrFormat, static_cast<int>(n));Диагностируя описанный тип ошибок, к сожалению, часто нет возможности отличить корректный код от не корректного кода. Данное предупреждение будет выдаваться на многие вызовы функций с переменным количеством аргументов, даже когда вызов совершенно верен. Это связано с принципиальной опасностью использования таких конструкций языка С++. Чаще всего проблемы возникают с использованием разновидности следующих функций: 'printf', 'scanf', 'CString::Format'. Общепринятой практикой является отказ от них и использование безопасных методик программирования. Мы настоятельно рекомендуем модифицировать код и использовать безопасные методы. Например, можно заменить 'printf' на 'cout', а 'sprintf' на 'boost::format' или 'std::stringstream'.
Примечание. Борьба с ложными срабатываниями при работе с функциями форматированного вывода
Диагностика V111 очень проста. Когда анализатор ничего не знает об эллипсис-функции, то он предупреждает о всех случаях, когда в функцию передается тип, меняющий свой размер. Когда информация о функции доступна анализатору, начинает работать более точная диагностика V576, и диагностика V111 не выдается. Если диагностика V576 отключена, то V111 выдается на всех функциях.
Соответственно, можно сократить количество ложных срабатываний, предоставив анализатору информацию о функциях форматирования. Анализатор сам знает о типовых функциях, таких как 'printf', 'sprintf' и так далее, поэтому речь сейчас идёт о разметке функций, реализованных самостоятельно. Как аннотировать функции рассказывается в описании диагностики V576.
Рассмотрим пример. Пользователь спрашивает: "Почему в случае N1 анализатор не выдает предупреждение V111, а в случае N2 выдаёт?".
void OurLoggerFn(wchar_t const* const _Format, ...)
{
....
}
void Foo(size_t length)
{
wprintf( L"%Iu", length ); // N1
OurLoggerFn( L"%Iu", length ); // N2
}Дело в том, что анализатор знает, как работает стандартная функция 'wprintf'. А вот что такое 'OurLoggerFn' он не знает и на всякий случай предупреждает о передаче memsize-типа данных (в данном случае это тип 'size_t') в качестве фактического аргумента в эллипсис функцию.
Чтобы предупреждение V111 исчезло, следует проаннотировать функцию 'OurLoggerFn' следующим образом:
//+V576, function:OurLoggerFn, format_arg:1, ellipsis_arg:2
void OurLoggerFn(wchar_t const* const _Format, ...)
.....Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 10. Паттерн 2. Функции с переменным количеством аргументов.
V112. Dangerous magic number N used.
Анализатор обнаружил использование опасной магической константы. Потенциальная ошибка может заключаться в использовании числовой константы в качестве специальных значений или размера memsize типа.
Примечание. Данная диагностика предназначена для решения узкоспециализированной задачи: найти магические числа на этапе портирования кода на 64-битную систему. Рационально один раз просмотреть все места, где используются потенциально опасные константы, после чего отключить диагностику. Нет смысла постоянно отвлекаться на предупреждения, сообщающие, что в коде используется, например константа 32. Регулярный просмотр таких сообщений утомляет и не приносит какой-либо пользы.
Рассмотрим первый пример.
size_t ArraySize = N * 4;
size_t *Array = (size_t *)malloc(ArraySize);Программист при написании программы полагался на то, что размер 'size_t' всегда будет равен 4 и записал вычисление размера массива как "N * 4". Данный код не учитывает, что тип 'size_t' на 64-битной системе будет занимать 8 байт и выделит меньшее количество памяти, чем необходимо. Исправление кода заключается в использовании оператора 'sizeof' вместо константы 4.
size_t ArraySize = N * sizeof(size_t);
size_t *Array = (size_t *)malloc(ArraySize);Второй пример.
size_t n = static_cast<size_t>(-1);
if (n == 0xffffffffu) { ... }Иногда в качестве кода ошибки или другого специального маркера используют значение "-1", записывая его как "0xffffffff". На 64-битной платформе записанное выражение некорректно, и следует явно использовать значение "-1".
size_t n = static_cast<size_t>(-1);
if (n == static_cast<size_t>(-1)) { ... }Перечислим магические константы, которые могут влиять на работоспособность приложения при переносе его на 64-битную систему и поэтому диагностируются анализатором.

Следует внимательно изучить код на наличия магических констант и заменить их безопасными константами и выражениями. Для этого можно использовать оператор 'sizeof()', специальные значения из <limits.h>, <inttypes.h> и так далее.
В ряде случаев использование магических констант не считается опасным. Например, на данный код предупреждение выдано не будет:
float Color[4];Дополнительные материалы по данной теме:
- Урок 9. Паттерн 1. Магические числа.
V113. Implicit type conversion from memsize to double type or vice versa.
Анализатор обнаружил потенциально возможную ошибку, связанную с неявным преобразованием memsize типа в тип 'double' или наоборот. Потенциальная ошибка может заключаться в невозможности хранения всего диапазона значений memsize типа в переменных типа 'double'.
Рассмотрим пример.
SIZE_T size = SIZE_MAX;
double tmp = size;
size = tmp; // x86: size == SIZE_MAX
// x64: size != SIZE_MAXТип 'double' имеет размер 64-бита, и совместим со стандартом IEEE-754 на 32-битных и 64-битных системах. Некоторые программисты используют тип 'double' для хранения и работы с целочисленными типами.
Приведенный пример еще можно пытаться оправдывать на 32-битной системе, так как тип 'double' имеет 52 значащих бит и способен без потери хранить 32-битное целое значение. Но при попытке сохранить в переменной типа 'double' 64-битное целое число точное значение может быть потеряно (см. рисунок).

Если приближенное значение применимо для алгоритма работы вашей программе, то никаких исправлений вносить не требуется. Но мы хотим предупредить вас об эффектах изменения поведения подобного кода на 64-битных системах. И в любом случае не рекомендуется смешивать целочисленную арифметику и арифметику с плавающей точкой.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 18. Паттерн 10. Хранение в double целочисленных значений.
V114. Dangerous explicit type pointer conversion.
Анализатор обнаружил потенциально возможную ошибку, связанную с опасным явным приведением указателя одного типа к указателю другого типа. Ошибка может заключаться в некорректной работе с объектами, на которые ссылается указатель.
Рассмотрим пример. В нем присутствует явное приведение указателя на 'int' к указателю на 'size_t'.
int array[4] = { 1, 2, 3, 4 };
size_t *sizetPtr = (size_t *)(array);
cout << sizetPtr[1] << endl;Как видите, результат вывода программы отличается в 32-битном и 64-битном варианте. На 32-битной системе доступ к элементам массива осуществляется корректно, так как размеры типов 'size_t' и 'int' совпадают, и мы видим вывод "2". На 64-битной системы мы получили в выводе "17179869187", так как именно значение 17179869187 находится в 1-ом элементе массива 'sizetPtr'.
Исправление описанной ситуации заключается в отказе от опасных приведений типов путем модернизации программы. Другим вариантом является создание нового массива и копирование в него значений из исходного массива.
Естественно, не все явные приведения типов указателей являются опасными. В показанном далее примере результат работы не зависит он разрядности системы, так как типы 'enum' и 'int' имеют одинаковый размер как на 32-битной, так и на 64-битной системе. Соответственно анализатор не выдаст на данный код никаких сообщений.
int array[4] = { 1, 2, 3, 4 };
enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };
ENumbers *enumPtr = (ENumbers *)(array);
cout << enumPtr[1] << endl;Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 14. Паттерн 6. Изменение типа массива.
- 64-битные уроки. Урок 15. Паттерн 7. Упаковка указателей.
V115. Memsize type is used for throw.
Анализатор обнаружил потенциально возможную ошибку, связанную с использованием memsize типа для генерации исключения. Ошибка может заключаться в некорректном перехвате и обработке таких исключений.
Рассмотрим пример. Рассмотрим код, генерирующий и обрабатывающий исключение.
char *ptr1, *ptr2;
...
try {
throw ptr2 - ptr1;
}
catch(int) {
Foo();
}Ошибка в том, что на 64-битной системе обработчик исключения не сработает и функция 'Foo()' не будет вызвана. Это связано с тем, что выражение "ptr2 - ptr1" имеет тип 'ptrdiff_t', который на 64-битной системе не совпадает с типом 'int'.
Исправление описанной ситуации заключается в использовании корректного типа для перехвата исключения. В данном случае - 'ptrdiff_t', как показано ниже.
try {
throw ptr2 - ptr1;
}
catch(ptrdiff_t) {
Foo();
}Более корректное исправление будет состоять в отказе от подобной практики программирования. Следует использовать специальные классы для передачи информации о возникшей ошибке.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 20. Паттерн 12. Исключения.
V116. Memsize type is used for catch.
Анализатор обнаружил потенциально возможную ошибку, связанную с использованием memsize типа для перехвата исключения. Ошибка может заключаться в некорректном перехвате и обработке исключений.
Рассмотрим пример. Рассмотрим код, генерирующий и обрабатывающий исключение.
try {
try {
throw UINT64(-1);
}
catch(size_t) {
cout << "x64 portability issues" << endl;
}
}
catch(UINT64) {
cout << "OK" << endl;
}Результат работы на 32-битной системе: OKРезультат работы на 64-битной системе: x64 portability issues
Изменение поведения связано с тем, что на 64-битной системе тип 'size_t' начинает совпадать с 'UINT64'.
Исправление описанной ситуации заключается в изменении кода для достижения необходимой логики работы.
Более корректное исправление будет состоять в отказе от подобной практики программирования. Следует использовать специальные классы для передачи информации о возникшей ошибке.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 20. Паттерн 12. Исключения.
V117. Memsize type is used in the union.
Анализатор обнаружил потенциально возможную ошибку, связанную с использованием memsize внутри объединения (union). Ошибка может возникнуть при работе с такими объединениями без учета изменения размеров memsize типов на 64-битной системе.
Следует внимательно относиться к объединениям, имеющим в своем составе указатели и другие члены типа memsize.
Первый пример.
Иногда возникает необходимость работать с указателем, как с целым числом. Приведенный в примере код удобен тем, что для работы с числовым представлением указателя не используются явные приведения типов.
union PtrNumUnion {
char *m_p;
unsigned m_n;
} u;
...
u.m_p = str;
u.m_n += delta;'m_n' на 64-битной системе, мы работаем только с частью указателя 'm_p'. Следует использовать тип, который будет соответствовать размеру указателя, как показано ниже.
union PtrNumUnion {
char *m_p;
size_t m_n; //type fixed
} u;Второй пример.
Другое частое использование объединения заключается в представлении одного члена, набором других более мелких. Например, нам может потребоваться разбить значение типа 'size_t' на байты для реализации табличного алгоритма подсчета количества нулевых битов в байте.
union SizetToBytesUnion {
size_t value;
struct {
unsigned char b0, b1, b2, b3;
} bytes;
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = TranslateTable[u.bytes.b0] +
TranslateTable[u.bytes.b1] +
TranslateTable[u.bytes.b2] +
TranslateTable[u.bytes.b3];Здесь допущена принципиальная алгоритмическая ошибка, заключающаяся в предположении, что тип 'size_t' состоит из 4 байт. Возможность автоматического поиска алгоритмических ошибок на данном этапе развития статических анализаторов не возможна, но осуществляет поиск всех объединений, в которых присутствуют memsize типы. Просмотрев список таких потенциально опасных объединений, пользователь может обнаружить логические ошибки. Найдя приведенное в примере объединение, пользователь может обнаружить алгоритмическую ошибку и переписать код следующим образом.
union SizetToBytesUnion {
size_t value;
unsigned char bytes[sizeof(value)];
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = 0;
for (size_t i = 0; i != sizeof(u.bytes); ++i)
zeroBitsN += TranslateTable[u.bytes[i]];Родственным диагностическим сообщением является V122.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 16. Паттерн 8. Memsize-типы в объединениях.
V118. malloc() function accepts a dangerous expression in the capacity of an argument.
Анализатор обнаружил потенциальную ошибку, связанную с использованием опасного выражения, являющегося фактическим аргументом для функции malloc. Ошибка может заключаться в некорректных представлениях о размерах типов, заданных в виде числовых констант.
Анализатор считает подозрительными те выражения, в которых присутствуют константные литералы кратные четырем, но отсутствует оператор sizeof().
Пример первый.
Некорректный код выделения памяти для матрицы размером 3x3 из элементов типа size_t может выглядеть следующим образом:
size_t *pMatrix = (size_t *)malloc(36); // V118Хотя такой код мог долгое время надежно работать в 32-битной системе, использование магического числа 36 некорректно. При компиляции 64-битной версии необходимо выделить уже 72 байта памяти. Исправление заключается в использовании оператора sizeof ():
size_t *pMatrix = (size_t *)malloc(9 * sizeof(size_t));Второй пример.
Некорректен для 64-битной системы и следующий код, основанный на предположении, что размер структуры Item равен 12 байт:
struct Item {
int m_a;
int m_b;
Item *m_pParent;
};
Item *items = (Item *)malloc(GetArraySize() * 12); // V118Исправление также заключается в использовании оператора sizeof() для корректного вычисления размера структуры:
Item *items = (Item *)malloc(GetArraySize() * sizeof(Item));Приведенные ошибки просты и легки в исправлении. Но от этого они не менее опасны и сложны для поиска в больших приложениях. Именно поэтому диагностика подобных ошибок реализована в виде отдельного правила.
Наличие константы в выражении, являющегося параметром для функции malloc(), вовсе не означает, что на него всегда выдается предупреждение V118. Если в выражении участвует оператор sizeof(), то такая конструкция считается безопасной. Пример кода, считающийся анализатором безопасным:
int *items = (int *)malloc(sizeof(int) * 12);Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 9. Паттерн 1. Магические числа.
V119. More than one sizeof() operator is used in one expression.
Анализатор обнаружил опасное арифметическое выражение, содержащее в себе несколько операторов sizeof(). Подобные выражения потенциально могут содержать ошибки, связанные с некорректным вычислением размеров структур без учета выравнивания полей.
Пример:
struct MyBigStruct {
unsigned m_numberOfPointers;
void *m_Pointers[1];
};
size_t n2 = 1000;
void *p;
p = malloc(sizeof(unsigned) + n2 * sizeof(void *));Для расчета размеры структуры, которая будет содержать 1000 указателей используется на первый взгляд корректное арифметическое выражение. Размеры базовых типов определяются через операторы sizeof(). Это хорошо, но недостаточно, чтобы правильно вычислить необходимый объем памяти. Дополнительно необходимо учитывать выравнивание полей.
Приведенный пример будет корректно работать в 32-битном режиме, так как размер указателей и типа unsigned совпадает. Оба типа имеют размер 4 байта. Выравниваются указатели и тип unsigned также кратно 4 байтам. И размер необходимой памяти будет вычислен корректно.
В 64-битном коде размер указателя составляет 8 байт. Также указатели выравниваются в памяти по границе 8 байт. Это приводит к тому, что после переменной m_numberOfPointers будут располагаться 4 дополнительных байта для выравнивания указателей по границе 8 байт.
Для вычисления корректного размера необходимо использовать функцию offsetof:
p = malloc(offsetof(MyBigStruct, m_Pointers) +
n * sizeof(void *));Во многих случаях использование нескольких операторов sizeof() в рамках одного выражения корректно и анализатор игнорирует подобные конструкции. Пример безопасных выражений с несколькими операторами sizeof:
int MyArray[] = { 1, 2, 3 };
size_t MyArraySize =
sizeof(MyArray) / sizeof(MyArray[0]);
assert(sizeof(unsigned) < sizeof(size_t));
size_t strLen = sizeof(String) - sizeof(TCHAR);Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 21. Паттерн 13. Выравнивание данных.
V120. Member operator[] of object 'foo' is declared with 32-bit type argument, but is called with memsize type argument.
Анализатор обнаружил потенциально возможную ошибку при работе с классами, в которых имеется operator[].
Классы с перегруженным operator[] обычно представляют собой разновидность массива и аргументом operator[] является индекс запрашиваемого элемента. Если operator[] имеет формальный аргумент 32-битного типа, а в качестве фактического аргумента используется memsize-тип, то это может свидетельствовать об ошибке. Рассмотрим пример, приводящий к сообщению V120:
class MyArray {
int m_arr[10];
public:
int &operator[](unsigned i) { return m_arr[i]; }
} Object;
size_t k = 1;
Object[k] = 44; //V120Данный пример не содержит ошибки, но может свидетельствовать об архитектурной недоработке. Необходимо или работать с классом MyArray используя 32-битные индексы или модифицировать operator[], чтобы он принимал аргумент типа size_t. Второй вариант предпочтительней, так как использование memsize-типов не только делает программу более надежной, но и в ряде случаев позволяет компилятору построить более эффективный код.
Родственными диагностическими сообщениями являются V108 и V302.
V121. Implicit conversion of the type of 'new' operator's argument to size_t type.
Анализатор обнаружил потенциально возможную ошибку, связанную с вызовом оператора new. В качестве аргумента оператору new передается значение не memsize-типа. Оператор new принимает значения типа size_t и передача 32-битного фактического аргумента может свидетельствовать о наличии ошибки переполнения при вычислении объема выделяемой памяти.
Рассмотрим пример.
unsigned a = 5;
unsigned b = 1024;
unsigned c = 1024;
unsigned d = 1024;
char *ptr = new char[a*b*c*d]; //V121В данном случае происходит переполнение при вычислении выражения "a*b*c*d" и в результате программа выделит меньшее количество памяти, чем планировалось. Исправление заключается в использовании типа size_t:
size_t a = 5;
size_t b = 1024;
size_t c = 1024;
size_t d = 1024;
char *ptr = new char[a*b*c*d]; //OkОшибка не будет диагностироваться, если значение задано безопасным 32-битным константным значением. Пример безопасного кода:
char *ptr = new char[100];
const int size = 3*3;
char *p2 = new char[size];Родственным диагностическим сообщением являются V106.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 17. Паттерн 9. Смешанная арифметика.
V122. Memsize type is used in the struct/class.
В некоторых случаях бывает необходимо найти все поля в структурах, имеющих memsize-тип. Такие поля можно обнаружить, используя диагностическое правило V122.
Необходимость просмотреть все memsize-поля может возникнуть при переносе программы, в которой присутствует сериализация структур, например в файл. Рассмотрим пример:
struct Header
{
unsigned m_version;
size_t m_bodyLen;
};
...
size_t size = fwrite(&header, 1, sizeof(header), file);
...Данный код записывает в файл различное количество байт, в зависимости от того скомпилирован он в режиме Win32 или Win64. Это может нарушить совместимость формата файлов или приводить к иным ошибкам.
Автоматизировать выявление подобных ошибок представляется практически не решаемой задачей. Однако, если имеются предпосылки считать, что код содержит подобные ошибки, то разработчики один раз могут проверить все структуры, которые участвую в сериализации. Для этого и может потребоваться проверка правила V122. По умолчанию оно отключено, так как дает ложное предупреждение в более чем 99% случаев.
В приведенном выше примере сообщение V122 будет выдано на строку "size_t m_bodyLen;". Исправление кода может заключаться в использовании типов фиксированного размера:
struct Header
{
My_UInt32 m_version;
My_UInt32 m_bodyLen;
};
...
size_t size = fwrite(&header, 1, sizeof(header), file);
...Рассмотрим другие примеры, где будет выдано сообщение V122:
class X
{
int i;
DWORD_PTR a; //V122
DWORD_PTR b[3]; //V122
float c[3][4];
float *ptr; //V122
};Родственным диагностическим сообщением является V117.
Примечание. Если есть уверенность, что структуры, содержавшие указатели, никогда не сериализуются, то можно использовать следующий комментарий:
//-V122_NOPTRОн подавит все предупреждения, которые относятся к указателям.
Этот комментарий следует вписать в заголовочный файл, который включается во все другие файлы. Например, таким файлом может быть "stdafx.h". Если вписать этот комментарий в "*.cpp" файл, то он будет действовать только для этого файла.
V123. Allocation of memory by the pattern "(X*)malloc(sizeof(Y))" where the sizes of X and Y types are not equal.
Анализатор обнаружил потенциально возможную ошибку, связанную с операцией выделения памяти. При вычислении размера выделяемой памяти используется оператор sizeof(X). Результат, возвращаемый функцией выделения памяти, приводится не к "(X *)", а к другому типу "(Y *)". Это может свидетельствовать о выделении недостаточного или излишнего количества памяти.
Рассмотрим первый пример:
int **ArrayOfPointers = (int **)malloc(n * sizeof(int));Здесь из-за опечатки в 64-битной программе будет выделяться в два раза меньше памяти, чем это необходимо. В 32-битной программе размер типа int и указателя на тип int совпадает и программа, несмотря на опечатку, успешно работает.
Исправленный вариант кода:
int **ArrayOfPointers = (int **)malloc(n * sizeof(int *));Рассмотрим другой пример, где происходит выделение большего количества памяти, чем это необходимо:
unsigned *p = (unsigned *)malloc(len * sizeof(size_t));Программа, содержащая подобный код, скорее всего, будет корректно работать как в 32-битном, так и в 64-битном варианте. Но в 64-битном варианте программа выделяет больше памяти, чем ей необходимо. Корректный вариант:
unsigned *p = (unsigned *)malloc(len * sizeof(unsigned));В ряде случаев, анализатор не выдает предупреждение, хотя типы X и Y не совпадают. Пример подобного корректного кода:
BYTE *simpleBuf = (BYTE *)malloc(n * sizeof(float));V124. Function 'Foo' writes/reads 'N' bytes. The alignment rules and type sizes have been changed. Consider reviewing this value.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что размер записываемых или читаемых данных явно задан константой.
При компиляции в 64-битном режиме изменяется размер некоторых типов, а также границы их выравнивания. Размеры основных типов и границы их выравнивания показаны на рисунке:

Анализатор обращает внимание на те места в коде, где размер записываемых/читаемых данных указан явным образом. Эти места программисту следует проверить. Пример кода:
size_t n = fread(buf, 1, 40, f_in);Константа 40 может являться некорректным значением в рамках 64-битной системы. Возможно, более правильно будет написать:
size_t n = fread(buf, 1, 10 * sizeof(size_t), f_in);V125. It is not advised to declare type 'T' as 32-bit type.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в 64-битном коде присутствует определение зарезервированных типов. При этом они определяются как 32-битные.
Пример:
typedef unsigned size_t;
typedef __int32 INT_PTR;Подобное определение типов может привести к различным ошибкам, так как в разных частях программы и библиотеках эти типы будут иметь различный размер. Следует использовать специальные заголовочные файлы, в которых корректно определены эти типы. Например, тип size_t определен в заголовочном файле stddef.h для языка C и в файле cstddef для языка C++.
Дополнительные ресурсы:
- База знаний. Можно заставить тип size_t быть 32-битным в 64-битной программе? http://www.viva64.com/ru/k/0021/
- База знаний. Является ли size_t стандартным типом в языке Си++? В языке Си? http://www.viva64.com/ru/k/0022/
V126. Be advised that the size of the type 'long' varies between LLP64/LP64 data models.
Данное диагностическое сообщение позволяет найти все типы 'long' используемые в программе.
Конечно, наличие типа 'long' в программе не является ошибкой. Однако иногда бывает полезно просмотреть все места в тексте программы, где используется этот тип. Такое может понадобиться при создании переносимого 64-битного кода, который должен функционировать в Windows и в Linux.
Windows и Linux используют различные модели данных для 64-битной архитектуры. Модель данных это соотношения размеров базовых типов данных, таких как int, float, указатель и так далее. Windows использует модель данных LLP64. В Linux используется модель данных LP64. В этих моделях различается размер типа 'long'.
В Windows (LLP64) размер типа 'long' равен 4 байта.
В Linux (LP64) размер типа 'long' равен 8 байт.
Различие размера типа 'long' может привести к несовместимости форматов файлов или ошибкам при разработке кода, выполняемого в Linux и Windows. При желании, используя PVS-Studio мы сможете просмотреть все участки кода, где используется тип 'long'.
Дополнительные ресурсы:
- Терминология. Модель данных. http://www.viva64.com/ru/t/0012/
V127. An overflow of the 32-bit variable is possible inside a long cycle which utilizes a memsize-type loop counter.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в длинном цикле может переполниться 32-битная переменная.
Анализатор, конечно, не может определить все возможные ситуации, когда происходит переполнение переменных в циклах. Но он поможет найти ряд типовых ошибочных конструкций.
Рассмотрим пример:
int count = 0;
for (size_t i = 0; i != N; i++)
{
if ((A[i] & MASK) != 0)
count++;
}Приведенный код корректно работает в 32-битной программе. Переменной типа 'int' достаточно, чтобы посчитать количество каких-то элементов в массиве. Однако в 64-битной программе количество таких элементов может превысить INT_MAX и произойдет переполнение переменной 'count'. Об этом и предупреждает анализатор, выдавая сообщение V127. Корректный вариант:
size_t count = 0;
for (size_t i = 0; i != N; i++)
{
if ((A[i] & MASK) != 0)
count++;
}Также анализатор содержит ряд дополнительных проверок, чтобы сократить количество ложных срабатываний. Например, сообщение V127 не будет выдано, если мы имеем дело с коротким циклом. Пример кода, который анализатор считает безопасным:
int count = 0;
for (size_t i = 0; i < 100; i++)
{
if ((A[i] & MASK) != 0)
count++;
}V128. A variable of the memsize type is read from a stream. Consider verifying the compatibility of 32 and 64 bit versions of the application in the context of a stored data.
Анализатор обнаружил потенциальную ошибку, связанную с несовместимостью данных, которыми обменивается 32-битная и 64-битная версия программы. В поток записываются или из потока читаются переменные memsize-типа. Ошибка может заключаться в том, что данные записанные в бинарный файл в 32-х битном приложении будут некорректно прочитаны 64-х битном приложением.
Рассмотрим пример такого кода:
std::vector<int> v;
....
ofstream os("myproject.dat", ios::binary);
....
os << v.size();Функция 'size()' возвращает значение с типом size_t. Его размер различен в 32-х и 64-х битных приложениях. Соответственно, в файл будет записано различное количество байт.
Способов избежать несовместимости данных достаточно много. Самый простой и грубый способ, это жестко задать размер читаемых и записываемых типов. Пример такого кода:
std::vector<int> v;
....
ofstream os("myproject.dat", ios::binary);
....
os << static_cast<__int64>(v.size());Естественно, жёсткий переход на 64-битные типы данных нельзя назвать хорошим решением. Например, этот способ не позволит читать данные, записанные старой 32-битной программой. Если читать и записывать данные как 32-битные значения, возникнет другая проблема. В этом случае, 64-битная программа не сможет записать информацию о массивах, состоящих более чем из 2^32 элементов. Это может быть неприятным ограничением. Ведь часто 64-битные программы создаются именно для того, чтобы работать с огромными массивами данных.
Выходом из этой ситуации может стать внесения понятия версии сохраненных данных. Например, 32-битная программа сможет открывать файлы, созданные только 32-битной версией. А 64-битная программа будет работать с данными, сгенерированными как 32-битной, так и 64-битной версией программы.
Ещё один вариант решения проблемы совместимости данных это хранение их в текстовом виде, или использовании XML формата данных.
Следует отметить, что далеко не во всех программах имеет место проблема совместимости данных. Если программа не создает проекты и иные файлы, которые нужно открывать на других компьютерах, то диагностику V128 можно просто отключить.
Также, нет смысла беспокоиться, если поток используется для распечатки значений на экране. PVS-Studio, по возможности, пытается определить такие ситуации и не выдавать сообщения. Однако, появление ложных сообщений весьма вероятно. В этом случае, вы можете воспользоваться одним из механизмов подавления ложных предупреждений, описанных в документации.
Дополнительные возможности
По просьбе пользователей реализована возможность самостоятельно указать, какие из функций используются для сохранения/чтения данных. Если в эти функции передаются memsize-типы, то это считается опасным кодом.
Формат расширения следующий: возле прототипа функции (или возле её реализации, или в общем заголовочном файле) пишется комментарий специального вида. Начнём с примера использования:
//+V128, function:write, non_memsize:2
void write(string name, char);
void write(string name, int32);
void write(string name, int64);
foo()
{
write("zz", array.size()); // warning V128
}Формат:
- Ключ function задаёт имя функции, на которую будет обращать внимание анализатор. Это обязательный ключ – без его указания расширение, разумеется, работать не будет.
- Ключ class – необязательный ключ, который позволяет указать класс, к которому относится функция (то есть в этом случае – метод класса). Без указания этого ключа анализатор будет обращать внимание на все функции с данным именем, с указанием – лишь на методы указанного класса.
- Ключ namespace – необязательный ключ, который позволяет указать пространство имён, к которому относится функция. Без указания ключа, опять же, анализатор будет обращать внимание на все функции, с указанием – лишь на функции, принадлежащие к заданному параметром пространству имён. Ключ может быть задан совместно с ключом class – тогда анализатор будет обращать внимание лишь на методы некоторого класса из некоторого пространства имён.
- Ключ non_memsize позволяет задавать номер аргумента, в который нельзя погружать аргумент меняющегося в зависимости от архитектуры размера. Номера считаются с единицы. Также имеется техническое ограничение – этот номер не должен превышать число 14. Ключей non_memsize может быть задано несколько, если требуется обращать внимание сразу на несколько аргументов.
Уровень диагностики в случае срабатывания на пользовательской функции – всегда первый.
Напоследок дадим наиболее полный пример использования:
// Предупреждать, когда в метод C класса B
// из пространства имён A во второй или третий
// аргумент была помещена переменная типа memsize:
//+V128,namespace:A,class:B,function:C,non_memsize:3,non_memsize:2V201. Explicit conversion from 32-bit integer type to memsize type.
Предупреждение информирует о наличии явного приведения 32-битного целочисленного типа к memsize типу, что может маскировать одну из следующих ошибок: V101, V102, V104, V105, V106, V108, V109. Вы можете обратиться к приведенному списку предупреждений, чтобы выявить причину появления диагностирующего сообщения V204.
Ранее предупреждение V201 распространялось и на приведение 32-битных целочисленных типов к указателю. Такие приведения весьма опасны. Поэтому они были выделены в отдельное диагностическое правило V204.
Учтите, что, скорее всего, большинство предупреждений этого типа будет выдано на корректный код. Приведем несколько примеров корректного и некорректного кода, на который будет выдано данное предупреждение.
Примеры некорректного кода.
int i;
ptrdiff_t n;
...
for (i = 0; (ptrdiff_t)(i) != n; ++i) { //V201
...
}
unsigned width, height, depth;
...
size_t arraySize = size_t(width * height * depth); //V201Примеры корректного кода.
const size_t seconds = static_cast<size_t>(60 * 60); //V201
unsigned *array;
...
size_t sum = 0;
for (size_t i = 0; i != n; i++) {
sum += static_cast<size_t>(array[i] / 4); //V201
}
unsigned width, height, depth;
...
size_t arraySize =
size_t(width) * size_t(height) * size_t(depth); //V201V202. Explicit conversion from memsize type to 32-bit integer type.
Оно информирует о наличии явного приведения целочисленного memsize типа к 32-битному типу, что может маскировать одну из следующих ошибок: V103, V107, V110. Вы можете обратиться к приведенному списку предупреждений, чтобы выявить причину появления диагностирующего сообщения V202.
Ранее предупреждение V202 распространялось и на приведение указателя к 32-битному целочисленному типу. Такие приведения весьма опасны. Поэтому они были выделены в отдельное диагностическое правило V205.
Учтите, что, скорее всего, большинство предупреждений этого типа будет выдано на корректный код. Приведем несколько примеров корректного и некорректного кода, на который будет выдано данное предупреждение.
Примеры некорректного кода.
size_t n;
...
for (unsigned i = 0; i != (unsigned)n; ++i) { //V202
...
}
UINT_PTR width, height, depth;
...
UINT arraySize = UINT(width * height * depth); //V202Примеры корректного кода.
const unsigned bits =
unsigned(sizeof(object) * 8); //V202
extern size_t nPane;
extern HICON hIcon;
BOOL result =
SetIcon(static_cast<int>(nPane), hIcon); //V202Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 15. Паттерн 7. Упаковка указателей.
V203. Explicit type conversion from memsize to double type or vice versa.
Анализатор обнаружил потенциально возможную ошибку, связанную с явным преобразованием memsize типа в 'double' тип или наоборот. Потенциальная ошибка может заключаться в невозможности хранения всего диапазона значений memsize типа в переменных типа 'double'.
Эта ошибка полностью аналогична ошибке V113. Отличие заключается только в том, что используется явное приведение типов, как например, показано ниже:
SIZE_T size = SIZE_MAX;
double tmp = static_cast<double>(size);
size = static_cast<SIZE_T>(tmp); // x86: size == SIZE_T
// x64: size != SIZE_TДля ознакомления с данным видом ошибок смотри описание ошибки V113.
Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 18. Паттерн 10. Хранение в double целочисленных значений.
V204. Explicit conversion from 32-bit integer type to pointer type.
Анализатор обнаружил явное приведение 32-битного целочисленного типа к указателю. Ранее подобную ситуацию можно было выявить с помощью диагностического правила V201. Однако явное приведение типа int к указателю гораздо опаснее, чем приведение int к типу intptr_t. Поэтому было создано отдельное правило для поиска явного приведения типов при работе с указателями.
Пример некорректного кода.
int n;
float *ptr;
...
ptr = (float *)(n);В 64-битной программе тип int имеет размер 4 байта и не может вместить в себя указатель размером 8 байт. Приведение типа, как показано в примере, практически всегда свидетельствует о наличии ошибки.
Отметим, что такие ошибки очень неприятны тем, что могут не сразу проявить себя. Программа может хранить указатели в 32-битных переменных и некоторое время корректно работать, пока все создаваемые в программе объекты располагаются в младших адресах оперативной памяти.
Если по каким-то причинам необходимо хранить указатель в переменной целочисленного типа, то для этого следует использовать memsize-типы данных. Например: size_t, ptrdiff_t, intptr_t, uintptr_t.
Пример корректного кода:
intptr_t n;
float *ptr;
...
ptr = (float *)(n);Возможна специфическая ситуация, когда указатель допустимо хранить в 32-битных типах. Речь идет о дескрипторах (handles), которые используются в Windows для работы с различными системными объектами. Примеры таких типов: HANDLE, HWND, HMENU, HPALETTE, HBITMAP и так далее. По сути, эти типы являются указателями. Например, HANDLE объявляется в заголовочных файлах как typedef void *HANDLE;.
Хотя дескрипторы являются 64-битными указателями, для большей совместимости (например, для возможности взаимодействия между 32-битынми и 64-битными процессами) в них используются только младшие 32-бита. Подробнее об этом можно прочитать здесь: "Microsoft Interface Definition Language (MIDL): 64-Bit Porting Guide" (USER and GDI handles are sign extended 32b values).
Такие указатели можно хранить в 32-битных типах данных (например, int, DWORD). Для преобразования таких указателей к 32-битным типам и обратно используются специальные функции:
void * Handle64ToHandle( const void * POINTER_64 h )
void * POINTER_64 HandleToHandle64( const void *h )
long HandleToLong ( const void *h )
unsigned long HandleToUlong ( const void *h )
void * IntToPtr ( const int i )
void * LongToHandle ( const long h )
void * LongToPtr ( const long l )
void * Ptr64ToPtr ( const void * POINTER_64 p )
int PtrToInt ( const void *p )
long PtrToLong ( const void *p )
void * POINTER_64 PtrToPtr64 ( const void *p )
short PtrToShort ( const void *p )
unsigned int PtrToUint ( const void *p )
unsigned long PtrToUlong ( const void *p )
unsigned short PtrToUshort ( const void *p )
void * UIntToPtr ( const unsigned int ui )
void * ULongToPtr ( const unsigned long ul )V205. Explicit conversion of pointer type to 32-bit integer type.
Анализатор обнаружил явное приведение указателя к 32-битному целочисленному типу. Ранее подобную ситуацию можно было выявить с помощью диагностического правила V202. Однако явное приведение указателя к типу int, гораздо опаснее, чем приведение intptr_t к типу int. Поэтому было создано отдельное правило для поиска явного приведения типов при работе с указателями.
Пример некорректного кода.
int n;
float *ptr;
...
n = (int)ptr;В 64-битной программе тип int имеет размер 4 байта и не может вместить в себя указатель размером 8 байт. Приведение типа, как показано в примере, практически всегда свидетельствует о наличии ошибки.
Отметим, что такие ошибки очень неприятны тем, что могут не сразу проявить себя. Программа может хранить указатели в 32-битных переменных и некоторое время корректно работать, пока все создаваемые в программе объекты располагаются в младших адресах оперативной памяти.
Если по каким-то причинам необходимо хранить указатель в переменной целочисленного типа, то для этого следует использовать memsize-типы данных. Например: size_t, ptrdiff_t, intptr_t, uintptr_t.
Пример корректного кода:
intptr_t n;
float *ptr;
...
n = (intptr_t)ptr;Возможна специфическая ситуация, когда указатель допустимо хранить в 32-битных типах. Речь идет о дескрипторах (handles), которые используются в Windows для работы с различными системными объектами. Примеры таких типов: HANDLE, HWND, HMENU, HPALETTE, HBITMAP и так далее. По сути, эти типы являются указателями. Например, HANDLE объявляется в заголовочных файлах как typedef void *HANDLE;.
Хотя дескрипторы являются 64-битными указателями, для большей совместимости (например, для возможности взаимодействия между 32-битынми и 64-битными процессами) в них используется только младшие 32-бита. Подробнее об этом можно прочитать здесь: "Microsoft Interface Definition Language (MIDL): 64-Bit Porting Guide" (USER and GDI handles are sign extended 32b values).
Такие указатели можно хранить в 32-битных типах данных (например, int, DWORD). Для преобразования таких указателей к 32-битным типам и обратно используются специальные функции:
void * Handle64ToHandle( const void * POINTER_64 h )
void * POINTER_64 HandleToHandle64( const void *h )
long HandleToLong ( const void *h )
unsigned long HandleToUlong ( const void *h )
void * IntToPtr ( const int i )
void * LongToHandle ( const long h )
void * LongToPtr ( const long l )
void * Ptr64ToPtr ( const void * POINTER_64 p )
int PtrToInt ( const void *p )
long PtrToLong ( const void *p )
void * POINTER_64 PtrToPtr64 ( const void *p )
short PtrToShort ( const void *p )
unsigned int PtrToUint ( const void *p )
unsigned long PtrToUlong ( const void *p )
unsigned short PtrToUshort ( const void *p )
void * UIntToPtr ( const unsigned int ui )
void * ULongToPtr ( const unsigned long ul )Рассмотрим пример:
HANDLE h = Get();
UINT uId = (UINT)h;Анализатор не выдаёт здесь сообщение, хотя HANDLE — это указатель. Его значения всегда помещаются в 32-бита. Следует учитывать, что невалидные дескрипторы (handles) объявлены следующим образом:
#define INVALID_HANDLE_VALUE ((HANDLE)(LONG_PTR)-1)Поэтому некорректно ниже будет написать так:
if (HANDLE(uID) == INVALID_HANDLE_VALUE)Т.к. переменная uID беззнаковая, то значение указателя будет равно не 0xFFFFFFFFFFFFFFFF, а 0x00000000FFFFFFFF.
Для подозрительной проверки, где unsigned будет превращаться в указатель, будет выдано предупреждение V204.
V206. Explicit conversion from 'void *' to 'int *'.
Предупреждение информирует о наличии явного приведения типа void *, byte * к указателю на функцию или к указателю на 32/64-битные целочисленные типы данных, или наоборот. Cамо по себе такое приведение типа не является ошибкой.
Достаточно часто указатель на какой-то буфер памяти передаётся в другую часть программы с помощью указателя на байт или void. Причины написать такой код могут быть различны. Часто это свидетельствует о плохом дизайне. Указатели на функцию тоже часто хранятся как void *.
В каком-то фрагменте программы указатель на массив/функцию сохраняется как void *, а в другом происходит обратное приведение типа. При портировании в таком коде появляются ошибки. В одном месте тип данных может быть изменён, а в другом — нет.
Рассмотрим пример:
size_t array[20];
void *v = array;
....
unsigned* sizes = (unsigned*)(v);Этот код корректно работает в 32-битном режиме, так как размеры типов unsigned и size_t совпадают. В 64-битном режиме размер типов отличается, и поведение программы также будет отличаться от ожидаемого. См. также: паттерн 6 — изменение типа массива.
Анализатор указывает на строку с явным приведением типа, которая содержит ошибку. Исправленный вариант кода может выглядеть так:
unsigned array[20];
void *v = array;
....
unsigned* sizes = (unsigned*)(v);Или так:
size_t array[20];
void *v = array;
....
size_t* sizes = (size_t*)(v);Аналогичную ошибку можно допустить при работе с указателями на функцию.
void Do(void *ptr, unsigned a)
{
typedef void (*PtrFoo)(DWORD);
PtrFoo f = (PtrFoo)(ptr);
f(a);
}
void Foo(DWORD_PTR a) { /*... */ }
void Call()
{
Do(Foo, 1);
}Исправленный вариант кода:
typedef void (*PtrFoo)(DWORD_PTR);Примечание. Анализатор распознает множество случаев, когда явное приведение типа безопасно. Например, он не обращает внимание на явное приведение указателя типа void *, который вернула функция malloc():
int *p = (int *)malloc(sizeof(int) * N);Как было отмечено в начале, явное приведение типа само по себе не является ошибкой. Поэтому несмотря на большое количество исключений из правила, анализатор всё равно генерирует много ложных предупреждений V206. Анализатор не знает, есть ли в программе другие места, где неправильно используются эти указатели, поэтому он выдаёт предупреждения на все потенциально опасные приведения типов.
Например, выше были приведены два примера некорректного кода и способы их исправления. Анализатор будет продолжать выдавать предупреждения на уже исправленный код.
Существует следующий способ работы с предупреждением: один раз внимательно просмотреть все сообщения V206, после чего отключить эту диагностику в настройках. Если ложных срабатываний немного, то можно воспользоваться один из методов подавления ложных предупреждений.
V207. A 32-bit variable is utilized as a reference to a pointer. A write outside the bounds of this variable may occur.
Предупреждение информирует о наличии явного приведения 32-битной целочисленной переменной к типу ссылки на указатель.
Рассмотрим простой синтетический пример:
int A;
(int *&)A = pointer;По какой-то причине в переменную типа 'int' следует поместить указатель. Чтобы это сделать, можно привести тип переменной 'A' к типу 'int *&' (ссылка на указатель).
Этот код волне работоспособен в 32-битной системе, так как размеры переменной 'int' и указателей совпадают. В 64-битной системе произойдёт запись за границу памяти, которую занимает переменная 'A', и дальнейшее поведение программы будет неопределено.
Чтобы исправить ошибку, следует использовать один из memsize-типов данных. Например, можно использовать тип intptr_t:
intptr_t A;
(intptr_t *&)A = pointer;Рассмотрим более сложный пример. Пример, составленный на основе кода, взятого из реального приложения:
enum MyEnum { VAL1, VAL2 };
void Get(void*& data) {
static int value;
data = &value;
}
void M() {
MyEnum e;
Get((void*&)e);
....
}Есть функция, которая возвращает значения, имеющие тип указателя. В одном месте полученное значение помещается в переменную типа 'enum'. Оставим в стороне, почему так было сделано. Нам важно, что этот код корректно работал, когда был 32-битным. Однако 64-битный вариант программы ведёт себя некорректно. Функция Get() меняет не только переменную 'e', но и память по соседству.
V220. Suspicious sequence of types castings: memsize -> 32-bit integer -> memsize.
Предупреждение информирует о наличии странной последовательности приведений типа. Memsize-тип явно приводится к 32-битному целочисленному типу. А затем тут же вновь явно или неявно приводится к memsize-типу. Такая последовательность приведений приводит к потере значений старших бит. Как правило, это свидетельствует о наличии серьезной ошибки.
Рассмотрим пример:
char *p1;
char *p2;
ptrdiff_t n;
...
n = int(p1 - p2);Здесь присутствует лишнее приведение к типу 'int'. Оно не нужно и может послужить причиной сбоя, если в 64-битной программе указатели p1 и p2 будут отстоять друг от друга больше чем на INT_MAX элементов.
Корректный вариант кода:
char *p1;
char *p2;
ptrdiff_t n;
...
n = p1 - p2;Рассмотрим другой пример:
BOOL SetItemData(int nItem, DWORD_PTR dwData);
...
CItemData *pData = new CItemData;
...
CListCtrl::SetItemData(nItem, (DWORD)pData);Этот код приведёт к ошибке, если объект типа CItemData будет создан за пределами четырех младших гигабайт памяти. Корректный вариант кода:
BOOL SetItemData(int nItem, DWORD_PTR dwData);
...
CItemData *pData = new CItemData;
...
CListCtrl::SetItemData(nItem, (DWORD_PTR)pData);Следует учитывать, что анализатор не выдаёт предупреждение, если конвертации подвергается такие типы данных, как HANDLE, HWND, HCURSOR и так далее. Хотя, по сути, это указатели (void *), их значения всегда вмещаются в младшие 32-бита. Это сделано специально, чтобы эти дескрипторы (handles) можно было передавать между 32-битными и 64-битными процессами. Подробнее: Как корректно привести указатель к int в 64-битной программе?
Рассмотрим пример:
typedef void * HANDLE;
HANDLE GetHandle(DWORD nStdHandle);
int _open_osfhandle(intptr_t _OSFileHandle, int _Flags);
....
int fh = _open_osfhandle((int)GetHandle(sh), 0);Здесь имеет место преобразование вида:
HANDLE -> int -> intptr_t
Т.е. вначале указатель превращается в 32-битный тип 'int', а замет расширяется до 'intptr_t'. Это не очень красиво. Лучше было бы написать "(intptr_t)GetHandle(STD_OUTPUT_HANDLE)". Однако, никакой ошибки здесь и нет, так как значения типа HANDLE помещаются в 'int'. Поэтому анализатор промолчит.
Если будет написано:
int fh = _open_osfhandle((unsigned)GetHandle(sh), 0);То анализатор выдаст предупреждение. Смешивание знаковых и беззнаковых типов всё портит. Представим, что GetHandle() вернёт INVALID_HANDLE_VALUE. Это значение задано в системных заголовочных файлах следующим образом.
#define INVALID_HANDLE_VALUE ((HANDLE)(LONG_PTR)-1)Посмотрим, что получитcя при преобразовании (intptr_t)(unsigned)((HANDLE)(LONG_PTR)-1):
-1 -> 0xffffffffffffffff -> HANDLE -> 0xffffffffu -> 0x00000000fffffffff
Значение -1 превратилось в 4294967295. Это может быть не учтено программистом и программа может работать некорректно, если функция GetHandle() вернёт INVALID_HANDLE_VALUE. Поэтому, для второго случая анализатор выдаст предупреждение.
V221. Suspicious sequence of types castings: pointer -> memsize -> 32-bit integer.
Предупреждение информирует о наличии странной последовательности приведений типа. Указатель явно приводится к memsize-типу. А затем вновь явно или неявно приводится к 32-битному целочисленному типу. Такая последовательность приведений приводит к потере значений старших бит. Как правило, это свидетельствует о наличии серьезной ошибки.
Рассмотрим пример:
int *p = Foo();
unsigned a, b;
a = size_t(p);
b = unsigned(size_t(p));В обоих случаях указатель преобразовывается в тип 'unsigned'. При этом старшая часть указателя будет потеряна. Если затем переменные 'a' или 'b' вновь превратить в указатель, эти указатели могут оказаться некорректными.
Различие между переменными 'a' и 'b' только в том, что второй случай тяжелей обнаружить. В первом случае, компилятор предупредит о потери значащих бит. Во втором случае он будет молчать, так как используется явное приведение типа.
Исправление ошибки заключается в том, чтобы хранить указатели только memsize-типах, например, в переменных типа size_t:
int *p = Foo();
size_t a, b;
a = size_t(p);
b = size_t(p);Иногда некоторое недопонимание вызывает предупреждение анализатора на код следующего вида:
BOOL Foo(void *ptr)
{
return (INT_PTR)ptr;
}Тип BOOL это не что иное как 32-битный тип 'int'. Поэтому возникает цепочка преобразований вида:
pointer -> INT_PTR -> int.
Может показаться, что здесь ошибки нет. Ведь нам только важно, что указатель равен или не раен нулю. Но на самом деле ошибка есть. Не следует путать как ведёт себя тип BOOL и bool.
Пусть у нас есть 64-битная переменная, значение которой равно 0x000012300000000. Тогда при приведении к bool и BOOL мы получим разные результаты:
int64_t v = 0x000012300000000ll;
bool b = (bool)(v); // true
BOOL B = (BOOL)(v); // FALSE
В случае 'BOOL' просто будут отброшены старшие биты. И ненулевое значение превратится в 0 (FALSE).
Аналогичная ситуация с указателем. При явном приведении указателя к BOOL отпросятся старшие биты и ненулевой указатель превратится в целочисленный 0 (FALSE). Вероятность такого события мала, но есть. Поэтому такой код неверен.
Для того чтобы код стал корректным, можно поступить двумя способами. Первый вариант - использовать тип 'bool':
bool Foo(void *ptr)
{
return (INT_PTR)ptr;
}Хотя конечно лучше и проще написать так:
bool Foo(void *ptr)
{
return ptr != nullptr;
}Показанный выше вариант не всегда возможен. Например, в языке Си нет типа 'bool'. Второй вариант исправления ошибки:
BOOL Foo(void *ptr)
{
return ptr != NULL;
}Следует учитывать, что анализатор не выдаёт предупреждение, если конвертации подвергается такие типы данных, как HANDLE, HWND, HCURSOR и так далее. Хотя по сути это указатели (void *), их значения всегда вмещаются в младшие 32-бита. Это сделано специально, чтобы эти дескрипторы (handles) можно было передавать между 32-битными и 64-битными процессами. Подробнее: Как корректно привести указатель к int в 64-битной программе?
V301. Unexpected function overloading behavior. See N argument of function 'foo' in derived class 'derived' and base class 'base'.
Анализатор обнаружил потенциально возможную ошибку, связанную с изменением поведения перекрытых виртуальных функций.
Пример изменения поведения виртуальных функций.
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
...
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
...
};Перед вами классический пример, с которым может столкнуться разработчик, переносящий свое приложение на 64-битную архитектуру. Проследим жизненный цикл разработки некоторого приложения. Пусть первоначально оно разрабатывалось под Visual Studio 6.0. когда, функция 'WinHelp' в классе 'CWinApp' имела следующий прототип:
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);Совершенно корректно было осуществить перекрытие виртуальной фукции в классе 'CSampleApp', как показано в примере. Затем проект был перенесен в Visual Studio 2005, где прототип функции в классе 'CWinApp' претерпел изменения, заключающиеся в смене типа 'DWORD' на тип 'DWORD_PTR'. На 32-битной платформе такая программа продолжит совершенно корректно работать, так как здесь типы 'DWORD' и 'DWORD_PTR' совпадают. Неприятности проявят себя при компиляции данного кода под 64-битную платформу. Получатся две функции с одинаковыми именами, но с различными параметрами, в результате чего перестанет вызываться пользовательский код.
Анализатор позволяет обнаруживать подобные ошибки, исправление которых не представляет сложности. Достаточно изменить прототип функции в классе наследника, как показано ниже:
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
...
};Дополнительные материалы по данной теме:
- 64-битные уроки. Урок 12. Паттерн 4. Виртуальные функции.
V302. Member operator[] of 'foo' class has a 32-bit type argument. Use memsize-type here.
Анализатор обнаружил потенциально возможную ошибку при работе с классами, в которых имеется operator[]. Классы с перегруженным operator[] обычно представляют собой разновидность массива и аргументом operator[] является индекс запрашиваемого элемента. Если operator[] имеет аргумент 32-битного типа, то это может свидетельствовать об ошибке.
Рассмотрим пример, приводящий к сообщению V302:
class MyArray {
std::vector<float> m_arr;
...
float &operator[](int i) //V302
{
DoSomething();
return m_arr[i];
}
} A;
...
int x = 2000;
int y = 2000;
int z = 2000;
A[x * y * z] = 33;Если класс спроектирован для работы с большим количеством аргументов, то такая реализация operator[] является некорректной, так как не позволяет обращаться к элементам с порядковыми номерами более UINT_MAX. Диагностировать ошибку в приведенном примере можно только указав на потенциально опасный operator[]. Выражение "x * y * z" не выглядит подозрительным, так как отсутствует неявное приведение типа. Когда мы исправим operator[] следующим образом:
float &operator[](ptrdiff_t i);анализатор PVS-Studio предупредит о возможной ошибке в строке "A[x * y * z] = 33;" и мы сможем сделать код программы окончательно корректным. Пример исправленного кода:
class MyArray {
std::vector<float> m_arr;
...
float &operator[](ptrdiff_t i) //V302
{
DoSomething();
return m_arr[i];
}
} A;
...
ptrdiff_t x = 2000;
ptrdiff_t y = 2000;
ptrdiff_t z = 2000;
A[x * y * z] = 33;Родственными диагностическими сообщениями являются V108 и V120.
V303. The function is deprecated in the Win64 system. It is safer to use the 'foo' function.
Ряд функций при переносе приложения на 64-битные системы лучше заменить на их новые варианты. В противном случае работа 64-битного приложения может быть некорректна. Анализатор предупреждает об использовании в коде устаревшей функции и предлагает вариант для замены.
Рассмотрим несколько примеров устаревших функций:
EnumProcessModules
Цитата из MSDN: To control whether a 64-bit application enumerates 32-bit modules, 64-bit modules, or both types of modules, use the EnumProcessModulesEx function.
SetWindowLong
Цитата из MSDN: This function has been superseded by the SetWindowLongPtr function. To write code that is compatible with both 32-bit and 64-bit versions of Windows, use the SetWindowLongPtr function.
GetFileSize
Цитата из MSDN: When lpFileSizeHigh is NULL, the results returned for large files are ambiguous, and you will not be able to determine the actual size of the file. It is recommended that you use GetFileSizeEx instead.
Примечание
Будьте аккуратны, если захотите заменить функцию 'lstrlen' на 'strlen'. Функция 'lstrlen' не сможет корректно подсчитать длину строки, если эта строка состоит более чем из 'INT_MAX' символов. Однако, на практике вряд ли можно ожидать встречу со столь длинными строками. Зато функция 'lstrlen' в отличии 'strlen' корректно обрабатывает ситуацию, когда ей на вход подаётся нулевой указатель: "If lpString is NULL, the function returns 0".
Если просто заменить 'lstrlen' на 'strlen', то программа может начать работать некорректно. Поэтому обычно менять 'lstrlen' на вызов какой-то другой функции вообще не стоит.
V501. Identical sub-expressions to the left and to the right of 'foo' operator.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит логическую ошибку. В тексте программы имеется оператор (<, >, <=, >=, ==, !=, &&, ||, -, /), слева и справа от которого расположены одинаковые подвыражения.
Рассмотрим пример:
if (a.x != 0 && a.x != 0)В данном случае оператор '&&' окружен одинаковыми подвыражениями "a.x != 0", что позволяет обнаружить ошибку, допущенную по невнимательности. Корректный код, который не вызовет подозрений у анализатора, будет выглядеть так:
if (a.x != 0 && a.y != 0)Рассмотрим другой пример ошибки, обнаруженный анализатором в коде реального приложения:
class Foo {
int iChilds[2];
...
bool hasChilds() const { return(iChilds > 0 || iChilds > 0); }
...
}В данном случае, хотя код успешно и без предупреждений компилируется, он не имеет смысла. Корректный код должен был выглядеть следующим образом:
bool hasChilds() const { return(iChilds[0] > 0 || iChilds[1] > 0);}Анализатор выдает предупреждение не во всех случаях, когда слева и справа от оператора находятся одинаковые подвыражения.
Первое исключение относится к конструкциям, где используются оператор инкремента ++, декремента --, а также += и -=. Пример взятый из реального приложения:
do {
} while (*++scan == *++match && *++scan == *++match &&
*++scan == *++match && *++scan == *++match &&
*++scan == *++match && *++scan == *++match &&
*++scan == *++match && *++scan == *++match &&
scan < strend);Данный код анализатор считает безопасным.
Второе исключение относится к сравнению двух одинаковых чисел. Этот прием часто используется программистами, чтобы выключить определенные ветки программы. Пример:
#if defined(_OPENMP)
#include <omp.h>
#else
#define omp_get_thread_num() 0
...
#endif
...
if (0 == omp_get_thread_num()) {Последнее исключение относится к сравнению, где используются макросы:
#define _WINVER_NT4_ 0x0004
#define _WINVER_95_ 0x0004
...
UINT winver = g_App.m_pPrefs->GetWindowsVersion();
if(winver == _WINVER_95_ || winver == _WINVER_NT4_)Следует понимать, что в ряде случаев анализатор может выдать предупреждение на корректную конструкцию. Например, анализатор не учитывает побочные эффекты (side effects) при вызове функций:
if (wr.takeChar() == '\0' && wr.takeChar() == '\0')Другой пример ложного срабатывания анализатора был замечен на юнит-тестах одного проекта, в той его части, где проверялось корректность работы перегруженного оператора '==':
CHECK(VDStringA() == VDStringA(), true);
CHECK(VDStringA("abc") == VDStringA("abc"), true);Диагностическое сообщение не выдается, если сравниваются два идентичных выражения типа float или double. Такое сравнение позволяет определить, является ли значение NaN. Пример кода, реализующего подобную проверку:
bool isnan(double X) { return X != X; }Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V501. |
V502. The '?:' operator may not work as expected. The '?:' operator has a lower priority than the 'foo' operator.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит логическую ошибку. В тексте программы имеется выражение, содержащее тернарный оператор '?:' и которое может вычисляться не так, как планировал программист.
Оператор '?:' имеет более низкий приоритет по сравнению с операторами ||, &&, |, ^, &, !=, ==, >=, <=, >, <, >>, <<, -, +, %, /, *. Это можно случайно забыть и написать ошибочный код, подобный приведенному ниже:
bool bAdd = ...;
size_t rightLen = ...;
size_t newTypeLen = rightLen + bAdd ? 1 : 0;Забыв, что оператор '+' более приоритетный, чем оператор '?:' программист ожидает, что код будет эквивалентен: "rightLen + (bAdd ? 1 : 0)". Но на самом деле код эквивалентен выражению: "(rightLen + bAdd) ? 1 : 0".
Анализатор диагностирует возможность существования ошибку, выполняя следующие проверки:
1) Слева от оператора '?:' находится переменная или подвыражение имеющие тип bool.
2) Это подвыражение сравнивается/складывается/умножается/... с переменной с типом отличной от bool.
Если эти условия выполняются, то высока вероятность наличия ошибки и анализатор выдает рассматриваемое предупреждение.
Рассмотрим еще некоторые примеры некорректного кода:
bool b;
int x, y, z, h;
...
x = y < b ? z : h;
x = y + (z != h) ? 1 : 2;Очевидно, что программистом, скорее всего, задумывался следующий корректный код:
bool b;
int x, y, z, h;
...
x = y < (b ? z : h);
x = y + ((z != h) ? 1 : 2);Если слева от оператора '?:' находится тип отличный от bool, то анализатор считает, что код написан в Си стиле (где нет bool), или с использование объектов классов и не может выявить, опасен данный код или нет.
Пример корректного кода в стиле языка Си, который анализатор также считает корректным:
int conditions1;
int conditions2;
int conditions3;
...
char x = conditions1 + conditions2 + conditions3 ? 'a' : 'b';Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V502. |
V503. Nonsensical comparison: pointer < 0.
Анализатор обнаружил фрагмент кода, содержащий бессмысленное сравнение. С большой вероятностью данный код содержит логическую ошибку.
Пример кода:
class MyClass {
public:
CObj *Find(const char *name);
...
} Storage;
if (Storage.Find("foo") < 0)
ObjectNotFound();Кажется практически невероятным, что подобный код может присутствовать в программе. Однако причина его появления может быть достаточно проста. Предположим, что в программе имеется следующий код:
class MyClass {
public:
// Если объект не найден, то функция
// Find возвращает значение -1.
ptrdiff_t Find(const char *name);
CObj *Get(ptrdiff_t index);
...
} Storage;
...
ptrdiff_t index = Storage.Find("ZZ");
if (index >= 0)
Foo(Storage.Get(index));
...
if (Storage.Find("foo") < 0)
ObjectNotFound();Это корректный, но не изящный код. В процессе рефакторинга класс MyClass может быть переписан следующим образом:
class MyClass {
public:
CObj *Find(const char *name);
...
} Storage;После такой модернизации класса, необходимо исправить все места в программе, использующие функцию Find(). Первый участок кода пропустить невозможно, так как он не скомпилируется и следовательно он обязательно будет исправлен:
CObj *obj = Storage.Find("ZZ");
if (obj != nullptr)
Foo(obj);Второй фрагмент кода успешно скомпилируется и его легко пропустить, тем самым создав рассматриваемую ошибку:
if (Storage.Find("foo") < 0)
ObjectNotFound();Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V503. |
V504. Semicolon ';' is probably missing after the 'return' keyword.
Анализатор обнаружил фрагмент кода, в котором возможно пропущена точка с запятой ';'.
Пример кода, который приводит к выдаче диагностического сообщения V504:
void Foo();
void Foo2(int *ptr)
{
if (ptr == NULL)
return
Foo();
...
}В данном коде планировалось завершить работу функции, если указатель ptr == NULL. Однако, после оператора return забыта точка с запятой ';', что приводит к вызову функции Foo(). Функция Foo() и Foo2() ничего не возвращают и поэтому данный код компилируется без ошибок и предупреждений.
Скорее всего, программист планировал написать:
void Foo();
void Foo2(int *ptr)
{
if (ptr == NULL)
return;
Foo();
...
}Если изначальный код все-таки корректен, то его лучше переписать следующим образом:
void Foo2(int *ptr)
{
if (ptr == NULL)
{
Foo();
return;
}
...
}Анализатор считает код безопасным, если отсутствует оператор "if" или вызов функции находится на той же строке, что и оператор "return". Такой код достаточно часто можно встретить в программах. Примеры безопасного кода:
void CPagerCtrl::RecalcSize()
{
return
(void)::SendMessageW((m_hWnd), (0x1400 + 2), 0, 0);
}
void Trace(unsigned int n, std::string const &s)
{ if (n) return TraceImpl(n, s); Trace0(s); }Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V504. |
V505. The 'alloca' function is used inside the loop. This can quickly overflow stack.
Анализатор обнаружил использование функции 'alloca' внутри цикла.
Функция 'alloca' выделяет память для заданного буфера внутри фрейма вызывающей функции. Эта область памяти будет очищена только вместе с уничтожением этого фрейма в момент её завершения.
Рассмотрим пример:
void foo ()
{
char *buffer = nullptr;
buffer = (char *) alloca(256); // <= (1)
// using buffer
....
} // <= (2)Пример синтетический, но на нём можно увидеть принцип работы функция 'alloca'. На строчке, помеченной как (1), происходит выделение блока памяти размеров в 256 байт на фрейме стека функции 'foo', который будет создан при её вызове. Фрейм функции будет уничтожен на строчке (2), когда она вернёт поток управления вызывающему коду. Это освободит всю выделенную под него память на стеке и позволит избежать утечек памяти.
Однако неаккуратное использование этой функции может привести к проблеме. Память стека исполняемой программы ограничена, и нужно следить за её переполнением.
Рассмотрим пример:
void bar(int n)
{
for (size_t i = 0; i < n; ++i)
{
char *buffer = nullptr;
if (buffer = (char*) alloca(256)) // <=
{
// using buffer
....
}
}
}Функция 'alloca' вызывается в цикле. Проблема заключается в том, что между его итерациями выделенная память не будет освобождена. При этом, если количество итераций 'n' будет достаточно большим, то стек программы может переполниться.
Исправить некорректный код в данном случае достаточно просто. Для этого можно перенести вызов функции 'alloca' за пределы цикла и использовать 'buffer' повторно на каждой итерации:
void bar(int n)
{
char *buffer = (char*)alloca(256);
for (size_t i = 0; i < n; ++i)
{
// using buffer
....
}
}Ещё один пример опасного кода:
// A2W defined in ATL using alloca
#define A2W(lpa) ....
void AtlExample()
{
....
size_t n = ....;
wchar_t** strings = { '\0' };
LPCSTR* pszSrc = { '\0' };
for (size_t i = 0; i < n; ++i)
{
if (wcscmp(strings[i], A2W(pszSrc[i])) == 0) // <=
{
....
}
}
}Макрос 'A2W' определён в библиотеке 'ATL' версии 3.0. Внутри него используется функция 'alloca'. Приведёт ли данный код к ошибке или нет, будет зависеть от длины обрабатываемых строк, их количества и размера доступного стека. Исправить опасный код можно использовав класс 'CA2W', определённый в библиотеке 'ATL' версии 7.0. В отличии от макроса, он выделяет память на стеке только для маленьких строк. Для длинных она выделяется через 'malloc'. Кроме того, память, выделенная на стеке, будет освобождена при выходе из области видимости объявления переменной. Следовательно, будет освобождаться после сравнения с 'strings[i]'.
Исправленный пример:
// using ATL 7.0
....
for (size_t i = 0; i < n; ++i)
{
if (wcscmp(strings[i], CA2W(pszSrc[i])) == 0) // <=
{
....
}
}Подробнее про функции библиотеки ATL можно почитать в документации.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V505. |
V506. Pointer to local variable 'X' is stored outside the scope of this variable. Such a pointer will become invalid.
Анализатор обнаружил потенциально возможную ошибку, связанную с хранением указателя на локальную переменную. Предупреждение выдается в том случае, если время жизни объекта меньше, чем время жизни указателя на него.
Первый пример:
class MyClass
{
size_t *m_p;
void Foo() {
size_t localVar;
...
m_p = &localVar;
}
};В данном случае адрес локальной переменной сохраняется внутри класса в переменную m_p и может затем быть по ошибке использован в другой функции, когда переменная localVar будет уже уничтожена.
Второй пример:
void Get(float **x)
{
float f;
...
*x = &f;
}Функция Get() вернет указатель на локальную переменную, которая уже в этот момент не будет существовать.
Это сообщение подобно сообщению V507.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V506. |
V507. Pointer to local array 'X' is stored outside the scope of this array. Such a pointer will become invalid.
Анализатор обнаружил потенциально возможную ошибку, связанную с хранением указателя на локальный массив. Предупреждение выдается в том случае, если время жизни массива меньше, чем время жизни указателя на него.
Первый пример:
class MyClass1
{
int *m_p;
void Foo()
{
int localArray[33];
...
m_p = localArray;
}
};Массив localArray создается в стеке и массив localArray перестанет существовать по завершению функции Foo(). Однако указатель на этот массив будет сохранен в переменной m_p и может по неаккуратности использоваться, что приведет к ошибке.
Второй пример:
struct CVariable {
...
char name[64];
};
void CRendererContext::RiGeometryV(int n, char *tokens[])
{
for (i=0;i<n;i++)
{
CVariable var;
if (parseVariable(&var, NULL, tokens[i])) {
tokens[i] = var.name;
}
}В этом примере указатель на массив, находящийся в переменной типа CVariable, сохраняется во внешнем массиве. В результате массив "tokens" после завершения функции RiGeometryV будет содержать указатели на уже несуществующие объекты.
Предупреждение V507 не всегда свидетельствует о наличии ошибки. Приведем сокращенный фрагмент кода, который анализатор считает опасным, но на самом деле этот код корректен:
png_infop info_ptr = png_create_info_struct(png_ptr);
...
BYTE trans[256];
info_ptr->trans = trans;
...
png_destroy_write_struct(&png_ptr, &info_ptr);В данном коде время жизни объекта info_ptr совпадает с временем жизни trans. Объект создается внутри png_create_info_struct (), а уничтожается внутри png_destroy_write_struct(). Анализатор не может разобрать данный случай и предполагает, что объект png_ptr поступает извне. Пример кода, где анализатор был бы прав:
void Foo()
{
png_infop info_ptr;
info_ptr = GetExternInfoPng();
BYTE trans[256];
info_ptr->trans = trans;
}Это сообщение подобно сообщению V506.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V507. |
V508. The 'new type(n)' pattern was detected. Probably meant: 'new type[n]'.
Анализатор обнаружил код, который может содержать опечатку и, как следствие, ошибку. Происходит динамическое создание одного единственного объекта целочисленного типа и его инициализация. Высока вероятность, что из-за опечатки используются круглые скобки вместо квадратных.
Пример:
int n;
...
int *P1 = new int(n);Происходит выделение памяти для одного объекта типа int. Это достаточно странно. Вероятно, корректный код должен выглядеть следующим образом:
int n;
...
int *P1 = new int[n];Анализатор выдает предупреждение только в том случае, если память выделяется для простых объектов. При этом аргумент в скобках должен иметь целочисленный тип. В результате, анализатор не будут выдавать предупреждения на следующий корректный код:
float f = 1.0f;
float *f2 = new float(f);
MyClass *p = new MyClass(33);Данная диагностика классифицируется как:
V509. Exceptions raised inside noexcept functions must be wrapped in a try..catch block.
Если в программе возникает исключение, начинается свертывание стека, в ходе которого объекты разрушаются путем вызова деструкторов. Если деструктор объекта, разрушаемого при свертывании стека, бросает еще одно исключение и это исключение покидает деструктор, библиотека C++ немедленно аварийно завершает программу, вызывая функцию terminate(). Из этого следует, что деструкторы никогда не должны распространять исключения. Исключение, брошенное внутри деструктора, должно быть обработано внутри того же деструктора.
Анализатор обнаружил деструктор, содержащий оператор throw вне блока try..catch. Пример:
LocalStorage::~LocalStorage()
{
...
if (!FooFree(m_index))
throw Err("FooFree", GetLastError());
...
}Данный код следует переписать таким образом, чтобы сообщить об ошибке, возникшей в деструкторе без использования механизма исключений. Если ошибка не критична, то ее можно игнорировать:
LocalStorage::~LocalStorage()
{
try {
...
if (!FooFree(m_index))
throw Err("FooFree", GetLastError());
...
}
catch (...)
{
assert(false);
}
}Так же исключения могут возникать при вызове оператора 'new'. При невозможности выделения памяти будет сгенерировано исключение 'bad_alloc'. Пример:
A::~A()
{
...
int *localPointer = new int[MAX_SIZE];
...
}Появление исключения возможно при использовании dynamic_cast<Type> при работе с ссылками. При невозможности приведения типов будет сгенерировано исключение 'bad_cast'. Пример:
B::~B()
{
...
UserType &type = dynamic_cast<UserType&>(baseType);
...
}Для исправления данных ошибок следует переписать код таким образом, чтобы 'new' или 'dynamic_cast' были помещены в блок 'try{...}'.
Начиная с C++11 функции могут быть размечены как 'noexcept'. Если такие функции выбрасывают исключение, это приводит к аварийному завершению программы. Анализатор обнаруживает вызовы, которые потенциально могут выбросить исключение, в 'noexcept' функциях. Пример:
int noexceptWithNew() noexcept
{
return *(new int{42});
}Анализатор выдаст предупреждение, так как оператор 'new' может выбросит исключение. Вызов 'new' в этом случае нужно обернуть в блок 'try..catch'.
Анализатор также обнаруживает вызовы функций, не размеченных как 'noexcept', из деструкторов и 'noexcept' функций. Такие вызовы потенциально опасны, так как они могут приводить к исключениям. Рассмотрим пример:
int allocate_memory()
{
return *(new int{ 42 });
}
int noexceptFunc() noexcept
{
return allocate_memory();
}Анализатор выдаст предупреждение на строке с вызовом функции 'allocate_memory'.
Обратите внимание, что даже если вызываемая функция не размечена как 'noexcept', но анализатор не нашел в ее коде операций, способных выбросить исключение, предупреждение на ее вызов выдано не будет.
Дополнительные материалы по данной теме:
- Bjarne Stroustrup's C++ Style and Technique FAQ. Can I throw an exception from a constructor? From a destructor? http://www.stroustrup.com/bs_faq2.html
- Throwing destructors. http://www.kolpackov.net/projects/c++/eh/dtor-1.xhtml
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V509. |
V510. The 'Foo' function receives class-type variable as Nth actual argument. This is unexpected behavior.
Вариативная функция (функция, последним формальным параметром которой является эллипсис) принимает в качестве фактического аргумента, являющегося частью эллипсиса, объект классового типа, что может свидетельствовать о логической ошибке. В качестве фактического параметра для эллипсиса могут выступать только POD-типы.
POD – это аббревиатура от "Plain Old Data", что можно перевести как "Простые данные в стиле C". Начиная с C++11, к POD-типам относятся:
- Скалярные типы: арифметические типы (целые и вещественные), указатели, указатели на нестатические поля или функции класса, перечисления ('enum') или 'std::nullptr_t' (могут быть 'const' / 'volatile' квалифицированными);
- Классовый тип ('class', 'struct' или 'union'), который удовлетворяет нижеприведенным требованиям:
- Конструкторы копирования/перемещения тривиальны (сгенерированы компилятором или помечены как '= default');
- Операторы копирования/перемещения тривиальны (сгенерированы компилятором или помечены как '= default');
- Имеет неудаленный тривиальный деструктор;
- Конструктор по умолчанию тривиален (сгенерирован компилятором или помечен как '= default');
- Все нестатические поля имеют одинаковый доступ ('private', 'protected' или 'public');
- Не имеет виртуальных функций или виртуальных базовых классов;
- Не имеет нестатических полей ссылочного типа;
- Все нестатические поля и базовые классы имеют тип со стандартным размещением в памяти;
- Не имеют базовых классов с нестатическими полями или не имеют полей в самом производном классе и не более одного базового класса с нестатическими полями;
- Не имеют базовых классов того же типа, что имеет первое нестатическое поле.
Если эллипсису функции в качестве параметра передается объект не POD-типа, это практически всегда свидетельствует о наличии ошибки в программе. Согласно стандарту C++11:
Passing a potentially-evaluated argument of class type having a non-trivial copy constructor, a non-trivial move constructor, or a non-trivial destructor, with no corresponding parameter, is conditionally-supported with implementation-defined semantics.
Пример кода с ошибкой:
void bar(size_t count, ...);
void foo()
{
std::string s1 = ....;
std::string s2 = ....;
std::string s3 = ....;
bar(3, s1, s2, s3);
}Начиная с C++11, для исправления ошибки можно воспользоваться вариативными шаблонами, благодаря которым информация о типах переданных аргументов будет сохранена:
template <typename T, typename ...Ts>
void bar(T &&arg, Ts &&...args);
void foo()
{
std::string s1 = ....;
std::string s2 = ....;
std::string s3 = ....;
bar(s1, s2, s3);
}Анализатор не будет выдавать предупреждение, если передача объекта не POD-типа происходит в невычисляемом контексте (например, внутри операторов 'sizeof' / 'alignof'):
int bar(size_t count, ...);
void foo()
{
auto res = sizeof(bar(2, std::string {}, std::string {}));
}На практике диагностическое правило V510 помогает выявлять ошибки при передаче аргументов в функции форматного ввода/вывода из C:
void foo(const std::wstring &ws)
{
wchar_t buf[100];
swprintf(buf, L"%s", ws);
}Вместо указателя на строку в стек попадает содержимое объекта. Такой код приведет к формированию в буфере "абракадабры" или к аварийному завершению программы.
Корректный вариант кода должен выглядеть так:
wchar_t buf[100];
std::wstring ws(L"12345");
swprintf(buf, L"%s", ws.c_str());Вместо printf-подобных функций в C++ рекомендуется использовать более безопасные аналоги. Например, 'boost::format', 'fmt::format', 'std::format' (C++20) и т.п.
Примечание. Диагностическое правило V510 также рассматривает объекты POD-типов при их передаче в функции форматного ввода/вывода. Несмотря на то, что такая передача безопасна, дальнейшая работа функции с такими аргументами может привести к непредвиденным результатам.
Если ложные срабатывания диагностического правила доставляют неудобства, их можно подавить на конкретной функции, вставив в код комментарий специального вида:
//-V:MyPrintf:510Особенность при использовании класса CString из библиотеки MFC
Ошибку, аналогичную приведенной выше, мы должны наблюдать и в следующем коде:
void foo()
{
CString s;
CString arg(L"OK");
s.Format(L"Test CString: %s\n", arg);
}Корректный вариант кода должен выглядеть так:
s.Format(L"Test CString: %s\n", arg.GetString());Или, как предлагается в MSDN, для получения указателя на строку можно использовать оператор явного приведения к 'LPCTSTR', реализованный в классе 'CString':
void foo()
{
CString kindOfFruit = "bananas";
int howmany = 25;
printf("You have %d %s\n", howmany, (LPCTSTR)kindOfFruit);
}Однако первый вариант 's.Format(L"Test CString: %s\n", arg);' также является корректным, как и остальные. Подробнее эта тема обсуждается в статье "Большой брат помогает тебе".
Разработчики MFC реализовали тип 'CString' специальным образом, чтобы его можно было передавать в функции вида 'printf' и 'Format'. Сделано это достаточно хитро, и те, кто интересуется, могут ознакомиться с реализацией класса 'CStringT'.
Таким образом, анализатор делает исключение для типа 'CString' и считает следующий код корректным:
void foo()
{
CString s;
CString arg(L"OK");
s.Format(L"Test CString: %s\n", arg);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования форматной строки. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V510. |
V511. The sizeof() operator returns pointer size instead of array size.
Оператор 'sizeof' возвращает размер указателя, а не массива, для случаев, когда массив был передан в функцию по копии.
Есть особенность языка, о которой легко забыть и допустить ошибку. Рассмотрим фрагмент кода:
char A[100];
void Foo(char B[100])
{
}В этом коде объект A является массивам и выражение sizeof(A) вернет значение 100.
Объект B является просто указателем. Значение 100 в квадратных скобках подсказывает программисту, что он работает с массивом из ста элементов. Но в функцию передается вовсе не массив из ста элементов, а только указатель. Таким образом выражение sizeof(B) будет возвращать значение 4 или 8 (размер указателя в 32-битной/64-битной системе).
Предупреждение V511 выдается в том случае, когда вычисляется размер указателя переданного в качестве аргумента в формате "имя_типа имя_массива[N]". Такой код с высокой вероятностью содержит ошибку. Рассмотрим пример:
void Foo(float array[3])
{
size_t n = sizeof(array) / sizeof(array[0]);
for (size_t i = 0; i != n; i++)
array[i] = 1.0f;
}Функция заполнит значением 1.0f не весь массив, а только 1 или 2 элемента, в зависимости от разрядности системы.
В Win32: sizeof(array) / sizeof(array[0]) = 4/4 = 1.
В Win64: sizeof(array) / sizeof(array[0]) = 8/4 = 2.
Для предотвращения подобных ошибок необходимо явно передавать размер массива. Корректный код:
void Foo(float *array, size_t arraySize)
{
for (size_t i = 0; i != arraySize; i++)
array[i] = 1.0f;
}Другой вариант, это использовать ссылку на массив:
void Foo(float (&array)[3])
{
size_t n = sizeof(array) / sizeof(array[0]);
for (size_t i = 0; i != n; i++)
array[i] = 1.0f;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V511. |
V512. Call of the 'Foo' function will lead to buffer overflow.
- Совместимость с предыдущими версиями
- Работа с неизвестными значениями аргументов для форматных строк
- Примечание касательно функции 'strncpy'
Анализатор обнаружил потенциально возможную ошибку, связанную с заполнением, копированием или сравнением буферов памяти. Ошибка может приводить к переполнению буфера (buffer overflow).
Примечание: ранее данная диагностика содержала в себе дополнительный функционал, но позже было решено вынести его в отдельную диагностику V1086. О причинах и последствиях такого решения можно прочитать в специальной заметке.
Это достаточно распространённый вид ошибки, возникающий из-за опечаток или невнимательности. В результате может произойти чтение или запись в область памяти, которая занята другими данными. Такой ошибкой могут воспользоваться злоумышленники для выполнения вредоносного программного кода, чтения чувствительной информации или вызова сбоев в работе операционной системы. Неприятность подобных ошибок заключается в том, что программа долгое время может работать стабильно.
Рассмотрим пример N1:
#define BYTES_COUNT 5
struct Example
{
unsigned char id[BYTES_COUNT];
unsigned char extended[BYTES_COUNT - 2];
unsigned char data[20];
};
void ClearID(Example *data)
{
memset(&data->id, 0, BYTES_COUNT);
memset(&data->extended, 0, BYTES_COUNT);
}В данном примере в функцию 'ClearID' передаётся указатель на объект типа 'Example'. Внутри функции происходит очистка полей 'id' и 'extended' с помощью функции 'memset'. Из-за невнимательного использования макроса 'BYTES_COUNT' при очистке поля 'extended' произойдёт переполнение буфера, которое приведёт к перезаписи соседнего поля 'data'.
Также переполнение буфера можно получить при неправильном приведении типов, как в примере N2:
struct MyTime
{
int timestamp;
....
};
MyTime s;
time((time_t*)&s.timestamp);Данный пример, на первый взгляд, не содержит в себе опасностей и даже будет корректно работать, пока совпадает размер типов 'int' и 'time_t'. Проблема проявится при использовании стандартной библиотеки, где тип 'time_t' может быть 64-битным. При этом переменная 'int' имеет размер 32 бита.
В таком случае при вызове функции 'time' произойдёт запись в переменную 'timestamp', а также в область памяти после неё. Корректный вариант:
struct MyTime
{
time_t time;
....
};
MyTime s;
time(&s.time);Совместимость с предыдущими версиями
Ранее диагностическое правило содержало в себе дополнительный функционал, который был перенесён в диагностику V1086. Новая диагностика выявляет случаи, когда буфер обработан не полностью.
До разделения была возможность тонко настроить поведение диагностики и отключить неактуальную часть с помощью специальных комментариев. В целях обеспечения обратной совместимости, осталась возможность отключить диагностику V512 с помощью специального комментария:
//-V512_OVERFLOW_OFFЭтот комментарий можно вписать в заголовочный файл, который включается во все другие файлы. Например, это может быть "stdafx.h". Если вписать этот комментарий в "*.cpp" файл, то он будет действовать только для этого файла.
Поскольку теперь диагностика V512 ищет только переполнение буфера, то этот комментарий стал эквивалентен полному отключению диагностики (//-V::512).
Работа с неизвестными значениями аргументов для форматных строк
Иногда анализатор при работе с форматной строкой может не знать точное значение аргумента – к примеру, когда он пришёл из параметра функции:
void foo(int someVar)
{
char buf[2];
sprintf(buf, "%d", someVar);
....
}По умолчанию здесь предупреждение выдаваться не будет. Чтобы включить его выдачу, добавьте следующий комментарий:
//V_512_WARN_ON_UNKNOWN_FORMAT_ARGSВ этом случае для работы анализатор будет использовать диапазон значений из типа аргумента.
Примечание касательно функции 'strncpy'
Неоднократно к нам в поддержку обращались пользователи, считая, что анализатор выдаёт ложное предупреждение на подобный код:
char buf[5];
strncpy(buf, "X", 100);На первый взгляд может показаться, что функция должна скопировать только 2 байта (символ 'X' и терминальный ноль). Но, на самом деле, здесь действительно произойдёт выход за пределы массива. Причиной тому является важное свойство функции 'strncpy':
Если требуемое количество символов (третий аргумент функции) больше длины исходной строки, то целевая строка будет дополнена нулевыми символами до требуемого размера.
Более подробно с этим или другими свойствами функции 'strncpy' можно ознакомиться на cppreference.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V512. |
V513. Use _beginthreadex/_endthreadex functions instead of CreateThread/ExitThread functions.
В программе обнаружено использование функции CreateThread или ExitThread. Если в параллельных потоках используются функции CRT (C run-time library), то вместо CreateThread/ ExitThread следует вызывать функции _beginthreadex/_endthreadex.
Приведем выдержки из 6-ой главы книги Джеффри Рихтера "Windows для профессионалов: создание эффективных Win32-приложений с учетом специфики 64-разрядной версии Windows" / Пер. с англ. - 4-е изд.
"CreateThread - это Windows-функция, создающая поток. Но никогда не вызывайте ее, если Вы пишете код на С/С++. Вместо нее Вы должны использовать функцию _beginthreadex из библиотеки Visual С++.
Чтобы многопоточные программы, использующие библиотеку С/С++ (CRT), работали корректно, требуется создать специальную структуру данных и связать ее с каждым потоком, из которого вызываются библиотечные функции. Более того, они должны знать, что, когда Вы к ним обращаетесь, нужно просматривать этот блок данных в вызывающем потоке чтобы не повредить данные в каком-нибудь другом потоке.
Так откуда же система знает, что при создании нового потока надо создать и этот блок данных? Ответ очень прост - не знает и знать не хочет Вся ответственность - исключительно на Вас. Если Вы пользуетесь небезопасными в многопоточной среде функциями, то должны создавать потоки библиотечной функцией _beginthreadex, а не Windows-функцией CreateThread .
Заметьте, что функция _beginthreadex существует только в многопоточных версиях библиотеки С/С++. Связав проект с однопоточной библиотекой, Вы получите от компоновщика сообщение об ошибке "unresolved external symbol". Конечно, это сделано специально, потому что однопоточная библиотека не может корректно работать в многопоточном приложении. Также обратите внимание на то, что при создании нового проекта Visual Studio по умолчанию выбирает однопоточную библиотеку. Этот вариант не самый безопасный, и для многопоточных приложений Вы должны сами выбрать одну из многопоточных версий библиотеки С/С++."
Соответственно, для уничтожения потока, созданного с помощью функции _beginthreadex, необходимо использовать функцию _endthreadex.
Дополнительные материалы по данной теме:
- Обсуждение на сайте Stack Overflow. "Windows threading: _beginthread vs _beginthreadex vs CreateThread C++". http://stackoverflow.com/questions/331536/windows-threading-beginthread-vs-beginthreadex-vs-createthread-c
- Форум на сайте CodeGuru. "_beginthread vs CreateThread". http://forums.codeguru.com/showthread.php?371305.html
- Обсуждение на форуме MSDN. "CreateThread vs _beginthreadex". https://social.msdn.microsoft.com/Forums/vstudio/en-US/c727ae29-5a7a-42b6-ad0b-f6b21c1180b2/createthread-vs-beginthreadex?forum=vclanguage
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V513. |
V514. Potential logical error. Size of a pointer is divided by another value.
Анализатор обнаружил потенциально возможную ошибку, связанную с делением размера указателя на некоторое значение. Деление размера указателя является странной операцией, так как не имеет практического смысла и, скорее всего, свидетельствует о наличии в коде ошибки или опечатки.
Рассмотрим пример:
const size_t StrLen = 16;
LPTSTR dest = new TCHAR[StrLen];
TCHAR src[StrLen] = _T("string for V514");
_tcsncpy(dest, src, sizeof(dest)/sizeof(dest[0]));В выражении "sizeof(dest)/sizeof(dest[0])" происходит деление размера указателя на размер элемента, на который ссылается указатель. В результате мы можем получить различное количество скопированных байтов в зависимости от размера указателя и типа TCHAR, но не то количество, что планировал программист.
С учетом того, что функция _tcsncpy сама по себе не является безопасный, корректный и более безопасный код может выглядеть следующим образом:
const size_t StrLen = 16;
LPTSTR dest = new TCHAR[StrLen];
TCHAR src[StrLen] = _T("string for V514");
_tcsncpy_s(dest, StrLen, src, StrLen);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V514. |
V515. The 'delete' operator is applied to non-pointer.
В коде оператор delete применяется не к указателю, а к объекту класса. С большой вероятностью это является ошибкой.
Рассмотрим пример кода:
CString str;
...
delete str;Оператор 'delete' можно применить к объекту типа CString,так как класс CString может быть автоматически приведен к указателю. Подобный код может привести к исключению или неопределенному поведению программы.
Корректный код, возможно должен был выглядеть так:
CString *pstr = new CString;
...
delete pstr;В некоторых случаях применение оператора 'delete' к объектам класса не является ошибкой. Подобный код, например, можно встретить при работе с классом QT::QBasicAtomicPointer. Анализатор игнорирует вызов операnора 'delete' для объектов этого типа. Если Вы знаете другие подобные классы, применение к которым оператора 'delete' является стандартной практикой, то сообщите нам о них. Мы добавим их в исключения.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V516. Non-null function pointer is compared to null. Consider inspecting the expression.
В коде имеется конструкция сравнения ненулевого указателя на функцию с нулем. Скорее всего, это означает, что в коде присутствует опечатка - забыты круглые скобки.
Рассмотрим пример:
int Foo();
void Use()
{
if (Foo == 0)
{
//...
}
}Условие "Foo == 0" не имеет смысла. Адрес функции 'Foo' всегда не равен нулю, а следовательно результатом сравнение всегда будет значение 'false'. В рассматриваемом коде случайно пропущены круглые скобки. Корректный вариант кода:
if (Foo() == 0)
{
//...
}Если в коде явно написано взятие адреса функции, то такой код считается корректным. Пример:
int Foo();
void Use()
{
if (&Foo != NULL)
//...
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V516. |
V517. Potential logical error. The 'if (A) {...} else if (A) {...}' pattern was detected.
Анализатор обнаружил потенциально возможную ошибку в конструкции, состоящей из условных операторов.
Рассмотрим пример:
if (a == 1)
Foo1();
else if (a == 2)
Foo2();
else if (a == 1)
Foo3();В данном примере функции 'Foo3()' никогда не получит управления. Вероятно, мы имеем дело с логической ошибкой и корректный код должен выглядеть так:
if (a == 1)
Foo1();
else if (a == 2)
Foo2();
else if (a == 3)
Foo3()На практике подобная ошибка может выглядеть следующим образом:
if (radius < THRESH * 5)
*yOut = THRESH * 10 / radius;
else if (radius < THRESH * 5)
*yOut = -3.0f / (THRESH * 5.0f) * (radius - THRESH * 5.0f) + 3.0f;
else
*yOut = 0.0f;Трудно сказать, как должно выглядеть корректное условие сравнения, но наличие в коде ошибки очевидно.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V517. |
V518. The 'malloc' function allocates suspicious amount of memory calculated by 'strlen(expr)'. Perhaps the correct expression is strlen(expr) + 1.
Анализатор обнаружил потенциально возможную ошибку, связанную с выделением недостаточного количества памяти. В коде подсчитывается длина строки и выделяется буфер памяти данного размера, но не учитывается наличие терминального '\0'.
Рассмотрим пример:
char *p = (char *)malloc(strlen(src));
strcpy(p, src);В данном случае просто забыто про +1. Правильный код:
char *p = (char *)malloc(strlen(src) + 1);
strcpy(p, src);Приведем другой пример некорректного кода, обнаруженный анализатором в одном из приложений:
if((t=(char *)realloc(next->name, strlen(name+1))))
{
next->name=t;
strcpy(next->name,name);
}Здесь по невнимательности неправильно поставлена правая скобочка ')'. В результате мы выделим на 2 байта меньше памяти, чем необходимо. Исправленный вариант:
if((t=(char *)realloc(next->name, strlen(name)+1)))Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V518. |
V519. The 'x' variable is assigned values twice successively. Perhaps this is a mistake.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что одной и той же переменной дважды подряд присваивается значение. Причем между этими присваиваниями сама переменная не используется.
Рассмотрим пример:
A = GetA();
A = GetB();То, что переменной 'A' два раза присваивается значение, может свидетельствовать о наличии ошибки. Высока вероятность, что код должен выглядеть следующим образом:
A = GetA();
B = GetB();Если переменная между присваиваниями используется, то этот код считается анализатором корректным:
A = 1;
A = A + 1;
A = Foo(A);Рассмотрим, как подобная ошибка может выглядеть на практике. Следующий код взят из реального приложения, где был реализован свой собственный класс CSize:
class CSize : public SIZE
{
...
CSize(POINT pt) { cx = pt.x; cx = pt.y; }Корректный вариант должен был выглядеть так:
CSize(POINT pt) { cx = pt.x; cy = pt.y; }Рассмотрим еще один пример. Вторая строка была написана для отладки или для того, чтобы посмотреть, как будет смотреться текст другого цвета. И, видимо, потом вторую строку забыли удалить:
m_clrSample = GetSysColor(COLOR_WINDOWTEXT);
m_clrSample = RGB(60,0,0);Иногда анализатор выдает ложные предупреждения, когда запись в переменные используется для отладочных целей. Пример подобного кода:
status = Foo1();
status = Foo2();В данной ситуации можно подавить ложные срабатывания, используя комментарий "//-V519". Можно убрать из кода ничего не значащие присваивания. И последнее. Возможно этот код все же некорректен, и необходимо проверять значение переменной 'status'.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V519. |
V520. Comma operator ',' in array index expression.
Анализатор обнаружил потенциальную ошибку, которая может являться следствием опечатки. В качестве индекса при работе с массивом используется выражение, содержащий оператор запятая ','.
Пример подозрительного кода:
float **array_2D;
array_2D[getx() , gety()] = 0;Скорее всего, здесь имелось в виду:
array_2D[ getx() ][ gety() ] = 0;Подобные ошибки могут быть допущены после работы с языком программирования, где индексы массивов разделяются запятыми.
Рассмотрим пример ошибки, найденный анализатором в одном из проектов:
float **m;
TextOutput &t = ...
...
t.printf("%10.5f, %10.5f, %10.5f,\n%10.5f, %10.5f, %10.5f,\n%10.5f,
%10.5f, %10.5f)",
m[0, 0], m[0, 1], m[0, 2],
m[1, 0], m[1, 1], m[1, 2],
m[2, 0], m[2, 1], m[2, 2]);Так как функция printf из класса TextOutput работает с переменным количеством аргументов, то она не может проверить, что место значений типа float ей будут переданы указатели. В результате мы распечатаем мусор вместо значений элементов матрицы. Корректный вариант:
t.printf("%10.5f, %10.5f, %10.5f,\n%10.5f, %10.5f, %10.5f,\n%10.5f,
%10.5f, %10.5f)",
m[0][0], m[0][1], m[0][2],
m[1][0], m[1][1], m[1][2],
m[2][0], m[2][1], m[2][2]);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V520. |
V521. Expressions that use comma operator ',' are dangerous. Make sure the expression is correct.
Оператор запятая ',' используется для выполнения стоящих по обе стороны от него выражений в порядке слева направо и получения значения правого выражения.
Анализатор обнаружил в коде программы выражение, в котором подозрительным образом используется оператор ','. Высока вероятность, что текст программы содержит опечатку.
Рассмотрим пример:
float Foo()
{
double A;
A = 1,23;
float f = 10.0f;
return 3,f;
}В данном коде переменной A будет присвоено значение 1, а вовсе не 1.23. Согласно правилам языка Си/Си++ выражение "A = 1,23" эквивалентно "(A = 1),23". Также функция Foo() вернет значение 10.0f, а не 3.0f. В обоих случаях ошибка связана с использованием символа запятая ',' вместо символа точки '.'.
Исправленный вариант кода:
float Foo()
{
double A;
A = 1.23;
float f = 10.0f;
return 3.f;
}Примечание. Были случаи, когда анализатор не мог разобраться в коде и выдавал предупреждения V521 на совершенно безобидные конструкции. Обычно это связано с использованием шаблонных классов или сложных макросов. Если при работе с анализатором вы заметили подобное ложное срабатывание, то просим сообщить о нем разработчикам. Для подавления ложных срабатываний можно использовать комментарий вида "//-V521".
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V521. |
V522. Possible null pointer dereference.
Анализатор обнаружил фрагмент кода, который может привести к использованию нулевого указателя.
Рассмотрим несколько примеров, для которых анализатор выдает диагностическое сообщение V522:
if (pointer != 0 || pointer->m_a) { ... }
if (pointer == 0 && pointer->x()) { ... }
if (array == 0 && array[3]) { ... }
if (!pointer && pointer->x()) { ... }Во всех условиях допущена логическая ошибка, которая приведет к разыменованию нулевого указателя. Ошибка может быть допущена при рефакторинге кода или из-за случайной опечатки.
Корректные варианты:
if (pointer == 0 || pointer->m_a) { ... }
if (pointer != 0 && pointer->x()) { ... }
if (array != 0 && array[3]) { ... }
if (pointer && pointer->x()) { ... }Конечно, это очень простые ситуации. На практике проверка указателя и его использование может находиться в разных местах. Если анализатор выдал предупреждение V522, изучите код расположенный выше и попробуйте понять, почему указатель может быть нулевым.
Пример кода, где проверка и использование указателя находятся в разных строках
if (ptag == NULL) {
SysPrintf("SPR1 Tag BUSERR\n");
psHu32(DMAC_STAT)|= 1<<15;
spr1->chcr = ( spr1->chcr & 0xFFFF ) |
( (*ptag) & 0xFFFF0000 );
return;
}Анализатор предупредит, об опасности в строке "( (*ptag) & 0xFFFF0000 )". Здесь или некорректно написано условие, или вместо 'ptag' должна использоваться другая переменная.
Особые случаи
Иногда в тестовых целях программисты сознательно используют разыменование нулевого указателя. Например, анализатор будет генерировать предупреждение там, где используется вот такой макрос:
/// This generate a coredump when we need a
/// method to be compiled but not usabled.
#define elxFIXME { char * p=0; *p=0; }Лишние предупреждения можно отключить, используя комментарий "//-V522" в тех строках, где используется макрос 'elxFIXME'. Альтернативный вариант, это написать рядом с макросом комментарий специального вида:
//-V:elxFIXME:522Комментарий может быть написан как до, так и после макроса. Это не имеет значения. Подробнее с методами подавления ложных предупреждений можно познакомиться здесь.
malloc, realloc
Частой причиной появления предупреждения является использование указателя, возвращённого такой функцией как 'malloc' и аналогичной ей, без предварительной проверки. Некоторые программисты считают, что проверять указатель необязательно. В случае ошибки выделения памяти программа всё равно не работоспособна, и её аварийное завершение в следствии записи по нулевому указателю является приемлемым сценарием.
Однако, всё гораздо сложнее и опаснее, чем может казаться на первый взгляд. Предлагаем ознакомиться с публикацией: "Почему важно проверять, что вернула функция malloc".
Если по каким-то причинам всё равно не планируете проверять такие указатели, далее рассказано о специализированной настройке анализатора.
Дополнительная настройка
Данная диагностика учитывает информацию, может ли тот или иной указатель быть нулевым. В ряде случаев, эта информация берется из таблиц разметки функций, которые находятся внутри самого анализатора.
Примером может служить функция 'malloc'. Эта функция может вернуть 'NULL'. Соответственно, если использовать указатель, который вернула функция 'malloc', без предварительной проверки, это может привести к разыменованию нулевого указателя.
Иногда у наших пользователей возникает желание изменить поведение анализатора и заставить его считать, что, например, функция 'malloc' не может вернуть 'NULL'. Пользователь может использовать системные библиотеки, в которых ситуации нехватки памяти обрабатываются особым образом.
Также может возникнуть желание подсказать анализатору, что определённая функция может вернуть нулевой указатель.
В этом случае вы можете воспользоваться дополнительными настройками, которые описаны в разделе "Как указать анализатору, что функция может или не может возвращать nullptr".
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V522. |
V523. The 'then' statement is equivalent to the 'else' statement.
Анализатор обнаружил ситуацию, когда истинная и ложная ветка оператора 'if' полностью совпадают. Часто это свидетельствует о наличии логической ошибки.
Пример:
if (X)
Foo_A();
else
Foo_A();Будет условие X ложно или истинно, все равно произойдет вызов функции Foo_A().
Корректный вариант кода:
if (X)
Foo_A();
else
Foo_B();Пример подобной ошибки, взятый из реального приложения:
if (!_isVertical)
Flags |= DT_BOTTOM;
else
Flags |= DT_BOTTOM;Наличие двух пустых веток считается корректной и безопасной ситуацией. Подробные конструкции можно часто встретить при использовании макросов. Пример безопасного кода:
if (exp) {
} else {
}Также анализатор считает подозрительным, если оператор 'if' не содержит блок 'else', а следующий за ним код идентичен блоку условного оператора. При этом блок кода заканчивается оператором return, break и т.п.
Подозрительный фрагмент кода:
if (X)
{
doSomething();
Foo_A();
return;
}
doSomething();
Foo_A();
return;Возможно программист забыл исправить скопированный фрагмент кода, либо написал лишний код.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V523. |
V524. It is suspicious that the body of 'Foo_1' function is fully equivalent to the body of 'Foo_2' function.
Данное предупреждение выдается в том случае, если анализатор обнаружил две функции, реализованные идентичным образом. Наличие двух одинаковых функций само по себе не является ошибкой, но является поводом обратить на них внимание.
Смысл данной диагностики в обнаружении следующей разновидности ошибок:
class Point
{
...
float GetX() { return m_x; }
float GetY() { return m_x; }
};Из-за допущенной опечатки две разные по смыслу функции выполняют одинаковые действия. Корректный вариант:
float GetX() { return m_x; }
float GetY() { return m_y; }В приведенном примере идентичность тел функций GetX() и GetY() явно свидетельствует о наличии ошибки. Однако если выдавать предупреждения на все одинаковые функции, то процент ложный срабатываний будет крайне большим. Поэтому анализатор руководствуется целым рядом исключений, когда не стоит предупреждать об одинаковых телах функций. Перечислим некоторые из них:
- Не сообщается об идентичности тел функций, если в них не используются переменные кроме аргументов. Пример: "bool IsXYZ() { return true; }".
- В функциях используются статические объекты, а, следовательно, функции имеют различные внутренние состояние. Пример: "int Get() { static int x = 1; return x++; }"
- Функции являются операторами приведения типа.
- Если функции с одинаковыми телами повторяются более двух раз.
- И так далее.
Однако все равно в ряде случаев анализатор не может понять, что одинаковые тела функций не являются подозрительной ситуацией. Вот код, который диагностируется как опасный, но по сути таковым не являющимся:
PolynomialMod2 Plus(const PolynomialMod2 &b) const
{return Xor(b);}
PolynomialMod2 Minus(const PolynomialMod2 &b) const
{return Xor(b);}Бороться с ложными срабатываниями можно несколькими способами. Если ложные срабатывания относятся к файлам внешних библиотек, то эту библиотеку (путь до нее) можно добавить в исключения. Если предупреждения относятся к вашему коду, то вы можете использовать комментарий вида "//-V524", который приведет к подавлению предупреждений. Если ложных срабатываний много, то вы можете в настройках анализатора полностью отключить использование данной проверки. Также вы можете модифицировать код таким образом, чтобы одна функция вызывала другую с тем же самым кодом.
Последний вариант часто является наиболее оптимальным, поскольку, во-первых, это сокращает объем кода, а во вторых делает его более простым в поддержке. Правки достаточно вносить только в одну, а не в две функции. Приведем пример реального кода, где вызов одной функции из другой будет полезен:
static void PreSave(void) {
int x;
for(x=0;x<TotalSides;x++) {
int b;
for(b=0; b<65500; b++)
diskdata[x][b] ^= diskdatao[x][b];
}
}
static void PostSave (void) {
int x;
for(x=0;x<TotalSides;x++) {
int b;
for(b=0; b<65500; b++)
diskdata[x][b] ^= diskdatao[x][b];
}
}Разумно заменить этот код на следующий вариант:
static void PreSave(void) {
int x;
for(x=0;x<TotalSides;x++) {
int b;
for(b=0; b<65500; b++)
diskdata[x][b] ^= diskdatao[x][b];
}
}
static void PostSave (void) {
PreSave();
}В этом коде не была исправлена ошибка. Но после рефакторинга предупреждение V524 исчезло, а код стал проще.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V524. |
V525. Code contains collection of similar blocks. Check items X, Y, Z, ... in lines N1, N2, N3, ...
Анализатор обнаружил код, который возможно содержит опечатку. Этот код можно разделить на более мелкие и похожие между собой фрагменты кода. Хотя фрагменты кода похожи, но все же различны. Высока вероятность, что подобный код был создан с использованием подхода Copy-Paste. Сообщение V525 будет выдано в том случае, если есть подозрение, что один из элементов не исправлен в скопированном тексте. Ошибка может находиться в одной из строк, номера которых содержатся в сообщении V525.
Недостатки сообщения V525:
1) Данное диагностическое правило основано на эвристических методах и нередко дает ложное срабатывание.
2) Реализация эвристического алгоритма сложна и занимает более 1000 строк кода на Си++. Поэтому его затруднительно описать в рамках документации. Как следствие пользователю может быть трудно понять, почему выдано то или иное сообщение V525.
3) Диагностическое сообщение относится к нескольким строкам, а не к одной. Указать только одну строку невозможно, так как ошибка может быть в любой из них.
Преимущества сообщения V525:
1) Можно обнаружить ошибки, которые крайне сложно заметить при обзоре кода (code review).
Рассмотрим вначале искусственный пример:
...
float rgba[4];
rgba[0] = object.GetR();
rgba[1] = object.GetG();
rgba[2] = object.GetB();
rgba[3] = object.GetR();Массив 'rgba' представляет собой цвет и прозрачность некоего объекта. При написании кода, заполняющего массив, вначале была написана строчка "rgba[0] = object.GetR();". Затем это строка была несколько раз скопирована и изменена. Однако в последней строке изменения сделаны не до конца и вместо функции 'GetA()' вызывается 'GetR()'. Анализатор выдает на данный код следующее предупреждение:
V525: The code containing the collection of similar blocks. Check items 'GetR', 'GetG', 'GetB', 'GetR' in lines 12, 13, 14, 15.
Просмотрев строки 12, 13, 14 и 15 можно обнаружить ошибку. Исправленный вариант кода:
rgba[3] = object.GetA();Теперь рассмотрим несколько примеров, взятых из кода реальных приложений. Первый пример:
tbb[0].iBitmap = 0;
tbb[0].idCommand = IDC_TB_EXIT;
tbb[0].fsState = TBSTATE_ENABLED;
tbb[0].fsStyle = BTNS_BUTTON;
tbb[0].dwData = 0;
tbb[0].iString = -1;
...
tbb[6].iBitmap = 6;
tbb[6].idCommand = IDC_TB_SETTINGS;
tbb[6].fsState = TBSTATE_ENABLED;
tbb[6].fsStyle = BTNS_BUTTON;
tbb[6].dwData = 0;
tbb[6].iString = -1;
tbb[7].iBitmap = 7;
tbb[7].idCommand = IDC_TB_CALC;
tbb[7].fsState = TBSTATE_ENABLED;
tbb[7].fsStyle = BTNS_BUTTON;
tbb[6].dwData = 0;
tbb[7].iString = -1;Фрагмент кода приведен далеко не полностью. Вырезано более чем половина. Фрагмент писался методом копирования и правки кода. Неудивительно, что в таком большом фрагменте затерялся неверный индекс. Анализатор выдает следующее диагностическое сообщение: "The code containing the collection of similar blocks. Check items '0', '1', '2', '3', '4', '5', '6', '6' in lines 589, 596, 603, 610, 617, 624, 631, 638". Просмотрев данные строки, мы можем исправить дважды повторяющийся индекс '6'. Исправленный вариант кода:
tbb[7].iBitmap = 7;
tbb[7].idCommand = IDC_TB_CALC;
tbb[7].fsState = TBSTATE_ENABLED;
tbb[7].fsStyle = BTNS_BUTTON;
tbb[7].dwData = 0;
tbb[7].iString = -1;Второй пример:
pPopup->EnableMenuItem(
ID_CONTEXT_EDITTEXT,MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_CLOSEALL, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_CLOSE, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_SAVELAYOUT, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_RESIZE, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_REFRESH, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_EDITTEXT, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_SAVE, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_EDITIMAGE,MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_CLONE,MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);Рассматривая данный код, очень сложно найти в нем ошибку. Однако ошибка здесь действительно присутствует. Дважды модифицируется состояние одного и того же пункта меню 'ID_CONTEXT_EDITTEXT'. Выделим две повторяющиеся строки:
------------------------------
pPopup->EnableMenuItem(
ID_CONTEXT_EDITTEXT,MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
------------------------------
pPopup->EnableMenuItem(
ID_CONTEXT_CLOSEALL, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_CLOSE, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_SAVELAYOUT, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_RESIZE, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_REFRESH, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
------------------------------
pPopup->EnableMenuItem(
ID_CONTEXT_EDITTEXT, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
------------------------------
pPopup->EnableMenuItem(
ID_CONTEXT_SAVE, MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_EDITIMAGE,MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);
pPopup->EnableMenuItem(
ID_CONTEXT_CLONE,MF_GRAYED|MF_DISABLED|MF_BYCOMMAND);Возможно это несерьезная погрешность, и одна из строк просто лишняя. А возможно, здесь забыли изменить состояние какого-то другого элемента меню.
К сожалению, анализатор, осуществляя данный вид диагностики, часто ошибается и генерирует ложные срабатывания. Пример кода, приводящий к ложному срабатыванию:
switch (i) {
case 0: f1 = 2; f2 = 3; break;
case 1: f1 = 0; f2 = 3; break;
case 2: f1 = 1; f2 = 3; break;
case 3: f1 = 1; f2 = 2; break;
case 4: f1 = 2; f2 = 0; break;
case 5: f1 = 0; f2 = 1; break;
}Здесь анализатору не нравится корректный столбец цифр: 2, 0, 1, 1, 2, 0. В подобных ситуациях можно воспользоваться подавлением предупреждений, вписав комментарий //-V525 в конце строки:
switch (i) {
case 0: f1 = 2; f2 = 3; break; //-V525
case 1: f1 = 0; f2 = 3; break;
case 2: f1 = 1; f2 = 3; break;
case 3: f1 = 1; f2 = 2; break;
case 4: f1 = 2; f2 = 0; break;
case 5: f1 = 0; f2 = 1; break;
}Если ложных предупреждений слишком много, то можно отключить данное диагностическое правило в настройках анализатора. Также мы будем благодарны, если вы напишите нам в поддержку о тех ситуациях, когда происходят ложные срабатывания, и мы постараемся улучшить алгоритм диагностики. Просьба в письме приводить соответствующие фрагменты кода.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V525. |
V526. The 'strcmp' function returns 0 if corresponding strings are equal. Consider inspecting the condition for mistakes.
Данное сообщение носит рекомендательный характер. Оно редко диагностирует логическую ошибку, но помогает сделать код более читабельным для молодых специалистов.
Анализатор обнаружил конструкцию сравнения двух строк, которую рационально записать более понятным способом. Такие функции как strcmp, strncmp, wcsncmp возвращают 0, если строки совпадает. Это может приводить к ошибкам в логике программы. Рассмотрим пример кода:
if (strcmp(s1, s2))Это условие выполнится в том случае, если строки НЕ СОВПАДАЮТ. Возможно, вы хорошо помните, что возвращает strcmp(). Однако человек, редко работающий со строковыми функциями может подумать, что функция strcmp() возвращает значение типа 'bool'. Тогда он прочитает этот код так: "условие истинно, если строки совпадают".
Лучше не экономить на лишних символах в тексте программы и написать так:
if (strcmp(s1, s2) != 0)Подобная запись подсказывает человеку, что функция strcmp() возвращает не тип bool, а некое числовое значение. Так снижается вероятность, что код будет неверно понят.
Если вам не нравится получать данное диагностическое сообщение, вы можете выключить его в настройках анализатора.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V526. |
V527. The 'zero' value is assigned to pointer. Probably meant: *ptr = zero.
Подобная ошибка возникает в двух схожих ситуациях.
1) Анализатор обнаружил потенциально возможною ошибку, связанную с тем, что указателю на тип bool присваивается значение false. Высока вероятность, что забыта операция разыменования указателя. Пример:
float Get(bool *retStatus)
{
...
if (retStatus != nullptr)
retStatus = false;
...
}В данном коде забыт оператор '*'. Вместо возвращения статуса произойдет обнуление указателя retStatus. Корректный вариант кода:
if (retStatus != nullptr)
*retStatus = false;2) Анализатор обнаружил потенциально возможною ошибку, связанную с тем, что указателю на тип char/wchar_t присваивается значение '\0' или L'\0'. Высока вероятность, что забыта операция разыменования указателя. Пример:
char *cp;
...
cp = '\0';Корректный вариант:
char *cp;
...
*cp = '\0';Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V527. |
V528. Pointer is compared with 'zero' value. Probably meant: *ptr != zero.
Подобная ошибка возникает в двух схожих ситуациях.
1) Анализатор обнаружил потенциально возможною ошибку, связанную с тем, что указатель на тип bool сравнивается со значением false. Высока вероятность, что забыта операция разыменования указателя. Пример:
bool *pState;
...
if (pState != false)
...В данном коде забыт оператор '*'. И получается, что мы сравниваем значение указателя pState с нулевым указателем nullptr. Корректный вариант кода:
bool *pState;
...
if (*pState != false)
...2) Анализатор обнаружил потенциально возможною ошибку, связанную с тем, что указатель на тип char/wchar_t сравнивается со значением '\0' или L'\0'. Высока вероятность, что забыта операция разыменования указателя. Пример:
char *cp;
...
if (cp != '\0')Корректный вариант:
char *cp;
...
if (*cp != '\0')Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V528. |
V529. Suspicious semicolon ';' after 'if/for/while' operator.
Анализатор обнаружил потенциально возможною ошибку, связанную с наличием точки с запятой ';' после оператора if, for или while.
Приведем пример:
for (i = 0; i < n; i++);
{
Foo(i);
}Корректный вариант:
for (i = 0; i < n; i++)
{
Foo(i);
}Использование точки с запятой ';' сразу после оператора for или while само по себе не является ошибкой и часто встречается в коде. Поэтому анализатор отсевает многие случаи, руководствуясь рядом дополнительных факторов. Например, следующий пример кода считается анализатором безопасным:
for (depth = 0, cur = parent; cur; depth++, cur = cur->parent)
;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V529. |
V530. Return value of 'Foo' function is required to be used.
Вызов некоторых функций не имеет смысла, если результат их работы не используется.
Рассмотрим первый пример:
void VariantValue::Clear()
{
m_vtype = VT_NULL;
m_bvalue = false;
m_ivalue = 0;
m_fvalue = 0;
m_svalue.empty();
m_tvalue = 0;
}Этот код очистки значений взят из реального приложения. Ошибка заключается в том, что вместо функции 'clear' объекта 'std::string' случайно вызывается функция 'empty', и содержимое строки остается неизменным. Ошибка диагностируется на основании того, что результат работы функции 'empty' обязательно должен быть использован. Например, результат должен быть с чем-то сравнен или записан в переменную.
Исправленный вариант кода:
void VariantValue::Clear()
{
m_vtype = VT_NULL;
m_bvalue = false;
m_ivalue = 0;
m_fvalue = 0;
m_svalue.clear();
m_tvalue = 0;
}Второй пример:
void unregisterThread() {
Guard<TaskQueue> g(_taskQueue);
std::remove(_threads.begin(), _threads.end(),
ThreadImpl::current());
}Функция 'std::remove' не удаляет элементы из контейнера. Она только сдвигает элементы и возвращает итератор на начало мусора. Пусть мы имеем контейнер 'vector<int>', содержащий элементы 1,2,3,1,2,3,1,2,3. Если выполнить код "remove( v.begin(), v.end(), 2 )", то контейнер будет содержать элементы 1,3,1,3,?,?,?, где ? - некий мусор. При этом функция вернет итератор на первый мусорный элемент, и если мы хотим удалить эти мусорные элементы, то должны написать код: "v.erase(remove(v.begin(), v.end(), 2), v.end())".
Как видно из объяснения, результат 'std::remove' должен быть обязательно использован. Корректный код:
void unregisterThread() {
Guard<TaskQueue> g(_taskQueue);
auto trash = std::remove(_threads.begin(), _threads.end(),
ThreadImpl::current());
_threads.erase(trash, _threads.end());
}Функций, результат которых должен быть обязательно использован, огромное количество. К ним можно отнести: 'malloc', 'realloc', 'fopen', 'isalpha', 'atof', 'strcmp' и многие, многие другие функции. Неиспользуемый результат свидетельствует об ошибке, чаще всего связанной с допущенной опечаткой. Однако анализатор предупреждает только об ошибках, связанных с использованием стандартной библиотеки. На это имеется две причины:
1) Допустить ошибку, не используя результат такой функции, как 'fopen' намного сложней, чем спутать 'std::clear' и 'std::empty'.
2) Данная функциональность будет дублировать возможности Code Analysis for C/C++, входящий в состав некоторых редакций Visual Studio (смотри предупреждение C6031). Однако в Visual Studio эти предупреждения не реализованы для функций стандартной библиотеки.
Если вы хотите предложить расширить список функций, поддерживаемых анализатором, то обратитесь в поддержку. Мы будем благодарны за интересные примеры и советы.
Безопасность
Помимо явных ошибок и опечаток, следует рассмотреть тему безопасности. Существуют функции, связанные с разграничением доступа. В качества примера назовём только функции LogonUser и SetThreadToken, но на самом деле их много. Нужно обязательно проверять статусы, которые возвращают эти функции. Неиспользование значений, которые вернули эти функции, является грубой ошибкой и потенциальной уязвимостью. Именно поэтому для таких функций анализатор также выдает предупреждение V530.
Дополнительные возможности
Можно указать имена пользовательских функций, для которых следует выполнять проверку, используется ли возвращаемое функцией значение.
Для этого используется специальная пользовательская аннотация. Пример использования:
//+V530, function: MyNamespace::MyClass::MyFunc
namespace MyNamespace {
class MyClass {
int MyFunc();
}
....
obj.MyFunc(); // warning V530
}Формат:
- Ключ 'function' задаёт полное имя функции, состоящее из названия пространства имён, имени класса и имени функции. Поддерживаются вложенные пространства имён и вложенные классы.
В проектах с особыми требованиями качества может понадобиться найти все функции, возвращаемое значение которых не используется. Для этого можно воспользоваться пользовательской аннотацией 'RET_USE_ALL'. Подробнее об этом можно прочитать в документации по пользовательским аннотациям.
Примечание. По умолчанию пользовательские аннотации не применяются к виртуальным функциям. О том, как включить данный функционал, вы можете прочитать здесь.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V530. |
V531. The sizeof() operator is multiplied by sizeof(). Consider inspecting the expression.
Код, в котором значение, возвращаемое оператором sizeof(), умножается на другой оператор sizeof(), практически всегда свидетельствует о наличии ошибки. Бессмысленно умножать размер одного объекта на размер другого объекта. Чаще всего подобные ошибки встречаются при работе со строками.
Рассмотрим реальный пример кода:
TCHAR szTemp[256];
DWORD dwLen =
::LoadString(hInstDll, dwID, szTemp,
sizeof(szTemp) * sizeof(TCHAR));Функция LoadString в качестве последнего аргумента принимает размер буфера в символах. В Unicode версии приложения мы сообщим функции, что размер буфера больше, чем он есть на самом деле. Это может привести к переполнению буфера. Заметим, что следующее исправление вовсе не является корректным:
TCHAR szTemp[256];
DWORD dwLen =
::LoadString(hInstDll, dwID, szTemp, sizeof(szTemp));Приведем на эту темы выдержку из MSDN:
"Using this function incorrectly can compromise the security of your application. Incorrect use includes specifying the wrong size in the nBufferMax parameter. For example, if lpBuffer points to a buffer szBuffer which is declared as TCHAR szBuffer[100], then sizeof(szBuffer) gives the size of the buffer in bytes, which could lead to a buffer overflow for the Unicode version of the function. Buffer overflow situations are the cause of many security problems in applications. In this case, using sizeof(szBuffer)/sizeof(TCHAR) or sizeof(szBuffer)/sizeof(szBuffer[0]) would give the proper size of the buffer."
Корректный вариант кода:
TCHAR szTemp[256];
DWORD dwLen =
::LoadString(hInstDll, dwID, szTemp,
sizeof(szTemp) / sizeof(TCHAR));Другой корректный вариант:
const size_t BUF_LEN = 256;
TCHAR szTemp[BUF_LEN];
DWORD dwLen =
::LoadString(hInstDll, dwID, szTemp, BUF_LEN);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V531. |
V532. Consider inspecting the statement of '*pointer++' pattern. Probably meant: '(*pointer)++'.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в коде присутствует разыменование указателя, но значение, на которое указывает указатель, никак не используется.
Рассмотрим пример:
int *p;
...
*p++;Выражение "*p++" выполняет следующие действия. Указатель "p" будет увеличен на единицу, но прежде этого из памяти будет извлечено значение типа "int". Это значение никак не используется, что странно. Получается, что операция разыменования "*" является лишней. Возможны следующие варианты, как следует поступить с кодом:
1) Удалить лишнее разыменование. Высказывание "*p++;" эквивалентно "p++;":
int *p;
...
p++;2) На самом деле хотели увеличить не указатель, а значение. Тогда следует написать:
int *p;
...
(*p)++;Если результат выражения "*p++" используется, то анализатор считает код корректным. Пример безопасного кода:
while(*src)
*dest++ = *src++;Рассмотрим пример взятый из реального приложения:
STDMETHODIMP CCustomAutoComplete::Next(
ULONG celt, LPOLESTR *rgelt, ULONG *pceltFetched)
{
...
if (pceltFetched != NULL)
*pceltFetched++;
...В данном случае забыты круглые скобки. Корректный вариант:
if (pceltFetched != NULL)
(*pceltFetched)++;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V532. |
V533. It is possible that a wrong variable is incremented inside the 'for' operator. Consider inspecting 'X'.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' увеличивается переменная, относящаяся к внешнему циклу.
В самом простом виде эта ошибка выглядит следующим образом:
for (size_t i = 0; i != 5; i++)
for (size_t j = 0; j != 5; i++)
A[i][j] = 0;Во внутреннем цикле происходит увеличение переменной 'i' вместо 'j'. В реальном приложении подобная ошибка может быть не так хорошо заметна. Корректный вариант кода:
for (size_t i = 0; i != 5; i++)
for (size_t j = 0; j != 5; j++)
A[i][j] = 0;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V533. |
V533. It is possible that a wrong variable is incremented inside the 'for' operator. Consider inspecting 'X'.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' увеличивается переменная, относящаяся к внешнему циклу.
В самом простом виде эта ошибка выглядит следующим образом:
for (size_t i = 0; i != 5; i++)
for (size_t j = 0; j != 5; i++)
A[i][j] = 0;Во внутреннем цикле происходит увеличение переменной 'i' вместо 'j'. В реальном приложении подобная ошибка может быть не так хорошо заметна. Корректный вариант кода:
for (size_t i = 0; i != 5; i++)
for (size_t j = 0; j != 5; j++)
A[i][j] = 0;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V533. |
V534. It is possible that a wrong variable is compared inside the 'for' operator. Consider inspecting 'X'.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' в условии используется переменная, относящаяся к внешнему циклу.
В самом простом виде эта ошибка выглядит следующим образом:
for (size_t i = 0; i != 5; i++)
for (size_t j = 0; i != 5; j++)
A[i][j] = 0;Во внутреннем цикле происходит сравнение 'i != 5' вместо 'j != 5'. В реальном приложении подобная ошибка может быть не так хорошо заметна. Корректный вариант кода:
for (size_t i = 0; i != 5; i++)
for (size_t j = 0; j != 5; j++)
A[i][j] = 0;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V534. |
V535. The 'X' variable is used for this loop and outer loops.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что вложенный цикл организован с использованием переменной, которая также используется и во внешнем цикле.
Схематически эта ошибка выглядит следующим образом:
size_t i, j;
for (i = 0; i != 5; i++)
for (i = 0; i != 5; i++)
A[i][j] = 0;Конечно, это искусственный пример и в реальном приложении ошибка может быть не так очевидна. Корректный вариант кода:
size_t i, j;
for (i = 0; i != 5; i++)
for (j = 0; j != 5; j++)
A[i][j] = 0;Использование одной переменной для внешнего и внутреннего цикла не всегда является ошибкой. Рассмотрим пример корректного кода, где анализатор не будет выдавать предупреждение:
for(c = lb; c <= ub; c++)
{
if (!(xlb <= xlat(c) && xlat(c) <= ub))
{
Range * r = new Range(xlb, xlb + 1);
for (c = lb + 1; c <= ub; c++)
r = doUnion(
r, new Range(xlat(c), xlat(c) + 1));
return r;
}
}В этом коде внутренний цикл "for (c = lb + 1; c <= ub; c++)" организован при помощи переменной "c". Внешний цикл также использует переменную "c". Но ошибки здесь нет. После того, как выполнится внутренний цикл, сразу произойдет выход из функции при помощи оператора "return r".
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V535. |
V536. Constant value is represented by an octal form.
Использование констант в восьмеричной системе счисления само по себе не является ошибкой. Эта система удобна при работе с битами и используется в коде, взаимодействующем с сетью или внешними устройствами. Однако средний программист редко использует эту систему счисления и поэтому может написать перед числом 0, забыв, что это превращает значение в восьмеричное.
Анализатор предупреждает о наличии восьмеричных констант, если рядом нет других восьмеричных констант. Такие "одиночные" восьмеричные константы часто являются ошибкой.
Рассмотрим пример, взятый из реального приложения. Пример достаточно большой, но хорошо демонстрирует суть проблемы.
inline
void elxLuminocity(const PixelRGBf& iPixel,
LuminanceCell< PixelRGBf >& oCell)
{
oCell._luminance = 0.2220f*iPixel._red +
0.7067f*iPixel._blue +
0.0713f*iPixel._green;
oCell._pixel = iPixel;
}
inline
void elxLuminocity(const PixelRGBi& iPixel,
LuminanceCell< PixelRGBi >& oCell)
{
oCell._luminance = 2220*iPixel._red +
7067*iPixel._blue +
0713*iPixel._green;
oCell._pixel = iPixel;
}Рассматривая подобный код непросто заметить ошибку, но она есть. Первая функция elxLuminocity корректна и работает со значения типа float. В коде имеются следующие константы: 0.2220f, 0.7067f, 0.0713f. Вторая функция аналогична первой, но работает с целыми значениями. Все целые значения умножены на 10000. Вот эти значения: 2220, 7067, 0713. Ошибка в том, что последняя константа "0713" задана в восьмеричной системе счисления и имеет значение вовсе не 713, а 459. Исправленный вариант кода:
oCell._luminance = 2220*iPixel._red +
7067*iPixel._blue +
713*iPixel._green;Как было сказано выше, предупреждение о восьмеричных константах выдается только в том случае, если вблизи от них нет других восьмеричных констант. Поэтому следующий пример кода считается анализатором безопасным и для него предупреждений выдано не будет:
static unsigned short bytebit[8] = {
01, 02, 04, 010, 020, 040, 0100, 0200 };Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V536. |
V537. Potential incorrect use of item 'X'. Consider inspecting the expression.
Анализатор обнаружил потенциально возможную опечатку в коде, связанную с неверным использованием схожих имен.
Данное правило пытается эвристическим методом обнаружить ошибку схожую со следующей:
int x = static_cast<int>(GetX()) * n;
int y = static_cast<int>(GetX()) * n;Во второй строке вместо функции 'GetY' используется 'GetX'. Корректный код:
int x = static_cast<int>(GetX()) * n;
int y = static_cast<int>(GetY()) * n;Для обнаружения этого подозрительного места анализатор следовал следующей логике. Мы имеем строку, где используется имя, включающее в себя фрагмент 'x'. Рядом с ней есть строка, где используется похожее имя, содержащая 'y'. Но при этом во второй строке также есть и 'X'. Так как выполнилось это и еще некоторые условия, данную конструкцию следует считать нуждающейся в проверке программистом. Если бы, например, слева не было переменных 'x' и 'y', то такой код не считался бы опасным. Пример кода, на который анализатор не обратит внимания:
array[0] = GetX() / 2;
array[1] = GetX() / 2;К сожалению, данное правило часто дает ложное срабатывание, так как анализатор не имеет представления об устройстве программы и предназначении кода. Пример ложного срабатывания:
halfWidth -= borderWidth + 2;
halfHeight -= borderWidth + 2;Анализатор предположил, что возможно второй строкой должно быть иное выражение, например: 'halfHeight -= borderHeight + 2'. На самом деле никакой ошибки нет. Размер границы ('border') одинаков по вертикали и горизонтали. Такой константы как 'borderHeight' просто не существует. Однако подобные высокоуровневые абстракции не доступны анализатору. Чтобы убрать предупреждение вы можете вписать в код комментарий '//-V537'.
Можно использовать и другой приём для предотвращения ложных срабатываний. Возьмём вот такой фрагмент кода:
bsdf->alpha_x = closure->alpha_x;
bsdf->alpha_y = bsdf->alpha_x;Этот код корректен, но выглядит подозрительно, причём не только с точки зрения анализатора. Человеку, который будет сопровождать код, будет сложно понять, ошибочен он или нет. Если переменным 'alpha_x' и 'alpha_y' хочется присвоить одно и тоже значение, то можно написать так:
bsdf->alpha_y = bsdf->alpha_x = closure->alpha_x;Этот код не вызовет вопроса у человека, а анализатор не выдаст предупреждение.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V537. |
V538. The line contains control character 0x0B (vertical tabulation).
В тексте программы встретились управляющие ASCII символы.
Таким символом может быть:
0x0B - LINE TABULATION (vertical tabulation) - Перемещает позицию печати к следующей позиции вертикальной табуляции. На терминалах этот символ обычно эквивалентен переводу строки.
Наличие подобных символов в тексте программы допустимо и такой текст успешно компилируется в Visual C++. Однако, скорее всего эти символы попали в текст программы случайно и лучше от них избавиться. Для этого есть 2 причины:
1) Если подобный управляющий символ находится в первых строках файла, то среда Visual Studio не может понять формат файла и открывает его не с помощью встроенного редактора, а в программе Notepad.
2) Некоторые внешние инструменты, работающие с текстами программ, могут некорректно обработать файлы, содержащие перечисленные управляющие символы.
Символы 0x0B не видны в редакторе Visual Studio 2010. Чтобы найти их в строке и удалить, можно открыть файл в программе Notepad или в другом редакторе, отображающим подобные управляющие символы.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V538. |
V539. Iterators are passed as arguments to 'Foo' function. Consider inspecting the expression.
Анализатор обнаружил код, выполняющий действия над контейнерами, который с большой вероятностью содержит ошибку. Рекомендуется внимательно проверить данный фрагмент кода.
Рассмотрим несколько примеров, демонстрирующих ситуации, когда будет выдано данное предупреждение:
Пример 1.
void X(std::vector<int> &X, std::vector<int> &Y)
{
std::for_each (X.begin(), X.end(), SetValue);
std::for_each (Y.begin(), X.end(), SetValue);
}В функции происходит заполнение двух массивов некими значениями. Из-за опечатки при втором вызове функции "std::for_each" ей передаются итераторы от различных контейнеров, что приведет к ошибке на этапе исполнения программы. Корректный код:
std::for_each (X.begin(), X.end(), SetValue);
std::for_each (Y.begin(), Y.end(), SetValue);Пример 2.
std::includes(a.begin(), a.end(), a.begin(), a.end());Данный код странен, и скорее всего планировалось обрабатывать две различные последовательности, а не одну. Корректный вариант кода:
std::includes(a.begin(), a.end(), b.begin(), b.end());Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V539. |
V540. Member 'x' should point to string terminated by two 0 characters.
В Windows API есть структуры, в которых указатели на строки должны заканчиваться двойным нулем.
В качестве примера можно привести член lpstrFilter в структуре OPENFILENAME.
Описание lpstrFilter в MSDN:
"LPCTSTR
A buffer containing pairs of null-terminated filter strings. The last string in the buffer must be terminated by two NULL characters."
Как следует из этого описания, в конце строки мы должны обязательно написать дополнительный ноль. Пример: lpstrFilter = "All Files\0*.*\0";
Однако многие забывают о дополнительном нуле в конце строки. Пример некорректного кода обнаруженный в одном из приложений:
lofn.lpstrFilter = L"Equalizer Preset (*.feq)\0*.feq";Подобный код приведет к тому, что в диалоге работы с файлом в поле фильтров мы можем увидеть мусор. Исправленный код:
lofn.lpstrFilter = L"Equalizer Preset (*.feq)\0*.feq\0";Мы явно в конце строки написали 0, и еще один ноль добавит компилятор. Некоторые для большей наглядности пишут так:
lofn.lpstrFilter = L"Equalizer Preset (*.feq)\0*.feq\0\0";Но здесь мы получим в конце не два, а три нуля. Это излишне, но зато хорошо заметно программисту.
Есть и другие структуры, помимо OPENFILENAME, в которых можно допустить схожие ошибки. Например, двойным нулем должны заканчиваться строки lpstrGroupNames, lpstrCardNames в структурах OPENCARD_SEARCH_CRITERIA, OPENCARDNAME.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V540. |
V541. String is printed into itself. Consider inspecting the expression.
Анализатор обнаружил потенциально возможную ошибку, связанную с печатью строки в саму себя. Результат подобного действия может быть весьма неожиданным.
Рассмотрим пример:
char s[100] = "test";
sprintf(s, "N = %d, S = %s", 123, s);В примере буфер 's' одновременно используется как буфер под новую строку и как один из элементов, из которых формируется текст. В результате работы этого кода хочется получить строку:
N = 123, S = test
Но на практике в буфере будет сформирована строка:
N = 123, S = N = 123, S =
В других ситуациях аналогичный код может привести не только к выводу некорректного текста, но и к переполнению буфера или аварийному завершению программы. Код может быть исправлен, если использовать для сохранения результата новый буфер.
Корректный код:
char s1[100] = "test";
char s2[100];
sprintf(s2, "N = %d, S = %s", 123, s1);Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования форматной строки, Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V541. |
V542. Suspicious type cast: 'Type1' to ' Type2'. Consider inspecting the expression.
Анализатор обнаружил очень подозрительное явное приведение типов. Это приведение типов может свидетельствовать о наличии ошибки. Рекомендуется проверить данный фрагмент кода.
Пример:
typedef unsigned char Byte;
void Process(wchar_t ch);
void Process(wchar_t *str);
void Foo(Byte *buf, size_t nCount)
{
for (size_t i = 0; i < nCount; ++i)
{
Process((wchar_t *)buf[i]);
}
}Мы имеем функцию Process, которая умеет обрабатывать как отдельные символы, так и строки. Также мы имеем функцию 'Foo', которая на вход получает указатель на буфер. Этот буфер обрабатывается как массив символов типа wchar_t. Но код содержит ошибку и анализатор предупреждает о том, что тип 'char' явно приводится к типу ' wchar_t *'. Причина в том, что выражение "(wchar_t *)buf[i]" эквивалентно "(wchar_t *)(buf[i])". В начале из массива извлекается значение типа 'char', а затем оно превращается в указатель. Исправленный вариант кода:
Process(((wchar_t *)buf)[i]);Однако не всегда, странные приведения типов являются ошибкой. Рассмотрим пример безопасного кода, взятого из реального приложения:
wchar_t *destStr = new wchar_t[len+1];
...
for (int j = 0 ; j < nbChar ; j++)
{
if (Case == UPPERCASE)
destStr[j] =
(wchar_t)::CharUpperW((LPWSTR)destStr[j]);
...Здесь присутствует явное приведение типа 'wchar_t ' к 'LPWSTR' и обратно от типа 'LPWSTR' к 'wchar_t '. Дело в том, что Windows API функция CharUpperW может работать с входным значением, и как с указателем, и как с символом. Прототип функции:
LPTSTR WINAPI CharUpperW(__inout LPWSTR lpsz);Если старшая часть указателя равна 0, то входное значение считается символом. В противном случае функция обрабатывает строку.
Анализатор знает про поведение функции CharUpperW и считает данный код безопасным. Однако в другой подобной ситуации анализатор может выдать ложное срабатывание.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V542. |
V543. It is suspicious that value 'X' is assigned to the variable 'Y' of HRESULT type.
Анализатор обнаружил потенциальную ошибку при работе с переменной типа HRESULT.
HRESULT — это 32-разрядное значение, разделенное на три различных поля: код серьезности ошибки, код устройства и код ошибки. Для работы со значением HRESULT служат специальные константы, такие как S_OK, E_FAIL, E_ABORT и так далее. А для проверки значений тип HRESULT предназначены такие макросы как SUCCEEDED, FAILED.
Предупреждение V543 выдается в том случае, если в переменную типа HRESULT пытаются записать значение -1, true или false. Рассмотрим пример:
HRESULT h;
...
if (bExceptionCatched)
{
ShowPluginErrorMessage(pi, errorText);
h = -1;
}Запись значения "-1" некорректна. Если хочется сообщить о какой-то непонятной ошибке, то следует использовать значение 0x80004005L (Unspecified failure). Эта и аналогичные константы, описаны в "WinError.h". Корректный код:
if (bExceptionCatched)
{
ShowPluginErrorMessage(pi, errorText);
h = E_FAIL;
}Дополнительные ресурсы:
- MSDN. Common HRESULT Values.
- Wikipedia. HRESULT.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V543. |
V544. It is suspicious that the value 'X' of HRESULT type is compared with 'Y'.
Анализатор обнаружил потенциальную ошибку при работе с переменной типа HRESULT.
HRESULT- это 32-разрядное значение, разделенное на три различных поля: код серьезности ошибки, код устройства и код ошибки. Для работы со значением HRESULT служат специальные константы, такие как S_OK, E_FAIL, E_ABORT и так далее. А для проверки значений тип HRESULT предназначены такие макросы как SUCCEEDED, FAILED.
Предупреждение V544 выдается в том случае, если переменную типа HRESULT пытаются сравнить с -1, true или false. Рассмотрим пример:
HRESULT hr;
...
if (hr == -1)
{
}Сравнение со значением "-1" некорректно. Коды ошибок могут быть различны. Например, это может быть 0x80000002L (Ran out of memory), 0x80004005L (unspecified failure), 0x80070005L (General access denied error) и так далее. Для проверки значения HRESULT в данном случае необходимо использовать макрос FAILED, объявленный в "WinError.h". Корректный вариант кода:
if (FAILED(hr))
{
}Дополнительные ресурсы:
- MSDN. Common HRESULT Values.
- Wikipedia. HRESULT.
Данная диагностика классифицируется как:
V545. Conditional expression of 'if' statement is incorrect for the HRESULT type value 'Foo'. The SUCCEEDED or FAILED macro should be used instead.
Анализатор обнаружил потенциальную ошибку при работе с переменной типа HRESULT.
HRESULT - это 32-разрядное значение, разделенное на три различных поля: код серьезности ошибки, код устройства и код ошибки. Для работы со значением HRESULT служат специальные константы, такие как S_OK, E_FAIL, E_ABORT и так далее. А для проверки значений тип HRESULT предназначены такие макросы как SUCCEEDED, FAILED.
Предупреждение V545 выдается в том случае, если переменная типа HRESULT используется в операторе 'if' как переменная типа bool. Пример:
HRESULT hr;
...
if (hr)
{
}HRESULT и тип bool это совершенно разные по смыслу типы. Показанный пример сравнения некорректен. Тип HRESULT имеет множество состояний. Это может быть 0L (S_OK), 0x80000002L (Ran out of memory), 0x80004005L (unspecified failure), и так далее. Обратите внимание, что состояние S_OK кодируется как 0.
Для проверки значения HRESULT необходимо использовать макрос SUCCEEDED или FAILED, объявленные в "WinError.h". Корректные варианты кода:
if (FAILED(hr))
{
}
if (SUCCEEDED(hr))
{
}Дополнительные ресурсы:
- MSDN. Common HRESULT Values.
- Wikipedia. HRESULT.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V545. |
V546. The 'Foo(Foo)' class member is initialized with itself.
Анализатор обнаружил опечатку, когда член класса инициализируется самим собой.
Рассмотрим пример конструктора:
C95(int field) : Field(Field)
{
...
}Здесь имя параметра и название члена класса отличается только одной буквой. Из-за этого допущена опечатка и член 'Field' останется неинициализированным. Исправленный вариант кода:
C95(int field) : Field(field)
{
...
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V546. |
V547. Expression is always true/false.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что условие всегда истинно или ложно. Подобные условия не всегда означают наличие ошибки, но эти фрагменты кода следует обязательно проверить.
Пример кода:
LRESULT CALLBACK GridProc(HWND hWnd,
UINT message, WPARAM wParam, LPARAM lParam)
{
...
if (wParam<0)
{
BGHS[SelfIndex].rows = 0;
}
else
{
BGHS[SelfIndex].rows = MAX_ROWS;
}
...
}Здесь ветка "BGHS[SelfIndex].rows = 0;" никогда не будет выполнена. Дело в том, что переменная wParam имеет беззнаковый тип WPARAM, который объявлен как "typedef UINT_PTR WPARAM".
Этот код или содержит логическую ошибку, или может быть сокращен до одной строки: "BGHS[SelfIndex].rows = MAX_ROWS;".
Теперь рассмотрим пример кода, который не является ошибочным, но он потенциально опасен и имеет бессмысленное сравнение:
unsigned int a = _ttoi(LPCTSTR(str1));
if((0 > a) || (a > 255))
{
return(FALSE);
}Программист хотел реализовать следующий алгоритм.
1) Превратить строку в число.
2) Если число лежит вне диапазона [0..255] то вернуть статус ошибки (return FALSE).
Ошибка заключается в использовании типа 'unsigned'. Если функция _ttoi вернет отрицательное значение, то оно превратится в большое положительное значение. Например, значение "-3" превратится в 4294967293. Сравнение '0 > a' всегда вернёт false. Программа корректно работает из-за того, что диапазон значений [0..255] проверяется условием 'a > 255'.
Данный фрагмент кода будет диагностирован так: "V547 Expression '0 > a' is always false. Unsigned type value is never < 0."
Этот фрагмент лучше исправить следующим образом:
int a = _ttoi(LPCTSTR(str1));
if((0 > a) || (a > 255))
{
return(FALSE);
}Рассмотрим один специальный случай. Анализатор выдает предупреждение:
V547 Expression 's == "Abcd"' is always false. To compare strings you should use strcmp() function.
на следующий код:
const char *s = "Abcd";
void Test()
{
if (s == "Abcd")
cout << "TRUE" << endl;
else
cout << "FALSE" << endl;
}Однако это не совсем верно. Этот код может все-таки распечатать "TRUE", если переменная 's' и функция Test() объявлены в одном модуле. Компилятор не плодит множество одинаковых константных строк, а использует одну. В результате, иногда кажется, что код вполне работоспособен. Однако надо понимать, что это очень плохой код и следует использовать специальные функции для сравнения.
Следующий пример:
if (lpszHelpFile != 0)
{
pwzHelpFile = ((_lpa_ex = lpszHelpFile) == 0) ?
0 : Foo(lpszHelpFile);
...
}Этот код работает вполне корректно, но он излишне запутан. Условие "((_lpa_ex = lpszHelpFile) == 0)" всегда ложно, так как указатель lpszHelpFile всегда не равен нулю. Этот код сложен для чтения, и его лучше переписать.
Упрощенный вариант кода:
if (lpszHelpFile != 0)
{
_lpa_ex = lpszHelpFile;
pwzHelpFile = Foo(lpszHelpFile);
...
}Следующий пример:
SOCKET csd;
csd = accept(nsd, (struct sockaddr *) &sa_client, &clen);
if (csd < 0)
....Функция accept в заголовочных файлах Visual Studio возвращает значение, имеющее беззнаковый тип SOCKET. Поэтому проверка 'csd < 0' недопустима, ведь её результат всегда ложь (false). Возвращенные значения надо явно сравнивать с различными константами, например, с SOCKET_ERROR:
if (csd == SOCKET_ERROR)Анализатор предупреждает далеко не про все условия, которые всегда ложны или истинны. Он диагностирует только те ситуации, где высока вероятность наличия ошибки. Рассмотрим некоторые примеры, которые анализатор считает абсолютно корректными:
// 1) Вечный цикл
while (true)
{
...
}
// 2) Развернутый в Release версии макрос
// MY_DEBUG_LOG("X=", x);
0 && ("X=", x);
// 3) assert(false);
if (error) {
assert(false);
return -1;
}Примечание. Время от времени в поддержку приходят однотипные письма, в которых люди пишут, что не понимают предупреждение V547. Попробуем внести ясность. Рассмотрим обобщенный текст письма, которое присылают люди: "Анализатор выдаёт предупреждение "Expression 'i == 1' is always true". Но ведь это не так. Переменная может быть равна не только единице, но и нулю. Наверное, надо исправить поведение анализатора."
for (int i = 0; i <= 1; i++)
{
if(i == 0)
A();
else if(i == 1) // V547
B();
}Даём пояснение. Сообщение анализатора не говорит, что переменная 'i' всегда равна 1. Анализатор говорит, что 'i' равно 1 в конкретном месте, и указывает на эту строчку в программе.
Когда выполняется проверка 'if (i == 1)' точно известно, что переменная 'i' будет равна 1. Других вариантов нет. Конечно, такой код не обязательно содержит ошибку. Однако, это то место программы, которое стоит внимательно проверить.
Как видите, анализатор выдаёт здесь предупреждение совершенно правомерно. Если вы столкнулись с подобным видом предупреждения, есть следующие варианты как с ним поступить:
- Если это ошибка, то её надо исправить.
- Если это не ошибка, а просто избыточная проверка, то эту лишнюю проверку можно удалить.
Упрощенный код:
for (int i = 0; i <= 1; i++)
{
if(i == 0)
A();
else
B();
}Если это избыточная проверка, но не хочется изменять код, то вы можете воспользоваться одним из методов подавления ложных срабатываний.
Рассмотрим еще один пример, в этот раз связанный с перечисляемыми типами.
enum state_t { STATE_A = 0, STATE_B = 1 }
state_t GetState()
{
if (someFailure)
return (state_t)-1;
return STATE_A;
}
state_t state = GetState();
if (state == STATE_A) // <= V547Автор хотел вернуть значение -1, если что-то пошло не так в процессе выполнения функции 'GetState'.
Анализатор выдаёт здесь предупреждение "V547 Expression 'state == STATE_A' is always true". На первый взгляд может показаться, что это ложное срабатывание, ведь мы не можем заранее предсказать, что нам вернёт функция. На самом деле, так сказывается на работе анализатора наличие в коде неопределённого поведения.
В 'state_t' не определена именованная константа со значением -1, и на самом деле 'return (state_t)-1' может вернуть из функции всё что угодно, так как здесь возникает неопределённое поведение. Кстати, анализатор предупредит о возникновении неопределённого поведения с помощью предупреждения "V1016 The value '-1' is out of range of enum values. This causes unspecified or undefined behavior', выданного на строку 'return (state_t)-1".
Итак, поскольку 'return (state_t)-1;' это undefined behavior, то анализатор не учитывает -1 как возможное значение, возвращаемое функцией. С точки зрения анализатора функция 'GetState' возвращает только значение 'STATE_A'. Это и является причиной выдачи сообщения V547.
Чтобы исправить ситуацию, следует добавить в перечисление константу, символизирующую ошибочный результат:
enum state_t { STATE_ERROR = -1, STATE_A = 0, STATE_B = 1 }
state_t GetState()
{
if (someFailure)
return STATE_ERROR;
return STATE_A;
}Теперь одновременно исчезнет предупреждение V547 и V1016.
Дополнительные ссылки:
- Интересный пример, когда срабатывание V547 кажется странным и неверным. Но если разобраться, то выясняется, что код действительно опасен. Обсуждение на сайте Stack Overflow: Does PVS-Studio know about Unicode chars?
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V547. |
V548. TYPE X[][] is not equivalent to TYPE **X. Consider inspecting type casting.
Анализатор обнаружил потенциально возможную ошибку, связанную с явным приведением типа. В программе массив, объявленный условно как "type Array[3][4]", приводится к типу "type **". Это приведение типа, скорее всего, не имеет смысла.
Типы "type[a][b]" и "type **" представляют собой разные структуры данных. Type[a][b] это единый участок памяти с которым можно работать как с двумерным массивом. Type ** - это массив указателей на какие-то участки памяти.
Пример:
void Foo(char **names, size_t count)
{
for(size_t i=0; i<count; i++)
printf("%s\n", names[i]);
}
void Foo2()
{
char names[32][32];
...
Foo((char **)names, 32); //Crash
}Исправленный вариант:
void Foo2()
{
char names[32][32];
...
char *names_p[32];
for(size_t i=0; i<32; i++)
names_p[i] = names[i];
Foo(names_p, 32); //OK
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V548. |
V549. The 'first' argument of 'Foo' function is equal to the 'second' argument.
Анализатор обнаружил потенциальную ошибку в программе, связанную с тем, что совпадают два фактических аргумента функции. Передача одного и того же значения в качестве двух аргументов для многих функций является нормальной ситуацией. Но если речь идет о таких функциях как memmove, memcpy, strstr, strncmp, то это очень подозрительная ситуация.
Пример из реального приложения:
#define str_cmp(s1, s2) wcscmp(s1, s2)
...
v = abs(str_cmp(a->tdata, a->tdata));Из-за опечатки функция wcscmp сравнивает строку саму с собой. Корректным вариантом кода должно было быть:
v = abs(str_cmp(a->tdata, b->tdata));Анализатор выдаст предупреждение в случае работы с функциями: memcpy, memmove, memcmp, _memicmp, strstr, strspn, strtok, strcmp, strncmp, wcscmp, _stricmp, wcsncmp и так далее. Если вы обнаружили подобную ошибку, которая не диагностируется анализатором, то просим сообщить нам имя функции, которая также не должна принимать в качестве первого и второго аргумента одинаковые значения.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V549. |
V550. Suspicious precise comparison. Consider using a comparison with defined precision: fabs(A - B) < Epsilon or fabs(A - B) > Epsilon.
Анализатор обнаружил потенциальную ошибку связанную с тем, что для сравнения чисел с плавающей точкой используется оператор == или !=. Нередко точное сравнение может быть источником ошибки.
Рассмотрим пример:
double a = 0.5;
if (a == 0.5) //OK
x++;
double b = sin(M_PI / 6.0);
if (b == 0.5) //ERROR
x++;Первое сравнение 'a == 0.5' истинно. Второе сравнение 'b == 0.5' может быть как истинно, так и ложно. Результат выражения 'b == 0.5' зависит от используемого процессора, версии и настроек компилятора. Например, значение переменной 'b' было равно 0.49999999999999994 при использовании компилятора Visual C++ 2010. Более корректно этот код можно написать следующим образом:
double b = sin(M_PI / 6.0);
if (fabs(b - 0.5) < DBL_EPSILON)
x++;В данном случае сравнение с погрешностью DBL_EPSILON верно, так как результат функции sin() лежит в диапазоне [-1, 1]. Однако, если мы работаем со значениями больше нескольких единиц, то такие погрешности как FLT_EPSILON, DBL_EPSILON будут слишком малы. И наоборот при работе со значениями типа 0.00001 эти погрешности слишком велики. Каждый раз следует выбирать погрешность адекватную диапазону возможных значений.
Возникает вопрос. Как же все-таки сравнить две переменных типа double?
double a = ...;
double b = ...;
if (a == b) // how?
{
}Одного единственно-правильного ответа нет. В большинстве случаев можно сравнит две переменных типа double, написав код следующего вида:
if (fabs(a-b) <= DBL_EPSILON * fmax(fabs(a), fabs(b)))
{
}Только осторожней с этой формулой, она работает только для чисел с одинаковым знаком. Также в ряде с большим количеством вычислений постоянно набегает ошибка, и константа 'DBL_EPSILON' может оказаться слишком маленьким значением.
А можно ли все-таки точно сравнивать значения в формате с плавающей точкой?
В некоторых случаях да. Но эти ситуации весьма ограничены. Сравнивать можно в том случае, если это и есть, по сути, одно и то же значение.
Пример, где допустимо точное сравнение:
// -1 - признак, что значение переменной не было установлено
float val = -1.0f;
if (Foo1())
val = 123.0f;
if (val == -1.0f) //OK
{
}В данном случае сравнение со значением "-1" допустимо, так как именно точно таким же значением мы инициализировали переменную ранее.
В рамках документации невозможно более подробно раскрыть тему сравнения float/double типов, поэтому мы отсылаем вас к внешнем источникам информации приведенных в конце.
Анализатор может только указать на потенциально опасные участки кода, где сравнение может не дать желаемого результата. Действительно ли код содержит ошибку, может понять только программист. Также мы не можем заранее дать в документации точные рекомендации, так как задачи, в которых используются типы с плавающей точкой слишком различны.
Диагностическое сообщение не выдается, если сравниваются два идентичных выражения типа float или double. Такое сравнение позволяет определить, является ли значение NaN. Пример кода, реализующего подобную проверку:
bool isnan(double X) { return X != X; }Впрочем, такой код нельзя назвать хорошим и лучше использовать стандартную функцию 'std::isnan'.
Дополнительные ресурсы:
- Bruce Dawson. Comparing floating point numbers, 2012 Edition.
- RSDN. Про сравнение double (RU).
- Андрей Карпов. 64-битные программы и вычисления с плавающей точкой.
- Wikipedia. Floating point.
- CodeGuru Forums. C++ General: How is floating point representated?
- Boost. Floating-point comparison algorithms.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V550. |
V551. Unreachable code under a 'case' label.
Анализатор обнаружил потенциальную ошибку связанную с тем, что одна из ветвей оператора switch() никогда не получит управление. Причина этого в том, что аргумент оператора switch() не может принять значение, которое прописано в операторе case.
Рассмотрим пример:
char ch = strText[i];
switch (ch)
{
case '<':
strHTML += "<";
bLastCharSpace = FALSE;
nNonbreakChars++;
break;
case '>':
strHTML += ">";
bLastCharSpace = FALSE;
nNonbreakChars++;
break;
case 0xB7:
case 0xBB:
strHTML += ch;
strHTML += "<wbr>";
bLastCharSpace = FALSE;
nNonbreakChars = 0;
break;
...
}Здесь ветка расположенная после "case 0xB7:" и "case 0xBB:" никогда не получит управление. Переменная 'ch' имеет тип 'char', а, следовательно, диапазон её значений лежит в пределах [-128..127]. Результатом сравнения "ch == 0xB7" и "ch==0xBB" всегда будет ложь (false). Чтобы код был корректен переменная 'ch' должна иметь тип 'unsigned char'. Исправленный код:
unsigned char ch = strText[i];
switch (ch)
{
...
case 0xB7:
case 0xBB:
strHTML += ch;
strHTML += "<wbr>";
bLastCharSpace = FALSE;
nNonbreakChars = 0;
break;
...
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V551. |
V552. A bool type variable is incremented. Perhaps another variable should be incremented instead.
Анализатор обнаружил потенциально опасную конструкция в коде, где происходит инкремент переменной типа bool.
Рассмотрим пример:
bool bValue = false;
...
bValue++;Во-первых, стандарт языка Си++ говорит:
The use of an operand of type bool with the postfix ++ operator is deprecated.
Это значит, что подобную конструкцию лучше не использовать.
Во-вторых, лучше явно присвоить переменной значение типа true. Это более понятный код:
bValue = true;В-третьих, возможно имеется опечатка и на самом деле хотелось увеличить другую переменную. Пример:
bool bValue = false;
int iValue = 1;
...
if (bValue)
bValue++;Случайно использовали не ту переменную и на самом деле должно быть:
bool bValue = false;
int iValue = 1;
...
if (bValue)
iValue++;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V552. |
V553. Length of function body or class declaration is more than 2000 lines. Consider refactoring the code.
Анализатор обнаружил в программе объявление класса или тело функции, которые занимают более 2000 строк. Этот класс или функция не обязательно содержат ошибки, но вероятность этого очень высокая. Чем больше функция, тем легче допустить в ней ошибку и тем сложнее ее отлаживать. Чем больше класс, тем сложнее разобраться в его интерфейсах.
Это сообщение хороший повод постараться все-таки найти время для рефакторинга кода. Да, всегда нужно делать что-то срочное. Но чем больше по размеру будут функции и классы, тем больший процент времени будет уходить не на написание новой функциональности, а на поддержание старого кода и устранение в нем ошибок.
Дополнительные материалы по данной теме:
- Макконнелл С. Совершенный код. Мастер-класс / Пер. с англ. - М. : Издательско-торговый дом "Русская редакция"; СПб.: Питер, 2005. - 896 стр.: ил. ISBN 5-7502-0064-7. (Смотрите часть 7.4. Насколько объемным может быть метод?).
V554. Incorrect use of smart pointer.
Анализатор обнаружил ситуацию, когда использование умного указателя может привести к неопределенному поведению, в частности, к повреждению кучи, аварийному завершению программы или неполному разрушению объектов. Ошибка заключается в том, что память выделяется и освобождается различными методиками.
Рассмотрим первый пример:
void Foo()
{
struct A
{
A() { cout << "A()" << endl; }
~A() { cout << "~A()" << endl; }
};
std::unique_ptr<A> p(new A[3]);
}По умолчанию класс unique_ptr использует для освобождения памяти оператор 'delete'. Поэтому будет разрушен только один объект класса 'A' и на экране будет распечатан следующий текст:
A()
A()
A()
~A()Чтобы исправить ошибку необходимо указать, что необходимо использовать оператор 'delete []'. Корректный вариант кода:
std::unique_ptr<A[]> p(new A[3]);Теперь будет вызываться равное количество конструкторов и деструкторов и будет распечатан текст:
A()
A()
A()
~A()
~A()
~A()Рассмотрим второй пример:
std::unique_ptr<int []> p((int *)malloc(sizeof(int) * 5));Память выделяется с использованием функции 'malloc()', а освобождается при помощи оператора 'delete []'. Это некорректно и следует указать, что освобождать память надо используя функцию 'free()'. Корректный вариант кода может выглядеть следующим образом:
int *d =(int *)std::malloc(sizeof(int) * 5);
unique_ptr<int, void (*)(void*)> p(d, std::free);Дополнительные материалы по данной теме:
- Обсуждение на сайте Stack Overflow. "How could pairing new[] with delete possibly lead to memory leak only?".
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V554. |
V555. Expression of the 'A - B > 0' kind will work as 'A != B'.
Анализатор обнаружил потенциальную ошибку в выражении вида "A - B > 0". Высока вероятность, что условие написано неверно, если подвыражение "A - B" имеет беззнаковый тип.
Условие "A - B > 0" выполняется во всех случаях, когда значение 'A' не равно значению 'B'. Это значит, что вместо выражения "A - B > 0" можно написать "A != B". Но скорее всего программист задумывал совсем другое.
Рассмотрим пример:
unsigned int *B;
...
if (B[i]-70 > 0)Программист хотел проверить, что i-тый элемент массива B больше значения 70. Это можно было записать так: "B[i] > 70". Исходя из каких-то своих соображений, программист записал эту проверку так: "B[i]-70 > 0". И допустил ошибку. Он забыл, что элементы массива 'B' имеют тип 'unsigned'. Это значит, что и выражение "B[i]-70" будет иметь тип 'unsigned'. Получается, что условие всегда истинно, за исключением случая, когда элемент 'B[i]' будет равен 70.
Поясним эту ситуацию.
Если 'B[i]' больше 70, то "B[i]-70" будет больше 0.
Если 'B[i]' меньше 70, то произойдет переполнение типа unsigned и мы получим очень большое значение. Пусть B[i] == 50. Тогда "B[i]-70" = 50u - 70u = 0xFFFFFFECu = 4294967276. Естественно, что 4294967276 > 0.
Демонстрационный пример:
unsigned A;
A = 10; cout << "A=10 " << (A-70 > 0) << endl;
A = 70; cout << "A=70 " << (A-70 > 0) << endl;
A = 90; cout << "A=90 " << (A-70 > 0) << endl;
// Будет распечатано
A=10 1
A=70 0
A=90 1Первый вариант исправленного кода:
unsigned int *B;
...
if (B[i] > 70)Второй вариант исправленного кода:
int *B;
...
if (B[i]-70 > 0)Отметим, что выражение вида "A - B > 0" далеко не всегда означает наличие ошибки. Рассмотрим код, где анализатор выдаст ложное предупреждение:
// Функции GetLength() и GetPosition() возвращают
// значение типа size_t.
while ((inStream.GetLength() - inStream.GetPosition()) > 0)
{ ... }Здесь GetLength() всегда больше или равно GetPosition(). Поэтому код корректен. Чтобы избавиться от ложного срабатывания можно использовать комментарий //-V555 или переписать код следующим образом:
while (inStream.GetLength() != inStream.GetPosition())
{ ... }Вот еще один случай, когда ошибки не возникнет.
__int64 A;
__uint32 B;
...
if (A - B > 0)Здесь подвыражение "A - B" имеет знаковый тип __int64 и ошибки не возникнет. Анализатор не выдает предупреждения в таких ситуациях.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V555. |
V556. Values of different enum types are compared.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в коде сравниваются enum значения, имеющие разные типы.
Пример:
enum ErrorTypeA { E_OK, E_FAIL };
enum ErrorTypeB { E_ERROR, E_SUCCESS };
void Foo(ErrorTypeB status) {
if (status == E_OK)
{ ... }
}В сравнении случайно использовано неверное имя, и логика работы программы будет нарушена. Корректный вариант:
void Foo(ErrorTypeB status) {
if (status == E_SUCCESS)
{ ... }
}Сравнение значений различных типов перечислений (enum) не обязательно является ошибкой. Но подобный код нуждается в проверке (code review).
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V556. |
V557. Possible array overrun.
Анализатор обнаружил потенциально возможный доступ к памяти за границами массива. Самым распространенным случаем является ошибка при записи символа '\0' после последнего элемента массива.
Рассмотрим соответствующий пример:
struct IT_SAMPLE
{
unsigned char filename[14];
...
};
static int it_riff_dsmf_process_sample(
IT_SAMPLE * sample, const unsigned char * data)
{
memcpy( sample->filename, data, 13 );
sample->filename[ 14 ] = 0;
...
}Последний элемент массива имеет индекс 13, а не 14. Поэтому корректный код должен иметь вид:
sample->filename[13] = 0;Конечно, в подобных случаях лучше использовать не явное значение индекса, а выражение использующее оператор sizeof(). Однако следует помнить, что и в этом случае можно допустить ошибку. Рассмотрим пример:
typedef wchar_t letter;
letter name[30];
...
name[sizeof(name) - 1] = L'\0';На первый взгляд выражение "sizeof(name) - 1" верно. Но здесь программист забыл, что он работает с типом 'wchar_t', а не 'char'. В результате символ '\0' будет записано далеко за пределами массива. Корректный вариант:
name[sizeof(name) / sizeof(*name) - 1] = L'\0';Для упрощения записи таких конструкций можно использовать специальный макрос:
#define str_len(arg) ((sizeof(arg) / sizeof(arg[0])) - 1)
name[str_len(name)] = L'\0';Анализатор выявляет некоторые ошибки, когда индексом является переменная, значение которой может выйти за пределами массива. Пример:
int buff[25];
for (int i=0; i <= 25; i++)
buff[i] = 10;Корректный вариант:
int buff[25];
for (int i=0; i < 25; i++)
buff[i] = 10;Следует учитывать, что при работе с подобными диапазонами значений анализатор может ошибаться и выдавать ложные срабатывания.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V557. |
V558. Function returns pointer/reference to temporary local object.
Анализатор обнаружил ситуацию, когда функция возвращает указатель на локальный объект. Этот объект будет уничтожен при выходе из функции, и использовать указатель на него будет нельзя.
В самом простом виде данное диагностическое сообщение будет выдано на следующий код:
float *F()
{
float f = 1.0;
return &f;
}Конечно, в таком виде ошибка вряд ли будет существовать. Рассмотрим более реальный пример кода.
int *Foo()
{
int A[10];
// ...
if (err)
return 0;
int *B = new int[10];
memcpy(B, A, sizeof(A));
return A;
}Мы работали с временным массивом A. При некотором условии мы должны вернуть указатель на новый массив B. Однако из-за опечатки мы возвращаем массив A, что повлечет за собой непредсказуемое поведение программы или её аварийное завершение. Исправленный вариант кода:
int *Foo()
{
...
int *B = new int[10];
memcpy(B, A, sizeof(A));
return B;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V558. |
V559. Suspicious assignment inside the condition expression of 'if/while/for' operator.
Анализатор обнаружил ситуацию, когда в условии оператора 'if' или 'while' присутствует оператор присваивания '='. Подобная конструкция часто свидетельствует о наличии ошибок. Высока вероятность, что вместо оператора '=' планировалось использовать оператор '=='.
Рассмотрим пример:
const int MAX_X = 100;
int x;
...
if (x = MAX_X)
{ ... }В коде допущена опечатка: вместо сравнения переменной 'x' c константной MAX_X произойдет изменение значения переменной 'x'. Корректный вариант кода:
if (x == MAX_X)
{ ... }Конечно, присваивание внутри условия часто ошибкой не является. Такой приём используется многими программистами для сокращения размера кода. Стоит отметить, что это плохая практика, так как работая с подобным кодом всегда подолгу приходится изучать его, чтобы понять: является ли он следствием опечатки или желанием сократить программу.
Мы предлагаем отказаться от присваивания внутри условия и использовать присваивание в качестве отдельной операции. Другой вариант - использовать дополнительные скобки вокруг присваивания:
while ((x = Foo()))
{
...
}Подобный код анализатор и многие компиляторы воспринимают как безопасный. Заодно, это подсказка человеку, что код не содержит ошибку.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V559. |
V560. Part of conditional expression is always true/false.
Анализатор обнаружил потенциально возможную ошибку внутри логического условия. Часть логического выражения всегда истинно и оценено как опасное.
Рассмотрим пример:
#define REO_INPLACEACTIVE (0x02000000L)
...
if (reObj.dwFlags && REO_INPLACEACTIVE)
m_pRichEditOle->InPlaceDeactivate();Программист хотел проверить состояние определенного бита в переменной dwFlags. Но из-за опечатки он написал оператор '&&', вместо оператора '&'. Корректный код:
if (reObj.dwFlags & REO_INPLACEACTIVE)
m_pRichEditOle->InPlaceDeactivate();Рассмотрим другой пример:
if (a = 10 || a == 20)Случайно вместо оператора сравнения '==' написан оператор присваивания '='. С точки зрения языка Си++, это выражение будет идентично выражению вида "if (a = (10 || a == 20))".
Выражение "10 || a == 20" анализатор считает опасным, так как левая его часть представляет собой константу. Корректный код:
if (a == 10 || a == 20)Иногда предупреждение V560 выявляет не ошибку, а просто избыточный код. Рассмотрим пример:
if (!mainmenu) {
if (freeze || winfreeze ||
(mainmenu && gameon) ||
(!gameon && gamestarted))
drawmode = normalmode;
}Анализатор предупредит, что в подвыражении (mainmenu && gameon) переменная mainmenu всегда равна 0. То, что переменная mainmenu равна нулю, следует из вышестоящей проверки " if (!mainmenu)". Этот код может быть вполне корректен. Однако он избыточен, и лучше его упростить. Это сделает программу более простой для понимания другими разработчиками.
Упрощенный вариант кода:
if (!mainmenu) {
if (freeze || winfreeze ||
(!gameon && gamestarted))
drawmode = normalmode;
}Рассмотрим более интересный случай.
int16u Integer = ReadInt16u(Liste);
int32u Exponent=(Integer>>10) & 0xFF;
if (Exponent==0 || Exponent==0xFF) // V560
return 0;Пользователь, приславший этот пример, был озадачен, почему анализатор выдаёт предупреждение, в котором утверждается, что подвыражение 'Exponent==0xFF' всегда ложное. Давайте разберемся. Для этого нам надо внимательно посчитать.
16-битная беззнаковая переменная 'Integer' имеет диапазон возможных значений [0..0b1111111111111111] или [0..0xFFFF].
При сдвиге вправо на 10 бит, диапазон возможных значений уменьшается: [0..0b111111] или [0..0x3F].
Далее выполняется операция '& 0xFF'.
В результате, никак невозможно получить значение '0xFF'. Максимум, это будет '0x3F'.
Ряд конструкций на языке Си++ анализатор считает безопасными, даже если в них часть выражения представляется константой. Примеры некоторых ситуаций, когда анализатор не считает код опасными:
- подвыражение содержит операторы sizeof(): if (a == b && sizeof(T) < sizeof(__int64)) {};
- выражение находится в макросе: assert(false);
- сравниваются две числовых константы: if (MY_DEFINE_BITS_COUNT == 4) {};
- и так далее.
Особые настройки диагностики V560
По дополнительной просьбе пользователей появилась возможность управлять поведением диагностики V560. В общем заголовочном файле или pvsconfig-файле можно написать комментарий специального вида:
//+V560 ENABLE_PEDANTIC_WARNINGSРежим 'ENABLE_PEDANTIC_WARNINGS' ослабляет исключения диагностики. Рассмотрим пример:
void foo()
{
bool debugCheck = false; // maybe in macros
if (x)
{
if (debugCheck)
{
....
}
}
}По умолчанию анализатор не будет считать такой код опасным, так как часто он пишется для отладки. Комментарий позволит ослабить исключение диагностики, чтобы анализатор мог сообщить о проблеме.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V560. |
V561. Consider assigning value to 'foo' variable instead of declaring it anew.
Анализатор обнаружил потенциально возможную ошибку, найдя в коде переменную, которая объявляется и инициализируется, но далее не используется. При этом во внешней области видимости имеется переменная, имеющая такое же имя и такой же тип. Высока вероятность, что следовало использовать уже имеющуюся переменную, а не объявлять новую.
Рассмотрим пример:
BOOL ret = TRUE;
if (m_hbitmap)
BOOL ret = picture.SaveToFile(fptr);Программист случайно объявил новую переменную 'ret', в результате чего предыдущая всегда будет иметь значение TRUE, вне зависимости от того успешно будет сохранена картина в файл или нет. Исправленный вариант кода:
BOOL ret = TRUE;
if (m_hbitmap)
ret = picture.SaveToFile(fptr);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V561. |
V562. Bool type value is compared with value of N. Consider inspecting the expression.
Анализатор обнаружил ситуацию, когда значение типа bool сравнивается с числом. Скорее всего, это свидетельствует о наличии в коде ошибки.
Рассмотрим пример:
if (0 < A < 5)Этим кодом программист, недостаточно хорошо знакомый с языком Си++, пытался определить, лежит значение в диапазоне от 0 до 5 или нет. На самом деле, вычисления будут происходить в следующей последовательности: ((0 < A) < 5). Результат выражения "0 < A" имеет тип bool, а значит всегда меньше 5.
Корректный вариант проверки:
if (0 < A && A < 5)Предыдущий пример, напоминает ошибку, которые делают студенты. Однако от подобных ошибок не застрахованы и профессиональные разработчики.
Рассмотрим второй пример:
if (! (fp = fopen(filename, "wb")) == -1) {
perror("opening image file failed");
exit(1);
}Здесь сразу 2 ошибки разного плана. Во-первых, функция "fopen" возвращает указатель, и сравнивать возвращаемое значение следует с NULL. Программист спутал функцию "fopen" с "open", которая как раз возвращает "-1" в случае ошибки. Второй недочет в коде связан с тем, что вначале выполняется операция отрицания "!", а только затем сравнение с "-1". Значение типа bool не имеет смысла сравнивать с "-1" и именно поэтому анализатор и обратил внимание на приведенный код.
Корректный вариант:
if ( (fp = fopen(filename, "wb")) == NULL) {
perror("opening image file failed");
exit(1);
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V562. |
V563. An 'else' branch may apply to the previous 'if' statement.
Анализатор обнаружил потенциально возможную ошибку в логических условиях. Логика работы кода не совпадает с тем, как этот код отформатирован.
Рассмотрим пример:
if (X)
if (Y) Foo();
else
z = 1;Форматирование кода сбивает с толку, и кажется, что присваивание "z = 1" произойдет в том случае, если X == false. Однако ветка 'else' относится к ближайшему оператору 'if'. Другими словами приведенный код на самом деле эквивалентен следующему коду:
if (X)
{
if (Y)
Foo();
else
z = 1;
}Таким образом, код работает не так, как может показаться на первый взгляд.
Если выдано предупреждение V563, то это может означать две вещи:
1) Код плохо отформатирован и ошибки на самом деле нет. Тогда, чтобы предупреждение V563 не выдавалось, а код был более понятен, его нужно отформатировать. Пример корректного форматирования:
if (X)
if (Y)
Foo();
else
z = 1;2) Найдена логическая ошибка. Тогда, код можно исправить, например, так:
if (X) {
if (Y)
Foo();
} else {
z = 1;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V563. |
V564. The '&' or '|' operator is applied to bool type value. Check for missing parentheses or use the '&&' or '||' operator.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что операторы '&' и '|' работают со значениями типа bool. Подобные выражения не обязательно являются ошибочными, но часто свидетельствуют об опечатках или об ошибках в условиях.
Рассмотрим пример:
int a, b;
#define FLAG 0x40
...
if (a & FLAG == b)
{
}Этот пример считается классическим. Очень легко ошибиться в приоритетах операций. Кажется, что последовательность вычислений следующая - "(a & FLAG) == b". Но на самом деле, последовательность вычислений будет следующая - "a & (FLAG == b)". И скорее всего, это ошибка.
Анализатор выдаст здесь предупреждение, так как странно использовать оператор '&' для переменных типа int и bool.
Если выяснится, что код содержит ошибку, то его можно исправить следующим образом:
if ((a & FLAG) == b)Конечно, код может оказаться корректным и работать именно так, как нужно. Однако и в этом случае рационально переписать его, чтобы он стал проще для понимания. Лучше использовать оператор && или дополнительные скобки:
if (a && FLAG == b)
if (a & (FLAG == b))После таких исправлений предупреждение V564 более выдаваться не будет, а код станет более прост для чтения.
Рассмотрим другой пример:
#define SVF_CASTAI 0x00000010
if ( !ent->r.svFlags & SVF_CASTAI ) {
...
}Здесь мы имеем дело с явной ошибкой. В начале будет вычислено подвыражение "!ent->r.svFlags" и получен результат true или fasle. Но это не имеет значения. Будем мы выполнять операцию "true & 0x00000010" или "false & 0x00000010", результат будет одинаков. Условие в данном примере всегда ложно.
Исправленный вариант:
if ( ! (ent->r.svFlags & SVF_CASTAI) )Примечание. Анализатор не будет выдавать предупреждение, если слава и справа от оператора '&' или '|' находятся значения типа bool. Такой код хотя и не очень красив, но корректен. Пример кода, который анализатор считает безопасным:
bool X, Y;
...
if (X | Y)
{ ... }Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V564. |
V565. Empty exception handler. Silent suppression of exceptions can hide errors in source code during testing.
Найден обработчик исключения, который ничего не делает.
Пример кода:
try {
...
}
catch (MyExcept &)
{
}Конечно, такой код вовсе не обязательно ошибочен. Но очень странно просто подавлять исключение, ничего не делая. Такая обработка исключений может скрывать дефекты в программе и усложнить тестирование программы.
Следует, как то реагировать на исключения. Например, рационально вписать хотя бы "assert(false)":
try {
...
}
catch (MyExcept &)
{
assert(false);
}Иногда подобные конструкции используют, чтобы вернуть управление из множества вложенных циклов или рекурсивных функций. Но это плохая практика, так как исключение очень ресурсоемкая операция. Исключения следует использовать по назначению, а именно при возникновении нештатных ситуаций, которые должны быть обработаны на более высоком уровне.
Единственное место, где допустимо просто подавлять исключения, это деструкторы. Деструктор не должен бросать исключений. Однако, в деструкторах часто не понятно, что делать с исключениями и обработчик вполне может быть пуст. Анализатор не предупреждает о пустых обработчиках внутри деструкторов:
CClass::~ CClass()
{
try {
DangerousFreeResource();
}
catch (...) {
}
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V565. |
V566. Integer constant is converted to pointer. Check for an error or bad coding style.
Анализатор обнаружил явное приведение числового значения к типу указателя. Чаще всего это предупреждение выдается для участков кода, где числа используются как статус состояния объекта. Подобные приемы не всегда являются ошибкой, но, как правило, свидетельствуют о плохом дизайне.
Рассмотрим пример:
const DWORD SHELL_VERSION = 0x4110400;
...
char *ptr = (char*) SHELL_VERSION;
...
if (ptr == (char*) SHELL_VERSION)В указателе сохраняется константное значение, которое отмечает некоторое специальное состояние. Подобный код может долгое время успешно работать. Но если будет создан объект по адресу 0x4110400, то не будет возможность отличить, это магический флаг или просто объект. Если хочется использовать специальный флаг, то лучше написать так:
const DWORD SHELL_VERSION = 0x4110400;
...
char *ptr = (char*)(&SHELL_VERSION);
...
if (ptr == (char*)(&SHELL_VERSION))Примечание. Чтобы сократить количество ложных срабатываний, сообщение V566 не выдается в целом ряде случаев. Например, если магическим числом являются такие значения, как: -1, 0, 0xcccccccc, 0xdeadbeef. Предупреждение не выдается, если число лежит в диапазоне от 0 до 65535 и приводится к указателю на строку. Это позволяет пропустить корректный код следующего вида:
CString sMessage( (LPCSTR)IDS_FILE_WAS_CHANGED ) ;Подобный способ загрузки строки из ресурсов достаточно распространен, хотя, конечно, лучше использовать MAKEINTRESOURCE. Есть и другие исключения.
Данная диагностика классифицируется как:
|
V567. Modification of variable is unsequenced relative to another operation on the same variable. This may lead to undefined behavior.
Анализатор обнаружил выражение, которое приводит к неопределённому поведению программы. Переменная неоднократно используется между двумя точками следования, при этом её значение изменяется. В результате невозможно предсказать результат работы такого выражения. Рассмотрим понятия "неопределённое поведение" и "точка следования" более подробно.
Неопределённое поведение (англ. undefined behavior) — свойство некоторых языков программирования (наиболее заметно в C и C++) в определённых ситуациях выдавать результат, зависящий от реализации компилятора. Другими словами, спецификация не определяет поведение языка в любых возможных ситуациях, а говорит: "при условии А результат операции Б не определён". Допускать такую ситуацию в программе считается ошибкой, даже если на некотором компиляторе программа успешно выполняется, она не будет кроссплатформенной и может отказать на другой машине, в другой ОС и даже при других настройках компилятора.
Точка следования (англ. sequence point) — в императивном программировании любая точка программы, в которой гарантируется, что все побочные эффекты предыдущих вычислений уже проявились, а побочные эффекты последующих еще отсутствуют.
Их часто упоминают, говоря о C и C++, поскольку в этих языках особенно просто записать выражение, значение которого может зависеть от неопределённого порядка проявления побочных эффектов. Добавление одной или нескольких точек следования задаёт порядок более жестко и является одним из методов достижения устойчивого (т.е. корректного) результата.
Стоит заметить, что в C++11 вместо точек следования ввели понятия sequenced before/after, sequenced и unsequenced. Многие выражения, приводящие к неопределённому поведению в C++03, стали определены (например, i = ++i). Эти правила также дополнялись в C++14 и C++17. Анализатор выдаёт срабатывание независимо от используемого стандарта. Определённость выражений вида i = ++i не служит оправданием к их использованию. Такие выражения лучше переписать, сделав их более понятными коллегам. Также, если потребуется поддержать более ранний стандарт, можно получить трудно отлаживаемый баг.
Примеры неопределённого поведения в зависимости от стандартов:
i = ++i + 2; // undefined behavior until C++11
i = i++ + 2; // undefined behavior until C++17
f(i = -2, i = -2); // undefined behavior until C++17
f(++i, ++i); // undefined behavior until C++17,
// unspecified after C++17
i = ++i + i++; // undefined behavior
cout << i << i++; // undefined behavior until C++17
a[i] = i++; // undefined behavior until C++17
n = ++i + i; // undefined behaviorТочки следования необходимы в ситуации, когда одна и та же переменная изменяется в выражении более одного раза. Часто в качестве примера приводят выражение i=i++, в котором происходит присваивание переменной i и её же инкремент. Какое значение примет i? Стандарт языка должен либо указать одно из возможных поведений программы как единственно допустимое, либо указать диапазон допустимых поведений, либо указать, что поведение программы в данном случае совершенно не определено. В языках C и C++ вычисление выражения i=i++ приводит к неопределённому поведению, поскольку это выражение не содержит внутри себя ни одной точки следования.
В C и C++ определены следующие точки следования:
- Между вычислением левого и правого операндов в операторах
&&(логическом И),||(логическом ИЛИ) и операторах-запятых. Например, в выражении*p++ != 0 && *q++ != 0все побочные эффекты левого операнда*p++ != 0проявятся до начала каких-либо действий в правом. - Между вычислением первого, второго или третьего операндов в операторе условия. В строке
a = (*p++) ? (*p++) : 0точка находится после первого операнда*p++. При вычислении второго выражения, переменнаяpуже увеличена на 1. - В конце всего выражения. Эта категория включает в себя инструкции-выражения (
a=b;), выражения в инструкцияхreturn, управляющие выражения в круглых скобках инструкций ветвленияifилиswitchи цикловwhileилиdo-whileи все три выражения в круглых скобках циклаfor. - Перед входом в вызываемую функцию. Порядок, в котором вычисляются аргументы, не определён, но эта точка следования гарантирует, что все её побочные эффекты проявятся на момент входа в функцию. В выражении
f(i++) + g(j++) + h(k++)каждая из трёх переменных:i,jиk, принимает новое значение перед входом вf,gиhсоответственно. Однако порядок вызова функцийf(),g(),h()не определён, следовательно, не определён и порядок инкрементаi,j,k. Значенияjиkв теле функции f оказываются неопределенными. Следует отметить, что вызов функции нескольких аргументовf(a,b,c)не является случаем применения оператора-запятой и не определяет порядок вычисления значений аргументов. - При возврате из функции на момент, когда возвращаемое значение будет скопировано в вызывающий контекст (Явно описана только в стандарте С++, в отличие от С).
- В объявлении с инициализацией на момент завершения вычисления инициализирующего значения, например, на момент завершения вычисления
(1+i++) в int a = (1+i++);. - В C++ перегруженные операторы выступают в роли функций, поэтому точкой следования является вызов перегруженного оператора.
Рассмотрим теперь несколько примеров, приводящих к неопределённому поведению:
int i, j;
...
X[i]=++i;
X[i++] = i;
j = i + X[++i];
i = 6 + i++ + 2000;
j = i++ + ++i;
i = ++i + ++i;Во всех этих случаях невозможно предсказать результат вычислений. Конечно, эти примеры искусственны и опасность в них видна сразу. Рассмотрим пример кода, взятого из реального приложения:
while (!(m_pBitArray[m_nCurrentBitIndex >> 5] &
Powers_of_Two_Reversed[m_nCurrentBitIndex++ & 31]))
{}
return (m_nCurrentBitIndex - BitInitial - 1);Компилятор может вычислить вначале как левый, так и правый аргумент оператора &. Это значит, что переменная m_nCurrentBitIndex может быть уже увеличена на единицу при вычислении m_pBitArray[m_nCurrentBitIndex >> 5]. А может быть ещё и не увеличена.
Этот код может долго и исправно работать. Однако следует учитывать, что гарантированно корректно он будет себя вести только при сборке определённой версией компилятора с неизменным набором параметров компиляции. Корректный вариант кода:
while (!(m_pBitArray[m_nCurrentBitIndex >> 5] &
Powers_of_Two_Reversed[m_nCurrentBitIndex & 31]))
{ ++m_nCurrentBitIndex; }
return (m_nCurrentBitIndex - BitInitial);Этот код более не содержит неоднозначностей. Заодно исчезла магическая константа -1.
Программисты часто считают, что неопределённое поведение может возникать только при использовании постинкремента, в то время как преинкремент безопасен. Это не так. Рассмотрим пример общения на эту тему.
Вопрос:
Скачал ознакомительную версию вашей студии, прогнал свой проект и получил такое предупреждение: V567 Undefined behavior. The 'i_acc' variable is modified while being used twice between sequence points.
Код
i_acc = (++i_acc) % N_acc;Как мне кажется, здесь нет undefined behavior, так как переменная i_acc не участвует в выражении дважды.
Ответ:
Неопределённое поведение здесь есть, хотя вероятность проявления ошибки весьма мала. Оператор = не является точкой следования. Это значит, что сначала компилятор может поместить значение переменной i_acc в регистр, затем увеличить значение в регистре, вычислить выражение и записать результат в переменную i_acc, после чего вновь записать в эту переменную регистр с увеличенным значением. В результате мы получим код вида:
REG = i_acc;
REG++;
i_acc = (REG) % N_acc;
i_acc = REG;Компилятор имеет на это полное право. Конечно, на практике, скорее всего он сразу увеличит значение переменной и тогда всё посчитается так, как ожидает программист. Но полагаться на это нельзя.
Рассмотрим ещё одну ситуацию, связанную с вызовом функций.
Порядок вычисления аргументов функции не определён. Если аргументами является изменяющаяся переменная, то результат будет непредсказуем. Это неуточнённое поведение. Рассмотрим пример:
int A = 0;
Foo(A = 2, A);Функция Foo может быть вызвана как с аргументами (2, 0), так и с аргументами (2, 2). Порядок вычисления аргументов функции зависит от компилятора и настроек оптимизации.
Дополнительные ресурсы
- Википедия. Неопределённое поведение.
- Википедия. Точка следования.
- Елена Сагалаева. Точки следования (sequence points).
- Klaus Kreft & Angelika Langer. Sequence Points and Expression Evaluation in C++.
- Дискуссия на сайте bytes.com. Sequence points.
- Дискуссия на сайте StackOverflow.com. Why is a = (a+b) - (b=a) a bad choice for swapping two integers?
- cppreference.com. Order of evaluation
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V567. |
V568. It is suspicious that the argument of sizeof() operator is the expression.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что аргументом оператора sizeof() является подозрительное выражение.
Подозрительные выражения можно разделить на три группы:
1. В выражении пытаются изменить какую-то переменную.
Оператор sizeof() вычисляет тип выражения и возвращает размер этого типа. Но само выражение не вычисляется. Пример подозрительного кода:
int A;
...
size_t size = sizeof(A++);Данный код не увеличивает переменную 'A'. Если необходимо увеличить 'A' то следует переписать код следующим образом:
size_t size = sizeof(A);
A++;2. В выражении используются такие операции, как сложение, умножение и так далее.
Сложные выражения являются признаком наличия ошибки. Чаще всего эти ошибки связаны с опечатками. Пример:
SendDlgItemMessage(
hwndDlg, RULE_INPUT_1 + i, WM_GETTEXT,
sizeof(buff - 1), (LPARAM) input_buff);Вместо "sizeof(buff) - 1" программист случайно написал "sizeof(buff - 1)". Корректный вариант:
SendDlgItemMessage(
hwndDlg, RULE_INPUT_1 + i, WM_GETTEXT,
sizeof(buff) - 1, (LPARAM) input_buff);Другой пример опечатки в тексте программы:
memset(tcmpt->stepsizes, 0,
sizeof(tcmpt->numstepsizes * sizeof(uint_fast16_t)));Корректный вариант:
memset(tcmpt->stepsizes, 0,
tcmpt->numstepsizes * sizeof(uint_fast16_t));3. Аргументом оператора sizeof() является указатель на класс. Чаще всего это означает, что программист забыл разыменовать указатель.
Пример:
class MyClass
{
public:
int a, b, c;
size_t getSize() const
{
return sizeof(this);
}
};Метод getSize() возвращает размер указателя, а не размер объекта. Корректный вариант:
size_t getSize() const
{
return sizeof(*this);
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V568. |
V569. Truncation of constant value.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что константное значение усекается при помещении в переменную.
Рассмотрим пример:
int A[100];
unsigned char N = sizeof(A);Размер массива 'A' (в Win32/Win64) составляет 400 байт. Диапазон значений типа unsigned char: 0..255. Следовательно, переменная 'N' не может хранить размер массива 'A'.
Предупреждение V569 указывает на то, что для хранения размера выбран неверный тип. Или что на самом деле планировалось вычислить количество элементов в массиве, а не размер массива.
Если выбран неверный тип, то код может быть исправлен следующим образом:
size_t N = sizeof(A);Если планировалось вычислить количество элементов в массиве, то код следует изменить так:
unsigned char N = sizeof(A) / sizeof(*A);Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V569. |
V570. Variable is assigned to itself.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что переменная присваивается сама себе.
Рассмотрим пример:
dst.m_a = src.m_a;
dst.m_b = dst.m_b;Из-за опечатки, значение переменной 'dst.m_b' не изменится. Исправленный вариант кода:
dst.m_a = src.m_a;
dst.m_b = src.m_b;Анализатор выдаёт предупреждение не только на копирующее присваивание, но и перемещающее. Пример:
dst.m_a = std::move(src.m_a);Анализатор не всегда выдает предупреждение, если встречает присваивание переменной самой себе. Например, если переменные взяты в скобки. Подобный приём часто используется для подавления предупреждений компилятора. Пример:
int Foo(int foo)
{
UNREFERENCED_PARAMETER(foo);
return 1;
}Макрос UNREFERENCED_PARAMETER объявлен в файле WinNT.h следующим образом:
#define UNREFERENCED_PARAMETER(P) \
{ \
(P) = (P); \
}Анализатор знает про такие ситуации и не выдаст предупреждение V570 на присваивание следующего вида:
(foo) = (foo);Если в вашем проекте такой подход не используется, то можно добавить следующий комментарий, чтобы включить предупреждение:
//V_WARN_ON_ARGUMENT_SELF_ASSIGNПримечание. Если предупреждение V570 относится к макросам, которые нельзя исправить, то можно воспользоваться механизмом подавления предупреждений в макросах. Достаточно написать специальный комментарий в файле, используемый во всём проекте (например, в StdAfx.h). Пример:
//-V:MY_MACROS:V570Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V570. |
V571. Recurring check. This condition was already verified in previous line.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что дважды проверяется одно и тоже условие.
Рассмотрим два примера:
// Example N1:
if (A == B)
{
if (A == B)
...
}
// Example N2:
if (A == B) {
} else {
if (A == B)
...
}В первом случае вторая проверка "if (A==B)" всегда истинна. Во втором случае, вторая проверка всегда ложна.
Высока вероятность, что подобный код содержит ошибку. Например, из-за опечатки используется ошибочное имя переменной. Корректный код:
// Example N1:
if (A == B)
{
if (A == C)
...
}
// Example N2:
if (A == B) {
} else {
if (A == C)
...
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V571. |
V572. Object created using 'new' operator is immediately cast to another type. Consider inspecting the expression.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что объект, созданный с помощью оператора 'new', явным образом приводится к другому типу.
Рассмотрим пример:
T_A *p = (T_A *)(new T_B());
...
delete p;Возможны три варианта, как появился такой код и что с ним делать.
1) T_B не является наследником от класса T_A.
Скорее всего, это досадная опечатка или грубая ошибка. Способ её исправления зависит от того, что должен делать данный код.
2) T_B наследуется от класса T_A. Класс T_A не имеет виртуального деструктора.
В этом случае приводить T_B к T_A нельзя, так как потом невозможно корректно уничтожить созданный объект. Корректный код:
T_B *p = new T_B();
...
delete p;3) T_B наследуется от класса T_A. Класс T_A имеет виртуальный деструктор.
В этом случае код корректен, но явное приведение типа не имеет смысла. Можно написать проще:
T_A *p = new T_B();
...
delete p;Бывают и другие ситуации, когда будет выдано предупреждение V572. Рассмотрим пример кода, взятый из реального приложения:
DWORD CCompRemoteDriver::Open(HDRVR,
char *, LPVIDEO_OPEN_PARMS)
{
return (DWORD)new CCompRemote();
}Программа для своих нужд работает с указателем, как с дескриптором. Для этого она явно приводит указатель к типу DWORD. Такой код будет корректно работать в 32-битных системах, но может привести к сбою в 64-битной программе. Можно избежать 64-битной ошибки, используя более подходящий тип данных DWORD_PTR:
DWORD_PTR CCompRemoteDriver::Open(HDRVR,
char *, LPVIDEO_OPEN_PARMS)
{
return (DWORD_PTR)new CCompRemote();
}Иногда, причиной для предупреждения V572 является атавизм, оставшийся со времен, когда код был написан на языке Си. Рассмотрим пример такого кода:
struct Joint {
...
};
joints=(Joint*)new Joint[n]; //malloc(sizeof(Joint)*n);Комментарий подсказывает нам, что раньше для выделения памяти использовалась функция 'malloc'. Теперь для этого используется оператор 'new'. Но удалить приведение забыли. Код корректен, но приведение типа здесь совершенно излишне. Можно написать более короткий код:
joints = new Joint[n];Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V572. |
V573. Use of uninitialized variable 'Foo'. The variable was used to initialize itself.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что объявляемая переменная для инициализации использует саму себя.
Рассмотрим простой синтетический пример:
int X = X + 1;Переменная X будет инициализирована случайным значениям. Конечно, этот пример надуман, но зато он прост и хорошо демонстрирует смысл предупреждения. На практике подобная ошибка может встречаться в более сложных выражениях. Рассмотрим пример:
void Class::Foo(const std::string &FileName)
{
if (FileName.empty())
return;
std::string FullName = m_Dir + std::string("\\") + FullName;
...
}Из-за опечатки в выражении случайно используется имя FullName, а не FileName. Корректный вариант кода:
std::string FullName = m_Dir + std::string("\\") + FileName;Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V573. |
V574. Pointer is used both as an array and as a pointer to single object.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, переменная используется одновременно как указатель на один объект и как массив.
Рассмотрим пример ошибки, которую анализатор нашёл сам в себе:
TypeInfo *factArgumentsTypeInfo =
new (GC_QuickAlloc) TypeInfo[factArgumentsCount];
for (size_t i = 0; i != factArgumentsCount; ++i)
{
Typeof(factArguments[i], factArgumentsTypeInfo[i]);
factArgumentsTypeInfo->Normalize();
}Подозрительно, что с переменной factArgumentsTypeInfo мы работаем как с массивом "factArgumentsTypeInfo[i]" и как с указателем на один объект "factArgumentsTypeInfo ->". На самом деле необходимо вызвать функцию Normalize() для всех элементов. Исправленный вариант кода:
TypeInfo *factArgumentsTypeInfo =
new (GC_QuickAlloc) TypeInfo[factArgumentsCount];
for (size_t i = 0; i != factArgumentsCount; ++i)
{
Typeof(factArguments[i], factArgumentsTypeInfo[i]);
factArgumentsTypeInfo[i].Normalize();
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V574. |
V575. Function receives suspicious argument.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в качестве фактического аргумента в функцию передаётся очень странное значение.
Рассмотрим пример:
bool Matrix4::operator==(const Matrix4 &other) const
{
if (memcmp(this, &other, sizeof(Matrix4) == 0))
return true;
....
}Здесь мы имеем дело с опечаткой. Круглая скобка поставлена не там, где нужно. К сожалению, это плохо заметно, и такая ошибка может очень долго присутствовать в коде. Из-за опечатки размер сравниваемой памяти вычисляется выражением sizeof(Matrix4) == 0. Так как результат выражение false, то сравнивается ноль байт памяти. Корректный вариант:
bool Matrix4::operator==(const Matrix4 &other) const
{
if (memcmp(this, &other, sizeof(Matrix4)) == 0)
return true;
....
}Другой пример. Диагностическое правило определяет случаи, когда массив, состоящий из элементов enum, заполняется с помощью функции memset. При этом подразумевается, что размер элемента не равен одному байту. Такое заполнение будет некорректным, т.к. в этом случае значением заполнится каждый байт, а не каждый элемент массива.
Некорректный код:
enum E { V0, V1, V2, V3, V4 };
E array[123];
memset(array, V1, sizeof(array));Если компилятор сделает размер каждого элемента равным, например, 4 байта, то все элементы массива будут равны значению 0x01010101, а вовсе не 0x00000001 (V1), как ожидает программист.
Корректный код для заполнения массива:
for (size_t i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
{
array[i] = V1;
}Или:
std::fill(begin(array), end(array), V1);Примечание. NULL - странный аргумент.
Иногда программисты пытаются вычислить, сколько требуется выделить памяти под буфер, используя код вот такого типа:
const char* format = getLocalizedString(id, resource);
int len = ::vsprintf(NULL, format, args);
char* buf = (char*) alloca(len);
::vsprintf(buf, format, args);Учтите, что вызов ::vsprintf(NULL, format, args) некорректен. Вот что про это сказано в MSDN:
int vsprintf(*buffer, char *format, va_list argptr);
....vsprintf and vswprintf return the number of characters written, not including the terminating null character, or a negative value if an output error occurs. If buffer or format is a null pointer, these functions invoke the invalid parameter handler, as described in Parameter Validation. If execution is allowed to continue, these functions return -1 and set errno to EINVAL.
Дополнительная настройка
Есть несколько вариантов дополнительной настройки данного диагностического правила.
Для нулевых указателей
Диагностическое правило учитывает информацию, может ли тот или иной указатель быть нулевым. В ряде случаев, эта информация берется из таблиц разметки функций, которые находятся внутри самого анализатора.
Примером может служить функция malloc. Эта функция может вернуть нулевой указатель. Соответственно, использование указателя, который вернула функция malloc, без предварительной проверки может привести к разыменованию нулевого указателя.
Иногда у наших пользователей возникает желание изменить поведение анализатора и заставить его считать, что, например, функция malloc не может вернуть нулевой указатель. Пользователь может использовать системные библиотеки, в которых ситуации нехватки памяти обрабатываются особым образом.
Также может возникнуть желание подсказать анализатору, что определённая функция может вернуть нулевой указатель.
В этом случае вы можете воспользоваться дополнительными настройками, которые описаны в разделе "Как указать анализатору, что функция может или не может возвращать nullptr".
Для передаваемого диапазона
Если функция принимает в качестве параметров границы некоторого диапазона, то можно разметить соответствующие параметры как верхнюю и нижнюю границу. Это даст анализатору дополнительную информацию, которая поможет найти нарушения предусловий функции (например, значение нижней границы больше, чем верхней).
Чтобы разметить параметры как нижнюю и верхнюю границы, необходимо воспользоваться механизмом пользовательских аннотаций в формате JSON и атрибутами lower_bound и upper_bound соответственно. Также, если есть параметр, значение которого проверяется на вхождение в диапазон, его нужно разметить как in_range_value (если такого параметра нет, то достаточно разметить только нижнюю и верхнюю границы).
Пример. Есть функция, семантически схожая с std::clamp, со следующей сигнатурой:
bool foo(int v, int lo, int hi);Эта функция проверяет, что значение первого параметра лежит в диапазоне, переданном в качестве второго (нижняя граница) и третьего (верхняя граница) параметров.
Предположим, что есть следующий вызов данной функции:
if (foo(x, 100, 0))
{
....
}Как мы видим, в вызове перепутаны местами аргументы для нижней и верхней границы. Тогда, чтобы получить срабатывание в месте вызова функции, необходимо разметить первый параметр функции foo как in_range_value, второй как lower_bound, а третий как upper_bound.
Исправленный код:
if (foo(x, 0, 100))
{
....
}Примеры разметки параметров функций можно посмотреть здесь.
Примечание. Данная разметка необходима только для пользовательских функций.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V575. |
V576. Incorrect format. Consider checking the Nth actual argument of the 'Foo' function.
Анализатор обнаружил потенциальную ошибку при использовании функций форматного вывода ('printf', 'sprintf', 'wprintf' и так далее). Строка форматирования не соответствует передаваемым в функцию фактическим аргументам.
Рассмотрим простой пример:
int A = 10;
double B = 20.0;
printf("%i %i\n", A, B);Согласно строке форматирования, функция 'printf' ожидает два фактических аргумента типа 'int'. Однако второй аргумент имеет значение типа 'double'. Подобное несоответствие приводит к неопределённому поведению программы. Например, к распечатке бессмысленных значений.
Корректный вариант:
int A = 10;
double B = 20.0;
printf("%i %f\n", A, B);Ошибочных вариантов использования функции 'printf' можно привести огромное количество. Рассмотрим только несколько типовых примеров, которые чаще всего можно встретить в программах.
Распечатка адреса
Очень часто значение указателя пытаются распечатать, используя следующий код:
int *ptr = new int[100];
printf("0x%0.8X\n", ptr);Этот код ошибочен, поскольку будет работать только в тех системах, где размер указателя совпадает с размером типа 'int'. А, например, в Win64 этот код уже распечатает только младшую часть указателя 'ptr'. Корректный вариант кода:
int *ptr = new int[100];
printf("0x%p\n", ptr);Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в качестве фактического аргумента в функцию передаётся очень странное значение.
Неиспользуемые аргументы
Часто в программах можно встретить вызов функций, где часть аргументов не используется. Пример:
int nDOW;
#define KEY_ENABLED "Enabled"
...
wsprintf(cDowKey, L"EnableDOW%d", nDOW, KEY_ENABLED);Очевидно, что параметр 'KEY_ENABLED' здесь лишний, или код должен был выглядеть следующим образом:
wsprintf(cDowKey, L"EnableDOW%d%s", nDOW, KEY_ENABLED);Недостаточное количество аргументов
Намного более опасной ситуацией является, когда в функцию передаётся меньше аргументов, чем необходимо. Это может легко привести к ошибке доступа к памяти, переполнению буфера или распечатке мусора. Рассмотрим пример функции выделения памяти, взятой из одной реальной программы:
char* salloc(register int nbytes)
{
register char* p;
p = (char*) malloc((unsigned)nbytes);
if (p == (char *)NULL)
{
fprintf(stderr, "%s: out of memory\n");
exit(1);
}
return (p);
}Если функция 'malloc' вернёт значение 'NULL', то программа не сможет корректно сообщить о нехватке памяти и завершить свою работу. Она аварийно завершится или распечатает непонятный текст. В любом случае, подобное поведение усложнит анализ причины неработоспособности программы.
Путаница с signed/unsigned
Очень часто программисты используют спецификатор печати знаковых значений (например '%i') для печати переменных типа 'unsigned'. И наоборот. Эта ошибка, как правило, не критична и так сильно распространена, что в анализаторе она имеет низкий приоритет. Во многих случаях подобный код успешно работает и даёт сбой только при больших или отрицательных значениях. Рассмотрим код, который хотя не корректен, но успешно работает:
int A = 10;
printf("A = %u\n", A);
for (unsigned i = 0; i != 5; ++i)
printf("i = %d\n", i);Хотя здесь имеется несоответствие, это код на практике печатает корректные значения. Конечно, всё равно так лучше не делать и написать корректно:
int A = 10;
printf("A = %d\n", A);
for (unsigned i = 0; i != 5; ++i)
printf("i = %u\n", i);Ошибка проявит себя в том случае, если в программе имеются большие или отрицательные значения. Пример:
int A = -1;
printf("A = %u", A);Вместо строки "A = -1" программа распечатает "A = 4294967295". Корректный вариант:
printf("A = %i", A);Широкие строки (Wide character string)
У Visual Studio есть неприятная особенность, что он нестандартно интерпретирует формат строки для печати широких символов. В результате анализатор помогает диагностировать ошибку, например, в таком коде:
const wchar_t *p = L"abcdef";
wprintf(L"%S", p);В Visual C++ считается, что '%S' предназначен для печати строки типа 'const char *'. Поэтому с точки зрения Visual C++ правильным является код:
wprintf(L"%s", p);Начиная с Visual Studio 2015 предлагается решение этой проблемы, чтобы писать переносимый код. Для совместимости с ISO C (C99) следует указать препроцессору макрос _CRT_STDIO_ISO_WIDE_SPECIFIERS.
В этом случае, код:
const wchar_t *p = L"abcdef";
wprintf(L"%S", p);является правильным.
Анализатор знает про '_CRT_STDIO_ISO_WIDE_SPECIFIERS' и учитывает его при анализе.
Кстати, если вы включили режим совместимости с ISO C (объявлен макрос '_CRT_STDIO_ISO_WIDE_SPECIFIERS'), вы можете в отдельных местах вернуть старое приведение, используя спецификатор формата '%Ts'.
Вся эта история с широкими символами достаточно запутанная и выходит за пределы документации. Чтобы лучше разобраться в вопросе, предлагаем ознакомиться со следующими ссылками:
- Bug 1121290 - distinguish specifier s and ls in the printf family of functions
- Visual Studio swprintf is making all my %s formatters want wchar_t * instead of char *
- Update. В 2019 году появилась статья, которая рассказывает, почему получилась путаница: The sad history of Unicode printf-style format specifiers in Visual C++.
Дополнительная настройка диагностики
Чтобы самостоятельно указать имена своих собственных функций, для которых следует выполнять проверку формата, можно использовать пользовательские аннотации. Подробнее об этом можно почитать здесь.
Дополнительные ресурсы:
- Wikipedia. Printf.
- MSDN. Format Specification Fields: printf and wprintf Functions.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования форматной строки. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V576. |
V577. Label is present inside switch(). Check for typos and consider using the 'default:' operator instead.
Анализатор обнаружил потенциальную ошибку внутри оператора switch. Используется метка с именем похожим на 'default'. Возможно это опечатка.
Рассмотрим пример:
int c = 10;
int r = 0;
switch(c){
case 1:
r = 3; break;
case 2:
r = 7; break;
defalt:
r = 8; break;
}Кажется после того, как этот код отработает, значение переменной 'r' будет 8. Но на самом деле значение 'r' останется равно нулю. Дело в том, что "defalt" это метка, а не оператор "default". Исправленный вариант кода:
int c = 10;
int r = 0;
switch(c){
case 1:
r = 3; break;
case 2:
r = 7; break;
default:
r = 8; break;
}Эта диагностика срабатывает также, когда имя метки начинается с "case". Есть вероятность, что пропущен пробел. Например, вместо метки "case1:", должно быть написано "case 1:".
Данная диагностика классифицируется как:
|
V578. Suspicious bitwise operation was detected. Consider inspecting it.
Анализатор обнаружил потенциальную ошибку в выражении, работающем с битами. Часть выражения не имеет смысла или является избыточным. Как правило, такие ошибки возникают из-за опечатки.
Рассмотрим пример:
if (up & (PARAMETER_DPDU | PARAMETER_DPDU | PARAMETER_NG))Здесь два раза используется константа PARAMETER_DPDU. В корректном коде должны использоваться две разных константы: PARAMETER_DPDU и PARAMETER_DPDV. Буква 'U' похожа на 'V' поэтому и возникла такая опечатка. Исправленный вариант:
if (up & (PARAMETER_DPDU | PARAMETER_DPDV | PARAMETER_NG))Другой пример. Здесь ошибки нет, но код избыточен:
if (((pfds[i].dwFlags & pPFD->dwFlags) & pPFD->dwFlags)
!= pPFD->dwFlags)Сокращенный вариант:
if ((pfds[i].dwFlags & pPFD->dwFlags) != pPFD->dwFlags)Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V578. |
V579. The 'Foo' function receives the pointer and its size as arguments. This may be a potential error. Inspect the Nth argument.
Анализатор обнаружил в коде подозрительный вызов функции. В качестве аргументов в функцию передается указатель и размер этого указателя. На самом деле, разработчики часто хотят передать в функцию не размер указателя, а размер буфера.
Рассмотрим, как подобная ошибка может возникнуть в коде. Предположим, в начале имелся код следующего вида:
char buf[100];
...
memset(buf, 0, sizeof(buf));Код корректен. Функция memset() очищает массив из 100 байт. Затем, код изменился, и буфер стал переменного размера. Код очистки буфера изменить забыли:
char *buf = new char[N];
...
memset(buf, 0, sizeof(buf));Теперь код некорректен. Оператор sizeof() возвращает размер указателя, а не размер буфера с данными. Как результат, функция memset() очищает только часть массива.
Рассмотрим другой пример, взятый из реального приложения:
apr_size_t ap_regerror(int errcode,
const ap_regex_t *preg, char *errbuf,
apr_size_t errbuf_size)
{
...
apr_snprintf(errbuf, sizeof errbuf,
"%s%s%-6d", message, addmessage,
(int)preg->re_erroffset);
...
}В таком коде заметить ошибку непросто. Функция apr_snprintf() принимает в качестве аргумента указатель 'errbuf' и размер этого указателя 'sizeof errbuf'. Анализатор считает этот код подозрительным и абсолютно прав. Размер буфера находится в переменной 'errbuf_size' и именно эту переменную следует использовать. Корректный код:
apr_snprintf(errbuf, errbuf_size,
"%s%s%-6d", message, addmessage,
(int)preg->re_erroffset);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V579. |
V580. Suspicious explicit type casting. Consider inspecting the expression.
Анализатор обнаружил подозрительное явное приведение типа. Это может быть ошибкой или потенциальной ошибкой.
Рассмотрим пример:
DWORD errCode = 0;
void* dwErrParams[MAX_MESSAGE_PARAMS];
dwErrParams[0] = *((void**)&errCode);Код содержит 64-битную ошибку. Тип 'DWORD' превращается в тип 'void *' . Этот код некорректно работает в 64-битных системах, где размер указателя не совпадает с размером типа DWORD. Корректный вариант:
DWORD_PTR errCode = 0;
void* dwErrParams[MAX_MESSAGE_PARAMS];
dwErrParams[0] = (void *)errCode;Данная диагностика классифицируется как:
|
V581. Conditional expressions of 'if' statements located next to each other are identical.
Анализатор обнаружил код, в котором рядом находятся два оператора 'if' с одинаковыми условиями. Это является потенциальной ошибкой или избыточным кодом.
Рассмотрим пример:
if (strlen(S_1) == SIZE)
Foo(A);
if (strlen(S_1) == SIZE)
Foo(B);Содержит этот код ошибку или нет, зависит от того, что хотел сделать программист. Если во втором условии нужно вычислить длину другой строки, то это ошибка. Исправленный код:
if (strlen(S_1) == SIZE)
Foo(A);
if (strlen(S_2) == SIZE)
Foo(B);Код может быть корректен. Но тогда он неэффективен, так как два раза приходится вычислять длину одной и той же строки. Оптимизированный код:
if (strlen(S_1) == SIZE) {
Foo(A);
Foo(B);
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V581. |
V582. Consider reviewing the source code that uses the container.
Анализатор обнаружил потенциальную ошибку при работе с контейнером фиксированного размера. Эту диагностику нам предложил реализовать один из наших пользователей. Вот как он сформулировал задачу.
Для работы с массивами константного размера мы используем следующий шаблонный класс:
template<class T_, int numElements > class idArray
{
public:
int Num() const { return numElements; };
.....
inline const T_ & operator[]( int index ) const {
idassert( index >= 0 );
idassert( index < numElements );
return ptr[index];
};
inline T_ & operator[]( int index ) {
idassert( index >= 0 );
idassert( index < numElements );
return ptr[index];
};
private:
T_ ptr[numElements];
};Класс позволяет обнаружить ошибки выхода за пределы массива при запуске DEBUG версии. При этом производительность RELESE версии не снижается. Пример некорректного кода:
idArray<int, 1024> newArray;
newArray[-1] = 0;
newArray[1024] = 0;Ошибки будут обнаружены при запуске отладочной версии. Однако хочется иметь возможность обнаруживать подобные ошибки с помощью статического анализа ещё на этапе компиляции.
Для выявления подобных ошибочных ситуаций и предназначена диагностика V582. Если в программе используется класс, реализующий функциональность контейнера фиксированного размера, то анализатор пытается проверить, что индекс не выходит за его границу. Пример диагностики:
idArray<float, 16> ArrA;
idArray<float, 8> ArrB;
for (size_t i = 0; i != 16; i++)
ArrA[i] = 1.0f;
for (size_t i = 0; i != 16; i++)
ArrB[i] = 1.0f;Здесь анализатор выдаст предупреждение:
V582 Consider reviewing the source code which operates the 'ArrB' container. The value of the index belongs to the range: [0..15].
Ошибка в том, что оба цикла обрабатывают 16 элементов, хотя второй массив содержит только 8 элементов. Корректный вариант:
for (size_t i = 0; i != 16; i++)
ArrA[i] = 1.0f;
for (size_t i = 0; i != 8; i++)
ArrB[i] = 1.0f;Следует отметить, что передача слишком больших или маленьких индексов не всегда означает ошибку в программе. Например, оператор [] может быть реализован следующим образом:
inline T_ & operator[]( int index ) {
if (index < 0) index = 0;
if (index >= numElements) index = numElements - 1;
return ptr[index];
};Если вы используете подобные классы и получаете много ложных срабатываний, то очевидно вам следует отключить диагностику V582.
Примечание. Анализатор не обладает искусственным интеллектом и поэтому его возможности поиска дефектов при работе с контейнерами ограничены. Мы работаем над усовершенствованием алгоритмов, поэтому если вы заметили явные ложные срабатывания или наоборот ситуации, в которых анализатор не выдал предупреждение, просим написать нам и прислать соответствующий пример кода.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
V583. The '?:' operator, regardless of its conditional expression, always returns the same value.
Анализатор обнаружил потенциальную ошибку при использовании тернарного оператора "?:". Независимо от условия, будет выполнено одно и тоже действие. Скорее всего, в коде имеется опечатка.
Рассмотрим самый простой пример:
int A = B ? C : C;В любом случае переменной A будет присвоено значение переменной C.
Рассмотрим, как подобная ошибка может выглядеть в коде реального приложения:
fovRadius[0] =
tan(DEG2RAD((rollAngleClamped % 2 == 0 ?
cg.refdef.fov_x : cg.refdef.fov_x) * 0.52)) * sdist;Здесь код отформатирован. В тексте программы это одна строка, и не удивительно, что легко просмотреть опечатку. Ошибка заключается, что два раза используется член структуры "fov_x". Корректный вариант:
fovRadius[0] =
tan(DEG2RAD((rollAngleClamped % 2 == 0 ?
cg.refdef.fov_x : cg.refdef.fov_y) * 0.52)) * sdist;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V583. |
V584. Same value is present on both sides of the operator. The expression is incorrect or can be simplified.
Анализатор обнаружил выражение, которое можно упростить. С большой вероятностью это выражение содержит опечатку.
Рассмотрим пример:
float SizeZ;
if (SizeZ + 1 < SizeZ)Анализатор считает, что это условие содержит ошибку, так как не имеет практического смысла. Скорее всего, хотелось выполнить совсем другую проверку. Корректный код:
if (SizeZ + 1 < maxSizeZ)Конечно, иногда программисты используют приемы, которые корректны, но выглядят странно. Анализатор по возможности старается распознать такие ситуации и не выдавать диагностические сообщения. Например, анализатор считает безопасными следующие проверки:
//Тест на переполнение при суммировании
int a, b;
if (a + b < a)
//Проверка, что X не равен 0, +бесконечность или -бесконечность.
double X;
if (X * 0.5f != X)Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V584. |
V585. Attempt to release memory that stores the 'Foo' local variable.
Анализатор обнаружил попытку освободить память, занятую локальной переменной. Подобные ошибки могут возникать в ходе неаккуратного рефакторинга или опечатки.
Рассмотрим пример некорректного кода:
void Foo()
{
int *p;
...
free(&p);
}Корректный код:
void Foo()
{
int *p;
...
free(p);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V586. The 'Foo' function is called twice to deallocate the same resource.
Анализатор обнаружил потенциальную ошибку повторного освобождения какого-то ресурса. При определённых обстоятельствах этот код может стать дефектом безопасности.
Ресурсом может быть память, файл или, например, объект HBRUSH.
Рассмотрим пример некорректного кода:
float *p1 = (float *)malloc(N * sizeof(float));
float *p2 = (float *)malloc(K * sizeof(float));
...
free(p1);
free(p1);В тексте программы имеется опечатка, из-за которой дважды освобождается одна и та же область памяти. Последствия выполнения такого кода предсказать сложно. Возможно, программа аварийно завершит свою работу. Или, возможно, продолжит свою работу, но возникнет утечка памяти (memory leak).
Более того, подобный код является дефектом безопасности и может привести к возникновению уязвимости. Например, уязвимости подвержена функция 'malloc' ('dmalloc') Дуга Ли (Doug Lea), которая используется в некоторых библиотеках как 'malloc' по умолчанию. Для возникновения уязвимости, связанной с двойным освобождением памяти, требуется несколько условий: блоки памяти, смежные с освобождаемым, не должны быть свободны, а список свободных блоков памяти должен быть пуст. В этом случае возможно создание эксплойта. Несмотря на то что подобные уязвимости сложно использовать из-за необходимости специфичной конфигурации памяти, существуют реальные примеры уязвимого кода, который был успешно взломан.
Корректный вариант:
float *p1 = (float *)malloc(N * sizeof(float));
float *p2 = (float *)malloc(K * sizeof(float));
...
free(p1);
free(p2);Иногда ошибка двойного освобождения ресурсов не является опасной:
vector<unsigned> m_arrStack;
...
m_arrStack.clear();
m_arrBlock.clear();
m_arrStack.clear();Случайно два раза очищаем массив. Код работает правильно, но его всё равно следует посмотреть и поправить. В процессе его изучения может выясниться, что забыли очистить другой массив.
Корректный вариант:
vector<unsigned> m_arrStack;
...
m_arrStack.clear();
m_arrBlock.clear();Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V586. |
V587. Suspicious sequence of assignments: A = B; B = A;.
Анализатор обнаружил потенциальную ошибку, связанную с бессмысленным взаимным присваиванием переменных.
Рассмотрим пример:
int A, B, C;
...
A = B;
C = 10;
B = A;Здесь присваивание "B = A" не имеет никакого практического смысла. Возможно, это опечатка или просто лишнее действие. Корректный вариант кода:
A = B;
C = 10;
B = A_2;Рассмотренный выше пример был искусственным. Рассмотрим, как эта ошибка может выглядеть в коде реального приложения:
// Swap; exercises counters
{
RCPFooRef temp = f2;
f2 = f3;
f3 = f2;
}Корректный вариант:
// Swap; exercises counters
{
RCPFooRef temp = f2;
f2 = f3;
f3 = temp;
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V587. |
V588. Expression of the 'A =+ B' kind is used. Possibly meant: 'A += B'. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку, так как в программе имеется последовательность символов '=+'. Возможно, это опечатка и следует использовать оператор '+='.
Рассмотрим пример:
size_t size, delta;
...
size=+delta;Этот код может быть корректен. Но с большой вероятностью имеется опечатка и на самом деле, хотели использовать оператор '+='. Исправленный вариант:
size_t size, delta;
...
size+=delta;Если код корректен, то чтобы убрать предупреждение V588 можно удалить '+' или поставить дополнительный пробел. Вариант корректного кода, где предупреждение не выдается:
size = delta;
size = +delta;Примечание. Для поиска опечаток вида 'A =- B' используется диагностическая проверка V589. Эта проверка сделана отдельно, так как возможно большое количество ложных срабатываний, и может возникнуть желание отключить её.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V588. |
V589. Expression of the 'A =- B' kind is used. Possibly meant: 'A -= B'. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку, так как в программе имеется последовательность символов '=-'. Возможно, это опечатка и следует использовать оператор '-='.
Рассмотрим пример:
size_t size, delta;
...
size =- delta;Этот код может быть корректен. Но с большой вероятностью имеется опечатка и на самом деле, хотели использовать оператор '-='. Исправленный вариант:
size_t size, delta;
...
size -= delta;Если код корректен, то чтобы убрать предупреждение V589 можно использовать дополнительный пробел между символами '=' и '-'. Вариант корректного кода, где предупреждение не выдается:
size = -delta;Чтобы уменьшить количество ложных срабатываний, для правила V589 действует ряд специфичных исключений. Например, анализатор не будет выдавать предупреждение, если программист не использует пробелов между переменными и операторами. Ряд примеров, код которых анализатор считает безопасным:
A=-B;
int Z =- 1;
N =- N;Примечание. Для поиска опечаток вида 'A =+ B' используется диагностическая проверка V588.
Данная диагностика классифицируется как:
V590. Possible excessive expression or typo. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку, так как в коде имеется избыточное сравнение.
Поясним на простом примере:
if (Aa[42] == 10 && Aa[42] != 3)Условие будет выполнено в том случае, если 'Aa[42] == 10'. Вторая часть выражения бессмысленна. Проанализировав код, можно прийти к одному из двух выводов:
1) Выражение можно упросить. Исправленный код:
if (Aa[42] == 10)2) Выражение содержит ошибку. Исправленный код:
if (Aa[42] == 10 && Aa[43] != 3)Рассмотрим практический пример. Здесь ошибки нет, но выражение избыточно, что может затруднять чтение кода:
while (*pBuff == ' ' && *pBuff != '\0')
pBuff++;Проверка " *pBuff != '\0' " не имеет смысла. Сокращенный вариант кода:
while (*pBuff == ' ')
pBuff++;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V590. |
V591. Non-void function must return value.
Анализатор обнаружил non-void функцию, для которой существует путь исполнения, не возвращающий значение. Вызов такой функции ведёт к неопределённому поведению.
Если при исполнении тела non-void функции достигнут конец её тела без 'return', то произойдёт неопределённое поведение.
Рассмотрим пример:
int GetSign(int arg)
{
if (arg > 0)
{
return 1;
}
else if (arg < 0)
{
return -1;
}
}Если в функцию 'GetSign' передать 0, то произойдёт неопределённое поведение. Исправленный вариант:
int GetSign(int arg)
{
if (arg > 0)
{
return 1;
}
else if (arg < 0)
{
return -1;
}
return 0;
}Исключением из правила являются функции 'main' и 'wmain'. Для этих функций достижение конца тела эквивалентно выполнению конструкции 'return 0;', поэтому неопределённого поведения не будет. Рассмотрим такой пример:
....
int main()
{
AnalyzeFile(FILE_NAME);
}В данном случае имеем дело с функцией 'main'. Здесь не будет неопределённого поведения. Соответственно, не будет и выдано предупреждение анализатора. Фрагмент кода эквивалентен следующему:
....
int main()
{
AnalyzeFile(FILE_NAME);
return 0;
}Заметим, что неопределённое поведение происходит, только если конец non-void функции действительно достигнут. В частности, если на пути исполнения тела такой функции произошёл бросок исключения, которое не было перехвачено в теле этой же функции, то неопределённого поведения не будет.
Анализатор не выдаст предупреждение на следующем фрагменте кода:
int Calc(int arg);
int Bar(int arg)
{
if (arg > 0)
{
return Calc(arg);
}
throw std::logic_error { "bad arg was passed to Bar" };
}Также неопределённого поведения не будет, если в ходе выполнения тела такой функции произошел вызов другой функции, которая не возвращает управление. Такие функции обычно помечают '[[noreturn]]'. Поэтому анализатор не выдаст предупреждение на следующем примере:
[[noreturn]] void exit(int exit_code);
int Foo()
{
....
exit(10);
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V591. |
V592. Expression is enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or typo is present.
Анализатор обнаружил двойные круглые скобки вокруг выражения. Есть вероятность, что одна из скобок поставлена не там, где надо.
Хочется подчеркнуть, что анализатор не ищет фрагменты кода, где два раза повторяются круглые скобки. Например, анализатор считает проверку "if ((A = B))" безопасной. Здесь дополнительные скобки используются, чтобы подавить предупреждения некоторых компиляторов. В этом выражении невозможно расставить скобки так, чтобы возникла ошибка.
Анализатор пытается обнаружить те ситуации, когда изменив местонахождение одной скобки, можно изменить смысл выражения. Рассмотрим пример:
if((!osx||howmanylevels))Этот код подозрителен. Непонятно, зачем здесь дополнительные круглые скобки. Возможно, выражение должно выглядеть так:
if(!(osx||howmanylevels))Если даже выражение корректно, то всё равно лучше убрать лишние круглые скобки. На это есть две причины.
1) Человек читающий код, может усомниться в его корректности, увидев дублирующиеся круглые скобки.
2) Если убрать лишние скобки, то анализатор перестанет выдавать ложное предупреждение.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V592. |
V593. Expression 'A = B == C' is calculated as 'A = (B == C)'. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку в выражении, которое, скорее всего, работает не так, как задумывал программист. Данный тип ошибок чаще всего можно встретить в выражениях, где одновременно проверяется результат работы функции и выполняется присваивание.
Рассмотрим простой пример:
if (handle = Foo() != -1)Создавая такой код, программист, как правило, хочет выполнить действия в следующем порядке:
if ((handle = Foo()) != -1)
Но приоритет оператора '!=' выше, чем приоритет оператора '='. Поэтому выражение вычистится так:
if (handle = (Foo() != -1))
Чтобы исправить ошибку, можно использовать скобки. Ещё лучше не жадничать на количестве строк кода. Текст вашей программы станет более читабелен, если написать так:
handle = Foo();
if (handle != -1)Рассмотрим, как подобная ошибка может выглядеть на практике:
if (hr = AVIFileGetStream(pfileSilence,
&paviSilence, typeAUDIO, 0) != AVIERR_OK)
{
ErrMsg("Unable to load silence stream");
return hr;
}Проверка в коде, что произошла ошибка, работает корректно и будет выдано сообщение "Unable to load silence stream". Беда в том, что переменная 'hr' будет хранить не код ошибки, а значение 1. Исправленный вариант кода:
if ((hr = AVIFileGetStream(pfileSilence,
&paviSilence, typeAUDIO, 0)) != AVIERR_OK)
{
ErrMsg("Unable to load silence stream");
return hr;
}Анализатор не всегда выдает предупреждения, обнаруживая конструкцию вида "if (x = a == b)". Например, анализатор понимает, что данный код безопасен:
char *from;
char *to;
bool result;
...
if (result = from == to)
{}Примечание. Если анализатор все-таки выдал ложное предупреждение, то есть два способа устранить его:
1) Добавить дополнительные скобки. Пример: "if (x = (a == b))".
2) Использовать комментарий для подавления предупреждения. Пример: "if (x = a == b) //-V593".
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V593. |
V594. Pointer to array is out of array bounds.
Анализатор обнаружил потенциальную ошибку при работе с указателями. В программе есть выражение, при вычислении которого получается, что указатель вышел за границу массива.
Проясним это простым примером:
int A[10];
fill(A, A + sizeof(A), 33);Мы хотим присвоить всем элементам массива значение 33. Ошибка в том, что указатель "A + sizeof(A)" ссылается далеко за пределы массива. В результате, мы изменим больше ячеек памяти, чем планировалось. Результат этой ошибки непредсказуем.
Правильный вариант кода:
int A[10];
fill(A, A + sizeof(A) / sizeof(A[0]), 33);Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V594. |
V595. Pointer was used before its check for nullptr. Check lines: N1, N2.
Анализатор обнаружил потенциальную ошибку, которая может привести к разыменовыванию нулевого указателя.
Анализатор заметил в коде следующую ситуацию. В начале, указатель используется. А уже затем этот указатель проверяется на значение NULL. Это может означать одно из двух:
1) Возникнет ошибка, если указатель будет равен NULL.
2) Программа всегда работает корректно, так как указатель всегда не равен NULL. Проверка является лишней.
Рассмотрим первый вариант. Ошибка есть.
buf = Foo();
pos = buf->pos;
if (!buf) return -1;Если указатель 'buf' окажется равен NULL, то выражение 'buf->pos ' приведёт к ошибке. Анализатор выдаст предупреждение на этот код, указав 2 строки. Первая строка - это то место, где используется указатель. Вторая строка - это то место, где указатель сравнивается со значением NULL.
Исправленный вариант кода:
buf = Foo();
if (!buf) return -1;
pos = buf->pos;Рассмотрим второй вариант. Ошибки нет.
void F(MyClass *p)
{
if (!IsOkPtr(p))
return;
printf("%s", p->Foo());
if (p) p->Clear();
}Этот код всегда работает корректно. Указатель всегда не равен NULL. Однако анализатор не разобрался в этой ситуации и выдал предупреждение. Чтобы оно исчезло, следует удалить проверку "if (p)". Она не имеет практического смысла и только может запутать программиста, читающего код.
Исправленный вариант:
void F(MyClass *p)
{
if (!IsOkPtr(p))
return;
printf("%s", p->Foo());
p->Clear();
}В случае если анализатор ошибается, то кроме изменения кода, можно использовать комментарий для подавления предупреждений. Пример: "p->Foo(); //-V595".
Примечание N1.
Некоторые пользователи сообщают, что анализатор выдает предупреждение V595 на корректный код, Пример:
static int Foo(int *dst, int *src)
{
*dst = *src; // V595 !
if (src == 0)
return 0;
return Foo(dst, src);
}
...
int a = 1, b = 2;
int c = Foo(&a, &b);Да, здесь анализатор выдает ложное срабатывание. Код корректен и указатель 'src' не может быть равен NULL в тот момент, когда выполняется присваивание "*dst = *src". Возможно, в дальнейшем мы реализуем исключение для подобных случаев, но пока не спешим это делать. Хотя здесь нет ошибки, анализатор выявил избыточность кода. Функцию можно сократить. При этом пропадет предупреждение V595, а код станет проще.
Улучшенный вариант:
int Foo(int *dst, int *src)
{
assert(dst && src);
*dst = *src;
return Foo(dst, src);
}Примечание N2.
Иногда в программах можно встретить код следующего вида:
int *x=&p->m_x; //V595
if (p==NULL) return(OV_EINVAL);Вычисляется указатель на член класса. Этот указатель не разыменовывается и кажется, что анализатор зря выдаёт диагностическое сообщение V595. Однако, этот код приводит к неопределённому поведению. Если программа работает, это везение и не более того. Нельзя вычислять выражение, если "&p->m_x", если указатель 'p' равен нулю.
С аналогичной ситуацией программист может встретиться, желая отсортировать массив:
int array[10];
std::sort(&array[0], &array[10]); // Undefined behaviorИспользование &array[10] приводит к неопределенному поведению, так как элемент array[10] уже лежит за границами массива. Но использование арифметики указателей вполне допустимо. Можно обратиться к указателю, который адресует конечный элемент массива. Поэтому, необходимо написать следующий корректный код:
int array[10];
std::sort(array, array+10); //okДополнительные материалы
- Андрей Карпов. Пояснение про диагностику V595. http://www.viva64.com/ru/b/0353/
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V595. |
V596. Object was created but is not used. Check for missing 'throw' keyword.
Анализатор обнаружил потенциальную ошибку, связанную с использованием класса std::exception или наследуемого от него класса. Анализатор выдает предупреждение в том случае, если создается объект типа std::exception / CException, но не используется.
Пример:
if (name.empty())
std::logic_error("Name mustn't be empty");Ошибка заключается в том, что случайно забыто ключевое слово 'throw'. В результате данный код не генерирует исключение в случае ошибочной ситуации. Исправленный вариант кода:
if (name.empty())
throw std::logic_error("Name mustn't be empty");Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V596. |
V597. Compiler may delete 'memset' function call that is used to clear 'Foo' buffer. Use the RtlSecureZeroMemory() function to erase private data.
Анализатор обнаружил потенциальную ошибку, когда массив, содержащий приватную информацию, не будет очищен.
Рассмотрим пример кода.
void Foo()
{
char password[MAX_PASSWORD_LEN];
InputPassword(password);
ProcessPassword(password);
memset(password, 0, sizeof(password));
}Функция на стеке создает временный буфер, предназначенный для хранения пароля. По окончанию работы с паролем, мы хотим очистить этот буфер. Если это не сделать, пароль останется в памяти, что может привести к неприятным последствиям. На эту тему есть хорошая статья "Перезаписывать память - зачем?".
К сожалению, приведенный код может оставить буфер неочищенным. Обратите внимание, что массив 'password' очищается в конце и более не используется. Поэтому при сборке Release версии программы, компилятор, скорее всего, удалит вызов функции memset(). На это компилятор имеет полное право. Такое изменение не влияет на наблюдаемое поведение, которое описано в Стандарте как последовательность вызова функций ввода-вывода и чтения-записи volatile данных. То есть с точки зрения языка Си/Си++, если удалить вызов функции memset(), это ничего не изменит!
Для очистки буферов содержащих приватную информацию необходимо использовать специальную функцию RtlSecureZeroMemory или memset_s (см. также статью "Безопасная очистка приватных данных").
Исправленный вариант кода:
void Foo()
{
char password[MAX_PASSWORD_LEN];
InputPassword(password);
ProcessPassword(password);
RtlSecureZeroMemory(password, sizeof(password));
}Кажется, что на практике, компилятор не может удалить вызов такой важной функции memset(). Может возникнуть впечатление, что речь идет о редких экзотических компиляторах. Нет, это не так. Возьмем для примера компилятор Visual C++ 10, входящий в состав Visual Studio 2010.
Рассмотрим две функции.
void F1()
{
TCHAR buf[100];
_stprintf(buf, _T("Test: %d"), 123);
MessageBox(NULL, buf, NULL, MB_OK);
memset(buf, 0, sizeof(buf));
}
void F2()
{
TCHAR buf[100];
_stprintf(buf, _T("Test: %d"), 123);
MessageBox(NULL, buf, NULL, MB_OK);
RtlSecureZeroMemory(buf, sizeof(buf));
}Функции отличаются тем, как они очищают буфер. Первая использует функцию memset(), а вторая RtlSecureZeroMemory(). Скомпилируем оптимизированный код, указав для компилятора Visual C++ 10 ключ "/O2". Рассмотрим получившийся ассемблерный код:

Рисунок 1. Функция memset() удалена.

Рисунок 2. Функция RtlSecureZeroMemory() заполняет память нулями.
Как видно в ассемблерном коде, функция memset() была удалена компилятором при оптимизации. Функция RtlSecureZeroMemory() выстроилась в код, поэтому теперь массив успешно обнуляется.
Дополнительные ссылки:
- Безопасная очистка приватных данных
- Однажды вы читали о ключевом слове volatile...
- Безопасность, безопасность! А вы её тестируете?
- Zero and forget - caveats of zeroing memory in C.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V597. |
V598. Memory manipulation function is used to work with a class object containing a virtual table pointer. The result of such an operation may be unexpected.
Анализатор обнаружил, что для работы с объектом класса используются такие низкоуровневые функции, как 'memset', 'memcpy', 'memmove', 'memcmp', 'memchr'. Это недопустимо, если класс содержит указатель на таблицу виртуальных функций (vtable).
Если указатель на объект передается в качестве целевого функциям 'memset', 'memcpy' или 'memmove', то они могут испортить vtable. Если указатель передается в качестве источника функциям 'memcpy' или 'memmove', то результат такого копирования может быть непредсказуемым. В случае с функциями 'memcmp' и 'memchr' сравнение или поиск при наличии vtable также может привести к нежелательному результату.
Рассмотрим пример кода:
class MyClass
{
public:
MyClass();
virtual ~MyClass();
private:
int A, B, C;
char buf[100];
};
MyClass::MyClass()
{
memset(this, 0, sizeof(*this));
}Обратите внимание, что в классе есть виртуальный деструктор. Это значит, что в классе присутствует vtable. Программист поленился очищать члены класса по отдельности. Для очистки он использовал функцию 'memset'. Это привет к порче vtable, так как функция 'memset' ничего про него не знает.
Корректный код:
MyClass::MyClass() : A(0), B(0), C(0)
{
memset(buf, 0, sizeof(buf));
}Начиная с C++11, можно переписать этот код следующим образом, если требуется инициализировать поля нулями:
class MyClass
{
public:
MyClass() = default;
virtual ~MyClass() = default;
private:
int A = {}, B = {}, C = {};
char buf[100] = {};
};Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V598. |
V599. The virtual destructor is not present, although the 'Foo' class contains virtual functions.
Анализатор обнаружил потенциальную ошибку, связанную с отсутствием в базовом классе виртуального деструктора.
Чтобы анализатор выдал предупреждение V599 необходимо, чтобы выполнились следующие условия:
- Объект класса уничтожается с помощью оператора
delete. - Класс имеет хотя бы одну виртуальную функцию.
Наличие виртуальных функций говорит о том, что класс могут использовать полиморфно. В этом случае виртуальный деструктор необходим, чтобы корректно разрушить объект.
Рассмотрим пример кода.
class Father
{
public:
Father() { .... }
~Father() { .... }
virtual void Foo() { .... }
};
class Son : public Father
{
public:
int *buffer;
Son() : Father() { buffer = new int[1024]; }
~Son() { delete[] buffer; }
virtual void Foo() { .... }
};
....
Father *object = new Son();
delete object; // Calls object->~Father(),
// not object->~Son()!!Нижеприведённый код является некорректным и приводит к утечке памяти. В момент уничтожения объекта (delete object;) вызывается только деструктор в классе Father. Чтобы вызвать деструктор класса 'Son' необходимо сделать деструктор виртуальным.
Корректный код:
class Father
{
public:
Father() { .... }
virtual ~Father() { .... }
virtual void Foo() { .... }
};Диагностическое правило V599 помогает выявить далеко не все проблемы, связанные с отсутствием виртуальных деструкторов. Приведем соответствующий пример: "Вы разрабатываете библиотеку. В ней есть класс XXX, в котором есть виртуальные функции, но нет виртуального деструктора. Вы в библиотеке сами не работаете с этим классом, и анализатор не предупредит об опасности. Проблема может возникнуть у программиста, использующего вашу библиотеку и наследующего свои классы от класса XXX."
Намного больше проблем позволяют выявлять предупреждения компиляторов, например, C4265 в MSVC и Wdelete-non-virtual-dtor в GCC/Clang. Это очень полезные предупреждения, но по умолчанию они выключены. Возможная причина: они дают много срабатываний в коде, где используется паттерн примесь (подмешивание, mixin). При использовании этого паттерна возникает множество интерфейсных классов. Они содержат виртуальные функции, но виртуальный деструктор в них не нужен.
Можно сказать, что диагностическое правило V599 является частным случаем описанных ранее предупреждений компиляторов. Оно дает меньше ложных срабатываний, но, к сожалению, позволяет выявить меньшее количество дефектов. Если вы хотите провести более тщательный анализ своего кода, то включите предупреждение C4265.
P.S. К сожалению, всегда объявлять деструктор виртуальным не является идеальной практикой программирования. Это приводит к дополнительным накладным расходам, так как в классе появляется указатель на таблицу виртуальных методов.
P.P.S. Родственным диагностическим правилом является V689.
Дополнительная информация:
- Wikipedia. Таблица виртуальных методов.
- Wikipedia. Виртуальный метод (виртуальная функция).
- Wikipedia. Деструктор.
- Сергей Олендаренко. Виртуальные функции и деструктор.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти), Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V599. |
V600. The 'Foo' pointer is always not equal to NULL. Consider inspecting the condition.
Анализатор обнаружил сравнение адреса массива с нулем. Такое сравнение не имеет смысла и может говорить о наличии ошибки в программе.
Рассмотрим пример кода.
void Foo()
{
short T_IND[8][13];
...
if (T_IND[1][j]==0 && T_IND[5]!=0)
T_buf[top[0]]= top[1]*T_IND[6][j];
...
}Программа обрабатывает двумерный массив. Код сложен для чтения и ошибка на первый взгляд не заметна. Однако анализатор предупредит, что сравнение "T_IND[5]!=0" не имеет смысла. Указатель "T_IND[5]" всегда не равен нулю.
Изучив предупреждения V600 можно найти ошибки, которые, как правило, связаны с опечатками. Например, может оказаться, что данный код должен выглядеть так:
if (T_IND[1][j]==0 && T_IND[5][j]!=0)Предупреждение V600 далеко не всегда означает наличие настоящей ошибки. Часто причиной появления V600 является неаккуратный рефакторинг. Рассмотрим наиболее распространенный случай. В начале код выглядел так:
int *p = (int *)malloc(sizeof(int) *ARRAY_SIZE);
...
if (!p)
return false;
...
free(p);Код менялся. Стало ясно, что значение ARRAY_SIZE небольшое и массив можно создавать на стеке. В результате получился следующий код:
int p[ARRAY_SIZE];
...
if (!p)
return false;
...Здесь выдается предупреждение V600. Однако код корректно работает. Просто получилось, что поверка "if (!p)" потеряла смысл и её можно удалить.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V600. |
V601. Suspicious implicit type casting.
Анализатор обнаружил подозрительное неявное приведение типа. Такое приведение типа может говорить о наличии ошибки или о неаккуратности в коде.
Рассмотрим первый пример.
std::string str;
bool bstr;
...
str = true;Любой программист удивится, увидев как переменной типа 'std::string' присваивают значение 'true'. Однако это вполне допустимая и работающая конструкция. Здесь программист просто ошибся и написал в коде не ту переменную.
Корректный вариант кода:
std::string str;
bool bstr;
...
bstr = true;Рассмотрим второй пример:
bool Ret(int *p)
{
if (!p)
return "p1";
...
}Строковый литерал "p1" превращается в значение 'true' и возвращается из функции. Это очень странный код.
Общие рекомендации по правке подобного кода дать сложно и каждый случай надо рассматривать отдельно.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V601. |
V602. The '<' operator should probably be replaced with '<<'. Consider inspecting this expression.
Анализатор обнаружил потенциальную ошибку, которая может возникнуть из-за опечатки. Высока вероятность, что в выражении вместо оператора '<' должен использоваться оператор '<<'.
Рассмотрим пример кода.
void Foo(unsigned nXNegYNegZNeg, unsigned nXNegYNegZPos,
unsigned nXNegYPosZNeg, unsigned nXNegYPosZPos)
{
unsigned m_nIVSampleDirBitmask =
(1 << nXNegYNegZNeg) | (1 < nXNegYNegZPos) |
(1 << nXNegYPosZNeg) | (1 << nXNegYPosZPos);
...
}Код содержит ошибку, так как случайно в выражении написан оператор '<'. Корректный вариант кода должен выглядеть так:
unsigned m_nIVSampleDirBitmask =
(1 << nXNegYNegZNeg) | (1 << nXNegYNegZPos) |
(1 << nXNegYPosZNeg) | (1 << nXNegYPosZPos);Примечание.
Анализатор считает подозрительными сравнения ('<', '>'), если полученный результат используется в двоичных операциях, таких как '&', '|' или '^'. Диагностика устроена более сложно, но надеемся, что общая идея понятна. Найдя такие выражения, анализатор выдает предупреждение V602.
Если анализатор выдает ложное срабатывание, то вы можете подавить его, используя комментарий "//-V602". Но чаще всего, этот код лучше переписать. С выражениями, которые имеют тип 'bool' лучше не работать, используя двоичные операторы. Это делает код неочевидным и затрудняет его чтение.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V602. |
V603. Object was created but not used. If you wish to call constructor, use 'this->Foo::Foo(....)'.
Анализатор обнаружил потенциальную ошибку, связанную с неправильным использованием конструктора. Программисты часто ошибаются, пытаясь явно вызвать конструктор для инициализации объекта.
Рассмотрим типичный пример, взятый из реального приложения:
class CSlideBarGroup
{
public:
CSlideBarGroup(CString strName, INT iIconIndex,
CListBoxST* pListBox);
CSlideBarGroup(CSlideBarGroup& Group);
...
};
CSlideBarGroup::CSlideBarGroup(CSlideBarGroup& Group)
{
CSlideBarGroup(Group.GetName(), Group.GetIconIndex(),
Group.GetListBox());
}В классе есть два конструктора. Для сокращения размера исходного кода программист решил вызвать один конструктор из другого, но этот код делает совсем не то, что ожидает разработчик.
Создаётся новый неименованный объект типа CSlideBarGroup и тут же разрушается. В результате поля класса остаются неинициализированными.
Правильным вариантом будет создать функцию инициализации и вызывать её из конструкторов. Корректный код:
class CSlideBarGroup
{
void Init(CString strName, INT iIconIndex,
CListBoxST* pListBox);
public:
CSlideBarGroup(CString strName, INT iIconIndex,
CListBoxST* pListBox)
{
Init(strName, iIconIndex, pListBox);
}
CSlideBarGroup(CSlideBarGroup& Group)
{
Init(Group.GetName(), Group.GetIconIndex(),
Group.GetListBox());
}
...
};Если требуется вызвать именно конструктор, то это можно записать следующим образом:
CSlideBarGroup::CSlideBarGroup(CSlideBarGroup& Group)
{
this->CSlideBarGroup::CSlideBarGroup(
Group.GetName(), Group.GetIconIndex(), Group.GetListBox());
}Другой аналогичный вариант:
CSlideBarGroup::CSlideBarGroup(CSlideBarGroup& Group)
{
new (this) CSlideBarGroup(
Group.GetName(), Group.GetIconIndex(),
Group.GetListBox());
}Приведённые примеры являются очень опасным кодом, и нужно хорошо понимать, как они работают!
Такой код приносит больше вреда, чем пользы. Рассмотрим пример, где такой вызов конструктора допустим, а где нет.
class SomeClass
{
int x,y;
public:
SomeClass() { SomeClass(0,0); }
SomeClass(int xx, int yy) : x(xx), y(yy) {}
};Код содержит ошибку. В конструкторе SomeClass() создаётся временный объект. В результате поля x и y остаются неинициализированными. Исправить код можно так:
class SomeClass
{
int x,y;
public:
SomeClass() { new (this) SomeClass(0,0); }
SomeClass(int xx, int yy) : x(xx), y(yy) {}
};Код безопасен и работает, так как класс содержит простые типы данных и не наследуется от других классов. В этом случае двойной вызов конструктора ничем не грозит.
Рассмотрим другой код, где явный вызов конструктора приводит к ошибке:
class Base
{
public:
char *ptr;
std::vector vect;
Base() { ptr = new char[1000]; }
~Base() { delete [] ptr; }
};
class Derived : Base
{
Derived(Foo foo) { }
Derived(Bar bar) {
new (this) Derived(bar.foo);
}
}Когда вызывается конструктор new (this) Derived(bar.foo);, объект Base уже создан и поля инициализированы. Повторный вызов конструктора приведёт к двойной инициализации. В ptr записывается указатель на вновь выделенный участок памяти. Результатом будет утечка памяти. Сложно предсказать, к чему приведёт двойная инициализация объекта типа std::vector, но такой код недопустим.
Вместо явного вызова конструктора рекомендуется создание функции инициализации. Явный вызов конструктора требуется только в крайне редких случаях.
Явный вызов одного конструктора из другого в C++11 (делегация)
Новый стандарт позволяет вызывать одни конструкторы класса из других (так называемая делегация). Это даёт возможность писать конструкторы, использующие поведение других конструкторов без внесения дублирующего кода.
Пример корректного кода:
class MyClass {
int m_x;
public:
MyClass(int X) : m_x(X) {}
MyClass() : MyClass(33) {}
};Конструктор MyClass без аргументов вызывает конструктор того же класса с целочисленным аргументом.
В C++03 объект считается до конца созданным, когда его конструктор завершает выполнение. В C++11 после выполнения хотя бы одного делегирующего конструктора остальные конструкторы будут работать уже над полностью сконструированным объектом. Несмотря на это объекты производного класса начнут конструироваться только после выполнения всех конструкторов базовых классов.
Дополнительная информация
- Дискуссия на Stack Overflow. C++'s "placement new".
- Дискуссия на Stack Overflow. Using new (this) to reuse constructors.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V603. |
V604. Number of iterations in loop equals size of a pointer. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку в конструкции, образующий цикл. Цикл подозрителен тем, что количество итераций, которое он выполняет, равно sizeof(указатель). Высока вероятность, что количество итераций должно соответствовать размеру массива, на который ссылается указатель.
Рассмотрим, как может возникнуть подобная ошибка. В начале, программа выглядела так:
char A[N];
for (size_t i=0; i < sizeof(A); ++i)
A[i] = 0;Затем, код программы менялся и массив 'A' стал иметь переменный размер. Код стал некорректен:
char *A = (char *)malloc(N);
for (size_t i=0; i < sizeof(A); ++i)
A[i] = 0;Теперь выражение "sizeof(A)" возвращает размер указателя, а не размер массива.
Корректный вариант кода:
char *A = (char *)malloc(N);
for (size_t i=0; i < N; ++i)
A[i] = 0;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V604. |
V605. Unsigned value is compared to the NN number. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку в выражении, где беззнаковая переменная сравнивается с отрицательным числом. Это достаточно редкая ситуация и не всегда такое сравнение является ошибкой. Однако предупреждение V605, это хороший повод, чтобы посмотреть и проверить код.
Пример кода, где будет выдано предупреждение V605:
unsigned u = ...;
if (u < -1)
{ ... }Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V605. |
V606. Ownerless token 'Foo'.
Анализатор обнаружил потенциальную ошибку, найдя в коде лишнюю лексему. Чаще всего, такие "потерянные" лексемы появляются в коде, когда забыли написать ключевое слово return.
Рассмотрим пример:
bool Run(int *p)
{
if (p == NULL)
false;
...
}Здесь случайно забыли написать "return". Код компилируется, но не имеет практического смысла.
Исправленный вариант:
bool Run(int *p)
{
if (p == NULL)
return false;
...
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V606. |
V607. Ownerless expression 'Foo'.
Анализатор обнаружил потенциальную ошибку, найдя в коде лишнее выражение. Чаще всего, такие "потерянные" выражения появляются в коде, когда забыли написать ключевое слово return или в процессе неаккуратного рефакторинга кода.
Рассмотрим пример:
void Run(int &a, int b, int c, bool X)
{
if (X)
a = b + c;
else
b - c;
}Из-за опечатки текст программы не закончен. Код компилируется, но не имеет практического смысла.
Исправленный вариант:
void Run(int &a, int b, int c, bool X)
{
if (X)
a = b + c;
else
a = b - c;
}Иногда "потерянные" выражения имеют практический смысл. Например, анализатор не будет выдавать предупреждение на следующий код:
struct A {};
struct B : public A {};
...
void Foo(B *p)
{
static_cast<A*>(p);
...
}Здесь выражение "static_cast<A*>(p);" проверяет, что класс 'B' наследуется от класса 'A'. Если это не так, то произойдет ошибка компиляции.
В качестве другого примера, можно привести подавление предупреждения компилятора о неиспользуемых переменных:
void Foo(int a, int b)
{
a, b;
}Здесь анализатор не выдаст предупреждение V607.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V607. |
V608. Recurring sequence of explicit type casts.
Анализатор обнаружил повторяющиеся последовательности, состоящие из операторов явного приведения типов. Как правило, подобный код появляется из-за опечаток и не приводит к возникновению ошибок. Однако разумно проверить фрагменты кода, где анализатор выдает предупреждение V608. Возможно, ошибка всё-таки есть. Или, по крайней мере, код можно упростить.
Рассмотрим пример:
m_hIcon = AfxGetApp()->LoadStandardIcon(
MAKEINTRESOURCE(IDI_ASTERISK));Анализатор выдаст предупреждение: V608 "Recurring sequence of explicit type casts: (LPSTR)(ULONG_PTR)(WORD) (LPSTR)(ULONG_PTR)(WORD)."
Давайте разберемся, откуда взялись две цепочки "(LPSTR)(ULONG_PTR)(WORD)".
Константное значение IDI_ASTERISK представляет собой макрос вида:
#define IDI_ASTERISK MAKEINTRESOURCE(32516)Это значит, что приведенный выше код эквивалентен этому:
m_hIcon = AfxGetApp()->LoadStandardIcon(
MAKEINTRESOURCE(MAKEINTRESOURCE(32516)));Макрос MAKEINTRESOURCE разворачивается в (LPSTR)((DWORD)((WORD)(i))). В результате получается следующая последовательность:
m_hIcon = AfxGetApp()->LoadStandardIcon(
(LPSTR)((DWORD)((WORD)((LPSTR)((DWORD)((WORD)((32516))))))
);Этот код будет корректно работать, но он избыточен. Код можно переписать без лишних приведений типов:
m_hIcon = AfxGetApp()->LoadStandardIcon(IDI_ASTERISK);Данная диагностика классифицируется как:
V609. Possible division or mod by zero.
Анализатор обнаружил ситуацию, когда может произойти деление на ноль.
Рассмотрим пример:
for (int i = -10; i != 10; ++i)
{
Foo(X / i);
}В процессе выполнения цикла, переменная 'i' примет значение, равное 0. В этот момент произойдёт деление на 0. Чтобы исправить ситуацию, необходимо специально обработать случай, когда итератор 'i' равен нулю.
Исправленный вариант:
for (int i = -10; i != 10; ++i)
{
if (i != 0)
Foo(X / i);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки деления на ноль. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V609. |
V610. Undefined behavior. Check the shift operator.
Анализатор обнаружил операцию сдвига, которая приводит к неопределенному или к неуточненному поведению (undefined behaviour/unspecified behavior).
Стандарт Си++11 описывает работу операторов сдвига следующим образом:
"The shift operators << and >> group left-to-right.
shift-expression << additive-expression
shift-expression >> additive-expression
The operands shall be of integral or unscoped enumeration type and integral promotions are performed.
1. The type of the result is that of the promoted left operand. The behavior is undefined if the right operand is negative, or greater than or equal to the length in bits of the promoted left operand.
2. The value of E1 << E2 is E1 left-shifted E2 bit positions; vacated bits are zero-filled. If E1 has an unsigned type, the value of the result is E1 * 2^E2, reduced modulo one more than the maximum value representable in the result type. Otherwise, if E1 has a signed type and non-negative value, and E1*2^E2 is representable in the result type, then that is the resulting value; otherwise, the behavior is undefined.
3. The value of E1 >> E2 is E1 right-shifted E2 bit positions. If E1 has an unsigned type or if E1 has a signed type and a non-negative value, the value of the result is the integral part of the quotient of E1/2^E2. If E1 has a signed type and a negative value, the resulting value is implementation-defined."
Приведем примеры, которые приводят к undefined или unspecified behavior:
int A = 1;
int B;
B = A << -3; // undefined behavior
B = A << 100; // undefined behavior
B = -1 << 5; // undefined behavior
B = -1 >> 5; // unspecified behaviorКонечно, это упрощенные примеры. В реальных программах ситуации сложнее. Рассмотрим практический пример:
SZ_RESULT
SafeReadDirectUInt64(ISzInStream *inStream, UInt64 *value)
{
int i;
*value = 0;
for (i = 0; i < 8; i++)
{
Byte b;
RINOK(SafeReadDirectByte(inStream, &b));
*value |= ((UInt32)b << (8 * i));
}
return SZ_OK;
}Функция пытается побайтно прочитать 64-битное значение. К сожалению, у неё это не получится, если число было больше 0x00000000FFFFFFFF. Обратите внимание на сдвиг "(UInt32)b << (8 * i)". Размер левого операнда составляет 32 бита. При этом сдвиг происходит от 0 до 56 бит. На практике это приведёт к тому, что старшая часть 64-битного значения останется заполнена нулями. Теоретически здесь вообще имеет место неопределенное поведение и результат непредсказуем.
Корректный код должен выглядеть так:
*value |= ((UInt64)b << (8 * i));Чтобы получить больше информации по рассмотренному вопросу предлагаю познакомиться со статьёй "Не зная брода, не лезь в воду. Часть третья".
Рассмотрим более подробно ситуацию, когда левый операнд отрицателен. Как правило, создаётся впечатление, что такой код всегда работает правильно. Можно подумать, что хотя это неопределённое поведение (undefined behavior), фактически все компиляторы ведут себя одинаковым образом. Это не так. Правильнее говорить, что большинство компиляторов ведут себя одинаковым образом. Если вас заботит переносимость кода, вы не должны использовать сдвиги отрицательных значений.
Подкрепим свои слова примером. Неожиданный результат можно получить, используя компилятор GCC для микропроцессора MSP430. Здесь описывается подобная ситуация. Хотя программист заявляет, что это ошибка компилятора, фактически мы имеем тот самый случай, когда компилятор ведёт себя по-другому.
Тем не менее, мы понимаем желание программистов отключить предупреждение для случаев, когда левый операнд отрицателен. Для этого можно вписать где-то в текст программы специальный комментарий:
//-V610_LEFT_SIGN_OFFЭтот комментарий следует вписать в заголовочный файл, который включается во все другие файлы. Например, таким файлом может быть "stdafx.h". Если вписать этот комментарий в "*.cpp" файл, то он будет действовать только для этого файла.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V610. |
V611. Memory allocation and deallocation methods are incompatible.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что память может выделятьcя и освобождаться несовместимыми между собой способами.
Например, анализатор предупредит, если память выделена с помощью оператора 'new', а освобождается с помощью функции 'free'.
Рассмотрим пример некорректного кода:
int *p = (int *)malloc(sizeof(int) * N);
...
...
delete [] p;Исправленный вариант:
int *p = (int *)malloc(sizeof(int) * N);
...
...
free(p);Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V611. |
V612. Unconditional 'break/continue/return/goto' within a loop.
Анализатор обнаружил подозрительный цикл. В теле цикла используется один из следующих операторов: break, continue, return, goto. Эти операторы выполняются всегда, без каких либо условий.
Рассмотрим соответствующие примеры:
do {
X();
break;
} while (Foo();)
for (i = 0; i < 10; i++) {
continue;
Foo();
}
for (i = 0; i < 10; i++) {
x = x + 1;
return;
}
while (*p != 0) {
x += *p++;
goto endloop;
}
endloop:Показанные выше примеры циклов конечно искусственны и малоинтересны. Давайте рассмотрим фрагмент кода, найденный в одном из настоящих приложений. Для большей наглядности код функции сокращён.
int DvdRead(....)
{
....
for (i=lsn; i<(lsn+sectors); i++){
....
// switch (mode->datapattern){
// case CdSecS2064:
((u32*)buf)[0] = i + 0x30000;
memcpy_fast((u8*)buf+12, buff, 2048);
buf = (char*)buf + 2064; break;
// default:
// return 0;
// }
}
....
}Часть строк в функции закомментировано. Беда в том, что забыли закомментировать оператор "break".
Когда комментариев не было, "break" был внутри тела "switch". Когда "switch" закомментировали, оператор "break" стал досрочно завершать цикл. В результате тело цикла выполняется только один раз.
Корректный вариант кода:
buf = (char*)buf + 2064; // break;Следует отметить, что диагностическое правило V612 достаточно сложно. Учитывается множество ситуаций, когда использование оператора break/continue/return/goto совершенно корректно. Рассмотрим для примера несколько ситуаций, когда предупреждение V612 выводиться не будет.
1) Наличие условия.
while (*p != 0) {
if (Foo(p))
break;
}2) Специальные приёмы, как правило, используемые в макросах:
do { Foo(x); return 1; } while(0);3) Обход оператора 'continue' с помощью 'goto':
for (i = 0; i < 10; i++) {
if (x == 7) goto skipcontinue;
continue;
skipcontinue: Foo(x);
}Возможны и другие приёмы, которые используются на практике, но про которые мы не знаем. Если вы заметили, что анализатор выдаёт ложное предупреждение V612, просим написать нам и прислать соответствующие примеры. Мы изучим их и постараемся реализовать исключения для подобных случаев.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V612. |
V613. Suspicious pointer arithmetic with 'malloc/new'.
Анализатор обнаружил потенциальную ошибку в коде, выделяющем память. Указатель, который возвращается функцией 'malloc' или аналогичной ей, складывается с каким-то числом. Это очень подозрительно и высока вероятность, что в коде имеется опечатка.
Рассмотрим пример:
a = ((int *)(malloc(sizeof(int)*(3+5)))+2);В выражении много лишних скобок и вероятно программист в них запутался. Давайте упростим этот код для наглядности:
a = (int *)malloc(sizeof(int)*8);
a += 2;Очень странно, прибавлять к указателю число 2. Даже если так надо и код правильный, он очень опасен. Например, очень легко забыть, что освобождать память надо так: "free(a - 2);".
Корректный вариант кода:
a = (int *)malloc(sizeof(int)*(3+5+2));Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V614. Use of 'Foo' uninitialized variable.
Анализатор обнаружил использование неинициализированной переменной. Использование неинициализированной переменной приводит к непредсказуемым результатам. Опасность подобных дефектов заключается в том, что они могут не проявляться годами, пока благодаря удачному стечению обстоятельств в неинициализированных переменных оказываются подходящие значения.
Рассмотрим простейший пример:
int Aa = Get();
int Ab;
if (Ab) // Ab - uninitialized variable
Ab = Foo();
else
Ab = 0;Будет или нет вызвана функция Foo(), зависит от стечения различных обстоятельств. Как правило, ошибки использования неинициализированных переменных, возникают из-за опечаток. Например, может оказаться, что в этом месте следовало использовать другую переменную. Корректный вариант кода:
int Aa = Get();
int Ab;
if (Aa) // OK
Ab = Foo();
else
Ab = 0;Предупреждение V614 выдается не только при использовании простых типов. Анализатор может выдавать предупреждение для переменных типа класс, которые имеют конструктор и, по сути, являются инициализированными. Однако их использование без предварительного присваивания не имеет смысла. Примером таких классов являются умные указатели и итераторы.
Рассмотрим примеры:
std::auto_ptr<CLASS> ptr;
UsePtr(ptr);
std::list<T>::iterator it;
*it = X;Корректный вариант кода:
std::auto_ptr<CLASS> ptr(Get());
UsePtr(ptr);
std::list<T>::iterator it;
it = Get();
*it = X;Бывает, что анализатор выдаёт ложные сообщения V614. Но иногда в этом виноват сам программист, написавший коварный код. Рассмотрим пример кода, взятый из реального приложения:
virtual size_t _fread(const void *ptr, size_t bytes){
size_t ret = ::fread((void*)ptr, 1, bytes, fp);
if(ret < bytes)
failbit = true;
return ret;
}
int read32le(uint32 *Bufo, EMUFILE *fp)
{
uint32 buf;
if(fp->_fread(&buf,4)<4) // False alarm: V614
return 0;
....
}Обратите внимание, что буфер, куда читаются данные из файла, объявлен как "const void *ptr". Чтобы код компилировался, используется явное приведение указателя к типу "(void*)". Неизвестно, что побудило программиста написать такой код. Бессмысленный квалификатор "const" путает анализатор. Анализатор считает, что функция _fread() будет использовать переменную 'buf' только для чтения. Так как переменная 'buf' не инициализирована, анализатор выдаёт предупреждение.
Этот код работает. Однако его нельзя назвать хорошим. Рационально будет его переписать. Во-первых, код станет короче и понятней. Во-вторых, исчезнет предупреждение V614.
Исправленный вариант кода:
virtual size_t _fread(void *ptr, size_t bytes){
size_t ret = ::fread(ptr, 1, bytes, fp);
if(ret < bytes)
failbit = true;
return ret;
}Есть ещё одна ситуация, когда предупреждение V614 может показаться ложным. Рассмотрим следующий синтетический пример:
std::shared_ptr<foo> GetFoo()
{
std::shared_ptr<foo> Bar;
return Bar; // V614
}Здесь создается умный указатель 'Bar' типа 'std::shared_ptr', для которого будет вызван конструктор по умолчанию. Поэтому 'Bar' всегда будет инициализирован 'nullptr'. Анализатор считает опасным использование умных указателей, созданных конструктором по умолчанию. Тем не менее, такой код имеет право на жизнь. Есть несколько способов убрать подобные предупреждения анализатора.
Можно поправить код следующим образом:
std::shared_ptr<foo> GetFoo()
{
std::shared_ptr<foo> Bar { nullptr };
return Bar; // no V614
}Такой код лучше читается, потому что теперь сразу понятно, что функция 'GetFoo' возвращает объект типа 'std::shared_ptr', содержащий нулевой указатель. В этом случае ревьюверу будет более очевидно, что предполагается именно нулевой указатель. Такая запись также является знаком анализатору, что программист знает, что он делает, и нулевой указатель возвращается осознанно, а не по ошибке.
Однако, если анализатор выдал на вашем коде много подобных предупреждений, и вы не хотите их видеть, то можно воспользоваться специальным комментарием:
//-V614_IGNORE_SMART_POINTERSЭтот комментарий следует вписать в заголовочный файл, который включается во все другие файлы. Например, таким файлом может быть "stdafx.h". Если вписать этот комментарий в "*.с" или "*.cpp" файл, то он будет действовать только для этого файла.
В ином случае можно воспользоваться механизмом подавления ложных срабатываний.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V614. |
V615. Suspicious explicit conversion from 'float *' type to 'double *' type.
Анализатор обнаружил подозрительное приведение типов указателей. Подобными подозрительными ситуациями является, когда указатель на float пытаются привести к указателю на double или наоборот. Дело в том, что типы float и double имеют различный размер и подобное приведение типов, скорее всего, свидетельствует об ошибке.
Рассмотрим простейший пример:
float *A;
double* B = (double*)(A);Несоответствие размеров приводимых типов приведет к тому, что 'B' будет указывать на некорректный для типа double формат числа. Такие ошибки приведения типов указателей возникают из-за опечаток или невнимательности. Например, может оказаться, что в этом месте следует использовать другой тип данных или другой указатель.
Корректный вариант кода:
double *A;
double* B = A;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V615. |
V616. Use of 'Foo' named constant with 0 value in bitwise operation.
Анализатор обнаружил использование нулевой константы в битовой операции И ( & ). Результатом такого выражения всегда будет нулевое значение. Это может привести к неправильной логике работы программы, если такое выражение используется в условиях или циклах.
Рассмотрим простейший пример:
enum { FirstValue, SecondValue };
int Flags = GetFlags();
if (Flags & FirstValue)
{...}Выражения в условии оператора 'if' всегда равно нулю. Это приводит к неверной логике выполнения программы. Как правило, ошибки использования нулевых констант в битовых операциях, возникают из-за опечаток или некорректного объявления констант. Например, может оказаться, что в этом месте следовало использовать другую константу. Корректный вариант кода:
enum { FirstValue, SecondValue };
int Flags = GetFlags();
if (Flags & SecondValue)
{...}Так же корректным может быть вариант, когда константа будет объявлена ненулевой. Пример кода:
enum { FirstValue = 1, SecondValue };
int Flags = GetFlags();
if (Flags & FirstValue)
{...}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V616. |
V617. Argument of the '|' bitwise operation always contains non-zero value. Consider inspecting the condition.
Анализатор обнаружил использование ненулевой константы в битовой операции ИЛИ ( | ). Результатом такого выражения всегда будет ненулевое значение. Это может привести к неправильной логике работы программы, если данное выражение будет использоваться в условиях или циклах.
Рассмотрим простейший пример:
enum { FirstValue, SecondValue };
int Flags = GetFlags();
if (Flags | SecondValue)
{...}Выражение в условии оператора 'if' всегда истинно. Как правило, ошибки использования ненулевых констант в битовых операциях, возникают из-за опечаток. Например, может оказаться, что в этом месте следовало использовать другую битовую операцию, например И ( & ). Корректный вариант кода:
enum { FirstValue, SecondValue };
int Flags = GetFlags();
if (Flags & SecondValue)
{...}Рассмотрим пример кода, найденный анализатором в реальном приложении:
#define PSP_HIDEHEADER 0x00000800
BOOL CResizablePageEx::NeedsRefresh(....)
{
if (m_psp.dwFlags | PSP_HIDEHEADER)
return TRUE;
...
return
CResizableLayout::NeedsRefresh(layout, rectOld, rectNew);
}Очевидно, что оператор 'if' будет всегда выполнять ветку 'return TRUE;', что не корректно. Исправленный вариант кода:
#define PSP_HIDEHEADER 0x00000800
BOOL CResizablePageEx::NeedsRefresh(....)
{
if (m_psp.dwFlags & PSP_HIDEHEADER)
return TRUE;
...
return
CResizableLayout::NeedsRefresh(layout, rectOld, rectNew);
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V617. |
V618. Dangerous call of 'Foo' function. The passed line may contain format specification. Example of safe code: printf("%s", str);
Анализатор обнаружил, что вызов функции форматного вывода может привести к некорректному результату. Более того, подобный код может стать объектом для атаки (подробнее см. эту статью).
Вывод строки осуществляется напрямую без использования спецификатора "%s". В результате, если в строке случайно или преднамеренно встретиться управляющий символ это приведёт к сбою в работе программы. Рассмотрим простейший пример:
char *p;
...
printf(p);Вызов функции printf(p) некорректен, поскольку отсутствует форматная строка вида "%s". Если в строке 'p' встретится спецификатор формата, то такой вывод скорее всего окажется некорректным. Безопасный вариант кода:
char *p;
...
printf ("%s", p);Предупреждение V618 может показаться несущественным. Но на самом деле это очень важный момент в создании качественных и надёжных программ.
Учтите, что совершенно неожиданно в строке вдруг могут встретиться спецификаторы формата (%i, %p и так далее). Это может произойти случайно, когда пользователь введёт некорректные входные данные. Это может произойти умышленно, когда некорректные данные будут поданы специально. Отсутствие спецификатора "%s" может привести к падению программы или в выводе куда-то приватных данных. Прежде чем отключить диагностику V618 ещё раз настаиваем на том, чтобы обязательно прочитать статью "Не зная брода, не лезь в воду. Часть вторая". Исправления в коде будут не так велики, чтобы проигнорировать данный вид дефекта.
Примечание. Анализатор старается не выдавать предупреждение V618, когда вызов функции не может привести к каким либо плохим последствиям. Пример, где анализатор не выдаёт предупреждение:
printf("Hello!");Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.), Ошибки использования форматной строки. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V618. |
V619. Array is used as pointer to single object.
Анализатор обнаружил, что к переменной, объявленной как массив данных, применяется оператор '->'. Подобный код может свидетельствовать о некорректном использовании структур данных, приводящее к неправильному заполнению полей структуры.
Рассмотрим пример некорректного кода:
struct Struct {
int r;
};
...
Struct ms[10];
for (int i = 0; i < 10; i++)
{
ms->r = 0;
...
}Такое использование некорректно, поскольку будет проинициализирован только первый элемент массива. Возможно, произошла опечатка или должна быть использована другая переменная. Корректный вариант кода:
Struct ms[10];
for (int i = 0; i < 10; i++)
{
ms[i].r = 0;
...
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V619. |
V620. Expression of sizeof(T)*N kind is summed up with pointer to T type. Consider inspecting the expression.
Анализатор обнаружил, что к переменной типа указатель прибавляется выражение, содержащее оператор sizeof(T). Такое использование может свидетельствовать о некорректной адресной арифметике.
Рассмотрим простейший пример:
int *p;
size_t N = 5;
...
p = p + sizeof(int)*N;Такое использование некорректно. Ожидается, что мы переместимся на N элементов структуры данных. Вместо этого происходит смещение на 20 элементов, поскольку sizeof(int) имеет значение 4 в 32-битных программах. В результате мы получим: "p = p + 20;". Возможно допущена опечатка или иная ошибка. Корректный вариант кода:
int *p;
size_t N = 5;
...
p = p + N;Примечание. Анализатор считает код корректным, если в нём работают с типом char. Рассмотрим пример, где анализатор не выдаёт предупреждение:
char *c;
size_t N = 5;
...
c = c + sizeof(float)*N;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V620. |
V621. Loop may execute incorrectly or may not execute at all. Consider inspecting the 'for' operator.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' используются странные начальное и конечное значения счетчика. Это может приводить к некорректному выполнению цикла и нарушению логики работы программы.
Рассмотрим пример:
signed char i;
for (i = -10; i < 100; i--)
{
...
};Возможно, произошла опечатка и перепутаны начальные и конечные значения. Так же ошибка может возникнуть, если перепутаны операторы '++' и '--'.
Корректный вариант кода:
for (i = -10; i < 100; i++)
{
...
};Также корректным будет следующий код:
for (i = 100; i > -10; i--)
{
...
};Рассмотрим код, найденный анализатором в реальном приложении:
void CertificateRequest::Build()
{
...
uint16 authCount = 0;
for (int j = 0; j < authCount; j++) {
int sz = REQUEST_HEADER + MIN_DIS_SIZE;
...
}
}Переменная 'authCount' инициализируется неправильным значением или здесь вообще должна быть использована другая переменная.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V621. |
V622. First 'case' operator may be missing. Consider inspecting the 'switch' statement.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в блоке оператора 'switch' первым оператором не является оператор 'case'. Это приводит к тому, что фрагмент кода никогда не получит управление.
Рассмотрим пример:
char B = '0';
int I;
...
switch(I)
{
B = '1';
break;
case 2:
B = '2';
break;
default:
B = '3';
break;
}Присваивание "B = '1';" никогда не будет выполнено. Корректный вариант кода:
switch(I)
{
case 1:
B = '1';
break;
case 2:
B = '2';
break;
default:
B = '3';
break;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V622. |
V623. Temporary object is created and then destroyed. Consider inspecting the '?:' operator.
Анализатор обнаружил возможную ошибку при работе с тернарным оператором '?:'. Если при работе с оператором '?:' совместно используются объект типа класс и любой другой тип, который может быть преобразован к данному классу, то создаются временные объекты. Временные объекты будут удалены по завершению оператора '?:'. Ошибка возникает, если мы при этом сохраняем результат в переменную типа указатель.
Рассмотрим пример:
CString s1(L"1");
wchar_t s2[] = L"2";
bool a = false;
...
const wchar_t *s = a ? s1 : s2;В результате выполнения этого кода переменная 's' будет указывать на данные, находящиеся внутри временного объекта. Беда в том, что этот объект уже уничтожен!
Корректный вариант кода:
wchar_t s1[] = L"1";
wchar_t s2[] = L"2";
bool a = false;
...
const wchar_t *s = a ? s1 : s2;Другой вариант корректного кода:
CString s1(L"1");
wchar_t s2[] = L"2";
bool a = false;
...
CString s = a ? s1 : s2;Предупреждение V623 требует со стороны программиста повышенного внимания. Беда в том, что ошибки данного типа хорошо прячутся. Код, содержащий подобные ошибки может успешно работать многие годы. Но это только иллюзия, что он работает. На самом деле используется освобождённая память. То, что в памяти находятся корректные данные - это только везение. Поведение программы может поменяться в любой момент. Это может произойти при смене версии компилятора. Это может произойти, после рефакторинга кода, когда появляется новый объект, использующий ту же область памяти. Рассмотрим это на примере.
Напишем, скомпилируем и запустим следующий код:
bool b = false;
CComBSTR A("ABCD");
wchar_t *ptr = b ? A : L"Test OK";
wcout << ptr << endl;Этот код мы скомпилировали с помощью Visual Studio 2010 и он распечатал "Test OK". Может показаться, что всё работает правильно. Но внесём в код небольшую правку:
bool b = false;
CComBSTR A("ABCD");
wchar_t *ptr = b ? A : L"Test OK";
wchar_t *tmp = b ? A : L"Error!";
wcout << ptr << endl;Кажется строчка, где инициализируется переменная 'tmp' ничего не изменит. Но это не так. Теперь программа печатает на экран: "Error!".
Дело в том, что новый временный объект использовал ту же области памяти, что и предыдущий. Кстати, следует учитывать, что данный код по стечению обстоятельств вполне может работать. Всё зависит от везения и фазы луны. Предугадать, где будут создаваться временные объекты невозможно. Поэтому не отказывайтесь от правки кода, основываясь на утверждении "этот код правильно работал несколько лет и значит, ошибки в нём нет".
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V623. |
V624. Use of constant NN. The resulting value may be inaccurate. Consider using the M_NN constant from <math.h>.
Анализатор обнаружил возможную ошибку при работе с константами типа double. Возможно, для математических расчетов используются константы недостаточной точности или константа записана с ошибкой.
Рассмотрим пример:
double pi = 3.141592654;Такая запись не совсем корректна и лучше использовать математические константы из заголовочного файла 'math.h'. Корректный вариант кода:
#include <math.h>
...
double pi = M_PI;Анализатор не считает ошибочной явную запись констант в формате 'float'. Это связано с тем, что тип 'float' имеет меньше значащих разрядов, по сравнению с типом 'double'. Пример кода:
float f = 3.14159f; //okДанная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V624. |
V625. Initial and final values of the iterator are the same. Consider inspecting the 'for' operator.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' совпадают начальное и конечное значения счетчика. Такое использование оператора 'for' приведет к тому, что цикл не будет выполнен ни разу или выполнен только один раз.
Рассмотрим пример:
void beginAndEndForCheck(size_t beginLine, size_t endLine)
{
for (size_t i = beginLine; i < beginLine; ++i)
{
...
}Тело цикла никогда не выполняется. Скорее всего, произошла опечатка и следует заменить "i < beginLine" на корректное выражение "i < endLine". Корректный вариант кода:
for (size_t i = beginLine; i < endLine; ++i)
{
...
}Другой пример:
for (size_t i = A; i <= A; ++i)
...Тело этого цикла будет выполнено только один раз. Скорее всего, это не то, что задумывал программист.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V625. |
V626. It's possible that ',' should be replaced by ';'. Consider checking for typos.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что вместо точки запятой ';' случайно написана запятая ','. Такая опечатка может привести к неправильной логике выполнения программы.
Рассмотрим пример:
int a;
int b;
...
if (a == 2)
a++,
b = a;В результате выражение "b = a;" будет выполняться только когда верно условие оператора 'if', скорее всего произошла опечатка и следует заменить ',' на ';'. Корректный вариант кода:
if (a == 2)
a++;
b = a;Анализатор не будет обнаруживать ошибку, если форматирование фрагмента кода отражает преднамеренное использовать оператор ','. Пример кода:
if (a == 2)
a++,
b = a;
if (a == 2)
a++, b = a;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V626. |
V627. Argument of sizeof() is a macro, which expands to a number. Consider inspecting the expression.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что аргументом оператор 'sizeof' является макрос, раскрывающийся в число. Такое использование оператора может привести к выделению некорректного размера памяти и иным ошибкам.
Рассмотрим пример:
#define NPOINT 100
...
char *point = (char *)malloc(sizeof(NPOINT));В результате выполнения данного кода будет выделен недостаточный объем памяти. Корректный вариант кода:
#define NPOINT 100
...
char *point = (char *)malloc(NPOINT);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V627. |
V628. It is possible that a line was commented out improperly, thus altering the program's operation logic.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что два последовательно идущих оператора 'if' оказались разделены закомментированной строкой. Высока вероятность, что неаккуратно был закомментирован фрагмент кода. Неаккуратность привела к тому, что существенно изменилась логика работы программы.
Рассмотрим пример:
if(!hwndTasEdit)
//hwndTasEdit = getTask()
if(hwndTasEdit)
{
...
}Программа потеряла смысл. Условие второго оператора 'if' никогда не выполняется. Корректный вариант кода:
//if(!hwndTasEdit)
//hwndTasEdit = getTask()
if(hwndTasEdit)
{
...
}Анализатор не выдает ошибки в коде, где форматирование кода соответствует преднамеренному использованию последовательно двух операторов 'if', разделенных строкой комментария. Пример кода:
if (Mail == ready)
// comment
if (findNewMail)
{
...
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V628. |
V629. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку в выражении, содержащем операцию сдвига. В программе выполняется сдвиг 32-битного значения. Затем полученный 32-битный результат явно или неявно преобразуется в 64-битный тип.
Рассмотрим пример некорректного кода:
unsigned __int64 X;
X = 1u << N;Данный код вызывает неопределенное поведение, если значение N больше 32. На практике это означает, что с помощью этого кода не получится записать в переменную 'X' значение более 0x80000000.
Код можно исправить, если тип левого аргумента будет 64-битным.
Исправленный вариант кода:
unsigned __int64 X;
X = 1ui64 << N;Обратите внимание, что диагностика V629 не относится к 64-битным ошибкам. Под 64-битными ошибками понимаются те ситуации, когда 32-битная версия программы работает корректно, а 64-битная некорректно.
Рассматриваемая здесь ситуация приводит к ошибке как в 32-битной, так и в 64-битной программе. Поэтому диагностика V629 относится к правилам общего назначения.
Анализатор не будет выдавать предупреждение, если результат выражения со сдвигом укладывается в 32-битный тип. Это означает, что значащие биты не потеряны и код корректен.
Пример безопасного кода:
char W = 7;
long long Q = W << 10;Этот код работает следующим образом. Вначале переменная 'W' расширяется до 32-битного типа 'int'. Затем происходит сдвиг и получается значение 0x00001C00. Это число помещается в 32-битный тип, а значит ошибки не возникнет. На последнем этапе это значение расширяется до 64-битного типа 'long long' и записывается в переменную 'Q'.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V629. |
V630. The 'malloc' function is used to allocate memory for an array of objects that are classes containing constructors/destructors.
Анализатор обнаружил потенциальную ошибку, связанную с использованием одной из функций динамического выделения памяти, такой как malloc, calloc, realloc. С выделенной памятью работают как с массивом объектов, имеющих конструктор или деструктор. При таком выделении памяти для класса не будет вызван конструктор. При освобождении памяти с помощью функции free не будет вызван деструктор. Это крайне подозрительно. Подобный код может привести к работе с неинициализированными переменными и другим ошибкам.
Рассмотрим пример некорректного кода:
class CL
{
int num;
public:
CL() : num(0) {...}
...
};
...
CL *pCL = (CL*)malloc(sizeof(CL) * 10);В результате переменная 'num' будет не инициализирована. Конечно, можно вызвать конструктор для каждого объекта "вручную", но более правильным будет использование оператора 'new'.
Исправленный вариант:
CL *pCL = new CL[10];Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V630. |
V631. Defining absolute path to file or directory is considered a poor coding style. Consider inspecting the 'Foo' function call.
Анализатор обнаружил потенциальную ошибку при вызове функции, предназначенную для работы с файлами. В одном из фактических аргументов в функцию передаётся абсолютный путь до файла или директории. Такое использование функции является опасным, поскольку могут встретиться случаи, когда данного пути не будет существовать на компьютере пользователя.
Рассмотрим пример некорректного кода:
FILE *text = fopen("c:\\TEMP\\text.txt", "r");Более корректным будет вариант получения пути к файлу исходя из определенных условий.
Исправленный вариант кода:
string fullFilePath = GetFilePath() + "text.txt";
FILE *text = fopen(fullFilePath.c_str(), "r");Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V631. |
V632. Argument is of the 'T' type. Consider inspecting the NN argument of the 'Foo' function.
Анализатор обнаружил потенциальную ошибку, связанную с передачей подозрительного аргумента в функцию. В функцию был передан аргумент в формате числа с плавающей точкой, хотя ожидался целочисленный тип данных. Такое использование является некорректным, поскольку значение аргумента будет приведено к целочисленному типу.
Рассмотрим пример некорректного кода:
double buf[N];
...
memset(buf, 1.0, sizeof(buf));Программист планировал заполнить массив значениями '1.0'. Однако этот код заполнит массив мусором.
Второй аргумент функции 'memset' имеет целочисленный тип. Этот аргумент определяет, каким значением заполнить каждый байт массива.
Произойдет приведение '1.0' к целочисленному значению '1'. Массив данных 'buf' будет заполнен побайтно единичными значениями. Такой результат отличается от заполнения каждого элемента массива значением '1.0'.
Исправленный вариант кода:
double buf[N];
...
for (size_t i = 0; i != N; ++i)
buf[i] = 1.0;Данная диагностика классифицируется как:
|
V633. The '!=' operator should probably be used here. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку. Возможно вместо оператора '=!' следует написать '!=' или '==!'. Подобные ошибки чаще всего возникают из-за опечатки.
Рассмотрим пример некорректного кода:
int A, B;
...
if (A =! B)
{
...
}С большой вероятностью здесь должна быть проверка, что переменная 'A' не равна 'B'. Если это так, то корректный вариант кода должен выглядеть следующим образом:
if (A != B)
{
...
}Анализатор учитывает форматирование в выражении. Поэтому если действительно требуется выполнить присваивание, а не сравнение, необходимо указать, используя скобки или пробелы. Следующие примеры кода считаются анализатором корректными:
if (A = !B)
...
if (A=(!B))
...Данная диагностика классифицируется как:
|
V634. Priority of '+' operation is higher than priority of '<<' operation. Consider using parentheses in the expression.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что операции сложения, вычитания, деления и умножения имеют более высокий приоритет, чем операции сдвига. Про это часто забывают. В результате выражение может давать совсем не тот результат, на который рассчитывал программист.
Рассмотрим пример некорректного кода:
int X = 1<<4 + 2;Скорее всего, программист ожидал, что результат сдвига '1' на '4' будет сложен с '2'. Но согласно приоритету операций в языке Си/Си++ вначале произойдет сложение, а уже потом сдвиг.
Можно порекомендовать во всех выражениях с редко используемыми вами операторами, писать скобки. Даже если скобки окажутся лишними, это не страшно. Зато код станет более легким для чтения и понимания и будет меньше подвержен ошибкам.
Корректный вариант кода:
int X = (1<<4) + 2;А как убрать ложное предупреждение, если действительно планировалась последовательность вычислений: сначала сложение, затем сдвиг?
Есть 3 варианта:
1) Самый плохой вариант. Можно использовать комментарий "//-V634" для подавления предупреждения в нужной строке.
int X = 1<<4 + 2; //-V6342) Можно добавить дополнительные скобки:
int X = 1<<(4 + 2);3) Можно уточнить ваши намерения, используя пробелы:
int X = 1 << 4+2;Дополнительные ресурсы:
- Терминология. Приоритет операций в языке Си/Си++. http://www.viva64.com/ru/t/0064/
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V634. |
V635. Length should be probably multiplied by sizeof(wchar_t). Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку, связанную c выделением некорректного размера памяти для хранения строки в формате UNICODE.
Как правило, такая ошибка возникает, если для вычисления размера массива используется функция 'strlen' или 'wcslen'. Нередко полученное количество символов забывают умножить на sizeof(wchar_t). В результате в программе может возникнуть доступ за границу массива.
Рассмотрим пример некорректного кода:
wchar_t src[] = L"abc";
wchar_t *dst = (wchar_t *)malloc(wcslen(src) + 1);
wcscpy(dst, src);В данном случае будет выделено всего 4 байта памяти. Так как тип 'wchar_t' имеет размер 2 или 4 байта в зависимости от модели данных, этой памяти может не хватить. Для исправления ошибки требуется умножить выражение внутри 'malloc' на 'sizeof(wchar_t)'.
Корректный вариант кода:
wchar_t *dst =
(wchar_t *)malloc((wcslen(src) + 1) * sizeof(wchar_t));Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V635. |
V636. Expression was implicitly cast from integer type to real type. Consider using an explicit type cast to avoid overflow or loss of a fractional part.
В выражении присутствует операция умножения или деления целочисленных типов данных. Полученное значение неявно преобразуется к типу с плавающей точкой. Обнаружив такую ситуацию, анализатор предупреждает о наличии потенциальной ошибки, которая может привести к переполнению или к вычислению неточного результата.
Рассмотрим возможные ошибки на примерах.
Ситуация первая. Переполнение.
int LX = 1000;
int LY = 1000;
int LZ = 1000;
int Density = 10;
double Mass = LX * LY * LZ * Density;Мы хотим вычислить массу объекта, зная его плотность и размеры. Мы знаем, что результирующее значение может быть большим. Поэтому, переменная 'Mass' имеет тип 'double'. Однако этот код не учитывает, что перемножаются переменные типа 'int'. В результате, в правой части выражения произойдет целочисленное переполнение и результат будет некорректен.
Исправить ситуацию можно двумя способами. Можно изменить типы переменных:
double LX = 1000.0;
double LY = 1000.0;
double LZ = 1000.0;
double Density = 10.0;
double Mass = LX * LY * LZ * Density;Другой способ - это использовать явное приведение типов:
int LX = 1000;
int LY = 1000;
int LZ = 1000;
int Density = 10;
double Mass = (double)(LX) * LY * LZ * Density;Достаточно привести к типу 'double' только первую переменную. Поскольку операция умножения относится к лево-ассоциативным операторам, то вычисление будет происходить следующим образом: (((double)(LX) * LY) * LZ) * Density. В результате каждый из операндов перед умножением будет преобразовываться к типу 'double' и мы получим корректный результат.
P.S. Напомним, что вот так, делать неправильно: Mass = (double)(ConstMass) + LX * LY * LZ * Density. Выражение справа от оператора '=' будет иметь тип 'double'. Но перемножаться будут по-прежнему переменные типа 'int'.
Ситуация вторая. Потеря точности.
int totalTime = 1700;
int operationNum = 900;
double averageTime = totalTime / operationNum;Программист может ожидать, что переменная 'averageTime' будет иметь значение '1.888(8)', однако при выполнении программы будет получен результат равный '1.0'. Это происходит потому, что операция деления выполняется с целочисленными типами и только затем приводится к типу с плавающей точкой.
Как и в предыдущем случае, ошибку можно исправить 2 способами.
Первый способ - изменить типы переменных:
double totalTime = 1700;
double operationNum = 900;
double averageTime = totalTime / operationNum;Второй способ - использовать явное приведение типов.
int totalTime = 1700;
int operationNum = 900;
double averageTime = (double)(totalTime) / operationNum;Примечание
Естественно, в некоторых случаях нужно произвести именно целочисленное деление. В таких случаях, чтобы скрыть ложное предупреждение, можно использовать комментарий вида:
//-V636
См. также: Документация. Подавление ложных предупреждений.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V636. |
V637. Use of two opposite conditions. The second condition is always false.
Анализатор обнаружил возможную логическую ошибку в программе. Ошибка заключается в том, что два условных оператора, идущих последовательно, содержат взаимоисключающие условия.
Примеры взаимоисключающих условий:
- 'A == B' и 'A != B';
- 'B < C' и 'B > C';
- 'X == Y' и 'X < Y';
- и так далее.
Как правило, такая ошибка возникает вследствие опечатки или неудачного рефакторинга. В результате логика выполнения программы нарушается.
Рассмотрим пример некорректного кода:
if (A == B)
if (B != A)
B = 5;В данном случае высказывание "B = 5;" никогда не будет выполнено. Скорее всего, в первом или втором условиях используется некорректная переменная. Следует посмотреть логику выполнения программы.
Корректный вариант кода:
if (A == B)
if (B != C)
B = 5;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V637. |
V638. Terminal null is present inside a string. Use of '\0xNN' characters. Probably meant: '\xNN'.
Анализатор обнаружил потенциальную ошибку, связанную с наличием внутри строки терминального нулевого символа.
Как правило, такая ошибка возникает вследствие опечатки. Например, последовательность "\0x0A" будет восприниматься как следующая последовательность из четырёх байт: { '\0', 'x', '0', 'A' }.
Если хочется задать код символа в шестнадцатеричном виде, то символ 'x' должен стоять сразу после символа '\'. Если написать "\0", то это будет воспринято как ноль (в формате восьмеричного числа). См. также:
- MSDN. C Character Constants.
- MSDN. Escape Sequences.
Рассмотрим пример некорректного кода:
const char *s = "string\0x0D\0x0A";Если попробовать распечатать эту строку, то управляющие символы для перевода строки использованы не будут. Функции вывода остановятся на символе конца строки '\0'. Для устранения этой ошибки следует заменить "\0x0D\0x0A" на "\x0D\x0A".
Корректный вариант кода:
const char *s = "string\x0D\x0A";Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V638. |
V639. One of closing ')' parentheses is probably positioned incorrectly. Consider inspecting the expression for function call.
Анализатор обнаружил потенциальную ошибку, связанную c подозрительным вызовом функции, за которой следуют запятые и выражения. Возможно, эти выражения должны быть частью вызова функции.
Как правило, такая ошибка возникает, если происходит вызов функции внутри условного оператора и функция имеет аргументы по умолчанию. В таком случае легко по ошибке поставить закрывающую скобку не в том месте, где необходимо. Опасность такого рода ошибок в том, что код компилируется без ошибок и выполняется. Рассмотрим пример некорректного кода:
bool rTuple(int a, bool Error = true);
....
if (rTuple(exp), false)
{
....
}Неправильно поставленная закрывающаяся скобка приведут сразу к двум ошибкам:
1) Аргумент 'Error' при вызове функции 'rTuple' будет равен 'true', хотя хотели 'false'.
2) Оператор запятая ',' возвращает значение правой части. Значит условие (rTuple(exp), false) будет всегда равно значению 'false'
Корректный вариант кода:
if (rTuple(exp, false))
{
....
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V639. |
V640. Code's operational logic does not correspond with its formatting.
Анализатор обнаружил потенциальную ошибку, связанную c тем, что форматирование кода, следующих за условным оператором, не соответствует логике выполнения программы. Высока вероятность, что пропущены открывающиеся и закрывающиеся фигурные скобки.
Рассмотрим пример некорректного кода:
if (a == 1)
b = c; d = b;В данном случае присваивание 'd = b;' будет выполняться всегда, независимо от условия 'a == 1'.
Если код ошибочен, то ситуацию можно исправить, используя фигурные скобки. Корректный вариант кода:
if (a == 1)
{ b = c; d = b; }Другой пример некорректного кода:
if (a == 1)
b = c;
d = b;Для исправления ошибки так же следует использовать фигурные скобки. Корректный вариант кода:
if (a == 1)
{
b = c;
d = b;
}Если код корректен, то чтобы исчезло предупреждение V640, следует отформатировать код следующим образом:
if (a == 1)
b = c;
d = b;Нередко данный класс ошибок можно встретить в программах, активно использующих макросы. Рассмотрим ошибку, найденную в реальном приложении:
#define DisposeSocket(a) shutdown(a, 2); closesocket(a)
...
if (sockfd > 0)
(void) DisposeSocket(sockfd);Вызов функции 'closesocket(a);' будет выполняться всегда. Это приведет к сбою, если переменная 'sockfd' окажется <= 0.
Можно исправить ошибку, используя в макросе фигурные скобки. Но лучше написать полноценную функцию. Код без макросов безопаснее и удобней при отладке.
Корректный пример кода может выглядеть следующим образом:
inline void DisposeSocket(int a) {
shutdown(a, 2);
closesocket(a);
}
...
if (sockfd > 0)
DisposeSocket(sockfd);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V640. |
V641. Buffer size is not a multiple of element size.
Анализатор обнаружил потенциальную ошибку, связанную c приведением указателя на исходный буфер к указателю на другой тип, при этом размер исходного буфера некратен размеру одного элемента полученного типа. Рассмотрим два класса ошибок, допускаемых при приведениях типов.
Первый класс ошибок связан с выделением некорректного размера памяти для хранения элементов массива с помощью функций 'malloc', 'calloc', 'alloca', 'realloc' и т.д.
Как правило, такие ошибки возникают, если размер выделяемой памяти задается константой (константами в случае 'calloc'). Для правильного выделения памяти под 'N' элементов массива типа 'T' рекомендуется использовать оператор 'sizeof(T)'. В зависимости от функции, аллоцирующей память, конструкция может иметь следующий вид:
int *p = (int*)malloc(N * sizeof(int));или
int *p = (int*)calloc(N, sizeof(int));В результате неправильного выделения памяти в программе может возникнуть выход за границу массива.
Рассмотрим пример некорректного кода с использованием функции 'malloc':
int *p = (int*)malloc(70);В данном случае будет выделено 70 байт памяти. Обращение к элементу 'p[17]' приведет к неопределенному поведению, поскольку произойдет выход за границу (необходимо 72 байта для корректного чтения 18-го элемента). Корректный вариант кода будет следующим:
p = (int*)malloc(72);Также возможен случай, когда требуется выделить память для хранения 70 элементов. Корректным будет такой вариант кода:
p = (int*)malloc(70 * sizeof(int));Рассмотрим пример некорректного кода из реального проекта с использованием функции 'calloc':
int data16len = MultiByteToWideChar(CP_UTF8,
0,
data,
datalen,
NULL,
0);
if (!data16)
{
data16 = (wchar_t*)calloc(data16len + 1, 1);
}
MultiByteToWideChar(CP_UTF8, 0, data, -1, data16, data16len);В данном случае хотели создать буфер для сохранения широкой (wide) строки после конвертации из UTF-8 строки. Однако размер 'wchar_t' не равен 1 байту (Windows - 2 байта, Linux - 4 байта). Корректный вариант кода будет выглядеть следующим образом:
data16 = (wchar_t*)calloc(data16len + 1, sizeof(wchar_t));Примечание к функции 'calloc'. Несмотря на то, что прототип функции выглядит следующим образом:
void* calloc(size_t num, size_t size );некоторые программисты полагают, что размер выделяемой памяти равен num*size и часто меняют аргументы местами. Такой код может приводить к ошибкам. Цитата из документации: "Due to the alignment requirements, the number of allocated bytes is not necessarily equal to num*size.".
Второй класс ошибок связан с преобразованием указателя на объект типа 'A' к указателю на объект типа 'B'. Рассмотрим пример:
struct A
{
int a, b;
float c;
unsigned char d;
};
struct B
{
int a, b;
float c;
unsigned short d;
};
....
A obj1;
B *obj2 = (B*)&obj1; //V641
std::cout << obj2->d;
....Как видно из примера, две структуры отличаются друг от друга последним полем. Поле 'd' у приведённых структур имеет разный размер типа. При преобразовании указателя 'A*' к 'B*' можно получить неопределенное поведение при обращении к полю 'd'. Отметим, что преобразование указателя 'B*' к 'A*' возможно (хотя это плохой код), и неопределенного поведения не будет.
Анализатор не будет выдавать предупреждения на преобразование указателя 'A*' к 'B*', если два класса (структуры) находятся в иерархии наследования.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V641. |
V642. Function result is saved inside the 'byte' type variable. Significant bits may be lost. This may break the program's logic.
Анализатор обнаружил потенциальную ошибку, связанную c сохранением результата работы функции в переменную, которая занимает всего 8 или 16 бит. Для некоторых функций, которые возвращают статус типа 'int', это может быть недопустимо. Могут быть потеряны значащие биты.
Рассмотрим пример некорректного кода:
char c = memcmp(buf1, buf2, n);
if (c != 0)
{
...
}Функция 'memcmp' возвращает следующие значения типа 'int':
- < 0 - buf1 less than buf2;
- 0 - buf1 identical to buf2;
- > 0 - buf1 greater than buf2;
Обратите внимание. "Больше 0", означает любые числа, а вовсе не 1. Этими числами могут быть: 2, 3, 100, 256, 1024, 5555, и так далее. Это значит, что этот результат нельзя поместить в переменную типа 'char'. Могут быть отброшены значащие биты, что приведет к нарушению логики выполнения программы.
Опасность такого рода ошибок заключается в том, что возвращаемое значение может зависеть от архитектуры и реализации конкретной функции на данной архитектуре. Например, программа будет корректно работать в 32-битном варианте и некорректно в 64-битном.
Корректный вариант кода:
int c = memcmp(buf1, buf2, n);
if (c != 0)
{
...
}Возможно, кому-то данная опасность покажется надуманной. Однако такая ошибка послужила причиной серьезной уязвимости в MySQL/MariaDB до версий 5.1.61, 5.2.11, 5.3.5, 5.5.22. Суть в том, что при подключении пользователя MySQL /MariaDB вычисляется токен (SHA от пароля и хэша), который сравнивается с ожидаемым значением функцией 'memcmp'. На некоторых платформах возвращаемое значение может выпадать из диапазона [-128..127]. В итоге, в 1 случае из 256 процедура сравнения хэша с ожидаемым значением всегда возвращает значение 'true', независимо от хэша. В результате, простая команда на bash даёт злоумышленнику рутовый доступ к уязвимому серверу MySQL, даже если он не знает пароль. Причиной этому стал такой код в файле 'sql/password.c':
typedef char my_bool;
...
my_bool check(...) {
return memcmp(...);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V642. |
V643. Suspicious pointer arithmetic. Value of 'char' type is added to a string pointer.
Анализатор обнаружил потенциальную ошибку, связанную c некорректным прибавлением символьной константы к указателю на строковый литерал.
Как правило, такая ошибка возникает в случае попытки объединения строкового литерала с символом.
Рассмотрим простейший пример некорректного кода:
std::string S = "abcd" + 'x';Ожидалось, что будет получена строка "abcdx", однако в данном случае к указателю на строку "abcd" будет прибавлено значение 120. Это гарантировано приведет к выходу за границу строкового литерала. Для предотвращения такой ситуации, следует избегать подобных арифметических операций со строковыми и символьными переменными.
Корректный вариант кода:
std::string S = std::string("abcd") + 'x';Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V643. |
V644. Suspicious function declaration. Consider creating a 'T' type object.
Анализатор обнаружил потенциальную ошибку, связанную c неправильным созданием объекта типа 'T'.
Как правило, такая ошибка возникает, если пропущен аргумент вызова конструктора данного типа. В таком случае вместо создания объекта нужного типа, получится объявление функции, возвращающей тип 'T'. Данная ошибка, как правило, возникает при использовании вспомогательных классов, упрощающих блокирование и разблокирование мьютексов. Например, в библиотеке 'Qt' таким классом является 'QMutexLocker', который упрощает работу с классом 'QMutex'.
Рассмотрим пример некорректного кода:
QMutex mutex;
...
QMutexLocker lock();
++objectVarCounter;Опасность такого рода ошибок в том, что данный код компилируется и выполняется без ошибок. Однако требуемого результата получено не будет. То есть не происходит блокирование других потоков, использующих переменную 'objectVarCounter'. Поэтому выявление таких ошибок может занять много времени и сил.
Корректный вариант кода:
QMutex mutex;
...
QMutexLocker lock(&mutex);
++objectVarCounter;Данная диагностика классифицируется как:
V645. Function call may lead to buffer overflow. Bounds should not contain size of a buffer, but a number of characters it can hold.
Анализатор обнаружил потенциальную ошибку, связанную c конкатенацией строк. Ошибка может приводить к переполнению буфера. Неприятность подобных ошибок заключается в том, что программа долгое время может работать стабильно, если на вход функции поступают только короткие строки.
Данному виду уязвимости подвержены такие функции, как 'strncat', 'wcsncat' и так далее [1].
Описание функции 'strncat':
char *strncat(
char *strDest,
const char *strSource,
size_t count
);Где:
- 'destination' - строка получатель;
- 'source' - строка источник;
- 'count' - максимальное число символов, которые можно добавить.
Функция 'strncat', пожалуй, одна из самых опасных строковых функций. Опасность возникает из-за того, что принцип её работы отличается от того, как представляют его себе программисты.
Третий аргумент указывает не размер буфера, а сколько ещё символов в него можно поместить. Вот цитата из описания этой функции в MSDN: "strncat does not check for sufficient space in strDest; it is therefore a potential cause of buffer overruns. Keep in mind that count limits the number of characters appended; it is not a limit on the size of strDest."
К сожалению, про это редко помнят и используют 'strncat' неправильными способами. Можно выделить три типа ошибок:
1) Разработчики считают, что аргумент 'count' — это размер буфера 'strDest'. В результате, можно видеть в программах следующий некорректный код:
char newProtoFilter[2048] = "....";
strncat(newProtoFilter, szTemp, 2048);
strncat(newProtoFilter, "|", 2048);Программист предполагает, что, передавая в качестве третьего аргумента число 2048, он защищает код от переполнения. Это не так. Он указывает, что к строке можно добавить ещё до 2048 символов!
2) Забывают, что после копирования символов, функция 'strncat' добавит терминальный 0. Пример опасного кода:
char filename[NNN];
...
strncat(filename,
dcc->file_info.filename,
sizeof(filename) - strlen(filename));На первый взгляд, кажется, что теперь программист защитился от переполнения буфера 'filename'. Но это не так. Он вычел из размера массива длину строки. Это значит, что если вся строка уже заполнена, выражение 'sizeof(filename) - strlen(filename)' вернет единицу. В результате к строке будет прибавлен ещё один символ, а терминальный ноль будет записан уже за границы буфера.
Поясним эту ошибку на более простом примере:
char buf[5] = "ABCD";
strncat(buf, "E", 5 - strlen(buf));В буфере уже нет места для новых символов. В нём находится 4 символа и терминальный ноль. Выражение "5 - strlen(buf)" равно 1. Функция strncpy() скопирует символ "E" в последний элемент массива 'buf'. Терминальный 0 будет записан уже за пределами буфера!
3) Забывают о факторе целочисленного переполнения. Рассмотрим пример такой ошибки:
struct A
{
....
char consoleText[512];
};
void foo(A a)
{
char inputBuffer[1024];
....
strncat(a.consoleText, inputBuffer,
sizeof(a.consoleText) - strlen(a.consoleText) - 5);
}Здесь в качестве третьего аргумента используется инфиксное выражение. При невнимательном изучении кода может показаться, что значение выражения "sizeof(a.consoleText) - strlen(a.consoleText) – 5" лежит в диапазоне [0, 507], и код корректен. Однако это не так:
- Результат функции 'strlen(a.consoleText)' может быть в диапазоне [0, 511].
- Если 'strlen(a.consoleText)' вернет значение от 0 до 507, то результирующее значение выражения также будет в диапазоне [0, 507], переполнения буфера 'a.consoleText' не происходит.
- Если 'strlen(a.consoleText)' вернет значение от 508 до 511, то в результирующем выражении произойдет беззнаковое переполнение. В случае если тип 'size_t' имеет размер 64-бита, то соответственно будет получен диапазон [0xFFFFFFFFFFFFFFFC, 0xFFFFFFFFFFFFFFFF]. Получается, что в буфер как будто можно записать огромное количество символов. Естественно, это не так, и как следствие в коде происходит переполнение буфера 'a.consoleText'.
Чтобы исправить приведённые выше примеры, их нужно переписать следующим образом:
// Sample N1
char newProtoFilter[2048] = "....";
strncat(newProtoFilter, szTemp,
2048 - 1 - strlen(newProtoFilter));
strncat(newProtoFilter, "|",
2048 - 1 - strlen(newProtoFilter));
// Sample N2
char filename[NNN];
...
strncat(filename,
dcc->file_info.filename,
sizeof(filename) - strlen(filename) - 1);
// Sample N3
void foo(A a)
{
char inputBuffer[1024];
....
size_t textSize = strlen(a.consoleText);
if (sizeof(a.consoleText) - textSize > 5u)
{
strncat(a.consoleText, inputBuffer,
sizeof(a.consoleText) - textSize - 5);
}
else
{
// ....
}
}Этот код нельзя назвать красивым или по-настоящему надежным. Гораздо лучшим решением будет отказ от функций типа 'strncat' в пользу более безопасных. Например, можно использовать класс 'std::string' или такие функции, как 'strncat_s', и так далее [2].
Дополнительные ресурсы
- MSDN. strncat, _strncat_l, wcsncat, wcsncat_l, _mbsncat _mbsncat_l
- MSDN. strncat_s, _strncat_s_l, wcsncat_s, _wcsncat_s_l, _mbsncat_s, _mbsncat_s_l
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V645. |
V646. The 'else' keyword may be missing. Consider inspecting the program's logic.
Оператор if расположен на той же строке, что и закрывающаяся скобка от предыдущего if. Возможно, в этом месте пропущено ключевое слово 'else' и программа работает не так, как ожидал программист.
Рассмотрим простой пример некорректного кода:
if (A == 1) {
Foo1(1);
} if (A == 2) {
Foo2(2);
} else {
Foo3(3);
}В случае если переменная 'A' принимает значение 1, то произойдет вызов не только функции 'Foo1', но и вызов функции 'Foo3'. Следует обратить внимание на логику выполнения программы, возможно так и должно быть. В случае ошибки следует добавить ключевое слово 'else'.
Корректный вариант кода:
if (A == 1) {
Foo1(1);
} else if (A == 2) {
Foo2(2);
} else {
Foo3(3);
}Так же корректным анализатор считает код, в котором в 'then' части первого условного оператора 'if' есть безусловный оператор 'return'. Поскольку в таком случае логика выполнения программы не нарушается, а присутствует только не совсем корректное форматирование кода. Пример такого кода:
if (A == 1) {
Foo1(1);
return;
} if (A == 2) {
Foo2(2);
} else {
Foo3(3);
}Если ошибки нет, то устранить предупреждение V646 можно, если перенести оператор 'if' на следующую строку. Пример такого кода:
if (A == 1) {
Foo1(1);
}
if (A == 2) {
Foo2(2);
} else {
Foo3(3);
}В приведенных выше примерах ошибка очевидна, и, кажется, что вряд ли она встретится в реальных программах. Однако, если код сложен, очень легко не заметить отсутствие оператора 'else'. Вот пример этой ошибки, взятый из реального приложения:
if( 1 == (dst->nChannels) ) {
ippiCopy_16s_C1MR((Ipp16s*)pDstCh, dstStep,
(Ipp16s*)pDst, dst->widthStep, roi, pMask, roi.width);
} if( 3 == (dst->nChannels) ) { //V646
ippiCopy_16s_C3R((Ipp16s*)pDst-coi, dst->widthStep,
(Ipp16s*)pTmp, dst->widthStep, roi);
ippiCopy_16s_C1C3R((Ipp16s*)pDstCh, dstStep,
(Ipp16s*)pTmp+coi, dst->widthStep, roi);
ippiCopy_16s_C3MR((Ipp16s*)pTmp, dst->widthStep,
(Ipp16s*)pDst-coi, dst->widthStep, roi, pMask, roi.width);
} else {
ippiCopy_16s_C4R((Ipp16s*)pDst-coi, dst->widthStep,
(Ipp16s*)pTmp, dst->widthStep, roi);
ippiCopy_16s_C1C4R((Ipp16s*)pDstCh, dstStep,
(Ipp16s*)pTmp+coi, dst->widthStep, roi);
ippiCopy_16s_C4MR((Ipp16s*)pTmp, dst->widthStep,
(Ipp16s*)pDst-coi, dst->widthStep, roi, pMask, roi.width);
}Этот код очень сложен для чтения и понимания. Однако анализатор не теряет бдительности.
В данном примере условия '3 == (dst->nChannels)' и '1 == (dst->nChannels)' не могут выполниться одновременно, и форматирование кода указывает на пропущенное ключевое слово 'else'. Корректный вариант должен выглядеть следующим образом:
if( 1 == (dst->nChannels) ) {
....
} else if( 3 == (dst->nChannels) ) {
....
} else {
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V646. |
V647. Value of 'A' type is assigned to a pointer of 'B' type.
Анализатор обнаружил, что выполняется некорректная операция с указателем. В указатель на целочисленный тип записывается целочисленное значение или константа. Скорее всего, в указатель следует поместить адрес переменной. Или следует поместить значение по адресу, который содержит указатель.
Рассмотрим пример некорректного кода:
void foo()
{
int *a = GetPtr();
int b = 10;
a = b; // <=
Foo(a);
}В данном случае указателю 'a' будет присвоено значение 10. Фактически мы получим не валидный указатель. Для исправления следует разыменовать указатель 'a' или взять адрес переменной 'b'.
Корректный вариант кода:
void foo()
{
int *a = GetPtr();
int b = 10;
*a = b;
Foo(a);
}Так же корректным будет такой код:
void foo()
{
int *a = GetPtr();
int b = 10;
a = &b;
Foo(a);
}Анализатор считает безопасным, когда в переменную типа указатель записываются такие магические значения, как: -1, 0xcccccccc, 0xbadbeef, 0xdeadbeef, 0xfeeefeee, 0xcdcdcdcd и т.д. Эти значения часто используются в целях отладки или как специальные маркеры.
Примечание N1.
Подобная ошибка возможна только в языке Си. В Си++ неявное приведение целочисленного значения (кроме 0) к указателю невозможно.
Примечание N2.
Иногда сообщения анализатора могут казаться странными. Рассмотрим такой случай:
char *page_range_split = strtok(page_range, ",");Анализатор выдаёт предупреждение, что значение типа 'int' помещается в указатель. Но ведь функция 'strtok' возвращает указатель, как же так?
Дело в том, что функция 'strtok' может быть не объявлена ранее! Разработчик мог забыть подключить нужный заголовочный файл. В языке C считается, что по умолчанию функция возвращает тип 'int'. Именно исходя из этих предположений и будет скомпилирован код. Это серьёзная ошибка, которая будет приводить к порче указателей в 64-битных программах. Подробнее эта тема разбирается в статье "Красивая 64-битная ошибка на языке Си".
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V647. |
V648. Priority of '&&' operation is higher than priority of '||' operation.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что приоритет логической операций '&&' выше приоритета логической операции '||'. Про это часто забывают. В результате логическое выражение может давать совсем не тот результат, на который рассчитывал программист.
Рассмотрим пример некорректного кода:
if ( c == 'l' || c == 'L' &&
!( token->subtype & TT_LONG ) )
{ .... }Скорее всего, программист ожидал, что вначале выполнится проверка равенства переменной 'c' значению 'l' или 'L'. И только затем выполнится операция '&&'. Но согласно приоритету операций в языке Си/Си++ вначале произойдет выполнение операции '&&', а уже потом '||'.
Можно порекомендовать во всех выражениях с редко используемыми вами операторами или там где нет уверенности, писать скобки. Даже если скобки окажутся лишними, это не страшно. Зато код станет более легким для понимания и будет меньше подвержен ошибкам.
Корректный вариант кода:
if ( ( c == 'l' || c == 'L' ) &&
!( token->subtype & TT_LONG ) )А как убрать ложное предупреждение, если действительно планировалась последовательность вычислений: сначала логическое '&&', затем логическое '||'?
Есть несколько вариантов:
1) Плохой вариант. Можно использовать комментарий "//-V648" для подавления предупреждения в нужной строке.
if ( c == 'l' || c == 'L' && //-V648
!( token->subtype & TT_LONG ) )2) Хороший вариант. Можно добавить дополнительные скобки:
if ( c == 'l' || ( c == 'L' &&
!( token->subtype & TT_LONG ) ) )Дополнительные скобки помогут вашим коллегам понять, что этот код корректен.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V648. |
V649. Two 'if' statements with identical conditional expressions. The first 'if' statement contains function return. This means that the second 'if' statement is senseless.
Анализатор обнаружил ситуацию, когда 'then' часть оператора 'if' никогда не получит управления. Это происходит из-за того, что ранее уже встречается оператор 'if' с таким же условием, содержащий в 'then' части безусловный оператор 'return'. Это может свидетельствовать как о логической ошибке в программе, так и избыточном втором операторе 'if'.
Рассмотрим пример некорректного кода:
if (l >= 0x06C0 && l <= 0x06CE) return true;
if (l >= 0x06D0 && l <= 0x06D3) return true;
if (l == 0x06D5) return true; // <=
if (l >= 0x06E5 && l <= 0x06E6) return true;
if (l >= 0x0905 && l <= 0x0939) return true;
if (l == 0x06D5) return true; // <=
if (l >= 0x0958 && l <= 0x0961) return true;
if (l >= 0x0985 && l <= 0x098C) return true;В данном случае условие 'l == 0x06D5' дублируется и для исправления кода достаточно убрать одно из них. Однако возможно, что во втором случае проверяемое значение должно отличаться от первого случая.
Корректный вариант кода:
if (l >= 0x06C0 && l <= 0x06CE) return true;
if (l >= 0x06D0 && l <= 0x06D3) return true;
if (l == 0x06D5) return true;
if (l >= 0x06E5 && l <= 0x06E6) return true;
if (l >= 0x0905 && l <= 0x0939) return true;
if (l >= 0x0958 && l <= 0x0961) return true;
if (l >= 0x0985 && l <= 0x098C) return true;Предупреждение V649 косвенно может указать на наличие ошибок совсем иного типа. Рассмотрим интересный пример некорректного кода:
AP4_Result AP4_StscAtom::WriteFields(AP4_ByteStream& stream)
{
AP4_Result result;
AP4_Cardinal entry_count = m_Entries.ItemCount();
result = stream.WriteUI32(entry_count);
for (AP4_Ordinal i=0; i<entry_count; i++) {
stream.WriteUI32(m_Entries[i].m_FirstChunk);
if (AP4_FAILED(result)) return result;
stream.WriteUI32(m_Entries[i].m_SamplesPerChunk);
if (AP4_FAILED(result)) return result;
stream.WriteUI32(m_Entries[i].m_SampleDescriptionIndex);
if (AP4_FAILED(result)) return result;
}
return result;
}Имеющиеся в цикле проверки 'if (AP4_FAILED(result)) return result;' бессмысленны. Переменная 'result' не изменяется при чтении данных из файлов.
Исправленный вариант кода:
AP4_Result AP4_StscAtom::WriteFields(AP4_ByteStream& stream)
{
AP4_Result result;
AP4_Cardinal entry_count = m_Entries.ItemCount();
result = stream.WriteUI32(entry_count);
for (AP4_Ordinal i=0; i<entry_count; i++) {
result = stream.WriteUI32(m_Entries[i].m_FirstChunk);
if (AP4_FAILED(result)) return result;
result = stream.WriteUI32(m_Entries[i].m_SamplesPerChunk);
if (AP4_FAILED(result)) return result;
result = stream.WriteUI32(m_Entries[i].m_SampleDescriptionIndex);
if (AP4_FAILED(result)) return result;
}
return result;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V649. |
V650. Type casting is used 2 times in a row. The '+' operation is executed. Probably meant: (T1)((T2)a + b).
Анализатор обнаружил потенциальную ошибку в выражении с адресной арифметикой. Операции сложения/вычитания выполняется с выражением, представляющим собой двойное приведение типов. Это может быть опечаткой - забыли заключить первое приведение типа и операцию сложения в скобки.
Рассмотрим пример некорректного кода:
ptr = (int *)(char *)p + offset_in_bytes;Скорее всего, программист ожидал, что переменная 'p' будет приведена к типу 'char *' и к ней будет добавлено смещение в байтах. Затем новый указатель будет приведен к типу 'int *'.
Однако пропущенные скобки превращают это выражение в двойное приведение типов и добавление смещения к указателю на 'int'. Полученный результат будет отличаться от ожидаемого результата. Подобная ошибка вполне может привести к выходу за границы массива.
Корректный вариант кода:
ptr = (int *)((char *)p + offset_in_bytes);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V650. |
V651. Suspicious operation of 'sizeof(X)/sizeof(T)' kind, where 'X' is of the 'class' type.
Анализатор обнаружил потенциальную ошибку в выражении вида 'sizeof(X)/sizeof(X[0])'. Подозрительно то, что объект 'X' является экземпляром класса.
Как правило, выражение 'sizeof(X)/sizeof(X[0]) применяется для определения количества элементов в массиве 'X'. Ошибка может возникнуть в ходе неаккуратного рефакторинга кода. Переменная 'X' изначально была обыкновенным массивом и была заменена на класс-контейнер, но вычисление числа элементов осталось прежним.
Рассмотрим пример некорректного кода:
#define countof( x ) (sizeof(x)/sizeof(x[0]))
Container<int, 4> arr;
for( int i = 0; i < countof(arr); i++ )
{ .... }Программист ожидал, что будет вычислено число элементов переменной 'arr'. Однако полученное значение будет представлять собой: размер класса, разделённый на размер переменной типа 'int'. Это значение, скорее всего, никак не связано с количеством элементов данных, хранящихся в контейнере.
Пример корректного кода:
const size_t count = 4;
Container<int, count> arr;
for( int i = 0; i < arr.size(); i++ )
{ .... }Данная диагностика классифицируется как:
V652. Operation is executed 3 or more times in a row.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что одна из операций '!', '~', '-' или '+' повторяется три или более раз. Такая ошибка может произойти в случае опечатки. Такое дублирование операторов бессмысленно и может содержать ошибку.
Рассмотрим пример некорректного кода:
if(B &&
C && !!!
D) { .... }Скорее всего, такая ошибка возникла вследствие опечатки. Например, были пропущены символы комментария или напечатан лишний символ операции.
Корректный вариант кода:
if (B &&
C && //!!!
D) { .... }Так же корректным будет следующий вариант кода:
if (B &&
C && !!D) { .... }Такой приём часто используется для приведения целочисленных типов данных к типу 'bool'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V652. |
V653. Suspicious string consisting of two parts is used for initialization. Comma may be missing.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что в объявлении, состоящем из строковых литералов, две строки объединяются в одну. Ошибка может быть следствием опечатки, когда пропущена запятая между строковыми литералами.
Такая ошибка может долго оставаться незамеченной. Например, она может редко проявлять себя, если массив строковых литералов используется для формирования сообщений об ошибках.
Рассмотрим пример некорректного кода:
const char *Array [] = {
"Min", "Max", "1",
"Begin", "End" "2" };Между литералами "End" и "2" пропущена запятая, и поэтому они будут объединены в один строковый литерал "End2". Для исправления такой ошибки следует разделить строковые литералы запятой.
Корректный вариант кода:
const char *Array [] = {
"Min", "Max", "1",
"Begin", "End", "2" };Анализатор не выдает предупреждающих сообщений, если объединённая строка окажется слишком большой (более 50 символов) или состоит более чем из двух фрагментов. Такой прием часто используется при оформлении кода с длинными строковыми литералами.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V653. |
V654. Condition of a loop is always true/false.
Анализатор обнаружил ситуацию, когда условие в операторе 'for' или 'while' всегда истинно или ложно. Подобная ситуация часто свидетельствует о наличии ошибок. Высока вероятность того, что произошла опечатка и следует обратить внимание на этот фрагмент кода.
Рассмотрим пример некорректного кода:
for (i = 0; 1 < 50; i++)
{ .... }В коде допущена опечатка. В условии вместо переменной 'i' была напечатана константа '1'. Исправить такой код не представляет больших трудностей. Корректный вариант кода:
for (i = 0; i < 50; i++)
{ .... }Анализатор не будет выдавать предупреждающее сообщение, если условие задано явно в виде константного выражения '1' или '0', 'true' или 'false'. Пример такого кода:
while (true)
{ .... }Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V654. |
V655. Strings were concatenated but not used. Consider inspecting the expression.
Анализатор обнаружил потенциальную ошибку, найдя в коде неиспользуемое объединение строковых переменных. Тип переменных: std::string, CString, QString, wxString. Чаще всего, такие выражения появляются в коде, когда пропускается оператор присваивания или в процессе неаккуратного рефакторинга кода.
Рассмотрим пример некорректного кода:
void Foo(std::string &s1, const std::string &s2)
{
s1 + s2;
}Код содержит опечатку. Вместо '+=' написано '+'. Код компилируется, но не имеет практического смысла. Исправленный вариант кода:
void Foo(std::string &s1, const std::string &s2)
{
s1 += s2;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V655. |
V656. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
Анализатор обнаружил потенциальную ошибку, найдя в коде инициализацию двух различных переменных одинаковыми выражениями. Анализатор считает опасными не все выражения, а только в которых используется вызов функций.
Рассмотрим наиболее простой случай:
x = X();
y = X();Возможны три варианта действий:
1) Код содержит ошибку. Необходимо исправить ошибку, заменив 'X()' на 'Y()'.
2) Код верен, но работает медленно. Если функция 'X()' требует много вычислений, то лучше написать 'y = x;'.
3) Код верен и работает быстро. Или функция 'X()' читает значение из файла. Тогда чтобы избавиться от ложного срабатывания, можно использовать комментарий "//-V654".
Теперь рассмотрим реальный пример:
while (....)
{
if ( strstr( token, "playerscale" ) )
{
token = CommaParse( &text_p );
skin->scale[0] = atof( token );
skin->scale[1] = atof( token );
continue;
}
}В данном коде нет ошибки. Однако код не оптимален. Его можно переписать таким образом, что бы исключить лишний вызов функции 'atof'. Учитывая то, что присваивание находится в цикле и может быть вызвано много раз, такое изменение может привести к заметному выигрышу в быстродействии функции. Исправленный вариант кода:
while (....)
{
if ( strstr( token, "playerscale" ) )
{
token = CommaParse( &text_p );
skin->scale[1] = skin->scale[0] = atof( token );
continue;
}
}Рассмотрим ещё один пример:
String path, name;
SplitFilename(strSavePath, &path, &name, NULL);
CString spath(path.c_str());
CString sname(path.c_str());В данном примере присутствует явная ошибка. Переменная 'path' используется два раза: для инициализации переменных 'spath' и 'sname'. Однако, по логике программы видно, что для инициализации переменной 'sname' должна быть использована переменная 'name'. Исправленный вариант кода:
....
CString spath(path.c_str());
CString sname(name.c_str());Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V656. |
V657. Function always returns the same value of NN. Consider inspecting the function.
Анализатор обнаружил странную функцию. Функция не имеет состояния, не изменяет глобальных переменных. При этом она имеет несколько точек возврата, возвращающих одно и то же числовое значение.
Такой код крайне подозрителен и может свидетельствовать о возможной ошибке. Скорее всего, функция должна возвращать различные числовые значения.
Рассмотрим простой пример такого кода:
int Foo(int a)
{
if (a == 33)
return 1;
return 1;
}Данный код содержит ошибку. Для ее исправления изменим одно из возвращаемых значений. Определить необходимые возвращаемые значения, как правило, можно только зная логику работы всего приложения в целом.
Вариант корректного кода:
int Foo(int a)
{
if (a == 33)
return 1;
return 2;
}Если код верен, то чтобы избавиться от ложного срабатывания следует использовать комментарий "//-V657".
Данная диагностика классифицируется как:
V658. Value is subtracted from unsigned variable. It can result in an overflow. In such a case, the comparison operation may behave unexpectedly.
Анализатор обнаружил потенциальную ошибку, связанную с переполнением.
Выполняются следующие действия:
- из переменной, имеющей беззнаковый тип, вычитается некоторое значение;
- полученный результат сравнивается с некоторым значением (используются операторы <, <=, >, >=).
Если при вычитании возможно переполнение, то результат проверки может отличаться от ожиданий программиста.
Рассмотрим наиболее простой случай:
unsigned A = ...;
int B = ...;
if (A - B > 1)
Array[A - B] = 'x';Такая проверка по замыслу программиста должна защитить от выхода за границу массива. Однако эта проверка не поможет, если переменная A < B.
Пусть: A = 3, B = 5;
Тогда: 0x00000003u - 0x00000005i = FFFFFFFEu
Выражение "A - B" согласно правилам языка Си++ имеет тип "unsigned int". Значит, "A - B" будет равно FFFFFFFEu. Это число больше единицы. В результате произойдёт обращение к памяти за границей массива.
Исправить код можно двумя способами. Во-первых, вычисления можно производить в переменных знаковых типов:
intptr_t A = ...;
intptr_t B = ...;
if (A - B > 1)
Array[A - B] = 'x';Во-вторых, можно изменить условие. Как именно следует изменить условие, зависит от желаемого результата и входных значений. Если B >= 0, то достаточно будет написать:
unsigned A = ...;
int B = ...;
if (A > B + 1)
Array[A - B] = 'x';Если код корректен, то можно отключить вывод диагностического сообщения в данной строке, используя комментарий "//-V658".
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V658. |
V659. Functions' declarations with 'Foo' name differ in 'const' keyword only, while these functions' bodies have different composition. It is suspicious and can possibly be an error.
Анализатор обнаружил в коде две функции с одинаковыми именами. Функции различаются константностью.
Объявления функции могут различаться:
- константностью возвращаемого значения;
- константностью аргументов;
- константностью самой функции (в случае методов класса).
Хотя имена функций совпадают, они работают по-разному. Это может свидетельствовать об ошибке.
Рассмотрим простой случай:
class CLASS {
DATA *m_data;
public:
char operator[](size_t index) const {
if (!m_data || index >= m_data->len)
throw MyException;
return m_data->data[index];
}
char &operator[](size_t index) {
return m_data->data[index];
}
};В константной функции 'operator[]' существует проверка и генерируется исключение в случае ошибки. В неконстантной функции такой поверки нет. Скорее всего, это недочёт, который должен быть исправлен.
Анализатор учитывает набор различных ситуаций, когда различия в телах функций оправданы. Однако всё исключительные ситуации учесть невозможно. Если анализатор выдал ложное срабатывание, то его можно подавить, используя комментарий "//-V659".
V660. Program contains an unused label and function call: 'CC:AA()'. Probably meant: 'CC::AA()'.
Анализатор обнаружил потенциальную ошибку, когда из-за опечатки написано ':', хотя необходимо '::'.
В коде метода класса найдена неиспользуемая метка. Вслед за этой меткой следует вызов функции. Анализатор считает опасным, если функция с таким именем находится в одном из базовых классов.
Рассмотрим пример:
class Employee {
public:
void print() const {}
};
class Manager: public Employee {
void print() const;
};
void Manager::print() const {
Employee:print();
}С большой вероятностью строчка 'Employee:print();' является ошибочной. Ошибка заключается в том, что будет вызвана функция не из класса 'Employee', как планировалось, а из своего же класса 'Manager'. Для исправления ошибки достаточно заменить ':' на '::'.
Корректный вариант кода:
void Manager::print() const {
Employee::print();
}Рассмотрим ещё один пример:
namespace Abcd
{
void Foo() {}
}
class Employee {
void Foo() {}
void X() { Abcd:Foo(); }
};Здесь ошибка заключается в том, что должна была быть вызвана функция, находящаяся в области видимости 'Abcd'. Ошибку легко исправить:
void X() { Abcd::Foo(); }Данная диагностика классифицируется как:
V661. Suspicious expression 'A[B < C]'. Probably meant 'A[B] < C'.
Анализатор обнаружил подозрительный фрагмент кода, в котором осуществляется доступ к элементу массива. В качестве индекса массива используется логическое выражение.
Примеры таких выражений: Array[A >= B], Array[A != B]. Возможно, что закрывающаяся квадратная скобка стоит не на своем месте. Подобные ошибки, чаще всего возникают из-за опечатки.
Рассмотрим пример некорректного кода:
if ((bs->inventory[INVENTORY_ROCKETLAUNCHER] <= 0 ||
bs->inventory[INVENTORY_ROCKETS < 10]) && <<== ERROR!
(bs->inventory[INVENTORY_RAILGUN] <= 0 ||
bs->inventory[INVENTORY_SLUGS] < 10)) {
return qfalse;
}Такой код компилируется, но работает неправильно. С большой вероятностью, здесь должно быть написано:
if ((bs->inventory[INVENTORY_ROCKETLAUNCHER] <= 0 ||
bs->inventory[INVENTORY_ROCKETS] < 10) &&
(bs->inventory[INVENTORY_RAILGUN] <= 0 ||
bs->inventory[INVENTORY_SLUGS] < 10)) {
return qfalse;
}Примечание. Анализатор выдает предупреждения не всегда, когда в квадратных скобках находится логическое выражение. Иногда это оправдано. Например, исключение составляет случай, когда массив состоит всего из двух элементов:
int A[2];
A[x != y] = 1;Взгляните на примеры ошибок, обнаруженных с помощью диагностики V661. |
V662. Different containers are used to set up initial and final values of iterator. Consider inspecting the loop expression.
Анализатор обнаружил подозрительный цикл. Для инициализации итератора используется контейнер A. Затем, этот итератор сравнивается с концом контейнера B. Высока вероятность, что это опечатка и код некорректен.
Рассмотрим пример, когда будет выдано данное предупреждение:
void useVector(vector<int> &v1, vector<int> &v2)
{
vector<int>::iterator it;
for (it = v1.begin(); it != v2.end(); ++it)
*it = rand();
....
}В цикле 'for' происходит заполнение массива. Для инициализации итератора и для проверки границы используются различные переменные (v1 и v2). Если на самом деле ссылки v1 и v2 указывают на разные массивы, это приведет к ошибке на этапе исполнения программы.
Исправить ошибку очень просто. Необходимо использовать один и тот же контейнер в обоих случаях. Корректный вариант кода:
void useVector(vector<int> &v1, vector<int> &v2)
{
vector<int>::iterator it;
for (it = v1.begin(); it != v1.end(); ++it)
*it = rand();
....
}Если переменная v1 и v2 ссылаются на один и тот же контейнер, то код корректен. В этом случае можно использовать механизм подавления ложных срабатываний анализатора. Но скорее всего, более удачным решением является рефакторинг кода. Такой код может запутать не только анализатор, но и программистов, которые будут сопровождать этот код.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V662. |
V663. Infinite loop is possible. The 'cin.eof()' condition is insufficient to break from the loop. Consider adding the 'cin.fail()' function call to the conditional expression.
Анализатор обнаружил потенциальную ошибку, из-за которой может возникнуть бесконечный цикл. При работе с классом 'std::istream' недостаточно вызова функции 'eof()' для завершения цикла. В случае возникновения сбоя при чтении данных, вызов функции 'eof()' будет всегда возвращать значение 'false'. Для завершения цикла в этом случае необходима дополнительная проверка значения, возвращаемого функцией 'fail()'.
Рассмотрим пример некорректного кода:
while (!cin.eof())
{
int x;
cin >> x;
}Исправить ошибку можно усложнив условие. Корректный вариант кода:
while (!cin.eof() && !cin.fail())
{
int x;
cin >> x;
}Впрочем, у этого варианта тоже есть недостатки. Наиболее простой и правильный вариант кода выглядит так:
int x;
while(cin >> x) {
....;
}Подробно вопрос чтения из потока разбирается здесь: Why is iostream::eof inside a loop condition (i.e. 'while (!stream.eof())') considered wrong?
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V663. |
V664. Pointer is dereferenced in the member initializer list before it is checked for null in the body of a constructor.
Указатель разыменовывается в списке инициализации конструктора, а затем проверяется в теле конструктора на неравенство нулю. Это может свидетельствовать о скрытой ошибке, которая может не проявляться долгое время.
Рассмотрим пример некорректного кода:
Layer(const Canvas *canvas) :
about(canvas->name, canvas->coord)
{
if (canvas)
{
....
}
}При разыменовании нулевого указателя возникает неопределенное поведение, то есть дальнейшее нормальное выполнение программы становится невозможным. Для исправления ошибки следует перенести инициализацию в тело конструктора в блок кода, где указатель заведомо неравен нулю. Корректный вариант кода:
Layer(const Canvas *canvas)
{
if (canvas)
{
about.set(canvas->name, canvas->coord);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V664. |
V665. Possible incorrect use of '#pragma warning(default: X)'. The '#pragma warning(push/pop)' should be used instead.
Анализатор обнаружил, что в коде находится некорректная последовательность директив '#pragma warning'.
Программисты часто считают, что после директивы "pragma warning(default : X)" опять начнут действовать предупреждения, отключенные ранее помощью "pragma warning(disable: X)". Это не так. Директива 'pragma warning(default : X)' устанавливает предупреждение с номером 'X' в состояние, которое действует ПО УМОЛЧАНИЮ. Это далеко не одно и то же.
Предположим, что файл компилируется с ключом /Wall. В этом случае, должно выдаваться предупреждение C4061. Если написать "#pragma warning(default : 4061)", то это предупреждение перестанет выдаваться, так как по умолчанию оно является отключенным.
Правильным способом возвращения предыдущего состояние предупреждения является использование "#pragma warning(push[ ,n ])" и "#pragma warning(pop)". С описанием этих директив можно познакомиться в документации к Visual C++: Pragma Directives. Warnings.
Рассмотрим пример некорректного кода:
#pragma warning(disable: 4001)
....
//Корректный код, выдающий предупреждение 4001
....
#pragma warning(default: 4001)В данном примере предупреждение 4001 будет установлено в значение по умолчанию. Но, скорее всего, планировалось вернуть предыдущее значение, которое было до его отключения. Для этого следует воспользоваться директивой 'pragma warning(push)' до отключения предупреждения и директивой 'pragma warning(pop)' после корректного кода.
Корректный вариант кода:
#pragma warning(push)
#pragma warning(disable: 4001)
....
// Корректный код, выдающий предупреждение 4001
....
#pragma warning(pop)Особенное внимание предупреждению V665 должны уделять разработчики библиотек. Неаккуратная работа с настройками предупреждений может вызвать массу неприятных моментов у пользователей такой библиотеки.
Хорошая статья по данной теме: "Итак, вы хотите заглушить это предупреждение в Visual C++".
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V665. |
V666. Value may not correspond with the length of a string passed with YY argument. Consider inspecting the NNth argument of the 'Foo' function.
Анализатор предполагает, что в функцию мог быть передан некорректный аргумент. Некорректным считается аргумент, числовое значение которого не совпадает с длиной строки, которая находится в предыдущем аргументе. Анализатор строит такие предположения, анализируя пары аргументов, состоящих из строкового литерала и целочисленной константы. Анализ производится по всем одноименным вызовам функций.
Рассмотрим пример некорректного кода:
if (!_strnicmp(szDir, "My Documents", 11)) // <<== Error!
nFolder = 1;
if (!_strnicmp(szDir, "Desktop", 7))
nFolder = 2;
if (!_strnicmp(szDir, "Network Favorites", 17))
nFolder = 3;В данном случае в первом вызове функции числовое значение 11 некорректно. Это может привести к тому, что если переменная 'szDir' будет указывать на строковый литерал "My Document", то сравнение пройдет успешно. Для исправления достаточно изменить длину строки на корректное значение, то есть 12.
Корректный вариант кода:
if (!_strnicmp(szDir, "My Documents", 12))
nFolder = 1;Диагностика V666 носит эмпирический характер. Если вы хотите понять его суть, то, к сожалению, придется прочитать сложное объяснение. Это можно не делать, но тогда просим внимательно проверить аргументы функции. Если вы уверены, что код совершенно корректен, то можно отключить вывод диагностического сообщения, добавив комментарий, вида "//-V666".
Давайте попробуем разобраться, как работает это диагностическое правило. Рассмотрим код:
foo("1234", 1, 4);
foo("123", 2, 3);
foo("321", 2, 2);Анализатор выберет пары аргументов: строковый литерал и числовое значение. Для них будут проанализированы все вызовы данной функции и построена таблица совпадения длины строки и числового аргумента.
{ { "1234", 1 }, { "1234", 4 } } -> { false, true }
{ { "123", 2 }, { "123", 3 } } -> { false, true }
{ { "321", 2 }, { "321", 2 } } -> { false, false }
Первый столбец не интересен. Не похоже, что это длина строки. А вот второй столбец, кажется, представляет собой длину строки. При этом один из вызовов содержит ошибку.
Конечно, это описание очень схематично, но позволяет понять общий принцип работы. Такой анализ, конечно же, не идеален и будут появляться ложные срабатывания. Однако он позволяет иногда находить интересные ошибки.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V666. |
V667. The 'throw' operator does not have any arguments and is not located within the 'catch' block.
Анализатор обнаружил, что оператор 'throw' не имеет аргументов и не находится внутри блока 'catch'. Такой код может являться ошибочным. Оператор 'throw' без аргументов используется внутри блока 'catch' для проброса пойманного исключения на верхний уровень. Согласно стандарту, вызов оператора 'throw' без аргумента, если еще не поймано исключение приведет к вызову функции 'std::terminate()'. Это означает, что программа будет завершена.
Рассмотрим пример некорректного кода:
try
{
if (ok)
return;
throw;
}
catch (...)
{
}Для исправления ошибки необходимо передать оператору 'throw' аргумент.
Корректный вариант кода:
try
{
if (ok)
return;
throw exception("Test");
}
catch (...)
{
}Однако, вызов оператора 'throw' вне 'catch' блока - это не всегда ошибка. Например, если функция вызывается из блока 'catch' и занимается перебросом исключения на верхний уровень, то ошибки не будет. Однако анализатор не может понять такого поведения программы и все равно будет выдано диагностическое сообщение. Пример такого кода:
void error()
{
try
{
....
if (ok)
return;
throw; <<== на самом деле здесь ошибки нет
}
catch (...)
{
throw;
}
}
void foo()
{
try
{
....
if (ok)
return;
throw exception("Test");
}
catch (...)
{
error();
}
}В таком случаем вывод диагностического сообщения анализатора можно подавить, используя комментарий вида '//-V667'.
Данная диагностика классифицируется как:
|
V668. Possible meaningless check for null, as memory was allocated using 'new' operator. Memory allocation will lead to an exception.
Анализатор обнаружил ситуацию, когда значение указателя возвращаемого оператором 'new' сравнивается с нулём. Как правило, это значит, что программа при невозможности выделить память будет вести себя не так, как ожидает программист.
Если оператор 'new' не смог выделить память, то согласно стандарту языка Си++, генерируется исключение std::bad_alloc(). Таким образом проверять указатель на равенство нулю не имеет смысла. Рассмотрим простейший случай:
MyStatus Foo()
{
int *p = new int[100];
if (!p)
return ERROR_ALLOCATE;
...
return OK;
}Указатель 'p' никогда не будет равен нулю. Функция никогда не вернет константное значение ERROR_ALLOCATE. Если выделить память невозможно, то возникнет исключение. Исправим код наиболее простым образом:
MyStatus Foo()
{
try
{
int *p = new int[100];
...
}
catch(const std::bad_alloc &)
{
return ERROR_ALLOCATE;
}
return OK;
}Отметим, что приведенный пример исправленного кода очень плох. Идеология работы с исключениями совсем иная. Исключения как раз позволяют избавиться от множества проверок и возвращаемых статусов. Лучше позволить исключению выйти за пределы функции 'Foo' и обработать его где-то на более высоком уровне. К сожалению, рассмотрение использования исключений выходит за рамки документации.
Рассмотрим, как подобная ошибка может выглядеть на практике. Вот код, взятый из реального приложения:
// For each processor; spawn a CPU thread to access details.
hThread = new HANDLE [nProcessors];
dwThreadID = new DWORD [nProcessors];
ThreadInfo = new PTHREADINFO [nProcessors];
// Check to see if the memory allocation happenned.
if ((hThread == NULL) ||
(dwThreadID == NULL) ||
(ThreadInfo == NULL))
{
char * szMessage = new char [128];
sprintf(szMessage,
"Cannot allocate memory for "
"threads and CPU information structures!");
MessageBox(hDlg, szMessage, APP_TITLE, MB_OK|MB_ICONSTOP);
delete szMessage;
return false;
}Пользователь никогда не увидит окошка с сообщением об ошибке. Если не удастся выделить память, программа аварийно завершится или выдаст неподходящее сообщение, обработав исключение в другом месте.
Частой причиной описанных проблем, является изменение в поведении оператора 'new'. Во времена Visual C++ 6.0, оператор 'new' в случае ошибки возвращал NULL. Следующие версии Visual C++ следуют стандарту и генерируют исключение. Помните про это изменение поведения. Таким образом, если вы адаптируете старый проект для сборки современным компилятором, вам стоит уделить повышенное внимание диагностике V668.
Примечание N1. Анализатор не будет выдавать предупреждение, если используется placement new или "new (std::nothrow) T". Пример такого кода:
T * p = new (std::nothrow) T; // OK
if (!p) {
// An error has occurred.
// No storage has been allocated and no object constructed.
...
}Примечание N2. Есть возможность слинковать проект с nothrownew.obj. В этом случае, оператор new не будет генерировать исключение. Такой возможностью, например, пользуются разработчики драйверов. Подробнее: new and delete operators. В этом случае, просто отключите предупреждение V668.
Дополнительные материалы по данной теме:
- Wikipedia. Placement syntax.
- Microsoft Support. Operator new does not throw a bad_alloc exception on failure in Visual C++.
- Stack Overflow. Will new return NULL in any case?
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V668. |
V669. Argument is a non-constant reference. The analyzer is unable to determine the position where this argument is modified. Consider checking the function for an error.
Анализатор обнаружил, что аргумент передается в функцию по ссылке, но не модифицируется в теле функции. Это может свидетельствовать о наличии ошибки.
Например, виной тому может быть опечатка.
Рассмотрим пример некорректного кода:
void foo(int &a, int &b, int c)
{
a = b == c;
}Из-за опечатки оператор присваивания ('=') превратился в оператор сравнения ('=='). В результате, переменная 'b' используется только для чтения, хотя это не константная ссылка. Как исправить некорректный код будет зависеть от каждого конкретного случая. Самое главное, такой код требует более подробного изучения.
Корректный вариант кода:
void foo(int &a, int &b, int c)
{
a = b = c;
}Примечание. Анализатор может ошибаться, пытаясь понять, модифицируется переменная в теле функции или нет. Если вы заметили явно ложное срабатывание, просьба прислать нам соответствующий пример кода.
Вы также можете комментарий "//-V669", чтобы подавить ложное предупреждение в конкретном месте.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V669. |
V670. Uninitialized class member is used to initialize another member. Remember that members are initialized in the order of their declarations inside a class.
Анализатор обнаружил возможную ошибку в списке инициализации конструктора класса. Согласно стандарту порядок инициализация членов класса в конструкторе происходит в порядке их объявления в классе. В программе есть конструктор, где инициализация одного члена класса зависит от другого. При этом используемая для инициализации переменная, в этот момент ещё не инициализирована.
Рассмотрим пример такого конструктора:
class Foo
{
int foo;
int bar;
Foo(int i) : bar(i), foo(bar + 1) { }
};Переменная 'foo' будет инициализироваться первой! В этот момент переменная 'bar' еще не инициализирована. Для исправления ошибки следует перенести объявление члена класса 'foo' выше объявления члена класса 'bar'. Исправленный вариант кода:
class Foo
{
int bar;
int foo;
Foo(int i) : bar(i), foo(bar + 1) { }
};Если изменить последовательность полей в классе нельзя, то следует изменить выражения для инициализации:
class Foo
{
int foo;
int bar;
Foo(int i) : bar(i), foo(i + 1) { }
};Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V670. |
V671. The 'swap' function may interchange a variable with itself.
Анализатор обнаружил потенциальную ошибку, которая может возникнуть при вызове функции с именем 'swap'. В функцию переданы одинаковые фактические аргументы. Передача для этой функции одного и того же аргумента очень подозрительная ситуация. Скорее всего, произошла опечатка.
Пример некорректного кода:
int arg1, arg2;
....
swap(arg1, arg1);
....Из-за опечатки функция swap() обменивает значение переменной 'arg1' само с собой. Корректным вариантом кода должно было быть:
swap(arg1, arg2);Так же подозрительным анализатор будет считать следующий код:
MyClass arg1, arg2;
....
arg1.Swap(arg1);
....Исправить его можно аналогичным образом:
arg1.Swap(arg2);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V671. |
V672. It is possible that creating a new variable is unnecessary. One of the function's arguments has the same name and this argument is a reference.
Анализатор обнаружил возможную ошибку в программе, связанную с объявлением переменной, с таким же именем, что и один из аргументов. Если аргумент является ссылкой, то эта ситуация очень подозрительна. Анализатор накладывает и другие условия, чтобы сократить количество ложных срабатываний, но описывать их в документации не имеет смысла.
Что бы лучше понять данный вид ошибки, рассмотрим пример:
bool SkipFunctionBody(Body*& body, bool t)
{
body = 0;
if (t)
{
Body *body = 0;
if (!SkipFunctionBody(body, true))
return false;
body = new Body(body);
return true;
}
return false;
}Для работы функции с функцией SkipFunctionBody () потребовалась временная переменная. Из-за невнимательности в блоке 'if' повторно объявляется временная переменная с именем 'body'. Это значит что аргумент 'body' не будет модифицирован внутри блока 'if'. Вместо него будет изменена локальная переменная. При выходе из функции значение переменной 'body' всегда будет равно NULL. Ошибка может проявиться не в данном месте программы, а где то далее, когда произойдет разыменование нулевого указателя. Для исправления ошибки следует создавать локальную переменную с другим именем. Корректный вариант кода:
bool SkipFunctionBody(Body*& body, bool t)
{
body = 0;
if (t)
{
Body *tmp_body = 0;
if (!SkipFunctionBody(tmp_body, true))
return false;
body = new Body(tmp_body);
return true;
}
return false;
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V672. |
V673. More than N bits are required to store the value, but the expression evaluates to the T type which can only hold K bits.
Анализатор обнаружил потенциальную ошибку в выражении, где используются операции сдвига (shift operations). В процессе сдвига возникает переполнение, и значения старших бит будут потеряны.
Для начала рассмотрим эту ситуацию на простом примере:
std::cout << (77u << 26);Значение выражения 77u << 26 равно 5167382528 (0x134000000). При этом выражение 77u << 26 имеет тип unsigned int. Это значит, что старшие биты будут отброшены, и на экран будет напечатано значение 872415232 (0x34000000).
Переполнения, возникающие при сдвигах, часто указывают на наличие логической ошибки или просто опечатки. Например, может быть, что число 77u хотели задать в восьмеричной системе счисления. Тогда корректный код должен выглядеть так:
std::cout << (077u << 26);Здесь переполнения уже не возникает. Значение выражения 077u << 26 равно 4227858432 (0xFC000000).
Если хочется распечатать на экране значение 5167382528, то число 77 должно быть задано с помощью 64-битного типа. Например, так:
std::cout << (77ui64 << 26);Перейдём к случаям, с которыми можно встретиться на практике. Для этого рассмотрим две ошибки, обнаруженные в реальных приложениях.
Первый пример.
typedef __UINT64 Ipp64u;
#define MAX_SAD 0x07FFFFFF
....
Ipp64u uSmallestSAD;
uSmallestSAD = ((Ipp64u)(MAX_SAD<<8));Программист хотел записать в 64-битную переменную uSmallestSAD значение 0x7FFFFFF00. Но на самом деле переменная будет иметь значение 0xFFFFFF00. Старшие биты будут отброшены, так как выражение MAX_SAD<<8 имеет тип int. Программист знал про это, поэтому решил использовать явное приведение типа, но ошибся, расставляя скобки. Этот пример хорошо демонстрирует, что подобные ошибки могут возникать из-за простой опечатки. Корректный код:
uSmallestSAD = ((Ipp64u)(MAX_SAD))<<8;Второй пример.
#define MAKE_HRESULT(sev,fac,code) \
((HRESULT) \
(((unsigned long)(sev)<<31) | \
((unsigned long)(fac)<<16) | \
((unsigned long)(code))) )
*hrCode = MAKE_HRESULT(3, FACILITY_ITF, messageID);Функция должна сформировать информацию об ошибке в переменной типа HRESULT. Для этого программист использовал макрос MAKE_HRESULT, но сделал это неправильно, посчитав, что первый параметр severity может лежать в приделах от 0 до 3. Вероятно, он перепутал это со способом формирования кодов ошибки, используемых при работе с функциями GetLastError()/SetLastError().
Макрос MAKE_HRESULT в качестве первого аргумента может принимать только 0 (success) или 1 (failure). Подробнее этот вопрос рассматривался на форуме сайта CodeGuru: Warning! MAKE_HRESULT macro doesn't work.
Так как в качестве первого фактического аргумента используется число 3, то возникает переполнение. Число 3 "превратится" в 1. Из-за этой случайности ошибка не повлияет на работу программы. Однако приведённый пример показывает, что нередко код работает исключительно благодаря везению, а не потому, что написан правильно.
Правильный код:
*hrCode = MAKE_HRESULT(SEVERITY_ERROR, FACILITY_ITF, messageID);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V673. |
V674. Expression contains a suspicious mix of integer and real types.
Анализатор обнаружил потенциальную ошибку в выражении, где совместно используются целочисленные и real-типы данных. Под real-типами понимаются такие типы, как float/double/long double.
Рассмотрим для начала самый простой случай. Литерал, имеющий тип 'double' неявно приводится к целочисленному типу. Это может указывать на наличии программной ошибки.
int a = 1.1;Этот код не имеет практического смысла. Скорее всего, переменная должна была быть инициализирована другим значением.
Показанный выше пример надуманный и не интересен. Давайте посмотрим, как проявляет себя эта ошибка на практике.
Пример 1.
int16u object_layer_width;
int16u object_layer_height;
if (object_layer_width == 0 ||
object_layer_height == 0 ||
object_layer_width/object_layer_height < 0.1 ||
object_layer_width/object_layer_height > 10)Здесь целочисленное значение сравнивается с константой '0.1'. Это очень подозрительно. Предположим, что переменные имеют следующие значения:
- object_layer_width = 20;
- object_layer_height = 100;
Программист ожидает, что при делении этих чисел результат будет равен '0.2'. Это подходящее значение, так оно попадает в диапазон [0.1..10].
На самом деле, результат деления будет равен 0. Деление осуществляется над целочисленными типами данных. Потом, при сравнении с '0.1' произойдет расширение до типа 'double', но будет уже поздно. Чтобы исправить код необходимо заранее использовать явное приведение типов:
if (object_layer_width == 0 ||
object_layer_height == 0 ||
(double)object_layer_width/object_layer_height < 0.1 ||
(double)object_layer_width/object_layer_height > 10.0)Второй пример.
// be_aas_reach.c
ladderface1vertical =
abs( DotProduct( plane1->normal, up ) ) < 0.1;Аргумент функции abs() имеет тип 'double'. На первый взгляд, код кажется абсолютно правильным и хочется заявить "анализатор здесь сглупил".
Но давайте разберёмся более детально. Давайте посмотрим, как объявлена функция abs() в заголовочных файлах.
int __cdecl abs( int _X);
#ifdef __cplusplus
extern "C++" {
inline long __CRTDECL abs(__in long _X) { .... }
inline double __CRTDECL abs(__in double _X) { .... }
inline float __CRTDECL abs(__in float _X) { .... }
}
#endifДа, в Си++ функции abs() перегружены для различных типов. Однако, мы имеем дело с кодом на языке Си (файл be_aas_reach.c).
Это значит, что выражение типа 'float' будет неявно преобразовано к типу 'int'. И результат работы функции abs() тоже будет иметь тип 'int'. Значение типа 'int' нет смысла сравнивать с '0.1'. Об этом и предупреждает анализатор.
В программах на языке Си для правильного вычисления модуля потребуется другая стандартная функция:
double __cdecl fabs(__in double _X);Исправленный код:
ladderface1vertical =
fabs( DotProduct( plane1->normal, up ) ) < 0.1;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V674. |
V675. Writing into read-only memory.
Анализатор обнаружил попытку записи в память, которая предназначена только для чтения.
Рассмотрим пример.
char *s = "A_string";
if (x)
s[0] = 'B';Здесь указатель 's' ссылается на область памяти, предназначенной только для чтения. Изменение этой памяти приведёт к неопределённому поведению программы. Скорее всего, это неопределенное поведение программы будет представлять собой access violation.
Исправленный вариант программы:
char s[] = "A_string";
if (x)
s[0] = 'B';На стеке создастся массив 's' и в него будет скопирована строка из read-only памяти. Теперь строку 's' можно изменять.
P.S.
Если "A_string" представляет собой "const char *", то почему этот тип неявно приводится к "char *"?
Такое поведение существует из-за соображений совместимости. Было написано ОЧЕНЬ много кода на Си, где используются не константные указатели. Разработчики стандарта/компиляторов не нашли в себе силы в этом месте сломать обратную совместимость с имеющимся кодом.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V675. |
V676. Incorrect comparison of BOOL type variable with TRUE.
Анализатор обнаружил, что значение типа BOOL сравнивается с константой TRUE (или 1). Это является потенциальной ошибкой, так как значение "истина" может быть любым числом, отличным от нуля.
Для начала вспомним, в чем отличие типа 'bool' и 'BOOL'.
Конструкция вида:
bool x = ....;
if (x == true) ....совершенно корректна. Тип 'bool' может принимать только два значения: true и false.
В случае с типом BOOL такие проверки недопустимы. Тип BOOL представляет на самом деле тип 'int'. Это значит, что он может хранить значения, отличные от нуля и единицы. Любое значение, отличное от нуля считается "истинным".
Отличные от 1 значения могут возвращаться, например, функциями из Windows SDK.
Константы FALSE/TRUE объявлены следующим образом:
#define FALSE 0
#define TRUE 1Это значит, что следующее сравнение может дать сбой:
BOOL ret = Some_SDK_Function();
if (TRUE == ret)
{
// do something
}Нет гарантии, что функция Some_SDK_Function() вернет именно единицу, если будет успешно выполнена. Правильно будет написать:
if (FALSE != ret)или:
if (ret)По данной тематике также можно порекомендовать познакомиться с FAQ на сайте CodeGuru: Visual C++ General: What is the difference between 'BOOL' and 'bool'?
В реальном приложении, ошибка может выглядеть следующим образом:
if (CDialog::OnInitDialog() != TRUE )
return FALSE;В описании функции CDialog::OnInitDialog() сказано: "If OnInitDialog returns nonzero, Windows sets the input focus to the default location, the first control in the dialog box. The application can return 0 only if it has explicitly set the input focus to one of the controls in the dialog box."
Обратите внимание, нигде не сказано про TRUE или про 1. Правильный код:
if (CDialog::OnInitDialog() == FALSE)
return FALSE;Этот код может долго и успешно работать, но нет никакой гарантии, что так будет всегда.
Относительно ложных срабатываний. Иногда, программист точно знает, что переменная типа BOOL всегда будет иметь значение 0 или 1. В этом случае, можно подавить ложное срабатывание, одним из нескольких методов. Однако, намного лучше все-таки поправить код. Код станет более надежен по отношению к будущим рефакторингам.
Близкой по смыслу к этой диагностике является V642.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V676. |
V677. Custom declaration of standard type. Consider using the declaration from system header files instead.
Анализатор обнаружил, что в программе объявляется один из стандартных типов данных. Это избыточный код, который потенциально может привести к ошибкам. Следует использовать системные файлы, где объявлены соответствующие типы.
Рассмотрим пример некорректного объявления типа:
typedef unsigned *PSIZE_T;Тип PSIZE_T объявлен как указатель на тип 'unsigned'. Такое объявление может привести к проблемам при попытке собрать 64-битное приложение. Программа не скомпилируется или будет вести себя не так, как задумано. В файле "BaseTsd.h" тип PSIZE_T объявлен следующим образом: "typedef ULONG_PTR SIZE_T, *PSIZE_T;". Однако следует не менять объявление типа, а включить соответствующий заголовочный файл.
Корректный код:
#include <BaseTsd.h>Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V677. |
V678. Object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' function.
Анализатор обнаружил вызов нестатической функции-члена класса, которой одним из аргументов передали этот же объект, на котором она была вызвана.
Рассмотрим пример:
A.Foo(A);Есть вероятность, что этот подозрительный код содержит ошибку. Например, из-за опечатки используется неверное имя переменной. Тогда, корректный код должен был быть таким:
A.Foo(B);или таким:
B.Foo(A);Давайте посмотрим, как такие опечатки проявляют себя на практике. Код реального приложения:
CXMLAttribute* pAttr1 =
m_pXML->GetAttribute(CXMLAttribute::schemaName);
CXMLAttribute* pAttr2 =
pXML->GetAttribute(CXMLAttribute::schemaName);
if ( pAttr1 && pAttr2 &&
!pAttr1->GetValue().CompareNoCase(pAttr1->GetValue()))
....Этот код должен сравнивать два атрибута. Но из-за опечатки, значение "pAttr1->GetValue()" сравнивается само с собой.
Корректный код:
if ( pAttr1 && pAttr2 &&
!pAttr1->GetValue().CompareNoCase(pAttr2->GetValue()))Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V678. |
V679. The 'X' variable was not initialized. This variable is passed by reference to the 'Foo' function in which its value will be used.
Анализатор обнаружил ситуацию, когда неинициализированная переменная передаётся в функцию по ссылке или по указателю. При этом функция читает значение из этой неинициализированной переменной.
Рассмотрим пример.
void Copy(int &x, int &y)
{
x = y;
}
void Foo()
{
int x, y;
x = 1;
Copy(x, y);
}Это конечно очень простой придуманный пример. Однако он хорошо показывает суть ошибки. Переменная 'y' является неинициализированной. Ссылка на эту переменную передаётся в функцию Copy(). Там происходит чтение из этой неинициализированной переменной.
Корректный код, может выглядеть так:
void Copy(int &x, int &y)
{
x = y;
}
void Foo()
{
int x, y;
y = 1;
Copy(x, y);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
|
V680. The 'delete A, B' expression only destroys the 'A' object. Then the ',' operator returns a resulting value from the right side of the expression.
Анализатор обнаружил подозрительную конструкцию, при которой подразумевалось освобождение памяти для произвольного числа указателей, но будет освобождена память только для первого.
Рассмотрим пример:
delete p1, p2;Такую конструкцию мог написать неопытный программист или человек давно не работавший с языком Си++. На первый взгляд, может показаться, что этот код должен удалить два объекта, адреса которых хранятся в указателях 'p1' и 'p2'. На самом деле, здесь два оператора. Первый - оператор 'delete'. Второй - оператор запятая ','.
В начале, выполнится оператор 'delete'. Затем, оператор запятая ',' вернет значение второго аргумента (а именно, 'p2').
Другими словами, этот код эквивалентен: (delete p1), p2;
Корректный код, должен выглядеть так:
delete p1;
delete p2;Примечание. Анализатор не выдает сообщение, если оператор запятая используется в практических целях. Пример безопасного кода:
if (x)
delete p, p = nullptr;После удаления объекта указатель обнуляется. Чтобы не писать фигурные скобки, два действия были объединены с помощью оператора запятая ','.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
V681. The language standard does not define order in which 'Foo' functions are called during evaluation of arguments.
Анализатор обнаружил потенциальную ошибку, связанную с последовательностью вызова функций.
Согласно стандарту языка Си++, не определена последовательность вычисления фактических аргументов функции. Для выражения 'A(B(), C())' нельзя сказать, вызовется в начале функция 'B()' или 'C()'. Какая функция будет вызвана первой, зависит от компилятора, параметров компиляции и так далее.
Изредка, это может порождать проблемы. Анализатор выдает предупреждения на код, который выглядит наиболее подозрительно. К сожалению, набор случаев, когда выдаётся предупреждение, сознательно сильно ограничен. Это сделано для того, чтобы он не выдавал ложные срабатывания. Уж очень часто, в качестве фактических аргументов используется вызовы других функций. И в большинстве случаев это безопасно.
Пример кода, для которого PVS-Studio выдаст предупреждение:
Point ReadPoint()
{
return Point(ReadFixed(), ReadFixed());
}Этот код может привести к тому, что значение X и Y могут быть перепутаны. Неизвестно, какой из аргументов начнет вычисляться первым.
Корректный код:
Point ReadPoint()
{
float x = ReadFixed();
return Point(x, ReadFixed());
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V681. |
V682. Suspicious literal: '/r'. It is possible that a backslash should be used instead: '\r'.
Анализатор обнаружил потенциальную ошибку, связанную с использованием прямого слеша.
Легко ошибиться и перепутать прямой и обратный слеш.
Пример:
if (x == '/n')Программист планировал сравнить переменную 'x' с кодом 0xA (перевод строки). Но он ошибся и использовал прямой слеш. В результате, переменная сравнивается со значением 0x2F6E.
Корректный код:
if (x == '\n')Такую ошибку можно допустить при работе со следующими управляющими последовательностями символов (escape sequences):
- newline - \n
- horizontal tab - \t
- vertical tab - \v
- backspace - \b
- carriage return - \r
- form feed - \f
- alert - \a
- backslash - \\
- the null character - \0
Дополнительные ссылки:
V683. The 'i' variable should probably be incremented instead of the 'n' variable. Consider inspecting the loop expression.
Анализатор обнаружил потенциальную ошибку в цикле. Возможно, из-за опечатки увеличивается/уменьшается не та переменная.
Пример подозрительного кода:
void Foo(float *Array, size_t n)
{
for (size_t i = 0; i != n; ++n)
{
....
}
}Вместо переменной 'i' увеличивается переменная 'n'. В результате, программа ведёт себя не так, как ожидал программист.
Исправленный вариант кода:
for (size_t i = 0; i != n; ++i)Данная диагностика классифицируется как:
V684. Value of variable is not modified. It is possible that '1' should be present instead of '0'. Consider inspecting the expression.
Анализатор обнаружил подозрительное выражение. Выражение написано для того, чтобы изменить определённые биты в переменной. Но значение переменной останется прежним.
Пример подозрительного кода:
MCUCR&=~(0<<SE);Код взят из программы для микроконтроллера ATtiny2313. Бит SE должен быть установлен в единицу для того, чтобы по команде SLEEP микроконтроллер перешел в спящий режим. Чтобы избежать случайного перехода в спящий режим, рекомендуется устанавливать бит SE в единичное состояние непосредственно перед вызовом команды SLEEP и сбрасывать его после пробуждения. Именно такой сброс и хотели сделать после пробуждения. Но из-за опечатки значение регистра MCUCR не изменится. Получается, что хотя программа работает, она менее безопасна, чем могла быть.
Исправленный вариант кода:
MCUCR&=~(1<<SE);Примечание. Иногда возникает множественное ложное предупреждение V684. Как правило, это связано с использованием больших и сложных макросов. Способы подавления ложных срабатываний для макросов описаны в соответствующем разделе документации.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V684. |
V685. The expression contains a comma. Consider inspecting the return statement.
Анализатор посчитал подозрительным значение, возвращаемое из функции. В нём используется оператор ',' (запятая). Это не всегда ошибка, но этот код стоит проверить.
Пример подозрительного кода:
int Foo()
{
return 1, 2;
}Функция вернёт значение 2. Наличие числа 1 здесь избыточно и не оказывает никакого влияния на поведение программы.
Если это просто опечатка, то следует убрать лишнюю единицу:
int Foo()
{
return 2;
}Но возможно, здесь скрывается настоящая ошибка. И именно поэтому, анализатор обращает внимание на такие конструкции. Например, вдруг в процессе рефакторинга случайно удалили вызов функции.
Тогда, исправленный вариант кода может быть таким:
int Foo()
{
return X(1, 2);
}Запятая иногда может быть полезна при работе с оператором 'return'. Например, следующий код можно сократить, использую запятую.
Длинный код:
if (A)
{
printf("hello");
return X;
}Сокращённый код:
if (A)
return printf("hello"), X; // Нет предупрежденияМы не считаем короткий вариант кода красивым и не рекомендуем его использовать. Однако, так часто пишут и такой код имеет смысл. Поэтому, анализатор не выдаёт предупреждение, если стоящее слева от запятой выражение, оказывает влияние на работу программы.
Данная диагностика классифицируется как:
V686. Pattern A || (A && ...) was detected. The expression is excessive or contains a logical error.
Анализатор обнаружил выражение, которое можно упросить. Иногда это может означать, что выражение содержит логическую ошибку.
Пример подозрительного кода:
int k,n,j;
...
if (n || (n && j))Это выражение избыточное. Если "n==0", то условие всегда ложно. Если "n!=0", то условие всегда истинно. Таким образом, условие не зависит от значения переменной 'j' и его можно упростить:
if (n)Иногда, избыточность означает наличие опечатки. Вдруг, например, на самом деле, условие должно быть таким:
if (k || (n && j))Рассмотрим более реальный пример, благодаря которому и появилась эта диагностика:
const char *Name = ....;
if (Name || (Name && Name[0] == 0))Здесь сразу есть и ошибка и избыточность. Условие должно выполняться, если строка, на которую ссылается указатель 'Name', пустая. Пустая строка может обозначаться нулевым указателем.
Из-за ошибки условие выполнится всегда, если Name != nullptr. Исправленный код:
if (!Name || (Name && Name[0] == 0))Теперь ошибки нет. Но дополнительно можно сократить количество проверок:
if (!Name || Name[0] == 0)Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V686. |
V687. Size of array calculated by sizeof() operator was added to a pointer. It is possible that the number of elements should be calculated by sizeof(A)/sizeof(A[0]).
Анализатор обнаружил, что к указателю, прибавляется размер массива. Это подозрительно. Возможно следовало прибавлять значение, равное количеству элементов в массиве, а не его размеру.
Примечание. Безопасным считается работа с массивами, состоящими из байт (char/unsigned char).
Пример ошибки:
int A[10];
...
std::sort(A, A + sizeof(A));Первый аргумент функции - итератор, указывающий на первый элемент сортируемой последовательности.
Второй аргумент функции - итератор, указывающий на элемент, стоящий после последнего сортируемого элемента.
Вызов функции написан с ошибкой. К указателю прибавляется размер массива, в результате чего, функция попытается отсортировать больше данных, чем следует.
Чтобы исправить ошибку, следует прибавлять количество элементов в массиве:
int A[10];
...
std::sort(A, A + sizeof(A) / sizeof(A[0]));Данная диагностика классифицируется как:
|
V688. The 'foo' local variable has the same name as one of class members. This can result in confusion.
Анализатор обнаружил, что имя локальной переменной совпадает с именем члена класса. Часто, это не ошибка. Однако, такой код ОЧЕНЬ опасен. В процессе рефакторинга такого кода, в нём очень легко возникают ошибки. Программист думает, что работает с членом класса, а на самом деле использует локальную переменную.
Пример подозрительного кода:
class M
{
int x;
void F() { int x = 1; foo(x); }
....
};Класс содержит член с именем 'x'. С таким же именем объявляется локальная переменная в функции F().
Когда функция маленькая как в этом примере, всё просто и понятно. И диагностика V688 кажется неинтересной. Но когда функции большие, неудачное именование переменных может доставить массу головной боли разработчикам, сопровождающим код.
Можно исправить ситуацию, используя другое имя для локальной переменной:
class M
{
int x;
void F() { int value = 1; foo(value); }
....
};Или можно использовать прифекс 'm_' для обозначения членов класса:
class M
{
int m_x;
void F() { int x = 1; foo(x); }
....
};Анализатор выдаёт предупреждение не всегда. Он использует некоторые эвристики, чтобы предотвратить ложные срабатывания. Например, этот код анализатор посчитает безопасным:
class M
{
int value;
void SetValue(int value) { this->value = value; }
....
};Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V688. |
V689. Destructor of 'Foo' class is not declared as virtual. A smart pointer may not destroy an object correctly.
Анализатор обнаружил, что умный указатель может неправильно разрушить объект. Причина ошибки в том, что в базовом классе отсутствует виртуальный деструктор.
Рассмотрим пример:
class Base
{
public:
~Base() { }
};
class Derived : public Base
{
public:
Derived()
{
data = new int[5];
}
~Derived()
{
delete [] data;
}
int* data;
};
void GO()
{
std::auto_ptr<Base> smartPtr(new Derived);
}Обратите внимание, что создаётся объект класса 'Derived'. Однако, умный указатель хранит ссылку на класс Base. В классе Base деструктор не является виртуальным. В результате возникнет ошибка, когда умный указатель попробует разрушить объект, отданный ему на хранение.
Исправленный вариант класса Base:
class Base
{
public:
virtual ~Base() { }
};P.S.
Родственным диагностическим сообщением является V599.
Дополнительная информация:
- Wikipedia. Таблица виртуальных методов.
- Wikipedia. Виртуальный метод (виртуальная функция).
- Wikipedia. Деструктор.
- Сергей Олендаренко. Виртуальные функции и деструктор.
Данная диагностика классифицируется как:
|
V690. The class implements a copy constructor/operator=, but lacks the operator=/copy constructor.
Анализатор обнаружил класс, в котором реализован конструктор копирования, но не реализован 'operator =', или наоборот, реализован 'operator =', но не реализован конструктор копирования.
Работать с такими классами очень опасно. Другими словами, нарушен "Закон Большой Двойки". Про этот закон, будет рассказано ниже.
Рассмотрим пример опасного класса. Пример длинный. Но сейчас важно только то, что в классе есть оператор присваивания, но нет конструктора копирования.
class MyArray
{
char *m_buf;
size_t m_size;
void Clear() { delete [] m_buf; }
public:
MyArray() : m_buf(0), m_size(0) {}
~MyArray() { Clear(); }
void Allocate(size_t s)
{ Clear(); m_buf = new char[s]; m_size = s; }
void Copy(const MyArray &a)
{ Allocate(a.m_size);
memcpy(m_buf, a.m_buf, a.m_size * sizeof(char)); }
char &operator[](size_t i) { return m_buf[i]; }
MyArray &operator =(const MyArray &a)
{ Copy(a); return *this; }
};Оставим в стороне практичность и полезность такого класса. Это всего лишь пример. Нам важно, что вот такой код, будет корректно работать:
{
MyArray A;
A.Allocate(100);
MyArray B;
B = A;
}Массив успешно копируется с помощью оператора присваивания.
Следующий фрагмент кода приведёт к неопределенному поведению. Приложение упадёт или его работа будете нарушена как-то ещё.
{
MyArray A;
A.Allocate(100);
MyArray C(A);
}Дело в том, что в классе не реализован конструктор копирования. При создание объекта 'C', указатель на массив будет просто скопирован. Это приведёт к двоёному освобождению памяти при разрушении объектов A и C.
Аналогичная проблема будет, если реализован конструктор копирования, но нет оператора копирования.
Что-бы исправить класс, следует добавить конструктор копирования:
MyArray &operator =(const MyArray &a)
{ Copy(a); return *this; }
MyArray(const MyArray &a) : m_buf(0), m_size(0)
{ Copy(a); }Если анализатор выдал предупреждение V690, то не ленитесь и реализуйте недостающий метод. Сделайте это, даже если код сейчас работает правильно, и вы помните, об особенностях класса. Пройдёт время, забудется отсутствие operator= или конструктора копирования. И вы или ваш коллега допустите ошибку, которую будет сложно найти. Когда поля класса скопированы автоматически, то часто, такой класс "почти работает". Неприятности проявляют себя позже в сосем другом месте программы.
Закон Большой Двойки
Как было сказано в начале, диагностика V690 находит классы, в которых нарушен "Закон Большой Двойки". Рассмотрим это подробнее. Но начать надо с "Правило трёх". Обратимся к Wikipedia:
Правило трёх (также известное как "Закон Большой Тройки" или "Большая Тройка") — правило в C++, гласящее, что если класс или структура определяет один из следующих методов, то они должны явным образом определить все три метода:
- деструктор;
- конструктор копирования;
- оператор присваивания копированием.
Эти три метода являются особыми членами-функциями, автоматически создаваемыми компилятором в случае отсутствия их явного объявления программистом. Если один из них должен быть определен программистом, то это означает, что версия, сгенерированная компилятором, не удовлетворяет потребностям класса в одном случае и, вероятно, не удовлетворит в остальных случаях.
Поправка к этому правилу заключается в том, что если используется RAII (от англ. Resource Acquisition Is Initialization), то используемый деструктор может остаться неопределённым (иногда упоминается как "Закон Большой Двойки").
Так как неявно определённые конструкторы и операторы присваивания просто копируют все члены-данные класса, определение явных конструкторов копирования и операторов присваивания копированием необходимо в случаях, когда класс инкапсулирует сложные структуры данных или может поддерживать эксклюзивный доступ к ресурсам. А также в случаях, когда класс содержит константные данные или ссылки.
Сам "Закон Большой Двойки" подробно рассматривается в этой статье: The Law of The Big Two.
Как видите, "Закон Большой Двойки" очень важен и поэтому мы реализовали соответствующую диагностику в анализаторе кода.
Начиная с C++11 появилась семантика перемещения, поэтому это правило расширилось до "Большой пятерки". Список методов, которые нужно определить все, если определён, хотя бы один из них:
- деструктор;
- конструктор копирования;
- оператор присваивания копированием;
- конструктор перемещения;
- оператор присваивания перемещением;
Поэтому всё, что справедливо для конструктора/оператора копирования, справедливо и для конструктора/оператора перемещения.
Примечание
Всегда ли диагностика V690 говорит о наличии проблемы? Нет. Иногда никакой ошибки нет, но есть лишняя функция. Рассмотрим пример из реального приложения:
struct wdiff {
int start[2];
int end[2];
wdiff(int s1=0, int e1=0, int s2=0, int e2=0)
{
if (s1>e1) e1=s1-1;
if (s2>e2) e2=s2-1;
start[0] = s1;
start[1] = s2;
end[0] = e1;
end[1] = e2;
}
wdiff(const wdiff & src)
{
for (int i=0; i<2; ++i)
{
start[i] = src.start[i];
end[i] = src.end[i];
}
}
};В этом классе есть конструктор копирования, но нет оператора присваивания. Но это не страшно. Массивы 'start' и 'end' состоят из простых типов 'int'. Они будут корректно скопированы компилятором. Что-бы устранить предупреждение V690 нужно удалить бессмысленный конструктор копирования. Компилятор построит код, копирует элементы класса не медленней, а возможно даже быстрее.
Исправленный вариант:
struct wdiff {
int start[2];
int end[2];
wdiff(int s1=0, int e1=0, int s2=0, int e2=0)
{
if (s1>e1) e1=s1-1;
if (s2>e2) e2=s2-1;
start[0] = s1;
start[1] = s2;
end[0] = e1;
end[1] = e2;
}
};Взгляните на примеры ошибок, обнаруженных с помощью диагностики V690. |
V691. Empirical analysis. Possible typo inside the string literal. The 'foo' word is suspicious.
Если анализатор находит два одинаковых строковых литерала, он пытается понять, является ли это последствием неудачного Copy-Paste. Хочется сразу предупредить, диагностика основана на эмпирическом алгоритме и иногда может выдавать странные ложные срабатывания.
Рассмотрим пример ошибки:
static const wchar_t left_str[] = L"Direction: left.";
static const wchar_t right_str[] = L"Direction: right.";
static const wchar_t up_str[] = L"Direction: up.";
static const wchar_t down_str[] = L"Direction: up.";Код писался с использованием Copy-Paste. В конце забыли изменить строковый литерал "up" на "down". Анализатор заподозрит неладное и укажет на подозрительное слово "up" в последней строчке.
Исправленный код:
static const wchar_t left_str[] = L"Direction: left.";
static const wchar_t right_str[] = L"Direction: right.";
static const wchar_t up_str[] = L"Direction: up.";
static const wchar_t down_str[] = L"Direction: down.";;Взгляните на примеры ошибок, обнаруженных с помощью диагностики V691. |
V692. Inappropriate attempt to append a null character to a string. To determine the length of a string by 'strlen' function correctly, use a string ending with a null terminator in the first place.
Анализатор обнаружил интересный паттерн ошибки. Чтобы записать терминальный ноль в конец строки, вычисляют её длину с помощью функции strlen(). Результат такого действия непредсказуем. Ведь для работы функции strlen() строка уже должна заканчиваться терминальным нулём.
Пример некорректного кода:
char *linkname;
....
linkname[strlen(linkname)] = '\0';Этот код не имеет смысла. Ноль будет записан как раз в ту ячейку, где был найден 0. При этом, функция strlen() может выйти далеко за пределы буфера, что приведет неопределенному поведению программы.
Чтобы исправить код, надо вычислить длину строки каким-то другим способом:
char *linkname;
size_t len;
....
linkname[len] = '\0';Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V692. |
V693. It is possible that 'i < X.size()' should be used instead of 'X.size()'. Consider inspecting conditional expression of the loop.
Анализатор обнаружил опечатку в условии остановки цикла.
Пример:
for (size_t i = 0; v.size(); ++i)
sum += v[i];Если массив 'v' не является пустым, то возникнет бесконечный цикл.
Исправленный вариант кода:
for (size_t i = 0; i < v.size(); ++i)
sum += v[i];Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V693. |
V694. The condition (ptr - const_value) is only false if the value of a pointer equals a magic constant.
Анализатор обнаружил очень подозрительное условие. К указателю прибавляется или из указателя вычитается константное значение. Результат сложения/вычитания сравнивается с нулём. Высока вероятность, что в коде имеется опечатка.
Рассмотрим пример со сложением:
int *p = ...;
if (p + 2)Это условие будет всегда истинным. Единственный случай, когда выражение будет равно 0, если специально записать в указатель магическое число "-2".
Исправленный вариант кода:
int *p = ...;
if (*p + 2)Теперь рассмотрим пример с подозрительным вычитанием:
char *begin = ...;
char *end = ...;
....
const size_t ibegin = 1;
....
if (end - ibegin)Из переменной 'end' следовало вычитать переменную 'begin'. Из-за неудачного именования переменных, случайно используется константная переменная 'ibegin', имеющая целочисленный тип.
Исправленный вариант кода:
char *begin = ...;
char *end = ...;
....
if (end - begin)Примечание. Предупреждение выводится только в том случае, если указатель является "настоящим". Например, он указывает на память, выделенную с помощью функции "malloc()". Если анализатор не знает, чему равен указатель, он не выдаст предупреждение, чтобы сократить число ложных срабатываний. Иногда, в указателях действительно передают "магические числа" и условия вида (ptr - 5 == 0) имеют смысл.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V694. |
V695. Range intersections are possible within conditional expressions.
Анализатор обнаружил потенциальную ошибку в условии. Программа должна совершать различные действия, в зависимости от того, в какой диапазон значений попадает некая переменная.
Для этого в коде используется следующая конструкция:
if ( MIN_A < X && X < MAX_A ) {
....
} else if ( MIN_B < X && X < MAX_B ) {
....
}Анализатор выдаёт предупреждение, если диапазоны, проверяемые в условиях, пересекаются. Пример:
if ( 0 <= X && X < 10)
FooA();
else if ( 10 <= X && X < 20)
FooB();
else if ( 20 <= X && X < 300)
FooC();
else if ( 30 <= X && X < 40)
FooD();Код содержит опечатку. Рука программиста дрогнула, и вместо условия "20 <= X && X < 30" была написано "20 <= X && X < 300". Если переменная X будет хранить, например, значение 35, то будет вызвана функция FooC(), а не FooD().
Исправленный код:
if ( 0 <= X && X < 10)
FooA();
else if ( 10 <= X && X < 20)
FooB();
else if ( 20 <= X && X < 30)
FooC();
else if ( 30 <= X && X < 40)
FooD();Рассмотрим ещё один пример:
const int nv_ab = 5;
const int nv_bc = 10;
const int nv_re = 15;
const int nv_we = 20;
const int nv_tw = 25;
const int nv_ww = 30;
....
if (n < nv_ab) { AB(); }
else if (n < nv_bc) { BC(); }
else if (n < nv_re) { RE(); }
else if (n < nv_tw) { TW(); } // <=
else if (n < nv_we) { WE(); } // <=
else if (n < nv_ww) { WW(); }В зависимости от значения переменной 'n' выполняются различные действия. Из-за неудачных названий переменных, легко запутаться. Так и получилось. В начале надо было сравнить переменную 'n' с 'nv_we', а только затем с 'nv_tw'.
Чтобы ошибка стала понятна, подставим значения констант:
if (n < 5) { AB(); }
else if (n < 10) { BC(); }
else if (n < 15) { RE(); }
else if (n < 25) { TW(); }
else if (n < 20) { WE(); } // Условие никогда не выполняется
else if (n < 30) { WW(); }Исправленный код:
if (n < nv_ab) { AB(); }
else if (n < nv_bc) { BC(); }
else if (n < nv_re) { RE(); }
else if (n < nv_we) { WE(); } // <=
else if (n < nv_tw) { TW(); } // <=
else if (n < nv_ww) { WW(); }Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V695. |
V696. The 'continue' operator will terminate 'do { ... } while (FALSE)' loop because the condition is always false.
Анализатор обнаружил код, который может ввести в заблуждение программиста. Оператор continue в цикле do { ... } while(0) останавливает цикл, а не возобновляет его.
Вот что говорит стандарт:
§6.6.2 in the standard: "The continue statement (...) causes control to pass to the loop-continuation portion of the smallest enclosing iteration-statement, that is, to the end of the loop." (Not to the beginning.)
Таким образом, после вызова оператора continue будет проверено условие (0) и цикл завершится, так как условие ложно.
Рассмотрим пример:
int i = 1;
do {
std::cout << i;
i++;
if(i < 3) continue;
std::cout << 'A';
} while(false);Программист может ожидать, что программа напечатает 12A. На самом деле будет напечатано 1.
Если именно так задумано и ошибки нет, то код всё равно лучше изменить. Можно воспользоваться оператором break:
int i=1;
do {
std::cout << i;
i++;
if(i < 3) break;
std::cout << 'A';
} while(false);Код стал более понятным. Сразу видно, что если условие (i < 3) выполняется, то цикл будет остановлен. Анализатор не будет выдавать предупреждение на этот код.
Если код некорректен, то его следует переписать. Здесь нельзя дать точных рекомендаций, всё зависит от логики работы кода. Например, чтобы напечатать 12A, лучше написать:
for (i = 1; i < 3; ++i)
std::cout << i;
std::cout << 'A';Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V696. |
V697. Number of elements in the allocated array equals the size of a pointer in bytes.
Количество элементов в массиве, выделяемого с помощью оператора 'new' равно размеру указателя в байтах. Это очень подозрительный участок кода.
Рассмотрим пример, как в программе может появиться такой код. В начале, в программе был фиксированный массив, состоящий из байт. Необходимо создать массив такого-же размера, но из элементов float. В результате был написан следующий код:
void Foo()
{
char A[10];
....
float *B = new float[sizeof(A)];
....
}Оставим в стороне качество этого кода. Главное, что в процессе рефакторинга, массив 'A' стал тоже динамическим. Фрагмент, где создаётся массив 'B' изменить забыли. В результате, появляется следующий некорректный код:
void Foo(size_t n)
{
char *A = new char[n];
....
float *B = new float[sizeof(A)];
....
}Количество элементов в массиве 'B' равно 4 или 8, в зависимости от разрядности платформы. Именно эту ситуацию и выявит анализатор кода.
Исправленный вариант кода:
void Foo(size_t n)
{
char *A = new char[n];
....
float *B = new float[n];
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V698. Functions of strcmp() kind can return any values, not only -1, 0, or 1.
Анализатор обнаружил в коде сравнение результата функции strcmp() или ей подобной с единицей или с минус единицей. В свою очередь, в спецификации языков C/С++ сказано, что функция strcmp() может вернуть любое положительное или любое отрицательное значение в случае неравенства строк, не только единицу или минус единицу.
В зависимости от реализации, функция strcmp() может в результате неравенства строк возвращать:
- -1 или любое отрицательное число, если первая строка меньше второй в лексикографическом порядке;
- 1 или любое положительное число, если первая строка больше второй.
Работоспособность конструкций вида strcmp() == 1 зависит от библиотек, компилятора, его настроек, операционной системы, её разрядности и так далее; требуется всегда в таком случае писать strcmp() > 0.
В качестве примера можно привести следующий некорректный код:
std::vector<char *> vec;
....
std::sort(vec.begin(), vec.end(), [](
const char * a, const char * b)
{
return strcmp(a, b) == 1;
});При смене компилятора, целевой операционной системы или разрядности компилируемого приложения данный код может начать работать некорректно.
Исправленный вариант кода:
std::vector<char *> vec;
....
std::sort(vec.begin(), vec.end(), [](
const char * a, const char * b)
{
return strcmp(a, b) > 0;
});Анализатором также считает код ошибочным, если в нём сравнивается результат работы двух strcmp() функций. Подобный код встречается крайне редко, однако на него в любом случае стоит обратить внимание.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V698. |
V699. It is possible that 'foo = bar == baz ? .... : ....' should be used here instead of 'foo = bar = baz ? .... : ....'. Consider inspecting the expression.
Анализатор обнаружил в коде выражение вида 'foo = bar = baz ? xyz : zzy'. Вполне возможно, что это является ошибкой: имелось в виду выражение вида 'foo = bar == baz ? xyz : zzy', однако по недосмотру программиста вместо сравнения выполняется присваивание.
В качестве примера можно привести следующий некорректный код:
int newID = currentID = focusedID ? focusedID : defaultID;Программист совершил ошибку и вместо оператора сравнения написал оператор присваивания. Исправленный вариант кода выглядит следующим образом:
int newID = currentID == focusedID ? focusedID : defaultID;Отметим, что приведённый ниже код не вызовет предупреждения, поскольку выражение перед тернарным оператором явно имеет тип bool, из-за чего анализатор предполагает, что именно так и было задумано.
result = tmpResult = someVariable == someOtherVariable? 1 : 0;Этот код достаточно очевиден. Он эквивалентен следующему более многословному коду:
if (someVariable == someOtherVariable)
tmpResult = 1;
else
tmpResult = 0;
result = tmpResult;Данная диагностика классифицируется как:
|
V700. It is suspicious that variable is initialized through itself. Consider inspecting the 'T foo = foo = x;' expression.
Анализатор обнаружил в коде выражение вида 'T foo = foo = X'. Переменная при инициализаторе сама же участвует в присваивании. В отличие от диагностики V593, переменная foo является инициализированной выражением X, однако этот код является крайне подозрительным: скорее всего, имелось в виду что-то другое.
В качестве примера можно привести следующий некорректный код:
int a = a = 3;Сложно сказать, что имелось в виду в этом случае. Возможно, корректный код выглядит так:
int a = 3;Также возможно, что подразумевалось инициализация через присваивание значения некоторой другой переменной:
int a = b = 3;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V700. |
V701. Possible realloc() leak: when realloc() fails to allocate memory, original pointer is lost. Consider assigning realloc() to a temporary pointer.
Анализатор обнаружил в коде выражение вида 'foo = realloc(foo, ...)'. Данное выражение является потенциально опасным: рекомендуется результат функции realloc сохранять в другой переменной.
Функция realloc(ptr, ...) производит изменение размера некоторого блока памяти. В случае, если размер блока памяти изменить удалось, не прибегая к перемещению данных, результирующий указатель совпадёт с исходным ptr. В случае, если изменение размера блока памяти осуществить невозможно без его перемещения, функция вернёт указатель на новый блок памяти, а старый блок памяти будет освобождён. Однако в том случае, если изменение размера блока памяти в данный момент вообще невозможно даже с перемещением, функция вернёт нулевой указатель. Такая ситуация может возникнуть в случае выделения большого массива данных, размер которого сопоставим с размером ОЗУ компьютера, а также при сильной сегментации памяти. Этот случай и является потенциально опасным: если realloc(ptr, ...) возвращает нулевой указатель, блок данных по адресу ptr не изменяет своего размера. Главная проблема заключается в том, что при использовании конструкции вида "ptr = realloc(ptr, ...)" указатель ptr на этот блок данных будет утерян.
В качестве примера можно привести следующий некорректный код, взятый из реального приложения:
void buffer::resize(unsigned int newSize)
{
if (capacity < newSize)
{
capacity = newSize;
ptr = (unsigned char *)realloc(ptr, capacity);
}
}Функция realloc(...) производит изменение размера буфера в случае, если требуемый размер буфера больше текущего. Однако, что случится, если realloc() не сможет выделить память? В результат ptr будет помещён NULL, что само по себе может привести к многочисленным проблемам, но более того: указатель на исходную область памяти будет утерян. Корректный код будет выглядеть следующим образом:
void buffer::resize(unsigned int newSize)
{
if (capacity < newSize)
{
capacity = newSize;
unsigned char * tmp = (unsigned char *)realloc(ptr, capacity);
if (tmp == NULL)
{
/* Handle exception; maybe throw something */
} else
ptr = tmp;
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V701. |
V702. Classes should always be derived from std::exception (and alike) as 'public'.
Анализатор обнаружил класс, унаследованный от класса std::exception (или аналогичных классов) через модификатор private или protected. Данное наследование опасно тем, что при непубличном наследовании при попытке поймать исключение std::exception оно будет пропущено.
Ошибка часто возникает из-за того, что забывают указать тип наследования. В соответствии с правилами языка, наследование по умолчанию - приватное. Как результат, обработчики исключений ведут себя не так, как задумывалось.
В качестве примера можно привести следующий некорректный код:
class my_exception_t : std::exception // <=
{
public:
explicit my_exception_t() { }
virtual const int getErrorCode() const throw() { return 42; }
};
....
try
{ throw my_exception_t(); }
catch (const std::exception & error)
{ /* Can't get there */ }
catch (...)
{ /* This code executed instead */ }Код, который должен будет перехватывать все стандартные и пользовательские исключения "catch (const std::exception & error)", не сможет отработать правильно, потому что приватное наследование исключает неявное преобразование типов.
Для того, чтобы код работал корректно, требуется добавить перед родительским классом std::exception в списке базовых классов модификатор public:
class my_exception_t : public std::exception
{
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V702. |
V703. It is suspicious that the 'foo' field in derived class overwrites field in base class.
Анализатор обнаружил в коде класса-наследника поле, совпадающее по типу и по имени с некоторым полем родительского класса. Данное объявление может является ошибочным Технология наследования сама по себе предполагает наличие всех полей родительского класса в дочернем. Объявив же в наследнике поля с таким же именем, мы вносим путаницу и усложняем жизнь программистам, которые будут сопровождать код.
В качестве примера можно привести следующий некорректный код:
class U {
public:
int x;
};
class V : public U {
public:
int x; // <=
int z;
};Данный код может быть опасен, поскольку теперь в классе V существует две переменных x: собственно 'V::x' и 'U::x'. Последствия, к которым это может привести, могут быть проиллюстрированы следующим кодом:
int main() {
V vClass;
vClass.x = 1;
U *uClassPtr = &vClass;
std::cout << uClassPtr->x << std::endl; // <=
....
}Здесь будет произведена печать неинициализированной переменной.
Для исправления проблемы достаточно удалить объявление переменной в классе-наследнике. Корректный код приведён ниже:
class U {
public:
int x;
};
class V : public U {
public:
int z;
};Существует некоторое количество спорных случаев, которые анализатором не считаются ошибочными:
- поля имеют различный тип;
- хотя бы одно из конфликтных полей объявлено как static;
- поле в базовом классе объявлено как private;
- используется приватное наследование;
- поле раскрылось через define;
- поле носит одно из особых имён наподобие "reserved" (такие имена указывают на то, что переменная на самом деле резервирует часть структуры класса в памяти на будущее).
Мы рекомендуем всегда проводить рефакторинг кода, где анализатор выдаёт предупреждение V703. Использование переменной с одним именем в базовом классе и в наследнике далеко не всегда является ошибкой. Но такой код очень опасен. Даже если сейчас программа корректно работает, в дальнейшем при модификации классов очень легко допустить ошибку.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V703. |
V704. The expression is always false on newer compilers. Avoid using 'this == 0' comparison.
Анализатор обнаружил в коде выражение вида this == 0. Данное выражение может оказаться работоспособным в ряде случаев, однако его использование крайне опасно по некоторым соображениям.
Рассмотрим простой пример:
class CWindow {
HWND handle;
public:
HWND GetSafeHandle() const
{
return this == 0 ? 0 : handle;
}
};Вызов метода CWindow::GetSafeHandle() для нулевого указателя this по стандарту С++ ведёт к неопределённому поведению. Однако, поскольку во время работы метода не производится доступа к полям этого класса, метод может работать. С другой стороны, существует два возможных неблагоприятных сценария выполнения данного кода. Во-первых, согласно стандарту С++, указатель this никогда не может быть нулевым; следовательно, компилятор может оптимизировать вызов метода, упростив его до:
return handle;Во-вторых, предположим, что существует следующий код:
class CWindow {
.... // CWindow из предыдущего примера
};
class MyWindowAdditions {
unsigned long long x; // 8 bytes
};
class CMyWindow: public MyWindowAdditions, public CWindow {
....
};
....
void foo()
{
CMyWindow * nullWindow = NULL;
nullWindow->GetSafeHandle();
}Этот код приведёт к чтению из памяти по адресу 0x00000008. В этом можно убедиться, написав следующую строку:
std::cout << nullWindow->handle << std::endl;Будет выведен адрес 0x00000008, поскольку исходный указатель NULL (0x00000000) был скорректирован таким образом, чтобы указывать на начало подобъекта класса CWindow. Для этого его надо сместить на sizeof(MyWindowAdditions) байт.
Теперь проверка this == 0 полностью теряет смысл. Указатель thisвсегда по меньшей мере равен значению 0x00000008.
С другой стороны, ошибка не проявит себя, если поменять местами базовые классы в объявлении CMyWindow:
class CMyWindow: public CWindow, public MyWindowAdditions{
....
};Всё это может приводить к крайне неочевидным ошибкам.
Исправление кода достаточно нетривиально. Корректным выходом в данном случае будет изменение метода класса на статический. Это повлечёт за собой большое количество изменений во всех местах, где встречался вызов метода.
class CWindow {
HWND handle;
public:
static HWND GetSafeHandle(CWindow * window)
{
return window == 0 ? 0 : window->handle;
}
};Второй вариант — использование паттерна Null Object, что тоже повлечёт за собой значительный объём работ.
class CWindow {
HWND handle;
public:
HWND GetSafeHandle() const
{
return handle;
}
};
class CNullWindow : public CWindow {
public:
HWND GetSafeHandle() const
{
return nullptr;
}
};
....
void foo(void)
{
CNullWindow nullWindow;
CWindow * windowPtr = &nullWindow;
// Выведет 0
std::cout << windowPtr->GetSafeHandle() << std::endl;
}Примечание. Данный дефект опасен тем, что на его обработку почти никогда нет времени, поскольку "всё и так работает", а затраты на рефакторинг велики. Однако то, что работало годами, может неожиданно дать сбой при малейшем изменении условий: сборка под другую ОС, изменение версии компилятора (в том числе и его обновление) и так далее.
Например: начиная с версии 4.9.0, компилятор GCCнаучился выбрасывать проверку на неравенство нулю разыменованного выше по коду указателя (см. диагностику V595):
int wtf( int* to, int* from, size_t count ) {
memmove( to, from, count );
if( from != 0 ) // <= после оптимизации условие всегда истинно
return *from;
return 0;
}Примеров проблемного кода из реальных приложений, оказавшегося "сломанным" из-за undefined behavior, достаточно много. Вот некоторые из них, чтобы подчеркнуть важность проблемы:
Пример N1. Уязвимость в ядре Linux
struct sock *sk = tun->sk; // initialize sk with tun->sk
....
if (!tun) // <= всегда false
return POLLERR; // if tun is NULL return errorПример N2. Некорректная работа srandomdev():
struct timeval tv;
unsigned long junk; // <= Не инициализирована специально
gettimeofday(&tv, NULL);
// LLVM: аналог srandom() от неинициализированной переменной,
// т.е. tv.tv_sec, tv.tv_usec и getpid() не учитываются.
srandom((getpid() << 16) ^ tv.tv_sec ^ tv.tv_usec ^ junk);Пример N3. Синтетический пример, очень наглядно показывающий и возможности компиляторов по агрессивной оптимизации в связи с undefined behavior, и новые возможности "прострелить себе ногу":
#include <stdio.h>
#include <stdlib.h>
int main() {
int *p = (int*)malloc(sizeof(int));
int *q = (int*)realloc(p, sizeof(int));
*p = 1;
*q = 2;
if (p == q)
printf("%d %d\n", *p, *q); // <= Clang r160635: Вывод: 1 2
}Насколько нам известно, на момент выхода этой диагностики вызов проверки this == 0 ещё не проигнорирован ни одним компилятором, однако в стандарте С++ явным образом написано (§9.3.1/1): "If a nonstatic member function of a class X is called for an object that is not of type X, or of a type derived from X, the behavior is undefined.". Иными словами, результат вызова любой нестатической функции для класса с this == 0 не определён. Это лишь дело времени, когда компиляторы начнут вместо (this == 0) подставлять false на этапе компиляции.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V704. |
V705. It is possible that 'else' block was forgotten or commented out, thus altering the program's operation logics.
Данная диагностика похожа на диагностику V628, однако относится к ветви else оператора if. Анализатор обнаружил подозрительное место в коде – возможно, забытый или некорректно закомментированный блок else.
Данную ситуацию лучше всего разобрать на примерах.
if (!x)
t = x;
else
z = t;В данном примере форматирование кода не совпадает с его логикой: выражение z = t выполнится лишь в случае, если (x == 0) – вряд ли это имелось в виду. Подобная же ситуация может возникнуть при неудачно закомментированном фрагменте кода:
if (!x)
t = x;
else
//t = -1;
z = t;В данном случае требуется либо исправить форматирование, превратив его в более удобочитаемое, либо исправить логическую ошибку, добавив недостающую ветвь оператора if.
Правда, иногда существуют случаи, в которых тяжело определить, является ли подобный код некорректным или таким образом стилизованным. Анализатор пытается уменьшать количество ложных срабатываний, связанных со стилизацией, путём некоторого эвристического анализа. К примеру, следующий код не приведёт к срабатыванию диагностического правила:
if (x == 1)
t = 42;
else
if (x == 2)
t = 84;
else
#ifdef __extended__x
if (x == 3)
t = 741;
else
#endif
t = 0;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V705. |
V706. Suspicious division: sizeof(X) / Value. Size of every element in X array is not equal to divisor.
Анализатор обнаружил в коде подозрительное деление результата оператора sizeof() на другой оператор sizeof() или число. Причём оператор sizeof() применяется к массиву и размер элемента не совпадает с значением делителя. Скорее всего, в коде присутствует ошибка.
Пример:
size_t A[10];
n = sizeof(A) / sizeof(unsigned);В режиме сборки 32-битной программы типы unsigned и size_t совпадают по своему размеру и 'n' будет равно десяти. Однако в режиме сборки 64-битной программы тип size_t имеет размер 8 байт, а тип unsigned имеет размер всего 4 байта. В итоге в переменную n будет записано число 20, что вряд ли является тем, чего хотел программист.
Также ошибочным будет считаться код следующего вида:
size_t A[9];
n = sizeof(A) / 7;Размер массива в случае компиляции 32-битной программы равен 4 * 9 = 36 байтам. Делить 36 на 7 очень странно. Что хотел программист? С эти кодом что-то не так.
Какие-то конкретные рекомендации в этом случае давать сложно, поскольку каждый случай требует индивидуального подхода - возможно, изменился размер типа, размер массива задан с ошибкой и так далее. Часто это ошибка бывает последствием опечатки или простой невнимательности.
Анализатор не будет выдавать предупреждение, если массив имеет тип char или uchar, поскольку подобные массивы часто используются в качестве буферов для хранения каких-либо данных другого типа. Пример кода, который анализатор считает безопасным:
char A[9];
n = sizeof(A) / 3;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V706. |
V707. Giving short names to global variables is considered to be bad practice.
Анализатор обнаружил в коде глобально объявленную переменную с коротким именем. Это, если и не приведёт к ошибкам, то является плохим стилем программирования и усложняет понимание программы.
Начнём с примера:
int i;Проблема в коротких именах переменных заключается в том, что достаточно легко ошибиться и использовать вместо локальной переменной глобальную внутри тела функции или метода класса. Например, вместо
void MyFunc()
{
for (i = 0; i < N; i++)
AnotherFunc();
....
}должно быть:
void MyFunc()
{
for (int i = 0; i < N; i++)
AnotherFunc();
....
}В данных ситуациях анализатор будет предлагать изменить имя переменной на более длинное. Минимальная длина, которая не является подозрительной для анализатора - три символа. Также анализатор не будет выдавать предупреждения на переменные с именами PI, SI, CR, LF.
Анализатор не выдаёт предупреждения на переменные с коротким именем, если они представляют собой структуры. Хотя это тоже плохой стиль кодирования, но случайно неправильно использовать структуру сложнее. Например, если случайно написать так:
struct T { int a, b; } i;
void MyFunc()
{
for (i = 0; i < N; i++)
AnotherFunc();
....
}То код просто не скомпилируется.
А вот на константы с короткими именами анализатор ругается. Их нельзя менять, но ничто не мешает сделать неправильную проверку. Пример:
const float E = 2.71828;
void Foo()
{
S *e = X[i];
if (E)
{
e->Foo();
}
....
}Исправленный код:
const float E = 2.71828;
void Foo()
{
S *e = X[i];
if (e)
{
e->Foo();
}
....
}Но лучше использовать более длинное имя или обернуть такие константы в специальный namesapce:
namespace Const
{
const float E = 2.71828;
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V707. |
V708. Dangerous construction is used: 'm[x] = m.size()', where 'm' is of 'T' class. This may lead to undefined behavior.
Анализатор обнаружил в коде программы случай неопределённого поведения, связанного с контейнерами типа map или схожими с ним.
Пример некорректного кода:
std::map<size_t, size_t> m;
....
m[0] = m.size();Этот пример приводит к неопределённому поведению, поскольку порядок вычисления операндов у оператора присваивания не определён. В случае, если в объекте уже существует элемент, ассоциированный с нулём, то проблем не возникнет. Однако в случае его отсутствия действия программы могут пойти по двум различным сценариям в зависимости от версии компилятора, операционной системы и так далее.
Предположим, что компилятор сначала вычисляет правый операнд и лишь потом – левый операнд операции присваивания. Поскольку контейнер пуст, m.size() возвращает ноль. Затем с нулём ассоциируется ноль. В итоге имеем, что m[0] == 0.
Теперь предположим, что компилятор сначала вычисляет левый операнд и лишь потом – правый. Сначала будет взят m[0]. Поскольку с нулём ничего не ассоциировано, будет создана пустая ассоциация. Затем вычисляется m.size(). Поскольку контейнер уже не пуст, m.size() возвращает единицу. После этого единица ассоциируется с нулём. В итоге имеем, что m[0] == 1.
Правильным решением для исправления кода будет использования временной переменной и заранее связать какое-то значение с нулём:
std::map<size_t, size_t> m;
....
m[0] = 0;
const size_t mapSize = m.size();
m[0] = mapSize;Несмотря на то, что данная ситуация может возникать достаточно редко в реальном коде, она опасна тем, что фрагмент кода, приводящий к неопределённому поведению, часто очень сложно выявить.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V708. |
V709. Suspicious comparison found: 'a == b == c'. Remember that 'a == b == c' is not equal to 'a == b && b == c'.
В коде обнаружено логическое выражение вида a == b == c. К сожалению, иногда программисты забывают, что правила языков С и С++ не совпадают с правилами, принятыми в математике (и на первый взгляд – со здравым смыслом) и таким сравнением можно проверить равенство трёх переменных. Однако на самом деле вместо проверки на равенство будет вычислено несколько не то, что хотелось.
Разберём пример.
if (a == b == c) ....Предположим, что a == 2, b == 2 и c == 2. Первое сравнение (a == b) окажется истинным, поскольку 2 == 2. В результате данное сравнение возвращает значение true (1). Второе же сравнение (... = c) вернёт уже значение false, поскольку true != 2. Для того, чтобы сравнение трёх (и более) переменных давало корректный результат, следует воспользоваться следующим выражением:
if (a == b && b == c) ....В данном случае действительно a == b вернёт true, b == c вернёт true, и результат логической операции AND будет также равен true.
Однако часто выражения, подобные ошибочным, пишутся для сокращения количества кода. Анализатор не выдаст предупреждение в случаях, если:
1) Третья переменная имеет тип bool, BOOL и т.п. или сама по себе равна 0, 1, true или false. В этом случае ошибка крайне маловероятна – скорее всего, программист написал правильный код:
bool compare(int a, int b, bool res)
{
return a == b == res;
}2) В выражении присутствуют скобки. В этом случае очевидно, что программист понимает логику и хочет, чтобы выражение выполнялось именно так, как написано:
if ((a == b) == c) ....В случае, если анализатор выдал ложное срабатывание V709, рекомендуемым путём его устранения является добавление скобок как в примере выше. Это позволить указать другим программистам, что код корректен.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V709. |
V710. Suspicious declaration. There is no point to declare constant reference to a number.
Анализатор обнаружил в коде подозрительный участок кода, где создаётся константная ссылка на числовой литерал. Это действие не имеет практического смысла и скорее всего является последствием какой-то опечатки. Возможно, используется не тот макрос или что-то ещё.
Пара примеров:
const int & u = 7;
const double & v = 4.2;Данное предупреждение лучше всего не подавить, а исправить путём удаления знака амперсанда, превращая ссылку в обычное константное значение (предварительно, разумеется, проверив, действительно ли так всё и задумывалось):
const int u = 7;
const double v = 4.2;V711. It is dangerous to create a local variable within a loop with a same name as a variable controlling this loop.
В теле цикла обнаружено объявление переменной, совпадающей с переменной, используемой для контроля цикла. В то время, как для цикла for и цикла foreach (C++11) это может и не нести серьёзной опасности, всё равно это является нехорошим стилем программирования. С циклами же do {} while и while {} всё намного опаснее. Возможно случайное изменение новой переменной в теле цикла вместо изменения переменной в условии цикла.
Разберём пример.
int ret;
....
while (ret != 0)
{
int ret;
ret = SomeFunctionCall();
while (ret != 0)
{
DoSomeJob();
ret--;
}
ret--;
}В данной ситуации может возникнуть вечный цикл, поскольку внешняя переменная 'ret' в теле цикла не изменяется вообще. Очевидным решением в данном случае будет изменить имя внутренней переменной:
int ret;
....
while (ret != 0)
{
int innerRet;
innerRet = SomeFunctionCall();
while (innerRet != 0)
{
DoSomeJob();
innerRet--;
}
ret--;
}Анализатор не всегда выдаёт предупреждение V711 в случае, если видит переменную с тем же именем, что используется в теле цикла. К примеру, следующий код не вызовет подозрений:
int ret;
....
while (--ret != 0)
{
int ret;
ret = SomeFunctionCall();
while (ret != 0)
{
DoSomeJob();
ret--;
}
}Также анализатор не выдаст предупреждения в случае, если подозрительные переменные имеют явно несоответствующие друг другу типы (к примеру, класс и указатель на int). В таком случае ошибиться намного сложнее.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V711. |
V712. Compiler may optimize out this loop or make it infinite. Use volatile variable(s) or synchronization primitives to avoid this.
Анализатор обнаружил в коде цикл с пустым телом, который может быть превращён компилятором после оптимизации в вечный цикл или убран из кода программы. Чаще всего подобные циклы используются для ожидания какого-либо события извне.
Пример:
bool AllThreadsCompleted = false; // Глобальная переменная
....
while (!AllThreadsCompleted);В данной ситуации оптимизирующий компилятор сделает цикл вечным. Посмотрим на ассемблерный код из Debug-версии:
; 8 : AllThreadsCompleted = false;
mov BYTE PTR ?AllThreadsCompleted@@3_NA, 0
; AllThreadsCompleted
$LN2@main:
; 9 :
; 10 : while (!AllThreadsCompleted);
movzx eax, BYTE PTR ?AllThreadsCompleted@@3_NA
; AllThreadsCompleted
test eax, eax
jne SHORT $LN1@main
jmp SHORT $LN2@main
$LN1@main:В данном случае проверка, очевидно, присутствует. Теперь же обратимся к Release-версии:
$LL2@main:
; 8 : AllThreadsCompleted = false;
; 9 :
; 10 : while (!AllThreadsCompleted);
jmp SHORT $LL2@mainВ Release-версии переход был оптимизирован в безусловный. Из-за подобного различия Debug-версии и Release-версии могут возникать сложные и трудно детектируемые ошибки.
Путей корректировки данной ситуации несколько. Если эта переменная и впрямь используется для контроля логики многопоточной программы, то лучше использовать средства синхронизации операционной системы, такие как мьютексы и семафоры. Другим вариантом исправления может стать добавление модификатора 'volatile' к объявлению переменной, запрещающему оптимизацию:
volatile bool AllThreadsCompleted; // Глобальная переменная
....
while (!AllThreadsCompleted);Соответствующий ассемблерный код в Release-версии:
$LL2@main:
; 9 :
; 10 : while (!AllThreadsCompleted);
movzx eax, BYTE PTR ?AllThreadsCompleted@@3_NC
; AllThreadsCompleted
test al, al
je SHORT $LL2@mainОднако иногда диагностика V712 выдаётся "совсем не там" и указывает на места, где вечного цикла вообще быть не должно. В таком случае, скорее всего, пустой цикл появился случайно из-за опечатки. В подобной ситуации диагностика часто (но не всегда) пересекается с диагностикой V715.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V712. |
V713. Pointer was used in the logical expression before its check for nullptr in the same logical expression.
Анализатор обнаружил в коде ситуацию, при котором проверка на nullptr некоторого указателя производится после его использования. В отличие от диагностики V595, данная диагностика работает в пределах одного логического выражения.
Ниже представлен некорректный пример.
if (P->x != 0 && P != nullptr) ....В этом случае вторая проверка бессмысленна. В случае, если 'P' равен nullptr, то произойдёт ошибка доступа к памяти при попытке разыменовывания нулевого указателя. В таком коде что-то явно не так. Наиболее простой рекомендацией будет поменять местами проверки в логическом выражении:
if (P != nullptr && P->x != 0) ....Однако в подобном случае всегда рекомендуется провести дополнительный обзор кода. Действительно ли имелось в виду именно это? Возможно, указатель сам по себе не может быть равен nullptr и проверка лишняя. Возможно, разыменовывается или проверяется на nullptr не та переменная. Подобные случаи индивидуальны и трудно дать какую-то общую рекомендацию по исправлению кода.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V713. |
V714. Variable is not passed into foreach loop by reference, but its value is changed inside of the loop.
Анализатор обнаружил в коде подозрительную ситуацию. Присутствует foreach, в котором имеется присваивание контрольной переменной цикла (loop control variable) некоторого значения. В то же время, передача контрольной переменной цикла идёт по значению. Скорее всего, имелась в виду передача по ссылке.
Пример:
for (auto t : myvector)
t = 17;Это приведёт к копированию переменной 't' на каждой итерации и изменению локальной копии, что вряд ли то, что хотел программист. Скорее всего, хотелось изменить значения в контейнере 'myvector'. Корректно данный участок кода будет выглядеть следующим образом:
for (auto & t : myvector)
t = 17;Данная диагностика диагностирует лишь самые простые случаи некорректного использования цикла foreach, поскольку в них проще всего совершить ошибку. В случае более сложных конструкций программист наверняка лучше знает, что он делает и следующие ситуации иногда встречаются в реальном коде:
for (auto t : myvector)
{
function(t); // Использовали t по назначению
// Далее t используется как локальная переменная
t = anotherFunction();
if (t)
break;
}На этот код анализатор не будет выдавать предупреждение V714.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V714. |
V715. The 'while' operator has empty body. This pattern is suspicious.
Анализатор обнаружил странный код, связанный с наличием оператора while с пустым телом в неожиданном месте. Оператор 'while' находится после закрывающейся скобки, относящейся к телу оператора 'if', 'for' или другого 'while'. Подобные ошибки могут возникать при работе со сложным кодом с высоким уровнем вложенности. Данная диагностика может иногда пересекаться с диагностикой V712.
Пример из реального приложения:
while (node != NULL) {
if ((node->hashCode == code) &&
(node->entry.key == key)) {
return true;
}
node = node->next;
} while (node != NULL);Пример полностью синтаксически корректен с точки зрения языка C++: первый цикл 'while' заканчивается закрывающей фигурной скобкой, следом за ним идёт второй цикл while с пустым телом. Более того, второй цикл никогда не станет вечным циклом, поскольку по выходу из первого цикла Node уже точно будет не равен NULL. Однако очевидно, что с этим кодом что-то не так. Возможно, программист сначала хотел написать цикл while, а затем передумал и решил сделать цикл do .... while, однако по какой-то причине не поменял первое условие на do. Возможно, сначала был реализован цикл do .... while, а затем не до конца исправлен на while. Вывод здесь может быть только один: требуется провести обзор кода, а затем переписать его таким образом, чтобы устранить бессмысленный цикл while.
В случае же, если код написан так, как и задумывался, мы советуем не размечать ложное срабатывание, а перенести while на следующую строку для того, чтобы явно указать, что while не относится к предыдущему блоку, и тем самым упростить труд других программистов, которые будут потом работать с проектом.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V715. |
V716. Suspicious type conversion: HRESULT -> BOOL (BOOL -> HRESULT).
Анализатор обнаружил в коде ситуацию, при которой явным или неявным образом производится преобразование типа bool или BOOL к HRESULT или наоборот. В то время, как такая операция вполне допустима с точки зрения языка C++, она не имеет практического смысла. Тип HRESULT предназначен для хранения статуса, имеет достаточно сложный формат и не имеет ничего общего с типом bool или BOOL.
Можно привести следующий пример из реального приложения:
BOOL WINAPI DXUT_Dynamic_D3D10StateBlockMaskGetSetting(....)
{
if( DXUT_EnsureD3D10APIs() &&
s_DynamicD3D10StateBlockMaskGetSetting != NULL )
....
else
return E_FAIL;
}Опасность заключается в том, что тип HRESULT представляет собой, на самом деле, тип 'long', а тип BOOL – это ни что иное как 'int'. Эти типы легко преобразуются друг в друга, и компилятор не видит ничего подозрительного в приведённом выше коде.
Однако с точки зрения программиста эти типы означают совершенно разное. В то время как BOOL обозначает логическую переменную, тип HRESULT устроен достаточно сложно и должен сигнализировать о том, прошла ли операция успешно, какой результат был возвращён после выполнения операции, в случае ошибки – где произошла ошибка, обстоятельства этой ошибки и так далее.
О типе HRESULT. Первый бит слева (то есть самый старший бит) хранит успешность операции: в случае, если операция прошла успешно, первый бит устанавливается в ноль, иначе – в единицу. Дальнейшие четыре бита характеризуют вид ошибки. Одиннадцать бит далее характеризуют модуль, в котором произошла исключительная ситуация. Последние, самые младшие шестнадцать бит характеризуют статус выполнения операции: в случае ошибки он может указывать на код ошибки, в случае успешного выполнения – статус успешного выполнения. Таким образом, неотрицательные значения обычно сигнализируют об успешном выполнении операции. При этом часто применяется макро константа 'S_OK', равная 0.
Более подробное описание HRESULT можно увидеть в статье на сайте MSDN. А на этой странице список наиболее часто применяемых значений.
Тип BOOL для индикации значения "ложь" должен быть равен нулю, в противном случае он указывает на значение "истина". Иными словами, эти два типа крайне похожи друг на друга в плане типов и их приведение друг к другу не влечёт за собой с точки зрения языка ничего страшного, однако операция приведения лишена смысла. Ведь по первоначальному замыслу тип HRESULT хранит в себе не только информацию об успехе или неудаче (и код ошибки в случае неудачи), но и может сохранять в себе некоторую дополнительную информацию в случае успешного вызова. Особенно подпортить жизнь может значение S_FALSE, равное 0x1. То, что ненулевые значения возвращаются в случае успешного вызова крайне редко, может стать причиной мучительных поисков ошибок, проявляющихся очень иногда и совсем изредка. Зачастую можно встретить конструкцию вида:
HRESULT result = someWinApiFunction(....);
if (!result)
{
// This is an error!
}Такой код абсолютно ошибочен, поскольку проверка на ошибку сработает, если функция вернёт 0 в случае успеха. При этом код обработки ошибки не сработает, когда функция просигнализирует о проблеме, вернув отрицательное число. При этом подобные неявные преобразования между целочисленным и логическим типом могут происходить в более сложных выражениях, где ошибку сложно заметить невооруженным глазом.
Для контроля возвращаемого значения типа HRESULT настоятельно предлагаем воспользоваться макросами SUCCEEDED и FAILED.
HRESULT someFunction(int x);
....
BOOL failure = FAILED(someFunction(q));В остальных случаях рефакторинг не так уж и прост, как кажется, и требует по крайней мере вдумчивого чтения и анализа кода.
Ещё раз о главном. Помните, что:
- FALSE == 0
- TRUE == 1
- S_OK == 0
- S_FALSE == 1
- E_FAIL == 0x80004005
- и так далее.
Никогда не смешивайте HRESULT и BOOL. Смешивание этих типов является серьёзной ошибкой в логике работы программы. Для проверки значений типа HRESULT используйте специальные макросы.
Для поиска ситуаций, когда в переменную типа HRESULT помещается true или false, существует родственная диагностика V543.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V716. |
V717. It is suspicious to cast object of base class V to derived class U.
Анализатор заметил в коде ситуацию необычного приведения типов: указатель на объект базового класса жёстко приводится к указателю на производный класс. Причём известно, что указатель на базовый класс действительно указывает на объект базового класса.
Приведение указателей производного класса к базовому – вполне типичная ситуация. А вот приведение базового класса к одному из производных, может иногда быть ошибочным. Если приведение типов выполнено неправильно, то попытка обращения к членам производного класса может привести к Access Violation или ко всему чему угодно.
Иногда программисты допускают ошибки, приводя к производному классу указатель именно на базовый класс. Пример из реального приложения:
typedef struct avatarCacheEntry { .... };
struct CacheNode : public avatarCacheEntry,
public MZeroedObject
{
....
BOOL loaded;
DWORD dwFlags;
int pa_format;
....
};
avatarCacheEntry tmp;
....
CacheNode *cc = arCache.find((CacheNode*)&tmp);
// Далее при попытке обращения, например, к
// cc->loaded, произойдёт ошибка времени выполнения.К сожалению, в данном случае сложно привести какие-то конкретные рекомендации по устранению некорректной ситуации – скорее всего, потребуется заняться рефакторингом кода с целью его улучшения и увеличения удобочитаемости, а также для предотвращения потенциальных ошибок в будущем. Например, если обращение к новым полям не требуется, то тогда можно подменить указатель на базовый класс на указатель на производный.
Следующий код анализатором считается корректным:
base * foo() { .... }
derived *y = (derived *)foo();Здесь дело в том, что функция foo() может на самом деле всегда возвращать указатель на один из производных классов, и приведение её результата к производному классу – вполне обыденное явление. Вообще, анализатор выдаёт предупреждение V717 только в том случае, если точно известно, что именно базовый класс приводится к производному. Однако, анализатор не будет выдавать предупреждение V717 в том случае, если в производном классе нет новых нестатических членов (хотя всё равно так делать нехорошо, но это уже ближе к нарушению хорошего стиля кода, нежели к настоящей ошибке):
struct derived : public base
{
static int b;
void bar();
};
....
base x;
derived *y = (derived *)(&x);Данная диагностика классифицируется как:
V718. The 'Foo' function should not be called from 'DllMain' function.
Внутри функции DllMain() нельзя вызывать многие функции, так как это может привести к зависанию приложения или иным ошибкам. Именно такой опасный вызов функции и был обнаружен анализатором.
Ситуация с DllMain хорошо описана в статье на сайте MSDN: Dynamic-Link Library Best Practices. Процитируем из неё некоторые фрагменты:
При вызове функции DllMain происходит блокировка загрузчика. По этой причине на функции, которые могут быть вызваны внутри DllMain, накладываются существенные ограничения. Как таковая, функция DllMain предназначена для выполнения задач по минимальной инициализации за счет использования небольшого подмножества Microsoft Windows API. Внутри нее нельзя вызывать функции, которые прямо или косвенно пытаются использовать загрузчик. В противном случае, Вы рискуете создать в программе такие условия, при которых произойдет ее аварийное завершение либо взаимная блокировка потоков. Ошибка в реализации DllMain может подвергнуть опасности весь процесс целиком и все его потоки.
В идеале функция DllMain должна представлять собой всего лишь пустую заглушку. Однако, учитывая сложность многих приложений, данное ограничение было бы слишком строгим. Поэтому на практике при работе с этой функцией следует откладывать инициализацию как можно дольше. Отложенная инициализация повышает надежность работы приложения, поскольку она не происходит, пока загрузчик заблокирован. Кроме того, отложенная инициализация позволяет безопасно использовать Windows API в значительно большем объеме.
Некоторые задачи инициализации не могут быть отложены. Например, DLL-библиотека, которая зависит от файла конфигурации, должна прерывать свою загрузку, если файл оказывается неправильно сформированным или содержит мусор. При таком типе инициализации DLL-библиотеки должны предпринимать попытку выполнить запланированное действие и в случае неудачи сразу же завершаться вместо того, чтобы тратить ресурсы, выполняя какую-то другую работу.
В любом случае никогда не выполняйте следующие задачи в пределах функции DllMain:
- Вызов LoadLibrary или LoadLibraryEx (напрямую или косвенно). Это может привести к взаимной блокировке потоков или аварийному завершению программы.
- Вызов GetStringTypeA, GetStringTypeEx или GetStringTypeW (напрямую или косвенно). Это может привести к взаимной блокировке потоков или аварийному завершению программы.
- Синхронизация с другими потоками. Это может привести к их взаимной блокировке.
- Захват объекта синхронизации, принадлежащего коду, который находится в ожидании захвата блокировки загрузчика. Это может привести к взаимной блокировке потоков.
- Инициализация COM-потоков с помощью CoInitializeEx. При определенных условиях данная функция может вызвать LoadLibraryEx.
- Вызов реестровых функций. Данные функции реализованы в Advapi32.dll. Если Advapi32.dll не была инициализирована раньше пользовательской DLL-библиотеки, последняя может обратиться к неинициализированной области памяти, что приведет к аварийному завершению процесса.
- Вызов CreateProcess. Создание процесса может повлечь за собой загрузку другой DLL-библиотеки.
- Вызов ExitThread. Выход из потока во время отсоединения DLL-библиотеки может повлечь за собой повторный захват блокировки загрузчика, что приведет к взаимной блокировке потоков или аварийному завершению программы.
- Вызов CreateThread. Если создаваемый поток не синхронизируется с другими потоками, то такая операция допустима, хотя и рискованна.
- Создание именованного конвейера или другого именованного объекта (только для Windows 2000). В Windows 2000 именованные объекты предоставляются библиотекой Terminal Services DLL. Если данная библиотека не инициализирована, ее вызовы могут привести к аварийному завершению процесса.
- Использование функций управления памятью из динамической библиотеки C Run-Time (CRT). Если данная библиотека не инициализирована, вызовы этих функций могут привести к аварийному завершению процесса.
- Вызов функций из библиотек User32.dll или Gdi32.dll. Некоторые функции загружают другие DLL-библиотеки, которые могут быть не инициализированы.
- Использование управляемого кода.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V718. |
V719. The switch statement does not cover all values of the enum.
Анализатор обнаружил подозрительный оператор 'switch'. Выбор варианта осуществляется по переменной enum-типа. При этом рассмотрены не все возможные варианты.
Поясним это на примере:
enum TEnum { A, B, C, D, E, F };
....
TEnum x = foo();
switch (x)
{
case A: Y(11); break;
case B: Y(22); break;
case C: Y(33); break;
case D: Y(44); break;
case E: Y(55); break;
}Перечисление TEnum содержит 6 именованных констант. Но в операторе 'switch' используется только 5 из них. Высока вероятность, что это ошибка.
Такая ошибка часто возникает в ходе рефакторинга. В 'TEnum' добавили константу 'F". После этого какие-то 'switch' поправили, а про какие-то забыли. В результате, значение 'F' начинает обрабатываться неправильно.
Анализатор предупредит о том, что константа 'F' не используется. И тогда программист может исправить оплошность:
switch (x)
{
case A: Y(11); break;
case B: Y(22); break;
case C: Y(33); break;
case D: Y(44); break;
case E: Y(55); break;
case F: Y(66); break;
}Анализатор выдает предупреждение далеко не всегда, когда в 'switch' используется не все константы из перечисления. Иначе, было бы слишком много ложных срабатываний. Действует целый ряд исключений эмпирического типа. Основные:
- Есть default-ветка;
- В перечислении всего 1 или 2 константы;
- В switch не используется более чем 4 константы;
- Отсутствующая константа содержит в имени: None, Unknown и т.п.
- Отсутствующая константа самая последняя в enum и содержит в имени "end", "num", "count" и т.п.
Пользователь может сам задать список имён, которые обозначают последний элемент в перечислении. В этом случае анализатор не использует список имён по умолчанию, такие как "num" или "count". Будут использованы только имена, указанные пользователем. Комментарий, управляющий поведением диагностики V719:
//-V719_COUNT_NAME=ABCD,FOOВы можете разметить этот комментарий в одном из файлов, включаемый во все другие. Например, в StdAfx.h.
Описанные исключения являются взвешенным решением, проверенными на практике. Единственное что стоит рассмотреть подробнее, это отсутствие предупреждений, когда есть 'default'. Не всегда это хорошо.
С одной стороны, анализатору нельзя ругаться если константы не используются, но при это есть 'default'. Будет слишком много ложных срабатываний и пользователи просто будут отключать эту диагностику. С другой стороны, весьма типовой ситуацией является, когда в 'switch' следует рассмотреть все варианты, а ветка 'default' используется для отлова аварийных ситуаций. Пример:
enum TEnum { A, B, C, D, E, F };
....
TEnum x = foo();
switch (x)
{
case A: Y(11); break;
case B: Y(22); break;
case C: Y(33); break;
case D: Y(44); break;
case E: Y(55); break;
default:
throw MyException("Ай! Забыли рассмотреть один из вариантов!");
}Ошибка может быть обнаружена только на этапе исполнения. Естественно есть желание отловить эту ситуацию и с помощью анализатора. В наиболее ответственных местах кода можно поступить следующим образом:
enum TEnum { A, B, C, D, E, F };
....
TEnum x = foo();
switch (x)
{
case A: Y(11); break;
case B: Y(22); break;
case C: Y(33); break;
case D: Y(44); break;
case E: Y(55); break;
#ifndef PVS_STUDIO
default:
throw MyException("Ай! Забыли рассмотреть один из вариантов!");
#endif
}Используется предопределённый макрос PVS_STUDIO. Этот макрос отсутствует при компиляции. Поэтому при компиляции исполняемого файла ветка 'default' остается на своём месте и в случае ошибки возникнет исключение.
При проверке кода с помощью PVS-Studio макрос PVS_STUDIO определён и поэтому анализатор не увидит default-ветку. Поэтому он проверит 'switch', обнаружит что не используется константа 'F' и выдаст предупреждение.
Исправленный вариант кода:
switch (x)
{
case A: Y(11); break;
case B: Y(22); break;
case C: Y(33); break;
case D: Y(44); break;
case E: Y(55); break;
case F: Y(66); break;
#ifndef PVS_STUDIO
default:
throw MyException("Ай! Забыли рассмотреть один из вариантов!");
#endif
}Описанный подход не очень красив. Однако, если вы очень переживаете за какой-то 'switch' и хотите максимально защитить его, то этот способ вполне подходит.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V719. |
V720. The 'SuspendThread' function is usually used when developing a debugger. See documentation for details.
- Почему никогда не стоит приостанавливать работу потока
- Функция SuspendThread приостанавливает поток, но делает это асинхронно
Анализатор обнаружил, что в программе используется функция SuspendThread() или Wow64SuspendThread(). Сам по себе вызов этих функций не является ошибкой. Однако разработчики часто используют их не по назначению. Из-за этого программа может вести себя не так, как ожидает программист.
Функция SuspendThread() должна помогать разрабатывать отладчики и подобные им приложения. Если вы используете эту функцию в прикладном программном обеспечении для задач синхронизации, то высока вероятность, что в вашей программе есть ошибка.
Суть проблемы неправильного использования функции SuspendThread() изложена в следующих статьях:
- Why you should never suspend a thread.
- The SuspendThread function suspends a thread, but it does so asynchronously.
Если в вашем коде функция SuspendThread() используется неправильно, то необходимо его переписать. Если всё хорошо, то просто отключите диагностику V720 в настройках анализатора.
Статьи в интернете иногда пропадают или меняют своё расположение. Поэтому, мы на всякий случай приводим в документации текст обеих статей.
Примечание. Для российских пользователей мы перевели текст статей. Ознакомиться с оригиналом вы можете, перейдя по ссылкам, приведённым ниже или переключить язык нашего сайта.
Почему никогда не стоит приостанавливать работу потока
Это практически так же плохо, как уничтожение потока.
Рассмотрим такую программу на (вздох) C#:
using System.Threading;
using SC = System.Console;
class Program {
public static void Main() {
Thread t = new Thread(new ThreadStart(Program.worker));
t.Start();
SC.WriteLine("Press Enter to suspend");
SC.ReadLine();
t.Suspend();
SC.WriteLine("Press Enter to resume");
SC.ReadLine();
t.Resume();
}
static void worker() {
for (;;) SC.Write("{0}\r", System.DateTime.Now);
}
}Когда вы запускаете эту программу и жмёте Enter, программа зависает. Но если вы измените функцию worker просто на "for(;;) {}", программа будет работать совершенно нормально. Давайте разберёмся, почему так происходит.
Рабочий поток тратит практически всё время своей работы на вызовы System.Console.WriteLine, поэтому, когда вы зовёте Thread.Suspend(), поток с наибольшей вероятностью и находится в System.Console.WriteLine.
Вопрос: Является ли метод System.Console.WriteLine потокобезопасным?
Да. Даже не нужно залезать в документацию, чтобы понять это. Наша программа зовёт его из двух разных потоков без какой-либо синхронизации, так что лучше бы ему быть потокобезопасным, иначе у нас начались бы большие неприятности ещё до того, как мы дошли до приостановки потока.
Вопрос: Каким образом обычно объекты делают потокобезопасными?
Вопрос: Каков результат приостановки потока в момент выполнения им потокобезопасной операции?
Вопрос: Что случится, если вы, в дальнейшем, попытаетесь обратиться к тому же объекту (в данном случае – к консоли) из другого потока?
Такой результат не специфичен именно для C#. Подобная логика применима как к потоковой модели Win32, так и к любой другой. В Win32, структура кучи процесса является потокобезопасным объектом, и, поскольку сложно что-либо сделать в Win32 без обращений к куче, приостановка потока в Win32 имеет большую вероятность привести к блокировке вашего процесса.
Но тогда зачем вообще появилась функция SuspendThread?
Отладчики используют её для "заморозки" всех потоков процесса в момент, когда происходит его отладка. Отладчики также могут использовать её при остановке всех потоков процесса, кроме одного, чтобы вы могли отлаживать потоки по одному. Это не создаёт взаимоблокировок в отладчике, ведь он является отдельным процессом.
Функция SuspendThread приостанавливает поток, но делает это асинхронно
Итак, коллега решил игнорировать совет, потому что он прогонял несколько экспериментов с потоковой безопасностью и взаимоблокирующими операциями, и приостановка потока была удобным способом обнаружения "окон", в которых могут возникать гонки доступа к объектам.
В процессе этих экспериментов, он обнаружил некоторое странное поведение.
LONG lValue;
DWORD CALLBACK IncrementerThread(void *)
{
while (1) {
InterlockedIncrement(&lValue);
}
return 0;
}
// This is just a test app, so we will abort() if anything
// happens we don't like.
int __cdecl main(int, char **)
{
DWORD id;
HANDLE thread = CreateThread(NULL, 0, IncrementerThread,
NULL, 0, &id);
if (thread == NULL) abort();
while (1) {
if (SuspendThread(thread) == (DWORD)-1) abort();
if (InterlockedOr(&lValue, 0) != InterlockedOr(&lValue, 0))
{
printf("Huh? The variable lValue was modified by a suspended
thread?\n");
}
ResumeThread(thread);
}
return 0;
}Странным здесь является то, что сообщение "Huh?" было распечатано. Разве может приостановленный поток модифицировать переменную? Возможно ли, что InterlockedIncrement начнёт увеличивать значение переменной, затем окажется "замороженным", но каким-то образом всё же закончит начатое позже?
Но ответ гораздо проще. Функция SuspendThread говорит планировщику заморозить поток, но не ждёт подтверждения от него о том, что "заморозка" уже произошла. На это намекает документация на SuspendThread, где говорится:
"Эта функция в основном разработана для использования отладчиками. Она не предназначена для синхронизации потоков".
Не следует использовать SuspendThread для синхронизации двух потоков, т.к. не предоставляется гарантий для такой синхронизации. На самом деле, SuspendThread просто сигнализирует планировщику приостановить поток и сразу выходит. Если планировщик занят чем-то другим, то возможно он и не сможет обработать запрос на "заморозку" сразу, поэтому приостанавливаемый поток продолжает работать, пока планировщик не обработает запрос, и поток наконец-то не окажется приостановленным на самом деле.
Если вы хотите убедиться в том, что поток на самом деле приостановлен, вам нужно выполнить синхронную операцию, которая зависит от факта приостановки потока. Это принуждает выполнение обработки запроса на приостановку, т.к. этот запрос является необходимым условием для вашей операции. И поскольку ваша операция синхронна, вы знаете, что к моменту, когда она завершится, приостановка потока гарантированно произойдёт.
Традиционный способ сделать это — вызвать GetThreadContext, поскольку ядру необходимо прочитать контекст приостановленного потока. Для этого требуется сохранить контекст, а значит — приостановить поток.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V721. The VARIANT_BOOL type is used incorrectly. The true value (VARIANT_TRUE) is defined as -1.
Анализатор обнаружил, что неправильно используется значение типа VARIANT_BOOL. Дело в том, что значение истина (VARIANT_TRUE) обозначается как -1. Многие программисты не ожидают такого подвоха и используют тип неправильно.
Вот как объявлен тип VARIANT_TRUE и константы для обозначения "истина" и "ложь":
typedef short VARIANT_BOOL;
#define VARIANT_TRUE ((VARIANT_BOOL)-1)
#define VARIANT_FALSE ((VARIANT_BOOL)0)Рассмотрим несколько примеров неправильной работы с типом VARIANT_TRUE. Во всех случаях программист ожидает, что условие будет истинно. Но на самом деле условие всегда ложно.
Пример N1.
VARIANT_BOOL variantBoolTrue = VARIANT_TRUE;
if (variantBoolTrue == true) // falseЕсли подставить значение в выражение, то мы получим: ((short)(-1) == true). При вычислении выражения, 'true' превратится в '1'. Условие (-1 == 1) ложно.
Правильный вариант:
if (variantBoolTrue == VARIANT_TRUE)Пример N2.
VARIANT_BOOL variantBoolTrue = TRUE;
if (variantBoolTrue == VARIANT_TRUE) //falseЗдесь программист ошибся и использовал TRUE вместо VARIANT_TRUE. В результате переменной variantBoolTrue будет присвоено значение 1. Это недопустимое значение для переменных типа VARIANT_BOOL.
Если подставить значение в выражение, то мы получим: (1 == (short)(-1)).
Правильный вариант:
VARIANT_BOOL variantBoolTrue = VARIANT_TRUE;Пример N3.
bool bTrue = true;
if (bTrue == VARIANT_TRUE) //falseРаскроем выражение: (true == (short)(-1)). При вычислении выражения 'true' превратится в '1'. Условие (1 == -1) ложно.
Правильный вариант привести затруднительно. Код в принципе неверен. Нельзя смешивать переменные типа 'bool' и значения типа 'VARIANT_TRUE'.
Подобных примеров можно придумать достаточно много. Например, формальный аргумент функции имеет тип VARIANT_BOOL. А в качестве фактического аргумента будет передано значение 'true'. Ещё вариант - функция возвращает неправильно значение. И так далее.
Самое главное - не смешивать тип VARIANT_BOOL с типами BOOL, bool и BOOLEAN.
Дополнительные ссылки:
- MSDN. VARIANT_BOOL.
- The Old New Thing. BOOL vs. VARIANT_BOOL vs. BOOLEAN vs. bool.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V721. |
V722. Abnormality within similar comparisons. It is possible that a typo is present inside the expression.
Анализатор обнаружил подозрительное условие, которое может содержать ошибку.
Диагностика носит эмпирический характер, поэтому проще показать на примере, как она работает, чем объяснить сам принцип работы анализатора.
Рассмотрим реальный пример:
if (obj.m_p == p &&
obj.m_forConstPtrOp == forConstVarOp &&
obj.m_forConstPtrOp == forConstPtrOp)Из-за того, что имена переменных очень похожи, в коде допущена опечатка. Ошибка находится во второй строке. Переменную 'forConstVarOp' следовало сравнить с 'm_forConstVarOp', а не с 'm_forConstPtrOp'. Даже читая этот текст сложно заметить ошибку. Обратите внимание на 'Var' и 'Ptr' внутри названий переменных.
Правильный вариант:
if (obj.m_p == p &&
obj.m_forConstVarOp == forConstVarOp &&
obj.m_forConstPtrOp == forConstPtrOp)Если анализатор выдал предупреждение V722, то внимательно изучите соответствующий фрагмент кода. Иногда опечатку бывает сложно заметить.
Данная диагностика классифицируется как:
|
V723. Function returns a pointer to the internal string buffer of a local object, which will be destroyed.
Анализатор обнаружил ситуацию, когда функция возвращает указатель на внутренний строковый буфер локального объекта. Такой объект будет автоматически уничтожен вместе со своим буфером при выходе из функции, и использовать указатель на него будет нельзя.
В самом простом виде данное диагностическое сообщение будет выдано на следующий код:
const char* Foo()
{
std::string str = "local";
return str.c_str();
}Здесь из функции Foo() возвращается C-строка, хранящаяся во внутреннем буфере объекта str, который будет автоматически уничтожен. В итоге мы получим неправильный указатель, использование которого в программе приведет к неопределённому поведению. Исправленный вариант кода:
const char* Foo()
{
static std::string str = "static";
return str.c_str();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V724. Converting integers or pointers to BOOL can lead to a loss of high-order bits. Non-zero value can become 'FALSE'.
Анализатор обнаружил в коде ситуацию, при которой преобразование указателей или переменных целочисленного типа к типу BOOL может приводить к потере старших разрядов. В результате ненулевое значение, которое по сути означает TRUE, может неожиданно превратиться в FALSE.
В программах тип BOOL (gboolean, UBool и т.д.) определяется как целочисленный тип. Любое отличное от нуля значение интерпретируется как истина, а равное нулю – ложь. Поэтому потеря старших битов при преобразовании типов вызовет ошибку в логике работы программы.
Рассмотрим пример:
typedef long BOOL;
__int64 lLarge = 0x12300000000i64;
BOOL bRes = (BOOL) lLarge;Здесь отличная от нуля переменная при преобразовании в BOOL срезается до нуля, что означает FALSE.
Рассмотрим другие случаи ошибочного преобразования:
int *p;
size_t s;
long long w;
BOOL x = (BOOL)p;
BOOL y = s;
BOOL z = (BOOL)s;
BOOL q = (BOOL)w;Для исправления таких ошибок необходимо выполнить проверку на ненулевое значение перед преобразованием в BOOL.
Различные способы исправления:
int *p;
size_t s;
long long w;
BOOL x = p != nullptr;
BOOL y = s != 0;
BOOL z = s ? TRUE : FALSE;
BOOL q = !!w;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V724. |
V725. Dangerous cast of 'this' to 'void*' type in the 'Base' class, as it is followed by a subsequent cast to 'Class' type.
Анализатор обнаружил опасные приведения указателя this к типу void* и последующее обратное приведение void* к типу класса. Само по себе преобразование this к типу void* не является ошибкой, но в ряде случаев ошибочным является обратное преобразование — от void* к типу указателя на класс. В результате таких преобразований возможно получение некорректного указателя.
Рассмотрим пример, где используется приведение this к void*, а после — некорректное обратное приведение к типу класса:
class A
{
public:
A() : firstPart(1){}
void printFirstPart() { std::cout << firstPart << " "; }
private:
int firstPart;
};
class B
{
public:
B() : secondPart(2){}
void* GetAddr() const { return (void*)this; }
void printSecondPart() { std::cout << secondPart << " "; }
private:
int secondPart;
};
class C: public A, public B
{
public:
C() : A(), B(), thirdPart(3){}
void printThirdPart() { std::cout << thirdPart << " "; }
private:
int thirdPart;
};
void func()
{
C someObject;
someObject.printFirstPart();
someObject.printSecondPart();
someObject.printThirdPart();
void *pointerToObject = someObject.GetAddr();
....
auto pointerC = static_cast<C*>(pointerToObject);
pointerC->printFirstPart();
pointerC->printSecondPart();
pointerC->printThirdPart();
}Можно было бы предположить, что вывод будет следующим:
1 2 3 1 2 3Однако на самом деле на экране отобразится это:
1 2 3 2 3 -858993460В итоге вывод для всех данных после преобразований является некорректным. Проблема кроется в том, что теперь указатель pointerC указывает не на начало объекта C, а на блок памяти, выделенной под объект B.
Кажется, что такая ошибка маловероятна и её трудно допустить, однако она очевидна только из-за того, что пример маленький и простой. В реальных программах со сложными иерархиями классов можно легко запутаться. Cложность в том, что если функцию GetAddr() расположить в классе A, то всё работает, а если в классе B, то нет. Давайте разберёмся в ситуации подробнее.
Чтобы было проще понять, из-за чего возникла ошибка, необходимо знать, как конструируются и располагаются в памяти объекты классов, созданных в результате множественного наследования.
Схематичный пример изображён на рисунке 1.

Рисунок 1 — Расположение в памяти объекта класса, полученного путём множественного наследования.
Из рисунка 1 видно, что объект класса С (который и получен в результате множественного наследования) состоит из объектов классов A и B, а также части объекта C.
Указатель this содержит адрес начала выделенного под объект блока памяти. На рисунке 2 изображены указатели this для всех трёх объектов.

Рисунок 2 — Указатели this и блоки памяти.
Так как объект класса C состоит из трёх частей, this для него будет указывать не на блок памяти, который добавлен дополнительно к базовым классам, а на начало всего непрерывного блока памяти. То есть в данном случае указатели this для классов A и C совпадут.
Указатель this для объекта класса B указывает на начало выделенного под него блока памяти, но при этом адрес начала этого участка памяти будет отличен от адреса начала участка памяти, выделенной под объект класса C.
Таким образом, при вызове метода GetAddr() будет возвращён адрес объекта B, и при обратном преобразовании этого указателя к типу C* будет получен некорректный указатель.
Т.е., если бы функция GetAddr() располагалась в классе A, то всё бы работало так, как и ожидал программист. Но если она расположена в B, то происходит сбой.
Во избежание подобных ошибок необходимо продумать, действительно ли стоит выполнять приведение this к void*, и если да, то тщательно проверить иерархию наследования, а также дальнейшие операции обратного преобразования от void* к типу указателя на класс.
Дополнительные ссылки:
- Joost's Dev Blog. Hardcore C++: why "this" sometimes doesn't equal "this".
Данная диагностика классифицируется как:
V726. Attempt to free memory containing the 'int A[10]' array by using the 'free(A)' function.
Анализатор обнаружил ошибочный код, в котором осуществляется попытка удаления массива через функцию free() или схожую с ней. При этом, память под этот массив не была выделена при помощи специальных функций, таких как malloc(). Подобные действия являются причиной неопределённого поведения.
Пример:
class A
{
int a[50];
public:
A(){}
~A(){ free(a); }
};Так как память не была выделена каким-то специальным образом, не стоит также и вызывать каких-либо специальных функций для её очистки – она будет произведена автоматически при уничтожении объекта. Следовательно, в данном случае корректный код должен был выглядеть следующим образом:
class A
{
int a[50];
public:
A(){}
~A(){}
};Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V726. |
V727. Return value of 'wcslen' function is not multiplied by 'sizeof(wchar_t)'.
Анализатор обнаружил выражение, которое на его взгляд предназначается для вычисления размера буфера в байтах, требуемого для хранения строки. В этом выражении допущена ошибка.
Когда стоит задача получения размера строки типа char, стандартным решением является использование конструкции "strlen(str) + 1". Функция strlen() вычисляет длину некой строки, а единица означает резервирование одного байта для терминального нуля. Но если речь идет о строке типа wchar_t, char16_t или char32_t, то следует не забывать умножать "длину строки + 1" на размер одного символа, то есть на 'sizeof(T)'.
Рассмотрим несколько синтетических примеров ошибок.
Пример N1:
wchar_t *str = L"Test";
size_t size = wcslen(str) + 1 * sizeof(wchar_t);Из-за пропущенных скобок происходит умножение 'sizeof' на единицу, а затем сложение с функцией, вычисляющей длину строки. Корректный код:
size_t size = (wcslen(str) + 1) * sizeof(wchar_t);Пример N2:
Выражение может быть записано и в другой последовательности, при которой сначала будет происходить умножение результата функции на 'sizeof', а затем сложение с единицей.
.... = malloc(sizeof(wchar_t) * wcslen(str) + 1);Порой может случиться такая ситуация, когда программист в процессе написания вспомнил, что длину строки следует умножать на "sizeof(wchar_t)", но по привычке добавил 1. В результате памяти будет выделено на 1 байт меньше, чем необходимо.
Корректные варианты кода:
.... = malloc(wcslen(str) * sizeof(wchar_t) + 1 * sizeof(wchar_t));
.... = malloc((wcslen(str) + 1) * sizeof(wchar_t));Данная диагностика классифицируется как:
|
V728. Excessive check can be simplified. The '||' operator is surrounded by opposite expressions 'x' and '!x'.
Анализатор обнаружил код, который можно упростить. Слева и справа от оператора '||' стоят противоположные по смыслу выражения. Данный код является избыточным, поэтому его можно упростить, сократив количество проверок.
Пример избыточного кода:
if (!Name || (Name && Name[0] == 0))В выражении "Name && Name[0] == 0" проверка 'Name' является избыточной, так как перед этим проверятся противоположное ему условие '!Name', причём эти выражения разеделены оператором '||'. Следовательно, излишнюю проверку в скобках можно опустить, упростив код:
if (!Name || Name[0] == 0)Наличие избыточности может свидетельствовать о наличии ошибки. Возможно, что в выражении случайно используется не та переменная. И корректный код на самом деле должен быть, например, таким:
if (!Foo || (Name && Name[0] == 0))Анализатор выдаёт предупреждения не только на конструкции вида 'x' и '!x', но и на прочие противоположные по смыслу выражения, например:
if (a > 5 || (a <= 5 && b))Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V728. |
V729. Function body contains the 'X' label that is not used by any 'goto' statements.
Анализатор обнаружил в теле функции метку, на которую не ссылается ни один оператор 'goto'. Возможно, программист ошибся и использует где-то переход не на ту метку.
Синтетический пример некорректного кода:
string SomeFunc(const string &fStr)
{
string str;
while(true)
{
getline(cin,str);
if (str == fStr)
goto retRes;
else if(str == "stop")
goto retRes;
}
retRes:
return str;
badRet:
return "fail";
}В теле функции есть метка 'badRet' на которую не ссылается ни один оператор 'goto', но при этом присутствует другая метка 'retRes', на которую есть ссылка. Программист ошибся и вместо перехода на метку 'badRet' продублировал переход на метку 'retRes'.
Тогда корректный код мог бы выглядеть так:
string SomeFunc(const string &fStr)
{
string str;
while(true)
{
getline(cin,str);
if (str == fStr)
goto retRes;
else if(str == "stop")
goto badRet;
}
retRes:
return str;
badRet:
return "fail";
}Другой пример некорректного кода:
int DeprecatedFunc(size_t lhs, size_t rhs, bool cond)
{
if (cond)
return lhs*3+rhs;
else
return lhs*2 + rhs*7;
badLbl:
return -1;
}В данном случае будет выдано сообщение с низким уровнем опасности, так как метка 'badLbl' осталась после изменения функции, а операторы 'goto', ссылающиеся на неё, были удалены.
Анализатор не будет выдавать предупреждение в случае, если в теле функции есть оператор 'goto', ссылающийся на данную метку, но он закомментирован или этот участок кода не компилируется из-за директивы '#ifdef'.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V729. |
V730. Not all members of a class are initialized inside the constructor.
Анализатор обнаружил конструктор, который по всей видимости инициализирует не все члены класса.
Рассмотрим простой синтетический пример:
struct MyPoint
{
int m_x, m_y;
MyPoint() { m_x = 0; }
void Print() { cout << m_x << " " << m_y; }
};
MyPoint Point;
Point.Print();При создании объекта Point вызовется конструктор, в котором не инициализируется член m_y. Соответственно при вызове функции Print будет использована неинициализированная переменная, и последствия этого непредсказуемы.
Корректный конструктор может выглядеть следующим образом:
MyPoint() { m_x = 0; m_y = 0; }Мы рассмотрели простой синтетический пример, где сразу всё понятно. Однако в реальном коде всё бывает гораздо сложнее. Поиск неинициализированных членов класса является набором эмпирических алгоритмов. Во-первых, члены классов можно инициализировать разнообразнейшими способами, и анализатор не всегда может понять, инициализирован член класса или нет. Во-вторых, не всегда нужно инициализировать все члены, и сообщения анализатора могут быть ложными, так как он не может угадать задумку программиста.
Поиск неинициализированных членов класса является сложным и неблагодарным занятием. Подробнее этот вопрос рассмотрен в статье: "Поиск неинициализированных членов класса". Поэтому просим в случае ложных срабатываний отнестись к анализатору с пониманием и использовать один из механизмов подавления ложных срабатываний.
Вы можете подавить предупреждение, отметив конструктор комментарием "//-V730". Вы также можете использовать базу данных для разметки ложных предупреждений. В крайнем случае, если ложных срабатываний слишком много, то разумно полностью отключить диагностику V730.
Однако это крайние меры. На практике разумно отключать анализ отдельных членов структур, не требующих инициализации в конструкторе. Рассмотрим искусственный пример:
const size_t MAX_STACK_SIZE = 100;
class Stack
{
size_t m_size;
int m_array[MAX_STACK_SIZE];
public:
Stack() : m_size(0) {}
void Push(int value)
{
if (m_size == MAX_STACK_SIZE)
throw std::exception("overflow");
m_array[m_size++] = value;
}
int Pop()
{
if (m_size == 0)
throw std::exception("underflow");
return m_array[--m_size];
}
};Этот класс реализует стек. Массив 'm_array' не инициализируется в конструкторе и это корректно, так как изначально стек считается пустым.
Анализатор выдаст предупреждение V730, так как не может понять принцип работы этого класса. Вы можете подсказать анализатору, пометив член 'm_array' комментарием "//-V730_NOINIT". Это укажет анализатору, что массив 'm_array' не требуется обязательно инициализировать.
Теперь, анализируя класс:
class Stack
{
size_t m_size;
int m_array[MAX_STACK_SIZE]; //-V730_NOINIT
public:
Stack() : m_size(0) {}
.....
};Анализатор не выдаст предупреждение.
Существует способ отключить предупреждения V730 на все поля классов определённого типа.
Рассмотрим пример:
class Field
{
public:
int f;
};
class Test
{
public:
Test() {}
Field field;
};На этом фрагменте кода будет выдано предупреждение: V730 Not all members of a class are initialized inside the constructor. Consider inspecting: field.
Чтобы исключить все предупреждения поля класса типа 'Field', следует добавить следующий комментарий в код или файл настроек:
//+V730:SUPPRESS_FIELD_TYPE, class:FieldФормат комментария:
//+V730:SUPPRESS_FIELD_TYPE, class:className, namespace:nsNameили
//+V730:SUPPRESS_FIELD_TYPE, class:className.NestedClassName, namespace:nsNameВыявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V730. |
V731. The variable of char type is compared with pointer to string.
Анализатор обнаружил сравнение переменной типа char с указателем на строку. Такое использование переменной вызвано тем, что были перепутаны одинарные (') и двойные кавычки (").
Рассмотрим пример подобной ошибки:
char ch = 'd';
....
if(ch == "\n")
....Этим кодом невнимательный программист хотел сравнить переменную 'ch' с символом новой строки, но по ошибке поставил не те кавычки. В результате значение переменной 'ch' сравнивается с адресом, по которому располагается строка "\n". Подобный код компилируется и выполняется в Си, но как правило не имеет смысла. В данном примере корректный код должен содержать одинарные кавычки вместо двойных:
char ch = 'd';
....
if(ch == '\n')
....Такая же ошибка может быть допущена при инициализации или присваивании переменной, которая в результате будет хранить младший байт адреса присваиваемой строки.
char ch = "d";В корректном коде должны использоваться одинарные кавычки.
char ch = 'd';Данная диагностика классифицируется как:
V732. Unary minus operator does not modify a bool type value.
Анализатор обнаружил, что операция унарного минуса применяется к значению типа bool, BOOL, _Bool, и т.п.
Пример ошибки:
bool a;
....
bool b = -a;Этот код не имеет смысла. Вычисление происходит следующим образом:
Если a == false, тогда 'false' превращается в значение типа int, равное 0. К этому значению применяется оператор '-'. На значение это, естественно, не влияет и в 'b' будет записано 0 (т.е. false).
Если a == true, тогда 'true' превращается в значение типа int, равное 1. К этому значению применяется оператор '-' и получается значение -1. Однако, -1 != 0, а значит при записи -1 в переменную типа bool мы вновь получим 'true'.
Таким образом значение 'false' останется 'false', а 'true' останется 'true'.
В корректном присваивании должен использоваться оператор '!':
bool a;
....
bool b = !a;Другой пример (BOOL есть не что иное как тип int):
BOOL a;
....
BOOL b = -a;Унарный минус может изменить численное значение переменной типа BOOL, но не её логическое значение. Всякое ненулевое значение будет обозначать истину, а ноль так и останется ложью.
Корректный вариант:
BOOL a;
....
BOOL b = !a;Примечание. Некоторые программисты могут умышленно использовать конструкции следующего вида:
int val = Foo();
int s;
s = -(val<0);Анализатор выдает предупреждение на подобные конструкции. Здесь нет ошибки, но подобный код нельзя рекомендовать к использованию.
В зависимости от значения 'val' переменной "s" хотят присвоить либо 0, либо -1. Применение унарного минуса к логическому выражению только усложняет чтение кода. Более подходящим будет использование тернарного оператора.
s = (val < 0) ? -1 : 0;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V732. |
V733. It is possible that macro expansion resulted in incorrect evaluation order.
Анализатор обнаружил потенциальную ошибку в коде, связанную с использованием макросов, раскрывающихся в арифметическое выражение. Обычно ожидается, что подвыражение, переданное как параметр в макрос будет выполняться в конечном выражении первым. Но это может быть не так, что приводит к трудно обнаруживаемым ошибкам.
Рассмотрим пример:
#define RShift(a) a >> 3
....
y = RShift(x & 0xFFF);Если раскрыть макрос, то мы получим:
y = x & 0xFFF >> 3;
Приоритет операции ">>" выше, чем у "&". Будет вычислено выражение "x & (0xFFF >> 3)", в то время, как программист рассчитывал получить "(x & 0xFFF) >> 3".
Для устранения недостатка требуется взять аргумент 'a' в круглые скобки:
#define RShift(a) (a) >> 3Однако, стоит сделать ещё одно усовершенствование. Полезно взять всё выражение в макросе ещё в одни скобки. Это является хорошим тоном и может предотвратить некоторые другие ошибки. Улучшенный вариант:
#define RShift(a) ((a) >> 3)Примечание. Родственной по смыслу диагностикой является V1003. Диагностика V1003 работает менее точно и даёт больше ложных срабатываний, так как анализирует объявление макроса, а не его использование. С другой стороны, не смотря на свои недостатки диагностика V1003 может помочь выявить ошибки, которые диагностика V733 бессильная обнаружить.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V733. |
V734. Excessive expression. Examine the substrings "abc" and "abcd".
Анализатор обнаружил потенциальную ошибку, связанную с тем, что в выражении ищется более длинная подстрока и более короткая. При этом более короткая строка, является частью более длинной. Получается, что одно из сравнений избыточно или допущена какая-то ошибка.
Рассмотрим пример:
if (strstr(a, "abc") != NULL || strstr(a, "abcd") != NULL)В случае если подстрока "abc" будет найдена, то дальнейшая проверка не будет выполняться. Если подстрока "abc" не будет найдена, то и поиск более длинной подстроки "abcd" не имеет смысла.
Для исправления ошибки необходимо проверить правильность подстрок или убрать из кода лишние проверки. Пример корректного варианта:
if (strstr(a, "abc") != NULL)Другой пример:
if (strstr(a, "abc") != NULL)
Foo1();
else if (strstr(a, "abcd") != NULL)
Foo2();В данном случае функция Foo2() никогда не будет вызвана. Устранить ошибку можно путем замены порядка проверки. То есть сначала следует искать более длинную подстроку, а потом более короткую:
if (strstr(a, "abcd") != NULL)
Foo2();
else if (strstr(a, "abc") != NULL)
Foo1();Взгляните на примеры ошибок, обнаруженных с помощью диагностики V734. |
V735. Possibly an incorrect HTML. The "</XX>" closing tag was encountered, while the "</YY>" tag was expected.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что в коде задан строковый литерал, в котором содержится разметка HTML с ошибками. Был открыт тег для элемента, которому требуется завершающий тег. Но следующим в строке обнаружен закрывающий тег, который не соответствует открывающему тегу.
Рассмотрим пример:
string html = "<B><I>This is a text, in bold italics.</B>";В данном случае открывающему тегу "<I>" должен соответствовать закрывающий тег "</I>", но при дальнейшем анализе HTML мы обнаружим закрывающий тег "</B>", что является ошибкой. В таком виде часть HTML кода является невалидной.
Для исправления ошибки необходимо проверить корректность последовательности открывающих и закрывающих тегов и устранить найденные ошибки.
Пример корректного варианта:
string html = "<B><I>This is a text, in bold italics.</I></B>";Взгляните на примеры ошибок, обнаруженных с помощью диагностики V735. |
V736. The behavior is undefined for arithmetic or comparisons with pointers that do not point to members of the same array.
Поведение не определено, если выполняется сравнение или арифметические операции над указателями, которые ссылаются на элементы, относящиеся к различным массивам.
Рассмотрим пример:
int a[10], b[20];
fill(a, b);
if (&a[1] > &b[2])Этот код содержит какую-то ошибку. Например, этот код мог получиться в результате неудачной автозамены фрагментов строк. Предположим, что здесь операторы '&' являются лишними. Тогда корректный код должен выглядеть так:
if (a[1] > b[2])Данная диагностика классифицируется как:
|
V737. It is possible that ',' comma is missing at the end of the string.
Анализатор заподозрил, что в списке инициализации массива случайно пропущена одна из запятых.
Рассмотрим пример:
int a[3][6] = { { -1, -2, -3
-4, -5, -6 },
{ ..... },
{ ..... } };После "-3" случайно пропущена запятая. Далее следует значение "-4". Получается выражение "-3-4". В результате код успешно и без предупреждений компилируется, но массив инициализирован неправильно. Значения "-5", и "-6" будут записаны не на свои позиции, а в последний элемент будет записан 0.
В итоге, на самом деле массив инициализируется так:
int a[3][6] = { { -1, -2, -7,
-5, -6, 0 },
..............Правильный вариант (добавлена пропущенная запятая):
int a[3][6] = { { -1, -2, -3,
-4, -5, -6 },
..............Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V737. |
V738. Temporary anonymous object is used.
Анализатор обнаружил, что используется временный анонимный объект, получившийся в результате работы постфиксного оператора ++ или --. Иногда это имеет смысл. Но когда речь заходит о изменении этого временного объекта или взятии его адреса, то это ошибка.
Рассмотрим первый пример:
vector<float>::iterator it = foo();
it++ = x;Создаётся временная копия итератора. Итератор инкрементируется. После чего к временному объекту применяется оператор присваивания. Этот код не имеет смысла. Автор кода хотел явно сделать что-то другое. Например, он хотел в начале выполнить присваивание, а уже затем воспользоваться инкрементом.
В этом случае корректный код должен выглядеть так:
it = x;
it++;Однако постфиксная операция для итераторов не эффективна. И будет лучше написать так:
it = x;
++it;Есть ещё один вариант:
it = x + 1;Рассмотрим второй пример:
const vector<int>::iterator *itp = &it++;Указатель 'itp' использовать нельзя. Он указывает на временный неименованный объект, который уже разрушен. Корректный вариант кода:
++it;
const vector<int>::iterator *itp = Данная диагностика классифицируется как:
|
V739. EOF should not be compared with a value of the 'char' type. Consider using the 'int' type.
Анализатор обнаружил, что константа EOF сравнивается с переменной типа 'char' или 'unsigned char'. Это свидетельствует о том, что некоторые символы будут обрабатываться программой неверно.
Рассмотрим, как объявлен EOF:
#define EOF (-1)Как видите, EOF есть ни что иное как '-1' типа 'int'. Посмотрим, к каким последствиям это может приводить. Первый пример:
unsigned char c;
while ((c = getchar()) != EOF)
{ .... }Беззнаковая переменная 'c' никогда не будет равна отрицательному значению '-1'. Поэтому выражение ((c = getchar) != EOF) всегда истинно, и возникает вечный цикл. Такая ошибка будет сразу замечена и исправлена. Поэтому не будем продолжать обсуждать тип 'unsigned char'.
Рассмотрим более интересный случай:
signed char c;
while ((c = getchar()) != EOF)
{ .... }Функция getchar() возвращает значения типа 'int'. А именно - она может вернуть число от 0 до 255 или -1 (EOF). Прочитанные значение помещаются в переменную типа 'char'. Из-за этого символ со значением 0xFF (255) превращается в -1 и интерпретируется точно также как конец файла (EOF).
Пользователи, использующие Extended ASCII Codes, иногда сталкиваются с ошибкой, когда один из символов их алфавита некорректно обрабатывается программами.
Например, последняя буква русского алфавита в кодировке Windows-1251 как раз имеет код 0xFF и воспринимается некоторыми программами как конец файла.
Исправленный вариант кода:
int c;
while ((c = getchar()) != EOF)Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V739. |
V740. Exception is of the 'int' type because NULL is defined as 0. Keyword 'nullptr' can be used for 'pointer' type exception.
Анализатор обнаружил, что будет сгенерировано исключение, имеющее тип 'int', в то время как программист планировал сгенерировать исключение типа "указатель".
Рассмотрим пример кода:
if (unknown_error)
throw NULL;В случае возникновения неизвестной ошибки программист решил "бросить" нулевой указатель. Однако он не учёл, что NULL это не что иное, как обыкновенный 0. Вот как определён макрос NULL в C++ программах:
#define NULL 0Ноль '0' имеет тип 'int'. Поэтому будет сгенерировано исключения типа 'int'.
Оставим в стороне вопрос, что использовать указатели для генерации исключений плохо и опасно. Предположим, что в этом есть настоящая необходимость. Тогда исправленный вариант кода может выглядеть так:
if (unknown_error)
throw nullptr;Почему не стоит использовать указатели при работе с исключениями хорошо описано в книге:
Стефан К. Дьюхэрст. Скользкие места С++. Как избежать проблем при проектировании и компиляции ваших программ. – М.: ДМК Пресс. – 264 с.: ил. ISBN 5-94074-083-9.
V741. Use of the throw (a, b); pattern. It is possible that type name was omitted: throw MyException(a, b);.
Анализатор обнаружил, что после ключевого слова throw следуют круглые скобки, в которых через запятую перечислены различные значения. Высока вероятность, что забыли указать тип генерируемого исключения.
Рассмотрим пример:
throw ("foo", 123);Хотя код выглядит странно, он успешно компилируется. В данном случае, результатом выполнения оператора запятая ',' является значение 123. В результате будет сгенерировано исключение типа 'int'.
Другими словами, приведённый код эквивалентен следующему:
throw 123;Правильный вариант кода:
throw MyException("foo", 123);Данная диагностика классифицируется как:
V742. Function receives an address of a 'char' type variable instead of pointer to a buffer.
Анализатор обнаружил ошибку, связанную с тем, что в функцию, работающую со строкой, передается адрес переменной типа 'char', вместо указателя на буфер символов. Это может привести к ошибкам времени исполнения программы, так как функции, работающие с указателями на буфер символов, ожидают несколько символов и, иногда, терминальный ноль в конце такого буфера.
Рассмотрим пример:
const char a = 'f';
size_t len = strlen(&a);В данном случае в функцию, которая должна вернуть длину строки передается указатель на переменную 'а'. Функция будет считать строкой всю область памяти, следующую за адресом этой переменной до встречи символа, который будет соответствовать терминальному нулю. Результат выполнения этой функции не определён. Функция может вернуть произвольное значение или возникнет исключение из-за ошибки доступа к памяти.
Описанный тип ошибки встречается крайне редко и обычно связан с неаккуратным редактированием кода или с массовой заменой каких-то подстрок.
Для исправления ошибки необходимо использовать набор данных соответствующий буферу символов или применять функции, обрабатывающие одиночные символы.
Пример корректного кода:
const char a[] = "f";
size_t len = strlen(a);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V742. |
V743. The memory areas must not overlap. Use 'memmove' function.
Анализатор обнаружил ошибку, связанную с тем, что в функции memcpy перекрываются области памяти источника и приемника. Использование функции memcpy в таком случае приведет к неопределенному поведению программы во время исполнения [1, 2].
Рассмотрим пример:
void func(int *x){
memcpy(x, x+2, 10 * sizeof(int));
}В данном случае указатель на источник данных (x+2) смещен относительно приемника данных на 8 байт (sizeof(int) * 2). Попытка копирования 40 байт в приемник из источника приведет к частичному перекрытию области памяти источника.
Для исправления ошибки необходимо использовать специальную функцию для таких операций – memmove(...) или скорректировать заданные смещения источника и приемника, чтобы не происходило перекрытия областей памяти.
Пример корректного кода:
void func(int *x){
memmove(x, x+2, 10 * sizeof(int));
}Дополнительные ссылки:
- Stack Overflow. What is the difference between memmove and memcpy? Answer.
- Stack Overflow. memcpy() vs memmove().
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V743. |
V744. Temporary object is immediately destroyed after being created. Consider naming the object.
Анализатор обнаружил ошибку, связанную с тем, что при создании объекта ему забыли дать имя. В этом случае будет сконструирован временный анонимный объект и тут же разрушен. Иногда в этом нет ничего плохого, и именно этого и хотел добиться программист. Но если речь идёт о таких классах как 'CWaitCursor' или 'CMultiLock', то это явная ошибка.
Рассмотрим пример:
void func(){
CMutex mtx;
CSingleLock(&mtx, TRUE);
foo();
}В данном примере будет создан временный анонимный объект типа 'CSingleLock', которой будет сразу же разрушен, еще до вызова функции foo(). В примере программист хотел обеспечить синхронизацию при исполнении функции foo(), но на самом деле функция будет вызвана без синхронизации, что может привести к серьезным ошибкам.
Для исправления ошибки необходимо дать создаваемому объекту имя.
Пример корректного кода:
void func(){
CMutex mtx;
CSingleLock lock(&mtx, TRUE);
foo();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V745. A 'wchar_t *' type string is incorrectly converted to 'BSTR' type string.
Анализатор обнаружил, что со строкой типа wchar_t * начинают работать как со строкой типа BSTR. Это очень подозрительно, и код, скорее всего, содержит ошибку. Чтобы лучше понять, в чем заключается опасность, сначала вспомним, что такое BSTR.
Далее мы процитируем статью с сайта MSDN. Важно понять, в чём проблема, так как предупреждение V745 часто сигнализирует о серьёзных ошибках.
typedef wchar_t OLECHAR;
typedef OLECHAR * BSTR;BSTR (basic string или binary string) — это строковый тип данных, который используется в COM, Automation и Interop-функциях. Тип BSTR следует использовать во всех интерфейсах. Представление BSTR:
- Префикс длины. Целое число размером 4 байта, которое отображает длину следующей за ним строки в байтах. Префикс длины указывается непосредственно перед первым символом строки и не учитывает символ-ограничитель.
- Строка данных. Строка символов в кодировке Unicode. Может содержать множественные вложенные нулевые символы.
- Ограничитель. Два нулевых символа.
Тип BSTR является указателем, который указывает на первый символ строки, а не на префикс длины.
Память для BSTR-строк выделяется с помощью функций выделения памяти COM, поэтому они могут возвращаться методами без необходимости контроля над выделением памяти.
Представленный ниже код является неправильным:
BSTR MyBstr = L"I am a happy BSTR";Данный пример собирается (компилируется и линкуется) успешно, но не будет работать должным образом, поскольку у строки отсутствует префикс длины. Если проверить расположение в памяти данной переменной с помощью отладчика, он покажет отсутствие префикса длины размером 4 байта перед началом строки данных.
Правильный вариант кода должен выглядеть так:
BSTR MyBstr = SysAllocString(L"I am a happy BSTR");Теперь отладчик покажет наличие префикса длины, который равен значению 34. Оно соответствует 17 символам, которые приводится к wide-character строке с помощью строкового модификатора L. Отладчик также покажет двухбайтовый символ-ограничитель (0x0000) в конце строки.
Если передать простую Unicode-строку в качестве аргумента функции COM, которая ожидает BSTR-строку, произойдёт сбой в работе этой функции.
Примечание. Анализатор не может точно предсказать, есть в коде настоящая ошибка или нет. Если неправильная BSTR-строка передаётся куда-то вовне, то произойдёт сбой. Если же BSTR-строка превращается обратно в wchar_t *, то всё хорошо.
Речь идет о подобном коде:
wchar_t *wstr = Foo();
BSTR tmp = wstr;
wchar_t *wstr2 = tmp;Здесь нет настоящей ошибки, но это "код с запахом", который следует поправить. Так он вызовет меньше недоумения у программиста, сопровождающего код, и анализатор не будет выдавать предупреждение. Следует использовать правильные типы данных:
wchar_t *wstr = Foo();
wchar_t *tmp = wstr;
wchar_t *wstr2 = tmp;Рекомендуем также ознакомиться со ссылками, приведёнными в конце статьи. Они помогут разобраться с BSTR-строками и тем, как их можно конвертировать в строки других типов.
Рассмотрим ещё один пример:
wchar_t *wcharStr = L"123";
wchar_t *foo = L"12345";
int n = SysReAllocString(&wcharStr, foo);Описание функции SysReAllocString:
INT SysReAllocString(BSTR *pbstr, const OLECHAR *psz);Она выделяет новую BSTR и копирует в неё заданную строку, затем освобождает BSTR, на которую указывает pbstr, и помещает по этому адресу указатель на новую BSTR.
В качестве первого аргумента функция ожидает указатель на переменную, содержащую адрес строки в формате BSTR. Но вместо этого ей передают указатель на обыкновенную строку. Так как тип wchar_t ** с точки зрения компилятора — то же самое, что и BSTR *, то этот код успешно компилируется. Но на практике он не имеет смысла и приведёт к ошибке на этапе исполнения.
Правильный вариант кода:
BSTR wcharStr = SysAllocString(L"123");
wchar_t *foo = L"12345";
int n = SysReAllocString(&wcharStr, foo);Дополнительно рассмотрим ситуацию, когда используется ключевое слово auto. Анализатор выдаёт предупреждение на следующий безобидный код:
auto bstr = ::SysAllocStringByteLen(foo, 3);
ATL::CComBSTR value;
value.Attach(bstr); // Warning: V745Это ложное срабатывание, но формально анализатор прав, выдавая предупреждение. Переменная bstr имеет тип wchar_t *. Компилятор языка C++ при выведении типа для auto-переменной не учитывает, что функция возвращает значение типа BSTR. При выведении auto, тип BSTR — это просто синоним whar_t *. Получается, что написанный код эквивалентен:
wchar_t *bstr = ::SysAllocStringByteLen(foo, 3);
ATL::CComBSTR value;
value.Attach(bstr);Поэтому анализатор PVS-Studio и выдаёт предупреждение, так как не рекомендуется хранить указатель на BSTR строку в обыкновенном wchar_t * указателе. Чтобы устранить предупреждение, следует отказаться в данном месте от auto и написать тип явно:
BSTR *bstr = ::SysAllocStringByteLen(foo, 3);
ATL::CComBSTR value;
value.Attach(bstr);Это интересный случай, когда оператор auto не помогает, а наоборот — теряет информацию о типе и ухудшает ситуацию.
Другой вариант устранить предупреждение — использовать один из механизмов подавления ложных срабатываний, описанных в документации.
Дополнительные ссылки:
- MSDN. BSTR.
- StackOverfow. Static code analysis for detecting passing a wchar_t* to BSTR.
- StackOverfow. BSTR to std::string (std::wstring) and vice versa.
- Robert Pittenger. Guide to BSTR and CString Conversions.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V745. |
V746. Object slicing. An exception should be caught by reference rather than by value.
Анализатор обнаружил потенциальную ошибку, связанную с перехватом исключения по значению. Намного лучше и безопасней перехватывать исключение по ссылке.
Вообще, перехват исключения по значению порождает две разновидности ошибок. Рассмотрим их поочередно.
Проблема N1. Срезка (slicing).
class Exception_Base {
....
virtual void Print() { .... }
};
class Exception_Ex : public Exception_Base { .... };
try
{
if (error) throw Exception_Ex(1, 2, 3);
}
catch (Exception_Base e)
{
e.Print();
throw e;
}Объявлено 2 класса: исключение базового типа и расширенное исключение, которое наследуется от первого.
Генерируется расширенное исключение. Это исключение планируется перехватить, распечатать о нём информацию и пробросить исключение дальше.
Исключение перехвачено по значению. Это значит, что с помощью конструктора копирования будет сконструирован новый объект 'e' типа Exception_Base. Это порождает сразу 2 ошибки.
Во-первых, часть информации об исключении потеряна. Всё что хранилось Exception_Ex нам более недоступно. Виртуальная функция Print() позволит вывести базовую информацию о проблеме.
Во-вторых, дальше будет проброшено уже новое исключение типа Exception_Base. Таким образом мы передали дальше урезанную информацию о возникшей проблеме.
Правильно будет использовать следующий код:
catch (Exception_Base &e)
{
e.Print();
throw;
}Теперь функция Print() распечатает всю нужную информацию. Оператор "throw" будет пробрасывать далее уже существующее исключение, и информация не будет потеряна (срезана).
Проблема N2. Изменение временного объекта.
catch (std::string s)
{
s += "Additional info";
throw;
}Программист хочет перехватить исключение, добавить какую-то дополнительную информацию и пробросить это исключение дальше. Ошибка в том, что изменяется переменная 's', а оператор "throw;" пробрасывает далее исходное исключение. Таким образом мы не изменили информацию о исключении.
Правильный вариант:
catch (std::string &s)
{
s += "Additional info";
throw;
}Подробнее про преимущества перехвата исключения по ссылке можно прочитать здесь:
- Stack Overflow. C++ catch blocks - catch exception by value or reference?
- Stack Overflow. Catch exception by pointer in C++.
- Стефан К. Дьюхэрст. Скользкие места С++. Как избежать проблем при проектировании и компиляции ваших программ. – М.: ДМК Пресс. – 264 с.: ил. ISBN 5-94074-083-9.
- Wikipedia. Object slicing.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V746. |
V747. Suspicious expression inside parentheses. A function name may be missing.
Анализатор обнаружил подозрительное выражение в скобках. В круглых скобках через запятую перечислены различные переменные и значение. При этом не похоже, что оператор запятая ',' использовался для сокращения кода.
Рассмотрим пример:
if (memcmp(a, b, c) < 0 && (x, y, z) < 0)При написании текста программы случайно забыли написать имя функции 'memcmp'. Тем не менее код успешно компилируется, хотя работает не так, как задумывалось. В правой части результатом работы двух операторов запятая (comma operator) является переменная 'z'. Именно она сравнивается с нулём. В итоге, приведённый выше код, эквивалентен следующему:
if (memcmp(a, b, c) < 0 && z < 0)Правильный вариант кода:
if (memcmp(a, b, c) < 0 && memcmp(x, y, z) < 0)Примечание. Иногда оператор ',' используется для сокращения кода. Поэтому анализатор далеко не всегда ругается на запятые внутри скобок. Например, он считает корректным следующий код:
if (((std::cin >> A), A) && .....)Мы не рекомендуем писать такие сложные выражения, так как вашим коллегам потом будет тяжело читать такой код. Но и ошибки здесь явно нет. Разработчику просто захотелось совместить в одном выражении и получение значения, и его проверку.
Ещё один аналогичный пример:
if (a)
return (b = foo(), fooo(b), b);Данная диагностика классифицируется как:
|
V748. Memory for 'getline' function should be allocated only by 'malloc' or 'realloc' functions. Consider inspecting the first parameter of 'getline' function.
Анализатор обнаружил ошибку, связанную с тем, что память для функции getline() была выделена без использования функции malloc()/realloc(). Функция getline() написана таким образом, что если в процессе работы не хватает выделенной ранее памяти, getline() вызовет realloc() для её увеличения (ISO/IEC TR 24731-2). Поэтому выделять память необходимо только при помощи malloc() или realloc().
Рассмотрим пример:
char* buf = new char[count];
getline(&buf, &count, stream);В данном примере память для функции getline() выделена с помощью оператора new. Если getline() не хватит выделенной памяти, она вызовет realloc(). Результат такого вызова непредсказуем.
Для исправления ошибки необходимо переписать код таким образом, чтобы память для функции getline() выделялась только с использованием malloc() или realloc().
Корректный код:
char* buf = (char*)malloc(count * sizeof(char));
getline(&buf, &count, stream);Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V749. Destructor of the object will be invoked a second time after leaving the object's scope.
Анализатор обнаружил ошибку, связанную с повторным вызовом деструктора. Если объект создается на стеке, то при выходе за пределы области видимости будет вызван деструктор. Анализатор обнаружил вызов деструктора для такого объекта напрямую.
Рассмотрим пример:
void func(){
X a;
a.~X();
foo();
}В данном примере для объекта 'a' напрямую вызывается деструктор. Но когда функция 'func' закончит свою работу, деструктор для объекта 'a' будет вызван еще раз.
Для исправления ошибки необходимо удалить ошибочный код или скорректировать код в соответствии с используемой моделью управления памятью.
Пример корректного кода:
void func(){
X a;
foo();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V749. |
V750. BSTR string becomes invalid. Notice that BSTR strings store their length before start of the text.
Анализатор обнаружил, что над указателем на строку в формате BSTR выполняются недопустимые операции. Указатель типа BSTR всегда должен ссылаться на первый символ строки. Если сдвинуть указатель хотя бы на один символ, то получим некорректную BSTR строку.
Такой код крайне опасен:
BSTR str = foo();
str++;Теперь 'str' нельзя использовать как BSTR строку. Если нужно пропустить один символ, следует написать следующий код:
BSTR str = foo();
BSTR newStr = SysAllocString(str + 1);Если вам не нужна BSTR строка, то можно написать следующий код:
BSTR str = foo();
const wchar_t *newStr = str;
newStr++;Или так:
BSTR str = foo();
const wchar_t *newStr = str + 1;Чтобы понять, почему недопустимо менять значение указателя типа BSTR, процитируем статью с сайта MSDN.
typedef wchar_t OLECHAR;
typedef OLECHAR * BSTR;BSTR (basic string или binary string) — это строковый тип данных, который используется в COM, Automation и Interop функциях. Тип BSTR следует использовать во всех интерфейсах. Представление BSTR:
- Префикс длины. Целое число размером 4 байта, которое отображает длину следующей за ним строки в байтах. Префикс длины указывается непосредственно перед первым символом строки и не учитывает символ-ограничитель.
- Строка данных. Строка символов в кодировке Unicode. Может содержат множественные вложенные нулевые символы.
- Ограничитель. Два нулевых символа.
Тип BSTR является указателем, который указывает на первый символ строки, а не на префикс длины.
Память для BSTR-строк выделяется с помощью функций выделения памяти COM, поэтому они могут возвращаться методами без необходимости контроля над выделением памяти.
Представленный ниже код является неправильным:
BSTR MyBstr = L"I am a happy BSTR";Данный пример собирается (компилируется и линкуется) успешно, но не будет работать должным образом, поскольку у строки отсутствует префикс длины. Если проверить расположение в памяти данной переменной с помощью отладчика, он покажет отсутствие префикса длины размером 4 байта перед началом строки данных.
Правильный вариант кода должен выглядеть так:
BSTR MyBstr = SysAllocString(L"I am a happy BSTR");Теперь отладчик покажет наличие префикса длины, который равен значению 34. Оно соответствует 17 символам, которые приводится к wide-character строке с помощью строкового модификатора L. Отладчик также покажет двухбайтовый символ-ограничитель (0x0000) в конце строки.
Если передать простую Unicode-строку в качестве аргумента функции COM, которая ожидает BSTR-строку, произойдёт сбой в работе этой функции.
Когда мы пишем код:
BSTR str = foo();
str += 3;Мы портим BSTR строку. Указатель ссылается не на начало строки, а куда-то в середину. Соответственно, если мы попытаемся взять длину строки по отрицательному смещению, то мы прочитаем случайное значение. Вернее, предыдущие символы будут интерпретированы как длина строки.
Дополнительные ссылки:
- MSDN. BSTR.
- StackOverfow. Static code analysis for detecting passing a wchar_t* to BSTR.
- StackOverfow. BSTR to std::string (std::wstring) and vice versa.
- Robert Pittenger. Guide to BSTR and CString Conversions.
V751. Parameter is not used inside function's body.
Анализатор обнаружил подозрительную функцию, один из параметров которой ни разу не используется. При этом другой его параметр используется несколько раз, что, возможно, свидетельствует о наличии ошибки.
Рассмотрим пример:
static bool CardHasLock(int width, int height)
{
const double xScale = 0.051;
const double yScale = 0.0278;
int lockWidth = (int)floor(width * xScale);
int lockHeight = (int)floor(width * yScale);
....
}Из кода видно, что параметр 'height' ни разу не используется в теле функции, при этом параметр 'width' используется дважды, в том числе при инициализации переменной 'lockHeight'. Скорее всего, здесь допущена ошибка, и код инициализации переменной 'lockHeight' должен был выглядеть следующим образом:
int lockHeight = (int)floor(height * yScale);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V751. |
V752. Creating an object with placement new requires a buffer of large size.
Анализатор обнаружил, что происходит попытка создать объект с помощью placement new, но размера выделенной для этого памяти не хватит для размещения создаваемого объекта. Будет использована память за пределами выделенного блока, что может привести к аварийному завершению программы или ее неправильному поведению.
Пример некорректного размещения объекта:
struct T { float x, y, z, q; };
char buf[12];
T *p = new (buf) T;В этом примере объект, размер которого составляет 16 байт, пытаются разместить в буфере 'buf', размер которого 12 байта. При использовании этого объекта произойдёт изменение памяти, лежащей за приделами буфера. Результат непредсказуем.
Для исправления ошибки необходимо скорректировать размер буфера или убедиться, что правильно задано смещение относительно начала буфера.
Вариант правильного кода:
struct T { float x, y, z, q; };
char buf[sizeof(T)];
T *p = new (buf) T;Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти), Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V753. The '&=' operation always sets a value of 'Foo' variable to zero.
Анализатор обнаружил, что в результате выполнения побитового оператора "И" значение переменной будет установлено в ноль, что выглядит подозрительно, так как нулевое значение можно получить простым присвоением.
Если же выполняются последовательные вычисления, то возможно данная операция выполняется некорректно, например, из-за опечатки используется не та переменная, что задумывалось или справа используется неправильная константа.
Возможны несколько вариантов возникновения данного предупреждения.
Первый пример - последовательное применение оператора к переменной с неизвестным значением с такими константами, с которыми результирующее значение будет равно нулю:
void foo(int A)
{
A &= 0xf0;
....
A &= 1;
// Теперь 'A' всегда равно 0.
}Результатом выполнения двух операций будет нулевое значение независимо от изначального значения переменной 'A'. Возможно этот код ошибочен, и программисту необходимо проверить правильность используемых констант.
Второй случай - это применение оператора к переменной, значение которой заведомо известно:
void foo()
{
int C;
....
C = 1;
....
C &= 2;
// C == 0
}В данном случае при применении оператора к переменной, значение которой известно, также будет получено нулевое значение. Как и в предыдущем случае программисту необходимо проверить правильность используемой константы.
Диагностика может сработать и в следующем, довольно часто использующемся, варианте применения оператора:
void foo()
{
int flags;
....
flags = 1;
....
flags &= ~flags;
....
}Этот прием программисты иногда используют для сброса набора флагов в нулевое значение. На наш взгляд такой способ не оправдан и может только запутать ваших коллег. Лучше использовать простое присвоение:
void foo()
{
int flags;
....
flags = 1;
....
flags = 0;
....
}Данная диагностика классифицируется как:
V754. The expression of 'foo(foo(x))' pattern is excessive or contains an error.
Анализатор обнаружил, что фактическим аргументом функции является вызов этой-же функции.
Пример некорректного кода:
char lower_ch = tolower(tolower(ch));В этом примере второй вызов функции избыточен. Возможно в коде допущена опечатка и подразумевался вызов другой функции. Если ошибки нет, то следует убрать лишний вызов, так как подобное выражение выглядит подозрительно:
char lower_ch = tolower(ch);Другой пример:
if (islower(islower(ch)))
do_something();Функция 'islower' возвращает значение типа int и может быть использовано в качестве аргумента к самой себе. Данное выражение содержит ошибку и не имеет практического смысла.
V755. Copying from potentially tainted data source. Buffer overflow is possible.
- Небезопасная работа с аргументами командной строки
- Небезопасная работа с потоками ввода
- Небезопасное возвращаемое значение
- Исключения
Анализатор обнаружил, что в буфер копируются данные из небезопасного источника.
Примерами таких источников являются:
- аргументы командной строки, длина которых неизвестна;
- потоки ввода стандартной библиотеки в сочетании с С-строками (нуль-терминированными строками);
- возвращаемое значение небезопасных функций.
Небезопасная работа с аргументами командной строки
Пример небезопасной работы с аргументами командной строки:
int main(int argc, char *argv[])
{
....
const size_t buf_size = 1024;
char *tmp = (char *) malloc(buf_size);
....
strcpy(tmp, argv[0]);
....
}В случае, когда размер копируемых данных превысит размер буфера, произойдёт его переполнение. Для того чтобы избежать этого, лучше вычислить требуемый объём памяти заранее:
int main(int argc, char *argv[])
{
....
char buffer[1024];
errno_t err = strncpy_s(buffer, sizeof(buffer), argv[0], 1024);
....
}Также можно выделять память по мере необходимости, используя функцию 'realloc'. В C++ для работы со строками можно использовать классы, такие как 'std::string'.
Небезопасная работа с потоками ввода
До стандарта С++20 была доступна возможность использовать C-строку в качестве буфера-приёмника для стандартных потоков ввода ('std::cin', 'std::ifstream'):
void BadRead(char *receiver)
{
std::cin >> receiver;
}К счастью, в С++ 20 такую возможность убрали, и теперь потоки ввода стандартной библиотеки можно использовать только с массивами известного размера. При этом происходит неявное ограничение максимально считываемого количества символов.
void Exception2Cpp20()
{
char *buffer1 = new char[10];
std::cin >> buffer1; // Won't compile since C++20
char buffer2[10];
std::cin >> buffer2; // no overflow
// max 9 chars will be read
}Более подробно это изменение (с примерами и применением) освещено в предложении P0487R1 к стандарту С++ 20.
Небезопасное возвращаемое значение
Злоумышленники могут манипулировать значением, возвращаемым некоторыми функциями, поэтому следует быть предельно аккуратными при работе с ними:
void InsecureDataProcessing()
{
char oldLocale[50];
strcpy(oldLocale, setlocale(LC_ALL, nullptr));
....
}В данном примере создаётся буфер фиксированного размера, в который происходит чтение из переменной окружения 'LC_ALL'. Если у злоумышленника имеется возможность повлиять на неё, то чтение может привести к переполнению буфера.
Исключения
Предупреждение не выдаётся в случаях, если источник данных неизвестен:
void Exception1(int argc, char *argv[])
{
char *src = GetData();
char *tmp = (char *)malloc(1024);
strcpy(tmp, src);
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V756. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что при написании двух и более вложенных циклов 'for', из-за опечатки не используется счётчик одного из циклов.
Рассмотрим синтетический пример некорректного кода:
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
sum += matrix[i][i];В коде планировали обойти все элементы матрицы и найти их сумму, но случайно написали переменную 'i' вместо 'j' при обращении к матрице.
Корректный вариант кода:
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
sum += matrix[i][j];В отличии от диагностических правил V533, и V534, здесь анализатор ищет ошибки с использованием индекса только в теле циклов.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V756. |
V757. It is possible that an incorrect variable is compared with null after type conversion using 'dynamic_cast'.
Анализатор обнаружил потенциальную ошибку, которая может привести к доступу по нулевому адресу.
Анализатор заметил в коде следующую ситуацию. Сначала указатель на базовый класс приводится к указателю на производный класс с помощью 'dynamic_cast'. А затем этот же указатель проверяется на значение 'nullptr', хотя в этом случае, скорее всего, предполагалось проверить на 'nullptr' указатель, полученный в результате приведения.
Рассмотрим следующий пример. Здесь возможна ситуация, когда указатель 'baseObj' не будет ссылаться на экземпляр класса 'Derived'. В этом случае при вызове функции произойдёт разыменование нулевого указателя. Анализатор выдаст предупреждение на этот код, указав две строки. Первая строка - это то место, где указатель проверяется на 'nullptr'. Вторая строка - это то место, где указатель на базовый класс приводится к указателю на производный класс.
Base *baseObj;
....
Derived *derivedObj = dynamic_cast<Derived *>(baseObj);
if (baseObj != nullptr)
{
derivedObj->Func();
}Скорее всего в этом примере перед использованием предполагалось проверить на 'nullptr' указатель, полученный в результате приведения. Исправленный вариант кода:
Base *baseObj;
....
Derived *derivedObj = dynamic_cast<Derived *>(baseObj)
if (derivedObj != null)
{
derivedObj->Func();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V757. |
V758. Reference was invalidated because of destruction of the temporary object returned by the function.
Анализатор обнаружил ссылку, которая может стать недействительной. Она ссылается на объект, находящийся под управлением умного указателя или контейнера, который возвращают из функции по значению. После разрушения временного объекта, при возврате из функции, будет разрушен и контролируемый им объект. Ссылка на него станет недействительной. Попытка использования такой ссылки приведет к неопределенному поведению.
Рассмотрим пример с умным указателем 'unique_ptr':
std::unique_ptr<A> Foo()
{
std::unique_ptr<A> pa(new A());
return pa;
}
void Foo2()
{
const A &ra = *Foo();
ra.foo();
}Ссылка указывает на объект, который находится под управлением умного указателя 'unique_ptr'. После выхода из функции временный объект 'unique_ptr' разрушается, и ссылка становится недействительной.
Чтобы избежать подобных проблем, необходимо отказаться от использования ссылки и переписать функцию 'Foo2()' следующим образом:
void Foo2()
{
A a(*Foo());
a.foo();
}Теперь мы используем не ссылку, а создаём новый объект типа 'A'. Причем, начиная с C++11, для инициализации переменной 'a' может использоваться конструктор перемещения и никаких потерь в производительности не произойдет.
Также можно использовать следующий вариант:
void Foo2()
{
std::unique_ptr<A> pa = Foo();
pa->foo();
}В данной ситуации произойдет передача владения объектом типа 'A'.
Рассмотрим пример с контейнером 'std::vector':
std::vector<A> Foo();
void Foo2()
{
const A &ra = Foo()[42];
ra.foo();
}Проблема точно такая же, что и с 'unique_ptr': временный объект 'vector' разрушается, и ссылка на его элемент становится недействительной.
То же самое относится и к методам, которые возвращают ссылки на элементы внутри контейнера: front(), back() и другие:
void Foo2()
{
const A &ra = Foo().front();
ra.foo();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V759. Violated the order of exception handlers. Exception caught handler for the base class.
Анализатор обнаружил множественные обработчики исключений с нарушенным порядком следования. Обработчик для базового класса исключений размещен перед обработчиком для производного класса. В таком случае все исключения, предназначенные для перехвата обработчиком производного класса, будут перехвачены обработчиком для базового класса.
Рассмотрим пример:
class Exception { .... };
class DerivedException : public Exception { ... };
void foo()
{
throw DerivedException;
}
void bar()
{
try
{
foo();
}
catch (Exception&)
{
// Все исключения, имеющие тип DerivedException попадут сюда
}
catch (DerivedException&)
{
// Код в этом обработчике никогда не выполняется
}
}Так как класс 'Exception' является базовым для класса 'DerivedException', исключения, которые генерирует функция 'foo()', перехватываются первым обработчиком.
Чтобы исправить ошибку, нужно поменять обработчики исключений местами:
void bar()
{
try
{
foo();
}
catch (DerivedException&)
{
// Перехватывает исключения типа DerivedException
}
catch (Exception&)
{
// Перехватывает исключения типа Exception
}
}Теперь каждый обработчик перехватывает исключения, предназначенные только для него.
Данная диагностика классифицируется как:
|
V760. Two identical text blocks were detected. The second block starts with NN string.
Анализатор обнаружил код, который возможно содержит опечатку. Высока вероятность, что подобный код был создан с использованием подхода Copy-Paste. Сообщение V760 выдаётся на два одинаковых блока текста, идущих один за другим. Данная диагностика в основном опирается на эвристический метод и поэтому может выдавать ложные срабатывания.
Рассмотрим пример:
void Example(int *a, int *b, size_t n)
{
....
for (size_t i = 0; i != n; i++)
a[i] = 0;
for (size_t i = 0; i != n; i++)
a[i] = 0;
....
}Код писался с помощью Copy-Paste. Во втором блоке забыли изменить имя массива. На самом деле, код должен быть таким:
void Example(int *a, int *b, size_t n)
{
....
for (size_t i = 0; i != n; i++)
a[i] = 0;
for (size_t i = 0; i != n; i++)
b[i] = 0;
....
}Анализатор не выдаёт сообщение, если найдено больше двух блоков текста. Пример:
void Foo();
void Example()
{
....
Foo();
Foo();
Foo();
Foo();
....
}Иногда может быть непонятно, что не нравится анализатору. Рассмотрим такой пример:
switch(t) {
case '!': InvokeMethod(&obj_Sylia, "!", 1); break;
case '~': InvokeMethod(&obj_Sylia, "~", 1); break;
case '+': InvokeMethod(&obj_Sylia, "+", 1); break;
case '-': InvokeMethod(&obj_Sylia, "-", 1); break;
break;
default:
SCRIPT_ERROR(PARSE_ERROR);
}Нужно присмотреться. В данном случае мы имеем дело с очень коротким повторяющимся блоком. Этот блок - оператор 'break'. Один из операторов здесь лишний. В данном примере это не приводит к настоящей ошибке, но лишний 'break' стоит удалить:
switch(t) {
case '!': InvokeMethod(&obj_Sylia, "!", 1); break;
case '~': InvokeMethod(&obj_Sylia, "~", 1); break;
case '+': InvokeMethod(&obj_Sylia, "+", 1); break;
case '-': InvokeMethod(&obj_Sylia, "-", 1); break;
default:
SCRIPT_ERROR(PARSE_ERROR);
}Примечание
Дублирование кода само по себе не является ошибкой. Однако, даже если ошибки нет, предупреждение V760 может служить подсказкой, что одинаковые блоки кода стоит вынести в функцию. См. также диагностику V761.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V760. |
V761. NN identical blocks were found.
Анализатор обнаружил код, который можно улучшить рефакторингом. Данная диагностика ищет одинаковые блоки текста, которые повторяются три или более раз. Вряд ли такой код содержит ошибку, но лучше постараться вынести одинаковый код в отдельную функцию.
В случае, когда код использует много локальных переменных, облегчить ситуацию могут лямбда-функции, с помощью который можно захватить данные по ссылке.
Диагностика может выдавать большое количество срабатываний на коде, где применяется большое количество ручных оптимизаций (например, ручная развёртка циклов). Если вы считаете, что диагностика V761 не актуальна в вашем проекте, то вы можете её отключить.
Рассмотрим синтетический пример, на который анализатор выдаёт предупреждение:
void process(char *&buf);
void func(size_t n, char *arr)
{
size_t i;
i = n;
while (i--)
arr[i] = 1;
for (i = 0; i != 10; i++)
arr[i] = 'a';
process(arr);
i = n;
while (i--)
arr[i] = 1;
for (i = 0; i != 10; i++)
arr[i] = 'a';
process(arr);
i = n;
while (i--)
arr[i] = 1;
for (i = 0; i != 10; i++)
arr[i] = 'a';
process(arr);
i = n;
while (i--)
arr[i] = 1;
for (i = 0; i != 10; i++)
arr[i] = 'a';
process(arr);
}Будет полезно вынести общий код в отдельную функцию:
void process(char*& buf);
void func_impl(size_t i, size_t *&arr)
{
while (i--)
arr[i] = 1;
for (i = 0; i != 10; i++)
arr[i] = 'a';
process(arr);
}
void func(size_t n, char *arr)
{
for (size_t i = 0; i < 4; ++i)
func_impl(n, arr);
}См. также диагностику V760.
V762. Consider inspecting virtual function arguments. See NN argument of function 'Foo' in derived class and base class.
Диагностика выявляет ошибки при переопределении виртуальных функций. Рассмотрим два возможных варианта.
Вариант N1. В базовом классе имеется виртуальная функция, в которой один из параметров имеет один тип. В наследнике есть точно такая же функция, но этот параметр имеет другой тип. При этом типы могут быть либо целочисленными типами, либо перечислениями, либо указателями или ссылками на базовый и унаследованный классы.
Эта диагностика помогает выявить ошибки, когда при большом рефакторинге меняют тип функции в одном из классов, но забывают изменить эту функцию в другом классе.
Рассмотрим пример:
struct Q { virtual int x(short) { return 1; } };
struct W : public Q { int x(int) { return 2; } };На самом деле, код должен быть таким:
struct Q { virtual int x(short) { return 1; } };
struct W : public Q { int x(short) { return 2; } };Если в базовом классе будет две функции 'x' с аргументами 'int' и 'short', то анализатор предупреждение V762 выдавать не будет.
Вариант N2. Диагностика выдаётся в случае, когда в функции базового класса добавили новый аргумент или наоборот удалили. При этом забыли поменять объявление функции в одном из классов-наследников.
Пример подобной ситуации:
struct Q { virtual int x(int, int=3) { return 1; } };
struct W : public Q { int x(int) { return 2; } };Корректный код:
struct Q { virtual int x(int, int=3) { return 1; } };
struct W : public Q { int x(int, int) { return 2; } };Сценарий возникновения ошибки может быть следующим. Есть иерархия классов. В какой-то момент в функцию базового класса или класса-наследника добавляют аргумент. В итоге объявляется новая функция, никак не связанная с функцией из базового класса.
Это выглядит подозрительно и может быть ошибкой. Может быть забыли поправить один из классов, может быть забыли про то, что функция является виртуальной. Но анализатор не может понять по смыслу функции, что данный код корректен. Если же данное поведение предусмотрено и ошибкой не является, можно воспользоваться одним из механизмов подавления ложных срабатываний.
Пример подозрительного кода:
struct CA
{
virtual void Do(int Arg);
};
struct CB : CA
{
virtual void Do(int Arg1, double Arg2);
};Для того чтобы избежать подобных ошибок при использовании C++11 и выше рекомендуется использовать ключевое слово 'override', которое предотвратит несовпадение сигнатур на этапе компиляции.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V762. |
V763. Parameter is always rewritten in function body before being used.
Анализатор нашёл потенциальную ошибку в теле функции. Один из его параметров перезаписывается перед тем, как используется. Таким образом, значение, пришедшее в функцию, попросту теряется.
Рассмотрим пример кода:
void Foo(Node A, Node B)
{
A = SkipParenthesize(A);
B = SkipParenthesize(A); // <=
AnalyzeNode(A);
AnalyzeNode(B);
}Здесь допущена опечатка, так как перепутаны параметры 'A' и 'B', из-за чего переменная 'B' примет неверное значение. Исправленный код выглядит так:
void Foo(Node A, Node B)
{
A = SkipParenthesize(A);
B = SkipParenthesize(B);
AnalyzeNode(A);
AnalyzeNode(B);
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V763. |
V764. Possible incorrect order of arguments passed to function.
Анализатор обнаружил подозрительную передачу аргументов в функцию. Некоторые имена аргументов не соответствуют именам параметров, в качестве которых они передаются. Это может свидетельствовать об ошибочной передаче значений в функцию.
Пусть имеется объявление функции следующего вида:
void SetRGB(unsigned r, unsigned g, unsigned b);Пример ошибочного кода:
void Foo()
{
unsigned R = 0, G = 0, B = 0;
....
SetRGB(R, B, G);
....
}Во время задания цвета объекта, перепутали значения синего и зелёного цветов.
Исправленный вариант кода должен выглядеть следующим образом:
SetRGB(R, G, B);Дополнительная настройка
Если функция принимает в качестве параметров границы некоторого диапазона, то можно разметить соответствующие параметры как верхнюю и нижнюю границу. Тогда в случае нарушения порядка передачи аргументов при вызове функции можно получить соответствующее срабатывание.
Пример. Есть функция, семантически схожая с 'std::clamp', со следующей сигнатурой:
bool foo(int v, int lo, int hi);Эта функция проверяет, что значение первого параметра лежит в диапазоне, переданном в качестве второго (нижняя граница) и третьего (верхняя граница) параметров.
Предположим, что есть следующий вызов данной функции:
if (foo(v, max, min))
{
....
}Как мы видим, в вызове перепутаны местами аргументы для нижней и верхней границы. Тогда, чтобы получить срабатывание в месте вызова функции, необходимо разметить второй параметр функции foo как lower_bound, а третий как upper_bound. Также для дополнительной настройки диагностики V575 можно разметить первый параметр функции foo как in_range_value.
Исправленный код:
if (foo(x, min, max))
{
....
}Примеры разметки параметров функций можно посмотреть здесь.
Примечание. Данная разметка необходима только для пользовательских функций.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V764. |
V765. Compound assignment expression 'X += X + N' is suspicious. Consider inspecting it for a possible error.
Анализатор нашёл потенциальную ошибку в арифметическом или логическом выражении. В составном присваивании переменная стоит и слева, и справа от оператора.
Рассмотрим пример кода:
void Foo(int x, int y, int z)
{
x += x + y;
....
}Возможно, что здесь допущена опечатка, и правильный код должен выглядеть так:
void Foo(int x, int y, int z)
{
x = x + y;
....
}Или так:
void Foo(int x, int y, int z)
{
x += z + y;
....
}Конечно, подобные выражения используют для того, чтобы хитро умножить число на два. Тем не менее такой код подозрителен, и его стоит перепроверить. Такие операции выглядят довольно запутанно и, возможно, стоит написать гораздо более простой и понятный код:
void Foo(int x, int y, int z)
{
x = x * 2 + y;
....
}Есть и более подозрительные выражения, работу которых стоит внимательно проверить:
void Foo(int x, int y)
{
x -= x + y;
}Данное выражение можно упростить следующим образом:
- x -= x + y;
- x = x - (x + y);
- x = -y;
Не понятно, является ли такое поведение преднамеренным или же это опечатка. В любом случае, этот код следует проверить.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V765. |
V766. An item with the same key has already been added.
Анализатор обнаружил подозрительную ситуацию, когда в словарь (контейнеры типа 'map' и т.п.) или в множество (контейнеры типа 'set' и т.п.) добавляются элементы с ключами, уже присутствующими в этих контейнерах. В результате добавление нового элемента будет проигнорировано. Это может свидетельствовать об опечатке и привести к неверному заполнению контейнера.
Рассмотрим пример со словарём:
map<char, int> dict = map<char, int>{
make_pair('a', 10),
make_pair('b', 20),
make_pair('a', 30) // <=
};В последней строке инициализации была допущена ошибка, так как ключ 'a' уже содержится в словаре. В результате данный словарь будет содержать 2 значения, причём значение, связанное с ключом 'a', будет равно 10.
Исправить ошибку можно, использовав правильное значение ключа:
map<char, int> dict = map<char, int>{
make_pair('a', 10),
make_pair('b', 20),
make_pair('c', 30)
};Схожую ошибку можно допустить и при инициализации множества:
set<string> someSet = set<string>{
"First",
"Second",
"Third",
"First", // <=
"Fifth"
};Из-за ошибки вместо ключа 'Fourth' в множество 'someSet' пытаются записать строку 'First', но так как такой ключ уже содержится в множестве, он будет проигнорирован.
Для исправления ошибки необходимо исправить список инициализации:
set<string> someSet = set<string>{
"First",
"Second",
"Third",
"Fourth",
"Fifth"
};Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V766. |
V767. Suspicious access to element by a constant index inside a loop.
Анализатор обнаружил возможную ошибку, связанную с тем, что в цикле 'for' на каждой итерации к элементу массива или контейнера обращаются по одному и тому же константному индексу.
Рассмотрим пример некорректного кода:
void Foo(vector<size_t> &vect)
{
for (size_t i = 0; i < vect.size(); i++)
vect[0] *= 2;
}В данной функции хотели изменить все значения, хранящиеся в векторе, однако из-за опечатки доступ к элементам вектора осуществляется не по счётчику цикла 'i', а по константному значению - 0. В итоге будет изменено только одно значение (если вектор не пустой).
Для исправления ошибки необходимо правильно переписать обращение к элементам контейнера:
void Foo(vector<size_t> &vect)
{
for (size_t i = 0; i < vect.size(); i++)
vect[i] *= 2;
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V767. |
V768. Variable is of enum type. It is suspicious that it is used as a variable of a Boolean-type.
Анализатор обнаружил подозрительный фрагмент кода, в котором именованная константа из перечисления либо переменная типа перечисления используется как булевое значение. Скорее всего, это свидетельствует о наличии ошибки в логике программы.
Рассмотрим пример.
enum Offset { left=10, right=15, top=20, bottom=25 };
void func(Offset offset)
{
....
if (offset || i < 10)
{
....
}
}В данном случае переменная типа перечисления 'offset' используется как булевое значение, но поскольку в перечислении 'Offset' все значения ненулевые, то условие будет выполняться всегда. Предупреждение анализатора в данном случае подсказывает, что выражение написано неверно и его следует исправить, например, так:
void func(Offset offset)
{
....
if (offset == top || i < 10)
{
....
}
}Рассмотрим еще один пример. Пусть у нас имеется перечисление следующего вида:
enum NodeKind
{
NK_Identifier = 64,
....
};И класс вида
class Node
{
public:
NodeKind _kind;
bool IsKind(ptrdiff_t kind) const { return _kind == kind; }
};Тогда ошибка может выглядеть следующим образом:
void foo(Node node)
{
if (node.IsKind(!NK_Identifier))
return;
....
}Подразумевалось прекращение выполнения функции, если текущий узел не является идентификатором. Но результат выражения '!NK_Identifier' будет равен '0', а перечисление 'NodeKind' не содержит элемента с таким значением. Как итог, метод 'IsKind' всегда будет возвращать значение 'false', и функция продолжит выполнение, независимо от того, чем является текущий узел.
Исправленный вариант кода выглядит так:
void foo(Node node)
{
if (!node.IsKind(NK_Identifier))
return;
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V768. |
V769. The pointer in the expression equals nullptr. The resulting value is senseless and it should not be used.
Анализатор обнаружил подозрительную операцию, применяемую к нулевому указателю. Полученный указатель не имеет смысла. Скорее всего, это свидетельствует о наличии ошибки в логике программы.
Пример:
void foo(bool isEmpty, char *str)
{
char *begin = isEmpty ? str : nullptr;
char *end = begin + strlen(str);
....
}Если указатель 'begin' равен nullptr, то выражение "nullptr + len" не имеет смысла: использовать его всё равно нельзя. Возможно, переменная дальше не используется. Тогда стоит провести рефакторинг кода таким образом, чтобы данная операция не осуществлялась над нулевым указателем: это потенциальный источник ошибок, если кто-то об этом забудет и попытается обратиться по указателю.
Например, код можно переписать так:
void foo(bool isEmpty, char *str)
{
char *begin = isEmpty ? str : nullptr;
if (begin != nullptr)
{
char *end = begin + strlen(str);
....
}
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V769. |
V770. Possible use of left shift operator instead of comparison operator.
Анализатор обнаружил потенциально возможную опечатку в коде, связанную с тем, что в условии цикла вместо операторов '<' и '<=' используются '<<' и '<<=', соответственно.
Рассмотрим пример такого кода:
void Foo(std::vector<int> vec)
{
for (size_t i = 0; i << vec.size(); i++) // <=
{
// Something
}
}Выражение "i << vec.size()" будет равно нулю. Это явно ошибка, поскольку тело цикла ни разу не выполняется. Корректный вариант кода:
void Foo(std::vector<int> vec)
{
for (size_t i = 0; i < vec.size(); i++)
{
// Something
}
}Примечание. Сдвиги вправо (>>, >>=) считаются нормальной ситуацией, так как они используются в различных алгоритмах, например, вычисление количества бит, равных 1. Пример:
size_t num;
unsigned short var = N;
for (num = var & 1 ; var >>= 1; num += var & 1);Данная диагностика классифицируется как:
V771. The '?:' operator uses constants from different enums.
Анализатор обнаружил потенциально возможную ошибку в коде, связанную с тем, что в тернарном операторе '?:' в качестве второго и третьего операндов используются константные значения из разных перечислений.
Рассмотрим пример такого кода:
enum OnlyOdd { Not_Odd, Odd };
enum OnlyEven { Not_Even, Even };
int isEven(int a)
{
return (a % 2) == 0 ? Even : Odd;
}Функция проверяет число на четность, но в возвращающемся значении используются константы из двух разных перечислений (OnlyEven::Even и OnlyOdd::Odd), приводимые к типу 'int'. В результате, независимо от переданного аргумента 'a', функция всегда будет возвращать 1 (истину). Корректный код должен выглядеть следующим образом:
enum OnlyOdd { Not_Odd, Odd };
enum OnlyEven { Not_Even, Even };
int isEven(int a)
{
return (a % 2) == 0 ? Even : Not_Even;
}Примечание. Нормальной ситуацией считается применение двух разных перечислений без имени, например:
enum
{
FLAG_FIRST = 0x01 << 0,
FLAG_SECOND = 0x01 << 1,
....
};
enum
{
FLAG_RW = FLAG_FIRST | FLAG_SECOND,
....
};
....
bool condition = ...;
int foo = condition ? FLAG_SECOND : FLAG_RW; // нет V771
....V772. Calling a 'delete' operator for a void pointer will cause undefined behavior.
Анализатор обнаружил потенциально возможную ошибку в коде, связанную с тем, что оператор 'delete' или 'delete[]' применяется для нетипизированного указателя (void*). Согласно стандарту C++20 (п. п. $7.6.2.8/3) такое применение ведет к неопределенному поведению.
Рассмотрим пример такого кода:
class Example
{
int *buf;
public:
Example(size_t n = 1024) { buf = new int[n]; }
~Example() { delete[] buf; }
};
....
void *ptr = new Example();
....
delete ptr;
....Подобный пример опасен тем, что компилятор в реальности не знает, к каком типу относится указатель 'ptr'. Поэтому, при удалении такого нетипизированного указателя могут произойти различные неприятности, например, может возникнуть утечка памяти: оператор 'delete' не вызовет деструктор объекта типа 'Example', на который ссылается указатель 'ptr'.
Если подразумевалась именно работа с нетипизированным указателем, то перед применением оператора 'delete' ('delete[]') его необходимо привести к изначальному типу, например так:
....
void *ptr = new Example();
....
delete (Example*)ptr;
....Иначе, во избежание ошибок, рекомендуется использовать только типизированные указатели совместно с оператором 'delete' ('delete[]'):
....
Example *ptr = new Example();
....
delete ptr;
....Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V772. |
V773. Function exited without releasing the pointer/handle. A memory/resource leak is possible.
Анализатор обнаружил потенциально возможную утечку памяти в коде. Такая ситуация возникает, когда память, выделенная с помощью 'malloc' или 'new', не была далее освобождена.
Рассмотрим пример такого кода:
int *NewInt()
{
int *p = new (std::nothrow) int;
....
return p;
}
bool Test()
{
int *p = NewInt();
int res = *p;
return res;
}В данном примере, выделение памяти спрятано в вызове другой функции. Соответственно после вызова нужно соответствующим образом освободить память.
Исправленный код, где не возникает утечка памяти:
int *NewInt()
{
int *p = new int;
....
return p;
}
bool Test()
{
int *p = NewInt();
int res = *p;
delete p;
return res;
}Часто подобные ошибки можно встретить в обработчиках ошибочных ситуаций, так как к ним невнимательно относятся при обзорах кода и слабо тестируют. Пример:
bool Test()
{
int *p = (int*)malloc(sizeof(int));
int *q = (int*)malloc(sizeof(int));
if (p == nullptr || q == nullptr)
{
std::cerr << "No memory";
return -1;
}
int res = *p + *q;
free(p);
free(q);
return res;
}Может сложиться ситуация, когда указатель 'p' будет хранить указатель на выделенную память, а 'q' будет равен 'nullptr'. Тогда выделенная память освобождена не будет. Кстати, может быть и наоборот. В параллельной программе реальна ситуация, когда первый раз не удастся выделить память, а потом удастся.
Помимо утечек памяти, анализатор может находить утечки ресурсов: незакрытые дескрипторы, файлы и т.д. Такие ошибки не сильно отличаются друг от друга, поэтому к ним относится всё вышесказанное. Приведём небольшой пример:
void LoadBuffer(char *buf, size_t len)
{
FILE* f = fopen("my_file.bin", "rb");
fread(buf, sizeof(char), len, f);
}Примечание. В современном C++ лучше обходиться без ручного управления ресурсами и использовать умные указатели. Например, можно рекомендовать использовать 'std::unique_ptr'. В этом случае вся память будет освобождена корректно во всех точках выхода функции. Также такое решение будет exception-safe.
У статического анализатора меньше информации об указателях, чем у динамического, поэтому анализатор может выдавать ложные предупреждения, если память освобождается нетривиально или далеко от места, где выделяется. Для отключения таких предупреждений предусмотрен специальный комментарий:
//+V773:SUPPRESS, class:className, namespace:nsNameПараметр 'namespace' является необязательным.
Рассмотрим пример:
void foo()
{
EVENT* event = new EVENT;
event->send();
}Объект класса 'EVENT' не должен удаляться в этой функции, поэтому отключить все предупреждения V773 на этот класс можно с помощью комментария:
//+V773:SUPPRESS, class:EVENTВыявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V773. |
V774. Pointer was used after the memory was released.
Анализатор обнаружил использование указателя, который ссылается на освобождённый участок памяти. Это является неопределённым поведением и может привести к разнообразнейшим последствиям.
Некоторые возможные варианты:
- при записи по такому указателю можно испортить какой-то другой объект в памяти;
- при чтении можно получить случайные значения;
- работа с указателем приведёт к аварийному завершению программы.
Рассмотрим пример такого кода:
for (node *p = head; p != nullptr; p = p->next)
{
delete p;
}В данном примере при выполнении выражения 'p = p->next' произойдёт разыменование указателя p, удалённого в теле цикла. Необходимо было сначала вычислить это выражение и только потом освободить память. Исправленный вариант кода:
node *p = head;
while (p != nullptr)
{
node *prev = p;
p = p->next;
delete prev;
}Неприятное в таких ошибках, что долгое время может казаться, что программа работает корректно. При этом, всё может сломаться после простого рефакторинга кода, добавлении новой переменной, смены компилятора и так далее.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V774. |
V775. It is suspicious that the BSTR data type is compared using a relational operator.
Анализатор обнаружил подозрительное сравнение элемента BSTR-типа, при помощи операторов отношения: >, <, >=, <=.
BSTR (basic string или binary string) - это строковый тип данных, который используется в COM, Automation и Interop функциях. Этот тип данных включает в себя префикс длины, строку данных и терминальный ноль.
Тип BSTR является указателем, который всегда указывает на первый символ строки данных, а не на префикс длины. По этой причине, каждый BSTR объект является уникальным и один BSTR не может быть частью другого, как это возможно с обычными строками.

Однако, обычная строка может являться частью BSTR (но не наоборот), поэтому сравнения вида "wchar_t* > BSTR" допустимы.

Рассмотрим пример:
void func(BSTR a, BSTR b)
{
if (a > b)
{
....
}
}Данный код является ошибочным, так как сравнение указателей 'a' и 'b' не имеет смысла.
Подробнее про BSTR можно прочитать на MSDN.
Данная диагностика классифицируется как:
V776. Potentially infinite loop. The variable from the loop exit condition does not change its value between iterations.
Анализатор обнаружил потенциально бесконечный цикл, условие выхода из которого зависит от переменной, значение которой никогда не меняется в нем.
Рассмотрим пример:
int Do(int x);
....
int n = Foo();
int x = 0;
while (x < n)
{
Do(x);
}Условие выхода из цикла зависит от переменной 'x', значение которой в цикле всегда будет равно нулю. Таким образом проверка 'x < 10' всегда будет истинной, что приведет к бесконечному циклу в данном случае. Правильный вариант мог бы выглядеть так:
int Do(int x);
int n = Foo();
int x = 0;
while (x < n)
{
x = Do(x);
}Рассмотрим еще один пример, когда условие выхода из цикла зависит от переменной, изменение значения этой которой зависит от других переменных, которые никогда не меняются внутри цикла. Пусть у нас имеется метод следующего вида:
int Foo(int a)
{
int j = 0;
while (true)
{
if (a >= 32)
{
return j * a;
}
if (j == 10)
{
j = 0;
}
j++;
}
}Условие выхода из цикла зависит от параметра 'a'. В случае если параметр 'a' не будет удовлетворять условие проверки 'a >= 32', то цикл будет бесконечным, так как его значение в цикле не изменяется. Корректный вариант мог бы выглядеть так:
int Foo(int a)
{
int j = 0;
while (true)
{
if (a >= 32)
{
return j * a;
}
if (j == 10)
{
j = 0;
a++; // <=
}
j++;
}
}Таким образом изменение параметра 'a' будет зависеть от локальной переменной 'j'.
Данная диагностика классифицируется как:
V777. A dangerous widening type conversion from an array of a derived class objects to a base class pointer.
Анализатор обнаружил потенциально возможную ошибку в коде, связанную с тем, что массив производных классов адресуется через указатель на базовый класс. При попытке доступа к ненулевому элементу массива через указатель на базовый класс произойдет ошибка.
Рассмотрим пример такого кода:
class Base
{
int buf[10];
public:
virtual void Foo() { ... }
virtual ~Base() { }
};
class Derived : public Base
{
char buf[10];
public:
virtual void Foo() override { ... }
virtual ~Derived() { }
};
....
size_t n = 5;
Base *ptr = new Derived[n]; // <=
....
for (size_t i = 0; i < n; ++i)
(ptr + i)->Foo();
....В примере объявлены базовый класс "Base" и производный от него "Derived". Каждый объект этих классов будут занимать в памяти 48 и 64 байта соответственно (вследствие выравнивания классов по ширине 8 байт; компилятор MSVC, 64-bit). При "i >= 1" для обращения к ненулевому элементу необходимо каждый раз перемещать указатель на "i * 64" байта, но, поскольку массив адресуется указателем на базовый класс Base, смещение на самом деле будет вычисляться как "i * 48" байт.
Так должно было вычисляться смещение указателя:

Однако вычислено смещение указателя будет так:

Фактически, программа начинает работать с объектами, содержащими случайный набор данных.
Корректный вариант кода:
....
size_t n = 5;
Derived *ptr = new Derived[n]; // <=
....
for (size_t i = 0; i < n; ++i)
(ptr + i)->Foo();
....Ошибочно также приводить указатель на указатель на производный класс к указателю на указатель на базовый класс:
....
Derived arr[3];
Derived *pDerived = arr;
Class5 **ppDerived = &pDerived;
....
Base **ppBase = (Derived**)ppDerived; // <=
....Для правильного хранения массива объектов производного класса полиморфически необходимо размещать объекты следующим образом:

Корректный код при этом будет выглядеть следующим образом:
....
size_t n = 5;
Base **ppBase = new Base*[n]; // <=
for (size_t i = 0; i < n; ++i)
ppBase[i] = new Derived();
....Если мы хотим подчеркнуть, что будем работать только с одним объектом, то можно написать так:
....
Derived *derived = new Derived[n];
Base *base = &derived[i];
....Такой код считается анализатором безопасным, и он не выдаёт предупреждение.
Не является также ошибкой применение указателя, который адресуется на массив объектов производного класса, содержащий один элемент.
....
Derived arr[1];
Derived *new_arr = new Derived[1];
Derived *malloc_arr = static_cast<Base*>(malloc(sizeof(Derived)));
....
Base *base = arr;
base = new_arr;
base = malloc_arr;
....Примечание. В случае одинакового размера базового и производного классов допускается адресоваться на массив объектов производного класса указателем на базовый класс, однако так делать не рекомендуется.
Данная диагностика классифицируется как:
|
V778. Two similar code fragments. Perhaps, it is a typo and 'X' variable should be used instead of 'Y'.
Анализатор обнаружил код, который, возможно, содержит опечатку. Высока вероятность, что подобный код был создан с использованием подхода Copy-Paste.
Данная диагностика выявляет два схожих по структуре блока текста, идущих один за другим и отличающихся именем одной переменной. Предупреждение V778 предназначено для выявления тех случаев, если второй блок был получен путем копирования первого, при этом во втором блоке были переименованы не все переменные.
Рассмотрим пример:
void Example(int a, int b)
{
....
if (a > 50)
doSomething(a);
else if (a > 40)
doSomething2(a);
else
doSomething3(a);
if (b > 50)
doSomething(b);
else if (a > 40) // <=
doSomething2(b);
else
doSomething3(b);
....
}Код писался с помощью Copy-Paste. Во втором блоке не уследили и забыли заменить все переменные 'a' на 'b'. На самом деле, код должен быть таким:
void Example(int a, int b)
{
....
if (a > 50)
doSomething(a);
else if (a > 40)
doSomething2(a);
else
doSomething3(a);
if (b > 50)
doSomething(b);
else if (b > 40)
doSomething2(b);
else
doSomething3(b);
....
}Теперь рассмотрим пример, взятый из реального проекта:
....
if(erendlinen>239) erendlinen=239;
if(srendlinen>erendlinen) srendlinen=erendlinen;
if(erendlinep>239) erendlinep=239;
if(srendlinep>erendlinen) srendlinep=erendlinep; // <=
....Заметить ошибку не так уж и просто по сравнению с предыдущим примером. Имена переменных похожи друг на друга, и поэтому выявление ошибки усложняется в разы. На самом деле во втором блоке вместо переменной 'erendlinen' должна стоять 'erendlinep'.
Имена переменных 'erendlinen' и 'erendlinep' выбраны явно неудачно. Такую ошибку почти невозможно заметить при Code Review. Да что уж там, даже когда анализатор указывает на строку с ошибкой и то сложно её заметить. Поэтому, встретив предупреждение V778, рекомендуем не спешить и внимательно изучить код.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V778. |
V779. Unreachable code was detected. It is possible that an error is present.
Анализатор обнаружил код, который никогда не будет выполнен. Возможно допущена ошибка в логике программы.
Данная диагностика находит блоки кода, до которых никогда не дойдёт управление.
Рассмотрим пример:
void Error()
{
....
exit(1);
}
FILE* OpenFile(const char *filename)
{
FILE *f = fopen(filename, "w");
if (f == nullptr)
{
Error();
printf("No such file: %s", filename);
}
return f;
}Функция 'printf(....)' никогда не напечатает сообщение об ошибке, так как функция 'Error()' не возвращает управление. Как правильно исправить код зависит от того, какую логику поведения задумывал программист изначально. Возможно, функция должна возвращать управление. Возможно, нарушен порядок выражений и корректный код должен быть таким:
FILE* OpenFile(const char *filename)
{
FILE *f = fopen(filename, "w");
if (f == nullptr)
{
printf("No such file: %s", filename);
Error();
}
return f;
}Рассмотрим ещё один пример:
void f(char *s, size_t n)
{
for (size_t i = 0; i < n; ++i)
{
if (s[i] == '\0')
break;
else
return;
s[i] = toupper(s[i]);
}
}Весь код, стоящий после 'if', не будет выполнен, так как обе ветви не возвращают управление. Скорее всего, нужно внести код в одну из ветвей или убрать noreturn выражение.
Например, можно исправить код следующим образом:
void f(char *s, size_t n)
{
for (size_t i = 0; i < n; ++i)
{
if (s[i] == '\0')
break;
s[i] = toupper(s[i]);
}
}Если реализация функции находится в другом файле, анализатору требуется подсказка, чтобы понять, что она всегда прекращает работу программы. В противном случае, он может не заметить ошибку. Для подсказки можно воспользоваться аннотациями при объявлении функции:
[[noreturn]] void my_abort(); // C++11
__declspec(noreturn) void my_abort(); // MSVC
__attribute__((noreturn)) void my_abort(); // GCCЕсть некоторые фрагменты кода, на которые анализатор не будет выдавать предупреждение, несмотря на формальное наличие ошибки. Пример:
int test()
{
throw 0;
return 0;
}Это связано с тем, что такой код часто пишут для подавления предупреждений компилятора или других анализторов.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V779. |
V780. The object of non-passive (non-PDS) type cannot be used with the function.
Анализатор обнаружил опасную работу со сложными типами. Если объект не является Passive Data Structure (PDS), то нельзя использовать низкоуровневые функции по работе с памятью: memset, memcpy и т.д. Это может нарушить логику работы класса и привести к утечке памяти, двойному очищению одного ресурса или Undefined Behavior.
Пример классов, над которыми нельзя совершать такие действия: std::vector, std::string и другие подобные контейнеры.
Иногда такая диагностика находит опечатки. Рассмотрим пример:
struct Buffer {
std::vector<char>* m_data;
void load(char *buf, size_t len) {
m_data->resize(len);
memcpy(&m_data[0], buf, len);
}
};Функция 'memcpy' копирует данные не в содержимое контейнера, а в объект, на который указывает 'm_data'. Такой код нужно переписать следующим образом:
memcpy(&(*m_data)[0], buf, len);или:
memcpy(m_data->data(), buf, len);Другой способ ошибиться - это использовать memset/memcpy для структуры, полями которой являются non-PDS объекты. Рассмотрим пример:
struct Buffer {
std::vector<char> m_data;
....
};
void F() {
Buffer a;
memset(&a, 0, sizeof(Buffer));
....
}Чтобы избежать таких ошибок можно рекомендовать использовать value initialization. Такой подход корректно работает и с POD-данными, и с объектами с нетривиальным конструктором.
Для копирования можно положиться на генерируемый компилятором конструктор копирования или написать свой.
Анализатор также ищет структуры, использование memset/memcpy над которыми может быть опасно, исходя из их логики или представления в памяти. К первому случаю относятся классы, в которых одновременно есть указатели, конструкторы и деструкторы. Если в классе содержится нетривиальная работа с указателями (например, управление памятью или ресурсом), то нельзя использовать для него memcpy/memset. Пример такого класса:
struct Buffer {
char *buf;
Buffer() : buf(new char[16]) {}
~Buffer() { delete[] buf; }
};
Buffer buf1, buf2;
memcpy(&buf1, &buf2, sizeof(Buffer));Ко второму случаю относятся классы, не являющиеся standard layout:
struct BufferImpl {
virtual bool read(char *, size_t) { return false; }
};
struct Buffer {
BufferImpl impl;
};
Buffer buf1, buf2;
memcpy(&buf1, &buf2, sizeof(Buffer));Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V780. |
V781. Value of a variable is checked after it is used. Possible error in program's logic. Check lines: N1, N2.
Анализатор заметил в коде следующую ситуацию. В начале, значение переменной используется в качестве размера или индекса массива. А уже затем это значение сравнивается с 0 или с размером массива. Это может указывать на наличие логической ошибки в коде или опечатку в одном из сравнений.
Рассмотрим пример
int idx = GetPos(buf);
buf[idx] = 42;
if (idx < 0) return -1;Если значение 'idx' окажется меньше нуля, то выражение 'buf[idx] ' приведёт к ошибке. Анализатор выдаст предупреждение на этот код, указав 2 строки. Первая строка - это то место, где используется переменная. Вторая строка - это то место, где переменная сравнивается с другим значением.
Исправленный вариант кода:
int idx = GetPos(buf);
if (idx < 0) return -1;
buf[idx] = 42;Точно также анализатор выдаёт предупреждение, если переменная сравнивается с размером массива:
int buf[10];
buf[idx] = 42;
if (idx < countof(buf)) return -1;Правильный вариант кода:
int buf[10];
if (idx < countof(buf)) return -1;
buf[idx] = 42;Помимо индексов, анализатор смотрит на использование переменных в качестве аргументов к функциям, которые принимают неотрицательные значения (memset, malloc и т.д.). Рассмотрим пример:
bool Foo(char *A, int size_A, char *B, int size_B)
{
if (size_A <= 0)
return false;
memset(A, 0, size_A);
....
if (size_A <= 0) // Error
return false;
memset(B, 0, size_B);
....
}В коде допущена опечатка, которая будет выявлена косвенным образом. В коде всё хорошо с массивом 'A'. Однако, размер массива 'B' проверяется неправильно. В результате возникает ситуация, что 'size_A' проверяется уже после использования.
Корректный код:
bool Foo(char *A, int size_A, char *B, int size_B)
{
if (size_A <= 0)
return false;
memset(A, 0, size_A);
....
if (size_B <= 0) // FIX
return false;
memset(B, 0, size_B);
....
}Так же анализатор может увидеть проблему, если использование переменной в качестве индекса массива и её проверка находятся в одном выражении:
void f(int *arr, const int size)
{
for (int i = 0; arr[i] < 10 && i < size; ++i)
arr[i] = 0;
}В этом случае на последней итерации цикла мы будем проверять значение, взятое за границей массива, а это является неопределённым поведением.
Исправленный вариант:
void f(int *arr, const int size)
{
for (int i = 0; i < size && arr[i] < 10; ++i)
arr[i] = 0;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V781. |
V782. There is no sense in evaluating the distance between elements from different arrays.
Анализатор обнаружил бессмысленный код для вычисления расстояния между элементами разных массивов.
Рассмотрим пример:
ptrdiff_t offset()
{
char path[9] = "test.txt";
char resources[9] = "resr.txt";
return path - resources;
}Вычитание адресов двух массивов, выделенных на стеке, не имеет никакого практического смысла и скорее всего является ошибкой.
Для рассмотрения всех подозрительных операций с указателями на массивы, разделим типы указателей на две условные группы:
- В группу 'A' входят указатели на массивы, размещённых на стеке. А также массивы, аллоцированные с помощью 'new' или 'malloc()', над которыми не были произведены операции смещения указателя.
- В группу 'B' входят указатели на массивы, аллоцированные с помощью 'new' или 'malloc', над которыми были совершенны операции смещения указателя. Либо это указатель, о котором у анализатора нет информации.
Тогда получим таблицу операций над указателями на массивы, вычисление которых не имеет практического смысла (таблица 1).

Таблица 1 - Бессмысленные операции над указателями.
Данная диагностика классифицируется как:
|
V783. Possible dereference of invalid iterator 'X'.
Анализатор обнаружил фрагмент кода, который может привести к использованию невалидного итератора.
Рассмотрим несколько примеров, для которых анализатор выдает данное диагностическое сообщение:
if (iter != vec.end() || *iter == 42) { ... }
if (iter == vec.end() && *iter == 42) { ... }Во всех условиях допущена логическая ошибка, которая приведет к разыменованию невалидного итератора. Ошибка может быть допущена при рефакторинге кода или из-за случайно опечатки.
Корректные варианты:
if (iter != vec.end() && *iter == 42) { ... }
if (iter == vec.end() || *iter == 42) { ... }Конечно, это очень простые ситуации. На практике проверка итератора и его использование может находиться в разных местах. Если анализатор выдал предупреждение V783, изучите код расположенный выше и попробуйте понять, почему итератор может быть невалидным.
Пример кода, где проверка и использование итератора находятся в разных строках:
if (iter == vec.end()) {
std::cout << "Error: " << *iter << std::endl;
throw std::runtime_error("foo");
}Анализатор предупредит об опасности в выражении '*iter'. Здесь или некорректно написано условие, или вместо 'iter' должна использоваться другая переменная.
Анализатор также находит ошибки, когда использование итератора находится до его проверки.
Пример:
std::cout << "Element is " << *iter << std::endl;
if (iter == vec.end()) {
throw std::runtime_error("");
}Здесь проверка не имеет смысла, так как если итератор невалидный, то выше по коду произойдёт его разыменование. Скорее всего нужно добавить дополнительную проверку итератора:
if (iter != vec.end()) {
std::cout << "Element is " << *iter << std::endl;
}
if (iter == vec.end()) {
throw std::runtime_error("");
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V783. |
V784. The size of the bit mask is less than the size of the first operand. This will cause the loss of higher bits.
Анализатор обнаружил подозрительную операцию при работе с битовыми масками. В качестве битовой маски используется переменная меньшей разрядности, чем другой операнд. Это приведёт к гарантированной потере старших бит.
Рассмотрим несколько примеров, для которых анализатор выдает данное диагностическое сообщение:
unsigned long long x;
unsigned y;
....
x &= ~y;Посмотрим подробнее, что происходит с битами после каждой операции на примере выражения:
x = 0xffff'ffff'ffff'ffff;
y = 0xff;
x &= ~y;
Как правило это не тот результат, который планировал получить программист:
0xffff’ffff’ffff’ff00 – ожидалось
0x0000’0000’ffff’ff00 – получилосьКод можно поправить, явно приведя переменную 'y' к типу, которая имеет переменная'x':
x &= ~(unsigned long long)y;В данном случае, сначала произойдёт преобразование типов, а потом отрицание. После операции все старшие биты будут равны единице. Рассмотрим, как изменится пример выше при данном порядке вычислений:

Анализатор также предупреждает о таком коде:
unsigned long long x;
unsigned y;
....
x &= y;Несмотря на то, что здесь не используются дополнительные операции, этот код всё равно выглядит подозрительно. Лучше явно преобразовать типы, дабы поведение было более очевидным, как для анализатора, так и для ваших коллег.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V784. |
V785. Constant expression in switch statement.
Анализатор обнаружил константное выражение в условии 'switch'. Чаще всего это сигнализирует о логической ошибке.
Рассмотрим синтетический пример:
int i = 1;
switch (i)
{
....
}В качестве условия 'switch' стоит переменная, значение которой может быть посчитано во время компиляции. Такая ситуация могла возникнуть в результате рефакторинга: раньше был код, который менял значение переменной, а потом его поменяли и оказалось, что переменной больше не присваивается никакое значение.
Анализатор не выдаёт предупреждение, когда переменная константная или в условии используется макросы. Такие конструкции часто используют намеренно для включения/выключения функционала во время компиляции.
Например, могут выполняться различные действия, в зависимости от того для какой операционной системы скомпилирован код:
switch (MY_PROJ_OS)
{
case MY_PROJ_WINDOWS:
....
case MY_PROJ_LINUX:
....
case MY_PROJ_MACOS:
....
}Данная диагностика классифицируется как:
|
V786. It is odd that value C is assigned to the X variable. The value range of variable: [A, B].
Анализатор обнаружил, что переменной пытаются присвоить значение, которое не входит в её диапазон возможных значений.
Рассмотрим несколько примеров, для которых анализатор выдает данное диагностическое сообщение:
bool b;
....
b = 100;Нет никакого смысла присваивать значение 100 переменной типа bool. Возможно, что мы имеем дело с опечаткой и вместо 'b' должна использоваться другая переменная.
Рассмотрим другой пример:
struct S
{
int flag : 1;
}
....
S s;
s.flag = 1;Битовое поле 'flag' может принимать значения из диапазона [-1, 0], а не [0, 1], как может показаться на первый взгляд. Причина в том, что тип переменной знаковый. Если вам нужно битовое поле с диапазоном в [0, 1], используйте тип 'unsigned':
struct S
{
unsigned flag : 1;
}
....
S s;
s.flag = 1;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V786. |
V787. Wrong variable is probably used in the for operator as an index.
Анализатор обнаружил, что счётчик в цикле используется в условии выхода из цикла в качестве индекса. Такой код выглядит подозрительно.
Рассмотрим пример:
for (int i = 0; i < n; ++i)
for (int j = 0; j < arr[j]; ++j)
....Скорее всего, вместо переменной 'j' нужно использовать 'i':
for (int i = 0; i < n; ++i)
for (int j = 0; j < arr[i]; ++j)
....V788. Consider reviewing a captured variable in lambda expression.
Анализатор обнаружил подозрительный захват переменной в лямбда функции.
Рассмотрим несколько вариантов срабатывания диагностики.
Пример 1:
int x = 0;
auto f = [x] { };
....
x = 42;
f();
...Переменную, значение которой может быть точно вычислено в compile-time, захватывают в лямбда функции по значению. Внутри этой функции значение переменной будет таким, которым оно было в момент захвата, а не то, которая имеет эта переменная в момент вызова лямбда функции. Возможно, необходимо захватить переменную по ссылке.
int x = 0;
auto f = [&x] { };
....
x = 42;
f();
...Также возможно, что в ходе рефакторинга был удалён код, который присваивал переменной какое-либо значение.
int x = 0;
if (condition) x = 42;
else x = 43;
auto f = [x] { };Если же необходимо захватить некую константу, то лучше явно указать в типе переменной 'const' или 'constexpr'.
constexpr int x = 0;
auto f = [x] { };Пример 2:
int x;
auto f = [x] { };Неинициализированная переменная захватывается по значению. Её использование приведёт к Undefined Behavior. Если предполагалось, что вызов функции должен проинициализировать переменную, то её необходимо захватить по ссылке.
int x;
auto f = [&x] { x = 42; };Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
|
V789. Iterators for the container, used in the range-based for loop, become invalid upon a function call.
Анализатор обнаружил инвалидацию итератора в range-based for цикле.
Пример:
std::vector<int> numbers;
for (int num : numbers)
{
numbers.push_back(num * 2);
}Данный код аналогичен следующему:
for (auto __begin = begin(numbers), __end = end(numbers);
__begin != __end; ++__begin) {
int num = *__begin;
numbers.push_back(num * 2);
}Теперь видно, что при операции 'push_back' может произойти инвалидация итераторов '__begin' и '__end', если произойдёт реаллокация памяти внутри вектора.
Если необходимо модифицировать контейнер и одновременно читать из него значения, лучше воспользоваться функциями, которые возвращают новый итератор после модификации, или индексами в случае класса 'std::vector'.
Дополнительные ссылки:
- https://stackoverflow.com/a/6442829 - правила инвалидации итераторов для STL контейнеров.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V789. |
V790. It is suspicious that the assignment operator takes an object by a non-constant reference and returns this object.
Анализатор обнаружил, что оператор присваивания принимает объект по неконстантной ссылке и именно его возвращает.
Пример:
class C {
C& operator = (C& other) {
....
return other;
}
};Если оператор присваивания будет реализован таким способом, то можно получить неожиданные и неприятные эффекты. Допустим, программист напишет код:
(A = B)++;Оставим в стороне тот факт, что такой код вообще лучше не писать. Предположим, что этот код нужен. Программист, возможно, ожидает, что код будет работать следующим образом:
A = B;
A++;Однако из-за неправильного оператора присваивания он работает так:
A = B;
B++;Чтобы предотвратить появление таких ошибок, лучше передавать аргумент по константной ссылке. Тогда код с реализаций оператора просто бы не скомпилировался.
Корректный код:
class C {
C& operator = (const C& other) {
....
return *this;
}
};V791. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
Анализатор выявил цикл, который может содержать ошибку или быть неоптимальным. Используется типичный паттерн кода, когда для всех пар элементов массива выполняется некая операция. При этом, как правило, нет смысла выполнять операцию для пары, состоящей из одного и того-же элемента при 'i == j'.
Пример:
for (int i = 0; i < size; i++)
for (int j = i; j < size; j++)
...Есть большая вероятность, что правильнее или эффективнее использовать следующий код для обхода массивов:
for (int i = 0; i < size; i++)
for (int j = i + 1; j < size; j++)
...Далее приведён пример кода из реального приложения, в котором реализовали собственный алгоритм сортировки устройств по приоритету и сделали это не оптимально:
/* Simple bubble sort */
for (i = 0; i < n_devices; ++i) {
for (uint32_t j = i; j < n_devices; ++j) {
if (devices[i]->prio > devices[j]->prio) {
struct device_t *tmp;
tmp = devices[i];
devices[i] = devices[j];
devices[j] = tmp;
}
}
}Исправленный вариант:
/* Simple bubble sort */
for (i = 0; i < n_devices - 1; ++i) {
for (uint32_t j = i + 1; j < n_devices; ++j) {
if (devices[i]->prio > devices[j]->prio) {
struct device_t *tmp;
tmp = devices[i];
devices[i] = devices[j];
devices[j] = tmp;
}
}
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V791. |
V792. The function located to the right of the '|' and '&' operators will be called regardless of the value of the left operand. Consider using '||' and '&&' instead.
Анализатор обнаружил возможную опечатку в логическом выражении. Вместо логического оператора (&& или ||) написали битовый оператор (& или |). Это означает, что правая часть будет выполнена независимо от результата левой части.
Пример:
if (foo() | bar()) {}Если в качестве операндов стоят довольно ресурсоемкие операции, то использование битовых операций не оптимально. Кроме того, такой код может привести к ошибке из-за разных типов выражения и разных приоритетов операций. Также возможна ситуация, когда правая часть не должна быть выполнена, если левая завершилась неудачно. В таком случае может произойти обращение к неинициализированным ресурсам. Также битовые операции не гарантируют порядок вычисления операндов.
Корректный код:
if (foo() || bar()) {}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V792. |
V793. It is suspicious that the result of the statement is a part of the condition. Perhaps, this statement should have been compared with something else.
Анализатор обнаружил возможную опечатку в логическом выражении. В качестве условного выражения используется арифметическая операция.
Пример:
int a;
int b;
if (a + b) {}Несмотря на то, что поведение такого кода может быть понятно его автору, лучше использовать явные проверки. Такой код аналогичен 'a + b != 0'. Человек, который будет читать и сопровождать этот код, постоянно будет задавать себе вопрос: "А не забыли ли сравнить с чем-то полученную сумму?". Возможно, результат операции хотели сравнить с некой константой, например, 42, и корректный код должен был быть таким:
if (a + b == 42) {}Пример из кода реального проекта:
// verify that time is well formed
if ( ( hh / 24 ) || ( mm / 60 ) ) {
return false;
}Код работает, как и задумывалось. Но он бы выглядел намного понятнее, если бы использовались операции сравнения.
// verify that time is well formed
if ( hh >= 24 || mm >= 60 ) {
return false;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V793. |
V794. The assignment operator should be protected from the case of 'this == &src'.
Анализатор обнаружил опасный оператор копирования/перемещения. В нём нет проверки на присвоение объекта самому себе. При этом в таком операторе есть операции, которые могут привести к утечкам памяти, использованию указателей после их освобождения и другим проблемам, если этому оператору передать ссылку на '*this' в качестве аргумента.
Пример:
class C {
char *p;
size_t len;
public:
C& operator = (const C& other) {
delete p;
len = other.len;
p = new char[len];
std::copy(other.p, other.p + len, p);
return *this;
}
};Ошибка проявится, если 'this == &other', а соответственно 'p == other.p'. В таком случае, при вызове 'std::copy' произойдёт копирование неинициализированного массива самого в себя.
Корректный код:
C& operator = (const C& other) {
if (this == std::addressof(other))
return *this;
delete p;
len = other.len;
p = new char[len];
std::copy(other.p, other.p + len, p);
return *this;
}Если же такой ситуации не может быть, то есть у этого оператора есть неявный контракт, то лучше формализовать его в виде 'assert':
C& operator = (const C& other) {
MyAssert(this != std::addressof(other));
....
}Примечание: в проверке на равенство самому себе лучше использовать функцию 'std::addressof' вместо оператора '&'. Такая проверка будет работать корректно, даже если класс содержит перегруженный оператор '&'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V794. |
V795. Size of the 'time_t' type is not 64 bits. After the year 2038, the program will work incorrectly.
Анализатор обнаружил, что в проекте используются 32-битные типы данных для хранения времени. Данная проблема затрагивает программы, использующие типы данных, представляющие собой количество секунд, прошедшее с 1 января 1970 года. Таким образом не удастся корректно работать с датами после 19 января 2038. Рекомендуется использовать 64-битные типы данных для хранения времени.
Стандарт языка С/C++ не определяет размер типа 'time_t', поэтому в зависимости от платформы и настроек проекта он может быть определён по-разному:
typedef /* unspecified */ time_t;В старых версиях Visual C++ тип 'time_t' являлся 32-разрядным типом в 32-разрядных версиях Windows. Начиная с Visual C++ 2005 тип 'time_t' по умолчанию представляет собой 64-разрядное целое число. В современных версиях Visual C++ можно принудительно установить размер типа 'time_t' равным 32 битам с помощью директивы '_USE_32BIT_TIME_T'. По возможности стоит избавиться от этой директивы и использовать 64-битный тип time_t.
В Linux тип 'time_t' является 64-разрядным типом только в 64-разрядных версиях ОС. На 32-битных Linux-системах, к сожалению, пока не существует стандартного способа сделать тип 'time_t' 64-разрядным. Возможно стоит отказаться от использования типа 'time_t' в пользу сторонних решений.
Дополнительные ресурсы:
- 2038: остался всего 21 год
- Проблема 2038 года
- https://msdn.microsoft.com/ru-ru/library/w4ddyt9h.aspx
V796. A 'break' statement is probably missing in a 'switch' statement.
В операторе 'switch' анализатор обнаружил ветвь, в которой отсутствует оператор 'break'. В таком случае поток управления перейдёт к следующему 'case'. Возможно, допущена опечатка, и необходимо добавить 'break'.
Пример:
for (char c : srcString)
{
switch (c)
{
case 't':
*s++ = '\t';
break;
case 'n':
*s++ = '\n';
break;
case 'f':
*s++ = '\f'; // <=
case '0':
*s++ = '\0';
}
}Если это ошибка, то следует добавить оператор 'break'. Если ошибки нет, то следует оставить подсказку анализатору и коллегам, которые будут поддерживать код в будущем.
Существует несколько вариантов указать, что данное поведение намеренное. Можно добавить комментарий:
case A:
foo();
// fall through
case B:
bar();Также поддерживаются атрибуты 'fallthrough':
__attribute__((fallthrough));
[[fallthrough]];
[[gnu::fallthrough]];
[[clang::fallthrough]];В диагностике также реализовано несколько эвристических правил, чтобы сократить количество ложных срабатываний. Например, в случае разворачивания цикла:
switch(num) {
case 3:
sum += arr[i + 2];
case 2:
sum += arr[i + 1];
case 1:
sum += arr[i];
}В этом случае диагностическое предупреждение не будет выдано.
Если в 'switch' уже есть комментарии или атрибуты 'fallthrough', то такие исключения не будут срабатывать, т.к. такой код выглядит ещё более подозрительным.
Диагностическое предупреждение не выдаётся, если вместо 'break' уже используются другие операторы, прерывающие работу 'switch' (это 'return', 'throw' и т.д.).
Т.к. анализатор не может однозначно определить, является ли найденное место ошибкой, возможны ложные срабатывания. Для их устранения рекомендуется пользоваться 'fallthrough' комментариями или атрибутами. Оставленные пояснения в первую очередь будут полезны для других разработчиков, которые будут заниматься поддержкой кода. Также такие пометки смогут считывать компиляторы и статические анализаторы.
Если срабатываний слишком много, то можно отключить эту диагностику или воспользоваться механизмом подавления ложных срабатываний.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V796. |
V797. The function is used as if it returned a bool type. The return value of the function should probably be compared with std::string::npos.
Анализатор обнаружил ошибку при поиске подстрок или символов в строке.
Пример:
std::string s = foo();
if (s.find("42")) { .... }Функция 'std::string::find' возвращает число типа 'std::string::size_type'. В случае, когда ничего не найдено, возвращается 'std::string::npos', равный '(size_t)-1'. Соответственно, для того чтобы проверить наличие подстроки, необходимо написать следующий код:
if (s.find("42") != std::string::npos) { .... }Несмотря на то, что код 'if (s.find(...))' компилируется и работает, логика работы такого кода крайне подозрительна. Он проверяет, что искомая подстрока не встречается или она не является началом строки 's'. Если действительно нужно такое поведение, то лучше написать явно:
const auto pos = s.find("42");
if (pos == std::string::npos || pos != 0) { .... }Также можно воспользоваться функцией 'boost::starts_with' или её аналогом.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V797. |
V798. The size of the dynamic array can be less than the number of elements in the initializer.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что размер динамического массива может оказаться меньше количества элементов в его инициализаторе. В этом случае при создании массива, в зависимости от того, какая версия оператора 'new' используется, будет либо выброшено исключение 'std::bad_array_new_length', либо возвращен нулевой указатель.
Рассмотрим пример:
int n = 2;
...
int* arr = new int[n] { 1, 2, 3 };Значение переменной 'n' меньше количества элементов в инициализаторе. Корректный код должен иметь вид:
int n = 3;
...
int* arr = new int[n] { 1, 2, 3 };Данная диагностика классифицируется как:
|
V799. Variable is not used after memory is allocated for it. Consider checking the use of this variable.
Анализатор обнаружил, что переменная не используется после того, как для нее была динамически выделена память. Стоит проверить код на наличие ошибки, либо удалить неиспользуемую переменную.
Рассмотрим пример:
void Func()
{
int *A = new int[X];
int *B = new int[Y];
int *C = new int[Z];
Foo(A, X);
Foo(B, Y);
Foo(B, Z); // <=
delete [] A;
delete [] B;
delete [] C;
}Здесь была допущена опечатка, и вместо массива 'C' третий вызов функции 'Foo' использует массив 'B'. Анализатор обнаруживает здесь аномалию, что выделяется и освобождается память, но при этом она никак не используется. Исправленный вариант кода выглядит следующим образом:
void Func()
{
int *A = new int[X];
int *B = new int[Y];
int *C = new int[Z];
Foo(A, X);
Foo(B, Y);
Foo(C, Z); // <=
delete [] A;
delete [] B;
delete [] C;
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V799. |
V1001. Variable is assigned but not used by the end of the function.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что перед выходом из функции в локальную переменную присваивается значение, которое потом нигде не используется.
Возможно, эта переменная должна участвовать в последующих операциях или возращена как результат функции, но из-за опечатки используется другая переменная, или программист забыл написать соответствующий код. Рассмотрим примеры.
Пример 1.
bool IsFitRect(TPict& pict)
{
TRect pictRect;
...
pictRect = pict.GetRect();
return otherRect.dx >= 16 && otherRect.dy >= 16;
}В этом примере в операторе 'return' вместо размеров 'pictRect' по ошибке используются размеры 'otherRect', в то время как переменная 'pictRect' больше нигде не участвует в вычислениях. Правильный код выглядит следующим образом:
bool IsFitRect(TPict& pict)
{
TRect pictRect;
...
pictRect = pict.GetRect();
return pictRect.dx >= 16 && pictRect.dy >= 16;
}Пример 2.
bool CreateMiniDump()
{
BOOL bStatus = FALSE;
CString errorMsg;
...
if (hDbgHelp == NULL)
{
errorMsg = _T("dbghelp.dll couldn't be loaded");
goto cleanup;
}
...
if (hFile == INVALID_HANDLE_VALUE)
{
errorMsg = _T("Couldn't create minidump file");
return FALSE;
}
...
cleanup:
if (!bStatus)
AddToReport(errorMsg);
return bStatus;
}В этом примере во всех блоках 'if' кроме одного после создания сообщения об ошибке выполняется переход в конец функции, где эта ошибка добавляется в отчёт. А при обработке одного из условий выполняется выход из функции сразу без добавления сообщения в отчёт, которое в итоге теряется. Корректный код выглядит следующим образом:
bool CreateMiniDump()
{
BOOL bStatus = FALSE;
CString errorMsg;
...
if (hDbgHelp == NULL)
{
errorMsg = _T("dbghelp.dll couldn't be loaded");
goto cleanup;
}
...
if (hFile == INVALID_HANDLE_VALUE)
{
errorMsg = _T("Couldn't create minidump file");
goto cleanup;
}
...
cleanup:
if (!bStatus)
AddToReport(errorMsg);
return bStatus;
}Иногда при работе с криптографическими функциями программисты очищают в конце переменные, записывая в них нулевое значение. Это неправильный подход, так компилятор скорее всего выбросит такой код при оптимизации, если переменная больше не используется. Например:
void ldns_sha256_update(...)
{
size_t freespace, usedspace;
...
/* Clean up: */
usedspace = freespace = 0;
}Для очистки памяти следует использовать специальные функции, которые не будут удалены компилятором во время оптимизации:
void ldns_sha256_update(...)
{
size_t freespace, usedspace;
...
/* Clean up: */
RtlSecureZeroMemory(&usedspace, sizeof(usedspace));
RtlSecureZeroMemory(&freespace, sizeof(freespace));
}Подробнее об этой ошибке можно прочитать в описании диагностики V597.
В некоторых случаях при борьбе с предупреждениями компилятора о неиспользуемых переменных, программисты присваивают им какие-то значения или присваивают значение переменной самой себе. Это не самый лучший способ, так как при отсутствии комментариев может вводить в заблуждение тех, кто будет потом сопровождать этот код:
static stbi_uc *stbi__tga_load(...)
{
// read in the TGA header stuff
int tga_palette_start = stbi__get16le(s);
int tga_palette_len = stbi__get16le(s);
int tga_palette_bits = stbi__get8(s);
...
// the things I do to get rid of an error message,
// and yet keep Microsoft's C compilers happy... [8^(
tga_palette_start = tga_palette_len = tga_palette_bits =
tga_x_origin = tga_y_origin = 0;
// OK, done
return tga_data;
}Для таких случаев есть более красивые решения, например, можно использовать функцию:
template<class T> void UNREFERENCED_VAR( const T& ) { }
static stbi_uc *stbi__tga_load(...)
{
// read in the TGA header stuff
int tga_palette_start = stbi__get16le(s);
...
UNREFERENCED_VAR(tga_palette_start);
...
// OK, done
return tga_data;
}Или использовать специальные макросы, объявленные в системных заголовочных файлах. Например, в Visual C++ таким макросом является UNREFERENCED_PARAMETER. В этом случае анализатор также не будет выдавать предупреждения.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1001. |
V1002. Class that contains pointers, constructor and destructor is copied by the automatically generated operator= or copy constructor.
Анализатор обнаружил потенциальную ошибку, связанную с вызовом конструктора копирования или оператора присваивания, которые сгенерированы автоматически.
Перечислим условия, при выполнении которых такой вызов автоматически сгенерированных компилятором функций считается опасным:
- У класса есть non-default конструктор.
- У класса есть non-default деструктор.
- Среди членов класса имеются указатели.
Высока вероятность, что указатель ссылается на буфер памяти, которая выделяется в конструкторе, а затем освобождается в деструкторе. Подобные объекты нельзя копировать с помощью таких функций как 'memcpy' или с помощью автосгенерированных функций (конструктор копирования, оператор присваивания).
Рассмотрим пример:
class SomeClass
{
int m_x, m_y;
int *m_storagePtr;
public:
SomeClass(int x, int y) : m_x(x), m_y(y)
{
m_storagePtr = new int[100];
....
}
....
~SomeClass()
{
delete[] m_storagePtr;
}
};
void Func()
{
SomeClass A(0, 0);
SomeClass B(A); // <=
....
}В данном примере при копировании объекта 'A' в объект 'B', происходит копирование указателя 'm_storagePtr' из объекта 'A' в объект 'B'. Вероятнее всего, это не является ожидаемым поведением, а программист задумывал, что при копировании объектов произойдет копирование данных, а не просто указателей. Корректный код должен выглядеть следующим образом:
class SomeClass
{
int m_x, m_y;
int *m_storagePtr;
public:
SomeClass(int x, int y) : m_x(x), m_y(y)
{
m_storagePtr = new int[100];
....
}
SomeClass(const SomeClass &other) : m_x(other.m_x), m_y(other.m_y)
{
m_storagePtr = new int[100];
memcpy(m_storagePtr, other.m_storagePtr, 100 * sizeof(int));
}
....
~SomeClass()
{
delete[] m_storagePtr;
}
};Аналогичным образом диагностика находит потенциальные ошибки, связанные с использованием оператора присваивания, определенного по умолчанию.
Конечно, анализатор может ошибиться и выдать предупреждение на вполне безопасный класс, однако лучше подстраховаться и изучить все предупреждения V1002. Если окажется, что ошибки нет, то лучше всего явно указать, что программист предполагал использование автосгенерированных функций и это безопасно. Для этого следует использовать ключевое слово 'default':
T(const T &x) = default;
SomeClass &operator=(const T &x) = default;В этом случае, человеку, который будет сопровождать код будет легче понять, что ошибки нет. А анализатор PVS-Studio не будет выдавать ложные предупреждения.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1002. |
V1003. Macro expression is dangerous or suspicious.
Анализатор обнаружил потенциально возможную ошибку в записи макроса.
Пример:
#define sqr(x) x * xЭтот макрос стоит переписать таким образом:
#define sqr(x) ((x) * (x))В изначальной реализации макроса есть две проблемы, которые могут привезти к ошибке. Во-первых, сам макрос стоит обернуть в скобки. Если этого не сделать, то это приведёт к ошибке при написании такого коде:
double d = 1.0 / sqr(M_PI); // 1.0 / M_PI * M_PI == 1.0По той же причине стоит поставить в скобки аргументы:
sqr(M_PI + 0.42); // M_PI + 0.42 * M_PI + 0.42Из-за того, что препроцессор работает на уровне лексем, не всегда получается получить корректное синтаксическое дерево из текста макроса. Рассмотрим пример:
#define FOO(A,B) A * BВ зависимости от контекста, это может быть, как умножением A на B, так и объявлением переменной B, которая будет являться указателем на A. Так как в момент объявления макроса нет никакой информации о его использовании, анализатор может выдать ложное срабатывание на корректны код. В таком случае, для подавления ложного срабатывания, вы можете воспользоваться одним из способов, описанных в документации.
Примечание. Родственной по смыслу диагностикой является V733. Диагностика V733 работает более точно и даёт меньше ложных срабатываний, так как анализирует уже раскрытый макрос, а не его объявлении. С другой стороны, возможности V733 более ограничены и диагностика не предупредит о многих ошибках.
Другой тип искомых ошибок может выглядеть следующим образом:
#if A
doA();
#else doB();
#endifВо время редактирования код был случайно удалён перенос строки и функция 'doB()' перестала вызываться. При этом код остался компилируемым.
Исправленный вариант кода:
#if A
doA();
#else
doB();
#endifВзгляните на примеры ошибок, обнаруженных с помощью диагностики V1003. |
V1004. Pointer was used unsafely after its check for nullptr.
Анализатор обнаружил потенциальное разыменование нулевого указателя. Сначала этот указатель проверялся на ноль, а потом использовался без проверки.
Пример:
if (p != nullptr)
{
*p = 42;
}
....
*p += 33;В случае, если указатель 'p' был равен нулю, в выражении '*p += 33' произойдёт разыменование нулевого указателя. Поэтому нужно добавить проверку:
if (p != nullptr)
{
*p = 42;
}
....
if (p != nullptr)
{
*p += 33;
}Либо в этом коде 'p' всегда ненулевой и тогда проверку стоит удалить:
*p = 42;
....
*p += 33;Анализатор может выдать ложное срабатывание в следующем случае:
if (p == nullptr)
{
MyExit();
}
....
*p += 42;Это происходит, потому что анализатор не может понять, возвращает ли функция 'MyExit' управление или нет. Чтобы подсказать ему эту информацию, следует проаннотировать функцию одним из следующих способов:
- Атрибут C++11: [[noreturn]] void MyExit();
- Атрибут gcc: __attribute__((noreturn)) void MyExit();
- Атрибут MSVC: __declspec((noreturn)) void MyExit();
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1004. |
V1005. The resource was acquired using 'X' function but was released using incompatible 'Y' function.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что ресурс может создаваться и освобождаться несовместимыми между собой способами.
Например, анализатор предупредит, если файл открыт с помощью функции 'fopen_s', а закрыт с помощью функции 'CloseHandle'.
Рассмотрим пример некорректного кода.
FILE* file = nullptr;
errno_t err = fopen_s(&file, "file.txt", "r");
...
CloseHandle(file);Невозможно предсказать, к каким последствиям приведёт выполнение такого кода. Возможно, функция 'CloseHandle' вернёт статус ошибки и в результате просто произойдёт утечка ресурса (файл не будет закрыт). Возможны и более серьезные последствия. При некорректном вызове некоторых функций возникает неопределённое поведение, что влечёт непредсказуемые последствия, вплоть до аварийного завершения работы приложения.
Исправленный вариант:
FILE* file = nullptr;
errno_t err = fopen_s(&file, "file.txt", "r");
...
fclose(file);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1005. |
V1006. Several shared_ptr objects are initialized by the same pointer. A double memory deallocation will occur.
Анализатор обнаружил ошибку, связанную с тем, что один и тот же указатель инициализирует сразу несколько объектов типа 'shared_ptr'. Это может привести к неопределённому поведению программы в момент, когда второй объект, имеющий тип 'shared_ptr', попытается освободить память, которая уже была освобождена благодаря первому объекту.
Рассмотрим пример некорректного кода.
void func()
{
S *rawPtr = new S(10, 20);
std::shared_ptr<S> shared1(rawPtr);
std::shared_ptr<S> shared2(rawPtr);
....
}При выходе из функции, объект 'shared1' освободит указатель 'rawPtr', после чего объект 'shared2' также попытается освободить его еще раз, что приведет к некорректной работе программы.
Корректный код:
void func()
{
std::shared_ptr<S> shared1(new S(10, 20));
std::shared_ptr<S> shared2(new S(10, 20));
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
|
V1007. Value from the uninitialized optional is used. It may be an error.
Анализатор обнаружил обращение к значению объекта класса 'optional', который ранее не был проинициализирован, т.е. не хранит никакого значения. Формально это приводит к неопределенному поведению, а также служит источником других ошибок.
Рассмотрим пример некорректного кода:
std::optional<Value> opt;
if (cond)
{
opt->max = 10;
opt->min = 20;
}
if (opt)
{
....
}В данном примере переменная 'opt' так и не была проинициализирован, что в свою очередь приводит к тому, что код под условием "if (opt)" никогда не выполняется.
Исправленный вариант:
std::optional<Value> opt;
if (cond)
{
opt = Value(10, 20);
}
if (opt)
{
....
}Также, анализатор умеет обнаруживать обращение к значению потенциально неинициализированного объекта типа optional. Например:
boost::optional<int> opt = boost::none;
opt = interpret(tr);
if (cond)
opt = {};
process(*opt);Исправленный вариант:
boost::optional<int> opt = boost::none;
opt = interpret(tr);
if (!cond)
process(*opt);Примечание. Диагностическое правило имеет специальную настройку, которая позволяет выдавать расширенное сообщение: в нём будет содержаться список функций, при помощи которых следует проверить объекта опционального типа перед получением значения. Для вывода расширенного сообщения нужно добавить комментарий следующего вида в файл с исходным кодом или в файл конфигурации диагностических правил (.pvsconfig):
//+V1007 PRINT_CHECKERSВыявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1007. |
V1008. No more than one iteration of the loop will be performed. Consider inspecting the 'for' operator.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' используются странные начальное и конечное значения счетчика. Это может приводить к нарушению логики работы программы.
Рассмотрим пример подозрительного кода:
int c = 0;
if (some_condition)
{
....
c = 1;
}
for (int i = 0; i < c; ++i) {
....
}В данном случае цикл выполнится 0 или 1 раз. Следовательно, цикл можно заменить на оператор 'if'.
int c = 0;
if (some_condition)
{
....
c = 1;
}
if (c != 0)
{
....
}Возможно, что в коде допущена ошибка при вычислении значения переменной, с которой сравнивается счётчик. Например, возможно требовалось написать такой код:
int c = 0;
if (some_condition)
{
....
c = 1 + n;
}
for (int i = 0; i < c; ++i)
{
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1008. |
V1009. Check the array initialization. Only the first element is initialized explicitly.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что при объявлении массива указано значение только для одного элемента. Таким образом, остальные элементы будут инициализированы неявно нулём или конструктором по умолчанию.
Рассмотрим пример подозрительного кода:
int arr[3] = {1};Возможно, программист ожидал, что 'arr' будет состоять из одних единиц, но это не так. Массив будет состоять из значений 1, 0, 0.
Корректный код:
int arr[3] = {1, 1, 1};Подобная путаница может произойти из-за схожести с конструкцией "arr = {0}", которая инициализирует весь массив нулями.
Если в вашем проекте активно используются подобные конструкции, вы можете отключить эту диагностику.
Также не рекомендуется пренебрегать наглядностью кода.
Например, код для кодирования значений цвета записан следующим образом:
int White[3] = { 0xff, 0xff, 0xff };
int Black[3] = { 0x00 };
int Green[3] = { 0x00, 0xff };Благодаря неявной инициализации, все цвета заданы правильно, но лучше переписать код более наглядно:
int White[3] = { 0xff, 0xff, 0xff };
int Black[3] = { 0x00, 0x00, 0x00 };
int Green[3] = { 0x00, 0xff, 0x00 };Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1009. |
V1010. Unchecked tainted data is used in expression.
Анализатор обнаружил использование данных, полученных извне, без предварительной проверки. Такой сценарий излишнего доверия может привести к различным негативным последствиям, в том числе - стать причиной уязвимостей.
На данный момент диагностическое правило V1010 выявляет ошибки по нескольким паттернам:
- Использование недостоверных данных в выражении, используемом как индекс.
- Использование недостоверных данных в качестве аргумента функции, который должен содержать проверенные данные.
- Порча указателя за счёт изменения его значения с использованием недостоверных данных.
- Деление на недостоверные данные.
Примечание. Начиная с версии 7.32, пользователь может самостоятельно разметить необходимые функции как источники и приёмники недостоверных данных. Примеры аннотаций можно увидеть здесь.
Рассмотрим все паттерны более подробно.
Пример подозрительного кода при использовании в индексе недостоверных данных.
size_t index = 0;
....
if (scanf("%zu", &index) == 1)
{
....
DoSomething(arr[index]); // <=
}Данный код может привести к доступу за границу массива 'arr' в случае, если пользователем будет введено значение отрицательное или превышающее максимально допустимый индекс массива 'arr'.
Безопасный код проверяет полученное значение:
if (index < ArraySize)
DoSomething(arr[index]);Пример подозрительного кода при использовании недостоверных данных в аргументе функции.
char buf[1024];
char username [256];
....
if (scanf("%255s", username) == 1)
{
if (snprintf(buf, sizeof(buf) - 1, commandFormat, username) > 0)
{
int exitCode = system(buf); // <=
....
}
....
}Этот код является уязвимым, т.к. пользовательский ввод передаётся командному интерпретатору без проверки полученных данных. Например, введя "&cmd", на Windows можно получить доступ к командному интерпретатору.
Правильный код должен осуществлять дополнительную проверку считанных данных:
if (IsValid(username))
{
if (snprintf(buf, sizeof(buf) - 1, commandFormat, username) > 0)
{
int exitCode = system(buf);
....
}
....
}
else
{
printf("Invalid username: %s", username);
....
}Пример подозрительного кода, связанного с порчей указателя.
size_t offset = 0;
int *pArr = arr;
....
if (scanf("%zu", &offset) == 1)
{
pArr += offset; // <=
....
DoSomething(pArr);
}В данном случае портится значение указателя 'pArr', т.к. в результате прибавления непроверенного значения 'offset' указатель может начать ссылаться за пределы массива. В результате можно испортить какие-то данные (на которые будет ссылаться 'pArr') с непредсказуемыми последствиями.
Правильный код проверяет допустимое смещение:
if (offset <= allowableOffset)
{
pArr += offset;
....
DoSomething(pArr);
}Пример подозрительного кода с делением на недостоверные данные:
if (fscanf(stdin, "%zu", &denominator) == 1)
{
targetVal /= denominator;
}Этот код может привести к делению на 0, если соответствующее значение будет введено пользователем.
Корректный код выполняет проверку допустимости значений:
if (fscanf(stdin, "%zu", &denominator) == 1)
{
if (denominator > MinDenominator && denominator < MaxDenominator)
{
targetVal /= denominator;
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1010. |
V1011. Function execution could be deferred. Consider specifying execution policy explicitly.
Анализатор обнаружил использование функции 'std::async', поведение которой может отличаться от того, которое было задумано программистом. 'std::async' принимает в качестве аргументов функцию, аргументы функции и, опционально, флаг, который влияет на политику вызова 'std::async'. Возвращаемым значением 'std::async' является 'std::future', значение которого будет выставлено по завершению функции.
Поведение 'std::async', зависит от переданных флагов следующим образом:
1) 'std::launch::async' - будет немедленно создан объект класса 'thread', с функцией и её аргументами в качестве аргументов нового потока. Т.е. 'std::async' инкапсулирует создание потока, получение 'std::future' и предоставляет однострочную запись для выполнения такого кода.
2) 'std::launch::deferred' - поведение функции поменяется, т.к. никакого асинхронного вызова не произойдёт. Вместо исполнения функции в новом потоке, она, вместе с аргументами, будет сохранена в 'std::future', чтобы быть вызванными позже. Это позже наступит тогда, когда кто-либо вызовет метод 'get' или 'wait' на 'future', которое вернул 'std::async'. При этот вызываемый объект выполнится в потоке, который вызывал 'get/wait'! Это поведение есть ни что иное, как отложенный вызов функции.
3) Флаг не выставлен (std::launch::async | std::launch::deferred ) - в этом случае будет выбрано одно из двух поведений описанных выше. Какое из двух? Неизвестно и зависит от имплементации.
Если используется функция 'std::async' без указания политики, то используется как раз третий случай. Чтобы избежать возможной неизвестности, анализатор выявляет такие случаи использования функции.
Future<int> foo = std::async(MyFunction, args...);После такого вызова функции есть вероятность, что на разных компьютерах с разными реализациями библиотек возможны отличные поведения функции.
Советуем обратить на это внимание и разрешить потенциальную неопределенность, указав первым параметром конкретную реализацию поведения функции. Надёжный вариант явного задания политики выполнения:
Future<int> foo = std::async(launch::async, MyFunction, args...)Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V1012. The expression is always false. Overflow check is incorrect.
Анализатор обнаружил неправильный способ определения переполнения, которое может возникать при сложении переменных типов 'unsigned short' или переменных типов 'unsigned char'.
Пример некорректно написанного кода:
bool IsValidAddition(unsigned short x, unsigned short y)
{
if (x + y < x)
return false;
return true;
}При сложении двух переменных типов 'unsigned short', обе переменные приводятся к типу 'int'. Результат сложения также будет иметь тип 'int'. Поэтому, независимо от того, какие значения будут в переменных 'x' и 'y', в результате их сложения переполнения никогда не возникнет. Далее выполняется операция сравнения. При этом правый операнд (переменная 'x') вновь расширяется до типа 'int'. В итоге, приведённый выше код эквивалентен этому:
bool IsValidAddition(unsigned short x, unsigned short y)
{
if ((int)(x) + (int)(y) < (int)(x))
return false;
return true;
}Получается, что выражение "x + y < x" всегда будет ложно. Вероятнее всего, компилятор оптимизирует функцию, подставив в места ее вызова значение 'true'. Итог: функция ничего на самом деле не проверяет и не защищает от переполнения.
Примечание: Если вы используете модель данных, где размер типа 'short' и типа 'int' совпадают, то такая проверка будет работать корректно и анализатор не будет выдавать предупреждение.
Чтобы получить корректно работающий код, нужно явно выполнить приведение результата сложения к типу 'unsigned short':
if ((unsigned short)(x + y) < x)
{
...
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
V1013. Suspicious subexpression in a sequence of similar comparisons.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит опечатку. В цепочке однотипных сравнений членов класса имеется выражение не похожее на остальные тем, что в нем сравниваются члены с разными именами, в то время как остальные выражения в цепочке сравнивают одноименные члены.
Рассмотрим пример:
if (a.x == b.x && a.y == b.y && a.z == b.y)В данном случае выражение 'a.z == b.y' отличается от остальных выражений в цепочке. Скорее всего, это выражение является ошибочным из-за опечатки при редактировании скопированного участка текста. Корректный код, который не вызовет подозрений у анализатора, будет выглядеть так:
if (a.x == b.x && a.y == b.y && a.z == b.z)Анализатор выдает предупреждение в тех случаях, когда длина цепочки сравнений более двух звеньев.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1013. |
V1014. Structures with members of real type are compared byte-wise.
Анализатор обнаружил подозрительный способ сравнения двух структур, которые содержат в себе члены типа float или double.
Пример:
struct Object
{
int Length;
int Width;
int Height;
float Volume;
};
bool operator == (const Object &p1, const Object &p2)
{
return memcmp(&p1, &p2, sizeof(Object)) == 0;
}Так как структура 'Object' содержит числа с плавающей точкой, то их сравнение через 'memcmp' может привести к неожиданному результату. Например, числа -0.0 и 0.0 эквивалентны, но имеют разное битовое представление. Два NaN имеют одинаковое представление, но они не эквивалентны. Возможно стоит использовать оператор == или сравнивать эти переменные с определённой точностью.
Допустим, мы хотим сравнивать члены классы с помощью оператора ==. В этом случае можно вообще удалить 'operator ==', так как компилятор сделает сам всё правильно, реализуя оператор сравнения по умолчанию. Однако, допустим мы хотим написать именно свою функцию, где будем сравнивать члены 'Volume' с определённой точностью. Тогда, исправленный вариант может выглядеть так:
bool operator == (const Object &p1, const Object &p2)
{
return p1.Length == p2.Length
&& p1.Width == p2.Width
&& p1.Height == p2.Height
&& fabs(p1.Volume - p2.Volume) <= FLT_EPSILON;
}Данная диагностика классифицируется как:
|
V1015. Suspicious simultaneous use of bitwise and logical operators.
Анализатор обнаружил подозрительное выражение, в котором смешаны логические и битовые операции. Возможно, в одной из них допущена опечатка.
Пример:
void write(int s);
void write(unsigned char a, unsigned char b,
unsigned char c, unsigned char d)
{
write((a << 24) | (b << 16) || (c << 8) | d);
}Это явная опечатка. В одном месте, вместо оператора '|' случайно воспользовались оператором '||'. Корректный код:
void write(unsigned char a, unsigned char b,
unsigned char c, unsigned char d)
{
write((a << 24) | (b << 16) | (c << 8) | d);
}Данная диагностика классифицируется как:
|
V1016. The value is out of range of enum values. This causes unspecified or undefined behavior.
Анализатор обнаружил опасное приведение числа к перечислению. Указанное число может не входить в диапазон значений 'enum'.
Примечание 1: Данное правило актуально только для языка C++. В качестве нижележащего типа 'enum' в языке C всегда используется тип 'int'.
Примечание 2: Данное правило актуально только для C++ компиляторов, рассчитывающих фактический размер 'enum' согласно стандарту. Например, такими компиляторами являются GCC и Clang. MSVC не является таким компилятором, так как рассчитывает размер 'enum' в целях обратной совместимости по правилам языка C и в качестве нижележащего типа всегда использует тип 'int', если специально не указан иной тип.
Результат приведения числа, чьё значение не входит в диапазон элементов 'enum', является неуточненным поведением до C++17 и неопределенным поведением, начиная с C++17.
Если у 'enum' указан нижележащий тип, то к типу этого 'enum' можно приводить все значения, которые можно уместить в этот тип.
Пример 1:
enum class byte : unsigned char {}; // Range: [0; 255]
byte b1 = static_cast<byte>(255); // okЧисло 256 уже не вмещается в тип 'char', и этот код некорректен:
byte b2 = static_cast<byte>(256); // UBЕсли не указан нижележащий тип, то, согласно стандарту, компилятор пытается уместить значения в зависимости от инициализатора в следующие типы:
int -> unsigned int -> long -> unsigned long ->
long long -> unsigned long longПри этом внутри выбранного типа компилятор использует минимально необходимое число бит (n), способное уместить максимальное число в перечислении. В такой 'enum' можно уместить диапазон значений [- (2^n) / 2; 2^n / 2 - 1] для 'enum' со знаковым нижележащим типом и [0; 2^n - 1] для 'enum' с беззнаковым нижележащим типом. Выход за границы этого диапазона является неуточненным поведением (до C++17) или неопределенным поведением (с C++17).
Пример 2:
enum foo { a = 0, b = UINT_MAX }; // Range: [0; UINT_MAX]
foo x = foo(-1); // UBНа первый взгляд, такой код является корректным, но на самом деле он может приводить к проблемам. Нижележащим типом 'enum' выбирается 'unsigned int'. Число '-1' не попадает в диапазон этого типа, поэтому такое присвоение может привести к неуточнённому или неопределённому поведению.
Пример 3:
enum EN { low = 2, high = 4 }; // Uses 3 bits, range: [0; 7]
EN a1 = static_cast<EN>(7); // okСогласно стандарту нижележащим типом для этого enum выберется 'int'. Внутри этого типа компилятор использует минимальное количество битовых полей, которое сможет вместить в себя все значения enum-констант.
В данном случае для вмещения всех значений (2 = 0b010 и 4 = 0b100) понадобится минимум 3 бита, поэтому переменная типа EN может вместить в себя числа от 0 (0b000) до 7 (0b111) включительно. Число 8 занимает уже четыре бита (0b1000), поэтому в тип EN оно уже не вмещается:
EN a2 = static_cast<EN>(8); // UBUndefinedBehaviorSanitizer также находит ошибку в этом примере: https://godbolt.org/z/GGYo7z.
При этом, если для EN указать нижележащий тип, например 'unsigned char', то это уже будет корректный вариант кода:
enum EN : unsigned char { low = 2, high = 4 }; // Range: [0; 255]
EN a2 = static_cast<EN>(8); // okДанная диагностика классифицируется как:
|
V1017. Variable of the 'string_view' type references a temporary object, which will be removed after evaluation of an expression.
Анализатор обнаружил инициализацию экземпляра класса 'std::string_view' временным объектом или присваивание экземпляру класса 'std::string_view' временного объекта.
Рассмотрим пример:
std::string hello = "Hello, ";
std::string_view helloWorldPtr = hello + "world\n";
std::cout << helloWorldPtr;В данном случае, во второй строке будет создан временный объект типа 'std::string', указатель на который будет скопирован при инициализации экземпляра класса 'std::string_view'. Далее, после вычисления выражения инициализации, временный объект будет уничтожен и в третьей строке произойдет использование указателя на освобожденную память.
Правильный вариант кода:
std::string hello = "Hello, ";
const std::string helloWorld = hello + "world\n";
std::string_view helloWorldPtr = helloWorld;
std::cout << helloWorldPtr;Данная диагностика классифицируется как:
V1018. Usage of a suspicious mutex wrapper. It is probably unused, uninitialized, or already locked.
Анализатор обнаружил ошибку при использовании обёртки над мьютексом (std::unique_lock и т.п.).
Рассмотрим пример:
std::unique_lock<std::mutex> lck;
lck.lock();В данном случае, во второй строке будет брошено исключение 'std::system_error', так как с обёрткой не связан мьютекс. Необходимо передать его в конструкторе:
std::unique_lock<std::mutex> lck(m, std::defer_lock);
lck.lock();или инициализировать методом 'swap()':
std::unique_lock<std::mutex> lck_global(mtx, std::defer_lock);
....
std::unique_lock<std::mutex> lck;
lck.swap(lck_global);
lck.lock();Также диагностика ищет случаи, когда критическая секция объявлена, но блокировка мьютекса по какой-то причине не выполняется:
std::unique_lock<std::mutex> lck(m, std::defer_lock);
//lck.lock();Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V1019. Compound assignment expression is used inside condition.
Анализатор обнаружил использование составного оператора присваивания внутри выражения, имеющего тип 'bool'.
Рассмотрим пример:
if (adj_number == (size_t)(roving->adj_count - 1) &&
(total_quantity += quantity_delta) < 0)
{
/* ... */
}В данном случае переменная 'total_quantity' изменяется внутри блока условия оператора 'if'. Дополнительную подозрительность этому коду придает тот факт, что изменение переменной 'total_quantity' произойдет только в том случае, если будет выполнено условие слева от оператора '&&'. Возможно, имеет место опечатка, и вместо составного оператора присваивания '+=' предполагается оператор сложения '+':
if (adj_number == (size_t)(roving->adj_count - 1) &&
(total_quantity + quantity_delta) < 0)
{
/* ... */
};Даже если первоначальный код был верен, всё равно крайне не рекомендуется писать такие сложные выражения. В логике подобного кода сложно разобраться и очень легко допустить ошибку, модифицируя подобный код.
Анализатор не может однозначно определить, содержит ли выявленный с помощью данной диагностики код настоящую ошибку, или программист перестарался, сокращая код. Мы изучили большое количество открытых проектов и выдели ряд паттернов программирования, когда используются рассмотренные конструкции кода и это не является ошибкой. С целью сокращения числа ложных срабатываний, предупреждение не выдаётся в следующих случаях:
- Левая часть составного оператора присваивания является указателем;
- Составной оператор присваивания является частью макроса;
- Составной оператор присваивания находится в теле цикла.
Если в вашем проекте срабатываний слишком много, то можно отключить эту диагностику или воспользоваться механизмом подавления ложных срабатываний.
Данная диагностика классифицируется как:
|
V1020. Function exited without performing epilogue actions. It is possible that there is an error.
Анализатор обнаружил в теле функции путь выполнения, начинающийся и заканчивающийся вызовом функций, имена которых содержат слова-антагонисты. При этом, между вызовами есть условие, которое приводит к возврату из анализируемой функции без вызова функции-эпилога.
Рассмотрим пример:
int pthread_cond_destroy(pthread_cond_t * cond)
{
EnterCriticalSection(&ptw32_cond_list_lock);
/* ... */
if (sem_wait (&(cv->semBlockLock)) != 0)
{
return errno; // <= V1020 Warning
}
/* ... */
LeaveCriticalSection(&ptw32_cond_list_lock);
return 0;
}В данном случае, в начале и конце функции присутствуют вызовы 'EnterCriticalSection' и 'LeaveCriticalSection' с соответствующими словами - антагонистами 'Enter' и 'Leave'. Между вызовами есть возврат из функции, перед которым по ошибке пропущен вызов 'LeaveCriticalSection'. Корректный код будет выглядеть следующим образом:
int pthread_cond_destroy(pthread_cond_t * cond)
{
EnterCriticalSection(&ptw32_cond_list_lock);
/* ... */
if (sem_wait (&(cv->semBlockLock)) != 0)
{
LeaveCriticalSection(&ptw32_cond_list_lock);
return errno;
}
/* ... */
LeaveCriticalSection(&ptw32_cond_list_lock);
return 0;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1020. |
V1021. The variable is assigned the same value on several loop iterations.
Анализатор обнаружил подозрительное присвоение в цикле, который может привести к бесконечному циклу.
Рассмотрим пример:
static void f(Node *n)
{
for (Node *it = n; it != nullptr; it = n->next)
....
}Это типичный код для обхода списков. В случае, когда 'n' не модифицируется,
этот цикл либо не выполнится ни разу, либо будет выполняться бесконечно.
Корректный код:
static void f(Node *n)
{
for (Node *it = n; it != nullptr; it = it->next)
....
}Данная диагностика классифицируется как:
V1022. Exception was thrown by pointer. Consider throwing it by value instead.
Анализатор обнаружил исключение, брошенное по указателю. Чаще всего принято бросать исключения по значению, а перехватывать по ссылке. Бросание указателя может привести к тому, что исключение не будет поймано, так как перехватывать его будут по ссылке. Также использование указателя вынуждает перехватывающую сторону вызвать оператор 'delete' для уничтожения созданного объекта, чтобы не возникали утечки памяти.
Пример:
throw new std::runtime_error("error");Корректный код:
throw std::runtime_error("error");Конечно, само по себе бросание исключения по указателю не является ошибкой. Такое исключение можно правильно перехватить и обработать. Однако на практике это неудобно и провоцирует ошибки. Недостатки использования указателя:
- Надо самостоятельно заботиться об уничтожении объекта, вызывая оператор 'delete'.
- Нельзя использовать 'catch(...)', так как непонятно, как уничтожить объект.
- Это нестандартный способ сообщить об ошибке, и другие части программы могут неправильно обрабатывать исключения.
- Если кончилась динамическая память, то попытка создать новый объект с помощью 'new' также может окончиться неудачей.
Таким образом, бросание исключения по указателю можно считать ошибочным паттерном и такой код следует переписать.
Дополнительные ссылки:
- Обсуждение на сайте Stack Overflow. throw new std::exception vs throw std::exception.
- Обсуждение на сайте Stack Overflow. C++: Throwing exceptions, use 'new' or not?
- Обсуждение на сайте Stack Overflow. c++ exception : throwing std::string.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1022. |
V1023. A pointer without owner is added to the container by the 'emplace_back' method. A memory leak will occur in case of an exception.
Анализатор обнаружил код добавления в контейнер умных указателей с помощью 'emplace_back(new X)'. Этот код может привести к утечке памяти.
Пример:
std::vector<std::unique_ptr<int>> pointers;
pointers.emplace_back(new int(42));В случае, если вектору понадобится реаллокация и он не сможет выделить память под новый массив, то он бросит исключение и указатель будет потерян.
Корректный код:
pointers.push_back(std::unique_ptr<int>(new int(42)));
pointers.push_back(std::make_unique<int>(42));Давайте разберёмся с этим видом ошибки более подробно.
Для добавлении элемента в конец контейнера типа 'std::vector<std::unique_ptr<X>>' нельзя просто написать 'v.push_back(new X)', так как нет неявного преобразования из 'X*' в 'std::unique_ptr<X>'.
Распространенным решением является написание 'v.emplace_back(new X)', так как он компилируется: метод 'emplace_back' конструирует элемент непосредственно из аргументов и поэтому может использовать явные конструкторы.
Тем не менее, это не безопасно. Если вектор полон, то происходит перевыделение памяти. Операция перевыделения памяти может закончиться неудачей, в результате чего будет сгенерировано исключение 'std::bad_alloc'. В этом случае указатель будет потерян, и созданный объект никогда не будет удален.
Безопасным решением является создание 'unique_ptr', который будет владеть указателем до того, как вектор попытается перевыделить память:
v.push_back(std::unique_ptr<X>(new X))Начиная с C++14 можно использовать 'std::make_unique':
v.push_back(std::make_unique<X>())Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1023. |
V1024. Potential use of invalid data. The stream is checked for EOF before reading from it but is not checked after reading.
Анализатор обнаружил возможное использование некорректных данных при их чтении.
Пример неправильного кода:
while (!in.eof()) {
in >> x;
foo(x);
}В случае, если операция чтения закончится неудачей, переменная 'x' будет содержать некорректные данные. При этом функция 'foo' всё равно будет вызвана. Необходимо либо добавить ещё одну проверку перед использованием переменной 'x', либо переписать цикл так, как показано дальше.
Корректный код:
while (in >> x) {
foo(x);
}Дополнительные ссылки:
- C++ Antipatterns. См. раздел: Testing for istream.eof() in a loop.
- Stackexchange.com. Why does ifstream.eof() not return TRUE after reading the last line of a file?
Данная диагностика классифицируется как:
|
V1025. New variable with default value is created instead of 'std::unique_lock' that locks on the mutex.
Анализатор обнаружил неправильное использование класса 'std::unique_lock', что может приводить к состоянию гонки.
Пример кода с ошибкой:
class C {
std::mutex m_mutex;
void foo() {
std::unique_lock <std::mutex>(m_mutex);
}
};В данном примере создаётся новая переменная с именем 'm_mutex', инициализированная по умолчанию. Соответственно, мьютекс захвачен не будет.
Корректный код:
void foo() {
std::unique_lock <std::mutex> var(m_mutex);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V1026. The variable is incremented in the loop. Undefined behavior will occur in case of signed integer overflow.
Анализатор обнаружил возможное переполнение знаковой переменной в цикле. Переполнение знаковых переменных приводит к неопределённому поведению.
Пример:
int checksum = 0;
for (....) {
checksum += ....;
}Перед нами абстрактный алгоритм подсчёта контрольной суммы. Алгоритм подразумевает возможность переполнения переменной 'checksum'. Однако переменная имеет знаковый тип, а, следовательно, её переполнение приводит к неопределённому поведению. Код некорректен и должен быть модифицирован.
Следует использовать беззнаковые типы, семантика переполнения которых определена.
Корректный код:
unsigned checksum = 0;
for (....) {
checksum += ...
}Некоторые программисты считают, что в переполнении знаковых переменных ничего страшного нет и они могут предсказать, как программа будет работать. Это не так. Может происходить всё что угодно.
Давайте рассмотрим, как могут проявляться ошибки этого типа на практике. Разработчик на форуме жалуется, что GCC глючит и неправильно компилирует его код в режиме оптимизации. Он приводит код следующей функции для подсчёта хеша строки:
int foo(const unsigned char *s)
{
int r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return r & 0x7fffffff;
}Претензия разработчика в том, что компилятор не генерирует код для оператора побитового И (&). Из-за этого функция возвращает отрицательные значения, хотя не должна.
Разработчик считает, что это глюк в компиляторе. Но это не так, неправ программист, который написал такой код. Функция работает неправильно из-за того, что в ней возникает неопределённое поведение.
Компилятор видит, что в переменной 'r' считается некоторая сумма. Согласно стандартам языков C и C++, переполнения знаковой переменной 'r' произойти не может. Иначе в программе содержится неопределённое поведение, которое компилятор никак не должен рассматривать и учитывать.
Итак, компилятор считает, что раз переменная 'r' после окончания цикла не переполняется, то она не сможет стать отрицательной. Следовательно, операция 'r & 0x7fffffff' для сброса знакового бита является лишней, и компилятор её удаляет. Он просто возвращает из функции значение переменной 'r'.
Диагностика V1026 как раз и предназначена для выявления подобных ошибок. Чтобы исправить код, достаточно считать хеш, используя для этого беззнаковую переменную.
Исправленный вариант кода:
int foo(const unsigned char *s)
{
unsigned r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return (int)(r & 0x7fffffff);
}Дополнительные ссылки:
- Андрей Карпов. Undefined behavior ближе, чем вы думаете.
- Will Dietz, Peng Li, John Regehr, and Vikram Adve. Understanding Integer Overflow in C/C++.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
V1027. Pointer to an object of the class is cast to unrelated class.
Анализатор обнаружил подозрительное приведение типов. Указатель на класс приводится к указателю на другой класс, при этом классы никак не связаны между собой наследованием.
Подозрительный код:
struct A {};
struct B {};
struct C : B {};
void f(A *a, B *b) {
C *c = (C*)a;
}Возможно, нужно было привести другую переменную. Исправленный код:
void f(A *a, B *b) {
C *c = (C*)b;
}Если же такое поведение является ожидаемым, то следует использовать 'reinterpret_cast':
void f(A *a, B *b) {
C *c = reinterpret_cast<C*>(a);
}В этом случае анализатор не будет выдавать предупреждение.
Примечание. В некоторых проектах, особенно выполняющих низкоуровневые операции, можно встретить очень много приведений между различными структурами, не связанных между собой наследованием, но связанных логически. Другими словами, такие приведения типов используются сознательно и необходимы. В этом случае предупреждения анализатора будут только создавать ненужный шум и будет рационально просто отключить диагностику V1027.
Данная диагностика классифицируется как:
V1028. Possible overflow. Consider casting operands, not the result.
Анализатор обнаружил подозрительное приведение типов. Результат бинарной операции над 32-битными числами приводят к 64-битному типу.
Пример кода с ошибкой:
unsigned a;
unsigned b;
....
uint64_t c = (uint64_t)(a * b);Такое преобразование избыточно. Тип 'unsigned' и так бы автоматически расширился до типа 'uint64_t' при присваивании.
Скорее всего, программист хотел защититься от переполнения, но не достиг цели. При перемножении переменных типа 'unsigned' всё равно произойдёт переполнение, и только уже бессмысленный результат умножения будет явно расширен до типа 'uint64_t'.
Следовало привести один из аргументов к этому типу, чтобы избежать переполнения. Корректный код:
uint64_t c = (uint64_t)a * b;Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1028. |
V1029. Numeric Truncation Error. Return value of function is written to N-bit variable.
Анализатор обнаружил, что длину контейнера или строки кладут в 16-битную или 8-битную переменную. Это опасно, так как даже на не очень больших данных может произойти ошибка из-за того, что размер не помещается в заданную переменную.
Некорректный код:
std::string str;
....
short len = str.length();Необходимо использовать тип 'size_t', который точно вместит в себя размер любой строки/контейнера:
size_t len = str.length();Или, если быть более точными и педантичными, то тип 'std::string::size_type':
std::string::size_type len = str.length();Или можно воспользоваться ключевым словом auto:
auto len = str.length();Рассмотренная ошибка может показаться безобидной. Программист может исходить из предположения, что строка просто не может быть длинной при любых адекватных сценариях работы программы. Но программист не учитывает, что подобные усечения данных могут сознательно использоваться как уязвимости. Т.е. злоумышленник может неким образом подать некорректные входные данные, чтобы получить очень длинные строки. Некорректная обработка очень длинных строк может открыть ему возможность как-то влиять на поведение программы. Другими словами, данная ошибка может представлять собой потенциальную уязвимость и должна быть обязательно исправлена.
Некоторые пользователи говорят, что анализатор неправ, выдавая предупреждение на следующий код:
size = static_cast<unsigned short>(array->size());Они считают, что раз есть 'static_cast', то всё хорошо и программист знает, что делает. Однако возможно, что с помощью приведения типа кто-то боролся с предупреждением компилятора. Таким образом, 'static_cast' только маскирует, а не устраняет проблему.
Если в проекте много кода, где используются подобные приведения типа, и вы доверяете этому коду, то можно просто отключить диагностику 1029. Другой вариант - это отключить предупреждения именно там, где используется 'static_cast'. Для этого вы можете написать в одном из глобальных заголовочных файлов или файле конфигурации диагностик (.pvsconfig) следующий комментарий:
//-V:static_cast:1029Примечание. Диагностика V1029 не ищет случаи, когда размер кладут в 32-битную переменную. Поиском подобных ситуаций занимаются диагностики для выявления паттернов 64-битных ошибок. См. в документации набор диагностик "Diagnosis of 64-bit errors (Viva64, C++)".
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
V1030. Variable is used after it is moved.
Анализатор обнаружил, что переменная используется после того, как она была перемещена.
std::string s1;
std::string s2;
....
s2 = std::move(s1);
return s1.size();После перемещения переменная существует в неуточнённом, но валидном для вызова деструктора состоянии. Полагаться на такое состояние объектов в своих программах опасно. Исключением является ряд классов, например, 'std::unique_ptr', поведение которых указано.
Данная диагностика классифицируется как:
|
V1031. Function is not declared. The passing of data to or from this function may be affected.
Анализатор обнаружил в файле использование функции без её предварительного объявления. В языке Си это допустимо, но такая возможность опасна, т.к. может стать причиной некорректной работы программы.
Рассмотрим простой пример.
char *CharMallocFoo(int length)
{
return (char*)malloc(length);
}Поскольку заголовочный файл <stdlib.h> не подключен, компилятор языка Си посчитает, что функция 'malloc' вернет тип 'int'. Неверная интерпретация возвращаемого значения компилятором может привести к проблемам во время выполнения программы, в том числе и к аварийному завершению.
Если программа 64-битная, то, скорее всего, будут потеряны старшие 32-бита возвращаемого адреса. Поэтому программа некоторое время будет работать корректно. Однако, когда свободная память в 4-х младших гигабайтах адресного пространства закончится или будет сильно фрагментирована, то будет выделен буфер за пределами 4-х младших гигабайт. Так как будут потеряны старшие биты указателя, то последствия будут крайне неприятны и непредсказуемы. Подробнее эта ситуация рассматривается в статье "Красивая 64-битная ошибка на языке Си".
Исправленный вариант кода:
#include <stdlib.h>
....
char *CharMallocFoo(int length)
{
return (char*)malloc(length);
}Данная диагностика классифицируется как:
|
V1032. Pointer is cast to a more strictly aligned pointer type.
Анализатор обнаружил преобразование указателя из одного типа в другой, которое приводит к неопределённому поведению. Разные типы объектов могут быть по-разному выравнены, и после приведения типа указателя выравнивание может быть изменено на некорректное. Если неправильный указатель будет разыменован, то программа может аварийно завершиться. Также операции с таким указателем могут приводить к потере информации.
Рассмотрим пример.
void foo(void) {
char ch = '1';
int *int_ptr = (int *)&ch;
char *char_ptr = (char *)int_ptr;
}При взятии адреса у переменой 'ch' и записи его в указатель типа 'int' возможна потеря данных. При обратном преобразовании выравнивание может быть изменено.
Обезопасить себя можно, например, используя одинаковые типы для операций:
void func(void) {
char ch = '1';
int i = ch;
int *int_ptr = &i;
}или вручную задав выравнивание:
#include <stdalign.h>
void func(void) {
alignas(int) char ch = '1';
int *int_ptr = (int *)&ch;
char * char_ptr = (char *)int_ptr;
}Рассмотрим другой случай, который можно встретить в коде приложений. На стеке выделен буфер байт, и его хотят использовать для хранения структуры. Такое бывает при работе с такими структурами, как BITMAPINFO. Вот как устроена эта структура:
typedef struct tagBITMAPINFOHEADER {
DWORD biSize;
LONG biWidth;
LONG biHeight;
WORD biPlanes;
WORD biBitCount;
DWORD biCompression;
DWORD biSizeImage;
LONG biXPelsPerMeter;
LONG biYPelsPerMeter;
DWORD biClrUsed;
DWORD biClrImportant;
} BITMAPINFOHEADER, *PBITMAPINFOHEADER;
....
typedef struct tagBITMAPINFO {
BITMAPINFOHEADER bmiHeader;
RGBQUAD bmiColors[1];
} BITMAPINFO, *LPBITMAPINFO, *PBITMAPINFO;Как видите, структура содержит переменные типа DWORD, LONG и т.д., которые должны быть правильно выравнены. Также, 'bmiColors' на самом деле это массив вовсе не из одного элемента. Элементов будет столько, сколько нужно, именно поэтому для создания этой структуры может использоваться массив байт. В результате, в приложениях можно встретить вот такой опасный код:
void foo()
{
BYTE buffer[sizeof(BITMAPINFOHEADER) + 3 * sizeof(RGBQUAD)] = {0};
BITMAPINFO *pBMI = (BITMAPINFO*)buffer;
....
}Скорее всего, буфер на стеке будет выравнен по границе 8 байт, и этот код будет работать. Однако этот код очень ненадёжен! Достаточно добавить в начало функции одну переменную, и можно всё сломать.
Неправильный код:
void foo()
{
char x;
BYTE buffer[sizeof(BITMAPINFOHEADER) + 3 * sizeof(RGBQUAD)] = {0};
BITMAPINFO *pBMI = (BITMAPINFO*)buffer;
....
}Теперь велик шанс, что 'buffer' будет начинаться с невыравненного адреса. Размер переменной 'x' и размер элементов массива 'buffer' равны. Следовательно, буфер можно расположить в стеке сразу после переменной 'x' без какого-либо отступа (выравнивания).
Конечно, всё зависит от компилятора. И программисту может вновь повезти, и код будет работать хорошо. Однако надеемся, что нам удалось объяснить, почему лучше так не делать.
Решить проблему можно, создавая массив в динамической памяти. Выделенный блок памяти всегда будет выравнен под любой тип.
Корректный код:
void foo()
{
char x;
BITMAPINFO *pBMI = (BITMAPINFO *)
calloc(sizeof(BITMAPINFOHEADER) + 3 * sizeof(RGBQUAD),
sizeof(BYTE));
....
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1032. |
V1033. Variable is declared as auto in C. Its default type is int.
Анализатор обнаружил переменную, объявленную с помощью ключевого слова 'auto' в языке Си. Ключевое слово 'auto' может запутать человека, привыкшего работать с C++11 и более старшими версиями языка C++. Вместо выведения типа компилятор будет интерпретировать ключевое слово 'auto' как тип 'int'.
Это может привести к неожиданным результатам для программиста, например, в арифметических операциях. Рассмотрим простой пример:
float d = 3.14f;
int i = 1;
auto sum = d + i;Значение переменной 'sum' будет равно '4', а не '4.14', как мог ожидать разработчик. В программах на языке Си необходимо явно объявить тип переменной:
float d = 3.14f;
int i = 1;
float sum = d + i;Первый пример полностью корректен для языка Си++. Эта диагностика поможет не ошибиться в проекте, который разрабатывается с использованием двух языков.
V1034. Do not use real-type variables as loop counters.
Анализатор обнаружил переменную вещественного типа в качестве счётчика цикла 'for'. Поскольку числа с плавающей точкой не могут точно отобразить все действительные числа, использование таких переменных в цикле может дать непостоянное количество итераций.
Рассмотрим пример:
void foo(void) {
for (float A = 0.1f; A <= 10.0f; A += 0.1f) {
....
}
}Количество итераций в этом цикле может быть 99 или 100. Точность операций с вещественными числами может зависеть от компилятора, режима оптимизации и многого другого.
Лучше переписать цикл следующим образом:
void foo(void) {
for (int count = 1; count <= 100; ++count) {
float A = count / 10.0f;
}
}Этот цикл выполнит ровно 100 итераций, а переменную 'A' можно использовать для необходимых вычислений.
Данная диагностика классифицируется как:
|
V1035. Only values returned from fgetpos() can be used as arguments to fsetpos().
Согласно стандарту языка Си, вызов функции 'fsetpos' с аргументом, полученным не из функции 'fgetpos', приводит к неопределённому поведению (UB, Undefined behavior).
Рассмотрим пример:
int foo()
{
FILE * pFile;
fpos_t position;
pFile = fopen("file.txt", "w");
memset(&position, 0, sizeof(position));
fputs("That is a sample", pFile);
fsetpos(pFile, &position);
fputs("This", pFile);
fclose(pFile);
return 0;
}Значение переменной 'position' не было получено функцией 'fgetpos', что может привести к сбою программы.
Исправленный вариант:
int foo()
{
FILE * pFile;
fpos_t position;
pFile = fopen("file.txt", "w");
fgetpos(pFile, &position);
fputs("That is a sample", pFile);
fsetpos(pFile, &position);
fputs("This", pFile);
fclose(pFile);
return 0;
}Данная диагностика классифицируется как:
|
V1036. Potentially unsafe double-checked locking.
Анализатор обнаружил потенциальную ошибку, связанную с небезопасным использованием паттерна "блокировки с двойной проверкой" (double checked locking). Блокировка с двойной проверкой - это паттерн, предназначенный для уменьшения накладных расходов получения блокировки. Сначала проверяется условие блокировки без синхронизации. И только если условие выполняется, поток попытается получить блокировку. Таким образом, блокировка будет выполнена только если она действительно была необходима.
Рассмотрим пример с ошибкой:
static std::mutex mtx;
class TestClass
{
public:
void Initialize()
{
if (!initialized)
{
std::lock_guard lock(mtx);
if (!initialized) // <=
{
resource = new SomeType();
initialized = true;
}
}
}
/* .... */
private:
bool initialized = false;
SomeType *resource = nullptr;
};
}В этом примере, оптимизация компилятором порядка назначений переменных 'resource' и 'initialized' может привести к ошибке. Т.е. в начале переменной 'initialized' будет присвоено значение 'true', а уже потом будет выделена память под объект типа 'SomeType' и проинициализирована переменная 'resource'.
Такая перестановка может привести к ошибке при доступе к объекту из параллельного потока. Получается, что переменная 'resource' будет еще не проинициализирована, а флаг 'intialized' уже будет выставлен в 'true'.
Одна из опасностей таких ошибок состоит в том, что часто кажется, будто программа работает корректно. Это происходит из-за того, что рассмотренная ситуация будет возникать не очень часто, в зависимости от архитектуры используемого процессора.
Дополнительные ссылки:
- Scott Meyers and Andrei Alexandrescu. C++ and the Perils of Double-Checked Locking.
- Stack Overflow. What the correct way when use Double-Checked Locking with memory barrier in c++?
- Double-Checked Locking is Fixed In C++11.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1036. |
V1037. Two or more case-branches perform the same actions.
Анализатор обнаружил ситуацию, когда в операторе switch разные метки case содержат одинаковые фрагменты кода. Часто это свидетельствует об избыточном коде, который можно улучшить объединением меток. Но нередко одинаковые фрагменты кода могут быть причиной copy-paste программирования и являться настоящими ошибками.
Рассмотрим пример с избыточным кодом:
switch (wParam)
{
case WM_MOUSEMOVE:
::PostMessage(hWndServer, wParam, 0, 0);
break;
case WM_NCMOUSEMOVE:
::PostMessage(hWndServer, wParam, 0, 0);
break;
....
default:
break
}Действия для нескольких событий мыши действительно могут быть одинаковыми, поэтому код можно написать более компактно:
switch (wParam)
{
case WM_MOUSEMOVE:
case WM_NCMOUSEMOVE:
::PostMessage(hWndServer, wParam, 0, 0);
break;
....
default:
break
}Рассмотрим пример из реального приложения, где разработчик допустил ошибку из-за опечатки:
GLOBAL(void)
jpeg_default_colorspace (j_compress_ptr cinfo)
{
switch (cinfo->in_color_space) {
case JCS_GRAYSCALE:
jpeg_set_colorspace(cinfo, JCS_GRAYSCALE);
break;
case JCS_RGB:
jpeg_set_colorspace(cinfo, JCS_YCbCr);
break;
case JCS_YCbCr:
jpeg_set_colorspace(cinfo, JCS_YCbCr);
break;
....
}
....
}В коде метки JCS_RGB допущена опечатка. Следовало передавать в функцию значение JCS_RGB, а не JCS_YCbCr.
Исправленный код:
GLOBAL(void)
jpeg_default_colorspace (j_compress_ptr cinfo)
{
switch (cinfo->in_color_space) {
case JCS_GRAYSCALE:
jpeg_set_colorspace(cinfo, JCS_GRAYSCALE);
break;
case JCS_RGB:
jpeg_set_colorspace(cinfo, JCS_RGB);
break;
case JCS_YCbCr:
jpeg_set_colorspace(cinfo, JCS_YCbCr);
break;
....
}
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1037. |
V1038. It is suspicious that a char or string literal is added to a pointer.
Анализатор обнаружил ситуацию, когда к символьному литералу прибавляется указатель. Скорее всего, это ошибка.
Например, к строке, имеющей тип 'const char*', программист хочет дописать символ:
const char* Foo()
{
return "Hello world!\n";
}
int main()
{
const char* bar = 'g' + Foo();
printf("%s", bar);
return 0;
}В этом случае произойдет прибавление к указателю числового значения символа 'g', в результате чего возможен выход за границы строки. Для исправления этой ошибки следует использовать, по возможности, специальный класс 'std::string' или производить операции с памятью:
const char* Foo()
{
return "Hello world!\n";
}
int main()
{
std::string bar = 'g' + std::string(Foo());
printf("%s", bar.c_str());
return 0;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
V1039. Character escape is used in multicharacter literal. This causes implementation-defined behavior.
Анализатор обнаружил код, в котором multicharacter-литерал содержит одновременно символы и escape-коды.
Multicharacter-литерал является implementation-defined, поэтому различные компиляторы могут кодировать эти литералы по-разному. К примеру, GCC и Clang задают значение основываясь на порядке символов в литерале, тогда как MSVC перемещает их в зависимости от типа символа (обычный или escape).
Рассмотрим пример. Код ниже, скомпилированный различными компиляторами, будет вести себя по-разному:
#include <stdio.h>
void foo(int c)
{
if (c == 'T\x65s\x74') // <= V1039
{
printf("Compiled with GCC or Clang.\n");
}
else
{
printf("It's another compiler (for example, MSVC).\n");
}
}
int main(int argc, char** argv)
{
foo('Test');
return 0;
}Программа, скомпилированная разными компиляторами, может напечатать разные сообщения на экран.
Для проекта, использующего определенный компилятор, это не будет заметно, однако при портировании могут возникнуть проблемы, поэтому следует заменить такие литералы простыми числовыми константами, к примеру, 'Test' поменять на '0x54657374'.
Чтобы продемонстрировать разницу между компиляторами, можно взять последовательности из 3-х и 4-х символов, например, 'GHIJ' и 'GHI', и вывести на экран их представление в памяти после компиляции.
Вывод утилиты, скомпилированной Visual C++:
Hex codes are: G(47) H(48) I(49) J(4A)
'GHIJ' : JIHG
'\x47\x48\x49\x4A' : GHIJ
'G\x48\x49\x4A' : HGIJ
'GH\x49\x4A' : JIHG
'G\x48I\x4A' : JIHG
'GHI\x4A' : JIHG
'GHI' : IHG
'\x47\x48\x49' : GHI
'GH\x49' : IHG
'\x47H\x49' : HGI
'\x47HI' : IHGВывод утилиты, скомпилированной GCC или Clang:
Hex codes are: G(47) H(48) I(49) J(4A)
'GHIJ' : JIHG
'\x47\x48\x49\x4A' : JIHG
'G\x48\x49\x4A' : JIHG
'GH\x49\x4A' : JIHG
'G\x48I\x4A' : JIHG
'GHI\x4A' : JIHG
'GHI' : IHG
'\x47\x48\x49' : IHG
'GH\x49' : IHG
'\x47H\x49' : IHG
'\x47HI' : IHGV1040. Possible typo in the spelling of a pre-defined macro name.
Анализатор обнаружил возможную опечатку в записи предопределенного макроса.
Пример:
#if defined (__linux__) || defined (__APPLE_)Это выражение без ошибки выглядит следующим образом:
#if defined (__linux__) || defined (__APPLE__)Ещё один пример возможной опечатки:
#ifdef __WLN32__Исправленный вариант:
#ifdef __WIN32__Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1040. |
V1041. Class member is initialized with dangling reference.
Диагностика выявляет случаи инициализации членов класса "плохим" указателем или ссылкой.
Пример:
class Foo {
int *x;
int &y;
Foo(int a, int b);
};
Foo::Foo(int a, int b) :
x(&a), // <=
y(b) // <=
{};Переменная 'x' является указателем, при инициализации ей присваивается адрес переменной 'a'. Переменная 'a' - аргумент и является локальной для конструктора, поэтому область ее видимости короче, чем у 'x'. После выхода из конструктора 'x' будет иметь неверный указатель.
То же самое верно и для ссылки 'y'.
Правильный вариант будет выглядеть таким образом:
class Foo {
int *x;
int &y;
Foo(int *a, int &b) :
x(a),
y(b)
{}
};
Foo::Foo(int *a, int &b) :
x(a),
y(b),
{}
};Теперь конструктору передаются адрес и ссылка напрямую, их область видимости все так же ограничена областью видимости конструктора, но область видимости их значений - нет.
Данная диагностика классифицируется как:
|
V1042. This file is marked with copyleft license, which requires you to open the derived source code.
Анализатор обнаружил в файле copyleft лицензию, которая обязывает открыть остальной исходный код. Это может быть неприемлемо для многих коммерческих проектов.
Если вы разрабатываете открытый проект, то можно просто игнорировать это предупреждение и отключить его.
Пример комментария, на который анализатор выдаст предупреждение:
/* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program. If not, see <https://www.gnu.org/licenses/>.
*/Для закрытых проектов
Если в закрытый проект добавить файл с такой лицензией (GPL3 в данном случае), то остальной исходный код необходимо будет открыть, из-за особенностей данной лицензии.
Такой тип copyleft лицензий называют "вирусными" лицензиями, из-за их свойства распространяться на остальные файлы проекта. Проблема в том, что использование хотя бы одного файла с подобной лицензией в закрытом проекте автоматически делает весь исходный код открытым и обязывает распространять его вместе с бинарными файлами.
Диагностика занимается поиском следующих "вирусных" лицензий:
- AGPL-3.0
- GPL-2.0
- GPL-3.0
- LGPL-3.0
Есть следующие варианты, как вы можете поступить, обнаружив в закрытым проекте использование файлов с copyleft лицензий:
- Отказаться от использования данного кода (библиотеки) в своём проекте;
- Заменить используемую библиотеку;
- Сделать свой проект открытым.
Для открытых проектов
Мы понимаем, что данная диагностика неуместна для открытых проектов. Команда PVS-Studio способствует развитию открытых проектов, помогая исправлять в них ошибки и предоставляя бесплатные варианты лицензий. Однако наш продукт является B2B решением, и поэтому данная диагностика по умолчанию включена.
Если же ваш код распространяется под одной из указанных выше copyleft лицензий, то вы можете отключить данную диагностику следующими способами:
- Если вы используете плагин PVS-Studio для Visual Studio, то перейдя в Options > PVS-Studio > Detectable Errors > 1.General Analysis > V1042 можно отключить отображение данной диагностики в окне вывода анализатора. Минус данного способа в том, что ошибка всё равно будет записана в лог анализатора при его сохранении (или если анализ запускался из командной строки). Поэтому, при открытии такого лога на другой машине или конвертации результатов анализа в другой формат, отключенные таким образом сообщения могут появиться снова.
- Если вы не используете плагин, хотите блокировать правило для всей команды или убрать сообщения его из отчёта анализатора, то можно добавить комментарий "//-V::1042" в файл конфигурации (.pvsconfig) или в один из глобальных заголовочных файлов. Для разработчиков, использующих Visual C++, хорошим вариантом будет добавить этот комментарий в файл "stdafx.h". Этот комментарий указывает анализатору отключить диагностику V1042. Подробнее об отключении диагностик с помощью комментариев рассказано в документации.
- Если для конвертации отчётов используется утилита Plog Converter, то можно отключить диагностику, используя ключ "-d".
Пополнение списка опасных лицензий
Если вам известны ещё типы "вирусных" лицензий, которые в данный момент не выявляет инструмент, то вы можете сообщить нам о них через форму обратной связи. И мы добавим их выявление в следующем релизе.
Дополнительные ссылки
- GNU General Public License
- "Вирусные" лицензии
- Бесплатные варианты лицензирования PVS-Studio
- Подавление ложных предупреждений
Данная диагностика классифицируется как:
V1043. A global object variable is declared in the header. Multiple copies of it will be created in all translation units that include this header file.
Анализатор обнаружил в объявление константного экземпляра класса в заголовочном файле. При включении такого файла через 'include' произойдет создание множественных копий объекта. Если в классе есть конструктор, его код выполнится при каждом включении заголовочного файла, что может привести к нежелательным побочным эффектам.
Пример:
//some_header.h
class MyClass
{
int field1;
int field2;
MyClass (int a, int b)
{
// ....
}
};
// ....
const MyClass object{1, 2}; // <=Диагностика не распространяется на классы и структуры, у которых не определены конструкторы. Следующий код не приведет к срабатыванию:
//some_header.h
struct MyStruct
{
int field1;
int field2;
};
// ....
const MyStruct object{1, 2};Также, чтобы избежать ошибки, можно объявить переменную как 'inline' (начиная с C++17) или 'extern'. В этом случае инициализация и вызов конструктора произойдет один раз.
Корректный пример:
//some_header.h
class MyClass
{
// ....
};
// ....
inline const MyClass object{1, 2};Примечание: использование ключевого слова 'constexpr' вместо 'const' при объявлении переменной не изменяет данное поведение. Согласно стандарту С++17, только constexpr-функции и constexpr-статические поля классов/структур объявляются со спецификатором inline неявно.
Более подробно данная проблема рассмотрена в статье "What Every C++ Developer Should Know to (Correctly) Define Global Constants".
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1043. |
V1044. Loop break conditions do not depend on the number of iterations.
Анализатор обнаружил цикл, условия выхода которого не зависят от количества итераций. Такой цикл может выполнится 0, 1, либо бесконечное количество раз.
Пример такого цикла:
void sq_settop(HSQUIRRELVM v, SQInteger newtop)
{
SQInteger top = sq_gettop(v);
if(top > newtop)
sq_pop(v, top - newtop);
else
while(top < newtop) sq_pushnull(v); // <=
}Ошибка здесь в цикле while - переменные, которые находятся в условии, никак не меняют своих значений, поэтому цикл никогда не завершится, либо никогда не запустится (если их значения равны).
Цикл может выполнятся всегда только один раз, если его первая итерация меняет условие:
while (buf != nullptr && buf != ntObj)
{
ntObj = buf;
}Если такое поведение является корректным, то цикл лучше заменить на if:
if (buf != nullptr && buf != ntObj)
{
ntObj = buf;
}Еще один пример:
#define PEEK_WORD(ptr) *((uint16*)(ptr))
....
for(;;)
{
// Verify the packet size
if (dwPacketSize >= 2)
{
dwMsgLen = PEEK_WORD(pbytePacket);
if ((dwMsgLen + 2) == dwPacketSize)
break;
}
throw CString(_T("invalid message packet"));
}Любой путь этого цикла ведет к выходу из него, а переменные, используемые в цикле, не меняются. Такой цикл, скорее всего, содержит ошибку, либо его просто стоит убрать.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1044. |
V1045. The DllMain function throws an exception. Consider wrapping the throw operator in a try..catch block.
Анализатор обнаружил код, выбрасывающий и не перехватывающий исключение в теле функции DllMain.
При загрузке динамической библиотеки в процесс эта функция принимает значение DLL_PROCESS_ATTACH в качестве аргумента 'fwdReason'. Если DllMain завершается с ошибкой, она обязана вернуть значение FALSE. В этом случае загрузчик вызывает эту функцию снова со значением DLL_PROCESS_DETACH в 'fwdReason', что приводит к выгрузке DLL. Если функция DllMain завершается в результате исключения, выгрузка библиотеки не происходит.
Пример:
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
....
throw 42;
....
}Ошибку следует обработать в блоке try...catch и корректно вернуть FALSE.
Корректный пример:
BOOL __stdcall DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
try
{
....
throw 42;
....
}
catch(...)
{
return FALSE;
}
}Также исключения могут возникать при вызове оператора 'new'. При невозможности выделения памяти будет сгенерировано исключение 'bad_alloc'. Пример:
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
....
int *localPointer = new int[MAX_SIZE];
....
}Появление исключения возможно при использовании dynamic_cast<Type> при работе со ссылками. При невозможности приведения типов будет сгенерировано исключение 'bad_cast'. Пример:
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
....
UserType &type = dynamic_cast<UserType&>(baseType);
....
}Для исправления данных ошибок следует переписать код таким образом, чтобы 'new' или 'dynamic_cast' были помещены в блок try...catch.
Анализатор также обнаруживает в DllMain вызовы функций, которые потенциально могут выбросить исключение. Пример:
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
....
potentiallyThrows();
....
}Если анализатор не нашел в коде вызываемой функции операций, способных выбросить исключение, предупреждение на ее вызов выдано не будет.
Аналогично предыдущим примерам, вызовы функций, потенциально бросающих исключения, следует обернуть в блок try...catch.
Данная диагностика классифицируется как:
V1046. Unsafe usage of the 'bool' and integer types together in the operation '&='.
Анализатор обнаружил небезопасное использование типа 'bool' и целочисленного типа вместе в операции побитового И. Проблема в том, что побитовое И вернет 'false' для четных чисел, так как младший разряд всегда равен нулю. Если же привести вручную численный тип к 'bool', то всё будет в порядке.
Рассмотрим синтетический пример:
int foo(bool a)
{
return a ? 0 : 2;
}
....
bool var = ....;
var &= foo(false);Независимо от начального значения переменной 'var', после выполнения операции '&=' эта переменная будет иметь значение 'false'. Допустим, функция 'foo' вернёт значение 2. Тогда операция 'var & 2' всегда даёт в результате 0, так как возможные значения 'var' это только 0 или 1.
Этот код следует исправить так:
var &= foo(false) != 0;или же можно изменить и возвращаемое функцией значение:
int foo(bool a)
{
return a ? 0 : 1;
}Если, например, функция будет возвращать только значения из диапазона [0;1], то всё в порядке, так как мы можем привести их без потерь к bool.
Пример ошибки, найденной с помощью этой диагностики в реальном проекте:
template<class FuncIterator>
bool SetFunctionList( FuncIterator begin, FuncIterator end) {
bool ret = true;
for (FuncIterator itr = begin; itr != end; ++itr) {
const ROOT::Math::IMultiGenFunction *f = *itr;
ret &= AddFunction(*f);
}
return ret;
}
int AddFunction(const ROOT::Math::IMultiGenFunction & func) {
ROOT::Math::IMultiGenFunction *f = func.Clone();
if (!f) return 0;
fFunctions.push_back(f);
return fFunctions.size();
}Предполагалось, что функция 'SetFunctionList' проверяет валидность переданных ей итераторов и возвращает 'false', если хоть один из них невалидный, иначе 'true'. Но программист допустил ошибку при работе с оператором '&='. Правый аргумент – функция, которая возвращает целое число в диапазоне от 0 до SIZE_MAX. При возвращении чётных чисел из функции 'AddFunction', переменная 'ret' будет обнуляться, хотя должна это делать только для невалидных итераторов.
Исправленная функция 'SetFunctionList', где результат функции 'AddFunction' предварительно приводится к типу 'bool':
template<class FuncIterator>
bool SetFunctionList( FuncIterator begin, FuncIterator end) {
bool ret = true;
for (FuncIterator itr = begin; itr != end; ++itr) {
const ROOT::Math::IMultiGenFunction *f = *itr;
ret &= (bool)AddFunction(*f);
}
return ret;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1046. |
V1047. Lifetime of the lambda is greater than lifetime of the local variable captured by reference.
Анализатор обнаружил подозрительный захват переменной в лямбда функции.
Рассмотрим варианты срабатывания диагностики:
Пример 1:
function lambda;
{
auto obj = dummy<int>{ 42 };
lambda = [&obj]() { .... };
}Переменную, которая будет уничтожена при выходе из блока, захватывают по ссылке. Время жизни лямбда функции при этом превышает время жизни объекта. Это приведет к использованию ссылки на уничтоженный объект при вызове лямбда функции.
Вероятно, объект нужно захватить по значению:
function lambda;
{
auto obj = dummy<int>{ 42 };
lambda = [obj]() { .... };
}Пример 2:
function lambda;
{
auto obj1 = dummy<int>{ 42 };
auto obj2 = dummy<int>{ 42 };
lambda = [&]() { .... };
}В этом случае диагностика определит, что обе переменные захвачены по ссылке и выдаст предупреждение на каждую из них.
Также возможно, что функция возвращает лямбду, захватившую локальную переменную по ссылке.
Пример 3:
auto obj = dummy<int>{ 42 };
return [&obj]() { .... };В этом случае вызывающий код получит из функции лямбду, вызов которой приведет к использованию невалидной ссылки.
Данная диагностика классифицируется как:
|
V1048. Variable 'foo' was assigned the same value.
Анализатор обнаружил присваивание переменной значения, которое уже содержится в ней. Скорее всего, это логическая ошибка.
Рассмотрим пример:
int i = foo();
if (i == 0)
{
i = 0; // <=
}Отмеченное присваивание не изменяет значение переменной, и код, скорее всего, содержит ошибку.
Анализатор также может находить случаи, когда точные значения переменных неизвестны:
void foo(int x, int y)
{
if (x == y)
{
x = y; // <=
}
}Хотя переменные 'x' и 'y' могут принимать любые значения, присваивание всё равно не имеет смысла из-за имеющейся выше проверки на равенство.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1048. |
V1049. The 'foo' include guard is already defined in the 'bar1.h' header. The 'bar2.h' header will be excluded from compilation.
Анализатор обнаружил объявление одного и того же include guard в разных заголовочных файлах, включенных в одну единицу трансляции. Это приводит к тому, что произойдёт "вставка" тела только одного файла, включенного первым.
Это диагностическое правило применяется к проектам на языке C.
Рассмотрим пример заголовочного файла header1.h:
// header1.h
#ifndef _HEADER_H_
#define _HEADER_H_
....
#endifи header2.h:
// header2.h
#ifndef _HEADER_H_
#define _HEADER_H_ // <=
....
#endifПри создании второго заголовочного файла, программист скопировал код из первого файла и забыл переименовать макрос '_HEADER_H_'.
Таким образом, при компиляции следующего фрагмента, код из header2.h не будет включён в итоговый файл:
....
#include "header1.h"
#include "header2.h"
...На первый взгляд кажется, что проблемы нет, так как должны возникать ошибки компиляции. Но на самом деле файл может успешно компилироваться.
Язык C позволяет вызывать необъявленные функции. В таких случаях предполагается, что функция возвращает значение типа 'int', и аргументы тоже имеют тип 'int'. Если заголовочный файл с объявлениями функций был исключен из компиляции, сборка проекта может пройти успешно, но во время выполнения программа будет работать некорректно. Подобная ситуация, например, описана в статье "Красивая 64-битная ошибка на языке Си".
Чтобы исправить ошибку, необходимо использовать уникальные имена include guard в заголовочных файлах.
См. также родственную диагностику: V1031. Function is not declared. The passing of data to or from this function may be affected.
V1050. Uninitialized class member is used when initializing the base class.
Анализатор обнаружил, что вызов базового конструктора в списке инициализации выполняется с использованием неинициализированных полей дочернего класса.
Рассмотрим пример:
struct C : public Base
{
C(int i) : m_i(i), Base(m_i) {};
....
int m_i;
};Согласно стандарту, сперва инициализируются базовые классы в порядке, указанном в объявлении. На момент вызова конструктора 'Base' переменная 'm_i' ещё не инициализирована, поэтому исправить код можно, например, так:
struct C : public Base
{
C(int i) : m_i(i), Base(i) {};
....
int m_i;
};Также анализатор может обнаружить использование неинициализированных переменных, находящихся не только внутри класса, но и внутри базовых классов:
struct Base1
{
Base1(int i) : m_base1(i) { };
virtual ~Base1() = default;
....
int m_base1;
};
struct Base2
{
Base2(int i) : m_base2(i) { };
virtual ~Base2() = default;
....
int m_base2;
};
struct C : public Base1, public Base2
{
C(int i) : m_i(i), Base1(m_base2), Base2(i) {};
....
int m_i;
};Если нужно инициализировать один из базовых классов полем другого, то нужно убедиться в том, что они инициализируются в нужном порядке:
struct C : public Base2, public Base1
{
C(int i) : m_i(i), Base1(m_base2), Base2(i) {};
....
int m_i;
};Похожие проблемы способна искать диагностика V670. Однако она занимается поиском проблем, связанных с порядком инициализации полей одного класса, когда порядок инициализации переменных зависит от порядка их объявления в классе.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
|
V1051. It is possible that an assigned variable should be checked in the next condition. Consider checking for typos.
Анализатор обнаружил ситуацию, когда проверка переменной может быть пропущена в следующем 'if' после присваивания или инициализации.
К примеру, ошибочным можно считать такой код:
int ret = syscall(....);
if (ret != -1) { .... }
....
int ret2 = syscall(....);
if (ret != -1) { .... } // <=Часто бывают случаи, когда надо проверить возвращаемое значение какой-либо функции. Однако можно допустить ошибку, указав другую переменную внутри условия 'if'. Чаще всего подобная ошибка возникает, когда фрагмент кода копируется, но в нём забывают заменить имя переменной в условии. В рассмотренном примере в условии забыли заменить имя 'ret' на 'ret2'.
Исправленный вариант:
int ret2 = syscall(....);
if (ret2 != -1) { .... }Или же можно допустить ошибку в таком случае:
obj->field = ....;
if (field) ....;Переменная и член класса имеют одинаковые имена, из-за чего их легко перепутать.
Диагностика является эвристической. Во время своей работы диагностика разбивает имена переменных на составные части, сравнивает их и на основании этого делает предположения о наличии опечатки. Также производится базовая проверка типов. Это сделано для того, чтобы сократить число ложных срабатываний.
Часто диагностика может выдавать срабатывание на подобные случаи:
var->m_abc = ....;
var->m_cba = ....;
if (var->m_abc) // <=
{
....
}Как правило это корректный код и ошибки нет. Можно либо подавить диагностику, либо поменять переменные местами, чтобы присваивание проверяемой переменной находилось перед 'if':
var->m_cba = ....;
var->m_abc = ....;
if (var->m_abc)
{
....
}Такая запись может сделать код более читаемым, т.к. присваивание и проверка находятся рядом.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1051. |
V1052. Declaring virtual methods in a class marked as 'final' is pointless.
Анализатор обнаружил присутствие виртуального метода в классе, помеченном как 'final'.
После рефакторинга или вследствие ошибочного проектирования класса могло получиться так, что класс был объявлен как завершенный ('final'), но при этом в него были добавлены непереопределенные виртуальные методы.
Такая структура класса не имеет смысла, и стоит проверить, не была ли нарушена логика наследования самого класса. Кроме этого, создание такого класса может приводить к хранению лишнего указателя на виртуальную таблицу методов и падению производительности.
Анализатор выдаст предупреждение для следующего класса:
struct Cl final // <= V1052
{
virtual ~Cl() {}
};
struct BaseClass
{
virtual void foo(int);
};
struct DerivedClass final : BaseClass // <= V1052
{
virtual void bar(float);
};Если виртуальный метод / деструктор завершенного класса переопределяет виртуальный метод / деструктор базового класса, предупреждение выдано не будет:
struct BaseClass
{
virtual void foo();
virtual ~BaseClass();
};
struct DerivedClass final : BaseClass // ok
{
virtual void foo() override;
virtual ~DerivedClass();
};V1053. Calling the 'foo' virtual function in the constructor/destructor may lead to unexpected result at runtime.
Анализатор обнаружил вызов виртуальной функции в конструкторе или деструкторе класса.
Рассмотрим пример:
struct Base
{
Base()
{
foo();
}
virtual ~Base() = default;
virtual void foo() const;
};Сам по себе вызов виртуального метода 'foo' в конструкторе класса 'Base' может не являться ошибкой, однако проблемы могут проявить себя в производных классах.
struct Child : Base
{
Child() = default;
virtual ~Child() = default;
virtual void foo() const override;
};Во время создания объекта типа 'Child' будет вызван метод 'Base::foo()' из конструктора базового класса, но не переопределенный метод 'Child::foo()' из производного класса.
Для исправления этой проблемы нужно уточнить вызов метода. Например, для класса 'Base':
struct Base
{
Base()
{
Base::foo();
}
virtual ~Base() = default;
virtual void foo() const;
};Теперь одного взгляда на код достаточно чтобы понять, какой именно метод будет вызван.
Также отметим, что использование указателя на себя 'this' при вызове виртуального метода не решает исходную проблему, и при использовании 'this' все также необходимо уточнить, из какого класса следует позвать виртуальную функцию:
struct Base
{
Base()
{
this->foo(); // bad
this->Base::foo(); // good
}
virtual ~Base() = default;
virtual void foo() const;
};Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1053. |
V1054. Object slicing. Derived class object was copied to the base class object.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что объект производного класса был скопирован в объект базового класса, т.е. произошла срезка типа.
Если базовый и производный классы являются полиморфными (т.е. содержат виртуальные функции), то при таком копировании информация о переопределенных виртуальных функциях в производных классах будет утеряна. Это может привести к нарушению полиморфного поведения.
Другим фактом является то, что объект базового класса теряет информацию о полях производного класса, если конструктор копирования сгенерирован компилятором неявно (возможно даже и в случае определенного пользователем).
Рассмотрим следующий пример:
struct Base
{
int m_i;
Base(int i) : m_i { i } { }
virtual int getN() { return m_i; }
};
struct Derived : public Base
{
int m_j;
Derived(int i, int j) : Base { m_i }, m_j { j } { }
virtual int getN() { return m_j; }
};
void foo(Base obj) { std::cout << obj.getN() << "\n"; }
void bar()
{
Derived d { 1, 2 };
foo(d);
}При передаче переменной 'd' в функцию 'foo' произойдет копирование, а функция 'getN' будет вызвана из класса 'Base'.
Чтобы избежать проблем, связанных со срезкой типа, стоит использовать указатели/ссылки:
void foo(Base &obj) { std::cout << obj.getN() << "\n"; }В этом случае копирования не произойдет, и 'getN' будет вызвана из класса 'Derived'.
Если срезка типа все же необходима, то желательно определить явную операцию, которая это делает. Это спасет читателей кода от путаницы:
struct Base
{
....
};
struct Derived : public Base
{
....
Base copy_base();
....
};
void foo(Base obj);
void bar()
{
Derived d { .... };
foo(d.copy_base());
}Анализатор не выдает срабатывание в случае, если иерархия классов не содержит виртуальных функций и все нестатические поля располагаются в базовом классе:
struct Base
{
int m_i;
int m_j;
Base(int i, int j) : m_i { i }, m_j { j } { }
int getI() { return m_i; }
int getJ() { return m_j; }
};
struct Derived : public Base
{
Derived(int i, int j) : Base(i, j) { }
virtual int getN() { return m_j; }
};Данная диагностика классифицируется как:
|
V1055. The 'sizeof' expression returns the size of the container type, not the number of elements. Consider using the 'size()' function.
Анализатор обнаружил в качестве аргумента оператора 'sizeof' переменную типа "STL-подобный контейнер".
Рассмотрим следующий пример:
#include <string>
void foo(const std::string &name)
{
auto len = sizeof(name) / sizeof(name[0]);
....
}Выражение 'sizeof(name)' возвращает не суммарный размер элементов в контейнере в байтах (или просто количество элементов), а именно размер типа контейнера, отведенный для имплементации. Например, типичная имплементация 'std::string' может содержать 3 указателя (стандартная библиотека libc++, 64-битная система), т.е. 'sizeof(name) == 24'. Размер же реальной хранимой строки чаще всего отличается от этого значения.
Ошибка подобного рода может появиться в проекте в результате рефакторинга старого кода:
#define MAX_LEN(str) ( sizeof((str)) / sizeof((str)[0]) - 1 )
typedef char MyString[256];
void foo()
{
MyString str { .... };
....
size_t max_len = MAX_LEN(str);
}При замене псевдонима 'MyString' с типа 'char[256]' на 'std::string' вычисление максимально допустимой длины строки станет некорректным.
Для получения реального размера STL-подобных контейнеров стоит использовать публичную функцию-член '.size()':
#include <string>
void foo(const std::string &name)
{
auto len = name.size();
}Если подразумевалось именно вычисление размера имплементации контейнера, то для лучшего понимания кода предпочтительнее передавать в качестве операнда оператора 'sizeof' тип контейнера, прямым способом или через оператор 'decltype' (C++11) для переменных:
#include <string>
void foo(const std::string &str)
{
auto string_size_impl1 = sizeof(std::string);
auto string_size_impl2 = sizeof(decltype(str));
}Диагностика также знает о существовании контейнера 'std::array' и не выдает на нем срабатывание при его использовании в качестве операнда оператора 'sizeof':
template <typename T, size_t N>
void foo(const std::array<T, N> &arr)
{
auto size = sizeof(arr) / sizeof(arr[0]); // ok
}Начиная со стандарта C++17, рекомендуется использовать свободную функцию 'std::size()', которая умеет работать как встроенными массивами, так и всеми типами контейнеров, имеющими публичную функцию-член '.size()':
#include <vector>
#include <string>
#include <set>
#include <list>
void foo()
{
int arr[256] { .... };
std::vector vec { .... };
std::string str { .... };
std::set set { .... };
std::list list { .... };
auto len1 = std::size(arr);
auto len2 = std::size(vec);
auto len3 = std::size(str);
auto len4 = std::size(set);
auto len5 = std::size(list);
}Данная диагностика классифицируется как:
V1056. The predefined identifier '__func__' always contains the string 'operator()' inside function body of the overloaded 'operator()'.
Анализатор обнаружил использование идентификатора '__func__' в теле перегруженного оператора '()'.
Рассмотрим пример:
class C
{
void operator()(void)
{
std::cout << __func__ << std::endl;
}
};
void foo()
{
C c;
c();
}При запуске будет выведено 'operator()'. На первый взгляд, это вполне ожидаемое поведение для подобного кода, поэтому перейдем к более неочевидному примеру:
void foo()
{
auto lambda = [] () { return __func__; };
std::cout << lambda() << std::endl;
}Важно учитывать тот факт, что '__func__' не является переменной в привычном смысле этого слова, поэтому следующие варианты не сработают, и по-прежнему будет выведено 'operator()':
void fooRef()
{
auto lambda = [&] () { return __func__; };
std::cout << lambda() << std::endl;
}
void fooCopy()
{
auto lambda = [=] () { return __func__; };
std::cout << lambda() << std::endl;
}Чтобы исправить это в случае с лямбдой, необходимо передать '__func__' явно через список захвата:
void foo()
{
auto lambda = [func = __func__] () { return func; };
std::cout << lambda() << std::endl;
}Для более полноценного вывода имени функции даже внутри перегруженного 'operator()' или тела лямбды можно воспользоваться специфичными для платформы/компилятора макросами. Так, компилятор MSVC предоставляет следующие три макроса:
- '__FUNCTION__' – выводит имя функции, не опуская при этом его область объявления. Например, для лямбды внутри функции main мы получим такой вывод: 'main::<lambda_....>::operator ()';
- '__FUNCSIG__' – выводит полную сигнатуру функции. Так же может быть полезным в связке с лямбдой: 'auto __cdecl main::<lambda_....>::operator ()(void) const';
- '__FUNCDNAME__' – выводит декорированное имя функции. Это достаточно специфичная информация, поэтому она не подходит для полноценной замены '__func__'.
Для компиляторов Clang и GCC доступны следующие макросы:
- '__FUNCTION__' – выводит то же имя, что и стандартный '__func__';
- '__PRETTY_FUNCTION__' – выводит полную сигнатуру функции, например для лямбды может быть следующий вывод: 'auto main()::(anonymous class)::operator()() const'.
V1057. Pseudo random sequence is the same at every program run. Consider assigning the seed to a value not known at compile-time.
Анализатор обнаружил подозрительный код, инициализирующий генератор псевдослучайных чисел константным значением.
// C
srand(0);
// C++
std::mt19937 engine(1);Числа, сгенерированные таким генератором, можно предугадать, либо же они будут воспроизводиться снова и снова при каждом запуске программы.
Чтобы этого избежать, стоит использовать какое-либо случайное число. К примеру, можно воспользоваться текущим системным временем:
srand(time(0));Но такой подход может вызвать проблемы в многопоточных программах – 'time(0)' может вернуть одинаковые значения в разных потоках. Также стоит учесть, что время может меняться пользователем.
Начиная с C++11, можно воспользоваться генератором 'std::random_device', реализующим интерфейс к генератору истинно случайных чисел:
std::random_device rd;
std::mt19937 engine(rd());Однако если таковой в системе отсутствует, то будет использован обычный генератор псевдослучайных чисел.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V1058. Nonsensical comparison of two different functions' addresses.
Анализатор обнаружил подозрительное сравнение адресов двух функций.
Пример:
namespace MyNamespace
{
int one() noexcept;
int two() noexcept;
}
using namespace MyNamespace;
void SomeFunction()
{
if (one != two)
{
// do something
}
....
}Сравнение в данном случае всегда вернет 'true', так как 'one' и 'two' – имена функций с совместимыми сигнатурами, объявленных в пространстве имен 'MyNamespace'. Вероятно, что в этом случае предполагалось сравнение возвращаемых значений, но автор кода забыл добавить к именам функций круглые скобки:
namespace MyNamespace
{
int one() noexcept;
int two() noexcept;
}
using namespace MyNamespace;
void SomeFunction()
{
if (one() != two())
{
// do something
}
}Также подобный код может быть результатом неудачного рефакторинга. Если внутри функции сравнивались локальные переменные, которые в какой-то момент были удалены из кода, при этом само условие сохранилось, то вполне возможно, что будет происходить сравнение функций с такими же именами.
Пример кода до рефакторинга:
namespace MyNamespace
{
int one() noexcept;
int two() noexcept;
}
using namespace MyNamespace;
void SomeFunction(int one, int two)
{
if (one != two)
{
// do something
}
}Данная диагностика классифицируется как:
|
V1059. Macro name overrides a keyword/reserved name. This may lead to undefined behavior.
Анализатор обнаружил макрос, имя которого перекрывает ключевое слово или зарезервированный стандартом идентификатор.
Пример:
#define sprintf std::printfЗдесь из-за коллизии имен вызовы стандартной функции 'sprintf' после препроцессирования заменятся на вызовы 'printf'. Такая замена приведет к некорректной работе программы.
Диагностика также сообщает об удалении предопределенных макросов.
Пример:
#undef assertДиагностика игнорирует переопределения ключевых слов, если они идентичны с точки зрения семантики.
Примеры:
#define inline __inline
#define inline __forceinline
#define template extern templateДанная диагностика классифицируется как:
|
V1060. Passing 'BSTR ' to the 'SysAllocString' function may lead to incorrect object creation.
Анализатор обнаружил передачу строки типа 'BSTR' в функцию 'SysAllocString'.
BSTR FirstBstr = ....;
BSTR SecondBstr = SysAllocString(FirstBstr);Если необходимо скопировать 'BSTR' строку, то ее передача в функцию 'SysAllocString' может привести к логической ошибке.
BSTR (basic string или binary string) – это строковый тип данных, который используется в COM, Automation и Interop функциях. Представление BSTR:
- Префикс длины. Целое число размером 4 байта, которое отображает длину следующей за ним строки в байтах. Префикс длины указывается непосредственно перед первым символом строки и не учитывает символ-ограничитель.
- Строка данных. Строка символов в кодировке Unicode. Может содержат множественные вложенные нулевые символы.
- Ограничитель. Два нулевых символа.
Тип BSTR является указателем, который указывает на первый символ строки, а не на префикс длины.
Функция 'SysAllocString' работает с 'BSTR' строкой также, как с обычной широкой C-строкой. Это значит, что если строка содержит множественные вложенные нулевые символы, то 'SysAllocString' создаст урезанную строку. Избежать непредвиденного поведения можно, переписав код, используя классы-обёртки над 'BSTR', такие как 'CComBSTR' или '_bstr_t'.
Например, правильно скопировать одну 'BSTR' строку в другую можно так:
CComBstr firstBstr(L"I am a happy BSTR.");
BSTR secoundBstr = firstBstr.Copy();или так:
_bstr_t firstBstr(L"I am a happy BSTR too.");
BSTR secoundBstr = firstBstr.copy();V1061. Extending 'std' or 'posix' namespace may result in undefined behavior.
Анализатор обнаружил расширение пространства имён 'std' или 'posix'. Несмотря на то, что такая программа успешно компилируется и исполняется, модификация данных пространств имён может привести к неопределённому поведению программы, если иное не указано стандартом.
Содержимое пространства имен 'std' определяется исключительно комитетом стандартизации, и стандарт запрещает добавлять в него:
- декларации переменных;
- декларации функций;
- декларации классов/структур/объединений;
- декларации перечислений;
- декларации шаблонов функций, классов и переменных (C++14);
Стандарт разрешает добавлять следующие специализации шаблонов, определенных в пространстве имен 'std', если они зависят хотя бы от одного определенного в программе типа (program-defined type):
- полная или частичная специализация шаблона класса;
- полная специализация шаблона функции (до C++20);
- полная или частичная специализация шаблона переменной, не лежащих в заголовочном файле '<type_traits>' (до C++20);
Однако, специализации шаблонов, лежащих внутри классов или шаблонов классов, запрещены.
Наиболее частым вариантом, когда пользователь расширяет пространство имен 'std', является добавление своей перегрузки функции 'std::swap' и полной/частичной специализации шаблона класса 'std::hash'.
Рассмотрим фрагмент кода с добавлением перегрузки 'std::swap':
template <typename T>
class MyTemplateClass
{
....
};
class MyClass
{
....
};
namespace std
{
template <typename T>
void swap(MyTemplateClass<T> &a, MyTemplateClass<T> &b) noexcept // UB
{
....
}
template <>
void swap(MyClass &a, MyClass &b) noexcept // UB since C++20
{
....
};
}Первый шаблон функции не является специализацией 'std::swap', и такая декларация ведет к неопределенному поведению. Второй шаблон функции является специализацией, и до C++20 поведение программы определено. Однако, в данном случае можно поступить иначе: можно вынести обе функции из пространства имен 'std' и поместить их в то пространство имен, где определены классы:
template <typename T>
class MyTemplateClass
{
....
};
class MyClass
{
....
};
template <typename T>
void swap(MyTemplateClass<T> &a, MyTemplateClass<T> &b) noexcept
{
....
}
void swap(MyClass &a, MyClass &b) noexcept
{
....
};Теперь, когда необходимо написать шаблон функции, который применяет функцию swap для двух объектов типа T, можно написать следующий код:
template <typename T>
void MyFunction(T& obj1, T& obj2)
{
using std::swap; // make std::swap visible for overload resolution
....
swap(obj1, obj2); // best match of 'swap' for objects of type T
....
}Теперь, компилятор выберет нужную перегрузку функции на основе поиска с учетом аргументов (argument-dependent lookup, ADL) – пользовательские функции 'swap' для класса 'MyClass' и для шаблона класса 'MyTemplateClass' и стандартную версию 'std::swap' для остальных типов.
Разберем следующий пример со специализацией шаблона класса 'std::hash':
namespace Foo
{
class Bar
{
....
};
}
namespace std
{
template <>
struct hash<Foo::Bar>
{
size_t operator()(const Foo::Bar &) const noexcept;
};
}С точки зрения стандарта этот код является валидным, и анализатор в этой ситуации не выдает предупреждение. Однако, начиная с C++11, можно и в этом случае поступить иначе, написав специализацию шаблона класса за пределами пространства имен 'std':
template <>
struct std::hash<Foo::Bar>
{
size_t operator()(const Foo::Bar &) const noexcept;
};В отличие от пространства имен 'std', стандарт C++ запрещает абсолютно любую модификацию пространства имён 'posix':
namespace posix
{
int x; // UB
}Дополнительная информация:
- Стандарт C++17 (working draft N4659), пункт 20.5.4.2.1
- Стандарт C++20 (working draft N4860), пункт 16.5.4.2.1
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1061. |
V1062. Class defines a custom new or delete operator. The opposite operator must also be defined.
Это диагностическое правило основано на пункте R.15 CppCoreGuidelines.
В классе определен оператор 'new' или 'delete', но при этом не определен обратный оператор.
Пример:
class SomeClass
{
....
void* operator new(size_t s);
....
};Для динамической аллокации объекта такого класса будет использоваться перегруженный оператор 'new', а для удаления – оператор 'delete', определенный по умолчанию.
Для симметрии операций аллокации/деаллокации следует определить также оператор 'delete':
class SomeClass
{
....
void* operator new(size_t s);
void operator delete(void*);
....
};Также операторы можно пометить как удаленные ('= delete'), если по какой-то причине необходимо запретить аллокацию или деаллокацию для объектов класса. При этом желательно одновременно запретить и аллокацию и деаллокацию, чтобы вызов любого из этих операторов приводил к ошибке времени компиляции, а не к трудно уловимому багу:
#include <cstddef>
class AutoTransaction
{
public:
/// Mark 'operator new' as deleted to prevent heap allocation
void* operator new (std::size_t) = delete;
};
void foo()
{
auto ptr = new AutoTransaction; // code doesn't compile
}
void bar()
{
AutoTransaction obj;
delete &obj; // code compiles, but contains an error
}Если также запретить деаллокацию, то компилятор не позволит совершить ошибку:
class SomeClass
{
....
void* operator new(size_t s) = delete;
void operator delete(void*) = delete;
....
};
void foo()
{
auto ptr = new AutoTransaction; // code doesn't compile
}
void bar()
{
AutoTransaction obj;
delete &obj; // code doesn't compile
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1062. |
V1063. The modulo by 1 operation is meaningless. The result will always be zero.
Анализатор обнаружил странное выражение, в котором производится деление по модулю 1. Результатом такого выражения всегда будет 0.
Частым паттерном данной ошибки является проверка делимости числа на что-то без остатка. Для этого необходимо поделить число по модулю и сравнить результат с 0 или 1. В этом месте легко сделать опечатку, так как раз ожидается значение 1, то кажется, что и поделить надо на 1. Пример:
if (x % 1 == 1)
{
....
}Здесь переменную 'x' поделили по модулю '1', и теперь вне зависимости от значения 'x' выражение 'x % 1' всегда будет равно 0. Следовательно, условие всегда будет ложным. Наиболее вероятно, что переменную 'x' следовало поделить по модулю '2':
if (x % 2 == 1)
{
....
}Рассмотрим пример из реального проекта (stickies):
void init (....)
{
srand(GetTickCount() + rand());
updateFreq1 = (rand() % 1) + 1;
updateFreq2 = (rand() % 1) + 1;
updateFreq3 = (rand() % 1) + 1;
updateFreq4 = (rand() % 1) + 1;
waveFreq1 = (rand() % 15);
waveFreq2 = (rand() % 3);
waveFreq3 = (rand() % 16);
waveFreq4 = (rand() % 4);
// ....
}Здесь переменные 'updateFreq1', 'updateFreq2', 'updateFreq3' и 'updateFreq4' будут всегда инициализированы значением 1. Возможно, что каждая переменная вероятно должна была быть проинициализирована каким-то псевдослучайным числом. И скорее всего, это [1..2]. Тогда корректный код должен быть таким:
updateFreq1 = (rand() % 2) + 1;
updateFreq2 = (rand() % 2) + 1;
updateFreq3 = (rand() % 2) + 1;
updateFreq4 = (rand() % 2) + 1;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1063. |
V1064. The left operand of integer division is less than the right one. The result will always be zero.
Анализатор обнаружил подозрительное выражение, в котором производится целочисленное деление, при котором левый операнд всегда меньше правого. Результат такого выражения всегда будет равен нулю.
Давайте рассмотрим пример:
if ( nTotal > 30 && pBadSource->m_nNegativeVotes / nTotal > 2/3 )
{
....
}Так как литералы '2' и '3' имеют целочисленный тип, результат их деления тоже будет целочисленным и, соответственно, равен нулю. А значит, данное условие эквивалентно следующему:
if ( nTotal > 30 && pBadSource->m_nNegativeVotes / nTotal > 0 )
{
....
}Правильным в данной ситуации будет явно привести один из операндов к типу с плавающей точкой. Примеры исправленного кода:
if ( nTotal > 30 && pBadSource->m_nNegativeVotes / nTotal >
static_cast<float>(2)/3 )
{
....
}Или:
if ( nTotal > 30 && pBadSource->m_nNegativeVotes / nTotal > 2.0f/3 )
{
....
}Также анализатор выдаст предупреждение, если он обнаружил подозрительное выражение, в котором производится взятие остатка по модулю, при котором делимое всегда меньше делителя. Результат такого выражения всегда будет равен значению делимого.
Давайте рассмотрим пример:
void foo()
{
unsigned int r = 12;
const unsigned int r3a = (16 + 5 - r) % 16;
}Здесь выражение '16+5-r' будет равно 9. Это значение меньше делителя '16'. Поэтому взятие остатка по модулю в данном случае не имеет смысла, результатом будет 9.
Рассмотрим более сложный пример:
int get_a(bool cond)
{
return cond ? 3 : 5;
}
int get_b(bool cond)
{
return cond ? 7 : 9;
}
int calc(bool cond1, bool cond2)
{
return get_a(cond1) % get_b(cond2);
}В функции 'calc' производится взятие остатка по модулю. Делимое принимает значения 3 или 5. Делитель принимает значения 7 или 9. Получаем четыре варианта вычислений операции взятия остатка по модулю: '3 % 7', '5 % 7', '3 % 9', '5 % 9'. В каждом из вариантов делимое меньше делителя. Значит, операция бессмысленна.
Если анализатор выдал предупреждение на вашем коде, рекомендуем изучить этот фрагмент кода на наличие логических ошибок. Возможно, вычисление одного из операндов взятия остатка по модулю происходит не так, как ожидалось. Также может быть, что вместо операции взятия остатка по модулю нужно использовать другую операцию.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1064. |
V1065. Expression can be simplified: check similar operands.
Анализатор обнаружил подозрительное выражение, в котором операнды могут быть сокращены. Это может свидетельствовать о наличии в коде логической ошибки или опечатки.
Рассмотрим простой синтетический пример:
void Foo(int A, int B, int C)
{
if (A - A + 1 < C)
Go(A, B);
}Из-за опечатки получилось избыточное выражение, которое можно сократить до '1 < C'. На самом деле, планировалось написать, например, так:
void Foo(int A, int B, int C)
{
if (A - B + 1 < C)
Go(A, B);
}В других случаях могут быть выявлены выражения, которые, хотя и не содержат ошибку, будет полезно упростить. Это может сделать выражения более простыми и понятными. Пример:
if ((rec.winDim.left + (rec.winDim.right - rec.winDim.left)) < inset) // <=
{
rec.winDim.left = -((rec.winDim.right – rec.winDim.left) - inset);
rec.winDim.right = inset;
}
if ((rec.winDim.top + (rec.winDim.bottom – rec.winDim.top)) < inset) // <=
{
rec.winDim.top = -((rec.winDim.bottom – rec.winDim.top) - inset);
rec.winDim.bottom = inset;
}В обоих условиях выражения могут быть упрощены путем устранения операндов 'rec.winDim.left' и 'rec.winDim.top' соответственно. Сокращённый вариант кода:
if (rec.winDim.right < inset)
{
rec.winDim.left = -((rec.winDim.right – rec.winDim.left) - inset);
rec.winDim.right = inset;
}
if (rec.winDim.bottom < inset)
{
rec.winDim.top = -((rec.winDim.bottom – rec.winDim.top) - inset);
rec.winDim.bottom = inset;
}Примечание. Иногда избыточность вовсе не уменьшает, а увеличивает читабельность кода. Например, избыточность может нести поясняющий смысл в математических формулах. В этом случае есть смысл не сокращать выражение, а использовать один из механизмов подавления ложных срабатываний.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1065. |
V1066. The 'SysFreeString' function should be called only for objects of the 'BSTR' type.
Анализатор обнаружил вызов функции 'SysFreeString' для объекта, тип которого отличен от 'BSTR'.
Функция 'SysFreeString' предназначена только для работы с типом 'BSTR'. Нарушение этого условия может привести к проблемам с освобождением памяти.
Рассмотрим простой синтетический пример:
#include <atlbase.h>
void foo()
{
CComBSTR str { L"I'll be killed twice" };
// ....
SysFreeString(str); //+V1066
}Здесь в функцию 'SysFreeString' передаётся объект типа 'CComBSTR'. Этот класс является обёрткой над типом 'BSTR' и имеет перегруженный оператор неявного преобразования 'operator BSTR()', который возвращает указатель на обёрнутую BSTR-строку. Поэтому приведённый выше код скомпилируется без предупреждений.
Однако, этот код содержит ошибку. После того, как функция 'SysFreeString' освободит ресурс, принадлежащий объекту 'str', произойдет выход из области видимости, и будет вызван деструктор объекта 'str'. Деструктор произведёт повторное освобождение уже освобождённого ресурса, что приведет к неопределённому поведению.
Иногда подобное поведение может случиться даже при передаче в 'SysFreeString' именно объекта типа 'BSTR'. Например, PVS-Studio также выдаст предупреждение на такой код:
#include <atlbase.h>
void foo()
{
CComBSTR str = { L"a string" };
BSTR bstr = str;
str.Empty();
SysFreeString(bstr); //+V1066
}Так как 'CComBSTR::operator BSTR()' возвращает указатель на собственное поле, после присвоения 'BSTR bstr = str;' оба объекта будут владеть одним и тем же ресурсом. Вызов метода 'str.Empty();' освободит этот ресурс, а 'SysFreeString(bstr)' попытается освободить уже освобождённый ресурс.
Одним из способов избежать общего владения ресурсом является создание копии или использование метода 'CComBSTR::Detach()'. Например, анализатор не будет выдавать предупреждение на следующий код:
#include <atlbase.h>
void foo()
{
CComBSTR ccombstr = { L"I am a happy CComBSTR" };
BSTR bstr1 = ccombstr.Copy();
SysFreeString(bstr1); // OK
BSTR bstr2;
ccombstr.CopyTo(&bstr2);
SysFreeString(bstr2); // OK
BSTR bstr3 = ccombstr.Detach();
SysFreeString(bstr3); // OK
}Данная диагностика классифицируется как:
|
V1067. Throwing from exception constructor may lead to unexpected behavior.
Анализатор обнаружил конструктор исключения, из которого может быть брошено другое исключение. Использование такого класса может привести к неожиданному поведению программы при обработке исключений.
Рассмотрим синтетический пример:
#include <stdexcept>
class divide_by_zero_error : public std::invalid_argument
{
public:
divide_by_zero_error() : std::invalid_argument("divide_by_zero")
{
....
if (....)
{
throw std::runtime_error("oops!"); // <=
}
}
};
void example(int a, int b)
{
try
{
if (b == 0)
throw divide_by_zero_error ();
....
}
catch (const divide_by_zero_error &e)
{
....
}
// my_exception thrown and unhandled
}В коде функции 'example' программист пытается обработать возникшее исключение 'divide_by_zero_error', однако вместо этого будет сформировано исключение 'std::runtime_error' и не перехвачено последующим 'catch'-блоком. Это приведет к тому, что исключение покинет функцию 'example', что может привести к следующим ситуациям:
- исключение будет обработано другим обработчиком исключений выше по стеку вызовов, что также может не являться желаемым поведением;
- соответствующего обработчика исключений может не оказаться выше по стеку вызовов, и тогда программа будет аварийно завершена функцией 'std::terminate' как только исключение покинет функцию 'main'.
При разработке и использовании собственных классов исключений нужно проявлять особую бдительность, поскольку исключения в их конструкторах могут возникнуть в неожиданных местах, например при вызове других функций. В следующем примере при создании логирующего исключения может возникнуть второе исключение из функции 'Log':
#include <ios>
static void Log(const std::string& message)
{
....
// std::ios_base::failure may be thrown by stream operations
throw std::ios_base::failure("log file failure");
}
class my_logging_exception : public std::exception
{
public:
explicit my_logging_exception(const std::string& message)
{
Log(message); // <=
}
};Данная диагностика классифицируется как:
V1068. Do not define an unnamed namespace in a header file.
Анализатор обнаружил анонимное пространство имен, объявленное в заголовочном файле. Такой заголовочный файл создаёт копии символов с "внутренним связыванием" (internal linkage) в каждой единице трансляции, включающей этот заголовочный файл. Это приводит к "раздуванию" объектных файлов, что может быть нежелательным поведением.
Рассмотрим простой пример заголовочного файла с анонимным пространством имен:
// utils.hpp
#pragma once
#include <iostream>
namespace
{
int global_variable;
void set_global_variable(int v)
{
std::cout << global_variable << std::endl;
global_variable = v;
}
}Каждая единица трансляции при включении заголовочного файла 'utils.hpp' получит свой экземпляр переменной 'global_variable', не связанной с другими экземплярами и не доступной из других единиц трансляции. Также будет сгенерировано несколько избыточных функций 'set_global_variable'. До стандарта C++17 такой код мог встречаться в header-only библиотеках для того, чтобы не нарушать One Definition Rule при включении заголовочных файлов в несколько единиц трансляции. Также подобный код может появиться из-за неаккуратного рефакторинга, например, при переносе анонимного пространства имен из компилируемого файла в заголовочный файл.
Стоит отметить, что данное правило распространяется и на безымянные пространства имен, вложенные в другие пространства имен:
namespace my_namespace
{
int variable1; // namespace-scope non-const variable
// 'variable1' has external linkage
namespace // <=
{
int variable2; // unnamed namespace applies 'static'
// 'variable2' has internal linkage
}
}Если необходимо создать ровно один экземпляр символа для header-only библиотеки, то можно воспользоваться спецификатором 'inline' (начиная с C++17, действует и для переменных):
// utils.hpp
#pragma once
#include <iostream>
inline int global_variable; // ok since C++17
inline void set_global_variable(int v)
{
std::cout << global_variable << std::endl;
global_variable = v;
}Если используется более ранняя версия стандарта, но библиотека не header-only, то можно объявить символы как 'extern' в заголовочном файле и определить их в одном из юнитов трансляции:
// utils.hpp
#pragma once
extern int global_variable;
void set_global_variable(int v); // functions implicitly
// have external linkage ('extern')// utils.cpp
#include "utils.hpp"
#include <iostream>
int global_variable;
void set_global_variable(int v)
{
std::cout << global_variable << std::endl;
global_variable = v;
}В том случае, когда используется более старая версия стандарта, но библиотека должна быть header-only, срабатывание можно подавить комментарием:
// utils.hpp
#pragma once
#include <iostream>
namespace //-V1068
{
int global_variable;
void set_global_variable(int v)
{
std::cout << global_variable << std::endl;
global_variable = v;
}
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1068. |
V1069. Do not concatenate string literals with different prefixes.
Анализатор обнаружил фрагмент кода, в котором происходит конкатенация строк с разными префиксами кодировок.
Рассмотрим синтетический пример:
// Until C99/C++11
L"Hello, this is my special "
"string literal with interesting behavior";До стандартов C11/C++11 в языках C и C++ существовало лишь два типа строковых литералов:
- "узкий" строковый литерал – " s-char-sequence "
- "широкий" строковый литерал – L" s-char-sequence "
Конкатенация таких строковых литералов разных типов до C99 и C++11 приводит к неопределенному поведению, и анализатор выдает предупреждение первого уровня на такой случай. Корректный код будет выглядеть так:
// Until C99/C++11
L"Hello, this is my special "
L"string literal with defined behavior";Начиная с C99 и C++11, если один из строковых литералов имеет префикс, а второй – нет, то поведение определено, и результирующий строковый литерал будет иметь тот же тип, что и строковый литерал с префиксом. В этом случае анализатор не выдает предупреждений:
// Since C99/C++11
L"Hello, this is my special "
"string literal with "
"defined behavior";Начиная со стандарта C11/C++11 в языки были добавлены следующие префиксированные строковые литералы:
- UTF-8 строковый литерал – u8" s-char-sequence "
- 16-битный "широкий" строковый литерал – u" s-char-sequence "
- 32-битный "широкий" строковый литерал – U" s-char-sequence "
Конкатенация UTF-8 и любого "широкого" строкового литерала ведет к ошибке этапа компиляции, и поэтому анализатор не выдает предупреждений:
L"Hello, this is my special "
u8"string literal that won't compile"; // compile-time errorЛюбые другие комбинации префиксированных строковых литералов ведут к неуточненному поведению. Анализатор в таких случаях выдает предупреждения второго уровня:
// Until C11/C++11
L"Hello, this is my special "
u"string literal with implementation-defined behavior";
L"Hello, this is my special "
U"string literal with implementation-defined behavior";
u"Hello, this is my special "
U"string literal with implementation-defined behavior";Анализатор также выдает предупреждения третьего уровня для случаев, когда конкатенируются 3 и более строковых литералов, "узкие" и один из префиксированных:
template <typename T>
void foo(T &&val) { .... }
....
void bar()
{
foo("This" L"is" "strange");
foo(L"This" "is" L"strange");
}Несмотря на то, что в современных стандартах поведение определено, такой код выглядит странно и, возможно, потребует дополнительного внимания. Другими словами, такой код провоцирует ошибки, и полезно рассмотреть вопрос о его рефакторинге.
V1070. Signed value is converted to an unsigned one with subsequent expansion to a larger type in ternary operator.
Анализатор обнаружил ситуацию, при которой результат тернарного оператора, операнды которого имеют целые типы, различные по знаку, сохраняется в целый тип большего размера любой знаковости. При таком преобразовании отрицательное значение станет положительным.
Рассмотрим синтетический пример:
long long foo(signed int a, unsigned int b, bool c)
{
return c ? a : b;
}Согласно правилам преобразования в C++, если второй и третий операнды тернарного оператора содержат разные типы, и размер беззнакового операнда не меньше размера знакового, то компилятор преобразует их к беззнаковому типу.
Таким образом, знаковая переменная с отрицательным значением (например, -1) будет приведена к беззнаковому типу. В случае 32-битного типа 'int' итоговое значение будет '0xFFFFFFFF'. Затем этот результат будет преобразован в целый тип большего размера (64-битный тип 'long long'), однако исходная знаковость уже была потеряна, и финальный результат так и останется в виде положительного числа.
Проблема сохраняется также для случая, когда результат тернарного оператора преобразуется в беззнаковый тип большей размерности:
unsigned long long f(signed int i, unsigned int ui, bool b)
{
return b ? i : ui;
}Если переменная 'i' имеет отрицательное значение (например, -1), то результатом тернарного оператора будет значение '0xFFFFFFFF'. Затем оно будет преобразовано в беззнаковый тип большего размера, и его значение станет '0x00000000FFFFFFFF'. Скорее всего программист ожидал, что результатом будет значение '0xFFFFFFFFFFFFFFFF'.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
V1071. Return value is not always used. Consider inspecting the 'foo' function.
Анализатор обнаружил, что возвращаемое значение функции игнорируется. При этом в большинстве случаев результат функции каким-либо образом используется.
Диагностика призвана помочь в тех случаях, когда функция или ее возвращающий тип не помечены стандартным атрибутом '[[nodiscard]]' (C23/C++17) или его аналогами. Если в большинстве случаев результат функции использовался каким-либо способом, и при этом в определенных ситуациях игнорируется, то это может свидетельствовать о возможной ошибке.
Рассмотрим синтетический пример:
int foo();
....
auto res = foo();
....
if (foo() == 42) { .... }
....
while (foo() != 42) { .... }
....
return foo();
....
foo();
....Здесь результат функции 'foo' используется четырьмя различными способами, а затем игнорируется в одном. Если результат не используется менее чем в 10% случаев от общего количества вызовов, анализатор выдаст предупреждение.
В некоторых ситуациях такой код мог быть написан намеренно. Например, если функция содержит некоторые побочные эффекты - операции с потоком, чтение/запись 'volatile'-переменных и т.п., и при этом результатом можно пренебречь.
Чтобы помочь программисту понять, что такое поведение было задумано, рекомендуется явно проигнорировать возвращаемое значение, приведя его к типу 'void':
....
(void) foo(); // or static_cast<void>(foo());
....Анализатор не выдает срабатывания для следующих случаев:
- конструкторов;
- перегруженных операторов.
V1072. Buffer needs to be securely cleared on all execution paths.
Анализатор обнаружил потенциальную ошибку, когда буфер, содержащий приватную информацию, не будет очищен.
Рассмотрим синтетический пример:
int f()
{
char password[size];
if (!use1(password))
return -1;
use2(password);
memset_s(password, sizeof(password), 0, sizeof(password));
return 0;
}Эта ситуация аналогична утечке памяти. Несмотря на то, что буфер очищается при помощи безопасной функции 'memset_s', если произойдет выход из функции под условием, данные останутся в памяти.
Чтобы избежать ошибки, буфер следует очищать на всех путях выполнения.
Исправленный пример:
int f()
{
char password[size];
if (use1(password))
{
use2(password);
memset_s(password, sizeof(password), 0, sizeof(password));
return 0;
}
return -1;
}Аналогичная ситуация произойдет, если функция выбросит исключение прежде, чем вызовется очистка буфера.
Пример:
int f()
{
char password[size];
if (!use1(password))
throw Exception{};
RtlSecureZeroMemory(password, size);
return 0;
}Возможный вариант исправления:
int f()
{
char password[size];
if (use1(password))
{
RtlSecureZeroMemory(password, size);
return 0;
}
throw Exception{};
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V1073. Check the following code block after the 'if' statement. Consider checking for typos.
Анализатор обнаружил возможную ошибку, связанную с тем, что блок кода ('{ .... }'), идущий после конструкции 'if', к ней не относится.
Рассмотрим первый синтетический пример:
if (a == 1) nop(); // <=
{
nop2();
}При беглом обзоре кода может показаться, что блок выполнится, если условие истинно, но на самом деле это не так. Блок будет выполняться всегда, независимо от условия. Это может ввести программиста в заблуждение.
Рассмотрим другие примеры кода, на которые анализатор выдаст срабатывание:
if (a == 2) nop(); else nop2(); // <=
{
nop3();
}
if (a == 3) nop();
else nop2(); // <=
{
nop3();
}Стоит отметить, что сам по себе такой паттерн может не являться ошибкой и встречается в коде. Поэтому анализатор отсеивает случаи, когда конструкция 'if' записана в одну строку, и в ее теле выполняется одна из следующих конструкций: 'return', 'throw', 'goto'. Например:
if (a == 4) return; // ok
{
nop();
}
if (a == 5) throw; // ok
{
nop();
}
....
label:
....
if (a == 6) goto label; // ok
{
nop();
}Также анализатор не выдаст срабатывание, если строки с конструкцией 'if' и несвязанным с ней блоком кода несмежные:
if (a == 7) nop();
// this is a block for initializing MyClass fields
{
....
}Если вы получили такое срабатывание, и оно ложное, вы можете подсказать об этом анализатору, добавив пустую строку между 'if' и блоком.
Также диагностика не выдаст срабатывание в том случае, когда тело 'if' содержит пустую конструкцию (';'), за это отвечает диагностическое правило V529.
Данная диагностика классифицируется как:
V1074. Boundary between numeric escape sequence and string is unclear. The escape sequence ends with a letter and the next character is also a letter. Check for typos.
Анализатор обнаружил подозрительную ситуацию внутри строкового или символьного литерала, при которой escape-последовательность, в конце которой стоит буква, не отделена от следующей за ней печатаемой буквы. Такая запись может привести к путанице. Возможно, это опечатка, и литерал записан некорректно.
Рассмотрим пример:
const char *str = "start\x0end";Предполагается, что символы внутри строки разделены нуль-терминалом. Однако на самом деле после 'start' идет символ с кодом '0xE', а затем 2 остальных символа – 'nd'.
Чтобы исправить проблему, можно:
- разделить строковый литерал на несколько частей;
- завершить числовую escape-последовательность другой escape-последовательностью.
Например, код выше можно переписать таким образом:
const char *str = "start\x0" "end";Escape-последовательность можно оставить обособленной от других частей строки:
const char *str = "start" "\x0" "end";Или ограничить другим спецсимволом, например табуляцией:
const char *str = "start\x0\tend";V1075. The function expects the file to be opened in one mode, but it was opened in different mode.
Анализатор обнаружил ситуацию, при которой файл был открыт в одном режиме, но вызываемая функция ожидает, что он будет находиться в другом.
Например, файл был открыт в режиме только для записи, но он используется для чтения:
bool read_file(void *ptr, size_t len)
{
FILE *file = fopen("file.txt", "wb"); // <=
if (file != NULL)
{
bool ok = fread(ptr, len, 1, file) == 1;
fclose(file);
return ok;
}
return false;
}Скорее всего, это опечатка. Для исправления следует использовать правильный режим:
bool read_file(void *ptr, size_t len)
{
FILE *file = fopen("file.txt", "rb"); // <=
if (file != NULL)
{
bool ok = fread(ptr, len, 1, file) == 1;
fclose(file);
return ok;
}
return false;
}Также возможна ситуация, когда происходит запись в закрытый файл:
void do_something_with_file(FILE* file)
{
// ....
fclose(file);
}
void foo(void)
{
FILE *file = fopen("file.txt", "w");
if (file != NULL)
{
do_something_with_file(file);
fprintf(file, "writing additional data\n");
}
}Следует проверить корректность такого использования ресурсов в программе и исправить проблему.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1075. |
V1076. Code contains invisible characters that may alter its logic. Consider enabling the display of invisible characters in the code editor.
Анализатор обнаружил в тексте программы символы, которые могут ввести программиста в заблуждение. Эти символы могут не отображаться и изменять видимое представление кода в среде разработки. Комбинации таких символов могут привести к тому, что человек и компилятор будут интерпретировать код по-разному.
Это может быть сделано специально. Такой вид атаки называется Trojan Source. Подробнее:
- Атака Trojan Source для внедрения в код изменений, незаметных для разработчика;
- Атака Trojan Source: скрытые уязвимости.
Анализатор выдаст предупреждение, если найдет один из следующих символов:
|
Обозначение |
Код |
Название |
Описание |
|---|---|---|---|
|
LRE |
U+202A |
LEFT-TO-RIGHT EMBEDDING |
Текст после символа LRE интерпретируется как вставленный и отображается слева направо. Действие LRE прерывается символом PDF или символом перевода строки. |
|
RLE |
U+202B |
RIGHT-TO-LEFT EMBEDDING |
Текст после символа RLE интерпретируется как вставленный и отображается справа налево. Действие RLE прерывается символом PDF или символом перевода строки. |
|
LRO |
U+202D |
LEFT-TO-RIGHT OVERRIDE |
Текст после символа LRO принудительно отображается слева направо. Действие LRO прерывается символом PDF или символом перевода строки. |
|
RLO |
U+202E |
RIGHT-TO-LEFT OVERRIDE |
Текст после символа RLO принудительно отображается справа налево. Действие RLO прерывается символом PDF или символом перевода строки. |
|
|
U+202C |
POP DIRECTIONAL FORMATTING |
Символ PDF прерывает действие одного из символов LRE, RLE, LRO или RLO, встреченного ранее. Прерывает ровно один, последний из встреченных, символ. |
|
LRI |
U+2066 |
LEFT‑TO‑RIGHT ISOLATE |
Текст после символа LRI отображается слева направо и интерпретируется как изолированный. Это означает, что другие управляющие символы не влияют на отображение этого фрагмента текста. Действие LRI прерывается символом PDI или символом перевода строки. |
|
RLI |
U+2067 |
RIGHT‑TO‑LEFT ISOLATE |
Текст после символа RLI отображается справа налево и интерпретируется как изолированный. Это означает, что другие управляющие символы не влияют на отображение этого фрагмента текста. Действие RLI прерывается символом PDI или символом перевода строки. |
|
FSI |
U+2068 |
FIRST STRONG ISOLATE |
Направление текста после символа FSI задается первым управляющим символом, не входящим в этот фрагмент текста. Другие управляющие символы не влияют на отображение этого текста. Действие FSI прерывается символом PDI или символом перевода строки. |
|
PDI |
U+2069 |
POP DIRECTIONAL ISOLATE |
Символ PDI прерывает действие одного из символов LRI, RLI или FSI, встреченного ранее. Прерывает ровно один, последний из встреченных, символ. |
|
LRM |
U+200E |
LEFT-TO-RIGHT MARK |
Текст после символа LRM отображается слева направо. Действие LRM прерывается символом перевода строки. |
|
RLM |
U+200F |
RIGHT-TO-LEFT MARK |
Текст после символа RLM отображается справа налево. Действие RLM прерывается символом перевода строки. |
|
ALM |
U+061C |
ARABIC LETTER MARK |
Текст после символа ALM отображается справа налево. Действие ALM прерывается символом перевода строки. |
|
ZWSP |
U+200B |
ZERO WIDTH SPACE |
Неотображаемый пробельный символ. Использование символа ZWSP привести к тому, что разные строки будут отображаться одинаково. Например, 'str[ZWSP]ing' отображается как 'string'. |
Рассмотрим следующий фрагмент кода:
#include <iostream>
int main()
{
bool isAdmin = false;
/*[RLO] } [LRI] if (isAdmin)[PDI] [LRI] begin admins only */ // (1)
std::cout << "You are an admin.\n";
/* end admins only [RLO]{ [LRI]*/ // (2)
return 0;
}Изучим детально строку (1).
[LRI] if (isAdmin)[PDI]Здесь символ [LRI] действует до символа [PDI]. Строка 'if (isAdmin)' будет отображаться слева направо и считается изолированной, получаем 'if (isAdmin)'.
[LRI] begin admins only */Здесь символ [LRI] действует до конца строки. Получаем изолированную строку: 'begin admins only */'
[RLO] {пробел1}, '}', {пробел2}, 'if (isAdmin)', 'begin admins only */'Здесь символ [RLO] действует до конца строки и отображает текст справа налево. Каждая из полученных в предыдущих пунктах изолированных строк рассматривается как отдельный неделимый символ. Получаем такую последовательность:
'begin admins only */', 'if (isAdmin)', {пробел2}, '{', {пробел1}Обратите внимание, что символ закрывающей фигурной скобки теперь отображается как '{' вместо '}'.
Итоговый вид строки (1), который может быть отображен в редакторе:
/* begin admins only */ if (isAdmin) {Похожие преобразования затронут и строку (2), которая отобразится так:
/* end admins only */ }Финальный вид кода, который может отобразиться в редакторе:
#include <iostream>
int main()
{
bool isAdmin = false;
/* begin admins only */ if (isAdmin) {
std::cout << "You are an admin.\n";
/* end admins only */ }
return 0;
}Ревьювер может посчитать, что в коде выполняется некоторая проверка перед выводом сообщения. Он проигнорирует комментарии и подумает, что код должен выполняться так:
#include <iostream>
int main()
{
bool isAdmin = false;
if (isAdmin) {
std::cout << "You are an admin.\n";
}
return 0;
}Однако, на самом деле, проверки нет. Для компилятора рассмотренный код выглядит так:
#include <iostream>
int main()
{
bool isAdmin = false;
std::cout << "You are an admin.\n";
return 0;
}Теперь рассмотрим более простой и в то же время более опасный пример использования неотображаемых символов:
#include <string>
#include <string_view>
enum class BlockCipherType { DES, TripleDES, AES, /*....*/ };
constexpr BlockCipherType
StringToBlockCipherType(std::string_view str) noexcept
{
if (str == "AES[ZWSP]")
return BlockCipherType::AES;
else if (str == "TripleDES[ZWSP]")
return BlockCipherType::TripleDES;
else
return BlockCipherType::DES;
}Функция 'StringToBlockCipherType' производит конвертацию строки в одно из значений перечисления 'BlockCipherType'. По коду можно сделать вывод, что функция возвращает три разных значения, однако это не так. Из-за того, что в конце каждого строкового литерала дописан неотображаемый пробельный символ [ZWSP], проверки на равенство со строками 'AES' и 'TriplesDES' будут ложными. В итоге из трех ожидаемых возвращаемых значений функция будет возвращать лишь 'BlockCipherType::DES'. В то же время код в редакторе может отображаться следующим образом:
#include <string>
#include <string_view>
enum class BlockCipherType { DES, TripleDES, AES, /*....*/ };
constexpr BlockCipherType
StringToBlockCipherType(std::string_view str) noexcept
{
if (str == "AES")
return BlockCipherType::AES;
else if (str == "TripleDES")
return BlockCipherType::TripleDES;
else
return BlockCipherType::DES;
}Если анализатор выдал предупреждение о неотображаемых символах на вашем коде, включите отображение невидимых символов в вашем редакторе и убедитесь, что они не изменяют логику выполнения программы.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1076. |
V1077. Conditional initialization inside the constructor may leave some members uninitialized.
Анализатор обнаружил конструктор, после выполнения которого могут остаться потенциально неинициализированные поля класса.
Рассмотрим простой синтетический пример:
struct Cat
{
int age;
Cat(bool isKitten)
{
if (isKitten)
{
age = 3;
}
}
};Если при конструировании объекта типа 'Cat' в качестве фактического параметра будет передано значение 'false', то нестатическое поле класса 'age' не будет проинициализировано. Последующий доступ к этому полю приведет к неопределённому поведению:
#include <iostream>
void Cat()
{
Cat instance { false };
std::cout << instance.x << std::endl; // UB
}Корректный конструктор может выглядеть следующим образом:
Cat(bool isKitten) : age { 0 }
{
if (isKitten)
{
age = 3;
}
}Если допускается, что какой-либо член класса может остаться неинициализированным после выполнения конструктора, то можно подавить для них предупреждения специальным комментарием "//-V1077_NOINIT":
struct Cat
{
int age; //-V1077_NOINIT
Cat(bool isKitten)
{
if (isKitten)
{
age = 3; // ok
}
}
};Вы можете подавить предупреждение, отметив конструктор комментарием "//-V1077". Вы также можете применить механизм массового подавления для устранения ложных срабатываний.
Диагностика также поддерживает возможность отключить предупреждения на все поля классов определенного типа. Для этого используется тот же комментарий, что и в диагностике V730 (поиск неинициализированных членов класса в конструкторах).
Рассмотрим формат комментария:
//+V730:SUPPRESS_FIELD_TYPE, class:className, namespace:nsNameЕсли указать в качестве аргумента параметра 'class' класс с названием 'className', то поля этого типа будут рассматриваться как исключения в диагностике V1077 и V730. Рассмотрим пример:
//+V730:SUPPRESS_FIELD_TYPE, class:Field
struct Field
{
int f;
};
class Test
{
Field someField;
public:
Test(bool cond, int someValue)
{
if (cond)
{
someField.f = someValue; // ok
}
}
};При указании специального комментария анализатор не будет выдавать предупреждение на поля, имеющие тип 'Field' ('someField' в нашем случае).
Для вложенных классов используется следующий синтаксис:
//+V730:SUPPRESS_FIELD_TYPE, class:className.NestedClassName,
namespace:nsNameКаждый вложенный класс отделяется точкой: "className.NestedClassName".
Мы не стали вводить отдельный комментарий для V1077 по следующим причинам. Если тип отмечен комментарием для V730, значит предполагается, что его экземпляры могут быть не проинициализированы вообще, а значит выдавать для него V1077 тоже бессмысленно. К тому же, если у вас уже есть разметка для V730, она будет работать и для V1077.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
V1078. An empty container is iterated. The loop will not be executed.
Анализатор обнаружил ситуацию, в которой производится попытка обхода пустого контейнера. В результате не произойдет ни одной итерации цикла, что может свидетельствовать об ошибке.
Рассмотрим следующий пример, который может возникнуть вследствие неудачного рефакторинга:
#include <vector>
#include <string_view>
std::vector<std::string_view> GetSystemPaths()
{
std::vector<std::string_view> paths;
#ifdef _WIN32
paths.emplace_back("C:/Program files (x86)/Windows Kits");
paths.emplace_back("C:/Program Files (x86)/Microsoft Visual Studio");
#elif defined(__APPLE__)
paths.emplace_back("/Applications");
paths.emplace_back("/Library");
paths.emplace_back("/usr/local/Cellar");
#elif defined(__linux__)
// TODO: Don't forget to add some specific paths
#endif
return paths;
}
bool IsSystemPath(std::string_view path)
{
static const auto system_paths = GetSystemPaths();
for (std::string_view system_path : system_paths)
{
if (system_path == path)
{
return true;
}
}
return false;
}Наполнение контейнера 'system_paths' зависит от операционной системы, под которую компилируется приложение. Для операционной системы семейства Linux и всех остальных, кроме Windows и macOS, в результате раскрытия директив препроцессора будет получен пустой контейнер.
В контексте этого примера это нежелательное поведение функции 'GetSystemPaths'. В случае с Linux, для исправления предупреждения, нужно добавить необходимые пути. При компиляции на новую операционную систему (например, FreeBSD) разработчику, возможно, стоит выдать ошибку при помощи static_assert. Возможное исправление кода:
#include <vector>
#include <string_view>
std::vector<std::string_view> GetSystemPaths()
{
std::vector<std::string_view> paths;
#ifdef _WIN32
....
#elif defined(__APPLE__)
....
#elif defined(__linux__)
paths.emplace_back("/usr/include/");
paths.emplace_back("/usr/local/include");
#else
static_assert(false, "Unsupported OS.");
#endif
return paths;
}В общем случае, если итерирование пустого контейнера было специально задумано программистом, то предупреждение можно подавить.
V1079. Parameter of 'std::stop_token' type is not used inside function's body.
Диагностическое правило сигнализирует о том, что функция принимает параметр типа 'std::stop_token' и никак не использует его. Такой код потенциально может привести к проблемам.
Начиная со стандарта C++20 в стандартной библиотеке появился класс 'std::jthread'. Это альтернатива классу 'std::thread', которая имеет две новых возможности. Первая — автоматическое присоединение, которое достигается за счёт вызова функций 'request_stop' и 'join' в деструкторе. Вторая — возможность прерывания этого потока при помощи объекта класса 'std::stop_token'. Рассмотрим синтетический пример:
#include <thread>
#include <vector>
struct HugeStruct { .... };
HugeStruct LoadHugeData(std::string_view key);
void worker(std::stop_token st, ....)
{
auto keys = ....;
for (auto key : keys)
{
auto data = LoadHugeData(key);
// Do something with data
}
}
void foo()
{
using namespace std::literals;
std::jthread thread { worker };
// ....
}Функция производит последовательную загрузку данных большого размера. Реализация имеет возможность прерывания такой операции, однако параметр 'st' для получения сигнала об остановке не используется. Такой код выглядит подозрительно и помечается анализатором как место потенциальной ошибки.
В качестве исправления можно предложить следующий вариант:
#include <thread>
#include <vector>
struct HugeStruct { .... };
HugeStruct LoadHugeData(std::string_view key);
void worker(std::stop_token st, ....)
{
auto keys = ....;
for (auto key : keys)
{
if (st.stop_requested())
{
// Stop execution here
}
auto data = LoadHugeData(key);
// Do something with data
}
}
void foo()
{
using namespace std::literals;
std::jthread thread { worker };
// ....
}Теперь последовательная загрузка данных может быть прервана. Функция 'worker' прекратит загрузку элементов в случае получения запроса отмены операции (функции 'request_stop') из другого потока.
V1080. Call of 'std::is_constant_evaluated' function always returns the same value.
Диагностическое правило сигнализирует о том, что возвращаемое значение функции 'std::is_constant_evaluated' никогда не изменится. Это может привести к недостижимому коду.
В рамках данного правила будут рассматриваться две ситуации:
- Данная функция вызывается в контексте, который всегда является контекстом времени компиляции и вернёт 'true'.
- Данная функция вызывается в контексте, который всегда является контекстом времени выполнения и вернёт 'false'.
Рассмотрим пример: мы хотим реализовать функцию, в которой будет две версии одного алгоритма, для времени компиляции и для времени выполнения. Для разграничения реализаций будет использоваться функция 'std::is_constant_evaluated'.
#include <type_traits>
constexpr void foo()
{
constexpr auto context = std::is_constant_evaluated();
//....
if (context)
{
// compile-time logic
}
else
{
// runtime logic
}
}В данном случае функция 'std::is_constant_evaluated' всегда возвращает 'true'. В 'else'-ветке находится недостижимый код.
Обратная ситуация может возникнуть, если мы уберём спецификатор 'constexpr' с переменной 'context' и функции 'foo'.
#include <type_traits>
void foo()
{
auto context = std::is_constant_evaluated();
//....
if (context)
{
// compile-time logic
}
else
{
// runtime logic
}
}Здесь переменная 'context' всегда 'false', и код недостижим уже в 'then'-ветке.
Функция 'std::is_constant_evaluated' всегда вернёт 'true', если вызов происходит:
- внутри 'static_assert';
- внутри 'consteval' функции;
- внутри условия 'if constexpr'.
Функция 'std::is_constant_evaluated' всегда вернёт 'false', если вызов происходит:
- внутри функции, непомеченной спецификаторами 'constexpr' / 'consteval'.
Данная диагностика классифицируется как:
V1081. Argument of abs() function is minimal negative value. Such absolute value can't be represented in two's complement. This leads to undefined behavior.
Наименьшее отрицательное значение знакового целочисленного типа не имеет соответствующей положительной величины. В результате вычисления модуля числа от такого значения функциями 'abs', 'labs', 'llabs' возникает переполнение. Это приводит к неопределённому поведению.
Рассмотрим пример:
#include <iostream>
#include <cmath>
#include <limits.h>
int main()
{
int min = INT_MIN;
// error: abs(-2147483648) = -2147483648
std::cout << "abs(" << min << ") = "
<< abs(min); // <=
return 0;
}Минимальное значение 32-битного знакового типа 'int' имеет значение 'INT_MIN', равное -2147483648. При этом максимальное значение 'INT_MAX' равно 2147483647, что на единицу меньше, чем настоящий модуль числа 'INT_MIN'. В данном случае в результате вычисления модуля получилось отрицательное число, равное исходному значению аргумента. Это может привести к ошибке в пограничном случае, когда код не рассчитан на обработку отрицательных чисел, полученных после вычисления модуля числа.
Для остальных значений функция вычисления модуля будет вести себя ожидаемым образом:
int main()
{
int notQuiteMin = INT_MIN + 1;
// ok: abs(-2147483647) = 2147483647
std::cout << "abs(" << notQuiteMin << ") = "
<< abs(notQuiteMin);
return 0;
}Возможно, перед расчётом модуля стоит сделать специальную проверку значения аргумента, чтобы не допустить возникновения пограничного случая:
void safe_abs_call(int value)
{
if (value == INT_MIN)
return;
std::cout << "abs(" << value << ") = " << abs(value);
}Срабатывание диагностики можно подавить в случаях, если де-факто диапазон передаваемых функциям 'abs', 'labs' и 'llabs' значений не может достигать минимальной величины.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
V1082. Function marked as 'noreturn' may return control. This will result in undefined behavior.
Анализатор обнаружил функцию, обозначенную как невозвращающую управление, которая тем не менее может вернуть управление на какой-либо из веток выполнения.
Рассмотрим в начале корректный пример:
[[ noreturn ]] void q() {
throw "error"; // OK
}Функция 'q' прервет своё выполнение броском исключения. Дальнейшее выполнение программы перейдет обработчику исключения, а не вызвавшему эту функцию коду. При этом компилятор понимает, что следующий за вызовом функции 'q' код будет недостижим и его можно оптимизировать.
[[ noreturn ]] void f(int i) { // behavior is undefined
// if called with an argument <= 0
if (i > 0)
throw "positive";
}То же самое случится при вызове функции 'f' с положительным значением аргумента. Однако если в процессе выполнения программы в функцию 'f' будет передано отрицательное значение или ноль, то согласно стандарту C++ возникнет неопределенное поведение:
9.12.9 Noreturn attribute [dcl.attr.noreturn]
2. If a function f is called where f was previously declared with the noreturn attribute and f eventually returns, the behavior is undefined.
Данная диагностика классифицируется как:
|
V1083. Signed integer overflow in arithmetic expression. This leads to undefined behavior.
Анализатор обнаружил арифметическое выражение, в котором может произойти переполнение знакового числа.
Рассмотрим пример:
long long foo()
{
long longOperand = 0x7FFF'FFFF;
long long y = longOperand * 0xFFFF;
return y;
}По правилам C и C++ результирующим типом выражения longOperand * 0xFFFF будет long. При использовании компилятора MSVC на Windows тип long имеет размер 4 байта. Максимальное значение, которое может быть представлено этим типом, равно 2'147'483'647 в десятичной системе или 0x7FFF'FFFF в шестнадцатеричной. При умножении переменной longOperand на 0xFFFF (65 535) ожидается результат 0x7FFF'7FFF'0001. Однако согласно стандарту C (см. стандарт С18 пункт 6.5 параграф 5) и C++ (см. стандарт С++20 пункт 7.1 параграф 4) переполнение знаковых чисел приводит к неопределённому поведению.
Исправить этот код можно несколькими способами.
Если требуется произвести корректные вычисления, необходимо использовать типы, размеры которых будут достаточны для отображения чисел. Если число не помещается в машинное слово, то можно воспользоваться одной из библиотек для работы с длинной арифметикой. Например, GMP, MPRF, cnl.
Пример выше можно исправить следующим образом:
long long foo()
{
long longOperand = 0x7FFF'FFFF;
long long y = static_cast<long long>(longOperand) * 0xFFFF;
return y;
}Если переполнение знаковых чисел является неожидаемым поведением и требует обработки, то можно воспользоваться специальными библиотеками для безопасной работы с числами. Например, boost::safe_numerics или Google Integers.
Если требуется реализовать циклическую арифметику для знаковых чисел с определённым по стандарту поведением, то для расчётов можно воспользоваться беззнаковыми числами. В случае их переполнения происходит "оборачивание" числа по модулю 2 ^ n, где n — количество бит в числе.
Рассмотрим одно из возможных решений на основе std::bit_cast (C++20):
#include <concepts>
#include <type_traits>
#include <bit>
#include <functional>
namespace detail
{
template <std::signed_integral R,
std::signed_integral T1,
std::signed_integral T2,
std::invocable<std::make_unsigned_t<T1>,
std::make_unsigned_t<T2>> Fn>
R safe_signed_wrapper(T1 lhs, T2 rhs, Fn &&op)
noexcept(std::is_nothrow_invocable_v<Fn,
std::make_unsigned_t<T1>,
std::make_unsigned_t<T2>>)
{
auto uLhs = std::bit_cast<std::make_unsigned_t<T1>>(lhs);
auto uRhs = std::bit_cast<std::make_unsigned_t<T2>>(rhs);
auto res = std::invoke(std::forward<Fn>(op), uLhs, uRhs);
using UR = std::make_unsigned_t<R>;
return std::bit_cast<R>(static_cast<UR>(res));
}
}Функция std::bit_cast приводит lhs' и 'rhs к соответствующим беззнаковым представлениям. Далее на двух преобразованных операндах выполняется некоторая арифметическая операция. Затем результат расширяется или сужается до нужного результирующего типа и превращается в знаковый.
При таком подходе знаковые числа будут повторять семантику беззнаковых в арифметических операциях, что исключает неопределённое поведение.
Например, по этой ссылке можно увидеть, что компилятор вправе оптимизировать код, если существует вероятность переполнения знакового числа.
Рассмотрим пример подробнее:
bool is_max_int(int32_t a)
{
return a + 1 < a;
}Если a равно MAX_INT, то условие a + 1 < a будет равно false. Таким образом часто проверяют не произошло ли переполнение.
Однако компилятор генерирует такой код:
is_max_int(int): # @is_max_int(int)
xor eax, eax
retИнструкция ассемблера xor eax, eax обнуляет результат выполнения функции is_max_int. В результате последняя всегда возвращает true вне зависимости от значения a. В данном случае это результат неопределённого поведения при переполнении.
В случае применения беззнакового представления такого не происходит:
is_max_int(int): # @is_max_int(int)
cmp edi, 2147483647
sete al
retКомпилятор сгенерировал код, который проверяет условие.
Примечание. Диагностическое правило поддерживает специальную настройку, позволяющую анализатору обнаруживать переполнение как знаковых, так и беззнаковых числовых типов.
Для активации этой настройки необходимо добавить следующий комментарий в исходный код или в файл конфигурации диагностических правил .pvsconfig:
//+V1083 CHECK_UNSIGNED_OVERFLOW:YES
Чтобы отключить настройку, используйте комментарий:
//+V1083 CHECK_UNSIGNED_OVERFLOW:NO
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1083. |
V1084. The expression is always true/false. The value is out of range of enum values.
Анализатор обнаружил странное сравнение переменной перечисления с числом. Указанное число не входит в диапазон значений перечисления, поэтому такое сравнение не имеет смысла.
Если у перечисления указан нижележащий тип, то с переменной такого перечисления имеет смысл сравнивать только значения, которые можно уместить в этот тип.
Рассмотрим следующий пример:
enum byte : unsigned char {}; // Range: [0; 255]
void foo(byte b1)
{
if (b1 == 256) // logic error : always false
{
//....
}
}Перечисление 'byte' имеет нижележащий тип 'unsigned char'. Число 256 не вмещается в тип 'unsigned char', поэтому сравнение 'b1 == 256' всегда ложное.
Пример корректного сравнения:
enum byte : unsigned char {}; // Range: [0; 255]
void foo(byte b1)
{
if (b1 == 255) // ok
{
//....
}
}Более сложным случаем является перечисление без явного указания нижележащего типа.
Для языка C компилятор всегда использует тип 'int' в качестве нижележащего типа. Диапазоном значений перечисления будет весь диапазон 'int'.
Для языка C++ компилятор подставит в качестве нижележащего типа 'int' для строго типизированных перечислений (scoped enum). Диапазоном значений такого перечисления также будет весь диапазон 'int'.
Для обычных перечислений вычисление диапазона значений и нижележащего типа перечисления происходит особым образом. Согласно стандарту С++, компилятор выведет нижележащий тип на основе значений констант перечисления, пытаясь уместить их в следующие типы:
int -> unsigned int -> long -> unsigned long ->
long long -> unsigned long longПри этом внутри выбранного типа компилятор использует минимально необходимое число бит (n), способное уместить весь диапазон констант в перечислении. Такие перечисления смогут обрабатывать диапазон значений [- (2 ^ n) / 2; (2 ^ n) / 2 - 1] для знакового и [0; (2 ^ n) - 1] для беззнакового нижележащего типа соответственно.
Поэтому следующий код на языке C++ содержит ошибку, если используется компилятор, отличный от MSVC (например, GCC или Clang):
enum EN { low = 2, high = 4 }; // Uses 3 bits, range: [0; 7]
void foo(EN en1)
{
if (en1 != 8) // logic error : always true
{
//....
}
}Согласно стандарту C++, нижележащим типом для этого перечисления выберется 'int'. Внутри этого типа компилятор использует минимальное количество битовых полей, которое сможет вместить в себя все значения enum-констант.
В данном случае для вмещения всех значений (2 = 0b010 и 4 = 0b100) понадобится минимум 3 бита, поэтому переменная типа 'EN' может вместить в себя числа от 0 (0b000) до 7 (0b111) включительно. Число 8 занимает уже четыре бита (0b1000), поэтому в тип 'EN' оно уже не вмещается. Чтобы исправить ошибку, можно явно указать нижележащий тип:
enum EN : int32_t { low = 2, high = 4 };
// Now range is: [−2 147 483 648, 2 147 483 647]
void foo(EN en1)
{
if (en1 != 8) // ok
{
//....
}
}Не все C++ компиляторы рассчитывают фактический размер перечисления согласно стандарту. Например, MSVC при компиляции C++ кода отходит от стандарта и рассчитывает размер перечисления в целях обратной совместимости по правилам языка C. Поэтому в качестве нижележащего типа MSVC всегда использует тип 'int', если специально не указан иной тип. В таком случае диапазоном значений перечисления будет диапазон 'int'. Поэтому в рассмотренном выше примере нет ошибки, если вы используете MSVC:
enum EN { low = 2, high = 4 };
// MSVC will use int as underlying type
// range is: [−2 147 483 648, 2 147 483 647]
void foo(EN en1)
{
if (en1 != 8) // no logic error
{
//....
}
}Однако писать такой код не стоит, потому что он будет непереносим на другие компиляторы. Следует явно указать 'int' в качестве нижележащего типа.
Если вы используете только компилятор MSVC и вас не интересует переносимость на другие компиляторы, то вы можете отключить предупреждения диагностики о непереносимости кода с помощью комментария:
//-V1084_TURN_OFF_ON_MSVCПредупреждения V1084, актуальные для MSVC, останутся.
Данная диагностика классифицируется как:
|
V1085. Negative value is implicitly converted to unsigned integer type in arithmetic expression.
Анализатор обнаружил ситуацию, в которой в арифметическом выражении происходит конвертация отрицательного числа к беззнаковому типу. Согласно правилам неявного преобразования C/C++, знаковое число той же размерности, что и беззнаковое, превращается в беззнаковое. При приведении отрицательного числа к беззнаковому типу происходит его "оборачивание" по модулю '(2 ^ n) + 1', где n – количество бит в числе. Такая ситуация не приводит к неопределённому поведению, но может привести к неожиданным результатам.
Рассмотрим пример:
void foo()
{
char *p = (char *) 64;
int32_t a = -8;
uint32_t b = 8;
p = p + a * b;
}На 32-битной системе в указателе получается 0x0. На 64-битной – 0x0000'0001'0000'0000, что может быть неожиданно для программиста. Давайте разберёмся, почему так происходит.
Переменная 'a' имеет знаковый тип 'int32_t'. Это означает, что её размер — 4 байта и она может принимать значения в диапазоне от -2'147'483'648 до 2'147'483'647. Переменная 'b' имеет тип 'uint32_t'. Она также имеет размер в 4 байта, но, в отличие от переменной 'a', может принимать значения в диапазоне от 0 до 4'294'967'295. Так происходит потому, что старший бит в знаковом числе зарезервирован под знак. Из-за этого ограничения максимальное значение знакового числа вдвое меньше, чем у беззнакового.
По правилам языка C++, если в бинарной операции операнды имеют типы с одинаковым рангом и один из операндов имеет знаковый тип, а другой — беззнаковый, то операнд, который имеет знаковый тип, неявно приводится к беззнаковому.
В выражении 'a * b' типы операндов ('int32_t' и 'uint32_t') имеют одинаковый ранг. Следовательно, операнд 'a', который хранит в себе значение '-8' неявно приводится к беззнаковому типу 'uint32_t'. В результате такого приведения его значение становится равным 4'294'967'288. Далее происходит умножение на переменную 'b', которая хранит значение '8'. Полученный результат, который равен 34'359'738'304, выходит за рамки диапазона возможных значений переменной типа 'uint32_t' и будет обернут по модулю '2 ^ 32'. Таким образом, результат выражения 'a * b' будет равен 34'359'738'304 % 4'294'967'296 = 4'294'967'232.
У оператора сложения 'p + a * b' типы операндов 'char *' и 'uint32_t' соответственно. Согласно стандарту C++, результирующий тип будет 'char *', а результат – сумма левого и правого операндов. При сложении 64 и 4'294'967'232 результат равен 4'294'967'296.
На 32-битной платформе размер указателя равен 4 байтам. Следовательно, его максимальное значение равно 4'294'967'295. Так как число 4'294'967'296 больше, то результат оборачивается по модулю '2 ^ 32', как и в предыдущей операции сложения, и будет равен 4'294'967'296 % 4'294'967'296 = 0. В итоге результат выражения 'p + a * b' равен нулю.
На 64-битной платформе размер указателя равен 8 байтам. И в отличие от 32-битной платформы его максимальное значение куда больше, чем 4'294'967'296. Так как оборачивания не будет происходить, то результат выражения 'p + a * b' равен 4'294'967'296 в десятичной системе или 0x0000'0001'0000'0000 в шестнадцатеричной.
Исправить приведённый выше пример можно, использовав знаковые типы для вычислений:
void foo()
{
char *p = (char *) 64;
int32_t a = -8;
uint32_t b = 8;
p = p + a * static_cast<int32_t>(b);
}Диагностика не будет сообщать обо всех конвертациях знаковых типов к беззнаковым. Это будет происходить только в тех выражениях, результат вычислений которых будет отличаться от такового при использовании только знаковых типов. Рассмотрим пример:
void foo()
{
unsigned num = 1;
unsigned res1 = num + (-1); // ok
unsigned res5 = num + (-2); //+V1085
unsigned res2 = num - (-1); // ok
unsigned res3 = num * (-1); //+V1085
unsigned res4 = num / (-1); //+V1085
unsigned res6 = num / (-2); // ok
unsigned num2 = 2;
unsigned res7 = num2 / (-1); //+V1085
}В строчках, отмеченных комментарием 'ok', не будет предупреждения V1085. Приведём результаты вычислений каждого выражения со знаковыми и беззнаковыми вариантами:
num + (signed)(-1) => 1 + (-1) => 0
num + (unsigned)(-1) => 1 + 4294967295 = 0
num + (signed)(-2) => 1 + (-2) => -1
num + (unsigned)(-2) => 1 + 4294967294 = 4294967295
num - (signed)(-1) => 1 – (-1) => 2
num - (unsigned)(-1) => 1 – (4294967295) => 2
num * (signed)(-1) => 1 * (-1) => -1
num * (unsigned)(-1) => 1 * (4294967295) => 4294967295
num / (signed)(-1) => 1 / (-1) => -1
num / (unsigned)(-1) => 1 / 4294967295 => 0
num / (signed)(-2) => 1 / (-2) => 0
num / (unsigned)(-2) => 1 / 4294967294 => 0
num2 / (signed)(-2) => 2 / (-2) => -1
num2 / (unsigned)(-2) => 2 / 4294967294 => 0В тех местах, где результаты совпадают, предупреждение будет отсутствовать.
Примечание. Рассмотренные проблемы пересекаются с темой переноса приложений с 32-битных на 64-битные системы. См. статью: "Коллекция примеров 64-битных ошибок в реальных программах".
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
V1086. Call of the 'Foo' function will lead to buffer underflow.
Анализатор обнаружил потенциально возможную ошибку, связанную с заполнением, копированием или сравнением буферов памяти. Ошибка может приводить к неполной обработке буфера (buffer underflow).
Примечание: ранее данная диагностика была частью другой диагностики – V512, но позже мы решили разделить их. О причинах и последствиях такого решения можно прочитать в специальной заметке.
Это достаточно распространённый вид ошибки, возникающий из-за опечаток или невнимательности. В результате может произойти неполная очистка данных и, как следствие, в дальнейшем использование неинициализированной/повреждённой памяти. Неприятность подобных ошибок заключается в том, что программа долгое время может работать стабильно.
Рассмотрим два примера, взятых из реальных приложений.
Пример N1:
MD5Context *ctx;
....
memset(ctx, 0, sizeof(ctx));Здесь из-за опечатки нулями заполняется не вся структура, а только её часть. Ошибка в том, что вычисляется размер указателя, а не структуры 'MD5Context'. Корректный вариант кода:
MD5Context *ctx;
....
memset(ctx, 0, sizeof(*ctx));Пример N2:
#define CONT_MAP_MAX 50
int _iContMap[CONT_MAP_MAX];
memset(_iContMap, -1, CONT_MAP_MAX);В данном примере также неверно указан размер заполняемого буфера. Корректный вариант:
#define CONT_MAP_MAX 50
int _iContMap[CONT_MAP_MAX];
memset(_iContMap, -1, CONT_MAP_MAX * sizeof(int));Совместимость с предыдущими версиями
Ранее диагностическое правило было частью другой диагностики – V512. В целях обеспечения обратной совместимости осталась возможность отключить данную диагностику с помощью специального комментария:
//-V512_UNDERFLOW_OFFЭтот комментарий может быть вписан в заголовочный файл, который включается во все другие файлы. Например, это может быть "stdafx.h". Если вписать этот комментарий в "*.cpp" файл, то он будет действовать только для этого файла.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки использования неинициализированных переменных. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1086. |
V1087. Upper bound of case range is less than its lower bound. This case may be unreachable.
Анализатор обнаружил ситуацию, когда верхняя граница диапазона в метке 'case' меньше, чем его нижняя граница. Возможно, это опечатка, из-за которой часть кода может быть недостижима.
В компиляторах GCC и Clang существует расширение Case Ranges, которое позволяет вместо единственного значения метки 'case' указать диапазон константных значений. Такой диапазон будет аналогичен последовательности меток 'case', включая граничные значения:
switch (....)
{
case 1 ... 3:
// Do something
break;
}
// Similar to the previous 'switch' statement
switch (....)
{
case 1:
case 2:
case 3:
// Do something
break;
}Однако если верхняя граница указанного диапазона будет меньше, чем его нижняя граница, то диапазон будет считаться пустым. Если указать такой диапазон, то при проверке условия управление никогда не сможет быть передано метке. Следовательно, ветка кода может быть недостижимой.
Рассмотрим синтетический пример:
void foo(int i)
{
switch (i)
{
case 1 ... 3:
// First case
break;
case 6 ... 4: // <=
// Second case
break;
case 7 ... 9:
// Third case
break;
}
}Здесь во второй метке были перепутаны местами константы '4' и '6', из-за чего управление никогда не будет передано метке. Исправленный пример:
void foo(int i)
{
switch (i)
{
case 1 ... 3:
// First case
break;
case 4 ... 6: // <=
// Second case
break;
case 7 ... 9:
// Third case
break;
}
}Ошибка такого рода может возникнуть при неверном использовании именованных констант или значений, возвращаемых 'constexpr'-функциями. Рассмотрим синтетический пример:
constexpr int for_yourself_min() noexcept { return 1; }
constexpr int for_yourself_max() noexcept { return 3; }
constexpr int for_neighbors_min() noexcept { return 4; }
constexpr int for_neighbors_max() noexcept { return 6; }
void distributeCats(int count)
{
switch (count)
{
case for_yourself_min() ... for_yourself_max():
// Keep for yourself
break;
case for_neighbors_max() ... for_neighbors_min(): // <=
// Give cats to neighbors
break;
default:
// Give cats to a cattery
break;
}
}Во второй метке из-за опечатки вызовы функций были перепутаны местами, и управление никогда не будет передано метке. Исправленный пример:
constexpr int for_yourself_min() noexcept { return 1; }
constexpr int for_yourself_max() noexcept { return 3; }
constexpr int for_neighbors_min() noexcept { return 4; }
constexpr int for_neighbors_max() noexcept { return 6; }
void distributeCats(int count)
{
switch (count)
{
case for_yourself_min() ... for_yourself_max():
// Keep for yourself
break;
case for_neighbors_min() ... for_neighbors_max(): // <=
// Give cats to neighbors
break;
default:
// Give cats to a cattery
break;
}
}Однако неправильный диапазон не всегда ведет к недостижимому коду. Если в метке 'case' выше отсутствует 'break', то после выполнения его ветки управление будет передано в 'case' с пустым диапазоном. Синтетический пример:
void foo(int i)
{
switch (i)
{
case 0: // no break
case 3 ... 1:
// First and second case
break;
case 4:
// Third case
default:
// Do something
}
}Несмотря на достижимость кода, пустой диапазон выглядит странно и бессмысленно. Это может быть опечатка или неправильное раскрытие макросов. Поэтому отсутствие 'break' в метке выше не является исключением для диагностики, а предупреждение будет выдано.
Данная диагностика классифицируется как:
V1088. No objects are passed to the 'std::scoped_lock' constructor. No locking will be performed. This can cause concurrency issues.
Анализатор обнаружил ситуацию, при которой объект типа 'std::scoped_lock' конструируется без переданных ему аргументов, т.е. без захвата объектов блокировки. Это может привести к проблемам в многопоточном приложении: состоянию гонки, гонке данных и т.д.
Начиная с C++17, в стандартной библиотеке присутствует шаблон класса 'std::scoped_lock'. Он был внедрен в качестве удобной альтернативы 'std::lock_guard', когда требуется захватить произвольное число объектов блокировки за раз. При этом используется алгоритм, позволяющий избежать взаимных блокировок.
Однако дизайн нового типа содержит определенные недостатки. Рассмотрим объявление одного из его конструкторов:
template <class ...MutexTypes>
class scoped_lock
{
// ....
public:
explicit scoped_lock(MutexTypes &...m);
// ....
};Конструктор принимает произвольное число аргументов типа 'MutexTypes' (parameter pack). Возможны ситуации, когда parameter pack 'MutexTypes' может быть пустым. Вследствие этого возможно создание RAII-объекта без блокировок:
void bad()
{
// ....
std::scoped_lock lock;
// ....
}Для исправления стоит инициализировать 'std::scoped_lock' объектом блокировки:
std::mutex mtx;
void good()
{
// ....
std::scoped_lock lock { mtx };
// ....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
V1089. Waiting on condition variable without predicate. A thread can wait indefinitely or experience a spurious wake-up.
Диагностическое правило основано на пункте CP.42 CppCoreGuidelines.
Анализатор обнаружил ситуацию, в которой одна из нестатических функций-членов класса 'std::condition_variable' – 'wait', 'wait_for' или 'wait_until' – вызывается без предиката. Это может привести к проблемам: ложному пробуждению потока или его зависанию.
Рассмотрим пример N1, приводящий к потенциальному зависанию:
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cond;
void consumer()
{
std::unique_lock<std::mutex> lck { mtx };
std::cout << "Waiting... " << std::endl;
cond.wait(lck); // <=
std::cout << "Working..." << std::endl;
}
void producer()
{
{
std::lock_guard<std::mutex> _ { mtx };
std::cout << "Preparing..." << std::endl;
}
cond.notify_one();
}
int main()
{
std::thread c { consumer };
std::thread p { producer };
c.join();
p.join();
}В примере есть состояние гонки. Программа может зависнуть, если она выполнится в следующем порядке:
- поток 'p' выигрывает гонку, захватывает мьютекс первым, печатает сообщение в 'std::cout' и отпускает мьютекс;
- поток 'c' захватывает мьютекс, но не успевает встать на ожидание через условную переменную 'cond';
- поток 'p' оповещает о наступившем событии, отправляя уведомление через вызов 'cond.notify_one()';
- поток 'c' встает на ожидание через условную переменную 'cond', ожидая нотификации.
Для исправления следует модифицировать код следующим образом:
- Поток, который производит оповещение, должен изменить некоторое общее наблюдаемое состояние под блокировкой мьютекса. Например, булеву переменную.
- Поток-обработчик должен вызвать перегрузку 'std::condition_variable::wait', принимающую предикат. Внутри него нужно проверить, произошло ли изменение общего состояния или нет.
Исправленный пример:
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cond;
bool pendingForWorking = false; // <=
void consumer()
{
std::unique_lock<std::mutex> lck { mtx };
std::cout << "Waiting... " << std::endl;
cond.wait(lck, [] { return pendingForWorking; }); // <=
std::cout << "Working..." << std::endl;
}
void producer()
{
{
std::lock_guard<std::mutex> _ { mtx };
pendingForWorking = true; // <=
std::cout << "Preparing..." << std::endl;
}
cond.notify_one();
}
int main()
{
std::thread c { consumer };
std::thread p { producer };
c.join();
p.join();
}Рассмотрим пример N2, в котором может произойти ложное пробуждение:
#include <iostream>
#include <fstream>
#include <sstream>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
std::queue<int> queue;
std::mutex mtx;
std::condition_variable cond;
void do_smth(int);
void consumer()
{
while (true)
{
int var;
{
using namespace std::literals;
std::unique_lock<std::mutex> lck { mtx };
if (cond.wait_for(lck, 10s) == std::cv_status::timeout) // <=
{
break;
}
var = queue.front();
queue.pop();
}
do_smth(var);
}
}
void producer(std::istream &in)
{
int var;
while (in >> var)
{
{
std::lock_guard<std::mutex> _ { mtx };
queue.push(var);
}
cond.notify_one();
}
}
void foo(std::ifstream &fin, std::istringstream &sin)
{
std::thread p1 { &producer, std::ref(fin) };
std::thread p2 { &producer, std::ref(sin) };
std::thread p3 { &producer, std::ref(std::cin) };
std::thread c1 { &consumer };
std::thread c2 { &consumer };
std::thread c3 { &consumer };
p1.join(); p2.join(); p3.join();
c1.join(); c2.join(); c3.join();
}Ложное пробуждение – явление, при котором ожидающий поток пробуждается и обнаруживает, что условие, которое он ожидал, не выполнено. Это может произойти в двух сценариях:
- Оповещающий поток меняет общее состояние и отправляет нотификацию. Один поток-обработчик пробуждается, обрабатывает общее состояние и засыпает. Другой поток-обработчик также пробуждается от нотификации, но обнаруживает, что общее состояние уже обработано.
- Ожидающий поток пробудился, даже если оповещающий поток ещё не отправил нотификацию. Такое может происходить в некоторых реализациях многопоточных API, например, WinAPI, POSIX Threads и др.
В примере N2 ложное пробуждение может произойти в потоках 'c1', 'c2' и 'c3'. В результате такого пробуждения очередь может оказаться пустой, и доступ к ней приведёт к неопределенному поведению.
Для исправления следует также вызвать перегрузку 'std::condition_variable::wait_for', принимающую предикат. Внутри него нужно проверить, пуста очередь или нет:
void consumer()
{
while (true)
{
int var;
{
using namespace std::literals;
std::unique_lock<std::mutex> lck { mtx };
bool res = cond.wait_for(lck,
10s,
[] { return !queue.empty(); }); // <=
if (!res)
{
break;
}
// no spurious wakeup
var = queue.front();
queue.pop();
}
do_smth(var);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1089. |
V1090. The 'std::uncaught_exception' function is deprecated since C++17 and is removed in C++20. Consider replacing this function with 'std::uncaught_exceptions'.
Анализатор обнаружил вызов функции 'std::uncaught_exception'. Применение этой функции может привести к неверной логике программы. Начиная с C++17, она признана устаревшей и должна быть заменена на функцию 'std::uncaught_exceptions'.
Функция 'std::uncaught_exception' обычно применяется для того, чтобы понять, вызывается ли код при раскрутке стека. Рассмотрим пример:
constexpr std::string_view defaultSymlinkPath = "system/logs/log.txt";
class Logger
{
std::string m_fileName;
std::ofstream m_fileStream;
Logger(const char *filename)
: m_fileName { filename }
, m_fileStream { m_fileName }
{
}
void Log(std::string_view);
~Logger()
{
fileStream.close();
if (!std::uncaught_exception())
{
std::filesystem::create_symlink(m_fileName, defaultSymlinkPath);
}
}
};
class Calculator
{
public:
int64_t Calc(const std::vector<std::string> ¶ms);
// ....
~Calculator()
{
try
{
Logger logger("log.txt");
Logger.Log("Calculator destroyed");
}
catch (...)
{
// ....
}
}
}
int64_t Process(const std::vector<std::string> ¶ms)
{
try
{
Calculator calculator;
return Calculator.Calc(params);
}
catch (...)
{
// ....
}
}В деструкторе класса 'Logger' вызывается функция 'std::filesystem::create_symlink', которая может бросить исключение. Например, если для использования пути 'system/logs/log.txt' у программы недостаточно прав. Если деструктор 'Logger' будет вызван напрямую в результате раскрутки стека, то бросать исключения из этого деструктора нельзя – программа будет аварийно прервана через 'std::terminate'. Поэтому перед вызовом функции программист сделал дополнительную проверку 'if (!std::uncaught_exception())'.
Однако такой код содержит ошибку. Предположим, что функция 'Calc' бросила исключение. Тогда перед выполнением catch-clause произойдёт вызов деструктора 'Calculator'. В нём будет создан экземпляр класса 'Logger', в лог запишется сообщение. Затем будет вызван деструктор 'Logger'. Внутри него произойдёт вызов функции 'std::uncaught_exception'. Эта функция вернёт 'true', потому что исключение, брошенное функцией 'Calc', ещё не перехвачено. Поэтому символическая ссылка для файла с логом не будет создана.
Однако в данном случае можно попробовать создать символическую ссылку. Дело в том, что деструктор 'Logger' будет вызван не напрямую в результате раскрутки стека, а из деструктора 'Calculator'. Поэтому из деструктора 'Logger' можно бросить исключение — нужно только перехватить его до выхода из деструктора 'Calculator'.
Для исправления необходимо воспользоваться функцией 'std::uncaught_exceptions' из C++17:
class Logger
{
std::string m_fileName;
std::ofstream m_fileStream;
int m_exceptions = std::uncaught_exceptions(); // <=
Logger(const char *filename)
: m_fileName { filename }
, m_fileStream { m_fileName }
{
}
~Logger()
{
fileStream.close();
if (m_exceptions == std::uncaught_exceptions())
{
std::filesystem::create_symlink(m_fileName, defaultSymlinkPath);
}
}
};Теперь при создании объекта класса 'Logger' в поле 'm_exceptions' сохранится текущее количество неперехваченных исключений. Если между созданием объекта и вызовом его деструктора не было брошено новых исключений, то условие будет истинным. Поэтому программа попробует создать символическую ссылку для файла с логом. Если при этом будет брошено исключение, то оно будет перехвачено и обработано в деструкторе 'Calculator', и программа продолжит выполнение.
Данная диагностика классифицируется как:
V1091. The pointer is cast to an integer type of a larger size. Casting pointer to a type of a larger size is an implementation-defined behavior.
Анализатор обнаружил приведение указателя к интегральному типу большего размера. Результат может отличаться от ожидаемого программистом.
Согласно стандартам C и C++, результат такого выражения зависит от реализации. Ожидаемый программистом результат в большинстве реализаций будет совпадать тогда, когда указатель приводится к интегральному типу того же размера.
Рассмотрим следующий синтетический пример:
void foo()
{
const void *ptr = reinterpret_cast<const void *>(0x80000000);
uint64_t ui64 = reinterpret_cast<uint64_t>(ptr); // <=
}В примере указатель 'ptr' преобразуется в тип 'uint64_t', имеющий размер 8 байт. На 32-битной платформе размер указателя равен 4 байтам. Результат такого преобразования зависит от реализации компилятора.
Так, если используется компилятор GCC или MSVC, то в переменную 'ui64' будет записано число 0xffff'ffff'8000'0000. В то же время Clang запишет число 0x0000'0000'8000'0000.
Чтобы преобразовать 32-битный указатель в 64-битное число и избежать поведения, определённого реализацией, нужно сделать следующее:
- Преобразовать 32-битный указатель к 32-битному числу
- Преобразовать полученное 32-битное число к 64-битному числу
Для исправления сначала преобразуем указатель к 'uintptr_t'. Это целочисленный беззнаковый тип, размер которого всегда равен размеру указателя. Затем полученное 32-битное число преобразуем к 64-битному. Исправленный код:
void foo()
{
const void *ptr = reinterpret_cast<const void*>(0x80000000);
uint64_t ui64 = static_cast<uint64_t>(reinterpret_cast<uintptr_t>(ptr));
}Данная диагностика классифицируется как:
|
V1092. Recursive function call during the static/thread_local variable initialization might occur. This may lead to undefined behavior.
Анализатор обнаружил ситуацию, в которой при инициализации переменной со static storage duration или thread storage duration происходит цепочка вызовов, приводящая к рекурсии. Согласно стандарту C++, это приводит к неопределенному поведению.
Рассмотрим пример:
int foo(int i)
{
static int s = foo(2*i); // <= undefined behavior
return i + 1;
}При инициализации переменной 's' происходит рекурсивный вызов функции 'foo'. Анализатор в таком случае выдаст предупреждение V1092.
Чаще к рекурсии может привести цепочка вывозов, как в следующем примере:
int foo(int i);
int bar(int i)
{
return foo(i); // <=
}
int foo(int i)
{
static int s = bar(2*i); // <= V1092
return i + 1;
}Цепочка вызовов, приводящая к рекурсии, проходит через 'foo -> bar -> foo'.
Анализатор не будет выдавать предупреждение в случае, если цепочка вызовов проходит через недостижимый код. Рассмотрим пример:
int foo();
int bar()
{
if (false)
{
return foo(); // <= unreachable
}
return 0;
}
int foo()
{
static int x = bar(); // <= ok
return x;
}Цепочка вызовов так же проходит через 'foo -> bar -> foo'. Однако, путь от 'bar' к 'foo' недостижим.
V1093. The result of the right shift operation will always be 0. The right operand is greater than or equal to the number of bits in the left operand.
Анализатор обнаружил бессмысленное действие: левый операнд побитово сдвигается вправо на такое количество бит, что в результате всегда получает ноль.
Рассмотрим пример:
void Metazone_Get_Flag(unsigned short* pFlag, int index)
{
unsigned char* temp = 0;
unsigned char flag = 0;
if (index >= 8 && index < 32)
{
temp = (u8*)pFlag;
flag = (*temp >> index) & 0x01; // <=
}
// ....
}Если обратить внимание на условие оператора 'if', то можно увидеть, что значение переменной 'index' будет лежать в диапазоне [8 .. 31]. Под указателем 'temp' лежит значение типа 'unsigned char'. При операции сдвига левый операнд типа 'unsigned char' вследствие integral promotion расширится до 'int', и старшие биты будут заполнены нулевыми значениями. Соответственно, при сдвиге вправо на большее количество бит, чем было в числе до его преобразования, результатом операции будет 0.
Это значит, что приведённый выше код не имеет практического смысла и скорее всего содержит логическую ошибку или опечатку.
Примечание
Подобное предупреждение может выдаваться для макросов, которые раскрыты для краевых/вырожденных случаев. Другими словами, такие макросы не содержат ошибку и 0 будет являться вполне ожидаемым результатом выражения. Если вы пишете подобный код и не хотите, чтобы анализатор выдавал на него срабатывания, то вы можете подавить их при помощи специального комментария, который содержит имя вашего макроса и номер данного диагностического правила:
//-V:YOUR_MACRO_NAME:1093Полезные ссылки:
V1094. Conditional escape sequence in literal. Its representation is implementation-defined.
Анализатор обнаружил символьный или строковый литерал, который содержит условную экранирующую последовательность. В такой последовательности за символом обратной косой черты ('\') следует символ, который не принадлежит набору стандартных экранирующих последовательностей.
Пример:
FILE* file = fopen("C:\C\Names.txt", "r");Программист хочет открыть файл "C:\C\Names.txt". Однако в качестве разделителя директорий используется неэкранированная обратная косая черта, которая в свою очередь начинает экранирующие последовательности '\C' и '\N'. Начиная с версии стандарта C++23, представление таких символов зависит от реализации компилятора. Например, экранирующий '\' может быть проигнорирован, и тогда будет использован следующий за ним символ. В результате получится некорректный путь "C:CNames.txt".
Чтобы исправить такой код, нужно продублировать косую черту:
FILE* file = fopen("C:\\C\\Names.txt", "r");Другие варианты последовательностей могут иметь специальное значение у разных компиляторов. Или вызывать предупреждения в процессе сборки, например, у Clang и GCC:
warning: unknown escape sequence: '\C'Подобное поведение, определяемое реализацией, может вызывать проблемы с переносимостью кода. А до C++23 этот момент не был описан в стандарте.
Заметить подобные последовательности глазами трудно, при этом их очень просто допустить из-за опечатки при copy-paste:
....
{ARM_EXT_V6, 0x06500f70, ...., "uqsubaddx%c\t%12-15r, %16-19r, %0-3r"},
{ARM_EXT_V6, 0x06500ff0, ...., "usub16%c\t%12-15r, %16-19r, %0-3r"},
{ARM_EXT_V6, 0x06500f50, ...., "usub8%c\t%12-15r, %16-19r, %0-3r"},
{ARM_EXT_V6, 0x06500f50, ...., "usubaddx%c\t%12-15r, %16-19r, %0-3r"},
{ARM_EXT_V6, 0x06bf0f30, ...., "rev%c\t\%12-15r, %0-3r"}, // <=
{ARM_EXT_V6, 0x06bf0fb0, ...., "rev16%c\t\%12-15r, %0-3r"}, // <=
{ARM_EXT_V6, 0x06ff0fb0, ...., "revsh%c\t\%12-15r, %0-3r"}, // <=
{ARM_EXT_V6, 0xf8100a00, ...., "rfe%23?id%24?ba\t\%16-19r%21'!"}, // <=
{ARM_EXT_V6, 0x06bf0070, ...., "sxth%c\t%12-15r, %0-3r"},
{ARM_EXT_V6, 0x06bf0470, ...., "sxth%c\t%12-15r, %0-3r, ror #8"},
....В этом примере есть последовательности '\%'.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1094. |
V1095. Usage of potentially invalid handle. The value should be non-negative.
Анализатор обнаружил, что в вызываемую функцию передаётся невалидный дескриптор, имеющий отрицательное значение. Данная диагностика используется только на POSIX-совместимых платформах, поскольку в Windows дескрипторы являются указателями и для них используется диагностика V575.
Рассмотрим синтетический пример:
void Process()
{
int fd = open("path/to/file", O_WRONLY | O_CREAT | O_TRUNC);
char buf[32];
size_t n = read(fd, buf, sizeof(buf)); // <=
// ....
}Программист забыл проверить результат функции 'open'. Если файл невозможно открыть, то функция 'open' вернёт значение -1, и это некорректное значение дескриптора будет передано в функцию 'read'.
Исправленный пример:
void Process()
{
int fd = open("path/to/file", O_WRONLY | O_CREAT | O_TRUNC);
if (fd < 0)
{
return;
}
char buf[32];
size_t n = read(fd, buf, sizeof(buf));
// ....
}Рассмотрим другой пример:
static intoss_setformat(ddb_waveformat_t *fmt)
{
// ....
if (fd)
{
close (fd);
fd = 0;
}
fd = open (oss_device, O_WRONLY);
// ....
}В функцию 'close' может быть передан неверный дескриптор из-за неаккуратной проверки. В таком случае дескриптор со значением 0 тоже может быть валидным и должен быть освобождён. Здесь же мы закрываем дескриптор, если значение 'fd' не равно нулю. Такая ошибка может быть допущена, например, после рефакторинга кода или вследствие незнания программистом того, что неверный дескриптор имеет значение '-1', а не '0'.
Исправим приведённый фрагмент кода:
static intoss_setformat(ddb_waveformat_t *fmt)
{
// ....
if (fd >= 0)
{
close (fd);
fd = -1;
}
fd = open (oss_device, O_WRONLY);
// ....
}Данная диагностика классифицируется как:
V1096. Variable with static storage duration is declared inside the inline function with external linkage. This may lead to ODR violation.
Анализатор обнаружил ситуацию, в которой внутри 'inline' функции, определённой в заголовочном файле, объявлена статическая переменная. Это может привести к нарушению правила ODR.
Рассмотрим пример:
// sample.h
class MySingleton
{
public:
static MySingleton& GetInstance()
{
static MySingleton Instance; // <=
return Instance;
}
};Класс 'MySingleton' содержит функцию-член 'GetInstance', который возвращает экземпляр статической переменной 'Instance'. Так как функция определена там же, где и объявлена, компилятор неявно пометит её как 'inline'. В таком случае компоновщик объединит определения функции 'GetInstance' во всех единицах трансляции.
Однако этого не произойдёт в случае объединения определений между модулем исполняемой программы и динамической библиотекой. В результате при выполнении программы будет создано уже два экземпляра статической переменной 'Instance', что нарушает правило ODR.
Чтобы исправить данную ситуацию, нужно разделить объявление и определение метода между заголовочным файлом и файлом с исходным кодом.
Исправленный пример:
// sample.h
class MySingleton
{
public:
static MySingleton& GetInstance();
};
// sample.cpp
MySingleton& MySingleton::GetInstance()
{
static MySingleton Instance;
return Instance;
}V1097. Line splice results in a character sequence that matches the syntax of a universal-character-name. Using this sequence lead to undefined behavior.
Анализатор обнаружил перенос линии исходного кода (символ '\' в конце строки), который при помощи синтаксиса universal-character-name образует символ Unicode. Согласно стандарту, такой код приводит к неопределённому поведению.
Пример:
void error()
{
auto p = "\\
u0041"; // maybe const char[2] "A" ?
}В указатель 'p' присваивается строковый литерал, который при помощи последовательности \u0041, образует символ заглавной латинской 'A'. При этом между знаками '\' и 'u' идёт перенос строки, который объединяется ещё одним символом '\'.
В результате второй фазы трансляции линии исходного кода, которые оканчиваются символом '\', должны быть объединены в одну. Это может применяться для повышения читаемости кода, если необходимо разбить на несколько строк макрос или длинный строковый литерал. В результате объединения строки могут сформировать экранированные последовательности. Однако стандарт явно декларирует появление неопределённого поведения, если таким образом формируется universal-character-name:
Except for splices reverted in a raw string literal, if a splice results in a character sequence that matches the syntax of a universal-character-name, the behavior is undefined.
Чтобы избежать такой ситуации, последовательность нужно полностью оставить на одной линии, или перенести на другую:
void ok1()
{
auto p = "\u0041"; // const char[2] "A"
}
void ok2()
{
auto p = "\
\u0041";
}V1098. The 'emplace' / 'insert' function call contains potentially dangerous move operation. Moved object can be destroyed even if there is no insertion.
- Функция 'try_emplace' для 'std::map' / 'std::unordered_map'
- Функции 'lower_bound' и 'emplace_hint' для 'std::set' / 'std::map'
- Примечание N1
- Примечание N2
Анализатор обнаружил потенциально опасное перемещение объекта в ассоциативный контейнер 'std::set' / 'std::map' / 'std::unordered_map' посредством вызова функции 'emplace' / 'insert' . Если элемент с указанным ключом уже существует в контейнере, перемещение может привести к преждевременному освобождению ресурсов.
Рассмотрим следующий пример:
using pointer_type = std::unique_ptr<void, void (*)(void *)>;
std::unordered_map<uintmax_t, pointer_type> Cont;
// Unique pointer should be moved only if
// there is no element in the container by the specified key
bool add_entry(uintmax_t key, pointer_type &&ptr)
{
auto [it, inserted] = Cont.emplace(key, std::move(ptr));
if (!inserted)
{
// dereferencing the potentially null pointer 'ptr' here
}
return inserted;
}В примере в функцию 'add_entry' передается умный указатель на некоторый ресурс и соответствующий ему ключ. По задумке программиста, умный указатель должен перемещаться в ассоциативный контейнер лишь в том случае, если ранее не было вставки с тем же ключом. Если вставки не произошло, то далее с ресурсом будет произведена некоторая работа через умный указатель.
Однако такой код содержит две проблемы:
- Если вставки не произошло, ресурс из указателя 'ptr' всё равно может быть перемещён. Это приведет к тому, что он будет освобождён раньше времени.
- Указатель 'ptr' может стать нулевым, а его разыменование приведёт к неопределенному поведению.
Рассмотрим возможные способы исправления проблем.
Функция 'try_emplace' для 'std::map' / 'std::unordered_map'
Начиная со стандарта С++17, для контейнеров 'std::map' и 'std::unordered_map' была добавлена функция 'try_emplace'. Она гарантирует, что если элемент с указанным ключом уже существует, то аргументы функции не будут скопированы или перемещены. Поэтому для контейнеров 'std::map' и 'std::unordered_map' рекомендуется использовать именно эту функцию вместо 'emplace' и 'insert'.
Исправленный код:
using pointer_type = std::unique_ptr<void, void (*)(void *)>;
std::unordered_map<uintmax_t, pointer_type> Cont;
bool add_entry(uintmax_t key, pointer_type &&ptr)
{
auto [it, inserted] = Cont.try_emplace(key, std::move(ptr));
if (!inserted)
{
// dereferencing the 'ptr' here
// 'ptr' is guaranteed to be non-null
}
return inserted;
}Функции 'lower_bound' и 'emplace_hint' для 'std::set' / 'std::map'
Если функция 'try_emplace' недоступна, то для ассоциативных упорядоченных контейнеров ('std::set', 'std::map') поиск и вставку можно разделить на две операции:
- функция 'lower_bound' позволит либо найти элемент по заданному ключу, либо позицию вставки для нового элемента;
- функция 'emplace_hint' позволит эффективно вставить элемент.
Рассмотрим предыдущий пример, заменив контейнер на 'std::map' и воспользовавшись функциями 'lower_bound' и 'emplace_hint':
using pointer_type = std::unique_ptr<void, void (*)(void *)>;
std::map<uintmax_t, pointer_type> Cont;
// Unique pointer should be moved only if
// there is no element in the container by the specified key
bool add_entry(uintmax_t key, pointer_type &&ptr)
{
bool inserted;
auto it = Cont.lower_bound(key);
if (it != Cont.end() && key == it->first)
{
// key exists
inserted = false;
}
else
{
// key doesn't exist
it = Cont.emplace_hint(it, key, std::move(ptr));
inserted = true;
}
if (!inserted)
{
// dereferencing the 'ptr' here
// 'ptr' is guaranteed to be non-null
}
return inserted;
}Примечание N1
Анализатор может выдавать срабатывания на похожий код:
using pointer_type = std::unique_ptr<void, void (*)(void *)>;
std::map<uintmax_t, pointer_type> Cont;
// Unique pointer should be moved only if
// there is no element in the container by the specified key
bool add_entry(uintmax_t key, pointer_type &&ptr)
{
bool inserted;
auto it = Cont.find(key);
if (it == Cont.end())
{
std::tie(it, inserted) = Cont.emplace(key, std::move(ptr)); // <=
}
else
{
inserted = false;
}
if (!inserted)
{
// dereferencing the 'ptr' here
// 'ptr' is guaranteed to be non-null
}
return inserted;
}В примере нет ошибки: если элемента по заданному ключу не существует, то гарантированно произойдет вставка. Однако код не оптимален: сначала ведется поиск элемента по ключу, затем поиск повторяется для нахождения позиции вставки внутри функции 'emplace'. Поэтому рекомендуется оптимизировать код одним из описанных ранее способов.
Примечание N2
Диагностика имеет два уровня достоверности. Первый уровень выдаётся для move-only объектов, т.е. когда пользовательский тип не имеет конструкторов и операторов копирования. Это значит, при неудачной вставке ресурс может быть освобождён раньше времени. Например, это актуально для типов 'std::unique_ptr' и 'std::unique_lock'. Иначе будет выдан второй уровень достоверности.
Диагностика не работает с типами, у которых отсутствует конструктор перемещения, т.к. в таком случае объекты будут копироваться.
Данная диагностика классифицируется как:
V1099. Using the function of uninitialized derived class while initializing the base class will lead to undefined behavior.
Анализатор обнаружил использование нестатической функции-члена производного класса при инициализации базового класса. Согласно стандарту, такой код приводит к неопределённому поведению.
Рассмотрим пример:
struct Base
{
Base(int);
};
struct Derived : public Base
{
int FuncFromDerived();
Derived() : Base(FuncFromDerived()) {} // <=
};Конструктор структуры 'Derived' вызывает конструктор базового класса 'Base' в списке инициализации. При этом, в качестве аргумента конструктора передаётся результат функции 'FuncFromDerived', которая принадлежит производной структуре. При создании объекта типа 'Derived' инициализация будет произведена в следующем порядке:
- Вызов функции 'Derived::FuncFromDerived()';
- Вызов конструктора 'Base';
- Вызов конструктора 'Derived'.
В результате произойдёт вызов функции у структуры, которая не была инициализирована, что нарушает правило стандарта:
Member functions (including virtual member functions, [class.virtual]) can be called for an object under construction.
Similarly, an object under construction can be the operand of the typeid operator ([expr.typeid]) or of a dynamic_cast ([expr.dynamic.cast]).
However, if these operations are performed in a ctor-initializer (or in a function called directly or indirectly from a ctor-initializer) before all the mem-initializers for base classes have completed, the program has undefined behavior.
Данная диагностика классифицируется как:
|
V1100. Unreal Engine. Declaring a pointer to a type derived from 'UObject' in a class that is not derived from 'UObject' is dangerous. The pointer may start pointing to an invalid object after garbage collection.
Анализатор обнаружил объявление нестатического поля класса в виде указателя на тип, унаследованный от 'UObject', внутри класса/структуры, который не унаследован от типа 'UObject'. Сборщик мусора Unreal Engine может уничтожить объект, адресуемый этим указателем.
Рассмотрим пример:
class SomeClass
{
UObject *ptr;
};Одним из ключевых инструментов, используемых в управлении памятью в Unreal Engine, является автоматическая сборка мусора на основе механизма подсчета ссылок. Для этого система рефлексии Unreal Engine отслеживает все классы, унаследованные от класса 'UObject', на наличие жёстких ссылок внутри них.
Жёсткими ссылками в Unreal Engine считаются:
- указатель на тип, унаследованный от 'UObject', помеченный атрибутом 'UPROPERTY()';
- контейнер указателей на тип, унаследованный от 'UObject', помеченный атрибутом 'UPROPERTY()';
- объект шаблона класса 'TSharedObjectPtr'.
Если класс, не унаследованный от 'UObject', содержит указатель на тип, унаследованный от 'UObject', то сборщик мусора не будет рассматривать его как жёсткую ссылку и может удалить объект в ненужный момент. При этом сборщик мусора не обновит указатель, и тот, в свою очередь, станет висячим.
Для исправления проблемы нужно определить тип связи между объектами – владение или использование – и выбрать нужный тип поля.
Владение. Если класс может наследоваться от 'UObject', пометьте указатель атрибутом 'UPROPERTY()' или воспользуйтесь шаблоном класса 'TSharedObjectPtr'. В противном случае замените указатель на объект типа 'TSharedObjectPtr<....>':
// Approach N1
class SomeClass : public UObject
{
UPROPERTY()
UObject *ptr;
};
// Approach N2
Class SomeClass
{
TSharedObjectPtr<UObject> ptr;
};Использование. Если связь не подразумевает отношение владения, замените указатель на объект типа 'TWeakObjectPtr<....>':
Class SomeClass
{
TWeakObjectPtr<UObject> ptr;
};Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
V1101. Changing the default argument of a virtual function parameter in a derived class may result in unexpected behavior.
Анализатор нашёл виртуальную функцию, имеющую параметр со значением по умолчанию. При этом значения по умолчанию определены в базовом и производном классах и различаются. Такое изменение значения по умолчанию параметра виртуальной функции само по себе не является ошибкой, но может привести к неожиданным результатам при использовании этих классов.
Рассмотрим пример:
struct Base
{
virtual void foo(int i = 0) const noexcept
{
std::cout << "Base::foo() called, i = " << i << std::endl;
}
};
struct Derived : Base
{
void foo(int i = 10) const noexcept override
{
std::cout << "Derived::foo() called, i = " << i << std::endl;
}
};В базовом классе 'Base' определена виртуальная функция 'foo' с одним параметром 'i' имеющим значение по умолчанию '0'. В классе 'Derived', унаследованном от 'Base', переопределяется виртуальная функция 'foo' и изменяется значение по умолчанию параметра 'i' на '10'.
Давайте разберёмся, к каким проблемам может привести такое переопределение. Допустим, мы используем код следующим образом:
int main()
{
Derived obj;
Base *ptr = &obj;
ptr->foo();
}В результате выполнения функции 'main' будет выведена неожиданная строка "Derived::foo() called, i = 0". При формировании вызова функции 'foo' компилятор берёт статический тип объекта под указателем 'ptr' - 'Base'. Поэтому в вызов функции будет подставлено значение по умолчанию '0' из базового класса. В то же время переменная 'ptr' в реальности указывает на объект типа 'Derived'. Поэтому будет выполнена виртуальная функция из производного класса.
Для того чтобы избежать подобного поведения, рекомендуется придерживаться одной из стратегий:
- не использовать аргументы со значением по умолчанию в виртуальных функциях;
- определять значение по умолчанию параметра виртуальной функции только в самом базовом классе.
Исправленный пример:
struct Base
{
virtual void foo(int i = 0) const noexcept
{
std::cout << "Base::foo() called, i = " << i << std::endl;
}
};
struct Derived : Base
{
void foo(int i) const noexcept override
{
std::cout << "Derived::foo() called, i = " << i << std::endl;
}
};Замечание. Анализатор не выдает предупреждений на следующий код:
struct Base
{
virtual void foo(int i = 0) const noexcept
{
std::cout << "Base::foo() called, i = " << i << std::endl;
}
};
struct Derived : Base
{
void foo(int i = 0) const noexcept override
{
std::cout << "Derived::foo() called, i = " << i << std::endl;
}
};Однако мы не рекомендуем писать такой код, потому что его сложнее поддерживать.
Данная диагностика классифицируется как:
V1102. Unreal Engine. Violation of naming conventions may cause Unreal Header Tool to work incorrectly.
Анализатор обнаружил объявление сущности, несоответствующей соглашениям о наименованиях для проектов, основанных на Unreal Engine. Соответствие этому соглашению требуется для корректной работы Unreal Header Tool.
Примечание. Анализатор применяет диагностическое правило только на тех анализируемых файлах, в которых обнаружено включение заголовочных файлов из Unreal Engine. Если вы хотите принудительно применить правило для произвольного файла, воспользуйтесь следующим механизмом.
Далее приведен перечень соглашений, поддерживаемых этим диагностическим правилом.
Имена классов, наследуемых от 'UObject', следует начинать с префикса 'U':
class USomeClass : public UObject
{
....
};Имена классов, наследуемых от 'AActor', следует начинать с префикса 'A':
class ASomeActor : public AActor
{
....
};Имена классов, наследуемых от 'SWidget', следует начинать с префикса 'S':
class SSomeWidget : public SWidget
{
....
};Имена абстрактных классов / интерфейсов следует начинать с префикса 'I':
class IAbstractClass
{
public:
virtual void DoSmth() = 0;
};Перечисления следует начинать с префикса 'E':
enum class ESomeEnum
{
....
};Имена шаблонов классов следует начинать с префикса 'T':
template <typename T>
class TClassTemplate
{
....
};Остальные классы следует начинать с префикса 'F':
class FSimpleClass
{
....
};Префикс типа и соответствующего ему псевдонима должны совпадать. Псевдоним инстанцированного шаблона следует помечать как конкретную сущность:
// usings
using UGameUIPolicy = USomeClass;
using AAIController = ASomeActor;
using SActorCanvas = SSomeWidget;
using EColorBits = ESomeEnum;
using FArrowSlot = FSimpleClass;
template <typename T>
using TMyArray = TClassTemplate<T>;
using FMyArrayFloat = TClassTemplate<float>;
using FMyArrayInt = TMyArray<int>;
// typedefs
typedef USomeClass UGameUIPolicy;
typedef ASomeActor AAIController;
typedef SSomeWidget SActorCanvas;
typedef ESomeEnum EColorBits;
typedef FSimpleClass FArrowSlot;
typedef TClassTemplate<int> FMyArrayInt;
typedef TClassTemplate<float> FMyArrayFloat;Анализатор будет выдавать предупреждение на любое нарушение указанных выше соглашений:
class GameUIPolicy: public UObject { .... };
class BoxActor : public AActor { .... };
class WidgetButton : public SWidget { .... };
class Weapon
{
public:
virtual void Shoot() = 0;
};
enum class Texture { .... };
class Enemy { .... };
template <typename T>
class DoubleLinkedList { .... };
typedef DoubleLinkedList<Enemy> EnemyList;Исправленные примеры:
class UGameUIPolicy: public UObject { .... };
class ABoxActor : public AActor { .... };
class SWidgetButton : public SWidget { .... };
class IWeapon
{
public:
virtual void Shoot() = 0;
};
enum class ETexture { .... };
class FEnemy { .... };
template <typename T>
class TDoubleLinkedList { .... };
typedef DoubleLinkedList<Enemy> FEnemyList;V1103. The values of padding bytes are unspecified. Comparing objects with padding using 'memcmp' may lead to unexpected result.
Анализатор обнаружил фрагмент кода, в котором сравниваются объекты структур, содержащие байты выравнивания.
Рассмотрим синтетический пример:
struct Foo
{
unsigned char a;
int i;
};
void bar()
{
Foo obj1 { 2, 1 };
Foo obj2 { 2, 1 };
auto result = std::memcmp(&obj1, &obj2, sizeof(Foo)); // <=
}Чтобы понять суть проблемы, надо рассмотреть расположение объектов класса 'C' в памяти:
[offset 0] unsigned char
[offset 1] padding byte
[offset 2] padding byte
[offset 3] padding byte
[offset 4] int, first byte
[offset 5] int, second byte
[offset 6] int, third byte
[offset 7] int, fourth byteДля того, чтобы корректно и эффективно работать с объектами в памяти, компилятор применяет выравнивание данных. На типовых моделях данных выравнивание типа 'unsinged char' равно 1, а типа 'int' – 4. Это означает, адрес поля 'Foo::i' должен быть кратен 4. Чтобы сделать это, компилятор вставит 3 байта выравнивания после поля 'Foo::a'.
Стандарты C и C++ не уточняют, будут ли занулены байты выравнивания при инициализации объекта. Следовательно, при попытке побайтового сравнения двух объектов с одинаковыми значениями полей при помощи функции 'memcmp' результат может не всегда равняться 0.
Исправить проблему можно несколькими способами.
Способ N1 (предпочтительный). Написать компаратор и сравнивать объекты при помощи него.
Для языка C:
struct Foo
{
unsigned char a;
int i;
};
bool Foo_eq(const Foo *lhs, const Foo *rhs)
{
return lhs->a == rhs->a && lhs->i == rhs->i;
}Для языка C++:
struct Foo
{
unsigned char a;
int i;
};
bool operator==(const Foo &lhs, const Foo &rhs) noexcept
{
return lhs.a == rhs.a && lhs.i == rhs.i;
}
bool operator!=(const Foo &lhs, const Foo &rhs) noexcept
{
return !(lhs == rhs);
}Начиная с C++20, код можно упростить, указав компилятору самостоятельно сгенерировать компаратор:
struct Foo
{
unsigned char a;
int i;
auto operator==(const Foo &) const noexcept = default;
};Способ N2. Предварительно занулять объекты.
struct Foo
{
unsigned char a;
int i;
};
bool Foo_eq(const Foo *lhs, const Foo *rhs)
{
return lhs->a == rhs->a && lhs->i == rhs->i;
}
void bar()
{
Foo obj1;
memset(&obj1, 0, sizeof(Foo));
Foo obj2;
memset(&obj2, 0, sizeof(Foo));
// initialization part
auto result = Foo_eq(&obj1, &obj2);
}Однако этот способ имеет недостатки:
- Вызов 'memset' вносит накладные расходы на зануление всего участка памяти.
- Перед вызовом 'memcmp' нужно также гарантировать, что память под объект была занулена. В проекте со сложным потоком управления об этом можно легко забыть.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1103. |
V1104. Priority of the 'M' operator is higher than that of the 'N' operator. Possible missing parentheses.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что приоритет операций побитового сдвига выше, чем приоритет побитовых операций '&', '|' и '^'. В результате выражение может давать совсем не тот результат, на который рассчитывал программист.
Рассмотрим пример некорректного кода:
unsigned char foo(unsigned char byte2, unsigned char disp)
{
disp |= byte2 & 0b10000000 >> 6;
return disp;
}Согласно правилам приоритета операций в языках C и C++, выражение будет вычисляться следующим образом:
( disp |= ( byte2 & ( 0b10000000 >> 6 ) ) )Побитовый сдвиг вправо маски '0b10000000' в этом случае выглядит подозрительно. Скорее всего, программист ожидал, что результат побитового "И" будет сдвинут на 6.
Корректный вариант:
unsigned char f(unsigned char byte2, unsigned char disp)
{
disp |= (byte2 & 0b10000000) >> 6;
return disp;
}Общая рекомендация: если в сложном выражении не понятен приоритет операций, то лучше обернуть часть выражения в скобки (CERT EXP00-C, ES.41 CppCoreGuidelines). Даже если скобки окажутся лишними, это нестрашно. Код станет более простым для понимания и будет меньше подвержен ошибкам.
Если вы считаете, что срабатывание ложное, то можно либо подавить его при помощи комментария '//-V1104', либо обернуть в скобки выражение:
// first option
disp |= byte2 & 0b10000000 >> 6; //-V1104
// second option
disp |= byte2 & (0b10000000 >> 6);Данная диагностика классифицируется как:
|
V1105. Suspicious string modification using the 'operator+='. The right operand is implicitly converted to a character type.
Анализатор обнаружил подозрительный код: строковая переменная типа 'std::basic_string' модифицируется с помощью оператора '+='. При этом правым операндом является выражение арифметического типа. Из-за неявных преобразований, проходимых перед вызовом оператора, может быть получен неожиданный результат.
Рассмотрим пример:
void foo()
{
std::string str;
str += 1000; // N1
str += ' ';
str += 4.5; // N2
str += ' ';
str += 400.52; // N3
}Разработчик хотел сформировать строку, состоящую из трёх чисел. Однако в результате исполнения этого кода получится следующее:
- В строке N1 произойдёт неявное преобразование из типа 'int' в 'char'. Результат такого преобразования зависит от знаковости типа 'char' и версии стандарта C++. Например, один из возможных вариантов — константа '1000' сконвертируется в значение '-24', что соответствует символу из расширенной ASCII таблицы.
- В строке N2 произойдёт неявное преобразование из типа 'double' в 'char'. Сначала будет отброшена дробная часть числа '4.5'. Поскольку полученное значение '4' умещается в диапазоне значений типа 'char', то в результате конверсии будет получен символ с ASCII кодом 4, который является непечатаемым символом.
- В строке N3 содержится неопределённое поведение. После отбрасывания дробной части числа '400.52' результат не умещается в диапазоне значений типа 'char' (даже в случае, если он беззнаковый).
Примечание. Обратите внимание, хоть оба значения — 1000 и 400.52 — не помещаются в 'char', последствия будут разными. В случае 1000 мы имеем дело с сужающим преобразованием. Такой код компилируется, однако может быть некорректен. В свою очередь, преобразование числа с плавающей точкой — 400.52 к типу 'char', согласно стандарту языка, является неопределённым поведением.
Во всех подобных случаях необходимо воспользоваться соответствующими функциями для явного преобразования. Например, функцией 'std::to_string' для конвертации чисел в строки:
void foo()
{
std::string str;
str += std::to_string(1000);
str += ' ';
str += std::to_string(4.5);
str += ' ';
str += std::to_string(400.52);
}Если же разработчик изначально планировал добавить символ в строку через его числовое представление, то читаемость такого кода однозначно ухудшается. Рекомендуется переписать такой код с применением символьного литерала, содержащего или нужный символ, или escape-последовательность:
void foo()
{
std::string str;
// first option
str += '*';
// second option
str += '\x2A';
}Диагностическое правило выдаёт срабатывание:
- достоверности уровня High, когда правый операнд вещественного типа;
- достоверности уровня Medium, когда правый операнд целого типа в результате неявного преобразования будет усечён;
- достоверности уровня Low, когда правый операнд целого типа в результате неявного преобразования останется с тем же значением и лежит в диапазоне [0 .. 127] (символы из нерасширенной таблицы ASCII).
V1106. Qt. Class inherited from 'QObject' should contain at least one constructor that takes a pointer to 'QObject'.
Анализатор обнаружил класс, унаследованный от 'QObject', который не содержит ни одного конструктора, принимающего указатель на 'QObject' в качестве параметра.
Объекты, производные от типа 'QObject', организуются в деревья со связями "родитель – ребёнок". При создании очередного объекта передаётся указатель на объект-родитель. В объекте-родителе создающийся объект добавляется в список дочерних. Благодаря этому, когда произойдёт удаление родительского объекта, также удалятся и все его дочерние объекты.
Поэтому при написании своих классов на основе библиотеки Qt считается хорошей практикой добавлять перегрузку, принимающую указатель на 'QObject'. Анализатор выдаст предупреждение, если не найдёт ни одного конструктора, который принимает такой указатель.
Рассмотрим пример:
class MyCounter : public QObject
{
Q_OBJECT;
public:
MyCounter (int startValue);
};В классе 'MyCounter' отсутствуют конструкторы, принимающие указатель на 'QObject'. Это можно исправить данным способом:
сlass MyCounter : public QObject
{
Q_OBJECT;
public:
MyCounter (int startValue, QObject *parent = nullptr); // ok
};Примечание. В силу специфики некоторых проектов анализатор не будет выдавать предупреждение, если будет найден хотя бы один конструктор, принимающий родителя.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
V1107. Function was declared as accepting unspecified number of parameters. Consider explicitly specifying the function parameters list.
Анализатор обнаружил декларацию функции с неуточнённым количеством параметров и её вызов с ненулевым количеством аргументов. Такой вызов может свидетельствовать об ошибке в коде. Возможно, планировалось вызвать другую функцию с похожим именем.
В языке С существует возможность объявить функцию с неуточнённым количеством параметров:
void foo();Может показаться, что такая декларация объявляет функцию, не принимающую параметров, как в C++. Однако это не так, и следующий код успешно скомпилируется:
void foo();
void bar()
{
foo("%d %d %d", 1, 2, 3); // No compiler checks
}При декларации функции 'foo' программист мог подразумевать одно из следующих поведений.
Вариант N1. Функция 'foo' не должна была принимать параметров, и компилятор должен был выдать ошибку. В таком случае до C23 в декларации функции следует явно указать 'void' в списке параметров:
void foo(void);
void bar()
{
foo("%d %d %d", 1, 2, 3); // Compile-time error
}Вариант N2. Функция 'foo' является вариативной и может принимать переменное количество параметров. В таком случае следует явно во время декларации указать эллипсис ('...').
void foo1(const char *, ...); // since C89
void foo2(...); // since C23
void bar()
{
foo1("%d %d %d", 1, 2, 3); // ok since C89
foo2("%d %d %d", 1, 2, 3); // ok since C23
}Примечание. Начиная с C23, компиляторы обязаны рассматривать следующие декларации как декларации функций, не принимающих параметров:
void foo(); // Takes no parameters
void bar(void); // Takes no parametersАнализатор знает об этом поведении и не выдаёт срабатывания для таких деклараций, начиная с C23.
V1108. Constraint specified in a custom function annotation on the parameter is violated.
Анализатор обнаружил нарушение ограничений, наложенных пользователем на параметр функции.
Механизм пользовательских аннотаций в формате JSON позволяет предоставить анализатору больше информации о типах и функциях. В том числе, позволяет установить ограничения на параметры аннотируемой функции.
Например, если вы хотите, чтобы анализатор сообщал вам, когда в функцию передаётся отрицательное значение или ноль, то ваша аннотация может выглядеть так:
{
"version": 1,
"annotations": [
{
"type": "function",
"name": "my_constrained_function",
"params": [
{
"type": "int",
"constraint": {
"disallowed": [ "..0" ]
}
}
]
}
]
}При подключении файла с такой аннотацией на следующем коде появится срабатывание V1108:
void my_constrained_function(int);
void caller(int i)
{
if (i < 0)
{
return;
}
my_constrained_function(i); // <=
}В данном случае программист совершил ошибку — перепутал оператор '<' с оператором '<='. Однако благодаря ограничениям в аннотации анализатор знает, что в функцию 'my_constrained_function' не должны передаваться отрицательные значения или ноль.
Исправленный код:
void my_constrained_function(int);
void caller(int i)
{
if (i <= 0)
{
return;
}
my_constrained_function(i);
}V1109. Function is deprecated. Consider switching to an equivalent newer function.
Анализатор обнаружил вызов устаревшей функции. Такая функция может не поддерживаться или быть убрана в следующих версиях библиотеки.
Рассмотрим вызов функции 'UpdateTraceW' из WinAPI, которая обновляет параметр свойства указанного сеанса трассировки событий:
....
status = UpdateTraceW((TRACEHANDLE)NULL, LOGGER_NAME, pSessionProperties);
....Согласно документации, эта функция устарела, и её следует заменить на 'ControlTraceW':
....
status = ControlTraceW((TRACEHANDLE)NULL, KERNEL_LOGGER_NAME,
pSessionProperties, EVENT_TRACE_CONTROL_QUERY);
....Данное диагностическое правило имеет информацию об устаревших функциях из следующих библиотек: WinAPI, GLib.
Если вам необходимо самостоятельно разметить нежелательные функции, то вы можете воспользоваться механизмом аннотирования функций и диагностическим правилом V2016.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V1109. |
V1110. Constructor of a class inherited from 'QObject' does not use a pointer to a parent object.
Анализатор обнаружил унаследованный от 'QObject' класс, конструктор которого принимает в качестве параметра указатель на 'QObject', но не использует его для организации связи "родитель — ребёнок".
Производные от типа 'QObject' объекты организуются в деревья со связями "родитель — ребёнок". При создании очередного объекта передаётся указатель на объект-родитель. В объекте-родителе создающийся объект добавляется в список дочерних. Благодаря этому, когда произойдёт удаление родительского объекта, также удалятся и все его дочерние объекты.
Рассмотрим пример:
class BadExample : public QObject
{
public:
BadExample(QObject *parent) : ui(new UI::BadExample)
{
ui->setupUi(this);
};
};В конструктор класса 'BadExample' передаётся указатель на родительский объект. Однако он не передаётся в конструктор базового класса и не используется внутри тела конструктора.
Исправленный пример:
class GoodExample1 : public QObject
{
public:
GoodExample1(QObject *parent)
: QObject (parent), ui(new UI::GoodExample)
{
/*....*/
};
};Анализатор не выдаст предупреждение в следующих случаях.
Случай N1. Параметр безымянный. Это значит, что программист не хочет отдавать управление объектом в систему отслеживания Qt:
class GoodExample2 : public QObject
{
public:
GoodExample2(QObject *) { /* .... */ };
};Случай N2. Параметр сознательно не используется для организации связи "родитель — ребёнок". В конструктор родительского класса явно передаётся нулевой указатель:
class GoodExample3 : public QObject
{
public:
GoodExample3(QObject *parent) : QObject { nullptr } { /* .... */ };
};Случай N3. Параметр передаётся в функцию QObject::setParent:
class GoodExample4 : public QObject
{
public:
GoodExample4(QObject *parent)
{
setParent(parent);
};
};Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
V1111. The index was used without check after it was checked in previous lines.
Анализатор обнаружил потенциальную ошибку, которая может привести к выходу за границу массива. В коде ранее присутствуют проверки индекса, однако на указанной строке контейнер использует индекс без проверки.
Рассмотрим синтетический пример:
#define SIZE 10
int buf[SIZE];
int do_something(int);
int some_bad_function(int idx)
{
int res;
if (idx < SIZE)
{
res = do_something(buf[idx]);
}
// ....
res = do_something(buf[idx]); // <=
return res;
}В данном примере, если в функцию придёт значение больше или равное 'SIZE', то, несмотря на проверку, после неё произойдёт выход за границу массива.
Следует как минимум добавить дополнительную проверку:
int some_good_function(int idx)
{
int res;
if (idx < SIZE)
{
res = do_something(buf[idx]);
}
// ....
if (idx < SIZE)
{
res = do_something(buf[idx]); //ok
}
return res;
}Примечание: в диагностическом правиле реализованы несколько исключений, которые добавлены для уменьшения количества ложных срабатываний. Для выдачи предупреждения должны быть выполнены следующие условия:
- Сравнение должно происходить с константным выражением.
- После сравнения не должно быть выхода из блока кода.
- Доступ по индексу должен происходить в вычислимом контексте.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
|
V1112. Comparing expressions with different signedness can lead to unexpected results.
Анализатор обнаружил подозрительное сравнение, в котором типы выражений имеют одинаковый ранг, но разные знаки. При этом ранги типов меньше, чем у 'int'. Из-за неявного преобразования таких выражений к типу 'int' или 'unsigned int' сравнение может приводить к неожиданным результатам.
Рассмотрим синтетический пример:
bool foo(char lhs, unsigned char rhs)
{
return lhs == rhs; // <=
}В примере присутствует сравнение переменных с типами разной знаковости: 'lhs' типа 'char' и 'rhs' типа 'unsigned char'. Будем считать, что нижележащий тип 'char' — это 'signed char' (например, на архитектуре x86_64). Тип 'unsigned char' может отразить диапазон значений от [0 .. 255], при этом тип 'char' – [-128 .. 127]. Согласно стандартам C и C++, перед сравнением значений переменных должно произойти неявное преобразование типов (integral promotion), в результате которого и может возникнуть проблема.
Компилятор превращает код со сравнением в следующий:
return (int) lhs == (int) rhs;Такое преобразование он делает, если тип 'int' может отобразить диапазон значений 'char' и 'unsigned char', иначе вместо 'int' выберется 'unsigned int'. На большинстве современных платформ тип 'int' занимает 4 байта и с лёгкостью может отобразить эти диапазоны.
В случае, если 'lhs' имел отрицательное значение, то оно же и сохранится в результате преобразования в левом операнде. При этом значение правого операнда после преобразования 'rhs' всегда будет неотрицательным, т.к. исходный тип был беззнаковым. В итоге результат сравнения будет вычисляться как 'false'. Возможна и обратная ситуация. Если в переменной 'rhs' находится значение в диапазоне [128 .. 255], то в этой ситуации результат сравнения будет также 'false'.
Такая ошибка может неожиданно проявить себя при смене компилятора или настроек, когда ранее тип 'char' был беззнаковым, а стал знаковым, и наоборот. Например, в таком случае при вызове функции 'foo' с аргументами '\xEE' и '\xEE' будет считаться, что переданы неравные значения. Хотя такое поведение логично с точки зрения стандарта, оно может быть неожиданным для разработчика.
Ошибки можно избежать двумя способами.
Способ N1. Преобразовать выражения к общему типу по знаку:
if ((unsigned char) lhs == rhs)Способ N2. Воспользоваться семейством функций 'std::cmp_*' (С++20) или их аналогами для сравнения выражений, типы которых имеют различную знаковость:
if (std::cmp_equal(lhs, rhs))Примечание. В диагностическом правиле реализованы несколько исключений, которые добавлены для уменьшения количества ложных срабатываний. Анализатор выдаёт срабатывание лишь в том случае, если он смог доказать, что диапазон значений одного из операндов не может быть отображён типом другого операнда. Если же требуется выявить все места в коде, где происходит такое сравнение операндов, разных по знаковости, можно воспользоваться следующим комментарием:
//+V1112, ENABLE_ON_UNKNOWN_VALUESПо этой причине анализатор не выдаёт срабатывание на приведённом ранее синтетическом примере без этой настройки.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
V1113. Potential resource leak. Calling the 'memset' function will change the pointer itself, not the allocated resource. Check the first and third arguments.
Анализатор обнаружил подозрительный код: в функцию 'memset' передаётся адрес указателя, который ссылается на динамически выделенную память. Такой код может привести к утечке памяти после использования функции 'memset'.
Рассмотрим следующую ситуацию. Допустим, что в проекте существовал следующий корректно работающий код:
void foo()
{
constexpr size_t count = ....;
char array[count];
memset(&array, 0, sizeof(array));
....
}На стеке создаётся массив, а затем его содержимое зануляется при помощи функции 'memset'. В исходном примере нет ошибок: первым аргументом передаётся адрес массива, а третьим аргументом – реальный размер массива в байтах.
Чуть позже программист по каким-либо причинам заменил аллокацию буфера со стека на кучу:
void foo()
{
constexpr size_t count = ....;
char *array = (char*) malloc(count * sizeof(char));
....
memset(&array, 0, sizeof(array)); // <=
....
}При этом он не изменил вызов функции 'memset'. Это означает, что теперь первым аргументом передаётся адрес указателя на стеке функции, а третьим аргументом — его размер. Это приводит к занулению указателя вместо содержимого массива и утечке памяти.
Пример исправленного кода:
void PointerFixed()
{
....
constexpr size_t count = ....;
char *array = (char*) malloc(count * sizeof(char));
....
memset(array, 0, count * sizeof(char));
....
}Теперь первым параметром передаётся адрес участка памяти на куче, а третьим параметром — его размер.
V1114. Suspicious use of type conversion operator when working with COM interfaces. Consider using the 'QueryInterface' member function.
Анализатор обнаружил подозрительное использование оператора преобразования типов при работе с COM-интерфейсами.
При такой работе может возникнуть ряд проблем. Вот некоторые из них:
- Не произойдет увеличения счётчика ссылок.
- Возможно преобразование в несовместимый тип или интерфейс. Например, при множественном наследовании, или после изменения версии интерфейса.
- Возможно нарушение совместимости на уровне ABI.
Правильным способом работы c COM-интерфейсами является использование функции 'QueryInterface', которая специально предназначена для этого. Причина в том, что COM – независимая от языка программирования технология. COM-объекты могут быть реализованы на языках программирования, отличных от C++, а также находиться в адресных пространствах, отличных от адресного пространства вызывающего процесса.
Функция 'QueryInterface' должна:
- проверять, что к запрашиваемому интерфейсу можно получить доступ;
- возвращать указатель на запрашиваемый интерфейс;
- увеличивать счётчик ссылок на объект.
Рассмотрим синтетический пример ошибки. Допустим, в коде есть COM-интерфейсы 'IDraw' и 'IShape', которые отвечают за работу с некой геометрической фигурой:
interface IDraw : public IUnknown
{
....
virtual HRESULT Draw() = 0;
....
};
interface IShape : public IUnknown
{
....
virtual HRESULT GetArea(double *area) = 0;
....
};Также у нас есть COM-объект 'Circle', который имплементирует интерфейсы 'IDraw' и 'IShape':
class Circle : public IDraw, public IShape
{
....
};Теперь рассмотрим пример неправильной работы с нашим COM-объектом через интерфейс 'IDraw':
void foo(IDraw *ptrIDraw)
{
IShape *ptrIShape = dynamic_cast<IShape*>(ptrIDraw);
....
if (ptrIShape)
ptrIShape->GetArea(area);
....
}В примере выше не произойдет увеличение счётчика ссылок на объект типа 'Circle'. Для увеличения и уменьшения счётчика должны зваться функции 'AddRef' и 'Release' соответственно. Поэтому будет правильно воспользоваться функцией 'QueryInterface', которая сама контролирует механизм счётчика ссылок.
Таким образом, корректный код выглядит так:
void foo(IDraw *ptrIDraw)
{
IShape *ptrIShape = nullptr;
....
if (SUCCEEDED(ptrIDraw->QueryInterface(IID_IShape, &ptrIShape))
....
}Данная диагностика классифицируется как:
V1115. Function annotated with the 'pure' attribute has side effects.
Анализатор обнаружил функцию, проаннотированную как чистая, которая таковой не является.
Функции могут быть проаннотированы следующими способами:
- Через С++ атрибуты. Например, через атрибут 'gnu::pure'.
- Через механизм пользовательских аннотаций в формате JSON.
Функция является чистой, если соответствует следующим требованиям:
- В ней отсутствуют побочные эффекты. Функция не должна изменять состояние программы вне своего собственного контекста. Это означает, что она не должна изменять объекты со static storage duration (локальные и глобальные) или изменять неконстантные объекты через переданные в функцию указатели/ссылки.
- Её поведение детерминировано. Для одного и того же набора входных данных функция всегда должна возвращать один и тот же результат.
Наиболее частые случаи нарушения чистоты функций:
- Использование в любом виде переменных со static storage duration;
- Вызов функции с побочными эффектами;
- Использование конструкций, которые приводят к побочным эффектам (например: 'new', 'delete');
- Использование параметров в виде lvalue-ссылок или указателей на не константы;
- Запись/чтение из потоков (например, 'std::cout', 'std:: fstream' и т.п.).
Рассмотрим пример нечистой функции, но проаннотированной как чистая:
[[gnu::pure]] void foo()
{
int *x = new int;
....
}Функция 'foo' проаннотирована в коде атрибутом 'gnu::pure'. При этом функция выделяет динамическую память в программе и нарушает требование об отсутствии побочных эффектов.
Для исправления необходимо либо убрать атрибут 'pure', либо исправить функцию следующим образом:
[[gnu::pure]] void foo()
{
int x;
....
}V1116. Creating an exception object without an explanatory message may result in insufficient logging.
Анализатор обнаружил создание объекта исключения без поясняющего сообщения. Такой подход может привести к недостаточному логированию и затруднить процесс выявления ошибок.
Рассмотрим следующий пример:
void DoSomething(const char *val)
{
if (!val) throw std::runtime_error { "" };
// do something...
}
void foo()
{
const char *val = ....;
try
{
DoSomething(val);
}
catch(std::runtime_error &err)
{
std::cerr << err.what() << std::endl;
}
}В функции 'DoSomething' выбрасывается исключение 'std::runtime_error', которое будет обработано в функции 'foo'. В процессе обработки ожидается, что в 'std::cerr' попадёт информация о причине создания исключения. Вместо этого в 'std::cerr' будет выдана пустая строка, что затруднит процесс обнаружения проблемы.
Корректный вариант может выглядеть так:
void DoSomething(const char *val)
{
if (!val)
{
throw std::runtime_error{ "[DoSomething]: "
"the poiner 'val' is nullptr." };
}
// do something...
}Анализатор сгенерирует предупреждение V1116, если обнаружит создание стандартного исключения без поясняющего сообщения. Если вы хотите обнаруживать подобные ситуации для пользовательских исключений, то можете воспользоваться механизмом пользовательских аннотаций.
Данная диагностика классифицируется как:
V1117. The declared function type is cv-qualified. The behavior when using this type is undefined.
Анализатор обнаружил в коде на языке C определение типа функции с использованием квалификаторов const или volatile. Согласно пункту 10 параграфа 6.7.4.1 стандарта С23, при использовании таких типов поведение не определено.
Пример кода, на котором анализатор сгенерирует предупреждения:
typedef int fun_t(void);
typedef const fun_t const_qual_fun_t; // V1117
typedef const fun_t * ptr_to_const_qual_fun_t; // V1117
void foo()
{
const fun_t c_fun_t; // V1117
const fun_t * ptr_c_fun_t; // V1117
}Для правильной работы программы следует убрать квалификатор const при определении типа функции. Таким образом, корректный код выглядит так:
typedef int fun_t(void);
typedef fun_t const_qual_fun_t; // ok
typedef fun_t * ptr_to_const_qual_fun_t; // ok
void foo()
{
fun_t c_fun_t; // ok
fun_t * ptr_c_fun_t; // ok
}V1118. Excessive file permissions can lead to vulnerabilities. Consider restricting file permissions.
Выставление избыточных прав доступа для файла свидетельствует об угрозе безопасности и может привести к уязвимости.
Анализатор просматривает следующие системные вызовы на наличие избыточных прав доступа: open, creat, openat, chmod, fchmod, fchmodat, mkdir, mkdirat, mkfifo, mkfifoat, mknod, mknodat, mq_open, sem_open.
Рассмотрим пример:
void foo(int param)
{
int parms = 0777;
int fd = open("/path/to/file", O_CREAT | O_RDONLY, parms);
if (fd < 0) return;
// some work
close(fd);
}В коде происходит вызов системного вызова open для открытия файла и последующей работы с информацией оттуда. Если файл не существует, он будет создан (флаг O_CREAT во втором аргументе) с правами доступа, переданными числом в качестве третьего аргумента. В данном случае маска 0777 позволяет любому произвольному пользователю читать, писать или исполнять этот файл, что может привести к уязвимости.
Исправить ошибку можно, изменив маску доступа:
void foo(int param)
{
int parms = 0644;
int fd = open("/path/to/file", O_CREAT | O_RDONLY, parms);
if (fd < 0) return;
// some work
close(fd);
}Данная диагностика классифицируется как:
V801. Decreased performance. It is better to redefine the N function argument as a reference. Consider replacing 'const T' with 'const .. &T' / 'const .. *T'.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. В функцию передается объект, представляющий собой класс или структуру. Этот объект передается по значению, но при этом не модифицируется, так как имеется ключевое слово const. Возможно, рационально передавать этот объект с помощью константной ссылки в языке Си++. Или с помощью указателя в языке Си.
Пример:
bool IsA(const std::string s)
{
return s == A;
}При вызове этой функции произойдет вызов конструктора копирования для класса std::string. Если подобное копирование объектов происходит часто, то это может существенно снижать производительность приложения. Данный код можно легко оптимизировать, добавив ссылку:
bool IsA(const std::string &s)
{
return s == A;
}Анализатор не выдаёт предупреждение, если по значению передаётся простая структура данных (POD), размером не больше размера указателя. Если передавать такую структуру по ссылке, то никакого выигрыша не будет.
Дополнительные ресурсы:
- Wikipedia. Reference (C++).
- Bjarne Stroustrup. The C++ Programming Language (Third Edition and Special Edition). 11.6 - Large Objects.
V802. On 32-bit/64-bit platform, structure size can be reduced from N to K bytes by rearranging the fields according to their sizes in decreasing order.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. В коде программы имеется структура данных, которая может приводить к неэффективному использованию оперативной памяти.
Рассмотрим пример структуры, о которой анализатор сообщит как о неэффективной:
struct LiseElement {
bool m_isActive;
char *m_pNext;
int m_value;
};Данная структура в 64-битном коде займет 24 байта, что связано с выравниванием данных. Но если поменять последовательность полей, то ее размер составит всего 16 байт. Оптимизированный вариант структуры будет выглядеть так:
struct LiseElement {
char *m_pNext;
int m_value;
bool m_isActive;
};Конечно, перестановка полей не всегда возможна или необходима. Но если подобные структуры используются миллионами, то есть смысл задуматься об оптимизации расходуемой памяти. Дополнительно сокращение размера структур может повысить производительность приложения, так как при таком же количестве элементов, будет требоваться меньшее количество обращений к памяти.
Отметим, что приведенная структура всегда занимает 12 байт в 32-битной программе, в какой бы последовательности не располагались поля. Поэтому, при проверке 32-битной конфигурации, сообщение V802 выдано не будет.
Естественно бывают и обратные ситуации, когда размер структуры можно оптимизировать в 32-битной конфигурации и нельзя в 64-битной. Рассмотрим пример такой структуры:
struct T_2
{
int *m_p1;
__int64 m_x;
int *m_p2;
}Эта структура в 32-битной программе из-за выравнивания будет занимать 24 байта. Если же переставить поля, как показано ниже, то она будет занимать только 16 байт.
struct T_2
{
__int64 m_x;
int *m_p1;
int *m_p2;
}В 64-битной программе расположение полей в структуре 'T_2' не имеет значения. В любом случае она займет 24 байта.
Метод сокращения объема структур достаточно прост. Достаточно расположить поля в порядке убывания их размера. В этом случае поля начнут располагаться без лишних зазоров. Например, возьмем следующую структуру размером 40 байт в 64-битной программе:
struct MyStruct
{
int m_int;
size_t m_size_t;
short m_short;
void *m_ptr;
char m_char;
};Простой сортировкой последовательности полей по убыванию размера:
struct MyStructOpt
{
void *m_ptr;
size_t m_size_t;
int m_int;
short m_short;
char m_char;
};мы получим из нее структуру размером 24 байт.
Анализатор не всегда выдает сообщение о неэффективности структур, так как старается сократить количество излишних предупреждений. Например, анализатор не выдает предупреждение на сложные классы, являющимися наследниками, поскольку такие объекты обычно создаются в малом количестве. Пример:
class MyWindow : public CWnd {
bool m_isActive;
size_t m_sizeX, m_sizeY;
char m_color[3];
...
};Размер данной структуры может быть сокращен, но это не имеет практического смысла.
V803. Decreased performance. It is more effective to use the prefix form of ++it. Replace iterator++ with ++iterator.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. В коде программы итератор изменяется посредством постфиксного оператора инкремента/декремента. Так как предыдущее значение итератора не используется, то постфиксный итератор можно заменить префиксным. В ряде случаев префиксный итератор будет работать быстрее постфиксного, особенно в Debug-версиях программы.
Пример:
std::vector<size_t>::const_iterator it;
for (it = a.begin(); it != a.end(); it++)
{ ... }Более быстрый вариант:
std::vector<size_t>::const_iterator it;
for (it = a.begin(); it != a.end(); ++it)
{ ... }Префиксный оператор инкремента изменяет состояние объекта и возвращает себя в уже изменённом виде. Оператор префиксного инкремента в классе итератора для работы с std::vector может выглядеть так:
_Myt& operator++()
{ // preincrement
++_Myptr;
return (*this);
}В случае постфиксного инкремента ситуация сложнее. Состояние объекта должно измениться, но при этом возвращено предыдущее состояние. Возникает дополнительный временный объект:
_Myt operator++(int)
{ // postincrement
_Myt _Tmp = *this;
++*this;
return (_Tmp);
}Если мы хотим только увеличить значение итератора, то получается, что префиксная форма предпочтительна. Поэтому, один из советов по микро-оптимизации программ писать "for (it = a.begin(); it != a.end(); ++it)" вместо "for (it = a.begin(); it != a.end(); it++)". В последнем случае происходит создание ненужного временного объекта, что снижает производительность.
Более подробно все это можно почитать в книге Скотта Мейерса "Наиболее эффективное использование С++. 35 новых рекомендаций по улучшению ваших программ и проектов" (Правило 6. Различайте префиксную форму операторов инкремента и декремента) [1].
Также в заметке "Есть ли практический смысл использовать для итераторов префиксный оператор инкремента ++it, вместо постфиксного it++?" [2] можно познакомиться с примерами замера скорости.
Библиографический список
- Мейерс С. Наиболее эффективное использование С++. 35 новых рекомендаций по улучшению ваших программ и проектов: Пер. с англ. - М.: ДМК Пресс, 2000. - 304 с.: ил. (Серия "Для программистов"). ISBN 5-94074-033-2. ББК 32.973.26-018.1.
- Андрей Карпов. Есть ли практический смысл использовать для итераторов префиксный оператор инкремента ++it, вместо постфиксного it++? http://www.viva64.com/ru/b/0093/
V804. Decreased performance. The 'Foo' function is called twice in the specified expression to calculate length of the same string.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. В одном выражении дважды вычисляется длина одной и той же строки. Для вычисления длины используются такие функции, как strlen, lstrlen, _mbslen и так далее. Если данное выражение вычисляется много раз или строки имеют большую длину, то данный участок кода рационально оптимизировать.
Для оптимизации можно предварительно вычислить длину строки и поместить её во временную переменную.
Рассмотрим пример:
if ((strlen(directory) > 0) &&
(directory[strlen(directory)-1] != '\\'))Скорее всего, данный код обрабатывает только одну строку и его оптимизировать не надо. Но если код вызывается очень часто, то его следует переписать. Улучшенный вариант кода:
size_t directoryLen = strlen(directory);
if ((directoryLen > 0) && (directory[directoryLen-1] != '\\'))Иногда предупреждение V804 помогает выявить гораздо более критические ошибки. Рассмотрим пример:
if (strlen(str_1) > 4 && strlen(str_1) > 8)Здесь используется некорректное имя переменной. Код должен выглядеть следующим образом:
if (strlen(str_1) > 4 && strlen(str_2) > 8)V805. Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) > 0' construct. A more efficient way is to check: str[0] != '\0'.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. Для того чтобы определить строка пустая или нет, используется функция strlen или аналогичная ей.
Пример кода:
if (strlen(strUrl) > 0)Этот код корректен, однако если он используется внутри длинного цикла или если мы работаем с длинными строками, то такая проверка может быть неэффективна. Для того чтобы проверить, пустая строка или нет, нам достаточно сравнить первый символ строки с 0. Оптимизированный вариант:
if (strUrl[0] != '\0')Иногда предупреждение V805 помогает выявить избыточный код. В одном из приложений, был найден приблизительно такой код:
string path;
...
if (strlen(path.c_str()) != 0)Скорее всего, такой код появился в ходе неаккуратного рефакторинга, когда тип переменной path был заменен с простого указателя на std::string. Упрощенный и быстрый вариант:
if (!path.empty())V806. Decreased performance. The expression of strlen(MyStr.c_str()) kind can be rewritten as MyStr.length().
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. Длина строки, находящейся в контейнере, вычисляется с помощью функции strlen() или аналогичной ей. Это лишнее действие, поскольку контейнер имеет специальную функцию для получения длины строки.
Рассмотрим пример:
static UINT GetSize(const std::string& rStr)
{
return (strlen(rStr.c_str()) + 1 );
}Этот код взят из реального приложения. Обычно такие забавные фрагменты кода получаются в процессе неаккуратного рефакторинга. Этот код медленен и более, того, он возможно вообще не нужен. Можно просто в нужных местах писать выражение "string::length() + 1".
Если всё-таки хочется сделать специальную функцию, для получения длины строки вместе с терминальным нулём, то она должна выглядеть так:
inline size_t GetSize(const std::string& rStr)
{
return rStr.length() + 1;
}Примечание
Следует помнить, что действия "strlen(MyString.c_str())" и "MyString.length()" не всегда дают одинаковый результат. Различия будут в том случае, если строка содержит нулевые символы помимо терминального нуля. Однако подобные ситуации можно считать плохим дизайном и сообщение V806 является поводом задуматься над рефакторингом. Даже если программист, написавший такой код, хорошо знает принципы его работы, этот код будет сложен для понимания его коллегам. Коллеги будут гадать, почему написано именно так и могут заменить вызов функции "strlen()" на "length()", внеся ошибку в программу. Следует не лениться и сделать код таким, чтобы принципы его работы были понятны стороннему программисту. Например, если в строке могут быть нулевые символы, то, скорее всего, это вовсе не строка, а массив байт. И тогда нужно использовать класс std::vector или завести свой собственный класс.
V807. Decreased performance. Consider creating a pointer/reference to avoid using the same expression repeatedly.
Анализатор обнаружил код, который потенциально можно оптимизировать. В коде присутствуют однотипные цепочки вызовов (message chains) для доступа, к какому-то объекту.
Под цепочкой вызовов понимаются следующие конструкции:
- Get(1)->m_point.x
- X.Foo().y
- next->next->Foo()->Z
Если цепочка вызовов повторяется более двух раз, то возможно следует провести рефакторинг кода.
Рассмотрим пример:
Some->getFoo()->doIt1();
Some->getFoo()->doIt2();
Some->getFoo()->doIt3();Если функция 'getFoo()' работают медленно или если этот код находится внутри цикла, то тогда код стоит переписать. Например, можно создать временный указатель:
Foo* a = Some->getFoo();
a->doIt1();
a->doIt2();
a->doIt3();Конечно, так написать можно не всегда. И тем более, не всегда такой рефакторинг даст выигрыш в производительности. Слишком много различных вариантов существует, чтобы давать общие рекомендации.
Однако, наличие цепочек вызовов как правило говорит о неаккуратном коде. Для улучшения такого кода можно использовать несколько вариантов рефакторинга:
V808. An array/object was declared but was not utilized.
Анализатор обнаружил код, который можно упростить. В коде функции присутствуют локальные переменные, которые нигде не используются.
Анализатор выдает предупреждение в следующих случаях:
- Создается, но не используется массив объектов. Это значит, что функция использует больше стековой памяти, чем необходимо. Во-первых, это может способствовать ситуации, когда произойдет переполнение стека. Во-вторых, это может снизить эффективность работы кэша в микропроцессоре.
- Создаются, но не используются объекты классов. Анализатор предупреждает не обо всех объектах, а о тех, которые гарантированно нет смысла создавать и при этом не использовать. Например, std::string или CString. Создание и уничтожение таких объектов пустая трата процессорного времени и стека.
Анализатор не выдаёт предупреждения, если создаются переменные простых типов. С этим хорошо справляется компилятор. Также это помогает избежать множества ложных срабатываний.
Рассмотрим пример:
void Foo()
{
int A[100];
string B[100];
DoSomething(A);
}Массив элементов типа 'string' объявлен, но не используется. Под массив выделяется память, вызываются конструкторы и деструкторы. Для оптимизации достаточно просто удалить объявление неиспользуемой локальной переменной или массива. Пример корректного кода:
void Foo()
{
int A[100];
DoSomething(A);
}V809. Verifying that a pointer value is not NULL is not required. The 'if (ptr != NULL)' check can be removed.
Анализатор обнаружил код, который можно упростить. Функция 'free()' и оператор 'delete' корректно обрабатывают нулевой указатель. Поэтому можно удалить проверку, в которой проверяется указатель.
Рассмотрим пример:
if (pointer != 0)
delete pointer;В данном случае проверка является избыточной, поскольку оператор 'delete' корректно обработает нулевой указатель. Пример исправленного кода:
delete pointer;Конечно, данное исправление нельзя назвать настоящей оптимизацией. Однако это позволяет удалить лишнюю строку, что сделает код короче и легче для понимания.
Есть только один случай, когда проверка указателя имеет смысл. Если функция 'free()' или оператор 'delete' вызывается ОЧЕНЬ много раз. И при этом, ПОЧТИ ВСЕГДА указатель равен нулю. Если в пользовательском коде будет проверка, то не произойдет вызов системных функций. Это может даже чуть сократить время работы.
Но на практике, нулевой указатель почти всегда свидетельствует о какой-то ошибке. В нормальном режиме работы программы указатели в 99.99% случаев будут ненулевыми. Поэтому проверку лучше удалить.
Стоит отметить, что данное предупреждение применимо и для других функций, которые корректно обрабатывают переданный нулевой указатель, например 'CoTaskMemFree'.
V810. Decreased performance. The 'A' function was called several times with identical arguments. The result should possibly be saved to a temporary variable, which then could be used while calling the 'B' function.
Анализатор обнаружил код, который потенциально можно оптимизировать. В коде присутствует вызов функции, которой в качестве аргументов передаются несколько вызовов одной и той же функции с одинаковыми аргументами.
Рассмотрим пример:
....
init(cos(-roty), sin(-roty),
-sin(-roty), cos(-roty));
....Вызов такой функции может работать медленно и эффект будет усиливаться, если этот код находится внутри цикла, то тогда код стоит переписать. Например, можно создать временную переменную. Рассмотрим вариант такого кода:
....
double cos_r = cos(-roty);
double sin_r = sin(-roty);
init(cos_r, sin_r, -sin_r, cos_r);
....Конечно, так изменить код можно не всегда. И тем более, не всегда такой рефакторинг может дать выигрыш в производительности. Однако иногда такие оптимизации могут быть весьма полезны.
V811. Decreased performance. Excessive type casting: string -> char * -> string.
Анализатор обнаружил код, который потенциально можно оптимизировать. В коде присутствует избыточное создание объекта типа 'std::string', от которого можно избавиться.
У объекта класса 'std::string' с помощью функции 'c_str()' берется указатель на массив символов. Затем из этих символов конструируется новый объект типа 'std::string'. Например, это возможно, если неоптимальное выражение является:
- аргументом вызова функции;
- операндом оператора присваивания;
- операндом оператора 'return'.
Рассмотрим пример для случая с вызовом функции:
void foo(const std::string &s)
{
....
}
....
void bar()
{
std::string str;
....
foo(str.c_str());
}Улучшить код очень просто - достаточно убрать вызов метода 'c_str()'. Рассмотрим пример упрощенного кода:
....
void bar()
{
std::string str;
....
foo(str);
}Пример некорректного кода для оператора присваивания будет иметь вид:
std::string str;
....
std::string s = str.c_str();Пример некорректного кода для оператора 'return' будет иметь вид:
std::string foo(const std::string &str)
{
....
return str.c_str();
}Исправить ошибку в этих случаях следует аналогично случаю для вызова функции.
V812. Decreased performance. Ineffective use of the 'count' function. It can possibly be replaced by the call to the 'find' function.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. Вызов функции 'count' или 'count_if' из стандартной библиотеки сравнивается с нулем. Это может быть потенциально медленно, потому что этим функциям необходимо обработать весь контейнер, чтобы посчитать количество нужных элементов. Если значение, которое вернула функция, сравнивается с нулем, то нам интересно есть ли хотя бы 1 такой элемент или их нет совсем. Такого же эффекта можно достичь более эффективно, если осуществить вызов функции 'find' или 'find_if'.
Пример неоптимального кода:
void foo(const std::multiset<int> &ms)
{
if (ms.count(10) != 0)
{
....
}
}Что бы сделать код быстрее, следует заменить неоптимальное выражение аналогичным, использую более подходящую функцию, в данном случае - 'find'. Пример оптимизированного кода:
void foo(const std::multiset<int> &ms)
{
if (ms.find(10) != ms.end())
{
....
}
}Так же неоптимальным будет и следующий код:
void foo(const std::vector<int> &v)
{
if (count(v.begin(), v.end(), 10) != 0)
{
....
}
}Провести оптимизацию можно аналогично предыдущему примеру. Тогда оптимизированный код примет такой вид:
void foo(const std::vector<int> &v)
{
if (find(v.begin(), v.end(), 10) != v.end())
{
....
}
}V813. Decreased performance. The argument should probably be rendered as a constant pointer/reference.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. Аргумент, представляющий собой структуру или класс, передается в функцию по значению. Анализатор, проверяя тело функции, пришел к выводу, что этот аргумент не модифицируется. С целью оптимизации такой аргумент можно передавать как константную ссылку. Это может ускорить выполнение программы, поскольку при вызове функции будет скопирован только адрес, а не весь объект класса. Особенно заметна оптимизация, если класс содержит внутри себя большой объем данных.
Рассмотрим пример:
void foo(Point p)
{
float x = p.x;
float y = p.y;
float z = p.z;
float k = p.k;
float l = p.l;
.... далее аргумент 'p' никак не используется....
}Исправить такой код очень легко - достаточно изменить объявление функции:
void foo(const Point &p)
{
float x = p.x;
float y = p.y;
float z = p.z;
float k = p.k;
float l = p.l;
.... далее аргумент 'p' никак не используется....
}Анализатор не выдаёт предупреждение, если структуры очень маленькие.
Примечание N1. Пользователь может сам указать размер структур, начиная с которого следует выдавать предупреждения.
Например, чтобы не выдавать сообщения для структур размером 32 байта и менее, можно написать комментарий:
//-V813_MINSIZE=33Число 33 задаёт размер структуры, начиная с которого следует выдавать предупреждения.
Можно разместить комментарий в одном из глобальных файлов (например в StdAfx.h), чтобы комментарий начал оказывать влияние на весь проект.
Значение по умолчанию: 17.
Примечание N2. Анализатор может ошибаться, пытаясь понять, модифицируется переменная в теле функции или нет. Если вы заметили явно ложное срабатывание, просьба прислать нам соответствующий пример кода.
Если код корректен, то избавиться от ложного сообщения об ошибке можно добавив комментарий "//-V813".
V814. Decreased performance. The 'strlen' function was called multiple times inside the body of a loop.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. При каждой итерации цикла вызывается функция strlen(S) или аналогичная ей. Строка 'S' не меняется, и значит, её длину можно вычислить заранее. В некоторых случаях это может дать существенный прирост производительности.
Рассмотрим первый пример.
for (;;) {
{
....
segment = next_segment + strlen("]]>");
....
}Внутри цикла много раз вычисляется длина строки "]]>". Конечно, строка короткая и функция strlen() Работает быстро. Но если цикл выполняет миллионы итераций, можно получить замедление "на ровном месте". Этот недочет легко исправить:
const size_t suffixLen = strlen("]]>");
for (;;) {
{
....
segment = next_segment + suffixLen;
....
}Ещё лучше использовать макрос, на подобии этого:
#define LiteralStrLen(S) (sizeof(S) / sizeof(S[0]) - 1)
....
segment = next_segment + LiteralStrLen("]]>");Если это Си++, то можно сделать шаблонную функцию:
template <typename T, size_t N>
char (&ArraySizeHelper(T (&array)[N]))[N];
template <typename T, size_t N>
size_t LiteralStrLen(T (&array)[N]) {
return sizeof(ArraySizeHelper(array)) - 1;
}
....
segment = next_segment + LiteralStrLen("]]>");Рассмотрим второй пример.
for(j=0; j<(int)lstrlen(text); j++)
{
if(text[j]=='\n')
{
lines++;
}
}Показанный фрагмент кода считает количество строк в тексте. Этот пример не надуманный, а взят из реального приложения.
Если текст будет большим, этот алгоритм будет крайне неэффективен. На каждой итерации цикла, будет вычисляться его длина, чтобы сравнить с ней значение переменной 'j'.
Быстрый вариант:
const int textLen = lstrlen(text);
for(j=0; j<textLen; j++)
{
if(text[j]=='\n')
{
lines++;
}
}V815. Decreased performance. Consider replacing the expression 'AA' with 'BB'.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. В классах строк, реализованы операторы, которые позволяют более эффективно очистить строку или проверить что строка является пустой.
Рассмотрим пример:
bool f(const std::string &s)
{
if (s == "")
return false;
....
}Этот код можно немного улучшить. Объект класса 'std::string' знает длину строки, которую он хранит. Но не известно с какой строкой его хотят сравнить. Поэтому, запускается цикл для сравнения строк. Намного проще, просто проверить, что длина строки равна 0. Для этого следует использовать функцию 'empty()':
if (s.empty())
return false;Аналогичная ситуация. Требуется очистить строку. Следующий код можно немного улучшить:
wstring str;
...
str = L"";Улучшенный вариант:
wstring str;
...
str.clear();Примечание. Описанные рекомендации спорны. Выигрыш от такой оптимизации крайне мал, но при этом возрастает риск допустить опечатку и использовать не ту функцию. Причина - неудачное именование функций. Например, в классе 'std::string' функция 'empty()' проверяет, что строка пустая. В классе 'CString', функция 'Empty()' очищает строку. Одно название, но разные действия. Поэтому, для улучшения читаемости кода вполне допустимо использовать конструкции: = "", == "", != "".
Выбор за вами. Если диагностика V815 вам не нравится, вы можете отключить её в настройках.
V816. It is more efficient to catch exception by reference rather than by value.
Анализатор обнаружил конструкцию, которую потенциально можно оптимизировать. Перехватывать исключение эффективнее по ссылке, а не по значению. В этом случае, не будет происходить копирование объекта.
Рассмотрим пример:
catch (MyException x)
{
Dump(x);
}Этот код можно немного улучшить. Сейчас при перехвате исключения конструируется новый объект типа MyExeption. Этого можно избежать, если перехватить исключение по ссылке. Особенно в этом есть смысл, если объект является "тяжёлым".
Улучшенный вариант кода:
catch (MyException &x)
{
Dump(x);
}Перехватывать исключение по ссылке рекомендуется не только с точки зрения оптимизации. Это позволяет избегать некоторых других ошибок. Например, так можно избежать проблему "срезки" (slice). Однако данная темы выходит за рамки описания данной диагностики. Для борьбы со срезкой существует диагностика V746.
Подробнее про преимущества перехвата исключения по ссылке можно прочитать здесь:
- Stack Overflow. C++ catch blocks - catch exception by value or reference?
- Stack Overflow. Catch exception by pointer in C++.
Данная диагностика классифицируется как:
|
V817. It is more efficient to seek 'X' character rather than a string.
Анализатор обнаружил код, который предназначен для поиска символа в строке и который потенциально можно оптимизировать.
Рассмотрим пример неэффективного кода:
bool isSharpPresent(const std::string& str)
{
return str.find("#") != std::string::npos;
}В таком случае лучше использовать перегруженную версию функции 'find', которая принимает вместо строки символ.
Улучшенный вариант кода:
bool isSharpPresent(const std::string& str)
{
return str.find('#') != std::string::npos;
}Приведем еще пример неэффективного кода, который можно потенциально оптимизировать:
const char* GetSharpSubStr(const char* str)
{
return strstr(str, "#");
}В таком случае, эффективнее использовать функцию 'strchr()', которая ищет символ:
const char* GetSharpSubStr(const char* str)
{
return strchr(str, '#');
}V818. It is more efficient to use an initialization list rather than an assignment operator.
Анализатор обнаружил, что конструктор реализован не оптимально и можно оптимизировать инициализацию членов класса.
Рассмотрим пример:
class UserInfo
{
std::string m_name;
public:
UserInfo(const std::string& name)
{
m_name = name;
}
};Сначала член 'm_name' инициализируется как пустая строка, а затем уже в этот член копируется строка из переменной 'name'. В C++03 это приведет к лишней аллокации для пустой строки. Как минимум, этот код можно улучшить, сразу вызвав конструктор копирования через список инициализации.
UserInfo(const std::string& name) : m_name(name)
{
}Если вы используете C++11, то можно пойти дальше. Посмотрим, как можно сконструировать объект UserInfo:
std::string name = "name";
UserInfo u1(name); // 1 copy
UserInfo u2("name"); // 1 ctor, dtor + 1 copy
UserInfo u3(GetSomeName()); // 1 copyЕсли строки достаточно длинные и не попадают под Small String Optimization, то здесь произойдут лишние аллокации памяти и лишние копирования. Чтобы этого избежать, сделаем передачу аргумента по значению:
UserInfo(std::string name) : m_name(std::move(name))
{
}Теперь все временные значения не будут порождать лишних копий, так как сработает move конструктор.
std::string name = "name";
UserInfo u1(name); // 1 copy + 1 move
UserInfo u2("name"); // 1 ctor, dtor + 1 move
UserInfo u3(GetSomeName()); // 2 move
UserInfo u4(std::move(name)); // 2 moveV819. Decreased performance. Memory is allocated and released multiple times inside the loop body.
Анализатор обнаружил конструкцию, которую можно оптимизировать. Блок памяти одного и того же размера выделяется и освобождается в теле цикла множество раз. В этом случае можно вынести выделение и освобождение памяти из цикла, что повысит производительность программы.
Рассмотрим пример неэффективного кода:
for (int i = 0; i < N; i++)
{
int *arr = new int[1024 * 1024];
SetValues(arr);
val[i] = GetP(arr);
delete [] arr;
}Здесь можно вынести выделение и освобождение памяти из тела цикла.
Улучшенный вариант кода:
int *arr = new int[1024 * 1024];
for (int i = 0; i < N; i++)
{
SetValues(arr);
val[i] = GetP(arr);
}
delete [] arr;Аналогично анализатор может предложить оптимизировать код при выделении памяти с помощью функции 'malloc' и т.п.
V820. The variable is not used after copying. Copying can be replaced with move/swap for optimization.
Анализатор обнаружил, что переменная не используется после того, как её скопировали в другую переменную. Такой код можно оптимизировать, избавившись от лишнего копирования.
Рассмотрим несколько ситуаций.
Пример 1:
class UserInfo
{
std::string m_name;
public:
void SetName(std::string name)
{
m_name = name;
}
};В приведённом примере произойдёт два копирования: первое при вызове функции 'SetName()', второе при копировании 'name' в 'm_name'. Можно избавиться от копирования, использовав move присвоение:
void SetName(std::string name)
{
m_name = std::move(name);
}Если объект не move assignable, то можно изменить сигнатуру функции 'SetName()', сделав переменную 'name' константной ссылкой. В таком случае копирование произойдёт только при присваивании.
void SetName(const std::string &name)
{
m_name = name;
}Пример 2:
bool GetUserName(int id, std::string &outName)
{
std::string tmp;
if (db->GetUserName(id, tmp))
{
outName = tmp;
return true;
}
return false;
}В данном случае есть локальная переменная 'tmp', которая копируется в 'outName' и дальше не используется. С точки зрения производительности эффективнее использовать 'move' или 'swap'.
bool GetName(int id, std::string &outName)
{
std::string tmp;
if (db->GetUserName(id, tmp))
{
outName = std::move(tmp);
return true;
}
return false;
}Пример 3:
void Foo()
{
std::vector<UserInfo> users = GetAllUsers();
{
std::vector<UserInfo> users1 = users;
DoSomethingWithUsers1(users1);
}
{
std::vector<UserInfo> users2 = users;
DoSomethingWithUsers2(users2);
}
}Иногда копирование можно заменить на ссылку, если вариант с swap/move для какого-то класса недоступен. Это может быть не лучшим решением с точки зрения красоты кода, но это будет лучше по производительности.
void Foo()
{
std::vector<UserInfo> users = GetAllUsers();
{
std::vector<UserInfo> users1 = users;
DoSomethingWithUsers1(users1);
}
{
std::vector<UserInfo> &users2 = users;
DoSomethingWithUsers2(users2);
}
}V821. The variable can be constructed in a lower level scope.
Анализатор обнаружил, что переменная может быть создана в меньшей области видимости. Изменив место создания объекта, можно оптимизировать код по скорости и количеству потребляемой памяти.
Например, если выделяется память под большой массив или создаётся "тяжёлый" объект класса, и при этом такая переменная используется только при некотором условии, то её лучше перенести в блок условного оператора.
Рассмотрим пример:
void SetToolInfoText(ToolInfo &info, int nResource, int nItem)
{
Text data(80); // <=
if (nResource)
{
info.text = GetResource(nResource);
}
else
{
GetDataForItem(data, nItem);
info.text = data.text();
}
}В приведенном примере имеет смысл конструировать объект 'data' только в ветке 'else'.
Улучшенный вариант кода:
void SetToolInfoText(ToolInfo &info, int nResource, int nItem)
{
if (nResource)
{
info.text = GetResource(nResource);
}
else
{
Text data(80); // <=
GetDataForItem(data, nItem);
info.text = data.test();
}
}Также анализатор может обнаружить динамическое выделение памяти, которое можно убрать в меньшую область видимости. Например:
void func(bool condition)
{
int *arr = new int[1000];
if (condition)
{
use(arr);
}
delete[] arr;
}В данном примере имеет смысл выделять (и освобождать) память только если выполняется условие.
Улучшенный вариант кода:
void func(bool condition)
{
if (condition)
{
int *arr = new int[1000];
use(arr);
delete[] arr;
}
}Стоит отметить, что анализатор старается выдавать предупреждения лишь в тех случаях, когда перенос переменной в меньшую область видимости даст реальный прирост производительности или экономию памяти. По этой причине предупреждения не выдаются для отдельных переменных базовых типов. Также предупреждения не выдаются для объектов, которые создаются конструктором без аргументов (как показали эксперименты, почти всегда для такого кода предупреждение является ложным срабатыванием).
Данная диагностика классифицируется как:
|
V822. Decreased performance. A new object is created, while a reference to an object is expected.
Анализатор обнаружил, что скорее всего хотели создать ссылку на объект, а не новый объект. Создание нового ненужного объекта может отнимать время и память.
Рассмотрим код, где справа привели переменную к ссылке, но при этом слева в объявлении её не указали:
auto test = static_cast<NotPOD &>(npod);В приведенном примере в правой части содержится приведение к ссылке на тип NotPOD, однако в левой части его нет. Из-за этого мы копируем объект вместо ожидаемой передачи по ссылке.
Есть два варианта как можно улучшить этот код. Первый – это заменить auto на decltype(auto):
decltype(auto) test = static_cast<NotPOD &>(npod);Теперь квалификатор '&' будет выводиться в соответствии с правой частью, но это достаточно громоздко, поэтому можно вручную добавить квалификатор:
auto &test = static_cast<NotPOD &>(npod);Если же копирование было действительно необходимо, тогда стоит убрать квалификатор из правой части, чтобы увеличить читаемость кода:
auto test = static_cast<NotPOD>(npod);V823. Decreased performance. Object may be created in-place in a container. Consider replacing methods: 'insert' -> 'emplace', 'push_*' -> 'emplace_*'.
Анализатор обнаружил потенциальное использование менее эффективного метода. При вставке временного объекта в контейнер при использовании методов 'insert' / 'push_*' он конструируется снаружи контейнера и затем перемещен/скопирован внутрь контейнера.
Методы 'emplace' / 'emplace_*' в свою очередь позволяют устранить один избыточный вызов конструктора перемещения / копирования и создают объект "по месту" внутри контейнера, идеально передавая параметры функции конструктору объекта.
Анализатор предлагает следующие замены:
- insert -> emplace
- insert_after -> emplace_after
- push_back -> emplace_back
- push_front -> emplace_front
Пример кода:
std::string str { "Hello, World" };
std::vector<std::string> vec;
std::forward_list<std::string> forward_list;
std::list<std::string> list;
std::map<std::string, std::string> map;
....
vec.push_back(std::string { 3, 'A' });
forward_list.push_front(std::string { str.begin(), str.begin() + 6 });
list.push_front(str.substr(7));
list.push_back(std::string { "Hello, World" });
map.insert(std::pair<std::string, std::string> { "Hello", "World" });Оптимизированный код:
std::vector<std::string> vec;
std::forward_list<std::string> forward_list;
std::list<std::string> list;
std::map<std::string, std::string> map;
....
vector.emplace_back(3, 'A');
forward_list.emplace_front(string.begin(), string.begin() + 6);
list.emplace_front(str.begin() + 7, str.end());
list.emplace_back("Hello, World");
map.emplace("Hello", "World");В некоторых случаях такая замена может привести к потере базовой гарантии безопасности исключений. Рассмотрим пример:
std::vector<std::unique_ptr<int>> vectUniqP;
vectUniqP.push_back(std::unique_ptr<int>(new int(0)));
auto *p = new int(1);
vectUniqP.push_back(std::unique_ptr<int>(p));В таком случае замена 'push_back' на 'emplace_back' может привести к утечке памяти, если 'emplace_back' бросит исключение в связи с отсутствием памяти. Анализатор не выдает срабатывания на подобные случаи и не предлагает замену. Если же код был изменен на ошибочный, анализатор выдаст предупреждение V1023.
Иногда замена вызовов методов 'insert' / 'push_*' на их аналог 'emplace' / 'emplace_*' не принесет оптимизации:
std::string foo()
{
std::string res;
// doing some heavy stuff
return res;
}
std::vector<std::string> vec;
....
vec.push_back(foo());В этом примере метод 'emplace_back' будет иметь такую же эффективность, что и вставка элемента через 'push_back'. Однако, предупреждение всё равно выдаётся для единообразия. Во всех подобных ситуациях рационально сделать замену, чтобы код смотрелся единообразно и при его просмотре не приходилось каждый раз задумываться, стоит использовать 'emplace*' или нет. Если пользователь не согласен с таким подходом, он может рассматривать подобные предупреждения как ложные и подавлять их.
Примечание. К описанной здесь рекомендации стоит подходить разумно, а не формально. Например, замена
widgets.push_back(Widget(foo, bar, baz));
// на
widgets.emplace_back(Widget(foo, bar, baz));не даёт никакого выигрыша в скорости работы программы. Более того, использование 'emplace_back' может замедлить скорость компиляции кода. Подробнее эта тема освящена в статье "Don't blindly prefer emplace_back to push_back". Наша команда выражает Arthur O'Dwyer благодарность за эту публикацию.
V824. It is recommended to use the 'make_unique/make_shared' function to create smart pointers.
Анализатор рекомендует создать умный указатель не путем вызова конструктора, принимающего "сырой" указатель на ресурс, а вызовом функции 'make_unique' / 'make_shared'.
Использование этих функций позволяет:
- улучшить читаемость кода, устраняя явные вызовы оператора 'new' для динамических аллокаций (сами умные указатели устраняют явный вызов оператора 'delete');
- повысить безопасность кода в случае броска исключения;
- может оптимизировать размещение объектов в памяти.
Рассмотрим пример кода:
void foo(std::unique_ptr<int> a, std::unique_ptr<int> b)
{
....
}
void bar()
{
foo( std::unique_ptr<int> { new int { 0 } },
std::unique_ptr<int> { new int { 1 } });
}Поскольку стандартом не регламентируется порядок вычисления аргументов функции, компилятор в целях оптимизации может сделать это в такой последовательности:
- Вызов 'new int { 0 }'
- Вызов 'new int { 1 }'
- Первый вызов конструктора 'std::unique_ptr<int>'
- Второй вызов конструктора 'std::unique_ptr<int>'
В этом случае, если второй вызов 'new' бросит исключение, произойдет утечка памяти – ресурс, выделенный первым вызовом 'new', никогда не будет освобожден. Создание указателя при помощи 'make_unique' решает эту проблему, гарантируя освобождение памяти в случае броска исключения.
Оптимизированный код:
void foo(std::unique_ptr<int> a, std::unique_ptr<int> b)
{
....
}
void bar()
{
foo( std::make_unique<int>(0), std::make_unique<int>(1));
}Начиная с C++17, хотя порядок вычисления аргументов остается неуточненным, вводятся дополнительные гарантии. Все побочные эффекты от аргумента функции должны быть вычислены до того, как произойдет вычисление следующего аргумента. Это снижает риски в случае исключений, но использовать 'make_unique' все равно предпочтительно.
Замечание по поводу 'make_shared'. При использовании этой функции контрольный блок указателя размещается в памяти рядом с объектом. Это уменьшает количество динамических аллокаций и оптимизирует использование кэша процессора.
Объект удаляется, когда счетчик ссылок становится нулевым, но контрольный блок существует до тех пор, пока существуют слабые ссылки на указатель. Если контрольный блок и объект были созданы при помощи 'make_shared' (т.е. размещены в одной области памяти), это приводит к тому, что память не может быть освобождена до тех пор, пока счетчик ссылок нулевой и на объект ссылается хотя бы один 'weak_ptr'. Для больших объектов такое поведение может быть нежелательным. Если функция 'make_shared' не используется сознательно, чтобы избежать размещения контрольного блока в одной области памяти с объектом, срабатывание диагностики можно подавить.
Ограничение, связанное с разными версиями стандарта C++: так как возможности функций 'make_unique' и 'make_shared' менялись, начиная с C++11, диагностика зависит от версии стандарта следующим образом:
- C++11: анализатор предлагает заменять аллокацию объекта и его последующую передачу в конструктор 'shared_ptr' на функцию 'make_shared'.
- C++14 или выше: анализатор дополнительно предлагает заменять аллокацию одного объекта или массива объектов на функцию 'make_unique'.
- C++20 или выше: анализатор дополнительно предлагает заменить конструктор 'shared_ptr' на функцию 'make_shared' также и для массива объектов.
V825. Expression is equivalent to moving one unique pointer to another. Consider using 'std::move' instead.
Анализатор обнаружил фрагмент кода, в котором совместно используются функции 'std::unique_ptr::reset' и 'std::unique_ptr::release'.
Рассмотрим простой пример кода:
void foo()
{
auto p = std::make_unique<int>(10);
....
std::unique_ptr<int> q;
q.reset(p.release());
....
}Формально, такой вызов эквивалентен перемещению умного указателя:
void foo()
{
auto p = std::make_unique<int>(10);
....
auto q = std::move(p);
....
}В данном случае, предложение анализатора заменить цепочку вызовов 'q.reset(p.release())' на 'q = std::move(p) ' улучшит прозрачность кода. Однако, может возникнуть ситуация, когда перемещение умного указателя будет являться обязательным. Например, при использовании пользовательского функционального объекта для освобождения ресурса:
class Foo { .... };
struct deleter
{
bool use_free;
template<typename T>
void operator()(T *p) const noexcept
{
if (use_free)
{
p->~T();
std::free(p);
}
else
{
delete p;
}
}
};Рассмотрим два небольших примера, первый с перемещением умного указателя с пользовательским функциональным объектом для освобождения ресурса, при помощи паттерна 'reset' - 'release':
void bar1()
{
std::unique_ptr<Foo, deleter> p { (int*) malloc(sizeof(Foo)),
deleter { true } };
new (p.get()) Foo { .... };
std::unique_ptr<Foo, deleter> q;
q.reset(p.release()); // 1
}и второй пример, с помощью функции 'std::move':
void bar2()
{
std::unique_ptr<Foo, deleter> p { (int*) malloc(sizeof(Foo)),
deleter { true } };
new (p.get()) Foo { .... };
std::unique_ptr<Foo, deleter> q;
q = std::move(p); // 2
}В втором примере при перемещении указателя 'p' в 'q' функция 'std::move' позволит переместить также и функциональный объект типа 'deleter' для освобождения ресурса. В первом примере цепочка вызовов 'q.reset(p.release())' этого не сделает. Это приведет к тому, что исходный объект типа 'Foo', аллоцированный на куче через вызов 'malloc' и сконструированный оператором 'placement new', будет неверно освобожден путем вызова оператора 'delete'. Такой код неминуемо приведёт к неопределённому поведению программы.
V826. Consider replacing standard container with a different one.
Анализатор обнаружил контейнер из стандартной библиотеки C++, который можно заменить на другой контейнер в целях оптимизации.
Для определения, какой именно контейнер лучше подойдет в конкретном случае, применяется эвристика, основанная на типах операций, которые производят с контейнером. Кроме этого, анализатор вычисляет алгоритмическую сложность всех операций и предлагает контейнер, у которого она будет ниже.
В сообщении указывается причина замены:
- "The size is known at compile time" – размер контейнера известен во время компиляции, возможна замена на статический массив (std::array).
- "Elements are added, read and erased only from front/back" – контейнер реализует LIFO-очередь, можно использовать 'std::stack'.
- "Elements are added to front/back, read and erased from the opposite side" – контейнер реализует FIFO-очередь, можно использовать 'std::queue'.
- "Insertion and removal of elements occur at either side of the container" – элементы добавляются или удаляются с головы и с хвоста. В этом случае эффективно использовать 'std::deque' или 'std::list'.
- "Insertions occur at the front side, and the container is traversed forward" – элементы добавляются только с головы и происходит обход в направлении хвоста. Контейнер используется, как 'std::forward_list'.
- "Insertions occur at the back side, and the container is traversed" – элементы добавляются в хвост, происходит обход в любом направлении. Для такого использования подходит 'std::vector'.
- "Contiguous placement of elements in memory can be more efficient" – если использовать 'std::vector', то алгоритмическая сложность операций не изменится, но последовательное расположение элементов в памяти может улучшить производительность.
- "Overall efficiency of operations will increase" – контейнер выбран на основании статистического анализа.
Пример:
void f()
{
std::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
for (auto value : v)
{
std::cout << value << ' ';
}
}Анализатор выдает следующее сообщение:
V826. Consider replacing the 'v' std::vector with std::array. The size is known at compile time.
Здесь размер вектора известен во время компиляции. Если использовать вместо него 'std::array', можно избежать динамической аллокации памяти. Оптимизированный код:
void f()
{
std::array a{1, 2, 3};
}Анализатор не предлагает такую замену, если суммарный размер элементов превышает 16 килобайт, а также если вектор приходит в функцию снаружи, возвращается из функции, или передается в другую функцию параметром.
В следующем фрагменте кода сообщение не выдается несмотря на то, что размер контейнера известен:
std::vector<int> f()
{
std::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
return v;
}Следующий пример, который можно оптимизировать:
void f(int n)
{
std::vector<int> v;
for (int i = 0; i < n; ++i)
{
v.push_back(i);
}
for (int i = 0; i < n; ++i)
{
std::cout << v.back() << ' ';
v.pop_back();
}
}Анализатор выдает следующее сообщение:
V826. Consider replacing the 'v' std::vector with std::stack. Elements are added, read and erased only from front/back.
Здесь элементы добавляются в хвост вектора, а затем происходит их последовательное чтение и удаление. Вектор используется, как 'std::stack'. Можно произвести замену. Оптимизированный код:
void f(int n)
{
std::stack<int> v;
for (int i = 0; i < n; ++i)
{
v.push(i);
}
for (int i = 0; i < n; ++i)
{
std::cout << v.top() << ' ';
v.pop();
}
}Следующий пример, который можно оптимизировать:
void f(int n)
{
std::deque<int> d;
for (int i = 0; i < n; i++)
{
d.push_back(i);
}
for (auto value : d)
{
std::cout << value << ' ';
}
}Анализатор выдает следующее сообщение:
V826. Consider replacing the 'd' std::deque with std::vector. Contiguous placement of elements in memory can be more efficient.
В этом случае 'std::deque' и 'std::vector' не отличаются с точки зрения алгоритмической сложности. Однако, в случае с вектором элементы в памяти будут расположены последовательно. Это может увеличить производительность, так как последовательный доступ к памяти позволяет эффективно использовать кэш процессора. Оптимизированный код:
void f(int n)
{
std::vector<int> d;
for (int i = 0; i < n; i++)
{
d.push_back(i);
}
for (auto value : d)
{
std::cout << value << ' ';
}
}V827. Maximum size of a vector is known at compile time. Consider pre-allocating it by calling reserve(N).
Анализатор обнаружил 'std::vector', максимальный размер которого известен на этапе компиляции. При этом перед заполнением вектора не вызывался метод 'reserve'.
Пример:
void f()
{
std::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
}В этом случае вызовы 'push_back' могут приводить к реаллокации внутреннего буфера в векторе и перемещении элементов в новую область памяти.
Чтобы уменьшить накладные расходы, можно заранее выделить буфер необходимого размера:
void testVectOK()
{
std::vector<int> v;
v.reserve(6);
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
}В сообщении анализатора указывается количество элементов, которое следует передать в метод 'reserve'.
В некоторых случаях анализатор не может точно вычислить размер контейнера, например, из-за того, что элементы добавляются под условием:
void f(bool half)
{
std::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
if (!half)
{
v.push_back(4);
v.push_back(5);
v.push_back(6);
}
}Количество элементов в контейнере здесь варьируется от 3 до 6 в зависимости от условия. В таких случаях анализатор будет ориентироваться на максимальный размер.
V828. Moving an object in a return statement may prevent copy elision.
Анализатор обнаружил ситуацию, когда локальная переменная, временный объект или параметр функции возвращаются из функции посредством вызова 'std::move'.
Рассмотрим пример:
struct T { .... };
T foo()
{
T t;
// ....
return std::move(t);
}На первый взгляд может показаться, что такой код более оптимизирован, так как первым будет гарантировано выбран конструктор перемещения, однако это не так. Использование 'std::move' в контексте возвращаемого выражения может запретить компилятору устранить вызов конструктора копирования / перемещения (copy elision, C++17) и применить RVO/NRVO для локальных объектов.
До появления семантики перемещения (C++11) компиляторы старались производить так называемую оптимизацию возвращаемого значения ([Named] Return Value Optimization) в обход вызова конструктора копирования, при которой возвращаемый объект создавался непосредственно в стеке вызывающей функции, а затем инициализировался вызванной функцией.
Такую оптимизацию компилятор может сделать лишь в том случае, если возвращаемый тип функции не является ссылкой, а операндом оператора 'return' является имя локальной не-'volatile' переменной, его тип должен совпадает с возвращаемым типом функции (игнорируя 'const' / 'volatile' квалификаторы).
Начиная с C++11, при возвращении из функции не-'volatile' локальной переменной компилятор попробует применить RVO/NRVO, затем конструктор перемещения, и лишь затем конструктор копирования. Поэтому, следующий код работает медленнее, чем ожидается:
struct T { .... };
T foo()
{
T t;
// ....
return std::move(t); // <= V828, pessimization
}В случае не-'volatile' формального параметра компилятор не может применить RVO/NRVO из-за технических ограничений, но попробует выбрать сначала конструктор перемещения, а затем конструктор копирования. Поэтому, следующий код содержит избыточный вызов функции 'std::move', который можно опустить:
struct T { .... };
T foo(T param)
{
T t;
// ....
return std::move(param); // <= V828, redundant 'std::move' call
}Также, начиная с C++17, если возвращаемое выражение имеет категорию prvalue (например, результат выполнения функции, которая возвращает не ссылку), то компилятор обязан оптимизировать код, удалив вызов конструктора копирования / перемещения (copy elision). Поэтому, следующий код работает медленнее, чем ожидается:
struct T { .... };
T bar();
T foo()
{
return std::move(bar()); // <= V828, pessimization
}Во всех представленных случаях рекомендуется удалить вызов функции 'std::move' в целях оптимизации или устранения лишнего кода.
Дополнительная информация:
- Стандарт С++20 (working draft N4860), пункт 11.10.5
- C++ Core Guidelines F.48: Do not return std::move(local)
V829. Lifetime of the heap-allocated variable is limited to the current function's scope. Consider allocating it on the stack instead.
Это диагностическое правило основано на пункте R.5 CppCoreGuidelines (Prefer scoped objects, don't heap-allocate unnecessarily).
Память для хранения локальной переменной выделяется динамически и освобождается перед выходом из функции. В этом случае переменную можно разместить на стеке, чтобы избежать накладных расходов, связанных с выделением и освобождением памяти.
Пример:
class Object { .... };
void DoSomething()
{
auto obj = new Object;
....
delete obj;
}Так как переменная существует только в рамках текущей области видимости, аллокацию памяти в большинстве случаев можно убрать.
Исправленный пример:
void DoSomething()
{
Object obj;
....
}Предупреждение не выдается, если выделенная память не освобождается, или в случаях утечки адреса наружу. На этом фрагменте кода указатель возвращают через выходной параметр функции:
void DoSomething(Object** ppObj)
{
auto obj = new Object;
if (obj->good())
{
*ppObj = obj;
return;
}
delete obj;
}V830. Decreased performance. Consider replacing the use of 'std::optional::value()' with either the '*' or '->' operator.
Анализатор обнаружил фрагмент кода, в котором используется доступ к содержимому заведомо инициализированного 'std::optional' с помощью метода 'std::optional::value()'.
Рассмотрим пример:
inline void LuaBlockLoader::loadColorMultiplier(
BlockState &state, const sol::table &table) const
{
std::optional<sol::table> colorMultiplier = table["color_multiplier"];
if (colorMultiplier != std::nullopt) {
state.colorMultiplier(gk::Color{
colorMultiplier.value().get<u8>(1),
colorMultiplier.value().get<u8>(2),
colorMultiplier.value().get<u8>(3),
colorMultiplier.value().get<u8>(4)
});
}
}Данный метод добавляет накладные расходы на проверку содержимого: если объект класса 'std::optional' равен 'std::nullopt', то будет выброшено исключение 'std::bad_optional_access'. Если известно, что объект инициализирован, можно упростить и ускорить код при помощи перегруженных операторов 'std::optional::operator*' или 'std::optional::operator->':
inline void LuaBlockLoader::loadColorMultiplier(
BlockState &state, const sol::table &table) const
{
std::optional<sol::table> colorMultiplier = table["color_multiplier"];
if (colorMultiplier != std::nullopt) {
state.colorMultiplier(gk::Color{
colorMultiplier->get<u8>(1),
colorMultiplier->get<u8>(2),
colorMultiplier->get<u8>(3),
colorMultiplier->get<u8>(4)
});
}
}V831. Decreased performance. Consider replacing the call to the 'at()' method with the 'operator[]'.
Анализатор обнаружил фрагмент кода, в котором используется доступ к элементу последовательного контейнера (std::array, std::vector или std::deque) с помощью метода 'at', при этом известно, что индекс является валидным.
Метод 'at' получает элемент контейнера по заданному индексу. Перед этим он проверяет находится ли индекс в допустимых пределах, и в случае выхода за границу контейнера генерирует исключение 'std::out_of_range'. Если известно, что при обращении по индексу выход за границу не случится, использование метода 'at' можно безопасно заменить на 'operator[]', который не выполняет дополнительных проверок. Удаление избыточной проверки ускорит выполнение кода.
Рассмотрим пример:
std::vector<std::string> namelessIds;
....
if (!namelessIds.empty()) {
LIST<char> userIds(1);
for (std::string::size_type i = 0; i < namelessIds.size(); i++) {
userIds.insert(mir_strdup(namelessIds.at(i).c_str())); // <=
}
....
}При обходе элементов вектора в цикле, выбираемый номер элемента не может стать больше номера самого последнего элемента. Таким образом, код можно упростить если заменить 'at' на квадратные скобки:
std::vector<std::string> namelessIds;
....
if (!namelessIds.empty()) {
LIST<char> userIds(1);
for (std::string::size_type i = 0; i < namelessIds.size(); i++) {
userIds.insert(mir_strdup(namelessIds[i].c_str()));
}
....
}V832. It's better to use '= default;' syntax instead of empty body.
Если в классе специальные функции объявляются с '= default', класс остается тривиально копируемым. Это потенциально поможет копировать и инициализировать такой класс более оптимально.
Правила формирования специальных функций сложные. Поэтому при написании классов/структур лучшим решением будет определить явно некоторые из них для лучшего понимания кода. Вот примеры таких специальных функций: конструктор по умолчанию, конструктор копирования, оператор копирования, деструктор, конструктор перемещения, оператор перемещения.
struct MyClass
{
int x;
int y;
MyClass() {}
~MyClass() {}
};или так:
// header
struct MyClass
{
int x;
int y;
};
// cpp-file
MyClass::MyClass() {}
MyClass::~MyClass() {}Такие функции (конструктор по умолчанию и деструктор в примере) программист определяет с пустым телом. Однако при таком подходе класс может стать нетривиально копируемым, из-за чего компилятор не всегда сможет сгенерировать более оптимальный код. Поэтому C++11 вводит синтаксис '= default' для специальных функций:
struct MyClass
{
int x;
int y;
MyClass() = default;
~MyClass() = default;
};Помимо того, что компилятор сам сгенерирует тела специальных функций, он сможет вывести спецификаторы 'constexpr' и 'noexcept' для них автоматически.
Стоит отметить, что при переносе определения специальных функций из тела класса компилятор считает их определенными пользователем. Это может привести к пессимизации, поэтому '= default' лучше по возможности добавлять непосредственно в теле класса.
Срабатывание не выдается, если:
- используемый стандарт ниже C++11;
- у конструктора есть список инициализации;
- класс не содержит нестатических полей.
Примечание про идиому PIMPL
Определения больших классов внутри заголовочного файла могут многократно увеличивать время компиляции проекта. Чтобы его сократить, можно вынести реализацию класса в отдельный компилируемый файл, а в заголовочном файле оставить только объявления методов и указатель на реализацию класса. Такой подход носит название PIMPL. Вот пример такого класса:
#include <memory>
// header
class MyClass
{
class impl;
std::unique_ptr<impl> pimpl;
public:
void DoSomething();
~MyClass();
};
// cpp-file
class MyClass::impl
{
public:
impl()
{
// does nothing
}
~impl()
{
// does nothing
}
void DoSomething()
{
// ....
}
};
void MyClass::DoSomething()
{
pimpl->DoSomething();
}
MyClass::~MyClass() {}Добавление '= default' к деструктору в теле класса приведет к ошибкам компиляции, т.к. деструктор класса 'MyClass::impl' на данном этапе неизвестен (деструктор нужен для 'std::unique_ptr'). Поэтому при таком подходе реализация специальных функций переносится в компилируемый файл.
При переносе определения специальных функций из тела класса их пустые тела также можно заменить на '= default'. Это не даст прироста производительности, однако сделает код чище и проще для восприятия:
MyClass::~MyClass() = default;V833. Using 'std::move' function with const object disables move semantics.
Анализатор обнаружил ситуацию, когда семантика перемещения не сработает, что приведёт к замедлению производительности.
- Когда в функцию 'std::move' в качестве аргумента передаётся lvalue-ссылка на константный объект.
- Когда результат функции 'std::move' передаётся в функцию, принимающую lvalue-ссылку на константу.
Рассмотрим пример:
#include <string>
#include <vector>
void foo()
{
std::vector<std::string> fileData;
const std::string alias = ....;
....
fileData.emplace_back(std::move(alias));
....
}Данный фрагмент кода cработает не так, как ожидает программист. Семантика перемещения невозможна для константных объектов. В результате компилятор выберет конструктор копирования для 'std::string' и желаемая оптимизация не произойдёт.
В данном случае код можно поправить, просто убрав константность с локальной переменной:
#include <string>
#include <vector>
void foo()
{
std::vector<std::string> fileData;
std::string alias = ....;
....
fileData.emplace_back(std::move(alias));
....
}Диагностика выдает срабатывания также и для случаев, когда 'std::move' применяется для формального параметра функции:
#include <string>
void foo(std::string);
void bar(const std::string &str)
{
....
foo(std::move(str));
....
}Дать универсальную рекомендацию по исправлению такого кода сложно, но можно применить следующие подходы.
Первый вариант
Можно дописать перегрузку функции, принимающую rvalue-ссылку:
#include <string>
void foo(std::string);
void bar(const std::string &str)
{
....
foo(str); // copy here
....
}
void bar(std::string &&str) // new overload
{
....
foo(std::move(str)); // move here
....
}Второй вариант
Можно переписать функцию в виде шаблона функции, принимающей forward-ссылку. При этом необходимо ограничить шаблонный параметр нужным типом. Затем применить на шаблонном аргументе функцию 'std::forward':
#include <string>
#include <type_traits> // until C++20
#include <concepts> // since C++20
void foo(std::string);
// ------------ Constraint via custom trait (since C++11) ------------
template <typename T>
struct is_std_string
: std::bool_constant<std::is_same<std::decay_t<T>,
std::string>::value>
{};
template <typename T,
std::enable_if_t<is_std_string<T>::value, int> = 0>
void bar(T &&str)
{
....
foo(std::forward<T>(str));
....
}
// -------------------------------------------------------------------
// ------------ Constraint via custom trait (since C++14) ------------
template <typename T>
static constexpr bool is_std_string_v =
std::is_same<std::decay_t<T>, std::string>::value;
template <typename T, std::enable_if_t<is_std_string_v<T>, int> = 0>
void bar(T &&str)
{
....
foo(std::forward<T>(str));
....
}
// -------------------------------------------------------------------
// ------------------ Constraint via C++20 concept -------------------
template <typename T>
void bar(T &&str) requires std::same_as<std::remove_cvref_t<T>,
std::string>
{
....
foo(std::forward<T>(str));
....
}
// -------------------------------------------------------------------Третий вариант
Если ранее описанные или другие приёмы невозможны, то следует убрать вызов 'std::move'. Диагностическое правило также сработает в случаях, когда результат функции 'std::move' передаётся в функцию, принимающую lvalue-ссылку на константу. Рассмотрим пример:
#include <string>
std::string foo(const std::string &str);
void bar(std::string str, ....)
{
....
auto var = foo(std::move(str));
....
}Хоть 'std::move' отработает и вернёт нам xvalue-объект, он всё равно будет скопирован, поскольку формальный параметр функции — lvalue-ссылка на константу. В данном случае результат вызова 'std::move' будет находиться в контексте, в котором вызов конструктора перемещения невозможен. Однако, если дописать перегрузку функции, принимающую rvalue-ссылку, или шаблон функции с forwarding-ссылкой, компилятор выберет её, и код отработает ожидаемым образом:
#include <string>
std::string foo(const std::string &str);
std::string foo(std::string &&str);
void bar(std::string str, ....)
{
....
auto var = foo(std::move(str));
....
}Теперь давайте рассмотрим случай, когда 'std::move' на ссылку на константу сработает:
template <typename T>
struct MoC
{
MoC(T&& rhs) : obj (std::move(rhs)) {}
MoC(const MoC& other) : obj (std::move(other.obj)) {}
T& get() { return obj; }
mutable T obj;
};Здесь представлена реализация идиомы MoC (Move on Copy). В конструкторе копирования выполняется перемещение. В данном случае это возможно потому, что нестатическое поле 'obj' имеет спецификатор 'mutable', и это явно говорит компилятору работать с ним не как с константным объектом.
V834. Incorrect type of a loop variable. This leads to the variable binding to a temporary object instead of a range element.
Анализатор обнаружил ситуацию, в которой на каждой итерации цикла происходит неявное копирование элементов контейнера. При этом программист предполагал, что переменная цикла ссылочного типа будет связываться с элементами контейнера без копирования. Это происходит из-за несоответствия типов переменной цикла и элементов контейнера.
Рассмотрим пример:
void foo(const std::unordered_map<int, std::string>& map)
{
for (const std::pair<int, std::string> &i : map)
{
std::cout << i.second;
}
}В данном фрагменте кода разработчик хочет перебрать в цикле все элементы контейнера 'std::unordered_map' и напечатать значения в поток вывода. Однако тип элементов не 'std::pair<int, std::string>', как ожидалось разработчиком, а 'std::pair<const int, std::string>'. Несоответствие аргументов шаблона 'std::pair' приводит к тому, что каждый элемент контейнера будет неявно конвертироваться ко временному объекту типа 'std::pair<const int, std::string>', а затем ссылка привязывается к нему.
Решить эту проблему можно двумя способами:
Первый способ. Использовать правильный тип переменной цикла. В общем случае достаточно посмотреть, значение какого типа возвращает итератор используемого контейнера при разыменовании (operator *).
void foo(const std::unordered_map<int, std::string> &map)
{
for (const std::pair<const int, std::string> &i : map)
{
std::cout << i.second;
}
}Второй способ. Использовать тип 'auto' для автоматического вывода типа элементов контейнера.
void foo(const std::unordered_map<int, std::string> &map)
{
for (const auto &i : map)
{
std::cout << i.second;
}
}Очевидно, что второй способ является более удобным, так как сокращает количество кода и исключает возможность написания неправильного типа.
V835. Passing cheap-to-copy argument by reference may lead to decreased performance.
Анализатор обнаружил функцию, которая принимает параметр по ссылке на константный объект, когда эффективнее это делать по копии.
Рассмотрим два примера для 64-битных систем.
В первом — функция принимает объекты типа 'const std::string_view &':
uint32_t foo_reference(const std::string_view &name) noexcept
{
return static_cast<uint32_t>(8 + name.size()) + name[0];
}Ассемблерный код:
foo_reference(std::basic_string_view<char, std::char_traits<char> > const&):
mov eax, dword ptr [rdi] // <= (1)
mov rcx, qword ptr [rdi + 8] // <= (2)
movsx ecx, byte ptr [rcx]
add eax, ecx
add eax, 8
retВ нем при каждом чтении данных из объекта типа 'const std::string_view &' происходит разыменование. Это инструкции 'mov eax, dword ptr [rdi]' (1) и 'mov rcx, qword ptr [rdi + 8] ' (2).
Во втором — функция принимает объекты типа 'std::string_view':
uint32_t foo_value(std::string_view name) noexcept
{
return static_cast<uint32_t>(8 + name.size()) + name[0];
}Ассемблерный код:
foo_value(std::basic_string_view<char, std::char_traits<char> >):
movsx eax, byte ptr [rsi]
add eax, edi
add eax, 8
retКомпилятор сгенерировал меньше кода для второго примера. Так происходит потому, что объект полностью помещается в регистры процессора и нет необходимости в адресации для доступа к нему.
Давайте разберёмся, какие объекты выгоднее передавать по копии, а какие по ссылке.
Обратимся к документу "System V Application Binary Interface AMD64 Architecture Processor Supplement". В нём описаны соглашения о вызовах функций для Unix-подобных систем. Пункт 3.2.3 описывает передачу параметров. Для каждого из них определяется свой класс. Если параметр имеет класс MEMORY, то он будет передаваться через стек. В противном случае параметр передаётся через регистры процессора, как в приведённом выше примере. Согласно подпункту 5 (C), если размер объекта превышает 16 байт, то он имеет класс MEMORY. Исключение составляют агрегатные типы размером до 64 байтов, первое поле которых имеют класс SSE, а все остальные SSEUP. Это означает, что объекты, имеющие больший размер, будут размещаться на стеке вызова функции, и для доступа к ним также необходима адресация.
Давайте рассмотрим ещё два примера для 64-битных систем.
В третьем — по копии принимается объект размером в 16 байт:
struct SixteenBytes
{
int64_t firstHalf; // 8-byte
int64_t secondHalf; // 8-byte
}; // 16-bytes
uint32_t foo_16(SixteenBytes obj) noexcept
{
return obj.firstHalf + obj.secondHalf;
}Ассемблерный код:
foo_16(SixteenBytes): # @foo_16(SixteenBytes)
lea eax, [rsi + rdi]
retКомпилятор сгенерировал эффективный код, разместив структуру в двух 64-битных регистрах.
Во четвертом примере по копии принимается структура размером в 24 байта:
struct MoreThanSixteenBytes
{
int64_t firstHalf; // 8-byte
int64_t secondHalf; // 8-byte
int32_t yetAnotherStuff; // 4-byte
}; // 24-bytes
uint32_t foo_more_than_16(MoreThanSixteenBytes obj) noexcept
{
return obj.firstHalf + obj.secondHalf + obj.yetAnotherStuff;
}Ассемблерный код:
foo_more_than_16(MoreThanSixteenBytes):
mov eax, dword ptr [rsp + 16]
add eax, dword ptr [rsp + 8]
add eax, dword ptr [rsp + 24]
retСогласно соглашению о вызовах, компилятор вынужден разместить структуру на стеке. Это приводит к тому, что доступ к ней происходит косвенно, через адрес, который вычисляется с помощью регистра 'rsp'. В таком случае будет выдано предупреждение V813.
На Windows аналогичные правила вызовов функций. Подробнее можно почитать в документации.
Диагностика отключена на 32-битной платформе x86, так как на ней правила вызова функций отличаются в силу того, что не хватает регистров процессора для передачи аргументов.
У диагностики возможны ложные срабатывания. У ссылок на константные объекты могут быть необычные применения. Например, функция, в которую передаётся некий объект по ссылке, может сохранить её в глобальное хранилище. При этом сам объект, на который она ссылается, может изменяться.
Рассмотрим пример:
struct RefStorage
{
const int &m_value;
RefStorage(const int &value)
: m_value { value }
{}
RefStorage(const RefStorage &value)
: m_value { value.m_value }
{}
};
std::shared_ptr<RefStorage> rst;
void SafeReference(const int &ref)
{
rst = std::make_shared<RefStorage>(ref);
}
void PrintReference()
{
if (rst)
{
std::cout << rst->m_value << std::endl;
}
}
void foo()
{
int value = 10;
SafeReference(value);
PrintReference();
++value;
PrintReference();
}Функция 'foo' вызывает функцию 'SafeReference' и передаёт ей в качестве параметра переменную 'value' по ссылке. Далее эта ссылка сохраняется в глобальное хранилище 'rst'. При этом переменная 'value' может изменяться, так как она сама не константная.
Приведённый код достаточно неестественный и плохо написан. В реальных проектах могут быть и более сложные случаи. Если программист знает, что делает, то диагностику можно подавить специальным комментарием '//-V835'.
Если в вашем проекте много таких мест, можно полностью отключить диагностику, добавив комментарий '//-V::835' в предкомпилированный заголовок или '.pvsconfig' файл. Подробнее о подавлении ложных предупреждений можно прочитать в документации.
V836. Expression's value is copied at the variable declaration. The variable is never modified. Consider declaring it as a reference.
Анализатор обнаружил ситуацию, в которой возможно лишнее копирование при объявлении переменной.
Рассмотрим пример:
void foo(const std::vector<std::string> &cont)
{
for (auto item : cont) // <=
{
std::cout << item;
}
}В цикле 'for' происходит обход контейнера, содержащего элементы типа 'std::string'. Согласно правилам вывода результирующий тип переменной 'item' будет 'std::string'. Из-за этого на каждой итерации будет происходить копирование элемента контейнера. Можно также заметить, что в теле цикла не происходит модификаций переменной 'item'. Следовательно, лишнего копирования можно избежать. Для этого надо заменить тип 'auto' на 'const auto &'.
Исправленный пример:
void foo(const std::vector<std::string> &containter)
{
for (const auto &item : containter) // <=
{
std::cout << item;
}
}Рассмотрим второй пример:
void use(const std::string &something);
void bar(const std::string &name)
{
auto myName = name;
use(myName);
}В этом случае также лучше заменить 'auto' на 'const auto &', так как 'myName' в теле функции не модифицируется. Исправленный пример:
void use(const std::string &something);
void bar(const std::string &name)
{
const auto &myName = name;
use(myName);
}V837. The 'emplace' / 'insert' function does not guarantee that arguments will not be copied or moved if there is no insertion. Consider using the 'try_emplace' function.
Анализатор обнаружил использование функции 'emplace' / 'insert' ассоциативного контейнера стандартной библиотеки ('std::map', 'std::unordered_map'), у которого существует функция 'try_emplace'. Функция 'emplace' / 'insert' может привести к копированию или перемещению аргументов, даже если вставки не произойдёт (элемент с указанным ключом уже присутствует в контейнере). Это может привести к замедлению программы, а в случае перемещения аргумента — к преждевременному освобождению ресурсов.
В зависимости от реализации стандартной библиотеки, функция 'emplace' / 'insert' перед проверкой наличия элемента с указанным ключом может создать временный объект типа 'std::pair', в который аргументы функции будут скопированы или перемещены. Начиная со стандарта С++17, для контейнеров 'std::map' и 'std::unordered_map' была добавлена функция 'try_emplace'. Она гарантирует, что если элемент с указанным ключом уже существует, то аргументы функции не будут скопированы или перемещены.
Рассмотрим пример кода:
class SomeClass
{
std::string name, surname, descr;
public:
// User-defined constructor
SomeClass(std::string name, std::string surname, std::string descr);
// ....
};
std::map<size_t, SomeClass> Cont;
bool add(size_t id,
const std::string &name,
const std::string &surname,
const std::string &descr)
{
return Cont.emplace(id, SomeClass { name, surname, descr })
.second;
}В примере в некоторый контейнер 'Cont' производят вставку объекта типа 'SomeClass' по ключу 'id'. Если объект по такому ключу уже ранее был добавлен, могут быть произведены следующие лишние операции:
- 3 вызова конструктора копирования строки при конструировании временного объекта типа 'SomeClass';
- 3 вызова конструктора перемещения строки при идеальной передаче временного объекта типа 'SomeClass' во временный объект типа 'std::pair<const size_t, SomeClass>'.
Используя функцию 'try_emplace' вместо 'emplace', можно избежать лишних операций по формированию временного объекта типа 'std::pair<const size_t, SomeClass>':
bool add(size_t id,
const std::string &name,
const std::string &surname,
const std::string &descr)
{
return Cont.try_emplace(id, SomeClass { name, surname, descr })
.second;
}Использование 'try_emplace' позволяет также конструировать объекты "по месту" внутри ассоциативного контейнера. В примере тип 'SomeClass' не является агрегатным и содержит определённый пользователем конструктор, поэтому можно избежать также и 3 вызовов конструкторов копирования строк:
bool add(size_t id,
const std::string &name,
const std::string &surname,
const std::string &descr)
{
return Cont.try_emplace(id, name, surname, descr)
.second;
}Начиная с C++20, функция 'try_emplace' работает также и с агрегатными типами:
struct SomeClass
{
std::string name, surname, descr;
};
bool add(size_t id,
const std::string &name,
const std::string &surname,
const std::string &descr)
{
return Cont.try_emplace(id, name, surname, descr)
.second;
}V838. Temporary object is constructed during lookup in ordered associative container. Consider using a container with heterogeneous lookup to avoid construction of temporary objects.
Анализатор обнаружил вызов функции поиска в ассоциативном упорядоченном контейнере ('std::set', 'std::miltiset', 'std::map' или 'std::multimap') c аргументом, тип которого отличается от типа ключа контейнера. В результате такого вызова произойдет создание временного объекта типа ключа из переданного аргумента.
Если конвертация типов является дорогой операцией (например, 'const char *' в 'std::string'), это может отразиться на производительности программы.
Начиная с C++14, можно избежать создания временного объекта. Для это нужно, чтобы компаратор упорядоченного ассоциативного контейнера поддерживал гетерогенный поиск. Для этого должны быть выполнены следующие условия:
- Компаратор умел сравнивать тип передаваемого аргумента с типом ключа.
- В компараторе объявлен псевдоним 'is_transparent'.
Анализатор выдает предупреждение в случае, если в компараторе не объявлено имя 'is_transparent'.
Рассмотрим пример кода:
void foo(const char *str)
{
static std::set<std::string> cont;
auto it = cont.find(str); // <=
if (it != cont.end())
{
// do smth
}
}В примере контейнер 'cont' по умолчанию объявлен с компаратором типа 'std::less<std::string>'. Этот компаратор не поддерживает гетерогенный поиск. Поэтому при каждом вызове функции 'find' происходит создание временного объекта 'std::string' из 'const char *'.
Чтобы избежать создания временного объекта типа 'std::string', нужно использовать контейнер с компаратором, поддерживающим гетерогенный поиск и умеющим сравнивать 'std::string' c 'const char *'. Например, можно использовать 'std::set' с компаратором 'std::less<>':
void foo(const char *str)
{
static std::set<std::string, std::less<>> cont;
auto it = cont.find(str);
if (it != cont.end())
{
// do smth
}
}Теперь при вызове функции 'find' временный объект типа 'std::string' не создается, и аргумент типа 'const char *' напрямую сравнивается с ключами.
V839. Function returns a constant value. This may interfere with move semantics.
Это диагностическое правило основано на пункте F.49 CppCoreGuidelines.
Анализатор обнаружил объявление функции, которая возвращает значения константного типа. Несмотря на то, что квалификатор 'const' по задумке автора специально не позволяет модифицировать временные объекты, такое поведение может препятствовать семантике перемещения. В результате возможно замедление из-за дорогостоящего копирования больших объектов.
Рассмотрим синтетический пример:
class Object { .... };
const std::vector<Object> GetAllObjects() {...};
void g(std::vector<Object> &vo)
{
vo = GetAllObjects();
}Из-за наличия квалификатора 'const' у возвращаемого типа функции 'GetAllObjects' при выборе перегрузки оператора '=' компилятор не будет рассматривать оператор перемещения и выберет оператор копирования. Собственно, будет выполнено копирования вектора объектов, возвращенного функцией.
Чтобы оптимизировать код, достаточно удалить квалификатор 'const':
class Object { .... };
std::vector<Object> GetAllObjects() {...};
void g(std::vector<Object> &vo)
{
vo = GetAllObjects();
}Теперь при вызове функции 'GetAllObjects' возвращаемый вектор объектов будет перемещен.
Обращаем внимание, что диагностическое правило применяется только для кода, написанного на C++11 или выше. Это поведение связано с семантикой перемещения, которая была добавлена в C++11.
Рассмотрим следующий код (реализация пользовательского типа для длинной арифметики):
class BigInt
{
private:
....
public:
BigInt& operator++();
BigInt& operator++(int);
BigInt& operator--();
BigInt& operator--(int);
friend const BigInt operator+(const BigInt &,
const BigInt &) noexcept;
// other operators
};
void foo(const BigInt &lhs, const BigInt &rhs)
{
auto obj = ++(lhs + rhs); // compile-time error
// can't call operator++()
// on const object
}Такой паттерн использовался в прошлом, когда семантика перемещения еще не была внедрена в C++, и при этом хотелось запретить вызывать модифицирующие операции на временном объекте.
Если возвращать из перегруженного оператора '+' не константный объект, то можно будет вызывать перегруженный оператор префиксного инкремента на временном объекте. Для встроенных арифметических типов такая семантика запрещена.
Начиная с C++11 код можно переделать при помощи ref-квалификаторов нестатических функций-членов и дать возможность компилятору применять семантику перемещения:
class BigInt
{
....
public:
BigInt& operator++() & noexcept;
BigInt& operator++(int) & noexcept;
BigInt& operator--() & noexcept;
BigInt& operator--(int) & noexcept;
friend BigInt operator+(const BigInt &,
const BigInt &) noexcept;
// other operators
};
void foo(const BigInt &lhs, const BigInt &rhs)
{
auto obj = ++(lhs + rhs); // compile-time error
// can't call BigInt::operator++()
// on prvalue
}V2001. Consider using the extended version of the 'foo' function here.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор позволяет обнаружить вызов функций, у которых существует "расширенный" аналог. Под термином "расширенные" понимаются функции, имеющие суффикс Ex, такие как VirtualAllocEx, SleepEx, GetDCEx, LoadLibraryEx, FindResourceEx.
Рассмотрим исходный код:
void foo();
void fooEx(float x);
void foo2();
...
void test()
{
foo(); // V2001
foo2(); // OK
}В месте вызова функции "foo", будет выдано диагностическое сообщение V2001, так как имеется функция с тем же именем, но оканчивающаяся на "Ex". Функция "foo2" не имеет альтернативного варианта, и диагностическое сообщение выдаваться не будет.
Сообщение V2001 будет также выдано для случая:
void fooA(char *p);
void fooExA(char *p, int x);
...
void test()
{
fooA(str); // V2001
}Родственным диагностическим сообщением является V2002.
Данная диагностика классифицируется как:
|
V2002. Consider using the 'Ptr' version of the 'foo' function here.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор позволяет обнаружить вызов функций, у которых существует 'Ptr' аналог. Имеются в виду функции, имеющие в составе своего названия суффикс 'Ptr', такие как: 'SetClassLongPtr', 'DSA_GetItemPtr'.
Рассмотрим исходный код:
void foo(int a);
void fooPtr(int a, bool b);
....
void test()
{
foo(1); // V2002
}В месте вызова функции 'foo', будет выдано предупреждение V2002, так как имеется функция с тем же именем, но оканчивающаяся на 'Ptr'. Функция 'foo2' не имеет альтернативного варианта, и предупреждение выдаваться не будет.
Сообщение V2002 будет также выдано для случая:
void fooA(char *p);
void fooPtrA(char *p, int x);
....
void test()
{
fooA(str); // V2002
}Предупреждение не выдается в случае, когда вызов одноименной функции происходит из её расширенной версии:
class A
{
....
void foo() { .... };
void fooPtr()
{
foo(); // ok
}
....
};Родственным диагностическим сообщением является V2001.
Данная диагностика классифицируется как:
|
V2003. Explicit conversion from 'float/double' type to signed integer type.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор позволяет обнаружить все явные приведения типов с плавающих точкой к целочисленным знаковым типам.
Примеры конструкций, на которые анализатор выдаст данное диагностическое сообщение:
float f;
double d;
long double ld;
int i;
short s;
...
i = int(f); // V2003
s = static_cast<short>(d); // V2003
i = (int)ld; // V2003Родственным диагностическим сообщением является V2004.
Данная диагностика классифицируется как:
|
V2004. Explicit conversion from 'float/double' type to unsigned integer type.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор позволяет обнаружить все явные приведения типов с плавающих точкой к целочисленным беззнаковым типам.
Примеры конструкций, на которые анализатор выдаст данное диагностическое сообщение:
float f;
double d;
long double ld;
unsigned u;
size_t s;
...
u = unsigned(f); // V2004
s = static_cast<size_t>(d); // V2004
u = (unsigned)ld; // V2004Родственным диагностическим сообщением является V2003.
Данная диагностика классифицируется как:
|
V2005. C-style explicit type casting is utilized. Consider using: static_cast/const_cast/reinterpret_cast.
Данное диагностическое предупреждение добавлено по просьбе пользователей.
Анализатор позволяет обнаружить явные приведения типов в программе на C++, написанные в старом стиле языка C. В языке C++ более безопасно явно приводить типы с использованием операторов 'static_cast', 'const_cast' и 'reinterpret_cast'.
Диагностическое правило V2005 помогает выполнить рефакторинг кода, поменять старый стиль приведения типов на новый. Иногда это позволяет выявить ошибки.
Примеры конструкций, на которые анализатор выдаст данное диагностическое сообщение:
int i;
double d;
size_t s;
void *p;
....
i = int(p); //+V2005
d = (double)i; //+V2005
s = (size_t)(d); //+V2005Диагностическое сообщение V2005 не выдается в следующих случаях:
1. Это программа на языке C.
2. Осуществляется приведение к типу 'void'. Такое приведение типа никакой опасности в себе не несёт и используется, чтобы подчеркнуть, что некий результат никак не используется. Пример:
(void)fclose(f);3. Приведение типа находится в макросе. Если выдавать предупреждения для макросов, то будет огромное количество срабатываний при использовании различных системных констант и макросов. Причем, поправить их все равно нет никакой возможности. Примеры:
#define FAILED(hr) ((HRESULT)(hr) < 0)
#define SRCCOPY (DWORD)0x00CC0020
#define RGB(r,g,b)\
((COLORREF)(((BYTE)(r)|((WORD)((BYTE)(g))<<8))\
|(((DWORD)(BYTE)(b))<<16)))Уровни достоверности диагностики
По умолчанию срабатывания V2005 диагностики имеют второй уровень достоверности (Medium). Если подозрительный код находится в шаблоне, а приведение происходит к типу шаблонного параметра, то уровень предупреждения снижается до третьего (Low).
Рассмотрим синтетический пример:
template <typename TemplateParam>
void foo(const std::vector<SomeType>& vec)
{
auto a = (TemplateParam)(vec[0]); //+V2005 //3rd level
auto b = TemplateParam(vec[3]); //+V2005 //3rd level
// ....
auto i = (int)a; //+V2005 //2 level
auto i = int(a); //+V2005 //2 level
// ....
}Без инстанцирований шаблона понять, что за тип скрывается под 'TemplateParam', сложно. Если же приведение происходит к известному типу внутри шаблона, то анализатор будет по-прежнему выдавать срабатывания второго уровня. В случае, если предупреждения третьего уровня не имеют практической пользы для вас, их можно подавить при помощи специального комментария:
//-V::2005:3Особые настройки диагностики V2005
По дополнительной просьбе пользователей появилась возможность управлять поведением диагностики V2005. В общем заголовочном файле или pvsconfig-файле пишется комментарий специального вида. Пример использования:
//+V2005 ALLСуществует три режима:
а) Режим по умолчанию: на каждое преобразование типов в стиле C выдаётся предупреждающее сообщение, которое гласит: используйте вместо преобразования типов конструкции вида 'static_cast', 'const_cast' и 'reinterpret_cast'.
б) ALL - на каждое преобразование типов в стиле C анализатор выдаёт рекомендацию о том, какое ключевое слово (ключевые слова) требуется использовать вместо него. Изредка возможны единичные неверные рекомендации, связанные с преобразованием сложных шаблонных типов. Также изредка возможна такая ситуация, что анализатор не сможет определить тип преобразования и выдал обыкновенное сообщение без точного указания типа приведения.
//+V2005 ALLв) NO_SIMPLE_CAST - аналогично предыдущему, но сообщение показывается только если в преобразовании участвует хотя бы один указатель или требуется преобразование сложнее чем static_cast.
//+V2005 NO_SIMPLE_CASTДополнительные ссылки:
- Терминология. Явное приведение типов.
- Wikipedia. Приведение типа.
V2006. Implicit type conversion from enum type to integer type.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор позволяет обнаружить все неявные приведения enum-типов к целочисленным типам.
Диагностическое правило V2006 помогает выполнить рефакторинг кода и иногда выявить ошибки.
Пример конструкции, на которую анализатор выдаст данное диагностическое сообщение:
enum Orientation {
Horizontal = 0x1,
Vertical = 0x2
};
Orientation orientation = Horizontal;
int pos = orientation; // V2006Диагностическое сообщение V2006 не выдается в следующих случаях.
Первое. Анализатор не предупреждает о сравнении именованной константы перечисления с переменной имеющий тип, например 'int'. Хотя перед началом сравнения константа неявно приводится к типу 'int', такое встречается слишком часто, чтобы выдавать на это предупреждение.
int pos = foo();
if (pos == Vertical) // Ok
{
....
}Второе. Сравниваются две константы перечисляемого типа:
enum E
{
ZERO, ONE, TWO
};
void foo(E e1, E e2)
{
if (e1 == e2) // ok
....
else if (e1 > e2) // ok
....
else if (e1 != e2) // ok
....
}Третье. Неявное преобразование типа происходит при сдвиге именованной константы, чтобы инициализировать другую именованную константу или элементы массива:
enum E
{
FIRST_BIT = 1,
SECOND_BIT = FISRT_BIT << 1, // ok
THIRD_BIT = FISRT_BIT << 2, // ok
....
};
int A[3] = {
FIRST_BIT,
FIRST_BIT << 1, // ok
FIRST_BIT << 2 // ok
};V2007. This expression can be simplified. One of the operands in the operation equals NN. Probably it is a mistake.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор позволяет обнаружить ряд мест с подозрительными бинарными операциями, где можно упростить код для повышения его читаемости.
Подозрительные бинарные операции:
- '^', '+', '-', '<<', '>>', где один из операндов равен 0;
- '&', где один из операндов равен -1;
- '*', '/', '%', где один из операндов равен 1.
Диагностическое правило V2007 помогает выполнять рефакторинг кода и иногда выявлять ошибки.
Примеры конструкций, на которые анализатор выдаст данное диагностическое сообщение:
int X = 1 ^ 0;
int Y = 2 / X;Приведённый код можно упростить. Пример корректного кода:
int X = 1;
int Y = 2;Для сокращения количества ложных сообщений, есть несколько исключений. Например, диагностическое сообщение V2007 не выдаётся в случае, если подозрительное выражение находится в макросе или является индексом массива.
Данная диагностика классифицируется как:
V2008. Cyclomatic complexity: NN. Consider refactoring the 'Foo' function.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор рассчитывает и выводит значения "Цикломатической сложности" для функций. Цикломатическая сложность - это одна из метрик исходного кода, используемая для оценки сложности программы.
Слишком большое значение цикломатической сложности указывает на необходимость обратить внимание на код функции, для которой было выдано диагностическое сообщение. Велика вероятность того, что необходим рефакторинг этих функций.
Сообщения выводятся только для тех функций, цикломатическая сложность которых превысила пороговое значение. По умолчанию оно равно 50.
Изменить пороговое значение можно добавив в код своей программы такой комментарий:
//-V2008_CYCLOMATIC_COMPLEXITY=N
N - пороговое значение для вывода цикломатической сложности. Значение должно быть больше 1. Комментарий действует в пределах единицы компиляции. Поэтому, если вы хотите задать пороговое значение для всего проекта, то поместите этот комментарий в один из базовых заголовочных файлов. Таким файлом, например, может быть stdafx.h.
Есть ещё одна дополнительная опция, включающая модифицированный вариант расчёта цикломатической сложности:
//-V2008_MODIFIED_CYCLOMATIC_COMPLEXITY
Этот комментарий говорит анализатору, считать цикломатическую сложность оператора switch() за единицу. Количество "case x:" значения не имеет.
Данная диагностика классифицируется как:
V2009. Consider passing the 'Foo' argument as a pointer/reference to const.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор предполагает, что формальный параметр в виде указателя/ссылки может ссылаться на константный объект.
Данное предупреждение может быть выдано на следующий код:
- Экземпляр структуры или класса передается в функцию по ссылке, но не модифицируется в теле функции;
- Аргумент функции является указателем на неконстантный тип, но он используется только для чтения данных.
Эта диагностика может помочь при рефакторинге кода или предотвращении программных ошибок в будущем.
Рассмотрим пример такого кода:
void foo(int *a)
{
int b = a[0] + a[1] + a[2];
.... переменная 'a' больше не используется
}Переменную 'a' лучше сделать указателем на константное значение. Таким образом, сразу станет понятно, что аргумент используется только для чтения.
Исправленный код:
void foo(const int *a)
{
int b = a[0] + a[1] + a[2];
.... переменная 'a' больше не используется
}Примечание. Анализатор может ошибаться, пытаясь понять, модифицируется переменная в теле функции или нет. Если вы заметили явно ложное срабатывание, просьба прислать нам соответствующий пример кода.
Иногда выдаваемые анализатором сообщения могут показаться несколько странными. Давайте рассмотрим один из таких случаев более подробно:
typedef struct tagPOINT {
int x, y;
} POINT, *PPOINT;
void foo(const PPOINT a, const PPOINT b) {
a->x = 1; // Данные можно изменить
a = b; // Ошибка компиляции
}Анализатор предлагает сделать тип, на который ссылается указатель, константным. Это может показаться странным, так как здесь присутствует ключевое слово 'const'. Дело в том, что 'const' означает константность указателя. Объекты, на которую ссылаются указатели, доступна для модификации.
Для того, чтобы сделать сами объекты константными, следует поступить так:
....
typedef const POINT *CPPOINT;
void foo(const CPPOINT a, const CPPOINT b) {
a->x = 1; // Ошибка компиляции
a = b; // Ошибка компиляции
}V2010. Handling of two different exception types is identical.
Данное диагностическое правило добавлено по просьбе пользователей.
Обработчики для разных типов исключений выполняют одно и то же действие. Возможно это ошибка или код можно упростить.
Рассмотрим пример:
try
{
....
}
catch (AllocationError &e)
{
WriteLog("Memory Allocation Error");
return false;
}
catch (IOError &e)
{
WriteLog("Memory Allocation Error");
return false;
}Код писался с помощью Copy-Paste и поэтому при ошибке чтения из файла, в лог запишется неверное сообщение. На самом деле, код должен был выглядеть, например, так:
try
{
....
}
catch (AllocationError &e)
{
WriteLog("Memory Allocation Error");
return false;
}
catch (IOError &e)
{
WriteLog("IO Error: %u", e.ErrorCode());
return false;
}Рассмотрим другой пример. Это корректный код, но его можно упростить:
try
{
....
}
catch (std::exception &)
{
Disconnect();
}
catch (CException &)
{
Disconnect();
}
catch (...)
{
Disconnect();
}Поскольку все обработчики одинаковы и перехватываются все виду исключений, то можно написать короче:
try
{
....
}
catch (...)
{
Disconnect();
}Рассмотрим ещё один пример.
class DBException : public std::exception { ... };
class SocketException : public DBException { ... };
class AssertionException : public DBException { ... };
....
try
{
....
}
catch (SocketException& e){
errorLog.push_back(e.what());
continue;
}
catch (AssertionException& e) {
errorLog.push_back(e.what());
continue;
}
catch(std::exception& e){
errorLog.push_back(e.what());
continue;
}Есть несколько классов, которые наследуются от класса 'std::exception'. Все обработчики исключений совпадают. Обратите внимание, что в том числе, перехватывается и исключение типа 'std::exception'. Этот код избыточен. Можно оставить только обработчик для 'std::exception'. Остальные исключения будут так-же перехвачены и обработаны, так как наследуются от 'std::exception'. Метод 'what()' является виртуальным, поэтому в 'errorLog' будет сохранена правильная информация о типе ошибки.
Упрощенный код:
try
{
....
}
catch(std::exception& e){
errorLog.push_back(e.what());
continue;
}V2011. Consider inspecting signed and unsigned function arguments. See NN argument of function 'Foo' in derived class and base class.
Данное диагностическое правило добавлено по просьбе пользователей.
Диагностика выявляет следующую ситуацию. В базовом классе имеется виртуальная функция, в которой один из параметров имеет знаковый тип. В наследнике есть точно такая-же функция, но этот параметр является беззнаковым. Или ситуация противоположная: в базовом классе беззнаковый тип, в наследнике - знаковый.
Эта диагностика помогает выявить ошибки, когда при большом факторинге меняют тип функции в одном из классов, но забывают изменить эту функцию в другом классе.
Рассмотрим пример:
struct Q { virtual int x(unsigned) { return 1; } };
struct W : public Q { int x(int) { return 2; } };На самом деле, код должен быть таким:
struct Q { virtual int x(unsigned) { return 1; } };
struct W : public Q { int x(unsigned) { return 2; } };Если в базовом классе будет две функции 'x' с аргументами 'int' и "unsigned', то анализатор предупреждение V2011 выдавать не будет.
V2012. Possibility of decreased performance. It is advised to pass arguments to std::unary_function/std::binary_function template as references.
Данное диагностическое правило добавлено по просьбе пользователей.
В коде обнаружен класс, унаследованный от 'std::unary_function' или 'std::binary_function'. При этом среди параметров его шаблона находятся классы, передаваемые по значению. Очевидно, передача по значению объекта класса (особенно "тяжёлого", с большим количеством полей или сложным конструктором) может повлечь за собой дополнительные расходы по времени и памяти. Конечно, передача объекта по значению не всегда плоха. Передача по значению имеет смысл, если надо сохранить исходный объект и работать с изменённой копией. Но иногда код, в котором происходит передача объекта по значению, получился случайно и является плохим решением.
Рассмотрим пример. Данный функтор при каждом вызове будет копировать два объекта типа 'std::string' вместо того, чтобы передать их по значению:
class example : public std::binary_function
<std::string, std::string, bool>
{
public:
result_type operator()(
first_argument_type first,
second_argument_type second)
{
return first == second;
};
};Разумеется, простейшим решением в данном случае может послужить передача параметров шаблона по ссылке, а не по значению:
class example : public std::binary_function
<const std::string &, const std::string &, bool> ....Анализатор также не выдаст предупреждение, если в теле функции все аргументы, переданные не по ссылке, изменяются:
class example : public std::binary_function
<std::string, std::string, bool>
{
public:
result_type operator()(
first_argument_type first,
second_argument_type second)
{
std::replace(first.begin(), first.end(), 'u', 'v');
std::replace(second.begin(), second.end(), 'a', 'b');
return first == second;
};
};V2013. Consider inspecting the correctness of handling the N argument in the 'Foo' function.
Данное диагностическое правило добавлено по просьбе пользователей. Оно весьма специфично и сделано для решения определённой задачи, которая вряд ли может быть интересна широкому кругу пользователей.
Бывает полезно отследить все вызовы COM-интерфейсов, где указатель на какой-то класс явно приводится к указателю целочисленного типа или просто к целочисленному типу. Некоторые пользователи хотят иметь возможность проверить, правильно ли обрабатываются переданные данные на стороне COM-сервера.
Предположим, имеется какой-то контейнер, содержащий в себе массив элементов типа unsigned. Он передаётся в функцию, которая интерпретирует его как массив элементов типа 'size_t'. Этот код будет корректно работать в 32-битной системе, но в 64-битной программе данные начнут интерпретироваться неправильно. Пример:
MyVector<unsigned> V;
pInterface->Foo((unsigned char *)(&V));
....
void IMyClass::Foo(unsigned char *p)
{
MyVector<size_t> *V = (V *)(p);
....
}Фактически, это 64-битная ошибка. Мы не стали включать в набор 64-битных диагностик, так как они слишком специфична. Диагностика позволяет найти потенциально опасные вызовы, а уже программист должен глазами изучить методы, принимающие данные и разобраться, имеет место ошибка или нет.
Данная диагностика классифицируется как:
V2014. Don't use terminating functions in library code.
Данное диагностическое правило добавлено по просьбе пользователей. Эта диагностика весьма специфична и предназначена для проверки кода библиотек.
Есть функции, которые прерывают или могут прерывать выполнение программы. Использовать их в своей программе хоть и некрасиво, но вполне можно, т.к. автор программы знает, чего он хочет и что делает.
А вот использовать эти функции в библиотеках нельзя! Неизвестно, как и где библиотека будет использоваться. Будет плохо, если библиотека завершит программу, и пользователь потеряет данные. Библиотеки в случае ошибок должны возвращать статус ошибки или кидать исключение, но не прекращать работу программы.
Рассмотрим пример:
char *CharMallocFoo(size_t length)
{
char *result = (char*)malloc(length);
if (!result)
abort();
return result;
}Функция 'CharMallocFoo' прервёт выполнение программы в случае неудачной попытки выделить динамическую память. Как вариант, лучше возращать из фукнции нулевой указатель для обработки такой ситации пользователем библиотеки.
Данная диагностика классифицируется как:
|
V2015. An identifier declared in an inner scope should not hide an identifier in an outer scope.
Данное диагностическое правило добавлено по просьбе пользователей.
Идентификатор, объявленный в области видимости и не отличающийся по имени от другого идентификатора, объявленного в обрамляющей области видимости, "скрывает" внешний идентификатор. Это может привести к путанице или программной ошибке.
Например, такая коллизия имен может привести к логической ошибке, как в примере ниже:
int foo(int param)
{
int i = 0;
if (param > 0)
{
int i = var + 1;
}
return i;
}При прочтении этого кода на первый взгляд кажется, что когда в функцию 'foo' передается положительное значение параметра, то результатом вычисления будет это значение, увеличенное на '1'. Однако это не так, и на самом деле функция всегда возвращает '0'. Чтобы показать, что происходит в действительности, исключим из кода коллизию идентификаторов:
int foo(int param)
{
int i_outer = 0;
if (param > 0)
{
int i_inner = var + 1;
}
return i_outer;
}Теперь видно, что присваивание внутри ветки 'if'в переменную 'i' не влияет на результат вычисления функции 'foo'. Внутренний идентификатор 'i' ('i_inner') скрывает внешний идентификатор 'i' ('i_outer'), что приводит к ошибке.
Данная диагностика классифицируется как:
|
V2016. Consider inspecting the function call. The function was annotated as dangerous.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор обнаружил вызов функции, которая помечена пользователем как опасная/запрещенная.
Часто использование некоторых функций в проекте может быть запрещено. Например, в соответствии со стилем кодирования, который принят в проекте. Анализатор может находить использование таких функций, если они были размечены пользовательской аннотацией следующего вида:
//+V2016, function:foo
//+V2016, class:SomeClass, function:foo
//+V2016, namespace:SomeNamespace, class:SomeClass, function:fooНапример, пользователь отметил функцию 'malloc' следующим образом:
//+V2016, function:mallocТеперь, если анализатор встретит вызов функции 'malloc', то выдаст предупреждение 1 уровня:
struct SomeStruct { .... };
void foo()
{
struct SomeStruct *p = (SomeStruct *) malloc(....);
}Пользователь может проаннотировать функцию, лежащую в любом пространстве имен и/или классе:
class A
{
// ....
void a(int);
// ....
};
namespace BN
{
class B
{
// ....
void b(double);
// ....
};
}
//+V2016, class:A, function:a
//+V2016, namespace:BN, class:B, function:b
void foo()
{
A a;
a.a(); // <=
BN::B b;
b.b(); // <=
}Примечание. По умолчанию пользовательские аннотации не применяются к виртуальным функциям. О том, как включить данный функционал, вы можете прочитать здесь.
Данная диагностика классифицируется как:
V2017. String literal is identical to variable name. It is possible that the variable should be used instead of the string literal.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор обнаружил подозрительное выражение со строковым литералом, текст которого совпадает с именем переменной строкового типа. Такое выражение может содержать опечатку, которую сложно выявить как на этапе ревью кода, так и при сборке.
Рассмотрим следующий синтетический пример:
bool CheckCredentials(const std::string& username,
const std::string& password)
{
return users[username].password == "password";
}Данная функция должна проверять, совпадает ли переданный пароль с тем, что был записан в хранилище данных пользователей. При работе с данными строковых типов зачастую можно случайно набрать лишние кавычки. Поскольку такое сравнение синтаксически корректно, оно будет успешно скомпилировано, хотя очевидно, что функция не работает как планировалось. Если такой код окружён однотипными выражениями для проверки других данных, то ревьювер может посчитать его слишком тривиальным и не уделить проверке должного внимания.
Еще один пример опечатки, найденный в реальном проекте:
qboolean QGL_Init( const char *dllname ) {
....
// NOTE: this assumes that 'dllname' is lower case (and it should be)!
if ( strstr( dllname, _3DFX_DRIVER_NAME ) ) {
if ( !GlideIsValid() ) {
ri.Printf( PRINT_ALL,
"...WARNING: missing Glide installation, assuming no 3Dfx available\n" );
return qfalse;
}
}
if ( dllname[0] != '!' && strstr( "dllname", ".dll" ) == NULL ) { // <=
Com_sprintf( libName, sizeof( libName ), "%s\\%s", systemDir, dllname );
} else
{
Q_strncpyz( libName, dllname, sizeof( libName ) );
}
....
}Фрагмент выражения 'strstr( "dllname", ".dll" ) == NULL' всегда будет иметь значение true, поскольку в строке "dllname" не содержится подстроки ".dll". На самом деле автор этого кода хотел проверить содержимое переменной 'dllname'.
К сожалению, эта диагностика часто выдаёт ложные срабатывания, поскольку сложно надёжно определить логику обработки тех или иных переменных. Например, переменные и текстовые литералы часто пересекаются при работе с key-value контейнерами, предназначенными для связывания данных с их именами. Впрочем, такие предупреждения не занимают много времени при просмотре отчёта и код можно быстро отрефакторить или подавить лишние предупреждения.
V2018. Cast should not remove 'const' qualifier from the type that is pointed to by a pointer or a reference.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор обнаружил ситуацию с удалением 'const'-квалификатора. Изменение объекта, объявленного с квалификатором 'const', через указатель/ссылку на не-'const' тип ведет к неопределенному поведению. Также зачастую такой код свидетельствует о плохом дизайне приложения.
Рассмотрим пример:
void read_settings(const char *buf);
const char* get_settings_file_name();
bool settings_present();
// ....
void init_settings()
{
const char name[MAX_PATH] = "default.cfg";
if (settings_present())
{
strcpy((char *)name, get_settings_file_name());
}
read_settings(name);
}Для того, чтобы избежать неопределённого поведения, нужно отказаться от константности при объявлении локальной переменной:
void read_settings(const char *buf);
const char* get_settings_file_name();
bool settings_present();
// ....
void init_settings()
{
char name[MAX_PATH] = "default.cfg";
if (settings_present())
{
strcpy(name, get_settings_file_name());
}
read_settings(name);
}V2019. Cast should not remove 'volatile' qualifier from the type that is pointed to by a pointer or a reference.
Данное диагностическое правило добавлено по просьбе пользователей.
Анализатор обнаружил ситуацию с удалением 'volatile'-квалификатора. Доступ к объекту, объявленному с квалификатором 'volatile', через указатель/ссылку на не-'volatile' тип ведет к неопределенному поведению.
Пример кода, на который анализатор выдаст предупреждение:
int foo(int &value)
{
while (value)
{
// do some stuff...
}
return 0;
}
int main()
{
volatile int value = 1;
return foo((int &) value);
}Другой пример кода, на который анализатор выдаст предупреждение:
#include <utility>
int foo()
{
int x = 30;
volatile int y = 203;
using std::swap;
swap(x, const_cast<int &>(y)); // <=
return x;
}V2020. The loop body contains the 'break;' / 'continue;' statement. This may complicate the control flow.
Данное диагностическое правило добавлено по просьбе пользователей.
Диагностическое правило позволяет обнаружить использование конструкций 'break;' и 'continue;' в телах циклов. Также оно помогает выполнить рефакторинг кода и избежать появления ошибок при изменении старого кода цикла на новый.
Рассмотрим синтетический пример кода:
namespace fs = std::filesystem;
std::vector<fs::path> existingPaths;
void SaveExistingPaths(const std::vector<fs::path> &paths)
{
for (auto &&path: paths)
{
if (!fs::exists(path))
{
break; // <=
}
existingPaths.emplace_back(path);
}
}В приведённом фрагменте кода задумывалось, что все существующие пути будут сохранены в отдельный контейнер. Однако на первом же несуществующем пути цикл прервётся из-за использования 'break;'. Вместо него здесь должна была использоваться конструкция 'continue;'. Ещё более правильным решением было бы совсем избавиться от 'break;' или 'continue;' в цикле:
namespace fs = std::filesystem;
std::vector<fs::path> existingPaths;
void SaveExistingPaths(const std::vector<fs::path> &paths)
{
for (auto &&path: paths)
{
if (fs::exists(path))
{
existingPaths.emplace_back(path);
}
}
}Примечание. Данная диагностика отключена по умолчанию, чтобы не выдавать большое количество срабатываний.
Для того, чтобы включить диагностическое правило на анализируемом файле, можно воспользоваться следующим комментарием:
//+V::2020Также этот комментарий можно расположить в общем заголовочном файле. Тогда диагностическое правило будет активировано на всех файлах, которые включают этот заголовочный файл. Например, для этого подходит 'stdafx.h'.
Для того, чтобы включить диагностику только на определённом блоке кода, можно воспользоваться директивой '#pragma pvs':
namespace fs = std::filesystem;
std::vector<fs::path> existingPaths;
#pragma pvs(push)
#pragma pvs(enable: 2020)
void SaveExistingPaths(const std::vector<fs::path> &paths)
{
for (auto &&path: paths)
{
if (!fs::exists(path))
{
break; // <= V2020
}
existingPaths.emplace_back(path);
}
}
#pragma pvs(pop)V2021. Using assertions may cause the abnormal program termination in undesirable contexts.
Данное диагностическое правило добавлено по просьбе пользователей.
Диагностическое правило позволяет обнаружить в коде вызов макроса, который может привести к аварийному завершению программы. Таким макросом может быть стандартный 'assert'. Несмотря на то, что его использование позволяет устранять ошибки и снизить вероятность возникновения уязвимостей, его вызов может быть недопустим в различных сценариях. Одним из таких вариантов может быть написание библиотечного кода.
Рассмотрим следующий код:
[[noreturn]] void assertHandler();
#define ASSERT(expr) (!!(expr) || (assertHandler(), 0))
void foo(int i)
{
if (i < 0)
{
ASSERT(false && "The 'i' parameter must be non-negative");
}
}В примере приведена пользовательская реализация макроса 'assert', которая вызывает функцию, не возвращающую поток управления вызывающей функции. Требуется, чтобы анализатор выдал срабатывание на вызов этого макроса. Для этого надо внести небольшие изменения в код:
[[noreturn]] void assertHandler(); // N1
#define ASSERT(expr) (!!(expr) || (assertHandler(), 0))
//V_PVS_ANNOTATIONS annotations.json // N2
//V_ASSERT_CONTRACT, assertMacro:ASSERT // N3
void foo(int i)
{
if (i < 0)
{
ASSERT(false); // <= V2021
}
}На этом примере рассмотрим, как настраивается механизм распознавания пользовательского макроса.
Разметка функции как noreturn. Функция 'assertHandler', расположенная внутри макроса 'ASSERT', должна быть размечена как 'noreturn' (строка N1). Это можно сделать как при помощи стандартных атрибутов (C23 и C++11):
[[noreturn]] void assertHandler(); // since C23 or C++11Так и специфичными для компилятора атрибутами (например, MSVC или GCC / Clang):
__declspec(noreturn) void assertHandler(); // MSVC
__attribute__((noreturn)) void assertHandler(); // GCC, ClangЕсли нет возможности изменить исходный код и разметить функцию атрибутом, то можно сделать это c помощью системы пользовательских аннотаций в формате JSON. Для этого нужно создать файл формата JSON со следующим содержимым:
{
"version": 1,
"annotations":
[
{
"type": "function",
"name": "assertHandler",
"parameters": [],
"attributes": [ "noreturn" ]
},
....
]
}Затем этот файл должен быть включён во время анализа одним из описанных способов. В примере это происходит в строке N2.
Разметка макроса. Необходимо, чтобы анализатор учитывал, что из-за макроса 'ASSERT' выполнение кода может прерваться. Делается это при помощи комментария на строке N3. Более подробно об этом механизме можно узнать здесь.
Задание имён функций, в которых допустим вызов макроса
Пользователь может отключить диагностическое правило для функции, если он уверен, что использование макроса безопасно в этом контексте. Сделать это можно с помощью разметки функции, в которой вызывается макрос, с помощью комментария:
//-V2021_IGNORE_ASSERT_IN_FUNCTION, function: My::Qualified::NameПримечание. Данная диагностическое правило срабатывает также и на стандартный 'assert', и поэтому отключено по умолчанию, чтобы не выдавать большое количество срабатываний.
Для того, чтобы включить диагностику, можно воспользоваться механизмом включения через комментарий или директивой '#pragma pvs'.
Данная диагностика классифицируется как:
|
V2022. Implicit type conversion from integer type to enum type.
Данное диагностическое правило добавлено по просьбе пользователей.
Правило позволяет найти все неявные приведения целочисленных типов к типам перечислений. Это помогает выполнить рефакторинг кода и иногда выявить ошибки.
Данное правило актуально только для языка C.
Рассмотрим примеры конструкций, на которые анализатор выдаст предупреждение.
Пример N1:
typedef enum
{
Horizontal = 0x1,
Vertical = 0x2
} Orientation;
void foo1()
{
int pos = 1;
Orientation orientation = pos; // V2022
}В этом примере происходят неявные приведения целочисленного значения 'pos' к переменной типа 'Orientation'.
Пример N2:
Orientation GetOrientation (int pos)
{
return pos; // V2022
}Функция 'GetOrientation' возвращает значение типа 'Orientation' и неявно приводит значение 'pos' к этому типу.
Пример N3:
Orientation GetOrientation (bool b)
{
int posOne = 1;
int posTwo = 2;
return b ? posOne : posTwo; // V2022
}В этом примере функция использует условный оператор (?:) для выбора между двумя целочисленными переменными 'posOne' и 'posTwo', что также приводит к неявному приведению.
Пример N4:
void foo2(Orientation o){}
void foo3()
{
foo2(Horizontal); //ok
foo2(Horizontal | Vertical); // V2022
}В результате операции 'Horizontal | Vertical' получается целое число, представляющее побитовый результат. При передаче этого значения в функцию 'foo2', принимающую аргумент типа 'Orientation', происходит неявное приведение типов, что может привести к передаче недопустимого значения.
V4001. Unity Engine. Boxing inside a frequently called method may decrease performance.
Анализатор обнаружил операцию упаковки внутри часто выполняемого метода. Упаковка является дорогим процессом, требующим выделения памяти в управляемой куче. Как следствие, большое количество операций упаковки может негативно сказаться на производительности приложения.
Рассмотрим пример:
Vector3 _value;
....
void OnGUI()
{
GUILayout.Label(string.Format(...., _value));
}В проектах, использующих игровой движок Unity, функция 'OnGUI' используется для отрисовки интерфейса и обработки связанных с ним событий. Она вызывается как минимум один раз за кадр, то есть её код выполняется достаточно часто.
В этом примере вызывается метод 'string.Format', последним аргументом которого является поле значимого типа ('Vector3'). При таком вызове используется перегрузка 'string.Format(string, object)'. Так как ожидается аргумент типа 'object', значение '_value' будет упаковано.
Упаковки можно избежать, вызвав у поля '_value' метод 'ToString':
Vector3 _value;
....
void OnGUI()
{
GUILayout.Label(string.Format(...., _value.ToString()));
}Рассмотрим ещё один пример:
struct ValueStruct { int a; int b; }
ValueStruct _previousValue;
void Update()
{
....
ValueStruct newValue = ....
....
if (CheckValue (newValue)
....
}
bool CheckValue(ValueStruct value)
{
....
if(_previousValue.Equals(value))
....
}Метод 'Update' также широко используется в проектах на Unity. Его код выполняется каждый кадр.
В коде 'Update' вызывается метод 'CheckValue'. В нём происходит неявная упаковка, так как значение 'value' передаётся в метод 'Equals' (параметр стандартного 'Equals' имеет тип 'object').
Одним из вариантов решения может быть добавление к типу 'ValueStruct' метода 'Equals', принимающего параметр типа 'ValueStruct':
struct ValueStruct
{
int a;
int b;
public bool Equals(ValueStruct other)
{
....
}
}В таком случае в методе 'CheckValue' будет использоваться перегрузка 'Equals(ValueStruct)', что позволит избежать упаковки.
Данная диагностика классифицируется как:
V4002. Unity Engine. Avoid storing consecutive concatenations inside a single string in performance-sensitive context. Consider using StringBuilder to improve performance.
Анализатор обнаружил возможность оптимизации операций конкатенации внутри часто выполняемого метода.
Конкатенация приводит к созданию нового объекта строки, а значит и к дополнительному выделению памяти в управляемой куче. В целях повышения производительности этого следует избегать в часто выполняемом коде. В случае если к значению строки нужно несколько раз добавить различные фрагменты, вместо конкатенации разработчиками Unity рекомендуется использовать тип 'StringBuilder'.
Рассмотрим пример:
[SerializeField] Text _stateText;
....
void Update()
{
....
string stateInfo = ....;
....
stateInfo += ....;
stateInfo += ....;
....
stateInfo += ....;
_stateText.text = stateInfo;
....
}Здесь реализовано построение строки 'stateInfo' путем нескольких операций конкатенации. Выполнение этого кода в методе 'Update' (вызывается несколько десятков раз в секунду), приведет к быстрому накоплению 'мусора' в памяти и к более частому вызову сборщика мусора для его очистки. Последнее может негативно отразиться на производительности. Избежать лишнего выделения памяти можно с помощью объекта 'StringBuilder':
[SerializeField] Text _stateText;
....
StringBuilder _stateInfo = new StringBuilder();
void Update()
{
_stateInfo.Clear();
....
_stateInfo.AppendLine(....);
_stateInfo.AppendLine(....);
....
_stateInfo.AppendLine(....);
_stateText.text = _stateInfo.ToString();
....
}Метод 'Clear' очищает содержимое 'StringBuilder', но при этом не освобождает выделенную память. Таким образом, дополнительное выделение памяти потребуется только в том случае, если уже используемой будет недостаточно для хранения нового текста.
Рассмотрим другой пример:
[SerializeField] Text _text;
....
List<string> _messages = new();
....
void LateUpdate()
{
....
string message = BuildMessage();
_text.text = message;
_messages.Clear();
}
string BuildMessage()
{
string result = "";
foreach (var msg in _messages)
result += msg + "\n";
return result;
}В этом примере сообщение, выводимое на интерфейс, формируется с помощью метода 'BuildMessage'. Так как он вызывается внутри 'LateUpdate' (так же часто, как и внутри 'Update'), его тоже стоит оптимизировать:
StringBuilder _message = new StringBuilder();
string BuildMessage()
{
_message.Clear();
foreach (var msg in _messages)
_message.AppendLine(msg);
return _message.ToString();
}V4003. Unity Engine. Avoid capturing variable in performance-sensitive context. This can lead to decreased performance.
Анализатор обнаружил захват переменной в лямбда-выражении внутри часто выполняемого метода. Захват переменных может приводить к снижению производительности из-за дополнительного выделения памяти.
Рассмотрим пример:
void Update()
{
....
List<int> numbers = GetNumbers();
int divisor = GetDivisor();
var result = numbers.Select(x => x / divisor);
....
}Здесь 'Update' — метод Unity, выполняющий покадровое обновление. Метод 'Update' — часто вызываемый, и его не рекомендуется нагружать лишними операциями.
В приведенном примере используется лямбда-выражение с захватом переменной 'divisor'. Как упоминалось ранее, захват переменной из внешнего контекста приводит к дополнительному созданию объекта.
Таким образом, представленный участок кода создает дополнительную нагрузку на GC.
Оптимальная реализация метода может выглядеть следующим образом:
void Update()
{
....
List<int> numbers = GetNumbers();
int divisor = GetDivisor();
var result = new List<int>(numbers.Count);
for (int i = 0; i < numbers.Count; i++)
{
result.Add(numbers[i]/divisor);
}
....
}Использование собственной реализации, аналогичной 'Select', позволяет избавиться от дополнительного выделения памяти и тем самым снизить нагрузку на GC.
Рассмотрим еще один пример:
void Update()
{
....
List<int> numbers = GetNumbers();
int divisor = GetDivisor();
if (AreAllMultipleOf(numbers, divisor))
....
}
bool AreAllMultipleOf(List<int> lst, int divisor)
{
return lst.All(elem => elem % divisor == 0);
}Здесь из метода 'Update' вызывается метод 'AreAllMultipleOf', который определяет, являются ли все полученные числа кратными значению 'divisor'. Так же, как и ранее: 'Update' — часто вызываемый метод, выполняющий покадровое обновление в Unity.
В представленном случае метод 'AreAllMultipleOf' регулярно выполняется внутри 'Update', а значит, также является часто вызываемым.
Метод 'AreAllMultipleOf' для выполнения проверки использует лямбда-выражение с захватом переменных. Это приводит к дополнительному выделению памяти, которое может негативно сказаться на производительности приложения.
Оптимальная реализация может выглядеть следующим образом:
void Update()
{
....
List<int> numbers = GetNumbers();
int divisor = GetDivisor();
if (AreAllMultipleOf(numbers, divisor))
....
}
bool AreAllMultipleOf(List<int> lst, int divisor)
{
foreach (int num in lst)
{
if (num % divisor != 0)
return false;
}
return true;
}Здесь мы в очередной раз воспользовались собственной реализацией, что позволило избежать дополнительного выделения памяти и снизить нагрузку на сборщик мусора.
V4004. Unity Engine. New array object is returned from method or property. Using such member in performance-sensitive context can lead to decreased performance.
Анализатор обнаружил, что в часто выполняемом коде производятся обращения к свойствам или методам, которые создают новый массив.
Все составляющие API Unity, возвращающие массивы, создают новую коллекцию при каждом обращении. Это приводит к выделению памяти в управляемой куче. Частое обращение к таким свойствам или методам может негативно сказаться на производительности приложения.
Рассмотрим пример:
void Update()
{
for (int i = 0; i < Camera.allCameras.Length; i++)
{
SetDepth(Camera.allCameras[i].depth);
SetName(Camera.allCameras[i].name);
SetMask(Camera.allCameras[i].eventMask);
....
}
}В методе 'Update' производится запись значений, соответствующих конкретной камере. Данный метод вызывается на каждый кадр. При обращении к свойству 'Camera.allCameras' создаётся новый массив. Таким образом, новая коллекция будет создаваться по четыре раза на каждой итерации 'for' (один раз при проверке условия цикла, три раза в теле).
Множественного создания новых коллекций можно избежать, если получить значение 'Camera.allCameras' перед циклом:
void Update()
{
var cameras = Camera.allCameras;
for (int i = 0; i < cameras.Length; i++)
{
SetDepth(cameras[i].depth);
SetName(cameras[i].name);
SetMask(cameras[i].eventMask);
....
}
}В данном случае обращение к 'Camera.allCameras' производится единожды. Значение этого свойства присваивается переменной 'cameras'. Далее для записи параметров камеры используется эта переменная, а не свойство 'Camera.allCameras'.
Рассмотрим ещё один пример:
void Update()
{
SetNecessaryGameObjectParameters();
}
void SetNecessaryGameObjectParameters()
{
for (int i = 0; i < GameObject.FindGameObjectsWithTag("Enemy").Length; i++)
{
SetName(GameObject.FindGameObjectsWithTag("Enemy")[i].name);
SetTag(GameObject.FindGameObjectsWithTag("Enemy")[i].tag);
....
}
}В методе 'SetNecessaryGameObjectParameters' записывается информация об объектах типа 'GameObject'. Объекты будут получены путём вызова 'GameObject.FindGameObjectsWithTag'. При каждом вызове этого метода создаётся новая коллекция. 'SetNecessaryGameObjectParameters' используется в методе 'Update', который является часто вызываемым.
Чтобы избавиться от множественного создания новых коллекций, можно вынести вызов метода за цикл:
void Update()
{
SetNecessaryGameObjectParameters();
}
void SetNecessaryGameObjectParameters()
{
var enemies = GameObject.FindGameObjectsWithTag("Enemy");
for (int i = 0; i < enemies.Length; i++)
{
SetName(enemies[i].name);
SetTag(enemies[i].tag);
....
}
}Теперь вызов 'GameObject.FindGameObjectsWithTag' производится единожды. Возвращаемое значение этого метода записывается в переменную 'enemies'. Далее информация об объектах типа 'GameObject' будет получена с помощью этой переменной, а не путём вызова 'GameObject.FindGameObjectsWithTag'.
V4005. Unity Engine. The expensive operation is performed inside method or property. Using such member in performance-sensitive context can lead to decreased performance.
Анализатор обнаружил, что в часто выполняемом коде производятся обращения к ресурсоёмким свойствам или методам.
Согласно документации Unity, ряд методов и свойств из API Unity производят ресурсоёмкие операции при обращении. Частое обращение к таким свойствам или методам может негативно сказаться на производительности приложения.
Рассмотрим пример:
public void Update()
{
foreach (var cameraHandler in CameraHandlers)
{
cameraHandler(Camera.main);
}
....
}В методе 'Update' производится обработка камеры. Данный метод вызывается на каждый кадр. При обращении к свойству 'Camera.main' осуществляется поиск в кэше, что создаёт нагрузку на процессор. Таким образом, ресурсоёмкая операция будет выполняться на каждой итерации цикла.
Множественного обращения к свойству 'Camera.main' можно избежать, если записать его значение в переменную:
public void Update()
{
var camera = Camera.main;
foreach (var cameraHandler in CameraHandlers)
{
cameraHandler(camera);
}
....
}В данном случае обращение к 'Camera.main' производится единожды. Значение этого свойства присваивается переменной 'camera'. Далее для обработки камеры используется эта переменная, а не свойство 'Camera.main'.
Рассмотрим ещё один пример:
public void Update()
{
ProcessCamera();
....
}
private void ProcessCamera()
{
if (GetComponent<Camera>() == null)
return;
var cameraDepth = GetComponent<Camera>().depth;
var cameraName = GetComponent<Camera>().name;
var cameraEvent = GetComponent<Camera>().eventMask;
}В методе 'ProcessCamera' записывается информация о камере. Сама камера будет получена путём вызова 'GetComponent<Camera>'. Этот метод осуществляет поиск объекта, соответствующего типу 'Camera'. Данная операция является ресурсоёмкой. При каждом вызове 'ProcessCamera', метод 'GetComponent<Camera>' выполнится четыре раза. 'ProcessCamera' используется в методе 'Update', который является часто вызываемым.
Чтобы избавиться от множественного выполнения ресурсоёмкой операции, можно записать результат 'GetComponent<Camera>' в переменную:
private void ProcessCamera()
{
var camera = GetComponent<Camera>();
if (camera == null)
return;
var cameraDepth = camera.depth;
var cameraName = camera.name;
var cameraEvent = camera.eventMask;
....
}Теперь вызов 'GetComponent<Camera>' производится единожды. Возвращаемое значение этого метода записывается в переменную 'camera'. Далее информация о камере будет получена с помощью этой переменной, а не путём вызова 'GetComponent<Camera>'.
V4006. Unity Engine. Multiple operations between complex and numeric values. Prioritizing operations between numeric values can optimize execution time.
Анализатор обнаружил возможность оптимизировать математическую операцию, что может положительно сказаться на производительности, если операция выполняется часто.
Рассмотрим синтетический пример:
[SerializedField] float _speed;
void Update()
{
....
Vector3 input = ....;
var move = input * _speed * Time.deltaTime;
....
}В методе 'Update' вычисляется значение переменной 'move' — вектор перемещения некоторого персонажа за один кадр. В ходе этого будет выполнено шесть операций умножения, ведь при умножении 'Vector3' на число выполняется умножение каждой из его трёх компонент (x, y, z) на это же число. Частота вызова 'Update' непостоянна и зависит от частоты смены кадров в секунду. Допустим, в нашем случае этот метод вызывается в среднем 60 раз в секунду. Тогда только для вычисления перемещения потребуется 60 * 6 = 360 операций в секунду.
Это значение можно уменьшить, сначала перемножив обычные числа между собой, а потом полученный результат умножив на вектор:
var move = input * (_speed * Time.deltaTime);Теперь для одного вычисления перемещения будет выполнено четыре операции умножения за один вызов 'Update' и 240 операций в секунду соответственно.
Стоит отметить, что чем больше обычных чисел будет участвовать в таком выражении, тем значительнее будет эффект от данной оптимизации.
V4007. Unity Engine. Avoid creating and destroying UnityEngine objects in performance-sensitive context. Consider activating and deactivating them instead.
Анализатор обнаружил создание Unity-объекта в часто выполняемом методе.
Регулярное создание/уничтожение игровых объектов не только нагружает центральный процессор, но и приводит к увеличению частоты вызовов сборщика мусора. Это негативно отражается на производительности.
Рассмотрим синтетический пример:
CustomObject _instance;
void Update()
{
if (....)
{
CreateCustomObject();
....
}
else if (....)
{
....
Destroy(_instance.gameObject); // <=
}
}
void CreateCustomObject()
{
var go = new GameObject(); // <=
_instance = go.AddComponent<CustomObject>();
....
}Здесь в методе 'Update' создаётся и уничтожается некоторый игровой объект '_instance'. Т. к. 'Update' выполняется при каждом обновлении кадров, по возможности рекомендуется избегать в нём этих операций.
Данный код можно оптимизировать. Для этого нужно один раз инициализировать '_instance', например, в методе 'Start', после чего в методе 'Update' использовать метод '_instance.gameObject.SetActive' для включения/отключения объекта вместо создания/уничтожения.
Пример реализации:
CustomObject _instance;
void Start()
{
CreateCustomObject();
_instance.gameObject.SetActive(false);
....
}
void Update()
{
if (....)
{
....
_instance.gameObject.SetActive(true);
}
else if (....)
{
....
_instance.gameObject.SetActive(false);
}
}
void CreateCustomObject()
{
var go = new GameObject();
_instance = go.AddComponent<CustomObject>();
....
}Такая же оптимизация актуальна и для компонентов 'MonoBehaviour'. В этом случае следует использовать свойство 'enabled' компонента для его включения/отключения.
Нередко требуется создавать/уничтожать множество временных объектов, например, снарядов. Такие случаи также можно оптимизировать заменой указанных выше операций на включение/отключение, но с применением пулов. Для таких случаев Unity предоставляет готовый набор универсальных пулов, находящихся в пространстве имён 'UnityEngine.Pool', например, 'ObjectPool<T>'. Подробности о принципе работы с этим классом можно найти на сайте Unity: тут или тут.
V4008. Unity Engine. Avoid using memory allocation Physics APIs in performance-sensitive context.
Анализатор обнаружил в часто выполняемом коде использование аллоцирующих память методов Physics.RaycastAll, Physics2D.OverlapSphere или подобных им.
Такие методы создают массив при каждом вызове, что может снизить производительность. Вместо них стоит использовать неаллоцирующие вариации методов, в которые можно передать предварительно выделенный массив.
Рассмотрим пример:
public class HitScript : MonoBehaviour
{
void Update()
{
AllocMethod();
}
void AllocMethod()
{
RaycastHit[] hitsTargets = Physics.RaycastAll(transform.position,
transform.forward);
foreach (RaycastHit hit in hitsTargets)
{
if (hit.collider.gameObject.name != "PlayerAdvanced")
{
....
}
}
}
}Update будет каждый кадр вызывать AllocMethod, использующий аллоцирующий метод RaycastAll. Из-за постоянного создания новых массивов, которые содержат попадания луча, производительность ухудшится.
Данный код можно оптимизировать. Для этого нужно заменить метод RaycastAll на неаллоцирующий метод RaycastNonAlloc и использовать его вместе с предварительно выделенным массивом.
Вариант оптимальной реализации:
public class HitScript : MonoBehaviour
{
void Update()
{
NonAllocMethod();
}
const int MAX_RAYCAST_HIT_COUNT = 10;
RaycastHit[] _hitsTargets = new RaycastHit[MAX_RAYCAST_HIT_COUNT];
void NonAllocMethod()
{
int countOfResults = Physics.RaycastNonAlloc(new Ray(transform.position,
transform.forward ),
_hitsTargets);
for(int i = 0; i < countOfResults; i++)
{
if (_hitsTargets[i].collider.gameObject.name != "PlayerAdvanced")
{
....
}
}
}
}Для использования RaycastNonAlloc заранее создан вспомогательный массив _hitsTargets. Максимальное количество попаданий луча ограничено размером этого массива. После вызова метода RaycastNonAlloc количество попаданий луча будет записано в переменную countOfResults, а сами попадания будут записаны в массив _hitsTargets. Таким образом, в каждом кадре будет использоваться массив _hitsTargets, под который память выделяется лишь один раз.
На момент написания документации к диагностике в классе Physics2D все методы с припиской "NonAlloc" помечены как устаревшие, им на замену можно использовать неаллоцирующие перегрузки обычных методов. Например, вместо Physics2D.BoxCastAll стоит использовать перегрузку Physics2D.BoxCast, принимающую массив для получения всех попаданий.
V2501. MISRA. Octal constants should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило различается для C и C++. В C восьмеричные числовые литералы не должны использоваться. В C++ помимо восьмеричных числовых литералов не должны использоваться экранирующие последовательности.
Использование восьмеричных литералов может затруднить восприятие кода, особенно при быстром просмотре. Неправильная интерпретация фактического числового значения может приводить к разнообразным ошибкам.
Пример кода, на который анализатор выдаст предупреждение:
if (val < 010)
{
....
}При быстром просмотре кода можно упустить из виду, что значение числового литерала – 8, а не 10. Чтобы анализатор не выдавал предупреждения, литерал стоит переписать в десятичной или шестнадцатеричной форме:
if (val < 8)
{
....
}Данная диагностика классифицируется как:
|
V2502. MISRA. The 'goto' statement should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Использование оператора 'goto' может привести к нарушению структуры программы и усложнению понимания кода. Данное диагностическое правило выявляет места использования оператора 'goto'.
Пример кода, на который анализатор выдаст предупреждение:
int foo(int value)
{
....
if (value==0)
goto bad_arg;
....
return OK;
bad_arg:
return BAD_ARG;
}Данная диагностика классифицируется как:
|
V2503. MISRA. Implicitly specified enumeration constants should be unique – consider specifying non-unique constants explicitly.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Анализатор обнаружил неуникальное значение среди неявно проинициализированных элементов перечисления, приводящее к дублированию значений констант.
Пример некорректного кода:
enum Suits
{
SUITS_SPADES = 1,
SUITS_CLUBS,
SUITS_DIAMONDS,
SUITS_HEARTS,
SUITS_UNKNOWN = 4
};Подобная инициализация привела к тому, что элементы 'SUITS_HEARTS' и 'SUITS_UNKNOWN' имеют одинаковые значения. Может быть неочевидно, сделано это специально, или код содержит ошибку.
Во избежание подобной ошибки следует явно инициализировать все элементы перечисления, имеющие неуникальные значения:
enum Suits
{
SUITS_SPADES = 1,
SUITS_CLUBS,
SUITS_DIAMONDS,
SUITS_HEARTS = 4,
SUITS_UNKNOWN = 4
};Данная диагностика классифицируется как:
|
V2504. MISRA. Size of an array is not specified.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Явное указание размера массива улучшает читаемость и понимание кода, уменьшая вероятность возникновения ошибок, связанных с выходом за границы массива из-за незнания его размера.
Анализатор выдаст предупреждение, если встретит объявление массива со спецификатором 'extern', при условии, что размер массива не задан явно:
extern int arr[];Для исправления следует явно указать размер массива:
extern int arr[12];Если размер массива можно вывести из инициализатора, предупреждение выдано не будет:
int arr1[] = { 1, 2, 3 };Данная диагностика классифицируется как:
|
V2505. MISRA. The 'goto' statement shouldn't jump to a label declared earlier.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Использование оператора 'goto', осуществляющего переход к метке, находящейся выше по коду, ухудшает читаемость кода и как следствие – усложняет его поддержку.
Пример кода, на который анализатор выдаст предупреждение:
void init(....)
{
....
again:
....
if (....)
if (....)
goto again;
....
}Чтобы анализатор не выдавал предупреждение, необходимо отказаться от использования оператора 'goto' или переписать код таким образом, чтобы метка, на которую ссылается 'goto', находилась ниже него.
Данная диагностика классифицируется как:
|
V2506. MISRA. A function should have a single point of exit at the end.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Функция должна содержать единственный оператор 'return'. Этот оператор должен быть последним в теле функции. Множественное использование операторов 'return' может усложнить чтение и понимание кода, а также его дальнейшую модификацию.
Пример кода, на который анализатор выдаст предупреждение.
obj foo (....)
{
....
if (condition) {
return a;
}
....
if (other_condition) {
return b;
}
....
}Исправленный вариант кода имеет одну точку выхода в конце функции:
obj foo (....)
{
....
if (condition) {
result = a;
} else {
....
if (other_condition) {
result = b;
}
}
....
return result;
}Подобный код также будет легче поддерживать, если понадобится добавить, например, предварительную обработку возвращаемого значения, так как сделать это придётся только в одном месте:
obj foo (....)
{
....
return cache(result);
}Данная диагностика классифицируется как:
|
V2507. MISRA. The body of a loop\conditional statement should be enclosed in braces.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Тела операторов 'while', 'do-while', 'for', 'if', 'if-else', 'switch' должны быть заключены в фигурные скобки.
Использование фигурных скобок четко определяет, какие выражения составляют тело, повышает читаемость кода и снижает вероятность возникновения ряда ошибок. Например, при отсутствии фигурных скобок программист может ошибочно воспринять выравнивание или не заметить символ ';', случайно поставленный после оператора.
Пример 1:
void example_1(....)
{
if (condition)
if (otherCondition)
DoSmt();
else
DoSmt2();
}Форматирование данного кода не соответствует логике его выполнения, что может сбивать с толку. Расстановка фигурных скобок устраняет возможную неоднозначность:
void example_1(....)
{
if (condition)
{
if (otherCondition)
{
DoSmt();
}
else
{
DoSmt2();
}
}
}Пример 2:
void example_2(....)
{
while (count < 10)
DoSmt1(); DoSmt2();
}Форматирование данного кода также не соответствует логике его исполнения, так как к циклу относится только выражение 'DoSmt1()'.
Исправленный вариант:
void example_2(....)
{
while (count < 10)
{
DoSmt1();
DoSmt2();
}
}Примечание: 'if', следующий сразу после 'else' не обязательно должен быть заключен в фигурные скобки. На фрагмент кода, приведённый ниже, анализатор не будет выдавать предупреждение.
if (condition1)
{ .... }
else if (condition2)
{ .... }Данная диагностика классифицируется как:
|
V2508. MISRA. The function with the 'atof/atoi/atol/atoll' name should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций: 'atof', 'atoi', 'atol', 'atoll'.
Неправильное использование этих функций может привести к возникновению неопределённого поведения. Это может произойти, если аргумент функции не является валидной С-строкой или если результирующее значение выходит за границы возвращаемого типа.
Пример кода, на который анализатор выдаст предупреждение:
void Foo(const char *str)
{
int val = atoi(str);
....
}Для C анализатор также выдаст предупреждение, если обнаружит определение макроса с одним из соответствующих имён.
Данная диагностика классифицируется как:
|
V2509. MISRA. The function with the 'abort/exit/getenv/system' name should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций 'abort', 'exit', 'getenv', 'system'.
Поведение перечисленных выше функций зависит от реализации. Кроме того, использование таких функций как 'system' может являться причиной возникновения уязвимостей.
Пример кода, на который анализатор выдаст предупреждение:
void Foo(FILE *pFile)
{
if (pFile == NULL)
{
abort();
}
....
}Для C анализатор также выдаст предупреждение, если обнаружит определение макроса с одним из соответствующих имён.
Данная диагностика классифицируется как:
|
V2510. MISRA. The function with the 'qsort/bsearch' name should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Анализатор выдаст предупреждение, если встретит использование одной из следующих функций: 'qsort', 'bsearch'.
Неправильное использование этих функций может стать причиной возникновения неопределённого поведения. Подробнее об этом можно прочесть в документации к функциям 'qsort' и 'bsearch'.
Пример кода, на который анализатор выдаст предупреждение:
qsort(arr, cnt, sizeof(int), comp);Также анализатор будет выдавать предупреждения на определения макросов с соответствующими именами.
Данная диагностика классифицируется как:
|
V2511. MISRA. Memory allocation and deallocation functions should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если встретит использование функций и операторов выделения \ освобождения динамической памяти, таких как 'malloc'; 'realloc'; 'calloc'; 'free'; 'new'; 'delete'.
Функции работы с динамической памятью являются потенциальным источником проблем, так как их неправильное использование может привести к утечкам памяти, неопределённому поведению и прочим ошибкам. Более того – это может стать причиной возникновения уязвимости в приложении.
Пример кода, на который анализатор выдаст предупреждение:
int* imalloc(size_t cnt)
{
return (int*)malloc(cnt * sizeof(int));
}Для C анализатор также выдаст предупреждение, если обнаружит определение макроса с одним из соответствующих имён.
Данная диагностика классифицируется как:
|
V2512. MISRA. The macro with the 'setjmp' name and the function with the 'longjmp' name should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование макроса 'setjmp' или функции 'longjmp', так как их неправильное использование может привести к неопределённому поведению.
Пример кода, на который анализатор выдаст предупреждение:
jmp_buf j_buf;
void foo()
{
setjmp(j_buf);
}
int main()
{
foo();
longjmp(j_buf, 0);
return 0;
}Функция 'longjmp' вызвана уже после выхода из функции, которая вызвала 'setjmp', результат в таком случае не определен.
Данная диагностика классифицируется как:
|
V2513. MISRA. Unbounded functions performing string operations should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C++. Анализатор выдаст предупреждение, если обнаружит использование следующих функций: 'strcpy'; 'strcmp'; 'strcat'; 'strchr'; 'strspn'; 'strcspn'; 'strpbrk'; 'strrchr'; 'strstr'; 'strtok'; 'strlen'.
Неправильное использование этих функций может стать причиной возникновения неопределенного поведения, так как они не защищены от чтения и записи вне границ буфера.
Пример кода, на который анализатор выдаст предупреждение:
int strcpy_internal(char *dest, const char *source)
{
int exitCode = FAILURE;
if (source && dest)
{
strcpy(dest, source);
exitCode = SUCCESS;
}
return exitCode;
}Данная диагностика классифицируется как:
|
V2514. MISRA. Unions should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит объявление объединения.
Неправильное использование объединений может приводить к различным проблемам, например, к получению неверных значений или к возникновению неопределённого поведения.
Например, в случае C++, неопределённое поведение может возникнуть, когда значение считывается не из члена, в который производилась запись в последний раз.
Пример кода, на который анализатор выдаст предупреждение:
union U
{
unsigned char uch;
unsigned int ui;
} uni;
....
uni.uch = 'w';
int ui = uni.ui;Данная диагностика классифицируется как:
|
V2515. MISRA. Declaration should contain no more than two levels of pointer nesting.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если встретит объявление, использующее более двух уровней вложенности указателей. Использование таких указателей ухудшает понимание кода и как следствие – может стать причиной возникновения различных ошибок.
Пример кода, на который анализатор выдаст предупреждение:
void foo(int **ppArr[])
{
....
}Данная диагностика классифицируется как:
|
V2516. MISRA. The 'if' ... 'else if' construct should be terminated with an 'else' statement.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Каждая последовательность 'if ... else if' должна заканчиваться 'else'. При отсутствии завершающего 'else' анализатор выдаст предупреждение. Наличие конечного 'else' показывает, что рассмотрены все возможные варианты, что помогает при чтении и понимании кода.
Пример кода, на который анализатор выдаст предупреждение:
if (condition)
{
....
}
else if (other_condition)
{
....
}Чтобы анализатор не выдавал предупреждение, а разработчик, читающий код, сразу понял, что рассмотрен случай, когда ни одно условие не выполнилось, стоит добавить 'else'-ветвь. В этой ветви следует разместить необходимые действия или поясняющий комментарий.
if (condition)
{
....
}
else if (other_condition)
{
....
}
else
{
// No action needed
}Данная диагностика классифицируется как:
|
V2517. MISRA. Literal suffixes should not contain lowercase characters.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило отличается для C и C++. В C необходимо использовать суффикс 'L' вместо 'l'. В C++ все буквенные суффиксы должны быть в верхнем регистре.
Использование суффиксов в нижнем регистре мешает визуальному восприятию кода. Например, суффикс 'l' можно спутать с единицей (1), что может стать причиной разнообразных ошибок.
Примеры литералов, на которые анализатор выдаст предупреждение:
12l; 34.0f; 23u;Форма записи литералов, на которую предупреждение выдано не будет:
12L; 34.0F; 23U;Данная диагностика классифицируется как:
|
V2518. MISRA. The 'default' label should be either the first or the last label of a 'switch' statement.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Метка 'default' должна быть либо первой, либо последней меткой в 'switch'. Следование этому правилу облегчает чтение кода.
Пример кода, на который анализатор выдаст предупреждение:
void example_1(int cond)
{
switch (cond)
{
case 1:
DoSmth();
break;
default:
DoSmth2();
break;
case 3:
DoSmth3();
break;
}
}Чтобы убрать предупреждение, код можно переписать, например, следующим образом:
void example_1(int cond)
{
switch (cond)
{
case 1:
DoSmth();
break;
case 3:
DoSmth3();
break;
default:
DoSmth2();
break;
}
}Данная диагностика классифицируется как:
|
V2519. MISRA. Every 'switch' statement should have a 'default' label, which, in addition to the terminating 'break' statement, should contain either a statement or a comment.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Метка 'default' должна присутствовать в каждом 'switch'.
Следование данному правилу гарантирует, что будут обработаны любые ситуации, в которых значение контролирующей переменной не соответствует ни одной метке.
Такие ситуации требуют принятия определенных мер, поэтому каждая метка 'default' должна содержать (помимо 'break') выражение или комментарий, объясняющий, почему никаких действий не предпринимается.
Пример 1:
enum WEEK
{
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
} weekDay;
void example_1()
{
int isWorkday;
switch (weekDay)
{
case MONDAY:
case TUESDAY:
case WEDNESDAY:
case THURSDAY:
case FRIDAY:
isWorkday = 1;
break;
case SATURDAY:
case SUNDAY:
isWorkday = 0;
break;
}Несмотря на то, что обработаны все значения из перечисления 'WEEK', нет гарантии, что 'weekDay' может принимать только эти значения. Чтобы анализатор не выдавал предупреждение, можно переписать код, например, следующим образом:
enum WEEK
{
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
} weekDay;
void example_1()
{
int isWorkday;
switch (weekDay)
{
case MONDAY:
case TUESDAY:
case WEDNESDAY:
case THURSDAY:
case FRIDAY:
isWorkday = 1;
break;
case SATURDAY:
case SUNDAY:
isWorkday = 0;
break;
default:
assert(false);
break;
}Данная диагностика классифицируется как:
|
V2520. MISRA. Every switch-clause should be terminated by an unconditional 'break' or 'throw' statement.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило различается для C и C++. Для обоих языков каждая метка в 'switch' должна быть завершена оператором 'break', не расположенным внутри условия. А для C++ последним оператором также может быть 'throw'.
Намеренное завершение каждой метки гарантирует, что поток управления не "провалится" в метку, расположенную ниже, и позволяет избежать ошибок при добавлении новых меток.
Исключением из этого правила являются пустые метки, расположенные последовательно.
Пример кода, на который анализатор выдаст предупреждение:
void example_1(int cond, int a)
{
switch (cond)
{
case 1:
case 2:
break;
case 3: // <=
if (a == 42)
{
DoSmth();
}
case 4: // <=
DoSmth2();
default: // <=
;
}
}Исправленный код:
void example_1(int cond, int a)
{
switch (cond)
{
case 1:
case 2:
break;
case 3:
if (a == 42)
{
DoSmth();
}
break;
case 4:
DoSmth2();
break;
default:
/* No action required */
break;
}
}Следует отметить, что метки не должны завершаться выражением 'return', так как это нарушает правило V2506.
Данная диагностика классифицируется как:
|
V2521. MISRA. Only the first member of enumerator list should be explicitly initialized, unless all members are explicitly initialized.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C++. Анализатор обнаружил совмещение явной и неявной инициализации элементов перечисления. Это может привести к неожиданному дублированию их значений.
Пример некорректного кода:
enum Suits
{
SUITS_SPADES = 1,
SUITS_CLUBS,
SUITS_DIAMONDS,
SUITS_HEARTS,
SUITS_UNKNOWN = 4
};Подобная инициализация привела к тому, что элементы 'SUITS_HEARTS' и 'SUITS_UNKNOWN' имеют одинаковые значения. Может быть неочевидно, сделано это специально, или код содержит ошибку.
Анализатор не будет выдавать предупреждение, если:
- явно инициализируется только первый элемент перечисления;
- все элементы перечисления инициализируются неявно;
- все элементы перечисления инициализируются явно.
Данная диагностика классифицируется как:
|
V2522. MISRA. The 'switch' statement should have 'default' as the last label.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C++. Последней меткой в 'switch' должна быть 'default'.
Наличие 'default' в конце каждого 'switch' облегчает чтение кода, а также гарантирует, что будут обработаны любые ситуации, в которых значение контролирующей переменной не соответствует ни одной метке. Так как такие ситуации требуют принятия определенных мер, каждая метка 'default' должна содержать (помимо 'break' или 'throw') выражение или комментарий, объясняющий, почему никаких действий не предпринимается.
Пример 1:
void example_1(int i)
{
switch (i)
{
case 1:
DoSmth1();
break;
default: // <=
DoSmth42();
break;
case 3:
DoSmth3();
break;
}
}Корректный код:
void example_1(int i)
{
switch (i)
{
case 1:
DoSmth1();
break;
case 3:
DoSmth3();
break;
default:
DoSmth42();
break;
}
}Пример 2:
enum WEEK
{
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
} weekDay;
void example_2()
{
int isWorkday;
switch (weekDay)
{
case MONDAY:
case TUESDAY:
case WEDNESDAY:
case THURSDAY:
case FRIDAY:
isWorkday = 1;
break;
case SATURDAY:
case SUNDAY:
isWorkday = 0;
break;
default: // <=
break;
}Исправленный код:
enum WEEK
{
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
} weekDay;
void example_2()
{
int isWorkday;
switch (weekDay)
{
case MONDAY:
case TUESDAY:
case WEDNESDAY:
case THURSDAY:
case FRIDAY:
isWorkday = 1;
break;
case SATURDAY:
case SUNDAY:
isWorkday = 0;
break;
default:
assert(false);
break;
}Данная диагностика классифицируется как:
|
V2523. MISRA. All integer constants of unsigned type should have 'u' or 'U' suffix.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор обнаружил использование целочисленного беззнакового литерала без суффикса 'U' / 'u' (суффикса 'U' в случае C++). Подобные литералы могут осложнить восприятие кода, так как их тип становится неочевиден. Более того, одни и те же литералы могут иметь разные типы на разных моделях данных.
Использование суффиксов для явного указания типа позволит избежать неоднозначностей при чтении числовых литералов.
Пример кода, на который анализатор выдаст предупреждение (если тип литерала на анализируемой платформе – беззнаковый):
auto typemask = 0xffffffffL;Данная диагностика классифицируется как:
|
V2524. MISRA. A switch-label should only appear at the top level of the compound statement forming the body of a 'switch' statement.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Область видимости, в которой находится метка, должна быть составным выражением, которое представляет собой тело 'switch'. Это означает, что метка не должна быть вложена ни в какой блок, кроме как в тело 'switch', и это тело должно быть составным выражением.
Следовательно, все метки, принадлежащие одному 'switch', должны находиться в одной области видимости. Следование этому правилу позволяет сохранить читаемость и структурированность кода.
Пример 1:
void example_1(int param, bool b)
{
switch (param)
{
case 1:
DoSmth1();
if (b)
{
case 2: // <=
DoSmth2();
}
break;
default:
assert(false);
break;
}
}Рассмотренный пример сложен для понимания. Чтобы анализатор не выдавал предупреждения, следует написать так:
void example_1(int param, bool b)
{
switch (param)
{
case 1:
DoSmth1();
if (b)
{
DoSmth2();
}
break;
case 2:
DoSmth2();
break;
default:
assert(false);
break;
}
}В следующем примере тело 'switch' не является составным, поэтому анализатор также выдаст предупреждение:
void example_2(int param)
{
switch (param)
default:
DoDefault();
}Исправленный вариант:
void example_2(int param)
{
switch (param)
{
default:
DoDefault();
break;
}
}Данная диагностика классифицируется как:
|
V2525. MISRA. Every 'switch' statement should contain non-empty switch-clauses.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило различается для языков C и C++. В C каждый 'switch' должен иметь по крайней мере две непустых метки, которыми могут быть 'case' или 'default'. В C++ каждый 'switch' должен иметь по крайней мере одну непустую метку 'case'.
Конструкции 'switch', не удовлетворяющие этим условиям, являются избыточными и могут являться признаком ошибки программиста.
Пример 1:
void example_1(int param)
{
switch(param)
{
case 0:
default:
Func();
break;
}
}Подобный 'switch' является излишним и не имеет никакого смысла. Независимо от значения переменной 'param', всегда будет выполняться только тело 'default'.
На следующий пример анализатор не будет выдавать предупреждение:
void example_2(int param)
{
switch(param)
{
case 0:
DoSmth1();
break;
case 1:
DoSmth2();
break;
....
default:
Func();
break;
}
}Пример кода, на который анализатор выдаст предупреждение только при использовании компилятора для языка C:
void example_3(int param)
{
switch(param)
{
case 10:
case 42:
DoMath();
break;
}
}Данная диагностика классифицируется как:
|
V2526. MISRA. The functions from time.h/ctime should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций: 'clock'; 'time'; 'difftime'; 'ctime'; 'asctime'; 'gmtime'; 'localtime'; 'mktime'.
Перечисленные функции имеют неуточненное поведение или поведение, определенное реализацией, и поэтому могут выдаваться разные форматы времени и даты (в зависимости от окружения, реализации стандартной библиотеки, и т. д.).
Пример кода, на который анализатор выдаст предупреждения:
const char* Foo(time_t *p)
{
time_t t = time(p);
return ctime(t);
}Для языка С анализатор также выдаст предупреждение, если обнаружит объявление макроса с одним из соответствующих имён.
Данная диагностика классифицируется как:
|
V2527. MISRA. A switch-expression should not have Boolean type. Consider using of 'if-else' construct.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Значение булевого типа может быть сконвертировано к целочисленному типу, поэтому его можно использовать в качестве управляющей переменной в выражении 'switch'. В этом случае использование конструкции 'if-else' является предпочтительным, так как оно дает более понятное и явное представление намерений программиста.
Пример:
int foo(unsigned a, unsigned b)
{
while (a != 0 && b != 0)
{
switch (a > b) // <=
{
case 0:
a -= b;
break;
default:
b -= a;
break;
}
}
return a;
}Вместо этого следует написать:
int foo(unsigned a, unsigned b)
{
while (a != 0 && b != 0)
{
if (a > b)
{
b -= a;
}
else
{
a -= b;
}
}
return a;
}Данная диагностика классифицируется как:
|
V2528. MISRA. The comma operator should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Не стоит использовать оператор 'запятая', так как он может привести к путанице при чтении кода.
Рассмотрим следующий пример:
int foo(int x, int y) { .... }
foo( ( 0, 3), 12 );Код может ввести программиста в заблуждение, если ему до прочтения вызова функции неизвестна ее сигнатура. Может показаться, что в функцию передается три аргумента, однако это не так: оператор 'запятая' в выражении '(0, 3)' вычислит левый и правый аргументы, а затем возвращает результат второго. В итоге, вызов функции на самом деле принимает вид:
foo( 3, 12 );Диагностика выдает предупреждение и для других случаев, таких как например этот:
int myMemCmp(const char *s1, const char *s2, size_t N)
{
for (; N > 0; ++s1, ++s2, --N) { .... }
}Данная диагностика классифицируется как:
|
V2529. MISRA. Any label should be declared in the same block as 'goto' statement or in any block enclosing it.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Чрезмерное использование 'goto' приводит к плохой структурированности кода, усложняя его понимание.
Для снижения визуальной сложности кода рекомендуется отказаться от переходов во вложенные блоки или между блоками, расположенными на одном уровне.
Пример 1:
void V2532_pos1()
{
...
goto label;
...
{
label:
...
}
}Здесь 'goto' ссылается во вложенный блок, что нарушает данное правило.
На следующий пример анализатор не будет выдавать предупреждение:
void V2532_neg1()
{
...
label:
...
{
goto label;
...
}
}Примечание: тела switch-меток рассматриваются как составные выражения, даже если они не обернуты в фигурные скобки. Поэтому прыжки в тело switch-метки из внешнего кода и прыжки между разными switch-метками нарушают данное правило.
Приведем примеры.
Прыжок в switch-метку из внешнего кода (ошибка):
void V2532_pos2(int param)
{
goto label;
switch (param)
{
case 0:
break;
default:
label:;
break;
}
}Прыжок между switch-метками (ошибка):
void V2532_pos3(int param)
{
switch (param)
{
case 0:
goto label;
break;
default:
label:
break;
}
}Прыжок из switch-метки во внешний код (ok):
void V2532_neg2(int param)
{
label:
switch (param)
{
case 0:
goto label;
break;
default:
break;
}
}Прыжок в пределах одной switch-метки (ok):
void neg3(int param)
{
switch (param)
{
case 0:
{
...
{
goto label;
}
}
label:
break;
default:
break;
}
}Данная диагностика классифицируется как:
|
V2530. MISRA. Any loop should be terminated with no more than one 'break' or 'goto' statement.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Ограничение количества выходов из цикла позволяет значительно снизить визуальную сложность кода.
Пример, на который анализатор выдаст предупреждение:
int V2534_pos_1(vector<int> ivec)
{
int sum = 0;
for (auto i = ivec.cbegin(); i != ivec.cend(); ++i)
{
if (*i < 0)
break;
sum += *i;
if (sum > 42)
break;
}
return sum;
}В следующем примере выход из цикла производится с помощью как 'break', так и 'goto':
short V2534_pos_2(string str)
{
short count = 0;
for (auto &c : str)
{
if (isalnum(c))
{
count++;
}
else if (isspace(c))
{
break;
}
else
{
goto error;
}
}
return count;
error:
...
}Данная диагностика классифицируется как:
|
V2531. MISRA. Expression of essential type 'foo' should not be explicitly cast to essential type 'bar'.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Значение одного сущностного типа не должно быть приведено явно к значению другого несоответствующего сущностного типа.
Стандарт MISRA определяет следующую модель сущностных типов (Essential type model), в которой переменная может иметь тип:
- Boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами, или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует без знаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- Именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'
Указатели в этой модели отсутствуют.
Таблица ситуаций, которые желательно избегать:

Исключения:
- Переменная типа 'enum' может быть приведена к синониму этого же типа.
- Переменные, имеющие константные значения '0' и '1', могут быть приведены из целочисленного типа к 'Boolean'.
Причины для явного преобразования типов:
- для внесения большей ясности;
- изменить тип, в котором последующая арифметическая операция будет выполнена;
- намеренное усечение (срез) значения (при касте из большего типа в меньший, например, 'long' -> 'short').
По некоторым причинам преобразование из одного сущностного типа к другому может быть опасно или лишено смысла, например:
- преобразование значения целочисленного знакового/без знакового типа к типу именованного 'enum' может быть опасно, поскольку оно может не входить в диапазон, определяемый максимальным размером данного 'enum' типа;
- преобразование булевого значения к любому другому обычно лишено смысла;
- преобразование между вещественными и символьными типами также лишено смысла, поскольку нет точного соответствия между этими двумя представлениями.
Пример, на который анализатор также выдаст соответствующие предупреждения:
enum A {ONE, TWO = 2};
float foo(int x, char ch)
{
enum A a = (enum A) x; // signed to enum, may lead to
// unspecified behavior
int y = int(x == 4); // Meaningless cast Boolean to signed
return float(ch) + .01; // Meaningless cast character to floating,
// there is no precise mapping between
// two representations
}Данная диагностика классифицируется как:
|
V2532. MISRA. String literal should not be assigned to object unless it has type of pointer to const-qualified char.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор обнаружил неявное снятие константности с строкового литерала. Так как любая попытка изменить строковый литерал приводит к неопределенному поведению, его следует присваивать лишь к объектам типа указателя на константный символ (pointer to const-qualified char).
Это правило также актуально для широкого строкового литерала.
Пример кода, на который анализатор выдаст предупреждение:
char* Foo(void)
{
return "Hello, world!";
}При модификации строкового литерала анализатор также выдает предупреждение:
"first"[1] = 'c';Данная диагностика классифицируется как:
|
V2533. MISRA. C-style and functional notation casts should not be performed.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило справедливо только для C++.
C-подобное (C-style cast) и приведение типов в функциональном стиле (functional cast) способны осуществлять преобразования между несвязанными типами, что может привести к ошибке.
Следует явно приводить типы с использованием операторов 'static_cast', 'const_cast' и 'reinterpret_cast'.
Примеры, на которые анализатор выдаст срабатывание:
int i;
double d;
size_t s;
void *p;
....
i = int(p); //V2533
d = (double)s; //V2533
s = (size_t)(i); //V2533
p = (void *)(d); //V2533Исключение: приведение к типу void не несёт в себе никакой опасности и используется, чтобы подчеркнуть, что некий результат никак не используется. Пример:
(void)fclose(f);Данная диагностика классифицируется как:
|
V2534. MISRA. The loop counter should not have floating-point type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Поскольку числа с плавающей точкой не могут точно отобразить все действительные числа, использование таких переменных в цикле может дать непостоянное количество итераций.
Рассмотрим пример:
void foo(void) {
for (float A = 0.1f; A <= 10.0f; A += 0.1f) {
....
}
}Количество итераций в этом цикле может быть 99 или 100. Точность операций с вещественными числами может зависеть от компилятора, режима оптимизации и многого другого.
Лучше переписать цикл следующим образом:
void foo(void) {
for (int count = 1; count <= 100; ++count) {
float A = count / 10.0f;
}
}Этот цикл выполнит ровно 100 итераций, а переменную 'A' можно использовать для необходимых вычислений.
Данная диагностика классифицируется как:
|
V2535. MISRA. Unreachable code should not be present in the project.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Присутствие недостижимого кода может являться признаком ошибки программиста и усложняет поддержку кода.
Компилятор в целях оптимизации вправе удалить недостижимый код. Недостижимый код, неудаленный компилятором, может расходовать ресурсы. Например, он может увеличивать размер бинарного файла или являться причиной излишнего кэширования инструкций.
Рассмотрим первый пример:
void Error()
{
....
exit(1);
}
FILE* OpenFile(const char *filename)
{
FILE *f = fopen(filename, "w");
if (f == nullptr)
{
Error();
printf("No such file: %s", filename);
}
return f;
}Функция 'printf(....)' никогда не напечатает сообщение об ошибке, так как функция 'Error()' не возвращает управление. Как правильно исправить код зависит от того, какую логику поведения задумывал программист изначально. Возможно, функция должна возвращать управление. Возможно, нарушен порядок выражений и корректный код должен быть таким:
FILE* OpenFile(const char *filename)
{
FILE *f = fopen(filename, "w");
if (f == nullptr)
{
printf("No such file: %s", filename);
Error();
}
return f;
}Рассмотрим второй пример:
char ch = strText[i];
switch (ch)
{
case '<':
...
break;
case '>':
...
break;
case 0xB7:
case 0xBB:
...
break;
...
}Здесь ветка расположенная после "case 0xB7:" и "case 0xBB:" никогда не получит управление. Переменная 'ch' имеет тип 'char', а, следовательно, диапазон её значений лежит в пределах [-128..127]. Результатом сравнения "ch == 0xB7" и "ch==0xBB" всегда будет ложь (false). Чтобы код был корректен, переменная 'ch' должна иметь тип 'unsigned char'. Исправленный код:
unsigned char ch = strText[i];
switch (ch)
{
case '<':
...
break;
case '>':
...
break;
case 0xB7:
case 0xBB:
...
break;
...
}Рассмотрим третий пример:
if (n < 5) { AB(); }
else if (n < 10) { BC(); }
else if (n < 15) { CD(); }
else if (n < 25) { DE(); }
else if (n < 20) { EF(); } // Это ветвь никогда не выполнится.
else if (n < 30) { FG(); }Из-за некорректного пересечения диапазонов, находящихся в условиях, одна из ветвей никогда не будет выполнена. Исправленный код:
if (n < 5) { AB(); }
else if (n < 10) { BC(); }
else if (n < 15) { CD(); }
else if (n < 20) { EF(); }
else if (n < 25) { DE(); }
else if (n < 30) { FG(); }Данная диагностика классифицируется как:
|
V2536. MISRA. Function should not contain labels not used by any 'goto' statements.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Наличие в теле функции меток, на которые не ссылается ни один оператор 'goto' может служить признаком допущенной программистом ошибки. Такие метки могут появиться, если программист случайно использовал переход не на ту метку или допустил опечатку при создании case-метки.
Рассмотрим первый пример:
string SomeFunc(const string &fStr)
{
string str;
while (true)
{
getline(cin, str);
if (str == fStr)
goto retRes;
else if (str == "stop")
goto retRes;
}
retRes:
return str;
badRet:
return "fail";
}В теле функции есть метка 'badRet' на которую не ссылается ни один оператор 'goto', но при этом присутствует другая метка 'retRes', на которую есть ссылка. Программист ошибся, и вместо перехода на метку 'badRet' продублировал переход на метку 'retRes'.
Корректный код может быть таким:
string SomeFunc(const string &fStr)
{
string str;
while(true)
{
getline(cin,str);
if (str == fStr)
goto retRes;
else if(str == "stop")
goto badRet;
}
retRes:
return str;
badRet:
return "fail";
}Рассмотрим второй пример:
switch (c)
{
case 0:
...
break;
case1: // <=
...
break;
defalt: // <=
...
break;
}Программист допустил две опечатки при написании тела 'switch', в результате чего появились две метки, на которые не ссылается ни один оператор 'goto'. Помимо того, что эти метки нарушают данное правило, код под ними оказался недостижим.
Исправленный код:
switch (c)
{
case 0:
...
break;
case 1:
...
break;
default:
...
break;
}Данная диагностика классифицируется как:
|
V2537. MISRA. Functions should not have unused parameters.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Неиспользованные параметры функции часто появляются после рефакторинга кода. Если сигнатура функции не соответствует её реализации, сложно сразу понять, является ли это ошибкой программиста.
Рассмотрим пример:
static bool CardHasLock(int width, int height)
{
const double xScale = 0.051;
const double yScale = 0.0278;
int lockWidth = (int)floor(width * xScale);
int lockHeight = (int)floor(width * yScale);
....
}Из кода видно, что параметр 'height' ни разу не используется в теле функции. Скорее всего, здесь допущена ошибка, и код инициализации переменной 'lockHeight' должен выглядеть следующим образом:
int lockHeight = (int)floor(height * yScale);Данная диагностика классифицируется как:
|
V2538. MISRA. The value of uninitialized variable should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Если переменная POD-типа не инициализируется явно и не имеет инициализатора по умолчанию, то её значение будет неопределённым. Использование такого значения приведет к неопределенному поведению.
Простой синтетический пример:
int Aa = Get();
int Ab;
if (Ab) // Ab - uninitialized variable
Ab = Foo();
else
Ab = 0;Как правило, ошибки использования неинициализированных переменных, возникают из-за опечаток. Например, может оказаться, что в этом месте следовало использовать другую переменную. Корректный вариант кода:
int Aa = Get();
int Ab;
if (Aa) // OK
Ab = Foo();
else
Ab = 0;Данная диагностика классифицируется как:
|
V2539. MISRA. Class destructor should not exit with an exception.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило справедливо только для C++. Бросание исключения в деструкторе объекта - плохая практика. Начиная с C++11, бросание исключения в теле деструктора приводит к вызову функции 'std::terminate'. Из этого следует, что исключение, брошенное внутри деструктора, должно быть обработано внутри того же деструктора.
Рассмотрим первый пример:
LocalStorage::~LocalStorage()
{
...
if (!FooFree(m_index))
throw Err("FooFree", GetLastError());
...
}Анализатор обнаружил деструктор, содержащий оператор throw вне блока try..catch. Данный код следует переписать таким образом, чтобы сообщить об ошибке, возникшей в деструкторе без использования механизма исключений. Если ошибка не критична, то ее можно игнорировать:
LocalStorage::~LocalStorage()
{
try {
...
if (!FooFree(m_index))
throw Err("FooFree", GetLastError());
...
}
catch (...)
{
assert(false);
}
}Также исключения могут возникать при вызове оператора 'new'. При невозможности выделения памяти будет сгенерировано исключение 'std::bad_alloc'. Рассмотрим второй пример:
A::~A()
{
...
int *localPointer = new int[MAX_SIZE];
...
}Появление исключения также возможно и при использовании dynamic_cast<Type> при работе с ссылками. При невозможности приведения типов будет сгенерировано исключение 'std::bad_cast'. Рассмотрим третий пример:
B::~B()
{
...
UserType &type = dynamic_cast<UserType&>(baseType);
...
}Для исправления данных ошибок следует переписать код таким образом, чтобы 'new' или 'dynamic_cast' были помещены в блок 'try-catch'.
Данная диагностика классифицируется как:
|
V2540. MISRA. Arrays should not be partially initialized.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Если один или несколько элементов массива инициализируются явно, то все элементы должны быть также явно инициализированы.
При инициализации с помощью списка в фигурных скобках все неинициализированные элементы будут инициализированы по умолчанию (например, нулем). Обеспечение явной инициализации каждого элемента гарантирует, что всем элементам было присвоено желаемое значение.
Исключения:
- Разрешается использование формы { 0 }, так как она явно указывает, что все элементы инициализируются нулем.
- Массив, инициализированный единственным строковым литералом не нуждается в явном инициализаторе для каждого элемента.
- Можно частично инициализировать массив, если используются только designated-инициализаторы.
Несколько примеров, нарушающих правило:
int White[4] = { 0xffff };
int RGBwhite[4] = { 0xffff, 0xffff, 0xffff };
char *a3[100] = { "string", "literals" };
char hi[5] = { 'H', 'i', '!' };
int designated_butNotAll[4] = { [0] = 3,[1] = 1, 0 };И несколько корректных:
char lpszTemp[5] = { '\0' };
char a1[100] = "string_literal";
char a2[100] = { "string_literal" };
int Black[4] = { 0 };
int CMYKwhite[4] = { 0, 0, 0, 0 };
int CMYKblack[4] = { 0xffff, 0xffff, 0xffff, 0xffff };
int designated_All[4] = { [0] = 3,[1] = 1,[2] = 4 };Данная диагностика классифицируется как:
|
V2541. MISRA. Function should not be declared implicitly.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило справедливо только для C. В языке C является допустимым использование функции без её предварительного объявления. Однако такое использование опасно, т. к. может стать причиной некорректной работы программы.
Рассмотрим простой пример.
char *CharMallocFoo(int length)
{
return (char*)malloc(length);
}Поскольку заголовочный файл <stdlib.h> не подключен, компилятор языка C посчитает, что функция 'malloc' вернет тип 'int'. Неверная интерпретация возвращаемого значения компилятором может привести к проблемам во время выполнения программы, в том числе и к аварийному завершению.
Если программа 64-битная, то, скорее всего, будут потеряны старшие 32-бита возвращаемого адреса. Поэтому программа некоторое время будет работать корректно. Однако, когда свободная память в 4-х младших гигабайтах адресного пространства закончится или будет сильно фрагментирована, то будет выделен буфер за пределами 4-х младших гигабайт. Так как будут потеряны старшие биты адреса, то последствия будут крайне неприятны и непредсказуемы. Подробнее эта ситуация рассматривается в статье "Красивая 64-битная ошибка на языке Си".
Исправленный вариант кода:
#include <stdlib.h>
....
char *CharMallocFoo(int length)
{
return (char*)malloc(length);
}Данная диагностика классифицируется как:
|
V2542. MISRA. Function with a non-void return type should return a value from all exit paths.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор обнаружил функцию с не-void возвращаемым типом, которая не возвращает значение на всех путях выполнения. Согласно стандарту C/C++, это может привести к неопределенному поведению.
Рассмотрим пример, в котором неопределенное значение возвращается только иногда:
BOOL IsInterestingString(char *s)
{
if (s == NULL)
return FALSE;
if (strlen(s) < 4)
return;
return (s[0] == '#') ? TRUE : FALSE;
}В коде допущена опечатка. Если длина строки меньше 4 символов, то функция вернет неопределенное значение. Корректный вариант:
BOOL IsInterestingString(char *s)
{
if (s == NULL)
return FALSE;
if (strlen(s) < 4)
return FALSE;
return (s[0] == '#') ? TRUE : FALSE;
}Примечание. Анализатор старается определить ситуации, когда отсутствие возвращаемого значения не является ошибкой. Пример кода, который анализатор сочтет безопасным:
int Foo()
{
...
exit(10);
}Данная диагностика классифицируется как:
|
V2543. MISRA. Value of the essential character type should be used appropriately in the addition/subtraction operations.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Значения essential character типа не должны использоваться в арифметических выражениях.
Стандарт MISRA определяет следующую модель сущностных типов (Essential type model), в которой переменная может иметь тип:
- boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами, или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует без знаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'.
Указатели в этой модели отсутствуют.
Согласно модели сущностных типов, значения essential character типа не должны использоваться в арифметических выражениях, так как представлены нечисловым типом.
Рассмотрим список правильных способов использовать переменные символьного типа в арифметических выражениях:
- При сложении один операнд должен иметь символьный тип, другой должен иметь знаковый или беззнаковый целый тип. Результат такой операции имеет символьный тип:
- character + [un]signed => character; (1)
- [un]signed + character => character; (2)
- При вычитании левый операнд должен иметь символьный тип, а правый операнд должен иметь знаковый или беззнаковый целый тип. Результатом такой операции будет значение символьного типа:
- character - [un]signed => character; (3)
- При вычитании оба операнда должны иметь символьный тип. Результатом такой операции будет значение знакового целого типа:
- character - character => signed; (4)
Пример кода, на который анализатором будут выданы предупреждения:
void foo(char ch, unsigned ui, float f, _Bool b, enum A eA)
{
ch + f; // Essential character type should not be used in
// the addition operation with expression
// of the essential floating type
ch + b; // Also relates to the essential Boolean
ch + eA; // Also relates to the essential enum <A> type
(ch + ui) + (ch - 6); // After the expressions in parentheses
// have been executed, both operands of the
// essential character type are used
// in addition operation
}Данная диагностика классифицируется как:
|
V2544. MISRA. The values used in expressions should have appropriate essential types.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Значения, использующиеся в выражениях, должны иметь соответствующие сущностные типы.
Стандарт MISRA определяет следующую модель сущностных типов (Essential type model), в которой переменная может иметь тип:
- Boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами, или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует без знаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- Именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'.
Указатели в этой модели отсутствуют.
В языке Си нет ограничений на операции с базовыми типами, но некоторые из этих операций могут иметь неуточненное/неопределенное поведение или вовсе не иметь смысла. Например:
- получать значение в массиве, используя индекс булева типа;
- пытаться сменить знак беззнакового целого числа;
- работать с битовым представлением, используя для этого переменные не беззнакового целого типа.
Также могут быть опасными неявные приведения к Boolean, т.к. не все десятичные дроби могут быть представлены в двоичной системе счисления.
void Foo(float f, _Bool other_expr)
{
If (f || other_expr) ....
}В следующей таблице отмечены знаком 'X' пересечения типов операндов и операций, из которых не следует составлять выражения.

Пример кода, на который будут выданы соответствующие сообщения:
void Foo(float f, _Bool b, int a[], enum E e)
{
if (~a[(e ? 1 : 2) >> (-b * f --> +b) << signed(-24U)]) ....;
}Исключение: выражение знакового типа с положительным значением может быть использовано в качестве правого операнда оператора сдвига (>>, <<).
void foo(signed vi, unsigned _)
{
assert(vi >= 0);
_ >> vi;
_ << vi;
}Данная диагностика классифицируется как:
|
V2545. MISRA. Conversion between pointers of different object types should not be performed.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Приведение указателя одного типа к указателю на другой может привести к неопределённому поведению, если выравнивание этих типов не совпадает.
Пример кода, на который анализатор выдаст предупреждения:
void foo( void )
{
int *pi;
double *pd = ....;
typedef int *PI;
pi = pd; // <=
pi = (int*) pd; // <=
pi = PI(pd); // <=
}Диагностика также проверяет квалификаторы типов, на которые ссылаются указатели при приведени типов:
void foo( void )
{
double **ppd = ....;
const double **ppcd = (const double **) ppd;
double * const *pcpd = ....;
const volatile double * const *pcvpd =
(const volatile double * const *) pcpd;
}Исключениями являются приведение указателя к указателю на типы 'char', 'signed char', 'unsigned char', 'void', поскольку стандарт явно определяет такое поведение.
Данная диагностика классифицируется как:
|
V2546. MISRA. Expression resulting from the macro expansion should be surrounded by parentheses.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор обнаружил потенциально возможную ошибку в записи макроса. Макрос и его параметры следует заключать в скобки.
В случае, когда параметры или само выражение не заключены в скобки, может быть нарушена задуманная последовательность действий после того, как макрос будет подставлен.
Пример кода, на который анализатор выдаст предупреждение:
#define DIV(x, y) (x / y)Пример использования макроса, приводящего к ошибке:
Z = DIV(x + 1, y + 2);В результате получим:
Z =(x + 1 / y + 2);Чтобы избежать нарушения последовательности действий, этот макрос стоит переписать следующим образом:
#define DIV(x,y) ((x) / (y))Данная диагностика классифицируется как:
|
V2547. MISRA. The return value of non-void function should be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Существует возможность вызвать non-void функцию и не использовать возвращаемое ею значение. Такое поведение программы может скрывать ошибку.
Результат non-void функции всегда должен быть использован. Пример кода, на который анализатор выдаст предупреждение:
int Foo(int x)
{
return x + x;
}
void Bar(int x)
{
Foo(x);
}В случае, если потеря возврщаемого значения была задумана разработчиком, можно использовать приведение к 'void' типу. Пример кода, на который анализатор не выдаст предупреждение:
void Bar(int x)
{
(void)Foo(x);
}Данная диагностика классифицируется как:
|
V2548. MISRA. The address of an object with local scope should not be passed out of its scope.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Копирование адреса объекта в указатель/ссылку с большим временем жизни может привести к возникновению "висячего" указателя/ссылки после того, как исходный объект перестанет существовать. Это является нарушением безопасности памяти. Использование данных, на которые указывает "висячий" указатель/ссылка, приводит к неопределенному поведению.
Первый пример кода, на который анализатор выдаст предупреждение:
int& Foo( void )
{
int some_variable;
....
return some_variable;
}Второй пример кода, на который анализатор выдаст предупреждение:
#include <stddef.h>
void Bar( int **ptr )
{
int some_variable;
....
if (ptr != NULL)
*ptr = &some_variable;
}Данная диагностика классифицируется как:
|
V2549. MISRA. Pointer to FILE should not be dereferenced.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило справедливо только для C. Указатель на стандартный тип FILE не должен быть явно или неявно разыменован. Копирование этого объекта бессмысленно, т. к. копия не даст того же самого поведения. Прямое управление объектом FILE запрещено, т. к. может быть несовместимо с дизайном, который принят для работы с потоками (stream) управления файлами.
Явное разыменование подразумевает обычное разыменование специально отведенными для этого операторами:
- *p;
- p->_Placeholder;
- p[0];
Неявное разыменование - вызов функции, которая внутри себя разыменовывает указатель, например, 'memcpy' или 'memcmp'.
Пример кода, на котором анализатор выдаст предупреждения:
void foo()
{
FILE *f = fopen(....);
FILE *d = fopen(....);
....
if (memcmp(f, d, sizeof(FILE)) == 0) { .... } // <=
memset(d, 0, sizeof(*d)); // <=
*d = *f; // <=
....
}Данная диагностика классифицируется как:
|
V2550. MISRA. Floating-point values should not be tested for equality or inequality.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило справедливо только для C++. При сравнении на равенство или неравенство значений вещественных типов в зависимости от используемого процессора и настроек компилятора часто можно получить неожиданный результат.
Пример кода, на который анализатор выдаст предупреждение:
const double PI_div_2 = 1.0;
const double sinValue = sin(M_PI / 2.0);
if (sinValue == PI_div_2) { .... }Чтобы сравнение значений вещественных типов не содержало ошибок, нужно либо использовать встроенные константы 'std::numeric_limits<float>::epsilon()' или 'std::numeric_limits<double>::epsilon()', либо создать собственную константу 'Epsilon' с заданной точностью.
Исправленный пример кода:
const double PI_div_2 = 1.0;
const double sinValue = sin(M_PI / 2.0);
// equality
if (fabs(a - b) <= std::numeric_limits<double>::epsilon()) { .... };
// inequality
if (fabs(a - b) > std::numeric_limits<double>::epsilon()) { .... };В некоторых случаях сравнение двух вещественных чисел через оператор '==' или '!=' допустимо. Например, когда переменная сравнивается с заведомо известным значением:
bool foo();
double bar();
double val = foo() ? bar() : 0.0;
if (val == 0.0) { .... }Анализатор не выдает предупреждений, если сравнивается одно и то же значение с самим собой. Такое сравнение позволяет определить, хранится ли в переменной NaN:
bool isnan(double value) { return value != value; }Впрочем, более хорошим стилем будет использовать для этой проверки функцию 'std::isnan'.
Данная диагностика классифицируется как:
|
V2551. MISRA. Variable should be declared in a scope that minimizes its visibility.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Переменные следует определять в минимально возможной области видимости. Это позволит избежать возможных ошибок, связанных со случайным использованием переменных вне предусмотренной для них области видимости, а также может помочь сэкономить потребление памяти и увеличить производительность программы.
Пример кода, на который анализатор выдаст предупреждение:
static void RenderThrobber(RECT *rcItem, int *throbbing, ....)
{
....
int width = rcItem->right - rcItem->left;
....
if (*throbbing)
{
RECT rc;
rc.right = width;
....
}
.... // width больше нигде не используется
}Переменная 'width' используется только внутри блока 'if', следовательно, будет разумным перенести переменную внутрь этого блока. Вычисление 'width' при этом будет происходить только при выполнении условия, что экономит время. Дополнительно это позволит избежать ошибочного использования этой переменной в дальнейшем.
Данная диагностика классифицируется как:
|
V2552. MISRA. Expressions with enum underlying type should have values corresponding to the enumerators of the enumeration.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Анализатор обнаружил опасное приведение числа к перечислению. Указанное число может не входит в диапазон значений enum.
Пример:
enum TestEnum { A, B, C };
TestEnum Invalid = (TestEnum)42;Так как стандарт не указывает базовый тип для enum, то результат приведения числа, чьё значение не входит диапазон элементов enum, является unspecified behavior до C++17 и undefined behavior начиная с C++17.
Для того чтобы этого избежать, необходимо проверять числа перед приведениями. Как вариант, можно явно указать базовый тип для enum или использовать 'enum class', базовый тип которого по умолчанию - 'int'.
Корректный код:
enum TestEnum { A, B, C, Invalid = 42 };Или:
enum TestEnum : int { A, B, C };
E Invalid = (E)42;Или:
enum class TestEnum { A, B, C };
TestEnum Invalid = (TestEnum)42;Данная диагностика классифицируется как:
|
V2553. MISRA. Unary minus operator should not be applied to an expression of the unsigned type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
При применении унарного минуса к переменной типа 'unsigned int', 'unsigned long' или 'unsigned long long' тип этой переменной не изменится и останется 'unsigned'. Таким образом, подобная операция является бессмысленной.
При применении унарного минуса к меньшему 'unsigned' целочисленному типу в результате целочисленного расширения возможно получение 'signed' числа, однако это не является хорошим подходом, и на такую операцию также будет выдано предупреждение.
Пример кода, на который анализатор выдаст предупреждение:
unsigned int x = 1U;
int y = -x;Данная диагностика классифицируется как:
|
V2554. MISRA. Expression containing increment (++) or decrement (--) should not have other side effects.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Не рекомендуется использование декремента (--) или инкремента (++) в одном выражении с другими операторами. Использование этих операторов в выражении, содержащем сторонние побочные эффекты приводит к ухудшению читаемости кода, а также может привести к возникновению неопределенного поведения (undefined behaviour). Безопасным подходом будет использование рассматриваемых операторов в отдельных выражениях.
Пример кода, на который анализатор выдаст предупреждение:
i = ++i + i--;Здесь происходит попытка изменить одну переменную в пределах одной точки следования. Это приводит к неопределенному поведению (undefined behaviour).
Данная диагностика классифицируется как:
|
V2555. MISRA. Incorrect shifting expression.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
При побитовом сдвиге значение правого операнда должно находиться в диапазоне [0 .. N - 1], где N - количество бит, которое необходимо для представления левого операнда. Несоблюдение этого правила ведет к неопределенному поведению.
На следующий код будут выданы соответствующие предупреждения:
(int32_t) 1 << 128u;
(unsigned int64_t) 2 >> 128u;
int64_X >>= 64u;
any_var << -2u;Рассмотрим пример из реального приложения, в котором происходит неопределенное поведение вследствие неверного побитового сдвига:
UINT32 m_color1_mask;
UINT32 m_color2_mask;
#define ARRAY_LENGTH(x) (sizeof(x) / sizeof(x[0]))
PALETTE_INIT( montecar )
{
static const UINT8 colortable_source[] =
{
0x00, 0x00, 0x00, 0x01,
0x00, 0x02, 0x00, 0x03,
0x03, 0x03, 0x03, 0x02,
0x03, 0x01, 0x03, 0x00,
0x00, 0x00, 0x02, 0x00,
0x02, 0x01, 0x02, 0x02,
0x00, 0x10, 0x20, 0x30,
0x00, 0x04, 0x08, 0x0c,
0x00, 0x44, 0x48, 0x4c,
0x00, 0x84, 0x88, 0x8c,
0x00, 0xc4, 0xc8, 0xcc
};
....
for (i = 0; i < ARRAY_LENGTH(colortable_source); i++)
{
UINT8 color = colortable_source[i];
if (color == 1)
state->m_color1_mask |= 1 << i; // <=
else if (color == 2)
state->m_color2_mask |= 1 << i; // <=
prom_to_palette(machine, i,
color_prom[0x100 + colortable_source[i]]);
}
....
}В коде в цикле на i-ой итерации сдвигают единицу на i позиций влево. В результате цикла переменная 'i' будет принимать значения в диапазоне [0 .. 43], что больше допустимого диапазона, начиная с 32-ой итерации цикла (в случае, если int - 32-х битовый тип данных).
Данная диагностика классифицируется как:
|
V2556. MISRA. Use of a pointer to FILE when the associated stream has already been closed.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило справедливо только для C. Использование указателя на стандартный тип 'FILE' после закрытия потока, на который он указывает, может привести к ошибкам, т. к. состояние этого объекта будет не определено.
На следующий участок кода будет выдано соответствующее предупреждение.
FILE* f = fopen("/path/to/file.log", "w");
if (f == NULL) { .... }
fprintf(f, "....");
if (....) // something went wrong
{
fclose(f);
fprintf(f, "...."); // Print log information
// after stream has been released.
}Данная диагностика классифицируется как:
|
V2557. MISRA. Operand of sizeof() operator should not have other side effects.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Оператор 'sizeof()' не выполняет переданное ему выражение, а только вычисляет тип результирующего выражения и возвращает его размер на этапе компиляции. Следовательно, для любого кода внутри 'sizeof()' компилятор не генерирует ассемблерного кода (невыполняемые контекст), и ожидаемые операции внутри не будут произведены.
Поэтому операнд, передаваемый 'sizeof()', не должен содержать каких-либо сторонних эффектов, чтобы избежать потери операций.
Пример кода, на который анализатор выдаст предупреждение:
int x = ....;
....
size_t s = n * sizeof(x++);Для получения ожидаемого эффекта нужно переписать код следующим образом:
int x = ....;
....
++x;
size_t s = n * sizeof(x);Данная диагностика классифицируется как:
|
V2558. MISRA. A pointer/reference parameter in a function should be declared as pointer/reference to const if the corresponding object was not modified.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C++. Анализатор обнаружил, что объект передается в функцию через указатель или ссылку, но не модифицируется в теле функции. Это может свидетельствовать о наличии ошибки. Также в случае, если такой аргумент функции действительно не изменяется, это делает сигнатуру функции неточной. Добавление константности объекту предотвращает потенциальные ошибки и делает определение функции более наглядным.
Пример кода, на который анализатор выдаст предупреждение:
size_t StringEval(std::string &str)
{
return str.size();
}Здесь переменная 'str' используется только для чтения, хотя она и передается по неконстантной ссылке. Явная константность в сигнатуре функции позволила бы с первого взгляда понять, что функция не изменяет объект, а также предотвратить потенциальные ошибки при изменении самой функции.
Корректный вариант кода:
size_t StringEval(const std::string &str)
{
return str.size();
}Данная диагностика классифицируется как:
|
V2559. MISRA. Subtraction, >, >=, <, <= should be applied only to pointers that address elements of the same array.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Согласно стандарту C/C++ (C11 § 6.5.8 п. 5; C++17 § 8.5.9 п. 3) применение одного из операторов '-', '>', '>=', '<' или '<=' к двум указателям, которые не указывают на элементы одного и того же массива, приводит к неопределенному/неуточненному поведению (undefined/unspecified behaviour). Таким образом, если два указателя указывают на разные объекты массива, тогда эти объекты массива должны входить в один и тот же массив для того, чтобы сравнить их.
Пример кода, на который анализатор выдаст предупреждение:
int arr1[10];
int arr2[10];
int *pArr1 = arr1;
if (pArr1 < arr2)
{
....
}Также следующий код является ошибочным:
int arr1[10];
int arr2[10];
int *pArr1 = &arr1[1];
int *pArr2 = &arr2[1];
int len = pArr1 - pArr2;Подробнее о том, почему использование указателей может привести к ошибке можно прочитать в статье: "Указатели в C абстрактнее, чем может показаться".
Данная диагностика классифицируется как:
|
V2560. MISRA. There should be no user-defined variadic functions.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C++. В коде не должно быть ни одной определённой вариативной пользовательской функции (содержащий эллипсис '...'). Аргументы, передаваемые в функцию через эллипсис, не проверяются компилятором на соответствие типов, что может привести к ошибкам. Имея только объявление без определения, можно перепутать тип аргументов. Также передача аргумента non-POD типа ведёт к неопределённому поведению.
Пример кода, на который анализатор выдаст предупреждение:
void foo(int _, ...) // <=
{
va_list ap;
va_start(ap, _);
....
va_end(ap);
}Стандарт, однако, разрешает объявление вариативных функций для использования существующих библиотечных функций. Допустимый код:
int printf(const char *fmt, ...);Данная диагностика классифицируется как:
|
V2561. MISRA. The result of an assignment expression should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Использование присвоения в подвыражениях привносит дополнительный побочный эффект, что уменьшает читаемость кода и повышает шанс внесения новой ошибки в код.
Более того, следование данному правилу значительно снижает вероятность путаницы между операторами '=' и '=='.
Пример кода, на который анализатор выдаст предупреждения:
int Inc(int i)
{
return i += 1; // <=
}
void neg(int a, int b)
{
int c = a = b; // <=
Inc(a = 1); // <=
if(a = b) {} // <=
}Данная диагностика классифицируется как:
|
V2562. MISRA. Expressions with pointer type should not be used in the '+', '-', '+=' and '-=' operations.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное правило актуально только для языка C. Указатели не должны использоваться в выражениях '+', '-', '+=' и '-='. При этом допускается использовать операцию индексирования '[]' и инкремент/декремент ('++'/'--').
Использование адресной арифметики усложняет чтение программы и может являться причиной неправильного понимания написанного когда. С другой стороны, использование индексирования является явным и легко читаемым, и даже если при его использовании будет внесена ошибка, её будет легче обнаружить. То же касается и операций инкремента/декремента: они явно дают понять, что мы последовательно обходим область памяти, представляющую собой непрерывную область данных.
Пример нарушения правила:
int arr[] = { 0, 1, 2 };
int *p = arr + 1; //+V2562
p += 1; //+V2562Корректный вариант кода:
int arr[] = { 0, 1, 2 };
int *p = &arr[1];
++p;
int *q = p[1];Данная диагностика классифицируется как:
|
V2563. MISRA. Array indexing should be the only form of pointer arithmetic and it should be applied only to objects defined as an array type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное правило актуально только для языка C++. Данное правило MISRA рекомендует не использовать адресную арифметику. Единственной формой адресной арифметики, допускаемой к использованию данным правилом, является операция индексирования ('[]'), применённая к сущности, объявленной как массив.
Исключение: допускается использовать инкремент и декремент ('++' и '--').
Использование адресной арифметики усложняет чтение программы и может являться причиной неправильного понимания написанного когда. С другой стороны, использование индексирования является явным и легко читаемым, и даже если при его использовании будет внесена ошибка, её будет легче обнаружить. То же касается и операций инкремента/декремента: они явно дают понять, что мы последовательно обходим область памяти, представляющую собой непрерывную область данных.
Пример нарушения правила:
int arr[] = { 0, 1, 2 };
int *p = arr + 1; //+V2563
p += 1; //+V2563
int *q = p[1]; //+V2563Корректный вариант кода:
int arr[] = { 0, 1, 2 };
int *p = &arr[1];
++p;Данная диагностика классифицируется как:
|
V2564. MISRA. There should be no implicit integral-floating conversion.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C++. В коде не должно быть неявных преобразований значений вещественного типа в целочисленный и наоборот.
Под целочисленными типами подразумеваются:
- 'signed char', 'unsigned char',
- 'short', 'unsigned short',
- 'int', 'unsigned int',
- 'long', 'unsinged long',
- 'long long', 'unsigned long long'.
Под типами с плавающей точкой подразумеваются:
- 'float',
- 'double',
- 'long double'.
При неявном преобразовании значений вещественных типов в целые может быть утеряна информация (например, дробная часть), а также возможно возникновение неопределенного поведения, если значение вещественного типа не может быть представлено целым типом.
Неявное преобразование значения целого типа в вещественный может привести к его неточному представлению, которое не соответствует ожиданиям разработчика.
Пример кода, на который анализатор выдаст предупреждения:
void foo1(int x, float y);
void foo2()
{
float y = 10;
int x = 10.5;
foo1(y, x);
}Пример правильного с точки зрения этой диагностики кода:
void foo1(int x, float y);
void foo2()
{
float y = static_cast<float>(10);
int x = static_cast<int>(10.5);
foo1(static_cast<int>(y), static_cast<float>(x));
}Данная диагностика классифицируется как:
|
V2565. MISRA. A function should not call itself either directly or indirectly.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Функции не должны вызывать себя ни напрямую, ни косвенно. Рекурсия может привести к сложно отлавливаемым ошибкам. Одной из них может быть переполнение стека при очень глубокой рекурсии.
Пример кода, на который анализатор выдаст предупреждения:
#include <stdint.h>
uint64_t factorial(uint64_t n)
{
return n > 1 ? n * factorial(n - 1) : 1;
}По возможности, стоит заменить рекурсивный вызов циклом. Вот как это можно сделать с предыдущим примером:
#include <stdint.h>
uint64_t factorial(uint64_t n)
{
uint64_t result = 1;
for (; n > 1; --n)
{
result *= n;
}
return result;
}Данная диагностика классифицируется как:
|
V2566. MISRA. Constant expression evaluation should not result in an unsigned integer wrap-around.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Согласно стандарту языка C, в выражениях беззнаковых типов при переполнении происходит перенос значений относительно нуля. Применение этого свойства беззнаковых типов при вычислениях на этапе выполнения является известной практикой (в отличие от знаковых типов, для которых переполнение ведёт к неопределённому поведению).
Однако, перенос значений относительно нуля для выражений, вычисленных на этапе компиляции, может сбивать с толку.
Пример кода, на который анализатор выдаст предупреждения:
#include <stdint.h>
#define C1 (UINT_MAX)
#define C2 (UINT_MIN)
....
void foo(unsigned x)
{
switch(x)
{
case C1 + 1U: ....; break;
case C2 - 1U: ....; break;
}
}Если в константном выражении беззнакового типа происходит перенос значения относительно нуля, то согласно текущему правилу он может трактовать не как ошибка в случае, если выражение никогда не будет вычислено:
#include <stdint.h>
#define C UINT_MAX
....
unsigned foo(unsigned x)
{
if(x < 0 && (C + 1U) == 0x42) ....;
return x + C;
}Выражение '(C + 1U)', содержащее переполнение не будет выполнено, т.к. выражение 'x < 0' всегда ложно. Следовательно, второй операнд логического выражения не будет вычислен.
Данная диагностика классифицируется как:
|
V2567. MISRA. Cast should not remove 'const' / 'volatile' qualification from the type that is pointed to by a pointer or a reference.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Удаление 'const' / 'volatile' квалификаторов может привести к проблемам.
Например:
- изменение объекта, объявленного с квалификатором 'const', через указатель/ссылку на не-'const' тип ведет к неопределенному поведению;
- доступ к объекту, объявленному с квалификатором 'volatile', через указатель/ссылку на не-'volatile' тип ведет к неопределенному поведению;
- компилятор вправе оптимизировать код в случае возникновения неопределенного поведения. Например, в следующем коде компилятор может сделать цикл бесконечным:
inline int foo(bool &flag)
{
while (flag)
{
// do some stuff...
}
return 0;
}
int main()
{
volatile bool flag = true;
return foo(const_cast<bool &>(flag));
}Другой пример кода, на который анализатор выдаст предупреждения:
void my_swap(const int *x, volatile int *y)
{
auto _x = const_cast<int*>(x);
auto _y = const_cast<int*>(y);
swap(_x, _y);
}
void foo()
{
const int x = 30;
volatile int y = 203;
my_swap(&x, &y); // <=
}Данная диагностика классифицируется как:
|
V2568. MISRA. Both operands of an operator should be of the same type category.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Если при преобразовании арифметических типов сущностные типы операндов не совпадают, это может привести к неочевидным проблемам.
Стандарт MISRA определяет следующую модель сущностных типов (Essential type model), в которой переменная может иметь тип:
- Boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами, или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует без знаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- Именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'.
Указатели в этой модели отсутствуют.
Язык С предоставляет свободу для проведения преобразования арифметических типов, что может повлечь за собой неочевидные проблемы как потеря знака, переполнение или потеря значимости. Несмотря на свою строгость, стандарт MISRA разрешает преобразования арифметических типов в случае, когда сущностные типы операндов совпадают.
Исключение: левый и правый операнды операторов '+', '-', '+=', '-=' могут иметь сущностные 'character' и 'signed' / 'unsigned' типы соответственно.
Пример кода, на который анализатор выдаст предупреждения:
enum { A };
int i;
unsigned u;
void foo()
{
A + u;
0.f - i;
A > (_Bool)0;
}Пример правильного с точки зрения этой диагностики кода:
void foo(unsigned short x, _Bool b)
{
x + 1UL;
if (b && x > 4U) ....
}Данная диагностика классифицируется как:
|
V2569. MISRA. The 'operator &&', 'operator ||', 'operator ,' and the unary 'operator &' should not be overloaded.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C++. Встроенные операторы '&&', '||', '&' (взятие адреса) и ',' имеют определённый порядок вычисления и семантику. После перегрузки этих функций разработчик может не знать о потере особенностей этих операторов.
1) После перегрузки логических операторов теряется сокращенное вычисление. Для встроенных операторов, если первый операнд '&&' оказался 'false' или первый операнд '||' оказался 'true', вычисление второго операнда не происходит. В результате может быть потеряна часть оптимизаций:
class Tribool
{
public:
Tribool(bool b) : .... { .... }
friend Tribool operator&&(Tribool lhs, Tribool rhs) { .... }
friend Tribool operator||(Tribool lhs, Tribool rhs) { .... }
....
};
// Do some heavy weight stuff
bool HeavyWeightFunction();
void foo()
{
Tribool flag = ....;
if (flag || HeavyWeightFunction()) // evaluate all operands
// no short-circuit evaluation
{
// Do some stuff
}
}Здесь компилятор не сможет произвести оптимизацию, и произойдет "тяжеловесной" функции, чего бы не произошло для встроенного оператора.
2) Перегрузка унарного оператора взятия адреса '&' также может привести к неочевидной ситуации. Рассмотрим пример:
// Example.h
class Example
{
public:
Example* operator&() ;
const Example* operator&() const;
};
// Foo.cc
#include "Example.h"
void foo(Example &x)
{
&x; // call overloaded "operator&"
}
// Bar.cc
class Foobar;
void bar(Example &x)
{
&x; // may call built-in or overloaded "operator&"!
}Во втором случае, согласно стандарту С++ ($8.3.1.5) такое поведение является неуточненным, и получение адреса объекта 'x' может вызвать как встроенный оператор, так и перегруженный.
3) Встроенный оператор "запятая" выполняет левый операнд и игнорирует результат, затем вычисляет правый операнд и возвращает результат правого операнда. Также, встроенный оператор гарантирует, что все побочные эффекты левого операнда будут выполнены до того, как начнется выполнение второго операнда.
Перегруженный оператор не дает эту гарантию (до стандарта C++17), поэтому нижеприведенный код может напечатать как 'foobar', так и 'barfoo':
#include <iostream>
template <typename T1, typename T2>
T2& operator,(const T1 &lhs, T2 &rhs)
{
return rhs;
}
int main()
{
std::cout << "foo", std::cout << "bar";
return 0;
}Данная диагностика классифицируется как:
|
V2570. MISRA. Operands of the logical '&&' or the '||' operators, the '!' operator should have 'bool' type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C++. Использование логических операторов '!', '&&' и '||' с переменными, имеющими отличный от 'bool' тип, не имеет смысла, вряд ли предназначено для этого и может указывать на присутствие ошибки. Возможно, должны были использоваться побитовые операторы ('&', '|' или '~').
Пример кода, на который анализатор выдаст предупреждение:
void Foo(int x, int y, int z)
{
if ((x + y) && z)
{
....
}
}
void Bar(int *x)
{
if (!x)
{
....
}
}Примеры правильного кода с точки зрения правила:
void Foo(int x, int y, int z)
{
if ((x + y) & z)
{
....
}
}
void Foo(int x, int y, int z)
{
if ((x < y) && (y < z))
{
....
}
}
void Bar(int *x)
{
if (x == NULL)
{
....
}
}Данная диагностика классифицируется как:
|
V2571. MISRA. Conversions between pointers to objects and integer types should not be performed.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Приведения между указателями на объект и целочисленными типами могут послужить причиной неопределенного, неуточненного или зависимого от реализации поведения. В связи с этим, MISRA рекомендует не использовать подобные приведения.
Пример нарушения 1 (для языка C):
int *p = (int *)0x0042;
int i = p;
enum en { A, B } e = (enum en) p;Пример нарушения 2 (для языка C++):
struct S { int16_t i; int16_t j; } *ps = ....;
int i64 = reinterpret_cast<int>(ps);Пример нарушения 3 (для языка C и С++):
void foo(int i) {}
void wrong_param_type()
{
char *pc = ....;
foo((int) pc);
}Пример нарушения 4 (для языка C и C++):
int wrong_return_type()
{
double *pd = ....;
return (int) pd;
}Данная диагностика классифицируется как:
|
V2572. MISRA. Value of the expression should not be converted to the different essential type or the narrower essential type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Язык C предоставляет свободу при проведении присваиваний между объектами различных арифметических типов. Однако подобные неявные преобразования могут приводить к неочевидным проблемам, таким как потеря знака, точности или значимости.
Стандарт MISRA определяет следующую модель сущностных типов (Essential type model), в которой переменная может иметь тип:
- Boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами, или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует беззнаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- Именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'.
Указатели в этой модели отсутствуют.
Используя модель сущностных типов, можно уменьшить количество подобных неочевидных проблем путем присваивания переменным значений одного и того же сущностного типа. При этом разрешается присваивать в переменную более широкого сущностного типа значения более узкого. Запрещается производить неявные преобразования значений из одного сущностного типа в другой.
Исключения:
- Неотрицательное константное выражение сущностного знакового типа может быть присвоено объекту сущностного беззнакового типа, если значение может быть представлено в этом типе.
- Инициализатор '{ 0 }' может использоваться для инициализации агрегатного типа или объединения.
Пример кода, на который анализатор выдаст предупреждения:
typedef enum ENUM {ONE} ENUM;
void Positive(signed char x)
{
unsigned char uchr = x; // <=
unsigned short usht = x; // <=
unsigned int uit = x; // <=
unsigned long ulg = x; // <=
unsigned long long ullg = x; // <=
long double ld = 0.0;
double d = ld; // <=
float f = d; // <=
ENUM e = x; // <=
}Пример правильного с точки зрения этой диагностики кода:
enum {ONE = 1, TWO, THREE, FOUR, FIVE, SIX,
MUCH = 123123, MORE = 0x7FFFFFFF-1};
void Negative()
{
signed char c = ONE; // ok
signed short h = TWO; // ok
signed int i = THREE; // ok
signed long long ll = FOUR; // ok
unsigned char uc = FIVE; // ok
unsigned short uh = SIX; // ok
unsigned int ui = MUCH; // ok
unsigned long long ull = MORE; // ok
float f = 0.0f; // ok
double d = f; // ok
long double ld = d; // ok
ENUM e = c; // ok
}Данная диагностика классифицируется как:
|
V2573. MISRA. Identifiers that start with '__' or '_[A-Z]' are reserved.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Согласно стандарту C++ идентификаторы и имена макросов, содержащие в себе '__', либо начинающиеся на '_[A-Z]', зарезервированы для использования в реализации языка и стандартной библиотеки. В языке C тоже есть такое правило, но '__' должно быть в начале идентификатора.
Объявление таких идентификаторов снаружи стандартной библиотеки может привести к проблемам. К примеру, код ниже может изменить поведение функции 'abs':
#define _BUILTIN_abs(x) (x < 0 ? -x : x)
#include <cmath>
int foo(int x, int y, bool c)
{
return abs(c ? x : y)
}если функция 'abs' реализована через использование встроенной функции компилятора (интринсик) следующим образом:
#define abs(x) (_BUILTIN_abs(x))Данная диагностика классифицируется как:
|
V2574. MISRA. Functions should not be declared at block scope.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C++. Функция, объявленная в области видимости блока, будет видна также в пространстве имён, обрамляющем блок.
Пример кода:
namespace Foo
{
void func()
{
void bar(); // <=
bar();
}
}
void Foo::bar() // Function 'bar' is visible here
{
}Программист хотел сузить область видимости функции, задекларировав её в блоке функции 'func'. Однако функция 'bar' видна также за пределами пространства имен 'Foo'. Поэтому следует задекларировать функцию явно в обрамляющем пространстве имён:
namespace Foo
{
void bar();
void func()
{
bar();
}
}
void Foo::bar() // Function 'bar' is visible
{
}Также, вследствие неоднозначности грамматики языка C++, декларация функции может выглядеть как декларация объекта:
struct A
{
void foo();
};
int main()
{
A a();
a.foo(); // compile-time error
}Данная проблема известна как "Most vexing parse": компилятор разрешает данную неоднозначность "задекларировать функцию или объект" в пользу "задекларировать функцию". Поэтому, несмотря на ожидание программиста задекларировать объект класса 'A' и вызвать нестатическую функцию-член класса 'A::foo', компилятор воспримет это как объявление функции 'a', не принимающей параметров и возвращающей тип 'A'.
Чтобы избежать путаницы, анализатор также предупреждает о таких объявлениях.
Данная диагностика классифицируется как:
|
V2575. MISRA. The global namespace should only contain 'main', namespace declarations and 'extern "C"' declarations.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C++. Объявления в глобальном пространстве, засоряют список доступных идентификаторов. Новые идентификаторы, добавленные в область видимости блока, могут быть схожими с идентификаторами в глобальном пространстве. Это может запутать разработчика и привести к ошибочному выбору идентификатора.
Чтобы гарантировать ожидания разработчика, все идентификаторы должны располагаться внутри соответствующих пространств имен.
Пример кода, на который анализатор выдает предупреждение:
int x1;
void foo();В соответствии с правилом данный код должен выглядеть следующим образом:
namespace N1
{
int x1;
void foo();
}Также допустимый вариант c extern "C" может выглядеть так:
extern "C"
{
int x1;
}
extern "C" void bar();Согласно стандарту MISRA разрешено использовать 'typedef' в глобальном пространстве имен в том случае, если имя псевдонима типа содержит в себе размер его итогового типа.
Пример кода, на который анализатор не выдает предупреждений:
typedef short int16_t;
typedef int INT32;
typedef unsigned long long Uint64;Пример кода, на который анализатор выдает предупреждения:
typedef std::map<std::string, std::string> TestData;
typedef int type1;Данная диагностика классифицируется как:
|
V2576. MISRA. The identifier 'main' should not be used for a function other than the global function 'main'.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C++. Функция 'main' должна присутствовать только в глобальном пространстве имён, чтобы разработчик точно понимал, что если она есть, то всегда является точкой входа в программу.
Пример кода, на который анализатор выдает предупреждение:
namespace N1
{
int main();
}Другой пример со срабатыванием анализатора:
namespace
{
int main();
}Код, переписанный в соответствии с правилом, может выглядеть так:
namespace N1
{
int start();
}Данная диагностика классифицируется как:
|
V2577. MISRA. The function argument corresponding to a parameter declared to have an array type should have an appropriate number of elements.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Если формальный параметр функции объявлен как массив с фиксированным размером, передаваемый в качестве фактического аргумента массив должен иметь размер не меньше, чем размер массива, принимаемый функцией.
В языке C передача массива в функцию происходит через передачу указателя на его начало, поэтому в такую функцию возможно передать массив любого размера. Однако, использование указателя в качестве формального параметра ухудшает понимание интерфейса функции – становится непонятно, работает она с одним элементом или с массивом.
Чтобы указать, что функция работает именно с некоторым количеством элементов, ее формальный параметр объявляется как массив, при этом размер часто указывается при помощи макроса. Макрос затем используется для обхода элементов массива:
#define ARRAY_SIZE 32
void foo(int arr[ARRAY_SIZE])
{
for (size_t i = 0; i < ARRAY_SIZE; ++i)
{
// Do something with elements
}
}Надо помнить, что такой массив по-прежнему является указателем. Следовательно, существует возможность передать массив с меньшим числом элементов, что может привести к выходу за его границы, что является неопределенным поведением:
#define ARRAY_SIZE 32
void foo(int arr[ARRAY_SIZE]);
void bar()
{
int array1[32] = { 1, ...., 32 };
int array2[28] = { 1, ...., 28 };
foo(array2); // <=
}В данном примере функция получила массив неподходящего размера. Правильным вариантом может быть:
#define ARRAY_SIZE 32
void foo(int arr[ARRAY_SIZE]);
void bar()
{
int array1[32] = { 1, ...., 32 };
int array2[28] = { 1, ...., 28 };
foo(array1); // <=
}Другим вариантом может быть изменение числа элементов переданного в функцию массива и заполнение добавленных элементов значениями по умолчанию:
#define ARRAY_SIZE 32
void foo(int arr[ARRAY_SIZE]);
void bar()
{
int array1[32] = { 1, ...., 32 };
int array2[32] = { 1, ...., 28 }; // <=
foo(array2);
}Если функция обрабатывает массивы разного размера, то правило разрешает использовать в качестве аргумента функции массив произвольного размера. Подразумевается, что размер массива будет передан иным способом, например так:
#define ARRAY_SIZE(arr) (sizeof(arr)/sizeof(arr[0]))
void foo(int arr[], size_t count);
void bar()
{
int array1[] = { 1, 2, 3, 4, 5 };
int array2[] = { 10, 20, 30 };
foo(array1, ARRAY_SIZE(array1));
foo(array2, ARRAY_SIZE(array2));
}Данная диагностика классифицируется как:
|
V2578. MISRA. An identifier with array type passed as a function argument should not decay to a pointer.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C++. Передача массива в функцию по указателю ведёт к потери размера массива. В результате функция может принять в качестве аргумента массив с меньшим количеством элементов, чем ожидается, и в процессе выполнения выйти за его границы, что приведёт к неопределённому поведению.
Чтобы избежать потери информации о размере массива, его стоит передавать только по ссылке. В случае, когда функция должна обрабатывать массивы разной длины, следует использовать класс для инкапсуляции массива и его размера.
Пример кода, несоответствующего правилу:
void foo(int *ptr);
void bar(int arr[5])
void bar(const char chars[30]);
int main
{
int array[5] = { 1, 2, 3 };
foo(array);
bar(array);
}Допустимый вариант:
void bar(int (&arr)[5]);
int main
{
int array[7] = { 1, 2, 3, 4, 5 };
bar(array);
}Другой пример кода, несоответствующий правилу:
void bar(const char chars[30]);
int main()
{
bar("something"); //const char[10]
}Допустимый вариант с использованием класса для инкапсуляции:
template <typename T>
class ArrayView
{
T *m_ptr;
size_t m_size;
public:
template <size_t N>
ArrayView(T (&arr)[N]) : m_ptr(arr), m_size(N) {}
// ....
};
void bar(ArrayView<const char> arr);
int main()
{
bar("something");
}Данная диагностика классифицируется как:
|
V2579. MISRA. Macro should not be defined with the same name as a keyword.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Анализатор обнаружил макрос, имя которого перекрывает ключевое слово.
Примеры:
#define if while
#define int float
#define while(something) for (;(something);)Изменение смысла ключевых слов сбивает с толку и может привести к некорректно работающему коду.
Исключение – переопределение слова 'inline', если используется стандарт языка C90.
Пример, который допустим в C90, но будет считаться ошибкой в C99 и более поздних стандартах:
#define inlineДиагностика также игнорирует переопределения ключевых слов, если они идентичны с точки зрения семантики, или макрос раскрывается в одноименное с ним ключевое слово.
Пример:
#define const constДанная диагностика классифицируется как:
|
V2580. MISRA. The 'restrict' specifier should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Запрещено использовать спецификатор 'restrict' в декларациях переменных, формальных параметров функций и полей структур/объединений. Несмотря на то, что компилятор может сгенерировать более оптимизированный код, это может привести к ошибкам, если два и более указателей ссылаются на одну и ту же область памяти.
Пример кода, на который анализатор выдаёт предупреждения:
void my_memcpy(void * restrict dest,
const void * restrict src,
size_t bytes)
{
// ...
}
typedef struct
{
void * restrict m_field;
} MyStruct;Данная диагностика классифицируется как:
|
V2581. MISRA. Single-line comments should not end with a continuation token.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Однострочные комментарии не должны заканчиваться токеном продолжения предыдущей строки ('\').
Пример:
// Some comment \Это может приводить к тому, что следующая за комментарием строка кода будет также закомментирована. В следующем примере условие на самом деле не проверяется, потому что 'if' попадает в комментарий, и блок кода выполняется всегда:
int startsWith(const char *str, const char *prefix);
void foo();
void foobar(const char *str)
{
// Check that the string doesn't start with foo\bar\
if (startsWith(str, "foo\\bar\\") == 0)
{
foo();
}
....
}Подобный код может успешно компилироваться и не приводить к предупреждениям компилятора.
Если после символа '\' в строке есть любые символы, кроме '\' или перевода строки, то следующая строка не будет считаться комментарием, и анализатор не выдаст предупреждение:
int startsWith(const char *str, const char *prefix);
void foo();
void foobar(const char *str)
{
// Check that the string doesn't start with "foo\bar\"
if (startsWith(str, "foo\\bar\\") == 0)
{
foo();
}
....
}Данная диагностика классифицируется как:
|
V2582. MISRA. Block of memory should only be freed if it was allocated by a Standard Library function.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Память, динамически выделенная при помощи функций 'malloc', 'calloc', 'realloc', должна быть освобождена функцией 'free'. Блок памяти, освобождённый при помощи функции 'free', нельзя передавать в 'free' повторно. Такие действия ведут к неопределённому поведению программы.
Рассмотрим первый пример:
void foo()
{
int arr[50];
// ....
free(arr);
}Здесь анализатор обнаружил ошибочный код, в котором осуществляется попытка удаления массива через функцию 'free'. Однако память под массив выделена на стеке и будет освобождена автоматически при выходе из функции.
Рассмотрим ещё пример:
void foo()
{
float *p1 = (float *)malloc(N * sizeof(float));
float *p2 = (float *)malloc(K * sizeof(float));
// ....
free(p1);
free(p1);
}В коде имеется опечатка, из-за которой дважды освобождается одна и та же область памяти по указателю 'p1'. В результате, во-первых, возникает утечка памяти, так как не освобождается буфер, адрес которого хранится в переменной 'p2'. Во-вторых, из-за повторного освобождения одного и того же буфера возникает неопределённое поведение.
Корректный вариант:
void foo()
{
float *p1 = (float *)malloc(N * sizeof(float));
float *p2 = (float *)malloc(K * sizeof(float));
// ....
free(p1);
free(p2);
}Данная диагностика классифицируется как:
|
V2583. MISRA. Line whose first token is '#' should be a valid preprocessing directive.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Директивы препроцессора (строки начинающиеся с '#') могут использоваться для условного включения или исключения кода из компиляции. Некорректно написанные препроцессорные директивы могут привести к некорректному включению или исключению кода, которое заранее не предполагалось. Поэтому все директивы предварительной обработки должны быть синтаксически корректны.
Рассмотрим пример:
// #define CIRCLE
#define SQUARE
float processArea(float x)
{
#ifdef CIRCLE
return 3.14 * x * x;
#elf defined(SQUARE)
return x * x;
#else1
return 0;
#endif
}Здесь неправильно написаны директивы препроцессора '#elif' и '#else', что приведет к исключению всего кода из тела функции. Корректный вариант:
// #define CIRCLE
#define SQUARE
float processArea(float x)
{
#ifdef CIRCLE
return 3.14 * x * x;
#elif defined(SQUARE)
return x * x;
#else
return 0;
#endif
}Данная диагностика классифицируется как:
|
V2584. MISRA. Expression used in condition should have essential Boolean type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. В условиях конструкций 'if' / 'for' / 'while' должны использоваться выражения, имеющие essential Boolean тип.
Стандарт MISRA определяет следующую модель сущностных типов (Essential type model), в которой переменная может иметь тип:
- Boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует беззнаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- Именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'
Таким образом, стандарт разрешает следующие виды выражений:
- выражение, имеющее тип bool (начиная с C99);
- выражение, в котором производится сравнение с помощью операторов '==', '!=', '<', '>', '<=', '>=';
- константы со значением 0 или 1.
Пример, на который анализатор выдаст предупреждение:
void some_func(int run_it)
{
if (run_it)
{
do_something();
}
// ....
}Здесь нужно явно проверить, что переменная не равна нулю:
void some_func(int run_it)
{
if (run_it != 0)
{
do_something();
}
// ....
}Еще один пример:
void func(void *p)
{
if (!p) return;
// ....
}Для устранения нарушения следует явно сравнить указатель с нулевым:
void func(void *p)
{
if (p == NULL) return;
// ....
}Анализатор не выдаст предупреждение на подобный код:
void fun(void)
{
while (1)
{
// ....
}
}Данная диагностика классифицируется как:
|
V2585. MISRA. Casts between a void pointer and an arithmetic type should not be performed.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Преобразование переменной или литерала арифметического типа к типу 'void *' и наоборот может послужить причиной неопределённого (для чисел с плавающей точкой) или зависимого от платформы поведения (для целочисленных типов).
Рассмотрим первый синтетический пример:
void* foo(void)
{
double pi = 3.14;
return pi;
}В данном случае переменная 'pi', имеющая тип 'double', неявно приводится к типу 'void *'. Такой код приведёт к неопределённому поведению.
Рассмотрим второй синтетический пример:
void bar(void)
{
int a = 5;
void* b = (void*)a;
}Здесь переменная типа 'int' явно приводится к типу 'void *'. Дальнейшее разыменование такого указателя может потенциально привести к ошибкам сегментации.
Данная диагностика классифицируется как:
|
V2586. MISRA. Flexible array members should not be declared.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Не рекомендуется определять структуры, содержащие flexible-массив. Такие структуры применяются, если предполагается динамически выделять под них память, и при этом размер хранимых данных заранее неизвестен.
Пример:
typedef struct
{
size_t len;
int data[]; // flexible array
} S;
S* alloc_flexible_array(size_t n)
{
S *obj = malloc(sizeof(S) + (n * sizeof(int)));
obj->len = n;
return obj;
}При таком объявлении структуры для массива 'data' размер будет определяться во время выполнения в зависимости от фактического объема данных.
Опасность таких структур состоит в том, что вызов 'sizeof' на них даст неверный результат.
Еще одна проблема состоит в том, что попытка создать копию структуры может приводить к неожиданным результатам, даже если размер вычислен верно. Рассмотрим соответствующий пример:
typedef struct
{
size_t len;
int data[];
} S;
S* make_copy(S *s)
{
S *copy = malloc(sizeof(S) + (s->len * sizeof(int)));
*copy = *s;
return copy;
}Здесь, несмотря на то что выделено правильное количество памяти, в копию структуры попадет только поле 'len'.
Часто для объявления flexible-массивов может использоваться такой некорректный паттерн:
typedef struct
{
size_t len;
int data[1];
} S;Компилятор может трактовать выход за границу такого массива в один элемент как неопределенное поведение и оптимизировать код непредсказуемым образом.
Данная диагностика классифицируется как:
|
V2587. MISRA. The '//' and '/*' character sequences should not appear within comments.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Внутри комментариев не должна присутствовать последовательность символов, которая обозначает начало комментария. Такое возможно, если блок комментариев не был закрыт последовательностью '*/' либо блок кода был закомментирован построчно через '//'.
Рассмотрим первый пример:
/* this comment is not closed
some_critical_function();
/* We're still inside the comment */Здесь первый блок комментариев не закрыт, и второй блок комментариев оказывается внутри первого. Такой код может привести к тому, что некоторые строки с критичным для выполнения кодом могут оказаться случайно закомментированными.
Подобная проблема может происходить при использовании однострочных комментариев. Рассмотрим второй пример:
int some_function(int x, int y)
{
return x // /*
+ y
// */
;
}Однострочный комментарий подавляет многострочный, и из-за этого итоговое выражение будет таким:
return x + y;вместо:
int x = y;Анализатор не выдает срабатывание, если последовательность '//' встречается внутри однострочного комментария:
....
// some_unecessary_call_1(); // probably, should not do this
// some_unecessary_call_2(); // probably, should not do this too
....Такой код мог получиться путем комментирования некоторого блока кода однострочными комментариями, и при этом блок кода ранее уже их содержал в конце строк.
Данная диагностика классифицируется как:
|
V2588. MISRA. All memory or resources allocated dynamically should be explicitly released.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Анализатор обнаружил потенциально возможную утечку памяти или ресурсов, выделенных такими функциями стандартной библиотеки, как: 'malloc', 'calloc', 'realloc' или 'fopen'.
Рассмотрим пример:
void foo()
{
int *a = (int*)malloc(40 * sizeof(int));
int *b = (int*)malloc(80 * sizeof(int));
....
free(a);
}Здесь в коде динамически выделено два буфера, а при выходе из функции освобожден только первый из них. В результате возникла утечка памяти.
Данный фрагмент можно исправить следующим образом:
void foo()
{
int *a = (int*)malloc(40 * sizeof(int));
int *b = (int*)malloc(80 * sizeof(int));
....
free(a);
free(b);
}Рассмотрим ещё один пример:
void bar(bool b)
{
FILE *f = fopen("tmp", "r");
if (b)
{
return;
}
....
fclose(f);
}В данном случае файл открывается для чтения, и на одном из путей выхода из функции он не закрывается. В результате возникает утечка файлового дескриптора.
Корректный вариант кода:
void bar(bool b)
{
FILE *f = fopen("tmp", "r");
if (b)
{
fclose(f);
return;
}
....
fclose(f);
}Данная диагностика классифицируется как:
|
V2589. MISRA. Casts between a pointer and a non-integer arithmetic type should not be performed.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Преобразование выражений нецелочисленных типов к указателю и наоборот может привести к неопределённому поведению.
Стандарт MISRA определяет следующую модель сущностных типов (Essential type model), в которой переменная может иметь тип:
- Boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует беззнаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- Именованный enum, если оперирует с именованным множеством определённых пользователем значений: 'enum name { .... };'
Преобразование сущностного 'Boolean', 'character' или 'enum' типа к указателю может привести к формированию указателя с неверным выравниванием, что ведёт к неопределённому поведению. Пример:
enum Nums
{
ONE,
TWO,
....
};
double* bar(Nums num)
{
....
return (double*)num;
}Преобразование указателя к вышеописанным сущностным типам может привести к тому, что результирующее значение не может быть представлено в выбранном сущностном типе, что также приводит к неопределённому поведению. Пример:
void foo(void)
{
....
char *a = "something";
char b = a;
....
}Преобразование сущностного 'floating' типа к указателю или наоборот ведёт к неопределенному поведению. Пример:
void foo(short *p)
{
// ....
float f = (float) p;
// ....
}Данная диагностика классифицируется как:
|
V2590. MISRA. Conversions should not be performed between pointer to function and any other type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Приведение типов между указателем на функцию и любым другим типом ведёт к неопределённому поведению. Приведение типов между указателями на функцию несоответствующего типа также станет причиной неопределённого поведения при вызове этой функции.
Ниже представлен пример, в котором происходит приведение типов между указателями на функцию несоответствующего типа, и оба приведения являются недопустимыми:
void foo(int32_t x);
typedef void (*fp)(int16_t x);
void bar(void)
{
fp fp1 = (fp)&foo;
int32_t(*fp2)(void) = (int32_t (*)(void))(fp1);
}Рассмотрим ещё один пример некорректного кода, где указатель на функцию приводится другим типам:
void* vp = (void*)fp1;
int32_t i32 = (int32_t)foo;
fp fp3 = (fp)i32;Вызов функции через полученные таким образом указатели может потенциально привести к ошибкам сегментации.
Исключения:
Константа нулевого указателя может быть приведена к указателю на функцию:
fp fp3 = NULL;Указатель на функцию может быть приведен к типу 'void':
(void) fp4;Функция может быть неявно приведена к указателю на такую же функцию:
(void(*)(int32_t)) foo;Данная диагностика классифицируется как:
|
V2591. MISRA. Bit fields should only be declared with explicitly signed or unsigned integer type
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. В зависимости от версии стандарта языка C, битовые поля должны быть объявлены только с подходящими для этого типами. Для C90: 'signed int' или 'unsigned int'. Для C99: 'signed int', 'unsigned int', '_Bool' или другой интегральный тип, разрешённый имплементацией, с явным указанием модификатора 'signed' или 'unsigned'.
Также разрешается использовать псевдоним ('typedef') для допустимого типа.
Битовое поле типа 'int' может быть как 'signed', так и 'unsigned' в зависимости от компилятора. Если для представления битового поля используется 'unsigned int', то все выделенные для поля биты будут значимыми. Такое битовое поле из 'n' битов имеет диапазон значений '[0, 2 ^ n - 1]'.
Если же для представления битового поля используется 'signed int', то 1 бит будет выделен как знаковый. Поэтому для записи значимой части значения битового поля будет использовано на 1 бит меньше выделенного. Такое битовое поле из 'n' битов имеет диапазон значений '[-2 ^ (n - 1), 2 ^ (n - 1) - 1]'.
Исходя из этого, в зависимости от компилятора битовые поля типа 'int' могут иметь разные диапазоны значений. Чтобы избежать ошибок, которые могут возникнуть из-за этого, нужно явно указывать модификатор знаковости.
Пример неправильного использования битового поля:
struct S
{
int b : 3; // <=
};
void foo()
{
S s;
s.b = 5;
if (s.b != 5)
{
Boom();
}
}В этом примере, если компилятор выберет беззнаковый тип для представления битового поля 'b', тогда все 3 бита, в которые записывается значение 5, будут значимыми. То есть фактически записывается остаток по модулю 8, и код будет работать как ожидается – в битовое поле будет записано значение 5.
Если компилятор выберет знаковый тип для представления битового поля 'b', то оно разбивается на 1 бит знака и 2 бита значимой части. При записи числа 5 в 'b' в значимую часть запишутся только 2 младших бита. В результате в битовое поле будет записано значение 1 вместо значения 5. Поэтому проверка будет пройдена, и будет вызвана функция 'Boom'.
Для исправления нужно явно указывать модификатор знаковости ('signed' / 'unsigned'):
struct S
{
unsigned int b : 3;
};
void foo()
{
S s;
s.b = 5;
if (s.b != 5)
{
Boom();
}
}Для того, чтобы явно указать, какие типы допускаются в объявлении битовых полей вашим компилятором, поддерживающим стандарт C99, в файл с исходными кодом или pvsconfig-файл можно добавить следующий комментарий:
//V_2591_ALLOWED_C99_TYPES:short,long longПосле двоеточия через запятую указываются допустимые типы без модификаторов знаковости:
- 'char'
- 'short'
- 'long'
- 'long long'
Данная диагностика классифицируется как:
|
V2592. MISRA. An identifier declared in an inner scope should not hide an identifier in an outer scope.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Идентификатор, объявленный в области видимости и не отличающийся по имени от другого идентификатора, объявленного в обрамляющей области видимости, "скрывает" внешний идентификатор. Это может привести к путанице или программной ошибке.
Например, такая коллизия имен может привести к логической ошибке, как в примере ниже:
int foo(int param)
{
int i = 0;
if (param > 0)
{
int i = var + 1;
}
return i;
}При прочтении этого кода на первый взгляд кажется, что когда в функцию 'foo' передается положительное значение параметра, то результатом вычисления будет это значение, увеличенное на '1'. Однако это не так, и на самом деле функция всегда возвращает '0'. Чтобы показать, что происходит в действительности, исключим из кода коллизию идентификаторов:
int foo(int param)
{
int i_outer = 0;
if (param > 0)
{
int i_inner = var + 1;
}
return i_outer;
}Теперь видно, что присваивание внутри ветки 'if' в переменную 'i' не влияет на результат вычисления функции 'foo'. Внутренний идентификатор 'i' ('i_inner') скрывает внешний идентификатор 'i' ('i_outer'), что приводит к ошибке.
Данная диагностика классифицируется как:
|
V2593. MISRA. Single-bit bit fields should not be declared as signed type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Однобитные битовые поля не стоит объявлять со знаковым типом. Согласно стандарту C99 §6.2.6.2, однобитное битовое поле знакового типа имеет один бит для знака и ноль — для значений. При любом представлении целых чисел ноль значащих бит не могут специализировать какое-либо значимое число.
Несмотря на то, что C90 не имеет такого описания, правило применяется также и для этой версии стандарта.
Рассмотрим пример:
struct S
{
int a : 1;
};
void foo()
{
struct S s;
s.a = 1;
if (s.a > 0)
{
DoWork();
}
}Несмотря на то, что в битовое поле явно присваивается '1', проверка на то, что оно больше нуля, не сработает. Поскольку в зависимости от реализации компилятора, единица в поле 's.a' может быть интерпретирована как знаковый бит. При привидении типов для сравнения к типу 'int' получится число '-1' (0xFFFFFFFF). В результате функция 'DoWork()' не будет выполнена, поскольку условие '-1 > 0' ложно. Корректный вариант:
struct S
{
unsigned a : 1;
};
void foo()
{
struct S s;
s.a = 1u;
if (s.a > 0u)
{
DoWork();
}
}Исключением являются безымянные битовые поля, поскольку нельзя использовать значение из такого поля:
struct S
{
int a : 31;
int : 1; // ok
};Данная диагностика классифицируется как:
|
V2594. MISRA. Controlling expressions should not be invariant.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Контролирующее выражение в управляющих конструкциях 'if', '?:', 'while', 'for', 'do', 'switch' не должно быть инвариантно, то есть не должно всегда приводить к выполнению одной и той же ветки кода. Если контролирующее выражение содержит инвариантное значение, то это может свидетельствовать о программной ошибке. Любой код, который недостижим из-за инвариантного выражения, может быть удалён компилятором. Выражения, содержащие 'volatile'-переменные, не являются инвариантными.
Исключения:
- циклы 'do' с контролирующим выражением сущностного 'Boolean' типа, которое вычисляется как '0';
- инварианты, которые используются для создания бесконечных циклов.
Примечание. Допустимыми инвариантами для создания бесконечных циклов считаются:
- литералы сущностного 'Boolean' типа: '1' или 'true' (C99);
- приведение константного литерала '1' к сущностному 'Boolean' типу (например, '(bool) 1');
- цикл 'for' без контролирующего выражения.
Рассмотрим пример:
void adjust(unsigned error)
{
if (error < 0)
{
increase_value(-error);
}
else
{
decrease_value(error);
}
}В данном примере допущена ошибка: из-за того, что функция принимает беззнаковое число, результат проверки условия всегда будет ложным. В результате всегда будет вызываться только функция 'decrease_value', а ветка кода с вызовом функции 'increase_value' может быть удалена компилятором.
Данная диагностика классифицируется как:
|
V2595. MISRA. Array size should be specified explicitly when array declaration uses designated initialization.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Когда для инициализации объектов массива используется назначенная инициализация (designated initialization), неявное указание размера массива может привести к ошибкам, так как изменение инициализаторов объектов будет неявно изменять размер массива. Явное указание количества элементов позволяет точно и быстро определить размер массива.
int arr[] = { [0] = 5, [7] = 5, [19] = 5, [3] = 2 };Если размер такого массива не указан явно, то определение размера происходит по наибольшему индексу инициализированных объектов. Когда инициализированных объектов много, разработчик не всегда может правильно определить размер массива.
Если размер массива не задан явно, то удаление или добавление инициализации объекта с наивысшим индексом может значительно изменить размер:
int arr[] = { [0] = 5, [7] = 5, [3] = 2 };Размер массива уменьшился с 20 до 8 элементов. В том месте, где ожидается этот массив с 20 элементами, может произойти выход за его границы.
Безопасное объявление массива в соответствии с правилом может выглядеть так:
int arr[20] = { [0] = 5, [7] = 5, [19] = 5, [3] = 2 };Данная диагностика классифицируется как:
|
V2596. MISRA. The value of a composite expression should not be assigned to an object with wider essential type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Язык C предоставляет свободу при проведении присваиваний между объектами различных арифметических типов. Однако подобные неявные преобразования могут приводить к неочевидным проблемам, таким как потеря знака, точности или значимости.
Рассмотрим следующий фрагмент кода:
void foo()
{
....
uint16_t var_a = 30000;
uint16_t var_b = 40000;
uint32_t var_sum;
var_sum = var_a + var_b; /* var_sum = 70000 or 4464? */
....
}При вычислении значения, которое будет присвоено в переменную 'var_sum', происходит неявное преобразование значения типа 'uint16_t' к 'int'. Как следствие, результат присваивания зависит от размера типа 'int'.
Если 'int' имеет 32-битный размер, то вычисления будут выполнены по модулю 2^32, и в переменную 'var_sum' будет записано ожидаемое значение '70000'.
Если 'int' имеет 16-битный размер, то вычисления будут выполнены по модулю 2^16, и в переменную 'var_sum' будет записано значение '70000 % 65536 == 4464'.
Для предотвращения подобных ошибок в стандарте MISRA определена модель сущностных типов (Essential type model). В этой модели переменная может иметь тип:
- Boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует беззнаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- Именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'.
Используя модель сущностных типов, можно уменьшить количество подобных неочевидных проблем. Для этого следует избегать присвоения составных выражений, имеющих меньший сущностный тип, в переменные и аргументы функций, имеющие более широкий сущностный тип.
Код выше можно исправить, используя явное преобразование к 'uint32_t':
void foo()
{
....
uint16_t var_a = 30 000;
uint16_t var_b = 40 000;
uint32_t var_sum;
var_sum = (uint32_t)var_a + var_b; /* var_sum = 70 000 */
....
};Теперь вычисления происходят по модулю 2^32 независимо от того, какой размер имеет 'int', и ошибка не возникает, даже если 'int' имеет 16-битный размер.
Данная диагностика классифицируется как:
|
V2597. MISRA. Cast should not convert pointer to function to any other pointer type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С++. Приведение указателя на функцию к любому другому указателю ведёт к неопределённому поведению. Приведение типов между указателями на функцию несоответствующего типа также станет причиной неопределённого поведения при вызове этой функции.
Пример кода с нарушениями правила, в котором все четыре приведения типа являются недопустимыми:
void foo(int32_t x);
typedef void (*fp)(int16_t x);
void bar()
{
fp fp1 = reinterpret_cast<fp>(&foo);
fp fp2 = (fp)foo;
void* vp = reinterpret_cast<void*>(fp1);
char* chp = (char*)fp1;
}Вызов функции через такие указатели может потенциально привести к ошибкам сегментации.
Данная диагностика классифицируется как:
|
V2598. MISRA. Variable length array types are not allowed.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Объявление массивов, имеющих неконстантный размер (variable-length array, VLA), может привести к переполнению стека и потенциальным уязвимостям в программе.
Рассмотрим следующий пример:
void foo(size_t n)
{
int arr[n];
// ....
}Передача большого числа 'n' может привести к переполнению стека, так как массив станет слишком большим и займет больше памяти, чем есть на самом деле.
Логичным решением выглядит ограничение размера массива:
#define MAX_SIZE 128
void foo(size_t n)
{
size_t size = n > MAX_SIZE ? MAX_SIZE : n;
int arr[size];
if (size < n) // error
// ....
}Однако в таком случае лучше использовать константу для упрощения логики программы:
#define SIZE 128
void foo()
{
int arr[SIZE];
// ....
}Также это позволит избежать проблем, связанных с VLA, например, вычислением 'sizeof' на таких массивах и их передачей в другие функции.
Данная диагностика классифицируется как:
|
V2599. MISRA. The standard signal handling functions should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Функции стандартной библиотеки из заголовочных файлов <signal.h> / <csignal> могут быть опасны. Их поведение зависит от реализации, а их использование может привести к неопределенному поведению.
Причиной неопределенного поведения, к примеру, является использование обработчиков сигналов в многопоточной программе. С другими причинами можно ознакомиться здесь.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций:
- signal;
- raise.
Пример кода, на который анализатор выдаст предупреждение:
#include <signal.h>
void handler(int sig) { .... }
void foo()
{
signal(SIGINT, handler);
}Данная диагностика классифицируется как:
|
V2600. MISRA. The standard input/output functions should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Функции стандартной библиотеки из заголовочных файлов '<stdio.h>' / '<cstdio>' и '<wchar.h>' могут быть опасны. Их поведение зависит от реализации, а их использование может привести к неопределенному поведению.
Рассмотрим следующий фрагмент кода:
#include <stdio.h>
void InputFromFile(FILE *file); // Read from 'file'
void foo()
{
FILE *stream;
....
InputFromFile(stream);
fflush(stream);
}В коде сначала происходит чтение из потока 'stream', а затем поток передается в функцию 'fflush'. Такая последовательность операций приводит к неопределенному поведению.
Анализатор выдаст предупреждение, если обнаружит использование любых функций, определенных в заголовочных файлах '<stdio.h>' / '<cstdio>' и '<wchar.h>':
- fopen;
- fclose;
- freopen;
- fflush;
- setbuf;
- setvbuf;
- etc.
Пример кода, на который анализатор выдаст предупреждение:
#include <stdio.h>
void foo(const char *filename, FILE *oldFd)
{
FILE *newFd = freopen(filename, "r", oldFd);
....
}Данная диагностика классифицируется как:
|
V2601. MISRA. Functions should be declared in prototype form with named parameters.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Использование объявлений функций в стиле "K&R", а также неименованных параметров функций небезопасно.
Функции, объявленные в старом стиле – "K&R" – не несут в себе информации о типах и количестве параметров, поэтому использование таких функций может привести к ошибкам.
Использование именованных параметров функций дает полезную информацию об интерфейсе функции, а также позволяет отследить ошибку, если имена в объявлении и определении различаются.
Рассмотрим пример:
// header
void draw();
// .c file
void draw(x, y)
double x;
double y;
{
// ....
}
// usage
void foo()
{
draw(1, 2);
}Декларация функции 'draw' не содержит параметров, так что при вызове функции 'draw' в нее будут переданы 2 параметра типа 'int', а не 'double', что является ошибкой. Объявление функции с использованием прототипа исправит проблему:
// header
void draw(double x, double y);
// .c file
void draw(double x, double y)
{
// ....
}Если функция не имеет параметров, то объявление с использованием пустых скобок не является правильным, т.к. такое объявление соответствует стилю "K&R":
void foo();Такая декларация допускает передачу любого числа аргументов. Чтобы явно указать, что функция не имеет параметров, нужно использовать ключевое слово 'void':
void foo(void);Неименованные параметры делают интерфейс функции менее понятным:
void draw(double, double);Поэтому следует давать параметрам имена, чтобы избежать ошибок в использовании функции:
void draw(double x, double y);Данная диагностика классифицируется как:
|
V2602. MISRA. Octal and hexadecimal escape sequences should be terminated.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Последовательности восьмеричных и шестнадцатеричных чисел внутри строковых и символьных литералов должны быть завершёнными. Это поможет избежать ошибок с определением позиции завершения escape-последовательности.
Рассмотрим пример:
const char *str = "\x0exit";Строковый литерал в данном примере имеет длину в 4 символа, а не 5, как может показаться на первый взгляд. Последовательность '\x0e' считается за один символ с кодом 0xE, а не символ с нулевым кодом и букву 'e'.
Поэтому escape-последовательность должна быть завершена одним из двух способов:
- завершением строкового литерала;
- началом новой escape-последовательности.
Следующие 2 примера представляют собой правильный вариант завершения escape-последовательности:
const char *str1 = "\x0" "exit";
const char *str2 = "\x1f\x2f";Данная диагностика классифицируется как:
|
V2603. MISRA. The 'static' keyword shall not be used between [] in the declaration of an array parameter.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Ключевое слово 'static' не должно использоваться в контексте указания размера массива, принимаемого функцией, так как оно может быть проигнорировано. По сути, оно является лишь указанием компилятору, на основании которого он может сгенерировать более эффективный код.
Рассмотрим пример:
void add(int left[static 10], int right[static 10])
{
for(size_t i = 0U; i < 10U; ++i)
{
left[i] += right[i];
}
}
extern int data1[10];
extern int data2[20];
extern int data3[5];
void foo(void)
{
add(data1, data2);
add(data1, data3);
}В коде несколько раз вызывается функция 'add', формальными параметрами которой являются два массива размером не менее 10 элементов. Второй вызов функции приведёт к неопределённому поведению, так как фактический размер массива (5) меньше ожидаемого (10).
Данная диагностика классифицируется как:
|
V2604. MISRA. Features from <stdarg.h> should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Тип 'va_list', а также макросы 'va_arg', 'va_start', 'va_end' и 'va_copy', необходимые для работы с функциями с переменным числом аргументов и определённые в заголовочном файле '<stdarg.h>', не должны использоваться. Их неправильное использование часто становится причиной неопределённого поведения.
Рассмотрим пример:
#include <stdint.h>
#include <stdarg.h>
void foo(va_list args)
{
double y;
y = va_arg(args, int);
}
void bar(uint16_t count, ...)
{
uint16_t x;
va_list ap;
va_start (ap, count); // <=
x = va_arg (ap, int);
foo(ap);
x = va_arg (ap, int);
}
void baz(void)
{
bar(1.25, 10.07);
}В приведенном выше коде есть несколько проблем, которые могут привести к неопределённому поведению (примечание: в списке перечислены не все опасности, содержащиеся в коде):
- В функции 'bar' вызывается макрос 'va_start', но не вызывается 'va_end'.
- Макрос 'va_arg' применяется к одному и тому же объекту 'va_list' в различных функциях. Проблема здесь в том, нет возможности проконтролировать состояние списка аргументов и количество извлеченных из него элементов после передачи в функцию.
- В функции 'baz' вызывается функция 'bar' с аргументами типа 'double', хотя она ожидает 'int'. Вызов данной функции может привести к потере данных.
Данная диагностика классифицируется как:
|
V2605. MISRA. Features from <tgmath.h> should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Запрещено использовать функции или макросы из заголовочного файла '<tgmath.h>'. Их использование может привести к неопределённому поведению.
Рассмотрим пример:
void bar(float complex fc)
{
ceil(fc); // undefined behavior
}Вызов функции 'ceil' с фактическим аргументом типа 'float complex' приведет к неопределенному поведению, так как в стандартной библиотеке отсутствует специализированная версия с таким типом формального параметра.
В случае, когда специализированная функция существует, следует использовать именно ее для того, чтобы избежать подобных ситуаций:
#include <tgmath.h>
float foo(float x)
{
return sin(x);
}Для функции 'sin' существует специализированная версия с формальным аргументом типа 'float' - 'sinf':
#include <math.h>
float foo(float x)
{
return sinf(x);
}Данная диагностика классифицируется как:
|
V2606. MISRA. There should be no attempt to write to a stream that has been opened for reading.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Стандарт C не определяет поведение, при котором происходит запись в файл, открытый только для чтения. Поэтому такое поведение некорректно.
Рассмотрим пример:
void foo(void)
{
FILE *file = fopen("file.txt", "r");
if (file != NULL)
{
fputs(file, "I am writing to the read-only file\n");
fclose(file);
}
}Файл file.txt был открыт в режиме только для чтения, но при этом в него происходит запись. Неизвестно, как поведет себя операционная система в этой ситуации.
Скорее всего, это опечатка, и режим открытия стоит изменить:
void foo(void)
{
FILE *file = fopen("file.txt", "w");
if (file != NULL)
{
fputs(file, "I am writing to the write-only file\n");
fclose(file);
}
}Данная диагностика классифицируется как:
|
V2607. MISRA. Inline functions should be declared with the static storage class.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Функции с квалификатором 'inline' должны быть объявлены с квалификатором 'static'.
Если inline-функция объявлена в некоторой единице трансляции и имеет 'external linkage', но не определена в этой единице трансляции, то это приведет к неопределенному поведению.
Проблема может возникнуть, даже если 'inline'-функция, имеющая 'external linkage', объявлена и вызывается в одной единице трансляции. Такой вызов является неуточненным поведением. Компилятор может как сгенерировать вызов функции, так и встроить тело этой функции на место вызова. Несмотря на то, что это не повлияет на поведение вызванной функции, это может повлиять на время выполнения программы, и, как следствие, повлиять на программу во время ее исполнения.
Пример кода, на который анализатор выдаст предупреждение:
#include <stdint.h>
extern inline int64_t sum(int64_t lhs, int64_t rhs);
extern inline int64_t sum(int64_t lhs, int64_t rhs)
{
return lhs + rhs;
};Данная диагностика классифицируется как:
|
V2608. MISRA. The 'static' storage class specifier should be used in all declarations of object and functions that have internal linkage.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Функция или объект, объявленный однажды с внутренним типом связывания, при повторном объявлении или определении будет также иметь внутреннее связывание. Это может быть неочевидно для разработчика, и поэтому следует явно указывать спецификатор 'static' в каждом объявлении и определении.
Для С++ это правило распространяется только на функции.
Следующий код не соответствует правилу, так как определение не отражает внутренний тип связывания, заданный в объявлении функции 'foo' с помощью ключевого слова 'static':
static void foo(int x); //in header.h
void foo(int x) //in source.cpp
{
....
}Код в соответствии с правилом должен быть следующим:
static void foo(int x); //in header.h
static void foo(int x) //in source.cpp
{
....
}В примере, приведенном ниже, определение функции 'foo' со спецификатором класса хранения 'extern' не задает внешний тип связывания, как могло показаться. Тип связывания остается внутренним:
static void foo(int x); //in header.h
extern void foo(int x) //in source.cpp
{
....
}Такой код разрешен стандартом языка С, но в данном случае вводит в заблуждение разработчика. Правильный вариант с точки зрения MISRA:
extern void foo(int x); //in header.h
extern void foo(int x) //in source.cpp
{
....
}Подобный пример с глобальной переменной, нарушающий правило MISRA C:
static short y; //in header.h
extern short y = 10; //in source.cПеременная 'y' будет иметь внутренний тип связывания. Это может быть неочевидным для разработчика. Допустимым вариантом будет:
static short y; //in header.h
static short y = 10; //in source.cили
extern short y; //in header.h
extern short y = 10; //in source.cДанная диагностика классифицируется как:
|
V2609. MISRA. There should be no occurrence of undefined or critical unspecified behaviour.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Если в программе возникает неопределённое поведение, то у программиста нет никаких гарантий относительно её исполнения. Такое поведение недопустимо.
Если в программе возникает критическое неуточнённое поведение, это означает, что в зависимости от компилятора и его конфигурации возможно различное исполнение кода. Такое поведение также недопустимо.
В общем случае нельзя сказать, может ли в программе произойти неопределённое или неуточнённое поведение или нет. Не все случаи неопределённого поведения можно распознать. Поэтому нет и не может быть алгоритма, который гарантировал бы отсутствие неопределённого или неуточнённого поведения в конкретной программе.
Однако существует множество ситуаций, которые могут привести к неопределённому или критическому неуточнённому поведению и которые можно распознать алгоритмически. Рассмотрим некоторые из таких случаев.
Часто можно определить потенциальное разыменование нулевого указателя. Рассмотрим следующий фрагмент кода:
void foo()
{
int len = GetLen();
char *str = (char *) malloc(mlen + 1);
str[len] = '\0';
}При выполнении этого фрагмента кода может произойти разыменование нулевого указателя. Если функция 'malloc' не сможет выделить память, то она запишет 'nullptr' в переменную 'str'. Тогда в выражении 'str[len]' произойдет разыменование 'nullptr', что является неопределенным поведением. Анализатор выдаст следующее предупреждение:
V2609 Undefined behaviour should not occur. There might be dereferencing of a potential null pointer 'str'. Check lines: 4, 5.
На первый взгляд может показаться, что подобные ошибки сразу приведут к аварийному завершению программы. Во многих операционных системах первые килобайты адресного пространства защищены от записи. И при попытке записи в них возникнет исключение/сигнал. А значит, ошибка не является критичной. Это совсем не так.
- В случае, если переменная 'len' имеет большое значение, выражение 'str[len]' может ссылаться на достаточно удаленные ячейки памяти доступные для записи. Запись туда нуля приведет к непредсказуемым последствиям. Т.е. к тому самому неопределенному поведению.
- Остановка программы — это тоже критическая ошибка для некоторых приложений.
- В некоторых микроконтроллерах младшие адреса адресного пространства не защищены от записи, и запись по нулевому указателю никак не будет отловлена операционной системой. Собственно, часто никакой операционной системы и нет.
Более подробно все это рассмотрено в статье "Почему важно проверять, что вернула функция malloc".
Еще одной ситуацией, которую можно распознать алгоритмически, является модификация переменной между двумя точками следования и неоднократное обращение к ней.
Рассмотрим следующий фрагмент кода:
void foo()
{
int *ptr;
....
*ptr++ = *(ptr + 1);
}Здесь предполагается, что сначала произойдет увеличение указателя 'ptr' на 1. Затем произойдет вычисление выражения 'ptr + 1', и использоваться будет уже новое значение 'ptr'.
Однако такое предположение программиста неверно. Дело в том, что между двумя точками следования происходит два обращения к переменной 'ptr', одно из которых модифицирует ее значение. В таком случае поведение программы неопределенное.
Анализатор выдаст следующее предупреждение:
V2609 Undefined behaviour should not occur. The 'bufl' variable is modified while being used twice between sequence points.
Также можно определить некорректное использование битовых операторов сдвига. Рассмотрим следующий код:
void foo()
{
int delta = -2;
....
int expr = DoSomeCalculations();
expr <<= delta;
}Здесь переменная 'expr' сдвигается влево на -2 бита. Сдвиг на отрицательное число битов является некорректной операцией и приводит к неопределенному поведению.
Данная диагностика классифицируется как:
|
V2610. MISRA. The ', " or \ characters and the /* or // character sequences should not occur in a header file name.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Использование некоторых символов в именах заголовочных файлов может привести к неопределённому поведению.
Правило запрещает использование следующих наборов символов:
- ', ", \, /*, // - в имени включаемого файла, указанном между символами '<' и '>';
- ', \, /*, // - в имени включаемого файла, указанном между символами двойных кавычек.
Пример:
#include <bad"include.h>
#include "bad'include.h"Чаще всего диагностика выявляет наличие в пути обратной косой черты (backslash). С точки зрения MISRA, такой код является некорректным:
#include "myLibrary\header.h"Однако допустимо использовать прямую косую черту (forward slash):
#include "myLibrary/header.h"Данная диагностика классифицируется как:
|
V2611. MISRA. Casts between a pointer to an incomplete type and any other type shouldn't be performed.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Преобразование с использованием указателя на неполный тип может привести к получению неверно выравненного указателя, что может повлечь за собой неопределённое поведение. Такая же ситуация происходит при преобразовании между указателями на неполный тип и числами с плавающей точкой.
Также указатели на неполный тип иногда используются для сокрытия реализации (идиома PIMPL), а приведение к указателю на объект нарушает эту инкапсуляцию.
Рассмотрим пример:
typedef struct _First First;
typedef struct _Second
{
int someVar;
} Second;
void foo(void)
{
First *f;
Second t;
...
f = &t; // <=
...
}
Second* bar(First *ptr)
{
return (Second*)ptr; // <=
}В приведённом выше коде объявляются структуры 'First' и 'Second'. При этом тип 'First' является не полным, т. к. отсутствует его определение. Далее в функции 'foo' происходит неявное приведение указателя к неполному типу, а в функции 'bar' – явное, но уже из неполного типа в полный. Оба эти случая могут привести к неопределённому поведению.
При этом у правила есть два исключения:
- Константа нулевого указателя ('NULL') может быть приведена к указателю на неполный тип.
- Указатель на неполный тип может быть преобразован в 'void'.
Оба этих случая можно рассмотреть в функции 'baz':
typedef struct _First First;
First* foo(void);
void baz(void)
{
First *f = NULL;
(void)foo();
}Данная диагностика классифицируется как:
|
V2612. MISRA. Array element should not be initialized more than once.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Язык C имеет специальный синтаксис инициализирующих выражений, называемый designated initializer. Он позволяет инициализировать элементы массива или структуры в произвольном порядке.
Например, можно инициализировать конкретные элементы массива:
int arr[4] = {
[1] = 1,
[3] = 2,
};Этот синтаксис работает и для структур:
struct point
{
int x;
int y;
};
struct point pt1 = {
.x = 1,
.y = 1,
};Однако при его использовании можно допустить ошибку и инициализировать один и тот же элемент дважды:
int arr[4] = {
[3] = 1,
[3] = 2,
};
struct point pt1 = {
.x = 1,
.x = 1,
};MISRA запрещает данную конструкцию, т.к. стандарт языка не определяет, должны ли проявляться побочные эффекты в данной ситуации или нет. Скорее всего, такая ситуация возникла из-за опечатки.
Данная диагностика классифицируется как:
|
V2613. MISRA. Operand that is a composite expression has more narrow essential type than the other operand.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Анализатор обнаружил ситуацию, при которой составное выражение, участвующее в арифметической операции, имеет более узкий сущностный тип, чем другой операнд этой операции. Вычисление такого составного выражения может привести к переполнению.
Рассмотрим следующий синтетический пример:
uint16_t w1;
uint16_t w2;
uint32_t dw1;
// ....
return w1 * w2 + dw1;Несмотря на то, что на типичных платформах (x86/ARM) тип 'uint16_t' соответствует типу 'unsigned short' и при вычислении выражения он расширится до типа 'int', на других платформах (например, 16-битных микроконтроллерах) 'uint16_t' может соответствовать типу 'unsigned int', поэтому расширения до 32 бит не произойдет, из-за чего в умножении возможно переполнение.
Диагностика способна определить такую ситуацию за счет модели сущностных типов (Essential Type Model) – она определяет тип выражения таким образом, как если бы расширения до 'int' (integer promotion) не происходило. В этой модели переменная может иметь тип:
- Boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует беззнаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- Именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'.
Чтобы исправить ситуацию, нужно привести один из операндов составного выражения к результирующему типу. Например:
return (uint32_t)w1 * w2 + dw1;Тогда вычисление всего выражения будет происходить в более широком типе 'uint32_t'.
Данная диагностика классифицируется как:
|
V2614. MISRA. External identifiers should be distinct.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Идентификаторы с внешним типом связывания должны быть различимы в пределах ограничений, накладываемых используемым стандартом.
Ограничения:
- до стандарта С99 – 6 значимых символов, не учитывая регистр;
- начиная со стандарта С99 – 31 значимый символ, учитывая регистр.
Рассмотрим первый пример:
// 123456789012345678901234567890123
extern int shrtfn(void); // OK
extern int longfuncname(void); // Error in С90,
// but ОК in С99
extern int longlonglonglonglongfunctionname1(void); // Error in bothДлинные идентификаторы затрудняют чтение кода, а также могут быть перепутаны с автоматически сгенерированными. Также, в случае если два идентификатора различаются только в незначащих символах, то поведение не определено.
На практике некоторые имплементации (компиляторов и компоновщиков) могут иметь собственные ограничения. Для их уточнения стоит обратиться к документации.
Рассмотрим второй пример:
// 123456789012345678901234567890123
extern int longFuncName1(int);
extern int longFuncName2(int);
extern int AAA;
extern int aaa;
void foo(void)
{
longFuncName2(AAA);
}В данном коде присутствует сразу несколько ошибок (рассмотрим на примере стандарта C90):
- Идентификаторы 'longFuncName1' и 'longFuncName2' будут сокращены до 6 первых символов ('longFu') и станут одинаковыми с точки зрения компоновщика.
- Согласно стандарту С90, идентификаторы не всегда являются регистрозависимыми, а поэтому идентификаторы 'AAA' и 'aaa' также могут стать одинаковыми для линковщика.
- В функции 'foo' происходит вызов функции 'longFuncName2', в которую передаётся значение переменной 'AAA'. Проблема здесь в том, что оба эти идентификатора не являются однозначными, а потому этот вызов приведёт к неопределённому поведению.
Данная диагностика классифицируется как:
|
V2615. MISRA. A compatible declaration should be visible when an object or function with external linkage is defined.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Не рекомендуется определять объекты и/или функции с внешним связыванием (external linkage) без предварительной декларации.
Смысл этого правила в том, чтобы избегать "ручного" использования внешних сущностей в местах, где они нужны. Декларации внешних объектов и функций стоит делать в заголовочном файле.
Например, следующий код определяет внешнюю переменную и функцию без предварительной декларации:
int foo;
void bar(void) {
// ....
}Декларации стоит поместить в заголовочный файл. Также стоит включить заголовочный файл в компилируемый:
// file.h
extern int foo;
extern void bar(void);
// file.c
#include "file.h"
int foo;
void bar(void) {
// ....
}Для объектов и функций с внутренним связыванием (internal linkage) предварительная декларация не нужна:
static int baz;
static void qux(void) {
// ....
}Данная диагностика классифицируется как:
|
V2616. MISRA. All conditional inclusion preprocessor directives should reside in the same file as the conditional inclusion directive to which they are related.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Директивы условной компиляции '#else', '#elif' и '#endif' должны находиться в том же файле, что и '#if', '#ifdef' или '#ifndef', к которым они относятся. Несоответствие этому правилу приводит к визуальному усложнению кода и увеличивает вероятность совершить ошибку при редактировании и обслуживании кода.
Замечание: при использовании современных компиляторов допустить данную ошибку невозможно. Неправильное использование директив условной компиляции в них приводит к ошибкам сборки программы.
Рассмотрим примеры:
#define Check_A 10
#ifdef Check_A // <=
#if Check_A > 5
static int a = 5;
#elif Check_A > 2
static int a = 2;
#else
static int a = 0;
#endif // <=
int main(void)
{
return a;
}В первом примере используется вложенное условие, состоящее из '#ifdef' и '#if', но в конце, закрывается только вторая директива условной компиляции ('#if'), а первая ('#ifdef') остаётся открытой, что может привести к созданию некорректного кода.
Рассмотрим другой пример:
/* File.h */
#ifdef Check_B
#include "SomeOtherFile.h" // <=
/* End of File.h */В данном примере не закрывается директива условной компиляции. Включение данного файла в другие с помощью директивы препроцессора '#include' может привести к трудноуловимым ошибкам.
Данная диагностика классифицируется как:
|
V2617. MISRA. Object should not be assigned or copied to an overlapping object.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Поведение не определено, когда создаются два объекта, которые частично перекрываются в памяти, и один из них присваивается или копируется в другой.
Такое может случиться, например, при использовании функции 'memcpy', когда перекрываются области памяти источника и приемника:
void func(int *x)
{
memcpy(x, x+2, 10 * sizeof(int));
}В данном случае указатель на источник данных '(x+2)' смещен относительно приемника данных на 8 байт ('sizeof(int) * 2'). Попытка копирования 40 байт в приемник из источника приведет к частичному перекрытию области памяти источника.
Для исправления ошибки необходимо использовать специальную функцию для таких операций – 'memmove' – или скорректировать заданные смещения источника и приемника, чтобы не происходило перекрытия областей памяти.
Пример корректного кода:
void func(int *x)
{
memmove(x, x+2, 10 * sizeof(int));
}Данная диагностика классифицируется как:
|
V2618. MISRA. Identifiers declared in the same scope and name space should be distinct.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Объявление двух идентификаторов в одной области видимости, различающихся только незначимыми символами, приводит к неопределённому поведению. Помимо этого, длинные идентификаторы затрудняют чтение кода, а также могут быть перепутаны с автоматически сгенерированными.
До стандарта С99 значимыми являются только первые 31 символ. Начиная со стандарта С99 – первые 63 символа. Остальные символы считаются незначимыми.
Данное правило не применяется, если оба идентификатора имеют external linkage, так как для этого случая предназначена диагностика V2614.
Данное правило не применяется, если один из идентификаторов - макрос.
Рассмотрим пример для С90:
// 1234567890123456789012345678901***
static int very_long_long_long_long__test_var1; // (1)
extern int very_long_long_long_long__test_var2; // (2)Идентификаторы 1 и 2 различаются только незначимыми символами 'var1' и 'var2', в то время как значимая часть 'long_long_long_long_long__test_' совпадает. Для того, чтобы избежать неопределенного поведения, необходимо сократить длину идентификатора:
// 1234567890123456789012345678901***
static int not_very_long__test_var1;
extern int not_very_long__test_var2;Рассмотрим второй пример:
// 1234567890123456789012345678901***
static int long_long_long_long_long__test_var3; // (3)
void foo()
{
// 1234567890123456789012345678901***
int long_long_long_long_long__test_var4; // (4)
}Здесь идентификаторы 3 и 4 также различаются только незначимыми символами, однако они находятся в разных областях видимости, поэтому нарушения правила здесь нет.
Данная диагностика классифицируется как:
|
V2619. MISRA. Typedef names should be unique across all name spaces.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Имена 'typedef' должны быть уникальны для всех пространств имен. Повторное использование имён 'typedef' может запутать разработчика.
Рассмотрим следующий пример:
void foo()
{
{
typedef unsigned char Id;
Id x = 128; // ok
}
{
typedef char Id;
Id x = 128; // error
}
}При работе с типом 'unsigned char' допускается диапазон значений от 0 до 255, а с типом 'signed char' от -128 до 127. Поработав со вторым 'typedef', программист может забыть, что тип поменялся. Это может привести к ошибке.
Рассмотрим второй пример:
void foo()
{
{
typedef unsigned char uId;
uId x = 128; // ok
}
{
typedef singned char sId;
sId x = 128; // ok
}
}В этом случае сложнее допустить ошибку, так как имена 'typedef' различаются.
В качестве исключения допускается дублировать имя 'typedef' при объявлении 'struct', 'union' или 'enum', если они ассоциированы с этим 'typedef'.
typedef struct list
{
struct list* next;
int element;
} list; // okДанная диагностика классифицируется как:
|
V2620. MISRA. Value of a composite expression should not be cast to a different essential type category or a wider essential type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Приведение результата составного выражения к сущностному типу другой категории или к более широкому типу может стать причиной потери значений старших битов.
Рассмотрим пример:
int32_t foo(int16_t x, int16_t y)
{
return (int32_t)(x * y);
}Несмотря на то, что на типичных платформах (x86/ARM) тип 'int16_t' соответствует типу 'short', и при вычислении выражения он расширится до типа 'int', на других платформах (например, 16-битных микроконтроллерах) 'int16_t' может соответствовать типу 'int', поэтому расширения до 32 бит не произойдет, из-за чего в умножении возможно переполнение.
Исправленным вариантом может быть:
int32_t foo(int16_t x, int16_t y)
{
return (int32_t)x * y;
}В этом случае вычисление всего выражения будет происходить в более широком типе 'int32_t'.
Рассмотрим другой пример:
int32_t sum(float x, float y)
{
return (int32_t)(x + y);
}Согласно модели сущностных типов, результирующий тип выражения относится к floating категории, а тип 'int32_t' к signed категории сущностных типов. Приведение результата сложения к целому типу ведет к потери точности. Результат сложения двух чисел типа 'float' также может быть больше, чем верхний предел диапазона типа 'int32_t'.
Допустимым вариантом может быть:
float sum(float x, float y)
{
return x + y;
}Если в дальнейшем требуется привести результат выражения к типу 'int', то необходимо выполнить:
- проверку на то, что конвертируемое значение входит в диапазон значений типа;
- использовать функцию округления до целого.
В модели сущностных типов (Essential Type Model) определено 6 категорий:
- boolean, если оперирует булевыми значениями true/false: '_Bool';
- signed, если оперирует знаковыми целыми числами или является безымянным enum: 'signed char', 'signed short', 'signed int', 'signed long', 'signed long long', 'enum { .... };';
- unsigned, если оперирует беззнаковыми целыми числами: 'unsigned char', 'unsigned short', 'unsigned int', 'unsigned long', 'unsigned long long';
- floating, если оперирует числами с плавающей точкой: 'float', 'double', 'long double';
- character, если оперирует только символами: 'char';
- именованный enum, если оперирует с именованным множеством определенных пользователем значений: 'enum name { .... };'.
Тип составного выражения в этой модели определяется таким образом, как если бы расширения до 'int' (integer promotion) не происходило.
Данная диагностика классифицируется как:
|
V2621. MISRA. Tag names should be unique across all name spaces.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. Имена структур, перечислений и объединений должны быть уникальны для всех пространств имён и блоков. Повторное использование имён тегов может запутать разработчика.
Рассмотрим следующий пример:
int foo()
{
{
struct MyStuct
{
unsigned char data; // (1)
};
struct MyStuct sample = { .data = 250 }; // ok
}
// ....
{
struct MyStruct
{
signed char data; // (2)
};
struct MyStruct sample = { .data = 250 }; // error
}
}При работе с типом 'unsigned char' допускается диапазон значений от 0 до 255, а с типом 'signed char' от -128 до 127. Поработав с первой структурой 'MyStruct', программист может привыкнуть, что член структуры 'data' имеет тип 'unsigned char'. После чего, во втором блоке легко совершить ошибку, записав 'sample.data' значение, которое приведет к переполнению.
Исправленный пример:
int foo()
{
{
struct MyStuctUnsigned
{
unsigned char data; // (1)
};
struct MyStuctUnsigned sample = { .data = 250 }; // ok
}
// ....
{
struct MyStructSigned
{
signed char data; // (2)
};
struct MyStructSigned sample = { .data = 127 }; // ok
}
}В этом случае сложнее допустить ошибку, так как имена структур различаются.
Псевдоним типа, объявляемый через 'typedef', может дублировать имя при объявлении 'struct', 'union' или 'enum', если они ассоциированы с этим 'typedef':
typedef struct list
{
struct list* next;
int element;
} list; // okДанная диагностика классифицируется как:
|
V2622. MISRA. External object or function should be declared once in one and only one file.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С. У любого объекта или функции с внешним связыванием должно быть ровно одно объявление.
Рассмотрим пример нарушения этого правила:
/* lib1.h */
extern int32_t var; // Declaration
/* lib2.h */
extern int32_t var; // Declaration
/* some.cpp */
#include "lib1.h"
#include "lib2.h"В данном примере переменная 'var' объявлена дважды: в 'lib1.h' и 'lib2.h'.
Здесь возможно несколько вариантов исправления:
- Может оказаться, что в файле 'some.cpp' один из заголовочных файлов не нужен, и тогда его включение можно убрать.
- Возможно, что объявление переменной 'var' в одном из заголовочных файлов является лишним, и его можно убрать.
- Можно объявить переменную 'var' в более обобщенном заголовочном файле и включить его везде, где используется эта переменная:
/* lib.h */
extern int32_t var; // Declaration
/* lib1.h */
#include "lib.h"
/* lib2.h */
#include "lib.h"
/* some.cpp */
#include "lib1.h"
#include "lib2.h"Данная диагностика классифицируется как:
|
V2623. MISRA. Macro identifiers should be distinct.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Данное диагностическое правило актуально только для C. Имя макроса должно быть различимо от имён уже ранее определённых макросов. Также имя параметра макроса должно быть различимо как от имени самого макроса, так и от всех других параметров.
Минимальное требование по различимости имён макросов и их параметров зависит от версии стандарта:
- C90 — первый 31 символ.
- C99 — первые 63 символа.
В реальности компиляторы дают большие лимиты. Но правило требует, чтобы имена макросов были различимы в рамках ограничений, налагаемых стандартом.
Нижеперечисленные примеры будут касаться C90.
Пример некорректного кода с именем макроса:
// 1234567890123456789012345678901
#define average_winter_air_temperature_monday awt_m
#define average_winter_air_temperature_tuesday awt_tИмя первого макроса неотличимо от второго, если брать первые 31 символ. Корректный код:
// 1234567890123456789012345678901
#define average_winter_air_temp_monday awt_m
#define average_winter_air_temp_tuesday awt_tПример некорректного кода с неразличимыми именем макроса и его параметрами:
#define average_winter_air_temp(average_winter_air_temp) awt_mКорректный код:
#define average_winter_air_temp(winter_air_temp) awt_mПример некорректного кода с неразличимыми именами параметров макроса:
#define air_temp(winter_air_temp, winter_air_temp) awt_mКорректный код:
#define air_temp(average_winter_air_temp, winter_air_temp) awt_mДанная диагностика классифицируется как:
|
V2624. MISRA. The initializer for an aggregate or union should be enclosed in braces.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Оно требует, чтобы инициализаторы для агрегатов и объединений оборачивались в фигурные скобки. Правило применимо как для объектов, так и для всех подобъектов.
Исключения:
- Для инициализации подобъектов используется инициализатор в виде '{ 0 }'.
- Массив инициализируется через строковый литерал.
- Структура или объединение с automatic storage duration инициализируется через выражение, совместимое со структурой или объединением.
- Для инициализации части подобъекта используется назначенная (designated) инициализация.
Рассмотрим пример:
int num[3][2] = { 1, 2, 3, 4, 5, 6 };В данном коде представлены инициализаторы массива, которые не оборачиваются в фигурные скобки. Корректный код:
int num[3][2] = { { 1, 2 }, { 3, 4 }, { 5, 6 } };Рассмотрим ещё один пример:
struct S1
{
char buf;
int num[3][2];
} s1[4] = {
'a', { 1, 2 }, { 0, 0 }, { 5, 6 },
'b', { 1, 2 }, { 0, 0 }, { 5, 6 },
'c', { 1, 2 }, { 0, 0 }, { 5, 6 },
'd', { 1, 2 }, { 0, 0 }, { 5, 6 }
};Правило требует, чтобы инициализаторы агрегатов также оборачивались в фигурные скобки. Корректный код будет выглядеть так:
struct S1
{
char buf;
int num [3][2];
} s1[4] = {
{ 'a', { { 1, 2 }, { 0, 0 }, { 5, 6 } } },
{ 'b', { { 1, 2 }, { 0, 0 }, { 5, 6 } } },
{ 'c', { { 1, 2 }, { 0, 0 }, { 5, 6 } } },
{ 'd', { { 1, 2 }, { 0, 0 }, { 5, 6 } } }
};Рассмотрим вот такой случай:
struct S2 {
char color[8];
int num;
} s2[3] = {
{ "Red", 1 },
{ "Green", 2 },
{ "Blue", 3 }
};В данном примере символьный литерал также должен оборачиваться в фигурные скобки. Корректный код:
struct S2 {
char color[8];
int num;
} s2[3] = {
{ { "Red" }, 1 },
{ { "Green" }, 2 },
{ { "Blue" }, 3 }
};Пример кода с назначенными (designated) инициализаторами:
int num[2][2] = { [0][1] = 0, { 0, 1 } };Примеры кода с инициализатором в виде '{ 0 }':
int num1[3][2] = { 0 };
int num2[3][2] = { { 1, 2 }, { 0 }, { 5, 6 } };
int num3[2][2] = { { 0 }, [1][1] = 1 };Данная диагностика классифицируется как:
|
V2625. MISRA. Identifiers that define objects or functions with external linkage shall be unique.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C. Идентификатор, имеющий внешний тип связывания, должен быть уникальным в программе. Это имя не должно быть переиспользовано другими идентификаторами, имеющими отличный от исходного тип связывания (нет связывания, внутреннее связывание) внутри функций или других юнитах трансляции. Правило применимо как для объектов, так и для функций.
Примечание. Для поиска неуникальных идентификаторов в разных юнитах трансляции требуется включить режим межмодульного анализа.
Рассмотрим пример:
int var; // external linkage
void foo()
{
short var; // no linkage
}В данном коде идентификатор 'var' с внешним типом связывания будет скрыт локальной переменной в функции 'foo'. Корректный код будет выглядеть так:
int var; // external linkage
void foo()
{
short temp; // no linkage
}Рассмотрим ещё один пример, но на основе содержимого двух файлов одного проекта:
// file1.c
int x; // external linkage
static int y; // internal linkage
static void bar(); // internal linkage
// file2.c
void bar() // external linkage
{
int y; // no linkage
}
void foo() // external linkage
{
int x; // no linkage
}Идентификаторы 'x' из 'file1.c' и 'bar' из 'file2.c' имеют внешний тип связывания и не являются уникальными, поэтому нарушают данное правило. Идентификатор 'y' не является уникальным, но поскольку в 'file1.c' он имеет внутреннее связывание, а в 'file2.c' не имеет связывания, то данное правило не нарушается для этого имени.
Корректный код:
// file1.c
static int x; // internal linkage
static int y; // internal linkage
static void func(); // internal linkage
// file2.c
void bar() // external linkage
{
int y; // no linkage
}
void foo() // external linkage
{
int x; // no linkage
}Данная диагностика классифицируется как:
|
V2626. MISRA. The 'sizeof' operator should not have an operand which is a function parameter declared as 'array of type'.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Оператор sizeof возвращает размер указателя, а не массива, для случаев, когда массив был передан в функцию по копии.
Рассмотрим фрагмент кода:
char A[100];
void Foo(char B[100])
{
}В этом коде объект A является массивом, и выражение sizeof(A) вернет значение 100.
Объект B, несмотря на то, как он задекларирован, является обычным указателем. Значение 100 в квадратных скобках является лишь подсказкой программисту, что передаваемый массив должен содержать сто элементов. Таким образом, выражение sizeof(B) будет равно размеру указателя, а размер последнего определяется реализацией (implementation-defined). Например, для 32-битных систем его размер равен 4 байтам, а для 64-битных систем — 8 байтам.
Предупреждение выдается в том случае, когда вычисляется размер указателя, переданного в качестве аргумента в формате имя_типа имя_массива[N]. Такой код с высокой вероятностью содержит ошибку. Рассмотрим пример:
void Foo(float array[3])
{
const size_t n = sizeof(array) / sizeof(array[0]);
for (size_t i = 0; i < n; ++i)
array[i] = 0.0f;
}Выражение sizeof(array) / sizeof(array[0]) неверно вычислит размер массива, из-за чего он не будет полностью заполнен значением 1.0f.
Для предотвращения подобных ошибок необходимо явно передавать количество элементов в массиве.
Корректный код:
void Foo(float *array, size_t count)
{
for (size_t i = 0; i < count; ++i)
array[i] = 1.0f;
}Данная диагностика классифицируется как:
|
V2627. MISRA. Function type should not be type qualified.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Анализатор обнаружил в коде объявление типа функции с использованием квалификаторов const, volatile, restrict или _Atomic. При использовании такого типа поведение программы не определено.
Примечание. Правило проверяет именно декларируемый тип функции, а не возвращаемый тип функции.
Пример кода, на котором анализатор сгенерирует предупреждения:
typedef int fun_t(void);
typedef const fun_t qual_fun_t; // <=
typedef const fun_t * ptr_to_qual_fun_t; // <=
void foo()
{
const fun_t c_fun_t; // <=
const fun_t * ptr_c_fun_t; // <=
}Для правильной работы программы следует убрать квалификатор const при определении типа функции. Таким образом, корректный код выглядит так:
typedef int fun_t(void);
typedef fun_t qual_fun_t; // ok
typedef fun_t * ptr_to_qual_fun_t; // ok
void foo()
{
fun_t c_fun_t; // ok
fun_t * ptr_c_fun_t; // ok
}Данная диагностика классифицируется как:
|
V2628. MISRA. The pointer arguments to the Standard Library functions memcpy, memmove and memcmp should be pointers to qualified or unqualified versions of compatible types.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Передача в функции memcpy, memmove и memcmp аргументов-указателей на разные, несовместимые между собой типы может сигнализировать об ошибке.
Рассмотрим пример кода:
void foo(int s1[CMP_SIZE], float s2[CMP_SIZE])
{
memcpy(s1, s2, CMP_SIZE * sizeof(int));
}В этом примере аргументы функции memcpy имеют разные типы: s1 — int *, а s2 — float *. Примечание: несмотря на то, что параметры s1 и s2 задекларированы как массивы, в силу специфики языка C на самом деле они являются указателями.
Корректный код выглядит так:
void foo(int s1[CMP_SIZE], int s2[CMP_SIZE])
{
memcpy(s1, s2, CMP_SIZE * sizeof(int));
}Данная диагностика классифицируется как:
|
V2629. MISRA. Pointer arguments to the 'memcmp' function should point to an appropriate type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Использование функции memcmp из стандартной библиотеки может приводить к неожиданным результатам при использовании с определёнными типами данных.
Функция производит побайтовое сравнение первых n байт двух объектов, переданных через указатели. Однако есть случаи, когда не следует использовать memcmp для побайтового сравнения.
Случай N1. Структуры или объединения. Из-за байтов выравнивания при логически равных объектах можно получить различный результат.
Пример:
struct S
{
int a;
char b;
};
bool equals(struct S *s1, struct S *s2)
{
return memcmp(s1, s2, sizeof(struct S)) == 0;
}Для дальнейшего понимания примем, что размер и выравнивание типа int равно 4, а для char – 1. Вследствие того, что процессор должен эффективно работать с данными в памяти, структура S будет располагаться в памяти следующим образом:
class S size(8):
+---
0 | a
4 | b
| <alignment member> (size=3)
+---Первое поле расположено по смещению 0x0 и занимает 4 байта. Следующее поле расположено по смещению 0x4 и занимает 1 байт. Помимо этого, начиная со смещения 0x5 в объекты класса добавляются 3 байта для того, чтобы выровнить объекты класса по максимальному выравниванию в 4 байта.
Стандарт языка C не гарантирует, как именно будут инициализированы байты выравнивания. Из-за этого сравнение двух объектов через функцию memcmp может произойти неверно.
Корректным способом сравнения двух объектов будет попарное сравнение всех полей класса:
struct S
{
int a;
char b;
};
bool equals(struct S *s1, struct S *s2)
{
return s1->a == s2->a && s1->b == s2->b;
}Случай N2. Вещественные числа. Рассмотрим пример:
bool equals(double *lhs, double *rhs, size_t length)
{
return memcmp(lhs, rhs, length * sizeof(double)) == 0;
}Функция производит сравнение двух массивов вещественных чисел размера length. Из-за особенностей формата представления вещественных чисел одинаковые значения могут иметь различные байтовые представления. Из-за этого memcmp вернёт не тот результат, что ожидает разработчик.
Более корректный способ сравнения выглядит следующим образом:
bool equals_d(double lhs, double rhs, double eps = DBL_EPSILON);
bool equals(double *lhs, double *rhs, size_t length)
{
for (size_t i = 0; i < length; ++i)
{
if (!equals_d(lhs[i], rhs[i])) return false;
}
return true;
}Функция сравнения двух вещественных чисел подбирается исходя из условий сравнения. Например, она может быть такой:
bool equals_d(double lhs, double rhs, double eps)
{
double diff = fabs(lhs - rhs);
lhs = fabs(lhs);
rhs = fabs(rhs);
double largest = (rhs > lhs) ? rhs : lhs;
return diff <= largest * eps;
}Случай N3. Символьные массивы. Рассмотрим пример:
bool equals(const char *lhs, const char *rhs, size_t length)
{
return memcmp(lhs, rhs, length) == 0;
}При применении memcmp при сравнении символьных массивов терминальный ноль может быть интерпретирован как данные, а не как сигнал об остановке алгоритма. Из-за этого может произойти либо неверное сравнение, либо выход за границу массива, что ведёт к неопределённому поведению.
Корректный способ сравнения символьных массивов:
bool equals(const char *lhs, const char *rhs, size_t length)
{
return strncmp(lhs, rhs, length) == 0;
}Данная диагностика классифицируется как:
|
V2630. MISRA. Bit field should not be declared as a member of a union.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Поле объединения не должно объявляться как битовое поле. Это связано с тем, что способ хранения битовых полей в пользовательских типах определяется реализацией компилятора. Если два битовых поля с одинаковым типом декларируются друг за другом, компилятор не обязан оптимизировать их расположение в едином блоке памяти. В результате может возникнуть неясность относительно того, к каким битам ранее сохранённого значения будет обращаться битовое поле.
Пример кода, в котором анализатор сгенерирует предупреждения:
union U1
{
int a : 8; // <=
int b;
};
union U2
{
int a : 8; // <=
int b : 24; // <=
};Правило не применяется к подобъектам внутри объединения, не являющимися объединениями.
union U3
{
struct
{
int a:4;
int b:4;
} c;
int d;
};Данная диагностика классифицируется как:
|
V2631. MISRA. Pointers to variably-modified array types should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Использование указателя на массив переменной длины (VLA) в объявлениях объектов или параметров функций может привести к потенциальным ошибкам, поэтому их использование не рекомендуется.
Массив переменной длины – это массив, который декларируется как параметр функции или локальный объект, и его размер не является константой времени компиляции. Язык C также позволяет определять указатели на массивы переменной длины.
Поведение не определено, когда два указателя на массивы указанных размеров используются любым способом, требующим их совместимости, при этом их размеры не равны. Например, такое может произойти при присвоении указателей, при этом один из них указывает на массив переменной длины.
Рассмотрим пример:
void foo(int n, int (*a)[n])
{
int (*b)[20] = a; // поведение не определено, пока n != 20
// при этом типы подразумеваются как совместимые
}
void bar(int n)
{
int a[n];
foo(n, &a);
}
void foobar()
{
bar(10);
}Функция foo принимает указатель на массив переменной длины a, размер которого определяется параметром n. Внутри функции этот указатель присваивается другому указателю b, который ожидает указатель на массив фиксированного размера в 20 элементов. Поведение такой операции не определено до тех пор, пока n != 20.
Для исправления стоит заменить тип у параметра a на массив переменной длины, а у указателя b убрать информацию о размере массива:
void foo(int n, int a[n])
{
int *b = a; // поведение всегда определено
}Данная диагностика классифицируется как:
|
V2632. MISRA. Object with temporary lifetime should not undergo array-to-pointer conversion.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Массивы в качестве временных объектов не должны конвертироваться в указатель. Это связано с тем, что временные объекты существуют только на время выполнения полного выражения и уничтожаются сразу после его завершения.
Массив может быть членом структуры или объединения и, следовательно, быть частью любого выражения (value expression). Поскольку при использовании массива в выражении он всегда конвертируется в указатель, в C есть возможность сформировать такой указатель на массив, который является подобъектом временного объекта. Модификация элементов временного массива, а также доступ к ним после окончания времени жизни ведёт к неопределённому поведению.
Рассмотрим пример кода:
struct S
{
int arr[10];
};
struct S getS(void);
void foo(int const *p);
void bar()
{
p = getS().arr; // <=
foo(getS().arr); // <=
int j = getS().arr[3];
getS().arr[3] = j; // <=
}Структура S в качестве поля содержит массив arr из 10 элементов. Анализатор выдаст предупреждение при попытке получить доступ к этому массиву через временный объект.
Для исправления нужно объявить объект с нормальным временем жизни:
struct S
{
int arr[10];
};
struct S s;
struct S getS(void);
void foo(int const* p);
void global_object()
{
int* p = s.arr;
s.arr[0] = 1;
p[1] = 1;
foo(s.arr);
}
void local_object()
{
struct S obj = getS();
int* p = obj.arr;
obj.arr[0] = 1;
p[1] = 1;
foo(obj.arr);
}Данная диагностика классифицируется как:
|
V2633. MISRA. Identifiers should be distinct from macro names.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Имена макросов должны отличаться от имён идентификаторов.
Минимальное требование к их различимости зависит от версии стандарта:
- C90 — первый 31 символ;
- C99 — первые 63 символа.
Правило требует, чтобы имена были различимы в рамках ограничений, налагаемых стандартом.
Нижеперечисленные примеры будут касаться C90.
Пример некорректного кода:
// 1234567890123456789012345678901
#define average_winter_air_temperature_Monday awt_m
static int average_winter_air_temperature_tuesday;Имена макроса и идентификатора неразличимы при сравнении первых 31 символов.
Корректный код:
// 1234567890123456789012345678901
#define average_winter_air_temp_Monday awt_m
static int average_winter_air_temp_tuesday;Данная диагностика классифицируется как:
|
V2634. MISRA. Features from <fenv.h> should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Правило актуально только для языка С.
Не следует использовать функции или макросы из заголовочного файла <fenv.h>. В некоторых ситуациях поведение программы может быть не уточнено или даже не определено при использовании функционала из этого файла.
Рассмотрим некоторые проблемы, которые могут возникать при использовании функционала <fenv.h>.
Проблема N1. Порядок, в котором выставляются флаги исключений при работе с вещественными числами, при вызове функции feraiseexcept не уточнён.
Проблема N2. Поведение не определено при вызове функций fesetenv и/или feupdateenv с аргументом, который не был получен путём вызова feholdexcept / fegetenv или раскрытия макроса FE_DFL_ENV.
Проблема N3. Некоторые реализации функции из заголовочного файла <math.h> поддерживают округление вещественных чисел только до ближайшего представимого значения (FE_TONEAREST). Если был установлен другой режим округления, то поведение при вызове таких функций может быть непредсказуемым.
Примеры, на которых анализатор выдаст срабатывания:
void clear_overflow_status()
{
feclearexcept(FE_OVERFLOW);
}
void change_rounding_direction()
{
fesetround(FE_DOWNWARD);
}
double some_computation(void)
{
int r = feraiseexcept(FE_OVERFLOW | FE_INEXACT);
printf("feraiseexcept() %s\n", (r?"fails":"succeeds"));
return 0.0;
}Данная диагностика классифицируется как:
|
V2635. MISRA. The function with the 'system' name should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Правило актуально для языка C.
Функция system не должна быть использована, и ни один макрос с подобным именем не должен быть раскрыт.
Использование этой функции может привести к уязвимостям, если переданный аргумент не был корректно проверен. Злоумышленник может выполнять произвольные команды или считывать и изменять данные в любом месте системы.
Пример кода, на который анализатор выдаст предупреждение:
void funcEx00()
{
system("mkdir tmp_dir");
system("chmod 777 ./myfile");
}Также анализатор будет выдавать предупреждения на использование макросов с соответствующим именем:
#define system printf("msg\n");
void PositiveTestMacro()
{
system("gcc --version");
}Данная диагностика классифицируется как:
|
V2636. MISRA. The functions with the 'rand' and 'srand' name of <stdlib.h> should not be used.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Правило актуально только для языка C.
Функции rand и srand из заголовочного файла <stdlib.h> не должны быть использованы. Ни один макрос с одним из этих имен не должен быть использован.
Функции srand и rand используются для работы с генератором псевдослучайных чисел. Первая функция инициализирует его начальным значением, а вторая генерирует псевдослучайное число.
Однако у этого функционала есть серьёзный недостаток: он не гарантирует качество псевдослучайной последовательности чисел. Поэтому данный функционал из заголовочного файла <stdlib.h> не рекомендуется использовать для серьёзных задач, связанных с использованием псевдослучайных чисел.
Пример кода, на который анализатор выдаст предупреждение:
int foo()
{
srand(time(NULL));
int random_variable = rand();
}Также анализатор будет выдавать предупреждения на использование макросов с соответствующими именами:
#define srand printf("msg%i\n", x);
void PositiveTestMacro()
{
int x = 42;
srand(x);
}Данная диагностика классифицируется как:
|
V2637. MISRA. A 'noreturn' function should have 'void' return type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С.
Функция, задекларированная со спецификатором _Noreturn (C11) или атрибутом [[noreturn]] (C23), не должна возвращать управление, так как это приведёт к неопределённому поведению. Следовательно, она не может вернуть никакого значения после её вызова, и её возвращаемый тип должен быть void.
Анализатор формирует предупреждение, когда обнаруживает у noreturn функции возвращаемый тип, отличный от void. Это подозрительный код, который может быть следствием опечатки или ошибки при проектировании.
Пример кода, на который анализатор выдаст предупреждение:
_Noreturn int sum(int a, int b) // _Noreturn is a typo
{
return a + b; // undefined behavior
}В синтетическом примере выше спецификатор _Noreturn был поставлен по ошибке. Чтобы убрать предупреждение анализатора, достаточно удалить лишний спецификатор:
int sum(int a, int b)
{
return a + b;
}Данная диагностика классифицируется как:
|
V2638. MISRA. Generic association should list an appropriate type.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для языка С.
Использование конструкции _Generic (C11) в совокупности с определёнными типами в списке ассоциаций может приводить к неожиданным результатам.
Перед тем как контролирующее выражение будет сопоставлено со списком ассоциаций, оно пройдёт цепочку неявных преобразований (lvalue conversion):
- отбрасываются
const/volatile/restrictквалификаторы верхнего уровня; - отбрасывается атомарность типа;
- массив будет превращён в указатель;
- функция будет превращена в указатель на функцию.
Поскольку стандарт C не накладывает никаких ограничений на типы, указанные в списке ассоциаций, может произойти ситуация, когда та или иная ветка никогда не будет выбрана. В связи с этим список ассоциаций не должен содержать любой из перечисленных ниже типов:
const/volatile/restrictквалифицированный тип;- атомарный тип;
- массив;
- функция;
- неименованная структура или объединение (могут быть обработаны только
default-ассоциацией).
Рассмотрим пример:
#define builtin_typename(expr) \
(_Generic( (expr) \
, char: "char" \
, const char: "const char" \
, volatile char: "volatile char" \
, const volatile char: "const volatile char" \
, short: "short" \
, const short: "const short" \
, volatile short: "volatile short" \
, const volatile short: "const volatile short" \
, ....) )В коде объявляется макрос builtin_typename, который конвертирует переданное выражение в строковый литерал, содержащий тип выражения. Для этого перебираются все встроенные типы с комбинациями const и volatile квалификаторов. Однако контролирующее выражение после неявных преобразований никогда не будет cv-квалифицированным. Поэтому такая конструкция _Generic содержит ассоциации, которые никогда не будут выбраны.
Исправленный код:
#define builtin_typename(expr) \
(_Generic( (expr) \
, char: "char" \
, short: "short" \
, ....) )Данная диагностика классифицируется как:
|
V2639. MISRA. Default association should appear as either the first or the last association of a generic selection.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для языка С.
Ассоциация по умолчанию (объявленная с ключевым словом default) в конструкции _Generic (С11) должна располагаться первой или последней в списке ассоциаций. Такая структура упрощает понимание кода другими программистами.
Рассмотрим пример:
#define abs(Y)( _Generic( (Y) \
, long : labs \
, default : abs \
, long long: llabs)(Y))
long foo(long x)
{
return abs(x);
}Ассоциация default располагается между двумя другими: int и char. Такой порядок списка ассоциаций усложняет конструкцию _Generic.
Исправленный код:
// First option
#define abs(Y)(_Generic( (Y) \
, default : abs \
, long : labs \
, long long: llabs)(Y))
// Second option
#define abs(Y)( _Generic( (Y) \
, long : labs \
, long long: llabs \
, default : abs)(Y))
long foo(long x)
{
return abs(x);
}Данная диагностика классифицируется как:
|
V2640. MISRA. Thread objects, thread synchronization objects and thread-specific storage pointers should have appropriate storage duration.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для C.
Объекты типа cnd_t, mtx_t, thrd_t и tss_t из Concurrency support library не должны иметь automatic или thread-local storage duration.
Доступ к объектам синхронизации обычно происходит из разных потоков. В таких случаях, при использовании automatic или thread-local storage duration программист рискует обратиться к объекту, у которого уже закончилось время жизни. Это приведёт к неопределённому поведению и неконтролируемому исполнению потоков. Данное диагностическое правило призвано уменьшить вероятность ошибки и исключить зависимость потоков от времени жизни объектов синхронизации.
Пример некорректного кода:
int Task1(void *mtx)
{
mtx_lock((mtx_t*)mtx); // can be dangling pointer
// do stuff
mtx_unlock((mtx_t*)mtx); // can be dangling pointer
return 0;
}
void RunTask()
{
thrd_t thread1;
mtx_t mtx;
mtx_init(&mtx, mtx_plain);
thrd_create(&thread1, Task1, &mtx);
}В приведённом выше синтетическом примере время жизни объекта mtx может закончиться раньше, чем произойдёт его блокировка/разблокировка в дочернем потоке.
Корректный код:
thrd_t thread1;
mtx_t mtx;
int Task1(void *mtx)
{
mtx_lock((mtx_t*)mtx);
// do stuff
mtx_unlock((mtx_t*)mtx);
return 0;
}
void RunTask()
{
mtx_init(&mtx, mtx_plain);
thrd_create(&thread1, Task1, &mtx);
}Данная диагностика классифицируется как:
|
V2641. MISRA. Types should be explicitly specified.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для С.
Язык С позволяет объявлять сущности без явного указания типа. По стандарту считается, что в таком случае тип сущности будет int. Использование такой особенности языка может привести к путанице или ошибке.
Рассмотрим пример:
// TU1.c
#include <stddef.h>
void *my_malloc (size_t n) { /* Implementation */ }
// TU2.c
#include <stddef.h>
extern my_malloc (size_t n);В файле TU1.c происходит определение аллоцируещей функции my_malloc, которая принимает размер в байтах и возвращает указатель на выделенную память. Для её использования в файле TU2.c программист вручную написал предварительную декларацию функции, но забыл указать возвращаемый тип. Компилятор в таком случае предполагает, что функция возвращает int. Это может привести к ошибкам на этапе работы программы в том случае, если размер указателя и размер int не совпадают.
Чтобы исправить ошибку, необходимо указать тип данных:
// TU2.c
#include <stddef.h>
extern void *my_malloc (size_t n);Анализатор также формирует предупреждения на следующие объявления сущностей:
extern var1; // variable declaration of 'int' type
func1() {} // function declaration with the no return type
static var2; // variable declaration of 'double' typeИсправленные примеры:
extern int var1; // variable declaration of 'int' type
void func1() {} // function declaration with the no return type
static double var2; // variable declaration of 'double' typeДанная диагностика классифицируется как:
|
V2642. MISRA. The '_Atomic' specifier should not be applied to the incomplete type 'void'.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для языка C.
Использование указателя на атомарный неполный тип (_Atomic void *) может привести к неожиданным результатам, и потому должно избегаться.
В языке C тип void * можно преобразовать к любому типу T * (C11, п. 6.3.2.3.1), однако стандарт не налагает никаких требований к размеру и выравниванию на указатель _Atomic void * (C11, п. 6.2.5.28). Вследствие этого, преобразование между указателем на атомарный неполный тип (_Atomic void *) и указателем на произвольный атомарный тип (_Atomic T *) может привести к неопределённому поведению.
Пример кода, на котором анализатор сгенерирует предупреждения:
int _Atomic a;
void main (void)
{
a = 5;
void _Atomic * avp1 = &a;
_Atomic(void)* avp2 = &a;
}Данная диагностика классифицируется как:
|
V2643. MISRA. All memory synchronization operation should be executed in sequentially consistent order.
Данное диагностическое правило основано на руководстве MISRA (Motor Industry Software Reliability Association) по разработке программного обеспечения.
Это правило актуально только для языка C.
При использовании функций для работы с атомарными операциями аргумент, отвечающий за тип модели памяти, должен всегда иметь значение memory_order::memory_order_seq_cst (последовательная согласованность).
При использовании в многопоточном коде атомарных операций может сложиться ситуация, когда один поток обратится к значению переменной раньше, чем другой поток это значение изменит. Для синхронизации операций чтения/записи в языке C существуют модели памяти, определённые в перечислении memory_order.
Выбранная модель памяти влияет на то, как компилятор и процессор оптимизируют код. Поведением по умолчанию является sequentially consistent ordering (последовательная согласованность). Эта модель поведения наиболее интуитивно понятна для человека. А также это самая строгая модель для компилятора и процессора. При её использовании операции чтения/записи будут выполняться чётко в том порядке, в котором они написаны в коде.
Данное диагностическое правило призвано уменьшить вероятность ошибки и исключить зависимость выполнения параллельного кода от оптимизаций процессора и компилятора.
Ниже перечислены функции из Concurrency support library, которые должны вызываться со значением memory_order::memory_order_seq_cst:
atomic_load_explicit,atomic_store_explicit,atomic_flag_test_and_set_explicit,atomic_flag_clear_explicit,atomic_exchange_explicit,atomic_compare_exchange_strong_explicit,atomic_compare_exchange_weak_explicit,atomic_fetch_add_explicit,atomic_fetch_sub_explicit,atomic_fetch_or_explicit,atomic_fetch_xor_explicit,atomic_fetch_and_explicit,atomic_thread_fence,atomic_signal_fence.
Помимо явной передачи аргумента можно использовать не *_explicit альтернативы вышеописанных функций. В таком случае будет неявно передан аргумент memory_order::memory_order_seq_cst.
Пример некорректного кода:
_Atomic int flag; // initialized elsewhere with non-zero value
void thread1()
{
// do stuff
atomic_store_explicit(&flag, 0, memory_order_release);
}
void thread2()
{
auto value = atomic_load_explicit(&flag, memory_order_acquire);
while (value != 0)
{
// do stuff
value = atomic_load_explicit(&flag, memory_order_acquire);
}
}В приведённом выше синтетическом примере порядок выполнения операций load и store не может быть заранее предсказан, поскольку нестрогая модель памяти позволит компилятору и процессору менять очередность операций.
Корректный код:
_Atomic int flag; // initialized elsewhere with non-zero value
void thread1()
{
// do some stuff
atomic_store_explicit(&flag, 0, memory_order_seq_cst);
// or use atomic_store(&flag, 0);
}
void thread2()
{
auto value = atomic_load_explicit(&flag, memory_order_seq_cst);
// or declaration via 'atomic_load'
// auto value = atomic_load(&flag);
while (value != 0)
{
// do some stuff
value = atomic_load_explicit(&flag, memory_order_seq_cst);
// or assignment via 'atomic_load'
// value = atomic_load(&flag);
}
}Данная диагностика классифицируется как:
|
V3001. There are identical sub-expressions to the left and to the right of the 'foo' operator.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит логическую ошибку. В тексте программы имеется оператор (<, >, <=, >=, ==, !=, &&, ||, -, /, &, |, ^), слева и справа от которого расположены одинаковые подвыражения.
Рассмотрим пример:
if (a.x != 0 && a.x != 0)В данном случае оператор '&&' окружен одинаковыми подвыражениями "a.x != 0", что позволяет обнаружить ошибку, допущенную по невнимательности. Корректный код, который не вызовет подозрений у анализатора, будет выгладить так:
if (a.x != 0 && a.y != 0)Рассмотрим другой пример ошибки, обнаруженный анализатором в коде приложения:
class Foo {
List<int> Childs { get; set; }
...
public bool hasChilds() { return(Childs[0] > 0 || Childs[0] > 0); }
...
}В данном случае, хотя код успешно и без предупреждений компилируется, он не имеет смысла. Корректный код должен был выглядеть следующим образом:
public bool hasChilds(){ return(Childs[0] > 0 || Childs[1] > 0);}Анализатор производит сравнение блоков с учетом перестановки частей выражения относительно операторов. Ошибка будет обнаружена и в следующем примере кода:
if (Name.Length > maxLength && maxLength < Name.Length)Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3001. |
V3002. The switch statement does not cover all values of the enum.
Анализатор обнаружил оператор 'switch', в котором выбор варианта осуществляется по переменной enum-типа. При этом в операторе 'switch' используются не все элементы перечисления, что может свидетельствовать о наличии ошибки.
Пример кода, в котором встретилась эта ошибка:
public enum Actions { Add, Remove, Replace, Move, Reset };
public void SomeMethod(Actions act)
{
switch (act)
{
case Actions.Add: Calculate(1); break;
case Actions.Remove: Calculate(2); break;
case Actions.Replace: Calculate(3); break;
case Actions.Move: Calculate(5); break;
}
}В данном случае перечисление 'Actions' содержит 5 именованных констант, а оператор 'switch', выбор в котором осуществляется по данному перечислению, реализует выбор только по 4 из них. Это место является потенциально ошибочным.
Возможно, в ходе рефакторинга в перечисление добавили новую константу, но забыли реализовать выбор по ней в операторе 'switch', или же, что может быть в случае с большими перечислениями, константу банально могли пропустить. В итоге пропущенное значение обрабатывается неправильно.
Тогда корректный код мог бы выглядеть следующим образом:
public void SomeMethod(Actions act)
{
switch (act)
{
case Actions.Add: Calculate(1); break;
case Actions.Remove: Calculate(2); break;
case Actions.Replace: Calculate(3); break;
case Actions.Move: Calculate(5); break;
case Actions.Reset: Calculate(6); break;
}
}Или так:
public void SomeMethod(Actions act)
{
switch (act)
{
case Actions.Add: Calculate(1); break;
case Actions.Remove: Calculate(2); break;
case Actions.Replace: Calculate(3); break;
case Actions.Move: Calculate(5); break;
default: Calculate(10); break;
}
}Анализатор выдает предупреждение далеко не всегда, когда в 'switch' используется не все константы из перечисления. Иначе, было бы слишком много ложных срабатываний. Действует целый ряд исключений эмпирического типа. Основные:
- Есть default-ветка;
- Отсутствующая константа содержит в имени: None, Unknown и т.п.
- Отсутствующая константа самая последняя в enum и содержит в имени "end", "num", "count" и т.п.
- В перечислении всего 1 или 2 константы;
- И так далее.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3002. |
V3003. The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence.
Анализатор обнаружил потенциально возможную ошибку в конструкции, состоящей из условных операторов.
Рассмотрим пример:
if (a == 1)
Foo1();
else if (a == 2)
Foo2();
else if (a == 1)
Foo3();В данном примере метод 'Foo3()' никогда не получит управления. Вероятно, мы имеем дело с логической ошибкой и корректный код должен выглядеть так:
if (a == 1)
Foo1();
else if (a == 2)
Foo2();
else if (a == 3)
Foo3();На практике подобная ошибка может выглядеть следующим более сложным образом.
Например, анализатором удалось найти следующую ошибочную конструкцию.
....
} else if (b.NodeType == ExpressionType.Or ||
b.NodeType == ExpressionType.OrEqual){
current.Condition = ConstraintType.Or;
} else if(...) {
....
} else if (b.NodeType == ExpressionType.OrEqual ||
b.NodeType == ExpressionType.Or){
current.Condition = ConstraintType.Or |
ConstraintType.Equal;
} else if(....В данном примере, в вышестоящей инструкции if было проверено условие, что
b.NodeType == ExpressionType.Or ||
b.NodeType == ExpressionType.OrEqual.А в нижестоящей инструкции if, условие было таким же по логике, но написано в обратном порядке, что является малозаметным с точки зрения человека, но приводит к ошибке выполнения кода.
b.NodeType == ExpressionType.OrEqual ||
b.NodeType == ExpressionType.OrДанная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3003. |
V3004. The 'then' statement is equivalent to the 'else' statement.
Анализатор обнаружил подозрительный фрагмент кода, в котором истинная и ложная ветви оператора 'if' полностью совпадают. Часто это свидетельствует о наличии ошибки.
Пример подобного кода:
if (condition)
result = FirstFunc(val);
else
result = FirstFunc(val);Вне зависимости от значения переменной, будут выполнены одни и те же операции. Понятно, что такой код является ошибочным. Тогда корректный вариант кода мог бы выглядеть следующим образом:
if (condition)
result = FirstFunc(val);
else
result = SecondFunc(val);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3004. |
V3005. The 'x' variable is assigned to itself.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что значение переменной присваивается само себе.
Рассмотрим пример, взятый из реального приложения:
public GridAnswerData(
int questionId, int answerId, int sectionNumber,
string fieldText, AnswerTypeMode typeMode)
{
this.QuestionId = this.QuestionId;
this.AnswerId = answerId;
this.FieldText = fieldText;
this.TypeMode = typeMode;
this.SectionNumber = sectionNumber;
}Из кода видно, что программист хотел изменить значения свойств объекта в соответствии с принятыми в методе параметрами, но ошибся и присвоил свойству 'QuestionId' вместо значения аргумента 'questionId' значение самого же свойства.
Тогда корректный код должен был бы выглядеть так:
public GridAnswerData(
int questionId, int answerId, int sectionNumber,
string fieldText, AnswerTypeMode typeMode)
{
this.QuestionId = questionId;
this.AnswerId = answerId;
this.FieldText = fieldText;
this.TypeMode = typeMode;
this.SectionNumber = sectionNumber;
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3005. |
V3006. The object was created but it is not being used. The 'throw' keyword could be missing.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что создаётся экземпляр класса, унаследованного от 'System.Exception', но при этом никак не используется.
Пример ошибочного кода:
public void DoSomething(int index)
{
if (index < 0)
new ArgumentOutOfRangeException();
else
....
}В данном коде пропущен оператор 'throw', из-за чего будет только создан экземпляр класса, унаследованного от 'System.Exception', но при этом он никак не будет использоваться, и исключение не будет сгенерировано. Корректный код может выглядеть следующим образом:
public void DoSomething(int index)
{
if (index < 0)
throw new ArgumentOutOfRangeException();
else
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3006. |
V3007. Odd semicolon ';' after 'if/for/while' operator.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что после одного из операторов 'for', 'while' или 'if' стоит точка с запятой ';'.
Рассмотрим пример:
int i = 0;
....
for(i = 0; i < arr.Count(); ++i);
arr[i] = i;В данном коде программист хотел выполнить присваивание для всех элементов массива, но по ошибке поставил ';' после закрывающей скобки цикла. Таким образом, операция присваивания выполнится только один раз. К тому же произойдёт выход за границу массива.
Корректный вариант кода:
int i = 0;
....
for(i = 0; i < arr.Count(); ++i)
arr[i] = i;Конечно, наличие точки с запятой ';' после данных операторов не всегда является ошибкой, и иногда для выполнения необходимых операций не требуется тела цикла. В таком случае наличие точки с запятой оправдано. Пример такого кода:
int i;
for (i = 0; !char.IsWhiteSpace(str[i]); ++i) ;
Console.WriteLine(i);Анализатор не будет выдавать предупреждение на этот код и в ряде других ситуаций.
Данная диагностика классифицируется как:
V3008. The 'x' variable is assigned values twice successively. Perhaps this is a mistake.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что одной и той же переменной дважды подряд присваивается значение. Причем между этими присваиваниями сама переменная не используется.
Рассмотрим пример:
A = GetA();
A = GetB();То, что переменной 'A' два раза присваивается значение, может свидетельствовать о наличии ошибки. Высока вероятность, что код должен выглядеть следующим образом:
A = GetA();
B = GetB();Если переменная между присваиваниями используется, то этот код считается анализатором корректным:
A = 1;
A = Foo(A);Рассмотрим, как подобная ошибка может выглядеть на практике. Следующий код взят из реального приложения:
....
if (bool.TryParse(setting, out value))
_singleSignOn = value;
_singleSignOn = false;
....Корректный вариант должен был выглядеть так:
....
if (bool.TryParse(setting, out value))
_singleSignOn = value;
else
_singleSignOn = false;
....Иногда анализатор выдает ложные предупреждения, когда запись в переменные используется для отладочных целей. Пример подобного кода:
status = Foo1();
status = Foo2();В данной ситуации:
- Можно подавить ложные срабатывания, используя комментарий "//-V3008".
- Можно запретить выдавать диагностику V3008 для всех случае, где используется переменная с именем 'status'. Для этого можно добавить комментарий "//-V:status:3008".
- Можно убрать из кода ничего не значащие присваивания.
- Возможно этот код все же некорректен, и необходимо проверять значение переменной 'status'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3008. |
V3009. It's odd that this method always returns one and the same value of NN.
Анализатор обнаружил странный метод. Метод не имеет состояния, не изменяет глобальных переменных. При этом он имеет несколько точек возврата, возвращающих одно и то же числовое, строковое, константное, enum значение, или то же самое значение поля, которое предназначено только для чтения.
Такой код крайне подозрителен и может свидетельствовать о возможной ошибке. Скорее всего, метод должна возвращать различные числовые значения.
Рассмотрим простой пример такого кода:
int Foo(int a)
{
if (a == 33)
return 1;
return 1;
}Данный код содержит ошибку. Для ее исправления изменим одно из возвращаемых значений. Определить необходимые возвращаемые значения, как правило, можно только зная логику работы всего приложения в целом.
Вариант корректного кода:
int Foo(int a)
{
if (a == 33)
return 1;
return 2;
}Если код верен, то чтобы избавиться от ложного срабатывания следует использовать комментарий "//-V3009".
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3009. |
V3010. The return value of function 'Foo' is required to be utilized.
Анализатор обнаружил подозрительный вызов метода, возвращаемое значение которого не учитывается. Вызов некоторых методов не имеет смысла без использования их возвращаемого значения.
Рассмотрим пример такого кода:
public List<CodeCoverageSequencePoint> SequencePoints
{ get; private set; }
....
this.SequencePoints.OrderBy(item => item.Line);Из кода видно, что для коллекции 'SequencePoints' вызывается метод-расширение 'OrderBy'. Данный метод выполняет сортировку коллекции по заданному критерию и возвращает отсортированную коллекцию. Так как метод 'OrderBy' не меняет коллекцию 'SequencePoints', то нет смысла вызывать его, не сохраняя при этом коллекцию, возвращённую методом.
Тогда корректный код мог бы выглядеть так:
var orderedList = this.SequencePoints.OrderBy(
item => item.Line).ToList();Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3010. |
V3011. Two opposite conditions were encountered. The second condition is always false.
Анализатор обнаружил возможную логическую ошибку, связанную с тем, что два условных оператора, идущих последовательно, содержат взаимоисключающие условия.
Примеры таких условий:
- "A == B" и "A != B";
- "A > B" и "A <= B";
- "A < B" и "B < A";
- и тому подобные.
Такая ошибка может возникнуть в результате опечатки или неудачного рефакторинга.
Пример некорректного кода:
if (x == y)
if (y != x)
DoSomething(x, y);В данном случае метод 'DoSomething' никогда не будет вызван, так как при истинности первого условия второе всегда будет ложным. Возможно, в сравнении используется некорректная переменная. Например, во втором условии следовало использовать не 'x', а 'z':
if (x == y)
if (y != z)
DoSomething(x, y);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3011. |
V3012. The '?:' operator, regardless of its conditional expression, always returns one and the same value.
Анализатор обнаружил потенциальную ошибку при использовании тернарного оператора "?:". Независимо от условия, будет выполнено одно и тоже действие. Скорее всего, в коде имеется опечатка.
Рассмотрим самый простой пример:
int A = B ? C : C;В любом случае переменной A будет присвоено значение переменной C.
Рассмотрим, как подобная ошибка может выглядеть в коде реального приложения:
fovRadius[0] = Math.Tan((rollAngleClamped % 2 == 0 ?
cg.fov_x : cg.fov_x) * 0.52) * sdist;Здесь код отформатирован. В тексте программы это может быть одной строкой, и неудивительно, что легко просмотреть опечатку. Ошибка в том, что два раза используется член класса "fov_x". Корректный вариант:
fovRadius[0] = Math.Tan((rollAngleClamped % 2 == 0 ?
cg.fov_x : cg.fov_y) * 0.52) * sdist;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3012. |
V3013. It is odd that the body of 'Foo_1' function is fully equivalent to the body of 'Foo_2' function.
Данное предупреждение выдается в том случае, если анализатор обнаружил две функции, реализованные идентичным образом. Наличие двух одинаковых функций само по себе не является ошибкой, но является поводом обратить на них внимание.
Смысл данной диагностики в обнаружении следующей разновидности ошибок:
class Point
{
....
float GetX() { return m_x; }
float GetY() { return m_x; }
};Из-за допущенной опечатки две разные по смыслу функции выполняют одинаковые действия. Корректный вариант:
float GetX() { return m_x; }
float GetY() { return m_y; }В приведенном примере идентичность тел функций GetX() и GetY() явно свидетельствует о наличии ошибки. Однако если выдавать предупреждения на все одинаковые функции, то процент ложный срабатываний будет крайне большим. Поэтому анализатор руководствуется целым рядом исключений, когда не стоит предупреждать об одинаковых телах функций. Перечислим некоторые из них:
- Не сообщается об идентичности тел функций, если в них не используются переменные кроме аргументов. Пример: "bool IsXYZ() { return true; }";
- Если функции с одинаковыми телами повторяются более двух раз;
- Тело функций состоит только из оператора throw();
- И так далее.
Бороться с ложными срабатываниями можно несколькими способами. Если ложные срабатывания относятся к файлам внешних библиотек или тестов, то путь до файлов или каталога с ними можно добавить в исключения. Если предупреждения относятся к вашему коду, то вы можете использовать комментарий вида "//-V3013", который приведет к подавлению предупреждений. Если ложных срабатываний много, то вы можете в настройках анализатора полностью отключить использование данной проверки. Также вы можете модифицировать код таким образом, чтобы одна функция вызывала другую.
Приведем пример кода из реального приложения, где разные по смыслу функции реализованы одинаково:
public void Pause(FrameworkElement target)
{
if (Storyboard != null)
{
Storyboard.Pause(target);
}
}
public void Stop(FrameworkElement target)
{
if (Storyboard != null)
{
Storyboard.Stop(target);
}
}
public void Resume(FrameworkElement target)
{
if (Storyboard != null)
{
Storyboard.Pause(target);
}
}Сделав несколько копий одной функции, забыли исправить последнюю функцию Resume().
Исправленный фрагмент кода:
public void Resume(FrameworkElement target)
{
if (Storyboard != null)
{
Storyboard.Resume(target);
}
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3013. |
V3014. It is likely that a wrong variable is being incremented inside the 'for' operator. Consider reviewing 'X'.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' увеличивается переменная, относящаяся к внешнему циклу.
В самом простом виде эта ошибка выглядит следующим образом:
for (int i = 0; i < 5; i++)
for (int j = 0; j < 5; i++)
A[i][j] = 0;Во внутреннем цикле происходит увеличение переменной 'i' вместо 'j'. В реальном приложении подобная ошибка может быть не так хорошо заметна. Корректный вариант кода:
for (int i = 0; i < 5; i++)
for (int j = 0; j < 5; j++)
A[i][j] = 0;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3014. |
V3015. It is likely that a wrong variable is being compared inside the 'for' operator. Consider reviewing 'X'.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' в условии используется переменная, относящаяся к внешнему циклу.
В самом простом виде эта ошибка выглядит следующим образом:
for (int i = 0; i < 5; i++)
for (int j = 0; i < 5; j++)
A[i][j] = 0;Во внутреннем цикле происходит сравнение 'i < 5' вместо 'j < 5'. В реальном приложении подобная ошибка может быть не так хорошо заметна. Корректный вариант кода:
for (int i = 0; i < 5; i++)
for (int j = 0; j < 5; j++)
A[i][j] = 0;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3015. |
V3016. The variable 'X' is being used for this loop and for the outer loop.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что вложенный цикл организован с использованием переменной, которая также используется и во внешнем цикле.
Схематически эта ошибка выглядит следующим образом:
int i = 0, j = 0;
for (i = 0; i < 5; i++)
for (i = 0; i < 5; i++)
A[i][j] = 0;Конечно, это искусственный пример и в реальном приложении ошибка может быть не так очевидна. Корректный вариант кода:
int i = 0, j = 0;
for (i = 0; i < 5; i++)
for (j = 0; j < 5; j++)
A[i][j] = 0;Использование одной переменной для внешнего и внутреннего цикла не всегда является ошибкой. Рассмотрим пример корректного кода, где анализатор не будет выдавать предупреждение:
for(c = lb; c <= ub; c++)
{
if (!(xlb <= xlat(c) && xlat(c) <= ub))
{
Range r = new Range(xlb, xlb + 1);
for (c = lb + 1; c <= ub; c++)
r = DoUnion(r, new Range(xlat(c), xlat(c) + 1));
return r;
}
}В этом коде внутренний цикл "for (c = lb + 1; c <= ub; c++)" организован при помощи переменной "c". Внешний цикл также использует переменную "c". Но ошибки здесь нет. После того, как выполнится внутренний цикл, сразу произойдет выход из функции при помощи оператора "return r".
Данная диагностика классифицируется как:
V3017. A pattern was detected: A || (A && ...). The expression is excessive or contains a logical error.
Анализатор обнаружил выражение, которое можно упростить. Иногда за такой избыточностью кроются логические ошибки.
Рассмотрим пример подозрительного кода:
bool firstCond, secondCod, thirdCond;
....
if (firstCond || (firstCond && thirdCond))
....Это выражение является избыточным. В случае, если 'firstCond == true', значение этого условия будет всегда истинным, независимо от значения 'thirdCond', если же 'firstCond == false', то значение выражения будет всегда ложно, опять же, независимо от значения переменной 'thirdCond'.
Возможно, что программист ошибся и написал не ту переменную во втором подвыражении. Тогда корректный код мог бы выглядеть так:
if (firstCond || (secondCod && thirdCond))Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3017. |
V3018. Consider inspecting the application's logic. It's possible that 'else' keyword is missing.
Анализатор обнаружил фрагмент кода, в котором оператор 'if' расположен на той же строке, что и закрывающая скобка предыдущего оператора 'if'. Возможно, что в этом месте пропущено ключевое слово 'else', из-за чего программа работает не так, как ожидал программист.
Рассмотрим пример подобного кода:
if (cond1) {
Method1(val);
} if (cond2) {
Method2(val);
} else {
Method3(val);
}В том случае, если истинно условие 'cond1', будет вызван не только метод 'Method1', но и 'Method2' или 'Method3'. Если подразумевалась именно такая логика, следует исправить форматирование и перенести второй оператор 'if' на следующую строку:
if (cond1) {
Method1(val);
}
if (cond2) {
Method2(val);
} else {
Method3(val);
}Такой код будет для большинства программистов более привычен и не вызовет подозрения на наличие ошибки. Также анализатор перестанет выдавать лишнее предупреждение.
Если же в такого поведения не подразумевалось и в логике работы программы допущена ошибка, необходимо добавить ключевое слово 'else'. Тогда корректный код будет выглядеть так:
if (cond1) {
Method1(val);
} else if (cond2) {
Method2(val);
} else {
Method3(val);
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3018. |
V3019. It is possible that an incorrect variable is compared with null after type conversion using 'as' keyword.
Анализатор обнаружил потенциальную ошибку, которая может привести к доступу по нулевой ссылке.
Анализатор заметил в коде следующую ситуацию. Сначала объект базового класса приводится к производному классу с помощью оператора 'as'. А затем этот же объект проверяется на значение null, хотя в этом случае скорее всего предполагалось проверить на null объект производного класса.
Рассмотрим следующий пример. Здесь возможна ситуация, когда объект baseObj не будет являться экземпляром класса Derived. В этом случае при вызове функции Func программа упадёт с NullReferenceException. Анализатор выдаст предупреждение на этот код, указав две строки. Первая строка - это то место, где объект базового класса проверяется на null. Вторая строка - это то место, где объект базового класса приводится к объекту производного класса.
Base baseObj;
Derived derivedObj = baseObj as Derived;
if (baseObj != null)
{
derivedObj.Func();
}Скорее всего в этом примере предполагалось проверить на null объект производного класса перед использованием. Исправленный вариант кода:
Base baseObj;
Derived derivedObj = baseObj as Derived;
if (derivedObj != null)
{
derivedObj.Func();
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3019. |
V3020. An unconditional 'break/continue/return/goto' within a loop.
Анализатор обнаружил подозрительный цикл, в котором используется один из следующих операторов: continue, break, return, goto, throw. Эти операторы выполняются всегда, без каких-либо условий.
Пример ошибочного кода:
while (k < max)
{
if (k == index)
value = Calculate(k);
break;
++k;
}В данном коде оператор 'break' не принадлежит к оператору 'if', из-за чего выполняться будет вне зависимости от истинности условия 'k == index' и для тела цикла будет выполнена только одна итерация. Тогда корректный код мог бы выглядеть так:
while (k < max)
{
if (k == index)
{
value = Calculate(k);
break;
}
++k;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3020. |
V3021. There are two 'if' statements with identical conditional expressions. The first 'if' statement contains method return. This means that the second 'if' statement is senseless.
Анализатор обнаружил ситуацию, когда 'then' часть оператора 'if' никогда не получит управления. Это происходит из-за того, что ранее уже встречается оператор 'if' с таким же условием, содержащий в 'then' части безусловный оператор 'return'. Это может свидетельствовать как о логической ошибке в программе, так и избыточном втором операторе 'if'.
Рассмотрим пример некорректного кода:
if (l >= 0x06C0 && l <= 0x06CE) return true;
if (l >= 0x06D0 && l <= 0x06D3) return true;
if (l == 0x06D5) return true; // <=
if (l >= 0x06E5 && l <= 0x06E6) return true;
if (l >= 0x0905 && l <= 0x0939) return true;
if (l == 0x06D5) return true; // <=
if (l >= 0x0958 && l <= 0x0961) return true;
if (l >= 0x0985 && l <= 0x098C) return true;В данном случае условие 'l == 0x06D5' дублируется и для исправления кода достаточно убрать одно из них. Однако возможно, что во втором случае проверяемое значение должно отличаться от первого случая.
Корректный вариант кода:
if (l >= 0x06C0 && l <= 0x06CE) return true;
if (l >= 0x06D0 && l <= 0x06D3) return true;
if (l == 0x06D5) return true;
if (l >= 0x06E5 && l <= 0x06E6) return true;
if (l >= 0x0905 && l <= 0x0939) return true;
if (l >= 0x0958 && l <= 0x0961) return true;
if (l >= 0x0985 && l <= 0x098C) return true;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3021. |
V3022. Expression is always true/false.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что условие всегда истинно или ложно. Подобные условия не всегда означают наличие ошибки, но эти фрагменты кода следует обязательно проверить.
Пример кода:
string niceUrl = GetUrl();
if (niceUrl != "#" || niceUrl != "") {
Process(niceUrl);
} else {
HandleError();
}Анализатор выдает предупреждение:
"V3022 Expression 'niceUrl != "#" || niceUrl != ""' is always true. Probably the '&&' operator should be used here. "
Здесь ветка else никогда не будет выполнена. Дело в том, что какое бы значение ни приняла переменная niceUrl, одно из сравнений со строкой всегда будет истинно. Чтобы исправить эту ошибку, следует использовать оператор && вместо оператора ||. Корректный вариант кода:
string niceUrl = GetUrl();
if (niceUrl != "#" && niceUrl != "") {
Process(niceUrl);
} else {
HandleError();
}Теперь рассмотрим пример кода, в котором имеется бессмысленное сравнение. Возможно этот код не является ошибочным, но на него обязательно следует обратить внимание:
byte type = reader.ReadByte();
if (type < 0)
recordType = RecordType.DocumentEnd;
else
recordType = GetRecordType(type);Ошибка заключается в сравнении переменной беззнакового типа с нулём. Данный фрагмент кода будет диагностирован так: "V3022 Expression 'type < 0' is always false. Unsigned type value is always >= 0.". В этом примере либо сравнение лишнее, либо случай достижения конца документа обработан неправильно.
Анализатор предупреждает не про все условия, которые всегда ложны или истинны. Он диагностирует только те ситуации, где высока вероятность наличия ошибки. Рассмотрим некоторые примеры, которые анализатор считает абсолютно корректными:
// 1) Временно убранный из компиляции блок кода
if (false && CheckCondition())
{
...
}
// 2) Выражения внутри Debug.Assert()
public enum Actions { None, Start, Stop }
...
Debug.Assert(Actions.Start > 0);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3022. |
V3023. Consider inspecting this expression. The expression is excessive or contains a misprint.
Анализатор обнаружил подозрительный фрагмент кода, в котором имеется избыточное сравнение. Этот код может содержать лишнюю проверку, тогда выражение можно упростить, или ошибку, тогда код необходимо исправить.
Рассмотрим пример подобного кода:
if (firstVal == 3 && firstVal != 5)Данный код избыточен, так как условие будет истинным, если 'firstVal == 3'. Вторая часть выражения бессмысленна.
В данном случае возможны 2 варианта:
1) Вторая проверка просто является избыточной и выражение можно упростить. Тогда корректный код будет выглядеть так:
if (firstVal == 3)2) Выражение содержит ошибку и вместо переменной 'firstVal' подразумевалась какая-то другая. Тогда корректный код мог бы выглядеть так:
if (firstVal == 3 && secondVal != 5)Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3023. |
V3024. An odd precise comparison. Consider using a comparison with defined precision: Math.Abs(A - B) < Epsilon or Math.Abs(A - B) > Epsilon.
Анализатор обнаружил подозрительный фрагмент кода, где для сравнения чисел с плавающей точкой используется оператор '==' или '!='. Такие участки кода могут служить источником ошибок.
Рассмотрим для начала корректный пример кода (на который тем не менее будет выдано предупреждение):
double a = 0.5;
if (a == 0.5) //ok
++x;В данном случае сравнение можно считать верным. Перед сравнением переменная 'a' явно инициализируется значением '0.5'. С этим же значением производится сравнение. Результатом выражения будет 'истина'.
Итак, в некоторых случаях точные сравнения допустимы. Но часто так сравнивать нельзя. Рассмотрим пример ошибочного кода:
double b = Math.Sin(Math.PI / 6.0);
if (b == 0.5) //err
++x;Условие 'b == 0.5' при проверке оказалось ложным из-за того, что значение выражения 'Math.Sin(Math.PI / 6.0)' равно 0.49999999999999994. Это число очень близко к '0.5', но ему не равно.
Одним из вариантов решения является сравнение разности значений с каким-то значением (погрешностью, в данном случае - переменная 'epsilon'):
double b = Math.Sin(Math.PI / 6.0);
if (Math.Abs(b - 0.5) < epsilon) //ok
++x;Необходимо выбирать адекватную погрешность в зависимости от того, какие величины сравниваются.
Анализатор указывает на участки кода, где в сравнении чисел с плавающей точкой используются операторы '!=' или '=='. Является это сравнение ошибочным или нет, может решить только программист.
Дополнительные ресурсы:
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3024. |
V3025. Incorrect format. Consider checking the N format items of the 'Foo' function.
Анализатор обнаружил потенциальную ошибку при использовании функций форматирования: String.Format, Console.WriteLine, Console.Write и т.п. Строка форматирования не соответствует передаваемым в функцию фактическим аргументам.
Рассмотрим простые примеры:
Неиспользуемые аргументы.
int A = 10, B = 20;
double C = 30.0;
Console.WriteLine("{0} < {1}", A, B, C);Не указан формат {2}, поэтому переменная 'С' не будет использована.
Возможные варианты исправленного кода:
//Удалим лишний аргумент
Console.WriteLine("{0} < {1}", A, B);
//Исправим строку форматирования
Console.WriteLine("{0} < {1} < {2}", A, B, C);Недостаточное количество аргументов.
int A = 10, B = 20;
double C = 30.0;
Console.WriteLine("{0} < {1} < {2}", A, B);
Console.WriteLine("{1} < {2}", A, B);Намного более опасной ситуацией является, когда в функцию передаётся меньше аргументов, чем необходимо. Это приводит к исключению FormatException.
Возможные варианты исправленного кода:
//Добавим недостающий аргумент
Console.WriteLine("{0} < {1} < {2}", A, B, C);
//Исправим индексы в строке форматирования
Console.WriteLine("{0} < {1}", A, B);Анализатор не выдаёт предупреждение если...
- Количество указанных форматов соответствует количеству аргументов.
- Объект форматирования используется несколько раз:
int row = 10;
Console.WriteLine("Line: {0}; Index: {0}", row);Пример ошибки в реальном приложении может выглядеть следующим образом :
var sql = string.Format(
"SELECT {0} FROM (SELECT ROW_NUMBER() " +
" OVER (ORDER BY {2}) AS Row, {0} FROM {3} {4}) AS Paged ",
columns, pageSize, orderBy, TableName, where);В функцию передаются 5 объектов форматирования, но переменная 'pageSize' не используется, т.к. пропущен формат {1}.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3025. |
V3026. The constant NN is being utilized. The resulting value could be inaccurate. Consider using the KK constant.
Анализатор обнаружил, что для математических расчетов используются константы недостаточной точности.
Рассмотрим пример:
double pi = 3.141592654;Такая запись не совсем корректна и лучше использовать математические константы из статического класса Math. Корректный вариант кода:
double pi = Math.PI;Анализатор не считает ошибочной явную запись констант в формате 'float'. Это связано с тем, что тип 'float' имеет меньше значащих разрядов по сравнению с типом 'double'. Поэтому на следующий код предупреждение выдано не будет:
float f = 3.14159f; //okДанная диагностика классифицируется как:
V3027. The variable was utilized in the logical expression before it was verified against null in the same logical expression.
Анализатор обнаружил в коде ситуацию, при которой проверка переменной на равенство 'null' осуществляется после её использования (вызов метода, обращение к свойству и т.п.). Данная диагностика ищет подобные ситуации в пределах одного логического выражения.
Рассмотрим пример некорректного кода:
if (rootDoc.Text.Trim() == documentName.Trim() && rootDoc != null)Из данного примера видно, что сначала идёт обращение к свойству 'Text' (и даже более - вызову метода 'Trim' у этого свойства), а лишь затем ссылка 'rootDoc' проверяется на равенство 'null'. В случае, если ссылка 'rootDoc' имеет значение 'null', будет сгенерировано исключение типа 'NullReferenceException'. Возможным способом исправления ошибки будет сначала проверить ссылку на равенство 'null', а лишь затем обращаться к свойству объекта:
if (rootDoc != null && rootDoc.Text.Trim() == documentName.Trim())Приведённый выше способ исправления ошибки - наиболее простой из возможных. При обнаружении подобных случаев программисту стоит внимательно изучить код, чтобы понять, как корректно исправить данную ошибку.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3027. |
V3028. Consider inspecting the 'for' operator. Initial and final values of the iterator are the same.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' совпадают начальное и конечное значения счетчика. Такое использование оператора 'for' приведет к тому, что цикл не будет выполнен ни разу или выполнен только один раз.
Рассмотрим пример:
void BeginAndEndForCheck(int beginLine, int endLine)
{
for (int i = beginLine; i < beginLine; i++)
{
...
}Тело цикла никогда не выполняется. Скорее всего, произошла опечатка и следует заменить "i < beginLine" на корректное выражение "i < endLine". Корректный вариант кода:
for (int i = beginLine; i < endLine; i++)
{
...
}Другой пример:
for (int i = A; i <= A; i++)
...Тело этого цикла будет выполнено только один раз. Скорее всего, это не то, что задумывал программист.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3028. |
V3029. The conditional expressions of the 'if' statements situated alongside each other are identical.
Анализатор обнаружил код, в котором рядом находятся два оператора 'if' с одинаковыми условиями. Это является потенциальной ошибкой или избыточным кодом.
Рассмотрим пример:
public void Logging(string S_1, string S_2)
{
if (!String.IsNullOrEmpty(S_1))
Print(S_1);
if (!String.IsNullOrEmpty(S_1))
Print(S_2);
}Этот код содержит ошибку во втором условии. В нём повтороно проверяется переменная 'S_1', а необходимо проверить переменную с именем 'S_2'.
Исправленный вариант:
public void Logging(string S_1, string S_2)
{
if (!String.IsNullOrEmpty(S_1))
Print(S_1);
if (!String.IsNullOrEmpty(S_2))
Print(S_2);
}Данная диагностика не всегда указывает на ошибку. Часто код просто избыточен:
public void Logging2(bool toFile, string S_1, string S_2)
{
if(toFile)
Print(S_1);
if (toFile)
Print(S_2);
}Этот код корректен. Но он немного неэффективен, так как два раза приходится проверять значение одной и той же логической переменной. Предлагаем переписать код следующим образом:
public void Logging2(bool toFile, string S_1, string S_2)
{
if(toFile)
{
Print(S_1);
Print(S_2);
}
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3029. |
V3030. Recurring check. This condition was already verified in previous line.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что дважды проверяется одно и тоже условие.
Рассмотрим два примера:
// Example N1:
if (A == B)
{
if (A == B)
....
}
// Example N2:
if (A == B) {
} else {
if (A == B)
....
}В первом случае вторая проверка "if (A == B)" всегда истинна. Во втором случае вторая проверка всегда ложна.
Высока вероятность, что подобный код содержит ошибку. Например, из-за опечатки используется ошибочное имя переменной. Корректный код:
// Example N1:
if (A == B)
{
if (A == C)
....
}
// Example N2:
if (A == B) {
} else {
if (A == C)
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3030. |
V3031. An excessive check can be simplified. The operator '||' operator is surrounded by opposite expressions 'x' and '!x'.
Анализатор обнаружил код, который можно упростить. Слева и справа от оператора '||' стоят противоположные по смыслу выражения. Данный код является избыточным, поэтому его можно упростить, сократив количество проверок.
Пример избыточного кода:
if (str == null || (str != null && str == "Unknown"))В выражении "str != null && str == "Unknown"" проверка "str != null" является избыточной, так как перед этим проверятся противоположное ему условие " str == null ", причём эти выражения разделены оператором '||'. Следовательно, излишнюю проверку в скобках можно опустить, упростив код:
if (str == null || str == "Unknown"))Избыточность кода может свидетельствовать о наличии ошибки. Возможно, что в выражении случайно используется не та переменная. И корректный код на самом деле должен быть, например, таким:
if (cond || (str != null && str == "Unknown"))Иногда условие записано в обратном порядке и на первый взгляд его упрощать нельзя:
if ((s != null && s == "Unknown") || s == null)Кажется, что здесь нельзя избавиться ни от проверки (s!=null), ни от проверки (s==null). Это не так. Это выражение, как и случай выше можно упростить:
if (s == null || s == "Unknown")Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3031. |
V3032. Waiting on this expression is unreliable, as compiler may optimize some of the variables. Use volatile variable(s) or synchronization primitives to avoid this.
Анализатор обнаружил в коде цикл, который может превратиться после оптимизации в вечный цикл. Чаще всего подобные циклы используются для ожидания какого-либо события извне.
Приведём пример:
private int _a;
public void Foo()
{
var task = new Task(Bar);
task.Start();
Thread.Sleep(10000);
_a = 0;
task.Wait();
}
public void Bar()
{
_a = 1;
while (_a == 1);
}Если выполнить данный код скомпилированный в Debug конфигурации, программа завершится корректно. Однако, если скомпилировать этот же код под Release, программа зависнет на цикле while. Причина такого поведения в том, что компилятор "закэширует" значение переменной '_a'.
Из-за подобного различия Debug-версии и Release-версии могут возникать сложные и трудно детектируемые ошибки. Путей корректировки данной ситуации несколько. Если эта переменная и впрямь используется для контроля логики многопоточной программы, то лучше использовать специализированные средства синхронизации, такие как мьютексы и семафоры. Другим вариантом исправления может стать добавление модификатора 'volatile' к объявлению переменной:
private volatile int _a;
...Обратите внимание на то, что даже после такой правки код примера не станет полностью безопасным, т.к. нет гарантии, что Bar() начнёт выполняться раньше, чем переменной '_a' будет присвоено значение 0. Мы привели данный пример лишь чтобы продемонстрировать потенциально опасную ситуацию, связанную с оптимизациями компилятора. Для того, чтобы сделать код примера полностью безопасным, необходимо добавить, например, дополнительную синхронизацию перед выражением _a = 0, которая гарантирует, что выражение _a = 1 было выполнено.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3032. |
V3033. It is possible that this 'else' branch must apply to the previous 'if' statement.
Анализатор обнаружил потенциально возможную ошибку в логических условиях. Логика работы кода не совпадает с тем, как этот код отформатирован.
Рассмотрим пример:
if (X)
if (Y) Foo();
else
z = 1;Форматирование кода сбивает с толку, и кажется, что присваивание "z = 1" произойдет в том случае, если X == false. Однако ветка 'else' относится к ближайшему оператору 'if'. Другими словами приведенный код на самом деле эквивалентен следующему коду:
if (X)
{
if (Y)
Foo();
else
z = 1;
}Таким образом, код работает не так, как может показаться на первый взгляд.
Если выдано предупреждение V3033, то это может означать две вещи:
1) Код плохо отформатирован и ошибки на самом деле нет. Тогда, чтобы предупреждение V3033 не выдавалось, а код был более понятен, его нужно отформатировать. Пример корректного форматирования:
if (X)
if (Y)
Foo();
else
z = 1;2) Найдена логическая ошибка. Тогда код можно исправить, например, так:
if (X) {
if (Y)
Foo();
} else {
z = 1;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3033. |
V3034. Consider inspecting the expression. Probably the '!=' should be used here.
Анализатор обнаружил потенциальную ошибку. Возможно вместо оператора '=!' следует написать '!=' или '== !'. Подобные ошибки чаще всего возникают из-за опечатки.
Рассмотрим пример некорректного кода:
bool a, b;
...
if (a =! b)
{
...
}С большой вероятностью здесь должна быть проверка, что переменная 'a' не равна 'b'. Если это так, то корректный вариант кода должен выглядеть следующим образом:
if (a != b)
{
...
}Анализатор учитывает форматирование в выражении. Поэтому если действительно требуется выполнить присваивание, а не сравнение, необходимо указать, используя скобки или пробелы. Следующие примеры кода считаются анализатором корректными:
if (a = !b)
...
if (a=(!b))
...Данная диагностика классифицируется как:
V3035. Consider inspecting the expression. Probably the '+=' should be used here.
Анализатор обнаружил потенциальную ошибку, так как в программе имеется последовательность символов '=+'. Возможно, это опечатка и следует использовать оператор '+='.
Рассмотрим пример:
int size, delta;
...
size=+delta;Этот код может быть корректен. Но с большой вероятностью имеется опечатка и на самом деле, хотели использовать оператор '+='. Исправленный вариант:
int size, delta;
...
size+=delta;Если код корректен, то чтобы убрать предупреждение V3035 можно удалить '+' или поставить дополнительный пробел. Вариант корректного кода, где предупреждение не выдается:
size = delta;
size = +delta;Примечание. Для поиска опечаток вида 'A =- B' используется диагностическая проверка V3036. Эта проверка сделана отдельно, так как возможно большое количество ложных срабатываний, и может возникнуть желание отключить её.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3035. |
V3036. Consider inspecting the expression. Probably the '-=' should be used here.
Анализатор обнаружил потенциальную ошибку, так как в программе имеется последовательность символов '=-'. Возможно, это опечатка и следует использовать оператор '-='.
Рассмотрим пример:
int size, delta;
...
size =- delta;Этот код может быть корректен. Но с большой вероятностью имеется опечатка и на самом деле, хотели использовать оператор '-='. Исправленный вариант:
int size, delta;
...
size -= delta;Если код корректен, то чтобы убрать предупреждение V3036 можно использовать дополнительный пробел между символами '=' и '-'. Вариант корректного кода, где предупреждение не выдается:
size = -delta;Чтобы уменьшить количество ложных срабатываний, для правила V3036 действует ряд специфичных исключений. Например, анализатор не будет выдавать предупреждение, если программист не использует пробелов между переменными и операторами. Ряд примеров, код которых анализатор считает безопасным:
A=-B;
int Z =- 1;
N =- N;Примечание. Для поиска опечаток вида 'A =+ B' используется диагностическая проверка V3035.
Данная диагностика классифицируется как:
V3037. An odd sequence of assignments of this kind: A = B; B = A;
Анализатор обнаружил потенциальную ошибку, связанную с бессмысленным взаимным присваиванием переменных.
Рассмотрим пример:
int a, b, c;
...
a = b;
c = 10;
b = a;Здесь присваивание "B = A" не имеет никакого практического смысла. Возможно, это опечатка или просто лишнее действие. Корректный вариант кода:
a = b;
c = 10;
b = a_2;Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3037. |
V3038. The argument was passed to method several times. It is possible that another argument should be passed instead.
Анализатор обнаружил потенциально возможную ошибку в программе, в связи с тем, что метод принимает два одинаковых аргумента при вызове. Передача одного и того же значения в качестве двух аргументов для многих методов является нормальной ситуацией, поэтому при разработке диагностики был предпринят ряд ограничений.
Диагностика сработает в случае если аргументы и параметры метода имеют общий паттерн, по которому их можно описать. Для примера рассмотрим данный код:
void Do(int mX, int mY, int mZ)
{
// Some action
}
void Foo(Vecor3i vec)
{
Do(vec.x, vec.y, vec.y);
}Если обратить внимание на сигнатуру метода 'Do' и его вызов, то можно заметить, что аргумент 'vec.y' передается в него дважды, и скорее всего в данной ситуации для параметра 'mZ' ожидался аргумент 'vec.z'. Корректный вариант мог бы выглядеть так:
Do(vec.x, vec.y, vec.z);Диагностика спрогнозирует возможные варианты исправления аргумента и в случае, если предложенная переменная присутствует в зоне видимости в месте вызова метода, будет выдано предупреждение о возможной опечатке с вариантом исправления.
V3038 The 'vec.y' argument was passed to 'Do' method several times. It is possible that the 'vec.z' argument should be passed to 'mZ' parameter.
Так же если речь идет о таких функциях как Math.Min, Math.Max, string.Equals и т.д., то передача одинаковых аргументов - это очень подозрительная ситуация.
Рассмотрим пример:
int count, capacity;
....
size = Math.Max(count, count);Из-за опечатки функция Math.Max сравнивает переменную саму с собой. Корректным вариантом кода должно было быть:
size = Math.Max(count, capacity);Если Вы обнаружили подобную ошибку, которая не диагностируется анализатором, то просим сообщить нам имя функции, которая не должна принимать в качестве некоторых аргументов одинаковые переменные.
Рассмотрим другой пример ошибки, обнаруженный анализатором в коде реального приложения:
return invariantString
.Replace(@"\", @"\\")
.Replace("'", @"\'")
.Replace("\"", @"""");Скорее всего из-за незнания особенностей строковых литералов, перед которыми стоит символ '@', произошла трудно заметная ошибка при написании @"""". Судя по коду, хотели добавить два символа кавычек подряд. Но из-за ошибки, одна кавычка будет заменена той же одной кавычкой. Данную ошибку можно поправить двумя способами:
.Replace("\"", "\"\"")Или
.Replace("\"", @"""""")Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3038. |
V3039. Consider inspecting the 'Foo' function call. Defining an absolute path to the file or directory is considered a poor style.
Анализатор обнаружил потенциальную ошибку при вызове функции, предназначенную для работы с файлами. В одном из фактических аргументов в функцию передаётся абсолютный путь до файла или директории. Такое использование функция является опасным, поскольку могут встретиться случаи, когда данного пути не будет существовать на компьютере пользователя.
Рассмотрим пример некорректного кода:
String[] file = File.ReadAllLines(
@"C:\Program Files\MyProgram\file.txt");Более корректным будет вариант получения пути к файлу исходя из определенных условий.
Исправленный вариант кода:
String appPath = Path.GetDirectoryName(
Assembly.GetExecutingAssembly().Location);
String[] fileContent = File.ReadAllLines(
Path.Combine(appPath, "file.txt"));В таком случае будет осуществлён поиск файла в директории, в которой находится приложение.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V3040. The expression contains a suspicious mix of integer and real types.
Анализатор обнаружил потенциальную ошибку в выражении, где совместно используются целочисленные и real-типы данных. Под real-типами понимаются такие типы, как 'float' и 'double'.
Рассмотрим пример из реального приложения:
public long ElapsedMilliseconds { get; }
....
var minutes = watch.ElapsedMilliseconds / 1000 / 60;
Assert.IsTrue(minutes >= 0.95 && minutes <= 1.05);Здесь переменная 'minutes' имеет тип 'long', и сравнение этой переменной со значениями 0.95 и 1.05 не имеет практического смысла. Единственное целочисленное значение, которое попадает в этот диапазон, это 1.
Возможно, программист ожидал при делении целочисленных типов результат будет иметь тип 'double'. Это не так. Здесь происходит целочисленное деление в переменную 'minutes' записывается значение целого типа.
Возможным вариантом решения будет явно преобразовать количество миллисекунд к типу 'double', до деления:
var minutes = (double)watch.ElapsedMilliseconds / 1000 / 60;
Assert.IsTrue(minutes >= 0.95 && minutes <= 1.05);Теперь результат деления будет более точным, а переменная 'minutes' будет имеет тип 'double'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3040. |
V3041. The expression was implicitly cast from integer type to real type. Consider utilizing an explicit type cast to avoid the loss of a fractional part.
В выражении присутствует операция деления целочисленных типов данных. Полученное значение неявно преобразуется к типу с плавающей точкой. Обнаружив такую ситуацию, анализатор предупреждает о наличии потенциальной ошибки, которая может привести к вычислению неточного результата.
Рассмотрим пример:
int totalTime = 1700;
int operationNum = 900;
double averageTime = totalTime / operationNum;Программист может ожидать, что переменная 'averageTime' будет иметь значение '1.888(8)', однако при выполнении программы будет получен результат равный '1.0'. Это происходит потому, что операция деления выполняется с целочисленными типами и только затем приводится к типу с плавающей точкой.
Как и в предыдущем случае, ошибку можно исправить 2 способами.
Первый способ - изменить типы переменных:
double totalTime = 1700;
double operationNum = 900;
double averageTime = totalTime / operationNum;Второй способ - использовать явное приведение типов.
int totalTime = 1700;
int operationNum = 900;
double averageTime = (double)(totalTime) / operationNum;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3041. |
V3042. Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the same object.
Анализатор обнаружил два различных способа обращения к членам одного объекта, через операторы "?." и ".". Как следствие, при обращении к части выражения через "?." предполагается, что предстоящий член выражения может быть равен null. Отсюда следует, что попытка доступа члену выражения через "." приведет к падению программы.
Рассмотрим пример:
if (A?.X == X || A.X == maxX)
...Из-за невнимательности, возникает ситуация в которой, если "A" будет null, первое условие вернет false, а при проверке второго условия возникнет исключение NullReferenceException. Исправленный вариант программы должен выглядеть так:
if (A?.X == X || A?.X == maxX)
...Рассмотрим другой пример ошибки, взятый из реального приложения:
return node.IsKind(SyntaxKind.IdentifierName) &&
node?.Parent?.FirstAncestorOrSelf<....>() != null;Как видно из примера, во второй части условия допускается, что "node" может быть null "node?.Parent", но при вызове функции "IsKind" данной проверки не производиться.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3042. |
V3043. The code's operational logic does not correspond with its formatting.
Анализатор обнаружил потенциальную ошибку, связанную c тем, что форматирование кода, следующего за условным оператором, не соответствует логике выполнения программы. Высока вероятность, что пропущены открывающиеся и закрывающиеся фигурные скобки.
Рассмотрим пример некорректного кода:
if (a == 1)
b = c; d = b;В данном случае присваивание 'd = b;' будет выполняться всегда, независимо от условия 'a == 1'.
Если код ошибочен, то ситуацию можно исправить, используя фигурные скобки. Корректный вариант кода:
if (a == 1)
{ b = c; d = b; }Другой пример некорректного кода:
if (a == 1)
b = c;
d = b;Для исправления ошибки так же следует использовать фигурные скобки. Корректный вариант кода:
if (a == 1)
{
b = c;
d = b;
}Если код корректен, то чтобы исчезло предупреждение V3043, следует отформатировать код следующим образом:
if (a == 1)
b = c;
d = b;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3043. |
V3044. WPF: writing and reading are performed on a different Dependency Properties.
Анализатор обнаружил потенциальную ошибку в программе, связанную с регистрацией свойств зависимостей [Dependency Properties]. При регистрации свойств зависимостей было ошибочно задано свойство, через которое происходит запись/чтение свойств.
class A : DependencyObject
{
public static readonly DependencyProperty CurrentTimeProperty =
DependencyProperty.Register("CurrentTime", ....);
public static readonly DependencyProperty OtherProperty =
DependencyProperty.Register("Other", ....);
public DateTime CurrentTime {
get { return (DateTime)GetValue(CurrentTimeProperty); }
set { SetValue(OtherProperty, value); } }
}
....Из-за копирования возникла следующая ситуация. В определении методов доступа get и set, свойства CurrentTime, используются соответственно методы GetValue и SetValue с различные DependencyProperty. Таким образом при чтении свойства CurrentTime значение будет получено из свойства зависимости CurrentTimeProperty, а при записи в свойство CurrentTime, значение будет записано в 'OtherProperty'.
Корректным обращением к DependencyProperty будет подобный вариант:
public DateTime CurrentTime {
get { return (DateTime)GetValue(CurrentTimeProperty); }
set { SetValue(CurrentTimeProperty, value); } }
}V3045. WPF: the names of the property registered for DependencyProperty, and of the property used to access it, do not correspond with each other.
Анализатор обнаружил потенциальную ошибку в программе, связанную с регистрацией свойства зависимости [Dependency Property]. При регистрации свойства зависимости было ошибочно задано имя свойства, через которое происходит обращение к свойству зависимости.
class A : DependencyObject
{
public static readonly DependencyProperty ColumnRulerPenProperty =
DependencyProperty.Register("ColumnRulerBrush", ....);
public DateTime ColumnRulerPen {
get { return (DateTime)GetValue(ColumnRulerPenProperty); }
set { SetValue(ColumnRulerPenProperty, value); }
}
....Из-за переименования возникла ситуация, при которой в свойстве, через которое происходит запись в свойство зависимости ColumnRulerPenProperty, было ошибочно задано имя свойства. В приведённом примере из реального приложения это ColumnRulerPen, вместо ColumnRulerBrush (согласно параметрам функции Register).
Подобное реализация свойств зависимости таит в себе потенциальную проблему. При первом обращении из XAML разметки к свойству ColumnRulerPen значение будет прочитано, но при изменении ColumnRulerPen значение не будет обновляться.
Корректным заданием свойства будет такой вариант:
public DateTime ColumnRulerBrush {
get { return (DateTime)GetValue(CurrentTimeProperty); }
set { SetValue(CurrentTimeProperty, value); }
}В реальных примерах встречается и следующий вариант ошибочного задания имени свойства зависимости:
public static readonly DependencyProperty WedgeAngleProperty =
DependencyProperty.Register("WedgeAngleProperty", ....);Предполагался, что слово "Property" будет отсутствовать в строковом литерале:
public static readonly DependencyProperty WedgeAngleProperty =
DependencyProperty.Register("WedgeAngle", ....);Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3045. |
V3046. WPF: the type registered for DependencyProperty does not correspond with the type of the property used to access it.
Анализатор обнаружил потенциальную ошибку в программе, связанную с регистрацией свойства зависимости [Dependency Property]. При регистрации свойства зависимости был ошибочно задан тип значения, который должен быть записан в свойство зависимости.
В приведённом далее примере, это CurrentTimeProperty:
class A : DependencyObject
{
public static readonly DependencyProperty CurrentTimeProperty =
DependencyProperty.Register("CurrentTime", typeof(int),....);
public DateTime CurrentTime
{
get { return (DateTime)GetValue(CurrentTimeProperty); }
set { SetValue(CurrentTimeProperty, value); }
}
....Из-за копирования возникла ситуация, в которой при регистрации свойства зависимости было указано, что данное свойство хранит значение типа int. При попытке записи или чтения в CurrentTimeProperty из свойства CurrentTime произойдёт ошибка.
Корректный вариант регистрации DependencyProperty выглядит следующим образом:
public static readonly DependencyProperty CurrentTimeProperty =
DependencyProperty.Register("CurrentTime", typeof(DateTime),....);Данная диагностика также проверят совпадение типов регистрируемого свойства зависимости и типа значения, заданного по умолчанию.
public static readonly DependencyProperty CurrentTimeProperty =
DependencyProperty.Register("CurrentTime", typeof(DateTime),
typeof(A),
new FrameworkPropertyMetadata(132));В данном примере значением по умолчанию является 132, при этом указано, что само свойство зависимости должно содержать значение типа DateTime.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3046. |
V3047. WPF: A class containing registered property does not correspond with a type that is passed as the ownerType.type.
Анализатор обнаружил потенциальную ошибку в программе, связанную с регистрацией свойства зависимости [Dependency Property]. При регистрации свойства зависимости был задан тип владельца свойства, отличный от класса, в котором объявлено само свойство зависимости.
class A : DependencyObject { .... }
class B : DependencyObject
{
public static readonly DependencyProperty CurrentTimeProperty =
DependencyProperty.Register("CurrentTime", typeof(DateTime),
typeof(A));
....Из-за копирования возникла ситуация, в которой при регистрации свойства зависимости было указано, что данное свойство имеет в качестве владельца класс 'A', хотя на самом деле оно определено в классе 'B'.
Корректный вариант регистрации DependencyProperty выглядит следующим образом:
class B : DependencyObject
{
public static readonly DependencyProperty CurrentTimeProperty =
DependencyProperty.Register("CurrentTime", typeof(DateTime),
typeof(B));V3048. WPF: several Dependency Properties are registered with a same name within the owner type.
Анализатор обнаружил потенциальную ошибку в программе, связанную с регистрацией свойств зависимостей [Dependency Properties]. При пределах одного класса были зарегистрированы два свойства зависимостей на одно и то же имя.
class A : DependencyObject
{
public static readonly DependencyProperty CurrentTimeProperty =
DependencyProperty.Register("CurrentTime",....);
public static readonly DependencyProperty OtherProperty =
DependencyProperty.Register("CurrentTime",....);
....Из-за копирования возникла ситуация, в которой, при регистрации свойства зависимости OtherProperty, было указано, что данному свойству нужно обращаться из XAML разметки по имени 'CurrentTime', а не по 'Other', как предполагалось разработчиком.
Корректный вариант регистрации свойств зависимостей выглядит следующим образом:
public static readonly DependencyProperty CurrentTimeProperty =
DependencyProperty.Register("CurrentTime",....);
public static readonly DependencyProperty OtherProperty =
DependencyProperty.Register("Other",....);V3049. WPF: readonly field of 'DependencyProperty' type is not initialized.
Анализатор обнаружил потенциальную ошибку в программе, связанную со свойствами зависимости [Dependency Property]. Свойство зависимости было объявлено, но не было проинициализировано, что приведет к ошибке при попытке доступа к нему через SetValue / GetValue.
class A : DependencyObject
{
public static readonly DependencyProperty CurrentTimeProperty;
static A(){ /* CurrentTimeProperty не инициализируется */ }
....После неаккуратного рефакторинга или из-за неудачного Copy-Paste возможна ситуация, когда свойство зависимости остается не зарегистрированным. Корректный вариант кода:
class A : DependencyObject
{
public static readonly DependencyProperty CurrentTimeProperty;
static A()
{
CurrentTimeProperty =
DependencyProperty.Register("CurrentTime", typeof(DateTime),
typeof(A));
}
....V3050. Possibly an incorrect HTML. The </XX> closing tag was encountered, while the </YY> tag was expected.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что в коде задан строковый литерал, в котором содержится разметка HTML с ошибками. Был открыт тег для элемента, которому требуется завершающий тег. Но следующим в строке обнаружен закрывающий тег, который не соответствует открывающему тегу.
Рассмотрим пример:
string html = "<B><I>This is a text, in bold italics.</B>";В данном случае открывающему тегу "<I>" должен соответствовать закрывающий тег "</I>", но при дальнейшем анализе HTML мы обнаружим закрывающий тег "</B>", что является ошибкой. В таком виде часть HTML кода является невалидной.
Для исправления ошибки необходимо проверить корректность последовательности открывающих и закрывающих тегов и устранить найденные ошибки.
Пример корректного варианта:
string html = "<B><I>This is a text, in bold italics.</I></B>";Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3050. |
V3051. An excessive type cast or check. The object is already of the same type.
В выражении присутствует избыточное использование оператора 'as' или 'is'. Нет смысла приводить объект к собственному типу или выполнять проверку на совместимость с ним же. Часто данный код просто является избыточным, но порой подобные ситуации могут свидетельствовать о наличии ошибки в коде.
Для того, чтобы лучше понять, о чём речь, рассмотрим несколько примеров.
Искусственный пример:
public void SomeMethod(String str)
{
var localStr = str as String;
....
}При инициализации переменной 'localStr' выполняется явное приведение объекта 'str' к типу 'String' при том, что явное приведение с использованием оператора 'as' избыточно, так как 'str' уже является объектом типа 'String'.
Тогда упрощённый код мог бы выглядеть так:
public void SomeMethod(String str)
{
String localStr = str;
....
}Вместо явного указания типа объекта 'localStr' можно было бы оставить ключевое слово 'var', но явное указание типа добавляет ясности программе.
Рассмотрим более интересный пример:
public object FindName(string name, FrameworkElement templatedParent);
....
lineArrow = (Grid)Template.FindName("lineArrow", this) as Grid;
if (lineArrow != null);
....Рассмотрим строку с приведениями более внимательно и проследим, что происходит:
- Метод 'FindName' возвращает объект типа 'object', который явно пытаются привести к типу 'Grid'.
- Если не удастся выполнить это приведение, на данном этапе будет сгенерировано исключение типа 'InvalidCastException'.
- Если же приведение будет выполнено успешно, то выполнится повторное приведение к тому же типу 'Grid' с использованием оператора 'as'. В таком случае успех этого приведения гарантирован. Это приведение является лишним.
- В итоге, в случае неудачного приведения 'lineArrow' никогда не примет значение 'null'.
Если посмотреть на следующую строку, видно, что предполагается, что 'lineArrow' может иметь значение 'null', следовательно, подразумевается именно использование оператора 'as'. Как объяснялось выше, 'lineArrow' не может принять значение 'null' в случае неудачного приведения. Следовательно, это не просто избыточное приведение, а явная ошибка.
Решением может послужить удаление лишней операции приведения из кода:
lineArrow = Template.FindName("lineArrow", this) as Grid;
if (lineArrow != null);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3051. |
V3052. The original exception object was swallowed. Stack of original exception could be lost.
Анализатор обнаружил ситуацию, когда исходный объект перехваченного исключения не был использован приемлемым образом при повторной генерации исключения из блока catch. Из-за этого ряд ошибок превращается в трудноотлаживаемые, так как теряется стек оригинального исключения.
Рассмотрим несколько примеров некорректного кода. Первый пример:
public Asn1Object ToAsn1Object()
{
try
{
return Foo(_constructed, _tagNumber);
}
catch (IOException e)
{
throw new ParsingException(e.Message);
}
}В данном случае перехваченное исключение ввода/вывода хотели трансформировать в другое исключение типа 'ParsingException'. При этом передали только сообщение из первого исключения, тем самым сократив количество полезной информации.
Корректный вариант кода:
public Asn1Object ToAsn1Object()
{
try
{
return Foo(_constructed, _tagNumber);
}
catch (IOException e)
{
throw new ParsingException(e.Message, e);
}
}В исправленном варианте исходное исключение передается в качестве внутреннего, что полностью сохраняет информацию об исходной ошибке.
Рассмотрим второй пример:
private int ReadClearText(byte[] buffer, int offset, int count)
{
int pos = offset;
try
{
....
}
catch (IOException ioe)
{
if (pos == offset) throw ioe;
}
return pos - offset;
}В данном случае перехваченное исключение ввода/вывода генерируется повторно и полностью "затирает" стек оригинальной ошибки. Чтобы этого избежать, достаточно сделать переброс оригинального исключения.
Корректный вариант кода:
private int ReadClearText(byte[] buffer, int offset, int count)
{
int pos = offset;
try
{
....
}
catch (IOException ioe)
{
if (pos == offset) throw;
}
return pos - offset;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3052. |
V3053. An excessive expression. Examine the substrings "abc" and "abcd".
Анализатор обнаружил потенциальную ошибку, связанную с тем, что в выражении ищется более длинная подстрока и более короткая. При этом более короткая строка, является частью более длинной. Получается, что одно из сравнений избыточно или допущена какая-то ошибка.
Рассмотрим пример:
if (str.Contains("abc") || str.Contains("abcd"))В случае если подстрока "abc" будет найдена, то дальнейшая проверка не будет выполняться. Если подстрока "abc" не будет найдена, то и поиск более длинной подстроки "abcd" не имеет смысла.
Для исправления ошибки необходимо проверить правильность подстрок или убрать из кода лишние проверки. Пример корректного варианта:
if (str.Contains("abc"))Другой пример:
if (str.Contains("abc"))
Foo1();
else if (str.Contains("abcd"))
Foo2();В данном случае метод Foo2() никогда не будет вызван. Устранить ошибку можно путем замены порядка проверки. То есть сначала следует искать более длинную подстроку, а потом более короткую:
if (str.Contains("abcd"))
Foo2();
else if (str.Contains("abc"))
Foo1();Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3053. |
V3054. Potentially unsafe double-checked locking. Use volatile variable(s) or synchronization primitives to avoid this.
Анализатор обнаружил потенциальную ошибку, связанную с небезопасным использованием шаблона "блокировки с двойной проверкой" (double checked locking). Блокировка с двойной проверкой - это шаблон, предназначенный для уменьшения накладных расходов получения блокировки. Сначала проверяется условие блокировки без синхронизации. И только если условие выполняется, поток попытается получить блокировку. Таким образом, блокировка будет выполнена только если она действительно была необходима.
Рассмотрим пример небезопасной реализации данного шаблона на языке C#:
private static MyClass _singleton = null;
public static MyClass Singleton
{
get
{
if(_singleton == null)
lock(_locker)
{
if(_singleton == null)
{
MyClass instance = new MyClass();
instance.Initialize();
_singleton = instance;
}
}
return _singleton;
}
}В данном примере шаблон используется для реализации "ленивой инициализации" - инициализация откладывается до тех пор, пока значение переменной не понадобится. Данный код будет корректно работать в программе, использующей объект '_singleton' из одного потока. Для обеспечения безопасной инициализации в многопоточной программе обычно используется конструкция 'lock', однако в нашем примере этого оказывается недостаточно.
Обратите внимание на вызов метода 'Initialize()' у объекта 'Instance'. В Release версии программы, компилятор может оптимизировать данный код и порядок назначения переменной '_singleton' и метода 'Initialize()' могут поменяться. Таким образом, другой поток, обратившись к 'Singleton' одновременно с инициализирующим потоком, может получить доступ к объекту до того, как инициализация будет завершена.
Рассмотрим другой пример использования шаблона блокировки с двойной проверкой:
private static MyClass _singleton = null;
private static bool _initialized = false;
public static MyClass Singleton;
{
get
{
if(!_initialized)
lock(_locker)
{
if(!_initialized)
{
_singleton = new MyClass();
_initialized = true;
}
}
return _singleton;
}
}Мы видим, что, как и в предыдущем примере, оптимизация компилятором порядка назначений переменных '_singleton' и '_initialized' может привести к ошибке. Т.е. в начале переменной '_initialized' будет присвоено значение 'true', а уже потом создастся новый объект типа 'MyClass' и ссылка не него будет записана в '_singleton'.
Такая перестановка может привести к ошибке при доступе к объекту из параллельного потока. Получается, что переменная '_singleton' будет ещё не назначена, а флаг '_intialize' уже будет выставлен в 'true'.
Одна из опасностей таких ошибок состоит в том, что часто кажется, будто программа работает корректно. Это происходит из-за того, что рассмотренная ситуация будет возникать не очень часто, в зависимости от архитектуры используемого процессора, версии CLR и т.п.
Есть несколько способов обеспечить потоко-безопасность для данного шаблона. Самым простым будет пометить проверяемую в условии if переменную ключевым словом volatile:
private static volatile MyClass _singleton = null;
public static MyClass Singleton
{
get
{
if(_singleton == null)
lock(_locker)
{
if(_singleton == null)
{
MyClass instance = new MyClass();
instance.Initialize();
_singleton = instance;
}
}
return _singleton;
}
}Использование ключевого слова 'volatile' предотвратит для переменной возможные оптимизации компилятора, связанные с перестановками инструкций записи\чтения и кэшированием её значения в регистрах процессора.
Из соображений производительности не всегда желательно объявлять переменную как 'volatile'. В этом случае можно организовать доступ к переменной с помощью методов: 'Thread.VolatileRead', 'Thread.VolatileWrite' и 'Thread.MemoryBarrier'. Эти методы создадут барьеры по чтению\записи памяти только там, где это необходимо.
Наконец, для реализации "ленивой инициализации" можно воспользоваться специально предназначенным для этого классом 'Lazy<T>', доступным начиная с .NET 4.
См. также статью: Выявление неправильной блокировки с двойной проверкой с помощью диагностики V3054.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3054. |
V3055. Suspicious assignment inside the condition expression of 'if/while/for' operator.
Анализатор обнаружил ситуацию, когда в условии оператора if/while/do while/for выполняется оператор присваивания '=' для операндов булевского типа. Есть вероятность, что вместо оператора '=' планировалось использовать оператор '=='.
Рассмотрим пример:
void foo(bool b1, bool b2)
{
if (b1 = b2)
....В коде допущена опечатка. Вместо сравнения переменных b1 и b2, в коде произойдет изменение значения переменной b1. Корректный вариант кода:
if (b1 == b2)Если в конструкции 'if' необходимо сделать присвоение, для сокращения кода, то рекомендуется оборачивать присвоение в круглые скобки. Обертывание присваивания в дополнительные скобки - это распространенный паттерн программирования, описываемый в книгах и распознаваемый различными компиляторами и анализаторами кода.
Условие с дополнительными скобками подсказывает программисту и анализаторам кода, что никой ошибки нет:
if ((b1 = b2))Более того, дополнительное обертывание в скобки не только делают код более читабельным, но и убережет от ошибок приоритета операций, как в следующим примере:
if ((a = b) || a == c)
{ }Если бы не было скобок, то, согласно приоритету операций, сначала выполнилась бы часть 'b || a == c', а после результат выполнения выражения присвоился бы переменной 'a'. Это поведение могло оказаться вовсе не таким, как задумывал программист.
Данная диагностика классифицируется как:
V3056. Consider reviewing the correctness of 'X' item's usage.
Анализатор выявляет случаи, когда для условных переменных 'x' и 'y' дважды использовался условный метод 'GetX', вместо 'GetX' и 'GetY' соответственно.
Рассмотрим пример:
int x = GetX() * n;
int y = GetX() * n;Во второй строке вместо функции GetY() используется GetX(). Корректный код:
int x = GetX() * n;
int y = GetY() * n;Для обнаружения этого подозрительного места анализатор следовал следующей логике. Мы имеем строку, где используется имя, включающее в себя фрагмент "X". Рядом с ней есть строка, где используется имя - антипод, содержащая "Y". Но при этом во второй строке также есть и "X". Если выполнилось это и ещё некоторые условия, то данная конструкцию считается опасной и анализатор предлагает программисту её проверить. Если бы, например, слева не было переменных "x" и "y" то такой код считался бы безопасным. Пример кода, на который анализатор не обратит внимания:
array[0] = GetX() / 2;
array[1] = GetX() / 2;К сожалению, данное правило имеет ложные срабатывания, так как анализатор не имеет представления об устройстве программы и предназначении кода. Например, в коде теста:
var t1 = new Thread { Name = "Thread 1" };
var t2 = new Thread { Name = "Thread 2" };
var m1 = new Message { Name = "Thread 1: Message 1", Thread = t1};
var m2 = new Message { Name = "Thread 1: Message 2", Thread = t1};
var m3 = new Message { Name = "Thread 2: Message 1", Thread = t2};Анализатор предположил, что при объявлении переменной 'm2' использовалось копирование кода и возникла ошибка: используется переменная 't1', а не 't2'. На самом деле ошибки нет. Исходя из текста сообщений, можно сделать вывод, что тест проверят вывод сообщений 'm1', 'm2' из одного потока 't1', а вывод сообщения 'm3' из потока 't2'. Для подобных случаев ошибочного анализа, есть возможность убрать предупреждение, вписав в код комментарий "//-V3056" или использовать другие методы подавления ложных предупреждений.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3056. |
V3057. Function receives an odd argument.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в качестве фактического аргумента в функцию передаётся очень странное значение.
Рассмотрим примеры:
Недопустимые символы в пути
string GetLogPath(string root)
{
return System.IO.Path.Combine(root, @"\my|folder\log.txt");
}В функцию 'Combine()' передаётся путь, содержащий недопустимый символ '|'. В результате чего функция сгенерирует исключение 'ArgumentException'.
Корректный вариант:
string GetLogPath(string root)
{
return System.IO.Path.Combine(root, @"\my\folder\log.txt");
}Странный аргумент функции форматирования
string.Format(mask, 1, 2, mask);Функция 'string.Format()' заменяет один или более элементов формата в указанной строке. Анализатор считает подозрительным, если в строку форматирования пытаются записать эту же строку.
Недопустимый индекс
var pos = mask.IndexOf('\0');
if (pos != 0)
asciiname = mask.Substring(0, pos);'IndexOf()' возращает позицию искомого аргумента. Если аргумент не найден, то функция возвращает значение '-1'. А если передать отрицательный индекс в функцию 'Substring()', то возникнет 'ArgumentOutOfRangeException'.
Корректный вариант:
var pos = mask.IndexOf('\0');
if (pos > 0)
asciiname = mask.Substring(0, pos);Обратите внимание, что анализатор может также выдать предупреждение, когда в метод передаётся корректный аргумент, но соответствующий параметр внутри метода может принять недопустимое значение.
static void Bar(string[] data, int index, int length)
{
if (index < 0)
throw new Exception(....);
if (data.Length < index + length)
length = data.Length - index; // <=
....
Array.Copy(data, index, result, 0, length); // <=
}
static void Foo(string[] args)
{
Bar(args, 4, 2); // <=
....
}В данном случае анализатор выдаст предупреждение, что при вызове метода 'Bar' соответствующий аргументу '2' параметр ('length') внутри метода может принять отрицательное значение, которое дальше используется при вызове метода 'Array.Copy'. Это приведёт к возникновению исключения 'ArgumentOutOfRangeException'.
И действительно, если размер массива 'args' ('data' внутри метода 'Bar') будет меньше 4, внутри метода 'Bar' в 'length' будет записано отрицательное значение несмотря на то, что в метод передаётся положительное значение - 2. Как следствие - при вызове 'Array.Copy' будет выброшено исключение.
В метод 'Bar' следует добавить проверку нового значения 'length' и необходимую обработку отрицательных значений:
if (data.Length < index + length)
length = data.Length - index;
if (length < 0)
.... // Error handlingДанная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3057. |
V3058. An item with the same key has already been added.
Анализатор обнаружил ситуацию, когда в словарь добавляются значения для ключа, который уже присутствует в словаре. На этапе выполнения это приведет к генерации исключения ArgumentException с сообщением: "An item with the same key has already been added.".
Рассмотрим пример некорректного кода:
var mimeTypes = new Dictionary<string, string>();
mimeTypes.Add(".aif", "audio/aiff");
mimeTypes.Add(".aif", "audio/x-aiff"); // ArgumentExceptionВ данном случае, при повторной попытке добавить значение по ключу ".aif", будет сгенерировано исключение ArgumentException.
Корректный вариант кода предполагает устранение дубликатов ключей при заполнении словаря:
var mimeTypes = new Dictionary<string, string>();
mimeTypes.Add(".aif", "audio/aiff");Данная диагностика классифицируется как:
V3059. Consider adding '[Flags]' attribute to the enum.
Анализатор посчитал подозрительным перечисление, элементы которого участвуют в битовых операциях или имеют значения, равные степеням 2. Но при этом само перечисление не отмечено атрибутом [Flags].
Если выполняется одно из этих условий, то для использования перечислений как битовых флагов, необходимо отметить перечисление атрибутом [Flags], что даст ряд преимуществ при работе с этим перечислением в коде.
Для того, чтобы лучше понять, как изменяет поведение программы применение атрибута [Flags] к перечислимому типу, рассмотрим несколько примеров:
enum Suits { Spades = 1, Clubs = 2, Diamonds = 4, Hearts = 8 }
// en1: 5
var en1 = (Suits.Spades | Suits.Diamonds);Без атрибута [Flags] результатом применения битовой операции OR для членов со значениями '1' и '4' будет значение '5'.
Поведение меняется, если для перечисления задан атрибут [Flags]:
[Flags]
enum SuitsFlags { Spades = 1, Clubs = 2, Diamonds = 4, Hearts = 8 }
// en2: SuitsFlags.Spades | SuitsFlags.Diamonds;
var en2 = (SuitsFlags.Spades | SuitsFlags.Diamonds);В таком случае результат операции OR рассматривается не как единственное целочисленное значение, а как набор битов, содержащих значения 'SuitsFlags.Spades' и 'SuitsFlags.Diamonds'.
Если у объектов 'en1' и 'en2' вызвать метод 'ToString', его результат также будет различаться. Данный метод попытается преобразовать числовое значение в символьный эквивалент, но у значения '5' нет символьного эквивалента. Однако обнаружив у типа атрибут [Flags], метод 'ToString' рассматривает числовое значение как набор битовых флагов. Следовательно, вызов метода 'ToString' для объектов 'en1' и 'en2' даст следующий вывод:
String str1 = en1.ToString(); // "5"
String str2 = en2.ToString(); // "SuitsFlags.Spades |
// SuitsFlags.Diamonds"По аналогии работают и получения числовых значений из строки при использовании статических методов 'Parse' и 'TryParse' класса 'Enum'.
Дополнительным преимуществом использования [Flags] является упрощение процесса отладки. Значение переменной 'en2' будет отображаться как набор именованных констант, а не как просто число:

Дополнительная информация:
- What does the [Flags] Enum Attribute mean in C#?
- CLR via C#. Jeffrey Richter. Chapter 15 - Enumerated Types and Bit Flags.
V3060. A value of variable is not modified. Consider inspecting the expression. It is possible that other value should be present instead of '0'.
Анализатор обнаружил подозрительное битовое выражение. Выражение написано для того, чтобы изменить определённые биты в переменной. Но значение переменной останется прежним.
Пример подозрительного кода:
A &= ~(0 << Y);
A = A & ~(0 << Y);Программист планировал сбросить определенный бит в переменной, но допустил ошибку. написав 0, вместо 1.
Обе строки идентичны по результату, поэтому рассмотрим вторую строку, как более наглядный пример. Предположим, что имеется следующие значение переменных в битовом представлении:
A = 0..0101
A = 0..0101 & ~(0..0000 << 0..00001)
Сдвиг влево на один бит значения 0 - ни к чему не приведет. В итоге получится следующие выражение:
A = 0..0101 & ~0..0000
Далее будет выполнена операции побитового отрицания, что приведет к следующему выражению:
A = 0..0101 & 11111111
После операции побитового "и", получится, что исходное и результирующее выражение равны:
A = 0..0101
Исправленный вариант кода должен выглядеть, следующим образом:
A &= ~(1 << Y);
A = A & ~(1 << Y);Данная диагностика классифицируется как:
V3061. Parameter 'A' is always rewritten in method body before being used.
Анализатор нашёл потенциальную ошибку в теле метода. Один из его параметров перезаписывается перед тем, как используется. Таким образом значение, пришедшее в метод, попросту теряется.
Эта ошибка имеет разные проявления. Рассмотрим пример кода:
void Foo1(Node A, Node B)
{
A = SkipParenthesize(A);
B = SkipParenthesize(A);
// do smt...
}Здесь допущена опечатка, из-за чего объект 'B' примет неверное значение. Исправленный код выглядит так:
void Foo1(Node A, Node B)
{
A = SkipParenthesize(A);
B = SkipParenthesize(B);
// do smt...
}Но данная ошибка может проявить себя и более интересно:
void Foo2(List<Int32> list, Int32 count)
{
list = new List<Int32>(count);
for (Int32 i = 0; i < count; ++i)
list.Add(GetElem(i));
}Данный метод должен был инициализировать список некоторыми значениями. В данном случае происходит копирование ссылки ('list'), хранящей адрес блока памяти в куче, в котором расположен список (или 'null', если память не была выделена). Поэтому, когда мы вновь выделяем память под список, адрес блока памяти записывается в локальную копию ссылки, а исходная (за пределами метода) остаётся неизменной. Таким образом выполняется лишняя работа для выделения памяти, инициализации списка и последующей уборки мусора.
Ошибка заключается в пропущенном модификаторе 'out'. Корректный вариант кода:
void Foo2(out List<Int32> list, Int32 count)
{
list = new List<Int32>(count);
for (Int32 i = 0; i < count; ++i)
list.Add(GetElem(i));
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3061. |
V3062. An object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' method.
Анализатор обнаружил вызов метода, в который в качестве аргумента передаётся сам объект, у которого вызывается метод. Вероятно, данный код содержит ошибку, и в метод должен передаваться другой объект.
Рассмотрим пример:
A.Foo(A);Здесь из-за опечатки используется неверное имя переменной. Тогда корректный код должен был быть таким:
A.Foo(B);или таким:
B.Foo(A);Пример кода из реального приложения:
private bool CanRenameAttributePrefix(....)
{
....
var nameWithoutAttribute =
this.RenameSymbol.Name.GetWithoutAttributeSuffix(isCaseSensitive:
true);
var triggerText = GetSpanText(document,
triggerSpan,
cancellationToken);
// nameWithoutAttribute, triggerText - String
return triggerText.StartsWith(triggerText);
}Результатом возвращаемого значения в данном случае всегда будет 'true', из-за того, что метод, проверяющий, что строка начинается с подстроки, принимает в качестве аргумента саму строку ('triggerText'). Скорее всего подразумевалась следующая проверка:
return triggerText.StartsWith(nameWithoutAttribute);Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3062. |
V3063. A part of conditional expression is always true/false if it is evaluated.
Анализатор обнаружил потенциально возможную ошибку внутри логического условия. Часть логического выражения всегда истинно/ложно и оценено, как подозрительное.
Рассмотрим пример:
uint i = length;
while ((i >= 0) && (n[i] == 0)) i--;Выражение "i >= 0" всегда истинно, т.к. переменная 'i' имеет тип uint. Поэтому, если значение 'i' дойдёт до нуля, то цикл while не будет остановлен, и 'i' примет максимальное значение типа uint. Попытка дальнейшего доступа к массиву 'n' приведёт к исключению OverflowException.
Корректный код:
int i = length;
while ((i >= 0) && (n[i] == 0)) i--;Рассмотрим другой пример:
public static double Cos(double d)
{
// -9223372036854775295 <= d <= 9223372036854775295
bool expected = !performCheck ||
!(-9223372036854775295 <= d || // <=
d <= 9223372036854775295);
if (!expected)
....Программист хотел проверить, что переменная d попадает в заданный диапазон (это видно по комментарию перед проверкой). Но из-за опечатки он написал оператор '||', вместо оператора '&&'. Корректный код:
bool expected = !performCheck ||
!(-9223372036854775295 <= d &&
d <= 9223372036854775295);Иногда предупреждение V3063 выявляет не ошибку, а просто избыточный код. Рассмотрим пример:
if (@char < 0x20 || @char > 0x7e) {
if (@char > 0x7e
|| (@char >= 0x01 && @char <= 0x08)
|| (@char >= 0x0e && @char <= 0x1f)
|| @char == 0x27
|| @char == 0x2d)Анализатор предупредит, что подвыражения @char == 0x27 и @char == 0x2d всегда ложны из-за предшествующего оператора if. Этот код может быть вполне корректен. Однако он избыточен, и лучше его упростить. Это сделает программу более простой для понимания другими разработчиками.
Упрощенный вариант кода:
if (@char < 0x20 || @char > 0x7e) {
if (@char > 0x7e
|| (@char >= 0x01 && @char <= 0x08)
|| (@char >= 0x0e && @char <= 0x1f))Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3063. |
V3064. Division or mod division by zero.
Анализатор обнаружил ситуацию, когда может произойти деление на ноль.
Рассмотрим пример:
if (maxHeight >= 0)
{
fx = height / maxHeight;
}В условии проверяется, что значение переменной maxHeight неотрицательно. Если эта переменная будет равна нулю, то внутри условия произойдёт деление на 0. Чтобы исправить ситуацию, необходимо выполнять деление только в том случае, когда maxHeight положительно.
Исправленный вариант:
if (maxHeight > 0)
{
fx = height / maxHeight;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки деления на ноль. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3064. |
V3065. Parameter is not utilized inside method's body.
Анализатор обнаружил подозрительный метод, один из параметров которого ни разу не используется. При этом другой его параметр используется несколько раз, что, возможно, свидетельствует о наличии ошибки.
Рассмотрим пример:
private static bool CardHasLock(int width, int height)
{
const double xScale = 0.051;
const double yScale = 0.0278;
int lockWidth = (int)Math.Round(height * xScale);
int lockHeight = (int)Math.Round(height * yScale);
....
}Из кода видно, что параметр 'width' ни разу не используется в теле метода, при этом параметр 'height' используется дважды, в том числе при инициализации переменной 'lockWidth'. Скорее всего, здесь допущена ошибка, и код инициализации переменной 'lockWidth' должен был выглядеть следующим образом:
int lockWidth = (int)Math.Round(width * xScale);Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3065. |
V3066. Possible incorrect order of arguments passed to method.
Анализатор обнаружил подозрительную передачу аргументов в метод. Возможно некоторые аргументы перепутаны местами.
Пример подозрительного кода:
void SetARGB(byte a, byte r, byte g, byte b)
{ .... }
void Foo(){
byte A = 0, R = 0, G = 0, B = 0;
....
SetARGB(A, R, B, G);
....
}Во время задания цвета объекта, перепутали синий и зелёный цвет.
Исправленный вариант кода должен выглядеть следующим образом:
SetARGB(A, R, G, B);Рассмотри более сложный пример опечатки из реального проекта:
public virtual string Qualify(string catalog,
string schema,
string table)
{ .... }
public Table AddDenormalizedTable(....) {
string key = subselect ??
dialect.Qualify(schema, catalog, name);
....
}Согласно логике, можем предположить, что код должен выглядеть следующим образом:
public Table AddDenormalizedTable(....) {
string key = subselect ??
dialect.Qualify(catalog, schema, name);
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3066. |
V3067. It is possible that 'else' block was forgotten or commented out, thus altering the program's operation logics.
Анализатор обнаружил подозрительное место в коде - возможно, забытый или некорректно закомментированный блок else.
Данную ситуацию лучше всего разобрать на примерах.
if (!x)
t = x;
else
z = t;В этом примере форматирование кода не совпадает с его логикой: выражение "z = t;" выполнится лишь в случае, если (x == false) - вряд ли это имелось в виду. Подобная же ситуация может возникнуть при неудачно закомментированном фрагменте кода:
if (!x)
t = x;
else
//t = -1;
z = t;В данном случае требуется либо исправить форматирование, превратив его в более удобочитаемое, либо исправить логическую ошибку, добавив недостающую ветвь оператора if.
Иногда встречаются случаи, в которых тяжело определить, является ли подобный код некорректным или таким образом стилизованным. Анализатор пытается уменьшать количество ложных срабатываний, связанных со стилизацией, не выдавая предупреждение, если код отформатирован с помощью и пробелов, и символов табуляции. Причём символов табуляции в разных строках содержится разное количество.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3067. |
V3068. Calling overrideable class member from constructor is dangerous.
Анализатор обнаружил потенциально возможную ошибку внутри конструктора класса - вызов перегружаемого (виртуального или абстрактного) метода.
Приведём пример, когда такая ситуация может привести к ошибке:
abstract class Base
{
protected Base()
{
Initialize();
}
protected virtual void Initialize()
{
...
}
}
class Derived : Base
{
Logger _logger;
public Derived(Logger logger)
{
_logger = logger;
}
protected override void Initialize()
{
_logger.Log("Initializing");
base.Initialize();
}
}В нашем примере, в конструкторе абстрактного класса Base присутствует вызов виртуального метода Initialize. В классе Derived, унаследованном от класса Base, мы переопределяем метод Initialize, и используем в переопределённом методе поле _logger, которое инициализируется в конструкторе класса Derived.
Однако, при создании экземпляра класса Derived сначала будет выполнен конструктор самого базового класса в цепочке наследования (в нашем случае это Base). Но при вызове из конструктора Base метода Initialize, будет выполнен метод Initialize непосредственно у того объекта, который мы создаём в runtime - т.е. метод Initialize у класса Derived. Обратите внимание, что при выполнении метода Initialize поле _logger окажется ещё неинициализированным - создание экземпляра класса Derived из нашего примера приведёт к исключению NullReferenceException.
Таким образом, вызов переопределяемых методов в конструкторе потенциально может примести к выполнению методов объекта, инициализация которого ещё не завершена.
Для того, чтобы исправить предупреждение PVS-Studio, пометьте вызываемый метод (или класс, его содержащий), как sealed, либо снимите его пометку, как виртуального.
В случае, если вы точно уверены, что вам нужно описанное поведение при инициализации объекта и вы хотите скрыть предупреждение от анализатора, пометьте сообщение как ложнопозитивное. Информация о том, как это сделать, вы можете посмотреть в нашей документации.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3068. |
V3069. It's possible that the line was commented out improperly, thus altering the program's operation logics.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что два последовательно идущих оператора 'if' оказались разделены закомментированной строкой. Высока вероятность, что неаккуратно был закомментирован фрагмент кода. Неаккуратность привела к тому, что существенно изменилась логика работы программы.
Рассмотрим пример:
if(!condition)
//condition = GetCondition();
if(condition)
{
...
}Программа потеряла смысл. Условие второго оператора 'if' никогда не выполняется. Корректный вариант кода:
//if(!condition)
//condition = GetCondition();
if(condition)
{
...
}Данная диагностика классифицируется как:
V3070. Uninitialized variables are used when initializing the 'A' variable.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что член класса будет инициализирован не тем значением, которое предполагалось.
Рассмотрим пример:
class AClass {
static int A = B + 1;
static int B = 10;
}В данном случае поле 'A' будет инициализировано значением '1', а не '11', как мог предположить программист. Дело в том, что на момент инициализации поля 'A', значение поля 'B' будет равно '0'. Это обусловлено тем, что изначально все члены типа (класса или структуры) инициализируются значениями по умолчанию ('0' для числовых типов, 'false' - для логического, и 'null' для ссылочных). И только после этого будет выполняться инициализация, установленная программистом. Решением проблемы будет изменение порядка следования полей:
class AClass {
static int B = 10;
static int A = B + 1;
}В таком случае на момент инициализации поля 'A', 'B' будет содержать в себе значение '10', как и предполагалось.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3070. |
V3071. The object is returned from inside 'using' block. 'Dispose' will be invoked before exiting method.
Анализатор обнаружил возврат из функции объекта, который используется в операторе using.
Пример подозрительного кода:
public FileStream Foo(string path)
{
using (FileStream fs = File.Open(path, FileMode.Open))
{
return fs;
}
}Т.к. переменная была проинициализирована в блоке using, то перед возвратом из метода у данной переменной будет вызван метод Dispose. Вследствие этого, использовать объект, который вернет функция, может быть небезопасно.
Вызов метода Dispose произойдет по причине того, что вышеописанный код будет преобразован компилятором таким образом:
public FileStream Foo(string path)
{
FileStream fs = File.Open(path, FileMode.Open)
try
{
return fs;
}
finally
{
if (fs != null)
((IDisposable)fs).Dispose();
}
}Исправленный вариант кода может выглядеть следующим образом:
public FileStream Foo(string path)
{
return File.Open(path, FileMode.Open)
}V3072. The 'A' class containing IDisposable members does not itself implement IDisposable.
Анализатор обнаружил в классе, не реализующим интерфейс 'IDisposable', поля или свойства, которые имеют тип реализующий интерфейс 'IDisposable'. Подобный код говорит о том, что программист, возможно, забывает очищать некоторые ресурсы после использования объекта своего класса.
Пример подозрительного кода:
class Logger
{
FileStream fs;
public Logger() {
fs = File.OpenWrite("....");
}
}В данном случае, класс-обёртка, позволяющий писать лог в файл, не реализует интерфейс 'IDisposable'. При этом он содержит переменную типа 'FileStream', позволяющую осуществлять запись в файл. В данном случае переменная 'fs' будет держать файл до тех пор, пока не вызовется метод Finalize у объекта 'fs' (это произойдёт, когда объект будет очищаться сборщиком мусора). Как следствие, мы получим плавающую ошибку доступа, к примеру, когда попытаемся открыть этот же файл из другого потока.
Исправить проблему можно несколькими способами. Самым правильным является следующий:
class Logger : IDisposable
{
FileStream fs;
public Logger() {
fs = File.OpenWrite("....");
}
public void Dispose() {
fs.Dispose();
}
}Но не всегда логика программы позволяет реализовать в классе 'Logger' интерфейс 'IDisposable'. Анализатор проверят множество ситуаций и сокращает число ложных срабатываний. Например, в данном случае, будет достаточно закрыть 'FileStream', который пишет в файл в отдельной функции.
class Logger
{
FileStream fs;
public Logger() {
fs = File.OpenWrite("....");
}
public void Close() {
fs.Close();
}
}V3073. Not all IDisposable members are properly disposed. Call 'Dispose' when disposing 'A' class.
При проверке класса, реализующего интерфейс 'IDisposable', была выявлена потенциальная ошибка. В методе 'Dispose', данного класса, не для всех полей, тип которых реализует интерфейс 'IDisposable', производится вызов метода 'Dispose'. Высока вероятность, что разработчик забыл очистить некоторые ресурсы после их использования.
Пример подозрительного кода:
class Logger : IDisposable
{
FileStream fs;
public Logger() {
fs = File.OpenWrite("....");
}
public void Dispose() { }
}В приведенном примере присутствует класс-обёртка 'Logger', реализующий интерфейс 'IDisposable', который позволяет писать информацию в лог-файл. Данный класс содержит переменную 'fs' с помощью которой и осуществляется запись в сам файл. Вследствие того, что в методе 'Dispose' класса 'Logger' забыли вызвать методы 'Dispose' или 'Close' возможно возникновение следующей ошибки.
Допустим, объект класс 'Logger' был создан в блоке 'using':
using(Logger logger = new Logger()){
....
}Вследствие этого, перед выходом из блока 'using' будет вызван метод 'Dispose' для объекта 'logger'.
Данное использование предполагает, что все ресурсы, используемые объектом класса 'Logger', освобождены и можно повторно к ним обращаться.
Но в нашем случае, поток 'fs', который пишет в файл, не будет закрыт. И при попытке повторного доступа к этому файлу, например, из другого потока, возможно возникновение ошибка доступа.
Данная ошибка будет иметь "плавающий" характер, поскольку объект 'fs', при очистке его сборщиком мусора, высвободит открытый файл. Однако, сборка объекта является недетерминированным событием, она не произойдёт гарантированно после выхода объекта logger из блока using. Ошибка доступа к файлу возникнет, если файл будет открыт до того, как сборщик мусора успеет очистить объект 'fs'.
Для исправления подобной проблемы, достаточно вызвать 'fs.Dispose()' в методе 'Dispose' класса 'Logger':
class Logger : IDisposable
{
FileStream fs;
public Logger() {
fs = File.OpenWrite("....");
}
public void Dispose() {
fs.Dispose();
}
}Это гарантирует в приведённом ранее примере, что файл, открытый объектом 'fs', будет освобождён на момент выхода из блока using.
V3074. The 'A' class contains 'Dispose' method. Consider making it implement 'IDisposable' interface.
Анализатор обнаружил в классе, не реализующем интерфейс 'IDisposable', метод с именем 'Dispose'. В данном случае, возможны два варианта развития событий.
Первый случай
Наиболее распространённым случаем является, простое несоответствие соглашениям о написании кода Microsoft. Метод c данным именем является реализацией стандартного интерфейса 'IDisposable' и применяется для детерминированной очистки ресурсов, в том числе unmanaged (неуправляемых) ресурсов.
Пример подозрительного кода:
class Logger
{
....
public void Dispose()
{
....
}
}Согласно соглашениям, метод 'Dispose' используется для очистки ресурсов. И его наличие предполагает, что сам класс реализует интерфейс IDisposable. В данном случае есть два варианта решения проблемы.
1) Дописать в объявлении класса реализацию интерфейса IDisposable:
class Logger : IDisposable
{
....
public void Dispose()
{
....
}
}Это позволит вам использовать объекты класса 'Logger' в блоке 'using', гарантирующем вызов метода Dispose при выходе из блока.
using(Logger logger = new Logger()){
....
}2) Исправить имя метода на нейтральное. Например, на 'Close':
class Logger
{
....
public void Close()
{
....
}
}Второй случай
Второй случай, где срабатывает данное предупреждение, таит в себе опасность неверного вызова метода, в случае приведения класса к интерфейсу 'IDisposable'.
Пример подозрительного кода:
class A : IDisposable
{
public void Dispose()
{
Console.WriteLine("Dispose A");
}
}
class B : A
{
public new void Dispose()
{
Console.WriteLine("Dispose B");
}
}В случае приведения объекта класса 'B' к интерфейсу 'IDisposable' или его использование в блоке 'using'. Например, так:
using(B b = new B()){
....
}Будет вызвана функция 'Dispose' из класса 'A', т.е. освобождение ресурсов класса 'B' не произойдёт.
Для вызова верной функции из класса 'B', нужно дополнительно реализовать в классе 'B' интерфейс 'IDisposable'. В таком случае, при приведении объекта класса 'B' к интерфейсу 'IDisposable' или его использование в блоке 'using', будет вызвана функция 'Dispose' именно из него.
Пример исправленного кода:
class B : A, IDisposable
{
public new void Dispose()
{
Console.WriteLine("Dispose B");
base.Dispose();
}
}V3075. The operation is executed 2 or more times in succession.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что одна из операций '!', '~', '-' или '+' повторяется два или более раз. Такая ошибка может произойти в случае опечатки. Такое дублирование операторов бессмысленно и может содержать ошибку.
Рассмотрим пример некорректного кода:
if (!(( !filter )))
{
....
}Скорее всего, такая ошибка возникла после проведения рефакторинга кода. Например, была удалена часть сложного логического выражения, а отрицание всего результата осталось. В итоге, получилось противоположное по смыслу выражение.
Корректный вариант кода:
if ( filter )
{
....
}Или:
if ( !filter )
{
....
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3075. |
V3076. Comparison with 'double.NaN' is meaningless. Use 'double.IsNaN()' method instead.
Анализатор обнаружил сравнение переменной типа float или double с float.NaN или double.NaN. В соответствии с документацией, если два значения double.NaN сравниваются с помощью оператора == , то результатом будет false. Таким образом какое бы значение типа double ни сравнивали с double.NaN, в результате всегда будет false.
Рассмотрим пример:
void Func(double d) {
if (d == double.NaN) {
....
}
}Проверка на NaN с помощью операторов == и != некорректна. Вместо этого следует использовать методы float.IsNaN() или double.IsNaN(). Исправленный вариант:
void Func(double d) {
if (double.IsNaN(d)) {
....
}
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3076. |
V3077. Property setter / event accessor does not utilize its 'value' parameter.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что в аксессорах свойств и событий не используется параметр 'value'.
Рассмотрим пример некорректного кода:
private bool _visible;
public bool IsVisible
{
get { return _visible; }
set { _visible = true; }
}Скорее всего, при задании нового значения свойству "IsVisible" планировали сохранить результат в переменную "_visible", но допустили ошибку, из-за чего изменение свойства никак не будет влиять на состояние объекта.
Корректный вариант кода:
public bool IsVisible
{
get { return _visible; }
set { _visible = value; }
}Анализатор может выдавать предупреждения на код следующего вида:
public bool Unsafe {
get { return (flags & Flags.Unsafe) != 0; }
set { flags |= Flags.Unsafe; }
}В этом случае метод 'set' используется для изменения состояния флага и в коде ошибки нет, но использование такого свойства может вводить в заблуждение разработчика, т.к. результат при присваиваниях "myobj.Unsafe = true" и "myobj.Unsafe = false" будет одинаковый.
Для сброса состояния внутренней переменной лучше воспользоваться функцией, а не свойством:
public bool Unsafe
{
get { return (flags & Flags.Unsafe) != 0; }
}
public void SetUnsafe()
{
flags |= Flags.Unsafe;
}Если от использования такого свойства нельзя отказаться, то можно пометить это место комментарием специального вида " //-V3077" и анализатор в дальнейшем не будет выдавать предупреждение для этого свойства:
public bool Unsafe {
get { return (flags & Flags.Unsafe) != 0; }
set { flags |= Flags.Unsafe; } //-V3077
}Все способы подавления ложных предупреждений описаны в документации.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3077. |
V3078. Sorting keys priority will be reversed relative to the order of 'OrderBy' method calls. Perhaps, 'ThenBy' should be used instead.
Анализатор обнаружил потенциальную ошибку: два раза подряд вызываются методы 'OrderBy' или 'OrderByDescending'. Результат такой сортировки может отличаться от ожидаемого.
Рассмотрим пример:
var seq = points.OrderBy(item => item.Primary)
.OrderBy(item => item.Secondary);Допустим, программист хотел отсортировать коллекцию так, чтобы элементы были сгруппированы и отсортированы по 'Primary', а внутри каждая группа была отсортирована по 'Secondary'.
Но на самом деле элементы коллекции будут сгруппированы и отсортированы по 'Secondary', а внутри каждая группа будет отсортирована по 'Primary'.
Для получения ожидаемого поведения второй вызов 'OrderBy' следует заменить на вызов метода 'ThenBy'.
var seq = points.OrderBy(item => item.Primary)
.ThenBy(item => item.Secondary);Используя два вызова 'OrderBy', получить предполагаемое поведение также можно, но для этого необходимо поменять вызовы местами:
var seq = points.OrderBy(item => item.Secondary)
.OrderBy(item => item.Primary);Аналогичную ошибку можно допустить при написании кода с использованием синтаксиса запроса:
var seq = from item in points
orderby item.Primary
orderby item.Secondary
select item;Код можно исправить следующим образом:
var seq = from item in points
orderby item.Primary, item.Secondary
select item;Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3078. |
V3079. The 'ThreadStatic' attribute is applied to a non-static 'A' field and will be ignored.
Анализатор обнаружил подозрительное объявление нестатического поля, к которому применяется атрибут 'ThreadStatic'.
Применение данного атрибута к статическому полю позволяет устанавливать индивидуальное значение этого поля для каждого потока. К тому же это запрещает совместное использование данного поля в разных потоках, что исключает возможность блокировок при обращении к полю. Однако при применении данного атрибута к нестатическому полю, атрибут будет проигнорирован.
Рассмотрим пример:
[ThreadStatic]
bool m_knownThread;Скорее всего данное поле является флагом, который должен иметь своё значение для каждого потока. Но так как поле не является статическим, применение данного атрибута не имеет смысла. Если все же логика работы программы основывается на факте, что значение поля должно быть уникальным для каждого потока (исходя из названия и наличия атрибута 'ThreadStatic'), возможна ошибка.
Для исправления ошибки необходимо добавить модификатор 'static' к объявлению поля:
[ThreadStatic]
static bool m_knownThread;Дополнительная информация:
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3079. |
V3080. Possible null dereference.
Анализатор обнаружил фрагмент кода, который может привести к доступу по нулевой ссылке.
Рассмотрим несколько примеров, для которых анализатор выдает диагностическое сообщение V3080:
if (obj != null || obj.Func()) { ... }
if (obj == null && obj.Func()) { ... }
if (list == null && list[3].Func()) { ... }Во всех условиях допущена логическая ошибка, которая приведет к доступу по нулевой ссылке. Ошибка может быть допущена при рефакторинге кода или из-за случайно опечатки.
Корректные варианты:
if (obj == null || obj.Func()) { .... }
if (obj != null && obj.Func()) { .... }
if (list != null && list[3].Func()) { .... }Конечно, это очень простые ситуации. На практике проверка объекта на null и его использование может находиться в разных местах. Если анализатор выдал предупреждение V3080, изучите код расположенный выше и попробуйте понять, почему ссылка может быть нулевой.
Пример кода, где проверка и использование объекта находятся в разных строках
if (player == null) {
....
var identity = CreateNewIdentity(player.DisplayName);
....
}Анализатор предупредит, об опасности в строке внутри блока 'if'. Здесь или некорректно написано условие, или вместо 'player' должна использоваться другая переменная.
Программисты иногда забывают о том, что при проверке двух объектов на null один из них может оказаться нулевым, а второй нет, в результате чего будет вычислено всё условие и произойдёт доступ по нулевой ссылке. Например,
if ((text == null && newText == null) || text.Equals(newText)) {
....
}Это условие можно переписать, например, так
if ((text == null && newText == null) ||
(text != null && newText != null && text.Equals(newText))) {
....
}Ещё один способ допустить ошибку заключается в использовании оператора логического AND (&) вместо условного AND (&&). Нужно помнить о том что, во-первых, при использовании логического AND всегда вычисляются обе части выражения, а во-вторых приоритет у логического AND выше чем у условного AND.
Пример:
public static bool HasCookies {
get {
var context = HttpContext;
return context != null
&& context.Request != null & context.Request.Cookies != null
&& context.Response != null && context.Response.Cookies != null;
}
}В этом примере обращение к context.Request.Cookies будет выполнено даже если context.Request равен null.
Также опасной является ситуация с разыменованием параметра, для которого значением по умолчанию является 'null'. Пример:
public NamedBucket(string name, List<object> items = null)
{
_name = name;
foreach (var item in items)
{
....
}
}Конструктор принимает коллекцию 'items' в качестве необязательного параметра. Однако если при вызове значение для 'items' не будет передано, то при попытке обхода коллекции в 'foreach' будет выброшено исключение типа 'NullReferenceException'.
В зависимости от ситуации решение этой проблемы может отличаться. Например, можно производить обход коллекции только в случае, если она не равна 'null'.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3080. |
V3081. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что при написании двух и более вложенных циклов 'for', из-за опечатки не используется счётчик одного из циклов.
Рассмотрим синтетический пример некорректного кода:
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
sum += matrix[i, i];В коде планировали обойти все элементы матрицы и найти их сумму, но случайно написали переменную 'i' вместо 'j' при обращении к матрице.
Корректный вариант кода:
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
sum += matrix[i, j];В отличие от диагностических правил V3014, V3015 и V3016, здесь анализатор ищет ошибки с использованием индекса только в теле циклов.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3081. |
V3082. The 'Thread' object is created but is not started. It is possible that a call to 'Start' method is missing.
Анализатор обнаружил подозрительный фрагмент кода, в котором создаётся объект типа 'Thread', но при этом созданный поток не запускается.
Рассмотрим пример:
void Foo(ThreadStart action)
{
Thread thread = new Thread(action);
thread.Name = "My Thread";
}В данном коде создаётся объект типа 'Thread', ссылка на который записывается в переменную 'thread'. Но при этом поток не запускается и никуда не передаётся. Таким образом, созданный объект просто будет удалён при следующей уборке мусора, при этом никак не использовавшись.
Для исправления ситуации у объекта необходимо вызвать метод 'Start', который запустит поток на выполнение. Тогда исправленный код может выглядеть так:
void Foo(ThreadStart action)
{
Thread thread = new Thread(action);
thread.Name = "My Thread";
thread.Start();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V3083. Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it.
Анализатор обнаружил потенциально небезопасный вызов обработчика события (event). Возможно возникновение исключения 'NullReferenceException'.
Рассмотрим пример опасного кода:
public event EventHandler MyEvent;
void OnMyEvent(EventArgs e)
{
if (MyEvent != null)
MyEvent(this, e);
}В данном примере происходит проверка на 'null' поля 'MyEvent', и затем происходит вызов данного события. Проверка на 'null' позволит избежать исключения в случае, если на событие никто не подписан на момент его вызова (в такой ситуации 'MyEvent' будет иметь значение 'null').
Однако, представим, что у события 'MyEvent' есть один подписчик. И в момент между проверкой на null и непосредственными вызовом обработчика события по 'MyEvent()' существует вероятность, что будет произведена отписка от события, например, в другом потоке:
MyEvent -= OnMyEventHandler;Теперь, если обработчик 'OnMyEventHandler' был единственным подписчиком события 'MyEvent', поле 'MyEvent' примет значение 'null'. Но, т.к., в другом потоке, где событие должно будет быть вызвано, в нашем гипотетическом примере проверка на 'null' уже произошла, будет выполнена следующая строка: 'MyEvent()'. Это приведёт к возникновению исключения 'NullReferenceException'.
Как мы видим, одной проверки на 'null' недостаточно, чтобы гарантировать безошибочное выполнение вызова события. Существует несколько способов, позволяющих избежать описанной выше потенциальной ошибки. Рассмотрим их.
Первый способ заключается в создании временной локальной переменной, в которую мы сохраняем ссылку на обработчики нашего события:
public event EventHandler MyEvent;
void OnMyEvent(EventArgs e)
{
EventHandler handler = MyEvent;
if (handler != null)
handler(this, e);
}Это позволит выполнить обработчики события без возникновения исключения. Даже если между проверкой 'handler' на 'null' и вызовом обработчика произойдёт отписка от события, как в нашем первом примере, переменная 'handler' всё равно будет содержать ссылку на первоначальный обработчик. И он будет корректно вызван несмотря на то, событие 'MyEvent' уже не содержит данный обработчик.
Другой способ избежать ошибки - изначально присвоить событию пустой обработчик в виде анонимного метода или лямбда выражения:
public event EventHandler MyEvent = (sender, args) => {};Такой код гарантирует, что поле 'MyEvent' никогда не будет иметь значения 'null', т.к. такой анонимный метод невозможно будет отписать (если он конечно не сохранён в отдельной переменной), что также позволяет избавиться от проверки на null перед вызовом события.
Наконец, начиная с версии языка C# 6.0 (Visual Studio 2015), можно обеспечить безопасный вызов события с помощью оператора '?.':
MyEvent?.Invoke(this, e);Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3083. |
V3084. Anonymous function is used to unsubscribe from event. No handlers will be unsubscribed, as a separate delegate instance is created for each anonymous function declaration.
Анализатор обнаружил потенциально ошибочную отписку от события с использованием анонимных функций.
Приведём пример некорректного кода:
public event EventHandler MyEvent;
void Subscribe()
{
MyEvent += (sender, e) => HandleMyEvent(e);
}
void UnSubscribe()
{
MyEvent -= (sender, e) => HandleMyEvent(e);
}В приведённом примере объявлены методы 'Subscribe' и 'UnSubscribe' для, соответственно, подписки и отписки от события 'MyEvent'. В качестве обработчика события используется лямбда выражение. Подписка на событие в методе 'Subscribe' будет успешно выполнена - обработчик (анонимная функция) будет добавлен в событие.
Однако, метод 'UnSubscribe' не выполнит отписку ранее назначенного в методе 'Subscribe' обработчика. После выполнения данного метода, событие 'MyEvent' по-прежнему будет содержать обработчик, назначенный в 'Subscribe'.
Такое поведение обусловлено тем, что каждое объявление анонимной функции приводит к созданию отдельного экземпляра делегата, в нашем случае, с типом EventHandler. Таким образом, в методе 'Subscribe' была произведена подписка 'делегата 1', а в методе Unsubscribe производится отписка уже для 'делегата 2', несмотря на то, что тела данных делегатов идентичны. Так как наше событие на момент отписки содержит только 'делегат 1', отписка от 'делегата 2' никак не изменит значения 'MyEvent'.
Для того, чтобы корректно использовать анонимные функции при подписке на события (если потребуется дальнейшая отписка), можно сохранять обработчик-лямбду в отдельную переменную, и использовать её как при подписке, так и при отписке от события:
public event EventHandler MyEvent;
EventHandler _handler;
void Subscribe()
{
_handler = (sender, e) => HandleMyEvent(sender, e);
MyEvent += _handler;
}
void UnSubscribe()
{
MyEvent -= _handler;
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3084. |
V3085. The name of 'X' field/property in a nested type is ambiguous. The outer type contains static field/property with identical name.
Анализатор обнаружил во вложенном классе поле или свойство, которое имеет такое же имя, что и статическое/константное поле или свойство во внешнем классе.
Пример подозрительного кода:
class Outside
{
public static int index;
public class Inside
{
public int index; // <= Одноименное поле
public void Foo()
{
index = 10;
}
}
}Использование подобной конструкции может привести к ошибочной работе программы. Наиболее опасен следующий сценарий. Допустим, изначально в классе 'Inside' не было поля 'index'. Это значит, что функция 'Foo' изменяла именно статическую переменную 'index' во внешнем классе 'Outside'. Когда мы добавили поле 'index' в класс 'Inside', то, без явного указания имени внешнего класса, функция 'Foo' станет изменять поле 'index' во внутреннем классе. Естественно, данный код начнёт работать не так, как первоначально было задумано разработчиком, хотя и не вызовет нареканий со стороны компилятора.
Исправить ошибку можно переименованием переменной:
class Outside
{
public static int index;
public class Inside
{
public int insideIndex;
public void Foo()
{
index = 10;
}
}
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3085. |
V3086. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
Анализатор обнаружил потенциальную ошибку, найдя в коде инициализацию двух различных переменных одинаковыми выражениями. Анализатор считает опасными не все выражения, а только в которых используется вызов функций (либо слишком длинное выражение).
Рассмотрим наиболее простой случай:
x = X();
y = X();Возможны три варианта действий:
- Код содержит ошибку. Необходимо исправить ошибку, заменив 'X()' на 'Y()'.
- Код верен, но работает медленно. Если функция 'X()' требует много вычислений, то лучше написать 'y = x;'.
- Код верен и работает быстро. Или функция 'X()' читает значение из файла. Тогда чтобы избавиться от ложного срабатывания, можно использовать комментарий "//-V3086".
Теперь рассмотрим реальный пример:
string frameworkPath =
Path.Combine(tmpRootDirectory, frameworkPathPattern);
string manifestFile =
Path.Combine(frameworkPath, "sdkManifest.xml");
string frameworkPath2 =
Path.Combine(tmpRootDirectory, frameworkPathPattern2);
string manifestFile2 =
Path.Combine(frameworkPath, "sdkManifest.xml");В данном коде закралась ошибка copy-paste, которую сложно заметить на первый взгляд. На самом деле, при получении сроки 'manifestFile2', ошибочно передали в функцию 'Path.Combine' первую часть пути. Согласно логике, в коде должна использоваться переменная 'frameworkPath2', а не 'frameworkPath', которая там сейчас находится.
Исправленный код должен выглядеть так:
string manifestFile2 =
Path.Combine(frameworkPath2, "sdkManifest.xml");V3087. Type of variable enumerated in 'foreach' is not guaranteed to be castable to the type of collection's elements.
Анализатор обнаружил потенциальную ошибку в цикле 'foreach'. Существует вероятность возникновения исключения InvalidCastException при обходе коллекции 'IEnumarable<T>'.
Рассмотрим пример:
List<object> numbers = new List<object>();
....
numbers.Add(1.0);
....
foreach (int a in numbers)
Console.WriteLine(a);В данном случае, шаблон коллекции 'numbers' инициализирован типом 'object', тем самым позволяя добавлять в неё объекты любого типа.
При обходе этой коллекцией, в цикле задано, что её члены должны иметь тип 'int'. Если в коллекции окажется объект другого типа, будет выполнено приведение и возможно возникновение исключения 'InvalidCastException'. В нашем примере исключение возникнет из-за невозможности распаковки (Unboxing) значения типа 'double', упакованного в элементе типа 'object' коллекции, в тип 'int'.
Для исправления данной ошибки можно привести тип шаблона коллекции и тип элемента в цикле 'foreach' к одному типу:
Вариант 1:
List<object> numbers = new List<object>();
....
foreach (object a in numbers)Вариант 2:
List<int> numbers = new List<int>();
....
foreach (int a in numbers)Часто подобная ошибка наблюдается, когда имеется коллекция с элементами базового интерфейса, а в цикле указывают тип одного из интерфейсов или классов, реализующих данный базовый интерфейс:
void Foo1(List<ITrigger> triggers){
....
foreach (IOperableTrigger trigger in triggers)
....
}
void Foo2(List<ITrigger> triggers){
....
foreach (IMutableTrigger trigger in triggers)
....
}Для обхода в коллекции объектов только одного конкретного типа, можно предварительно отфильтровать её с помощью функции 'OfType':
void Foo1(List<ITrigger> triggers){
....
foreach (IOperableTrigger trigger in
triggers.OfType<IOperableTrigger>())
....
}
void Foo2(List<ITrigger> triggers){
....
foreach (IMutableTrigger trigger in
triggers.OfType<IMutableTrigger>())
....
}Такой код гарантирует, что цикл foreach будет работать только с объектами нужного типа, и исключит возможность возникновения исключения 'InvalidCastException'.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3087. |
V3088. The expression was enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or misprint is present.
Анализатор обнаружил двойные круглые скобки вокруг выражения. Есть вероятность, что одна из скобок поставлена не там, где надо.
Хочется подчеркнуть, что анализатор не просто ищет фрагменты кода, где два раза повторяются круглые скобки, а пытается обнаружить те ситуации, когда, изменив местонахождение одной скобки, можно изменить смысл выражения. Рассмотрим пример:
if((!isLowLevel|| isTopLevel))Этот код подозрителен. Непонятно, зачем здесь дополнительные круглые скобки. Возможно, выражение должно выглядеть так:
if(!(isLowLevel||isTopLevel))Если даже выражение корректно, то всё равно лучше убрать лишние круглые скобки. На это есть две причины:
- Человек читающий код, может усомниться в его корректности, увидев дублирующиеся круглые скобки.
- Если убрать лишние скобки, то анализатор перестанет выдавать ложное предупреждение.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3088. |
V3089. Initializer of a field marked by [ThreadStatic] attribute will be called once on the first accessing thread. The field will have default value on different threads.
Анализатор обнаружил подозрительный фрагмент кода, в котором поле, отмеченное атрибутом [ThreadStatic] инициализируется при объявлении или в статическом конструкторе.
Если выполняется инициализация при объявлении, поле будет проинициализировано этим значением только у первого обратившегося потока. В остальных потоках это поле будет содержать значение, предусмотренное по умолчанию.
Схожая ситуация со статическим конструктором – он выполняется только один раз, и поле будет проинициализировано только в потоке, в котором статический конструктор выполнится.
Рассмотрим пример ситуации с инициализацией при объявлении:
class SomeClass
{
[ThreadStatic]
public static Int32 field = 42;
}
class EntryPoint
{
static void Main(string[] args)
{
new Task(() => { var a = SomeClass.field; }).Start(); // a == 42
new Task(() => { var a = SomeClass.field; }).Start(); // a == 0
new Task(() => { var a = SomeClass.field; }).Start(); // a == 0
}
}При обращении первого потока к полю 'field' оно будет проинициализировано заданным программистом значением. Таким образом, переменная 'a' будет иметь значение '42', равно как и поле 'field'.
При запуске последующих потоков и обращении к полю, оно уже будет проинициализировано значением по умолчанию ('0' в данном случае), поэтому во всех последующих потоков значение 'a' будет равно '0'.
Как упоминалось ранее, статический конструктор не является решением проблемы – он будет вызван 1 раз, при инициализации типа, поэтому проблема остаётся актуальной.
Решением может послужить использование свойства в качестве обёртки над полем, куда можно дописать дополнительную логику по инициализации поля. Это решает проблему, но опять же, не полностью – при обращении к полю, а не свойству (например, внутри класса), остаётся вероятность получить некорректное значение.
class SomeClass
{
[ThreadStatic]
private static Int32 field = 42;
public static Int32 Prop
{
get
{
if (field == default(Int32))
field = 42;
return field;
}
set
{
field = value;
}
}
}
class EntryPoint
{
static void Main(string[] args)
{
new Task(() => { var a = SomeClass.Prop; }).Start(); // a == 42
new Task(() => { var a = SomeClass.Prop; }).Start(); // a == 42
new Task(() => { var a = SomeClass.Prop; }).Start(); // a == 42
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3089. |
V3090. Unsafe locking on an object.
Анализатор обнаружил фрагмент кода с использованием небезопасной блокировки.
Данная диагностика срабатывает на ряд случаев:
- использование 'this' в качестве объекта блокировки;
- использование в качестве объекта блокировки экземпляра класса 'Type', 'MemberInfo', 'ParameterInfo', 'String', 'Thread';
- использование в качестве объекта блокировки публичного члена текущего класса;
- использование в качестве объекта блокировки объекта, полученного в результате упаковки;
- блокировка происходит по вновь создаваемым объектам.
Первые три случая могут привести к возникновению взаимной блокировки, два последних - к отсутствию желаемой синхронизации. Общая суть первых трёх случаев состоит в том, что к объекту, используемому для блокировки, имеется общий доступ. Такой объект может быть использован для блокировки в другом месте без ведома разработчика, использовавшего объект для блокировки в первый раз. Это, в свою очередь, создаёт вероятность возникновения взаимоблокировки на один и тот же объект.
Блокировка с использованием 'this' небезопасна, если класс не является приватным. Тогда в другом месте программист может установить блокировку на этот же объект после создания его экземпляра.
Аналогичная ситуация с публичными членами классов.
Для решения описанных выше ситуаций достаточно использовать, например, приватное поле класса в качестве объекта блокировки.
Приведём пример небезопасного кода с использованием оператора 'lock' и 'this' в качестве объекта блокировки:
class A
{
void Foo()
{
lock(this)
{
// do smt
}
}
}Для того, чтобы избежать возможных взаимных блокировок, в качестве объекта блокировки стоит использовать, например, приватное поле:
class A
{
private Object locker = new Object();
void Foo()
{
lock(locker)
{
// do smt
}
}
}С экземплярами класса 'Type', 'MemberInfo', 'ParameterInfo' ситуация несколько опаснее, так как здесь вероятность взаимной блокировки выше. Используя оператор 'typeof' или метод 'GetType', метод 'GetMember' и т.п. для разных экземпляров одного типа, результат будет одинаков - один и тот же экземпляр данного класса.
Отдельно стоят объекты типов 'String' и 'Thread'.
Доступ к объектам этих типов можно получить из любого места в программе, и даже из другого домена приложения (Application Domain), что ещё больше увеличивает опасность взаимной блокировки. Решение - не использовать в качестве объектов блокировки экземпляры этих типов.
Рассмотрим пример возникновения взаимной блокировки. Пусть имеется следующий код в каком-нибудь приложении (Sample.exe):
static void Main(string[] args)
{
var thread = new Thread(() => Process());
thread.Start();
thread.Join();
}
static void Process()
{
String locker = "my locker";
lock (locker)
{
....
}
}В другом приложении есть код следующего вида:
String locker = "my locker";
lock (locker)
{
AppDomain domain = AppDomain.CreateDomain("test");
domain.ExecuteAssembly(@"C:\Sample.exe");
}Результатом выполнения этого кода будет взаимная блокировка, возникшая в результате использования в качестве объекта блокировки экземпляра класса 'String'.
Мы создаём новый домен в рамках того же процесса и пытаемся выполнить в нём сборку, содержащуюся в другом файле (Sample.exe). В итоге возникает ситуация, когда оба оператора 'lock' используют в качестве объекта блокировки одинаковый строковый литерал. Для строковых литералов срабатывает механизм интернирования строк, за счёт которого в обоих случаях будут получены ссылки на один и тот же объект в памяти. Как следствие - оба оператора 'lock' выполняют блокировку по одному и тому же объекту, что и привело к взаимоблокировке.
Эта ошибка могла бы проявить себя и при исполнении в рамках одного домена.
Аналогичная ситуация с типом 'Thread', экземпляр которого можно легко получить, например, с помощью свойства 'Thread.CurrentThread'.
Решение - не использовать в качестве объектов блокировки объекты типов 'Thread' и 'String'.
Блокировка с использованием объекта значимого типа приведёт к тому, что синхронизация потоков осуществляться не будет. Стоит отметить, что конструкция 'lock' не позволяет выполнять блокировку на объектах значимого типа, но класс 'Monitor' с его методами 'Enter' и 'TryEnter' от этого не застрахован.
Методы 'Enter' и 'TryEnter' ожидают в качестве параметра объект типа 'Object', поэтому, если в метод передаётся объект значимого типа, будет выполнена его 'упаковка'. Это значит, что каждый раз для блокировки будет создаваться новый объект, следовательно - блокировка будет устанавливаться (и сниматься) по этому новому объекту. Результат - отсутствие желаемой синхронизации.
Рассмотрим пример ошибочного кода:
sealed class A
{
private Int32 m_locker = 10;
void Foo()
{
Monitor.Enter(m_locker);
// Do smt...
Monitor.Exit(m_locker);
}
}Программист хотел установить блокировку по приватному полю 'm_locker'. На самом же деле блокировка будет устанавливаться (и сниматься) не по желаемому полю, а по вновь созданным объектам, полученным в результате 'упаковки'.
Для исправления данной ошибки достаточно изменить тип поля 'm_locker' на допустимый ссылочный, например - 'Object'. Тогда пример корректного кода выглядел бы так:
sealed class A
{
private Object m_locker = new Object();
void Foo()
{
Monitor.Enter(m_locker);
// Do smt...
Monitor.Exit(m_locker);
}
}Схожая ошибка проявится и при использовании конструкции 'lock', если выполняется упаковка объекта в результате приведения:
Int32 val = 10;
lock ((Object)val)
{ .... }В этом коде блокировка будет устанавливаться по объектам, полученным в результате упаковки. Так как в результате упаковки будут создаваться новые объекты, синхронизации потоков не будет.
Ошибочным является блокировка по вновь создаваемым объектам. Пример подобного кода может выглядеть так:
lock (new Object())
{ .... }или так
lock (obj = new Object())
{ .... }Так как при выполнении этого кода каждый раз создаются новые объекты, блокировка также будет осуществляться по разным объектам, следовательно, потоки не будут синхронизироваться.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3090. |
V3091. Empirical analysis. It is possible that a typo is present inside the string literal. The 'foo' word is suspicious.
Если анализатор находит два одинаковых строковых литерала, он пытается понять, является ли это последствием неудачного Copy-Paste. Хочется сразу предупредить, диагностика основана на эмпирическом алгоритме и иногда может выдавать странные ложные срабатывания.
Рассмотрим пример ошибки:
string left_str = "Direction: left.";
string right_str = "Direction: right.";
string up_str = "Direction: up.";
string down_str = "Direction: up.";Код писался с использованием Copy-Paste. В конце забыли изменить строковый литерал "up" на "down". Анализатор заподозрит неладное и укажет на подозрительное слово "up" в последней строчке.
Исправленный код:
string left_str = "Direction: left.";
string right_str = "Direction: right.";
string up_str = "Direction: up.";
string down_str = "Direction: down.";Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3091. |
V3092. Range intersections are possible within conditional expressions.
Анализатор обнаружил потенциальную ошибку в условии. Программа должна совершать различные действия, в зависимости от того, в какой диапазон значений попадает некая переменная.
Для этого в коде используется следующая конструкция:
if ( MIN_A < X && X < MAX_A ) {
....
} else if ( MIN_B < X && X < MAX_B ) {
....
}Анализатор выдаёт предупреждение, если диапазоны, проверяемые в условиях, пересекаются. Пример:
if ( 0 <= X && X < 10)
FooA();
else if ( 10 <= X && X < 20)
FooB();
else if ( 20 <= X && X < 300)
FooC();
else if ( 30 <= X && X < 40)
FooD();Код содержит опечатку. Рука программиста дрогнула, и вместо условия "20 <= X && X < 30" была написано "20 <= X && X < 300". Если переменная X будет хранить, например, значение 35, то будет вызвана функция FooC(), а не FooD().
Исправленный код:
if ( 0 <= X && X < 10)
FooA();
else if ( 10 <= X && X < 20)
FooB();
else if ( 20 <= X && X < 30)
FooC();
else if ( 30 <= X && X < 40)
FooD();Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3092. |
V3093. The operator evaluates both operands. Perhaps a short-circuit operator should be used instead.
Анализатор обнаружил возможную ошибку, связанную с тем, что в логическом выражении перепутаны операторы & и && или | и ||.
Условные операторы И (&&) / ИЛИ (||) вычисляют второй операнд при необходимости (см. Short circuit), в то время как операторы & и | всегда вычисляют оба операнда. Возможно, программист не планировал такое выполнение кода.
Рассмотрим пример некорректного кода:
if ((i < a.m_length) & (a[i] % 2 == 0))
{
sum += a[i];
}Пусть объект 'a' это некий контейнер. Количество элементов в этом контейнере хранится в члене 'm_length'. Необходимо вычислить суммы чётных элементов, при этом надо контролировать, чтобы не выйти за границу массива.
Из-за опечатки, использовали не оператор '&&', а '&'. В результате, если индекс 'i' будет больше или равен 'a.m_length', произойдёт выход за границу массива при вычислении подвыражения (a[i] % 2 == 0). Независимо от того, истина или ложна левая часть выражения, правая часть в любом случае вычисляется.
Корректный вариант кода:
if ((i < a. m_length) && (a[i] % 2 == 0))
{
sum += a[i];
}Ещё один пример некорректного кода может выглядеть следующим образом:
if (x > 0 | BoolFunc())
{
....
}Вызов функции 'BoolFunc()' будет выполнен всегда, даже если условие '(x > 0)' будет истинным.
Корректный вариант кода:
if (x > 0 || BoolFunc())
{
....
}Участки кода, выявленные с помощью диагностического правила V3093, не всегда могут содержать серьёзные ошибки, но часто выражения являются неоптимальными с точки зрения производительности (особенно, если в выражении вызываются сложные функции).
Если же условное выражение записано так, как был задумано разработчиком, то можно пометить это место комментарием специального вида "//-V3093" и анализатор в дальнейшем не будет выдавать это предупреждение:
if (x > 0 | BoolFunc()) //-V3093
{
....
}Все способы подавления ложных предупреждений описаны в документации.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3093. |
V3094. Possible exception when deserializing type. The Ctor(SerializationInfo, StreamingContext) constructor is missing.
Анализатор обнаружил подозрительный класс, реализующий интерфейс 'ISerializable', но не реализующий конструктор сериализации.
Конструктор сериализации применяется при десериализации объекта и принимает 2 параметра, имеющих типы 'SerializationInfo' и 'StreamingContext'. Наследование от данного интерфейса обязует программиста реализовать метод 'GetObjectData', но не обязует реализовывать конструктор сериализации. Однако его отсутствие приведёт к возникновению исключения типа 'SerializationException'.
Рассмотрим пример ошибочного кода. Пусть где-то определен метод, выполняющий сериализацию и десериализацию объекта:
static void Foo(MemoryStream ms, BinaryFormatter bf, C1 obj)
{
bf.Serialize(ms, obj);
ms.Position = 0;
obj = (C1)bf.Deserialize(ms);
}А сам класс 'C1' определён следующим образом:
[Serializable]
sealed class C1 : ISerializable
{
public C1()
{ }
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
info.AddValue("field", field, typeof(String));
}
private String field;
}При попытке десериализовать объект будет сгенерировано исключение типа 'SerializationException'. Для того, чтобы объект типа 'C1' корректно проходил десериализацию, необходимо реализовать специальный конструктор. Тогда исправленное объявление класса будет выглядеть так:
[Serializable]
sealed class C1 : ISerializable
{
public C1()
{ }
private C1(SerializationInfo info, StreamingContext context)
{
field = (String)info.GetValue("field", typeof(String));
}
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
info.AddValue("field", field, typeof(String));
}
private String field;
}Примечание. Для данной диагностики доступна дополнительная настройка, задающаяся в конфигурационном файле (*.pvsconfig), имеющая следующий синтаксис:
//+V3094:CONF:{ IncludeBaseTypes: true }В таком случае анализатор просматривает не только непосредственно реализацию интерфейса 'ISerializable' самим классом, но и каким-либо из базовых. По умолчанию эта настройка отключена.
Дополнительную информацию о конфигурационных файлах можно прочитать здесь.
V3095. The object was used before it was verified against null. Check lines: N1, N2.
Анализатор обнаружил потенциальную ошибку, которая может привести к доступу по нулевой ссылке.
Анализатор заметил в коде следующую ситуацию. В начале, объект используется. А уже затем этот объект проверяется на null. Это может означать одно из двух:
1) Возникнет ошибка, если объект будет равен null.
2) Программа всегда работает корректно, так как объект всегда не равен null. Проверка является лишней.
Рассмотрим первый вариант. Ошибка есть.
obj = Foo();
result = obj.Func();
if (obj == null) return -1;Если объект 'obj' окажется равен null, то выражение 'obj.Func()' приведёт к ошибке. Анализатор выдаст предупреждение на этот код, указав 2 строки. Первая строка - это то место, где используется объект. Вторая строка - это то место, где объект сравнивается со значением null.
Исправленный вариант кода:
obj = Foo();
if (obj == null) return -1;
result = obj.Func();Рассмотрим второй вариант. Ошибки нет.
Stream stream = CreateStream();
while (stream.CanRead)
{
....
}
if (stream != null)
stream.Close();Этот код всегда работает корректно. Объект stream всегда не равен null. Однако анализатор не разобрался в этой ситуации и выдал предупреждение. Чтобы оно исчезло, следует удалить проверку "if (stream != null)". Она не имеет практического смысла и только может запутать программиста, читающего код.
Исправленный вариант:
Stream stream = CreateStream();
while (stream.CanRead)
{
....
}
stream.Close();В случае если анализатор ошибается, то кроме изменения кода, можно использовать комментарий для подавления предупреждений. Пример: "obj.Foo(); //-V3095".
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3095. |
V3096. Possible exception when serializing type. [Serializable] attribute is missing.
Анализатор обнаружил тип, реализующий интерфейс 'ISerializable', но не отмеченный атрибутом [Serializable]. При попытке сериализации экземпляров данного типа будет сгенерировано исключение типа 'SerializationException'. Реализации интерфейса 'ISerializable' недостаточно для того, чтобы во время выполнения программы было известно, что тип сериализуем. Для этого его необходимо декорировать атрибутом [Serializable].
Рассмотрим пример. Пусть имеется метод, выполняющий сериализацию и десериализацию объекта:
static void Foo(MemoryStream ms, BinaryFormatter bf, C1 obj)
{
bf.Serialize(ms, obj);
ms.Position = 0;
obj = (C1)bf.Deserialize(ms);
}Объявление класса 'C1' выглядит следующим образом:
sealed class C1 : ISerializable
{
public C1()
{ }
private C1(SerializationInfo info, StreamingContext context)
{
field = (String)info.GetValue("field", typeof(String));
}
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
info.AddValue("field", field, typeof(String));
}
private String field = "Some field";
}При попытке выполнить сериализацию экземпляря данного типа будет сгенерировано исключение типа 'SerializationException'. Для решения проблемы необходимо декорировать данный класс атрибутом [Serializable]. Тогда корректное определение класса будет выглядеть так:
[Serializable]
sealed class C1 : ISerializable
{
public C1()
{ }
private C1(SerializationInfo info, StreamingContext context)
{
field = (String)info.GetValue("field", typeof(String));
}
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
info.AddValue("field", field, typeof(String));
}
private String field = "Some field";
}Примечание. Для данной диагностики доступна дополнительная настройка, задающаяся в конфигурационном файле (*.pvsconfig), имеющая следующий синтаксис:
//+V3096:CONF:{ IncludeBaseTypes: true }В таком случае анализатор просматривает не только непосредственно реализацию интерфейса 'ISerializable' самим классом, но и каким-либо из базовых. По умолчанию эта функция анализа отключена.
Дополнительную информацию о конфигурационных файлах можно прочитать здесь.
V3097. Possible exception: type marked by [Serializable] contains non-serializable members not marked by [NonSerialized].
Анализатор обнаружил подозрительный класс, декорированный атрибутом [Serializable] и имеющий члены несериализуемых типов (т.е. типов, которые сами не декорированы этим атрибутом). При этом, несериализуемые члены не помечены атрибутом [NonSerialized]. Наличие таких членов может, при использовании некоторых стандартных классов для сериализации, привести к возникновению исключения типа 'SerializationException' при попытке сериализации экземпляра данного класса.
Рассмотрим пример. Предположим, что у нас есть метод, выполняющий сериализацию и десериализацию объекта:
static void Foo(MemoryStream ms, BinaryFormatter bf, C1 obj)
{
bf.Serialize(ms, obj);
ms.Position = 0;
obj = (C1)bf.Deserialize(ms);
}Имеются следующие определения классов 'C1' и 'NonSerializedClass':
sealed class NonSerializedClass { }
[Serializable]
class C1
{
private Int32 field1;
private NotSerializedClass field2;
}При попытке сериализации экземпляра класса 'C1' возникнет исключение типа 'SerializationException', так как декорирование класса атрибутом [Serializable] подразумевает, что все поля будут сериализованы. Но тип поля 'field2' не сериализуем, что приведёт к возникновению исключения. Для решения проблемы поле 'field2' необходимо декорировать атрибутом [NonSerialized]. Тогда корректное определение класса 'C1' может выглядеть так:
[Serializable]
class C1
{
private Int32 field1;
[NonSerialized]
private NotSerializedClass field2;
}Со свойствами ситуация несколько отличается. Рассмотрим пример ошибочного класса:
[Serializable]
class C2
{
private Int32 field1;
public NonSerializedClass Prop { get; set; }
}К свойствам нельзя применить атрибут [NonSerialized]. Тем не менее, при попытке сериализовать такой класс, например, с использованием 'BinaryFormatter', будет сгенерировано исключение. Дело в том, что автоматически реализуемые свойства компилятором раскрываются в поле и методы получения значения этого свойства и, возможно, записи. В этом случае будет выполняться сериализация не самого свойства, а поля, сгенерированного компилятором. Эта ситуация аналогична описанному ранее примеру с полем.
Ошибку можно исправить, явно реализовав свойство через какое-то поле. Тогда корректный код будет выглядеть так:
[Serializable]
class C2
{
private Int32 field1;
[NonSerialized]
private NonSerializedClass nsField;
public NonSerializedClass Prop
{
get { return nsField; }
set { nsField = value; }
}
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3097. |
V3098. The 'continue' operator will terminate 'do { ... } while (false)' loop because the condition is always false.
Анализатор обнаружил код, который может ввести в заблуждение программиста. Не все знают, что оператор continue в цикле "do { ... } while(false)" остановит цикл, а не возобновит его.
Таким образом, после вызова оператора 'continue' будет проверено условие '(false)', и цикл завершится так как условие ложно.
Рассмотрим пример:
int i = 1;
do
{
Console.Write(i);
i++;
if (i < 3)
continue;
Console.Write('A');
} while (false);Программист может ожидать, что программа напечатает '12A'. На самом деле будет напечатано '1'.
Если именно так задумано и ошибки нет, то код всё равно лучше изменить. Можно воспользоваться оператором 'break':
int i=1;
do {
Console.Write(i);
i++;
if(i < 3)
break;
Console.Write('A');
} while(false);Код стал более понятным. Сразу видно, что если условие (i < 3) выполняется, то цикл будет остановлен. В добавок, анализатор не будет выдавать предупреждение на этот код.
Если код некорректен, то его следует переписать. Здесь нельзя дать точных рекомендаций. Все зависит от логики работы кода. Например, чтобы напечатать '12A' лучше будет написать:
for (i = 1; i < 3; ++i)
Console.Write(i);
Console.Write('A');Данная диагностика классифицируется как:
V3099. Not all the members of type are serialized inside 'GetObjectData' method.
Анализатор обнаружил подозрительную реализацию метода 'GetObjectData', в котором сериализуются не все сериализуемые члены типа. Это может привести к неверной десериализации объекта или возникновению исключения типа 'SerializationException'.
Рассмотрим пример. Пусть имеется метод, выполняющий сериализацию и десериализацию объекта.
static void Foo(BinaryFormatter bf, MemoryStream ms, Derived obj)
{
bf.Serialize(ms, obj);
ms.Position = 0;
obj = (Derived)bf.Deserialize(ms);
}Объявление класса 'Base':
abstract class Base
{
public Int32 Prop { get; set; }
}Объявление класса 'Derived':
[Serializable]
sealed class Derived : Base, ISerializable
{
public String StrProp { get; set; }
public Derived() { }
private Derived(SerializationInfo info,
StreamingContext context)
{
StrProp = info.GetString(nameof(StrProp));
}
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
info.AddValue(nameof(StrProp), StrProp);
}
}В данном коде разработчик класса 'Derived' забыл сериализовать свойство базового класса 'Prop', из-за чего в результате сериализации объекта его состояние не будет сохранено полностью. При десериализации значение свойства 'Prop' будет установлено в значение по умолчанию, в данном случае, равное 0.
Для того, чтобы сохранить состояние объекта в результате сериализации, необходимо изменить код, добавив в реализацию метода 'GetObjectData' сохранение значения свойства 'Prop'в объекте типа 'SerializationInfo', а в конструкторе сериализации - его извлечение.
Тогда исправленный код реализации метода 'GetObjectData' и конструктора сериализации класса 'Derived' может выглядеть так:
private Derived(SerializationInfo info,
StreamingContext context)
{
StrProp = info.GetString(nameof(StrProp));
Prop = info.GetInt32(nameof(Prop));
}
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
info.AddValue(nameof(StrProp), StrProp);
info.AddValue(nameof(Prop), Prop);
}В примере, рассмотренном выше, разработчик базового класса не предусмотрел его сериализацию. Если же эта возможность предусмотрена и тип реализует интерфейс 'ISerializable', то для корректной сериализации членов базового класса необходимо вызвать метод 'GetObjectData' базового класса из производного:
public override void GetObjectData(SerializationInfo info,
StreamingContext context)
{
base.GetObjectData(info, context);
....
}Дополнительная информация:
Данная диагностика классифицируется как:
V3100. NullReferenceException is possible. Unhandled exceptions in destructor lead to termination of runtime.
Анализатор обнаружил код, который может привести к возникновению исключения NullReferenceException в деструкторе (финализаторе) класса.
Тело деструктора класса является критичным местом в программе. Начиная с версии .NET 2.0, возникновения неперехваченного исключения в теле деструктора приводит к полной остановке программы. Перехватить исключение, выпущенное из деструктора, в дальнейшем невозможно.
Из этого следует, что при обращении к объектам внутри деструктора, следует предварительно проверять их на null во избежание падения.
Рассмотрим пример:
class A
{
public List<int> numbers { get; set; }
~A()
{
if (numbers.Count > 0) {
....
}
}
}Т.к. изначально коллекция 'numbers' не была проинициализирована при объявлении, мы не можем утверждать, что при финализации объекта класса 'A', поле 'numbers' будет содержать ссылку на объект. Поэтому, стоит дополнительно проверить коллекцию на null, либо обернуть обращение к полю в блок try/catch.
Безопасный вариант кода может выглядеть следующим образом:
~A()
{
if (numbers != null)
{
if (numbers.Count > 0)
{
....
}
}
}Начиная с версии языка C# 6.0, с помощью оператора '?.', можно сократить проверку до:
~A()
{
if (numbers?.Count > 0) {
....
}
}Данная диагностика классифицируется как:
V3101. Potential resurrection of 'this' object instance from destructor. Without re-registering for finalization, destructor will not be called a second time on resurrected object.
Анализатор обнаружил подозрительный деструктор, содержащий потенциально некорректное "воскрешение" объекта.
Деструктор объекта вызывается сборщиком мусора .NET непосредственно перед тем, как объект будет удалён. Объявление деструктора объекта не является обязательным в языках .NET Framework - объект будет удалён сборщиком мусора и без явного определения деструктора. Обычно деструктор используется для освобождения одновременно с удалением самого .NET объекта неуправляемых ресурсов, которые этот объект использует. Например, это могут быть дескрипторы файловой системы. Такие неуправляемые ресурсы не будут освобождены сборщиком мусора автоматически.
Однако, в момент непосредственно перед удалением объекта, пользователь может (сознательно или несознательно) "воскресить" такой объект перед тем, как тот будут очищен сборщиком мусора. Напомним, что сборщик мусора очищает объекты, ставшие недоступными. Т.е. на такие объекты нигде не осталось ссылок. Однако, если присвоить ссылку на такой объект из его деструктора, например, в глобальную статическую переменную, то объект снова станет видим и из других частей программы, и, соответственно, "воскреснет". Заметим, что такую операцию можно производить неограниченное количество раз.
Далее приведём пример такого "воскрешения":
class HeavyObject
{
private HeavyObject()
{
HeavyObject.Bag.Add(this);
}
...
public static ConcurrentBag<HeavyObject> Bag;
~HeavyObject()
{
if (HeavyObject.Bag != null)
HeavyObject.Bag.Add(this);
}
}Предположим, что у нас есть объект HeavyObject, создание которого является очень ресурсозатратным дейстивем. При этом такой объект нельзя использовать из нескольких мест параллельно. Предположим также, что мы можем создать всего несколько экземпляров таких объектов. В нашем примере тип HeavyObject имеет открытое статическое поле Bag - коллекцию, в которую будут добавлены (в конструкторе) все созданные нами экземпляры объектов HeavyObject. Это позволит получить из любого места в программе экземпляр типа HeavyObject:
HeavyObject heavy;
HeavyObject.Bag.TryTake(out heavy);Метод TryTake удалит экземпляр heavy из коллекции Bag. Таким образом, в программе возможно будет использовать только ограниченное число заранее созданных экземпляров типа HeavyObject (его конструктор является закрытым). Далее, представим, что экземпляр heavy, полученный с помощью метода TryTake, стал более не нужен, и все ссылки на этот объект оказались удалены. Тогда для этого объекта, через какое-то время, сборщиком мусора будет вызван его деструктор, где этот объект снова будет добавлен в коллекцию Bag, т.е. "воскрешён", и снова станет доступен для пользователей программы, без необходимости его пересоздавать.
Однако, приведённый пример содержит ошибку, из-за которой он не будет работать так, как было описано выше. Ошибка эта - в предположении, что у "воскрешённого" объекта будет вызываться деструктор каждый раз, когда он перестаёт быть виден в программе (на него не остаётся ссылок). На самом деле, в приведённом примере деструктор будет вызван лишь один раз, т.е. мы "потеряем" объект при его повторной (второй) уборке сборщиком.
Для обеспечения корректной работы деструктора при "воскрешении" объекта, такой объект необходимо перерегистрировать с помощью метода GC.ReRegisterForFinalize:
~HeavyObject()
{
if (HeavyObject.Bag != null)
{
GC.ReRegisterForFinalize(this);
HeavyObject.Bag.Add(this);
}
}Это обеспечит вызов деструктора каждый раз перед очисткой объекта сборщиком мусора.
V3102. Suspicious access to element by a constant index inside a loop.
Анализатор обнаружил возможную ошибку, связанную с тем, что в цикле 'for' на каждой итерации к элементу массива или списка обращаются по одному и тому же константному индексу.
Рассмотрим пример некорректного кода:
ParameterInfo[] parameters = method.GetParameters();
for (int i = 0; i < parameters.Length; i++)
{
Type parameterType = parameters[0].ParameterType;
....
}Здесь на каждой итерации цикла планировали сохранять некое значение i-го элемента массива 'parameters' в переменную 'parameterType', но допустили опечатку, и на каждой итерации работают с одним и тем же - первым - элементом массива. Возможно также, что при написании кода программист отлаживался с использованием нулевого элемента, а потом забыл изменить значение индекса.
Корректный вариант кода:
ParameterInfo[] parameters = method.GetParameters();
for (int i = 0; i < parameters.Length; i++)
{
Type parameterType = parameters[i].ParameterType;
....
}Рассмотрим ещё один пример с ошибкой, взятый из реального приложения:
if (method != null && method.SequencePoints.Count > 0)
{
CodeCoverageSequence firstSequence = method.SequencePoints[0];
int line = firstSequence.Line;
int column = firstSequence.Column;
for (int i = 1; i < method.SequencePoints.Count; ++i)
{
CodeCoverageSequence sequencePoint = method.SequencePoints[0];
if (line > sequencePoint.Line)
{
line = sequencePoint.Line;
column = sequencePoint.Column;
}
}
// ....
}В этом фрагменте кода разработчик реализовал отдельную обработку нулевого элемента списка 'method.SequencePoints', а обход остальных элементов сделал в цикле. К сожалению, программист скопировал в тело цикла строку с доступом к нулевому элементу и переименовал только имя переменной с 'firstSequence' на 'sequencePoint', а изменить индекс забыл.
Корректный вариант кода:
if (method != null && method.SequencePoints.Count > 0)
{
CodeCoverageSequence firstSequence = method.SequencePoints[0];
int line = firstSequence.Line;
int column = firstSequence.Column;
for (int i = 1; i < method.SequencePoints.Count; ++i)
{
CodeCoverageSequence sequencePoint = method.SequencePoints[i];
if (line > sequencePoint.Line)
{
line = sequencePoint.Line;
column = sequencePoint.Column;
}
}
// ....
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3102. |
V3103. A private Ctor(SerializationInfo, StreamingContext) constructor in unsealed type will not be accessible when deserializing derived types.
Анализатор обнаружил странный модификатор доступа у конструктора сериализации.
Странными можно считать следующие ситуации:
- модификатор доступа – public;
- тип не запечатан (unsealed type), при этом его модификатор доступа – private.
Конструктор сериализации вызывается при десериализации объекта и не должен вызываться извне типа (исключение – вызов конструктора классом-наследником), поэтому не стоит объявлять его с модификатором 'public' или 'internal'.
Если конструктор объявлен с модификатором 'private', но класс не является запечатанным, классы-наследники не смогут вызывать этот конструктор, что приведёт к невозможности десериализации членов базового типа.
Рассмотрим пример:
[Serializable]
class C1 : ISerializable
{
....
private C1(SerializationInfo info, StreamingContext context)
{
....
}
....
}Класс 'C1' является незапечатанным, но при этом конструктор сериализации объявлен с модификатором доступа 'private', что приведёт к невозможности вызова этого конструктора из дочерних классов и, как следствие, к неверной десериализации объекта. Для исправления ситуации необходимо исправить модификатор доступа на 'protected':
[Serializable]
class C1 : ISerializable
{
....
protected C1(SerializationInfo info, StreamingContext context)
{
....
}
....
}Примечание. Для данной диагностики доступна дополнительная настройка, задающаяся в конфигурационном файле (*.pvsconfig), имеющая следующий синтаксис:
//+V3103:CONF:{ IncludeBaseTypes: true }В таком случае анализатор просматривает не только непосредственно реализацию интерфейса 'ISerializable' самим классом, но и каким-либо из базовых. По умолчанию эта настройка отключена.
Дополнительную информацию о конфигурационных файлах можно прочитать здесь.
V3104. The 'GetObjectData' implementation in unsealed type is not virtual, incorrect serialization of derived type is possible.
Анализатор обнаружил незапечатанный класс, реализующий интерфейс 'ISerializable', но не реализующий виртуальный метод 'GetObjectData'. Это может привести к ошибкам сериализации в производных классах.
Рассмотрим пример. Пусть у нас имеются объявления базового и производного классов следующего вида:
[Serializable]
class Base : ISerializable
{
....
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
....
}
}
[Serializable]
sealed class Derived : Base
{
....
public new void GetObjectData(SerializationInfo info,
StreamingContext context)
{
....
}
}Где-то есть код, выполняющий сериализацию объекта:
void Foo(BinaryFormatter bf, MemoryStream ms)
{
Base obj = new Derived();
bf.Serialize(ms, obj);
ms.Position = 0;
Derived derObj = (Derived)bf.Deserialize(ms);
}В таком случае сериализация выполнится неправильно из-за того, что будет вызван метод 'GetObjectData' не производного, а базового класса. Следовательно, члены производного класса не будут сериализованы. Если при десериализации из объекта 'SerializationInfo' будут извлекаться значения членов, добавляемых в методе 'GetObjectData' производного класса, будет сгенерировано исключение, так как объект 'SerializationInfo' не будет содержать запрашиваемых значений.
Для решения проблемы необходимо определить метод 'GetObjectData' в базовом классе с модификатором 'virtual', а в производном – 'override'. Тогда корректный код может выглядеть так:
[Serializable]
class Base : ISerializable
{
....
public virtual void GetObjectData(SerializationInfo info,
StreamingContext context)
{
....
}
}
[Serializable]
sealed class Derived : Base
{
....
public override void GetObjectData(SerializationInfo info,
StreamingContext context)
{
....
}
}Если в базовом классе определена только явная реализация интерфейса, стоит также добавить неявную реализацию виртуального метода 'GetObjectData'. Рассмотрим пример. Предположим, что у нас имеются определения классов следующего вида
[Serializable]
class Base : ISerializable
{
....
void ISerializable.GetObjectData(SerializationInfo info,
StreamingContext context)
{
....
}
}
[Serializable]
sealed class Derived : Base, ISerializable
{
....
public void GetObjectData(SerializationInfo info,
StreamingContext context)
{
....
}
}В таком случае из производного класса будет невозможно обратиться к методу 'GetObjectData' базового класса, а значит, часть членов не будет сериализована. Для исправления ошибки помимо явной реализации в базовый класс необходимо добавить неявную реализацию виртуального метода 'GetObjectData'. Тогда исправленный код может выглядеть так:
[Serializable]
class Base : ISerializable
{
....
void ISerializable.GetObjectData(SerializationInfo info,
StreamingContext context)
{
GetObjectData(info, context);
}
public virtual void GetObjectData(SerializationInfo info,
StreamingContext context)
{
....
}
}
[Serializable]
sealed class Derived : Base
{
....
public override void GetObjectData(SerializationInfo info,
StreamingContext context)
{
....
base.GetObjectData(info, context);
}
}Если же подразумевается, что у класса не должно быть наследников, следует добавить модификатор 'sealed' к объявлению класса, что сделает его запечатанным.
V3105. The 'a' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible.
Данная диагностика предупреждает вас о возможном возникновении 'NullReferenceException' при выполнении программы. Предупреждение возникает в том случае, если происходит обращение к полю переменной без проверки её на 'null'. Ключевым моментом является то, что значение переменной вычисляется с помощью выражения, где используется оператор null-conditional.
Рассмотрим пример:
public int Foo (Person person)
{
string parentName = person?.Parent.ToString();
return parentName.Length;
}В данном случае при инициализации объекта 'parentName' мы предполагаем, что 'person' может быть 'null'. В таком случае функция 'ToString()' не будет выполнена, а в переменную 'parentName' запишется 'null'. При попытке чтения свойства 'Length' из переменной 'parentName' возникнет исключение 'NullReferenceException'.
Исправленный код функции может быть следующим:
public int Foo (Person person)
{
string parentName = person?.Parent.ToString();
return parentName?.Length ?? 0;
}Теперь, если в переменной 'parentName' не было 'null', то мы вернем длину строки, а если был 'null', то 0.
Ошибка может возникнуть, если значение, полученное с помощью null-conditional, без проверки передаётся в метод, конструктор или присваивается свойству.
Рассмотрим пример:
void UsersProcessing(Users users)
{
IEnumerable<User> usersList = users?.GetUsersCollection();
LogUserNames(usersList);
}
void LogUserNames(IEnumerable<User> usersList)
{
foreach (var user in usersList)
{
....
}
}Переменная 'usersList' передаётся в качестве аргумента методу 'LogUserNames'. Она может иметь значение 'null', так как оно получено с помощью оператора null-conditional. Внутри 'LogUserNames' производится обход переданной коллекции. Для этого используется 'foreach' и, следовательно, у коллекции будет вызван метод 'GetEnumerator'. Если 'userList' имеет значение 'null', то будет выброшено исключение типа 'NullReferenceException'.
Вариант с исправлениями может выглядеть следующим образом:
void UsersProcessing(Users users)
{
IEnumerable<User> usersList = users?.GetUsersCollection();
LogUserNames(usersList ?? Enumerable.Empty<User>());
}
void LogUserNames(IEnumerable<User> usersList)
{
foreach (var user in usersList)
{
....
}
}Результат выполнения 'users?.GetUsersCollection()' присваивается переменной 'usersList'. Если значение этой переменной — 'null', то в метод 'LogUserNames' будет передаваться пустая коллекция. Это поможет избежать исключения типа 'NullReferenceException' при обходе 'usersList' в 'foreach'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3105. |
V3106. Possibly index is out of bound.
При доступе по индексу к переменной типа массив, список или строка может возникнуть исключение IndexOutOfRangeException, если значение индекса оказывается за пределами допустимого диапазона. Анализатор способен обнаружить некоторые ошибки такого рода.
Например, это может произойти во время обхода массива в цикле:
int[] buff = new int[25];
for (int i = 0; i <= 25; i++)
buff[i] = 10;Нужно помнить о том, что первый элемент массива имеет индекс 0, а последний – на единицу меньше размера массива. Корректный вариант:
int[] buff = new int[25];
for (int i = 0; i < 25; i++)
buff[i] = 10;Похожую ошибку можно сделать не только в цикле, но и при неправильной проверке индекса в условии:
void ProcessOperandTypes(ushort opCodeValue, byte operandType)
{
var OneByteOperandTypes = new byte[0xff];
if (opCodeValue < 0x100)
{
OneByteOperandTypes[opCodeValue] = operandType;
}
...
}Корректный вариант:
void ProcessOperandTypes(ushort opCodeValue, byte operandType)
{
var OneByteOperandTypes = new byte[0xff];
if (opCodeValue < 0xff)
{
OneByteOperandTypes[opCodeValue] = operandType;
}
...
}Также можно допустить ошибку при доступе к конкретному элементу массива или списка.
void Initialize(List<string> config)
{
...
if (config.Count == 16)
{
var result = new Dictionary<string, string>();
result.Add("Base State", config[0]);
...
result.Add("Sorted Descending Header Style", config[16]);
}
...
}В этом примере допущена ошибка в количестве записей в списке config. Исправленный вариант выглядит следующим образом:
void Initialize(List<string> config)
{
...
if (config.Count == 17)
{
var result = new Dictionary<string, string>();
result.Add("Base State", config[0]);
...
result.Add("Sorted Descending Header Style", config[16]);
}
...
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3106. |
V3107. Identical expression to the left and to the right of compound assignment.
Анализатор обнаружил одинаковые подвыражения в левой и правой части составного оператора присваивания (compound assignment operator). Возможно эта операция содержит ошибку, не имеет смысла, либо может быть упрощена.
Рассмотрим пример. Пусть у нас имеется выражение следующего вида:
x += x + 5;Возможно программист хотел просто прибавить к переменной 'x' значение 5. Тогда корректный код может выглядеть так:
x = x + 5;Либо же программист хотел прибавить 5, но случайно добавил лишнюю переменную 'x' в выражение. Тогда корректный код может выглядеть так:
x += 5;Впрочем, возможно код написан правильно. Однако согласитесь, читать такое выражения сложно и лучше переписать его. Более читабельный вариант может выглядеть так:
x = x * 2 + 5;Рассмотрим следующий пример:
x += x;Данная операция эквивалентна операции умножения на два. Более понятное выражение будет иметь следующий вид:
x *= 2;Рассмотрим еще одно выражение:
y += top - y;Мы пытаемся прибавить переменной 'y' разницу между переменной 'top' и переменной 'y'. Давайте разложим данное выражение:
y = y + top – y;Данное выражение можно упростить, так как переменная 'y' вычитается сама из себя, что является бессмысленным. Тогда простой и корректный код будет выглядеть так:
y = top;Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3107. |
V3108. It is not recommended to return null or throw exceptions from 'ToString()' method.
Анализатор обнаружил, что в переопределенном методе 'ToString()' возвращается значение null или выбрасывается исключение.
Рассмотрим пример. Пусть у нас имеется метод следующего вида:
public override string ToString()
{
return null;
}Есть вероятность, что в дальнейшем при работе программы или ее отладке будет вызван данный метод для получения текстового представления объекта. Т.к. разработчик скорее всего не станет проверять результат работы этой функции на null, дальнейшее его использование может повлечь за собой исключение 'NullReferenceException'. Если необходимо вернуть пустое или неизвестное значение текстового представление объекта, рекомендуется использовать для этого пустую строку:
public override string ToString()
{
return string.Empty;
}Другой пример плохой практики при реализации метода 'ToString()' - выбрасывание исключения из этого метода. Рассмотрим следующий пример:
public override string ToString()
{
if(hasError)
throw new Exception();
....
}Высока вероятность, что данный метод будет вызван пользователем класса в месте, не подразумевающем возможности возникновения и обработки исключений, например в деструкторе.
Если необходимо выдать сообщение об ошибке при генерации текстового представления объекта, лучше будет вернуть его текст в виде строки, либо каким-то образом залогировать эту ошибку:
public override string ToString()
{
if(hasError)
{
LogError();
return "Error encountered";
}
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3108. |
V3109. The same sub-expression is present on both sides of the operator. The expression is incorrect or it can be simplified.
Анализатор обнаружил одинаковые подвыражения в левой и правой части оператора сравнения (comparison operator). Возможно, эта операция содержит ошибку, не имеет смысла, либо может быть упрощена.
Рассмотрим пример. Допустим у нас имеется выражение следующего вида:
if ((x – y) >= (x - z)) {};Очевидно, что использование переменной 'x' в данном фрагменте кода является избыточным и переменная может быть сокращена в левой и правой частях выражения. Тогда упрощенный код может выглядеть так:
if (y <= z) {};Рассмотрим следующий пример:
if (x1 == x1 + 1) {};Данное выражение уже содержит явную ошибку, так как будет ложным при любом значении переменной 'x1'. Возможно, здесь присутствует опечатка и корректный код мог бы выглядеть так:
if (x2 == x1 + 1) {};Рассмотрим еще одно выражение:
if (x < x * y) {};В данном выражении также может быть сокращена переменная 'x'. При этом упрощенное и более понятное выражение могло бы иметь вид:
if (y > 1) {};V3110. Possible infinite recursion.
Анализатор обнаружил, что может возникать бесконечная рекурсия. Скорее всего это приведет к переполнению стека вызовов и возникновению исключения Stack Overflow.
Рассмотрим пример. Пусть у нас имеется свойство 'MyProperty' и поле '_myProperty', связанное с ним. Из-за опечатки можно допустить следующую ошибку:
private string _myProperty;
public string MyProperty
{
get { return MyProperty; } // <=
set { _myProperty = value; }
}При указании возвращаемого значения в методе доступа свойства, вместо поля '_myProperty' было указано свойство 'MyProperty', что приводится к возникновению бесконечной рекурсии при получении значения у свойства. Корректный код должен выглядеть так:
private string _myProperty;
public string MyProperty
{
get { return _myProperty; }
set { _myProperty = value; }
}Рассмотрим второй пример:
class Node
{
Node parent;
public void Foo()
{
// some code
parent.Foo(); // <=
}
}Вероятнее всего программист хотел рекурсивно обойти все поля 'parent', но не предусмотрел условия выхода из рекурсии. Эта ситуация более интересная: здесь может возникнуть не только переполнение стека, но и доступ по нулевой ссылке, когда мы дойдём до самой верхней родительской сущности. Корректный код мог бы выглядеть так:
class Node
{
Node parent;
public void Foo()
{
// some code
if (parent != null)
parent.Foo();
}
}Рассмотрим третий пример. Пусть у нас имеется метод с конструкцией 'try - catch - finally'.
void Foo()
{
try
{
// some code;
return;
}
finally
{
Foo(); // <=
}
}Вероятнее всего программист не учел, что блок 'finally' будет выполнен как в случае возникновения исключения внутри блока 'try', так и в случае выхода из метода оператором 'return'. Таким образом блок 'finally' всегда будет выполнять рекурсивный вызов метода 'Foo'. Для корректного выполнения рекурсии необходимо реализовать условие перед выполнением метода. К примеру корректный код мог бы выглядеть так:
void Foo()
{
try
{
// some code;
return;
}
finally
{
if (condition)
Foo();
}
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3110. |
V3111. Checking value for null will always return false when generic type is instantiated with a value type.
Анализатор обнаружил, что значение, имеющее обобщённый (generic) тип, сравнивается с 'null'. Если обобщённый тип никак не ограничен, то он может быть инстанциирован как значимым, так и ссылочным типом. В случае если он окажется значимым, проверка на 'null' всегда будет возвращать 'false', так как значимые типы не могут принимать нулевое (null) значение.
Рассмотрим пример.
class Node<T>
{
T value;
void LazyInit(T newValue)
{
if (value == null) // <=
{
value = newValue;
}
}
}В случае если тип 'T' будет определен как значимый, тело условия 'if' никогда не выполнится. В нашем примере это приведёт к тому, что переменная 'value' не будет проинициализирована переданным значением - её значение всегда останется равным 'default' значению 'T'.
Если необходимо обрабатывать объекты только ссылочного типа, то используйте ограничители. К примеру, generic тип 'T' из примера выше может быть ограничен только для ссылочных типов:
class Node<T> where T : class // <=
{
T value;
void LazyInit(T newValue)
{
if (value == null)
{
value = newValue;
}
}
}Если же generic тип должен принимать как значимые, так и ссылочные типы, и проверка должна осуществляться для обоих видов значений, то тогда необходимо использовать проверку на значение данного типа по умолчанию (default), вместо проверки на 'null':
class Node<T>
{
T value;
void LazyInit(T newValue)
{
if (object.Equals(value, default(T))) // <=
{
value = newValue;
}
}
}В данном случае проверка будет корректно работать как для ссылочных, так и для значимых типов. Если же подразумевалось, что данная проверка должна срабатывать только на ссылочные типы с нулевым значением (без ограничения типа 'T'), то тогда мы предлагаем использовать такой вариант.
class Node<T>
{
T value;
void LazyInit(T newValue)
{
if (typeof(T).IsClass && // <=
object.Equals(value, default(T)))
{
value = newValue;
}
}
}Метод 'IsClass' вернет 'true' если generic был инстанциирован ссылочным типом. Таким образом, проверка на значение по умолчанию будет происходить только для ссылочных типов, по аналогии с предыдущим примером.
V3112. An abnormality within similar comparisons. It is possible that a typo is present inside the expression.
Анализатор обнаружил подозрительное условие, которое может содержать ошибку.
Диагностика носит эмпирический характер, поэтому проще показать на примере, как она работает, чем объяснить сам принцип работы анализатора.
Рассмотрим пример:
if (m_a != a ||
m_b != b ||
m_b != c) // <=
{
....
}Из-за того, что имена переменных очень похожи, в коде допущена опечатка. Ошибка находится в третей строке. Переменную 'c' следовало сравнить с 'm_c', а не с 'm_b'. Даже читая этот текст сложно заметить ошибку. Обратите внимание на окончания в названии переменных.
Правильный вариант:
if (m_a != a ||
m_b != b ||
m_c != c) // <=
{
....
}Если анализатор выдал предупреждение V3112, то внимательно изучите соответствующий фрагмент кода. Иногда опечатку бывает сложно заметить.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3112. |
V3113. Consider inspecting the loop expression. It is possible that different variables are used inside initializer and iterator.
Анализатор обнаружил, что в разделе итератора (iterator section) оператора 'for' производится инкремент или декремент переменной, не являющейся счетчиком.
Рассмотрим пример. Допустим, у нас имеется выражение следующего вида:
for (int i = 0; i != N; ++N)Вероятно, данный фрагмент кода содержит ошибку и вместо переменной 'N' в выражении инкремента '++N' необходимо использовать переменную 'i'. Корректный вариант кода должен выглядеть так:
for (int i = 0; i != N; ++i)Рассмотрим следующий пример:
for (int i = N; i >= 0; --N)Данный фрагмент кода также ошибочен. В выражении декремента '‑‑N' должна быть использована переменная 'i':
for (int i = N; i >= 0; --i)Данная диагностика классифицируется как:
V3114. IDisposable object is not disposed before method returns.
Чтобы понять смысл данной диагностики, давайте для начала немного вспомним теорию.
Сборщик мусора автоматически освобождает память, связанную с контролируемым объектом, если он больше не используется и на него не осталось видимых ссылок. Тем не менее, невозможно предсказать, когда именно произойдёт сборка мусора (если не вызывать её вручную). Кроме того, сборщик мусора не имеет информации о таких неуправляемых ресурсах, как дескрипторы, окна или открытые файлы и потоки. Метод 'Dispose' обычно используется, чтобы освобождать такие неуправляемые ресурсы.
Понимая это, анализатор обнаружил локальную переменную, объект которой реализует интерфейс 'IDisposable' и не передается за пределы зоны видимости локальной переменной. При этом после использования данного объекта не был вызван метод 'Dispose' освобождающий принадлежащие ему неуправляемые ресурсы.
Если предположить, что данный объект содержит какой-либо дескриптор (например, файл), то он будет оставаться в памяти до следующей сборки мусора, которая произойдет через неопределенный промежуток времени вплоть до момента завершения работы программы. В результате файл может неопределённое время оставаться заблокированным, мешая нормальной работе других программ или операционной системе.
Рассмотрим пример такой ситуации:
string Foo()
{
var stream = new StreamReader(@"С:\temp.txt");
return stream.ReadToEnd();
}В данном случае объект 'StreamReader' будет хранить в себе дескриптор открытого файла даже после выхода из метода 'Foo', тем самым блокируя его для других программ и операционной системы до тех пор, пока сборщик мусора не очистит его.
Чтобы избежать этого - своевременно освобождайте ресурсы, используя метод 'Dispose' как в примере ниже:
string Foo()
{
var stream = new StreamReader(@"С:\temp.txt");
var result = stream.ReadToEnd();
stream.Dispose();
return result;
}Однако, для более надёжного освобождения ресурсов рекомендуется использовать конструкцию 'using'. Она обеспечит автоматическую очистку ресурсов используемого объекта после завершения:
string Foo()
{
using (var stream = new StreamReader(@"С:\temp.txt"))
{
return stream.ReadToEnd();
}
}Компилятор раскроет блок 'using' в блок 'try finally', и в 'finally' вставит вызов метода 'Dispose' - это гарантирует очистку объекта даже в случае возникновения исключений.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки утечек памяти, незакрытых файловых дескрипторов и дескрипторов сетевых соединений. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3114. |
V3115. It is not recommended to throw exceptions from 'Equals(object obj)' method.
Анализатор обнаружил, что в переопределенном методе 'Equals(object obj)' возможно возникновение исключения.
Рассмотрим пример. Пусть у нас имеется метод следующего вида:
public override bool Equals(object obj)
{
return obj.GetType() == this.GetType();
}В том случае, если аргумент 'obj' будет нулевым (null) - это повлечет за собой исключение 'NullReferenceException'. Вероятнее всего программист не предусмотрел подобную ситуацию при реализации данного метода. Для корректной работы можно использовать проверку на 'null':
public override bool Equals(object obj)
{
if (obj == null)
return false;
return obj.GetType() == this.GetType();
}Другой пример плохой практики при реализации метода 'Equals(object obj)' - явное выбрасывание исключения из этого метода. Рассмотрим следующий пример:
public override bool Equals(object obj)
{
if (obj == null)
throw new InvalidOperationException("Invalid argument.");
return obj == this;
}Высока вероятность, что данный метод будет вызван пользователем в месте, не подразумевающем возможности возникновения и обработки исключений.
Если один из объектов не соответствует условиям сравнения, лучше будет вернуть 'false':
public override bool Equals(object obj)
{
if (obj == null)
return false;
return obj == this;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3115. |
V3116. Consider inspecting the 'for' operator. It's possible that the loop will be executed incorrectly or won't be executed at all.
Анализатор обнаружил, что в операторе 'for' используются некорректные границы для итератора.
Рассмотрим пример:
for (int i = 0; i < 100; --i)Очевидно, что данный фрагмент кода содержит ошибку. Значение переменной 'i' будет всегда меньше 100. По крайней мере до тех пор, пока не произойдёт её переполнение. Но вряд ли такое поведение задумывал программист. Для исправления ошибки необходимо в указанном выражении либо заменить оператор декремента '‑‑i' на оператор инкремента '++i':
for (int i = 0; i < 100; ++i)либо указать корректные границы для переменной 'i', использовав при этом оператор сравнения '>' или '!= ':
for (int i = 99; i >= 0; --i)
for (int i = 99; i != -1; --i)Выбор наиболее подходящего варианта должен осуществлять автор кода на основе анализа конкретной ситуации.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3116. |
V3117. Constructor parameter is not used.
Анализатор обнаружил, что один из параметров конструктора не используется.
Рассмотрим пример.
public class MyClass
{
protected string _logPath;
public String LogPath { get { return _logPath; } }
public MyClass(String logPath) // <=
{
_logPath = LogPath;
}
}В данном случае программист скорее всего опечатался, написав 'LogPath' вместо 'logPath', в результате чего параметр конструктора нигде не используется. Корректный код должен выглядеть так:
public class MyClass
{
protected string _logPath;
public String LogPath { get { return _logPath; } }
public MyClass(String logPath) // <=
{
_logPath = logPath;
}
}Рассмотрим ещё один пример.
public class MyClass
{
public MyClass(String logPath) // <=
{
//_logPath = logPath;
}
}В случае, если программист умышленно не использует параметр конструктора, мы предлагаем пометить конструктор атрибутом 'Obsolete'.
public class MyClass
{
[Obsolete]
public MyClass(String logPath) // <=
{
//_logPath = logPath;
}
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3117. |
V3118. A component of TimeSpan is used, which does not represent full time interval. Possibly 'Total*' value was intended instead.
Анализатор обнаружил обращение к свойству 'Milliseconds', 'Seconds', 'Minutes' или 'Hours', у объекта типа 'TimeSpan', который является временным интервалом между несколькими датами или другими временными интервалами.
Возможно данное выражение содержит ошибку, так как в случае, если вы ожидаете суммарное значение временной единицы за весь интервал времени, данное свойство вернет только часть интервала.
Рассмотрим пример:
var t1 = DateTime.Now;
await SomeOperation(); // 2 минуты 10 секунд
var t2 = DateTime.Now;
Console.WriteLine("Execute time: {0}sec", (t2 - t1).Seconds);
// Результат - "Execute time: 10sec"В переменную 't1' мы записываем дату и время до выполнения операции. В переменную 't2' мы записываем дату и время после выполнения операции. Предположим, что метод 'SomeOperation' выполняется ровно 2 минуты 10 секунд. Далее мы выводим в консоль разницу в секундах между переменными, тем самым получаем временной интервал выполнения операции. В данном примере временной интервал будет равен 130 секунд, но свойство 'Seconds' вернет только 10 секунд. Корректный пример будет выглядеть так:
var t1 = DateTime.Now;
await SomeOperation(); // 2 минуты 10 секунд
var t2 = DateTime.Now;
Console.WriteLine("Execute time: {0}sec", (t2 - t1).TotalSeconds);
// Результат - "Execute time: 130sec"Необходимо использовать свойство 'TotalSeconds', чтобы получить суммарное количество секунд в данном временном интервале.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3118. |
V3119. Calling a virtual (overridden) event may lead to unpredictable behavior. Consider implementing event accessors explicitly or use 'sealed' keyword.
Анализатор обнаружил использование виртуального или переопределенного события. В случае, если данное событие будет переопределено в производном классе, это может привести к непредсказуемому поведению. MSDN не рекомендует использование переопределенных виртуальных событий: "Do not declare virtual events in a base class and override them in a derived class. The C# compiler does not handle these correctly and it is unpredictable whether a subscriber to the derived event will actually be subscribing to the base class event". https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/events/how-to-raise-base-class-events-in-derived-classes.
Рассмотрим пример:
class Base
{
public virtual event Action MyEvent;
public void FooBase() { MyEvent?.Invoke(); }
}
class Child: Base
{
public override event Action MyEvent;
public void FooChild() { MyEvent?.Invoke(); }
}
static void Main()
{
var child = new Child();
child.MyEvent += () => Console.WriteLine("Handler");
child.FooChild();
child.FooBase();
}Несмотря на то, что производится вызов обоих методов 'FooChild()' и 'FooBase()', результатом работы метода 'Main()' будет вывод на консоль одной строки:
HandlerИспользуя отладчик или тестовый вывод можно убедиться в том, что при вызове 'child.FooBase()' значение переменной 'MyEvent' будет равно 'null'. Таким образом, подписывание на событие 'MyEvent' для класса 'Child', наследника 'Base', переопределяющего это событие, не привело к подписыванию на событие 'MyEvent' базового класса. На первый взгляд, такое поведение не согласуется с поведением, например, виртуальных методов, однако его можно объяснить особенностью реализации событий в C#. При объявлении события компилятор автоматически создаёт для него 2 метода-аксессора 'add' и 'remove', и поле-делегат, в которое происходит добавление\удаление делегатов при подписке\отписке на события. В случае виртуального события, базовый и дочерний классы будут иметь индивидуальные (не виртуальные) поля, связанные с данным событием.
Данной проблемы можно избежать, объявив для события его аксессоры в явном виде:
class Base
{
public virtual Action _myEvent { get; set; }
public virtual event Action MyEvent
{
add
{
_myEvent += value;
}
remove
{
_myEvent -= value;
}
}
public void FooBase() { _myEvent?.Invoke(); }
}Мы настоятельно не рекомендуем использовать виртуальные или переопределенные события описанным в первом примере образом. В случае, если вы все же вынуждены использовать переопределенные события (например, при наследовании от абстрактного класса), используйте их с осторожностью, учитывая возможность неопределенного поведения. Используйте явное определение аксессоров 'add' и 'remove' либо используйте при объявлении класса или события ключевое слово 'sealed'.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3119. |
V3120. Potentially infinite loop. The variable from the loop exit condition does not change its value between iterations.
Анализатор обнаружил потенциально бесконечный цикл, условие выхода из которого зависит от переменной, значение которой никогда не меняется в нем.
Рассмотрим пример:
int x = 0;
while (x < 10)
{
Do(x);
}Условие выхода из цикла зависит от переменной 'x', значение которой в цикле всегда будет равно нулю. Таким образом проверка 'x < 10' всегда будет истинной, что приведет к бесконечному циклу в данном случае. Правильный вариант мог бы выглядеть так:
int x = 0;
while (x < 10)
{
x = Do(x);
}Рассмотрим еще один пример, когда условие выхода из цикла зависит от переменной, изменение значения этой которой зависит от других переменных, которые никогда не меняются внутри цикла. Пусть у нас имеется метод следующего вида:
int Foo(int a)
{
int j = 0;
while (true)
{
if (a >= 32)
{
return j * a;
}
if (j == 10)
{
j = 0;
}
j++;
}
}Условие выхода из цикла зависит от параметра 'a'. В случае если параметр 'a' не будет удовлетворять условие проверки 'a >= 32', то цикл будет бесконечным, так как его значение в цикле не изменяется. Корректный вариант мог бы выглядеть так:
int Foo(int a)
{
int j = 0;
while (true)
{
if (a >= 32)
{
return j * a;
}
if (j == 10)
{
j = 0;
a++; // <=
}
j++;
}
}Таким образом изменение параметра 'a' будет зависеть от локальной переменной 'j'.
Данная диагностика классифицируется как:
V3121. An enumeration was declared with 'Flags' attribute, but does not set any initializers to override default values.
Анализатор обнаружил использование атрибута 'Flags' (System.FlagsAttribute) при объявлении перечисления. При этом для констант в перечислении не задано ни одного значения, переопределяющего значения по умолчанию.
Рассмотрим пример:
[Flags]
enum DeclarationModifiers
{
Static,
New,
Const,
Volatile
}После указания атрибута 'Flags' перечисление будет вести себя не просто как набор именованных взаимоисключающих констант, а как битовое поле, то есть набор флагов. Значения флагов в этом случае обычно задают как степени числа 2, а перечисление используют, комбинируя значения при помощи битовой операции OR:
DeclarationModifiers result = DeclarationModifiers.New |
DeclarationModifiers.Const;При использовании перечисления с атрибутом 'Flags', для которого не заданы инициализаторы значений (используются значения по умолчанию), возможно перекрытие значений при их комбинировании. Приведенный выше пример, скорее всего, содержит ошибку. Она может быть исправлена следующим образом:
[Flags]
enum DeclarationModifiers
{
Static = 1,
New = 2,
Const = 4,
Volatile = 8
}Теперь перечисление удовлетворяет всем требованиям для битового поля.
Тем не менее, возможна ситуация, когда программист умышленно оставил значения констант по умолчанию в перечислении с атрибутом 'Flags'. Но при этом должны быть учтены все возможные комбинации значений. Пример такого перечисления:
[Flags]
enum Colors
{
None, // = 0 by default
Red, // = 1 by default
Green, // = 2 by default
Red_Green // = 3 by default
}В данном случае программист учел перекрывающиеся значения: в результате комбинации 'Colors.Red' и 'Colors.Green' будет получено ожидаемое значение 'Colors.Red_Green'. Здесь нет ошибки, но установить данный факт может лишь автор программы.
Проиллюстрируем отличие в работе перечислений с атрибутом 'Flags' без использования инициализации значений, а также с использованием инициализации значений:
[Flags]
enum DeclarationModifiers
{
Static, // = 0 by default
New, // = 1 by default
Const, // = 2 by default
Volatile // = 3 by default
}
[Flags]
enum DeclarationModifiers_Good
{
Static = 1,
New = 2,
Const = 4,
Volatile = 8
}
static void Main(....)
{
Console.WriteLine(DeclarationModifiers.New |
DeclarationModifiers.Const);
Console.WriteLine(DeclarationModifiers_Good.New |
DeclarationModifiers_Good.Const);
}Результат выполнения программы:
Volatile
New, ConstТак как в перечислении 'DeclarationModifiers' используются значения по умолчанию, то комбинация констант 'DeclarationModifiers.New' и 'DeclarationModifiers.Const' даст в результате значение 3, перекрывающее константу 'DeclarationModifiers.Volatile'. Это может стать неожиданностью для программиста. В то же время, для перечисления 'DeclarationModifiers_Good' получено правильное значение, являющееся именно комбинацией флагов 'DeclarationModifiers_Good.New ' и DeclarationModifiers_Good.Const'.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3121. |
V3122. Uppercase (lowercase) string is compared with a different lowercase (uppercase) string.
Анализатор обнаружил, что производится сравнение двух строк, которые имеют заведомо разный регистр символов.
Рассмотрим пример:
void Some(string s)
{
if (s.ToUpper() == "abcde")
{
....
}
}После того, как значение переменной 's' приводится к верхнему регистру, результат сравнивается со строкой, все символы которой в нижнем регистре. Так как такое сравнение будет всегда ложным, фрагмент кода содержит ошибку, которая может быть исправлена следующим образом:
void Some(string s)
{
if (s.ToLower() == "abcde")
{
....
}
}Рассмотрим еще один пример:
void Some()
{
string s = "abcde";
....
if (s.Contains("AbCdE"))
{
....
}
}Переменная 's' содержит символы только в нижнем регистре. При этом, для данной строки производится попытка поиска ее подстроки, содержащей символы в смешанном регистре. Очевидно, что в данном случае результатом работы метода 'Contains' всегда будет ложь. Приведенный фрагмент кода также содержит ошибку.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3122. |
V3123. Perhaps the '??' operator works in a different way than it was expected. Its priority is lower than priority of other operators in its left part.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит логическую ошибку. В тексте программы имеется выражение, содержащее оператор '??' или '?:', которое может вычисляться не так, как планировал программист.
Операторы '??' и '?:' имеют более низкий приоритет по сравнению с операторами ||, &&, |, ^, &, !=, ==, +, -, %, /, *. Это можно случайно забыть и написать ошибочный код, подобный приведенному ниже:
public bool Equals(Edit<TNode> other)
{
return _kind == other._kind
&& (_node == null) ? other._node == null :
node.Equals(other._node);
}Так как приоритет оператора '&&' выше чем оператора '?:', то сначала будет выполнено выражение '_kind == other._kind && (_node == null)'. Чтобы избежать таких ошибок, следует заключать всё выражение, содержащее оператор '?:', в скобки:
public bool Equals(Edit<TNode> other)
{
return _kind == other._kind
&& ((_node == null) ? other._node == null :
node.Equals(other._node));
}Рассмотрим другой пример с оператором '??':
public override int GetHashCode()
{
return ValueTypes.Aggregate(...)
^ IndexMap?.Aggregate(...) ?? 0;
}Приоритет оператора '^' выше чем приоритет оператора '??', поэтому если 'IndexMap' равен 'null', то и левая часть оператора '??' тоже будет иметь значение 'null', и значит функция всегда будет возвращать 0 вне зависимости от того что содержится в коллекции 'ValueTypes'.
Как и в случае оператора '?:', выражение с оператором '??' лучше заключать в скобки
public override int GetHashCode()
{
return ValueTypes.Aggregate(...)
^ (IndexMap?.Aggregate(...) ?? 0);
}Теперь функция 'GetHashCode()' будет возвращать разные значения в зависимости от содержимого коллекции 'ValueTypes' и в том случае когда 'IndexMap' будет равен 'null'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3123. |
V3124. Appending an element and checking for key uniqueness is performed on two different variables.
Анализатор обнаружил подозрительный фрагмент кода, в котором производится проверка на наличие ключа в одном словаре, после чего новый элемент добавляется в другой словарь. Возможно, допущена опечатка или логическая ошибка.
Рассмотрим пример:
Dictionary<string, string> dict = new Dictionary<string, string>();
Dictionary<string, string> _dict = new Dictionary<string, string>();
....
void Add(string key, string val)
{
if (!dict.ContainsKey(key))
_dict.Add(key, val);
}Здесь, вероятно, допущены сразу две ошибки. Первая - добавление элемента не в тот словарь, что может исказить логику работы программы. Вторая ошибка связана с тем, что проверка наличия ключа 'key' выполняется для словаря 'dict', а не для '_dict'. Если словарь '_dict' уже содержит значение для ключа 'key', в момент выполнения '_dict.Add(key, val)' будет выброшено исключение 'ArgumentException'. В данном случае возможны два варианта исправления данной конструкции (в обоих случаях на наличие ключа проверяется тот словарь, куда производится добавление нового элемента):
Dictionary<string, string> dict = new Dictionary<string, string>();
Dictionary<string, string> _dict = new Dictionary<string, string>();
....
void Add1(string key, string val)
{
if (!_dict.ContainsKey(key))
_dict.Add(key, val);
}
...
void Add2(string key, string val)
{
if (!dict.ContainsKey(key))
dict.Add(key, val);
}V3125. The object was used after it was verified against null. Check lines: N1, N2.
Анализатор обнаружил потенциальную ошибку, которая может привести к доступу по нулевой ссылке.
Анализатор заметил в коде следующую ситуацию. Сначала объект проверяется на null, а потом используется уже без проверки на null. Это может означать одно из двух:
1) Возникнет исключение, если объект будет равен null.
2) Программа всегда работает корректно, так как объект всегда не равен null. Проверка является лишней.
Рассмотрим первый вариант. Здесь может возникнуть исключение.
obj = Foo();
if (obj != null)
obj.Func1();
obj.Func2();Если объект 'obj' окажется равен null, то выражение 'obj.Func2()' приведёт к ошибке. Анализатор выдаст предупреждение на этот код, указав 2 строки. Первая строка - это то место, где используется объект. Вторая строка - это то место, где объект сравнивается со значением null.
Исправленный вариант кода:
obj = Foo();
if (obj != null) {
obj.Func1();
obj.Func2();
}Рассмотрим второй вариант. Проход по списку безопасный, проверка лишняя
List<string> list = CreateNotEmptyList();
if (list == null || list.Count == 0) { .... }
foreach (string item in list) { .... }Этот код всегда работает корректно. Список list всегда не пуст. Однако анализатор не разобрался в этой ситуации и выдал предупреждение. Чтобы оно исчезло, следует удалить проверку "if (list == null || list.Count == 0)". Она не имеет практического смысла и может только запутать программиста, читающего код.
Исправленный вариант:
List<string> list = CreateNotEmptyList();
foreach (string item in list) { .... }Ещё один вариант сообщения анализатора - когда проверка и использование расположены в разных ветках if\else или switch выражений. Например:
if (lines.Count == 1)
{
if (obj != null)
obj.Func1();
}
else
{
lines.Clear();
obj.Func2();
}В такой ситуации, несмотря на то, что обе ветки никогда не выполнятся одновременно, а будет выбрана только одна из веток, проверка на null в одной из них косвенно свидетельствует о возможности принятия переменной значения null и в другой ветке. Тогда, если управление придёт во вторую ветку, возникнет исключение.
Исправленный вариант:
if (lines.Count == 1)
{
if (obj != null)
obj.Func1();
}
else
{
lines.Clear();
if (obj != null)
obj.Func2();
}В случае если анализатор ошибается, то кроме изменения кода, можно использовать комментарий для подавления предупреждений. Пример: "obj.Foo(); //-V3125".
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3125. |
V3126. Type implementing IEquatable<T> interface does not override 'GetHashCode' method.
Анализатор обнаружил пользовательский тип, реализующий интерфейс 'IEquatable<T>'. При этом тип не переопределяет метод 'GetHashCode'.
Это может привести к ошибочным результатам при использовании типа, например, с методами из 'System.Linq.Enumerable', такими как: 'Distinct', 'Except', 'Intersect' или 'Union'.
Рассмотрим пример с использованием 'Distinct':
class Test : IEquatable<Test>
{
private string _data;
public Test(string data)
{
_data = data;
}
public override string ToString()
{
return _data;
}
public bool Equals(Test other)
{
return _data.Equals(other._data);
}
}
static void Main()
{
var list = new List<Test>();
list.Add(new Test("ab"));
list.Add(new Test("ab"));
list.Add(new Test("a"));
list.Distinct().ToList().ForEach(item => Console.WriteLine(item));
}В результате работы программы на консоль будет выведено:
ab
ab
aКак видим, несмотря на то, что тип 'Test' реализует интерфейс 'IEquatable<Test>' (объявлен метод 'Equals'), этого недостаточно. В ходе выполнения программы нам не удалось получить ожидаемого результата, и коллекция содержит повторяющиеся элементы. Для устранения этой проблемы в объявление типа 'Test' необходимо добавить переопределение метода 'GetHashCode':
class Test : IEquatable<Test>
{
private string _data;
public Test(string data)
{
_data = data;
}
public override string ToString()
{
return _data;
}
public bool Equals(Test other)
{
return _data.Equals(other._data);
}
public override int GetHashCode()
{
return _data.GetHashCode();
}
}
static void Main()
{
var list = new List<Test>();
list.Add(new Test("ab"));
list.Add(new Test("ab"));
list.Add(new Test("a"));
list.Distinct().ToList().ForEach(item => Console.WriteLine(item));
}Вновь выполним программу. В результате на консоль будет выведено:
ab
aМы получили корректный результат: коллекция содержит только уникальные элементы.
V3127. Two similar code fragments were found. Perhaps, this is a typo and 'X' variable should be used instead of 'Y'.
Анализатор обнаружил код, который, возможно, содержит опечатку. Высока вероятность, что подобный код был создан с использованием подхода Copy-Paste.
Данная диагностика выявляет два схожих по структуре блока кода, идущих один за другим и отличающихся переменной, которая несколько раз встречалась в первом блоке кода, но во втором встречается только один раз. Из этого можно сделать вывод, что переменная возможно была забыта и не заменена. Предупреждение V3127 предназначено для выявления тех случаев, если второй блок был получен путем копирования первого, при этом во втором блоке были переименованы не все переменные.
Рассмотрим пример:
if (x > 0)
{
Do1(x);
Do2(x);
}
if (y > 0)
{
Do1(y);
Do2(x); // <=
}Вероятнее всего во втором блоке вместо переменной 'x' должна идти переменная 'y'. Корректный вариант мог бы выглядеть так:
if (x > 0)
{
Do1(x);
Do2(x);
}
if (y > 0)
{
Do1(y);
Do2(y);
}Рассмотрим еще один пример, но уже более сложный.
....
if(erendlinen>239) erendlinen=239;
if(srendlinen>erendlinen) srendlinen=erendlinen;
if(erendlinep>239) erendlinep=239;
if(srendlinep>erendlinen) srendlinep=erendlinep; // <=
....Заметить ошибку не так уж и просто. Имена переменных похожи друг на друга, и поэтому выявление ошибки усложняется в разы. На самом деле во втором блоке вместо переменной 'erendlinen' должна стоять 'erendlinep'.
Корректный вариант будет выглядеть так:
....
if(erendlinen>239) erendlinen=239;
if(srendlinen>erendlinen) srendlinen=erendlinen;
if(erendlinep>239) erendlinep=239;
if(srendlinep>erendlinep) srendlinep=erendlinep; // <=
....Имена переменных 'erendlinen' и 'erendlinep' выбраны явно неудачно. Такую ошибку почти невозможно заметить при Code Review. Да что уж там, даже когда анализатор указывает на строку с ошибкой и то сложно её заметить. Поэтому, встретив предупреждение V3127, рекомендуем не спешить и внимательно изучить код.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3127. |
V3128. The field (property) is used before it is initialized in constructor.
Анализатор обнаружил использование поля (свойства) до его инициализации в конструкторе класса.
Рассмотрим пример:
class Test
{
List<int> mylist;
Test()
{
int count = mylist.Count; // <=
....
mylist = new List<int>();
}
}В конструкторе класса 'Test' производится доступ к свойству 'Count' списка 'mylist'. При этом инициализация списка производится позже. В результате выполнения приведенного фрагмента кода произойдет доступ по нулевой ссылке. В данном случае необходимо обеспечить предварительную инициализацию списка, например, при его объявлении:
class Test
{
List<int> mylist = new List<int>();
Test()
{
int count = mylist.Count;
....
}
}Рассмотрим еще один пример:
class Test2
{
int myint;
Test2(int param)
{
Foo(myint); // <=
....
myint = param;
}
}В данном случае в метод 'Foo' передают поле 'myint', которое имеет значение по умолчанию 0. Возможно, так и задумывалось, и ошибки нет. Однако, в некоторых случаях это может приводить к неожиданному поведению. Правильным решением будет явная инициализация поля 'myint', даже значением по умолчанию 0:
class Test2
{
int myint = 0;
Test2(int param)
{
Foo(myint);
....
myint = param;
}
}Теперь коллегам и анализатору очевидно, что программист не забыл про инициализацию поля 'myint'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3128. |
V3129. The value of the captured variable will be overwritten on the next iteration of the loop in each instance of anonymous function that captures it.
Анализатор обнаружил потенциально возможную ошибку, связанную с замыканием в анонимную функцию переменной, которая используется как итератор цикла. На этапе компиляции захваченная переменная будет обернута в анонимный класс-контейнер, и в дальнейшем только один экземпляр этого класса будет передан во все анонимные функции для каждой итерации цикла. Вероятнее всего, программист будет ожидать разные значения итератора внутри каждой анонимной функции, вместо последнего, что является неочевидным поведением и может привести к ошибке.
Давайте рассмотрим данную ситуацию более подробно на примере:
void Foo()
{
var actions = new List<Action>();
for (int i = 0; i < 10; i++)
{
actions.Add(() => Console.Write(i)); // <=
}
// SOME ACTION
actions.ForEach(x => x());
}Многие подумают, что в результате выполнения метода 'Foo' в консоль будут выведены числа от 0 до 9, так как по логике при замыкании переменной 'i' в анонимную функцию после компиляции будет создан анонимный класс-контейнер, а значение переменной 'i' скопировано в одно из его полей. Но на самом деле в консоль будет 10 раз выведено число 10. Это связано с тем, что анонимный класс-контейнер создается сразу после объявления переменной 'i', а не перед объявлением анонимной функции. Таким образом, для всех экземпляров анонимных функций при каждой итерации цикла замыкается не текущее значение итератора, а ссылка на анонимный класс-контейнер, содержащий в себе последнее значение итератора. Также стоит отметить, что при компиляции объявление переменной 'i' будет вынесено перед циклом.
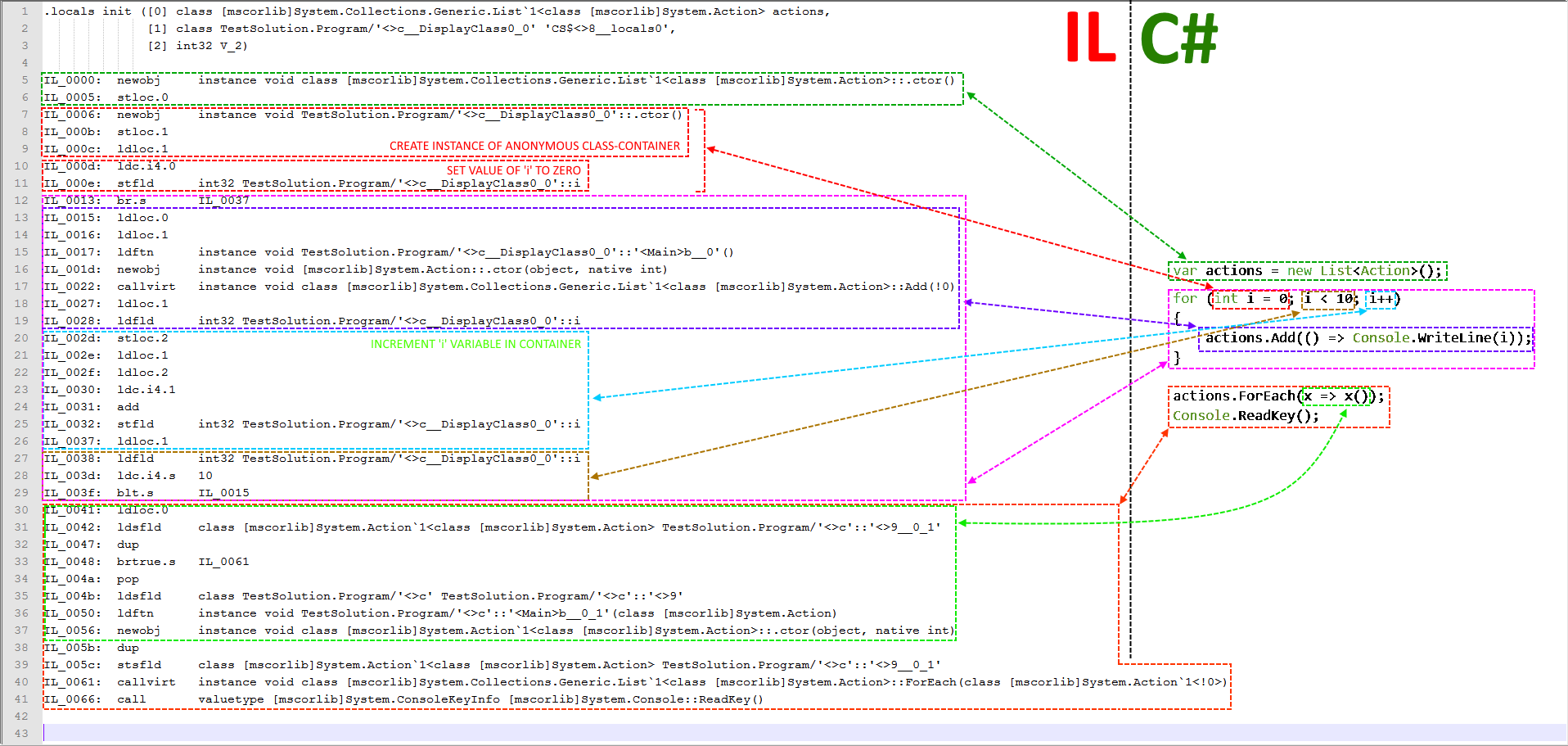
Во избежание данной ошибки необходимо следить, чтобы в анонимную функцию замыкалась локальная переменная для текущей итерации цикла. Корректный вариант мог бы выглядеть так:
void Foo()
{
var actions = new List<Action>();
for (int i = 0; i < 10; i++)
{
var curIndex = i;
actions.Add(() => Console.Write(curIndex)); // <=
}
// SOME ACTION
actions.ForEach(x => x());
}Таким образом, мы копируем значение итератора при каждой итерации в локальную переменную, и как уже нам известно, анонимный класс-контейнер будет создан при объявлении замыкаемой переменной, в данной случае - при объявлении переменной 'curIndex' со значением текущего итератора.
Давайте еще рассмотрим подозрительный код из проекта 'CodeContracts':
var tasks = new Task<int>[assemblies.Length];
Console.WriteLine("We start the analyses");
for (var i = 0; i < tasks.Length; i++)
{
tasks[i] = new Task<int>(() => CallClousotEXE(i, args)); // <=
tasks[i].Start();
}
Console.WriteLine("We wait");
Task.WaitAll(tasks);Несмотря на то, что создание и запуск задачи (Task) идет в пределах одной итерации цикла, свою работу она начнет не сразу, поэтому велика вероятность того, что это произойдет уже после текущей итерации, что в результате приведет к выше упомянутой ошибке.
К примеру, в данной ситуации на синтетическом примере все задачи стартовали уже после завершения работы цикла, и как следствие, переменная 'i' во всех задачах была равна последнему значению итератора (10).
Корректный вариант кода мог бы выглядеть так:
var tasks = new Task<int>[10];
Console.WriteLine("We start the analyses");
for (var i = 0; i < tasks.Length; i++)
{
var index = i;
tasks[i] = new Task<int>(() => CallClousotEXE(index, args));
tasks[i].Start();
}
Console.WriteLine("We wait");
Task.WaitAll(tasks);V3130. Priority of the '&&' operator is higher than that of the '||' operator. Possible missing parentheses.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что приоритет логического оператора '&&' выше приоритета логического оператора '||'. Про это часто забывают. В результате логическое выражение может давать совсем не тот результат, на который рассчитывал программист.
Рассмотрим пример некорректного кода:
if (c == 'l' || c == 'L' && !token.IsKeyword)
{ .... }Скорее всего, программист ожидал, что вначале выполнится проверка равенства переменной 'c' значению 'l' или 'L'. И только затем выполнится операция '&&'. Но согласно приоритету операторов, в языке C# вначале произойдет выполнение операции '&&', а уже потом '||'.
Можно порекомендовать во всех выражениях с редко используемыми вами операторами или там где нет уверенности, писать скобки. Даже если скобки окажутся лишними, это не страшно. Зато код станет более легким для понимания и будет меньше подвержен ошибкам.
Корректный вариант кода:
if ((c == 'l' || c == 'L') && !token.IsKeyword)
{ .... }А как убрать ложное предупреждение, если действительно планировалась последовательность вычислений: сначала логическое '&&', затем логическое '||'?
Есть несколько вариантов:
1) Плохой вариант. Можно использовать комментарий "//-V3130" для подавления предупреждения в нужной строке.
if (c == 'l' || c == 'L' && !token.IsKeyword) //-V3130
{ .... }2) Хороший вариант. Можно добавить дополнительные скобки:
if (c == 'l' || (c == 'L' && !token.IsKeyword))
{ .... }Дополнительные скобки помогут вашим коллегам понять, что этот код корректен.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3130. |
V3131. The expression is checked for compatibility with the type 'A', but is casted to the 'B' type.
Анализатор обнаружил потенциально возможную ошибку, связанную с проверкой выражения на принадлежность к одному типу и приведением этого выражения в блоке проверки к другому типу.
Давайте рассмотрим данную ситуацию более подробно на примере:
if (obj is A)
{
return (B)obj;
}Скорее всего программист ошибся, так как подобное приведение типов с большой вероятностью приведет к ошибке, и вероятнее всего подразумевалась либо проверка выражения на принадлежность к другому типу, либо приведение выражения к другому типу.
Корректный вариант мог бы выглядеть так:
if (obj is B)
{
return (B)obj;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3131. |
V3132. A terminal null is present inside a string. The '\0xNN' characters were encountered. Probably meant: '\xNN'.
Анализатор обнаружил потенциальную ошибку, связанную с наличием внутри строки терминального нулевого символа.
Как правило, такая ошибка возникает вследствие опечатки. Например, последовательность "\0x0A" будет восприниматься как следующая последовательность из четырёх байт: { '\0', 'x', '0', 'A' }.
Если хочется задать код символа в шестнадцатеричном виде, то символ 'x' должен стоять сразу после символа '\'. Если написать "\0", то это будет воспринято как ноль (в формате восьмеричного числа). См. также:
- MSDN. C Character Constants.
- MSDN. Escape Sequences.
Рассмотрим пример некорректного кода:
String s = "string\0x0D\0x0A";Если попробовать распечатать эту строку, то управляющие символы для перевода строки использованы не будут. Функции вывода остановятся на символе конца строки '\0'. Для устранения этой ошибки следует заменить "\0x0D\0x0A" на "\x0D\x0A".
Корректный вариант кода:
String s = "string\x0D\x0A";Данная диагностика классифицируется как:
V3133. Postfix increment/decrement is senseless because this variable is overwritten.
Анализатор обнаружил потенциальную ошибку, связанную с бессмысленным использованием постфиксного инкремента или декремента в выражении присвоения в эту же переменную.
Давайте рассмотрим пример:
int i = 5;
// Some code
i = i++;В данном случае инкремент будет бессмысленным, и после выполнения данного кода переменная 'i' будет иметь значение '5'.
Это связано с тем, что постфиксный инкремент и декремент выполняются после вычисления правого операнда оператора присваивания, а результат вычисления временно кэшируется, и после выполнения операций постфиксного инкремента или декремента присваивается левой части выражения. Таким образом результат выполнения постфиксного инкремента или декремента перезаписывается результатом всего выражения.
Для более глубокого понимания природы данного поведения давайте рассмотрим IL код вышеупомянутого примера:
-======- НАЧАЛО ОПЕРАЦИИ "int i = 5" -======-
// Объявление локальной переменной 'i'
// Текущий стек => []
.locals init ([0] int32 i)
// Передача числа 5 на верх стека
// Текущий стек => [5]
IL_0001: ldc.i4.5
// Присвоение переменной 'i' числа 5 со стека
// Текущий стек => []
IL_0002: stloc.0
-======- КОНЕЦ ОПЕРАЦИИ "int i = 5" -======-
-======- НАЧАЛО ОПЕРАЦИИ "i = i++" -======-
// Передача на верх стека значения переменной 'i'
// Текущий стек => [5]
IL_0003: ldloc.0
-======- НАЧАЛО ОПЕРАЦИИ "i++" -======-
// Копия верхнего значения на стеке
// Текущий стек => [5, 5]
IL_0004: dup
// Передача числа 1 на верх стека
// Текущий стек => [1, 5, 5]
IL_0005: ldc.i4.1
// Операция сложения 2 верхних чисел со стека (5 + 1)
// Результат вычисления (6) передается на верх стека
// Текущий стек => [6, 5]
IL_0006: add
// Присвоение переменной 'i' числа 6 со стека
// Текущий стек => [5]
IL_0007: stloc.0
-======- КОНЕЦ ОПЕРАЦИИ "i++" -======-
// Присвоение переменной 'i' числа 5 со стека
// Текущий стек => []
IL_0008: stloc.0
-======- КОНЕЦ ОПЕРАЦИИ "i = i++" -======-Корректный же пример может иметь разный вид в зависимости от изначальной задачи.
Это может быть опечатка, и на самом деле программист случайно написал 2 раза переменную 'i' в выражении присвоения. Тогда корректный вариант мог бы выглядеть так:
int i = 5;
// Some code
q = i++;Либо же программист не знал, что оператор постфиксного инкремента прибавляет единицу к значению переменной, но возвращает начальное ее значение. Тогда операция присвоения будет излишней, и корректный вариант мог бы выглядеть так:
int i = 5;
// Some code
i++;На первый взгляд может показаться, что это синтетический тест, и никто так не пишет, но на самом деле данную ошибку можно встретить и в серьезных проектах. Давайте рассмотрим аналогическую ошибку, найденную в проекте 'MSBuild'.
_parsePoint =
ScanForPropertyExpressionEnd(expression, parsePoint++);Инкремент переменной '_parsePoint' будет бессмысленным, так как будет вычислен после передачи изначального значения этой переменной в метод ' ScanForPropertyExpressionEnd', и никак не повлияет на результат выполнения данного метода. Вероятнее всего программист перепутал постфиксный инкремент с префиксным инкрементом. Тогда корректный вариант мог бы выглядеть следующим образом:
_parsePoint =
ScanForPropertyExpressionEnd(expression, ++_parsePoint);Данная диагностика классифицируется как:
V3134. Shift by N bits is greater than the size of type.
Анализатор обнаружил потенциальную ошибку, связанную со сдвигом целого числа на 'N' бит, при этом 'N' больше размера этого числового типа в битах.
Давайте рассмотрим пример:
UInt32 x = ....;
UInt32 y = ....;
UInt64 result = (x << 32) + y;В данном случае хотели собрать 64-битное число из 2-х 32-битных, сдвинув 'x' на 32 бита и сложив старшую и младшую часть. Но поскольку 'x' в момент сдвига является 32-битным числом, то сдвиг на 32 бита эквивалентен сдвигу на 0 бит, что приведет к некорректному результату.
Корректный вариант может выглядеть так:
UInt32 x = ....;
UInt32 y = ....;
UInt64 result = ((UInt64)x << 32) + y;Также давайте рассмотрим пример из реального проекта:
static long GetLong(byte[] bits)
{
return ((bits[0] & 0xff) << 0)
| ((bits[1] & 0xff) << 8)
| ((bits[2] & 0xff) << 16)
| ((bits[3] & 0xff) << 24)
| ((bits[4] & 0xff) << 32)
| ((bits[5] & 0xff) << 40)
| ((bits[6] & 0xff) << 48)
| ((bits[7] & 0xff) << 56);
}В методе 'GetLong' выполняется преобразование массива байт в 64-битное число. Поскольку операторы битового сдвига определены только для 32 и 64-битных чисел, то каждый байт будет неявно преобразован в 'Int32'. Диапазон битового сдвига 32-битного числа - [0..31], поэтому преобразование будет выполняться корректно только для первых 4 байт массива.
Если предположить, что массив байт был сформирован из 64-битного числа (К примеру из 'Int64.MaxValue'), то при обратном преобразовании из массива байт в Int64 данным методом возможна ошибка, в случае, если изначальное число не находилось в диапазоне [Int32.MinValue....Int32.MaxValue].
Для большей наглядности давайте рассмотрим работу данного кода для числа '289077008695033855'. Данное число после преобразования в массив байт будет иметь вид:
289077008695033855 => [255, 255, 255, 255, 1, 2, 3, 4]Передав этот массив байт в метод 'GetLong' перед операцией сдвига каждый байт будет неявно преобразован в Int32. Давайте выполним каждую операцию сдвига отдельно, чтобы понять в чем проблема.

Как видим, сдвиг выполняется для 32-битного числа, что в итоге приводит к пересечению диапазонов и как следствие к неправильному результату. Это происходит потому, что при попытке сдвинуть 32-битное число более чем на 32 бита мы начинаем сдвигать биты по кругу (сдвиг на 32, 40, 48 и 56 бит идентичен сдвигу на 0, 8, 16 и 24 соответственно)
Исправленный вариант данного метода мог бы выглядеть так:
static long GetLong(byte[] bits)
{
return ((long)(bits[0] & 0xff) << 0)
| ((long)(bits[1] & 0xff) << 8)
| ((long)(bits[2] & 0xff) << 16)
| ((long)(bits[3] & 0xff) << 24)
| ((long)(bits[4] & 0xff) << 32)
| ((long)(bits[5] & 0xff) << 40)
| ((long)(bits[6] & 0xff) << 48)
| ((long)(bits[7] & 0xff) << 56);
}Рассмотрев каждую операцию сдвига отдельно, мы увидим, что теперь сдвиг выполняется для 64-битного числа, что в итоге препятствует пересечению диапазонов.

Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3134. |
V3135. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
Анализатор выявил цикл, который может содержать ошибку или быть неоптимальным. Используется типичный паттерн кода, когда для всех пар элементов массива выполняется некая операция. При этом, как правило, нет смысла выполнять операцию для пары, состоящей из одного и того-же элемента при 'i == j'.
Пример:
for (int i = 0; i < size; i++)
for (int j = i; j < size; j++)
...Есть большая вероятность, что правильнее или эффективнее использовать следующий код для обхода массивов:
for (int i = 0; i < size; i++)
for (int j = i + 1; j < size; j++)
...Данная диагностика классифицируется как:
V3136. Constant expression in switch statement.
Анализатор обнаружил константное выражение в условии 'switch'. Чаще всего это сигнализирует о логической ошибке.
Рассмотрим синтетический пример:
int i = 1;
switch (i)
{
....
}В качестве условия 'switch' стоит переменная, значение которой может быть посчитано во время компиляции. Такая ситуация могла возникнуть в результате рефакторинга: раньше был код, который менял значение переменной, а потом его поменяли и оказалось, что переменной больше не присваивается никакое значение.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3136. |
V3137. The variable is assigned but is not used by the end of the function.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что локальной переменной присваивается значение, но переменная далее нигде не используется до выхода из метода.
Рассмотрим фрагмент кода:
private string GetDisplayName(string name)
{
MyStringId tmp = MyStringId.GetOrCompute(name);
string result;
if (!MyTexts.TryGet(tmp, out result))
result = name;
return name;
}Программист хотел, чтобы результатом метода была переменная 'result', которая инициализируется в зависимости от выполнения 'TryGet'. К сожалению, из-за опечатки метод всегда возвращает переменную 'name'. Правильный код должен выглядеть следующим образом:
private string GetDisplayName(string name)
{
MyStringId tmp = MyStringId.GetOrCompute(name);
string result;
if (!MyTexts.TryGet(tmp, out result))
result = name;
return result;
}Рассмотрим еще один фрагмент кода:
protected DateTimeOffset? GetFireTimeAfter()
{
DateTimeOffset sTime = StartTimeUtc;
DateTimeOffset? time = null;
....
if (....)
{
....
time = sTime;
}
else if (....)
{
....
time = sTime;
}
....
//apply the timezone before we return the time.
sTime = TimeZoneUtil.ConvertTime(time.Value, this.TimeZone);
return time;
}В нескольких блоках 'if' в переменную 'time' записывается значение 'sTime', хранящее некоторое стартовое время, увеличенное на некоторый интервал. В конце метода переменная 'time' возвращается. Перед возвращением 'time', судя по комментарию в коде, программист хочет скорректировать представление времени, учитывая временную зону. По ошибке корректируется временная зона переменной 'sTime', которая более нигде не используется. Правильный код, скорее всего, должен выглядеть следующим образом:
protected DateTimeOffset? GetFireTimeAfter()
{
DateTimeOffset sTime = StartTimeUtc;
DateTimeOffset? time = null;
....
//apply the timezone before we return the time.
time = TimeZoneUtil.ConvertTime(time.Value, this.TimeZone);
return time;
}Часто встречается код, в котором при объявлении переменной присваивается какое-то значение, а затем эта переменная более нигде не используется. Обычно это не является ошибкой. Например, это может быть сделано в соответствии с принятым в компании стандартом программирования, при котором требуется всегда сохранять в переменной результат работы любого метода, даже если этот результат никак не используется. Например:
void SomeMethod()
{
....
int result = DoWork();
....
}Для таких ситуаций в анализаторе сделано исключение и диагностика не выдаст предупреждение.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3137. |
V3138. String literal contains potential interpolated expression.
Анализатор обнаружил строку, которая могла бы содержать интерполированное выражение, но символ интерполяции '$' у литерала отсутствует.
Рассмотрим фрагмент кода:
string test = "someText";
....
Console.WriteLine("{test}");Из-за пропущенного знака '$' перед объявлением строки в консоль будет выведено имя переменной. Корректная запись будет выглядеть так:
string test = "someText";
....
Console.WriteLine($"{test}");Также потенциальными ошибками считаются строки, содержащие выражения:
int a = 1;
int b = 1;
string test = "{a:c} test";
string test1 = "{a+b} test1 {{{ a + b }}}";Исключениями считаются строковые литералы, передаваемые в методы в качестве аргумента, когда другими аргументами этих методов являются переменные, содержащиеся в этом литерале.
string test1 = ReplaceCustom("someText {test}", "{test}", test);В этом случае выражение в литерале часто бывает меткой для замены на значение переменной, также передаваемой в метод.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3138. |
V3139. Two or more case-branches perform the same actions.
Анализатор обнаружил ситуацию, когда в операторе switch разные метки case содержат одинаковые фрагменты кода. Часто это свидетельствует об избыточном коде, который можно улучшить объединением меток. Но нередко одинаковые фрагменты кода могут быть причиной copy-paste программирования и являться настоящими ошибками.
Рассмотрим пример с избыточным кодом:
switch (switcher)
{
case 0: Console.Write("0"); return;
case 1: Console.Write("0"); return;
default: Console.Write("default"); return;
}Действия для нескольких значений 'switcher' действительно могут быть одинаковыми, поэтому код можно написать более компактно:
switch (switcher)
{
case 0:
case 1: Console.Write("0"); return;
default: Console.Write("default"); return;
}Если вы используете 'case expression', то объединить такие выражения под одно условие у вас не получится:
private static void ShowCollectionInformation(object coll, bool cond)
{
switch (coll)
{
case Array arr:
if(cond)
{
Console.WriteLine (arr.ToString());
}
break;
case IEnumerable<int> arr:
if(cond)
{
Console.WriteLine (arr.ToString());
}
break;
}
}В таком случае, вы можете вынести общий код в метод, что облегчит дальнейшее редактирование и отладку.
Теперь, рассмотрим пример из реального приложения, где разработчик допустил ошибку:
switch (status.BuildStatus)
{
case IntegrationStatus.Success:
snapshot.Status = ItemBuildStatus.CompletedSuccess;
break;
case IntegrationStatus.Exception:
case IntegrationStatus.Failure:
snapshot.Status = ItemBuildStatus.CompletedSuccess;
break;
}В присвоение статуса попала ошибка: у перечисления 'ItemBuildStatus' есть элемент 'CompletedFailed', который следовало присвоить в случае ошибки или исключения.
Исправленный код:
switch (status.BuildStatus)
{
case IntegrationStatus.Success:
snapshot.Status = ItemBuildStatus.CompletedSuccess;
break;
case IntegrationStatus.Exception:
case IntegrationStatus.Failure:
snapshot.Status = ItemBuildStatus. CompletedFailed;
break;
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3139. |
V3140. Property accessors use different backing fields.
Анализатор обнаружил свойство, использующее разные поля в get и set методах доступа. Это может быть следствием опечатки или копирования тела другого свойства.
Рассмотрим пример из реального приложения, где разработчик допустил подобную ошибку:
String _heading; String _copyright;
public string Heading
{
get { return this._heading; }
set { this._heading = value; }
}
public string Copyright
{
get { return this._heading; }
set { this._copyright = value; }
}Метод доступа get свойства 'Copyright' должен был возвращать поле '_copyright', a не поле '_heading'.
Исправленный код будет выглядеть следующим образом:
String _heading; String _copyright;
public string Heading
{
get { return this._heading; }
set { this._heading = value; }
}
public string Copyright
{
get { return this._copyright; }
set { this._copyright = value; }
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3140. |
V3141. Expression under 'throw' is a potential null, which can lead to NullReferenceException.
Анализатор обнаружил передачу потенциального null значения в throw выражение. В случае передачи null в выражение throw, исполняемая среда .NET генерирует исключение разыменования нулевой ссылки (NullReferenceException), хотя фактического разыменования в вашем коде произведено не будет.
Например, в таком коде:
private Exception GetException(String message)
{
if (message == null)
return null;
return new Exception(message);
}
....
throw GetException(message);произойдёт передача в выражение throw значения null, если параметр 'message' имеет значение null.
С точки зрения дальнейшей работы с исключением, такое поведение может быть неочевидным или нежелательным. Во-первых, стек исключения NullReferenceException, сгенерированный на throw, будет указывать на сам throw, а не на причину, к нему приводящую (т.е. на возврат значения null из метода 'GetException'). Во-вторых, сама генерация в данной ситуации NullReferenceException выглядит неправильной, т.к. фактически разыменования нулевой ссылки не произошло, и это в дальнейшем может затруднить отладку.
Чтобы сделать последующую отладку подобной ситуации более удобной, лучше либо проверить перед выбрасыванием исключения значение, возвращаемое методом 'GetException', либо вместо возврата null в этом методе бросить более конкретное исключение, которое точнее будет описывать возникшую ситуацию с неожидаемым значением, приходящим в метод.
Исправленный код может выглядеть следующим образом:
private Exception GetException(String message)
{
if (message == null)
throw new ArgumentException();
return new Exception(message);
}V3142. Unreachable code detected. It is possible that an error is present.
Анализатор обнаружил код, который никогда не будет выполнен. Возможно, допущена ошибка в логике программы.
Данная диагностика находит блоки кода, до которых никогда не дойдёт управление.
Рассмотрим пример:
static void Foo()
{
Environment.Exit(255);
Console.WriteLine("Hello World!");
}Функция 'Console.WriteLine (....)' недостижима, так как функция 'Exit()' не возвращает управление. Как правильно исправить код, зависит от того, какую логику поведения задумывал программист изначально. Возможно, нарушен порядок выражений и корректный код должен быть таким:
static void Foo()
{
Console.WriteLine("Hello World!");
Environment.Exit(255);
}Рассмотрим ещё один пример:
static void ThrowEx()
{
throw new Exception("Programm Fail");
}
public void SetResponse(int response)
{
ThrowEx();
Debug.Assert(false); //should never reach here
}В данном примере межпроцедурный анализ проверяет метод 'ThrowEx' и предупреждает, что код после вызова метода недостижим. Если такое поведение ожидаемо - вы можете отметить предупреждение как ложное.
public void SetResponse(int response)
{
ThrowEx();
Debug.Assert(false); //should never reach here //-V3142
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3142. |
V3143. The 'value' parameter is rewritten inside a property setter, and is not used after that.
Анализатор обнаружил присвоение некоторого значения параметру 'value' внутри setter'а свойства. При этом, после этого присвоения параметр 'value' больше не использовался в теле этого setter'а, что возможно свидетельствует об ошибке или опечатке.
Рассмотрим пример из реального проекта:
public LoggingOptions Options
{
get { return m_loggingOptions; }
set { value = m_loggingOptions; }
}Здесь значение параметра 'value' перезаписывается сразу после входа в setter метод свойства. При этом изначальное значение параметра 'value' будет потеряно. Возможно, что разработчик опечатался и перепутал 'value' и 'm_loggingOptions' местами. Если же разработчик не хотел давать возможность записи в это свойство, то его можно было бы объявить с private set методом или вообще не объявлять setter.
Исправленный вариант может выглядеть так:
public LoggingOptions Options
{
get { return m_loggingOptions; }
set { m_loggingOptions = value; }
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3143. |
V3144. This file is marked with copyleft license, which requires you to open the derived source code.
Анализатор обнаружил в файле copyleft лицензию, которая обязывает открыть остальной исходный код. Это может быть неприемлемо для многих коммерческих проектов.
Если вы разрабатываете открытый проект, то можно просто игнорировать это предупреждение и отключить его.
Пример комментария, на который анализатор выдаст предупреждение:
/* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program. If not, see <https://www.gnu.org/licenses/>.
*/Для закрытых проектов
Если в закрытый проект добавить файл с такой лицензией (GPL3 в данном случае), то остальной исходный код необходимо будет открыть, из-за особенностей данной лицензии.
Такой тип copyleft лицензий называют "вирусными" лицензиями, из-за их свойства распространяться на остальные файлы проекта. Проблема в том, что использование хотя бы одного файла с подобной лицензией в закрытом проекте автоматически делает весь исходный код открытым и обязывает распространять его вместе с бинарными файлами.
Диагностика занимается поиском следующих "вирусных" лицензий:
- AGPL-3.0
- GPL-2.0
- GPL-3.0
- LGPL-3.0
Есть следующие варианты, как вы можете поступить, обнаружив в закрытым проекте использование файлов с copyleft лицензий:
- Отказаться от использования данного кода (библиотеки) в своём проекте;
- Заменить используемую библиотеку;
- Сделать свой проект открытым.
Для открытых проектов
Мы понимаем, что данная диагностика неуместна для открытых проектов. Команда PVS-Studio способствует развитию открытых проектов, помогая исправлять в них ошибки и предоставляя бесплатные варианты лицензий. Однако наш продукт является B2B решением, и поэтому данная диагностика по умолчанию включена.
Если же ваш код распространяется под одной из указанных выше copyleft лицензий, то вы можете отключить данную диагностику следующими способами:
- Если вы используете плагин PVS-Studio для Visual Studio, то перейдя в Options > PVS-Studio > Detectable Errors > 1.General Analysis > V3144 можно отключить отображение данной диагностики в окне вывода анализатора. Минус данного способа в том, что ошибка всё равно будет записана в лог анализатора при его сохранении (или если анализ запускался из командной строки). Поэтому, при открытии такого лога на другой машине или конвертации результатов анализа в другой формат, отключенные таким образом сообщения могут появиться снова.
- Если вы не используете плагин, хотите блокировать правило для всей команды или убрать его из отчёта анализатора,- то можно отключить диагностику, добавив в проект или solution файл конфигурации диагностических правил анализатора. Сделать это можно вручную или при помощи интерфейса Visual Studio (выбрать контекстное меню проекта\solution 'Add > New Item', затем выбрать PVS-Studio Filters File). Добавленный в систему контроля версий файл появится у всей вашей команды. Добавьте в файл строку: //-V::3144.Так вы настроите анализатор на отключение данной диагностики. Подробнее об отключении диагностик с помощью комментариев рассказано в документации.
- Если для конвертации отчётов используется утилита Plog Converter, то можно отключить диагностику, используя ключ "-d".
Пополнение списка опасных лицензий
Если вам известны ещё типы "вирусных" лицензий, которые в данный момент не выявляет инструмент, то вы можете сообщить нам о них через форму обратной связи. И мы добавим их выявление в следующем релизе.
Дополнительные ссылки
- GNU General Public License
- "Вирусные" лицензии
- Бесплатные варианты лицензирования PVS-Studio
- Подавление ложных предупреждений
V3145. Unsafe dereference of a WeakReference target. The object could have been garbage collected before the 'Target' property was accessed.
Анализатор обнаружил небезопасное использование объекта типа 'WeakReference', которое может привести к разыменованию нулевой ссылки.
Рассмотрим пример:
string Foo(WeakReference weak)
{
return weak.Target.ToString();
}Так как объект, на который 'WeakReference' хранит ссылку, может быть в любой момент очищен сборщиком мусора, всегда существует вероятность, что свойство 'Target' вернёт значение 'null'.
В таком случае, при попытке вызова метода 'ToString' может произойти разыменование нулевой ссылки и будет выброшено исключение 'NullReferenceException'. Один из вариантов защиты от потенциального удаления объекта – запись его в локальную переменную, на время работы с ним. Исправленный код будет выглядеть так:
string Foo(WeakReference weak)
{
var weakTarget = weak.Target;
return weakTarget != null ? weakTarget.ToString() : String.Empty;
}После записи ссылки в локальную переменную, сборщик мусора уже не сможет удалить этот объект, пока ссылка на него находится на стеке. Тем не менее, после записи объекта в локальную переменную её обязательно нужно проверить на 'null', т.к. в момент доступа к свойству 'Target' объект, на который 'Target' указывал, уже мог быть удалён сборщиком мусора.
Проверка на существование объекта внутри 'WeakReference' с помощью свойства 'IsAlive' также не защитит от возникновения 'NullReferenceException', так как между проверкой 'IsAlive' и разыменованием свойства 'Target' объект также может быть удалён сборщиком мусора:
char Foo(WeakReference weak)
{
if (weak.IsAlive)
return (weak.Target as String)[0];
return ' ';
}Корректное использование свойства 'IsAlive' может выглядеть так:
char Foo(WeakReference weak)
{
var str = weak.Target as String;
if (weak.IsAlive)
return str[0];
return ' ';
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3145. |
V3146. Possible null dereference. A method can return default null value.
Анализатор обнаружил небезопасное использование результата вызова одного из методов библиотеки System.Enumerable, которые могут вернуть 'default' значение.
Примеры таких методов: 'FirstOrDefault', 'LastOrDefault', 'SingleOrDefault' и 'ElementAtOrDefault'. Эти методы возвращают значение по умолчанию, если в массиве нет ни одного объекта, удовлетворяющего предикату поиска. Значением по умолчанию для ссылочных типов является пустая ссылка (null). Соответственно, прежде чем использовать полученную ссылку, её следует проверить.
Пример опасного разыменования:
public void TestMemberAccess(List<string> t)
{
t.FirstOrDefault(x => x == "Test message").ToString();
}В этом случае стоит добавить проверку возвращаемого элемента на null:
public void TestMemberAccess(List<string> t)
{
t.FirstOrDefault(x => x == "Test message")?.ToString();
}Повышенную опасность методы, возвращающие default значения, представляют в цепочках вызовов. Пример из открытого проекта:
public IViewCompiler GetCompiler()
{
....
_compiler = _services
.GetServices<IViewCompilerProvider>()
.FirstOrDefault()
.GetCompiler();
}
....
return _compiler;
}Если вы уверены, что при обработке массива в нём есть нужный вам элемент – мы советуем использовать метод, не возвращающий default значение:
public IViewCompiler GetCompiler()
{
....
_compiler = _services
.GetServices<IViewCompilerProvider>()
.First()
.GetCompiler();
}
....
return _compiler;
}В этом случае в случае ошибки вы получите не 'NullReferenceException', а 'InvalidOperationException' с более понятным сообщением: "Sequence contains no elements".
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3146. |
V3147. Non-atomic modification of volatile variable.
Анализатор обнаружил неатомарное изменение 'volatile' переменной, которое может привести к состоянию гонки.
Известно, что использование модификатора 'volatile' гарантирует, что все потоки будут видеть актуальное значение соответствующей переменной. Модификатор 'volatile' используется для того, чтобы указать CLR, что все операции присвоения этой переменной и все операции чтения из неё должны быть атомарными.
Можно посчитать, что пометки переменных как 'volatile' будет достаточно, чтобы безопасно использовать все возможные операции присвоения в многопоточном приложении.
Помимо простых операций присвоения, существуют также операции, изменяющие значение переменной перед записью. К таким операциям можно отнести:
- var++, ‑‑var, ...
- var += smt, var *= smt, ...
- ...
Такая запись выглядит как одна операция, но в действительности это целая последовательность операций чтения-изменения-записи.
Рассмотрим использование 'volatile' переменной в качестве счетчика (counter++).
class Counter
{
private volatile int counter = 0;
....
public void increment()
{
counter++; // counter = counter + 1
}
....
}В IL коде операция инкремента раскрывается в следующие команды:
IL_0001: ldarg.0
IL_0002: ldarg.0
IL_0003: volatile.
IL_0005: ldfld int32
modreq([mscorlib]System.Runtime.CompilerServices.IsVolatile)
VolatileTest.Test::val
IL_000a: ldc.i4.1
IL_000b: add
IL_000c: volatile.
IL_000e: stfld int32
modreq([mscorlib]System.Runtime.CompilerServices.IsVolatile)
VolatileTest.Test::valЗдесь и кроется состояние гонки. Предположим, что 2 потока одновременно работают с одним и тем же экземпляром объекта типа Counter и выполняют инкремент переменной 'counter', изначально проинициализированной значением 10. При этом, оба потока будут работать одновременно, выполняя промежуточные действия над переменной counter, каждый на своём собственном стеке (назовём эти промежуточные значения temp1 и temp2):
[counter == 10, temp1 == 10] Поток N1 считывает значение 'counter' на свой стек. (операция ldfld в IL)
[counter == 10, temp1 == 11] Поток N1 изменяет значение temp1 на своём стеке. (операция add в IL)
[counter == 10, temp2 == 10] Поток N2 считывает значение 'counter' на свой стек. (операция ldfld в IL)
[counter == 11, temp1 == 11] Поток N1 записывает temp1 в 'counter'. (операция stfld в IL)
[counter == 11, temp2 == 11] Поток N2 изменяет значение temp2 на своём стеке. (операция add в IL)
[counter == 11, temp2 == 11] Поток N2 записывает temp2 в 'counter'. (операция stfld в IL)
Ожидалось значение переменной 'counter' равное 12 (а не 11), так как 2 потока выполнили инкремент над одной и той же переменной. Также возможна ситуация, когда потоки выполнят инкремент друг за другом, и в таком случае все будет так, как и ожидалось.
Чтобы избежать подобного поведения неатомарных операций для разделяемых переменных, можно использовать:
- Блок 'lock'
- Методы атомарных операций класса Interlocked из библиотеки System.Threading
- Функциональность блокировок класса Monitor из библиотеки System.Threading
Пример корректного кода:
class Counter
{
private volatile int counter = 0;
....
public void increment()
{
Interlocked.Increment(ref counter);
}
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V3148. Casting potential 'null' value to a value type can lead to NullReferenceException.
Анализатор обнаружил небезопасное приведение ссылки, потенциально содержащей значение 'null', к значимому типу. Хотя в данном случае не происходит прямого разыменования, такое приведение типа приводит к выбросу 'NullReferenceException'.
Простейший пример получения такого исключения:
void Foo()
{
object b = null;
var c = (bool)b;
}Исправленный код будет выглядеть так:
void Foo()
{
object b = null;
var c = (bool)(b ?? false);
}Также предупреждение будет сгенерировано при приведении переменной с потенциальным 'null' значением к любому значимому типу, например, к структуре:
protected override void ProcessMessageAfterSend(....)
{
....
(DateTime)msg.GetMetadata(....);
....
}
public object GetMetadata(string tag)
{
object data;
if (metadata != null && metadata.TryGetValue(tag, out data))
{ return data; }
return null;
}Диагностика проверила результат вызова метода 'GetMetadata' и обнаружила там потенциальный 'null'. В данном случае также стоило добавить проверку на null перед приведением типа:
protected override void ProcessMessageAfterSend(....)
{
....
(DateTime)(msg.GetMetadata(....) ?? new DateTime());
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3148. |
V3149. Dereferencing the result of 'as' operator can lead to NullReferenceException.
Анализатор обнаружил небезопасное разыменование результата приведения типа через оператор 'as'.
Рассмотрим пример:
void Foo()
{
BaseItem a = GetItem();
var b = a as SpecificItem;
b.Bar();
}Возвращаемое методом значение может иметь тип, отличный от типа, к которому мы его приводим. Тогда при приведении типа с помощью оператора 'as' в переменную 'b' будет записано значение null. Хотя при самом приведении типа ошибки не будет, при последующем использовании этой переменной без проверки произойдёт выброс исключения 'NullReferenceException'. Исправленный код будет выглядеть так:
void Foo()
{
BaseItem a = GetItem();
var b = a as SpecificItem;
b?.Bar();
}Если вы уверены, что runtime тип значения у переменной, приводимой с помощью оператора 'as', всегда может быть успешно приведён к указанному типу, то лучше воспользоваться оператором явного приведения типа:
void Foo()
{
BaseItem a = GetItem();
var b = (SpecificItem)a;
b.Bar();
}В этом случае, если в будущем поведение программы поменяется и метод 'GetItem' перестанет всегда возвращать значение, гарантированно приводимое к заданному типу, в месте приведения будет сгенерировано исключение 'InvalidCastException', что позволит сразу идентифицировать проблемное место в коде. Напротив, используя оператор 'as' в такой ситуации, можно получить 'NullReferenceException' далее по коду, когда приведённая неуспешно переменная, содержащая null, будет разыменована. Причём это может произойти далеко от места, где производится приведение типов, например в другом методе, что затруднит локализацию и исправление такой ошибки.
Также диагностика указывает на возможные опечатки при проверках типа:
void Foo()
{
IDisposable a = GetItem();
if(a is NonSpecificItem)
{
var b = a as SpecificItem;
b.Bar();
}
}В данном примере типы SpecificItem и NonSpecificItem не связаны друг с другом и результатом приведения будет нулевой указатель. Для защиты от таких опечаток можно использовать возможности C# 7.0 и сделать проверку через Is Type Pattern синтаксис:
void Foo()
{
IDisposable a = GetItem();
if(a is NonSpecificItem item)
{
item.Bar();
}
}Приведём пример работы диагностики на коде из открытого проекта:
....
FuelDefinition = MyDefinitionManager.Static.GetPhysicalItemDefinition(FuelId);
MyDebug.AssertDebug(FuelDefinition != null);
....
String constraintTooltip = FuelDefinition.DisplayNameText;В данном примере метод 'GetPhysicalItemDefinition' возвращает объект типа MyPhysicalItemDefinition, полученный из массива объектов базового типа 'MyDefinitionBase':
public MyPhysicalItemDefinition GetPhysicalItemDefinition(MyDefinitionId id)
{
....
return m_definitions.m_definitionsById[id] as MyPhysicalItemDefinition;
}При этом после вызова метода 'GetPhysicalItemDefinition' присутствует проверка результата приведения на null (MyDebug.AssertDebug), что указывает на потенциальную возможность получения из метода объекта неподходящего типа. Однако данная проверка будет работать только в Debug версии приложения. В Release версии неудачное приведение приведёт к разыменованию нулевой ссылки далее по ходу выполнения программы (FuelDefinition.DisplayNameText).
Данная диагностика классифицируется как:
V3150. Loop break conditions do not depend on the number of iterations.
Анализатор обнаружил цикл, условия выхода которого не зависят от количества итераций. Такой цикл может выполнится 0, 1, либо бесконечное количество раз.
Пример такого цикла:
void Foo(int left, int right)
{
while(left < right)
{
Bar();
}
}Ошибка здесь в цикле while - переменные, которые находятся в условии, никак не меняют своих значений, поэтому цикл никогда не завершится, либо никогда не запустится.
Рассмотрим другой пример кода, на который сработает данная диагностика. Цикл может стать бесконечным, если в блоке 'try-catch' забыть перебросить исключение дальше по стеку:
while (condition)
{
try {
if(Foo())
{
throw new Exception();
}
}
catch (Exception ex)
{
....
}
}Чтобы такой цикл прервался выбросом исключения, можно, например, перебросить это исключение из catch секции с помощью выражения throw:
while (condition)
{
try {
if(Foo())
{
throw new Exception();
}
}
catch (Exception ex)
{
....
throw;
}
}V3151. Potential division by zero. Variable was used as a divisor before it was compared to zero. Check lines: N1, N2.
Анализатор обнаружил потенциальную ошибку, которая может привести к делению на ноль.
Анализатор заметил в коде следующую ситуацию. Сначала происходит деление на некоторую переменную. Затем эта переменная сравнивается с нулём. Это может означать одно из двух:
1) Возникнет ошибка, если число будет равно 0.
2) Программа всегда работает корректно, так как число всегда не равно 0. Проверка является лишней.
Рассмотрим пример кода, на который выдаётся предупреждение анализатора.
int Foo(int num)
{
result = 1 / num;
if (num == 0) return -1;
....
}Если число 'num' окажется равно нулю, то выражение '1 / num' приведёт к ошибке. Анализатор выдаст предупреждение на этот код, указав 2 строки. Первая строка - это то место, где происходит деление на число. Вторая строка - это то место, где число сравнивается с нулём.
Исправленный вариант кода:
int Foo(int num)
{
if (num == 0) return -1;
result = 1 / num;
....
}Рассмотрим второй вариант срабатывания, в котором нет ошибки, а проверка на ноль избыточна.
int num = MyOneTenRandom();
result = 1 % num;
if (num == 0) return -1;Этот код всегда работает корректно. Функция 'MyOneTenRandom' написана так, что никогда не возвращает ноль. Однако анализатор не разобрался в этой ситуации (например, если этот метод виртуальный и межпроцедурный анализ не смог выбрать, какая именно в runtime'е реализация метода будет вызвана), и выдал предупреждение. Чтобы оно исчезло, следует удалить проверку "if (num == 0)". Она не имеет практического смысла и может только запутать программиста, читающего данный код.
Исправленный вариант:
int num = MyOneTenRandom();
result = 1 % num;В случае если анализатор ошибается, то, кроме изменения кода, можно использовать комментарий для подавления предупреждений. Пример: "1 % num; //-V3151".
Данная диагностика классифицируется как:
V3152. Potential division by zero. Variable was compared to zero before it was used as a divisor. Check lines: N1, N2.
Анализатор обнаружил потенциальную ошибку, которая может привести к делению на ноль.
Анализатор заметил в коде следующую ситуацию. В начале вы сравниваете некоторое число с нулём, а потом делите на него уже без проверки. Это может означать одно из двух:
1) Возникнет ошибка, если число будет равно 0.
2) Программа всегда работает корректно, так как число всегда не равно 0. Проверка является лишней.
Рассмотрим первый вариант. Здесь может возникнуть исключение.
int num = Foo();
if (num != 0)
variable1 = 3 / num;
variable2 = 5 / num;Если значение переменной 'num' окажется равно нулю, то выполнение выражения '5 / num ' приведёт к ошибке. Анализатор выдаст предупреждение на этот код, указав на 2 строки. Первая строка - это то место, где происходит деление на переменную. Вторая строка - это то место, где переменная сравнивается с нулём.
Исправленный вариант кода:
int num = Foo();
if (num != 0)
{
variable1 = 3 / num;
variable2 = 5 / num;
}Рассмотрим второй вариант. Деление безопасное, проверка лишняя:
List<string> list = CreateNonEmptyList();
var count = list.Count;
if (count == 0) {....}
var variable = 10 / count;Предположим, что метод 'CreateNonEmptyList' возвращает список 'list' всегда с ненулевым числом элементов. Тогда приведённый выше код всегда будет работать корректно, а деления на 0 никогда не случится
Примечание: в данном примере не всегда будет сгенерировано предупреждение V3152 - если анализатор сможет понять, что данный метод возвращает всегда непустой список, то он выдаст на проверку 'list.Count == 0' предупреждение V3022 "данное выражение всегда истинно". Если не сможет (например, из-за сложной последовательности переприсвоений переменных, когда этот метод виртуальный, и т.п.) - будет сгенерировано предупреждение V3152. Тип сгенерированного предупреждения будет зависеть от реализации метода 'CreateNonEmptyList'.
Чтобы предупреждение исчезло, можно удалить проверку 'if (list == null || list.Count == 0)'. В данном случае она не имеет практического смысла и может только запутать программиста, читающего код.
Исправленный вариант:
List<string> list = CreateNonEmptyList();
var variable = 10 / list.Count;Ещё один вариант сообщения анализатора - когда проверка и использование расположены в разных ветках if\else или switch выражений. Например:
if (lines.Count == 1)
{
if (num != 0)
variable = 10 / num;
}
else
{
variable = 10 / num;
}В такой ситуации, несмотря на то что обе ветки никогда не выполняются одновременно, а будет выбрана только одна из веток, сравнение с нулём в одной из них косвенно свидетельствует о возможности принятия переменной значения ноль и в другой ветке. Тогда, если управление придёт во вторую ветку, произойдёт деление на ноль.
Исправленный вариант:
if (lines.Count == 1)
{
if (num != 0)
variable = 10 / num;
}
else
{
if (num != 0)
variable = 10 / num;
}В случае если анализатор ошибается, то кроме изменения кода, можно использовать комментарий для подавления предупреждений. Например:
variable = 10 / num; //-V3152Данная диагностика классифицируется как:
V3153. Dereferencing the result of null-conditional access operator can lead to NullReferenceException.
Анализатор обнаружил потенциальную ошибку, которая может привести к разыменованию нулевой ссылки. Результат работы оператора '?.' сразу явно или неявно разыменовывается.
Разыменование может произойти в нескольких случаях:
- после условного доступа к потенциально нулевому элементу результат null-conditional оператора взяли в скобки перед дальнейшим разыменованием;
- в перечислимом выражении в 'foreach' используется оператор условного доступа.
Сценарии выше могут привести к:
- Возникновению ошибки, если ссылка, по которой осуществлялся условный доступ, имеет значение 'null'.
- Корректной работе программы, так как ссылка, по которой осуществлялся условный доступ, всегда не равна 'null'. В этом случае такая проверка является лишней.
Рассмотрим первый вариант. Здесь может возникнуть исключение:
var t = (obj?.ToString()).GetHashCode();Если объект 'obj' окажется равен 'null', то в выражении 'obj?.ToString()' метод 'ToString()' не будет вызван. Это принцип работы оператора условного доступа. Но метод 'GetHashCode()' всё равно будет вызван, поскольку его вызов уже не будет относиться к оператору условного доступа.
Исправленный вариант кода:
var t = obj?.ToString().GetHashCode();Здесь, кроме отсутствия опасного разыменования, переменная 't' теперь будет иметь тип 'Nullable<int>', что корректно отражает её содержимое как потенциально содержащее значение 'null'.
Рассмотрим теперь случай, когда разыменование безопасное, а проверка лишняя:
object obj = GetNotNullString();
....
var t = ((obj as String)?.Length).GetHashCode();Этот код всегда работает корректно. Объект 'obj' всегда имеет тип 'String', а значит проверка после приведения типа избыточна.
Исправленный вариант:
var t = ((String)obj).Length.GetHashCode();Рассмотрим пример с циклом 'foreach':
void DoSomething(string[] args)
{
foreach (var str in args?.Where(arg => arg != null))
....
}В данном случае, если параметр 'args' равен 'null', то результат выражения 'args?.Where(....)' также будет равен 'null' из-за оператора '?.'. В таком случае будет выброшено исключение типа 'NullReferenceException' при попытке перебора коллекции в 'foreach'. Это произойдёт из-за того, что у результата выражения 'args?.Where(....)' неявно будет вызван метод 'GetEnumerator()', что приведет к разыменованию нулевой ссылки.
Исправленный вариант кода может быть таким:
void DoSomething(string[] args)
{
foreach (var str in args?.Where(arg => arg != null)
?? Enumerable.Empty<string>())
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3153. |
V3154. The 'a % b' expression always evaluates to 0.
Операция получения остатка от деления, выполненная на целочисленном типе, всегда возвращает 0. Это связано с тем, что справа от оператора находится значение 1 (-1). Скорее всего была допущена опечатка в правом операнде.
Частым паттерном данной ошибки является проверка делимости числа на 2 без остатка. Для этого необходимо поделить число по модулю и сравнить результат с 0 или 1. В этом месте легко сделать опечатку, так как раз ожидается значение 1, то кажется, что и поделить надо на 1. Пример:
if ((x % 1) == 1)
{
....
}Здесь вместо 2 написали 1 и теперь вне зависимости от значения 'x' выражение 'x % 1' всегда будет равно 0. Следовательно, условие всегда будет ложным.
Исправленный вариант:
if ((x % 2) == 1)
{
....
}Рассмотрим диагностику на реальном примере:
const int SyncReportFrequency = 1;
....
private void TimerOnElapsed(object sender, ElapsedEventArgs e)
{
if (_reportId % SyncReportFrequency == 0)
{
WriteSyncReport();
}
}Переменная 'SyncReportFrequency ' является константой равной единице. Поэтому при любом значении переменной '_reportId' условие в операторе 'if' всегда будет истинным.
Возможно, в данном фрагменте кода разработчик совершил опечатку или условие является излишним. Пример исправленного варианта кода:
const int SyncReportFrequency = 2;
....
private void TimerOnElapsed(object sender, ElapsedEventArgs e)
{
if (_reportId % SyncReportFrequency == 0)
{
WriteSyncReport();
}
}Данная диагностика классифицируется как:
V3155. The expression is incorrect or it can be simplified.
Анализатор обнаружил подозрительное выражение, результат которого всегда будет равен одному из его операндов. Такие выражения могут являются избыточными по задумке автора, и должны передать какую-то идею тем, кто будет сопровождать код. А возможно это просто ошибка.
Рассмотрим простой вариант, как может выглядеть ошибка:
var a = 11 - b + c * 1;Переменная 'c' умножается на '1', что является избыточным. Возможно, была допущена опечатка и вместо 1 должно быть написано, например 10:
var a = 11 - b + c * 10;Давайте теперь рассмотрим случай из реального проекта, когда избыточность была добавлена сознательно, но неудачно:
detail.Discount = i * 1 / 4M;Программист имел в виду, что переменная 'i' должна умножаться на значение одна четвёртая. Да, можно было сразу написать 0.25, но 1/4 лучше может передавать смысл алгоритма.
Однако, получилось не очень удачно. В начале выполняется умножение переменной 'i' на 1 и только затем происходит деление. Да, результат получится один и тот же. Но такой код может сбить с толку человека. И по этой причине он не нравится и анализатору, который выдаст здесь предупреждение.
Чтобы код стал более читаемым, а анализатор перестал выдавать предупреждение, лучше добавить скобки:
detail.Discount = i * (1 / 4M);Еще один пример из реального проекта:
public virtual ValueBuffer GetIncludeValueBuffer(int queryIndex)
{
return queryIndex == 0
? _activeQueries[_activeIncludeQueryOffset + queryIndex].Current
: _activeIncludeQueries[queryIndex - 1].Current;
}В данном случае '_activeIncludeQueryOffset' всегда будет складываться с нулем, так как выше находится проверка 'queryIndex == 0'. Скорее всего это не ошибка, но код можно упростить:
public virtual ValueBuffer GetIncludeValueBuffer(int queryIndex)
{
return queryIndex == 0
? _activeQueries[_activeIncludeQueryOffset].Current
: _activeIncludeQueries[queryIndex - 1].Current;
}Примечание. Анализатор не ругается на случаи, когда рядом с подозрительным выражением находится подобное ему выражение. Пример:
A[i+0]=1;
A[i+1]=10;
A[i+2]=100;
A[i+3]=1000;
A[i+4]=10000;Выражение 'i + 0' является избыточным. Но рядом располагаются подобные выражения вида 'i + литерал'. Поэтому можно сделать вывод, что сложение с 0 было сделано сознательно, для соблюдения общего стиля написания.
Данная диагностика классифицируется как:
V3156. The argument of the method is not expected to be null.
Анализатор обнаружил возможную ошибку, связанную с тем, что в метод в качестве аргумента, не ожидающего 'null', может передаваться значение 'null'.
Это может привести, например, к возникновению исключения или неправильному исполнению вызываемого метода.
При написании кода бывает сложно отследить, были ли добавлены проверки на 'null' во всех необходимых местах. Это особенно актуально, когда переменная, которая может иметь значение 'null', передается в метод, внутри которого используется как аргумент другого метода, не ожидающего значение 'null'.
Рассмотрим небольшой синтетический пример:
void Method(string[] args)
{
var format = args.Length != 0 ? args[0] : null;
....
var message = string.Format(format, _value);
// do something
}Если массив 'args' не содержит элементов, в переменную 'format' будет записано значение 'null'. Следовательно, в метод 'string.Format' в качестве первого аргумента будет передано значение 'null', что приведет к возникновению исключения. Исправить это можно следующим образом:
void Method(string[] args)
{
var format = args.Length != 0 ? args[0] : null;
....
if (format == null)
{
// process an error
return;
}
var message = string.Format(format, _value);
// do something
}Немного усложним пример выше:
void Method(string[] args)
{
var format = args.Length != 0 ? args[0] : null;
....
WriteInfo(format);
}
void WriteInfo(string format)
{
Console.Write(format, _value);
}Переменная 'format' все так же зависит от 'args.Length' и потенциально может быть 'null'. В данном случае считаем, что 'format == null'. Соответственно, в метод 'WriteInfo' также будет передано значение 'null'. Далее это же значение будет передано в качестве первого аргумента в метод 'Console.WriteLine', что приведёт к возникновению исключения типа 'ArgumentNullException'.
Исправим это аналогичным образом:
void Method(string[] args)
{
var format = args.Length != 0 ? args[0] : null;
....
WriteInfo(format);
}
void WriteInfo(string format)
{
if (format == null)
{
// process an error
return;
}
Console.Write(format, _value);
}Теперь рассмотрим реальный пример:
private static string HandleSuffixValue(object val, StringSegment suffixSegment)
{
....
var res = string.Format(suffixSegment.Value, val).TrimEnd(']');
return res == "" ? null : res;
}Первый аргумент метода 'string.Format' не должен быть равен 'null'. Давайте посмотрим, что возвращает 'suffixSegment.Value':
public string Value
{
get
{
if (HasValue)
{
return Buffer.Substring(Offset, Length);
}
else
{
return null;
}
}
}Если 'HasValue' будет 'false', то 'Value' вернет 'null'. Получается, что потенциально вызов метода 'string.Format' в данном случае может выбросить исключение. Пример исправленного варианта:
private static string HandleSuffixValue(object val, StringSegment suffixSegment)
{
....
if (suffixSegment.Value == null)
{
return null;
}
var res = string.Format(suffixSegment.Value, val).TrimEnd(']');
return res == "" ? null : res;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3156. |
V3157. Suspicious division. Absolute value of the left operand is less than the right operand.
Анализатор обнаружил одну из двух операций с целыми числами - деление или взятие остатка от деления - в которой значение левого операнда по модулю всегда меньше значения по модулю правого.
Результаты таких операций:
- для деления результатом будет 0;
- для взятия остатка от деления результатом будет левый операнд.
Скорее всего, такое выражение содержит ошибку или является избыточным.
Рассмотрим синтетический пример:
public void Method()
{
int a = 10;
int b = 20;
var c = a / b;
....
}В данном примере результатом выражения 'a / b' всегда будет 0, так как 'a < b'. В этом случае необходимо преобразовать тип переменной 'a' для выполнения вещественного деления:
public void Method()
{
int a = 10;
int b = 20;
var c = (double)a / b;
....
}Теперь рассмотрим реальный пример:
public override Shipper CreateInstance(int i)
{
....
return new Shipper
{
....
DateCreated = new DateTime(i + 1 % 3000, // <=
(i % 11) + 1,
(i % 27) + 1,
0,
0,
0,
DateTimeKind.Utc),
....
};
}Здесь допущена ошибка в приоритете операций. В выражении 'i + 1 % 3000' первым делом вычисляется выражение '1 % 3000', результатом которого всегда будет 1. Следовательно, 'i' всегда складывается с 1. Исправленный вариант может выглядеть следующим образом:
public override Shipper CreateInstance(int i)
{
....
return new Shipper
{
....
DateCreated = new DateTime((i + 1) % 3000, // <=
(i % 11) + 1,
(i % 27) + 1,
0,
0,
0,
DateTimeKind.Utc),
....
};
}Рассмотрим еще один реальный пример:
private void ValidateMultiRecords(StorageEnvironment env,
IEnumerable<string> trees,
int documentCount,
int i)
{
for (var j = 0; j < 10; j++)
{
foreach (var treeName in trees)
{
var tree = tx.CreateTree(treeName);
using (var iterator = tree.MultiRead((j % 10).ToString())) // <=
{
....
}
}
}
}В данном примере переменная 'j' изменяется в пределах [0..9]. Получается, что выражение 'j % 10' всегда будет равно 'j'. Упрощенный вариант может выглядеть следующим образом:
private void ValidateMultiRecords(StorageEnvironment env,
IEnumerable<string> trees,
int documentCount,
int i)
{
for (var j = 0; j < 10; j++)
{
foreach (var treeName in trees)
{
var tree = tx.CreateTree(treeName);
using (var iterator = tree.MultiRead(j.ToString())) // <=
{
....
}
}
}
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3157. |
V3158. Suspicious division. Absolute values of both operands are equal.
Анализатор обнаружил одну из двух операций с целыми числами - деление или взятие остатка от деления - в которой абсолютное значение левого операнда всегда равно значению правого.
Результаты таких операций:
- для деления результатом будет 1 (-1);
- для взятия остатка от деления результатом будет 0.
Скорее всего, такое выражение содержит ошибку или является избыточным.
Рассмотрим пример:
const int MinDimensionValue = 42;
const int MaxDimensionValue = 146;
static int GetSidesRatio(int width, int height)
{
if (width < MinDimensionValue || width > MinDimensionValue)
throw new ArgumentException(/*....*/);
if (height < MinDimensionValue || height > MinDimensionValue)
throw new ArgumentException(/*....*/);
return width / height;
}Анализатор предупреждает, что результат выражения 'width / height' всегда будет равен 1. Действительно, программа дойдет до выполнения операции деления только в том случае, если значение у 'width' будет строго равно 'MinDimensionValue'. При любых других значениях будет выброшено исключение. С 'height' ситуация аналогична.
В данном фрагменте кода была допущена опечатка, и вместо проверки 'width > MinDimensionValue' должна быть 'width > MaxDimensionValue' (аналогично и с 'height'). Исправленный вариант:
const int MinDimensionValue = 42;
const int MaxDimensionValue = 146;
static int GetSidesRatio(int width, int height)
{
if (width < MinDimensionValue || width > MaxDimensionValue)
throw new ArgumentException(/*....*/);
if (height < MinDimensionValue || height > MaxDimensionValue)
throw new ArgumentException(/*....*/);
return width / height;
}Данная диагностика классифицируется как:
V3159. Modified value of the operand is not used after the increment/decrement operation.
Анализатор обнаружил, что значение постфиксной или префиксной операции инкремента / декремента не используется. Скорее всего, или операция избыточна, или вместо постфиксной операции следует использовать префиксную.
Пример:
int CalculateSomething()
{
int value = GetSomething();
....
return value++;
}В данном примере имеется локальная переменная 'value'. Из метода возвращается ее инкрементированное значение. Однако постфиксная операция создаст копию 'value', после этого увеличит значение 'value' и вернет копию. Получается, что оператор '++' никак не повлияет на значение, которое вернет функция 'CalculateSomething'. Возможный исправленный вариант:
int CalculateSomething()
{
int value = GetSomething();
....
return ++value;
}Следующий вариант исправления кода ещё лучше подчёркивает, что следует вернуть значение на единицу больше:
int CalculateSomething()
{
int value = GetSomething();
....
return value + 1;
}Мы рекомендуем использовать второй вариант, так как его проще понять.
Рассмотрим ещё один синтетический пример:
void Foo()
{
int value = GetSomething();
Do(value++);
Do(value++);
Do(value++);
}Каждый раз функция 'Do' вызывается с аргументом на единицу больше. Последний инкремент не имеет смысла, так как увеличенное значение переменной далее не используется. Однако ошибки здесь нет, так как последний инкремент написан просто для красоты. Анализатор это поймет и не будет выдавать предупреждение. Предупреждение не выдаётся, если переменная последовательно инкрементируется более двух раз подряд.
Однако, мы все равно рекомендуем писать вот так:
void Foo()
{
int value = GetSomething();
Do(value++);
Do(value++);
Do(value);
}Или так:
void Foo()
{
int value = GetSomething();
Do(value + 0);
Do(value + 1);
Do(value + 2);
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3159. |
V3160. Argument of incorrect type is passed to the 'Enum.HasFlag' method.
Анализатор обнаружил, что тип объекта, вызывающего метод 'Enum.HasFlag', отличается от типа передаваемого аргумента. В результате такого вызова будет выброшено исключение типа 'ArgumentException'.
Рассмотрим синтетический пример:
bool DoSomethingIfAttachedToParent(TaskContinuationOptions options)
{
if (options.HasFlag(TaskCreationOptions.AttachedToParent))
{
// ....
return true;
}
else
{
return false;
}
}Обратите внимание: в данном примере 'HasFlag' вызывается у объекта типа 'TaskContinuationOptions', а в качестве аргумента передаётся объект типа 'TaskCreationOptions'. Выполнение этого кода приведёт к выбрасыванию исключения типа 'ArgumentException'.
Заметить такую ошибку может быть непросто, так как названия перечислений схожи, а элемент 'AttachedToParent' присутствует в обоих типах.
Чтобы поправить данный фрагмент, необходимо поменять тип аргумента или вызывающего объекта:
bool DoSomethingIfAttachedToParent(TaskContinuationOptions options)
{
if (options.HasFlag(TaskContinuationOptions.AttachedToParent))
{
// ....
return true;
}
else
{
return false;
}
}Данная диагностика классифицируется как:
V3161. Comparing value type variables with 'ReferenceEquals' is incorrect because compared values will be boxed.
Анализатор обнаружил подозрительный вызов метода 'Object.ReferenceEquals': один или оба переданных аргумента могут иметь значимый тип. Так как метод принимает параметры типа 'Object', при передаче значимых типов будет произведена упаковка. Таким образом, в 'Object.ReferenceEquals' будет передана ссылка на объект, созданный в куче при упаковке. Так как полученная ссылка не будет равна никакой другой, из этого следует, что метод будет возвращать 'false' независимо от значения переданного аргумента.
Рассмотрим простой синтетический пример:
void SyntheticMethod(Point x, object a)
{
if (Object.ReferenceEquals(x, a))
....
}В качестве аргументов в 'Object.ReferenceEquals' передаются 'x' и 'a'. Переменная 'x' имеет тип 'Point', следовательно, её значение будет упаковано при преобразовании в 'Object'. Таким образом, вызов 'Object.ReferenceEquals' всегда будет возвращать 'false' вне зависимости от того, какие аргументы переданы в 'SyntheticMethod'.
В качестве исправления можно заменить вызов метода на непосредственную проверку равенства значений:
void SyntheticMethod(Point x, object a)
{
if (a is Point pointA && pointA == x)
....
}Правило также применяется и к аргументам, типы которых являются generic-параметрами. Если значения такого параметра не ограничены ссылочными типами, то анализатор будет выдавать предупреждение. Пример:
void SomeFunction<T>(T genericObject,
object someObject)
{
if (Object.ReferenceEquals(genericObject, someObject))
....
}Здесь 'genericObject' может быть экземпляром как ссылочного, так и значимого типа. Для значимых типов 'Object.ReferenceEquals' всегда будет возвращать 'false'. Такое поведение может оказаться неожиданным и нежелательным. Чтобы быть уверенным в том, что в метод не будут передаваться объекты значимых типов, нужно добавить соответствующее ограничение параметра:
void SomeFunction<T>(T genericObject,
object someObject) where T : class
{
if (Object.ReferenceEquals(genericObject, someObject))
....
}Теперь на месте параметра может быть только ссылочный тип, и анализатор не будет выдавать предупреждение.
Рассмотрим ситуацию, в которой параметр ограничен интерфейсом:
void SomeFunction<T>(T genericObject,
object someObject) where T : ICloneable
{
if (Object.ReferenceEquals(genericObject, someObject))
....
}Анализатор выдаст предупреждение на данный код, так как объекты значимых типов могут реализовывать интерфейсы. Таким образом, ограничение 'where T : ICloneable' не защищает от вызова метода для структур, и результат такого вызова может оказаться неожиданным.
Отдельно рассмотрим одну особенность, связанную с nullable-типами. Они являются значимыми, следовательно, их преобразование в 'Object' приведёт к упаковке. Однако упаковка объектов таких типов производится особым образом. Если переменной присвоено значение, то при упаковке в кучу попадёт не объект nullable-типа, а само значение. Если же значение не задано, то при упаковке будет получена нулевая ссылка.
В следующем примере 'x' имеет тип 'Nullable<Point>'. Вполне возможно, что в результате упаковки 'x' будет возвращена нулевая ссылка. В таком случае вызов 'Object.ReferenceEquals' вернёт 'true', если аргумент 'a' также будет равен 'null'.
void SyntheticMethod(Point? x, object a)
{
if (Object.ReferenceEquals(x, a))
....
}Тем не менее, на этот код будет выдано предупреждение. Использование такого способа для проверки двух элементов на равенство 'null' выглядит подозрительно. Уместнее будет проверять наличие значений непосредственным сравнением с 'null' или с помощью свойства 'HasValue':
void SyntheticMethod(Point? x, object a)
{
if (!x.HasValue && a == null)
....
}Дополнительные материалы по теме особенностей nullable-типов:
- Хорошо ли вы помните nullable value types? Заглядываем "под капот"
- Nullable value types (C# reference)
- Boxing and Unboxing (C# Programming Guide)
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3161. |
V3162. Suspicious return of an always empty collection.
Анализатор обнаружил, что выражение 'return', всегда возвращает пустую коллекцию, которая была определена как локальная переменная. Чаще всего это происходит из-за того, что в коллекцию забыли добавить элементы.
Пример:
List<string> CreateDataList()
{
List<string> list = new List<string>();
string data = DoSomething();
return list;
}В данном примере забыли добавить элемент 'data' в 'list'. Поэтому метод всегда будет возвращать пустую коллекцию. Исправленный вариант:
List<string> CreateDataList()
{
List<string> list = new List<string>();
string data = DoSomething();
list.Add(data);
return list;
}Иногда программисты создают метод, который только и делает, что создает и возвращает коллекцию. Например, так:
List<List<CustomClass>> CreateEmptyDataList()
{
var list = new List<List<CustomClass>>();
return list;
}Или так:
List<List<CustomClass>> CreateEmptyDataList()
{
return new List<List<CustomClass>>();
}Это используется для некоторых паттернов программирования, или если тип коллекции имеет очень длинное название. Анализатор понимает такие ситуации и не выдаёт на них предупреждения.
V3163. An exception handling block does not contain any code.
Анализатор обнаружил пустой блок обработки исключения ('catch' или 'finally'). Отсутствие корректной обработки исключений может привести к снижению уровня надёжности приложения.
В некоторых случаях отсутствие корректной обработки исключительных ситуаций может стать причиной возникновения уязвимости. Недостаточное логирование и мониторинг выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A10:2017-Insufficient Logging & Monitoring.
Пример кода с пустым 'catch':
try
{
someCall();
}
catch
{
}Конечно, такой код вовсе не обязательно ошибочен. Но очень странно просто подавлять исключение, ничего не делая, так как такая обработка исключений может скрывать дефекты в программе.
В качестве обработки исключения можно использовать, например, логгирование. Это по крайней мере не позволит исключительной ситуации остаться незамеченной:
try
{
someCall();
}
catch (Exception e)
{
Logger.Log(e);
}Не менее подозрительным моментом является наличие в коде пустого блока 'finally'. Это может свидетельствовать о том, что какая-то логика, необходимая для надёжной работы приложения, не реализована. Например:
try
{
someCall();
}
catch
{ .... }
finally
{
}Подобный код с большой вероятностью свидетельствует об ошибке или попросту избыточен. В отличие от пустого блока 'catch', который может быть использован для подавления исключения, у пустого блока 'finally' нет какого-либо практического применения.
Данная диагностика классифицируется как:
V3164. Exception classes should be publicly accessible.
Анализатор обнаружил класс исключения, недоступного для других сборок. Если такое исключение будет выброшено, внешний код будет вынужден отлавливать объекты ближайшего доступного предка или вообще базового класса всех исключений – 'Exception'. В этом случае усложняется обработка конкретных исключительных ситуаций, ведь код других сборок не может чётко идентифицировать возникшую проблему.
Отсутствие чёткой идентификации возникшей проблемы несёт дополнительные риски с точки зрения безопасности, так как для каких-то определённых исключительных ситуаций может понадобиться специфичная обработка, а не общая. Недостаточное логирование и мониторинг (в том числе, обнаружение проблем) выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A10:2017-Insufficient Logging & Monitoring.
Простой пример из реального проекта:
internal sealed class ResourceException : Exception
{
internal ResourceException(string? name, Exception? inner = null)
: base(name, inner)
{
}
}Чтобы можно было корректно обработать конкретную исключительную ситуацию, необходимо задать в объявлении класса модификатор доступности 'public':
public sealed class ResourceException : Exception
{
internal ResourceException(string? name, Exception? inner = null)
: base(name, inner)
{
}
}Теперь другие сборки смогут отлавливать данное исключение и обрабатывать конкретную ситуацию.
Следует учитывать, что для вложенных классов модификатора 'public' у объявления исключения может быть недостаточно. Например:
namespace SomeNS
{
class ContainingClass
{
public class ContainedException : Exception {}
....
}
}В данном примере класс исключения вложен в 'ContainingClass', который неявно объявлен как 'internal'. Вследствие этого 'ContainedException' также будет видим только в пределах текущей сборки, хотя он и помечен модификатором 'public'. Анализатор обнаруживает такие случаи и выдаёт соответствующие предупреждения.
Данная диагностика классифицируется как:
V3165. The expression of the 'char' type is passed as an argument of the 'A' type whereas similar overload with the string parameter exists.
Анализатор обнаружил возможную ошибку при вызове конструктора или метода. В качестве одного из аргументов используется выражение типа 'char', которое неявно преобразуется к другому типу, в то время как обнаружена подходящая перегрузка, в которой соответствующий параметр представлен типом 'String'. Возможно, для вызова правильной перегрузки необходимо было использовать выражение типа 'String' вместо 'char'.
Рассмотрим пример:
public static string ToString(object[] a)
{
StringBuilder sb = new StringBuilder('['); // <=
if (a.Length > 0)
{
sb.Append(a[0]);
for (int index = 1; index < a.Length; ++index)
{
sb.Append(", ").Append(a[index]);
}
}
sb.Append(']');
return sb.ToString();
}Разработчик хотел, чтобы строка, хранящаяся в экземпляре типа 'StringBuilder', начиналась с квадратной скобки. Однако из-за опечатки будет получен объект ёмкостью под 91 элемент, не содержащий символов.
Это произошло из-за того, что вместо двойных кавычек использовались одинарные, что привело к вызову не той перегрузки конструктора:
....
public StringBuilder(int capacity);
public StringBuilder(string? value);
....При вызове конструктора символьный литерал '[' будет неявно приведен к соответствующему значению типа 'int' (91 в Unicode), из-за чего будет вызван конструктор с параметром типа 'int', задающим начальную вместимость, вместо конструктора, задающего начало строки.
Для исправления ошибки следует заменить символьный литерал на строковый, что позволит вызвать правильную перегрузку конструктора:
public static string ToString(object[] a)
{
StringBuilder sb = new StringBuilder("[");
....
}Данное диагностическое правило учитывает не только литералы, но и выражения, так что на следующий код также будет выдано предупреждение:
public static string ToString(object[] a)
{
var initSmb = '[';
StringBuilder sb = new StringBuilder(initSmb);
....
}Данная диагностика классифицируется как:
V3166. Calling the 'SingleOrDefault' method may lead to 'InvalidOperationException'.
Анализатор обнаружил, что вызов метода 'SingleOrDefault' без предиката может быть выполнен на коллекции, содержащей более одного элемента. Данное действие приведет к возникновению исключения типа 'System.InvalidOperationException'.
Такое поведение может быть неочевидным из-за поведения других 'OrDefault' методов. Например, методы 'FirstOrDefault', 'LastOrDefault', 'ElementAtOrDefault' возвращают 'default' значение типа элементов коллекции, если не удалось выполнить соответствующую операцию (если коллекция пуста, под предикат не попал ни один элемент и т. п.). При вызове метода 'SingleOrDefault' для пустой коллекции также будет возвращено значение 'default', но, если коллекция содержит более 1 элемента, будет выброшено исключение. Эта особенность может быть неочевидной.
Рассмотрим пример:
IEnumerable<State> GetStates()
{
var states = new List<State>();
if (usualCondition)
states.Add(GetCustomState());
if (veryRareCondition)
states.Add(GetAnotherState());
return states;
}
void AnalyzeState()
{
....
var state = GetStates().SingleOrDefault();
....
}Не зная особенностей поведения 'SingleOrDefault', разработчик хотел записать в переменную 'state' значение, полученное из метода 'GetStates', если в коллекции содержится только один элемент, или 'default' значение в остальных случаях (элементы отсутствуют или их больше одного). Однако, если одновременно сработают обычное и очень редкое условие (переменные 'usualCondition' и 'veryRareCondition'), метод 'GetStates' вернёт коллекцию из двух элементов. В этом случае вместо записи в 'state' значения 'default' будет выброшено исключение.
Возможный вариант исправления метода 'AnalyzeState':
void AnalyzeState()
{
....
var states = GetStates();
var state = states.Count() == 1 ? states.First()
: default;
....
}Данная диагностика классифицируется как:
V3167. Parameter of 'CancellationToken' type is not used inside function's body.
Анализатор обнаружил, что принимаемый методом параметр типа 'CancellationToken' не используется.
Объекты этого типа обычно применяются в случаях, когда может возникнуть необходимость прерывания операции, выполняемой в параллельном потоке. Метод, принимающий 'CancellationToken' в качестве параметра, может обращаться к нему во время выполнения, чтобы при необходимости завершить работу досрочно. Иногда токен также передаётся в качестве аргумента при вызове других методов, чтобы предоставить возможность досрочного завершения их работы.
Случаи, когда метод принимает 'CancellationToken', но не использует, выглядят подозрительно. Возможно, при разработке предполагалось использование этого параметра для обеспечения возможности отмены операции, но была допущена ошибка, из-за которой параметр оказался "лишним". Из-за этого может, к примеру, возникнуть ситуация, когда приложение не реагирует на запросы отмены от пользователя своевременно.
Рассмотрим пример:
public List<SomeStruct> LoadInfo(string[] keys, CancellationToken token)
{
List<SomeStruct> result = new List<SomeStruct>();
foreach (string key in keys)
{
SomeStruct item = LoadHugeData(key);
result.Add(item);
}
return result;
}Данный метод производит последовательную загрузку данных большого размера. Реализация возможности прерывания такой операции имеет смысл, однако, несмотря на это, параметр 'token' не используется. Такой код выглядит подозрительно и помечается анализатором как место потенциальной ошибки. В качестве исправления можно предложить следующий вариант:
public List<SomeStruct> LoadInfo(string[] keys, CancellationToken token)
{
List<SomeStruct> result = new List<SomeStruct>();
foreach (string key in keys)
{
if(token.IsCancellationRequested)
break;
SomeStruct item = LoadHugeData(key);
result.Add(item);
}
return result;
}Теперь последовательная загрузка данных может быть прервана. В случае получения запроса отмены операции метод 'LoadInfo' прекратит загрузку элементов и вернёт то, что было загружено до отмены операции.
Рассмотрим другой пример:
void ExecuteQuery(CancellationToken token = default)
{ .... }
public void ExecuteSomeActions(CancellationToken token)
{
....
ExecuteQuery();
....
}Метод 'ExecuteQuery' в качестве аргумента может принимать значение типа 'CancellationToken'. Однако при вызове в методе 'ExecuteSomeActions' параметр 'token' не передаётся в метод 'ExecuteQuery'. Как следствие, такой код может несвоевременно реагировать на действия отмены.
Для исправления проблемы необходимо передавать 'token' в качестве аргумента метода 'ExecuteQuery':
ExecuteQuery(token);Стоит отметить, что анализатор не будет выдавать предупреждения в случаях, когда метод помечен модификатором 'override' или является частью реализации интерфейса. Это исключение связано с тем, что при наследовании и переопределении сигнатура метода обязана содержать параметр типа 'CancellationToken' вне зависимости от того, предусматривает ли конкретная реализация его использование. Похожее исключение связано с virtual-методами: 'CancellationToken' в объявлении может быть предназначен не для стандартной реализации, а для наследников, которые будут данный метод переопределять.
Также предупреждение не будет выдаваться на лямбда-выражения, так как они достаточно часто используются в качестве обработчиков событий или передаются в качестве аргументов. В этих случаях функция будет вынуждена принимать определённый набор параметров даже в случаях, когда для её работы они не требуются.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V3168. Awaiting on expression with potential null value can lead to throwing of 'NullReferenceException'.
Анализатор обнаружил фрагмент, в котором оператор 'await' используется с выражением, значением которого может быть нулевая ссылка. При использовании 'await' с 'null' будет выброшено исключение типа 'NullReferenceException'.
Рассмотрим пример:
async void Broadcast(....)
{
await waiter.GetExplorerBehavior()?.SaveMatches();
....
}
ExplorerBehavior GetExplorerBehavior()
{
return _state == NodeState.HandShaked ? _Node.Behavior : null;
}В методе 'Broadcast' оператор 'await' используется с выражением, которое в определённых случаях может иметь значение 'null'. Дело в том, что метод 'GetExplorerBehaviour' при некоторых обстоятельствах возвращает 'null', который впоследствии попадёт в 'Broadcast'.
В результате, при использовании оператора 'await' с выражением, имеющим значение 'null', будет выброшено исключение типа 'NullReferenceException'.
В качестве исправления можно добавить в метод 'Broadcast' дополнительную проверку на 'null':
async void Broadcast(....)
{
var task = waiter.GetExplorerBehavior()?.SaveMatches();
if (task != null)
await task;
....
}Анализатор также предупреждает о случаях, когда потенциально нулевая ссылка передаётся в метод, конструктор или свойство, внутри которого она может быть использована с 'await'. Пример:
void ExecuteActionAsync(Action action)
{
Task task = null;
if (action != null)
task = new Task(action);
ExecuteTask(task); // <=
....
}
async void ExecuteTask(Task task)
{
....
await task;
}В данном фрагменте 'await' используется с параметром 'task', в который при вызове передаётся потенциально нулевая ссылка. Ниже представлен исправленный вариант метода 'ExecuteActionAsync':
void ExecuteActionAsync(Action action)
{
Task task = null;
if (action != null)
{
task = new Task(action);
ExecuteTask(task);
}
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3168. |
V3169. Suspicious return of a local reference variable which always equals null.
Анализатор обнаружил, что в выражении 'return' возвращается локальная переменная, значением которой всегда будет 'null'. Подобное может происходить как из-за того, что переменной забыли присвоить нужное значение, так и из-за потенциальной логической ошибки.
Рассмотрим пример с логической ошибкой, вследствие которой метод 'GetRootNode' всегда возвращает 'null':
public Node GetRootNode(Node node)
{
Node parentNode = node.Parent == null ? node : node.Parent;
while (parentNode != null)
{
parentNode = parentNode.Parent;
}
return parentNode;
}Условие в операторе 'while' будет выполняться до тех пор, пока переменная 'parentNode' не станет равной 'null'. Для того, чтобы исправить поведение метода, в условии оператора 'while' следует выполнять сравнение с 'null' не самой переменной 'parentNode', а её свойства 'Parent'. Исправленный вариант метода 'GetRootNode' будет выглядеть следующим образом:
public Node GetRootNode(Node node)
{
Node parentNode = node.Parent == null ? node : node.Parent;
while (parentNode.Parent != null)
{
parentNode = parentNode.Parent;
}
return parentNode;
}V3170. Both operands of the '??' operator are identical.
Анализатор обнаружил, что оба операнда, использующиеся в операторе '??' или '??=', одинаковы. Скорее всего, эта операция содержит ошибку. Подобные ошибки могут появиться в результате опечатки или невнимательного copy-paste.
Рассмотрим пример подобной ошибки при использовании оператора '??':
string SomeMethod()
{
String expr1 = Foo();
String expr2 = Bar();
....
return expr1 ?? expr1;
}Выражение 'expr1 ?? expr1' в методе 'SomeMethod' не имеет смысла, потому что данный метод будет возвращать одно и то же значение вне зависимости от того, содержит ли переменная 'expr1' значение 'null' или нет. Скорее всего, произошла опечатка, и правильный вариант выражения должен выглядеть так:
return expr1 ?? expr2;Подобная ошибка может быть допущена и при использовании оператора '??=':
void SomeMethod()
{
String expr1 = Foo();
String expr2 = Bar();
....
expr1 ??= expr1;
....
DoSmt(expr1);
}В данном случае была допущена ошибка, аналогичная описанной в предыдущем примере. Исправленный код:
expr1 ??= expr2;Данная диагностика классифицируется как:
V3171. Potentially negative value is used as the size of an array.
Анализатор обнаружил, что при создании массива в качестве значения для задания его длины может использоваться переменная или выражение, имеющие отрицательное значение.
Рассмотрим пример:
void ProcessBytes(byte[] bytes)
{
int length = BitConverter.ToUInt16(bytes, 0);
int[] newArr = new int[length - 2];
....
}Значение, возвращаемое методом 'ToUInt16' и присваиваемое переменной 'length', может оказаться равным нулю. Это произойдёт в том случае, если первые два байта в массиве 'bytes' равны нулю. Тогда при создании массива 'newArr' в качестве его длины будет выступать отрицательное значение. Это приведёт к выбросу исключения типа 'OverflowException'.
Исправленный вариант метода 'ProcessBytes' с дополнительной проверкой может выглядеть следующим образом:
void ProcessBytes(byte[] bytes)
{
int length = BitConverter.ToUInt16(bytes, 0);
if (length < 2)
return;
int[] newArr = new int[length - 2];
....
}Приведём ещё один пример кода. В нём при вызове метода 'SubArray' с определённым набором входных аргументов в качестве длины массива может быть использовано отрицательное значение:
public byte[] GetSubArray(byte[] bytes)
{
return bytes.SubArray(4, 2);
}
public static T[] SubArray<T>(this T[] arr, int index, int length)
{
if (length < 0)
throw new Exception($"Incorrect length value: {length}.");
if (index < 0)
throw new Exception($"Incorrect index value: {index}.");
if (arr.Length < index + length)
length = arr.Length - index;
var subArr = new T[length];
Array.Copy(arr, index, subArr, 0, length);
return subArr;
}Проблема метода 'SubArray' заключается в том, что он не учитывает случаи, когда длина массива 'arr' может оказаться меньше значения, записанного в переменной 'index'. В этом случае переменная 'length' получит отрицательное значение. Предположим, что длина массива 'arr' равна 3, а значение переменной 'index' - 4. Переменная 'length' в ходе выполнения метода получит значение равное -1, и будет произведена попытка создания массива с отрицательным размером.
Исправленный вариант метода 'SubArray' может выглядеть следующим образом:
public static T[] SubArray<T>(this T[] arr, int index, int length)
{
if (length < 0)
throw new Exception($"Incorrect length value: {length}.");
if (index < 0 || arr.Length <= index)
throw new Exception($"Incorrect index value: {index}.");
if (arr.Length < index + length)
length = arr.Length - index;
var subArr = new T[length];
Array.Copy(arr, index, subArr, 0, length);
return subArr;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3171. |
V3172. The 'if/if-else/for/while/foreach' statement and code block after it are not related. Inspect the program's logic.
Анализатор обнаружил возможную ошибку, связанную с тем, что блок кода ('{ .... }'), идущий после выражения 'if/if-else/for/while/foreach', к нему не относится.
Рассмотрим синтетический пример:
if (a == 1) DoSmt();
{
DoSmt2();
}При беглом обзоре кода может показаться, что блок выполнится, если условие истинно, но на самом деле это не так. Блок будет выполняться всегда, независимо от условия. Это может ввести программиста в заблуждение.
Рассмотрим ещё несколько примеров кода, на которые анализатор выдаст срабатывания:
if (a == 2) Nop(); else Nop2();
{
Nop3();
}
if (a == 3) Nop();
else Nop2();
{
Nop3();
}
foreach (var item in query) DoSmt1();
{
DoSmt2();
}Анализатор не выдаст срабатывание, если строки с оператором и несвязанным с ним блоком кода несмежные:
if (a == 7) DoSmt();
// this is a block for initializing MyClass fields
{
....
}Если вы получили такое срабатывание, и оно ложное, вы можете подсказать об этом анализатору, добавив пустую строку между оператором и блоком.
Также диагностика не выдаст срабатывание в том случае, когда тело оператора содержит пустую конструкцию (';'), за это отвечает диагностическое правило V3007.
if (a == 3) ;
{
DoSmt();
}Данная диагностика классифицируется как:
V3173. Possible incorrect initialization of variable. Consider verifying the initializer.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что пропущена инициализация переменной или свойства.
Рассмотрим это на примере:
class A
{
int field1;
string field2;
string field3;
....
public void foo(int value)
{
field1 = value;
field2 = // <=
field3 = GetInitialization(value);
}
}В данном примере разработчик отложил инициализацию поля 'field2' в надежде на то, что этот код не скомпилируется, и тем самым напомнит о пропущенной инициализации. Но в данном случае код будет успешно скомпилирован. Полю 'field2' будет присвоено значение поля 'field3'.
Похожая ситуация может возникнуть во время декларации, например:
int b, c;
int a =
b = c = 2;Этот код выглядит очень подозрительно. Непонятно чем хотели инициализировать переменную 'a'.
Анализатор не будет выдавать предупреждение в ряде случаев, когда понятно, что код написан подобным образом специально.
Например, есть отступы относительно первой строки:
var1 =
var2 = 100;Другой пример, если нет отступа, но подобным образом значение записывается в несколько переменных:
var1 =
var2 =
var3 =
var4 = 100;V3174. Suspicious subexpression in a sequence of similar comparisons.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит опечатку. В цепочке однотипных сравнений членов класса имеется выражение, не похожее на остальные. В нем сравниваются члены с разными именами, в то время как остальные выражения в цепочке сравнивают одноименные члены.
Рассмотрим пример:
public void Foo(TestClass a, TestClass b)
{
if (a.x == b.x && a.y == b.y && a.z == b.y)
{
....
}
}В данном случае выражение 'a.z == b.y' отличается от остальных звеньев в цепочке. Скорее всего, оно является ошибочным из-за опечатки при редактировании скопированного участка текста. Корректный код, который не вызовет подозрений у анализатора, будет выглядеть так:
public void Foo(TestClass a, TestClass b)
{
if (a.x == b.x && a.y == b.y && a.z == b.z)
{
....
}
}Анализатор выдает предупреждение в тех случаях, когда длина цепочки сравнений более двух звеньев.
Данная диагностика классифицируется как:
V3175. Locking operations must be performed on the same thread. Using 'await' in a critical section may lead to a lock being released on a different thread.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит ошибку. В критической секции, образованной вызовами методов класса 'Monitor', используется оператор 'await'. Это может привести к выбрасыванию исключения типа 'SynchronizationLockException'.
Рассмотрим пример:
static object _locker = new object();
public async void Foo()
{
Monitor.Enter(_locker);
await Task.Delay(TimeSpan.FromSeconds(5));
Monitor.Exit(_locker);
}Метод 'Monitor.Enter' получает блокировку объекта, переданного ему в качестве параметра. Блокировка позволяет ограничить доступ к коду, находящемуся после вызова этого метода. Ограничение распространяется на все потоки, кроме того, в котором была получена блокировка. Чтобы снять блокировку, необходимо вызвать метод 'Monitor.Exit', который освободит заблокированный объект и позволит получить доступ следующему потоку. Ограниченный подобным образом фрагмент кода называют критической секцией.
В данном примере после вызова 'Monitor.Enter' используется оператор 'await'. Скорее всего, выполнение кода после асинхронной операции будет производиться в потоке, отличном от того, в котором был вызван 'Monitor.Enter'. Таким образом, открытие и закрытие критической секции может производиться разными потоками. В таком случае будет выброшено исключение типа 'SynchronizationLockException'.
Корректный код, который не вызовет подозрений у анализатора, может выглядеть так:
static SemaphoreSlim _semaphore = new SemaphoreSlim(1);
private static async void Foo()
{
_semaphore.Wait();
await Task.Delay(TimeSpan.FromSeconds(1));
_semaphore.Release();
}Механизм блокировки реализован при помощи внутреннего счётчика экземпляра класса 'SemaphoreSlim'. Вызов 'Wait' приводит к уменьшению его значения на 1. Если счётчик равен 0, следующие вызовы 'Wait' будут блокировать вызывающий поток до тех пор, пока значение счётчика не станет положительным. Увеличение значения счётчика происходит при вызове 'Release' — при этом не важно, из какого потока он был вызван.
Если при создании объекта типа 'SemaphoreSlim' передать в конструктор 1, то между вызовами 'Wait' и 'Release' будет образован аналог критической секции. Использование оператора 'await' внутри образованной области кода не приведёт к выбрасыванию исключения типа 'SynchronizationLockException'.
Данная диагностика классифицируется как:
V3176. The '&=' or '|=' operator is redundant because the right operand is always true/false.
Анализатор обнаружил фрагмент кода, в котором правый операнд оператора '&=' или '|=' всегда имеет одно и то же значение.
Рассмотрим пример:
void Foo(bool status)
{
....
bool currentStatus = ....;
....
if(status)
currentStatus &= status;
....
}В блоке 'then' конструкции 'if' выполняется операция составного присваивания. Переменная 'currentStatus' примет значение, равное результату логической операции 'currentStatus & status'. Исходя из условия, 'status' всегда будет 'true', что делает бессмысленным использование оператора '&=', ведь после выполнения присваивания значение 'currentStatus' не изменится.
Если же правый операнд всегда равен 'false', использование оператора '&=' также является бессмысленным. В таких случаях он может быть заменён на обычное присваивание.
Использование оператора '|=' также не имеет смысла, если его правый операнд всегда имеет одно и то же значение:
- если этим значением будет 'false', то значения операндов останутся неизменными;
- если значение всегда равно 'true', то оно и будет присвоено левому операнду независимо от его изначального значения.
Все описанные выше случаи могут свидетельствовать как об избыточном использовании операторов '&=' и '|=', так и о наличии ошибки в логике работы приложения.
Например, корректный вариант вышеописанного метода может выглядеть следующим образом:
void Foo(bool status)
{
....
bool currentStatus = ....;
....
if(status)
currentStatus = status;
....
}Данная диагностика классифицируется как:
V3177. Logical literal belongs to second operator with a higher priority. It is possible literal was intended to belong to '??' operator instead.
Анализатор обнаружил фрагмент кода, который, возможно, содержит логическую ошибку. В условном выражении логический литерал находится между '??' и другим оператором с более высоким приоритетом.
Оператор '??' имеет приоритет ниже, чем операторы '||', '&&', '|', '^', '&', '!=', '=='. В случае отсутствия скобок, определяющих порядок проверки условия, может возникнуть ошибка, подобная приведенной ниже:
class Item
{
....
public bool flag;
....
}
void CheckItem(Item? item)
{
if (item?.flag ?? true || GetNextCheck(item))
{
....
}
return;
}Так как приоритет оператора '??' ниже чем '||', в первую очередь будет выполнена проверка выражения 'true || GetNextCheck()', которая всегда возвращает 'true', при этом метод 'GetNextCheck' никак не влияет на полученный результат.
В данном случае проблему можно решить, взяв часть выражения в скобки:
class Item
{
....
public bool flag;
....
}
void CheckItem(Item? item)
{
if ((item?.flag ?? true) || GetNextCheck(item))
{
....
}
return;
}В исправленном варианте условия сначала выполнится выражение 'item?.flag ?? true', и только потом отработает оператор '||'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3177. |
V3178. Calling method or accessing property of potentially disposed object may result in exception.
Анализатор обнаружил вызов метода или обращение к свойству объекта, у которого ранее был вызван метод 'Dispose' или его аналог. Подобные действия могут привести к выбрасыванию исключения.
Рассмотрим пример:
public void AppendFileInformation(string path)
{
FileStream stream = new FileStream(path,
FileMode.Open,
FileAccess.Read);
....
stream.Close();
....
if (stream.Length == stream.Position)
{
Console.WriteLine("End of file has been reached.");
....
}
....
}В условии проверяется, что файл был прочитан полностью. Для проверки сравнивают текущую позицию потока и его длину. Проблема в том, что при обращении к свойству 'Length' будет выброшено исключение типа 'ObjectDisposedException'. Это связано с тем, что перед условием у переменной 'stream' вызывается метод 'Close'. Для класса 'FileStream' этот метод является аналогом 'Dispose'. Следовательно, ресурсы 'stream' будут освобождены.
Рассмотрим корректную реализацию 'AppendFileInformation':
public void AppendFileInformation(string path)
{
using (FileStream stream = new FileStream(path,
FileMode.Open,
FileAccess.Read))
{
....
if (stream.Length == stream.Position)
{
Console.WriteLine("End of file has been reached.");
}
....
}
....
}Для корректной работы метода стоит использовать выражение 'using'. В этом случае:
- ресурсы объекта 'stream' будут автоматически освобождены после выхода из тела 'using';
- вне тела 'using' обратиться к объекту не получится – это даёт дополнительную защиту от исключений типа 'ObjectDisposedException';
- даже если в теле 'using' возникнет исключение, ресурсы всё равно будут освобождены.
Ещё один вариант ошибки выглядит следующим образом:
public void ProcessFileStream(FileStream stream)
{
....
bool flag = CheckAndCloseStream(stream);
AppendFileInformation(stream);
....
}
public bool CheckAndCloseStream(FileStream potentiallyInvalidStream)
{
....
potentiallyInvalidStream.Close();
....
}
public void AppendFileInformation(FileStream streamForInformation)
{
....
if (streamForInformation.Length == streamForInformation.Position)
{
Console.WriteLine("End of file has been reached.");
}
....
}После вызова 'CheckAndCloseStream' в методе 'ProcessFileStream' ресурсы объекта, на который ссылается переменная 'stream', будут освобождены. Далее эта переменная передаётся в метод 'AppendFileInformation'. Внутри него производится обращение к свойству 'Length', из-за чего будет выброшено исключение типа 'ObjectDisposedException'.
Корректная реализация 'ProcessFileStream' будет выглядеть следующим образом:
public void ProcessFileStream(FileStream stream)
{
....
AppendFileInformation(stream);
bool flag = CheckAndCloseStream(stream);
....
}Был изменён порядок вызовов методов 'CheckAndCloseStream' и 'AppendFileInformation'. Вследствие этого ресурсы будут освобождаться уже после выполнения действий над потоком. Следовательно, исключение выброшено не будет.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки управления динамической памятью (выделения, освобождения, использования освобожденной памяти). |
Данная диагностика классифицируется как:
V3179. Calling element access method for potentially empty collection may result in exception.
Анализатор обнаружил, что у потенциально пустой коллекции вызван метод, выбрасывающий исключение, если в коллекции нет элементов.
Чтобы лучше разобраться в проблеме, рассмотрим пример:
public static bool ComparisonWithFirst(List<string> list,
string strForComparison)
{
string itemForComparison = null;
if (list != null && !list.Any())
{
itemForComparison = list.First();
}
....
}При попытке получить первый элемент из коллекции будет выброшено исключение типа 'InvalidOperationException'. Внутри then-ветви коллекция будет пустой, так как выполняется проверка, что в 'list' нет элементов.
Исправленный вариант:
public static bool ComparisonWithFirst(List<string> list,
string strForComparison)
{
string itemForComparison = null;
if (list != null && list.Any())
{
itemForComparison = list.First();
}
....
}Подобная ошибка может возникать и при передаче пустой коллекции в метод, который не ожидает этого.
public static void ProcessList(List<string> list)
{
if (list.Any())
return;
CompareFirstWithAll(list);
}
public static void CompareFirstWithAll(List<string> list)
{
string itemForComparison = list.First();
....
}Из-за опечатки в методе 'ProcessList' коллекция 'list' передаётся в метод 'CompareFirstWithAll' пустой. Метод 'CompareFirstWithAll' не ожидает передачи в него пустой коллекции.
Исправленный вариант:
public static void ProcessList(List<string> list)
{
if (!list.Any())
return;
CompareFirstWithAll(list);
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3179. |
V3180. The 'HasFlag' method always returns 'true' because the value '0' is passed as its argument.
Анализатор обнаружил вызов метода 'HasFlag', который всегда возвращает 'true' из-за аргумента, равного '0'.
Рассмотрим пример:
public enum RuntimeEvent
{
Initialize = 1,
BeginRequest = 2,
BeginSessionAccess = 4,
ExecuteResource = 8,
EndSessionAccess = 16,
EndRequest = 32
}
public void FlagsTest()
{
....
RuntimeEvent support = GetSupportEvent();
....
Assert.True(support.HasFlag( RuntimeEvent.EndRequest
& RuntimeEvent.BeginRequest),
"End|Begin in End|SessionEnd");
....
}'support' – экземпляр перечисления типа 'RuntimeEvent'. Значение переменной – результат вызова метода 'GetSupportEvent'. После инициализации у 'support' проверяют наличие флага со значением побитового 'И' для 'EndRequest' и 'BeginRequest'.
Подобная проверка не имеет смысла, так как выражение '32 & 2' равно нулю. Если аргумент 'HasFlag' – ноль, то результатом вызова метода всегда будет 'true'. Получается, что тест проходит, независимо от значения 'support'. Такой код выглядит подозрительно.
Корректная реализация проверки может выглядеть следующим образом:
public void FlagsTest()
{
....
RuntimeEvent support = GetSupportEvent();
....
Assert.True(support.HasFlag( RuntimeEvent.EndRequest
| RuntimeEvent.BeginRequest),
"End|Begin in End|SessionEnd");
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3180. |
V3181. The result of '&' operator is '0' because one of the operands is '0'.
Анализатор обнаружил, что выполняется побитовая операция 'AND' (&) с операндом, равным 0. Возможно, использован неподходящий оператор или операнд.
Рассмотрим пример:
public enum TypeAttr
{
NotPublic = 0x0,
Public = 0x1,
NestedPublic = 0x2,
NestedPrivate = 0x3
}
public static bool IsNotPublic(TypeAttr type)
{
return (type & TypeAttr.NotPublic) == TypeAttr.NotPublic;
}Метод 'IsNotPublic' проверяет наличие флага 'NotPublic' у аргумента типа 'TypeAttr'.
Подобный метод проверки не имеет смысла так как флаг 'TypeAttr.NotPublic' имеет нулевое значение, а значит использование его как операнда оператора '&' приводит к всегда нулевому значению результата. Таким образом в представленной реализации мы всегда получаем истинное условие.
Корректная реализация проверки может выглядеть следующим образом:
public static bool IsNotPublic(TypeAttr type)
{
return type == TypeAttr.NotPublic;
}Также анализатор выдаст срабатывание на использование нулевого операнда с оператором '&='. Такой код также выглядит подозрительно, так как равенство нулю одного из операндов, означает, что и результат выражения будет равен нулю.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3181. |
V3182. The result of '&' operator is always '0'.
Анализатор обнаружил использование побитового 'AND' (&) с операндами, при которых результат операции всегда равен 0. Возможно, использован неподходящий оператор или операнд.
Рассмотрим пример:
public enum FlagType : ulong
{
Package = 1 << 1,
Import = 1 << 2,
Namespace = 1 << 3,
....
}
....
FlagType bitMask = FlagType.Package & FlagType.Import;Здесь 'bitMask' – объект типа перечисления 'FlagType', в котором создаётся битовая маска.
Подобный метод объединения флагов перечисления является некорректным. Побитовое 'AND' (&) между значениями 'FlagType.Package' и 'FlagType.Import' равно нулю, так как эти битовые флаги не содержат единиц в соответствующих разрядах.
Корректная реализация объединения флагов может выглядеть следующим образом:
FlagType bitMask = FlagType.Package | FlagType.Import;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3182. |
V3183. Code formatting implies that the statement should not be a part of the 'then' branch that belongs to the preceding 'if' statement.
Анализатор обнаружил инструкцию, относящуюся к оператору 'if'. При этом форматирование не соответствует логике исполнения: код может содержать ошибку.
Рассмотрим пример:
string GetArgumentPositionStr(Argument argument)
{
if (argument.first)
return "first";
if (argument.second)
if (argument.third)
return "third";
return String.Empty;
}В данном примере пропущена 'then' ветвь условной конструкции 'if (argument.second)'. Из-за этого ошибочный фрагмент кода будет работать так же, как и приведённый ниже:
if (argument.second)
{
if (argument.third)
return "third";
}Исправленный вариант:
string GetArgumentPositionStr(Argument argument)
{
if (argument.first)
return "first";
if (argument.second)
return "second";
if (argument.third)
return "third";
return String.Empty;
}Данная диагностика классифицируется как:
V3184. The argument's value is greater than the size of the collection. Passing the value into the 'Foo' method will result in an exception.
Анализатор обнаружил, что в метод передаётся индекс, который больше или равен количеству элементов коллекции. Это может привести к выбрасыванию исключения.
Чтобы лучше разобраться в проблеме, рассмотрим пример:
public static void Foo()
{
List<string> list = new List<string>(20) { "0", "1", "2" };
list.RemoveAt(list.Count);
}При попытке удалить элемент будет выброшено исключение. Метод 'RemoveAt' выбрасывает исключение, если первый аргумент больше или равен количеству элементов коллекции.
Исправленный вариант:
public static void Foo()
{
List<string> list = new List<string>(20) { "0", "1", "2" };
list.RemoveAt(list.Count - 1);
}Рассмотрим более сложный пример с ошибкой:
public static void ProcessList()
{
List<string> list = new List<string>(20) { "0", "1", "2" };
string str = GetStringOrNull(list, list.Count); // <=
}
public static string GetStringOrNull(List<string> list, int index)
{
if (index > list.Count)
return null;
return list.ElementAt(index);
}Коллекция 'list' передаётся в метод 'GetStringOrNull', который содержит ошибку в условии оператора 'if'. При подобных аргументах метод должен вернуть 'null', но из-за ошибки выбрасывает исключение.
Исправленный вариант:
public static void ProcessList()
{
List<string> list = new List<string>(20) { "0", "1", "2" };
string str = GetStringOrNull(list, list.Count);
}
public static string GetStringOrNull(List<string> list, int index)
{
if (index >= list.Count)
return null;
return list.ElementAt(index);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
V3185. An argument containing a file path could be mixed up with another argument. The other function parameter expects a file path instead.
Анализатор обнаружил странный аргумент, переданный в метод в качестве пути к файлу. Возможно, он был перепутан местами с другим аргументом этого метода.
Рассмотрим пример:
void AppendText(FileInfo file, string fileContent)
{
var filePath = file.FullName;
File.AppendAllText(fileContent, filePath);
}Приведённый выше метод 'AppendText' предназначен для добавления строки 'fileContent' в файл. В переменную 'filePath' записывается путь к файлу из 'file.FullName'. После этого 'filePath' и 'fileContent' используются в качестве аргументов метода 'File.AppendAllText', выполняющего добавление текста в файл. В качестве первого аргумента этот метод принимает путь к файлу, а в качестве второго – строку для записи. Однако в приведённом выше примере эти два аргумента перепутаны местами. Результат использования такого метода зависит от содержимого 'fileContent':
- В случае если 'fileContent' не подходит под формат файлового пути, будет выброшено исключение 'System.IOException';
- В обратном случае будет создан новый файл и в него записано значение 'filePath'.
Для решения этой проблемы нужно переставить аргументы метода 'File.AppendAllText' в правильном порядке:
void AppendText(FileInfo file, string fileContent)
{
var filePath = file.FullName;
File.AppendAllText(filePath, fileContent);
}Данная диагностика классифицируется как:
V3186. The arguments violate the bounds of collection. Passing these values into the method will result in an exception.
Анализатор обнаружил подозрительный вызов метода, выполняющего операции над фрагментом коллекции. Переданные в метод аргументы некорректны: их использование предполагает взаимодействие с элементами за границей коллекции. Это приводит к выбросу исключения.
Рассмотрим пример:
int[] arr = new int[] { 0, 1, 3, 4 };
var indexOfOdd = Array.FindIndex(arr,
startIndex: 2,
count: 3,
x => x % 2 == 1);Метод 'FindIndex' принимает следующие аргументы:
- 'arr' — массив, в котором будет происходить поиск индекса элемента;
- 'startIndex: 2' — индекс элемента, с которого начнется поиск;
- 'count: 3' — количество элементов, которые будут просмотрены, начиная со стартового;
- 'x => x % 2 == 1' — предикат, содержащий условие для сопоставления элемента.
Метод возвращает либо индекс первого элемента, соответствующего предикату, либо '-1'.
Массив 'arr' состоит из четырех элементов, значит индекс последнего элемента — '3'. Здесь же разработчик пытается получить доступ к элементу с индексом '4'. В таком случае будет выброшено соответствующее исключение.
Корректная реализация поиска индекса элемента может выглядеть следующим образом:
int[] arr = new int[] { 0, 1, 3, 4 };
var indexOfOdd = Array.FindIndex(arr,
startIndex: 2,
count: 2,
x => x % 2 == 1);Или же вы можете использовать перегрузку метода, не указывающую параметр 'count'. В таком случае обход всегда будет заканчиваться на последнем элементе коллекции:
int[] arr = new int[] { 0, 1, 3, 4 };
var indexOfOdd = Array.FindIndex(arr,
startIndex: 2,
x => x % 2 == 1);Также аргументы могут формировать секцию в обратную сторону. Например:
int[] arr = new int[] { 0, 1, 3, 4 };
var lastEvenInd = Array.FindLastIndex(arr,
startIndex: 1,
count: 3,
x => x % 2 == 0);Здесь аргументы выполняют те же самые роли, однако элементы будут просматриваться в обратном порядке. Область поиска здесь формируется из элемента с индексом '1' и двух элементов, стоящих перед ним. Таким образом, методу нужно будет обратиться по индексу '-1'. Так как такое поведение некорректно, будет выброшено исключение.
В этом случае корректная реализация поиска индекса может выглядеть так:
int[] arr = new int[] { 0, 1, 3, 4 };
var lastEvenInd = Array.FindLastIndex(arr,
startIndex: 1,
count: 2,
x => x % 2 == 0);Рассмотрим более сложный пример:
var list = new List<int> { 2, 3, 5, 7 };
var index = GetFirstEvenIndex(list, 1, list.Count);
....
public int GetFirstEvenIndex(List<int> lst, int startIndex, int count)
{
return lst.FindIndex(startIndex, count, x => x % 2 == 0);
}Параметры метода 'GetFirstEvenIndex':
- 'lst' – коллекция, в которой происходит поиск индекса первого четного числа в указанном диапазоне;
- 'startIndex' – индекс элемента, с которого начнется диапазон поиска;
- 'count' – количество элементов в обрабатываемом диапазоне.
Здесь формируется диапазон поиска от элемента с индексом '1' до элемента с индексом 'list.Count' включительно. Таким образом, методу нужно будет обратиться по индексу, лежащему за пределами коллекции. Так как такое поведение некорректно, будет выброшено исключение.
Корректный код передачи аргументов методу может выглядеть следующим образом:
var list = new List<int> { 2, 3, 5, 7 };
var startIndex = 1;
var index = GetFirstEvenIndex(list, startIndex, list.Count - startIndex);Данная диагностика классифицируется как:
V3187. Parts of an SQL query are not delimited by any separators or whitespaces. Executing this query may lead to an error.
Анализатор обнаружил, что в SQL-запросе, вероятно, пропущен пробел или какой-либо другой символ-разделитель между словами. Эта опечатка могла быть допущена в результате конкатенации, интерполяции или вызова метода 'String.Format' для получения строки SQL-запроса.
Рассмотрим пример:
public Customer GetCustomerData(ulong id)
{
string query = "SELECT c.Email, c.Phone, " +
"c.firstName, c.lastName FROM customers c" + // <=
$"WHERE customers.id = {id}";
var sqlCommand = new SqlCommand(query);
....
}Тут создается SQL-запрос на получение данных клиента по его ID. Обратите внимание, что этот запрос был получен путем конкатенации двух строк, в месте соединения которых отсутствует пробел. Из-за этой ошибки SQL-запрос будет содержать опечатку — "сWHERE" — что сделает его некорректным.
Чтобы исправить проблему, нужно подставить недостающий пробел:
public Customer GetCustomerData(ulong id)
{
string query = "SELECT c.Email, c.Phone, " +
"c.firstName, c.lastName FROM customers c " +
$"WHERE customers.id = {id}";
var sqlCommand = new SqlCommand(query);
....
}V3188. Unity Engine. The value of an expression is a potentially destroyed Unity object or null. Member invocation on this value may lead to an exception.
Анализатор обнаружил разыменование потенциально уничтоженного или имеющего значение 'null' объекта. Это может стать причиной выбрасывания исключения.
Рассмотрим пример:
void ProcessTarget(GameObject target)
{
if ((....) && target == null)
{
....
var position = target.transform.position;
}
}В данном примере обращение к свойству 'transform ' производится, когда 'target' либо является уничтоженным объектом, либо равен 'null'. Оба варианта приводят к выбрасыванию исключения.
В данном случае проблему можно исправить, изменив оператор сравнения:
void ProcessTarget(GameObject target)
{
if ((....) && target!= null)
{
....
var position = target.transform.position;
}
}V3189. The assignment to a member of the readonly field will have no effect when the field is of a value type. Consider restricting the type parameter to reference types.
Анализатор обнаружил, что члену 'readonly' поля присваивается значение, и при этом поле может иметь значимый тип. Если поле будет иметь значимый тип, то изменения члена поля не произойдёт.
Подобная ошибка возникает из-за того, что типы значений непосредственно содержат свои данные. Если тип поля явно определён как значимый, то подобную ошибку найдёт компилятор. Однако если типом поля является универсальный параметр, то код успешно скомпилируется. Из-за этого возможна ситуация, когда в член 'readonly' поля происходит запись, но его значение не изменяется.
Рассмотрим пример:
private interface ITable
{
int Rows { get; set; }
}
private class Table<T> where T : ITable
{
private readonly T _baseTable;
public void SetRows(int x)
{
_baseTable.Rows = x; // <=
}
}Класс имеет поле '_baseTable', типом которого является универсальный параметр. В методе 'SetRows' свойству 'Rows' данного поля присваивается значение аргумента.
Ниже представлен пример использования этого класса:
private struct RelationTable : ITable
{
public int Rows { get; set; }
}
....
static void DoSomething()
{
Table<RelationTable> table = new Table<RelationTable>();
table.SetRows(10);
}В данном случае вызов 'SetRows' никак не повлияет на значение свойства 'Rows'. Для того чтобы обезопасить код от подобных ошибок, нужно добавить ограничения типа:
private interface ITable
{
int Rows { get; set; }
}
private class Table<T> where T : class, ITable
{
private readonly T _baseTable;
public void SetRows(int x)
{
_baseTable.Rows = x;
}
}V3190. Concurrent modification of a variable may lead to errors.
Анализатор обнаружил возможную ошибку в коде: несколько потоков без синхронизации изменяют общий ресурс.
Рассмотрим пример:
ConcurrentBag<String> GetNamesById(List<String> ids)
{
String query;
ConcurrentBag<String> result = new();
Parallel.ForEach(ids, id =>
{
query = $@"SELECT Name FROM data WHERE id = {id}";
result.Add(ProcessQuery(query));
});
return result;
}Метод 'GetNamesById' возвращает имена в соответствии с переданным списком идентификаторов. Для этого методом 'Parallel.ForEach' обрабатываются все элементы коллекции 'ids': для каждого из них составляется и исполняется SQL-запрос.
Проблема в том, что захваченная локальная переменная 'query' является общим разделяемым ресурсом потоков, исполняющихся в 'Parallel.ForEach'. Разные потоки будут производить несинхронизированный доступ к одному объекту. Это может привести к некорректному поведению программы.
Ниже приведено описание возможной проблемной ситуации:
- В первом потоке в переменную 'query' записывается SQL-запрос с 'id' равным 42. Это значение должно далее передаваться в 'ProcessQuery'.
- Во втором потоке в 'query' записывается новый SQL-запрос с 'id' равным 12.
- Оба потока вызывают 'ProcessQuery', используя значение 'query' с 'id' равным 12.
- В результате 'ProcessQuery' вызван дважды с одним и тем же значением. При этом теряется значение, полученное при присваивании в первом потоке.
Корректная реализация метода может выглядеть следующим образом:
ConcurrentBag<String> GetNamesById(List<String> ids)
{
ConcurrentBag<String> result = new();
Parallel.ForEach(ids, id =>
{
String query = $@"SELECT Name FROM data WHERE id = {id}";
result.Add(ProcessQuery(query));
});
return result;
}Здесь каждый поток работает с собственной переменной 'query'. В таком случае проблем не будет, так как нет разделяемого между потоками ресурса.
Рассмотрим ещё один пример:
int CountFails(List<int> ids)
{
int count = 0;
Parallel.ForEach(ids, id =>
{
try
{
DoSomeWork(id);
}
catch (Exception ex)
{
count++;
}
});
return count;
}Метод 'CountFails' считает количество исключений при выполнении операций над элементами коллекции 'ids'. Этот код также содержит проблему несинхронизированного доступа к общему ресурсу. Операции инкремента и декремента не являются атомарными, поэтому корректный подсчёт количества исключений в этом случае не гарантирован.
Корректная реализация метода может выглядеть следующим образом:
int CountFails(List<int> ids)
{
int count = 0;
Parallel.ForEach(ids, id =>
{
try
{
DoSomeWork(id);
}
catch (Exception ex)
{
Interlocked.Increment(ref count);
}
});
return count;
}Здесь для корректного подсчета используется метод 'Interlocked.Increment', предоставляющий атомарную операцию инкремента переменной.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V3191. Iteration through collection makes no sense because it is always empty.
Анализатор обнаружил попытку обхода пустой коллекции. Такая операция не имеет смысла: скорее всего, код содержит ошибку.
Рассмотрим пример:
private List<Action> _actions;
....
public void Execute()
{
var remove = new List<Action>();
foreach (var action in _actions)
{
try
{
action.Invoke();
}
catch (Exception ex)
{
Logger.LogError(string.Format("Error invoking action:\n{0}", ex));
}
}
foreach (var action in remove)
_actions.Remove(action);
}Метод 'Execute' поочередно вызывает делегаты из списка '_actions', а также ловит и логирует возникающие в процессе выполнения ошибки. Помимо основного цикла, в конце метода есть еще один, который должен удалять из списка '_actions' делегаты, хранящиеся в коллекции 'remove'.
Проблема здесь в том, что коллекция 'remove' всегда будет пустой. Она создается в самом начале метода, но не заполняется в процессе. Таким образом, последний цикл никогда не будет выполнен.
Корректная реализация метода может выглядеть следующим образом:
public void Execute()
{
var remove = new List<Action>();
foreach (var action in _actions)
{
try
{
action.Invoke();
}
catch (Exception ex)
{
Logger.LogError(string.Format("Error invoking action:\n{0}", ex));
remove.Add(action);
}
}
foreach (var action in remove)
_actions.Remove(action);
}Теперь добавляем в коллекцию 'remove' делегаты, при исполнении которых возникли исключения, чтобы впоследствии удалить их.
Анализатор также может выдать предупреждение на вызов метода, выполняющего обход коллекции.
Рассмотрим пример:
int ProcessValues(int[][] valuesCollection,
out List<int> extremums)
{
extremums = new List<int>();
foreach (var values in valuesCollection)
{
SetStateAccordingToValues(values);
}
return extremums.Sum();
}Метод 'ProcessValues' принимает массивы чисел для обработки. В данном случае нас интересует коллекция 'extremums': она создается пустой и не заполняется в процессе выполнения метода. При этом 'ProcessValues' возвращает результат вызова метода 'Sum' на коллекции 'extremums'. Код выглядит ошибочным, так как вызов 'Sum' всегда возвращает 0.
Корректная реализация метода может выглядеть следующим образом:
int ProcessValues(int[][] valuesCollection,
out List<int> extremums)
{
extremums = new List<int>();
foreach (var values in valuesCollection)
{
SetStateAccordingToValues(values);
extremums.Add(values.Max());
}
return extremums.Sum();
}V3192. Type member is used in the 'GetHashCode' method but is missing from the 'Equals' method.
Анализатор обнаружил возможную ошибку, связанную с тем, что один из членов класса не используется в методе 'Equals' и при этом используется в методе 'GetHashCode'.
Рассмотрим пример:
public class UpnpNatDevice
{
private EndPoint hostEndPoint;
private string serviceDescriptionUrl;
private string controlUrl;
public override bool Equals(object obj)
{
if (obj is UpnpNatDevice other)
{
return hostEndPoint.Equals(other.hostEndPoint)
&& serviceDescriptionUrl == other.serviceDescriptionUrl;
}
return false;
}
public override int GetHashCode()
{
return hostEndPoint.GetHashCode()
^ controlUrl.GetHashCode()
^ serviceDescriptionUrl.GetHashCode();
}
}В данном примере поле 'controlUrl' не используется в методе 'Equals', но при этом присутствует в 'GetHashCode'. Это возможно в двух ситуациях:
- в методе 'Equals' забыли сравнить поле 'controlUrl';
- разработчики решили не использовать поле 'controlUrl' в методе 'Equals'.
Обе ситуации приводят к одной проблеме – метод 'GetHashCode' может возвращать разные значения для двух эквивалентных объектов. Исходя из документации Microsoft, метод 'GetHashCode' должен возвращать одинаковый хэш код для любых двух объектов, для которых вызов 'Equals' возвращает 'True'.
В данном случае для двух объектов с одинаковыми полями 'hostEndPoint' и 'serviceDescriptionUrl' метод 'Equals' вернёт 'True'. При этом результат 'GetHashCode' зависит ещё и от 'controlUrl'. Это может свидетельствовать об ошибке. Также подобная реализация может негативно сказаться на корректности работы с коллекциями 'Hashtable', 'Dictionary<TKey,TValue>' и другими.
Исправленный вариант:
public override bool Equals(object obj)
{
if (obj is UpnpNatDevice other)
{
return hostEndPoint.Equals(other.hostEndPoint)
&& serviceDescriptionUrl == other.serviceDescriptionUrl
&& controlUrl == other.controlUrl;
}
return false;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3192. |
V3193. Data processing results are potentially used before asynchronous output reading is complete. Consider calling 'WaitForExit' overload with no arguments before using the data.
Анализатор обнаружил, что результаты обработки вывода процесса могут быть использованы до завершения всех операций их формирования. В этом случае приложение будет использовать выходные данные процесса в некорректном или неполном виде.
Рассмотрим пример:
public void Run()
{
var process = new Process();
process.StartInfo.FileName = GetProcessFile();
process.StartInfo.UseShellExecute = false;
process.StartInfo.RedirectStandardOutput = true;
StringBuilder data = new StringBuilder();
process.OutputDataReceived +=
(sender, args) => data.AppendLine(args.Data); // <=
process.Start();
process.BeginOutputReadLine();
WriteData(data.ToString()); // <=
}Код в данном примере запускает процесс, сохраняет его вывод в переменную 'data', после чего собранные результаты передаются в метод 'WriteData'. Здесь возможна ситуация, при которой вызов 'data.ToString' будет выполнен до полной обработки всего вывода процесса. К примеру, если процесс выводит несколько строк, то к моменту вызова 'ToString' не все из них могут быть добавлены в переменную 'data'.
Для решения проблемы необходимо убедиться, что обработка всего вывода процесса была завершена. Для этого можно вызвать метод 'WaitForExit' без аргументов:
public void Run()
{
var process = new Process();
process.StartInfo.FileName = GetProcessFile();
process.StartInfo.UseShellExecute = false;
process.StartInfo.RedirectStandardOutput = true;
StringBuilder data = new StringBuilder();
process.OutputDataReceived +=
(sender, args) => data.AppendLine(args.Data);
process.Start();
process.BeginOutputReadLine();
process.WaitForExit();
WriteData(data.ToString());
}Такой вызов 'WaitForExit' возвращает управление только после того, как обработка вывода будет завершена. Обратите внимание, что вызов перегрузки 'WaitForExit(Int32)' не обладает данной особенностью. Поэтому следующий код может отрабатывать некорректно:
public void Run()
{
var process = new Process();
....
StringBuilder data = new StringBuilder();
process.OutputDataReceived +=
(sender, args) => data.AppendLine(args.Data); // <=
process.Start();
process.BeginOutputReadLine();
if (process.WaitForExit(3000))
{
WriteData(data.ToString()); // <=
}
else
{
.... // throw timeout error
}
}В данном примере получение значения из переменной 'data' производится после того, как процесс завершил работу. Тем не менее, обработка вывода процесса может быть не завершена к моменту вызова 'ToString'. Такое поведение описано в документации к методу 'WaitForExit'. Для того чтобы обработка была гарантированно завершена, необходимо дополнительно вызвать метод без аргументов:
public void Run()
{
var process = new Process();
....
StringBuilder data = new StringBuilder();
process.OutputDataReceived +=
(sender, args) => data.AppendLine(args.Data);
process.Start();
process.BeginOutputReadLine();
if (process.WaitForExit(3000))
{
process.WaitForExit();
WriteData(data.ToString());
}
else
{
.... // throw timeout error
}
}Данная диагностика классифицируется как:
V3194. Calling 'OfType' for collection will return an empty collection. It is not possible to cast collection elements to the type parameter.
Анализатор обнаружил ситуацию, когда в результате вызова 'OfType' будет возвращена пустая коллекция. Данное поведение обусловлено невозможностью преобразования типа элементов коллекции к типу, по которому фильтрует 'OfType'.
Рассмотрим пример:
public struct SyntaxToken {....}
public class InvocationExpressionSyntax : ExpressionSyntax {....}
public List<SyntaxToken> GetAllTokens() {....}
public List<ExpressionSyntax> GetAllExpressions() {....}
void ProcessInvocationExpressions()
{
var result = GetAllTokens().OfType<InvocationExpressionSyntax>();
....
}В 'ProcessInvocationExpressions' должны обрабатываться объекты типа 'InvocationExpressionSyntax'. Для этого производится фильтрация коллекции с помощью метода 'OfType'. Однако данный метод вызывается на коллекцию элементов типа 'SyntaxToken'. В результате фильтрации будет получена пустая коллекция, так как экземпляры структуры 'SyntaxToken' точно не могут являться 'InvocationExpressionSyntax'.
В вышеописанном примере был перепутан метод для получения коллекции объектов типа 'ExpressionSyntax'. Вместо 'GetAllTokens' должен использоваться 'GetAllExpressions'. Корректная реализация 'ProcessInvocationExpressions' будет выглядеть следующим образом:
void ProcessInvocationExpressions()
{
var result = GetAllExpressions().OfType<InvocationExpressionSyntax>();
....
}При такой реализации будет отфильтрована коллекция с элементами типа 'ExpressionSyntax'. Данный тип является базовым для 'InvocationExpressionSyntax'. Следовательно, преобразование из 'ExpressionSyntax' в 'InvocationExpressionSyntax' представляется возможным. В результате вызова 'OfType' может быть получена непустая коллекция.
Данная диагностика классифицируется как:
V3195. Collection initializer implicitly calls 'Add' method. Using it on member with default value of null will result in null dereference exception.
Анализатор обнаружил, что в результате инициализации коллекции будет выброшено исключение типа 'NullReferenceException'. Это может произойти, если коллекция является свойством/полем, которое инициализируется на этапе создания объекта.
Рассмотрим пример:
class Container
{
public List<string> States { get; set; }
}
void Process(string? message)
{
var container = new Container
{
States = { "Red", "Yellow", "Green" }
};
}В методе 'Process' создаётся объект типа 'Container'. На этапе создания объекта инициализируется список 'States'. При его инициализации будет выброшено исключение типа 'NullReferenceException'. Данное поведение обусловлено тем, что конструкция 'States = { "Red", "Yellow", "Green" }' раскрывается в три вызова метода 'Add' у свойства 'States'. По умолчанию объект типа 'List<string>' имеет значение 'null'. Следовательно, в данном случае метод 'Add' будет вызван у свойства, которое имеет значение 'null'.
Чтобы избежать возникновения исключения, можно присвоить значение свойству на этапе объявления:
class Container
{
public List<string> States { get; set; } = new List<string>();
}Теперь при инициализации на этапе создания объекта класса исключения не будет.
Рассмотрим ещё один способ:
void Process(string? message)
{
var container = new Container
{
States = new() { "Red", "Yellow", "Green" }
};
}В данном случае сначала будет создан объект списка с помощью 'new()', после чего в него будут добавлены элементы.
Данная диагностика классифицируется как:
V3196. Parameter is not utilized inside the method body, but an identifier with a similar name is used inside the same method.
Анализатор обнаружил подозрительный код, в котором один из параметров никак не используется. При этом в теле функции/конструктора используется значение переменной, поля или свойства с похожим названием. Возможно, это значение было по ошибке использовано вместо значения параметра метода.
Рассмотрим пример:
public GridAnswerData(int questionId, ....)
{
this.QuestionId = QuestionId;
....
}В данном конструкторе свойству присваивается собственное же значение. Очевидно, что это опечатка, и свойству 'this.QuestionId' должно быть присвоено значение параметра 'questionId'. В результате решение проблемы выглядит следующим образом:
public GridAnswerData(int questionId, ....)
{
this.QuestionId = questionId;
....
}Рассмотрим ещё один пример:
public async void Save(string filePath = null)
{
using(var writer = new StreamWriter(FilePath))
{
....
await writer.WriteAsync(Data);
}
}В данном случае в метод 'Save' в качества аргумента 'filePath' передаётся путь к файлу, в который должны быть сохранены какие-то данные. Однако вместо этого сохранение выполняется в другой файл, путь к которому возвращает свойство 'FilePath'. Можно предположить, что свойство 'FilePath' должно быть использовано только в случае, если аргумент 'filePath' имеет значение 'null'. В итоге исправленный код может выглядеть следующим образом:
public async void Save(string filePath = null)
{
var path = filePath ?? FilePath;
using(var writer = new StreamWriter(path))
{
....
await writer.WriteAsync(Data);
}
}Даже если это предположение ошибочно, наличие неиспользуемого параметра в сигнатуре метода может запутать и потенциально привести к ошибкам при использовании этого метода в будущем.
V3197. The compared value inside the 'Object.Equals' override is converted to a different type that does not contain the override.
Анализатор обнаружил возможную ошибку в переопределённом методе 'Equals', связанную с проверкой неверного типа.
Рассмотрим пример:
private class FirstClass
{
....
public override bool Equals(object obj)
{
SecondClass other = obj as SecondClass; // <=
if (other == null)
{
return false;
}
return Equals(other);
}
public bool Equals(FirstClass other)
{
....
}
}В переопределённом методе 'Equals' класса 'FirstClass' допущена ошибка при проверке типа 'obj': вместо 'SecondClass' должен быть 'FirstClass'.
В результате ошибки, если в переопределённый метод 'Equals' будет передан объект типа 'FirstClass', метод будет всегда возвращать 'false'.
Более того, если передать в качестве параметра объект типа 'SecondClass', тогда будет вызван этот же переопределённый метод 'Equals'. Это приведёт к рекурсии и выбрасыванию исключения типа 'StackOverflowException'.
Исправленный вариант:
private class FirstClass
{
....
public override bool Equals(object obj)
{
FirstClass other = obj as FirstClass;
if (other == null)
{
return false;
}
return Equals(other);
}
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3197. |
V3198. The variable is assigned the same value that it already holds.
Анализатор обнаружил ситуацию, когда переменной присваивается значение, которое она уже имеет.
Рассмотрим пример:
public long GetFactorial(long it)
{
long currentValue = 1;
for (int i = 1; i <= it; i++)
{
currentValue = currentValue * currentValue;
}
return currentValue;
}Метод 'GetFactorial' должен возвращать значение факториала, соответствующее параметру. Однако этот метод всегда будет возвращать единицу. Данная ситуация возникает из-за того, что на каждой итерации цикла переменной 'currentValue' присваивается значение, которое она уже имеет.
Для исправления нужно заменить один из множителей на 'i':
for (int i = 1; i <= it; i++)
{
currentValue = currentValue * i;
}Дополнительная настройка диагностики
Существует возможность игнорировать возвращаемые значения методов и свойств для данного диагностического правила. Для этого нужно добавить в файл '.pvsconfig' следующую команду:
//V_3198_IGNORE_RETURN_VALUE:NamespaseName.TypeName.MethodNameПри использовании команды из примера, данное диагностическое правило не будет выдавать предупреждения, если переменной присваивается возвращаемое значение метода 'NamespaseName.TypeName.MethodName'.
Аналогичным образом можно размечать свойства.
Данная диагностика классифицируется как:
V3199. The index from end operator is used with the value that is less than or equal to zero. Collection index will be out of bounds.
Анализатор обнаружил доступ к элементу коллекции с помощью оператора '^' со значением, которое меньше или равно 0. Это приводит к исключению типа 'IndexOutOfRangeException'.
Рассмотрим пример:
T GetLastItem<T>(T[] array)
{
return array[^0];
}Оператор '^' указывает, что индекс учитывается с конца последовательности. Может быть не очевидно, что '^0' равносильно 'array.Length'. При попытке получения последнего элемента коллекции с помощью '^0' будет выброшено исключение, как и при использовании 'array[array.Length]'.
Исправленный код:
T GetLastItem<T>(T[] array)
{
return array[^1];
}Данная диагностика классифицируется как:
V3200. Possible overflow. The expression will be evaluated before casting. Consider casting one of the operands instead.
Анализатор обнаружил подозрительное приведение типов. Результат бинарной операции приводится к типу с большим диапазоном.
Рассмотрим пример:
long Multiply(int a, int b)
{
return (long)(a * b);
}Такое преобразование избыточно. Тип 'int' и так бы автоматически расширился до типа 'long'.
Скорее всего, подобный паттерн приведения используется для защиты от переполнения, но он неправильный. При перемножении переменных типа 'int' всё равно произойдёт переполнение, и только уже бессмысленный результат умножения будет явно расширен до типа 'long'.
Для корректной защиты от переполнения можно привести один из аргументов к типу 'long'. Исправленный код:
long Multiply(int a, int b)
{
return (long)a * b;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
V3201. Return value is not always used. Consider inspecting the 'foo' method.
Анализатор обнаружил потенциально-ошибочное игнорирование возвращаемого значения метода, которое в большинстве остальных случаев используется.
Рассмотрим синтетический пример:
Audio _currentMusic = null;
void Foo1(....)
{
....
_currentMusic = PlayMusic();
}
void Foo2()
{
if (....)
_currentMusic = PlayMusic();
}
....
void Foo10()
{
....
PlayMusic(); // <=
}В данном примере возвращаемое значение метода 'PlayMusic' используется всегда, кроме одного случая. Анализатор выдаёт предупреждение, если возвращаемое значение метода игнорируется не более чем в 10% случаев. При этом отсутствуют признаки того, что оно намеренно не используется.
В некоторых ситуациях возвращаемое значение действительно не требуется как-то использовать. Например, если метод имеет побочные эффекты (изменение свойств, полей, запись/чтение файла и прочее), и возвращаемым значением можно пренебречь. Для улучшения читаемости кода рекомендуется явно обозначить это, присвоив результат метода discard-переменной:
_ = PlayMusic();В этом случае предупреждения не будет.
V3202. Unreachable code detected. The 'case' value is out of the range of the match expression.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что одна или несколько ветвей оператора 'switch' никогда не выполнятся. Причина этого в том, что сравниваемое выражение не может принять значение, записанное после оператора 'case'.
Рассмотрим синтетический пример:
switch (random.Next(0, 3))
{
case 0:
case 1:
Console.WriteLine("1");
break;
case 2:
Console.WriteLine("2");
break;
case 3: // <=
Console.WriteLine("3");
break;
default:
break;
}В данном случае код в 'case 3' никогда не выполнится. Дело в том, что в 'random.Next(0, 3)' верхняя граница не входит в возвращаемый диапазон значений. В результате выражение в 'switch' никогда не примет значение 3, и 'case 3' не выполнится.
Исправить эту ошибку можно двумя способами. В первом варианте можно просто избавиться от мертвого кода, удалив секцию 'case 3', которая не входит в диапазон 'random.Next(0, 3)':
switch (random.Next(0, 3))
{
case 0:
case 1:
Console.WriteLine("1");
break;
case 2:
Console.WriteLine("2");
break;
}Либо же можно увеличить верхнюю границу в методе 'next' - 'random.Next(0, 4)':
switch (random.Next(0, 4))
{
case 0:
case 1:
Console.WriteLine("1");
break;
case 2:
Console.WriteLine("2");
break;
case 3:
Console.WriteLine("3");
break;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V3202. |
V3203. Method parameter is not used.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что один или несколько параметров метода не были использованы.
Рассмотрим пример:
private List<uint> TranslateNgramHashesToIndexes(Language language, ....)
{
....
//var offset = (uint)Data.LanguageOffset[language];
....
if (Data.SubwordHashToIndex.TryGetValue(hashes[i]/* + offset*/,
out int index))
....
else if (....)
{
....
Data.SubwordHashToIndex.Add(hashes[i]/* + offset*/, index);
}
....
}Параметр 'language' используется только в закомментированном коде. В такой ситуации стоит убедиться, что этот код действительно должен быть закомментирован, а не случайно оставлен таким после отладки.
Рассмотрим ещё один пример:
private void DoConnect(EndPoint address)
{
ReportConnectFailure(() =>
{
_channel = DatagramChannel.Open();
_channel.ConfigureBlocking(false);
var socket = _channel.Socket;
....
_channel.Connect(_connect.RemoteAddress);
});
}В данном примере единственный параметр 'address' не используется. Это может привести к путанице при использовании этого метода, а в худшем случае и вовсе свидетельствует о наличии ошибки в реализации.
В случае, если параметр является устаревшим, можно пометить метод атрибутом 'Obsolete'. Если параметр намеренно не используется по какой-то другой причине, рекомендуется дать ему имя следующего вида: '_', '_1', '_2' и т. д.
V3204. The expression is always false due to implicit type conversion. Overflow check is incorrect.
Анализатор обнаружил не работающую из-за неявного приведения типа проверку на переполнение.
Рассмотрим пример:
bool IsValidAddition(ushort x, ushort y)
{
if (x + y < x)
return false;
return true;
}Цель данного метода — проверить, произойдет ли переполнение при сложении двух положительных чисел. В случае переполнения результат суммы должен оказаться меньше любого из её операндов.
Однако проверка не выполнит свою задачу, поскольку оператор '+' не имеет перегрузки для сложения чисел с типом 'ushort'. В результате оба числа будут в начале приведены к типу 'int', после чего выполнится их сложение. Так как складываются значения типа 'int', никакого переполнения не произойдёт.
Для исправления проверки нужно явно привести результат суммы к типу 'ushort':
bool IsValidAddition(ushort x, ushort y)
{
if ((ushort)(x + y) < x)
return false;
return true;
}Кромe типа 'ushort', перегрузка оператора суммы отсутствует и для чисел с типом 'byte'. Перед сложением эти числа также будут неявно приведены к 'int' типу.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
V3205. Unity Engine. Improper creation of 'MonoBehaviour' or 'ScriptableObject' object using the 'new' operator. Use the special object creation method instead.
Анализатор обнаружил нежелательное создание экземпляра классов 'MonoBehaviour' или 'ScriptableObject' с помощью оператора 'new'. Объекты, созданные таким образом, не будут связаны с движком, поэтому такие специфичные Unity-методы, как 'Update', 'Awake', 'OnEnable' и прочие, вызываться не будут.
Ниже приведён пример:
class ExampleSO: ScriptableObject
....
class ExampleComponent: MonoBehaviour
....
void Awake
{
var scriptableObject = new ExampleSO();
var component = new ExampleComponent();
}Чтобы избежать потенциальных проблем, вместо оператора 'new' для создания экземпляров этих классов следует использовать один из следующих методов:
- 'GameObject.AddComponent' — для создания экземпляра класса 'MonoBehaviour';
- 'ScriptableObject.CreateInstance' — для создания экземпляра класса 'ScriptableObject'.
Исправленный код:
class ExampleSO: ScriptableObject
....
class ExampleComponent: MonoBehaviour
....
void Awake
{
var scriptableObject = ScriptableObject.CreateInstance<ExampleSO>();
var component = this.gameObject.AddComponent<ExampleComponent>();
}V3206. Unity Engine. A direct call to the coroutine-like method will not start it. Use the 'StartCoroutine' method instead.
Анализатор обнаружил подозрительный вызов в Unity-скрипте метода, похожего на coroutine, возвращаемое значение которого не используется. Для запуска coroutine нужно использовать метод 'StartCoroutine'.
Рассмотрим пример:
class CustomComponent: MonoBehaviour
{
IEnumerator ExampleCoroutine()
{
....
yield return null;
....
}
void Start()
{
....
ExampleCoroutine();
....
}
}В данном случае код coroutine 'ExampleCoroutine' выполняться не будет, т. к. возвращаемый в результате вызова объект 'IEnumerator' никак не используется. Чтобы решить проблему, нужно передать его в метод 'MonoBehaviour.StartCoroutine':
void Start()
{
....
StartCoroutine(ExampleCoroutine());
....
}Дополнительные ссылки
- Unity Documentation. Coroutines.
- Unity Documentation. MonoBehaviour.StartCoroutine.
V3207. The 'not A or B' logical pattern may not work as expected. The 'not' pattern is matched only to the first expression from the 'or' pattern.
Анализатор обнаружил фрагмент кода, который, возможно, содержит логическую ошибку. В условном выражении был обнаружен паттерн 'is not * or *'. Приоритет оператора 'not' выше, чем у оператора 'or'. Вследствие этого отрицание не применяется к правой части 'or'.
Рассмотрим пример:
private void ShowWordDetails(string key)
{
if (key is not "" or null)
{
PanelReferenceBox.Controls.Clear();
CurrentWord = Words.Find(x => x.Name == key);
....
}
}Логика выражения 'key is not "" or null' нарушена. Если 'key' – null, то результатом логического выражения будет 'true', когда подразумевался 'false'.
Ошибка возникает, если разработчик не учитывает, что оператор 'not' имеет приоритет выше, чем 'or'. В данном паттерне второе подвыражение оператора 'or', как правило, оказывается бессмысленным. Например, в выражении 'key is not "" or null', если 'key' – null, при проверке на не пустую строку будет получен результат 'true'. Получается, что вторая часть выражения не будет влиять на конечный результат.
Для корректного порядка выполнения операторов стоит использовать скобки после оператора 'not'.
Исправленный код:
private void ShowWordDetails(string key)
{
if (key is not ("" or null))
{
PanelReferenceBox.Controls.Clear();
CurrentWord = Words.Find(x => x.Name == key);
....
}
}Теперь код работает, как ожидалось. В условии проверяется, что строка 'key' не пустая и не 'null', вместо проверки только на пустую строку.
Данная диагностика классифицируется как:
V3208. Unity Engine. Using 'WeakReference' with 'UnityEngine.Object' is not supported. GC will not reclaim the object's memory because it is linked to a native object.
Анализатор обнаружил использование экземпляра класса 'UnityEngine.Object' или его подкласса вместе с 'System.WeakReference'. Из-за неявного использования экземпляра самим движком поведение слабой ссылки может отличаться от ожидаемого.
Рассмотрим пример:
WeakReference<GameObject> _goWeakRef;
void UnityObjectWeakReference()
{
var go = new GameObject();
_goWeakRef = new WeakReference<GameObject>(go);
}В данном примере создается слабая ссылка на объект класса 'GameObject'. Даже если вы не создавали сильных ссылок на этот объект, сборщик мусора не сможет очистить его. Свойство 'IsAlive' у 'WeakReference' или результат метода 'TryGetTarget' у 'WeakReference<T>' будут иметь значение 'true' даже после уничтожения объекта при помощи метода 'Destroy' или 'DestroyImmediate'.
Больше информации об этом можно прочитать в документации Unity.
При обнаружении подобного использования 'WeakReference' стоит произвести рефакторинг кода для исключения использования слабой ссылки вместе с 'UnityEngine.Object' или его подклассами.
Так же анализатор выдаёт предупреждение, когда при помощи метода 'WeakReference.SetTarget' в качестве аргумента передают экземпляр класса 'UnityEngine.Object' или его подкласса.
Данная диагностика классифицируется как:
V3209. Unity Engine. Using await on 'Awaitable' object more than once can lead to exception or deadlock, as such objects are returned to the pool after being awaited.
Анализатор обнаружил более одного использования одного и того же 'UnityEngine.Awaitable' объекта с оператором 'await'. В целях оптимизации 'Awaitable' объекты хранятся в пуле-объектов. При использовании 'await' объект 'Awaitable' возвращается в пул. После этого при повторном применении 'await' к этой же ссылке объекта будет выброшено исключение, в некоторых случаях также возможна взаимная блокировка.
Рассмотрим синтетический пример:
async Awaitable<bool> AwaitableFoo() { .... }
async Awaitable ExampleFoo()
{
Awaitable<bool> awaitable = AwaitableFoo();
if (await awaitable)
{
var result = await awaitable;
....
}
}В этом коде будет выброшено исключение (или возникнет взаимная блокировка) при инициализации переменной 'result' значением, полученным при использовании 'await' к 'awaitable'. Это произойдёт из-за того, что ранее 'await' уже применялся к 'awaitable' в условии условной конструкции.
Чтобы обезопасить этот код, следует избегать записи 'Awaitable' в переменную. Вместо этого можно переиспользовать значение, полученное после вызова 'AwaitableFoo()' c использованием 'await':
async Awaitable<bool> AwaitableFoo() { .... }
async Awaitable ExampleFoo()
{
bool value = await AwaitableFoo();
if (value)
{
var result = value;
....
}
}Или повторно выполнять вызов с 'await' непосредственно метода 'AwaitableFoo' там, где это требуется:
async Awaitable<bool> AwaitableFoo() { .... }
async Awaitable ExampleFoo()
{
if (await AwaitableFoo())
{
var result = await AwaitableFoo();
....
}
}Такое решение также является корректным, ведь при каждом вызове 'AwaitableFoo()' будет возвращён новый объект 'Awaitable'.
Стоит отметить, что возможны и менее очевидные случаи возникновения проблемы. Например, когда повторное применение 'await' к значению 'Awaitable' происходит внутри другого метода, которому это значение было передано в качестве аргумента:
async Awaitable<bool> AwaitableFoo() { .... }
async Awaitable<Result> GetResult(Awaitable<bool> awaitable)
{
if (await awaitable){ .... } // <=
else { .... }
}
async Awaitable ExampleFoo()
{
Awaitable<bool> awaitable = AwaitableFoo();
if (await awaitable) // <=
{
....
}
var result = await GetResult(awaitable); // <=
}Решения проблемы в таких случаях полностью аналогичны решениям, описанным ранее.
V3210. Unity Engine. Unity does not allow removing the 'Transform' component using 'Destroy' or 'DestroyImmediate' methods. The method call will be ignored.
Анализатор обнаружил, что для вызова метода 'Destroy' или 'DestroyImmediate' класса 'UnityEngine.Object' используется аргумент типа 'UnityEngine.Transform'. Это приводит к ошибке во время вызова метода. Удаление компонента 'Transform' из игрового объекта не допускается в Unity.
Рассмотрим пример:
using UnityEngine;
class Projectile : MonoBehaviour
{
public void Update()
{
if (....)
{
Destroy(transform);
}
....
}
}Свойство 'transform' из базового класса 'MonoBehaviour' возвращает экземпляр класса 'Transform', который передается в качестве аргумента методу 'Destroy'. При таком вызове метода Unity выдаст сообщение об ошибке, а сам компонент не будет уничтожен.
Сообщение Unity:
Can't destroy Transform component of 'Projectile'. If you want to destroy the game object, please call 'Destroy' on the game object instead. Destroying the transform component is not allowed.
Один из вариантов исправления ошибочного кода:
using UnityEngine;
class Projectile : MonoBehaviour
{
public void Update()
{
if (....)
{
Destroy(gameObject);
}
....
}
}В этом случае будет уничтожен весь игровой объект, включая привязанный к нему компонент 'Transform'.
Данная диагностика классифицируется как:
V3211. Unity Engine. The operators '?.', '??' and '??=' do not correctly handle destroyed objects derived from 'UnityEngine.Object'.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что объект производный от UnityEngine.Object был использован с оператором условного null (?.) или null-объединения (?? и ??= ).
Согласно документации Unity, не рекомендуется использовать операторы ?., ?? и ??=. Поскольку их нельзя перегрузить, они не учитывают возможность уничтожения объектов, производных от UnityEngine.Object. Вследствие чего, проверка может иметь некорректный результат.
Рассмотрим пример:
class CustomComponent: MonoBehaviour
{
public bool HitConfirm(....)
{
Projectile bullet;
....
if(....)
Destroy(bullet);
....
if(bullet?.isJammed())
{....}
}
}В данном случае при обращении к bullet проверка с помощью оператора условного null (?. ) не будет учитывать возможность, что объект может быть уничтожен, так как этот оператор нельзя перегрузить.
Чтобы это исправить, рекомендуется использовать проверку с помощью оператора == или !=.
Исправленный вариант:
class CustomComponent: MonoBehaviour
{
public bool HitConfirm(....)
{
Projectile bullet;
....
if(....)
Destroy(bullet);
....
if(bullet != null ? bullet.isJammed() : null)
{....}
}
}V3212. Unity Engine. Pattern matching does not correctly handle destroyed objects derived from 'UnityEngine.Object'.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что производный от UnityEngine.Object объект был использован с pattern matching'ом для проверки на null.
Согласно документации Unity, не рекомендуется использовать pattern matching с объектами, производными от UnityEngine.Object.
Дело в том, что проверка на null с помощью pattern matching не учитывает возможность уничтожения объектов, производных от UnityEngine.Object. Вследствие чего проверка может иметь некорректный результат.
Рассмотрим пример:
class CustomComponent: MonoBehaviour
{
public bool HitConfirm(....)
{
Projectile bullet;
....
if(....)
Destroy(bullet);
if (bullet is not null)
{....}
}
}В данном случае, при проверке bullet с помощью pattern matching'a, не будет учитываться возможность, что объект может быть уничтожен.
Чтобы это исправить, лучше использовать проверку с помощью оператора == или !=.
Исправленный вариант:
class CustomComponent: MonoBehaviour
{
public bool HitConfirm(....)
{
Projectile bullet;
....
if(....)
Destroy(bullet);
if (bullet != null)
{....}
}
}V3213. Unity Engine. The 'GetComponent' method must be instantiated with a type that inherits from 'UnityEngine.Component'.
Анализатор обнаружил, что в качестве аргумента для метода GetComponent (либо схожего с ним) классов Component или GameObject передан тип, который не наследуется от UnityEngine.Component и не является интерфейсом. В таких случаях метод всегда возвращает null либо исключение. Некорректно использовать эти методы подобным образом.
Рассмотрим пример:
struct CameraAnchorData : IComponentData {}
class CameraController: MonoBehaviour
{
....
public GameObject Target;
private void Start()
{
if (Target.TryGetComponent<CameraAnchorData>(out var anchor))
{
....
}
}
}В качестве generic-аргумента метода TryGetComponent используется тип CameraAnchorData, который не наследуется от UnityEngine.Component. Вызов метода всегда будет вызывать исключение.
Кроме generic-аргумента, неверный тип компонента может передаваться и в качестве обычного аргумента:
struct CameraAnchorData : IComponentData {}
class CameraController: MonoBehaviour
{
....
public GameObject Target;
private void Start()
{
if (Target.TryGetComponent(typeof(CameraAnchorData), out var anchor))
{
....
}
}
}Вызов метода TryGetComponent с обычным аргументом typeof(CameraAnchorData) также приведет к исключению.
Данная диагностика классифицируется как:
V3214. Unity Engine. Using Unity API in the background thread may result in an error.
Анализатор обнаружил использование свойства, метода или конструктора после вызова Awaitable.BackgroundThreadAsync, которое при выполнении в фоновом потоке может привести к таким проблемам, как зависание или выброс исключения. Согласно документации Unity, все API, взаимодействующие с движком, должны использоваться строго из главного потока.
Рассмотрим пример:
private async Awaitable LoadSceneAndDoHeavyComputation()
{
await Awaitable.BackgroundThreadAsync();
await SceneManager.LoadSceneAsync("MainScene");
....
}
public async Awaitable Update()
{
if (....)
await LoadSceneAndDoHeavyComputation();
....
}При выполнении метода LoadSceneAndDoHeavyComputation вызывается метод Awaitable.BackgroundThreadAsync, который переносит выполнение последующего кода в рамках того же метода в фоновый поток. Из-за этого проблемы могут возникнуть при последующем вызове метода SceneManager.LoadSceneAsync.
Избежать этого можно, вернувшись в главный поток с помощью метода Awaitable.MainThreadAsync перед вызовом SceneManager.LoadSceneAsync:
private async Awaitable LoadSceneAndDoHeavyComputation()
{
await Awaitable.BackgroundThreadAsync();
....
await Awaitable.MainThreadAsync();
await SceneManager.LoadSceneAsync("MainScene");
}Или выполнив SceneManager.LoadSceneAsync перед переходом в фоновый поток:
private async Awaitable LoadSceneAndDoHeavyComputation()
{
await SceneManager.LoadSceneAsync("MainScene");
await Awaitable.BackgroundThreadAsync();
....
}Данная диагностика классифицируется как:
V3215. Unity Engine. Passing a method name as a string literal into the 'StartCoroutine' is unreliable.
Анализатор обнаружил, что в качестве аргумента для методов Invoke, InvokeRepeating, CancelInvoke, StartCoroutine или StopCoroutine класса UnityEngine.MonoBehaviour передан строковый литерал, что ненадёжно. Если по какой-то причине переданный строковый литерал перестанет соответствовать методу (в частности, если метод поменяет название или станет недоступен), то вызов будет проигнорирован без оповещения об этом.
Рассмотрим пример:
public class CoroutineAndInvoke : MonoBehaviour
{
void Start()
{
Invoke("CreateEnemyMethod", 1f);
StartCoroutine("DangerCheckCoroutine");
}
private void CreateEnemyMethod()
{
....
}
private IEnumerator DangerCheckCoroutine()
{
....
}
}В данном случае методы Invoke и StartCoroutine вызываются со строковыми литералами, которые соответствуют существующим методам CreateEnemyMethod и DangerCheckCoroutine. Скрипт отработает корректно, но надёжность нарушена, и анализатор выдаст предупреждение 3-го уровня.
Для того чтобы сохранить надёжность при вызове этих методов, стоит использовать nameof для получения имени метода, а для StartCoroutine прямой вызов корутины.
Пример кода с сохранением надёжности:
public class CoroutineAndInvoke : MonoBehaviour
{
void Start()
{
Invoke(nameof(CreateEnemyMethod), 1f);
StartCoroutine(DangerCheckCoroutine());
}
....
}При данном подходе не выйдет передать в качестве аргумента несуществующий метод. Ещё один плюс использования nameof и прямого вызова коруины — возможность переименовывать методы в процессе рефакторинга. При этом изменения будут автоматически отражены в аргументах методов Invoke и StartCoroutine.
Рассмотрим пример, где строковые литералы не соответствуют методам:
public class CoroutineAndInvoke : MonoBehaviour
{
void Start()
{
Invoke("CreateEnemy", 1f);
StartCoroutine("DangerCheck");
}
private void CreateEnemyMethod()
{
....
}
private IEnumerator DangerCheckCoroutine()
{
....
}
}В таком случае методы Invoke и StartCoroutine будут проигнорированы, так как не будут найдены методы, соответствующие переданным строковым литералам. Анализатор выдаст предупреждение 1-го уровня. Такая ошибка может произойти, например, из-за опечатки при написании названия метода в аргументе или при переименовании метода.
Данная диагностика классифицируется как:
V3216. Unity Engine. Checking a field with a specific Unity Engine type for null may not work correctly due to implicit field initialization by the engine.
Анализатор обнаружил ненадежную проверку на null поля, которое может быть инициализировано в инспекторе Unity. Ненадежной она является, потому что выполняется с помощью оператора, не имеющего перегрузку для учета специфики кода Unity-скриптов. В частности, Unity неявно инициализирует отображаемые в инспекторе поля базовым значением если их тип — UnityEngine.Object или производный от него (исключение – MonoBehaviour и ScriptableObject классы). Этот объект является эквивалентом null, однако операторы ?., ??, ??= и is не знают об этом и воспринимают его как обычное значение.
Рассмотрим пример:
public class ActivateTrigger: MonoBehaviour
{
[SerializeField]
GameObject _target;
private void DoActivateTrigger()
{
var target = _target ?? gameObject;
....
}
}В данном случае, если значение _target еще не менялось в процессе выполнения, проверка ?? будет считать _target не равным null, независимо от того, было назначено значение поля в инспекторе Unity или нет.
Решением проблемы является использование ==, != или сокращенных проверок (field, !field) для проверки на равенство/неравенство с null, которые учитывают специфичные для Unity-скриптов моменты.
Так, в данном случае исправленный код может выглядеть следующим образом:
public class ActivateTrigger: MonoBehaviour
{
[SerializeField]
GameObject _target;
private void DoActivateTrigger()
{
var target = _target;
if (target == null)
target = gameObject;
....
}
}Теперь вместо ?? используется проверка target на равенство null с помощью оператора ==. Данная операция имеет переопределение, учитывающее нюанс описанный в начале документации (так же как target != null), а потому проверка будет работать правильно в любом случае.
Данная диагностика классифицируется как:
V3217. Possible overflow as a result of an arithmetic operation.
Анализатор обнаружил арифметическую операцию, в результате которой возможно переполнение.
Рассмотрим пример:
private const int _halfMaximumValue = int.MaxValue / 2;
public void Calculate(int summand)
{
int sum;
if (summand > _halfMaximumValue + 1)
{
sum = _halfMaximumValue + summand;
}
....
}В методе Calculate высчитывается сумма переданного параметра и константы. Константа равна половине от максимального значения System.Int32. Перед сложением проверяется значение параметра, чтобы избежать арифметического переполнения.
Однако в условии была допущена ошибка. В данном случае проверяется, что summand больше, чем _halfMaximumValue + 1. Если это условие будет истинным, то при сложении гарантированно произойдёт арифметическое переполнение.
Чтобы проверка выполнялась корректно, нужно заменить оператор > на <:
private const int _halfMaximumValue = int.MaxValue / 2;
public void Calculate(int summand)
{
int sum;
if (summand < _halfMaximumValue + 1)
{
sum = _halfMaximumValue + summand;
}
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
V3218. Loop condition may be incorrect due to an off-by-one error.
Анализатор обнаружил, что в цикле используется некорректное максимальное или минимальное значение индекса коллекции. Оно отличается от правильного значения на единицу в большую или меньшую сторону. Обычно это происходит из-за ошибки в условии цикла.
Рассмотрим пример с циклом for:
void PrintArray(int[] numbers)
{
for (int i = 0; i <= numbers.Length; i++)
{
Console.WriteLine(numbers[i]);
}
}Условие цикла i <= numbers.Length охватывает диапазон индексов от 0 до numbers.Length включительно. Первый индекс — 0, значение индекса последнего элемента равноnumbers.Length - 1. Следовательно, значение numbers.Length на единицу превысит индекс последнего элемента коллекции, что приведёт к выходу за пределы массива.
Корректный код выглядит так:
void PrintArray(int[] numbers)
{
for (int i = 0; i < numbers.Length; i++)
{
Console.WriteLine(numbers[i]);
}
}Рассмотрим пример с обратным перебором массива:
void PrintArray(int[] numbers)
{
for (int i = numbers.Length - 1; i > 0; i--)
{
Console.WriteLine(numbers[i]);
}
}Поскольку условие i > 0 ограничивает индекс значением 1, первый элемент массива не будет выведен в консоль.
Корректный код в таком случае будет следующим:
void PrintArray(int[] numbers)
{
for (int i = numbers.Length - 1; i >= 0; i--)
{
Console.WriteLine(numbers[i]);
}
}Теперь условие цикла составлено правильно, и все элементы массива будут выведены в консоль.
Диагностика также охватывает циклы while и do while.
Рассмотрим пример с циклом while:
void PrintArray(List<int> numbersList)
{
int i = 0;
while (i <= numbersList.Count)
{
Console.WriteLine(numbersList[i]);
i++;
}
}Условие цикла включает значение индекса, равное размеру коллекции. Это приведёт к выходу за границы коллекции.
Корректный код:
void PrintArray(List<int> numbersList)
{
int i = 0;
while (i < numbersList.Count)
{
Console.WriteLine(numbersList[i]);
i++;
}
}После исправления коллекция будет перебрана полностью, а исключения не возникнет.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
V3219. The variable was changed after it was captured in a LINQ method with deferred execution. The original value will not be used when the method is executed.
Анализатор обнаружил изменение захваченной переменной, которая использовалась в LINQ методе с отложенным выполнением. При таком сценарии изначальное значение переменной не будет учитываться.
Рассмотрим пример:
private static List<string> _names = new() { "Tucker", "Bob", "David" };
public static void ProcessNames()
{
string startLetter = "T";
var names = _names.Where(c => !c.StartsWith(startLetter));
startLetter = "B";
names = names.Where(c => !c.StartsWith(startLetter))
.ToList();
}В методе ProcessNames производится фильтрация имён по первой букве. Ожидается, что в результате переменная names будет содержать имена, не начинающиеся на T и B. Однако поведение программы будет иным. При выполнении этого метода в names будет коллекция, состоящая из Tucker и David.
Подобное поведение обусловлено тем, что при вызове Where фильтрация выполняется не в момент вызова, а является отложенной. Так как между двумя вызовами Where переменной startLetter присваивается B, значение T не учитывается при итоговом вычислении.
Это происходит из-за того, что startLetter захвачена при первом вызове Where, и её значение изменилось перед вторым вызовом Where. Как следствие, будет получена коллекция, которая фильтруется только по B.
Подробнее об отложенном выполнении можно узнать здесь.
Чтобы метод работал корректно, нужно либо немедленно выполнить запрос (первый Where) и работать с результатом выполнения, либо использовать другую переменную в лямбда-выражении второго Where.
Рассмотрим первый сценарий:
private static List<string> _names = new() { "Tucker", "Bob", "David" };
public static void ProcessNames()
{
string startLetter = "T";
var names = _names.Where(c => !c.StartsWith(startLetter))
.ToList();
startLetter = "B";
names = names.Where(c => !c.StartsWith(startLetter))
.ToList();
}После первого метода Where вызывается ToList, при выполнении которого создаётся коллекция, отфильтрованная с помощью первого Where. На момент изменения захваченной переменной коллекция уже сформирована, следовательно, фильтрация будет выполняться корректно.
Рассмотрим второй вариант исправления:
private static List<string> _names = new() { "Tucker", "Bob", "David" };
public static void ProcessNames()
{
string startLetter1 = "T";
var names = _names.Where(c => !c.StartsWith(startLetter1));
string startLetter2 = "B";
names = names.Where(c => !c.StartsWith(startLetter2))
.ToList();
}В данном случае захваченной переменной не присваивается новое значение между вызовами Where, вместо этого используется переменная startLetter2. В результате фильтрация отработает корректно.
V3220. The result of the LINQ method with deferred execution is never used. The method will not be executed.
Анализатор обнаружил, что результат LINQ метода с отложенным выполнением не исполняется.
Рассмотрим пример:
public static void PrintNames(List<string> names, char startLetter)
{
int it = 0;
var filteredNames = names.Where(name =>
{
++it;
Console.WriteLine($"{it}) {name}");
return name.StartsWith(startLetter);
});
Console.WriteLine($"Type: '{filteredNames.GetType()}'");
Console.WriteLine(String.Join(',', names));
}В метод Where передаётся делегат, который, помимо условия фильтрации, выводит на консоль элементы и их позиции из исходной коллекции.
Однако ни вывода имён с позициями, ни фильтрации не произойдёт. В метод String.Join вместо filteredNamesпредаётся names. По этой причине отфильтрованная коллекция не будет выведена на консоль. Более того, фильтрация в принципе не будет выполнена. Подобное поведение обусловлено тем, что при вызове Where фильтрация выполняется не в момент вызова, а является отложенной. Следовательно, до тех пор, пока не будет произведено итерирование по коллекции, код делегата не выполнится.
Подробнее об отложенном выполнении можно узнать здесь.
Стоит отметить, что после вызова Where с помощью метода GetType выводится тип коллекции. При вызов данного метода не выполняется итерирование по коллекции, из чего следует, что делегат, переданный в Where, также не отработает.
Для исправления в String.Join нужно предавать не names, а filteredNames:
public static void PrintNames(List<string> names, char startLetter)
{
int it = 0;
var filteredNames = names.Where(name =>
{
++it;
Console.WriteLine($"{it}) {name}");
return name.StartsWith(startLetter);
});
Console.WriteLine($"Type: '{filteredNames.GetType()}'");
Console.WriteLine(String.Join(',', filteredNames));
}При вызове String.Join будет выполнено итерирование по filteredNames, что запустит фильтрацию коллекции. Следовательно, код делегата выполнится, и элементы с позициями будут выведены на консоль. Также на консоль выведется отфильтрованная коллекция.
Данная диагностика классифицируется как:
V3221. Modifying a collection during its enumeration will lead to an exception.
Анализатор обнаружил, что коллекция модифицируется во время итерации по ней. Это может привести к возникновению исключения InvalidOperationException.
Рассмотрим пример:
public void AppendMissingNames(List<string> currentNames,
List<string> otherNames)
{
foreach(string name in currentNames)
{
if (!otherNames.Contains(name))
{
currentNames.Add(name);
}
}
}В теле foreach вызывается метод Add для коллекции currentNames. Итерирование происходит по этой же коллекции. Модификация currentNames приведёт к возникновению исключения InvalidOperationException.
Исправленный код может выглядеть следующим образом:
public void AppendMissingNames(List<string> currentNames,
List<string> otherNames)
{
foreach(string name in currentNames)
{
if (!otherNames.Contains(name))
{
otherNames.Add(name);
}
}
}Вместо currentNames отсутствующие имена должны добавляться в otherNames. В данном случае коллекция, по которой происходит итерирование, не модифицируется.
Рассмотрим пример итерирования по коллекции с помощью метода ForEach:
collection.ForEach(name => { collection.Add(name); });Ошибка эквивалентна предыдущей: модифицируется коллекция, по которой происходит итерирование. Для исправления изменим коллекцию, в которую будут добавляться элементы:
collection.ForEach(name => { collectionForAppend.Add(name); });V5301. OWASP. An exception handling block does not contain any code.
Анализатор обнаружил пустой блок обработки исключения ('catch' или 'finally'). Отсутствие корректной обработки исключений может привести к снижению уровня надёжности приложения.
В некоторых случаях отсутствие корректной обработки исключительных ситуаций может стать причиной возникновения уязвимости. Недостаточное логирование и мониторинг выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A10:2017-Insufficient Logging & Monitoring.
Пример кода с пустым 'catch':
try
{
someCall();
}
catch (Exception e)
{
}Конечно, такой код вовсе не обязательно ошибочен. Но очень странно просто подавлять исключение, ничего не делая, так как такая обработка исключений может скрывать дефекты в программе.
В качестве обработки исключения можно использовать, например, логгирование. Это по крайней мере не позволит исключительной ситуации остаться незамеченной:
try
{
someCall();
}
catch (Exception e)
{
logger.error("Message", e);
}Не менее подозрительным моментом является наличие в коде пустого блока 'finally'. Это может свидетельствовать о том, что какая-то логика, необходимая для надёжной работы приложения, не реализована. Например:
try
{
someCall();
}
catch (Exception e)
{ .... }
finally
{
}Подобный код с большой вероятностью свидетельствует об ошибке или попросту избыточен. В отличие от пустого блока 'catch', который может быть использован для подавления исключения, у пустого блока 'finally' нет какого-либо практического применения.
Данная диагностика классифицируется как:
|
V5302. OWASP. Exception classes should be publicly accessible.
Анализатор обнаружил класс исключения, недоступный для внешних классов. Если такое исключение будет выброшено, внешний код будет вынужден отлавливать объекты ближайшего доступного предка или вообще базового класса всех исключений – 'Throwable'. В этом случае усложняется обработка конкретных исключительных ситуаций, ведь внешний код не сможет чётко идентифицировать возникшую проблему.
Отсутствие чёткой идентификации возникшей проблемы несёт дополнительные риски с точки зрения безопасности, так как для каких-то определённых исключительных ситуаций может понадобиться специфичная обработка, а не общая. Недостаточное логирование и мониторинг (в том числе, обнаружение проблем) выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A10:2017-Insufficient Logging & Monitoring.
Простой пример из реального проекта:
public class TxnLogToolkit implements Closeable
{
static class TxnLogToolkitException extends Exception
{
....
private int exitCode;
TxnLogToolkitException(int exitCode, ....)
{
super(....);
this.exitCode = exitCode;
}
int getExitCode()
{
return exitCode;
}
}
....
}Чтобы можно было корректно обработать конкретную исключительную ситуацию, необходимо задать в объявлении класса модификатор доступности 'public':
public class TxnLogToolkit implements Closeable
{
public static class TxnLogToolkitException extends Exception
{
....
private int exitCode;
public TxnLogToolkitException(int exitCode, ....)
{
super(....);
this.exitCode = exitCode;
}
public int getExitCode()
{
return exitCode;
}
}
....
}Теперь код внешних классов сможет отлавливать данное исключение и обрабатывать конкретную ситуацию.
Следует учитывать, что для вложенных классов модификатора 'public' у объявления исключения может быть недостаточно. Например:
class OperatorHelper
{
public static class OpCertificateException extends CertificateException
{
private Throwable cause;
public OpCertificateException(String msg, Throwable cause)
{
super(msg);
this.cause = cause;
}
public Throwable getCause()
{
return cause;
}
}
}В данном примере класс исключения вложен в класс 'OperatorHelper', который неявно объявлен как 'package-private'. Вследствие этого исключение 'OpCertificateException' также будет видимо только в пределах текущего пакета, несмотря на то, что имеет модификатор доступа 'public'. Анализатор обнаруживает такие случаи и выдаёт соответствующие предупреждения.
Данная диагностика классифицируется как:
|
V5303. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что создаётся экземпляр класса исключения, но при этом никак не используется.
Пример ошибочного кода:
int checkIndex(int index)
{
if (index < 0)
new IndexOutOfBoundsException("Index Out Of Bounds!!!");
return index;
}В данном коде пропущен оператор 'throw', из-за чего будет только создан экземпляр класса, но при этом он никак не будет использоваться, и исключение не будет сгенерировано. Корректный код может выглядеть следующим образом:
int checkIndex(int index)
{
if (index < 0)
throw new IndexOutOfBoundsException("Index Out Of Bounds!!!");
return index;
}Данная диагностика классифицируется как:
|
V5304. OWASP. Unsafe double-checked locking.
Анализатор обнаружил потенциальную ошибку, связанную с небезопасным использованием паттерна "блокировка с двойной проверкой" (double-checked locking).
Блокировка с двойной проверкой - это паттерн, предназначенный для уменьшения накладных расходов получения блокировки. Сначала проверяется условие блокировки без синхронизации. И только если условие выполняется, поток попытается получить блокировку. Таким образом, блокировка будет выполнена только в том случае, когда она действительно была необходима.
Основной ошибкой при реализации этого паттерна является публикация объекта перед его инициализацией:
class TestClass
{
private static volatile Singleton singleton;
public static Singleton getSingleton()
{
if (singleton == null)
{
synchronized (TestClass.class)
{
if (singleton == null)
{
singleton = new Singleton();
singleton.initialize(); // <=
}
}
}
return singleton;
}
}При многопоточном выполнении один из потоков может увидеть, что объект уже был создан и воспользоваться им, даже если инициализация этого объекта еще не произошла.
Похожая ошибка случится, когда в блоке синхронизации объект переприсваивается в зависимости от тех или иных условий. После первого присваивания какой-либо другой поток вполне может начать с ним работать, не подозревая, что далее в программе будет использоваться другой объект.
Исправление таких ошибок производится путем создания временной переменной:
class TestClass
{
private static volatile Singleton singleton;
public static Singleton getSingleton()
{
if (singleton == null)
{
synchronized (TestClass.class)
{
if (singleton == null)
{
Singleton temp = new Singleton();
temp.initialize();
singleton = temp;
}
}
}
return singleton;
}
}Другой распространённой ошибкой при реализации этого паттерна является пропуск модификатора 'volatile' в декларации поля, к которому производится доступ:
class TestClass
{
private static Singleton singleton;
public static Singleton getSingleton()
{
if (singleton == null)
{
synchronized (TestClass.class)
{
if (singleton == null)
{
Singleton temp = new Singleton();
temp.initialize();
singleton = temp;
}
}
}
return singleton;
}
}Объект класса 'Singleton' может быть создан несколько раз из-за того, что проверка 'singleton == null' увидит значение 'null', закешированное в потоке. Кроме того, компилятор может изменить порядок выполнения операций с не-volatile полями, из-за чего, например, вызов метода инициализации объекта и запись ссылки на этот объект в поле могут произойти в обратном порядке, что опять же приведет к использованию объекта, которому только предстоит пройти процедуру инициализации.
Одна из опасностей таких ошибок состоит в том, что в большинстве случаев программа работает корректно. В данном случае некорректное поведение программы может проявиться в зависимости от используемой JVM, уровня конкуретности, решений планировщика потоков и прочих факторов. Воспроизвести такие условия вручную крайне сложно.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
V5305. OWASP. Storing credentials inside source code can lead to security issues.
Анализатор обнаружил в коде данные, которые могут являться конфиденциальными.
В качестве таких данных могут выступать, например, пароли. Их хранение в исходном коде может привести к нарушению контроля доступа к данным и возможностям, не предназначенным для публичного использования. Имея байт-код, любой пользователь сможет извлечь все строковые литералы, которые в нем используются. В случае open-source проектов всё ещё проще, так как злоумышленник может изучать непосредственно исходный код.
Таким образом, все секретные данные могут оказаться публично доступными. Уязвимости, связанные с недостаточной защищённостью конфиденциальных данных, выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A2:2017-Broken Authentication.
Рассмотрим пример:
public static void main(String[] arg)
{
....
JSch jsch = new JSch();
Session session = jsch.getSession(user, host, 22);
session.setPassword("123fj");
....
}В указанном примере пароль хранится в коде. Следовательно, злоумышленник может легко получить эти данные.
Вместо хранения секретных данных в коде лучше использовать, например, хранилища, в которых данные будут храниться в зашифрованном виде, и к которым у обычных пользователей не будет прямого доступа.
В таком случае код может выглядеть, например, так:
public static void main(String[] arg)
{
....
JSch jsch = new JSch();
Session session = jsch.getSession(user, host, 22);
session.setPassword(dataStorage.getPassword);
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5306. OWASP. The original exception object was swallowed. Cause of original exception could be lost.
Анализатор обнаружил ситуацию, когда оригинальная информация об исключении была утеряна при повторной генерации из блока 'catch'. Из-за этого ошибки превращаются в трудноотлаживаемые.
Отсутствие чёткой идентификации возникшей проблемы несёт дополнительные риски с точки зрения безопасности. Недостаточное логирование и мониторинг (в том числе обнаружение проблем) выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A10:2017-Insufficient Logging & Monitoring.
Рассмотрим пример некорректного кода:
try {
sb.append((char) Integer.parseInt(someString));
....
} catch (NumberFormatException e) {
throw new IllegalArgumentException();
}В данном случае перехваченное исключение хотели перебросить и не передали полезную информацию в виде сообщения и stacktrace.
Корректный вариант кода:
try {
sb.append((char) Integer.parseInt(someString));
....
} catch (NumberFormatException e) {
throw new IllegalArgumentException(e);
}В исправленном варианте исходное исключение передаётся в качестве внутреннего, что полностью сохраняет информацию об исходной ошибке.
Другим вариантом исправления может являться выбрасывание исключения с сообщением пользователю:
try {
sb.append((char) Integer.parseInt(someString));
....
} catch (NumberFormatException e) {
throw new IllegalArgumentException(
"String " + someString + " is not number"
);
}В данной ситуации стек оригинальной ошибки был утерян, но описанная информация в новом исключении внесёт большую ясность при отладке этого кода.
Если потеря информации об исключении является ожидаемым поведением, то вы можете заменить имена 'catch'-параметров на "ignore" или "expected", и исключение выдаваться не будет.
Данная диагностика классифицируется как:
|
V5307. OWASP. Potentially predictable seed is used in pseudo-random number generator.
Данное диагностическое правило выявляет случаи использования псевдорандомного генератора случайных чисел, которые могут привести к недостаточно случайному распределению или предсказуемости генерируемого числа.
Случай 1
Создание нового объекта типа 'Random' каждый раз, когда требуется случайное значение. Это неэффективно и может привести к получению чисел, которые не являются достаточно случайными, в зависимости от JDK.
Рассмотрим пример:
public void test() {
Random rnd = new Random();
}Для большей эффективности и случайности распределения создайте один экземпляр класса 'Random', сохраните его и используйте повторно.
static Random rnd = new Random();
public void test() {
int i = rnd.nextInt();
}Случай 2
Анализатор обнаружил подозрительный код, инициализирующий генератор псевдослучайных чисел константным значением.
public void test() {
Random rnd = new Random(4040);
}Числа, сгенерированные таким генератором, можно предугадать — они будут воспроизводиться снова и снова при каждом запуске программы. Чтобы этого избежать, не стоит использовать константное число. К примеру, можно воспользоваться текущим системным временем:
static Random rnd = new Random(System.currentTimeMillis());
public void test() {
int i = rnd.nextInt();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5308. OWASP. Possible overflow. The expression will be evaluated before casting. Consider casting one of the operands instead.
Анализатор обнаружил подозрительное приведение типов. Результат бинарной операции приводится к типу с большим диапазоном.
Рассмотрим пример:
long multiply(int a, int b) {
return (long)(a * b);
}Такое преобразование избыточно. Тип 'int' и так бы автоматически расширился до типа 'long'.
Скорее всего, подобный паттерн приведения используется для защиты от переполнения, но он неправильный. При перемножении переменных типа 'int' всё равно произойдёт переполнение, и только уже бессмысленный результат умножения будет явно расширен до типа 'long'.
Для корректной защиты от переполнения можно привести один из аргументов к типу 'long'. Исправленный код:
long multiply(int a, int b) {
return (long)a * b;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
V5309. OWASP. Possible SQL injection. Potentially tainted data is used to create SQL command.
Анализатор обнаружил создание SQL-команды из данных, полученных из внешнего источника, без предварительной проверки. Это может стать причиной возникновения SQL-инъекции в случае, если данные будут скомпрометированы.
SQL-инъекции выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A1:2017-Injection.
Рассмотрим пример:
public static void getFoo(Connection conn, String bar) throws SQLException {
var st = conn.createStatement();
var rs = st.executeQuery("SELECT * FROM foo WHERE bar = '" + bar + "'");
// ....
}В данном случае при создании SQL-команды используется значение переменной 'bar', полученной из публичного метода. Так как метод публичный, туда могут попасть непроверенные данные из внешнего источника (контроллеров, форм и пр.). Использование данных без какой-либо проверки является опасным, так как открывает злоумышленникам разные способы внедрения команд.
Например, вместо ожидаемого значения имени пользователя злоумышленник может ввести специальную команду. Тогда из базы произойдёт извлечение данных всех пользователей, для которых будет запущена дальнейшая обработка.
Пример такой скомпрометированной строки для запроса выше:
' OR '1'='1Для защиты от подобных запросов следует использовать параметризированные команды:
public static void getFoo(Connection conn, String bar) throws SQLException {
var sql = "SELECT * FROM foo WHERE bar = ?";
var st = conn.prepareStatement(sql);
st.setString(1, bar);
var rs = st.executeQuery();
// ....
}Также безопасной альтернативой будет использование ORM, если нет необходимости в прямом исполнении SQL-запросов.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5310. OWASP. Possible command injection. Potentially tainted data is used to create OS command.
Анализатор обнаружил, что команда уровня операционной системы создаётся из непроверенных данных, которые были получены из внешнего источника. Это может стать причиной возникновения уязвимости command injection.
В классификации OWASP Top 10 данная уязвимость относится к категории A3:2021-Injection в списке 2021 года.
Рассмотрим пример:
public void doUsersCommand() throws IOException {
Scanner sc = new Scanner(System.in);
String command = sc.nextLine();
Runtime.getRuntime().exec(command);
}Строка command приходит извне и передаётся методу exec в качестве команды уровня ОС. Из-за того, что команда перед выполнением никак не проверяется, инструкция в ней может быть абсолютно любая, в том числе вредоносная.
Один из вариантов, как можно обезопаситься от данной уязвимости, это не использовать команды уровня ОС. Для большинства задач в Java существует соответствующий API.
Если всё же принято решение использовать команды уровня ОС, то один из вариантов защиты от command injection — создать перечень допустимых команд и проверять, находится ли пришедшая извне команда в нём.
Исправленный пример:
private final List<String>
acceptableCommands = List.of(
"dir",
"dir *.txt",
"dir *.logs"
);
public void doUsersCommand() throws IOException {
Scanner sc = new Scanner(System.in);
String command = sc.nextLine();
if (acceptableCommands.contains(command)) {
Runtime.getRuntime().exec(command);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5311. OWASP. Possible argument injection. Potentially tainted data is used to create OS command.
Анализатор обнаружил, что для формирования параметров команды уровня операционной системы используются непроверенные данные извне. Это может стать причиной уязвимости argument injection.
В классификации OWASP Top 10 данная уязвимость относится к категории A3:2021-Injection в списке 2021 года.
Рассмотрим пример:
public void deleteFileInAcceptableFolder() throws IOException {
Scanner sc = new Scanner(System.in);
String filename = sc.nextLine();
Runtime.getRuntime().exec("rm " + filename);
}В рамках этого примера строковый параметр для команды rm приходит из внешнего контекста. Ожидается, что пользователь передаст имя файла, который можно удалить в рамках предоставленной ему директории. Однако возможна ситуация, при которой извне придёт следующая строка:
../../filenameПодобная манипуляция параметром команды уровня ОС способна оказать вредоносное действие — файл будет удалён не из предоставленной пользователю директории.
Один из вариантов, как можно обезопаситься от данной уязвимости, это не использовать команды уровня ОС. Для большинства задач в Java существует соответствующий API.
Если всё же принято решение использовать команды уровня ОС, то один из вариантов защиты от argument injection — проверять приходящий извне параметр на наличие нежелательных символов.
Исправленная версия примера:
public void deleteFileInAcceptableFolder() throws IOException {
Scanner sc = new Scanner(System.in);
String filename = sc.nextLine();
if (filename.matches("^(?!.*\\.\\.)(?!.*/).+$")) {
Runtime.getRuntime().exec("rm " + filename);
}
}Здесь команда выполняется только в том случае, если параметр не содержит .. и / символов.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5312. OWASP. Possible XPath injection. Potentially tainted data is used in the XPath expression.
Анализатор обнаружил, что для формирования выражения на языке XPath используются непроверенные данные из внешнего источника. Это может стать причиной возникновения XPath-инъекции.
Уязвимости, связанные с инъекциями, относятся к категории A03:2021 – Injection списка OWASP Top 10 Application Security Risks.
Рассмотрим пример:
public class UserData {
HttpServletRequest request;
MessageDigest digest;
Document doc;
public void retrieveUserData() {
String user = request.getParameter("username");
String password = request.getParameter("password");
String passwordHash = Arrays.toString(
digest.digest(password.getBytes(StandardCharsets.UTF_8))
);
var xpath = XPathFactory.newInstance().newXPath();
String query = "//users/user[" +
"username/text() = '%s' and" +
"passwordHash/text() = '%s']" +
"/data/text()";
query = String.format(query, user, passwordHash);
try {
String result = xpath.evaluate(query, doc);
// ....
} catch (XPathExpressionException e) {
// ....
}
//....
}
}В этом примере XPath-выражение используется для получения данных пользователя из XML-файла. Имя пользователя хранится "как есть", а пароль хранится в зашифрованном виде.
Злоумышленник может передать в качестве имени пользователя и пароля любые данные. Проверка будет скомпрометирована, если во входных данных передать выражение, которое сделает XPath-условие всегда истинным. Так как пароль хранится в зашифрованном виде, то внедрять опасное выражение нужно вместе с именем пользователя.
Для примера, пусть имя пользователя будет john. Добавим к нему выражение такого вида:
' or ''='Вместо пароля может быть введён любой набор символов. Тогда XPath-выражение будет иметь такой вид:
[
username/text()='john' or ''='' and
passwordHash/text() = '750084105bcbe9d2c89ba9b'
]Теперь выражение содержит оператор or. Рассмотрим, как оно вычисляется:
- Так как имя пользователя существует, выражение
username/text()='john'является истинным. - В качестве пароля были введены случайные символы, поэтому выражение
passwordHash/text() = '750084105bcbe9d2c89ba9b'является ложным. - Выражение ''='' всегда истинно.
- Приоритет оператора
andвыше, чемor, поэтому происходит вычисление выражения''='' and passwordHash/text() = '750084105bcbe9d2c89ba9b'. Результатом является ложь. - Последним выполняется оператор
or. Выражениеusername/text()='john' or falseявляется истинным. Следовательно, всё условие является истинным.
Таким образом, результатом XPath-запроса будут данные пользователя 'john' независимо от того, правильный пароль был введён или нет. Это может привести к утечке данных.
Не следует использовать непроверенные внешние данные в XPath-выражениях. Для повышения безопасности стоит экранировать потенциально опасные символы во внешних данных. Примерами таких символов являются <, > и '. Экранирование может быть произведено с помощью простого replaceAll:
public class UserData {
HttpServletRequest request;
MessageDigest digest;
Document doc;
public void retrieveUserData() {
String user = request.getParameter("username")
.replaceAll("'", "&abos;");
String password = request.getParameter("password");
String passwordHash = Arrays.toString(
digest.digest(password.getBytes(StandardCharsets.UTF_8))
);
var xpath = XPathFactory.newInstance().newXPath();
String query = "//users/user[" +
"username/text() = '%s' and" +
"passwordHash/text() = '%s']" +
"/data/text()";
query = String.format(query, user, passwordHash);
try {
String result = xpath.evaluate(query, doc);
// ....
} catch (XPathExpressionException e) {
// ....
}
//....
}
}Apache Commons Text также содержит класс утилит StringEscapeUtils, двумя методами которого являются escapeXml10 и escapeXml11. Эти методы позволят экранировать все необходимые символы.
Существуют другие возможности для предотвращения XPath-инъекций. Например, Oracle предлагает возможность реализации класса-резолвера. Его можно использовать в объектах класса XPath. Это позволяет определить свои собственные переменные и функции внутри XPath-выражения, которые будут обработаны резолвером.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5313. OWASP. Do not use old versions of SSL/TLS protocols as it may cause security issues.
Анализатор обнаружил использование в коде устаревших версий протоколов SSL/TLS. Это может сделать приложение уязвимым к таким атакам, как man-in-the-middle, BEAST, и т.п.
Проблемы, связанные с применением устаревших протоколов, могут быть отнесены к двум категориям OWASP Top 10 2021:
Рассмотрим пример:
private void createSocket() {
SSLContext sslContext;
try {
sslContext = SSLContext.getInstance("TLSv1"); // <=
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException(e);
}
try {
sslContext.init(null, null, new SecureRandom());
var socketFactory = sslContext.getSocketFactory();
var socket = (SSLSocket) socketFactory.createSocket();
// ....
socket.close();
} catch (KeyManagementException | IOException e) {
throw new RuntimeException(e);
}
}В указанном фрагменте используется значение TLSv1, представляющее протокол TLS версии 1.0. Данная версия является устаревшей и не рекомендуется к использованию, так как TLS 1.0 уязвим к ряду атак, в числе которых упоминавшаяся ранее BEAST.
Рекомендуется использовать более новые версии протоколов, например, TLS 1.2:
private void createSocket() {
SSLContext sslContext;
try {
sslContext = SSLContext.getInstance("TLSv1.2");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException(e);
}
try {
sslContext.init(null, null, new SecureRandom());
var socketFactory = sslContext.getSocketFactory();
var socket = (SSLSocket) socketFactory.createSocket();
// ....
socket.close();
} catch (KeyManagementException | IOException e) {
throw new RuntimeException(e);
}
}Версии протоколов, являющиеся более старыми, чем TLS 1.2, не рекомендуются к использованию из-за возможных проблем с безопасностью. К таким протоколам относятся SSL версий 2.0 и 3.0, а также TLS версий 1.0 и 1.1.
Как правило, наиболее подходящим значением является TLS, представляющее выбор протокола передачи данных платформе. Если по каким-либо причинам данное значение не подходит, то рекомендуется задавать самую новую версию из доступных.
Дополнительные ссылки
- Transport Layer Security (TLS) Protocol Overview
- Testing for Weak SSL TLS Ciphers Insufficient Transport Layer Protection
- Transport Layer Security Cheat Sheet
- Описание атаки Man-in-the-middle
- Описание атаки Man-in-the-Browser
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V5314. OWASP. Use of an outdated hash algorithm is not recommended.
Анализатор обнаружил, что в приложении используется устаревший алгоритм хеширования. Такие алгоритмы не считаются безопасными, поскольку имеют проблемы коллизий.
Уязвимости, связанные с использованием небезопасных алгоритмов шифрования, могут быть отнесены к следующей категории OWASP Top 10 2021:
Рассмотрим пример:
public String calculateHash(String input) {
MessageDigest digest = null;
try {
digest = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException(e);
}
var output = digest.digest(input.getBytes(StandardCharsets.UTF_8));
return Arrays.toString(output);
}При проверке фрагмента анализатор сформирует предупреждение о том, что использование алгоритмов SHA1 и MD5 не рекомендуется. В данном случае проблема алгоритмов состоит в наличии широко известных проблем с коллизией. Таким образом, его использование не является безопасным.
Вместо устаревших алгоритмов следует использовать более современные. В примере, представленном выше, одним из решений может быть замена SHA1 на SHA256:
public String calculateHash(String input) {
MessageDigest digest = null;
try {
digest = MessageDigest.getInstance("SHA-256");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException(e);
}
var output = digest.digest(input.getBytes(StandardCharsets.UTF_8));
return Arrays.toString(output);
}На сайте Oracle доступна документация по стандартным реализациям различных алгоритмов хеширования. В случае хеширования в спецификации Java SE 21 присутствуют следующие небезопасные по современным стандартам алгоритмы:
- MD2
- MD5
- SHA1
Стоит отметить, что JavaDoc по MessageDigest гарантирует наличие лишь алгоритмов SHA-1 и SHA-256 на каждой реализации Java platform. На версиях Java до 11 в этом списке также присутствует MD5.
На официальном сайте OWASP по ссылке представлены различные методики проверки приложения на наличие потенциальных уязвимостей, связанных с использованием небезопасных алгоритмов шифрования.
Дополнительные ссылки
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V5315. OWASP. Use of an outdated cryptographic algorithm is not recommended.
Анализатор обнаружил, что в приложении используется устаревший алгоритм шифрования. Применение таких алгоритмов может привести к раскрытию конфиденциальных данных, утечке ключей, нарушению аутентификации и т. д.
Уязвимости, связанные с использованием небезопасных алгоритмов шифрования, могут быть отнесены к следующей категории OWASP Top 10 2021:
Рассмотрим пример:
public void encryptData(String data, SecretKey secretKey) {
Cipher cipher = null;
try {
cipher = Cipher.getInstance("DES"); // <=
} catch (NoSuchAlgorithmException | NoSuchPaddingException e) {
// ....
}
try {
cipher.init(Cipher.ENCRYPT_MODE, secretKey);
} catch (InvalidKeyException e) {
// ....
}
try {
byte[] encryptedData = cipher.doFinal(data.getBytes());
} catch (IllegalBlockSizeException | BadPaddingException e) {
// ....
}
// ....
}При проверке фрагмента анализатор сформирует предупреждение о том, что использование DES не рекомендуется.
Вместо устаревших алгоритмов следует использовать более современные. В примере, представленном выше, одним из решений может быть замена DES на AES:
public void encryptData(String data, SecretKey secretKey) {
Cipher cipher = null;
try {
cipher = Cipher.getInstance("AES/CBC/NoPadding");
} catch (NoSuchAlgorithmException | NoSuchPaddingException e) {
// ....
}
try {
cipher.init(Cipher.ENCRYPT_MODE, secretKey);
} catch (InvalidKeyException e) {
// ....
}
try {
byte[] encryptedData = cipher.doFinal(data.getBytes());
} catch (IllegalBlockSizeException | BadPaddingException e) {
// ....
}
// ....
}На сайте Oracle доступна документация по стандартным реализациям различных алгоритмов шифрования. Ниже приведены некоторые из них, нерекомендованные к использованию:
- DES
- DESede
- RC2
- RC4
- RC5
- Blowfish
Например, рекомендация к использованию уже упоминавшегося Data Encryption Standard (DES) была отозвана в 2005 году. К нему на замену пришёл Advanced Encryption Standard (AES).
На официальном сайте OWASP по ссылке представлены различные методики проверки приложения на наличие потенциальных уязвимостей, связанных с использованием небезопасных алгоритмов шифрования.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V5316. Do not use the 'HttpServletRequest.getRequestedSessionId' method because it uses a session ID provided by a client.
Анализатор обнаружил, что в приложении используется метод HttpServletRequest.getRequestedSessionId. Данный метод не рекомендуется к применению.
Уязвимости, связанные с использованием этого метода, могут быть отнесены к следующей категории OWASP Top 10 2021:
Рассмотрим пример:
boolean validate(HttpServletRequest request) {
var sessionId = request.getRequestedSessionId();
// ....
}При проверке фрагмента анализатор сформирует предупреждение о том, что использование getRequestedSessionId не рекомендуется, поскольку, скорее всего, является ошибочным.
Дело в том, что getRequestedSessionId возвращает ID, указанный клиентом. Jakarta JavaDoc также об этом сообщает:
This may not be the same as the ID of the current valid session for this request.
Для получения подлинного ID сессии можно использовать следующий вариант:
boolean validate(HttpServletRequest request) {
var sessionId = request.getSession().getId();
// ....
}Согласно всё той же документации Jakarta, getSession возвращает сессию запроса или создаёт новую:
Returns the current session associated with this request, or if the request does not have a session, creates one.
Таким образом, мы получаем корректный ID сессии.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5317. OWASP. Implementing a cryptographic algorithm is not advised because an attacker might break it.
Анализатор обнаружил, что в приложении создаётся собственный криптографический алгоритм. Создание или собственная реализация криптографических алгоритмов не рекомендуются.
Уязвимости, связанные с использованием собственных криптографических алгоритмов, могут быть отнесены к следующей категории OWASP Top 10 2021:
Так, ошибочным является создание класса-наследника MessageDigest:
public class CustomDigest extends MessageDigest {
public CustomDigest(String algorithm) {
super(algorithm);
// ....
}
// ....
}Одной из рекомендаций OWASP является использование современных и надёжных стандартных алгоритмов. MITRE также предлагает не разрабатывать собственные криптографические алгоритмы:
Do not develop custom or private cryptographic algorithms. They will likely be exposed to attacks that are well-understood by cryptographers. Reverse engineering techniques are mature. If the algorithm can be compromised if attackers find out how it works, then it is especially weak.
Вместо разработки собственного алгоритма лучше просто использовать, например, SHA-256:
var digest = MessageDigest.getInstance("SHA-256");Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V5318. OWASP. Setting POSIX file permissions to 'all' or 'others' groups can lead to unintended access to files or directories.
Анализатор обнаружил, что в приложении файлам задаются свободные права доступа, а именно доступ группе others.
Уязвимости, связанные с заданием свободных прав доступа к файлам, могут быть отнесены к следующей категории OWASP Top 10 2021:
Группа others относится ко всем пользователям и группам (кроме владельца ресурса). Установка этой группе прав к ресурсу может привести к возможности несанкционированного доступа.
Рассмотрим пример:
public void example() throws IOException {
Path path = Path.of("/path/to/resource");
Files.setPosixFilePermissions(
path,
PosixFilePermissions.fromString("rwxrwxrwx")
);
}В этом примере к ресурсу по пути path получает доступ (чтение, запись и исполнение) не только владелец, но и все остальные пользователи. Это нарушает принцип минимальных привилегий.
О максимальном ограничении доступа к файлам и директориям необходимо серьёзно задумываться, если они содержат конфиденциальную информацию.
Даже если это не критический ресурс, безопасным вариантом является установка прав на файл пользователю и группе, но не others:
public void example() throws IOException {
Path path = Path.of("/path/to/resource");
Files.setPosixFilePermissions(
path,
PosixFilePermissions.fromString("rwxrwx---")
);
}Анализатор также сформирует предупреждение на вызов команды chmod с установкой свободных прав:
public void example() throws IOException {
Runtime.getRuntime().exec("chmod a+rw resource.json");
}Аргумент a+rw означает добавление (+) прав чтения и записи (rw) для всех (a). Безопасным же вариантом является, например, следующая команда:
public void example() throws IOException {
Runtime.getRuntime().exec("chmod o-rwx,u+rw resource.json");
}В этом варианте у группы 'others' удаляются все права, а права на чтение и запись выдаются лишь пользователю.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5319. OWASP. Possible log injection. Potentially tainted data is written into logs.
Анализатор обнаружил логирование данных из внешнего источника без предварительной проверки. Это может нарушить процессы логирования или скомпрометировать содержание логов.
Ошибки, связанные с логированием данных, могут быть отнесены к следующей категории OWASP Top 10 Application Security Risks:
- A09:2021 – Security Logging and Monitoring Failures.
Если логирование пользовательского ввода производится без проверок, то злоумышленник может внедрить произвольные данные в лог.
Предположим, что логи хранятся в простом текстовом формате. Узнать формат хранения логов можно разными способами. Например, если проект имеет открытый исходный код или с помощью какой-либо другой атаки. Возможный лог может иметь такой вид:
INFO: User 'SomeUser' entered value: '2022'.
INFO: User 'SomeUser' logged out.
Код, осуществляющий логирование, может выглядеть так:
public class InputHelper {
private final Logger logger = LoggerFactory.getLogger(InputHelper.class);
private String username;
public void process(InputStream stream) {
Scanner scanner = new Scanner(stream);
String userInput = scanner.next();
String logMessage = "User '" + userName +
"' entered value: '" + userInput + "'.";
logger.info(logMessage); // <=
}
}В таком случае злоумышленник может внедрить произвольные данные о событиях, которые никогда не происходили.
Например, злоумышленник вводит такой текст:
2022/r/nINFO: User 'Admin' logged out.
Тогда в логах появится такая запись, которая может ввести в заблуждение человека, анализирующего логи:
INFO: User 'SomeUser' entered value: '2022'.
INFO: User 'Admin' logged out.
Рассмотрим другой вид атаки: если логи хранятся в формате XML, злоумышленник может внедрить данные, которые сделают содержимое отчёта некорректным. Также последующий процесс парсинга готовых логов может выдать неправильные данные или завершиться ошибкой.
Злоумышленник может внедрить незакрытый тег и сделать невозможным парсинг XML-файла.
Список возможных уязвимостей зависит от архитектуры и настроек ввода, логгера, вывода логов или иных частей системы логирования. Например, атака на XML-логи может иметь следующие последствия:
- нарушение процесса добавления новых записей в логи;
- нарушение процесса просмотра готовых логов;
- эксплуатация XEE-уязвимости;
- эксплуатация XXE-уязвимости;
- эксплуатация уязвимости небезопасной десериализации.
Некоторых атак можно избежать экранированием символов, чтобы они не рассматривались как часть XML-синтаксиса. Например, начальный символ тега < следует экранировать как <. Выполнить экранирование XML-лога можно следующим образом:
import org.apache.commons.text.StringEscapeUtils;
public class EscapedInputHelper {
private final Logger logger =
LoggerFactory.getLogger(EscapedInputHelper.class);
private String username;
public void process(InputStream stream) {
Scanner scanner = new Scanner(stream);
String userInput = scanner.next();
String escapedInput = StringEscapeUtils.escapeXml11(userInput);
String logMessage = "User '" + userName +
"' entered value: '" + escapedInput + "'.";
logger.info(logMessage);
}
}Ещё один пример: стандарт JSON запрещает наличие null-символов (\0) в файлах. Если злоумышленник использует этот символ, это может сломать процесс сохранения или просмотра готовых логов. Поэтому null-символ следует экранировать как \u0000.
Другой пример: если логи хранятся в реляционной СУБД, использующей SQL, отсутствие проверок входных данных может привести к SQL-инъекции (подробнее см. диагностическое правило V5309).
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5320. OWASP. Use of potentially tainted data in configuration may lead to security issues.
Анализатор обнаружил, что для конфигурации системы или базы данных используются данные из внешнего источника. Это может привести к возникновению дефекта безопасности.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Приведем пример:
public static class DataBaseController {
private String user;
private String password;
private void connectFromRequest(HttpServletRequest request) {
String dbName = request.getParameter("db");
String dbUrl = "jdbc:mysql://localhost:3306/" + dbName +
"?useUnicode=true&characterEncoding=utf8";
Connection db = DriverManager.getConnection(dbUrl, user, password);
}
}В этом примере формируется строка подключения к БД. В переменную dbUrl записываются данные, не прошедшие никакой валидации, благодаря чему злоумышленник может передать любое название базы данных. Подобным образом он может получить информацию, доступ к которой не был предусмотрен.
Для защиты от подобных атак стоить производить валидацию входных данных.
Пример корректного формирования строки подключения:
public static class SafeDataBaseController {
private final List<String> WHITE_LIST = new ArrayList<>();
private String user;
private String password;
private void safeConnectFromRequest(HttpServletRequest request) {
String db = request.getParameter("db");
if (!WHITE_LIST.contains(db)) {
return;
}
String dbUrl = "jdbc:mysql://localhost:3306/" + db +
"?useUnicode=true&characterEncoding=utf8";
Connection db = DriverManager.getConnection(dbUrl, user, password);
}
}В данном случае проверяется, что база данных db содержится в списке WHITE_LIST. Таким образом, пользователь будет иметь доступ лишь к определённому перечню баз данных, что не позволит получить приватную информацию.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5321. OWASP. Possible LDAP injection. Potentially tainted data is used in a search filter.
Анализатор обнаружил, что потенциально заражённые данные используются для формирования фильтра LDAP-запроса. Это может стать причиной LDAP-инъекции в случае, если данные будут скомпрометированы. По своей сути данная атака похожа на SQL-инъекции.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Рассмотрим пример:
public void search(HttpServletRequest request) throws NamingException {
String user = request.getParameter("user");
String password = request.getParameter("password");
String searchFilter = "(&(uid=" + user + ")(userPassword=" + password + "))";
DirContext context = new InitialDirContext(getEnv());
var result = context.search("ou=users,dc=example,dc=com",
searchFilter, null); // <=
if (result.hasMore()) {
....
}
}В данном примере формируется фильтр поиска для предоставления некоторых личных данных пользователю, обладающему подходящими логином и паролем. В фильтре используются значения переменных user и password, полученные из внешнего источника. Использование данных подобным образом опасно, так как даёт злоумышленнику возможность подделки фильтра поиска.
Для лучшего понимания атаки приведём несколько примеров.
Если в user будет записано PVS, а в password — Studio, то получится следующий запрос:
LDAP query: (&(uid=PVS)(userPassword=Studio))В этом случае мы получили от пользователя ожидаемые данные, и если такая комбинация пользователя и пароля существует, то будет предоставлен доступ.
Но допустим, что в переменных user и password будут записаны следующие значения:
user: PVS)(uid=PVS))(|(uid=PVS)
password: AnyПри подстановке этих строк в шаблон получится следующий фильтр:
LDAP query: (&(uid=PVS)(uid=PVS))(|(uid=PVS)(userPassword=Any))При использовании такого фильтра поиска доступ будет предоставлен в любом случае, даже если злоумышленник введёт неверный пароль. Это произойдёт из-за того, что LDAP будет обрабатывать только первый фильтр, а (|(uid=PVS)(userPassword=Any)) просто проигнорирует.
Чтобы защититься от подобной атаки, стоит проводить валидацию всех входных данных или экранировать все специальные символы в данных, которые приходят от пользователей.
Далее приведён пример кода, в котором используется метод экранирования для введённой пользователем информации:
private static String escapeLdapInput(String input) {
return input.replace("(", "\\28").replace(")", "\\29")
.replace("*", "\\2a").replace("|", "\\7c")
.replace("&", "\\26").replace("!", "\\21")
.replace("=", "\\3d").replace(">", "\\3e")
.replace("<", "\\3c").replace("\\", "\\5c");
}
public void safeSearch(HttpServletRequest request) throws NamingException {
String user = request.getParameter("user");
String password = request.getParameter("password");
String escapedUser = escapeLdapInput(user);
String escapedPassword = escapeLdapInput(password);
String searchFilter = "(&(uid=" + escapedUser +
")(userPassword=" + escapedPassword + "))";
DirContext context = new InitialDirContext(getEnv());
var result = context.search("ou=users,dc=example,dc=com",
searchFilter, null);
if (result.hasMore()) {
....
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5322. OWASP. Possible reflection injection. Potentially tainted data is used to select class or method.
Анализатор обнаружил загрузку класса через механизм рефлексии без его проверки.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Рассмотрим пример:
public void applyAction(HttpServletRequest request) {
String action = request.getParameter("action");
String className = action + "Controller";
Class<?> actionClass = Class.forName(className); // <=
Object actionClassObject = actionClass.newInstance();
Method applyMethod = actionClass.getMethod("apply");
applyMethod.invoke(actionClassObject);
}В данном примере сервер принимает запрос о выполнении некоторого действия, описанного строкой в параметре запроса. Действие реализовано в виде определенного класса с методом apply. Однако проверки того, какой конкретно класс будет использован, нигде нет. В таком случае злоумышленник сможет подстроить запрос так, что будет выбран неправильный класс и выполнено недопустимое действие. Это может привести к нарушению логики выполнения программы или проблемам с безопасностью.
В худшем случае, если злоумышленник изменит classpath, он может использовать рефлексию для загрузки вредоносного кода.
Для защиты от подобных атак стоит производить валидацию входных данных.
Пример корректного кода:
private List<String> ALLOWED_TYPES = new ArrayList<>();
public void validateAndApplyAction(HttpServletRequest request) {
String action = request.getParameter("action");
String className = action + "Controller";
if (!ALLOWED_TYPES.contains(className)) { // <=
return;
}
Class<?> actionClass = Class.forName(className);
Object actionClassObject = actionClass.newInstance();
Method applyMethod = actionClass.getMethod("apply");
applyMethod.invoke(actionClassObject);
}Также возможна ситуация, когда вместо некорректного класса могут вызывать некорректный метод:
public void useMethodWithName(HttpServletRequest request) {
String methodName = request.getParameter("methodName");
Method method = this.getClass().getMethod(methodName); // <=
method.invoke(this);
}Защититься от некорректного выбора метода можно аналогичным образом:
private List<String> ALLOWED_METHODS = new ArrayList<>();
public void useSafeMethodWithName(HttpServletRequest request) {
String methodName = request.getParameter("methodName");
if (ALLOWED_METHODS.contains(methodName)) { // <=
Method method = this.getClass().getMethod(methodName);
method.invoke(this);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5323. OWASP. Potentially tainted data is used to define 'Access-Control-Allow-Origin' header.
Анализатор обнаружил небезопасную конфигурацию Cross-origin resource sharing (CORS). Значение заголовка ответа сервера Access-Control-Allow-Origin формируется на основе непроверенных данных извне.
Если значение заголовка Access-Control-Allow-Origin конфигурируется на основе данных извне, которые никак не проверяются, то это небезопасно и, в зависимости от обстоятельств, чревато негативными последствиями разной степени серьёзности. Сайты злоумышленников смогут получать доступ к ресурсам вашей страницы, а при особых обстоятельствах возможно раскрытие конфиденциальной информации.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Пример небезопасной конфигурации:
@GetMapping("/test")
public ResponseEntity<?> getExample(@RequestParam("origin") String origin) {
var httpHeaders = new HttpHeaders();
httpHeaders.add("Access-Control-Allow-Origin", origin); // <=
return new ResponseEntity<>("ok", httpHeaders, HttpStatus.ACCEPTED);
}Чтобы исключить риски, необходимо проверять, соответствуют ли данные извне значениям из "белого листа".
Исправленный пример:
private static final List<String> ALLOWED_ORIGINS = List.of(
"https://first-allowed-domain.com",
"https://second-allowed-domain.com"
);
@GetMapping("/test")
public ResponseEntity<?> getExample(@RequestParam("origin") String origin) {
var httpHeaders = new HttpHeaders();
if (ALLOWED_ORIGINS.contains(origin)) {
httpHeaders.add("Access-Control-Allow-Origin", origin);
}
// ....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5324. OWASP. Possible open redirect vulnerability. Potentially tainted data is used in the URL.
Анализатор обнаружил перенаправление с одного ресурса на другой. Причём URL-адрес для перенаправления был получен из внешнего источника и не проверялся. Это может стать причиной возникновения уязвимости типа open redirect, если адрес будет скомпрометирован.
Уязвимости типа open redirect относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Приведём пример:
@GetMapping("/redirectExample")
public RedirectView redirect(@RequestParam("url") String url) {
return new RedirectView(url);
}В этом примере url может содержать заражённые данные, так как они получены из внешнего источника. Эти данные используются для перенаправления клиента на адрес, который записан в url. Подобная логика работы программы упрощает проведение фишинговых атак для кражи данных пользователя.
Пример скомпрометированного адреса:
URL: http://mySite.com/login?url=http://attacker.com/Возможный сценарий проведения атаки:
- пользователь получает ссылку от злоумышленника и под каким-то предлогом переходит по ней;
- он оказывается на известном сайте, который запрашивает авторизацию. После ввода логина и пароля произойдёт перенаправление на поддельный сайт, который выглядит в точности, как ожидаемый;
- фишинговый сайт также запрашивает логин и пароль. Пользователь думает, что ошибся и снова вводит данные для авторизации;
- соответственно, их получает злоумышленник, создавший поддельный сайт. После этого происходит перенаправление на оригинальный сайт. В итоге пользователь может даже не заметить, что его данные были украдены.
Главная опасность open redirect состоит в том, что ссылка, полученная от злоумышленника, фактически ведёт на сайт, которому пользователь доверяет. Следовательно, жертва с большей вероятностью перейдёт по ней.
Для защиты от open redirect стоит проверять, что перенаправление осуществляется на локальный адрес или на адрес из белого списка.
Исправленный пример:
private static final List<String> ALLOWED_SITES = List.of(
"https://goodsite.com",
"https://verygoodsite.com"
);
@GetMapping("/redirectExample")
public RedirectView redirect(@RequestParam("url") String url) {
if (ALLOWED_SITES.contains(url)) {
return new RedirectView(url);
}
// ....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5325. OWASP. Setting the value of the 'Access-Control-Allow-Origin' header to '*' is potentially insecure.
Анализатор обнаружил небезопасную конфигурацию Cross-origin resource sharing (CORS). Значение * у заголовка ответа сервера Access-Control-Allow-Origin позволяет веб-странице с абсолютно любого хоста получать содержимое ответов.
Если значением заголовка Access-Control-Allow-Origin будет *, веб-страницы с абсолютно любым доменом смогут получить содержимое ответа. Это небезопасно и, в зависимости от обстоятельств, чревато негативными последствиями разной степени серьёзности. Сайты злоумышленников смогут получать доступ к ресурсам вашей страницы, а при особых обстоятельствах возможно раскрытие конфиденциальной информации.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Примеры небезопасной конфигурации:
@CrossOrigin // <=
@GetMapping("/user")
public User getUser(....) {
// ....
}@CrossOrigin(origins = "*") // <=
@GetMapping("/user")
public User getUser(....) {
// ....
}Исправленный вариант:
@CrossOrigin(origins = "https://allowed.com") // <=
@GetMapping("/getUser")
public User getUser(....) {
// ....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5326. OWASP. A password for a database connection should not be empty
Анализатор обнаружил, что при установке соединения с базой данных используется пустой пароль. Пустой пароль не обеспечивает базовую защиту, что может привести к несанкционированному доступу к данным.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Пример небезопасной конфигурации:
var dataSource = new PGSimpleDataSource();
dataSource.setDatabaseName("db");
dataSource.setUser("server");
dataSource.setPassword("");
// ....Параметры доступа в рабочей среде должны удовлетворять следующим требованиям:
- пароли должны быть сложными и непредсказуемыми, чтобы их нельзя было обнаружить методом подбора. Это включает в себя: длину (от 8 символов), использование букв разного регистра, использование чисел и специальных символов;
- у владельца учётных данных должны быть только те права, которые ему нужны. Например, не нужно давать права на запись, если требуется только чтение данных;
- параметры доступа не должны храниться в коде. Вместо этого стоит использовать свойства, классы конфигурации или переменные среды окружения.
Исправленный пример выглядит так:
var dataSource = new PGSimpleDataSource();
dataSource.setDatabaseName("db");
dataSource.setUser(System.getProperty("db.user"));
dataSource.setPassword(System.getProperty("db.password"));
// ....Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5327. OWASP. Possible regex injection. Potentially tainted data is used to create regular expression
Анализатор обнаружил, что пришедшие извне данные используются в качестве регулярного выражения и не подвергаются проверке. Это делает приложение уязвимым к отказу в обслуживании (DoS).
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Если код выглядит таким образом:
@GetMapping("/check")
public String checkInput(@RequestParam("input") String input) {
var match = vulnerableString.matches(input); // <=
if (match) {
return "Valid input";
} else {
return "Invalid input";
}
}То злоумышленник сможет сделать неэффективное регулярное выражение, замедляющее работу приложения. В худшем случае, если атакующий сможет подобрать Evil Regex — регулярное выражение, из-за которого выполнение зависнет, — это приведёт к отказу в обслуживании. Такая атака называется ReDoS.
Чтобы защититься от таких атак, лучше всего экранировать ввод с помощью Pattern.quote:
@GetMapping("/check")
public String checkInput(@RequestParam("input") String input) {
var regex = Pattern.quote(input);
var match = vulnerableString.matches(input);
if (match) {
return "Valid input";
} else {
return "Invalid input";
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5328. OWASP. Using non-restrictive authorization checks could lead to security violations.
Анализатор обнаружил потенциальную ошибку, связанную со слабой проверкой авторизации пользователя. Предоставление неограниченного доступа всем пользователям может привести к уязвимостям безопасности и потенциальному нецелевому использованию критических функций программы.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Предполагается, что при проверке авторизации метод, принимающий решение, может отказать в авторизации в случае, если пользователь не имеет необходимых привилегий. Если же реализация не предусматривает отказа в авторизации, такой метод считается небезопасным, а проверка — ненадежной.
Например, реализация метода vote из класса AccessDecisionVoter возвращает всегда положительный ответ, даже в случае, если пользователь не имеет нужных привилегий:
@Override
public int vote(Authentication authentication,
FilterInvocation filterInvocation,
Collection<ConfigAttribute> attributes
) {
boolean isAdmin = hasAdminRole(authentication);
String requestMethod = filterInvocation.getRequest().getMethod();
if ("DELETE".equals(requestMethod) && !isAdmin) {
return ACCESS_GRANTED;
}
return ACCESS_GRANTED;
}Реализация считается безопасной, если она возвращает хотя бы одно отрицательное решение:
@Override
public int vote(Authentication authentication,
FilterInvocation filterInvocation,
Collection<ConfigAttribute> attributes
) {
boolean isAdmin = hasAdminRole(authentication);
String requestMethod = filterInvocation.getRequest().getMethod();
if ("DELETE".equals(requestMethod) && !isAdmin) {
return ACCESS_DENIED;
}
return ACCESS_GRANTED;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V5329. OWASP. Using non-atomic file creation is not recommended because an attacker might intercept file ownership.
Анализатор обнаружил использование небезопасного способа создания временных файлов. Это может сделать приложение уязвимым к атакам через файловую систему.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
Вызов небезопасной функции createTempFile из класса java.io.File считается заведомо небезопасным, если выполняется совместно с вызовом методов mkdir или mkdirs:
public File createTemporaryDirectory() {
File dir = new File(baseDirFactory.create(),
CollectionUtils.join("/", path));
GFileUtils.mkdirs(dir);
try {
File tmpDir = File.createTempFile("gradle",
"projectDir",
dir);
tmpDir.delete();
tmpDir.mkdir();
return tmpDir;
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}Создание временных файлов неатомарным способом может привести к состоянию гонки в поведении приложения. Из-за этого третья сторона может создать этот файл между тем, когда приложение выбирает его имя, и тем, когда оно его создает. В такой ситуации приложение будет использовать файл, который по-настоящему не контролирует.
Атакующий может получить доступ и контроль над временным файлом уязвимого приложения, а также поменять его таким образом, чтобы изменить логику работы приложения.
Безопасной в таком случае является реализация создания временного файла методом createTempDirectory из класса java.nio.file.Files:
public File createTemporaryDirectory() {
try {
File dir = new File(baseDirFactory.create(),
CollectionUtils.join("/", path));
GFileUtils.mkdirs(dir);
Path tempDir = Files.createTempDirectory(dir.toPath(),
"gradle");
return tempDir.toFile();
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5330. OWASP. Possible XSS injection. Potentially tainted data might be used to execute a malicious script.
Анализатор обнаружил ситуацию, при которой данные, полученные из внешнего источника, могут быть использованы для запуска вредоносного скрипта. Подобный код может быть уязвим к XSS.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021:
XSS (Cross-Site Scripting) — это уязвимость, которая позволяет злоумышленнику вставлять вредоносный JavaScript-код на веб-страницу, которую видит другой пользователь. В результате этого злоумышленник может украсть данные пользователя, провести фишинг-атаку или выполнить другие злонамеренные действия.
К XSS чаще всего уязвимы параметры URL, тело HTTP-запроса и поля ввода HTML-страниц.
Примером кода, подверженного XSS-инъекции, может быть такая обработка запроса в Servlet:
protected void doPost(HttpServletRequest req, HttpServletResponse res) {
String comment = req.getParameter("comment");
res.setContentType("text/html");
res.getWriter().write("<html><body>");
res.getWriter().write("<h3>User Comment:</h3>");
res.getWriter().write("<p>" + comment + "</p>");
res.getWriter().write("</body></html>");
}Данный метод принимает комментарий от пользователя и возвращает ответ, который затем будет отображён на странице. Но так как сообщение будет отправлено без предварительной фильтрации, злоумышленник может указать следующие значение для параметра comment:
<script>alert("XSS Injection")</script>Когда страница открывается, браузер пользователя выполняет этот вредоносный код, что приводит к всплывающему окну с сообщением "XSS Injection". В реальном случае злоумышленник может использовать более сложные и вредоносные скрипты для кражи cookies или выполнения других атак.
Исправить уязвимость можно с помощью методов, экранирующих ввод пользователя. В данном случае воспользуемся методом escapeHtml из библиотеки Apache Commons Lang:
protected void doPost(HttpServletRequest req, HttpServletResponse res) {
String comment = req.getParameter("comment");
res.setContentType("text/html");
res.getWriter().write("<html><body>");
res.getWriter().write("<h3>User Comment:</h3>");
res.getWriter().write("<p>" +
StringEscapeUtils.escapeHtml4(comment)
+ "</p>");
res.getWriter().write("</body></html>");
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5331. Hardcoded IP addresses are not secure.
Использование жёстко закодированных IP-адресов в коде может раскрыть детали сети, упрощая злоумышленнику анализ инфраструктуры приложения.
Например, прямое указание адреса SSH-сервера создаёт потенциальную уязвимость:
public static final String SSH_SERVER_ADDRESS = "117.107.58.59";
void connect() {
Socket socket = new Socket(SSH_SERVER_ADDRESS, 22);
// ....
}При попадании этого кода в публичный доступ или в руки злоумышленника внутренняя инфраструктура перестаёт быть конфиденциальной.
Такое решение также привязывает приложение к конкретному окружению, усложняя настройку и обновление.
Рекомендуется хранить конфиденциальные параметры во внешних источниках. Например, в переменных окружения:
public static final String SSH_SERVER_ADDRESS =
System.getenv("MYAPP.SSH_SERVER_ADDRESS");
void connect() {
Socket socket = new Socket(SSH_SERVER_ADDRESS, 22);
// ....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V3501. AUTOSAR. Octal constants should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Восьмеричные числовые литералы и экранирующие последовательности не должны использоваться. Использование восьмеричных литералов может затруднить восприятие кода, особенно при быстром просмотре. Неправильная интерпретация фактического числового значения может приводить к разнообразным ошибкам.
Пример кода, на который анализатор выдаст предупреждение:
if (val < 010)
{
....
}При быстром просмотре кода можно упустить из виду, что значение числового литерала – 8, а не 10. Чтобы анализатор не выдавал предупреждения, литерал стоит переписать в десятичной или шестнадцатеричной форме:
if (val < 8)
{
....
}Данная диагностика классифицируется как:
|
V3502. AUTOSAR. Size of an array is not specified.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Явное указание размера массива улучшает читаемость и понимание кода, уменьшая вероятность возникновения ошибок, связанных с выходом за границы массива из-за незнания его размера.
Анализатор выдаст предупреждение, если встретит объявление массива со спецификатором 'extern', при условии, что размер массива не задан явно:
extern int arr[];Для исправления следует явно указать размер массива:
extern int arr[12];Если размер массива можно вывести из инициализатора, предупреждение выдано не будет:
int arr1[] = {1, 2, 3};Данная диагностика классифицируется как:
|
V3503. AUTOSAR. The 'goto' statement shouldn't jump to a label declared earlier.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Использование оператора 'goto', осуществляющего переход к метке, находящейся выше по коду, ухудшает читаемость кода и как следствие – усложняет его поддержку.
Пример кода, на который анализатор выдаст предупреждение:
void init(....)
{
....
again:
....
if (....)
if (....)
goto again;
....
}Чтобы анализатор не выдавал предупреждение, необходимо отказаться от использования оператора 'goto' или переписать код таким образом, чтобы метка, на которую ссылается 'goto', находилась ниже него.
Данная диагностика классифицируется как:
|
V3504. AUTOSAR. The body of a loop\conditional statement should be enclosed in braces.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Тела операторов 'while', 'do-while', 'for', 'if', 'if-else', 'switch' должны быть заключены в фигурные скобки.
Использование фигурных скобок четко определяет, какие выражения составляют тело, повышает читаемость кода и снижает вероятность возникновения ряда ошибок. Например, при отсутствии фигурных скобок программист может ошибочно воспринять выравнивание или не заметить символ ';', случайно поставленный после оператора.
Пример 1:
void example_1(....)
{
if (condition)
if (otherCondition)
DoSmt();
else
DoSmt2();
}Форматирование данного кода не соответствует логике его выполнения, что может сбивать с толку. Расстановка фигурных скобок устраняет возможную неоднозначность:
void example_1(....)
{
if (condition)
{
if (otherCondition)
{
DoSmt();
}
else
{
DoSmt2();
}
}
}Пример 2:
void example_2(....)
{
while (count < 10)
DoSmt1(); DoSmt2();
}Форматирование данного кода также не соответствует логике его исполнения, так как к циклу относится только выражение 'DoSmt1()'.
Исправленный вариант:
void example_2(....)
{
while (count < 10)
{
DoSmt1();
DoSmt2();
}
}Примечание: 'if', следующий сразу после 'else' не обязательно должен быть заключен в фигурные скобки. На фрагмент кода, приведённый ниже, анализатор не будет выдавать предупреждение.
if (condition1)
{ .... }
else if (condition2)
{ .... }Данная диагностика классифицируется как:
|
V3505. AUTOSAR. The function with the 'atof/atoi/atol/atoll' name should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций: 'atof'; 'atoi'; 'atol'; 'atoll'.
Неправильное использование этих функций может привести к возникновению неопределённого поведения. Это может произойти, если аргумент функции не является валидной С-строкой или если результирующее значение выходит за границы возвращаемого типа.
Пример кода, на который анализатор выдаст предупреждение:
void Foo(const char *str)
{
int val = atoi(str);
....
}Данная диагностика классифицируется как:
|
V3506. AUTOSAR. The function with the 'abort/exit/getenv/system' name should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций: 'abort'; 'exit'; 'getenv'; 'system'.
Поведение перечисленных выше функций зависит от реализации. Кроме того, использование таких функций как 'system' может являться причиной возникновения уязвимостей.
Пример кода, на который анализатор выдаст предупреждение:
void Foo(FILE *pFile)
{
if (pFile == NULL)
{
abort();
}
....
}Данная диагностика классифицируется как:
|
V3507. AUTOSAR. The macro with the 'setjmp' name and the function with the 'longjmp' name should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование имен 'setjmp' или 'longjmp', так как их неправильное использование может привести к неопределённому поведению.
Пример кода, на который анализатор выдаст предупреждение:
jmp_buf j_buf;
void foo()
{
setjmp(j_buf);
}
int main()
{
foo();
longjmp(j_buf, 0);
return 0;
}Функция 'longjmp' вызвана уже после выхода из функции, которая вызвала 'setjmp', результат в таком случае не определен.
Данная диагностика классифицируется как:
|
V3508. AUTOSAR. Unbounded functions performing string operations should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций: 'strcpy'; 'strcmp'; 'strcat'; 'strchr'; 'strspn'; 'strcspn'; 'strpbrk'; 'strrchr'; 'strstr'; 'strtok'; 'strlen'.
Неправильное использование этих функций может стать причиной возникновения неопределённого поведения, так как они не защищены от чтения и записи вне границ буфера.
Пример кода, на который анализатор выдаст предупреждение:
int strcpy_internal(char *dest, const char *source)
{
int exitCode = FAILURE;
if (source && dest)
{
strcpy(dest, source);
exitCode = SUCCESS;
}
return exitCode;
}Данная диагностика классифицируется как:
|
V3509. AUTOSAR. Unions should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит объявление объединения.
Неправильное использование объединений может приводить к различным проблемам, например, к получению неверных значений или к возникновению неопределённого поведения.
Например, неопределённое поведение может возникнуть, когда значение считывается не из члена, в который производилась запись в последний раз.
Пример кода, на который анализатор выдаст предупреждение:
union U
{
unsigned char uch;
unsigned int ui;
} uni;
....
uni.uch = 'w';
int ui = uni.ui;Данная диагностика классифицируется как:
|
V3510. AUTOSAR. Declaration should contain no more than two levels of pointer nesting.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если встретит объявление, использующее более двух уровней вложенности указателей. Использование таких указателей ухудшает понимание кода и как следствие – может стать причиной возникновения различных ошибок.
Пример кода, на который анализатор выдаст предупреждение:
void foo(int **ppArr[])
{
....
}Данная диагностика классифицируется как:
|
V3511. AUTOSAR. The 'if' ... 'else if' construct should be terminated with an 'else' statement.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Каждая последовательность 'if ... else if' должна заканчиваться 'else'. При отсутствии завершающего 'else' анализатор выдаст предупреждение. Наличие конечного 'else' показывает, что рассмотрены все возможные варианты, что помогает при чтении и понимании кода.
Пример кода, на который анализатор выдаст предупреждение:
if (condition)
{
....
}
else if (other_condition)
{
....
}Чтобы анализатор не выдавал предупреждение, а разработчик, читающий код, сразу понял, что рассмотрен случай, когда ни одно условие не выполнилось, стоит добавить 'else'-ветвь. В этой ветви следует разместить необходимые действия или поясняющий комментарий.
if (condition)
{
....
}
else if (other_condition)
{
....
}
else
{
// No action needed
}Данная диагностика классифицируется как:
|
V3512. AUTOSAR. Literal suffixes should not contain lowercase characters.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Все буквенные суффиксы должны быть в верхнем регистре.
Использование суффиксов в нижнем регистре мешает визуальному восприятию кода. Например, суффикс 'l' можно спутать с единицей (1), что может стать причиной разнообразных ошибок.
Примеры литералов, на которые анализатор выдаст предупреждение:
12l; 34.0f; 23u;Форма записи литералов, на которую предупреждение выдано не будет:
12L; 34.0F; 23U;Данная диагностика классифицируется как:
|
V3513. AUTOSAR. Every switch-clause should be terminated by an unconditional 'break' or 'throw' statement.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Каждая метка в 'switch' должна быть завершена оператором 'break' или выражением 'throw', не расположенным внутри условия.
Намеренное завершение каждой метки гарантирует, что поток управления не "провалится" в метку, расположенную ниже, и позволяет избежать ошибок при добавлении новых меток.
Исключением из этого правила являются пустые метки, расположенные последовательно.
Пример кода, на который анализатор выдаст предупреждение:
void example_1(int cond, int a)
{
switch (cond)
{
case 1:
case 2:
break;
case 3: // <=
if (a == 42)
{
DoSmth();
}
case 4: // <=
DoSmth2();
default: // <=
;
}
}Исправленный код:
void example_1(int cond, int a)
{
switch (cond)
{
case 1:
case 2:
break;
case 3:
if (a == 42)
{
DoSmth();
}
break;
case 4:
DoSmth2();
break;
default:
/* No action required */
break;
}
}Данная диагностика классифицируется как:
|
V3514. AUTOSAR. The 'switch' statement should have 'default' as the last label.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Последней меткой в 'switch' должна быть 'default'.
Наличие 'default' в конце каждого 'switch' облегчает чтение кода, а также гарантирует, что будут обработаны любые ситуации, в которых значение контролирующей переменной не соответствует ни одной метке. Так как такие ситуации требуют принятия определенных мер, каждая метка 'default' должна содержать (помимо 'break' или 'throw') выражение или комментарий, объясняющий, почему никаких действий не предпринимается.
Пример 1:
void example_1(int i)
{
switch (i)
{
case 1:
DoSmth1();
break;
default: // <=
DoSmth42();
break;
case 3:
DoSmth3();
break;
}
}Корректный код:
void example_1(int i)
{
switch (i)
{
case 1:
DoSmth1();
break;
case 3:
DoSmth3();
break;
default:
DoSmth42();
break;
}
}Пример 2:
enum WEEK
{
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
} weekDay;
void example_2()
{
int isWorkday;
switch (weekDay)
{
case MONDAY:
case TUESDAY:
case WEDNESDAY:
case THURSDAY:
case FRIDAY:
isWorkday = 1;
break;
case SATURDAY:
case SUNDAY:
isWorkday = 0;
break;
default: // <=
break;
}Исправленный код:
enum WEEK
{
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
} weekDay;
void example_2()
{
int isWorkday;
switch (weekDay)
{
case MONDAY:
case TUESDAY:
case WEDNESDAY:
case THURSDAY:
case FRIDAY:
isWorkday = 1;
break;
case SATURDAY:
case SUNDAY:
isWorkday = 0;
break;
default:
assert(false);
break;
}Данная диагностика классифицируется как:
|
V3515. AUTOSAR. All integer constants of unsigned type should have 'U' suffix.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор обнаружил использование целочисленного беззнакового литерала без суффикса 'U'. Подобные литералы могут осложнить восприятие кода, так как их тип становится неочевиден. Более того, одни и те же литералы могут иметь разные типы на разных моделях данных.
Использование суффиксов для явного указания типа позволит избежать неоднозначностей при чтении числовых литералов.
Пример кода, на который анализатор выдаст предупреждение (если тип литерала на анализируемой платформе – беззнаковый):
auto typemask = 0xffffffffL;Данная диагностика классифицируется как:
|
V3516. AUTOSAR. A switch-label should only appear at the top level of the compound statement forming the body of a 'switch' statement.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Область видимости, в которой находится метка, должна быть составным выражением, которое представляет собой тело 'switch'. Это означает, что метка не должна быть вложена ни в какой блок, кроме как в тело 'switch', и это тело должно быть составным выражением.
Следовательно, все метки, принадлежащие одному 'switch', должны находиться в одной области видимости. Следование этому правилу позволяет сохранить читаемость и структурированность кода.
Пример 1:
void example_1(int param, bool b)
{
switch (param)
{
case 1:
DoSmth1();
if (b)
{
case 2: // <=
DoSmth2();
}
break;
default:
assert(false);
break;
}
}Рассмотренный пример сложен для понимания. Чтобы анализатор не выдавал предупреждения, следует написать так:
void example_1(int param, bool b)
{
switch (param)
{
case 1:
DoSmth1();
if (b)
{
DoSmth2();
}
break;
case 2:
DoSmth2();
break;
default:
assert(false);
break;
}
}В следующем примере тело 'switch' не является составным, поэтому анализатор также выдаст предупреждение:
void example_2(int param)
{
switch (param)
default:
DoDefault();
}Исправленный вариант:
void example_2(int param)
{
switch (param)
{
default:
DoDefault();
break;
}
}Данная диагностика классифицируется как:
|
V3517. AUTOSAR. The functions from time.h/ctime should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций: 'clock'; 'time'; 'difftime'; 'ctime'; 'asctime'; 'gmtime'; 'localtime'; 'mktime'.
Перечисленные функции имеют неуточнённое поведение или поведение, определённое реализацией, и поэтому могут выдаваться разные форматы времени и даты (в зависимости от окружения, реализации стандартной библиотеки и т. д.).
Пример кода, на который анализатор выдаст предупреждения:
const char* Foo(time_t *p)
{
time_t t = time(p);
return ctime(t);
}Данная диагностика классифицируется как:
|
V3518. AUTOSAR. A switch-expression should not have Boolean type. Consider using of 'if-else' construct.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Значение булевого типа может быть сконвертировано к целочисленному типу, поэтому его можно использовать в качестве управляющей переменной в выражении 'switch'. В этом случае использование конструкции 'if-else' является предпочтительным, так как оно дает более понятное и явное представление намерений программиста.
Пример:
int foo(unsigned a, unsigned b)
{
while (a != 0 && b != 0)
{
switch (a > b) // <=
{
case 0:
a -= b;
break;
default:
b -= a;
break;
}
}
return a;
}Вместо этого следует написать:
int foo(unsigned a, unsigned b)
{
while (a != 0 && b != 0)
{
if (a > b)
{
b -= a;
}
else
{
a -= b;
}
}
return a;
}Данная диагностика классифицируется как:
|
V3519. AUTOSAR. The comma operator should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Не стоит использовать оператор 'запятая', так как он может привести к путанице при чтении кода.
Рассмотрим следующий пример:
int foo(int x, int y) { .... }
foo( ( 0, 3), 12 );Код может ввести программиста в заблуждение, если ему до прочтения вызова функции неизвестна ее сигнатура. Может показаться, что в функцию передается три аргумента, однако это не так: оператор 'запятая' в выражении '(0, 3)' вычислит левый и правый аргументы, а затем возвращает результат второго. В итоге, вызов функции на самом деле принимает вид:
foo( 3, 12 );Диагностика выдает предупреждение и для других случаев, таких как например этот:
int myMemCmp(const char *s1, const char *s2, size_t N)
{
for (; N > 0; ++s1, ++s2, --N) { .... }
}Данная диагностика классифицируется как:
|
V3520. AUTOSAR. Any label should be declared in the same block as 'goto' statement or in any block enclosing it.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Чрезмерное использование 'goto' приводит к плохой структурированности кода, усложняя его понимание.
Для снижения визуальной сложности кода рекомендуется отказаться от переходов во вложенные блоки или между блоками, расположенными на одном уровне.
Пример 1:
void V2532_pos1()
{
...
goto label;
...
{
label:
...
}
}Здесь 'goto' ссылается во вложенный блок, что нарушает данное правило.
На следующий пример анализатор не будет выдавать предупреждение:
void V2532_neg1()
{
...
label:
...
{
goto label;
...
}
}Примечание: тела switch-меток рассматриваются как составные выражения, даже если они не обернуты в фигурные скобки. Поэтому прыжки в тело switch-метки из внешнего кода и прыжки между разными switch-метками нарушают данное правило.
Приведем примеры.
Прыжок в switch-метку из внешнего кода (ошибка):
void V2532_pos2(int param)
{
goto label;
switch (param)
{
case 0:
break;
default:
label:;
break;
}
}Прыжок между switch-метками (ошибка):
void V2532_pos3(int param)
{
switch (param)
{
case 0:
goto label;
break;
default:
label:
break;
}
}Прыжок из switch-метки во внешний код (ok):
void V2532_neg2(int param)
{
label:
switch (param)
{
case 0:
goto label;
break;
default:
break;
}
}Прыжок в пределах одной switch-метки (ok):
void neg3(int param)
{
switch (param)
{
case 0:
{
...
{
goto label;
}
}
label:
break;
default:
break;
}
}Данная диагностика классифицируется как:
|
V3521. AUTOSAR. The loop counter should not have floating-point type.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Поскольку числа с плавающей точкой не могут точно отобразить все действительные числа, использование таких переменных в цикле может дать непостоянное количество итераций.
Рассмотрим пример:
void foo(void) {
for (float A = 0.1f; A <= 10.0f; A += 0.1f) {
....
}
}Количество итераций в этом цикле может быть 99 или 100. Точность операций с вещественными числами может зависеть от компилятора, режима оптимизации и многого другого.
Лучше переписать цикл следующим образом:
void foo(void) {
for (int count = 1; count <= 100; ++count) {
float A = count / 10.0f;
}
}Этот цикл выполнит ровно 100 итераций, а переменную 'A' можно использовать для необходимых вычислений.
Данная диагностика классифицируется как:
|
V3522. AUTOSAR. Unreachable code should not be present in the project.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Присутствие недостижимого кода может являться признаком ошибки программиста и усложняет поддержку кода.
Компилятор в целях оптимизации вправе удалить недостижимый код. Недостижимый код, неудаленный компилятором, может расходовать ресурсы. Например, он может увеличивать размер бинарного файла или являться причиной излишнего кэширования инструкций.
Рассмотрим первый пример:
void Error()
{
....
exit(1);
}
FILE* OpenFile(const char *filename)
{
FILE *f = fopen(filename, "w");
if (f == nullptr)
{
Error();
printf("No such file: %s", filename);
}
return f;
}Функция 'printf(....)' никогда не напечатает сообщение об ошибке, так как функция 'Error()' не возвращает управление. Как правильно исправить код зависит от того, какую логику поведения задумывал программист изначально. Возможно, функция должна возвращать управление. Возможно, нарушен порядок выражений и корректный код должен быть таким:
FILE* OpenFile(const char *filename)
{
FILE *f = fopen(filename, "w");
if (f == nullptr)
{
printf("No such file: %s", filename);
Error();
}
return f;
}Рассмотрим второй пример:
char ch = strText[i];
switch (ch)
{
case '<':
...
break;
case '>':
...
break;
case 0xB7:
case 0xBB:
...
break;
...
}Здесь ветка расположенная после "case 0xB7:" и "case 0xBB:" никогда не получит управление. Переменная 'ch' имеет тип 'char', а, следовательно, диапазон её значений лежит в пределах [-128..127]. Результатом сравнения "ch == 0xB7" и "ch==0xBB" всегда будет ложь (false). Чтобы код был корректен, переменная 'ch' должна иметь тип 'unsigned char'. Исправленный код:
unsigned char ch = strText[i];
switch (ch)
{
case '<':
...
break;
case '>':
...
break;
case 0xB7:
case 0xBB:
...
break;
...
}Рассмотрим третий пример:
if (n < 5) { AB(); }
else if (n < 10) { BC(); }
else if (n < 15) { CD(); }
else if (n < 25) { DE(); }
else if (n < 20) { EF(); } // Это ветвь никогда не выполнится.
else if (n < 30) { FG(); }Из-за некорректного пересечения диапазонов, находящихся в условиях, одна из ветвей никогда не будет выполнена. Исправленный код:
if (n < 5) { AB(); }
else if (n < 10) { BC(); }
else if (n < 15) { CD(); }
else if (n < 20) { EF(); }
else if (n < 25) { DE(); }
else if (n < 30) { FG(); }Данная диагностика классифицируется как:
|
V3523. AUTOSAR. Functions should not have unused parameters.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Неиспользованные параметры функции часто появляются после рефакторинга кода. Если сигнатура функции не соответствует её реализации, сложно сразу понять, является ли это ошибкой программиста.
Рассмотрим пример:
static bool CardHasLock(int width, int height)
{
const double xScale = 0.051;
const double yScale = 0.0278;
int lockWidth = (int)floor(width * xScale);
int lockHeight = (int)floor(width * yScale);
....
}Из кода видно, что параметр 'height' ни разу не используется в теле функции. Скорее всего, здесь допущена ошибка, и код инициализации переменной 'lockHeight' должен выглядеть следующим образом:
int lockHeight = (int)floor(height * yScale);Данная диагностика классифицируется как:
|
V3524. AUTOSAR. The value of uninitialized variable should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Если переменная POD-типа не инициализируется явно и не имеет инициализатора по умолчанию, то её значение будет неопределённым. Использование такого значения приведет к неопределенному поведению.
Простой синтетический пример:
int Aa = Get();
int Ab;
if (Ab) // Ab - uninitialized variable
Ab = Foo();
else
Ab = 0;Как правило, ошибки использования неинициализированных переменных, возникают из-за опечаток. Например, может оказаться, что в этом месте следовало использовать другую переменную. Корректный вариант кода:
int Aa = Get();
int Ab;
if (Aa) // OK
Ab = Foo();
else
Ab = 0;Данная диагностика классифицируется как:
|
V3525. AUTOSAR. Function with a non-void return type should return a value from all exit paths.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор обнаружил функцию с не-void возвращаемым типом, которая не возвращает значение на всех путях выполнения. Согласно стандарту C++, это может привести к неопределенному поведению.
Рассмотрим пример, в котором неопределенное значение возвращается только иногда:
BOOL IsInterestingString(char *s)
{
if (s == NULL)
return FALSE;
if (strlen(s) < 4)
return;
return (s[0] == '#') ? TRUE : FALSE;
}В коде допущена опечатка. Если длина строки меньше 4 символов, то функция вернет неопределенное значение. Корректный вариант:
BOOL IsInterestingString(char *s)
{
if (s == NULL)
return FALSE;
if (strlen(s) < 4)
return FALSE;
return (s[0] == '#') ? TRUE : FALSE;
}Примечание. Анализатор старается определить ситуации, когда отсутствие возвращаемого значения не является ошибкой. Пример кода, который анализатор сочтет безопасным:
int Foo()
{
...
exit(10);
}Данная диагностика классифицируется как:
|
V3526. AUTOSAR. Expression resulting from the macro expansion should be surrounded by parentheses.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор обнаружил потенциально возможную ошибку в записи макроса. Макрос и его параметры следует заключать в скобки.
В случае, когда параметры или само выражение не заключены в скобки, может быть нарушена задуманная последовательность действий после того, как макрос будет подставлен.
Пример кода, на который анализатор выдаст предупреждение:
#define DIV(x, y) (x / y)Пример использования макроса, приводящего к ошибке:
Z = DIV(x + 1, y + 2);В результате получим:
Z =(x + 1 / y + 2);Чтобы избежать нарушения последовательности действий, этот макрос стоит переписать следующим образом:
#define DIV(x,y) ((x) / (y))Данная диагностика классифицируется как:
|
V3527. AUTOSAR. The return value of non-void function should be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Существует возможность вызвать non-void функцию и не использовать возвращаемое ею значение. Такое поведение программы может скрывать ошибку.
Результат non-void функции всегда должен быть использован. Пример кода, на который анализатор выдаст предупреждение:
int Foo(int x)
{
return x + x;
}
void Bar(int x)
{
Foo(x);
}В случае, если потеря возврщаемого значения была задумана разработчиком, можно использовать приведение к 'void' типу. Пример кода, на который анализатор не выдаст предупреждение:
void Bar(int x)
{
(void)Foo(x);
}Данная диагностика классифицируется как:
|
V3528. AUTOSAR. The address of an object with local scope should not be passed out of its scope.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Копирование адреса объекта в указатель/ссылку с большим временем жизни может привести к возникновению "висячего" указателя/ссылки после того, как исходный объект перестанет существовать. Это является нарушением безопасности памяти. Использование данных, на которые указывает "висячий" указатель/ссылка, приводит к неопределенному поведению.
Первый пример кода, на который анализатор выдаст предупреждение:
int& Foo( void )
{
int some_variable;
....
return some_variable;
}Второй пример кода, на который анализатор выдаст предупреждение:
#include <stddef.h>
void Bar( int **ptr )
{
int some_variable;
....
if (ptr != NULL)
*ptr = &some_variable;
}Данная диагностика классифицируется как:
|
V3529. AUTOSAR. Floating-point values should not be tested for equality or inequality.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
При сравнении на равенство или неравенство значений вещественных типов в зависимости от используемого процессора и настроек компилятора часто можно получить неожиданный результат.
Пример кода, на который анализатор выдаст предупреждение:
const double PI_div_2 = 1.0;
const double sinValue = sin(M_PI / 2.0);
if (sinValue == PI_div_2) { .... }Чтобы сравнение значений вещественных типов не содержало ошибок, нужно либо использовать встроенные константы 'std::numeric_limits<float>::epsilon()' или 'std::numeric_limits<double>::epsilon()', либо создать собственную константу 'Epsilon' с заданной точностью.
Исправленный пример кода:
const double PI_div_2 = 1.0;
const double sinValue = sin(M_PI / 2.0);
// equality
if (fabs(a - b) <= std::numeric_limits<double>::epsilon()) { .... };
// inequality
if (fabs(a - b) > std::numeric_limits<double>::epsilon()) { .... };В некоторых случаях сравнение двух вещественных чисел через оператор '==' или '!=' допустимо. Например, когда переменная сравнивается с заведомо известным значением:
bool foo();
double bar();
double val = foo() ? bar() : 0.0;
if (val == 0.0) { .... }Анализатор не выдает предупреждений, если сравнивается одно и то же значение с самим собой. Такое сравнение позволяет определить, хранится ли в переменной NaN:
bool isnan(double value) { return value != value; }Впрочем, более хорошим стилем будет использовать для этой проверки функцию 'std::isnan'.
Данная диагностика классифицируется как:
|
V3530. AUTOSAR. Variable should be declared in a scope that minimizes its visibility.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Переменные следует определять в минимально возможной области видимости. Это позволит избежать возможных ошибок, связанных со случайным использованием переменных вне предусмотренной для них области видимости, а также может помочь сэкономить потребление памяти и увеличить производительность программы.
Пример кода, на который анализатор выдаст предупреждение:
static void RenderThrobber(RECT *rcItem, int *throbbing, ....)
{
....
int width = rcItem->right - rcItem->left;
....
if (*throbbing)
{
RECT rc;
rc.right = width;
....
}
.... // width больше нигде не используется
}Переменная 'width' используется только внутри блока 'if', следовательно, будет разумным перенести переменную внутрь этого блока. Вычисление 'width' при этом будет происходить только при выполнении условия, что экономит время. Дополнительно это позволит избежать ошибочного использования этой переменной в дальнейшем.
Данная диагностика классифицируется как:
|
V3531. AUTOSAR. Expressions with enum underlying type should have values corresponding to the enumerators of the enumeration.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор обнаружил опасное приведение числа к перечислению. Указанное число может не входит в диапазон значений enum.
Пример:
enum TestEnum { A, B, C };
TestEnum Invalid = (TestEnum)42;Так как стандарт не указывает базовый тип для enum, то результат приведения числа, чьё значение не входит диапазон элементов enum, является unspecified behavior до C++17 и undefined behavior начиная с C++17.
Для того чтобы этого избежать, необходимо проверять числа перед приведениями. Как вариант, можно явно указать базовый тип для enum или использовать 'enum class', базовый тип которого по умолчанию - 'int'.
Корректный код:
enum TestEnum { A, B, C, Invalid = 42 };Или:
enum TestEnum : int { A, B, C };
E Invalid = (E)42;Или:
enum class TestEnum { A, B, C };
TestEnum Invalid = (TestEnum)42;Данная диагностика классифицируется как:
|
V3532. AUTOSAR. Unary minus operator should not be applied to an expression of the unsigned type.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
При применении унарного минуса к переменной типа 'unsigned int', 'unsigned long' или 'unsigned long long' тип этой переменной не изменится и останется 'unsigned'. Таким образом, подобная операция является бессмысленной.
При применении унарного минуса к меньшему 'unsigned' целочисленному типу в результате целочисленного расширения возможно получение 'signed' числа, однако это не является хорошим подходом, и на такую операцию также будет выдано предупреждение.
Пример кода, на который анализатор выдаст предупреждение:
unsigned int x = 1U;
int y = -x;Данная диагностика классифицируется как:
|
V3533. AUTOSAR. Expression containing increment (++) or decrement (--) should not have other side effects.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Не рекомендуется использование декремента (--) или инкремента (++) в одном выражении с другими операторами. Использование этих операторов в выражении, содержащем сторонние побочные эффекты приводит к ухудшению читаемости кода, а также может привести к возникновению неопределенного поведения (undefined behaviour). Безопасным подходом будет использование рассматриваемых операторов в отдельных выражениях.
Пример кода, на который анализатор выдаст предупреждение:
i = ++i + i--;Здесь происходит попытка изменить одну переменную в пределах одной точки следования. Это приводит к неопределенному поведению (undefined behaviour).
Данная диагностика классифицируется как:
|
V3534. AUTOSAR. Incorrect shifting expression.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
При побитовом сдвиге значение правого операнда должно находиться в диапазоне [0 .. N - 1], где N - количество бит, которое необходимо для представления левого операнда. Несоблюдение этого правила ведет к неопределенному поведению.
На следующий код будут выданы соответствующие предупреждения:
(int32_t) 1 << 128u;
(unsigned int64_t) 2 >> 128u;
int64_X >>= 64u;
any_var << -2u;Рассмотрим пример из реального приложения, в котором происходит неопределенное поведение вследствие неверного побитового сдвига:
UINT32 m_color1_mask;
UINT32 m_color2_mask;
#define ARRAY_LENGTH(x) (sizeof(x) / sizeof(x[0]))
PALETTE_INIT( montecar )
{
static const UINT8 colortable_source[] =
{
0x00, 0x00, 0x00, 0x01,
0x00, 0x02, 0x00, 0x03,
0x03, 0x03, 0x03, 0x02,
0x03, 0x01, 0x03, 0x00,
0x00, 0x00, 0x02, 0x00,
0x02, 0x01, 0x02, 0x02,
0x00, 0x10, 0x20, 0x30,
0x00, 0x04, 0x08, 0x0c,
0x00, 0x44, 0x48, 0x4c,
0x00, 0x84, 0x88, 0x8c,
0x00, 0xc4, 0xc8, 0xcc
};
....
for (i = 0; i < ARRAY_LENGTH(colortable_source); i++)
{
UINT8 color = colortable_source[i];
if (color == 1)
state->m_color1_mask |= 1 << i; // <=
else if (color == 2)
state->m_color2_mask |= 1 << i; // <=
prom_to_palette(machine, i,
color_prom[0x100 + colortable_source[i]]);
}
....
}В коде в цикле на i-ой итерации сдвигают единицу на i позиций влево. В результате цикла переменная 'i' будет принимать значения в диапазоне [0 .. 43], что больше допустимого диапазона, начиная с 32-ой итерации цикла (в случае, если int - 32-х битовый тип данных).
Данная диагностика классифицируется как:
|
V3535. AUTOSAR. Operand of sizeof() operator should not have other side effects.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Оператор 'sizeof()' не выполняет переданное ему выражение, а только вычисляет тип результирующего выражения и возвращает его размер на этапе компиляции. Следовательно, для любого кода внутри 'sizeof()' компилятор не генерирует ассемблерного кода (невыполняемые контекст), и ожидаемые операции внутри не будут произведены.
Поэтому операнд, передаваемый 'sizeof()', не должен содержать каких-либо сторонних эффектов, чтобы избежать потери операций.
Пример кода, на который анализатор выдаст предупреждение:
int x = ....;
....
size_t s = n * sizeof(x++);Для получения ожидаемого эффекта нужно переписать код следующим образом:
int x = ....;
....
++x;
size_t s = n * sizeof(x);Данная диагностика классифицируется как:
|
V3536. AUTOSAR. A pointer/reference parameter in a function should be declared as pointer/reference to const if the corresponding object was not modified.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Анализатор обнаружил, что объект передается в функцию через указатель или ссылку, но не модифицируется в теле функции. Это может свидетельствовать о наличии ошибки. Также в случае, если такой аргумент функции действительно не изменяется, это делает сигнатуру функции неточной. Добавление константности объекту предотвращает потенциальные ошибки и делает определение функции более наглядным.
Пример кода, на который анализатор выдаст предупреждение:
size_t StringEval(std::string &str)
{
return str.size();
}Здесь переменная 'str' используется только для чтения, хотя она и передается по неконстантной ссылке. Явная константность в сигнатуре функции позволила бы с первого взгляда понять, что функция не изменяет объект, а также предотвратить потенциальные ошибки при изменении самой функции.
Корректный вариант кода:
size_t StringEval(const std::string &str)
{
return str.size();
}Данная диагностика классифицируется как:
|
V3537. AUTOSAR. Subtraction, >, >=, <, <= should be applied only to pointers that address elements of the same array.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Согласно стандарту C++ (C++17 § 8.5.9 п. 3) применение одного из операторов '-', '>', '>=', '<' или '<=' к двум указателям, которые не указывают на элементы одного и того же массива, приводит к неопределенному/неуточненному поведению (undefined/unspecified behaviour). Таким образом, если два указателя указывают на разные объекты массива, тогда эти объекты массива должны входить в один и тот же массив для того, чтобы сравнить их.
Пример кода, на который анализатор выдаст предупреждение:
int arr1[10];
int arr2[10];
int *pArr1 = arr1;
if (pArr1 < arr2)
{
....
}Также следующий код является ошибочным:
int arr1[10];
int arr2[10];
int *pArr1 = &arr1[1];
int *pArr2 = &arr2[1];
int len = pArr1 - pArr2;Подробнее о том, почему использование указателей может привести к ошибке можно прочитать в статье: "Указатели в C абстрактнее, чем может показаться".
Данная диагностика классифицируется как:
|
V3538. AUTOSAR. The result of an assignment expression should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Использование присвоения в подвыражениях привносит дополнительный побочный эффект, что уменьшает читаемость кода и повышает шанс внесения новой ошибки в код.
Более того, следование данному правилу значительно снижает вероятность путаницы между операторами '=' и '=='.
Пример кода, на который анализатор выдаст предупреждения:
int Inc(int i)
{
return i += 1; // <=
}
void neg(int a, int b)
{
int c = a = b; // <=
Inc(a = 1); // <=
if(a = b) {} // <=
}Данная диагностика классифицируется как:
|
V3539. AUTOSAR. Array indexing should be the only form of pointer arithmetic and it should be applied only to objects defined as an array type.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Данное правило рекомендует не использовать адресную арифметику. Единственной формой адресной арифметики, допускаемой к использованию данным правилом, является операция индексирования ('[]'), примененная к сущности, объявленной как массив.
Исключение: допускается использовать инкремент и декремент ('++' и '--').
Использование адресной арифметики усложняет чтение программы и может являться причиной неправильного понимания написанного когда. С другой стороны, использование индексирования является явным и легко читаемым, и даже если при его использовании будет внесена ошибка, её будет легче обнаружить. То же касается и операций инкремента/декремента: они явно дают понять, что мы последовательно обходим область памяти, представляющую собой непрерывную область данных.
Пример нарушения правила:
int arr[] = { 0, 1, 2 };
int *p = arr + 1; //+V2563
p += 1; //+V2563
int *q = p[1]; //+V2563Корректный вариант кода:
int arr[] = { 0, 1, 2 };
int *p = &arr[1];
++p;Данная диагностика классифицируется как:
|
V3540. AUTOSAR. There should be no implicit integral-floating conversion.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
В коде не должно быть неявных преобразований значений вещественного типа в целочисленный и наоборот.
Под целочисленными типами подразумеваются:
- 'signed char', 'unsigned char',
- 'short', 'unsigned short',
- 'int', 'unsigned int',
- 'long', 'unsinged long',
- 'long long', 'unsigned long long'.
Под типами с плавающей точкой подразумеваются:
- 'float',
- 'double',
- 'long double'.
При неявном преобразовании значений вещественных типов в целые может быть утеряна информация (например, дробная часть), а также возможно возникновение неопределенного поведения, если значение вещественного типа не может быть представлено целым типом.
Неявное преобразование значения целого типа в вещественный может привести к его неточному представлению, которое не соответствует ожиданиям разработчика.
Пример кода, на который анализатор выдаст предупреждения:
void foo1(int x, float y);
void foo2()
{
float y = 10;
int x = 10.5;
foo1(y, x);
}Пример правильного с точки зрения этой диагностики кода:
void foo1(int x, float y);
void foo2()
{
float y = static_cast<float>(10);
int x = static_cast<int>(10.5);
foo1(static_cast<int>(y), static_cast<float>(x));
}Данная диагностика классифицируется как:
|
V3541. AUTOSAR. A function should not call itself either directly or indirectly.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Функции не должны вызывать себя ни напрямую, ни косвенно. Рекурсия может привести к сложно отлавливаемым ошибкам. Одной из них может быть переполнение стека при очень глубокой рекурсии.
Пример кода, на который анализатор выдаст предупреждения:
#include <stdint.h>
uint64_t factorial(uint64_t n)
{
return n > 1 ? n * factorial(n - 1) : 1;
}По возможности, стоит заменить рекурсивный вызов циклом. Вот как это можно сделать с предыдущим примером:
#include <stdint.h>
uint64_t factorial(uint64_t n)
{
uint64_t result = 1;
for (; n > 1; --n)
{
result *= n;
}
return result;
}Данная диагностика классифицируется как:
|
V3542. AUTOSAR. Constant expression evaluation should not result in an unsigned integer wrap-around.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Согласно стандарту языка C++ в выражениях беззнаковых типов при переполнении происходит перенос значений относительно нуля. Применение этого свойства беззнаковых типов при вычислениях на этапе выполнения является известной практикой (в отличие от знаковых типов, для которых переполнение ведет к неопределенному поведению).
Однако, перенос значений относительно нуля для выражений, вычисленных на этапе компиляции, может сбивать с толку.
Пример кода, на который анализатор выдаст предупреждения:
#include <stdint.h>
#define C1 (UINT_MAX)
#define C2 (UINT_MIN)
....
void foo(unsigned x)
{
switch(x)
{
case C1 + 1U: ....; break;
case C2 - 1U: ....; break;
}
}Если в константном выражении беззнакового типа происходит перенос значения относительно нуля, то согласно текущему правилу он может трактовать не как ошибка в случае, если выражение никогда не будет вычислено:
#include <stdint.h>
#define C UINT_MAX
....
unsigned foo(unsigned x)
{
if(x < 0 && (C + 1U) == 0x42) ....;
return x + C;
}Выражение '(C + 1U)', содержащее переполнение не будет выполнено, т.к. выражение 'x < 0' всегда истинно. Следовательно, второй операнд логического выражения не будет вычислен.
Данная диагностика классифицируется как:
|
V3543. AUTOSAR. Cast should not remove 'const' / 'volatile' qualification from the type that is pointed to by a pointer or a reference.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Удаление 'const' / 'volatile' квалификаторов может привести к неопределённому поведению.
- Изменение объекта, объявленного с квалификатором 'const', через указатель/ссылку на не-'const' тип ведёт к неопределённому поведению.
- Доступ к объекту, объявленному с квалификатором 'volatile', через указатель/ссылку на не-'volatile' тип ведёт к неопределённому поведению.
Компилятор вправе оптимизировать код в случае возникновения неопределённого поведения. Например, в следующем коде компилятор может сделать цикл бесконечным:
inline int foo(bool &flag)
{
while (flag)
{
// do some stuff...
}
return 0;
}
int main()
{
volatile bool flag = true;
return foo(const_cast<bool &>(flag));
}Другой пример кода, на который анализатор выдаст предупреждения:
void my_swap(const int *x, volatile int *y)
{
auto _x = const_cast<int*>(x);
auto _y = const_cast<int*>(y);
swap(_x, _y);
}
void foo()
{
const int x = 30;
volatile int y = 203;
my_swap(&x, &y); // <=
}Данная диагностика классифицируется как:
|
V3544. AUTOSAR. The 'operator &&', 'operator ||', 'operator ,' and the unary 'operator &' should not be overloaded.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Встроенные операторы '&&', '||', '&' (взятие адреса) и ',' имеют определенный порядок вычисления и семантику. После перегрузки этих функций разработчик может не знать о потере особенностей этих операторов.
1) После перегрузки логических операторов теряется сокращенное вычисление. Для встроенных операторов, если первый операнд '&&' оказался 'false' или первый операнд '||' оказался 'true', вычисление второго операнда не происходит. В результате может быть потеряна часть оптимизаций:
class Tribool
{
public:
Tribool(bool b) : .... { .... }
friend Tribool operator&&(Tribool lhs, Tribool rhs) { .... }
friend Tribool operator||(Tribool lhs, Tribool rhs) { .... }
....
};
// Do some heavy weight stuff
bool HeavyWeightFunction();
void foo()
{
Tribool flag = ....;
if (flag || HeavyWeightFunction()) // evaluate all operands
// no short-circuit evaluation
{
// Do some stuff
}
}Здесь компилятор не сможет произвести оптимизацию, и произойдет "тяжеловесной" функции, чего бы не произошло для встроенного оператора.
2) Перегрузка унарного оператора взятия адреса '&' также может привести к неочевидной ситуации. Рассмотрим пример:
// Example.h
class Example
{
public:
Example* operator&() ;
const Example* operator&() const;
};
// Foo.cc
#include "Example.h"
void foo(Example &x)
{
&x; // call overloaded "operator&"
}
// Bar.cc
class Foobar;
void bar(Example &x)
{
&x; // may call built-in or overloaded "operator&"!
}Во втором случае, согласно стандарту С++ ($8.3.1.5) такое поведение является неуточненным, и получение адреса объекта 'x' может вызвать как встроенный оператор, так и перегруженный.
3) Встроенный оператор "запятая" выполняет левый операнд и игнорирует результат, затем вычисляет правый операнд и возвращает результат правого операнда. Также, встроенный оператор гарантирует, что все побочные эффекты левого операнда будут выполнены до того, как начнется выполнение второго операнда.
Перегруженный оператор не дает эту гарантию (до стандарта C++17), поэтому нижеприведенный код может напечатать как 'foobar', так и 'barfoo':
#include <iostream>
template <typename T1, typename T2>
T2& operator,(const T1 &lhs, T2 &rhs)
{
return rhs;
}
int main()
{
std::cout << "foo", std::cout << "bar";
return 0;
}Данная диагностика классифицируется как:
|
V3545. AUTOSAR. Operands of the logical '&&' or the '||' operators, the '!' operator should have 'bool' type.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Использование логических операторов '!', '&&' и '||' с переменными, имеющими отличный от 'bool' тип, не имеет смысла, вряд ли предназначено для этого и может указывать на присутствие ошибки. Возможно, должны были использоваться побитовые операторы ('&', '|' или '~').
Пример кода, на который анализатор выдаст предупреждение:
void Foo(int x, int y, int z)
{
if ((x + y) && z)
{
....
}
}
void Bar(int *x)
{
if (!x)
{
....
}
}Примеры правильного кода с точки зрения правила:
void Foo(int x, int y, int z)
{
if ((x + y) & z)
{
....
}
}
void Foo(int x, int y, int z)
{
if ((x < y) && (y < z))
{
....
}
}
void Bar(int *x)
{
if (x == NULL)
{
....
}
}Данная диагностика классифицируется как:
|
V3546. AUTOSAR. Conversions between pointers to objects and integer types should not be performed.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Приведения между указателями на объект и целочисленными типами могут послужить причиной неопределенного, неуточненного или зависимого от реализации поведения. В связи с этим, рекомендуется не использовать подобные приведения.
Пример нарушения 1:
struct S { int16_t i; int16_t j; } *ps = ....;
int i64 = reinterpret_cast<int>(ps);Пример нарушения 2:
void foo(int i) {}
void wrong_param_type()
{
char *pc = ....;
foo((int) pc);
}Пример нарушения 3:
int wrong_return_type()
{
double *pd = ....;
return (int) pd;
}Данная диагностика классифицируется как:
|
V3547. AUTOSAR. Identifiers that start with '__' or '_[A-Z]' are reserved.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Согласно стандарту C++ идентификаторы и имена макросов, содержащие в себе '__', либо начинающиеся на '_[A-Z]', зарезервированы для использования в реализации языка и стандартной библиотеки. В языке C тоже есть такое правило, но '__' должно быть в начале идентификатора.
Объявление таких идентификаторов снаружи стандартной библиотеки может привести к проблемам. К примеру, код ниже может изменить поведение функции 'abs':
#define _BUILTIN_abs(x) (x < 0 ? -x : x)
#include <cmath>
int foo(int x, int y, bool c)
{
return abs(c ? x : y)
}если функция 'abs' реализована через использование встроенной функции компилятора (интринсик) следующим образом:
#define abs(x) (_BUILTIN_abs(x))Данная диагностика классифицируется как:
|
V3548. AUTOSAR. Functions should not be declared at block scope.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Функция, объявленная в области видимости блока, будет видна также в пространстве имён, обрамляющем блок.
Пример кода:
namespace Foo
{
void func()
{
void bar(); // <=
bar();
}
}
void Foo::bar() // Function 'bar' is visible here
{
}Программист хотел сузить область видимости функции, задекларировав ее в блоке функции 'func'. Однако функция 'bar' видна также за пределами пространства имен 'Foo'. Поэтому следует задекларировать функцию явно в обрамляющем пространстве имен:
namespace Foo
{
void bar();
void func()
{
bar();
}
}
void Foo::bar() // Function 'bar' is visible
{
}Также, вследствие неоднозначности грамматики языка C++, декларация функции может выглядеть как декларация объекта:
struct A
{
void foo();
};
int main()
{
A a();
a.foo(); // compile-time error
}Данная проблема известна как "Most vexing parse": компилятор разрешает данную неоднозначность "задекларировать функцию или объект" в пользу "задекларировать функцию". Поэтому, несмотря на ожидание программиста задекларировать объект класса 'A' и вызвать нестатическую функцию-член класса 'A::foo', компилятор воспримет это как объявление функции 'a', не принимающей параметров и возвращающей тип 'A'.
Чтобы избежать путаницы, анализатор также предупреждает о таких объявлениях.
Данная диагностика классифицируется как:
|
V3549. AUTOSAR. The global namespace should only contain 'main', namespace declarations and 'extern "C"' declarations.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Объявления в глобальном пространстве, засоряют список доступных идентификаторов. Новые идентификаторы, добавленные в область видимости блока, могут быть схожими с идентификаторами в глобальном пространстве. Это может запутать разработчика и привести к ошибочному выбору идентификатора.
Чтобы гарантировать ожидания разработчика, все идентификаторы должны располагаться внутри соответствующих пространств имен.
Пример кода, на который анализатор выдает предупреждение:
int x1;
void foo();В соответствии с правилом данный код должен выглядеть следующим образом:
namespace N1
{
int x1;
void foo();
}Также допустимый вариант c extern "C" может выглядеть так:
extern "C"
{
int x1;
}
extern "C" void bar();Согласно стандарту AUTOSAR разрешено использовать 'typedef' в глобальном пространстве имен в том случае, если имя псевдонима типа содержит в себе размер его итогового типа.
Пример кода, на который анализатор не выдает предупреждений:
typedef short int16_t;
typedef int INT32;
typedef unsigned long long Uint64;Пример кода, на который анализатор выдает предупреждения:
typedef std::map<std::string, std::string> TestData;
typedef int type1;Данная диагностика классифицируется как:
|
V3550. AUTOSAR. The identifier 'main' should not be used for a function other than the global function 'main'.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Функция 'main' должна присутствовать только в глобальном пространстве имен, чтобы разработчик точно понимал, что если она есть, то всегда является точкой входа в программу.
Пример кода, на который анализатор выдает предупреждение:
namespace N1
{
int main();
}Другой пример со срабатыванием анализатора:
namespace
{
int main();
}Код, переписанный в соответствии с правилом, может выглядеть так:
namespace N1
{
int start();
}Данная диагностика классифицируется как:
|
V3551. AUTOSAR. An identifier with array type passed as a function argument should not decay to a pointer.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Передача массива в функцию по указателю ведет к потери размера массива. В результате функция может принять в качестве аргумента массив с меньшим количеством элементов, чем ожидается, и в процессе выполнения выйти за его границы, что приведет к неопределенному поведению.
Чтобы избежать потери информации о размере массива, его стоит передавать только по ссылке. В случае, когда функция должна обрабатывать массивы разной длины, следует использовать класс для инкапсуляции массива и его размера.
Пример кода, не соответствующего правилу:
void foo(int *ptr);
void bar(int arr[5])
void bar(const char chars[30]);
int main
{
int array[5] = { 1, 2, 3 };
foo(array);
bar(array);
}Допустимый вариант:
Void bar(int (&arr)[5]);
int main
{
int array[7] = { 1, 2, 3, 4, 5 };
bar(array);
}Другой пример кода, несоответствующий правилу:
void bar(const char chars[30]);
int main()
{
bar("something"); //const char[10]
}Допустимый вариант с использованием класса для инкапсуляции:
template <typename T>
class ArrayView
{
T *m_ptr;
size_t m_size;
public:
template <size_t N>
ArrayView(T (&arr)[N]) noexcept: m_ptr(arr), m_size(N) {}
// ....
};
void bar(ArrayView<const char> arr);
int main()
{
bar("something");
}Данная диагностика классифицируется как:
|
V3552. AUTOSAR. Cast should not convert a pointer to a function to any other pointer type, including a pointer to function type.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Приведение указателя на функцию к любому другому указателю ведет к неопределенному поведению. Приведение типов между указателями на функцию несоответствующего типа также станет причиной неопределенного поведения при вызове этой функции.
Пример кода с нарушениями правила, в котором все четыре приведения типа являются недопустимыми:
void foo(int32_t x);
typedef void (*fp)(int16_t x);
void bar()
{
fp fp1 = reinterpret_cast<fp>(&foo);
fp fp2 = (fp)foo;
void* vp = reinterpret_cast<void*>(fp1);
char* chp = (char*)fp1;
}Вызов функции через такие указатели может потенциально привести к ошибкам сегментации.
Данная диагностика классифицируется как:
|
V3553. AUTOSAR. The standard signal handling functions should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Функции стандартной библиотеки из заголовочных файлов <signal.h> / <csignal> могут быть опасны. Их поведение зависит от реализации, а их использование может привести к неопределенному поведению.
Причиной неопределенного поведения, к примеру, является использование обработчиков сигналов в многопоточной программе. С другими причинами можно ознакомиться здесь.
Анализатор выдаст предупреждение, если обнаружит использование следующих функций:
- signal;
- raise.
Пример кода, на который анализатор выдает предупреждение:
#include <csignal>
void handler(int sig) { .... }
void foo()
{
signal(SIGINT, handler);
}Данная диагностика классифицируется как:
|
V3554. AUTOSAR. The standard input/output functions should not be used.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Функции стандартной библиотеки из заголовочных файлов '<stdio.h>' / '<cstdio>' и '<wchar.h>' могут быть опасны. Их поведение зависит от реализации, а их использование может привести к неопределенному поведению.
Рассмотрим следующий фрагмент кода:
#include <stdio.h>
void InputFromFile(FILE *file); // Read from 'file'
void foo()
{
FILE *stream;
....
InputFromFile(stream);
fflush(stream);
}В коде сначала происходит чтение из потока 'stream', а затем поток передается в функцию 'fflush'. Такая последовательность операций приводит к неопределенному поведению.
Анализатор выдаст предупреждение, если обнаружит использование любых функций, определенных в заголовочных файлах '<stdio.h>' / '<cstdio>' и '<wchar.h>':
- fopen;
- fclose;
- freopen;
- fflush;
- setbuf;
- setvbuf;
- etc.
Пример кода, на который анализатор выдаст предупреждение:
#include <stdio.h>
void foo(const char *filename, FILE *oldFd)
{
FILE *newFd = freopen(filename, "r", oldFd);
....
}Данная диагностика классифицируется как:
|
V3555. AUTOSAR. The 'static' storage class specifier should be used in all declarations of functions that have internal linkage.
Данное диагностическое правило основано на руководстве AUTOSAR (AUTomotive Open System ARchitecture) по разработке программного обеспечения.
Функция, объявленная однажды с 'internal linkage', при повторном объявлении или определении будет также иметь 'internal linkage'. Это может быть неочевидно для разработчика, и поэтому следует явно указывать спецификатор 'static' в каждом объявлении и определении.
Следующий код не соответствует правилу, так как определение не отражает тип связывания, заданный в объявлении функции 'foo'.
static void foo(int x);
void foo(int x)
{
....
}Код в соответствии с правилом должен быть следующим:
static void foo(int x);
static void foo(int x)
{
....
}В примере, приведенном ниже, определение функции 'foo' со спецификатором класса хранения 'extern' не задает 'external linkage', как могло показаться. Тип связывания остается 'internal linkage':
static void foo(int x);
extern void foo(int x)
{
....
}Правильный вариант:
extern void foo(int x);
extern void foo(int x)
{
....
}Данная диагностика классифицируется как:
|
V5001. OWASP. It is highly probable that the semicolon ';' is missing after 'return' keyword.
Анализатор обнаружил фрагмент кода, в котором возможно пропущена точка с запятой ';'.
Пример кода, который приводит к выдаче диагностического сообщения V5001:
void Foo();
void Foo2(int *ptr)
{
if (ptr == NULL)
return
Foo();
...
}В данном коде планировалось завершить работу функции, если указатель ptr == NULL. Однако, после оператора return забыта точка с запятой ';', что приводит к вызову функции Foo(). Функция Foo() и Foo2() ничего не возвращают и поэтому данный код компилируется без ошибок и предупреждений.
Скорее всего, программист планировал написать:
void Foo();
void Foo2(int *ptr)
{
if (ptr == NULL)
return;
Foo();
...
}Если изначальный код все-таки корректен, то его лучше переписать следующим образом:
void Foo2(int *ptr)
{
if (ptr == NULL)
{
Foo();
return;
}
...
}Анализатор считает код безопасным, если отсутствует оператор "if" или вызов функции находится на той же строке, что и оператор "return". Такой код достаточно часто можно встретить в программах. Примеры безопасного кода:
void CPagerCtrl::RecalcSize()
{
return
(void)::SendMessageW((m_hWnd), (0x1400 + 2), 0, 0);
}
void Trace(unsigned int n, std::string const &s)
{ if (n) return TraceImpl(n, s); Trace0(s); }Данная диагностика классифицируется как:
|
V5002. OWASP. An empty exception handler. Silent suppression of exceptions can hide the presence of bugs in source code during testing.
Примечание. Данное диагностическое правило применимо только к языку C++.
Анализатор обнаружил обработчик исключения, который ничего не делает.
Пример кода:
try {
...
}
catch (MyExcept &)
{
}Конечно, такой код вовсе не обязательно ошибочный. Но очень странно просто подавлять исключение, ничего не делая. Такая обработка исключений может скрывать дефекты в программе и усложнить тестирование программы.
Следует реагировать на исключения, например, вписать 'assert(false)':
try {
...
}
catch (MyExcept &)
{
assert(false);
}Иногда подобные конструкции используют, чтобы вернуть управление из множества вложенных циклов или рекурсивных функций. Но исключения — очень ресурсоёмкая операция и их следует использовать по назначению, а именно при возникновении нештатных ситуаций, которые должны быть обработаны на более высоком уровне.
Единственное место, где допустимо просто подавлять исключения — это деструкторы. Деструктор не должен бросать исключений. Однако в деструкторах часто непонятно, что делать с исключениями, и обработчик вполне может быть пуст. Анализатор не предупреждает о пустых обработчиках внутри деструкторов:
CClass::~ CClass()
{
try {
DangerousFreeResource();
}
catch (...) {
}
}Данная диагностика классифицируется как:
V5003. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
Примечание. Данное диагностическое правило применимо только к языку C++.
Анализатор обнаружил потенциальную ошибку, связанную с использованием класса 'std::exception' или наследуемого от него класса. Анализатор выдаёт предупреждение в том случае, если создаётся объект типа 'std::exception' / 'CException', но не используется.
Пример:
if (name.empty())
std::logic_error("Name mustn't be empty");Ошибка заключается в том, что случайно забыто ключевое слово 'throw'. В результате данный код не генерирует исключение в случае ошибочной ситуации. Исправленный вариант кода:
if (name.empty())
throw std::logic_error("Name mustn't be empty");Данная диагностика классифицируется как:
|
V5004. OWASP. Consider inspecting the expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type.
Анализатор обнаружил потенциальную ошибку в выражении, содержащем операцию сдвига. В программе выполняется сдвиг 32-битного значения. Затем полученный 32-битный результат явно или неявно преобразуется в 64-битный тип.
Рассмотрим пример некорректного кода:
unsigned __int64 X;
X = 1u << N;Данный код вызывает неопределенное поведение, если значение N больше 32. На практике это означает, что с помощью этого кода не получится записать в переменную 'X' значение более 0x80000000.
Код можно исправить, если тип левого аргумента будет 64-битным.
Исправленный вариант кода:
unsigned __int64 X;
X = 1ui64 << N;Анализатор не будет выдавать предупреждение, если результат выражения со сдвигом укладывается в 32-битный тип. Это означает, что значащие биты не потеряны и код корректен.
Пример безопасного кода:
char W = 7;
long long Q = W << 10;Этот код работает следующим образом. Вначале переменная 'W' расширяется до 32-битного типа 'int'. Затем происходит сдвиг и получается значение 0x00001C00. Это число помещается в 32-битный тип, а значит ошибки не возникнет. На последнем этапе это значение расширяется до 64-битного типа 'long long' и записывается в переменную 'Q'.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V5004. |
V5005. OWASP. A value is being subtracted from the unsigned variable. This can result in an overflow. In such a case, the comparison operation can potentially behave unexpectedly.
Анализатор обнаружил потенциальную ошибку, связанную с переполнением.
Выполняются следующие действия:
- из переменной, имеющей беззнаковый тип, вычитается некоторое значение;
- полученный результат сравнивается с некоторым значением (используются операторы <, <=, >, >=).
Если при вычитании возможно переполнение, то результат проверки может отличаться от ожиданий программиста.
Рассмотрим наиболее простой случай:
unsigned A = ...;
int B = ...;
if (A - B > 1)
Array[A - B] = 'x';Такая проверка по замыслу программиста должна защитить от выхода за границу массива. Однако эта проверка не поможет, если 'A < B'.
Пусть: A = 3, B = 5;
Тогда: 0x00000003u - 0x00000005i = FFFFFFFEu
Выражение 'A – B', согласно правилам языков C и C++, имеет тип 'unsigned int'. Значит, 'A – B' будет равно FFFFFFFEu. Это число больше единицы. В результате произойдёт обращение к памяти за границей массива.
Исправить код можно двумя способами. Во-первых, вычисления можно производить в переменных знаковых типов:
intptr_t A = ...;
intptr_t B = ...;
if (A - B > 1)
Array[A - B] = 'x';Во-вторых, можно изменить условие. Как именно следует изменить условие, зависит от желаемого результата и входных значений. Если 'B >= 0', то достаточно будет написать:
unsigned A = ...;
int B = ...;
if (A > B + 1)
Array[A - B] = 'x';Если код корректен, то можно отключить вывод диагностического сообщения в данной строке, используя комментарий '//-V5005'.
Данная диагностика классифицируется как:
|
V5006. OWASP. More than N bits are required to store the value, but the expression evaluates to the T type which can only hold K bits.
Анализатор обнаружил потенциальную ошибку в выражении, где используются операции сдвига (shift operations). В процессе сдвига возникает переполнение, и значения старших бит будут потеряны.
Для начала рассмотрим эту ситуацию на простом примере:
std::cout << (77u << 26);Значение выражения 77u << 26 равно 5167382528 (0x134000000). При этом выражение 77u << 26 имеет тип unsigned int. Это значит, что старшие биты будут отброшены, и будет напечатано значение 872415232 (0x34000000).
Переполнения, возникающие при сдвигах, часто указывают на наличие логической ошибки или просто опечатки. Например, может быть, что число 77u хотели задать в восьмеричной системе счисления. Тогда корректный код должен выглядеть так:
std::cout << (077u << 26);Здесь переполнения уже не возникает. Значение выражения 077u << 26 равно 4227858432 (0xFC000000).
Если хочется распечатать значение 5167382528, то число 77 должно быть задано с помощью 64-битного типа. Например, так:
std::cout << (77ui64 << 26);Перейдём к случаям, с которыми можно встретиться на практике. Для этого рассмотрим две ошибки, обнаруженные в реальных приложениях.
Первый пример.
typedef __UINT64 Ipp64u;
#define MAX_SAD 0x07FFFFFF
....
Ipp64u uSmallestSAD;
uSmallestSAD = ((Ipp64u)(MAX_SAD<<8));Программист хотел записать в 64-битную переменную uSmallestSAD значение 0x7FFFFFF00. Но на самом деле переменная будет иметь значение 0xFFFFFF00. Старшие биты будут отброшены, так как выражение MAX_SAD<<8 имеет тип int. Программист знал про это, поэтому решил использовать явное приведение типа, но ошибся, расставляя скобки. Этот пример хорошо демонстрирует, что подобные ошибки могут возникать из-за простой опечатки. Корректный код:
uSmallestSAD = ((Ipp64u)(MAX_SAD))<<8;Второй пример.
#define MAKE_HRESULT(sev,fac,code) \
((HRESULT) \
(((unsigned long)(sev)<<31) | \
((unsigned long)(fac)<<16) | \
((unsigned long)(code))) )
*hrCode = MAKE_HRESULT(3, FACILITY_ITF, messageID);Функция должна сформировать информацию об ошибке в переменной типа HRESULT. Для этого программист использовал макрос MAKE_HRESULT, но сделал это неправильно, посчитав, что первый параметр severity может лежать в приделах от 0 до 3. Вероятно, он перепутал это со способом формирования кодов ошибки, используемом при работе с функциями GetLastError() / SetLastError().
Макрос MAKE_HRESULT в качестве первого аргумента может принимать только 0 (success) или 1 (failure). Подробнее этот вопрос рассматривался на форуме сайта CodeGuru: Warning! MAKE_HRESULT macro doesn't work.
Так как в качестве первого фактического аргумента используется число 3, то возникает переполнение. Число 3 "превратится" в 1. Из-за этой случайности ошибка не повлияет на работу программы. Однако приведённый пример показывает, что нередко код работает исключительно благодаря везению, а не потому, что написан правильно.
Правильный код:
*hrCode = MAKE_HRESULT(SEVERITY_ERROR, FACILITY_ITF, messageID);Данная диагностика классифицируется как:
|
V5007. OWASP. Consider inspecting the loop expression. It is possible that the 'i' variable should be incremented instead of the 'n' variable.
Анализатор обнаружил потенциальную ошибку в цикле. Возможно, из-за опечатки увеличивается/уменьшается не та переменная.
Пример подозрительного кода:
void Foo(float *Array, size_t n)
{
for (size_t i = 0; i != n; ++n)
{
....
}
}Вместо переменной 'i' увеличивается переменная 'n'. В результате, программа ведёт себя не так, как ожидал программист.
Исправленный вариант кода:
for (size_t i = 0; i != n; ++i)Данная диагностика классифицируется как:
|
V5008. OWASP. Classes should always be derived from std::exception (and alike) as 'public'.
Примечание. Данное диагностическое правило применимо только к языку C++.
Анализатор обнаружил класс, унаследованный от класса 'std::exception' (или аналогичных классов) через модификатор 'private' или 'protected'. Данное наследование опасно тем, что при непубличном наследовании при попытке поймать исключение 'std::exception', оно будет пропущено.
Ошибка часто возникает из-за того, что забывают указать тип наследования. В соответствии с правилами языка, наследование по умолчанию приватное. Как результат, обработчики исключений ведут себя не так, как задумывалось.
В качестве примера можно привести следующий некорректный код:
class my_exception_t : std::exception // <=
{
public:
explicit my_exception_t() { }
virtual const int getErrorCode() const throw() { return 42; }
};
....
try
{ throw my_exception_t(); }
catch (const std::exception & error)
{ /* Can't get there */ }
catch (...)
{ /* This code executed instead */ }Код, который должен будет перехватывать все стандартные и пользовательские исключения (catch (const std::exception & error)), не сможет отработать правильно, потому что приватное наследование исключает неявное преобразование типов.
Для того, чтобы код работал корректно, требуется добавить перед родительским классом 'std::exception' в списке базовых классов модификатор 'public':
class my_exception_t : public std::exception
{
....
}Данная диагностика классифицируется как:
|
V5009. OWASP. Unchecked tainted data is used in expression.
Анализатор обнаружил использование данных, полученных извне, без предварительной проверки. Такой сценарий излишнего доверия может привести к различным негативным последствиям, в том числе - стать причиной уязвимостей.
На данный момент диагностическое правило V5009 выявляет ошибки по нескольким паттернам:
- Использование недостоверных данных в выражении, используемом как индекс.
- Использование недостоверных данных в качестве аргумента функции, который должен содержать проверенные данные.
- Порча указателя за счёт изменения его значения с использованием недостоверных данных.
- Деление на недостоверные данные.
Рассмотрим все паттерны более подробно.
Пример подозрительного кода при использовании в индексе недостоверных данных.
size_t index = 0;
....
if (scanf("%zu", &index) == 1)
{
....
DoSomething(arr[index]); // <=
}Данный код может привести к доступу за границу массива 'arr' в случае, если пользователем будет введено значение отрицательное или превышающее максимально допустимый индекс массива 'arr'.
Безопасный код проверяет полученное значение:
if (index < ArraySize)
DoSomething(arr[index]);Пример подозрительного кода при использовании недостоверных данных в аргументе функции.
char buf[1024];
char username [256];
....
if (scanf("%255s", username) == 1)
{
if (snprintf(buf, sizeof(buf) - 1, commandFormat, username) > 0)
{
int exitCode = system(buf); // <=
....
}
....
}Этот код является уязвимым, т.к. пользовательский ввод передаётся командному интерпретатору без проверки полученных данных. Например, введя "&cmd", на Windows можно получить доступ к командному интерпретатору.
Правильный код должен осуществлять дополнительную проверку считанных данных:
if (IsValid(username))
{
if (snprintf(buf, sizeof(buf) - 1, commandFormat, username) > 0)
{
int exitCode = system(buf);
....
}
....
}
else
{
printf("Invalid username: %s", username);
....
}Пример подозрительного кода, связанного с порчей указателя.
size_t offset = 0;
int *pArr = arr;
....
if (scanf("%zu", &offset) == 1)
{
pArr += offset; // <=
....
DoSomething(pArr);
}В данном случае портится значение указателя 'pArr', т.к. в результате прибавления непроверенного значения 'offset' указатель может начать ссылаться за пределы массива. В результате можно испортить какие-то данные (на которые будет ссылаться 'pArr') с непредсказуемыми последствиями.
Правильный код проверяет допустимое смещение:
if (offset <= allowableOffset)
{
pArr += offset;
....
DoSomething(pArr);
}Пример подозрительного кода с делением на недостоверные данные:
if (fscanf(stdin, "%zu", &denominator) == 1)
{
targetVal /= denominator;
}Этот код может привести к делению на 0, если соответствующее значение будет введено пользователем.
Корректный код выполняет проверку допустимости значений:
if (fscanf(stdin, "%zu", &denominator) == 1)
{
if (denominator > MinDenominator && denominator < MaxDenominator)
{
targetVal /= denominator;
}
}Данная диагностика классифицируется как:
V5010. OWASP. The variable is incremented in the loop. Undefined behavior will occur in case of signed integer overflow.
Анализатор обнаружил возможное переполнение знаковой переменной в цикле. Переполнение знаковых переменных приводит к неопределённому поведению.
Пример:
int checksum = 0;
for (....) {
checksum += ....;
}Перед нами абстрактный алгоритм подсчёта контрольной суммы. Алгоритм подразумевает возможность переполнения переменной 'checksum'. Однако переменная имеет знаковый тип, а, следовательно, её переполнение приводит к неопределённому поведению. Код некорректен и должен быть модифицирован.
Следует использовать беззнаковые типы, семантика переполнения которых определена.
Корректный код:
unsigned checksum = 0;
for (....) {
checksum += ...
}Некоторые программисты считают, что в переполнении знаковых переменных ничего страшного нет и они могут предсказать, как программа будет работать. Это не так. Может происходить всё что угодно.
Давайте рассмотрим, как могут проявляться ошибки этого типа на практике. Разработчик на форуме жалуется, что GCC глючит и неправильно компилирует его код в режиме оптимизации. Он приводит код следующей функции для подсчёта хеша строки:
int foo(const unsigned char *s)
{
int r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return r & 0x7fffffff;
}Претензия разработчика в том, что компилятор не генерирует код для оператора побитового И (&). Из-за этого функция возвращает отрицательные значения, хотя не должна.
Разработчик считает, что это глюк в компиляторе. Но это не так, неправ программист, который написал такой код. Функция работает неправильно из-за того, что в ней возникает неопределённое поведение.
Компилятор видит, что в переменной 'r' считается некоторая сумма. Переполнения переменной 'r' произойти не должно. Иначе это неопределённое поведение, которое компилятор никак не должен рассматривать и учитывать. Итак, компилятор считает, что раз переменная 'r' после окончания цикла не может быть отрицательной, то операция 'r & 0x7fffffff' для сброса знакового бита является лишней и компилятор просто возвращает из функции значение переменной 'r'.
Диагностика V5010 как раз и предназначена для выявления подобных ошибок. Чтобы исправить код, достаточно считать хеш, используя для этого беззнаковую переменную.
Исправленный вариант кода:
int foo(const unsigned char *s)
{
unsigned r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return (int)(r & 0x7fffffff);
}Дополнительные ссылки:
- Андрей Карпов. Undefined behavior ближе, чем вы думаете.
- Will Dietz, Peng Li, John Regehr, and Vikram Adve. Understanding Integer Overflow in C/C++.
Данная диагностика классифицируется как:
|
V5011. OWASP. Possible overflow. Consider casting operands, not the result.
Анализатор обнаружил подозрительное приведение типов. Результат бинарной операции над 32-битными числами приводят к 64-битному типу.
Пример кода с ошибкой:
unsigned a;
unsigned b;
....
uint64_t c = (uint64_t)(a * b);Такое преобразование избыточно. Тип 'unsigned' и так бы автоматически расширился до типа 'uint64_t' при присваивании.
Скорее всего, программист хотел защититься от переполнения, но не достиг цели. При перемножении переменных типа 'unsigned' всё равно произойдёт переполнение, и только уже бессмысленный результат умножения будет явно расширен до типа 'uint64_t'.
Следовало привести один из аргументов к этому типу, чтобы избежать переполнения. Корректный код:
uint64_t c = (uint64_t)a * b;Данная диагностика классифицируется как:
|
V5012. OWASP. Potentially unsafe double-checked locking.
Анализатор обнаружил потенциальную ошибку, связанную с небезопасным использованием паттерна "блокировки с двойной проверкой" (double checked locking). Блокировка с двойной проверкой - это паттерн, предназначенный для уменьшения накладных расходов получения блокировки. Сначала проверяется условие блокировки без синхронизации. И только если условие выполняется, поток попытается получить блокировку. Таким образом, блокировка будет выполнена только если она действительно была необходима.
Рассмотрим пример с ошибкой:
static std::mutex mtx;
class TestClass
{
public:
void Initialize()
{
if (!initialized)
{
std::lock_guard lock(mtx);
if (!initialized) // <=
{
resource = new SomeType();
initialized = true;
}
}
}
/* .... */
private:
bool initialized = false;
SomeType *resource = nullptr;
};
}В этом примере, оптимизация компилятором порядка назначений переменных 'resource' и 'initialized' может привести к ошибке. Т.е. в начале переменной 'initialized' будет присвоено значение 'true', а уже потом будет выделена память под объект типа 'SomeType' и проинициализирована переменная 'resource'.
Такая перестановка может привести к ошибке при доступе к объекту из параллельного потока. Получается, что переменная 'resource' будет еще не проинициализирована, а флаг 'intialized' уже будет выставлен в 'true'.
Одна из опасностей таких ошибок состоит в том, что часто кажется, будто программа работает корректно. Это происходит из-за того, что рассмотренная ситуация будет возникать не очень часто, в зависимости от архитектуры используемого процессора.
Дополнительные ссылки:
- Scott Meyers and Andrei Alexandrescu. C++ and the Perils of Double-Checked Locking.
- Stack Overflow. What the correct way when use Double-Checked Locking with memory barrier in c++?
Данная диагностика классифицируется как:
|
V5013. OWASP. Storing credentials inside source code can lead to security issues.
Анализатор обнаружил в коде данные, которые могут являться конфиденциальными. В качестве таких данных могут выступать учётные данные.
Хранение учетных данных в исходном коде может привести к нарушению контроля доступа к данным и возможностям, не предназначенным для публичного использования. Имея доступ к сборке, злоумышленник при помощи дизассемблера сможет увидеть все строковые литералы, которые в ней используются. В случае open-source проектов всё ещё проще, так как злоумышленник может изучать непосредственно исходный код.
Таким образом, все секретные данные могут оказаться публично доступными. Уязвимости, связанные с недостаточной защищённостью конфиденциальных данных, выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A2:2017-Broken Authentication.
Рассмотрим пример:
bool LoginAsAdmin(const std::string &userName,
const std::string &password)
{
if (userName == "admin" && password == "sRbHG$a%")
{
....
return true;
}
return false;
}В указанном примере пароль, используемый для входа в систему с правами администратора, хранится в коде. И злоумышленник может легко получить данные для авторизации, а, следовательно, все возможности администратора системы.
Вместо хранения секретных данных в коде лучше использовать, например, классы-хранилища, в которых данные будут храниться в зашифрованном виде и к которым у обычных пользователей нет прямого доступа. В таком случае код может выглядеть, например, так:
bool LoginAsAdmin(const DataStorage &secretStorage,
const std::string &userName,
const std::string &password)
{
var adminData = secretStorage.GetAdminData();
if ( userName == adminData.UserName
&& password == adminData.Password)
{
....
return true;
}
return false;
}Данная диагностика классифицируется как:
V5014. OWASP. Cryptographic function is deprecated. Its use can lead to security issues. Consider switching to an equivalent newer function.
Анализатор обнаружил вызов устаревшей криптографической функции. Использование такой функции может повлечь за собой проблемы с безопасностью.
Рассмотрим следующий пример:
BOOL ImportKey(HCRYPTPROV hProv, LPBYTE pbKeyBlob, DWORD dwBlobLen)
{
HCRYPTKEY hPubKey;
if (!CryptImportKey(hProv, pbKeyBlob, dwBlobLen, 0, 0, &hPubKey))
{
return FALSE;
}
if (!CryptDestroyKey(hPubKey))
{
return FALSE;
}
return TRUE;
}Согласно документации Microsoft функции 'CryptoImportKey' и 'CryptoDestroyKey' устарели. Их следует заменить на безопасные аналоги из Cryptography Next Generation ('BCryptoImportKey' и 'BCryptoDestroyKey'):
BOOL ImportKey(BCRYPT_ALG_HANDLE hAlgorithm,
BCRYPT_ALG_HANDLE hImportKey,
BCRYPT_KEY_HANDLE* phKey,
PUCHAR pbInput,
ULONG cbInput,
ULONG dwFlags)
{
if (!BCryptImportKey(
hAlgorithm,
hImportKey,
BCRYPT_AES_WRAP_KEY_BLOB,
phKey,
NULL,
0,
pbInput,
cbInput,
dwFlags))
{
return FALSE;
}
if (!BCryptDestroyKey(phKey))
{
return FALSE;
}
return TRUE;
}Данное диагностическое правило применяется к устаревшим криптографическим функциям Windows API, Linux Kernel Crypto API и GnuPG Made Easy.
Если вам необходимо самостоятельно разметить нежелательные функции, то вы можете воспользоваться механизмом аннотирования функций и диагностическим правилом V2016.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V5601. OWASP. Storing credentials inside source code can lead to security issues.
Анализатор обнаружил в коде данные, которые могут являться конфиденциальными.
В качестве таких данных могут выступать, например, пароли. Их хранение в исходном коде может привести к нарушению контроля доступа к данным и возможностям, не предназначенным для публичного использования. Имея доступ к сборке, любой пользователь сможет увидеть все строковые литералы, которые в ней используются. Для этого достаточно рассмотреть метаданные или изучить IL-код, используя утилиту ildasm. В случае open-source проектов всё ещё проще, так как злоумышленник может изучать непосредственно исходный код.
Таким образом, все секретные данные могут оказаться публично доступными. Уязвимости, связанные с недостаточной защищённостью конфиденциальных данных, выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A2:2017-Broken Authentication.
Рассмотрим пример:
bool LoginAsAdmin(string userName, string password)
{
if (userName == "admin" && password == "sRbHG$a%")
{
....
return true;
}
return false;
}В указанном примере пароль, используемый для входа в систему с правами администратора, хранится в коде. Изучив метаданные сборки или IL-код, злоумышленник может легко получить данные для авторизации, а следовательно - все возможности администратора системы.
Вместо хранения секретных данных в коде лучше использовать, например, хранилища, в которых данные будут храниться в зашифрованном виде и к которым у обычных пользователей нет прямого доступа. В таком случае код может выглядеть, например, так:
bool LoginAsAdmin(DataStorage secretStorage,
string userName,
string password)
{
var adminData = secretStorage.GetAdminData();
if ( userName == adminData.UserName
&& password == adminData.Password)
{
....
return true;
}
return false;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5602. OWASP. The object was created but it is not being used. The 'throw' keyword could be missing.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что создаётся экземпляр класса, унаследованного от 'System.Exception', но при этом никак не используется.
Пример ошибочного кода:
public void DoSomething(int index)
{
if (index < 0)
new ArgumentOutOfRangeException();
else
....
}В данном коде пропущен оператор 'throw', из-за чего будет только создан экземпляр класса, унаследованного от 'System.Exception', но при этом он никак не будет использоваться, и исключение не будет сгенерировано. Корректный код может выглядеть следующим образом:
public void DoSomething(int index)
{
if (index < 0)
throw new ArgumentOutOfRangeException();
else
....
}Данная диагностика классифицируется как:
|
V5603. OWASP. The original exception object was swallowed. Stack of original exception could be lost.
Анализатор обнаружил ситуацию, когда исходный объект перехваченного исключения не был использован приемлемым образом при повторной генерации исключения из блока catch. Из-за этого ряд ошибок превращается в трудноотлаживаемые, так как теряется стек оригинального исключения.
Рассмотрим несколько примеров некорректного кода. Первый пример:
public Asn1Object ToAsn1Object()
{
try
{
return Foo(_constructed, _tagNumber);
}
catch (IOException e)
{
throw new ParsingException(e.Message);
}
}В данном случае перехваченное исключение ввода/вывода хотели трансформировать в другое исключение типа 'ParsingException'. При этом передали только сообщение из первого исключения, тем самым сократив количество полезной информации.
Корректный вариант кода:
public Asn1Object ToAsn1Object()
{
try
{
return Foo(_constructed, _tagNumber);
}
catch (IOException e)
{
throw new ParsingException(e.Message, e);
}
}В исправленном варианте исходное исключение передается в качестве внутреннего, что полностью сохраняет информацию об исходной ошибке.
Рассмотрим второй пример:
private int ReadClearText(byte[] buffer, int offset, int count)
{
int pos = offset;
try
{
....
}
catch (IOException ioe)
{
if (pos == offset) throw ioe;
}
return pos - offset;
}В данном случае перехваченное исключение ввода/вывода генерируется повторно и полностью "затирает" стек оригинальной ошибки. Чтобы этого избежать, достаточно сделать переброс оригинального исключения.
Корректный вариант кода:
private int ReadClearText(byte[] buffer, int offset, int count)
{
int pos = offset;
try
{
....
}
catch (IOException ioe)
{
if (pos == offset) throw;
}
return pos - offset;
}Данная диагностика классифицируется как:
|
V5604. OWASP. Potentially unsafe double-checked locking. Use volatile variable(s) or synchronization primitives to avoid this.
Анализатор обнаружил потенциальную ошибку, связанную с небезопасным использованием шаблона "блокировки с двойной проверкой" (double checked locking). Блокировка с двойной проверкой - это шаблон, предназначенный для уменьшения накладных расходов получения блокировки. Сначала проверяется условие блокировки без синхронизации. И только если условие выполняется, поток попытается получить блокировку. Таким образом, блокировка будет выполнена только если она действительно была необходима.
Рассмотрим пример небезопасной реализации данного шаблона на языке C#:
private static MyClass _singleton = null;
public static MyClass Singleton
{
get
{
if(_singleton == null)
lock(_locker)
{
if(_singleton == null)
{
MyClass instance = new MyClass();
instance.Initialize();
_singleton = instance;
}
}
return _singleton;
}
}В данном примере шаблон используется для реализации "ленивой инициализации" - инициализация откладывается до тех пор, пока значение переменной не понадобится. Данный код будет корректно работать в программе, использующей объект '_singleton' из одного потока. Для обеспечения безопасной инициализации в многопоточной программе обычно используется конструкция 'lock', однако в нашем примере этого оказывается недостаточно.
Обратите внимание на вызов метода 'Initialize()' у объекта 'Instance'. В Release версии программы, компилятор может оптимизировать данный код и порядок назначения переменной '_singleton' и метода 'Initialize()' могут поменяться. Таким образом, другой поток, обратившись к 'Singleton' одновременно с инициализирующим потоком, может получить доступ к объекту до того, как инициализация будет завершена.
Рассмотрим другой пример использования шаблона блокировки с двойной проверкой:
private static MyClass _singleton = null;
private static bool _initialized = false;
public static MyClass Singleton;
{
get
{
if(!_initialized)
lock(_locker)
{
if(!_initialized)
{
_singleton = new MyClass();
_initialized = true;
}
}
return _singleton;
}
}Мы видим, что, как и в предыдущем примере, оптимизация компилятором порядка назначений переменных '_singleton' и '_initialized' может привести к ошибке. Т.е. в начале переменной '_initialized' будет присвоено значение 'true', а уже потом создастся новый объект типа 'MyClass' и ссылка не него будет записана в '_singleton'.
Такая перестановка может привести к ошибке при доступе к объекту из параллельного потока. Получается, что переменная '_singleton' будет ещё не назначена, а флаг '_intialize' уже будет выставлен в 'true'.
Одна из опасностей таких ошибок состоит в том, что часто кажется, будто программа работает корректно. Это происходит из-за того, что рассмотренная ситуация будет возникать не очень часто, в зависимости от архитектуры используемого процессора, версии CLR и т.п.
Есть несколько способов обеспечить потоко-безопасность для данного шаблона. Самым простым будет пометить проверяемую в условии if переменную ключевым словом volatile:
private static volatile MyClass _singleton = null;
public static MyClass Singleton
{
get
{
if(_singleton == null)
lock(_locker)
{
if(_singleton == null)
{
MyClass instance = new MyClass();
instance.Initialize();
_singleton = instance;
}
}
return _singleton;
}
}Использование ключевого слова 'volatile' предотвратит для переменной возможные оптимизации компилятора, связанные с перестановками инструкций записи\чтения и кэшированием её значения в регистрах процессора.
Из соображений производительности не всегда желательно объявлять переменную как 'volatile'. В этом случае можно организовать доступ к переменной с помощью методов: 'Thread.VolatileRead', 'Thread.VolatileWrite' и 'Thread.MemoryBarrier'. Эти методы создадут барьеры по чтению\записи памяти только там, где это необходимо.
Наконец, для реализации "ленивой инициализации" можно воспользоваться специально предназначенным для этого классом 'Lazy<T>', доступным начиная с .NET 4.
См. также статью: Выявление неправильной блокировки с двойной проверкой с помощью диагностики V3054.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
V5605. OWASP. Unsafe invocation of event, NullReferenceException is possible. Consider assigning event to a local variable before invoking it.
Анализатор обнаружил потенциально небезопасный вызов обработчика события (event). Возможно возникновение исключения 'NullReferenceException'.
Рассмотрим пример опасного кода:
public event EventHandler MyEvent;
void OnMyEvent(EventArgs e)
{
if (MyEvent != null)
MyEvent(this, e);
}В данном примере происходит проверка на 'null' поля 'MyEvent', и затем происходит вызов данного события. Проверка на 'null' позволит избежать исключения в случае, если на событие никто не подписан на момент его вызова (в такой ситуации 'MyEvent' будет иметь значение 'null').
Однако, представим, что у события 'MyEvent' есть один подписчик. И в момент между проверкой на 'null' и непосредственными вызовом обработчика события по 'MyEvent()' существует вероятность, что будет произведена отписка от события, например, в другом потоке:
MyEvent -= OnMyEventHandler;Теперь, если обработчик 'OnMyEventHandler' был единственным подписчиком события 'MyEvent', поле 'MyEvent' примет значение 'null'. Но, т.к., в другом потоке, где событие должно будет быть вызвано, в нашем гипотетическом примере проверка на 'null' уже произошла, будет выполнена следующая строка: 'MyEvent()'. Это приведёт к возникновению исключения 'NullReferenceException'.
Как мы видим, одной проверки на 'null' недостаточно, чтобы гарантировать безошибочное выполнение вызова события. Существует несколько способов, позволяющих избежать описанной выше потенциальной ошибки. Рассмотрим их.
Первый способ заключается в создании временной локальной переменной, в которую мы сохраняем ссылку на обработчики нашего события:
public event EventHandler MyEvent;
void OnMyEvent(EventArgs e)
{
EventHandler handler = MyEvent;
if (handler != null)
handler(this, e);
}Это позволит выполнить обработчики события без возникновения исключения. Даже если между проверкой 'handler' на 'null' и вызовом обработчика произойдёт отписка от события, как в нашем первом примере, переменная 'handler' всё равно будет содержать ссылку на первоначальный обработчик. И он будет корректно вызван несмотря на то, событие 'MyEvent' уже не содержит данный обработчик.
Другой способ избежать ошибки - изначально присвоить событию пустой обработчик в виде анонимного метода или лямбда выражения:
public event EventHandler MyEvent = (sender, args) => {};Такой код гарантирует, что поле 'MyEvent' никогда не будет иметь значения 'null', т.к. такой анонимный метод невозможно будет отписать (если он конечно не сохранён в отдельной переменной), что также позволяет избавиться от проверки на 'null' перед вызовом события.
Наконец, начиная с версии языка C# 6.0 (Visual Studio 2015), можно обеспечить безопасный вызов события с помощью оператора '?.':
MyEvent?.Invoke(this, e);Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
V5606. OWASP. An exception handling block does not contain any code.
Анализатор обнаружил пустой блок обработки исключения ('catch' или 'finally'). Отсутствие корректной обработки исключений может привести к снижению уровня надёжности приложения.
В некоторых случаях отсутствие корректной обработки исключительных ситуаций может стать причиной возникновения уязвимости. Недостаточное логирование и мониторинг выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A10:2017-Insufficient Logging & Monitoring.
Пример кода с пустым 'catch':
try
{
someCall();
}
catch
{
}Конечно, такой код вовсе не обязательно ошибочен. Но очень странно просто подавлять исключение, ничего не делая, так как такая обработка исключений может скрывать дефекты в программе.
В качестве обработки исключения можно использовать, например, логгирование. Это по крайней мере не позволит исключительной ситуации остаться незамеченной:
try
{
someCall();
}
catch (Exception e)
{
Logger.Log(e);
}Не менее подозрительным моментом является наличие в коде пустого блока 'finally'. Это может свидетельствовать о том, что какая-то логика, необходимая для надёжной работы приложения, не реализована. Например:
try
{
someCall();
}
catch
{ .... }
finally
{
}Подобный код с большой вероятностью свидетельствует об ошибке или попросту избыточен. В отличие от пустого блока 'catch', который может быть использован для подавления исключения, у пустого блока 'finally' нет какого-либо практического применения.
Данная диагностика классифицируется как:
V5607. OWASP. Exception classes should be publicly accessible.
Анализатор обнаружил класс исключения, недоступного для других сборок. Если такое исключение будет выброшено, внешний код будет вынужден отлавливать объекты ближайшего доступного предка или вообще базового класса всех исключений – 'Exception'. В этом случае усложняется обработка конкретных исключительных ситуаций, ведь код других сборок не может чётко идентифицировать возникшую проблему.
Отсутствие чёткой идентификации возникшей проблемы несёт дополнительные риски с точки зрения безопасности, так как для каких-то определённых исключительных ситуаций может понадобиться специфичная обработка, а не общая. Недостаточное логирование и мониторинг (в том числе, обнаружение проблем) выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A10:2017-Insufficient Logging & Monitoring.
Простой пример из реального проекта:
internal sealed class ResourceException : Exception
{
internal ResourceException(string? name, Exception? inner = null)
: base(name, inner)
{
}
}Чтобы можно было корректно обработать конкретную исключительную ситуацию, необходимо задать в объявлении класса модификатор доступности 'public':
public sealed class ResourceException : Exception
{
internal ResourceException(string? name, Exception? inner = null)
: base(name, inner)
{
}
}Теперь другие сборки смогут отлавливать данное исключение и обрабатывать конкретную ситуацию.
Следует учитывать, что для вложенных классов модификатора 'public' у объявления исключения может быть недостаточно. Например:
namespace SomeNS
{
class ContainingClass
{
public class ContainedException : Exception {}
....
}
}В данном примере класс исключения вложен в 'ContainingClass', который неявно объявлен как 'internal'. Вследствие этого 'ContainedException' также будет видим только в пределах текущей сборки, хотя он и помечен модификатором 'public'. Анализатор обнаруживает такие случаи и выдаёт соответствующие предупреждения.
Данная диагностика классифицируется как:
|
V5608. OWASP. Possible SQL injection. Potentially tainted data is used to create SQL command.
Анализатор обнаружил создание SQL-команды из данных, полученных из внешнего источника, без предварительной проверки. Это может стать причиной возникновения SQL-инъекции в случае, если данные будут скомпрометированы.
SQL инъекции выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A1:2017-Injection.
Рассмотрим пример:
void ProcessUserInfo()
{
using (SqlConnection connection = new SqlConnection(_connectionString))
{
....
String userName = Request.Form["userName"];
using (var command = new SqlCommand()
{
Connection = connection,
CommandText = "SELECT * FROM Users WHERE UserName = '" + userName + "'",
CommandType = System.Data.CommandType.Text
})
{
using (var reader = command.ExecuteReader())
....
}
}
}В данном случае при формировании SQL-команды используется значение переменной 'userName', полученной из внешнего источника — 'Request.Form'. Использование данных без какой-либо проверки является опасным, так как открывает злоумышленникам разные способы внедрения команд.
Например, вместо ожидаемого значения имени пользователя злоумышленник может ввести специальную команду. Тогда из базы произойдёт извлечение данных всех пользователей, для которых будет запущена дальнейшая обработка.
Пример такой скомпрометированной строки:
' OR '1'='1Для защиты от подобных запросов следует проводить валидацию входных данных или, например, использовать параметризованные команды.
Пример кода с использованием параметризированных команд:
void ProcessUserInfo()
{
using (SqlConnection connection = new SqlConnection(_connectionString))
{
....
String userName = Request.Form["userName"];
using (var command = new SqlCommand()
{
Connection = connection,
CommandText = "SELECT * FROM Users WHERE UserName = @userName",
CommandType = System.Data.CommandType.Text
})
{
var userNameParam = new SqlParameter("@userName", userName);
command.Parameters.Add(userNameParam);
using (var reader = command.ExecuteReader())
....
}
}
}Анализатор также считает небезопасными источниками параметры методов, доступных из других сборок. Пользователи таких сборок могут рассчитывать на то, что валидация данных будет происходить внутри вызываемого метода. Однако, так как ни пользователь библиотеки, ни её разработчик не провели валидацию входных данных, это может стать причиной возникновения уязвимостей при использовании скомпрометированных данных.
Рассмотрим пример:
public class DBHelper
{
public void ProcessUserInfo(String userName)
{
....
var command = "SELECT * FROM Users WHERE userName = '" + userName + "'";
ExecuteCommand(command);
....
}
private void ExecuteCommand(String rawCommand)
{
using (SqlConnection connection = new SqlConnection(_connectionString))
{
....
using (var sqlCommand = new SqlCommand(rawCommand, connection))
{
using (var reader = sqlCommand.ExecuteReader())
....
}
}
}
}Класс 'DBHelper' предоставляет метод 'ProcessUserInfo' для внешнего использования, так как он доступен из других сборок. Однако параметр этого метода - 'userName' - никак не проверяется перед использованием. Значение, полученное извне, напрямую используется для формирования команды (переменная 'command'). Далее полученная команда передаётся в метод 'ExecuteCommand', где без проверки используется для создания объекта типа 'SQLCommand'.
В данном случае анализатор выдаст предупреждение на вызов метода 'ExecuteCommand', принимающего в качестве аргумента заражённую строку.
Теперь рассмотрим возможный вариант использования метода 'ProcessUserInfo':
static void TestHelper(DBHelper helper)
{
var userName = Request.Form["userName"];
helper.ProcessUserInfo(userName);
}Разработчик, написавший подобный код, может не иметь доступа к коду класса 'DBHelper' и рассчитывать на то, что валидация входных данных будет происходить внутри метода 'ProcessUserInfo'. Так как ни текущий код, ни код метода 'ProcessUserInfo' не провёл валидацию данных, этот код будет уязвимым для SQL инъекций.
Хотя подобные случаи могут привести к возникновению уязвимости, явного внешнего источника данных при анализе кода 'DBHelper' нет. Поэтому анализатор выдаст предупреждение с низким уровнем достоверности, если источником входных данных считаются параметры методов, доступных внешним сборкам.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5609. OWASP. Possible path traversal vulnerability. Potentially tainted data is used as a path.
Анализатор обнаружил, что данные, полученные из внешнего источника, используются в качестве путей к файлам или папкам без предварительной проверки. Это может стать причиной уязвимости приложения к атакам path traversal.
Атаки этого типа выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A5:2017-Broken Access Control.
Рассмотрим пример:
HttpResponse response;
HttpRequest request;
private void SendUserFileContent(string userDirectory)
{
....
string userFileRelativePath = request.QueryString["relativePath"];
string fullPath = Path.Combine(userDirectory,
userFileRelativePath);
var content = File.ReadAllText(fullPath);
....
response.Write(content);
}Данный метод производит отправку содержимого некоторого файла из заданной папки пользователя. Предполагается, что пользователь должен иметь возможность получения содержимого только файлов, хранящихся внутри этой папки.
В качестве относительного пути здесь используется значение, полученное из внешнего источника – 'Request.QueryString'. Отсутствие каких-либо проверок позволяет злоумышленнику получить доступ к содержимому любых файлов в системе.
Например, в папке каждого пользователя может храниться файл userInfo.xml, в котором содержится различная (в том числе конфиденциальная) информация (при этом код выполняется на системе Windows). Тогда для получения доступа к данным пользователя 'admin' злоумышленник может передать в 'Request. QueryString["relativePath"]' следующую строку:
..\admin\userInfo.xmlДля защиты от такой атаки недостаточно простой проверки на наличие '..\' в начале строки. К примеру, для получения тех же данных может передаваться и строка
someFolder\..\..\admin\userInfo.xmlЕщё одна возможность для атаки – передача абсолютного пути вместо относительного. Если один из аргументов 'Path.Combine' представляет собой абсолютный путь, то все ранее записанные аргументы игнорируются. К примеру, метод может быть вызван следующим образом:
Path.Combine("folder", "childFolder", "C:\Users\Admin\secret.txt")В результате будет возвращена строка 'C:\Users\Admin\secret.txt '. Таким образом, отсутствие проверки входных данных позволяет злоумышленнику получить доступ к любому файлу в системе. Более подробно атаки типа path traversal и способы их проведения описаны на официальном сайте OWASP по ссылке.
Для обеспечения защиты от path traversal необходимо применять различные средства проверки входных данных. В примере, описанном выше, можно использовать проверку на наличие подстрок ":" и "..\":
HttpResponse response;
HttpRequest request;
private void SendUserFileContent(string userDirectory)
{
....
string userFileRelativePath = request.QueryString["relativePath"];
if ( !userFileRelativePath.Contains(":")
&& !userFileRelativePath.Contains(@"..\"))
{
string fullPath = Path.Combine(userDirectory,
userFileRelativePath);
var content = File.ReadAllText(fullPath);
....
response.Write(content);
}
else
{
....
}
}Анализатор также считает источниками небезопасных данных параметры методов, доступных из других сборок. Эта тема подробно раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов".
Рассмотрим пример кода, выполняющегося на ОС Windows:
public class UserFilesManager
{
private const string UsersDirectoryAbsolutePath = ....;
private HttpResponse response;
private string userName;
public void WriteUserFile(string relativePath)
{
string path = Path.Combine(UsersDirectoryAbsolutePath,
userName,
relativePath);
WriteFile(path);
}
private void WriteFile(string absolutePath)
{
response.Write(File.ReadAllText(absolutePath));
}
}Анализатор сформирует предупреждение низкого уровня достоверности на вызов метода 'WriteFile' внутри 'WriteUserFile'. После вызова 'Path.Combine' небезопасные данные из 'relativePath' передаются в 'path', после чего выступают в качестве аргумента вызова 'WriteFile', где используются в качестве пути. Таким образом, пользовательский ввод может попасть в метод 'File.ReadAllText' без проверки, из-за чего данный код уязвим к path traversal.
Для защиты от атаки необходимо проводить валидацию параметров. В данном случае важно провести её до вызова 'Path.Combine', так как возвращаемое им значение в любом случае будет абсолютным путём:
public void WriteUserFile(string relativePath)
{
if (relativePath.Contains(":") || relativePath.Contains(@"..\"))
{
....
return;
}
string path = Path.Combine(UsersDirectoryAbsolutePath,
userName,
relativePath);
WriteFile(path);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V5609. |
V5610. OWASP. Possible XSS vulnerability. Potentially tainted data might be used to execute a malicious script.
Анализатор обнаружил ситуацию, при которой данные, полученные из внешнего источника, могут быть использованы для запуска вредоносного скрипта. Подобный код может быть уязвим к XSS.
XSS выделен в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A7:2017-Cross-Site Scripting (XSS).
К XSS чаще всего уязвимы аргументы строки HTTP запроса, тело HTTP запроса и поля ввода HTML страниц.
Рассмотрим простейший пример XSS через параметры URL запроса:
void OpenHtmlPage()
{
WebBrowser.Navigate(TargetSiteUrl.Text);
}В данном случае пользователь в интерфейсе программы вводит в текстовое поле 'TargetSiteUrl.Text' строку и нажимает на кнопку. После нажатия кнопки в интерфейсе приложения открывается страница сайта, указанного в 'TargetSiteUrl.Text'.
Допустим, на веб странице отображается строка, указанная в URL параметре 'inputData'.

В таком случае, если в URL параметре 'inputData' в строке запроса к странице указать элемент <script>alert("XSS Injection")</script>, то при рендеринге страницы этот код будет выполнен, и в отдельном окне отобразится строка, использованная в скрипте:

Выполнение JavaSсript кода, переданного в URL параметре, является XSS атакой. Благодаря социальной инженерии злоумышленник может убедить пользователя вставить подобный запрос с вредоносным скриптом в поле 'TargetSiteUrl.Text'. В результате выполнения скрипта у злоумышленника может оказаться информация для доступа к аккаунту пользователя. Например, cookie, которые хранились в браузере. Воспользовавшись ей, он сможет похитить конфиденциальные данные или выполнить вредоносные действия от имени пользователя.
Данная XSS атака была бы изначально неудачной, если бы строка, которую ввел пользователь в поле 'TargetSiteUrl.Text', перед использованием в методе 'WebBrowser.Navigate' кодировала спец. символы HTML:
void OpenHtmlPage()
{
var encodedUrl = System.Net.WebUtility.HtmlEncode(TargetSiteUrl.Text);
WebBrowser.Navigate(encodedUrl);
}В таком случае код вредоносного скрипта не выполнился бы, а просто отобразился на странице:

Также XSS возможен и через поля ввода на сайте. Например, функционал сайта предоставляет возможность оставлять комментарии и просматривать комментарии других посетителей сайта, если вы авторизовались на сайте. Добавленные комментарии сохраняются в базу данных сайта и отображаются на странице комментариев, которая видна только авторизированным пользователям. Если перед отображением комментариев в них не кодируются спец. символы HTML, то возможна интересная XSS атака.
Злоумышленник зарегистрируется на сайте и оставит комментарий, в котором содержится вредоносный скрипт. Комментарий со скриптом сохранится в базу данных. После этого все авторизированные пользователи смогут просмотреть этот комментарий. Если при отображении комментария на странице в нем не кодируются спец. символы HTML, то вредоносный скрипт будет выполнен в браузере каждого авторизированного пользователя, который решил посмотреть комментарии. Таким образом злоумышленник сможет получить cookie не одного, а нескольких пользователей сайта. Если в cookie сохраняется токен авторизации на сайте, то он некоторое время будет иметь возможность войти в аккаунты других пользователей сайта.
Пример кода, отображающего комментарии пользователей на странице сайта:
using (var sqlConnection = ....)
{
var command = ....;
....
var reader = command.ExecuteReader();
while (reader.Read())
{
....
var userComment = reader.GetString(1);
....
Response.Write("<p>");
Response.Write(userComment);
Response.Write("</p>");
....
}
}Для защиты от подобной XSS атаки необходимо обрабатывать данные либо перед записью в базу данных, либо перед отображением на странице.
Исправленный код отображения комментариев из базы данных (данные кодируются перед отображением) может быть таким:
using (var sqlConnection = ....)
{
var command = ....;
....
var reader = command.ExecuteReader();
while (reader.Read())
{
....
var userComment = reader.GetString(1);
var encodedComment = WebUtility.HtmlEncode(userComment);
....
Response.Write("<p>");
Response.Write(encodedComment);
Response.Write("</p>");
....
}
}Анализатор также считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов".
Рассмотрим пример кода:
public class UriHelper
{
WebBrowser WebBrowser = new WebBrowser();
private string _targetSite = "http://mysite.com";
public void ProcessUrlQuery(string urlQuery)
{
var urlRequest = _targetSite + "?" + urlQuery;
OpenWebPage(urlRequest);
}
private void OpenWebPage(string urlWithQuery)
{
WebBrowser.Navigate(urlWithQuery);
}
}В данном случае анализатор выдаст предупреждение низкого уровня достоверности при анализе исходного кода метода 'ProcessUrlQuery' на вызов метода 'OpenWebPage'. Анализатор отследил передачу небезопасных данных из параметра 'urlQuery' в метод 'Navigate'.
Параметр 'urlQuery' используется при конкатенации строк, из-за чего переменная 'urlRequest' также будет содержать небезопасные данные. Далее 'urlRequest' передаётся в метод 'OpenWebPage', где выступает в качестве аргумента метода 'Navigate'. Таким образом, пользовательский ввод может попасть в метод 'Navigate' без проверки, из-за чего данный код уязвим к XSS.
Защититься от XSS в этом коде возможно тем же способом, что и в примере ранее - просто кодировать строку запроса перед передачей в метод 'Navigate':
public class UriHelper
{
WebBrowser WebBrowser = new WebBrowser();
private string _targetSite = "http://mysite.com";
public void ProcessUrlQuery(string urlQuery)
{
var urlRequest = _targetSite + "?" + urlQuery;
OpenWebPage(urlRequest);
}
private void OpenWebPage(string urlWithQuery)
{
var encodedUrlWithQuery =
System.Net.WebUtility.HtmlEncode(urlWithQuery);
WebBrowser.Navigate(encodedUrlWithQuery);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5611. OWASP. Potential insecure deserialization vulnerability. Potentially tainted data is used to create an object using deserialization.
Анализатор обнаружил ситуацию, при которой данные, полученные из внешнего источника, могут быть использованы для создания объекта при десериализации. Подобный код может быть причиной различных уязвимостей.
Небезопасная десериализация выделена в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A8:2017-Insecure Deserialization.
Рассмотрим синтетический пример:
[Serializable]
public class User
{
....
public bool IsAdmin { get; private set; }
....
}
private static User GetUserFromFile(string filePath)
{
User user = null;
using (var fileStream = new FileStream(filePath, FileMode.Open))
{
var soapFormatter = new SoapFormatter();
user = (User) soapFormatter.Deserialize(fileStream);
}
return user;
}
static void Main(string[] args)
{
Console.WriteLine("Please provide the path to the file.");
var userInput = Console.ReadLine();
User user = GetUserFromFile(userInput);
if (user?.IsAdmin == true)
// Performs actions with elevated privileges
else
// Performs actions with limited privileges
}При запуске метода 'Main' консольное приложение запросит у пользователя путь до файла. После указания пути до файла, содержимое файла будет десериализовано в объект типа 'User'. Если получилось провести десериализацию объекта из файла и его свойство 'IsAdmin' равно 'true', то дальше будут произведены действия с повышенными привилегиями. В противном случае будут произведены действия с ограниченными привилегиями. Учитывая то, что данные из файла десериализуются SOAP сериализатором в объект типа 'User', имеется возможность увидеть структуру объекта, находящегося в файле:
<SOAP-ENV:Envelope xmlns:xsi=....
xmlns:xsd=....
xmlns:SOAP-ENC=....
xmlns:SOAP-ENV=....
xmlns:clr=....
SOAP-ENV:encodingStyle=....>
<SOAP-ENV:Body>
<a1:Program_x002B_User id="ref-1" xmlns:a1=....>
<_x003C_UserId_x003E_k__BackingField>1</_x003C_UserId_x003E_k__BackingField>
<_x003C_UserName_x003E_k__.... id="ref-3">Name</_x003C_UserName_x003E_k__....>
<_x003C_IsAdmin_x003E_k__....>false</_x003C_IsAdmin_x003E_k__....>
</a1:Program_x002B_User>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>Благодаря этой информации злоумышленник может, например, изменить значение свойства 'IsAdmin' с приватным сеттером на 'true' вместо 'false':
<_x003C_IsAdmin_x003E_k__....>true</_x003C_IsAdmin_x003E_k__....>Это позволит злоумышленнику при десериализации объекта из файла получить повышенные привилегии для десериализованного объекта. В результате, в программе будут выполнены действия, которые изначально не были доступны объекту из файла. Например, злоумышленник сможет украсть конфиденциальные данные или совершить вредоносные действия, которые до модификации объекта из файла были ему не доступны.
Чтобы избавится от этой уязвимости, необходимо убедиться, что злоумышленник при получении доступа к файлу не сможет узнать структуру объекта. Для этого следует использовать шифрование данных, записывающихся в файл. В C# имеется класс 'CryptoStream', который поможет в этом:
private static void SerializeAndEncryptUser(User user,
string filePath,
byte[] key,
byte[] iv)
{
using (var fileStream = new FileStream(filePath, FileMode.CreateNew))
{
using (Rijndael rijndael = Rijndael.Create())
{
rijndael.Key = key;
rijndael.IV = iv;
var encryptor = rijndael.CreateEncryptor(rijndael.Key, rijndael.IV);
using (var cryptoStream = new CryptoStream(fileStream,
encryptor,
CryptoStreamMode.Write))
{
var soapFormatter = new SoapFormatter();
soapFormatter.Serialize(cryptoStream, user);
}
}
}
}Этот код зашифрует данные, полученные при сериализации объекта 'User', перед тем, как записать их в файл. При обработке содержимого файла в методе 'GetUserFromFile' перед десериализацией необходимо будет дешифровать данные, также используя 'CryptoStream':
private static User GetUserFromFile(string filePath, byte[] key, byte[] iv)
{
User user = null;
using (var fileStream = new FileStream(filePath, FileMode.Open))
{
using (Rijndael rijndael = Rijndael.Create())
{
rijndael.Key = key;
rijndael.IV = iv;
var decryptor = rijndael.CreateDecryptor(rijndael.Key,
rijndael.IV);
using (var cryptoStream = new CryptoStream(fileStream,
decryptor,
CryptoStreamMode.Read))
{
var soapFormatter = new SoapFormatter();
user = (User) soapFormatter.Deserialize(cryptoStream);
}
}
}
return user;
}Таким образом структура и содержимое объекта из файла останутся неизвестны злоумышленнику, и он не сможет получить повышенные привилегии при помощи изменения значения свойства 'IsAdmin' в файле. Следовательно, в описанном примере будет устранена проблема небезопасной десериализации.
Для более надежной защиты от уязвимостей этого типа в дополнение к шифрованию сериализованных данных стоит придерживаться еще нескольких правил, которые перечислены в соответствующем разделе OWASP Top 10.
Анализатор также считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов".
Рассмотрим пример:
public class DeserializationHelper
{
public T DesrializeFromStream<T>(Stream stream)
{
T deserializedObject = default;
using(var streamReader = new StreamReader(stream))
{
deserializedObject = DeserializeXml<T>(streamReader);
}
return deserializedObject;
}
private T DeserializeXml<T>(StreamReader streamReader)
{
return (T) new XmlSerializer(typeof(T)).Deserialize(streamReader);
}
}В данном случае анализатор выдаст предупреждение низкого уровня достоверности при анализе исходного кода метода 'DesrializeFromStream' на вызов метода 'DeserializeXml'. Анализатор отследил передачу небезопасных данных из параметра 'stream' в конструктор 'StreamReader', а передачу объекта 'streamReader' - в метод 'Deserialize'.
Защититься от небезопасной десериализации в этом коде возможно тем же способом, что и в примере ранее, при помощи класса 'CryptoStream':
public class DeserializationHelper
{
public T DesrializeFromFile<T>(Stream stream, ICryptoTransform transform)
{
T deserializedObject = default;
using (var cryptoStream = new CryptoStream(stream,
transform,
CryptoStreamMode.Read))
{
using (var streamReader = new StreamReader(cryptoStream))
{
deserializedObject = DeserializeXml<T>(streamReader);
}
}
return deserializedObject;
}
private T DeserializeXml<T>(StreamReader streamReader)
{
return (T) new XmlSerializer(typeof(T)).Deserialize(streamReader);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V5611. |
V5612. OWASP. Do not use old versions of SSL/TLS protocols as it may cause security issues.
Анализатор обнаружил использование в коде устаревших версий протоколов SSL/TLS. Это может сделать приложение уязвимым к таким атакам, как man-in-the-middle, BEAST, и т.п.
Проблемы, связанные с применением устаревших протоколов, могут быть отнесены к двум категориям OWASP Top Ten 2017:
Рассмотрим пример:
public void Run(ApplePushChannelSettings settings)
{
....
var certificates = new X509CertificateCollection();
....
var stream = new SslStream(....);
stream.AuthenticateAsClient(settings.FeedbackHost,
certificates,
SslProtocols.Tls, // <=
false);
....
}В указанном фрагменте используется значение 'SslProtocols.Tls', представляющее протокол TLS версии 1.0. Данная версия является устаревшей и не рекомендуется к использованию, так как TLS 1.0 уязвим к ряду атак, в числе которых упоминавшаяся ранее BEAST.
Рекомендуется использовать более новые версии протоколов, например - TLS 1.2:
public void Run(ApplePushChannelSettings settings)
{
....
var certificates = new X509CertificateCollection();
....
var stream = new SslStream(....);
stream.AuthenticateAsClient(settings.FeedbackHost,
certificates,
SslProtocols.Tls12,
false);
....
}Версии протоколов, являющиеся более старыми, чем TLS 1.2, не рекомендуются к использованию из-за возможных проблем с безопасностью. К таким протоколам относятся SSL версий 2.0 и 3.0, а также TLS версий 1.0 и 1.1.
Стоит отметить, что использование значения 'SslProtocols.Default' также не рекомендуется, так как оно соответствует разрешению использования протоколов SSL 3.0 или TLS 1.0, которые являются устаревшими.
Как правило, наиболее подходящими значениями являются 'SslProtocols.None' и 'SecurityProtocolType.SystemDefault', предоставляющие выбор протокола передачи данных операционной системе. Если по каким-либо причинам данные значения не подходят, то рекомендуется задавать самую новую версию из доступных.
Анализатор также сформирует предупреждение в случае, если непосредственное использование устаревших протоколов происходит внутри вызванного метода:
SslStream _sslStream;
public string TargetHost { get; set; }
public X509CertificateCollection Certificates { get; set; }
private void PrepareSslStream()
{
....
var protocol = SslProtocols.Ssl3 | SslProtocols.Tls12;
Authenticate(protocol); // <=
....
}
private void Authenticate(SslProtocols protocol)
{
_sslStream.AuthenticateAsClient(TargetHost,
Certificates,
protocol,
true);
}В качестве аргумента метода 'Authenticate' передаётся значение, представляющее протоколы SSL 3.0 и TLS 1.2. Внутри метода оно используется для задания протоколов, используемых стандартным методом 'AuthenticateAsClient'. Так как SSL 3.0 является устаревшим, его использование может привести к появлению уязвимостей, поэтому анализатор отобразит соответствующее предупреждение.
Исправление в данном случае то же, что и раньше – необходимо исключить небезопасный протокол из списка доступных:
private void PrepareSslStream()
{
....
var protocol = SslProtocols.Tls12;
Authenticate(protocol);
....
}Дополнительные ссылки
- Transport Layer Security (TLS) best practices with the .NET Framework
- Testing for Weak SSL TLS Ciphers Insufficient Transport Layer Protection
- Transport Layer Protection Cheat Sheet
- Описание атаки Man-in-the-middle
- Описание атаки Man-in-the-Browser
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V5613. OWASP. Use of outdated cryptographic algorithm is not recommended.
Анализатор обнаружил, что в приложении используется устаревший алгоритм шифрования или хеширования. Применение таких алгоритмов может привести к раскрытию конфиденциальных данных, утечке ключей, нарушению аутентификации и т. д.
Уязвимости, связанные с использованием небезопасных алгоритмов шифрования, могут быть отнесены к следующим категориям OWASP Top Ten 2017:
Рассмотрим пример:
private static string CalculateSha1(string text, Encoding enc)
{
var buffer = enc.GetBytes(text);
using var cryptoTransformSha1 = new SHA1CryptoServiceProvider(); // <=
var hash = BitConverter.ToString(cryptoTransformSha1.ComputeHash(buffer))
.Replace("-", string.Empty);
return hash.ToLower();
}При проверке фрагмента анализатор сформирует предупреждение о том, что использование алгоритма SHA1 не рекомендуется. В данном случае проблема алгоритма состоит в наличии широко известных проблем с коллизией. Таким образом, его использование не является безопасным.
Вместо устаревших алгоритмов следует использовать более современные. В примере, представленном выше, одним из решений может быть замена SHA1 на SHA256:
private static string CalculateSha256(string text, Encoding enc)
{
var buffer = enc.GetBytes(text);
using var cryptoTransformSha256 = new SHA256CryptoServiceProvider();
var hash = BitConverter.ToString(cryptoTransformSha256.ComputeHash(buffer))
.Replace("-", string.Empty);
return hash.ToLower();
}На сайте Microsoft доступна документация по стандартным реализациям различных алгоритмов шифрования. Как правило, классы, реализующие устаревшие алгоритмы, отмечены в документации специальным предупреждением. Ниже приведены некоторые из них:
Использование классов, наследующих указанные, также не рекомендуется.
На официальном сайте OWASP по ссылке представлены различные методики проверки приложения на наличие потенциальных уязвимостей, связанных с использованием небезопасных алгоритмов шифрования.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V5614. OWASP. Potential XXE vulnerability. Insecure XML parser is used to process potentially tainted data.
Анализатор обнаружил использование небезопасно сконфигурированного XML-парсера, который обрабатывает данные, полученные из внешнего источника. Это может сделать приложение уязвимым к XXE-атаке.
XXE-атаки выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2017: A4:2017 – XML External Entities (XXE) и включены в категорию A05:2021 – Security Misconfiguration OWASP Top 10 2021.
Суть XXE-атаки
Стандарт XML предусматривает использование DTD (document type definition). DTD даёт возможность определять и использовать XML-сущности. Сущности могут быть как полностью определены внутри документа (например, представлять собой какую-то строку), так и ссылаться на какой-то внешний ресурс. Отсюда и происходит название XXE-атаки: XML eXternal Entities.
Внешние сущности могут быть определены через URI, вследствие чего XML-парсер может обработать этот URI и подставить полученное содержимое в XML-документ.
Пример XML-документа, в котором определена внешняя сущность:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE foo [
<!ENTITY xxe SYSTEM "file://D:/XXETarget.txt">
]>
<foo>&xxe;</foo>Здесь определена сущность '&xxe;'. При обработке этого XML парсер подставит вместо '&xxe;' содержимое файла 'D:\XXETarget.txt'.
Таким образом, атака возможна, если:
- злоумышленник может передать приложению XML-файл с внешними сущностями, и приложение выполнит парсинг этого файла;
- XML-парсер имеет небезопасную конфигурацию;
- данные парсинга (значения сущностей) могут попасть обратно к злоумышленнику.
Как следствие, злоумышленник может, например, раскрыть содержимое данных с машины, на которой исполняется приложение и которая занимается парсингом XML-файла.
Примеры уязвимого кода
PVS-Studio выдаст предупреждение, если обнаружит в коде небезопасно сконфигурированный XML-парсер, который обрабатывает данные, которые могут быть получены из внешнего источника.
Рассмотрим простой пример. Есть приложение, которое принимает запросы в виде XML-файлов и обрабатывает товары с соответствующим идентификатором. Если идентификатор задан неверно, приложение сообщает об этом.
Формат XML-файла, с которым работает приложение:
<?xml version="1.0" encoding="utf-8" ?>
<shop>
<itemID>62</itemID>
</shop>Допустим, обработкой занимается следующий код:
static void ProcessItemWithID(String pathToXmlFile)
{
XmlReaderSettings settings = new XmlReaderSettings()
{
XmlResolver = new XmlUrlResolver(),
DtdProcessing = DtdProcessing.Parse
};
using (var fileReader = File.OpenRead(pathToXmlFile))
{
using (var reader = XmlReader.Create(fileReader, settings))
{
while (reader.Read())
{
if (reader.Name == "itemID")
{
var itemIDStr = reader.ReadElementContentAsString();
if (long.TryParse(itemIDStr, out var itemIDValue))
{
// Process item with the 'itemIDValue' value
Console.WriteLine(
$"An item with the '{itemIDValue}' ID was processed.");
}
else
{
Console.WriteLine($"{itemIDStr} is not valid 'itemID' value.");
}
}
}
}
}
}Для приведённого выше XML-файла приложение распечатает следующую строку:
An item with the '62' ID was processed.Если вместо номера в ID будет записано что-то другое (например, строка "Hello world"), приложение сообщит об ошибке:
"Hello world" is not valid 'itemID' value.Несмотря на то, что код делает то, что от него ожидается, он уязвим к XXE-атакам за счёт соблюдения всех перечисленных ранее факторов:
- содержимое XML поступает от пользователя;
- XML-парсер сконфигурирован таким образом, чтобы обрабатывать внешние сущности;
- вывод может передаваться обратно пользователю.
Ниже представлен XML-файл, через который можно скомпрометировать данный код:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE foo [
<!ENTITY xxe SYSTEM "file://D:/MySecrets.txt">
]>
<shop>
<itemID>&xxe;</itemID>
</shop>В этом файле объявляется внешняя сущность 'xxe', которая будет обработана парсером. Вследствие этого содержимое файла 'D:/MySecrets.txt' (например, такое: 'This is an XXE attack target.'), находящегося на машине, где запущено приложение, будет выдано пользователю:
This is an XXE attack target. is not valid 'itemID' value.Для того, чтобы обезопаситься от подобной атаки, можно запретить обработку внешних сущностей (присвоить свойству 'XmlResolver' значение 'null'), а также запретить или игнорировать обработку DTD (записать в свойство 'DtdProcessing' значение 'Prohibit' или 'Ignore' соответственно).
Пример безопасных настроек:
XmlReaderSettings settings = new XmlReaderSettings()
{
XmlResolver = null,
DtdProcessing = DtdProcessing.Prohibit
};Обратите внимание, что при использовании различных типов, уязвимость к XXE-атакам может выглядеть по-разному. Например, следующий код также уязвим к XXE-атаке:
static void ProcessXML(String pathToXmlFile)
{
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.XmlResolver = new XmlUrlResolver();
using (var xmlStream = File.OpenRead(pathToXmlFile))
{
xmlDoc.Load(xmlStream);
Console.WriteLine(xmlDoc.InnerText);
}
}Здесь загрузка XML происходит через экземпляр типа 'XmlDocument'. При этом для 'XmlResolver' явно выставлено опасное значение, а обработка DTD включена неявно. Чтобы запретить обработку внешних сущностей, достаточно записать в свойство 'XmlResolver' значение 'null'.
Анализатор также учитывает и межпроцедурные вызовы. Рассмотрим пример:
static FileStream GetXmlFileStream(String pathToXmlFile)
{
return File.OpenRead(pathToXmlFile);
}
static XmlDocument GetXmlDocument()
{
XmlDocument xmlDoc = new XmlDocument()
{
XmlResolver = new XmlUrlResolver()
};
return xmlDoc;
}
static void LoadXmlInternal(XmlDocument xmlDoc, Stream input)
{
xmlDoc.Load(input);
Console.WriteLine(xmlDoc.InnerText);
}
static void XmlDocumentTest(String pathToXmlFile)
{
using (var xmlStream = GetXmlFileStream(pathToXmlFile))
{
var xmlDoc = GetXmlDocument();
LoadXmlInternal(xmlDoc, xmlStream);
}
}В данном случае анализатор выдаст предупреждение на вызов метода 'LoadXmlInternal', так как отследит, что:
- парсер, полученный из метода 'GetXmlDocument', может обрабатывать внешние сущности;
- поток, полученный из метода 'GetXmlStream', содержит данные, полученные из внешнего источника (прочитанные из файла);
- парсер и 'заражённые' данные передаются в метод 'LoadXmlInternal', где выполняется обработка XML-файла.
Стоит отметить, что анализатор также считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов".
Например, на следующий код будет выдано предупреждение низкого уровня достоверности, так как источник небезопасных данных – параметр публично-доступного метода:
public static void XmlDocumentTest(Stream xmlStream)
{
XmlDocument doc = new XmlDocument()
{
XmlResolver = new XmlUrlResolver()
};
doc.Load(xmlStream);
Console.WriteLine(doc.InnerText);
}Обратите внимание, что настройки некоторых XML-парсеров менялись в разных версиях .NET Framework.
Рассмотрим следующий фрагмент кода:
static void XmlDocumentTest(String pathToXml)
{
var xml = File.ReadAllText(pathToXml);
XmlDocument doc = new XmlDocument();
doc.LoadXml(xml);
Console.WriteLine(doc.InnerText);
}Данный код является устойчивым к XXE-атакам в .NET Framework 4.5.2 и более новых версиях, так как свойство 'XmlResolver' по умолчанию имеет значение 'null'. Как следствие, внешние сущности не будут обработаны.
В версиях .NET Framework 4.5.1 и более старых данный код уязвим к XXE-атакам, так как по умолчанию 'XmlResolver' не равен 'null' и обрабатывает внешние сущности.
PVS-Studio также учитывает дефолтные настройки парсеров в зависимости от того, какая версия .NET Framework / .NET используется в анализируемом проекте.
Общая рекомендация по защите от XXE-атак – следить за тем, чтобы обработка DTD была отключена; обработка внешних сущностей – запрещена. В разных XML-парсерах настройки могут немного отличаться, но, как правило, за это отвечают свойства 'DtdProcessing' ('ProhibitDtd' в более старых версиях .NET Framework) и 'XmlResolver'.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5615. OWASP. Potential XEE vulnerability. Insecure XML parser is used to process potentially tainted data.
Анализатор обнаружил использование небезопасно сконфигурированного XML-парсера для обработки данных, полученных из внешнего источника. Это может сделать приложение уязвимым к XEE-атаке (альтернативные названия: 'billion laughs'-атака или атака с помощью XML-бомб).
XEE-атаки включены в категории OWASP Top 10 2017: A4:2017 – XML External Entities (XXE) и OWASP Top 10 2021: A05:2021 – Security Misconfiguration.
Суть XEE-атаки
Стандарт XML предусматривает использование DTD (document type definition). DTD даёт возможность определять и использовать XML-сущности. Сущности могут как ссылаться на какой-то внешний ресурс, так и быть полностью определены внутри документа. В последнем случае они могут быть представлены какой-то строкой или, например, другими сущностями.
XML-файл с примерами подобных сущностей:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE foo [
<!ENTITY lol "lol">
<!ENTITY lol1 "&lol;&lol;">
]>
<foo>&lol1;</foo>Здесь определены сущности 'lol' и 'lol1', причём первая определена через строку, а вторая – через другие сущности. Как следствие, значением сущности 'lol1' будет строка 'lollol'.
Вложенность и количество сущностей можно увеличивать. Например, так:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE foo [
<!ENTITY lol "lol">
<!ENTITY lol1 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;">
<!ENTITY lol2 "&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;">
]>
<foo>&lol2;</foo>Сущность 'lol2' раскрывается следующим образом:
lollollollollollollollollollollollollollollollollollollollollollollol
lollollollollollollollollollollollollollollollollollollollollollollol
lollollollollollollollollollollollollollollollollollollollollollollol
lollollollollollollollollollollollollollollollollollollollollollollol
lollollollollollollollolПо подобному принципу, путём увеличения количества вложенных сущностей, создаются так называемые XML-бомбы. Они представляют собой небольшие по размеру файлы, которые при раскрытии сущностей разрастаются до огромных размеров. Отсюда же происходят различные названия такого типа атак:
- XEE (XML Entity Expansion)
- billion laughs (из-за многократного повторения 'lol').
Таким образом, DoS-атака на приложение с использованием XML-бомб возможна, если:
- злоумышленник может передать приложению XML-бомбу;
- XML-парсер, который будет обрабатывать этот файл, имеет небезопасную конфигурацию.
Интересный реальный пример уязвимости приложения к XEE описан в статье "Как Visual Studio 2022 съела 100 Гб памяти и при чём здесь XML бомбы?".
Примеры уязвимого кода
Рассмотрим пример:
static void XEETarget(String pathToXml)
{
XmlReaderSettings settings = new XmlReaderSettings()
{
DtdProcessing = DtdProcessing.Parse,
MaxCharactersFromEntities = 0
};
using (var xml = File.OpenRead(pathToXml))
{
using (var reader = XmlReader.Create(xml, settings))
{
while (reader.Read())
{
if (reader.NodeType == XmlNodeType.Text)
Console.WriteLine(reader.Value);
}
}
}
}В данном примере с помощью XML-парсера 'reader' происходит чтение XML-файла. Однако данный парсер уязвим к XML-бомбам, т.к. он создан с небезопасными настройками, в которых:
- разрешена обработка DTD (свойство 'DtdProcessing' имеет значение 'DtdProcessing.Parse');
- не установлено ограничение на размер сущностей (свойство 'MaxCharactersFromEntities' имеет значение 0).
Как следствие, парсер может зависнуть в попытке разобрать XML-бомбу, начать потреблять большое количество памяти и т.п.
Стоит отметить, что обрабатываемые данные приходят из внешнего источника (считываются из файла по пути 'pathToXml'). Обнаружив сочетание всех перечисленных факторов, анализатор выдаст предупреждение.
Чтобы сделать парсер устойчивым к XEE-атакам, достаточно:
- запретить или игнорировать обработку DTD (установить для свойства 'DtdProcessing' значения 'Prohibit' или 'Ignore' соответственно). В более старых версиях .NET Framework вместо свойства 'DtdProcessing' используется 'ProhibitDtd'. Оно должно иметь значение 'true', чтобы обработка DTD была запрещена.
- установить ограничение на максимальный размер сущностей.
Пример настроек, в которых разрешена обработка DTD, но при этом ограничен максимальный размер сущностей:
XmlReaderSettings settings = new XmlReaderSettings()
{
DtdProcessing = DtdProcessing.Parse,
MaxCharactersFromEntities = 1024
};Если в ходе разбора XML-файла будет превышен установленный лимит, парсер сгенерирует исключение типа 'XmlException'.
Анализатор также отслеживает межпроцедурные вызовы. Изменим предыдущий пример:
static XmlReaderSettings GetDefaultSettings()
{
var settings = new XmlReaderSettings();
settings.DtdProcessing = DtdProcessing.Parse;
settings.MaxCharactersFromEntities = 0;
return settings;
}
public static void XEETarget(String pathToXml)
{
using (var xml = File.OpenRead(pathToXml))
{
using (var reader = XmlReader.Create(xml, GetDefaultSettings()))
{
ProcessXml(reader);
}
}
}
static void ProcessXml(XmlReader reader)
{
while (reader.Read())
{
// Process XML
}
}В данном случае анализатор выдаст предупреждение на вызов метода 'ProcessXml', так как отследит, что:
- внутри этого метода происходит обработка XML-файла;
- XML-парсер создан с небезопасными настройками, пришедшими из метода 'GetDefaultSettings';
- парсер обрабатывает потенциально опасные данные (считанные из файла 'pathToXml').
Кроме того, анализатор укажет на фрагменты кода, соответствующие перечисленным выше действиям.
Стоит отметить, что анализатор также считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов".
Пример:
public class XEETest
{
public static void XEETarget(Stream xmlStream)
{
var rs = new XmlReaderSettings()
{
DtdProcessing = DtdProcessing.Parse,
MaxCharactersFromEntities = 0
};
using (var reader = XmlReader.Create(xmlStream, rs))
{
while (reader.Read())
{
// Process XML
}
}
}
}Анализатор выдаст предупреждение низкого уровня достоверности на данный код, так как источник небезопасных данных – параметр публично-доступного метода – используется в опасно сконфигурированном XML-парсере.
Обратите внимание, что в разных версиях .NET Framework настройки по умолчанию могут отличаться. Как следствие, один и тот же код может либо быть уязвимым к XEE-атакам, либо устойчивым.
Пример подобного кода:
static void XEETarget(String pathToXml)
{
using (var xml = File.OpenRead(pathToXml))
{
var settings = new XmlReaderSettings()
{
DtdProcessing = DtdProcessing.Parse
};
using (var reader = XmlReader.Create(xml, settings))
{
while (reader.Read())
{
// Process XML
}
}
}
}Данный код уязвим к XEE-атакам в версиях .NET Framework 4.5.1 и более старых, так как не устанавливает ограничения на размер сущностей (значение свойства 'MaxCharactersFromEntities' - 0). В версиях .NET Framework 4.5.2 и более новых по умолчанию установлено ограничение на размер сущностей, как следствие – данный код в них будет устойчив к XEE.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5616. OWASP. Possible command injection. Potentially tainted data is used to create OS command.
Анализатор обнаружил создание команды уровня операционной системы из непроверенных данных, полученных из внешнего источника. Это может стать причиной возникновения уязвимости command injection.
В OWASP Top 10 Application Security Risks инъекции команд относятся к следующим категориям:
- A1:2017-Injection в списке 2017 года;
- A3:2021-Injection в списке 2021 года.
Рассмотрим пример:
HttpRequest _request;
string _pathToExecutor;
private void ExecuteOperation()
{
....
String operationNumber = _request.Form["operationNumber"];
Process.Start("cmd", $"/c {_pathToExecutor} {operationNumber}");
....
}В представленном коде из запроса считывается номер операции, которую должен выполнить вызываемый процесс. Таким образом, набор операций чётко ограничен. Тем не менее, злоумышленник может передать в качестве значения параметра "operationNumber" специальную строку, которая позволит выполнить дополнительные несанкционированные действия. К примеру, в "operationNumber" может храниться следующая строка:
0 & del /q /f /s *.*Допустим, что в '_pathToExecutor' записан путь 'executor.exe'. Тогда в результате вызова 'Process.Start' будет выполнена следующая команда:
cmd /c executor.exe 0 & del /q /f /s *.*Символ '&' здесь будет интерпретирован как разделитель команд. Инструкция 'del' с такими аргументами приведёт к удалению всех файлов в текущей и вложенных папках (за исключением тех, для которых у приложения нет достаточных прав доступа). Таким образом, правильно подобранное значение в параметре "operationNumber" позволяет совершить вредоносные действия.
Во избежание появления уязвимости рекомендуется всегда проверять входные данные. Конкретный способ проверки зависит от ситуации. В указанном выше примере будет достаточно убедиться, что в переменной 'operationNumber' записано число:
private void ExecuteOperation()
{
String operationNumber = _request.Form["operationNumber"];
if (uint.TryParse(operationNumber, out uint number))
Process.Start("cmd", $"/c {_pathToExecutor} {number}");
}Параметры методов, доступных из других сборок, также являются источниками небезопасных данных, хотя предупреждение для таких источников будет выдано с низким уровнем достоверности. Подробное объяснение данной позиции приведено в заметке "Почему важно проверять значения параметров общедоступных методов".
В качестве примера рассмотрим следующий код:
private string _userCreatorPath;
public void CreateUser(string userName, bool createAdmin)
{
string args = $"--name {userName}";
if (createAdmin)
args += " --roles ADMIN";
RunCreatorProcess(args); // <=
}
private void RunCreatorProcess(string arguments)
{
Process.Start(_userCreatorPath, arguments).WaitForExit();
}В данном коде пользователь создаётся с помощью процесса, запускаемого методом 'RunCreatorProcess'. Этот пользователь должен получить права администратора только в том случае, если флаг 'createAdmin' имеет значение 'true'.
Код из библиотеки, зависимой от текущей, может вызывать метод 'CreateUser' для создания пользователя. В параметр 'userName' может быть передано, к примеру, значение какого-нибудь параметра запроса. При этом высока вероятность того, что никаких проверок в вызывающем коде не производится, так как разработчик будет рассчитывать на их наличие в методе 'CreateUser'. Таким образом, и в библиотеке, и в использующем её коде отсутствует валидация 'userName'.
В результате правильно подобранное имя позволит злоумышленнику создать пользователя с правами администратора вне зависимости от значения флага 'createAdmin', который, очевидно, будет равен 'false' в большинстве случаев. Допустим, что в параметр 'userName' записана следующая строка:
superHacker --roles ADMINПосле подстановки строка аргументов будет выглядеть так же, как если бы в 'createAdmin' было записано значение 'true':
--name superHacker --roles ADMINТаким образом, даже не имея прав на создание администратора, злоумышленник сможет создать пользователя с правами администратора и использовать его далее в своих целях.
В данном случае для защиты нужно проверять имя пользователя на отсутствие запрещённых символов. Например, можно разрешить использование только латинских букв и цифр:
public void CreateUser(string userName, bool createAdmin)
{
if (!Regex.IsMatch(userName, @"^[a-zA-Z0-9]+$"))
{
// error handling
return;
}
string args = $"--name {userName}";
if (createAdmin)
args += " --roles ADMIN";
RunCreatorProcess(args);
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5617. OWASP. Assigning potentially negative or large value as timeout of HTTP session can lead to excessive session expiration time.
Анализатор обнаружил код, в котором производится установка бесконечного или очень большого срока действительности сессии. Это может привести к проблемам, связанным с безопасностью данных аутентифицированного пользователя.
Ошибки, связанные с установкой некорректного срока действительности сессии, относятся к следующим категориям OWASP Top 10 Application Security Risks:
- A2:2017-Broken Authentication в списке 2017 года;
- A7:2021-Identification and Authentication Failures в списке 2021 года.
Первый пример:
public void ConfigureSession(HttpContext current, ....)
{
HttpSessionState session = current.Session;
session.Timeout = -1;
....
}Значение, присваиваемое свойству 'HttpSessionState.Timeout', указывает срок действительности сессии в минутах.
Присваивание свойству 'Timeout' отрицательного значения приводит к установке потенциально бесконечного срока действительности сессии. Если пользователь не выполнил корректный выход из системы, то его данные будут в опасности. К примеру, следующий пользователь этой системы может получить доступ к данным предыдущего, потому что сессия последней аутентификации на сервере ещё активна.
В другом случае, злоумышленник, укравший токен аутентификации, может иметь больше времени на совершение неправомерного доступа. Токен аутентификации может украден, например, посредством проведения XSS-атаки.
Второй пример:
public void ConfigureSession(HttpContext current, ....)
{
HttpSessionState session = current.Session;
session.Timeout = 120;
....
}Опасность и эксплуатация уязвимости второго примера аналогична первому.
Пороговым значением, когда анализатор считает код корректным, является срок действия менее двух часов:
public void ConfigureSession(HttpContext current, ....)
{
HttpSessionState session = current.Session;
session.Timeout = 30;
....
}Большинство библиотек и фреймворков по умолчанию предлагают срок не более чем 30 минут.
Предупреждение для слишком большого присваиваемого значения имеет уровень Medium, а предупреждение о бесконечном сроке – уровень High.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
|
V5618. OWASP. Possible server-side request forgery. Potentially tainted data is used in the URL.
Анализатор обнаружил обращение к удаленному ресурсу без проверки предоставленного пользователем URL-адреса. Использование непроверенных внешних данных для формирования адреса может стать причиной возникновения Server-Side Request Forgery.
Уязвимости типа Server-Side Request Forgery выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2021: A10:2021-Server-Side Request Forgery.
Приведём пример:
void ServerSideRequestForgery()
{
var url = Request.QueryString["url"];
WebRequest request = WebRequest.Create(url);
WebResponse response = request.GetResponse();
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream))
{
....
}
}
response.Close();
} В данном примере 'url' может содержать заражённые данные, так как они приходят из внешнего источника. Из этого адреса формируется запрос, который будет выполнен от имени сервера. Он может быть отправлен на любой веб-ресурс или на сам сервер.
Таким образом, злоумышленник получает возможность совершать вредоносные действия, отправляя запросы к ресурсам, прямой доступ к которым у него отсутствует.
Пример скомпрометированных данных:
http://localhost/admin/delete?username=testSSRFПри выполнении запроса с таким адресом злоумышленник может удалить пользователя.
Также стоит заметить, что при борьбе с SSRF не стоит использовать запрещённый список или регулярные выражения. Злоумышленник может легко обойти эти ограничения:
- Перенаправление – злоумышленник может создать внешний ресурс, который в качестве ответа перенаправляет на другой URL.
- Альтернативные представления:
http://2130706433/ = http://127.0.0.1
http://0x7f000001/ = http://127.0.0.1 Пример борьбы с SSRF с использованием проверки предоставленных данных:
string ServerSideRequestForgery()
{
var url = Request.QueryString["url"];
if (!whiteList.Contains(url))
return "Forbidden URL";
WebRequest request = WebRequest.Create(url);
....
} Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5619. OWASP. Possible log injection. Potentially tainted data is written into logs.
Анализатор обнаружил логирование данных из внешнего источника без предварительной проверки. Это может нарушить процессы логирования или скомпрометировать содержание логов.
Ошибки, связанные с логированием данных, относятся к категории A09:2021 – Security Logging and Monitoring Failures списка OWASP Top 10 Application Security Risks.
Если логирование пользовательского ввода производится без проверок, то злоумышленник может внедрить произвольные данные в лог.
Рассмотрим пример. Предположим, что логи хранятся в простом текстовом формате. Узнать формат хранения логов можно разными способами. Например, если проект имеет открытый исходный код или с помощью какой-либо другой атаки. Возможный лог может иметь такой вид:
INFO: User 'SomeUser' entered value: '2022'.
INFO: User 'SomeUser' logged out.
Код, осуществляющий логирование, может выглядеть так:
public class InputHelper
{
HttpRequest Request {get; set;}
Logger logger;
string UserName;
void ProcessUserInput()
{
string userInput = Request["UserInput"];
string logMessage = "INFO: User '"
+ UserName
+ "' entered value: '"
+ userInput + "'.";
logger.Log(logMessage);
....
}
}В таком случае злоумышленник может внедрить произвольные данные о событиях, которые никогда не происходили.
Например, злоумышленник вводит такой текст:
2022/r/nINFO: User 'Admin' logged out.
Тогда в логах появится такая запись, которая может ввести человека, анализирующего логи, в заблуждение:
INFO: User 'SomeUser' entered value: '2022'.
INFO: User 'Admin' logged out.
Рассмотрим другой вид атаки. Например, если логи хранятся в формате XML, то злоумышленник может внедрить такие данные, которые сделают содержимое отчёта некорректным. Также последующий процесс парсинга готовых логов может выдать неправильные данные или завершиться ошибкой. Пример уязвимого кода:
public class InputHelper
{
HttpRequest Request {get; set;}
Logger logger;
void ProcessUserInput()
{
string userID = Request["userID"];
logger.Info(userID); // <=
....
}
}Злоумышленник может внедрить незакрытый тег и сделать невозможным парсинг XML-файла.
Список возможных уязвимостей зависит от архитектуры и настроек ввода, логгера, вывода логов или иных частей системы логирования. Например, атака на логи в формате XML может иметь следующие последствия:
- нарушение процесса добавления новых записей в логи;
- нарушение процесса просмотра готовых логов;
- эксплуатация XEE-уязвимости (подробнее: диагностика V5615);
- эксплуатация XXE-уязвимости (подробнее: диагностика V5614);
- эксплуатация уязвимости небезопасной десериализации (подробнее: диагностика V5611).
Некоторых атак можно избежать экранированием символов, чтобы они не рассматривались как часть XML-синтаксиса. Например, начальный символ тега "<" следует экранировать как "<". Некоторые стандартные методы .NET для работы с XML, например, наследники 'XNode', реализуют экранирование записываемых в XML-дерево данных. Также .NET предоставляет отдельные от инфраструктуры XML классы для обеспечения безопасности. Пример более безопасного кода, использующего кодирование:
public class InputHelper
{
HttpRequest Request {get; set;}
Logger logger;
string EscapeCharsForXmlLog(string userInput)
{
return SecurityElement.Escape(userInput);
}
void ProcessUserInput()
{
string userInput = Request["userID"];
userInput = EscapeCharsForXmlLog(userInput);
logger.Info(userInput); // <=
....
}
}Ещё один пример: стандарт JSON запрещает наличие null-символов ("\0") в файлах. Если злоумышленник внедрит этот символ, это может сломать процесс сохранения или просмотра готовых логов. Null-символ следует экранировать как "\u0000".
Другой пример: если логи хранятся в реляционной СУБД, использующей SQL, отсутствие проверок входных данных может привести к SQL-инъекции (подробнее: диагностика V5608).
Также анализатор считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов". Рассмотрим пример:
public class InputHelper
{
Logger logger;
public void ProcessInput(string input)
{
Log("Input logged:" + input);
}
private void Log(string input)
{
logger.Log(LogLevel.Information, input);
}
}В этом случае анализатор выдаст предупреждение низкого уровня достоверности на вызов метода 'Log'. Заражённый результат конкатенации строк используется для логирования.
Сделать этот код более безопасным можно также, как в примере выше — кодированием строки:
public class InputHelper
{
Logger logger;
public void ProcessInput(string input)
{
Log(SecurityElement.Escape("Input logged:" + input));
}
private void Log(string input)
{
logger.Log(LogLevel.Information, input);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5620. OWASP. Possible LDAP injection. Potentially tainted data is used in a search filter.
Анализатор обнаружил, что потенциально заражённые данные используются для формирования фильтра LDAP-запроса. Это может стать причиной LDAP-инъекции в случае, если данные будут скомпрометированы. По своей сути данная атака похожа на SQL-инъекции.
Уязвимости типа LDAP-инъекции относятся к категории рисков OWASP Top 10 Application Security Risks 2021: A3:2021-Injection.
Рассмотрим пример:
public void Search()
{
....
string user = textBox.Text;
string password = pwdBox.Password;
DirectoryEntry de = new DirectoryEntry();
DirectorySearcher search = new DirectorySearcher(de);
search.Filter = $"(&(userId={user})(UserPassword={password}))";
search.PropertiesToLoad.Add("mail");
search.PropertiesToLoad.Add("telephonenumber");
SearchResult sresult = search.FindOne();
if(sresult != null)
{
....
}
....
}В данном примере формируется фильтр поиска для предоставления некоторых личных данных пользователю, обладающему подходящими логином и паролем. В фильтре используются значения переменных 'user' и 'password', полученные из внешнего источника. Использование данных подобным образом опасно, так как даёт злоумышленнику возможность подделки фильтра поиска.
Для лучшего понимания атаки приведём несколько примеров.
Если в 'user' будет записано "PVS", а в 'password' – "Studio", то получится следующий запрос:
LDAP query: (&(userId=PVS)(UserPassword=Studio))В этом случае мы получили от пользователя ожидаемые данные и если такая комбинация пользователя и пароля существует, то будет предоставлен доступ.
Но допустим, что в переменных 'user' и 'password' будут записаны следующие значения:
user: PVS)(userId=PVS))(|(userId=PVS)
password: AnyПри подстановке этих строк в шаблон получится следующий фильтр:
LDAP query: (&(userId=PVS)(userId=PVS))(|(userId=PVS)(UserPassword=Any))При использовании такого фильтра поиска доступ будет предоставлен в любом случае, даже если злоумышленник введёт неверный пароль. Это произойдёт из-за того, что LDAP будет обрабатывать только первый фильтр, а (|(userId=PVS)(UserPassword=Any)) просто проигнорирует.
Чтобы защититься от подобной атаки, стоит проводить валидацию всех входных данных или экранировать все специальные символы в данных, которые приходят от пользователей. Существуют методы, которые автоматически экранируют все небезопасные значения.
Пример кода с использованием метода автоматического экранирования из пространства имён 'Microsoft.Security.Application.Encoder':
public void Search()
{
....
string user = textBox.Text;
string password = pwdBox.Password;
DirectoryEntry de = new DirectoryEntry();
DirectorySearcher search = new DirectorySearcher(de);
user = Encoder.LdapFilterEncode(user);
password = Encoder.LdapFilterEncode(password);
search.Filter = $"(&(userId={user})(UserPassword={password}))";
search.PropertiesToLoad.Add("mail");
search.PropertiesToLoad.Add("telephonenumber");
SearchResult sresult = search.FindOne();
if (sresult != null)
{
....
}
....
}Анализатор также считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов".
Рассмотрим пример:
public class LDAPHelper
{
public void Search(string userName)
{
var filter = "(&(objectClass=user)(employeename=" + userName + "))";
ExecuteQuery(filter);
}
private void ExecuteQuery(string filter)
{
DirectoryEntry de = new DirectoryEntry();
DirectorySearcher search = new DirectorySearcher(de);
search.Filter = filter;
search.PropertiesToLoad.Add("mail");
search.PropertiesToLoad.Add("telephonenumber");
SearchResult sresult = search.FindOne();
if (sresult != null)
{
....
}
}
}В данном случае анализатор выдаст предупреждение низкого уровня достоверности при анализе исходного кода метода 'Search' на вызов 'ExecuteQuery'. PVS-Studio отследил передачу небезопасных данных из параметра 'userName' в переменную 'filter' и после в 'ExecuteQuery'.
Защита в таком случае не отличается от приведённой ранее.
public class LDAPHelper
{
public void Search(string userName)
{
userName = Encoder.LdapFilterEncode(userName);
var filter = "(&(objectClass=user)(employeename=" + userName + "))";
ExecuteQuery(filter);
}
private void ExecuteQuery(string filter)
{
DirectoryEntry de = new DirectoryEntry();
DirectorySearcher search = new DirectorySearcher(de);
search.Filter = filter;
....
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5621. OWASP. Error message contains potentially sensitive data that may be exposed.
Анализатор обнаружил раскрытие потенциально чувствительных данных, содержащихся в сообщении об ошибке. К таким данным относятся сообщения и стеки исключений.
Ошибки, связанные с неявным раскрытием чувствительных данных, относятся к категории A04:2021 – Insecure Design списка OWASP Top 10 Application Security Risks.
Рассмотрим пример уязвимости:
public void Foo(string value)
{
try
{
int intVal = int.Parse(value);
....
}
catch (Exception e)
{
Console.WriteLine(e.StackTrace); // <=
}
}Не рекомендуется показывать пользователям стеки исключений. Это может привести к раскрытию информации о деталях реализации проекта. Например, могут быть раскрыты названия используемых в проекте библиотек, а они могут содержать известные уязвимости. Злоумышленник может использовать эту информацию для атаки на проект.
Также стек исключения для стандартных классов исключений .NET может быть раскрыт через метод 'ToString':
public void Foo(string value)
{
try
{
int intVal = int.Parse(value);
....
}
catch (Exception e)
{
Console.WriteLine(e.ToString()); // <=
}
}Следует помнить, что 'ToString' вызывается внутри методов вывода, принимающих 'object' в качестве аргумента:
Console.WriteLine(e);Решением этой проблемы архитектуры может быть предотвращение вывода чувствительной информации пользователю. Например, можно использовать ресурсы, явно связанные с исключениями, но не содержащие чувствительной информации. Простой пример с использованием 'enum':
enum ErrorCode
{
/// <summary>
/// ArgumentNull exception occurred
/// </summary>
ArgumentNull,
....
Unknown
}
public void Foo(string value)
{
try
{
int intVal = int.Parse(value);
....
}
catch (Exception e)
{
ErrorCode errCode = e switch
{
ArgumentNullException => ErrorCode.ArgumentNull,
....
_ => ErrorCode.Unknown
};
Console.WriteLine("An error has occurred: " + errCode); // <=
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5622. OWASP. Possible XPath injection. Potentially tainted data is used in the XPath expression.
Анализатор обнаружил, что для формирования выражения на языке XPath используются непроверенные данные из внешнего источника. Это может стать причиной возникновения XPath-инъекции.
Уязвимости, связанные с инъекциями, относятся к категории A03:2021 – Injection списка OWASP Top 10 Application Security Risks.
Рассмотрим пример:
class UserData
{
HttpRequest request;
XPathNavigator navigator;
void RetrieveUserData()
{
string username = request.Form["username"];
string password = request.Form["password"];
string hashedPassword = Hash(password);
string query = $@"//users/user[
username/text() = '{username}' and
passwordHash/text() = '{hashedPassword}']
/data/text()";
object res = navigator.Evaluate(query);
....
}
}В этом примере XPath-выражение используется для получения данных пользователя из XML-файла. Имя пользователя хранится "как есть", а пароль хранится в зашифрованном виде.
Злоумышленник может передать в качестве имени пользователя и пароля любые данные. Проверка будет скомпрометирована, если во входных данных передать выражение, которое сделает XPath-условие всегда истинным. Так как пароль хранится в зашифрованном виде, то внедрять опасное выражение нужно вместе с именем пользователя.
Для примера пусть имя пользователя будет 'john'. Добавим к нему выражение такого вида:
' or ''='Вместо пароля может быть введён любой набор символов. Тогда XPath-выражение будет иметь такой вид:
[
username/text()='john' or ''='' and
passwordHash/text() = '750084105bcbe9d2c89ba9b'
]Теперь выражение содержит оператор 'or'. Рассмотрим, как оно вычисляется:
- Так как имя пользователя существует, выражение "username/text()='john'" является истинным.
- В качестве пароля были введены случайные символы, поэтому выражение passwordHash/text() = '750084105bcbe9d2c89ba9b' является ложным.
- Выражение ''='' всегда истинно.
- Приоритет оператора 'and' выше, чем 'or', поэтому происходит вычисление выражения ''='' and passwordHash/text() = '750084105bcbe9d2c89ba9b'. Результатом является ложь.
- Последним выполняется оператор 'or'. Выражение "username/text()='john' or false" является истинным. Следовательно, всё условие является истинным.
Таким образом, результатом XPath-запроса будут данные пользователя 'john' независимо от того, правильный пароль был введён или нет. Это может привести к утечке данных.
Не следует использовать непроверенные внешние данные в XPath-выражениях. Для повышения безопасности стоит экранировать потенциально опасные символы во внешних данных. Примерами таких символов являются "<", ">" и "'". Экранирование может быть произведено с помощью метода 'SecurityElement.Escape':
class UserData
{
HttpRequest request;
XPathNavigator navigator;
void RetrieveUserData()
{
string username = request.Form["username"];
string password = request.Form["password"];
username = SecurityElement.Escape(username);
string hashedPassword = Hash(password);
string query = $@"//users/user[
username/text()= '{username}' and
passwordHash/text() ='{hashedPassword}']
/data/text()";
object res = navigator.Evaluate(query);
....
}
}Существуют другие возможности для предотвращения XPath-инъекций. Например, Microsoft предлагает возможность реализации класса-резолвера. Его можно использовать в методах класса 'XPathNavigator', которые принимают строку XPath-выражения и объект, реализующий интерфейс 'IXmlNamespaceResolver'.
Это позволяет определить свои собственные переменные и функции внутри XPath-выражения, которые будут обработаны резолвером. Само по себе это не является решением проблемы XPath-инъекции, но определение своиx переменных позволяет использовать подход, похожий на параметризацию SQL-запросов.
Также анализатор считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов". Рассмотрим пример:
public class UserData
{
XPathNavigator navigator;
public object RetrieveUserData(string username,
string password)
{
string hashedPassword = Hash(password);
string query = $@"//users/user[
username/text()= '{username}' and
passwordHash/text() = '{hashedPassword}']
/data/text()";
return EvaluateXpath(query);
}
private object EvaluateXpath(string xpath)
{
object res = navigator.Evaluate(xpath);
....
}
}В этом примере метод 'RetrieveUserData' доступен из других сборок. Параметры этого метода 'username' и 'password' не проверяются перед внедрением в XPath-запрос. Полученное выражение в переменной 'query' передаётся в метод 'EvaluateXpath', где используется без проверки. В таком случае анализатор выдаст предупреждение с низким уровнем достоверности.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5623. OWASP. Possible open redirect vulnerability. Potentially tainted data is used in the URL.
Анализатор обнаружил перенаправление с одного ресурса на другой. Причём URL-адрес для перенаправления был получен из внешнего источника и не был проверен. Это может стать причиной возникновения уязвимости типа open redirect, если адрес будет скомпрометирован.
Уязвимости типа open redirect относятся к категории рисков OWASP Top 10 Application Security Risks 2021: A1:2021- Broken Access Control.
Приведём пример:
void Foo()
{
string url = Request.QueryString["redirectUrl"];
....
if (loggedInSuccessfully)
Response.Redirect(url);
}В этом примере 'url' может содержать заражённые данные, так как они получены из внешнего источника. Эти данные используются для перенаправления клиента на адрес, который записан в 'url'. Подобная логика работы программы упрощает проведение фишинговых атак для кражи данных пользователя.
Пример скомпрометированного адреса:
URL: http://mySite.com/login?redirectUrl=http://attacker.com/Возможный сценарий проведения атаки:
- пользователь получает ссылку от злоумышленника и под каким-то предлогом переходит по ней;
- он оказывается на известном сайте, который запрашивает авторизацию. После ввода логина и пароля произойдёт перенаправление на поддельный сайт, который выглядит в точности как ожидаемый;
- фишинговый сайт также запрашивает логин и пароль. Пользователь думает, что ошибся и снова вводит данные для авторизации;
- соответственно, их получает злоумышленник, создавший поддельный сайт. После этого происходит перенаправление на оригинальный сайт. В итоге пользователь может даже не заметить, что его данные были украдены.
Главная опасность open redirect состоит в том, что ссылка, полученная от злоумышленника, фактически ведёт на сайт, которому пользователь доверяет. Следовательно, жертва с большей вероятностью перейдёт по ней.
Для защиты open redirect стоит проверять, что перенаправление осуществляется на локальный адрес или на адрес из белого списка.
Приведём пример борьбы с уязвимостью типа open redirect. Используя метод 'IsLocalUrl' из пространства имён 'Microsoft.AspNet.Membership.OpenAuth' можно проверить, что адрес является локальным:
void Foo()
{
string url = Request.QueryString["url"];
if (OpenAuth.IsLocalUrl(url))
Response.Redirect(url);
else
throw ....;
}Происходит проверка, что полученный URL-адрес является локальным и только в этом случае осуществляется переход по нему.
Анализатор также считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов".
Рассмотрим пример:
public class UriHelper
{
public void ProcessUrlQuery(HttpResponse resp, string url)
{
RedirectUrl(url, resp);
}
private void RedirectUrl(string redirectUrl, HttpResponse resp)
{
resp.Redirect(redirectUrl);
}
}Анализатор обнаружит, что небезопасные данные из параметра 'url' передаются в метод 'RedirectUrl', внутри которого они без проверки используются для перенаправления.
Защититься в данном случае можно тем же способом, что был приведён ранее.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5624. OWASP. Use of potentially tainted data in configuration may lead to security issues.
Анализатор обнаружил, что для конфигурации используются данные из внешнего источника. Это может привести к возникновению дефекта безопасности.
Уязвимости такого типа относятся к категории рисков OWASP Top 10 Application Security Risks 2021: A5:2021 - Security Misconfiguration.
Приведём пример:
public void ExecuteSqlQuery(....)
{
....
string catalog = Request.QueryString["catalog"];
using (SqlConnection dbConnection = IO.GetDBConnection())
{
dbConnection.ConnectionString = $"Data Source=....; " +
$"Initial Catalog={catalog}; " +
$"User ID=....; " +
$"Password=....;";
....
}
....
}В этом примере формируется строка подключения к БД. В параметр 'Initial Catalog' записываются данные, не прошедшие никакой валидации, благодаря чему злоумышленник может передать любое название каталога. Подобным образом он может получить информацию, доступ к которой не был предусмотрен.
Для защиты от подобных атак стоит производить валидацию входных данных. Пример корректного формирования строки подключения:
public void ExecuteSqlQuery(...., HashSet<string> validCatalogNames)
{
....
string catalog = Request.QueryString["catalog"];
if(!validCatalogNames.Contains(catalog))
return;
using(SqlConnection dbConnection = IO.GetDBConnection())
{
dbConnection.ConnectionString = $"Data Source=....; " +
$"Initial Catalog={catalog}; " +
$"User ID=....; " +
$"Password=....;";
....
}
....
}В данном случае проверяется, что 'catalog' содержится в коллекции 'validCatalogNames'. Таким образом, пользователь будет иметь доступ лишь к определённому перечню каталогов, что не позволит получить приватную информацию.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5625. OWASP. Referenced package contains vulnerability.
- В каких случаях появляется предупреждение?
- Что делать при появлении предупреждения?
- Подавление предупреждений об уязвимых зависимостях
Анализатор обнаружил, что в проекте используются сборки, которые могут содержать известные уязвимости. Использование таких зависимостей может привести к появлению уязвимостей в самом приложении.
Данной проблеме посвящена категория A6: Vulnerable and Outdated Components из списка OWASP Top Ten 2021.
В каких случаях появляется предупреждение?
К примеру, в проекте может использоваться сборка log4net версии 1.2.13. Это единственная сборка в пакете log4net 2.0.3, который содержит уязвимость CVE-2018-1285. Следовательно, работа с функционалом этой зависимости может привести к появлению уязвимостей и в использующем её проекте.
Анализатор также исследует и транзитивные зависимости, то есть зависимости библиотек, от которых зависит проект.
К примеру, одной из зависимостей пакета RepoDb.MySql 1.1.4 является MySql.Data версии 8.0.22 и выше. В свою очередь MySql.Data 8.0.22 зависит от пакетов Google.Protobuf (версии 3.11.4 и выше) и SSH.NET (версии 2016.1.0 и выше).

Анализатору известно, что:
- все версии пакета Google.Protobuf до 3.15.0 содержат уязвимость CVE-2021-22570;
- все версии пакета SSH.NET до 2020.0.2 содержат уязвимость CVE-2022-29245.
Таким образом, любой проект, использующий RepoDb.MySql 1.1.4, может транзитивно зависеть от уязвимых сборок SSH.NET и Google.Protobuf. Уязвимости в таких зависимостях также могут привести к различным проблемам в работе приложения. Тем не менее, вероятность этого меньше, чем в случае с прямыми зависимостями, поэтому уровень достоверности предупреждения будет ниже.
Что делать при появлении предупреждения?
Если зависимость проекта содержит уязвимость, то для обеспечения безопасности необходимо как-то от неё избавиться или защитить себя от возможных рисков. Для этого в первую очередь необходимо определить, каким образом проект связан с уязвимой библиотекой или пакетом.
Если проект ссылается на зависимость напрямую, то её название (и, возможно, версия) будет явно прописано в списке зависимостей проекта. К примеру, в случае с пакетами такую зависимость можно будет найти в окне NuGet Package Manager на вкладке списка установленных пакетов. В Visual Studio это окно выглядит следующим образом:
Для непрямых (транзитивных) зависимостей может понадобиться отследить цепочку пакетов или библиотек, которые "соединяют" проект и уязвимую зависимость. Для этого можно использовать различные программные средства. К примеру, в среде Visual Studio 2022 есть возможность поиска среди внешних компонентов:

Используя эту возможность, можно найти полную цепочку зависимостей от проекта до уязвимого пакета. Похожий функционал поиска присутствует и в среде JetBrains Rider.
Для получения иерархии зависимостей сборок могут быть полезны такие средства, как JetBrains dotPeek. В нём нужно открыть интересующую сборку и в контекстном меню выбрать пункт References Hierarchy:

На открывшейся панели будет отображено дерево зависимостей выбранной сборки:

Ниже представлены возможные варианты решения проблем с найденными уязвимыми зависимостями.
Обновление зависимости
Как правило, уязвимость присутствует лишь в некоторых версиях пакета или сборки. Если проект зависит от уязвимого компонента напрямую, то возможно, стоит использовать другую его версию.
Отдельно стоит рассмотреть ситуацию, когда проект использует уязвимую зависимость не напрямую. К примеру, проект зависит от сборки "A", зависящей от уязвимой сборки "B".

Если у "B" есть безопасные версии, то можно попробовать одно из следующих решений:
- Обновить сборку "A" – вполне возможно это приведёт к изменению используемой версии "B".
- Сделать сборку "B" прямой зависимостью проекта, указав при этом безопасную версию. Тогда и сборка "A" будет вынуждена её использовать. ВАЖНО: Используя этот вариант, нужно проверить, что зависимости проекта (включая "A") совместимы с новой версией "B". Если это не так, то можно попробовать обновить сборки до версий, которые будут совместимы с безопасной версией "B".
Похожим образом можно решать проблемы и с более "глубокими" зависимостями – к примеру, если проект зависит от сборки "A", которая зависит от сборки "B", зависящей от уязвимой сборки "C".
Замена зависимости
Если безопасные версии пакета/сборки отсутствуют, или их обновление невозможно по каким-то другим причинам, то, возможно, стоит рассмотреть использование другой библиотеки.
Ситуация несколько сложнее, если проект зависит от уязвимой библиотеки не напрямую. В этом случае замене подлежит прямая зависимость, из-за которой проект становится зависимым от уязвимой библиотеки. То есть если проект зависит от библиотеки "A", которая зависит от уязвимой библиотеки "B", то заменить придётся библиотеку "A".
Обеспечение безопасности на стороне проекта
Если предыдущие варианты решения не подходят, то необходимо понять, в чём состоит уязвимость используемой библиотеки, и как она может повлиять на работу приложения. Используя эту информацию, нужно внести в код приложения правки, защищающие от эксплуатации уязвимости. Например, можно добавить дополнительную валидацию входных данных или отказаться от использования части функционала зависимости в пользу более безопасных методов.
Скорее всего, в этом случае предупреждения диагностического правила будет нужно подавить. Данной теме посвящён следующей раздел.
Подавление предупреждений об уязвимых зависимостях
Так как V5625 является диагностикой уровня проекта, то её срабатывания не связаны с каким-то конкретным фрагментом кода. Поэтому предупреждения этой диагностики нельзя пометить как ложные с помощью добавления в код комментария типа "//-V5625". Также на данный момент отсутствует возможность baselining-а (подавления) таких срабатываний с помощью suppress-файлов.
Для подавления сообщений V5625 используйте файл конфигурации диагностик – текстовый файл с расширением pvsconfig, добавляемый в проект либо solution.
Например, в Visual Studio для добавления файла конфигурации нужно выделить проект или solution и в контекстном меню выбрать пункт 'Add New Item...'. В появившемся окне нужно выбрать 'PVS-Studio Filters File'.
Файл конфигурации, добавленный в проект, действует на все файлы данного проекта. Файл конфигурации, добавленный в solution, действует на все файлы всех проектов, добавленных в данный solution.
Для подавления срабатывания диагностики V5625 на конкретную библиотеку можно добавить в pvsconfig строку следующего вида:
//-V::5625::{Google.Protobuf 3.6.1}Тогда анализатор перестанет выдавать срабатывания V5625, содержащие в сообщении подстроку "Google.Protobuf 3.6.1".
Также есть возможность указать уровень:
//-V::5625:2:{Google.Protobuf 3.6.1}В этом случае диагностическое правило не будет выдавать срабатывание, если оно имеет второй уровень (Medium), и его сообщение содержит подстроку "Google.Protobuf 3.6.1".
Более подробное описание pvsconfig файлов приведено в документации.
Данная диагностика классифицируется как:
V5626. OWASP. Possible ReDoS vulnerability. Potentially tainted data is processed by regular expression that contains an unsafe pattern.
Анализатор обнаружил применение потенциально опасного регулярного выражения для обработки данных из внешнего источника. Это может сделать приложение уязвимым к ReDoS-атаке.
Суть ReDoS-атаки
ReDoS – отказ в обслуживании, причиной которого стало уязвимое регулярное выражение. Цель злоумышленника при проведении ReDoS-атаки – передать в регулярное выражение строку, оценка которой потребует максимального количества времени.
Регулярное выражение является уязвимым, если соответствует следующим условиям:
- Существует два подвыражения, при этом одно из них включено в другое и к каждому из них применяется один из следующих кванторов: '*', '+', '*?', '+?', '{...}' (к примеру, подвыражение 'x+' включено в '(x+)*');
- Существует такая строка, которую можно было бы сопоставить с обоими этими подвыражениями (строку 'xxxx' можно сопоставить как с шаблоном 'x+', так и с '(x+)*').
Таким образом, при получении предупреждения данной диагностики, следует проверить регулярное выражение на наличие подвыражений вида:
- ...(a+)+...
- ...(b?a*c?)+...
- ...(.+a+c?)*?...
- ...(a+){x}...
- ...(...|a...|...|a?...|...)+...
- и т. д.
Здесь 'a', 'b', 'c' могут быть:
- отдельными символами;
- набором символов в квадратных скобках '[...]';
- подвыражением в круглых скобках '(...)';
- любым классом символов, которые поддерживаются регулярным выражением ('\d', '\w', '.' и т. д.).
Также важно, чтобы после этих подвыражений было хотя бы одно подвыражение, не помеченное кванторами '?' или '*'. Например: '(x+)+y', '(x+)+$', '(x+)+(...)', ' (x+)+[...]' и т. д.
Разберем проблему этих выражений на примере '(x+)+y'. В этом выражении шаблону 'x+' может соответствовать любое количество символов 'x'. Строка, которая соответствует шаблону '(x+)+y', состоит из любого количества подстрок, сопоставленных с 'x+'. Как следствие, появляется большое множество вариантов сопоставлений одной и той же строки с регулярным выражением.
Несколько вариантов сопоставлений строки 'xxxx' с шаблоном '(x+)+y' продемонстрированы в таблице ниже:

Каждый раз, когда регулярному выражению не удаётся найти символ 'y' в конце строки, оно начинает проверку следующего варианта. Лишь проверив их все, регулярное выражение даст ответ – совпадений не найдено. Однако время выполнения этого процесса может оказаться катастрофически большим в зависимости от длины подстроки, соответствующей уязвимому паттерну.
График ниже отражает зависимость времени вычисления регулярного выражения (x+)+y от количества символов во входных строках вида 'xx....xx':

Рассмотрим пример кода:
Regex _datePattern = new Regex(@"^(-?\d+)*$");
public bool IsDateCorrect(string date)
{
if (_datePattern.IsMatch(date))
....
}В этом примере дата проверяется с помощью регулярного выражения. Если дата корректна, регулярное выражение отработает так, как и ожидалось. Ситуация изменится, если в качестве даты приложение получит следующую строку:
3333333333333333333333333333333333333333333333333333333333333 Hello ReDoS!В этом случае обработка регулярным выражением займёт очень много времени. Поступление нескольких запросов с подобными данными может создать сильную нагрузку на приложение.
Возможное решение – ограничить время обработки регулярным выражением входной строки:
Regex _datePattern = new Regex(@"^(-?\d+)*$",
RegexOptions.None,
TimeSpan.FromMilliseconds(10));Рассмотрим ещё один пример. В регулярном выражении намеренно добавлено подвыражение '(\d|[0-9]?)', чтобы показать суть проблемы.
Regex _listPattern = new Regex(@"^((\d|[0-9]?)(,\s|\.))+$(?<=\.)");
public void ProcessItems(string path)
{
using (var reader = new StreamReader(path))
{
while (!reader.EndOfStream)
{
string line = reader.ReadLine();
if (line != null && _listPattern.IsMatch(line))
....
}
}
}Здесь данные считываются из файла и проверяются регулярным выражением на соответствие следующему паттерну: строка должна представлять собой список, каждый элемент которого является цифрой или пустой строкой. Корректный ввод может выглядеть так:
3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4, 5, 3, 4.При обработке таких данных регулярное выражение отработает за нормальное время. Однако, если передать ту же строку, но без точки в конце, приложение затратит на обработку данных намного больше времени.
В регулярном выражении используются подвыражения '\d' и '[0-9]?', которые могут сопоставляться с одними и теми же значениями. Обратите внимание, что ко второму подвыражению применяется квантор '? ', а к родительскому подвыражению '((\d|[0-9]?)(,\s|\.))' – квантор '+'. Это приводит к появлению большого количества возможных сопоставлений в строке. Если бы не было хотя бы одного из этих двух кванторов, ReDoS-уязвимости не возникло бы.
В данном примере для устранения ReDoS-уязвимости достаточно убрать лишнее сопоставление:
Regex _listPattern = new Regex(@"^([0-9]?(,\s|\.))+$(?<=\.)");Еще больше узнать о ReDoS-уязвимостях можно, к примеру, на сайте OWASP.
Способы устранения ReDoS-уязвимости
Устранить ReDoS-уязвимость можно несколькими способами. Рассмотрим их на примере регулярного выражения '^(-?\d+)*$'.
Способ 1. Добавить ограничение на время обработки строки регулярным выражением. Это можно сделать, задав параметр 'matchTimeout' при создании объекта 'Regex' или при вызове статического метода:
RegexOptions options = RegexOptions.None;
TimeSpan timeout = TimeSpan.FromMilliseconds(10);
Regex datePattern = new Regex(@"^(-?\d+)*$", options, timeout);
Regex.IsMatch(date, @"^(-?\d+)*$", options, timeout);Способ 2. Использовать атомарные группы '(?>...)'. Атомарные группы отключают поиск всех возможных комбинаций символов, соответствующих подвыражению, ограничиваясь лишь одной:
Regex datePattern = new Regex(@"^(?>-?\d+)*$");Способ 3. Переписать регулярное выражение, убрав опасный паттерн. Предположим, что выражение '^(-?\d+)*$' предназначено для поиска даты вида '27-09-2022', в этом случае его можно заменить на более надёжный аналог:
Regex datePattern = new Regex (@"^(\d{2}-\d{2}-\d{4})$");В этом варианте любая подстрока сопоставляется не более чем с одним подвыражением из-за обязательной проверки символа '-' между шаблонами '\d{...}'.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V5626. |
V5627. OWASP. Possible NoSQL injection. Potentially tainted data is used to create query.
Анализатор обнаружил использование непроверенных данных из внешнего источника для формирования запроса к NoSQL базе данных. Это может стать причиной NoSQL-инъекции в случае, если данные скомпрометированы.
Инъекции выделены в отдельную категорию рисков в OWASP Top 10 Application Security Risks 2021: A3:2021-Injection.
Рассмотрим пример:
public IFindFluent<BsonDocument, BsonDocument> Authentication()
{
String log = Request.Form["login"];
String pass = Request.Form["password"];
String filter = "{$where: \"function() {" +
$"return this.login=='{log}' && this.password=='{pass}'"+
";}\"}";
return collection.Find(filter);
}Метод 'Authentication' ищет запись пользователя в NoSQL базе данных MongoDB по логину и паролю. Для этого создается строка 'filter', содержащая JavaScript код. С её помощью будут фильтроваться результаты поиска. Аналогом этой операции в SQL будет следующий запрос: SELECT * FROM collection WHERE login = @log AND password = @pass.
Для формирования фильтра используются значения строк 'log' и 'pass', полученные из внешнего источника. Подобное использование непроверенных данных позволяет злоумышленнику внедрить вредоносный код внутрь запроса.
Например, здесь злоумышленник может отправить вместо ожидаемого значения 'pass' строку следующего вида:
"-1' || this.login == 'admin"Тогда обращение к базе данных может выглядеть так:
{$where: "function()
{
return this.login == 'doesn't matter'
&& this.password == '-1'
|| this.login == 'admin';
}"}В таком случае запрос вернёт данные аккаунта администратора.
Для защиты от инъекций NoSQL базы предоставляют инструменты параметризированного создания запросов.
Пример создания безопасного запроса:
public IFindFluent<BsonDocument, BsonDocument> Authentication()
{
String log = Request.Form["login"];
String pass = Request.Form["password"];
var filter = Builders<BsonDocument>.Filter.Eq("login", log)
& Builders<BsonDocument>.Filter.Eq("password", pass);
return collection.Find(filter);
}Здесь фильтр создается при помощи специального класса 'Builders'. За счёт этого запрос будет параметризованным и внешние данные не смогут повлиять на логику фильтрации.
Анализатор также считает источниками небезопасных данных параметры методов, доступных из других сборок. Более подробно эта тема раскрыта в заметке "Почему важно проверять значения параметров общедоступных методов".
Рассмотрим пример:
public class MongoDBRep
{
public void DeleteItemsByCounter(string count)
{
DeleteMany(count);
}
private void DeleteMany(string count)
{
var filter = "{$where:\"function(){return this.count == "+count+";}\"}";
collection.DeleteMany(filter);
}
}Здесь потенциально заражённые данные из параметра 'count' передаются в метод 'DeleteMany', внутри которого они без проверки используются для удаления записей из базы данных.
Злоумышленник может сформировать запрос следующего вида:
{$where: "function()
{
return this.count == -999
|| 1 == 1;
}"}Исполнение этого запроса приведёт к удалению всех документов базы данных, независимо от значения поля 'count'.
В этом случае рекомендуется защититься тем же способом, что был приведён ранее.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
|
V5628. OWASP. Possible Zip Slip vulnerability. Potentially tainted data is used in the path to extract the file.
Анализатор обнаружил операцию извлечения файла по непроверенному пути, включающему имя файла. В случае наличия в имени файла "dot-dot-slash" последовательностей эта операция приведет к возникновению уязвимости Zip Slip в приложении.
Zip Slip проводится через передачу в приложение архива с вредоносными файлами внутри: они содержат в имени "dot-dot-slash" последовательности ("../../evil.csx"). Спровоцировав распаковку такого архива, злоумышленник может переписать любые файлы, к которым у приложения есть доступ.
В большинстве архиваторов или операционных систем создать файл с названием вида '../../evil.csx' не получится из-за встроенных ограничений. Тем не менее, существуют инструменты, допускающие эту операцию. Из-за этого атака Zip Slip и становится возможной.
Рассмотрим пример небезопасного кода:
public void ExtractArchive(ZipArchive archive, string destinationDirectory)
{
var entries = archive.Entries;
foreach (var entry in entries)
{
var extractPath = Path.Combine(destinationDirectory, entry.FullName);
entry.ExtractToFile(extractPath, true);
}
}Здесь внутри цикла файлы поочередно извлекаются из архива в директорию, расположенную по пути 'destinationDirectory'. Для каждого файла создаётся путь распаковки с помощью метода 'Path.Combine', после чего результат записывается в переменную 'extractPath'. Далее 'extractPath' используется в качестве аргумента метода 'entry.ExtractToFile', выполняющего разархивирование файла по заданному пути.
Предположим, что архив должен быть извлечён в директорию 'C:\ApplicationFiles\UserFiles'. Однако если свойство 'entry.FullName' вернёт строку вида '\..\config.ini', файл попадёт в корневой каталог приложения 'C:\ApplicationFiles'. В случае совпадения имени извлекаемого файла и, например, файла конфигурации приложения, будет выполнена перезапись последнего.
Обезопасить код в предыдущем примере можно, например, следующим образом:
public void ExtractArchive(ZipArchive archive, string destinationDirectory)
{
var destinationDirectoryFullPath = Path.GetFullPath(destinationDirectory);
foreach (var entry in archive.Entries)
{
var extractPath = Path.Combine(destinationDirectory, entry.FullName);
var extractFullPath = Path.GetFullPath(extractPath);
if (!extractFullPath.StartsWith(destinationDirectoryFullPath))
{
throw new IOException("Zip Slip vulnerability");
}
entry.ExtractToFile(extractFullPath);
}
}Здесь в переменную 'extractFullPath' записывается результат обработки пути 'extractPath' методом 'Path.GetFullPath'. В ходе этой операции путь, содержащий "dot-dot-slash" последовательности, будет заменен на аналогичный, не включающий их.
После этого с помощью метода 'extractFullPath.StartsWith' проверяется, не изменилась ли директория для распаковки файла в результате предыдущей операции. В случае если произошла подмена директории, выбрасывается исключение.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). |
Данная диагностика классифицируется как:
V5629. Code contains invisible characters that may alter its logic. Consider enabling the display of invisible characters in the code editor.
Анализатор обнаружил в тексте программы символы, которые могут ввести программиста в заблуждение. Эти символы могут не отображаться и изменять видимое представление кода в среде разработки. Комбинации таких символов могут привести к тому, что человек и компилятор будут интерпретировать код по-разному.
В некоторых случаях это делается намеренно. Такой вид атаки называется Trojan Source. Подробнее:
- Атака Trojan Source для внедрения в код изменений, незаметных для разработчика;
- Атака Trojan Source: скрытые уязвимости.
|
Обозначение |
Код |
Название |
Описание |
|---|---|---|---|
|
LRE |
U+202A |
LEFT-TO-RIGHT EMBEDDING |
Текст после символа LRE интерпретируется как вставленный и отображается слева направо. Действие LRE прерывается символом PDF или символом перевода строки. |
|
RLE |
U+202B |
RIGHT-TO-LEFT EMBEDDING |
Текст после символа RLE интерпретируется как вставленный и отображается справа налево. Действие RLE прерывается символом PDF или символом перевода строки. |
|
LRO |
U+202D |
LEFT-TO-RIGHT OVERRIDE |
Текст после символа LRO принудительно отображается слева направо. Действие LRO прерывается символом PDF или символом перевода строки. |
|
RLO |
U+202E |
RIGHT-TO-LEFT OVERRIDE |
Текст после символа RLO принудительно отображается справа налево. Действие RLO прерывается символом PDF или символом перевода строки. |
|
|
U+202C |
POP DIRECTIONAL FORMATTING |
Символ PDF прерывает действие одного из символов LRE, RLE, LRO или RLO, встреченного ранее. Прерывает ровно один символ, последний из встреченных. |
|
LRI |
U+2066 |
LEFT‑TO‑RIGHT ISOLATE |
Текст после символа LRI отображается слева направо и интерпретируется как изолированный. Это означает, что другие управляющие символы не влияют на отображение этого фрагмента текста. Действие LRI прерывается символом PDI или символом перевода строки. |
|
RLI |
U+2067 |
RIGHT‑TO‑LEFT ISOLATE |
Текст после символа RLI отображается справа налево и интерпретируется как изолированный. Это означает, что другие управляющие символы не влияют на отображение этого фрагмента текста. Действие RLI прерывается символом PDI или символом перевода строки. |
|
FSI |
U+2068 |
FIRST STRONG ISOLATE |
Направление текста после символа FSI задается первым управляющим символом, не входящим в этот фрагмент текста. Другие управляющие символы не влияют на отображение этого текста. Действие FSI прерывается символом PDI или символом перевода строки. |
|
PDI |
U+2069 |
POP DIRECTIONAL ISOLATE |
Символ PDI прерывает действие одного из символов LRI, RLI или FSI, встреченного ранее. Прерывает ровно один символ, последний из встреченных. |
|
LRM |
U+200E |
LEFT-TO-RIGHT MARK |
Текст после символа LRM отображается слева направо. Действие LRM прерывается символом перевода строки. |
|
RLM |
U+200F |
RIGHT-TO-LEFT MARK |
Текст после символа RLM отображается справа налево. Действие RLM прерывается символом перевода строки. |
|
ALM |
U+061C |
ARABIC LETTER MARK |
Текст после символа ALM отображается справа налево. Действие ALM прерывается символом перевода строки. |
|
ZWSP |
U+200B |
ZERO WIDTH SPACE |
Неотображаемый пробельный символ. Использование символа ZWSP привести к тому, что разные строки будут отображаться одинаково. Например, |
Рассмотрим следующий фрагмент кода:
bool isAdmin = false;
/*[RLO] } [LRI] if (isAdmin)[PDI] [LRI] begin admins only */ // (1)
Console.WriteLine("You are an admin.");
/* end admins only [RLO]{ [LRI]*/ // (2)Изучим детально строку (1).
[LRI] if (isAdmin)[PDI]Здесь символ [LRI] действует до символа [PDI]. Строка if (isAdmin) будет отображаться слева направо и считается изолированной, получаем if (isAdmin).
[LRI] begin admins only */Здесь символ [LRI] действует до конца строки. Получаем изолированную строку: begin admins only */
[RLO] {пробел1}, '}', {пробел2}, 'if (isAdmin)', 'begin admins only */'Здесь символ [RLO] действует до конца строки и отображает текст справа налево. Каждая из полученных в предыдущих пунктах изолированных строк рассматривается как отдельный неделимый символ. Получаем такую последовательность:
'begin admins only */', 'if (isAdmin)', {пробел2}, '{', {пробел1}Обратите внимание, что символ закрывающей фигурной скобки теперь отображается как { вместо }.
Итоговый вид строки (1), который может быть отображен в редакторе:
/* begin admins only */ if (isAdmin) {Похожие преобразования затронут и строку (2), которая отобразится так:
/* end admins only */ }Финальный вид кода, который может отобразиться в редакторе:
bool isAdmin = false;
/* begin admins only */ if (isAdmin) {
Console.WriteLine("You are an admin.");
/* end admins only */ }Ревьюер может посчитать, что в коде выполняется некоторая проверка перед выводом сообщения. Он проигнорирует комментарии и подумает, что код должен выполняться так:
bool isAdmin = false;
if (isAdmin) {
Console.WriteLine("You are an admin.");
}Однако на самом деле проверки нет. Для компилятора рассмотренный код выглядит так:
bool isAdmin = false;
Console.WriteLine("You are an admin.");Теперь рассмотрим более простой и в то же время более опасный пример использования неотображаемых символов:
enum BlockSipherType { DES, TripleDES, AES };
BlockSipherType StringToBlockSypherType(string str)
{
if (str == "AES[ZWSP]")
return BlockSipherType.AES;
else if (str == "TripleDES[ZWSP]")
return BlockSipherType.TripleDES;
else return BlockSipherType.DES;
}Метод StringToBlockCipherType производит конвертацию строки в одно из значений перечисления BlockCipherType. По коду можно сделать вывод, что функция возвращает три разных значения, однако это не так. Из-за того, что в конце каждого строкового литерала добавлен неотображаемый пробельный символ [ZWSP], проверки на равенство со строками AES и TripleDES будут ложными. В итоге из трех ожидаемых значений функция будет возвращать лишь BlockCipherType.DES. В то же время код в редакторе может отображаться следующим образом:
enum BlockSipherType { DES, TripleDES, AES };
BlockSipherType StringToBlockSypherType(string str)
{
if (str == "AES")
return BlockSipherType.AES;
else if (str == "TripleDES")
return BlockSipherType.TripleDES;
else return BlockSipherType.DES;
}Если анализатор выдал предупреждение о неотображаемых символах в коде, включите отображение невидимых символов в вашем редакторе и убедитесь, что они не изменяют логику выполнения программы.
Данная диагностика классифицируется как:
|
V6001. There are identical sub-expressions to the left and to the right of the 'foo' operator.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит логическую ошибку. В тексте программы имеется оператор (<, >, <=, >=, ==, !=, &&, ||, -, /, &, |, ^), слева и справа от которого расположены одинаковые подвыражения.
Рассмотрим пример:
if (a.x != 0 && a.x != 0)В данном случае оператор '&&' окружен одинаковыми подвыражениями "a.x != 0", что позволяет обнаружить ошибку, допущенную по невнимательности. Корректный код, который не вызовет подозрений у анализатора, будет выгладить так:
if (a.x != 0 && a.y != 0)Анализатор производит сравнение блоков с учетом перестановки частей выражения относительно операторов. Ошибка будет обнаружена и в следующем примере кода:
if (a.x > a.y && a.y < a.x)Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6001. |
V6002. The switch statement does not cover all values of the enum.
Анализатор обнаружил оператор 'switch', в котором выбор варианта осуществляется по переменной enum-типа. При этом в операторе 'switch' используются не все элементы перечисления, что может свидетельствовать о наличии ошибки.
Пример кода, в котором встретилась эта ошибка:
enum Fruit { APPLE, BANANA, PEAR, PINEAPPLE, ORANGE }
int SomeMethod(Fruit fruit)
{
int res = 0;
switch (fruit)
{
case APPLE:
res = calculate(10); break;
case BANANA:
res = calculate(20); break;
case PEAR:
res = calculate(30); break;
case PINEAPPLE:
res = calculate(40); break;
}
// code
return res;
}В данном случае перечисление 'Fruit' содержит 5 именованных констант, а оператор 'switch', выбор в котором осуществляется по данному перечислению, реализует выбор только по 4 из них. Это место является потенциально ошибочным.
Возможно, в ходе рефакторинга в перечисление добавили новую константу, но забыли реализовать выбор по ней в операторе 'switch', или же, что может быть в случае с большими перечислениями, константу банально могли пропустить. В итоге пропущенное значение обрабатывается неправильно.
Тогда корректный код мог бы выглядеть следующим образом:
int SomeMethod(Fruit fruit)
{
int res = 0;
switch (fruit)
{
case APPLE:
res = calculate(10); break;
case BANANA:
res = calculate(20); break;
case PEAR:
res = calculate(30); break;
case PINEAPPLE:
res = calculate(40); break;
case ORANGE:
res = calculate(50); break;
}
// code
return res;
}Анализатор выдает предупреждение далеко не всегда, когда в 'switch' используется не все константы из перечисления. Иначе, было бы слишком много ложных срабатываний. Действует целый ряд исключений эмпирического типа. Основные:
- Есть default-ветка;
- Отсутствующая константа содержит в имени: None, Unknown и т.п.
- Отсутствующая константа самая последняя в enum и содержит в имени "end", "num", "count" и т.п.
- В перечислении всего 1 или 2 константы;
- И так далее.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6002. |
V6003. The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence.
Анализатор обнаружил потенциально возможную ошибку в конструкции, состоящей из условных операторов.
Рассмотрим пример:
if (a == 1)
Foo1();
else if (a == 2)
Foo2();
else if (a == 1)
Foo3();В данном примере метод 'Foo3()' никогда не получит управления. Вероятно, мы имеем дело с логической ошибкой и корректный код должен выглядеть так:
if (a == 1)
Foo1();
else if (a == 2)
Foo2();
else if (a == 3)
Foo3();Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6003. |
V6004. The 'then' statement is equivalent to the 'else' statement.
Анализатор обнаружил подозрительный фрагмент кода, в котором истинная и ложная ветви оператора 'if' полностью совпадают. Часто это свидетельствует о наличии ошибки.
Пример подобного кода:
if (condition)
result = FirstFunc(val);
else
result = FirstFunc(val);Вне зависимости от значения переменной, будут выполнены одни и те же операции. Понятно, что такой код является ошибочным. Тогда корректный вариант кода мог бы выглядеть следующим образом:
if (condition)
result = FirstFunc(val);
else
result = SecondFunc(val);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6004. |
V6005. The 'x' variable is assigned to itself.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что значение переменной присваивается само себе.
Рассмотрим пример:
void change(int width, int height, int length)
{
this.mWidth = width;
this.mHeight = height;
this.mLength = this.mLength;
}Из кода видно, что предполагалось изменить значения свойств объекта в соответствии с принятыми в методе параметрами, но произошла ошибка и свойству 'mLength' вместо значения аргумента 'length' присвоилось значение самого же свойства.
Тогда корректный код должен был бы выглядеть так:
void change(int width, int height, int length)
{
this.mWidth = width;
this.mHeight = height;
this.mLength = length;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6005. |
V6006. The object was created but it is not being used. The 'throw' keyword could be missing.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что создаётся экземпляр класса исключения, но при этом никак не используется.
Пример ошибочного кода:
int checkIndex(int index)
{
if (index < 0)
new IndexOutOfBoundsException("Index Out Of Bounds!!!");
return index;
}В данном коде пропущен оператор 'throw', из-за чего будет только создан экземпляр класса, но при этом он никак не будет использоваться, и исключение не будет сгенерировано. Корректный код может выглядеть следующим образом:
int checkIndex(int index)
{
if (index < 0)
throw new IndexOutOfBoundsException("Index Out Of Bounds!!!");
return index;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6006. |
V6007. Expression is always true/false.
Анализатор выявляет некорректные условные выражения, которые при вычислении всегда являются истинными или ложными.
Случай 1.
Некорректно сформированное условие является всегда истинным или ложным.
Подобные условия не всегда означают наличие ошибки, но эти фрагменты кода следует обязательно проверить.
Пример некорректного кода:
String str = ...;
if (!str.equals("#") || !str.isEmpty()){
...
} else {
...
}Здесь ветка 'else' никогда не будет выполнена. Дело в том, что какое бы значение ни приняла переменная 'str', одно из сравнений со строкой всегда будет истинно. Чтобы исправить эту ошибку, следует использовать оператор && вместо оператора ||.
Корректный вариант кода:
String str = ...;
if (!str.equals("#") && !str.isEmpty()){
...
} else {
...
}Случай 2.
Два условных оператора, идущих последовательно, содержат взаимоисключающие условия.
Примеры взаимоисключающих условий:
- "A == B" и "A != B";
- "A > B" и "A <= B";
- "A < B" и "B < A";
- и тому подобные.
Такая ошибка может возникнуть в результате опечатки или неудачного рефакторинга.
Пример некорректного кода:
if (x == y)
if (y != x)
DoSomething(x, y);В данном случае метод 'DoSomething' никогда не будет вызван, так как при истинности первого условия второе всегда будет ложным. Возможно, в сравнении используется некорректная переменная. Например, во втором условии следовало использовать не 'x', а 'z':
if (x == y)
if (y != z)
DoSomething(x, y);Случай 3.
В выражении ищется более длинная подстрока и более короткая. При этом, более короткая строка является частью более длинной. Получается, что одно из сравнений избыточно или содержит какую-нибудь ошибку.
Рассмотрим пример:
if (str.contains("abc") || str.contains("abcd"))В случае, если подстрока "abc" будет найдена, то дальнейшая проверка не будет выполняться. Если подстрока "abc" не будет найдена, то и поиск более длинной подстроки "abcd" не имеет смысла.
Для исправления ошибки необходимо проверить правильность подстрок или убрать из кода лишние проверки. Пример корректного варианта:
if (str.contains("abc"))Другой пример:
if (str.contains("abc"))
Foo1();
else if (str.contains("abcd"))
Foo2();В данном случае метод 'Foo2' никогда не будет вызван. Устранить ошибку можно путем замены порядка проверки. То есть сначала следует искать более длинную подстроку, а потом более короткую:
if (str.contains("abcd"))
Foo2();
else if (str.contains("abc"))
Foo1();Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6007. |
V6008. Potential null dereference.
Анализатор обнаружил фрагмент кода, который может привести к доступу по нулевой ссылке.
Рассмотрим несколько примеров, для которых анализатор выдает диагностическое сообщение V6008:
if (obj != null || obj.isEmpty()) { ... }
if (obj == null && obj.isEmpty()) { ... }Во всех условиях допущена логическая ошибка, которая приведет к доступу по нулевой ссылке. Ошибка может быть допущена при рефакторинге кода или из-за случайной опечатки.
Корректные варианты:
if (obj == null || obj.isEmpty()) { .... }
if (obj != null && obj.isEmpty()) { .... }Конечно, это очень простые ситуации. На практике проверка объекта на null и его использование может находиться в разных местах. Если анализатор выдал предупреждение V6008, изучите код расположенный выше и попробуйте понять, почему ссылка может быть нулевой.
Пример кода, где проверка и использование объекта находятся в разных строках
if (player == null) {
....
String currentName = player.getName();
....
}Анализатор предупредит, об опасности в строке внутри блока 'if'. Здесь или некорректно написано условие, или вместо 'player' должна использоваться другая переменная.
Программисты иногда забывают о том, что при проверке двух объектов на null один из них может оказаться нулевым, а второй нет, в результате чего будет вычислено всё условие и произойдёт доступ по нулевой ссылке. Например,
if ((text == null && newText == null) && text.equals(newText)) {
....
}Это условие можно переписать, например, так
if ((text == null && newText == null) ||
(text != null && newText != null && text.equals(newText))) {
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6008. |
V6009. Function receives an odd argument.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в качестве фактического аргумента в функцию передаётся очень странное значение.
Рассмотрим примеры:
Недопустимый индекс
String SomeMethod(String mask, char ch)
{
String name = mask.substring(0, mask.indexOf(ch));
...
return name;
}IndexOf() возращает позицию искомого аргумента. Если аргумент не найден, то функция возвращает значение '-1'. А если передать отрицательный индекс в функцию substring(), то возникнет 'StringIndexOutOfBoundsException'.
Корректный вариант:
String SomeMethod(String mask, char ch)
{
int pos = mask.indexOf(ch);
if (pos < 0) return "error";
String name = mask.substring(0, pos);
...
return name;
}Null аргумент
String[] SplitFunc(String s, String d) {
...
if (d == null) {
return s.split(d);
}
return null;
}По ряду причин была произведена некорректная проверка, из-за чего в функцию split() передается аргумент равный null. В результате чего функция сгенерирует исключение 'NullPointerException'.
Корректный вариант:
String[] SplitFunc(String s, String d) {
...
if (d != null) {
return s.split(d);
}
return null;
}Сравнение с самим собой
...
return obj.equals(obj);Фрагмент кода возвращает результат сравнения некоторого объекта с самим собой. Не странно ли? Скорее всего имело место сравнение с каким-то другим объектом:
...
return obj.equals(obj2);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6009. |
V6010. The return value of function 'Foo' is required to be utilized.
Анализатор обнаружил подозрительный вызов метода, возвращаемое значение которого не учитывается. Вызов некоторых методов не имеет смысла без использования их возвращаемого значения.
Рассмотрим пример такого кода:
String prepare(String base, int a, double d)
{
String str = base + " /\\ " +
String.valueOf(a) + " /\\ " +
String.valueOf(d);
...
str.replace("/", "\\");
...
return str;
}Из кода видно, что строка вызывает метод 'replace', но при этом результат вызова игнорируется. Как известно, метод 'replace' возвращает новую измененную строку, при этом не меняет содержимое строки, что вызвала этот метод. Следовательно, строка с необходимой заменой так и не будет использована. Поэтому, чтобы изменения были учтены, необходимо подкорректировать код следующим образом:
String prepare(String base, int a, double d)
{
String str = base + " /\\ " +
String.valueOf(a) + " /\\ " +
String.valueOf(d);
...
str = str.replace("/", "\\");
...
return str;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6010. |
V6011. The expression contains a suspicious mix of integer and real types.
Анализатор обнаружил потенциальную ошибку в выражении, где совместно используются целочисленные и real-типы данных. Под real-типами понимаются такие типы, как 'float' и 'double'.
Давайте посмотрим, как может проявить себя ошибка на практике.
boolean IsInRange(int object_layer_width, int object_layer_height)
{
return object_layer_height != 0 &&
object_layer_width/object_layer_height > 0.1 &&
object_layer_width/object_layer_height < 10;
}Здесь целочисленное значение сравнивается с константой '0.1'. Это очень подозрительно. Предположим, что переменные имеют следующие значения:
- object_layer_width = 20;
- object_layer_height = 100;
Программист ожидает, что при делении этих чисел результат будет равен '0.2'. Это подходящее значение, так оно попадает в диапазон (0.1..10).
На самом деле, результат деления будет равен 0. Деление осуществляется над целочисленными типами данных. Потом, при сравнении с '0.1' произойдет расширение до типа 'double', но будет уже поздно. Чтобы исправить код, необходимо заранее использовать явное приведение типов:
boolean IsInRange(int object_layer_width, int object_layer_height)
{
return object_layer_height != 0 &&
(double)object_layer_width/object_layer_height > 0.1 &&
(double)object_layer_width/object_layer_height < 10;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6011. |
V6012. The '?:' operator, regardless of its conditional expression, always returns one and the same value.
Анализатор обнаружил потенциальную ошибку при использовании тернарного оператора "?:". Независимо от условия, будет выполнено одно и тоже действие. Скорее всего, в коде имеется опечатка.
Рассмотрим самый простой пример:
int A = B ? C : C;В любом случае переменной A будет присвоено значение переменной C.
Рассмотрим пример, где уже не так легко заметить подобную ошибку:
double calc(Box bx, int angle, double scale )
{
return Math.tan((angle % 2 == 0 ?
bx.side_x : bx.side_x) * 0.42) * scale;
};Здесь код отформатирован. В тексте программы это может быть одной строкой, и неудивительно, что легко просмотреть опечатку. Ошибка в том, что два раза используется член класса "side_x". Корректный вариант:
double calc(Box bx, int angle, double scale )
{
return Math.tan((angle % 2 == 0 ?
bx.side_x : bx.side_y) * 0.42) * scale;
};Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6012. |
V6013. Comparison of arrays, strings, collections by reference. Possibly an equality comparison was intended.
Анализатор обнаружил ситуацию, когда строки/массивы/коллекции сравниваются через оператор '=='. Скорее всего подразумевалось сравнение содержимого, а на самом деле происходит непосредственное сравнение ссылок на объекты.
Рассмотрим пример некорректного сравнения строк:
if (str1 == "example") {}
if (str1 == str2) {}В рассматриваемых случаях, если содержимое 'str1' и 'str2' будет совпадать и равно "example", то условия будут ложными, так как оператор '==' сравнивает адреса объектов, а не содержимое строк. Если необходимо сравнивать строки по содержимому, то корректный вариант кода примет следующий вид:
if (str1.equals("example")) {}
if (str1.equals(str2)) {}Рассмотрим пример некорректного сравнения массивов:
int[] a = ...;
int[] b = ...;
...
if (a.equals(b)) { ... }Для массивов вызов метода 'equals' тоже самое, что и оператор '=='. Сравниваются адреса объектов, а не содержимое. Для того, чтобы сравнивать массивы по содержимому, необходимо код переписать следующим образом:
if (Arrays.equals(a ,b){ ... }С коллекциями оператор '==' ведет себя также, как с массивами и строками.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6013. |
V6014. It's odd that this method always returns one and the same value of NN.
Анализатор обнаружил странный метод. Метод не имеет состояния, не изменяет глобальных переменных. При этом он имеет несколько точек возврата, возвращающих одно и то же числовое, строковое, константное, enum значение, или то же самое значение поля, которое предназначено только для чтения.
Такой код крайне подозрителен и может свидетельствовать о возможной ошибке. Скорее всего, метод должна возвращать различные числовые значения.
Рассмотрим простой пример такого кода:
int Foo(int a)
{
if (a == 33)
return 1;
return 1;
}Данный код содержит ошибку. Для ее исправления изменим одно из возвращаемых значений. Определить необходимые возвращаемые значения, как правило, можно только зная логику работы всего приложения в целом.
Вариант корректного кода:
int Foo(int a)
{
if (a == 33)
return 1;
return 2;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6014. |
V6015. Consider inspecting the expression. Probably the '!='/'-='/'+=' should be used here.
Анализатор обнаружил потенциальную ошибку, связанную со странным использованием пары операторов ('=!', '=-', '=+'). Скорее всего их использование ошибочно, и подразумевался один из следующих операторов: '!=', '-=', '+='.
Оператор '=!'
Пример подозрительного кода:
boolean a = ... ;
boolean b = ... ;
...
if (a =! b)
{
...
}С большой вероятностью здесь должна быть проверка, что переменная 'a' не равна 'b'. Если это так, то корректный вариант кода должен выглядеть следующим образом:
if (a != b)
{
...
}Анализатор учитывает форматирование в выражении. Поэтому, если действительно требуется выполнить присваивание, а не сравнение, необходимо указать, используя скобки или пробелы. Следующие примеры кода считаются анализатором корректными:
if (a = !b)
...
if (a=(!b))
...Оператор '=-'
Пример подозрительного кода:
int size = ... ;
int delta ... ;
...
size =- delta;Этот код может быть корректен. Но с большой вероятностью имеется опечатка, и на самом деле хотели использовать оператор '-='. Исправленный вариант:
size -= delta;Если код корректен, то, чтобы убрать предупреждение V6015 можно использовать дополнительный пробел между символами '=' и '-'. Вариант корректного кода, где предупреждение не выдается:
size = -delta;Оператор '=+'
Пример подозрительного кода:
int size = ... ;
int delta ... ;
...
size =+ delta;Исправленный вариант:
size+=delta;Если код корректен, то чтобы убрать предупреждение V6015 можно удалить '+' или поставить дополнительный пробел. Вариант корректного кода, где предупреждение не выдается:
size = delta;
size = +delta;Данная диагностика классифицируется как:
V6016. Suspicious access to element by a constant index inside a loop.
Анализатор обнаружил возможную ошибку, связанную с тем, что в цикле 'for' на каждой итерации к элементу массива или списка обращаются по одному и тому же константному индексу.
Рассмотрим пример некорректного кода:
void transform(List<Integer> parameters, ...)
{
for (int i = 0; i < parameters.size(); i++)
{
int element = parameters.get(0);
...
}
...
}Здесь на каждой итерации цикла планировали сохранять некое значение i-го элемента массива 'parameters' в переменную 'element', но допустили опечатку, и на каждой итерации работают с одним и тем же - первым - элементом массива. Возможно также, что при написании кода программист отлаживался с использованием нулевого элемента, а потом забыл изменить значение индекса.
Корректный вариант кода:
void transform(List<Integer> parameters, ...)
{
for (int i = 0; i < parameters.size(); i++)
{
int element = parameters.get(i);
...
}
...
}Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6016. |
V6017. The 'X' counter is not used inside a nested loop. Consider inspecting usage of 'Y' counter.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что при написании двух и более вложенных циклов 'for', из-за опечатки не используется счётчик одного из циклов.
Рассмотрим синтетический пример некорректного кода:
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
sum += matrix[i][i];В коде планировали обойти все элементы матрицы и найти их сумму, но случайно написали переменную 'i' вместо 'j' при обращении к матрице.
Корректный вариант кода:
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
sum += matrix[i][j];V6018. Constant expression in switch statement.
Анализатор обнаружил константное выражение в условии 'switch'. Чаще всего это сигнализирует о логической ошибке.
Рассмотрим синтетический пример:
int i = 1;
switch (i)
{
....
}В качестве условия 'switch' стоит переменная, значение которой может быть посчитано во время компиляции. Такая ситуация могла возникнуть в результате рефакторинга: раньше был код, который менял значение переменной, а потом его поменяли и оказалось, что переменной больше не присваивается никакое значение.
Данная диагностика классифицируется как:
|
V6019. Unreachable code detected. It is possible that an error is present.
Анализатор обнаружил код, который никогда не будет выполнен. Возможно допущена ошибка в логике программы.
Данная диагностика находит блоки кода, до которых никогда не дойдёт управление.
Рассмотрим пример:
void printList(List<Integer> list) {
if (list == null) {
System.exit(-999);
System.err.println("Error!!! Output empty!!! list == null");
}
list.forEach(System.out::println);
}Функция 'prinln(....)' никогда не напечатает сообщение об ошибке, так как функция 'System.exit(...)' не возвращает управление. Как правильно исправить код зависит от того, какую логику поведения задумывал программист изначально. Возможно, функция должна возвращать управление. Возможно, нарушен порядок выражений и корректный код должен быть таким:
void printList(List<Integer> list) {
if (list == null) {
System.err.println("Error!!! Output empty!!! list == null");
System.exit(-999);
}
list.forEach(System.out::println);
}Рассмотрим ещё один пример:
void someTransform(int[] arr, int n, boolean isErr, int num, int den)
{
if (den == 0 || isErr)
{
return;
}
...
for (int i = 0; i < n; ++i)
{
if (!isErr || arr[i] <= 0)
continue;
arr[i] += 2 * num/den;
}
...
}В данном фрагменте так и не выполнится код 'arr[i] += 2 * num/den;'. Проверки переменной 'isErr' в начале метода и в цикле противоречат друг другу, а изменения этой переменной между проверками нет. Вследствие чего будет выполняться оператор 'continue' на каждом шаге цикла. Скорее всего это произошло по причине рефакторинга.
Пример корректного код:
void someTransform(int[] arr, int n, boolean isErr, int num, int den)
{
if (den == 0 || isErr)
{
return;
}
...
for (int i = 0; i < n; ++i)
{
if (arr[i] <= 0)
continue;
arr[i] += 2 * num/den;
}
...
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6019. |
V6020. Division or mod division by zero.
Анализатор обнаружил ситуацию, когда может произойти деление на ноль.
Рассмотрим пример:
if (maxHeight >= 0)
{
fx = height / maxHeight;
}В условии проверяется, что значение переменной maxHeight неотрицательно. Если эта переменная будет равна нулю, то внутри условия произойдёт деление на 0. Чтобы исправить ситуацию, необходимо выполнять деление только в том случае, когда maxHeight положительно.
Исправленный вариант:
if (maxHeight > 0)
{
fx = height / maxHeight;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки деления на ноль. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6020. |
V6021. The value is assigned to the 'x' variable but is not used.
Данное диагностическое правило выявляет случаи, когда некоторое значение присваивается переменной, которая далее перетирается новым значением или вовсе не используется.
Случай 1.
Одной и той же переменной дважды подряд присваивается значение. Причем между этими присваиваниями сама переменная не используется.
Рассмотрим пример:
A = GetA();
A = GetB();То, что переменной 'A' два раза присваивается значение, может свидетельствовать о наличии ошибки. Высока вероятность, что код должен выглядеть следующим образом:
A = GetA();
B = GetB();Если переменная между присваиваниями используется, то этот код считается анализатором корректным:
A = 1;
A = Foo(A);Случай 2.
Локальной переменной присваивается значение, но переменная далее нигде не используется до выхода из метода.
Рассмотрим фрагмент кода:
String GetDisplayName(Titles titles, String name)
{
String result = null;
String tmp = normalize(name);
if (titles.isValidName(name, tmp)){
result = name;
}
return name;
}Программист хотел, чтобы результатом метода была переменная 'result', которая инициализируется в зависимости от выполнения 'isValidName'. К сожалению, из-за опечатки метод всегда возвращает переменную 'name'. Правильный код должен выглядеть следующим образом:
String GetDisplayName(Titles titles, String name)
{
String result = null;
String tmp = normalize(name);
if (titles.isValidName(name, tmp)){
result = name;
}
return result;
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6021. |
V6022. Parameter is not used inside method's body.
Анализатор обнаружил подозрительный метод, один из параметров которого ни разу не используется. При этом другой его параметр используется несколько раз, что, возможно, свидетельствует о наличии ошибки.
Рассмотрим пример:
private static bool CardHasLock(int width, int height)
{
const double xScale = 0.051;
const double yScale = 0.0278;
int lockWidth = (int)Math.Round(height * xScale);
int lockHeight = (int)Math.Round(height * yScale);
....
}Из кода видно, что параметр 'width' ни разу не используется в теле метода, при этом параметр 'height' используется дважды, в том числе при инициализации переменной 'lockWidth'. Скорее всего, здесь допущена ошибка, и код инициализации переменной 'lockWidth' должен был выглядеть следующим образом:
int lockWidth = (int)Math.Round(width * xScale);Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6022. |
V6023. Parameter 'A' is always rewritten in method body before being used.
Анализатор нашёл потенциальную ошибку в теле метода. Один из его параметров перезаписывается перед тем, как используется. Таким образом значение, пришедшее в метод, попросту теряется.
Эта ошибка имеет разные проявления. Рассмотрим пример кода:
void Foo1(int A, int B)
{
A = Calculate(A);
B = Calculate(A);
// do smt...
}Здесь допущена опечатка, из-за чего объект 'B' примет неверное значение. Исправленный код выглядит так:
void Foo1(int A, int B)
{
A = Calculate(A);
B = Calculate(B);
// do smt...
}Рассмотрим еще один пример данной ошибки:
void Foo2(List<Integer> list, int count)
{
list = new ArrayList<Integer>(count);
for (int i = 0; i < count; ++i)
list.add(MyRnd(i));
}Данный метод должен был инициализировать список некоторыми значениями. В данном случае происходит копирование ссылки ('list'), хранящей адрес блока памяти в куче, в котором расположен список (или 'null', если память не была выделена). Поэтому, когда мы вновь выделяем память под список, адрес блока памяти записывается в локальную копию ссылки, а исходная (за пределами метода) остаётся неизменной. Таким образом выполняется лишняя работа для выделения памяти, инициализации списка и последующей уборки мусора.
Возможно, следует переписать метод следующим образом:
List<Integer> Foo2(int count)
{
List<Integer> list = new ArrayList<>(count);
for (int i = 0; i < count; ++i)
list.add(MyRnd(i));
}
...
list = Foo2(count);Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6023. |
V6024. The 'continue' operator will terminate 'do { ... } while (false)' loop because the condition is always false.
Анализатор обнаружил код, который может ввести в заблуждение программиста. Не все знают, что оператор continue в цикле "do { ... } while(false)" остановит цикл, а не возобновит его.
Таким образом, после вызова оператора 'continue' будет проверено условие '(false)', и цикл завершится так как условие ложно.
Рассмотрим пример:
int i = 1;
do
{
System.out.print(i);
i++;
if (i < 3)
continue;
System.out.print('A');
} while (false);Программист может ожидать, что программа напечатает '12A'. На самом деле будет напечатано '1'.
Если именно так задумано и ошибки нет, то код всё равно лучше изменить. Можно воспользоваться оператором 'break':
int i = 1;
do
{
System.out.print(i);
i++;
if (i < 3)
break;
System.out.print('A');
} while (false);Код стал более понятным. Сразу видно, что если условие (i < 3) выполняется, то цикл будет остановлен. В добавок, анализатор не будет выдавать предупреждение на этот код.
Если код некорректен, то его следует переписать. Здесь нельзя дать точных рекомендаций. Все зависит от логики работы кода. Например, чтобы напечатать '12A' лучше будет написать:
for (int i = 1; i < 3; ++i)
System.out.print(i);
System.out.print('A');Данная диагностика классифицируется как:
V6025. Possibly index is out of bound.
При доступе по индексу к переменной типа массив, список или строка может возникнуть исключение IndexOutOfBoundsException, если значение индекса оказывается за пределами допустимого диапазона. Анализатор способен обнаружить некоторые ошибки такого рода.
Например, это может произойти во время обхода массива в цикле:
int[] buff = new int[25];
for (int i = 0; i <= 25; i++)
buff[i] = 10;Нужно помнить о том, что первый элемент массива имеет индекс 0, а последний – на единицу меньше размера массива. Корректный вариант:
int[] buff = new int[25];
for (int i = 0; i < 25; i++)
buff[i] = 10;Похожую ошибку можно сделать не только в цикле, но и при неправильной проверке индекса в условии:
void ProcessOperandTypes(int opCodeValue, byte operandType)
{
byte[] OneByteOperandTypes = new byte[0xff];
if (opCodeValue < 0x100)
{
OneByteOperandTypes[opCodeValue] = operandType;
}
...
}Корректный вариант:
void ProcessOperandTypes(int opCodeValue, byte operandType)
{
byte[] OneByteOperandTypes = new byte[0xff];
if (opCodeValue < 0xff)
{
OneByteOperandTypes[opCodeValue] = operandType;
}
...
}Также можно допустить ошибку при доступе к конкретному элементу массива или списка.
private Map<String, String> TransformListToMap(List<String> config)
{
Map<String, String> map = new HashMap<>();
if (config.size() == 10)
{
map.put("Base State", config.get(0));
...
map.put("Sorted Descending Header Style", config.get(10));
}
...
return map;
}В этом примере допущена ошибка в количестве записей в списке config. Исправленный вариант выглядит следующим образом:
private Map<String, String> TransformListToMap(List<String> config)
{
Map<String, String> map = new HashMap<>();
if (config.size() == 11)
{
map.put("Base State", config.get(0));
...
map.put("Sorted Descending Header Style", config.get(10));
}
...
return map;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6025. |
V6026. This value is already assigned to the 'b' variable.
Анализатор обнаружил потенциальную ошибку, связанную с бессмысленным взаимным присваиванием переменных.
Рассмотрим пример:
int a, b, c;
...
a = b;
c = 10;
b = a;Здесь присваивание "b = a" не имеет никакого практического смысла. Возможно, это опечатка или просто лишнее действие. Корректный вариант кода:
a = b;
c = 10;
b = a_2;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6026. |
V6027. Variables are initialized through the call to the same function. It's probably an error or un-optimized code.
Анализатор обнаружил потенциальную ошибку, найдя в коде инициализацию двух различных переменных одинаковыми выражениями. Анализатор считает опасными не все выражения, а только в которых используется вызов функций (либо слишком длинное выражение).
Рассмотрим наиболее простой случай:
sz1 = s1.length();
sz2 = s1.length();Двум разным переменным присваивается один и тот же размер строки. Глядя на переменные 'sz1' и 'sz2' можно сделать вывод, что произошла опечатка. Корректный фрагмент кода будет выглядеть следующим образом:
sz1 = s1.length();
sz2 = s2.length();Если анализатор выдал сообщение на фрагмент кода:
x = expression;
y = expression;Варианты действий следующие:
- Код содержит ошибку и необходимо подкорректировать 'expression'.
- Код верен. Если 'expression' требует много вычислений, то лучше написать 'y = x;'.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6027. |
V6028. Identical expression to the left and to the right of compound assignment.
Анализатор обнаружил одинаковые подвыражения в левой и правой части составного оператора присваивания (compound assignment operator). Возможно эта операция содержит ошибку, не имеет смысла, либо может быть упрощена.
Рассмотрим пример. Пусть у нас имеется выражение следующего вида:
x += x + 5;Возможно программист хотел просто прибавить к переменной 'x' значение 5. Тогда корректный код может выглядеть так:
x = x + 5;Либо же программист хотел прибавить 5, но случайно добавил лишнюю переменную 'x' в выражение. Тогда корректный код может выглядеть так:
x += 5;Впрочем, возможно код написан правильно. Однако согласитесь, читать такое выражения сложно и лучше переписать его. Более читабельный вариант может выглядеть так:
x = x * 2 + 5;Рассмотрим следующий пример:
x += x;Данная операция эквивалентна операции умножения на два. Более понятное выражение будет иметь следующий вид:
x *= 2;Рассмотрим еще одно выражение:
y += top - y;Мы пытаемся прибавить переменной 'y' разницу между переменной 'top' и переменной 'y'. Давайте разложим данное выражение:
y = y + top – y;Данное выражение можно упростить, так как переменная 'y' вычитается сама из себя, что является бессмысленным. Тогда простой и корректный код будет выглядеть так:
y = top;Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6028. |
V6029. Possible incorrect order of arguments passed to method.
Анализатор обнаружил подозрительную передачу аргументов в метод. Возможно некоторые аргументы перепутаны местами.
Пример подозрительного кода:
void SetARGB(short A, short R, short G, short B) { .... }
void Foo(){
short A = 0, R = 0, G = 0, B = 0;
....
SetARGB(A, R, B, G);
....
}Во время задания цвета объекта, перепутали синий и зелёный цвет.
Исправленный вариант кода должен выглядеть следующим образом:
SetARGB(A, R, G, B);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6029. |
V6030. The function located to the right of the '|' and '&' operators will be called regardless of the value of the left operand. Consider using '||' and '&&' instead.
Анализатор обнаружил возможную опечатку в логическом выражении. Вместо логического оператора (&& или ||) написали битовый оператор (& или |). Это означает, что правая часть будет выполнена независимо от результата левой части.
Пример:
if (foo() | bar()) {}Если в качестве операндов стоят довольно ресурсоемкие операции, то использование битовых операций не оптимально. Кроме того, такой код может привести к ошибке из-за разных типов выражения и разных приоритетов операций. Также возможна ситуация, когда правая часть не должна быть выполнена, если левая завершилась неудачно. В таком случае может произойти обращение к неинициализированным ресурсам. Также битовые операции не гарантируют порядок вычисления операндов.
Корректный код:
if (foo() || bar()) {}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6030. |
V6031. The variable 'X' is being used for this loop and for the outer loop.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что вложенный цикл организован с использованием переменной, которая также используется и во внешнем цикле.
Схематически эта ошибка выглядит следующим образом:
int i = 0, j = 0;
for (i = 0; i < 5; i++)
for (i = 0; i < 5; i++)
arr[i][j] = 0;Конечно, это искусственный пример и в реальном приложении ошибка может быть не так очевидна. Корректный вариант кода:
int i = 0, j = 0;
for (i = 0; i < 5; i++)
for (j = 0; j < 5; j++)
arr[i][j] = 0;Использование одной переменной для внешнего и внутреннего цикла не всегда является ошибкой. Рассмотрим пример корректного кода, где анализатор не будет выдавать предупреждение:
for (c = lb; c <= ub; c++)
{
if (!(xlb <= calc(c) && calc(c) <= ub))
{
Range r = new Range(xlb, xlb + 1);
for (c = lb + 1; c <= ub; c++)
r = DoUnion(r, new Range(calc(c), calc(c) + 1));
return r;
}
}В этом коде внутренний цикл "for (c = lb + 1; c <= ub; c++)" организован при помощи переменной "c". Внешний цикл также использует переменную "c". Но ошибки здесь нет. После того, как выполнится внутренний цикл, сразу произойдет выход из функции при помощи оператора "return r".
Данная диагностика классифицируется как:
|
V6032. It is odd that the body of 'Foo_1' function is fully equivalent to the body of 'Foo_2' function.
Данное предупреждение выдается в том случае, если анализатор обнаружил две функции, реализованные идентичным образом. Наличие двух одинаковых функций само по себе не является ошибкой, но является поводом обратить на них внимание.
Смысл данной диагностики в обнаружении следующей разновидности ошибок:
class Point
{
....
int GetX() { return mX; }
int GetY() { return mX; }
};Из-за допущенной опечатки две разные по смыслу функции выполняют одинаковые действия. Корректный вариант:
int GetX() { return mX; }
int GetY() { return mY; }В приведенном примере идентичность тел функций GetX() и GetY() явно свидетельствует о наличии ошибки. Однако, если выдавать предупреждения на все одинаковые функции, то процент ложных срабатываний будет крайне большим. Поэтому анализатор руководствуется целым рядом исключений, когда не стоит предупреждать об одинаковых телах функций. Перечислим некоторые из них:
- Не сообщается об идентичности тел функций, если в них не используются переменные кроме аргументов. Пример: "bool IsXYZ() { return true; }";
- Если функции с одинаковыми телами повторяются более двух раз;
- Тело функций состоит только из оператора throw();
- И так далее.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6032. |
V6033. An item with the same key has already been added.
Анализатор обнаружил подозрительную ситуацию, когда в словарь (контейнеры типа 'map' и т.п.) или в множество (контейнеры типа 'set' и т.п.) добавляются элементы с ключами, уже присутствующими в этих контейнерах. В результате добавление нового элемента будет проигнорировано. Это может свидетельствовать об опечатке и привести к неверному заполнению контейнера.
Рассмотрим пример со словарём:
Map<String, Integer> map = new HashMap<String, Integer>() {{
put("a", 10);
put("b", 20);
put("a", 30); // <=
}};В последней строке инициализации была допущена ошибка, так как ключ 'a' уже содержится в словаре. В результате данный словарь будет содержать 2 значения.
Исправить ошибку можно, использовав правильное значение ключа:
Map<String, Integer> map = new HashMap<String, Integer>() {{
put("a", 10);
put("b", 20);
put("c", 30);
}};Схожую ошибку можно допустить и при инициализации множества:
HashSet<String> someSet = new HashSet<String>(){{
add("First");
add("Second");
add("Third");
add("First"); // <=
add("Fifth");
}};Из-за ошибки вместо ключа 'Fourth' в множество 'someSet' пытаются записать строку 'First', но так как такой ключ уже содержится в множестве, он будет проигнорирован.
Для исправления ошибки необходимо исправить список инициализации:
HashSet<String> someSet = new HashSet<String>(){{
add("First");
add("Second");
add("Third");
add("Fourth");
add("Fifth");
}};Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6033. |
V6034. Shift by N bits is inconsistent with the size of type.
Анализатор обнаружил потенциальную ошибку, связанную со сдвигом целого числа на 'N' бит, при этом 'N' больше размера этого числового типа в битах.
Давайте рассмотрим пример:
long convert(int x, int y, int shift)
{
if (shift < 0 || shift > 32) {
return -1;
}
return (x << shift) + y;
}В данном случае хотели собрать 64-битное число из 2-х 32-битных, сдвинув 'x' на некоторое количество бит 'shift' и сложив старшую и младшую части. Есть вероятность того, что 'shift' может иметь значение равное 32. Поскольку 'x' в момент сдвига является 32-битным числом, то сдвиг на 32 бита эквивалентен сдвигу на 0 бит, что приведет к некорректному результату.
Корректный вариант может выглядеть так:
long convert(int x, int y, int shift)
{
if (shift < 0 || shift > 32) {
return -1;
}
return ((long)x << shift) + y;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6034. |
V6035. Double negation is present in the expression: !!x.
Анализатор обнаружил потенциальную ошибку, связанную с тем, что происходит двойное отрицание переменной. Такое дублирование сбивает с толку и, скорее всего, содержит ошибку.
Рассмотрим пример некорректного кода:
if (!(( !filter )))
{
...
}Скорее всего, такая ошибка возникла после проведения рефакторинга кода. Например, была удалена часть сложного логического выражения, а отрицание всего результата осталось. В итоге, получилось противоположное по смыслу выражение.
Корректный вариант кода:
if ( filter )
{
...
}Или:
if ( !filter )
{
...
}V6036. The value from the uninitialized optional is used.
Анализатор обнаружил обращение к объекту Optional, который в свое время является потенциально пустым. В таком случае будет исключение 'NoSuchElementException'.
Рассмотрим пример:
PClient getClient(boolean cond, String name, String company, /*args*/)
{
Optional<PClient> optClient = cond ?
Optional.of(new PClient(name, company)) : Optional.empty();
...
PClient pClient = optClient.get();
...
return pClient;
}После выполнения первой строки, объект 'optClient' в зависимости от условия может инициализироваться пустым Optional. В таком случае, строчка 'optClient.get()' без проверки вызовет исключение. Это могло возникнуть по невнимательности или после рефакторинга. Как вариант, можно исправить код следующим образом:
PClient getClient(boolean cond, String name, String company, /*args*/)
{
Optional<PClient> optClient = cond ?
Optional.of(new PClient(name, company)) : Optional.empty();
...
if (optClient.isPresent())
{
PClient pClient = optClient.get();
...
return pClient;
}
else
{
return null;
}
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6036. |
V6037. An unconditional 'break/continue/return/goto' within a loop.
Анализатор обнаружил подозрительный цикл, в котором используется один из следующих операторов: continue, break, return, goto, throw. Эти операторы выполняются всегда, без каких-либо условий.
Пример ошибочного кода:
for(int k = 0; k < max; k++)
{
if (k == index)
value = Calculate(k);
break;
}В данном коде оператор 'break' не принадлежит к оператору 'if', из-за чего выполняться будет вне зависимости от истинности условия 'k == index' и для тела цикла будет выполнена только одна итерация. Тогда корректный код мог бы выглядеть так:
for(int k = 0; k < max; k++)
{
if (k == index)
{
value = Calculate(k);
break;
}
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6037. |
V6038. Comparison with 'double.NaN' is meaningless. Use 'double.isNaN()' method instead.
Анализатор обнаружил сравнение переменной типа float или double с Float.NaN или Double.NaN. В соответствии с документацией (15.21.1), если два значения Double.NaN сравниваются с помощью оператора '==' , то результатом будет false. Таким образом, какое бы значение типа 'double' ни сравнивали с Double.NaN, в результате всегда будет false.
Рассмотрим пример:
void Func(double d) {
if (d == Double.NaN) {
....
}
}Проверка на NaN с помощью операторов '==' и '!= ' некорректна. Вместо этого следует использовать методы Float.isNaN() или Double.isNaN(). Исправленный вариант:
void Func(double d) {
if (Double.isNaN(d)) {
....
}
}Данная диагностика классифицируется как:
V6039. There are two 'if' statements with identical conditional expressions. The first 'if' statement contains method return. This means that the second 'if' statement is senseless.
Анализатор обнаружил ситуацию, когда 'then' часть оператора 'if' никогда не получит управления. Это происходит из-за того, что ранее уже встречается оператор 'if' с таким же условием, содержащий в 'then' части безусловный оператор 'return'. Это может свидетельствовать как о логической ошибке в программе, так и избыточном втором операторе 'if'.
Рассмотрим пример некорректного кода:
if (l >= 0x06C0 && l <= 0x06CE) return true;
if (l >= 0x06D0 && l <= 0x06D3) return true;
if (l == 0x06D5) return true; // <=
if (l >= 0x06E5 && l <= 0x06E6) return true;
if (l >= 0x0905 && l <= 0x0939) return true;
if (l == 0x06D5) return true; // <=
if (l >= 0x0958 && l <= 0x0961) return true;
if (l >= 0x0985 && l <= 0x098C) return true;В данном случае условие 'l == 0x06D5' дублируется и для исправления кода достаточно убрать одно из них. Однако возможно, что во втором случае проверяемое значение должно отличаться от первого случая.
Корректный вариант кода:
if (l >= 0x06C0 && l <= 0x06CE) return true;
if (l >= 0x06D0 && l <= 0x06D3) return true;
if (l == 0x06D5) return true;
if (l >= 0x06E5 && l <= 0x06E6) return true;
if (l >= 0x0905 && l <= 0x0939) return true;
if (l >= 0x0958 && l <= 0x0961) return true;
if (l >= 0x0985 && l <= 0x098C) return true;Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6039. |
V6040. The code's operational logic does not correspond with its formatting.
Анализатор обнаружил потенциальную ошибку, связанную c тем, что форматирование кода, следующего за условным оператором, не соответствует логике выполнения программы. Высока вероятность, что пропущены открывающиеся и закрывающиеся фигурные скобки.
Рассмотрим пример некорректного кода:
if (a == 1)
b = c; d = b;В данном случае присваивание 'd = b;' будет выполняться всегда, независимо от условия 'a == 1'.
Если код ошибочен, то ситуацию можно исправить, используя фигурные скобки. Корректный вариант кода:
if (a == 1)
{ b = c; d = b; }Другой пример некорректного кода:
if (a == 1)
b = c;
d = b;Для исправления ошибки так же следует использовать фигурные скобки. Корректный вариант кода:
if (a == 1)
{
b = c;
d = b;
}Если код корректен, то чтобы исчезло предупреждение V6040, следует отформатировать код следующим образом:
if (a == 1)
b = c;
d = b;Данная диагностика классифицируется как:
V6041. Suspicious assignment inside the conditional expression of 'if/while/do...while' statement.
Анализатор обнаружил ситуацию, когда в условии оператора 'if'/ 'while'/'do...while' присутствует оператор присваивания '='. Подобная конструкция часто свидетельствует о наличии ошибок. Высока вероятность, что вместо оператора '=' планировалось использовать оператор '=='.
Рассмотрим пример:
void func(int x, boolean skip, ...)
{
if (skip = true) {
return;
}
...
if ((x > 50) && (x < 150)) {
...
}
...
}В коде допущена опечатка: вместо проверки переменной 'skip' на истинность происходит изменение значения переменной 'skip'. В итоге, из-за опечатки условие будет истинно, и всегда будет выполняться оператор 'return'. Корректный вариант кода:
if (skip == true){
return;
}или
if (skip){
return;
}Данная диагностика классифицируется как:
|
V6042. The expression is checked for compatibility with type 'A', but is cast to type 'B'.
Анализатор обнаружил потенциально возможную ошибку, связанную с проверкой выражения на принадлежность к одному типу и приведением этого выражения в блоке проверки к другому типу.
Давайте рассмотрим данную ситуацию более подробно на примере:
if (a instanceof A)
{
return (B)a;
}Скорее всего программист ошибся, так как подобное приведение типов с большой вероятностью приведет к ошибке, и вероятнее всего подразумевалась либо проверка выражения на принадлежность к другому типу, либо приведение выражения к другому типу.
Корректный вариант мог бы выглядеть так:
if (a instanceof B)
{
return (B)a;
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6042. |
V6043. Consider inspecting the 'for' operator. Initial and final values of the iterator are the same.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что в операторе 'for' совпадают начальное и конечное значения счетчика. Такое использование оператора 'for' приведет к тому, что цикл не будет выполнен ни разу или выполнен только один раз.
Рассмотрим пример:
void BeginAndEndForCheck(int beginLine, int endLine)
{
for (int i = beginLine; i < beginLine; i++)
{
...
}
...
}Тело цикла никогда не выполняется. Скорее всего, произошла опечатка и следует заменить "i < beginLine" на корректное выражение "i < endLine". Корректный вариант кода:
for (int i = beginLine; i < endLine; i++)
{
...
}Другой пример:
for (int i = n; i <= n; i++)
...Тело этого цикла будет выполнено только один раз. Скорее всего, это не то, что задумывал программист.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6043. |
V6044. Postfix increment/decrement is senseless because this variable is overwritten.
Анализатор обнаружил потенциальную ошибку, связанную с бессмысленным использованием постфиксного инкремента или декремента в выражении присвоения в эту же переменную.
Давайте рассмотрим пример:
int i = 5;
// Some code
i = i++;В данном случае инкремент будет бессмысленным, и после выполнения данного кода переменная 'i' будет иметь значение '5'.
Это связано с тем, что постфиксный инкремент и декремент выполняются после вычисления правого операнда оператора присваивания, а результат вычисления временно кэшируется, и после выполнения операций постфиксного инкремента или декремента присваивается левой части выражения. Таким образом результат выполнения постфиксного инкремента или декремента перезаписывается результатом всего выражения.
Корректный же пример может иметь разный вид в зависимости от изначальной задачи.
Это может быть опечатка, и на самом деле программист случайно написал 2 раза переменную 'i' в выражении присвоения. Тогда корректный вариант мог бы выглядеть так:
int i = 5;
// Some code
q = i++;Либо же программист не знал, что оператор постфиксного инкремента прибавляет единицу к значению переменной, но возвращает начальное ее значение. Тогда операция присвоения будет излишней, и корректный вариант мог бы выглядеть так:
int i = 5;
// Some code
i++;Данная диагностика классифицируется как:
|
V6045. Suspicious subexpression in a sequence of similar comparisons.
Анализатор обнаружил фрагмент кода, который, скорее всего, содержит опечатку. В цепочке однотипных сравнений членов класса имеется выражение не похожее на остальные тем, что в нем сравниваются члены с разными именами, в то время как остальные выражения в цепочке сравнивают одноименные члены.
Рассмотрим пример:
if (a.x == b.x && a.y == b.y && a.z == b.y)В данном случае выражение 'a.z == b.y' отличается от остальных выражений в цепочке. Скорее всего, это выражение является ошибочным из-за опечатки при редактировании скопированного участка текста. Корректный код, который не вызовет подозрений у анализатора, будет выгладить так:
if (a.x == b.x && a.y == b.y && a.z == b.z)Анализатор выдает предупреждение в тех случаях, когда длина цепочки сравнений более двух звеньев.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6045. |
V6046. Incorrect format. Consider checking the N format items of the 'Foo' function.
Анализатор обнаружил потенциальную ошибку при использовании функций форматирования: String.format, System.out.format, System.err.format и т.п. Строка форматирования не соответствует передаваемым в функцию фактическим аргументам.
Рассмотрим простые примеры:
Неиспользуемые аргументы.
int A = 10, B = 20;
double C = 30.0;
System.out.format("%1$s < %2$s", A, B, C);Не указан формат '%3$s', поэтому переменная 'С' не будет использована.
Возможные варианты исправленного кода:
//Удалим лишний аргумент
System.out.format("%1$s < %2$s", A, B);
//Исправим строку форматирования
System.out.format("%1$s < %2$s < %3$s", A, B, C);Недостаточное количество аргументов.
int A = 10, B = 20;
double C = 30.0;
System.out.format("%1$s < %2$s < %3$s", A, B);Намного более опасной ситуацией является, когда в функцию передаётся меньше аргументов, чем необходимо. Это приводит к исключению.
Возможные варианты исправленного кода:
//Добавим недостающий аргумент
System.out.format("%1$s < %2$s < %3$s", A, B, C);
//Исправим индексы в строке форматирования
System.out.format("%1$s < %2$s", A, B);Анализатор не выдаёт предупреждение, если...
- Количество указанных форматов соответствует количеству аргументов.
- Объект форматирования используется несколько раз:
int row = 10;
System.out.format("Line: %1$s; Index: %1$s", row);Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6046. |
V6047. It is possible that this 'else' branch must apply to the previous 'if' statement.
Анализатор обнаружил потенциально возможную ошибку в логических условиях. Логика работы кода не совпадает с тем, как этот код отформатирован.
Рассмотрим пример:
if (X)
if (Y) Foo();
else
z = 1;Форматирование кода сбивает с толку, и кажется, что присваивание "z = 1" произойдет в том случае, если X == false. Однако ветка 'else' относится к ближайшему оператору 'if'. Другими словами, приведенный код на самом деле эквивалентен следующему коду:
if (X)
{
if (Y)
Foo();
else
z = 1;
}Таким образом, код работает не так, как может показаться на первый взгляд.
Если выдано предупреждение V6047, то это может означать две вещи:
1) Код плохо отформатирован и ошибки на самом деле нет. Тогда, чтобы предупреждение V6047 не выдавалось, а код был более понятен, его нужно отформатировать. Пример корректного форматирования:
if (X)
if (Y)
Foo();
else
z = 1;2) Найдена логическая ошибка. Тогда код можно исправить, например, так:
if (X) {
if (Y)
Foo();
} else {
z = 1;
}Данная диагностика классифицируется как:
V6048. This expression can be simplified. One of the operands in the operation equals NN. Probably it is a mistake.
Анализатор позволяет обнаружить подозрительные операции, такие как '+', '-', '<<', '>>', где один из операндов равен 0, или операции '*', '/', '%' с операндом, равным 1.
Диагностическое правило V6048 помогает выполнить рефакторинг кода и иногда выявить ошибки.
Примеры конструкций, на которые анализатор выдаст данное диагностическое сообщение:
int y = 1;
...
int z = x * y;Приведённый код можно упростить. Пример корректного кода:
int z = x;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6048. |
V6049. Classes that define 'equals' method must also define 'hashCode' method.
Анализатор обнаружил пользовательский тип, который переопределяет метод 'equals', но не переопределяет метод 'hashCode', и наоборот. Это может привести к неправильному функционированию пользовательского типа в сочетании с такими коллекциями как HashMap, HashSet и Hashtable, так как они активно используют 'hashCode' и 'equals' в своей работе.
Рассмотрим пример с использованием HashSet:
public class Employee {
String name;
int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public String getFullInfo() {
return this.name + " - " + String.valueOf(age);
}
@Override
public boolean equals(Object obj) {
if (obj == this)
return true;
if (!(obj instanceof Employee))
return false;
Employee employee = (Employee) obj;
return employee.getAge() == this.getAge()
&& employee.getName() == this.getName();
}
}
public static void main(String[] args)
{
HashSet<Employee> employees = new HashSet<>();
employees.add(new Employee("OLIVER", 25));
employees.add(new Employee("MUHAMMAD", 54));
employees.add(new Employee("OLIVER", 25));
employees.forEach(arg -> System.out.println(arg.getFullInfo()));
}В результате работы программы на консоль будет выведено:
OLIVER - 25
MUHAMMAD - 54
OLIVER - 25Как видим, несмотря на то, что тип 'Employee' переопределяет метод 'equals', этого недостаточно. В ходе выполнения программы нам не удалось получить ожидаемого результата, и коллекция содержит повторяющиеся элементы. Для устранения этой проблемы в объявление типа 'Employee' необходимо добавить переопределение метода 'hashCode':
public class Employee {
...
@Override
public boolean equals(Object obj) {
if (obj == this)
return true;
if (!(obj instanceof Employee))
return false;
Employee employee = (Employee) obj;
return employee.getAge() == this.getAge()
&& employee.getName() == this.getName();
}
@Override
public int hashCode() {
int result=17;
result=31*result+age;
result=31*result+(name!=null ? name.hashCode():0);
return result;
}
}
public static void main(String[] args)
{
HashSet<Employee> employees = new HashSet<>();
employees.add(new Employee("OLIVER", 25));
employees.add(new Employee("MUHAMMAD", 54));
employees.add(new Employee("OLIVER", 25));
employees.forEach(arg -> System.out.println(arg.getFullInfo()));
}Вновь выполним программу. В результате на консоль будет выведено:
MUHAMMAD - 54
OLIVER – 25Мы получили корректный результат: коллекция содержит только уникальные элементы.
Данная диагностика классифицируется как:
|
V6050. Class initialization cycle is present.
Данное диагностическое правило выявляет случаи неправильного порядка объявления статических полей внутри класса, а также случаи зависимостей статических полей от других классов. Такие случаи могут привести к сложному поддержанию кода или к ошибочной инициализации класса.
Случай 1.
Использование статического поля до того, как оно будет проинициализировано.
Рассмотрим синтетический пример некорректного кода:
public class Purse
{
static private Purse reserve = new Purse(10);
static private int scale = 5 + (int) (Math.random() * 5);
private int deposit;
Purse() {
deposit = 0;
}
Purse(int initial) {
deposit = initial * scale;
}
...
}Как известно, статические поля будут инициализироваться в порядке объявления самыми первыми при первом использовании класса. Следовательно, в данном примере сначала инициализируется 'reserve', а потом 'scale'.
Рассмотрим инициализацию статического поля 'reserve':
- Вызывается конструктор 'Purse' с аргументом 'initial = 10'.
- На момент выполнения выражения 'initial * scale' в вызываемом конструкторе, поле 'scale' еще не инициализировано, и будет равно значению по умолчанию (0), вместо значения из диапазона [5;10].
Вследствие чего, поле 'deposit' у объекта 'reserve' будет проинициализировано не так, как задумывалось.
Для того, чтобы исправить ситуацию, необходимо поменять порядок объявления статических полей:
public class Purse
{
static private int scale = 5 + (int) (Math.random() * 5);
static private Purse reserve = new Purse(10);
private int deposit;
Purse() {
deposit = 0;
}
Purse(int initial) {
deposit = initial * scale;
}
...
}Случай 2.
Взаимная зависимость статических полей разных классов.
Рассмотрим синтетический пример некорректного кода:
public class A {
public static int scheduleWeeks = B.scheduleDays / 7 + 1;
....
}
....
public class B {
public static int scheduleDays = A.scheduleWeeks * 7 + 7;
....
}Ситуация здесь такова, что статическое поле 'A.scheduleWeeks' зависит от статического поля 'B.scheduleDays', и наоборот. Порядок инициализации классов может меняться, отсюда меняется и порядок инициализации статических полей. Если инициализируется первым класс 'A', то 'A.scheduleWeeks' будет иметь значение 2, а 'B.scheduleDays' – 7. Если первым будет класс 'B', то 'A.scheduleWeeks' будет равен 1, а 'B.scheduleDays' – 14. Вряд ли такое поведение будет приятно наблюдать у себя в коде. В таком случае необходимо пересмотреть инициализацию этих полей и убрать зависимость друг от друга.
Например, можно одно из статических полей инициализировать константой, и эта зависимость исчезнет:
public class A {
public static int scheduleWeeks = B.scheduleDays / 7 + 1;
....
}
....
public class B {
public static int scheduleDays = 14;
....
}В таком случае 'B.scheduleDays' всегда будет равен 14, а 'A.scheduleWeeks' – 3.
Случай 3.
Инициализация статического поля в одном классе, используя статический метод второго класса, который в свою очередь использует статический метод или поле первого класса.
Рассмотрим синтетический пример некорректного кода:
public class A {
public static int scheduleWeeks = B.getScheduleWeeks();
public static int getScheduleDays() { return 21; }
....
}
....
public class B {
public static int getScheduleWeeks() {return A.getScheduleDays()/7;}
....
}Независимо от того, какой из классов первым будет инициализирован, поле 'A.scheduleWeeks' примет значение равное 3. Несмотря на это, такой способ инициализации сбивает с толку при чтении и поддержке такого кода.
Например, можно подкорректировать код следующим образом:
public class A {
public static int scheduleWeeks = B.getScheduleWeeks();
....
}
....
public class B {
public static int getScheduleDays() { return 21; }
public static int getScheduleWeeks() {return B.getScheduleDays()/7;}
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6050. |
V6051. Use of jump statements in 'finally' block can lead to the loss of unhandled exceptions.
Анализатор выявил использование операторов return/break/continue и т.п. внутри блока 'finally'. Их использование может привести к потере необработанного исключения, возникшего в блоках 'try' или 'catch'. Согласно JLS [14.20.2], в случае такого завершения блока 'finally', все сгенерированные исключения в 'try' или 'catch' будут подавлены.
Рассмотрим пример, когда анализатор выдаст предупреждение:
int someMethod(int a, int b, int c) throws SomeException
{
int value = -1;
...
try
{
value = calculateTransform(a, b, c);
...
}
finally
{
System.out.println("Result of someMethod()");
return value; // <=
}
}В данном примере, несмотря на то, что в сигнатуре метода указано, что может возникнуть исключение, метод 'someMethod' никогда не выбросит его, так как применение оператора 'return' подавит исключение, и оно не выйдет наружу.
Возможно, это намеренный способ подавления исключений. В таком случае, чтобы анализатор не ругался, достаточно убрать исключение из сигнатуры метода.
int someMethod(int a, int b, int c)
{
int value = -1;
...
try
{
value = calculateTransform(a, b, c);
...
}
finally
{
System.out.println("Result of someMethod()");
return value;
}
}Немного изменим предыдущий пример:
int someMethod(int a, int b, int c) throws SomeException
{
int value = -1;
...
try
{
value = calculateTransform(a, b, c);
...
}
catch (SomeException se)
{
...
throw se;
}
finally
{
System.out.println("Result of someMethod()");
return value; // <=
}
}Здесь анализатор тоже выдаст предупреждение. Есть обработчик исключения 'SomeException', который что-то делает и пробрасывает это исключение дальше. После чего отработает блок 'finally' и функция вернет значение 'value'. А что же исключение? А исключение, что было проброшено дальше в обработчике, так и не выйдет за пределы метода.
Чтобы исправить ситуацию, можно исправить код следующим образом:
int someMethod(int a, int b, int c) throws SomeException
{
int value = -1;
...
try
{
value = calculateTransform(a, b, c);
...
}
catch (SomeException se)
{
...
throw se;
}
finally
{
System.out.println("Result of someMethod()");
}
return value;
}В таком случае, если произошло исключение, то оно будет обязательно проброшено наружу, что и говорит сигнатура метода 'someMethod'.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6051. |
V6052. Calling an overridden method in parent-class constructor may lead to use of uninitialized data.
Выявлен случай использования метода в родительском конструкторе, который, в свою очередь, переопределяется в дочернем классе. Такое использование может привести к тому, что переопределенный метод будут использовать неинициализированные поля класса.
В JLS [12.5] описан порядок инициализации нового класса, и если пренебречь им, то может наблюдаться такое поведение.
Рассмотрим пример, который приведет к такому случаю:
public class Parent {
private String parentStr = "Black";
public Parent () {
printInfo();
}
public void printInfo () {
System.out.println("Parent::printInfo");
System.out.println("parentStr: " + parentStr);
System.out.println("-----------------");
}
....
}
public class Child extends Parent {
private int childInt;
private String childStr;
public Child() {
super();
this.childInt = 25;
this.childStr = "White";
}
public void printInfo () {
super.printInfo();
System.out.println("Child::printInfo");
System.out.println("childInt: "+childInt+";childStr: "+childStr);
System.out.println("-----------------");
}
....
}Если выполнить следующую строку кода:
Child obj = new Child();то на экран будет выведен такой текст:
Parent::printInfo
parentStr: Black
-----------------
Child::printInfo
childInt: 0 ; childStr: null
-----------------По распечатанному фрагменту видно, что был вызван переопределенный метод 'printInfo' из родительского конструктора класса 'Parent', когда дочерний класс 'Child' не был полностью проинициализирован. Отсюда и получается, что поля 'childInt' и 'childStr' распечатаны со значениями по умолчанию, а не с теми, что мы задали.
Вывод: никогда не используйте методы в конструкторе, которые могут быть в дальнейшем переопределены в дочерних классах. Если же в конструкторе используется метод класса, то он должен быть либо final, либо private.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6052. |
V6053. Collection is modified while iteration is in progress. ConcurrentModificationException may occur.
Анализатор обнаружил, что коллекция, не предназначенная для параллельного изменения, модифицируется во время итерации по ней. Это может привести к возникновению исключения 'ConcurrentModificationException'.
Рассмотрим несколько примеров кода с ошибкой.
Пример 1:
List<Integer> mylist = new ArrayList<>();
....
for (Integer i : mylist)
{
if (cond)
{
mylist.add(i * 2);
}
}Пример 2:
List<Integer> myList = new ArrayList<>();
....
Iterator iter = myList.iterator();
while (iter.hasNext())
{
if (cond)
{
Integer i = (Integer) iter.next();
myList.add(i * 2);
}
}Пример 3:
Set<Integer> mySet = new HashSet<>();
....
mySet.stream().forEach(i -> mySet.add(i * 2));При этом, анализатор не будет выдавать предупреждение если коллекция позволяет параллельное изменение:
List<Integer> mylist = new CopyOnWriteArrayList<>();
....
for (Integer i : mylist)
{
if (cond)
{
mylist.add(i + 1);
}
}Кроме того, предупреждение не будет выдано если сразу после модификации осуществляется выход из цикла:
List<Integer> mylist = new ArrayList<>();
....
for (Integer i : mylist)
{
if (cond)
{
mylist.add(i + 1);
break;
}
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6053. |
V6054. Classes should not be compared by their name.
Анализатор обнаружил ситуацию, когда сравнение классов осуществляется по имени. Такое сравнение является некорректным, т.к. согласно спецификации JVM классы имеют уникальное имя только внутри пакета.
Помимо логических ошибок, такой код может в некоторых случаях привести к различным уязвимостям, поскольку не известно, какое поведение у непроверенного класса.
Пример:
if (obj.getClass().getSimpleName().equals("Plane"))
{
....
}Такой код следует переписать следующим образом:
if(obj.getClass().equals(ArrayList.class))
{
....
}либо:
if (obj instanceof Plane)
{
....
}или же:
if (obj.getClass().isAssignableFrom(Plane.class))
{
....
}Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6054. |
V6055. Expression inside assert statement can change object's state.
Анализатор выявил случай, когда в 'assert' присутствует метод, который меняет состояние объекта. Вызов таких методов будет зависеть от настроек Java Virtual Machine, что может являться непредвиденным поведением для разработчика.
Рассмотрим пример такого случая:
void someFunction(List<String> listTokens)
{
....
assert "<:>".equals(listTokens.remove(0));
....
}Здесь нас интересует вызов 'listTokens.remove(0)'. Данный метод удаляет первый элемент в 'listTokens', тем самым модифицируя коллекцию. Далее возвращенная удаленная строка сравнивается с некоторой ожидаемой строкой. Проблема тут в том, что если в проекте будут отключены assert'ы, то выражение не будет вычистяться, и, следовательно, первый элемент в коллекции не будет удален, что может сказаться на дальнейшем поведении программы.
Чтобы избежать таких ситуаций, из assert'a следует убрать вызов функций, меняющих содержимое объектов.
Пример исправленного кода:
void someFunction(List<String> listTokens)
{
....
boolean isFirstStr = "<:>".equals(listTokens.remove(0));
assert isFirstStr;
....
}Данная диагностика классифицируется как:
|
V6056. Implementation of 'compareTo' overloads the method from a base class. Possibly, an override was intended.
Анализатор выявил случай, когда метод 'compareTo' перегружает одноименный метод родительского класса, который реализует интерфейс 'Comparable<T>'. Скорее всего, перегрузка метода родительского класса не то, что подразумевалось разработчиком.
Рассмотрим пример класса, который вместо переопределения метода осуществляет перегрузку:
public class Human implements Comparable<Human>
{
private String mName;
private int mAge;
....
Human(String name, int age)
{
mName = name;
mAge = age;
}
....
public int compareTo(Human human)
{
int result = this.mName.compareTo(human.mName);
if (result == 0)
{
result = Integer.compare(this.mAge, human.mAge);
}
return result;
}
}
public class Employee extends Human
{
int mSalary;
....
public Employee(String name, int age, int salary) {
super(name, age);
mSalary = salary;
}
....
public int compareTo(Employee employee)
{
return Integer.compare(this.mSalary, employee.mSalary);
}
}Итак, у нас есть два класса: базовый 'Human' и дочерний 'Employee'. 'Human' реализует интерфейс 'Comparable<Human>' и определяет метод 'compareTo'. Далее дочерний класс 'Employee' расширяет базовый класс и перегружает метод 'compareTo'. Результат метода сравнения таков:
- отрицательное число - если текущий объект меньше сравниваемого;
- 0 - если объекты равны;
- положительное число - если текущий объект больше сравниваемого;
Из этого может выйти следующий эффект:
1) Если мы представим объекты 'Employee' через ссылку на базовый класс, то вызвав метод 'compareTo' мы не достигнем нужного сравнения объектов:
Human emp1 = new Employee("Andrew", 25, 33000);
Human emp2 = new Employee("Madeline", 29, 31000);
System.out.println(emp1.compareTo(emp2));На экран будет выведено -12, и получается, что объект emp1 логически меньше emp2. Ведь это не так. Скорее всего, программистом подразумевалось, что эти объекты будут сравниваться на основе поля 'mSalary', и в таком случае, результат был бы противоположным. Это произошло из-за того, что программист перегрузил метод сравнения, а не переопределил. И когда произошел вызов метода, то вызвался метод из класса 'Human'.
2) Известно, что списки элементов, которые реализуют интерфейс 'Comparable<T>', могут автоматически быть отсортированы с помощью 'Collections.sort'/'Arrays.sort', а также такие элементы могут быть использованы в качестве ключей отсортированных коллекций, без явного указания компоратора. И в случае такой перегрузки сортировка будет осуществляться не так, как задумывалась, судя по реализации сравнения в дочернем классе. Опасность в том, что в таких случаях происходит неявный вызов метода сравнения, и сразу ошибку можно не найти.
Выполним следующий код:
List<Human> listEmployees = new ArrayList<>();
listEmployees.add(new Employee("Andrew", 25, 33000));
listEmployees.add(new Employee("Madeline", 29, 31000));
listEmployees.add(new Employee("Hailey", 45, 55000));
System.out.println("Before: ");
listEmployees.forEach(System.out::println);
Collections.sort(listEmployees);
System.out.println("After: ");
listEmployees.forEach(System.out::println);На экран будет выведен следующий текст:
Before:
Name: Andrew; Age: 25; Salary: 33000
Name: Madeline; Age: 29; Salary: 31000
Name: Hailey; Age: 45; Salary: 55000
After:
Name: Andrew; Age: 25; Salary: 33000
Name: Hailey; Age: 45; Salary: 55000
Name: Madeline; Age: 29; Salary: 31000Как видно из вывода, сортировка была осуществлена не по полю 'mSalary'. И все происходит по той же самой причине.
Решение этой проблемы сводится к тому, что метод сравнения должен быть переопределен, а не перегружен. Например:
public class Employee extends Human
{
....
public int compareTo(Human employee)
{
if (employee instanceof Employee)
{
return Integer.compare(this.mSalary,
((Employee)employee).mSalary);
}
return -1;
}
....
}И тогда будет все работать так, как задумывалось изначально.
В первом случае вывод будет 1 (emp1 логически больше emp2).
Во втором случае вывод будет следующим:
Name: Andrew; Age: 25; Salary: 33000
Name: Madeline; Age: 29; Salary: 31000
Name: Hailey; Age: 45; Salary: 55000
After:
Name: Madeline; Age: 29; Salary: 31000
Name: Andrew; Age: 25; Salary: 33000
Name: Hailey; Age: 45; Salary: 55000V6057. Consider inspecting this expression. The expression is excessive or contains a misprint.
Анализатор обнаружил избыточное сравнение, которое может быть потенциальной ошибкой.
Поясним на простом примере:
if (arr[42] == 10 && arr[42] != 3)Условие будет выполнено в том случае, если 'Aa[42] == 10'. Вторая часть выражения бессмысленна. Проанализировав код, можно прийти к одному из двух выводов:
1) Выражение можно упросить. Исправленный код:
if (arr[42] == 10)2) Выражение содержит ошибку. Исправленный код:
if (arr[42] == 10 && arr[43] != 3)Рассмотрим еще пример с условием, которое вызывает подозрение:
if ((3 < value) && (value > 10))Условие выполнится только тогда, когда 'value > 10'. Скорее всего это будет означать ошибку, и подразумевалось, что 'value' примет значение в интервале (3;10):
if ((3 < value) && (value < 10))Статья, в которой рассмотрены подобные ситуации и даны советы, как избежать таких ошибок: "Логические выражения в C/C++. Как ошибаются профессионалы".
Данная диагностика классифицируется как:
|
V6058. Comparing objects of incompatible types.
Анализатор обнаружил потенциальную ошибку, связанную с вызовом функции сравнения для несовместимых по типу объектов. Анализатор выдает предупреждения на некорректное использование таких функций как equals, assertEquals, assertArrayEquals и т.д.
Разберем ошибочные случаи сравнения:
Пример 1:
String param1 = ...;
Integer param2 = ...;
...
if (param1.equals(param2))
{...}Пример 2:
List<String> list = Arrays.asList("1", "2", "3");
Set<String> set = new HashSet<>(list);
if (list.equals(set))
{...}В обоих примерах сравниваются объекты с несовместимыми типами. Результат их сравнения всегда будет false, так как в реализациях 'equals' есть проверка на соответствие пришедшего объекта с текущим.
Для String:
public boolean equals(Object anObject)
{
...
if (anObject instanceof String)
{
...
}
return false;
}Для List:
public boolean equals(Object o)
{
...
if (!(o instanceof List))
return false;
...
}Если V6058 в вашем коде, то скорее всего это ошибка, и сравнивать надо другие объекты.
Пример 1:
...
String param1 = ...;
String param3 = ...;
...
if (param1.equals(param3))
{...}Пример 2:
...
List<String> list = Arrays.asList("1", "2", "3");
List<String> list2 = ...;
...
if (list.equals(list2))
{...}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6058. |
V6059. Odd use of special character in regular expression. Possibly, it was intended to be escaped.
Анализатор обнаружил странное регулярное выражение, использовав которое, программист получит результат, отличный от ожидаемого, либо при использовании которого полученный результат будет отличаться от ожидаемого.
Рассмотрим пример:
String[] arr = "Hot. Cool. Yours".split(".");После выполнения этой строчки кода в массиве не будет ожидаемого {"Hot", " Cool", " Yours"}, а будет пустой массив. Это связано с тем, что точка является специальным символом в регулярном выражении, у которой есть свое предназначение. Чтобы сделать точку разделителем в вашей строке, нужно использовать:
String[] arr = "Hot. Cool. Yours".split("\\.");Также анализатор предупредит, если ваше регулярное выражение будет состоять только из следующих символов:
- "|"
- "^"
- "$"
Данная диагностика классифицируется как:
V6060. The reference was used before it was verified against null.
Анализатор обнаружил потенциальную ошибку, которая может привести к использованию нулевого объекта.
Анализатор заметил в коде следующую ситуацию. Вначале объект используется. А уже затем этот объект проверяется на значение 'null'. Это может означать одно из двух:
1) Возникнет ошибка, если объект будет равен 'null'.
2) Программа всегда работает корректно, так как объект всегда не равен null. Проверка является лишней.
Рассмотрим фрагмент кода, на котором анализатор выдаст предупреждение:
boolean isSomething(String str)
{
String prepareStr = prepare(str);
if (prepareStr.contains("*?*"))
{
...
}
...
return prepareStr == null ? false : prepareStr.contains("?*?");
}Итак, в вышеприведенном примере потенциальная ошибка или лишнее сравнение? Сначала с переменной 'prepareStr' идут какие-то вычисления, а в конце она проверяется на null. Здесь имеет место быть возможен как первый, так и второй случай. Если все же метод 'prepare' может вернуть null, то необходимо внести изменения в код:
boolean isSomething(String str)
{
String prepareStr = prepare(str);
if (prepareStr == null) {
return false;
}
if (prepareStr.contains("*?*"))
{
//...
}
//...
return prepareStr.contains("?*?");
}Если же 'prepare' не возвращает 'null', то просто можно убрать сравнение с null, чтобы не путать ваших коллег-разработчиков.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6060. |
V6061. The used constant value is represented by an octal form.
Анализатор выявил подозрительное использование константы в восьмеричной системе счисления. Анализатор предупреждает о наличии восьмеричных констант, если рядом нет других восьмеричных констант. Такие "одиночные" восьмеричные константы часто являются ошибкой.
Использование констант в восьмеричной системе счисления само по себе не является ошибкой. Эта система удобна при работе с битами и используется в коде, взаимодействующем с сетью или внешними устройствами. Однако средний программист редко использует эту систему счисления и поэтому может написать перед числом 0, забыв, что это превращает значение в восьмеричное.
Рассмотрим ошибочный пример:
void compute(int red, int blue, int green)
{
int color = 2220 * red +
7067 * blue +
0713 * green;
// ...
}Рассматривая подобный код непросто заметить ошибку, но она есть. Ошибка в том, что последняя константа "0713" задана в восьмеричной системе счисления и имеет значение вовсе не 713, а 459. Исправленный вариант кода:
void compute(int red, int blue, int green)
{
int color = 2220 * red +
7067 * blue +
713 * green;
// ...
}Как было сказано выше, предупреждение о восьмеричных константах выдается только в том случае, если вблизи от них нет других восьмеричных констант. Поэтому следующий пример кода считается анализатором безопасным и для него предупреждений выдано не будет:
short bytebit[] = {01, 02, 04, 010, 020, 040, 0100, 0200 };Данная диагностика классифицируется как:
|
V6062. Possible infinite recursion.
Анализатор обнаружил, что может возникать бесконечная рекурсия. Скорее всего, это приведет к переполнению стека вызовов и возникновению исключения 'StackOverflow'.
Рассмотрим пример из реального проекта, который приводил к такой ситуации:
@Override
public void glGenTextures(IntBuffer textures) {
gl.glGenTextures(textures);
checkError();
}
@Override
public void glGenQueries(int num, IntBuffer ids) {
glGenQueries(num, ids); // <=
checkError();
}Программист допустил опечатку и вызвал не тот метод, что стало причиной возникновения бесконечной рекурсии. Метод 'glGenQueries' надо было вызывать у объекта 'gl', как это делается в других фукнциях.
Исправленный пример:
@Override
public void glGenTextures(IntBuffer textures) {
gl.glGenTextures(textures);
checkError();
}
@Override
public void glGenQueries(int num, IntBuffer ids) {
gl.glGenQueries(num, ids);
checkError();
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6062. |
V6063. Odd semicolon ';' after 'if/for/while' operator.
Анализатор обнаружил потенциально возможную ошибку, связанную с наличием точки с запятой ';' после оператора if, for или while.
Приведем пример:
int someMethod(int value, int a, int b, int c, ...)
{
int res = -1;
....
if (value > (a - b)/c);
{
....
res = calculate(value);
}
....
return res;
}Корректный вариант:
int someMethod(int value, int a, int b, int c, ...)
{
int res = -1;
....
if (value > (a - b)/c)
{
....
res = calculate(value);
}
....
return res;
}Данная диагностика классифицируется как:
|
V6064. Suspicious invocation of Thread.run().
Анализатор обнаружил подозрительный прямой вызов Thread.run(). Такой запуск потока может ввести в заблуждение. Когда метод run() объекта Thread вызывается напрямую, все действия в методе run() будут выполняться в текущем потоке, а не вновь созданном.
Рассмотрим некорректный вариант:
private class Foo implements Runnable
{
@Override
public void run() {/*...*/}
}
....
Foo foo = new Foo();
new Thread(foo).run();
....В данном примере выполнение тела метода run() будет в текущем потоке. Так ли задумывалось? Для того, чтобы тело метод run() выполнилось в новом потоке, необходимо использовать метод start().
Корректный вариант:
private class Foo implements Runnable
{
@Override
public void run() {/*...*/}
}
....
Foo foo = new Foo();
new Thread(foo).start();
....Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
V6065. A non-serializable class should not be serialized.
Анализатор обнаружил сериализацию объекта, в котором нет реализации интерфейса 'java.io.Serializable'. Для того, чтобы корректно выполнялись операции сериализации и десериализации, необходимо реализовать в классе объекта данный интерфейс.
Рассмотрим некорректный вариант:
class Dog
{
String breed;
String name;
Integer age;
....
}
....
Dog dog = new Dog();
....
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(dog);
....Если дойдет дело до сериализации объекта 'dog', то будет выдано исключение 'java.io.NotSerializableException'. Для того, чтобы все успешно отработало необходимо реализовать интерфейс 'java.io.Serializable' в классе 'Dog'.
Корректный вариант:
class Dog implements Serializable
{
String breed;
String name;
Integer age;
....
}
....
Dog dog = new Dog();
....
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(dog);
....V6066. Passing objects of incompatible types to the method of collection.
Анализатор обнаружил потенциальную ошибку, связанную с вызовом метода коллекции, в который передали объект, тип которого не совпадает с типом коллекции. Анализатор выдает предупреждения на такие функции как remove, contains, removeAll, containsAll, retainAll и т.д.
Давайте рассмотрим пример с ошибочным использованием метода 'remove':
List<String> list = ...;
Integer index = ...;
...
list.remove(index);Здесь хотели удалить объект из списка по индексу, но не учли, что индекс не примитивный целый тип, а объект типа 'Integer'. Будет использоваться перегруженный метод 'remove', который ожидает на вход объект, а не 'int'. Объекты 'Integer' и 'String' несовместимы, и поэтому использование метода будет ошибочным.
Если нет возможности изменить тип переменной "index", то можно исправить код следующим образом:
List<String> list = ...;
Integer index = ...;
...
list.remove(index.intValue());Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6066. |
V6067. Two or more case-branches perform the same actions.
Анализатор обнаружил ситуацию, когда в операторе switch разные метки case содержат одинаковые фрагменты кода. Часто это свидетельствует об избыточном коде, который можно улучшить объединением меток. Но нередко одинаковые фрагменты кода могут быть причиной copy-paste программирования и являться настоящими ошибками.
Рассмотрим пример с избыточным кодом:
public static String getSymmetricCipherName(SymmetricKeyAlgorithmTags tag)
{
switch (tag)
{
case DES:
return "DES";
case AES_128:
return "AES";
case AES_192:
return "AES";
case AES_256:
return "AES";
case CAMELLIA_128:
return "Camellia";
case CAMELLIA_192:
return "Camellia";
case CAMELLIA_256:
return "Camellia";
case TWOFISH:
return "Twofish";
default:
throw new IllegalArgumentException("....");
}
}В реальных проектах для различных case'ов возможны случаи, когда необходимо выполнить одинаковые действия. И для того, чтобы выглядело читабельнее, код можно написать более компактно:
public static String getSymmetricCipherName(SymmetricKeyAlgorithmTags tag)
{
switch (tag)
{
case DES:
return "DES";
case AES_128:
case AES_192:
case AES_256:
return "AES";
case CAMELLIA_128:
case CAMELLIA_192:
case CAMELLIA_256:
return "Camellia";
case TWOFISH:
return "Twofish";
default:
throw new IllegalArgumentException("....");
}
}Рассмотрим пример из реального приложения, где разработчик допустил ошибку из-за опечатки:
protected boolean condition(Actor actor) throws ....
{
....
if (fieldValue instanceof Number)
{
....
switch (tokens[2])
{
case "=":
case "==":
passing = (Double) fieldValue
==
Double.parseDouble(secondValue);
break;
case "!":
case "!=":
passing = (Double) fieldValue
==
Double.parseDouble(secondValue);
break;
case "<=":
passing = ((Number) fieldValue).doubleValue()
<=
Double.parseDouble(secondValue);
break;
....
}
....
}
....
}В коде меток '!' и '!=' допущена опечатка, которая возникла по всей видимости из-за copy-paste. Просмотрев остальные ветви case, можно прийти к выводу, что следовало использовать оператор сравнения '!=' вместо '=='.
Исправленный код:
protected boolean condition(Actor actor) throws ....
{
....
if (fieldValue instanceof Number)
{
....
switch (tokens[2])
{
case "=":
case "==":
passing = (Double) fieldValue
==
Double.parseDouble(secondValue);
break;
case "!":
case "!=":
passing = (Double) fieldValue
!=
Double.parseDouble(secondValue);
break;
case "<=":
passing = ((Number) fieldValue).doubleValue()
<=
Double.parseDouble(secondValue);
break;
....
}
....
}
....
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6067. |
V6068. Suspicious use of BigDecimal class.
Анализатор обнаружил использование класса BigDecimal, которое может вести себя не так, как ожидал разработчик.
Анализатор выдает предупреждения в следующих ситуациях:
1. Вызов конструктора, аргументом которого является число с плавающей точкой.
Пример такого использования:
BigDecimal bigDecimal = new BigDecimal(0.6);Про использование таким образом конструктора есть несколько примечаний в документации класса.
Если не вдаваться в подробности, то созданный таким образом объект будет иметь значение 0.59999999999999997779553950749686919152736663818359375 вместо 0,6. Это связано с невозможностью точного представления числа с плавающей точкой.
А ведь BigDecimal прежде всего необходим для вычислений с крайне высокими требованиями к точности. И примеру, есть ПО, в котором от точности вычислений может зависеть человеческая жизнь (ПО для самолетов, ракет или для медицинского оборудования). Поэтому погрешность даже в 30 разряде после запятой может сыграть свою роль.
Чтобы этого избежать, необходимо создавать объект BigDecimal одним из следующих способов:
BigDecimal bigDecimal1 = BigDecimal.valueOf(0.6);
BigDecimal bigDecimal2 = new BigDecimal("0.6");2. Вызов метода 'equals', так как вполне вероятно имелся ввиду метод 'compareTo'.
Принято считать, что для сравнения объектов нужно вызывать метод 'equals'. Тут не поспорить!
И когда разработчик работает с объектом этого класса, то может считать, что он просто работает с объектом, который может содержать очень большое вещественное число. И вызывая метод 'equals', подразумевает эквивалентность сравниваемых чисел.
В таком случае, следующий фрагмент кода может удивить разработчика:
BigDecimal bigDecimal1 = BigDecimal.valueOf(0.6);
BigDecimal bigDecimal2 = BigDecimal.valueOf(0.60);
....
if (bigDecimal1.equals(bigDecimal2)) // false
{
// code
}Нюанс кроется в том, что при сравнении через метод 'equals' сравнивается не только значение, но и количество значащих чисел после запятой. Как раз этого разработчик может и не ожидать. Чтобы сравнивать числа без учета значащих чисел после запятой необходимо использовать метод 'compareTo':
BigDecimal bigDecimal1 = BigDecimal.valueOf(0.6);
BigDecimal bigDecimal2 = BigDecimal.valueOf(0.60);
....
if (bigDecimal1.compareTo(bigDecimal2) == 0) // true
{
// code
}Данная диагностика классифицируется как:
|
V6069. Unsigned right shift assignment of negative 'byte' / 'short' value.
Анализатор обнаружил случай, когда над возможно отрицательным числом типа 'byte' или 'short' применяется беззнаковый сдвиг вправо с присваиванием (>>>=). Результат такого сдвига может отличаться от ожидаемого.
Часто требуется, чтобы при сдвиге вправо расширение знакового разряда не происходило, а освобождающиеся левые разряды независимо от знака старшего бита заполнялись бы нулями. С этой целью используется оператор беззнакового сдвига вправо >>>.
Также этот сдвиг можно совмещать со знаком равенства (>>>=). Однако при этом может возникнуть неочевидное поведение при использовании данного оператора с типами 'byte' или 'short'. Проблема заключается в том, что они сначала будут неявно преобразованы к типу 'int' и сдвинуты вправо, а затем обрезаны при возвращении к исходному типу.
Если Вы попробуете скомпилировать код со следующим содержимым:
void test(byte byteValue, boolean isFlag)
{
....
if (isFlag)
{
byteValue = byteValue >>> 5;
}
....
}, то получите ошибку:
error: incompatible types:
possible lossy conversion from int to byte
byteValue = byteValue >>> 5;
^Это подтверждает вышесказанные слова о расширении до 'int', и далее компилятор не даст Вам присвоить 'int' к 'byte' без явного указания. Это означает, что Вы знаете что делаете. Если скомпилировать тот же файл с небольшим исправлением:
....
byteValue >>>= 5;
...., то все в порядке. При выполнении этого кода произойдет расширение, смещение и сужение до исходного типа.
Из-за этого в таком сдвиге с присвоением кроется поведение, которое может не ожидаться разработчиком. В случае сдвига положительного числа будет работать так, как и ожидалось. А что с отрицательным числом?
Давайте разберем синтетический случай, когда смещается с присвоением значение -1 типа 'byte':
byte byteValue = -1; // 0xFF or 0b1111_1111
byteValue >>>= 4;
assertTrue(byteValue == 0x0F); // byteValue == 0b0000_1111Итак, разработчик думал, что у него есть 8 бит (byte), и, беззнаково смещая на 4 бита вправо, ожидает увидеть только 4 младших бита. И тут на удивление разработчика 'assertTrue' не отрабатывает!
Это происходит как раз из-за того, что 'byteValue' неявно расширяется до 'int', сдвигается и обрезается до 'byte':
byteValue == 0xFF (byte): 11111111
Расширение до 'int' : 11111111 11111111 11111111 11111111
Смещение на 4 : 00001111 11111111 11111111 11111111
Преобразование в 'byte' : 11111111По завершении операции может сложиться ощущение, что беззнаковый сдвиг (>>>=) работает некорректно. Но всё логично и правильно. Просто существует нюанс, который следует учитывать при работе с типами 'byte' или 'short'.
V6070. Unsafe synchronization on an object.
Анализатор обнаружил синхронизацию по объекту, которая может привести к скрытым проблемам параллелизма из-за того, что синхронизированный объект может неявно использоваться в других логически несвязанных частях программы.
Проблема заключается в том, что если производить синхронизацию по:
- 'this',
- объектам целочисленных классов оберток (Byte, Short, Integer, Long),
- объекту класса обертки для логического типа (Boolean),
- объекту класса String,
то это может приводить к потенциальным тупикам и недетерминированному поведению.
Причиной этому может служить то, что вышеперечисленные объекты могут повторно использоваться в разных частях программы.
Суть проблемы синхронизации по приведенным объектам состоит в том, что к объекту, используемому для блокировки, имеется общий доступ. Такой объект может быть использован для блокировки в другом месте без ведома разработчика, использовавшего объект для блокировки в первый раз. Это, в свою очередь, и создаёт вероятность возникновения взаимоблокировки на один и тот же объект.
Приведём синтетический пример взаимоблокировки при синхронизации по 'this':
class SynchroThis
{
void doSmt()
{
synchronized(this)
{
// do smt
}
}
}
....
SynchroThis obj = new SynchroThis();
synchronized(obj)
{
Thread t = new Thread(() -> obj.doSmt());
t.start();
t.join();
}
....В результате программа никогда не завершится, т.к. происходит deadlock по экземпляру класса SynchroThis (первая блокировка в основном потоке по 'obj', вторая - в потоке 't' по 'this').
Для того, чтобы избежать возможных взаимных блокировок, в качестве объекта блокировки стоит использовать, например, приватное поле:
class A
{
private final Object lock = new Object();
void foo()
{
synchronized(lock)
{
// do smt
}
}
}Рассмотрим синтетический пример синхронизации по объекту типа Byte:
class FirstClass
{
private final Byte idLock;
....
public FirstClass(Byte id, ....)
{
idLock = id;
....
}
....
public void calculateFromFirst(....)
{
synchronized (idLock) // <=
{
....
}
}
}
class SecondClass
{
private final Byte idLock;
....
public SecondClass(Byte id, ....)
{
idLock = id;
....
}
....
public void calculateFromSecond(....)
{
synchronized (idLock) // <=
{
....
}
}
}Обусловим, что поток N1 оперирует объектом класса 'FirstClass', а поток N2 - 'SecondClass'.
Теперь давайте рассмотрим сценарий:
- У объекта класса 'FirstClass' поле 'idLock' равно 100, у объекта класса 'SecondClass' тоже 100;
- Поток N1 начинает выполнять метод 'calculateFromFirst', и какое-то время выполняется;
- Поток N2 (сразу же следом) начинает выполнять метод 'calculateFromSecond'.
Итак, у нас 2 разных потока выполняют совершенно разную логику программы для разных объектов. Что же получится? А получится то, что поток N2 будет находиться в состоянии ожидания до тех пор, пока поток N1 не закончит работу в синхронизированном блоке по объекту 'idLock'. Почему же так получается?
Как и все объекты, переменные созданные с помощью классов оберток будут храниться в куче. У каждого такого объекта будет свой адрес в куче. Но есть небольшой нюанс, который нужно всегда учитывать. Целочисленные классы обертки, полученные при помощи автоупаковки, со значением в диапазоне [-128..127] кэшируются JVM. Поэтому такие обертки с одинаковыми значениями в этом диапазоне будут являться ссылками на один объект.
Так и получается в нашем случае. Синхронизация производится по одному и тому же объекту в памяти, чего вовсе и не ожидалось.
Также, помимо целочисленных классов оберток, не следует использовать для синхронизации объекты классов:
- Boolean;
- String (так как может получиться, что синхронизация будет производиться по строке, которая хранится в пуле строк).
Использование синхронизации по таким объектам небезопасно. Рекомендуется использовать вышеописанный способ с приватным полем, но если по каким-либо причинам Вам это не подходит, то создавайте объекты явно при помощи конструктора. Такой способ гарантирует, что у объектов будут разные адреса. Пример безопасного кода:
class FirstClass
{
private final Byte idLock;
....
public FirstClass(Byte id, ....)
{
idLock = new Byte(id);
....
}
....
public void calculateFromFirst(....)
{
synchronized (idLock)
{
....
}
}
}
....Дополнительную информацию можно посмотреть здесь.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
V6071. This file is marked with copyleft license, which requires you to open the derived source code.
Анализатор обнаружил в файле copyleft лицензию, которая обязывает открыть остальной исходный код. Это может быть неприемлемо для многих коммерческих проектов.
Если вы разрабатываете открытый проект, то можно просто игнорировать это предупреждение и отключить его.
Пример комментария, на который анализатор выдаст предупреждение:
/* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program. If not, see <https://www.gnu.org/licenses/>.
*/Для закрытых проектов
Если в закрытый проект добавить файл с такой лицензией (GPL3 в данном случае), то остальной исходный код необходимо будет открыть, из-за особенностей данной лицензии.
Такой тип copyleft лицензий называют "вирусными" лицензиями, из-за их свойства распространяться на остальные файлы проекта. Проблема в том, что использование хотя бы одного файла с подобной лицензией в закрытом проекте автоматически делает весь исходный код открытым и обязывает распространять его вместе с бинарными файлами.
Диагностика занимается поиском следующих "вирусных" лицензий:
- AGPL-3.0
- GPL-2.0
- GPL-3.0
- LGPL-3.0
Есть следующие варианты, как вы можете поступить, обнаружив в закрытым проекте использование файлов с copyleft лицензий:
- Отказаться от использования данного кода (библиотеки) в своём проекте;
- Заменить используемую библиотеку;
- Сделать свой проект открытым.
Для открытых проектов
Мы понимаем, что данная диагностика неуместна для открытых проектов. Команда PVS-Studio способствует развитию открытых проектов, помогая исправлять в них ошибки и предоставляя бесплатные варианты лицензий. Однако наш продукт является B2B решением, и поэтому данная диагностика по умолчанию включена.
Если же ваш код распространяется под одной из указанных выше copyleft лицензий, то вы можете отключить данную диагностику следующими способами:
- в плагине для IntelliJ IDEA снимите галочку с Settings > PVS-Studio > Warnings > V6071;
- в плагине для Gradle добавьте секцию disabledWarnings = ["V6071"];
- в плагине для Maven добавьте секцию <disabledWarnings>V6071</disabledWarnings>;
- параметр ‑‑disable V6071 при ручном запуске pvs-studio.jar.
Пополнение списка опасных лицензий
Если вам известны ещё типы "вирусных" лицензий, которые в данный момент не выявляет инструмент, то вы можете сообщить нам о них через форму обратной связи. И мы добавим их выявление в следующем релизе.
Дополнительные ссылки
- GNU General Public License
- "Вирусные" лицензии
- Бесплатные варианты лицензирования PVS-Studio
- Подавление ложных предупреждений
V6072. Two similar code fragments were found. Perhaps, this is a typo and 'X' variable should be used instead of 'Y'.
Анализатор обнаружил код, который, возможно, содержит опечатку. Высока вероятность, что подобный код был создан с использованием подхода Copy-Paste.
Данная диагностика выявляет два схожих по структуре блока кода, идущих один за другим и отличающихся переменной, которая несколько раз встречалась в первом блоке кода, но во втором встречается только один раз. Из этого можно сделать вывод, что переменная возможно была забыта и не заменена. Предупреждение V6072 предназначено для выявления тех случаев, если второй блок был получен путем копирования первого, при этом во втором блоке были переименованы не все переменные.
Рассмотрим пример:
if (x > 0)
{
Do1(x);
Do2(x);
}
if (y > 0)
{
Do1(y);
Do2(x); // <=
}Вероятнее всего во втором блоке вместо переменной 'x' должна идти переменная 'y'. Корректный вариант мог бы выглядеть так:
if (x > 0)
{
Do1(x);
Do2(x);
}
if (y > 0)
{
Do1(y);
Do2(y);
}Рассмотрим еще один пример, но уже более сложный.
....
if(erendlinen>239) erendlinen=239;
if(srendlinen>erendlinen) srendlinen=erendlinen;
if(erendlinep>239) erendlinep=239;
if(srendlinep>erendlinen) srendlinep=erendlinep; // <=
....Заметить ошибку не так уж и просто. Имена переменных похожи друг на друга, и поэтому выявление ошибки усложняется в разы. На самом деле во втором блоке вместо переменной 'erendlinen' должна стоять 'erendlinep'.
Корректный вариант будет выглядеть так:
....
if(erendlinen>239) erendlinen=239;
if(srendlinen>erendlinen) srendlinen=erendlinen;
if(erendlinep>239) erendlinep=239;
if(srendlinep>erendlinep) srendlinep=erendlinep; // <=
....Имена переменных 'erendlinen' и 'erendlinep' выбраны явно неудачно. Такую ошибку почти невозможно заметить при Code Review. Да что уж там, даже когда анализатор указывает на строку с ошибкой и то сложно её заметить. Поэтому, встретив предупреждение V6072, рекомендуем не спешить и внимательно изучить код.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6072. |
V6073. It is not recommended to return null or throw exceptions from 'toString' / 'clone' methods.
Анализатор обнаружил, что переопределенный метод 'toString' или 'clone' может вернуть значение 'null' или выбросить исключение.
Использование методов 'toString' / 'clone' на объекте должно всегда возвращать строку / объект соответственно. Возврат же недействительного значения противоречит неявному контракту метода.
Давайте поясним сказанное на примерах некорректного переопределения метода 'toString':
@Override
public String toString()
{
return null;
}Есть вероятность, что в дальнейшем при работе программы или ее отладке будет вызван данный метод для получения текстового представления объекта. Т.к. разработчик скорее всего не станет проверять результат работы этой функции на null, дальнейшее его использование может повлечь за собой исключение 'NullPointerException'. Если необходимо вернуть пустое или неизвестное значение текстового представление объекта, рекомендуется использовать для этого пустую строку:
@Override
public String toString()
{
return "";
}Другой пример плохой практики при реализации метода 'toString' – выбрасывание исключения. Рассмотрим следующий синтетический пример:
@Override
public String toString()
{
if(hasError)
{
throw new IllegalStateException("toString() method error encountered");
}
....
}Высока вероятность, что данный метод будет вызван пользователем класса в месте, не подразумевающем возможности возникновения и обработки исключений.
Если необходимо выдать сообщение об ошибке при генерации текстового представления объекта, лучше будет вернуть его текст в виде строки, либо каким-то образом залогировать эту ошибку:
....
@Override
public String toString()
{
if(hasError)
{
logger.warn("toString() method error encountered");
return "Error encountered";
}
....
}С методом 'clone' аналогичная ситуация. Работая с этим методом, разработчик в голове может держать только 2 возможных исхода:
- операция копирования не поддерживается для этого экземпляра класса, и он ожидает исключение 'CloneNotSupportedExcexption';
- раз копирование возможно, то обязательно должна создаться и вернуться корректная копия объекта.
Но он явно не ожидает того, что при работе с методом может произойти подобное:
- выбросится непредвиденное исключение;
- вместо корректной копии он получит null.
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6073. |
V6074. Non-atomic modification of volatile variable.
Анализатор обнаружил неатомарное изменение 'volatile' переменной, которое может привести к состоянию гонки.
Известно, что использование модификатора 'volatile' гарантирует, что все потоки будут видеть актуальное значение соответствующей переменной. К этому можно добавить, что модификатор 'volatile' используется для того, чтобы указать JVM, что все операции присвоения этой переменной и все операции чтения из неё должны быть атомарными.
Можно посчитать, что пометки переменных как 'volatile' будет достаточно, чтобы безопасно их использовать в многопоточном приложении! Но что будет, если изменять 'volatile' переменную, будущее значение которой зависит от текущего?
К таким операциям можно отнести:
- var++, ‑‑var, ...
- var += smt, var *= smt, ...
- ...
Рассмотрим использование 'volatile' переменной в качестве счетчика (counter++).
class Counter
{
private volatile int counter = 0;
....
public void increment()
{
counter++; // counter = counter + 1
}
....
}Такая операция выглядит как одна операция, но в действительности это целая последовательность операций чтения-изменения-записи. Здесь и кроется состояние гонки.
Предположим, что 2 потока одновременно работают с объектом класса Counter и выполняют инкремент переменной 'counter' (10):
[counter == 10, temp == 10] Поток N1 считывает значение 'counter'во временную переменную.
[counter == 10, temp == 11] Поток N1 изменяет временную переменную.
[counter == 10, temp == 10] Поток N2 считывает значение 'counter'во временную переменную.
[counter == 11, temp == 11] Поток N1 записывает временную переменную в 'counter'.
[counter == 11, temp == 11] Поток N2 изменяет временную переменную.
[counter == 11, temp == 11] Поток N2 записывает временную переменную в 'counter'.
Ожидалось значение переменной 'counter' равное 12 (а не 11), так как 2 потока выполнили инкремент над одной и той же переменной. Также возможна ситуация, когда потоки выполнят инкремент друг за другом, и в таком случае все будет так, как и ожидалось. Как итог, раз на раз не приходится!
Чтобы избежать подобного поведения неатомарных операций для разделяемых переменных, можно использовать:
- Блок 'synchronized',
- Классы из пакета java.util.concurrent.atomic,
- Функциональность блокировок из пакета java.util.concurrent.locks
Пример корректного кода:
class Counter
{
private volatile int counter = 0;
....
public synchronized void increment()
{
counter++;
}
....
}или
class Counter
{
private final AtomicInteger counter = new AtomicInteger(0);
....
public void increment()
{
counter.incrementAndGet();
}
....
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6074. |
V6075. The signature of method 'X' does not conform to serialization requirements.
Анализатор обнаружил пользовательский метод сериализации, который не соответствует требованиям интерфейса. В случае несоответствия пользовательская сериализация будет проигнорирована средствами Serialization API.
Если поведения сериализации по умолчанию для пользовательского класса недостаточно, то есть возможность его изменить, реализовав специальные методы:
private void writeObject(java.io.ObjectOutputStream out)
throws IOException
private void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException;
private void readObjectNoData()
throws ObjectStreamException;
ANY-ACCESS-MODIFIER Object writeReplace()
throws ObjectStreamException;
ANY-ACCESS-MODIFIER Object readResolve()
throws ObjectStreamException;Однако реализовывать эти методы необходимо строго по тем требованиям, которые формируются из сигнатур вышеуказанных методов. Если этого не сделать, то пользовательская реализация сериализации будет проигнорирована в пользу сериализации по умолчанию. Дополнительно можно почитать здесь.
Сложность заключается в том, что интерфейс 'java.io.Serializable' представляет собой пустой интерфейс и является лишь маркером для механизма сериализации. И в случае реализации своей логики, неправильно определенные методы не обнаруживаются при помощи, например, компилятора, так как они представляют собой обычные пользовательские методы.
Рассмотрим синтетический пример, который вполне имеет право на существование в реальном проекте:
class Base implements Serializable
{
....
}
class Example extends Base
{
....
void writeObject(java.io.ObjectOutputStream out)
throws IOException
{
throw new NotSerializableException("Serialization is not supported!");
}
void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException
{
throw new NotSerializableException("Deserialization is not supported!");
}
}Был базовый класс, который мог участвовать в сериализации. Со временем понадобилось создать дочерний класс, но сериализация была не нужна. Программист реализовал соответствующие методы-заглушки и продолжил писать код дальше. Через какое-то время обнаруживается, что наш дочерний класс, вопреки желанию автора кода, сериализуется! Это произошло именно из-за того, что реализованные методы не соответствуют требованиям. Для исправления ситуации необходимо default модификатор изменить на private:
class Base implements Serializable
{
....
}
class Example extends Base
{
....
private void writeObject(java.io.ObjectOutputStream out)
throws IOException
{
throw new NotSerializableException("Serialization is not supported!");
}
private void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException
{
throw new NotSerializableException("Deserialization is not supported!");
}
....
}Данная диагностика классифицируется как:
|
V6076. Recurrent serialization will use cached object state from first serialization.
Анализатор обнаружил ситуацию, когда объект однажды уже записанный в поток, спустя какое-то время записывается в него снова с измененным состоянием. Из-за нюансов 'java.io.ObjectOuputStream' это приведет к тому, что измененное состояние сериализуемого объекта будет проигнорировано в пользу исходного.
Класс 'java.io.ObjectOuputStream', который используется для сериализации, кэширует записываемые объекты. Это означает, что один и тот же объект не будет сериализоваться дважды. Один раз класс сериализует объект, а во второй раз просто запишет в поток ссылку на тот же самый первый объект. В этом и кроется подводный камень. Если мы сериализуем объект, изменим его, а после снова сериализуем, то 'java.io.ObjectOuputStream' об изменениях объекта ничего не узнает, поэтому сочтет объект тем же самым, который был сериализован ранее.
Рассмотрим некорректный синтетический пример, в котором будет проигнорировано изменение состояния объекта при сериализации:
ObjectOutputStream out = new ObjectOutputStream(....);
SerializedObject obj = new SerializedObject();
obj.state = 100;
out.writeObject(obj); // сохраняет объект с состоянием = 100
obj.state = 200;
out.writeObject(obj); // сохраняет объект с состоянием = 100 (а ожидалось 200)
out.close();Чтобы избежать подобного поведения, есть два способа.
Самым простым и надежным решением является создание нового экземпляра этого объекта с необходимым состоянием. Рассмотрим пример:
ObjectOutputStream out = new ObjectOutputStream(....);
SerializedObject obj = new SerializedObject();
obj.state = 100;
out.writeObject(obj);
obj = new SerializedObject();
obj.state = 200;
out.writeObject(obj);
out.close();Следующий способ менее тривиален. Он заключается в использовании метода 'reset' класса 'java.io.ObjectOuputStream'. Использовать данный способ рекомендуется только тогда, когда вы хорошо понимаете, что делаете и зачем, так как 'reset' обнулит информацию обо всех объектах, ранее записанных в поток. Рассмотрим пример:
ObjectOutputStream out = new ObjectOutputStream(....);
SerializedObject obj = new SerializedObject();
obj.state = 100;
out.writeObject(obj);
out.reset();
obj.state = 200;
out.writeObject(obj);
out.close();V6077. A suspicious label is present inside a switch(). It is possible that these are misprints and 'default:' label should be used instead.
Анализатор обнаружил потенциальную ошибку внутри оператора switch. Используется метка с именем похожим на 'default'. Возможно, это опечатка.
Рассмотрим пример:
int c = getValue();
double weightCoefficient = 0;
switch(c){
case 1:
weightCoefficient += 3 * (/*math formula #1*/);
case 2:
weightCoefficient += 7 * (/*math formula #2*/);
defalt:
weightCoefficient += 0.42;
}Кажется, после того, как этот код отработает, значение переменной 'weightCoefficient' будет 0.42. Но на самом деле значение 'weightCoefficient' останется равным нулю. Дело в том, что 'defalt' это метка, а не оператор 'default'. Исправленный вариант кода:
int c = getValue();
double weightCoefficient = 0;
switch(c){
case 1:
weightCoefficient += 3 * (/*math formula #1*/);
case 2:
weightCoefficient += 7 * (/*math formula #2*/);
default:
weightCoefficient += 0.42;
}Эта диагностика срабатывает также, когда имя метки начинается с 'case'. Есть вероятность, что пропущен пробел. Например, вместо метки 'case1:', должно быть написано 'case 1:'.
Данная диагностика классифицируется как:
|
V6078. Potential Java SE API compatibility issue.
- IntellJ IDEA
- Плагин для Gradle
- Плагин для Maven
- Использование ядра напрямую
- Пример срабатываний диагностики V6078
Данное диагностическое правило позволяет обнаружить Java SE API в вашем коде, которые будут удалены или помечены как устаревшие в более новых версиях Java SE.
Когда выходят новые версии Java SE, то они, как правило, обратно совместимы с более ранними версиями, то есть, например, приложение, разработанное на основе Java SE 8, должно без проблем запуститься на 11 версии Java. Однако, между различными версиями API Java SE могут быть небольшие несовместимости. Эти несовместимости заключаются в том, что некоторые API претерпевают изменения: удаляются методы и классы, меняется их поведение, методы помечаются как устаревшие, и так далее.
Если у вас в компании строго с предупреждениями компилятора, то часть проблем можно не откладывая решить - например, не использовать метод или класс, который помечен как устаревший. Это полезно делать, так как есть вероятность, что при использовании вновь вышедшей версии Javа ваше приложение поведет себя неожидаемым образом или вовсе упадет.
Также в комплекте JDK есть инструмент 'jdeps', который поможет вам обнаружить зависимость вашего приложения от внутренних API JDK. Но такой инструмент запускают, как правило, когда встает вопрос о миграции вашего приложения на более свежую версию Java. А этим вопросом хорошо бы озадачиться еще тогда, когда вы просто пишете код, и не завязываться на API, которое будет удалено в следующих выпусках Java SE.
Диагностика V6078 заранее предупредит вас о том, что ваш код зависим от некоторых функций и классов Java SE API, которые на следующих версиях Java могут доставить вам трудности. Например, вы столкнётесь с такими трудностями, когда обнаружится, что ваше приложение падает у вашего клиента на более свежей версии Java. С большой вероятностью вам рано или поздно в какой-то момент придётся очищать код от использования старых API - лучше делать это регулярно, а не накапливать технический долг на будущее.
Диагностическое правило выдает предупреждения в следующих случаях:
- Если метод/класс/пакет удалены в целевой версии Java;
- Если метод/класс/пакет помечены как устаревшие в целевой версии Java;
- Если у метода изменилась сигнатура.
Правило на данный момент позволяет проанализировать совместимость Oracle Java SE c 8-ой по 14-ую версии. Диагностика V6078 по умолчанию выключена., Чтобы она заработала, её необходимо активировать и настроить.
IntellJ IDEA
В IntelliJ IDEA плагине вам необходимо во вкладке Settings > PVS-Studio > API Compatibility Issue Detection включить правило и указать параметры, а именно:
- Source Java SE – версия Java, на которой разработано ваше приложение.
- Target Java SE – версия Java, на совместимость с которой вы хотите проверить API, используемое в вашем приложении (Source Java SE)
- Exclude packages – пакеты, которые вы хотите исключить из анализа совместимости (пакеты перечисляются через запятую)

Плагин для Gradle
Используя gradle плагин, вам необходимо сконфигурировать настройки анализатора в build.gardle:
apply plugin: com.pvsstudio.PvsStudioGradlePlugin
pvsstudio {
....
compatibility = true
sourceJava = /*version*/
targetJava = /*version*/
excludePackages = [/*pack1, pack2, ...*/]
}Плагин для Maven
Используя maven плагин, вам необходимо сконфигурировать настройки анализатора в pom.xml:
<build>
<plugins>
<plugin>
<groupId>com.pvsstudio</groupId>
<artifactId>pvsstudio-maven-plugin</artifactId>
....
<configuration>
<analyzer>
....
<compatibility>true</compatibility>
<sourceJava>/*version*/</sourceJava>
<targetJava>/*version*/</targetJava>
<excludePackages>/*pack1, pack2, ...*/</excludePackages>
</analyzer>
</configuration>
</plugin>
</plugins>
</build>Использование ядра напрямую
Если вы используете анализатор напрямую через командную строку, то, чтобы активировать анализ совместимости выбранных Java SE API, необходимо использовать следующие параметры:
java -jar pvs-studio.jar /*other options*/ --compatibility
--source-java /*version*/ --target-java /*version*/
--exclude-packages /*pack1 pack2 ... */Пример срабатываний диагностики V6078
Давайте предположим, что мы разрабатываем приложение на базе Java SE 8 и у нас есть класс со следующим содержимым:
/* imports */
import java.util.jar.Pack200;
public class SomeClass
{
/* code */
public static void someFunction(Pack200.Packer packer, ...)
{
/* code */
packer.addPropertyChangeListener(evt -> {/* code */});
/* code */
}
}Запустив статический анализ с различными параметрами настройки диагностического правила, мы будем наблюдать следующую картину:
- Source Java SE – 8, Target Java SE – 9
- The 'addPropertyChangeListener' method will be removed.
- Source Java SE – 8, Target Java SE – 11
- The 'addPropertyChangeListener' method will be removed.
- The 'Pack200' class will be marked as deprecated.
- Source Java SE – 8, Target Java SE – 14
- The 'Pack200' class will be removed.
Сначала в Java SE 9 был удален метод 'addPropertyChangeListener' в классе 'Pack200.Packer'. В 11 версии к этому добавился тот факт, что класс 'Pack200' пометили как устаревший. А в 14 версии и вовсе этот класс был удален.
Поэтому, запустив приложение на Java 11, вы получите 'java.lang.NoSuchMethodError', а если запустите на Java 14 – 'java.lang.NoClassDefFoundError'.
Зная эту информацию, при разработке своего приложения, вы заранее будете знать о потенциальных проблемах при использовании такого API, и сможете сразу рассмотреть возможность использовать альтернативное API для решения поставленной задачи.
V6079. Value of variable is checked after use. Potential logical error is present. Check lines: N1, N2.
Анализатор заметил в коде следующую ситуацию. В начале, значение переменной или выражения используется в качестве индекса массива / коллекции. А уже затем это значение сравнивается с 0 или с размером массива / коллекции. Это может указывать на наличие логической ошибки в коде или опечатку в одном из сравнений.
Рассмотрим пример
int idx = getPosition(buf);
buf[idx] = 42;
if (idx < 0) return -1;Если значение 'idx' окажется меньше нуля, то выражение 'buf[idx] ' приведёт к ошибке. Анализатор выдаст предупреждение на этот код, указав 2 строки. Первая строка - это то место, где переменная сравнивается с 0. Вторая строка - это то место, где до этой проверки использовалась переменная 'idx'.
Исправленный вариант кода:
int idx = getPosition(buf);
if (idx < 0) return -1;
buf[idx] = 42;Точно так же анализатор выдаёт предупреждение, если переменная сравнивается с размером массива:
int[] buf = getArrayValue(/*params*/);
buf[idx] = 42;
if (idx < buf.length) return;Правильный вариант кода:
int[] buf = getArrayValue(/*params*/);
if (idx < buf.length) return;
buf[idx] = 42;Также анализатор может увидеть проблему, если использование переменной в качестве индекса массива и её проверка находятся в одном выражении:
void f(int[] arr)
{
for (int i = 0; arr[i] < 10 && i < arr.length; i++)
{
System.out.println("arr[i] = " + arr[i]);
}
}В этом случае, если все элементы массива меньше 10, то на последней итерации цикла мы будем проверять значение, взятое за границей массива. А это ArrayIndexOutOfBoundsException!
Исправленный вариант:
void f(int[] arr)
{
for (int i = 0; i < arr.length && arr[i] < 10; i++)
{
System.out.println("arr[i] = " + arr[i]);
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки переполнения буфера (записи или чтения за пределами выделенной для буфера памяти). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6079. |
V6080. Consider checking for misprints. It's possible that an assigned variable should be checked in the next condition.
Анализатор обнаружил ситуацию, когда проверка переменной может быть пропущена в следующем 'if' после присваивания или инициализации.
К примеру, ошибочным можно считать такой код:
int ret = foo(....);
if (ret != -1) { .... }
....
int ret2 = bar(....);
if (ret != -1) { .... } // <=Часто бывают случаи, когда надо проверить возвращаемое значение какой-либо функции. Однако, можно допустить ошибку, указав другую переменную внутри условия 'if'. Чаще всего подобная ошибка возникает, когда фрагмент кода копируется, но в нём забывают заменить имя переменной в условии. В рассмотренном примере в условии забыли заменить имя 'ret' на 'ret2'.
Исправленный вариант:
int ret2 = bar(....);
if (ret2 != -1) { .... }Или же можно допустить ошибку в таком случае:
this.data = calculate(data, ....);
if (data != -1) ....;Переменная и поле имеют одинаковые имена, из-за чего их легко перепутать.
Диагностика является эвристической. Во время своей работы она сравнивает имена переменных и на основании этого делает предположения о наличии опечатки. Также производится базовая проверка типов для уменьшения количества ложных срабатываний.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6080. |
V6081. Annotation that does not have 'RUNTIME' retention policy will not be accessible through Reflection API.
Данное диагностическое правило позволяет обнаружить ошибочные ситуации, в которых при помощи Reflection API пытаются выявить наличие аннотаций, не имеющих политики удержания 'RUNTIME'.
Когда реализовывается аннотация, то ей необходимо прописать мета-аннотацию 'Retention', которая позволяет указать жизненный цикл аннотации:
- RetentionPolicy.SOURCE – аннотации будут присутствовать только в исходном коде.
- RetentionPolicy.CLASS - аннотации будут еще присутствовать в скомпилированном коде.
- RetentionPolicy.RUNTIME - аннотации также будут видны в процессе выполнения программы.
Если вы 'Retention' не упоминали, то будет значение по умолчанию: 'CLASS'.
Используя Reflection API для получения информации о присутствующих аннотациях, необходимо учесть то, что только аннотации с политикой удержания 'RUNTIME' будут доступны механизму рефлексии. Любая попытка получить информацию о аннотации с политикой удержания 'SOURCE' или 'CLASS' ничего вам не даст.
Рассмотрим синтетический пример. В проекте реализована следующая аннотация:
package my.package;
import java.lang.annotation.*;
@Target({ElementType.METHOD, ElementType.FIELD, ElementType.PARAMETER, ....})
public @interface MyAnnotation {
int field_id() default -1;
String field_name() default "";
....
}Разработчик, пытаясь определить наличие этой аннотации у определенного метода через Reflection API:
void runMethod(Method method, ....)
{
....
if (method.isAnnotationPresent(MyAnnotation.class))
{
....
}
....
}всегда будет получать false. Это происходит из-за того, что при определении аннотации не использовали мета-аннотацию 'Retention'. А как ранее было уже сказано, что в случае, если ее не указывают, значение применяется по умолчанию: 'CLASS'.
Чтобы до вашей аннотации можно было достучаться через Reflection API, вам нужно будет явно об этом позаботиться, указав 'RUNTIME':
package my.package;
import java.lang.annotation.*;
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.FIELD, ElementType.PARAMETER, ....})
public @interface MyAnnotation {
int field_id() default -1;
String field_name() default "";
....
}Помимо метода 'isAnnotationPresent', диагностическое правило проверяет: getAnnotation, getAnnotationsByType, getDeclaredAnnotation, getDeclaredAnnotationsByType.
V6082. Unsafe double-checked locking.
Анализатор обнаружил потенциальную ошибку, связанную с небезопасным использованием паттерна "блокировка с двойной проверкой" (double-checked locking).
Блокировка с двойной проверкой - это паттерн, предназначенный для уменьшения накладных расходов получения блокировки. Сначала проверяется условие блокировки без синхронизации. И только если условие выполняется, поток попытается получить блокировку. Таким образом, блокировка будет выполнена только в том случае, когда она действительно была необходима.
Основной ошибкой при реализации этого паттерна является публикация объекта перед его инициализацией:
class TestClass
{
private static volatile Singleton singleton;
public static Singleton getSingleton()
{
if (singleton == null)
{
synchronized (TestClass.class)
{
if (singleton == null)
{
singleton = new Singleton();
singleton.initialize(); // <=
}
}
}
return singleton;
}
}При многопоточном выполнении один из потоков может увидеть, что объект уже был создан и воспользоваться им, даже если инициализация этого объекта еще не произошла.
Похожая ошибка случится, когда в блоке синхронизации объект переприсваивается в зависимости от тех или иных условий. После первого присваивания какой-либо другой поток вполне может начать с ним работать, не подозревая, что далее в программе будет использоваться другой объект.
Исправление таких ошибок производится путем создания временной переменной:
class TestClass
{
private static volatile Singleton singleton;
public static Singleton getSingleton()
{
if (singleton == null)
{
synchronized (TestClass.class)
{
if (singleton == null)
{
Singleton temp = new Singleton();
temp.initialize();
singleton = temp;
}
}
}
return singleton;
}
}Другой распространённой ошибкой при реализации этого паттерна является пропуск модификатора 'volatile' в декларации поля, к которому производится доступ:
class TestClass
{
private static Singleton singleton;
public static Singleton getSingleton()
{
if (singleton == null)
{
synchronized (TestClass.class)
{
if (singleton == null)
{
Singleton temp = new Singleton();
temp.initialize();
singleton = temp;
}
}
}
return singleton;
}
}Объект класса 'Singleton' может быть создан несколько раз из-за того, что проверка 'singleton == null' увидит значение 'null', закешированное в потоке. Кроме того, компилятор может изменить порядок выполнения операций с не-volatile полями, из-за чего, например, вызов метода инициализации объекта и запись ссылки на этот объект в поле могут произойти в обратном порядке, что опять же приведет к использованию объекта, которому только предстоит пройти процедуру инициализации.
Одна из опасностей таких ошибок состоит в том, что в большинстве случаев программа работает корректно. В данном случае некорректное поведение программы может проявиться в зависимости от используемой JVM, уровня конкуретности, решений планировщика потоков и прочих факторов. Воспроизвести такие условия вручную крайне сложно.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6082. |
V6083. Serialization order of fields should be preserved during deserialization.
Данное диагностическое правило позволяет обнаружить несоответствие последовательностей сериализации и десериализации полей объекта.
При использовании интерфейса 'java.io.Serializable' весь контроль над сериализацией достается JVM. При всём удобстве этого подхода, часто оказывается, что он является недостаточно гибким или производительным.
Альтернативным способом сериализации, предоставляемым JVM, является использование интерфейса 'java.io.Externalizable' с переопределением методов 'writeExternal' и 'readExternal'. При этом очень легко перепутать порядок записи и чтения полей, что может привести к появлению трудноуловимой ошибки.
Рассмотрим пример:
public class ExternalizableTest implements Externalizable
{
public String name;
public String host;
public int port;
....
@Override
public void writeExternal(ObjectOutput out) throws IOException
{
out.writeInt(port); // <=
out.writeUTF(name);
out.writeUTF(host);
}
@Override
public void readExternal(ObjectInput in) throws IOException
{
this.name = in.readUTF(); // <=
this.host = in.readUTF();
this.port = in.readInt();
}
}В данном примере порядок сериализации полей объекта: port, name, host, type. Порядок десериализации: name, host, port, type. При сериализации первым полем идет целочисленное значение, а при десериализации – строка. Такое нарушение порядка десериализации приведет к исключению 'java.io.EOFException'. Можно сказать, что "повезло", так как эта ошибка проявит себя при первой же попытке десериализовать объект.
А что если чуть-чуть не "повезет"? Например, так:
public class ExternalizableTest implements Externalizable
{
public String name;
public String host;
public int port;
....
@Override
public void writeExternal(ObjectOutput out) throws IOException
{
out.writeInt(port);
out.writeUTF(name); // <=
out.writeUTF(host);
}
@Override
public void readExternal(ObjectInput in) throws IOException
{
this.port = in.readInt();
this.host = in.readUTF(); // <=
this.name = in.readUTF();
}
}Последовательность десериализации опять не соответствует последовательности сериализации: перепутаны местами строковые поля 'name' и 'host'. В этом случае падения никакого не будет и объект успешно восстановится, но значения этих полей будут перепутаны. Такое обнаружить уже будет не так легко.
Исправленный вариант:
public class ExternalizableTest implements Externalizable
{
public String name;
public String host;
public int port;
....
@Override
public void writeExternal(ObjectOutput out) throws IOException
{
out.writeInt(port);
out.writeUTF(name);
out.writeUTF(host);
}
@Override
public void readExternal(ObjectInput in) throws IOException
{
this.port = in.readInt();
this.name = in.readUTF();
this.host = in.readUTF();
}
}V6084. Suspicious return of an always empty collection.
Анализатор обнаружил выражение 'return', возвращающее всегда пустую коллекцию, которая была определена как локальная переменная.
Чаще всего это происходит из-за того, что в коллекцию забыли добавить элементы:
public List<Property> getProperties()
{
List<Property> properties = new ArrayList<>();
Property p1 = new Property();
p1.setName("property1");
p1.setValue(42);
return properties;
}Объект подходящего типа был создан, но разработчик пропустил вызов 'properties.add(p1)', из-за чего метод 'getProperties' возвращает некорректные данные. Исправленный фрагмент кода:
public List<Property> getProperties()
{
List<Property> properties = new ArrayList<>();
Property p1 = new Property();
p1.setName("property1");
p1.setValue(42);
properties.add(p1); // <=
return properties;
}В случае, когда необходимо вернуть пустую коллекцию, лучше сделать это явно:
public List<Property> getMutableProperties()
{
return new ArrayList<>();
}
public List<Property> getImmutableProperties()
{
return Collections.emptyList();
}V6085. An abnormality within similar comparisons. It is possible that a typo is present inside the expression.
Анализатор обнаружил подозрительное условие, которое может содержать copy-paste ошибку.
Диагностика носит эмпирический характер, поэтому проще показать на примере, как она работает, чем объяснить сам принцип работы анализатора. Рассмотрим пример:
if (m_a != a ||
m_b != b ||
m_b != c) // <=
{
....
}Из-за того, что имена переменных очень похожи, в коде допущена опечатка. Ошибка находится в третьей строке. Переменную 'c' следовало сравнить с 'm_c', а не с 'm_b'. Даже читая этот текст сложно заметить ошибку. Обратите внимание на окончания в названии переменных.
Правильный вариант:
if (m_a != a ||
m_b != b ||
m_c != c)
{
....
}Если анализатор выдал предупреждение V6085, то внимательно изучите соответствующий фрагмент кода. Иногда опечатку бывает сложно заметить.
Данная диагностика классифицируется как:
V6086. Suspicious code formatting. 'else' keyword is probably missing.
Анализатор обнаружил фрагмент кода, в котором оператор 'if' расположен на той же строке, что и закрывающая скобка предыдущего оператора 'if'. Возможно, что в этом месте пропущено ключевое слово 'else', из-за чего программа работает не так, как ожидал программист.
Рассмотрим пример подобного кода:
public void fillTrialMessage(User user, Response response)
{
if (user.getTrialTime() > 7) {
// Do not set message
} if (user.getTrialTime() > 0) { // <=
response.setTrialMessage("Trial ends soon");
} else {
response.setTrialMessage("Trial has ended");
}
}Здесь разработчик подразумевал, что сообщение в ответе заполнится только в случае, когда триальный период у пользователя подходит к концу или уже закончился. Однако, из-за пропущенного слова 'else', пользователь будет оповещён даже если до конца этого периода ещё несколько месяцев. После исправления фрагмент кода будет выглядеть следующим образом:
public void fillTrialMessage(User user, Response response)
{
if (user.getTrialTime() > 7) {
// Do not set message
} else if (user.getTrialTime() > 0) {
response.setTrialMessage("Trial ends soon");
} else {
response.setTrialMessage("Trial has ended");
}
}Если же использование конструкции else-if не подразумевалось, следует исправить форматирование и перенести второй 'if' на следующую строку:
public void doSomething()
{
if (condition1) {
foo();
}
if (condition2) {
bar();
} else {
baz();
}
}Такой код будет более привычен для большинства программистов и не вызовет подозрений. Кроме того, анализатор перестанет выдавать лишнее предупреждение.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6086. |
V6087. InvalidClassException may occur during deserialization.
Анализатор обнаружил ситуацию, когда отсутствие доступного конструктора по умолчанию при десериализации может привести к 'java.io.InvalidClassException'.
При использовании интерфейса 'java.io.Serializable' весь контроль над сериализацией достается JVM. Для выполнения десериализации под объект выделяется память, после чего его поля заполняются значениями из потока байтов без вызова конструктора. Стоит учесть, что если у сериализуемого класса имеется несериализуемый родитель, то механизм десериализации будет запускать его конструктор по умолчанию. В случае его отсутствия возникнет исключение 'java.io.InvalidClassException'.
Рассмотрим синтетический пример:
class Parent {
private String parentField;
public Parent(String field) {
this.parentField = field;
}
// ....
}
class Child extends Parent implements Serializable {
public String childField;
public Child() {
super("");
}
public Child(String field1, String field2) {
super(field1);
this.childField = field2;
}
// ....
}Так как родительский класс не является сериализуемым, то при десериализации объекта класса 'Child' встроенный механизм десериализации попытается вызвать конструктор по умолчанию и выбросит исключение при его отсутствии.
Чтобы все корректно проинициализировалось, достаточно в родительском классе определить доступный конструктор по умолчанию:
class Parent {
private String parentField;
public Parent() {
this.parentField = "";
}
public Parent(String field) {
this.parentField = field;
}
// ....
}При реализации интерфейса 'java.io.Externalizable' вызывается пользовательская логика: способ сериализации и десериализации описывается в методах 'writeExternal' и 'readExternal'. Во время десериализации всегда вызывается публичный конструктор по умолчанию, а потом уже на созданном объекте вызывается метод 'readExternal'. Если такого конструктора не будет, то возникнет 'java.io.InvalidClassException'.
class Parent implements Externalizable
{
private String field;
public Parent(String field) {
this.field = field;
}
public void writeExternal(ObjectOutput arg0) throws .... {
// serializable logic
}
public void readExternal(ObjectInput in) throws .... {
// deserializable logic
}
// ....
}Подходящий конструктор в данном классе отсутствует. Если сериализовать объект этого класса, то никаких проблем не возникнет. А вот если сериализованный ранее объект захотят восстановить, то возникнет исключение.
Для исправления ситуации достаточно прописать доступный конструктор без параметров:
class Parent implements Externalizable
{
private String field;
public Parent() {
this.field = "";
}
public Parent(String field) {
this.field = field;
}
// ....
}V6088. Result of this expression will be implicitly cast to 'Type'. Check if program logic handles it correctly.
Данное правило находит тернарные операторы, в которых происходит неявное приведение численных типов. Это может нарушить логику работы программы из-за неожиданной смены типа объекта.
Рассмотрим пример подобной ошибки:
public void writeObject(Serializer serializer, Object o)
{
....
else if (o instanceof Integer)
{
serializer.writeInt((Integer) o);
}
else if (o instanceof Double)
{
serializer.writeDouble((Double) o);
}
....
}
public void serialize(Serializer serializer)
{
Object data = condition ? 5 : 0.5; // <=
writeObject(serializer, data);
}В данном случае фактическим аргументом метода 'writeObject' всегда будет являться число типа 'double': 5.0 или 0.5. Из-за этого внутри 'writeObject' будет выполнена не та ветка конструкции if-else-if, которая подразумевалась программистом. Исправление этой ошибки заключается в замене тернарного оператора на блок if-else:
public void serialize(Serializer serializer)
{
if (condition)
{
writeObject(serializer, 5);
}
else
{
writeObject(serializer, 0.5);
}
// or
Object data;
if (condition)
{
data = 5;
}
else
{
data = 0.5;
}
writeObject(serializer, data);
}Особенность этой ошибки состоит в том, что взаимозаменяемые условный и тернарный операторы в реальности могут иметь различное поведение.
V6089. It's possible that the line was commented out improperly, thus altering the program's operation logics.
Анализатор обнаружил потенциально возможную ошибку, связанную с тем, что неаккуратно закомментированный фрагмент кода приводит к изменению логики выполнения программы.
Диагностическое правило ищет комментарии, похожие на код, между оператором 'if (...)' и его 'then'-ветвью, причем 'then'-ветвь отформатирована подозрительным образом. В этом случае можно предположить, что текущая 'then'-ветвь стала результатом неудачного рефакторинга.
Рассмотрим пример:
if (hwndTaskEdit == null)
// hwndTaskEdit = getTask(...);
if (hwndTaskEdit != null)
{
...
}Программа потеряла смысл: условие второго оператора 'if' никогда не выполняется.
Корректный вариант кода:
// if (hwndTaskEdit == null)
// hwndTaskEdit = getTask(...);
if (hwndTaskEdit != null)
{
...
}Анализатор не будет выдавать предупреждение, если форматирование кода будет соответствовать логике программы.
Пример кода:
if (isReady)
// some comment
if (isSmt)
{
...
}Данная диагностика классифицируется как:
|
V6090. Field 'A' is being used before it was initialized.
Анализатор обнаружил в конструкторе класса обращение к полю, которое ещё не было инициализировано.
Все поля в Java неявно инициализируются значениями по умолчанию соответствующих типов. Для ссылочных типов этим значением является 'null'.
Рассмотрим пример подобной ошибки:
public class Test
{
private Object data;
private DataProvider dataProvider;
public Test(DataProvider provider)
{
this.data = dataProvider.get();
this.dataProvider = dataProvider;
}
}Здесь производится обращение к полю класса, а не параметру конструктора, из-за чего возникает 'NullPointerException' при каждом вызове этого конструктора. Исправленный вариант:
public class Test
{
private Object data;
private DataProvider dataProvider;
public Test(DataProvider provider)
{
this.data = provider.get();
this.dataProvider = provider;
}
}Другой ошибкой, связанной с использованием неинициализированных ссылочных полей, является их сравнение с 'null'. В этом случае условия являются всегда истинными или всегда ложными, что показывает ошибку в построении логики программы.
public class Test
{
private DataProvider dataProvider;
public Test()
{
if (dataProvider != null)
{
dataProvider = new DataProvider();
}
}
}Анализатор не будет выдавать данное предупреждение, если поле было явно проинициализировано. В том числе, и значением 'null'.
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6090. |
V6091. Suspicious getter/setter implementation. The 'A' field should probably be returned/assigned instead.
Анализатор обнаружил геттер/сеттер, который обращается к полю, отличному от указанного в названии.
Такие ошибки обычно появляются вследствие невнимательности, неаккуратного использования автодополнения или copy-paste.
Рассмотрим пример, на котором анализатор выдаст предупреждение:
public class Vector2i
{
private int x;
private int y;
public void setX(int x)
{
this.x = x;
}
public int getX()
{
return x;
}
public void setY(int y)
{
this.y = y;
}
public int getY()
{
return x; // <=
}
}Корректный вариант кода:
public class Vector2i
{
private int x;
private int y;
public void setX(int x)
{
this.x = x;
}
public int getX()
{
return x;
}
public void setY(int y)
{
this.y = y;
}
public int getY()
{
return y;
}
}Для реализации таких методов лучше использовать возможности IDE или кодогенерацию, предоставляемую библиотекой Lombok.
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6091. |
V6092. A resource is returned from try-with-resources statement. It will be closed before the method exits.
Анализатор обнаружил возвращение из метода 'AutoCloseable' объекта, который используется в выражении try-with-resources.
Выражение try-with-resources автоматически закрывает все ресурсы при выходе из него, то есть возвращённый ресурс всегда будет уже закрытым. В подавляющем большинстве случаев закрытые ресурсы не имеют применения, а вызов их методов почти всегда приведёт к возникновению 'IOException'.
public InputStream getStreamWithoutHeader() throws IOException
{
try (InputStream stream = getStream())
{
stream.skip(HEADER_LENGTH);
return stream;
}
}В данном случае 'stream' будет закрыт перед передачей управления вызывающему методу и произвести какие-либо действия с этим потоком будет невозможно.
Вариант исправления:
public InputStream getStreamWithoutHeader() throws IOException
{
InputStream stream = getStream();
stream.skip(HEADER_LENGTH);
return stream;
}V6093. Automatic unboxing of a variable may cause NullPointerException.
Анализатор обнаружил фрагмент кода, в котором может произойти автоматическая распаковка null-значения, что приведёт к возникновению 'NullPointerException'.
Данную ошибку достаточно часто можно встретить внутри операторов сравнения. Например, 'Boolean' можно использовать как флаг с тремя значениями: ложным, истинным и неустановленным. Тогда при проверке того, что какой-либо флаг явно выставлен в нужное значение, можно написать:
public void doSomething()
{
Boolean debugEnabled = isDebugEnabled();
if (debugEnabled == true)
{
...
}
}Однако, при сравнении примитива с упакованным значением всегда происходит автоматическая распаковка, что и вызывает 'NullPointerException'. Исправить данный фрагмент можно несколькими способами:
public void doSomething()
{
Boolean debugEnabled = isDebugEnabled();
if (debugEnabled != null && debugEnabled == true)
{
...
}
// or
if (Objects.equals(debugEnabled, true))
{
...
}
}В отличие от большинства операторов, тернарный оператор позволяет смешивать в выражении примитивы и обёртки, производя автоматическую упаковку при приведении к общему типу. Это позволяет достаточно легко сделать опечатку:
boolean x = httpRequest.getAttribute("DEBUG_ENABLED") != null
? (boolean) httpRequest.getAttribute("DEBUG_ENABLED")
: null;Здесь выражение тернарного оператора имеет тип 'Boolean' как общий для его операндов, после чего распаковывается обратно в примитив при присвоении в переменную 'x'. После исправления:
boolean x = httpRequest.getAttribute("DEBUG_ENABLED") != null
? (boolean) httpRequest.getAttribute("DEBUG_ENABLED")
: false;Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки разыменования нулевого указателя. |
Данная диагностика классифицируется как:
|
V6094. The expression was implicitly cast from integer type to real type. Consider utilizing an explicit type cast to avoid the loss of a fractional part.
В выражении присутствует операция деления целочисленных типов данных. Полученное значение неявно преобразуется к типу с плавающей точкой. Обнаружив такую ситуацию, анализатор предупреждает о наличии потенциальной ошибки, которая может привести к вычислению неточного результата.
Рассмотрим пример:
int totalTime = 1700;
int operationNum = 900;
double averageTime = totalTime / operationNum;Программист может ожидать, что переменная 'averageTime' будет иметь значение '1.888(8)', однако при выполнении программы будет получен результат равный '1.0'. Это происходит потому, что операция деления выполняется с целочисленными типами и только затем приводится к типу с плавающей точкой.
Как и в предыдущем случае, ошибку можно исправить 2 способами.
Первый способ - изменить типы переменных:
double totalTime = 1700;
double operationNum = 900;
double averageTime = totalTime / operationNum;Второй способ - использовать явное приведение типов.
int totalTime = 1700;
int operationNum = 900;
double averageTime = (double)(totalTime) / operationNum;Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6094. |
V6095. Thread.sleep() inside synchronized block/method may cause decreased performance.
Анализатор обнаружил фрагмент кода, в котором внутри синхронизированной функции или блока синхронизации выполнен вызов 'Thread.sleep(....)'.
При вызове 'Thread.sleep(....)' текущий поток засыпает, продолжая удерживать захваченный монитор объекта. Это приводит к тому, что другие потоки, пытающиеся выполнить синхронизацию на этом объекте, будут простаивать в ожидании пробуждения потока. Это может привести к понижению производительности, а в некоторых случаях даже к взаимной блокировке потоков.
Рассмотрим пример подобного кода:
private final Object lock = new Object();
public void doSomething() {
synchronized(lock) {
....
Thread.sleep(1000);
....
}
}Вместо 'Thread.sleep()' лучше использовать метод 'lock.wait(....)', который переведет текущий поток в ожидание на указанное время с освобождением монитора, что позволит другим потокам не простаивать. Однако необходимо учитывать, что поток в этом случае может быть ''разбужен'' ранее указанного времени. Поэтому обычно следует проверять какое-либо условие, подтверждающее, что пробуждение потока произошло не ранее, чем планировалось разработчиком:
private final Object lock = new Object();
public void doSomething() {
synchronized(lock) {
....
while(!ready()) {
lock.wait(1000)
}
....
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
V6096. An odd precise comparison. Consider using a comparison with defined precision: Math.abs(A - B) < Epsilon or Math.abs(A - B) > Epsilon.
Анализатор обнаружил подозрительный фрагмент кода, где для сравнения чисел с плавающей точкой используется оператор '==' или '!='. Такие участки кода могут служить источником ошибок.
Рассмотрим для начала корректный пример кода:
double a = 0.5;
if (a == 0.5) //ok
++x;В данном случае сравнение можно считать верным. Перед сравнением переменная 'a' явно инициализируется значением '0.5'. С этим же значением производится сравнение. Результатом выражения будет 'истина'.
Итак, в некоторых случаях точные сравнения допустимы. Но часто так сравнивать нельзя. Рассмотрим пример ошибочного кода:
double b = Math.sin(Math.PI / 6.0);
if (b == 0.5) //err
++x;Условие 'b == 0.5' при проверке оказалось ложным из-за того, что значение выражения 'Math.sin(Math.PI / 6.0)' равно 0.49999999999999994. Это число очень близко к '0.5', но ему не равно.
Одним из вариантов решения является сравнение разности значений с каким-то значением (погрешностью, в данном случае - переменная 'epsilon'):
double b = Math.sin(Math.PI / 6.0);
if (Math.abs(b - 0.5) < epsilon) //ok
++x;Необходимо выбирать адекватную погрешность в зависимости от того, какие величины сравниваются.
Анализатор указывает на участки кода, где в сравнении чисел с плавающей точкой используются операторы '!=' или '=='. Является это сравнение ошибочным или нет, может решить только программист.
Дополнительные ресурсы:
Данная диагностика классифицируется как:
V6097. Lowercase 'L' at the end of a long literal can be mistaken for '1'.
Анализатор обнаружил фрагмент кода, в котором литерал типа 'long' объявлен с маленькой буквой 'l' в конце.
Рассмотрим пример:
long value = 1111l;В данном случае маленькую букву 'l' легко спутать с цифрой '1'. Все зависит от текущего шрифта, так как в некоторых случаях разница между данными символами вовсе незаметна, что повышает вероятность ошибочного восприятия значения литерала. Чтобы не произошла путаница, рекомендуется объявлять 'long' литералы с большой буквой 'L' на конце:
long value = 1111L;Диагностическое правило выдает предупреждение далеко не во всех случаях. Оно имеет ряд исключений, например, если:
- в одном выражении литерал с 'l' встречается более 2 раз;
- это литерал в объявлении поля serialVersionUID;
- и так далее.
Данная диагностика классифицируется как:
|
V6098. The method does not override another method from the base class.
Анализатор обнаружил, что метод не переопределяет метод базового класса или интерфейса, однако сигнатуры этих методов очень похожи.
Рассмотрим синтетический пример:
public class Base
{
public String someThing()
{
return "Base";
}
}
public class Derived extends Base
{
public String something() // <=
{
return "Derived";
}
}В приведенном примере, при переопределении метода 'someThing' в классе 'Derived' была допущена опечатка в названии метода. Из-за этой опечатки переопределения метода не произойдет. Эффект от этой ошибки проявится при использовании полиморфизма:
...
List<Base> list = new ArrayList<>();
list.add(new Base());
list.add(new Derived());
StringBuilder builder = new StringBuilder();
for (Base base : list)
{
builder.append(base.someThing());
}
String result = builder.toString();
...Из-за ошибки переопределения метода в переменной 'result' будет сохранена строка 'BaseBase', а не 'BaseDerived' как ожидалось.
Для защиты от ошибок переопределения метода в Java используется аннотация '@Override'. Если метод помечен этой аннотацией и не переопределяет никакой метод, то компилятор сообщит об ошибке и программа не скомпилируется.
Исправленный вариант кода:
public class Base
{
public String someThing()
{
return "Base";
}
}
public class Derived extends Base
{
@Override
public String someThing() //ok
{
return "Derived";
}
}Вот еще несколько примеров, когда произойдет срабатывание анализатора.
import first.A;
public class Base
{
public void someThing(A input)
{
...
}
}
import second.A;
public class Derived extends Base
{
public void someThing(A input) // <=
{
...
}
}Имена типов аргументов 'input' в объявлении методов одинаковые. Однако данные типы расположены в разных пакетах 'first' и 'second', из-за чего произойдет перегрузка метода вместо переопределения.
package first;
public class Base
{
void someThing()
{
...
}
}
package second;
import first.Base;
public class Derived extends Base
{
void someThing() // <=
{
...
}
}В этом примере классы 'Base' и 'Derived' расположены в разных пакетах, 'first' и 'second' соответственно. Метод 'someThing' в классе 'Base' объявлен без каких-либо модификаторов, поэтому имеет уровень доступа по умолчанию (package-private), из-за чего его не видно в классе 'Derived', который находится в другом пакете. Именно поэтому переопределения метода не произойдет, о чем и предупредит анализатор.
V6099. The initial value of the index in the nested loop equals 'i'. Consider using 'i + 1' instead.
Анализатор выявил цикл, который может содержать ошибку или быть неоптимальным. Используется типичный паттерн кода, когда для всех пар элементов массива выполняется некая операция. При этом, как правило, нет смысла выполнять операцию для пары, состоящей из одного и того-же элемента при 'i == j'.
Пример:
for (int i = 0; i < size; i++)
for (int j = i; j < size; j++)
....Есть большая вероятность, что правильнее или эффективнее использовать следующий код для обхода массивов:
for (int i = 0; i < size; i++)
for (int j = i + 1; j < size; j++)
....Данная диагностика классифицируется как:
V6100. An object is used as an argument to its own method. Consider checking the first actual argument of the 'Foo' method.
Анализатор обнаружил вызов метода, в который в качестве аргумента передаётся сам объект, у которого вызывается метод. Вероятно, данный код содержит ошибку, и в метод должен передаваться другой объект.
Рассмотрим пример:
a.foo(a);Здесь из-за опечатки используется неверное имя переменной. Тогда корректный код должен был быть таким:
a.foo(b);или таким:
b.foo(a);Пример кода из реального приложения:
public class ByteBufferBodyConsumer {
private ByteBuffer byteBuffer;
....
public void consume(ByteBuffer byteBuffer) {
byteBuffer.put(byteBuffer);
}
}Здесь в 'byteBuffer' пытаются вставить его собственные значения.
Корректный код должен выглядеть так:
public class ByteBufferBodyConsumer {
private ByteBuffer byteBuffer;
....
public void consume(ByteBuffer byteBuffer) {
this.byteBuffer.put(byteBuffer);
}
}Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6100. |
V6101. compareTo()-like methods can return not only the values -1, 0 and 1, but any values.
Анализатор обнаружил в коде сравнение результата метода 'Comparable.compareTo' или ему подобному с конкретным ненулевым значением (в частности, с 1 и -1). В свою очередь, в спецификации языка Java контракт этого метода подразумевает, что может вернуться любое положительное число или любое отрицательное.
Работоспособность конструкции 'compareTo == 1' зависит от реализации этого метода. Поэтому сравнивать результат с конкретным числом считается плохой практикой, которая в некоторых случаях может привести к трудноуловимым ошибкам. В таких случаях корректно писать 'compareTo > 0'.
В качестве примера можно привести следующий некорректный код:
void smt(SomeType st1, SomeType st2, ....)
{
....
if (st1.compareTo(st2) == 1)
{
// some logic
}
....
}Разработчик долгое время мог работать над другим проектом, где, в силу специфики реализации интерфейса 'Comparable', сравнивать результат 'compareTo' с 1 было корректно. Перейдя на следующий проект, он продолжил так сравнивать, но специфика реализации метода уже отличалась - в зависимости от тех или иных условий возвращались разные положительные числа.
Исправленный вариант кода:
void smt(SomeType st1, SomeType st2, ....)
{
....
if (st1.compareTo(st2) > 0)
{
// some logic
}
....
}Анализатор также считает код ошибочным, если в нём сравнивается результат работы двух 'compareTo' методов. Подобный код встречается крайне редко, однако на него в любом случае стоит обратить внимание.
Данная диагностика классифицируется как:
|
V6102. Inconsistent synchronization of a field. Consider synchronizing the field on all usages.
Анализатор обнаружил поле, к которому производится обращение без синхронизации, хотя большая часть обращений к данному полю производилась в синхронизированном контексте.
Неполная синхронизация является основной причиной возникновения состояния гонки, когда общее состояние изменяется несколькими потоками одновременно, и результат работы программы зависит от того, в каком порядке будет выполняться код в потоках. Это приводит к совершенно различным ошибкам, которые проявляются в непредсказуемые моменты времени, а попытка повторения ошибки в целях отладки со схожими условиями работы может оказаться безуспешной.
Иначе говоря, поля должны либо синхронизироваться во всех случаях использования, либо не синхронизироваться вообще, чтобы не запутать разработчиков, которые будут поддерживать этот код. Поэтому, если анализатор выдает вам предупреждение V6102, рекомендуется удостовериться, что все обращения к полю полностью синхронизированы.
Простой пример из реального проекта, где доступ к полю 'acked' синхронизирован во всех случаях, кроме одного:
public class FixedTupleSpout implements IRichSpout
{
private static final Map<String, Integer> acked = new HashMap<>();
....
public static int getNumAcked(String stormId)
{
synchronized (acked)
{
return get(acked, stormId, 0);
}
}
public static void clear(String stormId)
{
acked.remove(stormId); // <=
....
}
public int getCompleted()
{
synchronized (acked)
{
ackedAmt = acked.get(_id);
}
....
}
public void cleanup()
{
synchronized (acked)
{
acked.remove(_id);
}
....
}
}Из-за того, что доступ к 'acked' в методе 'clear' несинхронизирован, есть вероятность одновременного доступа к полю из разных потоков. Так как 'acked' непотокобезопасная коллекция HashMap, то велика вероятность испортить внутреннее состояние объекта. Чтобы исправить это, выражение 'acked.remove(stormId)' нужно заключить в блок 'synchronized':
public class FixedTupleSpout implements IRichSpout
{
private static final Map<String, Integer> acked = new HashMap<>();
....
public static int getNumAcked(String stormId)
{
synchronized (acked)
{
return get(acked, stormId, 0);
}
}
public static void clear(String stormId)
{
synchronized (acked))
{
acked.remove(stormId);
}
....
}
public int getCompleted()
{
synchronized (acked)
{
ackedAmt = acked.get(_id);
}
....
}
public void cleanup()
{
synchronized (acked)
{
acked.remove(_id);
}
....
}
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6102. |
V6103. Ignored InterruptedException could lead to delayed thread shutdown.
Анализатор обнаружил, что исключение 'InterruptedException' в блоке 'catch' было проигнорировано. В этом случае теряется информация о прерывании потока, что может подвергнуть риску способность приложения отменять функции или своевременно прекратить работу.
Каждый поток имеет статус прерывания – скрытое булево поле, которое хранит информацию о том, был поток прерван или нет. Для установки этого статуса нужно вызвать метод 'Thread.interrupt()'. По соглашению, любой метод (например, 'Object.wait()', 'Thread.sleep()' и так далее), который может выбросить 'InterruptedException', очищает статус прерывания, когда это происходит. Поэтому, если не обработать исключение должным образом, факт прерывания теряется, что не позволит вызывающей части программы среагировать на отмену выполнения. Однако возможны случаи, когда статус прерывания не будет сбрасываться при выбрасывании 'InterruptedException' (например, пользовательская реализация прерывания, методы сторонних библиотек), но рассчитывать на это не рекомендуется.
Чтобы информация о прерывании потока гарантированно не была потеряна, при поимке 'InterruptedException' следует либо вновь установить флаг прерывания с помощью 'Thread.interrupt()', либо пробросить пойманное исключение дальше без оборачивания его в какое-либо другое. В случае, когда обработка прерывания бессмысленна, данное исключение ловить не следует.
Рассмотрим ошибочный пример кода из реального приложения:
public void disconnect()
{
....
try
{
sendThread.join();
}
catch (InterruptedException ex)
{
LOG.warn("....", ex);
}
....
}Корректный код должен выглядеть так:
public void disconnect()
{
....
try
{
sendThread.join();
}
catch (InterruptedException ex)
{
Thread.currentThread().interrupt();
LOG.warn("....", ex);
}
....
}Данная диагностика классифицируется как:
V6104. A pattern was detected: A || (A && ...). The expression is excessive or contains a logical error.
Анализатор обнаружил выражение, которое можно упростить. Иногда за такой избыточностью кроются логические ошибки.
Рассмотрим пример подозрительного кода:
boolean firstCond, secondCond, thirdCond;
....
if (firstCond || (firstCond && thirdCond))
....Это выражение является избыточным. В случае, если 'firstCond == true', значение этого условия будет всегда истинным, независимо от значения 'thirdCond', если же 'firstCond == false', то значение выражения будет всегда ложно, опять же, независимо от значения переменной 'thirdCond'. Таким образом, выражение 'firstCond || (firstCond && thirdCond)' можно упростить:
if (firstCond)Возможно, что программист ошибся и написал не ту переменную во втором подвыражении. Тогда корректный код мог бы выглядеть так:
if (firstCond || (secondCond && thirdCond))V6105. Consider inspecting the loop expression. It is possible that different variables are used inside initializer and iterator.
Анализатор обнаружил, что в разделе итератора (iterator section) оператора 'for' производится инкремент или декремент переменной, не являющейся счетчиком.
Рассмотрим пример. Допустим, у нас имеется выражение следующего вида:
for (int i = 0; i != N; ++N)Вероятно, данный фрагмент кода содержит ошибку, и вместо переменной 'N' в выражении инкремента '++N' необходимо использовать переменную 'i'. Корректный вариант кода должен выглядеть так:
for (int i = 0; i != N; ++i)Рассмотрим следующий пример:
for (int i = N; i >= 0; --N)Данный фрагмент кода также ошибочен. В выражении декремента '‑‑N' должна быть использована переменная 'i':
for (int i = N; i >= 0; --i)Данная диагностика классифицируется как:
V6106. Casting expression to 'X' type before implicitly casting it to other type may be excessive or incorrect.
Анализатор обнаружил, что после явного приведения переменной к одному числовому типу данных осуществляется дальнейшее неявное приведение к другому числовому типу данных. Обычно это говорит о том, что явное приведение либо сделано ошибочно, либо является излишним.
В Java существует несколько видов преобразований над числовыми типами:
- Расширяющие (неявные) преобразования, когда меньший тип данных присваивается большему типу, например: byte -> short -> int -> long -> float -> double. Такие преобразования безопасны, так как не приводят к потере величины преобразуемого числового значения. Поэтому компилятор осуществляет такие преобразования сам, незаметно для разработчика.
- Сужающие (явные) преобразования, когда больший тип данных необходимо присвоить меньшему типу данных. В таких случаях есть риск потерять данные, поэтому явное приведение типов всегда производится вручную, под ответственность программиста.
Когда в одном контексте встречается последовательность явных и неявных преобразований, то это повод присмотреться к коду повнимательней.
Рассмотрим пример подозрительного приведения типов, встретившийся в одном из реальных проектов:
public void method(...., Object keyPattern, ....)
{
....
if (keyPattern instanceof Integer)
{
int intValue = (Integer) keyPattern;
....
}
else if (keyPattern instanceof Short)
{
int shortValue = (Short) keyPattern;
....
}
....
}После проверки 'keyPattern instanceof Short' переменную 'keyPattern' явно приводят к типу 'Short'. Но при присвоении значения переменой 'shortValue' происходит неявное приведение ранее сделанного каста к типу 'int', так как переменная 'shortValue' имеет тип 'int'. Компилятор Java не выдает здесь предупреждений, так как оба преобразования являются допустимыми, но программист, скорее всего, хотел указать для переменной 'shortValue' тип 'short'.
Исправленный вариант кода должен выглядеть так:
public void method(...., Object keyPattern, ....)
{
....
if (keyPattern instanceof Integer)
{
int intValue = (Integer) keyPattern;
....
}
else if (keyPattern instanceof Short)
{
short shortValue = (Short) keyPattern;
....
}
....
}Данная диагностика классифицируется как:
V6107. The constant NN is being utilized. The resulting value could be inaccurate. Consider using the KK constant.
Анализатор обнаружил, что для математических расчётов используются константы недостаточной точности.
Рассмотрим пример:
double pi = 3.141592654;Такая запись не совсем корректна и лучше использовать математические константы из статического класса Math. Корректный вариант кода:
double pi = Math.PI;Анализатор не считает ошибочной явную запись констант в формате 'float'. Это связано с тем, что тип 'float' имеет меньше значащих разрядов по сравнению с типом 'double'. Поэтому на следующий код предупреждение выдано не будет:
float f = 3.14159f; //okДанная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6107. |
V6108. Do not use real-type variables in 'for' loop counters.
Анализатор обнаружил переменную вещественного типа в качестве счётчика цикла 'for'. Поскольку числа с плавающей точкой не могут точно отобразить все действительные числа, использование таких переменных в цикле может привести к неожиданным результатам, таким как лишние итерации.
Рассмотрим подробнее:
for (double i = 0.0; i < 1.0; i += 0.1) {
....
}Количество итераций в этом цикле будет равно 11 вместо ожидаемых 10. При выполнении кода без модификатора 'strictfp' в версиях Java ниже 17-ой результат операций с плавающей точкой может также зависеть от платформы. Чтобы избежать возможных проблем, следует использовать целочисленный тип для счётчика, а вычисления производить внутри:
for (var i = 0; i < 10; i++) {
double counter = i / 10.0;
....
}Дополнительной причиной не использовать действительный тип может быть опасность бесконечного цикла. В качестве примера — следующий фрагмент:
for (float i = 100000000.0f; i <= 100000009.0f; i += 0.5f) {
....
}Он возникает из-за слишком маленького инкремента относительно количества значащих цифр. Для предотвращения такой ситуации лучше также использовать целочисленный тип счётчика, а во избежание потери точности использовать 'double' для хранения значения:
for (var i = 0; i < 19; i++) {
double value = 100000000.0d + i / 2d;
....
}Данная диагностика классифицируется как:
|
V6109. Potentially predictable seed is used in pseudo-random number generator.
Данное диагностическое правило выявляет случаи использования псевдорандомного генератора случайных чисел, которые могут привести к недостаточно случайному распределению или предсказуемости генерируемого числа.
Случай 1.
Создание нового объекта типа 'Random' каждый раз, когда требуется случайное значение. Это неэффективно и может привести к получению чисел, которые не являются достаточно случайными, в зависимости от JDK.
Рассмотрим пример:
public void test() {
Random rnd = new Random();
}Для большей эффективности и случайности распределения создайте один экземпляр класса 'Random', сохраните его и используйте повторно.
static Random rnd = new Random();
public void test() {
int i = rnd.nextInt();
}Случай 2.
Анализатор обнаружил подозрительный код, инициализирующий генератор псевдослучайных чисел константным значением.
public void test() {
Random rnd = new Random(4040);
}Числа, сгенерированные таким генератором, можно предугадать — они будут воспроизводиться снова и снова при каждом запуске программы. Чтобы этого избежать, не стоит использовать константное число. К примеру, можно воспользоваться текущим системным временем:
static Random rnd = new Random(System.currentTimeMillis());
public void test() {
int i = rnd.nextInt();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки некорректного использования системных процедур и интерфейсов, связанных с обеспечением информационной безопасности (шифрования, разграничения доступа и пр.). |
Данная диагностика классифицируется как:
V6110. Using an environment variable could be unsafe or unreliable. Consider using trusted system property instead
Данное диагностическое правило позволяет обнаружить использование переменных среды, которые можно заменить системным свойством.
Согласно документации, проблема может заключаться в том, что:
- Злоумышленник может контролировать все переменные среды, которые входят в программу.
- На разных ОС они могут иметь слегка разную семантику, или может отличаться чувствительность к регистру.
По этим причинам с большей вероятностью есть возможность получить непредвиденные побочные эффекты. Следовательно, если переменная среды содержит информацию, доступную другими способами, эту переменную использовать не следует.
Например, если операционная система предоставляет имя пользователя, оно всегда будет доступно в системном свойстве 'user.name'.
Плохая практика:
String user = System.getenv("USER");Исправление:
String user = System.getProperty("java.name");Помимо прямых вызовов метода 'System.getenv()', диагностика отслеживает методы по их сигнатурам, которые могут свидетельствовать о возвращении значений переменных среды.
Данная диагностика классифицируется как:
|
V6111. Potentially negative value is used as the size of an array.
Анализатор обнаружил, что при создании массива в качестве значения для задания его длины может использоваться переменная или выражение, имеющие отрицательное значение.
Рассмотрим пример:
void process(boolean isNotCsv) {
String str = "column1,column2";
if (isNotCsv) {
str = "content";
}
var arr = new String[str.indexOf(',')];
....
}Значение, возвращаемое методом 'indexOf', может оказаться равным -1. Это произойдёт в том случае, если в строке не окажется указанного символа. Тогда при создании массива 'arr' в качестве его длины будет выступать отрицательное значение. Это приведёт к выбросу исключения типа 'NegativeArraySizeException'.
Исправленный вариант метода 'process' может выглядеть следующим образом:
public static void process(boolean isNotCsv) {
String str = "column1,column2";
if (isNotCsv) {
str = "content";
} else {
var arr = new String[str.indexOf(',')];
....
}
....
}Данная диагностика классифицируется как:
V6112. Calling the 'getClass' method repeatedly or on the value of the '.class' literal will always return the instance of the 'Class<Class>' type.
Метод 'getClass' используется для получения типа объекта, у которого данный метод был вызван. Аналогично можно использовать литерал 'class' непосредственно с самим типом, а не объектом.
При использовании метода 'getClass' вместе с литералом 'class' будет получена информация о типе 'Class'. Рассмотрим пример:
var typeInfo = Integer.class.getClass();В результате вызова данного метода переменная 'typeInfo' будет хранить информацию о типе 'Class'. Это связано с тем, что литерал 'class' хранит информацию типа 'Class<Integer>'. Когда происходит вызов метода 'getClass', то информация будет, соответственно, о типе 'Class', а не о типе 'Integer'. Если нужно получать информацию о типе 'Integer', то достаточно использовать только литерал 'class':
var typeInfo = Integer.class;Помимо этого, может произойти случайное дублирование вызова 'getClass':
Integer i = 0;
var typeInfo = i.getClass().getClass();Как и в первом примере, при первом вызове 'getClass' будет получен объект типа 'Class<Integer>'. При повторном вызове 'getClass' будет получена информация о типе 'Class', а не о типе 'Integer'. Чтобы получить информацию именно о типе 'Integer', достаточно вызвать метод один раз:
Integer i = 0;
var typeInfo = i.getClass();Если требуется информация именно о типе 'Class', то достаточно такой конструкции:
var classType = Class.class;Допускается использование с 'Class.class' метода 'getClass', так как результат не меняется:
var classType = Class.class.getClass();V6113. Suspicious division. Absolute value of the left operand is less than the value of the right operand.
Анализатор обнаружил операцию деления или вычисления остатка от деления с целыми числами, в которой абсолютное значение левого операнда всегда меньше абсолютного значения правого операнда. Такое выражение содержит ошибку или является избыточным.
Рассмотрим пример:
int a = 5;
int b = 10;
int result = a / b; // Результат: 0В результате выполнения данного фрагмента кода переменная 'result' всегда будет равна нулю. Такие операции могут быть логическими ошибками: программист использовал некорректное значение или указал не ту переменную.
Если операнды указаны верно и требуется точное значение результата деления, исправить данный фрагмент кода можно путём явного приведения типов перед выполнением деления:
int a = 5;
int b = 10;
double result = (double)a / b; // Результат: 0.5Подобная ситуация не будет ошибкой, когда операция деления выполняется с вещественными числами:
double a = 5;
double b = 10;
double result = a / b; // Результат: 0.5При использовании операции остатка от деления, если абсолютное значение левого операнда меньше правого операнда, результат выражения всегда будет равен левому операнду. Такая операция является избыточной. Пример:
int a = 5;
int b = 10;
int result = a % b; // Результат: 5Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки деления на ноль. |
Данная диагностика классифицируется как:
Взгляните на примеры ошибок, обнаруженных с помощью диагностики V6113. |
V6114. The 'A' class containing Closeable members does not release the resources that the field is holding.
Анализатор обнаружил в классе поля, реализующие интерфейс 'Closeable' (или 'AutoCloseable'), но ни в одном методе анализируемого класса для них не был вызван метод 'close'. Такой код говорит о том, что ресурс может быть не закрыт.
class A {
private FileWriter resource;
public A(String name) throws IOException {
resource = new FileWriter(name);
}
....
}В данном примере поле 'resource' было инициализировано, но внутри класса 'A' для него не было вызова метода 'close'. Отсутствие вызова метода закрытия приводит к тому, что ресурс не будет освобождён, даже когда ссылка на объект класса 'A' будет утеряна. Из-за этого может произойти нарушение логики работы программы. Например, если ресурс не будет освобождён, то из-за этого будет невозможно получить доступ к нему из другой части кода.
Исправить подобную ситуацию можно несколькими способами. Одним из них является добавление в класс 'A' интерфейса 'Closeable' или 'AutoClosable' с методом 'close', внутри которого будет происходить закрытие ресурса:
class A implements Closeable {
private FileWriter resource;
public A(String name) throws IOException {
resource = new FileWriter(name);
}
public void close() throws IOException {
resource.close();
}
}Не всегда логика программы позволяет реализовать в классе этот интерфейс. Альтернативным решением будет закрытие ресурса в одном из методов класса 'A':
class A {
private FileWriter resource;
public A(String name) throws IOException {
resource = new FileWriter(name);
}
public void method() throws IOException {
....
resource.close();
....
}
}Данная диагностика классифицируется как:
V6115. Not all Closeable members are released inside the 'close' method.
Анализатор обнаружил в классе, реализующем интерфейс 'Closeable' (или 'AutoCloseable'), поля (ресурсы), которые также реализуют этот интерфейс, но не освобождаются в методе 'close' анализируемого класса.
сlass A implements Closeable {
private FileWriter resource;
public A(String name) {
resource = new FileWriter(name);
}
public void close() {
// Не освобождается resource
}
}В данном примере поле 'resource' было инициализировано, но внутри класса 'A' не было вызова 'close' для этого поля. Отсутствие вызова метода закрытия приводит к тому, что ресурс не будет освобожден, даже когда для объекта класса 'A' был вызван метод 'close'. Из-за этого может произойти нарушение логики работы программы. Например, если ресурс не будет освобожден, то из-за этого не получится получить доступ к нему из другой части кода.
Такая ошибка может сохраниться, даже если в одном из методов происходит закрытие ресурса:
сlass A implements Closeable {
private FileWriter resource;
public A(String name) {
resource = new FileWriter(name);
}
public void endWrite() {
resource.close();
}
public void close() {
// Не освобождается resource и не вызывается метод endWrite
}
}Исправить подобную ситуацию можно несколькими способами. Одним из них является освобождение ресурса внутри метода 'close' анализируемого класса:
сlass A implements Closeable {
private FileWriter resource;
public A(String name) {
resource = new FileWriter(name);
}
public void close() {
resource.close();
}
}Другой вариант исправления — добавление вызова метода, в котором происходит закрытие ресурса в метод close:
сlass A implements Closeable {
private FileWriter resource;
public A(String name) {
resource = new FileWriter(name);
}
public void endWrite() {
resource.close();
}
public void close() {
endWrite();
}
}Данная диагностика классифицируется как:
V6116. The class does not implement the Closeable interface, but it contains the 'close' method that releases resources.
Анализатор обнаружил метод 'close', внутри которого происходит освобождение полей (ресурсов). Однако сам класс не реализует интерфейс 'Closeable' или 'AutoCloseable'.
Такой код может привести к следующим проблемам:
- Без информации о реализованном интерфейсе другой разработчик может забыть вызвать метод 'close';
- IoC-контейнеры, управляющие жизненным циклом объекта, не смогут вызвать метод 'close', когда объект станет не нужным. Это связано с тем, что контейнеры анализируют информацию о реализованных интерфейсах объекта.
Во всех описанных случаях ресурсы, удерживаемые объектом, не будут освобождены. Из-за этого может произойти нарушение логики работы программы. Например, если ресурс не будет освобождён, то из-за этого не получится получить доступ к нему из другой части кода.
Пример кода, который может привести к ошибкам:
сlass SomeClass {
private FileWriter resource;
public SomeClass(String name) {
resource = new FileWriter(name);
}
public void close() {
resource.close();
}
}Исправленная версия класса 'SomeClass' будет выглядеть следующим образом:
сlass SomeClass implements Closeable {
private FileWriter resource;
public SomeClass(String name) {
resource = new FileWriter(name);
}
public void close() {
resource.close();
}
}Может быть ситуация, когда сам класс реализует интерфейс или наследуется от класса, который уже содержит метод 'close':
interface SomeInterface {
public void close();
}
class SomeInterfaceImpl implements SomeInterface {
private FileWriter resource;
public SomeInterfaceImpl(String name) {
resource = new FileWriter(name);
}
public void close() {
resource.close();
}
}В таком случае имеется три решения. Первое связано с объявлением у класса с методом 'close' интерфейса 'Closeable' (или 'AutoCloseable'):
class SomeInterfaceImpl implements SomeInterface, Closeable {
private FileWriter resource;
public SomeInterfaceImpl(String name) {
resource = new FileWriter(name);
}
public void close() {
resource.close();
}
}Второе решение связано с расширением интерфейса. В приведённом примере можно объявить у 'SomeInterface' родительский интерфейс 'Closeable' (или 'AutoCloseable'):
interface SomeInterface extends Closeable {
public void close();
}Если 'close' от 'SomeInterface' имеет реализации, в которых не происходит освобождение ресурсов, или наследовать 'Closeable' или 'AutoCloseable' по каким-то причинам нежелательно, тогда стоит переименовать данный метод, так как такое название характерно для этих интерфейсов:
interface SomeInterface {
public void shut();
}V6117. Possible overflow. The expression will be evaluated before casting. Consider casting one of the operands instead.
Анализатор обнаружил подозрительное приведение типов. Результат бинарной операции приводится к типу с большим диапазоном.
Рассмотрим пример:
long multiply(int a, int b) {
return (long)(a * b);
}Такое преобразование избыточно. Тип 'int' и так бы автоматически расширился до типа 'long'.
Скорее всего, подобный паттерн приведения используется для защиты от переполнения, но он неправильный. При перемножении переменных типа 'int' всё равно произойдёт переполнение, и только уже бессмысленный результат умножения будет явно расширен до типа 'long'.
Для корректной защиты от переполнения можно привести один из аргументов к типу 'long'. Исправленный код:
long multiply(int a, int b) {
return (long)a * b;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
V6118. The original exception object was swallowed. Cause of original exception could be lost.
Анализатор обнаружил ситуацию, когда оригинальная информация об исключении была утеряна при повторной генерации из блока 'catch'. Из-за этого ошибки превращаются в трудноотлаживаемые.
Рассмотрим пример некорректного кода:
try {
sb.append((char) Integer.parseInt(someString));
....
} catch (NumberFormatException e) {
throw new IllegalArgumentException();
}В данном случае перехваченное исключение хотели перебросить и не передали полезную информацию в виде сообщения и stacktrace.
Корректный вариант кода:
try {
sb.append((char) Integer.parseInt(someString));
....
} catch (NumberFormatException e) {
throw new IllegalArgumentException(e);
}В исправленном варианте исходное исключение передается в качестве внутреннего, что полностью сохраняет информацию об исходной ошибке.
Другим вариантом исправления может являться выбрасывание исключения с сообщением пользователю:
try {
sb.append((char) Integer.parseInt(someString));
....
} catch (NumberFormatException e) {
throw new IllegalArgumentException(
"String " + someString + " is not number"
);
}В данной ситуации стек оригинальной ошибки был утерян, но описанная информация в новом исключении внесёт большую ясность при отладке этого кода.
Если потеря информации об исключении является ожидаемым поведением, то вы можете заменить имена 'catch'-параметров на "ignore" или "expected", и исключение выдаваться не будет.
Данная диагностика классифицируется как:
V6119. The result of '&' operator is always '0'.
Анализатор обнаружил использование побитового 'AND' (&) с операндами, при которых результат операции всегда равен 0. Возможно, использован неподходящий оператор или операнд.
Пример:
final int ACCESS_READ = 0b001;
final int ACCESS_WRITE= 0b010;
final int adminMask = ACCESS_READ & ACCESS_WRITE; // <=В данном примере создаётся маска из битовых флагов ('final' переменных) для доступа к операциям с файлом. В результате выполнения операции побитового 'AND' в переменной 'adminMask' все биты будут равны нулю, и маска станет бесполезной.
Корректная реализация создания маски будет иметь вид:
final int adminMask = ACCESS_READ | ACCESS_WRITE;Данная диагностика классифицируется как:
V6120. The result of the '&' operator is '0' because one of the operands is '0'.
Анализатор обнаружил, что выполняется побитовая операция 'AND' (&) с операндом, равным 0. Возможно, использован неподходящий оператор или операнд.
Рассмотрим пример:
public class TypeAttribute {
private static final int NOT_PUBLIC = 0x0,
private static final int PUBLIC = 0x1,
private static final int NESTED_PUBLIC = 0x2,
private static final int NESTED_PRIVATE = 0x3
public static boolean isNotPublic(int type) {
return (type & NOT_PUBLIC) == NOT_PUBLIC;
}
}Метод 'isNotPublic' проверяет наличие флага 'NOT_PUBLIC' у аргумента 'type'.
Подобный метод проверки не имеет смысла, так как у флага 'NOT_PUBLIC' нулевое значение. Это значит, что использование его как операнда оператора '&' приводит к всегда нулевому значению результата. Поэтому в представленной реализации мы всегда получаем истинное условие.
Корректная реализация проверки может выглядеть следующим образом:
public static boolean isNotPublic(int type) {
return type == NOT_PUBLIC;
}Также анализатор выдаст срабатывание на использование нулевого операнда с оператором '&='. Такой код выглядит подозрительно, так как равенство нулю одного из операндов означает, что и результат выражения будет равен нулю.
Данная диагностика классифицируется как:
V6121. Return value is not always used. Consider inspecting the 'foo' method.
Анализатор обнаружил потенциально ошибочное игнорирование возвращаемого значения, которое в большинстве случаев каким-либо образом используется.
Рассмотрим синтетический пример:
class Item {
int getID() {
....
}
}
class ItemController {
int setNewItem(Item lastItem) {
Item newItem = new Item(lastItem.getID());
....
newItem.getID(); // <=
return newItem.getID();
}
}В данном примере возвращаемое значение метода 'getID' используется во всех случаях, кроме одного. Если результат не используется менее чем в 10% случаев от общего количества вызовов, анализатор выдаст предупреждение.
В некоторых ситуациях возвращаемое значение действительно не требуется использовать. Например, если метод имеет побочные эффекты (изменение свойств, полей, запись/чтение файла и прочее), возвращаемым значением можно пренебречь.
Чтобы помочь программисту понять, что такое поведение было задумано, можно оставить рядом с вызовом комментарий о том, что результат будет проигнорирован:
int updateItem() {
....
return 0;
}
....
void someMethod() {
....
updateItem(); // ignore result
}V6122. The 'Y' (week year) pattern is used for date formatting. Check whether the 'y' (year) pattern was intended instead.
Анализатор обнаружил потенциальную ошибку, связанную с использованием спецификатора 'Y' в паттерне форматирования даты. Возможно, предполагалось использовать спецификатор 'y'.
Рассмотрим пример:
Date date = new Date("2024/12/31");
String result = new SimpleDateFormat("dd-MM-YYYY").format(date); //31-12-2025'Y' литерал в паттерне даты обозначает не текущий год, а год относительно текущей недели.
По стандарту ISO-8601:
- День, с которого начинается неделя — понедельник.
- Первая неделя в году обязана состоять минимум из четырёх дней этого года.
Рассмотрим фрагмент календаря на конец 2024 и начало 2025 года:
|
ПН |
ВТ |
СР |
ЧТ |
ПТ |
СБ |
ВС |
|---|---|---|---|---|---|---|
|
30 |
31 |
1 |
2 |
3 |
4 |
5 |
Приведённая неделя будет считаться первой неделей 2025 года, поскольку соответствует условиям из вышеупомянутого стандарта. Поэтому, используя литерал 'Y' вместо ожидаемого 2024 года, мы получаем 2025.
Ошибочным будет и обратный пример:
Date date = new Date("2027/01/01");
String result =
new SimpleDateFormat("dd-MM-YYYY").format(date); // 01-01-2026Рассмотрим фрагмент календаря на конец 2026 и начало 2027 года:
|
ПН |
ВТ |
СР |
ЧТ |
ПТ |
СБ |
ВС |
|---|---|---|---|---|---|---|
|
28 |
29 |
30 |
31 |
1 |
2 |
3 |
Обратите внимание: 1, 2 и 3 января будут относиться к последней неделе декабря. Эта неделя условиям вышеупомянутого стандарта не соответствует.
В случае, если вы желаете отобразить год без учёта недели года, необходимо использовать литерал 'y' в паттерне форматирования даты.
Корректный пример:
Date date = new Date("2027/01/01");
String result = new SimpleDateFormat("dd-MM-yyyy").format(date) // 01-01-2027V6123. Modified value of the operand is not used after the increment/decrement operation.
Анализатор обнаружил, что значение постфиксной операции не используется. Скорее всего, или операция избыточна, или вместо постфиксной операции следует использовать префиксную.
Пример:
int calculateSomething() {
int value = getSomething();
....
return value++;
}В данном примере имеется локальная переменная 'value'. Ожидается, что метод вернёт её инкрементированное значение. Однако согласно JLS:
The value of the postfix increment expression is the value of the variable before the new value is stored.
Таким образом оператор '++' никак не повлияет на значение, которое вернёт метод 'calculateSomething'. Возможный исправленный вариант:
int calculateSomething() {
int value = getSomething();
....
return ++value;
}Следующий вариант исправления кода ещё лучше подчёркивает, что следует вернуть значение на единицу больше:
int calculateSomething() {
int value = getSomething();
....
return value + 1;
}Мы рекомендуем использовать второй вариант, так как его проще понять.
Рассмотрим ещё один синтетический пример:
void foo() {
int value = getSomething();
bar(value++);
bar(value++);
bar(value++);
}Каждый раз метод 'bar' вызывается с аргументом на единицу больше. Последний инкремент не имеет смысла, так как увеличенное значение переменной далее не используется. Однако ошибки здесь нет, так как последний инкремент написан из эстетических соображений. Предупреждение не выдаётся, если переменная последовательно инкрементируется более двух раз подряд.
Однако мы всё равно рекомендуем писать следующим образом:
void foo() {
int value = getSomething();
bar(value++);
bar(value++);
bar(value);
}Или так:
void foo() {
int value = getSomething();
bar(value + 0);
bar(value + 1);
bar(value + 2);
}Данная диагностика классифицируется как:
V6124. Converting an integer literal to the type with a smaller value range will result in overflow.
Анализатор обнаружил, что переменной целочисленного типа присвоили значение, выходящее за диапазон допустимых значений.
Пример:
public static void test() {
byte a = (byte) 256; // a = 0
short b = (short) 32768; // b = -32768
int c = (int) 2147483648L; // c = -2147483648
}В данном примере произойдёт переполнение, и в переменных будут храниться не те значения, которые программист попытался присвоить.
Происходит это потому, что под определённый целочисленный тип выделяется фиксированное количество байт. Если значение выходит за рамки того количества байт, которое под него выделили, то лишние биты у значения отсекаются. Опасность заключается в том, что Java даст скомпилировать и запустить такую программу, но при этом из-за допущенной ошибки программист получит не те значения, которые хотел изначально.
Возможно, стоит рассмотреть использование типа, включающего в себя больший диапазон значений:
public static void a() {
short s = (short) 256;
int i = 32768;
long l = 2_147_483_648L;
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки целочисленного переполнения и некорректного совместного использования знаковых и беззнаковых чисел. |
Данная диагностика классифицируется как:
V6125. Calling the 'wait', 'notify', and 'notifyAll' methods outside of synchronized context will lead to 'IllegalMonitorStateException'.
Анализатор обнаружил, что методы 'wait', 'notify', 'notifyAll' могут быть вызваны в несинхронизированном контексте.
public void someMethod() {
notify();
}
public void anotherMethod() throws InterruptedException {
wait();
}Методы 'wait', 'notify', 'notifyAll' работают с монитором объекта, по которому происходит синхронизация. То есть их вызов корректен только в синхронизированном контексте и только на объекте, по которому происходит синхронизация.
В случае, если методы 'wait', 'notify' или 'notifyAll' вызвать в несинхронизированном контексте или не на том объекте, по которому синхронизация происходит, произойдёт выброс исключения 'IllegalMonitorStateException'.
Пример корректного использования в 'synchronized' блоке:
private final Object lock = new Object();
public void someCorrectMethod() {
synchronized (lock) {
lock.notify();
}
}Поскольку синхронизация идёт по объекту 'lock', вызов метода 'notify' корректен только на объекте 'lock'.
Корректное использование в 'synchronized' методе:
public synchronized void anotherCorrectMethod() {
notifyAll();
}Фрагмент выше эквивалентен следующему:
public void anotherCorrectMethod() {
synchronized (this) {
notifyAll();
}
}Из этого следует, что в данной ситуации метод 'notifyAll' корректно вызывать только на 'this' объекте.
Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
V6126. Native synchronization used on high-level concurrency class.
Анализатор обнаружил, что в synchronized передан наследник java.util.concurrent.locks.Lock, java.util.concurrent.locks.Condition, java.util.concurrent.locks.ReadWriteLock и/или java.util.concurrent.locks.StampedLock.
Вышеперечисленные классы относятся к классам параллелизма высокого уровня, и их применение в synchronized является ошибочным. Вместо этого следует применять высокоуровневые средства блокировки, предоставляемые самим классом.
Использование synchronized с такими объектами создаёт две независимые системы синхронизации: на уровне монитора объекта (через synchronized) и на уровне собственного механизма блокировок класса. Это может привести к:
- нарушению целостности синхронизации;
- состоянию гонки (race condition);
- взаимным блокировкам (deadlock);
- непредсказуемому поведению программы.
Ошибочный код выглядит следующим образом:
Lock lock = new ReentrantLock();
synchronized(lock) {
....
}Исправленный вариант представлен ниже:
Lock lock = new ReentrantLock();
lock.lock();
try {
....
} finally {
lock.unlock();
}Выявляемые диагностикой ошибки классифицируются согласно ГОСТ Р 71207–2024 как критические и относятся к типу: Ошибки при работе с многопоточными примитивами (интерфейсами запуска потоков на выполнение, синхронизации и обмена данными между потоками и пр.). |
Данная диагностика классифицируется как:
|
V6127. Closeable object is not closed. This may lead to a resource leak.
Анализатор обнаружил, что объект, реализующий интерфейс Closeable, не закрывается во всех путях исполнения.
Интерфейс Closeable сигнализирует о том, что объект содержит в себе данные, которые можно закрыть. Такие данные именуются ресурсами. Ими могут быть файлы или открытые соединения.
В случае, если пропадёт ссылка на объект, который удерживает ресурс, закрыть его не получится. Это может привести к утечке памяти, ресурса ОС или другим негативным последствиям.
В данном примере открытый файл не закрывают после использования:
public void objectIsNotClosed(File f) {
try {
FileInputStream fis = new FileInputStream(f); // <=
int data;
while ((data = fis.read()) != -1) {
System.out.print((char) data);
}
} catch (IOException e) {
// Exception handling
}
}Объект не закрывается в блоке try, и после выхода из него возможности закрыть файловый поток не будет.
Чтобы избежать утечки дескриптора, необходимо у объекта файлового потока вызвать метод close:
public void objectIsClosedInFinally(File f) {
FileInputStream fis = null;
try {
fis = new FileInputStream(f);
int data;
while ((data = fis.read()) != -1) {
System.out.print((char) data);
}
} catch (IOException e) {
// Exception handling
} finally {
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
// Exception handling
}
}
}
}Также в Java 7 появилась более лаконичная и удобная возможность управлять ресурсами — try-with-resources. Подробнее про неё можно прочитать в документации.
Важно отметить, что в ней Oracle рекомендуют использовать именно try-with-resources, нежели предыдущий способ закрытия ресурса.
Предыдущий пример с использованием try-with-resources:
public void objectIsClosed(File f) {
try (FileInputStream fis = new FileInputStream(f)){
int data;
while ((data = fis.read()) != -1) {
System.out.print((char) data);
}
} catch (IOException e) {
// Exception handling
}
}Также в рамках диагностики рассматривается случай, когда Closeable объект создаётся в конструкторе, который потенциально может выбросить исключение. Такая реализация не является безопасной, потому что в случае выброса исключения Closeable объект создастся, но ссылка на него будет утрачена, и не будет возможности его закрыть.
Данная диагностика классифицируется как:
V6128. Using a Closeable object after it was closed can lead to an exception.
Анализатор обнаружил вызов метода объекта, у которого ранее был вызван метод close. Подобные действия могут привести к выбрасыванию исключения.
Рассмотрим пример:
public void appendFileInformation(String path) throws IOException {
FileInputStream is = new FileInputStream(path);
// ....
is.close();
// ....
if (is.available() == 0) {
System.out.println("EOF");
}
// ....
}В условии проверяется, что файл был прочитан полностью. Для проверки сравнивают количество оставшихся байтов с нулём. Проблема в том, что при вызове метода available будет выброшено исключение типа IOException с сообщением Stream Closed. Это связано с тем, что перед условием у переменной is вызывается метод close. Следовательно, ресурсы is будут освобождены.
Рассмотрим корректную реализацию appendFileInformation:
public void appendFileInformation(String path) throws IOException {
try (FileInputStream is = new FileInputStream("out.txt")) {
// ....
if (is.available() == 0) {
System.out.println("EOF");
}
// ....
}
}Для корректной работы метода стоит использовать try-with-resources. В этом случае:
- ресурсы объекта
isбудут автоматически освобождены после выхода из телаtry; - вне тела
tryобратиться к объекту не получится — это даёт дополнительную защиту от исключений типаIOException; - даже если в теле
tryвозникнет исключение, ресурсы всё равно будут освобождены.
Данная диагностика классифицируется как:
Информация о правах и торговых марках
Trademarks
Windows, Visual Studio, Visual C++ are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Other product and company names mentioned herein may be the trademarks of their respective owners.
C/C++
OpenC++ Library
Portions of PVS-Studio are based in part of OpenC++. Bellow you can read OpenC++ Copyright Notice.
*** Copyright Notice
Copyright (c) 1995, 1996 Xerox Corporation.
All Rights Reserved.
Use and copying of this software and preparation of derivative works based upon this software are permitted. Any copy of this software or of any derivative work must include the above copyright notice of Xerox Corporation, this paragraph and the one after it. Any distribution of this software or derivative works must comply with all applicable United States export control laws.
This software is made available AS IS, and XEROX CORPORATION DISCLAIMS ALL WARRANTIES, EXPRESS OR IMPLIED, INCLUDING WITHOUT LIMITATION THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE, AND NOTWITHSTANDING ANY OTHER PROVISION CONTAINED HEREIN, ANY LIABILITY FOR DAMAGES RESULTING FROM THE SOFTWARE OR ITS USE IS EXPRESSLY DISCLAIMED, WHETHER ARISING IN CONTRACT, TORT (INCLUDING NEGLIGENCE) OR STRICT LIABILITY, EVEN IF XEROX CORPORATION IS ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
*** Copyright Notice
Copyright (C) 1997-2001 Shigeru Chiba, Tokyo Institute of Technology.
Permission to use, copy, distribute and modify this software and its documentation for any purpose is hereby granted without fee, provided that the above copyright notice appear in all copies and that both that copyright notice and this permission notice appear in supporting documentation.
Shigeru Chiba makes no representations about the suitability of this software for any purpose. It is provided "as is" without express or implied warranty.
*** Copyright Notice
Permission to use, copy, distribute and modify this software and its documentation for any purpose is hereby granted without fee, provided that the above copyright notice appear in all copies and that both that copyright notice and this permission notice appear in supporting documentation. Other Contributors make no representations about the suitability of this software for any purpose. It is provided "as is" without express or implied warranty.
2001-2003 (C) Copyright by Other Contributors.
The LLVM Compiler
PVS-Studio can use Clang as preprocessor. Read Clang/LLVM license:
==============================================================================
LLVM Release License
==============================================================================
University of Illinois/NCSA
Open Source License
Copyright (c) 2007-2011 University of Illinois at Urbana-Champaign.
All rights reserved.
Developed by:
LLVM Team
University of Illinois at Urbana-Champaign
http://llvm.org
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal with the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
* Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimers.
* Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimers in the documentation and/or other materials provided with the distribution.
* Neither the names of the LLVM Team, University of Illinois at Urbana-Champaign, nor the names of its contributors may be used to endorse or promote products derived from this Software without specific prior written permission.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE CONTRIBUTORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS WITH THE SOFTWARE.
==============================================================================
The LLVM software contains code written by third parties. Such software will have its own individual LICENSE.TXT file in the directory in which it appears. This file will describe the copyrights, license, and restrictions which apply to that code.
The disclaimer of warranty in the University of Illinois Open Source License applies to all code in the LLVM Distribution, and nothing in any of the other licenses gives permission to use the names of the LLVM Team or the University of Illinois to endorse or promote products derived from this Software.
The following pieces of software have additional or alternate copyrights, licenses, and/or restrictions:
Program Directory
------- ---------
<none yet>
GNU C Library
PVS-Studio uses GNU C Library. GNU C Library is licensed under GNU LESSER GENERAL PUBLIC LICENSE Version 2.1. PVS-Studio provides object code in accordance with section 6.a of GNU LESSER GENERAL PUBLIC LICENSE. Bellow you can read GNU C Library License.
GNU LESSER GENERAL PUBLIC LICENSE
Version 2.1, February 1999
Copyright (C) 1991, 1999 Free Software Foundation, Inc.
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
[This is the first released version of the Lesser GPL. It also counts
as the successor of the GNU Library Public License, version 2, hence
the version number 2.1.]
Preamble
The licenses for most software are designed to take away your freedom to share and change it. By contrast, the GNU General Public Licenses are intended to guarantee your freedom to share and change free software--to make sure the software is free for all its users.
This license, the Lesser General Public License, applies to some specially designated software packages--typically libraries--of the Free Software Foundation and other authors who decide to use it. You can use it too, but we suggest you first think carefully about whether this license or the ordinary General Public License is the better strategy to use in any particular case, based on the explanations below.
When we speak of free software, we are referring to freedom of use, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for this service if you wish); that you receive source code or can get it if you want it; that you can change the software and use pieces of it in new free programs; and that you are informed that you can do these things.
To protect your rights, we need to make restrictions that forbid distributors to deny you these rights or to ask you to surrender these rights. These restrictions translate to certain responsibilities for you if you distribute copies of the library or if you modify it.
For example, if you distribute copies of the library, whether gratis or for a fee, you must give the recipients all the rights that we gave you. You must make sure that they, too, receive or can get the source code. If you link other code with the library, you must provide complete object files to the recipients, so that they can relink them with the library after making changes to the library and recompiling it. And you must show them these terms so they know their rights.
We protect your rights with a two-step method: (1) we copyright the library, and (2) we offer you this license, which gives you legal permission to copy, distribute and/or modify the library.
To protect each distributor, we want to make it very clear that there is no warranty for the free library. Also, if the library is modified by someone else and passed on, the recipients should know that what they have is not the original version, so that the original author's reputation will not be affected by problems that might be introduced by others.
Finally, software patents pose a constant threat to the existence of any free program. We wish to make sure that a company cannot effectively restrict the users of a free program by obtaining a restrictive license from a patent holder. Therefore, we insist that any patent license obtained for a version of the library must be consistent with the full freedom of use specified in this license.
Most GNU software, including some libraries, is covered by the ordinary GNU General Public License. This license, the GNU Lesser General Public License, applies to certain designated libraries, and is quite different from the ordinary General Public License. We use this license for certain libraries in order to permit linking those libraries into non-free programs.
When a program is linked with a library, whether statically or using a shared library, the combination of the two is legally speaking a combined work, a derivative of the original library. The ordinary General Public License therefore permits such linking only if the entire combination fits its criteria of freedom. The Lesser General Public License permits more lax criteria for linking other code with the library.
We call this license the "Lesser" General Public License because it does Less to protect the user's freedom than the ordinary General Public License. It also provides other free software developers Less of an advantage over competing non-free programs. These disadvantages are the reason we use the ordinary General Public License for many libraries. However, the Lesser license provides advantages in certain special circumstances.
For example, on rare occasions, there may be a special need to encourage the widest possible use of a certain library, so that it becomes a de-facto standard. To achieve this, non-free programs must be allowed to use the library. A more frequent case is that a free library does the same job as widely used non-free libraries. In this case, there is little to gain by limiting the free library to free software only, so we use the Lesser General Public License.
In other cases, permission to use a particular library in non-free programs enables a greater number of people to use a large body of free software. For example, permission to use the GNU C Library in non-free programs enables many more people to use the whole GNU operating system, as well as its variant, the GNU/Linux operating system.
Although the Lesser General Public License is Less protective of the users' freedom, it does ensure that the user of a program that is linked with the Library has the freedom and the wherewithal to run that program using a modified version of the Library.
The precise terms and conditions for copying, distribution and modification follow. Pay close attention to the difference between a "work based on the library" and a "work that uses the library". The former contains code derived from the library, whereas the latter must be combined with the library in order to run.
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
0. This License Agreement applies to any software library or other program which contains a notice placed by the copyright holder or other authorized party saying it may be distributed under the terms of this Lesser General Public License (also called "this License"). Each licensee is addressed as "you".
A "library" means a collection of software functions and/or data prepared so as to be conveniently linked with application programs (which use some of those functions and data) to form executables.
The "Library", below, refers to any such software library or work which has been distributed under these terms. A "work based on the Library" means either the Library or any derivative work under copyright law: that is to say, a work containing the Library or a portion of it, either verbatim or with modifications and/or translated straightforwardly into another language. (Hereinafter, translation is included without limitation in the term "modification".)
"Source code" for a work means the preferred form of the work for making modifications to it. For a library, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the library.
Activities other than copying, distribution and modification are not covered by this License; they are outside its scope. The act of running a program using the Library is not restricted, and output from such a program is covered only if its contents constitute a work based on the Library (independent of the use of the Library in a tool for writing it). Whether that is true depends on what the Library does and what the program that uses the Library does.
1. You may copy and distribute verbatim copies of the Library's complete source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice and disclaimer of warranty; keep intact all the notices that refer to this License and to the absence of any warranty; and distribute a copy of this License along with the Library.
You may charge a fee for the physical act of transferring a copy, and you may at your option offer warranty protection in exchange for a fee.
2. You may modify your copy or copies of the Library or any portion of it, thus forming a work based on the Library, and copy and distribute such modifications or work under the terms of Section 1 above, provided that you also meet all of these conditions:
a) The modified work must itself be a software library.
b) You must cause the files modified to carry prominent notices stating that you changed the files and the date of any change.
c) You must cause the whole of the work to be licensed at no charge to all third parties under the terms of this License.
d) If a facility in the modified Library refers to a function or a table of data to be supplied by an application program that uses the facility, other than as an argument passed when the facility is invoked, then you must make a good faith effort to ensure that, in the event an application does not supply such function or table, the facility still operates, and performs whatever part of its purpose remains meaningful.
(For example, a function in a library to compute square roots has a purpose that is entirely well-defined independent of the application. Therefore, Subsection 2d requires that any application-supplied function or table used by this function must be optional: if the application does not supply it, the square root function must still compute square roots.)
These requirements apply to the modified work as a whole. If identifiable sections of that work are not derived from the Library, and can be reasonably considered independent and separate works in themselves, then this License, and its terms, do not apply to those sections when you distribute them as separate works. But when you distribute the same sections as part of a whole which is a work based on the Library, the distribution of the whole must be on the terms of this License, whose permissions for other licensees extend to the entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest your rights to work written entirely by you; rather, the intent is to exercise the right to control the distribution of derivative or collective works based on the Library.
In addition, mere aggregation of another work not based on the Library with the Library (or with a work based on the Library) on a volume of a storage or distribution medium does not bring the other work under the scope of this License.
3. You may opt to apply the terms of the ordinary GNU General Public License instead of this License to a given copy of the Library. To do this, you must alter all the notices that refer to this License, so that they refer to the ordinary GNU General Public License, version 2, instead of to this License. (If a newer version than version 2 of the ordinary GNU General Public License has appeared, then you can specify that version instead if you wish.) Do not make any other change in these notices.
Once this change is made in a given copy, it is irreversible for that copy, so the ordinary GNU General Public License applies to all subsequent copies and derivative works made from that copy.
This option is useful when you wish to copy part of the code of the Library into a program that is not a library.
4. You may copy and distribute the Library (or a portion or derivative of it, under Section 2) in object code or executable form under the terms of Sections 1 and 2 above provided that you accompany it with the complete corresponding machine-readable source code, which must be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange.
If distribution of object code is made by offering access to copy from a designated place, then offering equivalent access to copy the source code from the same place satisfies the requirement to distribute the source code, even though third parties are not compelled to copy the source along with the object code.
5. A program that contains no derivative of any portion of the Library, but is designed to work with the Library by being compiled or linked with it, is called a "work that uses the Library". Such a work, in isolation, is not a derivative work of the Library, and therefore falls outside the scope of this License.
However, linking a "work that uses the Library" with the Library creates an executable that is a derivative of the Library (because it contains portions of the Library), rather than a "work that uses the library". The executable is therefore covered by this License. Section 6 states terms for distribution of such executables.
When a "work that uses the Library" uses material from a header file that is part of the Library, the object code for the work may be a derivative work of the Library even though the source code is not. Whether this is true is especially significant if the work can be linked without the Library, or if the work is itself a library. The threshold for this to be true is not precisely defined by law.
If such an object file uses only numerical parameters, data structure layouts and accessors, and small macros and small inline functions (ten lines or less in length), then the use of the object file is unrestricted, regardless of whether it is legally a derivative work. (Executables containing this object code plus portions of the Library will still fall under Section 6.)
Otherwise, if the work is a derivative of the Library, you may distribute the object code for the work under the terms of Section 6. Any executables containing that work also fall under Section 6, whether or not they are linked directly with the Library itself.
6. As an exception to the Sections above, you may also combine or link a "work that uses the Library" with the Library to produce a work containing portions of the Library, and distribute that work under terms of your choice, provided that the terms permit modification of the work for the customer's own use and reverse engineering for debugging such modifications.
You must give prominent notice with each copy of the work that the Library is used in it and that the Library and its use are covered by this License. You must supply a copy of this License. If the work during execution displays copyright notices, you must include the copyright notice for the Library among them, as well as a reference directing the user to the copy of this License. Also, you must do one of these things:
a) Accompany the work with the complete corresponding machine-readable source code for the Library including whatever changes were used in the work (which must be distributed under Sections 1 and 2 above); and, if the work is an executable linked with the Library, with the complete machine-readable "work that uses the Library", as object code and/or source code, so that the user can modify the Library and then relink to produce a modified executable containing the modified Library. (It is understood that the user who changes the contents of definitions files in the Library will not necessarily be able to recompile the application to use the modified definitions.)
b) Use a suitable shared library mechanism for linking with the Library. A suitable mechanism is one that (1) uses at run time a copy of the library already present on the user's computer system, rather than copying library functions into the executable, and (2) will operate properly with a modified version of the library, if the user installs one, as long as the modified version is interface-compatible with the version that the work was made with.
c) Accompany the work with a written offer, valid for at least three years, to give the same user the materials specified in Subsection 6a, above, for a charge no more than the cost of performing this distribution.
d) If distribution of the work is made by offering access to copy from a designated place, offer equivalent access to copy the above specified materials from the same place.
e) Verify that the user has already received a copy of these materials or that you have already sent this user a copy.
For an executable, the required form of the "work that uses the Library" must include any data and utility programs needed for reproducing the executable from it. However, as a special exception, the materials to be distributed need not include anything that is normally distributed (in either source or binary form) with the major components (compiler, kernel, and so on) of the operating system on which the executable runs, unless that component itself accompanies the executable.
It may happen that this requirement contradicts the license restrictions of other proprietary libraries that do not normally accompany the operating system. Such a contradiction means you cannot use both them and the Library together in an executable that you distribute.
7. You may place library facilities that are a work based on the Library side-by-side in a single library together with other library facilities not covered by this License, and distribute such a combined library, provided that the separate distribution of the work based on the Library and of the other library facilities is otherwise permitted, and provided that you do these two things:
a) Accompany the combined library with a copy of the same work based on the Library, uncombined with any other library facilities. This must be distributed under the terms of the Sections above.
b) Give prominent notice with the combined library of the fact that part of it is a work based on the Library, and explaining where to find the accompanying uncombined form of the same work.
8. You may not copy, modify, sublicense, link with, or distribute the Library except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense, link with, or distribute the Library is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
9. You are not required to accept this License, since you have not signed it. However, nothing else grants you permission to modify or distribute the Library or its derivative works. These actions are prohibited by law if you do not accept this License. Therefore, by modifying or distributing the Library (or any work based on the Library), you indicate your acceptance of this License to do so, and all its terms and conditions for copying, distributing or modifying the Library or works based on it.
10. Each time you redistribute the Library (or any work based on the Library), the recipient automatically receives a license from the original licensor to copy, distribute, link with or modify the Library subject to these terms and conditions. You may not impose any further restrictions on the recipients' exercise of the rights granted herein. You are not responsible for enforcing compliance by third parties with this License.
11. If, as a consequence of a court judgment or allegation of patent infringement or for any other reason (not limited to patent issues), conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot distribute so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not distribute the Library at all. For example, if a patent license would not permit royalty-free redistribution of the Library by all those who receive copies directly or indirectly through you, then the only way you could satisfy both it and this License would be to refrain entirely from distribution of the Library.
If any portion of this section is held invalid or unenforceable under any particular circumstance, the balance of the section is intended to apply, and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any patents or other property right claims or to contest validity of any such claims; this section has the sole purpose of protecting the integrity of the free software distribution system which is implemented by public license practices. Many people have made generous contributions to the wide range of software distributed through that system in reliance on consistent application of that system; it is up to the author/donor to decide if he or she is willing to distribute software through any other system and a licensee cannot impose that choice.
This section is intended to make thoroughly clear what is believed to be a consequence of the rest of this License.
12. If the distribution and/or use of the Library is restricted in certain countries either by patents or by copyrighted interfaces, the original copyright holder who places the Library under this License may add an explicit geographical distribution limitation excluding those countries, so that distribution is permitted only in or among countries not thus excluded. In such case, this License incorporates the limitation as if written in the body of this License.
13. The Free Software Foundation may publish revised and/or new versions of the Lesser General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Library specifies a version number of this License which applies to it and "any later version", you have the option of following the terms and conditions either of that version or of any later version published by the Free Software Foundation. If the Library does not specify a license version number, you may choose any version ever published by the Free Software Foundation.
14. If you wish to incorporate parts of the Library into other free programs whose distribution conditions are incompatible with these, write to the author to ask for permission. For software which is copyrighted by the Free Software Foundation, write to the Free Software Foundation; we sometimes make exceptions for this. Our decision will be guided by the two goals of preserving the free status of all derivatives of our free software and of promoting the sharing and reuse of software generally.
NO WARRANTY
15. BECAUSE THE LIBRARY IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY FOR THE LIBRARY, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE LIBRARY "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE LIBRARY IS WITH YOU. SHOULD THE LIBRARY PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR REDISTRIBUTE THE LIBRARY AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE LIBRARY (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE LIBRARY TO OPERATE WITH ANY OTHER SOFTWARE), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
END OF TERMS AND CONDITIONS
JSON for Modern C++
MIT License
Copyright (c) 2013-2017 Niels Lohmann
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Taywee/args C++ Library
MIT License
Copyright (c) 2016-2017 Taylor C. Richberger <taywee@gmx.com> and Pavel Belikov
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
CED C++ Library
PVS-Studio uses Compact Encoding Detection C++ Library. Bellow you can read CED License.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Scintilla
ScintillaNET uses Scintilla. This is Scintilla license:
License for Scintilla and SciTE
Copyright 1998-2003 by Neil Hodgson <neilh@scintilla.org>
All Rights Reserved
Permission to use, copy, modify, and distribute this software and its documentation for any purpose and without fee is hereby granted, provided that the above copyright notice appear in all copies and that both that copyright notice and this permission notice appear in supporting documentation.
NEIL HODGSON DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS, IN NO EVENT SHALL NEIL HODGSON BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
C#
SourceGrid Control
PVS-Studio uses SourceGrid control (sourcegrid.codeplex.com). Bellow you can read Source Grid License.
SourceGrid LICENSE (MIT style)
Copyright (c) 2009 Davide Icardi
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
ScintillaNET Control
C and C++ Compiler Monitoring UI uses ScintillaNET. This is ScintillaNET license:
The MIT License (MIT)
Copyright (c) 2017, Jacob Slusser, https://github.com/jacobslusser
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
ScintillaNET-FindReplaceDialog
C and C++ Compiler Monitoring UI uses ScintillaNet-FindReplaceDialog. This is ScintillaNet-FindReplaceDialog license:
MIT License
Copyright (c) 2017 Steve Towner
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
DockPanel Suite Library
C and C++ Compiler Monitoring UI uses DockPanel_Suite. This is DockPanel_Suite license:
The MIT License
Copyright (c) 2007 Weifen Luo (email: weifenluo@yahoo.com)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
PVS-Studio uses Font Awesome. Bellow you can read Font Awesome License.
This Font Software is licensed under the SIL Open Font License, Version 1.1.
This license is copied below, and is also available with a FAQ at:
http://scripts.sil.org/OFL
-----------------------------------------------------------
SIL OPEN FONT LICENSE Version 1.1 - 26 February 2007
-----------------------------------------------------------
PREAMBLE
The goals of the Open Font License (OFL) are to stimulate worldwide development of collaborative font projects, to support the font creation efforts of academic and linguistic communities, and to provide a free and open framework in which fonts may be shared and improved in partnership with others.
The OFL allows the licensed fonts to be used, studied, modified and redistributed freely as long as they are not sold by themselves. The fonts, including any derivative works, can be bundled, embedded, redistributed and/or sold with any software provided that any reserved names are not used by derivative works. The fonts and derivatives, however, cannot be released under any other type of license. The requirement for fonts to remain under this license does not apply to any document created using the fonts or their derivatives.
DEFINITIONS
"Font Software" refers to the set of files released by the Copyright Holder(s) under this license and clearly marked as such. This may include source files, build scripts and documentation. "Reserved Font Name" refers to any names specified as such after the copyright statement(s).
"Original Version" refers to the collection of Font Software components as distributed by the Copyright Holder(s).
"Modified Version" refers to any derivative made by adding to, deleting, or substituting -- in part or in whole -- any of the components of the Original Version, by changing formats or by porting the Font Software to a new environment.
"Author" refers to any designer, engineer, programmer, technical writer or other person who contributed to the Font Software.
PERMISSION & CONDITIONS
Permission is hereby granted, free of charge, to any person obtaining a copy of the Font Software, to use, study, copy, merge, embed, modify, redistribute, and sell modified and unmodified copies of the Font Software, subject to the following conditions:
1) Neither the Font Software nor any of its individual components, in Original or Modified Versions, may be sold by itself.
2) Original or Modified Versions of the Font Software may be bundled, redistributed and/or sold with any software, provided that each copy contains the above copyright notice and this license. These can be included either as stand-alone text files, human-readable headers or in the appropriate machine-readable metadata fields within text or binary files as long as those fields can be easily viewed by the user.
3) No Modified Version of the Font Software may use the Reserved Font Name(s) unless explicit written permission is granted by the corresponding Copyright Holder. This restriction only applies to the primary font name as presented to the users.
4) The name(s) of the Copyright Holder(s) or the Author(s) of the Font Software shall not be used to promote, endorse or advertise any Modified Version, except to acknowledge the contribution(s) of the Copyright Holder(s) and the Author(s) or with their explicit written permission.
5) The Font Software, modified or unmodified, in part or in whole, must be distributed entirely under this license, and must not be distributed under any other license. The requirement for fonts to remain under this license does not apply to any document created using the Font Software.
TERMINATION
This license becomes null and void if any of the above conditions are not met.
DISCLAIMER
THE FONT SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OF COPYRIGHT, PATENT, TRADEMARK, OR OTHER RIGHT. IN NO EVENT SHALL THE COPYRIGHT HOLDER BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, INCLUDING ANY GENERAL, SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF THE USE OR INABILITY TO USE THE FONT SOFTWARE OR FROM OTHER DEALINGS IN THE FONT SOFTWARE.
The .NET Compiler Platform ("Roslyn")
PVS-Studio uses Roslyn. This is Roslyn license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Command Line Parser Library
PVS-Studio uses Command Line Parser Library. This is Command Line Parser Library license:
The MIT License (MIT)
Copyright (c) 2005 - 2015 Giacomo Stelluti Scala & Contributors
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Protocol Buffers library for .NET
The core Protocol Buffers technology is provided courtesy of Google. At the time of writing, this is released under the BSD license. Full details can be found here:
http://code.google.com/p/protobuf/
This .NET implementation is Copyright 2008 Marc Gravell
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
MSBuild
PVS-Studio uses MSBuild. This is MSBuild license:
MSBuild
The MIT License (MIT)
Copyright (c) .NET Foundation and contributors
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Java
jsoup Library
PVS-Studio plugin for Jenkins uses jsoup. This is jsoup license:
The MIT License
Copyright © 2009 - 2017 Jonathan Hedley (jonathan@hedley.net)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Spoon Library
PVS-Studio uses Spoon. This is Spoon license:
CeCILL-C FREE SOFTWARE LICENSE AGREEMENT
Notice
This Agreement is a Free Software license agreement that is the result of discussions between its authors in order to ensure compliance with the two main principles guiding its drafting:
- firstly, compliance with the principles governing the distribution of Free Software: access to source code, broad rights granted to users,
- secondly, the election of a governing law, French law, with which it is conformant, both as regards the law of torts and intellectual property law, and the protection that it offers to both authors and holders of the economic rights over software.
The authors of the CeCILL-C (for Ce[a] C[nrs] I[nria] L[ogiciel] L[ibre]) license are:
Commissariat à l'Energie Atomique - CEA, a public scientific, technical and industrial research establishment, having its principal place of
business at 25 rue Leblanc, immeuble Le Ponant D, 75015 Paris, France. Centre National de la Recherche Scientifique - CNRS, a public scientific and technological establishment, having its principal place of business at 3 rue Michel-Ange, 75794 Paris cedex 16, France.
Institut National de Recherche en Informatique et en Automatique INRIA, a public scientific and technological establishment, having its principal place of business at Domaine de Voluceau, Rocquencourt, BP 105, 78153 Le Chesnay cedex, France.
Preamble
The purpose of this Free Software license agreement is to grant users the right to modify and re-use the software governed by this license.
The exercising of this right is conditional upon the obligation to make available to the community the modifications made to the source code of the software so as to contribute to its evolution.
In consideration of access to the source code and the rights to copy, modify and redistribute granted by the license, users are provided only with a limited warranty and the software's author, the holder of the economic rights, and the successive licensors only have limited liability.
In this respect, the risks associated with loading, using, modifying and/or developing or reproducing the software by the user are brought to the user's attention, given its Free Software status, which may make it complicated to use, with the result that its use is reserved for developers and experienced professionals having in-depth computer knowledge. Users are therefore encouraged to load and test the suitability of the software as regards their requirements in conditions enabling the security of their systems and/or data to be ensured and, more generally, to use and operate it in the same conditions of security. This Agreement may be freely reproduced and published, provided it is not altered, and that no provisions are either added or removed herefrom.
This Agreement may apply to any or all software for which the holder of the economic rights decides to submit the use thereof to its provisions.
Article 1 - DEFINITIONS
For the purpose of this Agreement, when the following expressions commence with a capital letter, they shall have the following meaning:
Agreement: means this license agreement, and its possible subsequent versions and annexes.
Software: means the software in its Object Code and/or Source Code form and, where applicable, its documentation, "as is" when the Licensee accepts the Agreement.
Initial Software: means the Software in its Source Code and possibly its Object Code form and, where applicable, its documentation, "as is" when it is first distributed under the terms and conditions of the Agreement.
Modified Software: means the Software modified by at least one Integrated Contribution.
Source Code: means all the Software's instructions and program lines to which access is required so as to modify the Software.
Object Code: means the binary files originating from the compilation of the Source Code.
Holder: means the holder(s) of the economic rights over the Initial Software.
Licensee: means the Software user(s) having accepted the Agreement.
Contributor: means a Licensee having made at least one Integrated Contribution.
Licensor: means the Holder, or any other individual or legal entity, who distributes the Software under the Agreement.
Integrated Contribution: means any or all modifications, corrections, translations, adaptations and/or new functions integrated into the Source Code by any or all Contributors.
Related Module: means a set of sources files including their documentation that, without modification to the Source Code, enables supplementary functions or services in addition to those offered by the
Software.
Derivative Software: means any combination of the Software, modified or not, and of a Related Module.
Parties: mean both the Licensee and the Licensor.
These expressions may be used both in singular and plural form.
Article 2 - PURPOSE
The purpose of the Agreement is the grant by the Licensor to the Licensee of a non-exclusive, transferable and worldwide license for the Software as set forth in Article 5 hereinafter for the whole term of the protection granted by the rights over said Software.
Article 3 - ACCEPTANCE
3.1 The Licensee shall be deemed as having accepted the terms and conditions of this Agreement upon the occurrence of the first of the following events:
- (i)loading the Software by any or all means, notably, by downloading from a remote server, or by loading from a physical medium;
- (ii) the first time the Licensee exercises any of the rights granted hereunder.
3.2 One copy of the Agreement, containing a notice relating to the characteristics of the Software, to the limited warranty, and to the fact that its use is restricted to experienced users has been provided to the Licensee prior to its acceptance as set forth in Article 3.1 hereinabove, and the Licensee hereby acknowledges that it has read and understood it.
Article 4 - EFFECTIVE DATE AND TERM
4.1 EFFECTIVE DATE
The Agreement shall become effective on the date when it is accepted by the Licensee as set forth in Article 3.1.
4.2 TERM
The Agreement shall remain in force for the entire legal term of protection of the economic rights over the Software.
Article 5 - SCOPE OF RIGHTS GRANTED
The Licensor hereby grants to the Licensee, who accepts, the following rights over the Software for any or all use, and for the term of the Agreement, on the basis of the terms and conditions set forth hereinafter.
Besides, if the Licensor owns or comes to own one or more patents protecting all or part of the functions of the Software or of its components, the Licensor undertakes not to enforce the rights granted by these patents against successive Licensees using, exploiting or modifying the Software. If these patents are transferred, the Licensor undertakes to have the transferees subscribe to the obligations set forth in this paragraph.
5.1 RIGHT OF USE
The Licensee is authorized to use the Software, without any limitation as to its fields of application, with it being hereinafter specified that this comprises:
1. permanent or temporary reproduction of all or part of the Software by any or all means and in any or all form.
2. loading, displaying, running, or storing the Software on any or all medium.
3. entitlement to observe, study or test its operation so as to determine the ideas and principles behind any or all constituent elements of said Software. This shall apply when the Licensee carries out any or all loading, displaying, running, transmission or storage operation as regards the Software, that it is entitled to carry out hereunder.
5.2 RIGHT OF MODIFICATION
The right of modification includes the right to translate, adapt, arrange, or make any or all modifications to the Software, and the right to reproduce the resulting software. It includes, in particular, the right to create a Derivative Software.
The Licensee is authorized to make any or all modification to the Software provided that it includes an explicit notice that it is the author of said modification and indicates the date of the creation thereof.
5.3 RIGHT OF DISTRIBUTION
In particular, the right of distribution includes the right to publish, transmit and communicate the Software to the general public on any or all medium, and by any or all means, and the right to market, either in consideration of a fee, or free of charge, one or more copies of the Software by any means.
The Licensee is further authorized to distribute copies of the modified or unmodified Software to third parties according to the terms and conditions set forth hereinafter.
5.3.1 DISTRIBUTION OF SOFTWARE WITHOUT MODIFICATION
The Licensee is authorized to distribute true copies of the Software in Source Code or Object Code form, provided that said distribution complies with all the provisions of the Agreement and is accompanied by:
1. a copy of the Agreement,
2. a notice relating to the limitation of both the Licensor's warranty and liability as set forth in Articles 8 and 9,
and that, in the event that only the Object Code of the Software is redistributed, the Licensee allows effective access to the full Source Code of the Software at a minimum during the entire period of its distribution of the Software, it being understood that the additional cost of acquiring the Source Code shall not exceed the cost of transferring the data.
5.3.2 DISTRIBUTION OF MODIFIED SOFTWARE
When the Licensee makes an Integrated Contribution to the Software, the terms and conditions for the distribution of the resulting Modified Software become subject to all the provisions of this Agreement.
The Licensee is authorized to distribute the Modified Software, in source code or object code form, provided that said distribution complies with all the provisions of the Agreement and is accompanied by:
1. a copy of the Agreement,
2. a notice relating to the limitation of both the Licensor's warranty and liability as set forth in Articles 8 and 9,
and that, in the event that only the object code of the Modified Software is redistributed, the Licensee allows effective access to the full source code of the Modified Software at a minimum during the entire period of its distribution of the Modified Software, it being understood that the additional cost of acquiring the source code shall not exceed the cost of transferring the data.
5.3.3 DISTRIBUTION OF DERIVATIVE SOFTWARE
When the Licensee creates Derivative Software, this Derivative Software may be distributed under a license agreement other than this Agreement, subject to compliance with the requirement to include a notice concerning the rights over the Software as defined in Article 6.4.
In the event the creation of the Derivative Software required modification of the Source Code, the Licensee undertakes that:
1. the resulting Modified Software will be governed by this Agreement,
2. the Integrated Contributions in the resulting Modified Software will be clearly identified and documented,
3. the Licensee will allow effective access to the source code of the Modified Software, at a minimum during the entire period of distribution of the Derivative Software, such that such modifications may be carried over in a subsequent version of the Software; it being understood that the additional cost of purchasing the source code of the Modified Software shall not exceed the cost of transferring the data.
5.3.4 COMPATIBILITY WITH THE CeCILL LICENSE
When a Modified Software contains an Integrated Contribution subject to the CeCILL license agreement, or when a Derivative Software contains a Related Module subject to the CeCILL license agreement, the provisions set forth in the third item of Article 6.4 are optional.
Article 6 - INTELLECTUAL PROPERTY
6.1 OVER THE INITIAL SOFTWARE
The Holder owns the economic rights over the Initial Software. Any or all use of the Initial Software is subject to compliance with the terms and conditions under which the Holder has elected to distribute its work and no one shall be entitled to modify the terms and conditions for the distribution of said Initial Software.
The Holder undertakes that the Initial Software will remain ruled at least by this Agreement, for the duration set forth in Article 4.2.
6.2 OVER THE INTEGRATED CONTRIBUTIONS
The Licensee who develops an Integrated Contribution is the owner of the intellectual property rights over this Contribution as defined by applicable law.
6.3 OVER THE RELATED MODULES
The Licensee who develops a Related Module is the owner of the intellectual property rights over this Related Module as defined by applicable law and is free to choose the type of agreement that shall govern its distribution under the conditions defined in Article 5.3.3.
6.4 NOTICE OF RIGHTS
The Licensee expressly undertakes:
1. not to remove, or modify, in any manner, the intellectual property notices attached to the Software;
2. to reproduce said notices, in an identical manner, in the copies of the Software modified or not;
3. to ensure that use of the Software, its intellectual property notices and the fact that it is governed by the Agreement is indicated in a text that is easily accessible, specifically from the interface of any Derivative Software.
The Licensee undertakes not to directly or indirectly infringe the intellectual property rights of the Holder and/or Contributors on the Software and to take, where applicable, vis-à-vis its staff, any and all measures required to ensure respect of said intellectual property rights of the Holder and/or Contributors.
Article 7 - RELATED SERVICES
7.1 Under no circumstances shall the Agreement oblige the Licensor to provide technical assistance or maintenance services for the Software.
However, the Licensor is entitled to offer this type of services. The terms and conditions of such technical assistance, and/or such maintenance, shall be set forth in a separate instrument. Only theLicensor offering said maintenance and/or technical assistance services shall incur liability therefor.
7.2 Similarly, any Licensor is entitled to offer to its licensees, underits sole responsibility, a warranty, that shall only be binding upon itself, for the redistribution of the Software and/or the Modified Software, under terms and conditions that it is free to decide. Said warranty, and the financial terms and conditions of its application, shall be subject of a separate instrument executed between the Licensor and the Licensee.
Article 8 - LIABILITY
8.1 Subject to the provisions of Article 8.2, the Licensee shall be entitled to claim compensation for any direct loss it may have suffered from the Software as a result of a fault on the part of the relevant Licensor, subject to providing evidence thereof.
8.2 The Licensor's liability is limited to the commitments made under this Agreement and shall not be incurred as a result of in particular: (i) loss due the Licensee's total or partial failure to fulfill its obligations, (ii) direct or consequential loss that is suffered by the Licensee due to the use or performance of the Software, and (iii) more generally, any consequential loss. In particular the Parties expressly agree that any or all pecuniary or business loss (i.e. loss of data, loss of profits, operating loss, loss of customers or orders, opportunity cost, any disturbance to business activities) or any or all legal proceedings instituted against the Licensee by a third party, shall constitute consequential loss and shall not provide entitlement to any or all compensation from the Licensor.
Article 9 - WARRANTY
9.1 The Licensee acknowledges that the scientific and technical state-of-the-art when the Software was distributed did not enable all possible uses to be tested and verified, nor for the presence of possible defects to be detected. In this respect, the Licensee's attention has been drawn to the risks associated with loading, using, modifying and/or developing and reproducing the Software which are reserved for experienced users.
The Licensee shall be responsible for verifying, by any or all means, the suitability of the product for its requirements, its good working order, and for ensuring that it shall not cause damage to either persons or properties.
9.2 The Licensor hereby represents, in good faith, that it is entitled to grant all the rights over the Software (including in particular the rights set forth in Article 5).
9.3 The Licensee acknowledges that the Software is supplied "as is" by the Licensor without any other express or tacit warranty, other than that provided for in Article 9.2 and, in particular, without any warranty as to its commercial value, its secured, safe, innovative or relevant nature.
Specifically, the Licensor does not warrant that the Software is free from any error, that it will operate without interruption, that it will be compatible with the Licensee's own equipment and software configuration, nor that it will meet the Licensee's requirements.
9.4 The Licensor does not either expressly or tacitly warrant that the Software does not infringe any third party intellectual property right relating to a patent, software or any other property right. Therefore, the Licensor disclaims any and all liability towards the Licensee arising out of any or all proceedings for infringement that may be instituted in respect of the use, modification and redistribution of the Software. Nevertheless, should such proceedings be instituted against the Licensee, the Licensor shall provide it with technical and legal assistance for its defense. Such technical and legal assistance shall be decided on a case-by-case basis between the relevant Licensor and the Licensee pursuant to a memorandum of understanding. The Licensor disclaims any and all liability as regards the Licensee's use of the name of the Software. No warranty is given as regards the existence of prior rights over the name of the Software or as regards the existence of a trademark.
Article 10 - TERMINATION
10.1 In the event of a breach by the Licensee of its obligations hereunder, the Licensor may automatically terminate this Agreement thirty (30) days after notice has been sent to the Licensee and has remained ineffective.
10.2 A Licensee whose Agreement is terminated shall no longer be authorized to use, modify or distribute the Software. However, any licenses that it may have granted prior to termination of the Agreement shall remain valid subject to their having been granted in compliance with the terms and conditions hereof.
Article 11 - MISCELLANEOUS
11.1 EXCUSABLE EVENTS
Neither Party shall be liable for any or all delay, or failure to perform the Agreement, that may be attributable to an event of force majeure, an act of God or an outside cause, such as defective functioning or interruptions of the electricity or telecommunications networks, network paralysis following a virus attack, intervention by government authorities, natural disasters, water damage, earthquakes, fire, explosions, strikes and labor unrest, war, etc.
11.2 Any failure by either Party, on one or more occasions, to invoke one or more of the provisions hereof, shall under no circumstances be interpreted as being a waiver by the interested Party of its right to invoke said provision(s) subsequently.
11.3 The Agreement cancels and replaces any or all previous agreements, whether written or oral, between the Parties and having the same purpose, and constitutes the entirety of the agreement between said Parties concerning said purpose. No supplement or modification to the terms and conditions hereof shall be effective as between the Parties unless it is made in writing and signed by their duly authorized representatives.
11.4 In the event that one or more of the provisions hereof were to conflict with a current or future applicable act or legislative text, said act or legislative text shall prevail, and the Parties shall make the necessary amendments so as to comply with said act or legislative text. All other provisions shall remain effective. Similarly, invalidity of a provision of the Agreement, for any reason whatsoever, shall not cause the Agreement as a whole to be invalid.
11.5 LANGUAGE
The Agreement is drafted in both French and English and both versions are deemed authentic.
Article 12 - NEW VERSIONS OF THE AGREEMENT
12.1 Any person is authorized to duplicate and distribute copies of this Agreement.
12.2 So as to ensure coherence, the wording of this Agreement is protected and may only be modified by the authors of the License, who reserve the right to periodically publish updates or new versions of the Agreement, each with a separate number. These subsequent versions may address new issues encountered by Free Software.
12.3 Any Software distributed under a given version of the Agreement may only be subsequently distributed under the same version of the Agreement or a subsequent version.
Article 13 - GOVERNING LAW AND JURISDICTION
13.1 The Agreement is governed by French law. The Parties agree to endeavor to seek an amicable solution to any disagreements or disputes that may arise during the performance of the Agreement.
13.2 Failing an amicable solution within two (2) months as from their occurrence, and unless emergency proceedings are necessary, the disagreements or disputes shall be referred to the Paris Courts having jurisdiction, by the more diligent Party.
Version 1.0 dated 2006-09-05.
Gson Library
PVS-Studio uses Gson. This is Gson license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
picocli Library
PVS-Studio uses picocli. This is picocli license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
fastutil Framework
PVS-Studio uses fastutil. This is fastutil license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
StreamEx Library
PVS-Studio uses StreamEx. This is StreamEx license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Maven Model
PVS-Studio uses Maven Model. This is Maven Model license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Maven Plugin Tools
PVS-Studio uses Maven Plugin Tools. This is Maven Plugin Tools license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Commons IO Library
PVS-Studio uses Commons IO Library. This is Commons IO Library license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Apache Commons Lang
PVS-Studio uses Apache Commons Lang. This is Apache Commons Lang license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
JetBrains Java Annotations
PVS-Studio uses JetBrains Java Annotations. This is JetBrains Java Annotations license:
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
JUnit Framework
PVS-Studio uses JUnit Framework. This is JUnit Framework license:
Eclipse Public License - v 1.0
THE ACCOMPANYING PROGRAM IS PROVIDED UNDER THE TERMS OF THIS ECLIPSE PUBLIC LICENSE ("AGREEMENT"). ANY USE, REPRODUCTION OR DISTRIBUTION OF THE PROGRAM CONSTITUTES RECIPIENT'S ACCEPTANCE OF THIS AGREEMENT.
1. DEFINITIONS
"Contribution" means:
a) in the case of the initial Contributor, the initial code and documentation distributed under this Agreement, and b) in the case of each subsequent Contributor:
i) changes to the Program, and
ii) additions to the Program;
where such changes and/or additions to the Program originate from and are distributed by that particular Contributor. A Contribution 'originates' from a Contributor if it was added to the Program by such Contributor itself or anyone acting on such Contributor's behalf. Contributions do not include additions to the Program which: (i) are separate modules of software distributed in conjunction with the Program under their own license agreement, and (ii) are not derivative works of the Program.
"Contributor" means any person or entity that distributes the Program.
"Licensed Patents " mean patent claims licensable by a Contributor which are necessarily infringed by the use or sale of its Contribution alone or when combined with the Program.
"Program" means the Contributions distributed in accordance with this Agreement.
"Recipient" means anyone who receives the Program under this Agreement, including all Contributors.
2. GRANT OF RIGHTS
a) Subject to the terms of this Agreement, each Contributor hereby grants Recipient a non-exclusive, worldwide, royalty-free copyright license to reproduce, prepare derivative works of, publicly display, publicly perform, distribute and sublicense the Contribution of such Contributor, if any, and such derivative works, in source code and object code form.
b) Subject to the terms of this Agreement, each Contributor hereby grants Recipient a non-exclusive, worldwide, royalty-free patent license under Licensed Patents to make, use, sell, offer to sell, import and otherwise transfer the Contribution of such Contributor, if any, in source code and object code form. This patent license shall apply to the combination of the Contribution and the Program if, at the time the Contribution is added by the Contributor, such addition of the Contribution causes such combination to be covered by the Licensed Patents. The patent license shall not apply to any other combinations which include the Contribution. No hardware per se is licensed hereunder.
c) Recipient understands that although each Contributor grants the licenses to its Contributions set forth herein, no assurances are provided by any Contributor that the Program does not infringe the patent or other intellectual property rights of any other entity. Each Contributor disclaims any liability to Recipient for claims brought by any other entity based on infringement of intellectual property rights or otherwise. As a condition to exercising the rights and licenses granted hereunder, each Recipient hereby assumes sole responsibility to secure any other intellectual property rights needed, if any. For example, if a third party patent license is required to allow Recipient to distribute the Program, it is Recipient's responsibility to acquire that license before distributing the Program.
d) Each Contributor represents that to its knowledge it has sufficient copyright rights in its Contribution, if any, to grant the copyright license set forth in this Agreement.
3. REQUIREMENTS
A Contributor may choose to distribute the Program in object code form under its own license agreement, provided that:
a) it complies with the terms and conditions of this Agreement; and
b) its license agreement:
i) effectively disclaims on behalf of all Contributors all warranties and conditions, express and implied, including warranties or conditions of title and non-infringement, and implied warranties or conditions of merchantability and fitness for a particular purpose;
ii) effectively excludes on behalf of all Contributors all liability for damages, including direct, indirect, special, incidental and consequential damages, such as lost profits;
iii) states that any provisions which differ from this Agreement are offered by that Contributor alone and not by any other party; and
iv) states that source code for the Program is available from such Contributor, and informs licensees how to obtain it in a reasonable manner on or through a medium customarily used for software exchange.
When the Program is made available in source code form:
a) it must be made available under this Agreement; and
b) a copy of this Agreement must be included with each copy of the Program.
Contributors may not remove or alter any copyright notices contained within the Program.
Each Contributor must identify itself as the originator of its Contribution, if any, in a manner that reasonably allows subsequent Recipients to identify the originator of the Contribution.
4. COMMERCIAL DISTRIBUTION
Commercial distributors of software may accept certain responsibilities with respect to end users, business partners and the like. While this license is intended to facilitate the commercial use of the Program, the Contributor who includes the Program in a commercial product offering should do so in a manner which does not create potential liability for other Contributors. Therefore, if a Contributor includes the Program in a commercial product offering, such Contributor ("Commercial Contributor") hereby agrees to defend and indemnify every other Contributor ("Indemnified Contributor") against any losses, damages and costs (collectively "Losses") arising from claims, lawsuits and other legal actions brought by a third party against the Indemnified Contributor to the extent caused by the acts or omissions of such Commercial Contributor in connection with its distribution of the Program in a commercial product offering. The obligations in this section do not apply to any claims or Losses relating to any actual or alleged intellectual property infringement. In order to qualify, an Indemnified Contributor must: a) promptly notify the Commercial Contributor in writing of such claim, and b) allow the Commercial Contributor to control, and cooperate with the Commercial Contributor in, the defense and any related settlement negotiations. The Indemnified Contributor may participate in any such claim at its own expense.
For example, a Contributor might include the Program in a commercial product offering, Product X. That Contributor is then a Commercial Contributor. If that Commercial Contributor then makes performance claims, or offers warranties related to Product X, those performance claims and warranties are such
Commercial Contributor's responsibility alone. Under this section, the Commercial Contributor would have to defend claims against the other Contributors related to those performance claims and warranties, and if a court requires any other Contributor to pay any damages as a result, the Commercial Contributor must pay those damages.
5. NO WARRANTY
EXCEPT AS EXPRESSLY SET FORTH IN THIS AGREEMENT, THE PROGRAM IS PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, EITHER EXPRESS OR IMPLIED INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OR CONDITIONS OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Each Recipient is solely responsible for determining the appropriateness of using and distributing the Program and assumes all risks associated with its exercise of rights under this Agreement, including but not limited to the risks and costs of program errors, compliance with applicable laws, damage to or loss of data, programs or equipment, and unavailability or interruption of operations.
6. DISCLAIMER OF LIABILITY
EXCEPT AS EXPRESSLY SET FORTH IN THIS AGREEMENT, NEITHER RECIPIENT NOR ANY CONTRIBUTORS SHALL HAVE ANY LIABILITY FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING WITHOUT LIMITATION LOST PROFITS), HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OR DISTRIBUTION OF THE PROGRAM OR THE EXERCISE OF ANY RIGHTS GRANTED HEREUNDER, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
7. GENERAL
If any provision of this Agreement is invalid or unenforceable under applicable law, it shall not affect the validity or enforceability of the remainder of the terms of this Agreement, and without further action by the parties hereto, such provision shall be reformed to the minimum extent necessary to make such provision valid and enforceable.
If Recipient institutes patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Program itself (excluding combinations of the Program with other software or hardware) infringes such Recipient's patent(s), then such Recipient's rights granted under Section 2(b) shall terminate as of the date such litigation is filed.
All Recipient's rights under this Agreement shall terminate if it fails to comply with any of the material terms or conditions of this Agreement and does not cure such failure in a reasonable period of time after becoming aware of such noncompliance. If all Recipient's rights under this Agreement terminate, Recipient agrees to cease use and distribution of the Program as soon as reasonably practicable. However, Recipient's obligations under this Agreement and any licenses granted by Recipient relating to the Program shall continue and survive.
Everyone is permitted to copy and distribute copies of this Agreement, but in order to avoid inconsistency the Agreement is copyrighted and may only be modified in the following manner. The Agreement Steward reserves the right to publish new versions (including revisions) of this Agreement from time to time. No one other than the Agreement Steward has the right to modify this Agreement. The Eclipse Foundation is the initial Agreement Steward. The Eclipse Foundation may assign the responsibility to serve as the Agreement Steward to a suitable separate entity. Each new version of the Agreement will be given a distinguishing version number. The Program (including Contributions) may always be distributed subject to the version of the Agreement under which it was received. In addition, after a new version of the Agreement is published, Contributor may elect to distribute the Program (including its Contributions) under the new version. Except as expressly stated in Sections 2(a) and 2(b) above, Recipient receives no rights or licenses to the intellectual property of any Contributor under this Agreement, whether expressly, by implication, estoppel or otherwise. All rights in the Program not expressly granted under this Agreement are reserved.
This Agreement is governed by the laws of the State of New York and the intellectual property laws of the United States of America. No party to this Agreement will bring a legal action under this Agreement more than one year after the cause of action arose. Each party waives its rights to a jury trial in any resulting litigation.
juniversalchardet
PVS-Studio uses juniversalchardet. This is juniversalchardet license:
MOZILLA PUBLIC LICENSE
Version 1.1
1. Definitions.
1.0.1. "Commercial Use" means distribution or otherwise making the Covered Code available to a third party.
1.1. "Contributor" means each entity that creates or contributes to the creation of Modifications.
1.2. "Contributor Version" means the combination of the Original Code, prior Modifications used by a Contributor, and the Modifications made by that particular Contributor.
1.3. "Covered Code" means the Original Code or Modifications or the combination of the Original Code and Modifications, in each case including portions thereof.
1.4. "Electronic Distribution Mechanism" means a mechanism generally accepted in the software development community for the electronic transfer of data.
1.5. "Executable" means Covered Code in any form other than Source Code.
1.6. "Initial Developer" means the individual or entity identified as the Initial Developer in the Source Code notice required by Exhibit A.
1.7. "Larger Work" means a work which combines Covered Code or portions thereof with code not governed by the terms of this License.
1.8. "License" means this document.
1.8.1. "Licensable" means having the right to grant, to the maximum extent possible, whether at the time of the initial grant or subsequently acquired, any and all of the rights conveyed herein.
1.9. "Modifications" means any addition to or deletion from the substance or structure of either the Original Code or any previous Modifications. When Covered Code is released as a series of files, a Modification is: A. Any addition to or deletion from the contents of a file containing Original Code or previous Modifications.
B. Any new file that contains any part of the Original Code or previous Modifications.
1.10. "Original Code" means Source Code of computer software code which is described in the Source Code notice required by Exhibit A as Original Code, and which, at the time of its release under this License is not already Covered Code governed by this License.
1.10.1. "Patent Claims" means any patent claim(s), now owned or hereafter acquired, including without limitation, method, process, and apparatus claims, in any patent Licensable by grantor.
1.11. "Source Code" means the preferred form of the Covered Code for making modifications to it, including all modules it contains, plus any associated interface definition files, scripts used to control compilation and installation of an Executable, or source code differential comparisons against either the Original Code or another well known, available Covered Code of the Contributor's choice. The Source Code can be in a compressed or archival form, provided the appropriate decompression or de-archiving software is widely available for no charge.
1.12. "You" (or "Your") means an individual or a legal entity exercising rights under, and complying with all of the terms of, this License or a future version of this License issued under Section 6.1. For legal entities, "You" includes any entity which controls, is controlled by, or is under common control with You. For purposes of this definition, "control" means (a) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (b) ownership of more than fifty percent (50%) of the outstanding shares or beneficial ownership of such entity.
2. Source Code License.
2.1. The Initial Developer Grant. The Initial Developer hereby grants You a world-wide, royalty-free, non-exclusive license, subject to third party intellectual property claims:
(a) under intellectual property rights (other than patent or trademark) Licensable by Initial Developer to use, reproduce, modify, display, perform, sublicense and distribute the Original Code (or portions thereof) with or without Modifications, and/or as part of a Larger Work; and
(b) under Patents Claims infringed by the making, using or selling of Original Code, to make, have made, use, practice, sell, and offer for sale, and/or otherwise dispose of the Original Code (or portions thereof).
(c) the licenses granted in this Section 2.1(a) and (b) are effective on the date Initial Developer first distributes Original Code under the terms of this License.
(d) Notwithstanding Section 2.1(b) above, no patent license is granted: 1) for code that You delete from the Original Code; 2) separate from the Original Code; or 3) for infringements caused by: i) the modification of the Original Code or ii) the combination of the Original Code with other software or devices.
2.2. Contributor Grant. Subject to third party intellectual property claims, each Contributor hereby grants You a world-wide, royalty-free, non-exclusive license
(a) under intellectual property rights (other than patent or trademark) Licensable by Contributor, to use, reproduce, modify, display, perform, sublicense and distribute the Modifications created by such Contributor (or portions thereof) either on an unmodified basis, with other Modifications, as Covered Code and/or as part of a Larger Work; and
(b) under Patent Claims infringed by the making, using, or selling of Modifications made by that Contributor either alone and/or in combination with its Contributor Version (or portions of such combination), to make, use, sell, offer for sale, have made, and/or otherwise dispose of: 1) Modifications made by that Contributor (or portions thereof); and 2) the combination of Modifications made by that Contributor with its Contributor Version (or portions of such combination).
(c) the licenses granted in Sections 2.2(a) and 2.2(b) are effective on the date Contributor first makes Commercial Use of the Covered Code.
(d) Notwithstanding Section 2.2(b) above, no patent license is granted: 1) for any code that Contributor has deleted from the Contributor Version; 2) separate from the Contributor Version; 3) for infringements caused by: i) third party modifications of Contributor Version or ii) the combination of Modifications made by that Contributor with other software (except as part of the Contributor Version) or other devices; or 4) under Patent Claims infringed by Covered Code in the absence of Modifications made by that Contributor.
3. Distribution Obligations.
3.1. Application of License. The Modifications which You create or to which You contribute are governed by the terms of this License, including without limitation Section 2.2. The Source Code version of Covered Code may be distributed only under the terms of this License or a future version of this License released under Section 6.1, and You must include a copy of this License with every copy of the Source Code You distribute. You may not offer or impose any terms on any Source Code version that alters or restricts the applicable version of this License or the recipients' rights hereunder. However, You may include an additional document offering the additional rights described in Section 3.5.
3.2. Availability of Source Code. Any Modification which You create or to which You contribute must be made available in Source Code form under the terms of this License either on the same media as an Executable version or via an accepted Electronic Distribution Mechanism to anyone to whom you made an Executable version available; and if made available via Electronic Distribution Mechanism, must remain available for at least twelve (12) months after the date it initially became available, or at least six
(6) months after a subsequent version of that particular Modification has been made available to such recipients. You are responsible for ensuring that the Source Code version remains available even if the Electronic Distribution Mechanism is maintained by a third party.
3.3. Description of Modifications.
You must cause all Covered Code to which You contribute to contain a file documenting the changes You made to create that Covered Code and the date of any change. You must include a prominent statement that the Modification is derived, directly or indirectly, from Original Code provided by the Initial Developer and including the name of the Initial Developer in (a) the Source Code, and (b) in any notice in an Executable version or related documentation in which You describe the origin or ownership of the Covered Code.
3.4. Intellectual Property Matters
(a) Third Party Claims.
If Contributor has knowledge that a license under a third party's intellectual property rights is required to exercise the rights granted by such Contributor under Sections 2.1 or 2.2, Contributor must include a text file with the Source Code distribution titled "LEGAL" which describes the claim and the party making the claim in sufficient detail that a recipient will know whom to contact. If Contributor obtains such knowledge after the Modification is made available as described in Section 3.2, Contributor shall promptly modify the LEGAL file in all copies Contributor makes available thereafter and shall take other steps (such as notifying appropriate mailing lists or newsgroups) reasonably calculated to inform those who received the Covered Code that new knowledge has been obtained.
(b) Contributor APIs.
If Contributor's Modifications include an application programming interface and Contributor has knowledge of patent licenses which are reasonably necessary to implement that API, Contributor must also include this information in the LEGAL file.
(c) Representations.
Contributor represents that, except as disclosed pursuant to Section 3.4(a) above, Contributor believes that Contributor's Modifications are Contributor's original creation(s) and/or Contributor has sufficient rights to grant the rights conveyed by this License.
3.5. Required Notices.
You must duplicate the notice in Exhibit A in each file of the Source Code. If it is not possible to put such notice in a particular Source Code file due to its structure, then You must include such notice in a location (such as a relevant directory) where a user would be likely to look for such a notice. If You created one or more Modification(s) You may add your name as a Contributor to the notice described in Exhibit A. You must also duplicate this License in any documentation for the Source Code where You describe recipients' rights or ownership rights relating to Covered Code. You may choose to offer, and to charge a fee for, warranty, support, indemnity or liability obligations to one or more recipients of Covered Code. However, You may do so only on Your own behalf, and not on behalf of the Initial Developer or any Contributor. You must make it absolutely clear than any such warranty, support, indemnity or liability obligation is offered by You alone, and You hereby agree to indemnify the Initial Developer and every Contributor for any liability incurred by the Initial Developer or such Contributor as a result of warranty, support, indemnity or liability terms You offer.
3.6. Distribution of Executable Versions. You may distribute Covered Code in Executable form only if the requirements of Section 3.1-3.5 have been met for that Covered Code, and if You include a notice stating that the Source Code version of the Covered Code is available under the terms of this License, including a description of how and where You have fulfilled the obligations of Section 3.2. The notice must be conspicuously included in any notice in an Executable version, related documentation or collateral in which You describe recipients' rights relating to the Covered Code. You may distribute the Executable version of Covered Code or ownership rights under a license of Your choice, which may contain terms different from this License, provided that You are in compliance with the terms of this License and that the license for the Executable version does not attempt to limit or alter the recipient's rights in the Source Code version from the rights set forth in this License. If You distribute the Executable version under a different license You must make it absolutely clear that any terms which differ from this License are offered by You alone, not by the Initial Developer or any Contributor. You hereby agree to indemnify the Initial Developer and every Contributor for any liability incurred by the Initial Developer or such Contributor as a result of any such terms You offer.
3.7. Larger Works.
You may create a Larger Work by combining Covered Code with other code not governed by the terms of this License and distribute the Larger Work as a single product. In such a case, You must make sure the requirements of this License are fulfilled for the Covered Code.
4. Inability to Comply Due to Statute or Regulation.
If it is impossible for You to comply with any of the terms of this License with respect to some or all of the Covered Code due to statute, judicial order, or regulation then You must: (a) comply with the terms of this License to the maximum extent possible; and (b) describe the limitations and the code they affect. Such description must be included in the LEGAL file described in Section 3.4 and must be included with all distributions of the Source Code. Except to the extent prohibited by statute or regulation, such description must be sufficiently detailed for a recipient of ordinary skill to be able to understand it.
5. Application of this License.
This License applies to code to which the Initial Developer has attached the notice in Exhibit A and to related Covered Code.
6. Versions of the License.
6.1. New Versions.
Netscape Communications Corporation ("Netscape") may publish revised and/or new versions of the License from time to time. Each version will be given a distinguishing version number.
6.2. Effect of New Versions.
Once Covered Code has been published under a particular version of the License, You may always continue to use it under the terms of that version. You may also choose to use such Covered Code under the terms of any subsequent version of the License published by Netscape. No one other than Netscape has the right to modify the terms applicable to Covered Code created under this License.
6.3. Derivative Works.
If You create or use a modified version of this License (which you may only do in order to apply it to code which is not already Covered Code governed by this License), You must (a) rename Your license so that the phrases "Mozilla", "MOZILLAPL", "MOZPL", "Netscape", "MPL", "NPL" or any confusingly similar phrase do not appear in your license (except to note that your license differs from this License) and (b) otherwise make it clear that Your version of the license contains terms which differ from the Mozilla Public License and Netscape Public License. (Filling in the name of the Initial Developer, Original Code or Contributor in the notice described in Exhibit A shall not of themselves be deemed to be modifications of this License.)
7. DISCLAIMER OF WARRANTY.
COVERED CODE IS PROVIDED UNDER THIS LICENSE ON AN "AS IS" BASIS, WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, WARRANTIES THAT THE COVERED CODE IS FREE OF DEFECTS, MERCHANTABLE, FIT FOR A PARTICULAR PURPOSE OR NON-INFRINGING. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE COVERED CODE IS WITH YOU. SHOULD ANY COVERED CODE PROVE DEFECTIVE IN ANY RESPECT, YOU (NOT THE INITIAL DEVELOPER OR ANY OTHER CONTRIBUTOR) ASSUME THE COST OF ANY NECESSARY SERVICING, REPAIR OR CORRECTION. THIS DISCLAIMER OF WARRANTY CONSTITUTES AN ESSENTIAL PART OF THIS LICENSE. NO USE OF ANY COVERED CODE IS AUTHORIZED HEREUNDER EXCEPT UNDER THIS DISCLAIMER.
8. TERMINATION.
8.1. This License and the rights granted hereunder will terminate automatically if You fail to comply with terms herein and fail to cure such breach within 30 days of becoming aware of the breach. All sublicenses to the Covered Code which are properly granted shall survive any termination of this License. Provisions which, by their nature, must remain in effect beyond the termination of this License shall survive.
8.2. If You initiate litigation by asserting a patent infringement claim (excluding declatory judgment actions) against Initial Developer or a Contributor (the Initial Developer or Contributor against whom You file such action is referred to as "Participant") alleging that:
(a) such Participant's Contributor Version directly or indirectly infringes any patent, then any and all rights granted by such Participant to You under Sections 2.1 and/or 2.2 of this License shall, upon 60 days notice from Participant terminate prospectively, unless if within 60 days after receipt of notice You either: (i) agree in writing to pay Participant a mutually agreeable reasonable royalty for Your past and future use of Modifications made by such Participant, or (ii) withdraw Your litigation claim with respect to the Contributor Version against such Participant. If within 60 days of notice, a reasonable royalty and payment arrangement are not mutually agreed upon in writing by the parties or the litigation claim is not withdrawn, the rights granted by Participant to You under Sections 2.1 and/or 2.2 automatically terminate at the expiration of the 60 day notice period specified above.
(b) any software, hardware, or device, other than such Participant's Contributor Version, directly or indirectly infringes any patent, then any rights granted to You by such Participant under Sections 2.1(b) and 2.2(b) are revoked effective as of the date You first made, used, sold, distributed, or had made, Modifications made by that Participant.
8.3. If You assert a patent infringement claim against Participant alleging that such Participant's Contributor Version directly or indirectly infringes any patent where such claim is resolved (such as by license or settlement) prior to the initiation of patent infringement litigation, then the reasonable value of the licenses granted by such Participant under Sections 2.1 or 2.2 shall be taken into account in determining the amount or value of any payment or license.
8.4. In the event of termination under Sections 8.1 or 8.2 above, all end user license agreements (excluding distributors and resellers) which have been validly granted by You or any distributor hereunder prior to termination shall survive termination.
9. LIMITATION OF LIABILITY.
UNDER NO CIRCUMSTANCES AND UNDER NO LEGAL THEORY, WHETHER TORT (INCLUDING NEGLIGENCE), CONTRACT, OR OTHERWISE, SHALL YOU, THE INITIAL DEVELOPER, ANY OTHER CONTRIBUTOR, OR ANY DISTRIBUTOR OF COVERED CODE, OR ANY SUPPLIER OF ANY OF SUCH PARTIES, BE LIABLE TO ANY PERSON FOR ANY INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES OF ANY CHARACTER INCLUDING, WITHOUT LIMITATION, DAMAGES FOR LOSS OF GOODWILL, WORK STOPPAGE, COMPUTER FAILURE OR MALFUNCTION, OR ANY AND ALL OTHER COMMERCIAL DAMAGES OR LOSSES, EVEN IF SUCH PARTY SHALL HAVE BEEN INFORMED OF THE POSSIBILITY OF SUCH DAMAGES. THIS LIMITATION OF LIABILITY SHALL NOT APPLY TO LIABILITY FOR DEATH OR PERSONAL INJURY RESULTING FROM SUCH PARTY'S NEGLIGENCE TO THE EXTENT APPLICABLE LAW PROHIBITS SUCH LIMITATION. SOME JURISDICTIONS DO NOT ALLOW THE EXCLUSION OR LIMITATION OF INCIDENTAL OR CONSEQUENTIAL DAMAGES, SO THIS EXCLUSION AND LIMITATION MAY NOT APPLY TO YOU.
10. U.S. GOVERNMENT END USERS.
The Covered Code is a "commercial item," as that term is defined in 48 C.F.R. 2.101 (Oct. 1995), consisting of "commercial computer software" and "commercial computer software documentation," as such terms are used in 48 C.F.R. 12.212 (Sept. 1995). Consistent with 48 C.F.R. 12.212 and 48 C.F.R. 227.7202-1 through 227.7202-4 (June 1995), all U.S. Government End Users acquire Covered Code with only those rights set forth herein.
11. MISCELLANEOUS.
This License represents the complete agreement concerning subject matter hereof. If any provision of this License is held to be unenforceable, such provision shall be reformed only to the extent necessary to make it enforceable. This License shall be governed by California law provisions (except to the extent applicable law, if any, provides otherwise), excluding its conflict-of-law provisions. With respect to disputes in which at least one party is a citizen of, or an entity chartered or registered to do business in the United States of America, any litigation relating to this License shall be subject to the jurisdiction of the Federal Courts of the Northern District of California, with venue lying in Santa Clara County, California, with the losing party responsible for costs, including without limitation, court costs and reasonable attorneys' fees and expenses. The application of the United Nations Convention on Contracts for the International Sale of Goods is expressly excluded. Any law or regulation which provides that the language of a contract shall be construed against the drafter shall not apply to this License.
12. RESPONSIBILITY FOR CLAIMS.
As between Initial Developer and the Contributors, each party is responsible for claims and damages arising, directly or indirectly, out of its utilization of rights under this License and You agree to work with Initial Developer and Contributors to distribute such responsibility on an equitable basis. Nothing herein is intended or shall be deemed to constitute any admission of liability.
13. MULTIPLE-LICENSED CODE.
Initial Developer may designate portions of the Covered Code as "Multiple-Licensed". "Multiple-Licensed" means that the Initial Developer permits you to utilize portions of the Covered Code under Your choice of the NPL or the alternative licenses, if any, specified by the Initial Developer in the file described in Exhibit A.
Common Weakness Enumeration (CWE)
PVS-Studio supports CWE. This is CWE license:
LICENSE
The MITRE Corporation (MITRE) hereby grants you a non-exclusive, royalty-free license to use Common Weakness Enumeration (CWE™) for research, development, and commercial purposes. Any copy you make for such purposes is authorized provided that you reproduce MITRE's copyright designation and this license in any such copy.
DISCLAIMERS
ALL DOCUMENTS AND THE INFORMATION CONTAINED THEREIN ARE PROVIDED ON AN "AS IS" BASIS AND THE CONTRIBUTOR, THE ORGANIZATION HE/SHE REPRESENTS OR IS SPONSORED BY (IF ANY), THE MITRE CORPORATION, ITS BOARD OF TRUSTEES, OFFICERS, AGENTS, AND EMPLOYEES, DISCLAIM ALL WARRANTIES, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTY THAT THE USE OF THE INFORMATION THEREIN WILL NOT INFRINGE ANY RIGHTS OR ANY IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE.
CWE is free to use by any organization or individual for any research, development, and/or commercial purposes, per these CWE Terms of Use. MITRE has copyrighted the CWE List, Top 25, CWSS, and CWRAF for the benefit of the community in order to ensure each remains a free and open standard, as well as to legally protect the ongoing use of it and any resulting content by government, vendors, and/or users. MITRE has trademarked ™ the CWE and related acronyms and the CWE and related logos to protect their sole and ongoing use by the CWE effort within the information security arena. Please contact cwe@mitre.org if you require further clarification on this issue.
Кроссплатформенная проверка C и C++ проектов в PVS-Studio
- Введение
- Активация лицензии
- Подготовка к анализу проекта
- Анализ проекта
- Использование файла конфигурации
- Подавление сообщений анализатора и фильтрация отчёта согласно правилам подавления
- Описание кодов возврата
Введение
PVS-Studio поддерживает проверку кроссплатформенных проектов на C и С++, независимо от используемой сборочной системы. Для проверки таких проектов существует специальная утилита. Она имеет различные названия в зависимости от платформы: для Linux и macOS — pvs-studio-analyzer, для Windows – CompilerCommandsAnalyzer.exe. Все примеры запуска, описанные в этой документации, будут использовать имя pvs-studio-analyzer.
Для проверки проектов Visual Studio следует воспользоваться следующий документацией:
- Работа PVS-Studio в Visual Studio
- Проверка проектов Visual Studio / MSBuild / .NET из командной строки с помощью PVS-Studio
На Windows вы также можете использовать сервер мониторинга компиляции.
Примечание: pvs-studio-analyzer и CompilerCommandsAnalyzer.exe являются одной и той же кроссплатформенной утилитой и имеют незначительные отличия. Платформо-зависимые особенности будут описаны в данном документе. Все примеры запуска pvs-studio-analyzer являются кроссплатформенными, если в описании к ним не говорится обратное.
Активация лицензии
Для работы анализатора необходимо активировать лицензию одним из способов, предложенных в документации.
Если у вас нет лицензии, вы можете запросить её через форму обратной связи.
Подготовка к анализу проекта
Для запуска анализа проекта утилите pvs-studio-analyzer необходимо иметь представление о параметрах запуска компиляции для каждой единицы трансляции. Эти параметры могут быть получены из JSON Compilation Database (compile_commands.json) либо из файла трассировки сборки.
Важно: Для анализа проект должен успешно собираться.
Использование базы данных компиляции (Windows, Linux, macOS)
Многие сборочные системы (CMake, Ninja и др.) позволяют сгенерировать файл compile_commands.json. Для сборочных систем, не предусматривающих получение compile_commands.json напрямую, существуют разные утилиты (Bear, Text Toolkit, intercept-build и др.), позволяющие сгенерировать его.
Процесс генерации JSON Compilation Database и анализа подробно описан здесь.
Создание файла трассировки компиляции (только Linux)
Если у вас нет возможности сгенерировать compile_commands.json для своего проекта, вы можете воспользоваться режимом трассировки компиляции. Данный режим работает только на Linux и использует утилиту strace для перехвата вызовов компилятора.
Примечание: для мониторинга компиляции на Windows следует воспользоваться сервером мониторинга компиляции CLMonitor.
Важно: для трассировки компиляции в системе должен быть установлен strace версии 4.11 или старше, и включён системный вызов PTRACE.
Примечание: во многих дистрибутивах PTRACE включен по умолчанию. Однако, бывают исключения. Для включения PTRACE измените значение параметра kernel.yama.ptrace_scope в файле /etc/sysctl.d/10-ptrace.conf на 1.
Результат трассировки записывается в файл с именем strace_out (по умолчанию) в текущей директории, который впоследствии использует анализатор для получения параметров компиляции. При помощи флага -o можно задать произвольный путь, в который будет записана трассировка.
Перед запуском трассировки убедитесь, что в сборочном каталоге нет артефактов предыдущей сборки. Иначе сборочная система может опустить вызовы компилятора для неизменённых файлов, если она использует инкрементальный режим сборки.
Для запуска трассировки компиляции воспользуйтесь следующей командой:
pvs-studio-analyzer trace [-o <FILE>] -- build_commandbuild_command — команда, используемая для сборки проекта.
Пример:
pvs-studio-analyzer trace -- cmake build .Анализ проекта
После формирования JSON Compilation Database или файла трассировки компиляции можно перейти к анализу проекта.
В общем случае для запуска анализа необходимо выполнить команду:
pvs-studio-analyzer analyze [-o /path/to/PVS-Studio.log] \
[-e /path/to/exclude-path]... \
[-j <N>]Далее будет приведено описание всех флагов запуска анализа.
Описание общих флагов
‑‑cfg [FILE] (-c [FILE]) — задаёт файл конфигурации *.cfg, в который можно поместить некоторые параметры запуска анализатора (например, exclude-path, lic-file и др.). В следующем разделе будет дано описание настроек файла конфигурации. Вы можете использовать файл конфигурации, чтобы вынести туда общие параметры проверки различных проектов.
‑‑lic-file [FILE] (-l [FILE]) — путь до файла с лицензией. Для данного параметра есть соответствующая настройка в файле конфигурации.
‑‑threads [N] (-j [N]) — задаёт число потоков, на которое будет распараллелен анализ.
‑‑output-file [FILE] (-o [FILE]) — имя файла, в который будет записан отчёт анализатора. По умолчанию, если данный флаг не указан, отчёт будет записан в файл PVS-Studio.log в текущей директории. Вы можете задать данный параметр в файле конфигурации (*.cfg).
‑‑exclude-path [DIR] (-e [DIR]) — задаёт путь, по которому следует исключить файлы из анализа. Вы можете задать абсолютный или относительный путь. Также можно использовать шаблоны (glob) для исключения набора файлов. Если есть несколько директорий, которые нужно исключить из проверки, добавьте каждую через данный флаг или пропишите их в файле конфигурации.
‑‑analysis-paths [MODE=PATH|GLOB] — определяет поведение анализа на указанных путях. Доступны следующие режимы:
skip-analysis— задаёт директорию, файлы из которой проверять не надо. Обычно это каталоги системных файлов или подключаемых библиотек.skip-settings— игнорирует настройки, расположенные в исходных файлах и файлах.pvsconfigпо указанному пути.isolate-settings— задаёт директорию, для которой следует изолировать настройки. При использовании данного режима файлы конфигурации правил.pvsconfigиз родительских каталогов не будут применяться для единиц трансляции в указанной директории и её подкаталогах. Поддерживаются абсолютные и относительные пути. Относительные пути раскрываются через текущий каталог. Для этого режима нельзя использовать шаблоныglob.skip— игнорирует настройки, расположенные в исходных файлах и файлах.pvsconfigпо указанному пути. Также будут отфильтрованы предупреждения, сгенерированные для файлов исходного кода по указанному пути или маске.
‑‑analysis-mode [MODE] (-a [MODE]) — задаёт группу предупреждений, которые будут активированы при анализе вашего проекта.
- 64 — группа диагностик, позволяющих выявлять 64-битные ошибки.
- GA — группа диагностик общего назначения.
- OP — диагностики микро-оптимизаций.
- CS — группа диагностик, добавленных по просьбе пользователей.
- MISRA — группа диагностик, предназначенных для проверки кода на соответствие стандартам MISRA.
- AUTOSAR — группа диагностик, предназначенных для проверки кода на соответствие стандартам AUTOSAR.
- OWASP — группа диагностик, предназначенных для проверки кода на соответствие стандартам OWASP.
Подробнее про MISRA, AUTOSAR и OWASP можно прочитать здесь.
Если вы хотите задать несколько групп предупреждений, то следует разделить их через символ ; или +. Например: GA;OP;64 или GA+OP+64. Вы можете не указывать кавычки, если используете в качестве разделителя +. Если вы используете в качестве разделителя символ ;, то следует обернуть выражение в кавычки или экранировать каждый символ "точка с запятой", т. к. в командной оболочке он обычно обозначает разделитель команд.
По умолчанию используется группа GA.
Также вы можете задать данный параметр в файле конфигурации (*.cfg).
‑‑sourcetree-root [DIR] (-r [DIR]) — флаг указывает, что в отчёте следует заменить корневую часть пути (DIR) на специальный символ. Таким образом путь до файла с предупреждением анализатора станет относительным. По умолчанию при генерации диагностических сообщений PVS-Studio выдаёт абсолютные пути до файлов, на которые анализатор выдал срабатывания. С помощью данной настройки можно задать корневую часть пути, которую анализатор будет автоматически подменять на специальный маркер. Замена произойдет, если путь до файла начинается с заданной корневой части ([DIR]). В дальнейшем отчёт с относительными путями можно использовать для просмотра результатов анализа в окружении с отличающимся расположением исходных файлов.
‑‑project-root — задаёт путь до корневой директории проекта. Можно указать абсолютный или относительный путь. Относительный путь будет раскрыт через текущий каталог. Если флаг не указан, то текущий каталог будет считаться корнем проекта.
‑‑apply-pvs-configs — флаг включает режим поиска и применения файлов конфигурации правил (.pvsconfig) для каждой единицы трансляции. Файлы конфигурации правил ищутся в каталоге единицы трансляции и всех родительских каталогах (вплоть до корня проекта). Для работы этого режима требуется указать корневую директорию проекта через флаг ‑‑project-root.
‑‑disableLicenseExpirationCheck — флаг устанавливает нулевой код возврата, если срок действия лицензии скоро истечёт. Данный флаг следует использовать, если вы встраиваете анализатор в системы непрерывной интеграции (Travis CI, CircleCI, GitLab CI/CD) или автоматизируете проверку коммитов и Pull Requests и срок действия вашей лицензии скоро закончится (осталось менее 30 дней).
Обратите внимание: если после обновления лицензии забыть убрать этот флаг, то pvs-studio-analyzer заменит возможный нулевой код возврата кодом 6.
‑‑file [FILE] (-f [FILE]) — задаёт путь до файла трассировки компиляции или JSON Compilation Database. По умолчанию, если этот флаг не указан, PVS-Studio ищет файл strace_out или compile_commands.json в текущем каталоге. Следует учесть, что PVS-Studio первым ищет файл compile_commands.json и только потом strace_out. Поэтому если у вас в рабочем каталоге лежат два этих файла, то предпочтение будет отдано первому. Если вы используете JSON Compilation DB, то обязательно указывайте расширение файла .json, иначе он будет считаться как файл трассировки.
Данный флаг следует задавать, если файл трассировки компиляции или JSON Compilation Database сохранён по нестандартному пути.
‑‑quiet — не отображать процесс анализа.
‑‑preprocessor [NAME] — задаёт тип препроцессора, который анализатор будет ожидать при разборе препроцессированных файлов (*.PVS-Studio.i) Возможные значения:
- visualcpp,
- clang,
- gcc,
- bcc,
- bcc_clang64,
- iar,
- keil5,
- keil5_gnu,
- c6000.
Во время работы препроцессора выполняется раскрытие макросов и подстановка содержимого файлов, включенных через #include, в результирующий препроцессированный файл. Для корректной навигации компилятора и различных утилит (в том числе и PVS-Studio) по такому файлу препроцессор вставляет специальные #line-директивы. Они указывают на файл, содержимое которого было вставлено в данное место.
PVS-Studio нужно знать тип препроцессора для корректной обработки директив #line, специфичных для разных компиляторов.
По умолчанию, если этот флаг не указан, анализатор пытается сам определить тип препроцессора. Однако бывают ситуации, когда анализатор может некорректно определить его. В таком случае препроцессор можно указать явно.
Данный параметр можно задать в файле конфигурации (*.cfg).
‑‑platform [NAME] — флаг позволяет задать целевую платформу, под которую производится компиляция проекта.
Данный флаг ожидает следующие параметры:
- для Windows:
win32,x64,Itanium,arm; - для Linux:
linux32,linux64,Itanium,arm; - для macOS:
macOS; - для Embedded:
pic8,tms(Texas instruments).
Информация о платформе нужна анализатору для корректного вывода модели данных.
По умолчанию, если вы не задали этот флаг, PVS-Studio попытается определить платформу на основе параметров запуска компилятора.
Также данный параметр может быть задан в файле конфигурации.
‑‑ignore-ccache — включает анализ всех исходных файлов, независимо от состояния ccache. Если в вашем проекте для ускорения сборки используется обёртка над вызовом компилятора (ccache), то анализ не найдёт файлы компиляции. Этот флаг позволяет опустить вызов ccache и обработать обёрнутую в него команду компилятора.
‑‑incremental (-i) — флаг включает инкрементальный анализ проекта.
‑‑source-files [FILE] (-S [FILE]) — задаёт список исходных файлов для режима проверки списка файлов. Этот список представляет собой текстовый файл, где путь до каждого файла исходного кода расположен на новой строке. Допустимо использовать абсолютные и относительные пути. Относительные пути следует указывать относительно директории, из которой вы хотите запускать анализ.
Такой подход удобно использовать при анализе коммитов и Pull Request'ов.
‑‑regenerate-depend-info [OPTION] — обновляет информацию о зависимостях компиляции для каждого исходного файла. Информация о зависимостях хранится в файле depend_info.json.
Флаг поддерживает следующие режимы:
run-analysis— обновить информацию о зависимостях и запустить анализ,skip-analysis— обновить информацию о зависимостях без запуска анализа.
Файл зависимостей нужен анализатору для корректной проверки списков файлов и для инкрементального анализа. Подробнее об этом можно прочитать здесь.
‑‑suppress-file [FILE] (-s [FILE]) — задаёт путь до файла с подавленными предупреждениями. Предупреждения, попавшие в файл подавления, игнорируются при формировании отчёта анализатора. Подробнее об этом можно узнать тут. По умолчанию файл подавления имеет имя suppress_file.suppress.json.
‑‑analyze-specified-system-paths — включение в анализ файлов из пользовательских системных каталогов, которые указаны через флаги компиляции: isystem, isysroot, system_include_dir и т. д.
‑‑compiler [COMPILER_NAME[=COMPILER_TYPE]] (-C [COMPILER_NAME[=COMPILER_TYPE]]) — позволяет задать имя и тип компилятора. Данный флаг следует использовать, когда PVS-Studio не может распознать вызовы компилятора (при анализе по файлу трассировки) или запускает компилятор с неправильными флагами препроцессирования, так как вычисляет неверный тип компилятора.
COMPILE_NAME используется для фильтрации команд компилятора при разборе файла трассировки (strace_out).
COMPILE_TYPE — задаёт тип компилятора, что позволяет анализатору правильно запустить команду препроцессирования файла. Возможные значения: gcc, clang, keil5, keil5gnu, keil6, tiarmcgt, cl, clangcl, gccarm, iararm_v7_orolder, iararm, qcc, xc8. Если тип компилятора не указан, то анализатор попытаться вывести его по имени или через информацию о версии. А если не сможет, то будет считать его как GCC (на Linux, macOS) или cl (на Windows).
Например, следующая команда указывает анализатору, что в файле strace_out есть неизвестный компилятор CustomCompiler и его следует воспринимать, как GCC:
pvs-studio-analyzer analyzer -f /path/to/strace_out \
-C CustomCompiler=gcc‑‑env [VAR=VALUE] (-E [VAR=VALUE]) — задаёт переменную окружения, с которой будет производиться препроцессирование.
‑‑rules-config [FILE] (-R [FILE]) — файл конфигурации диагностик (*.pvsconfig). Подробнее о конфигурации диагностик можно узнать здесь.
‑‑intermodular — включает режим межмодульного анализа. В этом режиме анализатор выполняет более глубокий анализ кода, но тратит на это больше времени.
Использование файла конфигурации
Файл конфигурации позволяет задать общие параметры запуска анализатора.
Для проекта можно создать отдельный файл конфигурации, в который следует поместить специфические параметры.
Параметры записываются как пара "ключ=значение". Вы можете использовать символ '#' для комментирования строк.
Возможные значения в конфигурационном файле:
exclude-path — задаёт путь (абсолютный или относительный) до файлов или директорий, которые должны быть исключены из анализа. Относительный путь следует указывать относительно директории, содержащей файл конфигурации. Также можно использовать шаблоны командных оболочек (glob) ? и * для указания пути.
analysis-paths — определяет поведение анализа на указанных путях. Доступны следующие режимы:
skip-analysis— задаёт директорию, файлы из которой проверять не надо. Обычно это каталоги системных файлов или подключаемых библиотек.skip-settings— игнорирует настройки, расположенные в исходных файлах и файлах.pvsconfigпо указанному пути.isolate-settings— задаёт директорию, для которой следует изолировать настройки. При использовании данного режима файлы конфигурации правил.pvsconfigиз родительских каталогов не будут применяться для единиц трансляции в указанной директории и её подкаталогах. Поддерживаются абсолютные и относительные пути. Относительные пути раскрываются через текущий каталог. Для этого режима нельзя использовать шаблоны glob.skip— игнорирует настройки, расположенные в исходных файлах и файлах.pvsconfigпо указанному пути. Также будут отфильтрованы предупреждения, сгенерированные для файлов исходного кода по указанному пути или маске.
timeout — задаёт время (в секундах), по истечении которого будет прерван анализ единицы трансляции. По умолчанию на анализ одного файла отводится 10 минут (600 секунд). Если передать в качестве значения 0, то ограничение на время будет снято. Однако учтите, что снятие временного ограничения может привести к зависанию анализа.
platform — задаёт используемую платформу. Возможные варианты: win32, x64, Itanium, linux32, linux64, macOS, pic8, tms.
preprocessor — задаёт используемый препроцессор. Возможные варианты: visualcpp, clang, gcc, bcc, bcc_clang64, iar, keil5, keil5_gnu, c6000.
lic-file — задаёт абсолютный или относительный путь до файла лицензии. Путь может быть задан относительно директории, содержащей файл конфигурации.
analysis-mode — задаёт тип выдаваемых предупреждений. Тип представляет собой битовую маску. С помощью "побитового ИЛИ" можно задать несколько групп диагностик, которые будут использованы при анализе.
Возможные значения:
- 0 — полный анализ;
- 1 — 64-битные диагностики;
- 4 — диагностики общего назначения (рекомендуется и используется по умолчанию);
- 8 — диагностики микрооптимизаций;
- 16 — диагностики, реализованные по просьбе пользователей;
- 32 — диагностики на соответствие кода рекомендациям MISRA;
- 64 — диагностики на соответствие кода рекомендациям AUTOSAR;
- 128 — диагностики на соответствие кода рекомендациям OWASP.
output-file — полный или относительный путь к файлу, в который следует записать отчёт работы анализатора. По умолчанию отчёт будет записан в файл PVS-Studio.log. Относительный путь следует указывать относительно каталога, из которого будет произведен запуск анализа. При распараллеливании анализа все процессы ядра PVS-Studio пишут отчёт в один файл. Следовательно, этот файл будет заблокирован пока последний процесс не запишет в него информацию.
funsigned-char — задаёт знаковость типа char. Если true — анализатор трактует char как unsigned char, если false — как знаковый char.
rules-config — задаёт путь до файла конфигурации диагностик (*.pvsconfig). Путь может быть задан относительно директории, содержащей файл конфигурации.
no-noise — позволяет исключить из отчёта все срабатывания 3-го уровня достоверности. Если true — срабатывания с низким уровнем достоверности не попадут в отчёт анализатора. По умолчанию — false.
errors-off — задаёт список деактивированных диагностик. Список задаётся через пробел или запятую: V1024 V591 или V1024, V591. Диагностики, перечисленные в этом списке, не будут применены во время анализа.
analyzer-errors — задаёт список активных диагностик. Список может быть задан через пробел или через запятую: V1024 V591 или V1024, V591. Во время анализа будут использованы только те диагностики, которые перечислены в этом списке.
Обратите внимание: список деактивированных диагностик, заданный через errors-off, имеет больший приоритет, чем список активированных.
Пример: зададим основные параметры запуска PVS-Studio в файле конфигурации и запустим анализ проекта, предав анализатору наш *.cfg файл.
Файл MyProject.cfg:
lic-file=~/.config/PVS-Studio/PVS-Studio.lic
exclude-path=*/tests/*
exclude-path=*/lib/*
exclude-path=*/third-party/*
platform=linux64
preprocessor=clang
analysis-mode=4
output-file=~/MyProject/MyProject.PVS-Studio.logЗапуск анализа (предполагается, что в текущем каталоге есть strace_out или compile_commands.json):
pvs-studio-analyzer analyze --cfg ./MyProject.cfg ....Использование файла конфигурации позволяет упростить интеграцию анализатора с системами CI/CD.
Подавление сообщений анализатора и фильтрация отчёта согласно правилам подавления
В PVS-Studio существует механизм подавления предупреждений, который подходит для следующих сценариев:
- при внедрении анализатора в проект, когда PVS-Studio выдаёт большое количество срабатываний на весь код. Все эти срабатывания можно подавить и вернуться к ним, когда на это появится время. В таком случае PVS-Studio будет выдавать срабатывания только на новом коде при регулярных проверках вашего проекта;
- если вы хотите подавить ложные срабатывания анализатора без модификации файлов исходного кода.
Утилита pvs-studio-analyzer позволяет подавить сообщения анализатора и провести фильтрацию отчёта, исключив из него подавленные сообщения.
Создание baseline-уровня сообщений
Для подавления сообщений создаётся специальный файл (по умолчанию имеет имя suppress_file.suppress.json), куда записываются предупреждения анализатора, которые следует игнорировать.
Общий синтаксис запуска режима подавления выглядит следующим образом:
pvs-studio-analyzer suppress [-a <TYPES>] [-f <FILE...>] \
[-v <NUMBER...>] [-o <FILE>] [log][log] — путь до отчёта, который был создан анализатором. По умолчанию анализатор будет искать файл PVS-Studio.log в текущем каталоге.
‑‑analyzer [TYPES] (-a [TYPES]) — позволяет указать, предупреждения каких групп диагностик и их уровней достоверности будут перемещены в файл подавления. Параметр принимает строку вида Diagnostic group: Diagnostic level [, Diagnostic level]*, где Diagnostic group определяет группу диагностик (возможные группы: GA, 64, OP, CS, MISRA, AUTOSAR, OWASP), а Diagnostic level — уровень достоверности (возможные уровни: 1, 2, 3). Объединение разных групп и их уровней возможно через символ ; или +.
Например: запись вида GA:1;OP:1 говорит анализатору, что при подавлении следует использовать только диагностики с первым уровнем достоверности из групп общего назначения и микрооптимизаций. По умолчанию фильтрация идёт по всем группам и уровням.
‑‑file [FILE...] (-f [FILE...]) — позволяет подавить все предупреждения для конкретного файла:
pvs-studio-analyzer suppress -f test.cpp -f test2.cpp /path/to/PVS-Studio.logили для конкретного файла и строки в нем:
pvs-studio-analyzer suppress -f test.cpp:15 /path/to/PVS=Studio.log‑‑warning [NUMBER...] (-v[NUMBER...]) — задает номер диагностики, срабатывания которой необходимо подавить из отчета:
pvs-studio-analyzer suppress -v512 -v /path/to/PVS-Studio.log‑‑output [FILE], (-o[FILE]) — задаёт путь и имя для файла подавления. По умолчанию PVS-Studio записывает всю информацию о подавлении срабатываний в файл suppress_file.suppress.json в текущей директории.
Примечание: флаги ‑‑file, ‑‑warning и ‑‑analyzer можно комбинировать. Например, данная команда подавит все предупреждения V1040 на строке 12:
pvs-studio-analyzer suppress -f test.cpp:12 -v1040 /path/to/PVS-Studio.logСледующая команда подавляет все диагностики общего назначения 3-его уровня для файла:
pvs-studio-analyzer suppress -f test.cpp -a 'GA:3' /path/to/PVS-Studio.logФильтрация отчёта по suppress-файлу
Вы можете отфильтровать предупреждения, которые ранее были помещены в файл подавления, из отчёта анализатора. Для этого следует выполнить команду:
pvs-studio-analyzer filter-suppressed [-o <FILE>] [-s <FILE>] [log]‑‑output [FILE] (-o [FILE]) — имя файла для записи отфильтрованного отчёта. По умолчанию, если флаг не задан, pvs-studio-analyzer перезапишет существующий файл отчёта.
‑‑suppress-file [FILE] (-s [FILE]) — файл подавления сообщений. По умолчанию pvs-studio-analyzer ищет файл suppress_file.suppress.json в каталоге запуска.
[log] — файл отчёта, из которого следует отфильтровать предупреждения.
Утилита pvs-studio-analyzer всегда ищет файл подавления в режиме анализа для создания фильтрованного отчёта. Если файл имеет нестандартный путь, вы можете указать его через флаг -s:
pvs-studio-analyzer analyze -s /path/to/suppress_file.suppress.json ....Описание кодов возврата
Утилита может возвращать следующие значения:
0 — анализ прошел успешно;
1 — разнообразные внутренние ошибки. Например, не удалось препроцессировать файл или при разборе файла трассировки произошла ошибка. Как правило, падение c таким кодом сопровождается описанием ошибки в stdout;
2 — срок действия лицензии истекает менее чем через месяц;
3 — во время анализа некоторых файлов произошла внутренняя ошибка;
5 — срок действия вашей лицензии истёк;
6 — утилита была запущена с флагом –disableLicenseExpirationCheck, и ей была передана новая лицензия сроком действия более 30 дней.
7 — ни одна единица компиляции не была принята к анализу. Например, все файлы были исключены из анализа с помощью настроек пользователя или путём маркировки всех каталогов исходного кода как путей к системным заголовкам.
8 — не было обнаружено ни одного вызова компилятора. Например, используется неизвестный компилятор или некорректно сгенерирован файл структуры проекта (strace_out или база данных команд компиляции).
В режиме trace, анализатор по умолчанию возвращает тот же код, что получил от запускаемой программы. Если же вы хотите, чтобы анализатор игнорировал настоящий код возврата и всегда возвращал 0, то можете воспользоваться флагом -i или -- ignoreTraceReturnCode. Например:
pvs-studio-analyzer trace -i -- ....Была ли полезна эта страница документации?